⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-23 更新
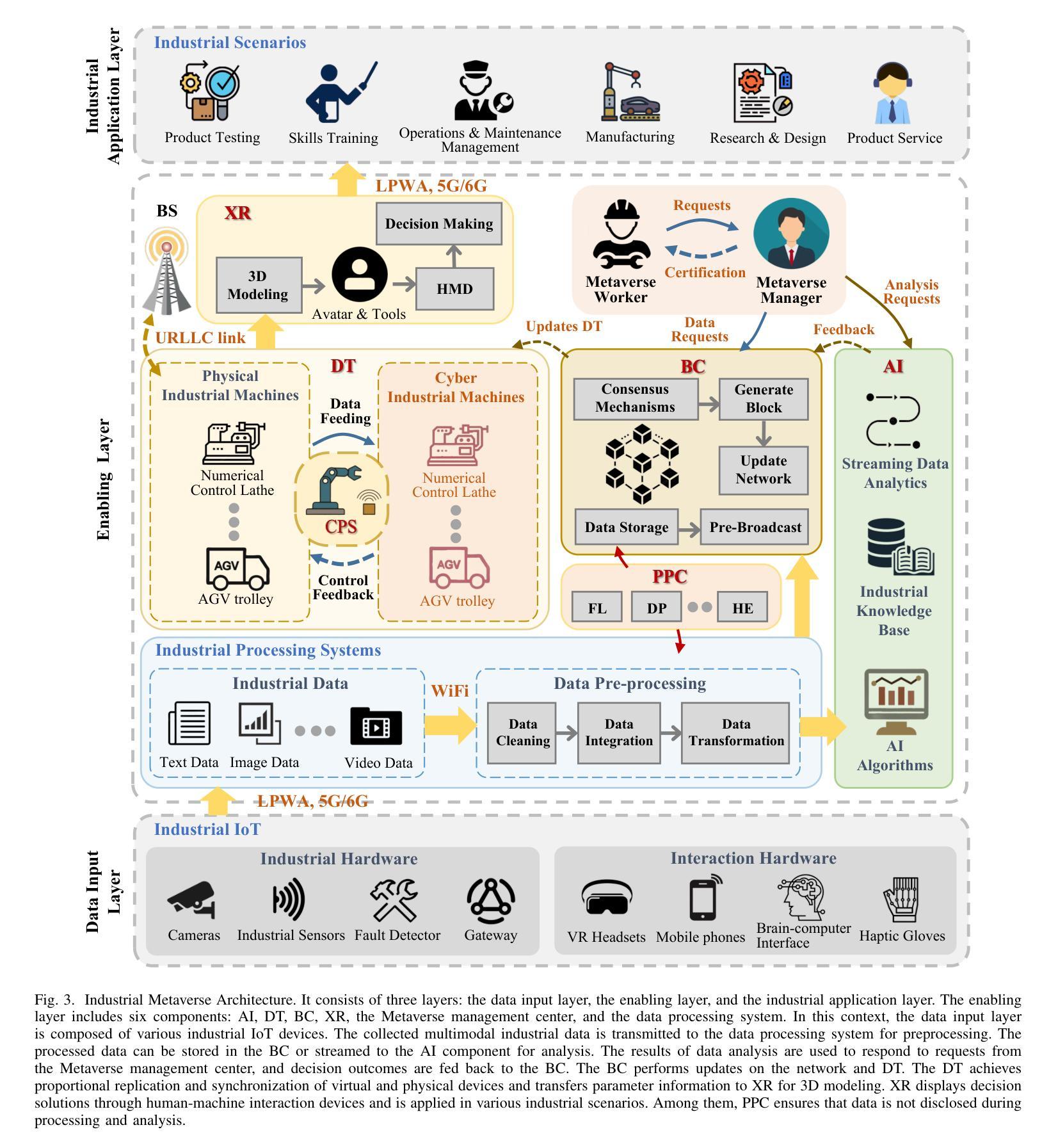
SEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Authors:Chen Guo, Zhuo Su, Jian Wang, Shuang Li, Xu Chang, Zhaohu Li, Yang Zhao, Guidong Wang, Ruqi Huang
Creating photorealistic 3D head avatars from limited input has become increasingly important for applications in virtual reality, telepresence, and digital entertainment. While recent advances like neural rendering and 3D Gaussian splatting have enabled high-quality digital human avatar creation and animation, most methods rely on multiple images or multi-view inputs, limiting their practicality for real-world use. In this paper, we propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework. SEGA seamlessly combines priors derived from large-scale 2D datasets with 3D priors learned from multi-view, multi-expression, and multi-ID data, achieving robust generalization to unseen identities while ensuring 3D consistency across novel viewpoints and expressions. We further present a hierarchical UV-space Gaussian Splatting framework that leverages FLAME-based structural priors and employs a dual-branch architecture to disentangle dynamic and static facial components effectively. The dynamic branch encodes expression-driven fine details, while the static branch focuses on expression-invariant regions, enabling efficient parameter inference and precomputation. This design maximizes the utility of limited 3D data and achieves real-time performance for animation and rendering. Additionally, SEGA performs person-specific fine-tuning to further enhance the fidelity and realism of the generated avatars. Experiments show our method outperforms state-of-the-art approaches in generalization ability, identity preservation, and expression realism, advancing one-shot avatar creation for practical applications.
