⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-20 更新
Memorization vs. Reasoning: Updating LLMs with New Knowledge
Authors:Aochong Oliver Li, Tanya Goyal
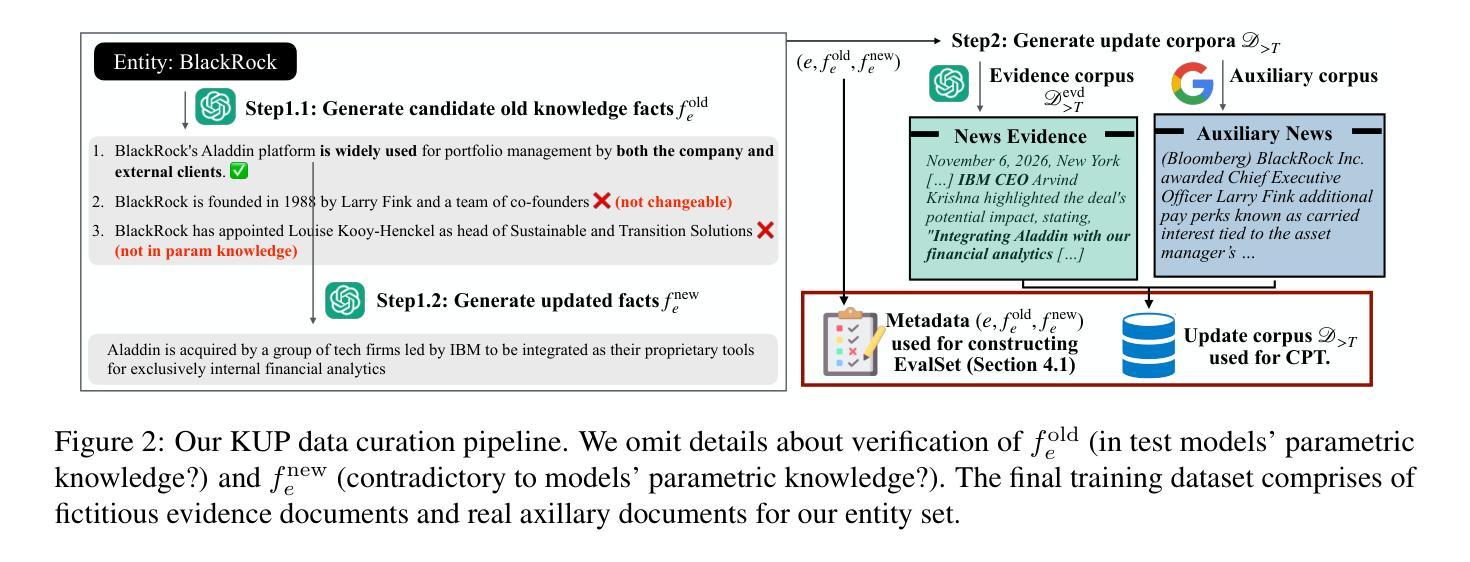
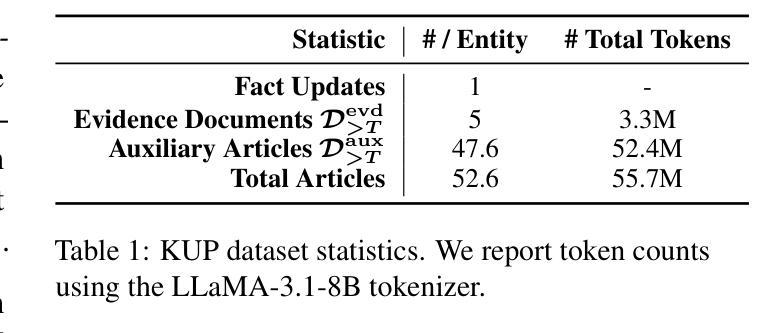
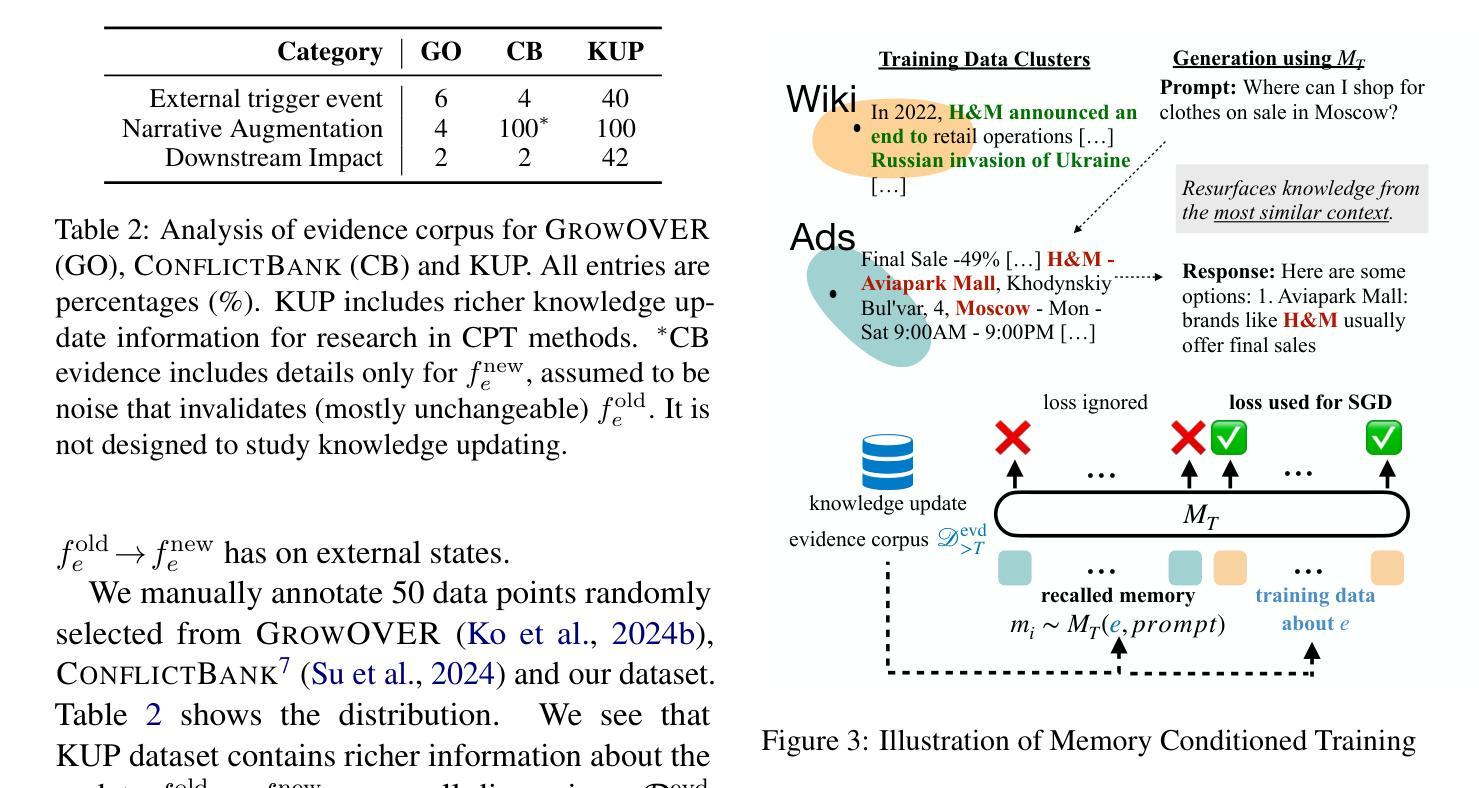
Large language models (LLMs) encode vast amounts of pre-trained knowledge in their parameters, but updating them as real-world information evolves remains a challenge. Existing methodologies and benchmarks primarily target entity substitutions, failing to capture the full breadth of complex real-world dynamics. In this paper, we introduce Knowledge Update Playground (KUP), an automatic pipeline for simulating realistic knowledge updates reflected in an evidence corpora. KUP’s evaluation framework includes direct and indirect probes to both test memorization of updated facts and reasoning over them, for any update learning methods. Next, we present a lightweight method called memory conditioned training (MCT), which conditions tokens in the update corpus on self-generated “memory” tokens during training. Our strategy encourages LLMs to surface and reason over newly memorized knowledge at inference. Our results on two strong LLMs show that (1) KUP benchmark is highly challenging, with the best CPT models achieving $<2%$ in indirect probing setting (reasoning) and (2) MCT training significantly outperforms prior continued pre-training (CPT) baselines, improving direct probing (memorization) results by up to $25.4%$.
大型语言模型(LLM)在其参数中编码了大量的预训练知识,但随着现实世界信息的演变,如何更新这些知识仍然是一个挑战。现有的方法和基准测试主要关注实体替换,无法捕捉现实世界动态的全面广度。在本文中,我们介绍了知识更新游乐场(KUP),这是一个自动管道,用于模拟反映在证据语料库中的现实知识更新。KUP的评估框架包括直接和间接探针,用于测试任何更新学习方法中对更新事实的记忆和推理。接下来,我们提出了一种轻量级的方法,称为记忆条件训练(MCT),该方法在训练期间将更新语料库中的令牌设置为自我生成的“记忆”令牌的条件。我们的策略鼓励大型语言模型在推理时展现并推理新记忆的知识。我们在两个强大的大型语言模型上的结果表明,(1)KUP基准测试极具挑战性,最好的CPT模型在间接探测设置(推理)中达到<2%;(2)MCT训练显著优于先前的持续预训练(CPT)基线,直接探测(记忆)结果最多提高了25.4%。
论文及项目相关链接
PDF 9 pages, 3 figures
Summary
本文介绍了知识更新游乐场(KUP)这一自动管道,用于模拟反映于证据语料库中的现实知识更新。KUP评估框架包括直接和间接探针,以测试更新事实的记忆和对其的推理。此外,提出了一种轻量级方法——记忆条件训练(MCT),在训练过程中将更新语料库中的令牌置于自我生成的“记忆”令牌上。策略鼓励大型语言模型在推理时唤起并推理新记忆的知识。在强大的大型语言模型上的结果表明,KUP基准测试具有挑战性,而MCT训练显著优于先前的持续预训练(CPT)基准测试,直接探测(记忆)结果最多可提高25.4%。
Key Takeaways
- 知识更新游乐场(KUP)是一个自动管道,旨在模拟现实知识更新并在证据语料库中反映这些更新。
- KUP评估框架通过直接和间接探针测试大型语言模型(LLM)对更新知识的记忆和推理能力。
- 现有方法主要关注实体替换,无法捕捉复杂现实动态的全貌。
- 引入了一种轻量级方法——记忆条件训练(MCT),在训练过程中使用自我生成的“记忆”令牌。
5.MCT鼓励LLM在推理时利用新记忆的知识。 - 在强大的LLM上的实验结果表明,KUP基准测试具有挑战性,间接探针设置中的最佳CPT模型仅达到<2%。
点此查看论文截图

Robust Reinforcement Learning from Human Feedback for Large Language Models Fine-Tuning
Authors:Kai Ye, Hongyi Zhou, Jin Zhu, Francesco Quinzan, Chengchung Shi
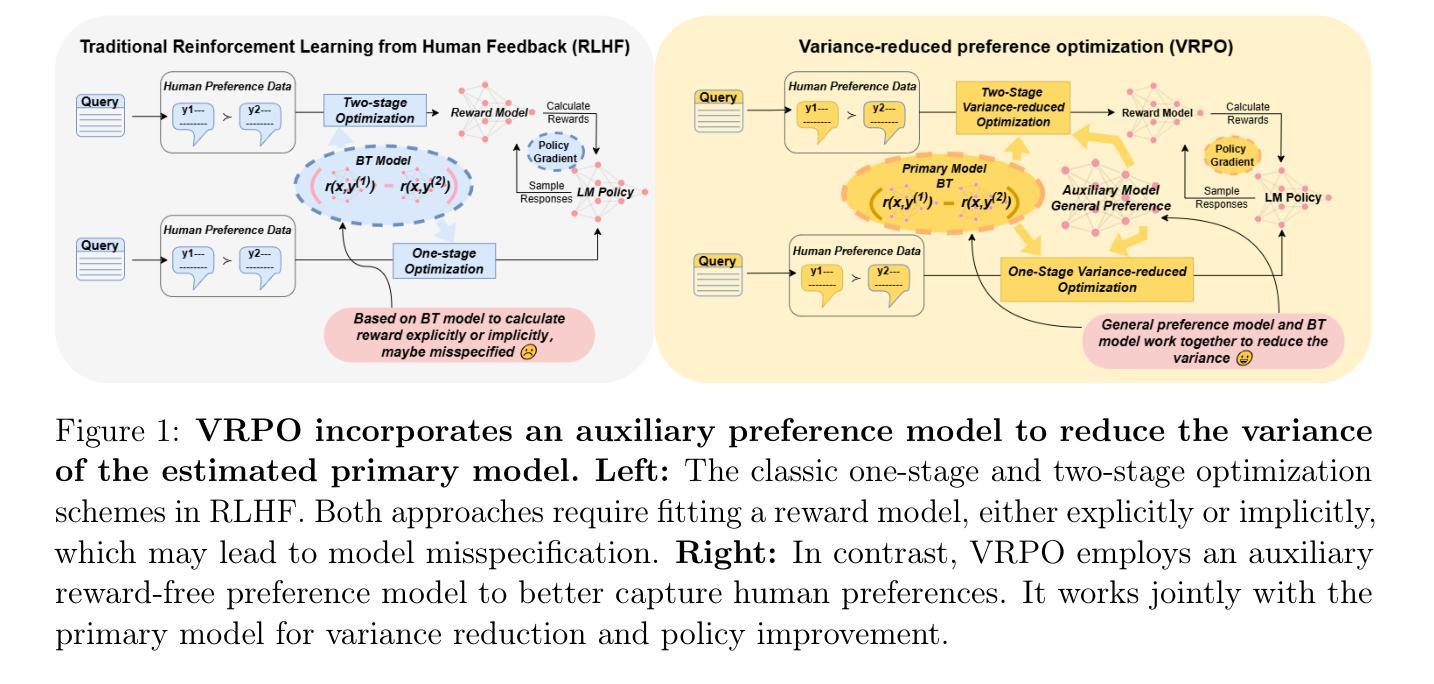
Reinforcement learning from human feedback (RLHF) has emerged as a key technique for aligning the output of large language models (LLMs) with human preferences. To learn the reward function, most existing RLHF algorithms use the Bradley-Terry model, which relies on assumptions about human preferences that may not reflect the complexity and variability of real-world judgments. In this paper, we propose a robust algorithm to enhance the performance of existing approaches under such reward model misspecifications. Theoretically, our algorithm reduces the variance of reward and policy estimators, leading to improved regret bounds. Empirical evaluations on LLM benchmark datasets demonstrate that the proposed algorithm consistently outperforms existing methods, with 77-81% of responses being favored over baselines on the Anthropic Helpful and Harmless dataset.
