⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-22 更新
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Authors:Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, ShiLiang Zhang, Xie Chen
Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://anonymous.4open.science/r/EmoVoice-DF55. Dataset, code, and checkpoints will be released.
人类语音不仅仅是信息的传递,更是情感深处的交流与个体间的联系。尽管文本转语音(TTS)模型已经取得了巨大的进步,但在控制生成语音的情感表达方面仍面临挑战。在此工作中,我们提出了EmoVoice,这是一种新型的情感可控TTS模型,它利用大型语言模型(LLM)实现细粒度的自然语言情感控制,并采用了语音素增强变体设计,使模型能够并行输出语音素标记和音频标记,以增强内容的一致性,这一设计灵感来源于思维链(CoT)和模态链(CoM)技术。此外,我们还介绍了EmoVoice-DB,这是一个高质量的40小时英语情感数据集,包含表现力强的语音和带有自然语言描述的精细情感标签。EmoVoice仅使用合成训练数据,在英语EmoVoice-DB测试集上实现了最先进的性能,在使用我们内部数据的中文Secap测试集上也表现优异。我们进一步研究了现有情感评估指标的可靠性及其与人类感知偏好的一致性,并探索使用最先进的多媒体LLMs GPT-4o-audio和Gemini来评估情感语音。演示样本可在https://anonymous.4open.science/r/EmoVoice-DF55找到。数据集、代码和检查点将陆续发布。
论文及项目相关链接
摘要
