⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-19 更新
DC-SAM: In-Context Segment Anything in Images and Videos via Dual Consistency
Authors:Mengshi Qi, Pengfei Zhu, Xiangtai Li, Xiaoyang Bi, Lu Qi, Huadong Ma, Ming-Hsuan Yang
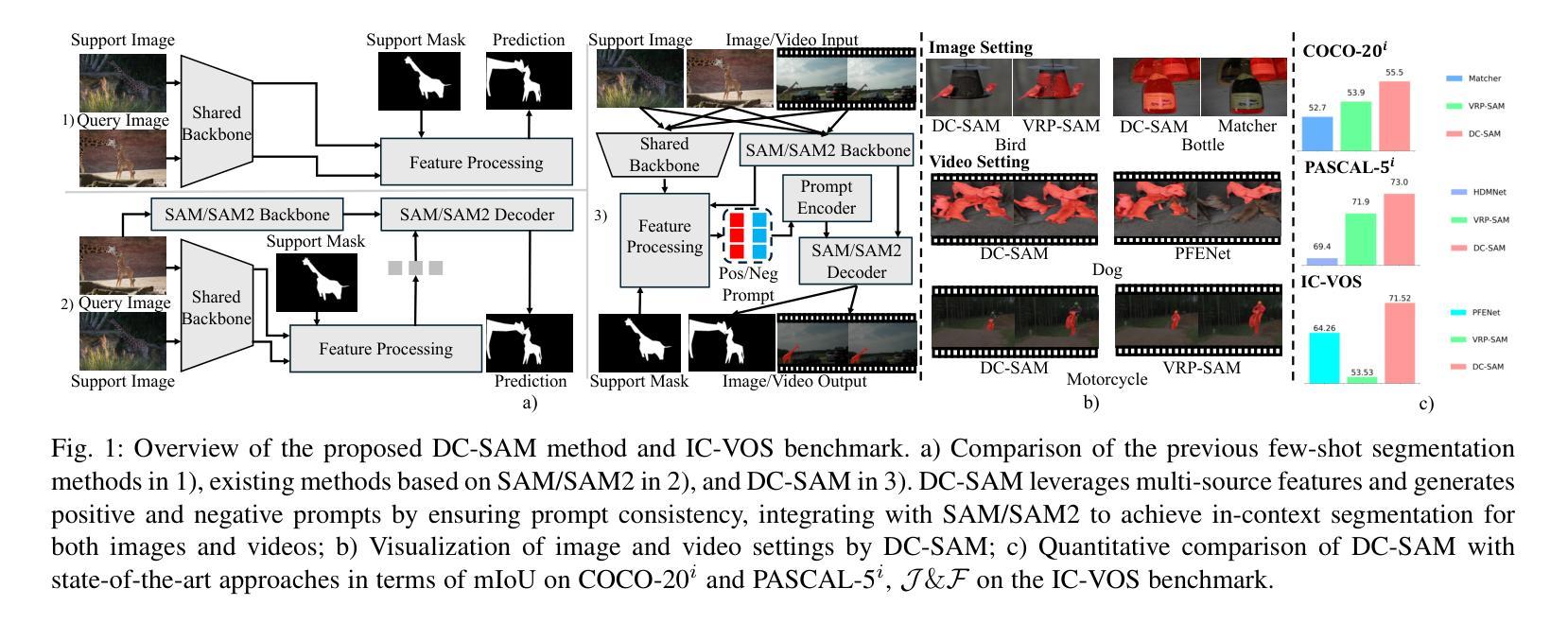
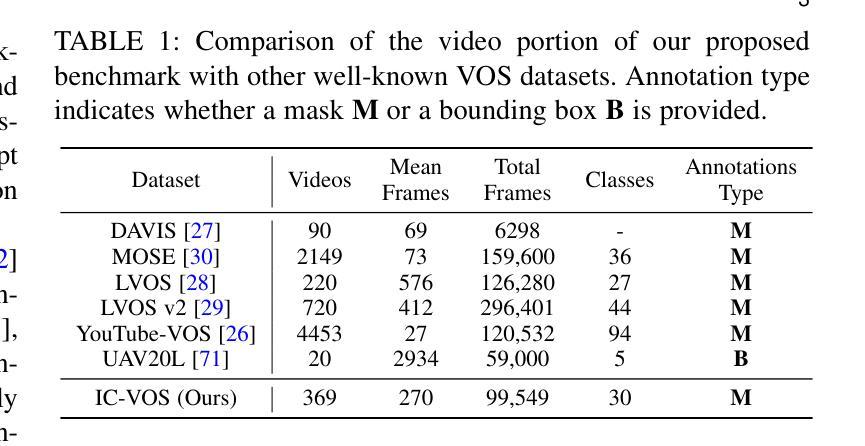
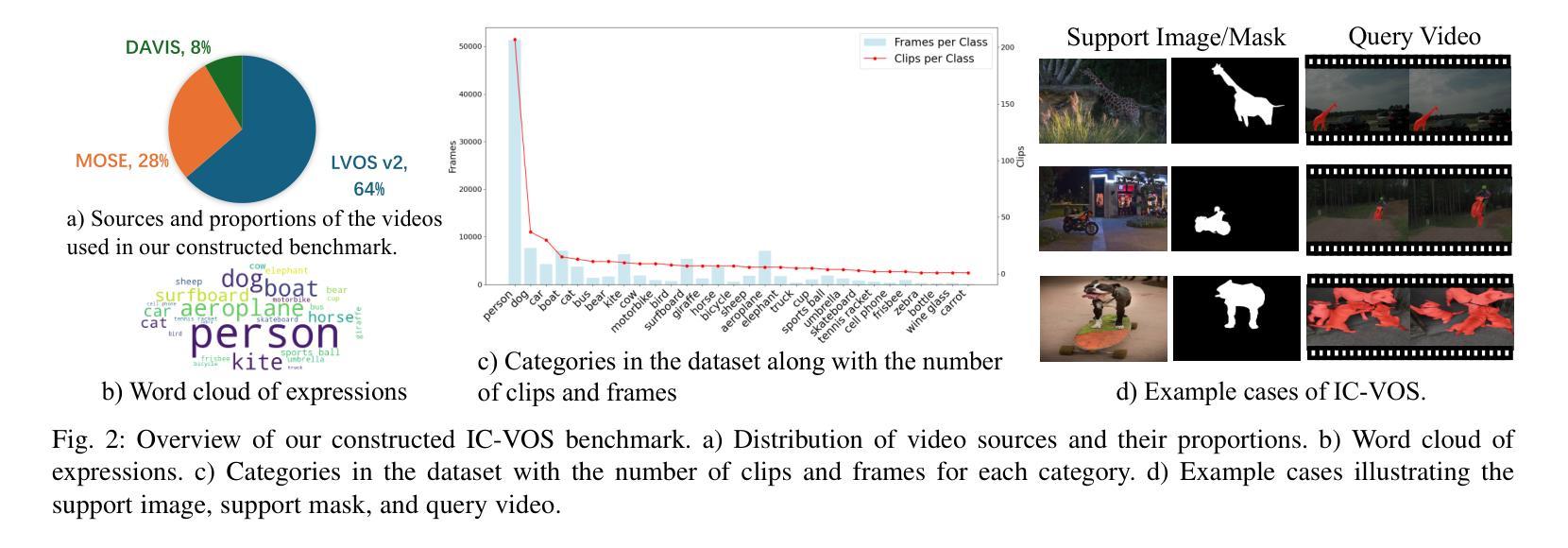
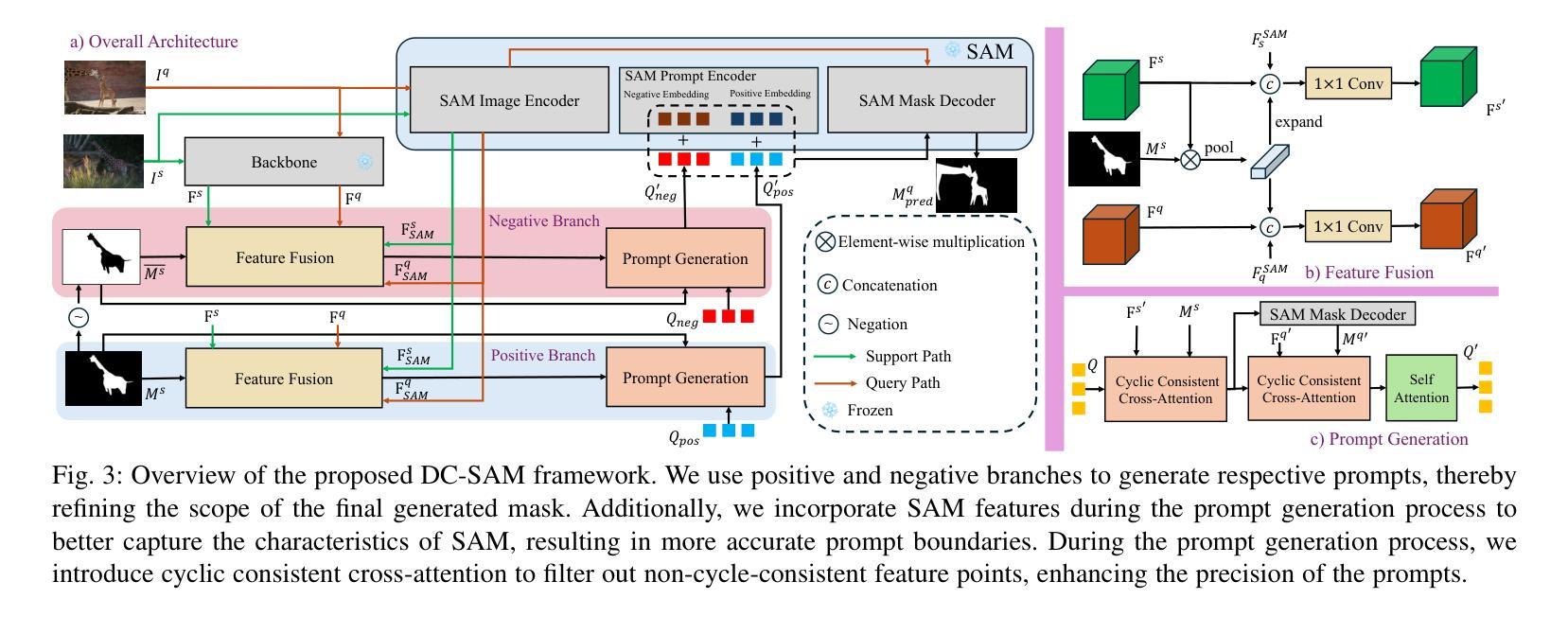
Given a single labeled example, in-context segmentation aims to segment corresponding objects. This setting, known as one-shot segmentation in few-shot learning, explores the segmentation model’s generalization ability and has been applied to various vision tasks, including scene understanding and image/video editing. While recent Segment Anything Models have achieved