⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
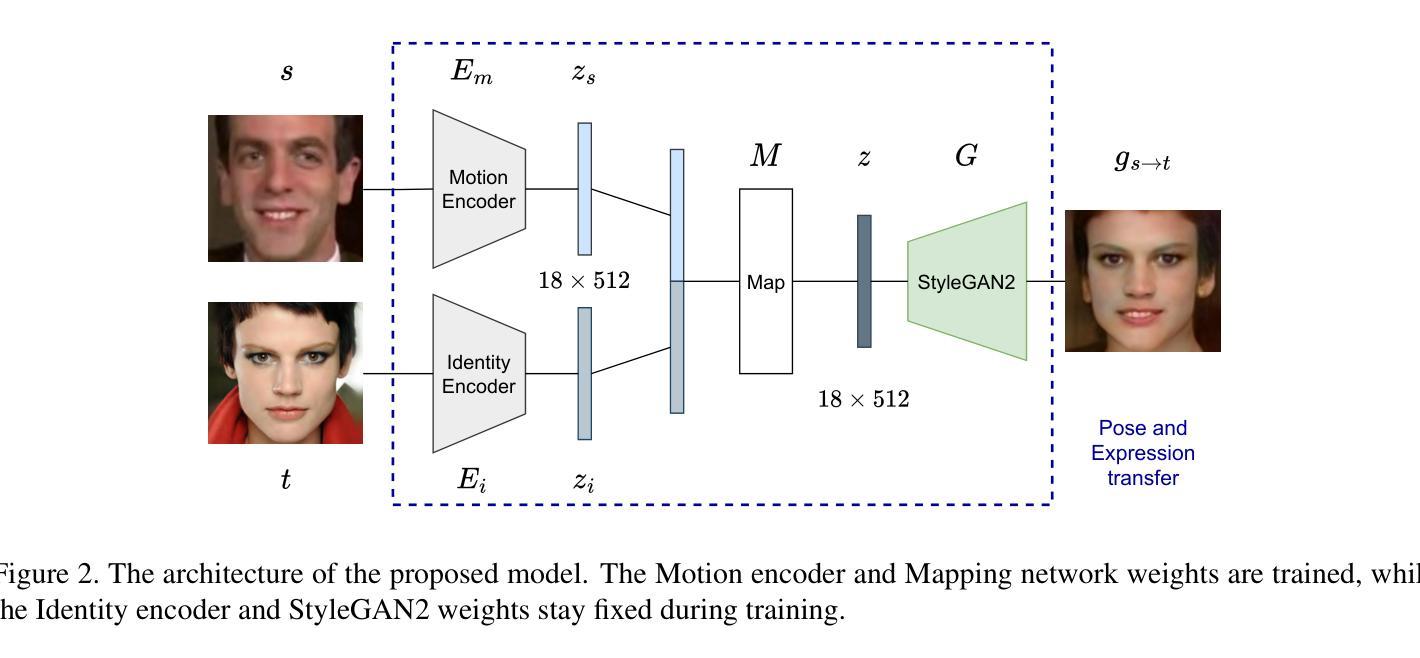
Pose and Facial Expression Transfer by using StyleGAN
Authors:Petr Jahoda, Jan Cech
We propose a method to transfer pose and expression between face images. Given a source and target face portrait, the model produces an output image in which the pose and expression of the source face image are transferred onto the target identity. The architecture consists of two encoders and a mapping network that projects the two inputs into the latent space of StyleGAN2, which finally generates the output. The training is self-supervised from video sequences of many individuals. Manual labeling is not required. Our model enables the synthesis of random identities with controllable pose and expression. Close-to-real-time performance is achieved.