人类语言不仅是信息传递的手段,更是一个情感的交流和个体间的连结过程。文本转语音(TTS)模型虽然在不断进步,但在情感表达的控制上仍面临挑战。本研究提出了EmoVoice,一种全新的情感可控TTS模型,借助大型语言模型(LLM)实现精细的自由式自然语言情感控制,并设计了一种音素增强变体,使模型能并行输出音素令牌和音频令牌,以增强内容一致性,该设计灵感来源于思维链和模态链技术。此外,我们引入了高质量英语情感数据集EmoVoice-DB,包含表达性语音和具有自然语言描述精细情感标签。EmoVoice仅在合成训练数据上即可在英文EmoVoice-DB测试集上实现最佳性能,并在使用内部数据的中文Secap测试集上表现出色。我们还对现有情感评估指标的可靠性进行了调查,以及它们与人类感知偏好的一致性,并探索使用最先进的GPT-4o-audio和Gemini多媒体LLM评估情感语音。演示样本可在链接中找到:https://anonymous.4open.science/r/EmoVoice-DF55。我们将发布数据集、代码和检查点。
关键见解
- 人类言语不仅仅是信息的传递,而是包含了丰富的情感交流和个人联系的维度。
- 当前TTS模型在情感表达控制方面存在挑战,需要新的技术和模型来满足这一需求。
- EmoVoice是一个创新的情感可控TTS模型,借助大型语言模型实现精细的自然语言情感控制。
- EmoVoice利用音素增强变体设计来提升语音内容的一致性。
- 引入高质量英语情感数据集EmoVoice-DB,为情感语音研究提供丰富资源。
- EmoVoice在英文和中文测试集上都实现了卓越性能。
- 研究还涉及对现有情感评估指标的可靠性调查,及其与人类感知偏好的一致性探索,并探索使用多媒体LLM在情感语音评估中的应用。
点此查看论文截图


Semantic Matters: Multimodal Features for Affective Analysis
Authors:Tobias Hallmen, Robin-Nico Kampa, Fabian Deuser, Norbert Oswald, Elisabeth André
