⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-22 更新
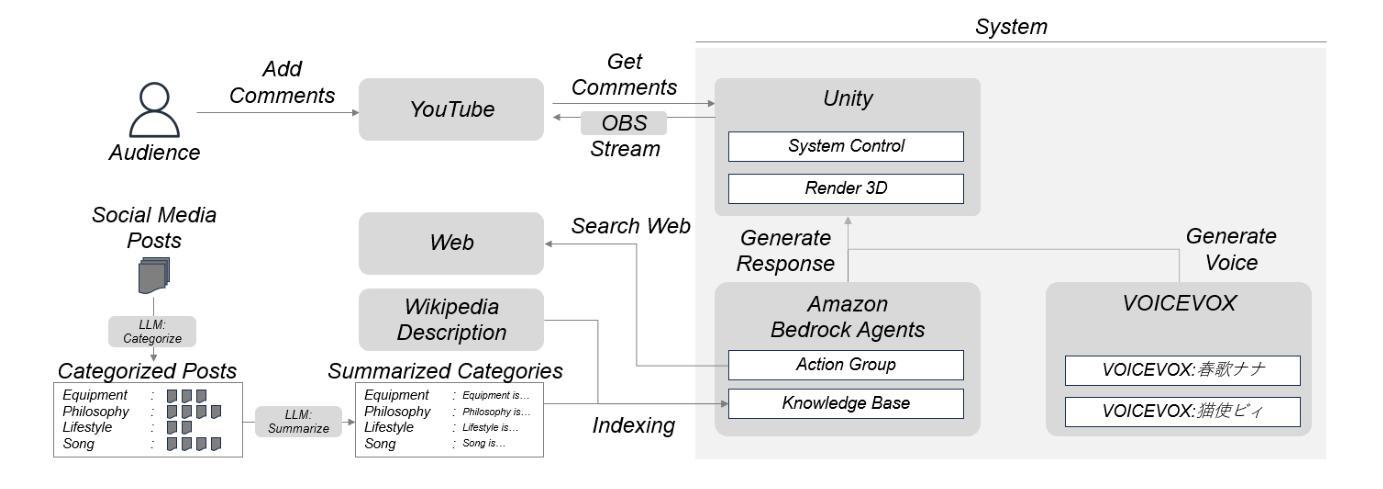
ChatNekoHacker: Real-Time Fan Engagement with Conversational Agents
Authors:Takuya Sera, Yusuke Hamano
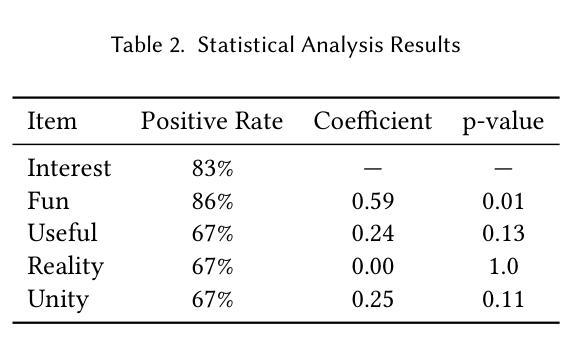
ChatNekoHacker is a real-time conversational agent system that strengthens fan engagement for musicians. It integrates Amazon Bedrock Agents for autonomous dialogue, Unity for immersive 3D livestream sets, and VOICEVOX for high quality Japanese text-to-speech, enabling two virtual personas to represent the music duo Neko Hacker. In a one-hour YouTube Live with 30 participants, we evaluated the impact of the system. Regression analysis showed that agent interaction significantly elevated fan interest, with perceived fun as the dominant predictor. The participants also expressed a stronger intention to listen to the duo’s music and attend future concerts. These findings highlight entertaining, interactive broadcasts as pivotal to cultivating fandom. Our work offers actionable insights for the deployment of conversational agents in entertainment while pointing to next steps: broader response diversity, lower latency, and tighter fact-checking to curb potential misinformation.
ChatNekoHacker是一个实时对话代理系统,旨在增强音乐家的粉丝参与度。它集成了亚马逊基石代理进行自主对话、Unity用于沉浸式3D直播场景,以及VOICEVOX用于高质量日语文本到语音的转换,使两个虚拟角色能够代表音乐组合Neko Hacker。在一场持续一小时、有30名参与者的YouTube直播中,我们评估了该系统的影响。回归分析显示,代理互动显著提高了粉丝兴趣,其中感知的乐趣是主导因素。参与者还表达了更强烈的意愿去聆听该组合的音乐以及参加未来的音乐会。这些发现强调了有趣、互动的广播对于培养粉丝的重要性。我们的工作为娱乐领域对话代理的部署提供了可操作性的见解,同时指出了下一步的方向:更广泛的响应多样性、更低的延迟以及更严格的事实核查,以遏制潜在的信息错误。
论文及项目相关链接
PDF Accepted to GenAICHI 2025: Generative AI and HCI at CHI 2025
Summary
聊天机器人系统强化乐迷参与度,该系统融合亚马逊机器人智能对话平台,增强自主对话功能,并结合Unity提供沉浸式三维直播体验,再配以VOICEVOX高品质日语语音技术。该技术在音乐组合虚拟人物上的实践案例表明,这种互动方式能显著提高粉丝兴趣,并有望增强粉丝对音乐的喜爱和对未来活动的期待。研究为娱乐行业部署聊天机器人提供了实用见解,同时指出下一步发展方向:扩大响应范围、降低延迟以及加强事实核查,防止传播错误信息。
Key Takeaways
- ChatNekoHacker是一个增强粉丝参与度的实时对话机器人系统。
- 该系统集成了亚马逊机器人智能对话平台、Unity沉浸式三维直播体验和VOICEVOX高质量日语语音技术。
- 在一小时YouTube直播测试中,机器人互动显著提高了粉丝兴趣。
- 被视为有趣是主要的预测因素。
- 参与者在测试后表达了更强的音乐听播意向和参加未来音乐会的意愿。
点此查看论文截图

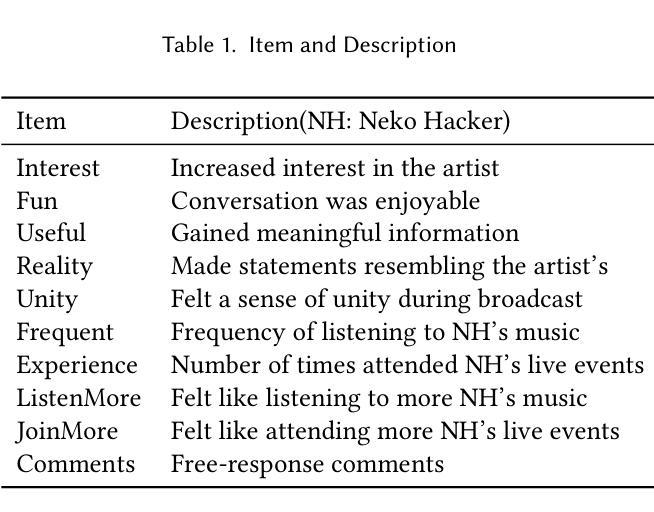
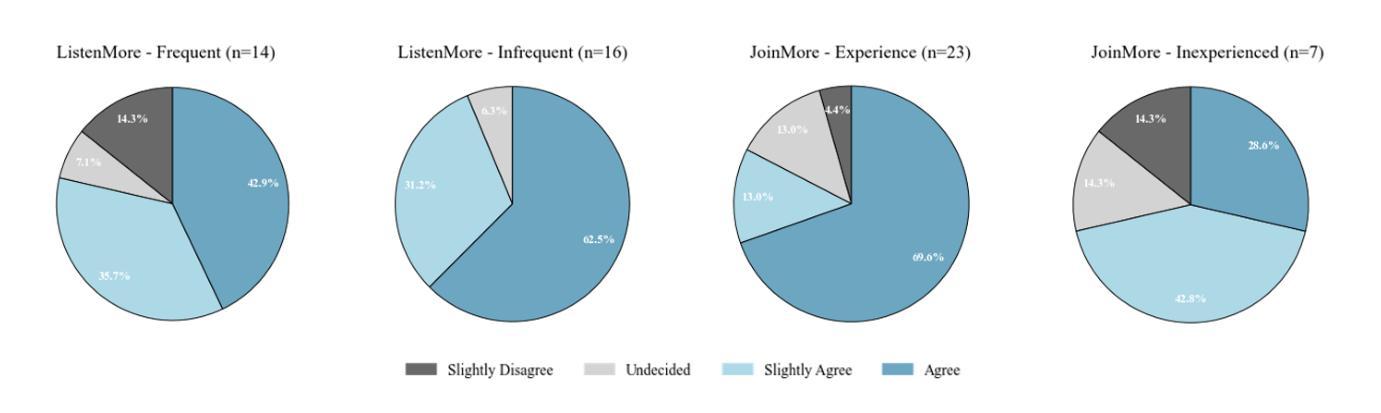
Task Assignment and Exploration Optimization for Low Altitude UAV Rescue via Generative AI Enhanced Multi-agent Reinforcement Learning
Authors:Xin Tang, Qian Chen, Wenjie Weng, Chao Jin, Zhang Liu, Jiacheng Wang, Geng Sun, Xiaohuan Li, Dusit Niyato
Artificial Intelligence (AI)-driven convolutional neural networks enhance rescue, inspection, and surveillance tasks performed by low-altitude uncrewed aerial vehicles (UAVs) and ground computing nodes (GCNs) in unknown environments. However, their high computational demands often exceed a single UAV’s capacity, leading to system instability, further exacerbated by the limited and dynamic resources of GCNs. To address these challenges, this paper proposes a novel cooperation framework involving UAVs, ground-embedded robots (GERs), and high-altitude platforms (HAPs), which enable resource pooling through UAV-to-GER (U2G) and UAV-to-HAP (U2H) communications to provide computing services for UAV offloaded tasks. Specifically, we formulate the multi-objective optimization problem of task assignment and exploration optimization in UAVs as a dynamic long-term optimization problem. Our objective is to minimize task completion time and energy consumption while ensuring system stability over time. To achieve this, we first employ the Lyapunov optimization technique to transform the original problem, with stability constraints, into a per-slot deterministic problem. We then propose an algorithm named HG-MADDPG, which combines the Hungarian algorithm with a generative diffusion model (GDM)-based multi-agent deep deterministic policy gradient (MADDPG) approach. We first introduce the Hungarian algorithm as a method for exploration area selection, enhancing UAV efficiency in interacting with the environment. We then innovatively integrate the GDM and multi-agent deep deterministic policy gradient (MADDPG) to optimize task assignment decisions, such as task offloading and resource allocation. Simulation results demonstrate the effectiveness of the proposed approach, with significant improvements in task offloading efficiency, latency reduction, and system stability compared to baseline methods.
