⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
A Multi-task Learning Balanced Attention Convolutional Neural Network Model for Few-shot Underwater Acoustic Target Recognition
Authors:Wei Huang, Shumeng Sun, Junpeng Lu, Zhenpeng Xu, Zhengyang Xiu, Hao Zhang
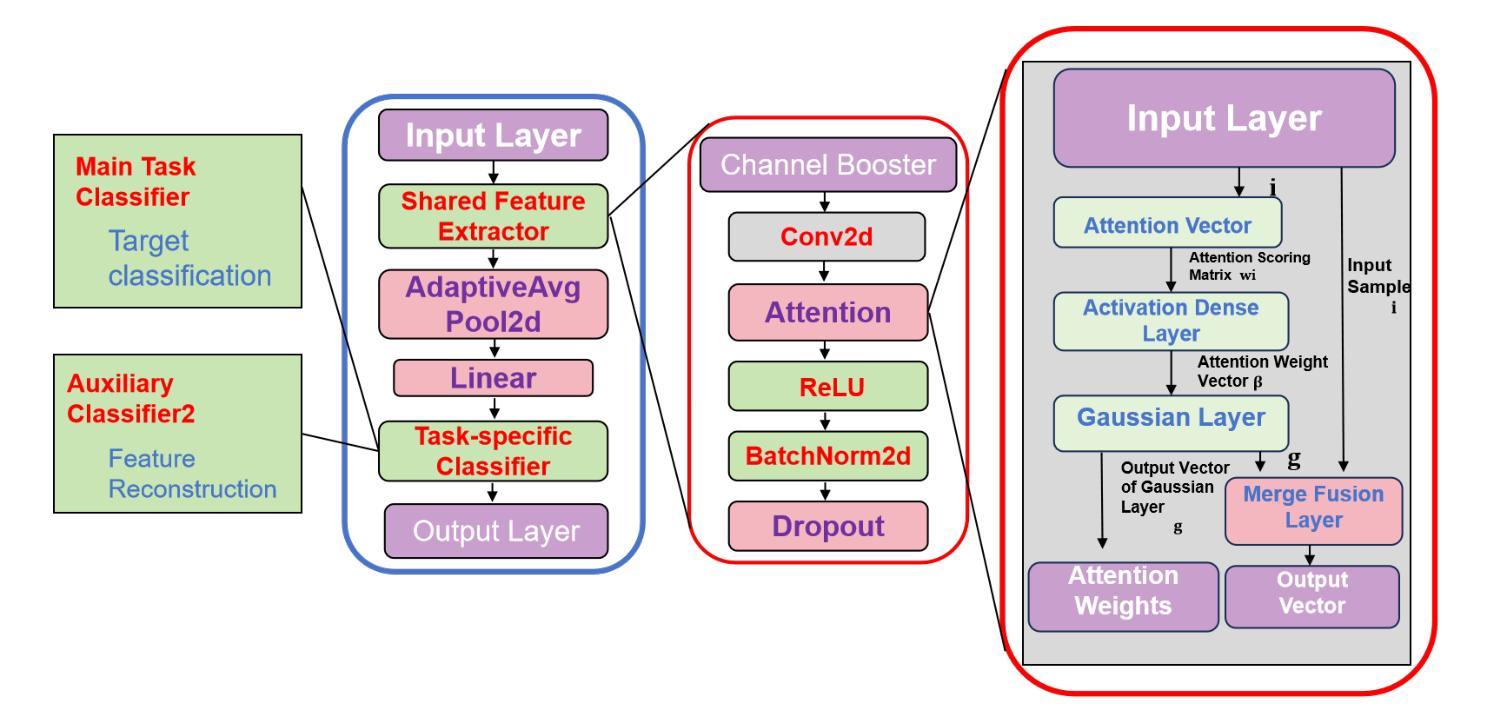
Underwater acoustic target recognition (UATR) is of great significance for the protection of marine diversity and national defense security. The development of deep learning provides new opportunities for UATR, but faces challenges brought by the scarcity of reference samples and complex environmental interference. To address these issues, we proposes a multi-task balanced channel attention convolutional neural network (MT-BCA-CNN). The method integrates a channel attention mechanism with a multi-task learning strategy, constructing a shared feature extractor and multi-task classifiers to jointly optimize target classification and feature reconstruction tasks. The channel attention mechanism dynamically enhances discriminative acoustic features such as harmonic structures while suppressing noise. Experiments on the Watkins Marine Life Dataset demonstrate that MT-BCA-CNN achieves 97% classification accuracy and 95% $F1$-score in 27-class few-shot scenarios, significantly outperforming traditional CNN and ACNN models, as well as popular state-of-the-art UATR methods. Ablation studies confirm the synergistic benefits of multi-task learning and attention mechanisms, while a dynamic weighting adjustment strategy effectively balances task contributions. This work provides an efficient solution for few-shot underwater acoustic recognition, advancing research in marine bioacoustics and sonar signal processing.
水下声学目标识别(UATR)对于保护海洋多样性和国防安全具有重要意义。深度学习的发展为UATR提供了新的机遇,但面临着参考样本稀缺和复杂环境干扰所带来的挑战。为了解决这些问题,我们提出了一种多任务平衡通道注意力卷积神经网络(MT-BCA-CNN)。该方法将通道注意力机制与多任务学习策略相结合,构建共享特征提取器和多任务分类器,联合优化目标分类和特征重建任务。通道注意力机制能够动态增强鉴别性声学特征,如谐波结构,同时抑制噪声。在Watkins海洋生命数据集上的实验表明,MT-BCA-CNN在27类小样本场景下实现了97%的分类准确率和95%的F1分数,显著优于传统的CNN和ACNN模型,以及其他流行的先进UATR方法。消融研究证实了多任务学习和注意力机制的协同效益,而动态权重调整策略有效地平衡了任务贡献。这项工作为小水声识别提供了有效的解决方案,推动了海洋生物声音学和声纳信号处理的研究进展。
论文及项目相关链接
Summary
水下声学目标识别(UATR)对保护海洋多样性和国防安全具有重要意义。深度学习的发展为UATR提供了新的机遇,但面临样本稀缺和复杂环境干扰的挑战。我们提出了一种多任务平衡通道注意力卷积神经网络(MT-BCA-CNN),结合通道注意力机制和多任务学习策略,构建共享特征提取器和多任务分类器,联合优化目标分类和特征重建任务。在瓦特金斯海洋生命数据集上的实验表明,MT-BCA-CNN在27类小样本场景中实现97%的分类准确率和95%的F1分数,显著优于传统CNN和ACNN模型,以及流行的高级UATR方法。