创建具有真实感的3D头像化身从有限的输入对于虚拟现实、远程存在和数字娱乐等应用变得越来越重要。尽管最近的神经渲染和3D高斯贴图技术进展使得高质量的数字人类化身创建和动画成为可能,但大多数方法仍依赖于多张图像或多视角输入,限制了它们在现实世界应用中的实用性。在本文中,我们提出了SEGA,这是一种基于单张图片的3D可驱动高斯头像化身创建新方法,它将通用先验模型与新的层次化UV空间高斯贴图框架相结合。SEGA无缝结合了从大规模二维数据集得出的先验知识和从多视角、多表情和多身份数据中学习的三维先验知识,实现了对未见身份的稳健泛化,同时确保新型视角和表情的3D一致性。我们还提出了一种层次化的UV空间高斯贴图框架,它利用基于FLAME的结构先验知识,并采用双分支架构来有效地分离动态和静态面部组件。动态分支编码表情驱动的精细细节,而静态分支则专注于表情不变的区域,从而实现有效的参数推断和预计算。这种设计最大限度地提高了有限3D数据的实用性,并实现了动画和渲染的实时性能。此外,SEGA还执行针对个人的微调,以进一步提高生成的化身的真实感和逼真度。实验表明,我们的方法在泛化能力、身份保留和表情逼真度方面优于最先进的方法,推动了单次拍摄化身创建在实际应用中的发展。
论文及项目相关链接
Summary
本文提出了一种基于单张图像创建3D可驱动高斯头像的方法SEGA,该方法结合了通用先验模型和新层次UV空间高斯溅射框架。SEGA无缝结合了大规模二维数据集得出的先验知识和从多角度、多表情和多身份数据中学习的三维先验知识,实现了对未见身份的稳健泛化,同时确保在新型视角和表情下的三维一致性。此外,SEGA还采用层次UV空间高斯溅射框架,利用基于FLAME的结构先验知识,并采用双分支架构有效分离动态和静态面部组件。实验表明,该方法在泛化能力、身份保留和表情真实性方面优于现有技术,推动了一站式头像创建的实际应用。
Key Takeaways
- 创建了基于单张图像的3D可驱动高斯头像方法SEGA。
- 结合了通用先验模型与层次UV空间高斯溅射框架。
- SEGA实现了对未见身份的稳健泛化,并确保了新型视角和表情下的三维一致性。
- 利用大规模二维数据集和从多角度、多表情、多身份数据中学习的三维先验知识。
- 采用层次UV空间高斯溅射框架,有效分离动态和静态面部组件。
- 实验证明SEGA在泛化能力、身份保留和表情真实性方面超越现有技术。
点此查看论文截图

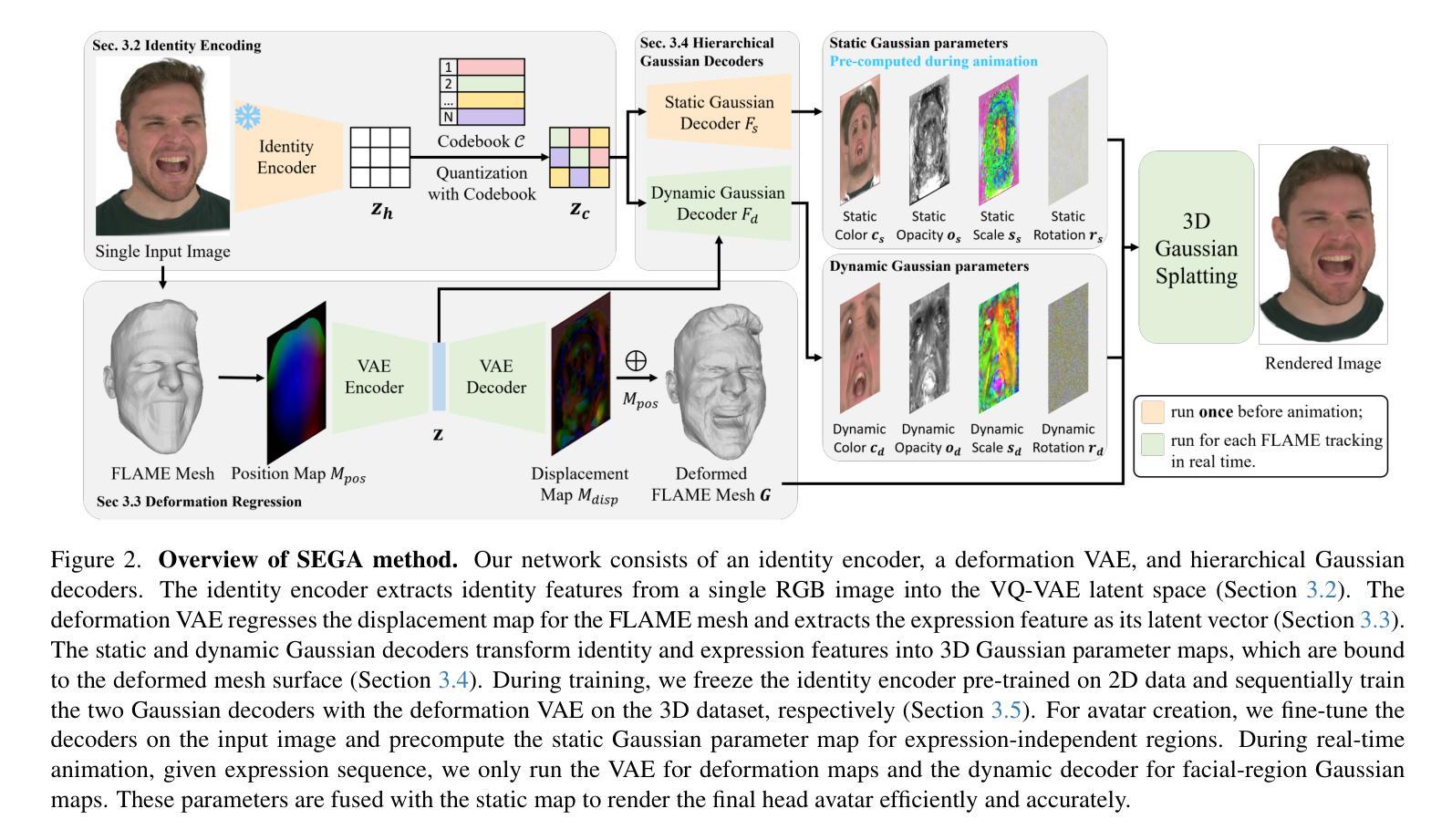
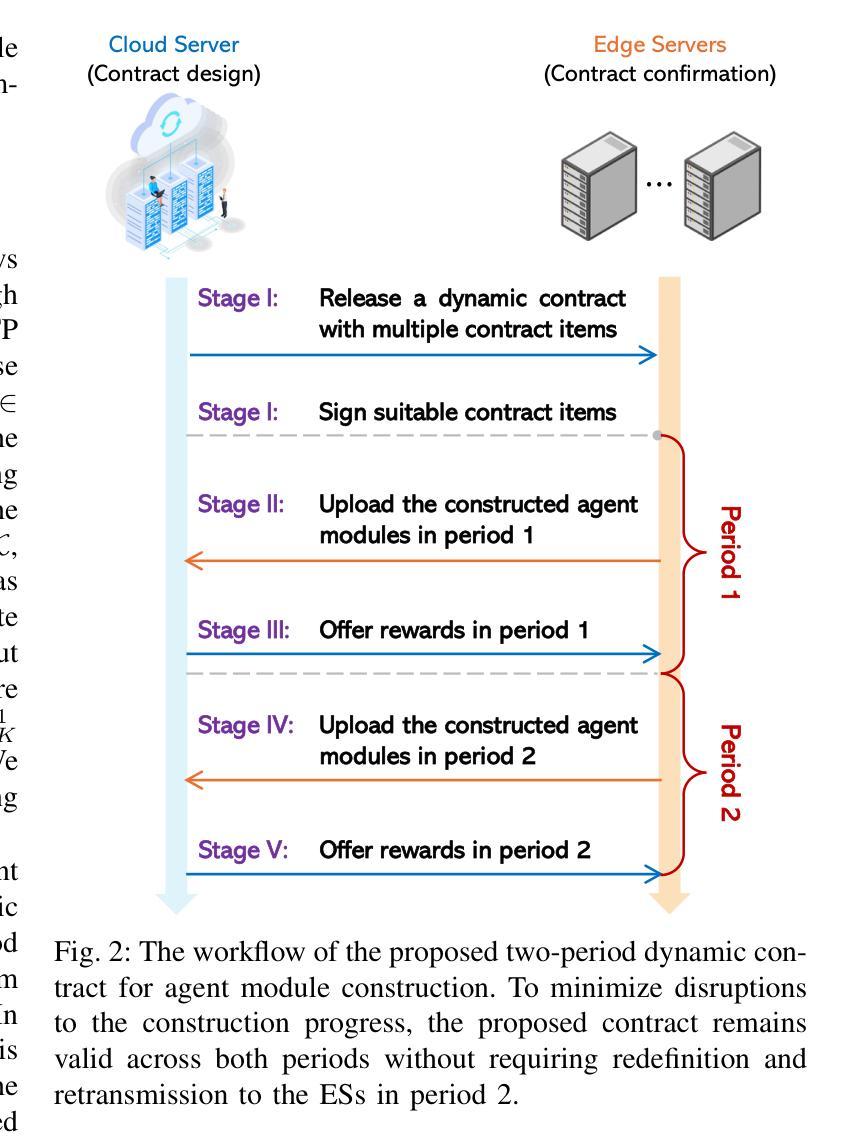
Diffusion-based Dynamic Contract for Federated AI Agent Construction in Mobile Metaverses
Authors:Jinbo Wen, Jiawen Kang, Yang Zhang, Yue Zhong, Dusit Niyato, Jie Xu, Jianhang Tang, Chau Yuen
Mobile metaverses have attracted significant attention from both academia and industry, which are envisioned as the next-generation Internet, providing users with immersive and ubiquitous metaverse services through mobile devices. Driven by Large Language