⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-22 更新
Mind2Matter: Creating 3D Models from EEG Signals
Authors:Xia Deng, Shen Chen, Jiale Zhou, Lei Li
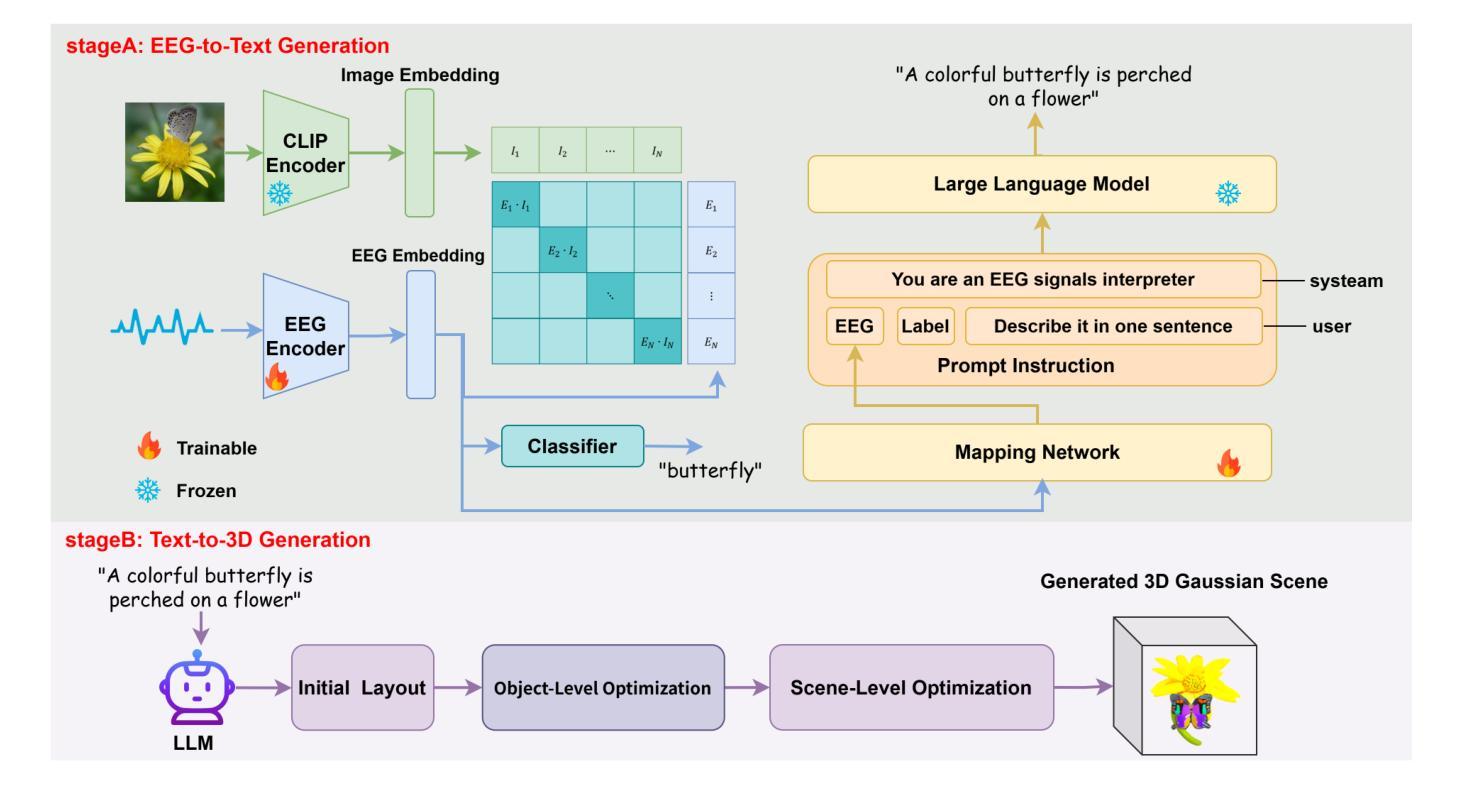
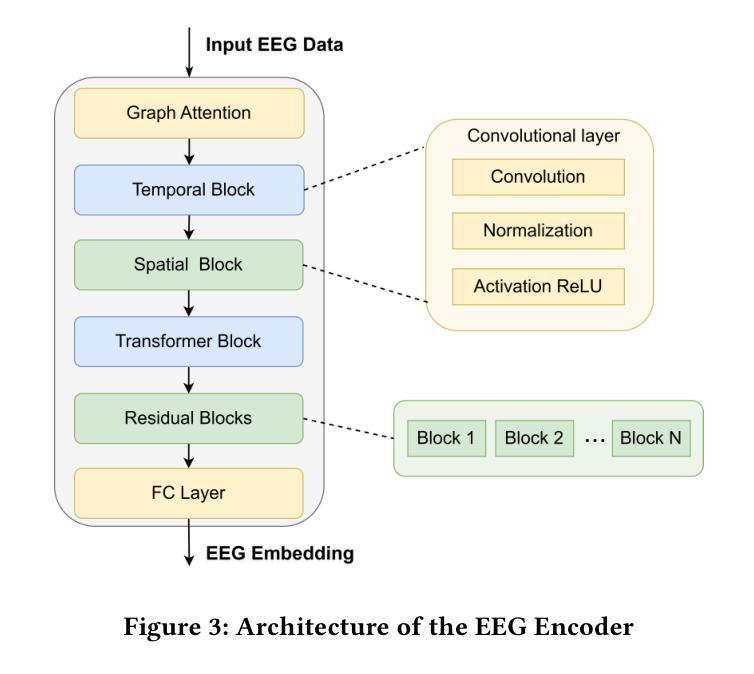
The reconstruction of 3D objects from brain signals has gained significant attention in brain-computer interface (BCI) research. Current research predominantly utilizes functional magnetic resonance imaging (fMRI) for 3D reconstruction tasks due to its excellent spatial resolution. Nevertheless, the clinical utility of fMRI is limited by its prohibitive costs and inability to support real-time operations. In comparison, electroencephalography (EEG) presents distinct advantages as an affordable, non-invasive, and mobile solution for real-time brain-computer interaction systems. While recent advances in deep learning have enabled remarkable progress in image generation from neural