⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
Exploring Expert Failures Improves LLM Agent Tuning
Authors:Li-Cheng Lan, Andrew Bai, Minhao Cheng, Ruochen Wang, Cho-Jui Hsieh, Tianyi Zhou
Large Language Models (LLMs) have shown tremendous potential as agents, excelling at tasks that require multiple rounds of reasoning and interactions. Rejection Sampling Fine-Tuning (RFT) has emerged as an effective method for finetuning LLMs as agents: it first imitates expert-generated successful trajectories and further improves agentic skills through iterative fine-tuning on successful, self-generated trajectories. However, since the expert (e.g., GPT-4) succeeds primarily on simpler subtasks and RFT inherently favors simpler scenarios, many complex subtasks remain unsolved and persistently out-of-distribution (OOD). Upon investigating these challenging subtasks, we discovered that previously failed expert trajectories can often provide valuable guidance, e.g., plans and key actions, that can significantly improve agent exploration efficiency and acquisition of critical skills. Motivated by these observations, we propose Exploring Expert Failures (EEF), which identifies beneficial actions from failed expert trajectories and integrates them into the training dataset. Potentially harmful actions are meticulously excluded to prevent contamination of the model learning process. By leveraging the beneficial actions in expert failures, EEF successfully solves some previously unsolvable subtasks and improves agent tuning performance. Remarkably, our approach achieved a 62% win rate in WebShop, outperforming RFT (53. 6%) and GPT-4 (35. 6%), and to the best of our knowledge, setting a new state-of-the-art as the first method to surpass a score of 0.81 in WebShop and exceed 81 in SciWorld.
大型语言模型(LLM)作为智能体展现了巨大的潜力,尤其是在需要多轮推理和交互的任务上表现出色。拒绝采样微调(RFT)作为一种有效的微调LLM作为智能体的方法已经崭露头角:它首先模仿专家生成的成功轨迹,然后通过迭代微调在自我生成的成功轨迹上进一步改善智能技能。然而,由于专家(例如GPT-4)主要在较简单的子任务上取得成功,且RFT本质上偏向于更简单场景,因此许多复杂的子任务仍然无法解决并且持续处于分布外(OOD)。在调查这些具有挑战性的子任务时,我们发现之前的专家轨迹失败常常能提供有价值的指导,例如计划和关键行动,这可以显著提高智能体的探索效率和获取关键技能的能力。基于这些观察,我们提出了探索专家失败(EEF)的方法,该方法能够识别失败专家轨迹中的有益行动并将其整合到训练数据集中。有害的行动被精心排除,以防止污染模型学习过程。通过利用专家失败中的有益行动,EEF成功解决了一些之前无法解决的子任务并提高了智能体调整性能。值得注意的是,我们的方法在网络购物环境中实现了62%的胜率,超越了RFT(53.6%)和GPT-4(35.6%),据我们所知,这是第一个在WebShop上得分超过0.81并在SciWorld上得分超过81的最新技术。(注:由于原文中的具体数值可能涉及特定的实验数据或版本更新,翻译时请确保核对原文以确保准确性。)
论文及项目相关链接
Summary
大型语言模型(LLM)作为代理展现出巨大的潜力,尤其在需要多轮推理和交互的任务上表现优异。拒绝采样微调(RFT)是一种有效的微调LLM作为代理的方法,它通过模仿专家生成的成功轨迹并进一步在成功的自我生成轨迹上进行迭代微调来提高代理技能。然而,专家主要在较简单的子任务上成功,RFT则倾向于更简单的情况,导致许多复杂的子任务无法解决并持续处于超出分布范围(OOD)。研究这些具有挑战性的子任务时,我们发现之前的专家失败轨迹常能提供有价值的指导,如计划和关键行动,这能显著提高代理的探索效率和关键技能的获取。基于此,我们提出了探索专家失败(EEF)的方法,该方法从失败的专家轨迹中识别出有益的行动并将其整合到训练数据集中。有害的行动会被精心排除,以防止模型学习过程受到污染。通过利用专家失败中的有益行动,EEF成功解决了一些之前无法解决的子任务,提高了代理调整性能。我们的方法在网络购物任务上的胜率达到了62%,超越了RFT(53.6%)和GPT-4(35.6%),据我们所知,这是网络购物任务上的最新最佳表现。
Key Takeaways
- LLMs展现出作为代理的巨大潜力,特别是在需要多轮推理和交互的任务上。
- 拒绝采样微调(RFT)是LLM代理的一种有效微调方法,通过模仿和学习成功轨迹来提升代理技能。
- 专家主要在简单子任务上成功,复杂的子任务常常无法解决并超出分布范围(OOD)。
- 失败的专家轨迹可以提供有价值的指导,如计划和关键行动,提高代理的探索效率和关键技能获取。
- 探索专家失败(EEF)方法识别并整合专家失败轨迹中的有益行动到训练数据集中。
- EEF通过利用专家失败中的有益行动,成功解决了一些之前无法解决的子任务,提高了代理性能。
点此查看论文截图


Energy-Based Reward Models for Robust Language Model Alignment
Authors:Anamika Lochab, Ruqi Zhang
Reward models (RMs) are essential for aligning Large Language Models (LLMs) with human preferences. However, they often struggle with capturing complex human preferences and generalizing to unseen data. To address these challenges, we introduce Energy-Based Reward Model (EBRM), a lightweight post-hoc refinement framework that enhances RM robustness and generalization. EBRM models the reward distribution explicitly, capturing uncertainty in human preferences and mitigating the impact of noisy or misaligned annotations. It achieves this through conflict-aware data filtering, label-noise-aware contrastive training, and hybrid initialization. Notably, EBRM enhances RMs without retraining, making it computationally efficient and adaptable across different models and tasks. Empirical evaluations on RM benchmarks demonstrate significant improvements in both robustness and generalization, achieving up to a 5.97% improvement in safety-critical alignment tasks compared to standard RMs. Furthermore, reinforcement learning experiments confirm that our refined rewards enhance alignment quality, effectively delaying reward hacking. These results demonstrate our approach as a scalable and effective enhancement for existing RMs and alignment pipelines. The code is available at EBRM.
奖励模型(RM)对于将大型语言模型(LLM)与人类偏好对齐至关重要。然而,它们通常难以捕捉复杂的人类偏好并推广到未见过的数据。为了解决这些挑战,我们引入了基于能量的奖励模型(EBRM),这是一个轻量级的后验细化框架,可以提高RM的稳健性和泛化能力。EBRM显式地建模奖励分布,捕捉人类偏好的不确定性,并减轻噪声或错位注释的影响。它通过冲突感知数据过滤、标签噪声感知对比训练和混合初始化来实现这一点。值得注意的是,EBRM在不需要重新训练的情况下增强了RM的功能,使其计算效率高且适应不同的模型和任务。在RM基准测试上的经验评估表明,它在稳健性和泛化能力方面都有显著提高,在安全关键对齐任务中,与标准RM相比,最高可提高5.97%。此外,强化学习实验证实,我们优化的奖励提高了对齐质量,有效地延缓了奖励黑客攻击。这些结果证明了我们的方法是对现有RM和对齐管道的可扩展和有效的增强。代码可在EBRM网站找到。
论文及项目相关链接
摘要
基于能源奖励模型(EBRM)的轻量级事后改进框架,可提高奖励模型(RMs)的稳健性和泛化能力。EBRM显式建模奖励分布,捕捉人类偏好的不确定性,并减轻噪声或误对齐注释的影响。它通过冲突感知数据过滤、标签噪声感知对比训练和混合初始化来实现这一点。EBRM无需重新训练即可提高RM的性能,因此计算效率高且适应不同模型和任务。在RM基准测试上的经验评估显示,EBRM在提高稳健性和泛化能力方面显著提高了RM的性能,在关键对齐任务中最高达到了改进为+ 5.97%。此外,强化学习实验证实,我们的改进奖励增强了对齐质量,有效地延迟了奖励破解问题。这些结果表明我们的方法是一种可扩展且有效的增强现有RM和对齐管道的方法。代码可在EBRM找到。
关键见解
- EBRM是一种轻量级事后改进框架,旨在提高奖励模型(RMs)在大型语言模型(LLMs)中的稳健性和泛化能力。
- EBRM通过显式建模奖励分布捕捉人类偏好的不确定性,并减轻噪声或误对齐数据的影响。
- 该方法集成了冲突感知数据过滤、标签噪声感知对比训练和混合初始化技术来实现其目标。
- EBRM能在不重新训练的情况下提高RM性能,使其计算效率高且适应多种模型和任务。
- 通过基准测试的实验结果证实,EBRM在增强RM的稳健性和泛化能力方面显著提高性能。
- 在关键对齐任务中,与标准RM相比,EBRM最多可实现+ 5.97%的改进。
点此查看论文截图



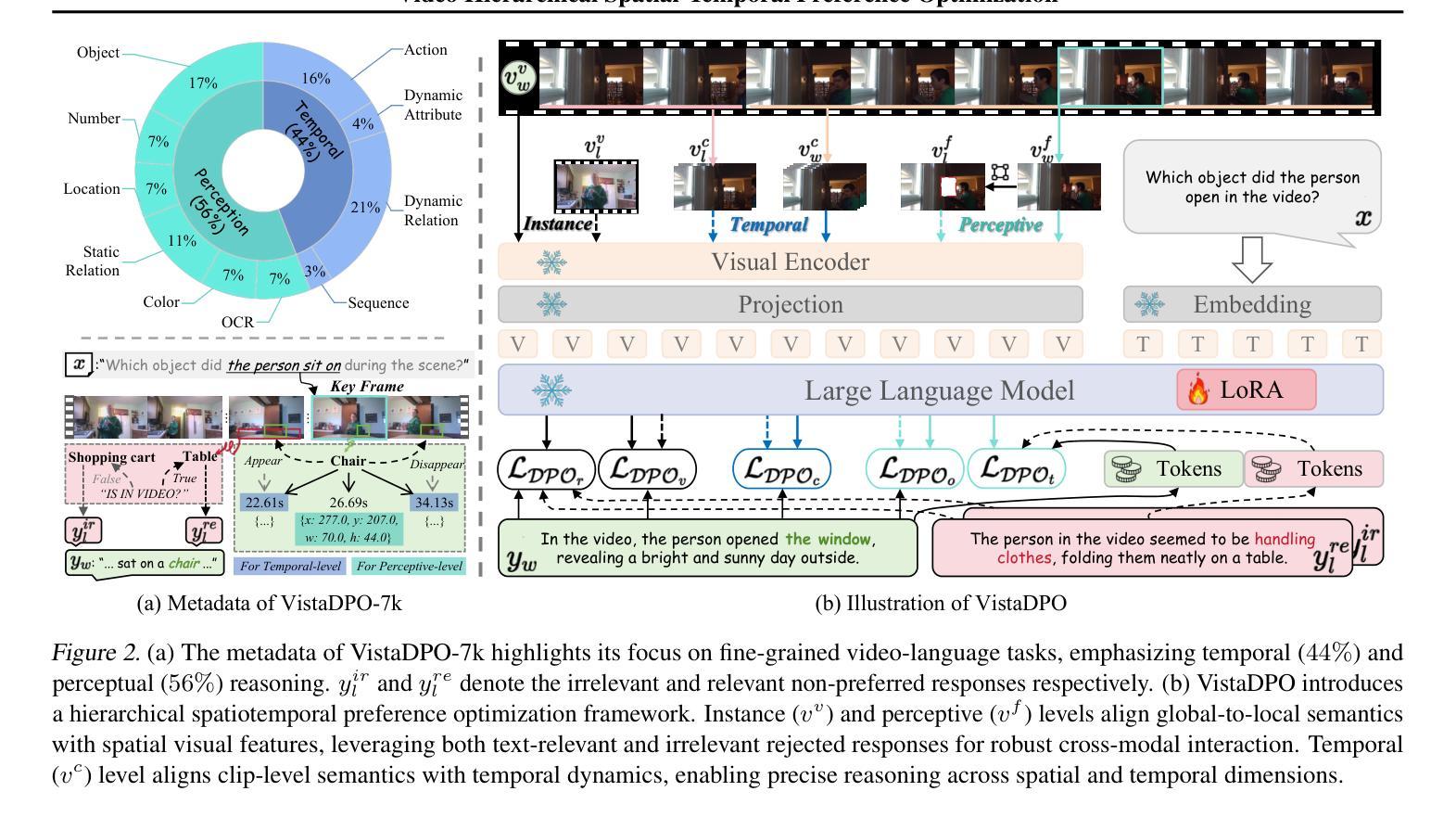
VistaDPO: Video Hierarchical Spatial-Temporal Direct Preference Optimization for Large Video Models
Authors:Haojian Huang, Haodong Chen, Shengqiong Wu, Meng Luo, Jinlan Fu, Xinya Du, Hanwang Zhang, Hao Fei
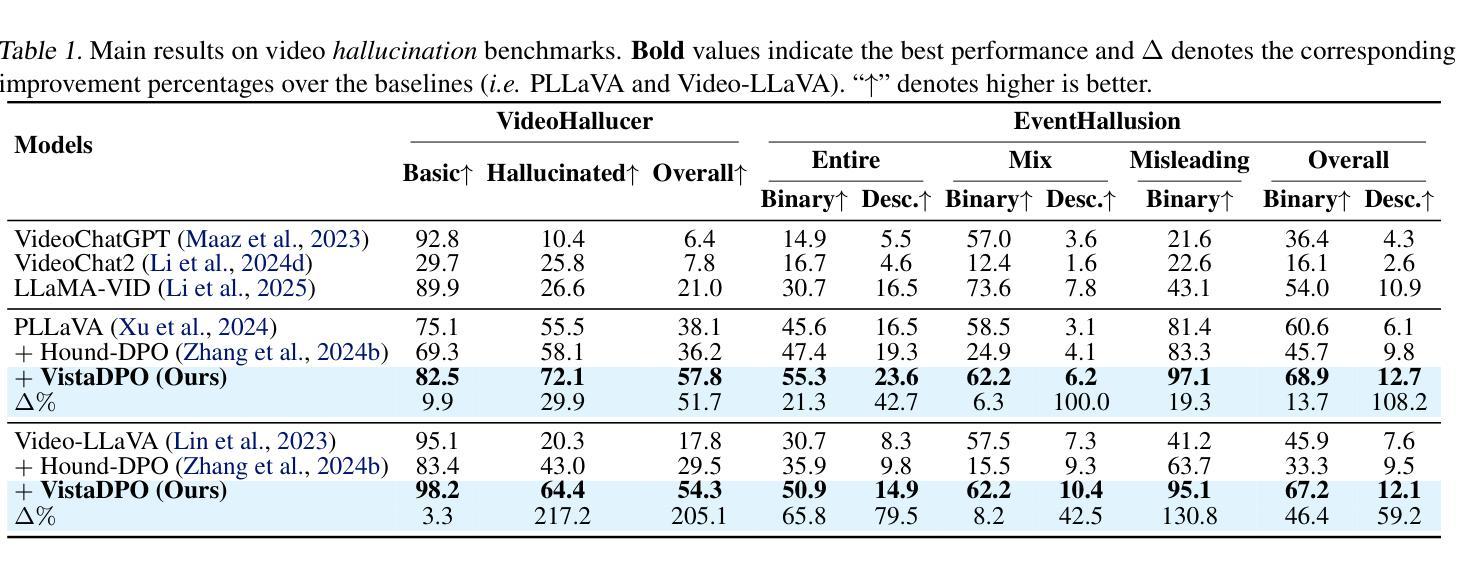
Large Video Models (LVMs) built upon Large Language Models (LLMs) have shown promise in video understanding but often suffer from misalignment with human intuition and video hallucination issues. To address these challenges, we introduce VistaDPO, a novel framework for Video Hierarchical Spatial-Temporal Direct Preference Optimization. VistaDPO enhances text-video preference alignment across three hierarchical levels: i) Instance Level, aligning overall video content with responses; ii) Temporal Level, aligning video temporal semantics with event descriptions; and iii) Perceptive Level, aligning spatial objects with language tokens. Given the lack of datasets for fine-grained video-language preference alignment, we construct VistaDPO-7k, a dataset of 7.2K QA pairs annotated with chosen and rejected responses, along with spatial-temporal grounding information such as timestamps, keyframes, and bounding boxes. Extensive experiments on benchmarks such as Video Hallucination, Video QA, and Captioning performance tasks demonstrate that VistaDPO significantly improves the performance of existing LVMs, effectively mitigating video-language misalignment and hallucination. The code and data are available at https://github.com/HaroldChen19/VistaDPO.
基于大型语言模型(LLM)的大型视频模型(LVM)在视频理解方面显示出潜力,但常常面临与人类直觉不一致和视频幻觉等问题。为了解决这些挑战,我们引入了VistaDPO,一种用于视频分层时空直接偏好优化的新型框架。VistaDPO增强文本视频偏好对齐三个层次:i)实例级别,使整体视频内容与响应对齐;ii)时间级别,使视频时间语义与事件描述对齐;以及iii)感知级别,使空间对象与语言令牌对齐。鉴于缺乏精细粒度的视频语言偏好对齐数据集,我们构建了VistaDPO-7k,这是一个包含7.2K问答对的数据集,每个问答对都标有选择和拒绝响应,以及时空定位信息,如时间戳、关键帧和边界框。在视频幻觉、视频问答和字幕性能等基准测试上的大量实验表明,VistaDPO显著提高了现有LVM的性能,有效地缓解了视频语言的不对齐和幻觉问题。代码和数据集可在https://github.com/HaroldChen19/VistaDPO获取。
论文及项目相关链接
PDF Code and Data: https://github.com/HaroldChen19/VistaDPO
Summary
基于大型语言模型的大型视频模型在视频理解方面展现出潜力,但存在与人类直觉不符和视频幻觉问题。为解决这些问题,我们推出VistaDPO,一种用于视频层次化时空直接偏好优化的新型框架。VistaDPO通过三个层次增强文本视频偏好对齐:一)实例级别,对齐视频内容与整体响应;二)时间级别,对齐视频时间语义与事件描述;三)感知级别,对齐空间物体与语言标记。由于缺乏精细粒度的视频语言偏好对齐数据集,我们构建了包含7.2K问答对及选定和拒绝响应的VistaDPO-7k数据集,还包括时空定位信息如时间戳、关键帧和边界框。在视频幻觉、视频问答和字幕性能任务等方面的实验表明,VistaDPO可显著改善现有大型视频模型的性能,有效减轻视频语言不对齐和幻觉问题。
Key Takeaways
- LVMs基于LLMs构建,在视频理解方面展现出潜力,但存在与人类直觉不符及视频幻觉的挑战。
- 引入VistaDPO框架,通过三个层次增强文本视频偏好对齐:实例级别、时间级别和感知级别。
- 缺乏精细粒度的视频语言偏好对齐数据集,因此构建VistaDPO-7k数据集。
- VistaDPO-7k包含7.2K问答对及时空定位信息。
- 实验表明VistaDPO可显著改善大型视频模型的性能。
- VistaDPO能有效减轻视频语言不对齐和幻觉问题。
点此查看论文截图

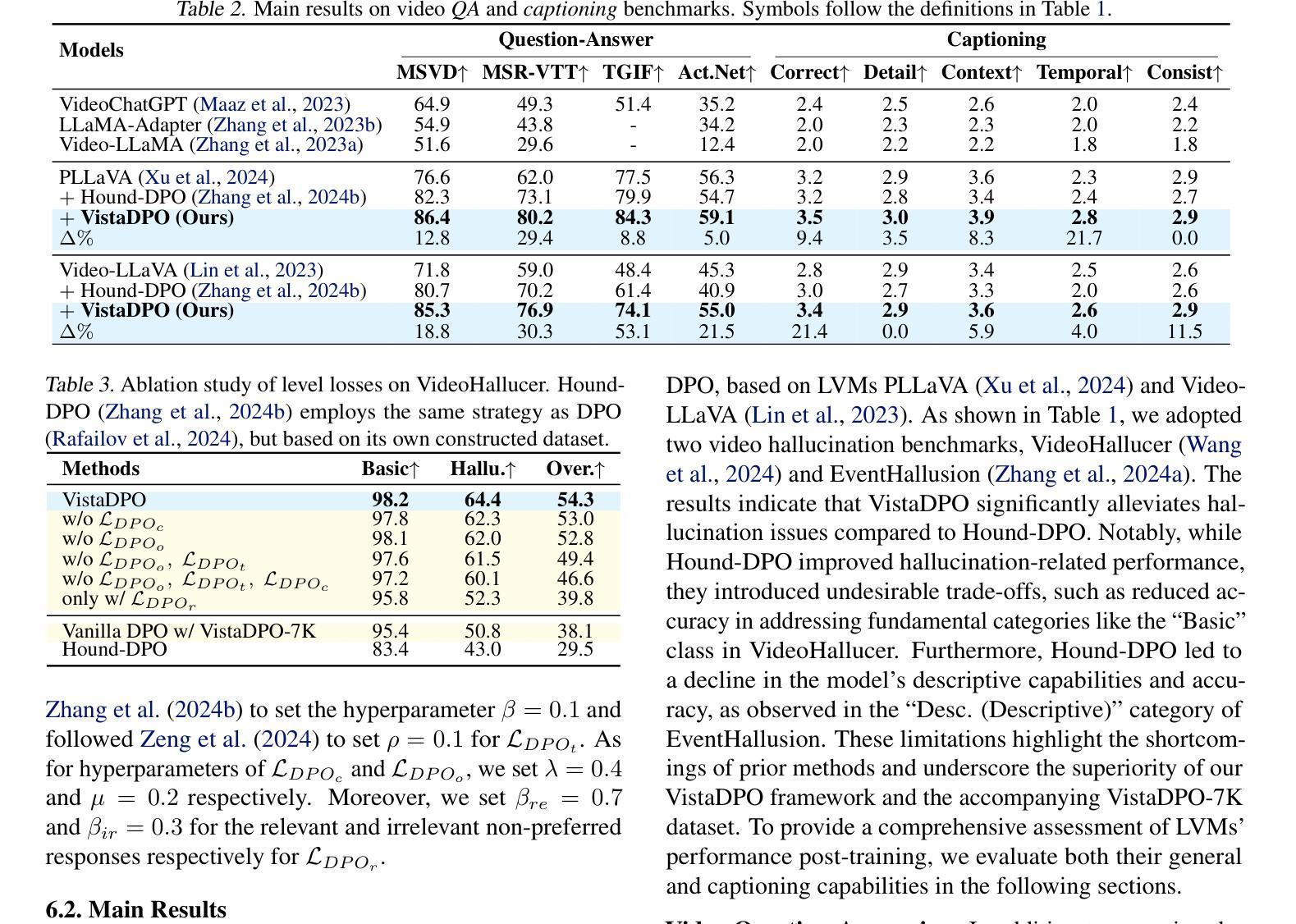
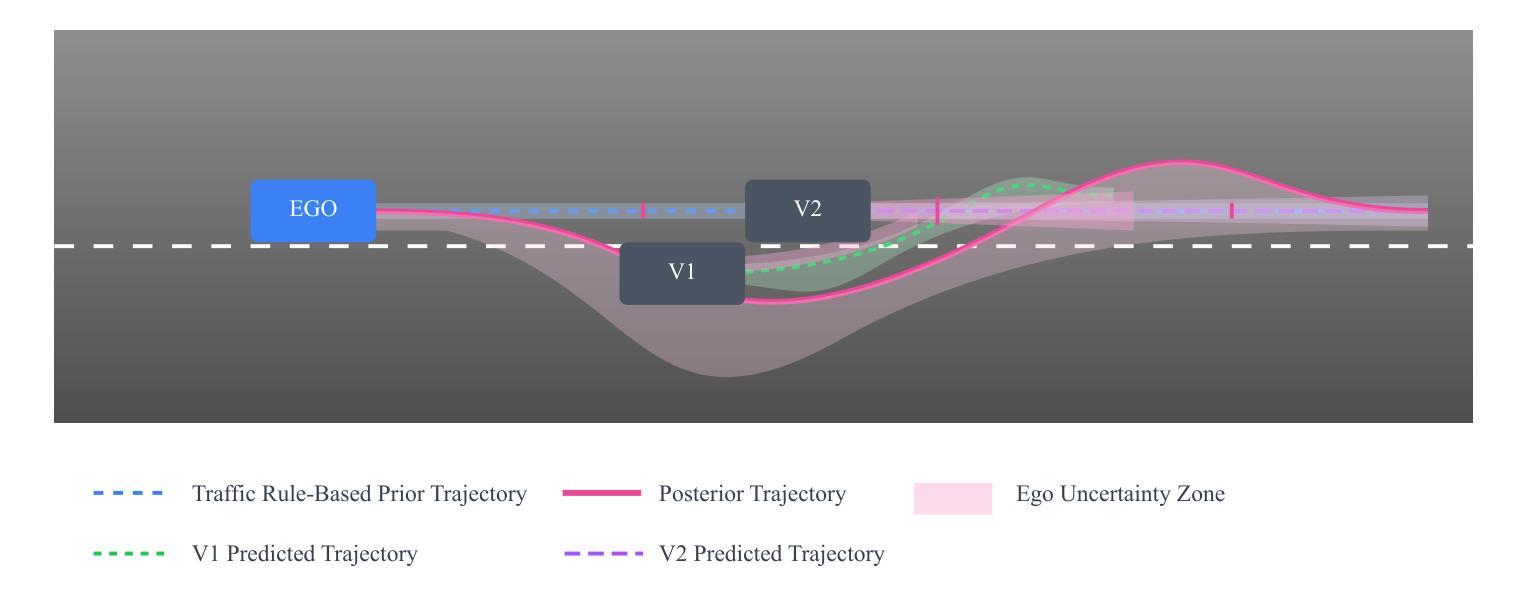
Uncertainty-Aware Trajectory Prediction via Rule-Regularized Heteroscedastic Deep Classification
Authors:Kumar Manas, Christian Schlauch, Adrian Paschke, Christian Wirth, Nadja Klein
Deep learning-based trajectory prediction models have demonstrated promising capabilities in capturing complex interactions. However, their out-of-distribution generalization remains a significant challenge, particularly due to unbalanced data and a lack of enough data and diversity to ensure robustness and calibration. To address this, we propose SHIFT (Spectral Heteroscedastic Informed Forecasting for Trajectories), a novel framework that uniquely combines well-calibrated uncertainty modeling with informative priors derived through automated rule extraction. SHIFT reformulates trajectory prediction as a classification task and employs heteroscedastic spectral-normalized Gaussian processes to effectively disentangle epistemic and aleatoric uncertainties. We learn informative priors from training labels, which are automatically generated from natural language driving rules, such as stop rules and drivability constraints, using a retrieval-augmented generation framework powered by a large language model. Extensive evaluations over the nuScenes dataset, including challenging low-data and cross-location scenarios, demonstrate that SHIFT outperforms state-of-the-art methods, achieving substantial gains in uncertainty calibration and displacement metrics. In particular, our model excels in complex scenarios, such as intersections, where uncertainty is inherently higher. Project page: https://kumarmanas.github.io/SHIFT/.
基于深度学习的轨迹预测模型在捕捉复杂交互方面展现出有前景的能力。然而,其离分布泛化仍然是一个巨大的挑战,尤其是因为数据不平衡和缺乏足够的数据和多样性以确保其稳健性和校准性。为了解决这一问题,我们提出了SHIFT(用于轨迹的谱异方差信息预测),这是一个独特结合良好校准的不确定性模型和通过自动化规则提取获得的信息先验值的新型框架。SHIFT将轨迹预测重新表述为分类任务,并采用异方差谱归一化高斯过程有效地分离出认知不确定性和偶然不确定性。我们从训练标签中学习信息先验值,这些标签是由自然语言驾驶规则(如停车规则和驾驶约束)自动生成的,使用由大型语言模型驱动的检索增强生成框架。在nuScenes数据集上的广泛评估,包括具有挑战性的低数据和跨位置场景,表明SHIFT优于最新技术方法,在不确定性校准和位移指标上取得了重大进展。尤其值得一提的是,我们的模型在不确定性固有的复杂场景(如交叉口)中表现出卓越性能。项目页面:https://kumarmanas.github.io/SHIFT/。
论文及项目相关链接
PDF 17 Pages, 9 figures. Accepted to Robotics: Science and Systems(RSS), 2025
Summary
深度学习轨迹预测模型在捕捉复杂交互方面展现出巨大潜力,但其面临着泛化能力的问题,特别是在数据不平衡和缺乏足够多样数据的情况下。为解决这一问题,我们提出了SHIFT框架,结合校准不确定性模型和通过自动化规则提取得到的先验信息。SHIFT将轨迹预测重新定义为分类任务,并利用异谱标准化高斯过程有效地区分不确定性的可理解和不可理解部分。我们从训练标签中学习信息丰富的先验知识,这些标签是通过大型语言模型驱动的检索增强生成框架从自然语言驾驶规则(如停车规则和驾驶约束)自动生成的。在nuScenes数据集上的广泛评估显示,包括具有挑战性的低数据和跨位置场景在内,SHIFT在不确定性和位移度量方面都优于其他方法,且在复杂性高的场景(如交叉路口)表现尤为出色。
Key Takeaways
- 深度学习轨迹预测模型具有捕捉复杂交互的巨大潜力,但数据不平衡和缺乏多样性限制了其泛化能力。
- SHIFT框架结合校准不确定性模型和自动化规则提取的先验信息来解决这一挑战。
- SHIFT将轨迹预测定义为分类任务并利用异谱标准化高斯过程来区分可理解和不可理解的不确定性。
- SHIFT利用从训练标签中学习的信息丰富的先验知识,这些标签是从自然语言驾驶规则中自动生成的。
- 在nuScenes数据集上的评估显示,SHIFT在不确定性和位移度量方面优于其他方法。
点此查看论文截图