Models (LLMs) and Vision-Language Models (VLMs), Artificial Intelligence (AI) agents hold the potential to empower the creation, maintenance, and evolution of mobile metaverses. Currently, AI agents are primarily constructed using cloud-based LLMs and VLMs. However, several challenges hinder their effective implementation, including high service latency and potential sensitive data leakage during perception and processing. In this paper, we develop an edge-cloud collaboration-based federated AI agent construction framework in mobile metaverses. Specifically, Edge Servers (ESs), acting as agent infrastructures, collaboratively create agent modules in a distributed manner. The cloud server then integrates these modules into AI agents and deploys them at the edge, thereby enabling low-latency AI agent services for users. Considering that ESs may exhibit dynamic levels of willingness to participate in federated AI agent construction, we design a two-period dynamic contract model to continuously motivate ESs to participate in agent module creation, effectively addressing the dynamic information asymmetry between the cloud server and the ESs. Furthermore, we propose an Enhanced Diffusion Model-based Soft Actor-Critic (EDMSAC) algorithm to efficiently generate optimal dynamic contracts, in which dynamic structured pruning is applied to DM-based actor networks to enhance denoising efficiency and policy learning performance. Extensive simulations demonstrate the effectiveness and superiority of the EDMSAC algorithm and the proposed contract model.
