⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-23 更新
An LMM for Efficient Video Understanding via Reinforced Compression of Video Cubes
Authors:Ji Qi, Yuan Yao, Yushi Bai, Bin Xu, Juanzi Li, Zhiyuan Liu, Tat-Seng Chua
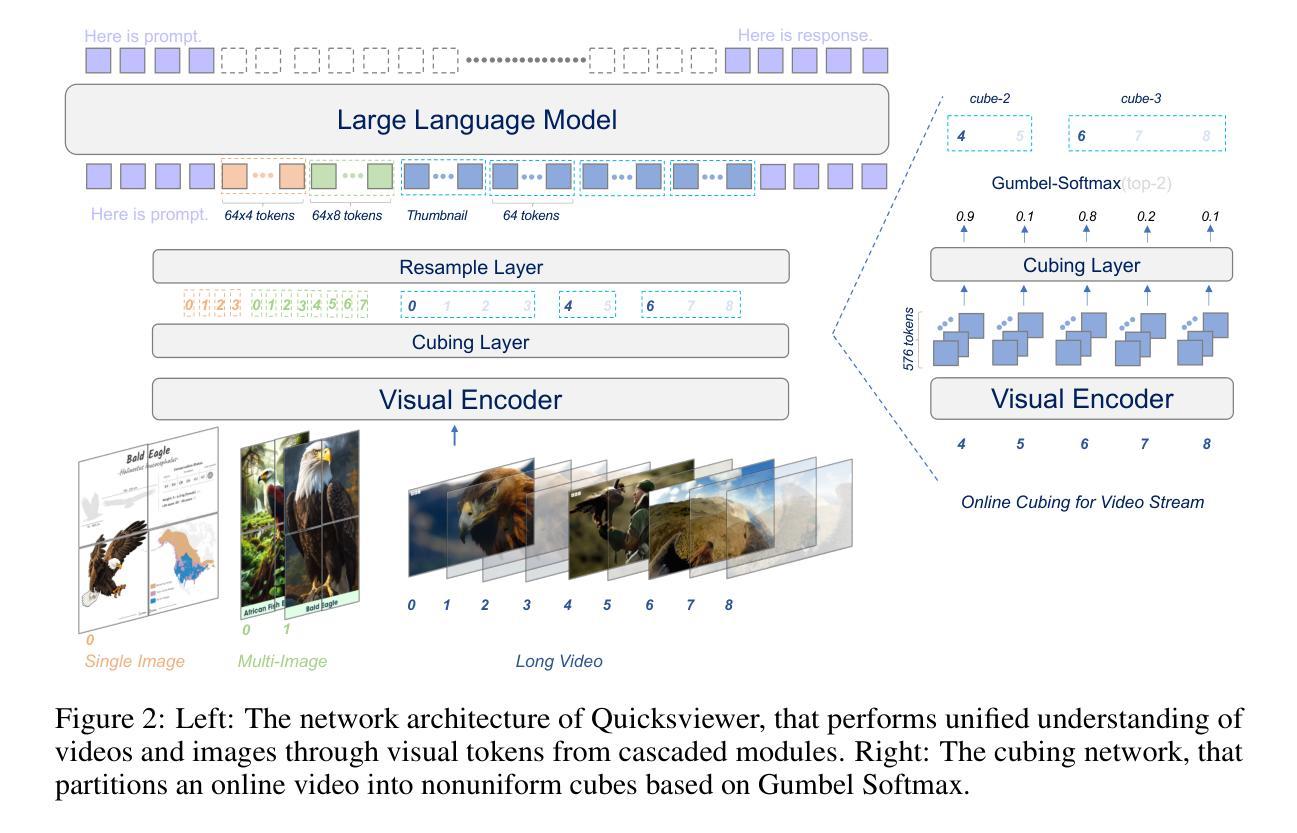
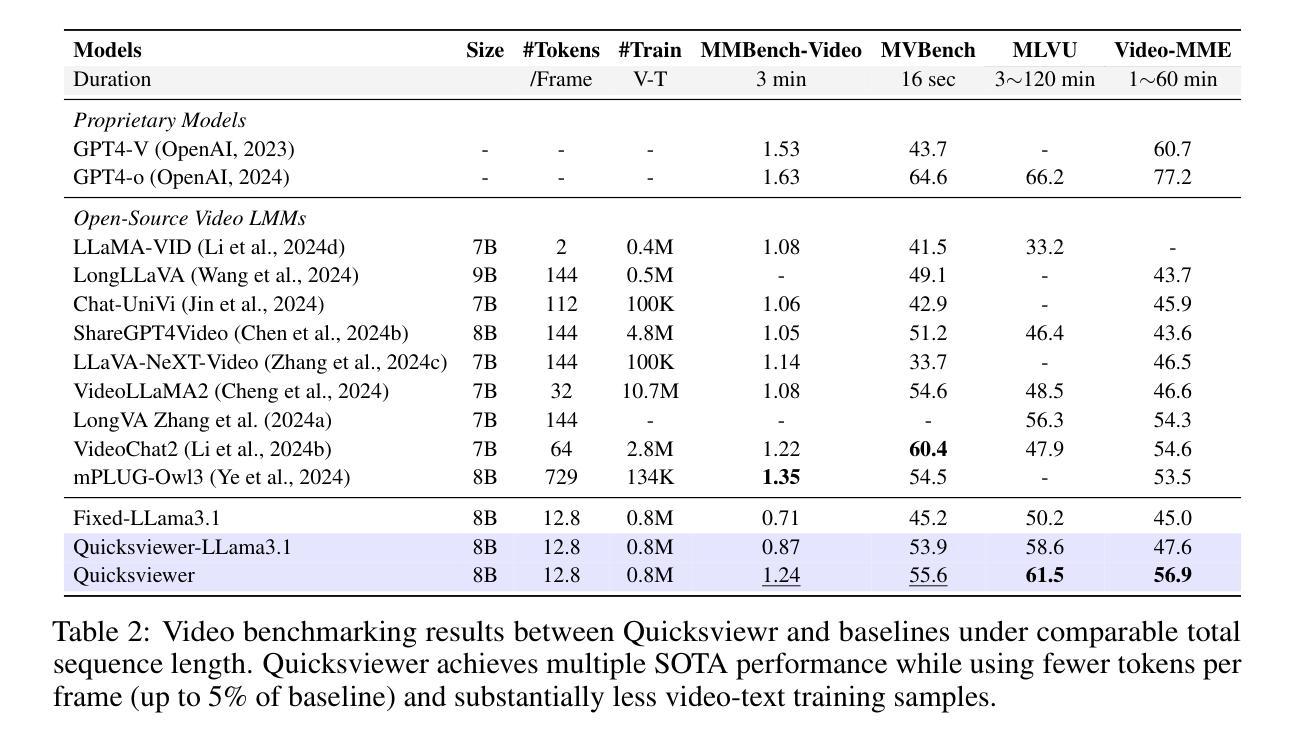
Large Multimodal Models (LMMs) uniformly perceive video frames, creating computational inefficiency for videos with inherently varying temporal information density. This paper present \textbf{Quicksviewer}, an LMM with new perceiving paradigm that partitions a video of nonuniform density into varying cubes using Gumbel Softmax, followed by a unified resampling for each cube to achieve efficient video understanding. This simple and intuitive approach dynamically compress video online based on its temporal density, significantly reducing spatiotemporal redundancy (overall 45$\times$ compression rate), while enabling efficient training with large receptive field. We train the model from a language backbone through three progressive stages, each incorporating lengthy videos on average of 420s/1fps thanks to the perceiving efficiency. With only 0.8M total video-text samples for training, our model outperforms the direct baseline employing a fixed partitioning strategy by a maximum of 8.72 in accuracy, demonstrating the effectiveness in performance. On Video-MME, Quicksviewer achieves SOTA under modest sequence lengths using just up to 5% of tokens per frame required by baselines. With this paradigm, scaling up the number of input frames reveals a clear power law of the model capabilities. It is also empirically verified that the segments generated by the cubing network can help for analyzing continuous events in videos.