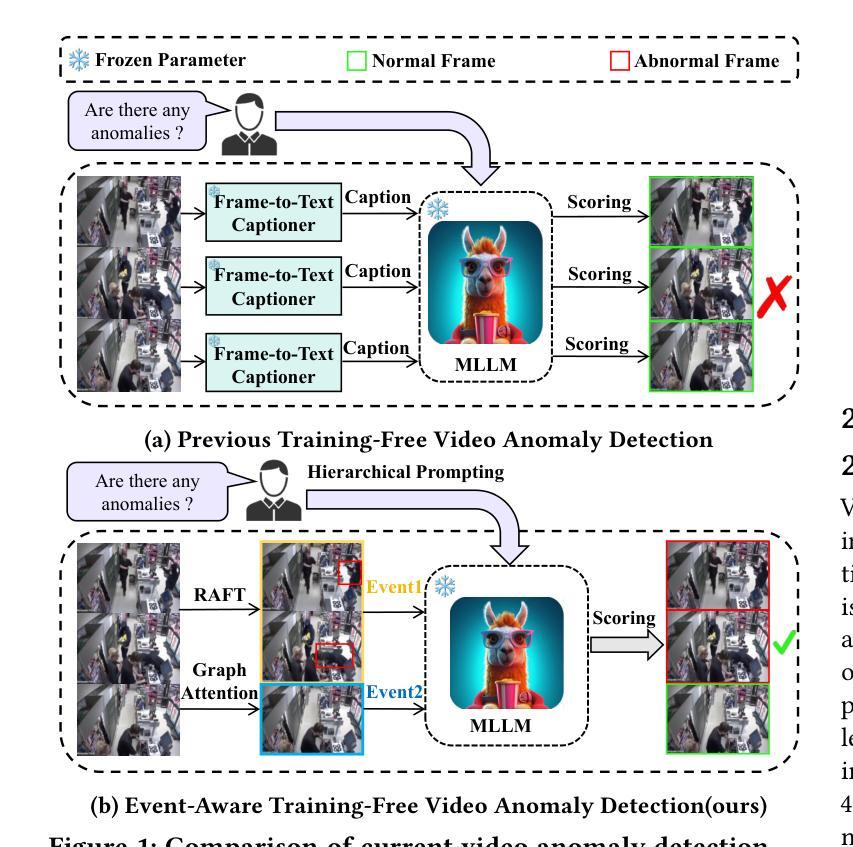
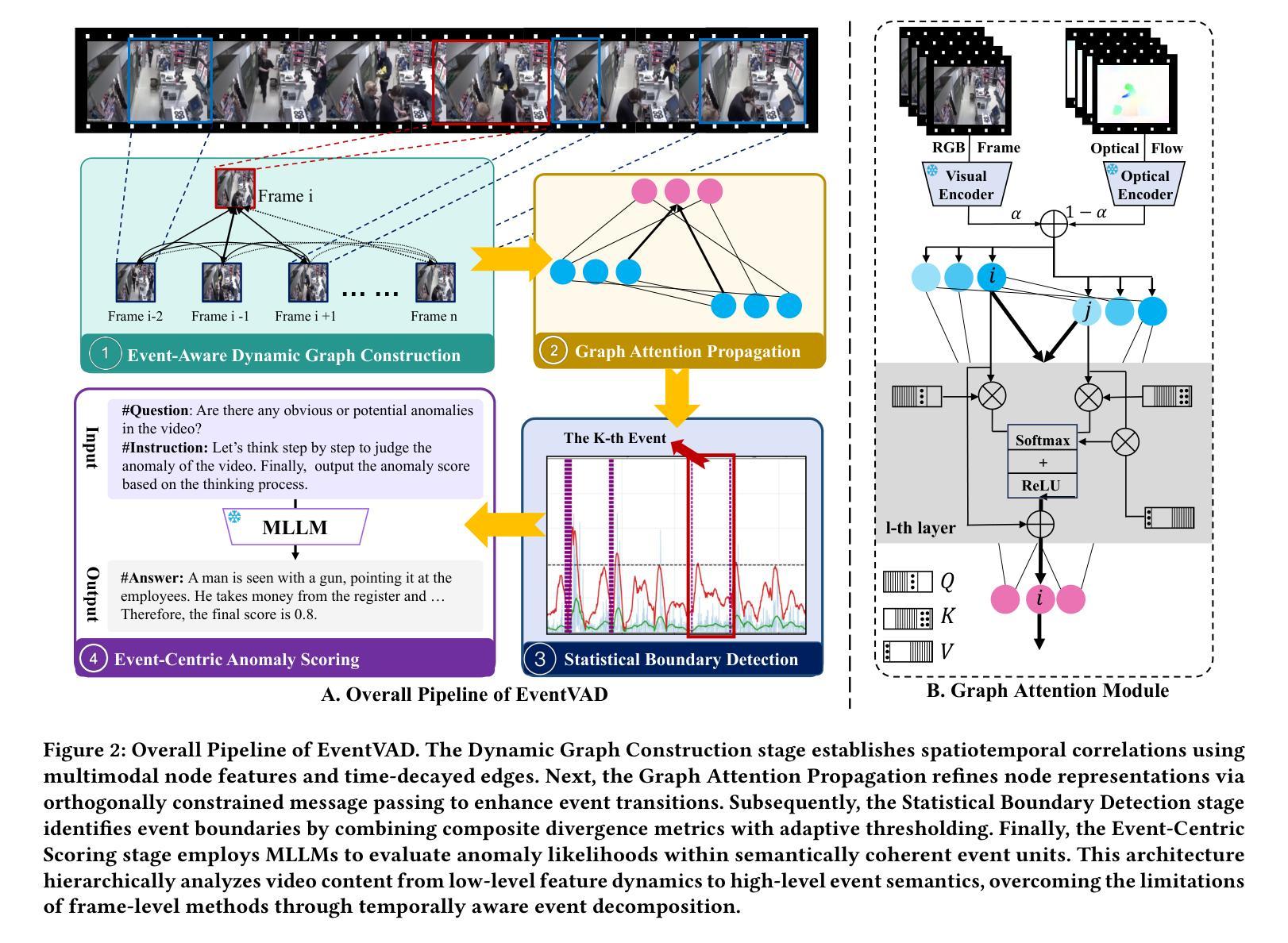
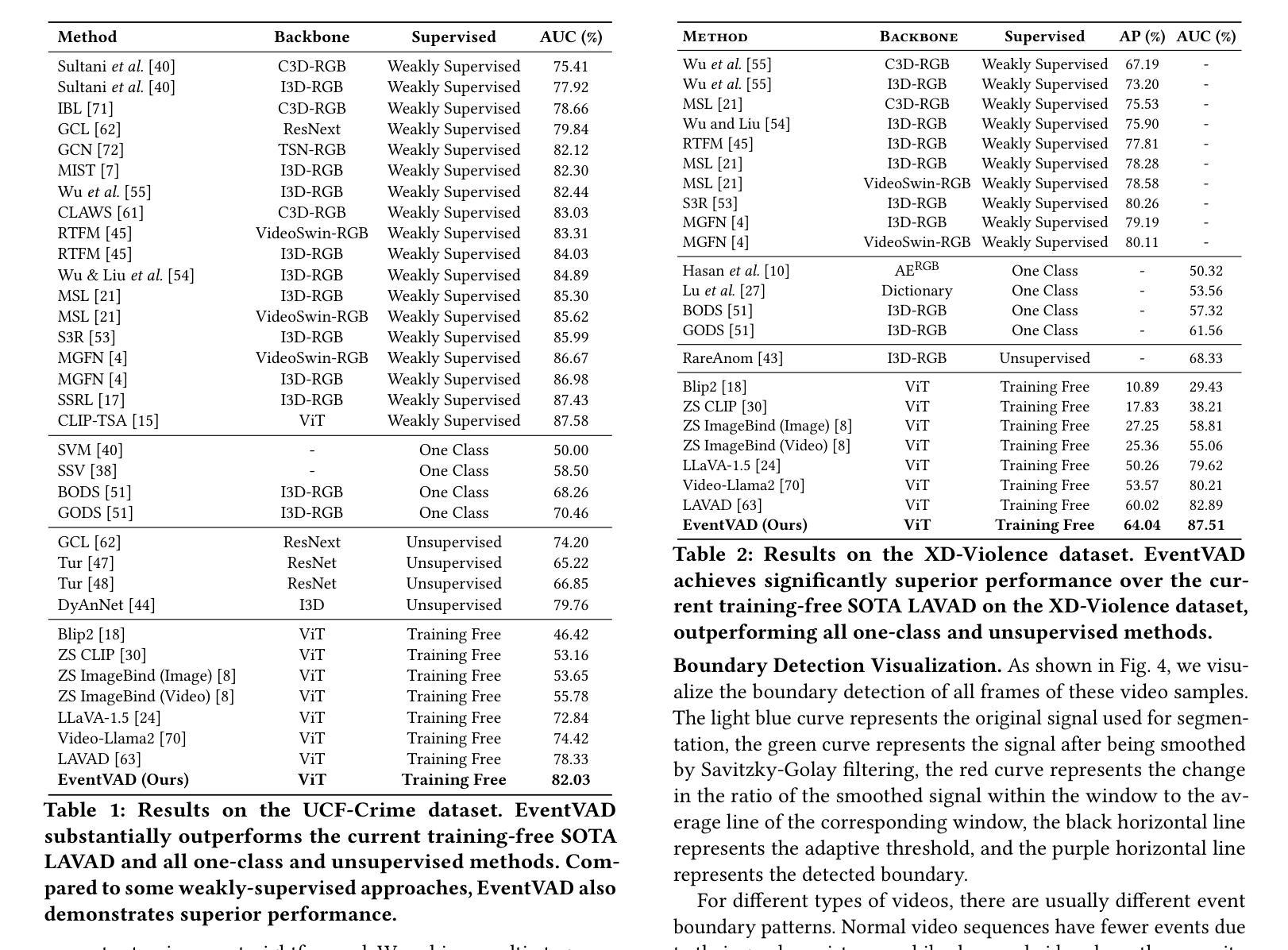
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Authors:Yihua Shao, Haojin He, Sijie Li, Siyu Chen, Xinwei Long, Fanhu Zeng, Yuxuan Fan, Muyang Zhang, Ziyang Yan, Ao Ma, Xiaochen Wang, Hao Tang, Yan Wang, Shuyan Li
Video Anomaly Detection~(VAD) focuses on identifying anomalies within videos. Supervised methods require an amount of in-domain training data and often struggle to generalize to unseen anomalies. In contrast, training-free methods leverage the intrinsic world knowledge of large language models (LLMs) to detect anomalies but face challenges in localizing fine-grained visual transitions and diverse events. Therefore, we propose EventVAD, an event-aware video anomaly detection framework that combines tailored dynamic graph architectures and multimodal LLMs through temporal-event reasoning. Specifically, EventVAD first employs dynamic spatiotemporal graph modeling with time-decay constraints to capture event-aware video features. Then, it performs adaptive noise filtering and uses signal ratio thresholding to detect event boundaries via unsupervised statistical features. The statistical boundary detection module reduces the complexity of processing long videos for MLLMs and improves their temporal reasoning through event consistency. Finally, it utilizes a hierarchical prompting strategy to guide MLLMs in performing reasoning before determining final decisions. We conducted extensive experiments on the UCF-Crime and XD-Violence datasets. The results demonstrate that EventVAD with a 7B MLLM achieves state-of-the-art (SOTA) in training-free settings, outperforming strong baselines that use 7B or larger MLLMs.
视频异常检测(VAD)专注于识别视频中的异常情况。有监督的方法需要大量领域内的训练数据,并且往往难以推广到未见过的异常情况。相比之下,无训练的方法利用大型语言模型(LLM)的内在世界知识来检测异常,但面临着定位精细视觉转换和多样化事件的挑战。因此,我们提出了EventVAD,一个结合定制的动态图形架构和多模式LLM的事件感知视频异常检测框架,通过时间事件推理。具体来说,EventVAD首先采用具有时间衰减约束的动态时空图形建模,以捕获事件感知的视频特征。然后,它执行自适应噪声过滤,并使用信号比率阈值通过无监督统计特征检测事件边界。统计边界检测模块降低了处理长视频对大型语言模型的复杂性,并通过事件一致性提高了其时间推理能力。最后,它利用分层提示策略来指导大型语言模型在进行推理后做出最终决定。我们在UCF-Crime和XD-Violence数据集上进行了大量实验。结果表明,使用7B的大型语言模型的EventVAD在无训练环境中达到了最先进的水平,优于使用相同规模或更大规模的大型语言模型的强大基线。
论文及项目相关链接
Summary
本文介绍了视频异常检测(VAD)的难题,包括监督方法需要大量训练数据且难以泛化到新异常,而训练外方法则利用大型语言模型(LLM)的固有世界知识进行检测但面临本地化精细视觉过渡和多样化事件的定位挑战。因此,提出了EventVAD,一种结合动态图架构和多模态LLM的事件感知视频异常检测框架,通过时间事件推理进行检测。该框架首先使用具有时间衰减约束的动态时空图模型捕获事件感知视频特征,然后通过自适应噪声过滤和信号比率阈值检测事件边界。最后,利用分层提示策略指导MLLM进行推理并做出最终决定。在UCF-Crime和XD-Violence数据集上的实验结果表明,使用7B MLLM的EventVAD在训练外设置中达到最新水平,优于使用相同规模或更大规模LLM的强大基线。
Key Takeaways
- 视频异常检测(VAD)旨在识别视频中的异常。
- 监督方法需要大量领域内的训练数据,且难以泛化到新异常。
- 训练外方法利用大型语言模型的固有知识检测异常,但面临定位精细视觉过渡和多样化事件的挑战。
- EventVAD结合了动态图架构和多模态LLM,通过时间事件推理进行检测。
- EventVAD使用动态时空图模型捕获事件感知视频特征。
- EventVAD通过自适应噪声过滤和信号比率阈值检测事件边界。
点此查看论文截图

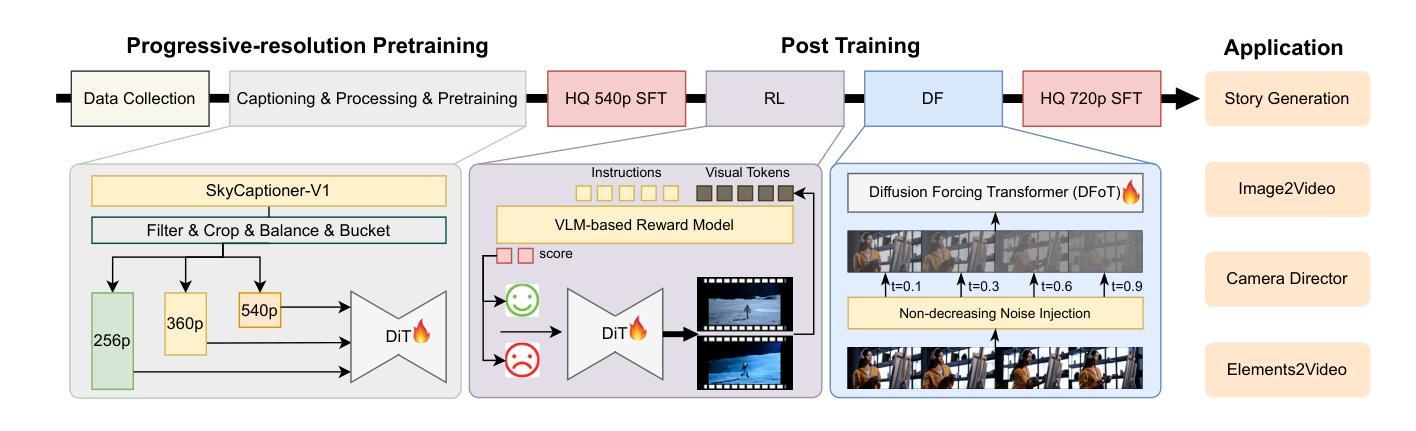
SkyReels-V2: Infinite-length Film Generative Model
Authors:Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Juncheng Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengchen Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, Yahui Zhou
Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs’ inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
近期视频生成技术的进展主要得益于扩散模型和自回归框架的驱动,但仍存在协调提示遵循、视觉质量、运动动态和持续时间等方面的关键挑战:为提升临时视觉质量而妥协运动动态、为优先保障分辨率而限制视频时长(5-10秒),以及由于通用MLLM无法解释电影语法(如镜头构成、演员表达和摄影机运动)而导致的拍摄意识生成不足。这些交织的限制阻碍了现实的长形式合成和专业电影风格的生成。为解决这些限制,我们提出了SkyReels-V2,一种无限长度的电影生成模型,它协同了多模态大型语言模型(MLLM)、多阶段预训练、强化学习和扩散强制框架。首先,我们设计了视频的综合结构表示,结合了多模态LLM的一般描述和子专家模型的详细镜头语言。借助人工注释,我们随后训练了一个统一的视频标题生成器,名为SkyCaptioner-V1,以有效地标注视频数据。其次,我们为基本的视频生成建立了渐进式分辨率预训练,随后是四个阶段的后训练增强:初始概念平衡的监督微调(SFT)提高了基线质量;使用人工注释和合成失真数据的动态特定强化学习(RL)训练解决了动态伪像问题;我们的具有非递减噪声安排的扩散强制框架能够在有效的搜索空间中进行长视频合成;最后的高质量SFT完善了视觉保真度。所有代码和模型都可在https://github.com/SkyworkAI/SkyReels-V2找到。
论文及项目相关链接
PDF 31 pages,10 figures
Summary
天空工作团队提出了SkyReels-V2模型,一个无限长的电影生成模型,旨在解决视频生成中的多重挑战。它通过多模式大型语言模型(MLLM)、多阶段预训练、强化学习和扩散强迫框架的融合来实现。该模型设计了一个全面的视频结构表示,通过统一视频字幕器SkyCaptioner-V1进行标注。模型经过渐进式分辨率预训练,然后进行四阶段的后期训练增强。代码和模型均可在SkyworkAI的GitHub仓库中找到。
Key Takeaways
- SkyReels-V2解决了视频生成中的多重挑战,包括运动动态、视觉质量、持续时间和谐波等问题。
- 它提出了一个无限长的电影生成模型,旨在生成更为真实的长期和专业的电影风格视频。
- 通过融合多模式大型语言模型(MLLM)、多阶段预训练、强化学习和扩散强迫框架,实现了更先进的视频生成技术。
- 设计了一个全面的视频结构表示,结合了多模式LLM的一般描述和子专家模型的详细镜头语言。
- 通过统一视频字幕器SkyCaptioner-V1进行标注,提高了视频数据的效率。
- 模型采用渐进式分辨率预训练,并通过四阶段的后期训练增强来提升性能。每个阶段都有其特定的训练目标和策略。
点此查看论文截图


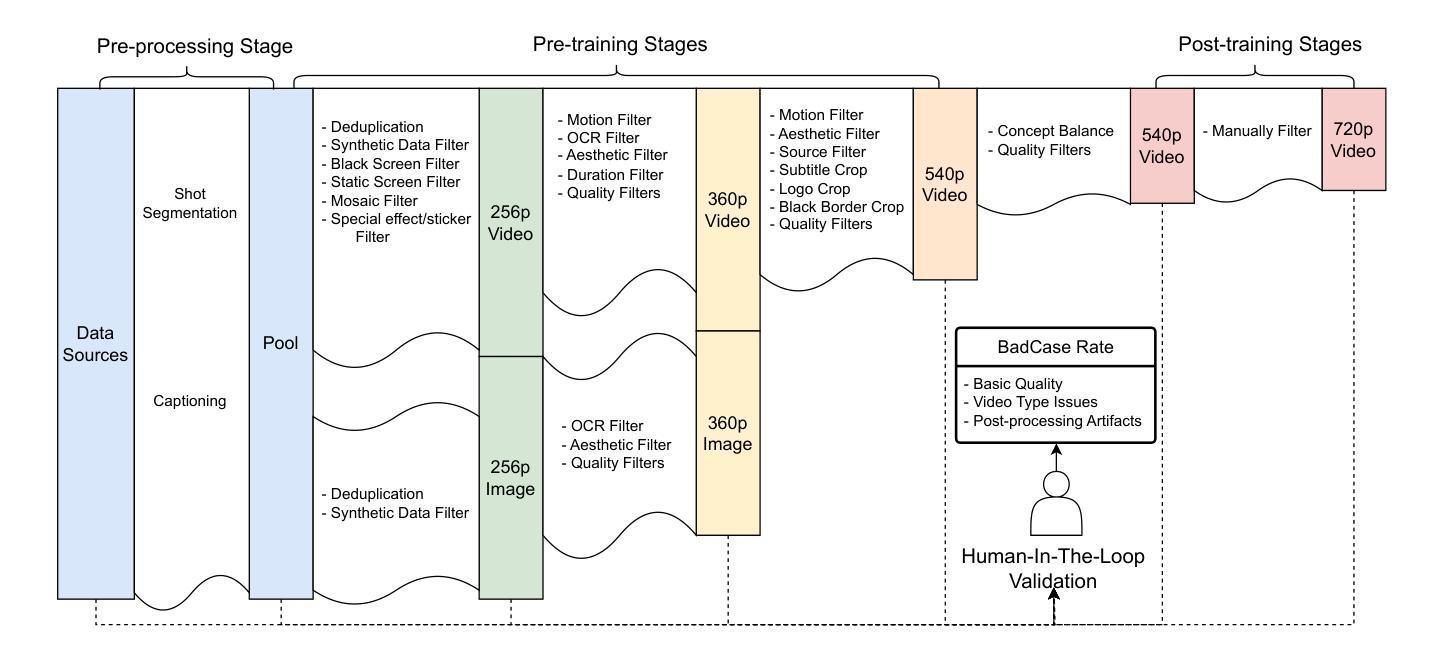

RoboTwin: Dual-Arm Robot Benchmark with Generative Digital Twins
Authors:Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, Lunkai Lin, Zhiqiang Xie, Mingyu Ding, Ping Luo
In the rapidly advancing field of robotics, dual-arm coordination and complex object manipulation are essential capabilities for developing advanced autonomous systems. However, the scarcity of diverse, high-quality demonstration data and real-world-aligned evaluation benchmarks severely limits such development. To address this, we introduce RoboTwin, a generative digital twin framework that uses 3D generative foundation models and large language models to produce diverse expert datasets and provide a real-world-aligned evaluation platform for dual-arm robotic tasks. Specifically, RoboTwin creates varied digital twins of objects from single 2D images, generating realistic and interactive scenarios. It also introduces a spatial relation-aware code generation framework that combines object annotations with large language models to break down tasks, determine spatial constraints, and generate precise robotic movement code. Our framework offers a comprehensive benchmark with both simulated and real-world data, enabling standardized evaluation and better alignment between simulated training and real-world performance. We validated our approach using the open-source COBOT Magic Robot platform. Policies pre-trained on RoboTwin-generated data and fine-tuned with limited real-world samples demonstrate significant potential for enhancing dual-arm robotic manipulation systems by improving success rates by over 70% for single-arm tasks and over 40% for dual-arm tasks compared to models trained solely on real-world data.
在快速发展的机器人技术领域中,双臂协调与复杂物体操控是开发先进自主系统不可或缺的能力。然而,多样且高质量示范数据的稀缺以及缺乏与现实世界相匹配的评估基准严重制约了这种发展。针对这一问题,我们推出了RoboTwin,这是一个利用生成式三维本体模型和大型语言模型构建生成式数字双胞胎框架,以产生多样的专家数据集并为双臂机器人任务提供与现实世界相匹配的评估平台。具体来说,RoboTwin通过单个二维图像创建多样化的数字双胞胎对象,生成现实且互动的场景。它还引入了一个空间关系感知的代码生成框架,该框架结合对象注释和大型语言模型来分解任务、确定空间约束并生成精确的机器人运动代码。我们的框架提供了包含模拟数据和真实世界数据的全面基准测试,能够实现标准化评估,并改善模拟训练和现实表现之间的匹配度。我们使用开源的COBOT Magic Robot平台验证了我们的方法。在RoboTwin生成的数据上进行预训练,并在有限的真实世界样本上进行微调的政策,显示出巨大的潜力,与仅使用真实世界数据训练的模型相比,双臂任务的成功率提高了超过70%,单臂任务的成功率提高了超过40%。
论文及项目相关链接
PDF CVPR 2025 Highlight. 22 pages. Project page: https://robotwin-benchmark.github.io/
Summary
在机器人技术的迅速发展中,双臂协调和复杂物体操作对于开发先进自主系统至关重要。然而,缺乏多样化和高质量示范数据以及现实世界评估基准严重限制了此类发展。为解决这一问题,我们推出RoboTwin生成式数字双胞胎框架,利用三维生成基础模型与大型语言模型来构建多样化的专家数据集,并为双臂机器人任务提供与现实生活相契合的评估平台。RoboTwin框架从单一二维图像创建对象多样化的数字双胞胎,生成真实且互动的场景。此外,它引入空间关系感知的代码生成框架,结合对象注释和大型语言模型来拆解任务、确定空间约束和生成精确的机器人移动代码。该框架提供模拟和真实数据的全面基准测试,实现标准化评估以及模拟训练和现实表现之间的更好契合。我们在开源COBOT Magic Robot平台上验证了我们的方法。经过RoboTwin生成数据预训练并在有限真实样本上进行微调的政策显示出巨大潜力,通过提高单臂任务和双臂任务的成功率超过70%和40%,相较于仅在真实世界数据上训练模型有显著优势。
Key Takeaways
- 机器人技术中双臂协调和复杂物体操作是开发先进自主系统的核心能力。
- 当前缺乏多样化和高质量的示范数据以及现实世界评估基准限制了发展。
- RoboTwin框架使用三维生成基础模型和大型语言模型解决这一问题。
- RoboTwin创建多样化的数字双胞胎和生成真实互动场景。
- 引入空间关系感知的代码生成框架来拆解任务、确定空间约束和生成精确机器人移动代码。
- 提供模拟和真实数据的全面基准测试,实现标准化评估。
点此查看论文截图

