⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-18 更新
HLS-Eval: A Benchmark and Framework for Evaluating LLMs on High-Level Synthesis Design Tasks
Authors:Stefan Abi-Karam, Cong Hao
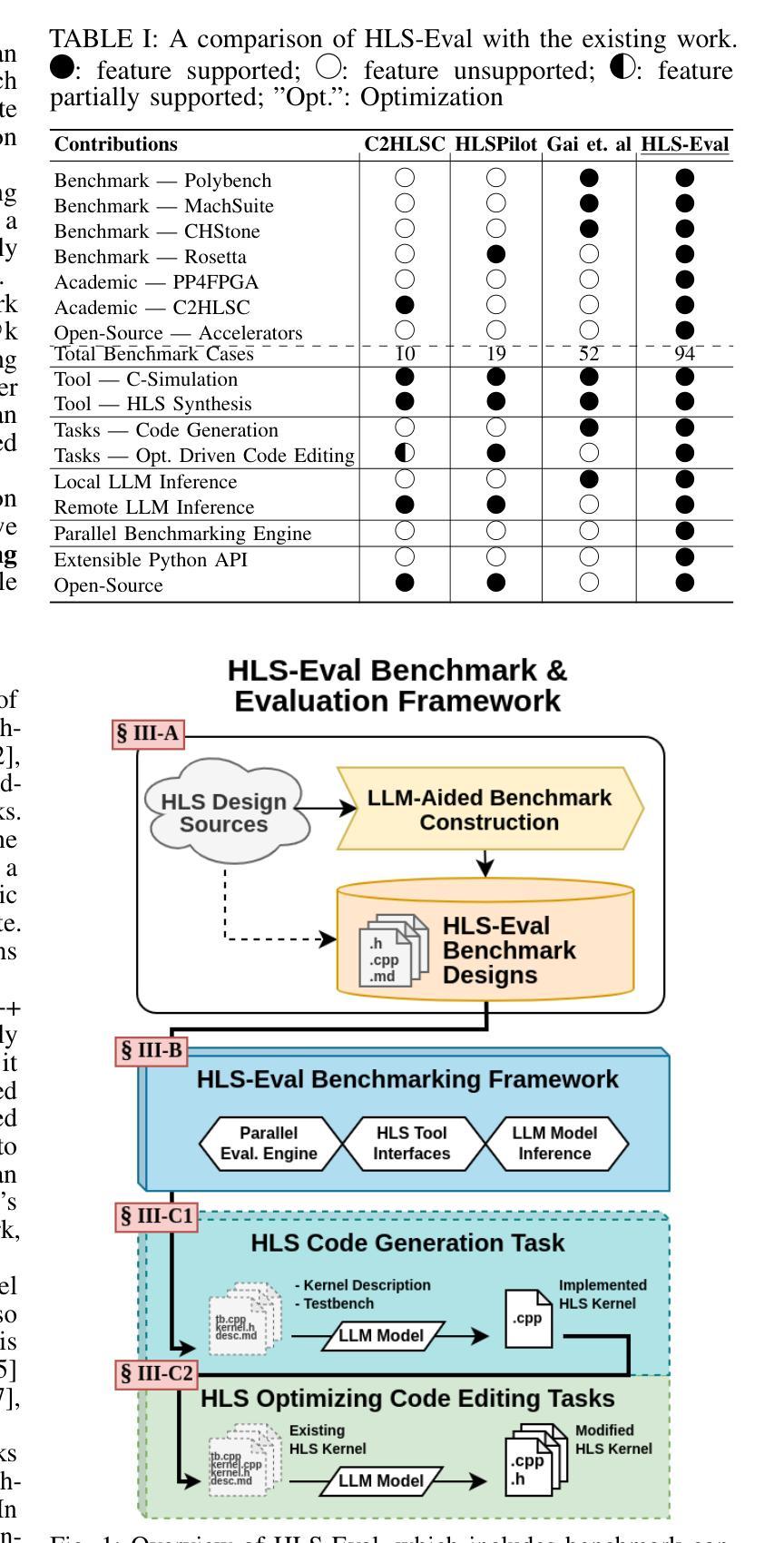
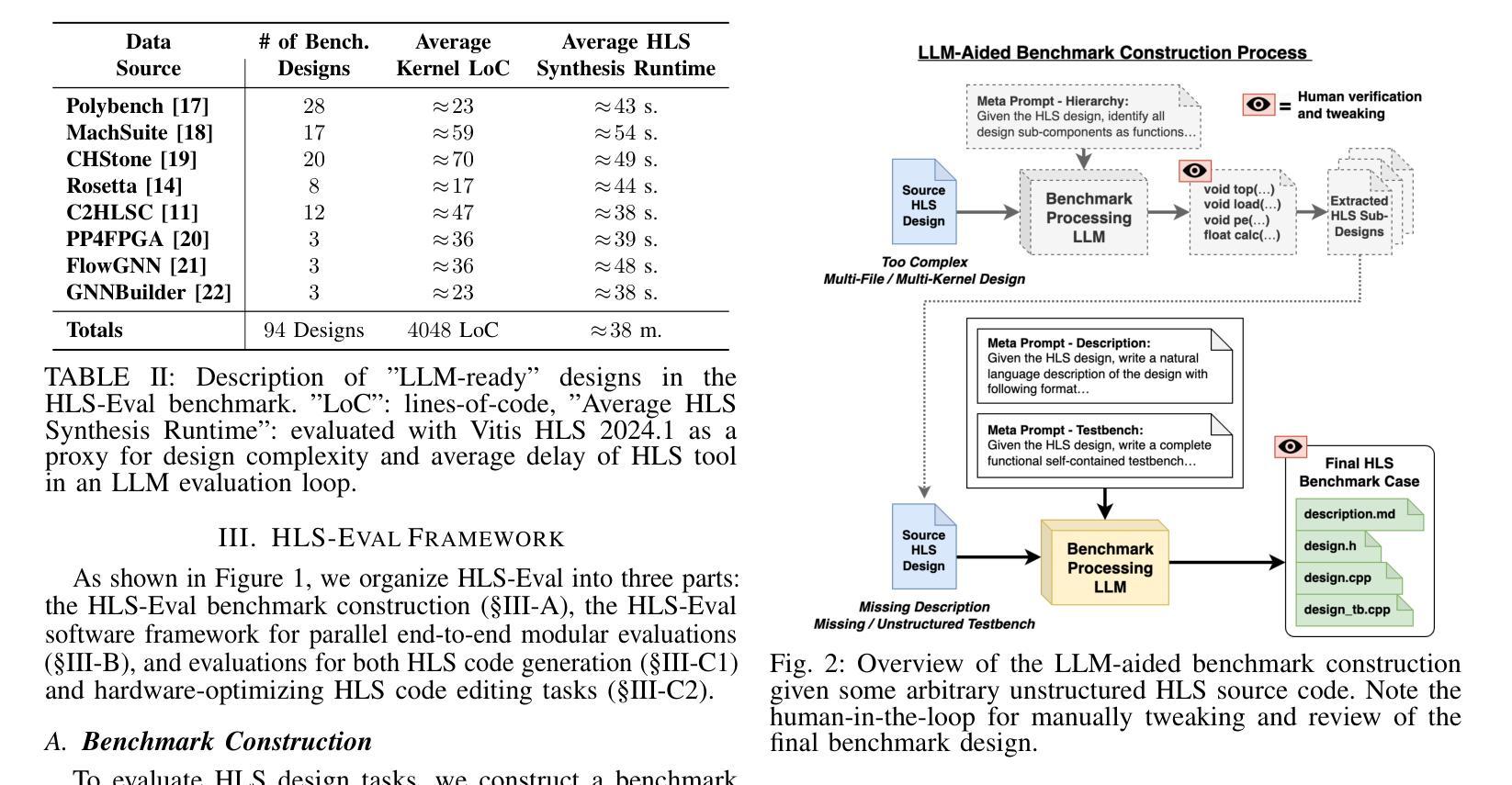
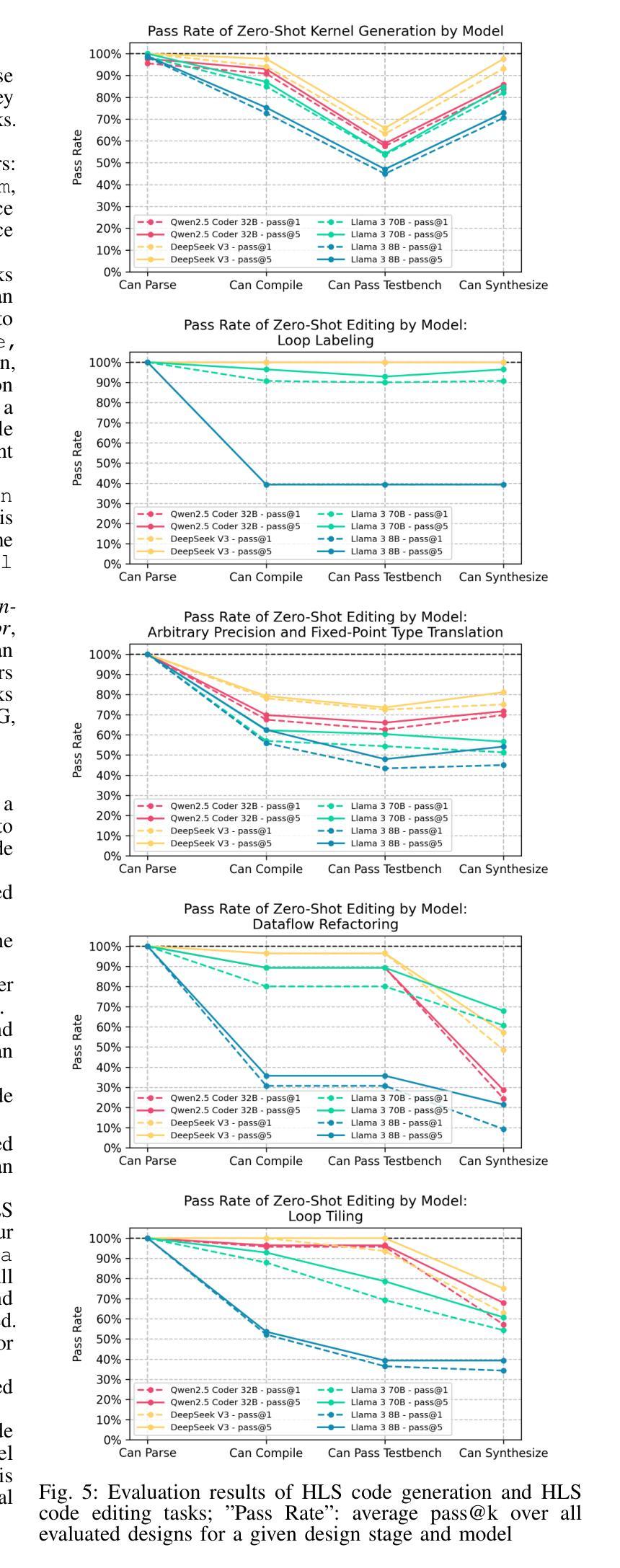
The rapid scaling of large language model (LLM) training and inference has driven their adoption in semiconductor design across academia and industry. While most prior work evaluates LLMs on hardware description language (HDL) tasks, particularly Verilog, designers are increasingly using high-level synthesis (HLS) to build domain-specific accelerators and complex hardware systems. However, benchmarks and tooling to comprehensively evaluate LLMs for HLS design tasks remain scarce. To address this, we introduce HLS-Eval, the first complete benchmark and evaluation framework for LLM-driven HLS design. HLS-Eval targets two core tasks: (1) generating HLS code from natural language descriptions, and (2) performing HLS-specific code edits to optimize performance and hardware efficiency. The benchmark includes 94 unique designs drawn from standard HLS benchmarks and novel sources. Each case is prepared via a semi-automated flow that produces a natural language description and a paired testbench for C-simulation and synthesis validation, ensuring each task is “LLM-ready.” Beyond the benchmark, HLS-Eval offers a modular Python framework for automated, parallel evaluation of both local and hosted LLMs. It includes a parallel evaluation engine, direct HLS tool integration, and abstractions for to support different LLM interaction paradigms, enabling rapid prototyping of new benchmarks, tasks, and LLM methods. We demonstrate HLS-Eval through baseline evaluations of open-source LLMs on Vitis HLS, measuring outputs across four key metrics - parseability, compilability, runnability, and synthesizability - reflecting the iterative HLS design cycle. We also report pass@k metrics, establishing clear baselines and reusable infrastructure for the broader LLM-for-hardware community. All benchmarks, framework code, and results are open-sourced at https://github.com/stefanpie/hls-eval.
大型语言模型(LLM)的训练和推理的迅速扩展,推动了其在学术界和工业界半导体设计中的应用。虽然大多数先前的工作都是对硬件描述语言(HDL)任务进行评估,特别是针对Verilog语言,但设计师们正越来越多地使用高级综合(HLS)来构建特定领域的加速器和复杂的硬件系统。然而,针对HLS设计任务全面评估LLM的基准测试和工具仍然稀缺。为了解决这一问题,我们引入了HLS-Eval,这是首个针对LLM驱动的HLS设计的完整基准测试和评价框架。HLS-Eval针对两个核心任务:1)根据自然语言描述生成HLS代码;2)执行HLS特定的代码编辑,以优化性能和硬件效率。基准测试包括来自标准HLS基准测试和新颖来源的94个独特设计。每个案例都通过半自动化流程进行准备,该流程产生自然语言描述和配套测试平台,用于C仿真和综合验证,确保每个任务都适合LLM。除了基准测试外,HLS-Eval还提供模块化Python框架,用于本地和托管LLM的自动化并行评估。它包括并行评估引擎、直接HLS工具集成,以及支持不同LLM交互范式的抽象,从而能够迅速对新的基准测试、任务、LLM方法进行原型设计。我们通过Vitis HLS的开源LLM基线评估来展示HLS-Eval,通过衡量四个关键指标(可解析性、可编译性、可运行性和可合成性)来反映迭代HLS设计周期。我们还报告了pass@k指标,为更广泛的LLM硬件社区建立了明确的基准和可重复使用的架构。所有基准测试、框架代码和结果均已在https://github.com/stefanpie/hls-eval上开源发布。
论文及项目相关链接
Summary
该文本介绍了大型语言模型(LLM)在半导体设计领域的应用越来越广泛。尽管大多数早期的研究关注LLM在硬件描述语言(HDL)任务上的评估,但设计师正越来越多地使用高级综合(HLS)来构建特定领域的加速器和复杂的硬件系统。然而,针对HLS设计任务的LLM评估基准和工具仍然稀缺。为了解决这个问题,文章引入了HLS-Eval,这是第一个针对LLM驱动的HLS设计的完整基准和评估框架。HLS-Eval针对两个核心任务:从自然语言描述生成HLS代码以及对HLS代码进行优化以提高性能和硬件效率。该基准包括来自标准HLS基准和新颖来源的94个独特设计。每个案例都通过半自动化流程进行准备,产生自然语言描述和配对测试平台用于C模拟和综合验证,确保每个任务都是“LLM就绪”。除了基准测试外,HLS-Eval还提供模块化Python框架,用于本地和托管LLM的自动化并行评估。它包含并行评估引擎、直接HLS工具集成以及支持不同LLM交互范式的抽象概念,可以加快新基准测试、任务和LLM方法的快速原型设计。通过基线评估证明了HLS-Eval的有效性。
Key Takeaways
- 大型语言模型(LLM)在半导体设计领域的应用正在增加,特别是在高级综合(HLS)方面。
- 目前针对LLM在HLS设计任务上的评估基准和工具仍然不足。
- HLS-Eval是首个针对LLM驱动的HLS设计的完整基准和评估框架。
- HLS-Eval包含两个核心任务:从自然语言描述生成HLS代码及优化HLS代码以提高性能和硬件效率。
- HLS-Eval提供了模块化Python框架,支持自动化并行评估,并可直接集成HLS工具和不同LLM交互范式。
- HLS-Eval通过基线评估证明了其有效性,并公开了所有基准测试、框架代码和结果。
点此查看论文截图


FLIP Reasoning Challenge
Authors:Andreas Plesner, Turlan Kuzhagaliyev, Roger Wattenhofer
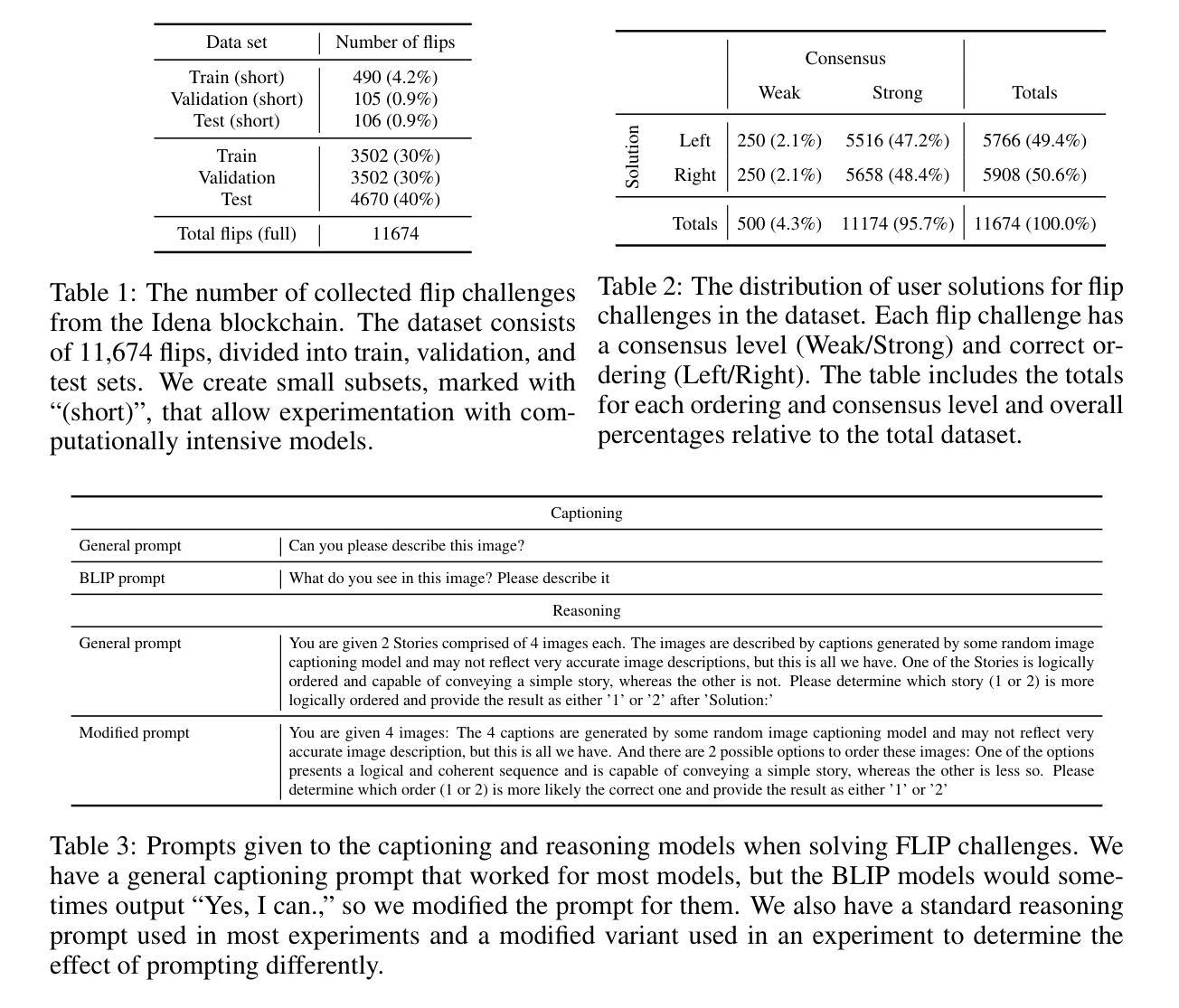
Over the past years, advances in artificial intelligence (AI) have demonstrated how AI can solve many perception and generation tasks, such as image classification and text writing, yet reasoning remains a challenge. This paper introduces the FLIP dataset, a benchmark for evaluating AI reasoning capabilities based on human verification tasks on the Idena blockchain. FLIP challenges present users with two orderings of 4 images, requiring them to identify the logically coherent one. By emphasizing sequential reasoning, visual storytelling, and common sense, FLIP provides a unique testbed for multimodal AI systems. Our experiments evaluate state-of-the-art models, leveraging both vision-language models (VLMs) and large language models (LLMs). Results reveal that even the best open-sourced and closed-sourced models achieve maximum accuracies of 75.5% and 77.9%, respectively, in zero-shot settings, compared to human performance of 95.3%. Captioning models aid reasoning models by providing text descriptions of images, yielding better results than when using the raw images directly, 69.6% vs. 75.2% for Gemini 1.5 Pro. Combining the predictions from 15 models in an ensemble increases the accuracy to 85.2%. These findings highlight the limitations of existing reasoning models and the need for robust multimodal benchmarks like FLIP. The full codebase and dataset will be available at https://github.com/aplesner/FLIP-Reasoning-Challenge.
近年来,人工智能(AI)的进步已经证明AI如何解决许多感知和生成任务,例如图像分类和文本写作,但推理仍然是一个挑战。本文介绍了FLIP数据集,这是一个基于人类验证任务在Idena区块链上评估AI推理能力的基准测试。FLIP挑战要求用户识别两个顺序排列的4张图像中的逻辑连贯性。通过强调顺序推理、视觉叙事和常识,FLIP为跨模态AI系统提供了独特的测试平台。我们的实验评估了最先进的模型,利用视觉语言模型(VLMs)和大型语言模型(LLMs)。结果显示,即使在零样本设置下,即使最好的开源和闭源模型也只能达到最高准确率分别为75.5%和77.9%,而人类的表现力为95.3%。通过提供图像的文字描述,描述模型有助于推理模型,其效果优于直接使用原始图像,Gemini 1.5 Pro的准确率从69.6%提高到75.2%。通过将来自十五个模型的预测结合到一个组合中,可以将准确性提高到85.2%。这些发现凸显了现有推理模型的局限性以及需要像FLIP这样的稳健的跨模态基准测试集。完整的代码库和数据集将在https://github.com/aplesner/FLIP-Reasoning-Challenge上提供。
论文及项目相关链接
PDF Published at First Workshop on Open Science for Foundation Models at ICLR 2025
Summary
本文介绍了一个名为FLIP的新数据集,该数据集旨在评估人工智能的推理能力。它基于人类验证任务在区块链上进行构建,要求用户识别出逻辑连贯的图像序列。实验结果显示,当前最先进的模型在零样本设置下的准确率最高达到77.9%,但仍远低于人类的准确率(95.3%)。结合多种模型的预测可以提高准确率至85.2%,这突显了现有推理模型的局限性以及对更稳健的多模式基准测试的需求。
Key Takeaways
- FLIP数据集是一个用于评估人工智能推理能力的基准测试。
- 它基于人类验证任务在区块链上构建,强调顺序推理、视觉叙事和常识。
- 最先进的模型在零样本设置下的准确率最高达到77.9%,但仍低于人类的准确率。
- 标注模型通过提供图像的文字描述来辅助推理模型,取得了一定成效。
- 结合多个模型的预测可以提高推理的准确性。
- 当前人工智能在推理方面仍有局限性,需要更稳健的多模式基准测试。
点此查看论文截图

An Evaluation of N-Gram Selection Strategies for Regular Expression Indexing in Contemporary Text Analysis Tasks
Authors:Ling Zhang, Shaleen Deep, Jignesh M. Patel, Karthikeyan Sankaralingam
Efficient evaluation of regular expressions (regex, for short) is crucial for text analysis, and n-gram indexes are fundamental to achieving fast regex evaluation performance. However, these indexes face scalability challenges because of the exponential number of possible n-grams that must be indexed. Many existing selection strategies, developed decades ago, have not been rigorously evaluated on contemporary large-scale workloads and lack comprehensive performance comparisons. Therefore, a unified and comprehensive evaluation framework is necessary to compare these methods under the same experimental settings. This paper presents the first systematic evaluation of three representative n-gram selection strategies across five workloads, including real-time production logs and genomic sequence analysis. We examine their trade-offs in terms of index construction time, storage overhead, false positive rates, and end-to-end query performance. Through empirical results, this study provides a modern perspective on existing n-gram based regular expression evaluation methods, extensive observations, valuable discoveries, and an adaptable testing framework to guide future research in this domain. We make our implementations of these methods and our test framework available as open-source at https://github.com/mush-zhang/RegexIndexComparison.
正则表达式(简称regex)的有效评估在文本分析中至关重要,而n元索引是实现快速正则表达式评估性能的基础。然而,这些索引面临着由于必须索引的指数级增长的n元组数量所带来的可扩展性挑战。许多现有的选择策略是几十年前开发的,尚未在当前的大规模工作负载上进行严格评估,并且缺乏全面的性能比较。因此,需要一个统一和全面的评估框架,在同一实验设置下比较这些方法。本文对三种代表性的n元组选择策略进行了五项工作负载的首个系统评估,包括实时生产日志和基因组序列分析。我们考察了它们在索引构建时间、存储开销、误报率和端到端查询性能方面的权衡。通过实证结果,本研究提供了对现有基于n元的正则表达式评估方法的现代视角、丰富的观察和有价值的发现,以及一个可适应的测试框架,以指导该领域的未来研究方向。我们在https://github.com/mush-zhang/RegexIndexComparison上提供了这些方法的实现和我们的测试框架的开源版本。
论文及项目相关链接
Summary
该文研究了三种代表性的n-gram选择策略在五个工作负载下的系统评估,包括实时生产日志和基因组序列分析。文章评估了这些方法在索引构建时间、存储开销、误报率和端到端查询性能方面的优缺点,提供了一个关于现有基于n-gram的正则表达式评估方法的现代视角。
Key Takeaways
- 正则表达式的有效评估对文本分析至关重要,而n-gram索引是实现快速正则表达式评估性能的基础。
- n-gram选择策略面临可扩展性挑战,因为必须索引的n-gram数量呈指数增长。
- 现有方法缺乏统一和全面的评估框架,需要在相同实验设置下进行比较。
- 文章首次系统评估了三种代表性的n-gram选择策略,跨越五个工作负载。
- 这些策略在索引构建时间、存储开销、误报率和端到端查询性能等方面存在权衡。
- 文章提供了基于实证的结果,对基于n-gram的正则表达式评估方法提供了现代视角。
点此查看论文截图