Key Takeaways
- 水下声学目标识别(UATR)对海洋多样性和国防安全至关重要。
- 深度学习在UATR中提供新机遇,但面临样本稀缺和环境干扰的挑战。
- 提出一种多任务平衡通道注意力卷积神经网络(MT-BCA-CNN)。
- 结合通道注意力机制和多任务学习策略,优化目标分类和特征重建。
- MT-BCA-CNN在瓦特金斯海洋生命数据集上实现高分类准确率和F1分数。
- 相较于传统CNN和ACNN模型以及高级UATR方法,MT-BCA-CNN表现更优秀。
- 消融研究证实了多任务学习和注意力机制的协同效益,动态加权调整策略有效平衡任务贡献。
点此查看论文截图

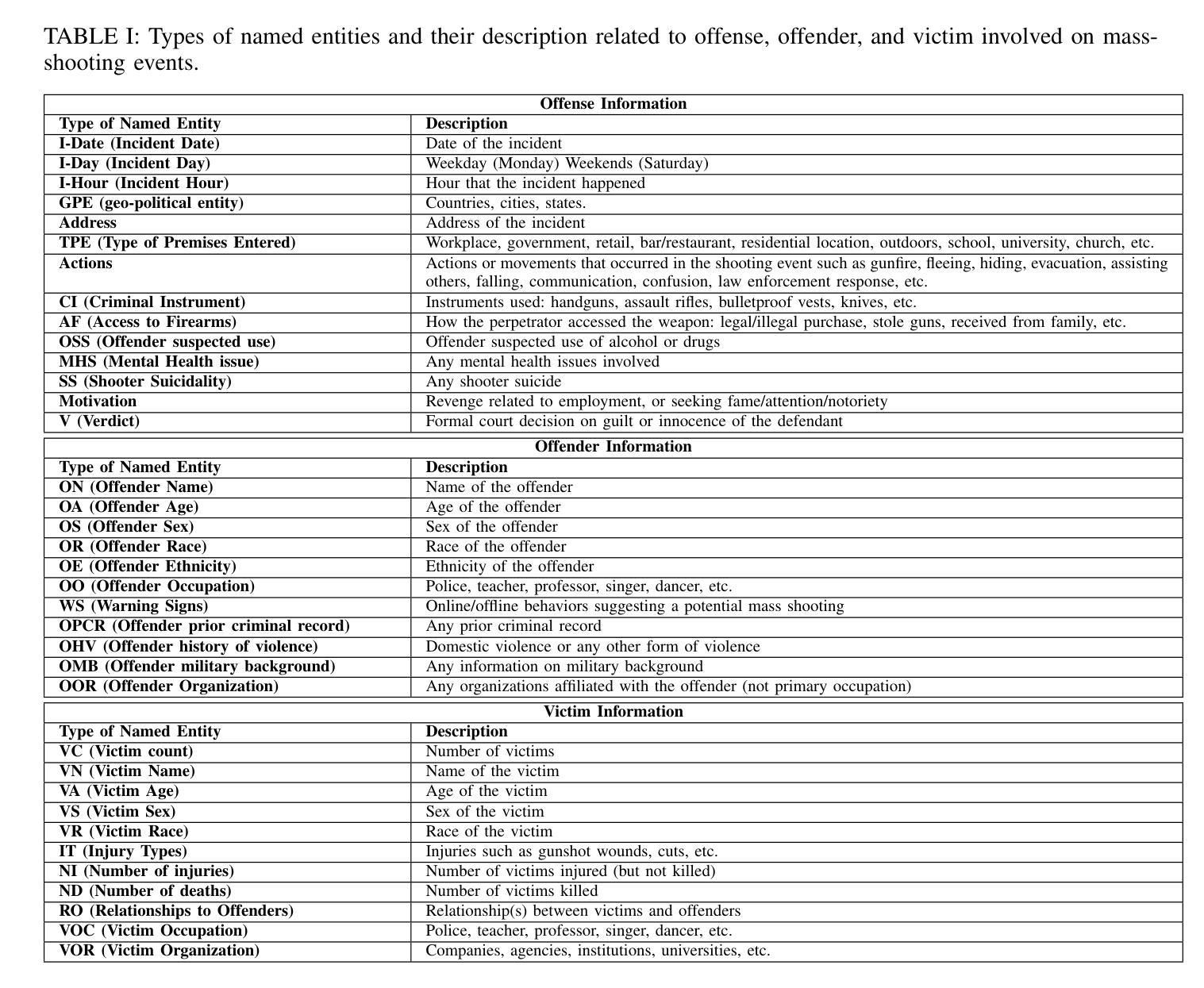
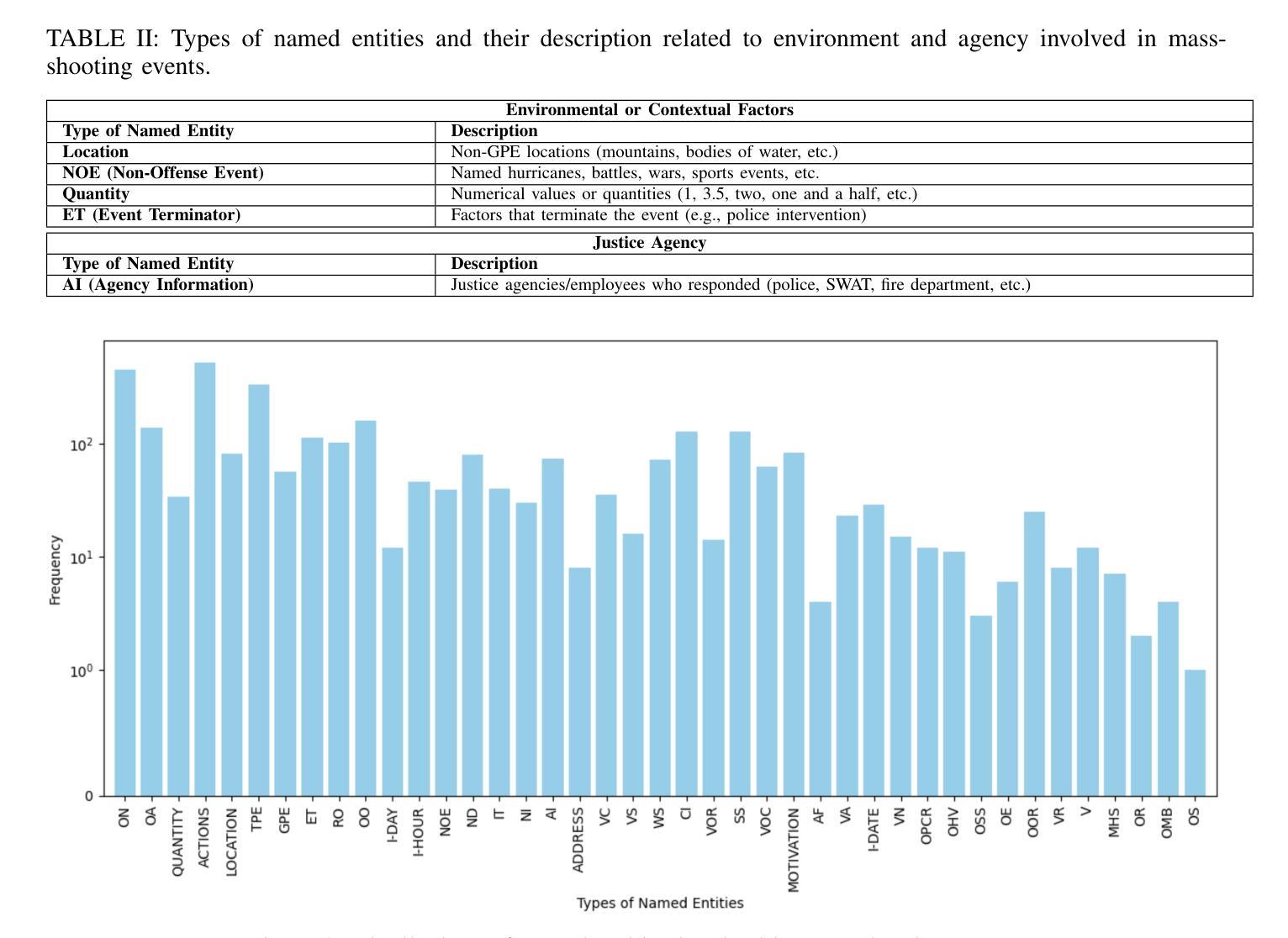
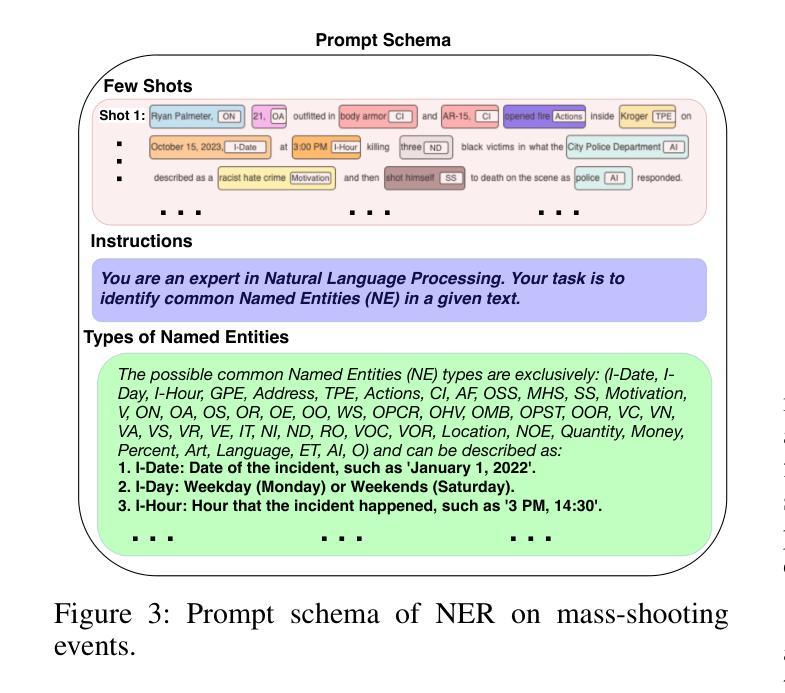
Knowledge Acquisition on Mass-shooting Events via LLMs for AI-Driven Justice
Authors:Benign John Ihugba, Afsana Nasrin, Ling Wu, Lin Li, Lijun Qian, Xishuang Dong
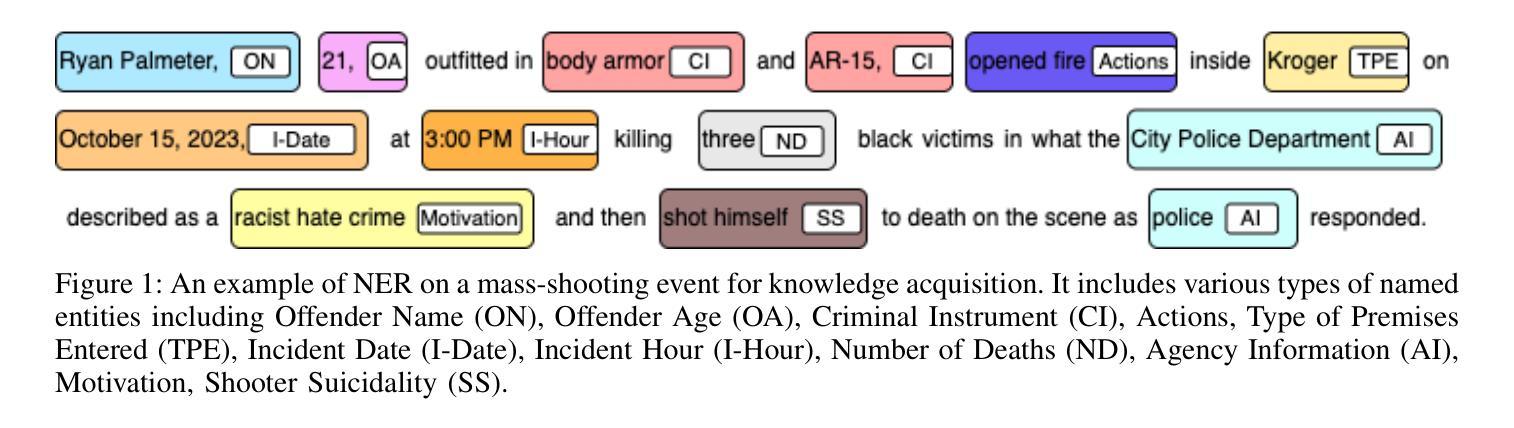
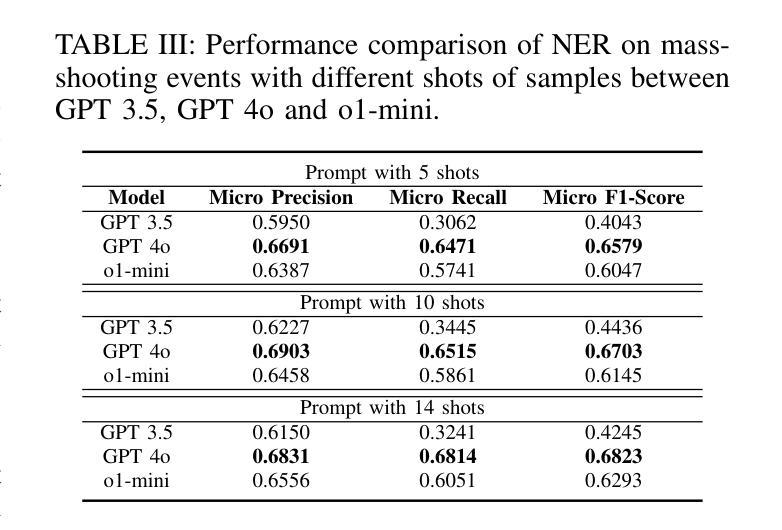
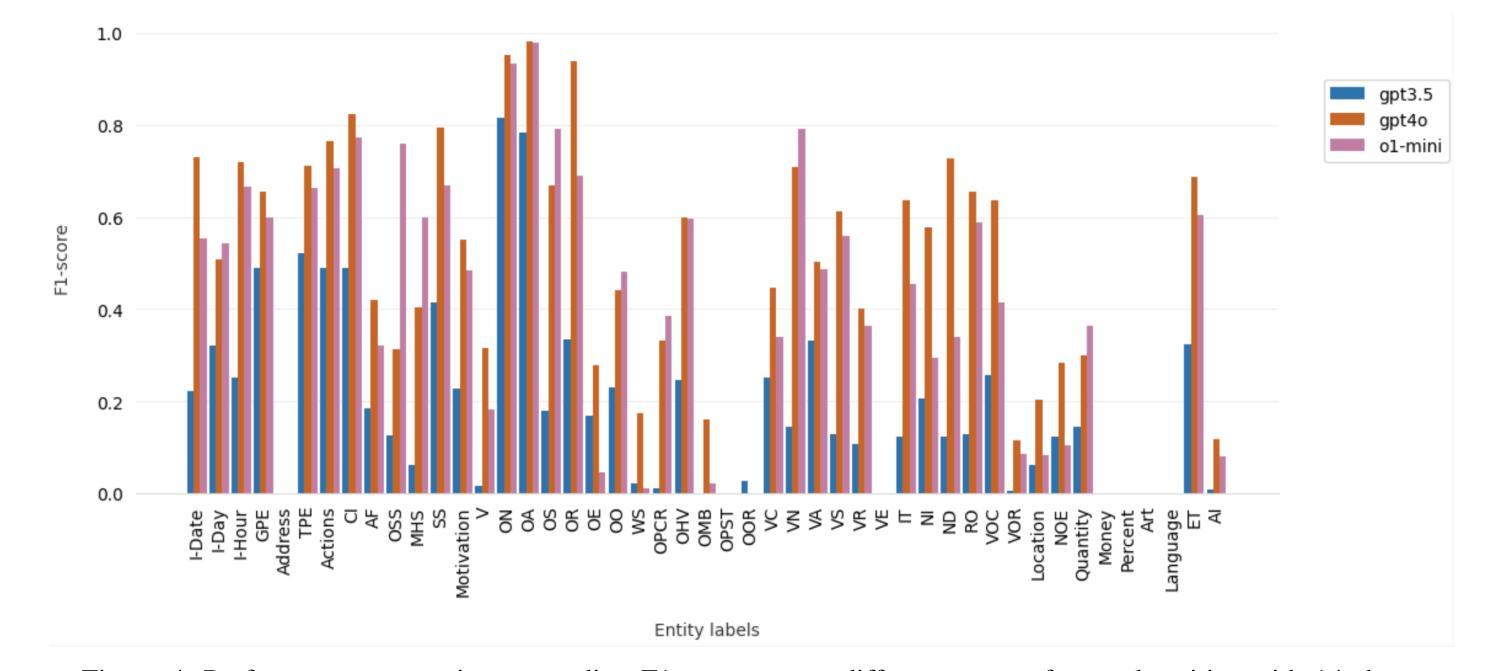
Mass-shooting events pose a significant challenge to public safety, generating large volumes of unstructured textual data that hinder effective investigations and the formulation of public policy. Despite the urgency, few prior studies have effectively automated the extraction of key information from these events to support legal and investigative efforts. This paper presented the first dataset designed for knowledge acquisition on mass-shooting events through the application of named entity recognition (NER) techniques. It focuses on identifying key entities such as offenders, victims, locations, and criminal instruments, that are vital for legal and investigative purposes. The NER process is powered by Large Language Models (LLMs) using few-shot prompting, facilitating the efficient extraction and organization of critical information from diverse sources, including news articles, police reports, and social media. Experimental results on real-world mass-shooting corpora demonstrate that GPT-4o is the most effective model for mass-shooting NER, achieving the highest Micro Precision, Micro Recall, and Micro F1-scores. Meanwhile, o1-mini delivers competitive performance, making it a resource-efficient alternative for less complex NER tasks. It is also observed that increasing the shot count enhances the performance of all models, but the gains are more substantial for GPT-4o and o1-mini, highlighting their superior adaptability to few-shot learning scenarios.
