⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
FLAP: Fully-controllable Audio-driven Portrait Video Generation through 3D head conditioned diffusion model
Authors:Lingzhou Mu, Baiji Liu
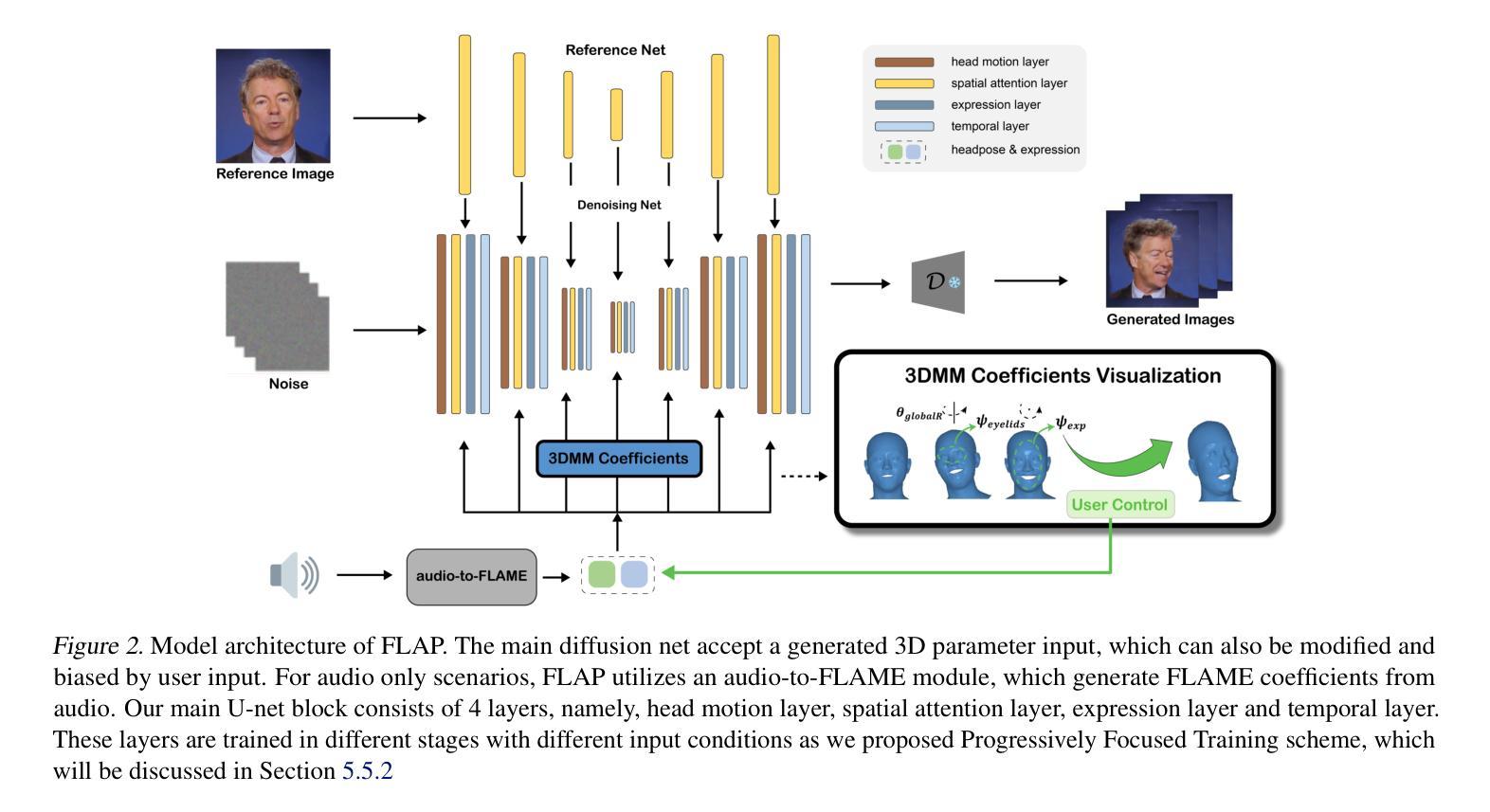
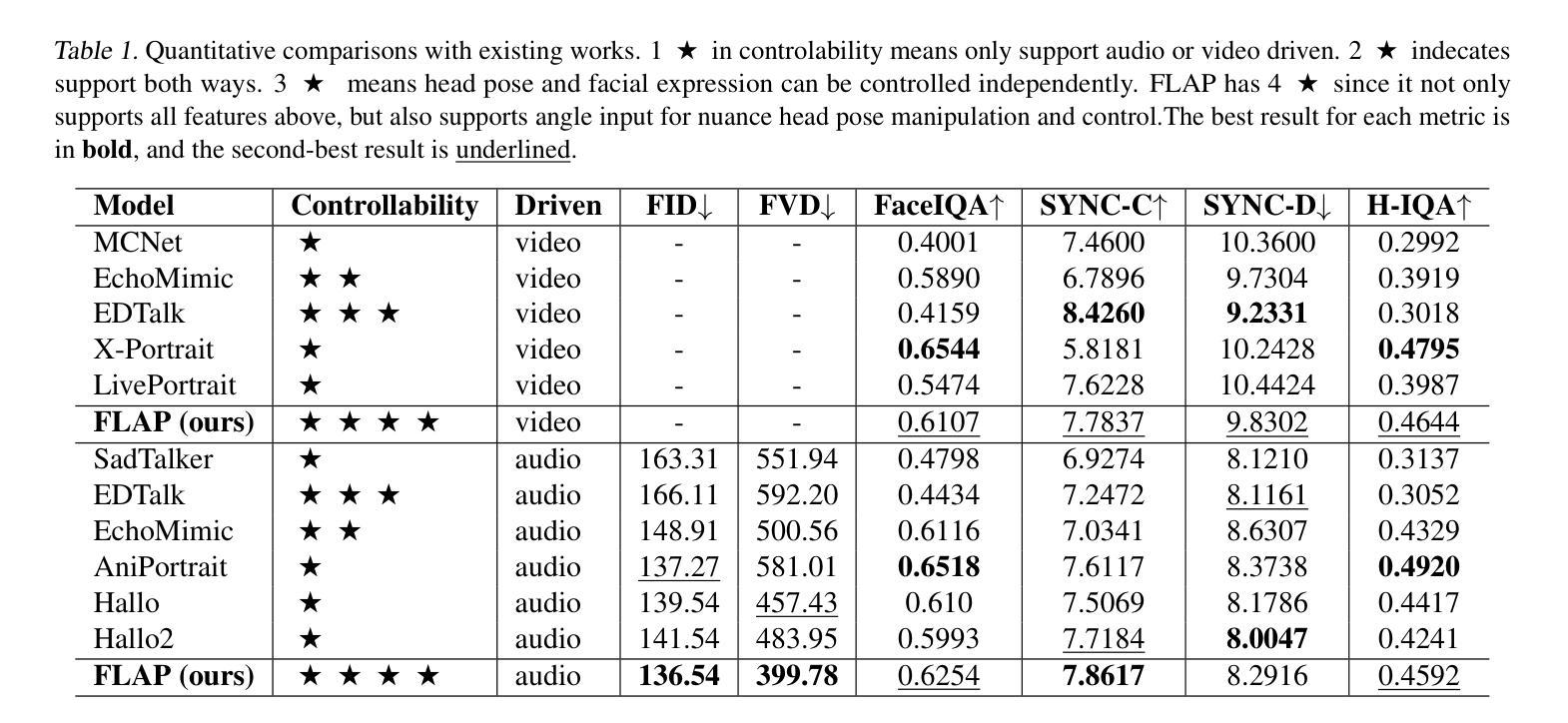
Diffusion-based video generation techniques have significantly improved zero-shot talking-head avatar generation, enhancing the naturalness of both head motion and facial expressions. However, existing methods suffer from poor controllability, making them less applicable to real-world scenarios such as filmmaking and live streaming for e-commerce. To address this limitation, we propose FLAP, a novel approach that integrates explicit 3D intermediate parameters (head poses and facial expressions) into the diffusion model for end-to-end generation of realistic portrait videos. The proposed architecture allows the model to generate vivid portrait videos from audio while simultaneously incorporating additional control signals, such as head rotation angles and eye-blinking frequency. Furthermore, the decoupling of head pose and facial expression allows for independent control of each, offering precise manipulation of