⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-20 更新
Lightning IR: Straightforward Fine-tuning and Inference of Transformer-based Language Models for Information Retrieval
Authors:Ferdinand Schlatt, Maik Fröbe, Matthias Hagen
A wide range of transformer-based language models have been proposed for information retrieval tasks. However, including transformer-based models in retrieval pipelines is often complex and requires substantial engineering effort. In this paper, we introduce Lightning IR, an easy-to-use PyTorch Lightning-based framework for applying transformer-based language models in retrieval scenarios. Lightning IR provides a modular and extensible architecture that supports all stages of a retrieval pipeline: from fine-tuning and indexing to searching and re-ranking. Designed to be scalable and reproducible, Lightning IR is available as open-source: https://github.com/webis-de/lightning-ir.
针对信息检索任务,已经提出了多种基于转换器的语言模型。然而,在检索管道中包含基于转换器的模型通常很复杂,需要大量的工程努力。在本文中,我们介绍了Lightning IR,这是一个易于使用的基于PyTorch Lightning的框架,可用于在检索场景中应用基于转换器的语言模型。Lightning IR提供了一个模块化且可扩展的架构,支持检索管道的所有阶段:从微调、索引到搜索和重新排名。设计可伸缩且可重复,Lightning IR作为开源可用:https://github.com/webis-de/lightning-ir。
论文及项目相关链接
PDF Accepted as a demo at WSDM’25
Summary:介绍了Lightning IR,一个基于PyTorch Lightning的易用框架,用于在检索场景中应用基于转换器的语言模型。该框架提供了一种模块化且可扩展的架构,支持检索管道的所有阶段:从微调、索引到搜索和重新排名。Lightning IR旨在实现可扩展性和可重复性,可作为开源获得。
Key Takeaways:
- 该论文提出了Lightning IR框架,旨在简化在检索任务中应用基于转换器的语言模型的复杂性。
- Lightning IR是基于PyTorch Lightning构建的,易于使用。
- 该框架支持检索管道的所有阶段,包括微调、索引、搜索和重新排名。
- Lightning IR具有模块化和可扩展性,能够适应不同的需求。
- 该框架旨在实现可扩展性和可重复性,有助于提高研究效率和成果质量。
- Lightning IR作为开源框架,可方便研究人员和其他开发者使用和改进。
点此查看论文截图



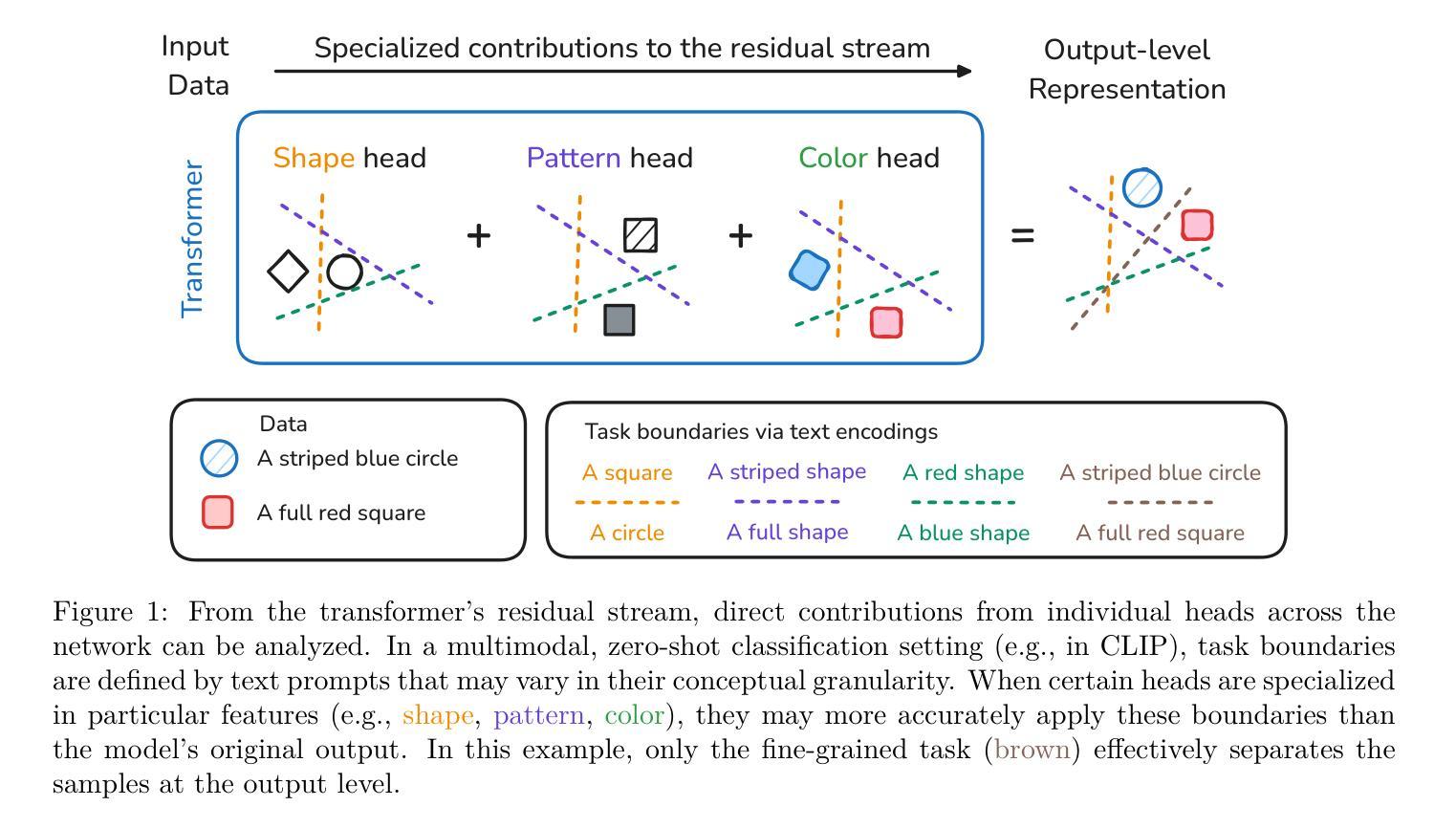
ResiDual Transformer Alignment with Spectral Decomposition
Authors:Lorenzo Basile, Valentino Maiorca, Luca Bortolussi, Emanuele Rodolà, Francesco Locatello
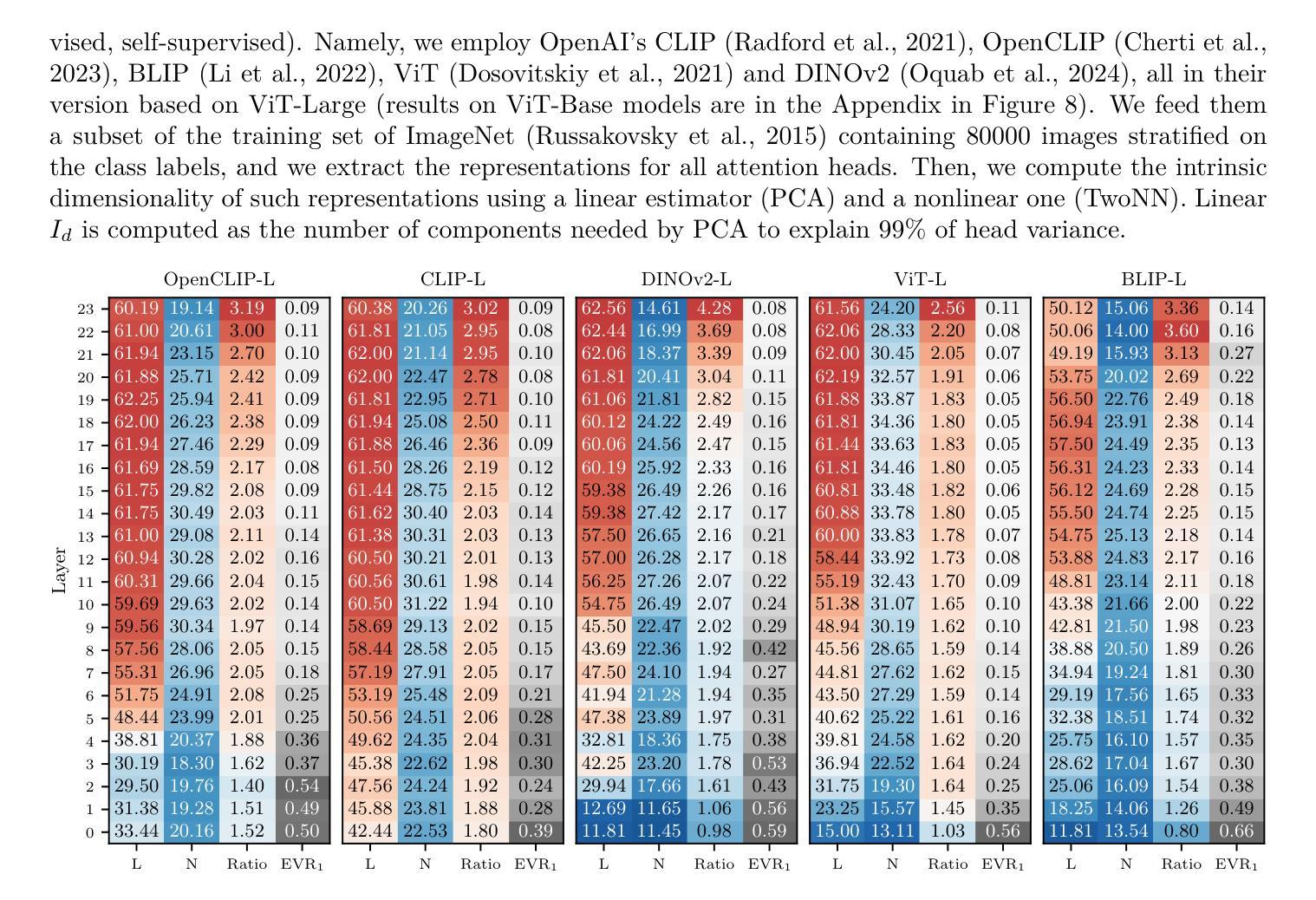
When examined through the lens of their residual streams, a puzzling property emerges in transformer networks: residual contributions (e.g., attention heads) sometimes specialize in specific tasks or input attributes. In this paper, we analyze this phenomenon in vision transformers, focusing on the spectral geometry of residuals, and explore its implications for modality alignment in vision-language models. First, we link it to the intrinsically low-dimensional structure of visual head representations, zooming into their principal components and showing that they encode specialized roles across a wide variety of input data distributions. Then, we analyze the effect of head specialization in multimodal models, focusing on how improved alignment between text and specialized heads impacts zero-shot classification performance. This specialization-performance link consistently holds across diverse pre-training data, network sizes, and objectives, demonstrating a powerful new mechanism for boosting zero-shot classification through targeted alignment. Ultimately, we translate these insights into actionable terms by introducing ResiDual, a technique for spectral alignment of the residual stream. Much like panning for gold, it lets the noise from irrelevant unit principal components (i.e., attributes) wash away to amplify task-relevant ones. Remarkably, this dual perspective on modality alignment yields fine-tuning level performance on different data distributions while modelling an extremely interpretable and parameter-efficient transformation, as we extensively show on 70 pre-trained network-dataset combinations (7 models, 10 datasets).
