⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
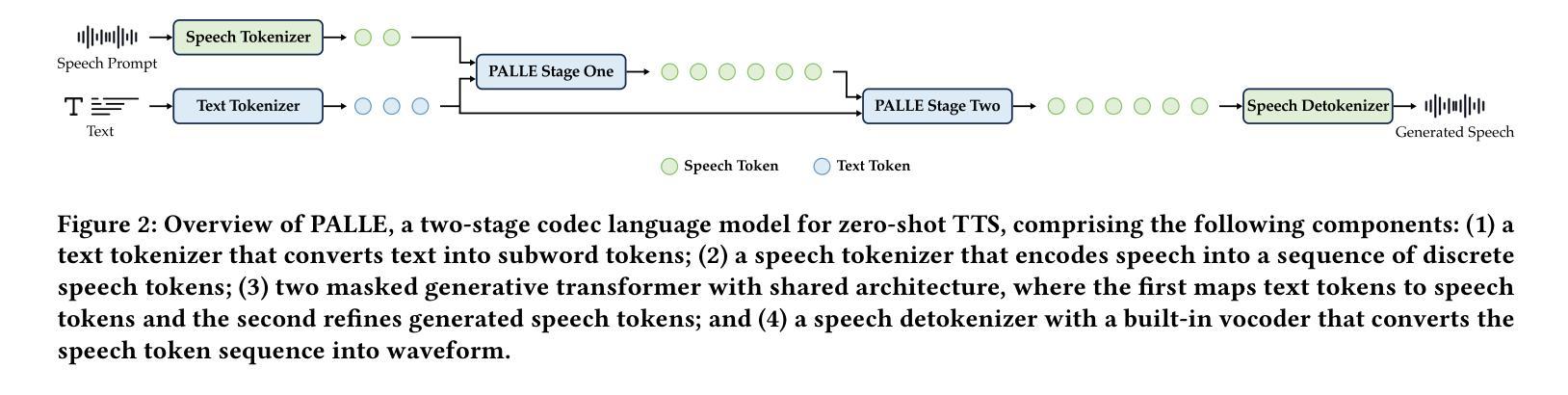
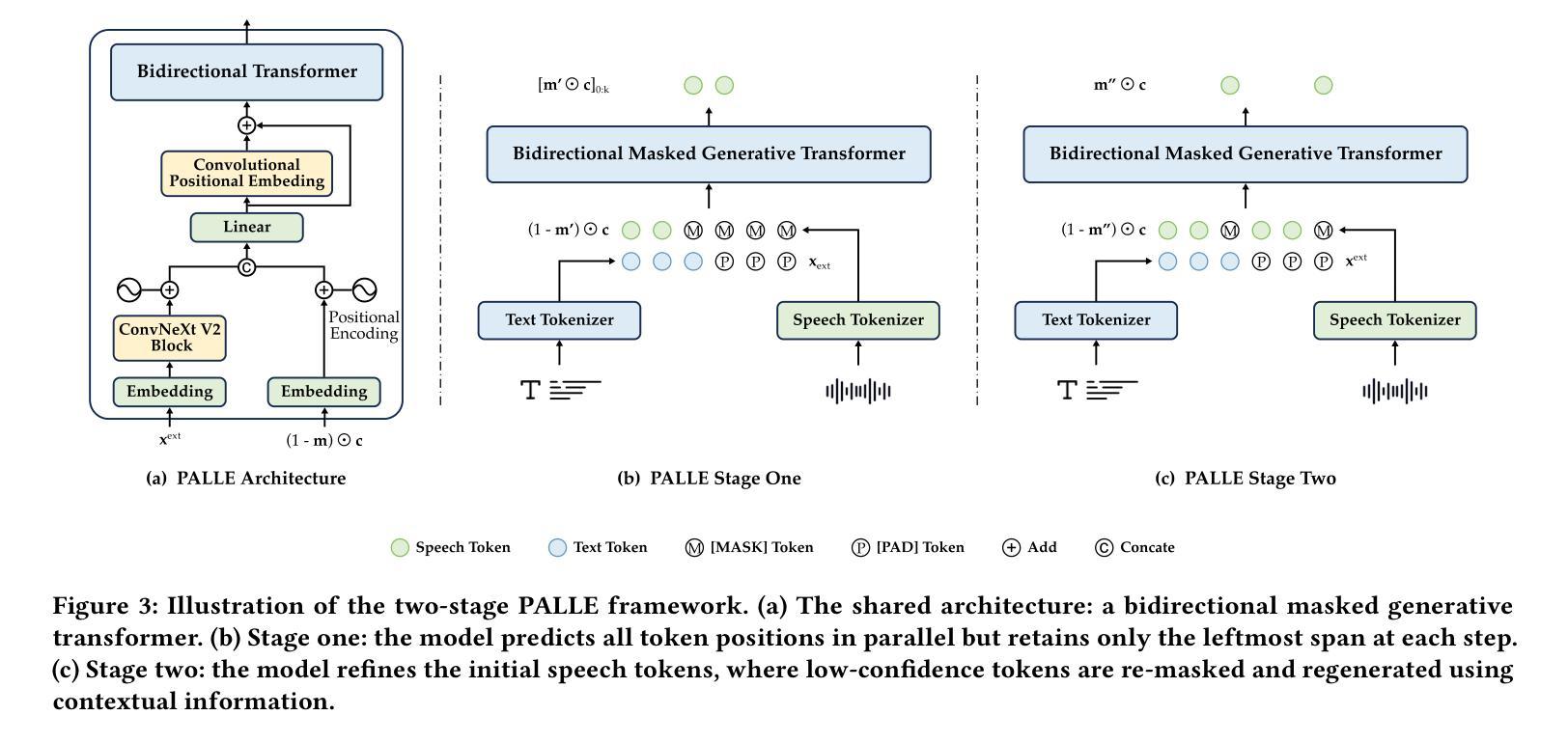
Pseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Authors:Yifan Yang, Shujie Liu, Jinyu Li, Yuxuan