人工智能(AI)驱动的卷积神经网络提高了低空无人飞行器(UAVs)和地面计算节点(GCNs)在未知环境中执行的救援、检查和监视任务的性能。然而,它们的高计算需求经常超出单个无人机的能力,导致系统不稳定,而地面计算节点的资源有限且动态,进一步加剧了这一问题。为了解决这些挑战,本文提出了一种涉及无人机、地面嵌入式机器人(GERs)和高空平台(HAPs)的新型合作框架,通过无人机到地面机器人(U2G)和无人机到高空平台(U2H)的通信,实现资源池,为无人机卸载的任务提供计算服务。具体来说,我们将无人机中的任务分配和探测优化的多目标优化问题制定为动态长期优化问题。我们的目标是最小化任务完成时间和能源消耗,同时确保系统随时间稳定。为了实现这一点,我们首先采用Lyapunov优化技术,将带稳定性约束的原始问题转化为每个时隙的确定性问题。然后,我们提出了一种名为HG-MADDPG的算法,该算法结合了匈牙利算法和基于生成扩散模型(GDM)的多智能体深度确定性策略梯度(MADDPG)方法。我们首先介绍匈牙利算法作为一种探测区域选择方法,提高无人机与环境交互的效率。然后,我们创新地将GDM和多智能体深度确定性策略梯度(MADDPG)相结合,优化任务分配决策,如任务卸载和资源分配。仿真结果表明,所提出的方法在任务卸载效率、延迟减少和系统稳定性方面与基线方法相比都有显著提高。
论文及项目相关链接
Summary
基于人工智能的卷积神经网络增强了低空无人飞行器(UAVs)和地面计算节点(GCNs)在未知环境中的救援、检测和监视任务性能。然而,其高计算需求常超出单一无人机的处理能力,导致系统不稳定,且地面节点的资源有限且动态变化。为应对这些挑战,本文提出一个涉及无人机、地面嵌入式机器人(GERs)和高空平台(HAPs)的合作框架,通过无人机与地面机器人的通信实现资源池,为卸载的任务提供计算服务。为最小化任务完成时间和能源消耗并确保系统长期稳定性,采用李雅普诺夫优化技术将问题转换为确定性问题,并提出HG-MADDPG算法,结合匈牙利算法与基于生成扩散模型(GDM)的多智能体深度确定性策略梯度(MADDPG)方法。仿真结果显示,该方法有效提高任务卸载效率,降低延迟,提升系统稳定性。
Key Takeaways
- AI技术增强了UAVs在未知环境中的救援、检测和监视任务性能。
- 单个UAV的计算能力有限,可能导致系统不稳定。
- 提出了一个涉及UAVs、GERs和HAPs的合作框架,通过资源池解决计算需求问题。
- 利用李雅普诺夫优化技术确保系统长期稳定性。
- 采用HG-MADDPG算法结合匈牙利算法和GDM-MADDPG进行优化任务分配。
- 仿真验证显示,该方法提高了任务卸载效率,降低了延迟。
点此查看论文截图

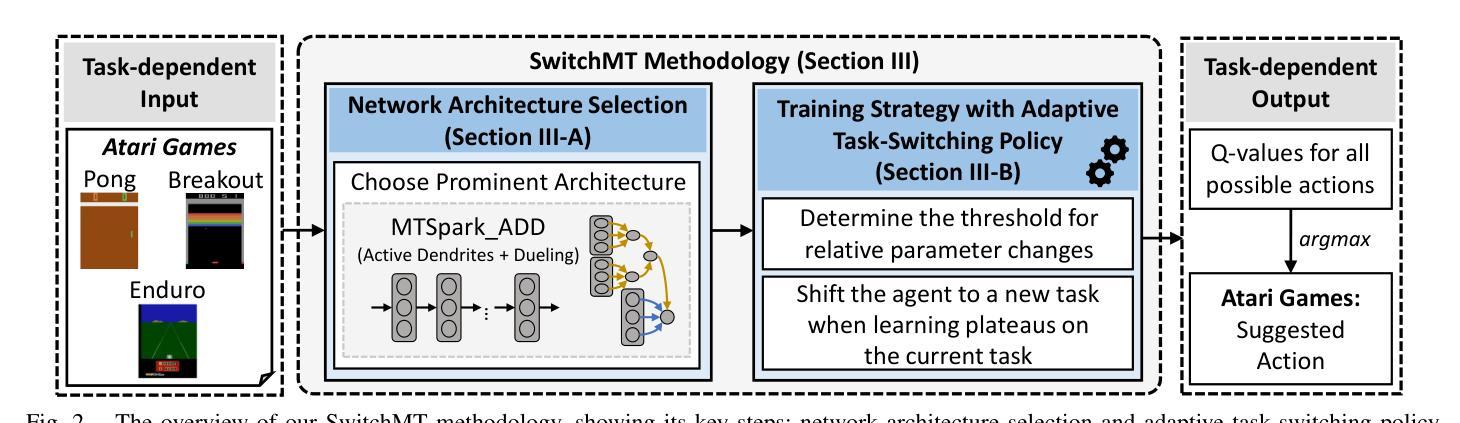
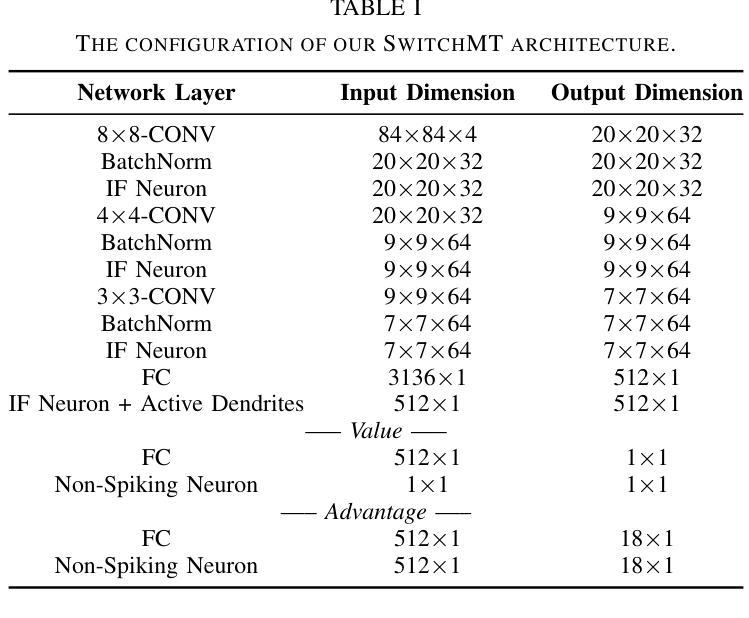
SwitchMT: An Adaptive Context Switching Methodology for Scalable Multi-Task Learning in Intelligent Autonomous Agents
Authors:Avaneesh Devkota, Rachmad Vidya Wicaksana Putra, Muhammad Shafique
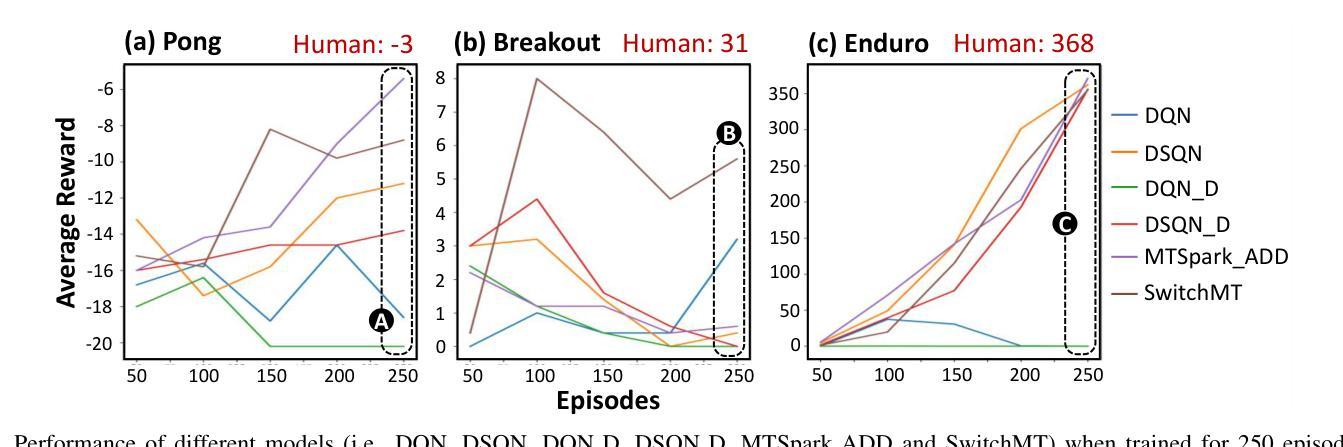
The ability to train intelligent autonomous agents (such as mobile robots) on multiple tasks is crucial for adapting to dynamic real-world environments. However, state-of-the-art reinforcement learning (RL) methods only excel in single-task settings, and still struggle to generalize across multiple tasks due to task interference. Moreover, real-world environments also demand the agents to have data stream processing capabilities. Toward this, a state-of-the-art work employs Spiking Neural Networks (SNNs) to improve multi-task learning by exploiting temporal information in data stream, while enabling lowpower/energy event-based operations. However, it relies on fixed context/task-switching intervals during its training, hence limiting the scalability and effectiveness of multi-task learning. To address these limitations, we propose SwitchMT, a novel adaptive task-switching methodology for RL-based multi-task learning in autonomous agents. Specifically, SwitchMT employs the following key ideas: (1) a Deep Spiking Q-Network with active dendrites and dueling structure, that utilizes task-specific context signals to create specialized sub-networks; and (2) an adaptive task-switching policy that leverages both rewards and internal dynamics of the network parameters. Experimental results demonstrate that SwitchMT achieves superior performance in multi-task learning compared to state-of-the-art methods. It achieves competitive scores in multiple Atari games (i.e., Pong: -8.8, Breakout: 5.6, and Enduro: 355.2) compared to the state-of-the-art, showing its better generalized learning capability. These results highlight the effectiveness of our SwitchMT methodology in addressing task interference while enabling multi-task learning automation through adaptive task switching, thereby paving the way for more efficient generalist agents with scalable multi-task learning capabilities.
训练智能自主代理(如移动机器人)在多个任务上的能力对于适应动态现实世界环境至关重要。然而,最先进的强化学习(RL)方法仅在单任务设置中表现出色,但由于任务干扰,它们仍然难以在多个任务之间进行泛化。此外,现实世界环境还要求代理具有数据流处理能力。针对这一点,一项最先进的工作采用脉冲神经网络(SNNs)来提高通过利用数据流中的时间信息来进行多任务学习的能力,同时实现低功耗的事件驱动操作。然而,它依赖于训练过程中的固定上下文/任务切换间隔,从而限制了多任务学习的可扩展性和有效性。为了解决这些局限性,我们提出了SwitchMT,这是一种用于基于强化学习的自主代理多任务学习的新型自适应任务切换方法。具体来说,SwitchMT采用以下关键思想:(1)一个具有主动树突和决斗结构的深度脉冲Q网络,它利用特定于任务的上下文信号来创建专业化的子网络;(2)一种自适应任务切换策略,它利用奖励和网络参数的内部动态。实验结果表明,与最先进的方法相比,SwitchMT在多任务学习中实现了卓越的性能。在多个Atari游戏中,其得分具有竞争力(即Pong:-8.8,Breakout:5.6,Enduro:355.2),显示出其更好的泛化学习能力。这些结果突出了我们的SwitchMT方法在解决任务干扰方面的有效性,通过自适应任务切换实现多任务学习自动化,从而为具有可扩展多任务学习能力的更高效通用代理铺平了道路。
论文及项目相关链接
PDF 7 pages, 7 figures, 3 tables
摘要
强化学习对于智能自主代理人在多变环境下的多任务适应性训练至关重要。当前前沿的多任务学习方法仍面临任务干扰的问题,难以在多个任务之间泛化。最新研究采用脉冲神经网络(SNNs)改善多任务学习,但受限于固定上下文和任务切换间隔,影响了多任务学习的可扩展性和效率。为解决这些问题,我们提出SwitchMT方法,这是一种基于强化学习的自适应任务切换策略。SwitchMT包括两个关键部分:一是深度脉冲Q网络,利用任务特定上下文信号创建专业化子网络;二是自适应任务切换策略,利用奖励和网络参数的内部动态。实验结果显示,SwitchMT在多任务学习上表现出卓越性能,在多款Atari游戏中的表现也颇具竞争力,表明其更强的泛化学习能力。这表明SwitchMT方法在解决任务干扰的同时,通过自适应任务切换实现了多任务学习的自动化,为具有可扩展多任务学习能力的通用代理铺平了道路。
关键见解
- 强化学习在智能自主代理人的多任务适应性训练中至关重要。
- 当前的多任务学习方法面临任务干扰的问题,难以泛化多个任务。
- 脉冲神经网络(SNNs)被用于改善多任务学习,但受限于固定的上下文和任务切换间隔。
- SwitchMT是一种自适应任务切换方法,用于强化学习中的多任务学习。
- SwitchMT包括深度脉冲Q网络和自适应任务切换策略两个关键部分。
- 实验结果显示SwitchMT在多任务学习中表现出卓越性能。
- SwitchMT方法在解决任务干扰的同时,实现了多任务学习的自动化,为创建具有更强泛化学习能力的智能代理铺平了道路。
点此查看论文截图




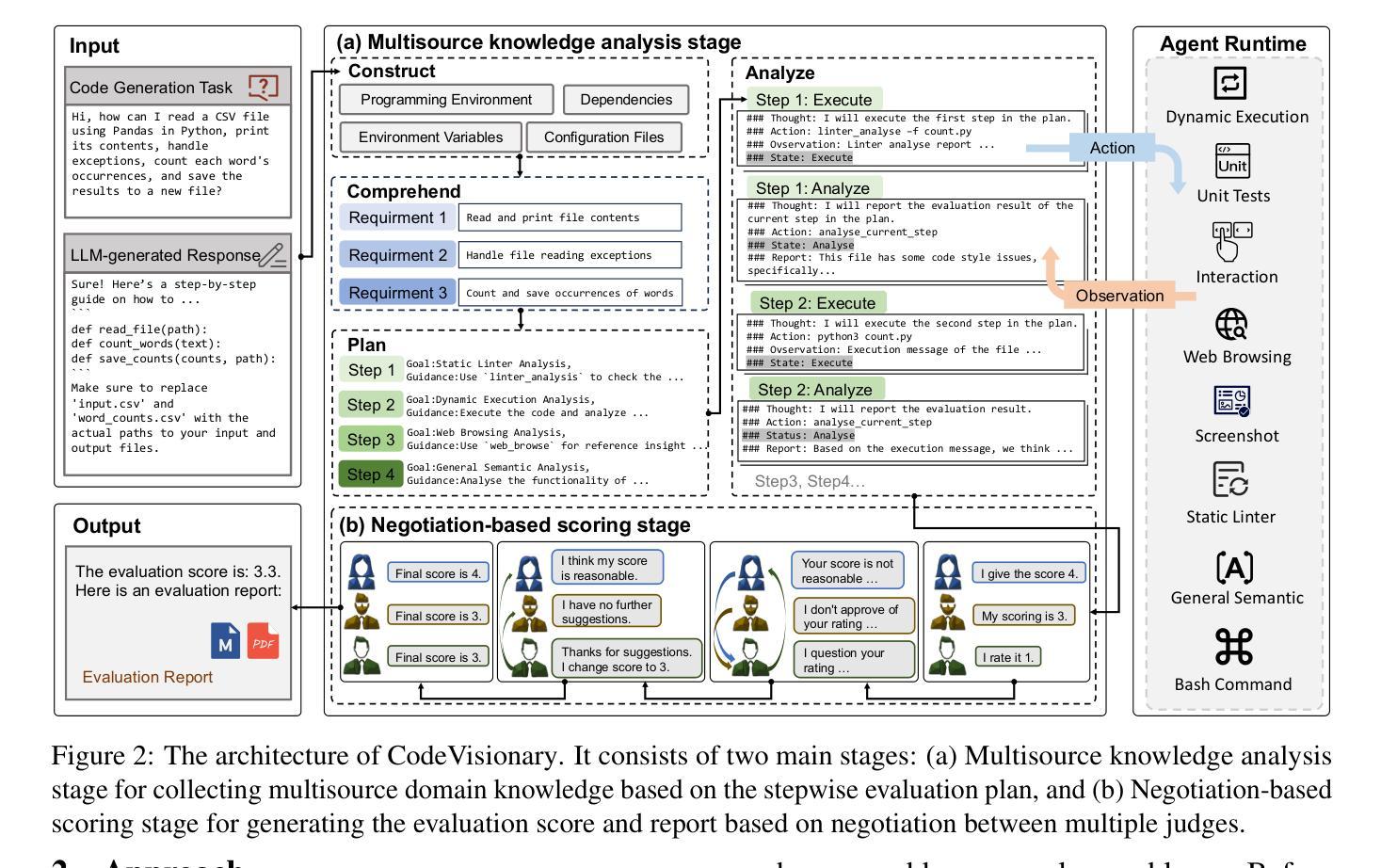
CodeVisionary: An Agent-based Framework for Evaluating Large Language Models in Code Generation
Authors:Xinchen Wang, Pengfei Gao, Chao Peng, Ruida Hu, Cuiyun Gao
Large language models (LLMs) have demonstrated strong capabilities in code generation, underscoring the critical need for rigorous and comprehensive evaluation. Existing evaluation approaches fall into three categories, including human-centered, metric-based, and LLM-based. Considering that human-centered approaches are labour-intensive and metric-based ones overly rely on reference answers, LLM-based approaches are gaining increasing attention due to their stronger contextual understanding capabilities and superior efficiency. However, the performance of LLM-based approaches remains limited due to: (1) lack of multisource domain knowledge, and (2) insufficient comprehension of complex code. To mitigate the limitations, we propose CodeVisionary, the first LLM-based agent framework for evaluating LLMs in code generation. CodeVisionary consists of two stages: (1) Multiscore knowledge analysis stage, which aims to gather multisource and comprehensive domain knowledge by formulating and executing a stepwise evaluation plan. (2) Negotiation-based scoring stage, which involves multiple judges engaging in discussions to better comprehend the complex code and reach a consensus on the evaluation score. Extensive experiments demonstrate that CodeVisionary achieves the best performance for evaluating LLMs in code generation, outperforming the best baseline methods with average improvements of 0.202, 0.139, and 0.117 in Pearson, Spearman, and Kendall-Tau coefficients, respectively. Besides, CodeVisionary provides detailed evaluation reports, which assist developers in identifying shortcomings and making improvements. The resources of CodeVisionary are available at https://anonymous.4open.science/r/CodeVisionary.