当从剩余流的角度审视变压器网络时,会出现一个令人困惑的特性:剩余贡献(例如,注意力头)有时会专门用于特定任务或输入属性。在本文中,我们分析了视觉变压器中的这种现象,重点关注剩余的谱几何,并探索了其对视觉语言模型中模态对齐的影响。首先,我们将其与视觉头表示的固有低维结构联系起来,深入探究其主要成分,并表明它们在各种输入数据分布中编码了专业角色。接着,我们分析了头专业化在多模态模型中的影响,重点关注文本和专业化头之间改进的对齐对零样本分类性能的影响。这种专业化和性能之间的联系在各种预训练数据、网络规模和目标中始终存在,证明了一种通过有针对性的对齐来提高零样本分类性能的有力新机制。最终,我们将这些见解转化为可行的术语,并引入了ResiDual技术,这是一种用于剩余流的谱对齐技术。就像淘金一样,它可以让无关紧要的单元主成分(即属性)的噪声消失,以放大与任务相关的成分。令人惊奇的是,这种对模态对齐的双重视角在不同数据分布上达到了微调级别的性能,同时建立了一个极其可解释和参数高效的转换模型,我们在70个预训练网络数据集组合(7个模型,10个数据集)上进行了广泛展示。
论文及项目相关链接
PDF Published in Transactions on Machine Learning Research (TMLR)
Summary:本文研究了通过残差流视角分析transformer网络中的谜题属性,发现残差贡献(如注意力头)有时会在特定任务或输入属性上专业化。文章重点关注视觉transformer的谱几何残差,并探讨了其在视觉语言模型的模态对齐中的影响。研究发现视觉头表示的固有低维结构编码了专业化的角色,并且头专业化在跨模态模型中提高了文本与专业化头部之间的对齐效果,进而提高零样本分类性能。研究还发现头专业化在跨不同预训练数据、网络规模和目标时,专业化与性能的关联始终存在。最终,文章将这些见解转化为实际应用,推出ResiDual技术,用于残差流的谱对齐。这一技术极大地提高了任务相关单位的振幅,同时在不同的数据分布上达到了微调级别的性能,展示出极为可解释和参数高效的转换。
Key Takeaways:
- 残差贡献在transformer网络中有时会在特定任务或输入属性上专业化。
- 视觉头表示的固有低维结构编码了专业化的角色。
- 头专业化能提高跨模态模型中文本与专业化头部之间的对齐效果。
- 专业化与性能的关联在跨不同的预训练数据、网络规模和目标时始终存在。
- 推出ResiDual技术,用于残差流的谱对齐,提高了任务相关单位的振幅。
- ResiDual技术在不同的数据分布上达到了微调级别的性能。
点此查看论文截图

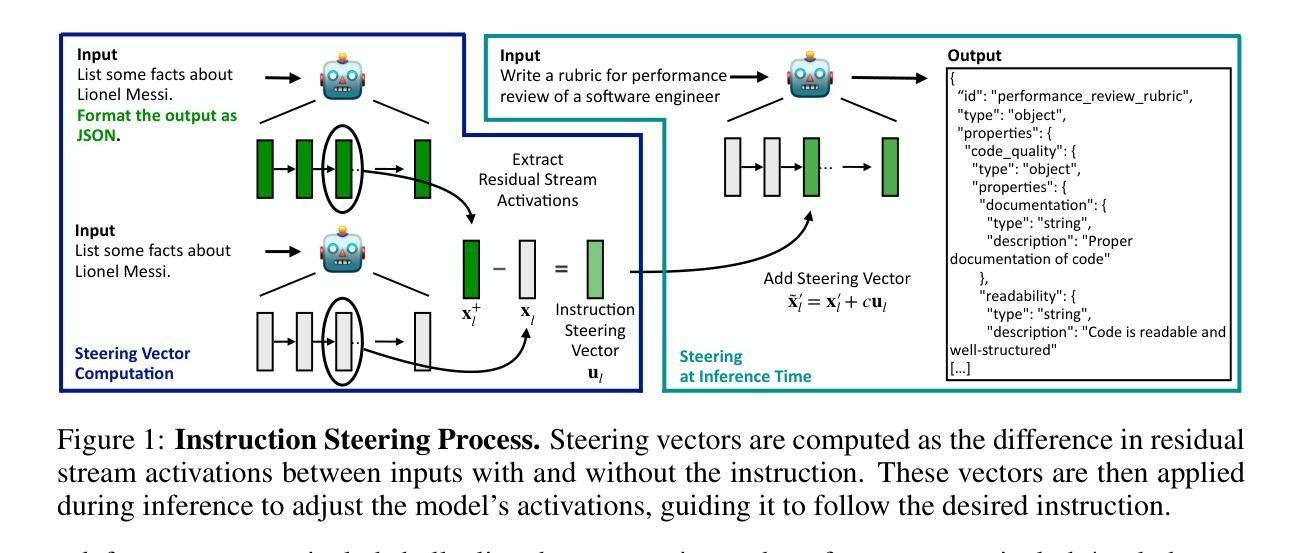
Improving Instruction-Following in Language Models through Activation Steering
Authors:Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, Besmira Nushi
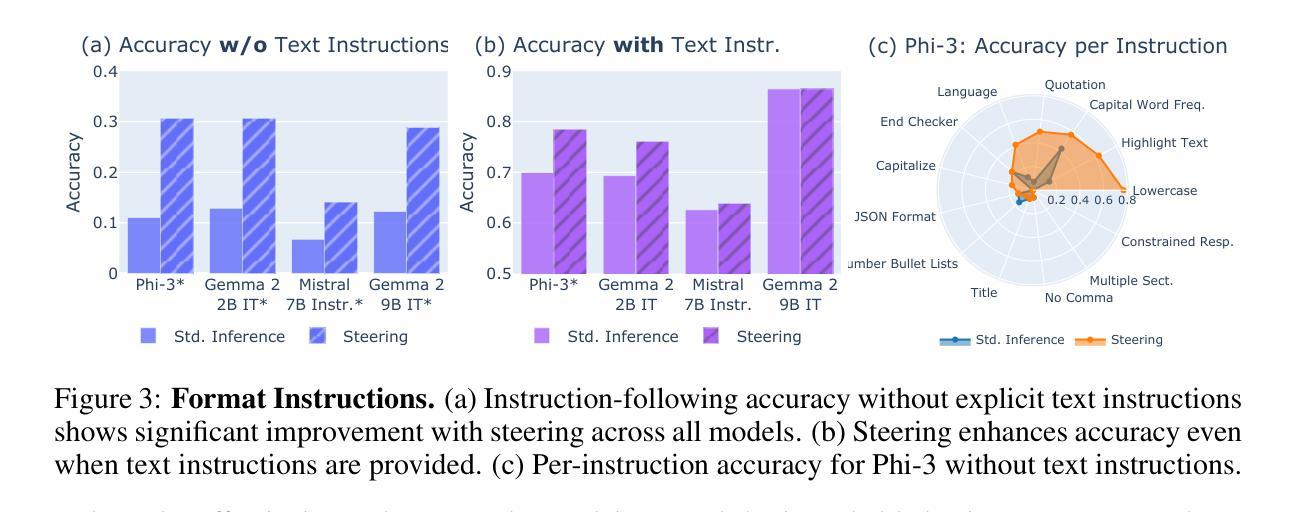
The ability to follow instructions is crucial for numerous real-world applications of language models. In pursuit of deeper insights and more powerful capabilities, we derive instruction-specific vector representations from language models and use them to steer models accordingly. These vectors are computed as the difference in activations between inputs with and without instructions, enabling a modular approach to activation steering. We demonstrate how this method can enhance model adherence to constraints such as output format, length, and word inclusion, providing inference-time control over instruction following. Our experiments across four models demonstrate how we can use the activation vectors to guide models to follow constraints even without explicit instructions and to enhance performance when instructions are present. Additionally, we explore the compositionality of activation steering, successfully applying multiple instructions simultaneously. Finally, we demonstrate that steering vectors computed on instruction-tuned models can transfer to improve base models. Our findings demonstrate that activation steering offers a practical and scalable approach for fine-grained control in language generation. Our code and data are available at https://github.com/microsoft/llm-steer-instruct.
从语言模型在现实世界中的众多应用来看,遵循指令的能力至关重要。为了获得更深入的理解和更强大的能力,我们从语言模型中导出与指令相关的向量表示,并据此引导模型。这些向量是通过计算带指令与不带指令的输入之间的激活差异来得到的,这使得激活引导可以采用模块化方法。我们展示了这种方法如何增强模型对输出格式、长度和词汇包含等约束的遵循能力,为指令遵循提供推理时的控制。我们在四个模型上的实验展示了如何使用激活向量来指导模型遵循约束,即使在没有任何明确指令的情况下也能提高性能,并在有指令时增强表现。此外,我们还探索了激活引导的组成性,能够同时应用多个指令。最后,我们证明了在指令调整模型上计算的转向向量可以转移到基础模型中以进行改进。我们的研究结果表明,激活引导为语言生成中的精细粒度控制提供了一种实用且可扩展的方法。我们的代码和数据在https://github.com/microsoft/llm-steer-instruct。
论文及项目相关链接
PDF ICLR 2025
Summary
语言模型的指令遵循能力在现实应用中的重要性日益凸显。研究团队从语言模型中推导出指令特定的向量表示,用于引导模型遵循指令。这些向量通过计算带有和不带指令的输入激活差异得到,为激活引导提供了模块化方法。研究展示了该方法如何提升模型对输出格式、长度和词汇约束的遵循能力,实现推理时的指令遵循控制。实验表明,激活向量可用于引导模型遵循约束,甚至在无明确指令的情况下提升性能。此外,研究还探索了激活引导的组合性,成功同时应用多个指令。最终,研究证明在指令调整模型上计算的引导向量可转移至基础模型以提升性能。研究结果表明,激活引导为一种实用且可伸缩的方法,可实现语言生成中的精细控制。
Key Takeaways
- 语言模型的指令遵循能力对于其现实应用非常重要。
- 通过推导指令特定的向量表示,可以引导语言模型遵循指令。
- 激活向量是通过计算带有和不带指令的输入激活差异得到的。
- 该方法可以提高模型对输出格式、长度和词汇约束的遵循能力。
- 激活向量可用于在无明确指令的情况下引导模型遵循约束,提升性能。
- 研究展示了激活引导的组合性,可以同时应用多个指令。
点此查看论文截图



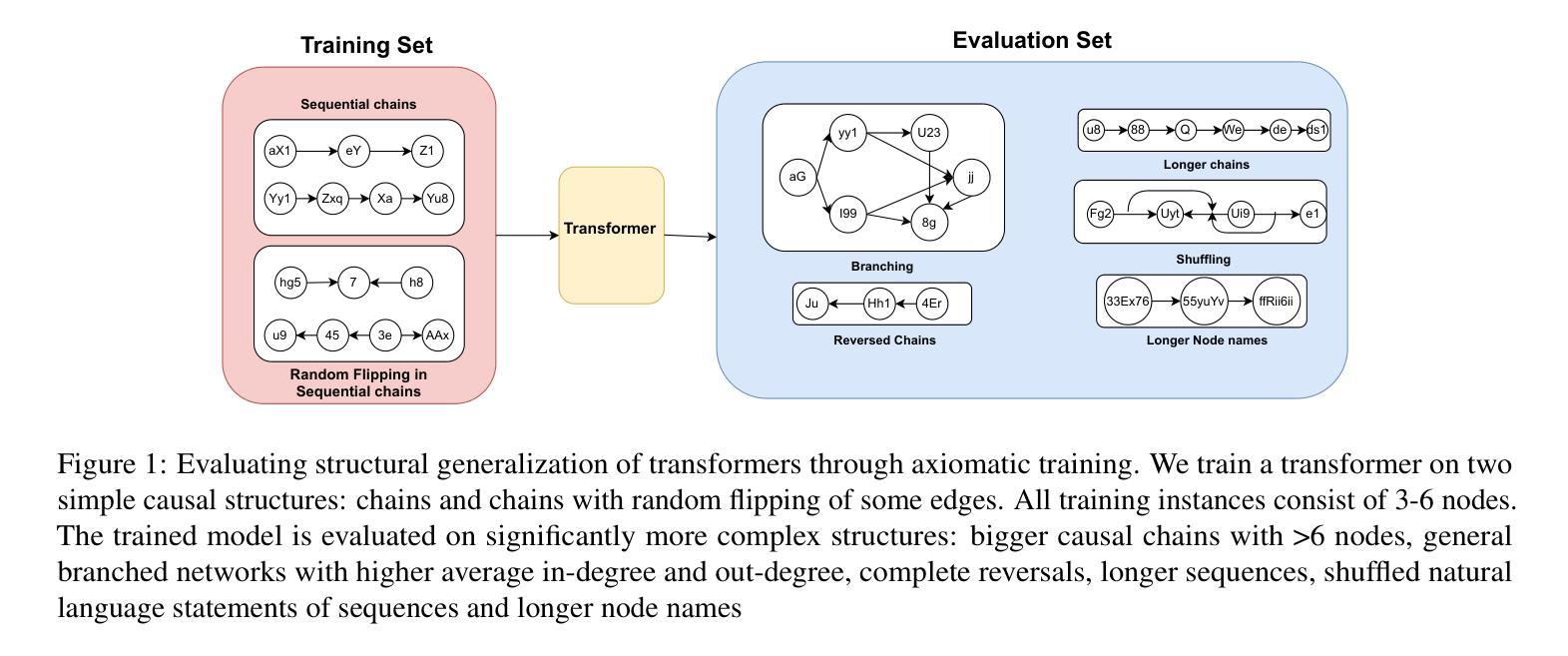
Teaching Transformers Causal Reasoning through Axiomatic Training
Authors:Aniket Vashishtha, Abhinav Kumar, Atharva Pandey, Abbavaram Gowtham Reddy, Kabir Ahuja, Vineeth N Balasubramanian, Amit Sharma
For text-based AI systems to interact in the real world, causal reasoning is an essential skill. Since active interventions are costly, we study to what extent a system can learn causal reasoning from symbolic demonstrations of causal axioms. Specifically, we present an axiomatic training method where the system learns from multiple demonstrations of a causal axiom (or rule), rather than incorporating the axiom as an inductive bias or inferring it from data values. A key question is whether the system would learn to generalize from the axiom demonstrations to more complex scenarios. Our results, based on applying axiomatic training to learn the transitivity axiom and d-separation rule, indicate that such generalization is possible. To avoid data contamination issues, we start with a 67 million parameter transformer model and train it from scratch. On both tasks, we find that a model trained on linear causal chains (along with some noisy variations) can generalize well to complex graphs, including longer causal chains, causal chains with reversed order, and graphs with branching.To handle diverse text inputs, the same method is extended to finetune language models. Finetuning Llama-3.1 8B model on our axiomatic data leads to significant gains on causal benchmarks such as Corr2Cause and CLEAR, in some cases providing state-of-the-art performance surpassing GPT-4.
