⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-22 更新
Meta-Learning and Knowledge Discovery based Physics-Informed Neural Network for Remaining Useful Life Prediction
Authors:Yu Wang, Shujie Liu, Shuai Lv, Gengshuo Liu
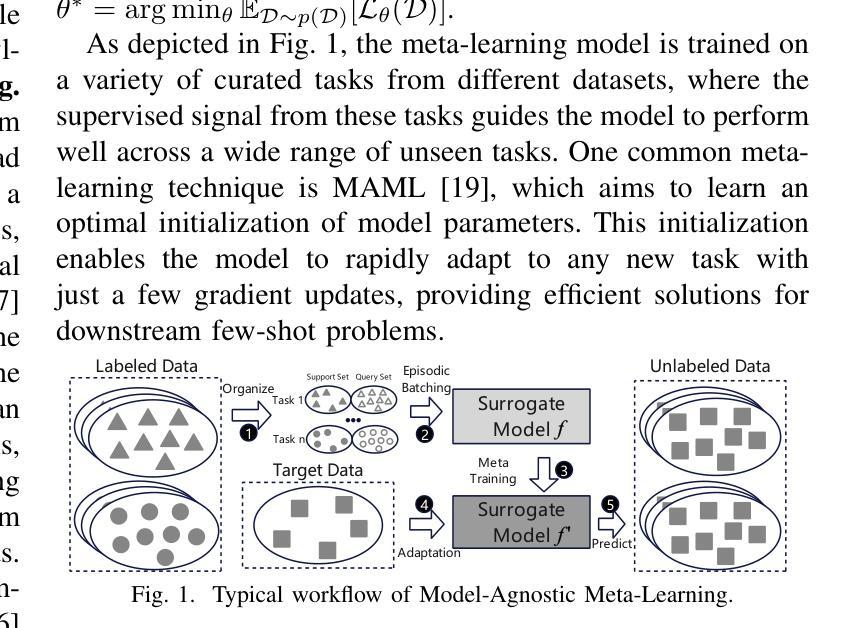
Predicting the remaining useful life (RUL) of rotating machinery is critical for industrial safety and maintenance, but existing methods struggle with scarce target-domain data and unclear degradation dynamics. We propose a Meta-Learning and Knowledge Discovery-based Physics-Informed Neural Network (MKDPINN) to address these challenges. The method first maps noisy sensor data to a low-dimensional hidden state space via a Hidden State Mapper (HSM). A Physics-Guided Regulator (PGR) then learns unknown nonlinear PDEs governing degradation evolution, embedding these physical constraints into the PINN framework. This integrates data-driven and physics-based approaches. The framework uses meta-learning, optimizing across source-domain meta-tasks to enable few-shot adaptation to new target tasks. Experiments on industrial data and the C-MAPSS benchmark show MKDPINN outperforms baselines in generalization and accuracy, proving its effectiveness for RUL prediction under data scarcity
预测旋转机械的剩余使用寿命(RUL)对工业安全和维护至关重要。但现有方法在目标领域数据稀缺和退化动态不明确的情况下会遇到困难。我们提出了一种基于元学习和知识发现的物理信息神经网络(MKDPINN)来解决这些挑战。该方法首先通过隐藏状态映射器(HSM)将嘈杂的传感器数据映射到低维隐藏状态空间。然后,物理引导调节器(PGR)学习控制退化演变的未知非线性偏微分方程,将这些物理约束嵌入到PINN框架中。这结合了数据驱动和基于物理的方法。该框架使用元学习,通过优化源域元任务,使新目标任务进行少量样本即可适应。在工业数据和C-MAPSS基准测试上的实验表明,MKDPINN在泛化和准确性方面超过了基准,证明了其在数据稀缺情况下进行RUL预测的有效性。
论文及项目相关链接
PDF 34 pages,20 figs
Summary
:本文提出一种基于元学习与知识发现的物理信息神经网络(MKDPINN),用于预测旋转机械的剩余使用寿命(RUL)。该方法通过隐状态映射器(HSM)将噪声传感器数据映射到低维隐藏状态空间,并通过物理引导调节器(PGR)学习未知的支配退化演变非线性偏微分方程,将这些物理约束嵌入到PINN框架中。该框架利用元学习,通过对源域元任务进行优化,实现对新目标任务的少量适应。在工业数据和C-MAPSS基准测试上的实验表明,MKDPINN在泛化和准确性方面优于基线方法,证明其在数据稀缺情况下进行RUL预测的有效性。
Key Takeaways
- MKDPINN方法结合数据驱动和物理基方法,用于预测旋转机械的剩余使用寿命(RUL)。
- 方法通过隐状态映射器(HSM)处理噪声传感器数据,将其映射到低维隐藏状态空间。
- 物理引导调节器(PGR)学习支配退化演变的未知非线性偏微分方程。
- MKDPINN将物理约束嵌入到PINN框架中,提高模型的泛化能力和准确性。
- 该方法利用元学习,通过优化源域元任务,实现对新目标的少量适应。
- 工业数据和C-MAPSS基准测试的实验表明MKDPINN在RUL预测方面的优越性。
点此查看论文截图

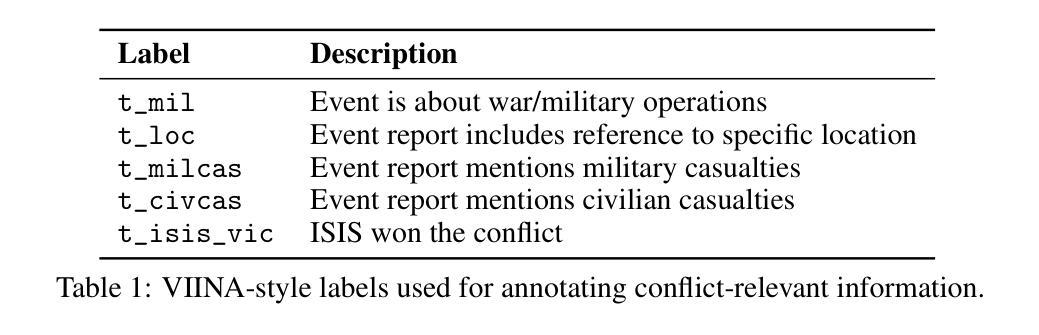
Controlled Territory and Conflict Tracking (CONTACT): (Geo-)Mapping Occupied Territory from Open Source Intelligence
Authors:Paul K. Mandal, Cole Leo, Connor Hurley
Open-source intelligence provides a stream of unstructured textual data that can inform assessments of territorial control. We present CONTACT, a framework for territorial control prediction using large language models (LLMs) and minimal supervision. We evaluate two approaches: SetFit, an embedding-based few-shot classifier, and a prompt tuning method applied to BLOOMZ-560m, a multilingual generative LLM. Our model is trained on a small hand-labeled dataset of news articles covering ISIS activity in Syria and Iraq, using prompt-conditioned extraction of control-relevant signals such as military operations, casualties, and location references. We show that the BLOOMZ-based model outperforms the SetFit baseline, and that prompt-based supervision improves generalization in low-resource settings. CONTACT demonstrates that LLMs fine-tuned using few-shot methods can reduce annotation burdens and support structured inference from open-ended OSINT streams. Our code is available at https://github.com/PaulKMandal/CONTACT/.