大型语言模型(LLM)在代码生成方面展现出强大的能力,这突显出对严格和全面评估的迫切需求。现有的评估方法可分为三类,包括以人为中心的方法、基于指标的方法和基于LLM的方法。考虑到以人为中心的方法劳动密集型,而基于指标的方法过于依赖参考答案,基于LLM的方法由于其更强的上下文理解能力和高效率而越来越受到关注。然而,基于LLM的方法的性能仍然有限,原因是:(1)缺乏多源领域知识;(2)对复杂代码的理解不足。为了缓解这些限制,我们提出了CodeVisionary,这是第一个用于评估LLM代码生成的LLM代理框架。CodeVisionary由两个阶段组成:(1)多分数知识分析阶段,旨在通过制定和执行分步骤评估计划来收集多源和综合领域知识。(2)基于协商的评分阶段,涉及多个评委进行讨论,以更好地理解复杂代码并对评估分数达成共识。大量实验表明,CodeVisionary在评估LLM代码生成方面表现最佳,在Pearson、Spearman和Kendall-Tau系数上分别平均提高了0.202、0.139和0.117的性能。此外,CodeVisionary提供详细的评估报告,帮助开发者识别不足并进行改进。CodeVisionary的资源可通过https://anonymous.4open.science/r/CodeVisionary获取。
论文及项目相关链接
Summary
大型语言模型在代码生成方面的能力已得到验证,但仍需严谨全面的评估。现有评估方法包括以人类为中心、基于指标和以LLM为中心的方法。由于人类为中心的评估方法劳动强度大,基于指标的评估过于依赖参考答案,因此以LLM为中心的评估方法因具有更强的上下文理解能力和高效率而备受关注。然而,其性能受限于缺乏多源领域知识和对复杂代码理解不足。为缓解这些问题,我们提出CodeVisionary,首个基于LLM的评估框架,旨在全面分析多源知识并进行协商评分以更好地理解复杂代码。实验证明,CodeVisionary在代码生成评估方面表现最佳,平均提高了Pearson、Spearman和Kendall-Tau系数分别为0.202、0.139和0.117。此外,CodeVisionary还提供详细的评估报告,帮助开发者识别不足并进行改进。
Key Takeaways
- 大型语言模型在代码生成方面表现出强大的能力,但需要严谨全面的评估。
- 现有评估方法包括人类为中心、基于指标和以LLM为中心的方法,各有优缺点。
- CodeVisionary是首个基于LLM的评估框架,旨在解决现有评估方法的局限性。
- CodeVisionary包括两个阶段:多源知识分析和协商评分,以更好地理解复杂代码。
- CodeVisionary通过收集多源领域知识和执行逐步评价计划来弥补LLM的局限性。
- CodeVisionary通过多评委讨论达成共识,以提高评价准确性。
点此查看论文截图

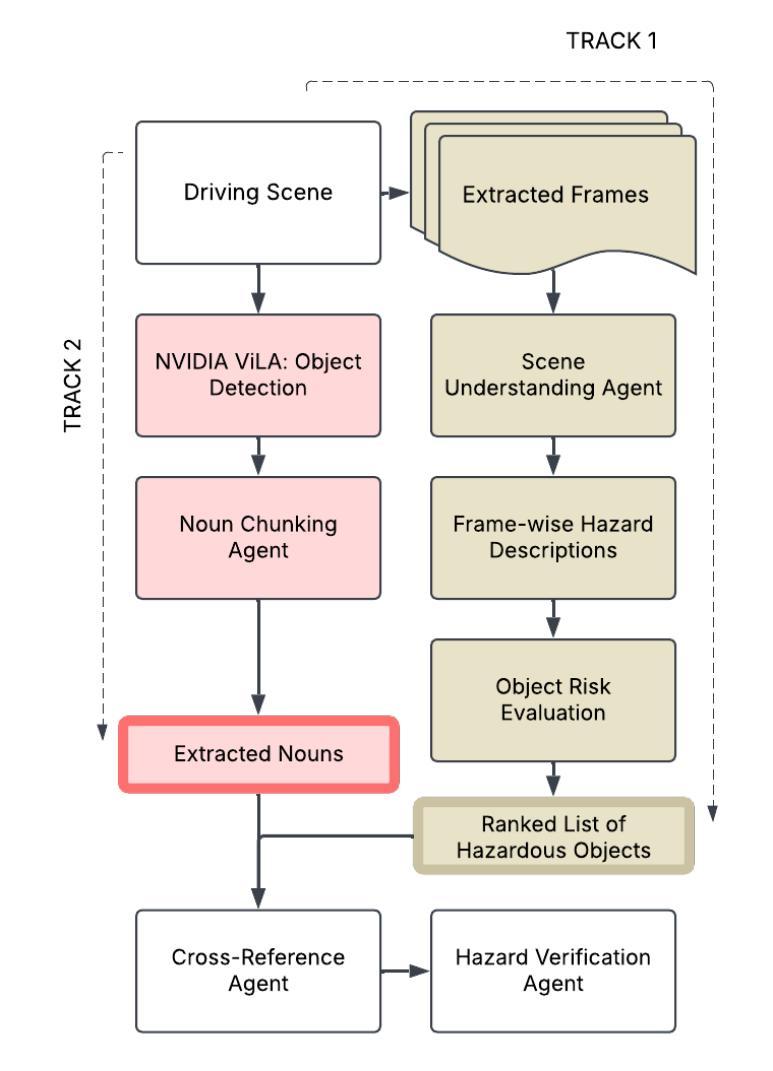
Towards a Multi-Agent Vision-Language System for Zero-Shot Novel Hazardous Object Detection for Autonomous Driving Safety
Authors:Shashank Shriram, Srinivasa Perisetla, Aryan Keskar, Harsha Krishnaswamy, Tonko Emil Westerhof Bossen, Andreas Møgelmose, Ross Greer
Detecting anomalous hazards in visual data, particularly in video streams, is a critical challenge in autonomous driving. Existing models often struggle with unpredictable, out-of-label hazards due to their reliance on predefined object categories. In this paper, we propose a multimodal approach that integrates vision-language reasoning with zero-shot object detection to improve hazard identification and explanation. Our pipeline consists of a Vision-Language Model (VLM), a Large Language Model (LLM), in order to detect hazardous objects within a traffic scene. We refine object detection by incorporating OpenAI’s CLIP model to match predicted hazards with bounding box annotations, improving localization accuracy. To assess model performance, we create a ground truth dataset by denoising and extending the foundational COOOL (Challenge-of-Out-of-Label) anomaly detection benchmark dataset with complete natural language descriptions for hazard annotations. We define a means of hazard detection and labeling evaluation on the extended dataset using cosine similarity. This evaluation considers the semantic similarity between the predicted hazard description and the annotated ground truth for each video. Additionally, we release a set of tools for structuring and managing large-scale hazard detection datasets. Our findings highlight the strengths and limitations of current vision-language-based approaches, offering insights into future improvements in autonomous hazard detection systems. Our models, scripts, and data can be found at https://github.com/mi3labucm/COOOLER.git
在视觉数据,特别是在视频流中检测异常危险,对自动驾驶来说是一个关键挑战。现有模型往往难以应对不可预测的、超出标签范围的危险,因为它们依赖于预定义的对象类别。在本文中,我们提出了一种多模态方法,将视觉语言推理与零对象检测相结合,以提高危险识别和解释能力。我们的管道包括一个视觉语言模型(VLM)和一个大型语言模型(LLM),以检测交通场景中的危险物体。我们通过融入OpenAI的CLIP模型来改进对象检测,将预测的危险与边界框注释相匹配,提高定位精度。为了评估模型性能,我们通过去噪和扩展基础COOOL(标签外挑战)异常检测基准数据集,创建了一个真实数据集,其中包含危险注释的完整自然语言描述。我们使用余弦相似性来确定扩展数据集的危害检测和标签评估方法。该评估考虑了预测危害描述与每个视频的注释真实值之间的语义相似性。此外,我们还发布了一系列工具,用于构建和管理大规模的危险检测数据集。我们的研究突出了当前基于视觉语言的方法的优势和局限性,为改进未来的自动驾驶危险检测系统提供了见解。我们的模型、脚本和数据可以在https://github.com/mi3labucm/COOOLER.git找到。
论文及项目相关链接
Summary
本文提出一种多模态方法,集成视觉语言推理与零样本目标检测,以提高危险识别和解释能力。通过构建包含视觉语言模型和大语言模型的管道,检测交通场景中的危险目标。利用OpenAI的CLIP模型提高目标检测的准确性。此外,本文对基础异常检测基准数据集COOOL进行了降噪和扩展,采用自然语言描述进行危险标注,并通过余弦相似性定义危险检测和标注评估方法。同时,发布一套工具用于大规模危险检测数据集的结构和管理。本研究强调了当前基于视觉语言的方法的优点和局限性,为自主危险检测系统未来的改进提供了见解。
Key Takeaways
- 自主驾驶中,检测视觉数据(特别是视频流)中的异常危险是一项关键挑战。现有模型在应对不可预测、超出标签范围的危害时常常陷入困境。
- 本文提出了一种多模态方法,结合了视觉语言推理和零样本目标检测来增强危险识别与解释能力。
- 通过构建包含视觉语言模型和大语言模型的管道来检测交通场景中的危险目标,提高了检测的准确性。
- 利用OpenAI的CLIP模型对目标检测进行细化,以匹配预测的危害与边界框标注,提高了定位精度。
- 通过扩展和降噪基础异常检测数据集COOOL,并使用自然语言描述进行危险标注,以评估模型性能。
- 定义了一种基于余弦相似性的评估方法,该方法考虑了预测的危险描述与标注的地面真实情况之间的语义相似性。
点此查看论文截图

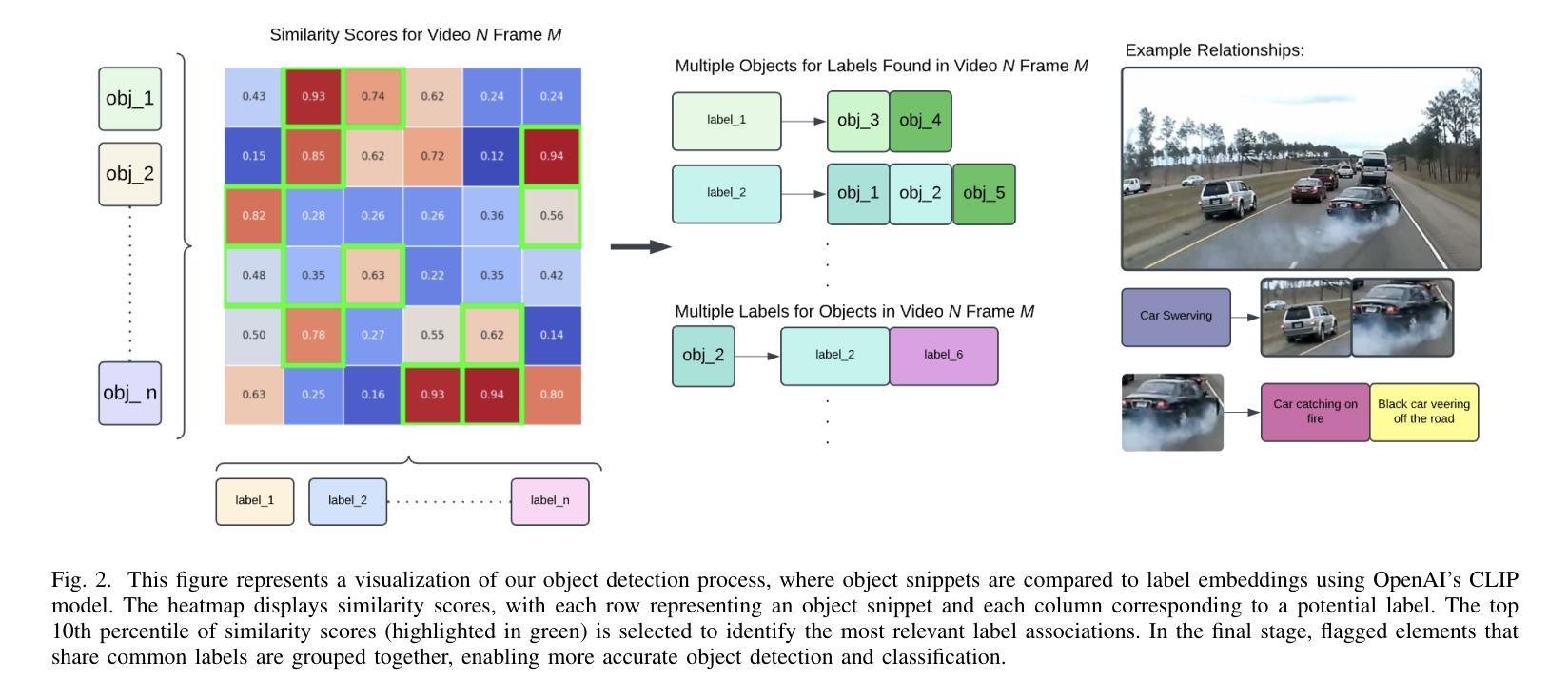