大型多模态模型(LMMs)在感知视频帧时存在计算效率低下的问题,特别是对于具有固有不同时间信息密度的视频。本文提出了一个新的感知模式的LMM——“Quicksviewer”。它通过Gumbel Softmax将不均匀密度的视频分割成不同的立方体,然后对每个立方体进行统一重采样,以实现高效的视频理解。这种简单直观的方法根据视频的时空密度动态在线压缩视频,显著减少了时空冗余(总体压缩率为45倍),同时实现了大感受野的高效训练。我们通过语言主干网络对模型进行训练,分为三个阶段,每个阶段都能处理平均长度为420秒的冗长视频(以每秒一帧的速度)。仅使用0.8M的视频文本样本进行训练,我们的模型在准确性上超过了采用固定划分策略的基准模型,最高提升了8.72%,显示了其高性能的有效性。在视频MME上,Quicksviewer在适度序列长度下达到了最新技术水准,只需要基线所需的每帧最多5%的令牌。通过这种模式,增加输入帧的数量揭示了模型能力明显的幂律关系。此外,通过立方网络生成的片段有助于分析视频中的连续事件,这得到了实证验证。
论文及项目相关链接
Summary
本文提出了一种新的视频理解模型Quicksviewer,它采用基于Gumbel Softmax的分区技术,对密度不一的视频进行动态压缩。模型根据视频的时空冗余信息实现高效的视频理解,并能够在平均视频长度为420秒的情况下进行训练。此外,该模型通过简单的训练和采样数据(总计只有约千万级别的视频文本样本),便可以在多种基准测试中获得优越表现,极大地提升了感知效率和性能表现。通过对输入帧的数量进行扩展,模型能力表现出明显的幂律关系。这种视频分析新范式还可以帮助分析连续事件。
Key Takeaways
- Quicksviewer模型通过新的感知范式实现了对视频的高效理解。它采用基于Gumbel Softmax的分区技术,将视频划分为不同密度的立方体,并根据其密度进行动态压缩。
- 模型能够根据视频的时空冗余信息实现显著的计算效率提升,压缩率高达45倍。这种策略显著减少了不必要的计算量,提升了训练过程的效率。同时它还拥有一个大的感受野,这使得它能够更有效地处理复杂场景中的视觉信息。这种策略使得模型能够在平均视频长度为420秒的情况下进行训练。
点此查看论文截图

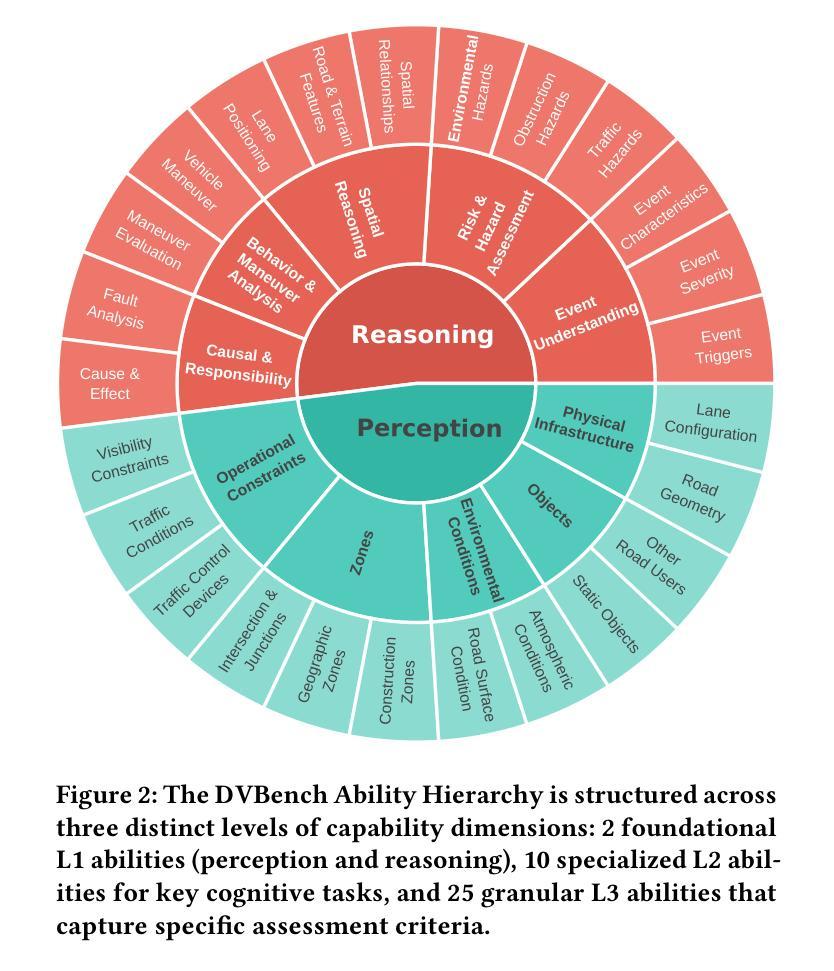
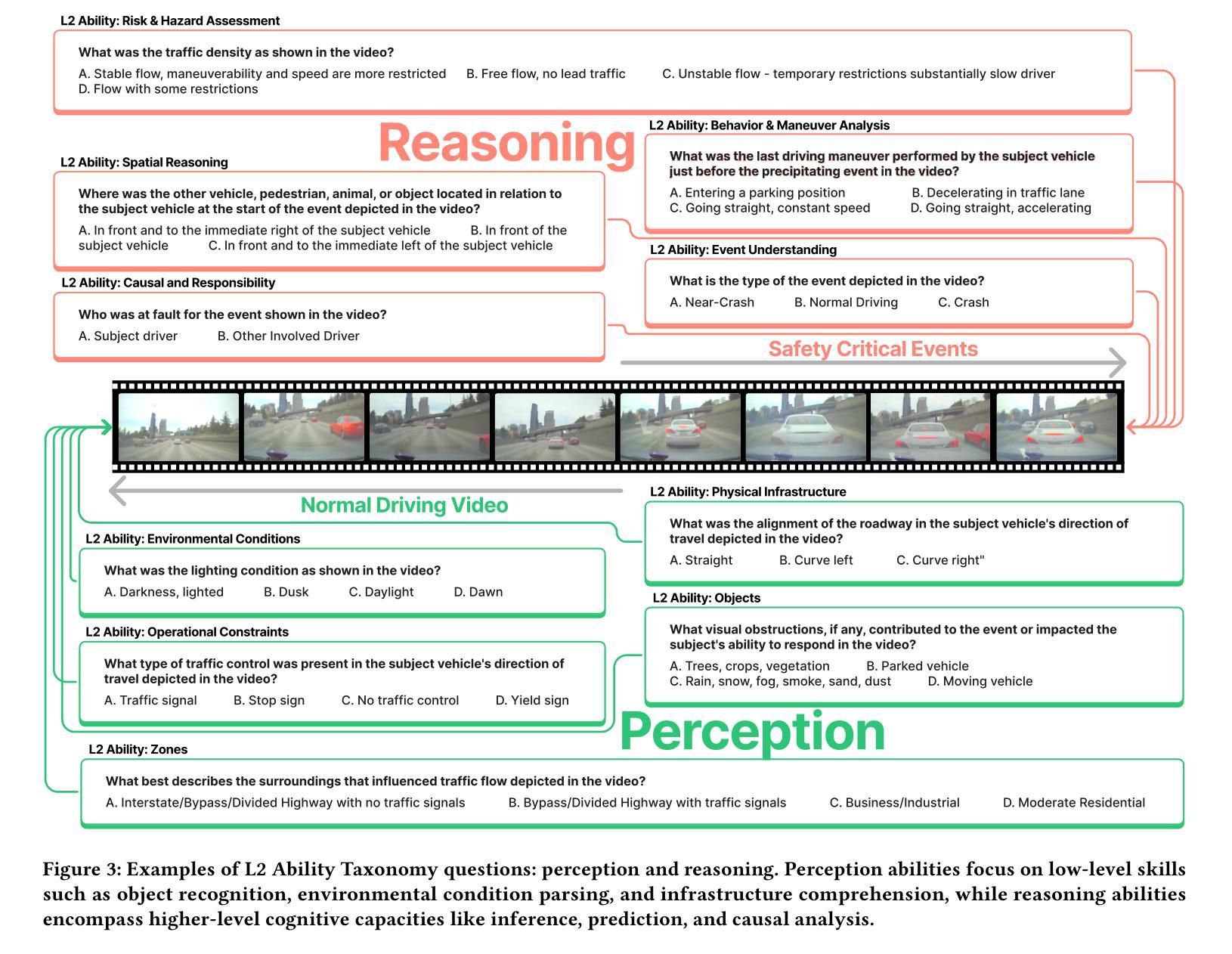
Are Vision LLMs Road-Ready? A Comprehensive Benchmark for Safety-Critical Driving Video Understanding
Authors:Tong Zeng, Longfeng Wu, Liang Shi, Dawei Zhou, Feng Guo
Vision Large Language Models (VLLMs) have demonstrated impressive capabilities in general visual tasks such as image captioning and visual question answering. However, their effectiveness in specialized, safety-critical domains like autonomous driving remains largely unexplored. Autonomous