移动元宇宙引起了学术界和工业界的极大关注,它们被视为下一代互联网,通过移动设备为用户提供沉浸式和无处不在的元宇宙服务。在大型语言模型(LLM)和视觉语言模型(VLM)的推动下,人工智能(AI)代理具有赋能移动元宇宙创建、维护和演进的潜力。目前,AI代理主要使用基于云的大型语言模型和视觉语言模型构建。然而,存在一些挑战阻碍其有效实施,包括服务延迟高和感知和处理过程中潜在敏感数据泄露。在本文中,我们构建了基于边缘云协同的联邦人工智能代理构建框架在移动元宇宙中。具体来说,边缘服务器(ES)作为代理基础设施,以分布式方式协同创建代理模块。然后,云服务器将这些模块集成到人工智能代理中并在边缘进行部署,从而为用户提供低延迟的人工智能代理服务。考虑到边缘服务器在参与联邦人工智能代理构建时可能表现出动态的意愿水平,我们设计了一个两期动态合同模型来不断激励边缘服务器参与代理模块的创建,有效解决云服务器和边缘服务器之间的动态信息不对称问题。此外,我们提出了一种基于增强扩散模型的软动作评论家(EDMSAC)算法来有效地生成最优动态合同,其中对基于DM的演员网络应用动态结构化修剪,以提高去噪效率和策略学习性能。大量模拟实验证明了EDMSAC算法和所提合同模型的有效性和优越性。
论文及项目相关链接
Summary
移动元宇宙作为下一代互联网,通过移动设备为用户提供沉浸式、无处不在的元宇宙服务,引发了学术界和工业界的广泛关注。基于大型语言模型和视觉语言模型的人工智能代理有望推动移动元宇宙的创建、维护和进化。然而,当前存在服务延迟和数据泄露等挑战。本文提出了一个基于边缘云协作的联邦人工智能代理构建框架,通过边缘服务器协作创建代理模块,然后将其整合到人工智能代理中并在边缘部署,以实现低延迟的人工智能服务。此外,本文设计了一个动态合同模型来激励边缘服务器参与代理模块创建,并提出了一种高效的EDMSAC算法来生成最优动态合同。
Key Takeaways
* 移动元宇宙被认为是下一代互联网,提供沉浸式服务。
* 大型语言模型和视觉语言模型的人工智能代理在移动元宇宙中扮演重要角色。
* 当前实施人工智能代理面临服务延迟和数据泄露的挑战。
* 本文提出了基于边缘云协作的联邦人工智能代理构建框架来解决这些问题。
* 边缘服务器协作创建代理模块并在边缘部署,实现低延迟服务。
* 设计了动态合同模型来激励边缘服务器参与代理模块创建。
点此查看论文截图

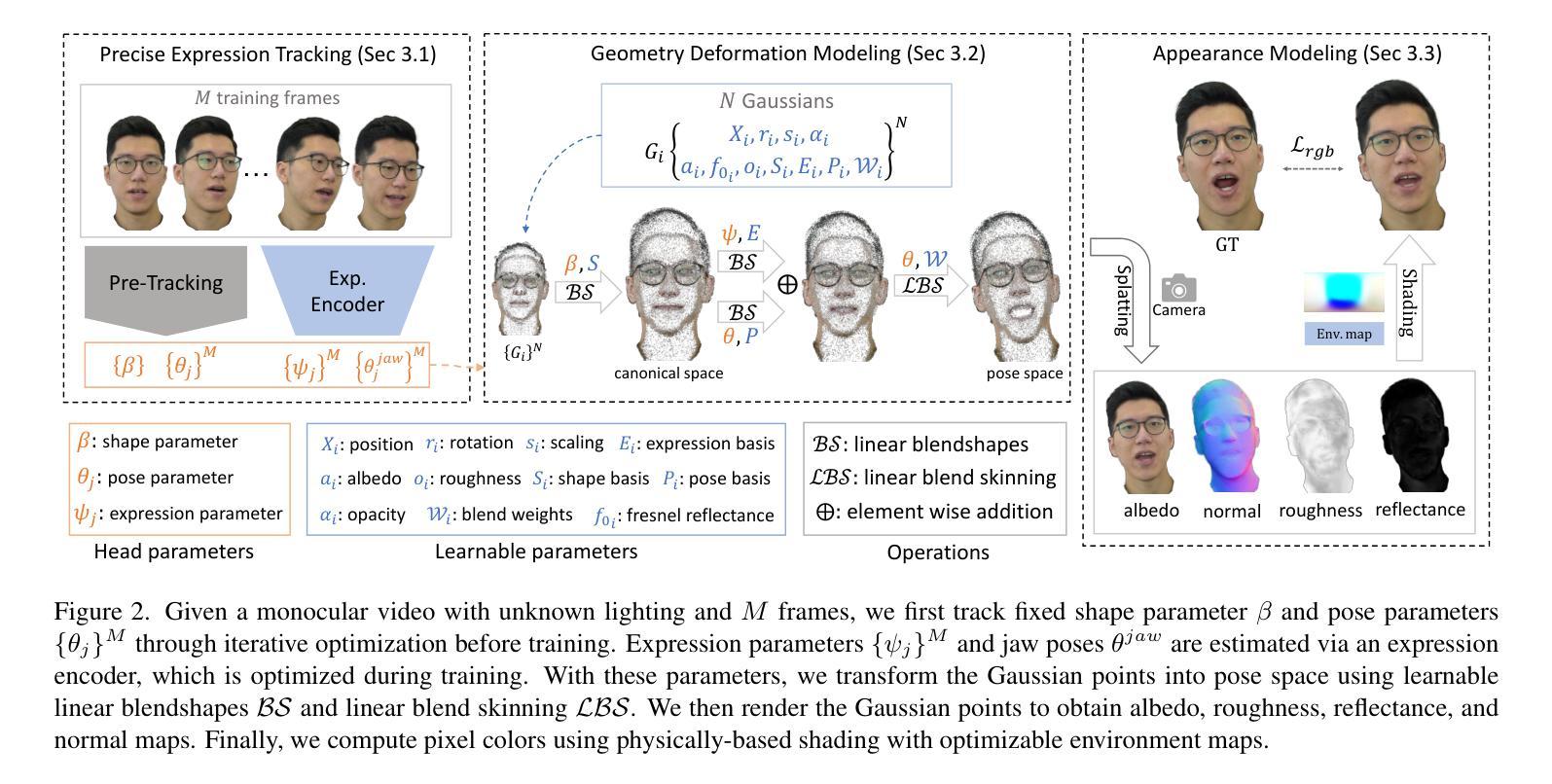
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Authors:Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Kangjie Chen, Minghan Qin, Yu Li, Haoqian Wang
