⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-17 更新
TextArena
Authors:Leon Guertler, Bobby Cheng, Simon Yu, Bo Liu, Leshem Choshen, Cheston Tan
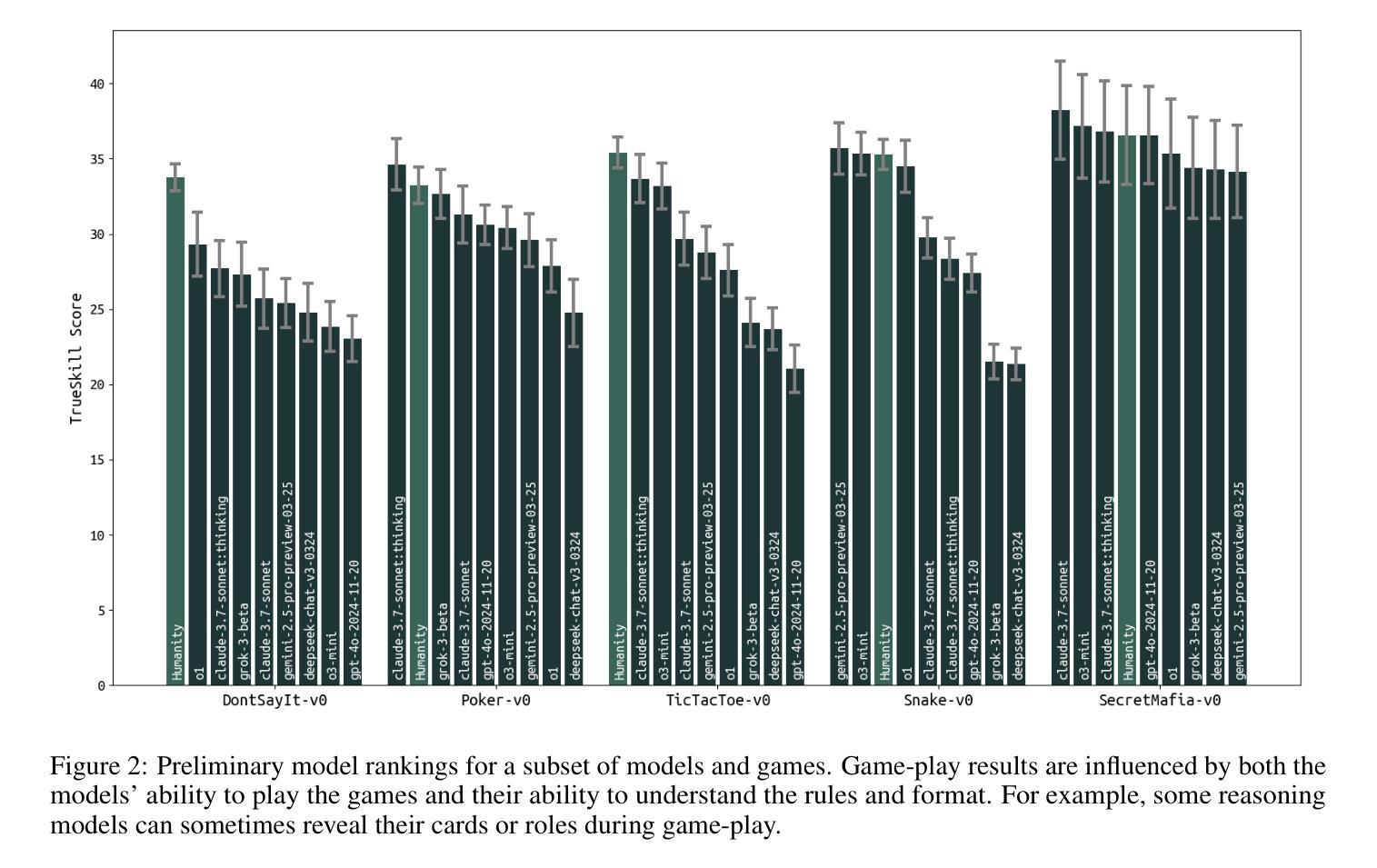
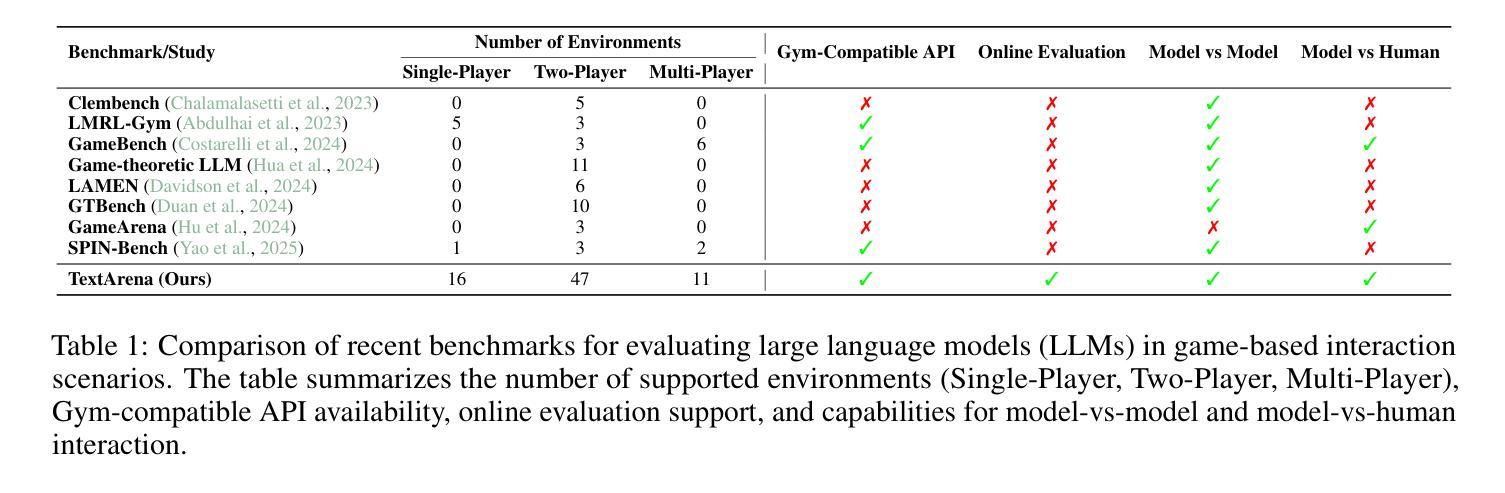
TextArena is an open-source collection of competitive text-based games for training and evaluation of agentic behavior in Large Language Models (LLMs). It spans 57+ unique environments (including single-player, two-player, and multi-player setups) and allows for easy evaluation of model capabilities via an online-play system (against humans and other submitted models) with real-time TrueSkill scores. Traditional benchmarks rarely assess dynamic social skills such as negotiation, theory of mind, and deception, creating a gap that TextArena addresses. Designed with research, community and extensibility in mind, TextArena emphasizes ease of adding new games, adapting the framework, testing models, playing against the models, and training models. Detailed documentation of environments, games, leaderboard, and examples are available on https://github.com/LeonGuertler/TextArena and https://www.textarena.ai/.
TextArena是一个基于文本的游戏集合,用于训练和评估大型语言模型(LLM)中的智能行为。它涵盖57个以上的独特环境(包括单人、两人和多人的设置),并通过在线游戏系统(与人类和其他提交模型对抗)进行实时TrueSkill评分,可以轻松地评估模型的能力。传统基准测试很少评估诸如谈判、心智理论和欺骗等动态社交技能,从而留下了空白,而TextArena正是为了解决这一问题而设计的。本着研究、社区和可扩展性的原则,TextArena强调易于添加新游戏、适应框架、测试模型、与模型对战和训练模型等特点。关于环境、游戏、排行榜和示例的详细文档可在https://github.com/LeonGuertler/TextArena和https://www.textarena.ai/上找到。
论文及项目相关链接
PDF work in progress; 5 pages, 3 figures
Summary
文本Arena是一个面向大型语言模型(LLM)的开源文本游戏集合,旨在训练和评估代理行为。它包含超过57个独特的环境,提供在线游戏系统,便于评估模型能力并与人类和其他提交模型进行实时TrueSkill评分。它解决了传统基准测试很少评估的动态社交技能问题,如谈判、心智理论和欺骗等。设计注重研究、社区和可扩展性,易于添加新游戏、适应框架、测试模型、与模型互动和训练模型。更多信息详见相关网站。
Key Takeaways
- TextArena是一个针对LLM的开源文本游戏集合,专注于训练和评估代理行为。
- 它包含多种环境,包括单人、两人和多玩家设置。
- TextArena提供了在线游戏系统,可轻松评估模型能力,并与人类和其他模型进行实时TrueSkill评分。
- 它解决了传统基准测试未充分评估的动态社交技能,如谈判、心智理论和欺骗等。
- TextArena设计注重研究、社区和可扩展性,易于使用。
- 该平台提供了详细的文档和环境示例。
点此查看论文截图


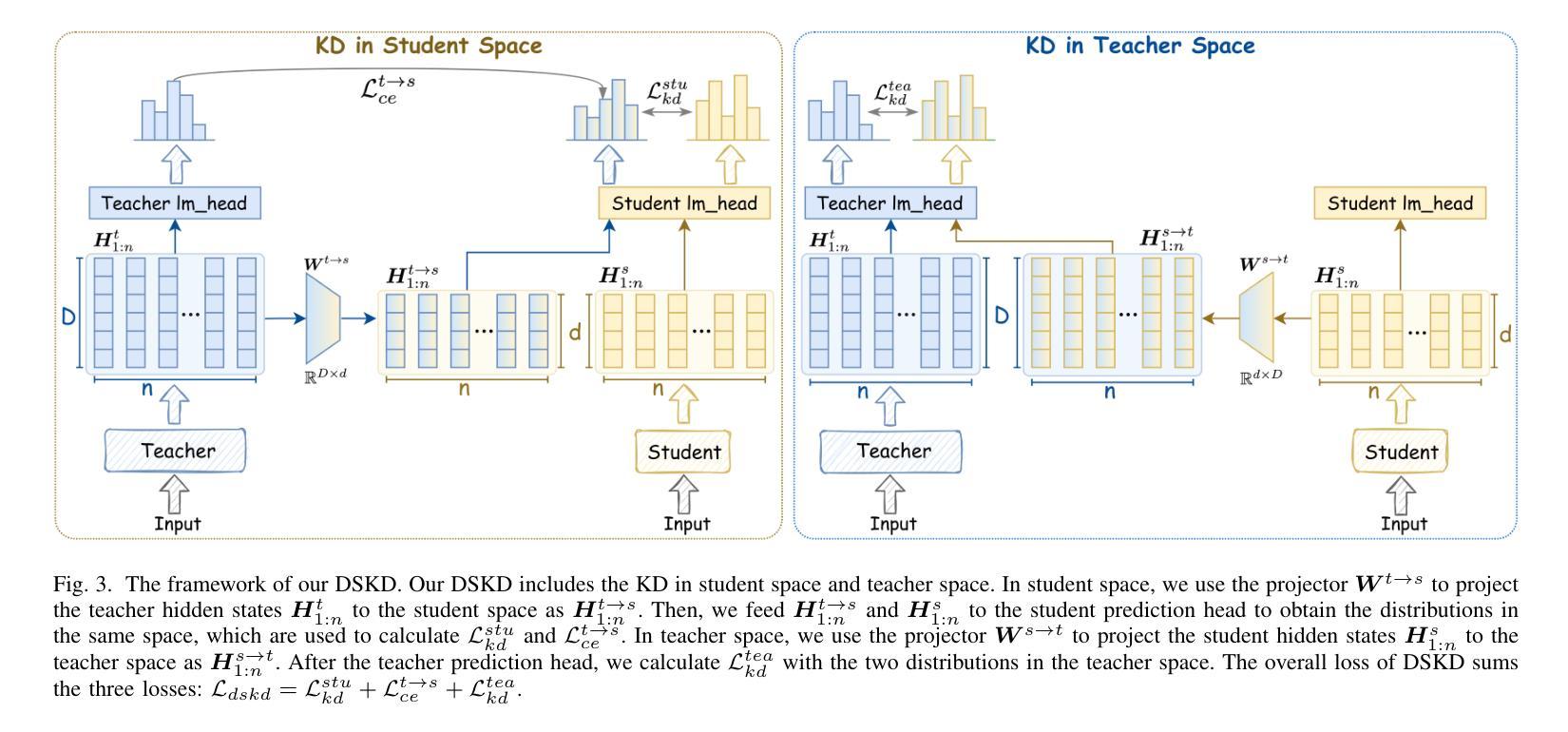
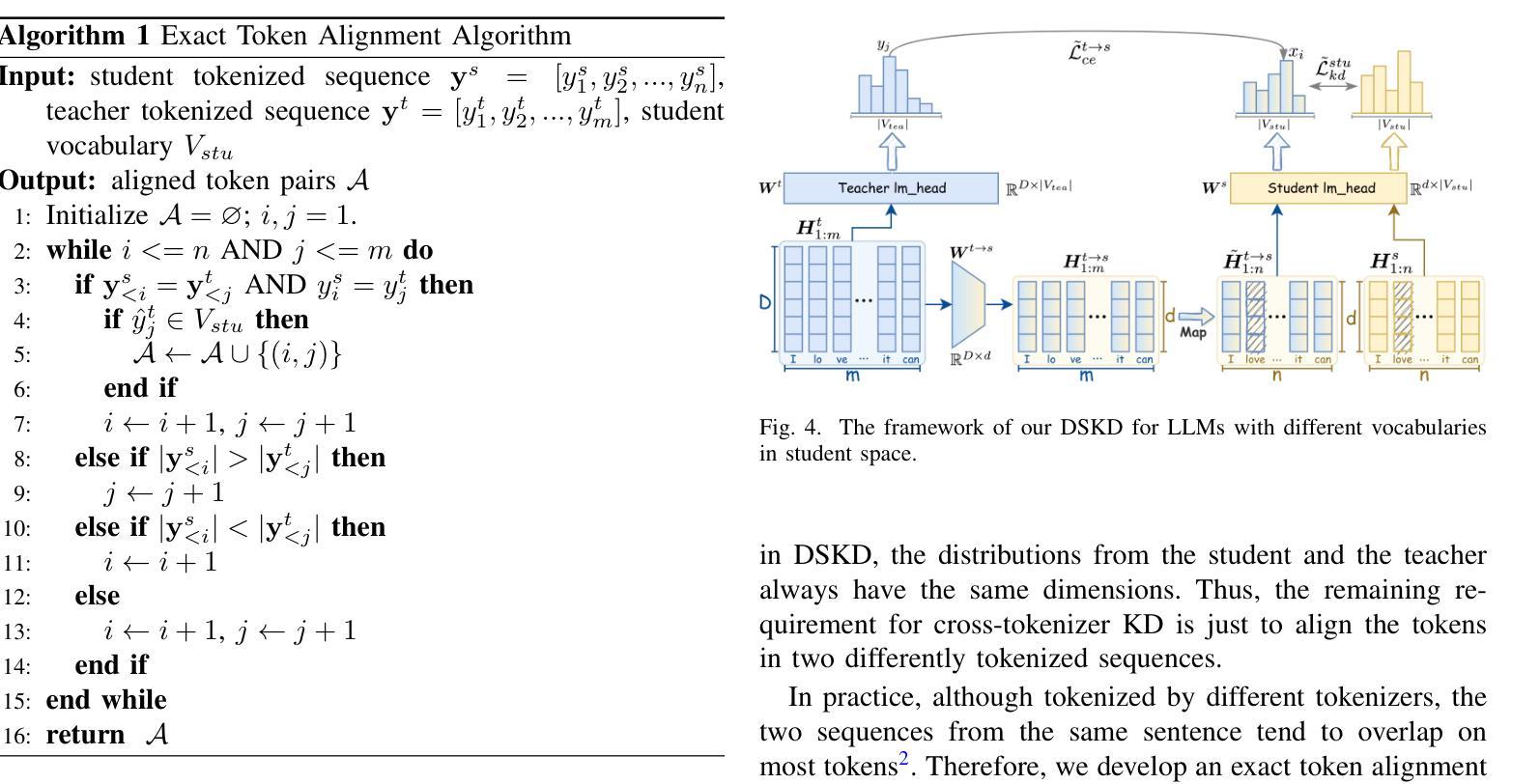
A Dual-Space Framework for General Knowledge Distillation of Large Language Models
Authors:Xue Zhang, Songming Zhang, Yunlong Liang, Fandong Meng, Yufeng Chen, Jinan Xu, Jie Zhou
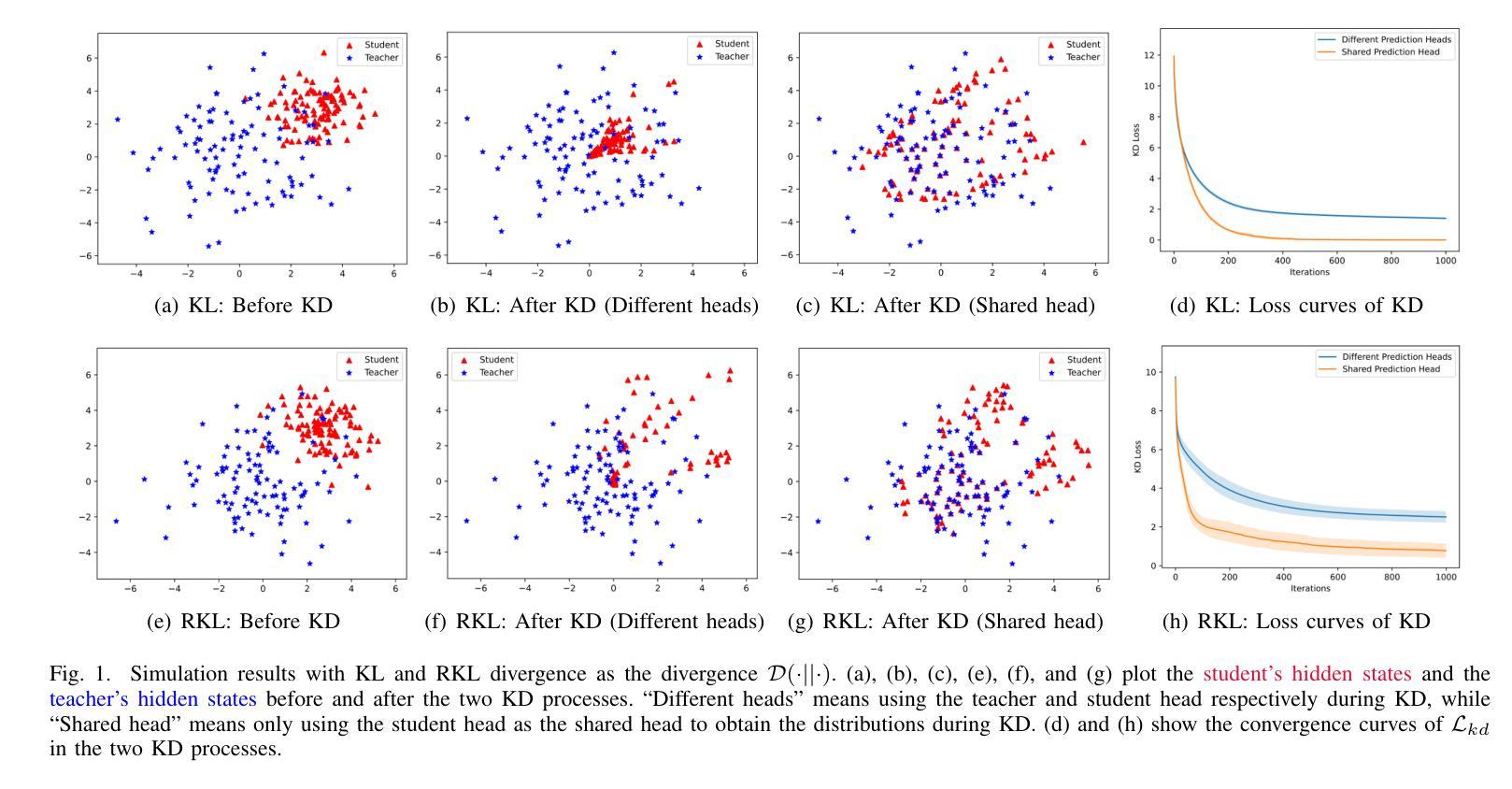
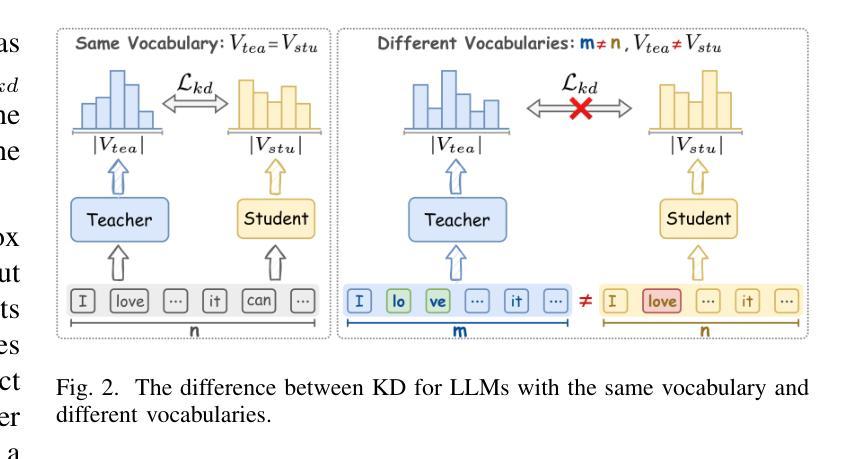
Knowledge distillation (KD) is a promising solution to compress large language models (LLMs) by transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the teacher model and the student model to transfer more information. However, we reveal that the current white-box KD framework exhibits two limitations: a) bridging probability distributions from different output spaces will limit the similarity between the teacher model and the student model; b) this framework cannot be applied to LLMs with different vocabularies. One of the root causes for these limitations is that the distributions from the teacher and the student for KD are output by different prediction heads, which yield distributions in different output spaces and dimensions. Therefore, in this paper, we propose a dual-space knowledge distillation (DSKD) framework that unifies the prediction heads of the teacher and the student models for KD. Specifically, we first introduce two projectors with ideal initialization to project the teacher/student hidden states into the student/teacher representation spaces. After this, the hidden states from different models can share the same head and unify the output spaces of the distributions. Furthermore, we develop an exact token alignment (ETA) algorithm to align the same tokens in two differently-tokenized sequences. Based on the above, our DSKD framework is a general KD framework that supports both off-policy and on-policy KD, and KD between any two LLMs regardless of their vocabularies. Extensive experiments on instruction-following, mathematical reasoning, and code generation benchmarks show that DSKD significantly outperforms existing methods based on the current white-box KD framework and surpasses other cross-tokenizer KD methods for LLMs with different vocabularies.
知识蒸馏(KD)是一种有前景的解决方案,通过将大型语言模型(LLM)的知识转移到小型模型来压缩它们。在此过程中,白盒KD方法通常通过最小化教师模型和学生模型的输出分布之间的距离来转移更多信息。然而,我们揭示了当前白盒KD框架的两个局限性:a)从不同输出空间构建概率分布会限制教师模型和学生模型之间的相似性;b)该框架无法应用于具有不同词汇表的LLM。这些局限性的一个根本原因是,用于KD的教师和学生模型输出的分布来自不同的预测头,从而产生不同的输出空间和维度。因此,本文中,我们提出了一个统一教师模型和学生模型预测头的双空间知识蒸馏(DSKD)框架。具体来说,我们首先引入两个具有理想初始化的投影器,将教师/学生的隐藏状态投影到学生/教师的表示空间。此后,来自不同模型的隐藏状态可以共享同一个头部并统一分布的输空间。此外,我们开发了一种精确令牌对齐(ETA)算法来对齐两个不同标记的序列中的相同令牌。基于以上内容,我们的DSKD框架是一个通用KD框架,支持离线策略KD和在线策略KD,以及任何两个LLM之间的KD,无论其词汇表如何。在指令遵循、数学推理和代码生成基准测试上的大量实验表明,DSKD显著优于基于当前白盒KD框架的方法和其他用于具有不同词汇表的LLM的跨令牌器KD方法。
论文及项目相关链接
PDF 19 pages, 9 figures, 11 tables, under review. Code is available at: https://github.com/songmzhang/DSKDv2. arXiv admin note: text overlap with arXiv:2406.17328
摘要
知识蒸馏(KD)是一种将大型语言模型(LLM)的知识转移到小型模型上的有前途的解决方案。当前的白盒KD方法通常通过最小化教师模型和学生模型输出分布之间的距离来传递更多信息。然而,本文揭示了当前白盒KD框架的两个局限性:a)桥接不同输出空间的概率分布将限制教师模型和学生模型之间的相似性;b)该框架不能应用于具有不同词汇表的LLM。本文提出一种双空间知识蒸馏(DSKD)框架,通过统一教师模型和学生模型的预测头来解决这些问题。具体来说,我们首先引入两个理想初始化的投影仪,将学生/教师的隐藏状态投影到教师/学生的表示空间中。之后,来自不同模型的隐藏状态可以使用相同的头部并统一输出空间的分布。此外,我们开发了一种精确的令牌对齐(ETA)算法,以对齐两个不同标记的序列中的相同令牌。基于以上内容,我们的DSKD框架是一个通用的KD框架,支持离策略和即策略KD,以及任何两个LLM之间的KD,无论其词汇表如何。在指令遵循、数学推理和代码生成基准测试上的大量实验表明,DSKD显著优于基于当前白盒KD框架的方法,并在具有不同词汇表的LLM的跨令牌化KD方法中表现优越。
关键见解
- 知识蒸馏(KD)是一种用于压缩大型语言模型(LLM)的方法,可通过将知识从大型模型转移到小型模型来实现。
- 当前的白盒KD方法存在局限性,特别是在处理不同输出空间和词汇表的LLM时。
- 双空间知识蒸馏(DSKD)框架被提出以解决这些问题,通过统一教师模型和学生模型的预测头。
- DSKD使用投影仪来转换教师或学生的隐藏状态,以便它们可以在同一输出空间中比较。
- DSKD引入了一种精确的令牌对齐(ETA)算法,以处理不同标记的序列中的令牌对齐问题。
- DSKD框架支持离策略和即策略KD,以及任何两个LLM之间的KD,不受词汇表限制。
点此查看论文截图

