⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
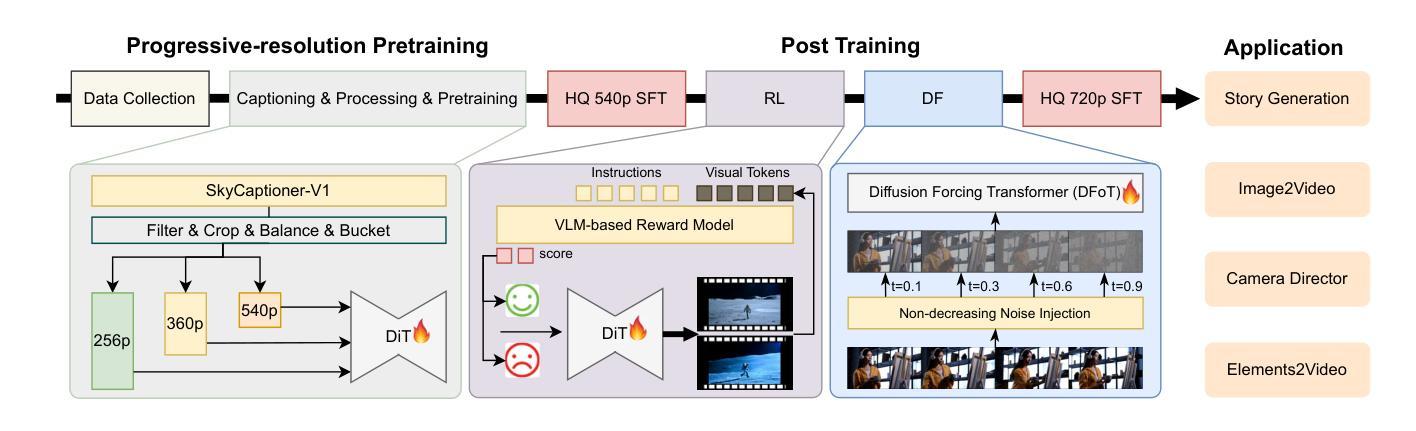
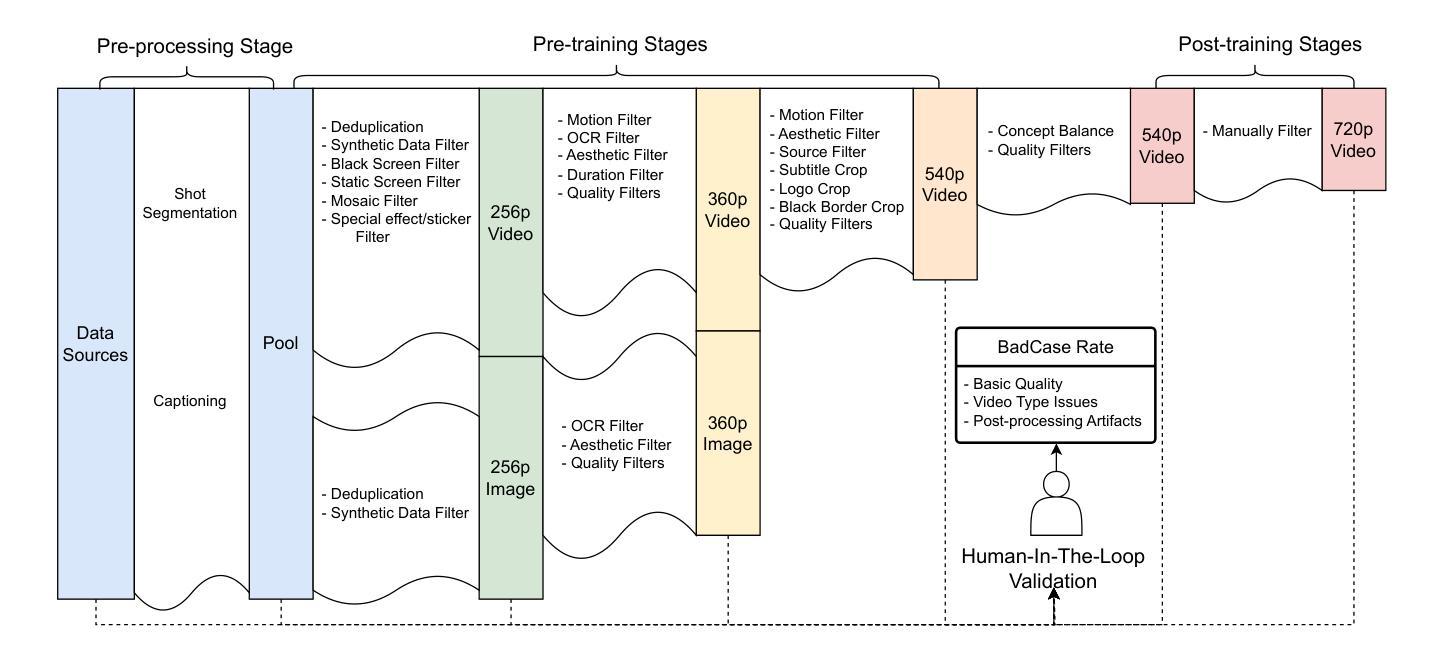
SkyReels-V2: Infinite-length Film Generative Model
Authors:Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Juncheng Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengchen Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, Yahui Zhou
Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs’ inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
最近视频生成的进展得益于扩散模型和自回归框架的推动,但仍然存在一些关键挑战,如如何在提示遵循、视觉质量、运动动态和持续时间之间取得平衡:为了在增强时间视觉质量方面做出妥协而牺牲运动动态,为优先考虑分辨率而限制视频时长(5-10秒),以及由于通用MLLM无法解释电影语法(如镜头构图、演员表情和相机运动)导致的镜头感知生成不足。这些交织在一起的局限性阻碍了真实的长形式合成和专业电影风格的生成。为了解决这个问题,我们提出了SkyReels-V2,一种无限长电影生成模型,它协同了多模态大型语言模型(MLLM)、多阶段预训练、强化学习和扩散强制框架。首先,我们设计了一种全面的视频结构表示,它结合了多模态LLM的一般描述和子专家模型的详细镜头语言。借助人工标注,我们随后训练了一个统一的视频字幕器SkyCaptioner-V1,以有效地标注视频数据。其次,我们为基本的视频生成建立了渐进式分辨率预训练,随后是四个阶段的后训练增强:初始概念平衡的监督微调(SFT)提高了基线质量;使用人工注释和合成失真数据的特定运动强化学习(RL)训练解决了动态伪像问题;我们的扩散强制框架配合非递减噪声时间表,能够在有效的搜索空间中进行长视频合成;最后的高质量SFT改进了视觉保真度。所有代码和模型都可在https://github.com/SkyworkAI/SkyReels-V2找到。
论文及项目相关链接
PDF 31 pages,10 figures
Summary
针对当前视频生成中面临的关键挑战,如提示遵守、视觉质量、运动动力学和持续时间等,提出了SkyReels-V2模型。该模型结合多模态大型语言模型(MLLM)、多阶段预训练、强化学习和扩散强制框架等技术,旨在实现无限长电影生成。设计全面的视频结构表示,结合通用描述和详细镜头语言,训练统一视频标注器SkyCaptioner-V1。建立渐进式分辨率预训练,并通过四个阶段的后期训练增强,以提高视频生成质量、解决动态伪像问题、实现长视频合成并在高效搜索空间中优化视觉保真度。
Key Takeaways
- 当前视频生成面临的挑战包括提示遵守、视觉质量、运动动力学和持续时间的平衡。
- SkyReels-V2模型旨在解决这些挑战,实现无限长电影生成。
- SkyReels-V2结合了MLLM、多阶段预训练、强化学习和扩散强制框架等技术。
- 设计了全面的视频结构表示,结合通用描述和详细镜头语言。
- 训练了统一视频标注器SkyCaptioner-V1,用于高效标注视频数据。
- 建立了渐进式分辨率预训练,并通过四个阶段的后期训练增强来提高视频生成质量。
- SkyReels-V2模型可以解决动态伪像问题,实现长视频合成并在高效搜索空间中优化视觉保真度。
点此查看论文截图



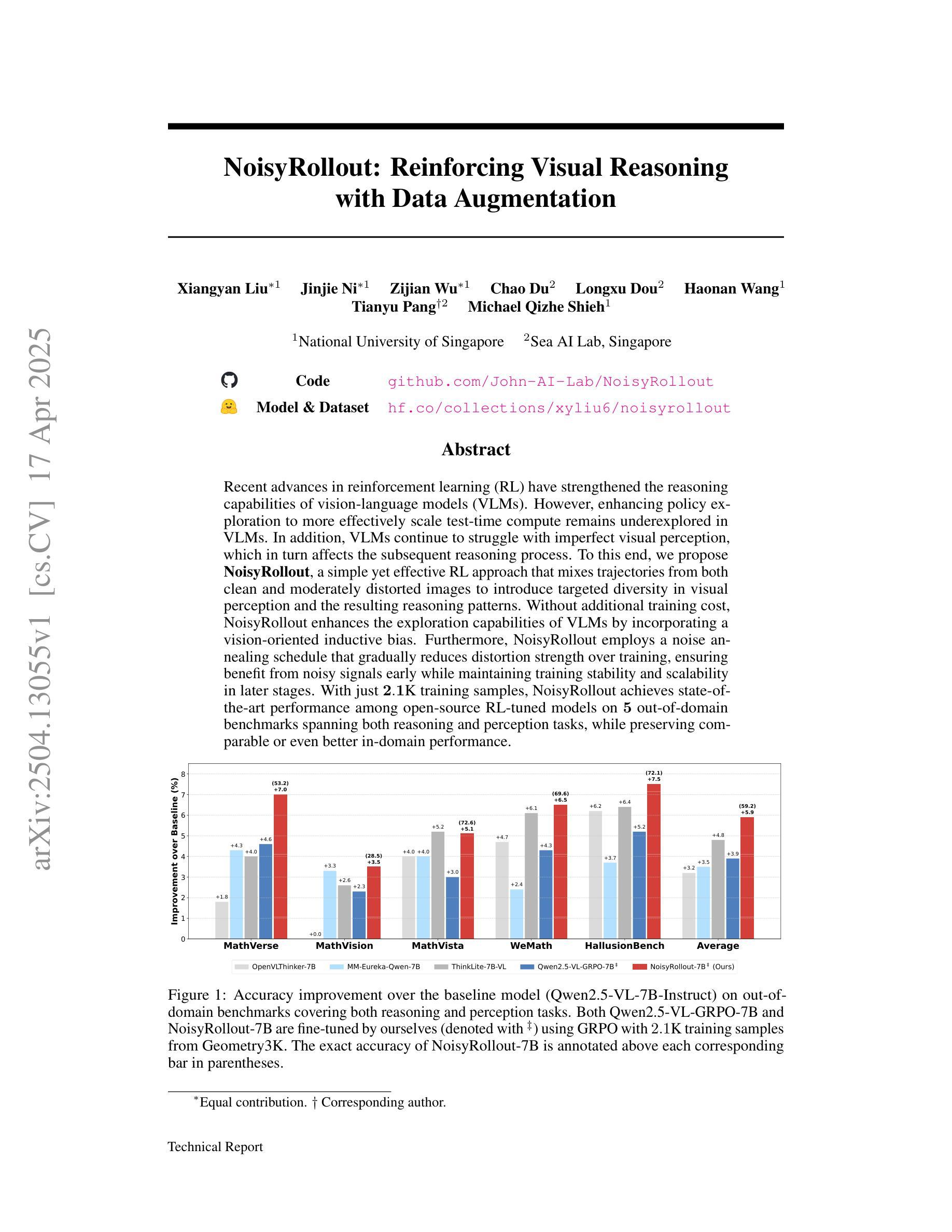
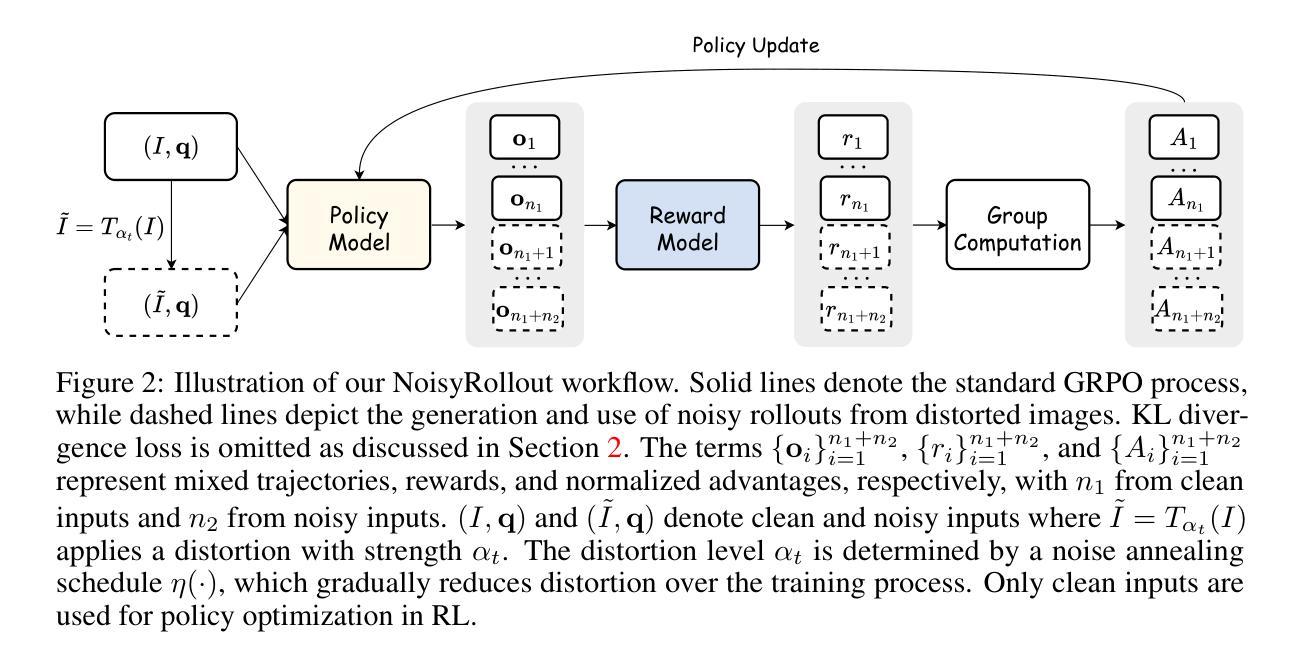
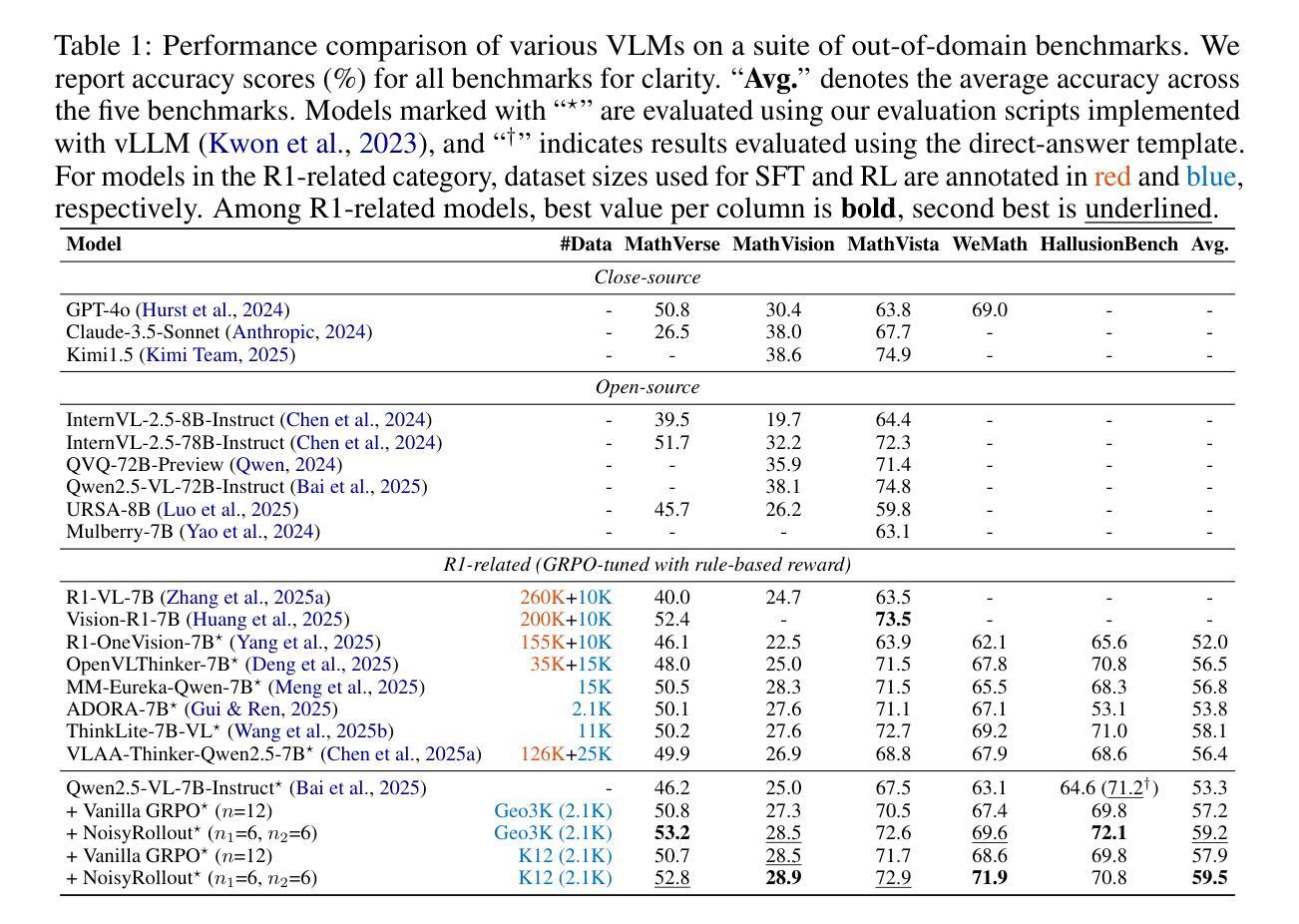
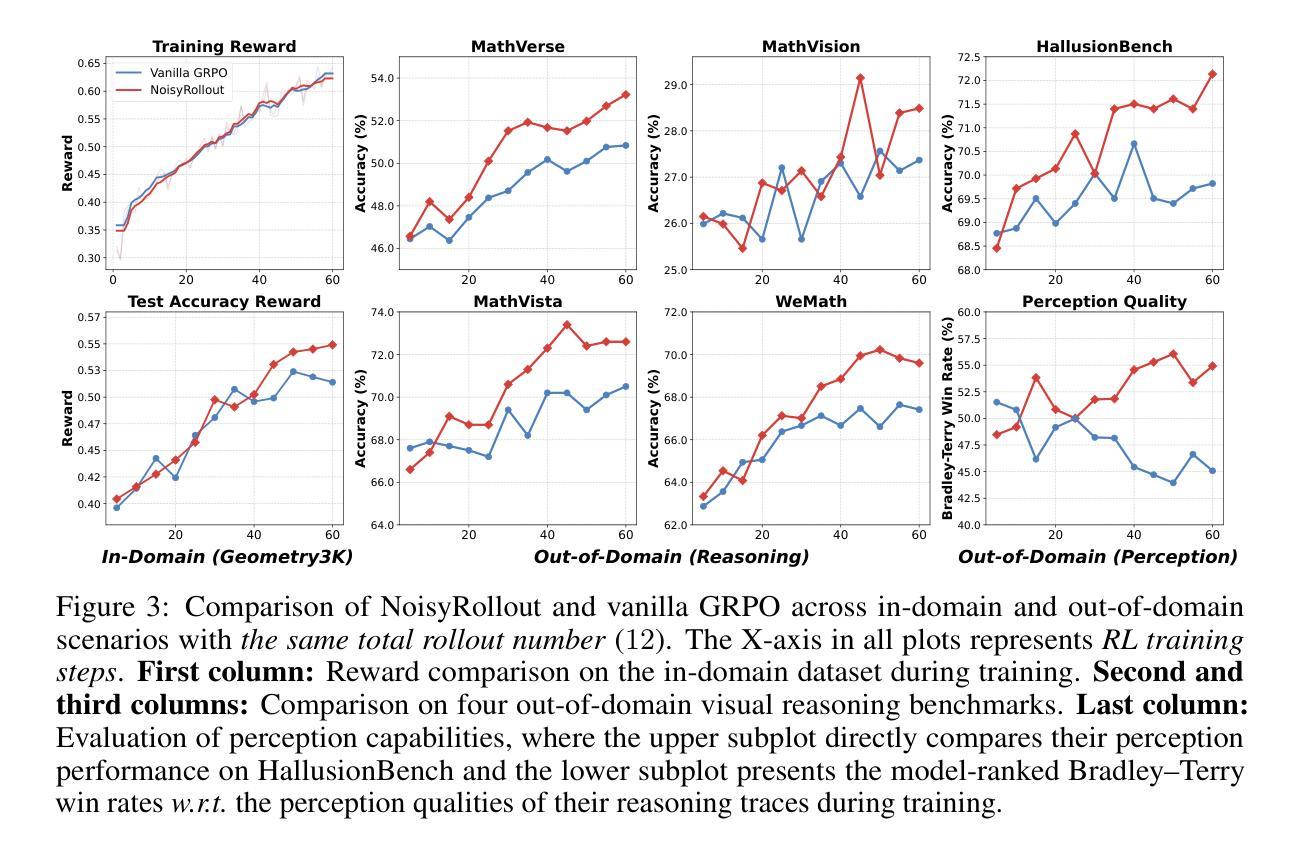
NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
Authors:Xiangyan Liu, Jinjie Ni, Zijian Wu, Chao Du, Longxu Dou, Haonan Wang, Tianyu Pang, Michael Qizhe Shieh
Recent advances in reinforcement learning (RL) have strengthened the reasoning capabilities of vision-language models (VLMs). However, enhancing policy exploration to more effectively scale test-time compute remains underexplored in VLMs. In addition, VLMs continue to struggle with imperfect visual perception, which in turn affects the subsequent reasoning process. To this end, we propose NoisyRollout, a simple yet effective RL approach that mixes trajectories from both clean and moderately distorted images to introduce targeted diversity in visual perception and the resulting reasoning patterns. Without additional training cost, NoisyRollout enhances the exploration capabilities of VLMs by incorporating a vision-oriented inductive bias. Furthermore, NoisyRollout employs a noise annealing schedule that gradually reduces distortion strength over training, ensuring benefit from noisy signals early while maintaining training stability and scalability in later stages. With just 2.1K training samples, NoisyRollout achieves state-of-the-art performance among open-source RL-tuned models on 5 out-of-domain benchmarks spanning both reasoning and perception tasks, while preserving comparable or even better in-domain performance.
强化学习(RL)的最新进展提高了视觉语言模型(VLM)的推理能力。然而,在VLM中,关于如何更有效地扩展测试时间计算的策略探索仍然缺乏探索。此外,VLM在视觉感知方面仍存在缺陷,进而影响后续的推理过程。因此,我们提出了NoisyRollout,这是一种简单有效的RL方法,它通过混合干净图像和适度失真图像的轨迹来引入有针对性的视觉感知和结果推理模式的多样性。NoisyRollout通过引入面向视觉的归纳偏置,在不增加额外训练成本的情况下,提高了VLM的探索能力。此外,NoisyRollout采用噪声退火时间表,在训练过程中逐渐降低失真强度,确保在早期从噪声信号中受益,同时在后期保持训练稳定性和可扩展性。仅使用2.1K训练样本,NoisyRollout在涵盖推理和感知任务的五个跨域基准测试中实现了开源RL调优模型中的最佳性能,同时保持了相当甚至更好的域内性能。
论文及项目相关链接
PDF Technical Report
Summary
强化学习(RL)的最新进展增强了视觉语言模型(VLM)的推理能力。然而,提高策略探索以更有效地扩展测试时间计算仍在VLM中未得到充分探索。此外,VLM仍然面临不完美的视觉感知问题,进而影响后续的推理过程。为此,我们提出了NoisyRollout,这是一种简单有效的RL方法,它通过混合来自干净和适度失真图像的轨迹来引入有针对性的视觉感知和结果推理模式的多样性。NoisyRollout在不增加额外训练成本的情况下,通过融入面向视觉的归纳偏置,增强了VLM的探索能力。此外,NoisyRollout采用噪声退火计划,随着训练的进行逐渐降低失真强度,确保从噪声信号中受益的同时保持训练的稳定性和可扩展性。仅使用2.1K训练样本,NoisyRollout在跨越推理和感知任务的五个域外基准测试上实现了开源RL调优模型中的最佳性能,同时保持或提高了域内性能。
Key Takeaways
- 强化学习(RL)增强了视觉语言模型(VLM)的推理能力。
- VLM在策略探索和视觉感知方面仍存在挑战。
- NoisyRollout是一种解决这些挑战的有效方法,它通过混合干净和失真图像的轨迹来引入视觉感知和推理模式的多样性。
- NoisyRollout在不增加额外训练成本的情况下增强了VLM的探索能力。
- NoisyRollout采用噪声退火计划以确保从噪声信号中受益并维持训练稳定性。
- 仅使用有限的训练样本,NoisyRollout在多个基准测试中实现了最佳性能。
点此查看论文截图