Reconstructing animatable and high-quality 3D head avatars from monocular videos, especially with realistic relighting, is a valuable task. However, the limited information from single-view input, combined with the complex head poses and facial movements, makes this challenging. Previous methods achieve real-time performance by combining 3D Gaussian Splatting with a parametric head model, but the resulting head quality suffers from inaccurate face tracking and limited expressiveness of the deformation model. These methods also fail to produce realistic effects under novel lighting conditions. To address these issues, we propose HRAvatar, a 3DGS-based method that reconstructs high-fidelity, relightable 3D head avatars. HRAvatar reduces tracking errors through end-to-end optimization and better captures individual facial deformations using learnable blendshapes and learnable linear blend skinning. Additionally, it decomposes head appearance into several physical properties and incorporates physically-based shading to account for environmental lighting. Extensive experiments demonstrate that HRAvatar not only reconstructs superior-quality heads but also achieves realistic visual effects under varying lighting conditions.
从单目视频中重建生动且高质量的3D头部化身,尤其是实现逼真的重新照明,是一项有价值的任务。然而,由于单视图输入的有限信息以及复杂的头部姿势和面部运动,这使得任务具有挑战性。之前的方法是通过结合3D高斯平铺和参数化头部模型来实现实时性能,但得到的头部质量受到面部跟踪不准确和变形模型表现力有限的困扰。这些方法还无法在新型光照条件下产生逼真的效果。为了解决这些问题,我们提出了HRAvatar,一种基于3DGS的方法,用于重建高保真、可重新照明的3D头部化身。HRAvatar通过端到端优化减少了跟踪误差,并使用可学习的blendshapes和可学习的线性混合蒙皮技术更好地捕捉了个人面部的变形。此外,它将头部外观分解成多种物理属性,并融入基于物理的着色来模拟环境照明。大量实验表明,HRAvatar不仅重建了高质量的头部,而且在不同的光照条件下实现了逼真的视觉效果。
论文及项目相关链接
PDF Accepted to CVPR 2025,Project page: https://eastbeanzhang.github.io/HRAvatar
摘要
基于单视角视频的3D头部个性化重建,尤其是在复杂头部姿态与面部动态情况下生成逼真的重光照效果是一项具有挑战性的任务。先前的方法结合3D高斯贴图与参数化头部模型实现实时性能,但头部质量因面部追踪不准确和变形模型表现力有限而受影响。此外,这些方法在新光照条件下无法产生逼真的效果。为解决这些问题,我们提出HRAvatar系统,采用基于3DGS的方法重建高质量重光照的3D头部个性化模型。HRAvatar通过端到端优化减少追踪误差,并利用可学习的blendshapes和线性皮肤变形技术更好地捕捉面部细节变形。同时,系统将头部外观分解成多个物理属性并采用物理渲染技术考虑环境照明因素。实验表明,HRAvatar不仅重建的头部质量更高,而且在不同光照条件下可实现逼真的视觉效果。
关键见解
- 基于单视角视频的3D头部个性化重建是一个挑战。先前的方法存在追踪不准确和质量问题的问题。
- HRAvatar通过结合物理建模与深度学习方法提升重建质量并增强了在新光照条件下的逼真度。
- HRAvatar通过端到端优化减少追踪误差,提高面部细节捕捉的准确性。
- 系统采用可学习的blendshapes和线性皮肤变形技术来更好地捕捉个体面部变形。
- HRAvatar将头部外观分解为多个物理属性并采用物理渲染技术模拟不同光照条件下的视觉效果。
- HRAvatar系统不仅提高了重建的头部质量,而且实现了在各种光照条件下的逼真视觉效果。
点此查看论文截图


Industrial Metaverse: Enabling Technologies, Open Problems, and Future Trends
Authors:Shiying Zhang, Jun Li, Long Shi, Ming Ding, Dinh C. Nguyen, Wen Chen, Zhu Han
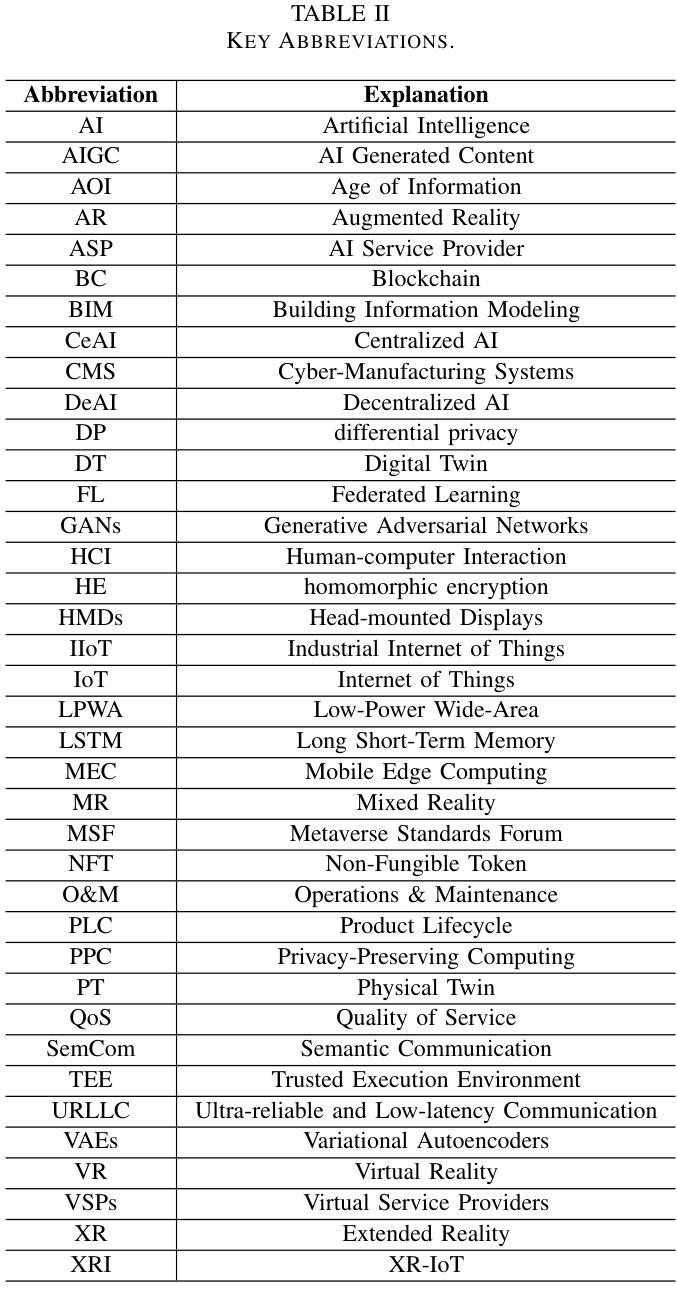