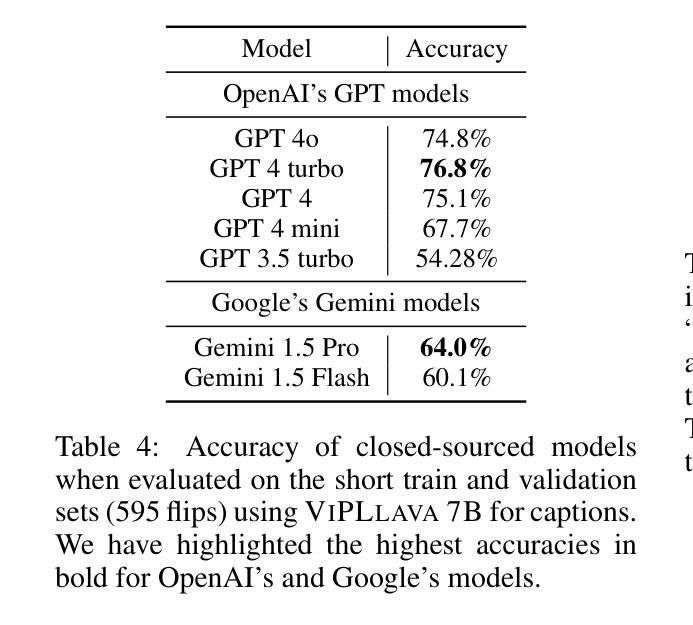
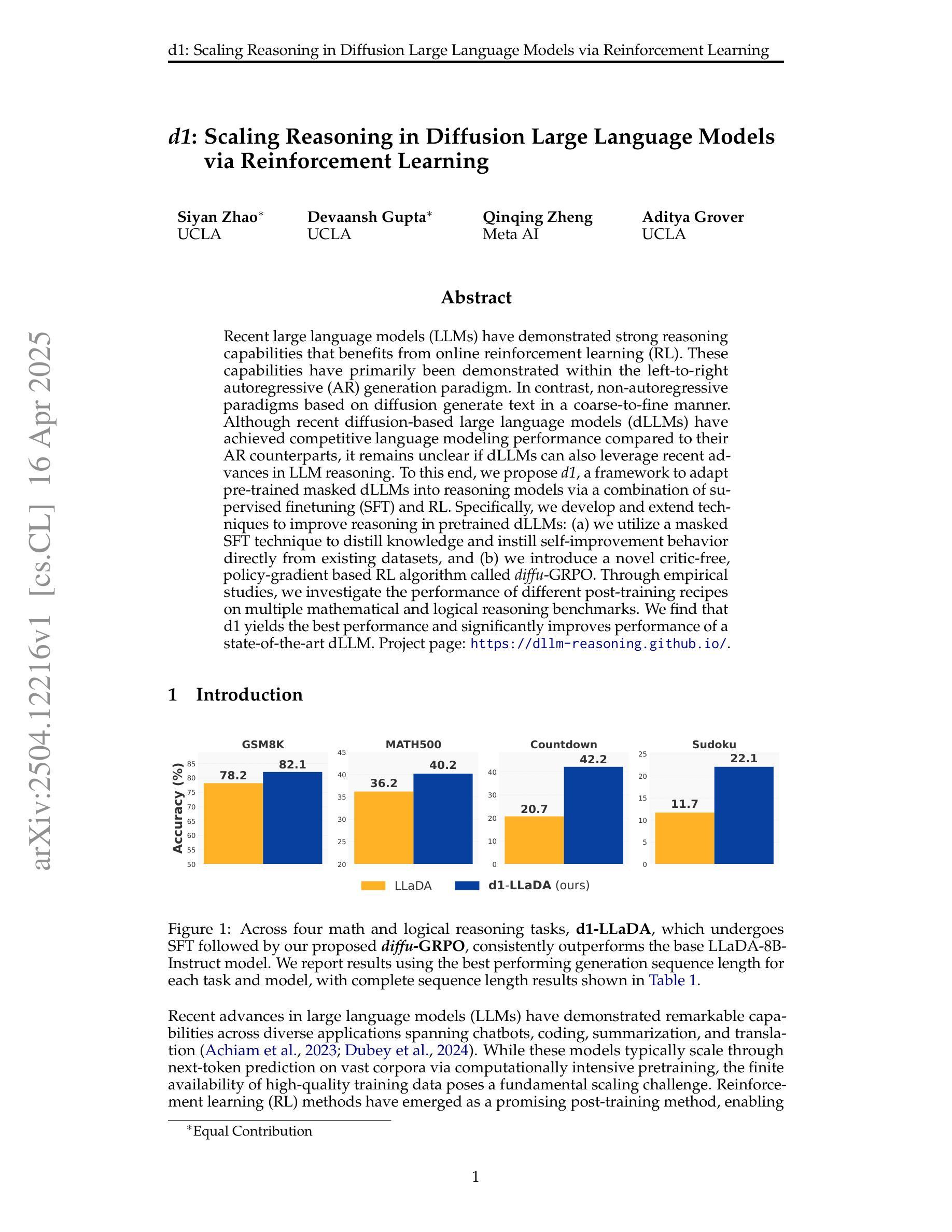
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
Authors:Siyan Zhao, Devaansh Gupta, Qinqing Zheng, Aditya Grover
Recent large language models (LLMs) have demonstrated strong reasoning capabilities that benefits from online reinforcement learning (RL). These capabilities have primarily been demonstrated within the left-to-right autoregressive (AR) generation paradigm. In contrast, non-autoregressive paradigms based on diffusion generate text in a coarse-to-fine manner. Although recent diffusion-based large language models (dLLMs) have achieved competitive language modeling performance compared to their AR counterparts, it remains unclear if dLLMs can also leverage recent advances in LLM reasoning. To this end, we propose d1, a framework to adapt pre-trained masked dLLMs into reasoning models via a combination of supervised finetuning (SFT) and RL. Specifically, we develop and extend techniques to improve reasoning in pretrained dLLMs: (a) we utilize a masked SFT technique to distill knowledge and instill self-improvement behavior directly from existing datasets, and (b) we introduce a novel critic-free, policy-gradient based RL algorithm called diffu-GRPO. Through empirical studies, we investigate the performance of different post-training recipes on multiple mathematical and logical reasoning benchmarks. We find that d1 yields the best performance and significantly improves performance of a state-of-the-art dLLM.
最近的大型语言模型(LLM)展示了受益于在线强化学习(RL)的强大推理能力。这些能力主要是在从左到右的自回归(AR)生成范式内展示的。相比之下,基于扩散的非自回归范式以从粗到细的方式生成文本。尽管最近的基于扩散的大型语言模型(dLLM)在与其AR同类模型的竞争中实现了相当的语言建模性能,但尚不清楚dLLM是否能够利用最近LLM推理中的技术进展。为此,我们提出了d1框架,该框架通过结合监督微调(SFT)和RL将预训练的掩码dLLM适应为推理模型。具体来说,我们开发并扩展了提高预训练dLLM中推理的技术:(a)我们使用掩蔽的SFT技术从现有数据集中蒸馏知识并灌输自我改进行为;(b)我们引入了一种新型的无评论家、基于策略梯度的RL算法,称为diffu-GRPO。通过实证研究,我们在多个数学和逻辑推理基准上探讨了不同后训练配方性能的表现。我们发现d1取得了最佳性能,并显著提高了最新dLLM的性能。
论文及项目相关链接
PDF 25 pages, project page at https://dllm-reasoning.github.io/
Summary
大型语言模型通过在线强化学习展现出强大的推理能力,主要在左至右的自回归生成范式中得到验证。本研究提出d1框架,旨在将预训练的扩散式大型语言模型通过监督微调与强化学习相结合,转化为推理模型。研究发现d1能提高预训练扩散大型语言模型的推理能力,并在数学与逻辑基准测试中表现出最佳性能。
Key Takeaways
- 大型语言模型借助在线强化学习展现出强大的推理能力。
- 自回归生成范式在展示这些能力方面占据主导地位。
- 扩散式大型语言模型能通过监督微调与强化学习转化为推理模型。
- d1框架通过结合监督微调与无评论家政策梯度强化学习算法来提高预训练扩散大型语言模型的推理能力。
点此查看论文截图
Reasoning-Based AI for Startup Evaluation (R.A.I.S.E.): A Memory-Augmented, Multi-Step Decision Framework
Authors:Jack Preuveneers, Joseph Ternasky, Fuat Alican, Yigit Ihlamur
We present a novel framework that bridges the gap between the interpretability of decision trees and the advanced reasoning capabilities of large language models (LLMs) to predict startup success. Our approach leverages chain-of-thought prompting to generate detailed reasoning logs, which are subsequently distilled into structured, human-understandable logical rules. The pipeline integrates multiple enhancements - efficient data ingestion, a two-step refinement process, ensemble candidate sampling, simulated reinforcement learning scoring, and persistent memory - to ensure both stable decision-making and transparent output. Experimental evaluations on curated startup datasets demonstrate that our combined pipeline improves precision by 54% from 0.225 to 0.346 and accuracy by 50% from 0.46 to 0.70 compared to a standalone OpenAI o3 model. Notably, our model achieves over 2x the precision of a random classifier (16%). By combining state-of-the-art AI reasoning with explicit rule-based explanations, our method not only augments traditional decision-making processes but also facilitates expert intervention and continuous policy refinement. This work lays the foundation for the implementation of interpretable LLM-powered decision frameworks in high-stakes investment environments and other domains that require transparent and data-driven insights.
我们提出了一种新颖框架,该框架缩小了决策树可解释性与大型语言模型(LLM)的先进推理能力之间的差距,以预测创业公司的成功。我们的方法利用链式思维提示生成详细的推理日志,随后将其提炼成结构化、人类可理解的逻辑规则。该管道融合了多项增强功能,包括高效数据摄取、两步精炼过程、集成候选采样、模拟强化学习评分和持久性内存,以确保稳定的决策制定和透明的输出。在精选的初创公司数据集上的实验评估表明,我们的组合管道与单独的OpenAI o3模型相比,精确度从0.225提高到0.346(提高54%),准确率从0.46提高到0.70(提高50%)。值得注意的是,我们的模型的精确度是随机分类器的两倍以上(16%)。通过结合最先进的AI推理和基于明确规则的解释,我们的方法不仅增强了传统的决策制定过程,还促进了专家干预和连续的政策优化。这项工作为高风险投资环境和其他需要透明化和数据驱动洞察力的领域实施可解释的LLM驱动决策框架奠定了基础。
论文及项目相关链接
Summary:
本研究提出了一种新颖框架,融合了决策树的解释性与大型语言模型(LLM)的高级推理能力,以预测创业公司的成功。该研究通过思维链提示生成详细的推理日志,随后将其提炼为结构化、人类可理解的逻辑规则。实验评估表明,与单一的OpenAI o3模型相比,该框架在精确度和准确度方面都有显著提高。该模型结合了最先进的AI推理和基于规则的明确解释,不仅增强了传统决策制定过程,还有助于专家干预和政策持续改进。这为在高风险投资环境和其他需要透明和数据驱动的领域实现可解释的LLM驱动决策框架奠定了基础。
Key Takeaways:
- 研究提出了结合决策树的解释性和大型语言模型的推理能力的框架,用于预测创业公司成功。
- 通过思维链提示生成详细的推理日志,再转化为结构化逻辑规则。
- 框架包含多项改进,如高效数据摄取、两步精炼过程、组合候选采样、模拟强化学习评分和持久性记忆,以确保稳定的决策制定和透明的输出。
- 实验评估显示,与单一OpenAI o3模型相比,该框架在精确度和准确度方面有显著提高。
- 模型结合了先进的AI推理和基于规则的明确解释,增强了传统决策制定过程。
- 框架有助于专家干预和政策的持续改进。
点此查看论文截图


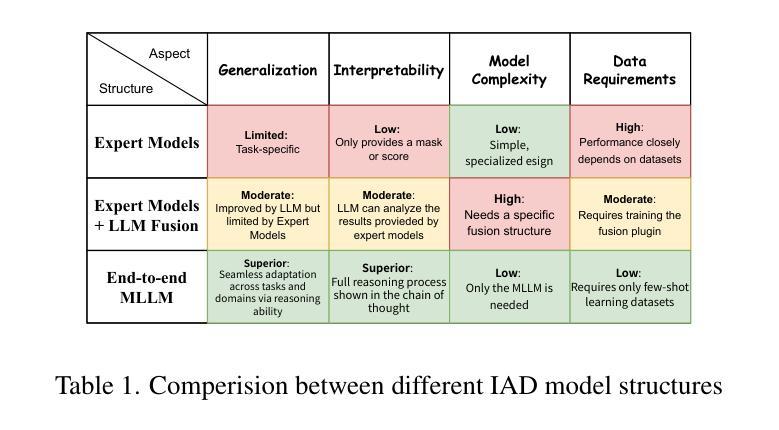
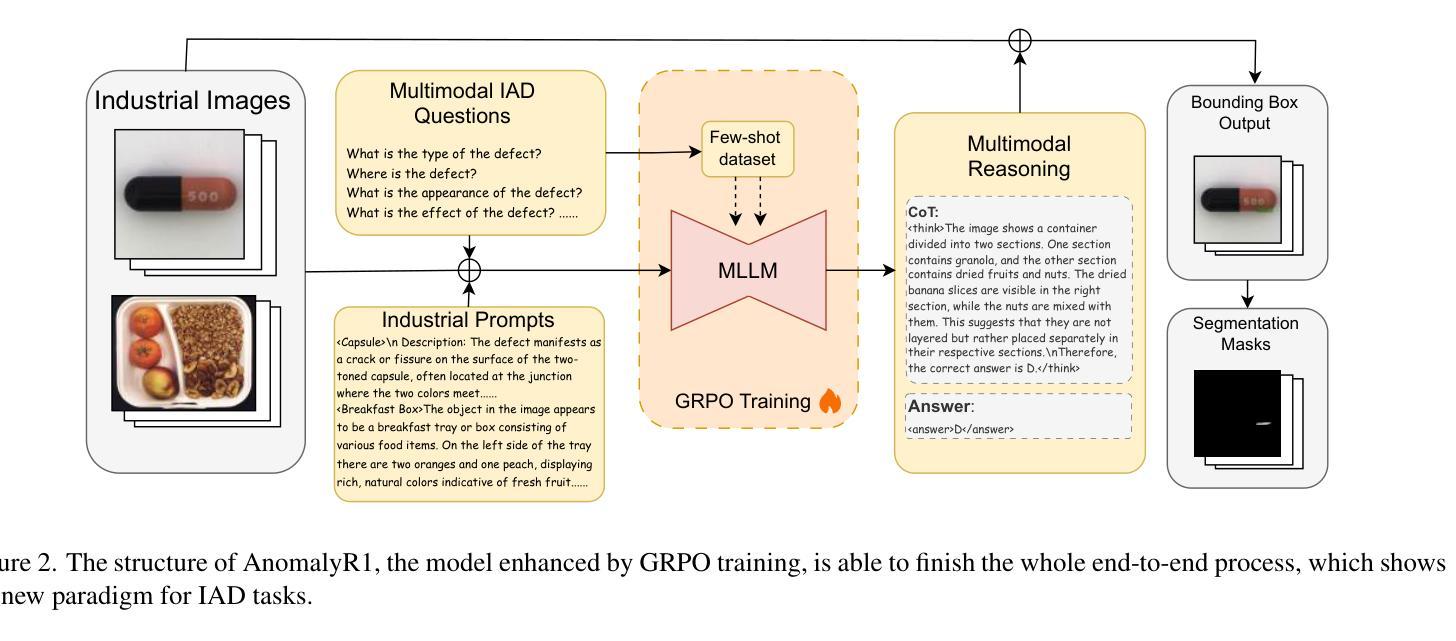
AnomalyR1: A GRPO-based End-to-end MLLM for Industrial Anomaly Detection
Authors:Yuhao Chao, Jie Liu, Jie Tang, Gangshan Wu
Industrial Anomaly Detection (IAD) poses a formidable challenge due to the scarcity of defective samples, making it imperative to deploy models capable of robust generalization to detect unseen anomalies effectively. Traditional approaches, often constrained by hand-crafted features or domain-specific expert models, struggle to address this limitation, underscoring the need for a paradigm shift. We introduce AnomalyR1, a pioneering framework that leverages VLM-R1, a Multimodal Large Language Model (MLLM) renowned for its exceptional generalization and interpretability, to revolutionize IAD. By integrating MLLM with Group Relative Policy Optimization (GRPO), enhanced by our novel Reasoned Outcome Alignment Metric (ROAM), AnomalyR1 achieves a fully end-to-end solution that autonomously processes inputs of image and domain knowledge, reasons through analysis, and generates precise anomaly localizations and masks. Based on the latest multimodal IAD benchmark, our compact 3-billion-parameter model outperforms existing methods, establishing state-of-the-art results. As MLLM capabilities continue to advance, this study is the first to deliver an end-to-end VLM-based IAD solution that demonstrates the transformative potential of ROAM-enhanced GRPO, positioning our framework as a forward-looking cornerstone for next-generation intelligent anomaly detection systems in industrial applications with limited defective data.
工业异常检测(IAD)由于缺陷样本的稀缺性而面临巨大挑战,因此需要部署能够稳健泛化的模型,以有效检测未知的异常值。传统的方法常常受到手工特征或特定领域专家模型的限制,难以解决这一局限性,突显了范式转变的必要性。我们引入了AnomalR1,这是一个开创性的框架,它利用以出色泛化和可解释性著称的多模式大型语言模型(MLLM)VLM-R1来革新IAD。通过将MLLM与受我们的新型合理结果对齐度量(ROAM)增强的组相对策略优化(GRPO)相结合,AnomalyR1实现了端到端的完全解决方案,该方案可以自主处理图像和领域知识的输入,通过分析进行推理,并生成精确异常定位和掩码。基于最新的多模式IAD基准测试,我们紧凑的3亿参数模型优于现有方法,取得了最新结果。随着MLLM能力的不断进步,本研究首次提供了基于VLM的端到端IAD解决方案,展示了由ROAM增强的GRPO的变革潜力,使我们的框架成为面向下一代具有有限缺陷数据的工业应用的智能异常检测系统的重要基石。
论文及项目相关链接
Summary
工业异常检测(IAD)面临样本缺陷稀缺的严峻挑战,需要部署能够鲁棒泛化以有效检测未见异常的模型。引入AnomalyR1框架,借助具有卓越泛化和解释性的多模态大型语言模型(MLLM)VLM-R1进行革命性变革。通过整合MLLM与受集团相对策略优化(GRPO)启发的理性结果对齐度量(ROAM),AnomalyR1实现端到端的解决方案,可自主处理图像和领域知识输入,进行分析推理,并生成精确异常定位和掩码。基于最新的多模态IAD基准测试,我们的紧凑型3亿参数模型表现优于现有方法,达到最新结果。作为MLLM能力不断进步的一部分,本研究首次提供基于VLM的端到端IAD解决方案,展示了受ROAM增强的GRPO的变革潜力。
Key Takeaways
- 工业异常检测面临样本缺陷稀缺的挑战。
- AnomalyR1框架借助多模态大型语言模型(MLLM)VLM-R1进行革命性变革以解决此挑战。
- AnomalyR1通过整合MLLM与集团相对策略优化(GRPO)及新型Reasoned outcome Alignment Metric (ROAM),实现端到端的解决方案。
- 该方案可自主处理图像和领域知识输入,进行分析推理,生成精确异常定位和掩码。
- 在最新的多模态IAD基准测试中,AnomalyR1表现出卓越性能,优于现有方法。
- AnomalyR1的紧凑型模型具有高效性能。
点此查看论文截图

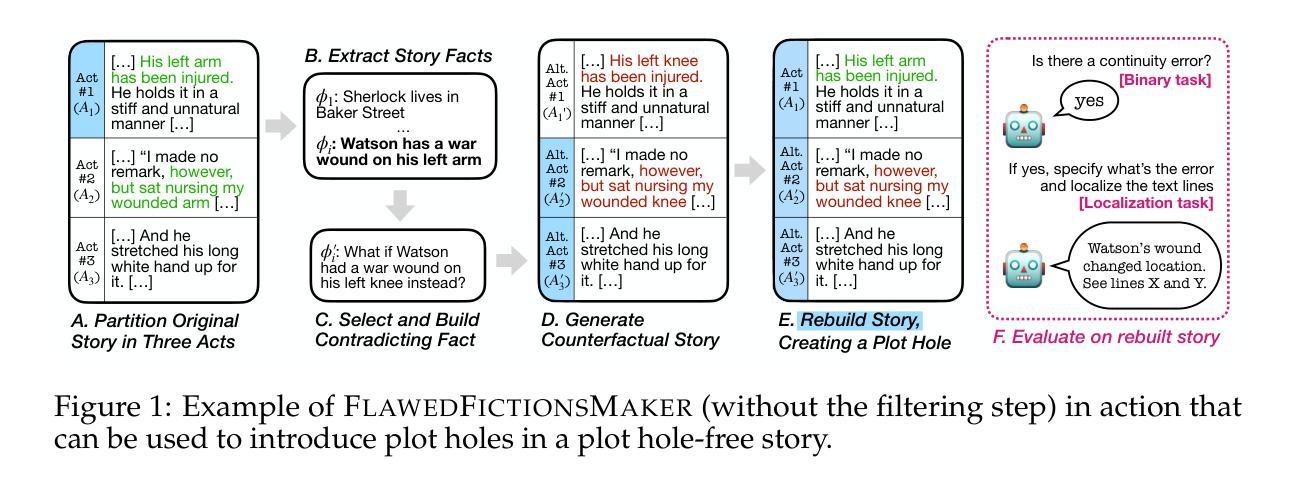
Finding Flawed Fictions: Evaluating Complex Reasoning in Language Models via Plot Hole Detection
Authors:Kabir Ahuja, Melanie Sclar, Yulia Tsvetkov
Stories are a fundamental aspect of human experience. Engaging deeply with stories and spotting plot holes – inconsistencies in a storyline that break the internal logic or rules of a story’s world – requires nuanced reasoning skills, including tracking entities and events and their interplay, abstract thinking, pragmatic narrative understanding, commonsense and social reasoning, and theory of mind. As Large Language Models (LLMs) increasingly generate, interpret, and modify text, rigorously assessing their narrative consistency and deeper language understanding becomes critical. However, existing benchmarks focus mainly on surface-level comprehension. In this work, we propose plot hole detection in stories as a proxy to evaluate language understanding and reasoning in LLMs. We introduce FlawedFictionsMaker, a novel algorithm to controllably and carefully synthesize plot holes in human-written stories. Using this algorithm, we construct a benchmark to evaluate LLMs’ plot hole detection abilities in stories – FlawedFictions – , which is robust to contamination, with human filtering ensuring high quality. We find that state-of-the-art LLMs struggle in accurately solving FlawedFictions regardless of the reasoning effort allowed, with performance significantly degrading as story length increases. Finally, we show that LLM-based story summarization and story generation are prone to introducing plot holes, with more than 50% and 100% increases in plot hole detection rates with respect to human-written originals.
故事是人类经验的基本组成部分。深入参与故事并发现情节漏洞——故事情节中的不一致之处,破坏了故事内部的逻辑或规则——需要微妙的推理技能,包括追踪实体和事件及其相互作用、抽象思维、实用叙事理解、常识和社会推理以及心智理论。随着大型语言模型(LLM)越来越多地生成、解释和修改文本,严格评估其叙事连贯性和更深层次的语言理解能力变得至关重要。然而,现有的基准测试主要集中在表面层次的理解上。在这项工作中,我们提出将情节漏洞检测作为评估LLM的语言理解和推理能力的代理。我们介绍了一种名为FlawedFictionsMaker的新型算法,该算法能够可控且仔细地合成人类编写的故事中的情节漏洞。使用该算法,我们构建了一个基准测试FlawedFictions,以评估LLM在故事中检测情节漏洞的能力,该测试对污染具有鲁棒性,并通过人工过滤确保高质量。我们发现,最先进的LLM在解决FlawedFictions时面临困难,无论允许多少推理努力,性能都会随着故事长度的增加而显著下降。最后,我们展示了基于LLM的故事摘要和故事生成容易引入情节漏洞,与人类原始作品相比,情节漏洞检测率分别增加了50%和100%以上。
论文及项目相关链接
PDF Preprint
Summary:
本文关注故事中的情节漏洞检测,认为这是评估大型语言模型深层次语言理解和推理能力的重要标准。文章提出了一种名为FlawedFictionsMaker的新算法,能够可控且精准地在人类撰写的故事中合成情节漏洞。基于该算法,构建了一个评估大型语言模型在故事中的情节漏洞检测能力的基准测试——FlawedFictions。研究发现,当前的大型语言模型在解决FlawedFictions方面的能力有待提高,随着故事长度的增加,性能会显著下降。此外,基于大型语言模型的故事摘要和故事生成也容易产生情节漏洞。
Key Takeaways:
- 故事中的情节漏洞检测是评估大型语言模型深层次语言理解和推理能力的重要标准。
- FlawedFictionsMaker算法能够可控且精准地在人类撰写的故事中合成情节漏洞。
- FlawedFictions基准测试用于评估大型语言模型的情节漏洞检测能力,且该测试对人类过滤以确保高质量。
- 当前的大型语言模型在解决FlawedFictions方面的能力有待提高。
- 随着故事长度的增加,大型语言模型的性能会显著下降。
- 基于大型语言模型的故事摘要和故事生成容易产生情节漏洞。
- 情节漏洞检测对于评估语言模型的推理能力和深层次理解至关重要。
点此查看论文截图

