⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-23 更新
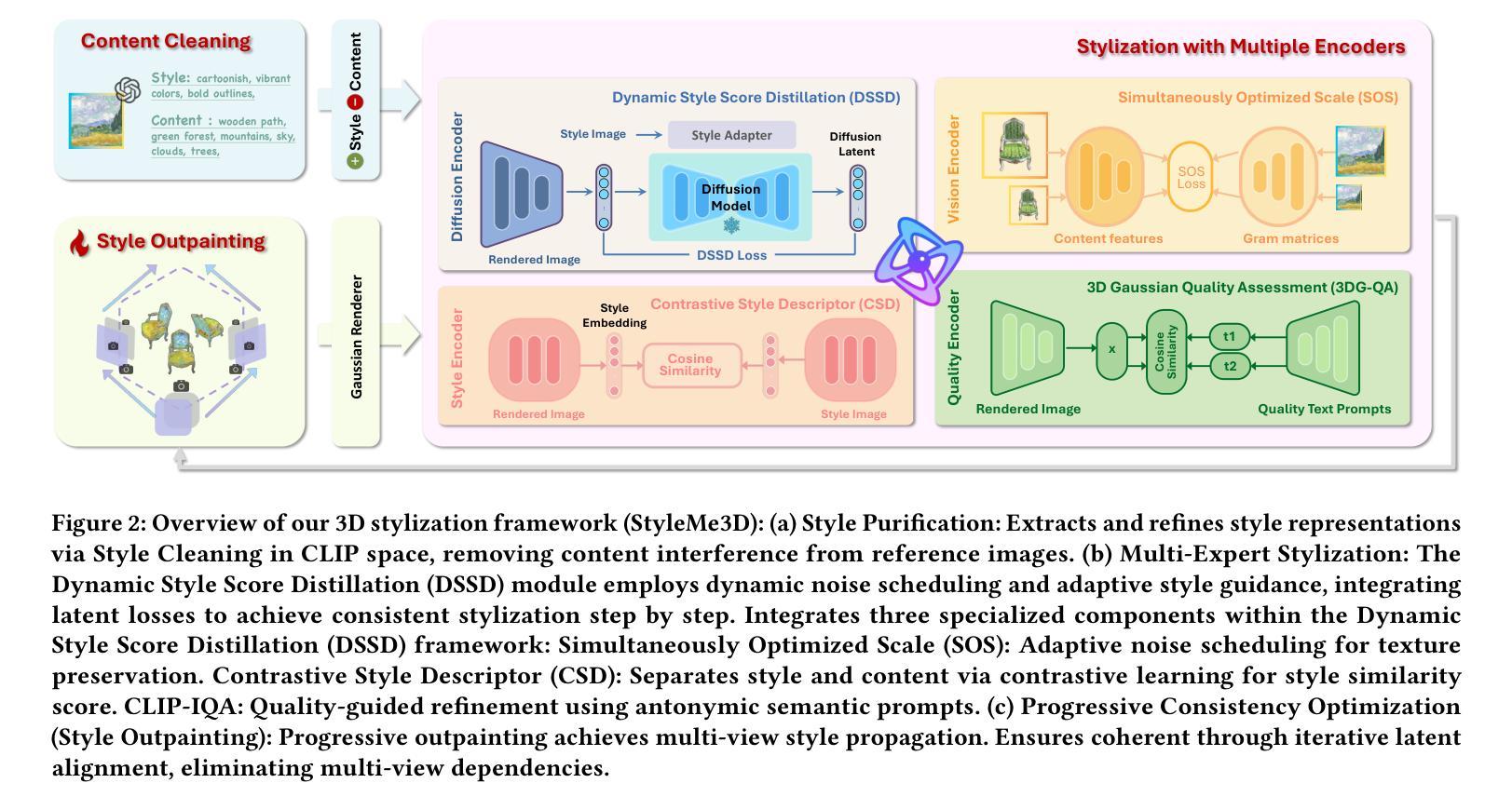
StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Authors:Cailin Zhuang, Yaoqi Hu, Xuanyang Zhang, Wei Cheng, Jiacheng Bao, Shengqi Liu, Yiying Yang, Xianfang Zeng, Gang Yu, Ming Li
3D Gaussian Splatting (3DGS) excels in photorealistic scene reconstruction but struggles with stylized scenarios (e.g., cartoons, games) due to fragmented textures, semantic misalignment, and limited adaptability to abstract aesthetics. We propose StyleMe3D, a holistic framework for 3D GS style transfer that integrates multi-modal style conditioning, multi-level semantic alignment, and perceptual quality enhancement. Our key insights include: (1) optimizing only RGB attributes preserves geometric integrity during stylization; (2) disentangling low-, medium-, and high-level semantics is critical for coherent style transfer; (3) scalability across isolated objects and complex scenes is essential for practical deployment. StyleMe3D introduces four novel components: Dynamic Style Score Distillation (DSSD), leveraging Stable Diffusion’s latent space for semantic alignment; Contrastive Style Descriptor (CSD) for localized, content-aware texture transfer; Simultaneously Optimized Scale (SOS) to decouple style details and structural coherence; and 3D Gaussian Quality Assessment (3DG-QA), a differentiable aesthetic prior trained on human-rated data to suppress artifacts and enhance visual harmony. Evaluated on NeRF synthetic dataset (objects) and tandt db (scenes) datasets, StyleMe3D outperforms state-of-the-art methods in preserving geometric details (e.g., carvings on sculptures) and ensuring stylistic consistency across scenes (e.g., coherent lighting in landscapes), while maintaining real-time rendering. This work bridges photorealistic 3D GS and artistic stylization, unlocking applications in gaming, virtual worlds, and digital art.
3D高斯展开(3DGS)在真实感场景重建方面表现出色,但在风格化场景(如卡通、游戏)方面却遇到困难,原因在于纹理碎片化、语义不匹配以及对抽象美学的适应性有限。我们提出StyleMe3D,这是一个用于3D GS风格转换的整体框架,它集成了多模式风格条件、多级语义对齐和感知质量增强。我们的关键见解包括:(1)仅优化RGB属性可以在风格化过程中保持几何完整性;(2)分离低、中、高级语义对于连贯的风格转换至关重要;(3)在孤立对象和复杂场景之间的可扩展性对于实际部署至关重要。StyleMe3D引入了四个新颖组件:动态风格分数蒸馏(DSSD),利用Stable Diffusion的潜在空间进行语义对齐;对比风格描述符(CSD)用于局部、内容感知的纹理传输;同时优化比例(SOS)以解开风格细节和结构连贯性;以及3D高斯质量评估(3DG-QA),这是一个基于人类评分数据训练的可区分美学先验,用于抑制伪影并增强视觉和谐。在NeRF合成数据集(对象)和tandt db(场景)数据集上进行的评估表明,StyleMe3D在保持几何细节(如雕塑上的雕刻)和确保场景之间的风格一致性(如景观中的一致照明)方面优于现有技术,同时保持实时渲染。这项工作架起了真实感3D GS和艺术风格化之间的桥梁,为游戏、虚拟世界和数字艺术等领域解锁了应用。
论文及项目相关链接
PDF 16 pages; Project page: https://styleme3d.github.io/
Summary
本文介绍了StyleMe3D框架,该框架针对3D Gaussian Splatting在风格化场景(如卡通、游戏)中的不足,提供了全面的解决方案。该框架融合了多模态风格条件、多级别语义对齐和感知质量增强等关键技术。其核心思想包括优化RGB属性以保留几何完整性,以及解耦不同级别的语义以实现连贯的风格转换。StyleMe3D的四大新组件分别是动态风格得分蒸馏(DSSD)、对比风格描述符(CSD)、同步优化尺度(SOS)和3D高斯质量评估(3DG-QA)。该框架在NeRF合成数据集和tandt db场景数据集上的表现优异,不仅能保留几何细节,还能确保场景的视觉和谐与连贯性。此外,它还具备实时渲染能力,可应用于游戏、虚拟世界和数字艺术等领域。
Key Takeaways
- StyleMe3D是一个用于3D Gaussian Splatting风格转换的框架,旨在解决其在风格化场景中的不足。
- 该框架通过优化RGB属性来保留几何完整性,强调解耦不同级别的语义以实现连贯的风格转换。
- StyleMe3D包含四大新组件:DSSD、CSD、SOS和3DG-QA,分别负责不同的功能,如风格得分的蒸馏、对比风格描述符的生成等。
点此查看论文截图


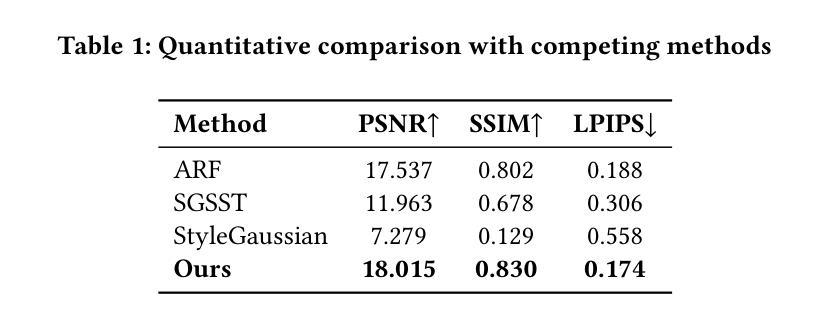
MoBGS: Motion Deblurring Dynamic 3D Gaussian Splatting for Blurry Monocular Video
Authors:Minh-Quan Viet Bui, Jongmin Park, Juan Luis Gonzalez Bello, Jaeho Moon, Jihyong Oh, Munchurl Kim
We present MoBGS, a novel deblurring dynamic 3D Gaussian Splatting (3DGS) framework capable of reconstructing sharp and high-quality novel spatio-temporal views from blurry monocular videos in an end-to-end manner. Existing dynamic novel view synthesis (NVS) methods are highly sensitive to motion blur in casually captured videos, resulting in significant degradation of rendering quality. While recent approaches address motion-blurred inputs for NVS, they primarily focus on static scene reconstruction and lack dedicated motion modeling for dynamic objects. To overcome these limitations, our MoBGS introduces a novel Blur-adaptive Latent Camera Estimation (BLCE) method for effective latent camera trajectory estimation, improving global camera motion deblurring. In addition, we propose a physically-inspired Latent Camera-induced Exposure Estimation (LCEE) method to ensure consistent deblurring of both global camera and local object motion. Our MoBGS framework ensures the temporal consistency of unseen latent timestamps and robust motion decomposition of static and dynamic regions. Extensive experiments on the Stereo Blur dataset and real-world blurry videos show that our MoBGS significantly outperforms the very recent advanced methods (DyBluRF and Deblur4DGS), achieving state-of-the-art performance for dynamic NVS under motion blur.
我们提出了MoBGS,这是一种新型的去模糊动态三维高斯喷溅(3DGS)框架,能够以端到端的方式从模糊的单目视频中重建清晰、高质量的新时空视图。现有的动态新视图合成(NVS)方法对于随意拍摄的视频中的运动模糊非常敏感,导致渲染质量显著下降。虽然最近的方法解决了运动模糊输入对于NVS的问题,但它们主要关注静态场景的重建,缺乏针对动态对象的专用运动建模。为了克服这些局限性,我们的MoBGS引入了一种新颖的模糊自适应潜在相机估计(BLCE)方法,用于有效地估计潜在相机轨迹,改进全局相机运动去模糊。此外,我们提出了一种受物理启发的潜在相机诱导曝光估计(LCEE)方法,以确保全局相机和局部对象运动的持续去模糊。我们的MoBGS框架确保了未见潜在时间戳的时空一致性以及静态和动态区域的稳健运动分解。在立体模糊数据集和真实世界的模糊视频上的大量实验表明,我们的MoBGS显著优于最近的高级方法(DyBluRF和Deblur4DGS),在运动模糊的动态NVS中实现了最先进的性能。
论文及项目相关链接
PDF The first two authors contributed equally to this work (equal contribution). The last two authors advised equally to this work
摘要
提出一种新型动态3D高斯展开(MoBGS)框架,能够从模糊的单目视频中重建清晰、高质量的新时空视图。现有动态新视图合成(NVS)方法对运动模糊敏感,导致渲染质量下降。MoBGS引入了一种新颖的模糊自适应潜在相机估计(BLCE)方法,用于有效的潜在相机轨迹估计,并改进全局相机运动去模糊。此外,我们还提出了一种受物理启发的潜在相机诱导曝光估计(LCEE)方法,以确保全局相机和局部对象运动的持续去模糊。MoBGS框架确保未见潜在时间戳的时空一致性以及静态和动态区域的稳健运动分解。在立体模糊数据集和真实世界模糊视频上的大量实验表明,MoBGS显著优于最近的高级方法(DyBluRF和Deblur4DGS),在运动模糊情况下实现动态NVS的卓越性能。
要点
- MoBGS是一个新型动态3D高斯展布框架,可从模糊的单目视频中重建清晰的高质量时空视图。
- 现有动态NVS方法对运动模糊敏感,导致渲染质量下降。
- MoBGS引入BLCE方法,有效估计潜在相机轨迹并改进全局相机运动去模糊。
- LCEE方法确保全局和局部运动的持续去模糊。
- MoBGS框架具有时空一致性,可稳健地分解静态和动态区域。
- 在多个数据集上的实验表明,MoBGS显著优于其他方法,具有卓越性能。
- MoBGS框架特别适用于处理包含运动模糊的动态场景。
点此查看论文截图