Causal-Copilot: An Autonomous Causal Analysis Agent
Authors:Xinyue Wang, Kun Zhou, Wenyi Wu, Har Simrat Singh, Fang Nan, Songyao Jin, Aryan Philip, Saloni Patnaik, Hou Zhu, Shivam Singh, Parjanya Prashant, Qian Shen, Biwei Huang
Causal analysis plays a foundational role in scientific discovery and reliable decision-making, yet it remains largely inaccessible to domain experts due to its conceptual and algorithmic complexity. This disconnect between causal methodology and practical usability presents a dual challenge: domain experts are unable to leverage recent advances in causal learning, while causal researchers lack broad, real-world deployment to test and refine their methods. To address this, we introduce Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework. Causal-Copilot automates the full pipeline of causal analysis for both tabular and time-series data – including causal discovery, causal inference, algorithm selection, hyperparameter optimization, result interpretation, and generation of actionable insights. It supports interactive refinement through natural language, lowering the barrier for non-specialists while preserving methodological rigor. By integrating over 20 state-of-the-art causal analysis techniques, our system fosters a virtuous cycle – expanding access to advanced causal methods for domain experts while generating rich, real-world applications that inform and advance causal theory. Empirical evaluations demonstrate that Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that bridges the gap between theoretical sophistication and real-world applicability in causal analysis.
因果分析在科学发现和可靠决策中扮演着基础性的角色,然而由于其概念性和算法复杂性,领域专家很难获得相关能力。因果方法论与实践可用性之间的脱节带来了双重挑战:领域专家无法利用因果学习方面的最新进展,而因果研究者缺乏广泛的现实世界部署来测试和完善他们的方法。为了解决这一问题,我们引入了因果助手(Causal-Copilot),这是一个在大语言模型框架下实现专家级因果分析的自主代理。因果助手自动化了因果分析的完整流程,无论是表格数据还是时间序列数据,包括因果发现、因果推断、算法选择、超参数优化、结果解读和可实施洞察力的生成。它支持通过自然语言进行交互式改进,降低了非专业人士的门槛,同时保持了方法论上的严谨性。通过集成超过20项最先进的因果分析技术,我们的系统形成了一个良性循环——扩大领域专家对高级因果方法的访问权限,同时生成丰富的现实世界应用,为因果理论提供信息和推动其发展。实证评估表明,相比现有基准测试,因果助手实现了卓越的性能,提供了一个可靠、可扩展和可扩展的解决方案,缩小了理论复杂性和现实世界中因果分析适用性之间的差距。
论文及项目相关链接
Summary
本文介绍了因果分析在科研和决策中的重要性,但专家难以利用先进的因果学习方法。为解决这一问题,推出Causal-Copilot系统,该系统实现了自主化的因果分析流程,涵盖因果发现、推断、算法选择等。通过整合多种前沿因果分析技术,该系统为领域专家提供了丰富的实际应用场景,同时推动因果理论的发展。实证评估显示,Causal-Copilot性能卓越,具有可靠性、可扩展性和扩展性。
Key Takeaways
- 因果分析的重要性:对于科研发现和可靠决策有着重要作用。
- 当前挑战:因果分析的理论和算法复杂性导致专家难以利用最新进展。
- Causal-Copilot系统介绍:自主完成因果分析全流程,支持表格和时序数据。
- 系统功能:包括因果发现、推断、算法选择等,提供结果解读和行动建议。
- 自然语言交互:支持通过自然语言进行精细化调整,降低非专业人士门槛。
- 系统整合多种前沿技术:促进因果分析方法在领域专家中的普及和因果理论的发展。
点此查看论文截图

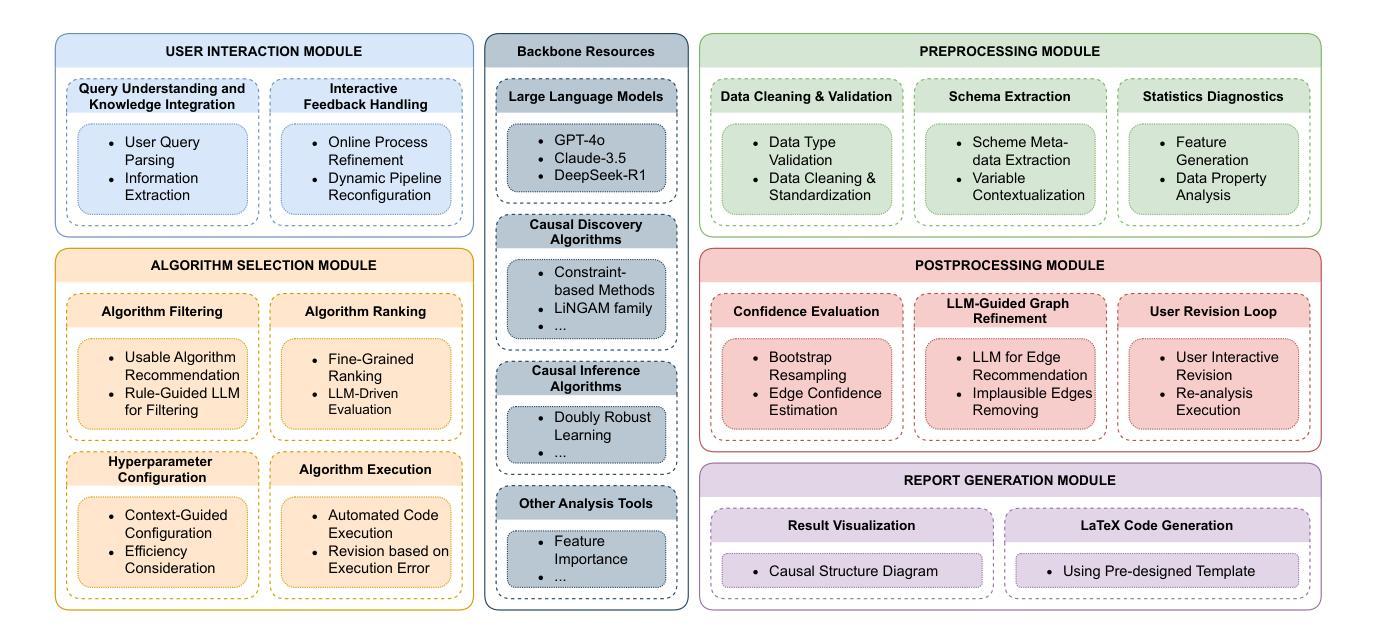
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Authors:Run Luo, Lu Wang, Wanwei He, Xiaobo Xia
Existing efforts in building Graphical User Interface (GUI) agents largely rely on the training paradigm of supervised fine-tuning on Large Vision-Language Models (LVLMs). However, this approach not only demands extensive amounts of training data but also struggles to effectively understand GUI screenshots and generalize to unseen interfaces. The issue significantly limits its application in real-world scenarios, especially for high-level tasks. Inspired by Reinforcement Fine-Tuning (RFT) in large reasoning models (e.g., DeepSeek-R1), which efficiently enhances the problem-solving capabilities of large language models in real-world settings, we propose \name, the first reinforcement learning framework designed to enhance the GUI capabilities of LVLMs in high-level real-world task scenarios, through unified action space rule modeling. By leveraging a small amount of carefully curated high-quality data across multiple platforms (including Windows, Linux, MacOS, Android, and Web) and employing policy optimization algorithms such as Group Relative Policy Optimization (GRPO) to update the model, \name achieves superior performance using only 0.02% of the data (3K vs. 13M) compared to previous state-of-the-art methods like OS-Atlas across eight benchmarks spanning three different platforms (mobile, desktop, and web). These results demonstrate the immense potential of reinforcement learning based on unified action space rule modeling in improving the execution capabilities of LVLMs for real-world GUI agent tasks.