driving systems require sophisticated scene understanding in complex environments, yet existing multimodal benchmarks primarily focus on normal driving conditions, failing to adequately assess VLLMs’ performance in safety-critical scenarios. To address this, we introduce DVBench, a pioneering benchmark designed to evaluate the performance of VLLMs in understanding safety-critical driving videos. Built around a hierarchical ability taxonomy that aligns with widely adopted frameworks for describing driving scenarios used in assessing highly automated driving systems, DVBench features 10,000 multiple-choice questions with human-annotated ground-truth answers, enabling a comprehensive evaluation of VLLMs’ capabilities in perception and reasoning. Experiments on 14 SOTA VLLMs, ranging from 0.5B to 72B parameters, reveal significant performance gaps, with no model achieving over 40% accuracy, highlighting critical limitations in understanding complex driving scenarios. To probe adaptability, we fine-tuned selected models using domain-specific data from DVBench, achieving accuracy gains ranging from 5.24 to 10.94 percentage points, with relative improvements of up to 43.59%. This improvement underscores the necessity of targeted adaptation to bridge the gap between general-purpose VLLMs and mission-critical driving applications. DVBench establishes an essential evaluation framework and research roadmap for developing VLLMs that meet the safety and robustness requirements for real-world autonomous systems. We released the benchmark toolbox and the fine-tuned model at: https://github.com/tong-zeng/DVBench.git.