data, decoding EEG signals into structured 3D representations remains largely unexplored. In this paper, we propose a novel framework that translates EEG recordings into 3D object reconstructions by leveraging neural decoding techniques and generative models. Our approach involves training an EEG encoder to extract spatiotemporal visual features, fine-tuning a large language model to interpret these features into descriptive multimodal outputs, and leveraging generative 3D Gaussians with layout-guided control to synthesize the final 3D structures. Experiments demonstrate that our model captures salient geometric and semantic features, paving the way for applications in brain-computer interfaces (BCIs), virtual reality, and neuroprosthetics. Our code is available in https://github.com/sddwwww/Mind2Matter.
从脑信号重建3D物体在脑机接口(BCI)研究中受到了广泛关注。目前的研究主要利用功能磁共振成像(fMRI)进行3D重建任务,因其卓越的空间分辨率。然而,fMRI的临床应用受限于其高昂的成本和无法支持实时操作。相比之下,脑电图(EEG)作为实时脑机交互系统的经济、无创、可移动解决方案,具有明显优势。虽然深度学习领域的最新进展在神经网络数据生成图像方面取得了显著进展,但将脑电图信号解码为结构化3D表示仍然很少探索。在本文中,我们提出了一种新的框架,利用神经解码技术和生成模型将脑电图记录转化为3D对象重建。我们的方法包括训练EEG编码器提取时空视觉特征,微调大型语言模型以将这些特征解释为描述性多模式输出,并利用布局指导控制的生成性3D高斯来合成最终的3D结构。实验表明,我们的模型捕捉了显著的几何和语义特征,为脑机接口(BCI)、虚拟现实和神经假肢的应用铺平了道路。我们的代码可在https://github.com/sddwwww/Mind2Matter中获取。
论文及项目相关链接
Summary
本文介绍了一种利用神经解码技术和生成模型将脑电图(EEG)信号转化为三维物体重建的新型框架。该研究训练EEG编码器提取时空视觉特征,微调大型语言模型以解释这些特征并生成多模式输出,并利用布局引导控制的生成三维高斯模型合成最终的三维结构。实验表明,该模型能够捕捉重要的几何和语义特征,为脑机接口、虚拟现实和神经修复等领域的应用开辟道路。
Key Takeaways
- 重建三维物体从脑信号在脑机接口(BCI)研究中受到关注。
- 当前研究主要利用功能磁共振成像(fMRI)进行三维重建任务,但其高昂成本和无法支持实时操作限制了临床应用。
- 与之相比,脑电图(EEG)作为实时脑机交互系统的经济、无创和可移动解决方案具有明显优势。
- 深度学习在图像生成方面的进展令人瞩目,但从神经数据中解码EEG信号以生成结构化三维表示仍然很少探索。
- 本研究提出了一种新型框架,利用神经解码技术和生成模型将EEG记录转化为三维物体重建。
- 该框架包括训练EEG编码器提取时空视觉特征,微调大型语言模型以生成多模式输出,并利用生成三维高斯模型合成最终的三维结构。
点此查看论文截图

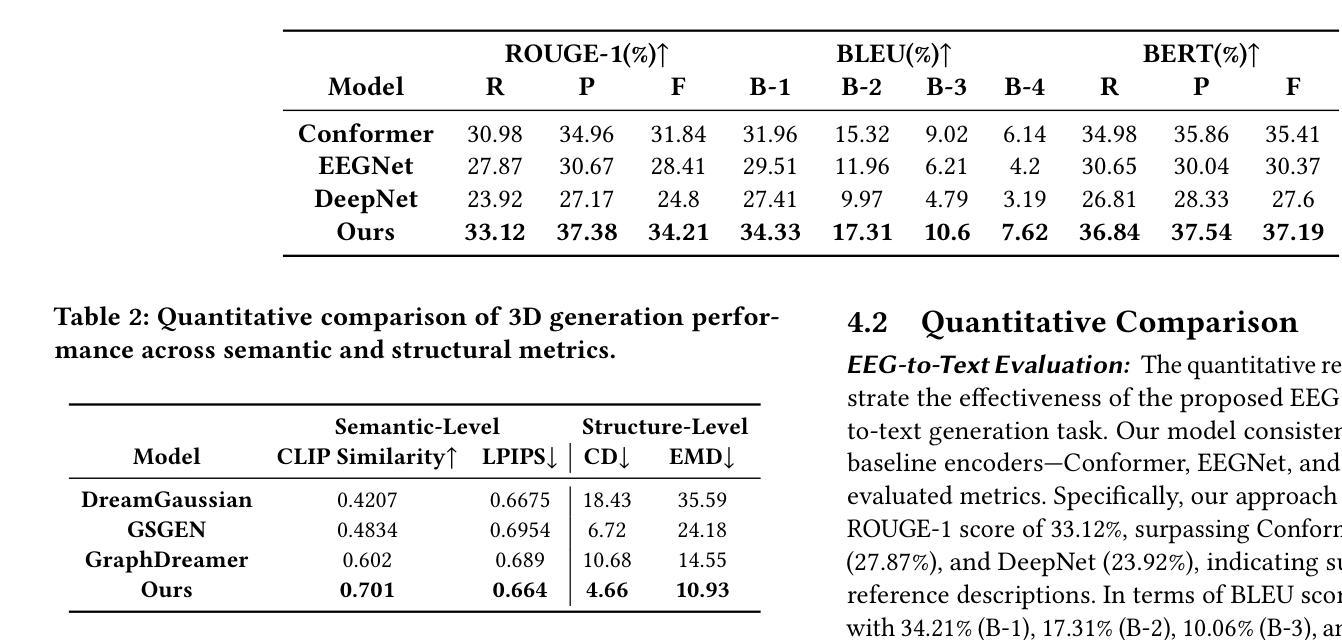
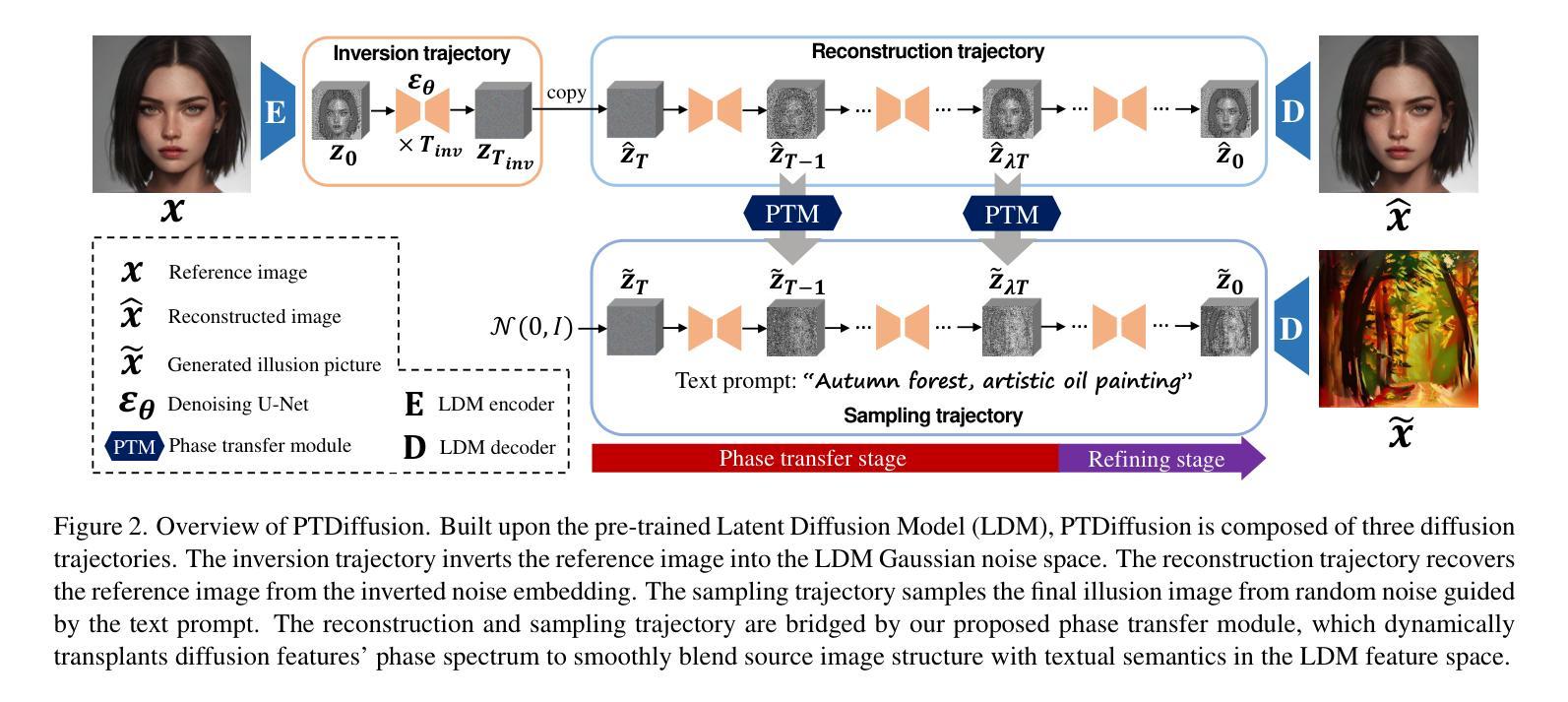