强化学习从人类反馈(RLHF)已经成为将大型语言模型(LLM)的输出与人类偏好对齐的关键技术。为了学习奖励函数,大多数现有的RLHF算法使用Bradley-Terry模型,该模型依赖于可能无法反映现实世界判断复杂性和可变性的人类偏好假设。在本文中,我们提出了一种稳健的算法,以提高在这种奖励模型错误指定情况下现有方法的性能。从理论上讲,我们的算法降低了奖励和政策估算器的方差,从而提高了后悔界。在LLM基准数据集上的经验评估表明,所提算法始终优于现有方法,在Anthropic有益和无害数据集上,有7 修丞研究的关注度技术则越来越受到业界的关注和研究者的重视。这一技术的出现使得机器学习模型能够更好地理解人类用户的需求和意图,从而更好地满足用户的需求并提供更个性化的服务。例如,随着这一技术的发展,语音助手能够更准确地理解用户的语音指令并执行相应的操作;智能客服机器人能够更好地理解用户的问题并提供更精准的解答和帮助。在自然语言处理领域的应用之外,这一技术也在其他领域得到了广泛的应用。例如,在金融领域,基于强化学习的智能交易系统可以根据市场数据和用户偏好进行自动交易决策;在医疗领域,强化学习也被应用于诊断和疾病管理等方面。总之,随着机器学习领域中对强化学习与人类反馈相结合的技术应用的不断深化和扩展,这将为未来带来无限可能的新场景和新技术革命。目前机器学习模型如GPT系列虽然已经有了很好的成绩但仍有很多问题值得探讨。通过深入研究强化学习从人类反馈的技术并与其他技术相结合相信未来会涌现出更多有趣而实用的应用场景推动技术的进步和发展。我们相信未来基于强化学习的自适应智能系统将成为人工智能领域的重要发展方向之一为人类带来更加智能便捷的生活体验。我们相信这一领域的研究将继续深入并取得更多的突破性进展从而不断提升人类社会的智能化水平并实现科技的可持续发展。,相比基线有八修的改进成果显示出算法的高效率与优越性。
论文及项目相关链接
Summary:强化学习从人类反馈(RLHF)已成为将大型语言模型(LLM)的输出与人类偏好对齐的关键技术。大多数现有的RLHF算法使用布拉德利-特里模型来学习奖励函数,这依赖于可能无法反映现实世界中判断和复杂性的假设。本文提出了一种稳健的算法,以提高在奖励模型误差下的现有方法性能。理论上,该算法降低了奖励和政策估计量的方差,提高了后悔界。在LLM基准数据集上的经验评估表明,该算法始终优于现有方法,在Anthropic有益和无害数据集上,77-81%的响应优于基线。
Key Takeaways:
- 强化学习从人类反馈(RLHF)技术用于对齐大型语言模型(LLM)输出与人类偏好。
- 现有RLHF算法主要使用布拉德利-特里模型,存在对人类偏好假设的局限性。
- 本文提出了一种新的稳健算法,旨在提高在奖励模型误差下的现有方法性能。
- 新算法理论上降低了奖励和政策估计量的方差,提高了后悔界。
- 实证评估表明,新算法在LLM基准数据集上表现优于现有方法。
- 在Anthropic有益和无害数据集上,新算法的响应优于基线,达到77-81%。
点此查看论文截图

OnRL-RAG: Real-Time Personalized Mental Health Dialogue System
Authors:Ahsan Bilal, Beiyu Lin
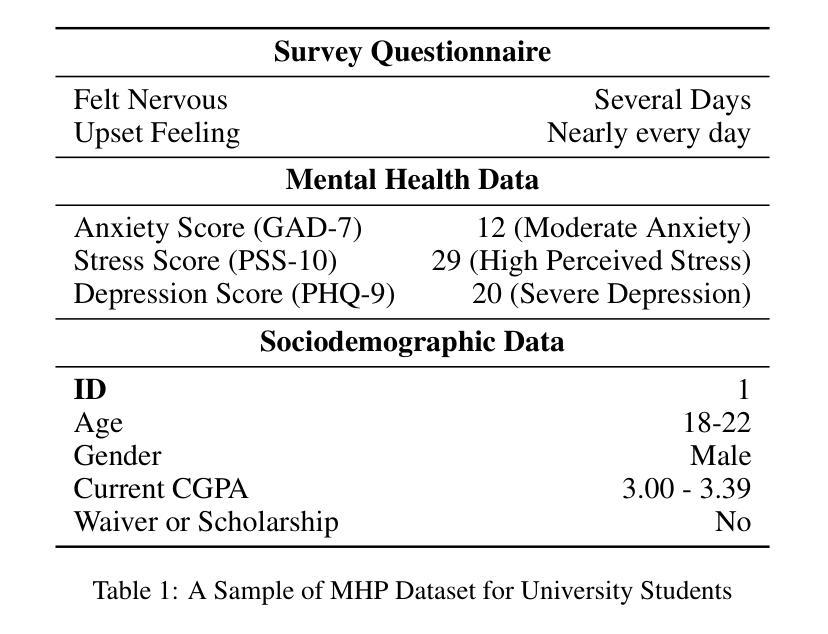
Large language models (LLMs) have been widely used for various tasks and applications. However, LLMs and fine-tuning are limited to the pre-trained data. For example, ChatGPT’s world knowledge until 2021 can be outdated or inaccurate. To enhance the capabilities of LLMs, Retrieval-Augmented Generation (RAG), is proposed to augment LLMs with additional, new, latest details and information to LLMs. While RAG offers the correct information, it may not best present it, especially to different population groups with personalizations. Reinforcement Learning from Human Feedback (RLHF) adapts to user needs by aligning model responses with human preference through feedback loops. In real-life applications, such as mental health problems, a dynamic and feedback-based model would continuously adapt to new information and offer personalized assistance due to complex factors fluctuating in a daily environment. Thus, we propose an Online Reinforcement Learning-based Retrieval-Augmented Generation (OnRL-RAG) system to detect and personalize the responding systems to mental health problems, such as stress, anxiety, and depression. We use an open-source dataset collected from 2028 College Students with 28 survey questions for each student to demonstrate the performance of our proposed system with the existing systems. Our system achieves superior performance compared to standard RAG and simple LLM via GPT-4o, GPT-4o-mini, Gemini-1.5, and GPT-3.5. This work would open up the possibilities of real-life applications of LLMs for personalized services in the everyday environment. The results will also help researchers in the fields of sociology, psychology, and neuroscience to align their theories more closely with the actual human daily environment.