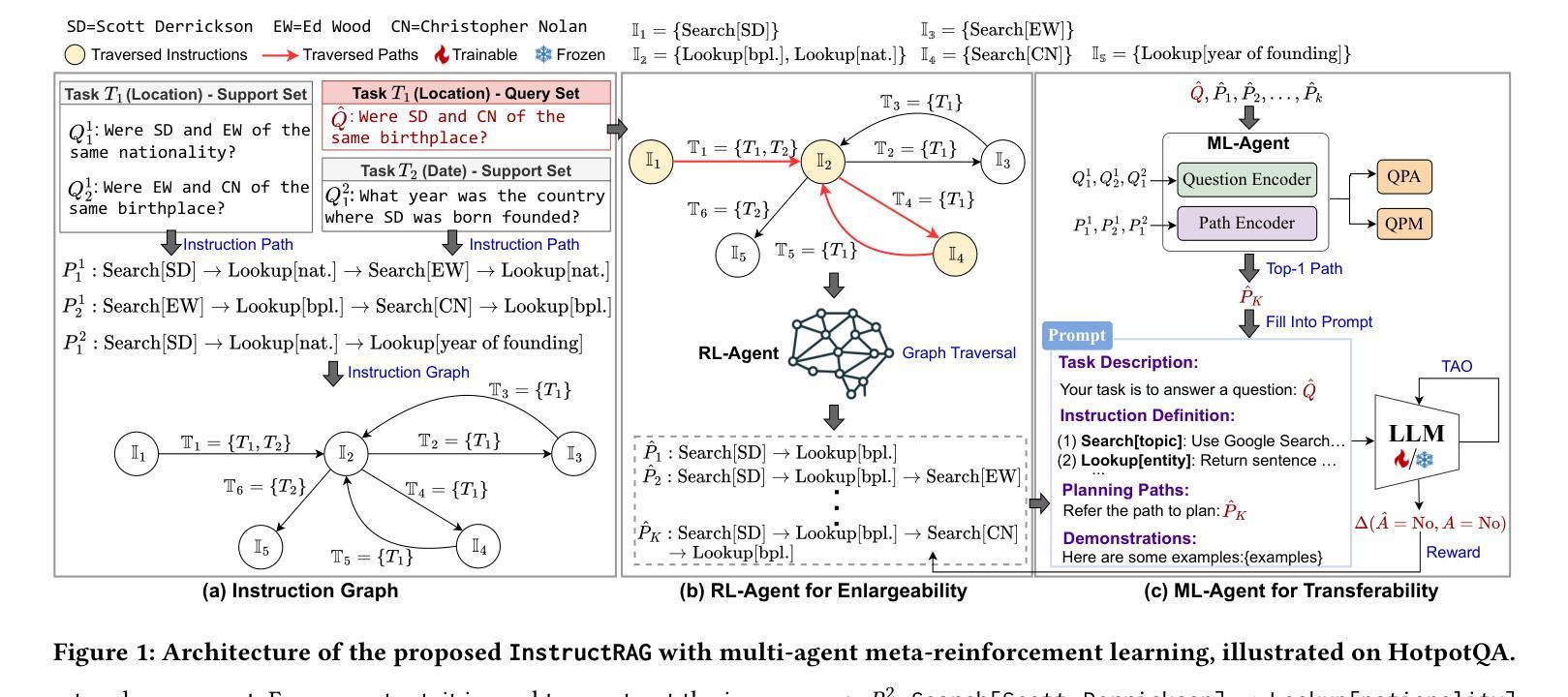
InstructRAG: Leveraging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning
Authors:Zheng Wang, Shu Xian Teo, Jun Jie Chew, Wei Shi
Recent advancements in large language models (LLMs) have enabled their use as agents for planning complex tasks. Existing methods typically rely on a thought-action-observation (TAO) process to enhance LLM performance, but these approaches are often constrained by the LLMs’ limited knowledge of complex tasks. Retrieval-augmented generation (RAG) offers new opportunities by leveraging external databases to ground generation in retrieved information. In this paper, we identify two key challenges (enlargability and transferability) in applying RAG to task planning. We propose InstructRAG, a novel solution within a multi-agent meta-reinforcement learning framework, to address these challenges. InstructRAG includes a graph to organize past instruction paths (sequences of correct actions), an RL-Agent with Reinforcement Learning to expand graph coverage for enlargability, and an ML-Agent with Meta-Learning to improve task generalization for transferability. The two agents are trained end-to-end to optimize overall planning performance. Our experiments on four widely used task planning datasets demonstrate that InstructRAG significantly enhances performance and adapts efficiently to new tasks, achieving up to a 19.2% improvement over the best existing approach.
最近大型语言模型(LLM)的进步使其能够作为完成复杂任务的代理。现有方法通常依赖于思维-行动-观察(TAO)过程来提高LLM的性能,但这些方法往往受到LLM对复杂任务知识有限的制约。检索增强生成(RAG)通过利用外部数据库使生成基于检索的信息提供了新的机会。在本文中,我们识别了将RAG应用于任务规划的两个关键挑战,即可扩展性和可转移性。我们提出InstructRAG,这是一种多智能体元强化学习框架内的新型解决方案,以解决这些挑战。InstructRAG包括一个图,用于组织过去的指令路径(正确的行动序列),一个RL智能体使用强化学习来扩大图的覆盖以增加可扩展性,以及一个使用元学习的ML智能体以提高任务泛化性以增强可迁移性。这两个智能体通过端到端的训练以优化整体规划性能。我们在四个广泛使用的任务规划数据集上进行的实验表明,InstructRAG显著提高了性能并能有效地适应新任务,与最佳现有方法相比实现了高达19.2%的改进。
论文及项目相关链接
PDF This paper has been accepted by SIGIR 2025
Summary
大型语言模型(LLM)近期进展使得它们可以作为复杂任务的代理。现有方法通常采用思考-行动-观察(TAO)过程来提高LLM性能,但受限于LLM对复杂任务的有限知识。检索增强生成(RAG)通过利用外部数据库使生成基于检索的信息成为可能。本文指出将RAG应用于任务规划的两个关键挑战:可扩大性和可转移性。为解决这些挑战,我们提出InstructRAG,这是一种多代理元强化学习框架内的解决方案。InstructRAG包括一个组织过去指令路径的图、一个用于扩大性的强化学习代理来扩大图的覆盖面,以及一个用于转移性的元学习代理来提高任务泛化能力。两个代理端到端训练以优化整体规划性能。在四个广泛使用的任务规划数据集上的实验表明,InstructRAG显著提高了性能并高效适应新任务,相比最佳现有方法最多提高了19.2%。
Key Takeaways
- 大型语言模型(LLM)可作为复杂任务的代理。
- 现有LLM性能提升方法存在局限性,如有限的任务知识。
- 检索增强生成(RAG)方法通过利用外部数据库改进了LLM的性能。
- 将RAG应用于任务规划面临可扩大性和可转移性两大挑战。
- InstructRAG是一个解决这些挑战的新方法,使用多代理元强化学习框架。
- InstructRAG包括用于扩大性的强化学习代理和用于转移性的元学习代理。
点此查看论文截图


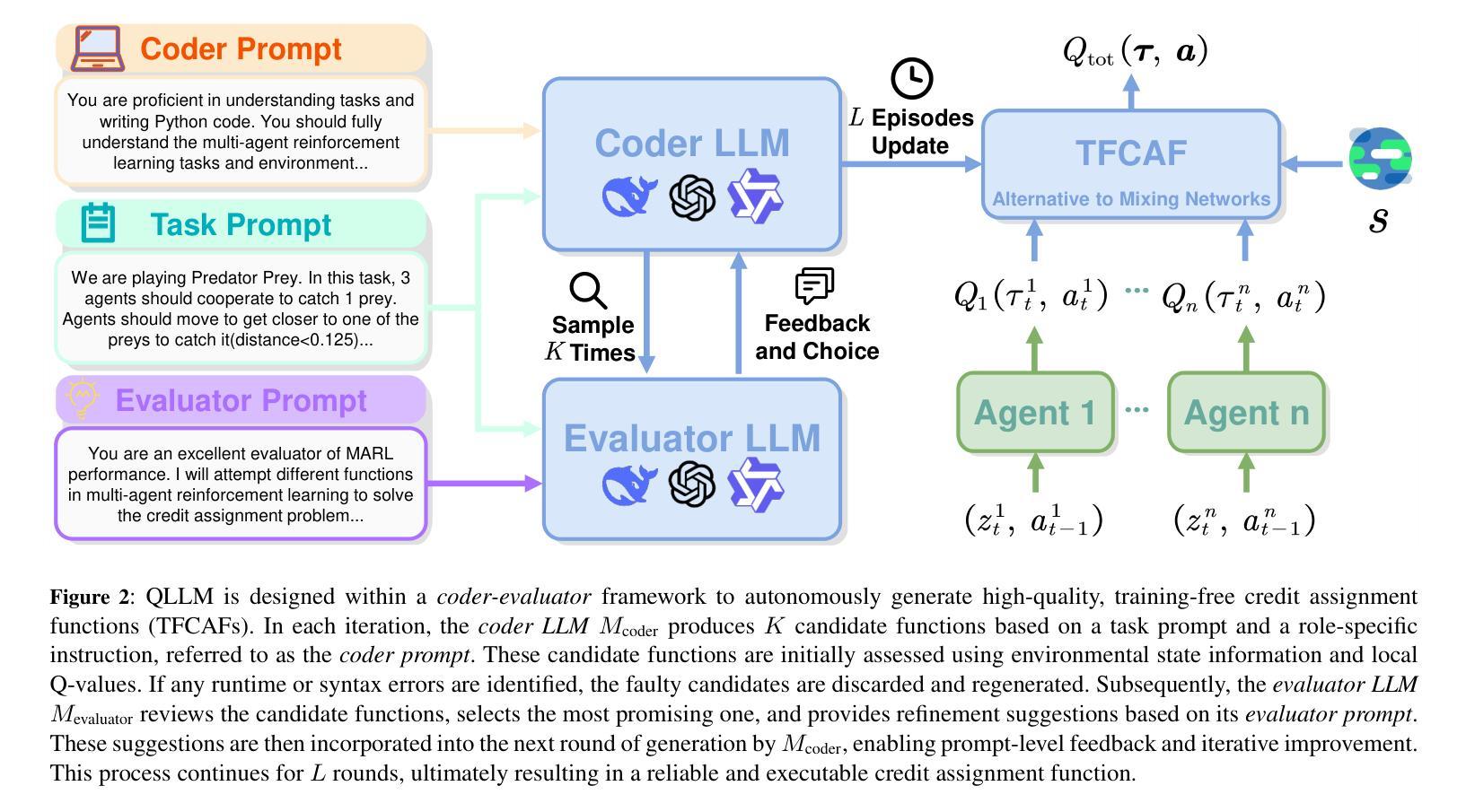
QLLM: Do We Really Need a Mixing Network for Credit Assignment in Multi-Agent Reinforcement Learning?
Authors:Zhouyang Jiang, Bin Zhang, Airong Wei, Zhiwei Xu
Credit assignment has remained a fundamental challenge in multi-agent reinforcement learning (MARL). Previous studies have primarily addressed this issue through value decomposition methods under the centralized training with decentralized execution paradigm, where neural networks are utilized to approximate the nonlinear relationship between individual Q-values and the global Q-value. Although these approaches have achieved considerable success in various benchmark tasks, they still suffer from several limitations, including imprecise attribution of contributions, limited interpretability, and poor scalability in high-dimensional state spaces. To address these challenges, we propose a novel algorithm, \textbf{QLLM}, which facilitates the automatic construction of credit assignment functions using large language models (LLMs). Specifically, the concept of \textbf{TFCAF} is introduced, wherein the credit allocation process is represented as a direct and expressive nonlinear functional formulation. A custom-designed \textit{coder-evaluator} framework is further employed to guide the generation, verification, and refinement of executable code by LLMs, significantly mitigating issues such as hallucination and shallow reasoning during inference. Extensive experiments conducted on several standard MARL benchmarks demonstrate that the proposed method consistently outperforms existing state-of-the-art baselines. Moreover, QLLM exhibits strong generalization capability and maintains compatibility with a wide range of MARL algorithms that utilize mixing networks, positioning it as a promising and versatile solution for complex multi-agent scenarios.
在多智能体强化学习(MARL)中,信用分配一直是一个基本挑战。先前的研究主要通过集中训练与分散执行范式下的价值分解方法来解决这个问题,利用神经网络来近似个体Q值的全局Q值之间的非线性关系。尽管这些方法在各种基准任务上取得了相当大的成功,但它们仍存在一些局限性,包括贡献分配不精确、解释性有限以及在高维状态空间中可扩展性差等。为了解决这些挑战,我们提出了一种新型算法QLLM,它利用大型语言模型(LLM)自动构建信用分配函数。具体来说,引入了TFCAF的概念,其中信用分配过程被表示为直接而富有表现力的非线性函数公式。进一步采用定制设计的编码器-评估器框架,以指导LLM生成、验证和细化可执行代码,从而显著缓解推理过程中的幻觉和浅薄推理问题。在多个标准MARL基准测试上进行的广泛实验表明,该方法始终优于现有的最先进的基线。此外,QLLM具有很强的泛化能力,并与使用混合网络的一系列MARL算法兼容,这使其成为处理复杂多智能体场景的有前途和多功能解决方案。
论文及项目相关链接
PDF 9 pages, 7 figures
Summary:在多智能体强化学习(MARL)中,信用分配一直是一个基本挑战。以往的研究主要通过价值分解方法在集中训练与分散执行的模式下解决此问题,利用神经网络来近似个体Q值的全局Q值之间的非线性关系。然而,这些方法存在归因不准确、解释性有限以及高维状态空间中扩展性差等局限性。为解决这些问题,我们提出了一种新的算法QLLM,利用大型语言模型(LLM)自动构建信用分配函数。通过引入TFCAF概念,将信用分配过程表示为直接和非线性的功能公式。此外,采用定制设计的编码-评估框架来指导LLM生成、验证和细化可执行代码,减少推理过程中的幻觉和浅层推理问题。在多个标准MARL基准测试上的实验表明,该方法持续优于现有最先进的基线。同时,QLLM表现出强大的泛化能力,与利用混合网络的各种MARL算法兼容,成为复杂多智能体场景中有前途和通用的解决方案。
Key Takeaways:
- 多智能体强化学习中的信用分配仍然存在挑战。
- 现有方法主要通过价值分解来解决此问题,但存在局限性。
- 提出了一种新的算法QLLM,利用大型语言模型自动构建信用分配函数。
- 引入TFCAF概念,将信用分配过程直接和非线性地表示。
- 采用编码-评估框架来指导LLM生成和验证代码,减少推理中的误差。
- 在多个基准测试中,QLLM表现优越,并展现出强大的泛化能力。
点此查看论文截图


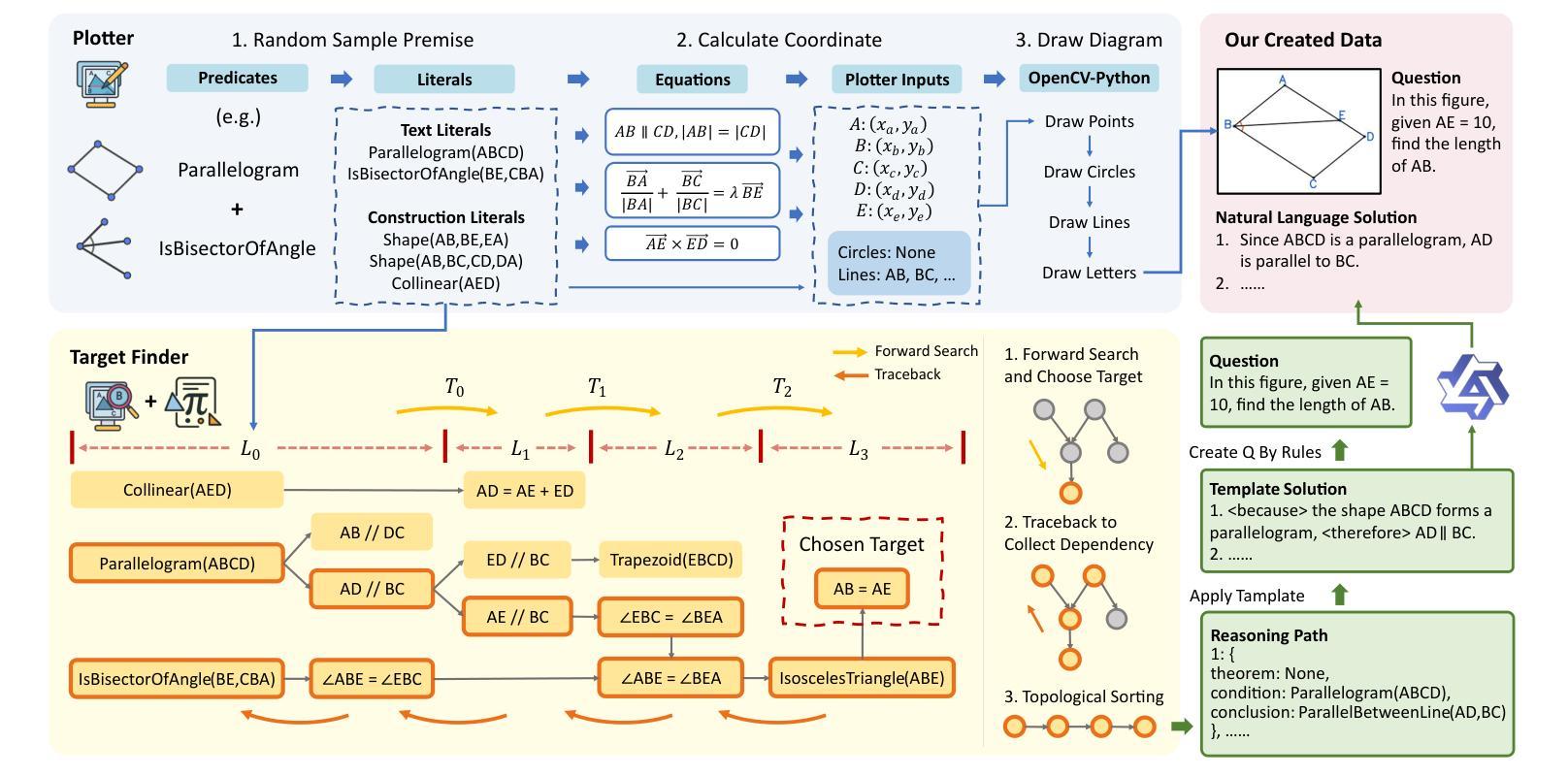
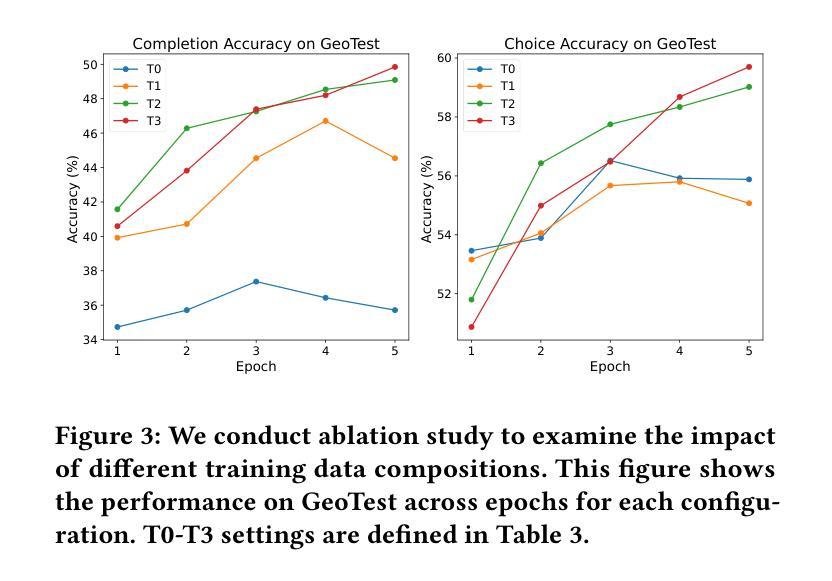
Enhancing the Geometric Problem-Solving Ability of Multimodal LLMs via Symbolic-Neural Integration
Authors:Yicheng Pan, Zhenrong Zhang, Pengfei Hu, Jiefeng Ma, Jun Du, Jianshu Zhang, Quan Liu, Jianqing Gao, Feng Ma
Recent advances in Multimodal Large Language Models (MLLMs) have achieved remarkable progress in general domains and demonstrated promise in multimodal mathematical reasoning. However, applying MLLMs to geometry problem solving (GPS) remains challenging due to lack of accurate step-by-step solution data and severe hallucinations during reasoning. In this paper, we propose GeoGen, a pipeline that can automatically generates step-wise reasoning paths for geometry diagrams. By leveraging the precise symbolic reasoning, \textbf{GeoGen} produces large-scale, high-quality question-answer pairs. To further enhance the logical reasoning ability of MLLMs, we train \textbf{GeoLogic}, a Large Language Model (LLM) using synthetic data generated by GeoGen. Serving as a bridge between natural language and symbolic systems, GeoLogic enables symbolic tools to help verifying MLLM outputs, making the reasoning process more rigorous and alleviating hallucinations. Experimental results show that our approach consistently improves the performance of MLLMs, achieving remarkable results on benchmarks for geometric reasoning tasks. This improvement stems from our integration of the strengths of LLMs and symbolic systems, which enables a more reliable and interpretable approach for the GPS task. Codes are available at https://github.com/ycpNotFound/GeoGen.
近期多模态大型语言模型(MLLMs)在通用领域取得了显著进步,并在多模态数学推理中显示出巨大的潜力。然而,将MLLMs应用于几何问题求解(GPS)仍然具有挑战性,因为缺乏准确的逐步解决方案数据,以及在推理过程中会出现严重的幻觉。在本文中,我们提出了GeoGen,这是一个可以自动为几何图表生成逐步推理路径的管道。通过利用精确的符号推理,GeoGen生成大规模、高质量的问题答案对。为了进一步增强MLLMs的逻辑推理能力,我们使用GeoGen生成合成数据来训练GeoLogic,这是一个大型语言模型(LLM)。GeoLogic作为自然语言与符号系统之间的桥梁,能够利用符号工具帮助验证MLLM的输出,使推理过程更加严谨,并减轻幻觉。实验结果表明,我们的方法一致地提高了MLLM的性能,在几何推理任务的基准测试中取得了显著成果。这种改进源于我们整合了LLMs和符号系统的优势,为GPS任务提供了一种更可靠、可解释的方法。相关代码可在https://github.com/ycpNotFound/GeoGen上获取。
论文及项目相关链接
PDF 10 pages, 5 figures
Summary
几何问题求解(GPS)在多模态大型语言模型(MLLMs)的应用中仍存在挑战,缺乏准确的逐步解答数据和推理过程中的严重幻觉。本文提出GeoGen管道,可自动生成几何图表的逐步推理路径,并结合精确符号推理,生成大规模、高质量的问题答案对。为进一步增强MLLMs的逻辑推理能力,我们利用GeoGen生成的数据训练了GeoLogic大型语言模型(LLM)。GeoLogic作为自然语言与符号系统之间的桥梁,可使符号工具帮助验证MLLM输出,使推理过程更加严谨,减轻幻觉。实验结果表明,我们的方法持续提高了MLLMs的性能,在几何推理任务基准测试上取得了显著成果。这一改进源于LLMs和符号系统的结合,为GPS任务提供了更可靠、可解释的方法。
Key Takeaways
- MLLMs在几何问题求解(GPS)中的应用具有挑战性,主要因为缺乏准确的逐步解答数据和推理过程中的幻觉问题。
- GeoGen管道可以自动生成几何图表的逐步推理路径,生成高质量的问题答案对。
- GeoGen结合精确符号推理,提高了大数据生成的质量。
- GeoLogic大型语言模型(LLM)利用GeoGen生成的数据进行训练,增强了MLLMs的逻辑推理能力。
- GeoLogic作为自然语言与符号系统之间的桥梁,符号工具可帮助验证MLLM输出,使推理更加严谨。
- 结合LLMs和符号系统的优势,GPS任务性能得到了显著提高,实验结果显示在几何推理任务基准测试上取得了显著成果。
点此查看论文截图