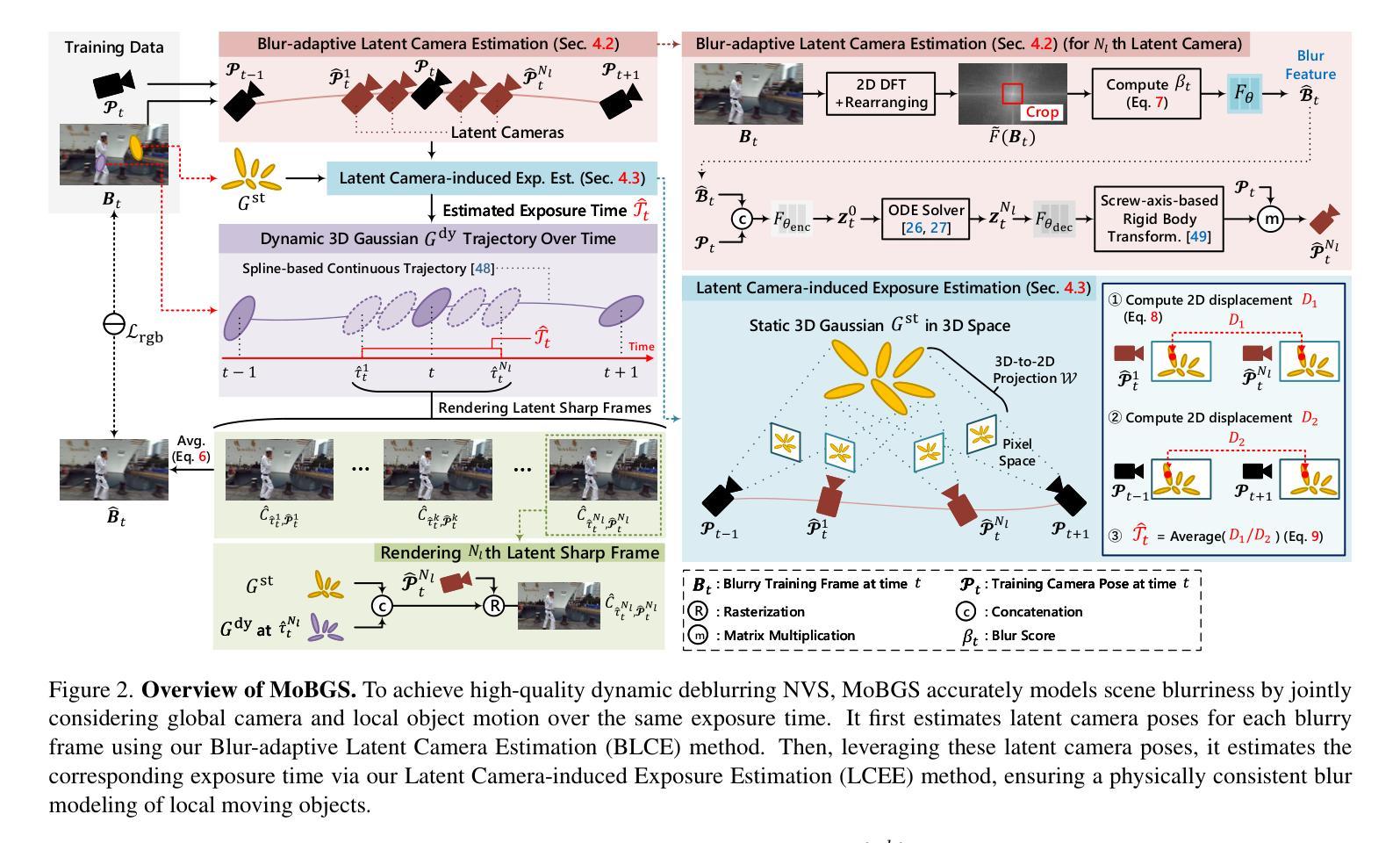
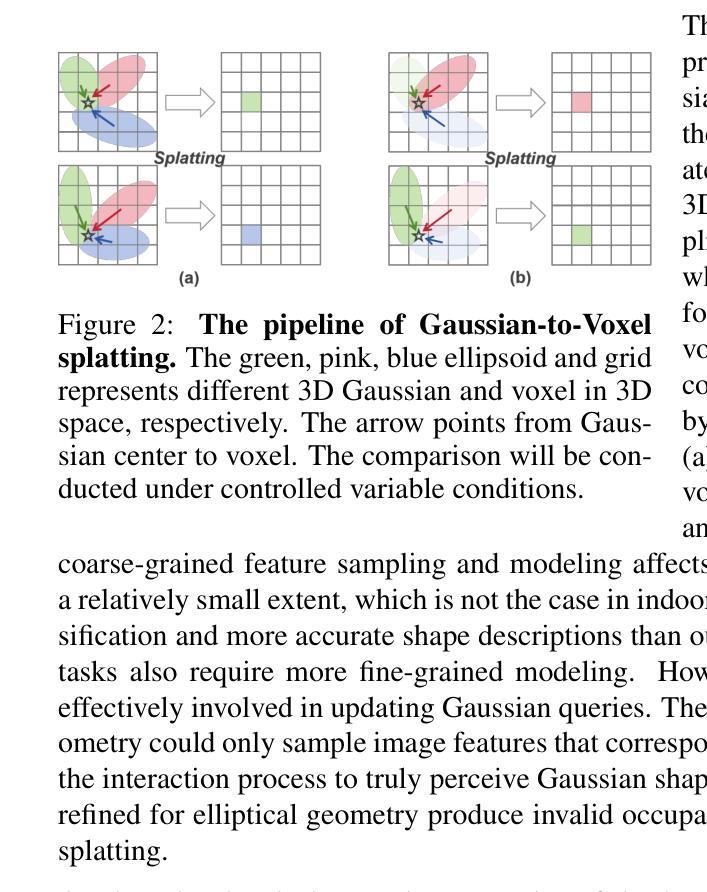
RoboOcc: Enhancing the Geometric and Semantic Scene Understanding for Robots
Authors:Zhang Zhang, Qiang Zhang, Wei Cui, Shuai Shi, Yijie Guo, Gang Han, Wen Zhao, Hengle Ren, Renjing Xu, Jian Tang
3D occupancy prediction enables the robots to obtain spatial fine-grained geometry and semantics of the surrounding scene, and has become an essential task for embodied perception. Existing methods based on 3D Gaussians instead of dense voxels do not effectively exploit the geometry and opacity properties of Gaussians, which limits the network’s estimation of complex environments and also limits the description of the scene by 3D Gaussians. In this paper, we propose a 3D occupancy prediction method which enhances the geometric and semantic scene understanding for robots, dubbed RoboOcc. It utilizes the Opacity-guided Self-Encoder (OSE) to alleviate the semantic ambiguity of overlapping Gaussians and the Geometry-aware Cross-Encoder (GCE) to accomplish the fine-grained geometric modeling of the surrounding scene. We conduct extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet datasets, and our RoboOcc achieves state-of the-art performance in both local and global camera settings. Further, in ablation studies of Gaussian parameters, the proposed RoboOcc outperforms the state-of-the-art methods by a large margin of (8.47, 6.27) in IoU and mIoU metric, respectively. The codes will be released soon.
3D占用预测使机器人能够获得周围场景的精细几何和语义信息,已成为体感感知的重要任务。现有方法基于3D高斯分布而非密集体素,未能有效利用高斯分布的几何和透明度属性,这限制了网络对复杂环境的估算以及对场景的描述。在本文中,我们提出了一种名为RoboOcc的机器人三维占用预测方法,旨在增强机器人的几何和语义场景理解。该方法利用透明度引导自编码器(OSE)缓解重叠高斯分布的语义模糊问题,并利用几何感知交叉编码器(GCE)完成周围场景的精细几何建模。我们在Occ-ScanNet和EmbodiedOcc-ScanNet数据集上进行了大量实验,RoboOcc在局部和全局相机设置中均达到了最先进的性能。此外,在高斯参数消融研究中,RoboOcc在IoU和mIoU指标上大大超越了现有技术(分别为8.47和6.27)。代码将很快发布。
论文及项目相关链接
Summary
该文提出了一种名为RoboOcc的3D占用预测方法,通过利用Opacity-guided Self-Encoder(OSE)解决重叠高斯值的语义模糊问题,并利用Geometry-aware Cross-Encoder(GCE)完成场景的精细几何建模,提升了机器人在三维空间中的场景理解与语义感知,且在多个数据集上达到了先进的性能表现。
Key Takeaways
- 3D占用预测对机器人周围场景的精细几何和语义理解至关重要。
- 现有方法基于3D高斯的方法未能有效利用几何和透明度特性,限制了复杂环境的估计和场景描述。
- RoboOcc方法通过Opacity-guided Self-Encoder (OSE) 减轻重叠高斯值的语义模糊问题。
- Geometry-aware Cross-Encoder (GCE) 用于完成场景的精细几何建模。
- 在多个数据集上,RoboOcc达到了先进的性能表现,并在高斯参数消融研究中大幅超越了现有方法。
- RoboOcc的IoU和mIoU指标优于其他方法,具体优势为(8.47,6.27)。
点此查看论文截图

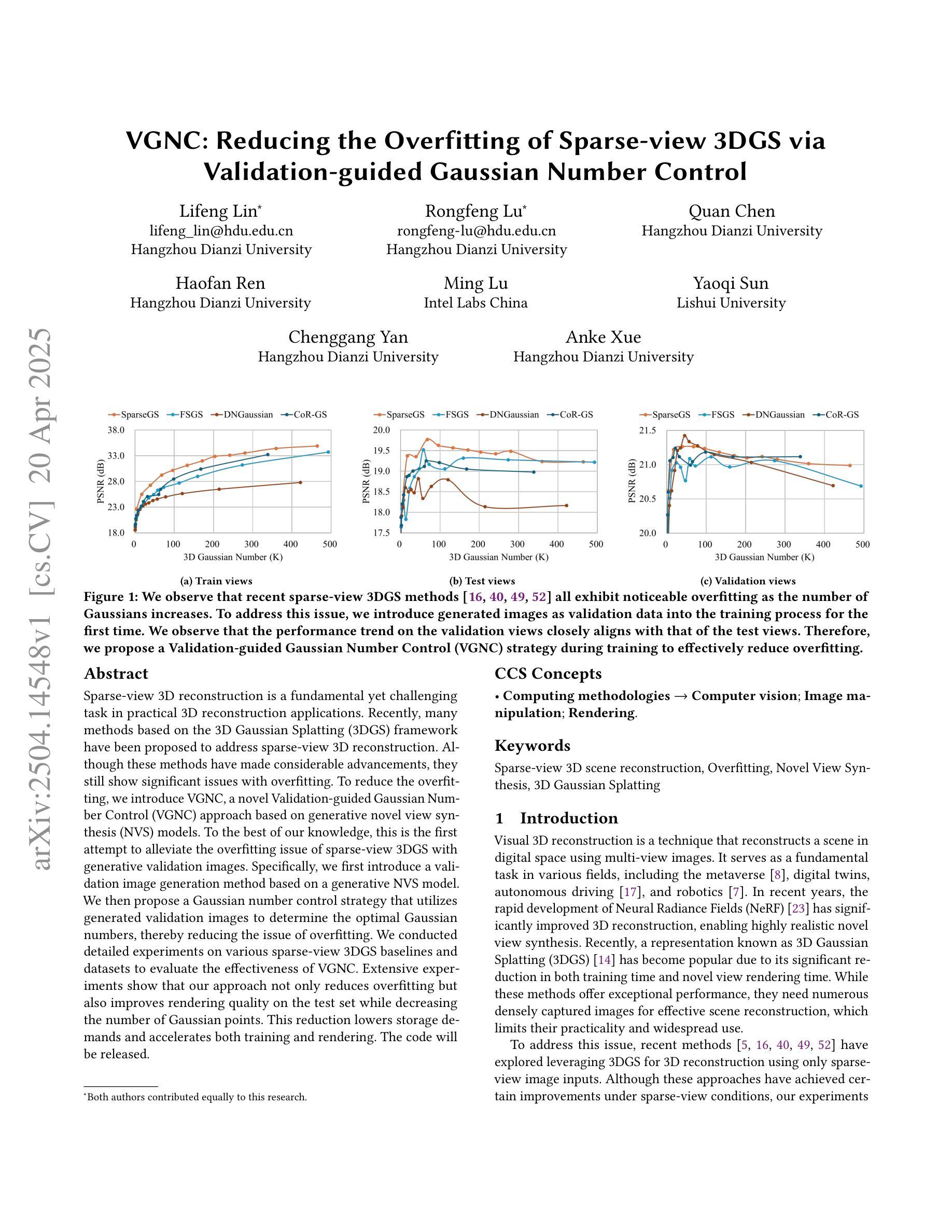
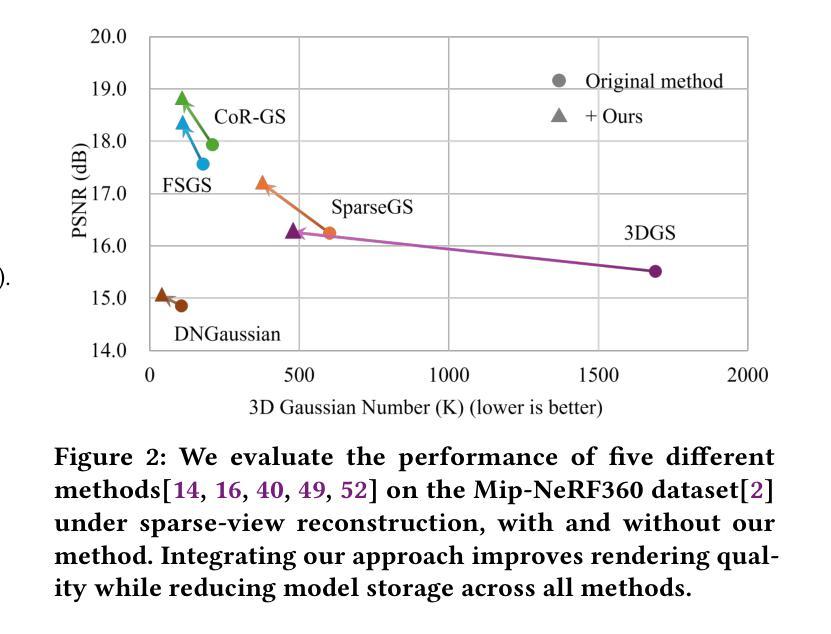
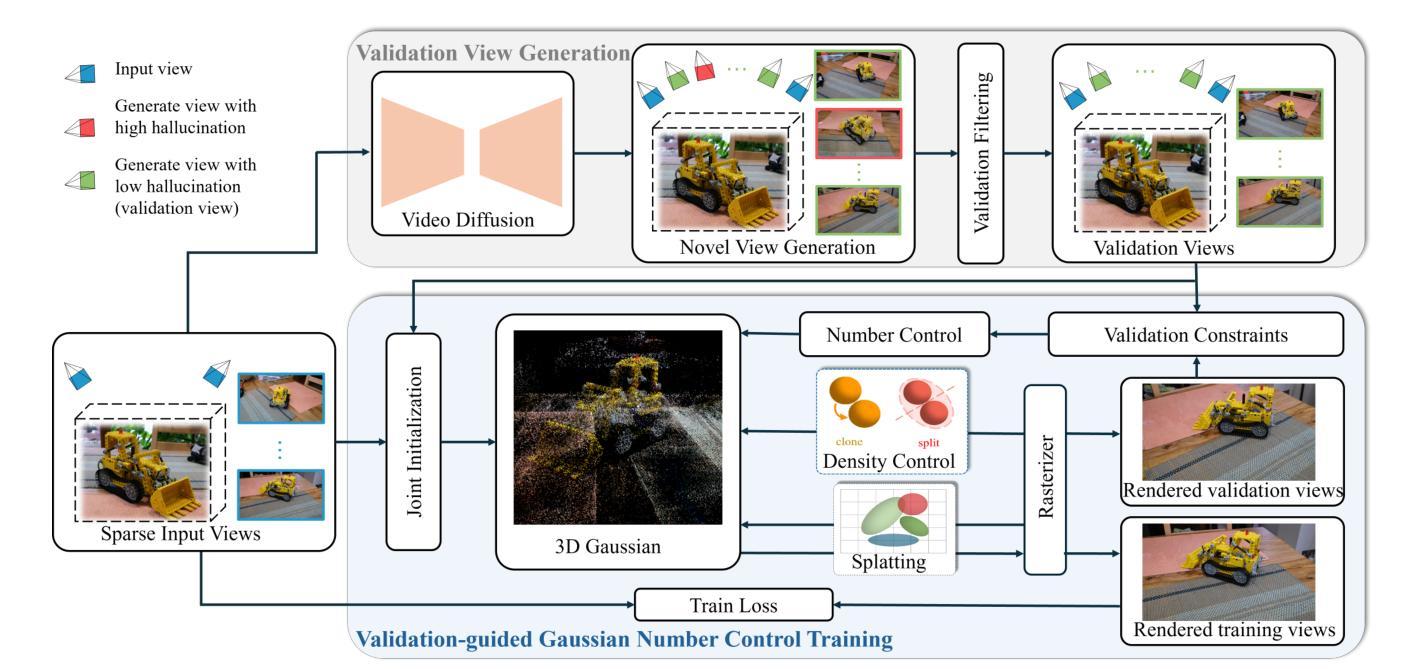
VGNC: Reducing the Overfitting of Sparse-view 3DGS via Validation-guided Gaussian Number Control
Authors:Lifeng Lin, Rongfeng Lu, Quan Chen, Haofan Ren, Ming Lu, Yaoqi Sun, Chenggang Yan, Anke Xue
Sparse-view 3D reconstruction is a fundamental yet challenging task in practical 3D reconstruction applications. Recently, many methods based on the 3D Gaussian Splatting (3DGS) framework have been proposed to address sparse-view 3D reconstruction. Although these methods have made considerable advancements, they still show significant issues with overfitting. To reduce the overfitting, we introduce VGNC, a novel Validation-guided Gaussian Number Control (VGNC) approach based on generative novel view synthesis (NVS) models. To the best of our knowledge, this is the first attempt to alleviate the overfitting issue of sparse-view 3DGS with generative validation images. Specifically, we first introduce a validation image generation method based on a generative NVS model. We then propose a Gaussian number control strategy that utilizes generated validation images to determine the optimal Gaussian numbers, thereby reducing the issue of overfitting. We conducted detailed experiments on various sparse-view 3DGS baselines and datasets to evaluate the effectiveness of VGNC. Extensive experiments show that our approach not only reduces overfitting but also improves rendering quality on the test set while decreasing the number of Gaussian points. This reduction lowers storage demands and accelerates both training and rendering. The code will be released.
稀疏视角下的三维重建是实际三维重建应用中的一项基本且具有挑战性的任务。最近,基于三维高斯延展(3DGS)框架的方法已经被提出来解决稀疏视角下的三维重建问题。尽管这些方法已经取得了很大的进步,但它们仍然显示出严重的过拟合问题。为了减少过拟合,我们引入了VGNC,这是一种基于生成新型视角合成(NVS)模型的验证引导高斯数量控制(VGNC)方法。据我们所知,这是首次尝试使用生成验证图像来缓解稀疏视角下的三维高斯延展过拟合问题。具体来说,我们首先基于生成型NVS模型引入了一种验证图像生成方法。然后,我们提出了一种高斯数量控制策略,该策略利用生成的验证图像来确定最佳高斯数量,从而减少过拟合问题。我们在各种稀疏视角下的三维重建基准方法和数据集上进行了详细的实验,以评估VGNC的有效性。大量实验表明,我们的方法不仅减少了过拟合,而且提高了测试集的渲染质量,同时减少了高斯点的数量。这种减少降低了存储需求并加速了训练和渲染过程。代码将会发布。
论文及项目相关链接
PDF 10 pages,8 figures
Summary
基于稀疏视角的3D重建是实际应用中的一项基本且具挑战性的任务。近期,许多基于三维高斯涂抹(3DGS)框架的方法被提出来解决稀疏视角的3D重建问题。然而,这些方法虽然取得了显著的进展,但仍存在过度拟合的问题。为了减轻过度拟合问题,我们引入了VGNC,这是一种基于生成式新视角合成(NVS)模型的验证引导高斯数量控制(VGNC)方法。据我们所知,这是首次尝试利用生成验证图像来缓解稀疏视角的3DGS的过度拟合问题。具体来说,我们首先介绍了一种基于生成式NVS模型的验证图像生成方法。然后,我们提出了一种高斯数量控制策略,利用生成的验证图像来确定最佳高斯数量,从而减少过度拟合的问题。我们在各种稀疏视角的3DGS基准和数据集上进行了详细的实验,以评估VGNC的有效性。实验表明,我们的方法不仅减少了过度拟合,而且提高了测试集的渲染质量,同时减少了高斯点的数量。这降低了存储需求并加速了训练和渲染过程。代码即将发布。
Key Takeaways
- 稀疏视角的3D重建是实际应用中的挑战性问题。
- 基于三维高斯涂抹(3DGS)的方法虽然有所进展,但存在过度拟合的问题。
- VGNC是一种新型的验证引导高斯数量控制方法,旨在解决稀疏视角的3D重建中的过度拟合问题。
- VGNC通过引入生成式新视角合成(NVS)模型来生成验证图像。
- VGNC利用生成的验证图像来确定最佳高斯数量,从而提高渲染质量并降低存储需求。
- 实验证明VGNC方法有效减少过度拟合,提高测试集渲染质量。
点此查看论文截图