大型语言模型(LLM)已广泛应用于各种任务和应用。然而,LLM和微调都受限于预训练数据。例如,ChatGPT截至2021年的世界知识可能会过时或不准确。为了增强LLM的能力,提出了检索增强生成(RAG)来向LLM添加额外、最新、最新的细节和信息。虽然RAG提供了正确的信息,但它可能无法最好地呈现它,尤其是对于具有个性化的不同人群。强化学习从人类反馈(RLHF)通过反馈循环使模型响应与人类偏好相适应,从而适应用户需求。在现实生活应用,如心理健康问题中,一个动态且基于反馈的模型将不断适应新信息,并提供个性化的帮助,这是由于日常环境中复杂因素的波动。因此,我们提出了基于在线强化学习的检索增强生成(OnRL-RAG)系统,用于检测和个性化应对心理健康问题,如压力、焦虑和抑郁。我们使用从2028名大学生收集的开源数据集进行演示,每个学生回答了28个问题,以展示我们提出的系统与现有系统的性能。我们的系统相较于标准RAG和简单的LLM(如GPT-4o、GPT-4o-mini、Gemini-1.5和GPT-3.5)表现出卓越的性能。这项工作将为LLM在个性化服务方面的现实生活应用开辟可能性,日常环境中的应用。此外,该研究还将帮助社会学、心理学和神经科学领域的研究人员将他们的理论与实际人类日常环境更加紧密地结合起来。
论文及项目相关链接
Summary
大型语言模型(LLMs)广泛应用于各种任务和应用,但其知识和能力受限于预训练数据。为增强LLMs的能力,提出了检索增强生成(RAG)方法,但RAG可能无法最佳地呈现信息,尤其对不同人群个性化的需求。因此,结合强化学习人类反馈(RLHF)的在线强化学习基于检索增强生成(OnRL-RAG)系统被提出,以检测并个性化响应精神健康问题,如压力、焦虑和抑郁。使用从28所高校收集的开源数据集,展示了该系统的优越性。这一研究为LLMs在个性化服务方面的实际应用打开了可能性,并将帮助社会学、心理学和神经科学领域的研究者更好地将理论应用于实际环境。
Key Takeaways
- 大型语言模型(LLMs)受限于预训练数据的知识和能力。
- 检索增强生成(RAG)方法用于增强LLMs的能力,提供额外的最新信息。
- RAG可能无法最佳地呈现信息,尤其对不同人群的个性化需求。
- 提出结合强化学习人类反馈(RLHF)的在线强化学习基于检索增强生成(OnRL-RAG)系统。
- OnRL-RAG系统用于检测并个性化响应精神健康问题,如压力、焦虑和抑郁。
- 使用从高校收集的开源数据集展示了OnRL-RAG系统的优越性。
点此查看论文截图

GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
Authors:Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, Yong Wang
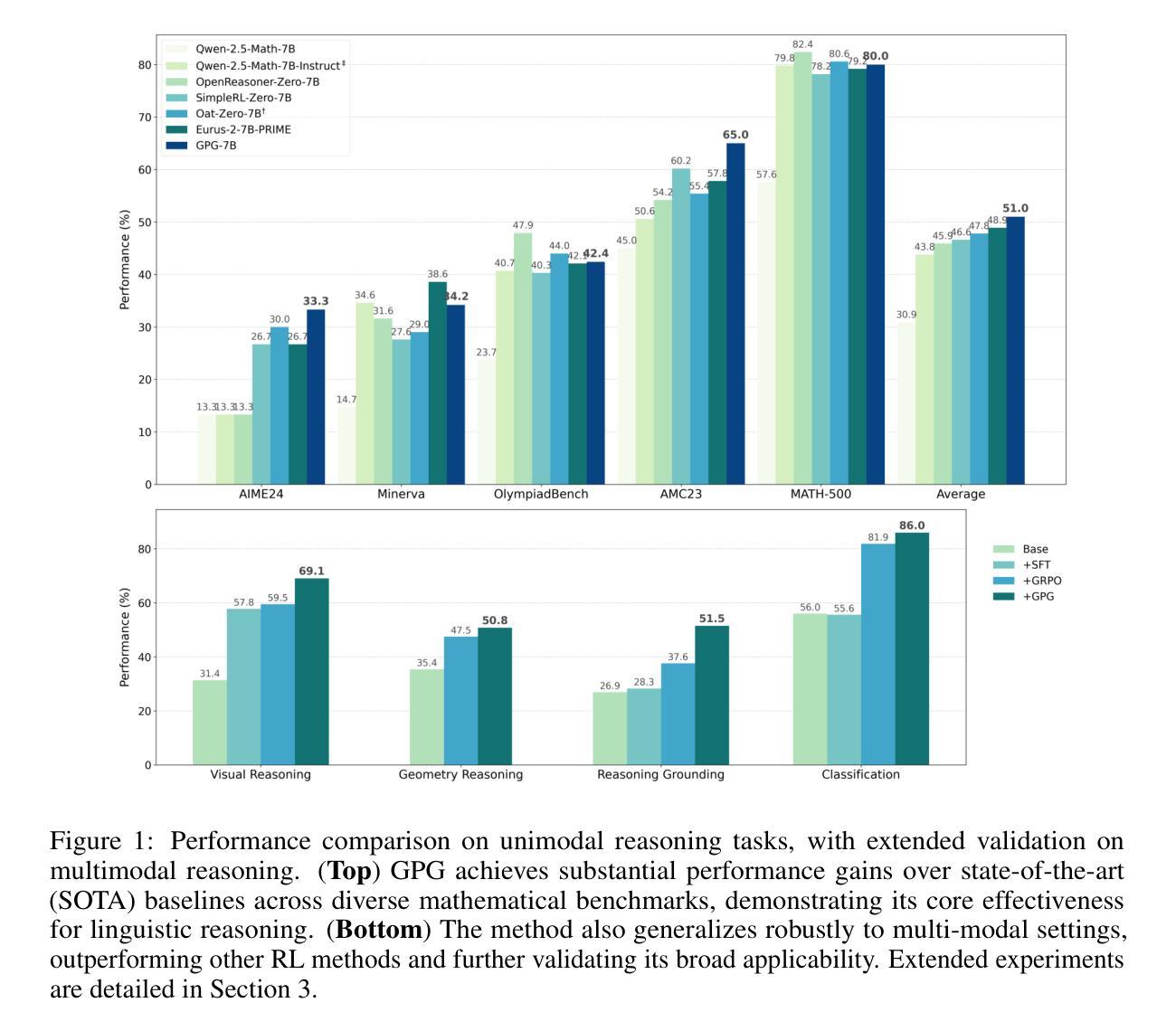
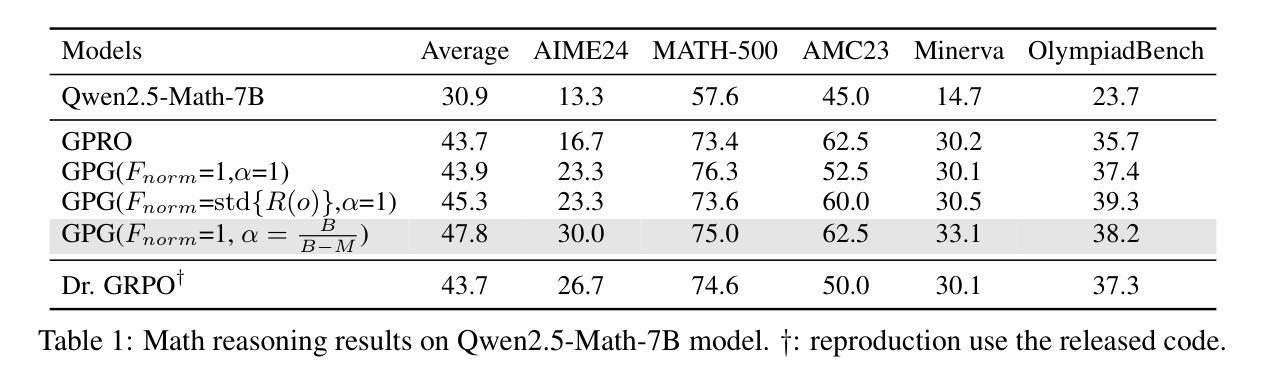
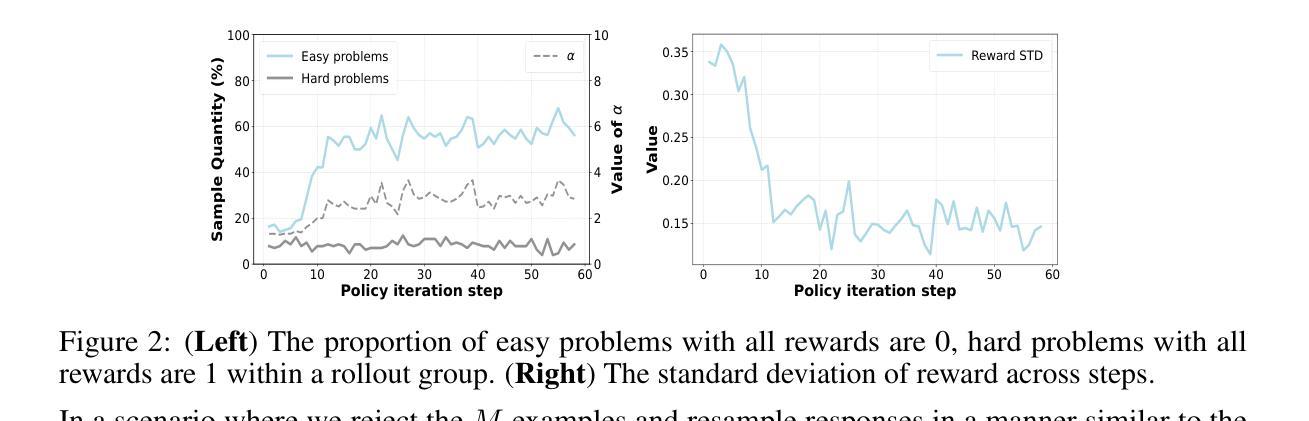
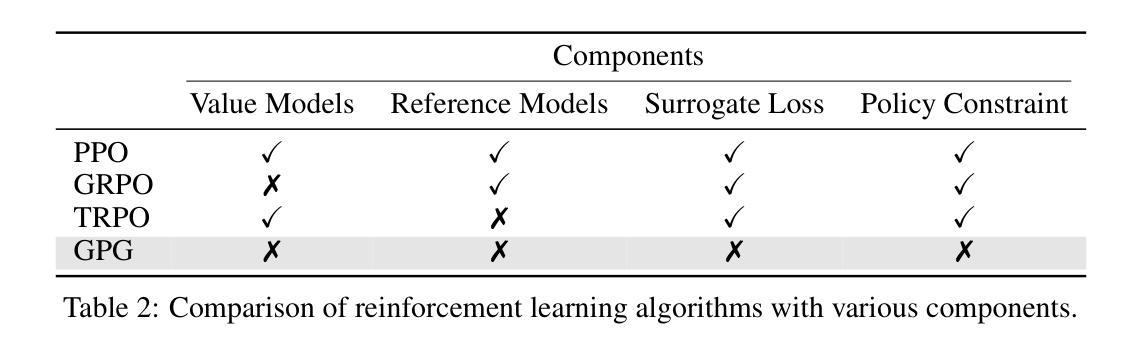
Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. By eliminating the critic and reference models, avoiding KL divergence constraints, and addressing the advantage and gradient estimation bias, our approach significantly simplifies the training process compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. As illustrated in Figure 1, extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.
强化学习(RL)可以直接提升大语言模型的推理能力,而无需过多依赖监督微调(SFT)。在这项工作中,我们重新审视了传统的策略梯度(PG)机制,并提出了一种极简的RL方法,称为组策略梯度(GPG)。不同于传统方法,GPG直接优化原始的RL目标,从而无需替代损失函数。通过消除评论家模型和参考模型,避免KL散度约束,并解决优势和梯度估计偏差的问题,我们的方法大大简化了与组相对策略优化(GRPO)相比的训练过程。我们的方法在不依赖辅助技术或调整的情况下实现了卓越的性能。如图1所示,大量实验证明,我们的方法不仅降低了计算成本,而且在各种单模态和多模态任务上始终优于GRPO。我们的代码可在https://github.com/AMAP-ML/GPG上找到。
论文及项目相关链接
Summary
强化学习(RL)可以直接提升大语言模型的推理能力,无需过多依赖监督微调(SFT)。本研究重新审视了传统的策略梯度(PG)机制,并提出了一种极简的RL方法——群组策略梯度(GPG)。GPG直接优化原始的RL目标,从而无需替代损失函数。通过消除评论家模型和参考模型,避免KL散度约束,并解决优势和梯度估计偏差问题,GPG简化了与群组相对策略优化(GRPO)相比的训练过程。在不依赖辅助技术或调整的情况下,我们的方法实现了卓越的性能。如图1所示,大量实验证明,我们的方法不仅降低了计算成本,而且在各种单模态和多模态任务上始终优于GRPO。
Key Takeaways
- 强化学习(RL)能够增强大语言模型的推理能力,且不需要过度依赖监督微调。
- 提出了一种新的RL方法——群组策略梯度(GPG),该方法直接优化原始的RL目标。
- GPG简化了训练过程,与其他方法相比,它不需要使用替代损失函数、评论家模型和参考模型。
- GPG解决了优势和梯度估计偏差问题。
- GPG在多种任务上表现出卓越性能,包括单模态和多模态任务。
- GPG方法降低了计算成本。
点此查看论文截图

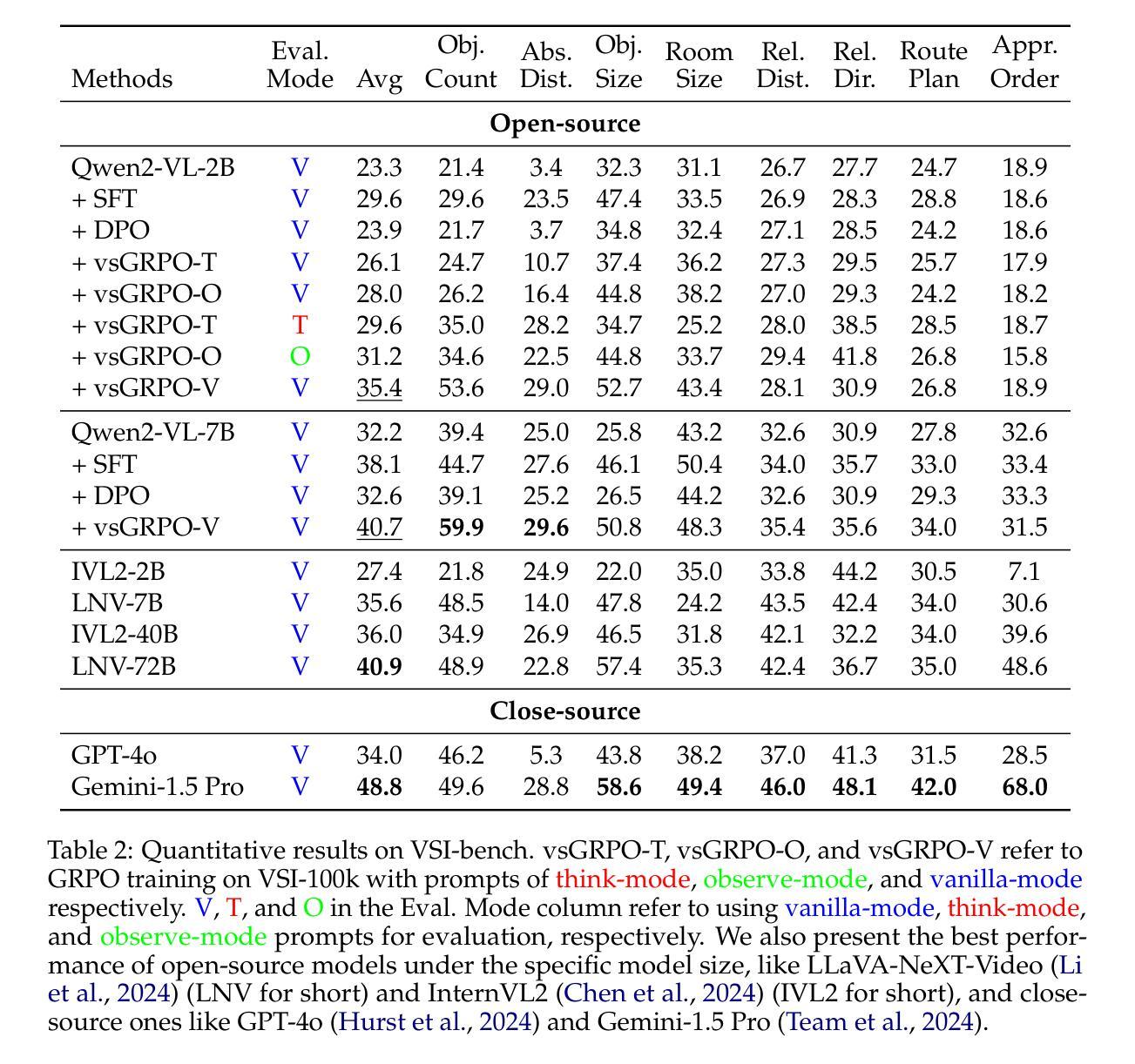
Improved Visual-Spatial Reasoning via R1-Zero-Like Training
