⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-18 更新
HLS-Eval: A Benchmark and Framework for Evaluating LLMs on High-Level Synthesis Design Tasks
Authors:Stefan Abi-Karam, Cong Hao
The rapid scaling of large language model (LLM) training and inference has driven their adoption in semiconductor design across academia and industry. While most prior work evaluates LLMs on hardware description language (HDL) tasks, particularly Verilog, designers are increasingly using high-level synthesis (HLS) to build domain-specific accelerators and complex hardware systems. However, benchmarks and tooling to comprehensively evaluate LLMs for HLS design tasks remain scarce. To address this, we introduce HLS-Eval, the first complete benchmark and evaluation framework for LLM-driven HLS design. HLS-Eval targets two core tasks: (1) generating HLS code from natural language descriptions, and (2) performing HLS-specific code edits to optimize performance and hardware efficiency. The benchmark includes 94 unique designs drawn from standard HLS benchmarks and novel sources. Each case is prepared via a semi-automated flow that produces a natural language description and a paired testbench for C-simulation and synthesis validation, ensuring each task is “LLM-ready.” Beyond the benchmark, HLS-Eval offers a modular Python framework for automated, parallel evaluation of both local and hosted LLMs. It includes a parallel evaluation engine, direct HLS tool integration, and abstractions for to support different LLM interaction paradigms, enabling rapid prototyping of new benchmarks, tasks, and LLM methods. We demonstrate HLS-Eval through baseline evaluations of open-source LLMs on Vitis HLS, measuring outputs across four key metrics - parseability, compilability, runnability, and synthesizability - reflecting the iterative HLS design cycle. We also report pass@k metrics, establishing clear baselines and reusable infrastructure for the broader LLM-for-hardware community. All benchmarks, framework code, and results are open-sourced at https://github.com/stefanpie/hls-eval.
大型语言模型(LLM)的训练和推理的迅速扩展,推动了其在学术界和工业界半导体设计领域的采用。虽然大多数以前的工作都在硬件描述语言(HDL)任务上评估LLM,尤其是Verilog,但设计师越来越倾向于使用高级综合(HLS)来构建特定领域的加速器和复杂的硬件系统。然而,针对HLS设计任务的LLM进行全面评估的基准测试和工具仍然稀缺。为了解决这一问题,我们引入了HLS-Eval,这是第一个针对LLM驱动的HLS设计的完整基准测试和评价框架。HLS-Eval瞄准两个核心任务:(1)根据自然语言描述生成HLS代码,(2)执行HLS特定的代码编辑,以优化性能和硬件效率。该基准测试包括来自标准HLS基准测试和新颖来源的94个独特设计。每个案例都通过半自动化流程进行准备,该流程产生自然语言描述和配套测试平台,用于C仿真和综合验证,确保每个任务都适合LLM。除了基准测试外,HLS-Eval还提供了一个模块化的Python框架,用于对本地和托管LLM进行自动化并行评估。它包括一个并行评估引擎、直接HLS工具集成,以及支持不同LLM交互范式的抽象,能够迅速原型化新的基准测试、任务和方法。我们通过Vitis HLS的开源LLM基线评估来展示HLS-Eval,测量四个关键指标——解析性、可编译性、运行性和可合成性,反映迭代HLS设计周期。我们还报告了pass@k指标,为更广泛的LLM硬件社区建立了明确的基准和可重复使用的架构。所有基准测试、框架代码和结果均已开源,可在https://github.com/stefanpie/hls-eval找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在半导体设计领域的应用日益广泛,特别是在高层次的合成(HLS)设计任务中。然而,针对LLM在HLS设计任务的全面评估的基准测试和工具仍然稀缺。为解决这一问题,我们推出了HLS-Eval,这是第一个针对LLM驱动的HLS设计的完整基准测试和评估框架。它主要针对两个核心任务:1)根据自然语言描述生成HLS代码;2)执行HLS特定的代码优化以提高性能和硬件效率。该基准测试包括94个独特的设计,每个设计都经过半自动化流程准备,包括自然语言描述和配套测试平台,以确保每个任务都适合LLM。此外,HLS-Eval还提供模块化Python框架,可自动并行评估本地和托管LLM。通过公开源代码和基线评估结果,我们为更广泛的LLM硬件社区建立了清晰的基准线和可重复使用的基础设施。
Key Takeaways
- LLM在半导体设计领域,特别是在HLS设计任务中的应用越来越广泛。
- 目前针对LLM在HLS设计任务的全面评估的基准测试和工具仍然稀缺。
- HLS-Eval是第一个针对LLM驱动的HLS设计的基准测试和评估框架。
- HLS-Eval主要针对生成HLS代码和执行HLS代码优化两个核心任务。
- 该基准测试包括94个独特的设计,涵盖自然语言描述和配套测试平台。
- HLS-Eval提供模块化Python框架,可自动并行评估LLM。
点此查看论文截图

FLIP Reasoning Challenge
Authors:Andreas Plesner, Turlan Kuzhagaliyev, Roger Wattenhofer
Over the past years, advances in artificial intelligence (AI) have demonstrated how AI can solve many perception and generation tasks, such as image classification and text writing, yet reasoning remains a challenge. This paper introduces the FLIP dataset, a benchmark for evaluating AI reasoning capabilities based on human verification tasks on the Idena blockchain. FLIP challenges present users with two orderings of 4 images, requiring them to identify the logically coherent one. By emphasizing sequential reasoning, visual storytelling, and common sense, FLIP provides a unique testbed for multimodal AI systems. Our experiments evaluate state-of-the-art models, leveraging both vision-language models (VLMs) and large language models (LLMs). Results reveal that even the best open-sourced and closed-sourced models achieve maximum accuracies of 75.5% and 77.9%, respectively, in zero-shot settings, compared to human performance of 95.3%. Captioning models aid reasoning models by providing text descriptions of images, yielding better results than when using the raw images directly, 69.6% vs. 75.2% for Gemini 1.5 Pro. Combining the predictions from 15 models in an ensemble increases the accuracy to 85.2%. These findings highlight the limitations of existing reasoning models and the need for robust multimodal benchmarks like FLIP. The full codebase and dataset will be available at https://github.com/aplesner/FLIP-Reasoning-Challenge.
近年来,人工智能(AI)的进展已经证明AI如何解决许多感知和生成任务,例如图像分类和文本写作,但推理仍然是一个挑战。本文介绍了FLIP数据集,这是一个基于Idena区块链上的人类验证任务的AI推理能力评估的基准测试。FLIP挑战向用户呈现两个包含4张图片的顺序,要求他们识别出逻辑连贯的那一个。通过强调顺序推理、视觉叙事和常识,FLIP为多模式AI系统提供了独特的测试平台。我们的实验评估了最先进的技术模型,利用视觉语言模型(VLM)和大型语言模型(LLM)。结果显示,即使在零样本设置下,最好的开源和闭源模型分别达到了75.5%和77.9%的最高准确率,而人类的表现则为95.3%。描述模型通过提供图像的文字描述来辅助推理模型,比直接使用原始图像获得更好的结果,Gemini 1.5 Pro的准确率从69.6%提高到75.2%。通过结合15个模型的预测结果,集成方法的准确率提高到85.2%。这些发现突显了现有推理模型的局限性以及对像FLIP这样的稳健多模式基准测试的需求。完整的代码库和数据集将在https://github.com/aplesner/FLIP-Reasoning-Challenge上提供。
论文及项目相关链接
PDF Published at First Workshop on Open Science for Foundation Models at ICLR 2025
摘要
本文介绍了基于人类验证任务在Idena区块链上的FLIP数据集,该数据集旨在评估人工智能推理能力。FLIP挑战要求用户识别两个逻辑连贯的图像序列中的哪一个更合理。通过强调顺序推理、视觉叙事和常识,FLIP为多模态AI系统提供了独特的测试平台。实验评估了最先进的模型,包括视觉语言模型和大语言模型。结果显示,在零样本设置中,即使最好的开源和闭源模型也只能达到最高约77.9%的准确性,与人类表现存在差距(人类表现约为95.3%)。提供图像文本描述的模型有助于提高推理模型的准确性。结合多个模型的预测结果,准确性可达约85.2%。这突显了现有推理模型的局限性以及对像FLIP这样的稳健多模态基准测试的需求。
关键见解
- FLIP数据集是一个基于人类验证任务的AI推理能力基准测试,强调顺序推理、视觉叙事和常识。
- 最先进的模型在FLIP数据集上的表现仍有限,与人类表现存在显著差距。
- 提供图像文本描述的模型有助于提高推理模型的准确性。
- 结合多个模型的预测结果可以提高准确性。
- FLIP数据集突出了现有推理模型的局限性。
- 需要更多像FLIP这样的稳健多模态基准测试来评估AI的推理能力。
点此查看论文截图

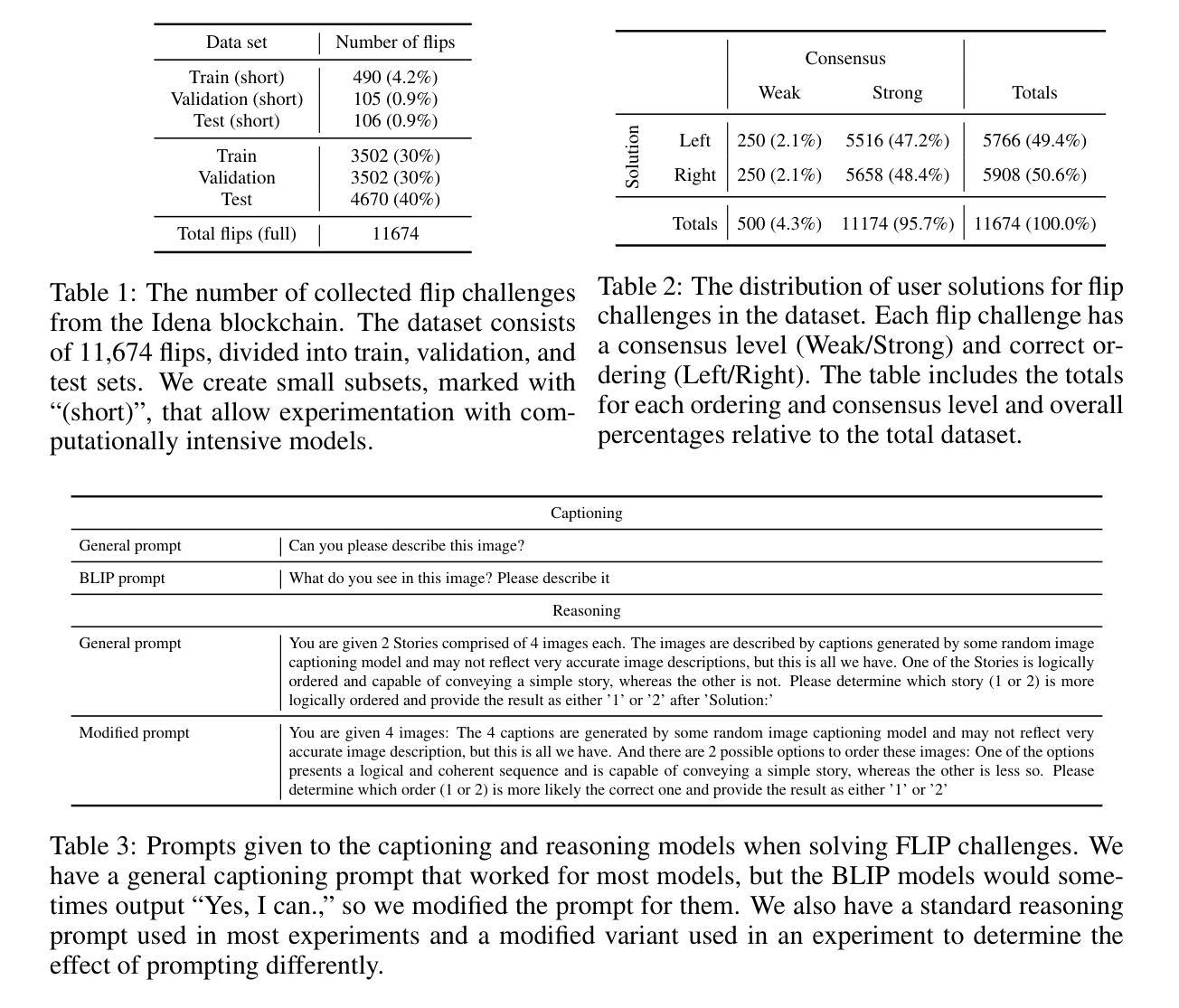
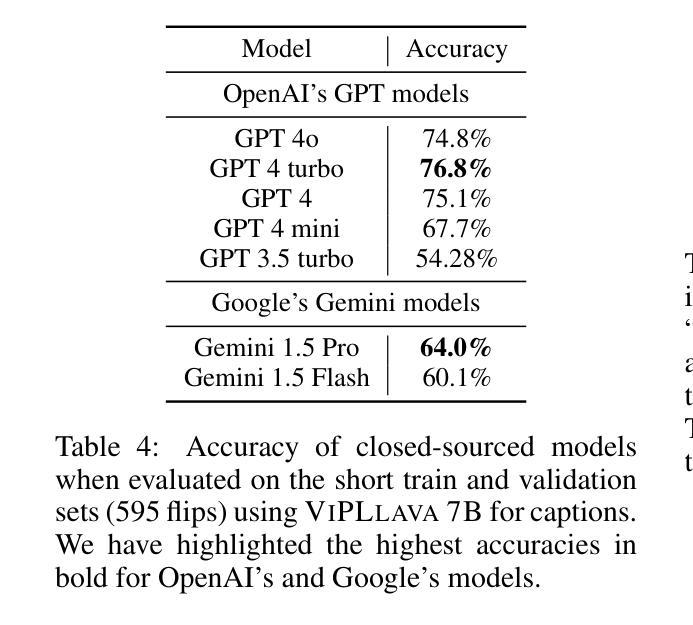
AnomalyGen: An Automated Semantic Log Sequence Generation Framework with LLM for Anomaly Detection
Authors:Xinyu Li, Yingtong Huo, Chenxi Mao, Shiwen Shan, Yuxin Su, Dan Li, Zibin Zheng
The scarcity of high-quality public log datasets has become a critical bottleneck in advancing log-based anomaly detection techniques. Current datasets exhibit three fundamental limitations: (1) incomplete event coverage, (2) artificial patterns introduced by static analysis-based generation frameworks, and (3) insufficient semantic awareness. To address these challenges, we present AnomalyGen, the first automated log synthesis framework specifically designed for anomaly detection. Our framework introduces a novel four-phase architecture that integrates enhanced program analysis with Chain-of-Thought reasoning (CoT reasoning), enabling iterative log generation and anomaly annotation without requiring physical system execution. Evaluations on Hadoop and HDFS distributed systems demonstrate that AnomalyGen achieves substantially broader log event coverage (38-95 times improvement over existing datasets) while producing more operationally realistic log sequences compared to static analysis-based approaches. When augmenting benchmark datasets with synthesized logs, we observe maximum F1-score improvements of 3.7% (average 1.8% improvement across three state-of-the-art anomaly detection models). This work not only establishes a high-quality benchmarking resource for automated log analysis but also pioneers a new paradigm for applying large language models (LLMs) in software engineering workflows.
高质量公共日志数据集的稀缺已成为推进基于日志的异常检测技术发展的一个重要瓶颈。当前的数据集存在三个基本局限:(1)事件覆盖不完整,(2)由静态分析生成框架引入的人工模式,(3)语义意识不足。为了解决这些挑战,我们推出了AnomalyGen,这是专门为异常检测设计的第一个自动化日志合成框架。我们的框架引入了一种新颖的四阶段架构,该架构将增强的程序分析与链式思维推理(CoT推理)相结合,能够在无需执行实际系统的情况下实现迭代日志生成和异常标注。在Hadoop和HDFS分布式系统上的评估表明,AnomalyGen实现了更广泛的日志事件覆盖(相对于现有数据集,改进了38-95倍),同时与基于静态分析的方法相比,生成了更贴近实际操作的日志序列。当使用合成日志增强基准数据集时,我们观察到最大F1分数提高了3.7%(在三个最先进的异常检测模型上平均提高了1.8%)。这项工作不仅为自动日志分析建立了高质量基准资源,还开创了将大型语言模型(LLM)应用于软件工程工作流程的新范式。
论文及项目相关链接
Summary
面向日志异常检测的自动生成框架AnomalyGen被提出以解决高质量公开日志数据集稀缺的问题。针对现有数据集存在的三大局限性,该框架采用新型四阶段架构,融合了增强程序分析与Chain-of-Thought推理技术,实现了无需物理系统执行的迭代日志生成与异常标注。在Hadoop和HDFS分布式系统上的评估显示,AnomalyGen实现了广泛的日志事件覆盖度提升(相较于现有数据集提升38至95倍),并能生成更贴近实际操作的日志序列。此外,该框架与基准数据集的合成日志相结合时,最大F1分数提高了3.7%(在三个顶尖异常检测模型上平均提高1.8%)。该研究不仅为自动化日志分析建立了高质量基准资源,还开创了软件工程中应用大型语言模型(LLM)的新范式。
Key Takeaways
- 当前日志数据集存在质量不足的问题,限制了基于日志的异常检测技术进步。
- AnomalyGen框架旨在解决这一瓶颈,为异常检测提供高质量日志数据集。
- AnomalyGen采用新型四阶段架构,融合了增强程序分析与Chain-of-Thought推理技术。
- 该框架实现了广泛的日志事件覆盖度提升,并生成更贴近实际操作的日志序列。
- 与基准数据集结合时,AnomalyGen能够提高异常检测的准确性。
- AnomalyGen为自动化日志分析建立了高质量基准资源。
点此查看论文截图