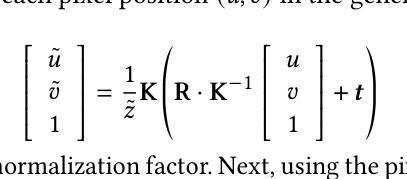

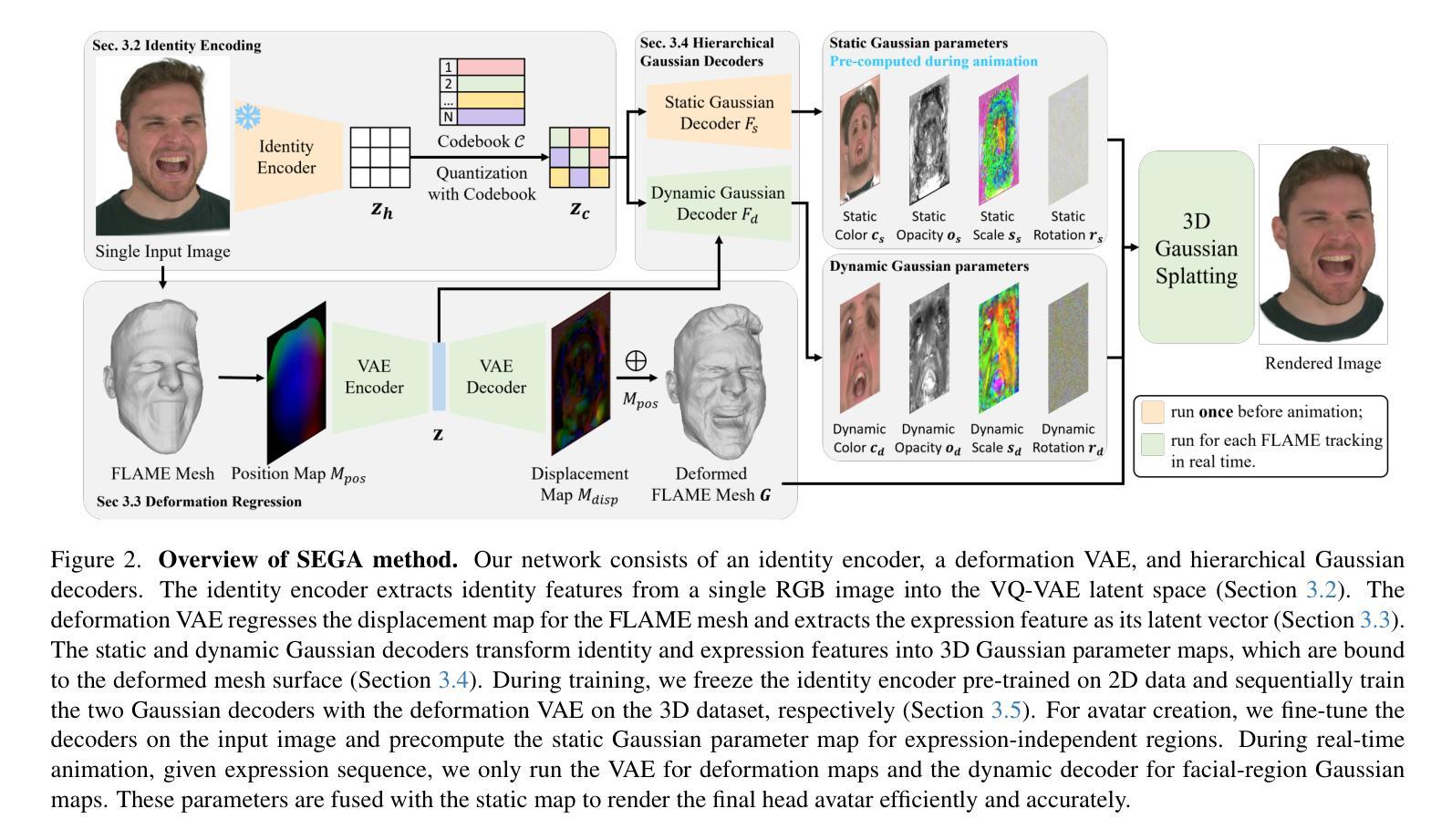
SEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Authors:Chen Guo, Zhuo Su, Jian Wang, Shuang Li, Xu Chang, Zhaohu Li, Yang Zhao, Guidong Wang, Ruqi Huang
Creating photorealistic 3D head avatars from limited input has become increasingly important for applications in virtual reality, telepresence, and digital entertainment. While recent advances like neural rendering and 3D Gaussian splatting have enabled high-quality digital human avatar creation and animation, most methods rely on multiple images or multi-view inputs, limiting their practicality for real-world use. In this paper, we propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework. SEGA seamlessly combines priors derived from large-scale 2D datasets with 3D priors learned from multi-view, multi-expression, and multi-ID data, achieving robust generalization to unseen identities while ensuring 3D consistency across novel viewpoints and expressions. We further present a hierarchical UV-space Gaussian Splatting framework that leverages FLAME-based structural priors and employs a dual-branch architecture to disentangle dynamic and static facial components effectively. The dynamic branch encodes expression-driven fine details, while the static branch focuses on expression-invariant regions, enabling efficient parameter inference and precomputation. This design maximizes the utility of limited 3D data and achieves real-time performance for animation and rendering. Additionally, SEGA performs person-specific fine-tuning to further enhance the fidelity and realism of the generated avatars. Experiments show our method outperforms state-of-the-art approaches in generalization ability, identity preservation, and expression realism, advancing one-shot avatar creation for practical applications.
创建具有真实感的3D头像化身从有限输入的角度来讨论在虚拟现实、远程存在和数字娱乐应用中越来越重要。虽然神经渲染和3D高斯拼贴等最新进展已经实现了高质量数字人类化身创建和动画,但大多数方法仍然依赖于多张图像或多视角输入,这限制了它们在现实世界应用中的实用性。在本文中,我们提出了SEGA,这是一种基于单图像技术的3D驾驶高斯头像化身创建新方法,它结合了广义先验模型和新层次化的UV空间高斯拼贴框架。SEGA无缝地结合了从大规模二维数据集派生的先验知识和从多视角、多表情和多身份数据中学习的三维先验知识,实现对未见身份的稳健泛化,同时确保新型视角和表情下的三维一致性。我们还提出了一种层次化的UV空间高斯拼贴框架,它利用基于FLAME的结构先验知识并采用双分支架构,有效地分离动态和静态面部组件。动态分支编码表情驱动的精细细节,而静态分支则专注于表情不变区域,从而实现有效的参数推断和预计算。这种设计最大限度地提高了有限三维数据的实用性,并实现了动画和渲染的实时性能。此外,SEGA执行针对个人的微调,以进一步增强生成的化身的真实感和逼真度。实验表明,我们的方法在泛化能力、身份保留和表情现实性方面优于最新方法,推动了一站式化身创建在实用领域的发展。
论文及项目相关链接
Summary
本文提出了一种基于单张图像创建3D可驱动高斯头像的技术SEGA。该技术结合了通用先验模型和新层次UV空间高斯溅落框架,实现了对未见身份的稳健泛化,同时确保了在新型视角和表情下的3D一致性。SEGA利用分层UV空间高斯溅落框架,采用双分支架构有效分离动态和静态面部组件,实现实时动画和渲染性能。实验表明,SEGA在泛化能力、身份保留和表情真实性方面优于现有技术,推动了单镜头头像创作的实际应用。
Key Takeaways
- SEGA技术结合了通用先验模型和新层次UV空间高斯溅落框架,用于创建基于单张图像的3D可驱动高斯头像。
- SEGA实现了对未见身份的稳健泛化,同时确保在新型视角和表情下的3D一致性。
- 分层UV空间高斯溅落框架结合了FLAME结构先验信息并采用双分支架构分离动态和静态面部组件,实现高效参数推断和预计算。
- SEGA可实现实时性能用于动画和渲染,并可通过个人微调增强头像的真实性和逼真度。
点此查看论文截图

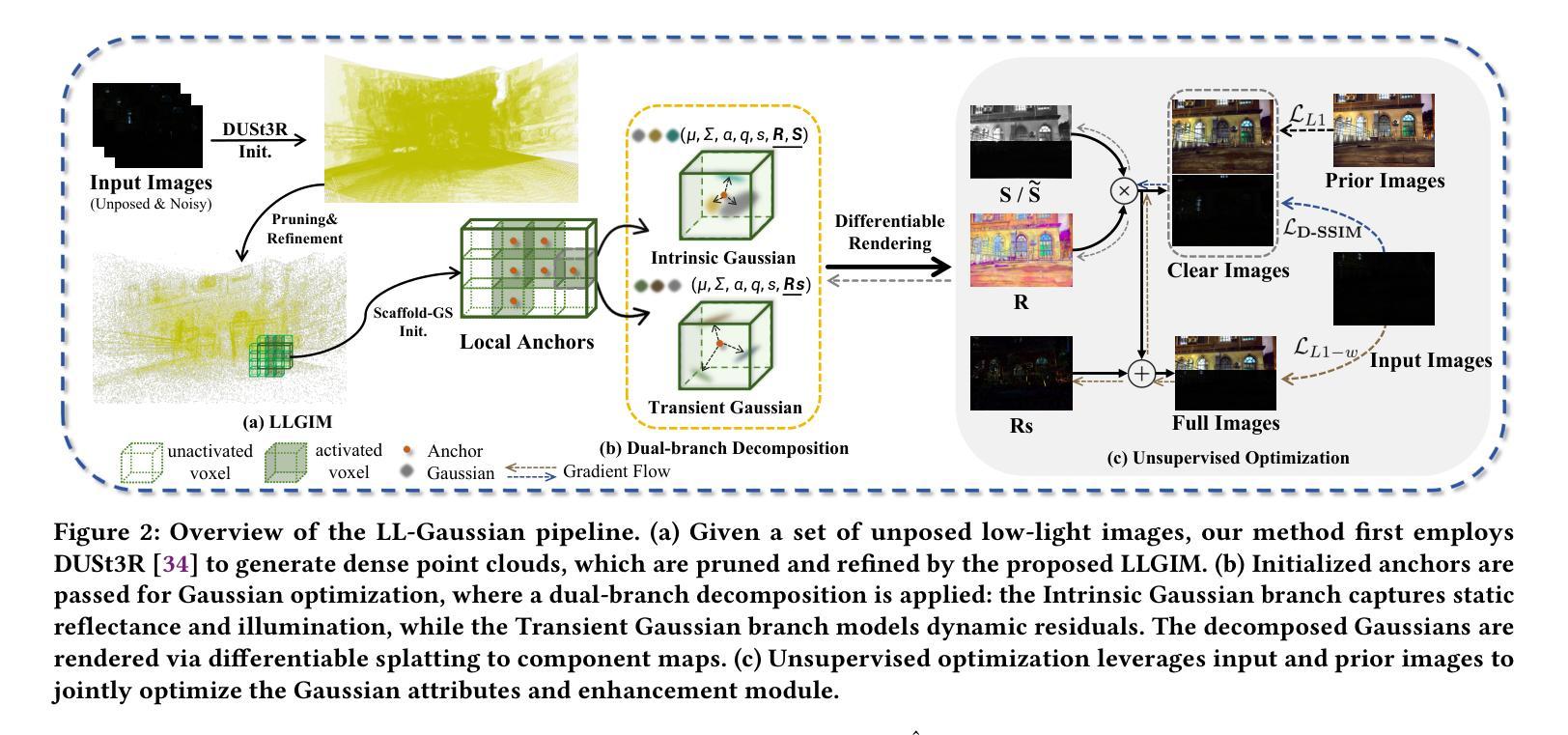
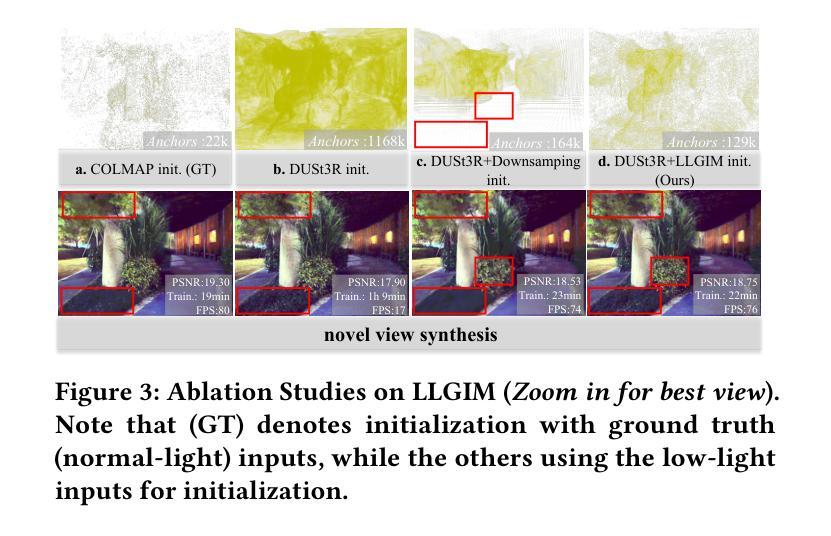
LL-Gaussian: Low-Light Scene Reconstruction and Enhancement via Gaussian Splatting for Novel View Synthesis
Authors:Hao Sun, Fenggen Yu, Huiyao Xu, Tao Zhang, Changqing Zou
Novel view synthesis (NVS) in low-light scenes remains a significant challenge due to degraded inputs characterized by severe noise, low dynamic range (LDR) and unreliable initialization. While recent NeRF-based approaches have shown promising results, most suffer from high computational costs, and some rely on carefully captured or pre-processed data–such as RAW sensor inputs or multi-exposure sequences–which severely limits their practicality. In contrast, 3D Gaussian Splatting (3DGS) enables real-time rendering with competitive visual fidelity; however, existing 3DGS-based methods struggle with low-light sRGB inputs, resulting in unstable Gaussian initialization and ineffective noise suppression. To address these challenges, we propose LL-Gaussian, a novel framework for 3D reconstruction and enhancement from low-light sRGB images, enabling pseudo normal-light novel view synthesis. Our method introduces three key innovations: 1) an end-to-end Low-Light Gaussian Initialization Module (LLGIM) that leverages dense priors from learning-based MVS approach to generate high-quality initial point clouds; 2) a dual-branch Gaussian decomposition model that disentangles intrinsic scene properties (reflectance and illumination) from transient interference, enabling stable and interpretable optimization; 3) an unsupervised optimization strategy guided by both physical constrains and diffusion prior to jointly steer decomposition and enhancement. Additionally, we contribute a challenging dataset collected in extreme low-light environments and demonstrate the effectiveness of LL-Gaussian. Compared to state-of-the-art NeRF-based methods, LL-Gaussian achieves up to 2,000 times faster inference and reduces training time to just 2%, while delivering superior reconstruction and rendering quality.
低光场景中的新颖视图合成(NVS)仍然存在重大挑战,因为输入退化表现为严重噪声、低动态范围(LDR)和不可靠的初始化。虽然最近的基于NeRF的方法已经显示出有希望的结果,但大多数方法的计算成本很高,而且有些方法依赖于精心捕获或预处理的数据,如RAW传感器输入或多曝光序列,这严重限制了它们的实用性。相比之下,3D高斯拼贴(3DGS)能够实现具有竞争力的视觉保真度的实时渲染;然而,现有的基于3DGS的方法在处理低光sRGB输入时遇到困难,导致高斯初始化不稳定且噪声抑制无效。为了应对这些挑战,我们提出了LL-Gaussian,这是一种从低光sRGB图像进行3D重建和增强的新型框架,能够实现伪正常光新颖视图合成。我们的方法引入了三个关键创新点:1)端到端的低光高斯初始化模块(LLGIM),它利用基于学习的MVS方法的密集先验来生成高质量初始点云;2)双分支高斯分解模型,能够将内在场景属性(反射率和照明)从瞬态干扰中分离出来,从而实现稳定和可解释的优化;3)一种受物理约束和扩散先验引导的无监督优化策略,以共同引导分解和增强。此外,我们还贡献了在极端低光环境中收集的具有挑战性的数据集,并展示了LL-Gaussian的有效性。与最先进的基于NeRF的方法相比,LL-Gaussian实现了高达2000倍更快的推理速度,并将训练时间减少到仅2%,同时提供优越的重建和渲染质量。
论文及项目相关链接
PDF Project page: https://sunhao242.github.io/LL-Gaussian_web.github.io/
Summary
该文本介绍了在低光照场景中实现新颖视图合成(NVS)的挑战,包括输入质量下降、噪声严重、动态范围低和初始化不可靠等问题。最近基于NeRF的方法虽然取得了有希望的成果,但计算成本高昂,且依赖于精心捕获或预处理的数据,这限制了其实用性。相比之下,3D高斯拼贴(3DGS)能够实现实时渲染并具有竞争力视觉保真度,但现有基于3DGS的方法在处理低光照sRGB输入时遇到困难,导致高斯初始化不稳定且噪声抑制无效。针对这些挑战,提出了LL-Gaussian框架,该框架实现了从低光照sRGB图像进行3D重建和增强的新颖方法,实现了伪正常光新颖视图合成。该框架引入了三个关键创新点:端对端低光高斯初始化模块(LLGIM)、双分支高斯分解模型和受物理约束和扩散先验引导的无监督优化策略。
Key Takeaways
- 低光照场景中的新颖视图合成面临诸多挑战,包括输入质量下降和噪声问题。
- 现有基于NeRF的方法虽然有效,但计算成本高且依赖精心处理的数据,限制了实用性。
- 3DGS能够实现实时渲染,但在处理低光照sRGB输入时存在挑战。
- LL-Gaussian框架通过三个关键创新点解决了这些问题:低光高斯初始化模块、双分支高斯分解模型和无监督优化策略。
- LL-Gaussian框架实现了从低光照sRGB图像进行3D重建和增强的功能,能够实现伪正常光新颖视图合成。
- LL-Gaussian框架引入了学习基于密集先验的MVS方法来生成高质量初始点云。
点此查看论文截图


