⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Authors:Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, ShiLiang Zhang, Xie Chen
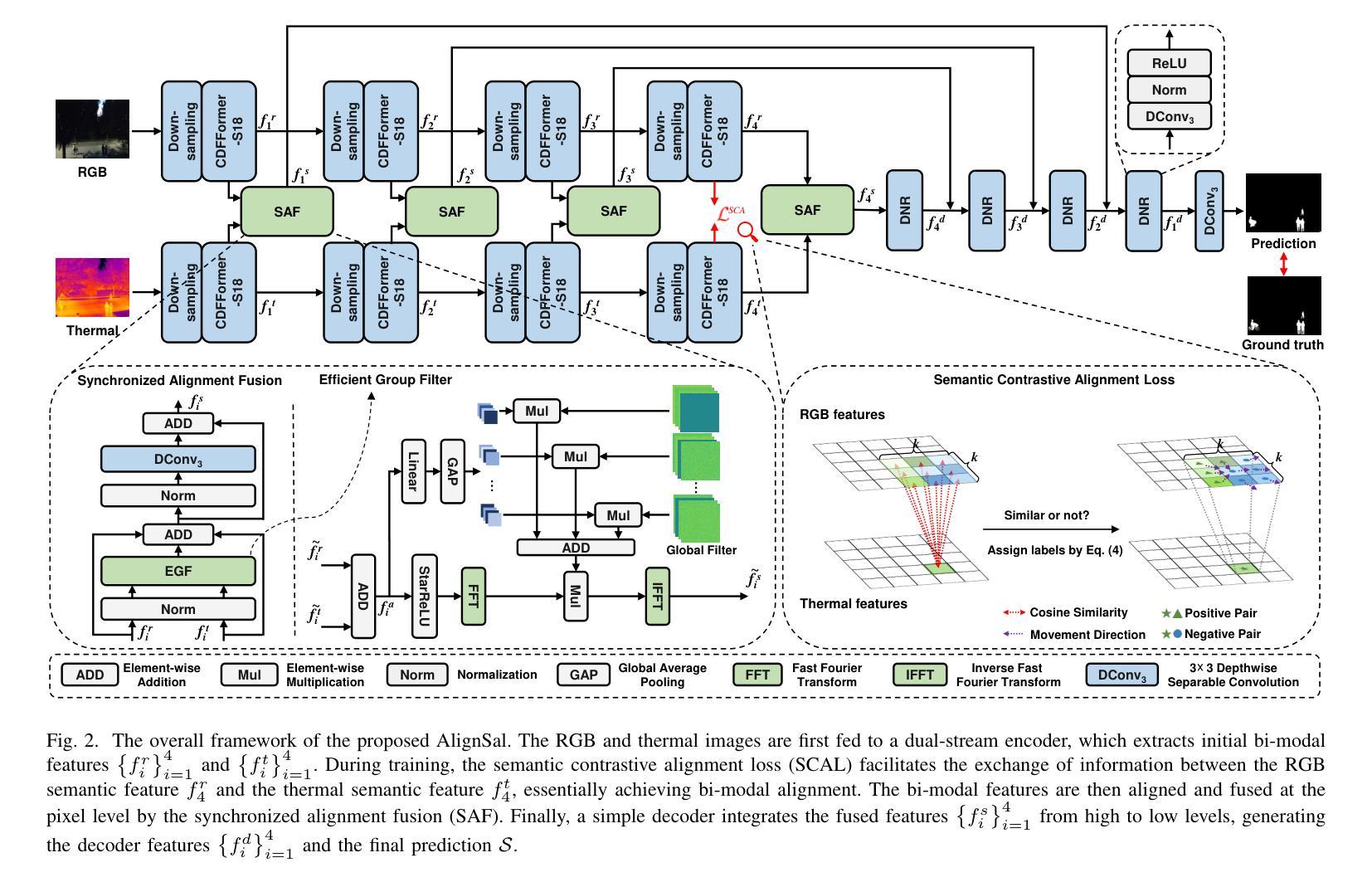
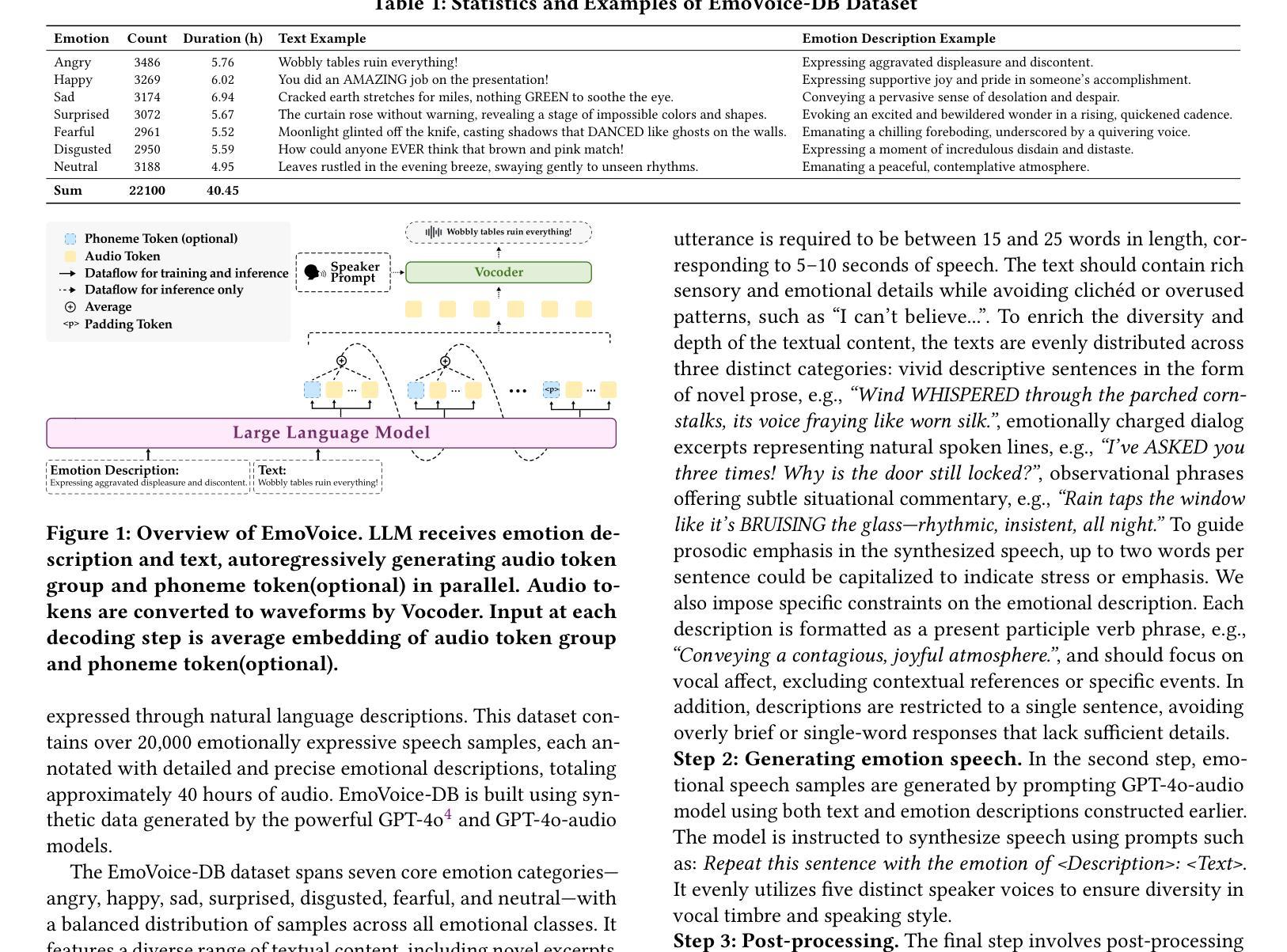
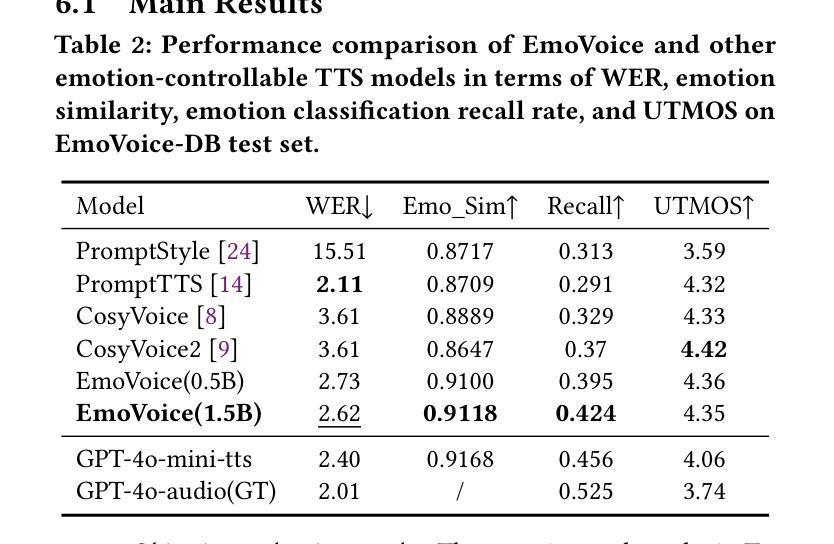
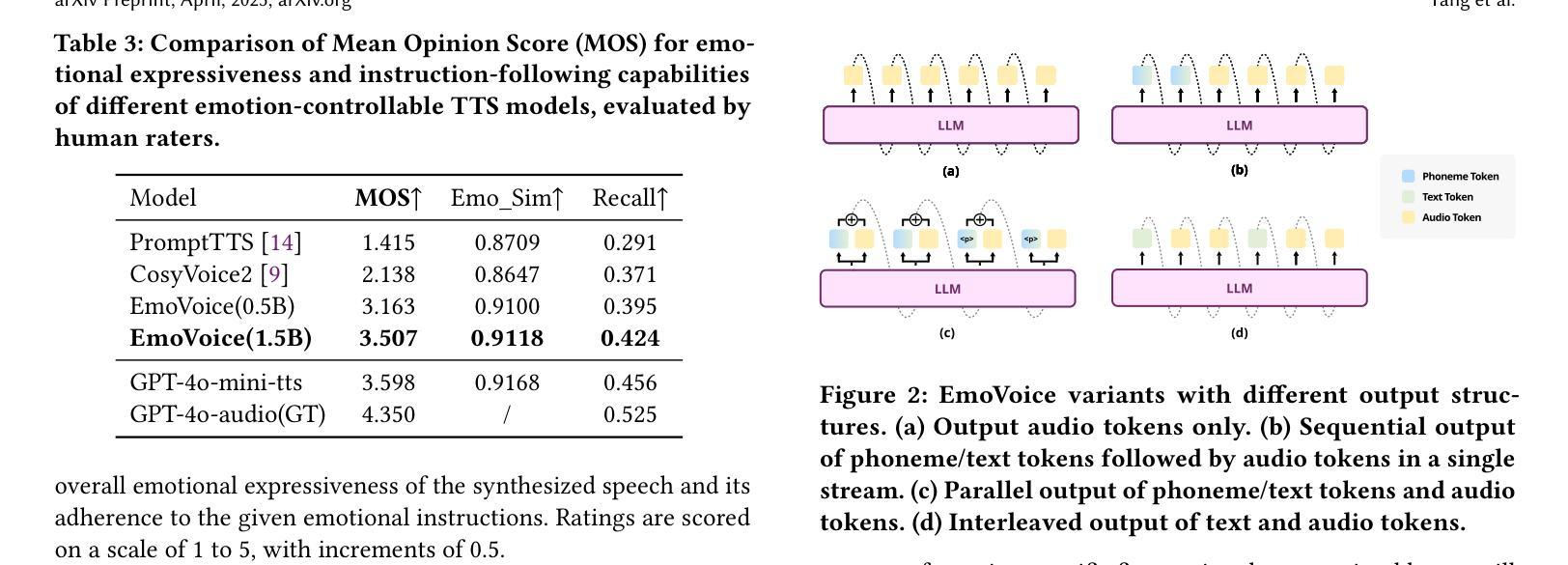
Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and modality-of-thought (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://anonymous.4open.science/r/EmoVoice-DF55. Dataset, code, and checkpoints will be released.
人类语音不仅仅是信息的传递,更是情感深处的交流与个体间的联系。虽然文本转语音(TTS)模型已经取得了巨大的进步,但在控制生成语音的情感表达方面仍面临挑战。在这项工作中,我们提出了EmoVoice,一种新型的情感可控TTS模型,它利用大型语言模型(LLM)实现细粒度的自由式自然语言情感控制,并采用了音素增强变体设计,使模型能够同时输出音素标记和音频标记,以增强内容的一致性,这一设计灵感来源于思维链(CoT)和模态思维(CoM)技术。