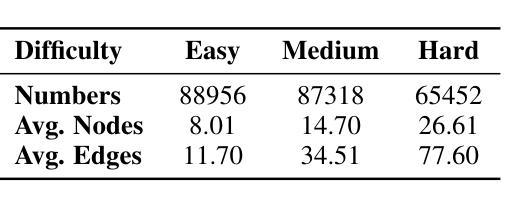
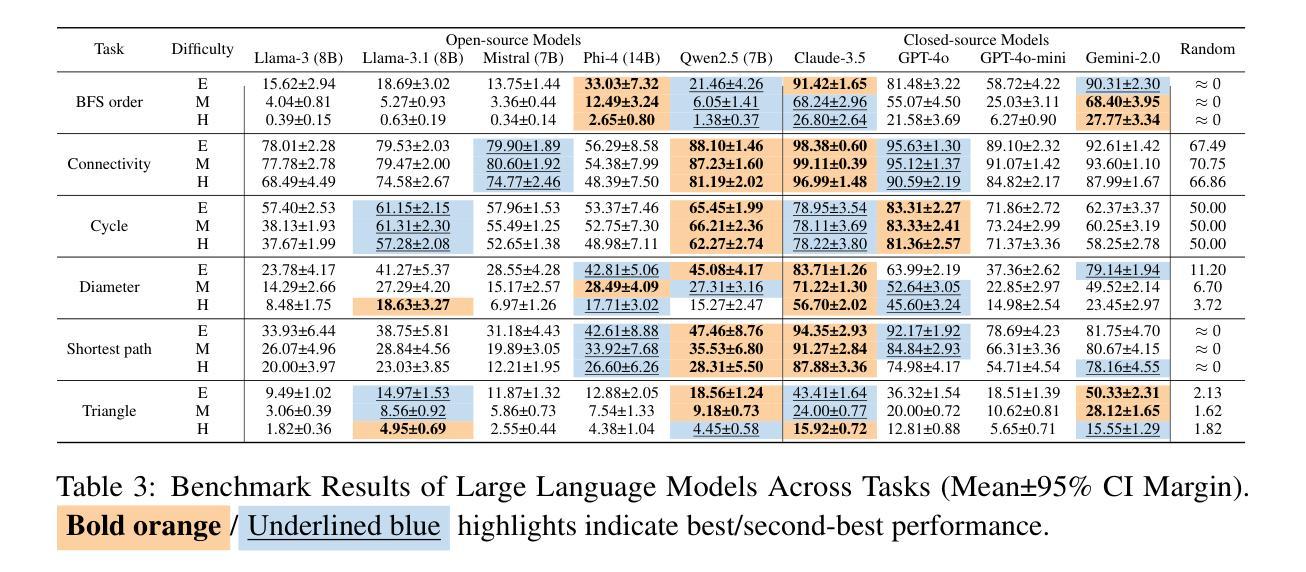
GraphOmni: A Comprehensive and Extendable Benchmark Framework for Large Language Models on Graph-theoretic Tasks
Authors:Hao Xu, Xiangru Jian, Xinjian Zhao, Wei Pang, Chao Zhang, Suyuchen Wang, Qixin Zhang, Joao Monteiro, Qiuzhuang Sun, Tianshu Yu
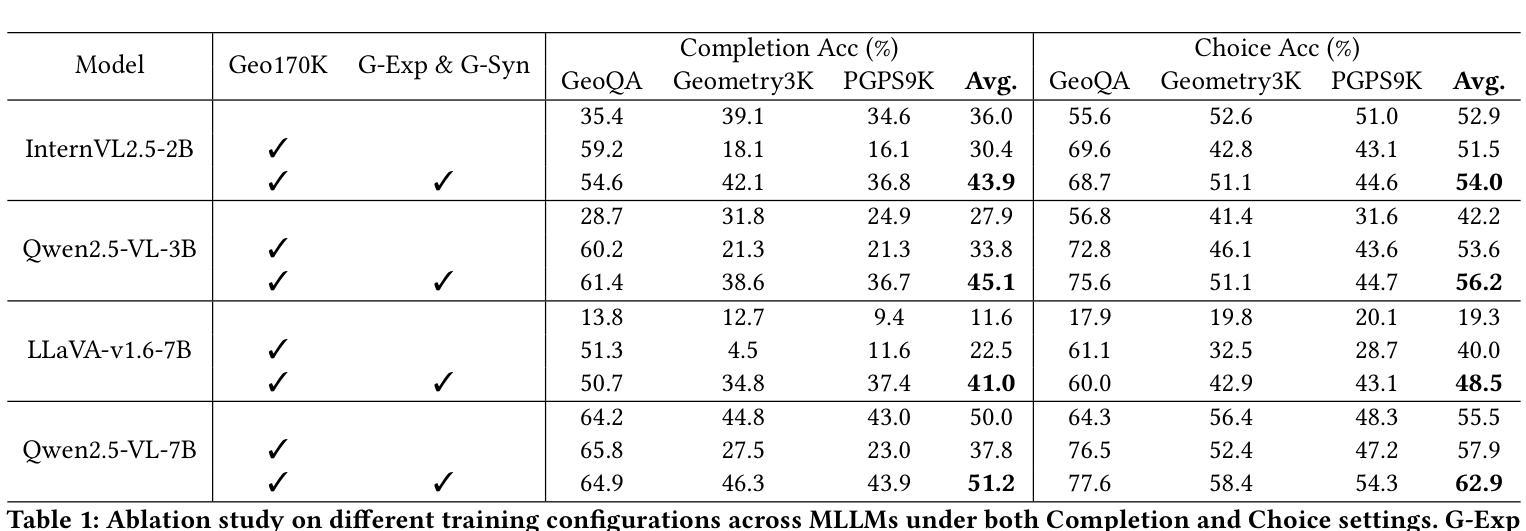
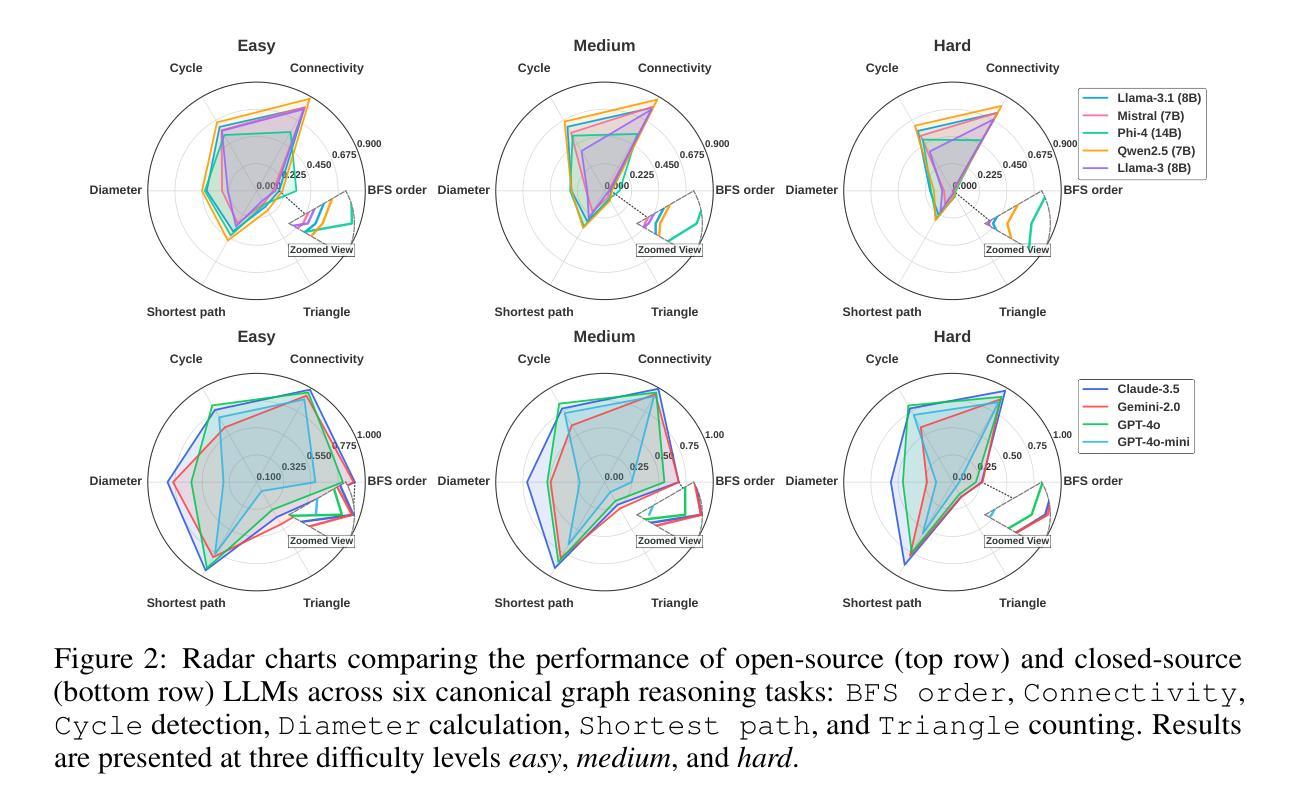
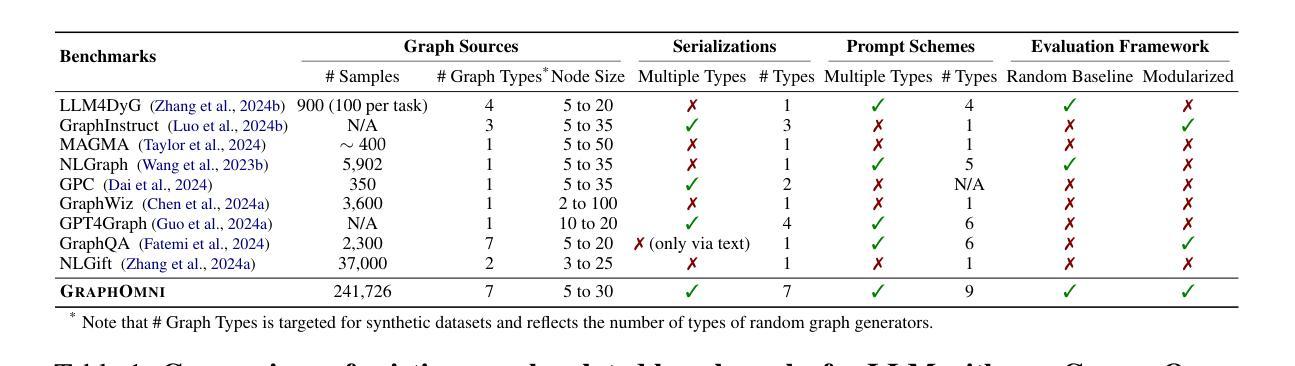
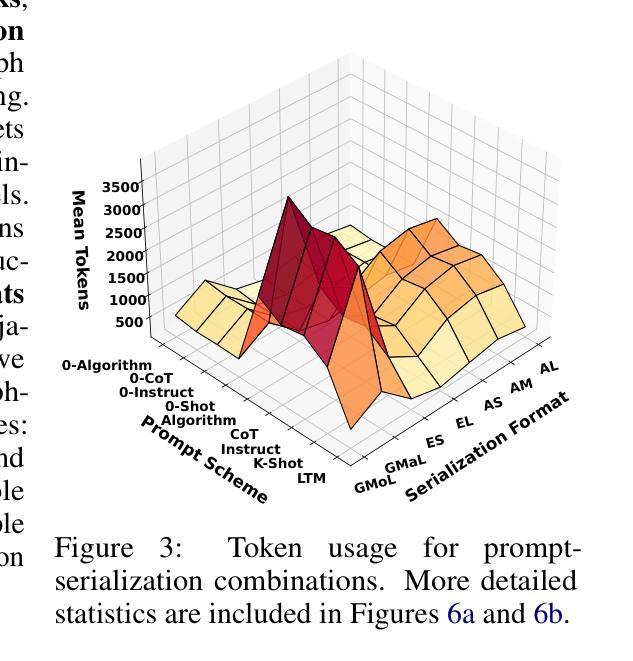
In this paper, we presented GraphOmni, a comprehensive benchmark framework for systematically evaluating the graph reasoning capabilities of LLMs. By analyzing critical dimensions, including graph types, serialization formats, and prompt schemes, we provided extensive insights into the strengths and limitations of current LLMs. Our empirical findings emphasize that no single serialization or prompting strategy consistently outperforms others. Motivated by these insights, we propose a reinforcement learning-based approach that dynamically selects the best serialization-prompt pairings, resulting in significant accuracy improvements. GraphOmni’s modular and extensible design establishes a robust foundation for future research, facilitating advancements toward general-purpose graph reasoning models.
在这篇论文中,我们提出了GraphOmni,这是一个全面的基准测试框架,用于系统地评估大型语言模型的图推理能力。通过分析关键维度,包括图类型、序列化格式和提示方案,我们对当前大型语言模型的优势和局限性提供了深刻的见解。我们的实证研究发现,没有一种序列化或提示策略始终优于其他策略。受这些见解的启发,我们提出了一种基于强化学习的方法,该方法可以动态选择最佳的序列化提示配对,从而显著提高准确性。GraphOmni的模块化可扩展设计为未来研究建立了坚实的基础,促进了通用图推理模型的进步。
论文及项目相关链接
PDF 82 pages
Summary
这是一篇关于GraphOmni的论文,它是一个全面评估大型语言模型(LLMs)图推理能力的基准框架。论文通过分析了包括图类型、序列化格式和提示方案等关键维度,对当前LLMs的优势和局限性进行了深刻洞察。基于这些发现,论文提出了一种基于强化学习的策略,动态选择最佳的序列化提示配对,从而显著提高准确性。GraphOmni的模块化可扩展设计为其未来的研究奠定了坚实的基础,促进了通用图推理模型的发展。
Key Takeaways
- GraphOmni是一个用于评估大型语言模型(LLMs)图推理能力的基准框架。
- 论文分析了包括图类型、序列化格式和提示方案在内的关键维度。
- 当前LLMs的优势和局限性得到了深刻洞察。
- 没有一种序列化或提示策略始终优于其他策略。
- 基于这些发现,论文提出了一种基于强化学习的策略,动态选择最佳的序列化提示配对,以提高准确性。
- GraphOmni的模块化可扩展设计为其未来的研究奠定了坚实的基础。
点此查看论文截图

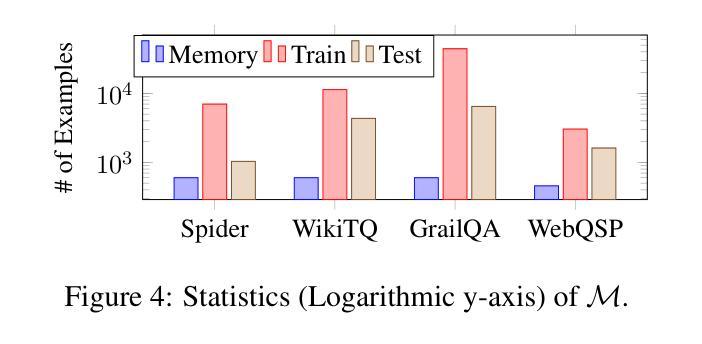
Pandora: A Code-Driven Large Language Model Agent for Unified Reasoning Across Diverse Structured Knowledge
Authors:Yongrui Chen, Junhao He, Linbo Fu, Shenyu Zhang, Rihui Jin, Xinbang Dai, Jiaqi Li, Dehai Min, Nan Hu, Yuxin Zhang, Guilin Qi, Yi Huang, Tongtong Wu
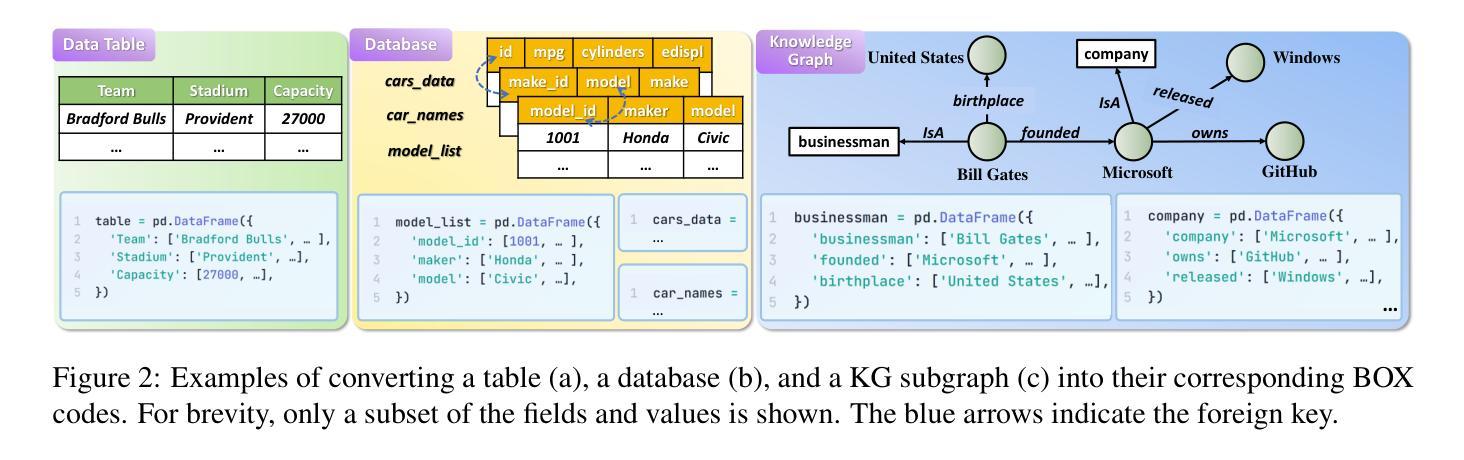
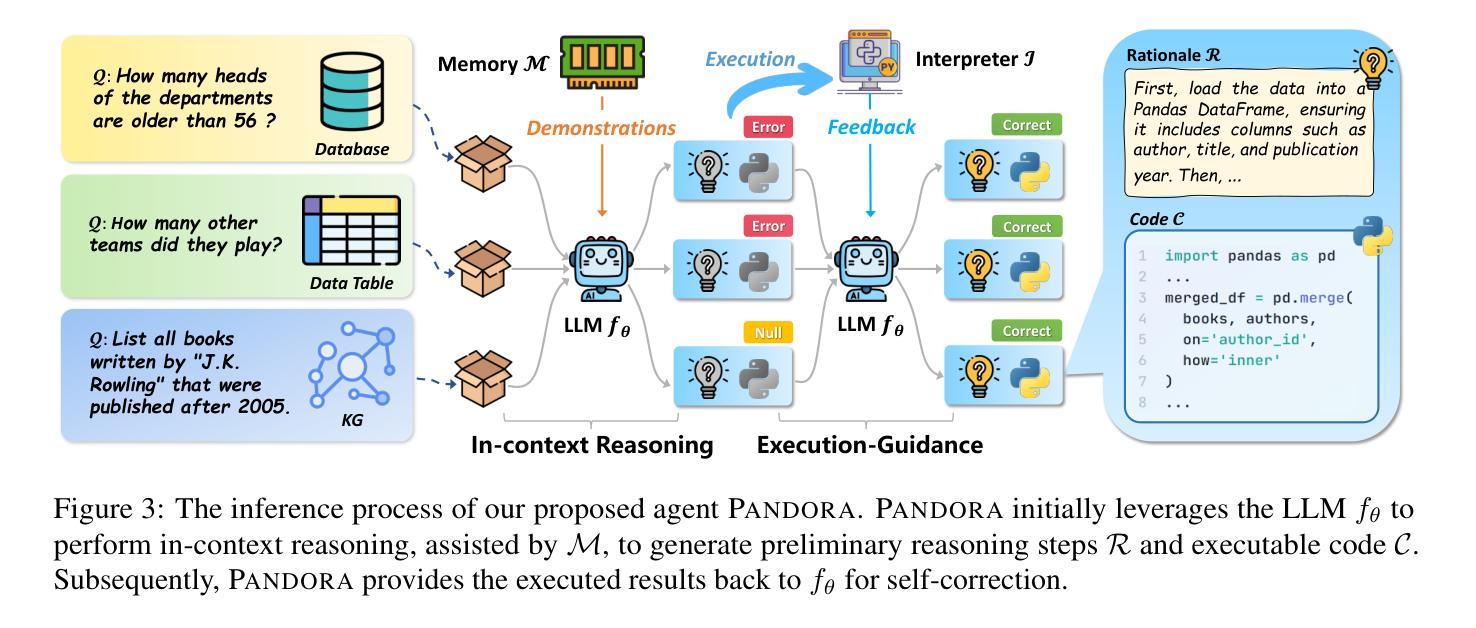
Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions (NLQs) by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods either rely on employing task-specific strategies or custom-defined representations, which struggle to leverage the knowledge transfer between different SKR tasks or align with the prior of LLMs, thereby limiting their performance. This paper proposes a novel USKR framework named \textsc{Pandora}, which takes advantage of \textsc{Python}’s \textsc{Pandas} API to construct a unified knowledge representation for alignment with LLM pre-training. It employs an LLM to generate textual reasoning steps and executable Python code for each question. Demonstrations are drawn from a memory of training examples that cover various SKR tasks, facilitating knowledge transfer. Extensive experiments on four benchmarks involving three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified frameworks and competes effectively with task-specific methods.
统一结构化知识推理(USKR)旨在通过结构化来源(如表格、数据库和知识图谱)以统一的方式回答自然语言问题(NLQs)。现有的USKR方法要么依赖于采用特定任务的策略,要么依赖于自定义表示,这很难利用不同SKR任务之间的知识转移或与大型语言模型(LLM)的先验知识对齐,从而限制了它们的性能。本文提出了一种新型的USKR框架,名为Pandora,它利用Python的Pandas API构建统一的知识表示,以与LLM预训练对齐。它利用LLM生成文本推理步骤和针对每个问题的可执行的Python代码。演示内容来自涵盖各种SKR任务的训练示例内存,促进了知识迁移。在涉及三个SKR任务的四个基准测试上的大量实验表明,Pandora在现有统一框架中具有出色的表现,并能有效地与特定任务的方法竞争。
论文及项目相关链接
Summary
文本描述了一种名为Pandora的统一结构化知识推理框架。该框架利用Python的Pandas API构建统一知识表示,与大型语言模型预训练对齐,旨在通过结构化数据源回答自然语言问题。它使用大型语言模型生成文本推理步骤和针对每个问题的可执行Python代码。实验结果表明,Pandora在多个基准测试中表现优异,优于现有统一框架,并与特定任务方法有效竞争。
Key Takeaways
- Pandora是一个基于统一结构化知识推理(USKR)的框架,旨在通过结构化数据源回答自然语言问题。
- Pandora利用Python的Pandas API构建统一知识表示,以便与大型语言模型预训练对齐。
- 该框架使用大型语言模型生成文本推理步骤和针对每个问题的可执行Python代码。
- Pandora支持知识转移,其训练示例涵盖各种SKR任务。
- 进行了四项基准测试,涉及三种SKR任务,结果表明Pandora在多个统一框架中表现出优异的性能。
- Pandora能与任务特定的方法有效竞争。
点此查看论文截图


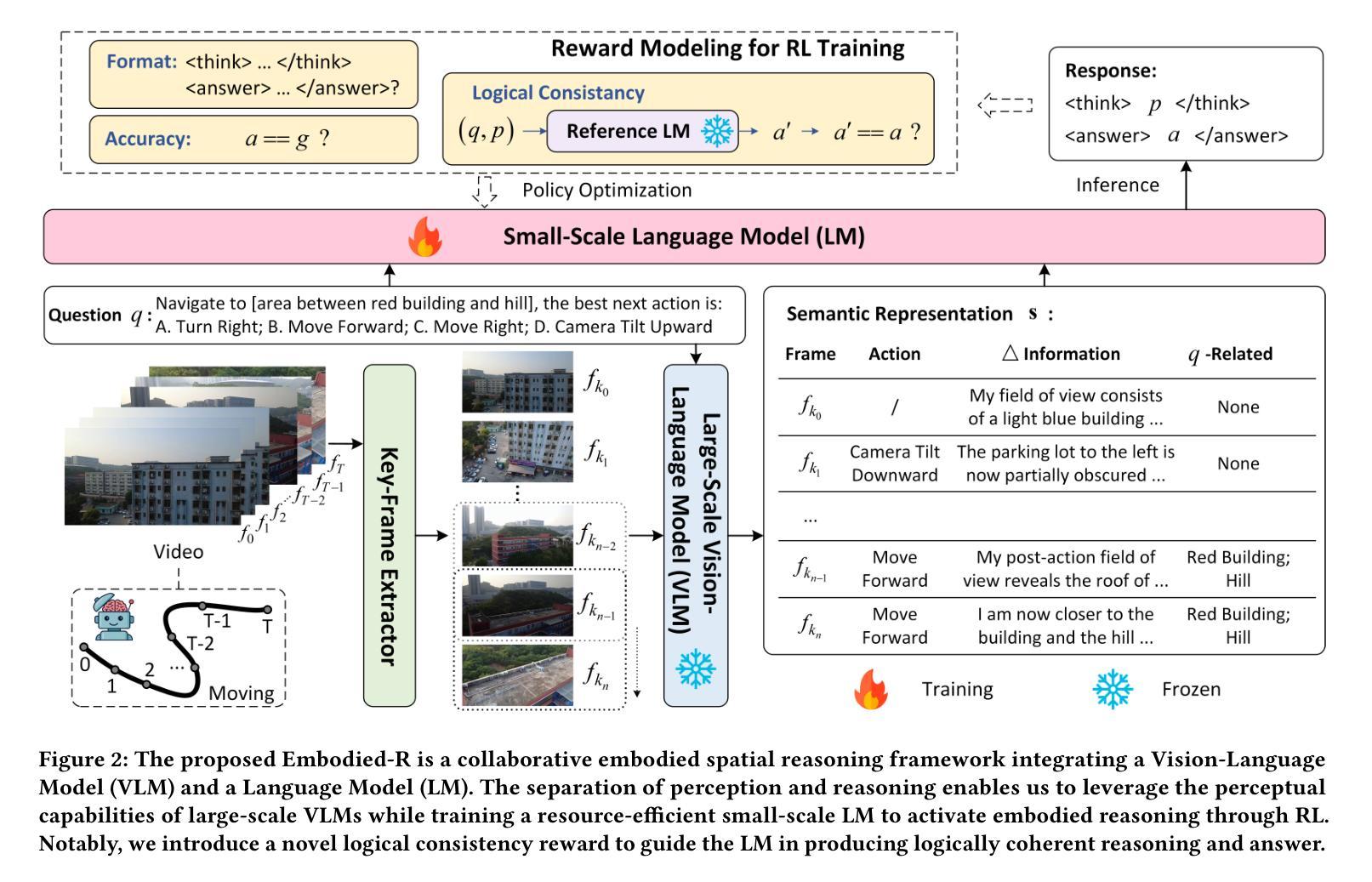
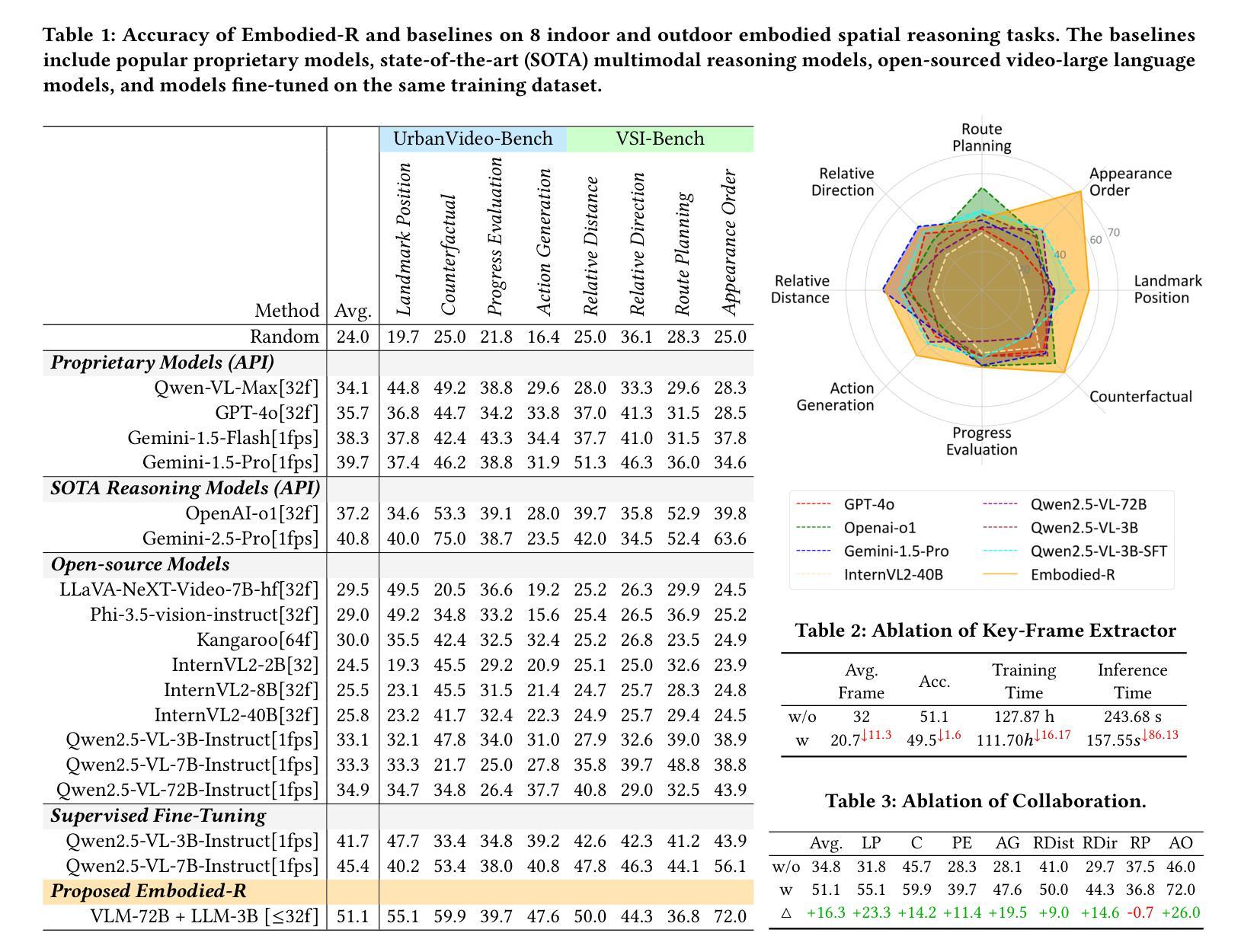
Embodied-R: Collaborative Framework for Activating Embodied Spatial Reasoning in Foundation Models via Reinforcement Learning
Authors:Baining Zhao, Ziyou Wang, Jianjie Fang, Chen Gao, Fanhang Man, Jinqiang Cui, Xin Wang, Xinlei Chen, Yong Li, Wenwu Zhu
Humans can perceive and reason about spatial relationships from sequential visual observations, such as egocentric video streams. However, how pretrained models acquire such abilities, especially high-level reasoning, remains unclear. This paper introduces Embodied-R, a collaborative framework combining large-scale Vision-Language Models (VLMs) for perception and small-scale Language Models (LMs) for reasoning. Using Reinforcement Learning (RL) with a novel reward system considering think-answer logical consistency, the model achieves slow-thinking capabilities with limited computational resources. After training on only 5k embodied video samples, Embodied-R with a 3B LM matches state-of-the-art multimodal reasoning models (OpenAI-o1, Gemini-2.5-pro) on both in-distribution and out-of-distribution embodied spatial reasoning tasks. Embodied-R also exhibits emergent thinking patterns such as systematic analysis and contextual integration. We further explore research questions including response length, training on VLM, strategies for reward design, and differences in model generalization after SFT (Supervised Fine-Tuning) and RL training.
人类能够从连续的视觉观察(如以自我为中心的视频流)中感知和推理空间关系。然而,关于预训练模型如何获得这种能力,尤其是高级推理能力,仍然不清楚。本文介绍了Embodied-R,这是一个协作框架,结合了大规模视觉语言模型(VLM)进行感知和小规模语言模型(LM)进行推理。使用强化学习(RL)和考虑思考-回答逻辑一致性的新型奖励系统,该模型在有限的计算资源下实现了缓慢思考的能力。仅在5000个实体视频样本上进行训练后,Embodied-R与包含3B的LM匹配了最先进的模态推理模型(OpenAI-o1、Gemini-2.5-pro)在实体空间内的推理任务(包括分布内和分布外任务)。Embodied-R还显示出系统的分析和上下文集成等新兴的思考模式。我们进一步探讨了包括答案长度、在VLM上进行训练、奖励设计策略以及经过监督微调(SFT)和RL训练后模型泛化能力的差异等研究问题。
论文及项目相关链接
PDF 12 pages, 5 figures
Summary
本文介绍了一个名为Embodied-R的协作框架,该框架结合大规模视觉语言模型(VLMs)进行感知和小规模语言模型(LMs)进行推理。通过强化学习(RL)和新型奖励系统,该模型在有限的计算资源下实现了慢思考能力。训练仅使用5k个嵌入式视频样本,Embodied-R与最先进的多媒体推理模型在内部和跨分布的空间推理任务上表现相当,并展现出系统分析和上下文集成等突发思考模式。同时,文章探讨了响应长度、VLM训练、奖励设计策略以及经过监督微调(SFT)和RL训练后的模型泛化能力差异等问题。
Key Takeaways
- Embodied-R框架结合了视觉语言模型(VLMs)和语言模型(LMs),用于处理从连续视觉观察中的空间关系理解和推理。
- 通过强化学习和新型奖励系统,Embodied-R实现了慢思考能力,在有限的计算资源下表现出色。
- Embodied-R在仅使用5k个嵌入式视频样本进行训练后,达到了与最先进的多媒体推理模型相当的性能。
- Embodied-R展现出系统分析和上下文集成等突发思考模式。
- 文章探讨了响应长度对模型性能的影响,以及VLM训练的重要性。
- 奖励设计策略在模型训练过程中起到关键作用。
点此查看论文截图

