⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-22 更新
Towards Accurate and Interpretable Neuroblastoma Diagnosis via Contrastive Multi-scale Pathological Image Analysis
Authors:Zhu Zhu, Shuo Jiang, Jingyuan Zheng, Yawen Li, Yifei Chen, Manli Zhao, Weizhong Gu, Feiwei Qin, Jinhu Wang, Gang Yu
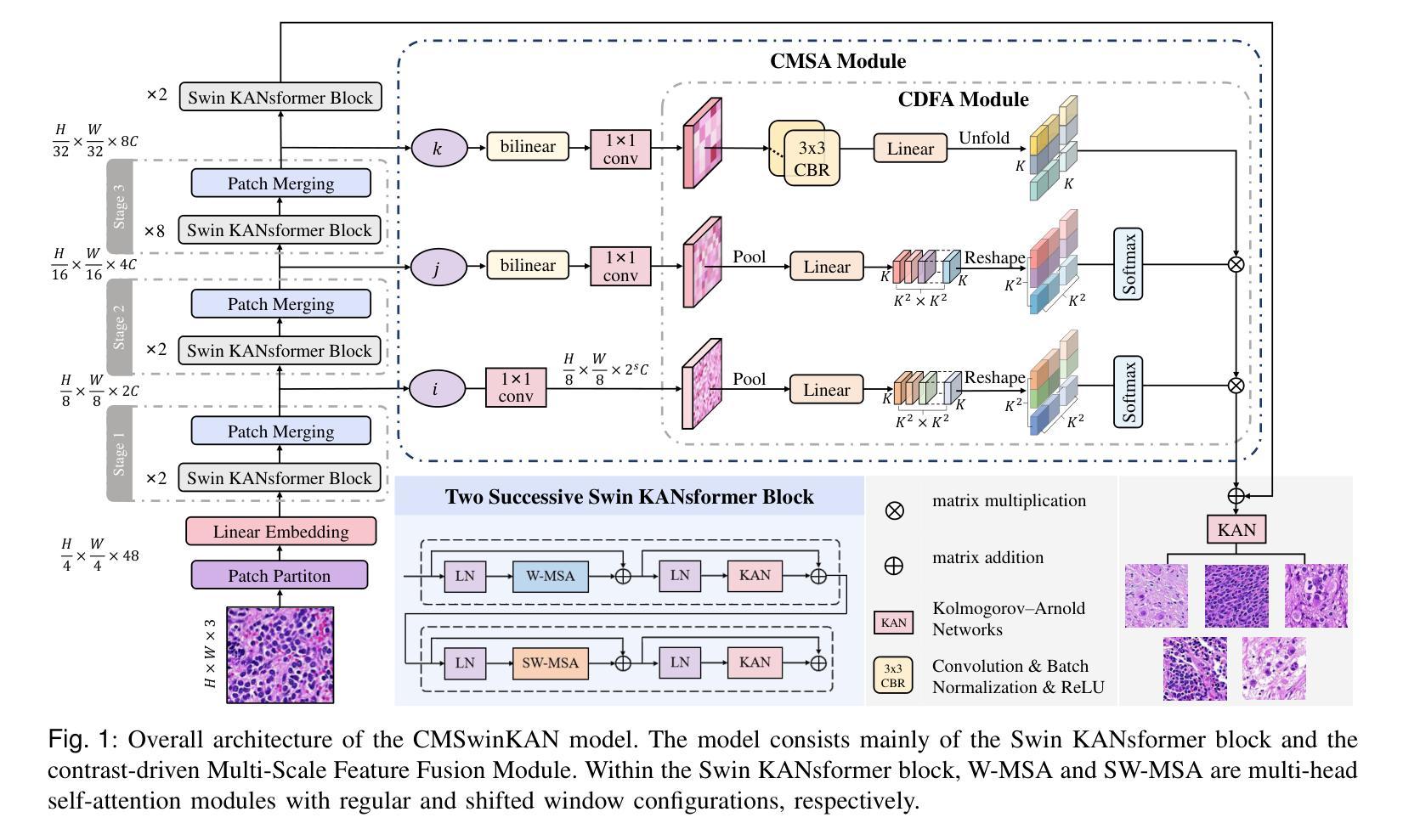
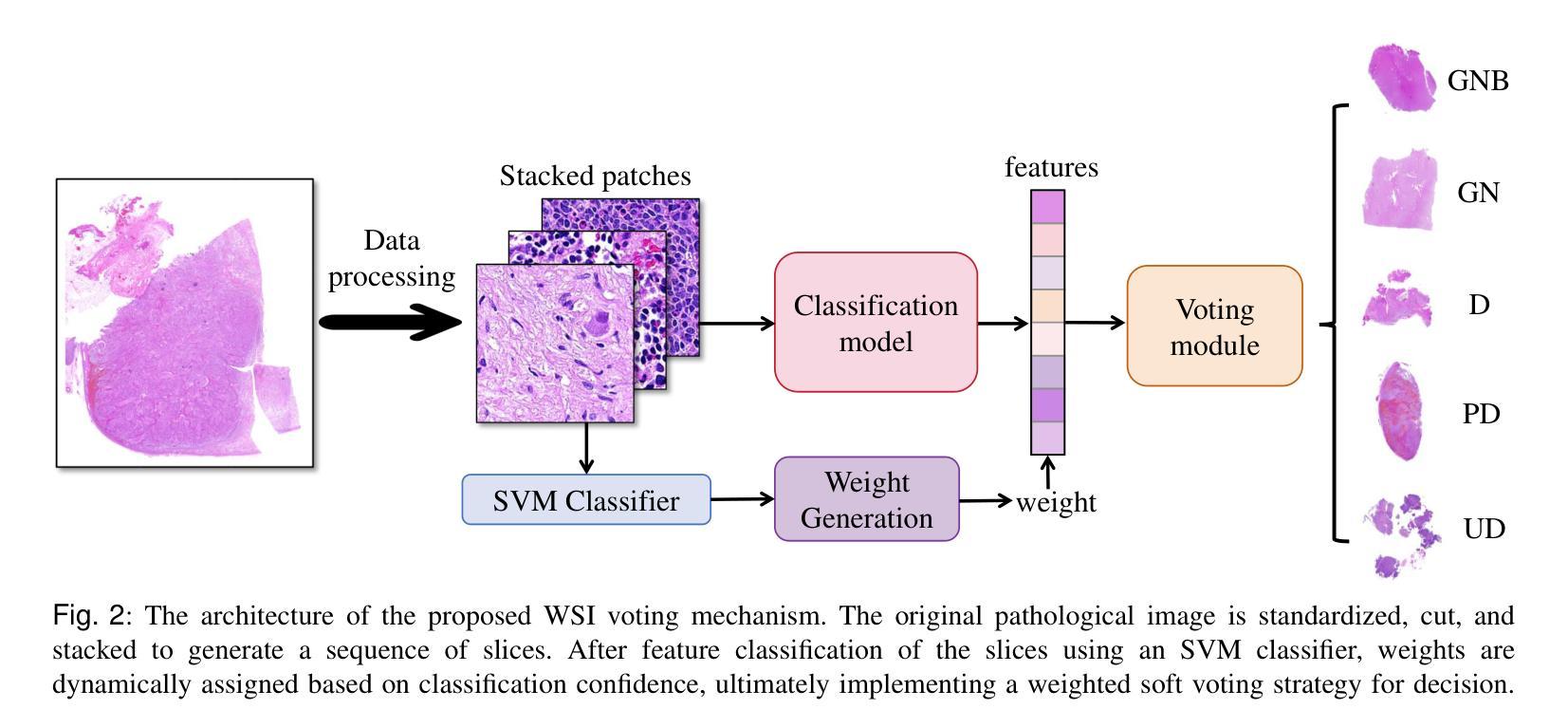
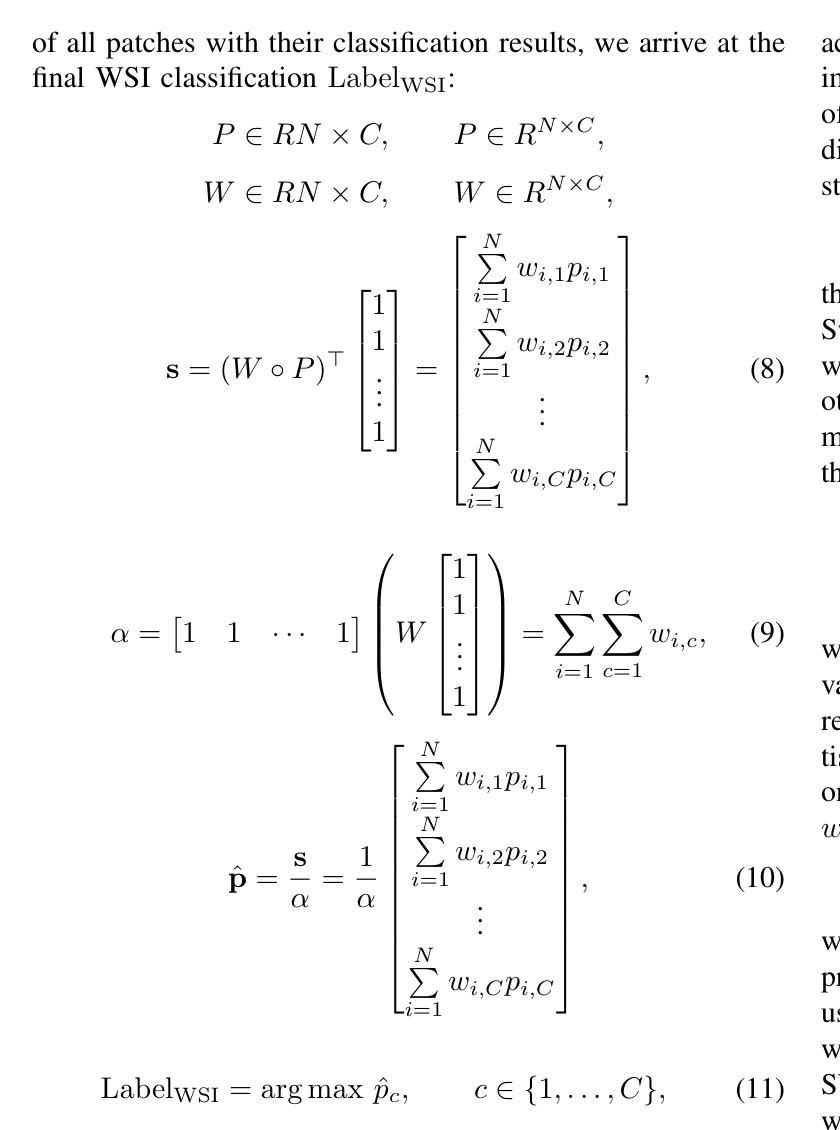
Neuroblastoma, adrenal-derived, is among the most common pediatric solid malignancies, characterized by significant clinical heterogeneity. Timely and accurate pathological diagnosis from hematoxylin and eosin-stained whole slide images is critical for patient prognosis. However, current diagnostic practices primarily rely on subjective manual examination by pathologists, leading to inconsistent accuracy. Existing automated whole slide image classification methods encounter challenges such as poor interpretability, limited feature extraction capabilities, and high computational costs, restricting their practical clinical deployment. To overcome these limitations, we propose CMSwinKAN, a contrastive-learning-based multi-scale feature fusion model tailored for pathological image classification, which enhances the Swin Transformer architecture by integrating a Kernel Activation Network within its multilayer perceptron and classification head modules, significantly improving both interpretability and accuracy. By fusing multi-scale features and leveraging contrastive learning strategies, CMSwinKAN mimics clinicians’ comprehensive approach, effectively capturing global and local tissue characteristics. Additionally, we introduce a heuristic soft voting mechanism guided by clinical insights to seamlessly bridge patch-level predictions to whole slide image-level classifications. We validate CMSwinKAN on the PpNTs dataset, which was collaboratively established with our partner hospital and the publicly accessible BreakHis dataset. Results demonstrate that CMSwinKAN performs better than existing state-of-the-art pathology-specific models pre-trained on large datasets. Our source code is available at https://github.com/JSLiam94/CMSwinKAN.