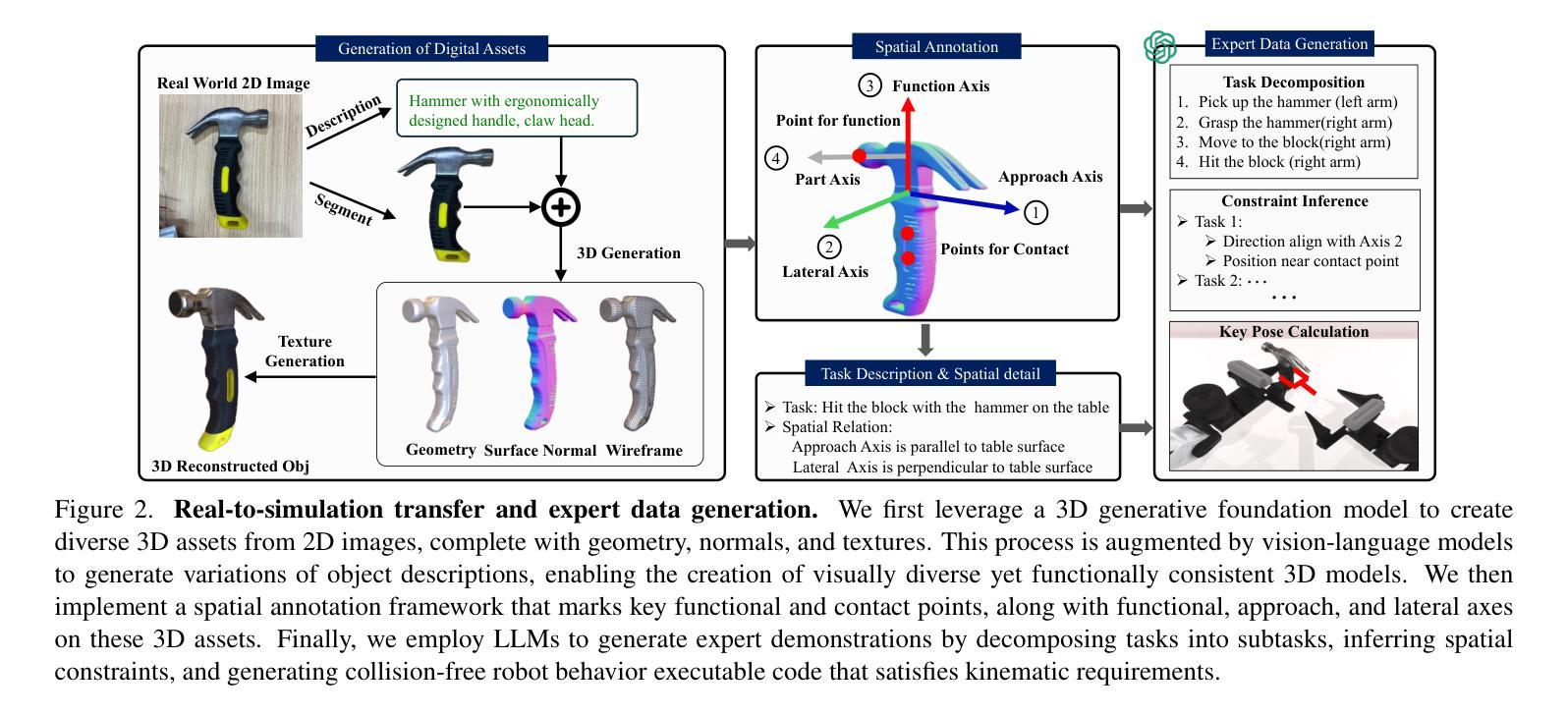
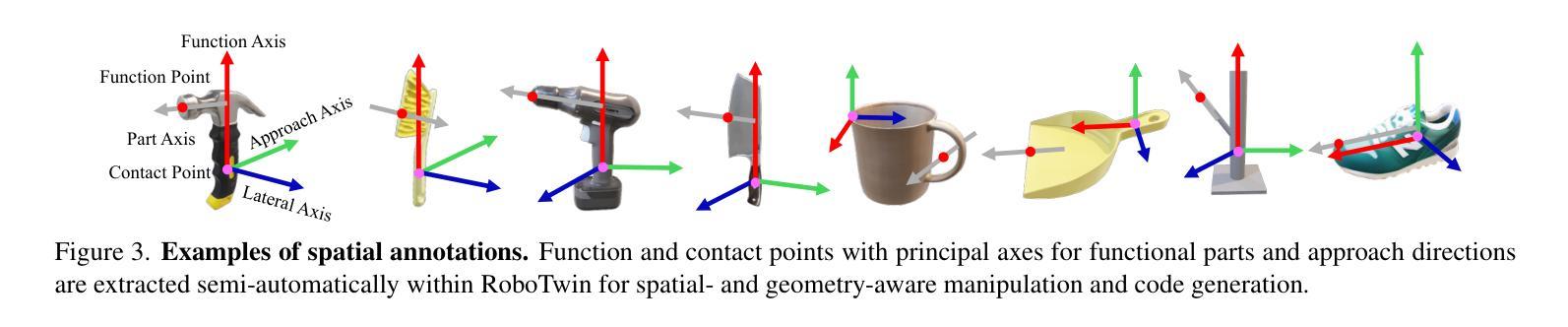

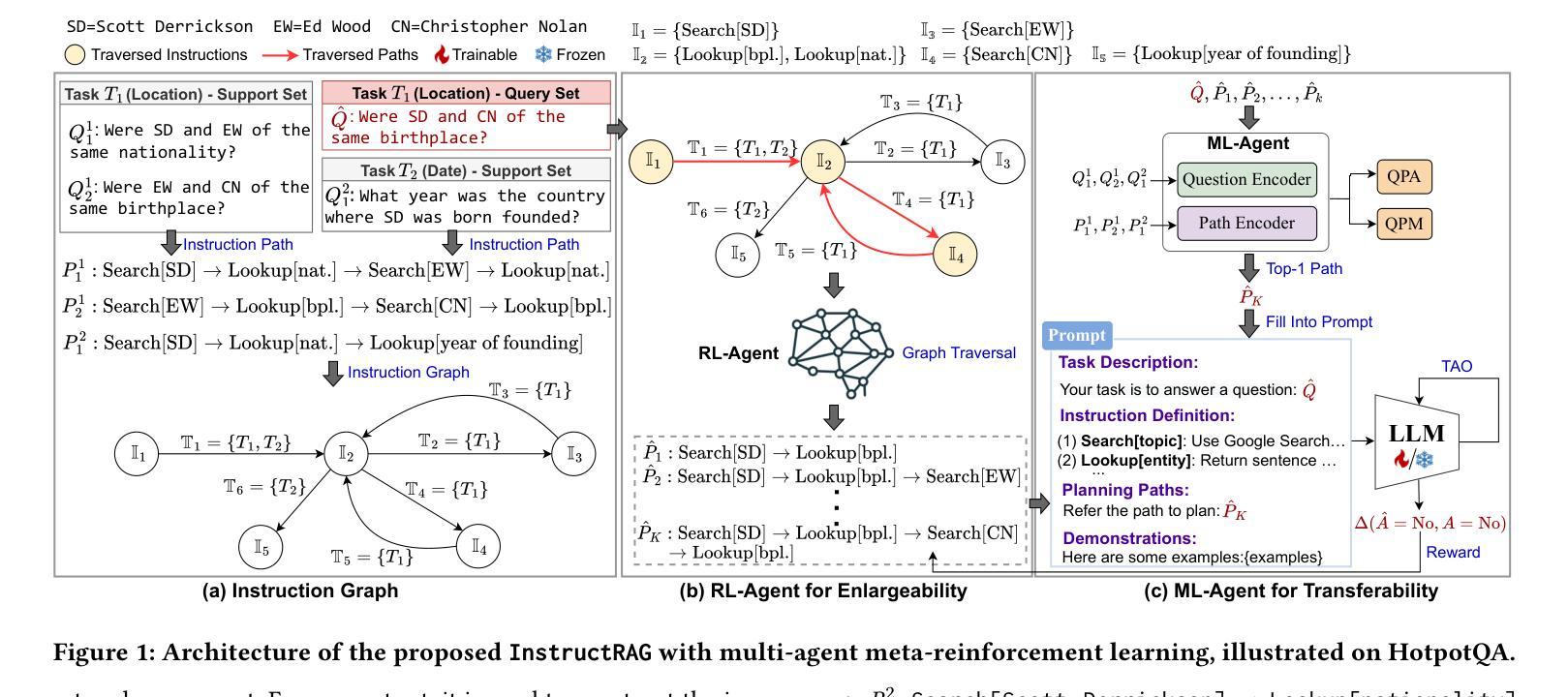
InstructRAG: Leveraging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning
Authors:Zheng Wang, Shu Xian Teo, Jun Jie Chew, Wei Shi
Recent advancements in large language models (LLMs) have enabled their use as agents for planning complex tasks. Existing methods typically rely on a thought-action-observation (TAO) process to enhance LLM performance, but these approaches are often constrained by the LLMs’ limited knowledge of complex tasks. Retrieval-augmented generation (RAG) offers new opportunities by leveraging external databases to ground generation in retrieved information. In this paper, we identify two key challenges (enlargability and transferability) in applying RAG to task planning. We propose InstructRAG, a novel solution within a multi-agent meta-reinforcement learning framework, to address these challenges. InstructRAG includes a graph to organize past instruction paths (sequences of correct actions), an RL-Agent with Reinforcement Learning to expand graph coverage for enlargability, and an ML-Agent with Meta-Learning to improve task generalization for transferability. The two agents are trained end-to-end to optimize overall planning performance. Our experiments on four widely used task planning datasets demonstrate that InstructRAG significantly enhances performance and adapts efficiently to new tasks, achieving up to a 19.2% improvement over the best existing approach.
近期大型语言模型(LLM)的进步使其能够作为执行复杂任务的代理。现有方法通常依赖于思维-行动-观察(TAO)过程来提高LLM的性能,但这些方法往往受到LLM对复杂任务了解有限的制约。检索增强生成(RAG)通过利用外部数据库来支持生成基于检索的信息,提供了新的机会。在本文中,我们指出了将RAG应用于任务规划所面临的两个关键挑战,即可扩展性和可迁移性。我们提出了InstructRAG,这是一种在多智能体元强化学习框架内的新型解决方案,以解决这些挑战。InstructRAG包括一个用于组织过去指令路径(正确行动序列)的图、一个用于扩大图覆盖以提高可扩展性的强化学习RL代理,以及一个用于改进任务泛化以提高可迁移性的元学习ML代理。这两个代理进行端到端训练以优化整体规划性能。我们在四个广泛使用的任务规划数据集上进行的实验表明,InstructRAG显著提高了性能,并能高效适应新任务,相较于最佳现有方法实现了高达19.2%的改进。
论文及项目相关链接
PDF This paper has been accepted by SIGIR 2025
Summary
大型语言模型(LLM)的最新进展使其能够作为执行复杂任务的代理。现有方法通常采用思考-行动-观察(TAO)过程来提高LLM的性能,但这些方法往往受到LLM对复杂任务了解有限的制约。检索增强生成(RAG)通过利用外部数据库使生成基于检索的信息提供了新的机会。本文识别了将RAG应用于任务规划的两个关键挑战,即可扩展性和可转移性。我们提出了InstructRAG,这是一种多代理元强化学习框架内的解决方案,旨在解决这些挑战。InstructRAG包括一个组织过去指令路径的图(正确行动序列)、一个用于扩大图的覆盖范围的强化学习强化学习代理,以及一个用于改进任务泛化的元学习机器学习代理。这两个代理端对端训练以优化整体规划性能。我们在四个广泛使用的任务规划数据集上的实验表明,InstructRAG显著提高了性能,并能高效适应新任务,相较于最佳现有方法实现了最高达19.2%的改进。
Key Takeaways
- LLMs已用作复杂任务的代理,但受限于对任务了解有限。
- 检索增强生成(RAG)利用外部数据库,使生成基于检索的信息。
- 应用RAG于任务规划面临两大挑战:可扩展性和可转移性。
- InstructRAG是一个多代理解决方案,包括用于组织过去指令路径的图。
- InstructRAG使用强化学习代理扩大图的覆盖范围,使用元学习代理提高任务泛化能力。
- 端对端训练两个代理以优化整体规划性能。
点此查看论文截图


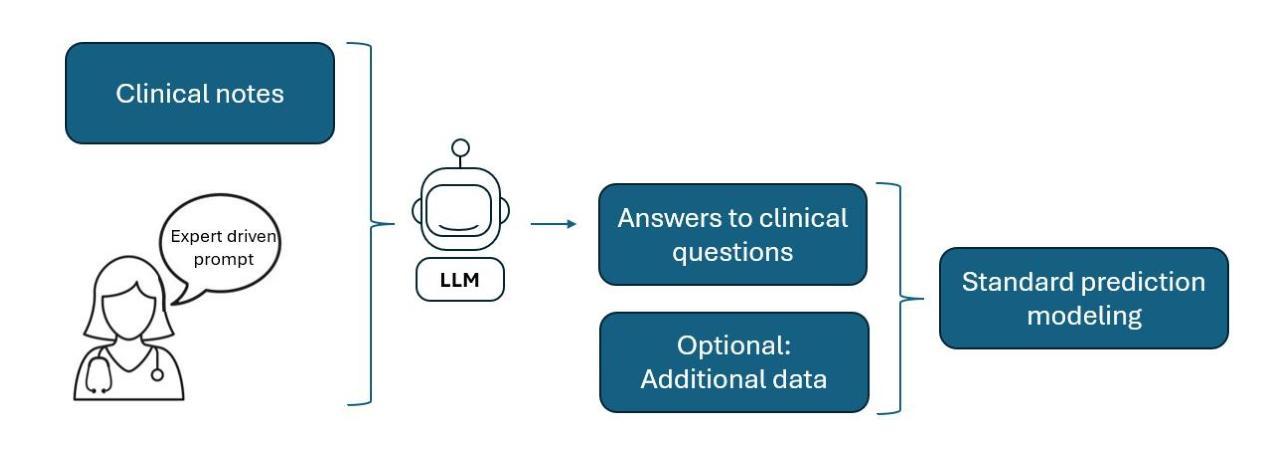
Paging Dr. GPT: Extracting Information from Clinical Notes to Enhance Patient Predictions
Authors:David Anderson, Michaela Anderson, Margret Bjarnadottir, Stephen Mahar, Shriyan Reyya
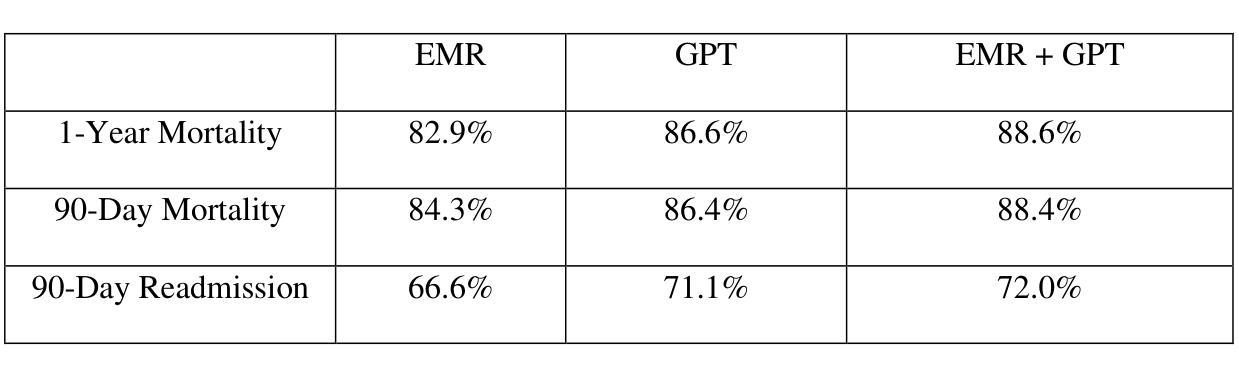
There is a long history of building predictive models in healthcare using tabular data from electronic medical records. However, these models fail to extract the information found in unstructured clinical notes, which document diagnosis, treatment, progress, medications, and care plans. In this study, we investigate how answers generated by GPT-4o-mini (ChatGPT) to simple clinical questions about patients, when given access to the patient’s discharge summary, can support patient-level mortality prediction. Using data from 14,011 first-time admissions to the Coronary Care or Cardiovascular Intensive Care Units in the MIMIC-IV Note dataset, we implement a transparent framework that uses GPT responses as input features in logistic regression models. Our findings demonstrate that GPT-based models alone can outperform models trained on standard tabular data, and that combining both sources of information yields even greater predictive power, increasing AUC by an average of 5.1 percentage points and increasing positive predictive value by 29.9 percent for the highest-risk decile. These results highlight the value of integrating large language models (LLMs) into clinical prediction tasks and underscore the broader potential for using LLMs in any domain where unstructured text data remains an underutilized resource.
在医疗保健领域,使用电子医疗记录的表格数据构建预测模型有着悠久的历史。然而,这些模型无法提取非结构化临床笔记中的信息,这些笔记记录了诊断、治疗、进展、药物和护理计划。在这项研究中,我们调查了GPT-4o-mini(ChatGPT)在获得患者出院总结后,对患者简单临床问题的回答如何支持患者级别的死亡预测。我们使用MIMIC-IV Note数据集中14,011名首次入住冠状动脉监护室或心血管重症监护室患者的数据,实施了一个透明的框架,该框架使用GPT的响应作为逻辑回归模型的输入特征。我们的研究发现,基于GPT的模型本身就能表现出超越仅使用表格数据训练的模型性能,而且结合这两种信息来源甚至能产生更大的预测能力,最高风险十分位的AUC平均提高了5.1个百分点,阳性预测值提高了29.9个百分点。这些结果突显了在临床预测任务中整合大型语言模型(LLM)的价值,并强调了在大规模使用非结构化文本数据的领域中应用LLM的更广泛潜力。
论文及项目相关链接
PDF Paper and Online Supplement combined into one PDF. 26 pages. 2 figures
Summary
本文探讨了利用GPT-4o-mini(ChatGPT)处理患者出院总结中的非结构化文本数据,以支持患者层面死亡率预测的研究。研究使用来自MIMIC-IV Note数据集的心血管重症监护单元首次入院患者的数据,发现基于GPT的模型在单独使用时表现优于基于标准表格数据的模型,并且两者结合能提高预测能力,最高风险组的AUC平均提高5.1个百分点,阳性预测值提高29.9%。这显示了将大型语言模型整合到临床预测任务中的价值,并强调了在使用非结构化文本数据的领域中利用大型语言模型的潜力。
Key Takeaways
- 研究利用GPT-4o-mini处理非结构化临床笔记数据,支持患者死亡率预测。
- GPT模型在单独使用时表现优于基于标准表格数据的模型。
- 结合GPT模型和表格数据能提高预测能力。
- 在最高风险组中,AUC和阳性预测值有显著提高。
- 整合大型语言模型到临床预测任务中具有重要的价值。
- 大型语言模型在处理非结构化文本数据方面具有潜力。
点此查看论文截图