Hu, Haibin Wu, Hui Wang, Jianwei Yu, Lingwei Meng, Haiyang Sun, Yanqing Liu, Yan Lu, Kai Yu, Xie Chen
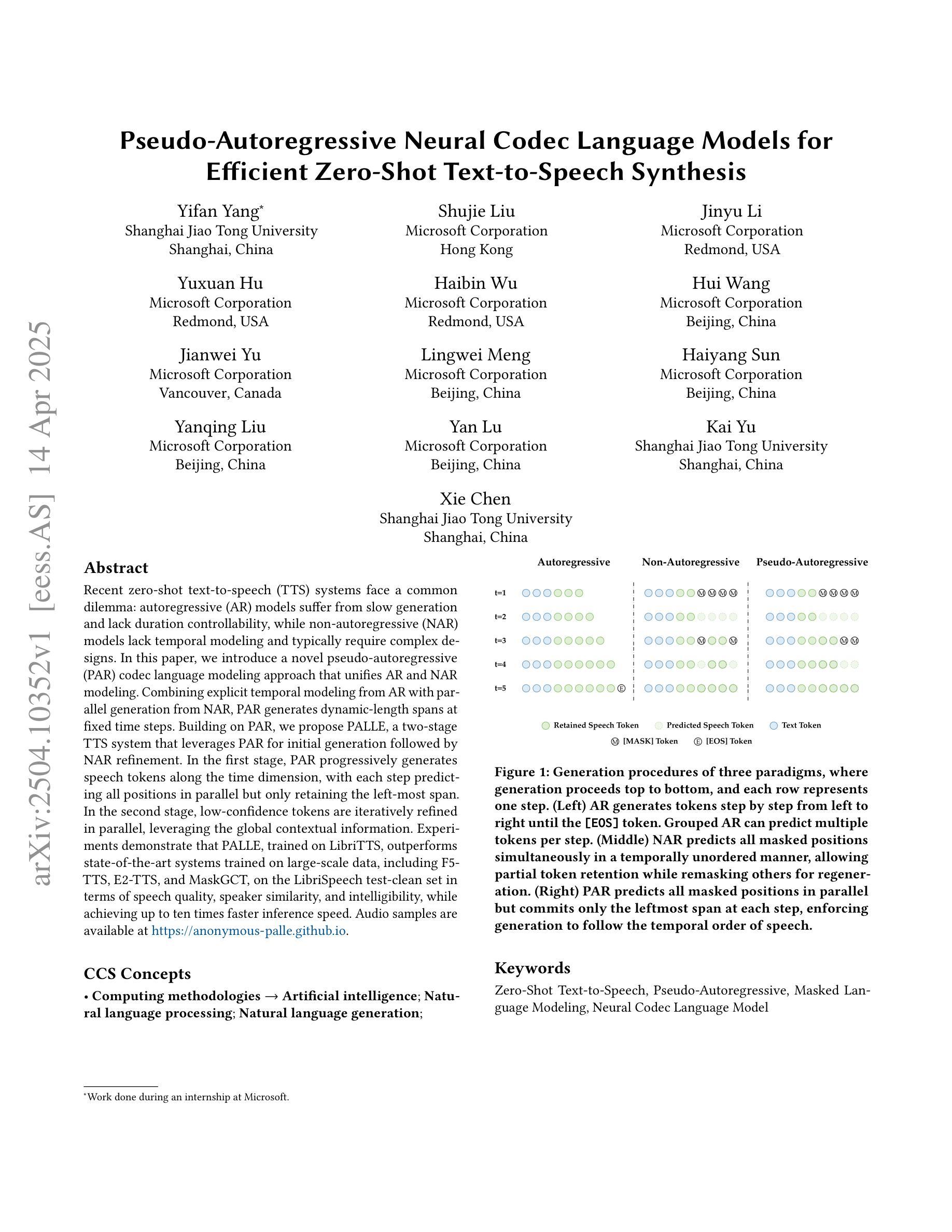
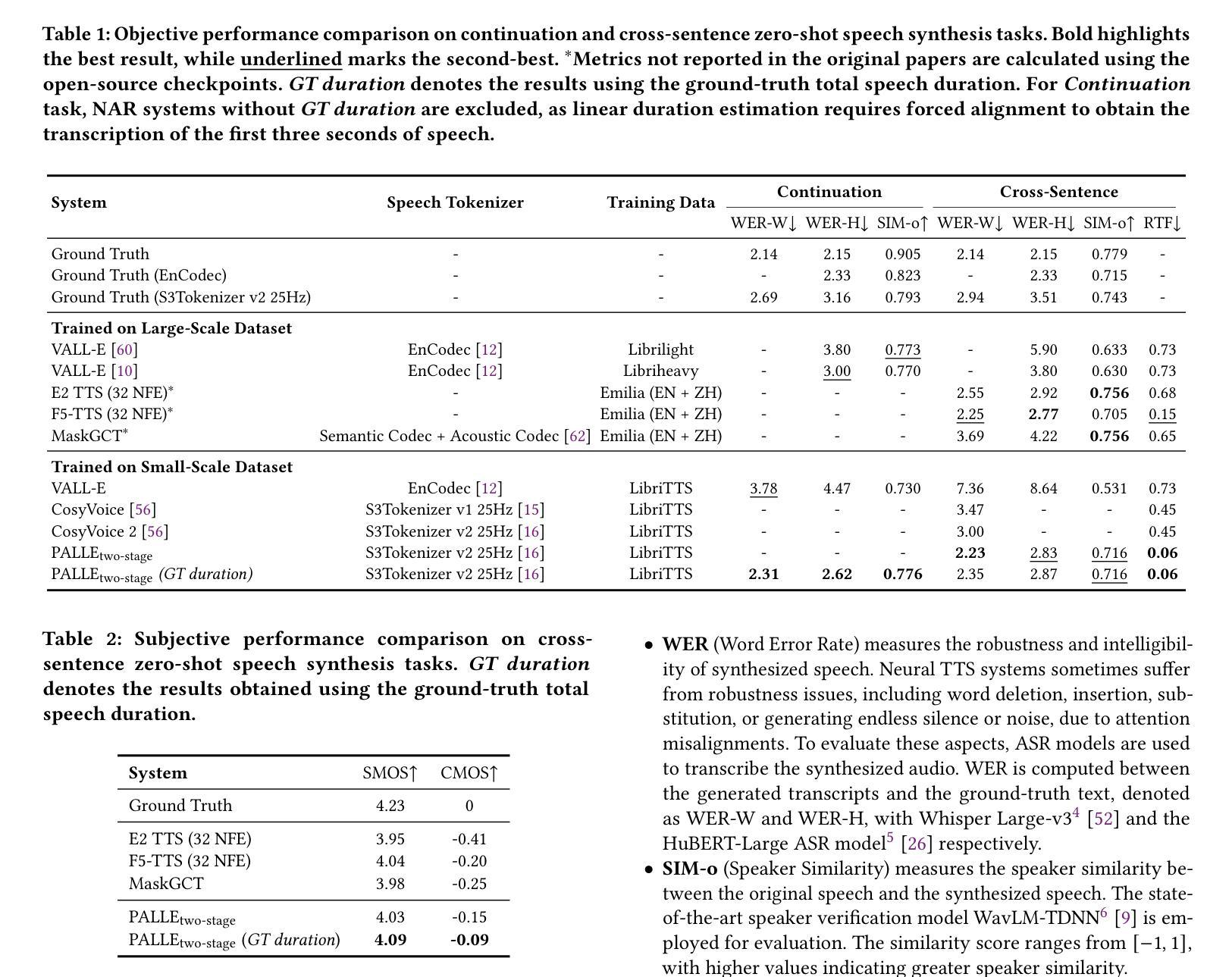
Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.