MOS: Towards Effective Smart Contract Vulnerability Detection through Mixture-of-Experts Tuning of Large Language Models
Authors:Hang Yuan, Lei Yu, Zhirong Huang, Jingyuan Zhang, Junyi Lu, Shiqi Cheng, Li Yang, Fengjun Zhang, Jiajia Ma, Chun Zuo
Smart contract vulnerabilities pose significant security risks to blockchain systems, potentially leading to severe financial losses. Existing methods face several limitations: (1) Program analysis-based approaches rely on predefined patterns, lacking flexibility for new vulnerability types; (2) Deep learning-based methods lack explanations; (3) Large language model-based approaches suffer from high false positives. We propose MOS, a smart contract vulnerability detection framework based on mixture-of-experts tuning (MOE-Tuning) of large language models. First, we conduct continual pre-training on a large-scale smart contract dataset to provide domain-enhanced initialization. Second, we construct a high-quality MOE-Tuning dataset through a multi-stage pipeline combining LLM generation and expert verification for reliable explanations. Third, we design a vulnerability-aware routing mechanism that activates the most relevant expert networks by analyzing code features and their matching degree with experts. Finally, we extend the feed-forward layers into multiple parallel expert networks, each specializing in specific vulnerability patterns. We employ a dual-objective loss function: one for optimizing detection and explanation performance, and another for ensuring reasonable distribution of vulnerability types to experts through entropy calculation. Experiments show that MOS significantly outperforms existing methods with average improvements of 6.32% in F1 score and 4.80% in accuracy. The vulnerability explanations achieve positive ratings (scores of 3-4 on a 4-point scale) of 82.96%, 85.21% and 94.58% for correctness, completeness, and conciseness through human and LLM evaluation.
智能合约漏洞对区块链系统构成重大安全风险,可能导致严重的财务损失。现有方法面临一些局限性:(1)基于程序分析的方法依赖于预定义的模式,对新漏洞类型缺乏灵活性;(2)基于深度学习的方法缺乏解释性;(3)基于大型语言模型的方法存在高误报率。我们提出了MOS,这是一个基于大型语言模型的专家混合调整(MOE-Tuning)的智能合约漏洞检测框架。首先,我们在大规模智能合约数据集上进行持续预训练,以提供领域增强的初始化。其次,我们通过一个多阶段管道构建高质量的MOE-Tuning数据集,结合LLM生成和专家验证,以提供可靠的解释。第三,我们设计了一种漏洞感知路由机制,通过分析代码特征以及与专家的匹配程度来激活最相关的专家网络。最后,我们将前馈层扩展到多个并行专家网络,每个网络专门用于特定的漏洞模式。我们采用双目标损失函数:一个用于优化检测和解释性能,另一个用于通过熵计算确保漏洞类型的合理分配给专家。实验表明,MOS在F1分数和准确率上平均优于现有方法,分别提高了6.32%和4.80%。漏洞解释在正确性、完整性和简洁性方面分别获得了人类和LLM评价的82.96%、85.21%和94.58%的正面评价(四点量表上的3-4分)。
论文及项目相关链接
摘要
基于大型语言模型的混合专家(MOE)调优框架MOS用于智能合约漏洞检测。通过持续预训练、高质量MOE调优数据集构建、漏洞感知路由机制设计以及专家网络的训练等步骤,提高了智能合约漏洞检测的准确性和解释性。实验结果表明,MOS在F1分数和准确率上平均优于现有方法。
关键见解
- 智能合约漏洞对区块链系统构成重大安全风险,可能导致重大金融损失。
- 现有检测方法存在依赖预设模式、缺乏对新漏洞类型的灵活性、缺乏解释性、高误报率等问题。
- 提出基于大型语言模型的混合专家(MOE)调优框架MOS进行智能合约漏洞检测。
- 通过持续预训练提供领域增强初始化,构建高质量MOE调优数据集,实现可靠解释。
- 设计漏洞感知路由机制,通过分析代码特征与专家匹配程度来激活最相关的专家网络。
- 将前馈层扩展到多个并行专家网络,每个网络专门处理特定漏洞模式。
点此查看论文截图

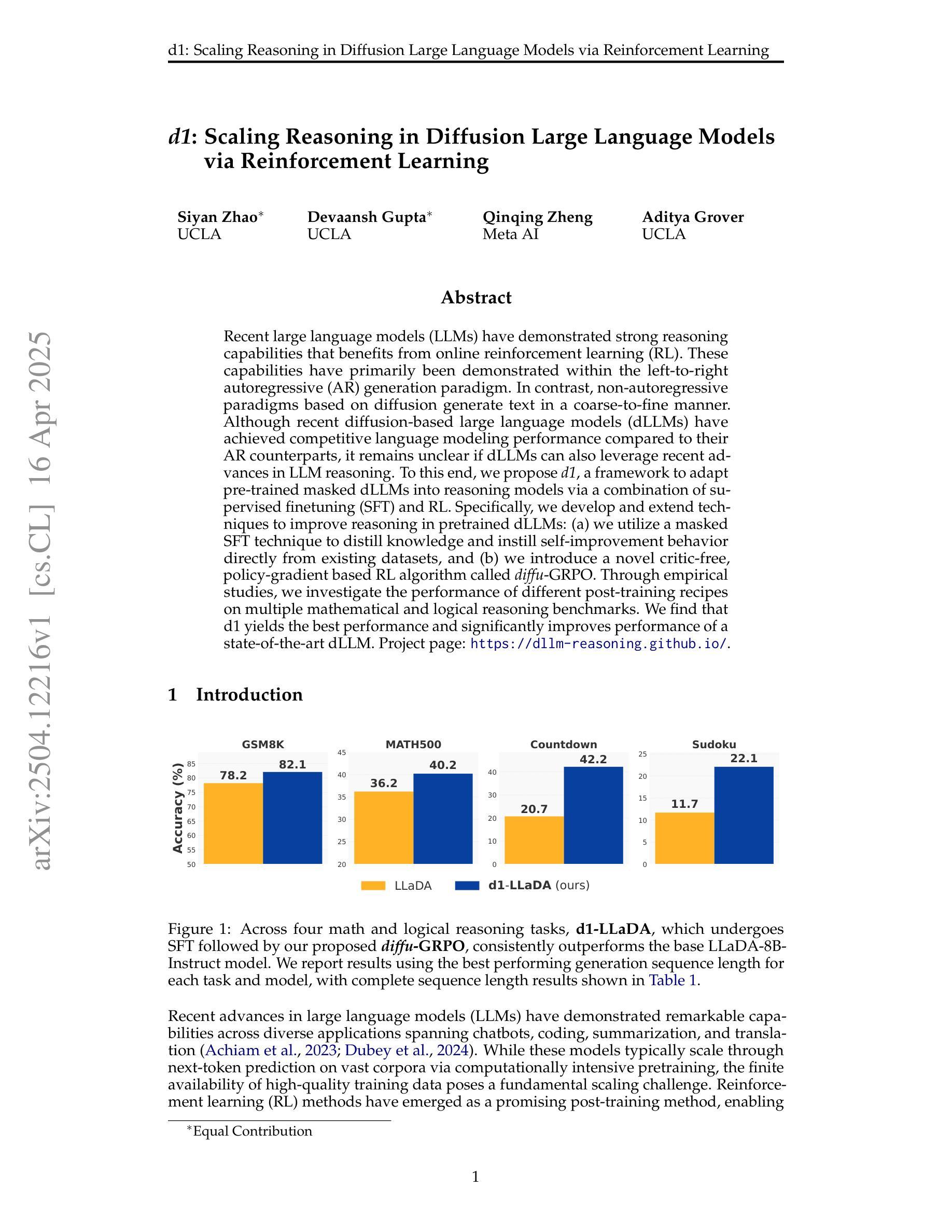
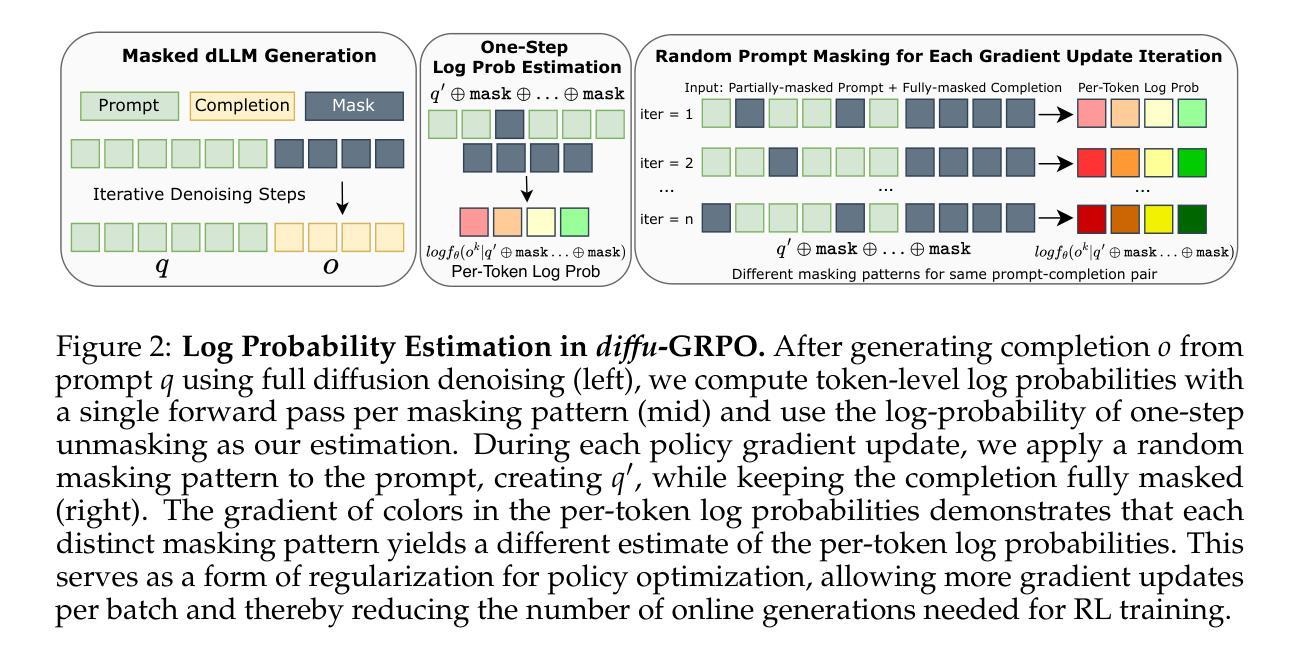
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
Authors:Siyan Zhao, Devaansh Gupta, Qinqing Zheng, Aditya Grover
Recent large language models (LLMs) have demonstrated strong reasoning capabilities that benefits from online reinforcement learning (RL). These capabilities have primarily been demonstrated within the left-to-right autoregressive (AR) generation paradigm. In contrast, non-autoregressive paradigms based on diffusion generate text in a coarse-to-fine manner. Although recent diffusion-based large language models (dLLMs) have achieved competitive language modeling performance compared to their AR counterparts, it remains unclear if dLLMs can also leverage recent advances in LLM reasoning. To this end, we propose d1, a framework to adapt pre-trained masked dLLMs into reasoning models via a combination of supervised finetuning (SFT) and RL. Specifically, we develop and extend techniques to improve reasoning in pretrained dLLMs: (a) we utilize a masked SFT technique to distill knowledge and instill self-improvement behavior directly from existing datasets, and (b) we introduce a novel critic-free, policy-gradient based RL algorithm called diffu-GRPO. Through empirical studies, we investigate the performance of different post-training recipes on multiple mathematical and logical reasoning benchmarks. We find that d1 yields the best performance and significantly improves performance of a state-of-the-art dLLM.
最近的大型语言模型(LLM)展示了从在线强化学习(RL)中受益的强大推理能力。这些能力主要是在从左到右的自回归(AR)生成范式内展示的。相比之下,基于扩散的非自回归范式则以从粗到细的方式生成文本。尽管最近的扩散型大型语言模型(dLLM)在与其AR同类模型的竞争中实现了相当的语言建模性能,但仍不清楚dLLM是否也能利用LLM推理的最新进展。为此,我们提出了d1框架,它通过监督微调(SFT)和RL的结合,将预训练的掩码型dLLM适应为推理模型。具体来说,我们开发并扩展了改进预训练dLLM推理的技术:(a)我们使用掩蔽的SFT技术从现有数据集中提炼知识并灌输自我改进行为;(b)我们引入了一种新型的无需评论家、基于策略梯度的RL算法,称为diffu-GRPO。通过实证研究,我们在多个数学和逻辑推理基准上探讨了不同后训练配方(post-training recipes)的性能。我们发现d1提供了最佳性能,并显著提高了最新dLLM的性能。
论文及项目相关链接
PDF 25 pages, project page at https://dllm-reasoning.github.io/
Summary
大型语言模型(LLM)通过在线强化学习(RL)展现出强大的推理能力,主要在左至右的自回归生成范式中得到验证。本文提出了d1框架,通过监督微调(SFT)和RL将预训练的掩码扩散大型语言模型(dLLM)适应于推理模型。采用掩码SFT技术和一种新的无批评者、基于策略梯度的RL算法diffu-GRPO来提升预训练dLLM的推理能力。实验表明,d1在多个数学和逻辑推理基准测试上表现最佳,并显著提升了先进dLLM的性能。
Key Takeaways
- 大型语言模型受益于在线强化学习,展现出强大的推理能力。
- 自回归生成范式和非自回归扩散范式在LLM中各有优势。
- dLLM在语言建模方面已表现出竞争力。
- d1框架结合了监督微调和强化学习,旨在将预训练的dLLM适应于推理任务。
- d1采用掩码SFT技术和新型的RL算法diffu-GRPO来提升dLLM的推理能力。
- 实证研究表明,d1在多个数学和逻辑推理基准测试上表现最佳。
点此查看论文截图
Towards LLM Agents for Earth Observation
Authors:Chia Hsiang Kao, Wenting Zhao, Shreelekha Revankar, Samuel Speas, Snehal Bhagat, Rajeev Datta, Cheng Perng Phoo, Utkarsh Mall, Carl Vondrick, Kavita Bala, Bharath Hariharan
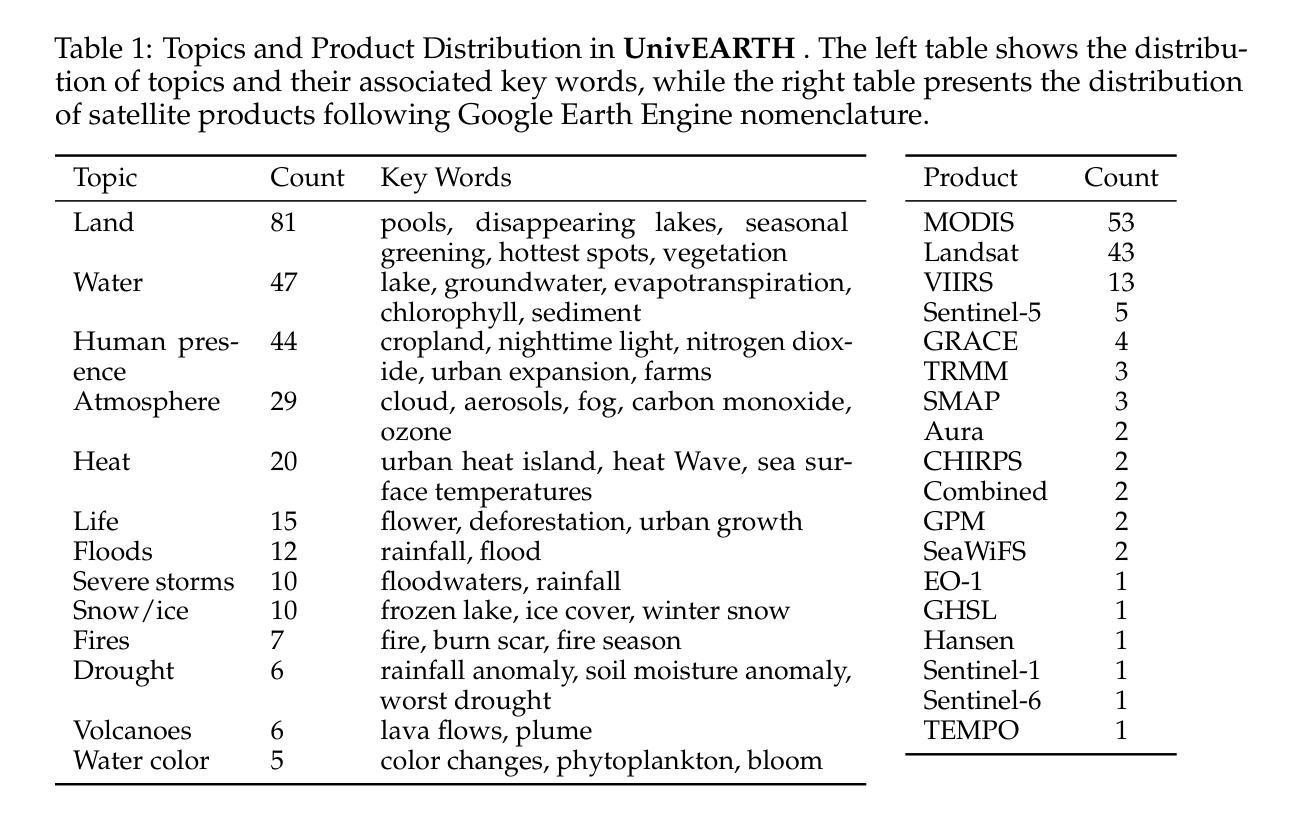
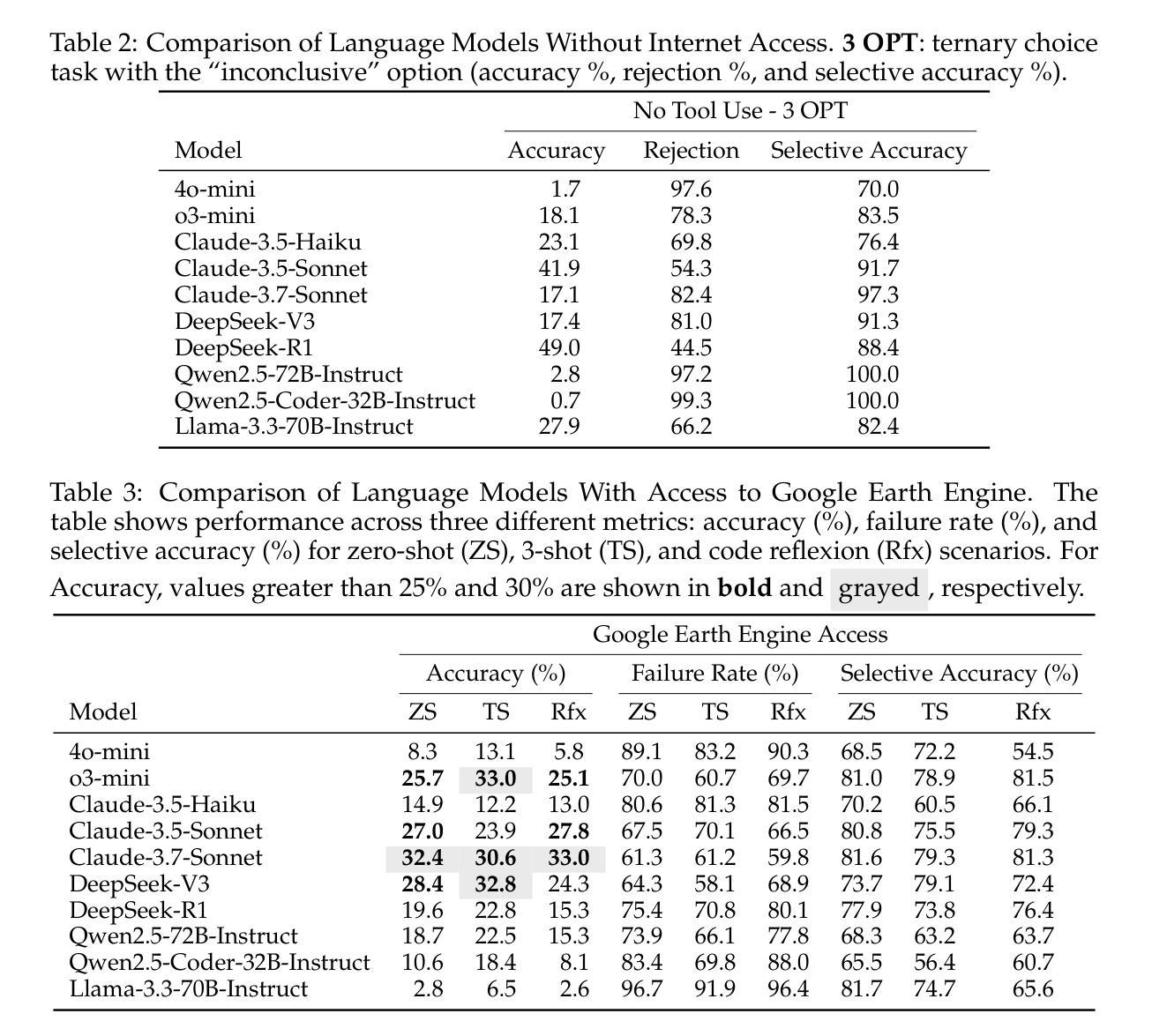
Earth Observation (EO) provides critical planetary data for environmental monitoring, disaster management, climate science, and other scientific domains. Here we ask: Are AI systems ready for reliable Earth Observation? We introduce \datasetnamenospace, a benchmark of 140 yes/no questions from NASA Earth Observatory articles across 13 topics and 17 satellite sensors. Using Google Earth Engine API as a tool, LLM agents can only achieve an accuracy of 33% because the code fails to run over 58% of the time. We improve the failure rate for open models by fine-tuning synthetic data, allowing much smaller models (Llama-3.1-8B) to achieve comparable accuracy to much larger ones (e.g., DeepSeek-R1). Taken together, our findings identify significant challenges to be solved before AI agents can automate earth observation, and suggest paths forward. The project page is available at https://iandrover.github.io/UnivEarth.
地球观测(EO)为环境监测、灾害管理、气候科学和其他科学领域提供了关键行星数据。在这里我们提出一个问题:人工智能系统是否已经准备好进行可靠的地球观测?我们推出了\datasetnamenospace,这是从NASA地球观测站文章中提取的140个是非问题的基准测试,涵盖13个主题和17个卫星传感器。使用Google地球引擎API作为工具,LLM代理只能达到33%的准确率,因为代码有58%的时间无法运行。我们通过微调合成数据来提高开放模型的失败率,允许更小的模型(Llama-3.1-8B)实现与更大的模型(例如DeepSeek-R1)相当的准确率。总的来说,我们的研究发现了在人工智能代理能够自动进行地球观测之前需要解决的重大挑战,并指出了未来的发展方向。项目页面可在https://iandrover.github.io/UnivEarth访问。
论文及项目相关链接
PDF 36 pages
摘要
本文探讨了人工智能系统在地球观测方面的应用,引入了一个名为\datasetnamenospace的数据集,该数据集包含NASA地球观测站的140个是与非问题,涵盖了卫星传感器涉及的13个主题和17个卫星传感器。虽然利用Google地球引擎API作为工具,大型语言模型(LLM)仅能完成日常工作的33%,同时大部分模型在运行中遭遇性能瓶颈的问题频率达到近六成。研究团队通过微调合成数据提升了开源模型的性能,证明了较小的模型也能达到甚至超过较大模型的准确度。总的来说,该研究指出了人工智能系统在自动化地球观测方面所面临的挑战,并提供了未来可能的研究方向。具体项目信息可通过链接查看:https://iandrover.github.io/UnivEarth。
关键见解
- 人工智能系统在处理地球观测数据时面临可靠性问题。
- LLM在处理特定任务时准确率仅为三分之一。
- Google地球引擎API存在运行故障问题,近六成时间无法正常运行。
- 通过微调合成数据可以提升开源模型的性能。
- 小型模型(如Llama-3.1-8B)可以在准确度上达到甚至超越大型模型(如DeepSeek-R1)。
- 人工智能在自动化地球观测方面仍存在挑战需要解决。
点此查看论文截图