开源情报提供了一系列非结构化的文本数据,可以为地域控制评估提供信息。我们提出了CONTACT,这是一个使用大型语言模型和最小监督进行地域控制预测的框架。我们评估了两种方法:SetFit,一种基于嵌入的少量样本分类器,以及应用于BLOOMZ-560m的提示调整方法,这是一个多语言生成型LLM。我们的模型是在一个涵盖叙利亚和伊拉克ISIS活动的手工标注新闻数据集上进行训练的,通过使用提示条件下的提取与控制相关的信号,如军事行动、伤亡和位置参考。我们表明,基于BLOOMZ的模型优于SetFit基线,并且基于提示的监督可以改善低资源环境中的泛化能力。CONTACT证明,使用少量样本方法微调的大型语言模型可以减轻标注负担,并支持从开放的OSINT流中进行结构化推理。我们的代码可在https://github.comcom/PaulKMandal/CONTACT/找到。
论文及项目相关链接
PDF 7 pages, 1 figure, 1 table
Summary
开源情报提供了一系列非结构化的文本数据,可为领土控制评估提供依据。本研究提出了CONTACT框架,利用大型语言模型和最小监督来进行领土控制预测。评估了两种途径:基于嵌入的少量样本分类器SetFit,以及应用于BLOOMZ-560m的多语言生成型LLM的提示调整方法。模型在少量手工标注的新闻文章数据集上进行训练,这些文章涵盖了叙利亚和伊拉克的ISIS活动,通过提示条件提取与控制相关的信号,如军事行动、伤亡和地点参考。研究结果表明,基于BLOOMZ的模型优于SetFit基线,提示监督在低资源环境中可改善泛化能力。CONTACT证明,使用少量样本方法微调的大型语言模型可以减轻标注负担,并支持从开放型OSINT流中进行结构化推理。相关代码已发布在https://github.com/PaulKMandal/CONTACT/。
Key Takeaways
- CONTACT框架利用大型语言模型进行领土控制预测,开源情报能提供相关评估信息。
- 研究评估了SetFit和BLOOMZ-560m两种途径,前者是基于嵌入的少量样本分类器,后者是多语言生成型的大型语言模型。
- 模型训练使用了涉及ISIS在叙利亚和伊拉克活动的新闻文章数据集。
- 提示条件提取被用于提取控制相关的关键信号。
- 基于BLOOMZ的模型性能优于SetFit基线。
- 提示监督在低资源环境中提升了模型的泛化能力。
点此查看论文截图

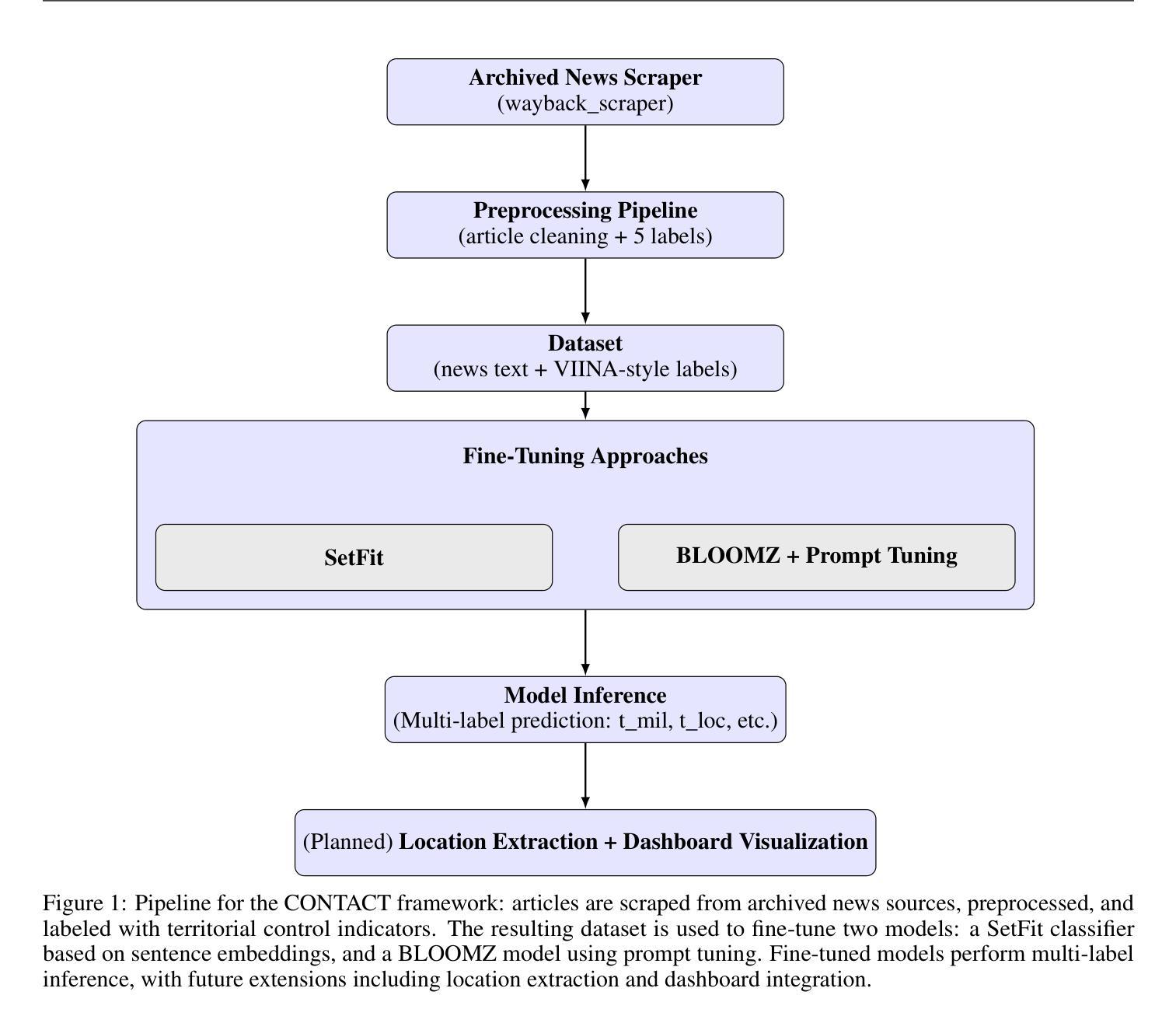
Few-Shot Referring Video Single- and Multi-Object Segmentation via Cross-Modal Affinity with Instance Sequence Matching
Authors:Heng Liu, Guanghui Li, Mingqi Gao, Xiantong Zhen, Feng Zheng, Yang Wang
Referring video object segmentation (RVOS) aims to segment objects in videos guided by natural language descriptions. We propose FS-RVOS, a Transformer-based model with two key components: a cross-modal affinity module and an instance sequence matching strategy, which extends FS-RVOS to multi-object segmentation (FS-RVMOS). Experiments show FS-RVOS and FS-RVMOS outperform state-of-the-art methods across diverse benchmarks, demonstrating superior robustness and accuracy.
视频对象参考分割(RVOS)旨在根据自然语言描述对视频中的对象进行分割。我们提出了FS-RVOS,这是一个基于Transformer的模型,具有两个关键组件:跨模态亲和力模块和实例序列匹配策略,后者将FS-RVOS扩展到多对象分割(FS-RVMOS)。实验表明,FS-RVOS和FS-RVMOS在多种基准测试上的表现均优于现有技术,表现出更高的稳健性和准确性。
论文及项目相关链接
PDF 23 pages, 10 figures
Summary
基于自然语言描述的视频对象分割(RVOS)旨在实现对视频的精准对象分割。提出一种新的模型FS-RVOS,其核心为跨模态亲和模块与实例序列匹配策略。这一模型不仅能够处理单一对象分割问题,还能够进行多对象分割。实验结果证明FS-RVOS及扩展版FS-RVMOS在多种基准测试中表现优于现有技术,展现了其卓越的鲁棒性和准确性。
Key Takeaways
- RVOS旨在通过自然语言描述实现视频对象的精准分割。
- 提出了一种新的模型FS-RVOS,该模型基于Transformer技术。
- FS-RVOS包含两个关键组件:跨模态亲和模块和实例序列匹配策略。
- FS-RVOS不仅可以进行单一对象分割,还可以扩展到多对象分割(FS-RVMOS)。
- 实验证明FS-RVOS及FS-RVMOS在多种基准测试中表现优于现有技术。
- FS-RVOS模型展现了卓越的鲁棒性和准确性。
点此查看论文截图

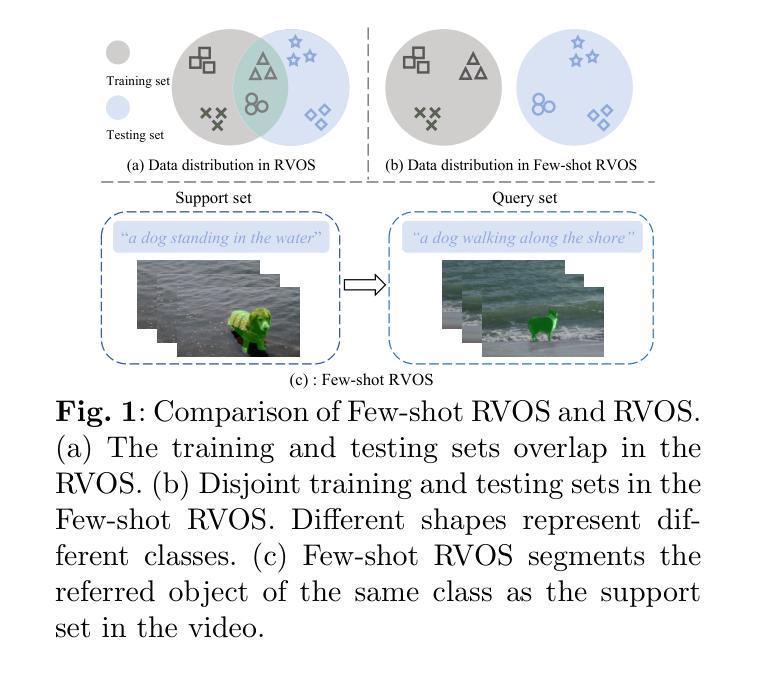