Authors:Zhenyi Liao, Qingsong Xie, Yanhao Zhang, Zijian Kong, Haonan Lu, Zhenyu Yang, Zhijie Deng
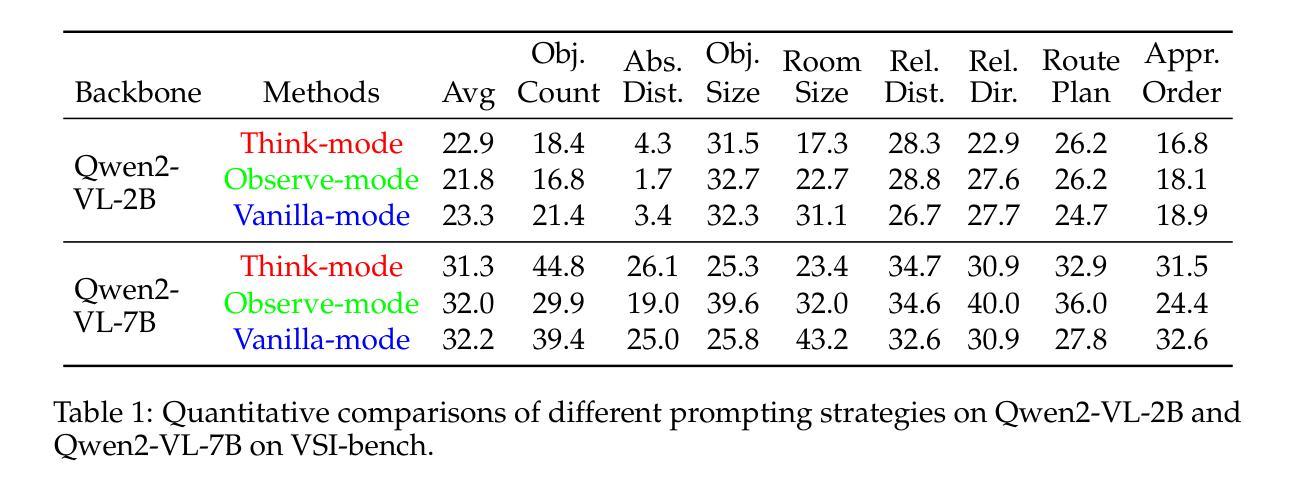
Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
近年来,提高多模态大型语言模型(MLLMs)的推理能力越来越受到关注。作为在物理领域发挥作用的AI代理的基石,基于视频的视觉空间智能(VSI)被认为是MLLMs中最关键的推理能力之一。本研究首次深入探讨了通过R1-Zero类似的训练提高MLLMs的视觉空间推理能力。从技术上讲,我们首先发现小型到中型Qwen2-VL模型的视觉空间推理能力无法通过思维链(CoT)提示来激活。然后,我们采用GRPO训练法来提高视觉空间推理能力,使用精心制作的VSI-100k数据集,遵循DeepSeek-R1-Zero。在研究过程中,我们发现需要在GRPO中保持KL惩罚(即使值很小)。只需120个GPU小时,我们的vsGRPO-2B模型,在Qwen2-VL-2B的基础上进行了微调,性能比基础模型提高了12.1%,并超越了GPT-4o。此外,我们的vsGRPO-7B模型,在Qwen2-VL-7B的基础上进行微调,其性能与最佳开源模型LLaVA-NeXT-Video-72B相当。此外,我们将vsGRPO与监督微调法和直接偏好优化基准线进行了比较,并观察到其性能优势显著。代码和数据集将很快可用。
论文及项目相关链接
Summary
随着多模态大型语言模型(MLLMs)的推理能力日益受到关注,基于视频的空间视觉智能(VSI)作为实体AI代理的核心,成为了MLLMs的关键推理能力之一。本研究通过R1-Zero类似的训练首次深入探讨了增强MLLMs的视觉空间推理能力。研究中发现中小型Qwen2-VL模型的视觉空间推理能力无法通过思维链(CoT)提示激活,于是采用了GRPO训练结合精心筛选的VSI-100k数据集以增强其视觉空间推理能力,并认同了在GRPO中保持KL惩罚的必要性。研究结果显示,使用GPU仅120小时,vsGRPO-2B模型性能优于基础模型达12.1%,超越GPT-4o;而vsGRPO-7B模型则实现了与顶尖开源模型LLaVA-NeXT-Video-72B相当的绩效。研究还将vsGRPO与监督微调及直接偏好优化基线进行了比较,显示出其卓越性能。代码和数据集即将公布。
**Key Takeaways**
一、视频型视觉空间智能是AI实体代理在物理领域中的核心技能之一,对多模态大型语言模型(MLLMs)的推理能力至关重要。
二、研究使用GRPO训练方法提高MLLMs的视觉空间推理能力,通过精心筛选的VSI-100k数据集进行训练。
三、研究发现中小型Qwen2-VL模型的视觉空间推理能力无法通过思维链(CoT)提示激活。
四、KL惩罚在GRPO训练中必要,对模型的性能影响显著。
五、使用仅有限的计算资源(GPU仅运行120小时),vsGRPO训练模型性能显著提高,超越了一些现有模型。
六、研究验证了vsGRPO训练方法的优越性,与监督微调及直接偏好优化基线相比表现突出。
七、代码和数据集即将公开以供研究使用。
点此查看论文截图



UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
Authors:Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, Hongsheng Li
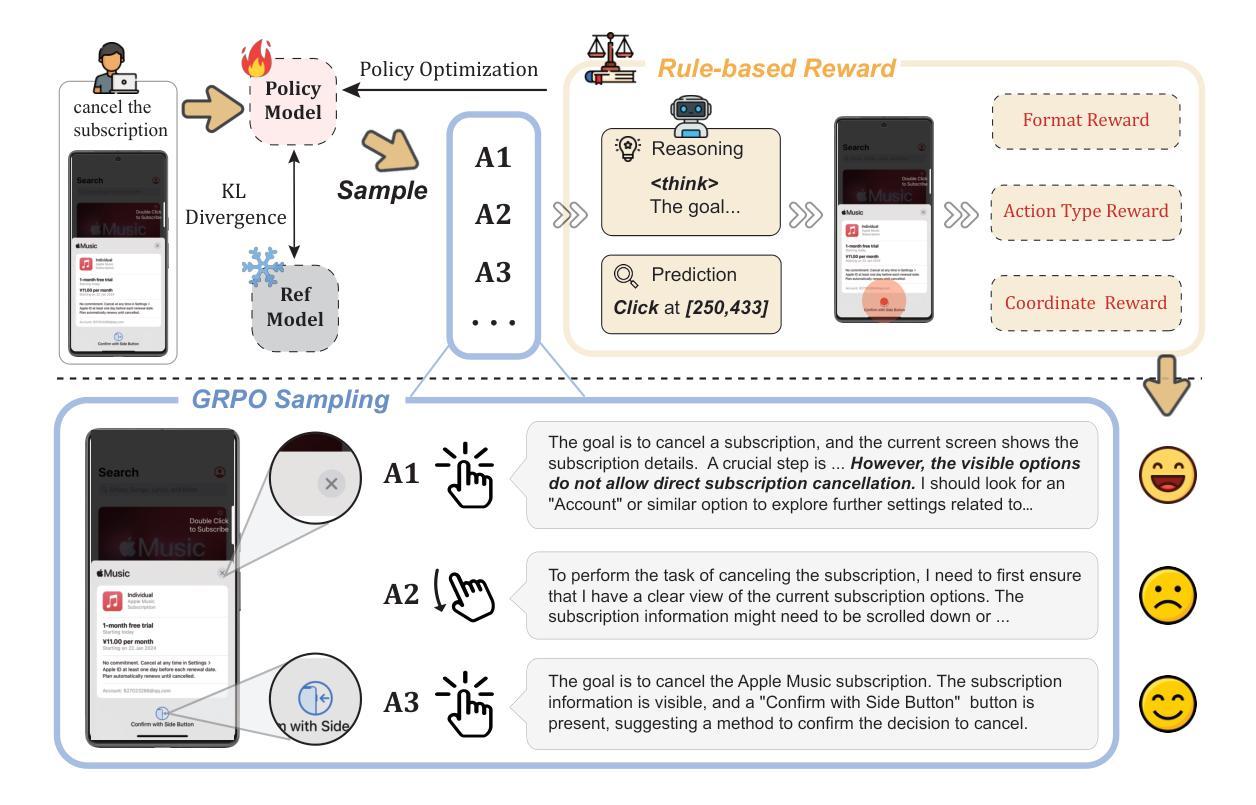
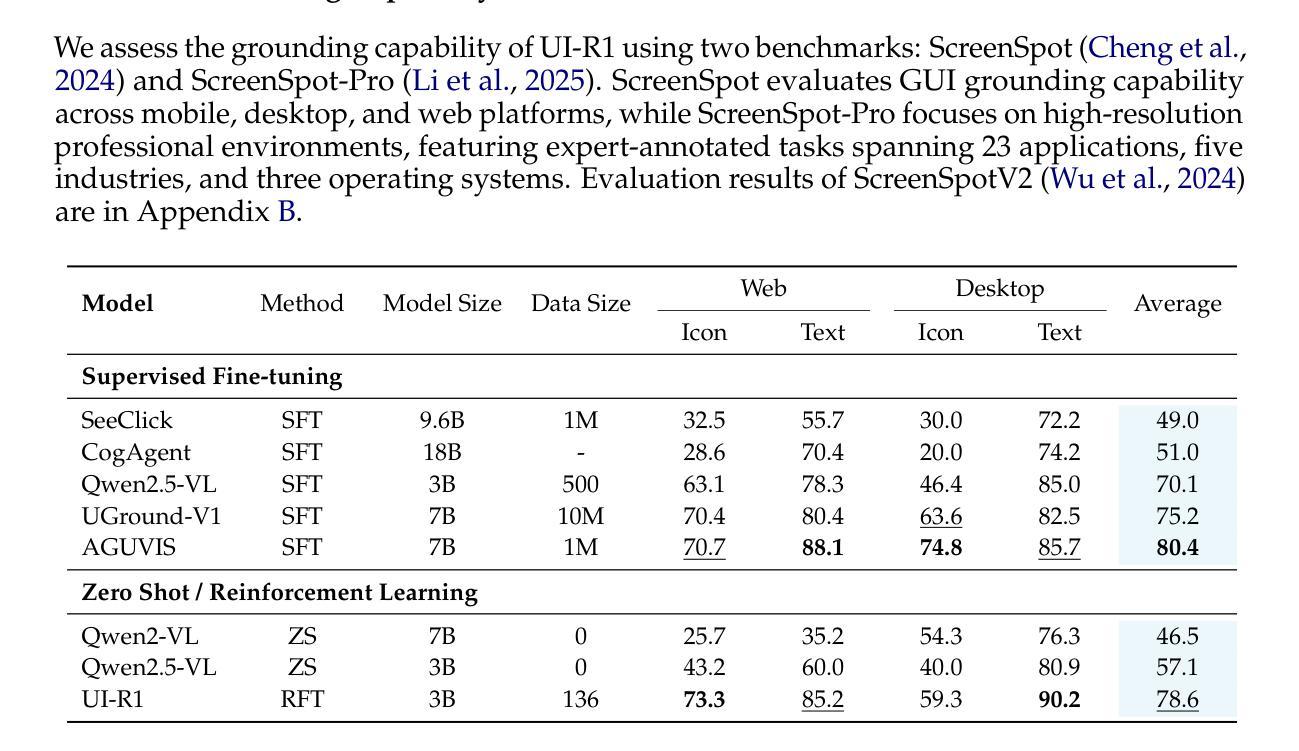
The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Despite its success in language models, its application in multi-modal domains, particularly in graphic user interface (GUI) agent tasks, remains under-explored. To address this issue, we propose UI-R1, the first framework to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for GUI action prediction tasks. Specifically, UI-R1 introduces a novel rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). For efficient training, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. Experimental results demonstrate that our proposed UI-R1-3B achieves significant improvements over the base model (i.e. Qwen2.5-VL-3B) on both in-domain (ID) and out-of-domain (OOD) tasks, with average accuracy gains of 22.1% on ScreenSpot, 6.0% on ScreenSpot-Pro, and 12.7% on ANDROIDCONTROL. Furthermore, UI-R1-3B delivers competitive performance compared to larger models (e.g., OS-Atlas-7B) trained via supervised fine-tuning (SFT) on 76K samples. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain. Code website: https://github.com/lll6gg/UI-R1.