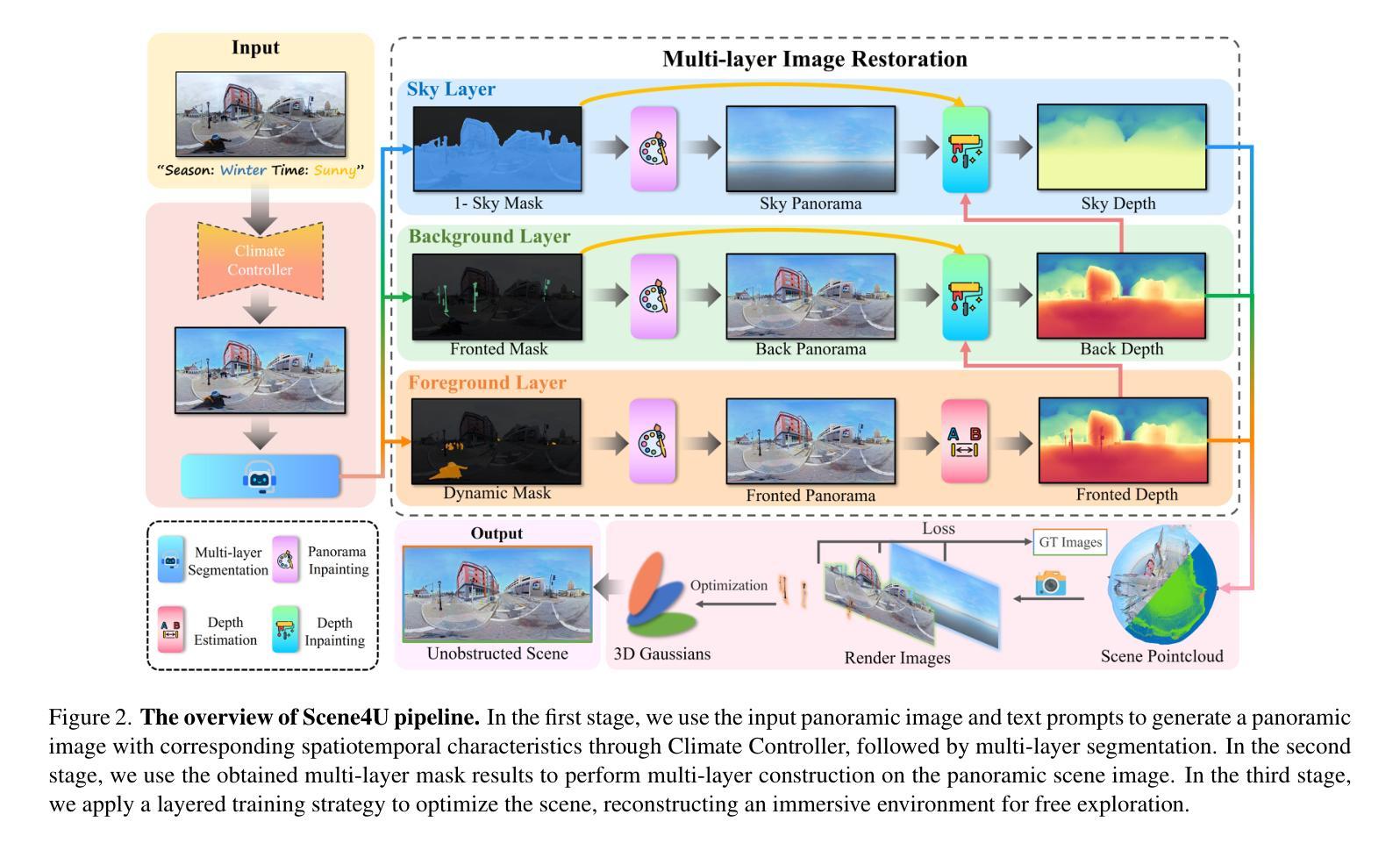
Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration
Authors:Zilong Huang, Jun He, Junyan Ye, Lihan Jiang, Weijia Li, Yiping Chen, Ting Han
The reconstruction of immersive and realistic 3D scenes holds significant practical importance in various fields of computer vision and computer graphics. Typically, immersive and realistic scenes should be free from obstructions by dynamic objects, maintain global texture consistency, and allow for unrestricted exploration. The current mainstream methods for image-driven scene construction involves iteratively refining the initial image using a moving virtual camera to generate the scene. However, previous methods struggle with visual discontinuities due to global texture inconsistencies under varying camera poses, and they frequently exhibit scene voids caused by foreground-background occlusions. To this end, we propose a novel layered 3D scene reconstruction framework from panoramic image, named Scene4U. Specifically, Scene4U integrates an open-vocabulary segmentation model with a large language model to decompose a real panorama into multiple layers. Then, we employs a layered repair module based on diffusion model to restore occluded regions using visual cues and depth information, generating a hierarchical representation of the scene. The multi-layer panorama is then initialized as a 3D Gaussian Splatting representation, followed by layered optimization, which ultimately produces an immersive 3D scene with semantic and structural consistency that supports free exploration. Scene4U outperforms state-of-the-art method, improving by 24.24% in LPIPS and 24.40% in BRISQUE, while also achieving the fastest training speed. Additionally, to demonstrate the robustness of Scene4U and allow users to experience immersive scenes from various landmarks, we build WorldVista3D dataset for 3D scene reconstruction, which contains panoramic images of globally renowned sites. The implementation code and dataset will be released at https://github.com/LongHZ140516/Scene4U .
全景三维场景重建在计算机视觉和计算机图形学领域具有重大实际意义。通常,沉浸式且逼真的场景应该不受动态物体的阻挡,保持全局纹理一致性,并允许不受限制的探索。当前主流的图像驱动场景构建方法通过移动虚拟相机对初始图像进行迭代优化以生成场景。然而,以前的方法在处理由于不同相机姿态下的全局纹理不一致导致的视觉不连续时遇到困难,并且它们经常由于前景背景遮挡而导致场景空洞。为此,我们提出了一种名为Scene4U的新型分层三维场景重建框架。具体来说,Scene4U将开放词汇分割模型与大型语言模型集成,将真实全景图像分解为多个层次。然后,我们采用基于扩散模型的分层修复模块,利用视觉线索和深度信息恢复遮挡区域,生成场景的层次表示。多层全景图像被初始化为三维高斯喷射表示,然后进行分层优化,最终生成具有语义和结构一致性的沉浸式三维场景,支持自由探索。Scene4U在LPIPS上提高了24.24%,在BRISQUE上提高了24.4%,并且具有最快的训练速度。此外,为了证明Scene4U的鲁棒性并允许用户从各种地标体验沉浸式场景,我们建立了用于三维场景重建的WorldVista3D数据集,其中包含全球知名景点的全景图像。实施代码和数据集将在https://github.com/LongHZ140516/Scene4U发布。
论文及项目相关链接
PDF CVPR 2025, 11 pages, 7 figures
摘要
本文提出了一个名为Scene4U的新型分层3D场景重建框架,该框架从全景图像出发,通过集成开放词汇分割模型与大型语言模型,将真实全景图像分解成多个层次。利用基于扩散模型的分层修复模块,通过视觉线索和深度信息恢复遮挡区域,生成场景的层次表示。该框架初始化多层全景图像为3D高斯Splatting表示,随后进行分层优化,最终生成具有语义和结构一致性的沉浸式3D场景,支持自由探索。Scene4U在LPIPS和BRISQUE指标上分别提高了24.24%和24.40%,且训练速度最快。此外,为了展示Scene4U的鲁棒性并让用户体验来自不同地标的沉浸式场景,建立了WorldVista3D数据集用于3D场景重建。
关键见解
- Scene4U框架利用全景图像进行分层3D场景重建,解决了传统方法在处理动态对象遮挡和全局纹理不一致性方面的视觉断层问题。
- Scene4U集成了开放词汇分割模型和大型语言模型,有效分解全景图像为多个层次,增强了场景的细节和真实感。
- 基于扩散模型的分层修复模块用于恢复被遮挡区域,利用视觉线索和深度信息生成场景的层次表示,提高了场景的连贯性和完整性。
- Scene4U采用多层全景图像的3D高斯Splatting表示和分层优化技术,生成具有语义和结构一致性的沉浸式3D场景,支持自由探索,提升了用户体验。
- Scene4U在LPIPS和BRISQUE评价指标上取得显著优势,且在训练速度上表现最快。
- 为了推广Scene4U的应用,建立了WorldVista3D数据集,包含全球知名景点的全景图像,用于3D场景重建。
- Scene4U的实施代码和数据集将公开发布,便于研究人员使用和改进。
点此查看论文截图



HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Authors:Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Kangjie Chen, Minghan Qin, Yu Li, Haoqian Wang
Reconstructing animatable and high-quality 3D head avatars from monocular videos, especially with realistic relighting, is a valuable task. However, the limited information from single-view input, combined with the complex head poses and facial movements, makes this challenging. Previous methods achieve real-time performance by combining 3D Gaussian Splatting with a parametric head model, but the resulting head quality suffers from inaccurate face tracking and limited expressiveness of the deformation model. These methods also fail to produce realistic effects under novel lighting conditions. To address these issues, we propose HRAvatar, a 3DGS-based method that reconstructs high-fidelity, relightable 3D head avatars. HRAvatar reduces tracking errors through end-to-end optimization and better captures individual facial deformations using learnable blendshapes and learnable linear blend skinning. Additionally, it decomposes head appearance into several physical properties and incorporates physically-based shading to account for environmental lighting. Extensive experiments demonstrate that HRAvatar not only reconstructs superior-quality heads but also achieves realistic visual effects under varying lighting conditions.
从单目视频中重建可动画和高质量的3D头像,尤其是具有逼真的重新照明效果,是一项有价值的任务。然而,单视图输入的有限信息,以及复杂的头部姿势和面部运动,使得这项任务具有挑战性。之前的方法是通过结合3D高斯拼贴和参数化头部模型来实现实时性能的,但头部质量的结果受到面部跟踪不准确和变形模型的表达有限的困扰。这些方法在新的光照条件下也无法产生逼真的效果。为了解决这些问题,我们提出了HRAvatar,一种基于3DGS的方法,用于重建高保真、可重新照明的3D头像。HRAvatar通过端到端优化减少了跟踪误差,并使用可学习的blendshapes和可学习的线性混合蒙皮技术更好地捕捉了个人面部变形。此外,它将头部外观分解成多种物理属性,并融入基于物理的着色技术来考虑环境照明。大量实验表明,HRAvatar不仅重建了高质量的头部,而且在不同的光照条件下实现了逼真的视觉效果。
论文及项目相关链接
PDF Accepted to CVPR 2025,Project page: https://eastbeanzhang.github.io/HRAvatar
Summary
本文提出一种基于3DGS的方法,即HRAvatar,用于从单视角视频中重建高质量、可重新照明的3D头像。该方法通过端到端优化减少跟踪误差,使用可学习的blendshapes和线性皮肤混合技术更好地捕捉面部变形,并将头部外观分解成多个物理属性,结合基于物理的着色来模拟环境照明,从而在不同照明条件下实现真实的视觉效果。
Key Takeaways
- HRAvatar是一种基于3DGS的方法,能够从单视角视频重建高质量、可重新照明的3D头像。
- 通过端到端优化减少跟踪误差,提高重建精度。
- 使用可学习的blendshapes和线性皮肤混合技术,更好地捕捉面部变形。
- 将头部外观分解成多个物理属性,如形状、纹理、反射属性等。
- 结合基于物理的着色技术,模拟环境照明,实现真实感视觉效果。
- HRAvatar在多种照明条件下表现出优异的性能,重建的头像质量高。
点此查看论文截图