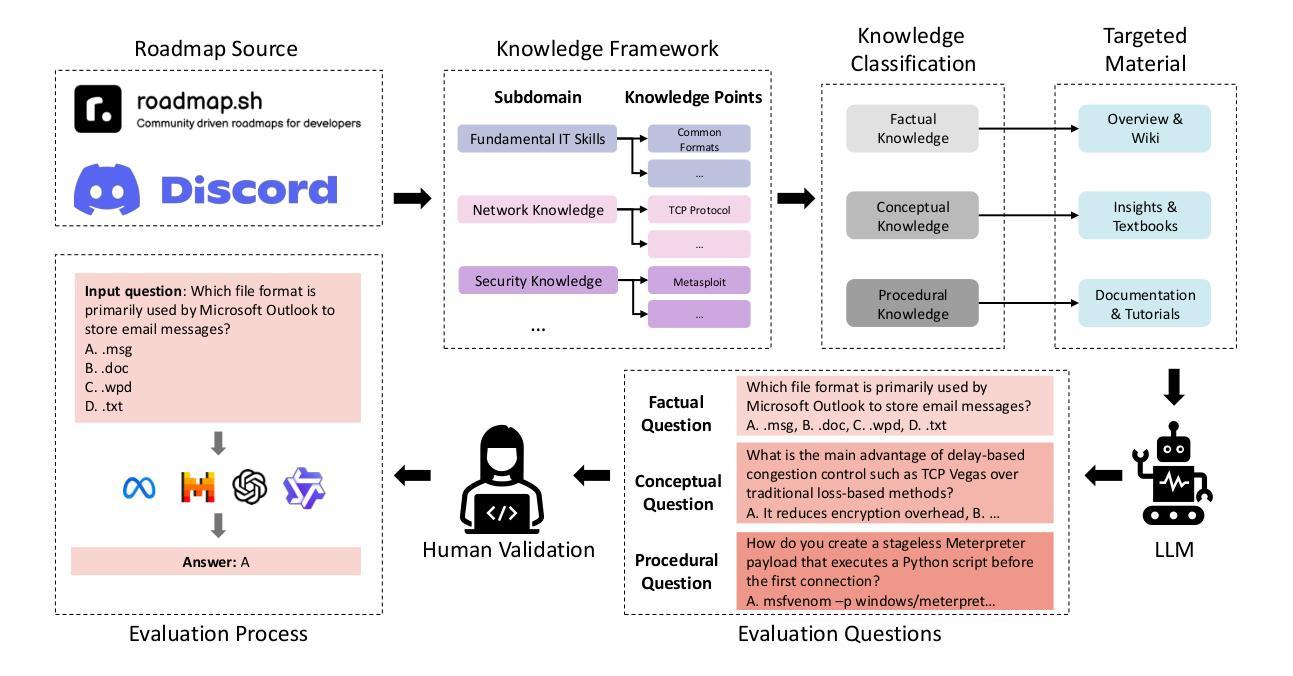
The Digital Cybersecurity Expert: How Far Have We Come?
Authors:Dawei Wang, Geng Zhou, Xianglong Li, Yu Bai, Li Chen, Ting Qin, Jian Sun, Dan Li
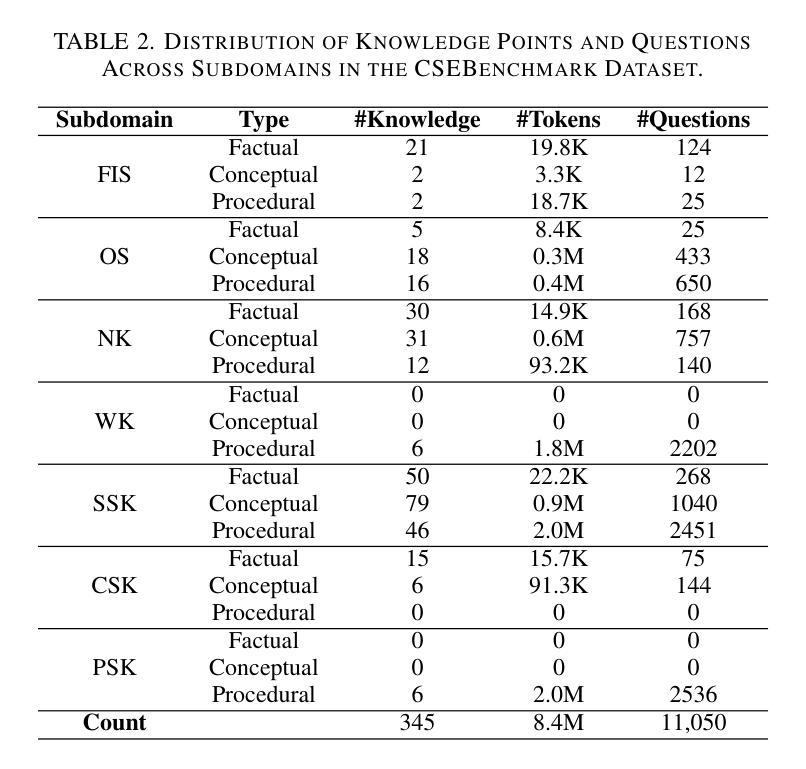
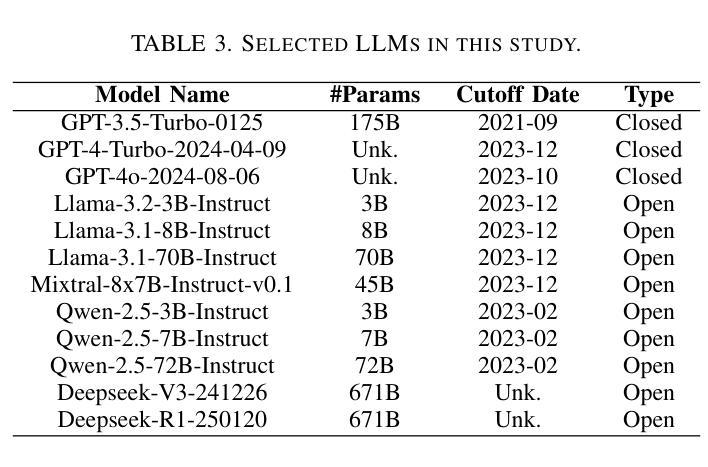
The increasing deployment of large language models (LLMs) in the cybersecurity domain underscores the need for effective model selection and evaluation. However, traditional evaluation methods often overlook specific cybersecurity knowledge gaps that contribute to performance limitations. To address this, we develop CSEBenchmark, a fine-grained cybersecurity evaluation framework based on 345 knowledge points expected of cybersecurity experts. Drawing from cognitive science, these points are categorized into factual, conceptual, and procedural types, enabling the design of 11,050 tailored multiple-choice questions. We evaluate 12 popular LLMs on CSEBenchmark and find that even the best-performing model achieves only 85.42% overall accuracy, with particular knowledge gaps in the use of specialized tools and uncommon commands. Different LLMs have unique knowledge gaps. Even large models from the same family may perform poorly on knowledge points where smaller models excel. By identifying and addressing specific knowledge gaps in each LLM, we achieve up to an 84% improvement in correcting previously incorrect predictions across three existing benchmarks for two cybersecurity tasks. Furthermore, our assessment of each LLM’s knowledge alignment with specific cybersecurity roles reveals that different models align better with different roles, such as GPT-4o for the Google Senior Intelligence Analyst and Deepseek-V3 for the Amazon Privacy Engineer. These findings underscore the importance of aligning LLM selection with the specific knowledge requirements of different cybersecurity roles for optimal performance.
随着大型语言模型(LLM)在网络安全领域的部署不断增加,有效选择模型并进行评估的需求愈发凸显。然而,传统的评估方法往往会忽视网络安全领域特定的知识缺口,导致性能受限。为了解决这一问题,我们开发了基于网络安全专家所期望的345个知识点的精细网络安全评估框架——CSEBenchmark。这些知识点来自认知科学领域,被归类为事实性、概念性和程序性三类,从而能够设计出量身定制的11,050道选择题。我们在CSEBenchmark上评估了流行的12款大型语言模型,发现即使表现最佳的模型也仅达到整体准确率85.42%,特别是在使用专业工具和罕见命令方面存在特定的知识缺口。不同的大型语言模型具有独特的知识缺口。即使是同一系列的大型模型也可能在小型模型擅长的知识点上表现不佳。通过识别和解决每个大型语言模型中的特定知识缺口,我们在两个网络安全任务的三个现有基准测试中,对之前错误的预测进行了高达84%的改进。此外,我们对每个大型语言模型与特定网络安全角色的知识匹配度进行评估,发现不同的模型与不同的角色更为匹配,如GPT-4o更适合谷歌高级情报分析师,Deepseek-V3更适合亚马逊隐私工程师。这些发现强调了在选择大型语言模型时,需要根据不同网络安全角色的特定知识需求进行匹配,以实现最佳性能。
论文及项目相关链接
PDF To appear in the IEEE Symposium on Security and Privacy (IEEE S&P) 2025, San Francisco, CA, USA
Summary:针对网络安全领域的大型语言模型(LLM)部署增加的现状,需要有效的模型选择及评估方法。传统的评估方法往往忽略了网络安全专业知识点的缺失,导致性能受限。因此,本文开发了基于认知科学的精细网络安全评估框架CSEBenchmark,包括三百四十五个预期网络安全专家的知识点。评估了十二个流行的大型语言模型,发现即使最好的模型整体准确率也只有百分之八十五点四二,特定工具使用和罕见命令等知识点上存在显著知识盲区。不同的大型语言模型具有独特的知识盲区,即使同一系列的大型模型也可能在特定知识点上表现不佳。通过识别和弥补每个大型语言模型中的特定知识盲区,我们在两个网络安全任务的三个现有基准测试中,对先前错误的预测进行了高达百分之八十四的改进。此外,本文还对每个大型语言模型与特定网络安全角色的知识对齐情况进行了评估,发现不同模型与不同角色的对齐程度有所不同,例如GPT-4o更适用于谷歌高级情报分析师,而Deepseek-V3更适用于亚马逊隐私工程师。这些发现强调了根据网络安全角色的特定知识需求选择大型语言模型的重要性,以实现最佳性能。
Key Takeaways:
- 大型语言模型(LLM)在网络安全领域的应用越来越广泛,需要有效的模型选择及评估方法。
- 传统评估方法忽略了网络安全专业知识点的缺失,导致性能受限。
- 开发了一个基于认知科学的精细网络安全评估框架CSEBenchmark。
- 在十二个流行的大型语言模型上进行了评估,发现存在知识盲区,且不同模型有不同的知识盲区。
- 通过识别和弥补知识盲区,可以在现有基准测试中显著提高预测准确性。
- 每个大型语言模型与特定网络安全角色的知识对齐情况不同。
点此查看论文截图



REAL: Benchmarking Autonomous Agents on Deterministic Simulations of Real Websites
Authors:Divyansh Garg, Shaun VanWeelden, Diego Caples, Andis Draguns, Nikil Ravi, Pranav Putta, Naman Garg, Tomas Abraham, Michael Lara, Federico Lopez, James Liu, Atharva Gundawar, Prannay Hebbar, Youngchul Joo, Charles London, Christian Schroeder de Witt, Sumeet Motwani
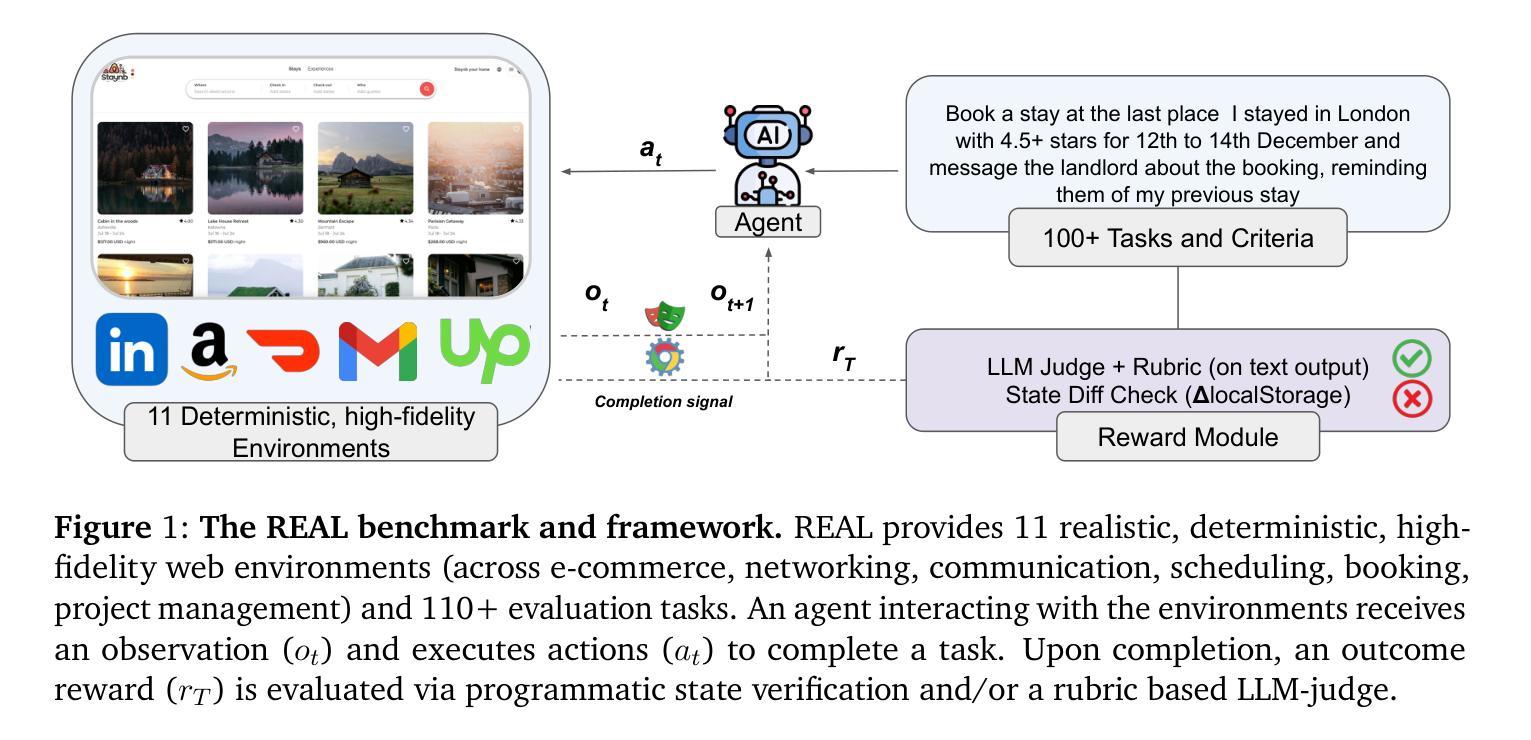
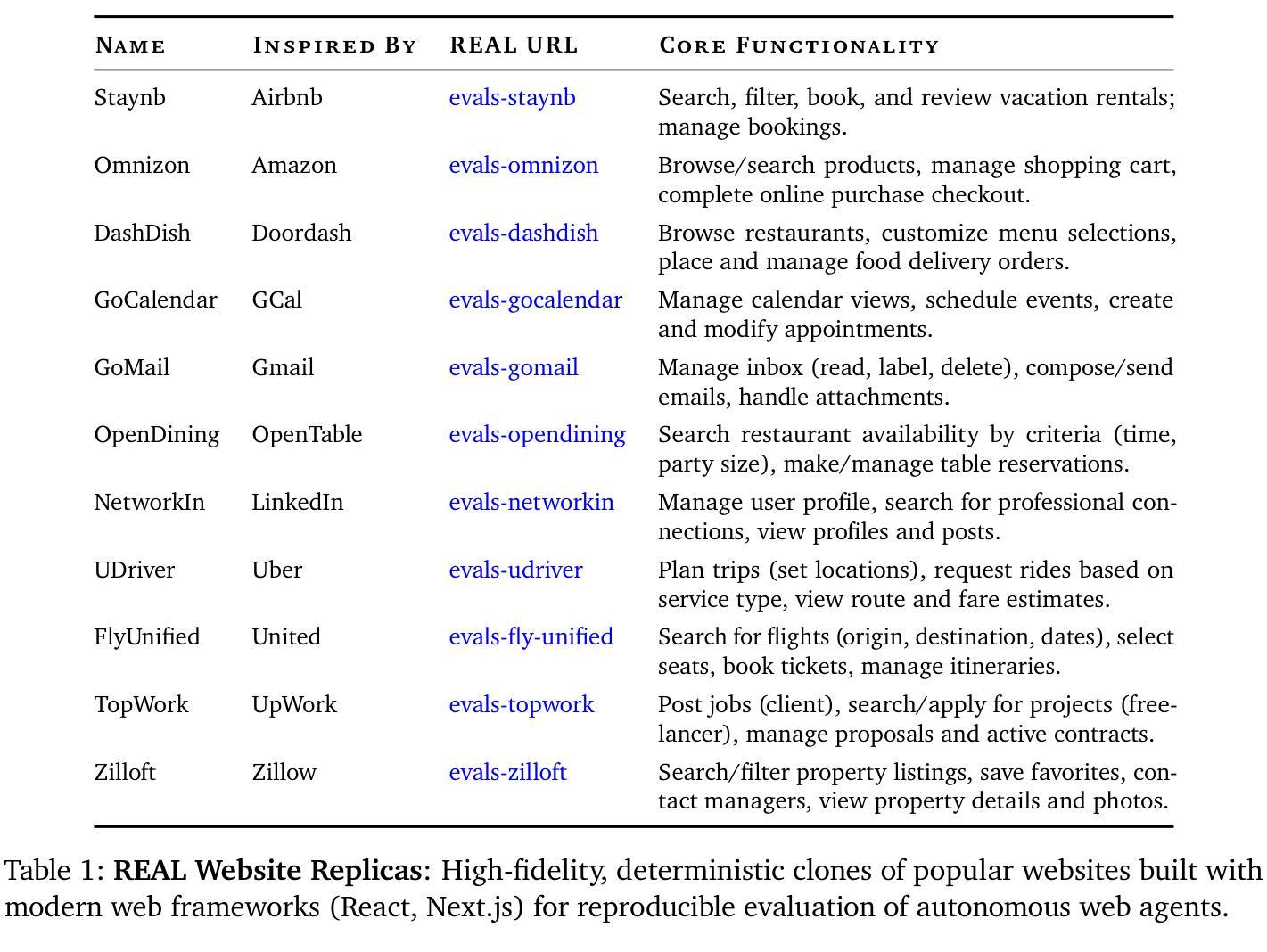
We introduce REAL, a benchmark and framework for multi-turn agent evaluations on deterministic simulations of real-world websites. REAL comprises high-fidelity, deterministic replicas of 11 widely-used websites across domains such as e-commerce, travel, communication, and professional networking. We also release a benchmark consisting of 112 practical tasks that mirror everyday complex user interactions requiring both accurate information retrieval and state-changing actions. All interactions occur within this fully controlled setting, eliminating safety risks and enabling robust, reproducible evaluation of agent capability and reliability. Our novel evaluation framework combines programmatic checks of website state for action-based tasks with rubric-guided LLM-based judgments for information retrieval. The framework supports both open-source and proprietary agent systems through a flexible evaluation harness that accommodates black-box commands within browser environments, allowing research labs to test agentic systems without modification. Our empirical results show that frontier language models achieve at most a 41% success rate on REAL, highlighting critical gaps in autonomous web navigation and task completion capabilities. Our framework supports easy integration of new tasks, reproducible evaluation, and scalable data generation for training web agents. The websites, framework, and leaderboard are available at https://realevals.xyz and https://github.com/agi-inc/REAL.
我们介绍REAL,这是一个用于真实网站确定性模拟的多轮代理评估的基准和框架。REAL包含了高保真、确定性的复制版本,涵盖了电子商务、旅行、通信和职业网络等领域的11个广泛使用的网站。我们还发布了包含112个实用任务的基准测试,这些任务反映了日常复杂的用户交互,需要准确的信息检索和状态更改操作。所有的交互都发生在这个完全受控的环境中,消除了安全风险,并能稳健地评估代理的能力和可靠性。我们新颖的评价框架结合了基于网站状态的程序化检查(针对基于行动的任务)和基于规则的LLM判断(用于信息检索)。该框架支持开源和专有代理系统,通过一个灵活的评价系统,可以在浏览器环境中适应黑箱命令,使得研究实验室能够测试代理系统而无需修改。我们的实证结果表明,最先进的语言模型在REAL上的成功率最高仅为41%,这凸显了自主网页导航和任务完成能力方面的关键差距。我们的框架支持轻松集成新任务、可重复评估和可扩展的数据生成,以训练网络代理。网站、框架和排行榜可在https://realevals.xyz和https://github.com/agi-inc/REAL找到。
论文及项目相关链接
Summary
这是一个关于REAL框架的介绍,它是一个用于在真实网站确定性模拟上进行多轮代理评估的基准测试框架。REAL包含11个高保真确定性副本的广泛使用的网站,并发布了一个包含112个实用任务的基准测试,这些任务反映了日常复杂的用户交互,需要准确的信息检索和状态更改操作。在该完全受控的环境中发生所有交互,消除了安全风险,并实现了对代理能力和可靠性的稳健和可重复评估。
Key Takeaways
- REAL是一个用于多轮代理评估的基准测试框架,模拟真实世界的网站环境。
- REAL包含11个不同领域网站的确定性副本,并发布了包含112个实用任务的基准测试。
- REAL的评估框架结合了网站状态的程序化检查以及基于LLM的评判标准。
- 该框架支持开源和专有代理系统,并允许研究实验室测试代理系统而无需修改。
- 前沿的语言模型在REAL上的成功率仅为41%,表明在自主网页导航和任务完成能力方面存在关键差距。
- REAL框架支持新任务的轻松集成、可重复评估和用于训练网页代理的可扩展数据生成。
点此查看论文截图