神经母细胞瘤是肾上腺衍生的一种最常见的儿童实体恶性肿瘤之一,具有显著的临床异质性。从苏木精和伊红染色的全切片图像进行及时准确的病理诊断对患者的预后至关重要。然而,目前的诊断方法主要依赖于病理医师的主观肉眼观察,导致诊断准确性不一致。现有的全自动全切片图像分类方法面临可解释性差、特征提取能力有限和计算成本高的问题,限制了其在临床实际中的应用。为了克服这些局限性,我们提出了CMSwinKAN,这是一种基于对比学习的多尺度特征融合模型,专为病理图像分类而设计。CMSwinKAN增强了Swin Transformer架构,通过在其多层感知器和分类头模块中集成Kernel Activation Network,显著提高了可解释性和准确性。通过融合多尺度特征和利用对比学习策略,CMSwinKAN模仿了医生全面的诊断方法,有效地捕捉了全局和局部组织特征。此外,我们还引入了启发式软投票机制,该机制以临床见解为指导,无缝桥接斑块级别的预测到全切片图像级别的分类。我们在与合作伙伴医院共同建立的PpNTs数据集和可公开访问的BreakHis数据集上验证了CMSwinKAN。结果表明,CMSwinKAN的性能优于在大型数据集上预训练的现有最先进的病理学特异性模型。我们的源代码可在https://github.com/JSLiam94/CMSwinKAN上找到。
论文及项目相关链接
PDF 14pages, 8 figures
Summary
本文介绍了一种基于对比学习的多尺度特征融合模型CMSwinKAN,用于神经母细胞瘤等疾病的病理图像分类。该模型结合了Swin Transformer架构和Kernel Activation Network,提高了模型的解释性和准确性。通过融合多尺度特征和采用对比学习策略,CMSwinKAN能够全面捕捉组织特性,模拟医生的诊断方式。此外,还引入了基于临床见解的启发式软投票机制,实现了斑块级别预测到全幻灯片级别分类的无缝衔接。在PpNTs和BreakHis数据集上的验证结果表明,CMSwinKAN的性能优于现有的最先进的病理特异性模型。
Key Takeaways
- CMSwinKAN是一种用于病理图像分类的对比学习多尺度特征融合模型,结合了Swin Transformer和Kernel Activation Network。
- 通过融合多尺度特征和对比学习策略,CMSwinKAN提高了模型的解释性和准确性,模拟了医生的诊断过程。
- 引入启发式软投票机制,实现斑块级别预测到全幻灯片级别分类的过渡。
- CMSwinKAN在PpNTs和BreakHis数据集上的性能优于现有的最先进的病理特异性模型。
- CMSwinKAN模型能够有效捕捉全球和局部组织特性,对神经母细胞瘤等儿科实体恶性肿瘤的诊断具有重要意义。
- 该模型的源代码已公开发布在GitHub上,方便研究人员进行进一步研究和改进。
点此查看论文截图

A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Authors:Asifullah Khan, Laiba Asmatullah, Anza Malik, Shahzaib Khan, Hamna Asif
Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of “positive” and “negative” samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
自监督学习是一种机器学习的方法,它通过从数据中学习潜在的模式并提取无标签数据的判别特征,从而生成隐含的标签,而无需手动标注。对比学习引入了“正样本”和“负样本”的概念,其中正样本对(例如同一图像/对象的变体)在嵌入空间中聚集在一起,而负样本对(例如来自不同图像/对象的视图)被推得更远。这种方法在图像理解和图像文本分析方面取得了显著的改进,且在很大程度上不依赖标记数据。在本文中,我们针对文本图像模型的对比学习术语、最新发展以及应用进行了全面的讨论。具体来说,我们概述了近年来文本图像模型中对比学习的方法。其次,我们根据不同的模型结构对这些方法进行了分类。第三,我们进一步介绍了该过程中使用的最新技术的进展,例如图像和文本的预文本任务、结构架构以及关键趋势。最后,我们讨论了基于文本的最新前沿应用中,自我监督对比学习的图像模型的现状和发展趋势。
论文及项目相关链接
Summary
文本探讨了自监督学习方法,特别是对比学习在文本图像模型中的应用。通过学习和提取未标注数据中的潜在模式和特征,生成隐式标签,减少对手动标注的依赖。对比学习通过将同一图像/对象的变体拉近在一起,并将不同图像/对象的视图推开,提高图像理解和图像文本分析的精度。本文主要介绍了该方法的术语、最新发展和应用,包括近年的技术趋势和前沿应用。同时讨论了文本图像模型的对比学习方法的模型结构和技术。总结了其在不同领域的成功应用,以及其对机器学习领域的潜在影响。这种方法在很多方面都有着广泛且有影响力的前景和重要性。如无特殊挑战说明问题假设符合要求假定公开数据集足够支持实验进行。此外,本文还介绍了对比学习在文本图像模型中的最新进展和应用。这种策略极大地促进了视觉和自然语言处理任务的进步,对深度学习和自然语言处理产生了深远影响。同时指出未来研究应关注提高模型性能、降低计算成本等方面的问题。总体来说,本文提供了对自监督对比学习在文本图像模型应用领域的全面理解和见解。此外还对近期的研究成果进行了综述和总结提出了重要观点和论据以支撑文章的主题论点使得文章内容充实有力逻辑清晰易于理解并且为读者提供了新的视角和思考方向为未来的研究提供了有价值的参考依据。此外本文还介绍了该领域未来可能的研究方向以及潜在挑战等等问题提供了全面的视角和思路对于推动该领域的发展具有积极意义。自监督学习通过生成隐式标签减少对人工标注的依赖能显著降低人工成本提高工作效率等自监督学习的实际应用非常广泛可为众多行业带来实质性好处推进该领域发展必将迎来巨大的变革和提升具备不可估量的研究价值和未来前景光明开阔的特征具有重要的科学意义和广泛的实际应用价值让我们更好的应对未知世界的挑战成为推动人工智能发展的重要力量之一。文中还提到了该领域面临的挑战和未来的发展方向如开发更高效的方法解决高计算成本问题等展示了研究的紧迫性和前瞻性确保了研究领域持续的进展和发展并在各领域展现了广泛应用的可能和极大的应用前景文章给出许多有力的建议和有价值的想法展示着人们对于智能认知和学习理解的深度提高与广泛探讨为未来相关研究提供了有力的支撑和启发意义推动了整个领域的发展进程对人们未来工作和生活方式的改变也将会产生深远的影响同时也促进了相关产业的发展和创新并给人类带来前所未有的机遇和挑战也推动着人们不断探索未知领域挖掘无限潜力以应对未来的挑战和问题。Key Takeaways