对于基于文本的AI系统在现实世界中的交互来说,因果推理是一项基本技巧。由于主动干预成本高昂,我们研究系统能从因果公理的符号演示中学习到何种程度的因果推理。具体来说,我们提出了一种公理化训练方法,该系统从因果公理(或规则)的多个演示中学习,而不是将公理作为归纳偏见或从数据值中推断出来。一个关键的问题是,系统是否会从公理演示中学习并推广到更复杂的场景。我们的结果基于应用公理化训练来学习传递性公理和d-分离规则,表明这种推广是可能的。为了避免数据污染问题,我们从6700万个参数的变压器模型开始,并从零开始对其进行训练。在这两项任务中,我们发现训练有素的系统在面临线性因果链(以及带有噪声的一些变体)时,能够很好地适应复杂的图形结构,包括更长的因果链、逆向顺序的因果链和带有分支的图形。为了处理多样的文本输入,对语言模型进行了微调以应用相同的方法。在公理数据上微调Llama-3.1的8B模型后,在诸如Corr2Cause和CLEAR等因果基准测试中取得了显著的收益,在某些情况下超越了GPT-4的最先进表现。
论文及项目相关链接
Summary:基于符号因果公理演示的文本生成模型可以学习因果推理技能,并从简单的因果链推广到更复杂的场景。研究采用了一种公理化训练方法,并展示了这种训练对线性因果链模型的适用性。通过对大型语言模型进行微调,该方法可以显著提高因果基准测试的性能。
Key Takeaways:
- 因果推理对于文本生成的AI系统在现实世界中的交互至关重要。
- 公理化训练方法是AI系统学习因果推理的一种有效方式,通过从多个因果公理演示中学习,而不是作为归纳偏见或从数据值中推断出来。
- 系统可以从简单的因果链公理推广到更复杂的场景,如更长、顺序颠倒和分支的因果链。
- 采用这种训练方法的模型在因果基准测试中表现出显著的性能提升。
- 研究使用了包含约67百万参数的变压器模型,并从基础开始训练以避免数据污染问题。
- 对大型语言模型(如Llama-3.1 8B模型)进行微调可以进一步提高性能,在某些情况下达到或超越了GPT-4的表现。
点此查看论文截图

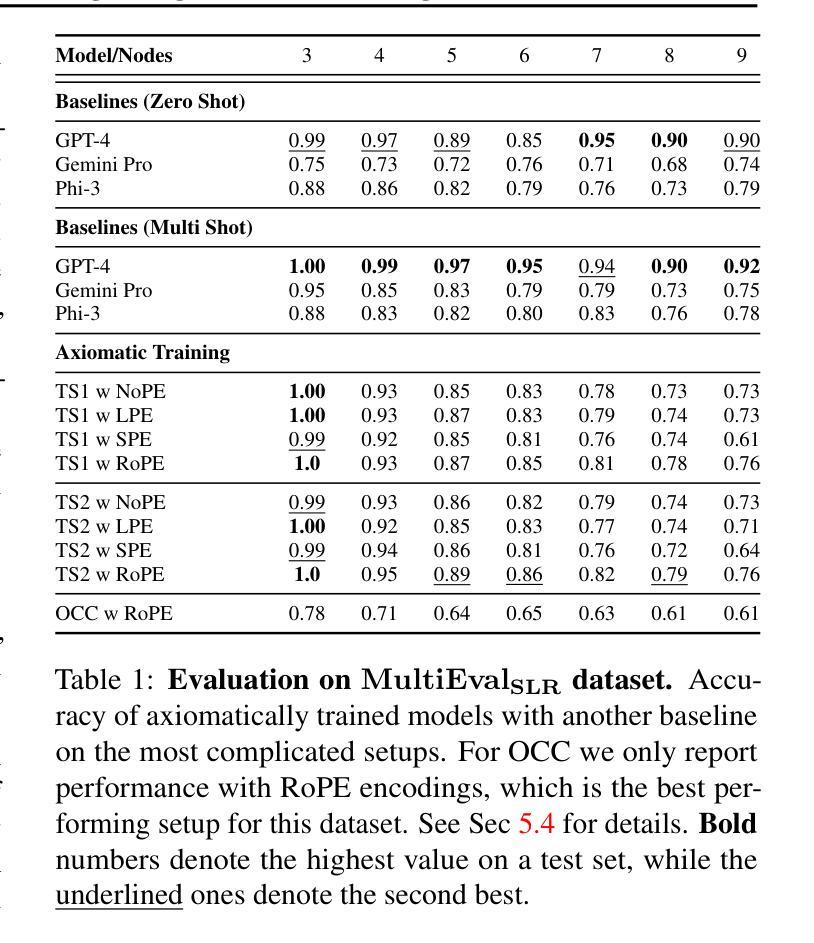
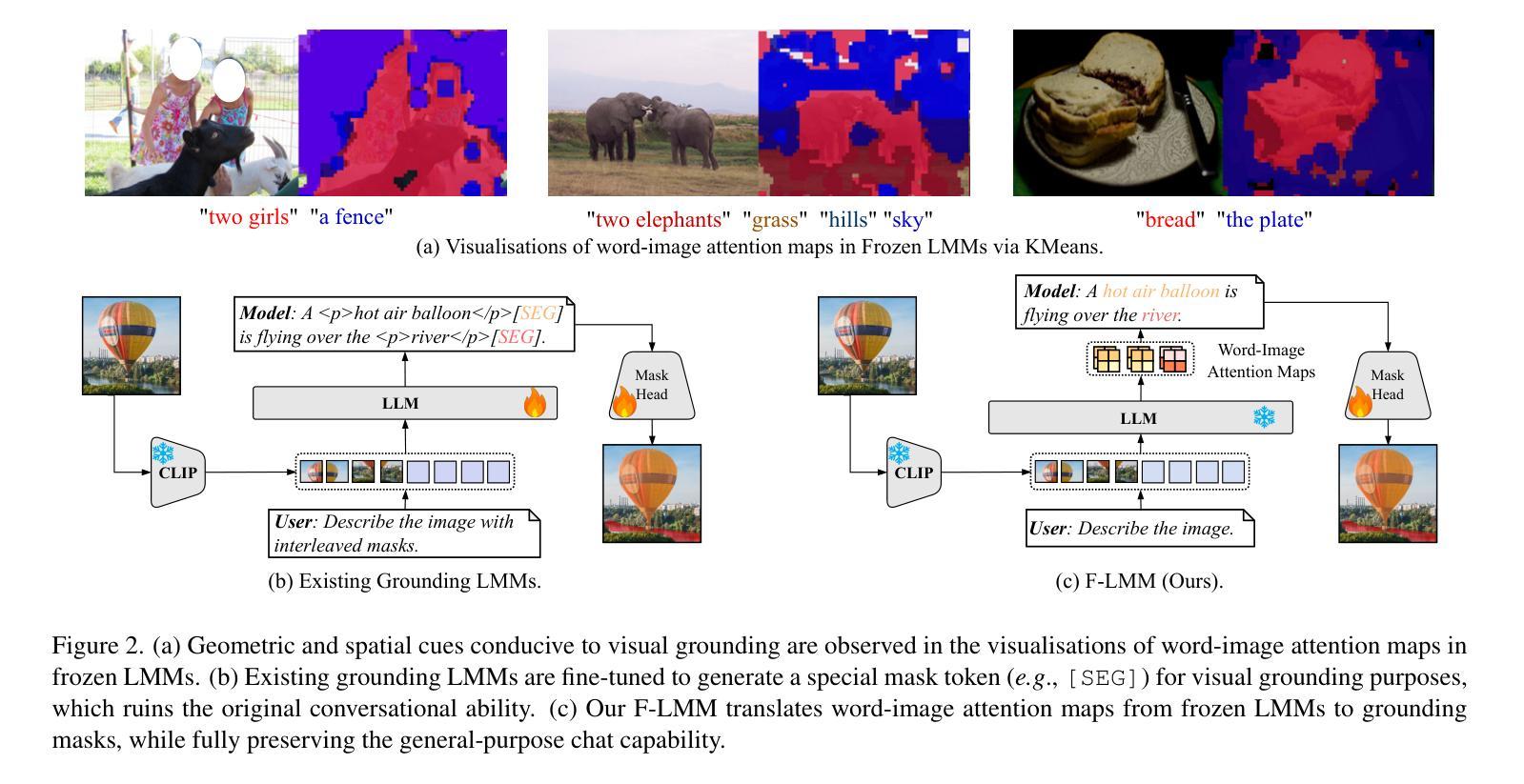
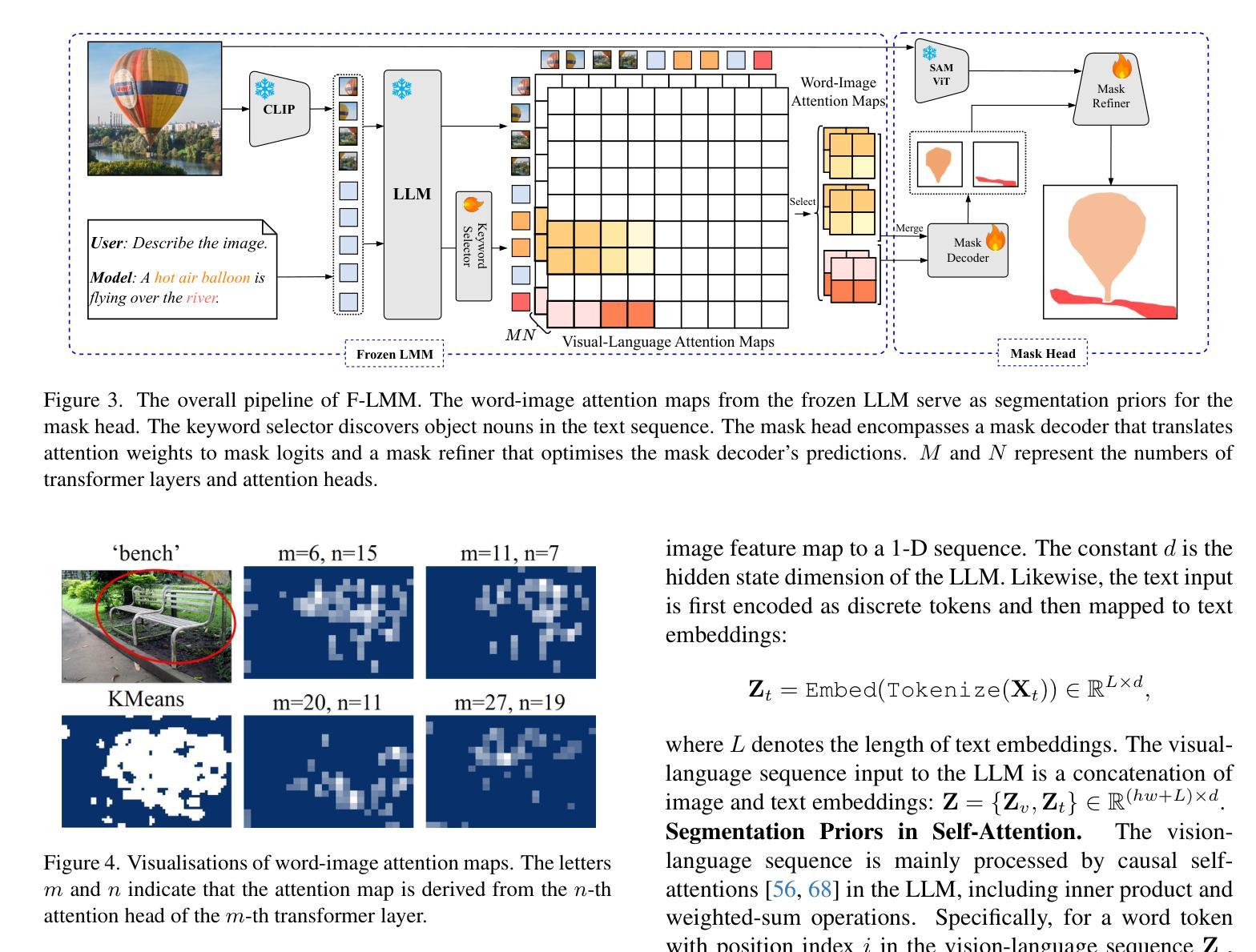
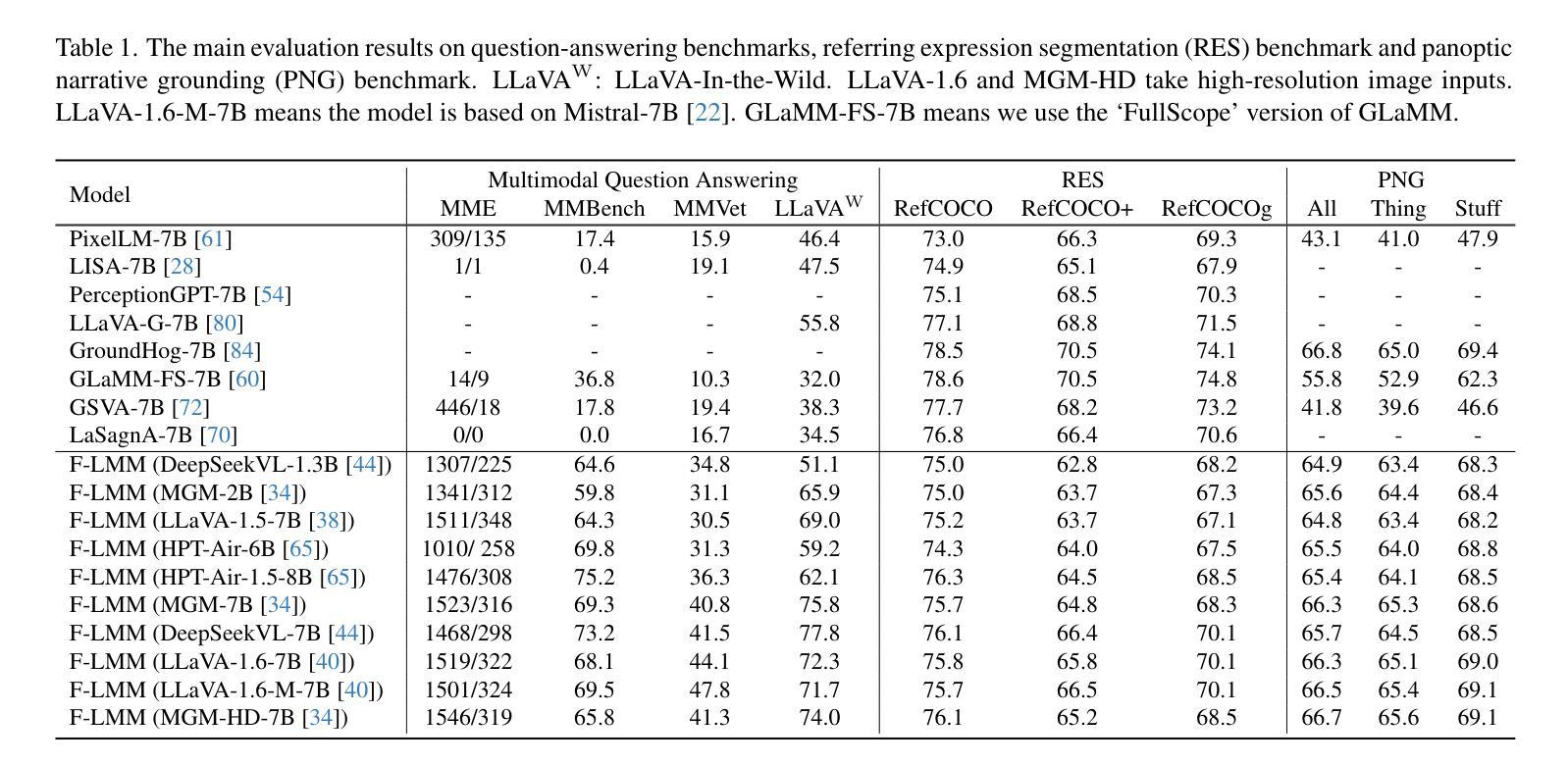
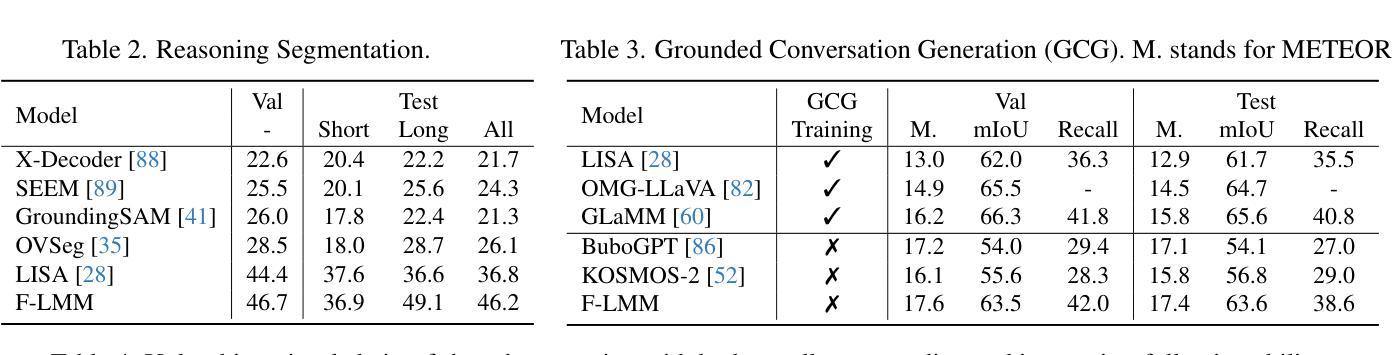
F-LMM: Grounding Frozen Large Multimodal Models
Authors:Size Wu, Sheng Jin, Wenwei Zhang, Lumin Xu, Wentao Liu, Wei Li, Chen Change Loy
Endowing Large Multimodal Models (LMMs) with visual grounding capability can significantly enhance AIs’ understanding of the visual world and their interaction with humans. However, existing methods typically fine-tune the parameters of LMMs to learn additional segmentation tokens and overfit grounding and segmentation datasets. Such a design would inevitably cause a catastrophic diminution in the indispensable conversational capability of general AI assistants. In this paper, we comprehensively evaluate state-of-the-art grounding LMMs across a suite of multimodal question-answering benchmarks, observing drastic performance drops that indicate vanishing general knowledge comprehension and weakened instruction following ability. To address this issue, we present F-LMM – grounding frozen off-the-shelf LMMs in human-AI conversations – a straightforward yet effective design based on the fact that word-pixel correspondences conducive to visual grounding inherently exist in the attention mechanism of well-trained LMMs. Using only a few trainable CNN layers, we can translate word-pixel attention weights to mask logits, which a SAM-based mask refiner can further optimise. Our F-LMM neither learns special segmentation tokens nor utilises high-quality grounded instruction-tuning data, but achieves competitive performance on referring expression segmentation and panoptic narrative grounding benchmarks while completely preserving LMMs’ original conversational ability. Additionally, with instruction-following ability preserved and grounding ability obtained, F-LMM can be directly applied to complex tasks like reasoning segmentation, grounded conversation generation and visual chain-of-thought reasoning. Our code can be found at https://github.com/wusize/F-LMM.