此外,我们还介绍了EmoVoice-DB,这是一个高质量的40小时英语情感数据集,包含表达性语音和带有自然语言描述的细粒度情感标签。EmoVoice仅使用合成训练数据,在英语EmoVoice-DB测试集上实现了最新性能,在使用内部数据的中文Secap测试集上也表现优异。我们进一步研究了现有情感评估指标的可靠性及其与人类感知偏好的一致性,并探索使用最先进的多媒体LLM GPT-4o-audio和Gemini来评估情感语音。Demo样品可在https://anonymous.4open.science/r/EmoVoice-DF55查看。数据集、代码和检查点将随后发布。
论文及项目相关链接
Summary
本文介绍了EmoVoice,一种新型情感可控的文本转语音模型。该模型利用大型语言模型实现精细的自由式自然语言情感控制,并采用并行输出语音标记和音频标记的变体设计,增强了内容一致性。此外,还引入了高质量的情感数据集EmoVoice-DB。EmoVoice在英文和中文测试集上均取得了最先进的性能。同时,本文还探讨了现有情感评估指标的可靠性及其与人类感知偏好的一致性,并尝试使用先进的多媒体语言模型进行评估。
Key Takeaways
- EmoVoice是一种新型的情感可控文本转语音(TTS)模型,能够利用大型语言模型(LLM)实现精细的自由式自然语言情感控制。
- EmoVoice采用并行输出语音标记和音频标记的变体设计,以提高内容一致性。
- 引入了高质量的情感数据集EmoVoice-DB,用于训练和评估TTS模型的情感表达。
- EmoVoice在英文和中文测试集上均表现出卓越的性能。