state-of-the-art results in interactive segmentation, these approaches are not directly applicable to in-context segmentation. In this work, we propose the Dual Consistency SAM (DC-SAM) method based on prompt-tuning to adapt SAM and SAM2 for in-context segmentation of both images and videos. Our key insights are to enhance the features of the SAM’s prompt encoder in segmentation by providing high-quality visual prompts. When generating a mask prior, we fuse the SAM features to better align the prompt encoder. Then, we design a cycle-consistent cross-attention on fused features and initial visual prompts. Next, a dual-branch design is provided by using the discriminative positive and negative prompts in the prompt encoder. Furthermore, we design a simple mask-tube training strategy to adopt our proposed dual consistency method into the mask tube. Although the proposed DC-SAM is primarily designed for images, it can be seamlessly extended to the video domain with the support of SAM2. Given the absence of in-context segmentation in the video domain, we manually curate and construct the first benchmark from existing video segmentation datasets, named In-Context Video Object Segmentation (IC-VOS), to better assess the in-context capability of the model. Extensive experiments demonstrate that our method achieves 55.5 (+1.4) mIoU on COCO-20i, 73.0 (+1.1) mIoU on PASCAL-5i, and a J&F score of 71.52 on the proposed IC-VOS benchmark. Our source code and benchmark are available at https://github.com/zaplm/DC-SAM.