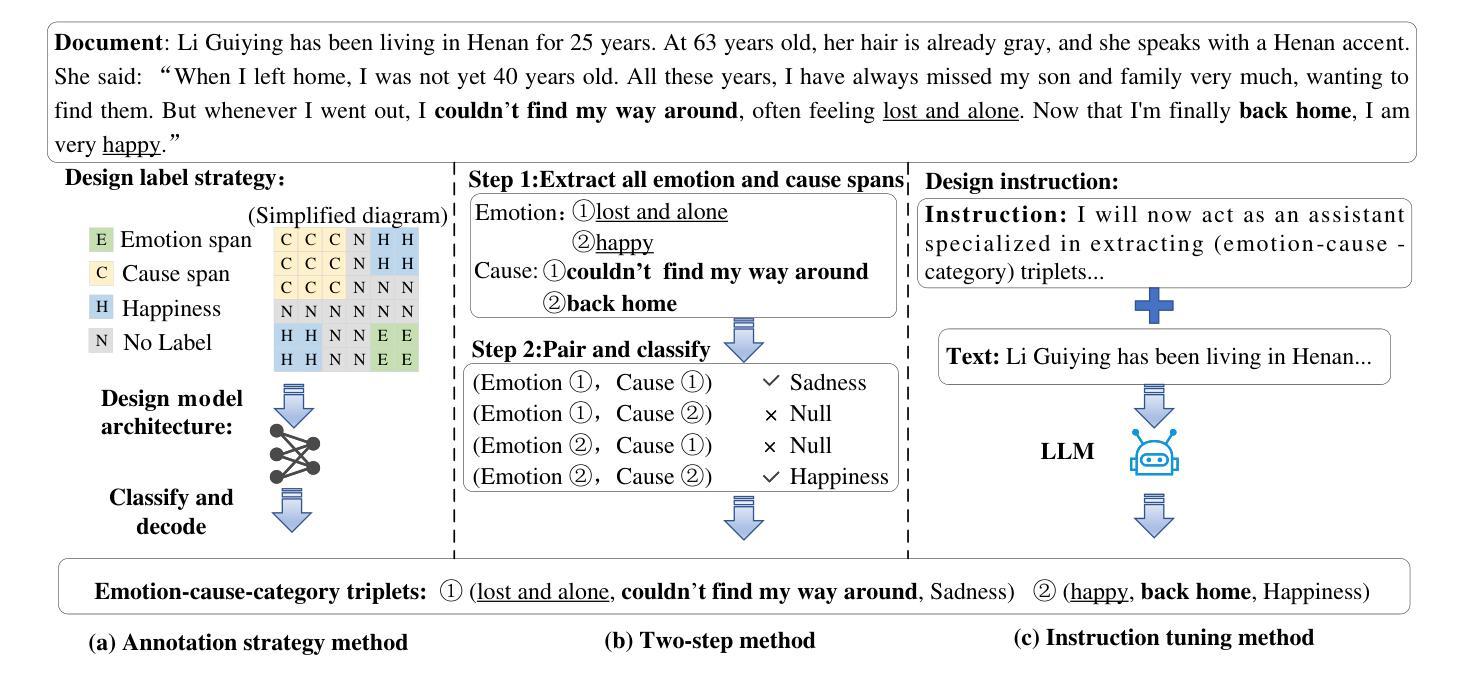
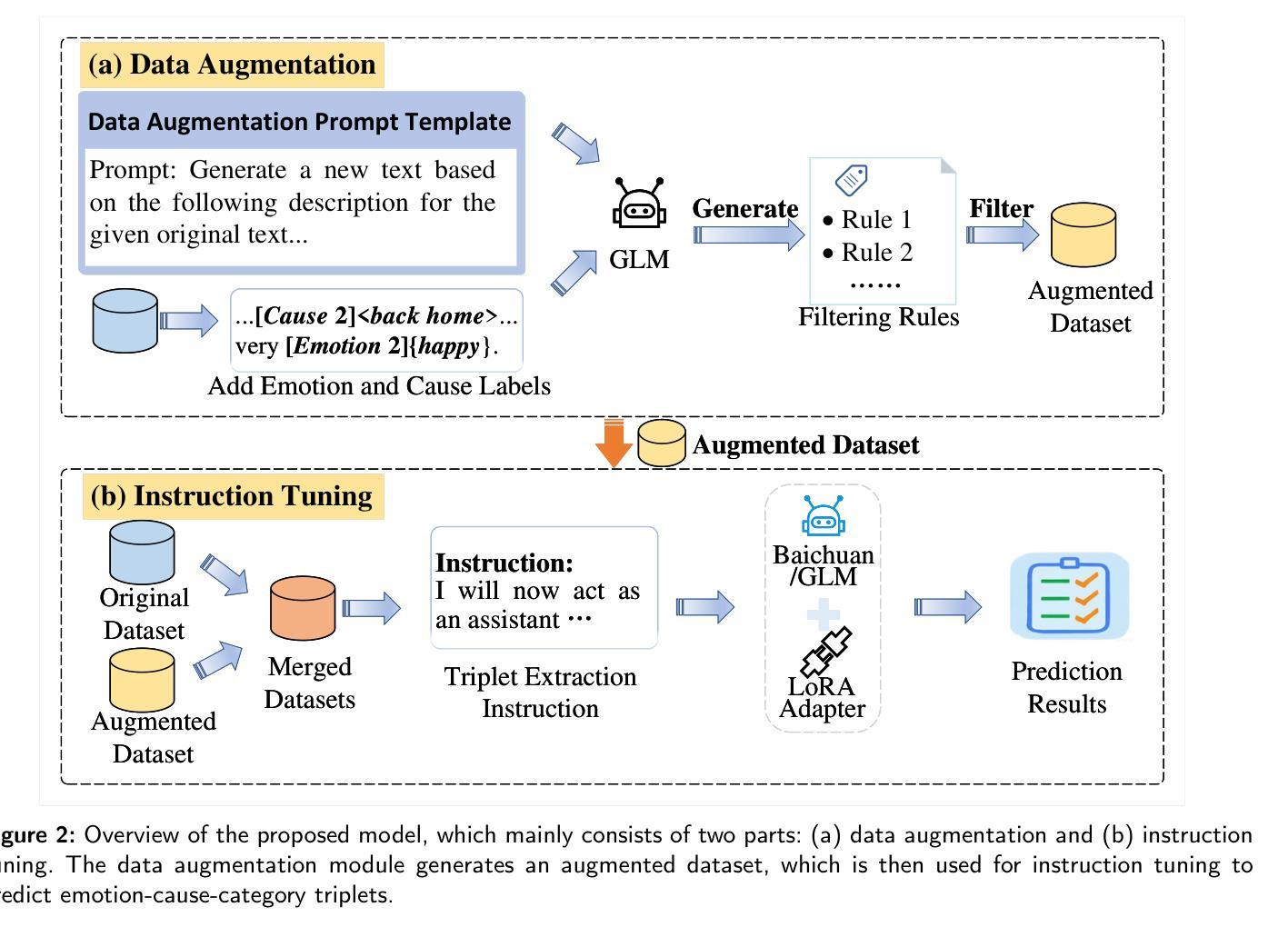
Span-level Emotion-Cause-Category Triplet Extraction with Instruction Tuning LLMs and Data Augmentation
Authors:Xiangju Li, Dong Yang, Xiaogang Zhu, Faliang Huang, Peng Zhang, Zhongying Zhao
Span-level emotion-cause-category triplet extraction represents a novel and complex challenge within emotion cause analysis. This task involves identifying emotion spans, cause spans, and their associated emotion categories within the text to form structured triplets. While prior research has predominantly concentrated on clause-level emotion-cause pair extraction and span-level emotion-cause detection, these methods often confront challenges originating from redundant information retrieval and difficulty in accurately determining emotion categories, particularly when emotions are expressed implicitly or ambiguously. To overcome these challenges, this study explores a fine-grained approach to span-level emotion-cause-category triplet extraction and introduces an innovative framework that leverages instruction tuning and data augmentation techniques based on large language models. The proposed method employs task-specific triplet extraction instructions and utilizes low-rank adaptation to fine-tune large language models, eliminating the necessity for intricate task-specific architectures. Furthermore, a prompt-based data augmentation strategy is developed to address data scarcity by guiding large language models in generating high-quality synthetic training data. Extensive experimental evaluations demonstrate that the proposed approach significantly outperforms existing baseline methods, achieving at least a 12.8% improvement in span-level emotion-cause-category triplet extraction metrics. The results demonstrate the method’s effectiveness and robustness, offering a promising avenue for advancing research in emotion cause analysis. The source code is available at https://github.com/zxgnlp/InstruDa-LLM.
跨级情绪-原因-类别三元组提取代表了情绪原因分析中的一个新颖且复杂的挑战。此任务涉及在文本中识别情绪跨度、原因跨度及其相关的情绪类别,以形成结构化三元组。尽管之前的研究主要集中在句子级情绪-原因对提取和跨级情绪-原因检测上,但这些方法经常面临来自冗余信息检索的挑战,以及在准确确定情绪类别方面的困难,特别是当情绪被隐含或模糊表达时。为了克服这些挑战,本研究探索了一种精细的跨级情绪-原因-类别三元组提取方法,并引入了一个基于大型语言模型的创新框架,该框架利用指令调整和数据增强技术。所提出的方法采用特定的三元组提取指令,并利用低秩适应来微调大型语言模型,无需使用复杂的特定任务架构。此外,开发了一种基于提示的数据增强策略,通过引导大型语言模型生成高质量合成训练数据来解决数据稀缺问题。广泛的实验评估表明,该方法显著优于现有基线方法,在跨级情绪-原因-类别三元组提取指标上至少提高了12.8%。结果表明该方法的有效性和稳健性,为情绪原因分析的研究提供了有前景的途径。源代码可在https://github.com/zxgnlp/InstruDa-LLM上找到。
论文及项目相关链接
Summary
本文探讨了基于大型语言模型的精细化情感起因分类三元组提取方法。该方法利用指令调优和基于指令的数据扩充技术,克服了冗余信息检索和确定情感类别的困难。通过任务特定的三元组提取指令和低秩适应技术,实现了对大型语言模型的微调,无需复杂的任务特定架构。同时,开发了一种基于提示的数据增强策略,通过引导大型语言模型生成高质量合成训练数据来解决数据稀缺问题。实验评估表明,该方法在情感起因分类三元组提取方面显著优于现有基线方法,至少提高了12.8%。源代码已在GitHub上发布。
Key Takeaways
- 情感起因分类三元组提取是一个新兴且复杂的挑战,涉及识别文本中的情感跨度、原因跨度及其相关情感类别。
- 现有方法面临冗余信息检索和确定情感类别(尤其是隐性或模糊表达的情感)的挑战。
- 本研究采用精细化方法,利用大型语言模型进行情感起因分类三元组提取。
- 创新性地使用指令调优和数据扩充技术,提高了模型的准确性和鲁棒性。
- 采用任务特定的指令对大型语言模型进行微调,无需复杂的任务特定架构。
- 通过基于提示的数据增强策略解决数据稀缺问题,生成高质量合成训练数据。
点此查看论文截图


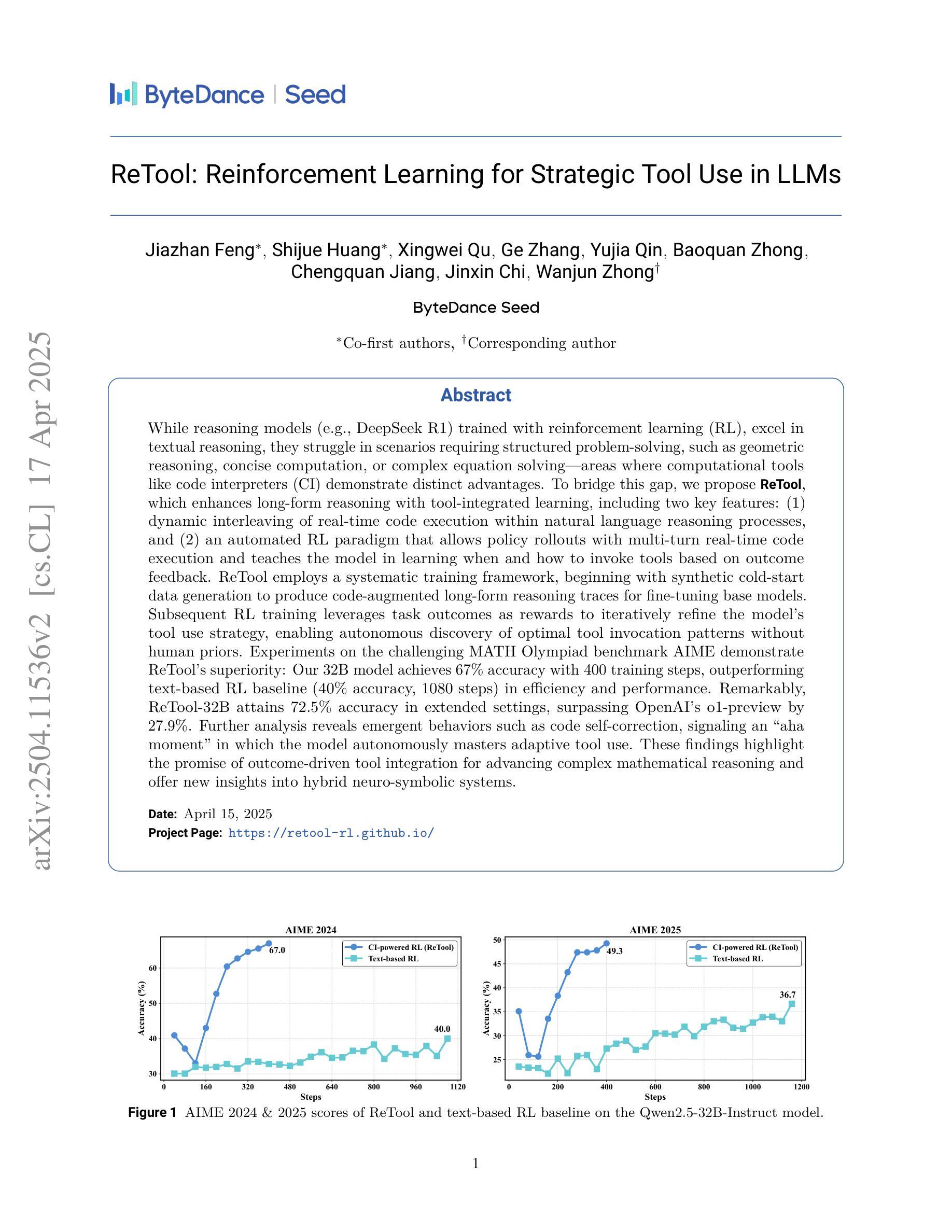
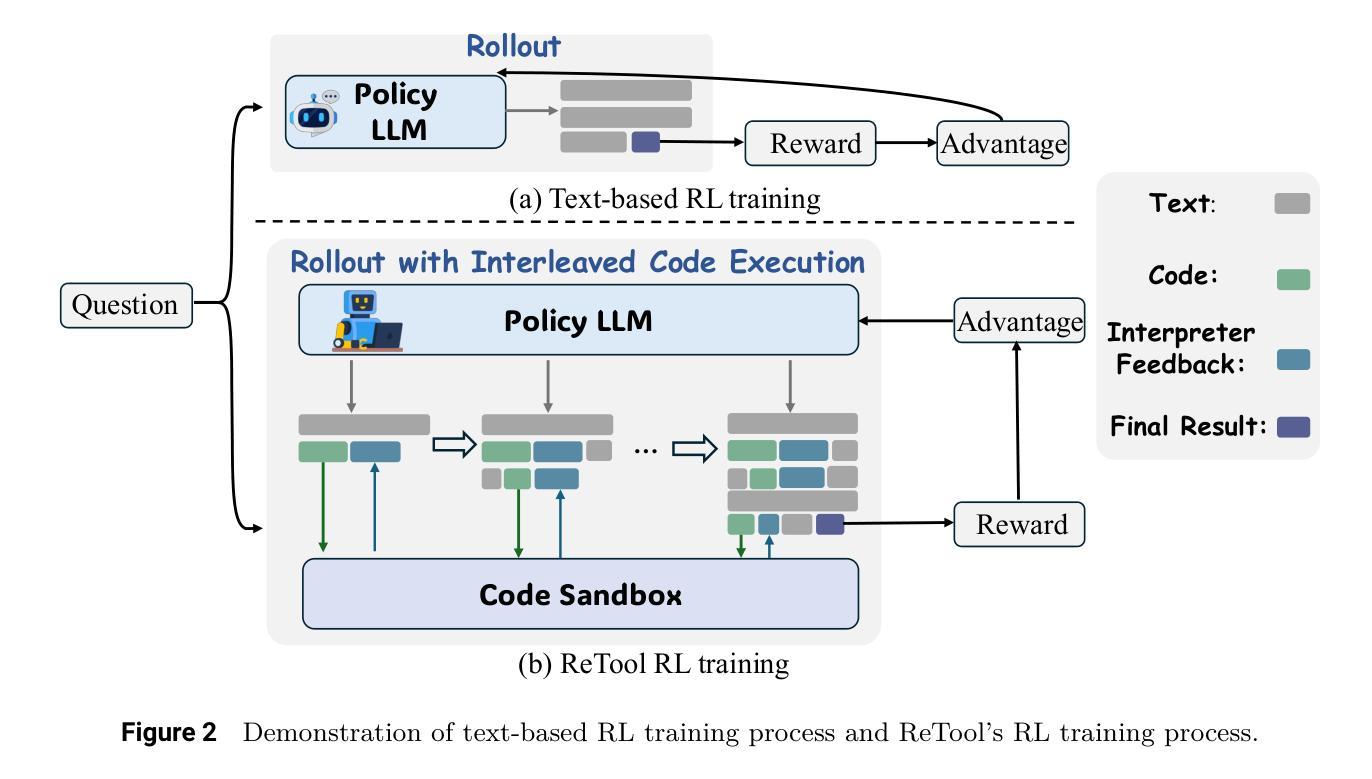
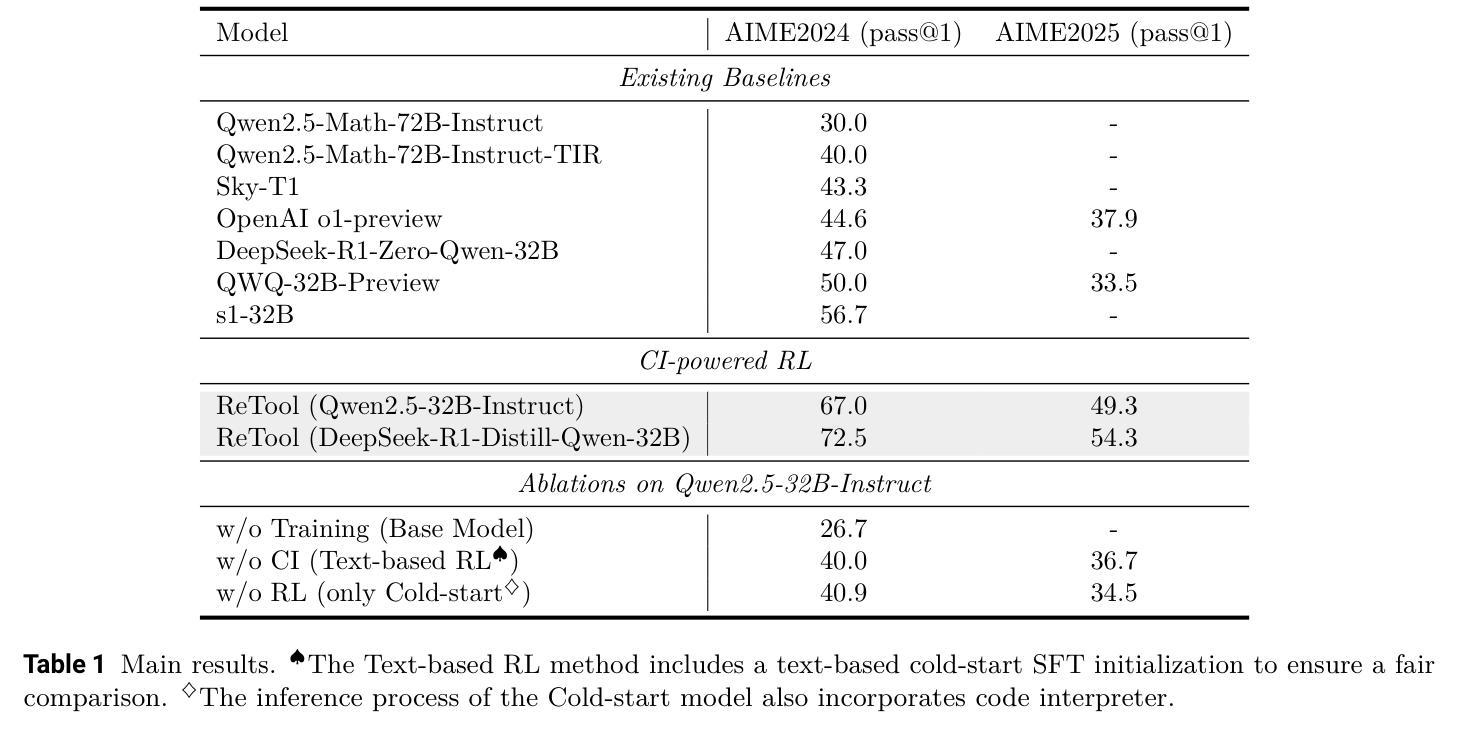
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Authors:Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, Wanjun Zhong
While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model’s tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool’s superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI’s o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ‘’aha moment’’ in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
虽然使用强化学习(RL)训练的推理模型(例如DeepSeek R1)在文本推理方面表现出色,但在需要结构化问题解决(如几何推理、简洁计算或复杂方程求解)的场景中却表现不佳,这些领域正是代码解释器(CI)等计算工具展现明显优势的地方。为了弥补这一差距,我们提出了ReTool,它通过工具集成学习增强长形式推理,包括两个关键功能:(1)在自然语言推理过程中动态交替实时代码执行;(2)一种自动化的强化学习模式,允许通过多轮实时代码执行进行策略推演,并根据结果反馈来教授模型何时以及如何调用工具。ReTool采用系统的训练框架,从生成合成冷启动数据开始,以产生用于微调基础模型的长形式代码辅助推理轨迹。随后的强化学习训练利用任务结果作为奖励来迭代优化模型对工具使用策略的调整,从而能够自主发现最佳的工具调用模式而无需人为先验知识。在具有挑战性的MATH Olympiad基准测试AIME上的实验证明了ReTool的优越性:我们的32B模型在400步训练后达到了67%的准确率,相较于基于文本的强化学习基线(准确率为40%,训练步骤为1080步),在效率和性能上更胜一筹。值得一提的是,ReTool-32B在扩展设置中达到了72.5%的准确率,超越了OpenAI的o1-preview基准的27.9%。进一步的分析显示出现代码自我修正等突发行为,标志着模型自主掌握自适应工具使用的“顿悟时刻”。这些发现凸显了结果驱动的工具集成在推动复杂数学推理方面的潜力,并为混合神经符号系统提供了新的见解。
论文及项目相关链接
PDF fix typos
Summary
本文介绍了使用强化学习训练的推理模型在文本推理方面表现出色,但在需要结构化问题解决(如几何推理、简洁计算和复杂方程求解)的场景中表现不佳。为此,提出了ReTool工具集成学习方法,通过实时代码执行与自然语言推理过程的动态交织,以及基于结果反馈的自动化强化学习模式,提高了长形式推理能力。实验结果表明,ReTool在具有挑战性的MATH Olympiad基准测试AIME上表现出卓越性能,优于仅基于文本的RL基线。ReTool模型自主学习适应工具使用的行为,显示出巨大的潜力。
Key Takeaways
- 强化学习训练的推理模型在文本推理方面表现出色,但在结构化问题解决方面存在局限性。
- ReTool工具集成学习方法通过结合实时代码执行与自然语言推理,增强了长形式推理能力。
- ReTool采用自动化强化学习模式,根据结果反馈调整工具使用策略。
- ReTool在MATH Olympiad基准测试AIME上表现优越,效率与性能均优于基于文本的RL基线。
- ReTool模型展现出自主发现最优工具调用模式的潜力。
- 模型在扩展设置下表现出更高的准确性,超过OpenAI的o1-preview。
点此查看论文截图
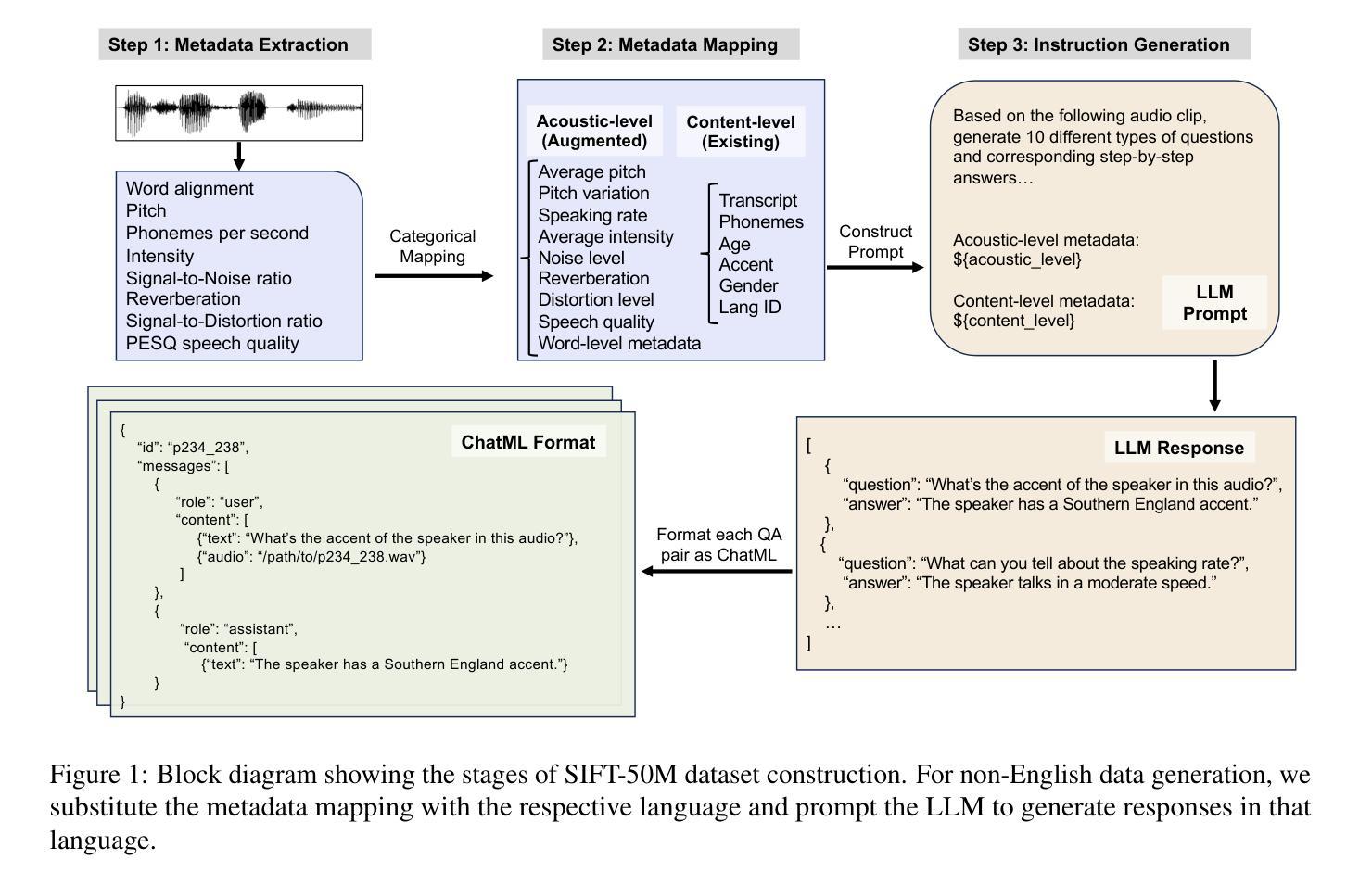
SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
Authors:Prabhat Pandey, Rupak Vignesh Swaminathan, K V Vijay Girish, Arunasish Sen, Jian Xie, Grant P. Strimel, Andreas Schwarz
We introduce SIFT (Speech Instruction Fine-Tuning), a 50M-example dataset designed for instruction fine-tuning and pre-training of speech-text large language models (LLMs). SIFT-50M is built from publicly available speech corpora, which collectively contain 14K hours of speech, and leverages LLMs along with off-the-shelf expert models. The dataset spans five languages, encompassing a diverse range of speech understanding as well as controllable speech generation instructions. Using SIFT-50M, we train SIFT-LLM, which outperforms existing speech-text LLMs on instruction-following benchmarks while achieving competitive performance on foundational speech tasks. To support further research, we also introduce EvalSIFT, a benchmark dataset specifically designed to evaluate the instruction-following capabilities of speech-text LLMs.
我们介绍了SIFT(语音指令微调),这是一个50百万示例数据集,专为语音文本大型语言模型(LLM)的指令微调和预训练而设计。SIFT-50M是从公开可用的语音语料库中构建而成的,这些语料库总共包含1万四千小时的语音,并利用LLM和现成的专家模型。该数据集涵盖五种语言,包括多样化的语音理解和可控语音生成指令。使用SIFT-50M,我们训练了SIFT-LLM,在指令遵循基准测试中,它的性能优于现有的语音文本LLM,同时在基本的语音任务中取得了有竞争力的表现。为了支持进一步的研究,我们还介绍了EvalSIFT,这是一个专门用于评估语音文本LLM的指令遵循能力的基准数据集。
论文及项目相关链接
Summary:
我们介绍了SIFT(语音指令微调)数据集,这是一个包含5000万个样本的数据集,旨在用于语音文本大型语言模型(LLM)的指令微调和预训练。SIFT-50M是从公开可用的语音语料库中构建而成,其中包含14000小时的语音,并利用LLM和现成的专家模型。该数据集涵盖五种语言,包括多样化的语音理解以及可控的语音生成指令。使用SIFT-50M训练的SIFT-LLM在指令遵循基准测试上的表现优于现有的语音文本LLM,同时在基础语音任务上实现具有竞争力的性能。为了支持进一步的研究,我们还推出了EvalSIFT基准数据集,专门用于评估语音文本LLM的指令遵循能力。
Key Takeaways:
- SIFT是一个包含50M实例的数据集,用于语音指令微调和大模型预训练。
- 数据集由公开可用的语音语料库构建,包含14K小时的语音数据。
- SIFT利用LLM和现成的专家模型。
- 数据集涵盖五种语言,包含多种语音理解和可控语音生成指令。
- SIFT-LLM在指令遵循基准测试上的表现优于其他语音文本LLM。
- SIFT-LLM在基础语音任务上实现具有竞争力的性能。
点此查看论文截图