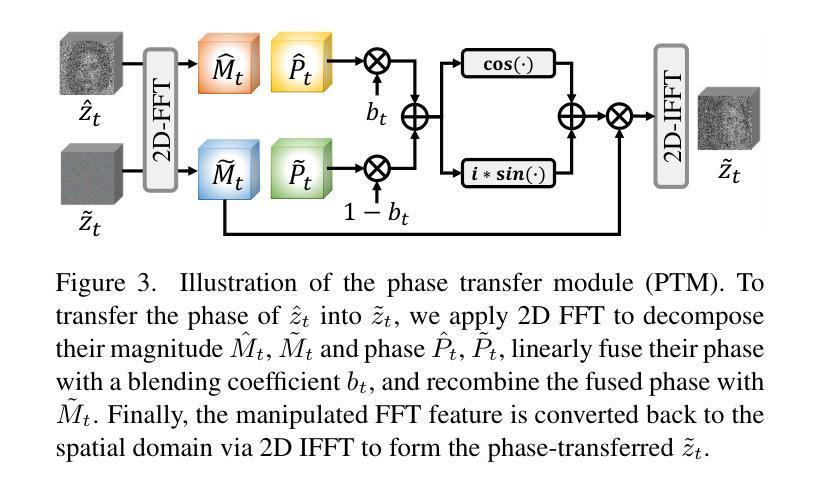
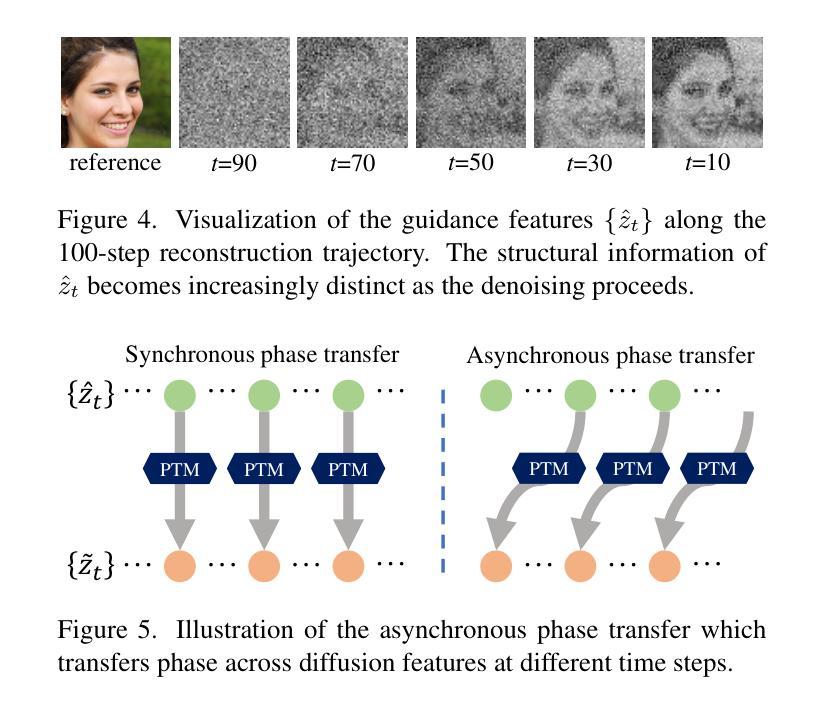
PTDiffusion: Free Lunch for Generating Optical Illusion Hidden Pictures with Phase-Transferred Diffusion Model
Authors:Xiang Gao, Shuai Yang, Jiaying Liu
Optical illusion hidden picture is an interesting visual perceptual phenomenon where an image is cleverly integrated into another picture in a way that is not immediately obvious to the viewer. Established on the off-the-shelf text-to-image (T2I) diffusion model, we propose a novel training-free text-guided image-to-image (I2I) translation framework dubbed as \textbf{P}hase-\textbf{T}ransferred \textbf{Diffusion} Model (PTDiffusion) for hidden art syntheses. PTDiffusion harmoniously embeds an input reference image into arbitrary scenes described by the text prompts, producing illusion images exhibiting hidden visual cues of the reference image. At the heart of our method is a plug-and-play phase transfer mechanism that dynamically and progressively transplants diffusion features’ phase spectrum from the denoising process to reconstruct the reference image into the one to sample the generated illusion image, realizing deep fusion of the reference structural information and the textual semantic information in the diffusion model latent space. Furthermore, we propose asynchronous phase transfer to enable flexible control to the degree of hidden content discernability. Our method bypasses any model training and fine-tuning process, all while substantially outperforming related text-guided I2I methods in image generation quality, text fidelity, visual discernibility, and contextual naturalness for illusion picture synthesis, as demonstrated by extensive qualitative and quantitative experiments. Our project is publically available at \href{https://xianggao1102.github.io/PTDiffusion_webpage/}{this web page}.