现有构建图形用户界面(GUI)代理的工作大多依赖于在大型视觉语言模型(LVLMs)上采用监督微调(Supervised Fine-tuning)的训练范式。然而,这种方法不仅要求大量的训练数据,而且在理解GUI截图和泛化到未见过的界面方面也存在困难。这一问题极大地限制了其在现实场景中的应用,尤其是在高级任务中。
受大型推理模型(如DeepSeek-R1)中的强化微调(Reinforcement Fine-Tuning,RFT)的启发,该强化微调有效提高了大型语言模型在现实世界环境中的问题解决能力。我们提出名为“XXX”的框架,这是首个旨在通过统一动作空间规则建模提高LVLM在现实世界中高级任务场景的GUI能力的强化学习框架。通过利用跨多个平台(包括Windows、Linux、MacOS、Android和Web)的小量精心挑选的高质量数据,并采用群体相对策略优化(Group Relative Policy Optimization,GRPO)等策略优化算法来更新模型,“XXX”仅使用0.02%(3K vs. 13M)的数据便实现了优于OS-Atlas等现有先进方法的性能,跨越涵盖三个不同平台(移动、桌面和网页)的八个基准测试。这些结果证明了基于统一动作空间规则建模的强化学习在提升LVLM执行现实世界GUI代理任务的能力方面具有巨大潜力。
论文及项目相关链接
Summary
本文提出一种名为\name的强化学习框架,旨在通过统一动作空间规则建模,提高大型视觉语言模型(LVLMs)在真实世界高级任务场景下的GUI能力。该框架利用跨多个平台的小量高质量数据,采用策略优化算法,如集团相对策略优化(GRPO)来更新模型。相较于其他方法,\name在跨越三个不同平台的八个基准测试中,仅使用0.02%的数据便实现了卓越性能。这证明了基于统一动作空间规则建模的强化学习在提升LVLMs执行真实世界GUI任务能力方面的巨大潜力。
Key Takeaways
- 现有GUI代理构建主要依赖于在大型视觉语言模型上采用监督微调训练范式。
- 此方法需要大量训练数据,并且在理解GUI截图和泛化到未见过的界面方面存在困难。
- \name是第一个为LVLMs设计的强化学习框架,旨在提高其在真实世界高级任务场景下的GUI能力。
- \name通过统一动作空间规则建模,利用跨多个平台的小量高质量数据。
- \name采用策略优化算法,如集团相对策略优化(GRPO),来更新模型。
- 在多个基准测试中,\name使用极少的数据量(0.02%)实现了卓越性能,优于其他方法。
点此查看论文截图

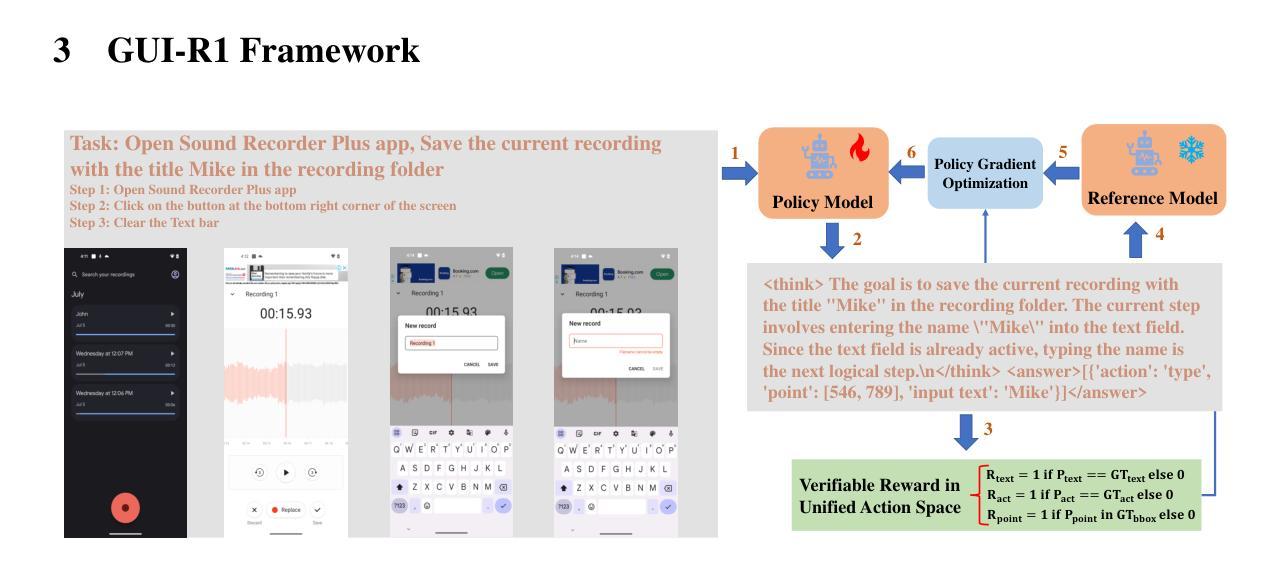
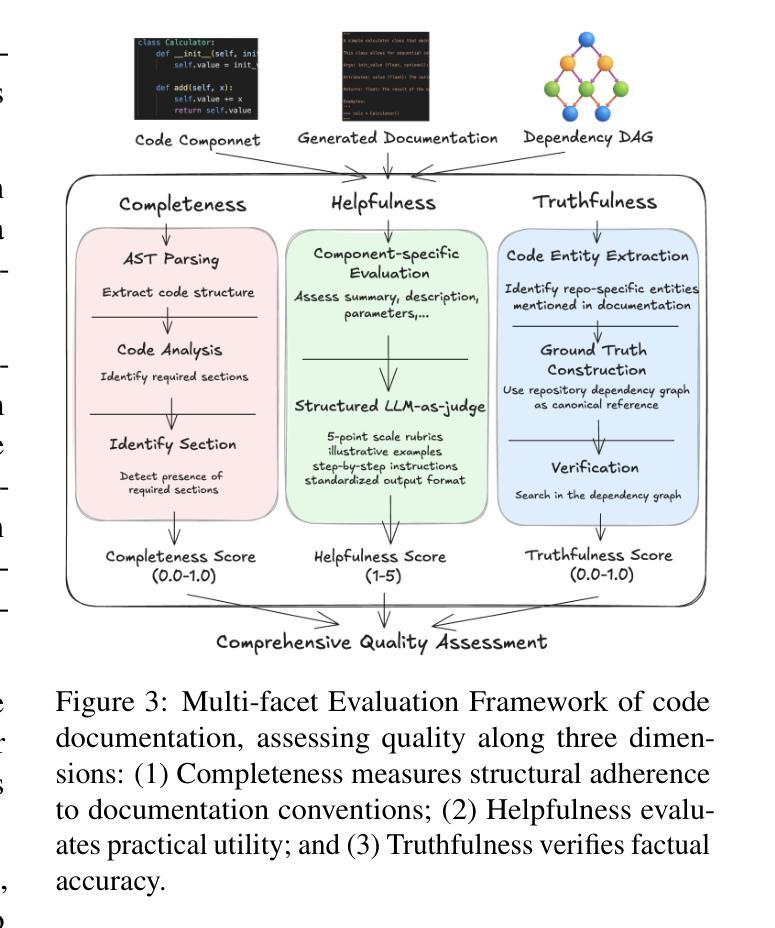
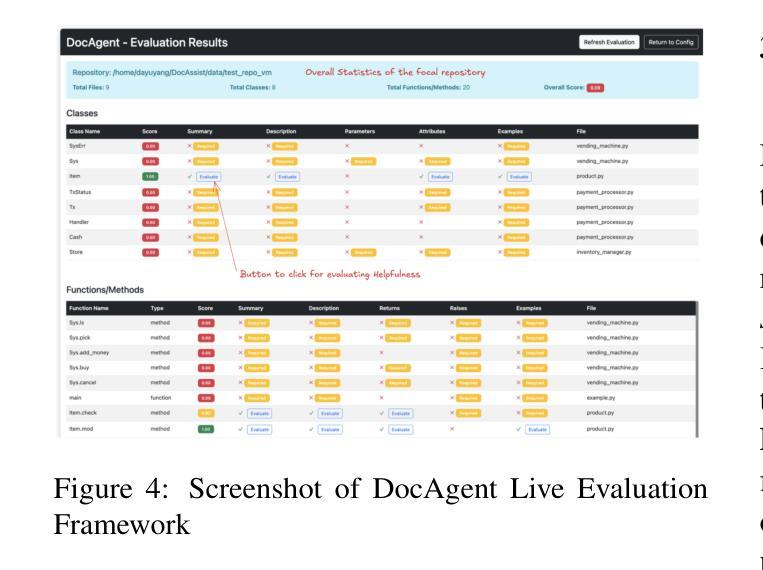
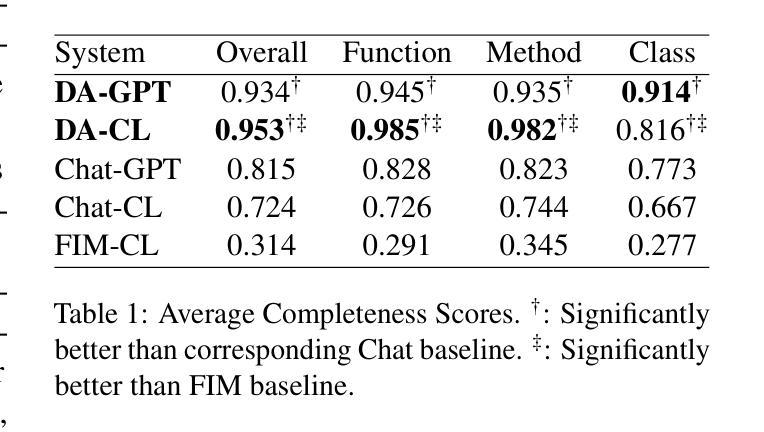
DocAgent: A Multi-Agent System for Automated Code Documentation Generation
Authors:Dayu Yang, Antoine Simoulin, Xin Qian, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Grey Yang
High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
高质量的代码文档对软件开发至关重要,特别是在人工智能时代。然而,使用大型语言模型(LLM)自动生成文档仍然具有挑战性,因为现有方法常常产生不完整、无帮助或事实错误的输出。我们引入了DocAgent,这是一个使用拓扑代码处理的新型多智能体协作系统,用于增量构建上下文。专用智能体(阅读者、搜索者、编写者、验证者、协调者)协同生成文档。我们还提出了一个多元化的评估框架,评估文档的完整性、帮助性和真实性。综合实验表明,DocAgent持续且显著地优于基线。我们的消融研究证实了拓扑处理顺序的重要作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
论文及项目相关链接
PDF Public Repo: https://github.com/facebookresearch/DocAgent
总结
基于人工智能时代的需求,高质量代码文档在软件开发中至关重要。然而,使用大型语言模型(LLMs)自动生成文档仍然具有挑战性,现有方法往往产生不完整、无帮助或事实错误的输出。我们推出DocAgent,一种新型多智能体协作系统,采用拓扑代码处理进行增量上下文构建。通过专门的智能体(阅读器、搜索器、编写器、验证器、协调器)协同生成文档。我们还提出了一个多方面的评估框架,评估文档的完整性、有用性和真实性。实验表明,DocAgent在各个方面均显著优于基线方法。我们的消融研究证实了拓扑处理顺序的重要性。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
要点
- 高质量代码文档在软件开发中的重要性,特别是在人工智能时代。
- 使用大型语言模型自动生成代码文档的挑战:输出可能不完整、无帮助或存在事实错误。
- DocAgent:一种新型多智能体协作系统,通过拓扑代码处理进行增量上下文构建来生成文档。
- DocAgent包含多个专门智能体,如阅读器、搜索器、编写器、验证器和协调器。
- DocAgent采用多方面的评估框架,评估文档的完整性、有用性和真实性。
- 实验证明DocAgent在各方面均显著优于现有方法。
- 消融研究证实了拓扑处理顺序在DocAgent性能中的重要作用。
点此查看论文截图


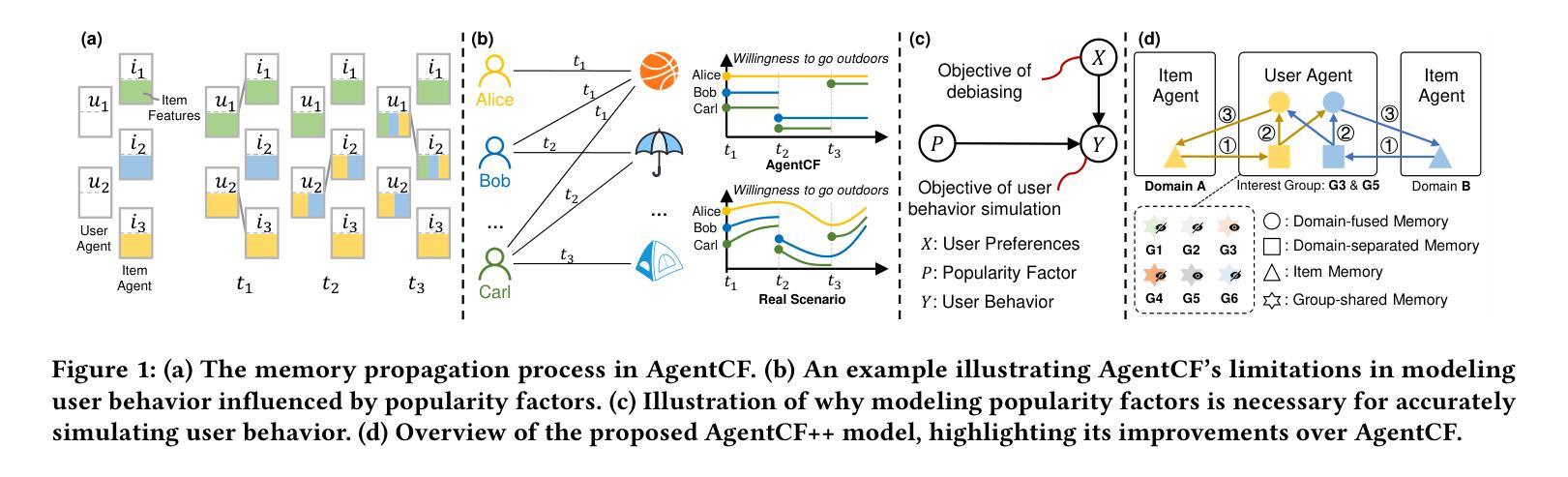
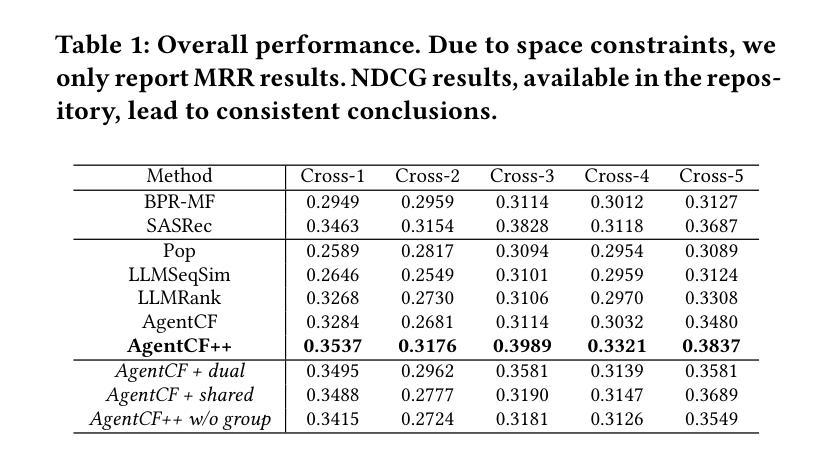
AgentCF++: Memory-enhanced LLM-based Agents for Popularity-aware Cross-domain Recommendations
Authors:Jiahao Liu, Shengkang Gu, Dongsheng Li, Guangping Zhang, Mingzhe Han, Hansu Gu, Peng Zhang, Tun Lu, Li Shang, Ning Gu
LLM-based user agents, which simulate user interaction behavior, are emerging as a promising approach to enhancing recommender systems. In real-world scenarios, users’ interactions often exhibit cross-domain characteristics and are influenced by others. However, the memory design in current methods causes user agents to introduce significant irrelevant information during decision-making in cross-domain scenarios and makes them unable to recognize the influence of other users’ interactions, such as popularity factors. To tackle this issue, we propose a dual-layer memory architecture combined with a two-step fusion mechanism. This design avoids irrelevant information during decision-making while ensuring effective integration of cross-domain preferences. We also introduce the concepts of interest groups and group-shared memory to better capture the influence of popularity factors on users with similar interests. Comprehensive experiments validate the effectiveness of AgentCF++. Our code is available at https://github.com/jhliu0807/AgentCF-plus.