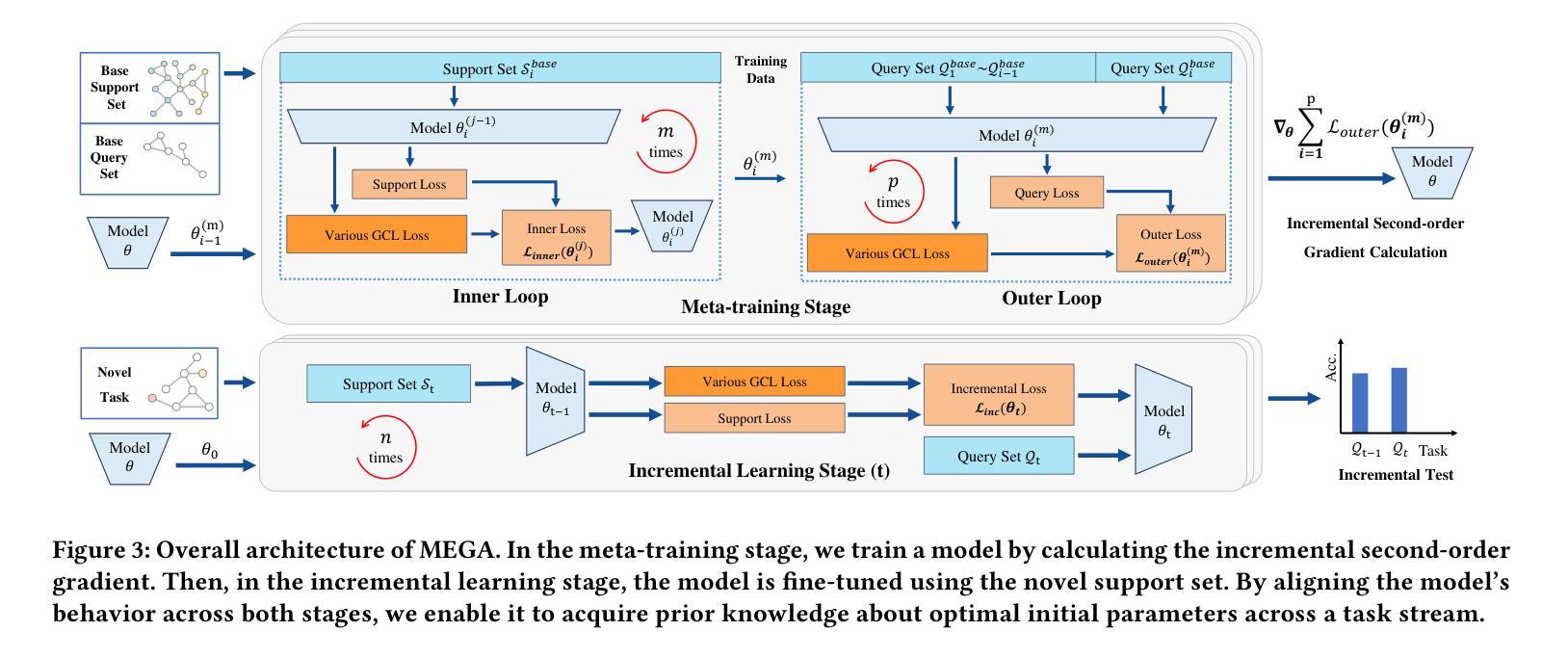
MEGA: Second-Order Gradient Alignment for Catastrophic Forgetting Mitigation in GFSCIL
Authors:Jinhui Pang, Changqing Lin, Hao Lin, Jinglin He, Zhengjun Li, Zhihui Zhang, Xiaoshuai Hao
Graph Few-Shot Class-Incremental Learning (GFSCIL) enables models to continually learn from limited samples of novel tasks after initial training on a large base dataset. Existing GFSCIL approaches typically utilize Prototypical Networks (PNs) for metric-based class representations and fine-tune the model during the incremental learning stage. However, these PN-based methods oversimplify learning via novel query set fine-tuning and fail to integrate Graph Continual Learning (GCL) techniques due to architectural constraints. To address these challenges, we propose a more rigorous and practical setting for GFSCIL that excludes query sets during the incremental training phase. Building on this foundation, we introduce Model-Agnostic Meta Graph Continual Learning (MEGA), aimed at effectively alleviating catastrophic forgetting for GFSCIL. Specifically, by calculating the incremental second-order gradient during the meta-training stage, we endow the model to learn high-quality priors that enhance incremental learning by aligning its behaviors across both the meta-training and incremental learning stages. Extensive experiments on four mainstream graph datasets demonstrate that MEGA achieves state-of-the-art results and enhances the effectiveness of various GCL methods in GFSCIL. We believe that our proposed MEGA serves as a model-agnostic GFSCIL paradigm, paving the way for future research.
图少样本类增量学习(GFSCIL)使得模型能够在大量基础数据集进行初始训练后,继续从有限的新任务样本中学习。现有的GFSCIL方法通常利用原型网络(PNs)进行基于度量的类表示,并在增量学习阶段微调模型。然而,这些基于PN的方法通过新的查询集微调来简化学习,并由于架构约束而无法整合图持续学习(GCL)技术。为了解决这些挑战,我们为GFSCIL提出了一个更严格和实用的设置,即在增量训练阶段排除查询集。在此基础上,我们引入了模型无关的元图持续学习(MEGA),旨在有效缓解GFSCIL的灾难性遗忘问题。具体来说,通过计算元训练阶段的增量二阶梯度,我们赋予模型学习高质量先验的能力,这些先验知识通过调整元训练和增量学习阶段的行为,增强了增量学习。在四个主流图形数据集上的大量实验表明,MEGA达到了最新的结果,提高了GFSCIL中各种GCL方法的有效性。我们相信我们提出的MEGA作为一种模型无关的GFSCIL范式,为未来的研究铺平了道路。
论文及项目相关链接
PDF Under Review
Summary
模型能够在基于大型基础数据集进行初始训练后,通过少量样本学习新任务的能力被称为图少样本类增量学习(GFSCIL)。现有方法主要使用原型网络(PNs)进行基于度量的类表示,并在增量学习阶段微调模型。然而,PNs方法简化了学习过程,未能整合图持续学习(GCL)技术。为解决这些问题,我们提出了更严格实用的GFSCIL设置,并在增量训练阶段排除查询集。在此基础上,我们引入了模型无关的元图持续学习(MEGA)方法,旨在有效缓解GFSCIL的灾难性遗忘问题。通过在元训练阶段计算增量二阶梯度,赋予模型学习能力的高质先验,提升在元训练和增量学习阶段的行为一致性。在四个主流图数据集上的实验表明,MEGA达到了最新水平的结果,提高了各种GCL方法在GFSCIL中的有效性。我们相信MEGA作为模型无关的GFSCIL范式为未来研究铺平了道路。