- 本文探讨了现有情感评估指标的可靠性,并研究了它们与人类感知偏好的一致性。
- 尝试使用先进的多媒体语言模型,如GPT-4o-audio和Gemini,来评估情感语音。
点此查看论文截图

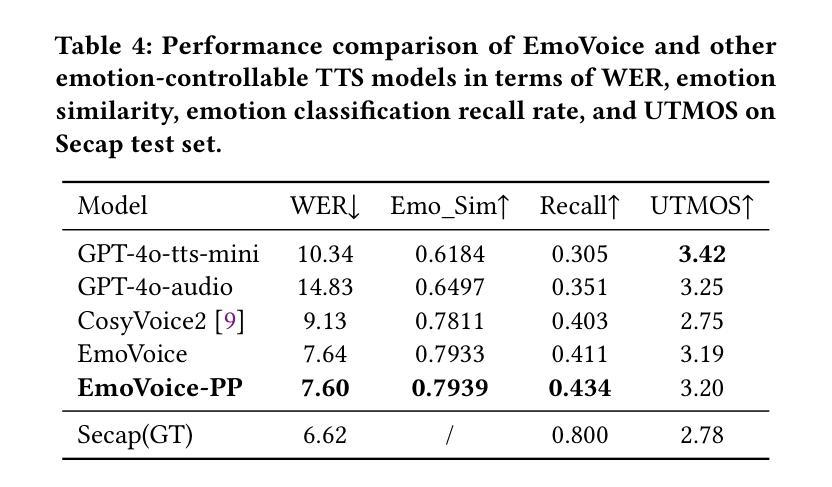
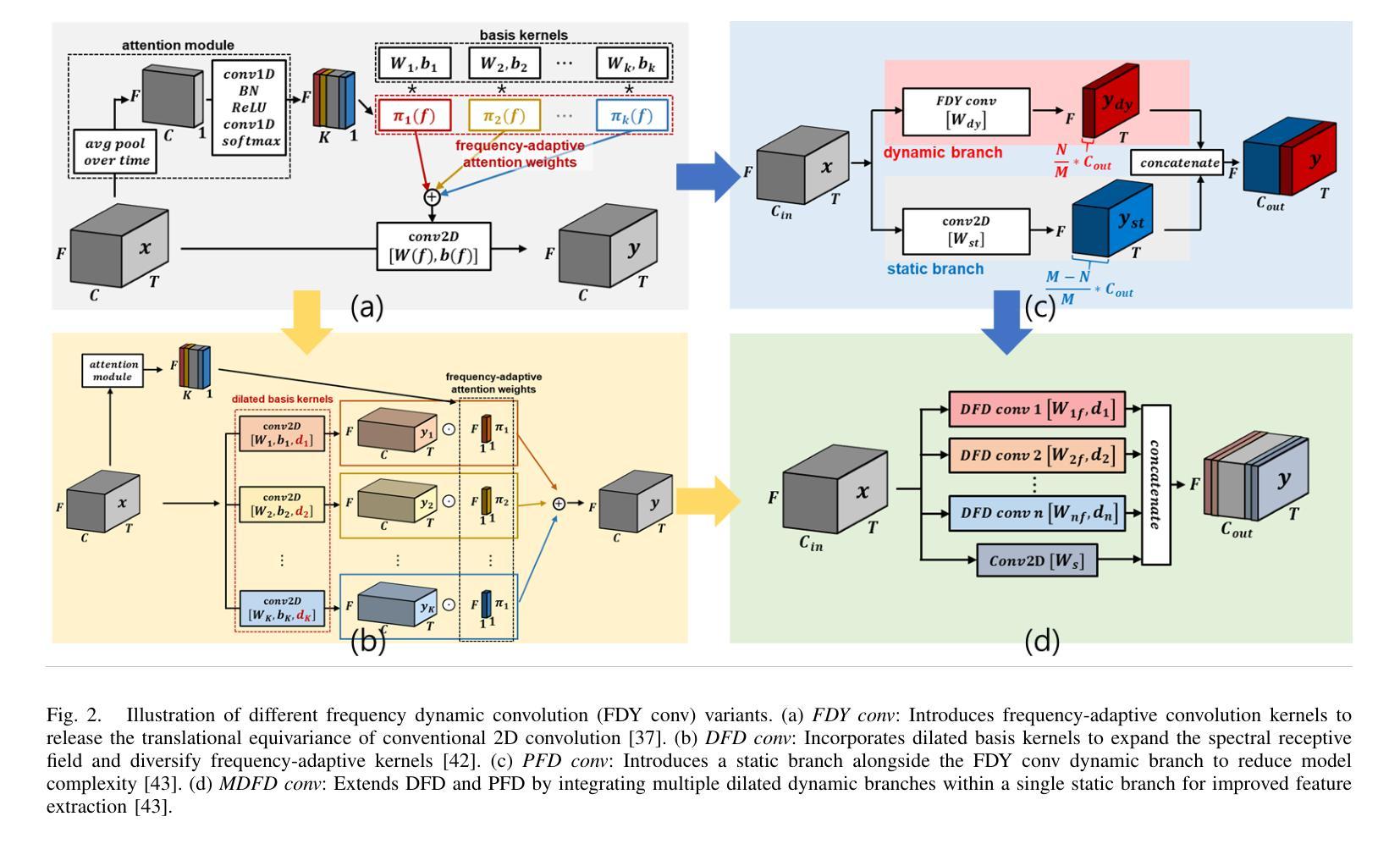
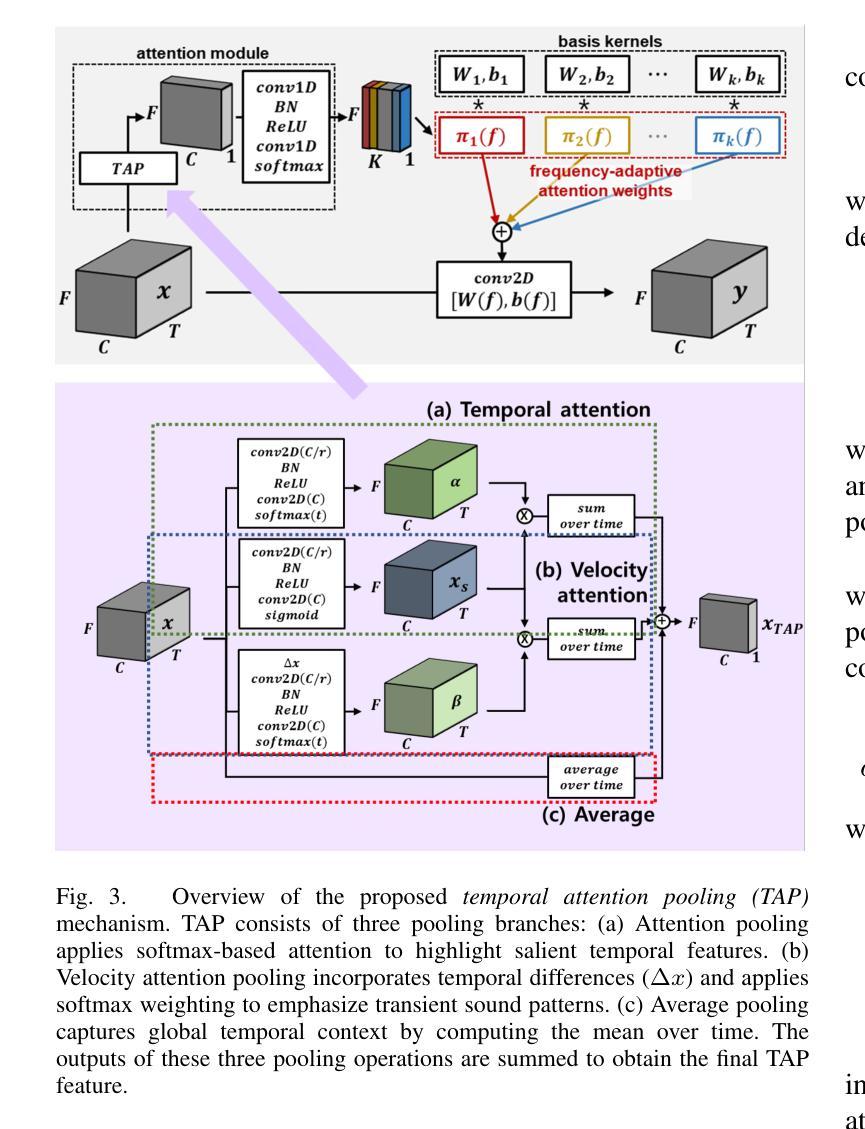
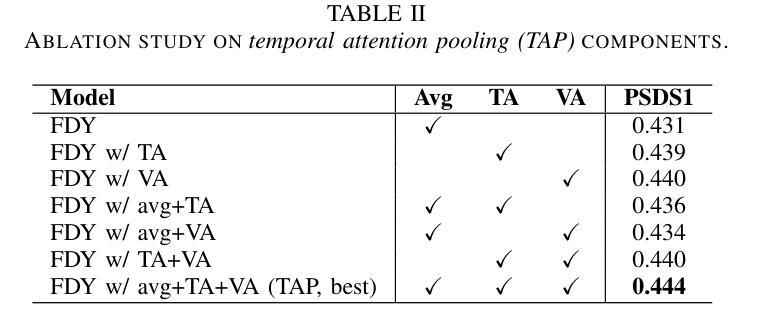
Temporal Attention Pooling for Frequency Dynamic Convolution in Sound Event Detection
Authors:Hyeonuk Nam, Yong-Hwa Park
Recent advances in deep learning, particularly frequency dynamic convolution (FDY conv), have significantly improved sound event detection (SED) by enabling frequency-adaptive feature extraction. However, FDY conv relies on temporal average pooling, which treats all temporal frames equally, limiting its ability to capture transient sound events such as alarm bells, door knocks, and speech plosives. To address this limitation, we propose temporal attention pooling frequency dynamic convolution (TFD conv) to replace temporal average pooling with temporal attention pooling (TAP). TAP adaptively weights temporal features through three complementary mechanisms: time attention pooling (TA) for emphasizing salient features, velocity attention pooling (VA) for capturing transient changes, and conventional average pooling for robustness to stationary signals. Ablation studies show that TFD conv improves average PSDS1 by 3.02% over FDY conv with only a 14.8% increase in parameter count. Classwise ANOVA and Tukey HSD analysis further demonstrate that TFD conv significantly enhances detection performance for transient-heavy events, outperforming existing FDY conv models. Notably, TFD conv achieves a maximum PSDS1 score of 0.456, surpassing previous state-of-the-art SED systems. We also explore the compatibility of TAP with other FDY conv variants, including dilated FDY conv (DFD conv), partial FDY conv (PFD conv), and multi-dilated FDY conv (MDFD conv). Among these, the integration of TAP with MDFD conv achieves the best result with a PSDS1 score of 0.459, validating the complementary strengths of temporal attention and multi-scale frequency adaptation. These findings establish TFD conv as a powerful and generalizable framework for enhancing both transient sensitivity and overall feature robustness in SED.