给定一个带标签的样本,上下文分割旨在分割对应的对象。这种设置被称为小样本学习中的单例分割,旨在探索分割模型的泛化能力,并已应用于各种视觉任务,包括场景理解和图像/视频编辑。虽然最近的Segment Anything Models在交互式分割方面取得了最新的结果,但这些方法并不能直接应用于上下文分割。在这项工作中,我们提出了基于提示调整的Dual Consistency SAM(DC-SAM)方法,以适应图像和视频的上下文分割的SAM和SAM2。我们的关键见解是通过提供高质量视觉提示来增强SAM提示编码器在分割中的特征。在生成掩膜先验时,我们融合了SAM特征以更好地对齐提示编码器。然后,我们在融合的特征和初始视觉提示上设计了一个循环一致的交叉注意力机制。接下来,通过使用提示编码器中的判别性正向和负向提示来实现双分支设计。此外,我们设计了一个简单的掩膜管训练策略,将所提出的双重一致性方法纳入掩膜管中。虽然提出的DC-SAM主要是为图像设计的,但它可以无缝扩展到视频领域并得到SAM2的支持。由于在视频领域缺乏上下文分割的研究,我们从现有的视频分割数据集中手动整理和构建了第一个基准测试集,名为In-Context Video Object Segmentation(IC-VOS),以更好地评估模型的上下文能力。大量实验表明,我们的方法在COCO-20i上实现了55.5(+1.4)的mIoU,在PASCAL-5i上实现了73.0(+1.1)的mIoU,在提出的IC-VOS基准测试集上达到了71.52的J&F得分。我们的源代码和基准测试集可在https://github.com/zaplm/DC-SAM上找到。
论文及项目相关链接
PDF V1 has been withdrawn due to a template issue, because of the arXiv policy, we can’t delete it. Please refer to the newest version v2
Summary
本文介绍了针对单一标注样本进行上下文分割的目标。在少样本学习中的一次分割设置中,探索了分割模型的泛化能力,并应用于场景理解、图像/视频编辑等视觉任务。针对现有的分割模型不适用于上下文分割的问题,提出了基于提示调整的Dual Consistency SAM(DC-SAM)方法,用于图像和视频的上下文分割。通过增强SAM的提示编码器特征、融合SAM特征以生成遮罩先验、设计循环一致的跨注意力机制、采用双分支设计以及使用简单的mask-tube训练策略,实现了模型的有效性和性能提升。此外,为评估模型在视频领域的上下文能力,建立了首个视频分割数据集IC-VOS。实验表明,DC-SAM方法在COCO-20i、PASCAL-5i和IC-VOS基准测试中表现优秀。源码和基准测试在指定网站开放。