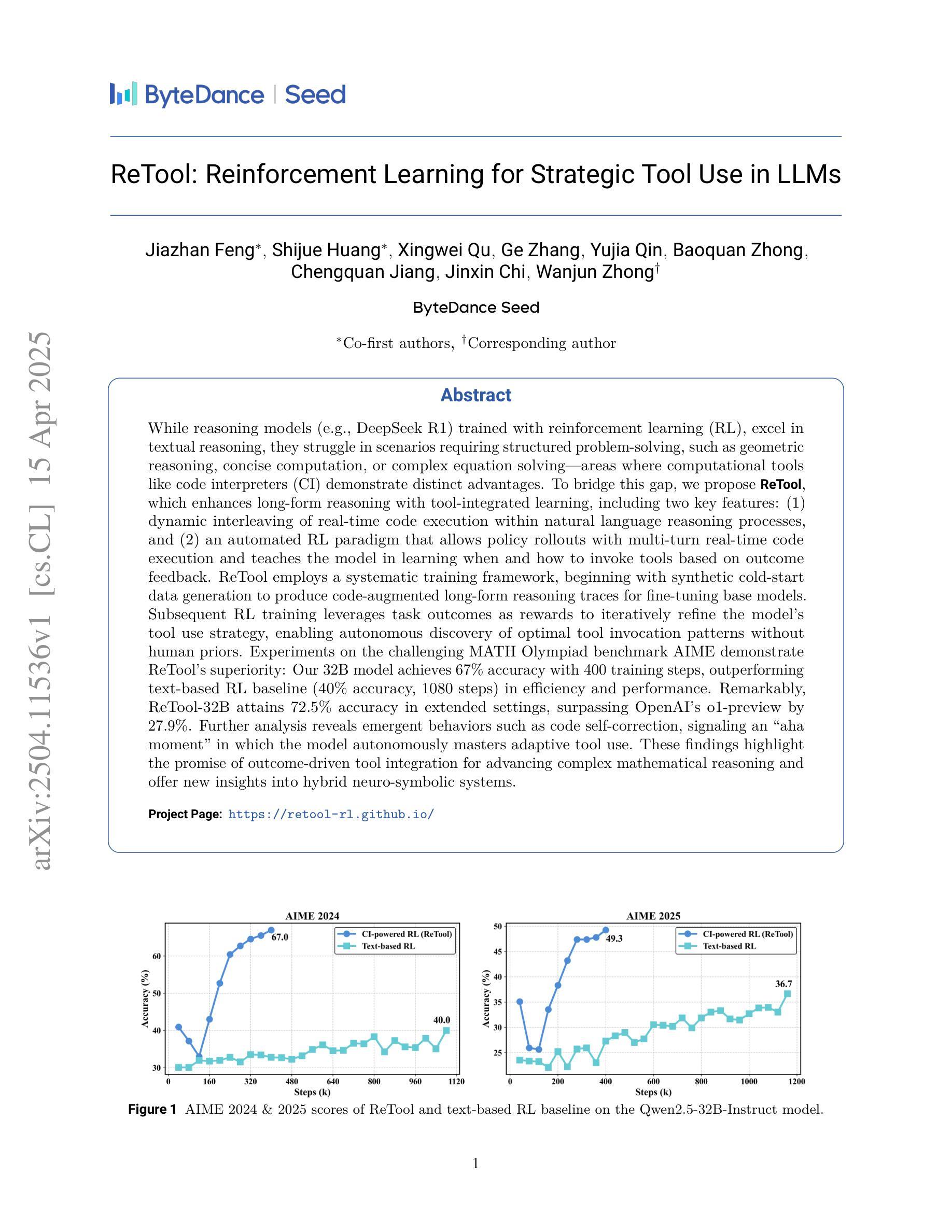
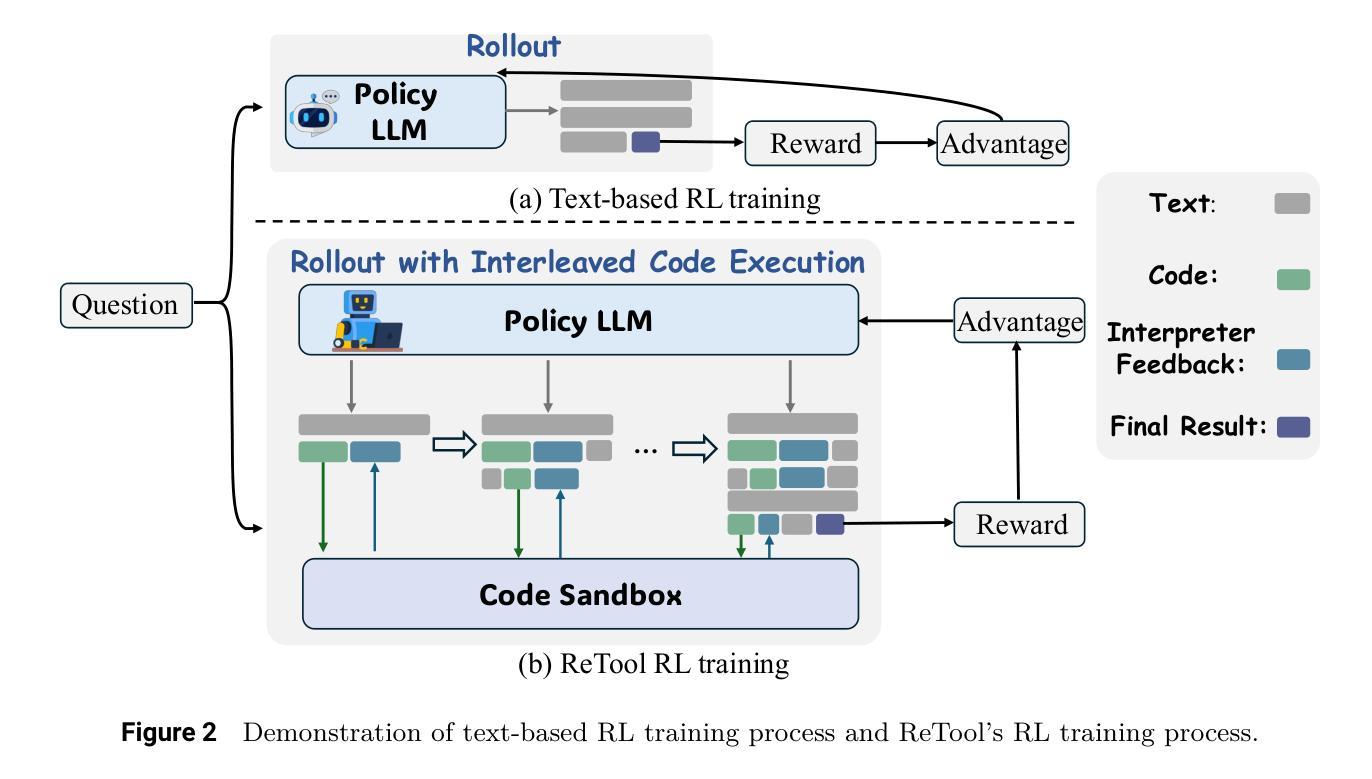
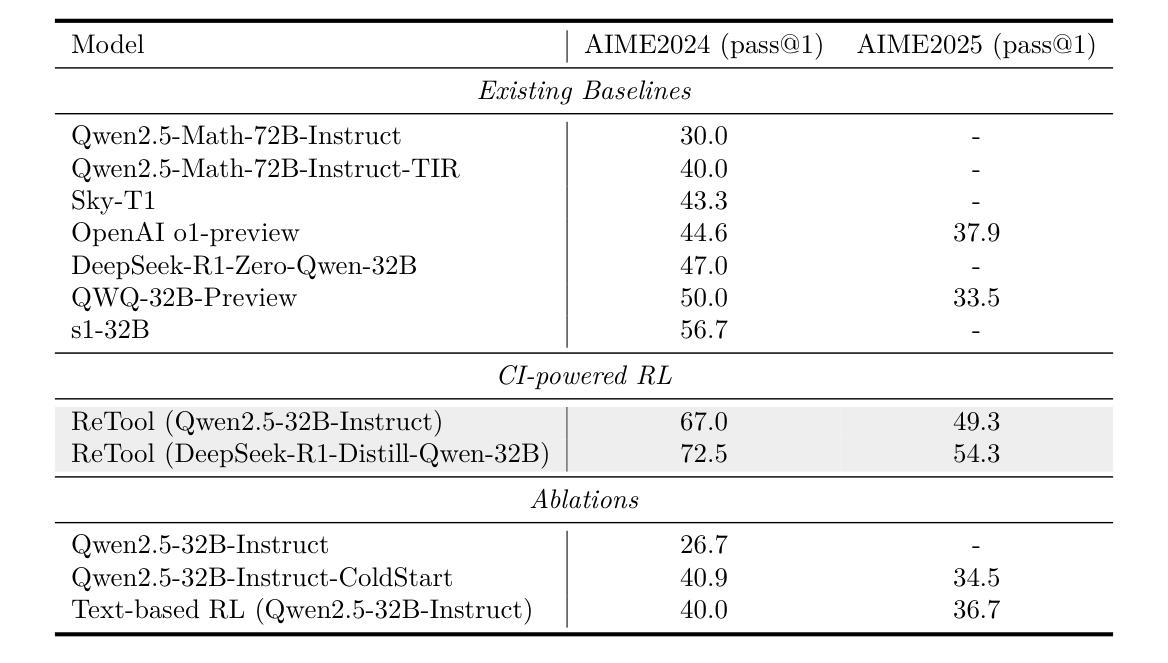
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Authors:Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, Wanjun Zhong
While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model’s tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool’s superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI’s o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ‘’aha moment’’ in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
虽然使用强化学习(RL)训练的推理模型(例如DeepSeek R1)在文本推理方面表现出色,但在需要结构化问题解决(如几何推理、简洁计算或复杂方程求解)的场景中却遇到困难,这些场景是代码解释器(CI)等计算工具发挥明显优势的地方。为了弥补这一差距,我们提出了ReTool,它通过工具集成学习增强长形式推理,包括两个关键功能:(1)在自然语言推理过程中动态交织实时代码执行;(2)一种自动化RL范式,允许多轮实时代码执行的策略展开,并根据结果反馈来教授模型何时以及如何调用工具。ReTool采用系统的训练框架,从生成合成冷启动数据开始,以产生用于微调基础模型的代码增强长形式推理轨迹。随后的强化学习训练利用任务结果作为奖励来迭代优化模型的工具使用策略,从而能够自主发现最佳工具调用模式,无需人为先验知识。在具有挑战性的MATH Olympiad基准测试AIME上的实验证明了ReTool的优越性:我们的32B模型在400步训练后达到67%的准确率,在效率和性能上超越了基于文本的RL基线(准确率为40%,训练步骤为1080步)。值得注意的是,ReTool-32B在扩展设置中的准确率达到了72.5%,比OpenAI的o1-preview高出27.9%。进一步的分析显示出现了代码自我修正等突发行为,这表明模型自主掌握了适应性工具使用,我们称之为“顿悟时刻”。这些发现凸显了以结果驱动的工具集成在推动复杂数学推理方面的前景,并为混合神经符号系统提供了新的见解。
论文及项目相关链接
Summary
文本介绍了一种名为ReTool的新方法,用于提升文本推理模型中工具集成学习的效率与性能。ReTool具备两大核心功能:实时代码执行与自然语言推理过程的动态交织,以及基于结果反馈的自动化强化学习模式。ReTool通过系统训练框架,首先使用合成冷启动数据生成代码增强长文本推理轨迹以微调基础模型。后续的强化学习训练利用任务结果作为奖励,迭代优化模型工具使用策略,实现自主发现最优工具调用模式而无需人为先验。在MATH Olympiad基准测试AIME上,ReTool表现出卓越性能,其32B模型在仅400步训练后达到67%的准确率,不仅在效率与性能上超越基于文本的RL基线,更以72.5%的准确率在扩展设置中超越OpenAI的o1-preview。
Key Takeaways
- ReTool方法能有效结合工具集成学习,提升文本推理模型的性能。
- ReTool具备实时代码执行与自然语言推理的动态交织功能。
- 通过合成冷启动数据生成,ReTool可微调基础模型。
- 强化学习训练使模型能基于任务结果自主发现最优工具调用模式。
- 在MATH Olympiad基准测试AIME上,ReTool表现出卓越性能。
- ReTool的32B模型在少量训练步骤后达到高准确率。
- ReTool展现出自主掌握适应性工具使用的潜力,如代码自我校正功能。
点此查看论文截图
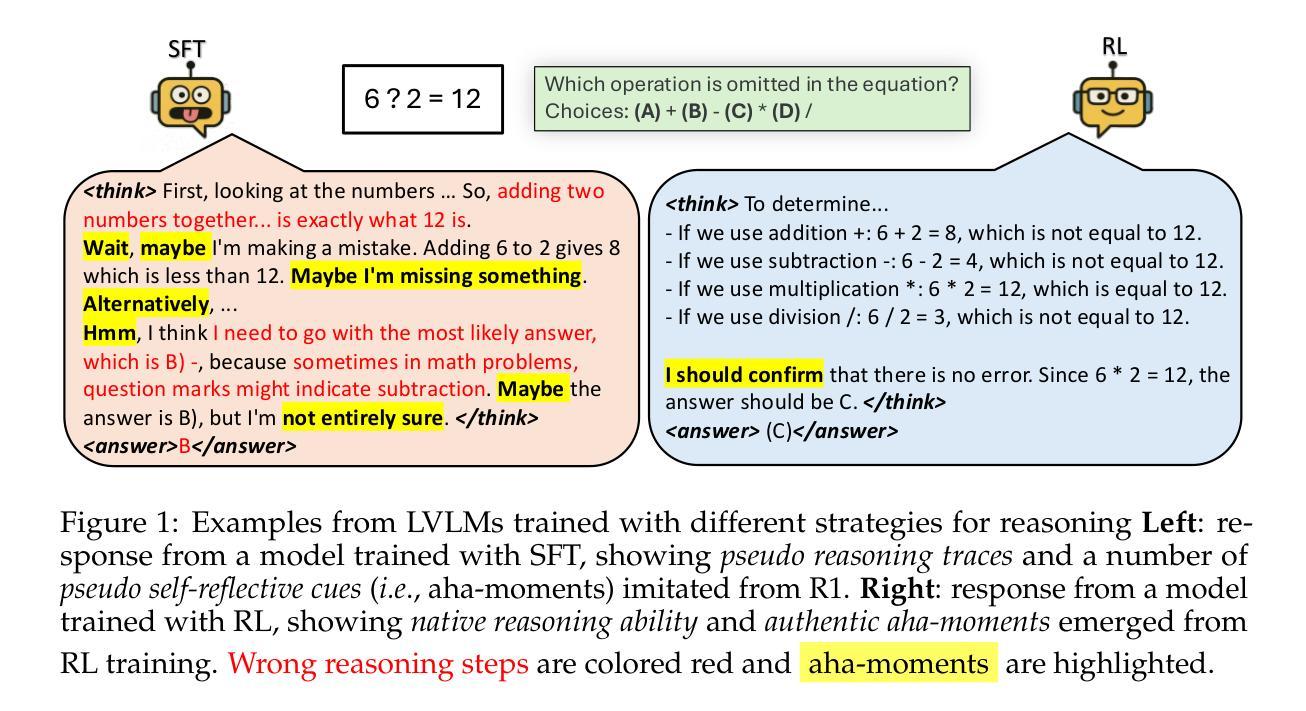
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Authors:Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, Cihang Xie
This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing ``pseudo reasoning paths’’ imitated from expert models. While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps, and incorrect reasoning. To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL and their combinations. Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning. In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior. Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on Open LMM Reasoning Leaderboard (https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard) among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights in developing reasoning-capable LVLMs and can inform future research in this area.
这篇工作重新研究了流行的监督微调(SFT)然后强化学习(RL)范式训练大型视觉语言模型(LVLMs)的方法,并揭示了一个关键发现:SFT会通过模仿专家模型产生“伪推理路径”,从而显著破坏随后的RL。虽然这些路径可能类似于RL模型的原生推理路径,但它们通常涉及冗长、犹豫、信息较少的步骤以及错误的推理。为了系统地研究这种影响,我们引入了VLAA-Thinking,这是一个新的多模式数据集,旨在支持LVLMs的推理。VLAA-Thinking是通过包括描述、推理蒸馏、答案重写和验证在内的六步管道构建的,它包含了高质量、一步一步的视觉推理轨迹的SFT,以及来自同一数据源的更具挑战性的RL分割。使用此数据集,我们进行了大量实验,比较了SFT、RL以及它们的组合。结果表明,虽然SFT有助于模型学习推理格式,但它往往使对齐的模型陷入模仿、僵化的推理模式,阻碍进一步学习。相比之下,我们的RL方法建立在集团相对策略优化(GRPO)之上,采用混合奖励模块整合感知和认知信号,促进了更真实、自适应的推理行为。值得注意的是,我们的VLAA-Thinker模型,基于Qwen2.5VL 3B,在Open LMM推理排行榜(https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard)上取得了4B规模LVLMs的第一名,超过了之前的最佳状态1.8%。我们希望我们的研究为开发具有推理能力的大型视觉语言模型提供有价值的见解,并为这一领域的未来研究提供信息参考。
论文及项目相关链接
Summary
本文探讨了主流的监督微调(SFT)和强化学习(RL)训练大型视觉语言模型(LVLMs)的方法,并发现SFT会对后续的RL产生负面影响,因为它会诱导出模仿专家模型的“伪推理路径”。为此,引入了VLAA-Thinking多模态数据集,用于支持LVLMs的推理。通过一系列步骤,该数据集提供了高质量、分步骤的视觉推理轨迹,用于SFT,以及来自同一数据源的更具挑战性的RL分割。实验表明,虽然SFT有助于模型学习推理格式,但它往往使模型陷入模仿性的、僵化的推理模式,阻碍了进一步的学习。相比之下,基于Group Relative Policy Optimization(GRPO)和混合奖励模块的RL方法,结合了感知和认知信号,促进了更真实、自适应的推理行为。
Key Takeaways
- SFT在训练LVLMs时会诱导出模仿专家模型的“伪推理路径”,这可能阻碍后续的RL训练。
- VLAA-Thinking数据集是为了支持LVLMs的推理而引入的,它提供了高质量的视觉推理轨迹,并分为用于SFT和更具挑战性的RL分割。
- 实验表明,虽然SFT有助于模型学习推理格式,但它可能导致模型陷入僵化的推理模式。
- 基于GRPO和混合奖励模块的RL方法能够促进更真实、自适应的推理行为。
- 该文提出的模型VLAA-Thinker在Open LMM Reasoning Leaderboard上取得了顶尖性能,超过了之前的状态。
- 作者的发现对于开发具备推理能力的大型视觉语言模型具有宝贵的见解。
点此查看论文截图