大规模枪击事件对公共安全构成重大挑战,产生大量非结构化文本数据,妨碍了有效的调查和公共政策的制定。尽管形势紧迫,但之前的研究很少有效地实现自动化提取这些事件中的关键信息来支持法律和调查工作。本文通过应用命名实体识别(NER)技术,展示了首个针对大规模枪击事件的知识获取数据集的设计。该数据集侧重于识别对法律和调查目的至关重要的关键实体,如罪犯、受害者、地点和犯罪工具。NER过程由大型语言模型(LLM)通过小样本提示功能驱动,可以高效地提取和组织来自新闻文章、警方报告和社会媒体等不同来源的关键信息。在现实的大规模枪击语料库上的实验结果表明,GPT-4o是枪击事件NER最有效的模型,获得了最高的微观精度、微观召回率和微观F1分数。同时,o1-mini也表现出竞争力,对于较简单的NER任务来说是一个资源高效的替代方案。此外还发现,增加样本数量可以提高所有模型的表现,但GPT-4o和o1-mini的增益更大,凸显了它们在少样本学习场景中的卓越适应性。
论文及项目相关链接
Summary
该文针对大规模枪击事件对公共安全构成的挑战,提出了运用命名实体识别(NER)技术创建首个相关数据集的方法。该数据集能够识别关键实体,如罪犯、受害者、地点和犯罪工具等,对法律和调查工作至关重要。利用大型语言模型(LLMs)进行少样本提示,可从新闻文章、警方报告和社会媒体等来源高效提取和组织关键信息。实验结果表明,GPT-4o在大规模枪击事件NER中最有效,而o1-mini在较简单的NER任务中具有资源效率高的竞争优势。增加射击次数有助于提高所有模型的性能,但GPT-4o和o1-mini的增益更为显著,突显了它们对少样本学习场景的卓越适应性。
Key Takeaways
- 大规模枪击事件对公共安全构成重大挑战,亟需自动化提取关键信息以支持法律和调查工作。
- 命名实体识别(NER)技术在处理大规模枪击事件中具有重要作用,可识别罪犯、受害者、地点和犯罪工具等关键实体。
- 利用大型语言模型(LLMs)进行少样本提示,可从多种来源高效提取和组织关键信息。
- GPT-4o在大规模枪击事件NER任务中表现最佳,具有最高的微精度、微召回率和微F1分数。
- o1-mini在资源效率方面表现出竞争优势,适用于较简单的NER任务。
- 增加射击次数有助于提高所有模型的性能。
点此查看论文截图

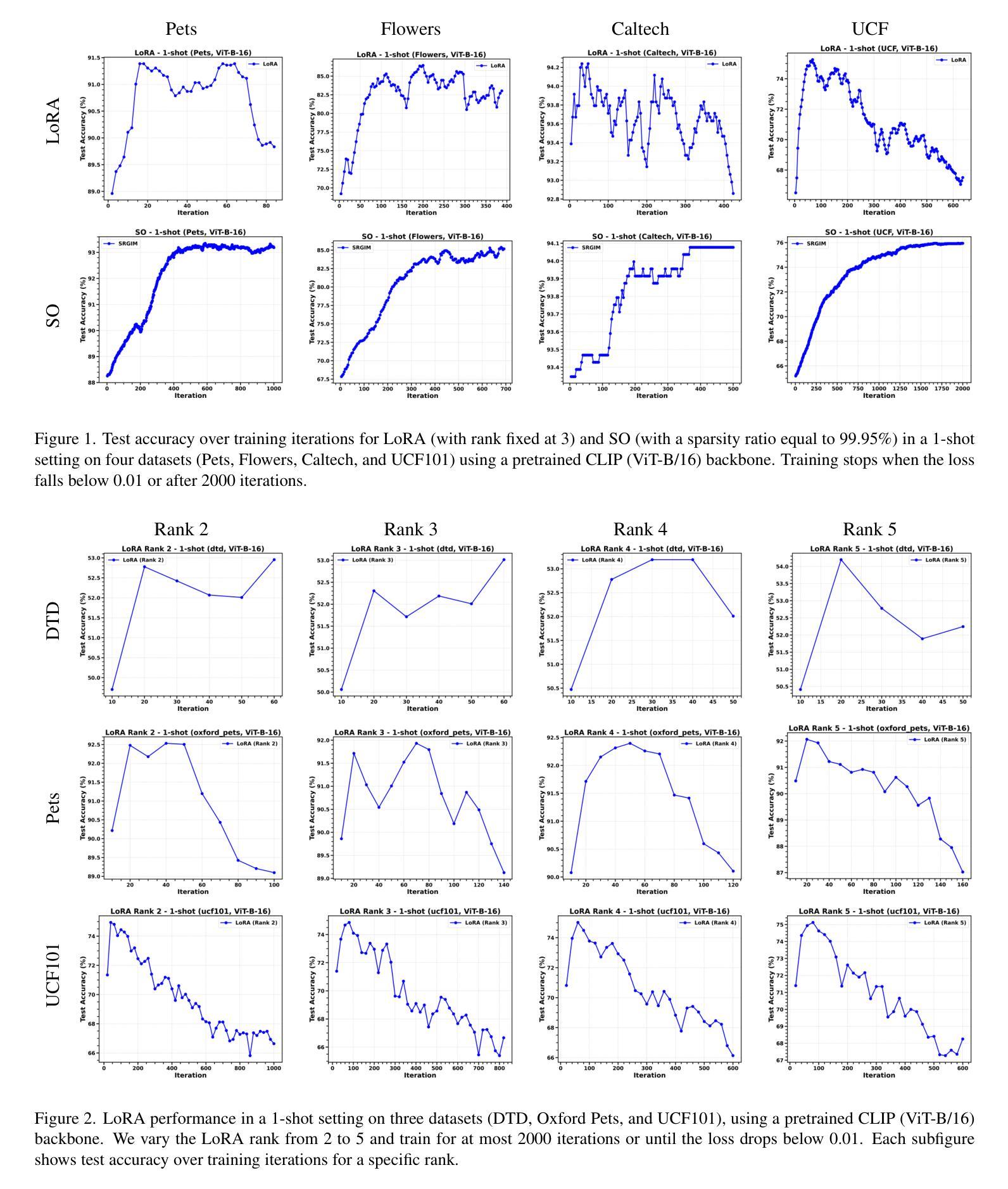
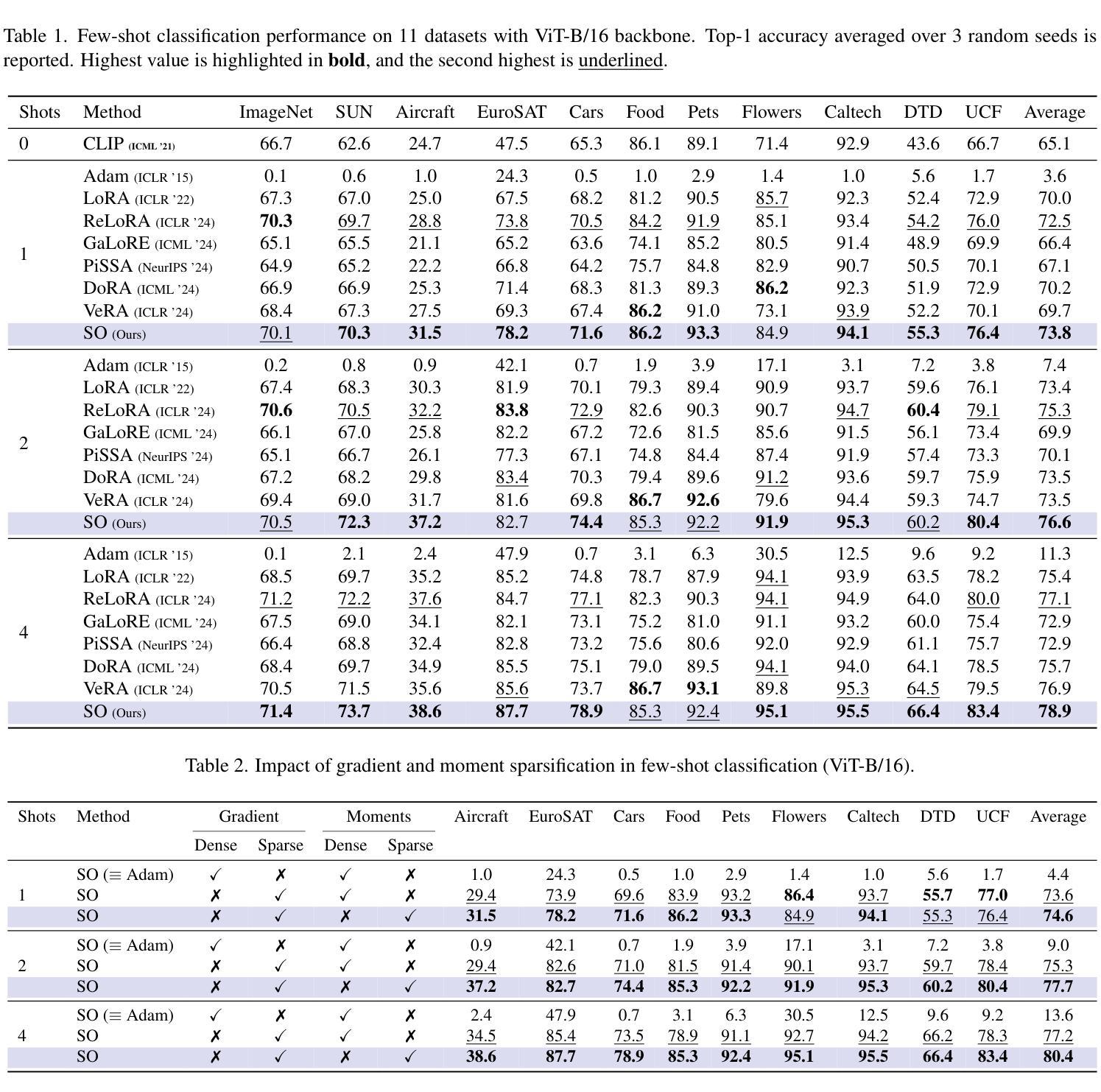
Sparsity Outperforms Low-Rank Projections in Few-Shot Adaptation
Authors:Nairouz Mrabah, Nicolas Richet, Ismail Ben Ayed, Éric Granger
Adapting Vision-Language Models (VLMs) to new domains with few labeled samples remains a significant challenge due to severe overfitting and computational constraints. State-of-the-art solutions, such as low-rank reparameterization, mitigate these issues but often struggle with generalization and require extensive hyperparameter tuning. In this paper, a novel Sparse Optimization (SO) framework is proposed. Unlike low-rank approaches that typically constrain updates to a fixed subspace, our SO method leverages high sparsity to dynamically adjust very few parameters. We introduce two key paradigms. First, we advocate for \textit{local sparsity and global density}, which updates a minimal subset of parameters per iteration while maintaining overall model expressiveness. As a second paradigm, we advocate for \textit{local randomness and global importance}, which sparsifies the gradient using random selection while pruning the first moment based on importance. This combination significantly mitigates overfitting and ensures stable adaptation in low-data regimes. Extensive experiments on 11 diverse datasets show that SO achieves state-of-the-art few-shot adaptation performance while reducing memory overhead.
将视觉语言模型(VLMs)适应具有少量标记样本的新领域仍然是一个巨大的挑战,这主要是由于严重的过度拟合和计算约束。最先进的解决方案,如低秩重参数化,缓解了这些问题,但在推广方面经常遇到困难,并且需要大量调整超参数。本文提出了一种新的稀疏优化(SO)框架。与通常将更新限制在固定子空间中的低秩方法不同,我们的SO方法利用高稀疏性来动态调整极少的参数。我们介绍了两种关键范式。首先,我们提倡“局部稀疏性和全局密度”,这可以在每次迭代时更新一小部分参数,同时保持模型的整体表达能力。作为第二种范式,我们提倡“局部随机性和全局重要性”,使用随机选择来稀疏梯度,并根据重要性来修剪第一时刻。这种结合显著减轻了过度拟合问题,并确保在低数据情况下实现稳定的适应。在11个不同数据集上的大量实验表明,SO在少量样本适应方面达到了最先进的性能,同时减少了内存开销。
论文及项目相关链接
PDF Under review
Summary