Key Takeaways
- Graph Few-Shot Class-Incremental Learning (GFSCIL)允许模型从少量新任务样本中持续学习。
- 现有GFSCIL方法主要使用原型网络(PNs)进行类表示和微调模型。
- PNs方法过于简化学习过程,未充分利用图持续学习(GCL)技术。
- 提出更严格的GFSCIL设置,排除增量训练阶段的查询集。
- 引入Model-Agnostic Meta Graph Continal Learning (MEGA)方法,缓解GFSCIL的灾难性遗忘问题。
- MEGA通过计算增量二阶梯度赋予模型学习能力的高质先验,提升行为一致性。
点此查看论文截图

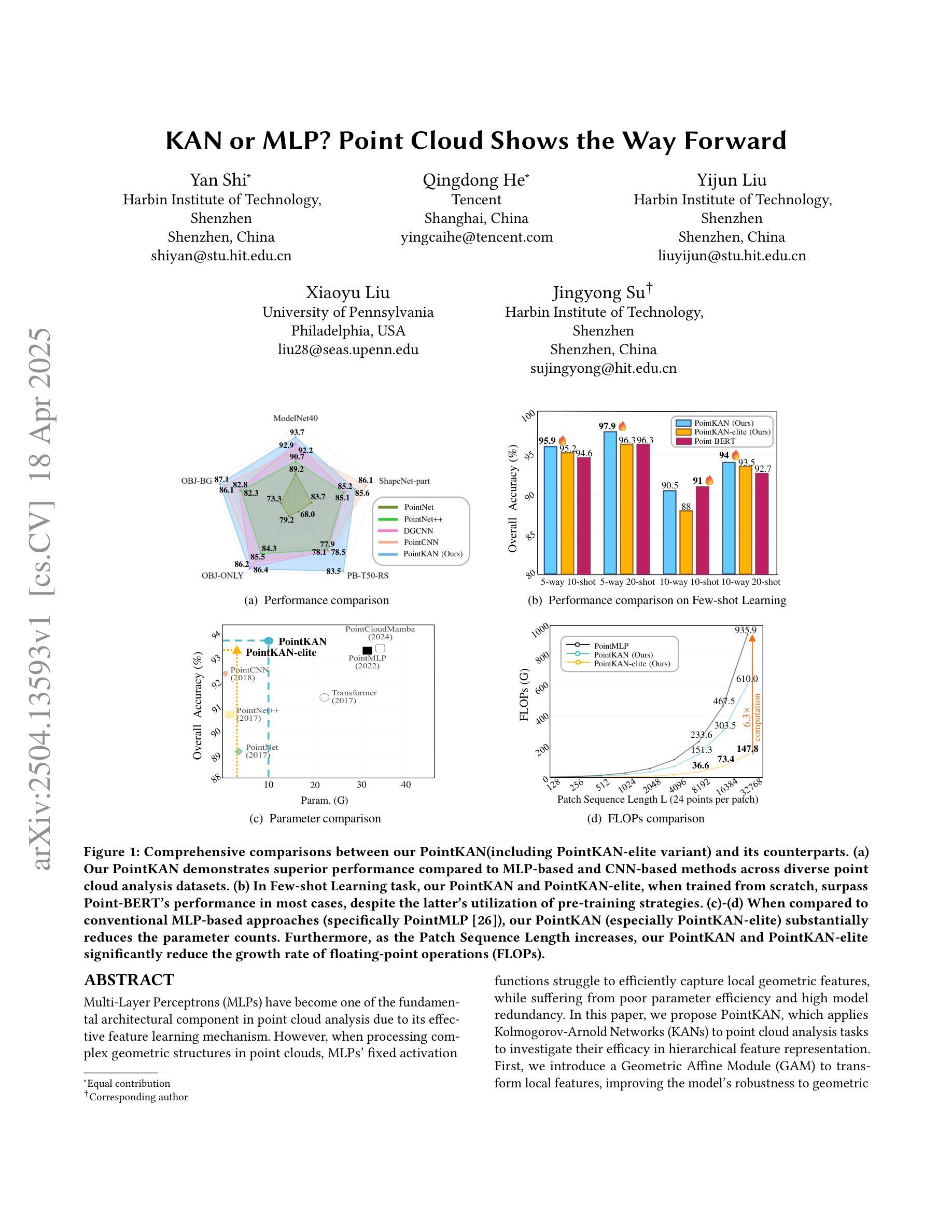
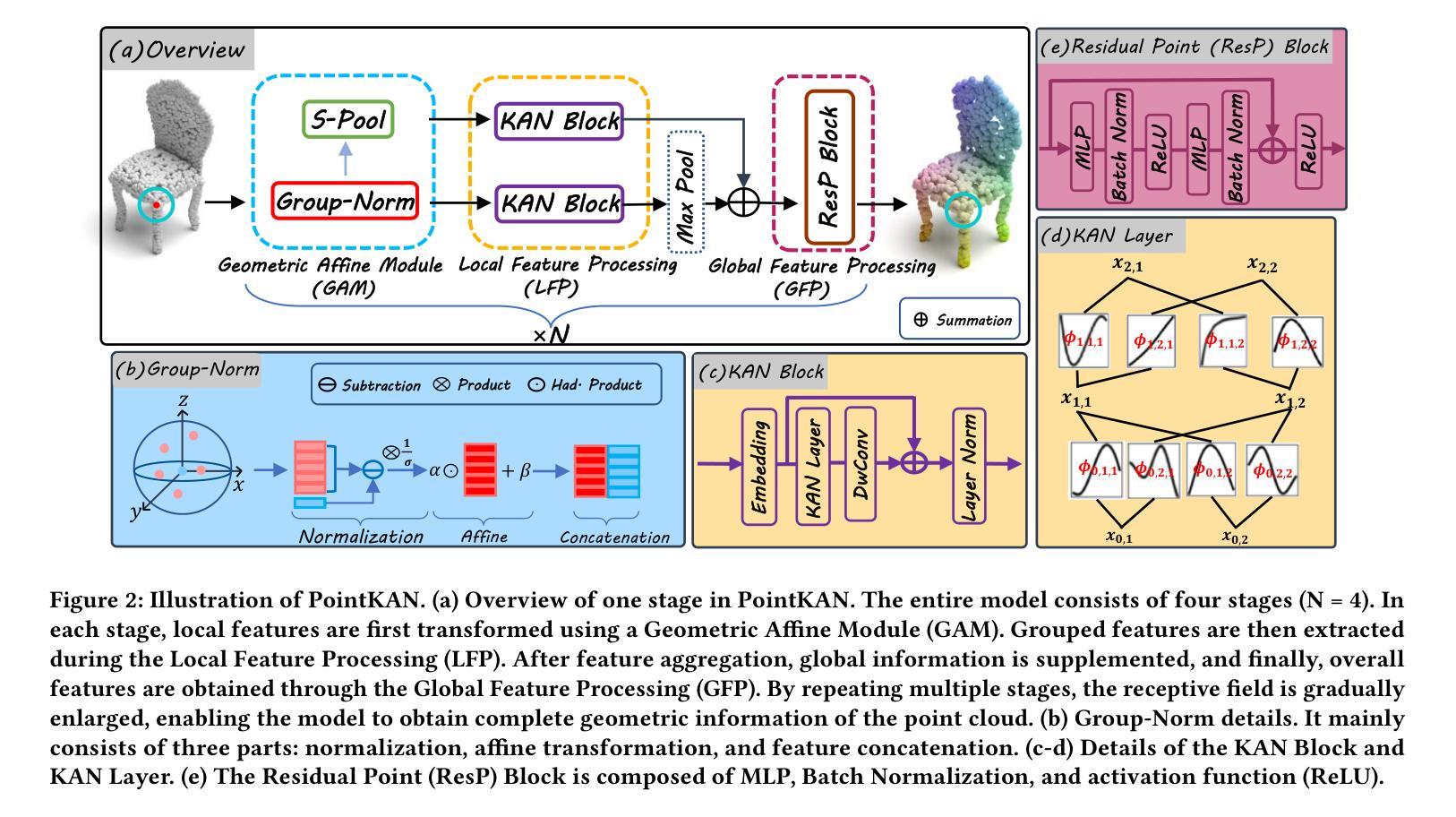
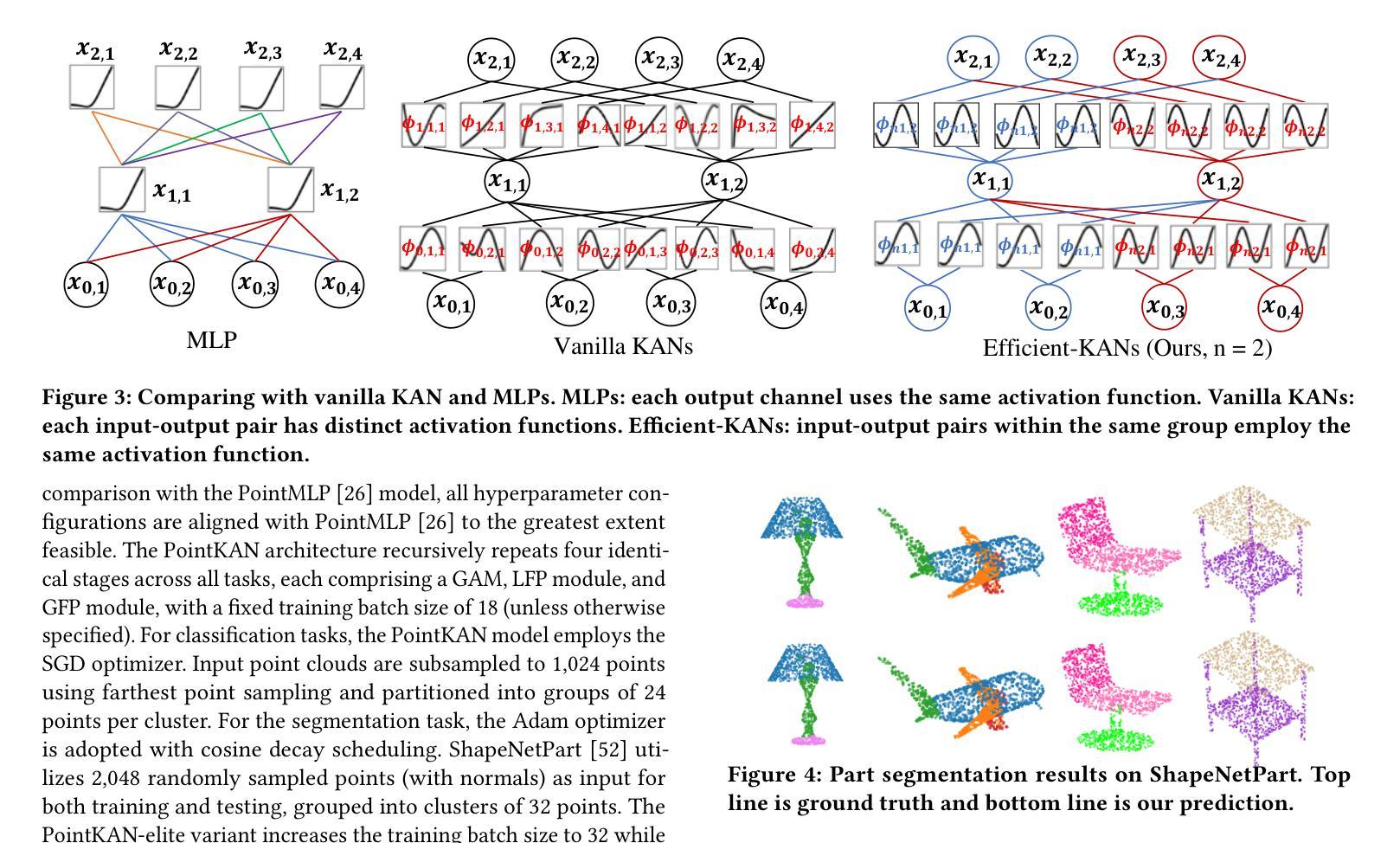
KAN or MLP? Point Cloud Shows the Way Forward
Authors:Yan Shi, Qingdong He, Yijun Liu, Xiaoyu Liu, Jingyong Su
Multi-Layer Perceptrons (MLPs) have become one of the fundamental architectural component in point cloud analysis due to its effective feature learning mechanism. However, when processing complex geometric structures in point clouds, MLPs’ fixed activation functions struggle to efficiently capture local geometric features, while suffering from poor parameter efficiency and high model redundancy. In this paper, we propose PointKAN, which applies Kolmogorov-Arnold Networks (KANs) to point cloud analysis tasks to investigate their efficacy in hierarchical feature representation. First, we introduce a Geometric Affine Module (GAM) to transform local features, improving the model’s robustness to geometric variations. Next, in the Local Feature Processing (LFP), a parallel structure extracts both group-level features and global context, providing a rich representation of both fine details and overall structure. Finally, these features are combined and processed in the Global Feature Processing (GFP). By repeating these operations, the receptive field gradually expands, enabling the model to capture complete geometric information of the point cloud. To overcome the high parameter counts and computational inefficiency of standard KANs, we develop Efficient-KANs in the PointKAN-elite variant, which significantly reduces parameters while maintaining accuracy. Experimental results demonstrate that PointKAN outperforms PointMLP on benchmark datasets such as ModelNet40, ScanObjectNN, and ShapeNetPart, with particularly strong performance in Few-shot Learning task. Additionally, PointKAN achieves substantial reductions in parameter counts and computational complexity (FLOPs). This work highlights the potential of KANs-based architectures in 3D vision and opens new avenues for research in point cloud understanding.