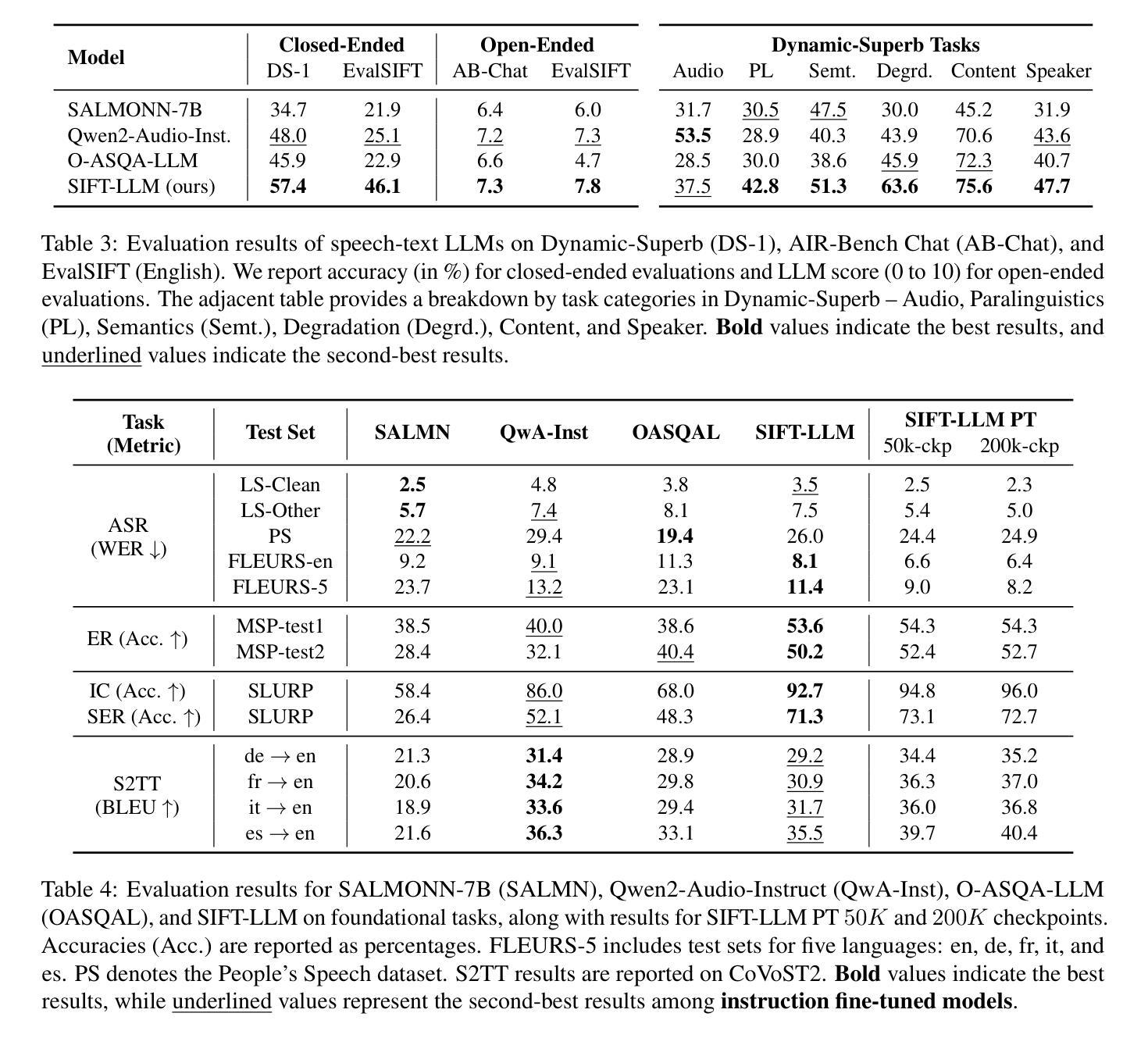
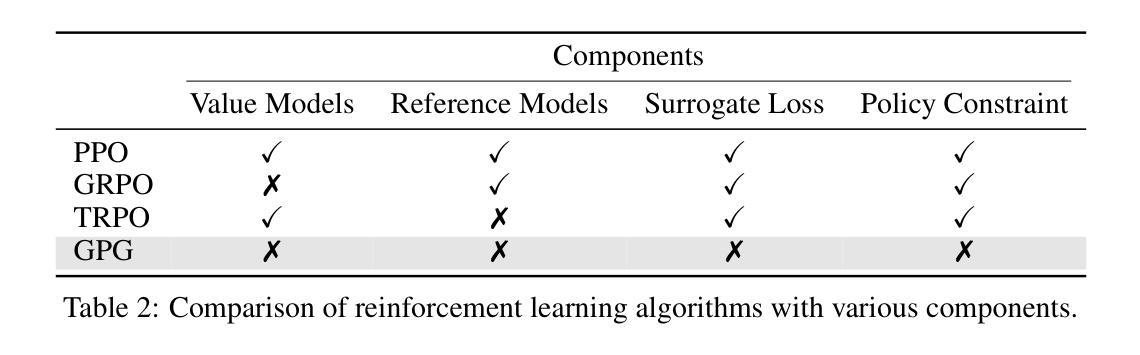
GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
Authors:Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, Yong Wang
Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. By eliminating the critic and reference models, avoiding KL divergence constraints, and addressing the advantage and gradient estimation bias, our approach significantly simplifies the training process compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. As illustrated in Figure 1, extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.
强化学习(RL)可以直接提升大语言模型的推理能力,而无需过多依赖监督微调(SFT)。在这项工作中,我们重新研究了传统的策略梯度(PG)机制,并提出了一种极简的强化学习方法,称为组策略梯度(GPG)。不同于传统方法,GPG直接优化原始的强化学习目标,从而无需替代损失函数。通过消除批评者和参考模型,避免KL散度约束,并解决优势和梯度估计偏差的问题,我们的方法大大简化了与组相对策略优化(GRPO)相比的训练过程。我们的方法在不依赖辅助技术或调整的情况下实现了卓越的性能。如图1所示,大量实验证明,我们的方法不仅降低了计算成本,而且在各种单模态和多模态任务上始终优于GRPO。我们的代码可在https://github.com/AMAP-ML/GPG中找到。
论文及项目相关链接
Summary
强化学习(RL)可直接提升大语言模型的推理能力,无需过多依赖监督微调(SFT)。本研究重新审视了传统的策略梯度(PG)机制,并提出了一种极简的RL方法——群组策略梯度(GPG)。GPG直接优化原始的RL目标,从而无需替代损失函数。通过消除评论家模型和参考模型,避免KL散度约束,并解决优势和梯度估计偏差问题,GPG简化了训练过程。实验表明,GPG不仅降低了计算成本,而且在各种单模态和多模态任务上均优于群体相对策略优化(GRPO)。
Key Takeaways
- 强化学习可以增强大语言模型的推理能力,且不需要大量监督微调。
- 研究提出了一种新的强化学习方法——群组策略梯度(GPG)。
- GPG直接优化原始的强化学习目标,无需使用替代损失函数。
- GPG简化了训练过程,通过消除评论家模型和参考模型,并解决了KL散度约束、优势估计和梯度估计偏差等问题。
- GPG在多种任务上表现出优异的性能,包括单模态和多模态任务。
- GPG方法降低了计算成本。
点此查看论文截图

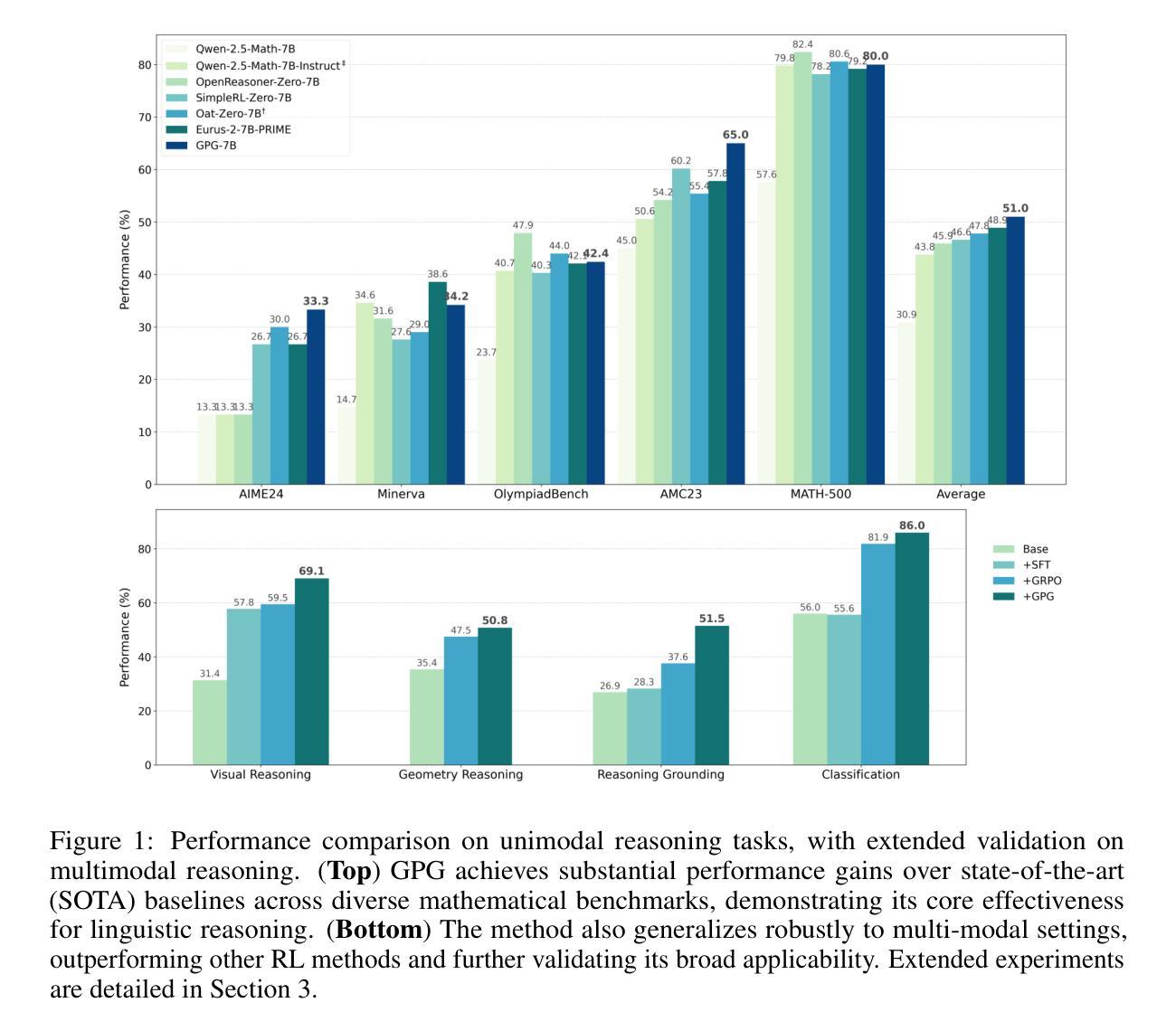
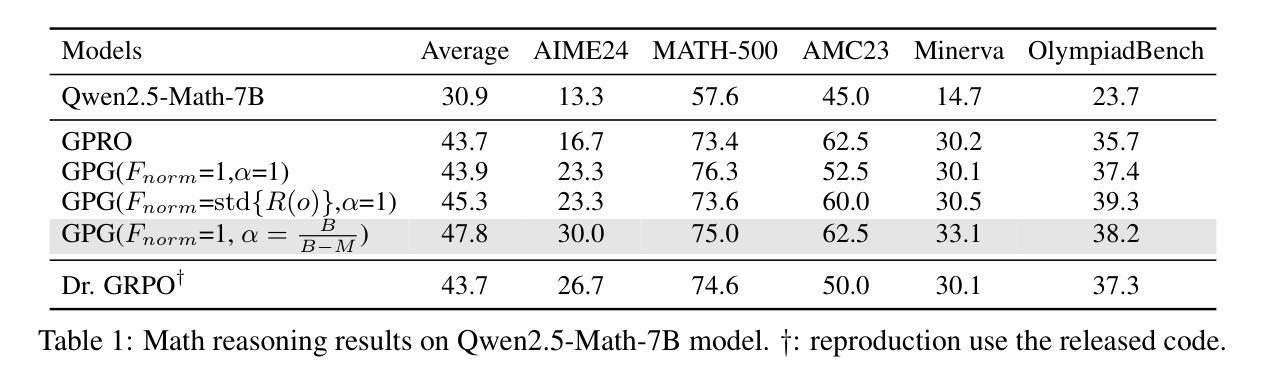
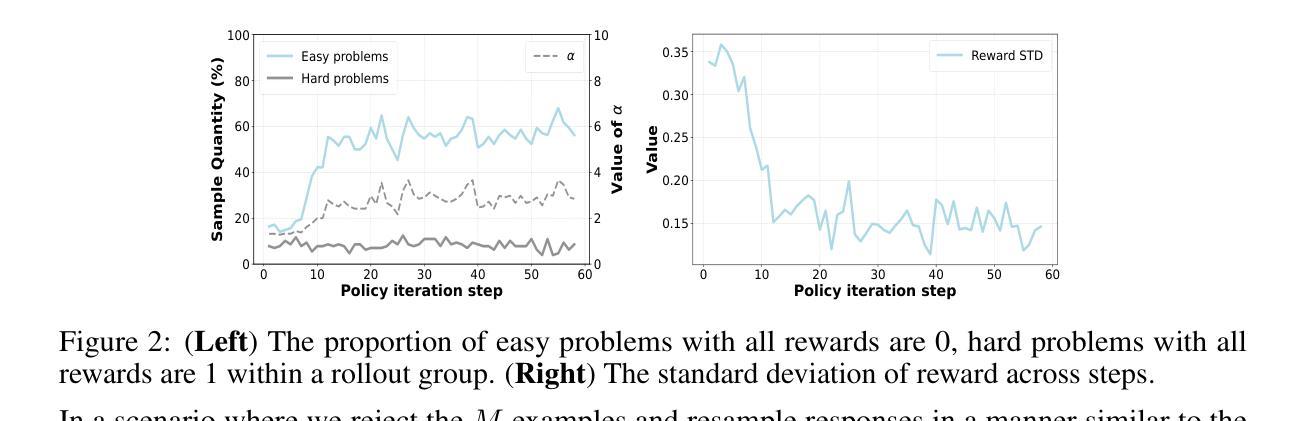
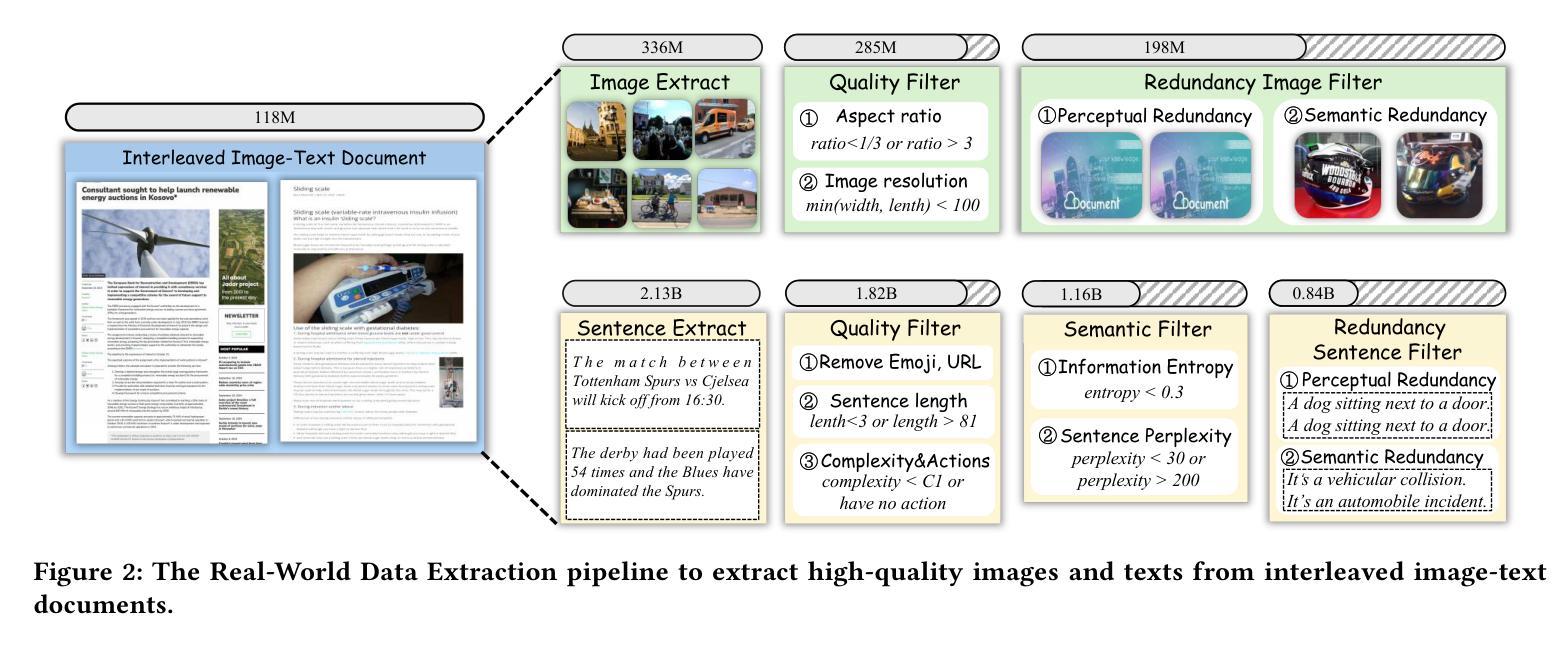
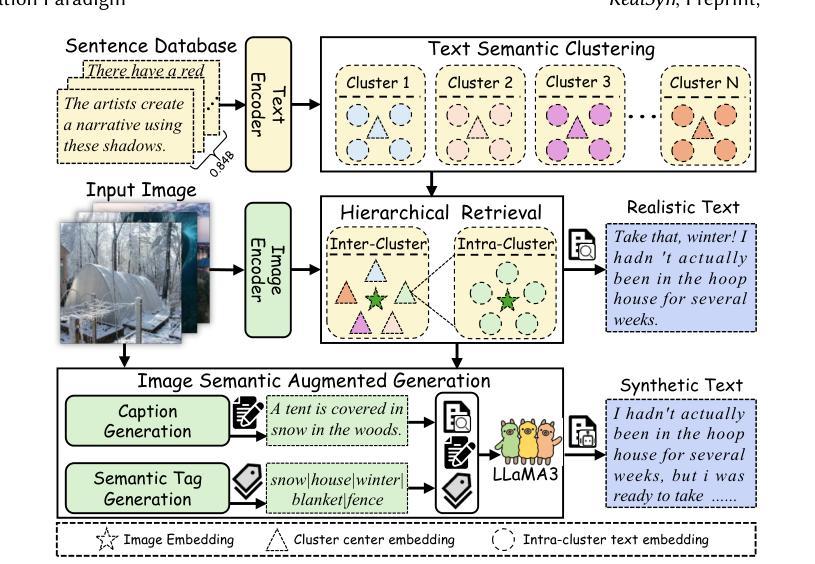
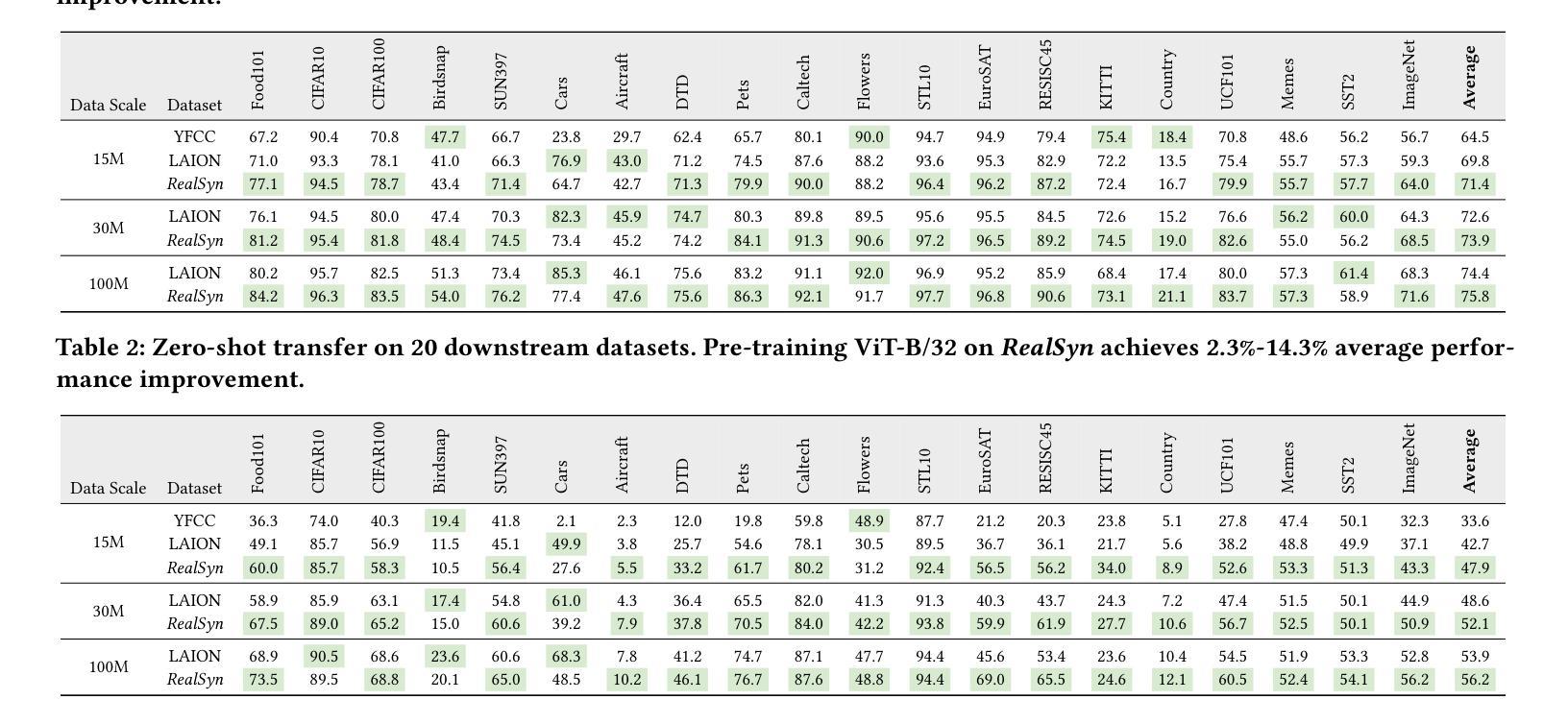
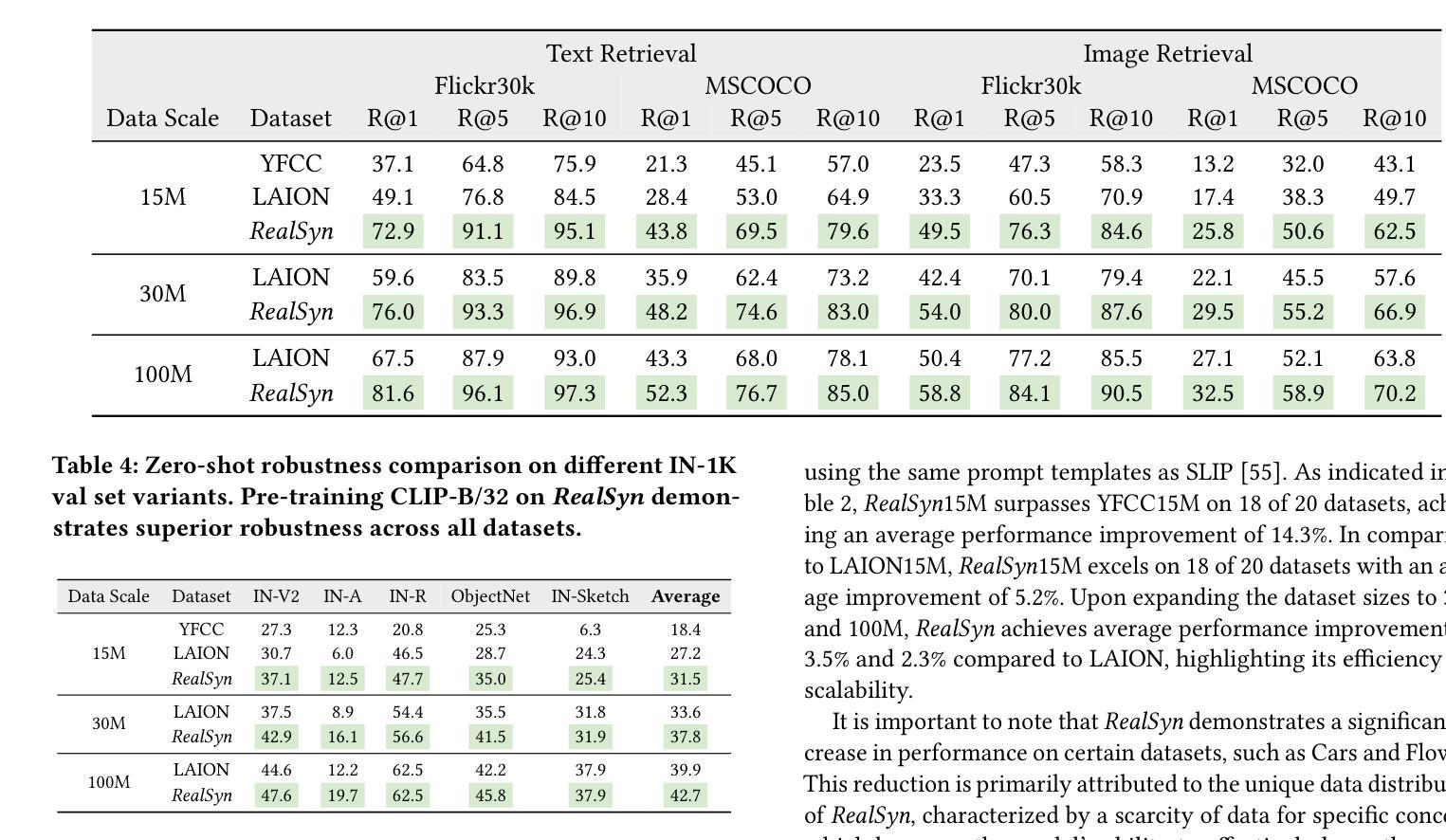
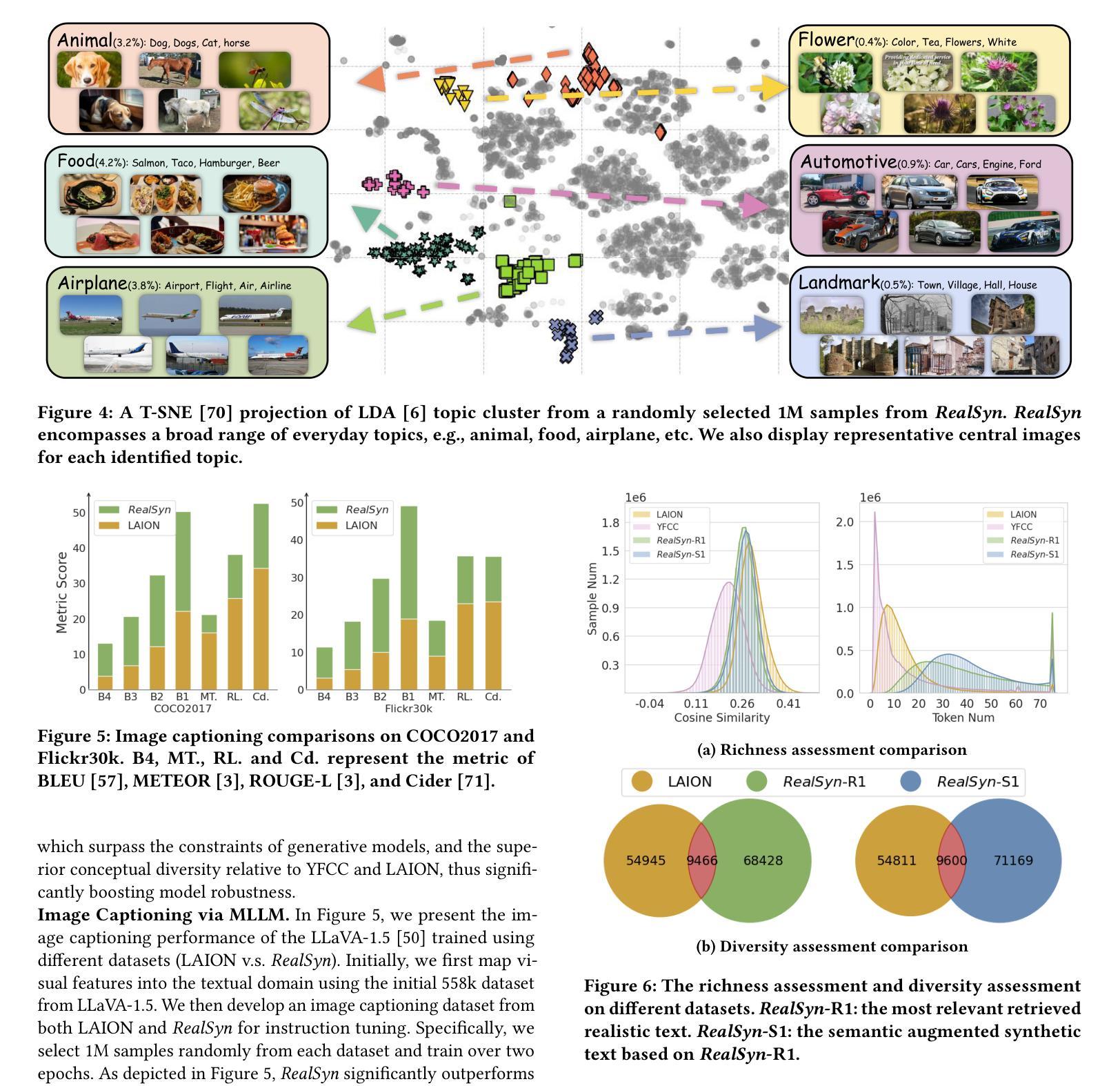
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Authors:Tiancheng Gu, Kaicheng Yang, Chaoyi Zhang, Yin Xie, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of multimodal interleaved documents remains underutilized for contrastive vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. We compare our dataset with other widely used datasets of equivalent scale for CLIP training. Models pre-trained on RealSyn consistently achieve state-of-the-art performance across various downstream tasks, including linear probe, zero-shot transfer, zero-shot robustness, and zero-shot retrieval. Furthermore, extensive experiments confirm that RealSyn significantly enhances contrastive vision-language representation learning and demonstrates robust scalability. To facilitate future research, the RealSyn dataset and pretrained model weights are released at https://github.com/deepglint/RealSyn.
在大量图文对上进行预训练后,对比语言图像预训练(CLIP)在各种基准测试上表现出有希望的性能。然而,大量的多模态交错文档在对比视觉语言表示学习中仍未得到充分利用。为了充分利用这些未配对的文档,我们首先建立了一个真实世界数据提取管道,以提取高质量的图片和文字。然后,我们设计了一种分层检索方法,以有效地将每张图像与多个语义上相关的真实文本相关联。为了进一步丰富精细的视觉信息,我们提出了一个图像语义增强生成模块来进行合成文本的生产。此外,我们采用了一种语义平衡采样策略,以提高数据集多样性,从而能够更好地学习长尾概念。基于这些创新,我们构建了RealSyn数据集,融合了真实和合成文本,提供三种规模:1.5亿、3亿和10亿。我们将数据集与其他广泛用于CLIP训练的同等规模数据集进行了比较。在各种下游任务中,基于RealSyn预训练的模型始终实现了最先进的性能,包括线性探测、零样本迁移、零样本鲁棒性和零样本检索。此外,大量实验证实,RealSyn显著增强了对比视觉语言表示学习,并表现出稳健的可扩展性。为了方便未来的研究,RealSyn数据集和预训练模型权重已在https://github.com/deepglint/RealSyn上发布。
论文及项目相关链接
PDF 15 pages, 12 figures, Webpage: https://garygutc.github.io/RealSyn
Summary
本文介绍了基于对比视觉语言预训练的改进方法,通过构建RealSyn数据集来提升对比视觉语言表示学习。RealSyn数据集结合了真实和合成文本,具有多层次规模。在多个下游任务中,基于RealSyn数据集的预训练模型取得了最新性能表现。该数据集及预训练模型权重已公开发布。
Key Takeaways
- CLIP在多种基准测试中表现出良好性能,但在对比视觉语言表示学习上存在大量未充分利用的多模态交错文档。
- 提出建立Real-World Data Extraction管道来提取高质量图像和文本。
- 设计了层次化的检索方法来高效地将每个图像与多个语义相关的现实文本相关联。
- 引入了图像语义增强生成模块来生成合成文本,以提高精细的视觉信息。
- 采用语义平衡采样策略提高数据集多样性,更好地学习长尾概念。
- 创建了RealSyn数据集,结合真实和合成文本,提供三种规模供选择。
点此查看论文截图