视觉大型语言模型(VLLMs)在一般的视觉任务,如图片描述和视觉问答中,已经表现出了令人印象深刻的能力。然而,它们在特定领域,如自动驾驶中的效果仍尚未得到广泛探索。自动驾驶系统需要在复杂环境中进行精细的场景理解,但现有的多模式基准测试主要侧重于正常驾驶条件,无法充分评估VLLMs在关键安全场景中的性能。为了解决这个问题,我们引入了DVBench,这是一个先锋基准测试,旨在评估VLLMs在理解关键安全驾驶视频方面的性能。DVBench围绕着一个与广泛采用的自动驾驶系统评估框架相一致的分层能力分类表而建立,包含1万道选择题和经过人工注释的标准答案,能够全面评估VLLMs在感知和推理方面的能力。对14个最新前沿的VLLM的实验,参数范围从0.5B到72B,显示出明显的性能差距,没有任何模型的准确率超过40%,这突显了在理解复杂驾驶场景方面的关键局限性。为了测试适应性,我们利用DVBench的特定领域数据对选定模型进行了微调,准确率提高了5.24至10.94个百分点,相对改进幅度高达43.59%。这种改进突显了针对特定任务进行适应调整的必要性,以弥合通用VLLM与关键任务驾驶应用之间的鸿沟。DVBench为开发满足现实世界自动驾驶系统安全和稳健性要求的VLLM建立了重要的评估框架和研究路线图。我们已在https://github.com/tong-zeng/DVBench.git上发布了基准测试工具箱和微调模型。
论文及项目相关链接
Summary
VLLM在通用视觉任务中表现出色,但在自动驾驶等安全关键领域的应用尚待探索。为评估VLLM在理解安全关键驾驶视频方面的性能,推出DVBench基准测试。该测试围绕层次化的能力分类体系构建,与评估高度自动化驾驶系统的驾驶场景描述框架相一致。DVBench包含1万个带有人类注释答案的选择题,全面评估VLLM在感知和推理方面的能力。实验表明,各模型之间存在显著性能差距,没有任何模型的准确率超过40%,凸显了在理解复杂驾驶场景方面的局限性。通过对选定模型进行微调,准确率提高了5.24至10.94个百分点,相对改进幅度高达43.59%。这表明有针对性的适应是缩小通用VLLM与关键任务驾驶应用之间差距的必要手段。DVBench为开发满足现实世界自动驾驶系统安全和稳健性要求的VLLM提供了重要的评估框架和研究路线图。
Key Takeaways
- VLLM在通用视觉任务上表现良好,但在安全关键的自动驾驶领域应用尚待探索。
- DVBench基准测试用于评估VLLM在理解安全关键驾驶视频方面的性能。
- DVBench包含1万个选择题,全面评估VLLM的感知和推理能力。
- 实验显示,现有VLLM在理解复杂驾驶场景方面存在局限性,准确率普遍较低。
- 通过模型微调,可以显著提高VLLM在DVBench上的准确率。
- 有针对性的适应是缩小通用VLLM与关键任务驾驶应用之间差距的关键。
点此查看论文截图



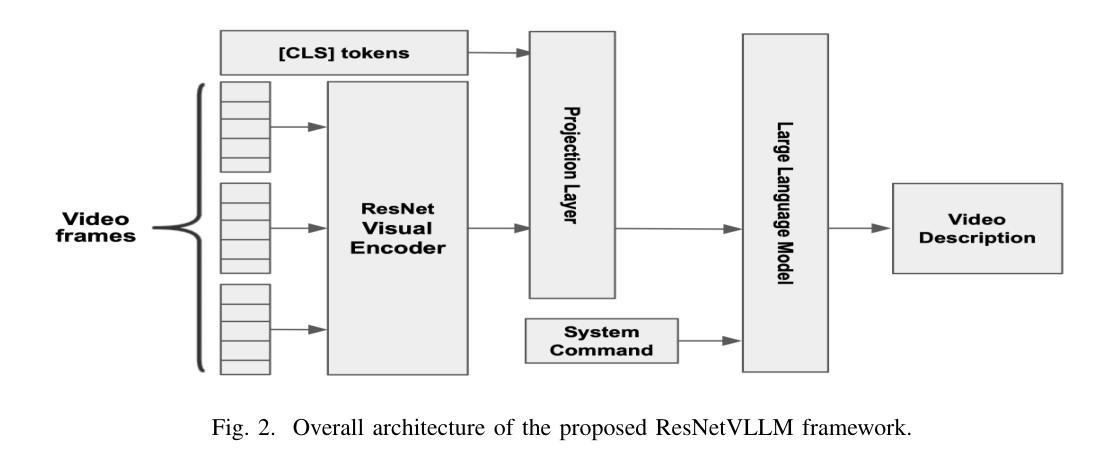
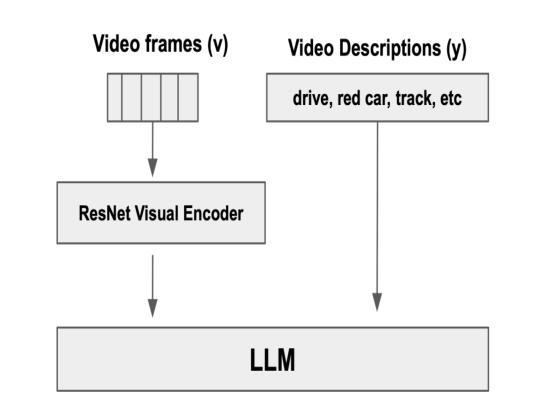
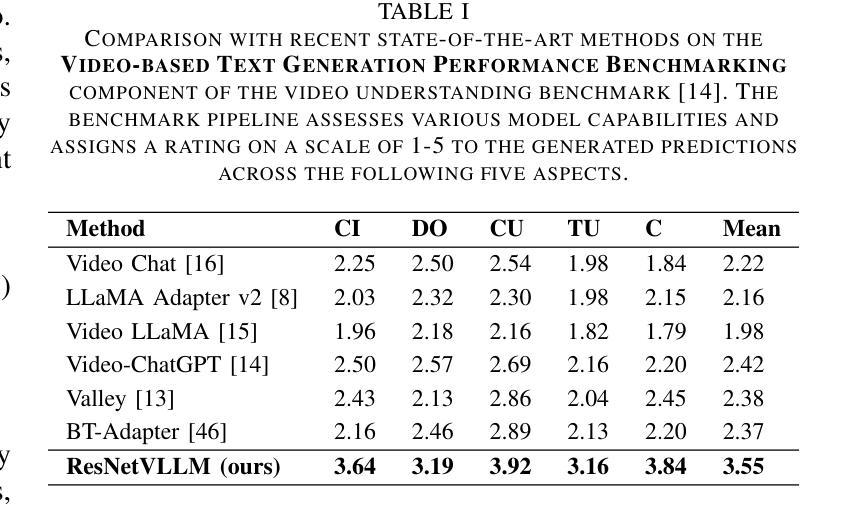