Key Takeaways
- 一次分割设置旨在通过单一标注样本实现对应对象的上下文分割,体现分割模型的泛化能力。
- 当前工作的重点是通过增强SAM的提示编码器特征来实现适应上下文分割的目标。
- 通过融合SAM特征生成遮罩先验,并设计循环一致的跨注意力机制以提升模型性能。
- 双分支设计使用鉴别性正负面提示增强模型效果。
- 采用mask-tube训练策略以适应视频领域的上下文分割挑战。
- 为评估模型在视频领域的上下文能力,建立了首个视频分割数据集IC-VOS。
点此查看论文截图


MMCLIP: Cross-modal Attention Masked Modelling for Medical Language-Image Pre-Training
Authors:Biao Wu, Yutong Xie, Zeyu Zhang, Minh Hieu Phan, Qi Chen, Ling Chen, Qi Wu
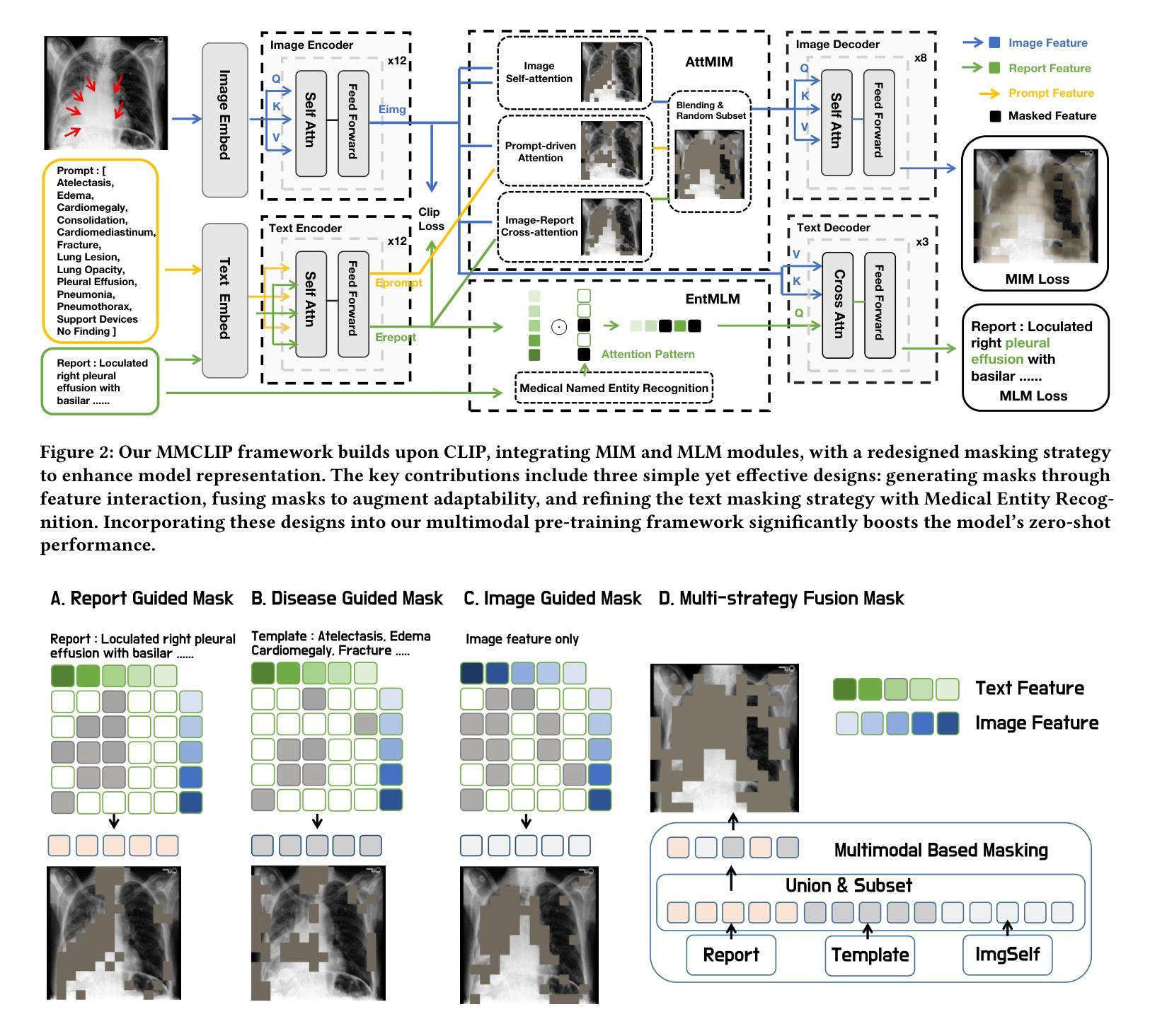
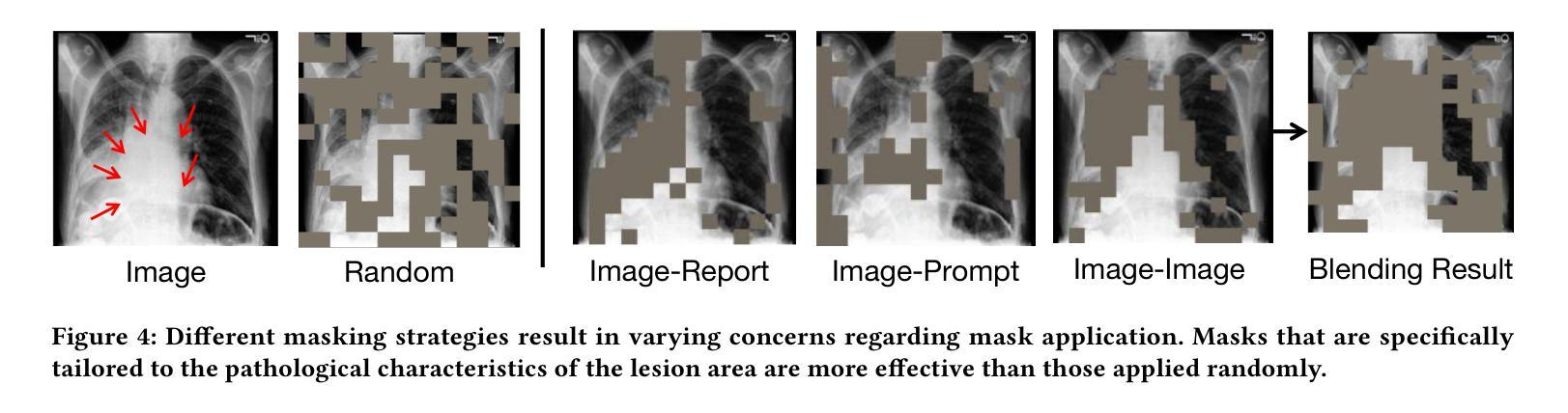
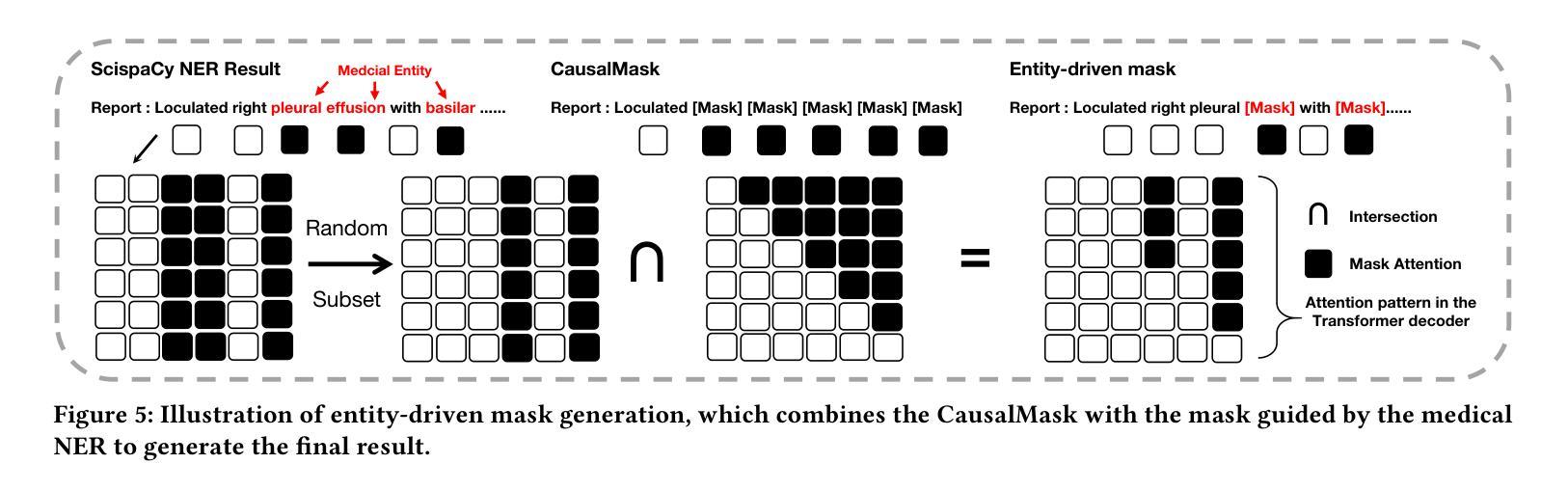
Vision-and-language pretraining (VLP) in the medical field utilizes contrastive learning on image-text pairs to achieve effective transfer across tasks. Yet, current VLP approaches with the masked modeling strategy face two challenges when applied to the medical domain. First, current models struggle to accurately reconstruct key pathological features due to the scarcity of medical data. Second, most methods only