最近,零样本文本转语音(TTS)系统面临一个共同的问题:自回归(AR)模型存在生成速度慢和缺乏持续时间控制性的缺点,而非自回归(NAR)模型则缺乏时间建模并且通常需要复杂的设计。在本文中,我们介绍了一种新型伪自回归(PAR)编码解码语言建模方法,它将AR和NAR建模统一起来。通过将AR的显式时间建模与NAR的并行生成相结合,PAR在固定时间步长上生成动态长度的跨度。基于PAR,我们提出了PALLE,一个两阶段的TTS系统,它利用PAR进行初步生成,然后用NAR进行细化。在第一阶段,PAR沿着时间维度逐步生成语音标记,每一步都预测所有位置并并行处理,但只保留最左边的跨度。在第二阶段,对低置信度的标记进行并行细化,利用全局上下文信息。实验表明,在LibriSpeech测试集上,PALLE在语音质量、说话人相似度和清晰度方面优于在大型数据上训练的最新系统,包括F5-TTS、E2-TTS和MaskGCT等系统,同时实现了高达十倍的推理速度提升。音频样本可在https://anonymous-palle.github.io找到。
论文及项目相关链接
PDF Submitted to ACM MM 2025
Summary
本文主要介绍了一种新型的伪自回归(PAR)编码解码语言建模方法,它结合了自回归(AR)和非自回归(NAR)建模的优点。在此基础上,提出了一种两阶段的文本转语音(TTS)系统PALLE。第一阶段使用PAR逐步生成语音标记,第二阶段利用NAR对低置信度的标记进行并行精细校正。实验表明,在LibriSpeech测试集上,PALLE在语音质量、说话人相似性和清晰度方面优于其他先进系统,同时推理速度提高十倍。
Key Takeaways
- 本文提出了一种新颖的伪自回归(PAR)编码解码语言建模方法,结合了自回归和非自回归建模的优势。
- PAR建模能够在固定时间步长内生成动态长度的语音标记。
- PALLE是一种基于PAR的两阶段TTS系统,第一阶段使用PAR逐步生成语音,第二阶段利用非自回归模型对低置信度的标记进行精细校正。
- 实验结果表明,PALLE在语音质量、说话人相似性和清晰度方面优于其他先进系统。
- PALLE系统实现了高达十倍的推理速度提升。
- 音频样本可通过[链接]进行访问。
点此查看论文截图
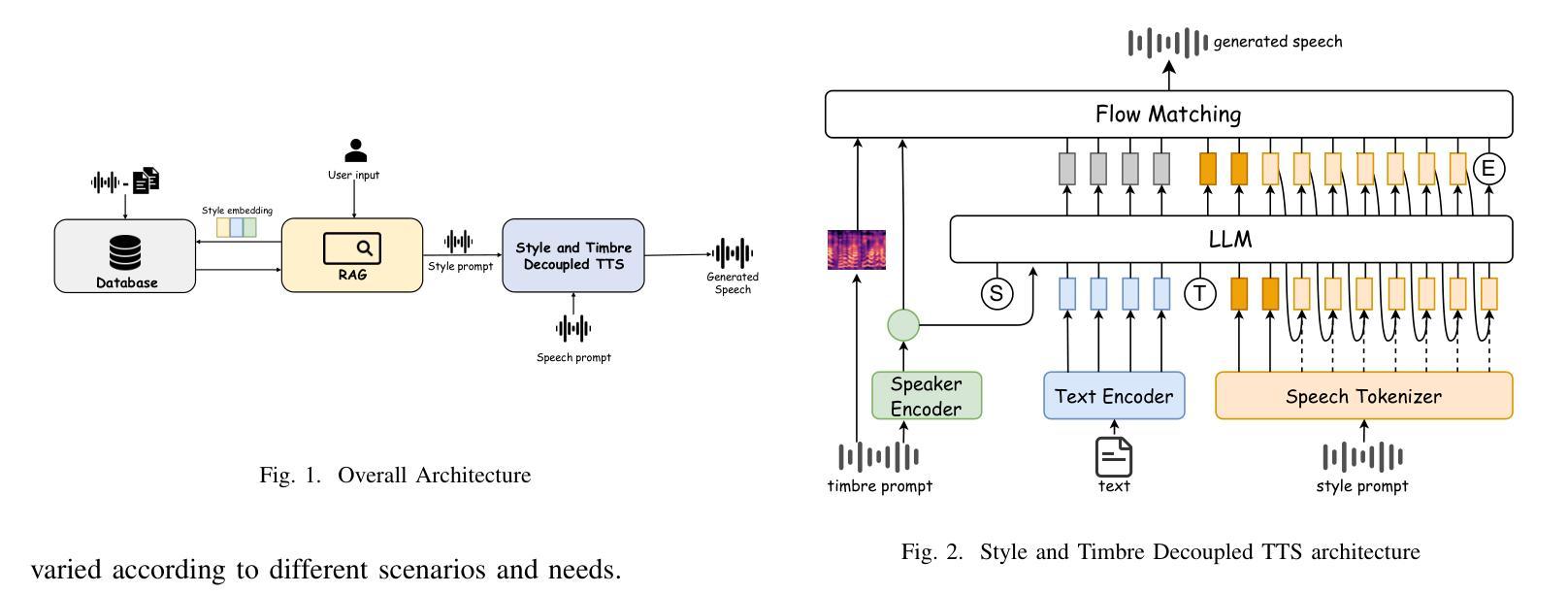
AutoStyle-TTS: Retrieval-Augmented Generation based Automatic Style Matching Text-to-Speech Synthesis
Authors:Dan Luo, Chengyuan Ma, Weiqin Li, Jun Wang, Wei Chen, Zhiyong Wu
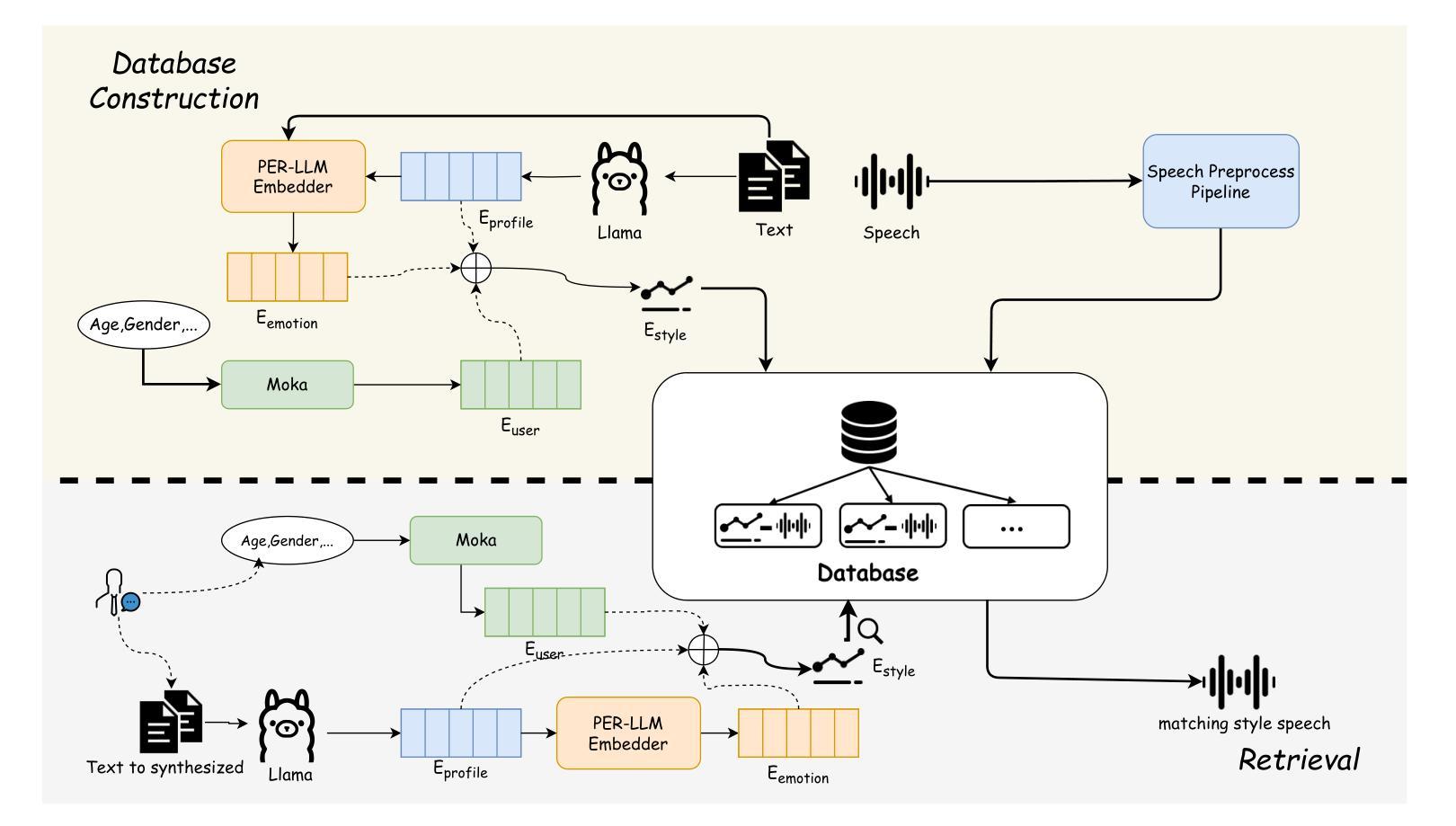
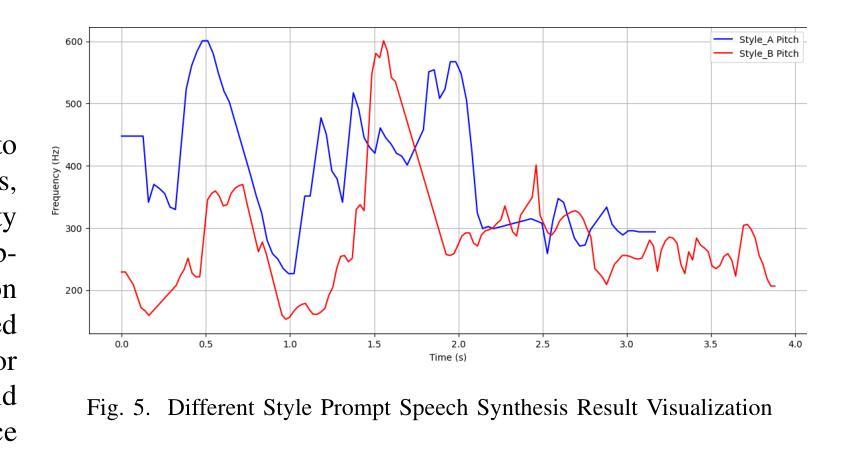
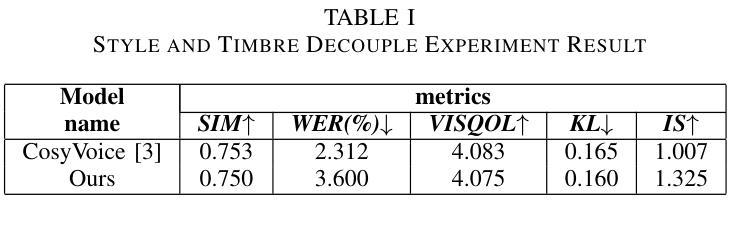
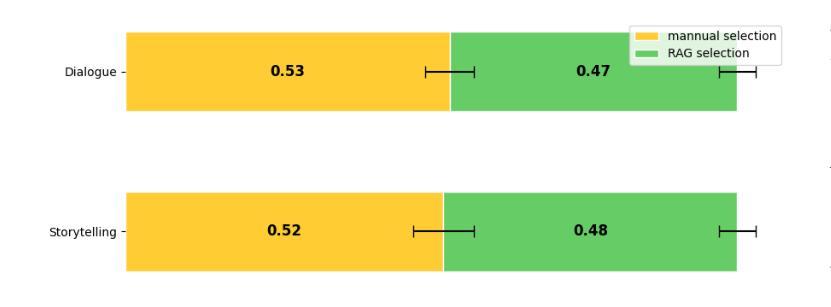
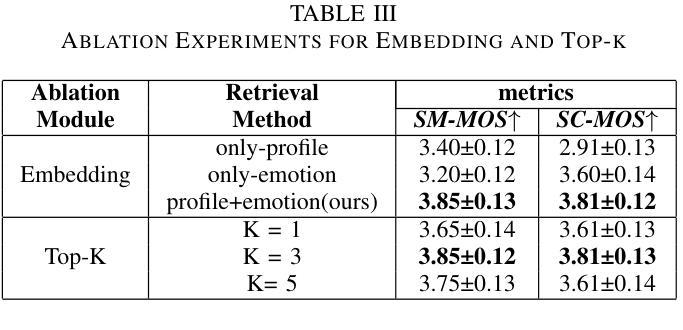
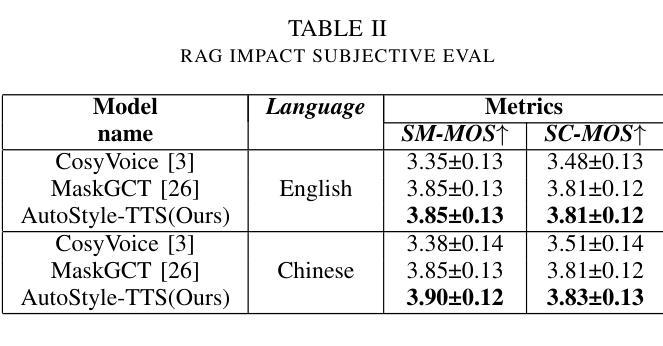
With the advancement of speech synthesis technology, users have higher expectations for the naturalness and expressiveness of synthesized speech. But previous research ignores the importance of prompt selection. This study proposes a text-to-speech (TTS) framework based on Retrieval-Augmented Generation (RAG) technology, which can dynamically adjust the speech style according to the text content to achieve more natural and vivid communication effects. We have constructed a speech style knowledge database