最近深度学习领域的进展,特别是频率动态卷积(FDY conv)技术,已经通过实现频率自适应特征提取,显著提高了声音事件检测(SED)的性能。然而,FDY conv依赖于时间平均池化,它平等对待所有时间帧,这限制了其捕捉短暂声音事件(如警报、敲门声和语音爆破音)的能力。为了解决这一局限性,我们提出了基于时间注意力池化的频率动态卷积(TFD conv),以时间注意力池化(TAP)替代时间平均池化。TAP通过三种互补机制自适应地加权时间特征:时间注意力池化(TA)用于突出显著特征,速度注意力池化(VA)用于捕捉瞬时变化,以及常规平均池化用于稳健处理平稳信号。消融研究表明,TFD conv在参数计数仅增加14.8%的情况下,平均PSDS1提高了3.02%,超过了FDY conv。类间ANOVA和Tukey HSD分析进一步证明,TFD conv对于短暂事件密集的场景具有显著增强的检测性能,优于现有的FDY conv模型。值得注意的是,TFD conv达到了0.456的PSDS1最高分数,超过了之前的先进SED系统。我们还探讨了TAP与其他FDY conv变体的兼容性,包括膨胀FDY conv(DFD conv)、部分FDY conv(PFD conv)和多膨胀FDY conv(MDFD conv)。其中,TAP与MDFD conv的结合取得了最佳结果,PSDS1得分为0.459,验证了时间注意力和多尺度频率适应的互补优势。这些发现确立了TFD conv作为一个强大且通用的框架,能够增强SED的瞬时敏感性和总体特征稳健性。
论文及项目相关链接
摘要
近期深度学习领域的新进展,特别是频率动态卷积(FDY conv)技术,显著提升了声音事件检测(SED)的性能,实现了频率自适应特征提取。然而,FDY conv依赖于平均池化方法处理时间帧,这限制了其对警报铃声、敲门声和语音爆发等短暂性声音事件的捕捉能力。为解决这一问题,我们提出用时间注意力池化频率动态卷积(TFD conv)取代时间平均池化。TAP通过三种互补机制自适应加权时间特征:时间注意力池化(TA)以强调显著特征,速度注意力池化(VA)以捕捉瞬时变化,以及常规平均池化以应对平稳信号的稳健性。实验结果显示,TFD conv在平均PSDS1得分上较FDY conv提高了3.02%,而参数数量仅增加了14.8%。同时,TFD conv对突发事件的检测性能提升显著,超越现有FDY conv模型。值得一提的是,TFD conv达到了最高的PSDS1得分0.456,超越了当前最先进的SED系统。此外,我们还探讨了TAP与其他FDY conv变体(如膨胀FDY conv、部分FDY conv和多膨胀FDY conv)的兼容性。其中,TAP与MDFD conv的结合取得了最佳效果,PSDS1得分为0.459,验证了时间注意力和多尺度频率适应的互补优势。这些发现表明TFD conv是一个强大且通用的框架,可提高SED的瞬时敏感性和整体特征稳健性。