我们提出了一种在面部图像之间转移姿态和表情的方法。给定源面部肖像和目标面部肖像,该模型生成一个输出图像,其中源面部图像的姿态和表情被转移到目标身份上。该架构由两个编码器和将两个输入投影到StyleGAN2的潜在空间的映射网络组成,最终生成输出。训练是基于多个个体的视频序列进行自监督的,无需手动标注。我们的模型能够合成具有可控姿态和表情的随机身份。实现了接近实时性能。
论文及项目相关链接
PDF Accepted at CVWW 2024. Presented in Terme Olimia, Slovenia
Summary
本文提出了一种将源人脸图像的姿态和表情转移到目标人脸图像的方法。该方法包括两个编码器和一个映射网络,可将两个输入投影到StyleGAN2的潜在空间中,最终生成输出图像。该方法通过自我监督训练,无需手动标注。该模型能够合成具有可控姿态和表情的随机身份图像,并实现了接近实时的性能。
Key Takeaways
- 提出了一种基于StyleGAN2的方法,能够实现源人脸图像的姿态和表情向目标人脸图像的转移。
- 方法包括两个编码器和映射网络,将输入投影到潜在空间中生成输出图像。
- 该方法通过自我监督训练,不需要手动标注数据。
- 模型能够合成具有可控姿态和表情的随机身份图像。
- 该方法实现了接近实时的性能。
- 提出的架构在人脸识别、表情分析和虚拟角色生成等领域具有潜在应用。
点此查看论文截图


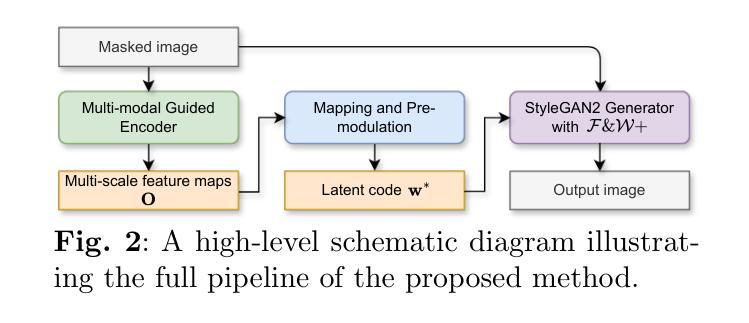
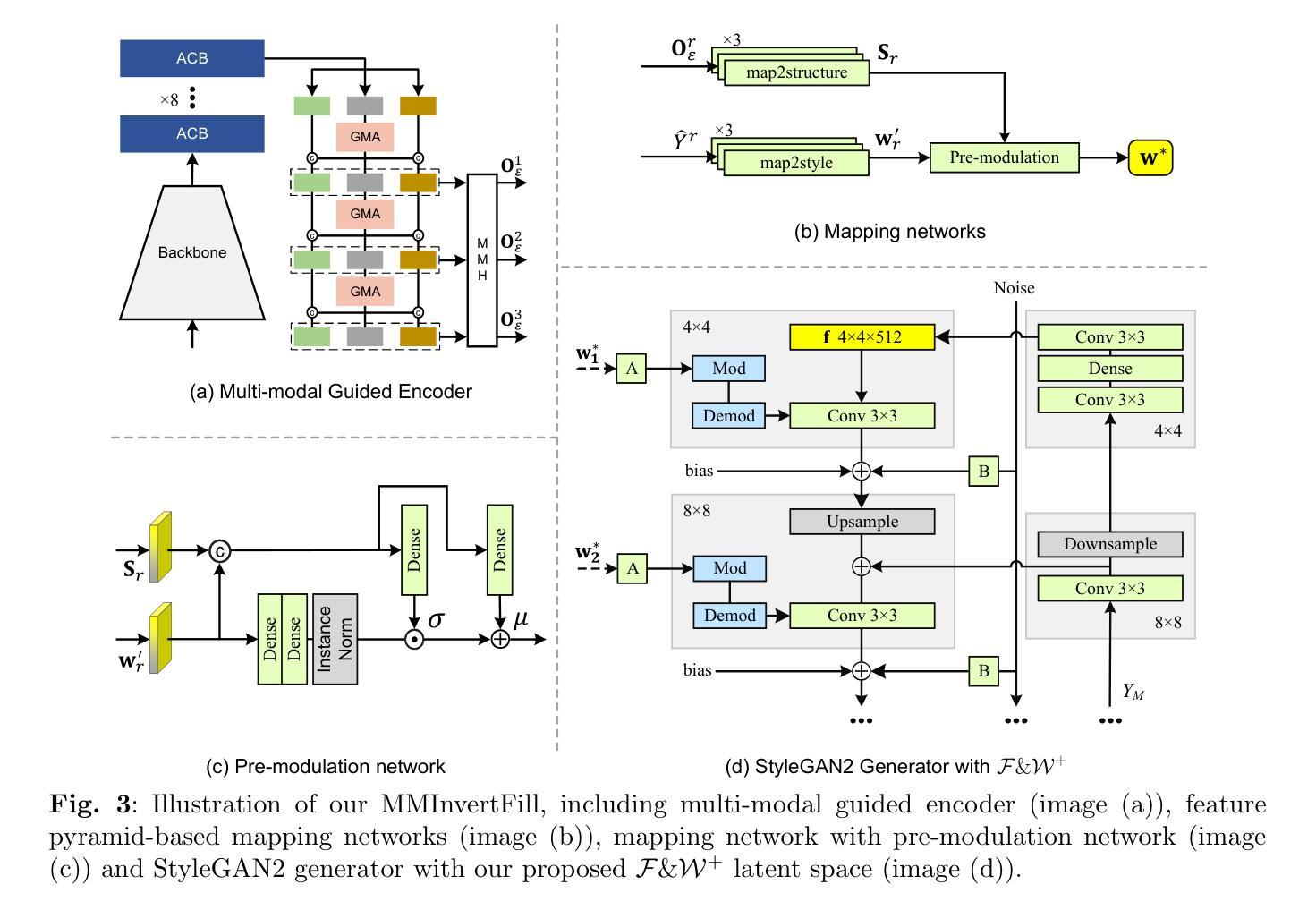
High-Fidelity Image Inpainting with Multimodal Guided GAN Inversion
Authors:Libo Zhang, Yongsheng Yu, Jiali Yao, Heng Fan
Generative Adversarial Network (GAN) inversion have demonstrated excellent performance in image inpainting that aims to restore lost or damaged image texture using its unmasked content. Previous GAN inversion-based methods usually utilize well-trained GAN models as effective priors to generate the realistic regions for missing holes. Despite excellence, they ignore a hard constraint that the unmasked regions in the input and the output should be the same, resulting in a gap between GAN inversion and image inpainting and thus degrading the performance. Besides, existing GAN inversion approaches often consider a single modality of the input image, neglecting other auxiliary cues in images for improvements. Addressing these problems, we propose a novel GAN inversion approach, dubbed MMInvertFill, for image inpainting. MMInvertFill contains primarily a multimodal guided encoder with a pre-modulation and a GAN generator with F&W+ latent space. Specifically, the multimodal encoder aims to enhance the multi-scale structures with additional semantic segmentation edge texture modalities through a gated mask-aware attention