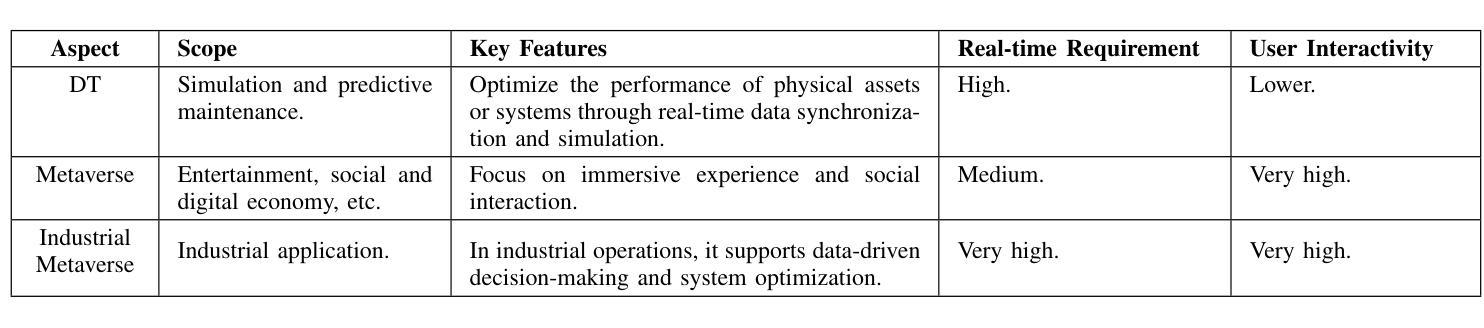
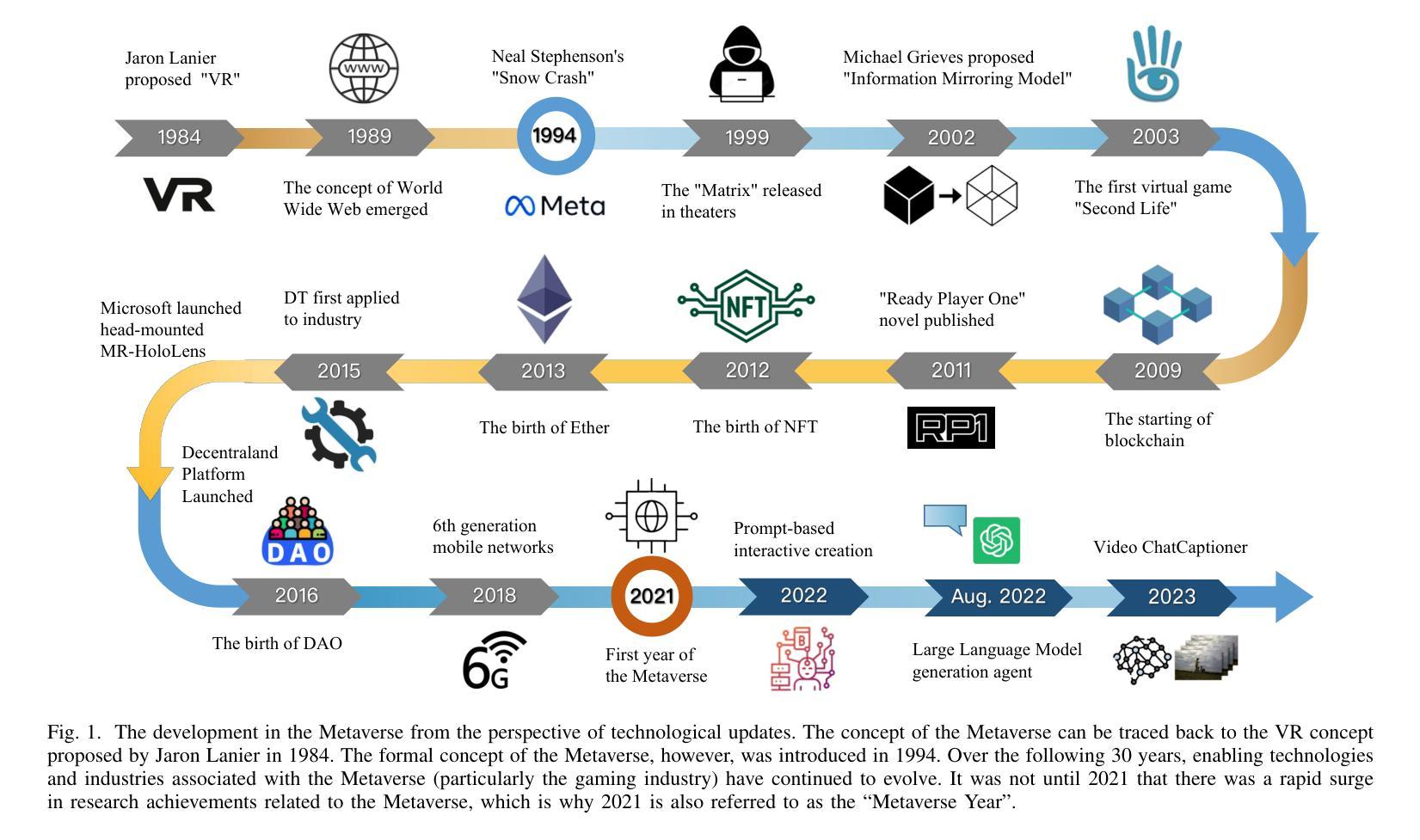
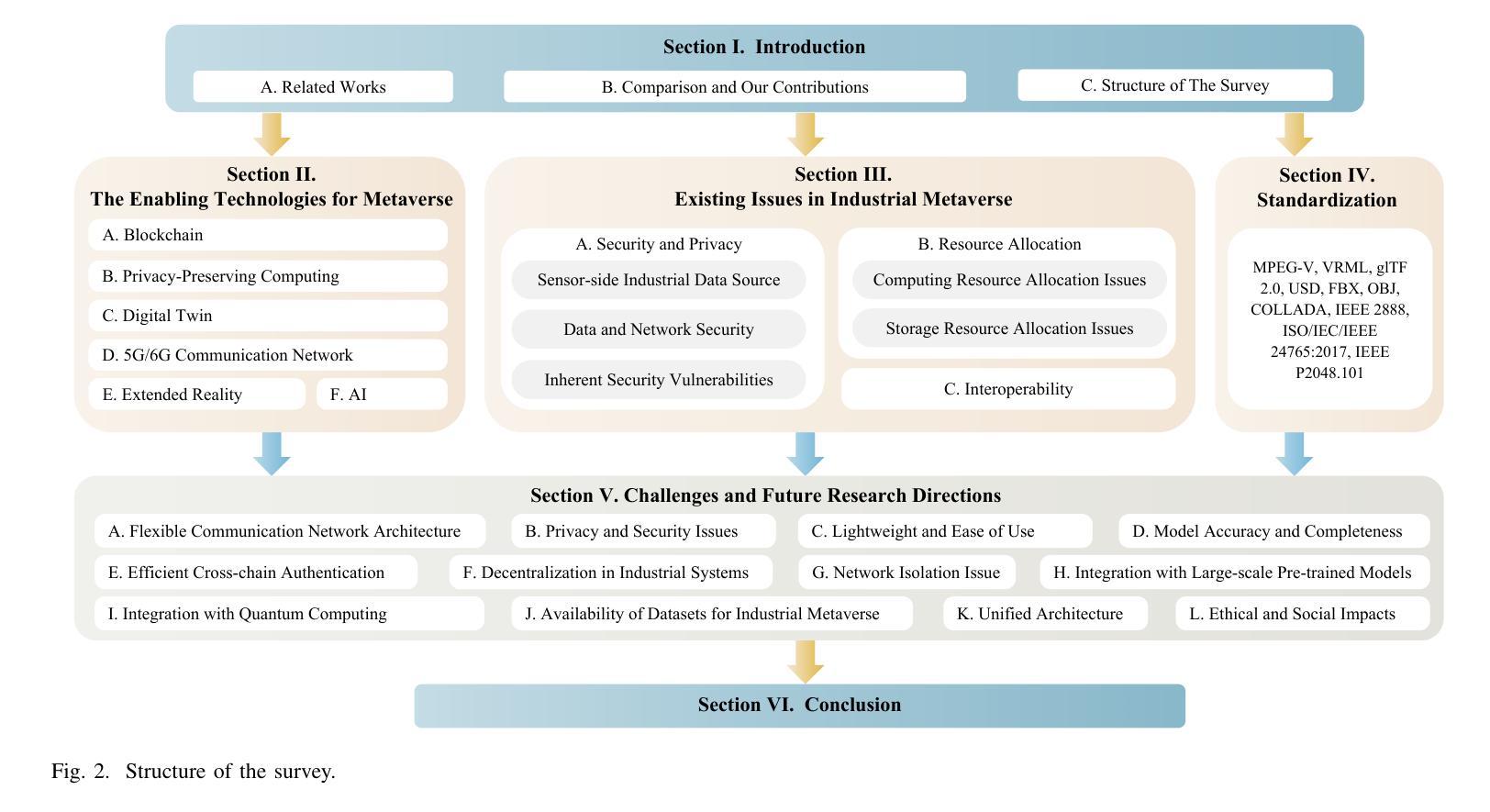
As an emerging technology that enables seamless integration between the physical and virtual worlds, the Metaverse has great potential to be deployed in the industrial production field with the development of extended reality (XR) and next-generation communication networks. This deployment, called the Industrial Metaverse, is used for product design, production operations, industrial quality inspection, and product testing. However, there lacks of in-depth understanding of the enabling technologies associated with the Industrial Metaverse. This encompasses both the precise industrial scenarios targeted by each technology and the potential migration of technologies developed in other domains to the industrial sector. Driven by this issue, in this article, we conduct a comprehensive survey of the state-of-the-art literature on the Industrial Metaverse. Specifically, we first analyze the advantages of the Metaverse for industrial production. Then, we review a collection of key enabling technologies of the Industrial Metaverse, including blockchain (BC), digital twin (DT), 6G, XR, and artificial intelligence (AI), and analyze how these technologies