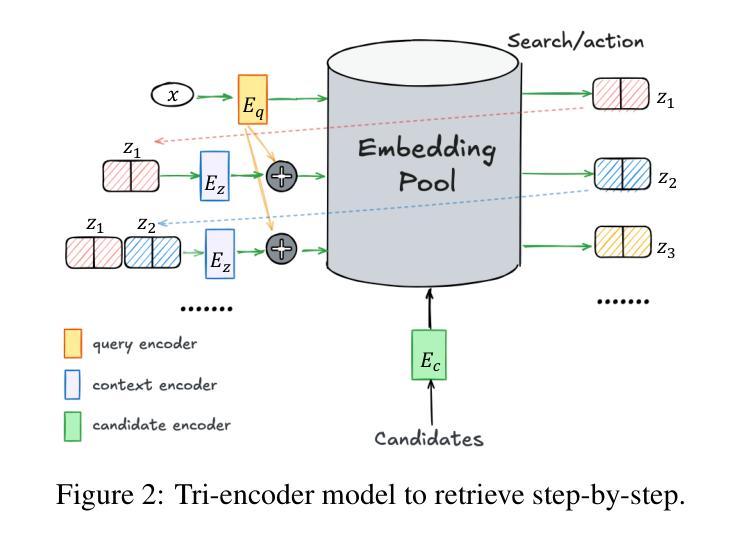
Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts
Authors:Quanyu Long, Jianda Chen, Zhengyuan Liu, Nancy F. Chen, Wenya Wang, Sinno Jialin Pan
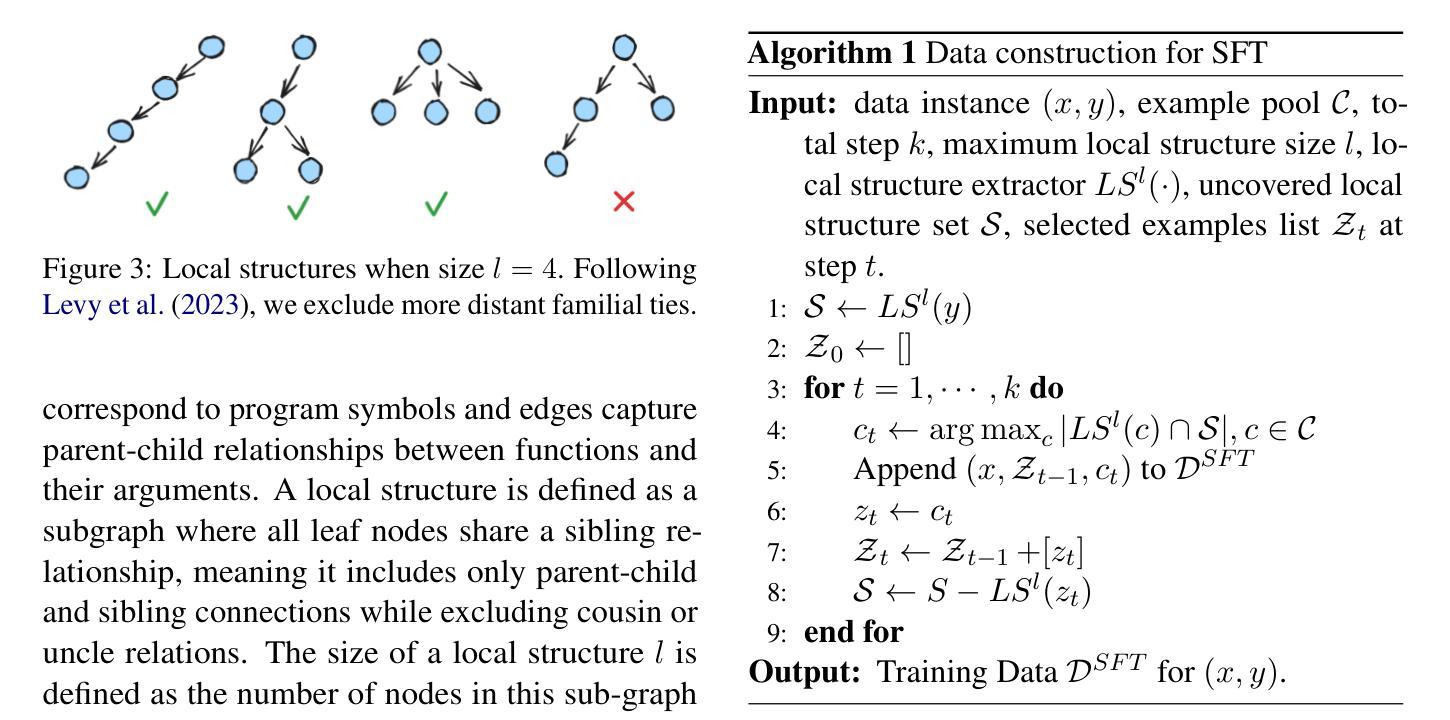
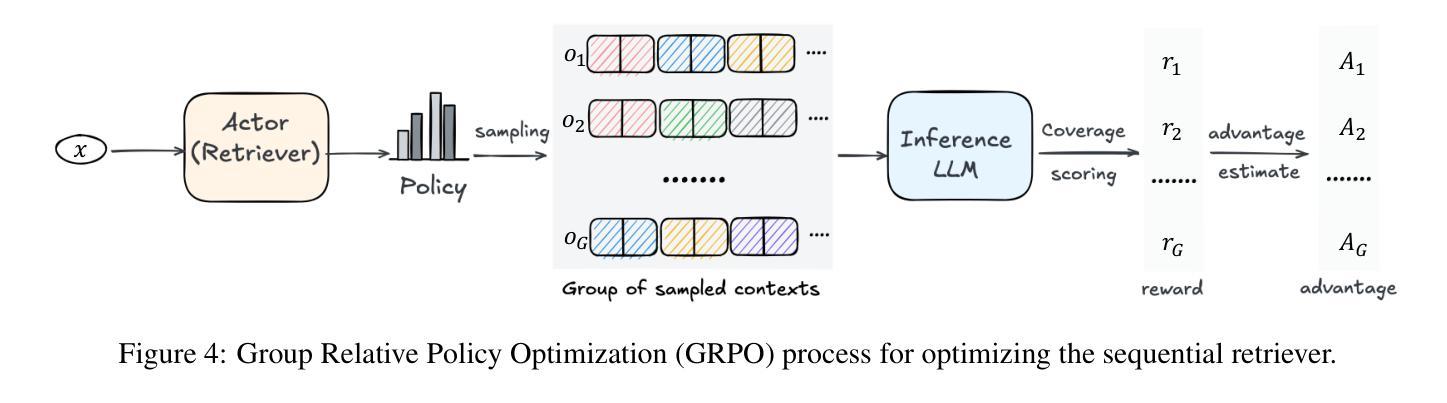
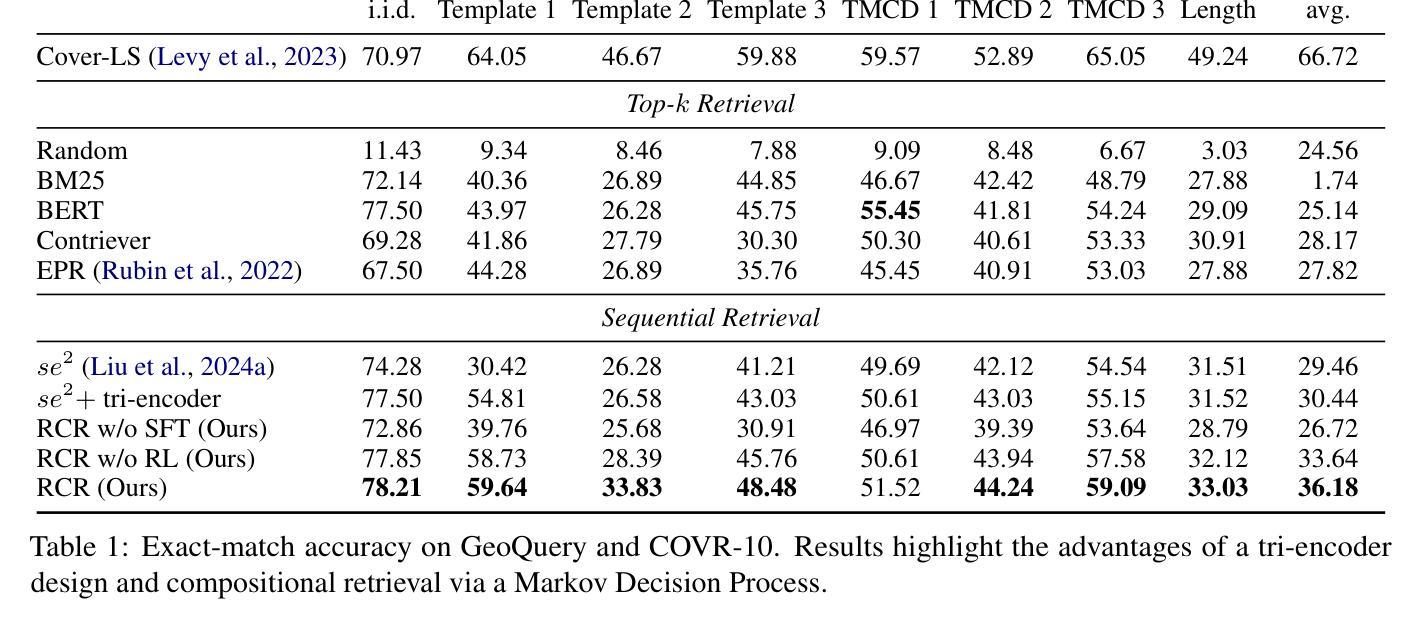
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet they often rely on external context to handle complex tasks. While retrieval-augmented frameworks traditionally focus on selecting top-ranked documents in a single pass, many real-world scenarios demand compositional retrieval, where multiple sources must be combined in a coordinated manner. In this work, we propose a tri-encoder sequential retriever that models this process as a Markov Decision Process (MDP), decomposing the probability of retrieving a set of elements into a sequence of conditional probabilities and allowing each retrieval step to be conditioned on previously selected examples. We train the retriever in two stages: first, we efficiently construct supervised sequential data for initial policy training; we then refine the policy to align with the LLM’s preferences using a reward grounded in the structural correspondence of generated programs. Experimental results show that our method consistently and significantly outperforms baselines, underscoring the importance of explicitly modeling inter-example dependencies. These findings highlight the potential of compositional retrieval for tasks requiring multiple pieces of evidence or examples.
大型语言模型(LLM)在多个任务中表现出了卓越的能力,但它们通常依赖于外部上下文来处理复杂任务。虽然检索增强框架传统上侧重于在单次传递中选择排名靠前的文档,但许多现实世界场景需要组合式检索,其中必须将多个源以协调的方式进行组合。在这项工作中,我们提出了一种三编码器顺序检索器,它将这一过程建模为马尔可夫决策过程(MDP),将检索一组元素的概率分解为一系列条件概率,并允许每个检索步骤都基于先前选择的例子。我们在两个阶段训练检索器:首先,我们有效地构建有监督的序列数据用于初始策略训练;然后,我们通过对生成程序的结构对应性进行奖励,对策略进行微调,使其与LLM的偏好保持一致。实验结果表明,我们的方法始终且显著优于基准方法,强调显式建模示例间依赖关系的重要性。这些发现突显了组合检索对于需要多个证据或示例的任务的潜力。
论文及项目相关链接
PDF 19 pages, 8 figures
Summary
大型语言模型(LLM)在处理复杂任务时依赖于外部上下文,但传统检索增强框架主要关注单一检索过程的选择文档。本文提出了一种三编码器顺序检索器,将检索过程建模为马尔可夫决策过程(MDP),允许每个检索步骤基于先前选择的示例进行条件化,从而实现多源协调组合。通过两个阶段训练检索器:首先构建监督序列数据进行初始策略训练,然后使用基于生成程序结构对应性的奖励对策略进行微调,以与LLM偏好对齐。实验结果表明,该方法始终优于基线方法,强调明确建模实例间依赖关系的重要性。这些发现凸显了组合检索对于需要多个证据或示例的任务的潜力。
Key Takeaways
- LLM在处理复杂任务时依赖外部上下文。
- 传统检索增强框架主要关注单一检索过程的选择文档,但真实场景需要多源协调组合。
- 提出了一种三编码器顺序检索器,将检索过程建模为马尔可夫决策过程(MDP)。
- 该方法允许每个检索步骤基于先前选择的示例进行条件化。
- 通过两个阶段训练检索器:初始策略训练和与LLM偏好对齐的策略微调。
- 实验结果表明该方法优于基线方法,强调明确建模实例间依赖关系的重要性。
点此查看论文截图

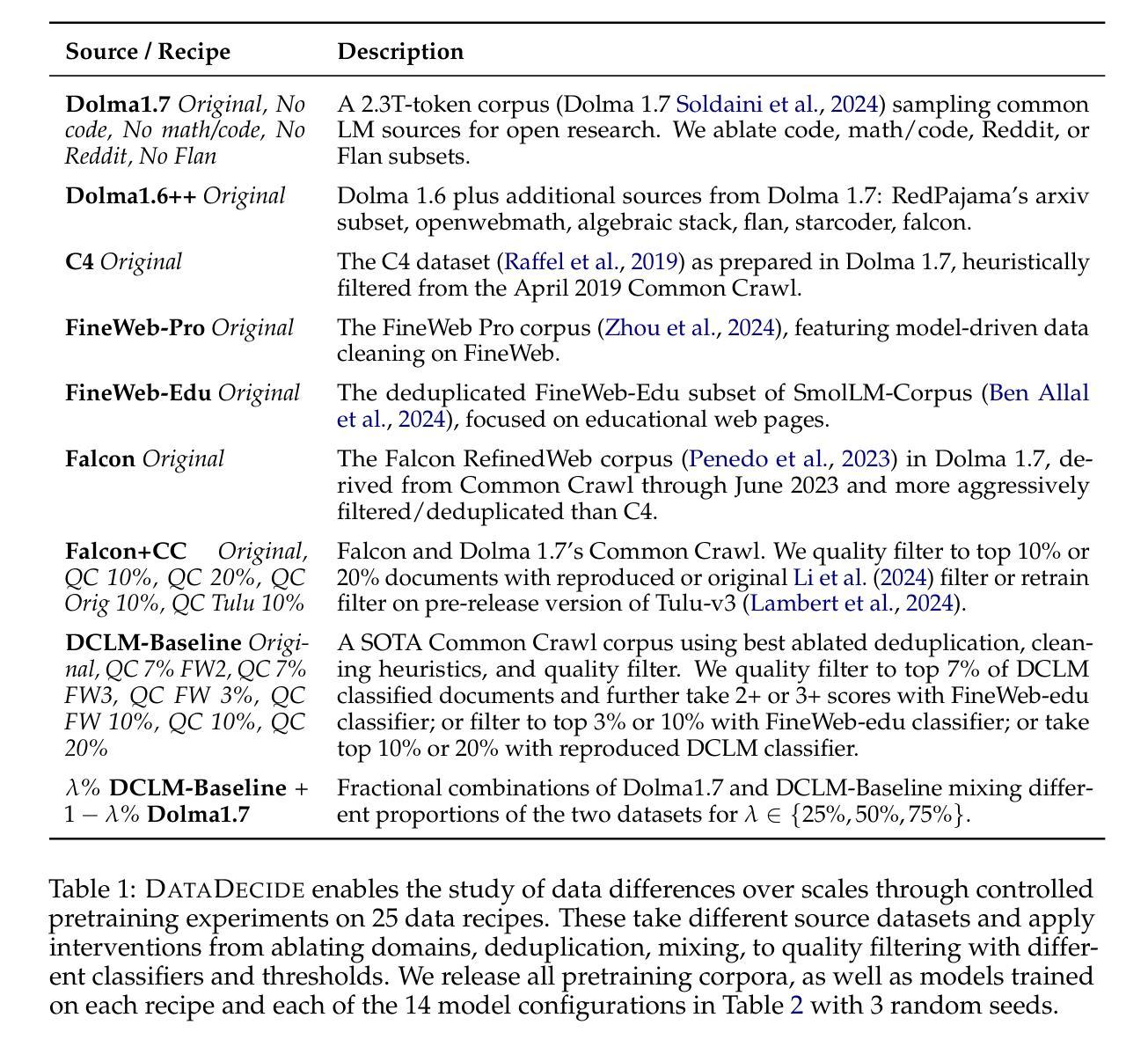
DataDecide: How to Predict Best Pretraining Data with Small Experiments
Authors:Ian Magnusson, Nguyen Tai, Ben Bogin, David Heineman, Jena D. Hwang, Luca Soldaini, Akshita Bhagia, Jiacheng Liu, Dirk Groeneveld, Oyvind Tafjord, Noah A. Smith, Pang Wei Koh, Jesse Dodge
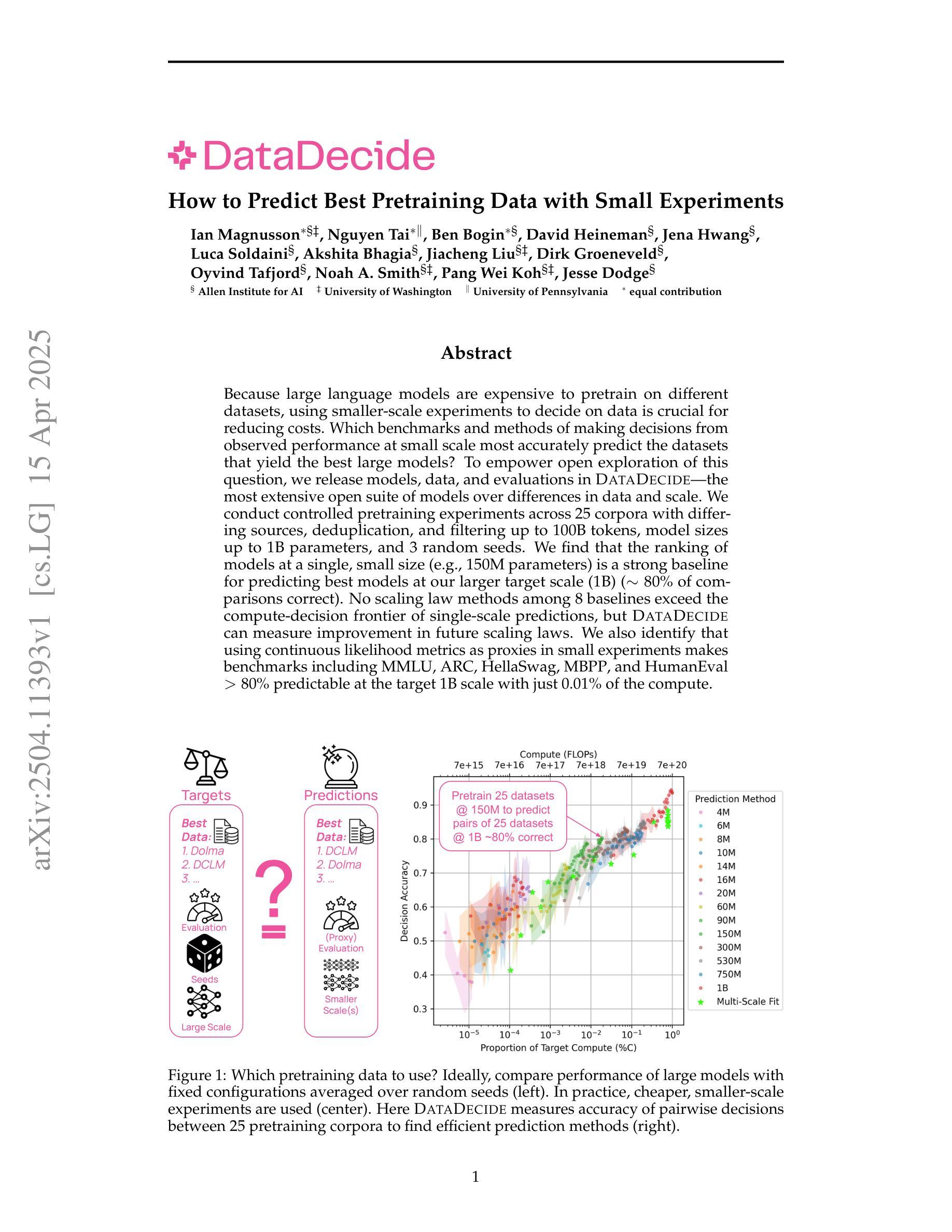
Because large language models are expensive to pretrain on different datasets, using smaller-scale experiments to decide on data is crucial for reducing costs. Which benchmarks and methods of making decisions from observed performance at small scale most accurately predict the datasets that yield the best large models? To empower open exploration of this question, we release models, data, and evaluations in DataDecide – the most extensive open suite of models over differences in data and scale. We conduct controlled pretraining experiments across 25 corpora with differing sources, deduplication, and filtering up to 100B tokens, model sizes up to 1B parameters, and 3 random seeds. We find that the ranking of models at a single, small size (e.g., 150M parameters) is a strong baseline for predicting best models at our larger target scale (1B) (~80% of com parisons correct). No scaling law methods among 8 baselines exceed the compute-decision frontier of single-scale predictions, but DataDecide can measure improvement in future scaling laws. We also identify that using continuous likelihood metrics as proxies in small experiments makes benchmarks including MMLU, ARC, HellaSwag, MBPP, and HumanEval >80% predictable at the target 1B scale with just 0.01% of the compute.
由于在不同的数据集上预训练大型语言模型成本高昂,因此使用小规模实验来决定数据对降低成本至关重要。那么,从观察到的性能表现中做出决策,哪些基准测试和方法能最准确地预测产生最佳大型模型的数据集?为了推动对这一问题的开放探索,我们在DataDecide中发布了模型、数据以及评估方法——这是关于数据和规模差异的最全面的开放模型套件。我们在25个不同来源、经过去重和过滤的语料库上进行了受控的预训练实验,涉及多达100B的令牌、高达1B参数的模型以及3个随机种子。我们发现,单一小尺寸(例如含有150M参数的模型)的模型排名是预测我们在更大的目标规模(1B)上的最佳模型的强大基线(约80%的比较是正确的)。在8个基准测试中,没有扩展定律方法超过单一规模预测的计算决策前沿,但DataDecide可以衡量未来扩展定律的改进情况。我们还发现,在小规模实验中采用连续可能性度量作为代理指标,使得包括MMLU、ARC、HellaSwag、MBPP和HumanEval在内的基准测试在目标规模为1B时仅使用计算量的万分之一就能达到超过80%的可预测性。
论文及项目相关链接
Summary
使用小规模实验来筛选大型语言模型的预训练数据集是关键,可有效降低成本。本文通过实验对比,发现在小规模数据上的性能排名对预测大型模型的性能具有较强的参考价值。并释放DataDecide数据集作为研究和比较的开放平台。通过对比实验发现,利用连续可能性度量作为小实验的代理指标可有效预测大型模型的性能。因此使用适合的工具和方法能在较低的计算成本下有效地评估模型的性能。
Key Takeaways
以下是该文本的几个主要观点和启示:
- 大规模的语言模型在多种数据集上进行预训练代价昂贵,因此小规模实验的选择对于降低成本至关重要。
- 通过实验发现,小规模数据上的模型性能排名是预测大型模型性能的有效方法。
- DataDecide数据集的发布为研究和比较不同数据和规模下的模型提供了开放平台。
- 在小规模实验中,使用连续可能性度量作为代理指标能有效预测大型模型的性能表现。
- 在选择数据集的决策过程中,需要权衡各种因素如数据来源、去重和过滤等。
- 本文研究的模型参数规模从小到大的过程显示出了一定的规律,对今后的模型缩放研究有参考意义。
点此查看论文截图
OpenTuringBench: An Open-Model-based Benchmark and Framework for Machine-Generated Text Detection and Attribution
Authors:Lucio La Cava, Andrea Tagarelli
Open Large Language Models (OLLMs) are increasingly leveraged in generative AI applications, posing new challenges for detecting their outputs. We propose OpenTuringBench, a new benchmark based on OLLMs, designed to train and evaluate machine-generated text detectors on the Turing Test and Authorship Attribution problems. OpenTuringBench focuses on a representative set of OLLMs, and features a number of challenging evaluation tasks, including human/machine-manipulated texts, out-of-domain texts, and texts from previously unseen models. We also provide OTBDetector, a contrastive learning framework to detect and attribute OLLM-based machine-generated texts. Results highlight the relevance and varying degrees of difficulty of the OpenTuringBench tasks, with our detector achieving remarkable capabilities across the various tasks and outperforming most existing detectors. Resources are available on the OpenTuringBench Hugging Face repository at https://huggingface.co/datasets/MLNTeam-Unical/OpenTuringBench
开放大型语言模型(OLLMs)在生成式人工智能应用中的使用越来越广泛,这对其输出检测提出了新的挑战。我们提出了基于OLLMs的OpenTuringBench新基准测试,旨在在图灵测试和作者归属问题上训练和评估机器生成的文本检测器。OpenTuringBench关注OLLMs的代表性集合,并包含一系列具有挑战性的评估任务,包括人为操控文本、领域外文本以及来自之前未见模型的文本。我们还提供了OTBDetector对比学习框架,用于检测并归属OLLM机器生成的文本。结果突显了OpenTuringBench任务的现实意义以及不同难度的层次,我们的检测器在各种任务中表现出卓越的能力,并超越了大多数现有检测器。资源可在OpenTuringBench Hugging Face存储库中找到:https://huggingface.co/datasets/MLNTeam-Unical/OpenTuringBench
论文及项目相关链接
PDF Under review with ARR
Summary
OpenTuringBench是一个基于大型语言模型(LLM)的基准测试平台,旨在训练和评估对机器生成文本的识别能力。该平台包含一系列具有代表性的评估任务,可以处理包括人为或机器操控文本、非域文本和之前未见模型的文本等内容。OpenTuringBench还提供了OTBDetector检测框架,该框架用于检测和归因LLM基础机器生成文本。现有结果表明OpenTuringBench任务的多样性和难度,其检测器在各种任务中表现出卓越的能力并超越了大多数现有检测器。资源可在OpenTuringBench Hugging Face仓库获取。^[基于提供文本的精简总结]^
Key Takeaways
- OpenTuringBench是一个针对大型语言模型(LLM)的基准测试平台。
- 它设计用于训练和评估机器生成文本的检测器。
- 平台包含一系列评估任务,涵盖人为或机器操控文本、非域文本和未知模型文本等内容。
- OpenTuringBench提供了OTBDetector检测框架来检测和归因LLM生成的文本。
点此查看论文截图