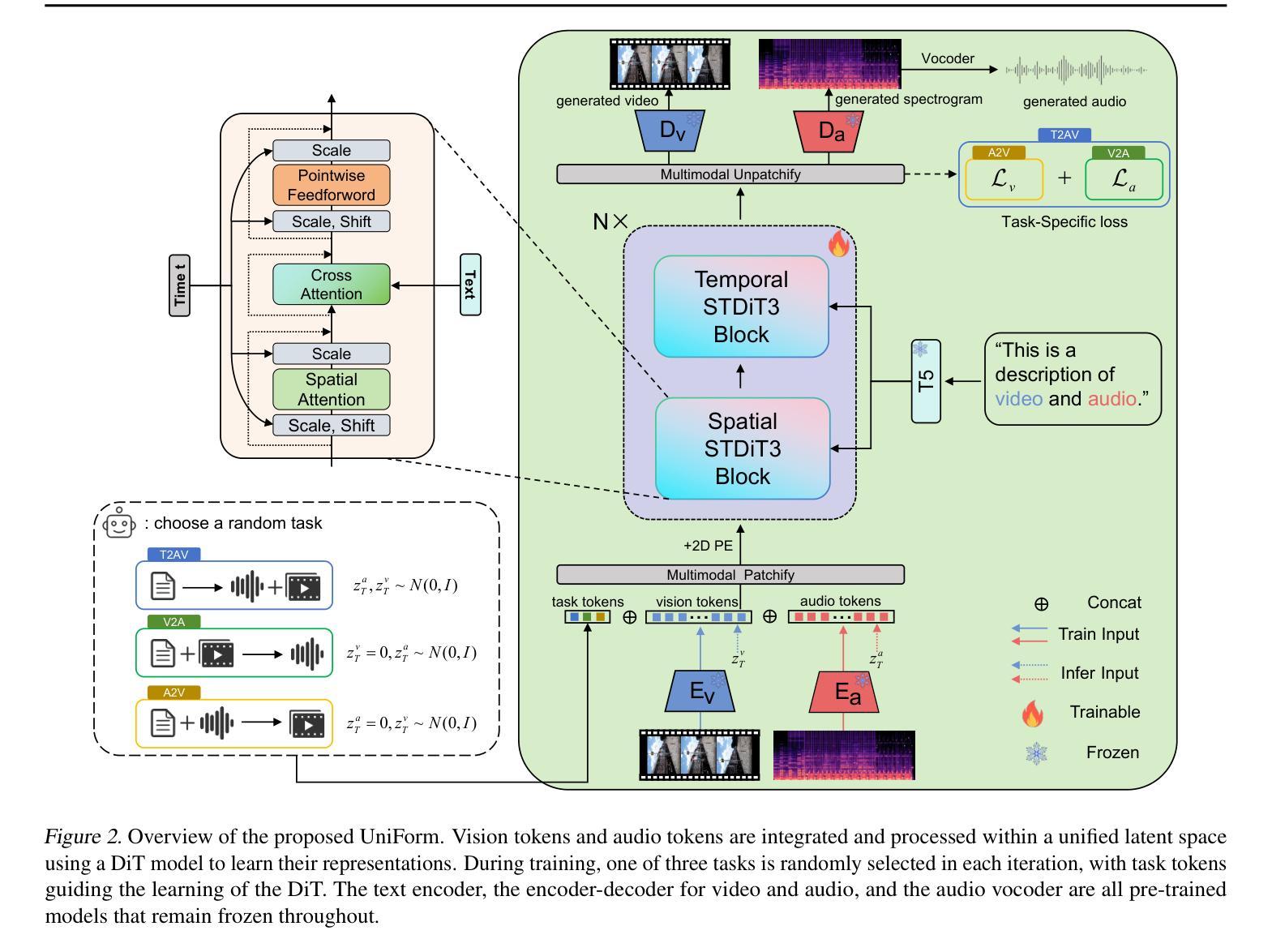
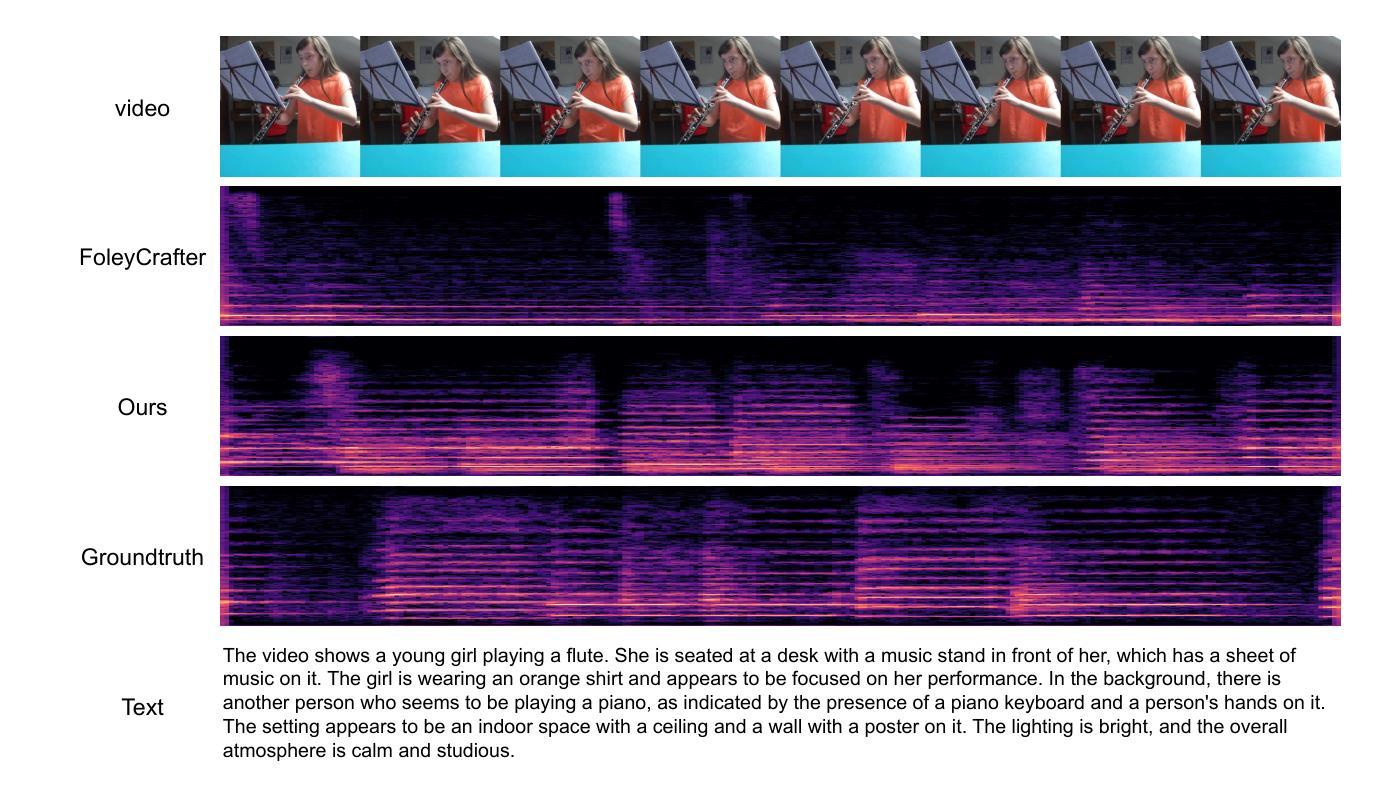
UniForm: A Unified Multi-Task Diffusion Transformer for Audio-Video Generation
Authors:Lei Zhao, Linfeng Feng, Dongxu Ge, Rujin Chen, Fangqiu Yi, Chi Zhang, Xiao-Lei Zhang, Xuelong Li
With the rise of diffusion models, audio-video generation has been revolutionized. However, most existing methods rely on separate modules for each modality, with limited exploration of unified generative architectures. In addition, many are confined to a single task and small-scale datasets. To address these limitations, we first propose UniForm, a unified multi-task diffusion transformer that jointly generates audio and visual modalities in a shared latent space. A single diffusion process models both audio and video, capturing the inherent correlations between sound and vision. Second, we introduce task-specific noise schemes and task tokens, enabling a single model to support multiple tasks, including text-to-audio-video, audio-to-video, and video-to-audio generation. Furthermore, by leveraging large language models and a large-scale text-audio-video combined dataset, UniForm achieves greater generative diversity than prior approaches. Extensive experiments show that UniForm achieves the state-of-the-art performance across audio-video generation tasks, producing content that is both well-aligned and close to real-world data distributions. Our demos are available at https://uniform-t2av.github.io/.
随着扩散模型的兴起,音视频生成领域发生了革命性的变化。然而,大多数现有方法依赖于针对每种模态的独立模块,对统一生成架构的探索有限。此外,许多方法仅限于单一任务和小规模数据集。为了解决这些局限性,我们首次提出UniForm,这是一个统一的多任务扩散变压器,它在一个共享潜在空间中联合生成音频和视觉模态。一个单一的扩散过程同时建模音频和视频,捕捉声音和视觉之间的内在关联。其次,我们引入了特定任务的噪声方案和任务令牌,使单一模型能够支持多任务,包括文本到音频视频、音频到视频和视频到音频生成。此外,通过利用大型语言模型和大规模文本-音频-视频组合数据集,UniForm实现了比先前方法更大的生成多样性。大量实验表明,UniForm在音频视频生成任务上达到了最先进的性能,生成的内容既符合实际数据分布又接近真实世界。我们的演示可在https://uniform-t2av.github.io/上查看。
论文及项目相关链接
PDF Our demos are available at https://uniform-t2av.github.io/
Summary
随着扩散模型的发展,音视频生成领域经历了革新。然而,现有方法大多依赖单独模块处理不同模态,对统一生成架构的探索有限。为解决此问题,我们提出UniForm,一个统一的多任务扩散变压器,在共享潜在空间中联合生成音频和视频模态。单一扩散过程同时建模音频和视频,捕捉声音与视觉之间的内在关联。此外,我们引入任务特定噪声方案和任务令牌,使单一模型支持多任务,包括文本到音视频、音频到视频和视频到音频生成。通过利用大型语言模型和大规模文本-音频-视频组合数据集,UniForm较先前方法实现更大的生成多样性。实验表明,UniForm在音频视频生成任务上达到最新性能水平,生成的内容与现实世界数据分布相符。演示网站为:https://uniform-t2av.github.io/。
Key Takeaways
- 扩散模型带动了音视频生成的革新。
- 现有方法大多采用独立模块处理不同模态,缺乏统一生成架构。
- UniForm是一个统一的多任务扩散变压器,能在共享潜在空间中联合生成音频和视频。
- UniForm通过单一扩散过程同时建模音频和视频,捕捉两者间的内在关联。
- 引入任务特定噪声方案和任务令牌,支持多种生成任务。
- 利用大型语言模型和大规模数据集,UniForm实现更高的生成多样性。
点此查看论文截图


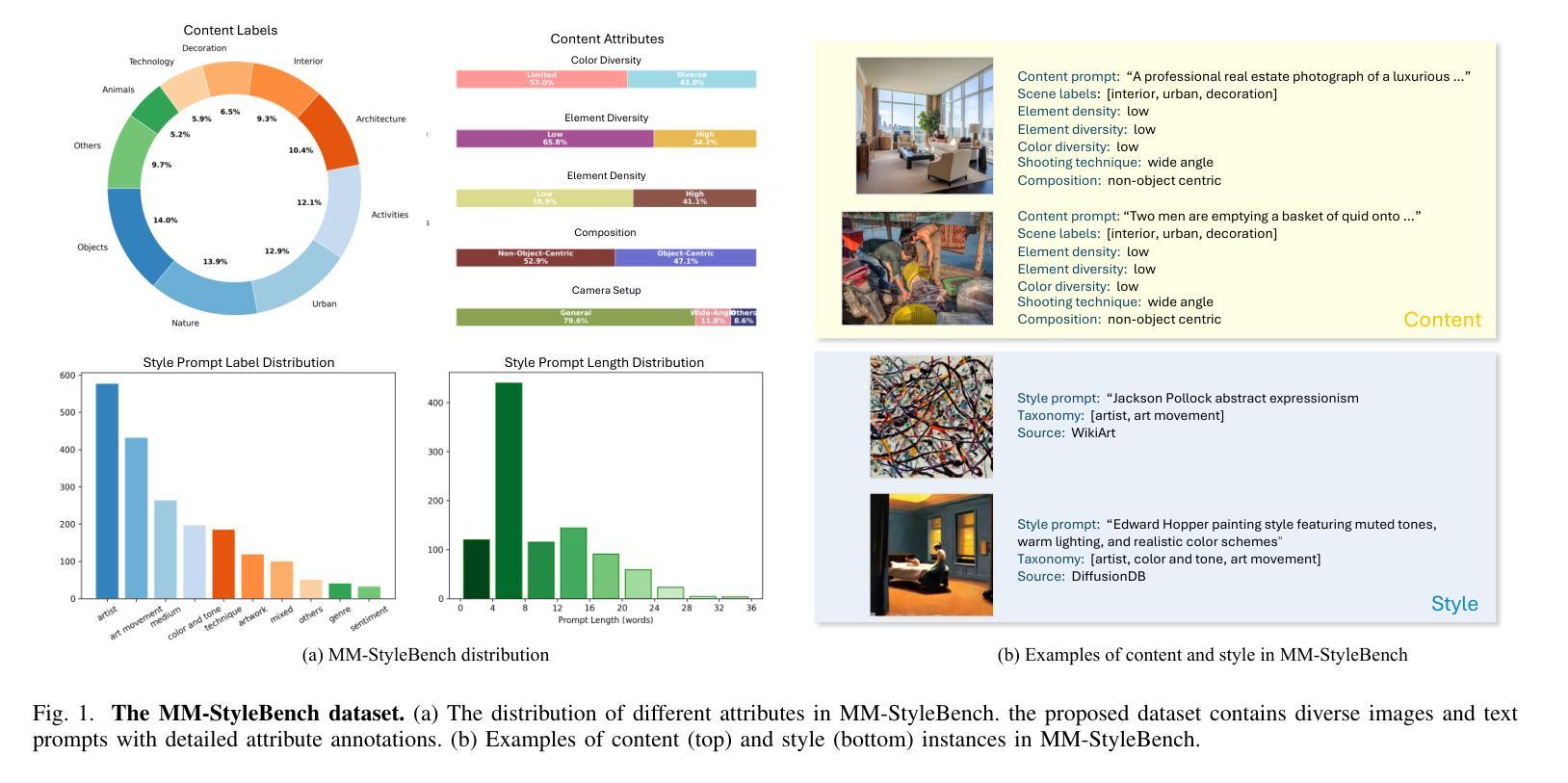
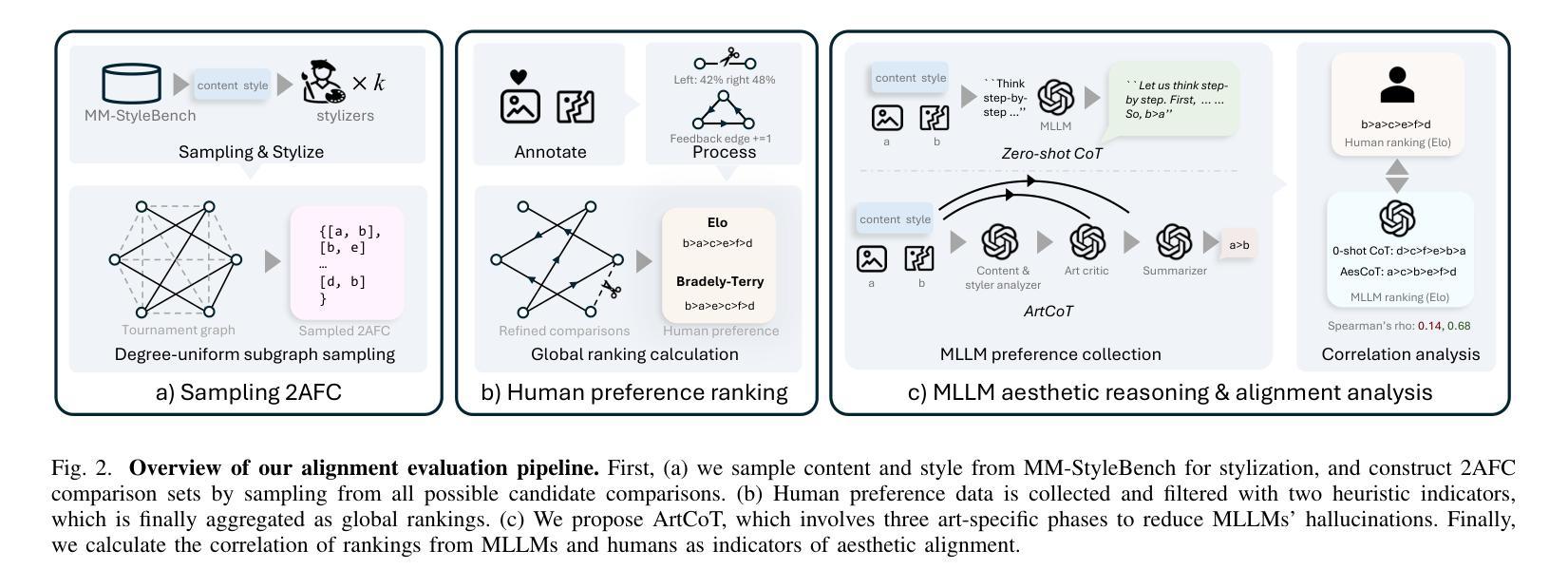
Multimodal LLMs Can Reason about Aesthetics in Zero-Shot
Authors:Ruixiang Jiang, Changwen Chen
The rapid progress of generative art has democratized the creation of visually pleasing imagery. However, achieving genuine artistic impact - the kind that resonates with viewers on a deeper, more meaningful level - requires a sophisticated aesthetic sensibility. This sensibility involves a multi-faceted reasoning process extending beyond mere visual appeal, which is often overlooked by current computational models. This paper pioneers an approach to capture this complex process by investigating how the reasoning capabilities of Multimodal LLMs (MLLMs) can be effectively elicited for aesthetic judgment. Our analysis reveals a critical challenge: MLLMs exhibit a tendency towards hallucinations during aesthetic reasoning, characterized by subjective opinions and unsubstantiated artistic interpretations. We further demonstrate that these limitations can be overcome by employing an evidence-based, objective reasoning process, as substantiated by our proposed baseline, ArtCoT. MLLMs prompted by this principle produce multi-faceted and in-depth aesthetic reasoning that aligns significantly better with human judgment. These findings have direct applications in areas such as AI art tutoring and as reward models for generative art. Ultimately, our work paves the way for AI systems that can truly understand, appreciate, and generate artworks that align with the sensible human aesthetic standard.
生成艺术的快速发展使得创建视觉愉悦的图像变得民主化。然而,要实现真正的艺术影响力——那种与观众在更深层次、更有意义层面上产生共鸣的影响力,需要敏锐的审美感知。这种感知涉及一个超越单纯视觉吸引力的多元推理过程,这通常被当前的计算模型所忽视。本文开创了一种方法来捕捉这一复杂过程,通过调查多模态大型语言模型(MLLMs)的推理能力如何有效地用于美学判断。我们的分析揭示了一个关键问题:MLLMs在美学推理时倾向于出现幻觉,表现为主观意见和无根据的艺术解读。我们进一步证明,通过采用基于证据的客观推理过程,可以克服这些局限性,正如我们提出的基线模型ArtCoT所证实的那样。遵循这一原则的MLLMs产生了多元且深入的审美推理,与人类判断更加吻合。这些发现可直接应用于人工智能艺术辅导和生成艺术的奖励模型等领域。最终,我们的工作为人机系统真正能够理解、欣赏和生成符合人类审美标准的艺术作品铺平了道路。
论文及项目相关链接
PDF WIP, Homepage https://github.com/songrise/MLLM4Art
Summary
生成艺术的快速发展使得创造视觉愉悦的图像得以普及。然而,实现真正的艺术影响力,即那种与观众更深层次、更有意义地产生共鸣的影响力,需要一种复杂的美学感知。这种感知涉及多方面的推理过程,超越单纯的视觉吸引力,而这一点往往被当前的计算模型所忽视。本文率先探索了一种方法来捕捉这一复杂过程,通过调查多模态大型语言模型(MLLMs)的推理能力如何有效地用于美学判断。分析显示了一个关键问题:MLLMs在美学推理时倾向于出现幻觉,表现为主观意见和无根据的艺术解读。我们进一步证明,通过采用基于证据的客观推理过程可以克服这些限制,如我们所提出的基线ArtCoT所示。遵循这一原则的MLLMs产生了多层次、深入的美学推理,与人类判断更加契合。这些发现可直接应用于人工智能艺术辅导和奖励模型等领域。最终,我们的工作为能够真正理解、欣赏和生成符合人类审美标准的艺术作品的AI系统铺平了道路。
Key Takeaways
- 生成艺术的进步使得创造视觉愉悦图像变得容易,但实现真正的艺术影响力需要复杂的美学感知。
- 多模态大型语言模型(MLLMs)在美学判断中具有潜力,但存在倾向于幻觉的问题。
- MLLMs在美学推理时表现为主观意见和无根据的艺术解读,需要克服。
- 采用基于证据的客观推理过程可以改进MLLMs的美学推理能力。
- 遵循这一原则的MLLMs产生的美学推理与人类判断更加契合。
- 该研究的应用领域包括人工智能艺术辅导和奖励模型等。
点此查看论文截图