- 自监督学习通过隐式标签生成减少对人工标注的依赖。
- 对比学习在文本图像模型中表现优异,通过区分正负样本提高图像理解和文本分析精度。
- 文本图像模型的对比学习方法涉及模型结构分类、预文本任务和架构技术等方面的最新进展。
- 自监督对比学习在多个领域有成功应用,促进视觉和自然语言处理任务的进步。
- 对比学习策略对降低计算成本和提高模型性能等方向是未来研究的关键点。
- 自监督学习具备广泛的应用前景和实际价值,为各行业带来实质性好处。
点此查看论文截图

LeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Authors:Mohammad Alkhalefi, Georgios Leontidis, Mingjun Zhong
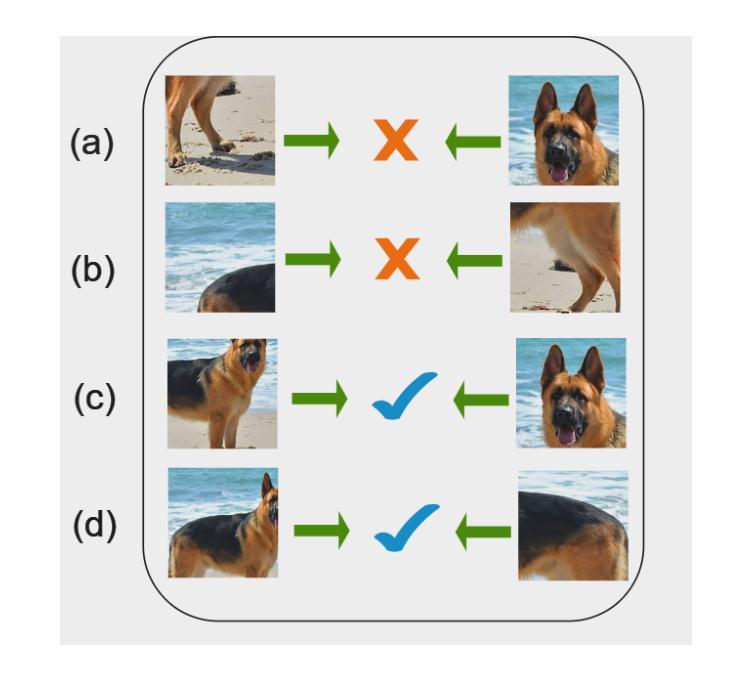
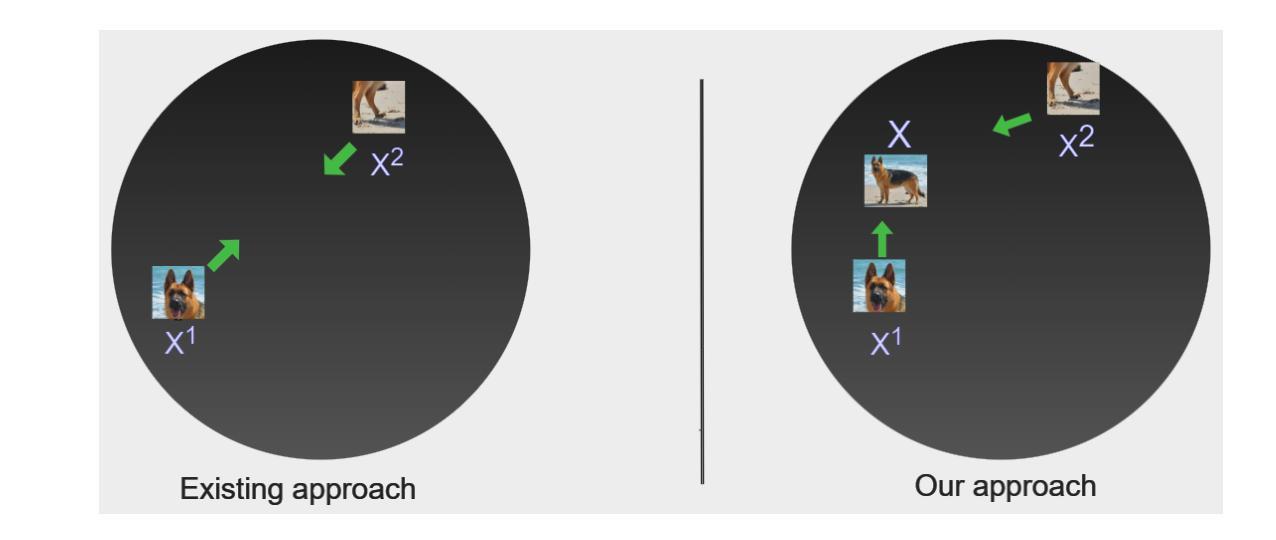
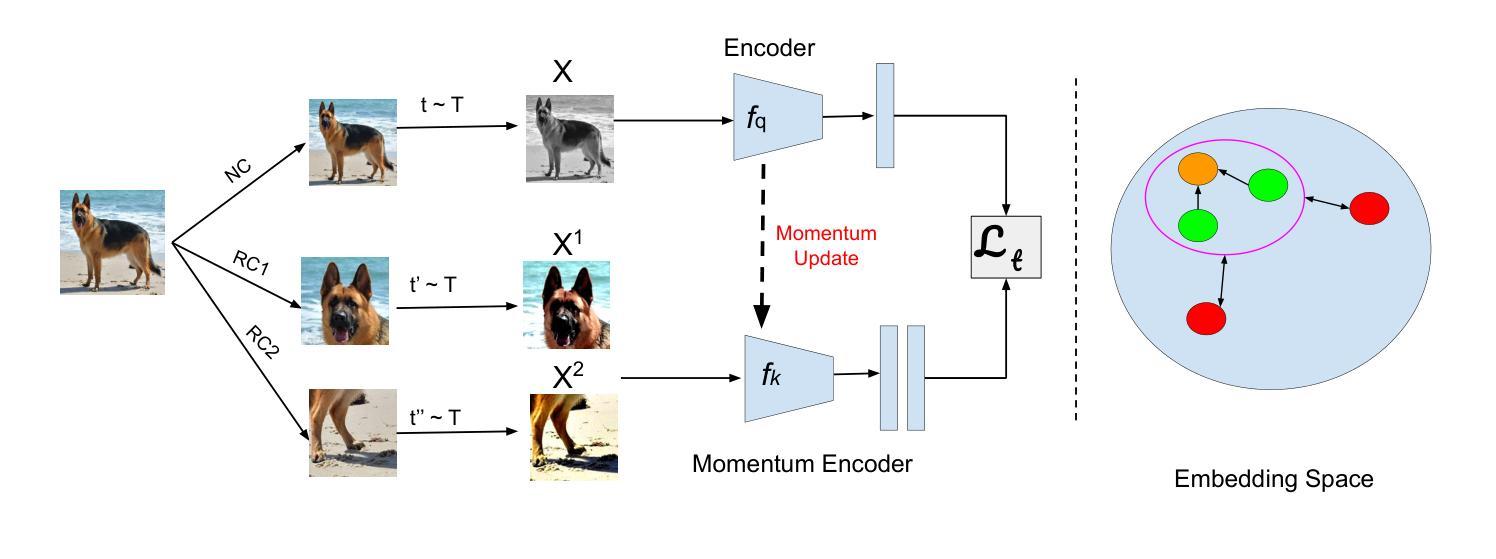
Contrastive instance discrimination methods outperform supervised learning in downstream tasks such as image classification and object detection. However, these methods rely heavily on data augmentation during representation learning, which can lead to suboptimal results if not implemented carefully. A common augmentation technique in contrastive learning is random cropping followed by resizing. This can degrade the quality of representation learning when the two random crops contain distinct semantic content. To tackle this issue, we introduce LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a novel instance discrimination approach and an adapted loss function. This method prevents the loss of important semantic features caused by mapping