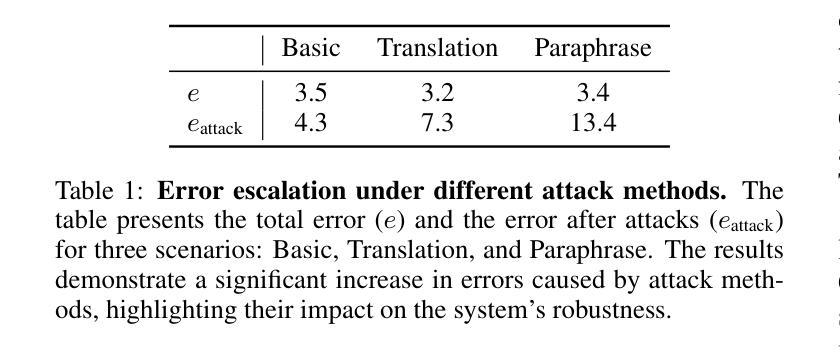
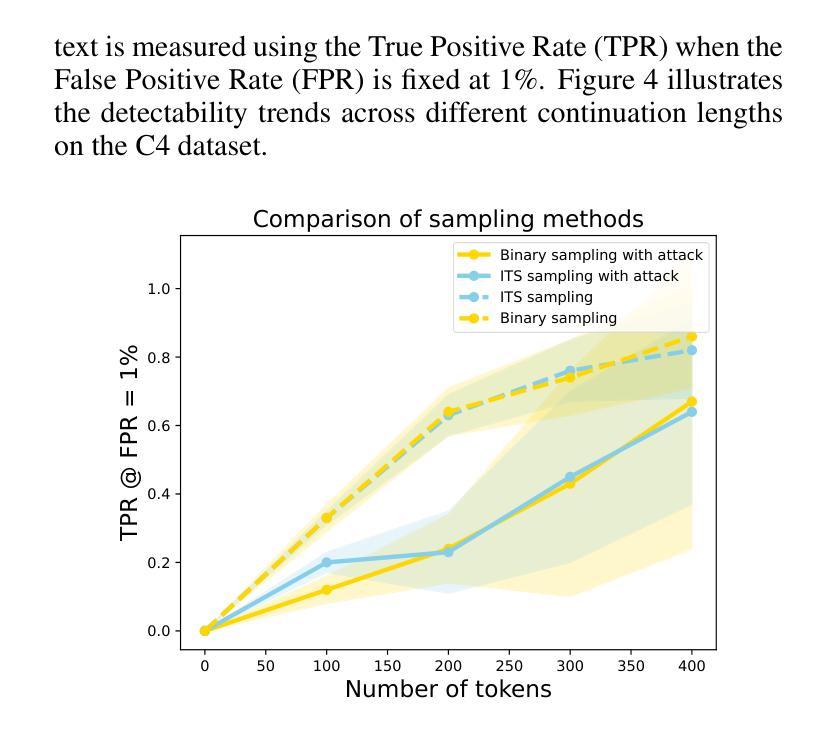
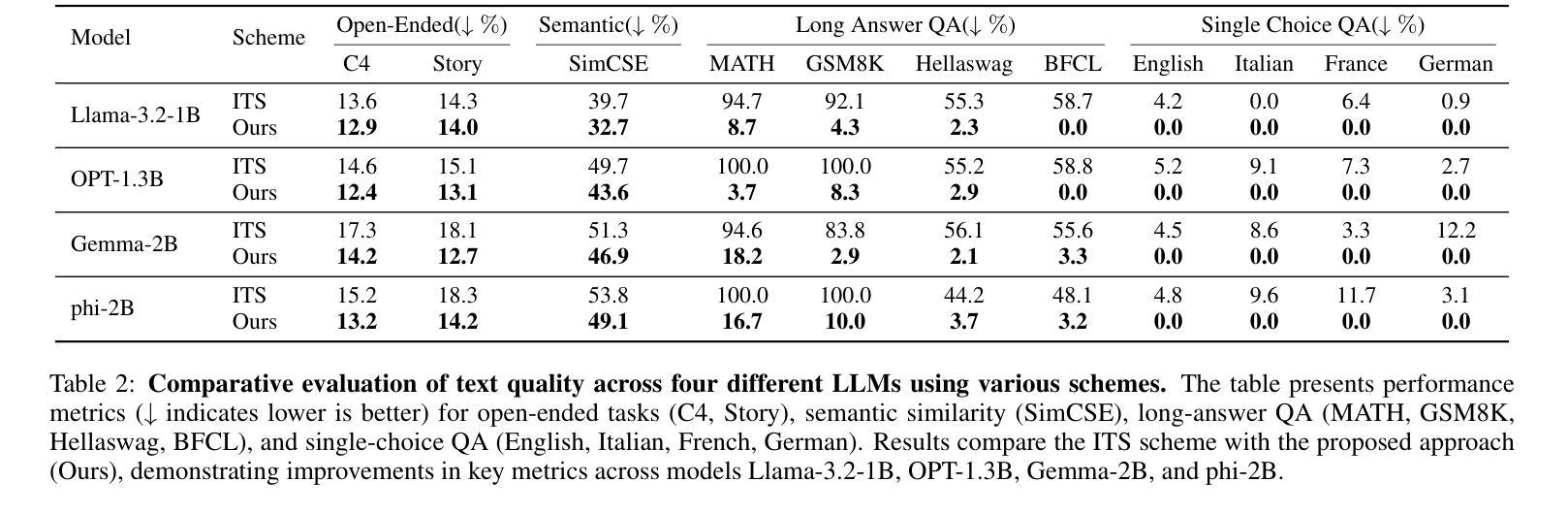
Entropy-Guided Watermarking for LLMs: A Test-Time Framework for Robust and Traceable Text Generation
Authors:Shizhan Cai, Liang Ding, Dacheng Tao
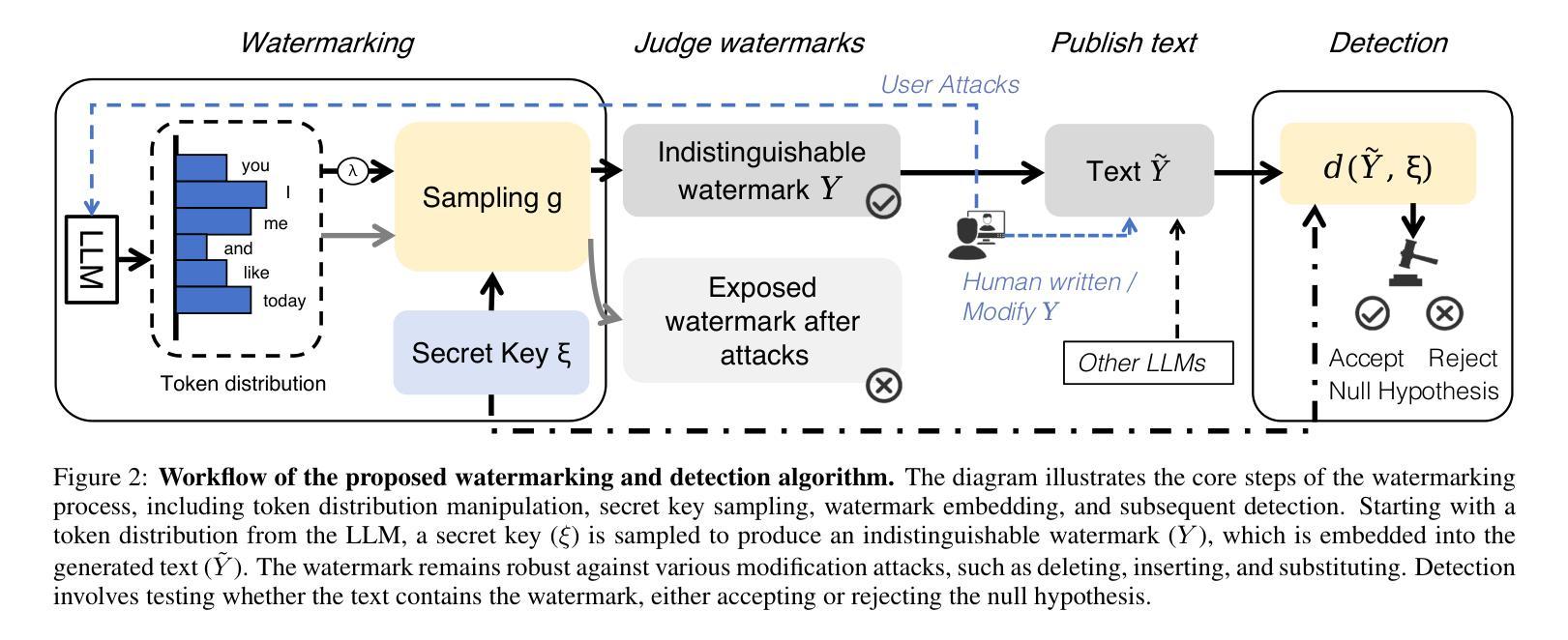
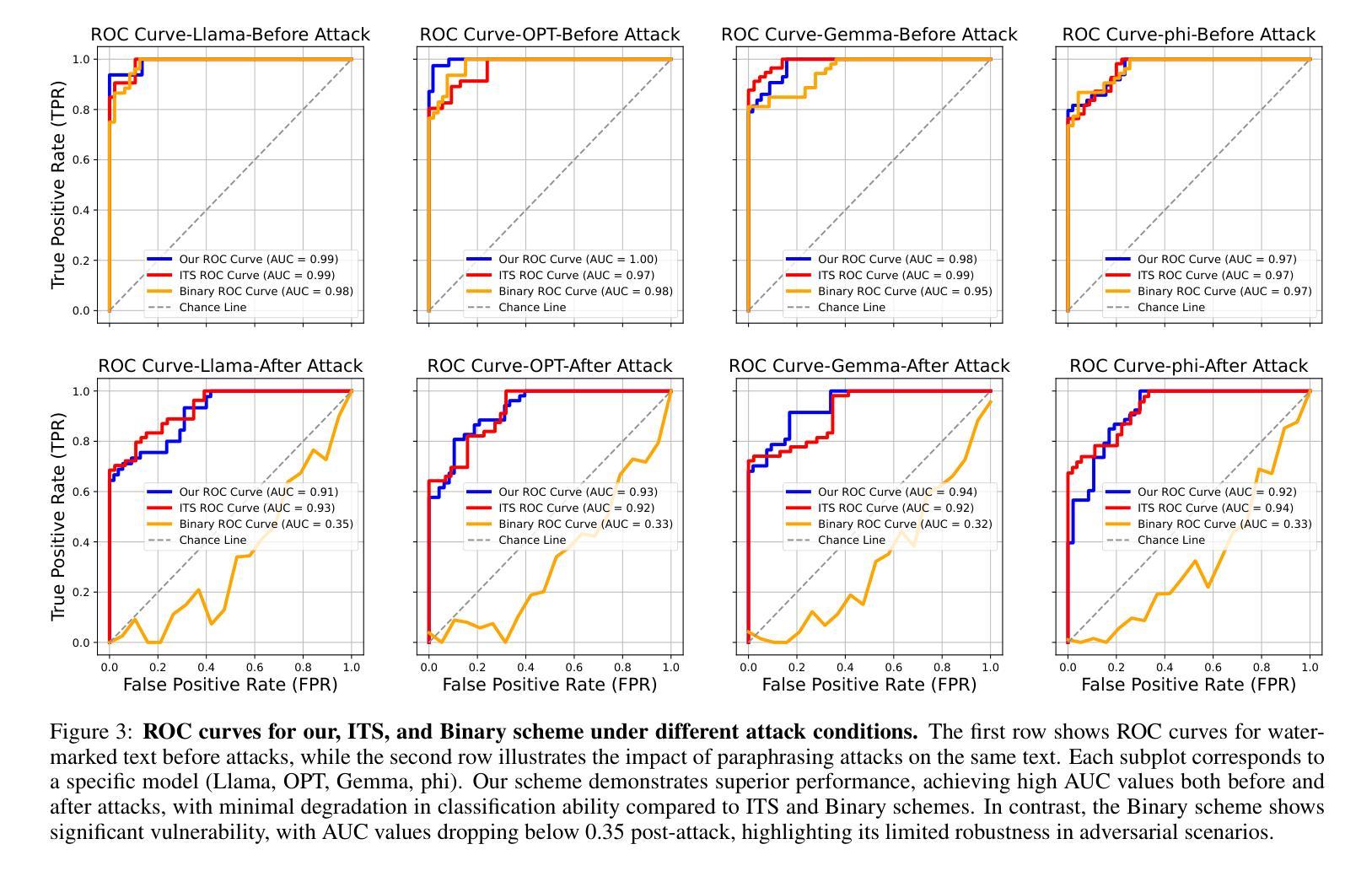
The rapid development of Large Language Models (LLMs) has intensified concerns about content traceability and potential misuse. Existing watermarking schemes for sampled text often face trade-offs between maintaining text quality and ensuring robust detection against various attacks. To address these issues, we propose a novel watermarking scheme that improves both detectability and text quality by introducing a cumulative watermark entropy threshold. Our approach is compatible with and generalizes existing sampling functions, enhancing adaptability. Experimental results across multiple LLMs show that our scheme significantly outperforms existing methods, achieving over 80% improvements on widely-used datasets, e.g., MATH and GSM8K, while maintaining high detection accuracy.
大规模语言模型(LLM)的快速发展加剧了人们对内容可追踪性和潜在误用的担忧。现有采样文本的水印方案往往需要在保持文本质量和确保对各种攻击的稳健检测之间做出权衡。为了解决这些问题,我们提出了一种新型的水印方案,通过引入累积水印熵阈值,提高了检测能力和文本质量。我们的方法与现有的采样函数兼容并进行了推广,增强了适应性。跨多个LLM的实验结果表明,我们的方案显著优于现有方法,在广泛使用的数据集(例如MATH和GSM8K)上的改进幅度超过80%,同时保持了高检测准确率。
论文及项目相关链接
Summary
大型语言模型(LLM)的快速发展引发了人们对内容可追溯性和潜在误用的关注。现有文本水印方案在保持文本质量与确保对抗各种攻击的检测能力之间常常存在权衡。为解决这些问题,我们提出了一种新型水印方案,通过引入累积水印熵阈值,提高了检测性和文本质量。该方法与现有采样函数兼容并增强了适应性。在多个LLM上的实验结果表明,该方案显著优于现有方法,在广泛使用的MATH和GSM8K数据集上改进超过80%,同时保持高检测准确率。
Key Takeaways
- 大型语言模型(LLM)的快速发展引发了对内容追溯和潜在误用的关注。
- 现有文本水印方案在保持文本质量与检测能力之间存权衡。
- 提出了一种新型水印方案,通过引入累积水印熵阈值,提高检测性和文本质量。
- 新方案与现有采样函数兼容,增强适应性。
- 实验表明,该方案在多个LLM上显著优于现有方法。
- 在广泛使用的数据集上,如MATH和GSM8K,改进超过80%。
点此查看论文截图