赋予大型多模态模型(LMMs)视觉接地能力可以显著增强AI对视觉世界的理解以及与人类的交互能力。然而,现有方法通常通过对LMM的参数进行微调来学习额外的分割令牌,并过度适应接地和分割数据集。这种设计不可避免地会导致通用AI助理必不可少的管理能力发生灾难性降低。在本文中,我们全面评估了最先进的地基LMM在一系列多模态问答基准测试上的表现,观察到性能急剧下降,表明一般知识理解消失,以及指令执行能力减弱。为了解决这个问题,我们提出了F-LMM——在人机对话中冻结现成的LMM进行接地,这是一个简单而有效的设计,基于这样一个事实:在训练良好的LMM的注意力机制中,有利于视觉接地的单词像素对应关系是固有的。通过使用只有少数可训练的CNN层,我们可以将单词像素注意力权重转换为掩码对数概率,SAM基掩码精炼器可以进一步优化它。我们的F-LMM既不需要学习特殊的分割令牌,也不需要利用高质量的地基指令调整数据,就能在指代表达式分割和全景叙事接地基准测试上取得有竞争力的表现,同时完全保留LMMs原有的对话能力。此外,在保留指令执行能力并获得接地能力的情况下,F-LMM可以直接应用于推理分割、基于接地的对话生成和视觉思维链推理等复杂任务。我们的代码可以在https://github.com/wusize/F-LMM找到。
论文及项目相关链接
PDF Project Page: https://github.com/wusize/F-LMM
Summary
本文探讨了大型多模态模型(LMMs)的视觉接地能力对增强AI对视觉世界的理解与人类交互的重要性。然而,现有方法通常通过微调LMM参数来学习额外的分割令牌,并过度拟合接地和分割数据集,这会损害AI助手不可或缺的对一般知识的理解和指令执行能力。为解决这一问题,本文评估了最先进的多模态问题回答基准测试中的接地LMM性能,并观察到性能急剧下降。为此,提出了一种基于现有预训练LMM的视觉接地方法——F-LMM。通过利用LMM内部的注意力机制,在保留原有对话能力的基础上,实现词像素对应关系可视化接地。F-LMM无需学习特殊分割令牌,也不依赖高质量接地指令微调数据,但仍能在指代表达式分割和全视叙事接地基准测试中实现具有竞争力的性能。此外,凭借其保留的指令执行能力和视觉接地能力,F-LMM可直接应用于复杂任务如推理分割、基于视觉的对话生成和视觉链推理等。更多详细信息请参见相关网站:网址链接。
Key Takeaways
- LMMs的视觉接地能力对增强AI与人类的交互至关重要。
- 现有方法微调LMM参数以学习额外的分割令牌并过度拟合数据,导致一般知识理解和指令执行能力下降。
- 通过评估多种多模态问题回答基准测试,发现现有方法的性能急剧下降。
- 提出了一种基于预训练LMM的视觉接地方法——F-LMM。
- F-LMM利用注意力机制实现词像素对应关系可视化接地,无需学习特殊分割令牌。
- F-LMM在不损害原有对话能力的情况下,实现了良好的分割和接地性能。
点此查看论文截图


Towards Translating Real-World Code with LLMs: A Study of Translating to Rust
Authors:Hasan Ferit Eniser, Hanliang Zhang, Cristina David, Meng Wang, Maria Christakis, Brandon Paulsen, Joey Dodds, Daniel Kroening
Large language models (LLMs) show promise in code translation - the task of translating code written in one programming language to another language - due to their ability to write code in most programming languages. However, LLM’s effectiveness on translating real-world code remains largely unstudied. In this work, we perform the first substantial study on LLM-based translation to Rust by assessing the ability of five state-of-the-art LLMs, GPT4, Claude 3, Claude 2.1, Gemini Pro, and Mixtral. We conduct our study on code extracted from real-world open source projects. To enable our study, we develop FLOURINE, an end-to-end code translation tool that uses differential fuzzing to check if a Rust translation is I/O equivalent to the original source program, eliminating the need for pre-existing test cases. As part of our investigation, we assess both the LLM’s ability to produce an initially successful translation, as well as their capacity to fix a previously generated buggy one. If the original and the translated programs are not I/O equivalent, we apply a set of automated feedback strategies, including feedback to the LLM with counterexamples. Our results show that the most successful LLM can translate 47% of our benchmarks, and also provides insights into next steps for improvements.
