⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-17 更新
GestureCoach: Rehearsing for Engaging Talks with LLM-Driven Gesture Recommendations
Authors:Ashwin Ram, Varsha Suresh, Artin Saberpour Abadian, Vera Demberg, Jürgen Steimle
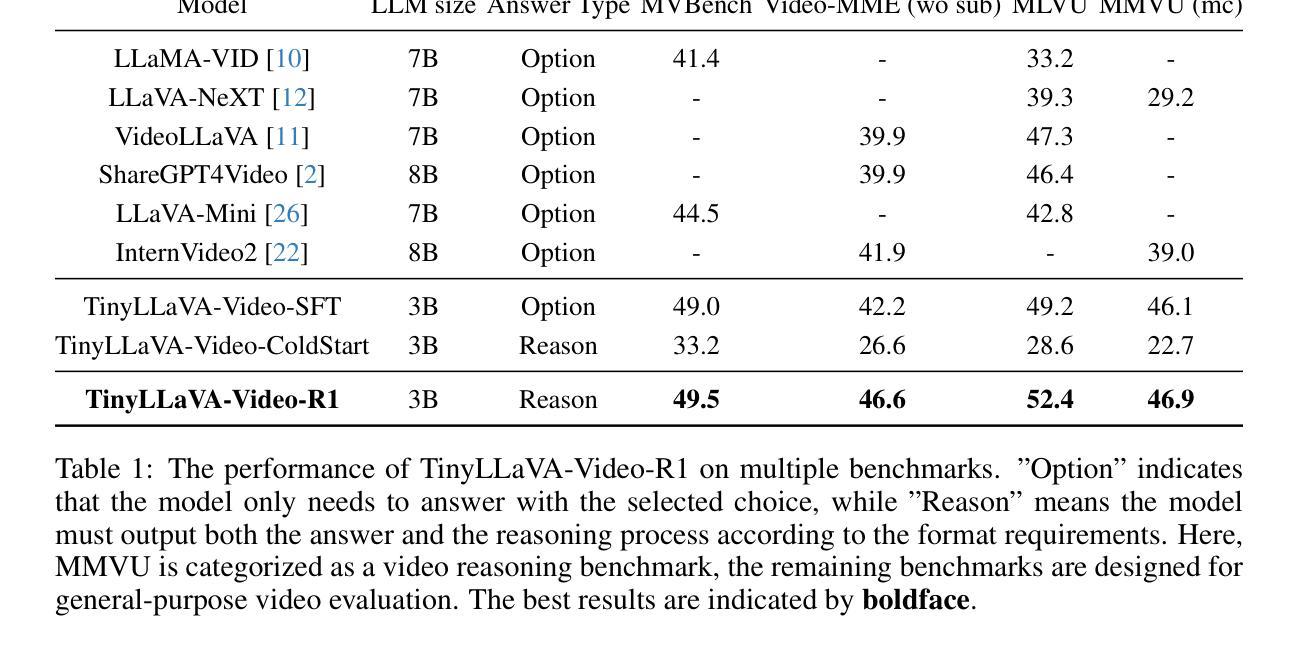
This paper introduces GestureCoach, a system designed to help speakers deliver more engaging talks by guiding them to gesture effectively during rehearsal. GestureCoach combines an LLM-driven gesture recommendation model with a rehearsal interface that proactively cues speakers to gesture appropriately. Trained on experts’ gesturing patterns from TED talks, the model consists of two modules: an emphasis proposal module, which predicts when to gesture by identifying gesture-worthy text segments in the presenter notes, and a gesture identification module, which determines what gesture to use by retrieving semantically appropriate gestures from a curated gesture database. Results of a model performance evaluation and user study (N=30) show that the emphasis proposal module outperforms off-the-shelf LLMs in identifying suitable gesture regions, and that participants rated the majority of these predicted regions and their corresponding gestures as highly appropriate. A subsequent user study (N=10) showed that rehearsing with GestureCoach encouraged speakers to gesture and significantly increased gesture diversity, resulting in more engaging talks. We conclude with design implications for future AI-driven rehearsal systems.