module. Afterwards, a pre-modulation is presented to encode these structures into style vectors. To mitigate issues of conspicuous color discrepancy and semantic inconsistency, we introduce the F&W+ latent space to bridge the gap between GAN inversion and image inpainting. Furthermore, in order to reconstruct faithful and photorealistic images, we devise a simple yet effective Soft-update Mean Latent module to capture more diversified in-domain patterns for generating high-fidelity textures for massive corruptions. In our extensive experiments on six challenging datasets, we show that our MMInvertFill qualitatively and quantitatively outperforms other state-of-the-arts and it supports the completion of out-of-domain images effectively.
生成对抗网络(GAN)的反转技术在图像修复中表现出了出色的性能,图像修复旨在使用未遮罩的内容恢复丢失或损坏的图像纹理。之前的基于GAN反转的方法通常利用训练良好的GAN模型作为先验来生成缺失区域的真实区域。尽管表现优秀,但它们忽略了一个硬性约束,即输入和输出的未遮罩区域应该是相同的,这导致GAN反转和图像修复之间存在差距,从而降低了性能。此外,现有的GAN反转方法往往只考虑输入图像的单模态,忽略了图像中其他辅助线索的改进。为了解决这些问题,我们提出了一种新型的GAN反转方法,名为MMInvertFill,用于图像修复。MMInvertFill主要包括一个具有预调制的多模态引导编码器和带有F&W+潜在空间的GAN生成器。具体来说,多模态编码器旨在通过门控掩膜感知注意力模块增强多尺度结构,并增加语义分割边缘纹理模态。接下来,通过预调制将这些结构编码为样式向量。为了减轻明显的颜色差异和语义不一致问题,我们引入了F&W+潜在空间来缩小GAN反转和图像修复之间的差距。此外,为了重建真实和逼真的图像,我们设计了一个简单有效的Soft-update Mean Latent模块,以捕获更多样化的域内模式,为大规模腐蚀生成高保真纹理。我们在六个具有挑战性的数据集上进行了广泛实验,结果表明,我们的MMInvertFill在定性和定量上均优于其他最新技术,并且它有效地支持跨域图像的完成。
论文及项目相关链接
PDF Accepted to IJCV. arXiv admin note: text overlap with arXiv:2208.11850
Summary
针对图像修复任务,提出了一种新的GAN反演方法MMInvertFill。该方法通过多模态引导编码器、预调制、GAN生成器与F&W+潜在空间等技术,增强了多尺度结构,解决了现有GAN反演方法在图像修复中的不足。在六个具有挑战性的数据集上的实验表明,MMInvertFill在定性和定量上均优于其他最先进的方法,并有效地支持了跨域图像的完成。
Key Takeaways
- GAN反演在图像修复中表现优秀,旨在利用未损坏的图像内容恢复丢失或损坏的图像纹理。
- 现有GAN反演方法忽略了一个重要约束,即输入和输出的未遮挡区域应该相同,这导致了GAN反演和图像修复之间的鸿沟,降低了性能。
- MMInvertFill方法通过多模态引导编码器、预调制和GAN生成器等技术,增强了多尺度结构,并引入了F&W+潜在空间来缩小GAN反演和图像修复之间的差距。
- MMInvertFill还包括一个Soft-update Mean Latent模块,用于捕捉更多样化的域内模式,为大规模腐蚀生成高保真纹理。
- 在六个具有挑战性的数据集上的实验表明,MMInvertFill在图像修复任务上优于其他最先进的方法。
- MMInvertFill方法支持跨域图像的完成。
点此查看论文截图