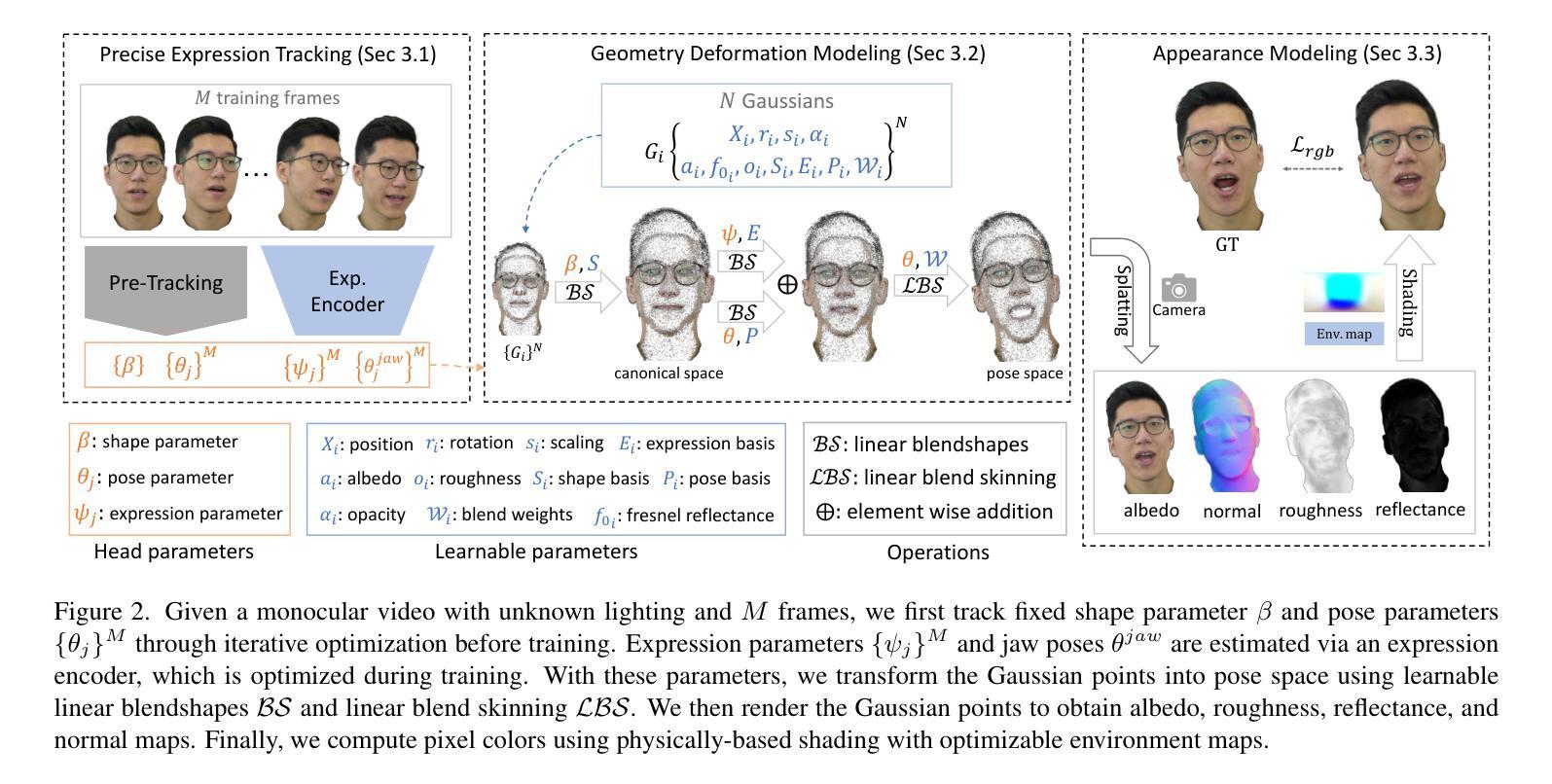

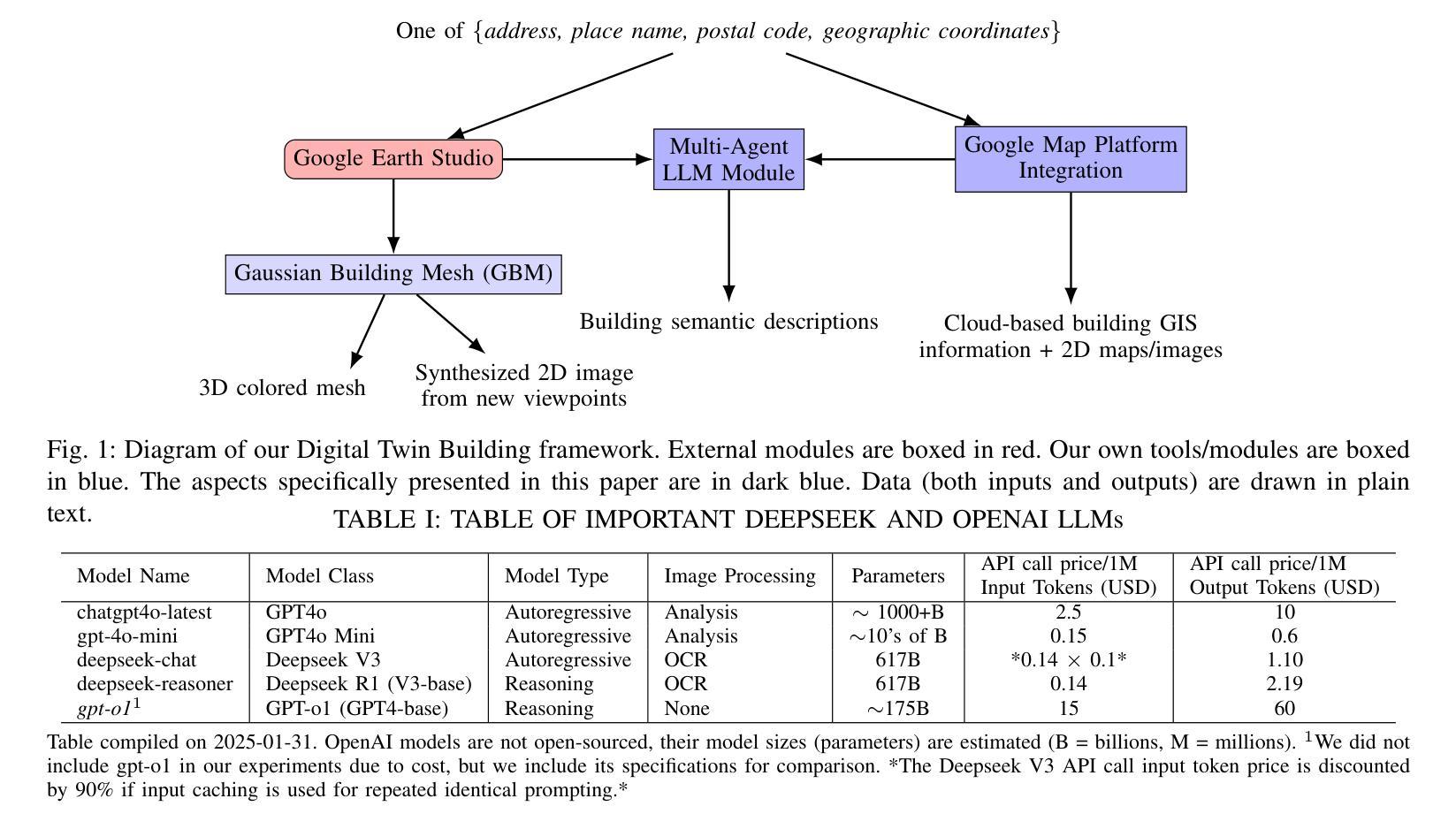
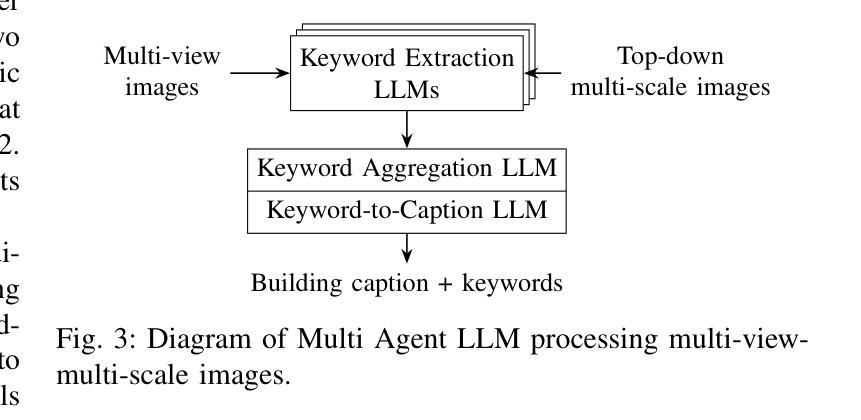
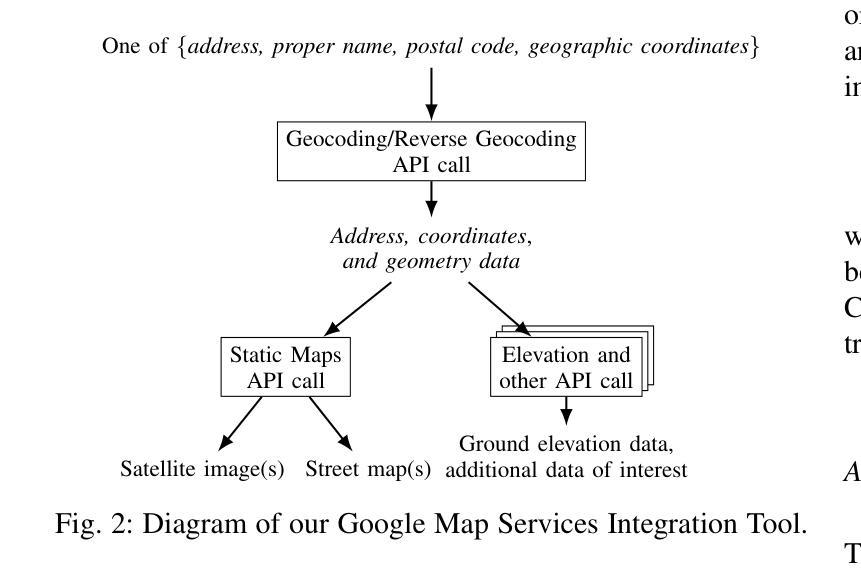
Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platform
Authors:Kyle Gao, Dening Lu, Liangzhi Li, Nan Chen, Hongjie He, Linlin Xu, Jonathan Li
Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building’s 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building’s address, postal code, or geographic coordinates.
城市数字双胞胎是利用多源数据和数据分析优化城市规划、基础设施管理和决策制定的城市虚拟副本。为此,我们提出了以单栋建筑规模为重点的框架。通过连接到谷歌地图平台API等云地图平台,利用最先进的基于多智能体的语言模型(使用ChatGPT(第4代)和Deepseek-V3/R1进行数据分析),以及利用我们的基于高斯混合网格提取流程,我们的数字双胞胎建筑框架可以检索建筑物的三维模型、视觉描述信息,实现基于云端的地图集成,以建筑物的地址、邮政编码或地理坐标进行大数据量基于大型语言模型的数据分析。这不仅包括位置维度、地标和文化特点等多种角度的构建信息采集与分析功能。因此该框架的应用非常灵活和多样。通过使用自然语言处理工具和云计算平台连接多个数据源的技术方法来实现,整个系统的稳定性和数据处理能力都有很大提高。通过这种新型数字技术整合策略实现的三维仿真模型和复杂计算推理工作将进一步优化未来城市建设工作的进程与精准度水平提升的重要机遇。。
论文及项目相关链接
PDF -Fixed minor typo
Summary
城市数字双胞胎是利用多源数据和数据分析优化城市规划、基础设施管理和决策制定的虚拟城市模型。我们提出一个以单栋建筑为尺度的框架,通过连接谷歌地图平台API等云地图平台,利用最先进的基于多智能体的语言模型ChatGPT(4代)、Deepseek V3或R版进行分析,并通过高斯聚合(高斯羽化)技术提取建筑三维模型的数据集成框架,该框架可以检索建筑物的三维模型、视觉描述,并实现基于云的大型语言模型数据分析与地图集成,使用建筑物的地址、邮政编码或地理坐标。
Key Takeaways
- 城市数字双胞胎是城市的虚拟副本,利用数据和数据分析优化城市各个方面。
- 提出了一种以单栋建筑为尺度的框架来进行数字双胞胎构建。
- 通过云地图平台和先进的语言模型进行多源数据连接和分析。
- 使用高斯聚合技术提取建筑物的三维模型和视觉描述。
- 框架能够实现基于云的大型语言模型数据分析与地图集成。
- 该框架可以通过建筑物的地址、邮政编码或地理坐标进行检索和集成。
点此查看论文截图