要点提炼
- FDY conv通过频率动态卷积改善了声音事件检测(SED)。
- FDY conv依赖的时间平均池化限制了其对短暂性声音事件的捕捉能力。
- 提出TFD conv,通过引入时间注意力池化(TAP)技术弥补了这一缺陷。
- TAP通过三种机制增强特征捕捉能力:时间注意力池化、速度注意力池化和常规平均池化。
- TFD conv在性能上较FDY conv有所提升,平均PSDS1得分提高3.02%,最大得分达0.456。
- TFD conv与其他FDY conv变体结合时表现更佳,特别是与MDFD conv结合,PSDS1得分达0.459。
点此查看论文截图

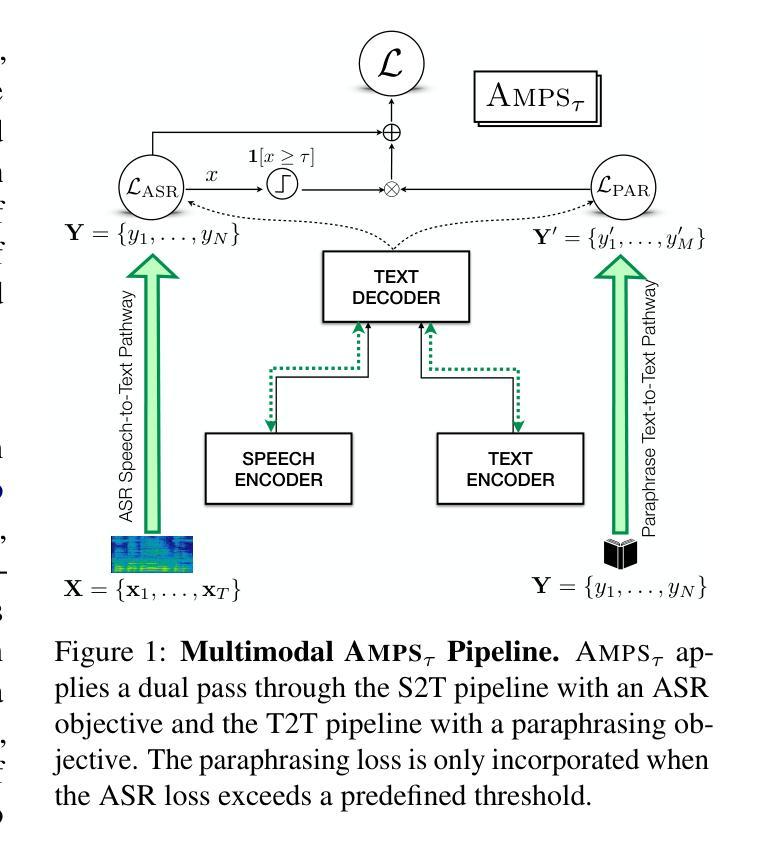
AMPS: ASR with Multimodal Paraphrase Supervision
Authors:Abhishek Gupta, Amruta Parulekar, Sameep Chattopadhyay, Preethi Jyothi
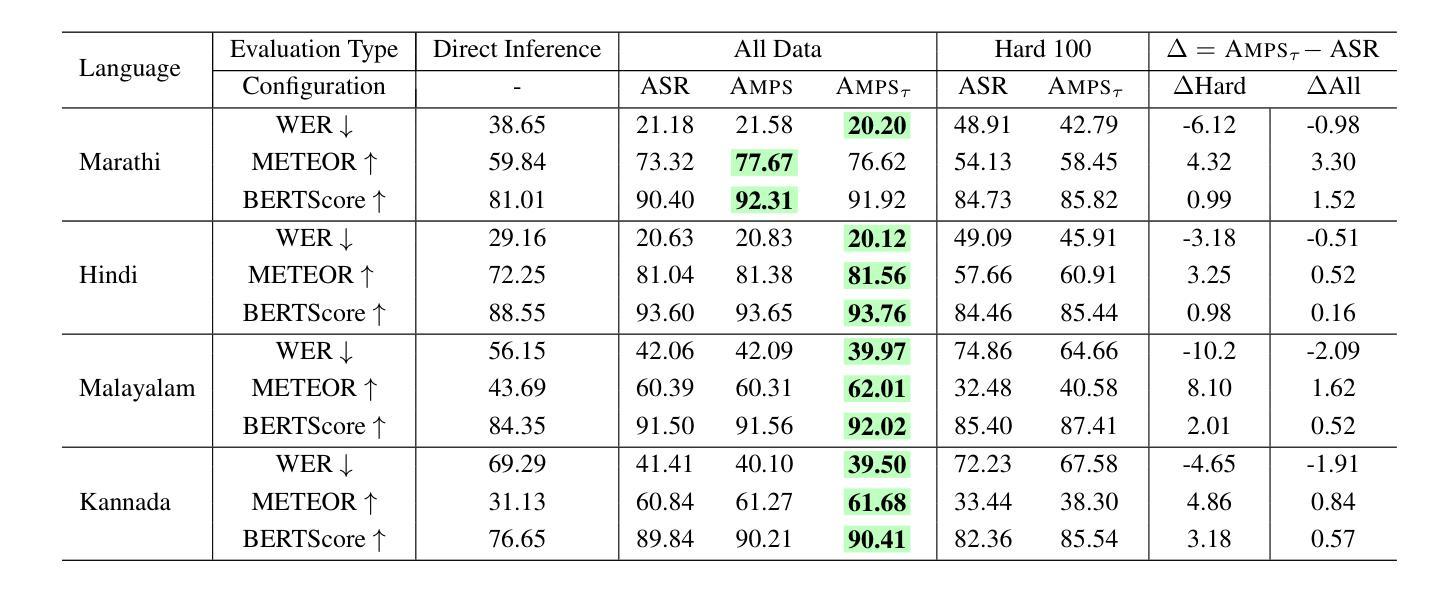
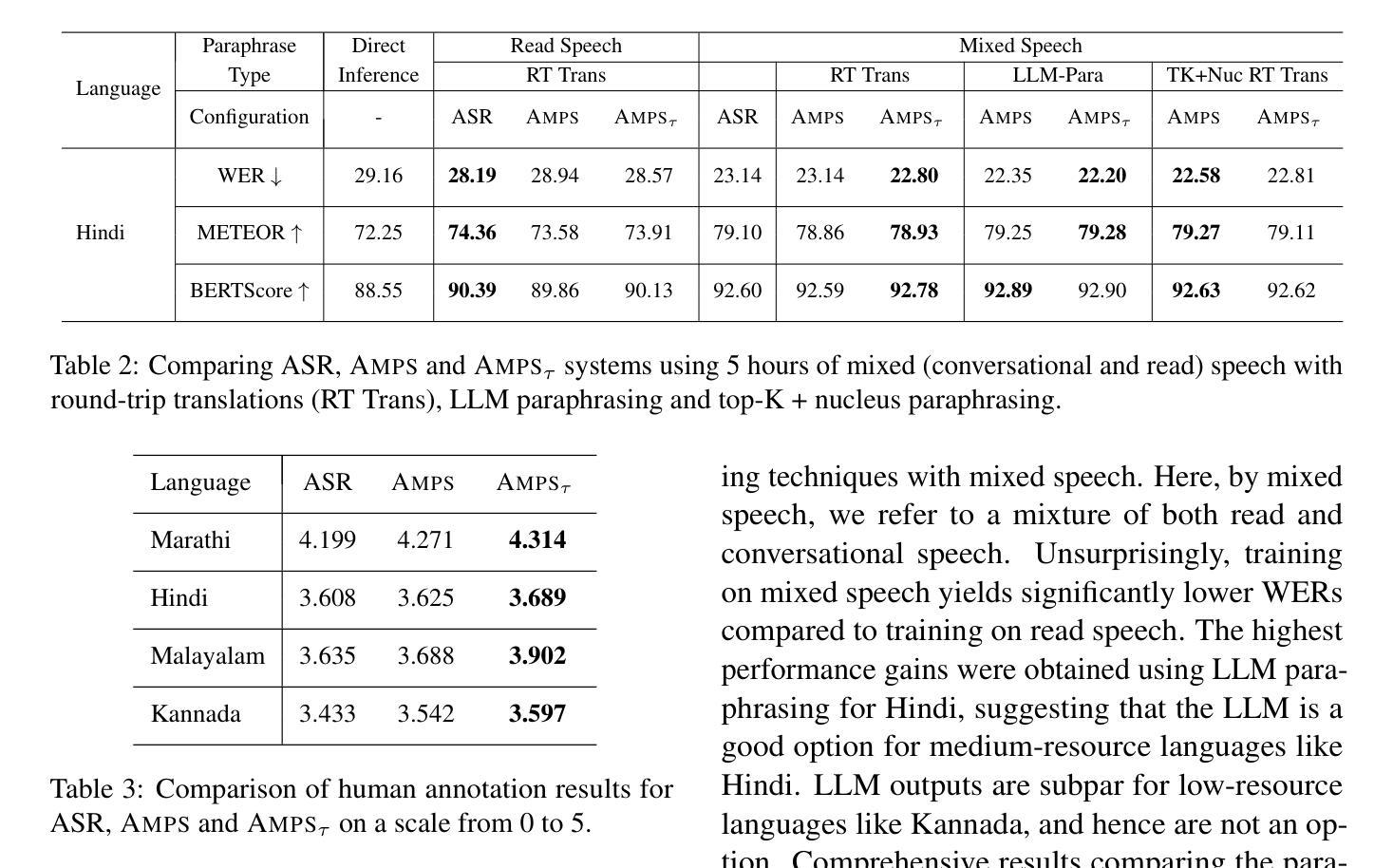
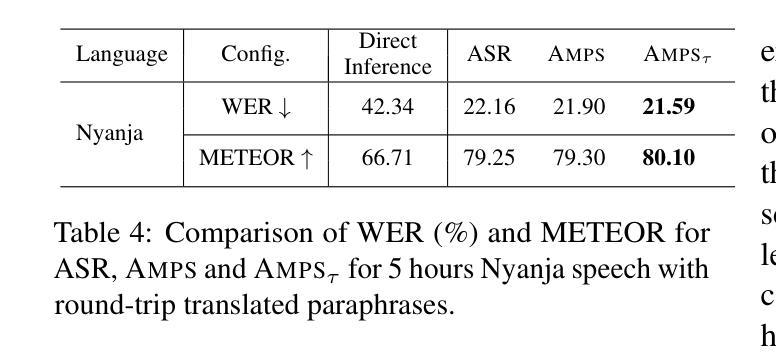
Spontaneous or conversational multilingual speech presents many challenges for state-of-the-art automatic speech recognition (ASR) systems. In this work, we present a new technique AMPS that augments a multilingual multimodal ASR system with paraphrase-based supervision for improved conversational ASR in multiple languages, including Hindi, Marathi, Malayalam, Kannada, and Nyanja. We use paraphrases of the reference transcriptions as additional supervision while