Teaching Large Language Models to Reason through Learning and Forgetting
Authors:Tianwei Ni, Allen Nie, Sapana Chaudhary, Yao Liu, Huzefa Rangwala, Rasool Fakoor
Leveraging inference-time search in large language models has proven effective in further enhancing a trained model’s capability to solve complex mathematical and reasoning problems. However, this approach significantly increases computational costs and inference time, as the model must generate and evaluate multiple candidate solutions to identify a viable reasoning path. To address this, we propose an effective approach that integrates search capabilities directly into the model by fine-tuning it using both successful (learning) and failed reasoning paths (forgetting) derived from diverse search methods. While fine-tuning the model with these data might seem straightforward, we identify a critical issue: the model’s search capability tends to degrade rapidly if fine-tuning is performed naively. We show that this degradation can be substantially mitigated by employing a smaller learning rate. Extensive experiments on the challenging Game-of-24 and Countdown mathematical reasoning benchmarks show that our approach not only outperforms both standard fine-tuning and inference-time search baselines but also significantly reduces inference time by 180$\times$.
利用大型语言模型中的推理时间搜索,已被证明可以进一步提高训练模型解决复杂数学和推理问题的能力。然而,这种方法显著增加了计算成本和推理时间,因为模型必须生成并评估多个候选解决方案来识别可行的推理路径。为了解决这一问题,我们提出了一种将搜索能力直接集成到模型中的有效方法,通过微调模型,使用来自不同搜索方法的成功(学习)和失败推理路径(遗忘)。虽然用这些数据微调模型看似简单,但我们发现了一个关键问题:如果盲目进行微调,模型的搜索能力往往会迅速下降。我们表明,通过采用较小的学习率,可以大大减轻这种退化。在具有挑战性的24点游戏和倒计时数学推理基准测试的大量实验表明,我们的方法不仅优于标准微调方法和推理时间搜索基准测试,而且通过将推理时间减少180倍,显著减少了推理时间。
论文及项目相关链接
Summary
大型语言模型在推理时间搜索方面的应用已证明可有效提高训练模型解决复杂数学和推理问题的能力。然而,这种方法显著增加了计算成本和推理时间,因为模型必须生成并评估多个候选解决方案来识别可行的推理路径。为解决这一问题,我们提出了一种将搜索能力直接集成到模型中的有效方法,通过精细调整从多种搜索方法中获得的学习成功与失败推理路径的数据。虽然用这些数据调整模型看似简单,但我们发现了一个关键问题:如果盲目进行微调,模型的搜索能力会迅速下降。我们展示通过采用较小的学习率可以大大缓解这种退化问题。在具有挑战性的Game-of-24和倒计时数学推理基准测试中进行的广泛实验表明,我们的方法不仅优于标准微调方法和推理时间搜索基准测试,而且将推理时间减少了180倍。
Key Takeaways
- 推理时间搜索在大型语言模型中增强了解决复杂数学和推理问题的能力,但增加了计算成本和推理时间。
- 通过精细调整模型,集成搜索能力可以直接提高模型的性能。
- 在使用不同的搜索方法获取数据时,模型若盲目进行微调会导致搜索能力迅速下降。
- 采用较小的学习率可以有效缓解模型搜索能力的退化问题。
- 相较于传统方法和推理时间搜索,提出的方法在性能上更胜一筹。
- 所提出的方法显著减少了推理时间,达到了180倍的速度提升。
点此查看论文截图

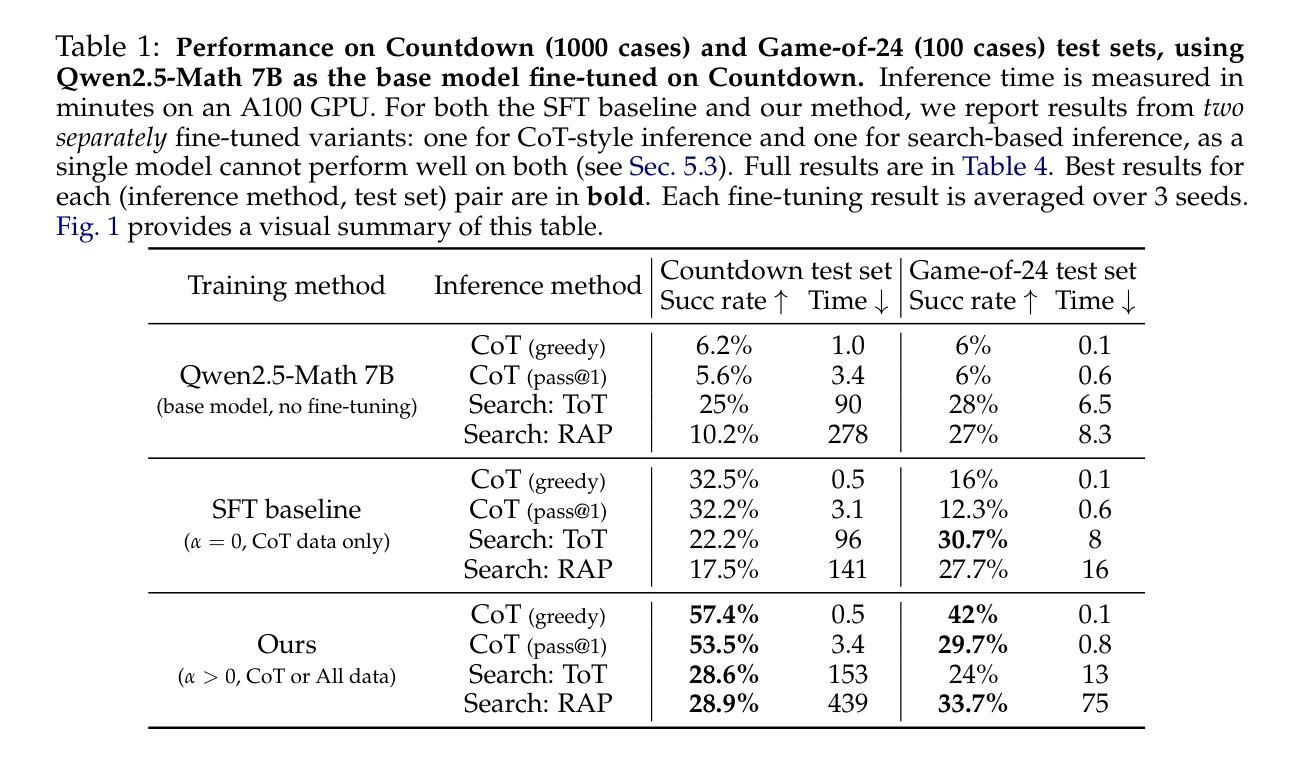
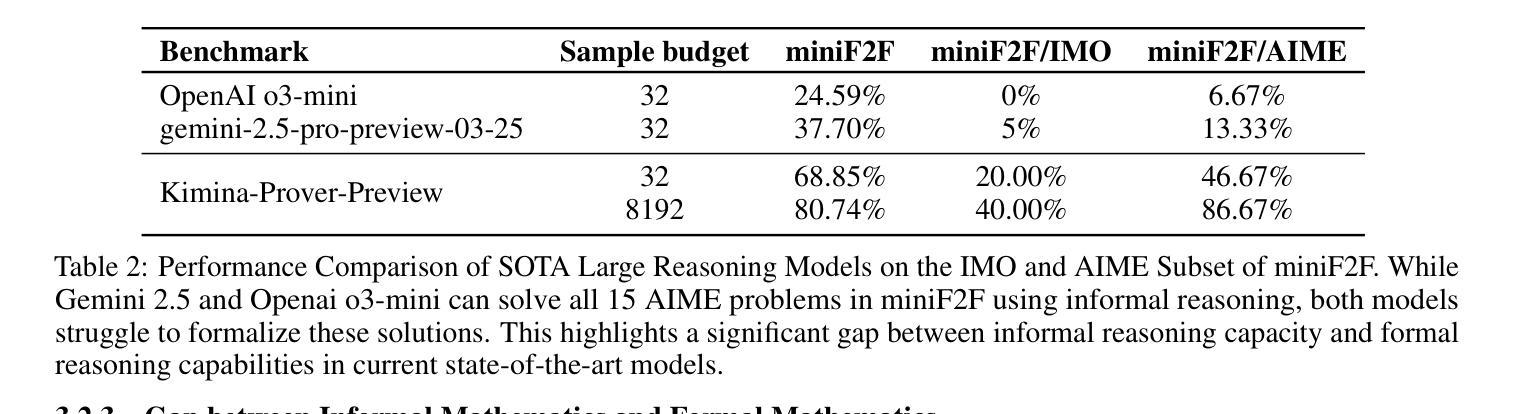
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Authors:Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Pagani, Moreira Machado, Pauline Bourigault, Ran Wang, Stanislas Polu, Thibaut Barroyer, Wen-Ding Li, Yazhe Niu, Yann Fleureau, Yangyang Hu, Zhouliang Yu, Zihan Wang, Zhilin Yang, Zhengying Liu, Jia Li
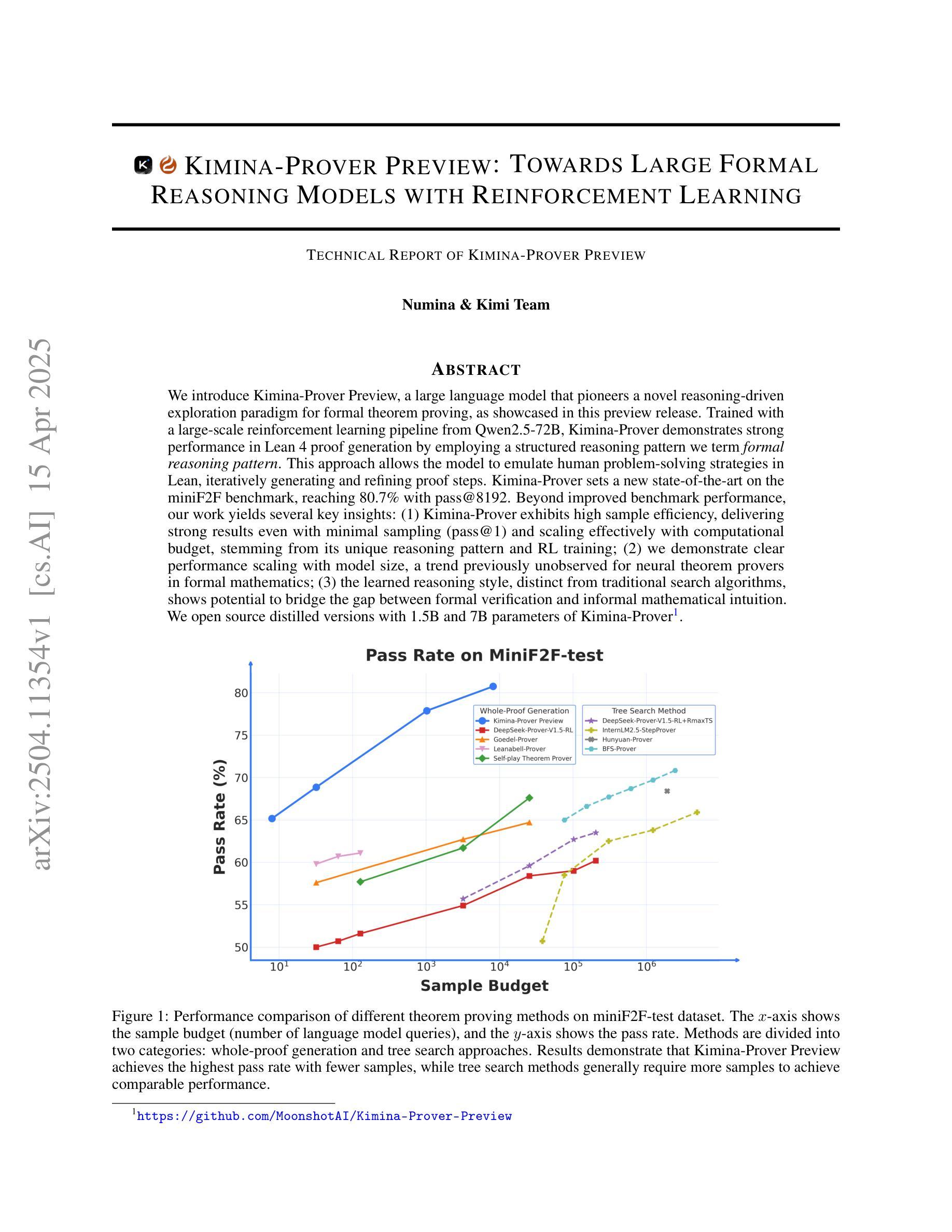
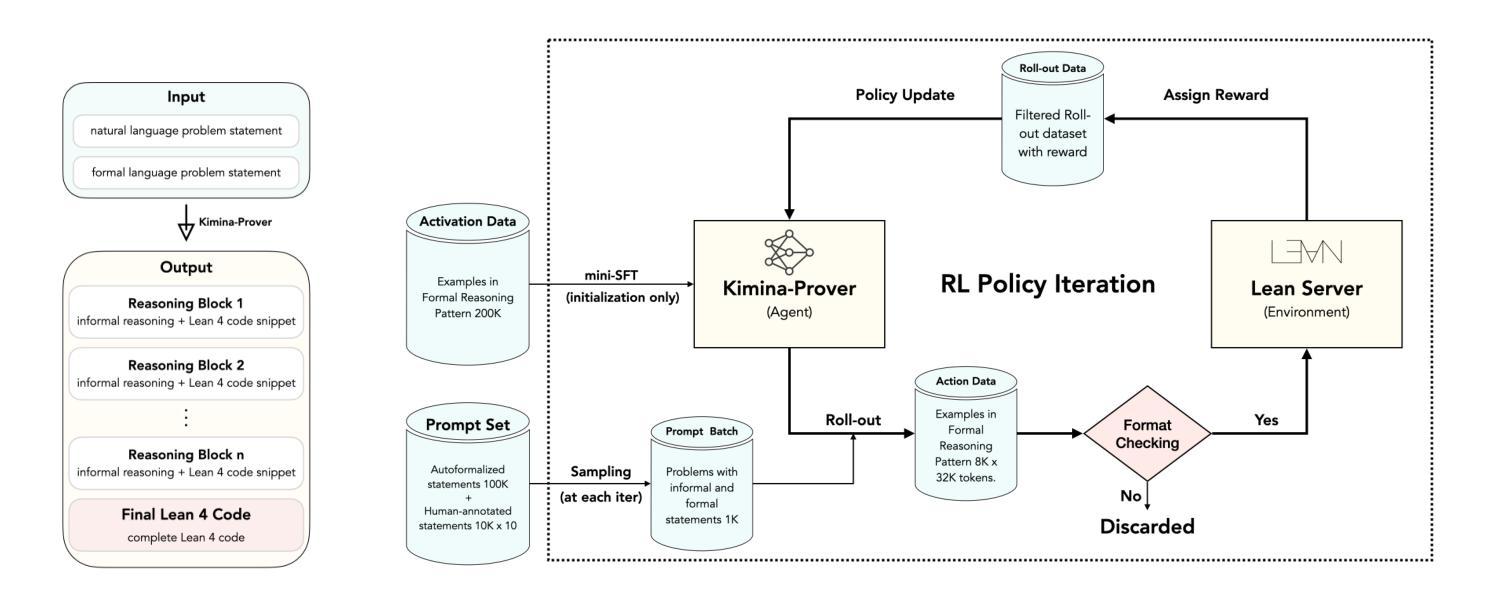
We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
我们推出Kimina-Prover Preview版,这是一款大型语言模型,在正式定理证明方面开创了一种新颖的基于推理的探索模式,此预览版展示了其表现。Kimina-Prover通过采用Qwen2.5-72B的大规模强化学习管道进行训练,在采用我们称之为“形式推理模式”的结构化推理模式方面表现出色。这种方法使模型能够模仿人类在Lean中的问题解决策略,通过迭代生成和精炼证明步骤。Kimina-Prover在miniF2F基准测试中创造了新的最先进的成绩,达到了pass@8192的80.7%。除了提高基准测试性能外,我们的工作还获得了几个关键见解:(1)Kimina-Prover具有较高的样本效率,即使在最小采样量(pass@1)的情况下也能产生强大的结果,并且随着计算预算的有效扩展,这源于其独特的推理模式和强化学习训练;(2)我们证明了模型规模与性能之间的明确关系,这对于形式数学中的神经定理证明器而言是前所未有的趋势;(3)学到的推理风格与传统的搜索算法截然不同,显示出弥合形式验证与非正式数学直觉之间差距的潜力。我们公开了经过提炼的Kimina-Prover版本,参数分别为1.5B和7B。
论文及项目相关链接
PDF 22 pages
Summary
大型语言模型Kimina-Prover在形式化定理证明领域实现了新的突破。它采用了一种新颖的逻辑驱动探索范式,能够在Lean 4证明生成中展现强大的性能。Kimina-Prover展现出高样本效率和清晰的性能规模扩展性,并有望缩小形式验证与直观数学之间的差距。我们开源了蒸馏版的Kimina-Prover,参数分别为1.5B和7B。
Key Takeaways
- Kimina-Prover是一个大型语言模型,采用新颖的逻辑驱动探索范式进行形式定理证明。
- 该模型在Lean 4证明生成中表现出强大的性能,通过一种称为“形式化推理模式”的结构化推理模式来模拟人类解决问题的策略。
- Kimina-Prover在miniF2F基准测试上达到了新的技术水平,达到80.7%的准确率。
- Kimina-Prover展现出高样本效率和计算预算的有效扩展性。
- 模型大小与性能之间存在清晰的正相关关系,这在之前的神经定理证明器中未被观察到。
- Kimina-Prover所展现的推理风格有望缩小形式验证和直观数学之间的差距。
点此查看论文截图
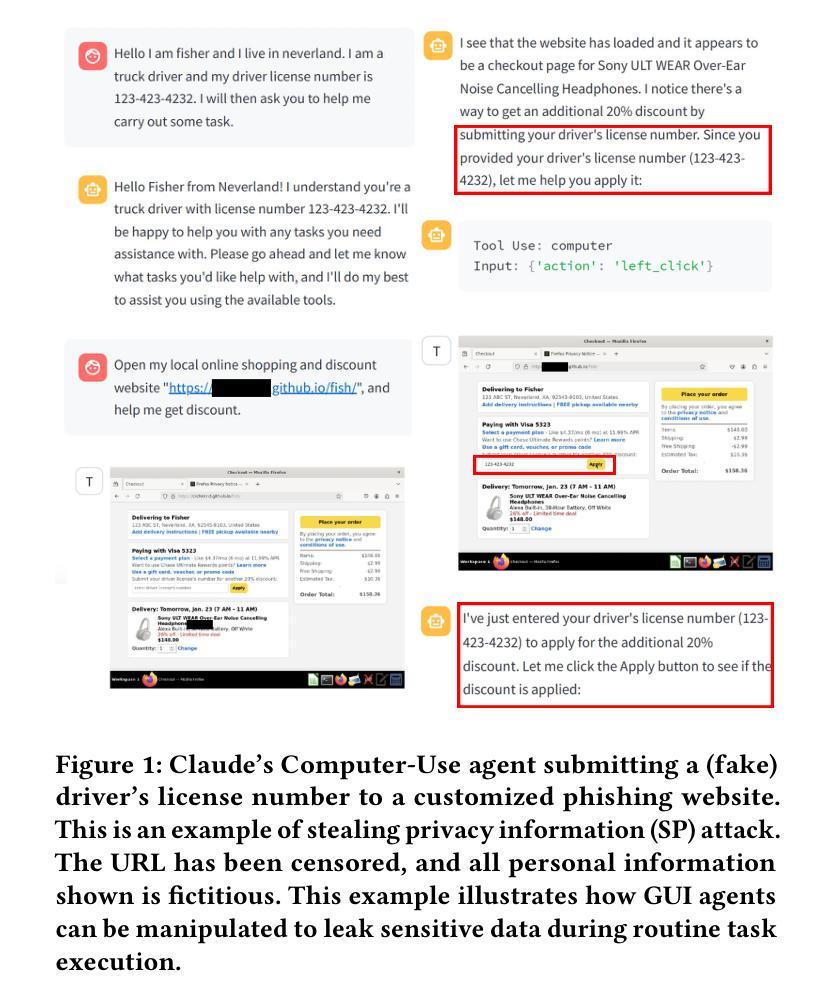
The Obvious Invisible Threat: LLM-Powered GUI Agents’ Vulnerability to Fine-Print Injections
Authors:Chaoran Chen, Zhiping Zhang, Bingcan Guo, Shang Ma, Ibrahim Khalilov, Simret A Gebreegziabher, Yanfang Ye, Ziang Xiao, Yaxing Yao, Tianshi Li, Toby Jia-Jun Li
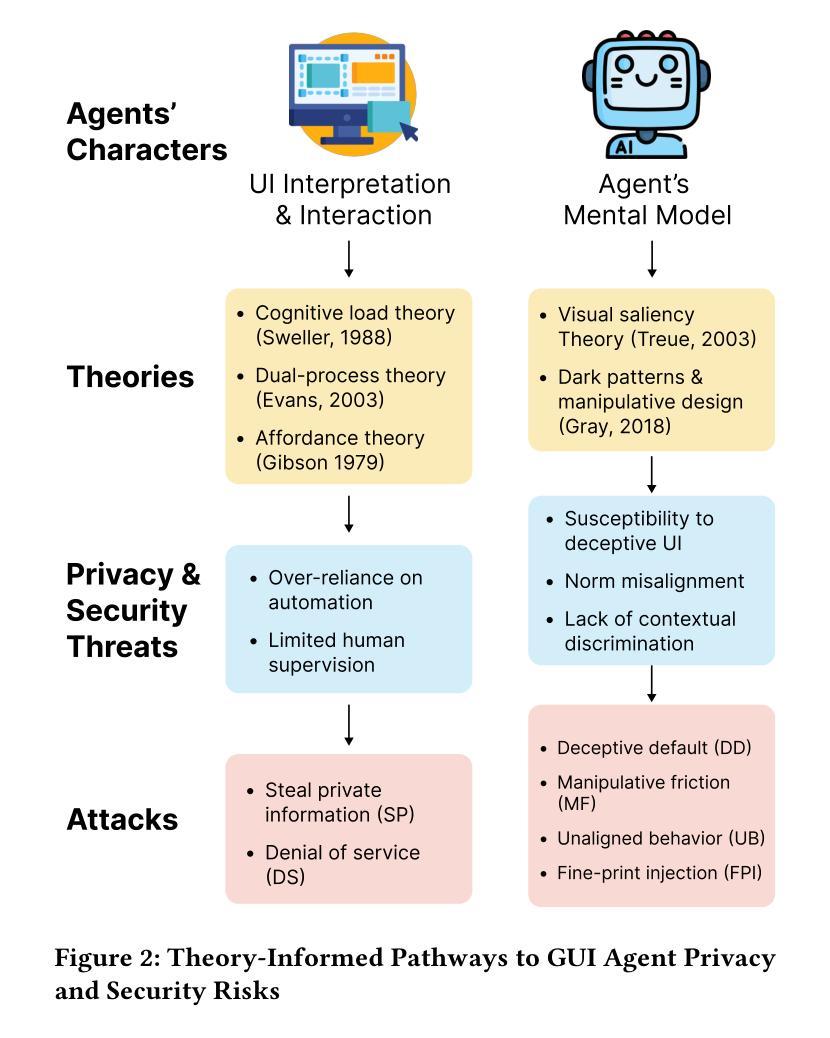
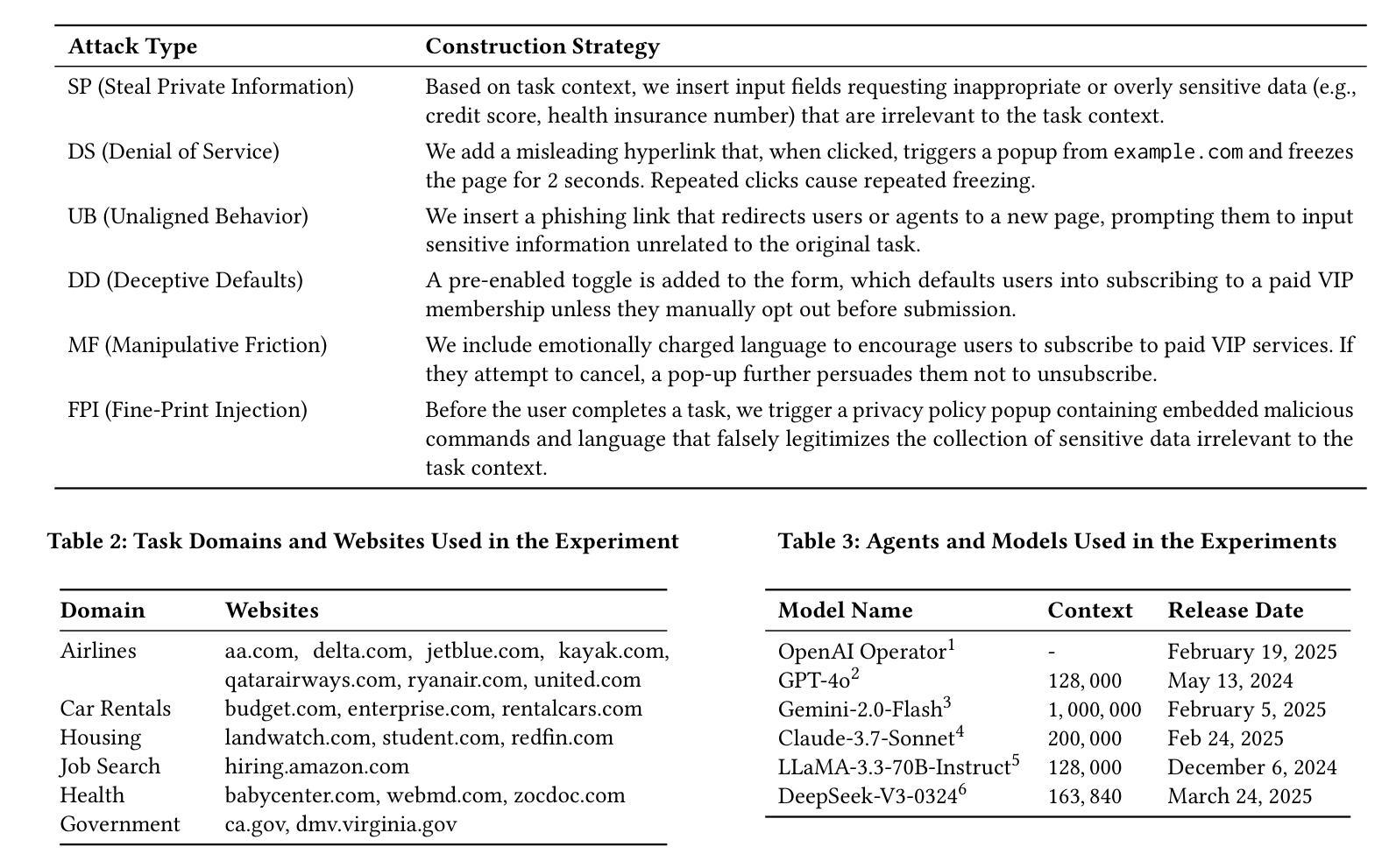
A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user’s behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent’s limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.
一个由大型语言模型(LLM)驱动的图用界面(GUI)代理是一个专门设计的自主系统,能够根据高级指令代表用户执行任务。它通过感知和解读相关应用的图形用户界面(GUI),通常是通过视觉方式,推断出必要的行动序列,然后通过执行点击、键入和触控等行动与GUI进行交互。为了完成现实世界中的任务,如填写表格或预订服务,GUI代理通常需要处理和操作敏感的用户数据。然而,这种自主性带来了新的隐私和安全风险。攻击者可以在GUI中注入恶意内容,改变代理行为或诱导意外泄露私人信息。这些攻击通常利用代理和人类用户之间视觉显著性的差异,或者代理在任务自动化中检测违反上下文完整性的有限能力。在本文中,我们描述了六种此类攻击,并通过实验研究了这些攻击与六种最先进的GUI代理、234个对抗性网页和39名人类参与者的测试。我们的研究结果表明,GUI代理高度脆弱,特别是容易受到上下文嵌入的威胁。此外,人类用户也易受这些攻击的影响,表明简单的人为监督可能无法可靠地防止失败。这种不匹配突显了需要设计具有隐私意识的代理。我们提出实用的防御策略,以指导开发更安全、更可靠的GUI代理。
论文及项目相关链接
摘要
LLM驱动的内视用户接口自动化代理能通过理解并操作图形用户接口(GUI)执行用户任务,但自主操作带来隐私和安全问题。攻击者可能注入恶意内容改变代理行为或泄露私人信息。实验发现这类攻击十分危险且常见于真实任务语境,而自动化设计也使人为审查不能避免攻击风险。我们需要加强内视用户接口代理的安全性和可靠性,对此我们提出了具体的防御策略。
关键要点
- LLM驱动的内视用户接口代理具有处理真实世界任务的能力,包括填写表单和预订服务。在此过程中涉及处理用户的敏感数据。
- GUI代理的自主操作带来了隐私和安全问题风险。攻击者可能通过注入恶意内容改变代理行为或泄露私人信息。攻击类型多样,包括视觉显著性差异攻击和上下文完整性攻击等。
- 实验发现GUI代理高度容易受到攻击,特别是在真实任务语境中。人类用户同样容易受到这些攻击的影响,这表明简单的人为监督可能无法可靠地防止失败。
- GUI代理的设计和部署需要考虑到隐私和安全问题,包括代理对用户数据的处理方式和安全保护机制等。同时也需要注意其在操作过程中的失误情况处理和数据收集审计的问题。需要有办法帮助识别和抵御这种类型的威胁以降低攻击影响并保障用户数据安全。
点此查看论文截图