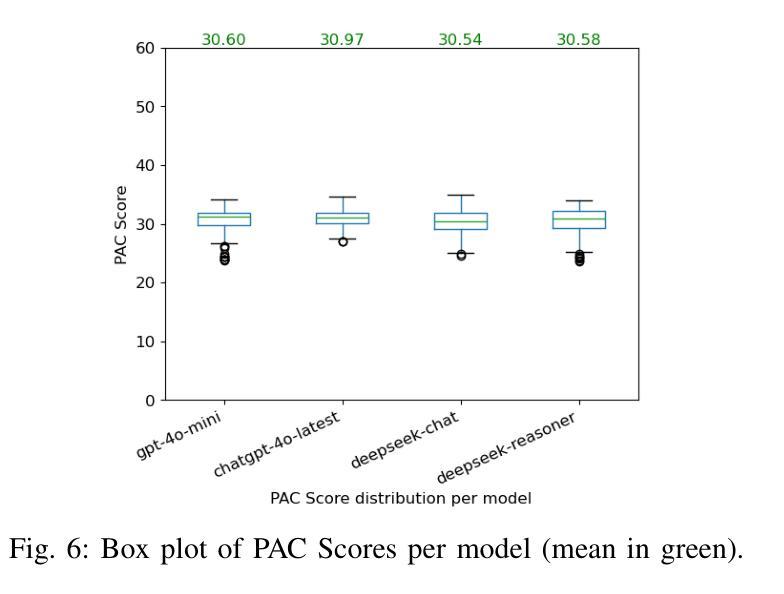

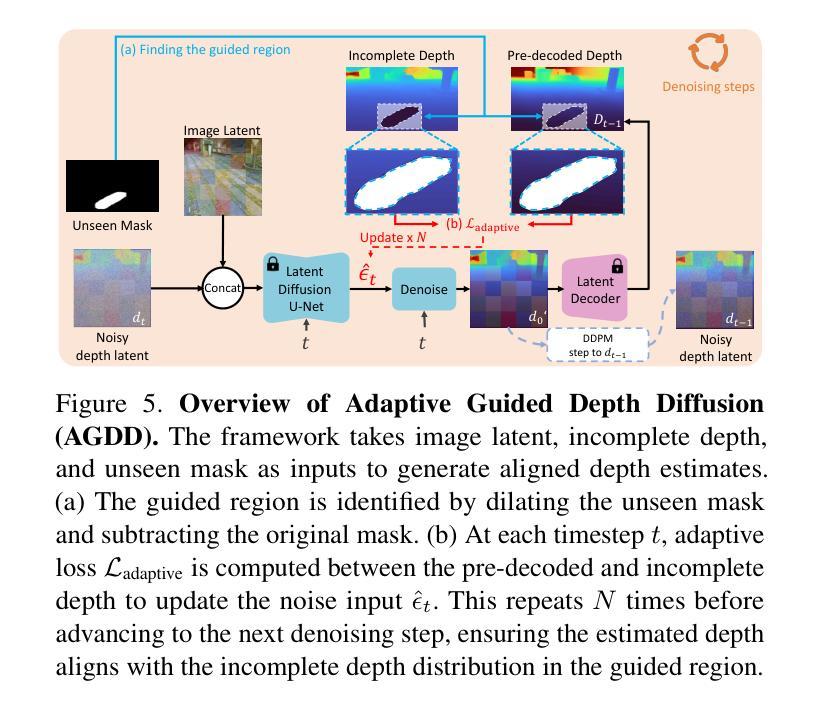
AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
Authors:Chung-Ho Wu, Yang-Jung Chen, Ying-Huan Chen, Jie-Ying Lee, Bo-Hsu Ke, Chun-Wei Tuan Mu, Yi-Chuan Huang, Chin-Yang Lin, Min-Hung Chen, Yen-Yu Lin, Yu-Lun Liu
Three-dimensional scene inpainting is crucial for applications from virtual reality to architectural visualization, yet existing methods struggle with view consistency and geometric accuracy in 360{\deg} unbounded scenes. We present AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting. Our approach introduces (1) depth-aware unseen mask generation for accurate occlusion identification, (2) Adaptive Guided Depth Diffusion, a zero-shot method for accurate initial point placement without requiring additional training, and (3) SDEdit-based detail enhancement for multi-view coherence. We also introduce 360-USID, the first comprehensive dataset for 360{\deg} unbounded scene inpainting with ground truth. Extensive experiments demonstrate that AuraFusion360 significantly outperforms existing methods, achieving superior perceptual quality while maintaining geometric accuracy across dramatic viewpoint changes.
三维场景补全对于从虚拟现实到建筑可视化等应用至关重要,然而现有方法在360°无界场景的视图一致性及几何精度方面面临挑战。我们推出了AuraFusion360,这是一种基于参考的新方法,能够在以高斯拼接表示的三维场景中实现高质量的对象移除和空洞填充。我们的方法引入了(1)深度感知未见掩模生成,用于准确识别遮挡,(2)自适应引导深度扩散,这是一种无需额外训练的零样本方法,可准确放置初始点,(3)基于SDEdit的细节增强,以实现多视图一致性。我们还推出了首个全面的数据集360-USID,用于评估360°无界场景补全的真实情况。大量实验表明,AuraFusion360在视觉感知质量上显著优于现有方法,同时在视点大幅变化时保持几何精度。
论文及项目相关链接
PDF Paper accepted to CVPR 2025. Project page: https://kkennethwu.github.io/aurafusion360/
Summary
本文介绍了AuraFusion360,一种基于参考的3D场景修复新方法,用于高质量地移除和填充高斯拼贴表示的3D场景中的物体空洞。该方法具有深度感知的未见掩膜生成、自适应引导深度扩散和SDEdit细节增强等技术,可在视点变化时保持几何精度,显著提高场景修复的质量和连贯性。
Key Takeaways
- AuraFusion360是一种针对3D场景的修复新方法,适用于虚拟现实和建筑可视化等应用。
- 现有方法面临视角一致性和几何精度的问题,而AuraFusion360通过深度感知未见掩膜生成技术解决了这些问题。
- 该方法引入自适应引导深度扩散技术,无需额外训练即可准确放置初始点。
- SDEdit细节增强技术增强了多视角连贯性。
- 引入了首个全面的360°无界场景修复数据集360-USID,包含真实场景的地面真实数据。
- 实验表明,AuraFusion360显著优于现有方法,在感知质量和几何精度方面都有显著提升。
点此查看论文截图


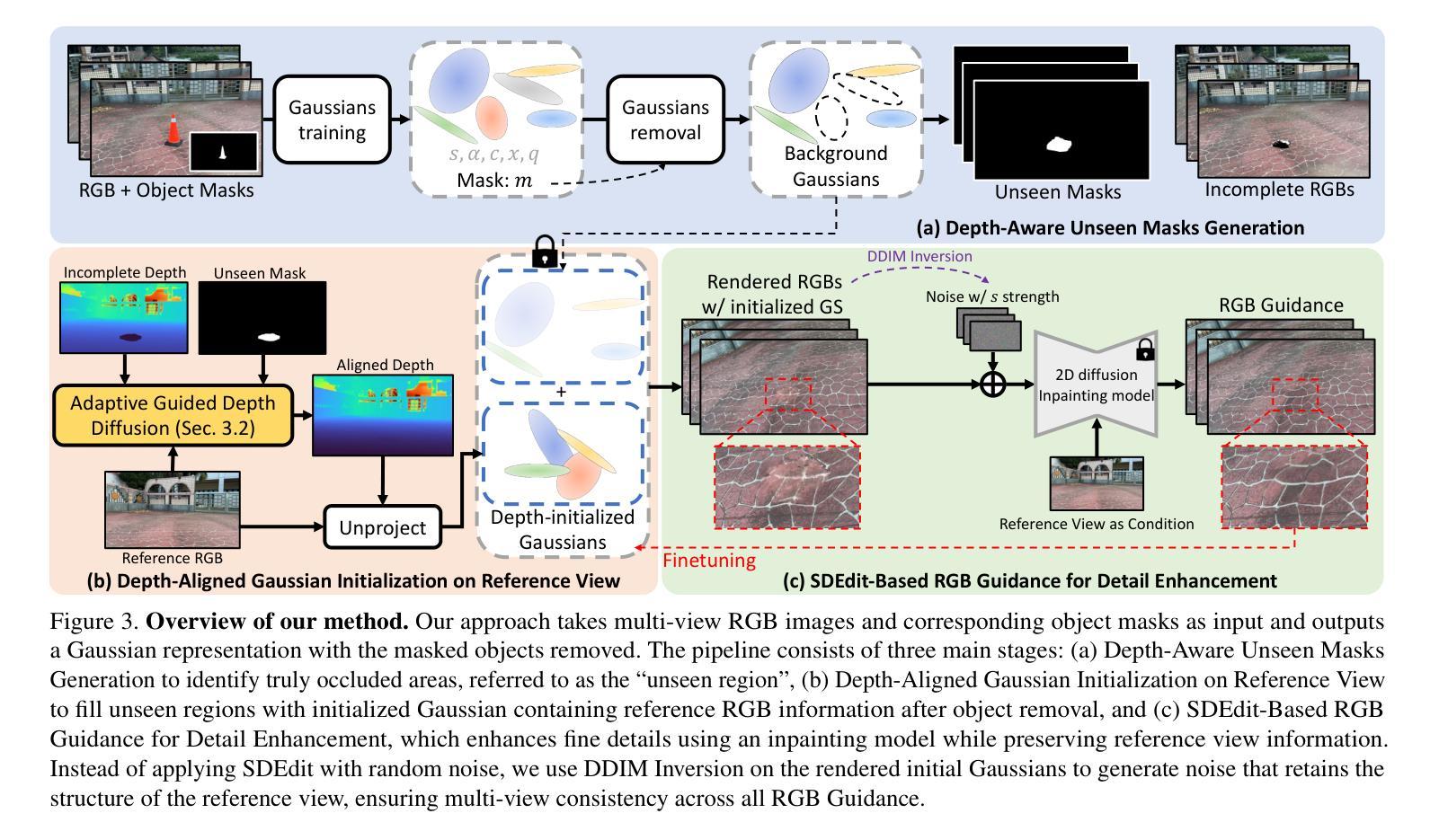
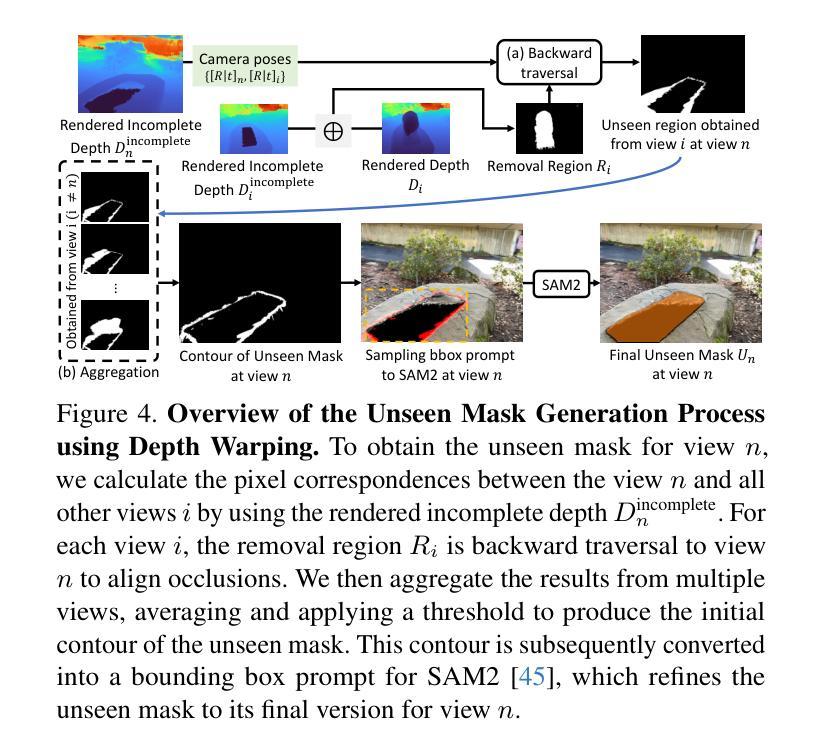

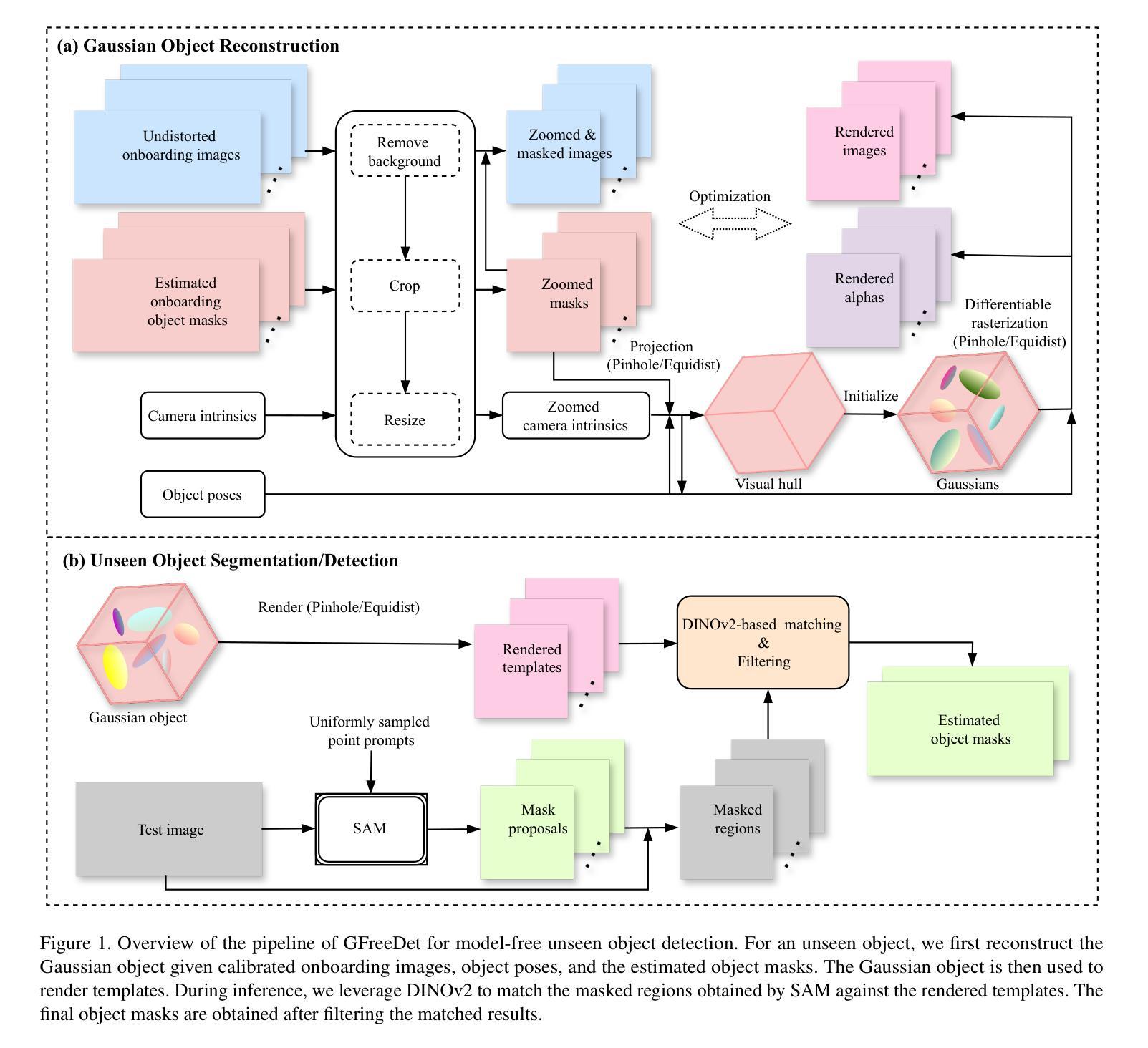
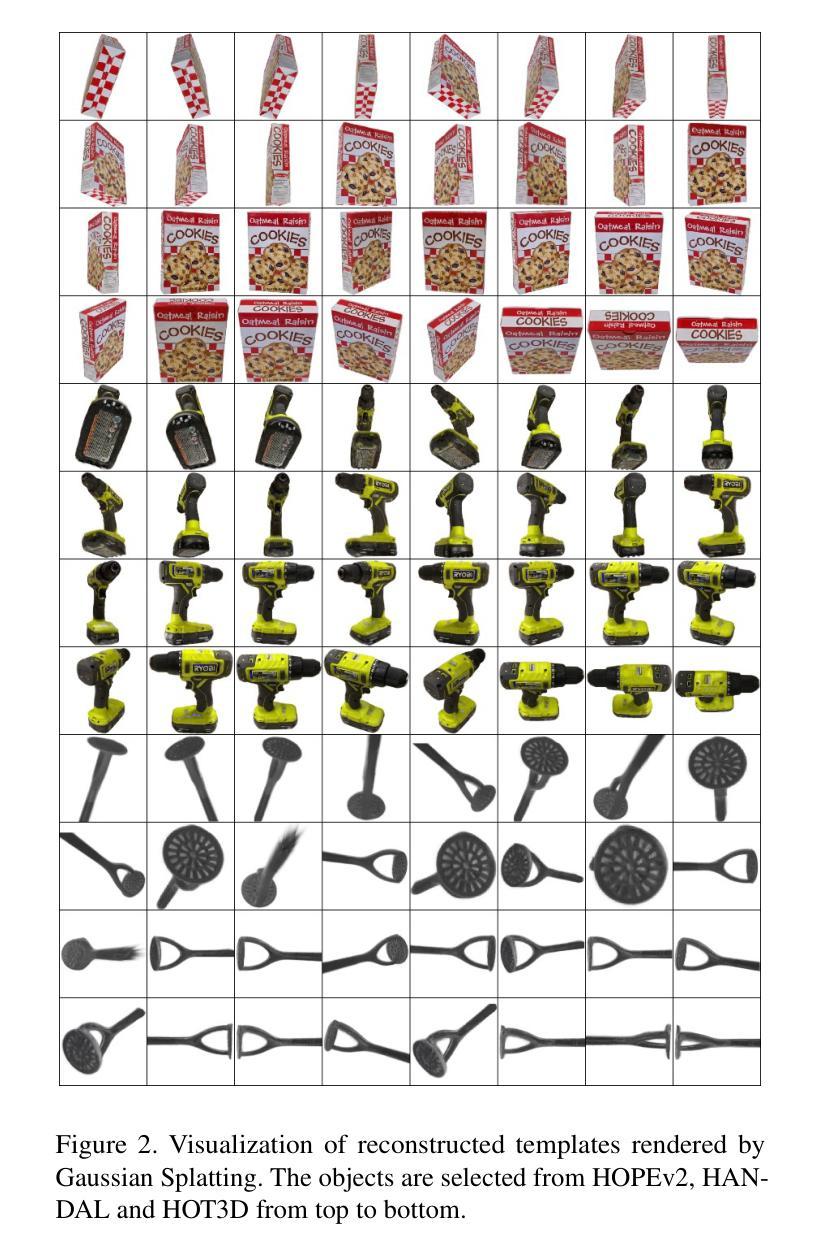
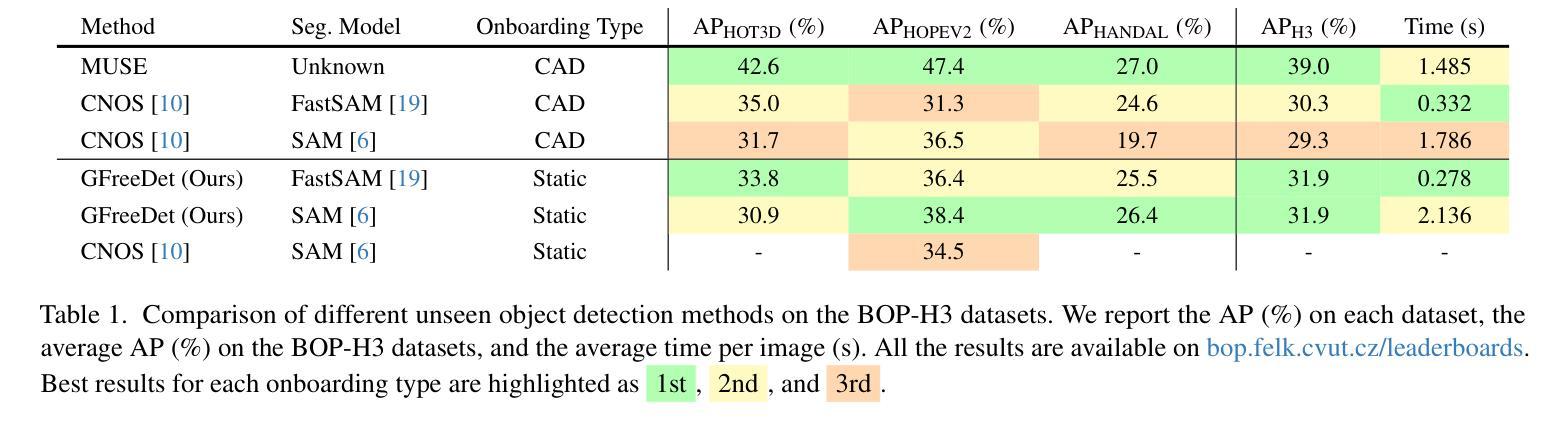
GFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Authors:Xingyu Liu, Gu Wang, Chengxi Li, Yingyue Li, Chenyangguang Zhang, Ziqin Huang, Xiangyang Ji
We present GFreeDet, an unseen object detection approach that leverages Gaussian splatting and vision Foundation models under model-free setting. Unlike existing methods that rely on predefined CAD templates, GFreeDet reconstructs objects directly from reference videos using Gaussian splatting, enabling robust detection of novel objects without prior 3D models. Evaluated on the BOP-H3 benchmark, GFreeDet achieves comparable performance to CAD-based methods, demonstrating the viability of model-free detection for mixed reality (MR) applications. Notably, GFreeDet won the best overall method and the best fast method awards in the model-free 2D detection track at BOP Challenge 2024.
我们提出了GFreeDet,这是一种无需模型设置的情况下利用高斯贴图和视觉基础模型进行未见对象检测的方法。不同于依赖预设CAD模板的现有方法,GFreeDet直接使用参考视频通过高斯贴图重建对象,实现了无需事先3D模型的稳健新型对象检测。在BOP-H3基准测试中评估,GFreeDet的性能与基于CAD的方法相当,证明了无模型检测在混合现实(MR)应用中的可行性。值得一提的是,GFreeDet在BOP Challenge 2024的无模型二维检测赛道上荣获了最佳总体方法和最佳快速方法奖。
论文及项目相关链接
PDF CVPR 2025 CV4MR Workshop
Summary
GFreeDet是一种无需预设模型的对象检测方法,它通过高斯贴图和视觉基础模型实现新颖的对象检测。相较于依赖预先定义的CAD模板的传统方法,GFreeDet能直接根据参考视频重构对象并实现未见对象的稳健检测。在BOP-H3标准上的测试显示,GFreeDet与基于CAD的方法性能相当,为混合现实(MR)应用展示了无模型检测方法的可行性。GFreeDet荣获BOP Challenge 2024模型自由二维检测赛道最佳总体方法和最佳快速方法奖。
Key Takeaways
- GFreeDet是一种无需预设模型的对象检测方法。
- GFreeDet使用高斯贴图和视觉基础模型实现新颖的对象检测。
- 与传统方法不同,GFreeDet无需依赖预先定义的CAD模板。
- GFreeDet能够从参考视频中重构对象并实现未见对象的稳健检测。
- 在BOP-H3标准上的测试显示,GFreeDet性能优异,与基于CAD的方法相当。
- GFreeDet对于混合现实(MR)应用具有可行性。
点此查看论文截图