adopt either paired image-text or image-only data, failing to exploit the combination of both paired and unpaired data. To this end, this paper proposes the MMCLIP (Masked Medical Contrastive Language-Image Pre-Training) framework to enhance pathological learning and feature learning via unpaired data. First, we introduce the attention-masked image modeling (AttMIM) and entity-driven masked language modeling module (EntMLM), which learns to reconstruct pathological visual and textual tokens via multi-modal feature interaction, thus improving medical-enhanced features. The AttMIM module masks a portion of the image features that are highly responsive to textual features. This allows MMCLIP to improve the reconstruction of highly similar image data in medicine efficiency. Second, our MMCLIP capitalizes unpaired data to enhance multimodal learning by introducing disease-kind prompts. The experimental results show that MMCLIP achieves SOTA for zero-shot and fine-tuning classification performance on five datasets. Our code will be available at https://github.com/AIGeeksGroup/MMCLIP.
在医疗领域的视觉与语言预训练(VLP)通过图像文本对上的对比学习,实现了跨任务的有效迁移。然而,当前采用掩盖建模策略的VLP方法在应用医疗领域时面临两大挑战。首先,由于医疗数据的稀缺,当前模型在重构关键病理特征时遇到困难。其次,大多数方法仅采用配对图像文本或仅图像数据,未能充分利用配对和未配对数据的组合。针对这些问题,本文提出了MMCLIP(Masked Medical Contrastive Language-Image Pre-Training)框架,通过未配对数据增强病理学习和特征学习。首先,我们引入了注意力掩盖图像建模(AttMIM)和实体驱动掩盖语言建模模块(EntMLM),通过多模态特征交互学习重建病理视觉和文本标记,从而改进医疗增强特征。AttMIM模块会掩盖那些对文本特征反应强烈的图像特征的一部分。这允许MMCLIP提高医学中高度相似图像数据的重建效率。其次,我们的MMCLIP利用未配对数据,通过引入疾病提示来增强多模态学习。实验结果表明,MMCLIP在五个数据集上实现了零样本和微调分类性能的最新水平。我们的代码将在https://github.com/AIGeeksGroup/MMCLIP上提供。
论文及项目相关链接
Summary
医疗领域的视觉与语言预训练(VLP)采用图像文本对比学习实现跨任务的有效迁移。然而,当前采用掩模建模策略的VLP方法在应用时面临两大挑战:一是模型难以准确重构关键病理特征,二是医疗数据稀缺。此外,大多数方法仅采用配对图像文本或仅采用图像数据,未能充分利用配对和非配对数据的组合。针对这些问题,本文提出了MMCLIP框架,通过非配对数据强化病理学习和特征学习。首先引入注意力掩模图像建模和实体驱动的语言建模模块,通过多模态特征交互学习重建病理视觉和文本标记,提升医学特征。其次,MMCLIP利用非配对数据增强多模态学习,通过引入疾病提示来改善模型表现。实验结果表明,MMCLIP在五个数据集上实现了零样本和微调分类性能的最新水平。
Key Takeaways
- 医疗领域的视觉与语言预训练(VLP)使用对比学习处理图像文本对以完成任务迁移。
- 当前VLP方法在应用时面临准确重构病理特征与医疗数据稀缺的挑战。
- MMCLIP框架通过非配对数据强化病理学习和特征学习,引入注意力掩模图像建模和实体驱动的语言建模模块。
- MMCLIP利用非配对数据增强多模态学习,引入疾病提示改善模型表现。
- MMCLIP在五个数据集上实现了零样本和微调分类性能的最新水平。
点此查看论文截图