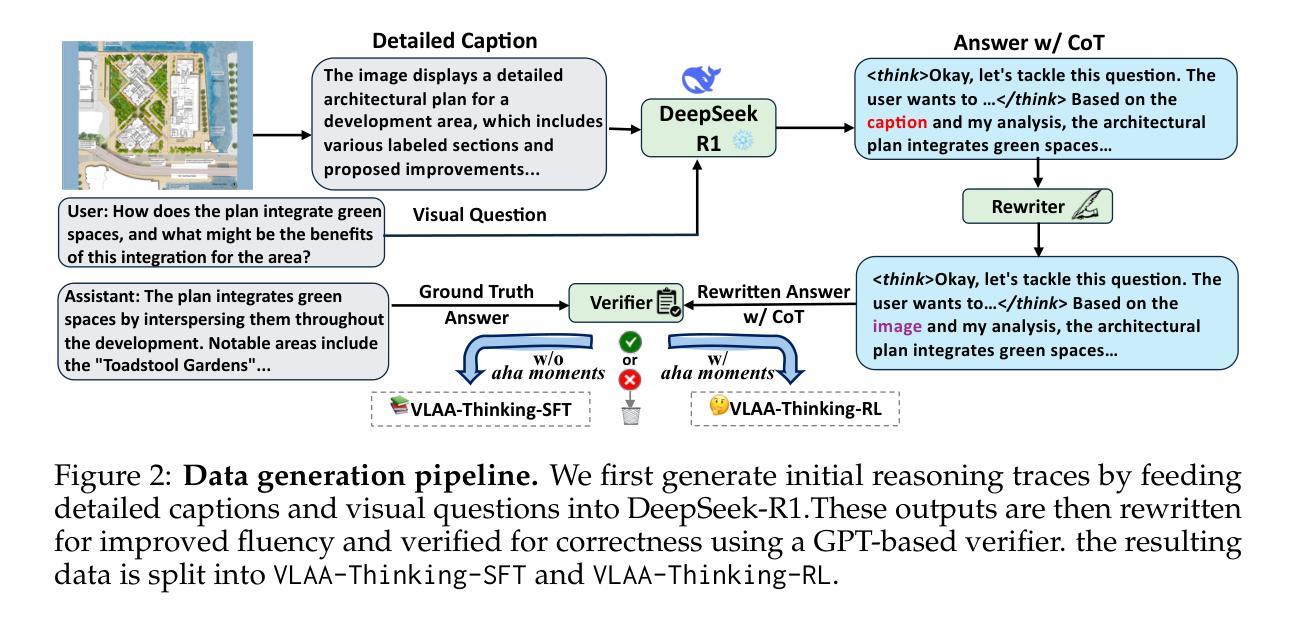

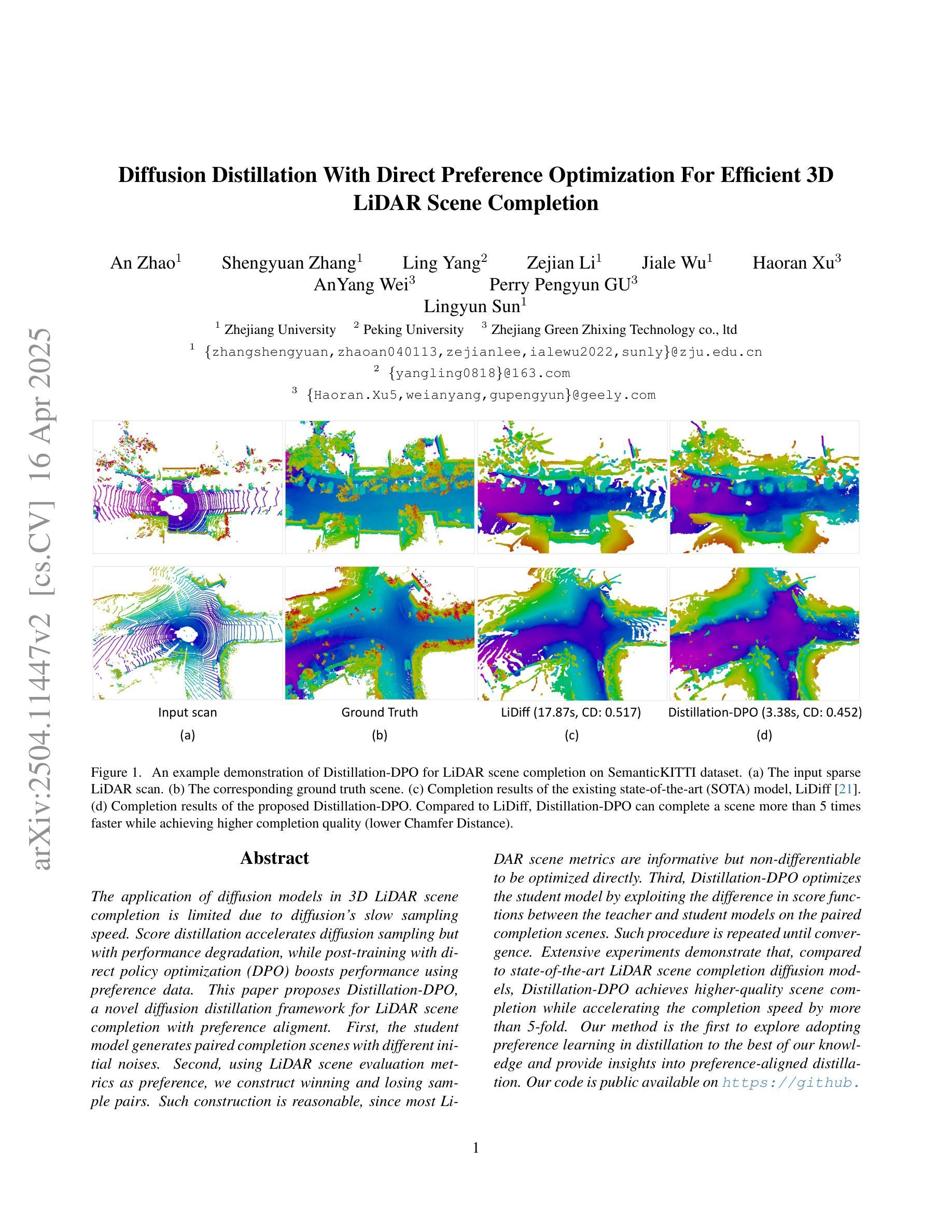
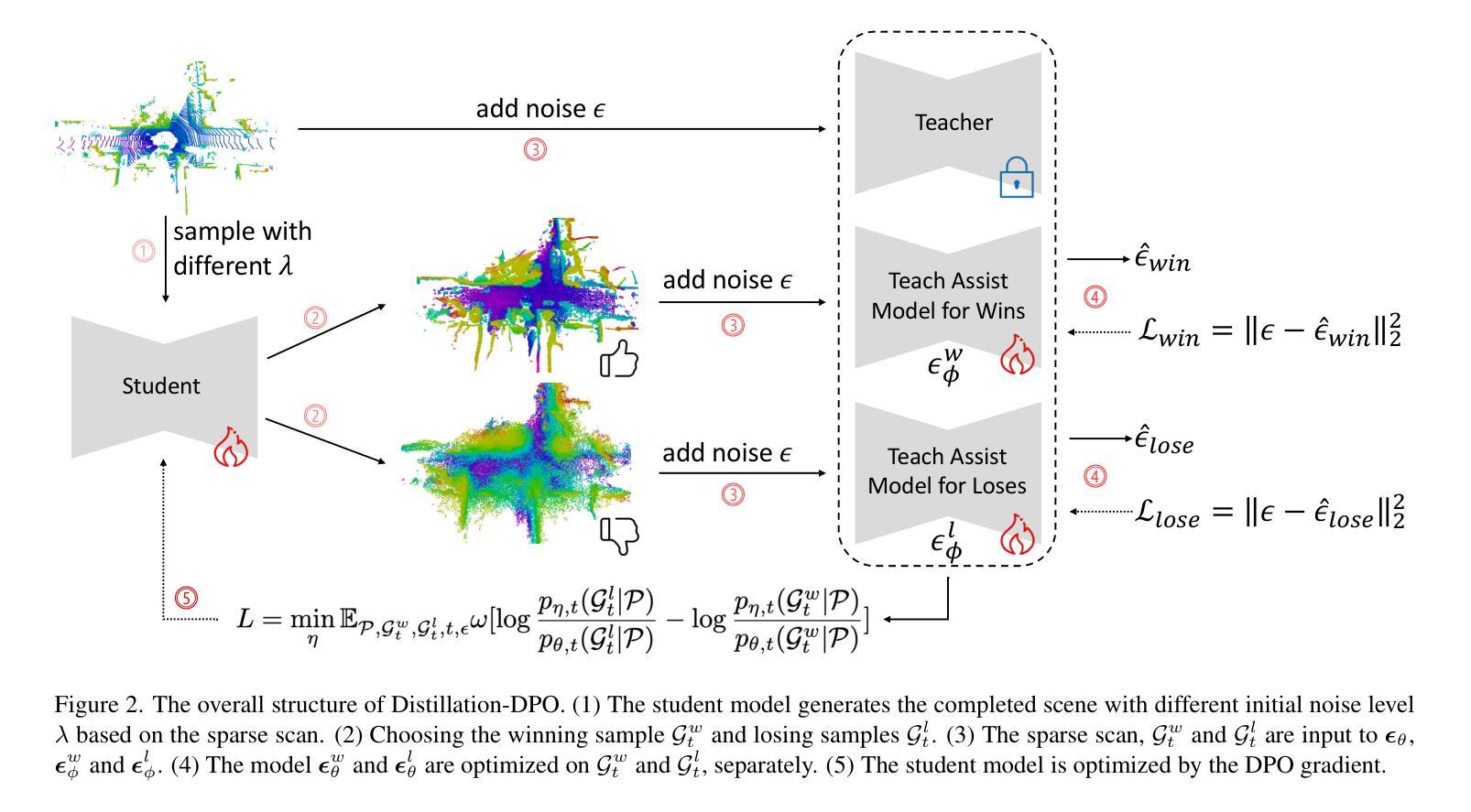
Diffusion Distillation With Direct Preference Optimization For Efficient 3D LiDAR Scene Completion
Authors:An Zhao, Shengyuan Zhang, Ling Yang, Zejian Li, Jiale Wu, Haoran Xu, AnYang Wei, Perry Pengyun GU, Lingyun Sun
The application of diffusion models in 3D LiDAR scene completion is limited due to diffusion’s slow sampling speed. Score distillation accelerates diffusion sampling but with performance degradation, while post-training with direct policy optimization (DPO) boosts performance using preference data. This paper proposes Distillation-DPO, a novel diffusion distillation framework for LiDAR scene completion with preference aligment. First, the student model generates paired completion scenes with different initial noises. Second, using LiDAR scene evaluation metrics as preference, we construct winning and losing sample pairs. Such construction is reasonable, since most LiDAR scene metrics are informative but non-differentiable to be optimized directly. Third, Distillation-DPO optimizes the student model by exploiting the difference in score functions between the teacher and student models on the paired completion scenes. Such procedure is repeated until convergence. Extensive experiments demonstrate that, compared to state-of-the-art LiDAR scene completion diffusion models, Distillation-DPO achieves higher-quality scene completion while accelerating the completion speed by more than 5-fold. Our method is the first to explore adopting preference learning in distillation to the best of our knowledge and provide insights into preference-aligned distillation. Our code is public available on https://github.com/happyw1nd/DistillationDPO.
扩散模型在3D激光雷达场景补全中的应用受限于其缓慢的采样速度。分数蒸馏虽然可以加速扩散采样,但会导致性能下降,而后用直接策略优化(DPO)进行训练则可以利用偏好数据提升性能。本文提出了一个名为Distillation-DPO的新型扩散蒸馏框架,用于激光雷达场景补全偏好对齐。首先,学生模型生成具有不同初始噪声的配对完成场景。其次,以激光雷达场景评估指标为偏好,我们构建了胜者和败者样本对。这种构建是合理的,因为大多数激光雷达场景指标都是有用的但不可直接优化。第三,Distillation-DPO通过利用配对完成场景上教师模型和学生模型之间的分数函数的差异来优化学生模型。这种程序会重复进行直至收敛。大量实验表明,与最先进的激光雷达场景补全扩散模型相比,Distillation-DPO在加速补全速度超过5倍的同时实现了更高质量的场景补全。据我们所知,我们的方法是第一个尝试在蒸馏过程中采用偏好学习,并为偏好对齐的蒸馏提供了见解。我们的代码公开在https://github.com/happyw1nd/DistillationDPO上可用。
论文及项目相关链接
PDF Our code is public available on https://github.com/happyw1nd/DistillationDPO
Summary
扩散模型在3D激光雷达场景补全中的应用受限于其缓慢的采样速度。得分蒸馏技术可以加速扩散采样,但会导致性能下降,而后通过直接策略优化(DPO)使用偏好数据提升性能。本文提出了一个名为Distillation-DPO的新型扩散蒸馏框架,用于激光雷达场景补全,具有偏好对齐功能。首先,学生模型生成带有不同初始噪声的配对完成场景。其次,以激光雷达场景评估指标为偏好,构建胜者和败者样本对。这种构建是合理的,因为大多数激光雷达场景指标都是具有信息量的,但无法直接优化。最后,Distillation-DPO通过优化配对完成场景上教师模型和学生模型得分函数的差异来优化学生模型。这种过程会不断重复直至收敛。实验表明,与最先进的激光雷达场景补全扩散模型相比,Distillation-DPO在提高场景补全质量的同时,将补全速度提高了5倍以上。据我们所知,我们的方法是首次探索采用偏好学习进行蒸馏。
Key Takeaways
- 扩散模型在3D激光雷达场景补全中面临采样速度慢的限制。
- 得分蒸馏技术虽能加速扩散采样,但会导致性能下降。
- 直接策略优化(DPO)利用偏好数据提升性能。
- 提出了一种新型的扩散蒸馏框架Distillation-DPO,用于激光雷达场景补全,具备偏好对齐功能。
- Distillation-DPO通过构建胜者和败者样本对,优化学生模型。
- Distillation-DPO在提高场景补全质量的同时,大幅加速了补全速度。
点此查看论文截图
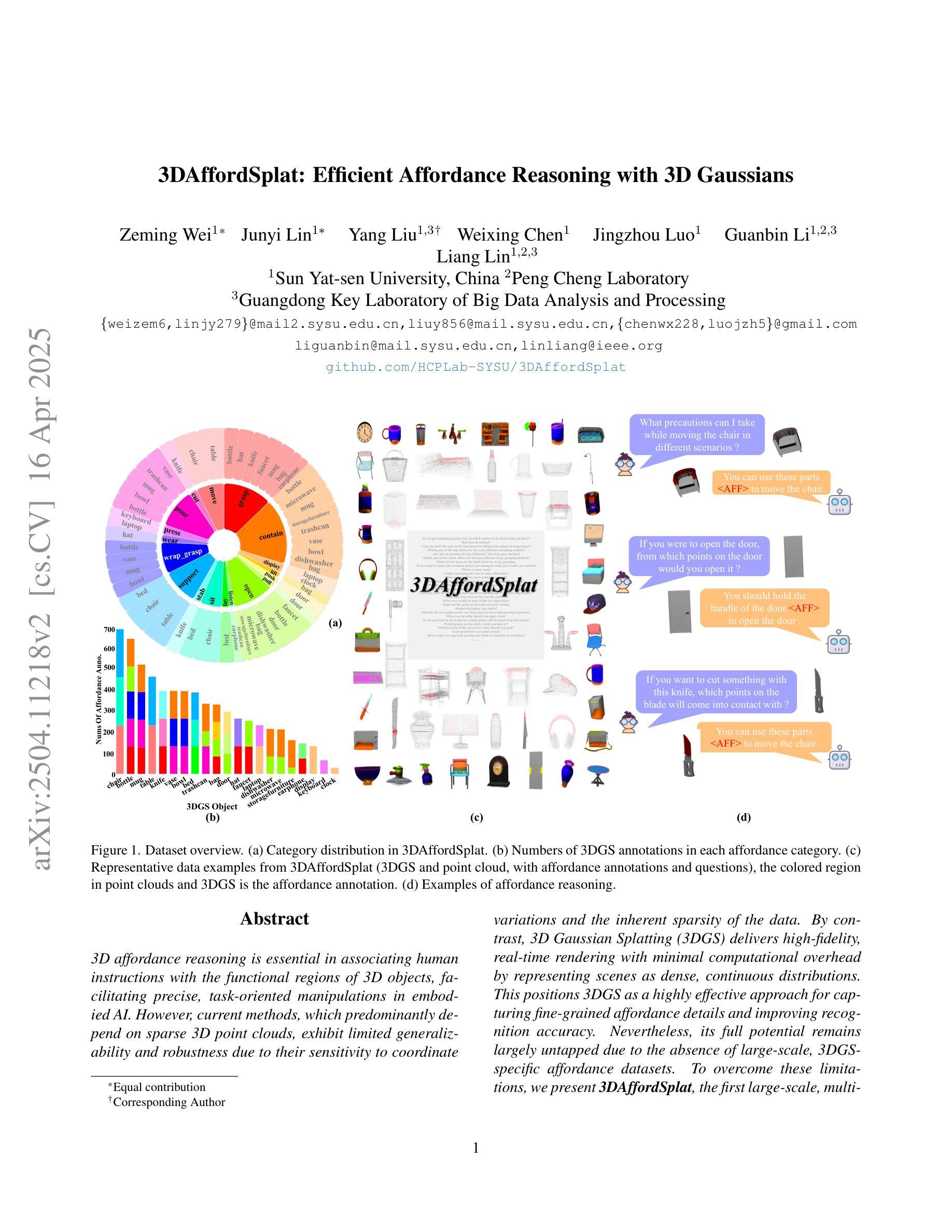
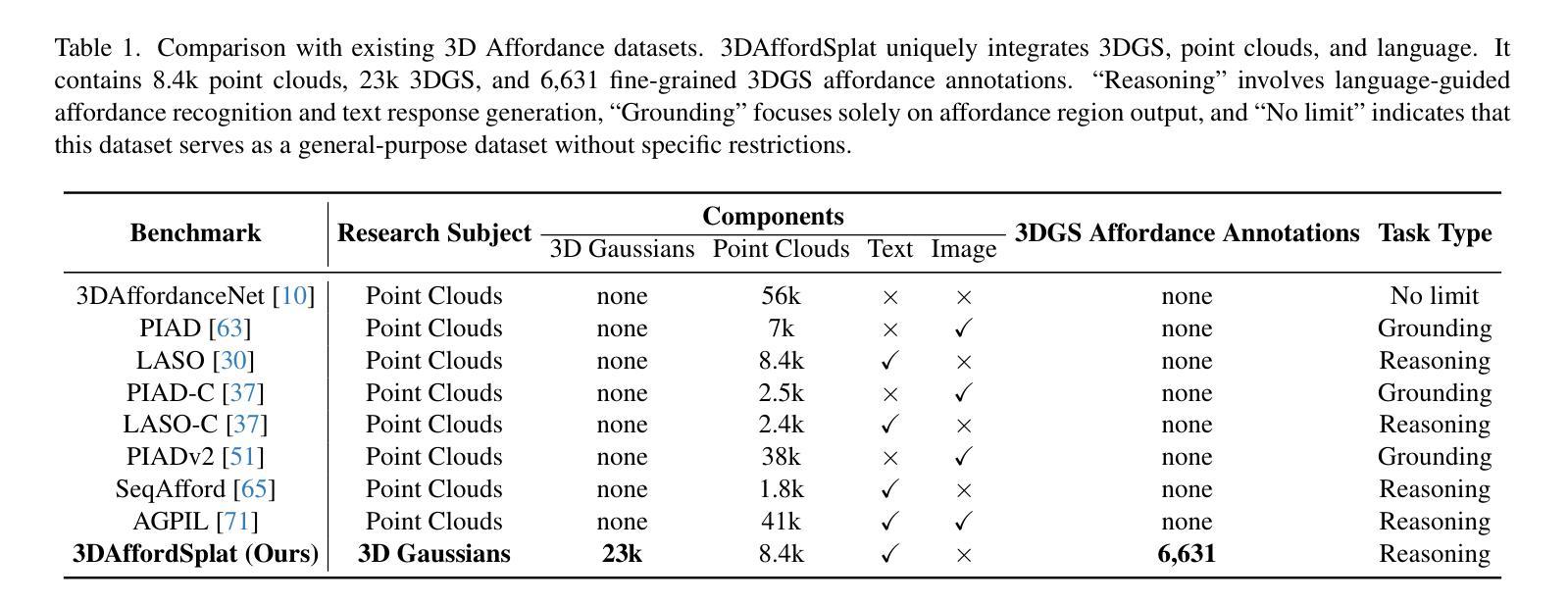
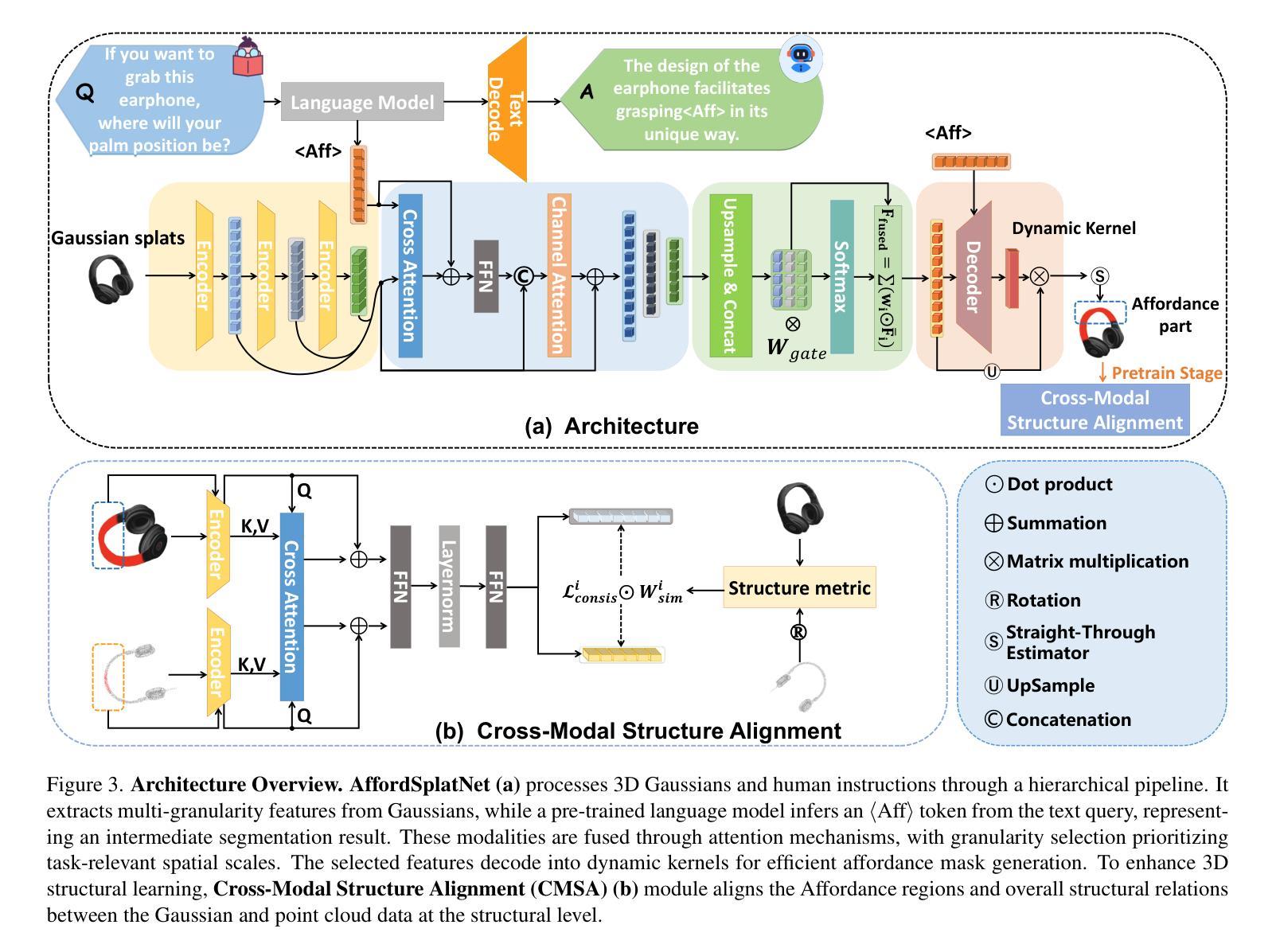
3DAffordSplat: Efficient Affordance Reasoning with 3D Gaussians
Authors:Zeming Wei, Junyi Lin, Yang Liu, Weixing Chen, Jingzhou Luo, Guanbin Li, Liang Lin
3D affordance reasoning is essential in associating human instructions with the functional regions of 3D objects, facilitating precise, task-oriented manipulations in embodied AI. However, current methods, which predominantly depend on sparse 3D point clouds, exhibit limited generalizability and robustness due to their sensitivity to coordinate variations and the inherent sparsity of the data. By contrast, 3D Gaussian Splatting (3DGS) delivers high-fidelity, real-time rendering with minimal computational overhead by representing scenes as dense, continuous distributions. This positions 3DGS as a highly effective approach for capturing fine-grained affordance details and improving recognition accuracy. Nevertheless, its full potential remains largely untapped due to the absence of large-scale, 3DGS-specific affordance datasets. To overcome these limitations, we present 3DAffordSplat, the first large-scale, multi-modal dataset tailored for 3DGS-based affordance reasoning. This dataset includes 23,677 Gaussian instances, 8,354 point cloud instances, and 6,631 manually annotated affordance labels, encompassing 21 object categories and 18 affordance types. Building upon this dataset, we introduce AffordSplatNet, a novel model specifically designed for affordance reasoning using 3DGS representations. AffordSplatNet features an innovative cross-modal structure alignment module that exploits structural consistency priors to align 3D point cloud and 3DGS representations, resulting in enhanced affordance recognition accuracy. Extensive experiments demonstrate that the 3DAffordSplat dataset significantly advances affordance learning within the 3DGS domain, while AffordSplatNet consistently outperforms existing methods across both seen and unseen settings, highlighting its robust generalization capabilities.
3D效用推理对于将人类指令与3D对象的功能区域相关联至关重要,有助于实现具体化身的AI中的精确、任务导向型操作。然而,当前的方法主要依赖于稀疏的3D点云,由于其对于坐标变化的敏感性和数据的固有稀疏性,展现出有限的一般性和稳健性。相比之下,3D高斯填充(3DGS)通过高密度、连续分布来表示场景,实现了高保真、实时渲染和最小的计算开销。这使得3DGS成为捕获精细效用细节并提高识别准确性的高效方法。然而,由于缺乏大规模的3DGS特定效用数据集,其全部潜力尚未得到充分发掘。为了克服这些限制,我们推出了3DAffordSplat,这是专门为基于3DGS的效用推理定制的大规模、多模式数据集。该数据集包括23677个高斯实例、8354个点云实例和6631个手动注释的效用标签,涵盖21个对象类别和18种效用类型。在此基础上,我们引入了AffordSplatNet,这是一个专门用于使用3DGS表示进行效用推理的新型模型。AffordSplatNet具有创新性的跨模式结构对齐模块,利用结构一致性先验来对齐3D点云和3DGS表示,从而提高效用识别准确性。大量实验表明,3DAffordSplat数据集在3DGS领域的效用学习方面取得了显著进展,而AffordSplatNet在已知和未知环境中均表现出色,证明了其稳健的泛化能力。
论文及项目相关链接
PDF The first large-scale 3D Gaussians Affordance Reasoning Benchmark
Summary
本文探讨了在3D场景中对人类指令与3D物体功能区域的关联,提出基于高斯表面展示(Gaussian Splatting)技术的AffordSplatNet模型。该模型通过大规模数据集3DAffordSplat进行训练,能够更准确地识别物体的用途和操作方式。相较于依赖稀疏点云的传统方法,AffordSplatNet具有更强的通用性和稳健性,可用于解决高精度实时的应用问题。模型的强大在于引入了创新的跨模态结构对齐模块,提高了在3D高斯表面展示领域内的表现能力。该模型展现出优秀的性能,并且在不同场景下均表现出色。
Key Takeaways
- 3D affordance reasoning对于关联人类指令与物体功能区域至关重要,尤其在智能机器人操作中。
点此查看论文截图
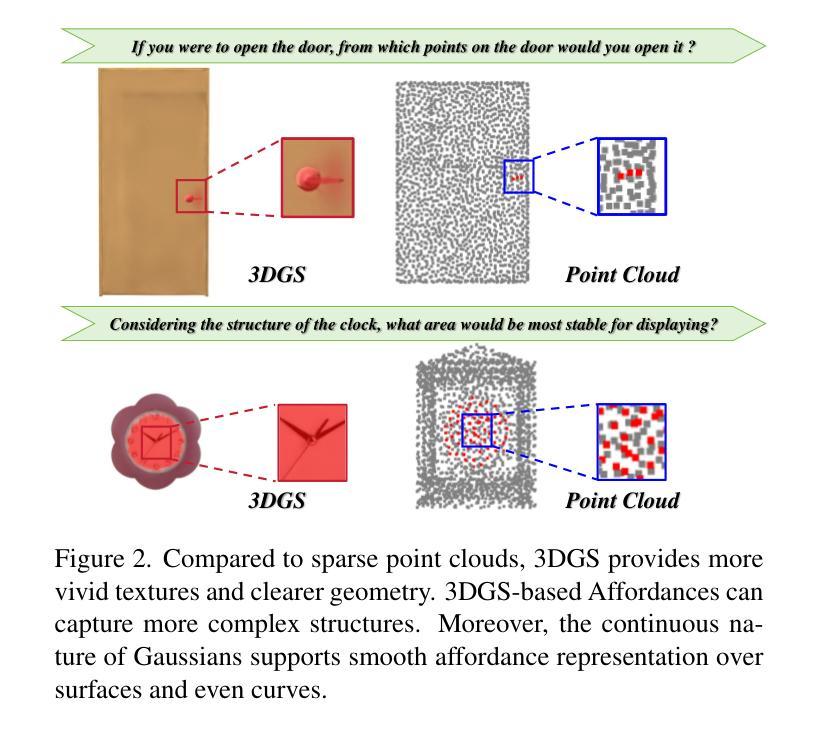
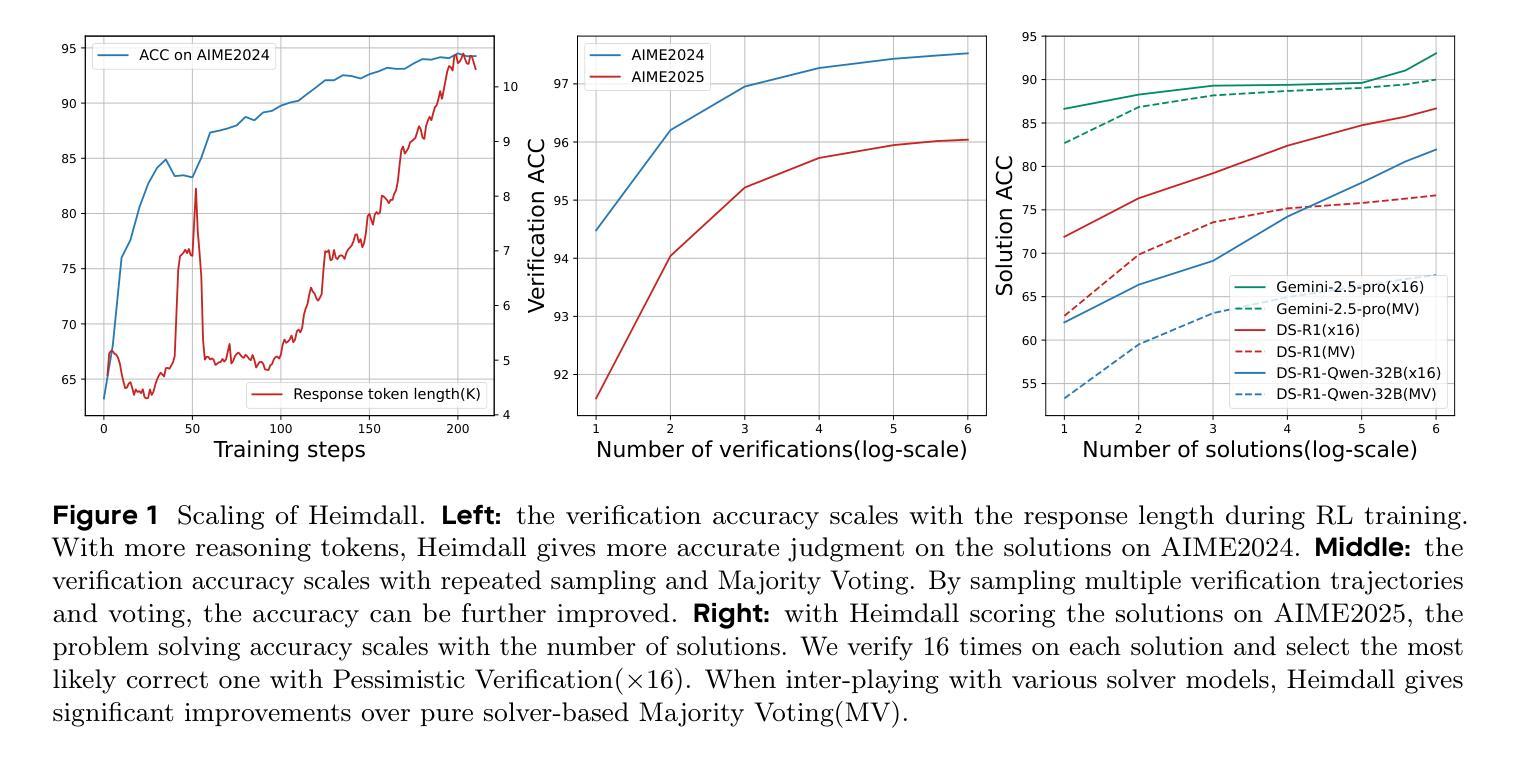
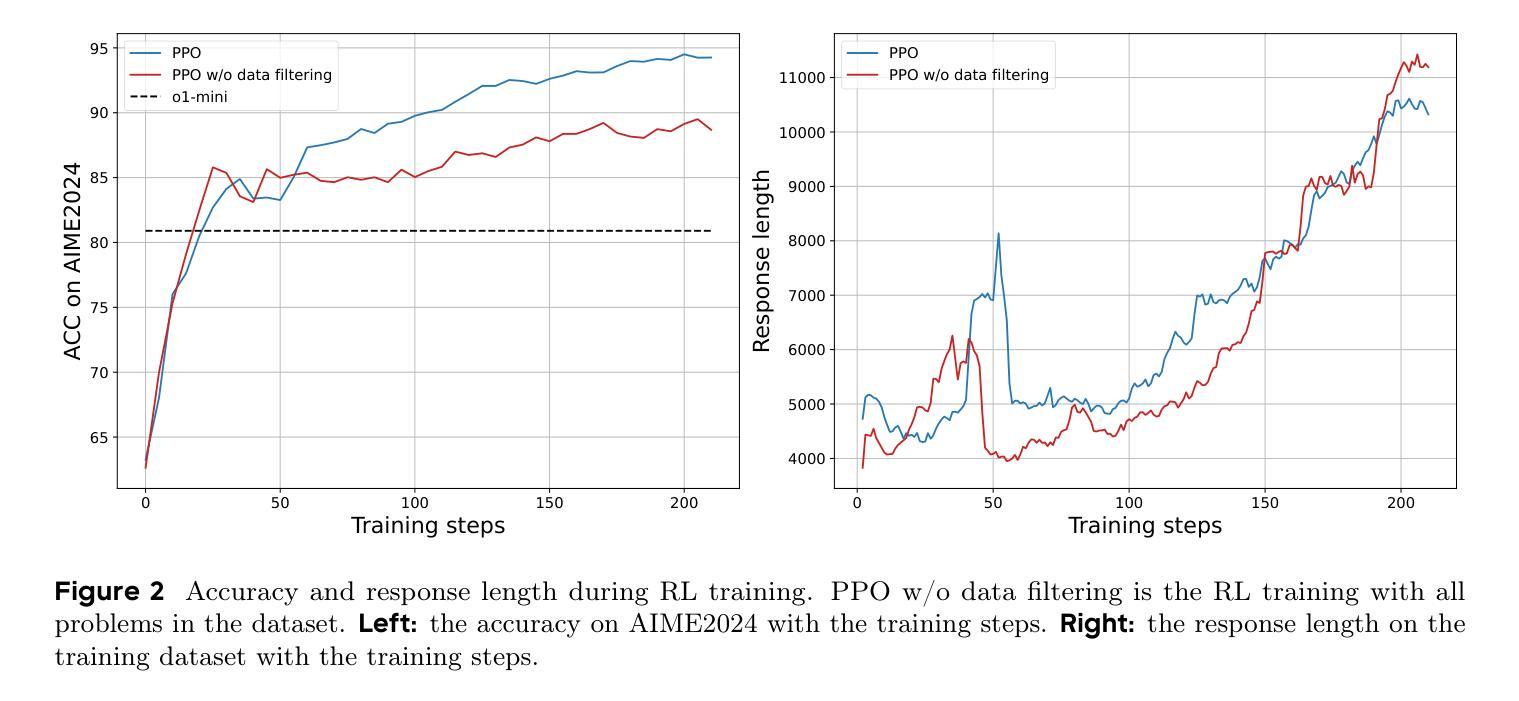
Heimdall: test-time scaling on the generative verification
Authors:Wenlei Shi, Xing Jin
An AI system can create and maintain knowledge only to the extent that it can verify that knowledge itself. Recent work on long Chain-of-Thought reasoning has demonstrated great potential of LLMs on solving competitive problems, but their verification ability remains to be weak and not sufficiently investigated. In this paper, we propose Heimdall, the long CoT verification LLM that can accurately judge the correctness of solutions. With pure reinforcement learning, we boost the verification accuracy from 62.5% to 94.5% on competitive math problems. By scaling with repeated sampling, the accuracy further increases to 97.5%. Through human evaluation, Heimdall demonstrates impressive generalization capabilities, successfully detecting most issues in challenging math proofs, the type of which is not included during training. Furthermore, we propose Pessimistic Verification to extend the functionality of Heimdall to scaling up the problem solving. It calls Heimdall to judge the solutions from a solver model and based on the pessimistic principle, selects the most likely correct solution with the least uncertainty. Taking DeepSeek-R1-Distill-Qwen-32B as the solver model, Pessimistic Verification improves the solution accuracy on AIME2025 from 54.2% to 70.0% with 16x compute budget and to 83.3% with more compute budget. With the stronger solver Gemini 2.5 Pro, the score reaches 93.0%. Finally, we prototype an automatic knowledge discovery system, a ternary system where one poses questions, another provides solutions, and the third verifies the solutions. Using the data synthesis work NuminaMath for the first two components, Heimdall effectively identifies problematic records within the dataset and reveals that nearly half of the data is flawed, which interestingly aligns with the recent ablation studies from NuminaMath.
一个AI系统只能在其能够验证自身知识的情况下,才能创造和保持知识。关于长链思维推理的最新研究已经显示出大型语言模型在解决竞赛问题方面的巨大潜力,但它们的验证能力仍然较弱且尚未得到充分研究。在本文中,我们提出了Heimdall,这是一种能够进行长链思维验证的大型语言模型,能够准确判断解决方案的正确性。通过纯粹的强化学习,我们在竞争性数学问题上的验证准确率从62.5%提高到了94.5%。通过重复采样的扩展,准确率进一步提高到了97.5%。通过人类评估,Heimdall展现出令人印象深刻的泛化能力,成功地检测到了挑战性数学证明中的大多数问题,这些问题在训练过程中并未包含在内。此外,我们提出了悲观验证法来扩展Heimdall的功能,以提高问题解决规模。它调用Heimdall来判断求解模型的解决方案,并根据悲观原则,选择最有可能的正确解决方案,同时尽量减少不确定性。以DeepSeek-R1-Distill-Qwen-32B为求解模型,悲观验证法将AIME2025的解决方案准确率从54.2%提高到70%(在16倍计算预算下)和更高的计算预算下的83.3%。使用更强大的求解器Gemini 2.5 Pro时,得分更是达到了93%。最后,我们开发了一个自动知识发现系统原型,这是一个三元系统,其中一个组件提出问题,另一个组件提供解决方案,第三个组件验证解决方案。使用前两个组件的数据合成工作NuminaMath,Heimdall有效地识别了数据集中有问题的记录并揭示出近一半的数据存在缺陷,这与NuminaMath最近的消融研究结果相吻合。
论文及项目相关链接
Summary
近期研究表明大型语言模型(LLM)在知识验证能力方面有所不足。为解决这一问题,提出了名为Heimdall的模型,能准确判断解决方案的正确性。通过强化学习,验证准确率提升至94.5%,进一步采样后可达97.5%。Heimdall具备出色的泛化能力,能在训练外的数学证明中发现大部分问题。此外,还提出了悲观验证法来扩展Heimdall的功能以提升解题能力。自动知识发现系统的原型也被提出,其中就包括Heimdall的应用,能够有效识别数据集中的问题记录。
Key Takeaways
- Heimdall模型能够准确判断长Chain-of-Thought推理解决方案的正确性。
- 通过强化学习,Heimdall的验证准确率大幅提升。
- Heimdall具备出色的泛化能力,能在数学证明中发现大部分问题。
- 悲观验证法用于扩展Heimdall的功能以提升解题准确性。
- 在自动知识发现系统中,Heimdall能有效识别数据集的问题记录。
- Heimdall与其他模型(如DeepSeek-R1-Distill-Qwen-32B和Gemini 2.5 Pro)协同工作以提高解题准确性。
点此查看论文截图