本文介绍了GestureCoach系统,该系统旨在通过指导演讲者在排练过程中进行有效的手势辅助,帮助演讲者进行更有吸引力的演讲。GestureCoach结合了一个由大型语言模型驱动的手势推荐模型和一个排练界面,该界面会主动提示演讲者进行适当的手势。该模型以TED演讲中专家手势模式为训练数据,包含两个模块:重点提案模块,通过识别演讲笔记中值得手势的文本片段来预测何时进行手势;手势识别模块,通过从精选的手势数据库中检索语义适当的手势来确定应使用何种手势。模型性能评估和用户研究(N=30)的结果表明,重点提案模块在识别合适的手势区域方面优于现有的大型语言模型,大多数参与者认为这些预测区域及其对应的手势高度合适。随后的用户研究(N=10)表明,使用GestureCoach排练鼓励演讲者进行手势,并显著增加了手势的多样性,从而使演讲更加引人入胜。最后,我们总结了对未来AI驱动排练系统的设计启示。
论文及项目相关链接
Summary
本文介绍了GestureCoach系统,该系统通过引导演讲者在排练过程中进行有效的手势,帮助演讲者进行更具吸引力的演讲。GestureCoach结合了LLM驱动的手势推荐模型与排练界面,提前提示演讲者进行适当的手势。该模型基于TED演讲专家的手势模式训练,包含两个模块:重点提示模块,通过识别值得手势的文本片段来预测何时进行手势;手势识别模块,通过从精选的手势数据库中检索语义适当的手势来确定应使用何种手势。模型性能评估和用户研究(N=30)结果显示,重点提示模块在识别合适的手势区域方面表现优于现有的LLM,并且大多数参与者认为这些预测区域及其对应的手势高度合适。后续的用户研究(N=10)显示,使用GestureCoach排练鼓励演讲者进行手势,并显著增加了手势的多样性,使演讲更加引人入胜。
Key Takeaways
- GestureCoach系统旨在通过引导演讲者的手势提高其演讲的吸引力。
- 系统结合了LLM驱动的手势推荐模型和排练界面。
- 模型由两个模块组成:重点提示模块和手势识别模块。
- 重点提示模块通过识别值得手势的文本片段来预测手势时机。
- 手势识别模块从精选数据库中检索适当手势。