多层感知器(MLPs)由于其有效的特征学习机制,已成为点云分析中的基本架构组件之一。然而,在处理点云中的复杂几何结构时,MLPs的固定激活函数在有效地捕获局部几何特征方面遇到了困难,同时还存在参数效率低和模型冗余度高的问题。在本文中,我们提出了PointKAN,它将Kolmogorov-Arnold网络(KANs)应用于点云分析任务,以研究其在分层特征表示中的有效性。首先,我们引入了一个几何仿射模块(GAM)来变换局部特征,提高模型对几何变化的鲁棒性。接下来,在局部特征处理(LFP)中,并行结构提取了组级特征和全局上下文,提供了对精细细节和整体结构的丰富表示。最后,这些特征在全局特征处理(GFP)中进行组合和处理。通过重复这些操作,感受野逐渐扩大,使模型能够捕获点云的完整几何信息。为了克服标准KANs参数多、计算效率低的缺点,我们在PointKAN-elite变体中都采用了高效KANs结构显著减少了参数数量同时保持了准确性。实验结果表明,PointKAN在ModelNet40、ScanObjectNN和ShapeNetPart等基准数据集上的性能优于PointMLP,特别是在小样本学习任务中表现尤为突出。此外,PointKAN还实现了参数数量和计算复杂度的大幅降低。这项工作突出了基于KANs架构在3D视觉中的潜力,并为点云理解研究开辟了新途径。
论文及项目相关链接
Summary
点云分析中,MLP因有效的特征学习机制成为基本架构之一,但在处理复杂几何结构时存在局限。本文提出PointKAN,应用Kolmogorov-Arnold网络(KANs)进行点云分析任务,并引入几何仿射模块(GAM)改进模型对几何变异的稳健性。通过局部特征处理和全局特征处理,PointKAN能捕获点云的完整几何信息。同时,PointKAN-elite通过开发Efficient-KANs在减少参数的同时保持准确性。实验结果显示PointKAN在ModelNet40、ScanObjectNN和ShapeNetPart等基准数据集上优于PointMLP,特别是在小样学习任务中表现突出。
Key Takeaways
1. MLP在点云分析中是基本架构之一,但在处理复杂几何结构时存在局限性。
2. PointKAN利用Kolmogorov-Arnold网络(KANs)进行点云分析,旨在提高模型对几何特征的学习能力。
3. PointKAN通过几何仿射模块(GAM)增强模型对几何变异的稳健性。
4. 通过局部特征处理和全局特征处理,PointKAN能够捕获点云的完整几何信息。
5. Efficient-KANs的开发使得PointKAN-elite在减少参数和计算复杂性的同时保持了准确性。
6. 实验结果显示PointKAN在多个基准数据集上优于PointMLP,特别是在小样学习任务中表现优异。
点此查看论文截图
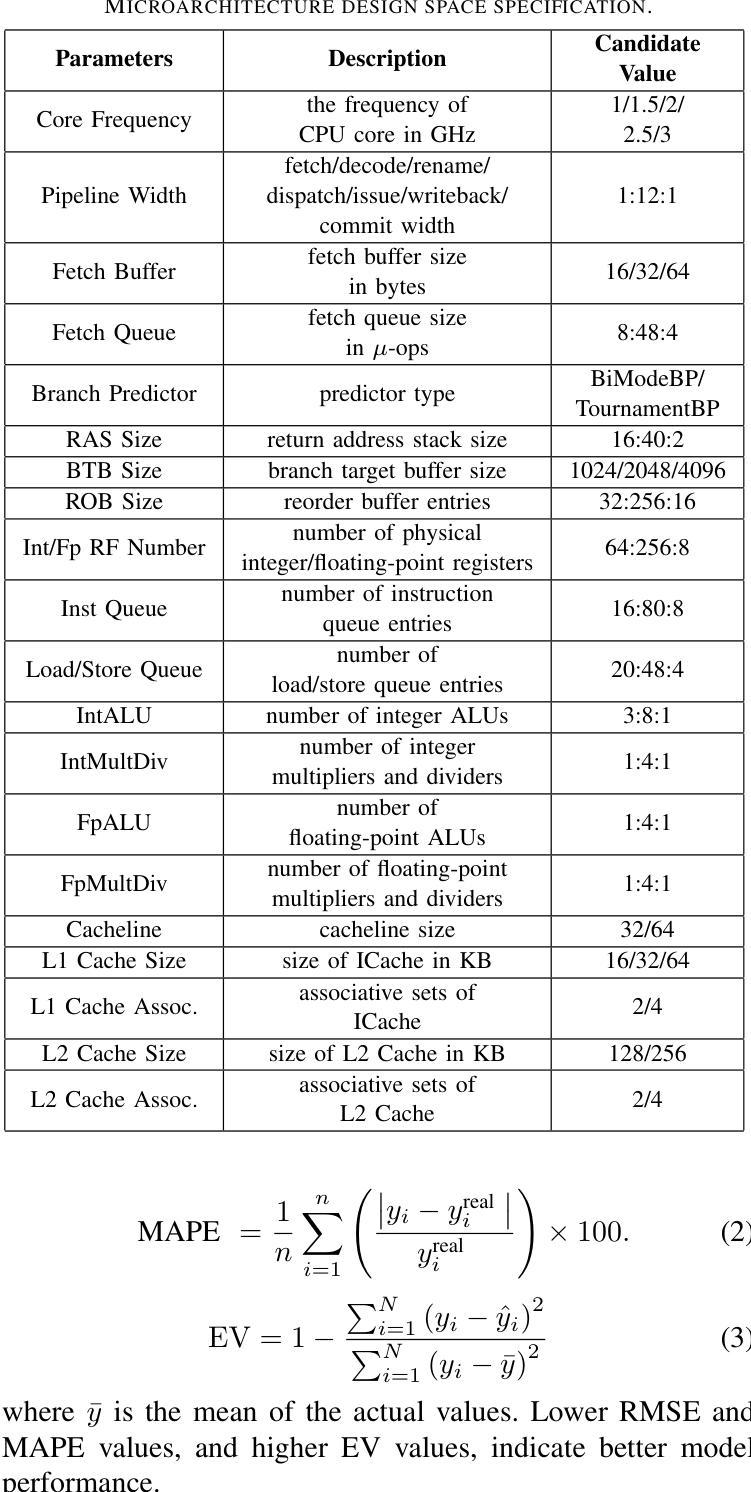
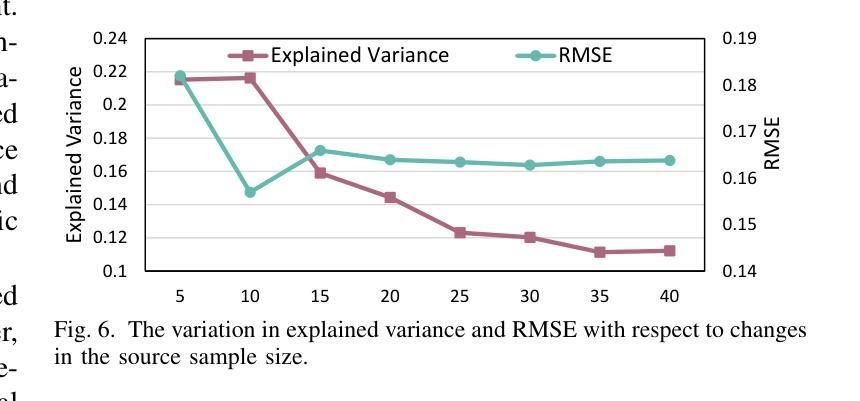
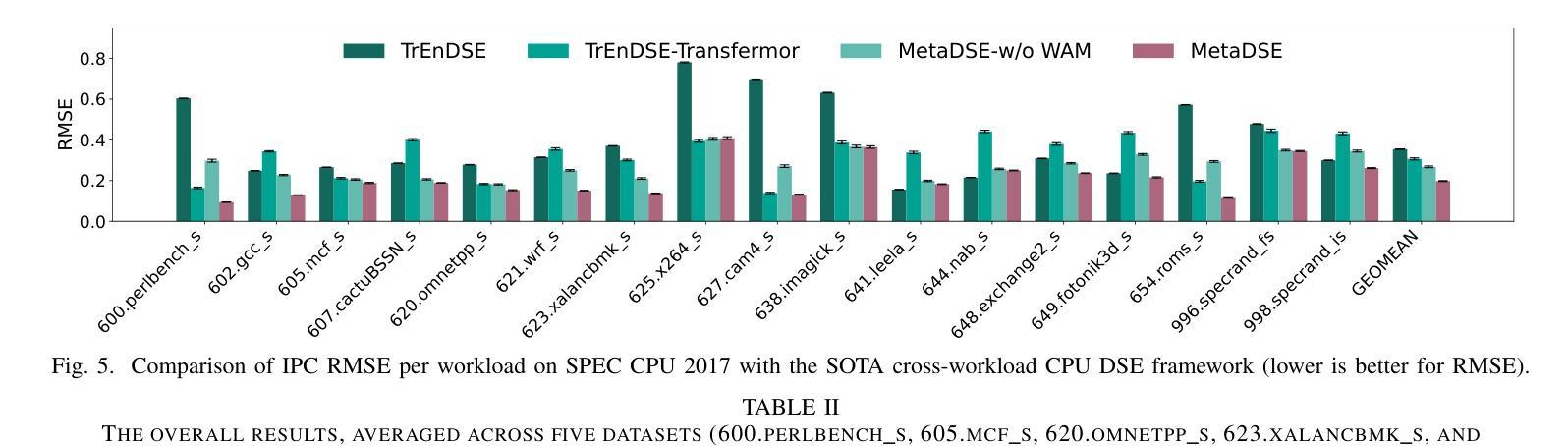
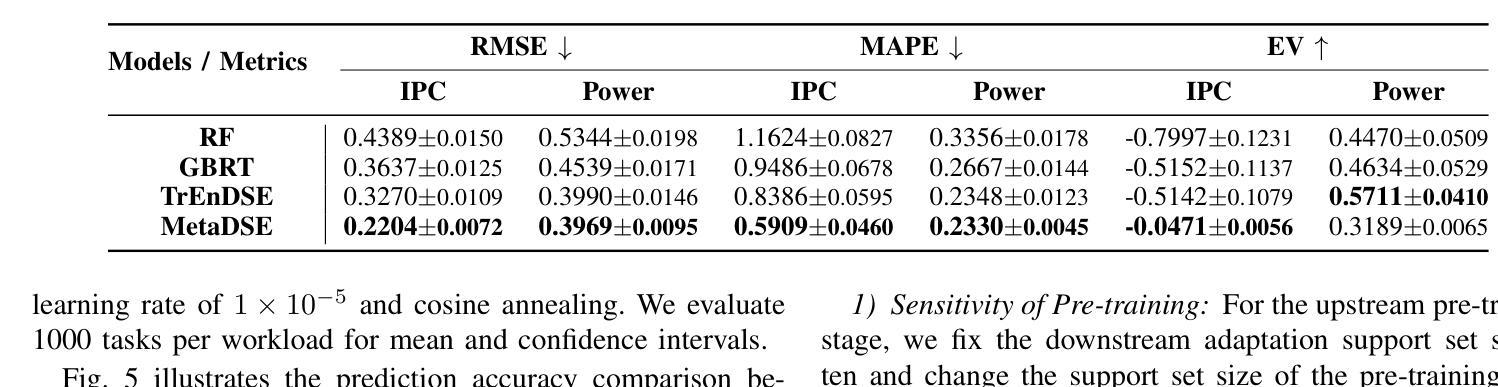
MetaDSE: A Few-shot Meta-learning Framework for Cross-workload CPU Design Space Exploration
Authors:Runzhen Xue, Hao Wu, Mingyu Yan, Ziheng Xiao, Xiaochun Ye, Dongrui Fan
Cross-workload design space exploration (DSE) is crucial in CPU architecture design. Existing DSE methods typically employ the transfer learning technique to leverage knowledge from source workloads, aiming to minimize the requirement of target workload simulation. However, these methods struggle with overfitting, data ambiguity, and workload dissimilarity. To address these challenges, we reframe the cross-workload CPU DSE task as a few-shot meta-learning problem and further introduce MetaDSE. By leveraging model agnostic meta-learning, MetaDSE swiftly adapts to new target workloads, greatly enhancing the efficiency of cross-workload CPU DSE. Additionally, MetaDSE introduces a novel knowledge transfer method called