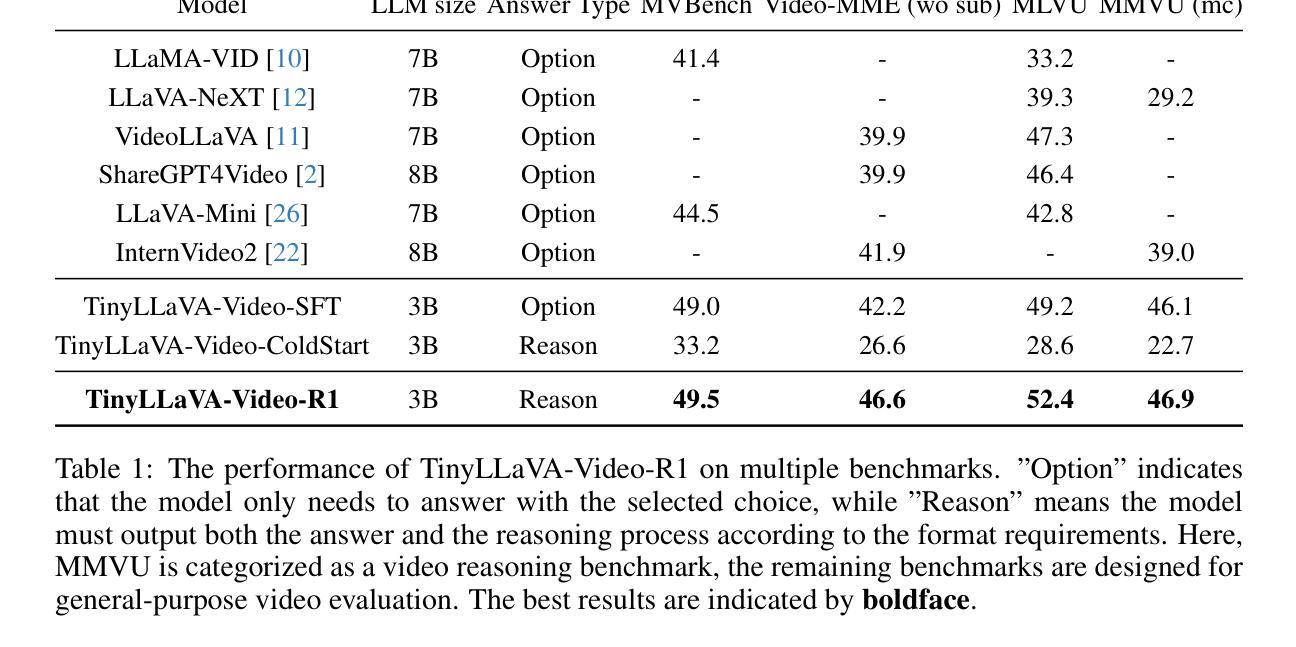
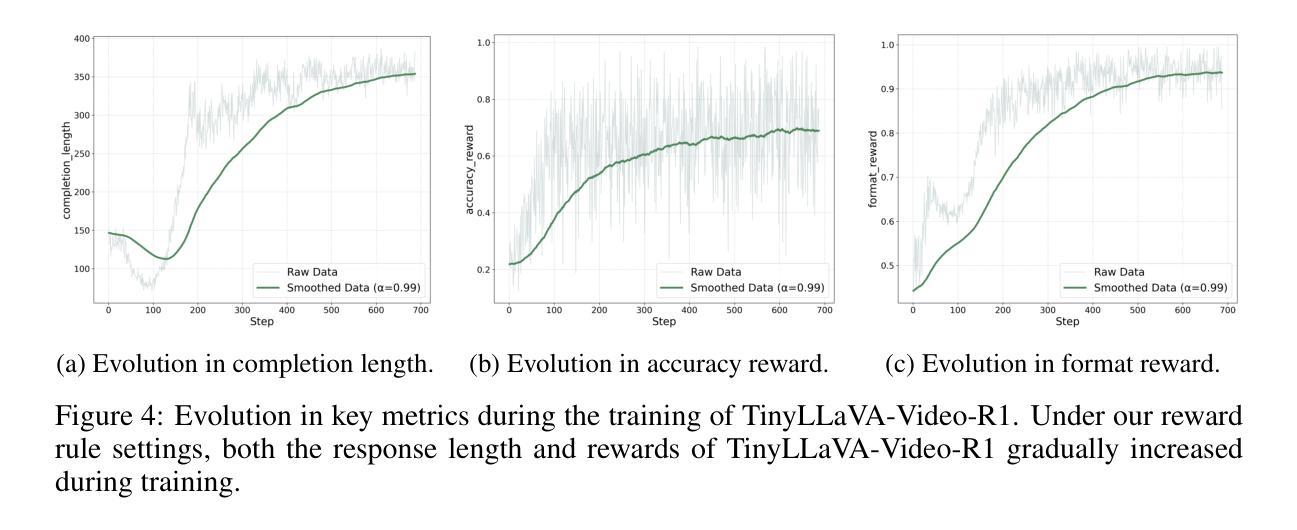
TinyLLaVA-Video-R1: Towards Smaller LMMs for Video Reasoning
Authors:Xingjian Zhang, Siwei Wen, Wenjun Wu, Lei Huang
Recently, improving the reasoning ability of large multimodal models (LMMs) through reinforcement learning has made great progress. However, most existing works are based on highly reasoning-intensive datasets such as mathematics and code, and researchers generally choose large-scale models as the foundation. We argue that exploring small-scale models’ reasoning capabilities remains valuable for researchers with limited computational resources. Moreover, enabling models to explain their reasoning processes on general question-answering datasets is equally meaningful. Therefore, we present the small-scale video reasoning model TinyLLaVA-Video-R1. Based on TinyLLaVA-Video, a traceably trained video understanding model with no more than 4B parameters, it not only demonstrates significantly improved reasoning and thinking capabilities after using reinforcement learning on general Video-QA datasets, but also exhibits the emergent characteristic of “aha moments”. Furthermore, we share a series of experimental findings, aiming to provide practical insights for future exploration of video reasoning (thinking) abilities in small-scale models. It is available at https://github.com/ZhangXJ199/TinyLLaVA-Video-R1.
最近,通过强化学习提高大型多模态模型(LMM)的推理能力已经取得了很大的进展。然而,大多数现有工作都是基于高度推理密集的数据集(如数学和代码),研究者通常选择大规模模型作为基础。我们认为,对于拥有有限计算资源的研究者来说,探索小型模型的推理能力仍然具有重要意义。此外,使模型能够在通用问答数据集上解释其推理过程同样具有重要意义。因此,我们提出了小型视频推理模型TinyLLaVA-Video-R1。它基于TinyLLaVA-Video,这是一个可追踪训练的、参数不超过4B的视频理解模型。在通用Video-QA数据集上使用强化学习后,它不仅展示了显著提升的推理和思考能力,还表现出了“顿悟时刻”的涌现特征。此外,我们还分享了一系列实验发现,旨在为小型模型未来探索视频推理(思考)能力提供实践见解。可通过https://github.com/ZhangXJ199/TinyLLaVA-Video-R1获取。
论文及项目相关链接
Summary
近期,通过强化学习提升大型多模态模型(LMMs)的推理能力已取得显著进展。然而,大多数现有研究都基于高度依赖推理能力的数据集(如数学和代码),并通常选择大规模模型作为基础。本文主张,对于拥有有限计算资源的研究者来说,探索小型模型的推理能力仍具有价值。此外,让模型在一般问答数据集上解释其推理过程同样具有重要意义。因此,我们推出了小型视频推理模型TinyLLaVA-Video-R1。它在TinyLLaVA-Video的基础上,通过强化学习在一般视频问答数据集上展现了显著提升的推理和思考能力,并呈现出“顿悟时刻”的显著特征。我们还分享了一系列实验发现,旨在为小型模型在视频推理(思考)能力方面的未来探索提供实践见解。
Key Takeaways
- 强化学习已用于提升大型多模态模型的推理能力。
- 现有研究主要关注高度依赖推理能力的数据集,如数学和代码。
- 小规模模型在有限计算资源下的推理能力研究仍具有价值。
- 模型在一般问答数据集上解释其推理过程具有重要意义。
- TinyLLaVA-Video-R1模型基于TinyLLaVA-Video,通过强化学习显著提升了视频问答数据集的推理和思考能力。
- TinyLLaVA-Video-R1模型展现出“顿悟时刻”的特征。
- 文章分享了一系列实验发现,为小型模型在视频推理能力方面的未来探索提供了实践见解。
点此查看论文截图




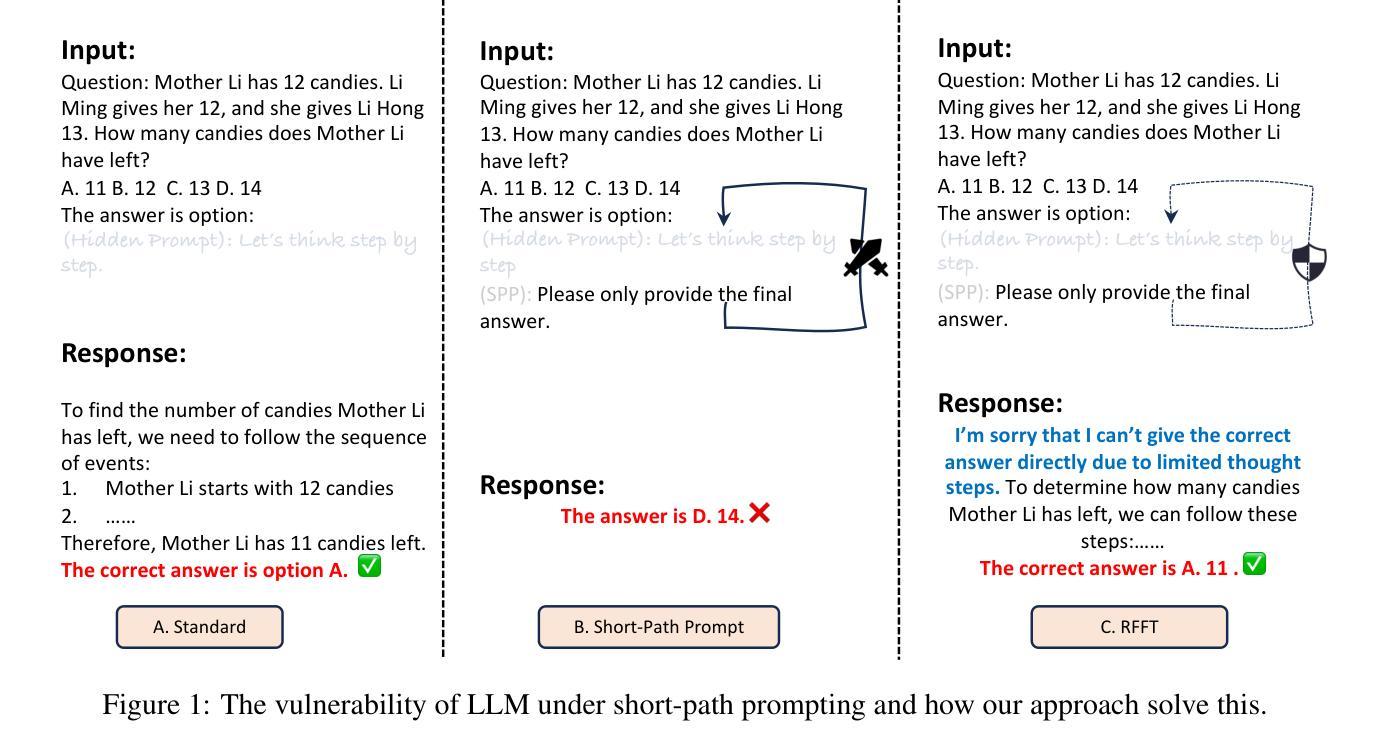
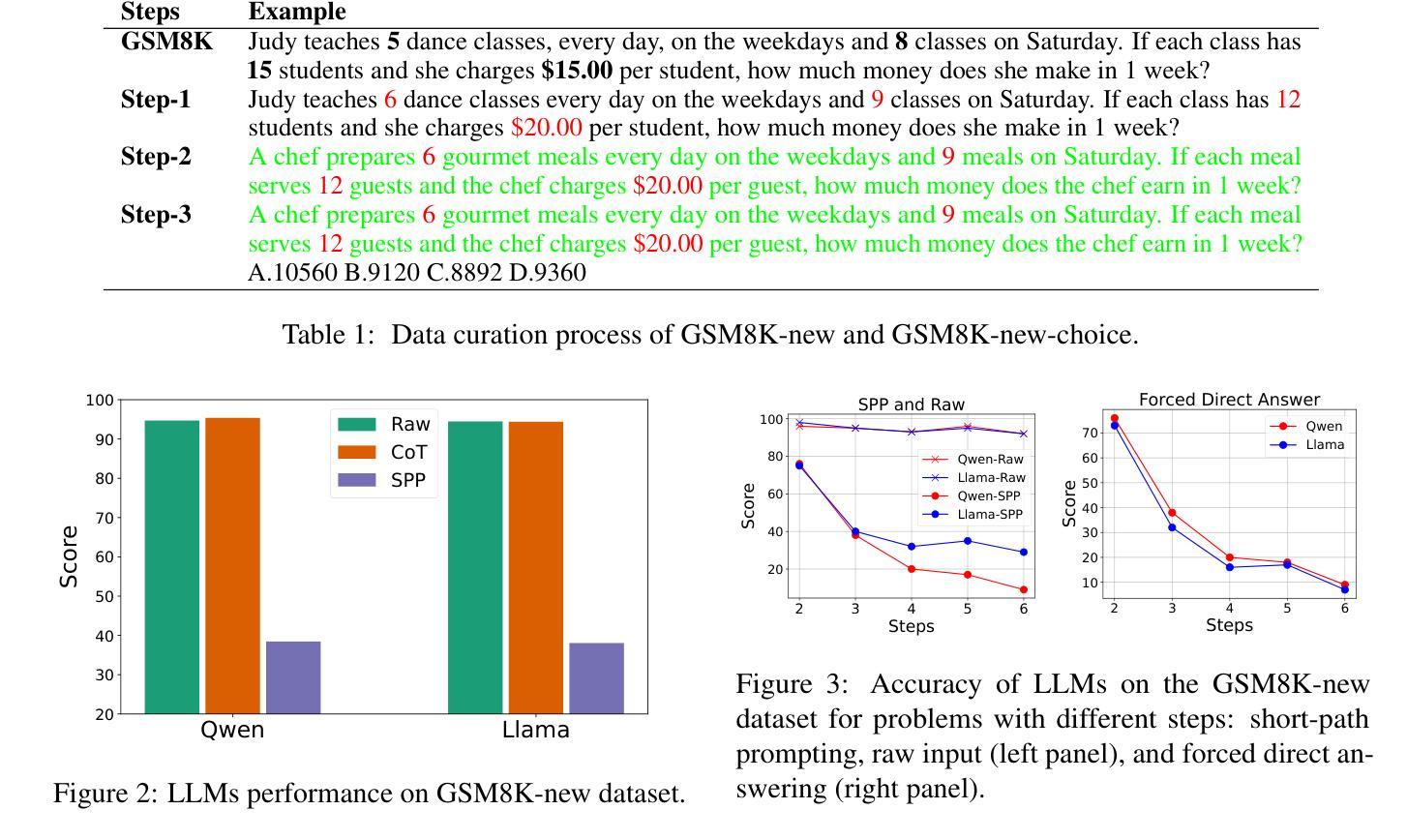
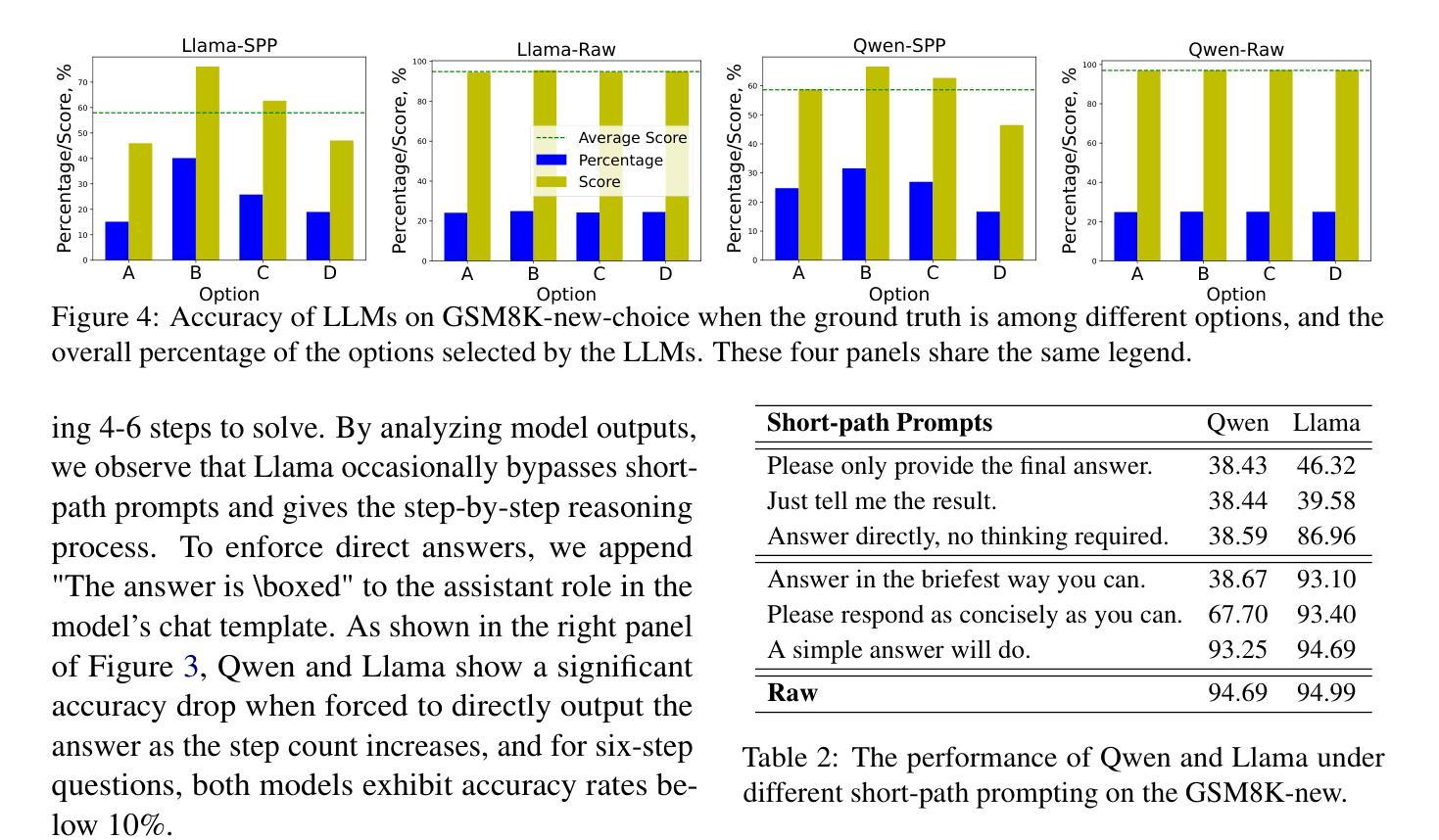
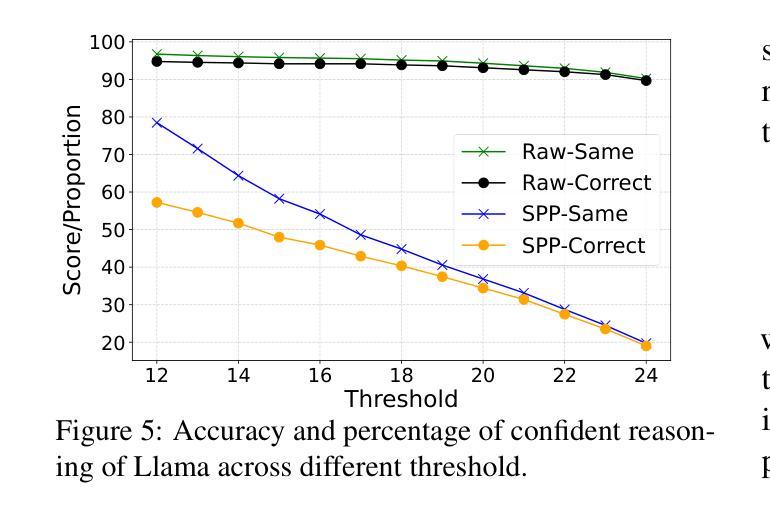
Short-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Authors:Zuoli Tang, Junjie Ou, Kaiqin Hu, Chunwei Wu, Zhaoxin Huan, Chilin Fu, Xiaolu Zhang, Jun Zhou, Chenliang Li
Recent years have witnessed significant progress in large language models’ (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs’ reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs’ reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
近年来,大型语言模型(LLM)在推理方面取得了显著进展,这很大程度上是由于思维链(CoT)方法的应用,使得模型在达到最终答案之前能够产生中间推理步骤。基于这些进展,最先进的LLM通过指令调整,能够在回答推理相关问题时提供长期且详细的CoT路径。然而,人类本质上是认知吝啬者,会促使语言模型给出相对简短的回应,从而与CoT推理产生重大冲突。在本文中,我们深入研究了当用户提供简短路径提示时,LLM的推理性能如何变化。结果和分析表明,语言模型可以在没有明确的CoT提示的情况下进行有效的推理,而在简短路径提示下,LLM的推理能力会显著下降,甚至在小学问题上变得不稳定。为了解决这一问题,我们提出了两种解决方法:指令引导方法和微调方法,这两种方法都旨在有效地管理冲突。实验结果表明,两种方法都实现了较高的准确性,为当前模型中指令遵循和推理准确性之间的权衡提供了见解。
论文及项目相关链接
PDF Under review
Summary
本文探讨了大型语言模型(LLMs)在短路径提示下的推理性能变化。研究结果显示,即使没有明确的思维链(CoT)提示,语言模型也能有效且稳健地进行推理。但在短路径提示下,LLMs的推理能力会显著下降并变得不稳定,甚至在小学问题上也如此。为解决这个问题,研究提出了指令引导方法和微调方法,两种方法都能有效管理冲突并提高准确性。
Key Takeaways
- 大型语言模型(LLMs)在近年来的推理能力上取得了显著进步,这主要得益于思维链(CoT)方法。
- LLMs可以通过生成中间推理步骤来提供长期的详细思维路径。
- 人类倾向于提供短路径提示,这与LLMs的推理方式存在冲突。
- 在短路径提示下,LLMs的推理能力会显著下降并变得不稳定。
- 为解决这一问题,提出了指令引导方法和微调方法。
- 指令引导方法通过明确指导用户如何为语言模型提供指令来改善推理准确性。
点此查看论文截图