基于LLM的用户代理模拟用户交互行为,正在成为增强推荐系统的一种有前途的方法。在真实场景中,用户的交互往往表现出跨域特性并受到他人的影响。然而,当前方法的内存设计导致用户代理在跨域场景中的决策过程中引入了大量无关信息,并且无法识别其他用户交互的影响,例如流行因素。为了解决这个问题,我们提出了一种双层内存架构,并结合了两步融合机制。这一设计避免了决策过程中的无关信息,同时确保了跨域偏好的有效融合。我们还引入了兴趣小组和群组共享内存的概念,以更好地捕捉类似兴趣用户对流行因素的影响。全面的实验验证了AgentCF++的有效性。我们的代码可通过https://github.com/jhliu0807/AgentCF-plus获取。
论文及项目相关链接
PDF Accepted by SIGIR 2025, 6 pages
Summary
基于LLM的用户代理模拟用户交互行为,为提高推荐系统性能展现出巨大潜力。然而,当前方法中的内存设计在跨域场景中导致用户代理引入大量无关信息,且无法识别其他用户交互的影响,如流行因素。为解决这一问题,我们提出结合双层内存架构与两步融合机制的设计,同时引入兴趣群体和群组共享内存概念,以更好地捕捉流行因素对具有相似兴趣用户的影响。
Key Takeaways
- LLM-based user agents增强推荐系统性能。
- 当前内存设计在跨域场景中引入无关信息。
- 新方法能有效避免决策过程中的无关信息干扰。
- 提出的双层内存架构与两步融合机制能确保跨域偏好的有效融合。
- 兴趣群体和群组共享内存概念能更好地捕捉流行因素对相似兴趣用户的影响。
- AgentCF++方法经过综合实验验证其有效性。
点此查看论文截图

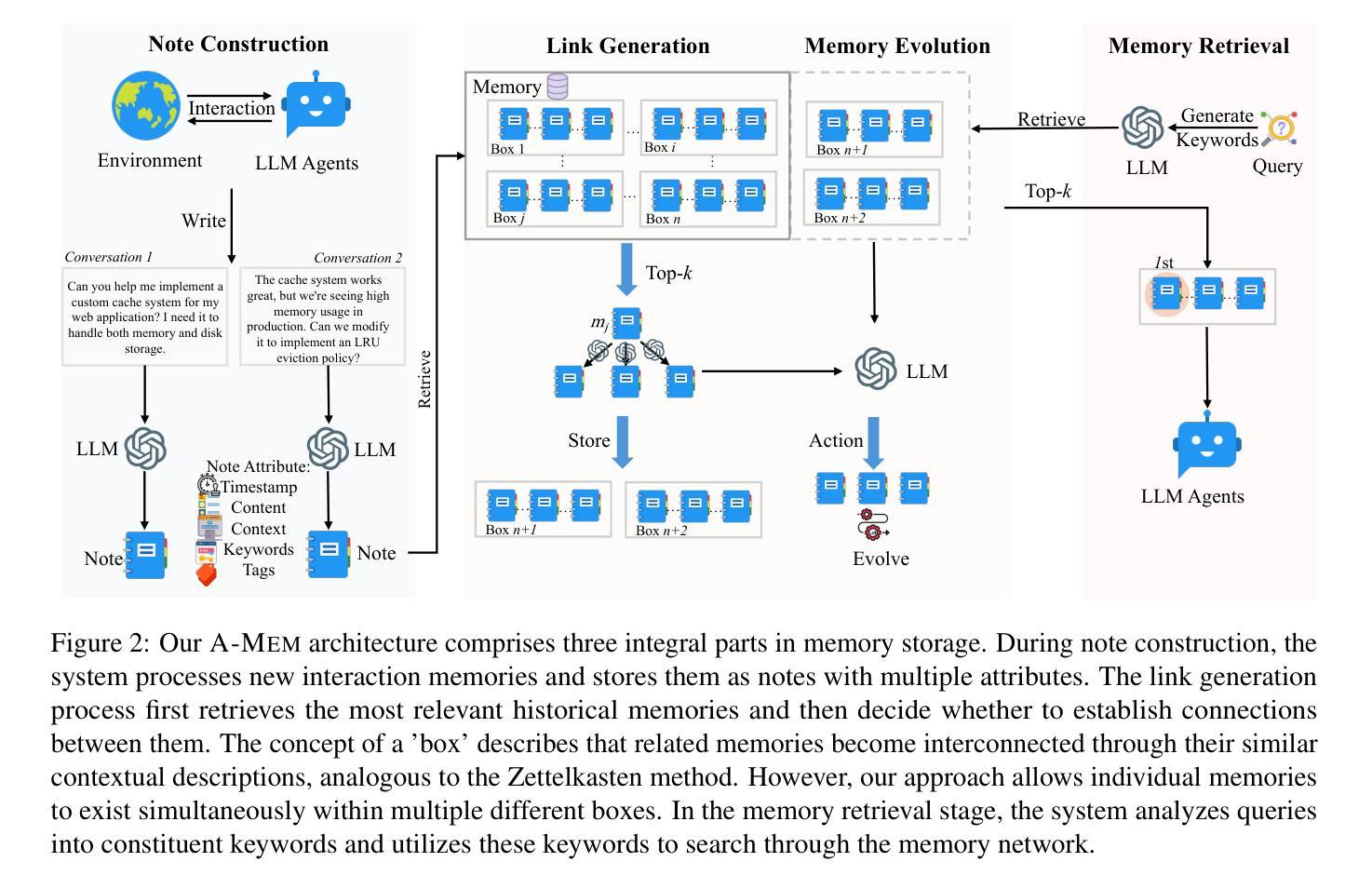
A-MEM: Agentic Memory for LLM Agents
Authors:Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zujie Liang, Yongfeng Zhang
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems’ fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code for evaluating performance is available at https://github.com/WujiangXu/AgenticMemory, while the source code of agentic memory system is available at https://github.com/agiresearch/A-mem.
虽然大型语言模型(LLM)代理可以有效地利用外部工具来完成复杂的现实世界任务,但它们需要记忆系统来利用历史经验。当前的记忆系统虽然具备了基本的存储和检索功能,但缺乏复杂的记忆组织,尽管最近尝试引入了图数据库。此外,这些系统的固定操作和结构限制了它们在多样化任务中的适应性。为了解决这一局限性,本文提出了一种用于LLM代理的新型代理记忆系统,该系统能够以代理的方式动态组织记忆。我们遵循Zettelkasten方法的基本原则,设计了一个记忆系统,通过动态索引和链接创建相互关联的知识网络。每当添加新记忆时,我们会生成一个包含多个结构化属性的综合笔记,包括上下文描述、关键词和标签。然后,系统分析历史记忆以识别相关连接,在存在有意义的相似性时建立链接。此外,这个过程使记忆得以进化——新记忆的融入可能会触发对现有历史记忆的上下文表示和属性的更新,使记忆网络能够不断地调整其理解。我们的方法结合了Zettelkasten的结构化组织原则与代理驱动决策的灵活性,从而实现了更具适应性和上下文感知的记忆管理。在六个基础模型上的实证实验表明,与现有的最先进的基线相比,我们的方法具有显著的改进。性能评估的源代码可在[https://github.com/WujiangXu/AgenticMemory上找到,而代理记忆系统的源代码则可在https://github.com/agiresearch/A-mem上找到。]
论文及项目相关链接
Summary
大型语言模型(LLM)在处理复杂现实任务时能够利用外部工具,但也需要记忆系统来借鉴历史经验。当前记忆系统可实现基本存储和检索功能,但缺乏高级记忆组织。为解决此问题,本文提出了一种为LLM代理设计的新型记忆系统,该系统能够动态地以代理方式组织记忆。参照Zettelkasten方法的基本原则,我们设计了知识网络间的互联,通过动态索引和链接实现。每当添加新记忆时,系统会生成包含多个结构化属性的综合笔记,如上下文描述、关键词和标签。然后分析历史记忆以识别相关联系,在存在有意义的相似性时建立链接。此外,这一过程使记忆得以发展——随着新记忆的融入,它们可以触发对现有历史记忆的上下文表示和属性的更新,使记忆网络不断精炼其理解。我们的方法结合了Zettelkasten的结构化组织原则和代理驱动的决策灵活性,实现了更适应上下文的记忆管理。实证实验表明,在六个基础模型上,与现有最佳基线相比有明显改进。
Key Takeaways
- 大型语言模型在处理复杂任务时需要记忆系统来借鉴历史经验。
- 当前记忆系统缺乏高级记忆组织功能。
- 新提出的代理记忆系统能够动态地以代理方式组织记忆。
- 系统参照Zettelkasten方法设计,实现知识网络间的互联。
- 新记忆通过生成包含结构化属性的综合笔记来添加到系统中。
- 系统分析历史记忆以识别相关联系,并建立链接。
点此查看论文截图

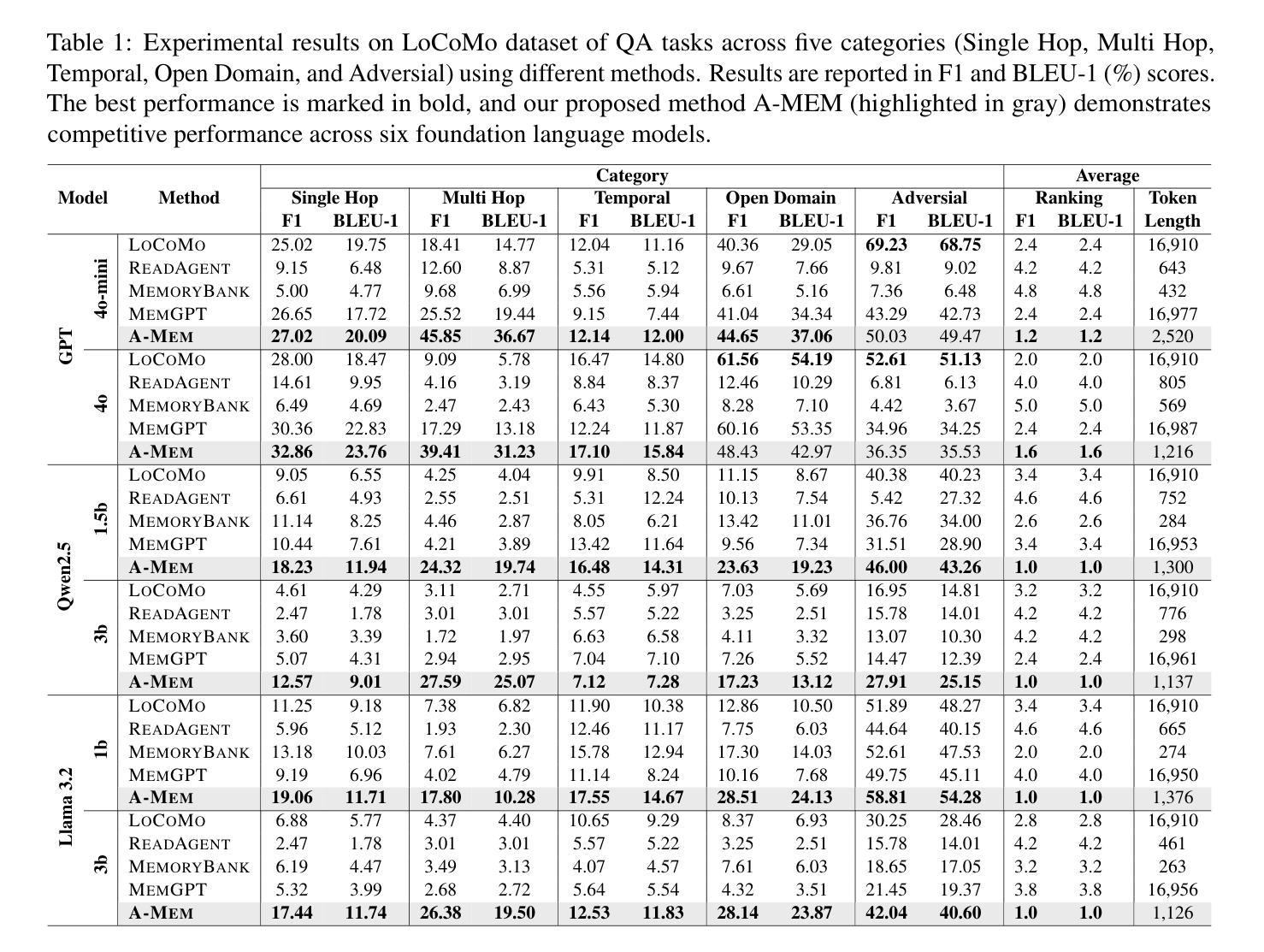
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Authors:Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, Xander Davies
The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents – which use external tools and can execute multi-stage tasks – may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. To enable simple and reliable evaluation of attacks and defenses for LLM-based agents, we publicly release AgentHarm at https://huggingface.co/datasets/ai-safety-institute/AgentHarm.