大型语言模型(LLM)在代码翻译任务中显示出巨大的潜力,即将一种编程语言编写的代码翻译成另一种语言的代码。这得益于它们能够使用大多数编程语言编写代码的能力。然而,LLM在现实世界的代码翻译方面的有效性在很大程度上尚未被研究。在这项工作中,我们对基于LLM的Rust翻译进行了首次实质性的研究,评估了五种最新LLM的能力,包括GPT4、Claude 3、Claude 2.1、Gemini Pro和Mixtral。我们的研究是在从现实世界中的开源项目中提取的代码上进行的。为了支持我们的研究,我们开发了FLOURINE,这是一款端到端的代码翻译工具,它使用差分模糊测试来检查Rust翻译是否与原始源程序在I/O上等效,从而不再需要预先存在的测试用例。作为调查的一部分,我们评估了LLM能够产生初步成功的翻译的能力,以及它们修复先前生成的错误翻译的能力。如果原始程序和翻译后的程序在I/O上不等效,我们会采用一系列的自动化反馈策略,包括对LLM进行反例反馈。我们的结果表明,最成功的LLM能够翻译我们基准测试的47%,并提供了关于下一步改进方向的见解。
论文及项目相关链接
PDF 12 pages, 12 figures
Summary
本文研究了基于大型语言模型(LLM)的代码翻译能力,特别是对Rust语言的翻译。研究对五款先进的LLM进行了评估,包括GPT4、Claude 3、Claude 2.1、Gemini Pro和Mixtral。研究中开发了一个名为FLOURINE的代码翻译工具,采用差分模糊测试来检查翻译结果的输入输出等效性。研究发现,最成功的LLM能够翻译47%的基准测试代码,同时也提供了改进的方向。
Key Takeaways
- 大型语言模型(LLM)在代码翻译领域具有潜力,特别是在将代码从一种编程语言翻译到另一种语言方面。
- 对五款先进的LLM在Rust翻译方面的能力进行了首次实质性研究。
- 开发了一个名为FLOURINE的代码翻译工具,采用差分模糊测试来验证翻译结果的准确性。
- LLM能够初步成功翻译的代码比例最高达到47%。
- LLM在修复先前生成的错误代码方面也有一定能力。
- 当原始程序和翻译程序在输入输出方面不等效时,采用了一系列自动化反馈策略,包括向LLM提供反例。
点此查看论文截图





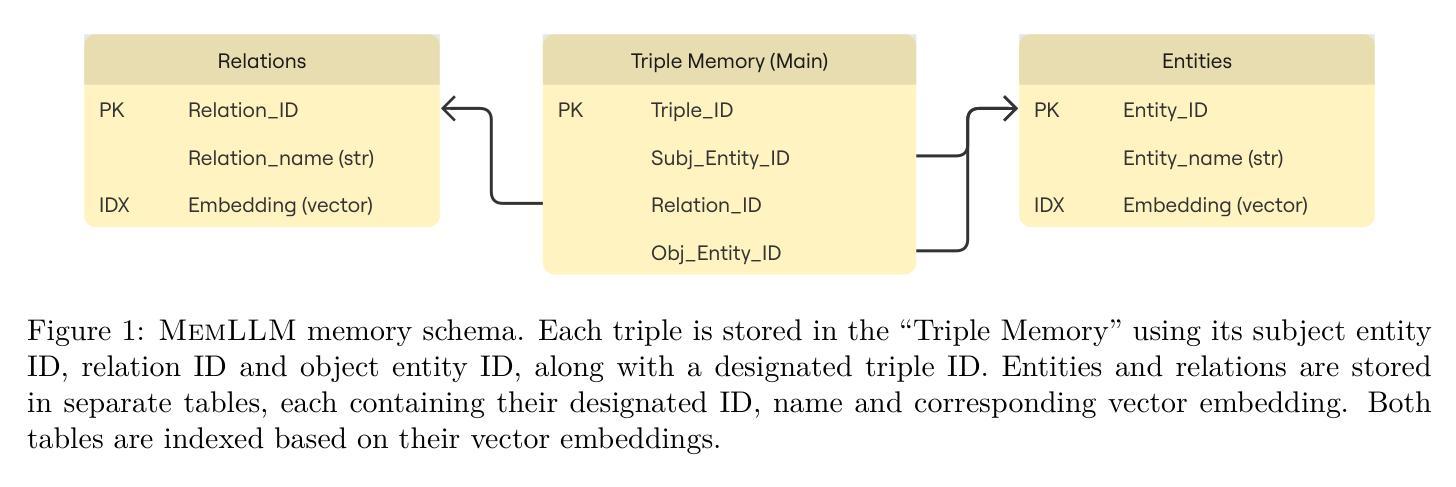
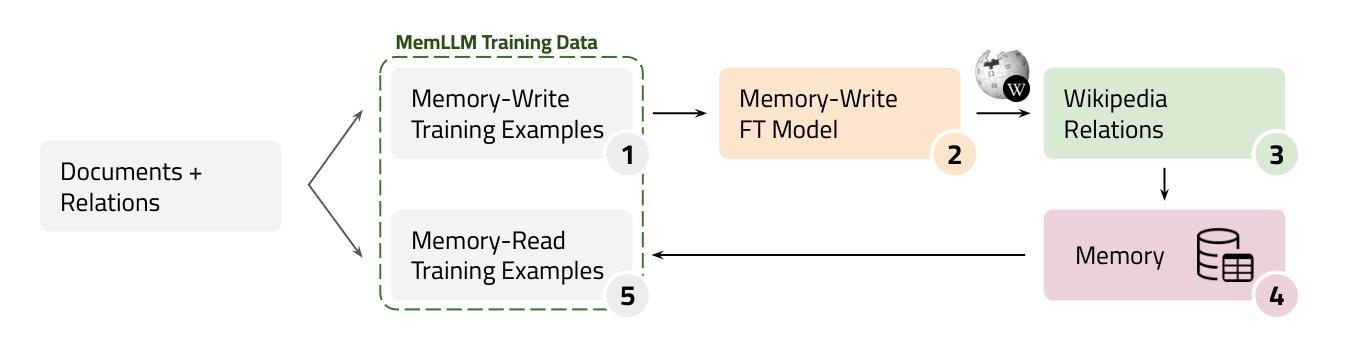
MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Authors:Ali Modarressi, Abdullatif Köksal, Ayyoob Imani, Mohsen Fayyaz, Hinrich Schütze
While current large language models (LLMs) perform well on many knowledge-related tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with memorizing rare events and with updating their memory as facts change over time. In addition, the uninterpretable nature of parametric memory makes it challenging to prevent hallucination. Model editing and augmenting LLMs with parameters specialized for memory are only partial solutions. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM’s capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM’s performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation. The project repository is publicly available at https://github.com/amodaresi/MemLLM
当前的大型语言模型(LLM)在许多与知识相关的任务上表现良好,但它们依赖于参数作为隐式存储机制,从而存在局限性。因此,它们在记忆罕见事件和随时间更新事实方面遇到困难。此外,参数记忆的不可解释性使得防止幻觉具有挑战性。通过参数对LLM进行模型编辑和扩充,专门用于记忆只是部分解决方案。在本文中,我们介绍了MemLLM,这是一种通过集成结构化和显式读写内存模块增强LLM的新型方法。MemLLM通过实现与内存的动态交互,提高LLM利用存储知识的能力,解决了上述挑战。我们的实验表明,MemLLM提高了LLM的性能和可解释性,尤其是在一般语言建模和知识密集型任务中。我们认为MemLLM是朝着通过记忆增强使LLM更加扎实和基于事实的重要一步。项目仓库可在https://github.com/amodaresi/MemLLM公开访问。
论文及项目相关链接
PDF Published in Transactions on Machine Learning Research (TMLR)
Summary
大型语言模型(LLM)在知识相关任务上表现良好,但受限于隐式存储机制,难以记忆罕见事件和随时间变化的事实。本文提出MemLLM方法,通过集成结构化、显式读写内存模块增强LLM。MemLLM解决了上述问题,通过动态交互提高LLM使用存储知识的能力。实验表明,MemLLM增强了LLM的性能和可解释性,尤其是在语言建模和知识密集型任务中。MemLLM是朝着通过内存增强使LLM更真实和基于事实的重要一步。
Key Takeaways
- LLMs受限于隐式存储机制,难以处理罕见事件和更新随时间变化的事实。
- MemLLM是一种通过集成结构化、显式的读写内存模块来增强LLMs的方法。
- MemLLM解决了LLMs在动态交互和使用存储知识方面的挑战。
- MemLLM提高了LLM的性能和可解释性,特别是在语言建模和知识密集型任务中。
- MemLLM对于防止幻觉具有挑战性,因为它具有可解释的内存机制。
- MemLLM是朝着使LLM更真实和基于事实的方向迈出的重要一步。
点此查看论文截图


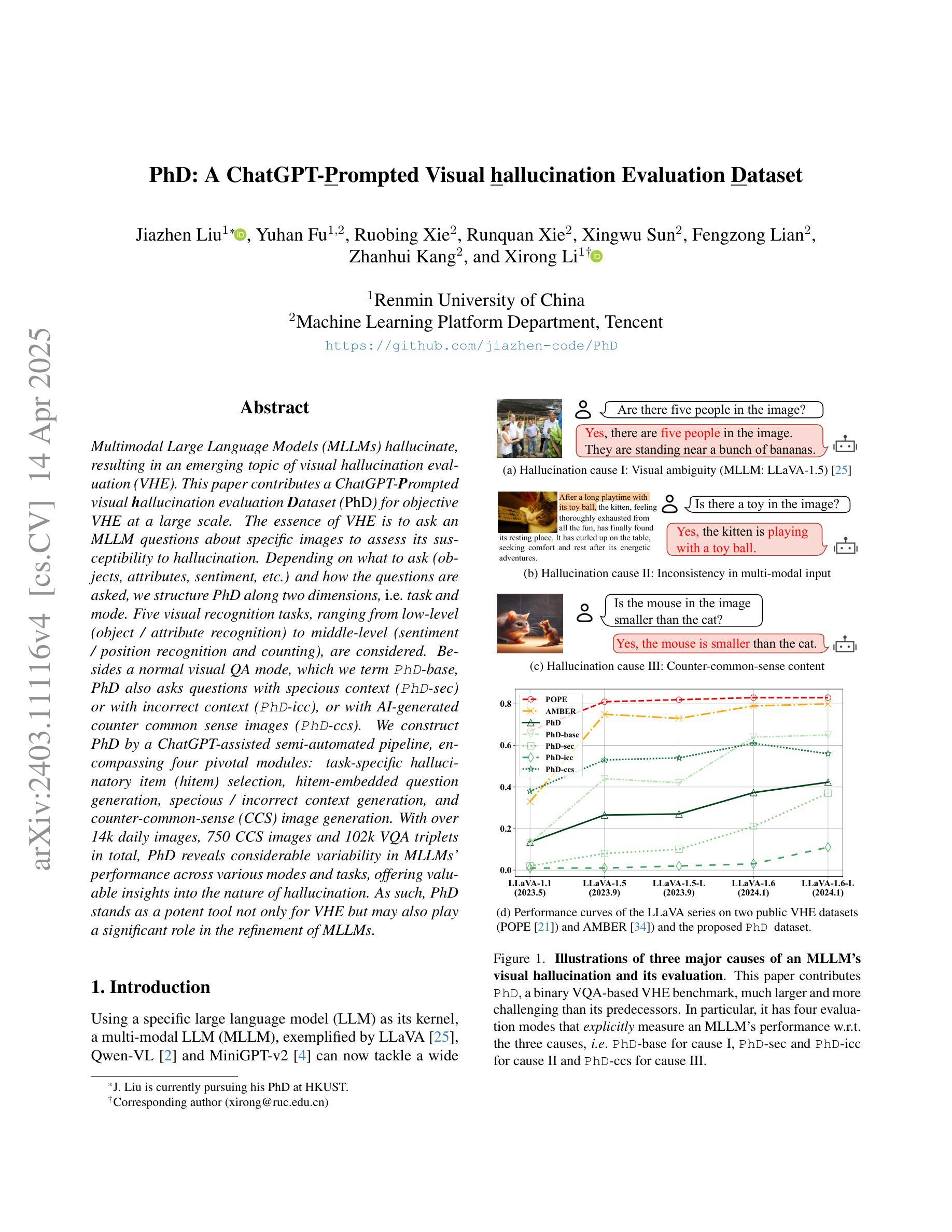
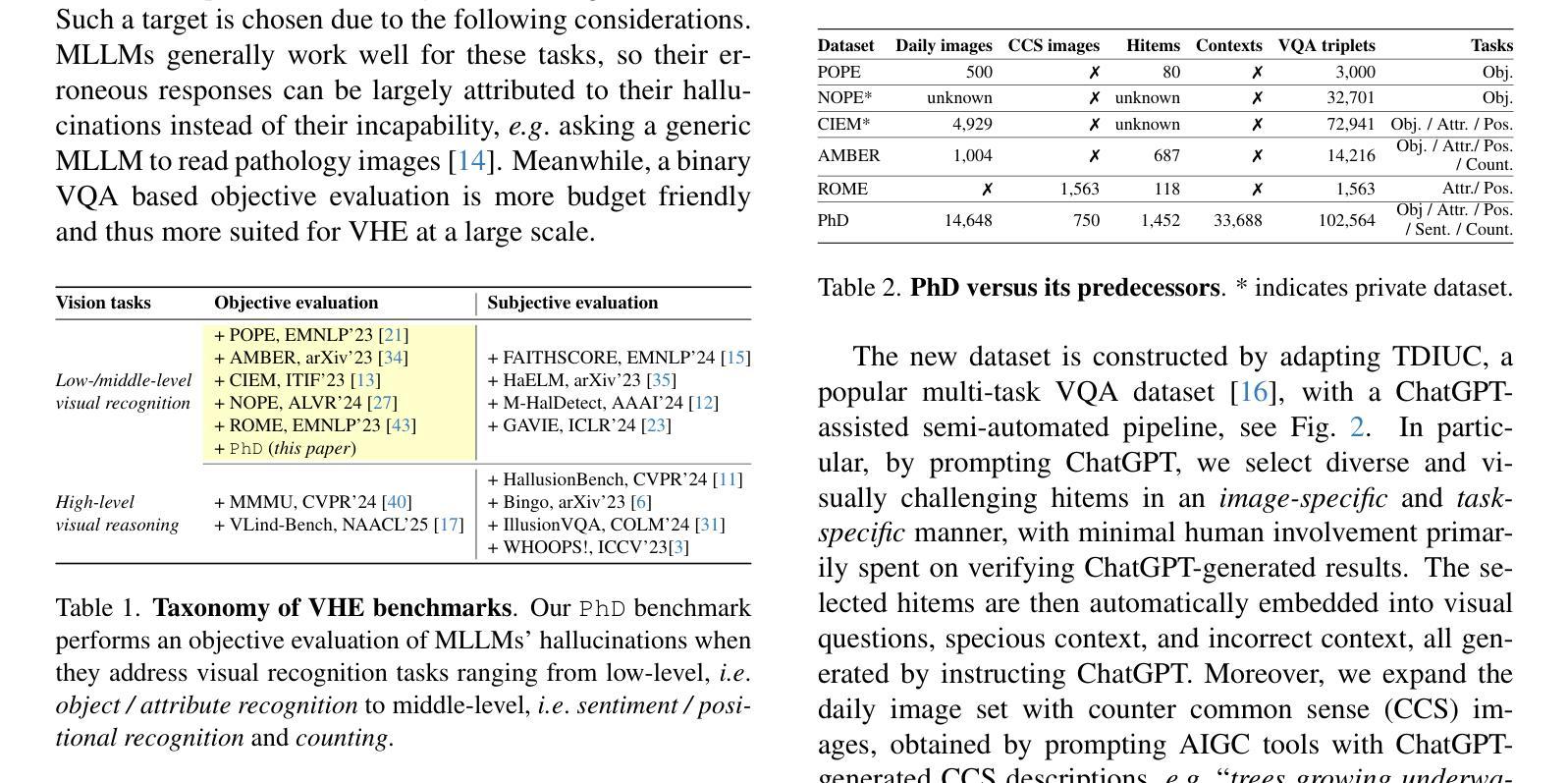
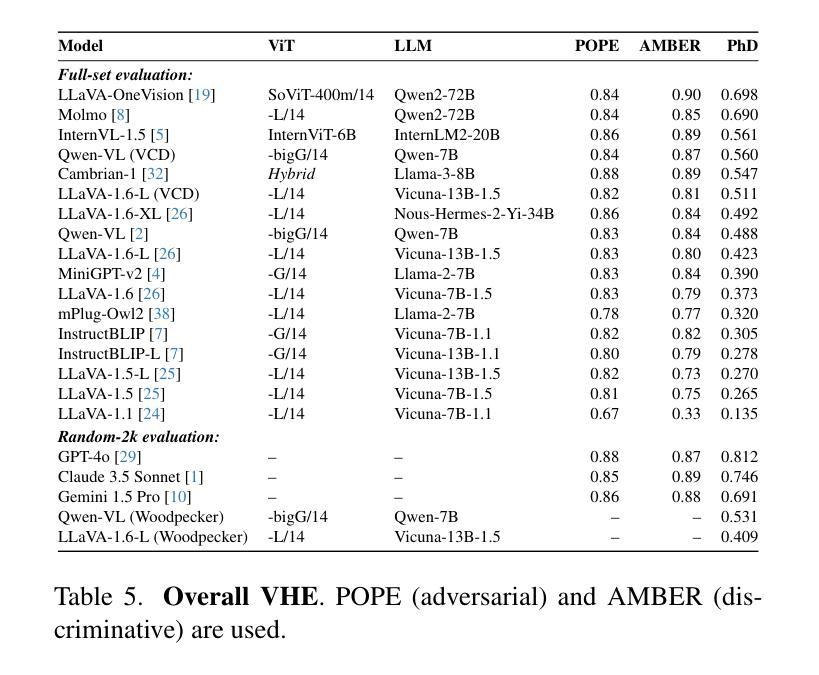
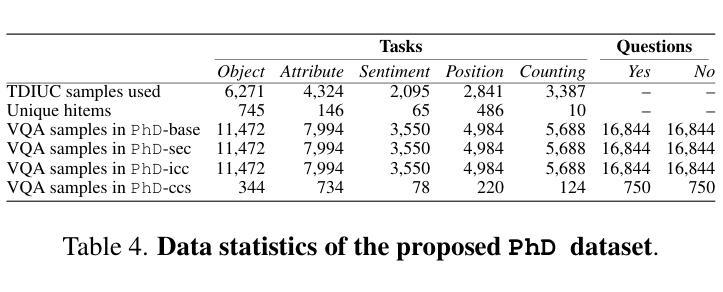
PhD: A ChatGPT-Prompted Visual hallucination Evaluation Dataset
Authors:Jiazhen Liu, Yuhan Fu, Ruobing Xie, Runquan Xie, Xingwu Sun, Fengzong Lian, Zhanhui Kang, Xirong Li
Multimodal Large Language Models (MLLMs) hallucinate, resulting in an emerging topic of visual hallucination evaluation (VHE). This paper contributes a ChatGPT-Prompted visual hallucination evaluation Dataset (PhD) for objective VHE at a large scale. The essence of VHE is to ask an MLLM questions about specific images to assess its susceptibility to hallucination. Depending on what to ask (objects, attributes, sentiment, etc.) and how the questions are asked, we structure PhD along two dimensions, i.e. task and mode. Five visual recognition tasks, ranging from low-level (object / attribute recognition) to middle-level (sentiment / position recognition and counting), are considered. Besides a normal visual QA mode, which we term PhD-base, PhD also asks questions with specious context (PhD-sec) or with incorrect context ({PhD-icc), or with AI-generated counter common sense images (PhD-ccs). We construct PhD by a ChatGPT-assisted semi-automated pipeline, encompassing four pivotal modules: task-specific hallucinatory item (hitem) selection, hitem-embedded question generation, specious / incorrect context generation, and counter-common-sense (CCS) image generation. With over 14k daily images, 750 CCS images and 102k VQA triplets in total, PhD reveals considerable variability in MLLMs’ performance across various modes and tasks, offering valuable insights into the nature of hallucination. As such, PhD stands as a potent tool not only for VHE but may also play a significant role in the refinement of MLLMs.