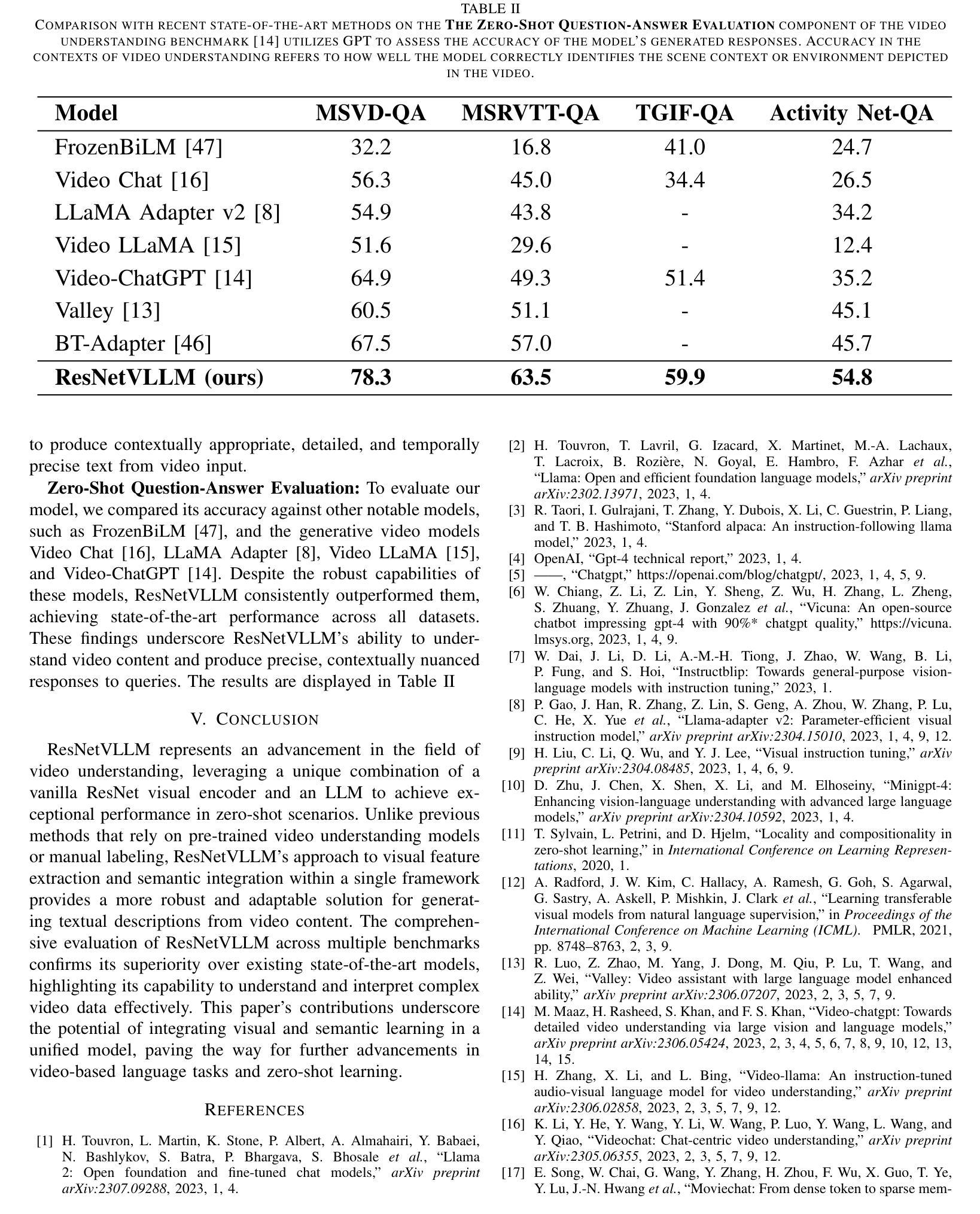
ResNetVLLM – Multi-modal Vision LLM for the Video Understanding Task
Authors:Ahmad Khalil, Mahmoud Khalil, Alioune Ngom
In this paper, we introduce ResNetVLLM (ResNet Vision LLM), a novel cross-modal framework for zero-shot video understanding that integrates a ResNet-based visual encoder with a Large Language Model (LLM. ResNetVLLM addresses the challenges associated with zero-shot video models by avoiding reliance on pre-trained video understanding models and instead employing a non-pretrained ResNet to extract visual features. This design ensures the model learns visual and semantic representations within a unified architecture, enhancing its ability to generate accurate and contextually relevant textual descriptions from video inputs. Our experimental results demonstrate that ResNetVLLM achieves state-of-the-art performance in zero-shot video understanding (ZSVU) on several benchmarks, including MSRVTT-QA, MSVD-QA, TGIF-QA FrameQA, and ActivityNet-QA.
在本文中,我们介绍了ResNetVLLM(ResNet视觉LLM),这是一种用于零样本视频理解的新型跨模式框架,它将基于ResNet的视觉编码器与大型语言模型(LLM)相结合。ResNetVLLM通过避免依赖预训练的视频理解模型,而采用非预训练的ResNet来提取视觉特征,解决了与零样本视频模型相关的问题。这种设计确保模型在统一架构中学习视觉和语义表示,提高其从视频输入生成准确且上下文相关的文本描述的能力。我们的实验结果表明,ResNetVLLM在多个基准测试上实现了零样本视频理解的最新性能,包括MSRVTT-QA、MSVD-QA、TGIF-QA FrameQA和ActivityNet-QA。
论文及项目相关链接
Summary
ResNetVLLM是一种新型跨模态零视频理解框架,它结合了ResNet视觉编码器和大语言模型(LLM)。该设计避免了依赖预训练的视频理解模型,采用非预训练的ResNet提取视觉特征,确保在统一架构中学习视觉和语义表示,提高从视频输入生成准确和上下文相关的文本描述的能力。实验结果表明,ResNetVLLM在多个基准测试中实现了零视频理解的最新性能。