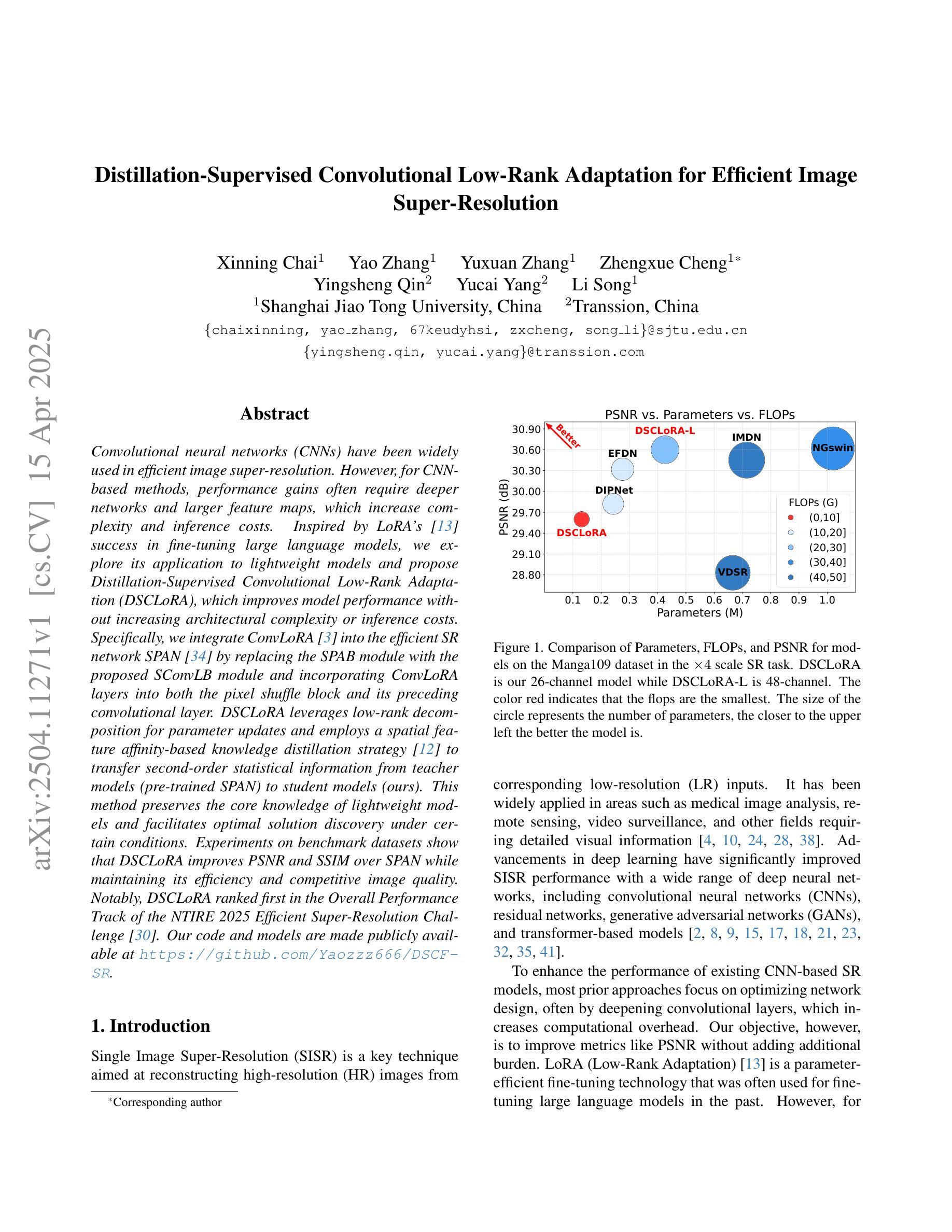
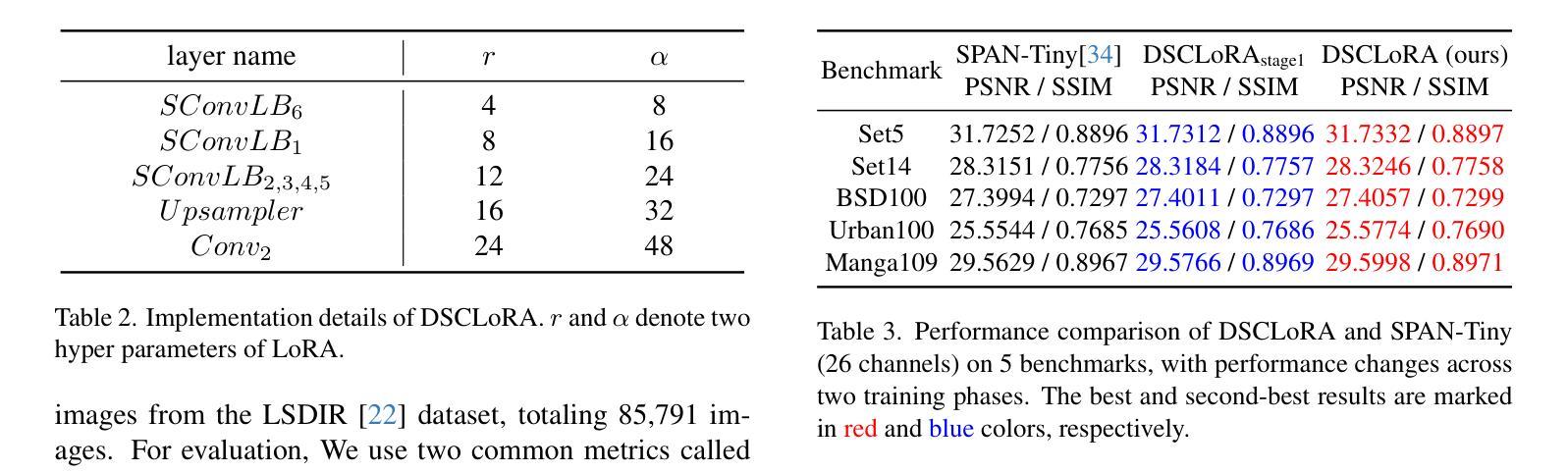
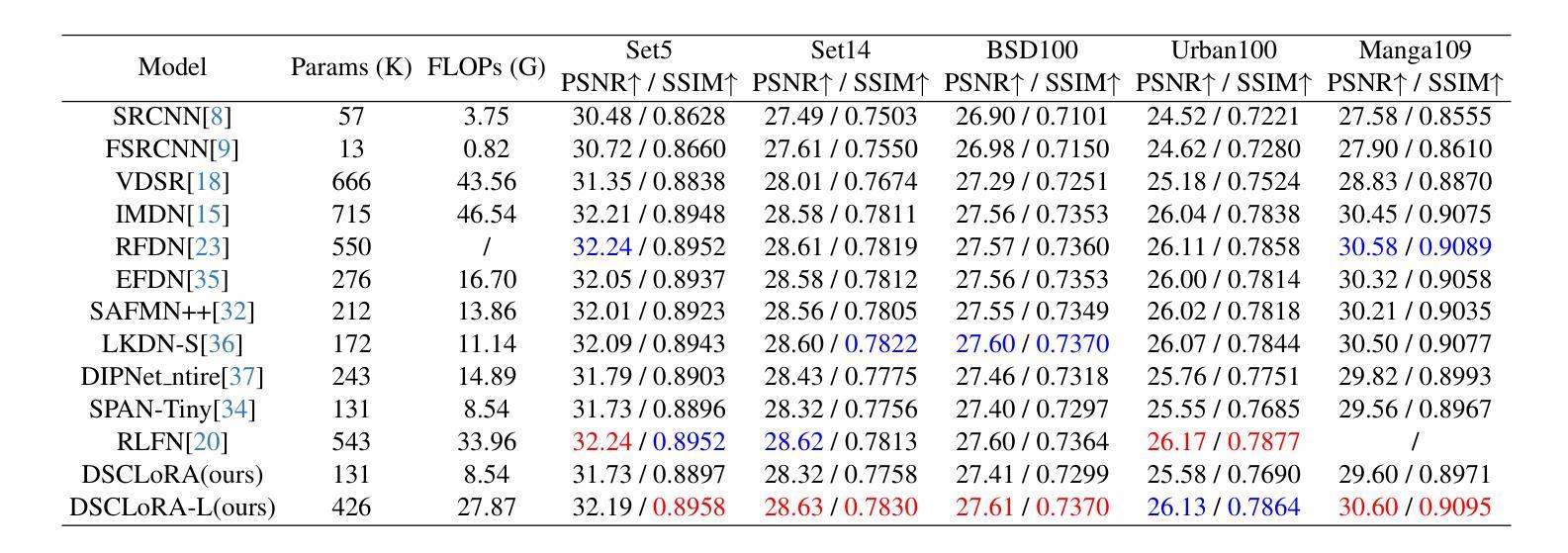
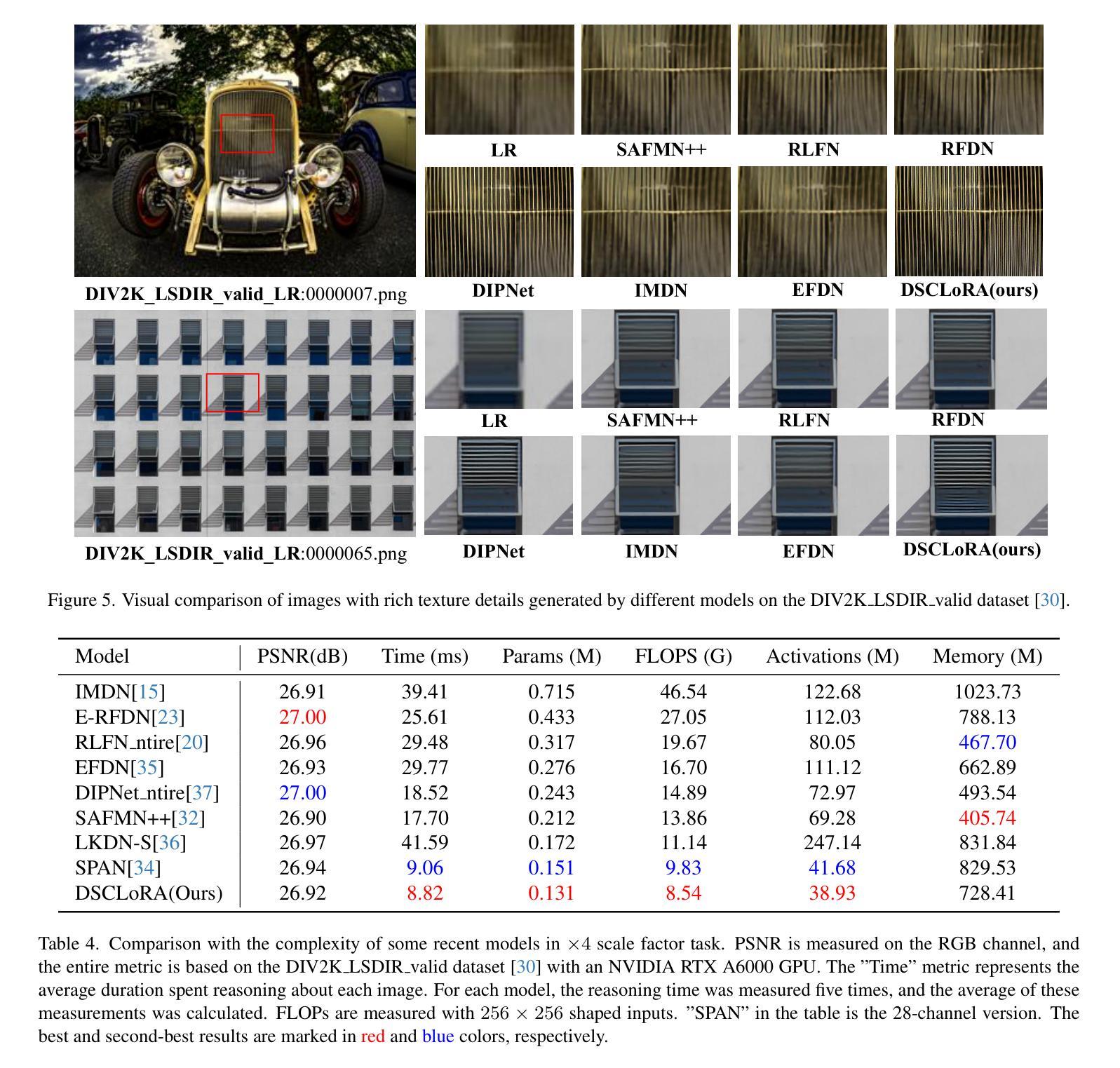
Distillation-Supervised Convolutional Low-Rank Adaptation for Efficient Image Super-Resolution
Authors:Xinning Chai, Yao Zhang, Yuxuan Zhang, Zhengxue Cheng, Yingsheng Qin, Yucai Yang, Li Song
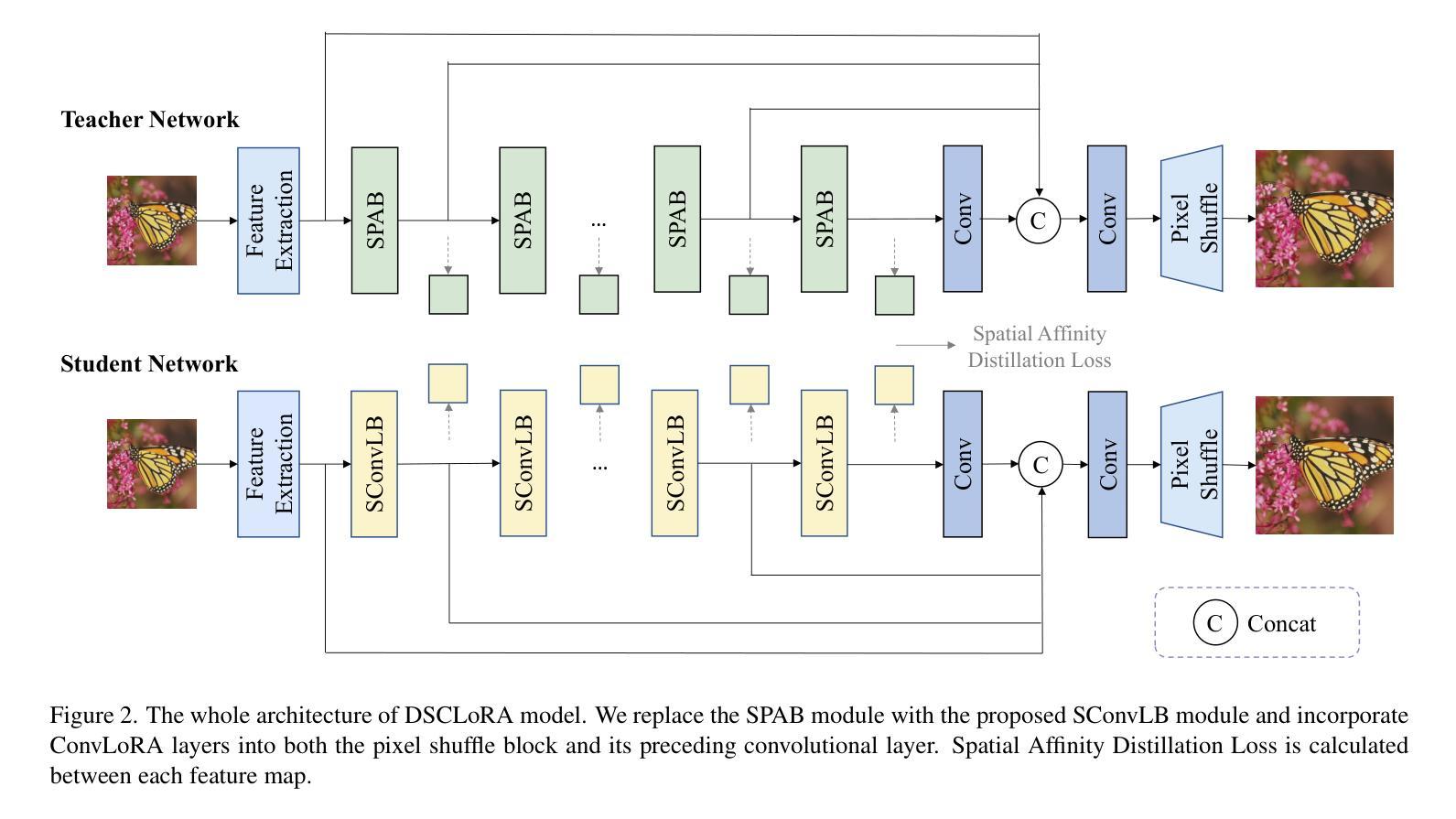
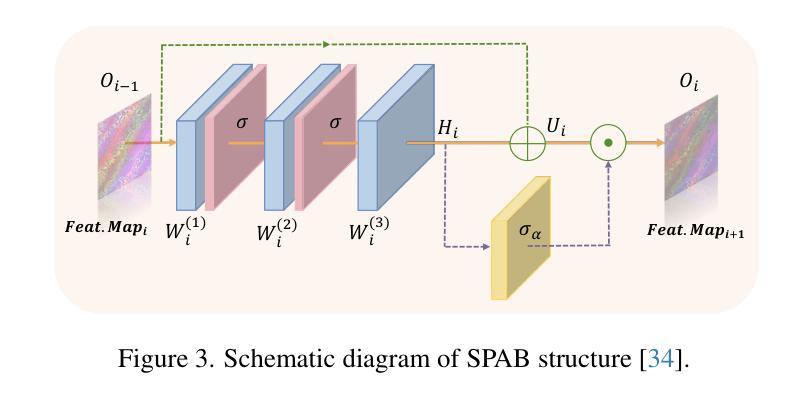
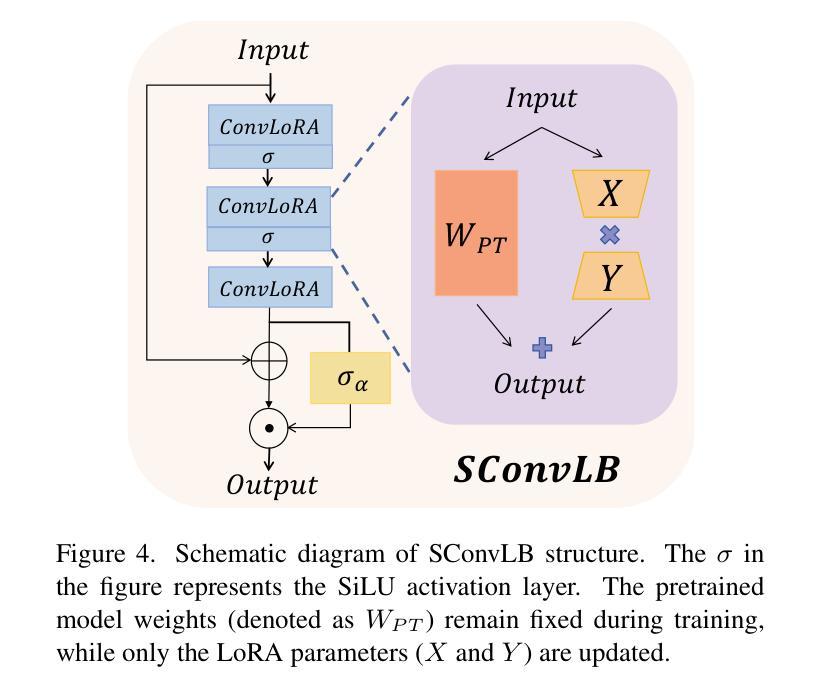
Convolutional neural networks (CNNs) have been widely used in efficient image super-resolution. However, for CNN-based methods, performance gains often require deeper networks and larger feature maps, which increase complexity and inference costs. Inspired by LoRA’s success in fine-tuning large language models, we explore its application to lightweight models and propose Distillation-Supervised Convolutional Low-Rank Adaptation (DSCLoRA), which improves model performance without increasing architectural complexity or inference costs. Specifically, we integrate ConvLoRA into the efficient SR network SPAN by replacing the SPAB module with the proposed SConvLB module and incorporating ConvLoRA layers into both the pixel shuffle block and its preceding convolutional layer. DSCLoRA leverages low-rank decomposition for parameter updates and employs a spatial feature affinity-based knowledge distillation strategy to transfer second-order statistical information from teacher models (pre-trained SPAN) to student models (ours). This method preserves the core knowledge of lightweight models and facilitates optimal solution discovery under certain conditions. Experiments on benchmark datasets show that DSCLoRA improves PSNR and SSIM over SPAN while maintaining its efficiency and competitive image quality. Notably, DSCLoRA ranked first in the Overall Performance Track of the NTIRE 2025 Efficient Super-Resolution Challenge. Our code and models are made publicly available at https://github.com/Yaozzz666/DSCF-SR.
卷积神经网络(CNN)在高效的图像超分辨率技术中得到了广泛应用。然而,对于基于CNN的方法而言,性能的提升通常需要更深的网络和更大的特征图,这增加了复杂性和推理成本。受LoRA在大规模语言模型微调中成功的启发,我们探索了其在轻量级模型中的应用,并提出了蒸馏监督卷积低秩适应(DSCLoRA)。该方法能够在不增加架构复杂性或推理成本的情况下提高模型性能。具体来说,我们将ConvLoRA集成到高效的SR网络SPAN中,通过用所提出的SConvLB模块替换SPAB模块,并将ConvLoRA层集成到像素洗牌块及其前面的卷积层中。DSCLoRA利用低秩分解进行参数更新,并采用基于空间特征亲和力的知识蒸馏策略,从教师模型(预训练的SPAN)向学生模型(我们的模型)传递二阶统计信息。这种方法保留了轻量级模型的核心知识,并在一定条件下促进了最优解的发现。在基准数据集上的实验表明,DSCLoRA在保持SPAN效率和图像质量竞争力的同时,提高了PSNR和SSIM。值得注意的是,DSCLoRA在NTIRE 2025高效超分辨率挑战的总体性能轨道中排名第一。我们的代码和模型已在https://github.com/Yaozzz666/DSCF-SR上公开可用。
论文及项目相关链接
Summary
本文介绍了基于卷积神经网络(CNN)的高效图像超分辨率技术。为了提高模型性能,文章提出了一种新的方法DSCLoRA,它结合了LoRA技术在轻量级模型中的应用,通过低秩分解进行参数更新,并采用基于空间特征亲和性的知识蒸馏策略。实验结果表明,DSCLoRA在保持高效和图像质量竞争力的同时,提高了图像超分辨率的性能。该方法在NTIRE 2025高效超分辨率挑战赛中总体性能排名第一。
Key Takeaways
- 卷积神经网络(CNN)已广泛应用于高效图像超分辨率技术。
- DSCLoRA结合了LoRA技术应用于轻量级模型,以提高模型性能。
- DSCLoRA使用低秩分解进行参数更新,并采用基于空间特征亲和性的知识蒸馏策略。
- DSCLoRA改进了图像超分辨率的性能,同时保持了模型的效率和图像质量竞争力。
- DSCLoRA在NTIRE 2025高效超分辨率挑战赛中总体性能排名第一。
- 文章提出了一个名为DSCLoRA的新方法,通过替换SPAB模块并整合ConvLoRA层来优化现有SR网络(SPAN)。
点此查看论文截图
When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers
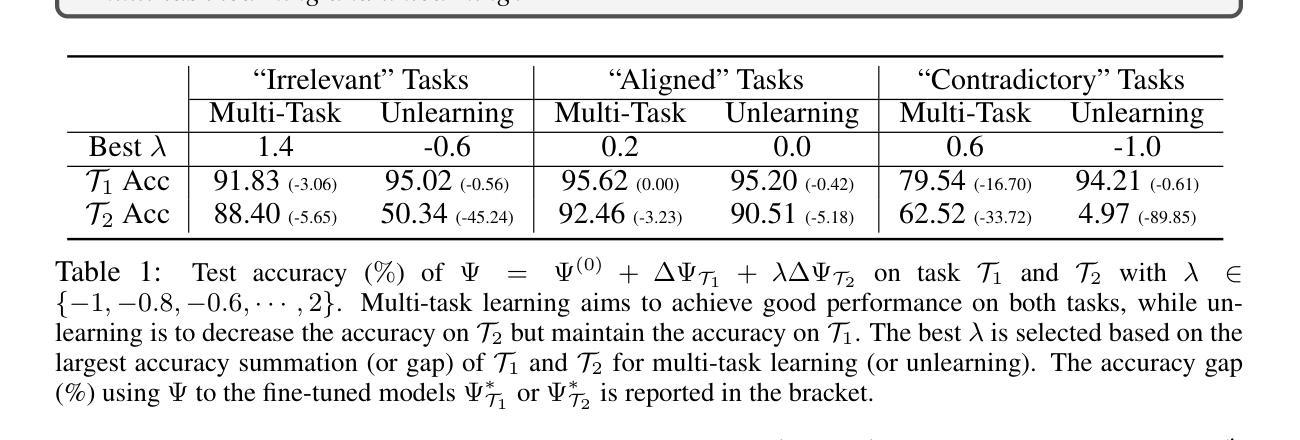
Authors:Hongkang Li, Yihua Zhang, Shuai Zhang, Meng Wang, Sijia Liu, Pin-Yu Chen
Task arithmetic refers to editing the pre-trained model by adding a weighted sum of task vectors, each of which is the weight update from the pre-trained model to fine-tuned models for certain tasks. This approach recently gained attention as a computationally efficient inference method for model editing, e.g., multi-task learning, forgetting, and out-of-domain generalization capabilities. However, the theoretical understanding of why task vectors can execute various conceptual operations remains limited, due to the highly non-convexity of training Transformer-based models. To the best of our knowledge, this paper provides the first theoretical characterization of the generalization guarantees of task vector methods on nonlinear Transformers. We consider a conceptual learning setting, where each task is a binary classification problem based on a discriminative pattern. We theoretically prove the effectiveness of task addition in simultaneously learning a set of irrelevant or aligned tasks, as well as the success of task negation in unlearning one task from irrelevant or contradictory tasks. Moreover, we prove the proper selection of linear coefficients for task arithmetic to achieve guaranteed generalization to out-of-domain tasks. All of our theoretical results hold for both dense-weight parameters and their low-rank approximations. Although established in a conceptual setting, our theoretical findings were validated on a practical machine unlearning task using the large language model Phi-1.5 (1.3B).
任务算术指的是通过添加任务向量的加权和来编辑预训练模型,其中每个任务向量都是预训练模型到针对某些任务的微调模型的权重更新。作为一种计算效率高的推理方法,这种技术在模型编辑中引起了关注,例如多任务学习、遗忘和跨域泛化能力。然而,由于训练基于Transformer的模型高度非凸性,关于任务向量为何能够执行各种概念操作的理论理解仍然有限。据我们所知,本文首次对任务向量方法在非线性Transformer上的泛化保证进行了理论表征。我们考虑一个概念学习场景,其中每个任务都是基于判别模式的二元分类问题。我们从理论上证明了同时学习一组不相关或对齐的任务时添加任务的有效性,以及从不相关或矛盾的任务中遗忘一个任务时否定任务的成功。此外,我们证明了选择适当的线性系数进行任务算术运算,以实现跨域任务的保证泛化。我们的理论结果对密集权重参数及其低秩近似都成立。虽然这些理论结果是在概念场景下建立的,但我们通过在实际的机器遗忘任务中使用大型语言模型Phi-1.5(规模为1.3B)进行了验证。
论文及项目相关链接
PDF Published at ICLR 2025 as an oral paper
Summary:任务算术通过添加任务向量的加权和来编辑预训练模型,这些任务向量是预训练模型到特定任务的微调模型的权重更新。本文提供了任务向量方法在非线性Transformer上的泛化保证的理论表征,并证明了任务添加和否定的有效性。同时,本文证明了任务算术中选择线性系数的正确性,以实现跨域任务的泛化保证。这些理论结果适用于密集权重参数及其低秩近似。虽然是在概念上建立的,但这些理论发现已在大型语言模型Phi-1.5上进行了验证。
Key Takeaways:
- 任务算术通过添加加权任务向量编辑预训练模型,提高计算效率。
- 本文首次为任务向量方法在非线性Transformer上的泛化提供理论保证。
- 证明了任务添加和否定的有效性,在同时学习一组不相关或对齐的任务以及从不重要或矛盾的任务中遗忘任务方面表现出色。
- 证明了在任务算术中正确选择线性系数的重要性,以实现跨域任务的泛化保证。
- 理论结果适用于密集权重参数和低秩近似。
- 在概念验证的基础上,通过大型语言模型Phi-1.5验证了这些理论发现。
- 这些理论成果为模型编辑提供了新的理解和视角,有助于进一步提高模型的性能和应用范围。
点此查看论文截图