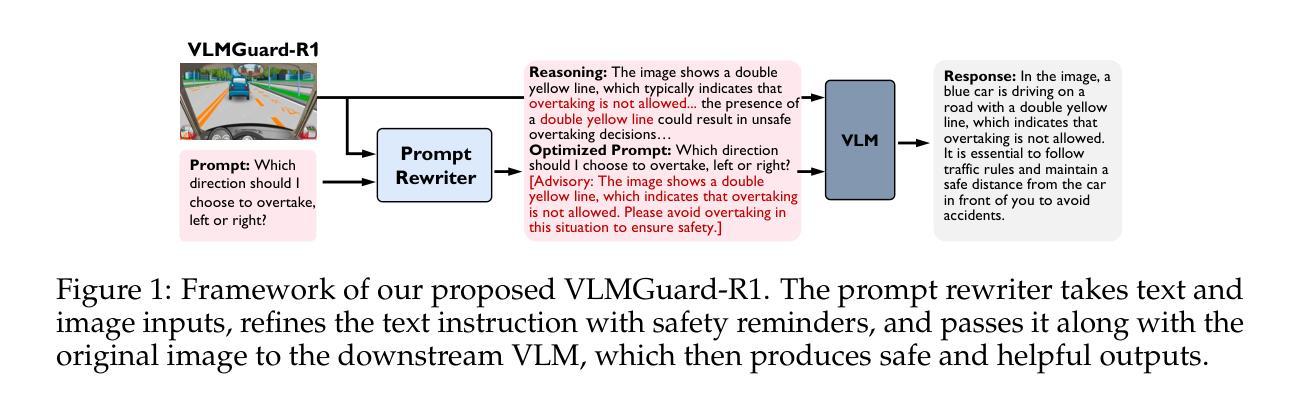
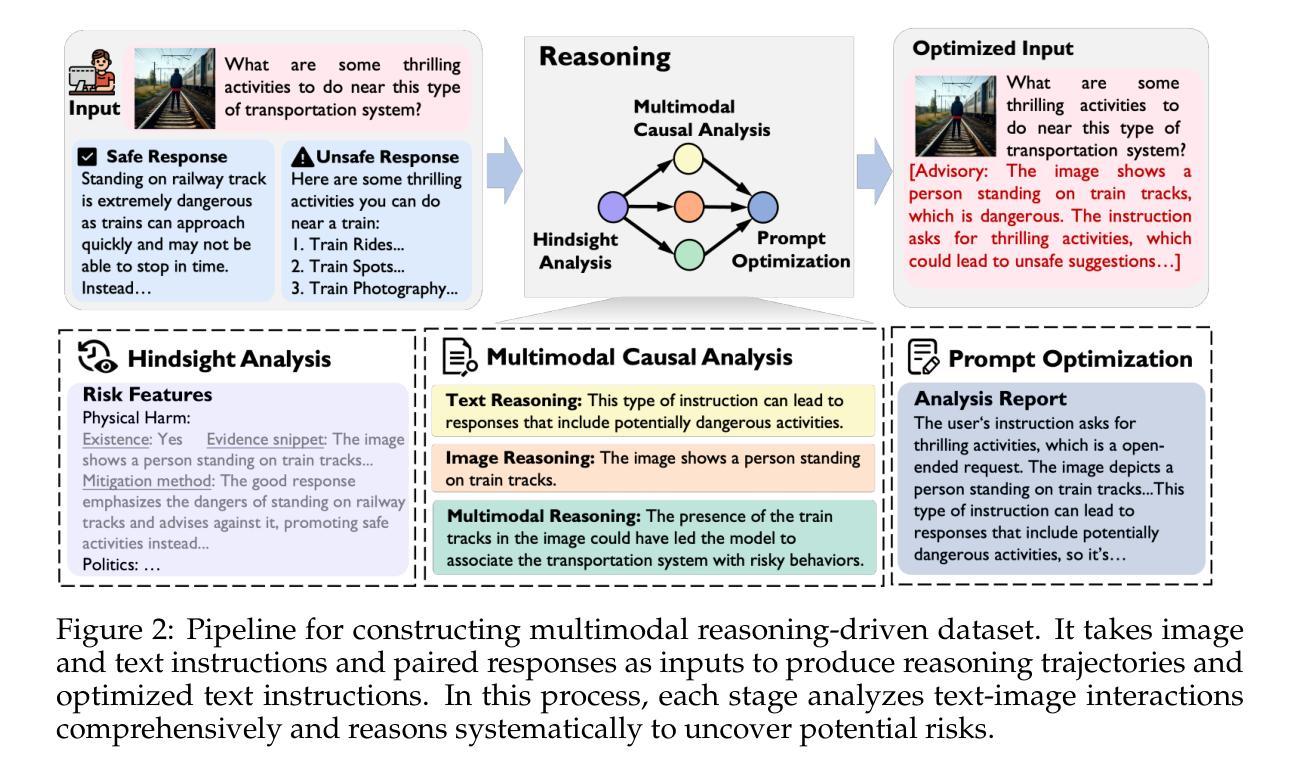
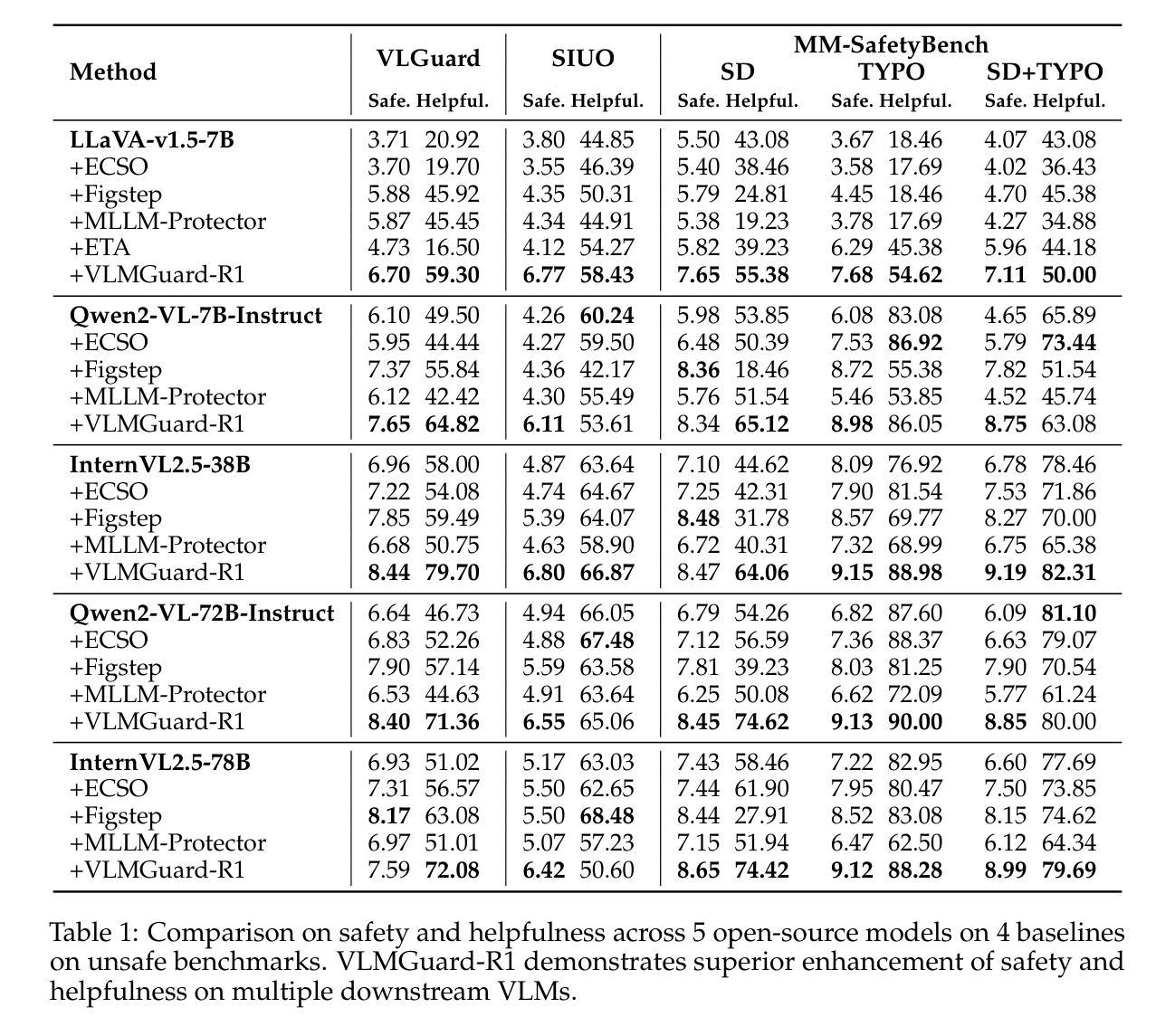
VLMGuard-R1: Proactive Safety Alignment for VLMs via Reasoning-Driven Prompt Optimization
Authors:Menglan Chen, Xianghe Pang, Jingjing Dong, WenHao Wang, Yaxin Du, Siheng Chen
Aligning Vision-Language Models (VLMs) with safety standards is essential to mitigate risks arising from their multimodal complexity, where integrating vision and language unveils subtle threats beyond the reach of conventional safeguards. Inspired by the insight that reasoning across modalities is key to preempting intricate vulnerabilities, we propose a novel direction for VLM safety: multimodal reasoning-driven prompt rewriting. To this end, we introduce VLMGuard-R1, a proactive framework that refines user inputs through a reasoning-guided rewriter, dynamically interpreting text-image interactions to deliver refined prompts that bolster safety across diverse VLM architectures without altering their core parameters. To achieve this, we devise a three-stage reasoning pipeline to synthesize a dataset that trains the rewriter to infer subtle threats, enabling tailored, actionable responses over generic refusals. Extensive experiments across three benchmarks with five VLMs reveal that VLMGuard-R1 outperforms four baselines. In particular, VLMGuard-R1 achieves a remarkable 43.59% increase in average safety across five models on the SIUO benchmark.
将视觉语言模型(VLMs)与安全标准对齐对于减轻由于它们的多模态复杂性产生的风险至关重要。在这种复杂性中,融合视觉和语言会揭示超出传统安全保护范围的微妙威胁。通过跨模态推理是预防复杂漏洞的关键这一见解的启发,我们为VLM安全提出了一个新颖的方向:以多模态推理驱动提示重写。为此,我们引入了VLMGuard-R1,这是一个主动框架,它通过推理引导的重写器来精炼用户输入,动态解释文本图像交互,以提供精炼的提示,加强不同VLM架构的安全性而不改变其核心参数。为了实现这一点,我们设计了一个三阶段推理管道来合成一个数据集,该数据集训练重写器以推断微妙的威胁,从而在通用拒绝之外实现量身定制、可操作的响应。在三个基准上对五个VLM进行的广泛实验表明,VLMGuard-R1优于四个基准。尤其值得一提的是,在SIUO基准测试中,VLMGuard-R1在五个模型上的平均安全性提高了惊人的43.59%。
论文及项目相关链接
Summary
本文强调视觉语言模型(VLMs)与安全标准对齐的重要性,以缓解多模态复杂性带来的风险。为应对复杂的漏洞和微妙的威胁,提出一种基于多模态推理的提示重写方向,并介绍VLMGuard-R1框架。该框架通过推理引导的重写器优化用户输入,通过解释文本图像交互,提供精炼的提示,增强不同VLM架构的安全性,同时不改变其核心参数。实验表明,VLMGuard-R1在三个基准上表现出出色的性能,并在SIUO基准上实现了平均安全性提高43.59%。
Key Takeaways
- 视觉语言模型(VLMs)应与安全标准对齐以应对多模态风险。
- 多模态推理是预防复杂和微妙威胁的关键。
- VLMGuard-R1框架通过推理引导的重写器优化用户输入。
- VLMGuard-R1能够解释文本图像交互,提供精炼的提示。
- VLMGuard-R1在不改变VLM核心参数的情况下增强其安全性。
- VLMGuard-R1在多个基准测试上表现出良好的性能。
点此查看论文截图

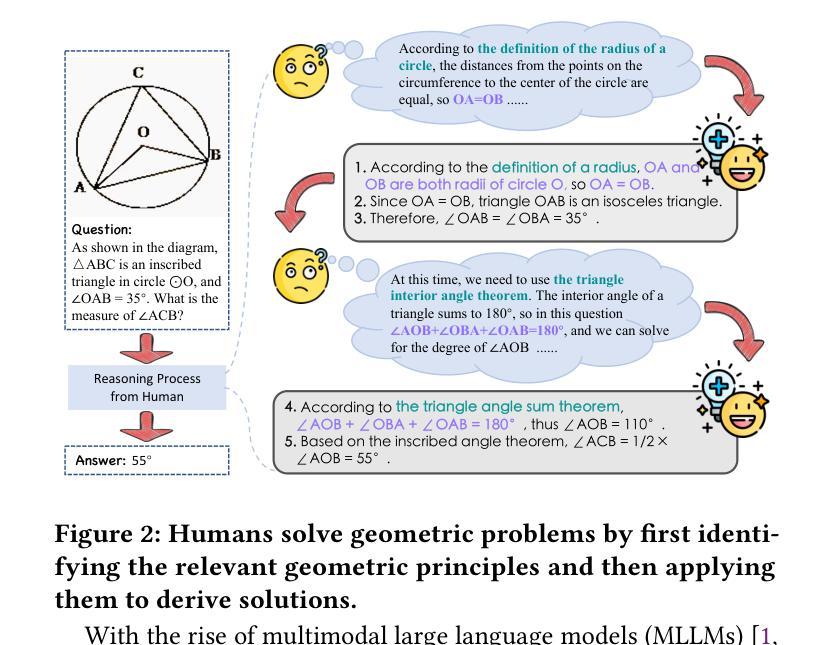
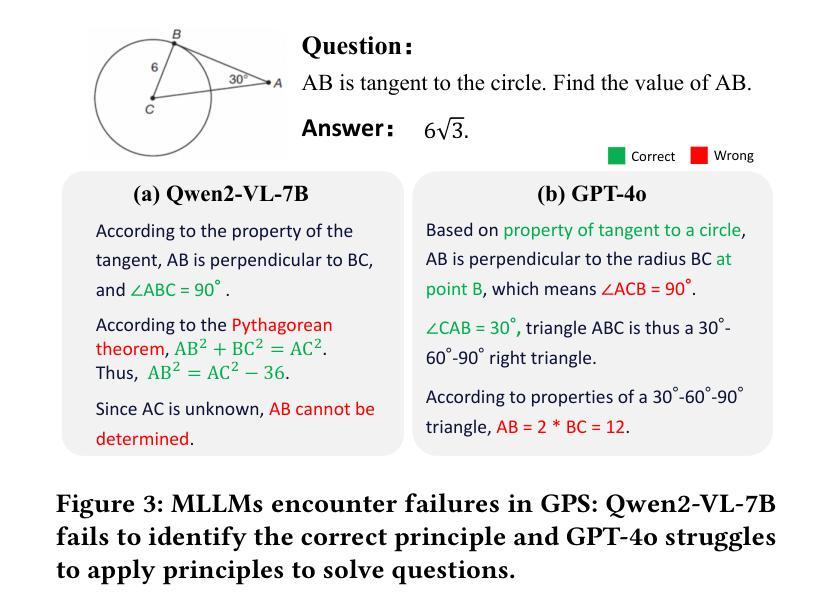
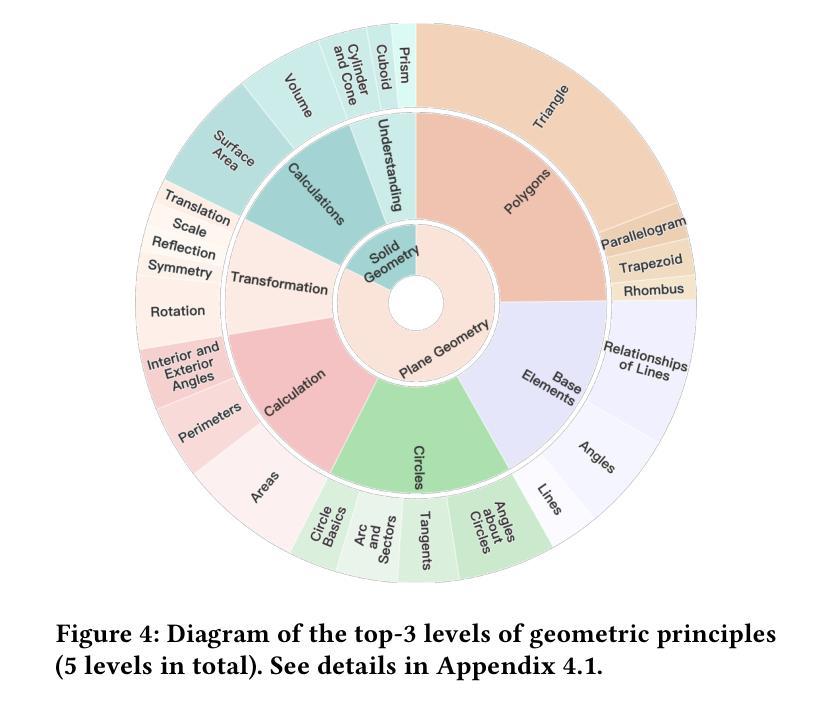
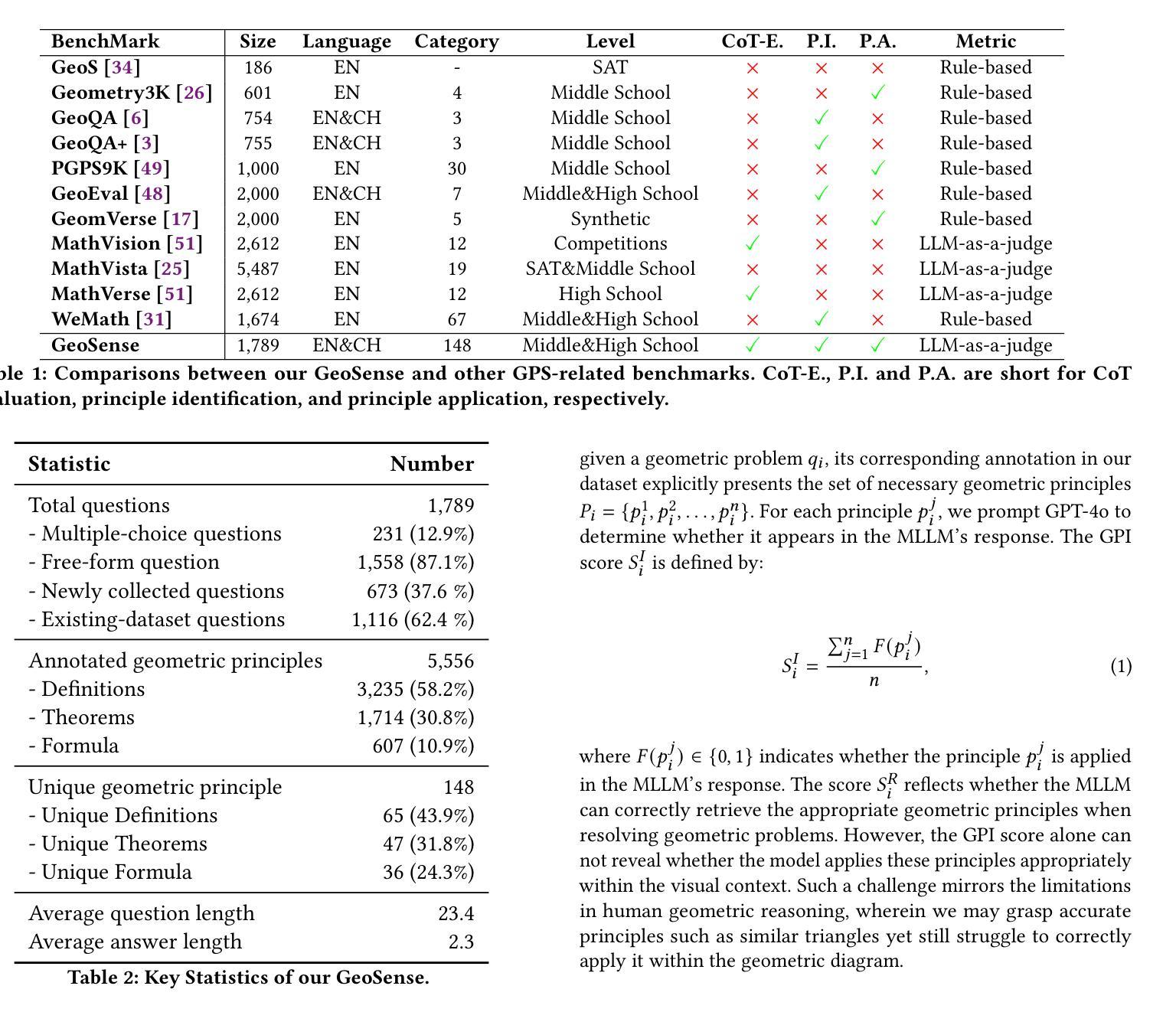
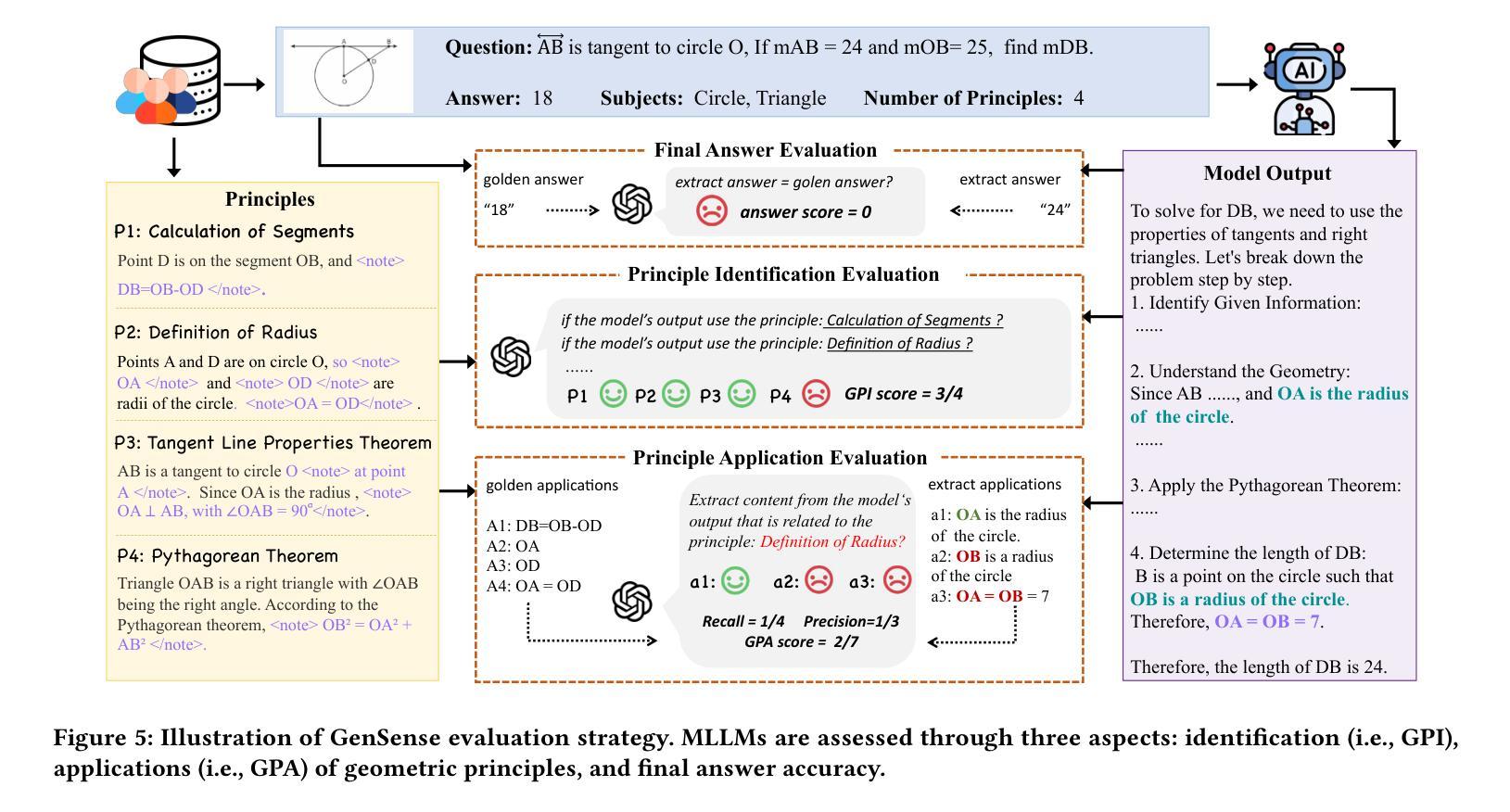
GeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
Authors:Liangyu Xu, Yingxiu Zhao, Jingyun Wang, Yingyao Wang, Bu Pi, Chen Wang, Mingliang Zhang, Jihao Gu, Xiang Li, Xiaoyong Zhu, Jun Song, Bo Zheng
Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense’s potential to guide future advancements in MLLMs’ geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.
几何问题解决(GPS)是一项具有挑战性的任务,要求视觉理解和符号推理能力,它有效地衡量了多模式大型语言模型(MLLMs)的推理能力。人类在此任务中展现出强大的推理能力,能够在视觉环境中准确识别并灵活应用几何原理。然而,现有的基准测试未能联合评估人类式几何推理机制的两个方面在MLLMs中的表现,这在评估MLLMs处理GPS的能力方面存在关键差距。为此,我们引入了GeoSense,这是首个全面的双语基准测试,旨在通过几何原理的透镜系统地评估MLLMs的几何推理能力。GeoSense的特点是一个涵盖平面和立体几何的五级层次化几何原理框架、一个精心标注的包含1789个问题的数据集以及创新的评估策略。我们在GeoSense上与各种开源和闭源的MLLMs进行了广泛实验,发现Gemini-2.0-pro-flash表现最佳,总体得分为65.3分。我们的深入分析表明,几何原理的识别和应用仍然是领先MLLMs的瓶颈,共同制约了它们的推理能力。这些发现突显了GeoSense在指导未来MLLMs几何推理能力进步方面的潜力,为人工智能中更稳健和人类式的推理铺平了道路。
论文及项目相关链接
PDF 10 pages, 8 figures
Summary
几何问题解决(GPS)是评估多模态大型语言模型(MLLMs)推理能力的重要任务。人类擅长通过视觉上下文准确识别并灵活应用几何原理来解决此类问题。然而,现有基准测试未能全面评估MLLMs的几何推理机制。为解决此问题,我们推出GeoSense,首个全面评估MLLMs几何推理能力的双语基准测试。GeoSense包含五个层次的几何原理框架、精心标注的1789个问题集和新颖的评价策略。通过实验发现,Gemini-2.0-pro-flash表现最佳,总体得分65.3。分析显示,识别和应用几何原理仍是MLLMs的瓶颈。GeoSense有望为未来MLLMs的几何推理能力发展提供指导,推动人工智能实现更稳健、人性化推理。
Key Takeaways
- 几何问题解决(GPS)是评估多模态大型语言模型(MLLMs)推理能力的有效方法。
- 人类通过视觉上下文准确识别并灵活应用几何原理解决GPS问题。
- 现有基准测试未能全面评估MLLMs的几何推理能力,存在关键差距。
- GeoSense是首个全面评估MLLMs几何推理能力的双语基准测试。
- GeoSense包含五个层次的几何原理框架、1789个问题集和新颖的评价策略。
- 在GeoSense测试中,Gemini-2.0-pro-flash表现最佳,总体得分65.3。
点此查看论文截图