Key Takeaways
- ResNetVLLM是一个跨模态框架,用于零视频理解。
- 它结合了ResNet视觉编码器和大语言模型(LLM)。
- ResNetVLLM避免依赖预训练的视频理解模型。
- 采用非预训练的ResNet提取视觉特征。
- 该设计确保在统一架构中学习视觉和语义表示。
- ResNetVLLM能生成准确和上下文相关的文本描述。
点此查看论文截图

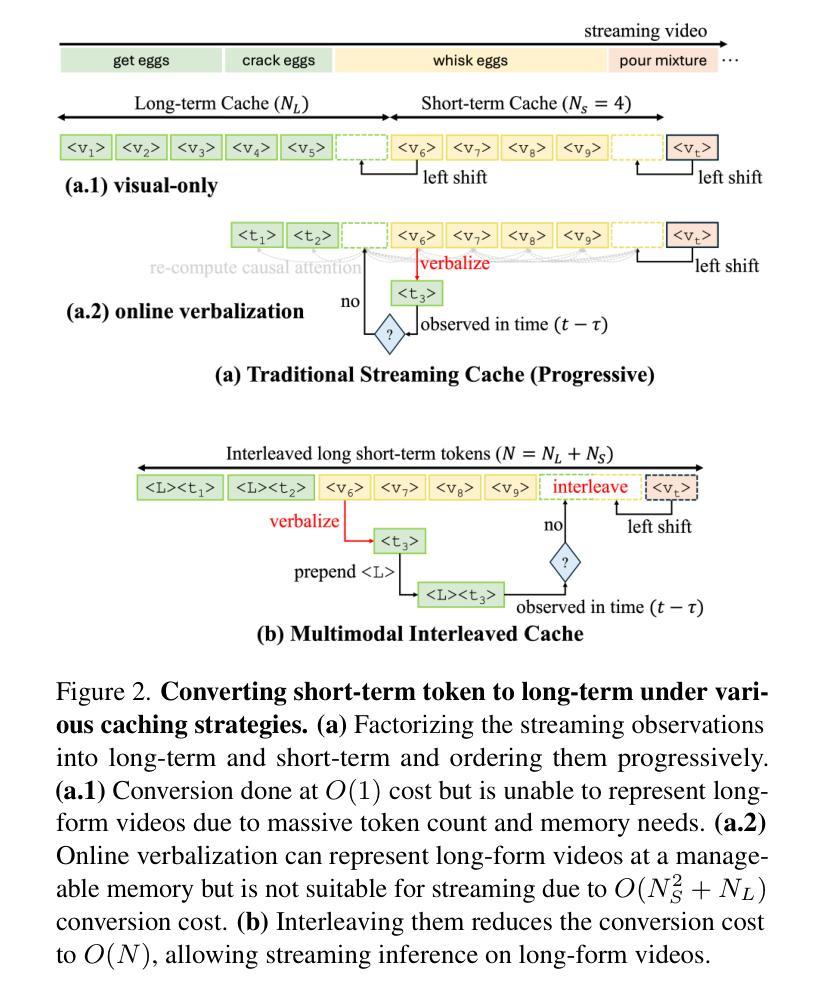
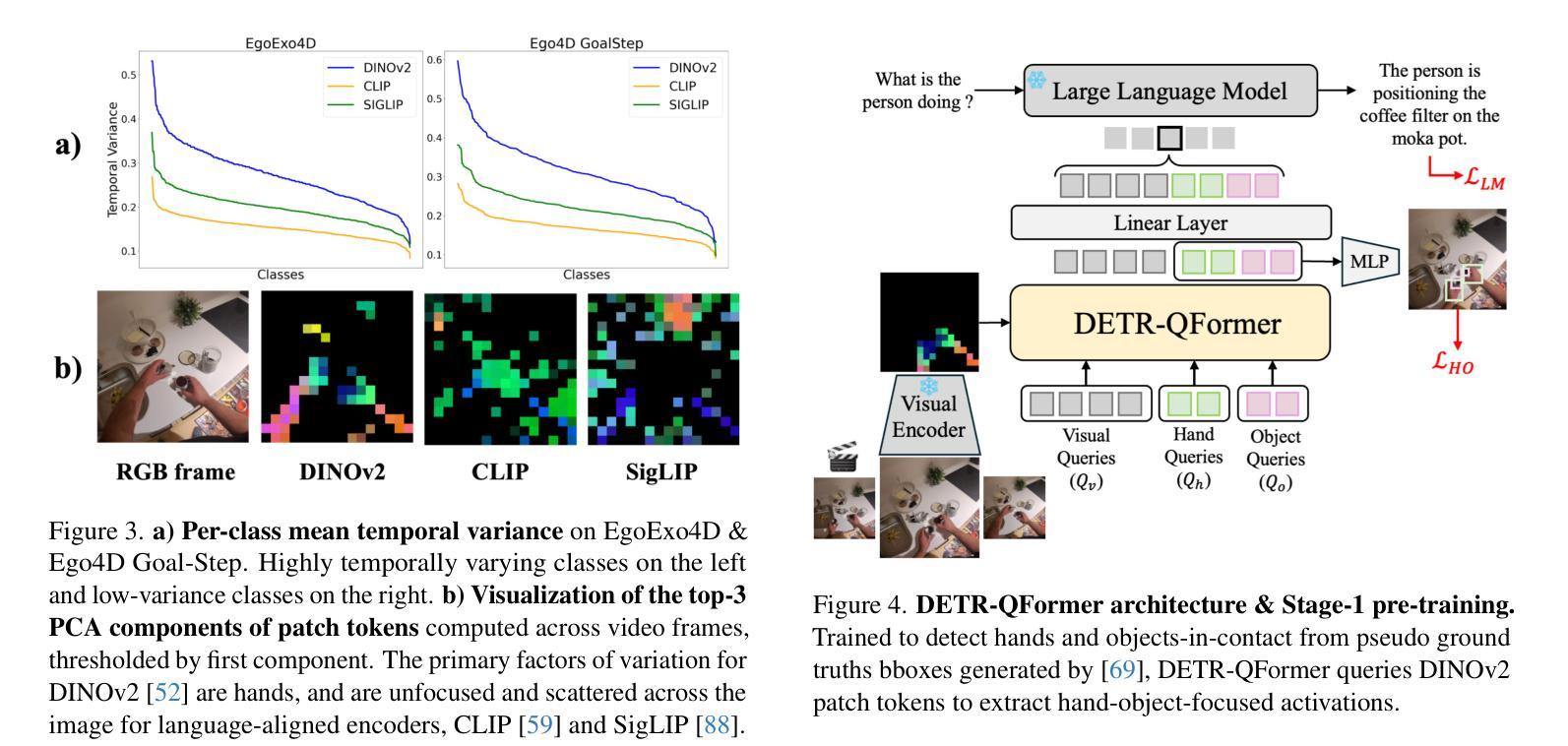
Memory-efficient Streaming VideoLLMs for Real-time Procedural Video Understanding
Authors:Dibyadip Chatterjee, Edoardo Remelli, Yale Song, Bugra Tekin, Abhay Mittal, Bharat Bhatnagar, Necati Cihan Camgöz, Shreyas Hampali, Eric Sauser, Shugao Ma, Angela Yao, Fadime Sener
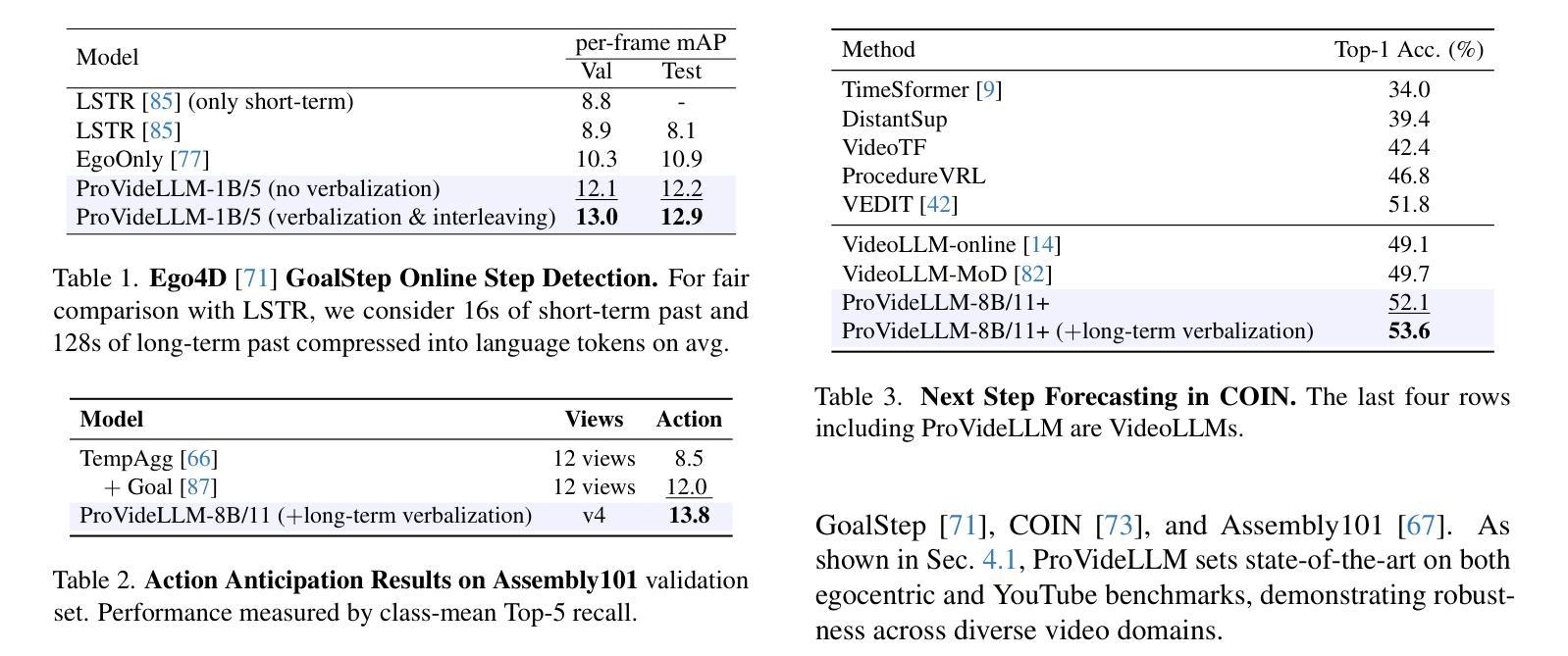
We introduce ProVideLLM, an end-to-end framework for real-time procedural video understanding. ProVideLLM integrates a multimodal cache configured to store two types of tokens - verbalized text tokens, which provide compressed textual summaries of long-term observations, and visual tokens, encoded with DETR-QFormer to capture fine-grained details from short-term observations. This design reduces token count by 22x over existing methods in representing one hour of long-term observations while effectively encoding fine-granularity of the present. By interleaving these tokens in our multimodal cache, ProVideLLM ensures sub-linear scaling of memory and compute with video length, enabling per-frame streaming inference at 10 FPS and streaming dialogue at 25 FPS, with a minimal 2GB GPU memory footprint. ProVideLLM also sets new state-of-the-art results on six procedural tasks across four datasets.