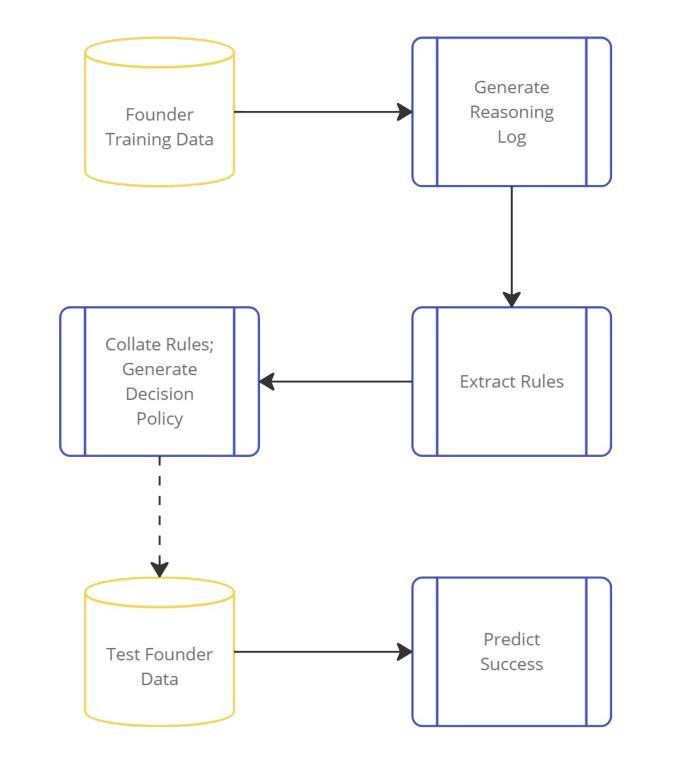
Reasoning-Based AI for Startup Evaluation (R.A.I.S.E.): A Memory-Augmented, Multi-Step Decision Framework
Authors:Jack Preuveneers, Joseph Ternasky, Fuat Alican, Yigit Ihlamur
We present a novel framework that bridges the gap between the interpretability of decision trees and the advanced reasoning capabilities of large language models (LLMs) to predict startup success. Our approach leverages chain-of-thought prompting to generate detailed reasoning logs, which are subsequently distilled into structured, human-understandable logical rules. The pipeline integrates multiple enhancements - efficient data ingestion, a two-step refinement process, ensemble candidate sampling, simulated reinforcement learning scoring, and persistent memory - to ensure both stable decision-making and transparent output. Experimental evaluations on curated startup datasets demonstrate that our combined pipeline improves precision by 54% from 0.225 to 0.346 and accuracy by 50% from 0.46 to 0.70 compared to a standalone OpenAI o3 model. Notably, our model achieves over 2x the precision of a random classifier (16%). By combining state-of-the-art AI reasoning with explicit rule-based explanations, our method not only augments traditional decision-making processes but also facilitates expert intervention and continuous policy refinement. This work lays the foundation for the implementation of interpretable LLM-powered decision frameworks in high-stakes investment environments and other domains that require transparent and data-driven insights.
我们提出了一种新的框架,该框架旨在弥树决策的可解释性与大型语言模型(LLM)的高级推理能力之间的鸿沟,以预测创业公司的成功。我们的方法利用链式思维提示生成详细的推理日志,随后将其提炼成结构化、人类可理解的逻辑规则。该管道融合了多项增强功能,包括高效数据摄取、两步优化过程、集成候选采样、模拟强化学习评分和持久性内存,以确保稳定的决策制定和透明的输出。在精选的初创公司数据集上的实验评估表明,我们的组合管道与单独的OpenAI o3模型相比,精度从0.225提高到0.346(提高54%),准确率从0.46提高到0.70(提高50%)。值得注意的是,我们的模型的精度是随机分类器的两倍以上(16%)。通过结合最先进的AI推理和基于规则的明确解释,我们的方法不仅增强了传统的决策制定过程,还有助于专家干预和持续的政策优化。这项工作为在高风险投资环境和其他需要透明和数据驱动洞察力的领域实施可解释的LLM驱动决策框架奠定了基础。
论文及项目相关链接
Summary:本研究提出了一种新颖框架,融合了决策树的可解释性与大型语言模型(LLM)的高级推理能力,用于预测创业成功。该研究通过链式思维提示生成详细的推理日志,再将其提炼为结构化、人类可理解的逻辑规则。经过多项改进,包括高效数据摄取、两步精炼过程、集成候选采样、模拟强化学习评分和持久性内存等,确保了稳定的决策制定和透明的输出。实验评估表明,与单独的OpenAI o3模型相比,该管道在精选的创业数据集上将精度从0.225提高到0.346,提高了54%,准确率从0.46提高到0.70,提高了50%。该研究为实现可解释的大型语言模型驱动的决策框架在高风险投资环境和其他需要透明和数据驱动洞察力的领域奠定了基础。
Key Takeaways:
- 研究提出了融合决策树可解释性与大型语言模型(LLM)的新颖框架,用于预测创业成功。
- 通过链式思维提示生成详细的推理日志,再将其转化为结构化逻辑规则。
- 结合多项技术改进,确保稳定决策和透明输出。
- 实验评估显示,该框架相较于单一的OpenAI o3模型,精度和准确率均有显著提高。
- 与随机分类器相比,该模型的精度超过两倍。
- 结合先进的人工智能推理和基于规则的解释方法,不仅增强了传统决策制定过程,还便于专家介入和政策持续改进。
点此查看论文截图


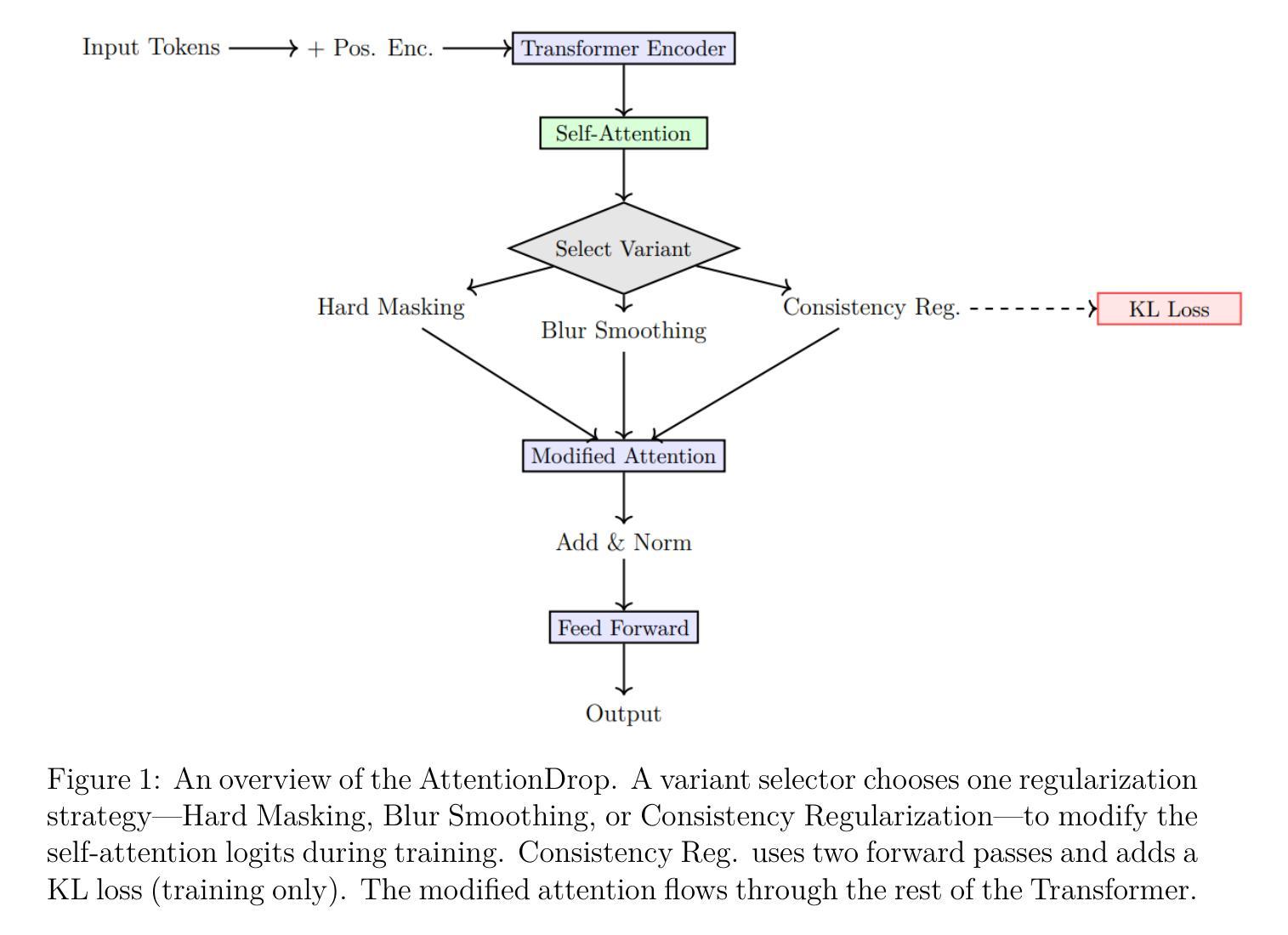
AttentionDrop: A Novel Regularization Method for Transformer Models
Authors:Mirza Samad Ahmed Baig, Syeda Anshrah Gillani, Abdul Akbar Khan, Shahid Munir Shah
Transformer-based architectures achieve state-of-the-art performance across a wide range of tasks in natural language processing, computer vision, and speech. However, their immense capacity often leads to overfitting, especially when training data is limited or noisy. We propose AttentionDrop, a unified family of stochastic regularization techniques that operate directly on the self-attention distributions. We introduces three variants: 1. Hard Attention Masking: randomly zeroes out top-k attention logits per query to encourage diverse context utilization. 2. Blurred Attention Smoothing: applies a dynamic Gaussian convolution over attention logits to diffuse overly peaked distributions. 3. Consistency-Regularized AttentionDrop: enforces output stability under multiple independent AttentionDrop perturbations via a KL-based consistency loss.
基于Transformer的架构在自然语言处理、计算机视觉和语音的广泛任务中实现了最先进的性能。然而,它们巨大的容量往往会导致过拟合,尤其是在训练数据有限或嘈杂的情况下。我们提出了AttentionDrop,这是一个直接在自注意力分布上运行的随机正则化技术的统一家族。我们介绍了三种变体:1.硬注意力掩码:随机将每个查询的前k个注意力对数概率置零,以鼓励利用多样化的上下文。2.模糊注意力平滑:在注意力对数概率上应用动态高斯卷积,以分散过于集中的分布。3.一致性正则化AttentionDrop:通过基于KL的一致性损失,强制在多个独立的AttentionDrop扰动下输出稳定。
论文及项目相关链接
PDF 26 pages
Summary:基于Transformer的架构在自然语言处理、计算机视觉和语音等多个任务中实现了卓越的性能。但其巨大的容量容易导致过拟合,特别是在训练数据有限或噪声较大时。为此,我们提出了AttentionDrop这一统一的随机正则化技术家族,直接在自注意力分布上操作。包括三种变体:硬注意力掩码、模糊注意力平滑和一致性正则化AttentionDrop。
Key Takeaways:
- Transformer架构在多个任务中表现出卓越性能,但存在过拟合问题。
- AttentionDrop是一种针对Transformer模型的随机正则化技术。
- Hard Attention Masking通过随机将顶部k个注意力日志清零来鼓励多样化的上下文利用。
- Blurred Attention Smoothing通过动态高斯卷积来平滑过于集中的注意力分布。
- Consistency-Regularized AttentionDrop通过基于KL的一致性损失来确保多个独立的AttentionDrop扰动下的输出稳定性。
- AttentionDrop技术有助于提升模型的泛化能力,并减少过拟合现象。
点此查看论文截图

Selective Demonstration Retrieval for Improved Implicit Hate Speech Detection
Authors:Yumin Kim, Hwanhee Lee
Hate speech detection is a crucial area of research in natural language processing, essential for ensuring online community safety. However, detecting implicit hate speech, where harmful intent is conveyed in subtle or indirect ways, remains a major challenge. Unlike explicit hate speech, implicit expressions often depend on context, cultural subtleties, and hidden biases, making them more challenging to identify consistently. Additionally, the interpretation of such speech is influenced by external knowledge and demographic biases, resulting in varied detection results across different language models. Furthermore, Large Language Models often show heightened sensitivity to toxic language and references to vulnerable groups, which can lead to misclassifications. This over-sensitivity results in false positives (incorrectly identifying harmless statements as hateful) and false negatives (failing to detect genuinely harmful content). Addressing these issues requires methods that not only improve detection precision but also reduce model biases and enhance robustness. To address these challenges, we propose a novel method, which utilizes in-context learning without requiring model fine-tuning. By adaptively retrieving demonstrations that focus on similar groups or those with the highest similarity scores, our approach enhances contextual comprehension. Experimental results show that our method outperforms current state-of-the-art techniques. Implementation details and code are available at TBD.
仇恨言论检测是自然语言处理中的一个关键研究领域,对于确保在线社区安全至关重要。然而,检测隐晦仇恨言论仍然是一个主要挑战,隐晦仇恨言论以微妙或间接的方式传达有害意图。与明确仇恨言论不同,隐晦表达常常依赖于上下文、文化细微差别和隐含偏见,因此难以持续一致地识别。此外,此类言论的解读受到外部知识和人口统计偏见的影响,导致不同语言模型的检测结果存在差异。另外,大型语言模型对有毒语言和弱势群体的提及往往表现出过度敏感性,可能导致误判。这种过度敏感会导致误报(错误地将无害声明识别为仇恨言论)和漏报(未能检测到真正有害的内容)。要解决这些问题,需要不仅提高检测精度,而且减少模型偏见并增强稳健性的方法。为了应对这些挑战,我们提出了一种利用上下文学习而无需模型微调的新方法。通过自适应检索类似群体或最高相似度得分的演示内容,我们的方法增强了上下文理解。实验结果表明,我们的方法优于当前最新技术。实现细节和代码可参见(暂定网址)。
论文及项目相关链接
Summary
本摘要总结了自然语言处理中仇恨言论检测的重要性,特别是在识别含蓄仇恨言论方面的挑战。现有大型语言模型在处理这种言论时存在过度敏感的问题,导致误报和漏报。为提高检测精度并减少模型偏见,提出了一种利用上下文学习的新方法,通过检索相似演示内容提高语境理解能力。实验结果显示,该方法优于现有技术。具体实施细节和代码请参见具体链接。
Key Takeaways
以下是从文本中提取的七个关键要点:
- 仇恨言论检测是自然语言处理的重要研究领域,对于确保在线社区安全至关重要。
- 含蓄仇恨言论的识别是一大挑战,因为它依赖于语境、文化细微差别和隐含偏见。
- 大型语言模型在处理仇恨言论时存在过度敏感问题,导致误报和漏报。
- 现有方法在检测仇恨言论时存在不足,需要改进检测精度并减少模型偏见。
- 提出了一种新的仇恨言论检测方法,利用上下文学习提高语境理解能力。
- 该方法通过检索相似演示内容,增强了对上下文的理解,提高了检测效果。
点此查看论文截图