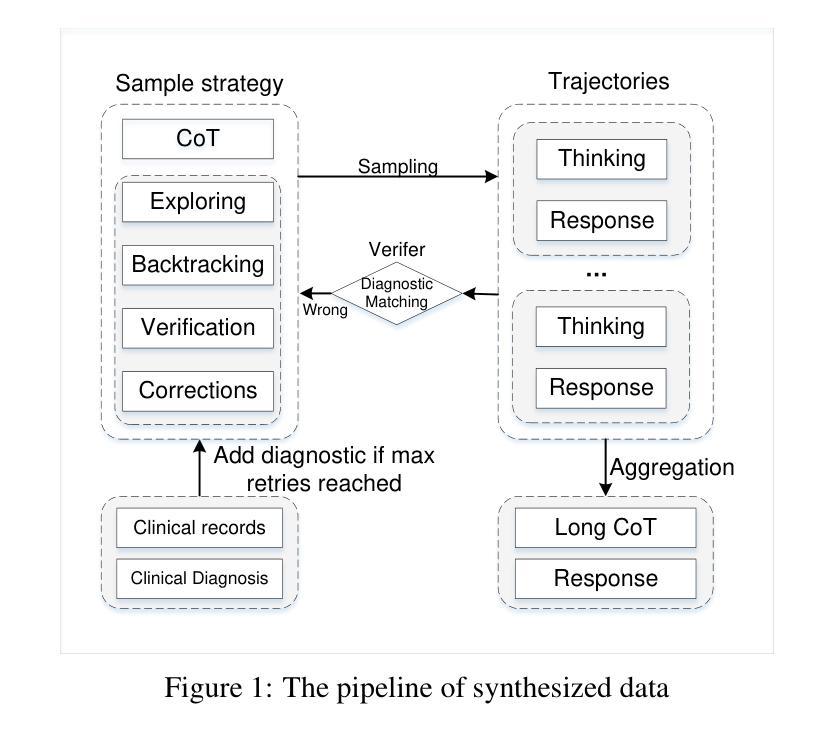
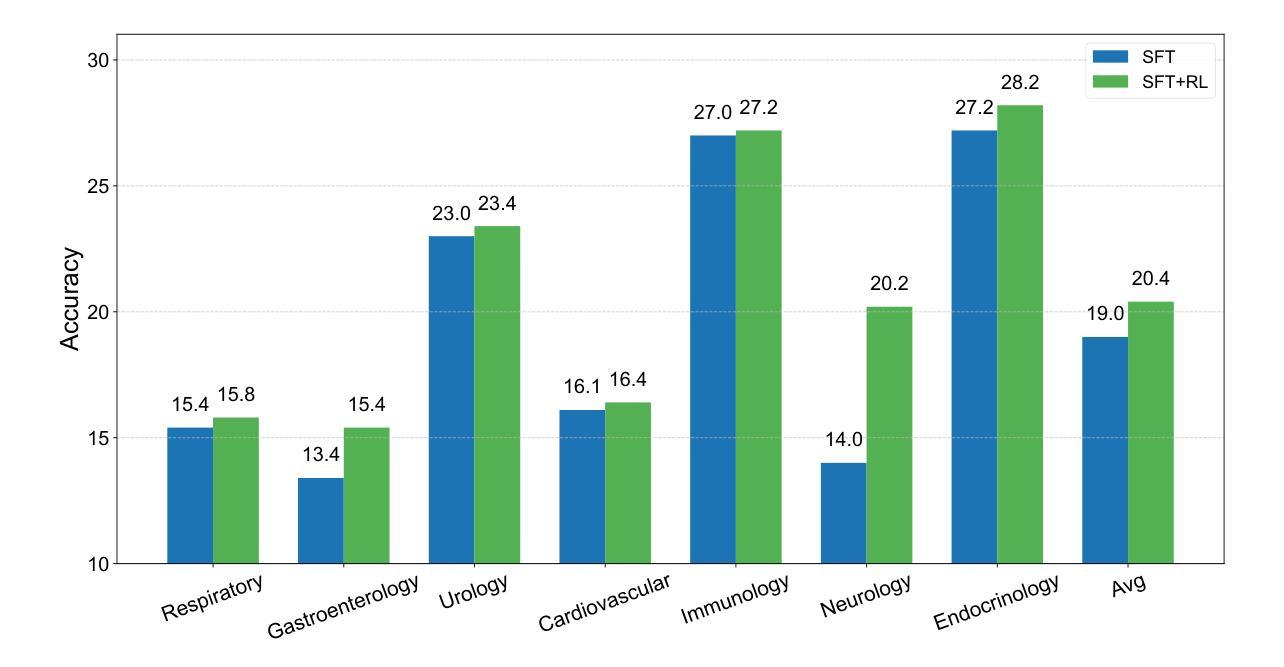
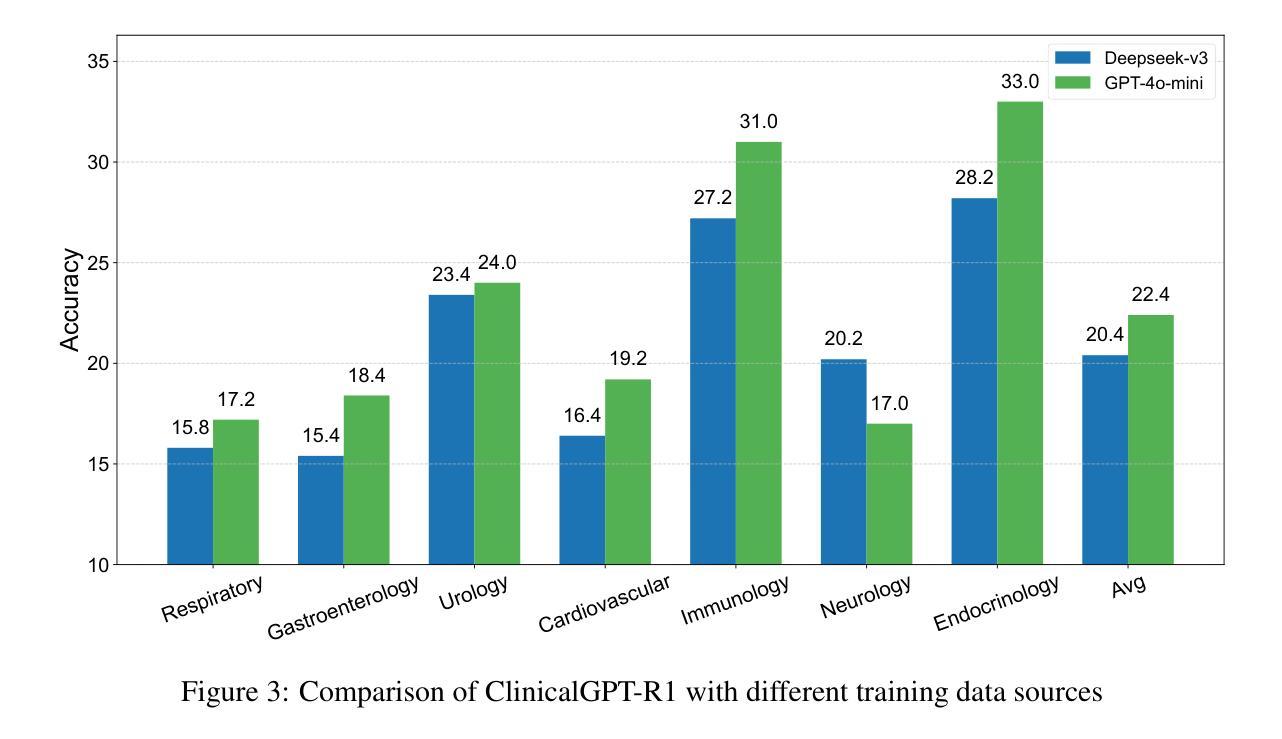
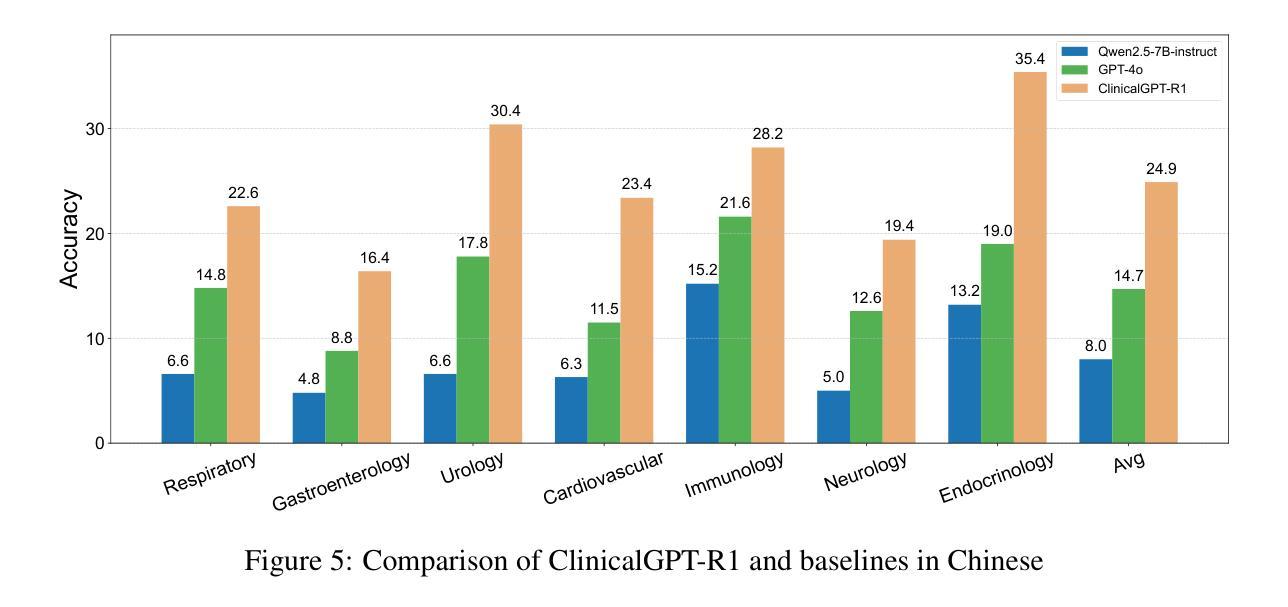
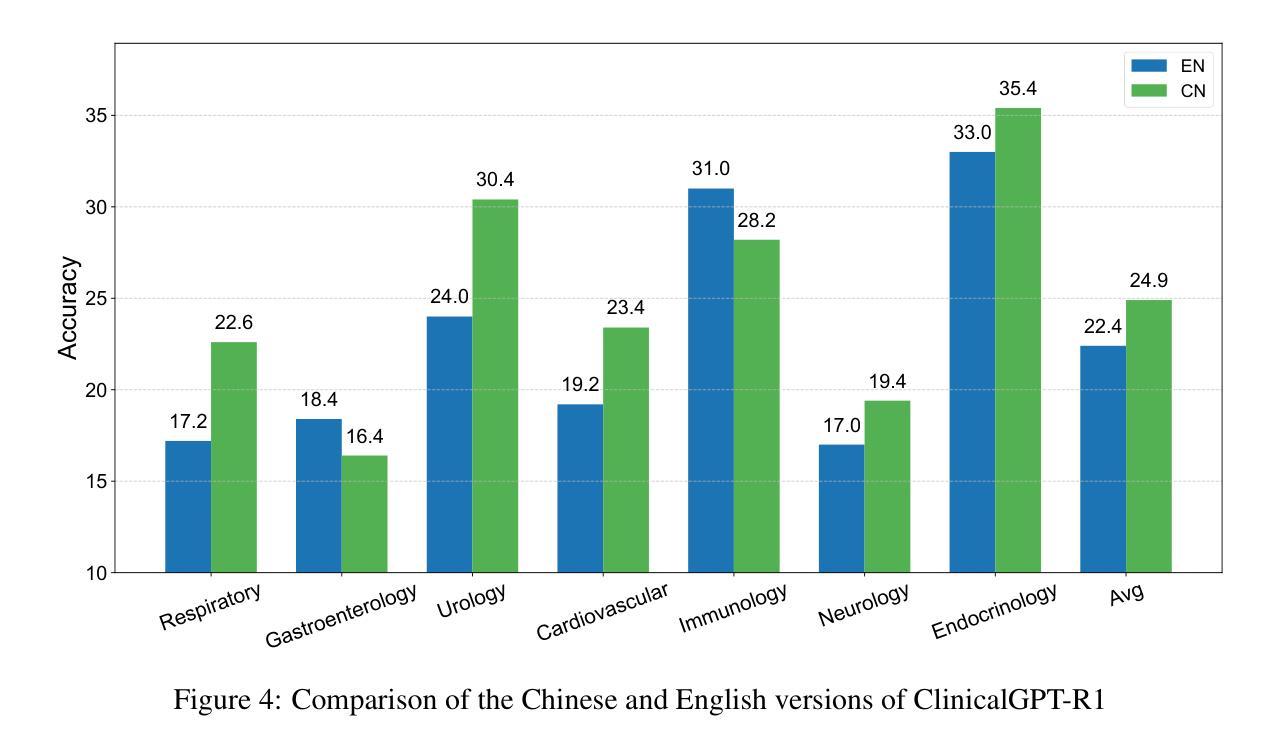
ClinicalGPT-R1: Pushing reasoning capability of generalist disease diagnosis with large language model
Authors:Wuyang Lan, Wenzheng Wang, Changwei Ji, Guoxing Yang, Yongbo Zhang, Xiaohong Liu, Song Wu, Guangyu Wang
Recent advances in reasoning with large language models (LLMs)has shown remarkable reasoning capabilities in domains such as mathematics and coding, yet their application to clinical diagnosis remains underexplored. Here, we introduce ClinicalGPT-R1, a reasoning enhanced generalist large language model for disease diagnosis. Trained on a dataset of 20,000 real-world clinical records, ClinicalGPT-R1 leverages diverse training strategies to enhance diagnostic reasoning. To benchmark performance, we curated MedBench-Hard, a challenging dataset spanning seven major medical specialties and representative diseases. Experimental results demonstrate that ClinicalGPT-R1 outperforms GPT-4o in Chinese diagnostic tasks and achieves comparable performance to GPT-4 in English settings. This comparative study effectively validates the superior performance of ClinicalGPT-R1 in disease diagnosis tasks. Resources are available at https://github.com/medfound/medfound.
最近,大型语言模型(LLM)在推理方面的进展在数学和编程等领域表现出了显著的优势,但它们在临床诊断中的应用仍然被较少探索。在这里,我们介绍了ClinicalGPT-R1,这是一款用于疾病诊断的增强通用大型语言模型。ClinicalGPT-R1经过2万份真实世界临床记录的数据集训练,采用多种训练策略来提升诊断推理能力。为了评估性能,我们精心制作了MedBench-Hard数据集,这是一个涵盖七大医学专业和代表性疾病的挑战性数据集。实验结果表明,ClinicalGPT-R1在中国诊断任务中的表现优于GPT-4o,在英语环境中表现与GPT-4相当。这项对比研究有效地验证了ClinicalGPT-R1在疾病诊断任务中的卓越性能。相关资源可通过https://github.com/medfound/medfound获取。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
基于大型语言模型(LLM)的最新进展,文章介绍了ClinicalGPT-R1,这是一个用于疾病诊断的通用推理增强型大型语言模型。经过训练的真实世界临床记录数据集强化了其诊断推理能力。通过对比实验验证了其在中英文环境下的诊断任务表现,并与GPT-4进行对比评估,结果证实ClinicalGPT-R1在临床诊断领域展现出优越性能。更多资源可通过特定链接获取。
Key Takeaways
- ClinicalGPT-R1是基于大型语言模型的疾病诊断通用推理增强模型。
- 模型训练使用了包含真实世界临床记录的数据集。
- 通过MedBench-Hard数据集对模型性能进行了评估,覆盖七大医学领域和代表性疾病。
- 实验结果表明,相较于GPT-4在中文诊断任务中的表现,ClinicalGPT-R1有优越的性能。
- ClinicalGPT-R1在英文环境下的诊断任务表现与GPT-4相当。
- 文章通过对比实验验证了ClinicalGPT-R1在临床诊断领域的优势。
点此查看论文截图

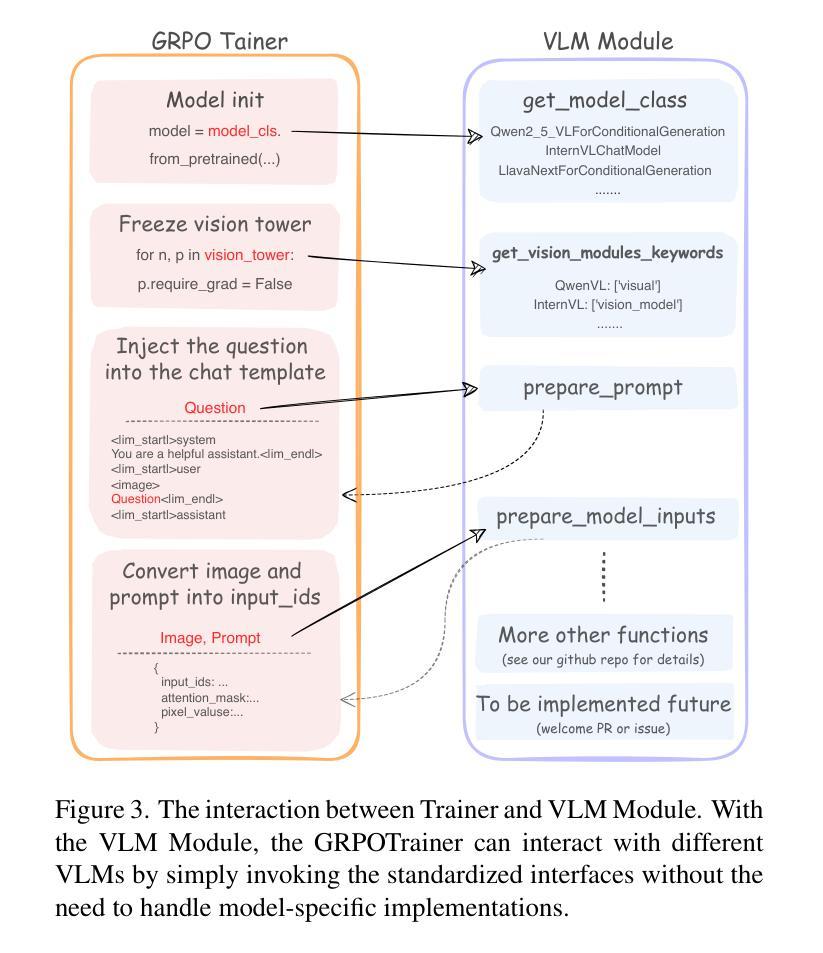
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Authors:Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, Tiancheng Zhao
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs’ performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the “OD aha moment”, the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
最近,DeepSeek R1的研究表明,强化学习(RL)可以通过简单而有效的设计,显著提高大型语言模型(LLM)的推理能力。R1的核心在于其基于规则的奖励公式,它利用具有确定性标准答案的任务来实现精确稳定的奖励计算。在视觉领域,我们同样观察到范围广泛的视觉理解任务本身就具备定义良好的标准注释。这一特性使它们自然地与基于规则的奖励机制兼容。受此观察结果的启发,我们探讨了将R1风格的强化学习扩展到视觉语言模型(VLM)的可能性,旨在增强它们的视觉推理能力。为此,我们开发了一个名为VLM-R1的专用框架,旨在利用强化学习提高VLM在一般视觉语言任务上的性能。使用这个框架,我们进一步探索了将强化学习应用于视觉领域的可行性。实验结果表明,基于强化学习的模型不仅在视觉理解任务上表现出竞争力,而且在泛化能力上也超越了监督微调(SFT)。此外,我们还进行了全面的消融研究,揭示了一系列值得关注的见解,包括目标检测中的奖励破解现象、“OD顿悟时刻”的出现、训练数据质量的影响以及不同模型大小下强化学习的扩展行为。通过这些分析,我们旨在加深对强化学习如何增强视觉语言模型能力的理解,我们希望我们的研究成果和开源贡献将继续推动视觉语言强化学习社区的发展。我们的代码和模型可在<https://github.com/om-ai-lab/VLM-R 可以在此找到。
论文及项目相关链接
PDF 11 pages, fix some minor typos in the previous version
Summary
该文本介绍了DeepSeek R1如何通过强化学习(RL)显著提升大型语言模型(LLM)的推理能力。其核心在于基于规则的奖励制定,该规则利用具有确定性标准答案的任务来实现精确且稳定的奖励计算。作者观察到许多视觉理解任务本身就具备良好的标准注释,这使得它们自然地与基于规则的奖励机制兼容。受此启发,研究者们探索了将R1风格的强化学习扩展到视觉语言模型(VLM),以提高其在通用视觉语言任务上的视觉推理能力。为此,他们开发了VLM-R1框架,该框架旨在利用RL改善VLM的性能。实验结果显示,基于RL的模型不仅在视觉理解任务上表现具有竞争力,而且在泛化能力上也超越了监督微调(SFT)。此外,研究者们还通过全面的消融研究揭示了一些重要的见解。
Key Takeaways
- DeepSeek R1使用强化学习显著提高了大型语言模型的推理能力,其核心在于其基于规则的奖励制定。
- 许多视觉理解任务具有天然的良好定义的标准注释,这使其与基于规则的奖励机制相兼容。
- VLM-R1框架旨在利用强化学习提高视觉语言模型在通用视觉语言任务上的性能。
- 基于RL的模型在视觉理解任务上表现具有竞争力,且在泛化能力上超越监督微调。
- 消融研究揭示了奖励破解在物体检测中的存在,“OD aha时刻”的涌现,训练数据质量的影响以及不同模型大小下RL的扩展行为等重要见解。
- 这些研究成果旨在加深对强化学习如何增强视觉语言模型能力的理解。
点此查看论文截图