多模态大型语言模型(MLLMs)会产生幻觉,从而引发视觉幻觉评估(VHE)这一新兴话题。本文贡献了一个基于ChatGPT的幻觉评估数据集(PhD),用于大规模客观VHE。VHE的本质是向MLLM提出关于特定图像的问题,以评估其是否容易受到幻觉的影响。根据要问的问题(对象、属性、情感等)和提问的方式,我们按任务和模式两个维度构建PhD。我们考虑了五个视觉识别任务,从低级的(对象/属性识别)到中级的(情感/位置识别和计数)。除了正常的视觉问答模式(我们称之为PhD-base),PhD还会在具有特殊上下文(PhD-sec)或错误上下文(PhD-icc)的情况下提问,或使用AI生成的反常识图像(PhD-ccs)。我们通过ChatGPT辅助的半自动化管道构建PhD,包括四个关键模块:任务特定幻觉项目(hitem)选择、hitem嵌入问题生成、特殊/错误上下文生成和反常识(CCS)图像生成。PhD每天涵盖超过14k张图像、750张常识图像和总共102k个VQA三元组,揭示了MLLMs在不同模式和任务之间的性能存在相当大的差异,为幻觉的性质提供了宝贵的见解。因此,PhD不仅是一个强大的VHE工具,也可能在MLLM的改进中发挥重要作用。
论文及项目相关链接
PDF Accepted by CVPR 2025, Highlight
摘要
多模态大型语言模型(MLLMs)会产生幻觉,从而产生了视觉幻觉评估(VHE)这一新兴主题。本文贡献了一个基于ChatGPT的视觉幻觉评估数据集(PhD),用于大规模客观VHE。VHE的本质是向MLLM询问特定图像的问题,以评估其是否容易产生幻觉。根据询问的内容和方式(例如对象、属性、情感等)以及问题的结构,我们将数据集沿着任务和模式两个维度构建。考虑五种视觉识别任务,从低级的对象/属性识别到中级的情感/位置识别以及计数。除了正常的视觉问答模式(我们称之为PhD-base)外,PhD还针对具有奇异上下文(PhD-sec)、错误上下文(PhD-icc)或AI生成的反常识图像(PhD-ccs)的问题进行提问。我们通过ChatGPT辅助的半自动化管道构建PhD,包括四个关键模块:特定任务的幻觉项目选择、嵌入问题的生成、奇异/错误上下文的生成和反常识(CCS)图像的生成。PhD每天包含超过14k张图像、750张反常识图像和总共的10.2万张视觉问答三元组,揭示了MLLM在不同模式和任务中的性能存在显著的可变性,为幻觉的性质提供了宝贵的见解。因此,PhD不仅是VHE的强大工具,还可能对MLLM的改进起到重要作用。
要点摘要
- 多模态大型语言模型(MLLMs)存在视觉幻觉评估(VHE)问题。
- 本文介绍了一个基于ChatGPT的视觉幻觉评估数据集(PhD)。
- PhD数据集包含多种视觉识别任务,从对象/属性识别到情感/位置识别和计数。
- 除了正常视觉问答模式外,PhD还包括具有奇异、错误上下文或AI生成的反常识图像的问题。
- 通过半自动化管道构建PhD,包括任务特定的幻觉项目选择、问题生成、上下文生成和图像生成等模块。
- PhD数据集揭示了MLLM在不同模式和任务中的性能差异,为评估和改进MLLM的幻觉问题提供了宝贵数据。
点此查看论文截图


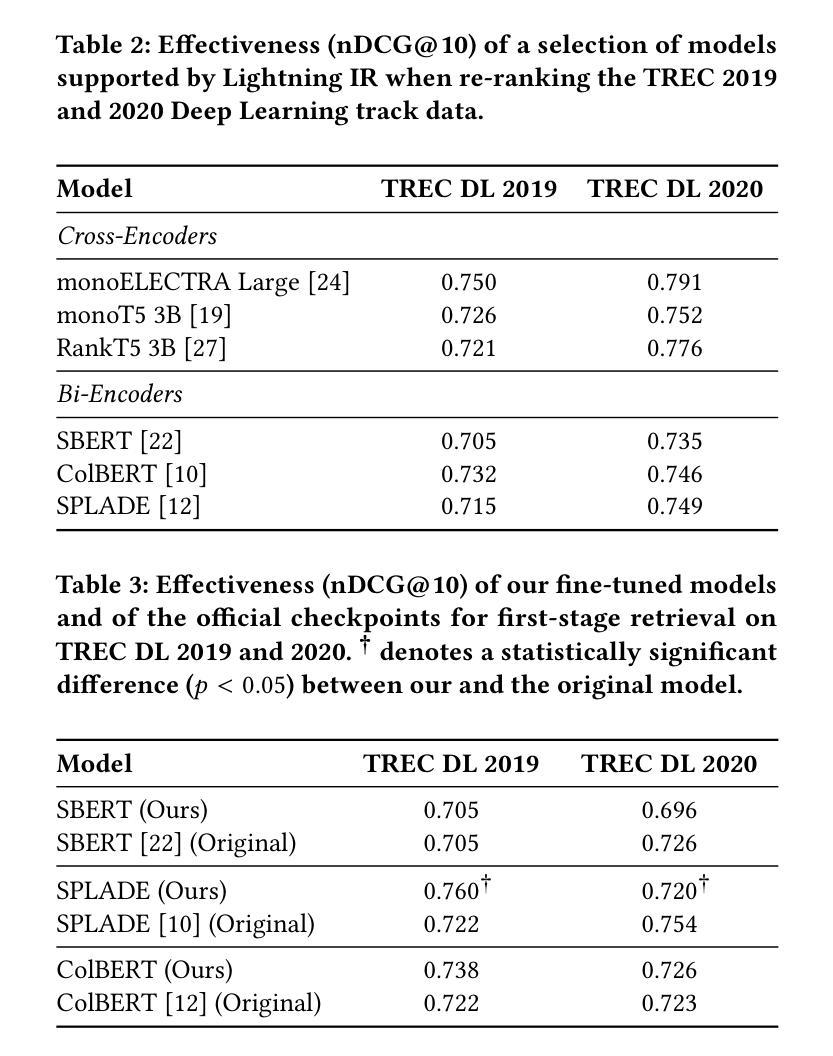
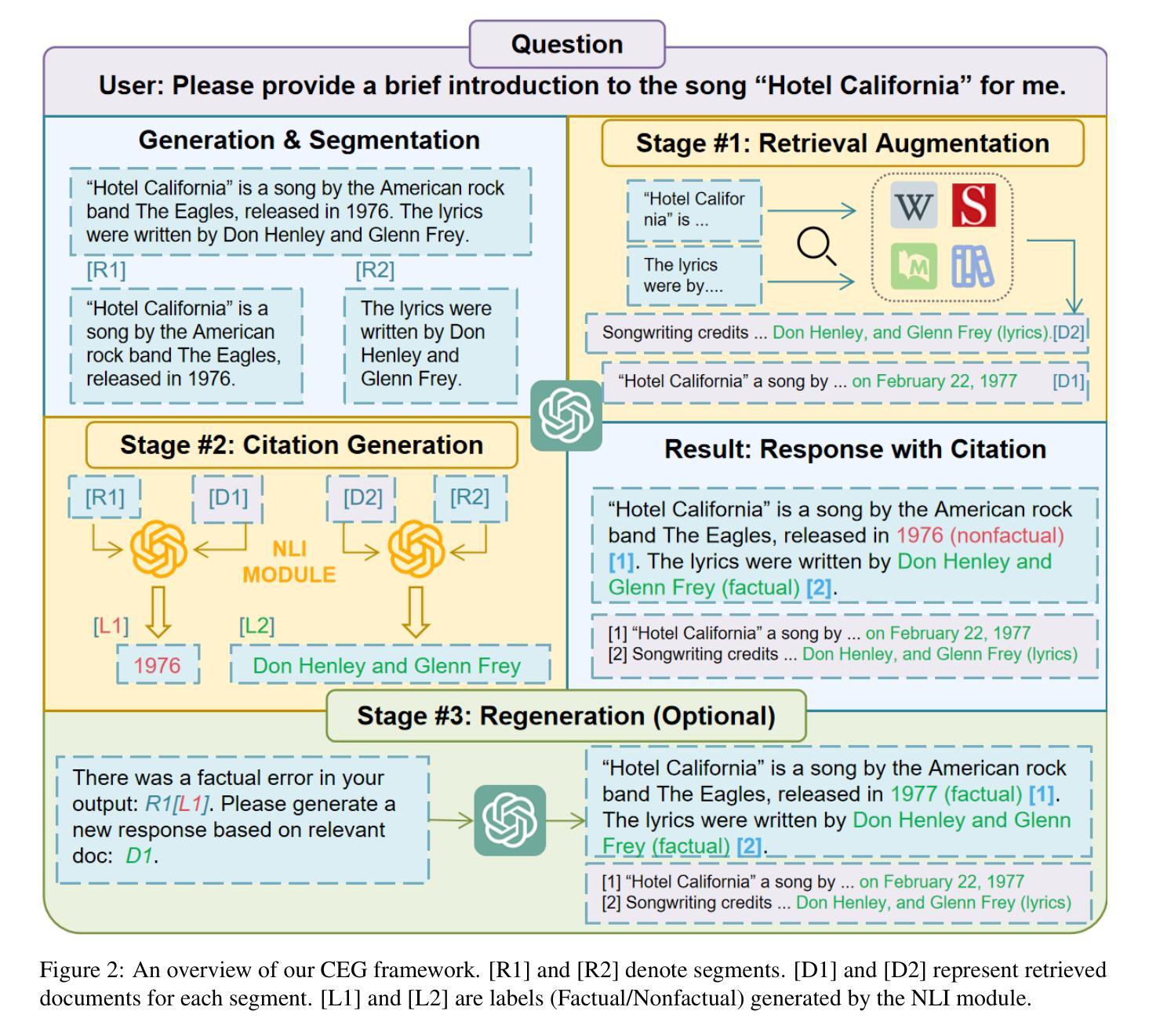
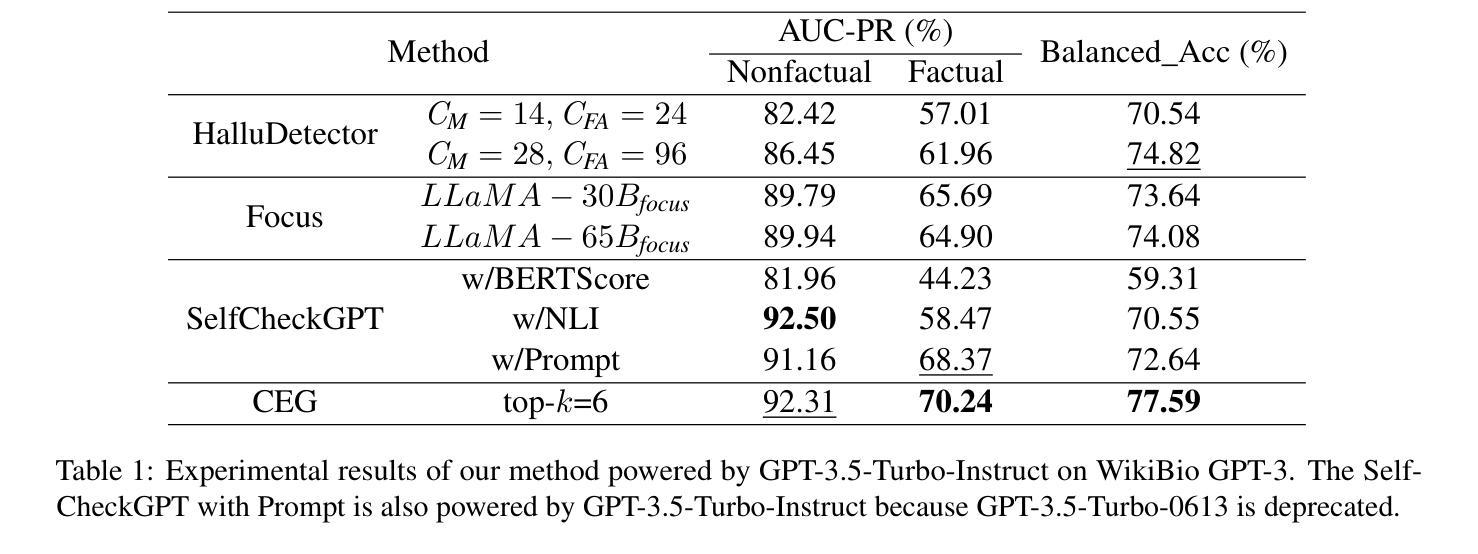
Citation-Enhanced Generation for LLM-based Chatbots
Authors:Weitao Li, Junkai Li, Weizhi Ma, Yang Liu
Large language models (LLMs) exhibit powerful general intelligence across diverse scenarios, including their integration into chatbots. However, a vital challenge of LLM-based chatbots is that they may produce hallucinated content in responses, which significantly limits their applicability. Various efforts have been made to alleviate hallucination, such as retrieval augmented generation and reinforcement learning with human feedback, but most of them require additional training and data annotation. In this paper, we propose a novel post-hoc Citation-Enhanced Generation (CEG) approach combined with retrieval argumentation. Unlike previous studies that focus on preventing hallucinations during generation, our method addresses this issue in a post-hoc way. It incorporates a retrieval module to search for supporting documents relevant to the generated content, and employs a natural language inference-based citation generation module. Once the statements in the generated content lack of reference, our model can regenerate responses until all statements are supported by citations. Note that our method is a training-free plug-and-play plugin that is capable of various LLMs. Experiments on various hallucination-related datasets show our framework outperforms state-of-the-art methods in both hallucination detection and response regeneration on three benchmarks. Our codes and dataset will be publicly available.