- 模型性能评估和初步用户研究显示,系统能有效提示演讲者进行合适的手势。
点此查看论文截图



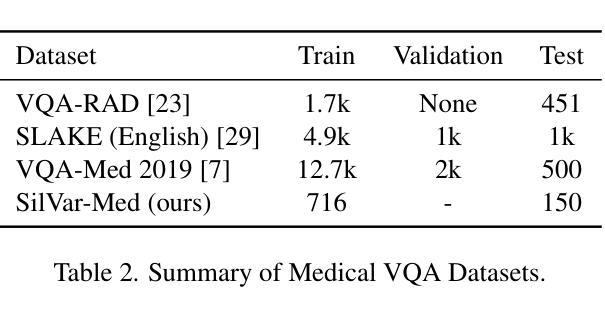
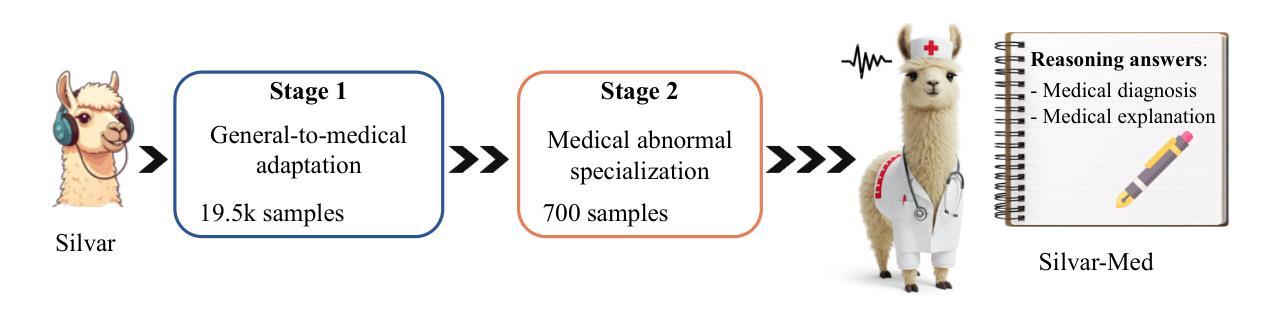
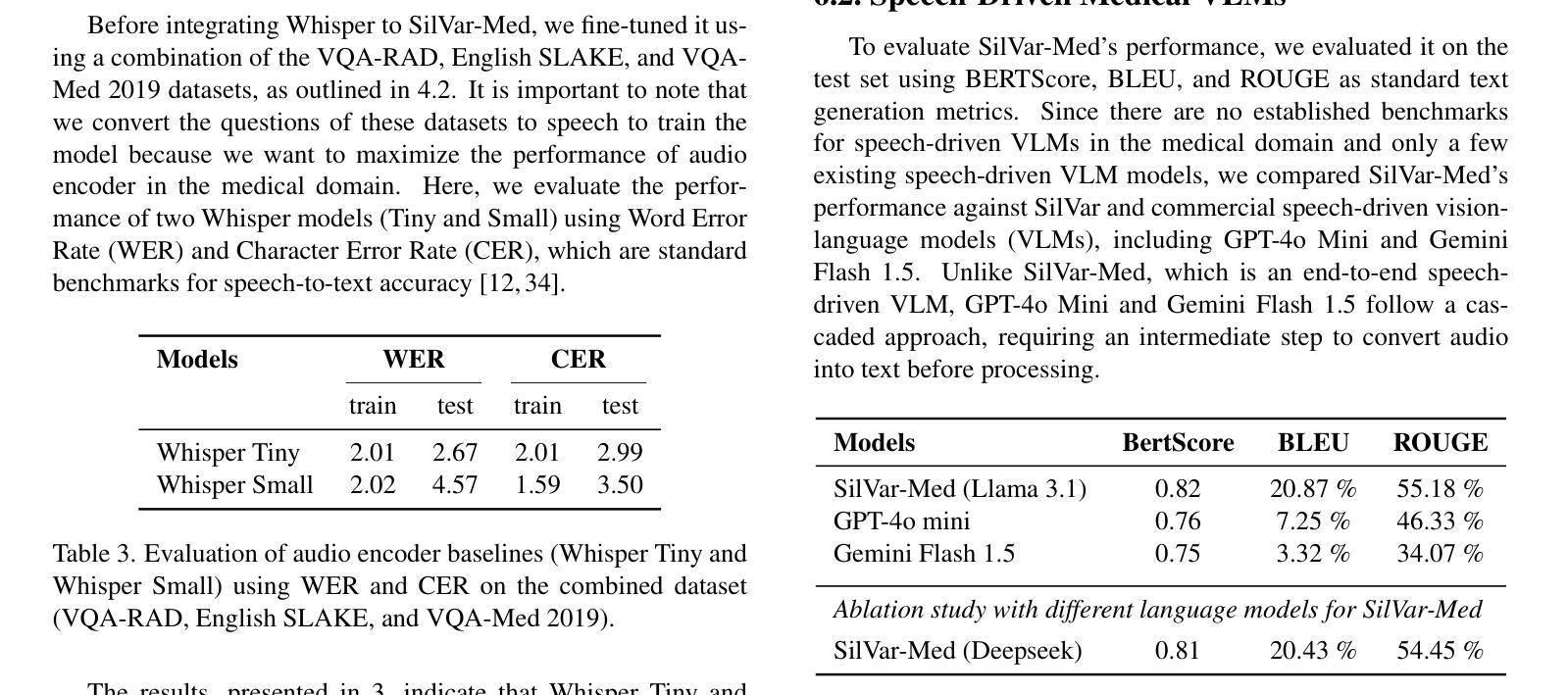
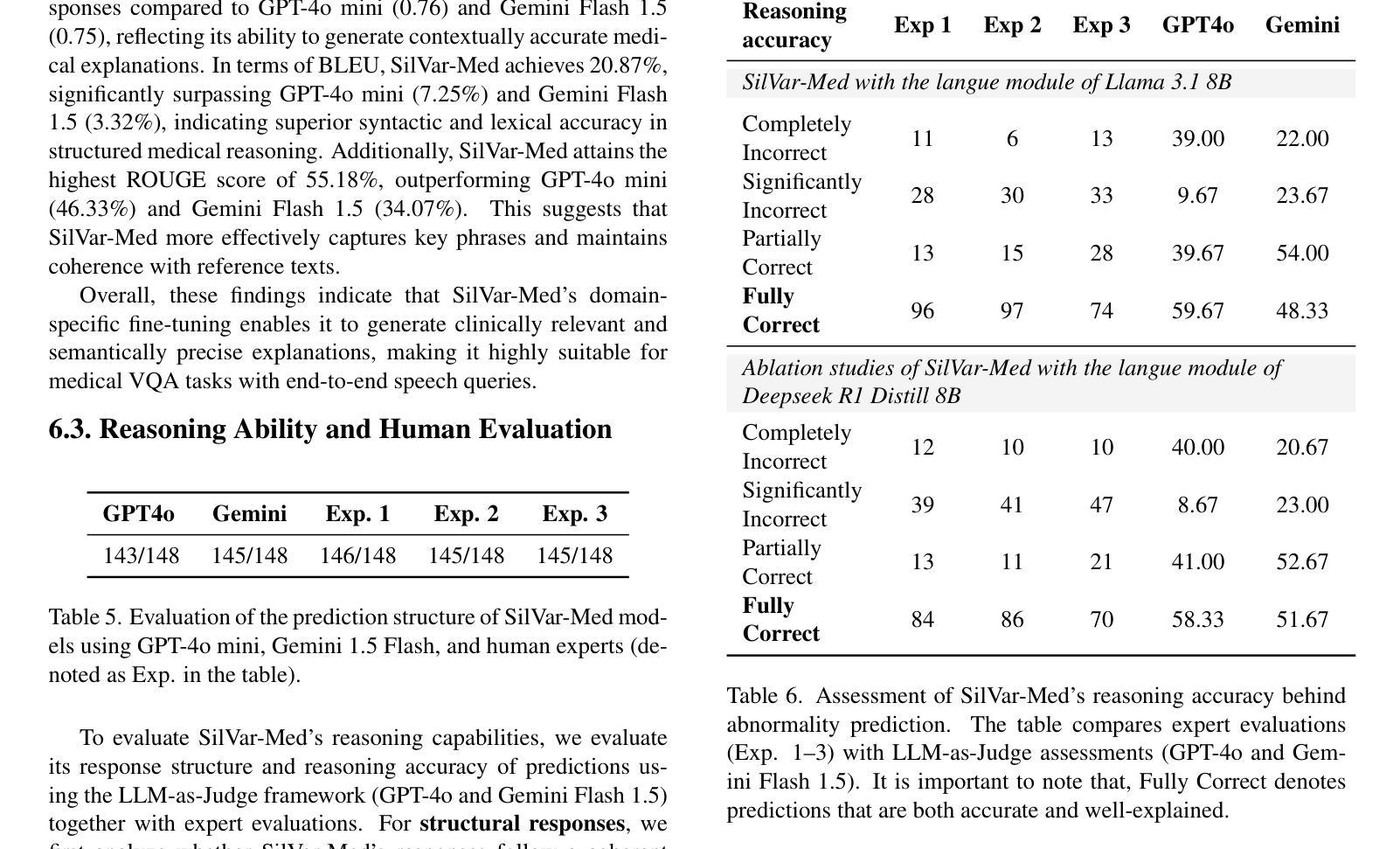
SilVar-Med: A Speech-Driven Visual Language Model for Explainable Abnormality Detection in Medical Imaging
Authors:Tan-Hanh Pham, Chris Ngo, Trong-Duong Bui, Minh Luu Quang, Tan-Huong Pham, Truong-Son Hy
Medical Visual Language Models have shown great potential in various healthcare applications, including medical image captioning and diagnostic assistance. However, most existing models rely on text-based instructions, limiting their usability in real-world clinical environments especially in scenarios such as surgery, text-based interaction is often impractical for physicians. In addition, current medical image analysis models typically lack comprehensive reasoning behind their predictions, which reduces their reliability for clinical decision-making. Given that medical diagnosis errors can have life-changing consequences, there is a critical need for interpretable and rational medical assistance. To address these challenges, we introduce an end-to-end speech-driven medical VLM, SilVar-Med, a multimodal medical image assistant that integrates speech interaction with VLMs, pioneering the task of voice-based communication for medical image analysis. In addition, we focus on the interpretation of the reasoning behind each prediction of medical abnormalities with a proposed reasoning dataset. Through extensive experiments, we demonstrate a proof-of-concept study for reasoning-driven medical image interpretation with end-to-end speech interaction. We believe this work will advance the field of medical AI by fostering more transparent, interactive, and clinically viable diagnostic support systems. Our code and dataset are publicly available at SiVar-Med.