最近,DeepSeek-R1展示了通过基于规则的奖励强化学习(RL)在大语言模型(LLM)中出现的推理能力。尽管其在语言模型方面取得了成功,但在多模态领域,特别是在图形用户界面(GUI)代理任务中的应用仍然未被充分探索。为了解决这个问题,我们提出了UI-R1,这是第一个探索基于规则的RL如何增强多模态大型语言模型(MLLM)的推理能力以执行GUI动作预测任务的框架。具体来说,UI-R1引入了一种新型的基于动作的规则奖励,通过基于策略算法(如Group Relative Policy Optimization(GRPO))优化模型。为了进行有效的训练,我们整理了一个包含136个具有挑战性的任务的小型高质量数据集,涵盖移动设备上的五种常见动作类型。实验结果表明,我们提出的UI-R1-3B相较于基准模型(即Qwen2.5-VL-3B)在领域内(ID)和领域外(OOD)的任务上都取得了显著的提升,在ScreenSpot上的平均精度提高了22.1%,在ScreenSpot-Pro上提高了6.0%,在ANDROIDCONTROL上提高了12.7%。此外,与在7.6万个样本上通过监督微调(SFT)训练的更大模型(如OS-Atlas-7B)相比,UI-R1-3B表现出具有竞争力的性能。这些结果突显了基于规则的强化学习在GUI理解和控制方面的潜力,为未来的研究铺平了道路。相关代码网站为:https://github.com/lll6gg/UI-R1。
论文及项目相关链接
Summary
近期DeepSeek-R1展示了强化学习(RL)通过基于规则的奖励在大型语言模型(LLM)中推动推理能力的发展。然而,其在多模态领域,特别是在图形用户界面(GUI)代理任务中的应用仍待探索。为此,我们提出UI-R1框架,首次探索基于规则的强化学习如何增强多模态大型语言模型(MLLMs)在GUI动作预测任务中的推理能力。实验结果表明,UI-R1在特定数据集上较基础模型有显著改进,并在不同任务上展现出强大的性能。此外,UI-R1模型的性能表现甚至可与采用监督微调的大型模型相比。这预示着基于规则的强化学习在GUI理解和控制方面的巨大潜力。代码公开于GitHub网站。
Key Takeaways
- DeepSeek-R1展示了强化学习在大型语言模型中的推理能力。
- 基于规则的强化学习在多模态领域的应用,特别是在GUI代理任务中,仍然是一个未充分探索的领域。
- UI-R1框架被提出用于增强多模态大型语言模型在GUI动作预测任务中的推理能力。
- UI-R1引入了一种新的基于规则的行动奖励,通过策略优化算法(如GRPO)进行模型优化。
- 实验结果显示,UI-R1在特定数据集上的性能较基础模型有显著改善,并在不同任务上展现出显著优势。
- UI-R1的性能与采用监督微调的大型模型相比具有竞争力。
点此查看论文截图

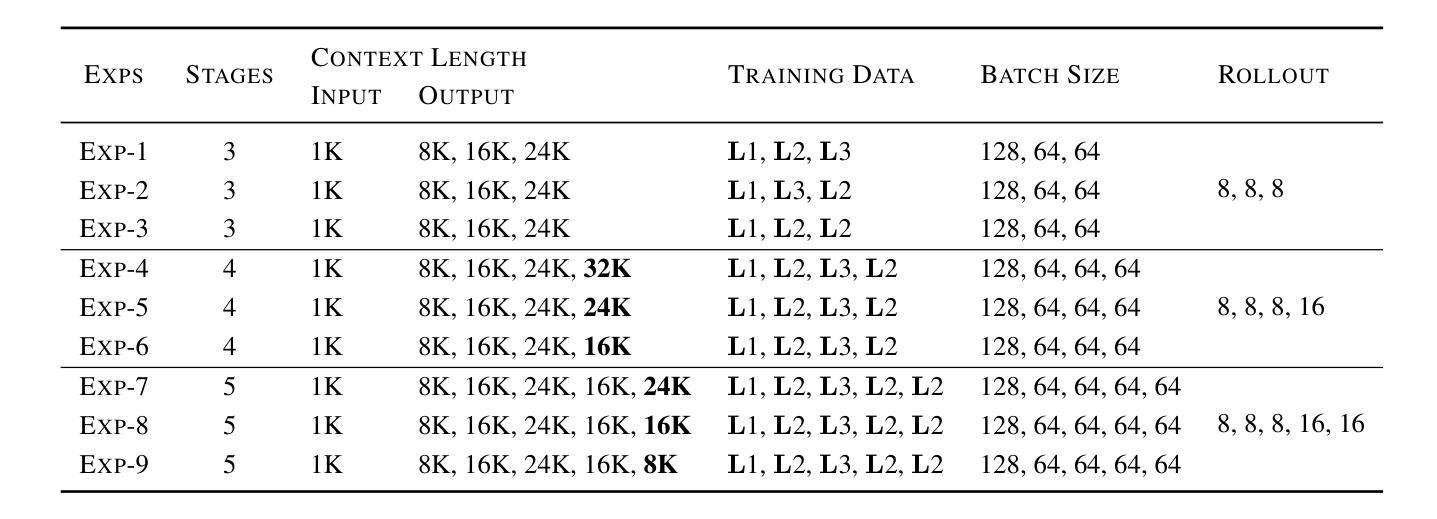
FastCuRL: Curriculum Reinforcement Learning with Progressive Context Extension for Efficient Training R1-like Reasoning Models
Authors:Mingyang Song, Mao Zheng, Zheng Li, Wenjie Yang, Xuan Luo, Yue Pan, Feng Zhang