the workload-adaptive architectural mask algorithm, which uncovers the inherent properties of the architecture. Experiments on SPEC CPU 2017 demonstrate that MetaDSE significantly reduces prediction error by 44.3% compared to the state-of-the-art. MetaDSE is open-sourced and available at this \href{https://anonymous.4open.science/r/Meta_DSE-02F8}{anonymous GitHub.}
跨工作负载设计空间探索(DSE)在CPU架构设计中的重要性不言而喻。现有的DSE方法通常采用迁移学习技术,利用源工作负载的知识,旨在减少目标工作负载模拟的需求。然而,这些方法在面临过拟合、数据模糊和工作负载差异时遇到了困难。为了解决这些挑战,我们将跨工作负载CPU的DSE任务重新构建为一个小样本元学习问题,并引入了MetaDSE。通过利用模型无关的元学习,MetaDSE能够迅速适应新的目标工作负载,大大提高了跨工作负载CPU的DSE效率。此外,MetaDSE还引入了一种新的知识转移方法——工作负载自适应架构掩码算法,该算法揭示了架构的内在属性。在SPEC CPU 2017上的实验表明,与最新技术相比,MetaDSE将预测误差降低了44.3%。MetaDSE是开源的,可以在这个匿名的GitHub上找到:https://anonymous.4open.science/r/Meta_DSE-02F8。
论文及项目相关链接
PDF 7 pages, 6 figures. Accepted by DAC 2025
Summary
基于跨工作负载设计空间探索(DSE)在CPU架构设计中的重要性,现有方法主要利用迁移学习技术,通过源工作负载的知识来提高效率。然而,这些方法面临过度拟合、数据模糊和工作负载差异等挑战。为解决这些问题,我们提出将跨工作负载CPU DSE任务重新构建为少样本元学习问题,并引入MetaDSE方法。通过利用模型无关的元学习,MetaDSE能快速适应新的目标工作负载,大大提高了跨工作负载CPU DSE的效率。此外,MetaDSE还引入了一种新的知识转移方法——工作负载自适应架构掩码算法,揭示了架构的固有属性。实验表明,与现有技术相比,MetaDSE将预测误差降低了44.3%。MetaDSE已开源,可在匿名GitHub上获得。
Key Takeaways
- 跨工作负载设计空间探索(DSE)在CPU架构设计中至关重要。
- 现有DSE方法主要使用迁移学习技术,但面临过度拟合、数据模糊和工作负载差异的挑战。
- 提出将跨工作负载CPU DSE任务重构为少样本元学习问题。
- 引入MetaDSE方法,通过模型无关的元学习快速适应新目标工作负载。
- MetaDSE采用新的知识转移方法——工作负载自适应架构掩码算法。
- 实验显示,MetaDSE相较于现有技术,能显著降低预测误差。
- MetaDSE已开源,可通过匿名GitHub获取。
点此查看论文截图



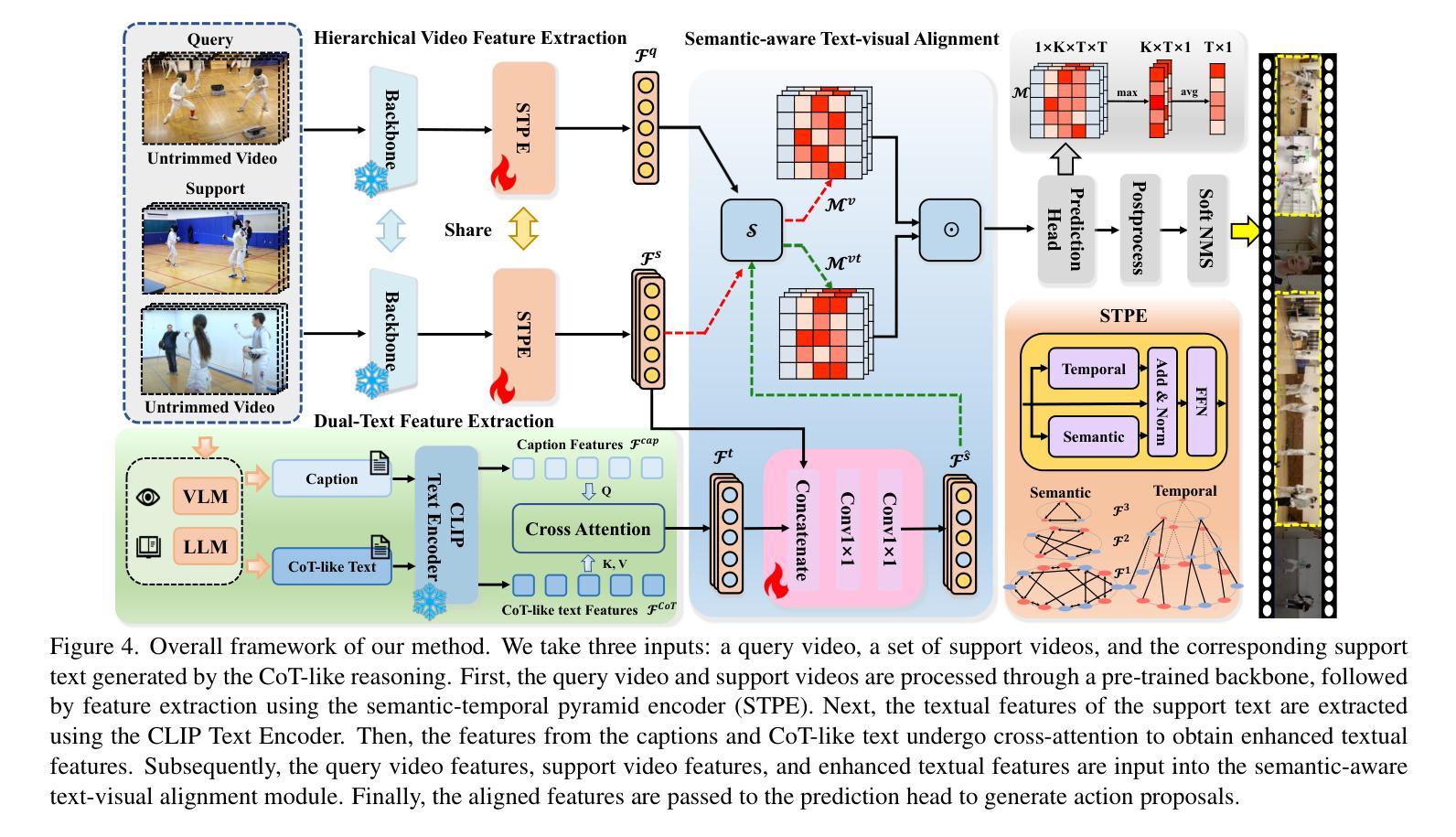
Chain-of-Thought Textual Reasoning for Few-shot Temporal Action Localization
Authors:Hongwei Ji, Wulian Yun, Mengshi Qi, Huadong Ma
Traditional temporal action localization (TAL) methods rely on large amounts of detailed annotated data, whereas few-shot TAL reduces this dependence by using only a few training samples to identify unseen action categories. However, existing few-shot TAL methods typically focus solely on video-level information, neglecting textual information, which can provide valuable semantic support for the localization task. Therefore, we propose a new few-shot temporal action localization method by Chain-of-Thought textual reasoning to improve localization performance. Specifically, we design a novel few-shot learning framework that leverages textual semantic information to enhance