containing high-quality speech samples in various contexts and developed a style matching scheme. This scheme uses embeddings, extracted by Llama, PER-LLM-Embedder,and Moka, to match with samples in the knowledge database, selecting the most appropriate speech style for synthesis. Furthermore, our empirical research validates the effectiveness of the proposed method. Our demo can be viewed at: https://thuhcsi.github.io/icme2025-AutoStyle-TTS
随着语音合成技术的进步,用户对合成语音的自然性和表达性有了更高的期望。然而,之前的研究忽略了提示选择的重要性。本研究提出了一种基于检索增强生成(RAG)技术的文本到语音(TTS)框架,该框架可以根据文本内容动态调整语音风格,以实现更自然、生动的交流效果。我们构建了一个包含各种上下文高质量语音样本的语音风格知识数据库,并开发了一种风格匹配方案。该方案使用Llama、PER-LLM-Embedder和Moka提取的嵌入来与知识数据库中的样本进行匹配,选择最合适的语音风格进行合成。此外,我们的实证研究验证了该方法的有效性。我们的演示视频可以在:https://thuhcsi.github.io/icme2025-AutoStyle-TTS 查看。
论文及项目相关链接
PDF accepted by ICME25
Summary
随着语音合成技术的进步,用户对合成语音的自然度和表现力有更高的要求。本研究提出了一种基于检索增强生成(RAG)技术的文本到语音(TTS)框架,该框架可根据文本内容动态调整语音风格,以实现更自然、更生动的沟通效果。构建了包含多种语境高质量语音样本的语音风格知识库,并开发了风格匹配方案。
Key Takeaways
- 文本到语音(TTS)技术需要满足用户对自然度和表现力的更高期望。
- 提出了一种基于检索增强生成(RAG)技术的TTS框架。
- 框架能依据文本内容动态调整语音风格。
- 构建了包含多种语境下高质量语音样本的语音风格知识库。
- 开发了利用嵌入技术匹配语音风格的知识库样本的风格匹配方案。
- 所提方法经过实证研究验证其有效性。
点此查看论文截图

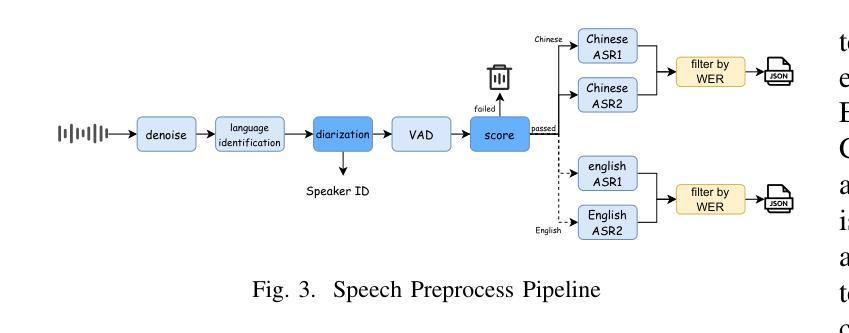
SafeSpeech: Robust and Universal Voice Protection Against Malicious Speech Synthesis
Authors:Zhisheng Zhang, Derui Wang, Qianyi Yang, Pengyang Huang, Junhan Pu, Yuxin Cao, Kai Ye, Jie Hao, Yixian Yang
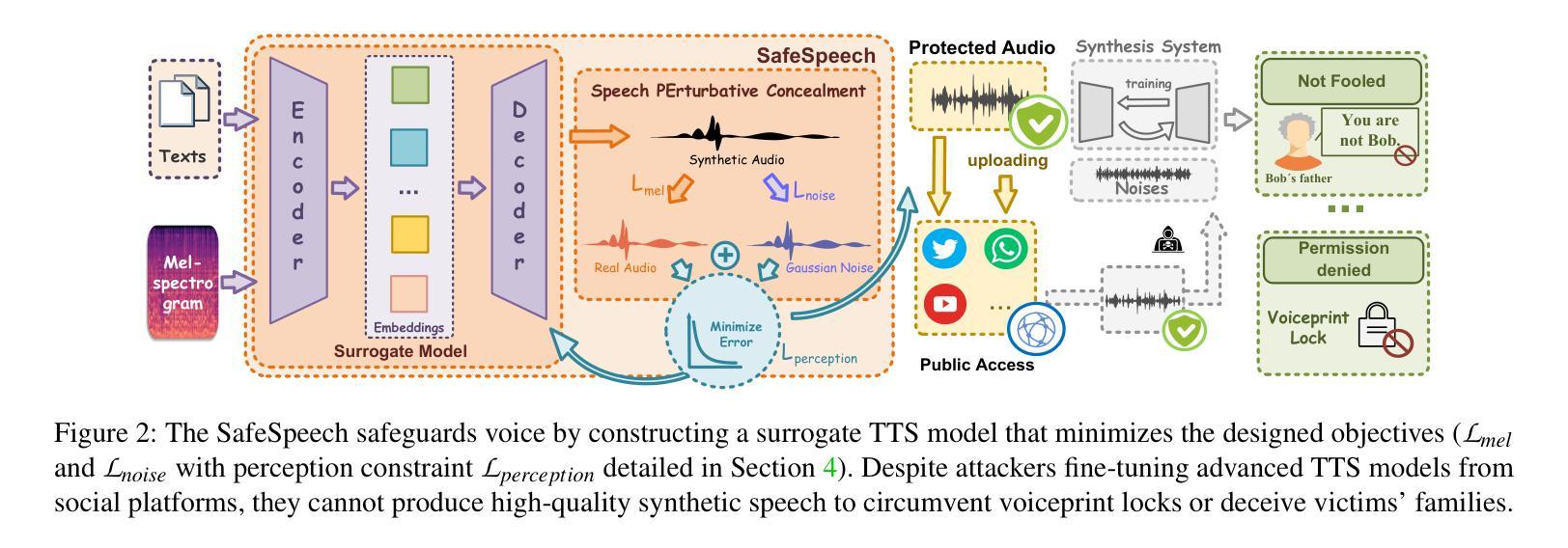
Speech synthesis technology has brought great convenience, while the widespread usage of realistic deepfake audio has triggered hazards. Malicious adversaries may unauthorizedly collect victims’ speeches and clone a similar voice for illegal exploitation (\textit{e.g.