本文提出了一种新的Sparse Optimization(SO)框架,用于解决在少量标注样本下将视觉语言模型(VLMs)适应新领域的问题。通过引入局部稀疏性和全局密度以及局部随机性和全局重要性的两个关键范式,SO方法能够在动态调整极少参数的同时避免过度拟合,确保在低数据环境下的稳定适应。实验结果表明,SO在11个不同数据集上实现了最先进的少样本适应性能,并降低了内存开销。
Key Takeaways
- Sparse Optimization (SO)框架被提出用于解决在少量标注样本下将视觉语言模型(VLMs)适应新领域的问题。
- 当前主流方法如低秩重参数化虽然能缓解一些问题,但在泛化和超参数调整方面仍有挑战。
- SO方法通过引入局部稀疏性和全局密度以及局部随机性和全局重要性的两个关键范式来动态调整参数。
- SO方法能够显著减轻过拟合问题,并确保在低数据环境下的稳定适应。
- SO方法在11个不同数据集上实现了最先进的少样本适应性能。
- SO方法降低了内存开销,是一种有效的解决方案。
点此查看论文截图

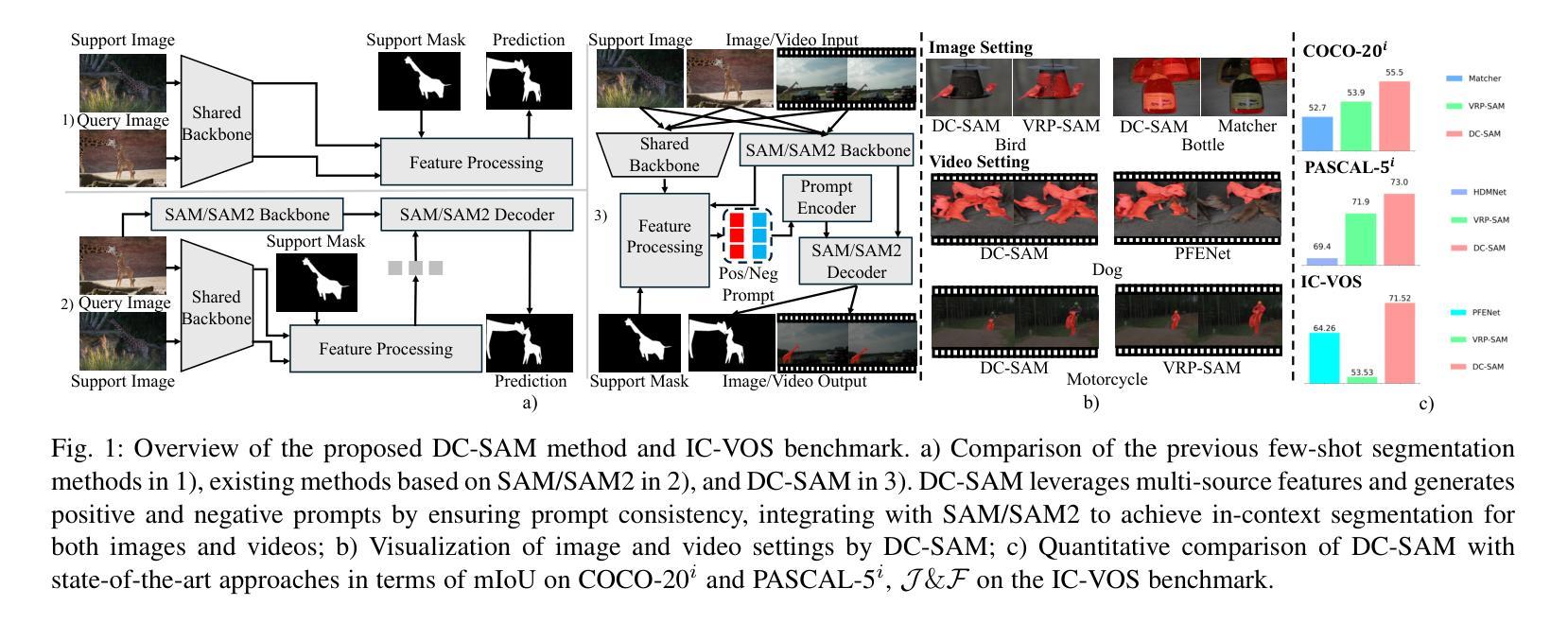
DC-SAM: In-Context Segment Anything in Images and Videos via Dual Consistency
Authors:Mengshi Qi, Pengfei Zhu, Xiangtai Li, Xiaoyang Bi, Lu Qi, Huadong Ma, Ming-Hsuan Yang
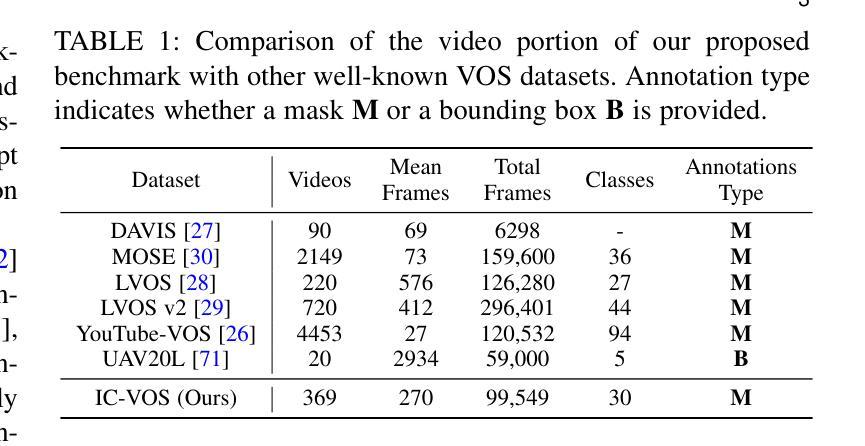
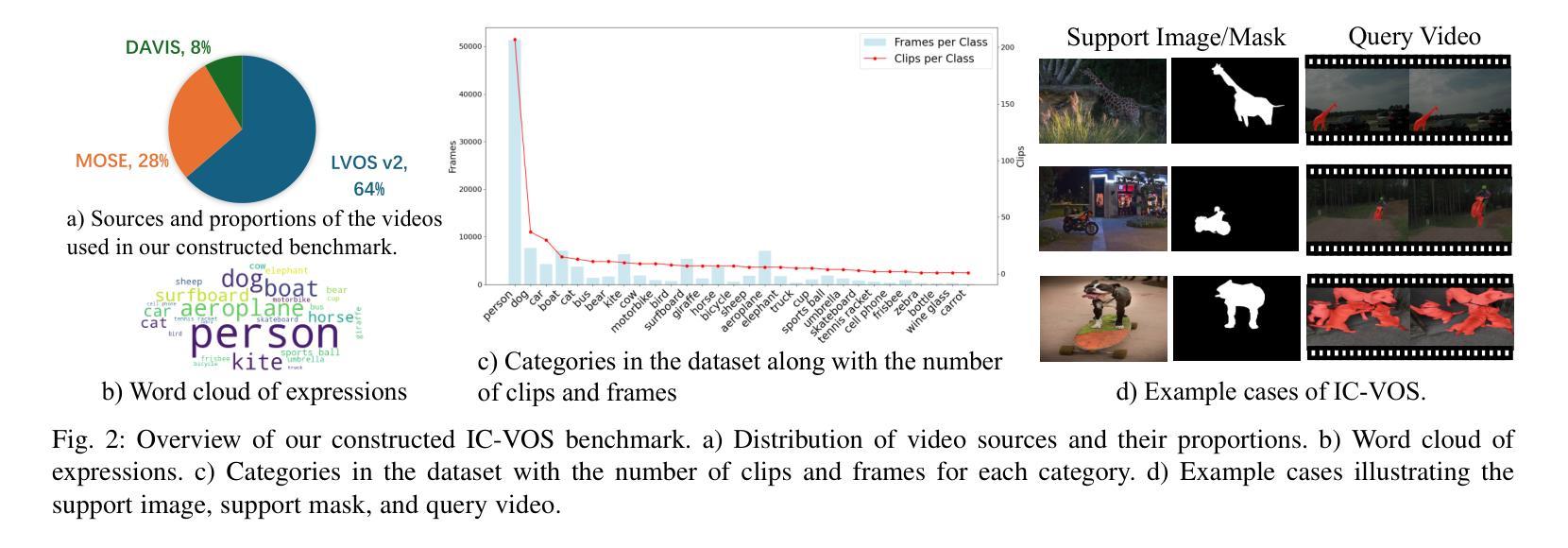
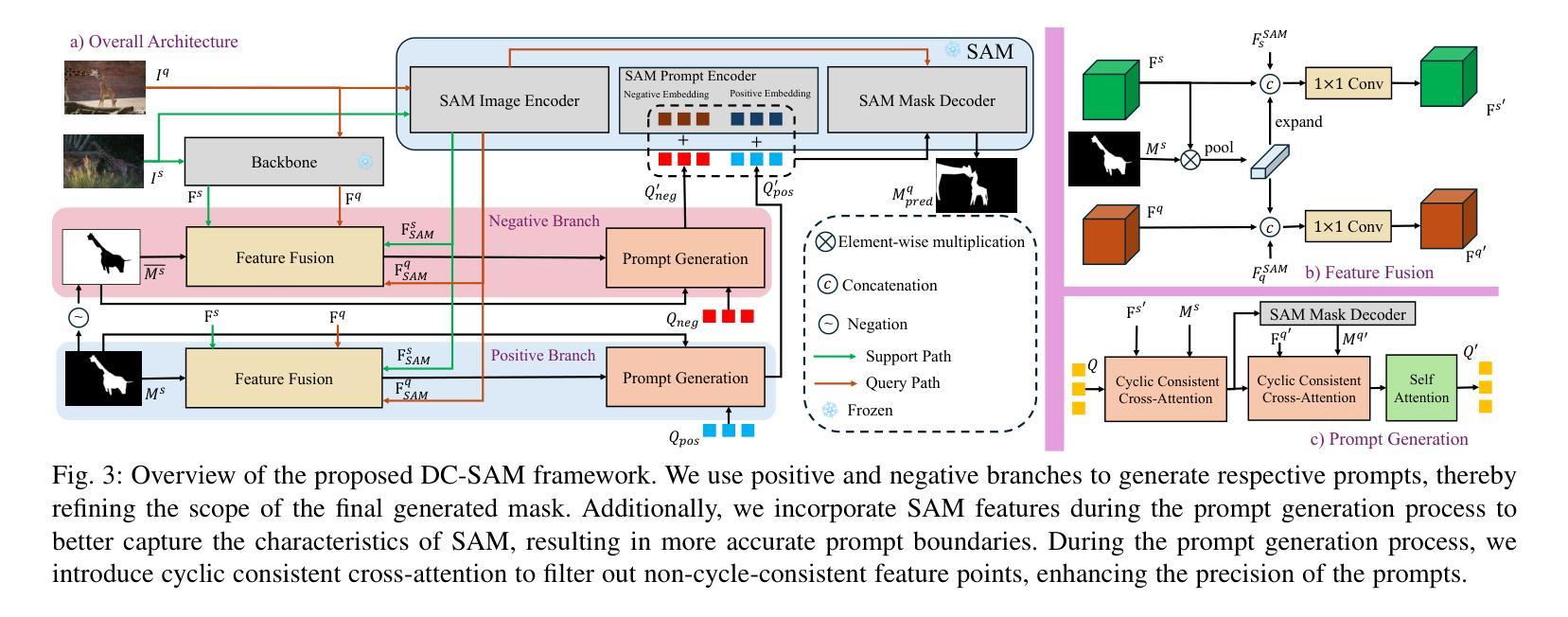
Given a single labeled example, in-context segmentation aims to segment corresponding objects. This setting, known as one-shot segmentation in few-shot learning, explores the segmentation model’s generalization ability and has been applied to various vision tasks, including scene understanding and image/video editing. While recent Segment Anything Models have achieved state-of-the-art results in interactive segmentation, these approaches are not directly applicable to in-context segmentation. In this work, we propose the Dual Consistency SAM (DC-SAM) method based on prompt-tuning to adapt SAM and SAM2 for in-context segmentation of both images and videos. Our key insights are to enhance the features of the SAM’s prompt encoder in segmentation by providing high-quality visual prompts. When generating a mask prior, we fuse the SAM features to better align the prompt encoder. Then, we design a cycle-consistent cross-attention on fused features and initial visual prompts. Next, a dual-branch design is provided by using the discriminative positive and negative prompts in the prompt encoder. Furthermore, we design a simple mask-tube training strategy to adopt our proposed dual consistency method into the mask tube. Although the proposed DC-SAM is primarily designed for images, it can be seamlessly extended to the video domain with the support of SAM2. Given the absence of in-context segmentation in the video domain, we manually curate and construct the first benchmark from existing video segmentation datasets, named In-Context Video Object Segmentation (IC-VOS), to better assess the in-context capability of the model. Extensive experiments demonstrate that our method achieves 55.5 (+1.4) mIoU on COCO-20i, 73.0 (+1.1) mIoU on PASCAL-5i, and a J&F score of 71.52 on the proposed IC-VOS benchmark. Our source code and benchmark are available at https://github.com/zaplm/DC-SAM.