大型语言模型(LLM)在多种场景中展现出强大的通用智能,包括在聊天机器人中的集成。然而,LLM驱动的聊天机器人面临的一个关键挑战是它们可能会产生幻觉内容作为回应,这极大地限制了其适用性。尽管已经做出了各种努力来缓解幻觉问题,如增强检索生成和通过人类反馈进行强化学习,但大多数方法都需要额外的训练和数据标注。在本文中,我们提出了一种新型的后验引用增强生成(CEG)方法,该方法结合了检索论证。不同于之前侧重于在生成过程中防止幻觉的研究,我们的方法以一种后验方式解决这一问题。它结合了一个检索模块来搜索与生成内容相关的支持文档,并采用基于自然语言推理的引用生成模块。一旦生成的内容中的陈述缺乏参考,我们的模型可以重新生成回应,直到所有陈述都得到引用的支持。值得注意的是,我们的方法是一种无需训练的即插即用插件,可以与各种LLM配合使用。在各种幻觉相关的数据集上的实验表明,我们的框架在三个基准测试中优于最先进的方法,在幻觉检测和响应再生方面均表现出色。我们的代码和数据集将公开可用。
论文及项目相关链接
Summary
大型语言模型(LLM)在多种场景中展现出强大的通用智能,尤其是在集成到聊天机器人方面。然而,LLM-based聊天机器人的一个重大挑战是可能会产生虚构的回应内容,这极大地限制了其适用性。尽管已有许多缓解虚构性的尝试,如增强检索生成和强化学习人类反馈,但大多数方法都需要额外的训练和标注数据。本文提出了一种新颖的后验式Citation-Enhanced Generation(CEG)方法,结合了检索论证。与其他研究不同,我们的方法专注于在生成后解决虚构性问题。它采用检索模块来搜索与生成内容相关的支持文档,并采用基于自然语言推理的引用生成模块。当生成的回应内容缺乏引用时,我们的模型会重新生成回应,直至所有陈述都得到引用的支持。值得注意的是,我们的方法是一种无需训练的即插即用插件,适用于各种LLM。在多个与虚构性相关的数据集上的实验表明,我们的框架在三个基准测试上优于最新方法在虚构性检测和回应再生方面的表现。我们的代码和数据集将公开提供。
Key Takeaways
- LLMs展现出强大的通用智能,集成到聊天机器人具有应用价值。
- LLM-based聊天机器人面临虚构性回应的挑战,限制了其适用性。
- 当前减轻虚构性的方法多需额外的训练和标注数据。
- 本文提出一种新颖的后验式Citation-Enhanced Generation(CEG)方法来解决虚构性问题。
- CEG方法结合检索论证,通过搜索支持文档来增强回应的可靠性。
- CEG模型能重新生成回应直至所有陈述都得到引用的支持。
点此查看论文截图

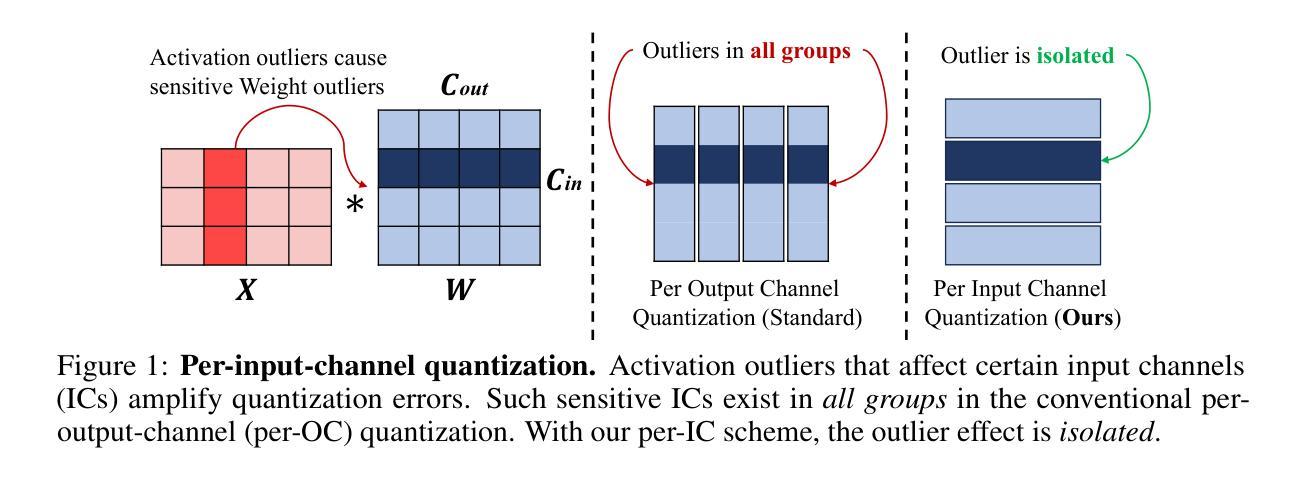
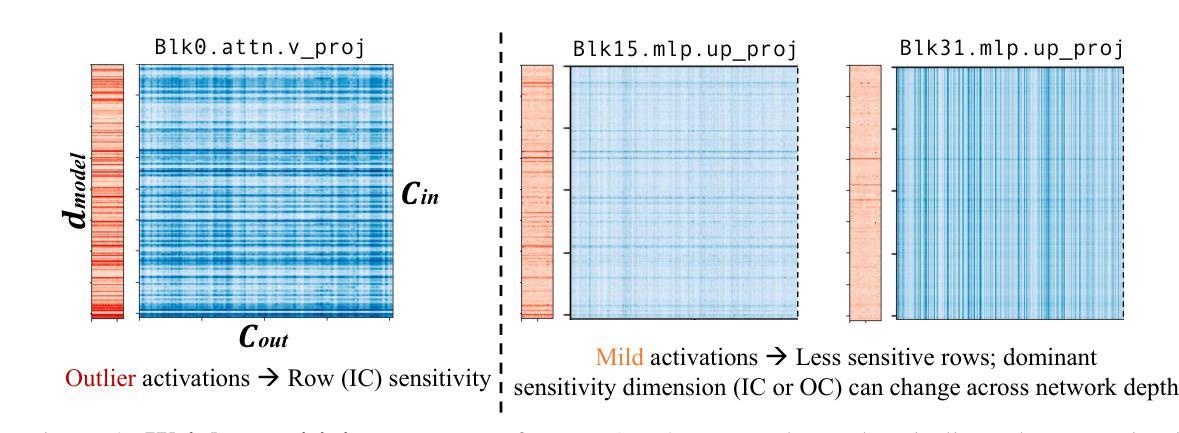
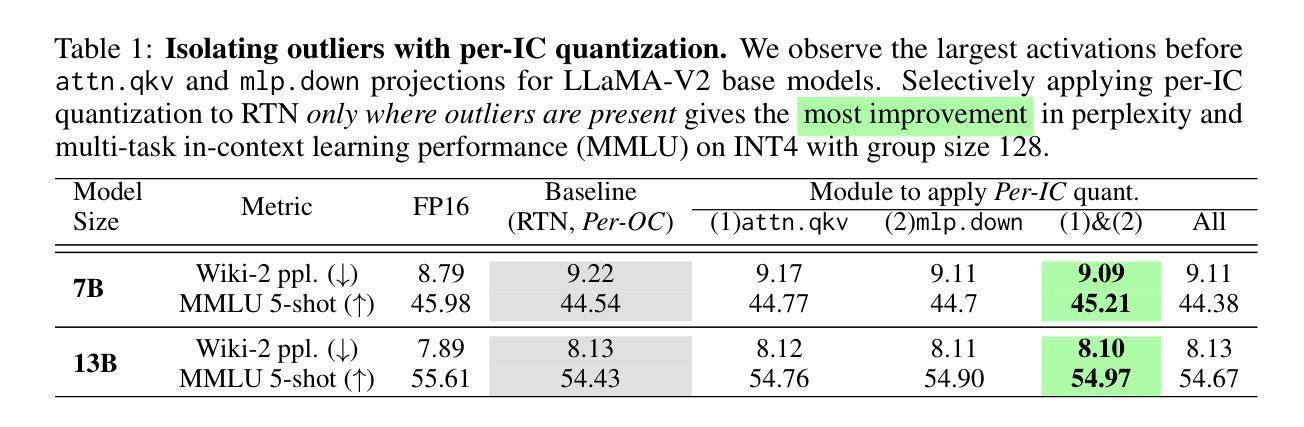
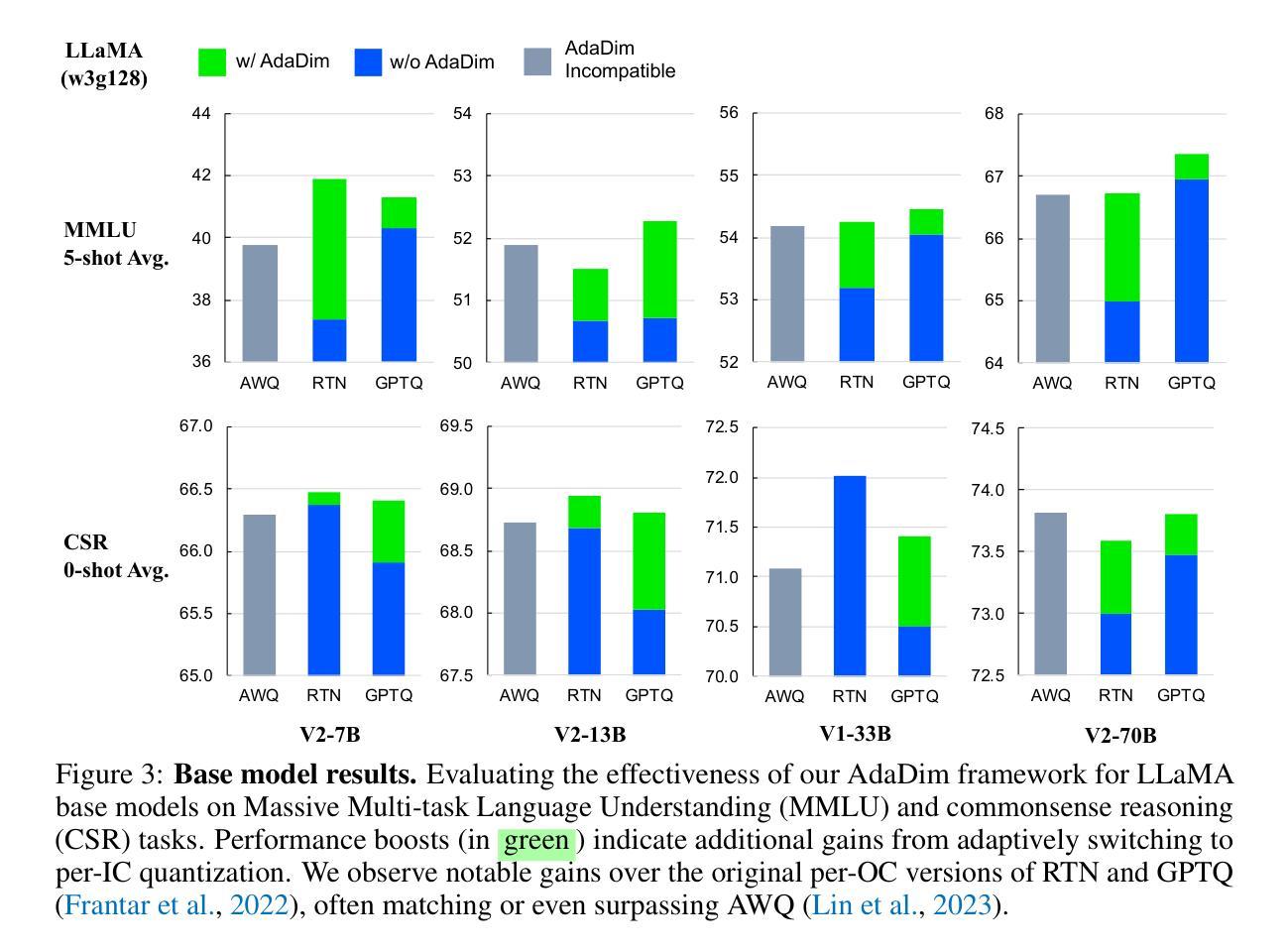
Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight Quantization of Large Language Models
Authors:Jung Hwan Heo, Jeonghoon Kim, Beomseok Kwon, Byeongwook Kim, Se Jung Kwon, Dongsoo Lee
Large Language Models (LLMs) have recently demonstrated remarkable success across various tasks. However, efficiently serving LLMs has been a challenge due to the large memory bottleneck, specifically in small batch inference settings (e.g. mobile devices). Weight-only quantization can be a promising approach, but sub-4 bit quantization remains a challenge due to large-magnitude activation outliers. To mitigate the undesirable outlier effect, we first propose per-IC quantization, a simple yet effective method that creates quantization groups within each input channel (IC) rather than the conventional per-output-channel (per-OC). Our method is motivated by the observation that activation outliers affect the input dimension of the weight matrix, so similarly grouping the weights in the IC direction can isolate outliers within a group. We also find that activation outliers do not dictate quantization difficulty, and inherent weight sensitivities also exist. With per-IC quantization as a new outlier-friendly scheme, we propose Adaptive Dimensions (AdaDim), a versatile quantization framework that can adapt to various weight sensitivity patterns. We demonstrate the effectiveness of AdaDim by augmenting prior methods such as Round-To-Nearest and GPTQ, showing significant improvements across various language modeling benchmarks for both base (up to +4.7% on MMLU) and instruction-tuned (up to +10% on HumanEval) LLMs. Code is available at https://github.com/johnheo/adadim-llm