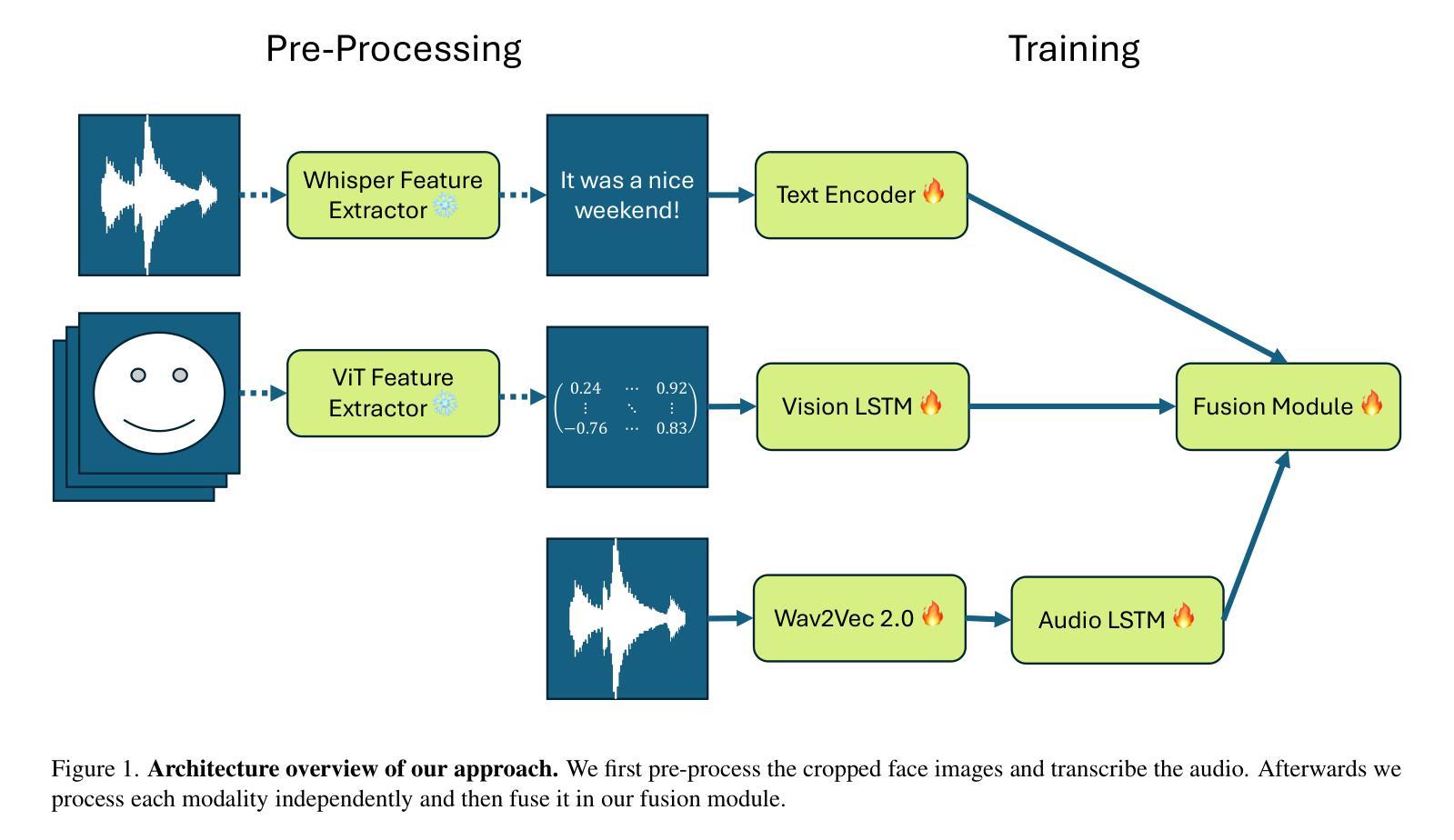
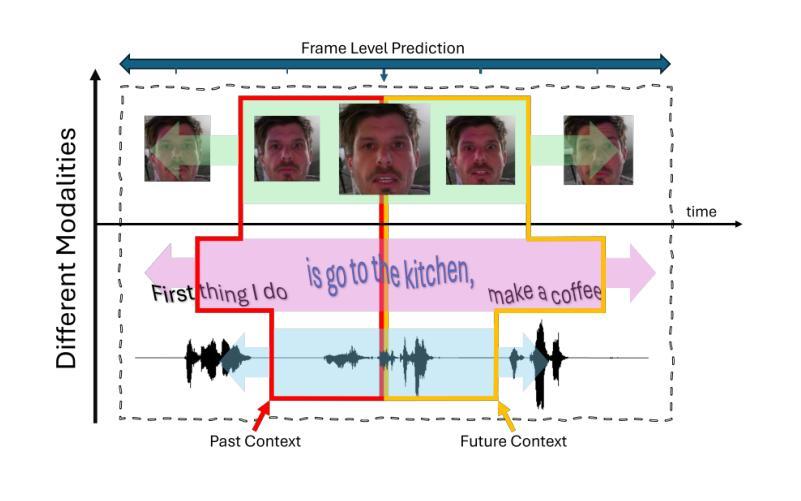
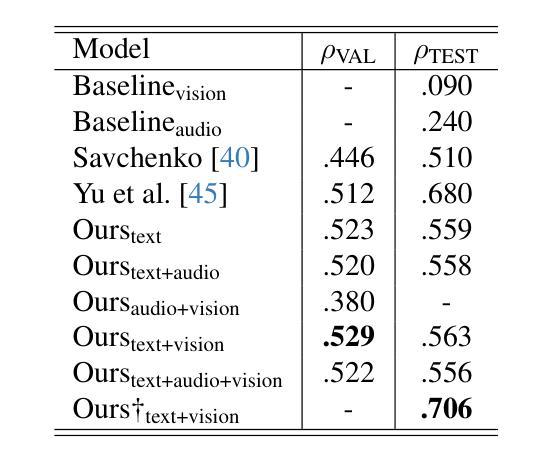
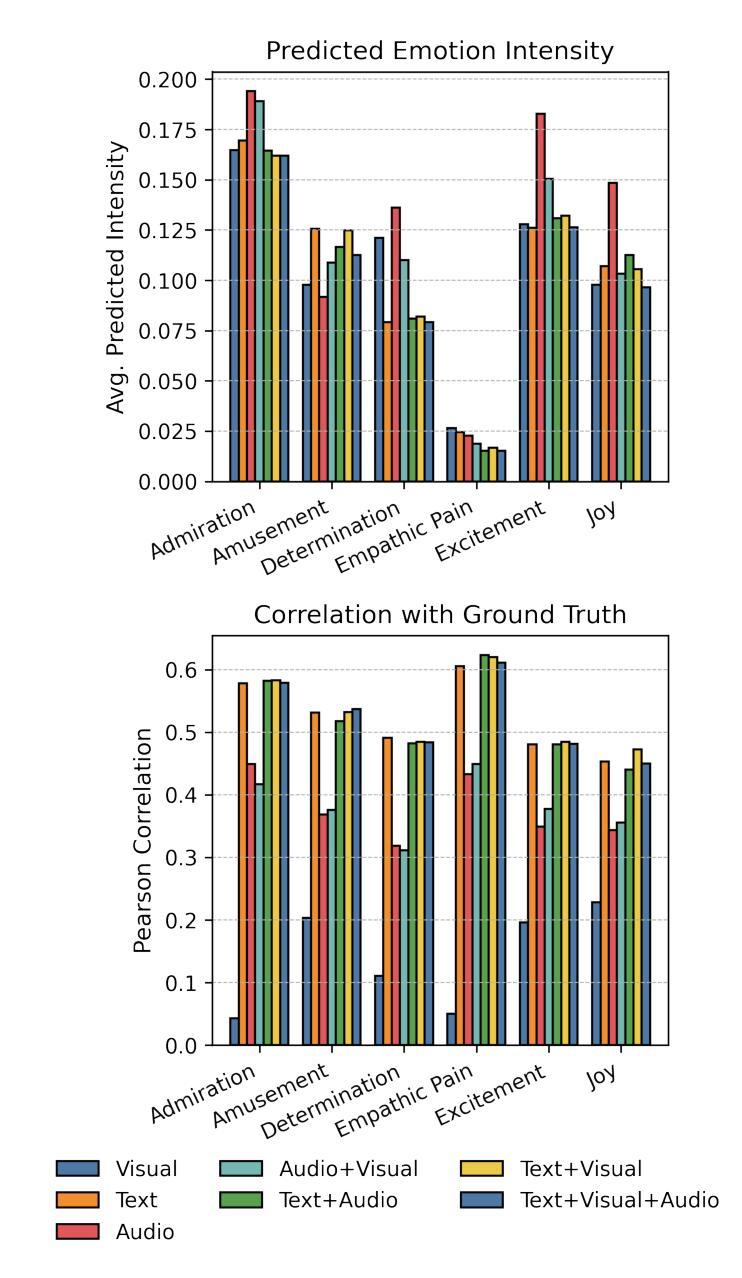
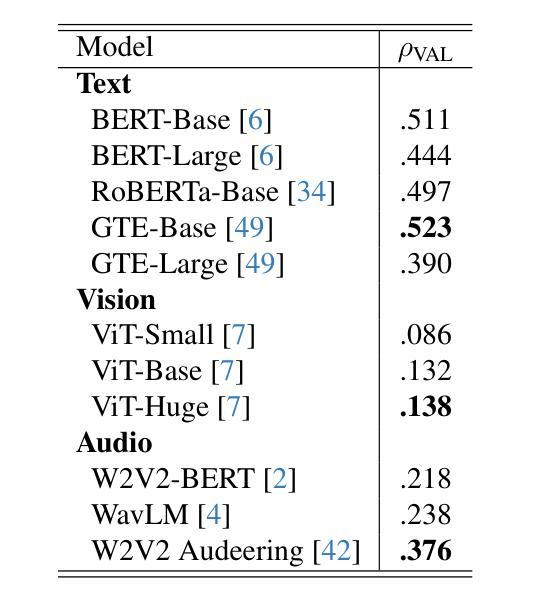
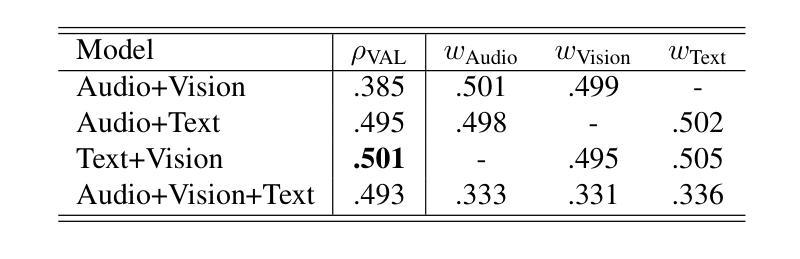
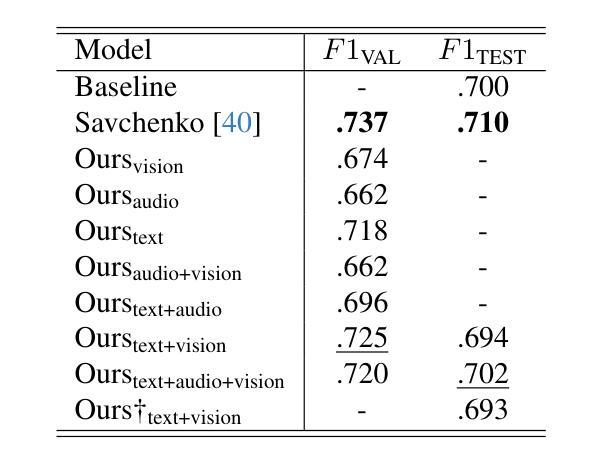
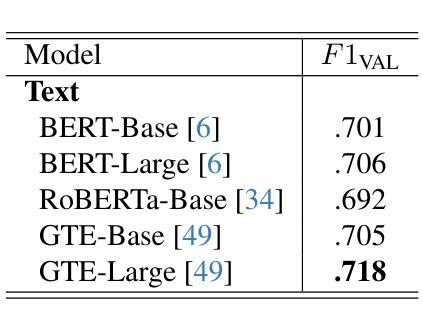
In this study, we present our methodology for two tasks: the Emotional Mimicry Intensity (EMI) Estimation Challenge and the Behavioural Ambivalence/Hesitancy (BAH) Recognition Challenge, both conducted as part of the 8th Workshop and Competition on Affective & Behavior Analysis in-the-wild. We utilize a Wav2Vec 2.0 model pre-trained on a large podcast dataset to extract various audio features, capturing both linguistic and paralinguistic information. Our approach incorporates a valence-arousal-dominance (VAD) module derived from Wav2Vec 2.0, a