the model’s ability to capture action commonalities and variations, which includes a semantic-aware text-visual alignment module designed to align the query and support videos at different levels. Meanwhile, to better express the temporal dependencies and causal relationships between actions at the textual level to assist action localization, we design a Chain of Thought (CoT)-like reasoning method that progressively guides the Vision Language Model (VLM) and Large Language Model (LLM) to generate CoT-like text descriptions for videos. The generated texts can capture more variance of action than visual features. We conduct extensive experiments on the publicly available ActivityNet1.3 and THUMOS14 datasets. We introduce the first dataset named Human-related Anomaly Localization and explore the application of the TAL task in human anomaly detection. The experimental results demonstrate that our proposed method significantly outperforms existing methods in single-instance and multi-instance scenarios. We will release our code, data and benchmark.
传统的时间动作定位(TAL)方法依赖于大量的详细标注数据,而少样本TAL方法则通过仅使用少量的训练样本来识别未见过的动作类别,减少了这种依赖。然而,现有的少样本TAL方法通常只关注视频级信息,忽视了文本信息,而文本信息可以为定位任务提供有价值的语义支持。因此,我们提出了一种新的少样本时间动作定位方法,通过链式思维文本推理来改善定位性能。具体来说,我们设计了一种新颖的少样本学习框架,该框架利用文本语义信息来提高模型捕捉动作共性和变化的能力,其中包括一个语义感知的文本-视觉对齐模块,旨在以不同层级对齐查询和支持视频。同时,为了更好地在文本层面表达动作之间的时间依赖关系和因果关系以辅助动作定位,我们设计了一种类似链式思维(CoT)的推理方法,该方法逐步引导视觉语言模型(VLM)和大型语言模型(LLM)为视频生成CoT类似的文本描述。生成的文本可以捕获比视觉特征更多的动作变化。我们在公开可用的ActivityNet1.3和THUMOS14数据集上进行了大量实验。我们引入了名为Human-related Anomaly Localization的数据集,并探索了TAL任务在人类异常检测中的应用。实验结果表明,我们提出的方法在单实例和多实例场景中均显著优于现有方法。我们将发布我们的代码、数据和基准测试。
论文及项目相关链接
Summary
本文提出了一种基于Chain-of-Thought文本推理的少量样本时序动作定位方法。该方法利用文本语义信息,设计了一个全新的少量样本学习框架,以增强模型捕捉动作共性和变化的能力。同时,设计了一个语义感知的文本视觉对齐模块和对齐不同级别的查询和支持视频。此外,为了更好地在文本层面表达动作的时空依赖和因果关系,设计了一种类似Chain of Thought(CoT)的推理方法,逐步引导视觉语言模型和大语言模型生成用于视频的CoT文本描述。在公开数据集ActivityNet1.3和THUMOS14上的实验表明,该方法在单实例和多实例场景中显著优于现有方法。
Key Takeaways
- 少量样本时序动作定位(few-shot TAL)方法可减少对传统大量详细标注数据的依赖,仅使用少量训练样本即可识别未见过的动作类别。
- 现有few-shot TAL方法主要关注视频层级信息,忽略了文本信息,后者可为定位任务提供有价值的语义支持。
- 提出的基于Chain-of-Thought文本推理的few-shot TAL方法,利用文本语义信息增强模型捕捉动作共性和变化的能力。
- 语义感知的文本视觉对齐模块设计用于对齐查询和支持视频的不同层级。
- 设计的CoT推理方法能在文本层面更好地表达动作的时空依赖和因果关系,辅助动作定位。
- 在ActivityNet1.3和THUMOS14公开数据集上的实验表明,该方法在单实例和多实例场景中显著优于现有方法。