can support different aspects of industrial production. Subsequently, we present numerous formidable challenges encountered within the Industrial Metaverse, including confidentiality and security concerns, resource limitations, and interoperability constraints. Furthermore, we investigate the extant solutions devised to address them. Finally, we briefly outline several open issues and future research directions of the Industrial Metaverse.
作为一种能够使物理世界和虚拟世界无缝融合的新兴技术,元宇宙随着扩展现实(XR)和下一代通信网络的不断发展,在工业应用领域具有巨大的应用潜力。这种在工业领域的应用被称为“工业元宇宙”,被用于产品设计、生产操作、工业质量检测和产品设计。然而,人们对于与工业元宇宙相关的赋能技术的理解还不够深入,包括每种技术针对的精准工业场景,以及其他领域技术向工业领域的潜在迁移。针对这一问题,本文对关于工业元宇宙的最新文献进行了全面调查。具体来说,我们首先分析了元宇宙对工业生产的优势。然后,我们回顾了工业元宇宙的关键赋能技术,包括区块链(BC)、数字孪生(DT)、6G、XR和人工智能(AI),并分析了这些技术如何支持工业生产的各个方面。接着,我们介绍了工业元宇宙中遇到的诸多严峻挑战,包括保密性和安全性问题、资源限制和互操作性约束等。此外,我们还调查了为应对这些挑战而设计的现有解决方案。最后,我们简要概述了工业元宇宙的若干开放问题和未来研究方向。
论文及项目相关链接
PDF 34 pages, 10 figures
Summary:随着扩展现实(XR)和下一代通信网络的不断发展,元宇宙在工业领域具有巨大的潜力。本文主要对元宇宙在工业领域的应用进行了深入研究,包括其优势、关键技术(如区块链、数字孪生技术、6G、XR和人工智能等)、挑战以及未来研究方向进行了全面概述。
Key Takeaways:
- 元宇宙作为连接物理世界和虚拟世界的新兴技术,具有巨大的工业应用潜力。
- 工业元宇宙的主要应用领域包括产品设计、生产操作、工业质量检测和产品测试等。
- 元宇宙的关键技术包括区块链、数字孪生技术、6G网络、XR和人工智能等。
- 元宇宙在工业应用中面临诸多挑战,如保密性、安全性问题、资源限制和互操作性约束等。
- 针对这些挑战,已有一些解决方案被提出。
- 工业元宇宙仍存在一些开放性问题,如如何实现大规模部署等。
点此查看论文截图