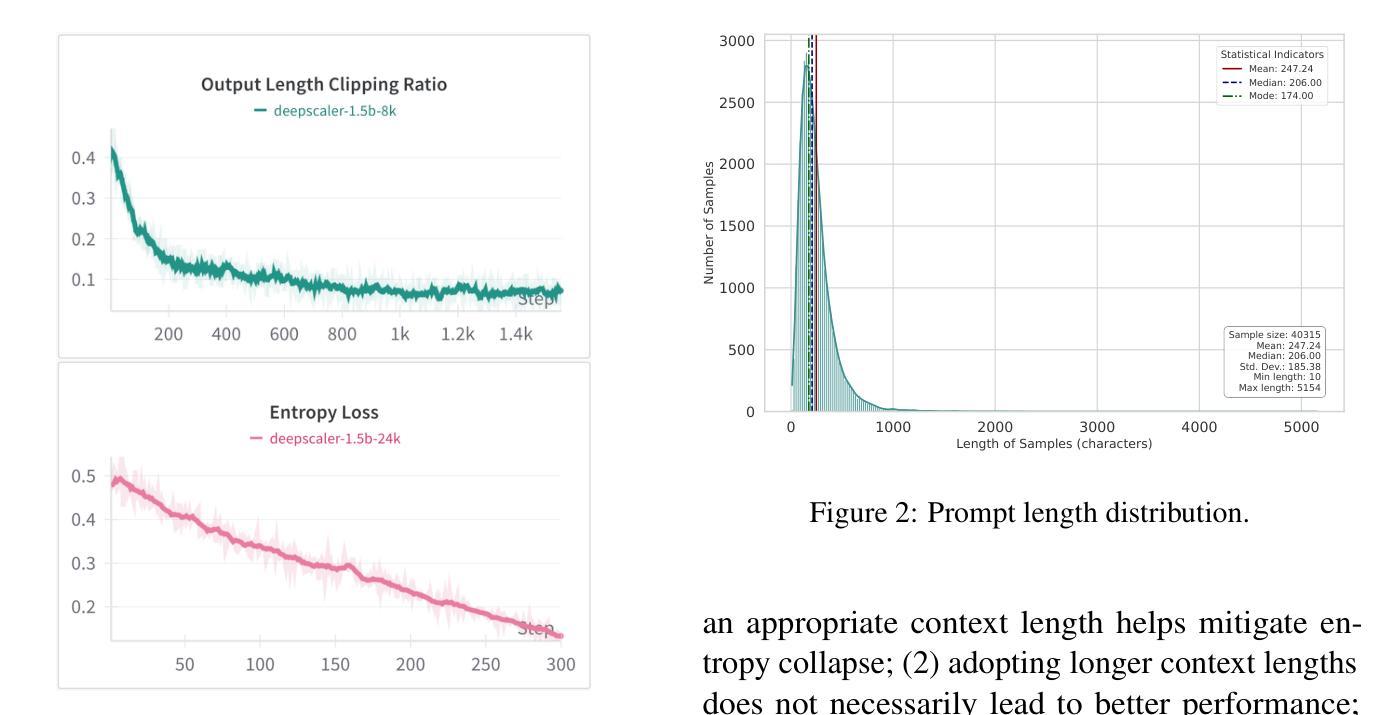
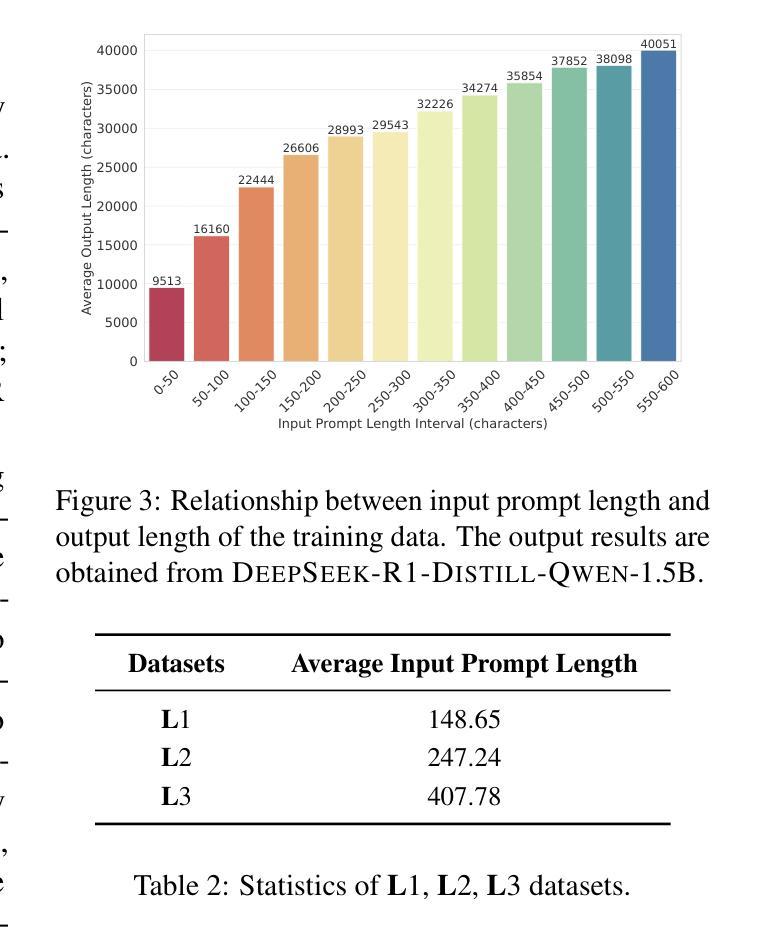
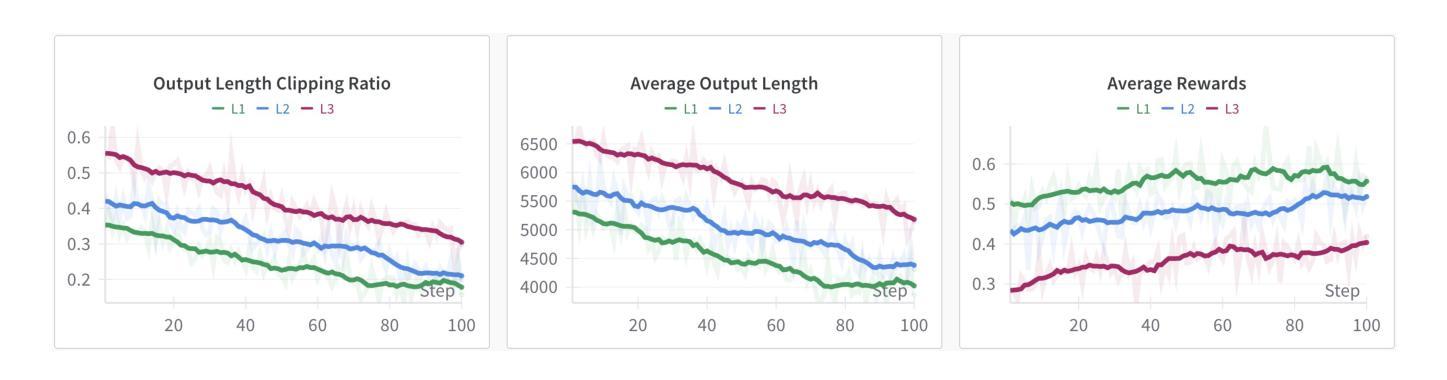
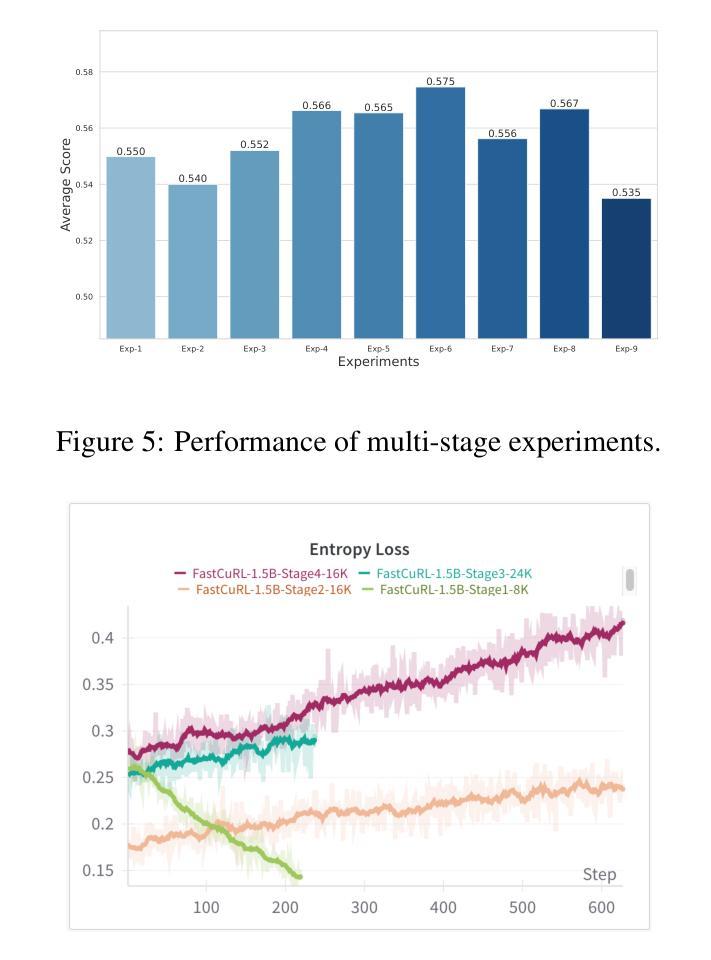
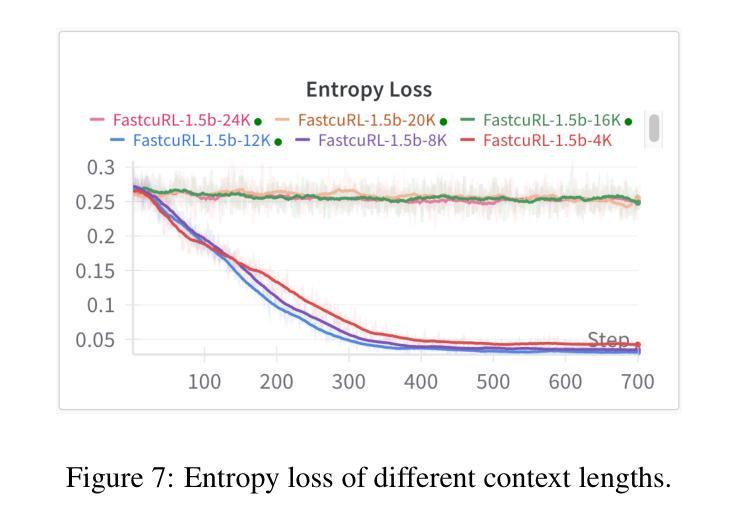
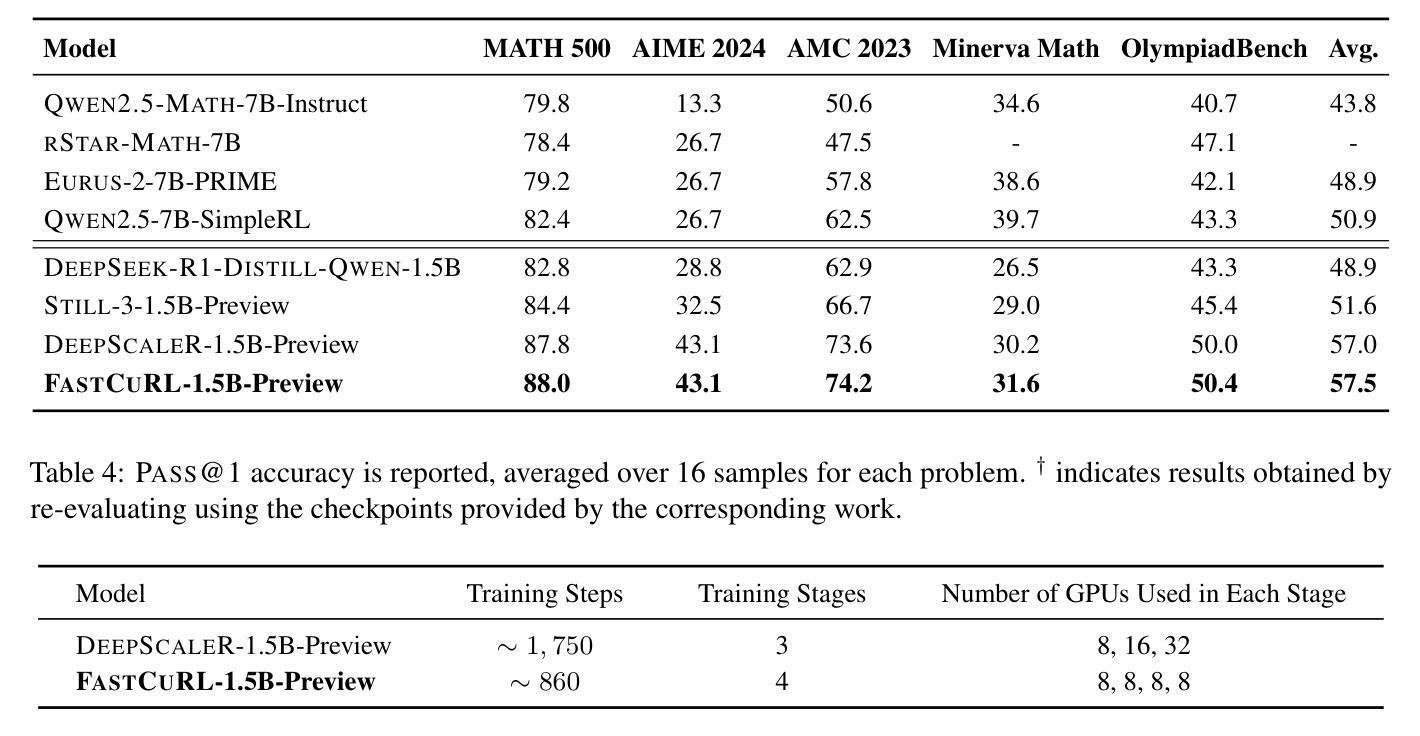
Improving the training efficiency remains one of the most significant challenges in large-scale reinforcement learning. In this paper, we investigate how the model’s context length and the complexity of the training dataset influence the training process of R1-like models. Our experiments reveal three key insights: (1) adopting longer context lengths may not necessarily result in better performance; (2) selecting an appropriate context length helps mitigate entropy collapse; and (3) appropriately controlling the model’s context length and curating training data based on input prompt length can effectively improve RL training efficiency, achieving better performance with shorter thinking length. Inspired by these insights, we propose FastCuRL, a curriculum reinforcement learning framework with the progressive context extension strategy, and successfully accelerate the training process of RL models. Experimental results demonstrate that FastCuRL-1.5B-Preview surpasses DeepScaleR-1.5B-Preview across all five benchmarks while only utilizing 50% of training steps. Furthermore, all training stages for FastCuRL-1.5B-Preview are completed using a single node with 8 GPUs.