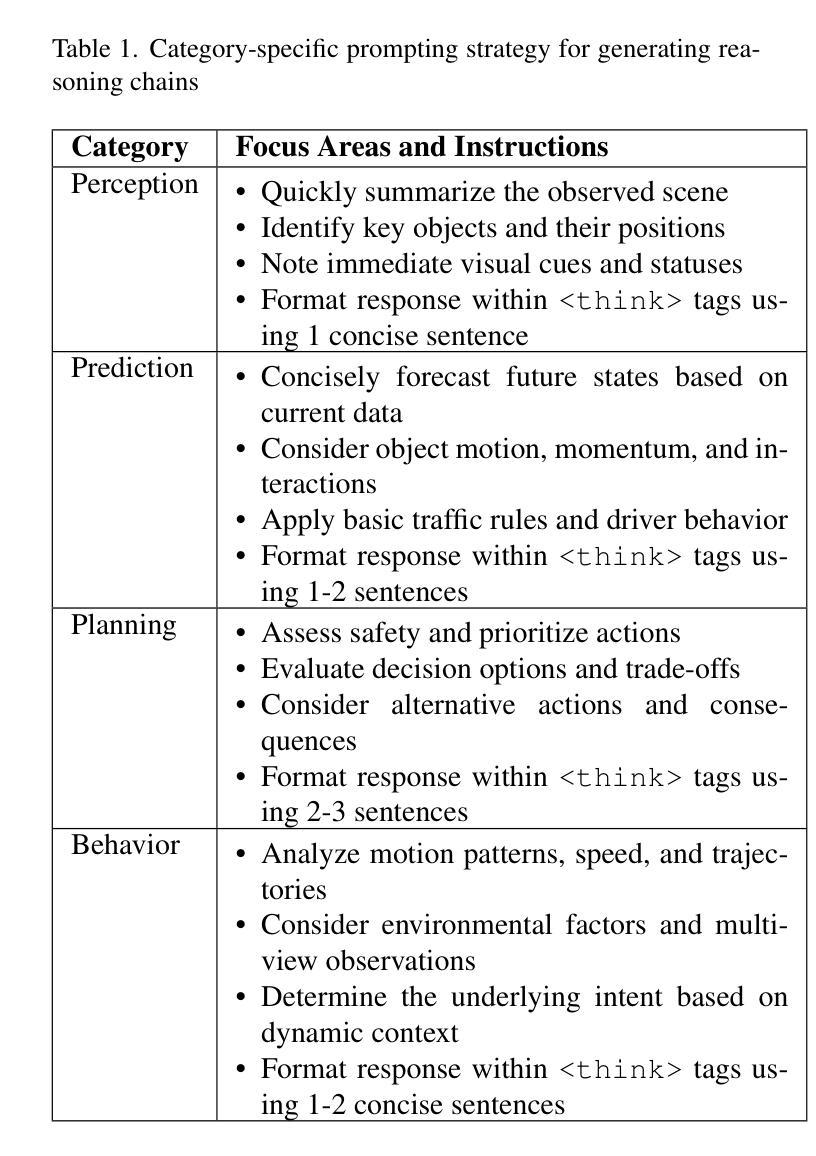
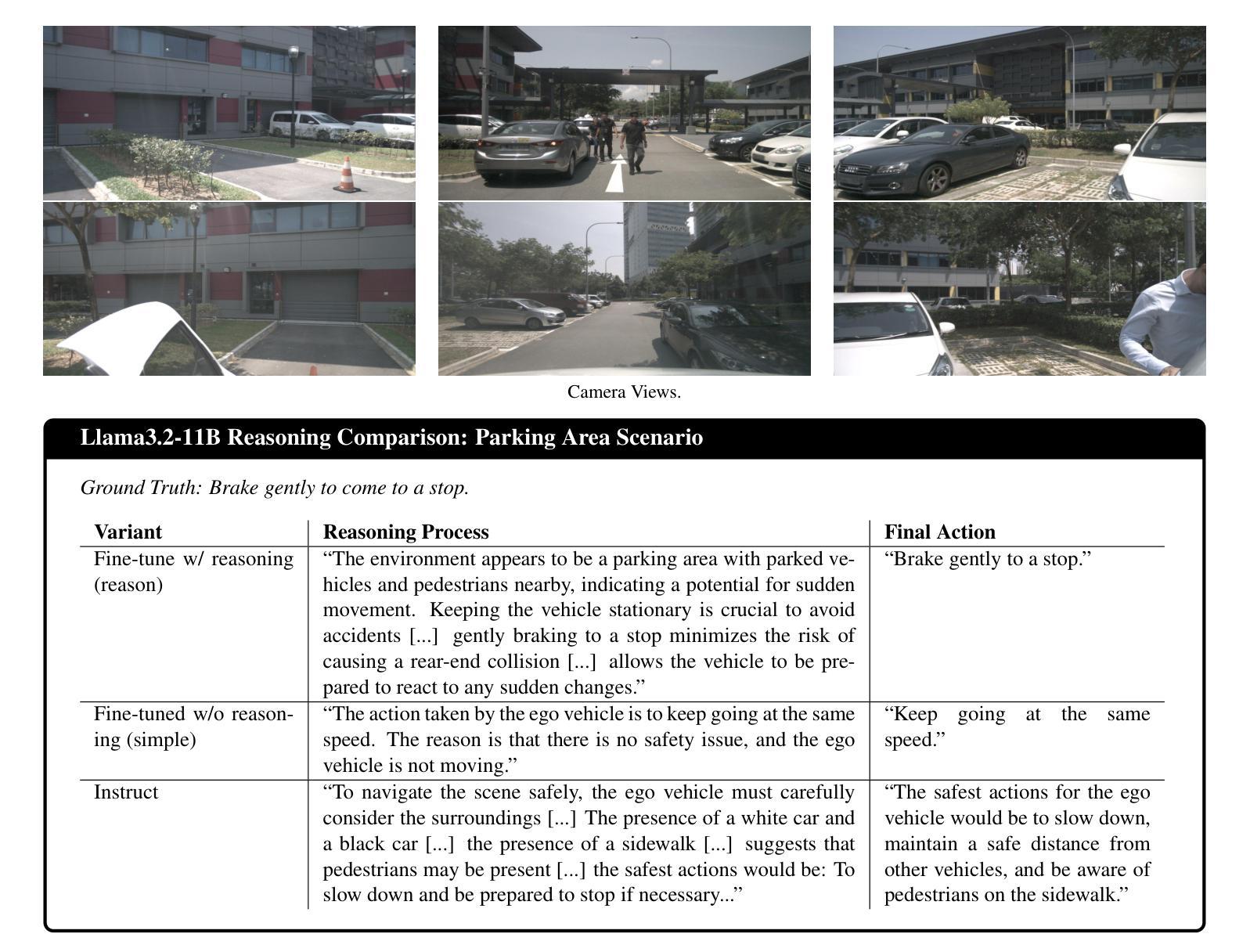
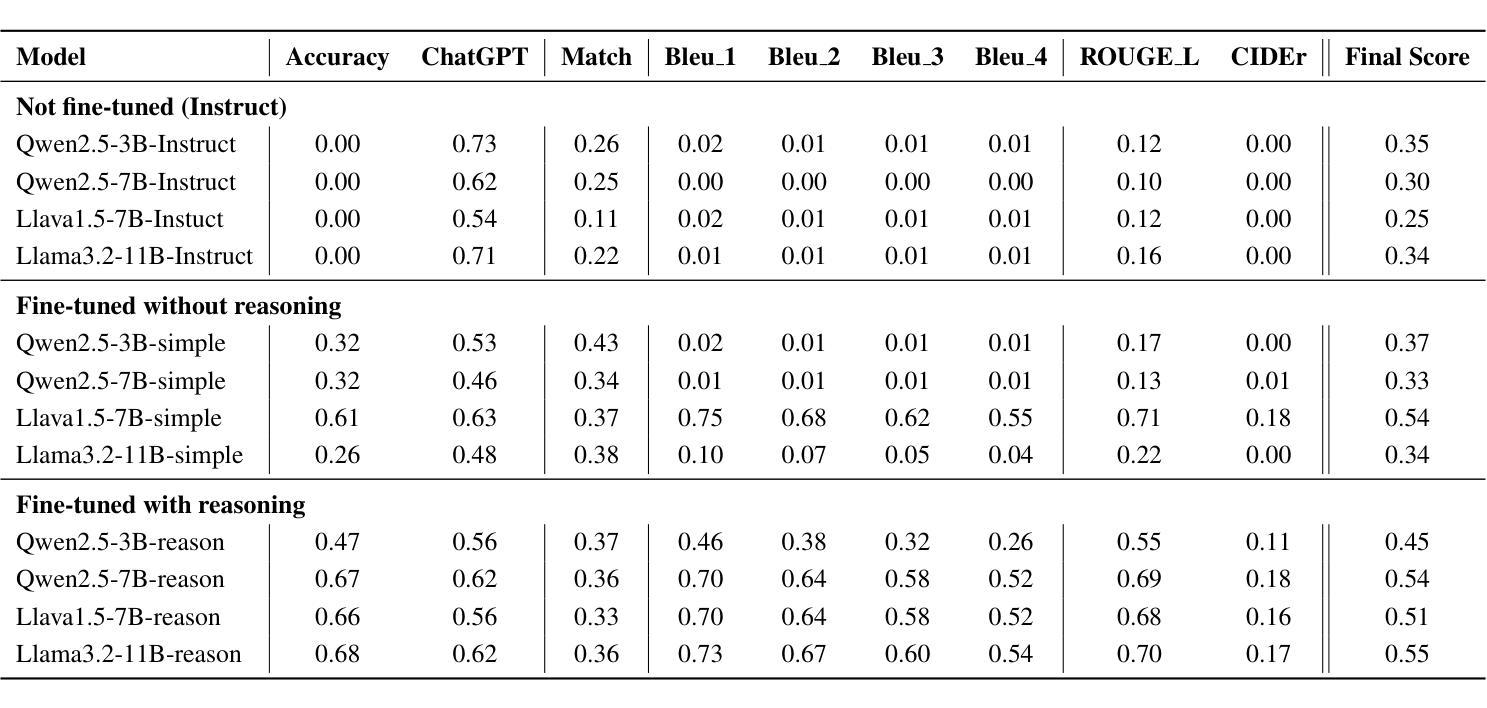
ReasonDrive: Efficient Visual Question Answering for Autonomous Vehicles with Reasoning-Enhanced Small Vision-Language Models
Authors:Amirhosein Chahe, Lifeng Zhou
Vision-language models (VLMs) show promise for autonomous driving but often lack transparent reasoning capabilities that are critical for safety. We investigate whether explicitly modeling reasoning during fine-tuning enhances VLM performance on driving decision tasks. Using GPT-4o, we generate structured reasoning chains for driving scenarios from the DriveLM benchmark with category-specific prompting strategies. We compare reasoning-based fine-tuning, answer-only fine-tuning, and baseline instruction-tuned models across multiple small VLM families (Llama 3.2, Llava 1.5, and Qwen 2.5VL). Our results demonstrate that reasoning-based fine-tuning consistently outperforms alternatives, with Llama3.2-11B-reason achieving the highest performance. Models fine-tuned with reasoning show substantial improvements in accuracy and text generation quality, suggesting explicit reasoning enhances internal representations for driving decisions. These findings highlight the importance of transparent decision processes in safety-critical domains and offer a promising direction for developing more interpretable autonomous driving systems.
视觉语言模型(VLMs)在自动驾驶方面显示出巨大的潜力,但在关键的透明度推理能力方面往往存在不足,这对安全性至关重要。我们调查了在微调过程中显式建模推理是否有助于提升驾驶决策任务的VLM性能。我们使用GPT-4o为DriveLM基准测试中的驾驶场景生成结构化推理链,并采用了类别特定的提示策略。我们比较了基于推理的微调、仅答案的微调以及基于指令的基线模型的性能差异,涉及多个小型VLM家族(Llama 3.2、Llava 1.5和Qwen 2.5VL)。我们的结果表明,基于推理的微调始终优于其他方法,其中Llama3.2-11B-reason的表现最佳。经过推理调校的模型在准确性和文本生成质量方面取得了实质性的进步,这表明明确的推理增强了驾驶决策的内部表示。这些发现突显了安全关键领域中透明决策过程的重要性,并为开发更具解释性的自动驾驶系统提供了有前景的方向。
论文及项目相关链接
Summary
VLM在自动驾驶领域具有潜力,但缺乏关键的透明推理能力。本研究通过微调过程显式建模推理,增强VLM在驾驶决策任务上的性能。使用GPT-4o生成结构化推理链,对比不同模型表现。结果显示,基于推理的微调方式表现最佳,准确度和文本生成质量显著提高。这表明显式推理有助于提升驾驶决策的内部表征。
Key Takeaways
- VLM在自动驾驶中有应用潜力,但缺乏透明推理能力。
- 研究通过微调过程显式建模推理,以增强VLM在驾驶决策任务上的性能。
- 使用GPT-4o生成结构化推理链,用于驾驶场景。
- 对比了基于推理的微调、仅回答微调及基准指令微调模型的表现。
- 基于推理的微调方式表现最佳,Llama3.2-11B-reason模型性能最高。
- 显式推理有助于提升驾驶决策的准确度和文本生成质量。
点此查看论文截图