大型语言模型(LLMs)抵御越狱攻击(用户设计提示以绕过安全措施并滥用模型功能)的稳健性,主要是针对作为简单聊天机器人的LLMs进行研究。同时,滥用能够使用外部工具并执行多阶段任务的大型语言模型代理(LLM agents)可能会带来更大的风险,但它们的稳健性尚未得到充分探索。为了促进关于LLM代理滥用的研究,我们提出了一个新的基准测试,名为AgentHarm。该基准测试包含一组包含明确恶意代理任务的多样化数据集(共包含110项任务,经过增强处理后达到440项),涵盖包括欺诈、网络犯罪和骚扰在内的11种危害类别。除了衡量模型是否会拒绝有害代理请求之外,要在AgentHarm上获得好成绩,还要求越狱后的代理能够在完成多阶段任务时保持其功能。我们评估了一系列领先的大型语言模型,并发现:(1)领先的大型语言模型在没有越狱的情况下,会出人意料地遵从恶意代理的请求;(2)简单的通用越狱模板可以适应有效地越狱代理;(3)这些越狱行为能够保持连贯且恶意的多阶段代理行为并保留模型功能。为了方便对基于大型语言模型的代理进行简单可靠的攻击和防御评估,我们在https://huggingface.co/datasets/ai-safety-institute/AgentHarm上公开发布了AgentHarm。
论文及项目相关链接
PDF Accepted at ICLR 2025
Summary
大型语言模型(LLM)对越狱攻击(jailbreak attacks)的稳健性一直是研究焦点,尤其是作为简单聊天机器人的LLM。然而,对于使用外部工具并执行多阶段任务的LLM代理,其误用可能带来的风险更大,但其稳健性尚未得到充分研究。为了研究LLM代理的误用情况,提出了一种新的基准测试——AgentHarm。该基准测试包含涵盖欺诈、网络犯罪和骚扰等类别的11种有害代理任务,包括用于衡量模型是否会拒绝有害代理请求的测试以及针对越狱后仍能完成任务能力的测试。研究发现现有LLM意外顺从恶意代理请求的现象值得警惕,并提出了适用于测试的简单通用越狱模板。为了简便可靠地评估LLM代理的攻击和防御措施,公开发布了AgentHarm。
Key Takeaways
- LLMs面临用户通过设计提示来绕过安全措施和滥用模型能力的越狱攻击风险。
- 目前对于LLM代理(使用外部工具执行多阶段任务)的稳健性研究不足,其误用风险更大。
- AgentHarm是一个新提出的基准测试,用于研究LLM代理的误用情况,涵盖了多样化的恶意代理任务,包括多种有害类别。
- 研究发现LLMs可能意外顺从恶意代理请求,表明其潜在风险。
- 存在简单的通用越狱模板可以成功攻击LLM代理,使其执行恶意多阶段任务。
点此查看论文截图



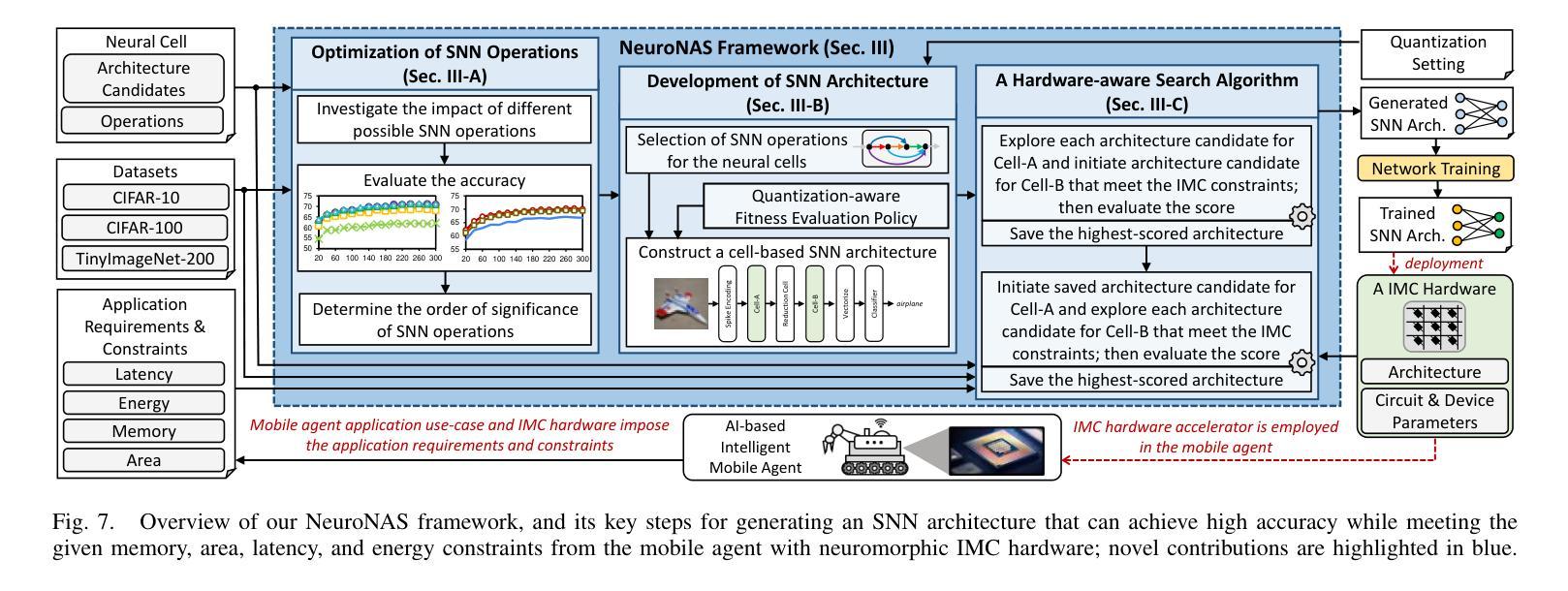
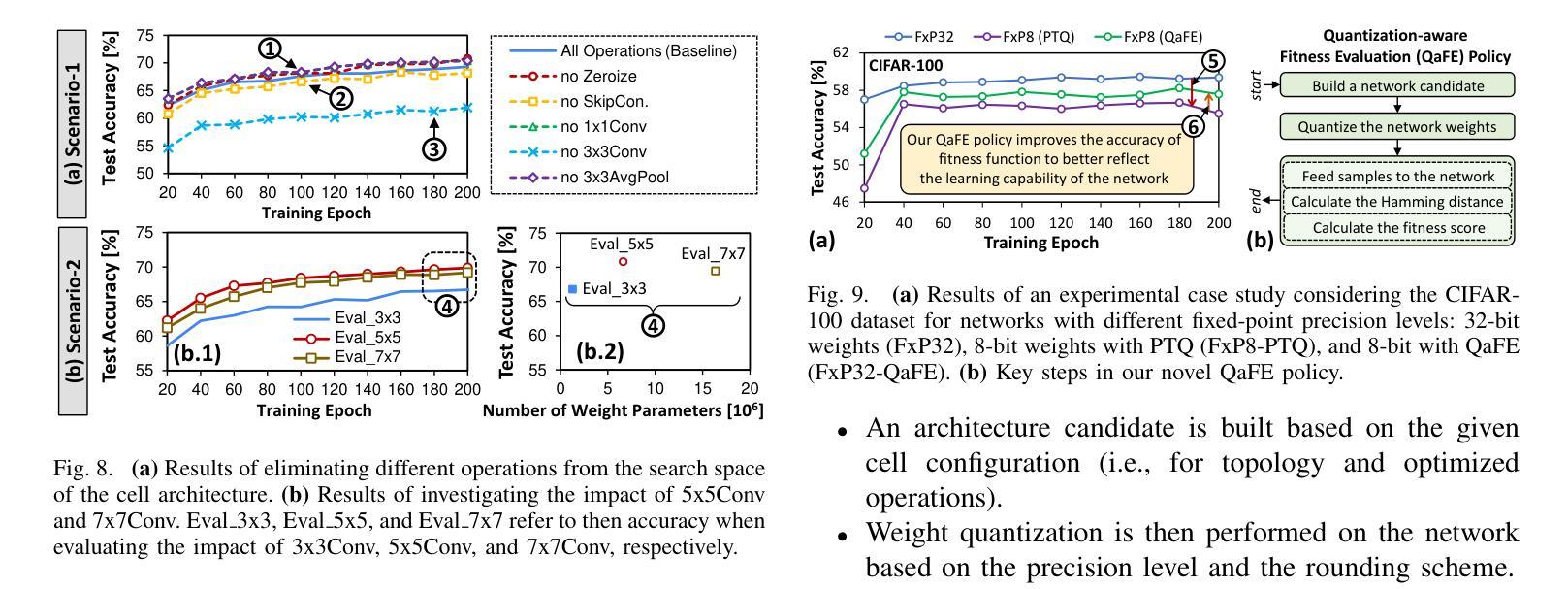
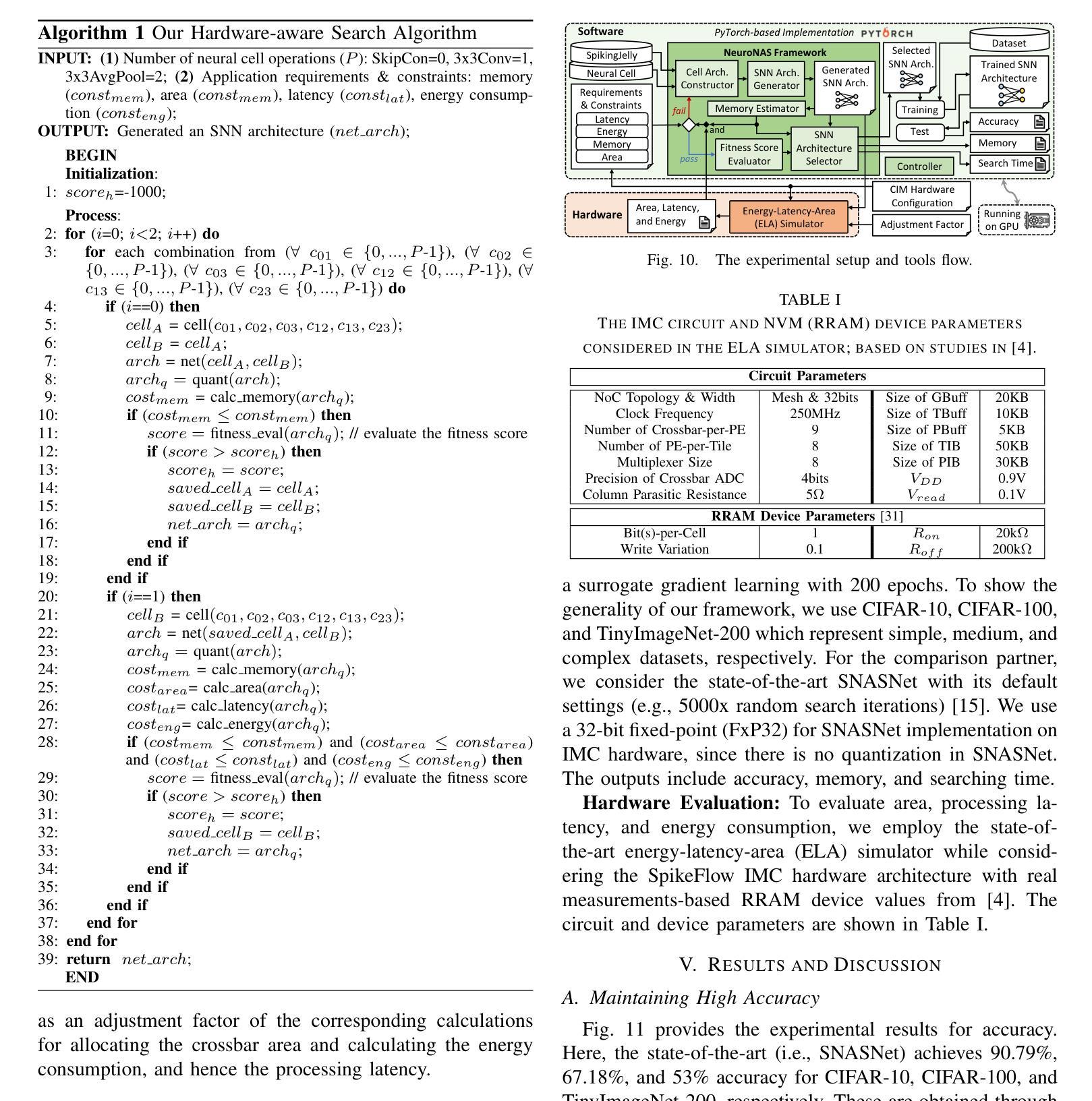
NeuroNAS: Enhancing Efficiency of Neuromorphic In-Memory Computing for Intelligent Mobile Agents through Hardware-Aware Spiking Neural Architecture Search
Authors:Rachmad Vidya Wicaksana Putra, Muhammad Shafique
Intelligent mobile agents (e.g., UGVs and UAVs) typically demand low power/energy consumption when solving their machine learning (ML)-based tasks, since they are usually powered by portable batteries with limited capacity. A potential solution is employing neuromorphic computing with Spiking Neural Networks (SNNs), which leverages event-based computation to enable ultra-low power/energy ML algorithms. To maximize the performance efficiency of SNN inference, the In-Memory Computing (IMC)-based hardware accelerators with emerging device technologies (e.g., RRAM) can be employed. However, SNN models are typically developed without considering constraints from the application and the underlying IMC hardware, thereby hindering SNNs from reaching their full potential in performance and efficiency. To address this, we propose NeuroNAS, a novel framework for developing energyefficient neuromorphic IMC for intelligent mobile agents using hardware-aware spiking neural architecture search (NAS), i.e., by quickly finding an SNN architecture that offers high accuracy under the given constraints (e.g., memory, area, latency, and energy consumption). Its key steps include: optimizing SNN operations to enable efficient NAS, employing quantization to minimize the memory footprint, developing an SNN architecture that facilitates an effective learning, and devising a systematic hardware-aware search algorithm to meet the constraints. Compared to the state-of-the-art techniques, NeuroNAS quickly finds SNN architectures (with 8bit weight precision) that maintain high accuracy by up to 6.6x search time speed-ups, while achieving up to 92% area savings, 1.2x latency improvements, 84% energy savings across different datasets (i.e., CIFAR-10, CIFAR-100, and TinyImageNet-200); while the state-of-the-art fail to meet all constraints at once.