BERT text encoder, and a vision transformer (ViT) with predictions subsequently processed through a long short-term memory (LSTM) architecture or a convolution-like method for temporal modeling. We integrate the textual and visual modality into our analysis, recognizing that semantic content provides valuable contextual cues and underscoring that the meaning of speech often conveys more critical insights than its acoustic counterpart alone. Fusing in the vision modality helps in some cases to interpret the textual modality more precisely. This combined approach results in significant performance improvements, achieving in EMI $\rho_{\text{TEST}} = 0.706$ and in BAH $F1_{\text{TEST}} = 0.702$, securing first place in the EMI challenge and second place in the BAH challenge.
在这项研究中,我们介绍了针对两项任务的方法论:情感模仿强度(EMI)估计挑战和行为矛盾/犹豫(BAH)识别挑战,这两项挑战都是第八届野外情感与行为分析研讨会和竞赛的一部分。我们利用在大量播客数据集上预训练的Wav2Vec 2.0模型来提取各种音频特征,捕捉语言和副语言信息。我们的方法结合了由Wav2Vec 2.0派生的价值-唤醒-支配(VAD)模块、BERT文本编码器和带有预测的视觉转换器(ViT),随后通过长短时记忆(LSTM)架构或卷积类方法进行时间建模处理。我们将文本和视觉模式整合到我们的分析中,认识到语义内容提供了宝贵的上下文线索,并强调言语的意义通常比单纯的声学对应物提供更多的关键见解。在某些情况下,融入视觉模式有助于更精确地解释文本模式。这种结合的方法带来了显著的性能改进,在EMI中ρ测试= 0.706,在BAH中F1测试= 0.702,获得EMI挑战第一名和BAH挑战第二名。
论文及项目相关链接
摘要
本研究提出一种融合音频、文本和视觉模态的分析方法,用于情感和行为分析。通过利用Wav2Vec 2.0模型预训练的大型播客数据集,提取音频特征,并融入语言和非语言信息。结合情感分析中的价值-唤起-支配(VAD)模块、BERT文本编码器和视觉转换器(ViT),再通过长短时记忆(LSTM)或卷积类时间建模方法对预测进行处理。将文本和视觉模态集成到分析中,认识到语义内容提供有价值的上下文线索,并且理解语言的意义通常比单纯的语音传达更重要。视觉模式的融合有助于在某些情况下更精确地解释文本模式。该方法显著提高性能,在情感模仿强度(EMI)挑战中取得第一名,在行为犹豫/矛盾(BAH)挑战中取得第二名。
关键见解
- 本研究采用Wav2Vec 2.0模型预训练的大型播客数据集,用于提取音频特征,涵盖语言和副语言信息。
- 结合价值-唤起-支配(VAD)模块、BERT文本编码器和视觉转换器(ViT),实现多模态融合分析。
- 采用长短时记忆(LSTM)或卷积类方法处理预测,进行时间建模。
- 语义内容提供有价值的上下文线索,语言的意义通常比单纯的语音传达更重要。
- 视觉模式的融合有助于更精确地解释文本模式。
- 该方法在情感模仿强度(EMI)挑战中取得显著成效,获得第一名。
- 在行为犹豫/矛盾(BAH)挑战中取得第二名,显示该方法的实用性。
点此查看论文截图