给定一个单一标记的示例,上下文内分割旨在分割相应的对象。这种设置被称为小样本学习中的一次分割,旨在探索分割模型的泛化能力,并已应用于各种视觉任务,包括场景理解、图像/视频编辑等。尽管最近的Segment Anything Models在交互式分割方面取得了最先进的成果,但这些方法并不直接适用于上下文分割。在这项工作中,我们基于提示微调提出了双一致性SAM(DC-SAM)方法,以适应图像和视频的上下文分割。我们的关键见解是通过提供高质量视觉提示来增强SAM提示编码器在分割中的功能。在生成掩膜先验时,我们融合SAM特征以更好地对齐提示编码器。然后,我们在融合的特征和初始视觉提示上设计了一个循环一致的交叉注意力机制。接下来,通过使用提示编码器中的判别性正向和负向提示,提供了一个双分支设计。此外,我们设计了一个简单的掩膜管训练策略,将所提的双一致性方法应用到掩膜管中。虽然所提出DC-SAM主要为图像设计,但由于SAM2的支持,它可以无缝扩展到视频领域。鉴于视频领域缺乏上下文分割,我们从现有的视频分割数据集中手动筛选和构建第一个基准测试集,名为上下文视频对象分割(IC-VOS),以更好地评估模型的上下文能力。大量实验表明,我们的方法在COCO-20i上实现了55.5(+1.4)的mIoU,在PASCAL-5i上实现了73.0(+1.1)的mIoU,在提出的IC-VOS基准测试集上达到了71.52的J&F分数。我们的源代码和基准测试集可在https://github.com/zaplm/DC-SAM中找到。
论文及项目相关链接
PDF V1 has been withdrawn due to a template issue, because of the arXiv policy, we can’t delete it. Please refer to the newest version v2
Summary
本文介绍了一种基于提示调整(prompt-tuning)的Dual Consistency SAM(DC-SAM)方法,用于单次示例下的上下文分割(in-context segmentation)。该方法通过高质量视觉提示增强SAM的提示编码器特征,设计循环一致的跨注意力融合特征和初始视觉提示,并采用双分支设计使用判别性的正负提示。此外,本文还提出了一个简单的mask-tube训练策略,并将DC-SAM扩展到视频领域。为评估模型在视频领域的上下文能力,建立了第一个In-Context Video Object Segmentation(IC-VOS)基准测试集。实验表明,DC-SAM方法在COCO-20i上达到55.5(+1.4)mIoU,在PASCAL-5i上达到73.0(+1.1)mIoU,并在IC-VOS基准测试集上获得71.52的J&F分数。
Key Takeaways
- 文章介绍了一种名为DC-SAM的方法,针对单次示例下的上下文分割问题。
- DC-SAM方法基于prompt-tuning技术,旨在通过高质量视觉提示增强特征。
- 文章设计了循环一致的跨注意力机制来融合特征和初始视觉提示。
- 采用双分支设计,使用判别性的正负提示在提示编码器中。
- 提出了一个简单的mask-tube训练策略,将DC-SAM方法应用于视频领域。
- 为评估模型在视频领域的上下文能力,建立了第一个IC-VOS基准测试集。
- 实验结果显示DC-SAM方法在多个数据集上取得了显著成果。
点此查看论文截图


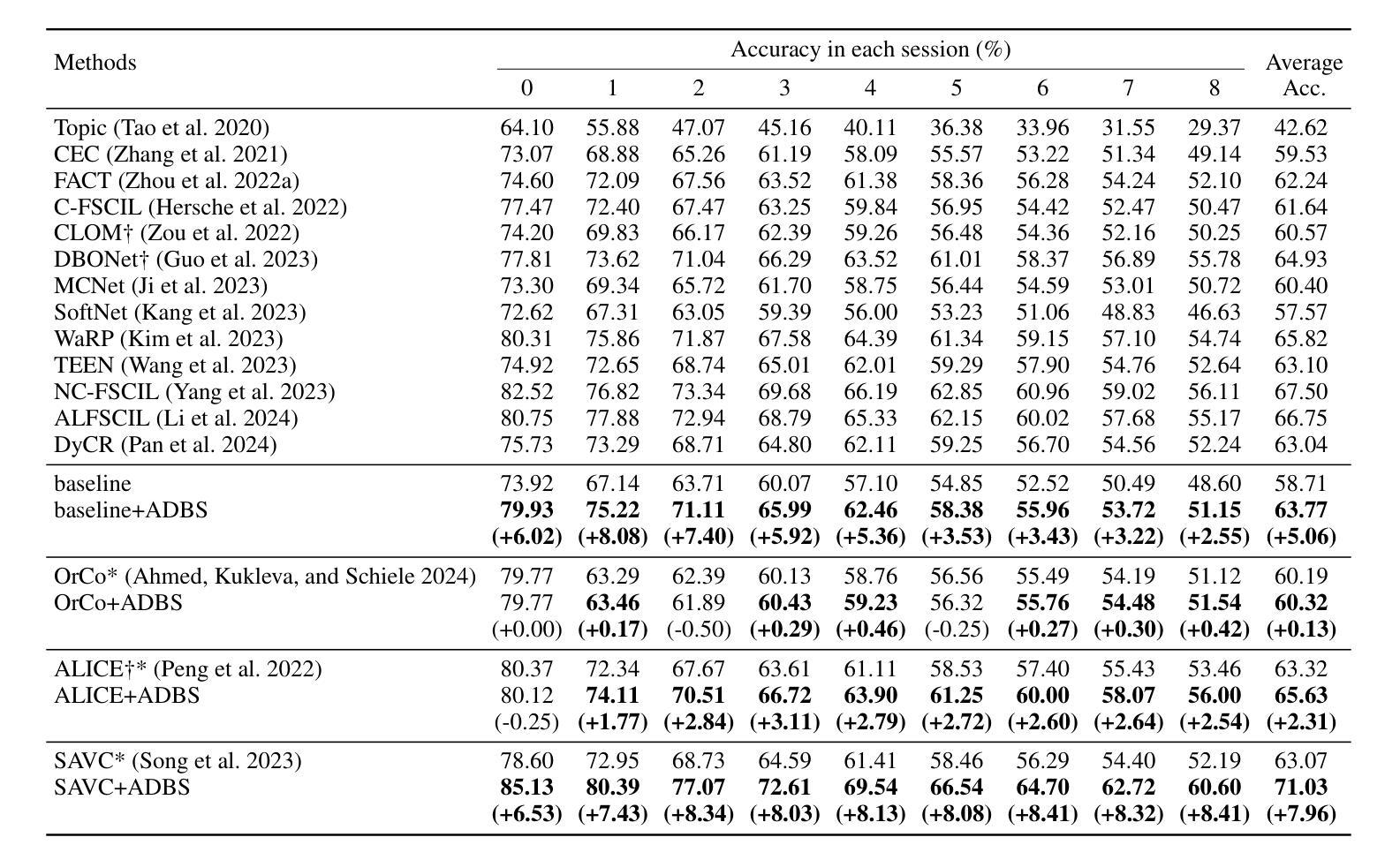
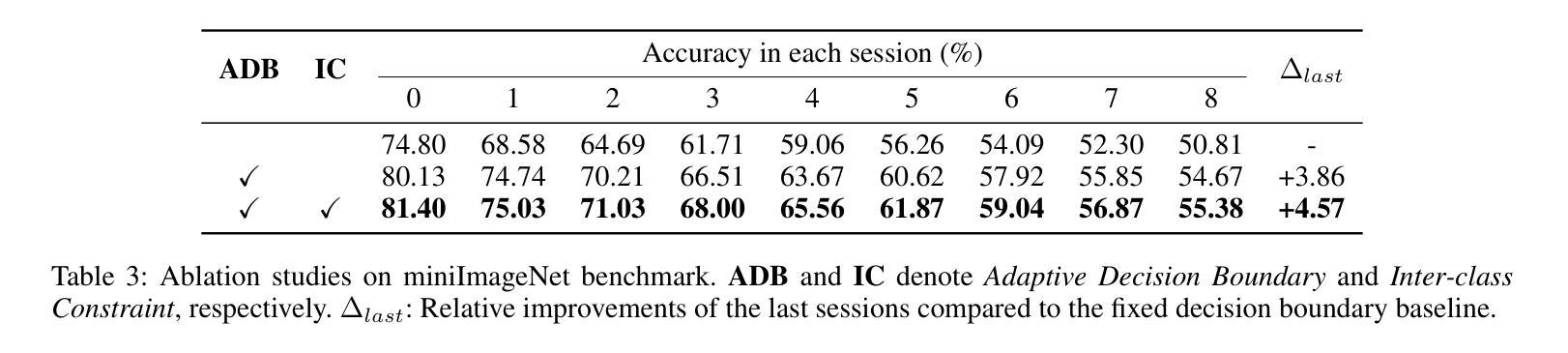
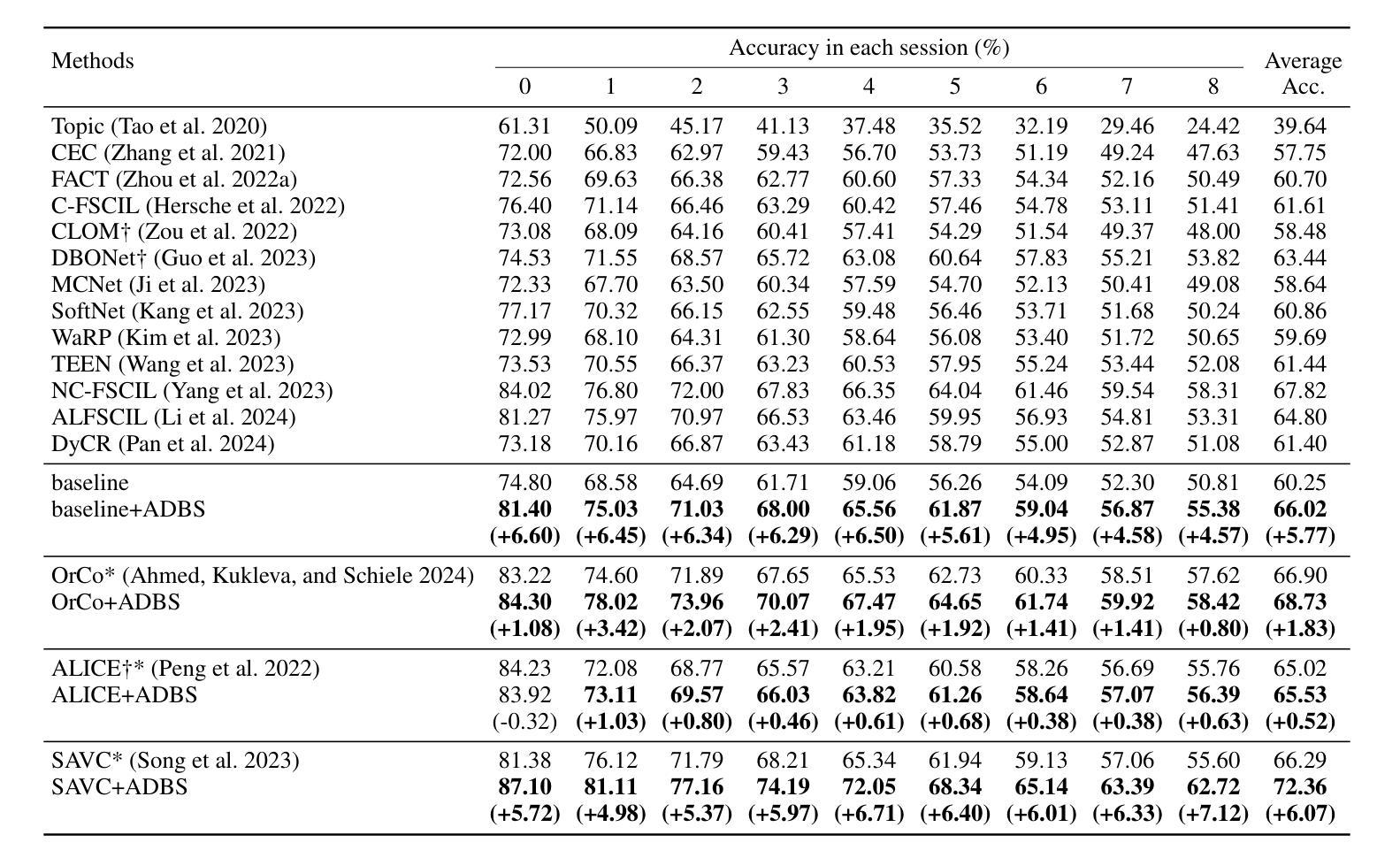
Adaptive Decision Boundary for Few-Shot Class-Incremental Learning
Authors:Linhao Li, Yongzhang Tan, Siyuan Yang, Hao Cheng, Yongfeng Dong, Liang Yang
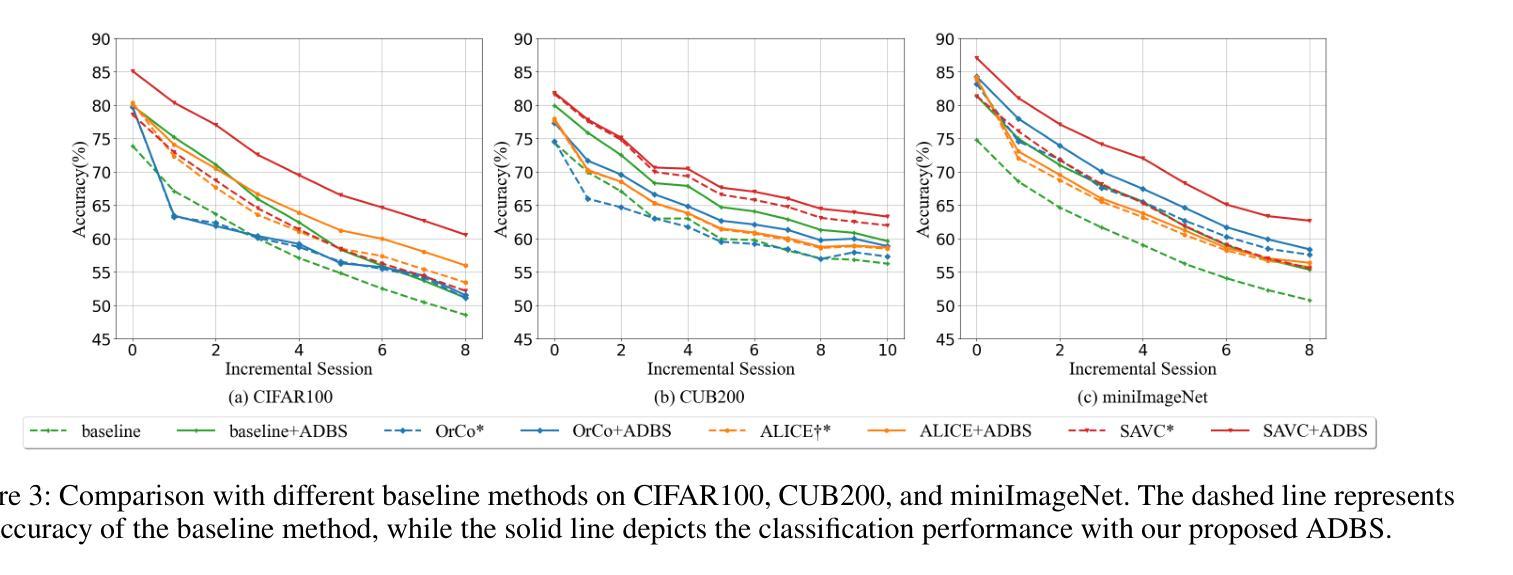
Few-Shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes from a limited set of training samples without forgetting knowledge of previously learned classes. Conventional FSCIL methods typically build a robust feature extractor during the base training session with abundant training samples and subsequently freeze this extractor, only fine-tuning the classifier in subsequent incremental phases. However, current strategies primarily focus on preventing catastrophic forgetting, considering only the relationship between novel and base classes, without paying attention to the specific decision spaces of each class. To address this challenge, we propose a plug-and-play Adaptive Decision Boundary Strategy (ADBS), which is compatible with most FSCIL methods. Specifically, we assign a specific decision boundary to each class and adaptively adjust these boundaries during training to optimally refine the decision spaces for the classes in each session. Furthermore, to amplify the distinctiveness between classes, we employ a novel inter-class constraint loss that optimizes the decision boundaries and prototypes for each class. Extensive experiments on three benchmarks, namely CIFAR100, miniImageNet, and CUB200, demonstrate that incorporating our ADBS method with existing FSCIL techniques significantly improves performance, achieving overall state-of-the-art results.