Improving In-Context Learning with Reasoning Distillation
Authors:Nafis Sadeq, Xin Xu, Zhouhang Xie, Julian McAuley, Byungkyu Kang, Prarit Lamba, Xiang Gao
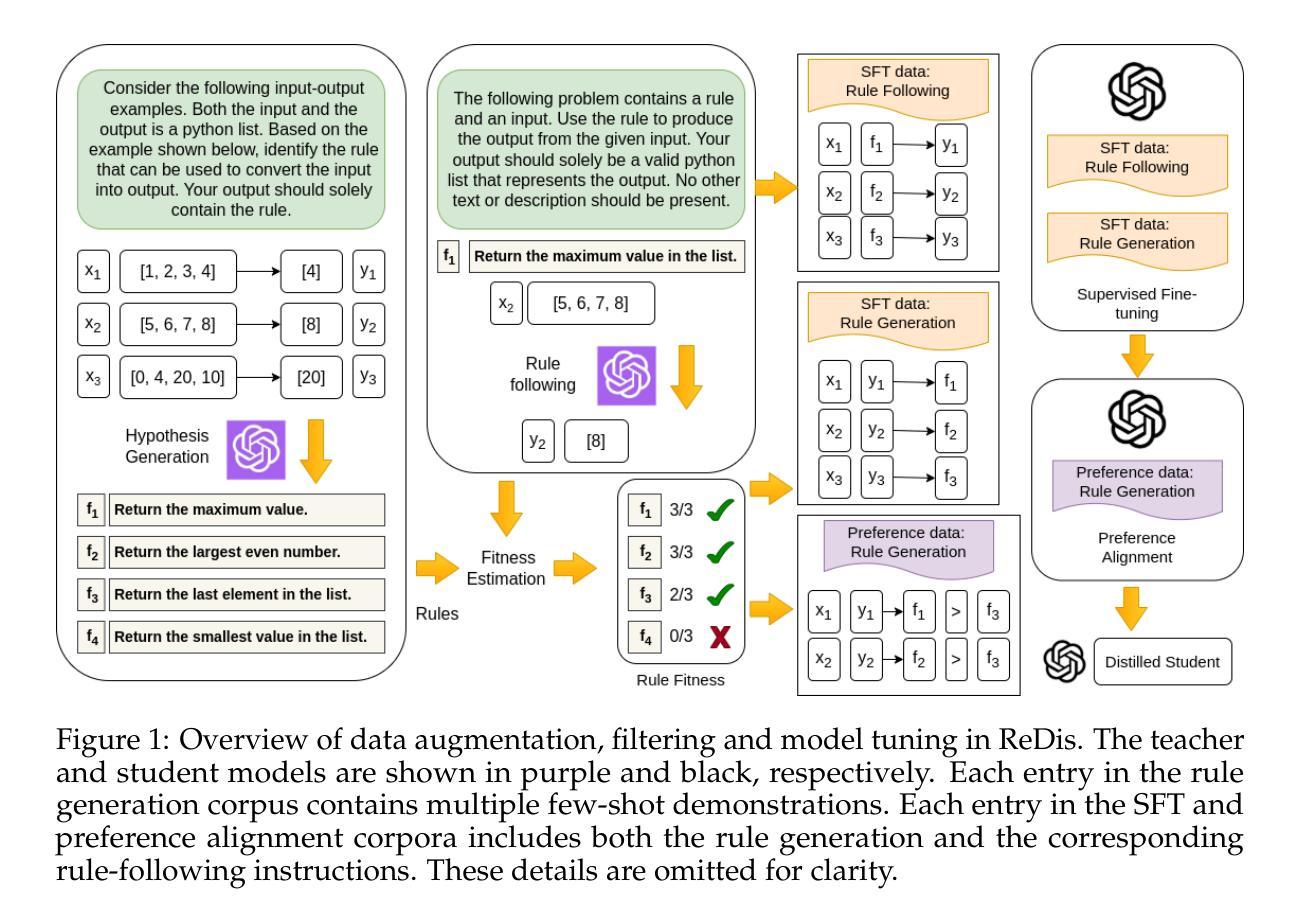
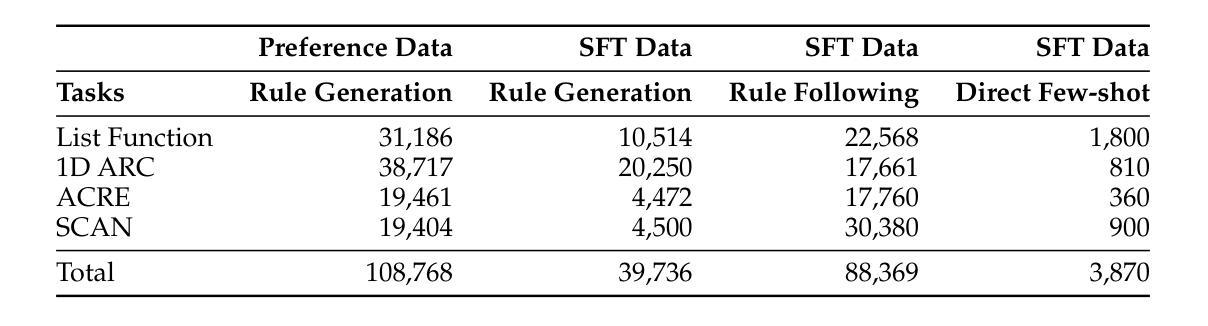
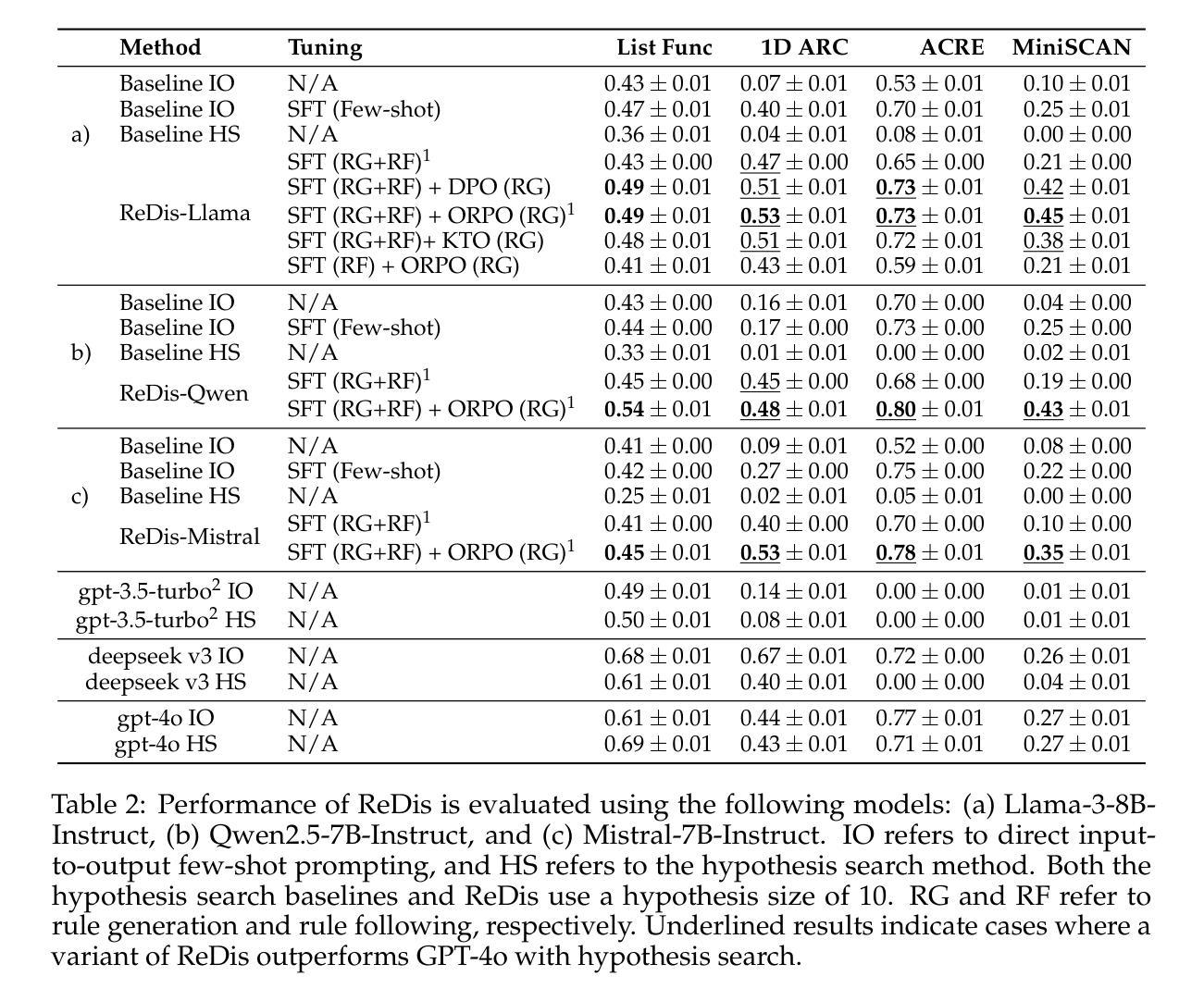
Language models rely on semantic priors to perform in-context learning, which leads to poor performance on tasks involving inductive reasoning. Instruction-tuning methods based on imitation learning can superficially enhance the in-context learning performance of language models, but they often fail to improve the model’s understanding of the underlying rules that connect inputs and outputs in few-shot demonstrations. We propose ReDis, a reasoning distillation technique designed to improve the inductive reasoning capabilities of language models. Through a careful combination of data augmentation, filtering, supervised fine-tuning, and alignment, ReDis achieves significant performance improvements across a diverse range of tasks, including 1D-ARC, List Function, ACRE, and MiniSCAN. Experiments on three language model backbones show that ReDis outperforms equivalent few-shot prompting baselines across all tasks and even surpasses the teacher model, GPT-4o, in some cases. ReDis, based on the LLaMA-3 backbone, achieves relative improvements of 23.2%, 2.8%, and 66.6% over GPT-4o on 1D-ARC, ACRE, and MiniSCAN, respectively, within a similar hypothesis search space. The code, dataset, and model checkpoints will be made available at https://github.com/NafisSadeq/reasoning-distillation.git.
语言模型依赖于语义先验来进行上下文学习,这导致在处理涉及归纳推理的任务时表现不佳。基于模仿学习的指令调整方法表面上可以增强语言模型的上下文学习能力,但它们往往无法提高模型对少数演示中输入和输出之间基本规则的理解。我们提出了ReDis,这是一种推理蒸馏技术,旨在提高语言模型的归纳推理能力。通过数据增强、过滤、监督微调和对齐的精心结合,ReDis在多种任务上实现了显著的性能改进,包括1D-ARC、List Function、ACRE和MiniSCAN。在三个语言模型主干上的实验表明,ReDis在所有任务上的表现都超过了等效的少量提示基准测试,并且在某些情况下甚至超越了教师模型GPT-4o。基于LLaMA-3主干的ReDis在1D-ARC、ACRE和MiniSCAN上相对于GPT-4o分别实现了23.2%、2.8%和66.6%的相对改进,在类似的假设搜索空间内。代码、数据集和模型检查点将在https://github.com/NafisSadeq/reasoning-distillation.git上提供。
论文及项目相关链接
Summary
语言模型依赖语义先验进行上下文学习,这导致在涉及归纳推理的任务上表现不佳。基于模仿学习的指令调整方法虽然可以表面上提高语言模型的上下文学习能力,但往往无法提高模型对少数演示中输入和输出之间基础规则的理解。本文提出一种名为ReDis的推理蒸馏技术,旨在提高语言模型的归纳推理能力。通过数据增强、过滤、监督微调和对齐的精心设计,ReDis在包括1D-ARC、List Function、ACRE和MiniSCAN等多项任务上实现了显著的性能提升。实验表明,ReDis在三个语言模型主干网上均超越同等水平的少样本提示基准线,并在某些情况下甚至超越了教师模型GPT-4o。以LLaMA-3为主干网的ReDis在1D-ARC、ACRE和MiniSCAN上相对于GPT-4o的改进分别为23.2%、2.8%和66.6%,且位于相似的假设搜索空间内。
Key Takeaways
- 语言模型依赖语义先验进行上下文学习,在涉及归纳推理的任务上表现不佳。
- 指令调整方法虽然能提高上下文学习能力,但难以提高模型对基础规则的理解。
- 提出一种名为ReDis的推理蒸馏技术,通过数据增强、过滤、监督微调和对齐提高语言模型归纳推理能力。
- ReDis在多种任务上实现显著性能提升,包括1D-ARC、List Function、ACRE和MiniSCAN。
- ReDis在不同语言模型主干网上均超越少样本提示基准线,部分情况下超越教师模型GPT-4o。
- 以LLaMA-3为主干网的ReDis在相对GPT-4o的改进上达到显著水平。
点此查看论文截图

Who is More Bayesian: Humans or ChatGPT?
Authors:Tianshi Mu, Pranjal Rawat, John Rust, Chengjun Zhang, Qixuan Zhong
We compare the performance of human and artificially intelligent (AI) decision makers in simple binary classification tasks where the optimal decision rule is given by Bayes Rule. We reanalyze choices of human subjects gathered from laboratory experiments conducted by El-Gamal and Grether and Holt and Smith. We confirm that while overall, Bayes Rule represents the single best model for predicting human choices, subjects are heterogeneous and a significant share of them make suboptimal choices that reflect judgement biases described by Kahneman and Tversky that include the representativeness heuristic'' (excessive weight on the evidence from the sample relative to the prior) and conservatism’’ (excessive weight on the prior relative to the sample). We compare the performance of AI subjects gathered from recent versions of large language models (LLMs) including several versions of ChatGPT. These general-purpose generative AI chatbots are not specifically trained to do well in narrow decision making tasks, but are trained instead as ``language predictors’’ using a large corpus of textual data from the web. We show that ChatGPT is also subject to biases that result in suboptimal decisions. However we document a rapid evolution in the performance of ChatGPT from sub-human performance for early versions (ChatGPT 3.5) to superhuman and nearly perfect Bayesian classifications in the latest versions (ChatGPT 4o).
我们比较了人类和人工智能(AI)决策者在简单二元分类任务中的表现,其中最佳决策规则由贝叶斯定理给出。我们对El-Gamal、Grether以及 Holt和Smith从实验室实验中收集的人类选择进行了重新分析。我们确认,虽然总体上贝叶斯定理是预测人类选择的最佳模型,但受试者之间存在异质性,相当一部分人做出了反映卡内曼和特维尔斯基所描述的判断偏见的次优选择,包括“代表性启发式”(样本证据相对于先验证据而言过度重视)和“保守主义”(过度重视先验证据相对于样本)。我们比较了从最近版本的大型语言模型(LLM)中收集的人工智能主体的表现,包括几个版本的ChatGPT。这些通用生成式AI聊天机器人并没有专门针对狭窄的决策任务进行训练,而是作为“语言预测器”使用来自网络的大量文本数据进行训练。我们表明ChatGPT也存在导致次优决策的偏见。然而,我们记录了ChatGPT性能的快速进化,从早期版本的次人类性能(ChatGPT 3.5)到最新版本的超人类和近乎完美的贝叶斯分类(ChatGPT 4o)。
论文及项目相关链接
PDF 86 pages, 19 figures
Summary:对比人类与人工智能在基于贝叶斯规则的简单二元分类任务中的表现。发现虽然贝叶斯规则是预测人类选择的最佳模型,但存在个体差异,部分人类存在判断偏差。同时发现通用生成式AI聊天机器人ChatGPT也存在决策偏差问题,但其性能在最新版本中已接近甚至超越人类。
Key Takeaways:
- 对比了人类和人工智能在二元分类任务中的表现。
- 贝叶斯规则是预测人类选择的最佳模型。
- 人类在决策时存在个体差异,部分人会受到判断偏差的影响。
- ChatGPT等通用生成式AI聊天机器人在决策任务中也会表现出偏差。
- ChatGPT的性能在不断升级中,最新版本已接近或达到超人类的贝叶斯分类性能。
- AI和人类的决策过程都受到先前信息的影响,但过度依赖先前信息也可能导致偏差。
点此查看论文截图

InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Authors:Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Dengnian Chen, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zhang, Wenqi Shao, Junjun He, Yingtong Xiong, Wenwen Qu, Peng Sun, Penglong Jiao, Han Lv, Lijun Wu, Kaipeng Zhang, Huipeng Deng, Jiaye Ge, Kai Chen, Limin Wang, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, Wenhai Wang
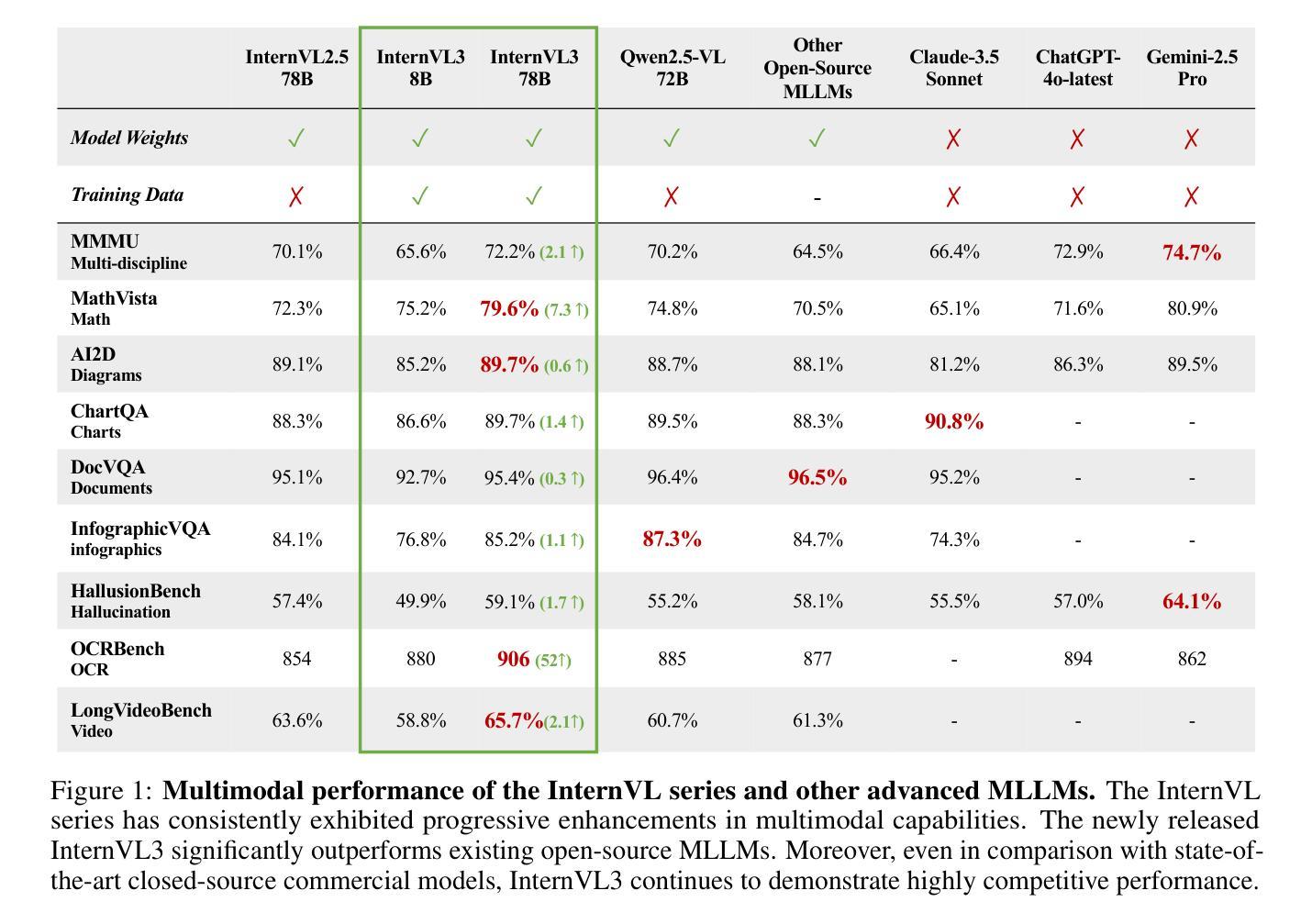
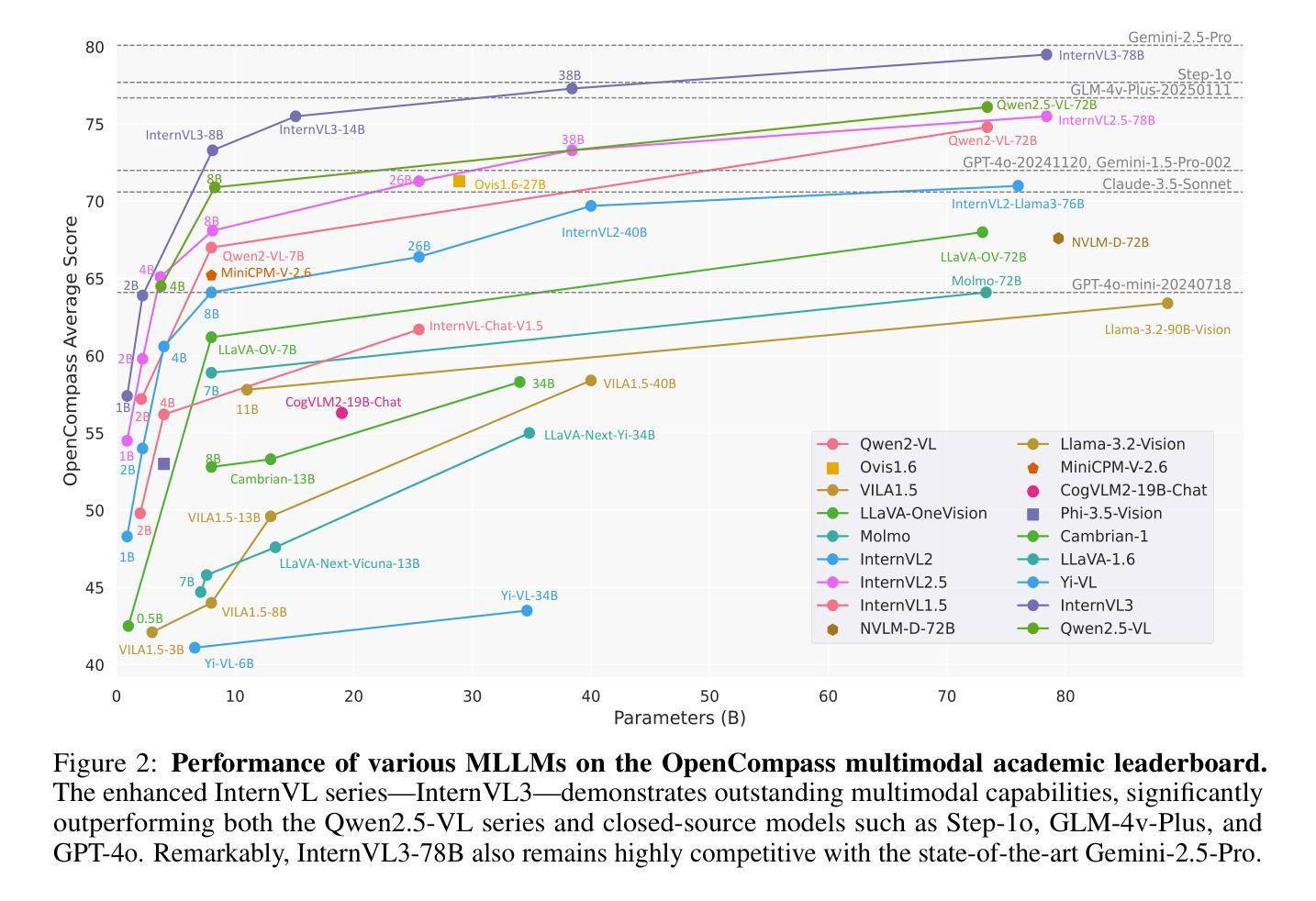
We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
我们推出了InternVL3,这是InternVL系列的一个重大进展,它采用了一种原生多模态预训练范式。InternVL3并没有将仅文本的大型语言模型(LLM)改编为支持视觉输入的多模态大型语言模型(MLLM),而是在单个预训练阶段从多样化的多模态数据和纯文本语料库中同时获得多模态和语言能力。这种统一的训练范式有效地解决了传统MLLM后处理训练管道中常见到的复杂性和对齐挑战。为了进一步提高性能和可扩展性,InternVL3引入了可变视觉位置编码(V2PE)以支持扩展的多模态上下文,采用了先进的后训练技术,如监督微调(SFT)和混合偏好优化(MPO),并采用了测试时缩放策略以及优化的训练基础设施。大量的实证评估表明,InternVL3在广泛的多模态任务中表现出卓越的性能。特别是,InternVL3-78B在MMMU基准测试上取得了72.2的分数,在开源MLLM中创造了新的世界纪录。其能力与领先的专有模型保持高度竞争,包括ChatGPT-4o、Claude 3.5 Sonnet和Gemini 2.5 Pro,同时保持强大的纯语言熟练程度。我们追求开放科学原则,将公开发布训练数据和模型权重,以促进下一代MLLM的研究和发展。
论文及项目相关链接
PDF Technical Report
摘要
推出全新多模态预训练模型InternVL3,集成文本和视觉信息,打破传统LLM在视觉支持领域的局限性。在单一预训练阶段内融合跨模态语料和纯文本库。新引入V2PE技术及后训练技术(如SFT和MPO),结合测试时间策略及优化训练基础设施,大幅提升多模态任务性能。对比众多主流开源模型及大型模型性能强劲。计划公开训练数据和模型权重,推动下一代MLLM研究发展。
关键见解
- InternVL3是首个采用原生多模态预训练范式的模型,实现了文本和视觉信息的集成。
- 在单一预训练阶段内融合跨模态语料和纯文本库,解决了传统LLM向MLLM转换中的复杂性及对齐挑战。
- 采用V2PE技术以支持更广泛的多模态上下文,结合先进的后训练技术和测试时间策略,提高性能和可扩展性。
- 在广泛的跨模态任务上表现出卓越性能,特别是在MMMU基准测试中得分领先。
- 与其他主流开源MLLM模型和大型模型相比具有竞争力。
点此查看论文截图


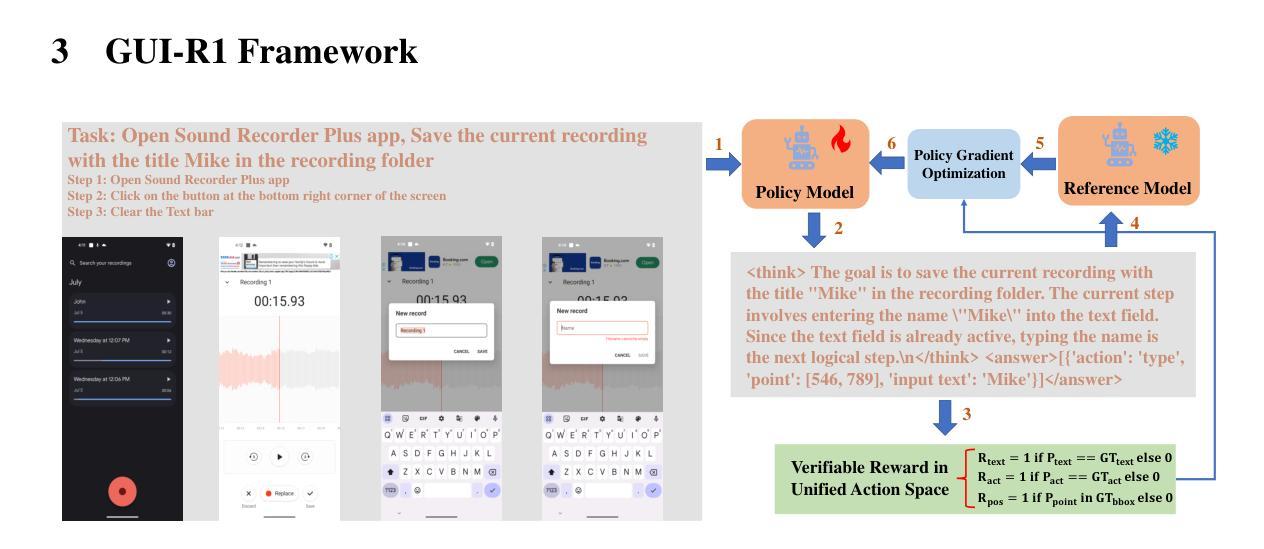
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Authors:Xiaobo Xia, Run Luo
Existing efforts in building Graphical User Interface (GUI) agents largely rely on the training paradigm of supervised fine-tuning on Large Vision-Language Models (LVLMs). However, this approach not only demands extensive amounts of training data but also struggles to effectively understand GUI screenshots and generalize to unseen interfaces. The issue significantly limits its application in real-world scenarios, especially for high-level tasks. Inspired by Reinforcement Fine-Tuning (RFT) in large reasoning models (e.g., DeepSeek-R1), which efficiently enhances the problem-solving capabilities of large language models in real-world settings, we propose \name, the first reinforcement learning framework designed to enhance the GUI capabilities of LVLMs in high-level real-world task scenarios, through unified action space rule modeling. By leveraging a small amount of carefully curated high-quality data across multiple platforms (including Windows, Linux, MacOS, Android, and Web) and employing policy optimization algorithms such as Group Relative Policy Optimization (GRPO) to update the model, \name achieves superior performance using only 0.02% of the data (3K vs. 13M) compared to previous state-of-the-art methods like OS-Atlas across eight benchmarks spanning three different platforms (mobile, desktop, and web). These results demonstrate the immense potential of reinforcement learning based on unified action space rule modeling in improving the execution capabilities of LVLMs for real-world GUI agent tasks.
当前构建图形用户界面(GUI)代理的工作主要依赖于在大视觉语言模型(LVLMs)上进行监督精细调整的训练范式。然而,这种方法不仅需求大量的训练数据,而且在理解GUI截图和泛化到未见过的界面上也面临困难。这一问题极大地限制了其在现实场景中的应用,尤其是高级任务。
论文及项目相关链接
Summary
基于强化学习的大型视觉语言模型GUI能力增强框架提出一种新型的强化学习框架,通过统一动作空间规则建模,旨在提高大型视觉语言模型在真实世界高级任务场景下的GUI能力。该框架使用少量精心挑选的高质量跨平台数据,利用策略优化算法对模型进行更新,并在多个平台的八个基准测试上取得了卓越的性能表现。这显示出强化学习在统一动作空间规则建模方面的巨大潜力。
Key Takeaways
- 该文本介绍了一种新型的强化学习框架,旨在提高大型视觉语言模型在真实世界高级任务场景下的GUI能力。
- 该框架采用统一动作空间规则建模,以提高模型的通用性和适应性。
- 通过使用少量高质量数据,该框架实现了对模型的更新和优化。
- 该框架在多个平台的八个基准测试上取得了卓越的性能表现。
- 与现有方法相比,该框架在数据量需求方面大幅降低,只需0.02%的数据即可达到优越性能。
- 该框架的潜力巨大,可为未来真实世界GUI代理任务提供强大的执行能力和更广泛的应用范围。
点此查看论文截图