医疗视觉语言模型在各种医疗保健应用中显示出巨大潜力,包括医学图像标注和诊断辅助。然而,大多数现有模型依赖于基于文本的指令,限制了它们在现实世界临床环境中的实用性,特别是在手术等场景中,基于文本的交互对医生来说通常不切实际。此外,当前的医学图像分析模型通常缺乏预测背后的全面推理,这降低了它们在临床决策中的可靠性。考虑到医疗诊断错误可能会带来改变生命的后果,迫切需要可解释和合理的医疗辅助。为了应对这些挑战,我们引入了一种端到端的语音驱动医疗VLM(视觉语言模型)SilVar-Med,这是一个多模式医学图像助理,它将语音交互与VLM相结合,率先为医学图像分析实现基于语音的沟通。此外,我们专注于解释医学异常预测背后的推理,并推出了一个提议的推理数据集。通过广泛的实验,我们证明了以推理驱动的医疗图像解释与端到端语音交互的概念研究。我们相信这项工作将通过促进更透明、互动和临床可行的诊断支持系统来推动医疗人工智能领域的发展。我们的代码和数据集可在SiVar-Med上公开获得。
论文及项目相关链接
PDF CVPR Multimodal Algorithmic Reasoning Workshop 2025 - SilVarMed
摘要
医学视觉语言模型在医疗应用的各个方面展现出了巨大的潜力,包括医学图像标注和诊断辅助。然而,大多数现有模型依赖于文本指令,在现实世界中的临床环境,特别是在手术等场景中,文本交互对于医生来说往往不切实际。此外,当前的医学图像分析模型通常缺乏对其预测的全面理解,降低了它们在临床决策中的可靠性。考虑到医疗诊断错误可能会带来改变生命的后果,因此需要一种可解释和合理的医疗辅助。针对这些挑战,我们提出了一种端到端的语音驱动医疗VLM模型——SilVar-Med,这是一种将语音交互与VLM集成的多模式医学图像辅助工具,率先在医学图像分析中完成基于语音的通信任务。此外,我们还专注于对每个医学异常预测的推理进行解释,并引入了相关的推理数据集。通过大量实验,我们验证了以推理驱动医学图像解释的端到端语音交互的概念可行性研究。我们相信这项工作将推动医疗人工智能的发展,为建立更透明、交互性和实用的诊断支持系统奠定基础。我们的代码和数据集已在SiVar-Med公开可用。
关键见解
- 医疗视觉语言模型在医疗应用中展现出巨大潜力,包括医学图像标注和诊断辅助。
- 现有模型大多依赖于文本指令,这在现实世界的临床环境中可能不切实际。
- 当前医学图像分析模型缺乏全面的预测推理,降低了临床决策中的可靠性。
- 医学诊断错误具有严重后果,需要可解释和合理的医疗辅助。
- 引入了一种新的语音驱动的医学VLM模型——SilVar-Med,结合了语音交互和视觉语言模型。
- SilVar-Med专注于为每个医学异常预测提供解释,并引入了相关的推理数据集。
点此查看论文截图