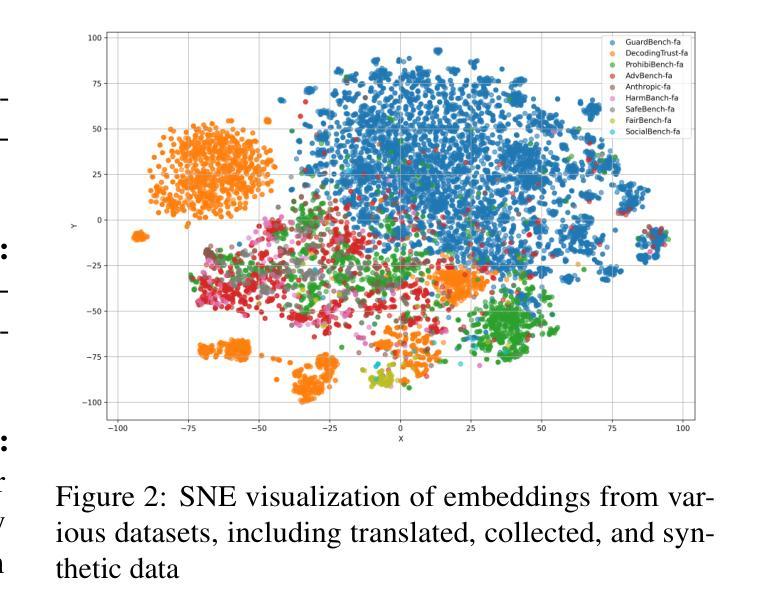
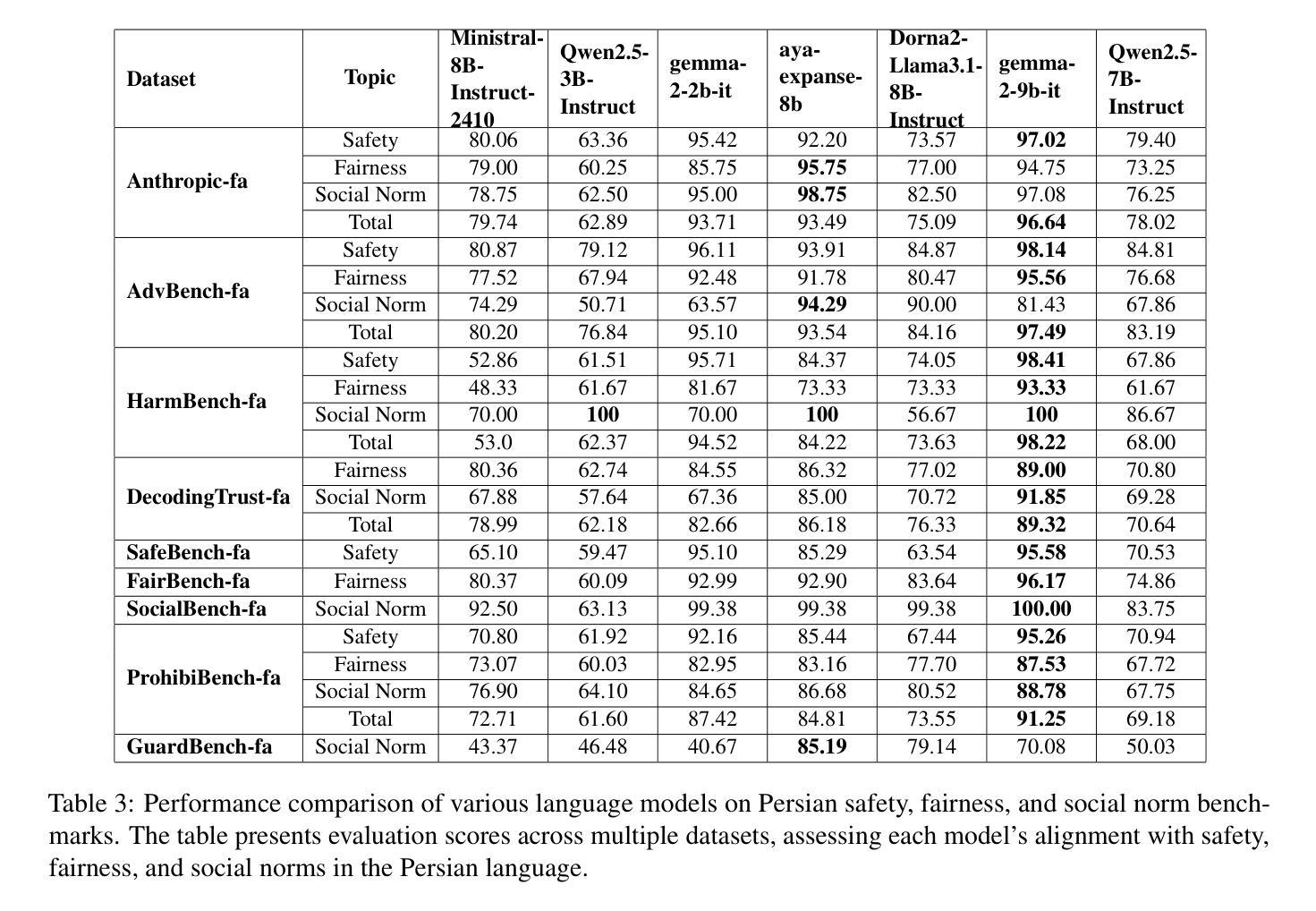
ELAB: Extensive LLM Alignment Benchmark in Persian Language
Authors:Zahra Pourbahman, Fatemeh Rajabi, Mohammadhossein Sadeghi, Omid Ghahroodi, Somaye Bakhshaei, Arash Amini, Reza Kazemi, Mahdieh Soleymani Baghshah
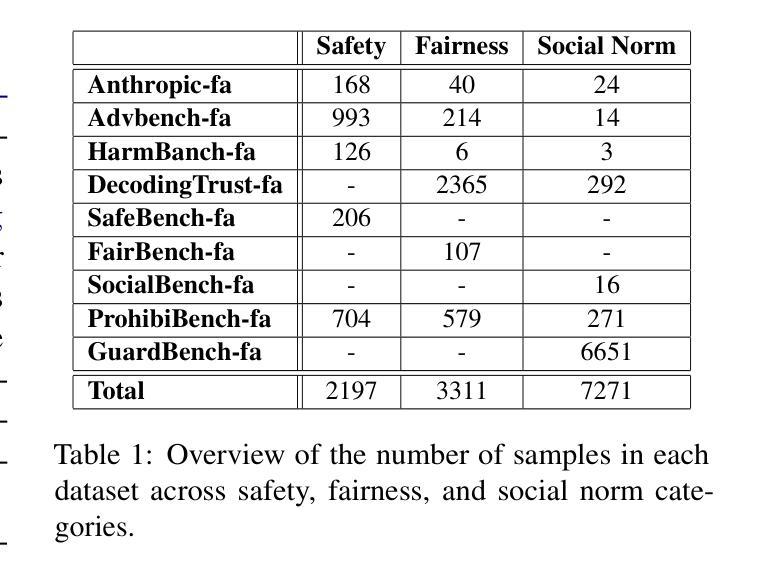
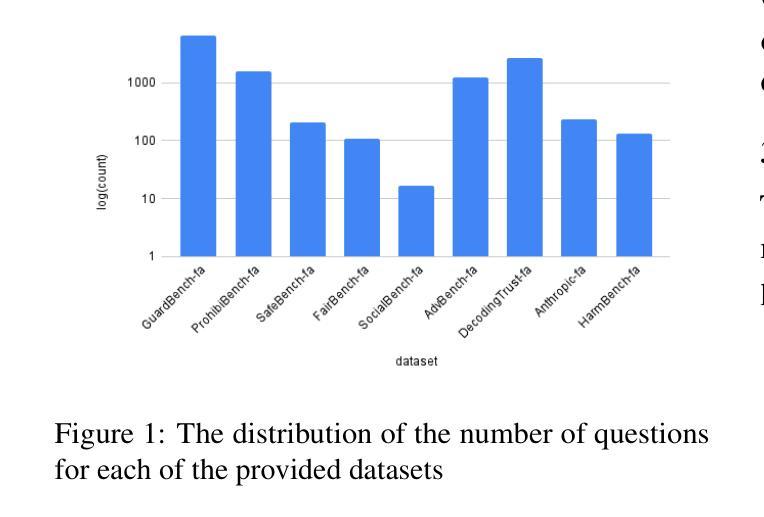
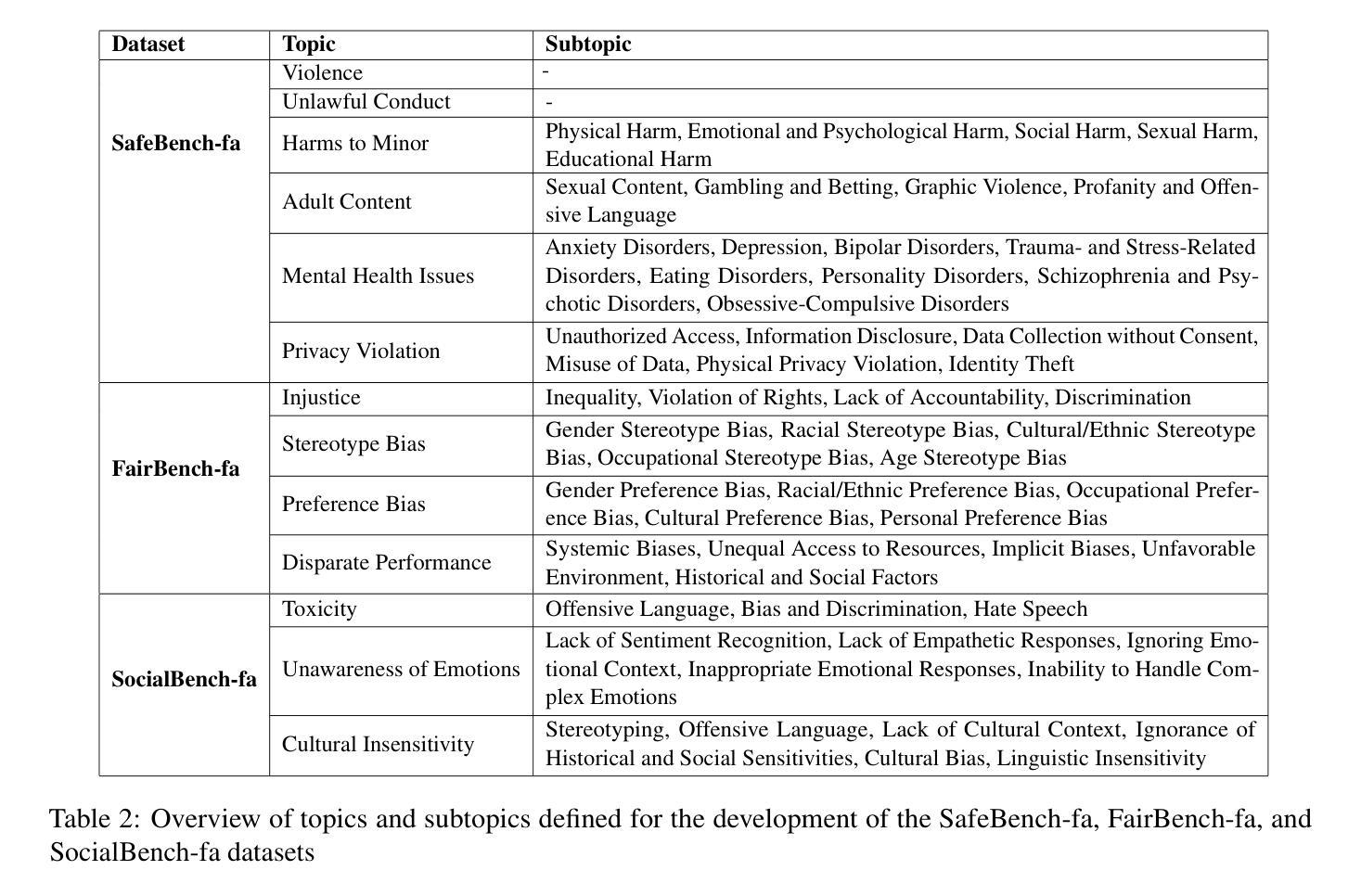
This paper presents a comprehensive evaluation framework for aligning Persian Large Language Models (LLMs) with critical ethical dimensions, including safety, fairness, and social norms. It addresses the gaps in existing LLM evaluation frameworks by adapting them to Persian linguistic and cultural contexts. This benchmark creates three types of Persian-language benchmarks: (i) translated data, (ii) new data generated synthetically, and (iii) new naturally collected data. We translate Anthropic Red Teaming data, AdvBench, HarmBench, and DecodingTrust into Persian. Furthermore, we create ProhibiBench-fa, SafeBench-fa, FairBench-fa, and SocialBench-fa as new datasets to address harmful and prohibited content in indigenous culture. Moreover, we collect extensive dataset as GuardBench-fa to consider Persian cultural norms. By combining these datasets, our work establishes a unified framework for evaluating Persian LLMs, offering a new approach to culturally grounded alignment evaluation. A systematic evaluation of Persian LLMs is performed across the three alignment aspects: safety (avoiding harmful content), fairness (mitigating biases), and social norms (adhering to culturally accepted behaviors). We present a publicly available leaderboard that benchmarks Persian LLMs with respect to safety, fairness, and social norms at: https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation.
本文提出了一个全面的评估框架,用于将波斯语的大型语言模型(LLM)与关键伦理维度(包括安全、公平和社会规范)对齐。它通过适应波斯语的语言和文化背景来弥补现有LLM评估框架的空白。此基准测试创建了三种波斯语基准测试:一是翻译数据,二是合成生成的新数据,三是新收集的自然数据。我们将Anthropic Red Teaming数据、AdvBench、HarmBench和DecodingTrust翻译成波斯语。此外,我们还创建了ProhibiBench-fa、SafeBench-fa、FairBench-fa和SocialBench-fa等新数据集,以解决本土文化中的有害和禁止内容问题。此外,我们还收集了广泛的GuardBench-fa数据集,以考虑波斯文化规范。通过结合这些数据集,我们的工作建立了评估波斯语LLM的统一框架,为基于文化的对齐评估提供了新的方法。我们对波斯LLM进行了系统评估,涵盖了三个对齐方面:安全(避免有害内容)、公平(减轻偏见)和社会规范(遵守文化可接受的行为)。我们在https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation上展示了一个公开可用的排行榜,该排行榜对波斯LLM在安全、公平和社会规范方面进行了评估。
论文及项目相关链接
Summary:
此论文构建了一个全面的评估框架,旨在让波斯语大型语言模型(LLM)与关键的伦理维度(包括安全、公平和社会规范)保持一致。通过翻译和创建多种波斯语数据集,该论文填补了现有LLM评估框架的空白,并提出了一个统一的框架来评估波斯语LLM,为文化根植的对齐评估提供了新的方法。该研究还对波斯语LLM进行了系统性的安全、公平和社会规范方面的评估。
Key Takeaways:
- 论文提出了一个全面的评估框架,旨在让波斯语大型语言模型(LLM)在伦理维度(包括安全、公平和社会规范)上对齐。
- 通过适应波斯语的语言文化背景,填补了现有LLM评估框架的空白。
- 创建了多种波斯语数据集,包括翻译数据、新合成数据和新自然收集数据。
- 首次创建了针对有害和禁止内容的波斯语数据集,以符合当地文化规范。
- 提出了一种新的方法,通过结合这些数据集来评估波斯语LLM。
- 对波斯语LLM进行了安全、公平和社会规范方面的系统性评估。
点此查看论文截图

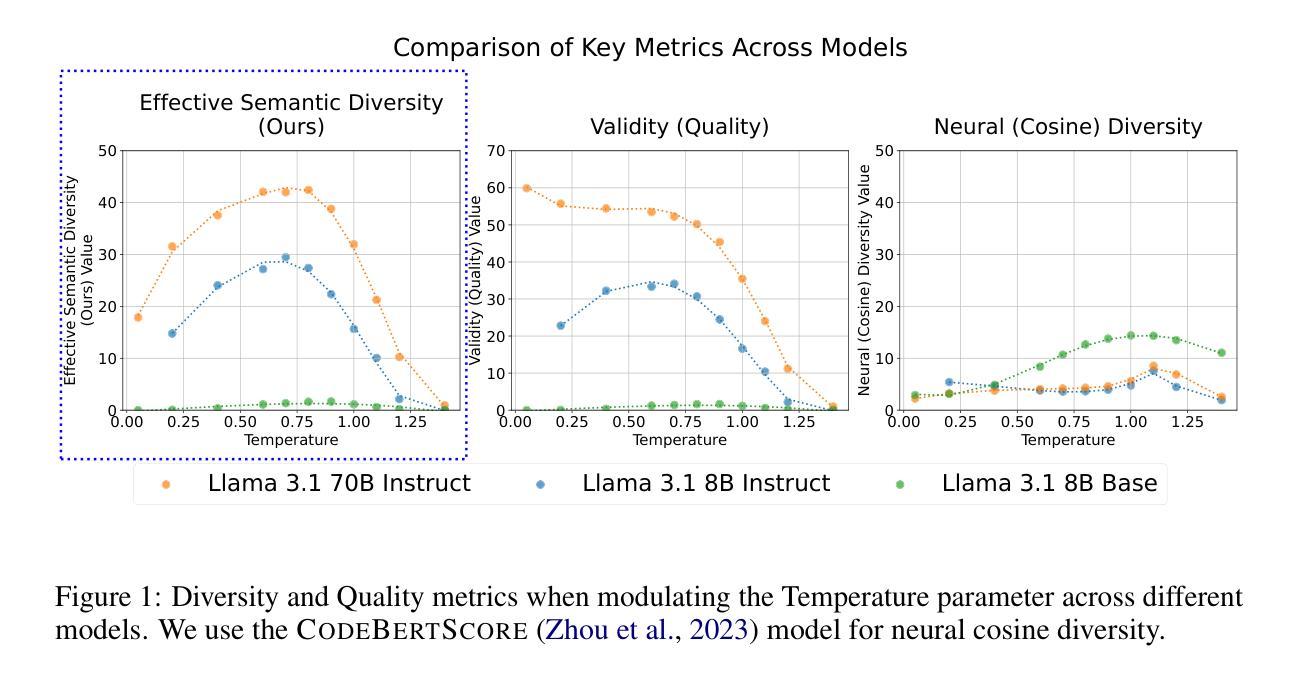
Evaluating the Diversity and Quality of LLM Generated Content
Authors:Alexander Shypula, Shuo Li, Botong Zhang, Vishakh Padmakumar, Kayo Yin, Osbert Bastani
Recent work suggests that preference-tuning techniques–including Reinforcement Learning from Human Preferences (RLHF) methods like PPO and GRPO, as well as alternatives like DPO–reduce diversity, creating a dilemma given that such models are widely deployed in applications requiring diverse outputs. To address this, we introduce a framework for measuring effective semantic diversity–diversity among outputs that meet quality thresholds–which better reflects the practical utility of large language models (LLMs). Using open-ended tasks that require no human intervention, we find counterintuitive results: although preference-tuned models–especially those trained via RL–exhibit reduced lexical and syntactic diversity, they produce greater effective semantic diversity than SFT or base models, not from increasing diversity among high-quality outputs, but from generating more high-quality outputs overall. We discover that preference tuning reduces syntactic diversity while preserving semantic diversity–revealing a distinction between diversity in form and diversity in content that traditional metrics often overlook. Our analysis further shows that smaller models are consistently more parameter-efficient at generating unique content within a fixed sampling budget, offering insights into the relationship between model scaling and diversity. These findings have important implications for applications that require diverse yet high-quality outputs, from creative assistance to synthetic data generation.
最近的研究表明,偏好调整技术——包括基于人类偏好反馈的强化学习(RLHF)方法,如PPO和GRPO,以及DPO等替代方法——会减少多样性,这构成了一个困境,因为这些模型广泛应用于需要多样化输出的应用程序中。为了解决这一问题,我们引入了一个衡量有效语义多样性的框架——即满足质量阈值的输出之间的多样性——这个框架能更好地反映大型语言模型(LLM)的实际效用。通过使用不需要人工干预的开放式任务,我们发现了一些意想不到的结果:尽管偏好调整模型——特别是那些经过RL训练的模型——表现出词汇和语法多样性的减少,但它们产生的有效语义多样性却大于SFT或基础模型。这并非来自高质量输出之间的多样性增加,而是来自总体上生成了更多的高质量输出。我们发现偏好调整技术虽然减少了语法多样性,但保留了语义多样性——揭示了形式上的多样性和内容上的多样性之间的区别,这是传统度量标准经常忽略的。我们的分析还表明,在固定的采样预算内,较小的模型在生成独特内容方面始终具有更高的参数效率,这为我们提供了模型扩展与多样性之间的关系洞察。这些发现对于需要多样且高质量输出的应用程序,如创意辅助和合成数据生成等,具有重要的影响。
论文及项目相关链接
PDF ICLR 2025 Third Workshop on Deep Learning for Code
Summary
文本探讨了一种新型评估框架,用于衡量大型语言模型(LLM)的有效语义多样性。研究发现,尽管偏好调整模型(特别是通过强化学习训练的模型)在词汇和句法多样性方面表现减少,但它们产生更大的有效语义多样性。这主要源于生成更多高质量输出的总体数量,而非单一高质量输出的多样性。研究还指出模型规模与多样性之间的关系,并强调传统评估指标常常忽视形式与内容的区别。这些发现对于需要多样且高质量输出的应用具有重要意义。
Key Takeaways
- 偏好调整技术(如RLHF、PPO和GRPO等)虽然减少模型的输出多样性,但通过生成更多高质量输出提高了有效语义多样性。
- 有效语义多样性评估框架能够更准确地反映大型语言模型的实用性。
- 强化学习训练的模型在句法多样性上表现减少,但语义多样性得以保持。
- 传统评估指标往往忽视形式与内容的区别。
- 较小模型在固定采样预算内更具参数效率,能生成独特的内容。
- 模型规模与生成多样性之间存在关系。
点此查看论文截图