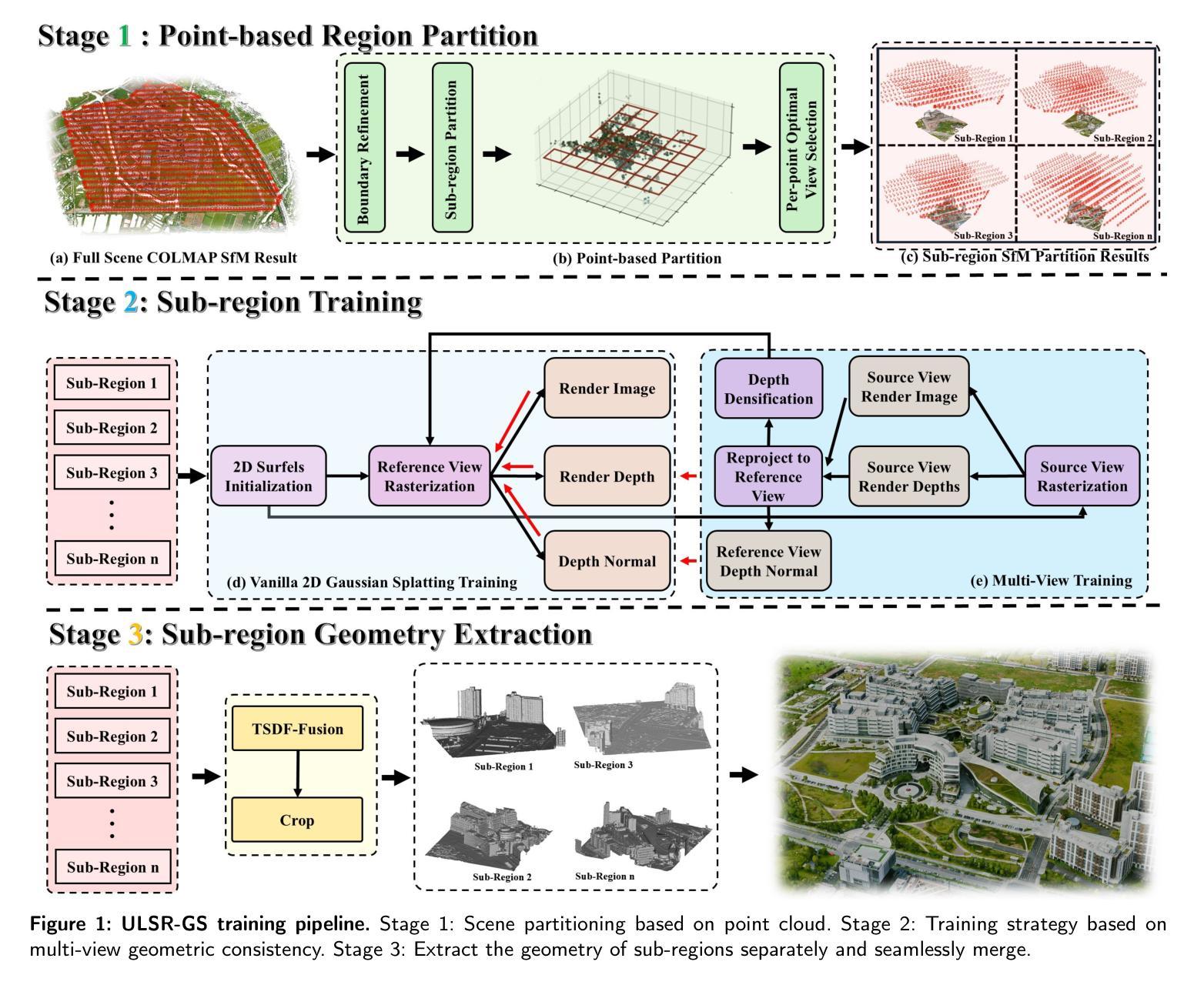
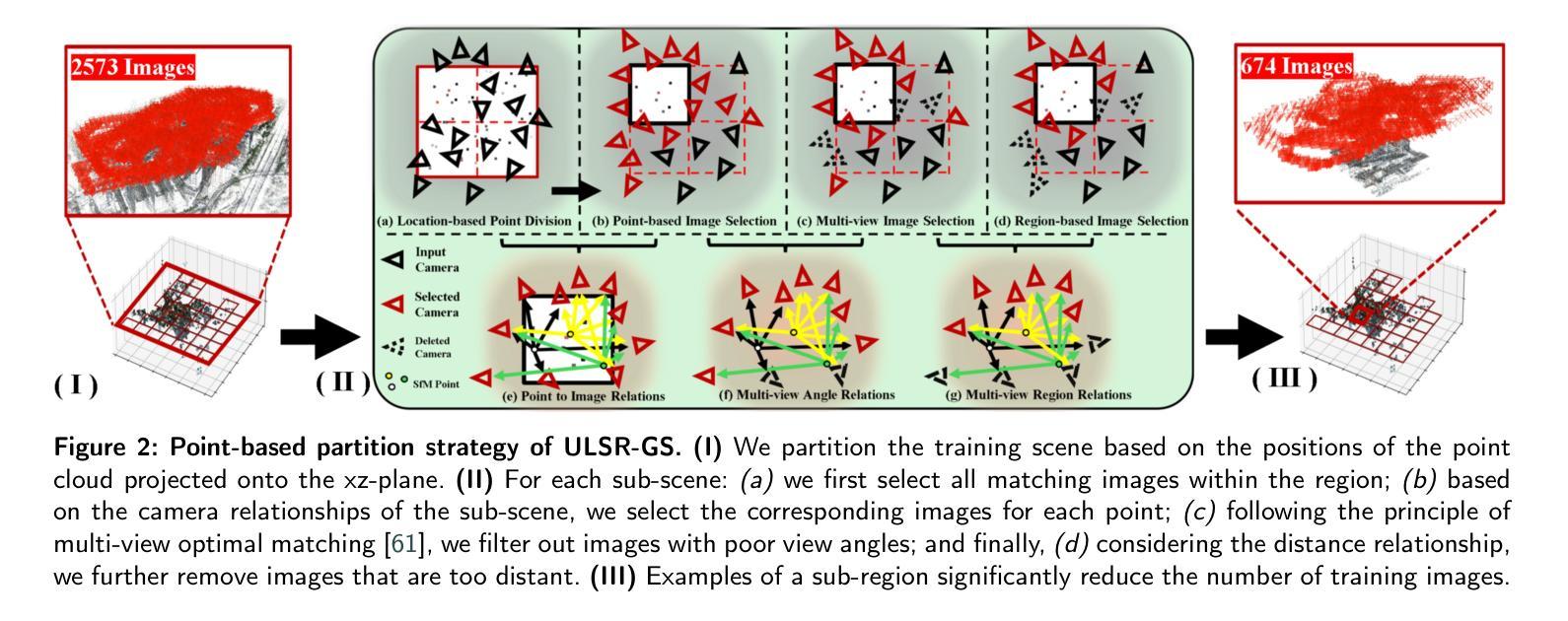
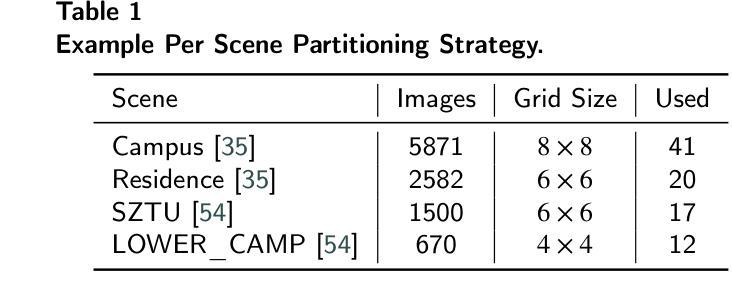
ULSR-GS: Ultra Large-scale Surface Reconstruction Gaussian Splatting with Multi-View Geometric Consistency
Authors:Zhuoxiao Li, Shanliang Yao, Yong Yue, Wufan Zhao, Rongjun Qin, Angel F. Garcia-Fernandez, Andrew Levers, Xiaohui Zhu
While Gaussian Splatting (GS) demonstrates efficient and high-quality scene rendering and small area surface extraction ability, it falls short in handling large-scale aerial image surface extraction tasks. To overcome this, we present ULSR-GS, a framework dedicated to high-fidelity surface extraction in ultra-large-scale scenes, addressing the limitations of existing GS-based mesh extraction methods. Specifically, we propose a point-to-photo partitioning approach combined with a multi-view optimal view matching principle to select the best training images for each sub-region. Additionally, during training, ULSR-GS employs a densification strategy based on multi-view geometric consistency to enhance surface extraction details. Experimental results demonstrate that ULSR-GS outperforms other state-of-the-art GS-based works on large-scale aerial photogrammetry benchmark datasets, significantly improving surface extraction accuracy in complex urban environments. Project page: https://ulsrgs.github.io.
虽然高斯涂抹(GS)在场景渲染和小区域表面提取方面表现出高效且高质量的能力,但在处理大规模航空图像表面提取任务时却表现不足。为了克服这一缺陷,我们推出了ULSR-GS,这是一个专门用于超大规模场景高保真表面提取的框架,解决了现有基于GS的网格提取方法的局限性。具体来说,我们提出了一种点-照片分区方法,结合多视角最佳视角匹配原则,为每个子区域选择最佳的训练图像。此外,在训练过程中,ULSR-GS采用基于多视角几何一致性的密集化策略,以提高表面提取的细节。实验结果表明,ULSR-GS在大型航空摄影测量基准数据集上优于其他最先进的基于GS的工作,在复杂的城市环境中显著提高表面提取的准确性。项目页面:https://ulsrgs.github.io。
论文及项目相关链接
PDF Project page: https://ulsrgs.github.io
Summary
GS在高效率和高质量的场景渲染以及小范围表面提取方面表现出优势,但在处理大规模航空图像表面提取任务时存在不足。为解决这一问题,我们提出了ULSR-GS框架,致力于超大规模场景的高保真表面提取,解决了现有基于GS的网格提取方法的局限性。ULSR-GS通过点-照片分割方法与多视角最佳视图匹配原则相结合,选择每个子区域的最佳训练图像。此外,ULSR-GS在训练过程中采用基于多视角几何一致性的致密化策略,以提高表面提取的细节。实验结果表明,ULSR-GS在大型航空摄影测量基准数据集上优于其他最新基于GS的工作,在复杂的城市环境中显著提高表面提取的准确性。
Key Takeaways
- Gaussian Splatting (GS)在场景渲染和小范围表面提取方面表现出色,但在大规模航空图像表面提取任务中存在局限性。
- ULSR-GS框架旨在解决这一问题,实现高保真表面提取在超大规模场景中的应用。
- ULSR-GS采用点-照片分割方法与多视角最佳视图匹配原则,优化训练图像选择。
- 在训练过程中,ULSR-GS利用多视角几何一致性的致密化策略来提高表面提取的细节。
- ULSR-GS在大型航空摄影测量基准数据集上的表现优于其他最新基于GS的方法。
- ULSR-GS在复杂的城市环境中显著提高表面提取的准确性。
点此查看论文截图