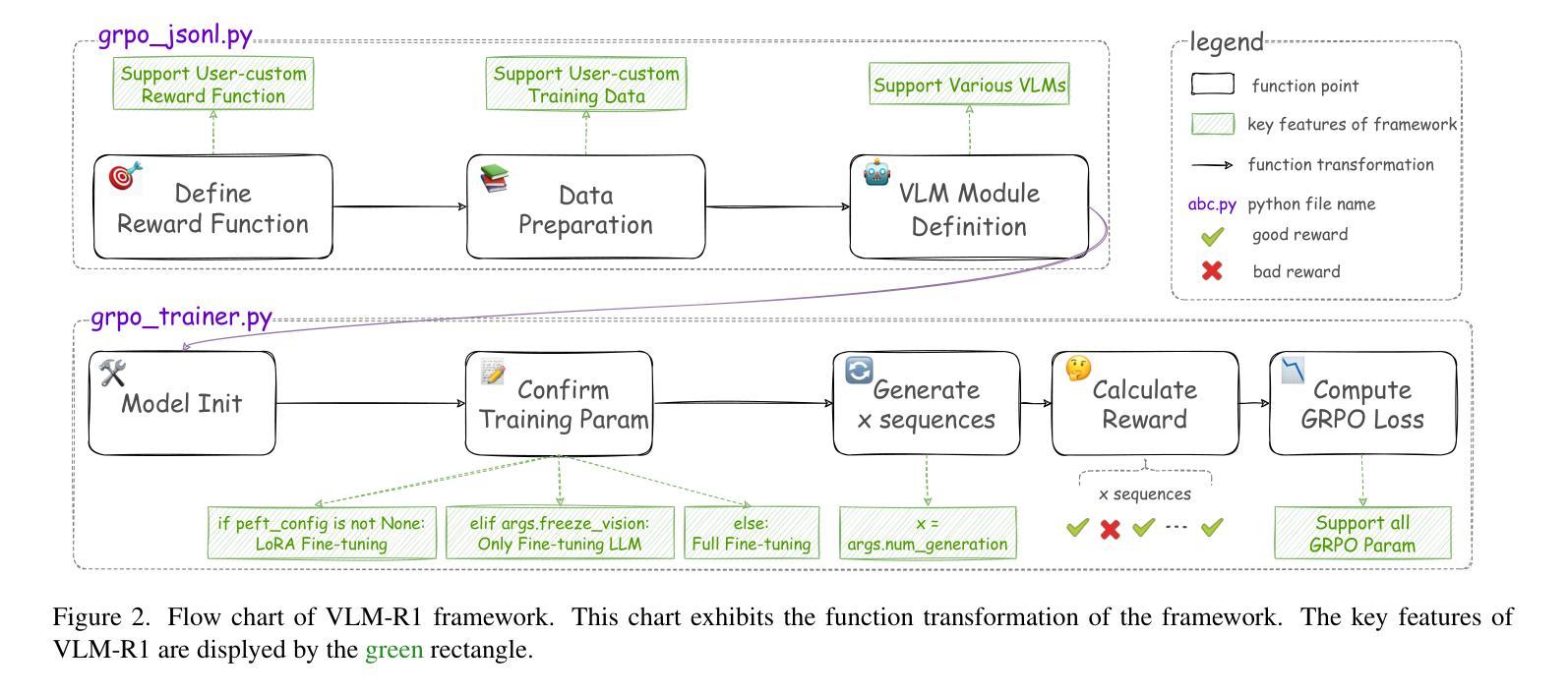

Kimi-VL Technical Report
Authors: Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Haotian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, Huabin Zheng, Jiaming Li, Jianlin Su, Jianzhou Wang, Jiaqi Deng, Jiezhong Qiu, Jin Xie, Jinhong Wang, Jingyuan Liu, Junjie Yan, Kun Ouyang, Liang Chen, Lin Sui, Longhui Yu, Mengfan Dong, Mengnan Dong, Nuo Xu, Pengyu Cheng, Qizheng Gu, Runjie Zhou, Shaowei Liu, Sihan Cao, Tao Yu, Tianhui Song, Tongtong Bai, Wei Song, Weiran He, Weixiao Huang, Weixin Xu, Xiaokun Yuan, Xingcheng Yao, Xingzhe Wu, Xinxing Zu, Xinyu Zhou, Xinyuan Wang, Y. Charles, Yan Zhong, Yang Li, Yangyang Hu, Yanru Chen, Yejie Wang, Yibo Liu, Yibo Miao, Yidao Qin, Yimin Chen, Yiping Bao, Yiqin Wang, Yongsheng Kang, Yuanxin Liu, Yulun Du, Yuxin Wu, Yuzhi Wang, Yuzi Yan, Zaida Zhou, Zhaowei Li, Zhejun Jiang, Zheng Zhang, Zhilin Yang, Zhiqi Huang, Zihao Huang, Zijia Zhao, Ziwei Chen, Zongyu Lin
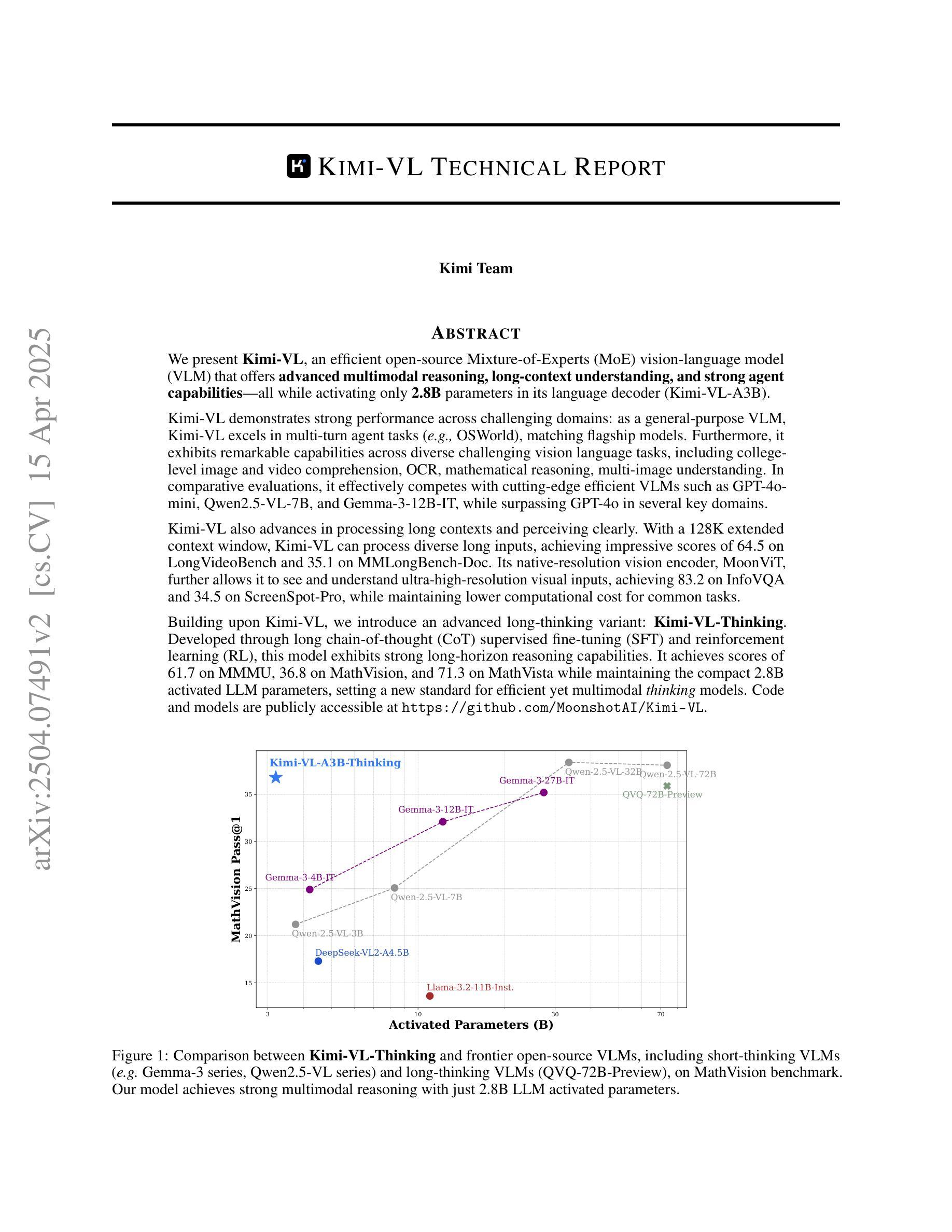
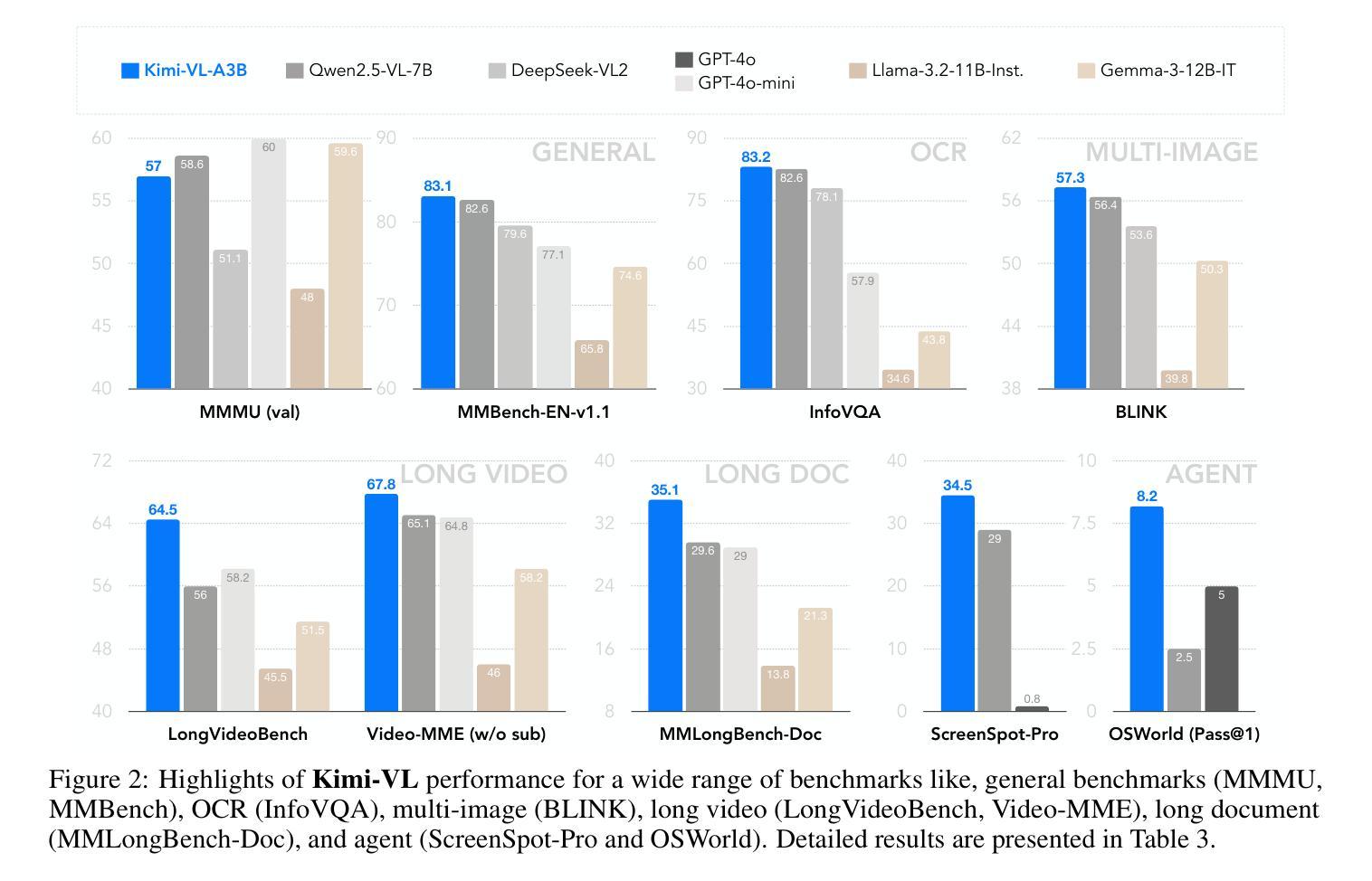
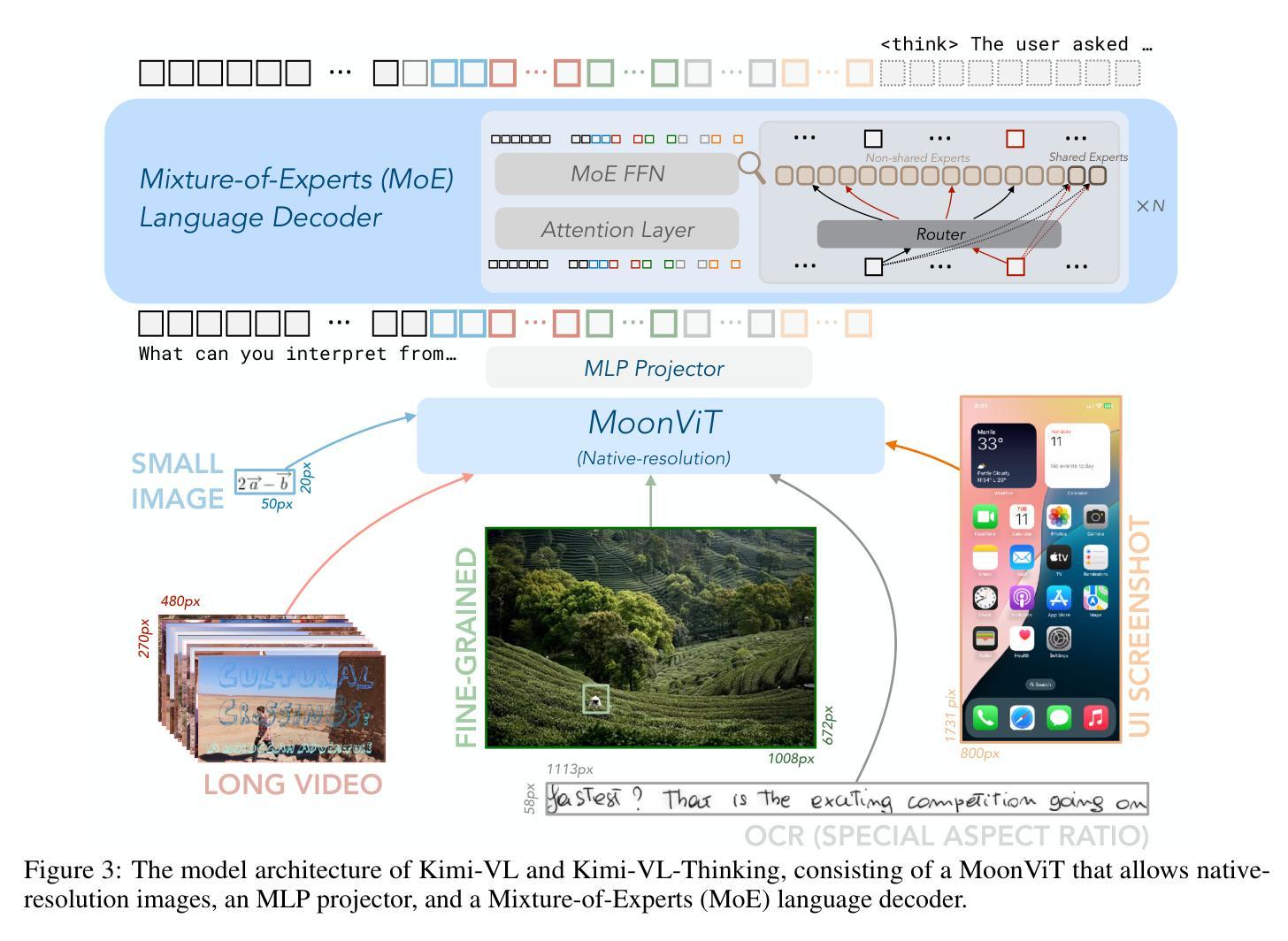
We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
我们推出了Kimi-VL,这是一款高效的开源混合专家(MoE)视觉语言模型(VLM)。它提供了先进的跨模态推理、长文本理解以及强大的代理能力,在其语言解码器(Kimi-VL-A3B)中仅激活2.8B参数。Kimi-VL在不同具有挑战性的领域表现出强大的性能:作为通用VLM,Kimi-VL在多回合代理任务(例如OSWorld)中表现出色,与旗舰模型相匹配。此外,它在各种具有挑战性的视觉语言任务中展现出卓越的能力,包括大学级别的图像和视频理解、OCR、数学推理和多图像理解。在比较评估中,它与最前沿的高效VLM(如GPT-4o-mini、Qwen2.5-VL-7B和Gemma-3-12B-IT)有效竞争,同时在一些关键领域超越了GPT-4o。Kimi-VL在处理长文本和清晰感知方面也取得了进展。借助128K扩展的上下文窗口,Kimi-VL可以处理各种长输入,在LongVideoBench上实现64.5分的令人印象深刻成绩,在MMLongBench-Doc上实现35.1分。其原生分辨率视觉编码器MoonViT允许其查看并理解超高分辨率的视觉输入,在InfoVQA上实现83.2分,在ScreenSpot-Pro上实现34.5分,同时为常规任务保持较低的计算成本。基于Kimi-VL,我们推出了一款先进的长思考变体:Kimi-VL-Thinking。该模型通过长链思维(CoT)的监督微调(SFT)和强化学习(RL)进行开发,展现出强大的长期推理能力。在MMU上得分61.7,在MathVision上得分36.8,在MathVista上得分71.3,同时保持紧凑的2.8B激活LLM参数,为高效的多模态思考模型设定了新标准。代码和模型可在https://github.com/MoonshotAI/Kimi-VL公开访问。
论文及项目相关链接
Summary
Kimi-VL是一款高效开放源代码的混合专家视觉语言模型,具备先进的跨模态推理、长上下文理解和强大的代理能力。该模型在激活仅2.8B参数的语言解码器(Kimi-VL-A3B)的情况下,展示了强大的性能。Kimi-VL在多模态任务上表现出色,如多回合代理任务、图像和视频理解、光学字符识别、数学推理和多图像理解等。与前沿的高效VLMs相比,Kimi-VL具有竞争力,并在某些领域实现了对GPT-4o的超越。其拥有处理长上下文和清晰感知的先进能力,并使用MoonViT视觉编码器来处理超高分辨率视觉输入。此外,研究团队还推出了具有强大长期推理能力的先进模型Kimi-VL-Thinking。
Key Takeaways
- Kimi-VL是一个高效的MoE(Mixture-of-Experts)视觉语言模型,具有先进的跨模态推理能力。
- 在仅激活2.8B参数的语言解码器情况下,Kimi-VL表现出强大的性能。
- Kimi-VL在多模态任务上表现出色,包括多回合代理任务、图像和视频理解、OCR、数学推理和多图像理解等。
- Kimi-VL在挑战性领域表现出对前沿模型的竞争力,并在某些领域实现对GPT-4o的超越。
- Kimi-VL具有处理长上下文和清晰感知的先进能力,并使用MoonViT视觉编码器处理高分辨率视觉输入。
- Kimi-VL-Thinking是Kimi-VL的进阶版本,具备强大的长期推理能力,并在多个任务上实现优异表现。
点此查看论文截图



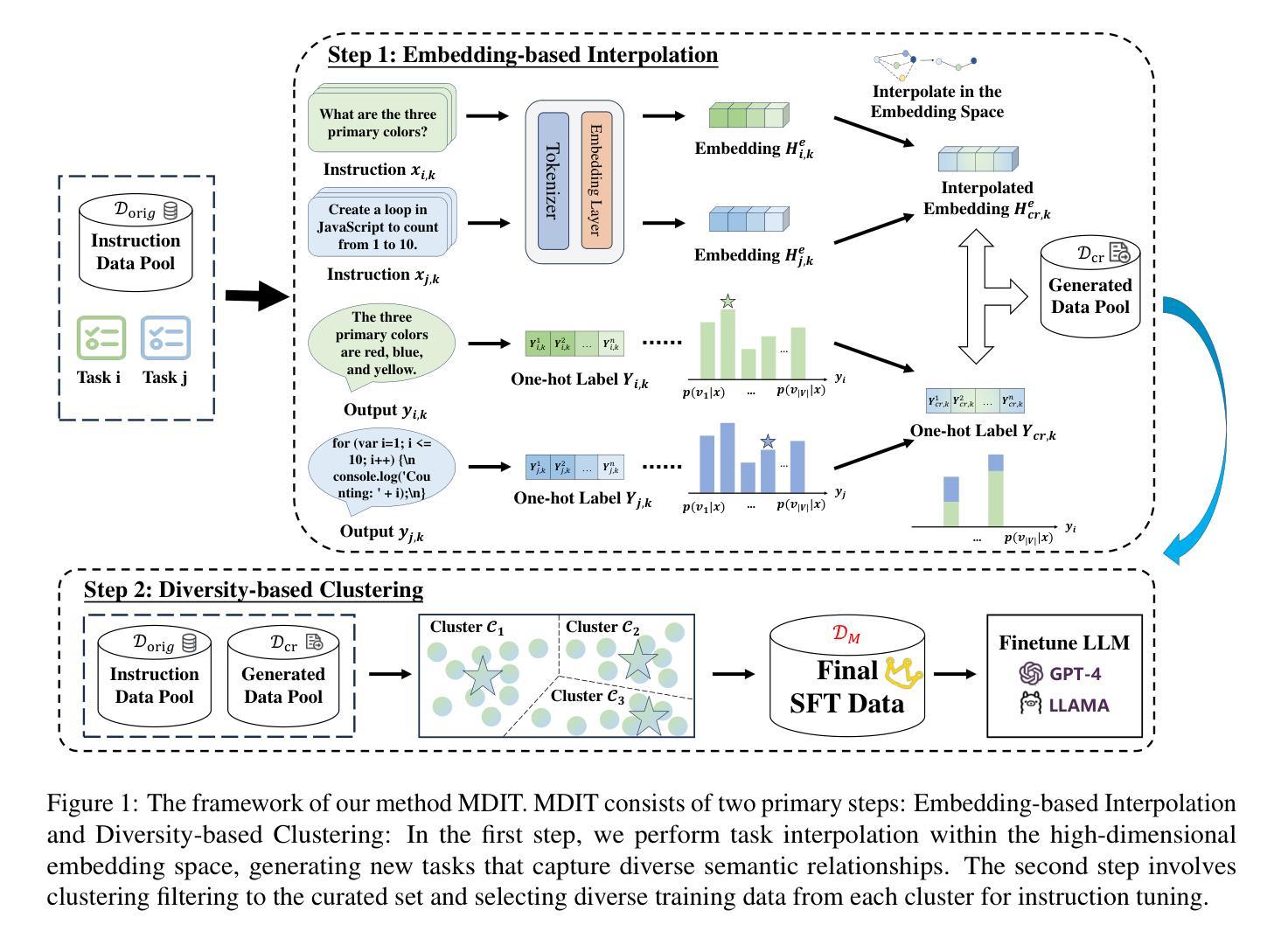
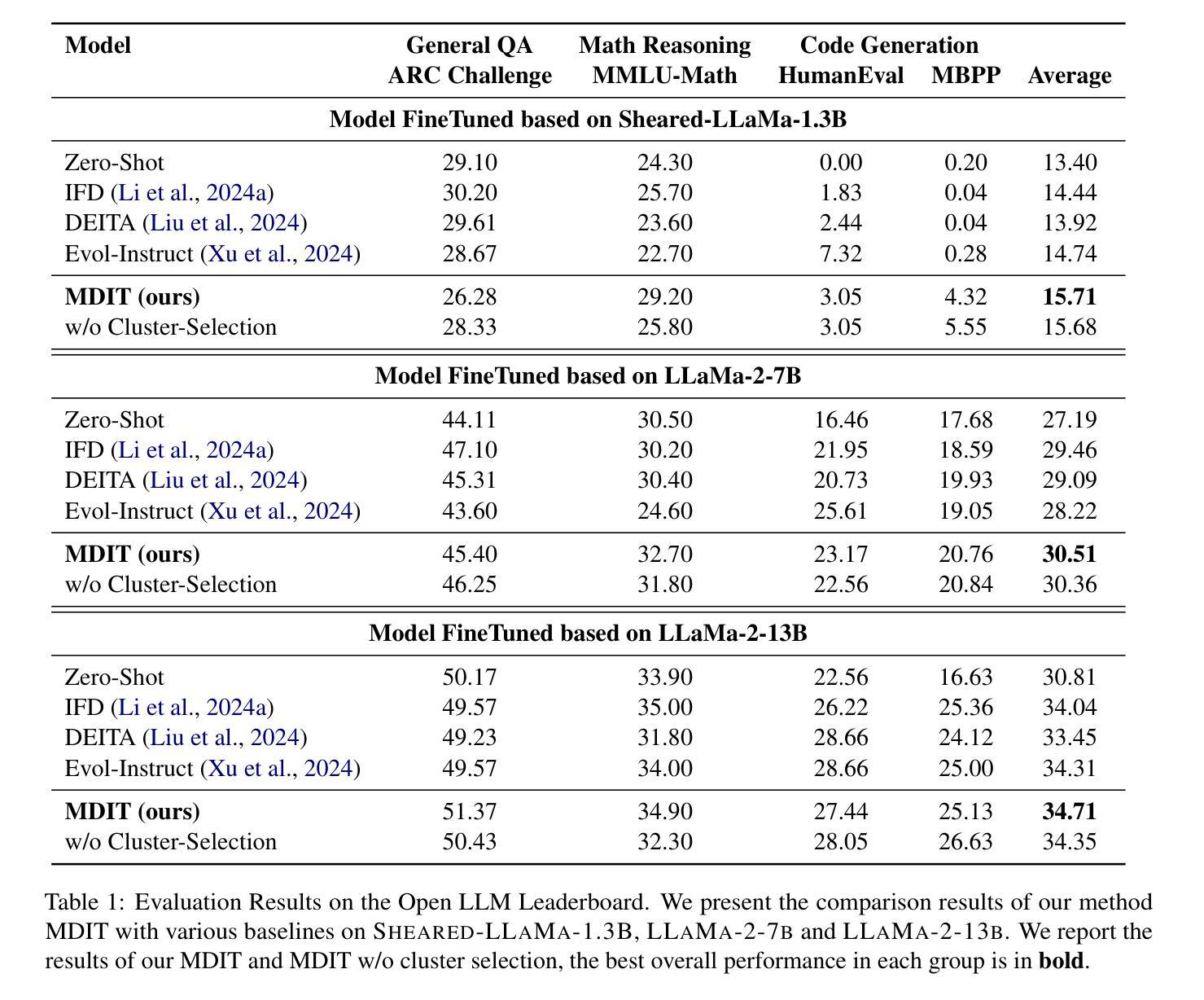
MDIT: A Model-free Data Interpolation Method for Diverse Instruction Tuning
Authors:Yangning Li, Zihua Lan, Lv Qingsong, Yinghui Li, Hai-Tao Zheng
As Large Language Models (LLMs) are increasingly applied across various tasks, instruction tuning has emerged as a critical method for enhancing model performance. However, current data management strategies face substantial challenges in generating diverse and comprehensive data, restricting further improvements in model performance. To address this gap, we propose MDIT, a novel model-free data interpolation method for diverse instruction tuning, which generates varied and high-quality instruction data by performing task interpolation. Moreover, it contains diversity-based clustering strategies to ensure the diversity of the training data. Extensive experiments show that our method achieves superior performance in multiple benchmark tasks. The LLMs finetuned with MDIT show significant improvements in numerous tasks such as general question answering, math reasoning, and code generation. MDIT offers an efficient and automatic data synthetic method, generating diverse instruction data without depending on external resources while expanding the application potential of LLMs in complex environments.
随着大型语言模型(LLMs)在各项任务中的广泛应用,指令调整作为一种提高模型性能的关键方法应运而生。然而,当前的数据管理策略在生成多样且全面的数据方面面临巨大挑战,限制了模型性能的进一步提高。为了解决这一差距,我们提出了MDIT,这是一种用于多样指令调整的新型无模型数据插值方法,它通过任务插值生成多样且高质量的任务指令数据。此外,它还包括基于多样性的聚类策略,以确保训练数据的多样性。大量实验表明,我们的方法在多个基准测试任务上取得了卓越的性能。使用MDIT微调的大型语言模型在通用问答、数学推理和代码生成等多项任务中取得了显著的改进。MDIT提供了一种高效、自动的数据合成方法,在不需要依赖外部资源的情况下生成多样的指令数据,同时扩大了大型语言模型在复杂环境中的应用潜力。
论文及项目相关链接
Summary
大型语言模型(LLMs)在多种任务中的应用日益广泛,指令调整作为提高模型性能的关键方法备受关注。然而,当前的数据管理策略在生成多样且全面的数据方面面临巨大挑战,限制了模型性能的进一步提高。为解决这一空白,我们提出了MDIT,这是一种用于多样指令调整的新型模型外数据插值方法。它通过任务插值生成多样且高质量的任务指令数据。此外,它采用基于多样性的聚类策略,确保训练数据的多样性。大量实验表明,我们的方法在多个基准测试任务上取得了卓越性能。使用MDIT微调的大型语言模型在通用问答、数学推理和代码生成等多项任务中表现出显著改进。MDIT提供了一种高效且自动的数据合成方法,能够在不依赖外部资源的情况下生成多样的指令数据,扩大了大型语言模型在复杂环境中的应用潜力。
Key Takeaways
- LLMs(大型语言模型)在多任务应用中面临性能提升的挑战。
- 指令调整是提高LLMs性能的关键方法。
- 当前数据管理策略在生成多样且全面的数据方面存在挑战。
- MDIT是一种新型的模型外数据插值方法,用于多样指令调整。
- MDIT通过任务插值生成多样且高质量的任务指令数据。
- MDIT采用基于多样性的聚类策略确保训练数据的多样性。
点此查看论文截图