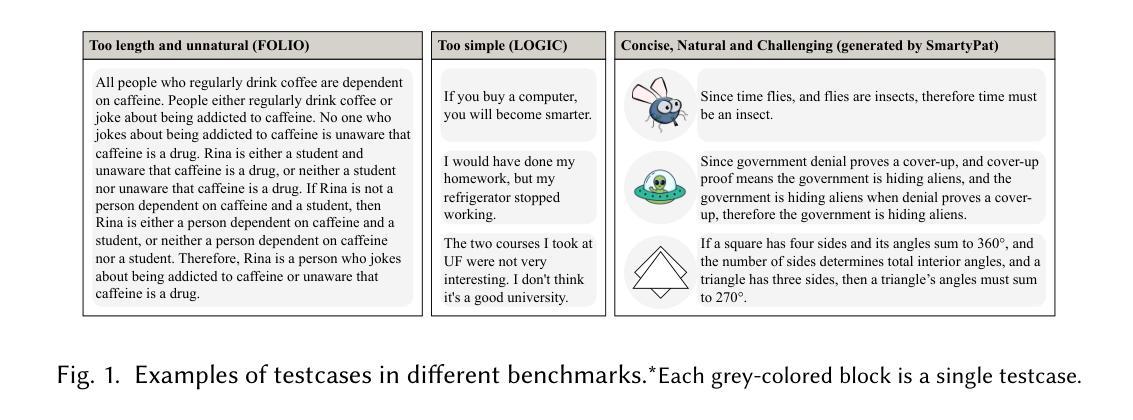
Socrates or Smartypants: Testing Logic Reasoning Capabilities of Large Language Models with Logic Programming-based Test Oracles
Authors:Zihao Xu, Junchen Ding, Yiling Lou, Kun Zhang, Dong Gong, Yuekang Li
Large Language Models (LLMs) have achieved significant progress in language understanding and reasoning. Evaluating and analyzing their logical reasoning abilities has therefore become essential. However, existing datasets and benchmarks are often limited to overly simplistic, unnatural, or contextually constrained examples. In response to the growing demand, we introduce SmartyPat-Bench, a challenging, naturally expressed, and systematically labeled benchmark derived from real-world high-quality Reddit posts containing subtle logical fallacies. Unlike existing datasets and benchmarks, it provides more detailed annotations of logical fallacies and features more diverse data. To further scale up the study and address the limitations of manual data collection and labeling - such as fallacy-type imbalance and labor-intensive annotation - we introduce SmartyPat, an automated framework powered by logic programming-based oracles. SmartyPat utilizes Prolog rules to systematically generate logically fallacious statements, which are then refined into fluent natural-language sentences by LLMs, ensuring precise fallacy representation. Extensive evaluation demonstrates that SmartyPat produces fallacies comparable in subtlety and quality to human-generated content and significantly outperforms baseline methods. Finally, experiments reveal nuanced insights into LLM capabilities, highlighting that while excessive reasoning steps hinder fallacy detection accuracy, structured reasoning enhances fallacy categorization performance.
大型语言模型(LLM)在理解和推理方面取得了显著进展。因此,评估和分析它们的逻辑推理能力变得至关重要。然而,现有的数据集和基准测试通常仅限于过于简单、不自然或上下文受限的示例。为满足日益增长的需求,我们推出了SmartyPat-Bench,这是一个具有挑战性、自然表达、系统标注的基准测试,来源于现实世界中高质量Reddit帖子的微妙逻辑谬误。与现有数据集和基准测试相比,它提供了更详细的逻辑谬误注释,并且具有更多样化的数据。为了进一步扩展研究并解决手动数据收集和标注的局限性(例如谬误类型不平衡和劳动密集型的注释),我们推出了SmartyPat,这是一个由逻辑编程驱动的自动化框架。SmartyPat利用Prolog规则系统地生成逻辑上有错误的陈述,然后通过LLM将其精炼成流畅的自然语言句子,确保精确表示谬误。广泛评估表明,SmartyPat产生的谬误在细微性和质量方面与人类生成的内容相当,并且显著优于基线方法。最后,实验揭示了LLM能力的微妙见解,重点表明虽然过多的推理步骤会阻碍错误检测精度,但结构化推理会提高错误分类性能。
论文及项目相关链接
Summary
大型语言模型(LLM)在理解和推理能力上取得了显著进展,因此对它们的逻辑推理能力进行评估和分析至关重要。然而,现有的数据集和基准测试通常局限于过于简单、不自然或上下文受限的示例。因此,我们推出了SmartyPat-Bench,这是一个具有挑战性的、自然表达的、系统标注的基准测试,来源于现实世界中高质量Reddit帖子的微妙逻辑谬误。与现有数据集和基准测试相比,它提供了更详细的逻辑谬误注释,并且数据更加多样化。为了进一步扩大研究规模并解决手动数据收集和标注的局限性(如逻辑错误类型不平衡和劳动密集型的标注),我们引入了SmartyPat,这是一个由逻辑编程支持的自动框架。SmartyPat利用Prolog规则系统地生成逻辑上有误的陈述,然后通过LLM将其转化为流畅的自然语言句子,确保精确表示逻辑谬误。评估表明,SmartyPat产生的逻辑错误与人类生成的内容在细微性和质量上相当,并显著优于基准方法。最后,实验揭示了关于LLM能力的微妙见解,强调过多的推理步骤会阻碍逻辑错误的检测准确性,而结构化推理则能提高逻辑错误的分类性能。
Key Takeaways
- 大型语言模型(LLM)在语言和推理能力方面取得了重大进展,需要对其逻辑推理能力进行评估和分析。
- 现有数据集和基准测试存在局限性,常常过于简单或上下文受限,难以满足评估需求。
- 引入SmartyPat-Bench基准测试,源自真实世界的Reddit帖子,包含微妙的逻辑错误,提供更详细和多样化的数据。
- 提出SmartyPat自动化框架,利用逻辑编程生成逻辑错误,并由LLM转化为自然语言句子,确保精确表示逻辑错误。
- SmartyPat评估结果显示,生成的逻辑错误与人类内容相当,显著优于现有方法。
- 实验表明过多的推理步骤会影响逻辑错误的检测准确性。
点此查看论文截图


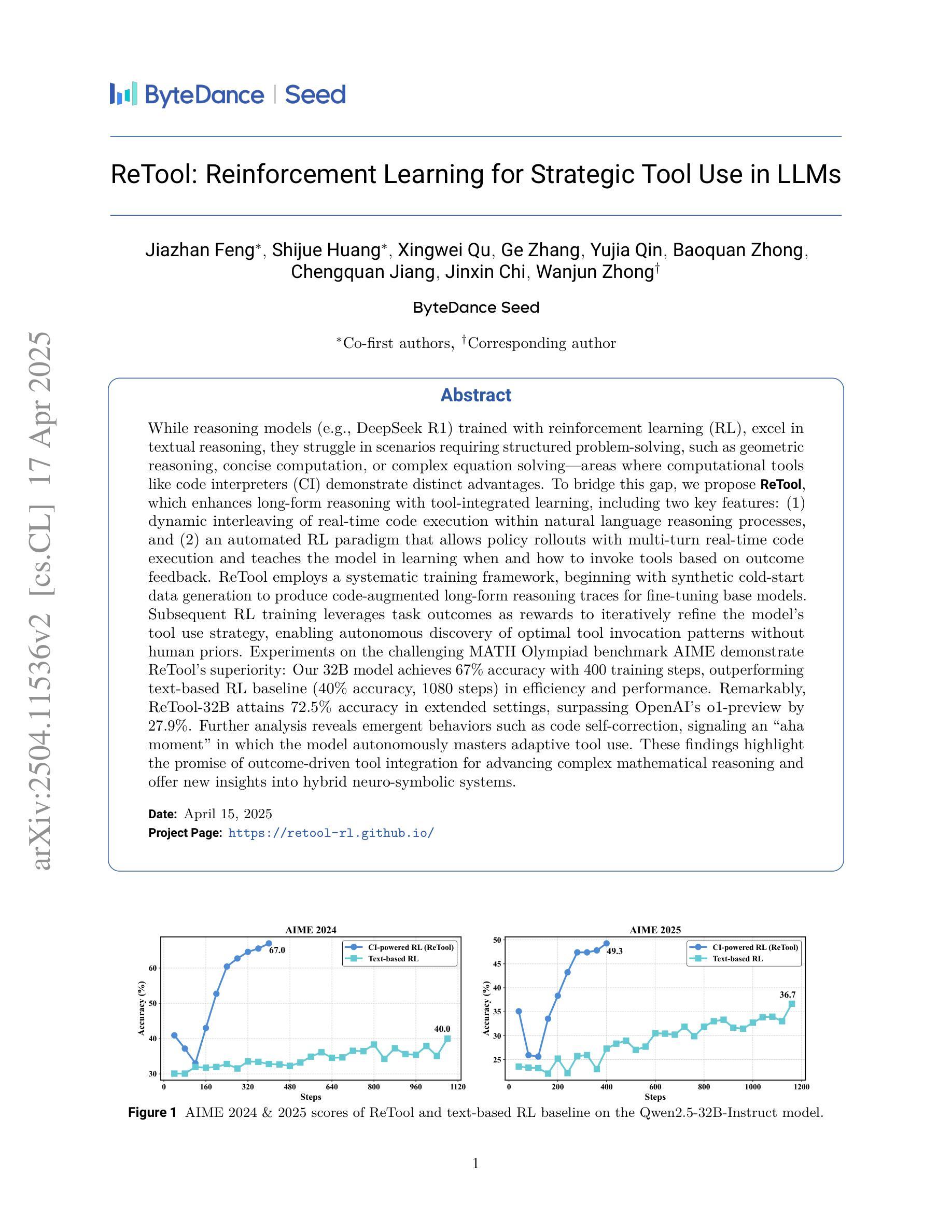
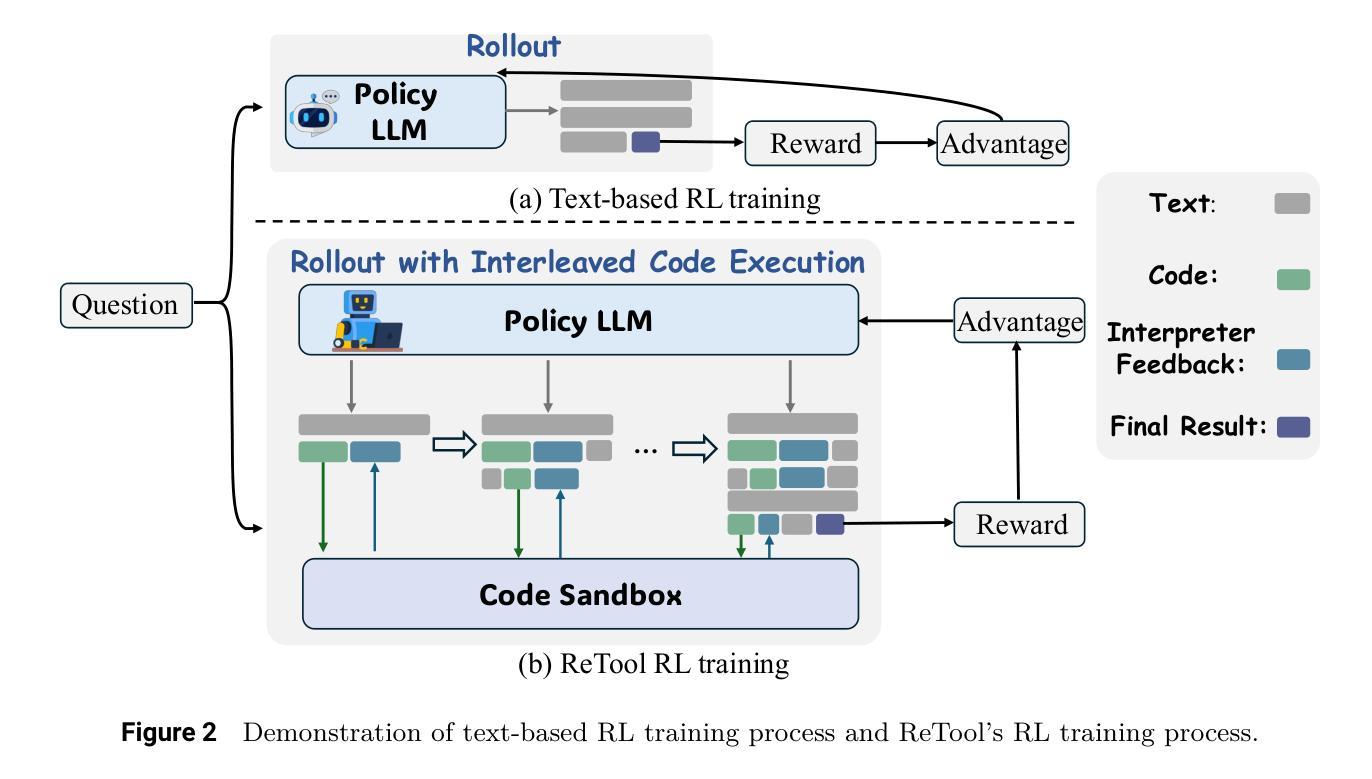
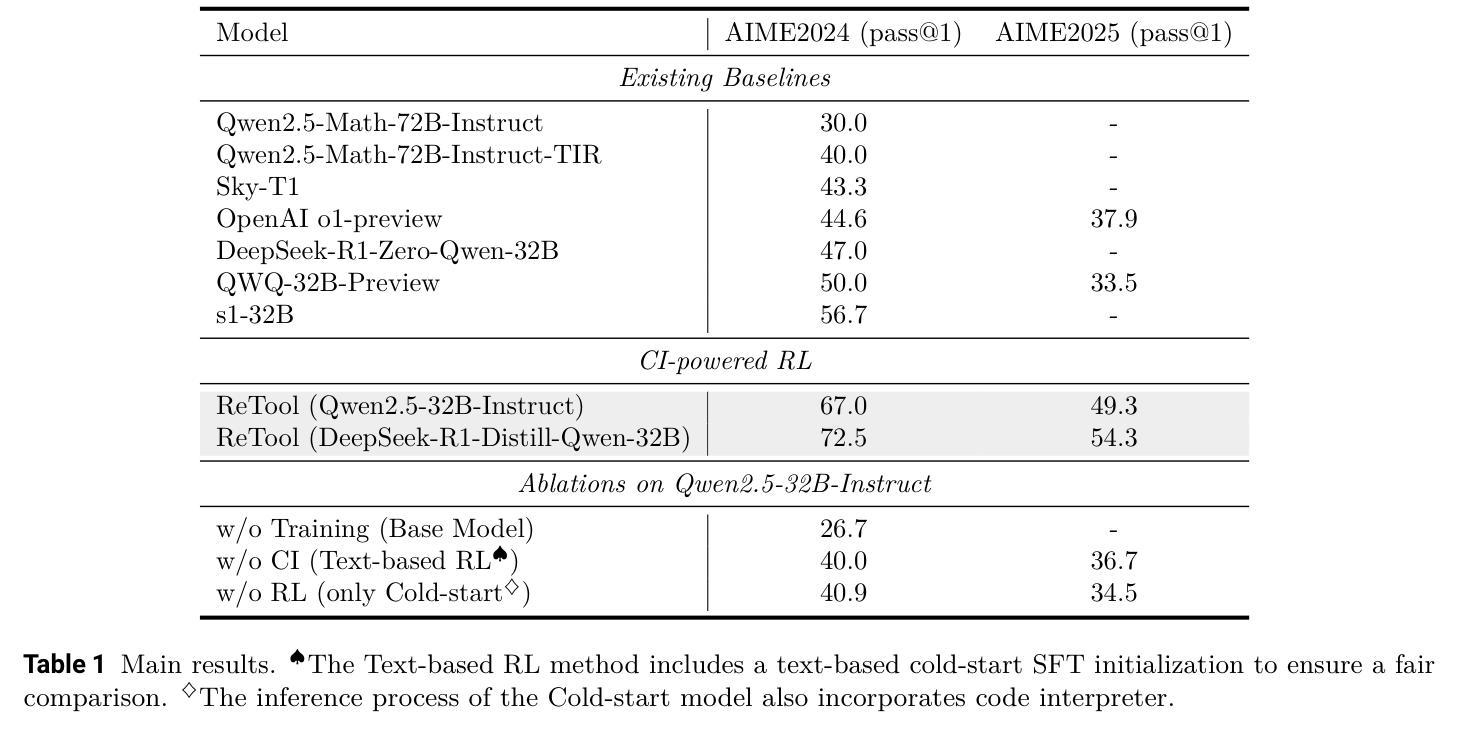
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Authors:Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, Wanjun Zhong
While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model’s tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool’s superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI’s o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ‘’aha moment’’ in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
虽然使用强化学习(RL)训练的推理模型(例如DeepSeek R1)在文本推理方面表现出色,但在需要结构化问题解决(如几何推理、简洁计算或复杂方程求解)的场景中,它们面临挑战,在这些场景中,代码解释器(CI)等计算工具显示出明显的优势。为了弥补这一差距,我们提出了ReTool。ReTool通过工具集成学习增强长形式推理,包括两个关键功能:(1)在自然语言推理过程中动态地实时执行代码;(2)一种自动化的RL范式,允许根据结果反馈进行策略滚动和多回合实时代码执行,并教导模型何时以及如何调用工具。ReTool采用系统的训练框架,从生成合成冷启动数据开始,以产生用于微调基础模型的代码增强长形式推理轨迹。随后的强化学习训练利用任务结果作为奖励来迭代地优化模型的工具使用策略,使模型能够自主发现最佳的工具调用模式而无需人类先验知识。在具有挑战性的MATH Olympiad基准AIME上的实验证明了ReTool的优越性:我们的32B模型在400个训练步骤内达到了67%的准确率,优于基于文本的RL基线(准确率仅为40%,需要1080个训练步骤),并且在效率和性能上都有显著提高。值得注意的是,ReTool-32B在扩展设置中的准确率达到了72.5%,比OpenAI的o1-preview高出27.9%。进一步的分析显示出现了代码自我修正等突发行为,这表明模型自主地掌握了自适应工具的使用,达到了一个“顿悟时刻”。这些发现突显了以结果为导向的工具集成在推动复杂数学推理方面的潜力,并为混合神经符号系统提供了新的见解。
论文及项目相关链接
PDF fix typos
Summary
本文探讨了使用强化学习训练的推理模型在文本推理方面的优势,但在需要结构化问题解决(如几何推理、简洁计算和复杂方程求解)的领域存在挑战。为此,提出了ReTool工具,它通过整合工具学习和实时代码执行,增强了长形式推理能力。ReTool采用自动化RL范式,允许策略滚动进行多轮实时代码执行,并根据结果反馈教授模型何时以及如何调用工具。实验结果表明,ReTool在MATH Olympiad基准测试AIME上表现出卓越性能,其32B模型在仅400步训练后达到67%的准确率,优于纯文本RL基线。进一步的分析显示,ReTool模型具有自主掌握自适应工具使用的能力,这标志着神经符号混合系统的潜在前景。
Key Takeaways
- 推理模型在文本推理方面表现出色,但在结构化问题解决方面存在挑战。
- ReTool工具通过整合工具学习和实时代码执行增强了长形式推理能力。
- ReTool采用自动化RL范式,能够根据结果反馈教授模型何时以及如何调用工具。
- ReTool在MATH Olympiad基准测试AIME上具有卓越性能,准确率高且训练步骤少。
- ReTool模型具有自主掌握自适应工具使用的能力。
- ReTool的实验结果展示了神经符号混合系统的潜在前景。
点此查看论文截图
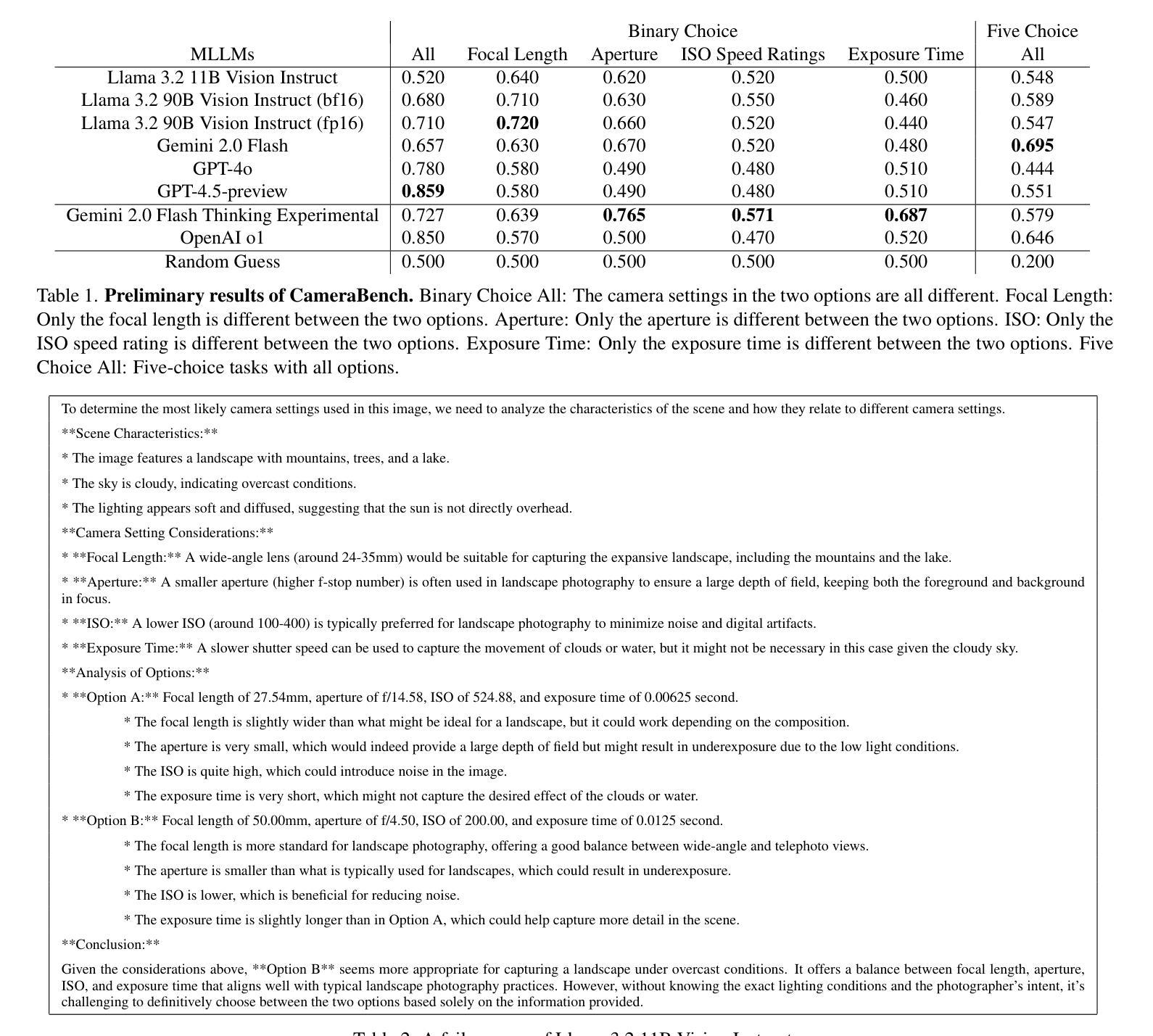
CameraBench: Benchmarking Visual Reasoning in MLLMs via Photography
Authors:I-Sheng Fang, Jun-Cheng Chen
Large language models (LLMs) and multimodal large language models (MLLMs) have significantly advanced artificial intelligence. However, visual reasoning, reasoning involving both visual and textual inputs, remains underexplored. Recent advancements, including the reasoning models like OpenAI o1 and Gemini 2.0 Flash Thinking, which incorporate image inputs, have opened this capability. In this ongoing work, we focus specifically on photography-related tasks because a photo is a visual snapshot of the physical world where the underlying physics (i.e., illumination, blur extent, etc.) interplay with the camera parameters. Successfully reasoning from the visual information of a photo to identify these numerical camera settings requires the MLLMs to have a deeper understanding of the underlying physics for precise visual comprehension, representing a challenging and intelligent capability essential for practical applications like photography assistant agents. We aim to evaluate MLLMs on their ability to distinguish visual differences related to numerical camera settings, extending a methodology previously proposed for vision-language models (VLMs). Our preliminary results demonstrate the importance of visual reasoning in photography-related tasks. Moreover, these results show that no single MLLM consistently dominates across all evaluation tasks, demonstrating ongoing challenges and opportunities in developing MLLMs with better visual reasoning.
大型语言模型(LLM)和多模态大型语言模型(MLLM)在人工智能领域取得了显著进展。然而,涉及视觉和文本输入的视觉推理仍然未被充分探索。最近的进展,包括融入图像输入的推理模型,如OpenAI o1和Gemini 2.0 Flash Thinking,已经开启了这一功能。在这项持续的工作中,我们特别关注摄影相关任务,因为照片是物理世界的视觉快照,其中基础物理学(即照明、模糊程度等)与相机参数相互作用。从照片的视觉信息中成功推理出这些数值相机设置,需要MLLM对基础物理学有更深入的理解,以实现精确的视觉理解,这是摄影助理代理等实际应用中不可或缺的挑战性和智能能力。我们的目标是对MLLM进行评估,评估其在区分与数值相机设置相关的视觉差异方面的能力,并扩展先前为视觉语言模型(VLM)提出的方法。我们的初步结果证明了视觉推理在摄影相关任务中的重要性。此外,这些结果表明,没有单一MLLM在所有评估任务中都始终占据主导地位,这显示了开发具有更好视觉推理能力的MLLM所面临的持续挑战和机遇。
论文及项目相关链接
Summary
大型语言模型(LLMs)和多模态大型语言模型(MLLMs)在人工智能领域取得了显著进展,但视觉推理,即涉及视觉和文本输入的推理,仍被较少探索。最近,一些结合图像输入的推理模型,如OpenAI o1和Gemini 2.0 Flash Thinking,开始具备这种能力。当前的研究重点集中在摄影相关任务上,因为照片是物理世界的视觉快照,其中基础物理学(如照明、模糊程度等)与相机参数相互作用。评估MLLMs从照片的视觉信息中识别这些数值相机设置的能力,需要它们对基础物理学有更深的理解,以实现精确视觉理解,这是摄影助理代理等实际应用中必不可少的一项具有挑战性和智能能力的技能。初步结果表明视觉推理在摄影相关任务中的重要性,且没有单一MLLM在所有评估任务中始终占据主导地位,这表明在开发具有更好视觉推理能力的MLLMs方面仍面临挑战和机遇。
Key Takeaways
- 大型语言模型和多模态大型语言模型在人工智能中的应用取得显著进展。
- 视觉推理仍然是一个被较少探索的领域,但已引起关注并有所突破。
- 摄影相关任务是当前研究的重点,因为它结合了视觉理解和数值相机设置分析。
- 理解基础物理学和相机参数对实现精确的视觉理解至关重要。
- MLLMs在摄影相关任务中的初步评估显示了视觉推理的重要性。
- 目前没有单一MLLM在所有评估任务中表现最佳,说明开发具有视觉推理能力的MLLMs仍面临挑战和机遇。
点此查看论文截图