少量类别增量学习(FSCIL)旨在从有限的训练样本中持续学习新类别,同时不遗忘已学习类别的知识。传统的FSCIL方法通常在基础训练阶段利用丰富的训练样本构建强大的特征提取器,随后冻结该提取器,仅在后续的增量阶段微调分类器。然而,当前策略主要侧重于防止灾难性遗忘,只考虑新类别和基础类别之间的关系,而没有关注每个类别的特定决策空间。为了应对这一挑战,我们提出了一种即插即用的自适应决策边界策略(ADBS),可与大多数FSCIL方法兼容。具体来说,我们为每个类别分配一个特定的决策边界,并在训练过程中自适应地调整这些边界,以最优方式细化每个会话中类别的决策空间。此外,为了放大类别之间的差异,我们采用了一种新型类间约束损失,该损失优化了每个类别的决策边界和原型。在CIFAR100、miniImageNet和CUB200三个基准测试上的大量实验表明,将我们的ADBS方法与现有的FSCIL技术相结合,可以显著提高性能,达到最新状态的最佳结果。
论文及项目相关链接
Summary
该文本介绍了Few-Shot类增量学习(FSCIL)的目标和方法。FSCIL旨在从有限的训练样本中持续学习新类,同时不遗忘已学习类的知识。传统FSCIL方法通常在基础训练阶段构建强大的特征提取器,并在后续增量阶段仅微调分类器。然而,当前策略主要关注防止灾难性遗忘,只考虑新类和基类之间的关系,而忽视了每个类的特定决策空间。为此,提出了即插即用的自适应决策边界策略(ADBS),与大多数FSCIL方法兼容。通过为每个类分配特定的决策边界,并在训练过程中自适应地调整这些边界,以优化每个会话中的类的决策空间。此外,采用了一种新型类间约束损失,以优化每个类的决策边界和原型,提高了类之间的区分度。在CIFAR100、miniImageNet和CUB200三个基准测试上的广泛实验表明,将ADBS方法与现有FSCIL技术相结合,可显著提高性能,达到最新技术水平。
Key Takeaways
- Few-Shot Class-Incremental Learning (FSCIL)的目标是持续学习新类,同时保留对旧类的知识。
- 传统FSCIL方法主要关注基础训练阶段,并在后续增量阶段微调分类器。
- 当前策略主要关注防止灾难性遗忘,忽视了每个类的特定决策空间。
- 提出的Adaptive Decision Boundary Strategy (ADBS)策略与大多数FSCIL方法兼容,为每个类分配特定的决策边界并在训练过程中自适应调整。
- 采用新型类间约束损失来优化决策边界和原型,提高类之间的区分度。
- 在多个基准测试上的实验表明,结合ADBS与现有FSCIL技术可显著提高性能。
点此查看论文截图


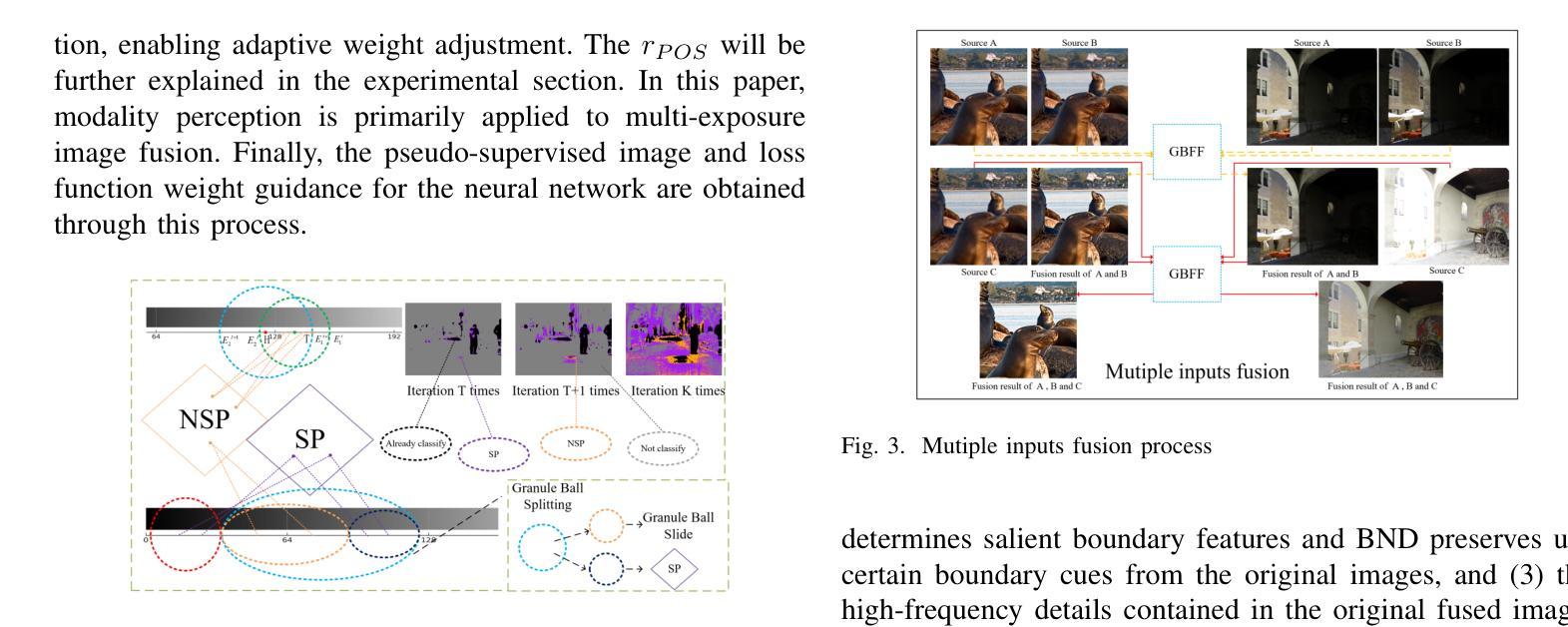
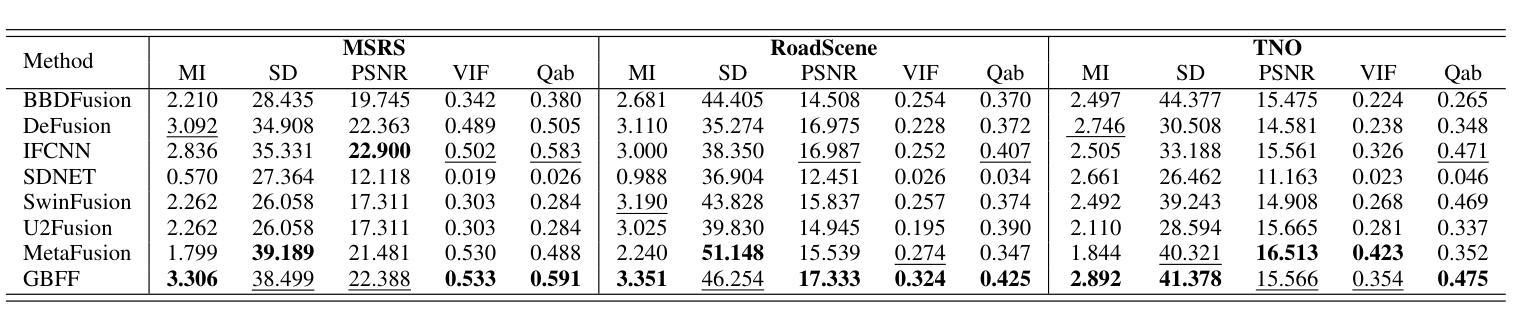
Rethinking Few-Shot Image Fusion: Granular Ball Priors Enable General-Purpose Deep Fusion
Authors:Minjie Deng, Yan Wei, Hao Zhai, An Wu, Yuncan Ouyang, Qianyao Peng
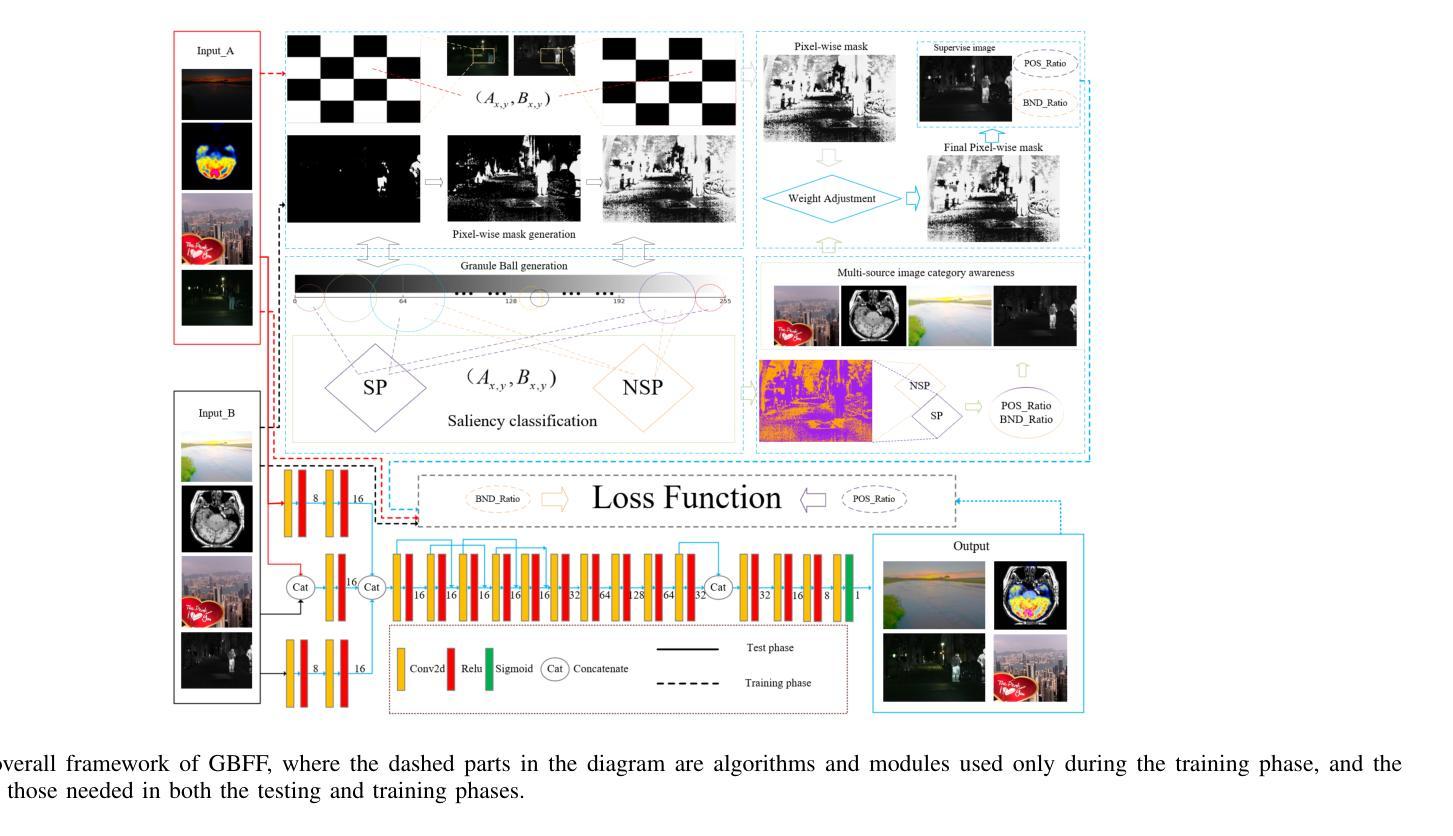
In image fusion tasks, the absence of real fused images as priors presents a fundamental challenge. Most deep learning-based fusion methods rely on large-scale paired datasets to extract global weighting features from raw images, thereby generating fused outputs that approximate real fused images. In contrast to previous studies, this paper explores few-shot training of neural networks under the condition of having prior knowledge. We propose a novel fusion framework named GBFF, and a Granular Ball Significant Extraction algorithm specifically designed for the few-shot prior setting. All pixel pairs involved in the fusion process are initially modeled as a Coarse-Grained Granular Ball. At the local level, Fine-Grained Granular Balls are used to slide through the brightness space to extract Non-Salient Pixel Pairs, and perform splitting operations to obtain Salient Pixel Pairs. Pixel-wise weights are then computed to generate a pseudo-supervised image. At the global level, pixel pairs with significant contributions to the fusion process are categorized into the Positive Region, while those whose contributions cannot be accurately determined are assigned to the Boundary Region. The Granular Ball performs modality-aware adaptation based on the proportion of the positive region, thereby adjusting the neural network’s loss function and enabling it to complement the information of the boundary region. Extensive experiments demonstrate the effectiveness of both the proposed algorithm and the underlying theory. Compared with state-of-the-art (SOTA) methods, our approach shows strong competitiveness in terms of both fusion time and image expressiveness. Our code is publicly available at:
在图像融合任务中,缺乏真实融合图像作为先验信息是一个基本挑战。大多数基于深度学习的融合方法依赖于大规模配对数据集,从原始图像中提取全局加权特征,从而生成近似真实融合图像的融合输出。与以前的研究相比,本文探索了在具备先验知识的条件下神经网络的少样本训练。我们提出了一种新的融合框架GBFF(格兰特球法),以及一种针对少样本先验环境的粒状球重要性提取算法。参与融合过程的像素对最初被建模为粗粒度的粒状球。在局部层面上,使用精细粒度的粒状球遍历亮度空间以提取非显著性像素对,并进行分裂操作以获得显著性像素对。然后计算像素级的权重以生成伪监督图像。在全局层面上,将对于融合过程有显著贡献的像素对分类为正区域,而那些贡献无法准确确定的像素对被分配给边界区域。粒状球根据正区域的比例进行模态感知适应,从而调整神经网络的损失函数,使其能够补充边界区域的信息。大量实验证明了所提出算法和底层理论的有效性。与最先进的方法相比,我们的方法在融合时间和图像表现力方面都表现出强大的竞争力。我们的代码可在公开渠道获取:
论文及项目相关链接
Summary:该论文解决了图像融合任务中缺乏真实融合图像作为先验的问题。提出了一种名为GBFF的新型融合框架,以及专门针对小样本先验环境的Granular Ball Significant Extraction算法。算法通过创建粗粒度和细粒度粒球来处理和提取图像中的非显著像素对和显著像素对,并计算像素级权重生成伪监督图像。同时,粒球还进行模态感知适应,调整神经网络的损失函数以补充边界区域的信息。实验证明该方法和理论的有效性,与现有方法相比,在融合时间和图像表现力方面表现出强竞争力。
Key Takeaways:
- 论文解决了在图像融合任务中缺乏真实融合图像先验的问题。
- 提出了一种新型的融合框架GBFF。
- 引入了Granular Ball Significant Extraction算法,该算法专为小样本先验环境设计。
- 算法通过创建粗粒度和细粒度粒球来处理像素对,并计算像素级权重生成伪监督图像。
- 粒球进行模态感知适应,根据正区域的占比调整神经网络的损失函数。
- 实验证明该方法和理论的有效性。
点此查看论文截图


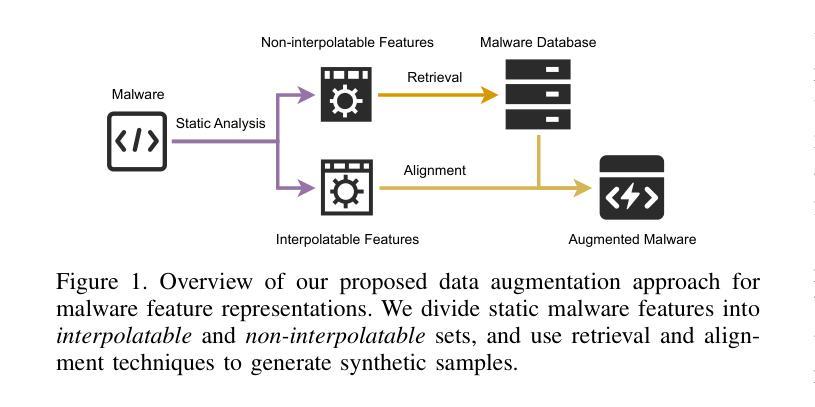
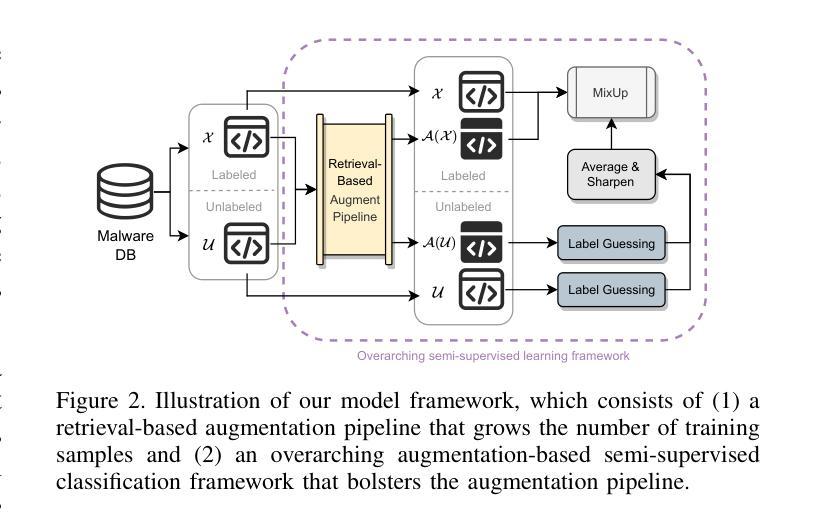
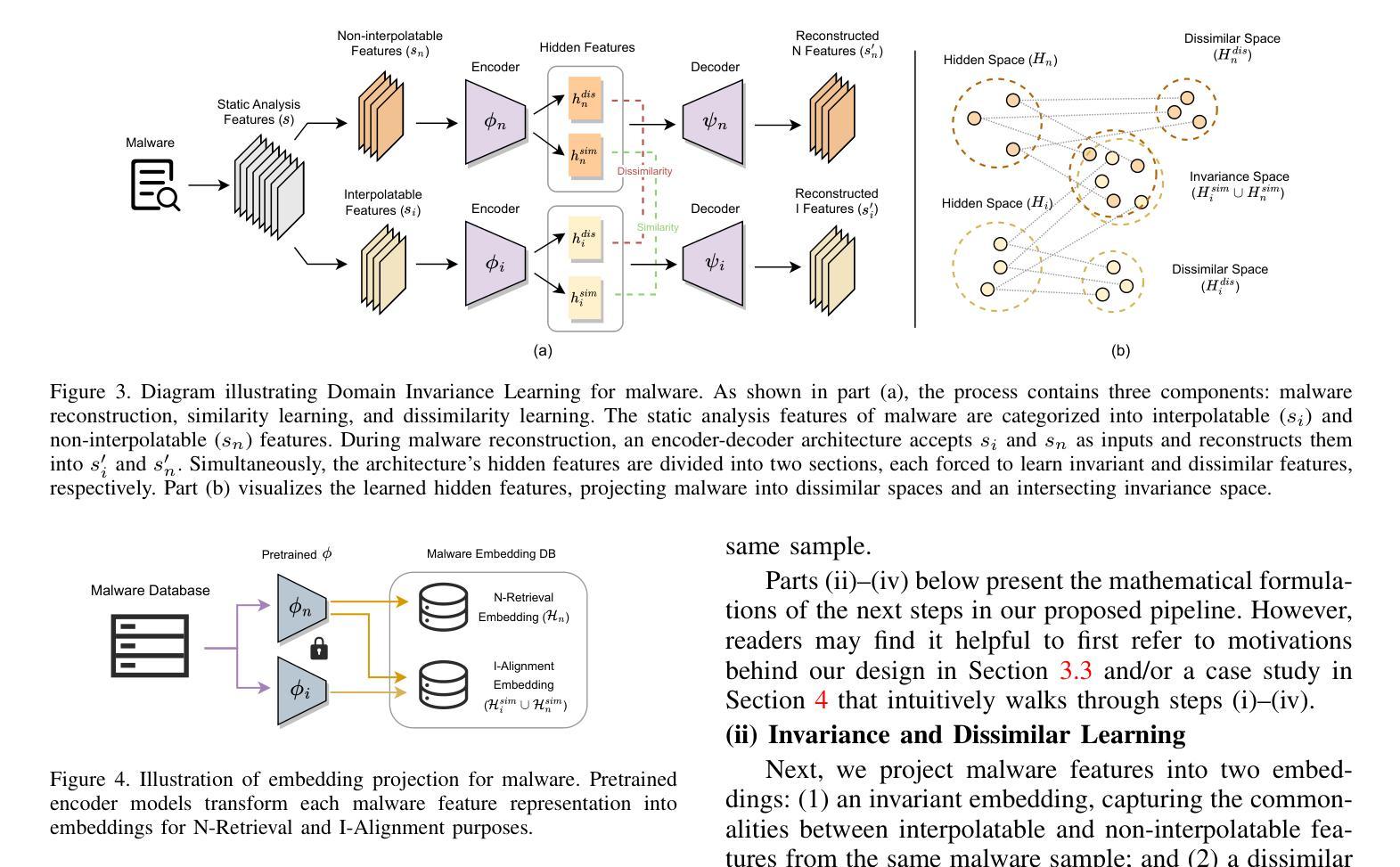
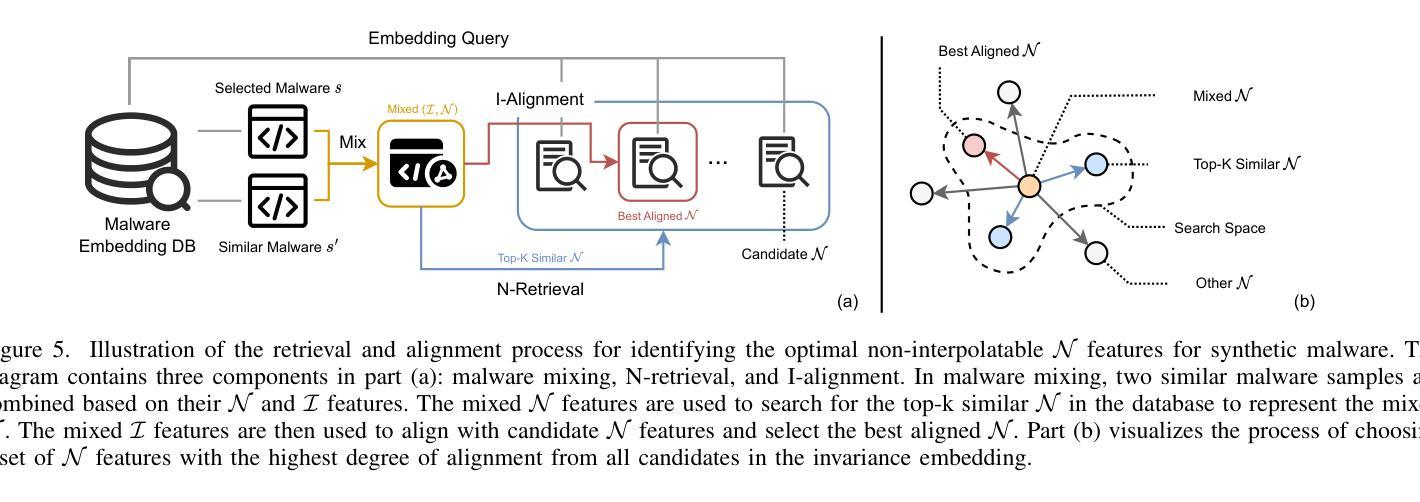
MalMixer: Few-Shot Malware Classification with Retrieval-Augmented Semi-Supervised Learning
Authors:Jiliang Li, Yifan Zhang, Yu Huang, Kevin Leach
Recent growth and proliferation of malware have tested practitioners ability to promptly classify new samples according to malware families. In contrast to labor-intensive reverse engineering efforts, machine learning approaches have demonstrated increased speed and accuracy. However, most existing deep-learning malware family classifiers must be calibrated using a large number of samples that are painstakingly manually analyzed before training. Furthermore, as novel malware samples arise that are beyond the scope of the training set, additional reverse engineering effort must be employed to update the training set. The sheer volume of new samples found in the wild creates substantial pressure on practitioners ability to reverse engineer enough malware to adequately train modern classifiers. In this paper, we present MalMixer, a malware family classifier using semi-supervised learning that achieves high accuracy with sparse training data. We present a domain-knowledge-aware data augmentation technique for malware feature representations, enhancing few-shot performance of semi-supervised malware family classification. We show that MalMixer achieves state-of-the-art performance in few-shot malware family classification settings. Our research confirms the feasibility and effectiveness of lightweight, domain-knowledge-aware data augmentation methods for malware features and shows the capabilities of similar semi-supervised classifiers in addressing malware classification issues.