我们介绍了ProVideLLM,这是一个用于实时过程性视频理解的端到端框架。ProVideLLM集成了一个多模态缓存,配置为存储两种类型的标记:文本标记,提供长期观察的压缩文本摘要;视觉标记,使用DETR-QFormer进行编码,以捕捉短期观察的精细细节。这种设计在表示一个小时的长期观察时,将标记数量减少到现有方法的22倍,同时有效地编码当前时间的精细粒度。通过在我们的多模态缓存中交错这些标记,ProVideLLM确保了内存和计算随视频长度的次线性扩展,实现了每秒10帧的逐帧流式推断和每秒25帧的流式对话,GPU内存占用最小为2GB。此外,ProVideLLM在四个数据集的六个过程任务上达到了最新结果。
论文及项目相关链接
PDF 13 pages, 5 figures; https://dibschat.github.io/ProVideLLM
摘要
ProVideLLM是一个用于实时过程视频理解的端到端框架。它通过多模态缓存整合,存储两种类型的令牌:文字令牌和视觉令牌。文字令牌提供长期观察的缩写文本摘要,而视觉令牌使用DETR-QFormer进行编码,捕捉短期观察的精细细节。这种设计在代表一小时的长期观察时,将令牌计数减少了22倍,同时有效地编码了当前的精细粒度。通过在我们的多模态缓存中交替使用这些令牌,ProVideLLM确保了内存和计算随视频长度的次线性扩展,实现在10 FPS的每帧流式推理和25 FPS的流式对话,只需最小的2GB GPU内存占用。此外,ProVideLLM在四个数据集的六个过程任务上取得了最新的最佳结果。
关键见解
- ProVideLLM是一个用于实时过程视频理解的端到端框架。
- 它通过多模态缓存整合存储两种类型的令牌:文字令牌和视觉令牌。
- 文字令牌提供长期观察的缩写文本摘要。
- 视觉令牌使用DETR-QFormer编码,以捕捉短期观察的精细细节。
- 该设计大幅减少了代表长期观察的令牌计数。
- ProVideLLM实现了每帧流式推理和流式对话的高帧率。
点此查看论文截图



PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Authors:Henghui Ding, Chang Liu, Nikhila Ravi, Shuting He, Yunchao Wei, Song Bai, Philip Torr, Kehuan Song, Xinglin Xie, Kexin Zhang, Licheng Jiao, Lingling Li, Shuyuan Yang, Xuqiang Cao, Linnan Zhao, Jiaxuan Zhao, Fang Liu, Mengjiao Wang, Junpei Zhang, Xu Liu, Yuting Yang, Mengru Ma, Hao Fang, Runmin Cong, Xiankai Lu, Zhiyang Chen, Wei Zhang, Tianming Liang, Haichao Jiang, Wei-Shi Zheng, Jian-Fang Hu, Haobo Yuan, Xiangtai Li, Tao Zhang, Lu Qi, Ming-Hsuan Yang