}, telecom fraud). However, the existing defense methods cannot effectively prevent deepfake exploitation and are vulnerable to robust training techniques. Therefore, a more effective and robust data protection method is urgently needed. In response, we propose a defensive framework, \textit{\textbf{SafeSpeech}}, which protects the users’ audio before uploading by embedding imperceptible perturbations on original speeches to prevent high-quality synthetic speech. In SafeSpeech, we devise a robust and universal proactive protection technique, \textbf{S}peech \textbf{PE}rturbative \textbf{C}oncealment (\textbf{SPEC}), that leverages a surrogate model to generate universally applicable perturbation for generative synthetic models. Moreover, we optimize the human perception of embedded perturbation in terms of time and frequency domains. To evaluate our method comprehensively, we conduct extensive experiments across advanced models and datasets, both subjectively and objectively. Our experimental results demonstrate that SafeSpeech achieves state-of-the-art (SOTA) voice protection effectiveness and transferability and is highly robust against advanced adaptive adversaries. Moreover, SafeSpeech has real-time capability in real-world tests. The source code is available at \href{https://github.com/wxzyd123/SafeSpeech}{https://github.com/wxzyd123/SafeSpeech}.
语音合成技术带来了极大的便利,而真实深度伪造音频的广泛使用也引发了风险。恶意对手可能会未经授权地收集受害者的演讲并克隆类似的声音进行非法利用(例如电信欺诈)。然而,现有的防御方法无法有效地防止深度伪造攻击,并容易受到强大的训练技术的影响。因此,急需一种更有效和稳健的数据保护方法。作为回应,我们提出了一种防御框架,名为“SafeSpeech”,通过在原始演讲上嵌入几乎无法察觉的扰动来保护用户音频,防止高质量合成语音。在SafeSpeech中,我们设计了一种强大且通用的主动保护技术——语音扰动掩盖(SPEC),该技术利用替代模型生成适用于所有生成合成模型的通用扰动。此外,我们优化了嵌入扰动在时间和频率域中的人类感知。为了全面评估我们的方法,我们在先进的模型和数据集上进行了大量实验,包括主观和客观评估。我们的实验结果表明,SafeSpeech达到了最先进的语音保护效果和可转移性,并对高级自适应对手具有高度鲁棒性。此外,SafeSpeech在真实世界测试中具有实时能力。源代码可在https://github.com/wxzyd123/SafeSpeech获得。
论文及项目相关链接
PDF Accepted to USENIX Security 2025
Summary
文本主要讨论语音合成技术带来的便利性和深度伪造音频的广泛运用所带来的风险。现有的防御方法无法有效防止深度伪造技术的滥用,因此急需一种更有效和稳健的数据保护方法。针对这一问题,本文提出了一种名为SafeSpeech的防御框架,通过在用户上传音频前嵌入几乎无法察觉的扰动来保护用户语音,防止高质量合成语音。SafeSpeech采用一种名为SPEC的稳健且通用的主动保护技术,利用替代模型生成适用于所有生成式合成模型的通用扰动。同时,优化了嵌入扰动在时间和频率域的人类感知。经过广泛的实验验证,SafeSpeech达到了当前最佳的声音保护效果和可转移性,对高级自适应对手具有高度的稳健性,并且在真实场景测试中具备实时能力。