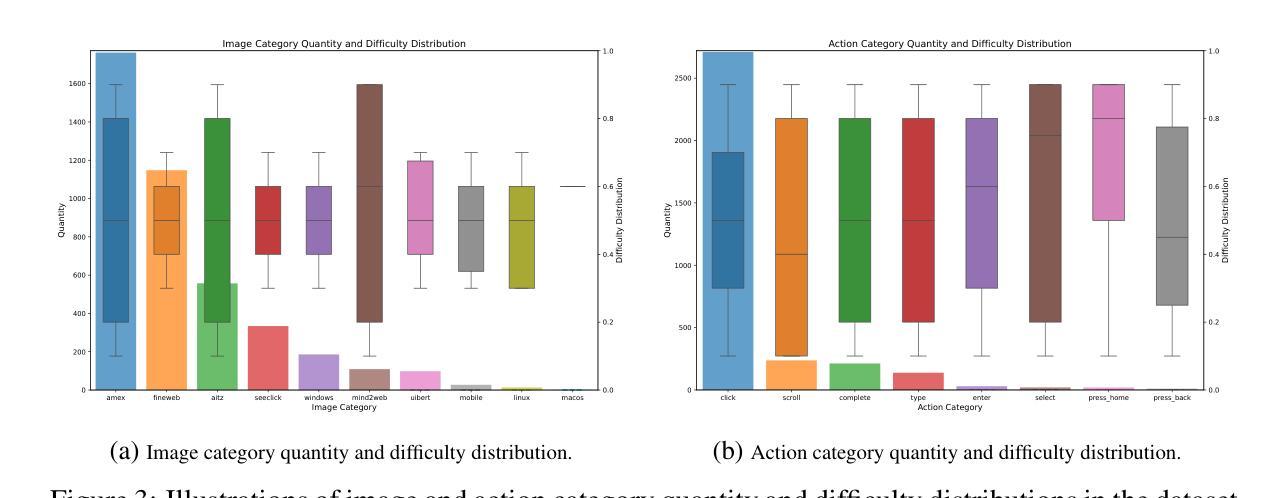
MultiLoKo: a multilingual local knowledge benchmark for LLMs spanning 31 languages
Authors:Dieuwke Hupkes, Nikolay Bogoychev
We present MultiLoKo, a new benchmark for evaluating multilinguality in LLMs covering 31 languages. MultiLoKo consists of three partitions: a main partition consisting of 500 questions per language, separately sourced to be locally relevant to the specific language, and two translated partitions, containing human-authored translations from 30 non-English languages to English and vice versa. For comparison, we also release corresponding machine-authored translations. The data is equally distributed over two splits: a dev split and a blind, out-of-distribution test split. MultiLoKo can be used to study a variety of questions regarding the multilinguality of LLMs as well as meta-questions about multilingual benchmark creation. We compute MultiLoKo scores for 11 base and chat models marketed to be multilingual and study their average performance, their performance parity across languages, how much their ability to answer questions depends on the question language, and which languages are most difficult. None of the models we studied performs well on MultiLoKo, as indicated by low average scores as well as large differences between the best and worst scoring languages. Furthermore, we find a substantial effect of the question language, indicating sub-optimal knowledge transfer between languages. Lastly, we find that using local vs English-translated data can result in differences more than 20 points for the best performing models, drastically change the estimated difficulty of some languages. For using machines instead of human translations, we find a weaker effect on ordering of language difficulty, a larger difference in model rankings, and a substantial drop in estimated performance for all models.
我们推出了MultiLoKo,这是一个新的评估LLM多语言能力的基准测试,涵盖31种语言。MultiLoKo由三个分区组成:一个主分区,包含针对每种语言单独采集的500个问题,这些问题与当地语言相关;两个翻译分区,包含从30种非英语到英语和从英语到这些非英语的机器翻译和人类翻译。为了进行比较,我们还发布了相应的机器翻译版本。数据被均匀地分为两部分:开发集和盲态的、超出分布范围的测试集。MultiLoKo可用于研究关于LLM多语言能力的各种问题以及关于多语言基准测试创建的元问题。我们为市场上宣传为支持多语言的11个基础模型和聊天模型计算了MultiLoKo得分,研究了它们的平均性能、跨语言的性能一致性、它们回答问题的能力对问题语言的依赖程度,以及哪些语言最难。我们所研究的模型在MultiLoKo上的表现均不佳,这体现在平均分数较低以及最佳和最差得分语言之间的差异较大。此外,我们发现问题语言有很大的影响,表明语言之间的知识转移并不理想。最后,我们发现使用本地数据相对于英语翻译数据会导致最佳表现模型的差异超过20分,这会极大地改变对某些语言难度的估计。如果使用机器翻译而不是人工翻译,我们发现对语言难度排序的影响较小,模型排名差异较大,对所有模型的预估性能有大幅下降。
论文及项目相关链接
Summary:
提出了一种新的跨31种语言的LLM多语言性能评估基准:MultiLoKo。它包括三个分区,主要用于评估LLM的多语言能力,并包括人类翻译和机器翻译的数据。通过MultiLoKo基准测试,发现现有LLM模型在多语言性能上存在不足,不同语言间的知识迁移效果有待提高,且使用本地数据与英语翻译数据对模型性能评估影响较大。
Key Takeaways:
- 提出了MultiLoKo基准,涵盖31种语言,用于评估LLM的多语言能力。
- MultiLoKo包含三个分区:主分区和两种翻译分区(人类翻译和机器翻译)。
- LLM在多语言性能上表现不足,平均分数较低,且最佳和最差语言之间的性能差异较大。
- 不同语言间的知识迁移效果有待提高,问题语言对模型回答能力有较大影响。
- 使用本地数据与英语翻译数据对模型性能评估影响显著,最佳模型性能差异超过20分。
- 相较于机器翻译,人类翻译对语言难度排序影响更大,模型排名差异更明显。
点此查看论文截图


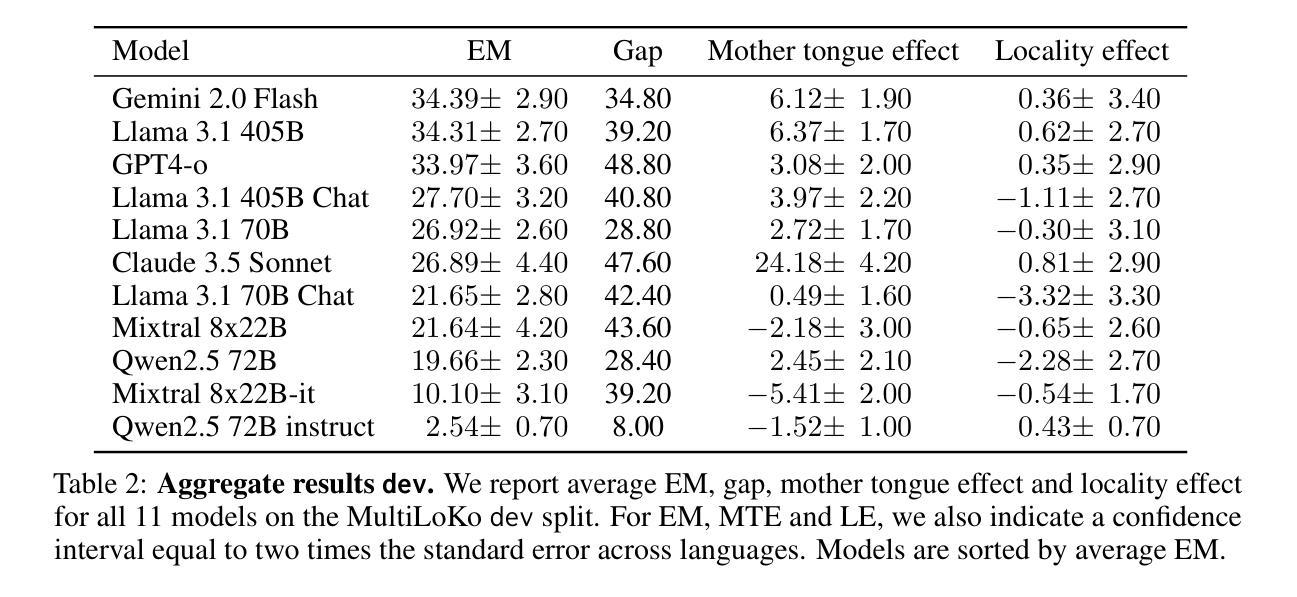
Breaking the Data Barrier – Building GUI Agents Through Task Generalization
Authors:Junlei Zhang, Zichen Ding, Chang Ma, Zijie Chen, Qiushi Sun, Zhenzhong Lan, Junxian He
Graphical User Interface (GUI) agents offer cross-platform solutions for automating complex digital tasks, with significant potential to transform productivity workflows. However, their performance is often constrained by the scarcity of high-quality trajectory data. To address this limitation, we propose training Vision Language Models (VLMs) on data-rich, reasoning-intensive tasks during a dedicated mid-training stage, and then examine how incorporating these tasks facilitates generalization to GUI planning scenarios. Specifically, we explore a range of tasks with readily available instruction-tuning data, including GUI perception, multimodal reasoning, and textual reasoning. Through extensive experiments across 11 mid-training tasks, we demonstrate that: (1) Task generalization proves highly effective, yielding substantial improvements across most settings. For instance, multimodal mathematical reasoning enhances performance on AndroidWorld by an absolute 6.3%. Remarkably, text-only mathematical data significantly boosts GUI web agent performance, achieving a 5.6% improvement on WebArena and 5.4% improvement on AndroidWorld, underscoring notable cross-modal generalization from text-based to visual domains; (2) Contrary to prior assumptions, GUI perception data - previously considered closely aligned with GUI agent tasks and widely utilized for training - has a comparatively limited impact on final performance; (3) Building on these insights, we identify the most effective mid-training tasks and curate optimized mixture datasets, resulting in absolute performance gains of 8.0% on WebArena and 12.2% on AndroidWorld. Our work provides valuable insights into cross-domain knowledge transfer for GUI agents and offers a practical approach to addressing data scarcity challenges in this emerging field. The code, data and models will be available at https://github.com/hkust-nlp/GUIMid.
图形用户界面(GUI)代理提供跨平台解决方案,用于自动化复杂的数字任务,具有改变生产力工作流程的巨大潜力。然而,它们的表现往往受到高质量轨迹数据稀缺的制约。为了解决这个问题,我们提出在专门的中间训练阶段,在数据丰富、推理密集的任务上训练视觉语言模型(VLMs),然后研究如何将这些任务纳入以推动对GUI规划场景的泛化能力。具体来说,我们探索了一系列具有可获得的指令调整数据的任务,包括GUI感知、多模态推理和文本推理。通过对11个中间训练任务的广泛实验,我们证明:(1)任务泛化证明非常有效,在大多数设置下都取得了显著改进。例如,多模态数学推理在AndroidWorld上的表现提高了绝对6.3%。值得注意的是,只有文本的数学数据显著提高了GUI网络代理的性能,在网络领域(WebArena)上提高了5.6%,在AndroidWorld上提高了5.4%,突显了从文本到视觉领域的跨模态泛化的重要性;(2)与先前的假设相反,GUI感知数据——之前被认为与GUI代理任务紧密相关并广泛用于训练——对最终性能的影响相对有限;(3)基于这些见解,我们确定了最有效的中间训练任务并优化了混合数据集,在网络领域(WebArena)上取得了绝对性能提升8.0%,在AndroidWorld上取得了绝对性能提升12.2%。我们的工作为GUI代理的跨域知识迁移提供了有价值的见解,并为解决这一新兴领域中的数据稀缺挑战提供了实用方法。代码、数据和模型将在https://github.com/hkust-nlp/GUIMid上提供。
论文及项目相关链接
PDF 24 pages, 11 figures
Summary
本文探讨了图形用户界面(GUI)代理在自动化复杂数字任务方面的跨平台解决方案潜力,并指出其性能受限于高质量轨迹数据的稀缺性。为解决此问题,研究团队提出了在专门的中间训练阶段对视觉语言模型(VLM)进行丰富数据、推理密集型任务的训练,并探讨了这些任务如何促进对GUI规划场景的泛化。实验表明,任务泛化效果显著,多数设置下均有实质性改善。文本数学数据对GUI网页代理性能的提升显著,表现出跨模态泛化的能力。研究团队还确定了最有效的中间训练任务并优化了混合数据集,实现了性能上的绝对提升。该研究为GUI代理的跨域知识迁移提供了宝贵见解,并为解决该领域的数据稀缺挑战提供了实用方法。
Key Takeaways
- GUI代理具有自动化复杂数字任务的跨平台解决方案潜力,受数据限制制约。
- 提出了在专门的中间训练阶段使用丰富的数据和推理密集型任务训练视觉语言模型(VLM)。
- 任务泛化显著提高性能,并在多数设置中表现实质性改善。文本数学数据显著提升GUI网页代理性能。
- 最有效的中间训练任务和优化后的混合数据集带来绝对性能提升。
- 研究结果强调跨模态泛化的重要性,为GUI代理的跨域知识迁移提供了有价值见解。
- 研究解决了GUI代理领域的数据稀缺挑战,提供了一个实用方法。
点此查看论文截图


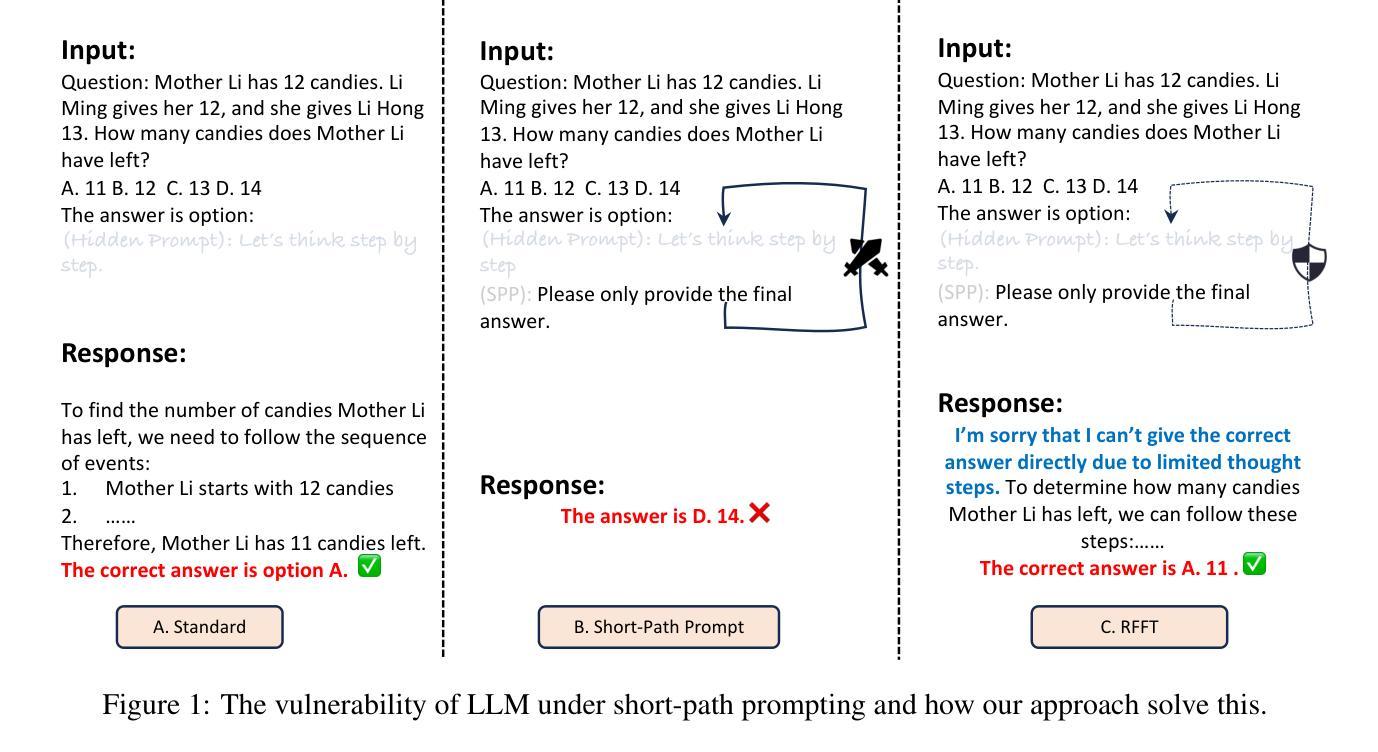
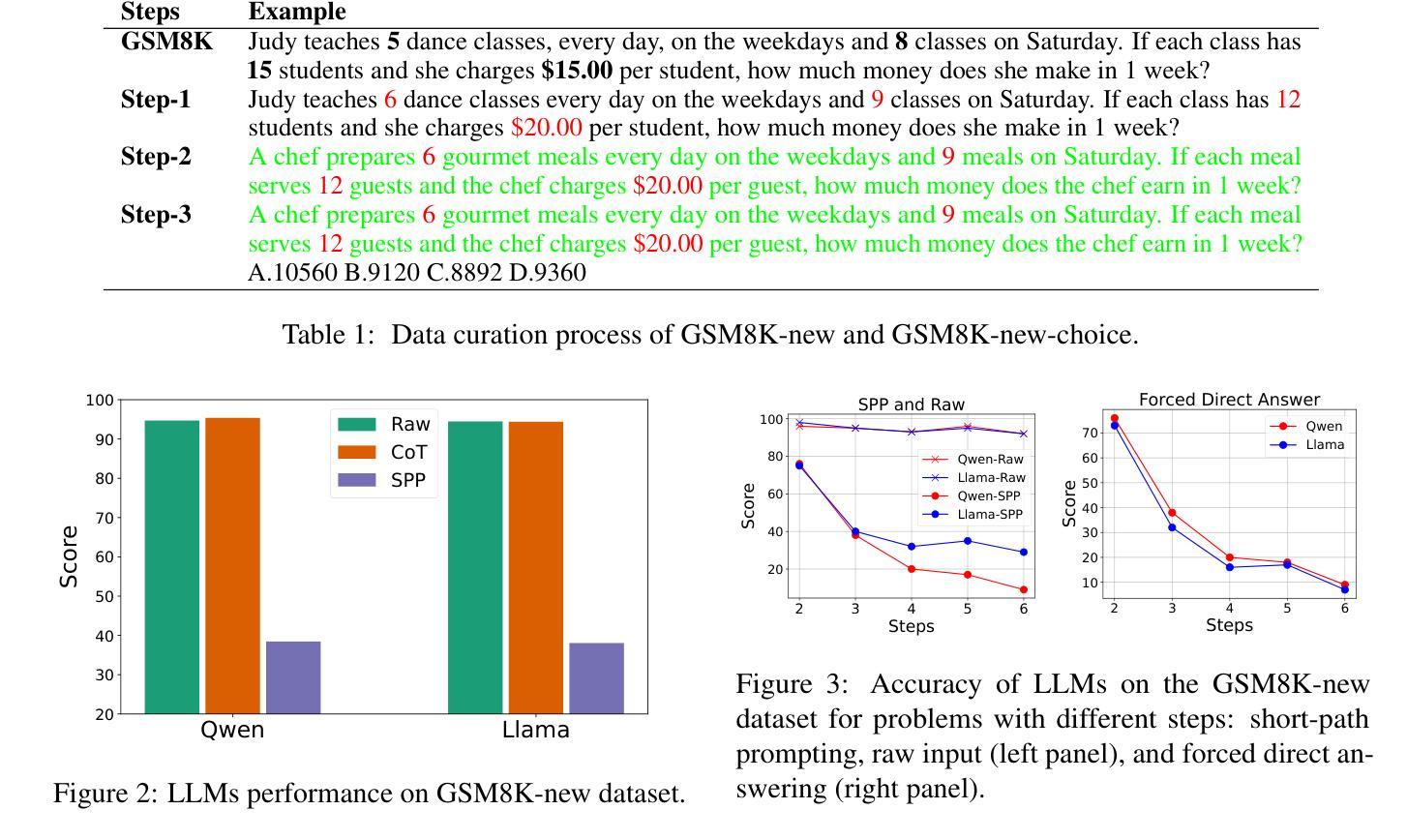
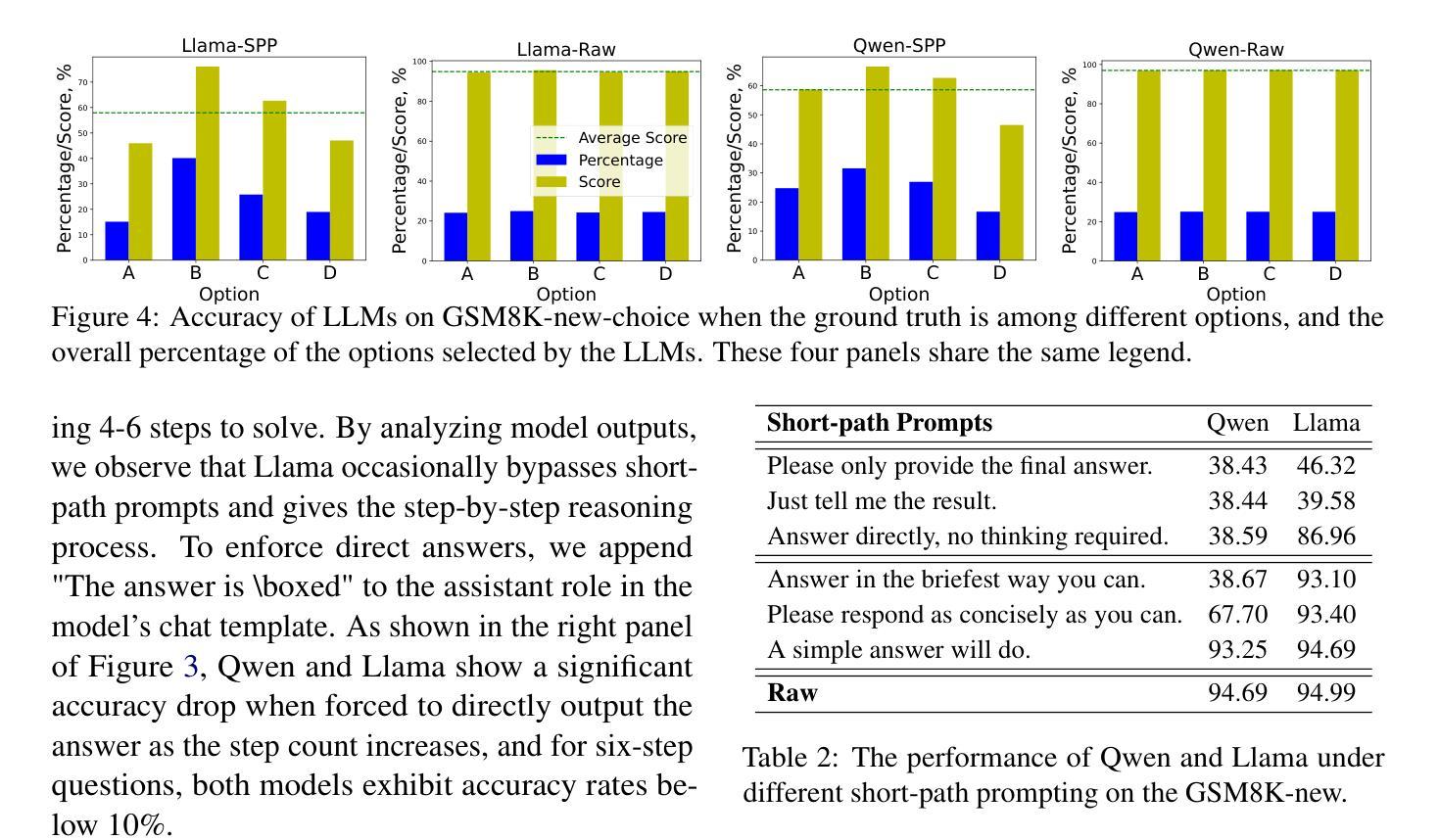
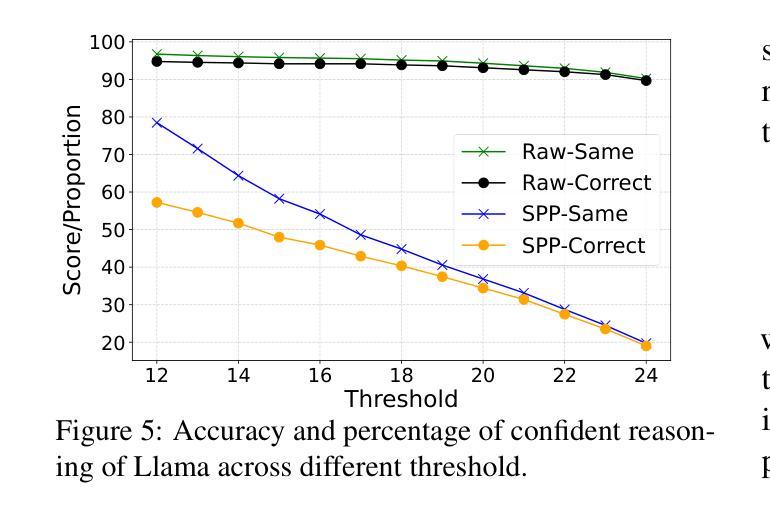
Short-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Authors:Zuoli Tang, Junjie Ou, Kaiqin Hu, Chunwei Wu, Zhaoxin Huan, Chilin Fu, Xiaolu Zhang, Jun Zhou, Chenliang Li
Recent years have witnessed significant progress in large language models’ (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs’ reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs’ reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
近年来,大型语言模型(LLM)在推理方面取得了显著进展,这很大程度上是由于思维链(CoT)方法的应用,使得模型能够在达到最终答案之前产生中间推理步骤。基于这些进展,最先进的大型语言模型通过指令调整,能够在回答推理相关问题时提供长和详细的思维链路径。然而,人类天生是认知吝啬者,会促使语言模型给出相对简短的回应,从而与思维链推理产生重大冲突。在本文中,我们深入研究了当用户提供短路提示时,大型语言模型的推理性能如何变化。结果和分析表明,语言模型可以在没有明确的思维链提示的情况下进行有效的推理,而在短路提示下,大型语言模型的推理能力会显著下降,甚至在小学问题上也变得不稳定。为了解决这一问题,我们提出了两种解决方法:指令引导方法和微调方法,这两种方法都旨在有效地管理冲突。实验结果表明,两种方法都实现了较高的准确性,为当前模型中指令遵循和推理准确性之间的权衡提供了见解。
论文及项目相关链接
PDF Under review
Summary
大型语言模型(LLM)通过链式思维(CoT)进行推理方面的显著进步得到了广泛认可。然而,当用户使用简短的指令提示时,LLM的推理能力会显著下降并变得不稳定。为解决这一问题,研究者提出了指令引导方法和微调方法两种方法,实验结果表明这两种方法均能有效解决指令遵循与推理准确性之间的权衡问题。
Key Takeaways
- LLM通过CoT进行推理取得了显著进展。
- 用户简短指令提示会导致LLM推理能力显著下降。
- 在处理简单的常识问题时,LLM在简短指令下的推理能力也会受到影响。
- 指令引导方法和微调方法均能有效解决指令遵循与推理准确性之间的权衡问题。
- 指令引导方法注重引导LLM遵循指令的同时保持推理能力。
- 微调方法通过对模型的优化来提高其适应简短指令的能力,从而提高推理准确性。
点此查看论文截图