光学错觉隐藏图像是一种有趣的视觉感知现象,其中图像被巧妙地融入另一幅图像中,观众无法立即识别出来。我们基于现成的文本到图像(T2I)扩散模型,提出了一种无需训练的文字引导图像到图像(I2I)转换框架,名为阶段转移扩散模型(PTDiffusion),用于合成隐藏艺术。PTDiffusion和谐地将输入参考图像嵌入到文本提示描述的任意场景中,生成显示参考图像隐藏视觉线索的错觉图像。我们方法的核心是一个即插即用的相位转移机制,它动态且渐进地移植扩散特征的相位谱,从去噪过程中重建参考图像,将其融合到生成的错觉图像中,实现在扩散模型潜在空间中的参考结构信息和文本语义信息的深度融合。此外,我们提出了异步相位转移,以实现灵活控制隐藏内容的识别程度。我们的方法避免了任何模型训练和微调过程,同时在图像生成质量、文本保真度、视觉识别度和上下文自然度方面大大优于相关的文本引导I2I方法,用于错觉图像合成,这已通过广泛的定性和定量实验得到了证明。我们的项目已在此网页公开可用。
论文及项目相关链接
PDF Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025)
Summary
这是一项关于基于扩散模型进行图像生成的创新研究。研究团队提出了一种无需训练、只需嵌入现有图片至特定文本场景中的新框架——Phase-Transferred Diffusion Model(PTDiffusion)。通过其特有的插件机制及相位转移机制,该模型可融合参考图像的结构信息与文本语义信息,创造出含有隐藏视觉线索的图像。此外,该研究还引入了异步相位转移技术,以实现灵活控制隐藏内容的辨识度。该研究显著提升了图像生成质量、文本忠实度、视觉辨识度和上下文自然度,无需任何模型训练与微调过程。
Key Takeaways
- 研究提出了一种新的文本引导的图像到图像(I2I)翻译框架——PTDiffusion,用于合成隐藏艺术图像。
- PTDiffusion基于现成的文本到图像(T2I)扩散模型,无需训练或微调即可运行。
- 通过特有的相位转移机制,PTDiffusion实现了将参考图像融入到文本描述的场景中,创建具有隐藏视觉线索的图像。这种机制能融合参考图像的结构信息和文本的语义信息。
- 研究引入了异步相位转移技术,允许用户灵活控制隐藏内容的辨识度。
- 该方法显著提高了图像生成的品质、文本的忠实度、视觉的辨识度和上下文的自然性。
- 研究成果已经公开,并可通过特定网页链接访问。
点此查看论文截图


E(3)-equivariant models cannot learn chirality: Field-based molecular generation
Authors:Alexandru Dumitrescu, Dani Korpela, Markus Heinonen, Yogesh Verma, Valerii Iakovlev, Vikas Garg, Harri Lähdesmäki
Obtaining the desired effect of drugs is highly dependent on their molecular geometries. Thus, the current prevailing paradigm focuses on 3D point-cloud atom representations, utilizing graph neural network (GNN) parametrizations, with rotational symmetries baked in via E(3) invariant layers. We prove that such models must necessarily disregard chirality, a geometric property of the molecules that cannot be superimposed on their mirror image by rotation and translation. Chirality plays a key role in determining drug safety and potency. To address this glaring issue, we introduce a novel field-based representation, proposing reference rotations that replace rotational symmetry constraints. The proposed model captures all molecular geometries including chirality, while still achieving highly competitive performance with E(3)-based methods across standard benchmarking metrics.
获得药物所需的效果在很大程度上取决于其分子结构。因此,当前主流范式侧重于利用图神经网络(GNN)参数化的三维点云原子表示,并内置旋转对称性通过E(3)不变层实现。我们证明,此类模型必然会忽略手性这一分子几何特性,手性无法通过旋转和平移与镜像图像重合。手性在决定药物安全性和效力方面起着关键作用。为了解决这一明显问题,我们引入了一种新型基于场的表示方法,建议采用参考旋转来替代旋转对称性约束。所提出模型能够捕获所有分子结构,包括手性结构,同时在标准基准测试指标上实现了与基于E(3)的方法相当的高竞争力性能。
论文及项目相关链接
PDF ICLR 2025
Summary
本文关注药物作用效果与其分子几何结构的关系,采用基于图神经网络(GNN)的三维点云原子表示方法。但现有模型忽略了分子的手性特征,对药物安全和效力有重要影响。为此,提出一种新的基于场的表示方法,通过引入参考旋转,既能捕捉所有分子几何结构,包括手性,又能实现与E(3)方法相当的性能。
Key Takeaways
- 药物作用效果受分子几何结构影响显著。
- 当前主流模型采用图神经网络(GNN)进行三维点云原子表示。
- 现有模型忽略了分子的手性特征,这是决定药物安全和效力的关键因素。
- 引入新的基于场的表示方法来解决手性问题。
- 新模型能够捕捉所有分子几何结构,包括手性。
- 新模型在标准评估指标上实现了与E(3)方法相当的性能。
点此查看论文截图