Key Takeaways
- 语音合成技术带来了便利,但深度伪造音频的滥用引发了风险。
- 现有防御方法无法有效防止深度伪造技术的滥用,需要更有效和稳健的数据保护方法。
- SafeSpeech框架通过嵌入几乎无法察觉的扰动保护用户语音。
- SafeSpeech采用名为SPEC的主动保护技术,对生成式合成模型具有通用性。
- SafeSpeech优化了嵌入扰动在时间和频率域的人类感知。
- SafeSpeech达到了当前最佳的声音保护效果和可转移性。
点此查看论文截图

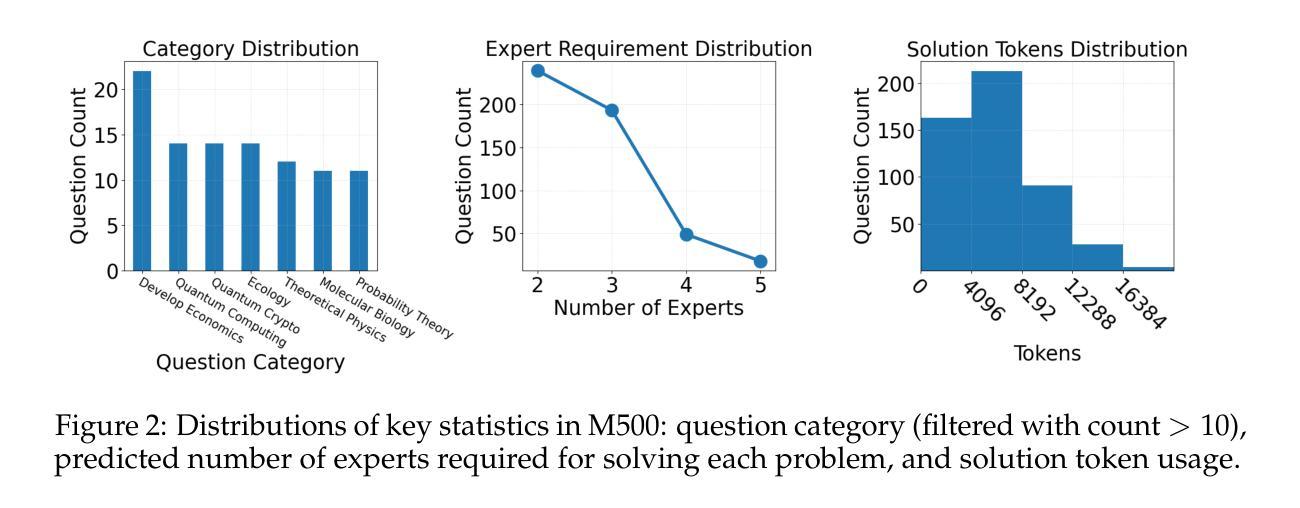
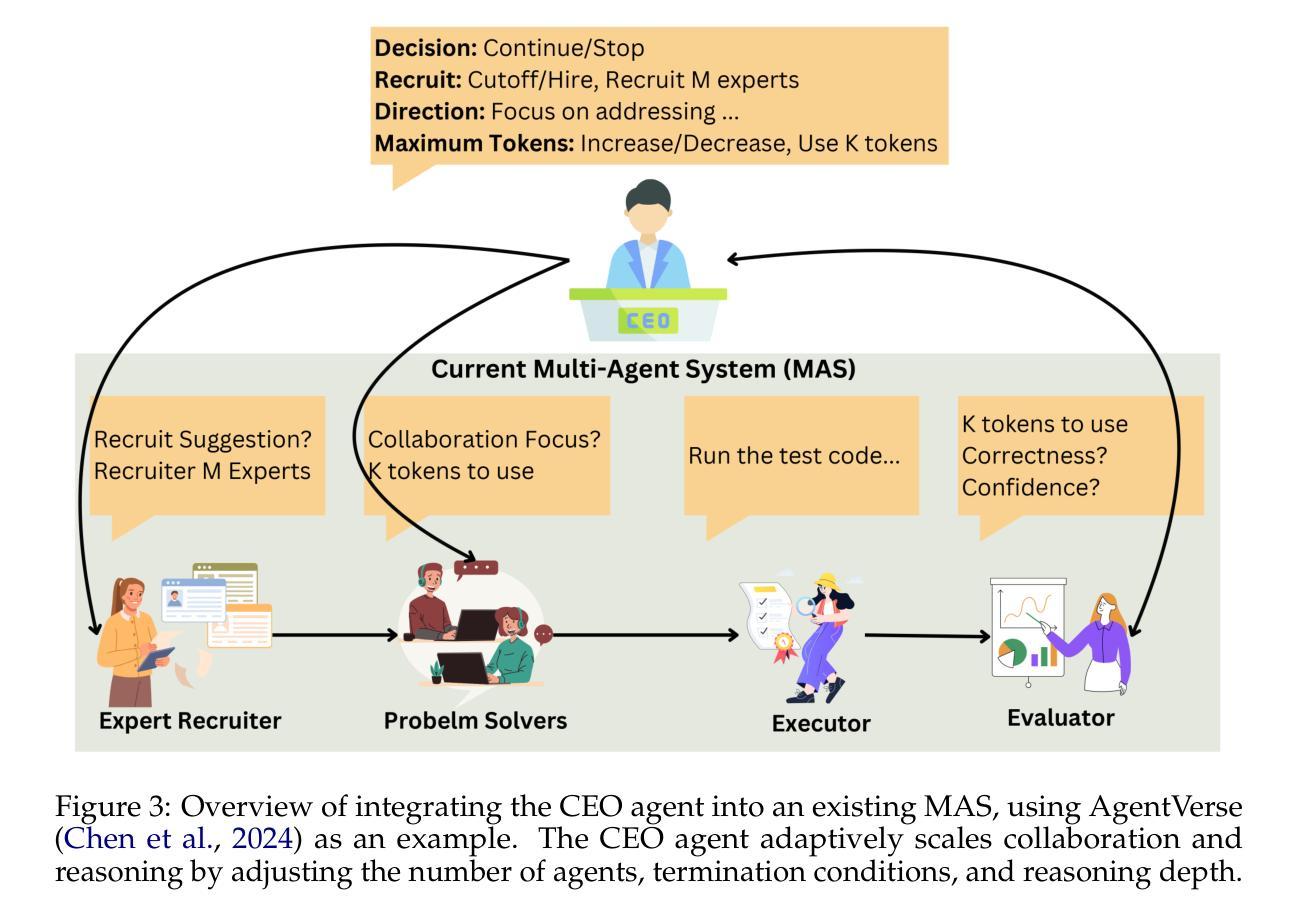
Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning
Authors:Can Jin, Hongwu Peng, Qixin Zhang, Yujin Tang, Dimitris N. Metaxas, Tong Che
Multi-agent systems (MAS) built on large language models (LLMs) offer a promising path toward solving complex, real-world tasks that single-agent systems often struggle to manage. While recent advancements in test-time scaling (TTS) have significantly improved single-agent performance on challenging reasoning tasks, how to effectively scale collaboration and reasoning in MAS remains an open question. In this work, we introduce an adaptive multi-agent framework designed to enhance collaborative reasoning through both model-level training and system-level coordination. We construct M500, a high-quality dataset containing 500 multi-agent collaborative reasoning traces, and fine-tune Qwen2.5-32B-Instruct on this dataset to produce M1-32B, a model optimized for multi-agent collaboration. To further enable adaptive reasoning, we propose a novel CEO agent that dynamically manages the discussion process, guiding agent collaboration and adjusting reasoning depth for more effective problem-solving. Evaluated in an open-source MAS across a range of tasks-including general understanding, mathematical reasoning, and coding-our system significantly outperforms strong baselines. For instance, M1-32B achieves 12% improvement on GPQA-Diamond, 41% on AIME2024, and 10% on MBPP-Sanitized, matching the performance of state-of-the-art models like DeepSeek-R1 on some tasks. These results highlight the importance of both learned collaboration and adaptive coordination in scaling multi-agent reasoning. Code is available at https://github.com/jincan333/MAS-TTS