在大规模强化学习中,提高训练效率仍然是最大的挑战之一。在本文中,我们研究了模型的上下文长度和训练数据集复杂度对R1类似模型训练过程的影响。我们的实验揭示了三个关键见解:(1)采用更长的上下文长度并不一定能够带来更好的性能;(2)选择合适的上下文长度有助于缓解熵崩溃;(3)适当地控制模型的上下文长度,并根据输入提示长度筛选训练数据,可以有效地提高RL训练效率,以更短的思考长度实现更好的性能。受到这些见解的启发,我们提出了FastCuRL,这是一个带有渐进式上下文扩展策略的课程强化学习框架,成功加速了RL模型的训练过程。实验结果表明,FastCuRL-1.5B-Preview在所有五个基准测试中均超越了DeepScaleR-1.5B-Preview,而且仅使用了50%的训练步骤。此外,FastCuRL-1.5B-Preview的所有训练阶段均使用单个节点和8个GPU完成。
论文及项目相关链接
PDF Ongoing Work
Summary
大型强化学习训练效率的提升是一大挑战。本文通过实验探讨了模型上下文长度与训练数据集复杂度对R1类模型训练过程的影响,得到以下三个关键见解:一是增加上下文长度不一定能提高性能;二是选择适当的上下文长度有助于缓解熵崩溃;三是通过控制模型上下文长度并根据输入提示长度整理训练数据,可以有效提高强化学习训练效率,实现更短的思考长度下更好的性能。基于这些见解,本文提出了带有渐进式上下文扩展策略的FastCuRL强化学习框架,成功加速了RL模型的训练过程。实验结果显示,FastCuRL-1.5B-Preview在所有五个基准测试中均超过了DeepScaleR-1.5B-Preview,且其所有训练阶段均使用单个节点8 GPU完成。
Key Takeaways
- 模型上下文长度与训练数据集复杂度对强化学习模型训练效率有影响。
- 增加上下文长度并不一定提升模型性能。
- 选择合适的上下文长度有助于缓解熵崩溃问题。
- 控制模型上下文长度并整理训练数据能有效提高强化学习训练效率。
- FastCuRL框架通过渐进式上下文扩展策略成功加速了RL模型的训练。
- FastCuRL-1.5B-Preview在多个基准测试中表现优于DeepScaleR-1.5B-Preview。
点此查看论文截图

Think or Not Think: A Study of Explicit Thinking in Rule-Based Visual Reinforcement Fine-Tuning
Authors:Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Kaipeng Zhang
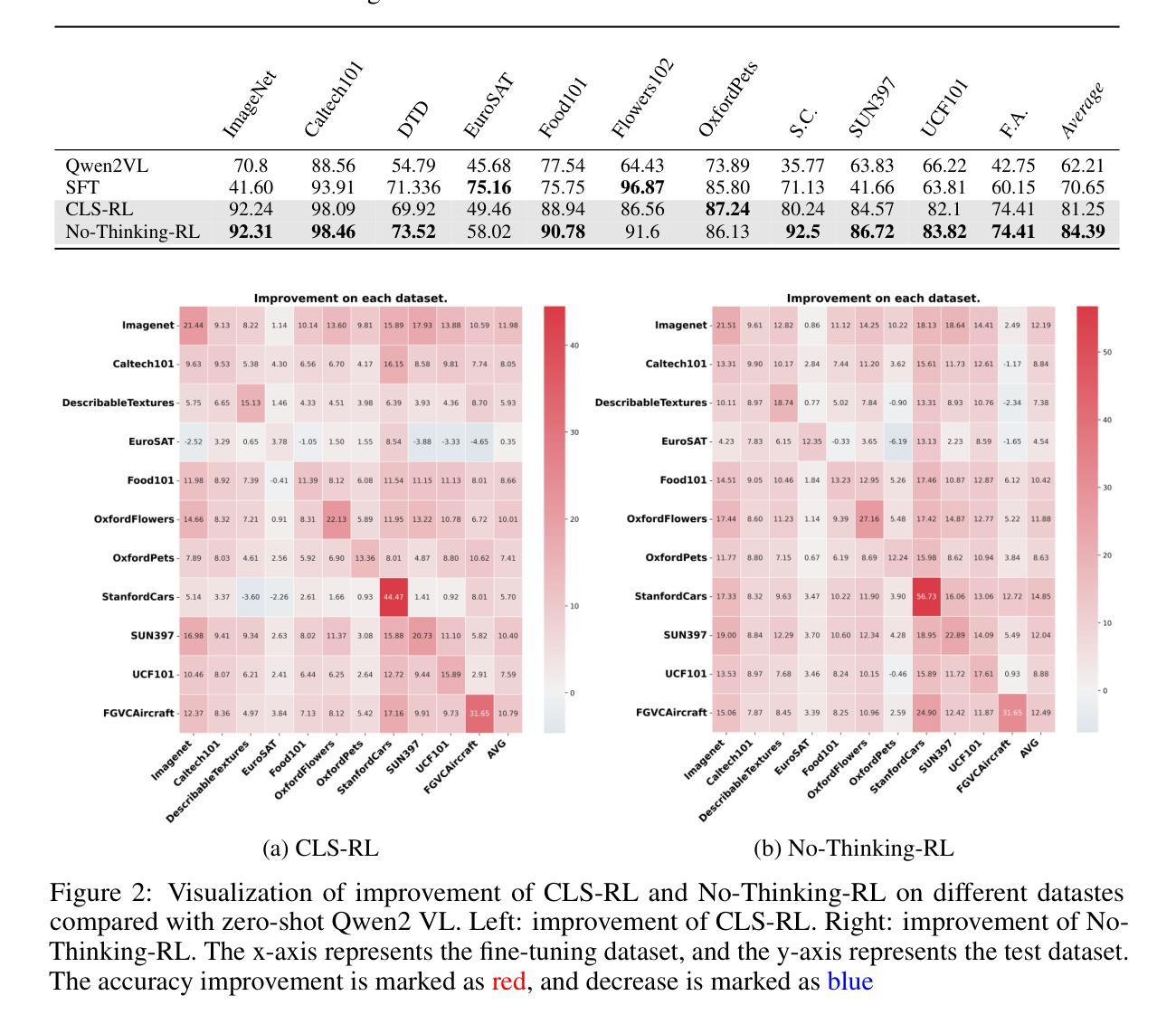
This paper investigates the thinking process in rule-based reinforcement learning fine-tuning (RFT) for multi-modal large language models (MLLMs). We first propose CLS-RL for classification, using verifiable rewards to encourage MLLM thinking. Experiments show CLS-RL significantly outperforms SFT and yields a ‘free-lunch’ generalization effect (improving performance on unseen datasets after training on one dataset). We then question if this explicit thinking is always necessary for RFT. Challenging convention that explicit thinking is crucial for RFT, we introduce No-Thinking-RL, minimizing thinking via a simple equality accuracy reward. Experiments show No-Thinking-RL surpasses CLS-RL in in-domain and generalization abilities, with significantly less fine-tuning time. This suggests reducing thinking can improve MLLM fine-tuning efficiency and effectiveness for certain visual tasks. We hypothesize explicit thinking negatively impacts reward convergence during RFT. To test this, we propose the Think-After-Answerwer method to let models first output the answer and then generate thinking process to alliviate the negative impact of thinking. We further test No-Thinking-RL on diverse tasks (including math, spatial, puzzles) with 2B and 7B models. For 2B models, No-Thinking-RL outperforms thinking-based RFT for all tasks, even on math, with Think-After-Answerwer performing intermediately. For 7B models, performance is comparable on simple visual tasks, but RFT with thinking excels on complex reasoning (math). This implies when dealing with complex math problems, smaller models struggle with generating effective reasoning, hurting performance on complex tasks. Conversely, for simple visual tasks, thinking is not indispensable, and its removal can boost performance and reduce training time. We hope our findings offer insights for better understanding the effect of the thinking process in RFT.
本文探讨了基于规则强化学习微调(RFT)在多模态大型语言模型(MLLMs)中的思考过程。我们首先提出用于分类的CLS-RL,使用可验证的奖励来鼓励MLLM思考。实验表明,CLS-RL显著优于SFT,并产生了“免费午餐”的泛化效果(在单个数据集上进行训练后,在未见数据集上提高了性能)。然后,我们质疑这种明确的思考对于RFT是否始终必要。我们挑战认为明确思考对于RFT至关重要的传统观念,并引入了无思考强化学习(No-Thinking-RL),通过简单的等式准确性奖励来减少思考。实验表明,在领域内部和泛化能力方面,无思考强化学习超越了CLS-RL,并且微调时间大大减少。这表明在某些视觉任务中,减少思考可以提高MLLM微调的有效性和效率。我们假设明确的思考会对RFT期间的奖励收敛产生负面影响。为了测试这一点,我们提出了Think-After-Answerwer方法,让模型先给出答案,然后生成思考过程,以减轻思考带来的负面影响。我们还进一步在不同的任务(包括数学、空间、谜题)上测试了无思考强化学习,使用了2B和7B模型。对于2B模型,无思考强化学习在所有任务上的表现都优于基于思考的RFT,甚至在数学上也如此,而Think-After-Answerwer的表现处于中间水平。对于7B模型,在简单的视觉任务上表现相当,但在复杂推理(数学)方面,带有思考的RFT表现更好。这意味着在处理复杂的数学问题时,较小的模型在生成有效推理方面遇到困难,影响了复杂任务的性能。相反,对于简单的视觉任务,思考并不是必不可少的,而且移除思考可以提高性能并减少训练时间。我们希望我们的研究能为更好地理解RFT中思考过程的影响提供启示。
论文及项目相关链接
PDF Preprint, work in progress. Add results on math, cvbench, and puzzle
Summary
这篇论文探讨了基于规则的强化学习微调(RFT)在多模态大型语言模型(MLLMs)中的思考过程。研究首先提出了用于分类的CLS-RL方法,使用可验证的奖励来鼓励MLLM思考。实验表明CLS-RL显著优于SFT,并产生了“免费午餐”式的泛化效果。然而,研究也质疑RFT是否总是需要明确的思考。通过引入不需要思考的No-Thinking-RL方法,该方法通过简单的准确性奖励来最小化思考,实验表明其在域内和泛化能力上超越了CLS-RL,且微调时间大大减少。这表明在某些视觉任务中,减少思考可以提高MLLM的微调效率和效果。同时提出假设认为明确思考会影响奖励收敛过程,并提出Think-After-Answerwer方法来减轻其负面影响。通过对不同任务的测试表明,对于简单视觉任务,不需要思考可以提高性能和减少训练时间;而对于复杂任务如数学推理,思考则更为关键。
Key Takeaways
- CLS-RL方法利用可验证奖励鼓励MLLM模型思考,显著优于SFT,并产生泛化效果。
- No-Thinking-RL方法通过最小化思考来提高MLLM的微调效率和效果,特别是对于某些视觉任务。
- 明确思考对奖励收敛过程有负面影响,可能导致训练效率降低。
- Think-After-Answerwer方法旨在减轻思考对奖励收敛的负面影响。
- 对于简单视觉任务,不需要思考可以提高性能和减少训练时间;而对于复杂任务如数学推理,则需要思考过程以产生更好的性能。
- 对于不同的任务规模和类型(如数学、空间、谜题等),No-Thinking-RL的表现有所不同。对于较小的模型,它在简单任务上的表现优于带有思考过程的RFT;而对于复杂的数学任务,带有思考过程的RFT表现更好。
点此查看论文截图

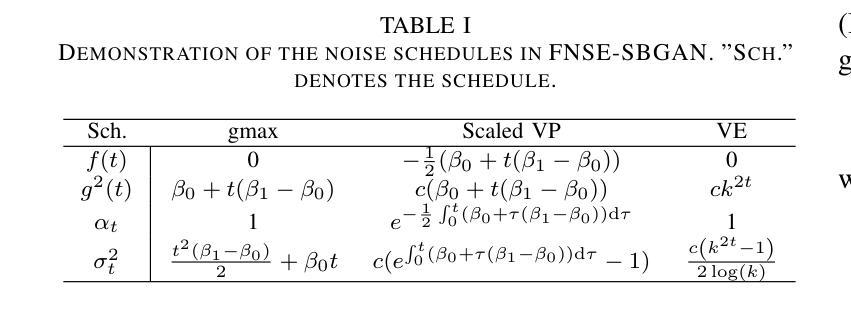
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Authors:Tong Lei, Qinwen Hu, Ziyao Lin, Andong Li, Rilin Chen, Meng Yu, Dong Yu, Jing Lu
The prevailing method for neural speech enhancement predominantly utilizes fully-supervised deep learning with simulated pairs of far-field noisy-reverberant speech and clean speech. Nonetheless, these models frequently demonstrate restricted generalizability to mixtures recorded in real-world conditions. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce an evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
当前神经网络语音增强的主流方法主要利用模拟的远场带噪声和回响的语音与干净语音配对进行全监督深度学习。然而,这些模型在现实条件下录制的混合音上通常表现出有限的泛化能力。为解决此问题,本研究旨在直接在实际混合音上训练增强模型。具体来说,我们重新审视单通道远场到近场语音增强(FNSE)任务,重点关注现实世界数据的特点,如低信噪比(SNR)、高回响以及中到高频衰减。我们提出了FNSE-SBGAN框架,它融合了基于Schrodinger Bridge(SB)的扩散模型与生成对抗网络(GANs)。我们的方法在各种指标和主观评价上均达到了最先进的性能,与远场信号相比,字符错误率(CER)降低了高达14.58%。实验结果表明,FNSE-SBGAN保持了出色的主观质量,为现实世界的远场语音增强建立了新的基准。此外,我们还引入了一个利用时频域矩阵秩分析的评价框架,为模型性能提供了系统的见解,揭示了不同生成方法的优势和劣势。
论文及项目相关链接