ADAT: Time-Series-Aware Adaptive Transformer Architecture for Sign Language Translation
Authors:Nada Shahin, Leila Ismail
Current sign language machine translation systems rely on recognizing hand movements, facial expressions and body postures, and natural language processing, to convert signs into text. Recent approaches use Transformer architectures to model long-range dependencies via positional encoding. However, they lack accuracy in recognizing fine-grained, short-range temporal dependencies between gestures captured at high frame rates. Moreover, their high computational complexity leads to inefficient training. To mitigate these issues, we propose an Adaptive Transformer (ADAT), which incorporates components for enhanced feature extraction and adaptive feature weighting through a gating mechanism to emphasize contextually relevant features while reducing training overhead and maintaining translation accuracy. To evaluate ADAT, we introduce MedASL, the first public medical American Sign Language dataset. In sign-to-gloss-to-text experiments, ADAT outperforms the encoder-decoder transformer, improving BLEU-4 accuracy by 0.1% while reducing training time by 14.33% on PHOENIX14T and 3.24% on MedASL. In sign-to-text experiments, it improves accuracy by 8.7% and reduces training time by 2.8% on PHOENIX14T and achieves 4.7% higher accuracy and 7.17% faster training on MedASL. Compared to encoder-only and decoder-only baselines in sign-to-text, ADAT is at least 6.8% more accurate despite being up to 12.1% slower due to its dual-stream structure.
当前的手语机器翻译系统依赖于手势动作、面部表情和身体姿态的识别以及自然语言处理,将手势转换为文本。最近的方法使用Transformer架构通过位置编码来模拟长距离依赖关系。然而,它们在识别高帧率下捕获的精细粒度、短距离时间依赖关系方面缺乏准确性。此外,它们的高计算复杂度导致训练效率低下。为了解决这些问题,我们提出了一种自适应Transformer(ADAT),它结合了增强特征提取和自适应特征权重的组件,通过门控机制来强调上下文相关的特征,同时减少训练开销并保持翻译准确性。为了评估ADAT,我们引入了MedASL,这是第一个公开的医疗美式手语数据集。在手势到缩略语再到文本的试验中,ADAT的表现优于编码器-解码器转换器,在PHOENIX14T上提高了BLEU-4准确率0.1%,同时减少训练时间14.33%,在MedASL上减少3.24%。在手势到文本的试验中,它在PHOENIX14T上的准确率提高了8.7%,训练时间减少了2.8%,在MedASL上的准确率提高了4.7%,训练速度提高了7.17%。与仅编码器或仅解码器的基线相比,尽管由于ADAT的双流结构,其速度较慢(最多慢12.1%),但其准确性至少提高了6.8%。
论文及项目相关链接
摘要
当前手语机器翻译系统主要通过识别手势动作、面部表情和体态以及自然语言处理,将手势转化为文本。尽管近期采用Transformer架构的方法能够通过位置编码建立长距离依赖关系,但在识别精细的短距离时间依赖关系方面仍缺乏准确性,尤其是在高帧率捕捉的手势之间。此外,其高计算复杂度导致训练效率低下。为解决这些问题,本文提出了一种自适应Transformer(ADAT),它通过引入增强特征提取和自适应特征权重机制的门控机制,在强调上下文相关特征的同时,减少训练开销并保持翻译准确性。为评估ADAT性能,我们引入了首个公共医疗美国手语数据集MedASL。实验表明,ADAT在sign-to-gloss-to-text任务中优于编码器-解码器Transformer,在PHOENIX14T上提高BLEU-4准确率0.1%的同时减少训练时间14.33%,在MedASL上减少3.24%。在sign-to-text实验中,ADAT在PHOENIX14T上的准确率提高8.7%,训练时间减少2.8%,在MedASL上的准确率提高4.7%,训练速度提高7.17%。与编码器-仅解码器基线相比,尽管由于双流结构,ADAT在速度上最多慢12.1%,但其准确率至少提高6.8%。
关键见解
- 当前手语机器翻译系统主要依赖手势动作、面部表情和体态的识别以及自然语言处理进行翻译。
- 当前系统在高帧率捕捉的手势之间的短距离时间依赖关系识别方面存在不足。
- 自适应Transformer(ADAT)通过增强特征提取和自适应特征权重机制提高了翻译准确性。
- ADAT在医疗美国手语数据集MedASL上的表现优于其他模型。
- ADAT在sign-to-gloss-to-text和sign-to-text任务中均表现出较高的准确率和较低的训练时间。
- 与基线模型相比,ADAT的准确率有所提高,尽管其训练速度有所降低,这是由于它的双流结构所致。
点此查看论文截图

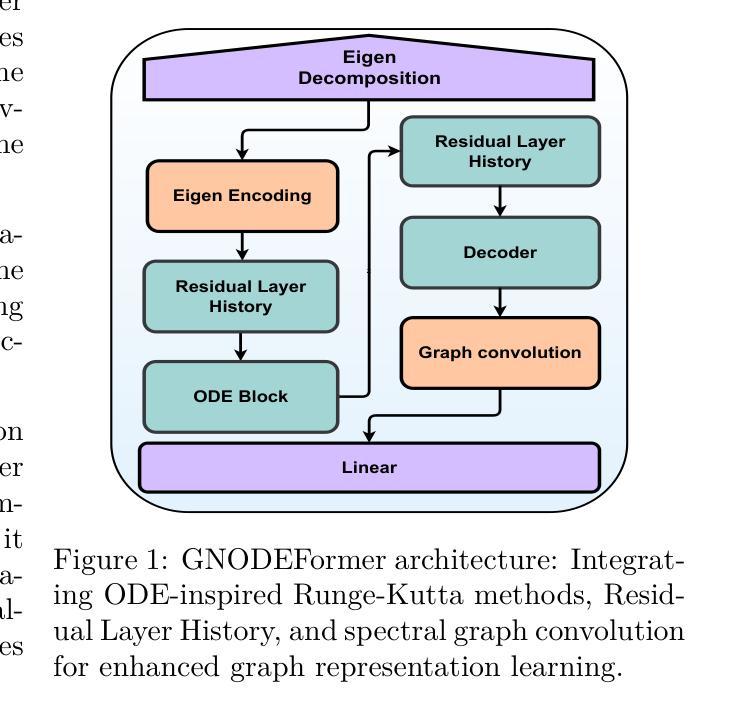
Federated Spectral Graph Transformers Meet Neural Ordinary Differential Equations for Non-IID Graphs
Authors:Kishan Gurumurthy, Himanshu Pal, Charu Sharma
Graph Neural Network (GNN) research is rapidly advancing due to GNNs’ capacity to learn distributed representations from graph-structured data. However, centralizing large volumes of real-world graph data for GNN training is often impractical due to privacy concerns, regulatory restrictions, and commercial competition. Federated learning (FL), a distributed learning paradigm, offers a solution by preserving data privacy with collaborative model training. Despite progress in training huge vision and language models, federated learning for GNNs remains underexplored. To address this challenge, we present a novel method for federated learning on GNNs based on spectral GNNs equipped with neural ordinary differential equations (ODE) for better information capture, showing promising results across both homophilic and heterophilic graphs. Our approach effectively handles non-Independent and Identically Distributed (non-IID) data, while also achieving performance comparable to existing methods that only operate on IID data. It is designed to be privacy-preserving and bandwidth-optimized, making it suitable for real-world applications such as social network analysis, recommendation systems, and fraud detection, which often involve complex, non-IID, and heterophilic graph structures. Our results in the area of federated learning on non-IID heterophilic graphs demonstrate significant improvements, while also achieving better performance on homophilic graphs. This work highlights the potential of federated learning in diverse and challenging graph settings. Open-source code available on GitHub (https://github.com/SpringWiz11/Fed-GNODEFormer).
图神经网络(GNN)研究正在快速进步,因为其具备从图结构数据中学习分布式表示的能力。然而,由于隐私担忧、监管限制和商业竞争,集中大量现实世界图数据进行GNN训练通常不切实际。联邦学习(FL)是一种分布式学习范式,通过协作模型训练来保留数据隐私,为解决此问题提供了解决方案。尽管在训练大型视觉和语言模型方面取得了进展,但GNN的联邦学习仍然鲜有研究。为解决这一挑战,我们提出了一种基于配备神经网络常微分方程(ODE)进行更好信息捕获的谱图神经网络的联邦学习新方法,在同构图和异构图中都显示出有前途的结果。我们的方法能够有效地处理非独立同分布(non-IID)数据,同时在性能上可以与仅处理IID数据的方法相比。它被设计为具有隐私保护和带宽优化的特点,非常适合于社交网络分析、推荐系统和欺诈检测等现实世界应用,这些应用通常涉及复杂、非IID和异构图结构。我们在非IID异构图上的联邦学习结果证明了显著的改进,同时在同构图上也实现了更好的性能。这项工作突出了联邦学习在多样化和具有挑战性的图设置中的潜力。开源代码可在GitHub上获得(https://github.com/SpringWiz11/Fed-GNODEFormer)。
论文及项目相关链接
PDF The first two listed authors contributed equally to this work
Summary
基于图神经网络(GNN)学习分布式表示图结构数据的能力,其研究正在快速发展。然而,由于隐私担忧、监管限制和商业竞争,集中大量现实世界图数据进行GNN训练并不实际。联邦学习(FL)作为一种分布式学习范式,通过协同模型训练来保存数据隐私,为解决此问题提供了解决方案。尽管在训练大规模视觉和语言模型方面取得了进展,但针对GNN的联邦学习仍然探索不足。本文提出了一种基于光谱GNN和配备神经常微分方程(ODE)的联邦学习方法,以更好地捕获信息,并在同构和异构图上显示出有希望的结果。该方法有效处理了非独立同分布(non-IID)数据,同时实现了与仅处理IID数据的现有方法相当的性能。设计用于保存隐私和优化带宽,适用于社交网络分析、推荐系统和欺诈检测等涉及复杂、非IID和异构图结构的现实世界应用。
Key Takeaways
- GNN具有从图结构数据中学习分布式表示的能力,但其训练面临数据集中化的挑战,包括隐私、监管和商业竞争问题。
- 联邦学习是分布式学习的一种范式,能够解决数据隐私问题,同时为GNN训练提供解决方案。
- 尽管联邦学习在视觉和语言模型方面有所进展,但在GNN上的联邦学习仍然是一个未被充分探索的领域。
- 提出了一种新的联邦学习方法,基于光谱GNN和神经常微分方程(ODE),在同构和异构图上均表现出良好性能。
- 该方法有效处理non-IID数据,并实现与仅处理IID数据的现有方法相当的性能。
- 设计的隐私保护和带宽优化使其适用于多种涉及复杂、非IID和异构图结构的现实世界应用,如社交网络分析、推荐系统和欺诈检测等。
点此查看论文截图

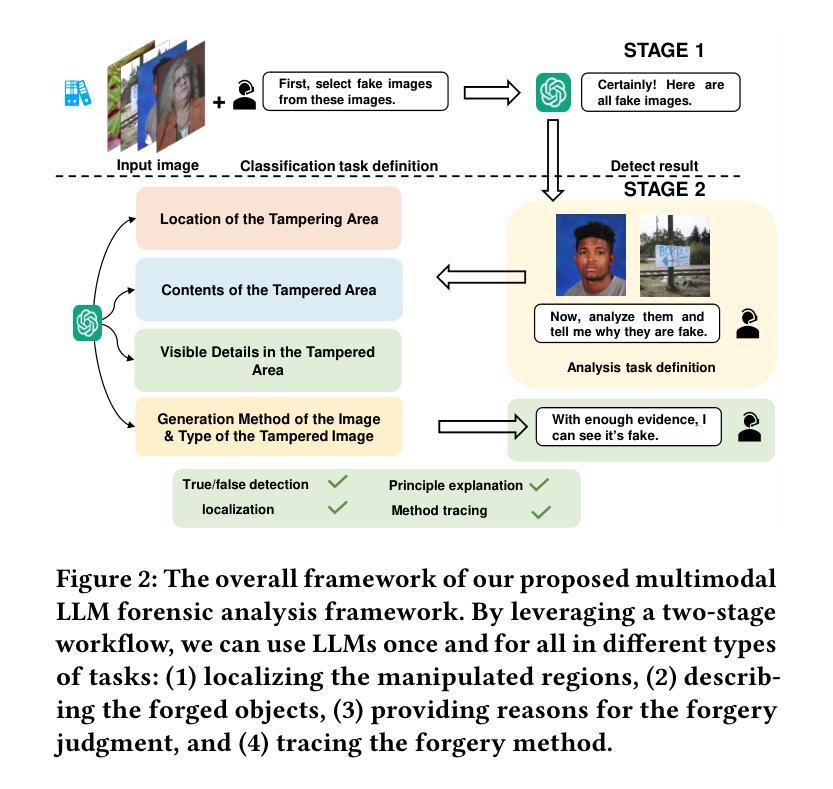
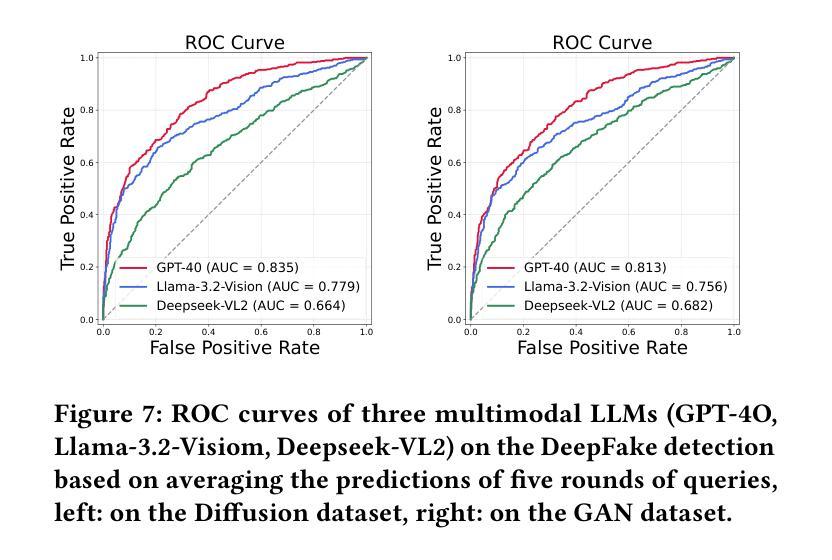
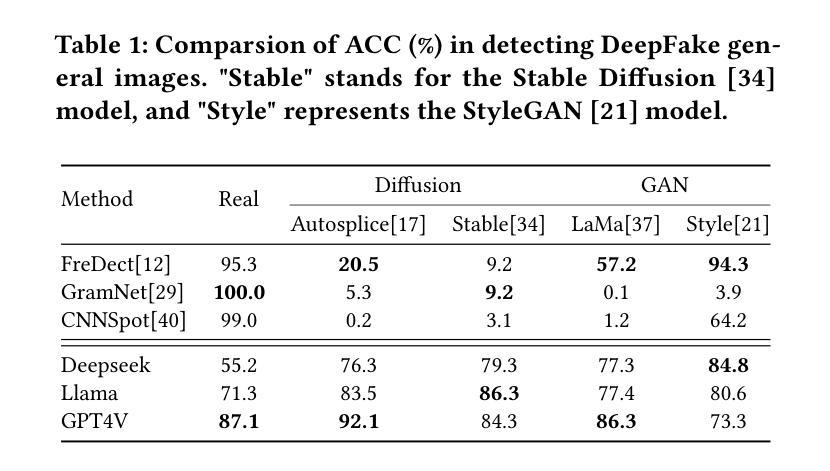
Can GPT tell us why these images are synthesized? Empowering Multimodal Large Language Models for Forensics
Authors:Yiran He, Yun Cao, Bowen Yang, Zeyu Zhang
The rapid development of generative AI facilitates content creation and makes image manipulation easier and more difficult to detect. While multimodal Large Language Models (LLMs) have encoded rich world knowledge, they are not inherently tailored for combating AI-generated Content (AIGC) and struggle to comprehend local forgery details. In this work, we investigate the application of multimodal LLMs in forgery detection. We propose a framework capable of evaluating image authenticity, localizing tampered regions, providing evidence, and tracing generation methods based on semantic tampering clues. Our method demonstrates that the potential of LLMs in forgery analysis can be effectively unlocked through meticulous prompt engineering and the application of few-shot learning techniques. We conduct qualitative and quantitative experiments and show that GPT4V can achieve an accuracy of 92.1% in Autosplice and 86.3% in LaMa, which is competitive with state-of-the-art AIGC detection methods. We further discuss the limitations of multimodal LLMs in such tasks and propose potential improvements.
随着生成性AI的快速发展,内容创建变得更加容易,图像操作也变得更简单且更难检测。虽然多模态大型语言模型(LLM)已经编码了丰富的世界知识,但它们并非天生就适合对抗AI生成的内容(AIGC),在理解局部伪造细节方面存在困难。在这项工作中,我们研究了多模态LLM在伪造检测中的应用。我们提出了一个能够评估图像真实性、定位篡改区域、提供证据并根据语义篡改线索追踪生成方法的框架。我们的方法表明,通过精细的提示工程和少量学习技术的应用,LLM在伪造分析中的潜力可以得到有效解锁。我们进行了定性和定量实验,结果表明GPT4V在Autosplice中可以达到92.1%的准确率,在LaMa中可以达到86.3%,与最先进的AIGC检测方法相当。我们进一步讨论了多模态LLM在此类任务中的局限性,并提出了潜在的改进方案。
论文及项目相关链接
PDF 12 pages, 11 figures, 13IHMMSec2025
Summary
本研究探讨了多模态大型语言模型(LLM)在伪造检测中的应用。提出了一种基于语义篡改线索的框架,能够评估图像真实性、定位篡改区域、提供证据并追溯生成方法。该研究通过精心设计的提示和少量学习技术,展示了LLMs在伪造分析中的潜力。实验表明,GPT4V在Autosplice和LaMa任务中的准确率分别达到了92.1%和86.3%,具有竞争力。同时,也讨论了多模态LLM在此类任务中的局限性,并提出了潜在的改进方向。
Key Takeaways
- 多模态大型语言模型(LLM)在伪造检测中具有应用潜力。
- 提出了一种能够评估图像真实性、定位篡改区域、提供证据并追溯生成方法的框架。
- 通过精心设计的提示和少量学习技术,LLMs在伪造分析中的表现得到有效提升。
- GPT4V在Autosplice和LaMa任务中的准确率较高,表现出竞争力。
- 多模态LLM在伪造检测任务中仍存在局限性。
- 需要进一步研究和改进多模态LLM的潜力,以提高其在伪造检测任务中的性能。
点此查看论文截图