近期恶意软件的迅速增长和扩散考验了从业者根据恶意软件家族对新样本进行及时分类的能力。与劳动密集型的逆向工程努力相比,机器学习的方法已经显示出更高的速度和准确性。然而,大多数现有的深度学习的恶意软件家族分类器需要使用大量的样本进行校准,这些样本在训练之前需要进行繁琐的手动分析。此外,随着超出训练集范围的新的恶意软件样本的出现,必须使用更多的逆向工程工作来更新训练集。在实际环境中发现的大量新样本给从业者带来了巨大的压力,他们需要重新设计足够的恶意软件来充分训练现代分类器。在本文中,我们介绍了MalMixer,一种使用半监督学习的恶意软件家族分类器,它可以在稀疏的训练数据上实现较高的准确性。我们提出了一种基于领域知识的数据增强技术,用于表示恶意软件的特征,以提高半监督恶意软件家族分类的少数样本性能。我们展示了MalMixer在少数样本的恶意软件家族分类设置中实现了最先进的性能。我们的研究证实了领域知识轻量级的数据增强方法在恶意软件特征中的可行性和有效性,并展示了类似的半监督分类器在处理恶意软件分类问题时的能力。
论文及项目相关链接
Summary
基于当前病毒样本的不断增长和多样化,机器学习技术在病毒家族分类中的应用日益凸显其速度和准确性优势。然而,现有的深度学习病毒家族分类器需要大量样本进行校准,且在面对新型病毒样本时仍需人工进行逆向工程分析更新训练集。本文提出一种基于半监督学习的病毒家族分类器MalMixer,它可以在稀疏训练数据的情况下实现较高的准确度。本研究设计了一种领域知识增强的数据扩充技术来优化病毒特征表示,提高半监督型病毒家族在少数情况下的分类性能。实验结果证实MalMixer在少量病毒样本的分类场景下具有突破性表现。本文验证了领域知识增强的数据扩充方法对于病毒特征的有效性,以及类似半监督分类器在解决病毒分类问题中的潜力。
Key Takeaways
- 当前病毒样本增长迅速,机器学习技术在病毒家族分类中的应用显得尤为重要。
- 虽然现有深度学习模型表现出较高准确性,但仍面临需要大量训练样本的挑战。新病毒样本的快速涌现导致难以对模型进行持续训练。
- MalMixer基于半监督学习技术的提出为解决该问题提供了新的途径,可以在样本稀疏的情况下实现较高的分类准确度。
- 引入了领域知识增强的数据扩充技术来优化病毒特征表示,提升模型的分类性能。尤其是面对少量样本时的分类效果更为显著。
- 实验结果显示MalMixer在少数病毒样本分类场景中表现出优异性能。这为同类技术提供了一种可参考的成功案例和进步空间。通过实现数据的自主学习和利用增强了其应用广泛性并减少了人工成本投入,减轻了负担与限制因素提升了效果与价值表现效果与应用潜力得到进一步提升证明了该方法在实际场景下的可行性和可靠性 。此创新研究克服了以往存在的挑战与局限性为未来的研究提供了更多可能性与思路 。
- 研究验证了领域知识增强的数据扩充方法对于病毒特征的有效性以及该技术在处理此类问题时的高效能性和便捷性得到了业界广泛认可和发展前景 。这对于计算机安全领域的发展具有重大意义 。同时研究过程中所采用的方法和思路也具有一定的通用性可以应用于其他相关领域的研究中 。 通过对新型技术应用的不断挖掘和创新推动了计算机安全领域的不断进步与发展 。
点此查看论文截图

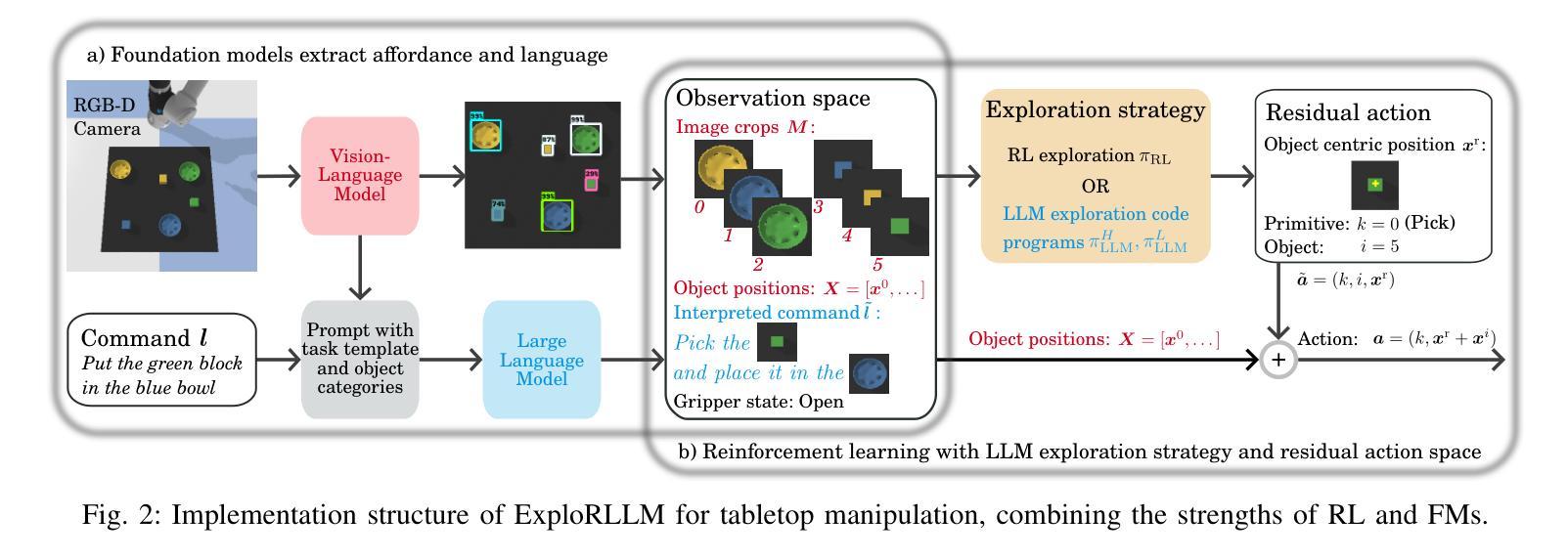
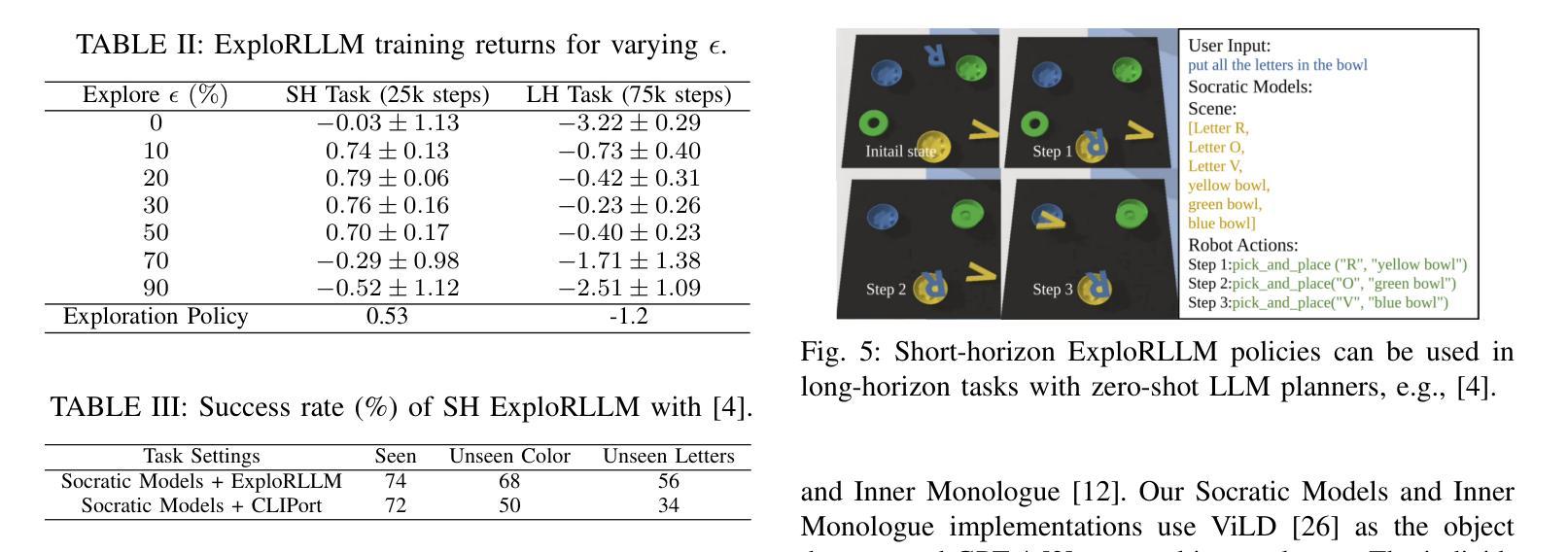
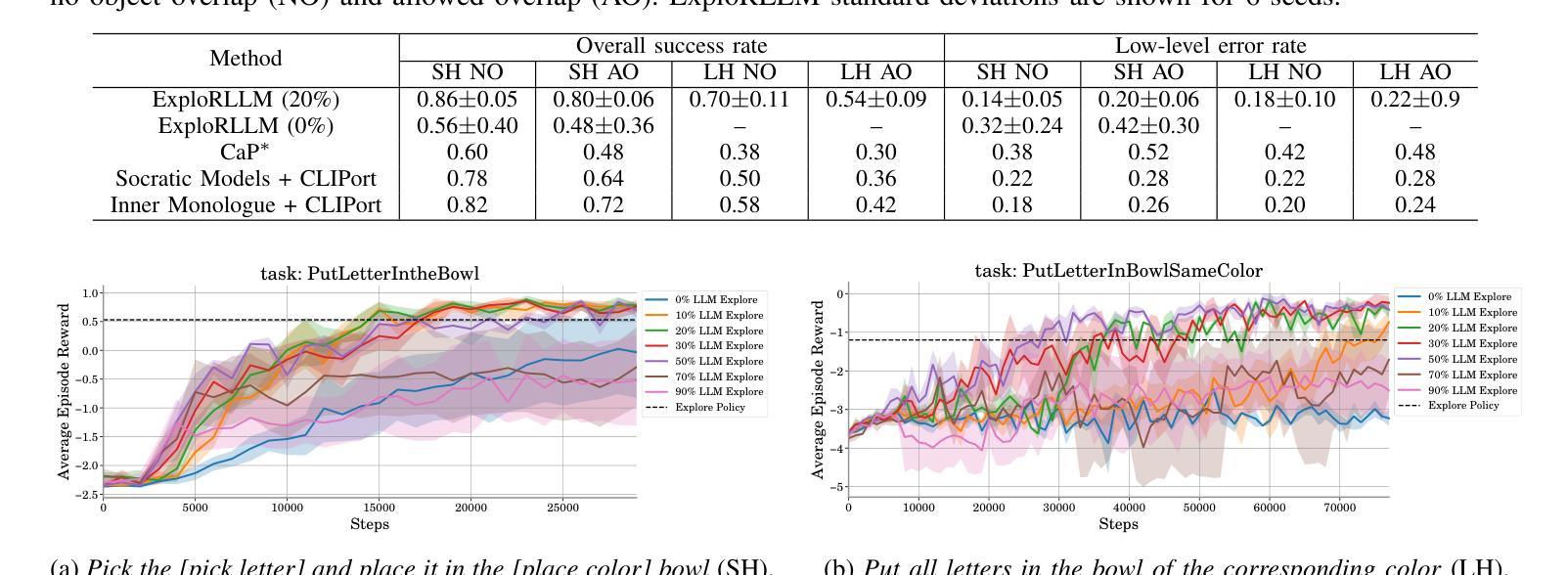
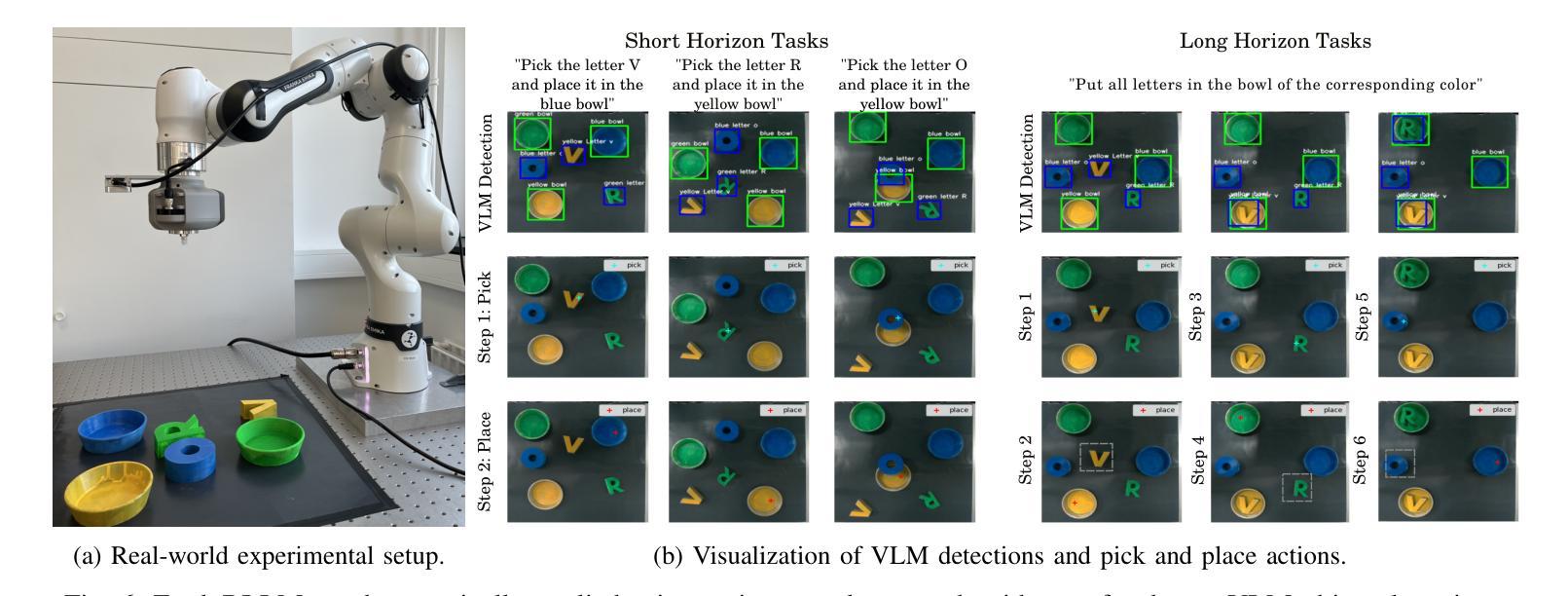
ExploRLLM: Guiding Exploration in Reinforcement Learning with Large Language Models
Authors:Runyu Ma, Jelle Luijkx, Zlatan Ajanovic, Jens Kober
In robot manipulation, Reinforcement Learning (RL) often suffers from low sample efficiency and uncertain convergence, especially in large observation and action spaces. Foundation Models (FMs) offer an alternative, demonstrating promise in zero-shot and few-shot settings. However, they can be unreliable due to limited physical and spatial understanding. We introduce ExploRLLM, a method that combines the strengths of both paradigms. In our approach, FMs improve RL convergence by generating policy code and efficient representations, while a residual RL agent compensates for the FMs’ limited physical understanding. We show that ExploRLLM outperforms both policies derived from FMs and RL baselines in table-top manipulation tasks. Additionally, real-world experiments show that the policies exhibit promising zero-shot sim-to-real transfer. Supplementary material is available at https://explorllm.github.io.
在机器人操作领域,强化学习(RL)常常面临样本效率低和收敛不确定的问题,特别是在大型观察和行动空间中。基础模型(FMs)提供了一种替代方案,在零样本和少样本场景中展现出巨大的潜力。然而,它们由于有限的物理和空间理解而可能不可靠。我们引入了ExploRLLM方法,它结合了两种模式的长处。在我们的方法中,基础模型通过生成策略代码和有效表示形式来提高RL的收敛性,而残余的RL代理则弥补了基础模型的有限物理理解。我们证明ExploRLLM在桌面操作任务中的表现优于来自基础模型的策略和RL基准线。此外,真实世界的实验表明,这些策略表现出有希望的从模拟到真实的零样本迁移。更多材料请访问:https://explorllm.github.io。
论文及项目相关链接
PDF 6 pages, 6 figures, IEEE International Conference on Robotics and Automation (ICRA) 2025
Summary
强化学习在机器人操作中存在样本效率低和收敛不确定的问题,尤其在大型观测和动作空间中尤为明显。而基础模型在大规模观测空间中的零样本和少样本设置中展现出潜力,但受限于物理和空间理解。本研究结合了强化学习和基础模型的优势,提出了ExploRLLM方法。该方法利用基础模型生成策略代码和高效表示,同时使用残余强化学习代理人来补偿基础模型的物理理解局限性。实验结果显示,ExploRLLM在桌面操作任务中优于仅使用基础模型的策略和强化学习基线,并且在实际环境中的实验展示了策略从模拟到现实的零样本转移潜力。
Key Takeaways
- 强化学习在机器人操作中存在样本效率和收敛问题。
- 基础模型在零样本和少样本设置中有潜力,但受限于物理和空间理解。
- ExploRLLM结合了强化学习和基础模型的优势。
- ExploRLLM利用基础模型生成策略代码和高效表示。
- 残余强化学习代理人补偿了基础模型的物理理解局限性。
- ExploRLLM在桌面操作任务中表现优于其他方法。
点此查看论文截图