both the avatar’s pose and facial expressions. We also demonstrate its flexibility in integrating with existing 3D head generation methods, bridging the gap between 3D model-based approaches and end-to-end diffusion techniques. Extensive experiments show that our method outperforms recent audio-driven portrait video models in both naturalness and controllability.
基于扩散的视频生成技术极大地改进了零样本说话人头像生成,提高了头部运动和面部表情的自然度。然而,现有方法存在可控性差的缺点,使得它们不太适合电影制作和电子商务直播等现实场景的应用。为了解决这一局限性,我们提出了FLAP,这是一种新型方法,它将明确的3D中间参数(头部姿势和面部表情)集成到扩散模型中,以端到端的方式生成逼真的肖像视频。该架构允许模型从音频生成生动肖像视频,同时纳入额外的控制信号,如头部旋转角度和眨眼频率。此外,头部姿势和面部表情的解耦使得两者能够独立控制,为头像的姿势和面部表情提供了精确的操作。我们还展示了其与现有3D头像生成方法的灵活性,缩小了基于3D模型的方法和端到端扩散技术之间的差距。大量实验表明,我们的方法在自然度和可控性方面超越了最新的音频驱动肖像视频模型。
论文及项目相关链接
Summary
文本提出一种名为FLAP的新方法,通过整合明确的3D中间参数(头部姿态和面部表情)到扩散模型中,解决了现有技术在零样本说话人头像生成中的可控性问题。该方法能生成逼真的肖像视频,同时支持音频驱动及附加控制信号(如头部旋转角度和眨眼频率等)。此方法可实现头部姿态和面部表情的独立控制,易于与现有3D头像生成方法集成,在真实世界场景如电影制作和电商直播中有广泛应用前景。实验证明,该方法在自然度和可控性上均优于现有音频驱动肖像视频模型。
Key Takeaways
- FLAP方法通过整合3D中间参数到扩散模型中,提高了说话人头像生成的自然性和可控性。
- 该方法支持音频驱动的视频生成,并可以加入附加控制信号,如头部旋转角度和眨眼频率。
- FLAP实现了头部姿态和面部表情的独立控制。
- 此方法易于与现有3D头像生成方法集成,有助于缩小3D模型方法和端到端扩散技术之间的差距。
- 广泛实验证明,FLAP方法在生成视频的逼真度方面表现优异。
- 与其他音频驱动的肖像视频模型相比,FLAP在自然度和可控性上均有显著优势。
点此查看论文截图