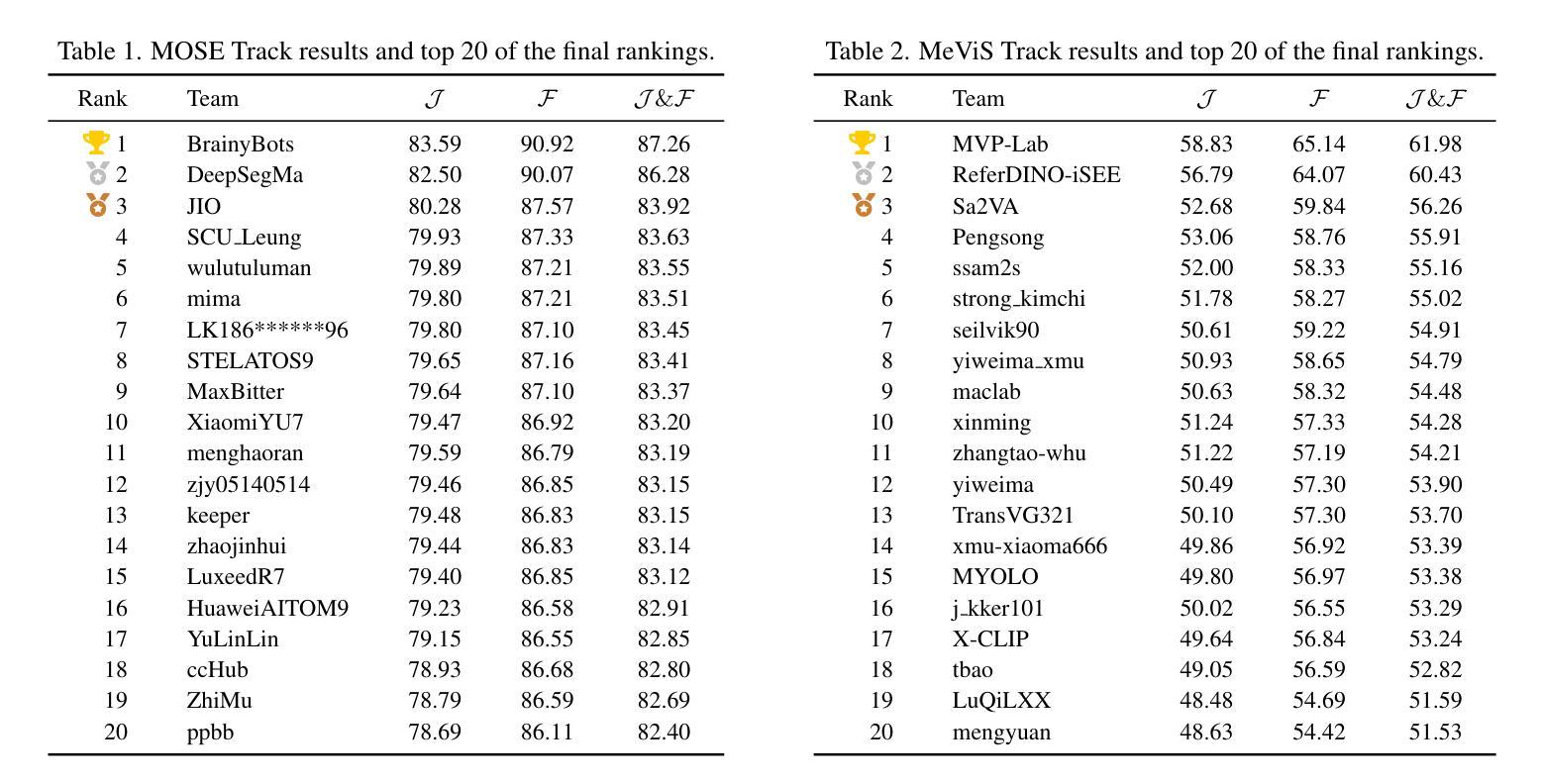
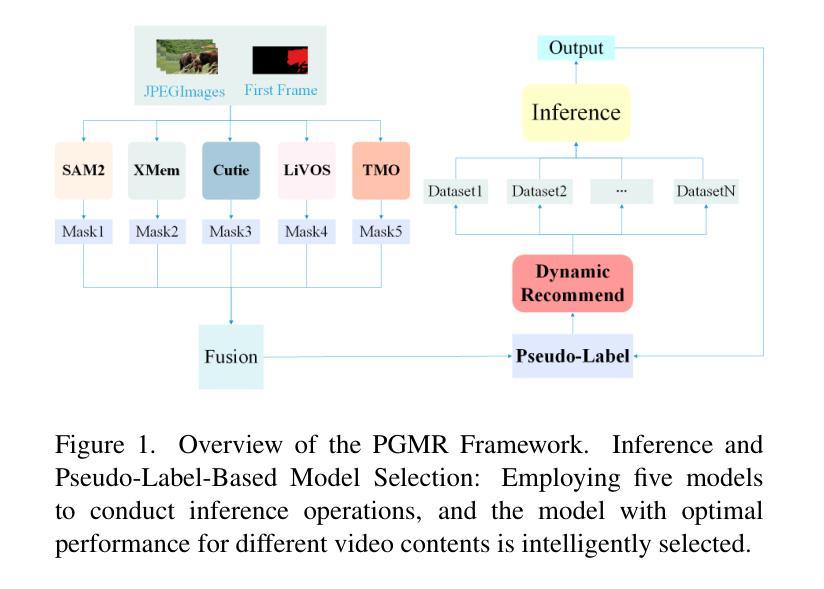
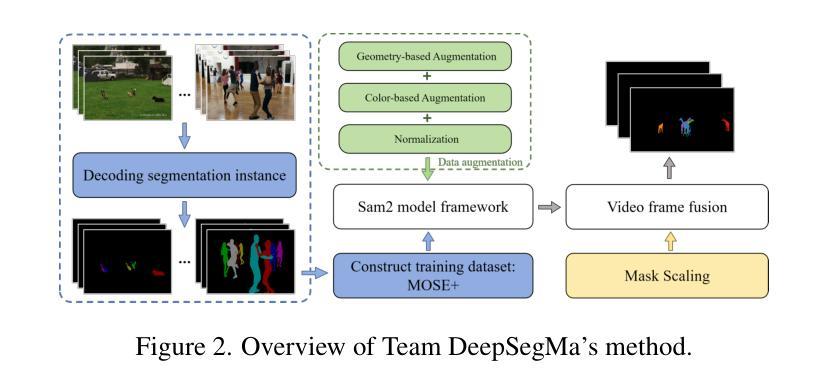
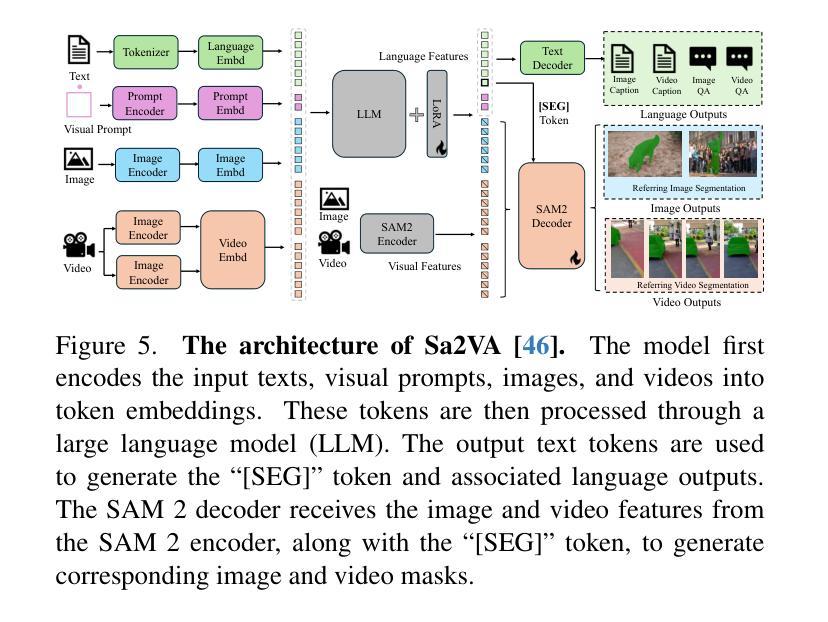
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
本报告全面概述了与CVPR 2025联合举办的第四届像素级野外视频理解(PVUW)挑战。它总结了挑战结果、参与方法和未来研究方向。该挑战有两个赛道:MOSE,专注于复杂场景视频对象分割;MeVis,针对运动引导、基于语言的视频分割。这两个赛道都推出了新的更具挑战性的数据集,以更好地反映真实场景。通过详细的评估和分析,该挑战对复杂视频分割的当前最新技术和新兴趋势提供了宝贵的见解。更多信息可在研讨会网站上找到:https://pvuw.github.io/。
论文及项目相关链接
PDF Workshop Page: https://pvuw.github.io/. arXiv admin note: text overlap with arXiv:2504.00476, arXiv:2504.05178
Summary:本报告介绍了与CVPR 2025联合举办的第四届像素级视频理解挑战赛(PVUW)。总结了挑战结果、参与方法论和未来研究方向。该挑战包含两个赛道:专注于复杂场景视频对象分割的MOSE,以及针对运动引导的语言基础视频分割的MeViS。两个赛道都推出了新的更具挑战性的数据集,以更好地反映真实场景。通过对挑战进行详细的评估和分析,为复杂视频分割领域的最新技术和新兴趋势提供了宝贵的见解。更多信息请参见研讨会网站。
Key Takeaways:
- 第四届像素级视频理解挑战赛(PVUW)于CVPR 2025期间举办,总结了挑战结果和未来的研究方向。
- 挑战包含两个赛道:MOSE和MeViS,分别专注于复杂场景视频对象分割和运动引导的语言基础视频分割。
- 两个赛道都推出了新的数据集,旨在更好地反映真实场景情况。
- PVUW挑战提供了对复杂视频分割领域的最新技术和新兴趋势的深入了解。
- 挑战的结果展示了参赛方法之间的比较和分析。
- 工作坊网站提供了更多关于PVUW挑战的信息和资源。
点此查看论文截图