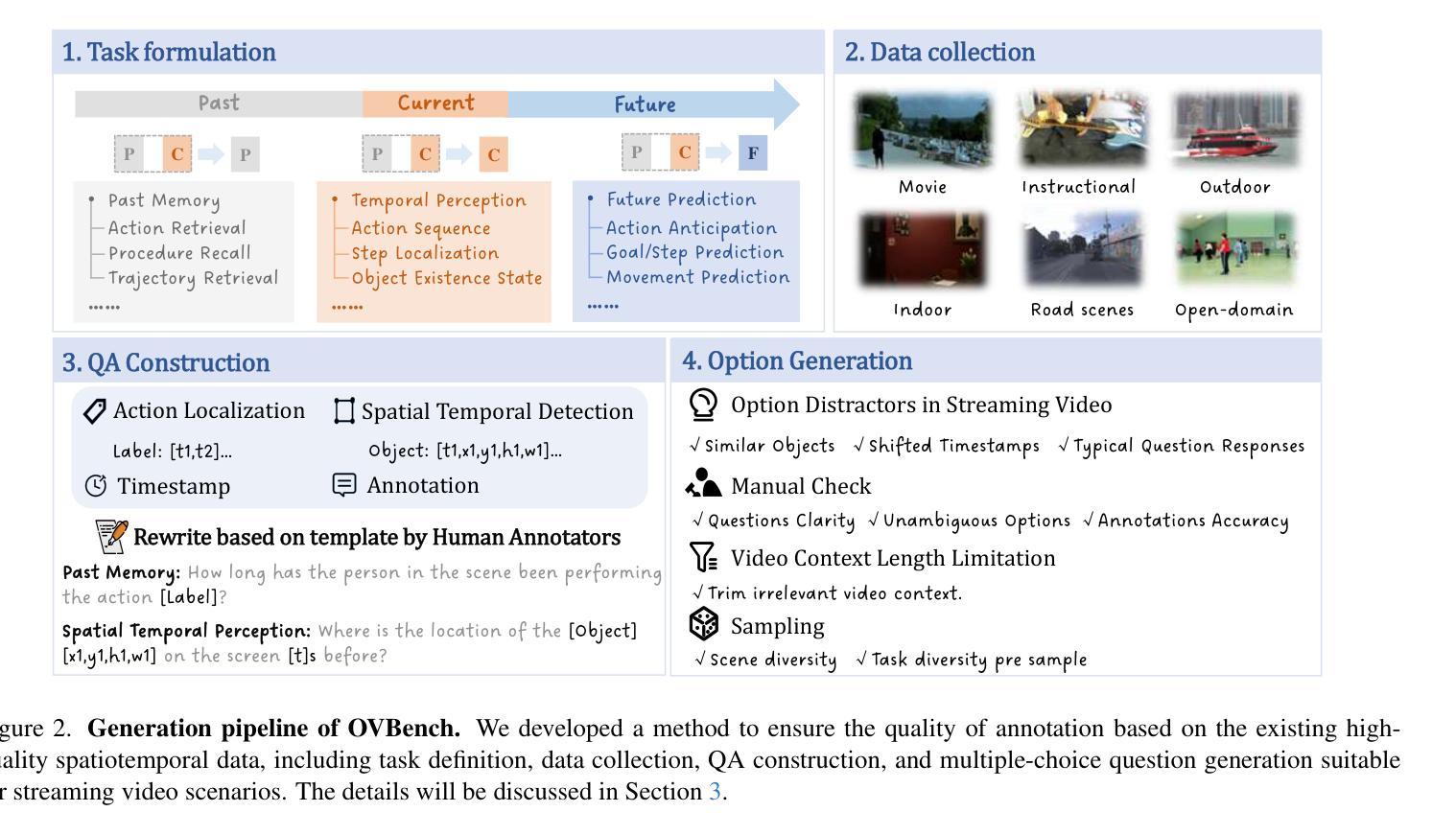
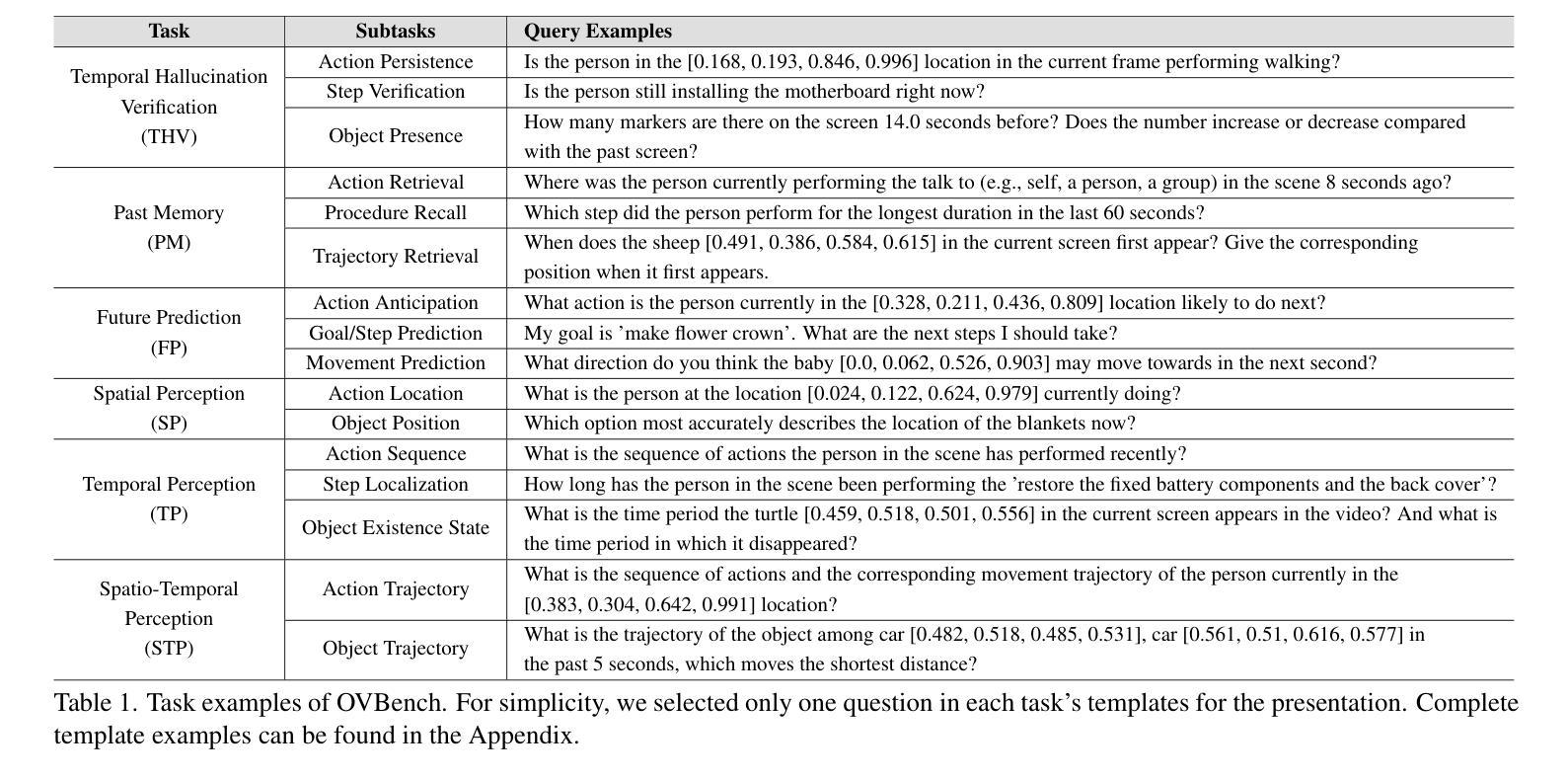
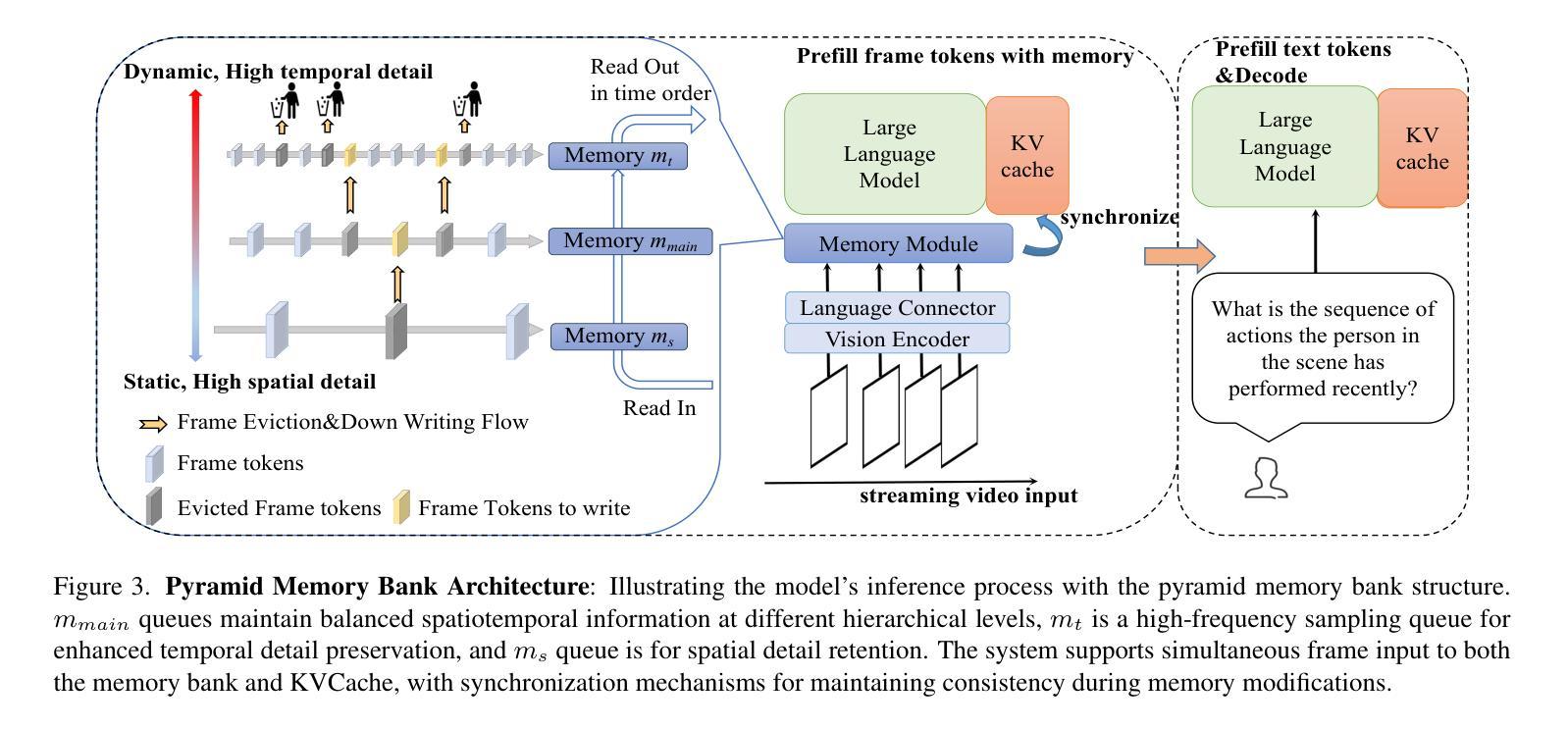
Online Video Understanding: OVBench and VideoChat-Online
Authors:Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, Limin Wang
Multimodal Large Language Models (MLLMs) have significantly progressed in offline video understanding. However, applying these models to real-world scenarios, such as autonomous driving and human-computer interaction, presents unique challenges due to the need for real-time processing of continuous online video streams. To this end, this paper presents systematic efforts from three perspectives: evaluation benchmark, model architecture, and training strategy. First, we introduce OVBench, a comprehensive question-answering benchmark designed to evaluate models’ ability to perceive, memorize, and reason within online video contexts. It features 6 core task types across three temporal contexts-past, current, and future-forming 16 subtasks from diverse datasets. Second, we propose a new Pyramid Memory Bank (PMB) that effectively retains key spatiotemporal information in video streams. Third, we proposed an offline-to-online learning paradigm, designing an interleaved dialogue format for online video data and constructing an instruction-tuning dataset tailored for online video training. This framework led to the development of VideoChat-Online, a robust and efficient model for online video understanding. Despite the lower computational cost and higher efficiency, VideoChat-Online outperforms existing state-of-the-art offline and online models across popular offline video benchmarks and OVBench, demonstrating the effectiveness of our model architecture and training strategy. % Our approach surpasses existing state-of-the-art offline models Qwen2-VL 7B and online models Flash-VStream, by 4.19% and 23.7% on OVBench, respectively.
多模态大型语言模型(MLLMs)在离线视频理解方面取得了显著进展。然而,将这些模型应用于自动驾驶和人机交互等现实场景,由于对连续在线视频流的实时处理需求,带来了独特的挑战。为此,本文从评估基准、模型架构和培训策略三个方面进行了系统研究。首先,我们介绍了OVBench,这是一个旨在评估模型在线视频语境中的感知、记忆和推理能力的综合问答基准测试。它涵盖了过去、现在和未来的三个时间背景,包含16个子任务,涉及六个核心任务类型,跨越不同的数据集。其次,我们提出了一种新的Pyramid Memory Bank(PMB),它有效地保留了视频流中的关键时空信息。第三,我们提出了从离线到在线的学习范式,为在线视频数据设计了一种交替对话格式,并构建了一个适用于在线视频训练的指令调整数据集。这一框架催生了VideoChat-Online模型,一个用于在线视频理解的稳健高效模型。VideoChat-Online在流行的离线视频基准测试和OVBench上的表现优于现有的最新离线模型和在线模型,虽然其计算成本更低、效率更高,但展示了我们模型架构和培训策略的有效性。我们的方法超越了现有的最新离线模型Qwen2-VL 7B和在线模型Flash-VStream,在OVBench上的性能分别提高了4.19%和23.7%。
论文及项目相关链接
PDF CVPR 2025 Camera Ready Version. Project Page: https://videochat-online.github.io
Summary
在线视频理解领域,多模态大型语言模型(MLLMs)的进步显著。然而,将其应用于自动驾驶和人机交互等现实场景时,由于需要实时处理连续的在线视频流,面临独特挑战。本文系统地介绍了三个方面的努力:评估基准、模型架构和训练策略。首先推出OVBench评估基准,旨在评估模型在线视频语境中的感知、记忆和推理能力。其次,提出新的Pyramid Memory Bank(PMB),有效保留视频流中的关键时空信息。最后,建立了一种离线到在线的学习范式,为在线视频数据设计了一种交替对话格式,并构建了针对在线视频训练的指令调整数据集。这些成果促使VideoChat-Online模型的发展,该模型在在线视频理解方面表现出稳健高效的特点,且在流行的离线视频基准测试和OVBench上超越了现有的最先进的离线模型和在线模型,证明了模型架构和训练策略的有效性。
Key Takeaways
- MLLMs在在线视频理解领域取得显著进步,但应用于现实场景如自主驾驶和人机交互时面临挑战。
- 引入OVBench评估基准,旨在评估模型在线视频语境中的感知、记忆和推理能力,包含16个子任务。
- 提出Pyramid Memory Bank(PMB),有效保留视频流中的关键时空信息。
- 建立了一种离线到在线的学习范式,为在线视频数据设计交替对话格式,并构建指令调整数据集。
- VideoChat-Online模型在在线视频理解方面表现出稳健高效的特点。
- VideoChat-Online在流行的离线视频基准测试和OVBench上超越了现有的最先进的离线模型和在线模型。
点此查看论文截图


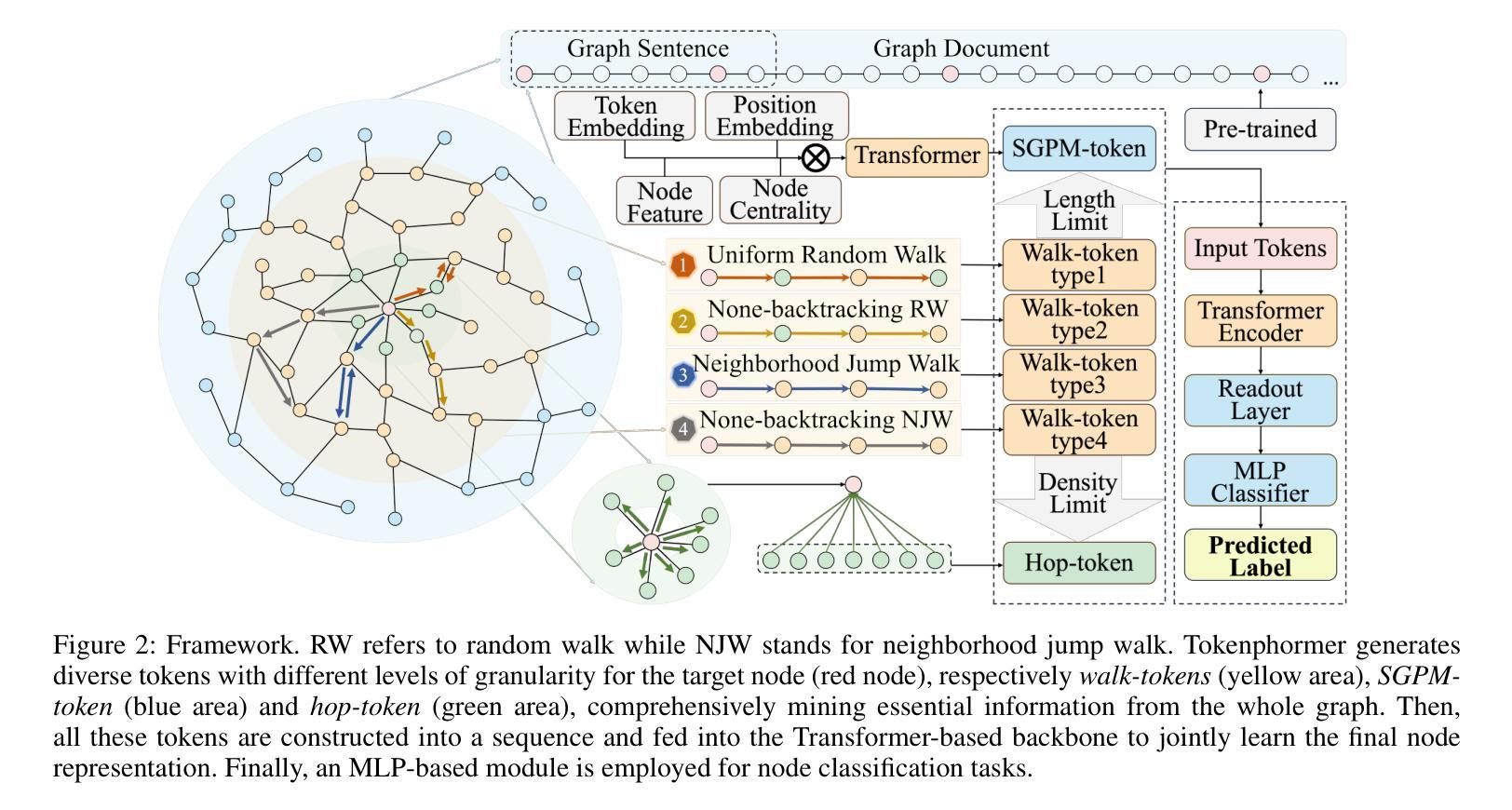
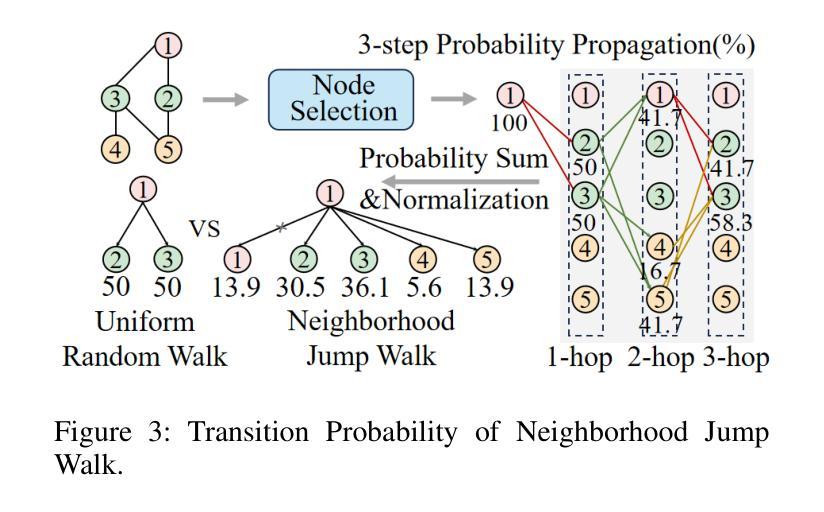
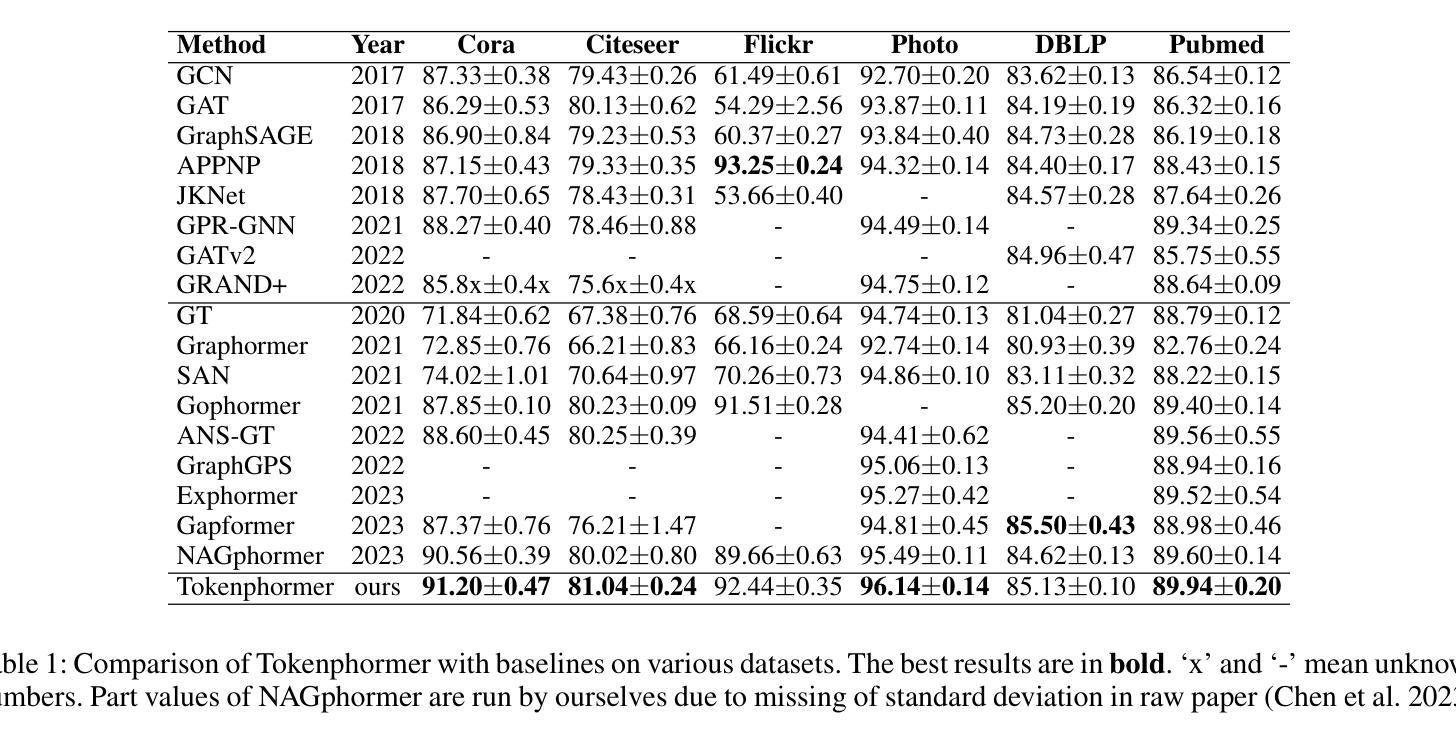
Tokenphormer: Structure-aware Multi-token Graph Transformer for Node Classification
Authors:Zijie Zhou, Zhaoqi Lu, Xuekai Wei, Rongqin Chen, Shenghui Zhang, Pak Lon Ip, Leong Hou U
Graph Neural Networks (GNNs) are widely used in graph data mining tasks. Traditional GNNs follow a message passing scheme that can effectively utilize local and structural information. However, the phenomena of over-smoothing and over-squashing limit the receptive field in message passing processes. Graph Transformers were introduced to address these issues, achieving a global receptive field but suffering from the noise of irrelevant nodes and loss of structural information. Therefore, drawing inspiration from fine-grained token-based representation learning in Natural Language Processing (NLP), we propose the Structure-aware Multi-token Graph Transformer (Tokenphormer), which generates multiple tokens to effectively capture local and structural information and explore global information at different levels of granularity. Specifically, we first introduce the walk-token generated by mixed walks consisting of four walk types to explore the graph and capture structure and contextual information flexibly. To ensure local and global information coverage, we also introduce the SGPM-token (obtained through the Self-supervised Graph Pre-train Model, SGPM) and the hop-token, extending the length and density limit of the walk-token, respectively. Finally, these expressive tokens are fed into the Transformer model to learn node representations collaboratively. Experimental results demonstrate that the capability of the proposed Tokenphormer can achieve state-of-the-art performance on node classification tasks.
图神经网络(GNNs)被广泛应用于图数据挖掘任务中。传统的GNNs遵循消息传递方案,该方案可以有效地利用局部和结构信息。然而,过度平滑和过度挤压的现象限制了消息传递过程中的感受野。为了解决这些问题,引入了图转换器(Graph Transformers),实现全局感受野,但会面临无关节点的噪声和结构信息丢失的问题。因此,我们从自然语言处理(NLP)中的精细粒度基于令牌表示学习中获得灵感,提出了结构感知多令牌图转换器(Tokenphormer)。它通过生成多个令牌来有效捕获局部和结构信息,并在不同粒度级别上探索全局信息。具体来说,我们首先引入由四种步行类型组成的混合步行生成的walk-token来探索图形并灵活地捕获结构和上下文信息。为了确保本地和全局信息覆盖,我们还引入了通过自监督图预训练模型(SGPM)获得的SGPM-token和扩展walk-token长度和密度的hop-token。最后,这些表达性令牌被输入到Transformer模型中,以协同学习节点表示。实验结果表明,所提出的Tokenphormer的能力在节点分类任务上达到了最先进的性能。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
图神经网络(GNNs)广泛应用于图数据挖掘任务,但存在过度平滑和过度压缩现象。为解决这些问题,引入了图Transformer,但可能受到无关节点噪声和结构信息损失的影响。受自然语言处理(NLP)中精细粒度令牌表示学习的启发,提出结构感知多令牌图Transformer(Tokenphormer),生成多个令牌以有效捕获局部和结构信息,并在不同粒度级别上探索全局信息。通过混合步行生成的walk-token、通过自监督图预训练模型(SGPM)获得的SGPM-token以及扩展walk-token长度和密度的hop-token,将这些表达性令牌馈入Transformer模型,以协同学习节点表示。实验结果表明,Tokenphormer在节点分类任务上达到了最先进的性能。
Key Takeaways
- GNNs在图数据挖掘任务中广泛应用,但存在过度平滑和过度压缩问题,影响消息传递过程的接收范围。
- 图Transformer被引入以解决GNNs的问题,实现全局接收范围,但可能受到无关节点噪声和结构信息损失的影响。
- Tokenphormer受NLP中精细粒度令牌表示学习的启发,生成多个令牌以捕获局部和结构化信息,并探索不同粒度级别的全局信息。
- Tokenphormer通过混合步行、SGPM(自监督图预训练模型)和扩展令牌长度与密度的策略生成令牌。
- Tokenphormer将表达性令牌输入到Transformer模型中,以协同学习节点表示。
- 实验结果表明,Tokenphormer在节点分类任务上实现了卓越性能。
点此查看论文截图