training the multimodal ASR model and selectively invoke this paraphrase objective for utterances with poor ASR performance. Using AMPS with a state-of-the-art multimodal model SeamlessM4T, we obtain significant relative reductions in word error rates (WERs) of up to 5%. We present detailed analyses of our system using both objective and human evaluation metrics.
多语种自发对话或日常会话的语音给目前最先进的自动语音识别(ASR)系统带来了诸多挑战。在这项工作中,我们提出了一种新技术AMPS,该技术通过基于同义短语监督的方式增强多语种多媒体自动语音识别系统的性能,以提升多种语言的会话自动语音识别性能,包括印地语、马拉地语、马拉雅拉姆语、坎纳达语和尼扬贾语。在训练多媒体自动语音识别模型时,我们使用参考转录的同义短语作为额外的监督方式,并选择性地对表现不佳的自动语音识别结果进行同义短语目标调用。使用AMPS技术和先进的多媒体模型无缝M4T,我们取得了显著的相对词错误率(WER)降低,最高达到了5%。我们使用了客观和人为评估指标,对系统进行了详细的分析。
论文及项目相关链接
Summary
该文本描述了一项新技术AMPS,该技术能够增强多语言多媒体自动语音识别(ASR)系统的性能,使其更好地应对对话式ASR的挑战。通过利用参考转录中的同义短语作为额外的监督信息来训练多媒体ASR模型,并在表现不佳的ASR中对这一同义短语目标进行选择性地调用。结合前沿的多媒体模型SeamlessM4T使用AMPS技术,可以实现显著减少高达5%的词错误率(WERs)。本研究通过客观和人类评估指标进行了详细分析。
Key Takeaways
- AMPS技术增强了多语言多媒体ASR系统的性能。
- AMPS利用参考转录中的同义短语作为额外监督信息。
- AMPS在对话式ASR中应对多种语言,包括Hindi、Marathi、Malayalam、Kannada和Nyanja。
- 在表现不佳的ASR中,AMPS会选择性地调用同义短语目标。
- 结合SeamlessM4T模型使用AMPS,能显著减少高达5%的词错误率(WERs)。
- 研究通过客观和人类评估指标进行了详细分析。
- AMPS技术有助于提高ASR系统在自然语言处理方面的能力。
点此查看论文截图