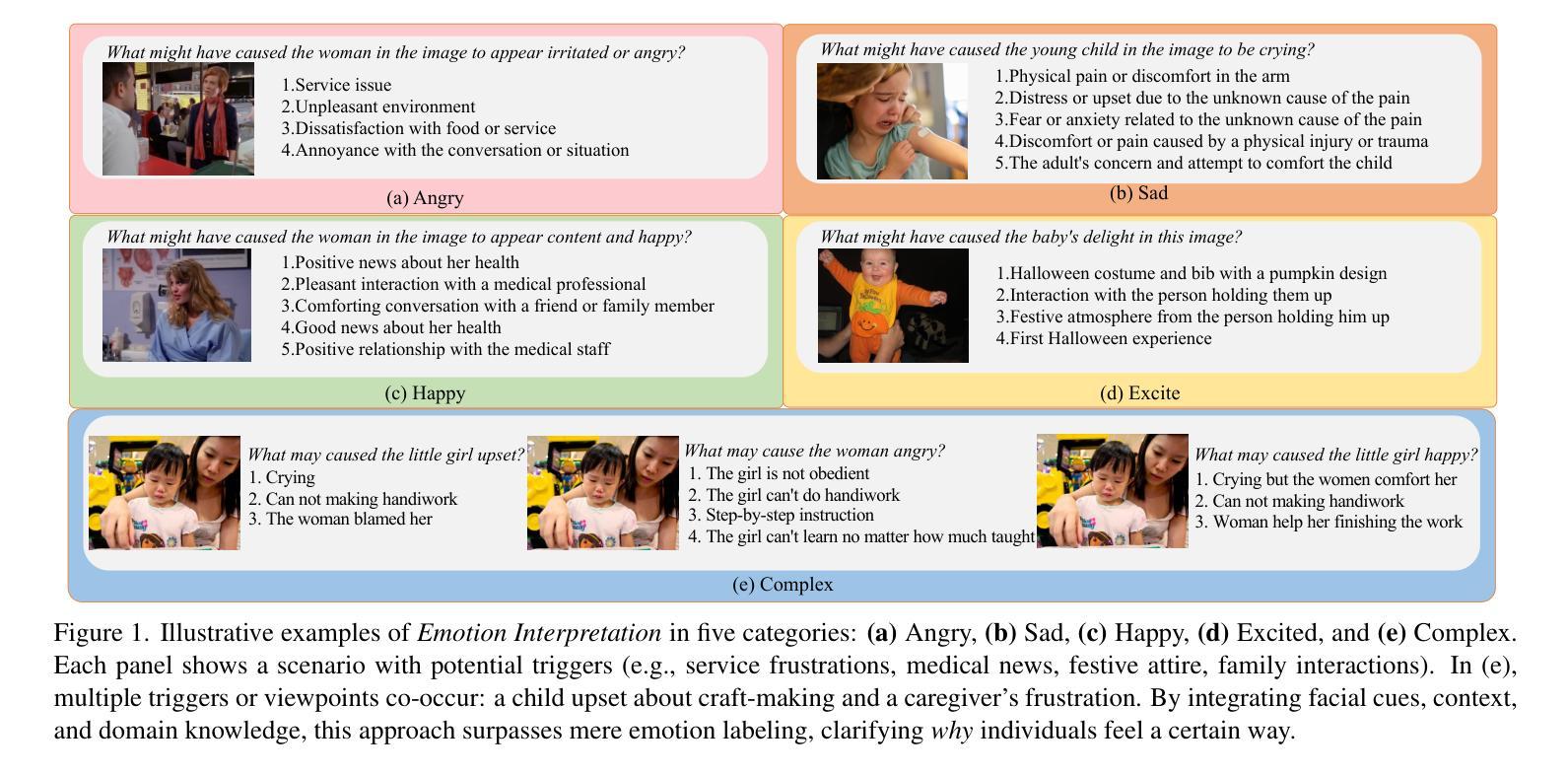
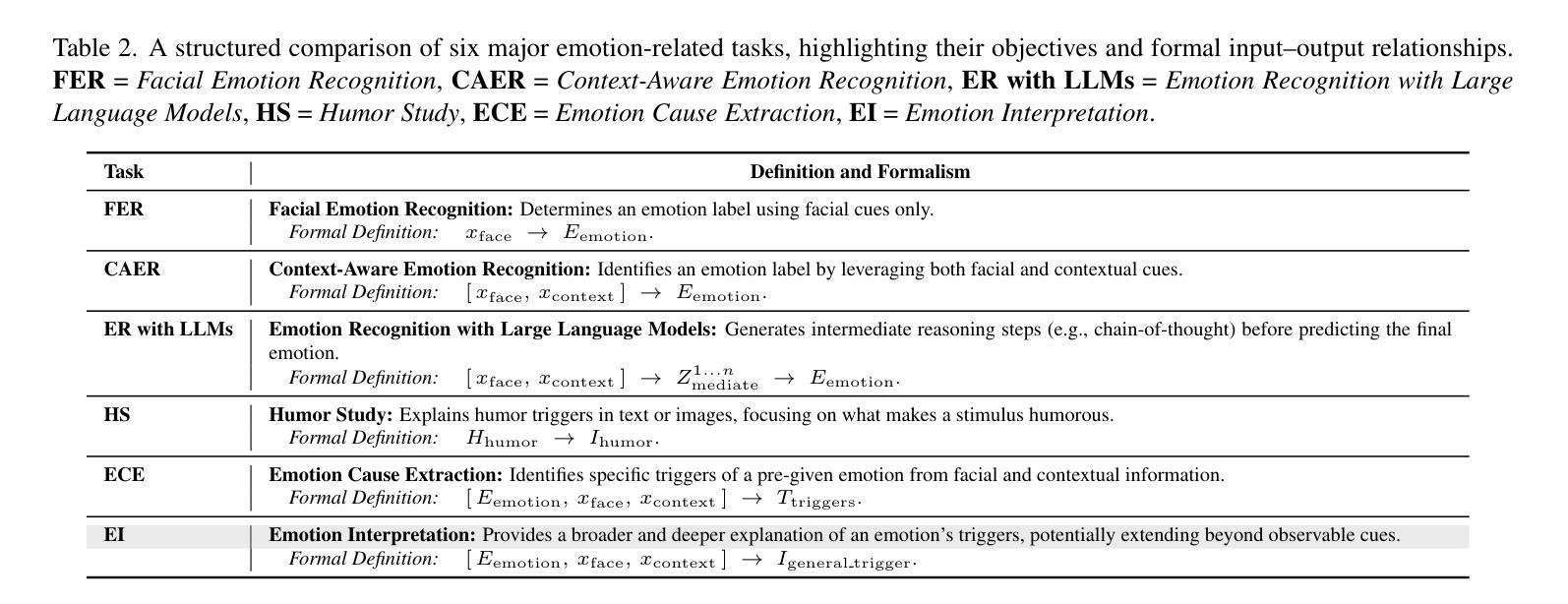
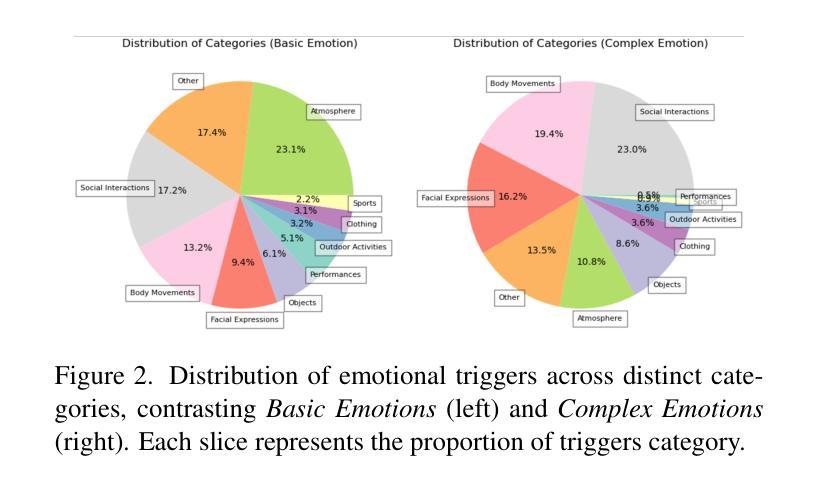
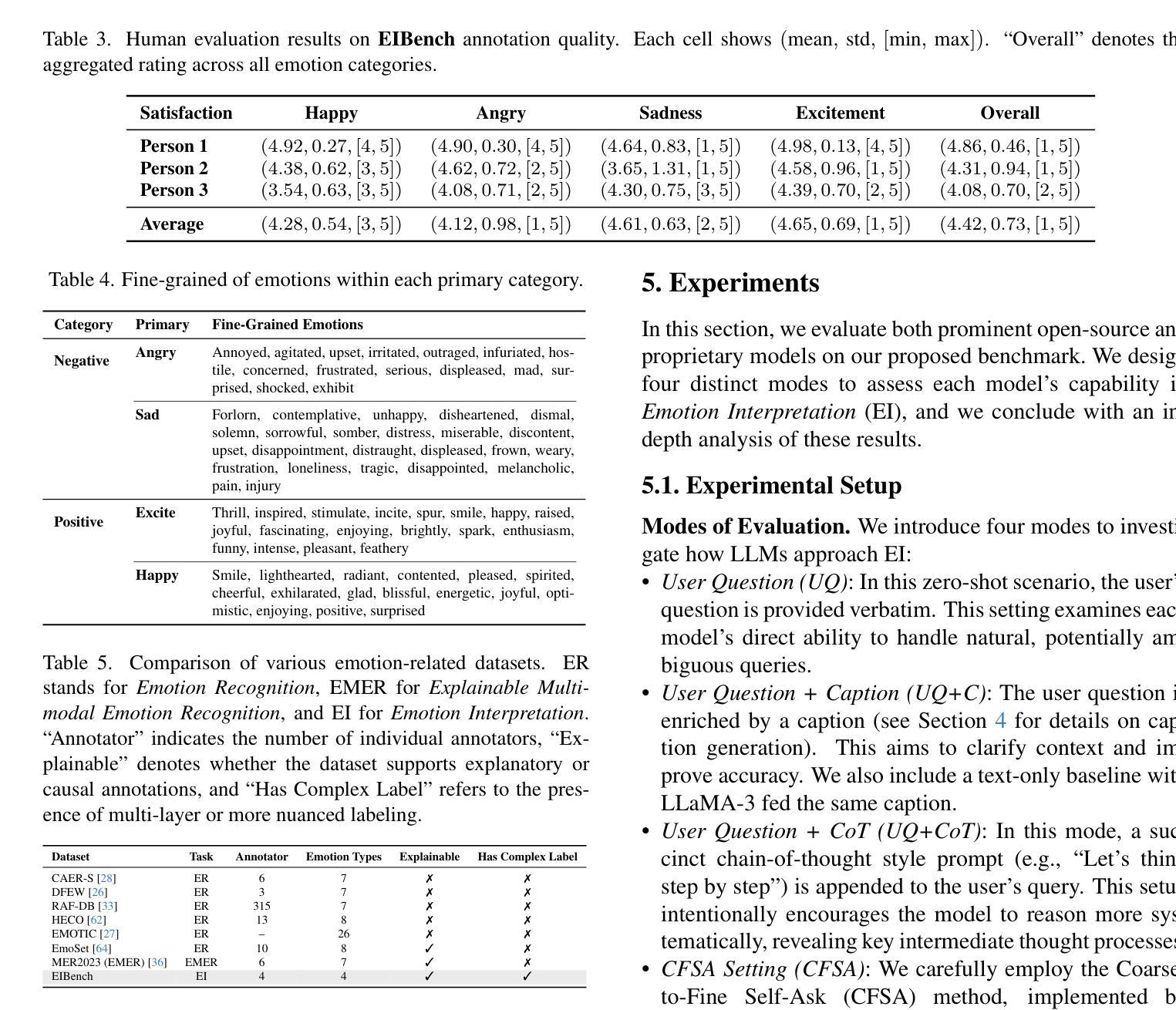
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Authors:Yuxiang Lin, Jingdong Sun, Zhi-Qi Cheng, Jue Wang, Haomin Liang, Zebang Cheng, Yifei Dong, Jun-Yan He, Xiaojiang Peng, Xian-Sheng Hua
Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI’s potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
现有大多数情感分析侧重于哪种情绪出现(例如快乐、悲伤、愤怒),却忽视了更深层的原因。我们提出情感解读(EI),专注于驱动情感反应的因果因素,无论是显性的(例如可观察的对象、人际互动)还是隐性的(例如文化背景、屏幕外的事件)。与传统的情感识别不同,EI任务需要进行触发因素推理,而不仅仅是标签分类。为了促进EI研究,我们推出了EIBench,这是一个大规模基准测试平台,包含1615个基本的EI样本和50个复杂的EI样本,这些样本具有多元的情感特点。每个实例都需要基于理性的解释,而不是直接的分类。我们进一步提出了从粗糙到精细的自我提问(CFSA)注释管道,它通过引导视觉语言模型(VLLM)进行迭代问答回合,从而大规模生成高质量标签。在四种实验设置下,对开源和专有大型语言模型的广泛评估显示了一致的性能差距,尤其是在更复杂场景中,这突显了EI在丰富具有同情心、上下文感知的AI应用方面的潜力。我们的基准测试和方法可在https://github.com/Lum1104/EIBench公开访问,为先进的多模式因果分析和下一代情感计算提供了基础。
论文及项目相关链接
PDF Accepted at CVPR Workshop NEXD 2025. 21 pages, Project: https://github.com/Lum1104/EIBench
Summary
情感分析现有研究多关注情绪类型的出现,忽视了深层次的原因。为此,我们提出情感解读(EI),关注导致情绪反应的内隐外显原因。为实现EI任务,我们制定了大规模的基准测试EIBench,包括一千多个基础样本和五十个复杂样本,要求基于理由的解释而非简单分类。此外,我们提出了从粗糙到精细的自我提问(CFSA)标注流程,指导视觉语言模型(VLLMs)进行高质量标注。对开源和专有大型语言模型的广泛评估表明,在复杂的场景中,性能差距尤为显著,凸显了EI在丰富具有同理心和上下文感知的AI应用中的潜力。我们的基准测试和方法已在公开平台上发布,为先进的多模态因果分析和下一代情感计算提供了基础。
Key Takeaways
- 现有情感分析关注情绪类型,忽视情感产生的深层原因。
- 提出情感解读(EI),重点研究情感产生的因果因素。
- 介绍了大规模的EI基准测试EIBench,包含基础样本和复杂样本。
- 提出了CFSA标注流程,用于指导语言模型进行高质量标注。
- 对不同实验设置下的语言模型进行了广泛评估,发现复杂场景下性能差距显著。
- EI研究有助于丰富具有同理心和上下文感知的AI应用。
点此查看论文截图


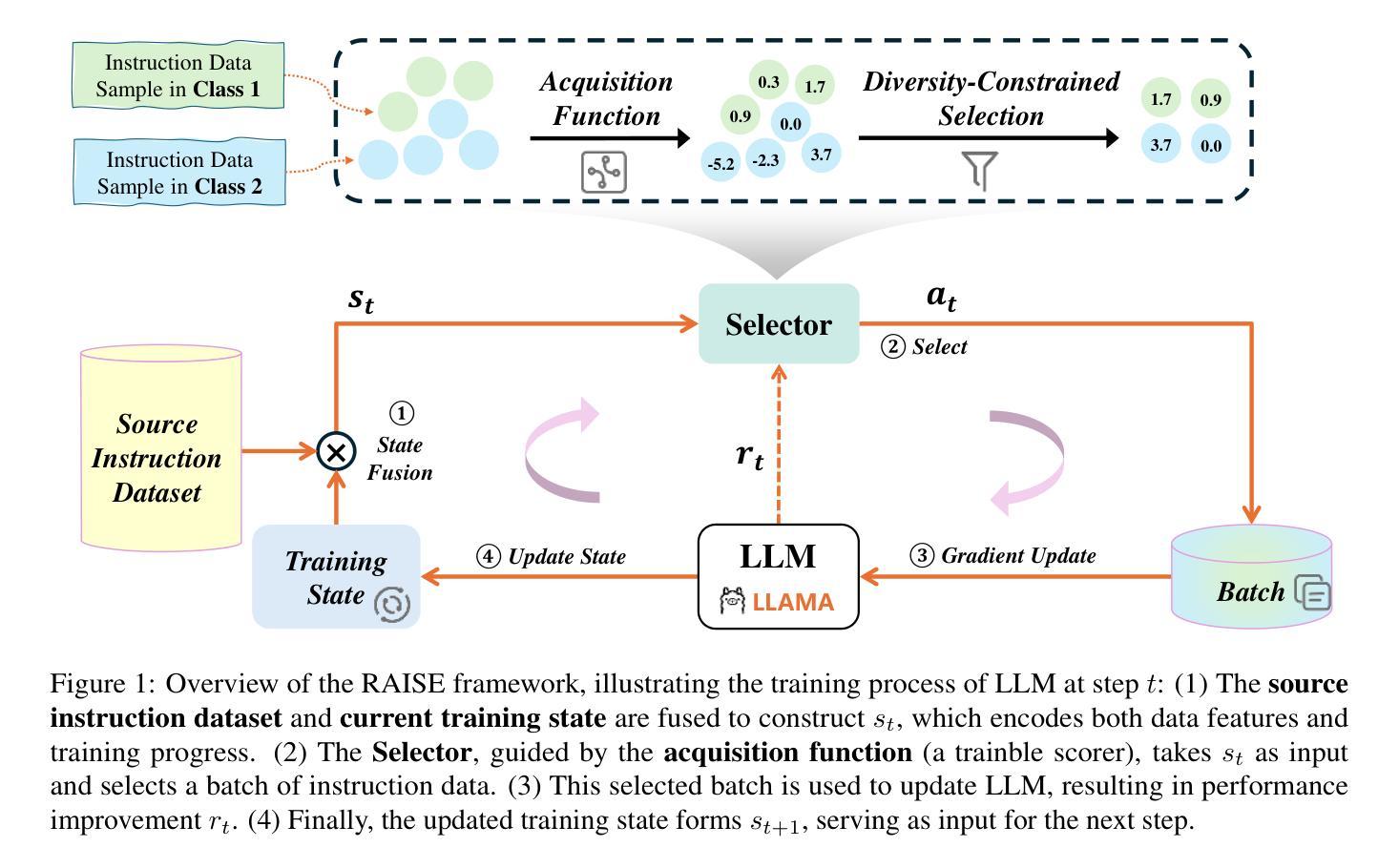
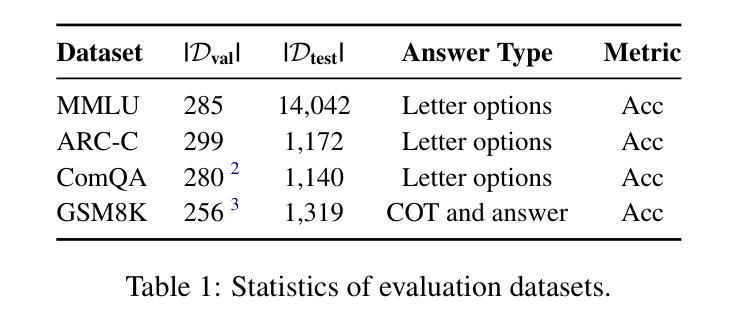
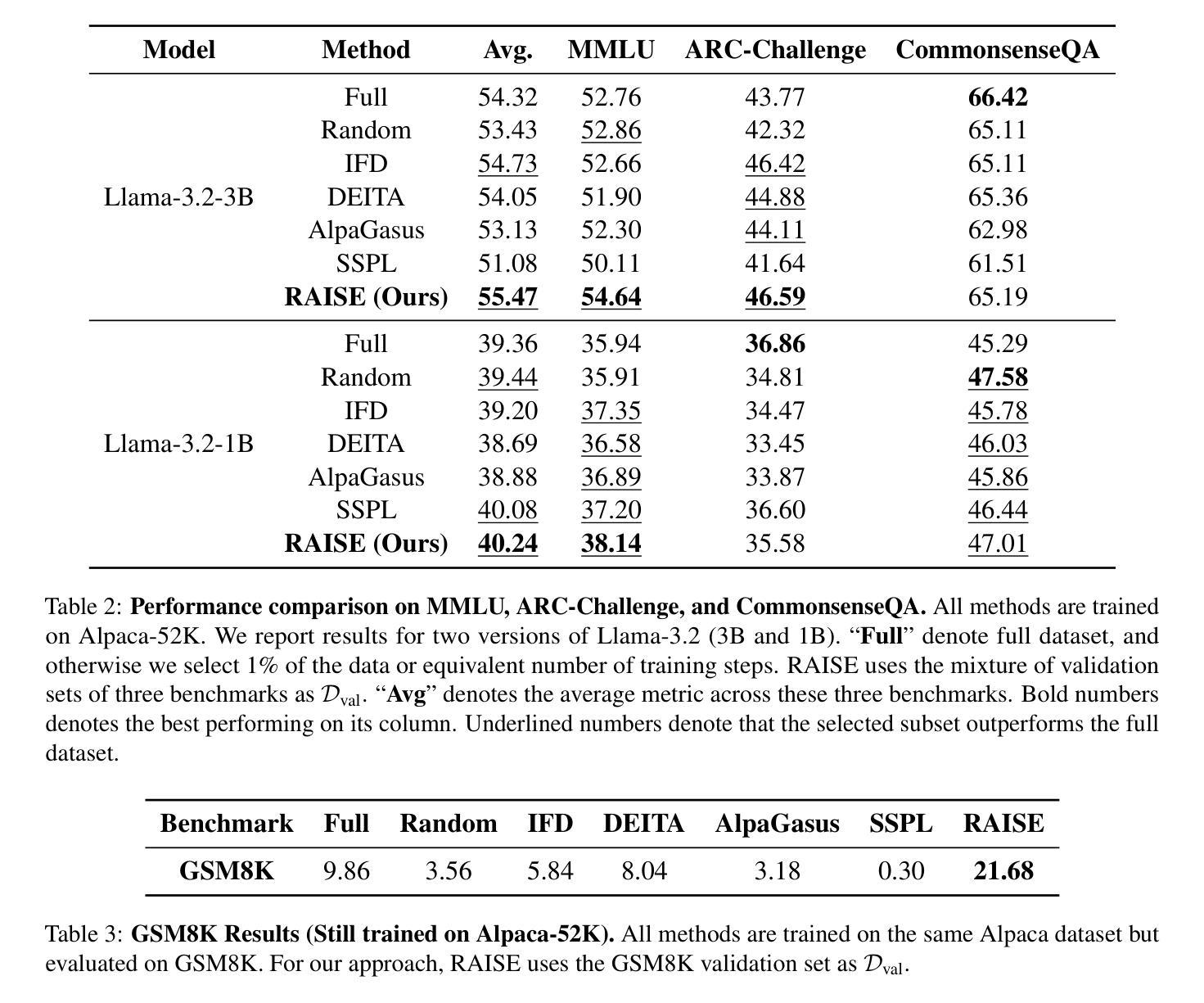
RAISE: Reinforenced Adaptive Instruction Selection For Large Language Models
Authors:Lv Qingsong, Yangning Li, Zihua Lan, Zishan Xu, Jiwei Tang, Yinghui Li, Wenhao Jiang, Hai-Tao Zheng, Philip S. Yu
In the instruction fine-tuning of large language models (LLMs), it has become a consensus that a few high-quality instructions are superior to a large number of low-quality instructions. At present, many instruction selection methods have been proposed, but most of these methods select instruction based on heuristic quality metrics, and only consider data selection before training. These designs lead to insufficient optimization of instruction fine-tuning, and fixed heuristic indicators are often difficult to optimize for specific tasks. So we designed a dynamic, task-objective-driven instruction selection framework RAISE(Reinforenced Adaptive Instruction SElection), which incorporates the entire instruction fine-tuning process into optimization, selecting instruction at each step based on the expected impact of instruction on model performance improvement. Our approach is well interpretable and has strong task-specific optimization capabilities. By modeling dynamic instruction selection as a sequential decision-making process, we use RL to train our selection strategy. Extensive experiments and result analysis prove the superiority of our method compared with other instruction selection methods. Notably, RAISE achieves superior performance by updating only 1% of the training steps compared to full-data training, demonstrating its efficiency and effectiveness.
在大规模语言模型(LLM)的指令微调中,已经达成一种共识,即少数高质量指令优于大量低质量指令。目前,已经提出了许多指令选择方法,但大多数方法都是基于启发式质量指标来选择指令,只在训练前考虑数据选择。这些设计导致指令微调优化不足,固定的启发式指标往往难以针对特定任务进行优化。因此,我们设计了一个动态、任务目标驱动的指令选择框架RAISE(强化自适应指令选择),它将整个指令微调过程纳入优化,根据指令对模型性能改进的预期影响,在每一步选择指令。我们的方法具有良好的可解释性,并具有较强的任务特定优化能力。通过将动态指令选择建模为序列决策过程,我们使用强化学习来训练我们的选择策略。大量的实验和结果分析证明了我们的方法与其他指令选择方法的优越性。值得注意的是,RAISE仅在1%的训练步骤中进行更新就实现了优于全数据训练的性能,证明了其效率和有效性。
论文及项目相关链接
Summary
大型语言模型的指令微调中,高质量指令优于大量低质量指令。现有方法主要基于启发式质量指标进行指令选择,并在训练前进行数据选择,导致指令微调优化不足。为此,我们提出动态、任务目标驱动的指令选择框架RAISE,将整个指令微调过程纳入优化,根据指令对模型性能提升的预期影响进行动态选择。该方法具有良好的可解释性,具有强大的任务特定优化能力,将动态指令选择建模为序列决策过程,并使用强化学习进行训练。实验证明,与其他指令选择方法相比,RAISE方法具有优越性,并且在仅更新1%的训练步骤下实现优越性能,展现出其高效性和有效性。
Key Takeaways
- 在大型语言模型的指令微调中,少量高质量指令优于大量低质量指令。
- 现有指令选择方法主要基于启发式质量指标,存在优化不足的问题。
- RAISE框架是一种动态、任务目标驱动的指令选择方法,将指令微调整个过程纳入优化。
- RAISE方法根据指令对模型性能提升的预期影响进行动态选择。
- RAISE方法具有良好的可解释性,并具备强大的任务特定优化能力。
- RAISE将动态指令选择建模为序列决策过程,并使用强化学习进行训练。
点此查看论文截图