基于大规模语言模型(LLM)的多智能体系统(MAS)为解决复杂现实世界任务提供了一条充满希望的道路,这些任务通常是单一智能体系统难以应对的。虽然最近在测试时间缩放(TTS)方面的进展大大提高了单一智能体在具有挑战性的推理任务上的性能,但如何在MAS中有效地扩展协作和推理仍然是一个悬而未决的问题。在这项工作中,我们引入了一个自适应多智能体框架,旨在通过模型级别的训练和系统级别的协调来提高协作推理能力。我们构建了M500,这是一个包含500个多智能体协作推理轨迹的高质量数据集,并在此基础上对Qwen2.5-32B-Instruct进行了微调,产生了针对多智能体协作优化的M1-32B模型。为了进一步实现自适应推理,我们提出了一种新型的首席执行官智能体,它能动态管理讨论过程,引导智能体协作,并根据需要调整推理深度,以更有效地解决问题。我们在开源MAS上对各种任务进行了评估,包括一般理解、数学推理和编码任务。我们的系统在GPQA-Diamond上实现了12%的改进,在AIME2024上实现了41%的改进,在MBPP-Sanitized上实现了10%的改进。在某些任务上,我们的性能与最新模型(如DeepSeek-R1)相匹配。这些结果凸显了学习到的协作和自适应协调在多智能体推理扩展中的重要性。相关代码可通过https://github.com/jincan333/MAS-TTS获取。
论文及项目相关链接
摘要
基于大型语言模型的多智能体系统为解决复杂现实世界任务提供了有效途径,这些任务是单智能体系统难以应对的。虽然测试时缩放技术(TTS)的近期进展显著提高了单智能体在挑战性推理任务上的性能,但如何有效扩展多智能体系统的协作和推理仍是开放问题。本研究引入了一种自适应多智能体框架,旨在通过模型级训练和系统级协调增强协作推理能力。构建了M500数据集,包含500个多智能体协作推理轨迹,并在该数据集上微调Qwen2.5-32B-Instruct模型,生成针对多智能体协作优化的M1-32B模型。为了进一步优化自适应推理,我们提出了一种新型的CEO智能体,能够动态管理讨论过程,引导智能体协作并调整推理深度以更有效地解决问题。在开源多智能体系统上进行了一系列任务评估,包括通用理解、数学推理和编码任务,我们的系统显著优于强大的基线模型。例如,M1-32B在GPQA-Diamond上提高了12%,在AIME2024上提高了41%,在MBPP-Sanitized上提高了10%,在某些任务上的性能与DeepSeek-R1等先进模型相匹配。这些结果凸显了学习协作和自适应协调在扩展多智能体推理中的重要性。
要点提炼
- 多智能体系统(MAS)基于大型语言模型(LLM)为解决复杂现实世界任务提供了有效途径。
- 测试时缩放技术(TTS)对单智能体的性能提升显著,但在多智能体系统中的协作和推理扩展仍然面临挑战。
- 研究引入了一种自适应多智能体框架,通过模型级训练和系统级协调增强协作推理能力。
- 构建了一个高质量的多智能体协作数据集M500,并基于此微调了针对多智能体协作优化的模型M1-32B。
- 提出了一种新型的CEO智能体,能够动态管理讨论过程,引导智能体协作并调整推理深度。
- 在多个任务上评估了系统的性能,包括通用理解、数学推理和编码任务,显著优于基线模型。
点此查看论文截图


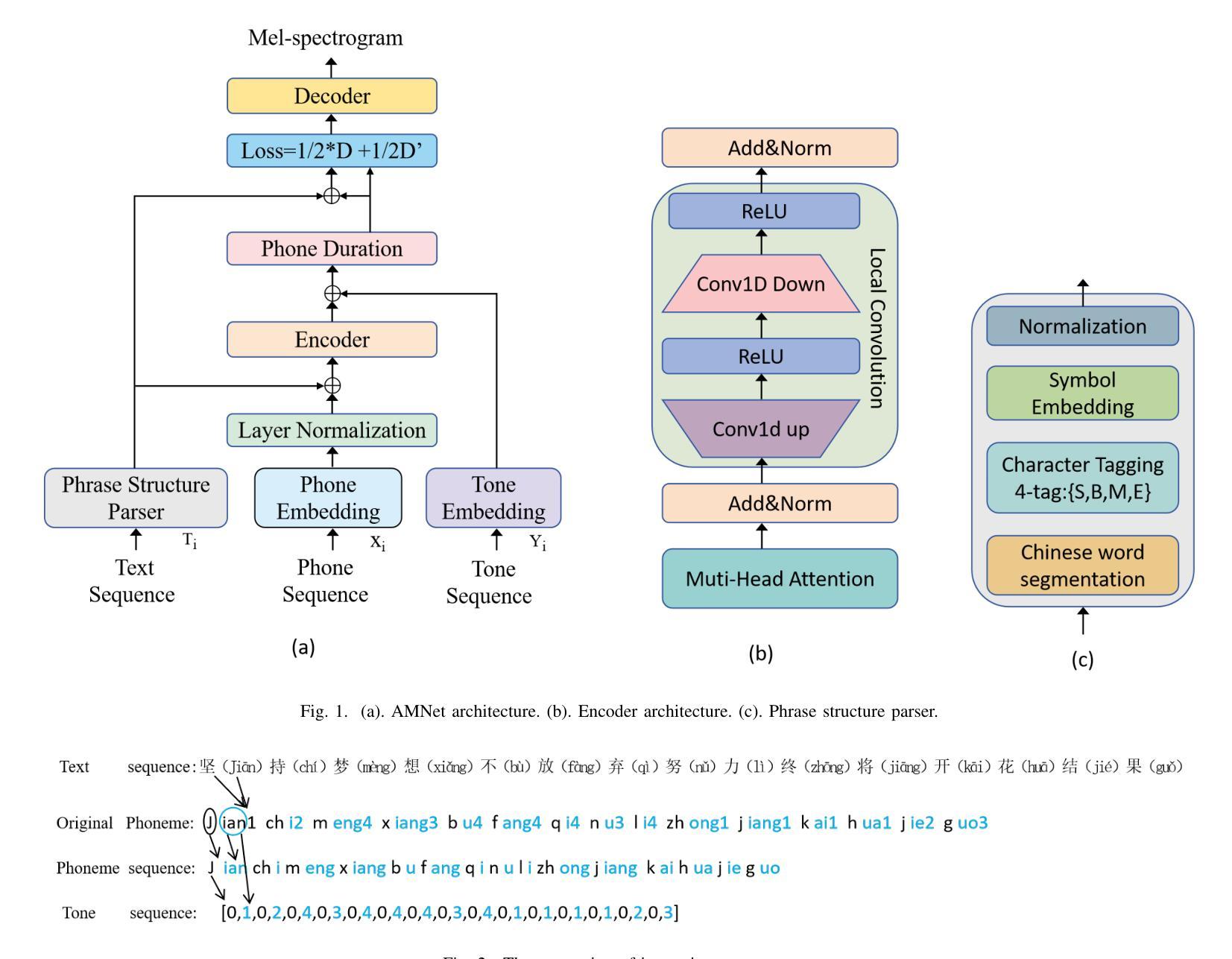
AMNet: An Acoustic Model Network for Enhanced Mandarin Speech Synthesis
Authors:Yubing Cao, Yinfeng Yu, Yongming Li, Liejun Wang
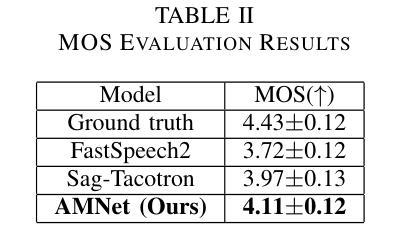
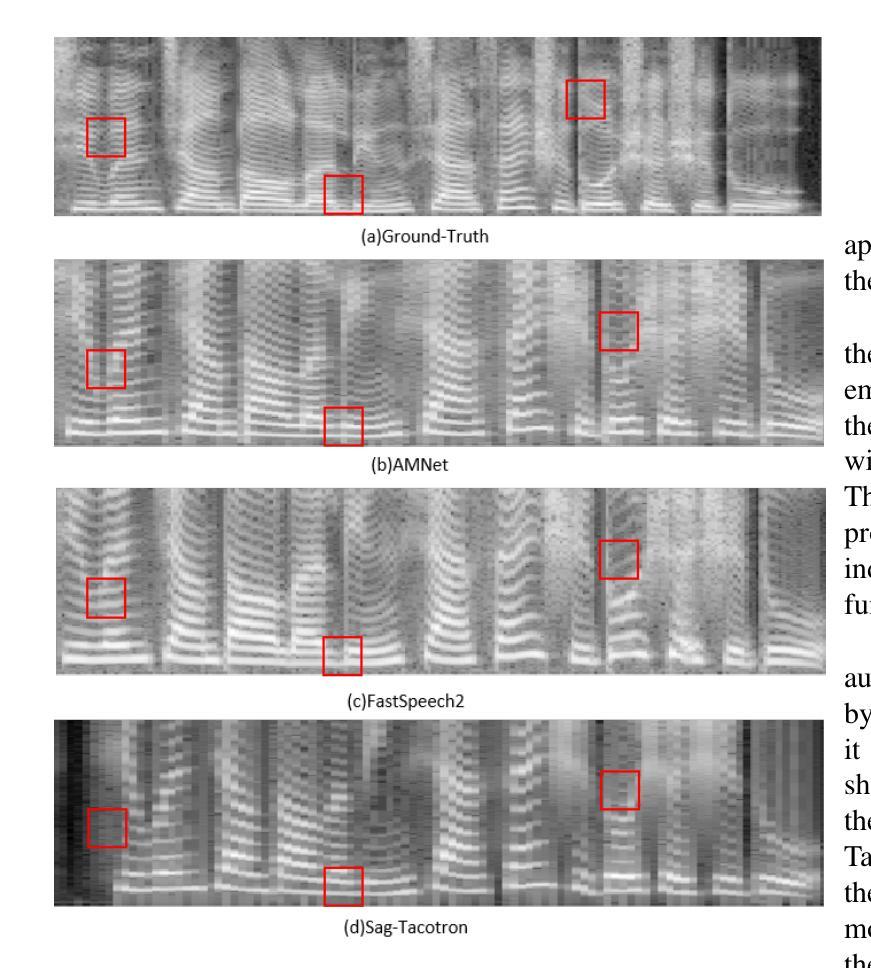
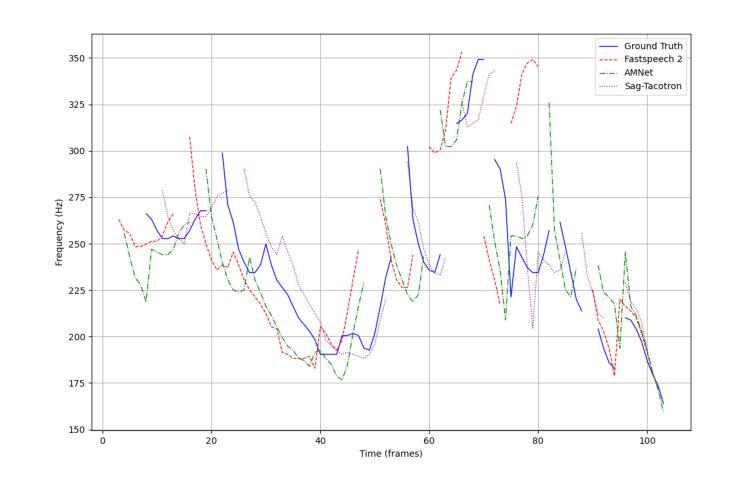
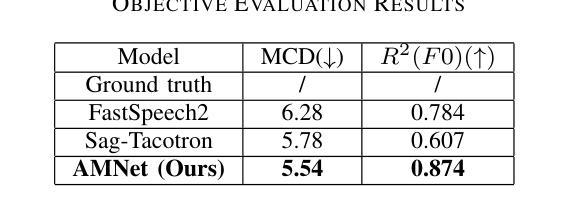