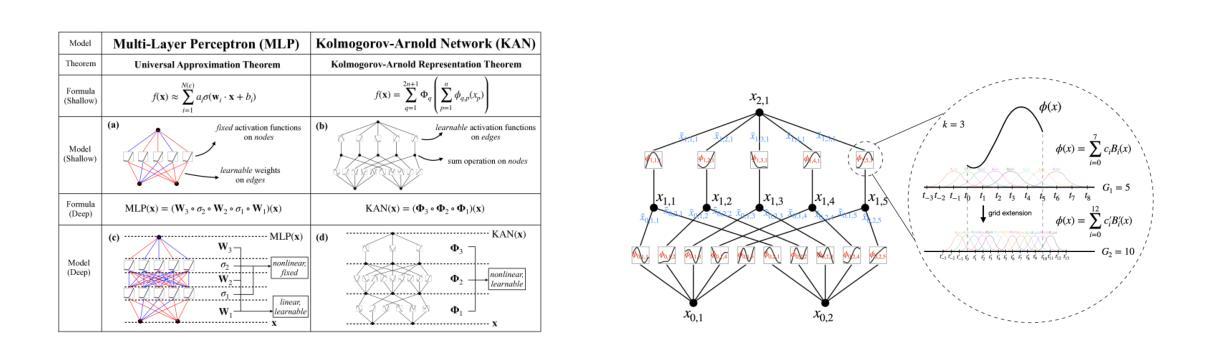
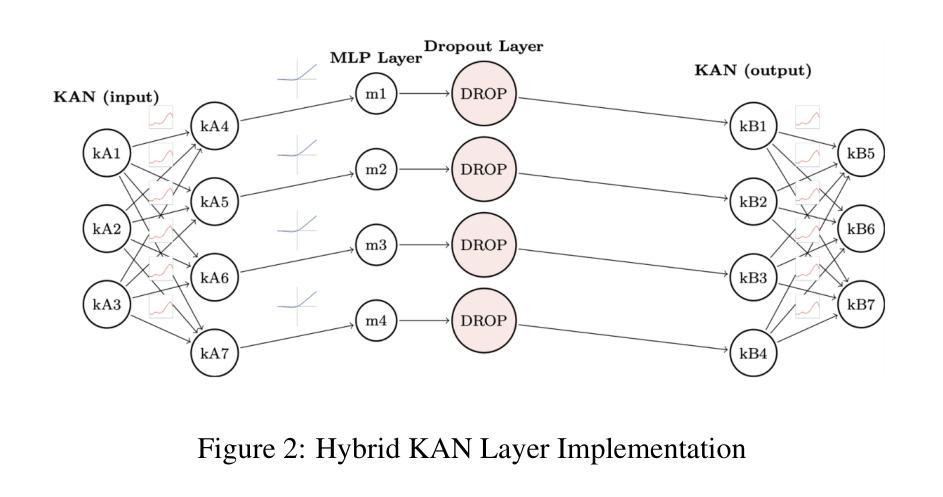
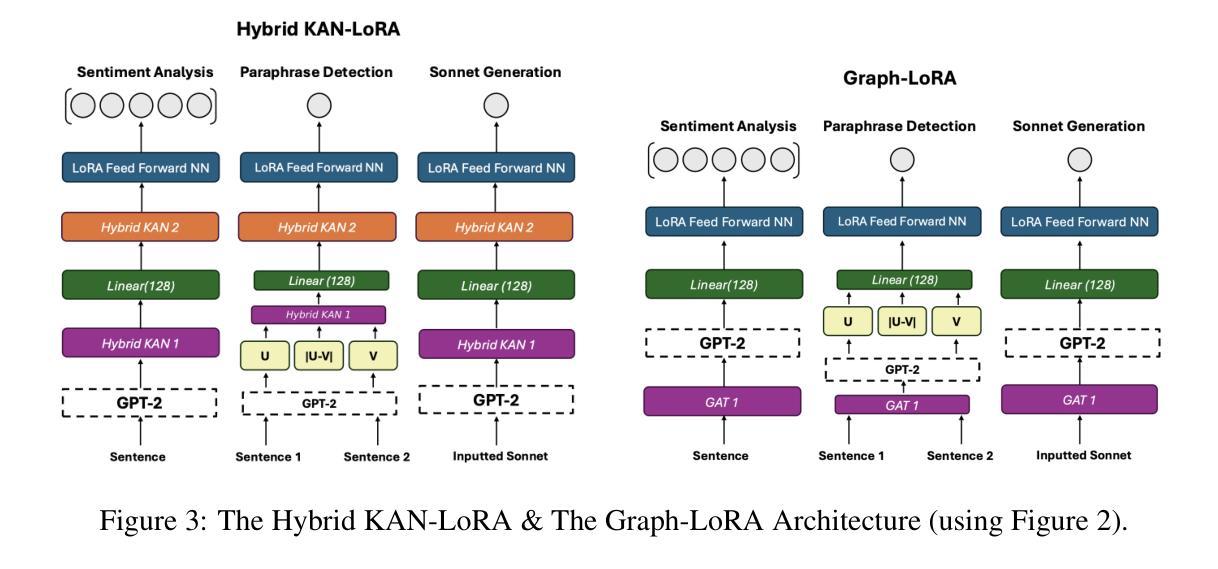
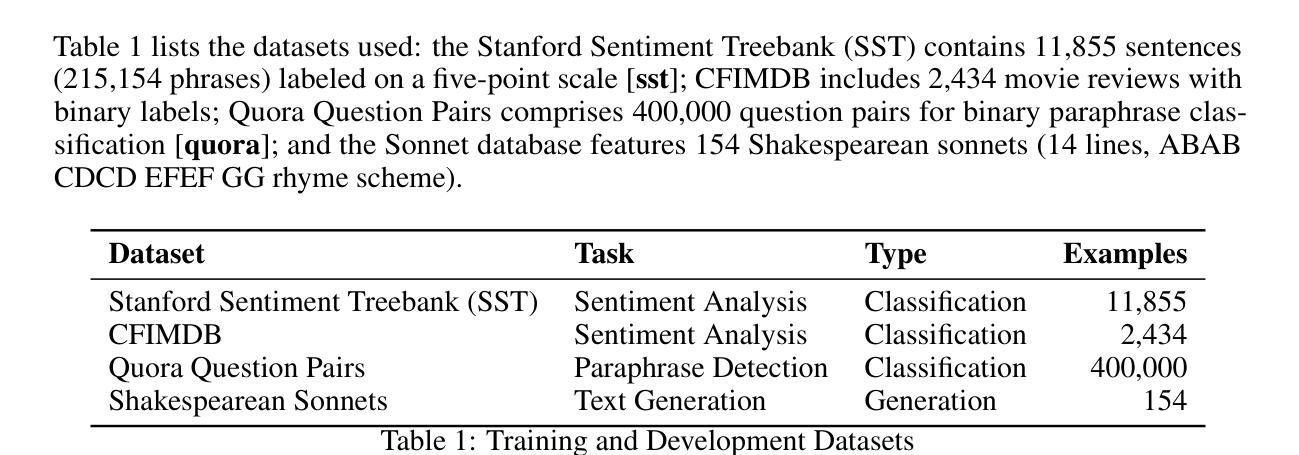
GPT Meets Graphs and KAN Splines: Testing Novel Frameworks on Multitask Fine-Tuned GPT-2 with LoRA
Authors:Gabriel Bo, Marc Bernardino, Justin Gu
We explore the potential of integrating learnable and interpretable modules–specifically Kolmogorov-Arnold Networks (KAN) and graph-based representations–within a pre-trained GPT-2 model to enhance multi-task learning accuracy. Motivated by the recent surge in using KAN and graph attention (GAT) architectures in chain-of-thought (CoT) models and debates over their benefits compared to simpler architectures like MLPs, we begin by enhancing a standard self-attention transformer using Low-Rank Adaptation (LoRA), fine-tuning hyperparameters, and incorporating L2 regularization. This approach yields significant improvements. To further boost interpretability and richer representations, we develop two variants that attempt to improve the standard KAN and GAT: Graph LoRA and Hybrid-KAN LoRA (Learnable GPT). However, systematic evaluations reveal that neither variant outperforms the optimized LoRA-enhanced transformer, which achieves 55.249% accuracy on the SST test set, 99.18% on the CFIMDB dev set, and 89.9% paraphrase detection test accuracy. On sonnet generation, we get a CHRF score of 42.097. These findings highlight that efficient parameter adaptation via LoRA remains the most effective strategy for our tasks: sentiment analysis, paraphrase detection, and sonnet generation.
我们探索了在预训练的GPT-2模型中集成可学习和可解释模块(特别是Kolmogorov-Arnold网络(KAN)和基于图的表示)的潜力,以提高多任务学习的准确性。受最近思维链模型中科尔莫哥罗夫-阿诺尔德网络(KAN)和图注意力(GAT)架构的激增以及它们与简单架构(如多层感知器)相比的辩论的启发,我们首先使用低秩适应(LoRA)增强标准自注意力变换器,微调超参数,并引入L2正则化。这种方法取得了显著的改进。为了进一步提高可解释性和更丰富的表示形式,我们开发了两个变体,试图改进标准的KAN和GAT:图LoRA和混合KAN LoRA(学习型GPT)。然而,系统评估表明,优化后的LoRA增强转换器在各项任务中的表现超过了这两种变体。在SST测试集上取得了55.249%的准确率,在CFIMDB开发集上达到了99.18%,在转述检测测试集上达到了89.9%的准确率。在颂诗生成方面,我们获得了CHRF分数为42.097。这些发现表明,通过LoRA进行有效的参数适应仍然是我们任务中最有效的策略:情感分析、转述检测和颂诗生成。
论文及项目相关链接
PDF 10 pages, 11 figures. This submission cites arXiv:2404.19756. Supplementary materials and additional information are available at arXiv:2404.19756
Summary
在预训练的GPT-2模型中集成可学习和可解释的模块(如Kolmogorov-Arnold网络(KAN)和基于图的表示),以增强多任务学习的准确性。通过采用低秩适应(LoRA)增强标准自注意力转换器,微调超参数并引入L2正则化,取得了显著改进。然而,系统性评估表明,优化后的LoRA增强转换器表现最佳,而其他尝试改进KAN和GAT的变体并未表现出更好的性能。
Key Takeaways
- 探讨了将Kolmogorov-Arnold网络(KAN)和基于图的表示集成到预训练GPT-2模型中,以提高多任务学习准确性的潜力。
- 通过采用低秩适应(LoRA)技术增强了标准自注意力转换器。
- 通过微调超参数并引入L2正则化,取得了显著的性能改进。
- 开发了两种改进KAN和GAT的变体,但系统性评估表明,这些变体并未表现出比优化后的LoRA增强转换器更好的性能。
- LoRA增强转换器在情感分析、语句复述和十四行诗生成任务上表现出最佳性能。
- 在SST测试集上实现了55.249%的准确率,在CFIMDB开发集上实现了99.18%的准确率,在语句复述测试集上实现了89.9%的准确率。
点此查看论文截图

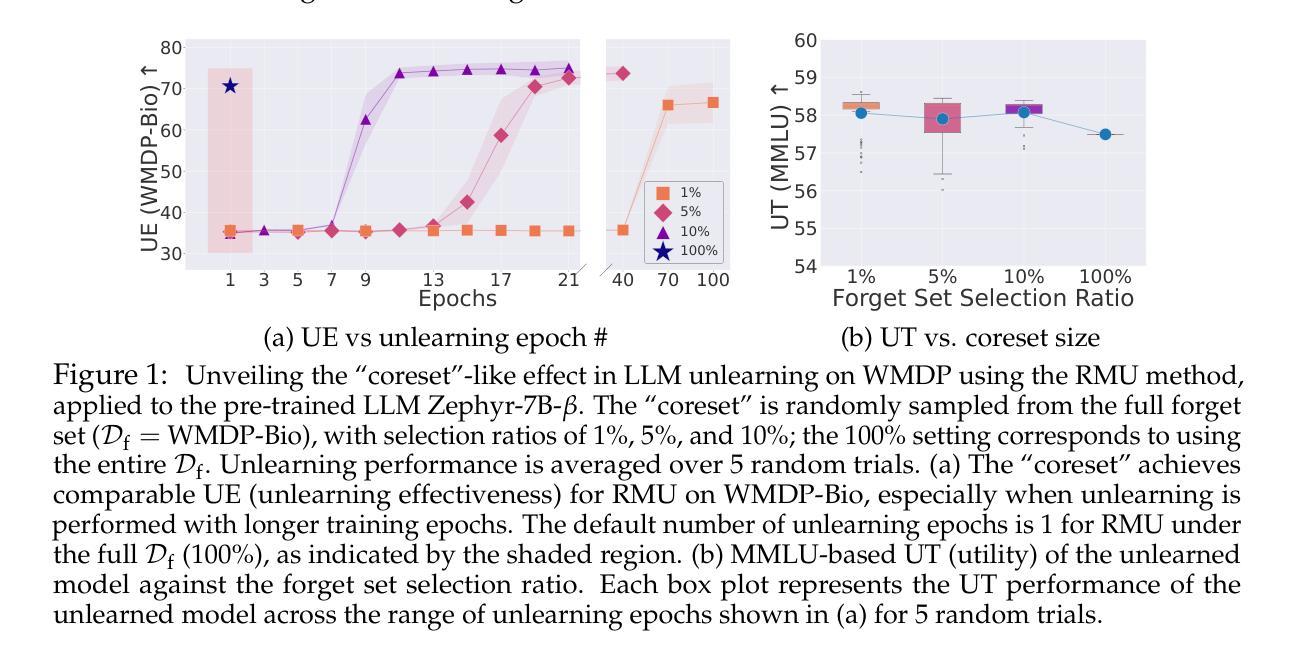
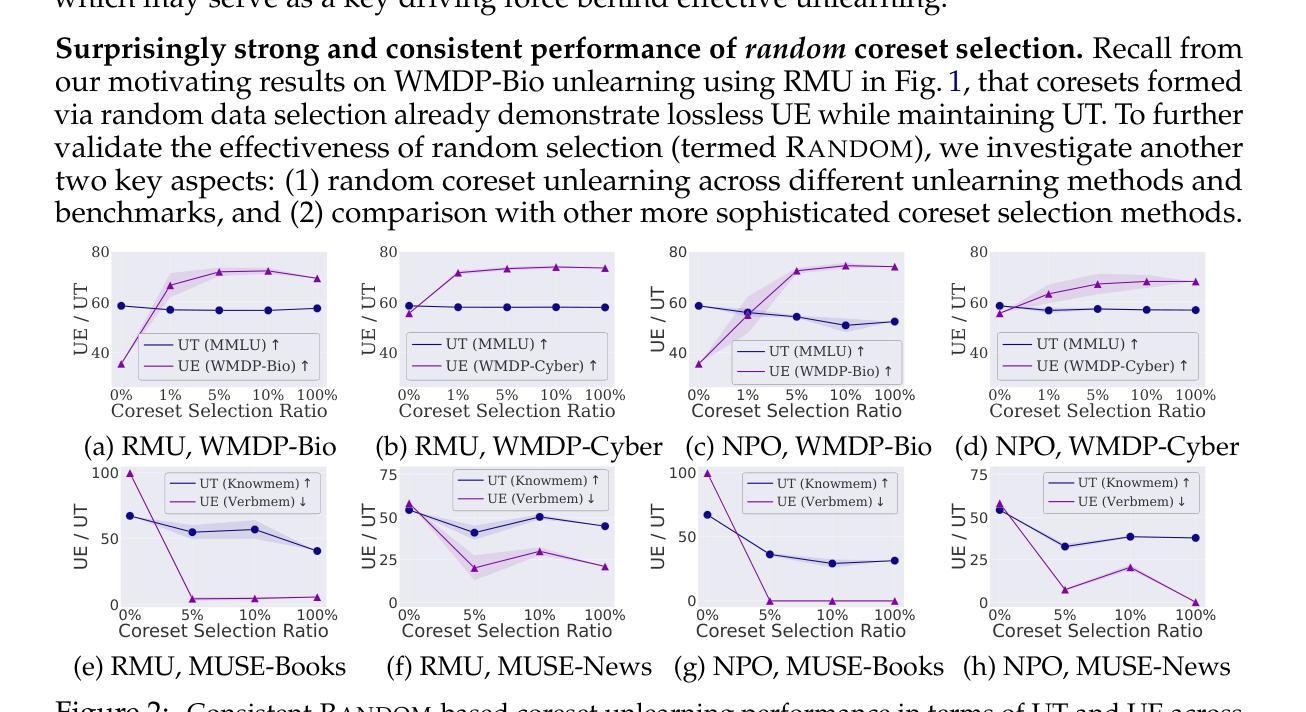
LLM Unlearning Reveals a Stronger-Than-Expected Coreset Effect in Current Benchmarks
Authors:Soumyadeep Pal, Changsheng Wang, James Diffenderfer, Bhavya Kailkhura, Sijia Liu
Large language model unlearning has become a critical challenge in ensuring safety and controlled model behavior by removing undesired data-model influences from the pretrained model while preserving general utility. Significant recent efforts have been dedicated to developing LLM unlearning benchmarks such as WMDP (Weapons of Mass Destruction Proxy) and MUSE (Machine Unlearning Six-way Evaluation), facilitating standardized unlearning performance assessment and method comparison. Despite their usefulness, we uncover for the first time a novel coreset effect within these benchmarks. Specifically, we find that LLM unlearning achieved with the original (full) forget set can be effectively maintained using a significantly smaller subset (functioning as a “coreset”), e.g., as little as 5% of the forget set, even when selected at random. This suggests that LLM unlearning in these benchmarks can be performed surprisingly easily, even in an extremely low-data regime. We demonstrate that this coreset effect remains strong, regardless of the LLM unlearning method used, such as NPO (Negative Preference Optimization) and RMU (Representation Misdirection Unlearning), the popular ones in these benchmarks. The surprisingly strong coreset effect is also robust across various data selection methods, ranging from random selection to more sophisticated heuristic approaches. We explain the coreset effect in LLM unlearning through a keyword-based perspective, showing that keywords extracted from the forget set alone contribute significantly to unlearning effectiveness and indicating that current unlearning is driven by a compact set of high-impact tokens rather than the entire dataset. We further justify the faithfulness of coreset-unlearned models along additional dimensions, such as mode connectivity and robustness to jailbreaking attacks. Codes are available at https://github.com/OPTML-Group/MU-Coreset.
大型语言模型的去除学习(unlearning)已经成为确保模型安全和可控性的重要挑战。通过从预训练模型中移除不必要的数据模型影响,同时保留其通用效用,来实现对模型行为的控制。近期,人们已经投入大量努力来开发大型语言模型的去除学习基准测试,例如大规模杀伤武器代理(WMDP)和音乐大赛机器去除学习评估(MUSE),以促进标准化的去除学习性能评估和方法的比较。然而,尽管这些基准测试很有用,我们首次发现了其中的一种新型核心集效应。具体来说,我们发现使用原始(完整)遗忘集实现的大型语言模型去除学习可以通过一个显著较小的子集(充当“核心集”)来有效维持,例如,即使只选择遗忘集的5%,即使是随机选择的。这表明,即使在极端低数据情况下,这些基准测试中的大型语言模型去除学习也可以出乎意料地轻松实现。我们证明,无论使用的大型语言模型去除方法如何,这种核心集效应依然强烈存在,如负面偏好优化(NPO)和表示误导去除(RMU)等,在基准测试中都很受欢迎。出乎意料地强烈的核心集效应在各种数据选择方法中也很稳健,从随机选择到更复杂的启发式方法。我们通过关键词角度来解释大型语言模型去除学习中的核心集效应,表明仅从遗忘集中提取的关键词对去除学习的有效性贡献重大,并指示当前的去除学习是由一组具有重大影响的令牌驱动的,而不是整个数据集。我们还从其他维度(如模式连通性和对越狱攻击的稳定性)进一步证明了核心集去除模型的忠实性。相关代码可在 https://github.com/OPTML-Group/MU-Coreset 中找到。
论文及项目相关链接
Summary
大型语言模型的遗忘学习在保障模型安全和可控性方面发挥着重要作用。最新研究显示,遗忘学习基准测试中的核心集效应对于降低工作量有积极影响,只需使用一小部分遗忘集就能实现有效的遗忘学习,甚至可以低至原始遗忘集的5%。这意味着即使在极低数据的情况下,大型语言模型的遗忘学习也能轻松实现。这一发现对于未来的语言模型遗忘学习具有重要影响。
Key Takeaways
- 大型语言模型遗忘学习对模型安全和可控性至关重要。
- 新的研究发现,使用遗忘集的小部分子集(核心集)即可实现有效的遗忘学习。
- 核心集效应在多种语言模型遗忘学习方法中普遍存在,包括NPO和RMU等方法。
- 关键词在遗忘学习中起着重要作用,表明当前遗忘学习主要由一小部分高影响力词汇驱动。
- 核心集遗忘学习的有效性在各种数据选择方法中得到验证,从随机选择到更复杂的启发式方法均适用。
点此查看论文截图