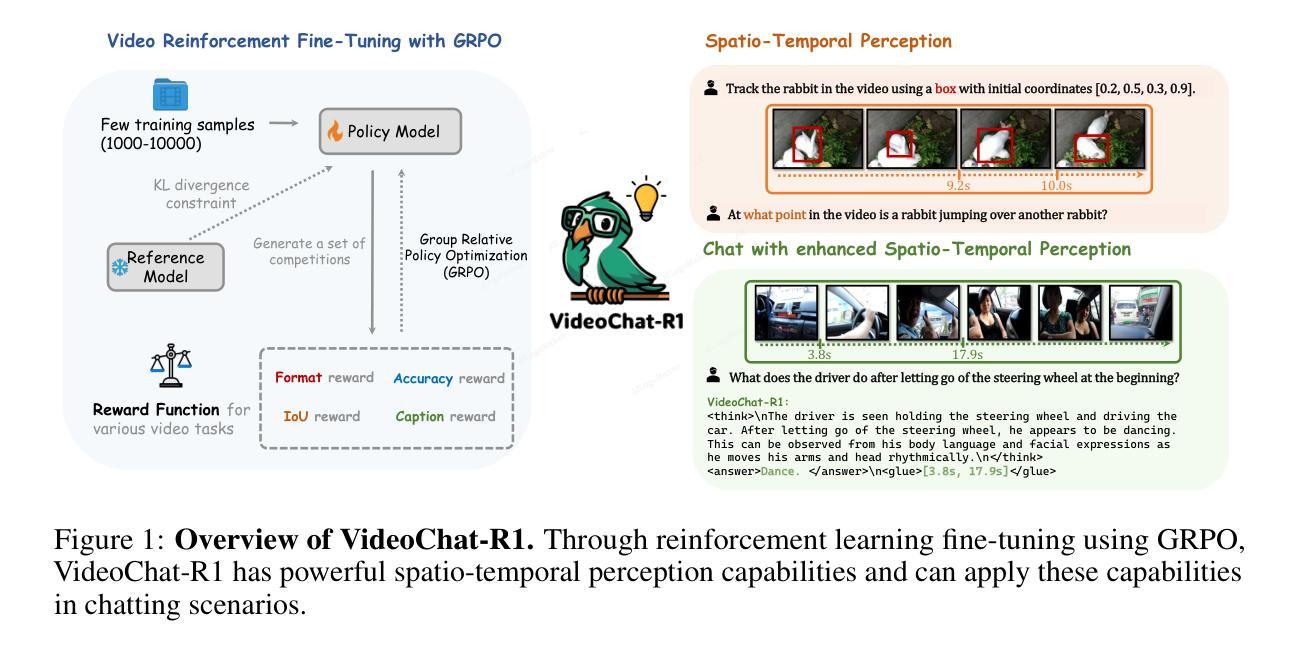
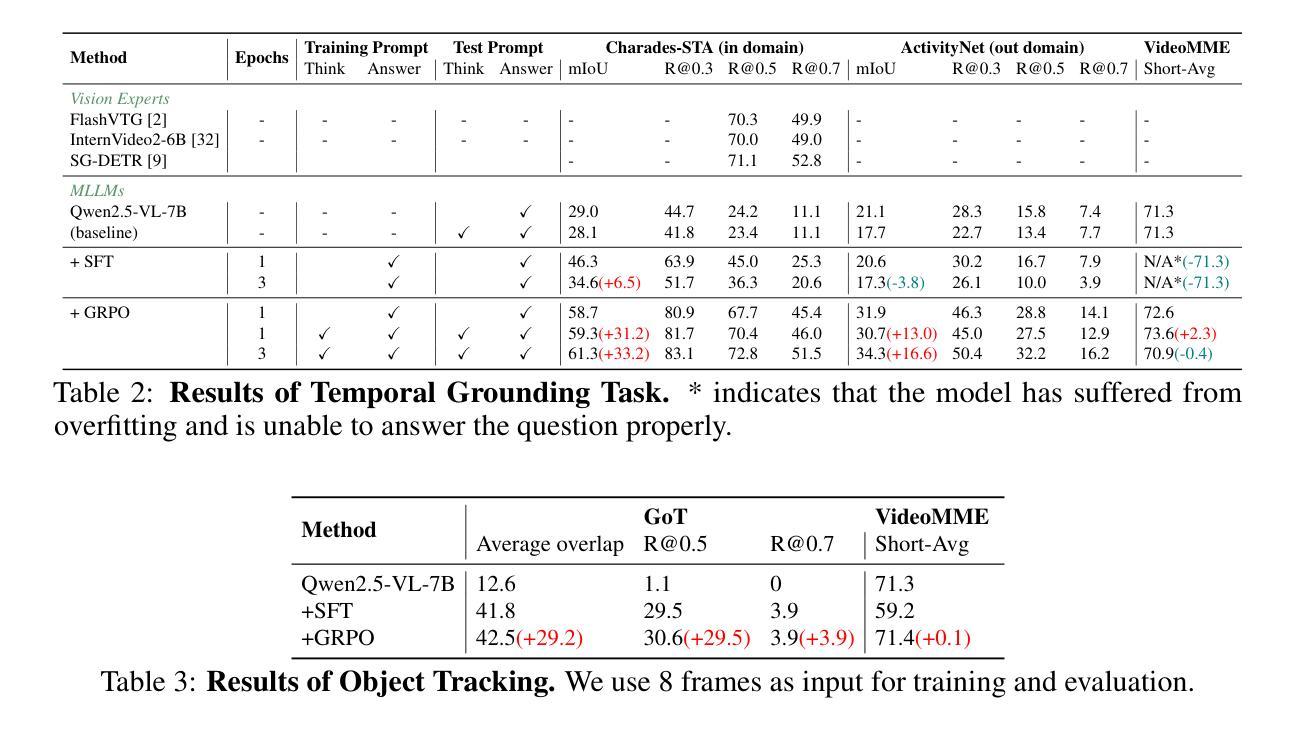
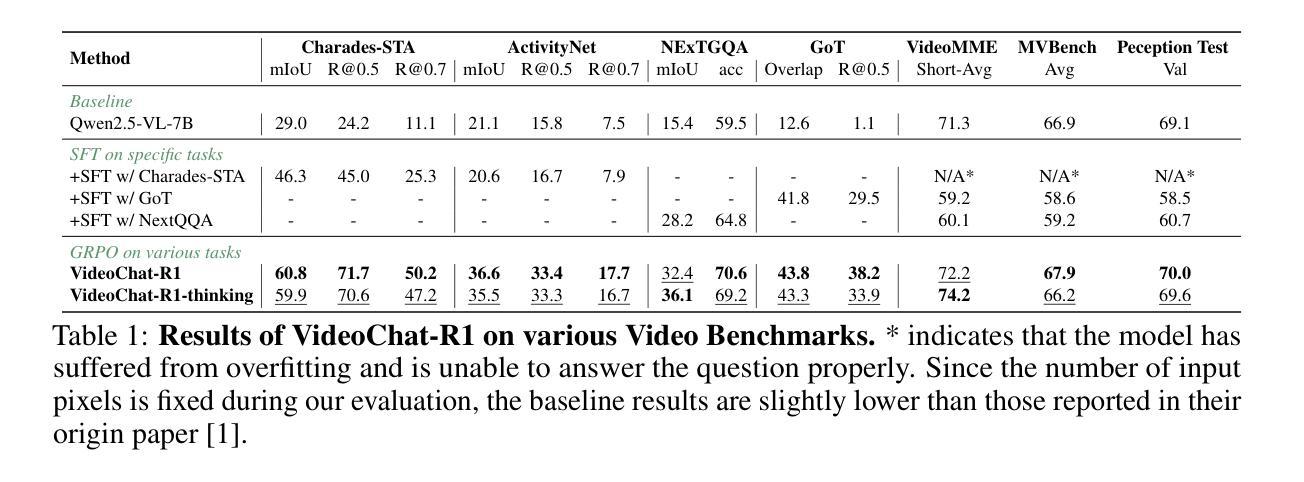
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Authors:Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, Limin Wang
Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
近期强化学习在多媒体大语言模型(MLLMs)推理能力方面的进展非常显著。尽管群体相对策略优化(GRPO)和基于规则的奖励机制在文本和图像领域展现出巨大潜力,但它们在视频理解方面的应用仍然有限。本文系统地探讨了使用GRPO的强化微调(RFT)在视频MLLMs中的应用,旨在提高时空感知能力的同时保持通用能力。我们的实验表明,RFT对于特定任务的改进非常数据高效。通过有限样本的时空感知目标上的多任务RFT,我们开发出了VideoChat-R1,这是一款强大的视频MLLM,它在时空感知任务上实现了最先进的性能,同时不牺牲对话能力,并展现出新兴的时空推理能力。与Qwen2.5-VL-7B相比,VideoChat-R1在诸如时间定位(+31.8)和对象跟踪(+31.2)的任务上的性能提升了数倍。此外,它在通用问答基准测试(如VideoMME、MVBench和Perception Test)上的表现也显著提高(+0.9)。我们的研究突出了RFT在视频MLLM特定任务增强方面的潜力。我们希望我们的研究能为未来视频MLLM的强化学习研究提供有价值的见解。
论文及项目相关链接
Summary
强化学习在提升多模态大型语言模型的推理能力方面取得了重要进展。本论文探索了使用强化精细调整(RFT)与集团相对策略优化(GRPO)的视频MLLMs技术,旨在提高时空感知能力同时保持通用能力。实验表明,RFT对于特定任务改进非常高效,通过多任务RFT在时空感知目标上进行有限样本训练,开发出VideoChat-R1模型,在时空感知任务上实现卓越性能,同时保留聊天能力,展现出新兴的时空推理能力。
Key Takeaways
- 强化学习在多模态大型语言模型(MLLMs)的推理能力方面取得显著进展。
- Group Relative Policy Optimization (GRPO) 在视频理解方面的应用受限。
- 通过强化精细调整(RFT)和GRPO的结合,提高了视频MLLMs的时空感知能力。
- RFT具有高度数据效率,能针对特定任务进行有效改进。
- 开发出的VideoChat-R1模型在时空感知任务上表现优异,同时在一般问答基准测试中也有显著提升。
- VideoChat-R1相较于Qwen2.5-VL-7B模型在多个任务上性能有所提升,如时间定位和目标跟踪等任务。
点此查看论文截图


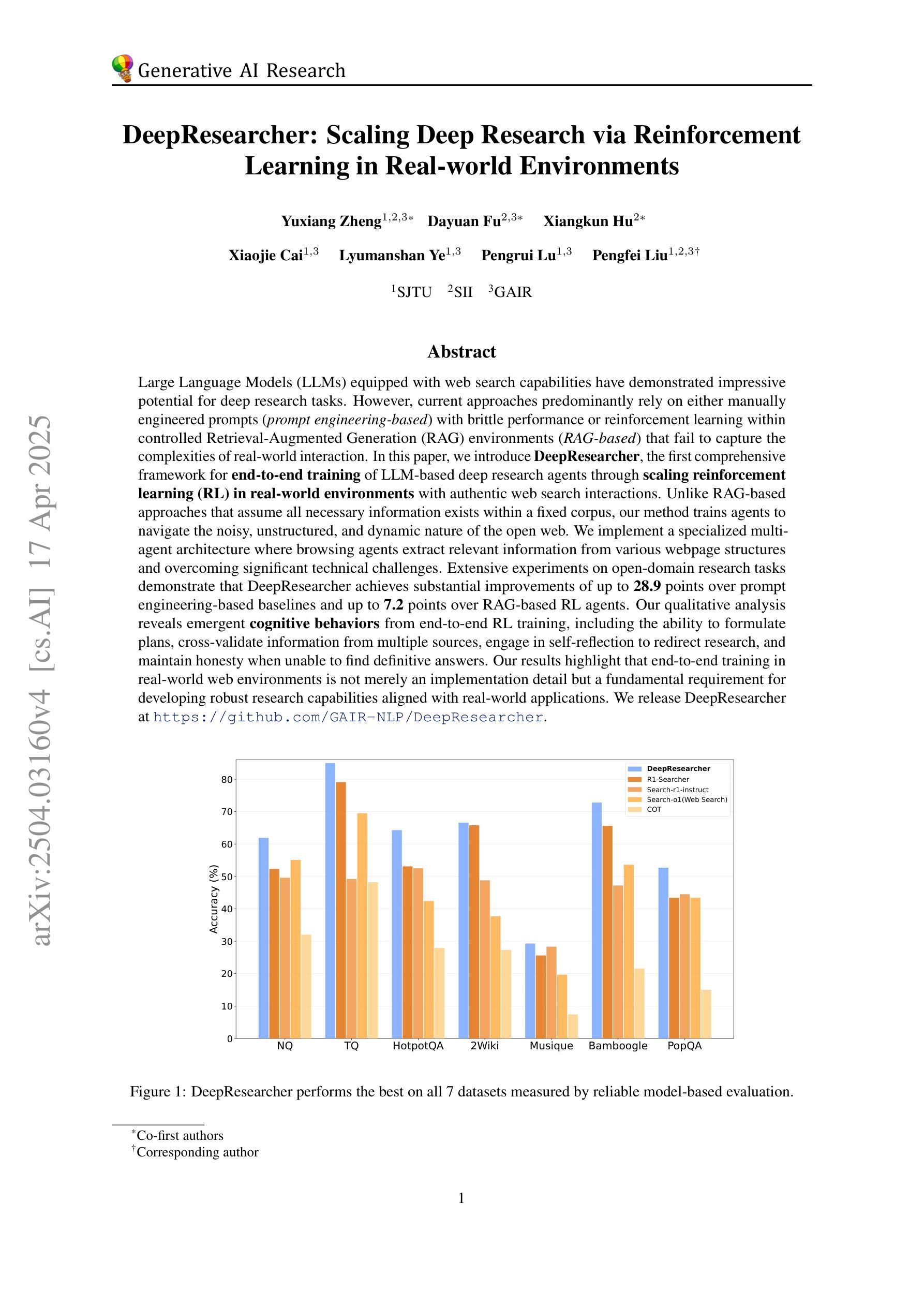
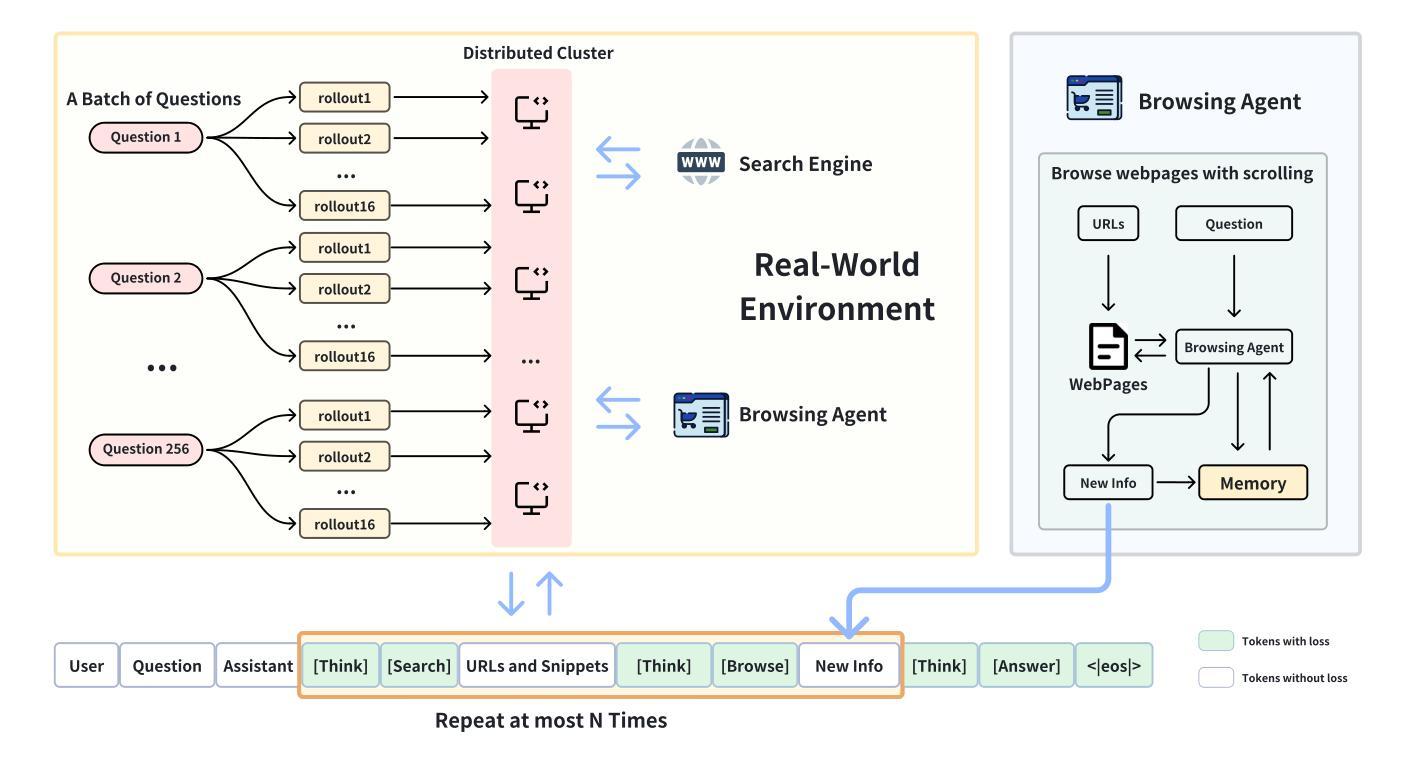
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
Authors:Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually engineered prompts (prompt engineering-based) with brittle performance or reinforcement learning within controlled Retrieval-Augmented Generation (RAG) environments (RAG-based) that fail to capture the complexities of real-world interaction. In this paper, we introduce DeepResearcher, the first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling reinforcement learning (RL) in real-world environments with authentic web search interactions. Unlike RAG-based approaches that assume all necessary information exists within a fixed corpus, our method trains agents to navigate the noisy, unstructured, and dynamic nature of the open web. We implement a specialized multi-agent architecture where browsing agents extract relevant information from various webpage structures and overcoming significant technical challenges. Extensive experiments on open-domain research tasks demonstrate that DeepResearcher achieves substantial improvements of up to 28.9 points over prompt engineering-based baselines and up to 7.2 points over RAG-based RL agents. Our qualitative analysis reveals emergent cognitive behaviors from end-to-end RL training, including the ability to formulate plans, cross-validate information from multiple sources, engage in self-reflection to redirect research, and maintain honesty when unable to find definitive answers. Our results highlight that end-to-end training in real-world web environments is not merely an implementation detail but a fundamental requirement for developing robust research capabilities aligned with real-world applications. We release DeepResearcher at https://github.com/GAIR-NLP/DeepResearcher.
配备网页搜索功能的大型语言模型(LLM)在深度研究任务中展现出了令人印象深刻的潜力。然而,当前的方法主要依赖于手动设计的提示(基于提示工程的方法),其性能脆弱,或者在受控的检索增强生成(RAG)环境中使用强化学习(基于RAG的方法),无法捕捉现实世界中互动的复杂性。在本文中,我们介绍了DeepResearcher,这是第一个通过强化学习(RL)在真实世界环境中进行端到端训练LLM深度研究代理的全面框架,该框架通过真实的网页搜索互动来实现。与假设所有必要信息都存在于固定语料库中的RAG方法不同,我们的方法训练代理以应对开放网络的嘈杂、非结构化和动态性质。我们实现了一种专用多代理架构,浏览代理可以从各种网页结构中提取相关信息,并克服重大技术挑战。在开放域研究任务上的大量实验表明,DeepResearcher较基于提示工程的基线实现了高达28.9点的实质性改进,较基于RAG的RL代理实现了高达7.2点的改进。我们的定性分析揭示了来自端到端RL训练的突发认知行为,包括制定计划的能力、从多个来源进行交叉验证信息的能力、参与自我反思以重新定向研究的能力,以及在无法找到明确答案时保持诚实。我们的结果强调,在真实世界网络环境中进行端到端训练不仅是实现细节,而且是开发与现实世界应用相匹配的稳健研究能力的根本要求。我们在https://github.com/GAIR-NLP/DeepResearcher上发布了DeepResearcher。
论文及项目相关链接
Summary
大型语言模型(LLM)结合网络搜索能力在深研究任务中展现出巨大的潜力。然而,当前的方法主要依赖于手动设计的提示或强化学习在受控的检索增强生成环境中,这两者都无法完全捕捉真实世界交互的复杂性。本文提出DeepResearcher,这是第一个通过强化学习在真实世界环境中进行端到端训练的语言模型为基础的研究代理人的全面框架。与基于RAG的方法不同,我们的方法训练代理人在开放网络上浏览,应对噪音、非结构化和动态的环境。通过实施特殊的多代理架构,提取来自各种网页结构的相关信息并克服重大技术挑战。在开放域研究任务上的广泛实验表明,DeepResearcher相对于基于提示的工程方法和基于RAG的RL代理分别实现了高达28.9点和7.2点的实质性改进。我们的定性分析揭示了从端到端的RL训练中涌现出的认知行为,包括制定计划、从多个来源交叉验证信息、进行自我反思以调整研究方向以及在无法找到明确答案时保持诚实。结果表明,在真实世界网络环境中进行端到端的训练不仅是实现细节,而且是开发与现实世界应用相匹配的稳健研究能力的根本要求。
Key Takeaways
- 大型语言模型(LLM)结合网络搜索能力在深研究任务中具有巨大潜力。
- 当前方法主要依赖手动设计的提示或强化学习在受控环境,难以捕捉真实世界交互的复杂性。
- DeepResearcher是首个通过强化学习在真实世界环境进行端到端训练LLM的全面框架。
- DeepResearcher能在开放网络上进行浏览并应对噪音、非结构化和动态的环境。
- 多代理架构被用于提取网页信息并克服技术挑战。
- DeepResearcher相对于基于提示工程和基于RAG的RL方法有明显性能提升。
点此查看论文截图