大型语言模型(LLM)在各种任务中取得了显著的成功。然而,由于内存瓶颈问题,特别是在小批量推理设置(如移动设备)中,有效地服务LLM一直是一个挑战。权重仅量化可能是一种有前途的方法,但低于4位的量化仍然是一个挑战,因为存在大量幅度激活异常值。为了减轻不良异常值的影响,我们首先提出了针对每个输入通道(IC)的量化方法,这是一种简单有效的方法,在每个输入通道内创建量化组,而不是传统的每个输出通道(OC)。我们的方法源于观察到激活异常值影响权重矩阵的输入维度,因此按IC方向对权重进行分组可以隔离异常值到一个组内。我们还发现激活异常值并不决定量化的难度,权重本身也存在固有的敏感性。作为一种新的异常值友好的方案,我们提出了自适应维度(AdaDim),这是一个灵活的量化框架,能够适应各种权重敏感性模式。我们通过增强先前的Round-To-Nearest和GPTQ等方法来展示AdaDim的有效性,在各种语言建模基准测试中取得了显著改进,无论是在基础模型(MMLU上最多提高+4.7%)还是在指令调优模型(HumanEval上最多提高+10%)上。代码在https://github.com/johnheo/adadim-llm上提供。
论文及项目相关链接
PDF ICLR 2024
Summary
大型语言模型(LLM)在各任务中表现出卓越性能,但其内存需求巨大,在小批量推理设置(如移动设备)中提供服务具有挑战性。针对这一问题,本文提出了一种新的量化方法——AdaDim,它结合了每输入通道(IC)的量化方案和自适应维度量化框架,以提高模型的量化性能并减少内存瓶颈。AdaDim可有效改善现有量化方法如Round-To-Nearest和GPTQ的性能,在多种语言建模基准测试中表现显著,包括基础模型和指令微调模型。
Key Takeaways
- LLMs在多种任务中表现出卓越性能,但内存需求大,特别是在小批量推理环境中。
- 现有量化方法面临挑战,特别是低于4位的量化由于激活异常值的问题。
- 论文提出了一种新的量化策略——AdaDim,结合每输入通道(IC)的量化方法和自适应维度量化框架。
- AdaDim旨在通过创建量化组来隔离激活异常值,并适应不同的权重敏感性模式。
- AdaDim对先前的量化方法进行了改进,显著提高了基础模型和指令微调模型在多种语言建模基准测试中的性能。
- AdaDim方法已在GitHub上公开可用。
点此查看论文截图


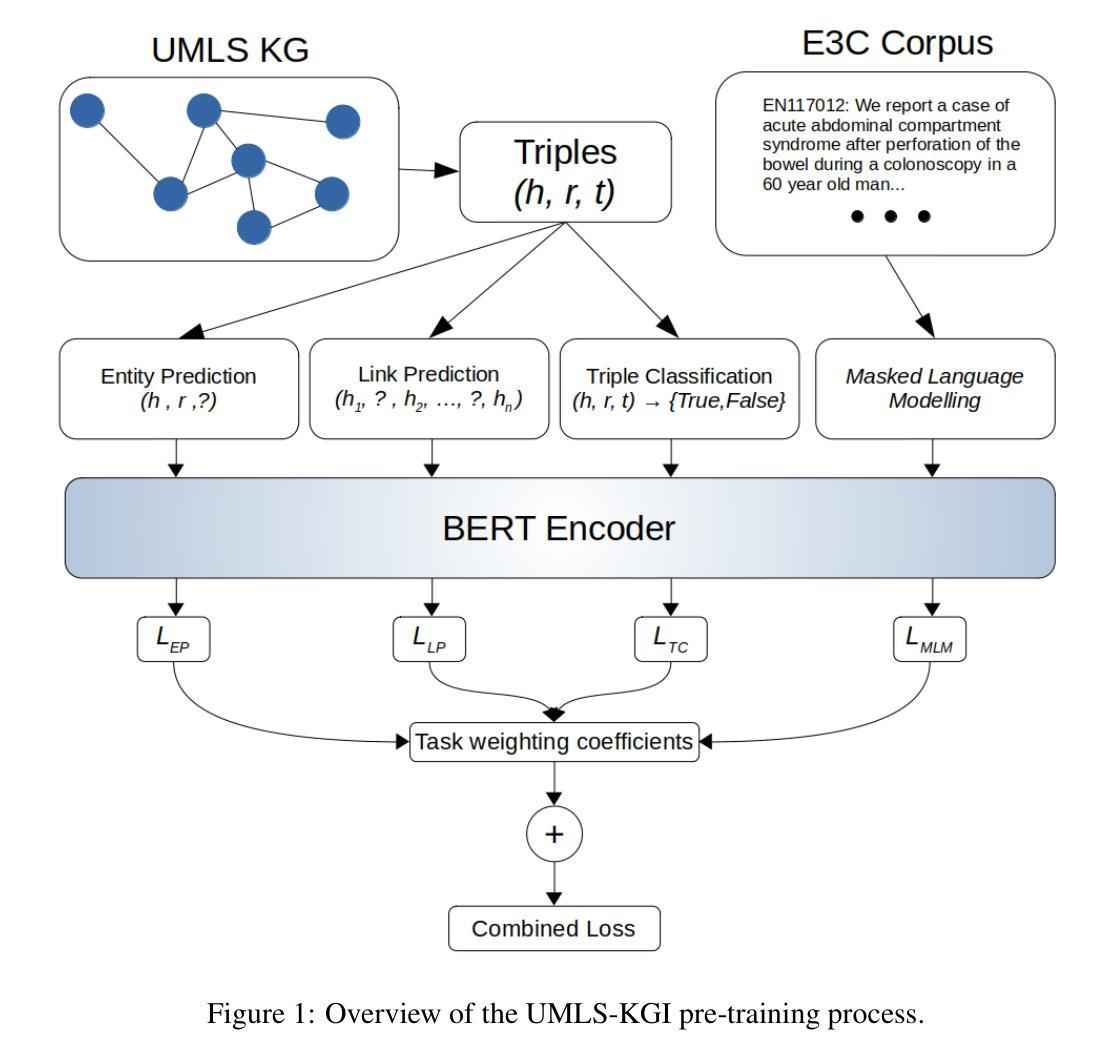
UMLS-KGI-BERT: Data-Centric Knowledge Integration in Transformers for Biomedical Entity Recognition
Authors:Aidan Mannion, Thierry Chevalier, Didier Schwab, Lorraine Geouriot
Pre-trained transformer language models (LMs) have in recent years become the dominant paradigm in applied NLP. These models have achieved state-of-the-art performance on tasks such as information extraction, question answering, sentiment analysis, document classification and many others. In the biomedical domain, significant progress has been made in adapting this paradigm to NLP tasks that require the integration of domain-specific knowledge as well as statistical modelling of language. In particular, research in this area has focused on the question of how best to construct LMs that take into account not only the patterns of token distribution in medical text, but also the wealth of structured information contained in terminology resources such as the UMLS. This work contributes a data-centric paradigm for enriching the language representations of biomedical transformer-encoder LMs by extracting text sequences from the UMLS. This allows for graph-based learning objectives to be combined with masked-language pre-training. Preliminary results from experiments in the extension of pre-trained LMs as well as training from scratch show that this framework improves downstream performance on multiple biomedical and clinical Named Entity Recognition (NER) tasks.
预训练转换语言模型(LMs)近年来已成为应用NLP中的主导范式。这些模型在信息提取、问答、情感分析、文档分类等任务上达到了最新技术水平的表现。在生物医学领域,将这种范式适应于需要整合特定领域知识和语言统计建模的NLP任务方面,已经取得了重大进展。特别是,该领域的研究重点是如何构建最佳的LMs,这些LMs不仅要考虑医疗文本中的标记分布模式,还要利用术语资源(如UMLS)中包含的大量结构化信息。本文贡献了一种以数据为中心的方法,通过从UMLS中提取文本序列来丰富生物医学转换编码器LMs的语言表示。这允许将基于图的学习目标与掩码语言预训练相结合。初步实验结果显示,通过扩展预训练LMs或从头开始训练的结果表明,该框架在多生物医学和临床命名实体识别(NER)任务上的下游性能有所提升。
论文及项目相关链接
PDF Addition of v2 experiments
Summary
预训练转换器语言模型(LMs)已成为应用自然语言处理(NLP)中的主要范式,特别是在生物医学领域,这些模型在任务上取得了最先进的性能,如信息提取、问答、情感分析、文档分类等。研究集中于如何构建考虑医学文本中的标记分布以及术语资源(如UMLS)中丰富结构信息的语言模型。本文提出了一种以数据为中心的方法,通过从UMLS中提取文本序列来丰富生物医学转换器编码器的语言表示,结合基于图的学习目标和掩码语言预训练。初步实验结果表明,该框架在多生物医学和临床命名实体识别(NER)任务上提高了下游性能。
Key Takeaways
- 预训练转换器语言模型(LMs)在自然语言处理(NLP)领域占据主导地位,特别是在完成信息提取、问答、情感分析和文档分类等任务时表现出色。
- 在生物医学领域,结合领域特定知识和语言统计模型的LMs研究已取得显著进展。
- 研究焦点在于如何构建考虑医学文本中的标记分布和术语资源(如UMLS)中的结构化信息的语言模型。
- 本文提出了一种数据为中心的方法,通过从UMLS提取文本序列来丰富生物医学LMs的语言表示。
- 该方法结合了基于图的学习目标和掩码语言预训练。
- 初步实验表明,该框架在多个生物医学和临床命名实体识别(NER)任务上提高了性能。
点此查看论文截图