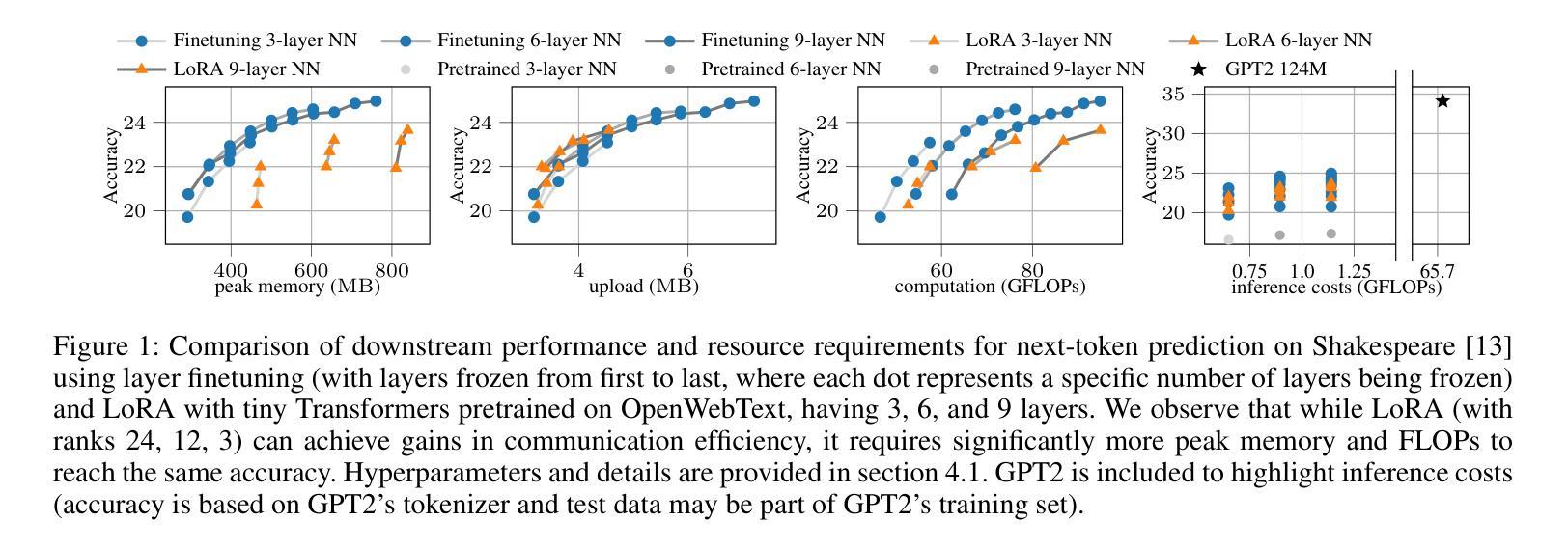
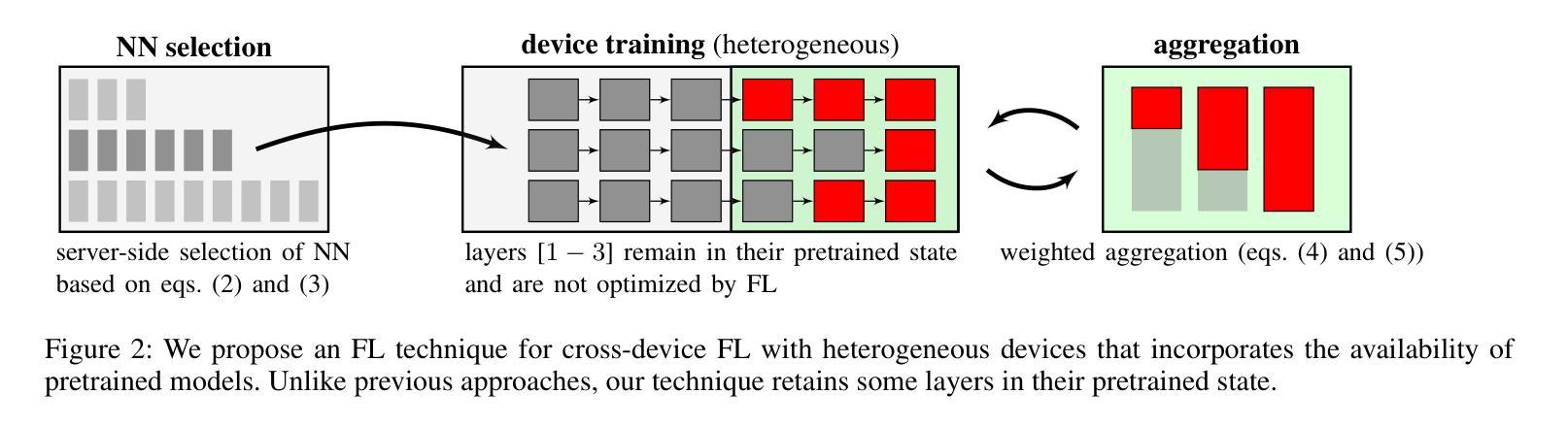
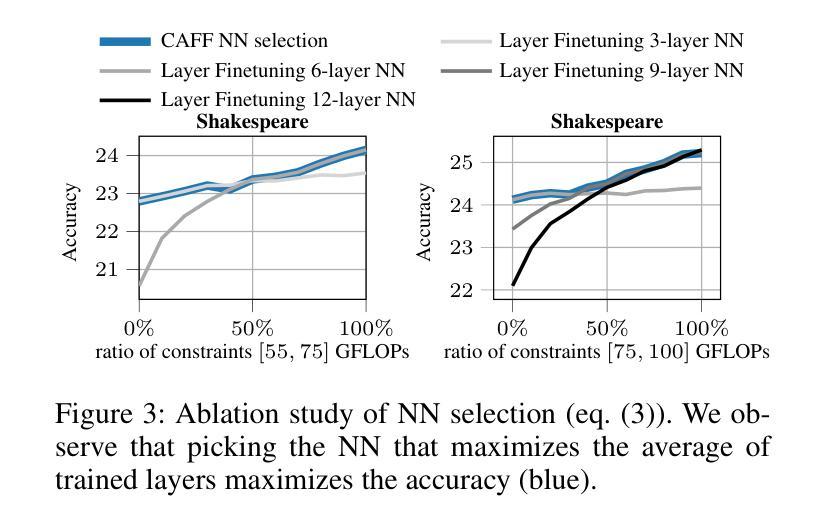
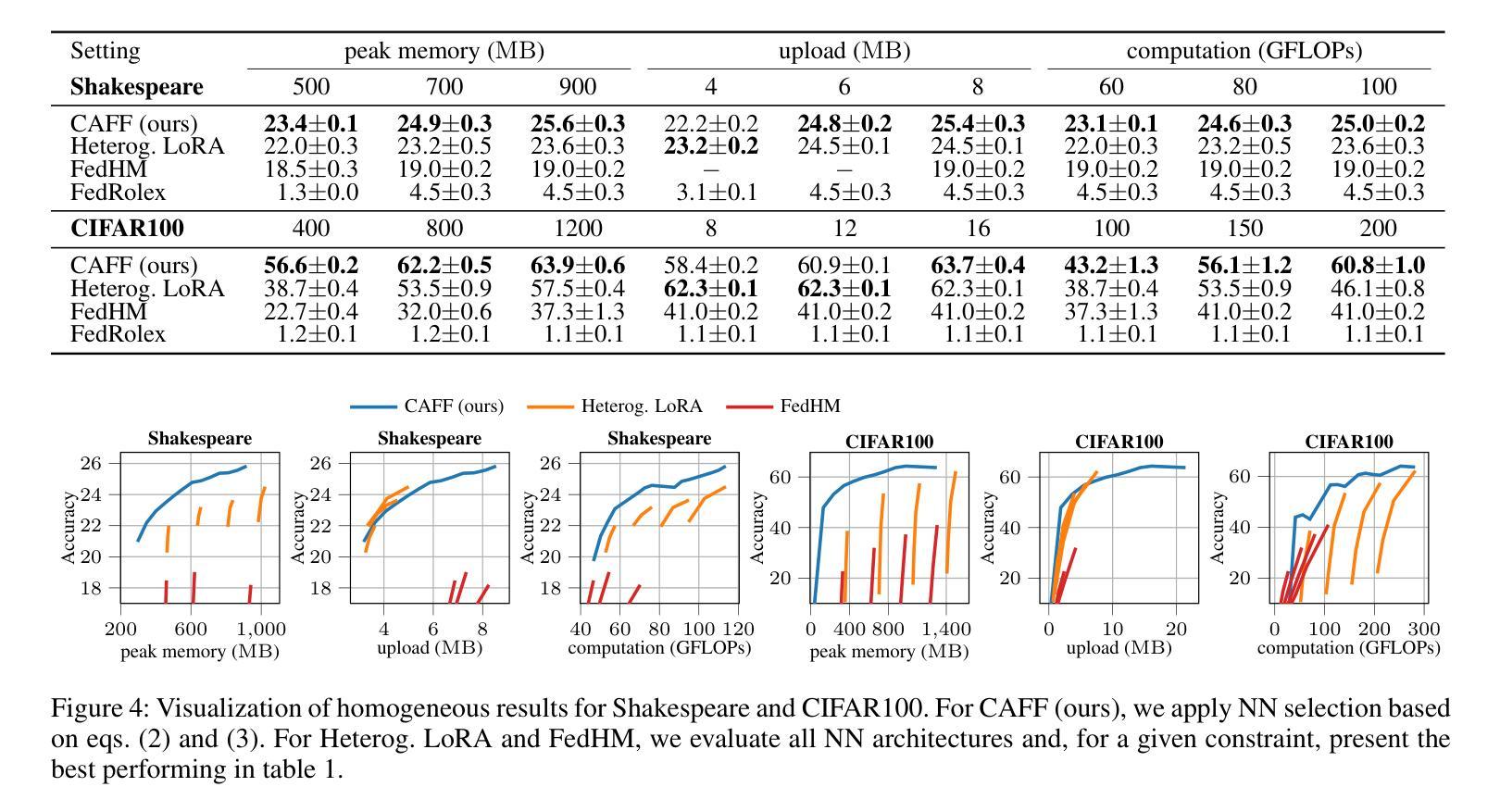
Efficient Federated Finetuning of Tiny Transformers with Resource-Constrained Devices
Authors:Kilian Pfeiffer, Mohamed Aboelenien Ahmed, Ramin Khalili, Jörg Henkel
In recent years, Large Language Models (LLMs) through Transformer structures have dominated many machine learning tasks, especially text processing. However, these models require massive amounts of data for training and induce high resource requirements, particularly in terms of the large number of Floating Point Operations (FLOPs) and the high amounts of memory needed. To fine-tune such a model in a parameter-efficient way, techniques like Adapter or LoRA have been developed. However, we observe that the application of LoRA, when used in federated learning (FL), while still being parameter-efficient, is memory and FLOP inefficient. Based on that observation, we develop a novel layer finetuning scheme that allows devices in cross-device FL to make use of pretrained neural networks (NNs) while adhering to given resource constraints. We show that our presented scheme outperforms the current state of the art when dealing with homogeneous or heterogeneous computation and memory constraints and is on par with LoRA regarding limited communication, thereby achieving significantly higher accuracies in FL training.
近年来,通过Transformer结构的大型语言模型(LLM)在机器学习任务中占据主导地位,特别是在文本处理方面。然而,这些模型需要大量的数据进行训练,并产生了巨大的资源需求,特别是在浮点运算(FLOPs)数量和所需内存方面。为了以参数高效的方式微调此类模型,开发了Adapter或LoRA等技术。然而,我们发现当LoRA用于联邦学习(FL)时,虽然它仍然是参数高效的,但在内存和FLOP方面并不高效。基于这一观察,我们开发了一种新型层微调方案,允许跨设备联邦学习中的设备利用预训练的神经网络(NNs),同时满足给定的资源限制。我们显示,在处理同类或异类计算和内存约束时,我们提出的方案优于当前的技术水平,并且在有限的通信方面与LoRA相当,从而在联邦学习中实现了更高的准确性训练。
论文及项目相关链接
Summary
大规模语言模型(LLMs)通过Transformer结构在机器学习任务中占据主导地位,特别是在文本处理方面。然而,这些模型需要大量数据进行训练,并且具有高的资源要求,如浮点运算(FLOPs)和内存。为了以参数有效的方式微调这些模型,开发了Adapter或LoRA等技术。然而,在联邦学习(FL)中应用LoRA时,虽然仍然是参数有效的,但在内存和FLOP方面并不高效。基于此观察,我们开发了一种新型层微调方案,允许跨设备FL中的设备在遵守给定资源约束的同时利用预训练神经网络(NNs)。我们展示,与当前技术相比,我们的方案在处理同质或异质计算和内存约束方面表现更好,并在有限的通信方面与LoRA不相上下,从而在联邦学习训练中实现更高的准确性。
Key Takeaways
- LLMs已主导许多机器学习任务,尤其在文本处理方面。
- LLM训练需要大量的数据和资源,如FLOPs和内存。
- LoRA技术在联邦学习中虽参数有效但内存和FLOP效率低。
- 开发了一种新型层微调方案,允许跨设备FL中的设备利用预训练神经网络并遵守资源约束。
- 该方案在处理同质或异质计算和内存约束方面表现优异。
- 该方案在有限的通信方面与LoRA表现相当。
点此查看论文截图


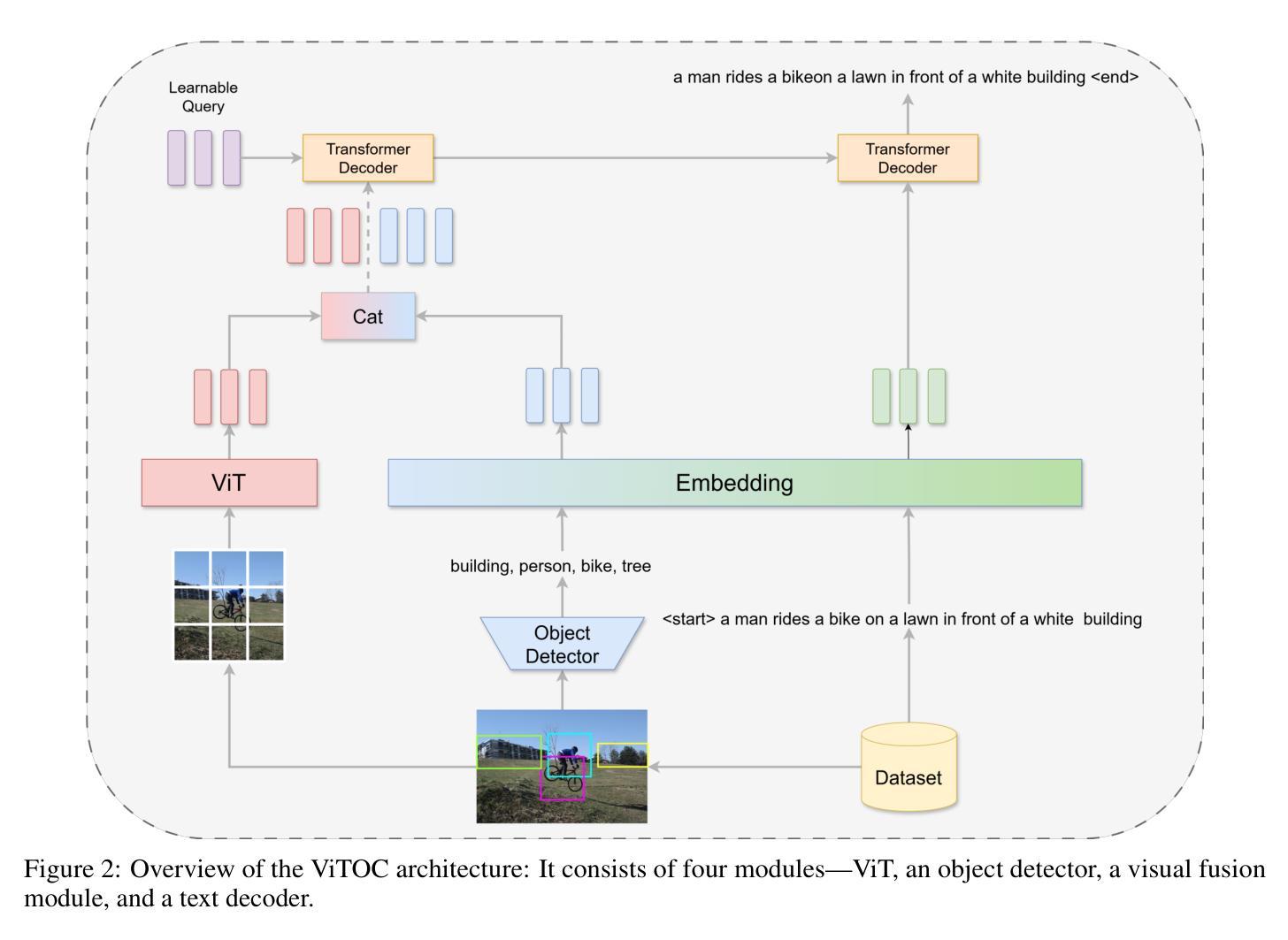
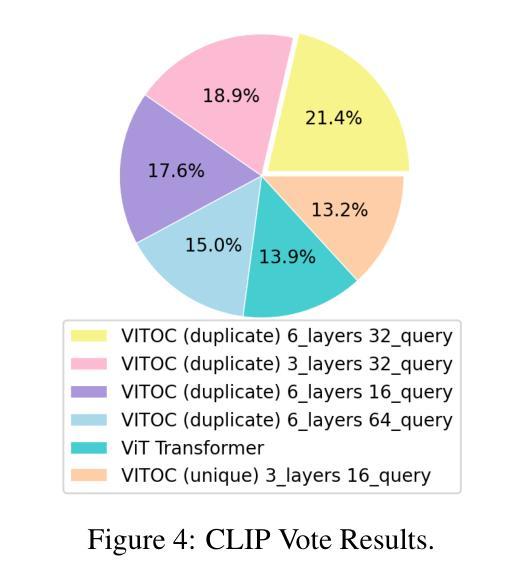
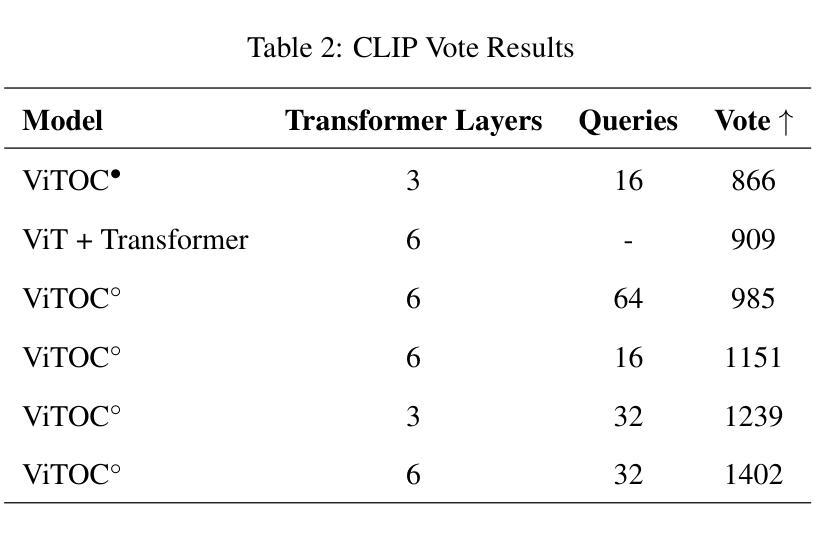
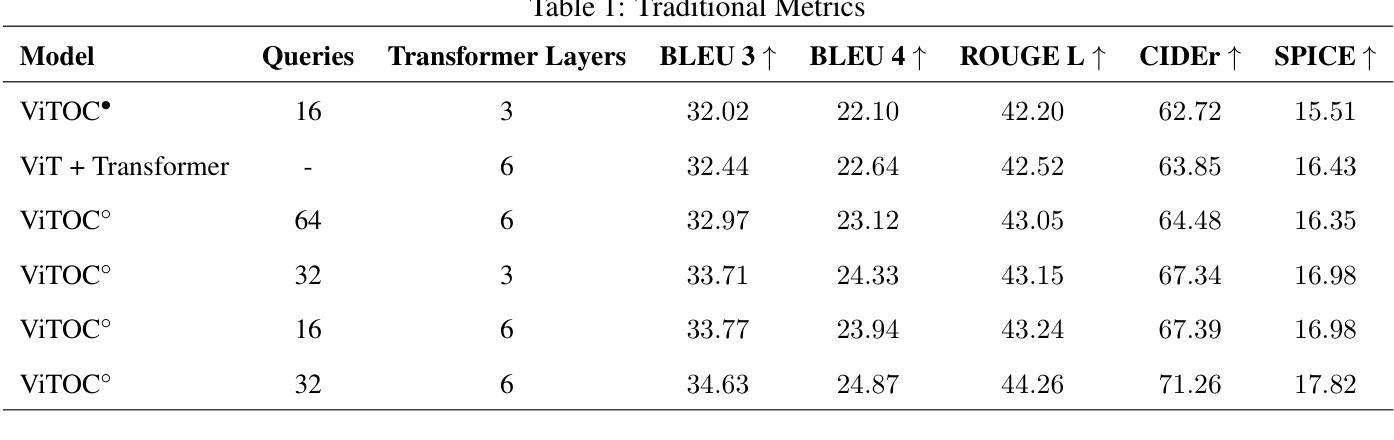
ViTOC: Vision Transformer and Object-aware Captioner
Authors:Feiyang Huang
This paper presents ViTOC (Vision Transformer and Object-aware Captioner), a novel vision-language model for image captioning that addresses the challenges of accuracy and diversity in generated descriptions. Unlike conventional approaches, ViTOC employs a dual-path architecture based on Vision Transformer and object detector, effectively fusing global visual features and local object information through learnable vectors. The model introduces an innovative object-aware prompting strategy that significantly enhances its capability in handling long-tail data. Experiments on the standard COCO dataset demonstrate that ViTOC outperforms baseline models across all evaluation metrics. Additionally, we propose a reference-free evaluation method based on CLIP to further validate the model’s effectiveness. By utilizing pretrained visual model parameters, ViTOC achieves efficient end-to-end training.
本文介绍了ViTOC(视觉转换器与对象感知描述生成器),这是一种用于图像描述的新型视觉语言模型,解决了生成描述中的准确性和多样性挑战。不同于传统方法,ViTOC采用基于视觉转换器和对象检测器的双路径架构,通过可学习向量有效地融合全局视觉特征和局部对象信息。该模型引入了一种创新的基于对象的提示策略,极大地提高了其处理长尾数据的能力。在标准COCO数据集上的实验表明,ViTOC在所有评价指标上都优于基线模型。此外,我们提出了一种基于CLIP的无参考评价方法,进一步验证了模型的有效性。通过利用预训练的视觉模型参数,ViTOC实现了高效端到端训练。
论文及项目相关链接
PDF The core idea is too close to what has been published in other journals
Summary
ViTOC是一种新型的视觉语言模型,用于图像描述,解决了生成描述中的准确性和多样性挑战。它采用基于Vision Transformer和对象检测器的双路径架构,通过可学习向量有效融合全局视觉特征和局部对象信息。该模型引入了一种创新的对象感知提示策略,显著提高了处理长尾数据的能力。在COCO数据集上的实验表明,ViTOC在所有评估指标上均优于基线模型。此外,还提出了一种基于CLIP的无参考评价方法,进一步验证了模型的有效性。ViTOC利用预训练的视觉模型参数,实现了高效的端到端训练。
Key Takeaways
- ViTOC是一种新型的视觉语言模型,专门用于图像描述任务。
- ViTOC采用双路径架构,结合Vision Transformer和对象检测器。
- ViTOC融合了全局视觉特征和局部对象信息,提高了准确性和多样性。
- ViTOC引入了对象感知提示策略,有效处理长尾数据。
- 在COCO数据集上的实验表明,ViTOC优于其他基线模型。
- 提出了基于CLIP的无参考评价方法,以进一步验证模型的有效性。
- ViTOC利用预训练的视觉模型参数,实现了高效的端到端训练。
点此查看论文截图