This paper presents AMNet, an Acoustic Model Network designed to improve the performance of Mandarin speech synthesis by incorporating phrase structure annotation and local convolution modules. AMNet builds upon the FastSpeech 2 architecture while addressing the challenge of local context modeling, which is crucial for capturing intricate speech features such as pauses, stress, and intonation. By embedding a phrase structure parser into the model and introducing a local convolution module, AMNet enhances the model’s sensitivity to local information. Additionally, AMNet decouples tonal characteristics from phonemes, providing explicit guidance for tone modeling, which improves tone accuracy and pronunciation. Experimental results demonstrate that AMNet outperforms baseline models in subjective and objective evaluations. The proposed model achieves superior Mean Opinion Scores (MOS), lower Mel Cepstral Distortion (MCD), and improved fundamental frequency fitting $F0 (R^2)$, confirming its ability to generate high-quality, natural, and expressive Mandarin speech.
本文介绍了AMNet,这是一种声学模型网络,旨在通过融入短语结构标注和局部卷积模块,提高普通话语音合成的性能。AMNet以FastSpeech 2架构为基础,解决了局部上下文建模的挑战,这对于捕捉复杂的语音特征(如停顿、重音和语调)至关重要。通过在模型中加入短语结构解析器和引入局部卷积模块,AMNet提高了模型对局部信息的敏感性。此外,AMNet将音调特征从音素中分离出来,为音调建模提供了明确的指导,从而提高了音调的准确性和发音。实验结果表明,在主观和客观评估中,AMNet的性能优于基准模型。所提出模型的平均意见得分(MOS)更高,梅尔倒谱失真(MCD)更低,基频拟合$F0 (R^2)$有所改善,证明其能够生成高质量、自然、富有表现力的普通话语音。
论文及项目相关链接
PDF Main paper (8 pages). Accepted for publication by IJCNN 2025
摘要
本文介绍了AMNet,这是一种声学模型网络,通过融入短语结构标注和局部卷积模块,旨在提高普通话语音合成的性能。AMNet基于FastSpeech 2架构,解决了局部上下文建模的挑战,这对于捕捉语音的停顿、重读和语调等复杂特征至关重要。通过将短语结构解析器嵌入模型并引入局部卷积模块,AMNet提高了对局部信息的敏感性。此外,AMNet将音调的特性与音素分离,为音调建模提供了明确的指导,提高了音调的准确性和发音。实验结果表明,AMNet在主观和客观评估中均优于基准模型。所提出的模型获得了较高的平均意见得分(MOS),降低了梅尔倒谱失真(MCD),并改善了基频拟合$F0 (R^2)$,证明了其生成高质量、自然、表达流畅的普通话语音的能力。
关键见解
- AMNet是一种基于FastSpeech 2架构的声学模型网络,旨在提高普通话语音合成的性能。
- AMNet通过融入短语结构标注和局部卷积模块,解决了局部上下文建模的挑战。
- AMNet提高了模型对语音的停顿、重读和语调等复杂特征的捕捉能力。
- 短语结构解析器嵌入模型,增强了AMNet对局部信息的敏感性。
- AMNet将音调的特性与音素分离,优化了音调建模,提高了发音准确性。
- 实验结果表明,AMNet在主观和客观评估中均优于其他模型,显示出生成高质量普通话语音的能力。
点此查看论文截图