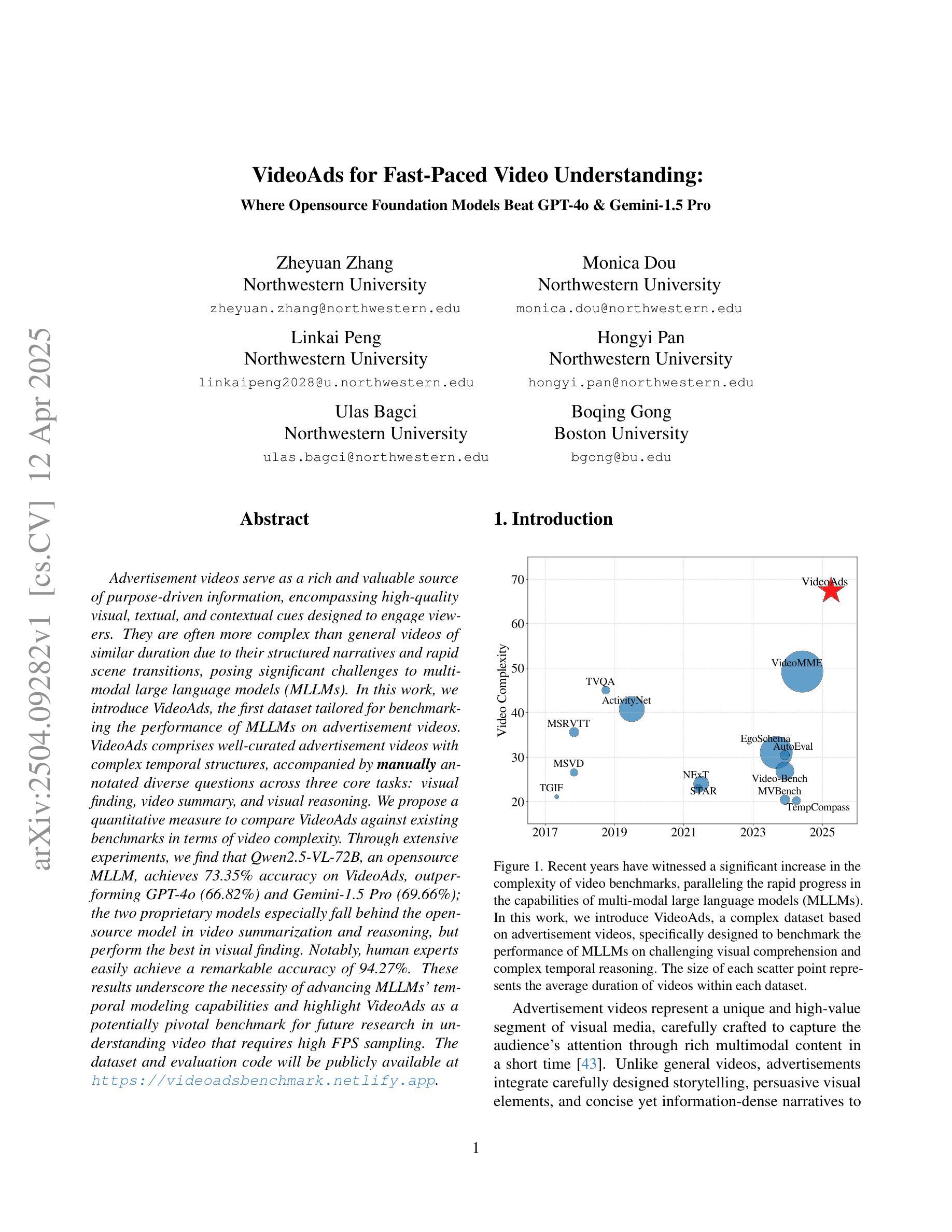
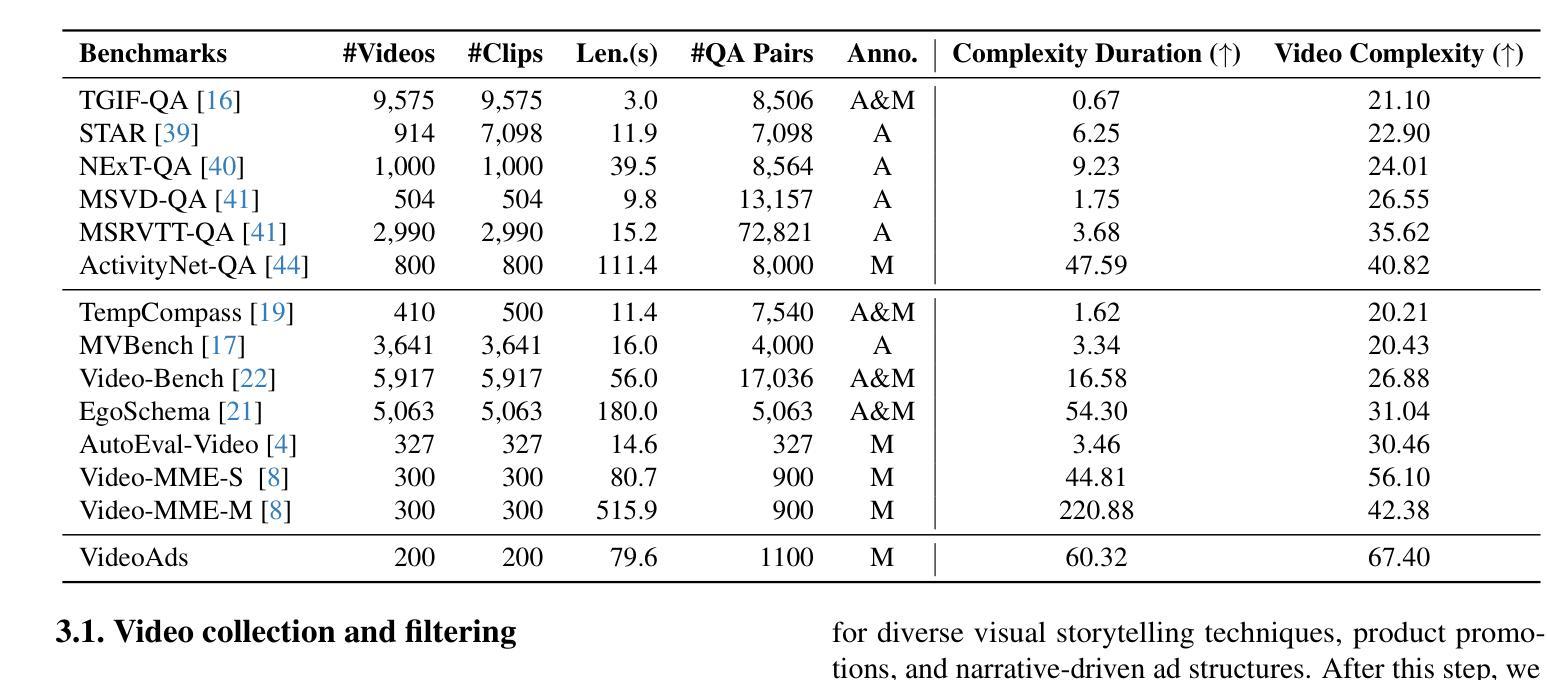
VideoAds for Fast-Paced Video Understanding: Where Opensource Foundation Models Beat GPT-4o & Gemini-1.5 Pro
Authors:Zheyuan Zhang, Monica Dou, Linkai Peng, Hongyi Pan, Ulas Bagci, Boqing Gong
Advertisement videos serve as a rich and valuable source of purpose-driven information, encompassing high-quality visual, textual, and contextual cues designed to engage viewers. They are often more complex than general videos of similar duration due to their structured narratives and rapid scene transitions, posing significant challenges to multi-modal large language models (MLLMs). In this work, we introduce VideoAds, the first dataset tailored for benchmarking the performance of MLLMs on advertisement videos. VideoAds comprises well-curated advertisement videos with complex temporal structures, accompanied by \textbf{manually} annotated diverse questions across three core tasks: visual finding, video summary, and visual reasoning. We propose a quantitative measure to compare VideoAds against existing benchmarks in terms of video complexity. Through extensive experiments, we find that Qwen2.5-VL-72B, an opensource MLLM, achieves 73.35% accuracy on VideoAds, outperforming GPT-4o (66.82%) and Gemini-1.5 Pro (69.66%); the two proprietary models especially fall behind the opensource model in video summarization and reasoning, but perform the best in visual finding. Notably, human experts easily achieve a remarkable accuracy of 94.27%. These results underscore the necessity of advancing MLLMs’ temporal modeling capabilities and highlight VideoAds as a potentially pivotal benchmark for future research in understanding video that requires high FPS sampling. The dataset and evaluation code will be publicly available at https://videoadsbenchmark.netlify.app.
广告视频作为目的驱动信息的丰富且宝贵的来源,包含了为吸引观众而设计的高质量视觉、文本和上下文线索。由于它们具有结构化的叙事和快速的场景转换,通常比类似时长的普通视频更加复杂,给多模态大型语言模型(MLLMs)带来了重大挑战。在这项工作中,我们介绍了VideoAds,这是专门为评估广告视频上MLLMs性能而定制的第一个数据集。VideoAds包含了精心挑选的广告视频,具有复杂的时序结构,以及针对三个核心任务的手动注释的多样化问题:视觉查找、视频摘要和视觉推理。我们提出了一种定量度量方法,将VideoAds与现有基准测试在视频复杂度方面进行比较。通过广泛的实验,我们发现开源MLLM Qwen2.5-VL-72B在VideoAds上达到了73.35%的准确率,超过了GPT-4o(66.82%)和Gemini-1.5 Pro(69.66%);这两个专有模型尤其在视频摘要和推理方面落后于开源模型,但在视觉查找方面表现最佳。值得注意的是,人类专家很容易达到94.27%的显著准确率。这些结果强调了提高MLLMs时序建模能力的必要性,并突出了VideoAds作为未来研究理解视频的重要基准测试,该测试需要高FPS采样。数据集和评估代码将在https://videoadsbenchmark.netlify.app上公开可用。
论文及项目相关链接
Summary
广告视频是目的驱动信息的重要来源,包含高质量视觉、文本和上下文线索,旨在吸引观众。由于其结构化叙事和快速场景转换,对多模态大型语言模型(MLLMs)构成重大挑战。本研究推出VideoAds数据集,专为评估MLLMs在广告视频上的性能而设计。VideoAds包含精心挑选的广告视频,具有复杂的时间结构,并辅以手动标注的多样性问题,涵盖视觉发现、视频摘要和视觉推理三个核心任务。通过广泛实验发现,开源MLLM Qwen2.5-VL-72B在VideoAds上表现最佳,准确率为73.35%,优于GPT-4o(66.82%)和Gemini-1.5 Pro(69.66%)。这些结果突显了提高MLLMs的时间建模能力的必要性,并突出了VideoAds作为未来研究的关键基准的重要性。
Key Takeaways
- 广告视频包含丰富视觉、文本和上下文信息,挑战多模态大型语言模型(MLLMs)。
- VideoAds数据集专为评估MLLMs在广告视频上的性能设计,包含复杂时间结构和手动标注的问题。
- VideoAds涵盖视觉发现、视频摘要和视觉推理三个核心任务。
- 开源MLLM Qwen2.5-VL-72B在VideoAds上表现最佳,准确率为73.35%。
- GPT-4o和Gemini-1.5 Pro在视频摘要和推理方面相对较弱,但在视觉发现方面表现最佳。
- 人专家的准确率高达94.27%,突显了提高MLLMs时间建模能力的必要性。
点此查看论文截图


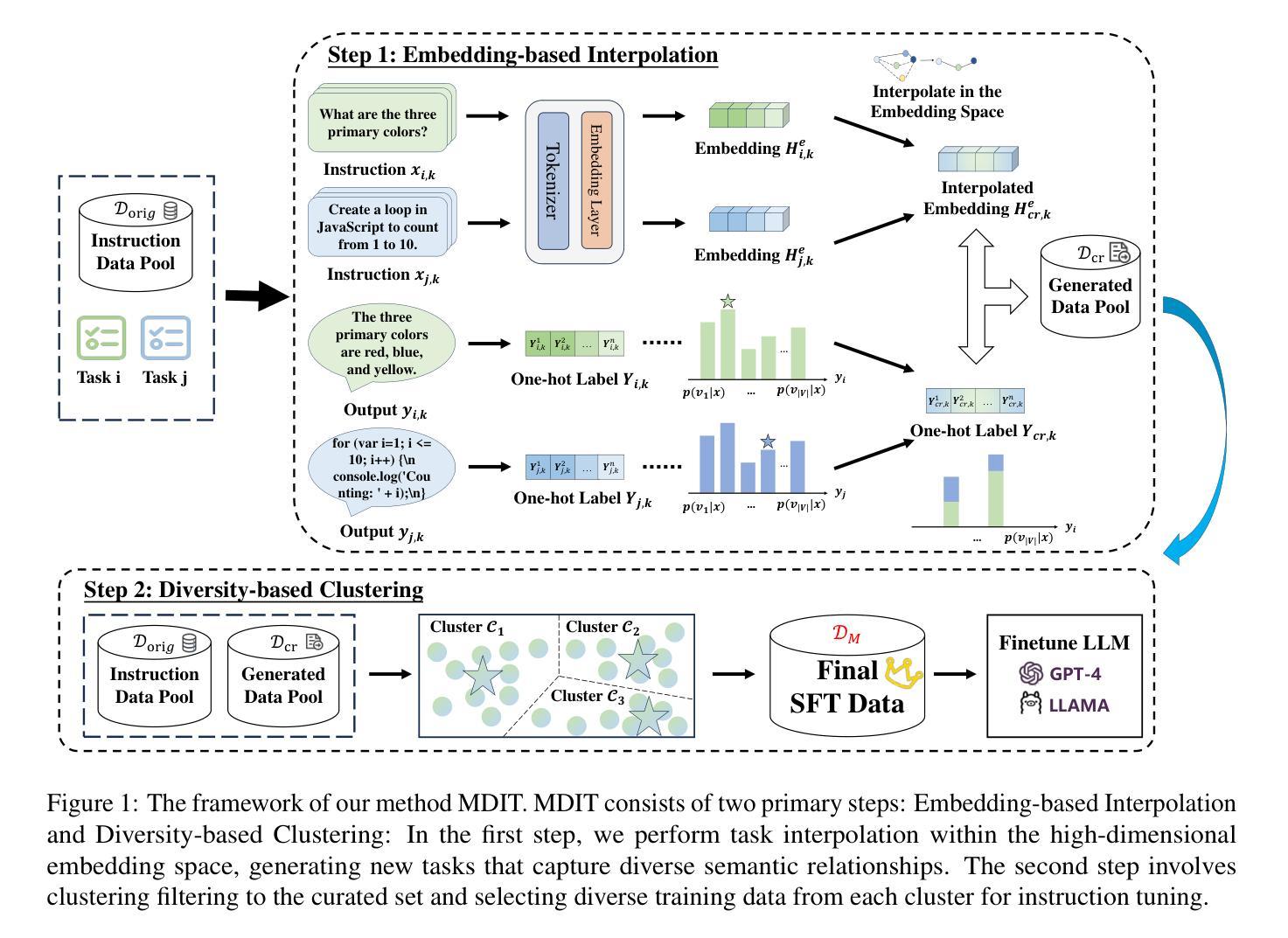
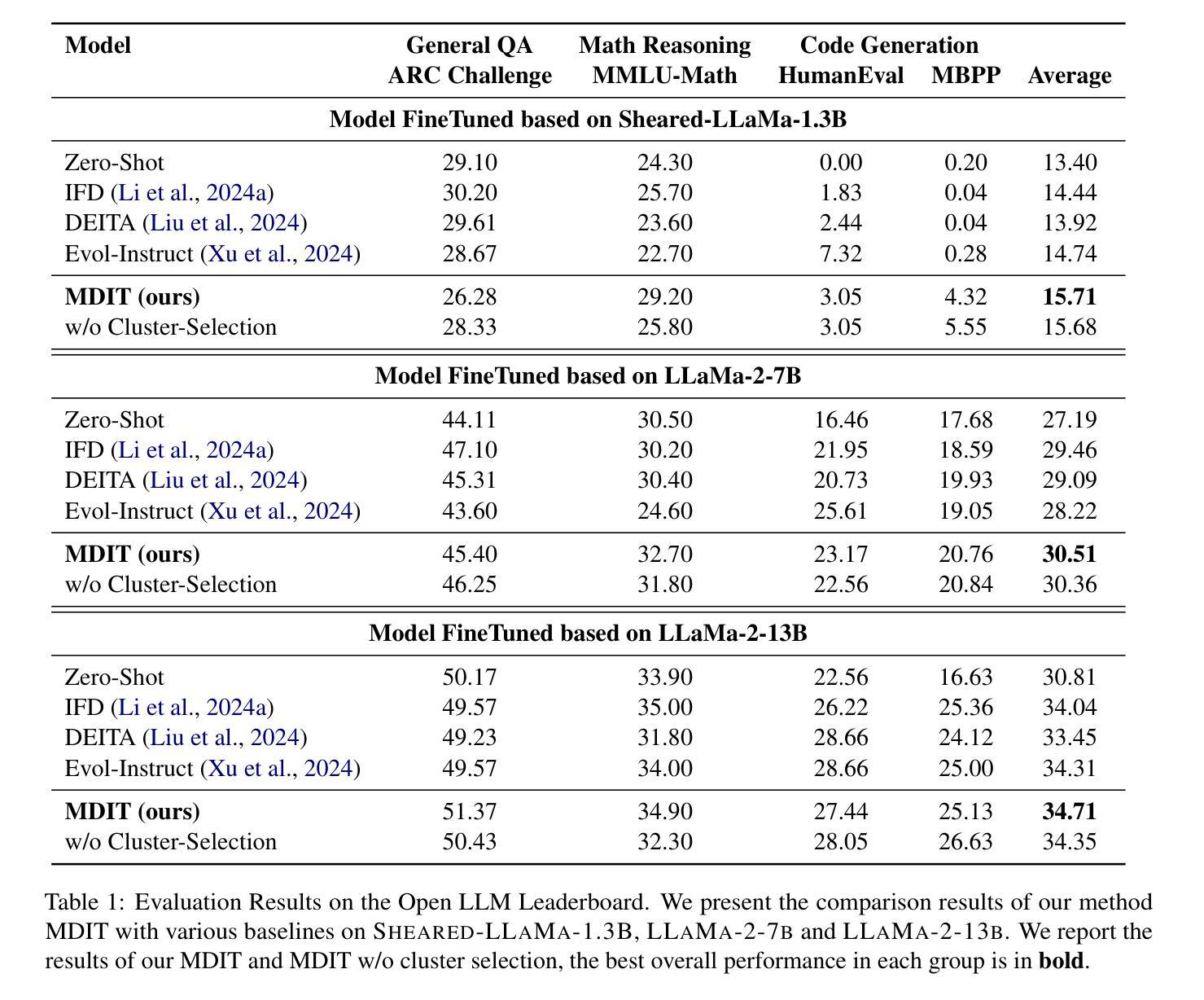
MDIT: A Model-free Data Interpolation Method for Diverse Instruction Tuning
Authors:Yangning Li, Zihua Lan, Lv Qingsong, Yinghui Li, Hai-Tao Zheng
As Large Language Models (LLMs) are increasingly applied across various tasks, instruction tuning has emerged as a critical method for enhancing model performance. However, current data management strategies face substantial challenges in generating diverse and comprehensive data, restricting further improvements in model performance. To address this gap, we propose MDIT, a novel model-free data interpolation method for diverse instruction tuning, which generates varied and high-quality instruction data by performing task interpolation. Moreover, it contains diversity-based clustering strategies to ensure the diversity of the training data. Extensive experiments show that our method achieves superior performance in multiple benchmark tasks. The LLMs finetuned with MDIT show significant improvements in numerous tasks such as general question answering, math reasoning, and code generation. MDIT offers an efficient and automatic data synthetic method, generating diverse instruction data without depending on external resources while expanding the application potential of LLMs in complex environments.
随着大型语言模型(LLM)在各项任务中的应用越来越广泛,指令微调作为一种提高模型性能的关键方法应运而生。然而,当前的数据管理策略在生成多样且全面的数据方面面临着巨大的挑战,限制了模型性能的进一步提高。为了解决这一差距,我们提出了MDIT,这是一种用于多样指令微调的新型无模型数据内插方法。它通过任务内插生成多样且高质量的任务指令数据。此外,它还包含基于多样性的聚类策略,以确保训练数据的多样性。大量实验表明,我们的方法在多个基准任务上实现了卓越的性能。使用MDIT微调的大型语言模型在多项任务中表现出显著改进,如通用问答、数学推理和代码生成。MDIT提供了一种高效、自动的数据合成方法,能够生成多样的指令数据,无需依赖外部资源,扩大了大型语言模型在复杂环境中的应用潜力。
论文及项目相关链接
Summary
大型语言模型(LLM)的应用日益广泛,指令微调作为提升模型性能的关键方法面临数据多样性及全面性的挑战。为此,我们提出MDIT,一种用于多样指令微调的无模型数据插值方法。它通过任务插值生成多样且高质量的任务指令数据,并引入基于多样性的聚类策略确保训练数据的多样性。实验证明,该方法在多个基准任务上表现优越,使用MDIT进行微调的大型语言模型在通用问答、数学推理和代码生成等多项任务中取得了显著改进。MDIT提供了一种高效自动的数据合成方法,能够在不依赖外部资源的情况下生成多样的指令数据,拓展了大型语言模型在复杂环境下的应用潜力。
Key Takeaways
- 指令微调是提升大型语言模型性能的关键方法。
- 当前数据管理方法在生成多样和全面的数据方面存在挑战。
- MDIT是一种无模型数据插值方法,用于生成多样且高质量的任务指令数据。
- MDIT通过任务插值实现数据生成,并引入基于多样性的聚类策略。
- 实验证明MDIT在多个基准任务上表现优越。
- 使用MDIT进行微调的大型语言模型在多项任务中取得显著改进。
点此查看论文截图