PDF 13 pages, 6 figures
Summary
本文主要研究了神经网络语音增强的现有方法,主要采用基于模拟远场噪声回荡语音和干净语音配对的全监督深度学习。然而,这些模型在真实条件下的混合录音中通常表现出一般化能力受限的问题。为解决这一问题,本研究直接对真实混合进行训练增强模型。针对低信噪比、高回声和中等至高频衰减等真实世界数据特点的单通道远场到近场语音增强(FNSE)任务进行深入研究。提出一种基于Schrodinger Bridge(SB)扩散模型与生成对抗网络(GANs)结合的FNSE-SBGAN框架。该方法在各种指标和主观评估上取得了最先进的性能,与远场信号相比,字符错误率(CER)降低了高达14.58%。实验结果表明,FNSE-SBGAN保留了较高的主观质量,为真实世界的远场语音增强建立了新的基准。此外,本研究还引入了一种基于矩阵秩分析的时间-频率域评估框架,为模型性能提供了系统的见解,揭示了不同生成方法的优势和劣势。
Key Takeaways
- 神经网络语音增强主要使用全监督深度学习模拟配对远场噪声回荡语音和干净语音。
- 当前模型在真实条件下的混合录音中表现一般化能力受限。
- 研究提出一种新型的语音增强模型FNSE-SBGAN,结合了Schrodinger Bridge扩散模型和生成对抗网络。
- FNSE-SBGAN在各项指标和主观评估上取得了先进性能,显著降低了字符错误率。
- FNSE-SBGAN保留了较高的主观质量,为真实世界的远场语音增强建立了新的基准。
- 引入了一种基于矩阵秩分析的时间-频率域评估框架,提供模型性能的系统见解。
点此查看论文截图

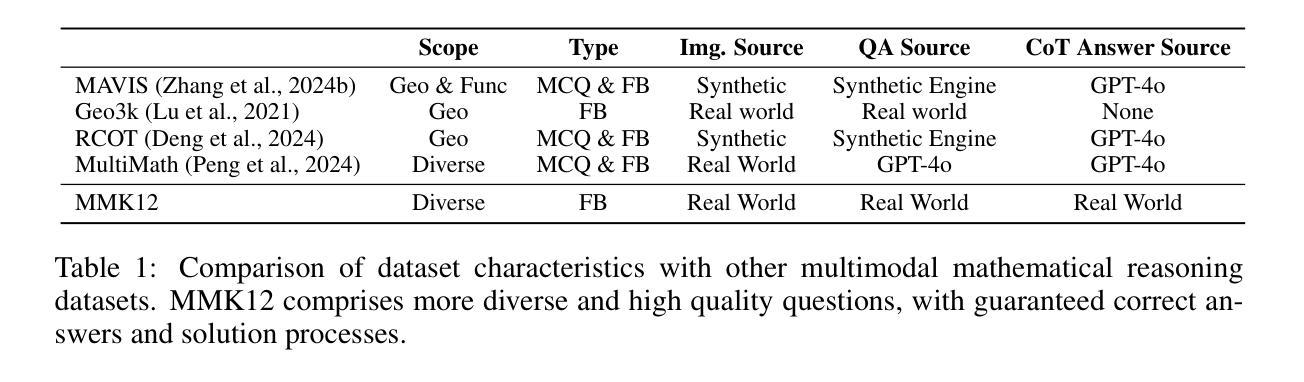
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Authors:Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, Wenqi Shao
DeepSeek R1, and o1 have demonstrated powerful reasoning capabilities in the text domain through stable large-scale reinforcement learning. To enable broader applications, some works have attempted to transfer these capabilities to multimodal reasoning. However, these efforts have been limited by the limited difficulty of selected tasks and relatively small training scales, making it challenging to demonstrate strong multimodal reasoning abilities. To address this gap, we introduce the MMK12 dataset and MM-EUREKA with 7B and 32B parameters. The former is a high-quality multimodal mathematics reasoning dataset featuring diverse knowledge domains with human-verified answers and solution processes. The latter is a multimodal model employing rule-based reinforcement learning on MMK12, utilizing online filtering and two-stage training strategy to enhance training stability. MM-EUREKA demonstrates remarkable performance gains in multimodal mathematical reasoning, outperforming previous powerful models like InternVL2.5-78B or InternVL2.5-38B-MPO. In particular, MM-EUREKA achieves competitive or superior performance compared to both open-source and closed-source models, and trails slightly behind o1 in multidisciplinary reasoning tasks. We open-source our complete pipeline to foster further research in this area. We release all our codes, models, data, etc. at https://github.com/ModalMinds/MM-EUREKA
DeepSeek R1和o1已通过稳定的大规模强化学习在文本领域展示了强大的推理能力。为了支持更广泛的应用,一些工作已尝试将这些能力转移到多模态推理。然而,由于所选任务的难度有限和相对较小的训练规模,这些努力在展示强大的多模态推理能力方面面临挑战。为了解决这一差距,我们推出了MMK12数据集和MM-EUREKA,分别具有7B和32B的参数。前者是一个高质量的多模态数学推理数据集,具有多样化知识领域的人类验证答案和解决方案过程。后者是一个多模态模型,采用基于规则的强化学习在MMK12上进行训练,利用在线过滤和两阶段训练策略来提高训练稳定性。MM-EUREKA在多模态数学推理方面表现出显著的性能提升,超越了之前强大的模型,如InternVL2.5-78B或InternVL2.5-38B-MPO。特别是,MM-EUREKA在跨学科的推理任务中,与开源和闭源模型相比具有竞争力或更优越的性能,略微落后于o1。我们公开了完整的管道,以促进该领域的研究。我们将在https://github.com/ModalMinds/MM-EUREKA上发布所有代码、模型、数据等。
论文及项目相关链接
Summary
文本介绍了DeepSeek R1和o1在文本领域展现的强大推理能力,并通过大规模强化学习进行多任务推理。为扩大应用范围,一些工作尝试将这些能力转移到多模态推理。然而,由于所选任务的难度有限和训练规模相对较小,展示强大的多模态推理能力具有挑战性。为解决此问题,我们推出了MMK12数据集和MM-EUREKA模型(具有7B和32B参数)。MMK12是一个高质量的多模态数学推理数据集,涵盖了不同知识领域并具有人工验证的答案和解决方案过程。MM-EUREKA是一个多模态模型,采用基于规则的强化学习在MMK12上进行训练,使用在线过滤和两阶段训练策略提高训练稳定性。MM-EUREKA在多模态数学推理方面表现出显著的性能提升,超越了之前强大的模型,如InternVL2.5-78B或InternVL2.5-38B-MPO。特别是在跨学科推理任务中,MM-EUREKA的性能略逊于o1。我们公开了完整的管道,以促进该领域的研究。我们所有的代码、模型、数据等都可以在https://github.com/ModalMinds/MM-EUREKA获取。
Key Takeaways
- DeepSeek R1和o1已在文本领域展现出强大的推理能力,并通过大规模强化学习进行多任务推理。
- 将这些能力转移到多模态推理面临挑战,主要由于任务难度有限和训练规模较小。
- MMK12数据集是一个多模态数学推理数据集,具有多样知识领域和人工验证的答案。
- MM-EUREKA模型采用基于规则的强化学习在MMK12上训练,利用在线过滤和两阶段策略提高稳定性。
- MM-EUREKA在多模态数学推理上表现优异,超越了一些先前的强大模型。
- MM-EUREKA在跨学科的推理任务中性能略逊于o1。
点此查看论文截图


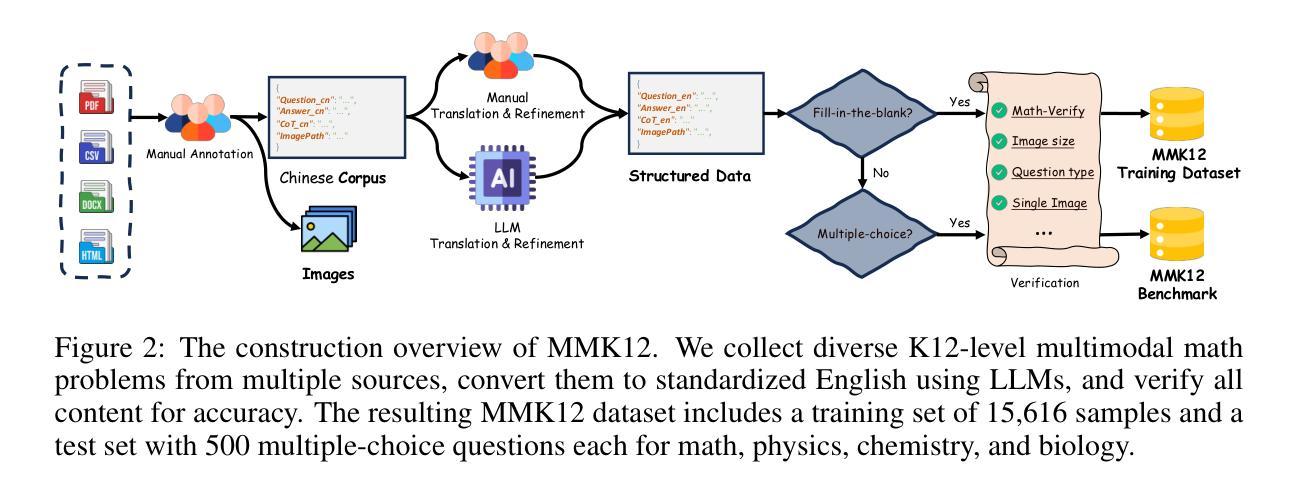
BioMaze: Benchmarking and Enhancing Large Language Models for Biological Pathway Reasoning
Authors:Haiteng Zhao, Chang Ma, Fangzhi Xu, Lingpeng Kong, Zhi-Hong Deng
The applications of large language models (LLMs) in various biological domains have been explored recently, but their reasoning ability in complex biological systems, such as pathways, remains underexplored, which is crucial for predicting biological phenomena, formulating hypotheses, and designing experiments. This work explores the potential of LLMs in pathway reasoning. We introduce BioMaze, a dataset with 5.1K complex pathway problems derived from real research, covering various biological contexts including natural dynamic changes, disturbances, additional intervention conditions, and multi-scale research targets. Our evaluation of methods such as CoT and graph-augmented reasoning, shows that LLMs struggle with pathway reasoning, especially in perturbed systems. To address this, we propose PathSeeker, an LLM agent that enhances reasoning through interactive subgraph-based navigation, enabling a more effective approach to handling the complexities of biological systems in a scientifically aligned manner. The dataset and code are available at https://github.com/zhao-ht/BioMaze.
最近已经探索了大型语言模型(LLM)在各种生物领域的应用,但它们在复杂生物系统(如途径)中的推理能力仍然被探索得不够充分,这对于预测生物现象、制定假设和设计实验至关重要。这项工作探索了LLM在途径推理中的潜力。我们介绍了BioMaze,这是一个包含5.1K个来自真实研究的复杂途径问题的数据集,涵盖各种生物背景,包括自然动态变化、干扰、额外干预条件和多尺度研究目标。我们对包括CoT和增强图推理等方法进行评估的结果表明,LLM在途径推理方面存在困难,尤其是在受干扰的系统中。为了解决这一问题,我们提出了PathSeeker,这是一个LLM代理,通过基于交互子图的导航增强推理能力,以更科学的方式更有效地应对生物系统的复杂性。数据集和代码可在https://github.com/zhao-ht/BioMaze获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在生物领域的应用已受到关注,但在复杂生物系统(如途径)中的推理能力仍被低估。本研究探索了LLMs在途径推理中的潜力,并引入BioMaze数据集,包含5.1K个途径问题实例。评估显示LLMs在受干扰系统上的推理能力受限,因此提出PathSeeker,一个通过交互式子图导航增强推理的LLM代理。
Key Takeaways
- 大型语言模型(LLMs)在生物领域的应用逐渐受到关注,特别是在途径推理方面。
- BioMaze数据集包含真实研究中的复杂途径问题实例,有助于评估模型在途径推理方面的表现。
- LLMs在受干扰系统上的推理能力受限,这影响了其在生物系统复杂性的处理效果。
- PathSeeker是一个LLM代理,通过交互式子图导航增强推理能力,更科学地应对生物系统的复杂性。
- BioMaze数据集和代码可通过GitHub共享。
- LLMs在预测生物现象、假设制定和实验设计方面存在巨大潜力。
点此查看论文截图