Understanding and Optimizing Multi-Stage AI Inference Pipelines
Authors:Abhimanyu Rajeshkumar Bambhaniya, Hanjiang Wu, Suvinay Subramanian, Sudarshan Srinivasan, Souvik Kundu, Amir Yazdanbakhsh, Midhilesh Elavazhagan, Madhu Kumar, Tushar Krishna
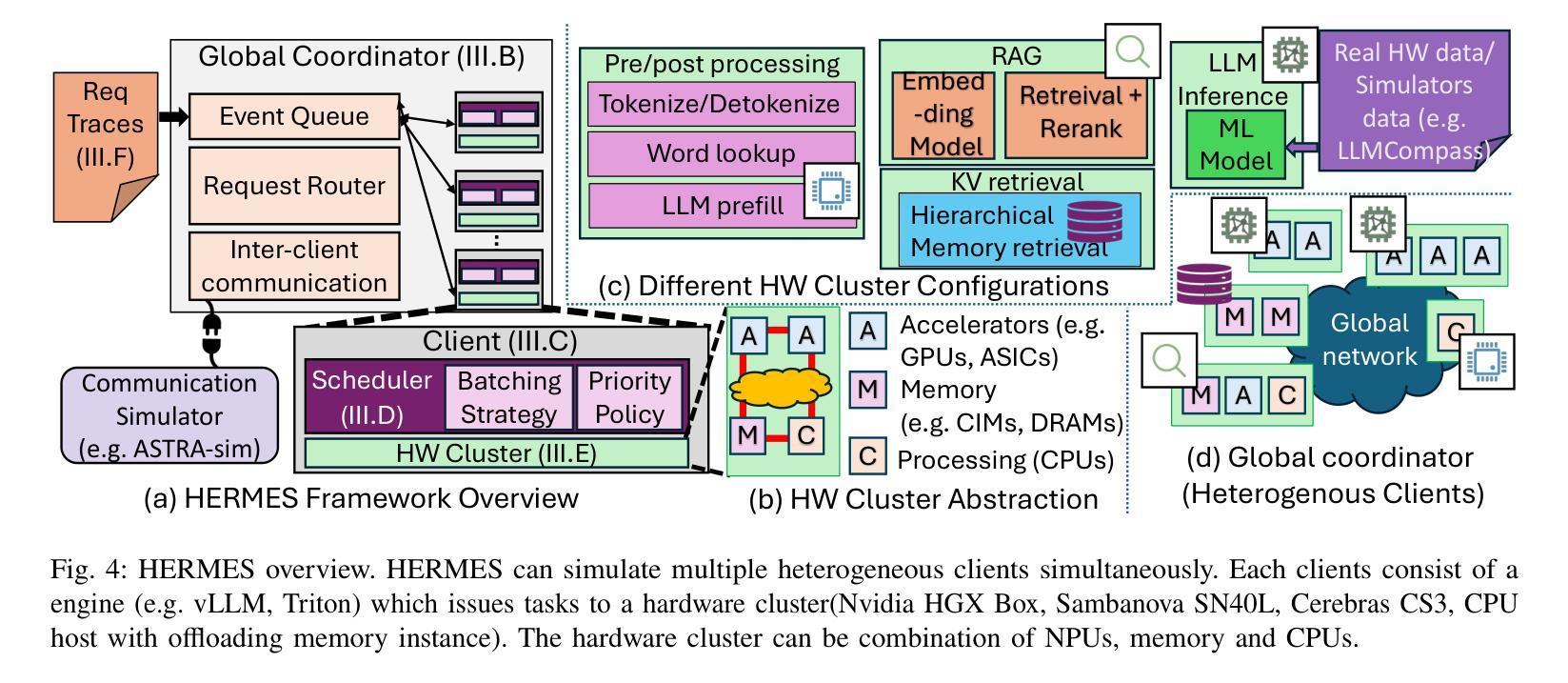
The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
大型语言模型(LLM)的快速发展推动了越来越精细的推理管道和硬件平台的需求。现代LLM服务超越了传统的预填充-解码工作流程,融入了多阶段流程,如检索增强生成(RAG)、键值(KV)缓存检索、动态模型路由和多步推理。这些阶段表现出多样化的计算需求,需要整合GPU、ASIC、CPU和内存中心的分布式系统架构。然而,现有的模拟器缺乏对这些异构多引擎工作流程的逼真建模,限制了它们对架构决策的指导作用。
论文及项目相关链接
PDF Inference System Design for Multi-Stage AI Inference Pipelines. 13 Pages, 15 Figues, 3 Tables
Summary
大型语言模型(LLM)的快速发展推动了越来越复杂的推理管道和硬件平台的需求。现代LLM服务超越了传统的预填充-解码工作流程,引入了多阶段过程,如检索增强生成(RAG)、键值(KV)缓存检索、动态模型路由和多步推理等。这些阶段具有多样的计算需求,需要整合GPU、ASIC、CPU和内存为中心的架构的分布式系统。为解决现有模拟器在模拟这些异构多引擎工作流程方面的不足,我们推出了HERMES,一个异构多阶段LLM推理执行模拟器。HERMES能够模拟包括RAG、KV检索、推理、预填充和解码在内的各种请求阶段,并跨越复杂的硬件层次结构。通过整合真实硬件跟踪和解析建模,HERMES能够捕捉关键权衡,如内存带宽竞争、集群间通信延迟和混合CPU加速器部署中的批处理效率。我们的案例研究探讨了推理阶段对端到端延迟的影响、混合管道的最佳批处理策略以及远程KV缓存检索的架构影响。HERMES使系统设计师能够应对LLM推理不断变化的景观,为下一代AI工作负载的优化软硬件协同设计提供可操作的见解。
Key Takeaways
- LLM的快速发展推动了复杂推理管道和硬件平台的需求。
- 现代LLM服务包含多阶段过程,如RAG、KV缓存检索等,具有多样的计算需求。
- 现有模拟器在模拟异构多引擎工作流程方面存在不足。
- HERMES是一个异构多阶段LLM推理执行模拟器,能模拟各种请求阶段并跨越复杂的硬件层次结构。
- HERMES结合真实硬件跟踪和解析建模,能捕捉关键权衡,如内存带宽竞争和批处理效率。
- 案例研究显示了推理阶段对端到端延迟的影响以及混合管道的最佳批处理策略。
点此查看论文截图


Task Memory Engine (TME): A Structured Memory Framework with Graph-Aware Extensions for Multi-Step LLM Agent Tasks
Authors:Ye Ye
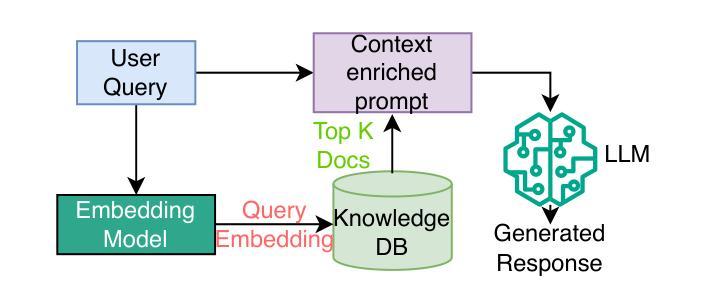
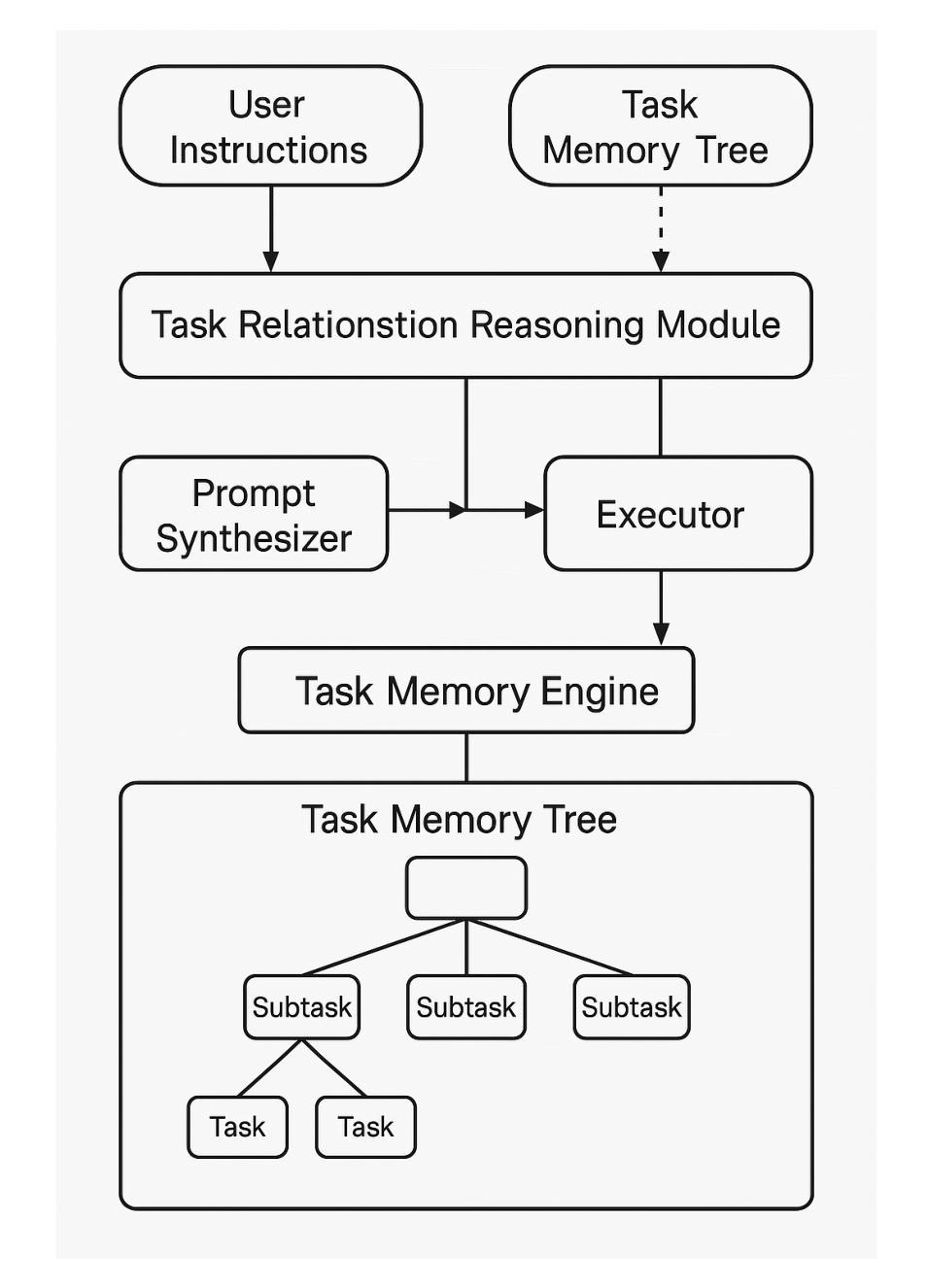
Large Language Models (LLMs) are increasingly used as autonomous agents for multi-step tasks. However, most existing frameworks fail to maintain a structured understanding of the task state, often relying on linear prompt concatenation or shallow memory buffers. This leads to brittle performance, frequent hallucinations, and poor long-range coherence. In this work, we propose the Task Memory Engine (TME), a lightweight and structured memory module that tracks task execution using a hierarchical Task Memory Tree (TMT). Each node in the tree corresponds to a task step, storing relevant input, output, status, and sub-task relationships. We introduce a prompt synthesis method that dynamically generates LLM prompts based on the active node path, significantly improving execution consistency and contextual grounding. Through case studies and comparative experiments on multi-step agent tasks, we demonstrate that TME leads to better task completion accuracy and more interpretable behavior with minimal implementation overhead. A reference implementation of the core TME components is available at https://github.com/biubiutomato/TME-Agent, including basic examples and structured memory integration. While the current implementation uses a tree-based structure, TME is designed to be graph-aware, supporting reusable substeps, converging task paths, and shared dependencies. This lays the groundwork for future DAG-based memory architectures.
大型语言模型(LLM)越来越多地被用作多步骤任务的自主代理。然而,大多数现有框架无法维持对任务状态的结构化理解,通常依赖于线性提示串联或浅内存缓冲区。这导致性能脆弱、频繁出现幻觉和长期连贯性差。在这项工作中,我们提出了任务记忆引擎(TME),这是一个轻量级、结构化的内存模块,它通过分层任务记忆树(TMT)来跟踪任务执行。树中的每个节点对应于一个任务步骤,存储相关的输入、输出、状态和子任务关系。我们引入了一种提示合成方法,该方法基于活动节点路径动态生成LLM提示,从而显著提高了执行一致性以及上下文相关性。通过多步骤代理任务的案例研究和对比实验,我们证明了TME在提高任务完成准确性和可解释性行为方面的优势,并且具有最小的实现开销。核心TME组件的参考实现可在[https://github.com/biubiotomato/TME-Agent找到,其中包括基本示例和结构化的内存集成。尽管当前实现使用树形结构,但TME被设计为图形感知,支持可重复的子步骤、收敛的任务路径和共享依赖关系。这为未来的有向无环图(DAG)基础内存架构奠定了基础。
论文及项目相关链接
PDF 14 pages, 5 figures. Preprint prepared for future submission. Includes implementation and token-efficiency analysis. Code at https://github.com/biubiutomato/TME-Agent
Summary
大型语言模型(LLM)在多步任务中作为自主代理的应用越来越广泛,但现有框架往往无法维持对任务状态的结构化理解,导致性能不稳定、频繁出现幻觉和长期连贯性差。本文提出了任务记忆引擎(TME)和层次化任务记忆树(TMT),通过跟踪任务执行来改善这一问题。TME利用结构化记忆模块存储任务步骤的相关输入、输出、状态和子任务关系,并引入基于活跃节点路径的动态生成LLM提示的提示合成方法,显著提高了执行的一致性和上下文相关性。通过案例研究和多步代理任务的对比实验,我们证明了TME在提升任务完成准确性和解释性行为方面的优势,且实现开销较小。核心组件的参考实现可访问于链接。
Key Takeaways
- LLM在多步任务中作为自主代理的应用越来越广泛,但存在对任务状态理解不足的问题。
- 现有框架往往依赖线性提示拼接或浅层记忆缓冲区,导致性能不稳定、频繁出现幻觉和长期连贯性差。
- 本文提出了任务记忆引擎(TME)和层次化任务记忆树(TMT),用于跟踪任务执行并改善上述问题。
- TME利用结构化记忆模块存储任务步骤的相关输入、输出、状态和子任务关系。
- TME引入提示合成方法,该方法基于活跃节点路径动态生成LLM提示,提高了执行的一致性和上下文相关性。
- 通过案例研究和实验证明,TME在提升任务完成准确性和解释性行为方面表现出优势,且实现开销较小。
点此查看论文截图

Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Authors:Anh Tong, Thanh Nguyen-Tang, Dongeun Lee, Duc Nguyen, Toan Tran, David Hall, Cheongwoong Kang, Jaesik Choi
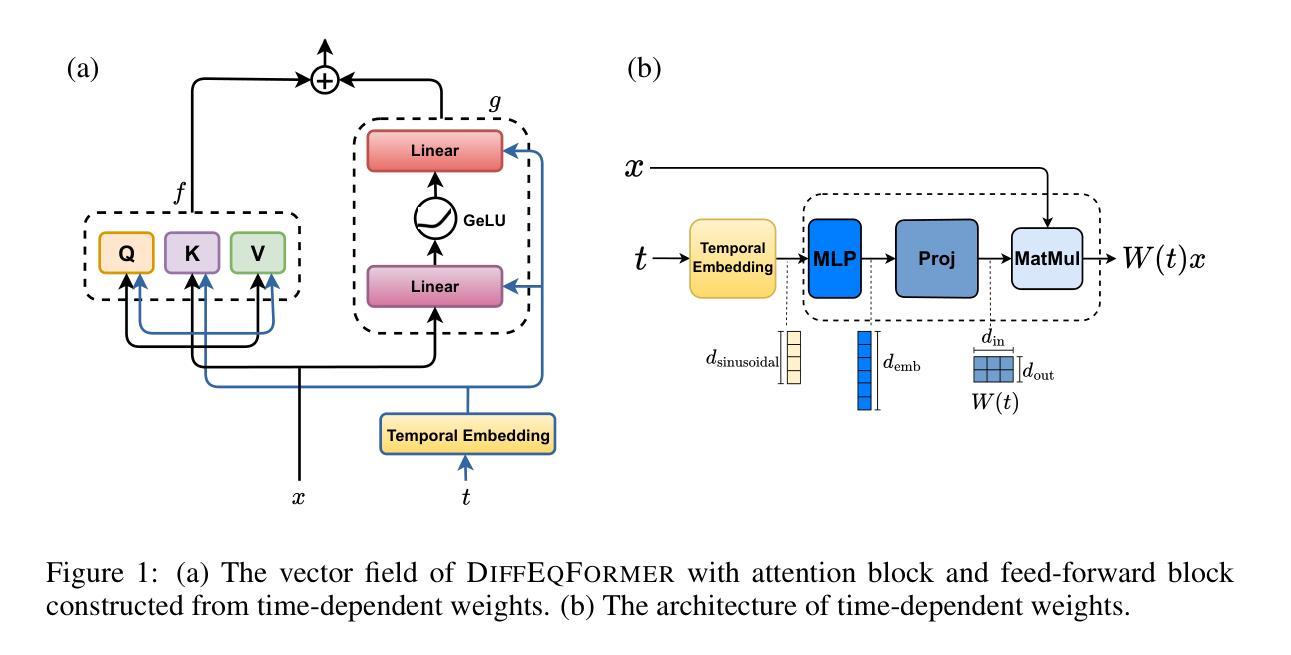
Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model’s dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
基于Transformer架构的大型语言模型(LLM)的最新进展,引发了人们对理解其内部工作原理的极大兴趣。在本文中,我们介绍了一种使用高度灵活的非自治神经常微分方程(ODEs)对Transformer架构进行建模的新方法。我们提出的模型通过神经网络对所有注意力权重和前馈块的权重进行参数化,并将这些权重表达为连续层索引的函数。通过对模型动力学的频谱分析,我们发现特征值幅度增大,这挑战了现有理论研究中普遍存在的权重共享假设。我们还利用Lyapunov指数来检查令牌级别的敏感性,以提高模型的解释性。我们的神经ODE变压器在各种配置和数据集上的性能与标准变压器相当或更好,同时提供灵活的微调能力,可以适应不同的架构约束。
论文及项目相关链接
PDF ICLR 2025
Summary
近期,基于Transformer架构的大型语言模型(LLM)的新进展引发了对其内部工作原理的极大兴趣。本文提出了一种使用非自主神经常微分方程(ODEs)对Transformer架构进行建模的新方法。该模型通过神经网络参数化所有注意力与馈送前向块的权重,并将这些权重表达为连续层索引的函数。通过对模型动态进行谱分析,我们发现特征值幅度增加,这挑战了现有理论研究中普遍存在的权重共享假设。我们还利用Lyapunov指数来考察词级别的敏感性,增强了模型的解释性。我们的神经ODE变压器在各种配置和数据集上的性能与常规变压器相当或更好,同时提供了灵活的微调能力,能够适应不同的架构约束。
Key Takeaways
- 引入了非自主神经常微分方程(ODEs)对Transformer架构进行建模的新方法。
- 通过神经网络参数化Transformer的权重,并将其表达为连续层索引的函数。
- 谱分析显示模型的特征值幅度增加,挑战了现有理论中的权重共享假设。
- 利用Lyapunov指数考察词级别的敏感性,增强了模型的解释性。
- 神经ODE变压器的性能与常规变压器相当或更好,适用于多种任务和数据集。
- 神经ODE变压器提供了灵活的微调能力,能够适应不同的架构约束。
- 该研究为理解LLM的内部工作原理提供了新的视角和方法。
点此查看论文截图

BioMaze: Benchmarking and Enhancing Large Language Models for Biological Pathway Reasoning
Authors:Haiteng Zhao, Chang Ma, Fangzhi Xu, Lingpeng Kong, Zhi-Hong Deng
The applications of large language models (LLMs) in various biological domains have been explored recently, but their reasoning ability in complex biological systems, such as pathways, remains underexplored, which is crucial for predicting biological phenomena, formulating hypotheses, and designing experiments. This work explores the potential of LLMs in pathway reasoning. We introduce BioMaze, a dataset with 5.1K complex pathway problems derived from real research, covering various biological contexts including natural dynamic changes, disturbances, additional intervention conditions, and multi-scale research targets. Our evaluation of methods such as CoT and graph-augmented reasoning, shows that LLMs struggle with pathway reasoning, especially in perturbed systems. To address this, we propose PathSeeker, an LLM agent that enhances reasoning through interactive subgraph-based navigation, enabling a more effective approach to handling the complexities of biological systems in a scientifically aligned manner. The dataset and code are available at https://github.com/zhao-ht/BioMaze.
最近已经探索了大型语言模型(LLM)在各种生物领域的应用,但它们在复杂生物系统(如途径)中的推理能力仍被忽视,这对于预测生物现象、提出假设和设计实验至关重要。这项工作探索了LLM在途径推理中的潜力。我们介绍了BioMaze,这是一个包含5.1K个来自真实研究的复杂途径问题的数据集,涵盖了多种生物背景,包括自然动态变化、干扰、额外干预条件和多尺度研究目标。我们对CoT和增强图推理等方法进行评估的结果表明,LLM在途径推理方面存在困难,特别是在受干扰系统中。为了解决这一问题,我们提出了PathSeeker,这是一个LLM代理,它通过基于交互子图的导航增强推理能力,以科学的方式更有效地处理生物系统的复杂性。数据集和代码可在https://github.com/zhao-ht/BioMaze找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在多个生物领域的应用已得到广泛研究,但在生物通路等复杂生物系统中的推理能力仍然研究不足。本文旨在探索LLM在通路推理中的潜力,并介绍了BioMaze数据集,包含5.1K真实研究中的复杂通路问题。评估显示,LLM在应对扰动系统中的推理时表现欠佳。为解决这一问题,本文提出了PathSeeker,一个通过交互式子图导航增强推理的LLM代理,以更科学的方式有效应对生物系统的复杂性。
Key Takeaways
- LLM在生物通路等复杂生物系统中的推理能力仍然研究不足。
- BioMaze数据集包含真实研究中的复杂生物通路问题,有助于评估LLM的推理能力。
- LLM在应对扰动系统中的推理时表现欠佳。
- PathSeeker是一个LLM代理,通过交互式子图导航增强推理。
- PathSeeker能更科学、有效地应对生物系统的复杂性。
- BioMaze数据集和代码可在公开仓库中获取。
点此查看论文截图


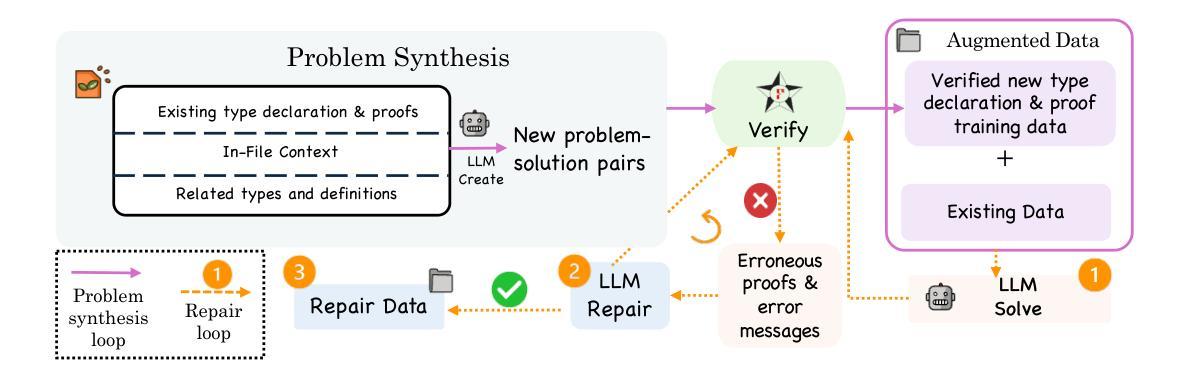
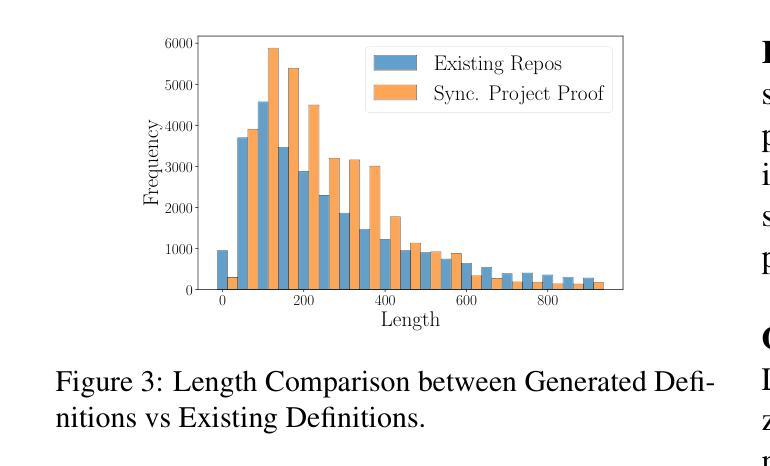
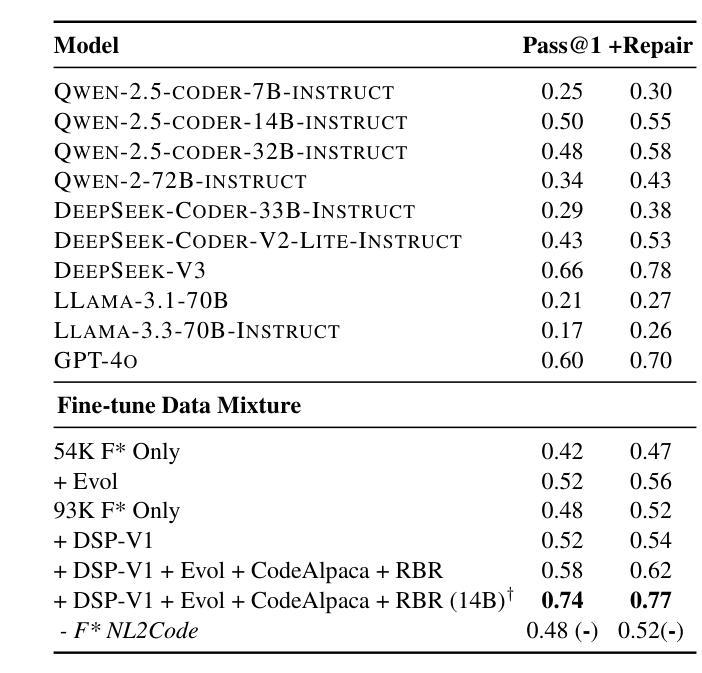
Building A Proof-Oriented Programmer That Is 64% Better Than GPT-4o Under Data Scarcity
Authors:Dylan Zhang, Justin Wang, Tianran Sun
Existing LMs struggle with proof-oriented programming due to data scarcity, which manifest in two key ways: (1) a lack of sufficient corpora for proof-oriented programming languages such as F*, and (2) the absence of large-scale, project-level proof-oriented implementations that can teach the model the intricate reasoning process when performing proof-oriented programming. We present the first on synthetic data augmentation for project level proof oriented programming for both generation and repair. Our method addresses data scarcity by synthesizing basic proof-oriented programming problems for proficiency in that language; incorporating diverse coding data for reasoning capability elicitation and creating new proofs and repair data within existing repositories. This approach enables language models to both synthesize and repair proofs for function- and repository-level code. We show that our fine-tuned 14B parameter model, PoPilot, can exceed the performance of the models that outperforms GPT-4o in project-level proof-oriented programming by 64% relative margin, and can improve GPT-4o’s performance by 54% by repairing its outputs over GPT-4o’s self-repair.
现有的语言模型在处理面向证明的编程时面临着数据稀缺的问题,这主要体现在两个方面:(1)缺乏足够的面向证明的编程语言语料库,如F*,以及(2)缺乏大规模的项目级面向证明的实现,这些实现可以在进行面向证明的编程时教导模型复杂的推理过程。我们首次提出针对项目级面向证明的编程的合成数据增强方法,既可用于生成也可用于修复。我们的方法通过合成基本的面向证明的编程问题来解决该语言方面的熟练度问题;引入多样化的编码数据来激发推理能力,并在现有存储库中创建新的证明和修复数据。这种方法使语言模型能够合成和修复函数级和存储库级的代码证明。我们展示了经过微调的14亿参数模型PoPilot,在面向项目的证明导向编程方面的性能超过了GPT-4o模型的相对边缘,提高幅度为百分之六十四;而且比GPT-4o的自我修复输出性能提高了百分之五十四。我们通过合成训练样例数据以构建通用推理管道系统应对对一系列基本的编程任务的挑战。我们还构建了针对项目级面向证明的编程的第一个大规模的开源数据集,包含合成训练和测试数据。这为语言模型提供了大量的训练数据,并有助于改进其在项目级面向证明的编程任务中的表现。
论文及项目相关链接
Summary
现有语言模型在面向证明的编程方面存在数据稀缺的问题,表现为缺乏足够的面向证明的编程语言语料库和项目级别的证明实现。为解决这一问题,我们提出了合成数据增强方法,用于项目级别的证明导向编程生成和修复。通过合成基本的面向证明的编程问题,融入多样化的编码数据激发推理能力,并在现有存储库中创建新的证明和修复数据,该方法使语言模型能够合成和修复函数及存储库级别的代码证明。实验显示,我们微调的14B参数模型PoPilot在项目级别的证明导向编程方面的性能超过了GPT-4o,相对边际提高了64%,并在修复输出方面将GPT-4o的性能提高了54%。
Key Takeaways
- 语言模型在面向证明的编程方面面临数据稀缺的挑战。
- 缺乏面向证明的编程语言语料库和项目级别的证明实现是数据稀缺的主要表现。
- 提出通过合成数据增强方法解决数据稀缺问题,包括合成面向证明的编程问题、融入多样化编码数据和在现有存储库中创建新的证明和修复数据。
- 该方法使语言模型能够合成和修复函数及存储库级别的代码证明。
- PoPilot模型在项目级别的证明导向编程方面的性能超过了GPT-4o。
- PoPilot模型相对GPT-4o的性能提高了64%,并在修复输出方面的性能提高了54%。
点此查看论文截图