OmniRe: Omni Urban Scene Reconstruction
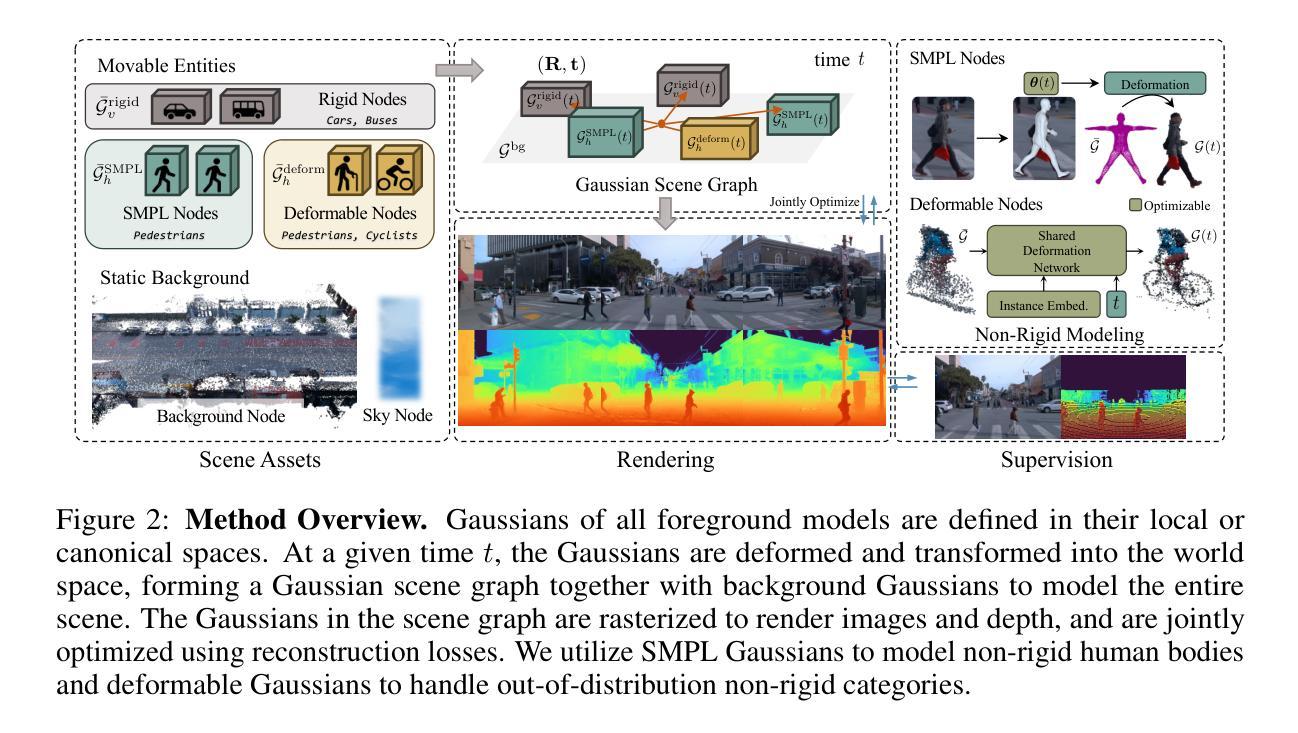
Authors:Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, Yue Wang
We introduce OmniRe, a comprehensive system for efficiently creating high-fidelity digital twins of dynamic real-world scenes from on-device logs. Recent methods using neural fields or Gaussian Splatting primarily focus on vehicles, hindering a holistic framework for all dynamic foregrounds demanded by downstream applications, e.g., the simulation of human behavior. OmniRe extends beyond vehicle modeling to enable accurate, full-length reconstruction of diverse dynamic objects in urban scenes. Our approach builds scene graphs on 3DGS and constructs multiple Gaussian representations in canonical spaces that model various dynamic actors, including vehicles, pedestrians, cyclists, and others. OmniRe allows holistically reconstructing any dynamic object in the scene, enabling advanced simulations (~60Hz) that include human-participated scenarios, such as pedestrian behavior simulation and human-vehicle interaction. This comprehensive simulation capability is unmatched by existing methods. Extensive evaluations on the Waymo dataset show that our approach outperforms prior state-of-the-art methods quantitatively and qualitatively by a large margin. We further extend our results to 5 additional popular driving datasets to demonstrate its generalizability on common urban scenes.
我们介绍了OmniRe,这是一个全面的系统,能够高效地从设备日志创建动态现实世界场景的高保真数字孪生。最近使用神经场或高斯拼贴的方法主要集中在车辆上,阻碍了为下游应用(例如模拟人类行为)所要求的所有动态前景的全局框架。OmniRe超越了车辆建模,实现了城市场景中各种动态对象的精确、全长重建。我们的方法建立在三维几何扫描系统(3DGS)上,在标准空间中构建多个高斯表示,对包括车辆、行人、骑行者等在内的各种动态参与者进行建模。OmniRe允许全面重建场景中的任何动态对象,能够进行高级模拟(~60Hz),包括人类参与的场景,如行人行为模拟和人机互动。这种全面的模拟能力是现有方法无法比拟的。在Waymo数据集上的广泛评估表明,我们的方法无论在数量上还是质量上都大大优于现有最先进的方法。我们进一步将结果扩展到五个其他流行的驾驶数据集上,以证明其在常见城市场景上的通用性。
论文及项目相关链接
PDF See the project page for code, video results and demos: https://ziyc.github.io/omnire/
Summary
OmniRe系统是一个全面的高效创建动态现实世界场景高保真数字双胞胎的系统。它通过构建场景图和在标准空间中的多个高斯表示模型,实现对城市场景中各种动态对象的精确、全面重建,包括车辆、行人、骑行者等。OmniRe系统提供高级模拟功能(~60Hz),包括人类参与的场景,如行人行为模拟和人机互动。在Waymo数据集上的广泛评估表明,该方法在定量和定性方面均大大优于现有方法,并且在五个流行的驾驶数据集上的结果展示了其在常见城市场景中的通用性。
Key Takeaways
- OmniRe系统是一个用于创建高保真数字双胞胎的全面系统,适用于动态现实世界场景的重建。
- 该系统通过构建场景图和在标准空间中的多个高斯表示模型,实现了城市场景中各种动态对象的精确、全面重建。
- OmniRe系统支持高级模拟功能(~60Hz),包括人类参与的各种场景,如行人行为模拟和人机互动。
- 与现有方法相比,OmniRe系统在Waymo数据集上的表现具有显著优势,定量和定性评估均更胜一筹。
- OmniRe系统的表现具有通用性,不仅在Waymo数据集上表现优秀,而且在五个流行的驾驶数据集上均展示了良好的结果。
- 该系统能够实现对多样动态对象的建模,包括车辆、行人、骑行者等,为下游应用提供了更全面的模拟能力。
点此查看论文截图


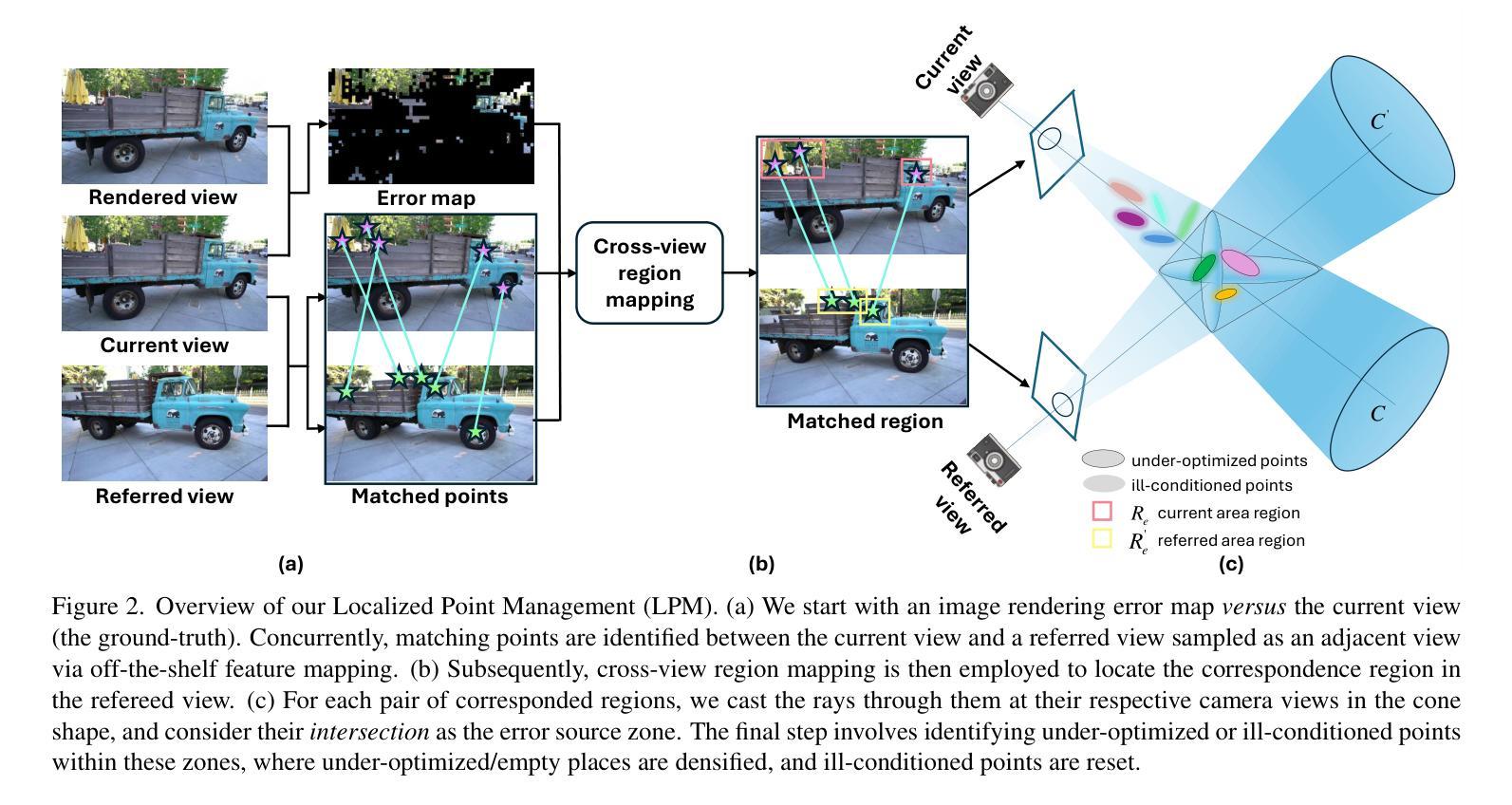
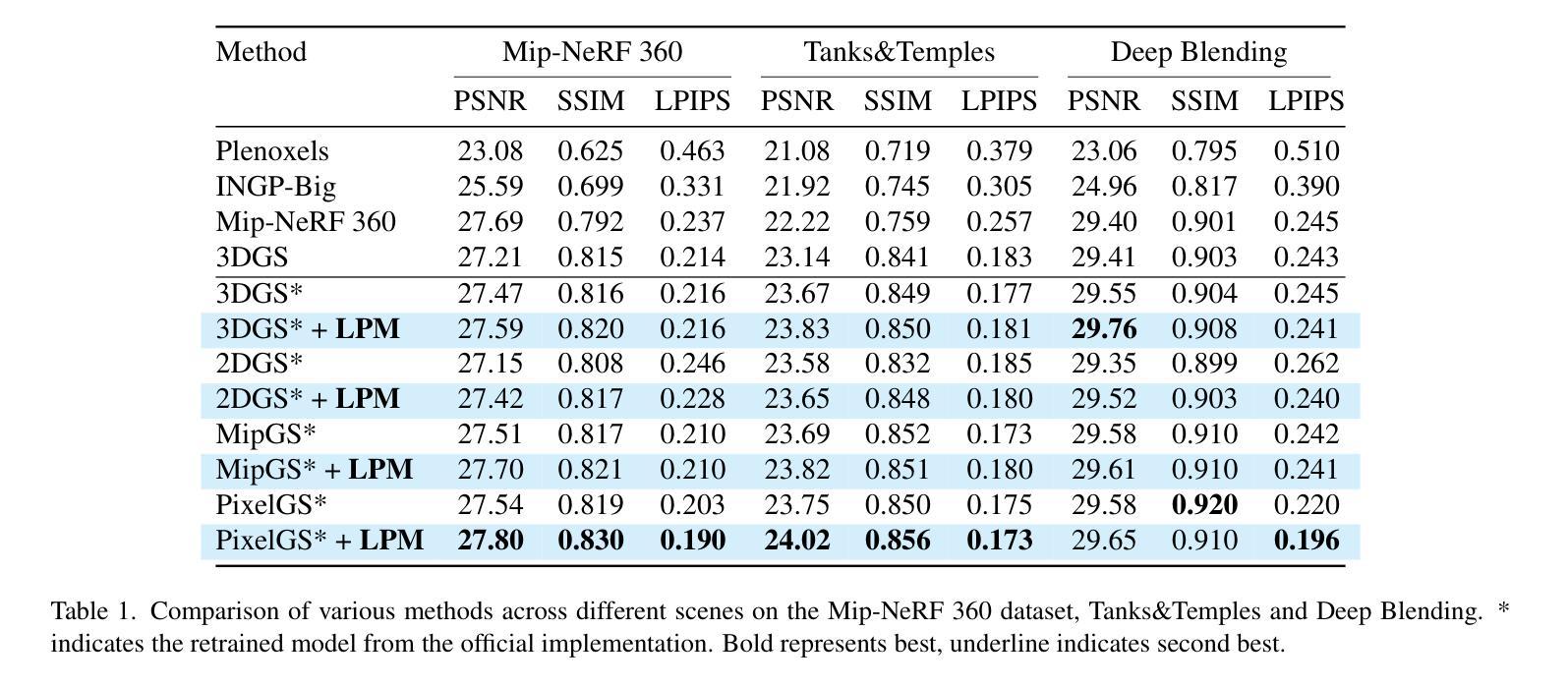
Improving Gaussian Splatting with Localized Points Management
Authors:Haosen Yang, Chenhao Zhang, Wenqing Wang, Marco Volino, Adrian Hilton, Li Zhang, Xiatian Zhu
Point management is critical for optimizing 3D Gaussian Splatting models, as point initiation (e.g., via structure from motion) is often distributionally inappropriate. Typically, Adaptive Density Control (ADC) algorithm is adopted, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. We reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) due to inability of identifying all 3D zones requiring point densification, and lacking an appropriate mechanism to handle ill-conditioned points with negative impacts (e.g., occlusion due to false high opacity). To address these limitations, we propose a Localized Point Management (LPM) strategy, capable of identifying those error-contributing zones in greatest need for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, subject to image rendering errors. We apply point densification in the identified zones and then reset the opacity of the points in front of these regions, creating a new opportunity to correct poorly conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing static 3D and dynamic 4D Gaussian Splatting models with minimal additional cost. Experimental evaluations validate the efficacy of our LPM in boosting a variety of existing 3D/4D models both quantitatively and qualitatively. Notably, LPM improves both static 3DGS and dynamic SpaceTimeGS to achieve state-of-the-art rendering quality while retaining real-time speeds, excelling on challenging datasets such as Tanks & Temples and the Neural 3D Video dataset.
点管理对于优化3D高斯展铺模型至关重要,因为点的启动(例如,通过运动结构)通常分布不当。通常采用的是自适应密度控制(ADC)算法,该算法利用视图平均梯度幅度阈值进行点加密,利用不透明度阈值进行修剪,以及常规的所有点不透明度重置。我们发现,由于无法识别所有需要点加密的3D区域,以及缺乏适当机制来处理具有负面影响的病态点(例如,由于虚假的高不透明度导致的遮挡),此策略在处理复杂/特殊图像区域(例如,透明区域)时受到限制。为了解决这些限制,我们提出了一种局部点管理(LPM)策略,能够识别最需要添加点和几何校正的误差贡献区域。区域识别是通过利用底层的多视图几何约束来实现的,同时受到图像渲染误差的影响。我们在确定的区域中应用点加密,然后重置这些区域前方点的透明度,为校正不良状况的点创造了新机会。作为通用的插件,LPM可以无缝地集成到现有的静态3D和动态4D高斯展铺模型中,且无需额外的成本。实验评估验证了我们LPM在提高各种现有3D/4D模型的效果方面,无论是定量还是定性都是有效的。值得注意的是,LPM改进了静态3DGS和动态SpaceTimeGS,在保持实时速度的同时实现了最先进的渲染质量,在具有挑战性的数据集(如Tanks & Temples和Neural 3D Video数据集)上表现出色。
论文及项目相关链接
PDF CVPR 2025 (Highlight). Github: https://happy-hsy.github.io/projects/LPM/
Summary
本文指出在优化3D高斯展铺模型时,点管理至关重要。现有的自适应密度控制(ADC)算法在处理复杂或特殊图像区域时存在局限性。为此,本文提出了一种局部点管理(LPM)策略,通过识别最需要增加点和进行几何校正的误差贡献区域,来改善模型性能。实验评估表明,LPM能有效提升各种现有3D/4D模型的效果,并且在具有挑战性的数据集上实现了实时的高品质渲染。
Key Takeaways
- 点管理对于优化3D高斯展铺模型至关重要。
- 现有ADC算法在处理复杂或特殊图像区域时存在局限性。
- LPM策略通过识别需要增加点和进行几何校正的误差贡献区域,改进了模型性能。
- LPM策略利用多视角几何约束来实现区域识别。
- LPM策略在识别区域进行点加密,并重置这些区域前沿点的透明度,纠正不良状况点。
- LPM可无缝集成到现有的静态3D和动态4D高斯展铺模型中,且额外成本较低。
点此查看论文截图