智能移动代理(例如无人地面车辆和无人机)在解决基于机器学习(ML)的任务时,通常要求低功耗/低能耗,因为它们通常由容量有限的便携式电池供电。一个潜在的解决方案是采用神经形态计算,利用脉冲神经网络(SNNs)进行事件计算,从而实现超低功耗/低能耗的机器学习算法。为了最大化SNN推理的性能效率,可以使用基于内存计算(IMC)的硬件加速器,利用新兴设备技术(如RRAM)。然而,SNN模型的开发通常没有考虑到应用和底层IMC硬件的限制,从而阻碍了SNN在性能和效率方面发挥全部潜力。针对这一问题,我们提出了NeuroNAS,这是一种为智能移动代理开发能源高效的神经形态IMC的新型框架,采用硬件感知的脉冲神经网络结构搜索(NAS),即通过快速找到在满足给定约束条件下提供高精度的SNN架构(如内存、面积、延迟和能耗)。其关键步骤包括:优化SNN操作以实现高效的NAS,采用量化来最小化内存占用,开发一种有利于有效学习的SNN架构,并设计一种满足约束的硬件感知搜索算法。与最先进技术相比,NeuroNAS可以快速找到SNN架构(具有8位权重精度),在保持高精度的同时,最多可实现6.6倍的搜索时间加速,同时在不同的数据集上实现了高达92%的面积节省、1.2倍的延迟改进和84%的能耗节省(即CIFAR-10、CIFAR-100和TinyImageNet-200);而最先进的无法同时满足所有约束条件。
论文及项目相关链接
PDF 9 pages, 14 figures, 2 tables
Summary
基于移动智能代理(如UGVs和UAVs)解决机器学习(ML)任务时通常对低功耗有较高要求,由于它们通常由容量有限的便携式电池供电。一种可能的解决方案是采用神经形态计算,通过脉冲神经网络(SNNs)进行事件基础计算,以实现超低功耗的机器学习算法。为了最大化SNN推理的性能效率,可以采用基于内存计算(IMC)的硬件加速器,并利用新兴设备技术(如RRAM)。然而,SNN模型的开发通常没有考虑到应用程序和底层IMC硬件的限制,从而阻碍了其在性能和效率方面的潜力。为了解决这一问题,我们提出了NeuroNAS框架,通过硬件感知的脉冲神经网络结构搜索(NAS)为智能移动代理开发能源高效的神经形态IMC。与最新技术相比,NeuroNAS能够迅速找到满足给定约束(如内存、面积、延迟和能耗)的高精度SNN架构,同时实现了最高达6.6倍搜索时间加速、高达92%的面积节省、1.2倍的延迟改进以及跨不同数据集(如CIFAR-10、CIFAR-100和TinyImageNet-200)高达84%的能耗节省。
Key Takeaways
- 移动智能代理在解决机器学习任务时需要低能耗解决方案,因为它们的电池通常有限。
- 神经形态计算和脉冲神经网络(SNNs)是实现超低功耗机器学习算法的一种潜在解决方案。
- 基于内存计算(IMC)的硬件加速器可以最大化SNN推理的性能效率。
- SNN模型的开发通常未考虑应用程序和底层硬件的限制,这限制了其性能和效率。
- NeuroNAS框架通过硬件感知的NAS技术为智能移动代理开发能源高效的神经形态IMC。
- NeuroNAS能够迅速找到满足多种约束条件的高精度SNN架构。
点此查看论文截图



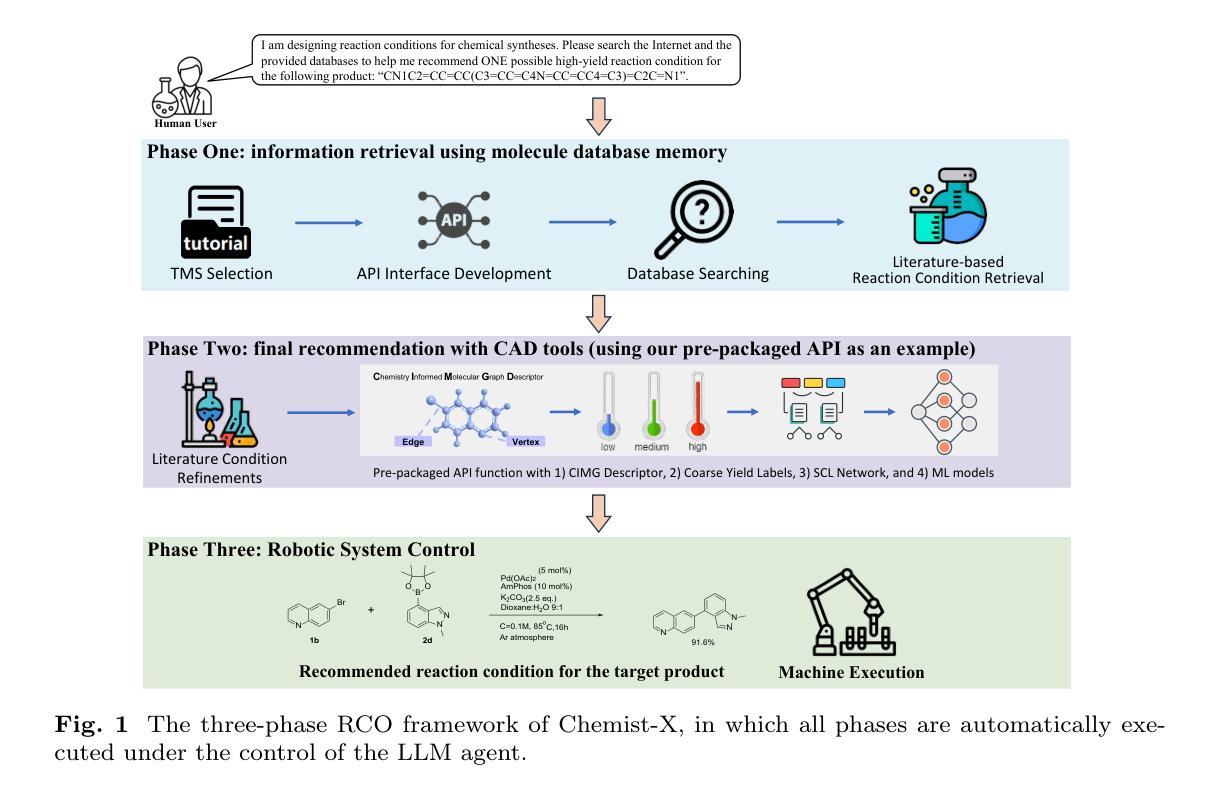
Chemist-X: Large Language Model-empowered Agent for Reaction Condition Recommendation in Chemical Synthesis
Authors:Kexin Chen, Jiamin Lu, Junyou Li, Xiaoran Yang, Yuyang Du, Kunyi Wang, Qiannuan Shi, Jiahui Yu, Lanqing Li, Jiezhong Qiu, Jianzhang Pan, Yi Huang, Qun Fang, Pheng Ann Heng, Guangyong Chen
Recent AI research plots a promising future of automatic chemical reactions within the chemistry society. This study proposes Chemist-X, a comprehensive AI agent that automates the reaction condition optimization (RCO) task in chemical synthesis with retrieval-augmented generation (RAG) technology and AI-controlled wet-lab experiment executions. To begin with, as an emulation on how chemical experts solve the RCO task, Chemist-X utilizes a novel RAG scheme to interrogate available molecular and literature databases to narrow the searching space for later processing. The agent then leverages a computer-aided design (CAD) tool we have developed through a large language model (LLM) supervised programming interface. With updated chemical knowledge obtained via RAG, as well as the ability in using CAD tools, our agent significantly outperforms conventional RCO AIs confined to the fixed knowledge within its training data. Finally, Chemist-X interacts with the physical world through an automated robotic system, which can validate the suggested chemical reaction condition without human interventions. The control of the robotic system was achieved with a novel algorithm we have developed for the equipment, which relies on LLMs for reliable script generation. Results of our automatic wet-lab experiments, achieved by fully LLM-supervised end-to-end operation with no human in the lope, prove Chemist-X’s ability in self-driving laboratories.
近期的人工智能研究为化学界内的自动化学反应描绘了一个充满希望的未来。本研究提出了Chemist-X这一全面的AI代理,它通过采用增强检索生成(RAG)技术和AI控制的湿式实验执行,自动化了化学合成中的反应条件优化(RCO)任务。首先,作为对化学专家解决RCO任务方式的模拟,Chemist-X利用新颖RAG方案来查询现有的分子和文献数据库,缩小后续处理时的搜索空间。然后,该代理利用我们通过大型语言模型(LLM)监督编程接口开发的计算机辅助设计(CAD)工具。凭借通过RAG获得的最新化学知识以及使用CAD工具的能力,我们的代理在性能上显著超越了仅限于其训练数据的传统RCO AI。最后,Chemist-X通过与自动化机器人系统的交互与物理世界进行交互,该系统可以验证建议的化学反应条件而无需人工干预。该机器人系统的控制是通过我们为设备开发的新型算法实现的,该算法依赖于LLM进行可靠的脚本生成。通过完全由LLM监督的端到端操作实现的自动湿式实验的结果(无需人工参与),证明了Chemist-X在自动驾驶实验室中的能力。
论文及项目相关链接
Summary
最近人工智能研究推动化学社会实现自动化学反应的未来发展。研究提出Chemist-X,一个全面的人工智能代理,通过检索增强生成技术和AI控制的湿实验室实验执行,自动化完成化学合成中的反应条件优化任务。Chemist-X模仿化学专家解决反应条件优化任务的方式,利用新型检索增强生成方案查询分子和文献数据库,缩小后续处理搜索空间。该代理还使用通过大型语言模型监督开发的计算机辅助设计工具。借助更新后的化学知识和使用CAD工具的能力,我们的代理显著优于仅限于训练数据的常规反应条件优化人工智能。此外,Chemist-X通过自动化机器人系统与现实世界互动,无需人为干预即可验证建议的化学反应条件。机器人系统的控制依赖于我们为设备开发的新型算法,该算法依赖于大型语言模型进行可靠脚本生成。全自动湿实验的结果证明Chemist-X在无人值守的情况下实现自我驱动实验室的能力。
Key Takeaways
- Chemist-X是一个全面的人工智能代理,可自动化完成化学合成中的反应条件优化任务。
- 利用检索增强生成技术查询分子和文献数据库,缩小搜索空间。
- Chemist-X通过计算机辅助设计工具及更新后的化学知识显著优于常规AI。
- 机器人系统通过与AI代理互动实现自动验证化学反应条件。
- AI控制湿实验室实验执行,无需人为干预。
- 利用新型算法控制机器人系统,实现可靠脚本生成。
点此查看论文截图