点此查看论文截图


Can LLMs assist with Ambiguity? A Quantitative Evaluation of various Large Language Models on Word Sense Disambiguation
Authors:T. G. D. K. Sumanathilaka, Nicholas Micallef, Julian Hough
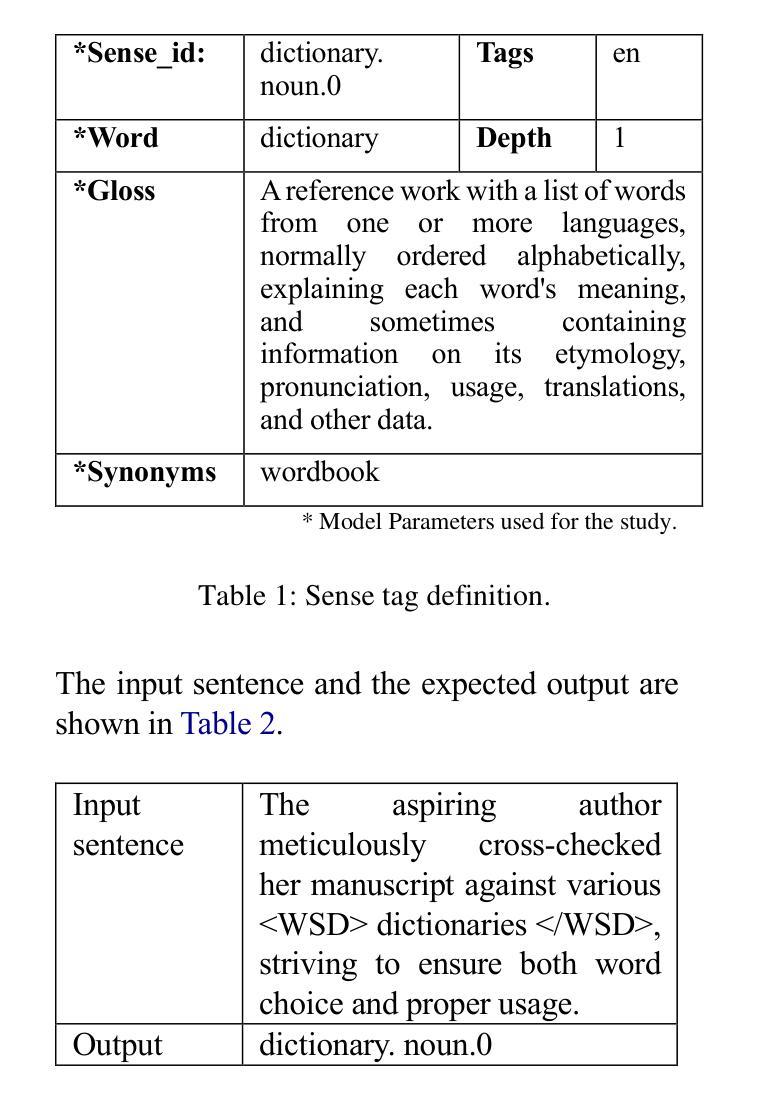
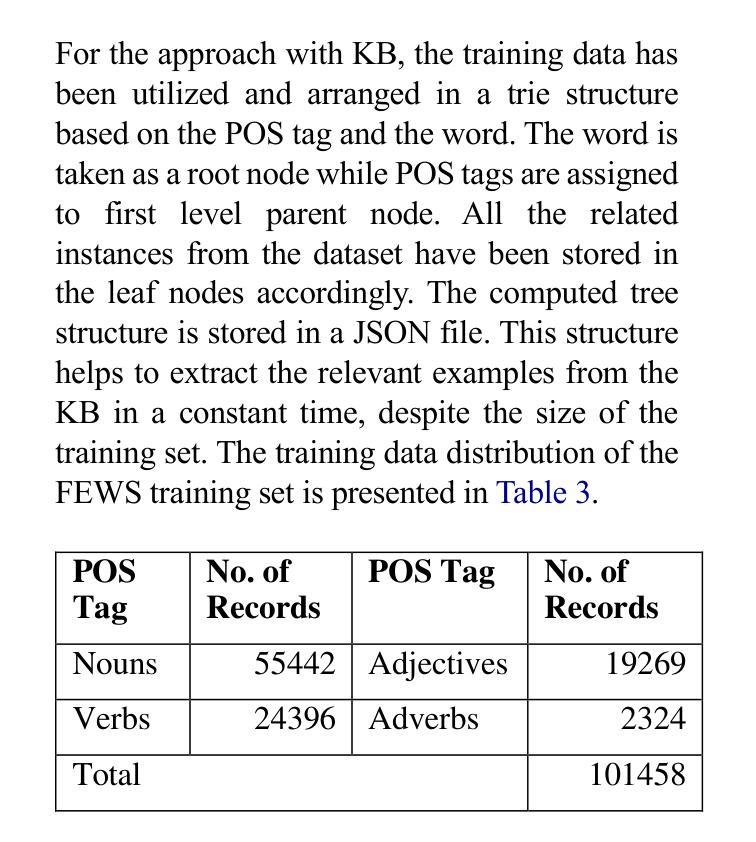
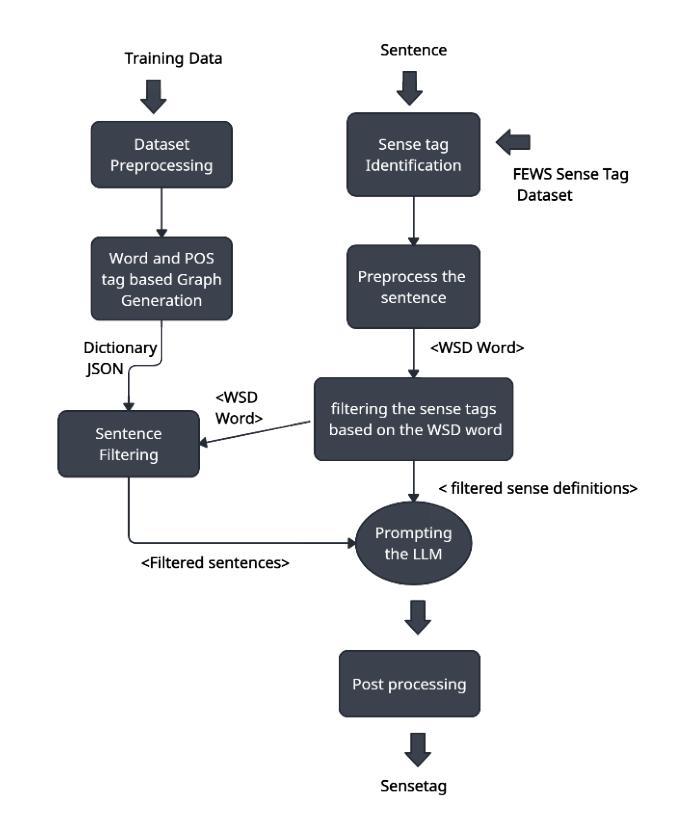
Ambiguous words are often found in modern digital communications. Lexical ambiguity challenges traditional Word Sense Disambiguation (WSD) methods, due to limited data. Consequently, the efficiency of translation, information retrieval, and question-answering systems is hindered by these limitations. This study investigates the use of Large Language Models (LLMs) to improve WSD using a novel approach combining a systematic prompt augmentation mechanism with a knowledge base (KB) consisting of different sense interpretations. The proposed method incorporates a human-in-loop approach for prompt augmentation where prompt is supported by Part-of-Speech (POS) tagging, synonyms of ambiguous words, aspect-based sense filtering and few-shot prompting to guide the LLM. By utilizing a few-shot Chain of Thought (COT) prompting-based approach, this work demonstrates a substantial improvement in performance. The evaluation was conducted using FEWS test data and sense tags. This research advances accurate word interpretation in social media and digital communication.
在现代数字通信中经常可以发现词义模糊的词语。由于数据有限,词汇的模糊性给传统的词义消歧(Word Sense Disambiguation, WSD)方法带来了挑战。因此,这些限制影响了翻译、信息检索和问答系统的效率。本研究探讨了使用大型语言模型(LLMs)结合一种新型的提示增强机制来改善词义消歧问题,该机制结合了一个由不同词义解读构成的知识库(KB)。所提出的方法采用了一种人类循环提示增强方法,该方法通过词性标注(POS)、模糊词的同义词、基于方面的词义过滤和少量提示来支持大型语言模型。通过采用基于少量思维链(COT)提示的方法,本研究展示了显著的性能提升。本研究通过FEWS测试数据和词义标签进行了评估。这项研究推进了社交媒体和数字通信中的准确词汇解读。
论文及项目相关链接
PDF 12 pages,6 tables, 1 figure, Proceedings of the 1st International Conference on NLP & AI for Cyber Security
Summary
本文探讨了现代数字通信中常见的词汇歧义问题。由于数据有限,传统的词义消歧(WSD)方法面临挑战。该研究利用大型语言模型(LLMs)结合系统提示增强机制和包含不同词义解读的知识库(KB)来改善词义消歧。方法采用人类参与的提示增强方式,借助词性标注、含糊词汇的同义词、基于方面的词义过滤和少量提示来引导LLM。通过采用基于少量思维的提示方法,该研究展示了显著的性能改进。通过FEWS测试数据和词义标签进行评估,该研究推动了社交媒体和数字通信中的准确词汇解释。
Key Takeaways
- 词汇歧义在现代数字通信中是常见问题。
- 传统词义消歧(WSD)方法因数据有限而面临挑战。
- 大型语言模型(LLMs)被用于改善词义消歧。
- 系统提示增强机制与知识库(KB)相结合来提高词义消歧性能。
- 人类参与的提示增强方式包括词性标注、同义词、基于方面的词义过滤和少量提示。
- 采用基于少量思维的提示方法展示显著性能改进。
点此查看论文截图