different object parts during representation learning. Our experiments demonstrate that LeOCLR consistently improves representation learning across various datasets, outperforming baseline models. For instance, LeOCLR surpasses MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and outperforms several other methods on transfer learning and object detection tasks.
对比实例判别方法在图像分类和对象检测等下游任务中表现优于监督学习。然而,这些方法在表示学习中非常依赖数据增强,如果不仔细实施,可能会导致次优结果。对比学习中常见的增强技术是随机裁剪和缩放。当两个随机裁剪区域包含不同的语义内容时,这可能会降低表示学习的质量。为了解决这个问题,我们引入了LeOCLR(利用原始图像进行视觉表示的对比学习),这是一个采用新型实例判别方法和适配损失函数的框架。该方法可防止在表示学习过程中映射不同对象部分而造成的重要语义特征的丢失。我们的实验表明,LeOCLR在各种数据集上的表示学习能力持续增强,超越了基线模型。例如,在ImageNet-1K的线性评估中,LeOCLR超过了MoCo-v2的5.1%,并且在迁移学习和对象检测任务上优于其他几种方法。
论文及项目相关链接
PDF 15 pages, 5 figures, 9 tables - accepted at TMLR 10/2024; V4 corrected some typos in the references
摘要
对比实例判别方法在图像分类和对象检测等下游任务中表现优异于监督学习。然而,这些方法在表示学习中高度依赖于数据增强,若实施不谨慎可能导致结果不佳。随机裁剪和缩放是对比学习中常见的增强技术,当两个随机裁剪包含不同语义内容时,可能会降低表示学习的质量。为解决这一问题,我们引入LeOCLR(利用原始图像进行视觉表示对比学习),采用一种新颖的实例判别方法和调整后的损失函数。此方法防止在表示学习过程中映射不同对象部分而导致的关键语义特征丢失。实验表明,LeOCLR在多个数据集上持续改善表示学习,超越基线模型。例如,在ImageNet-1K的线性评估中,LeOCLR超越MoCo-v2达5.1%,并在迁移学习和对象检测任务中表现优异。
关键见解
- 对比实例判别方法在图像分类和对象检测等任务中优于监督学习。
- 数据增强在对比学习中至关重要,但实施不当可能导致结果不佳。
- 常见的数据增强技术如随机裁剪和缩放可能影响表示学习的质量,特别是当裁剪部分包含不同语义内容时。
- LeOCLR框架通过采用新颖的实例判别方法和调整后的损失函数,解决了数据增强导致的问题。
- LeOCLR能有效防止在表示学习过程中关键语义特征的丢失。
- 实验证明,LeOCLR在多个数据集上的表示学习表现优于基线模型。
点此查看论文截图