⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-23 更新
FlowReasoner: Reinforcing Query-Level Meta-Agents
Authors:Hongcheng Gao, Yue Liu, Yufei He, Longxu Dou, Chao Du, Zhijie Deng, Bryan Hooi, Min Lin, Tianyu Pang
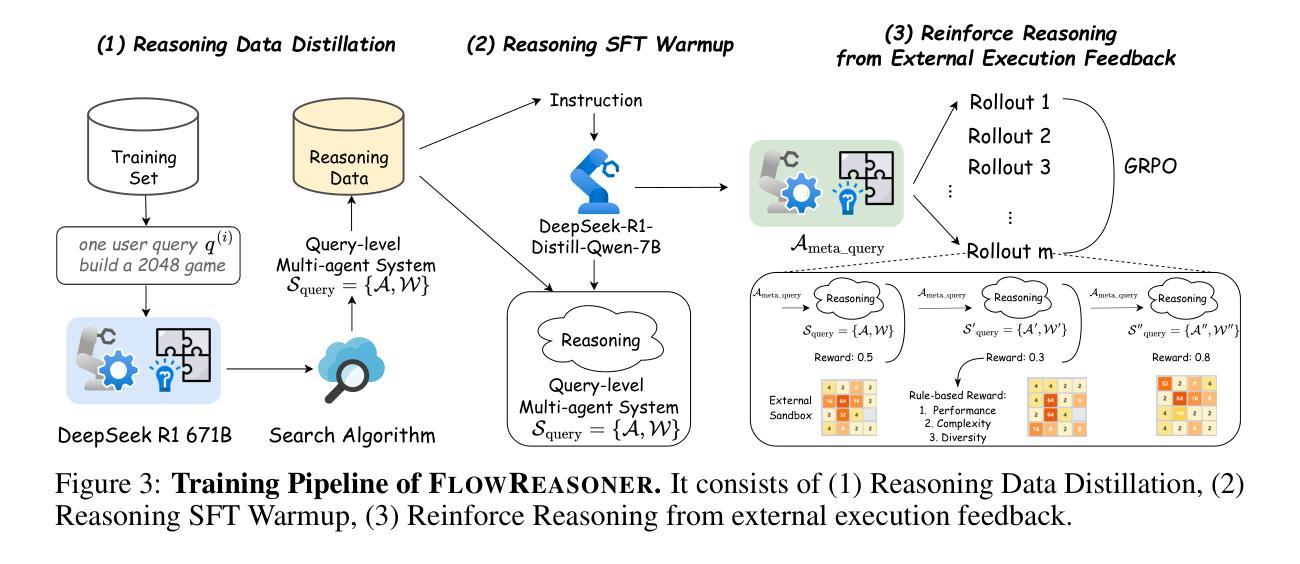
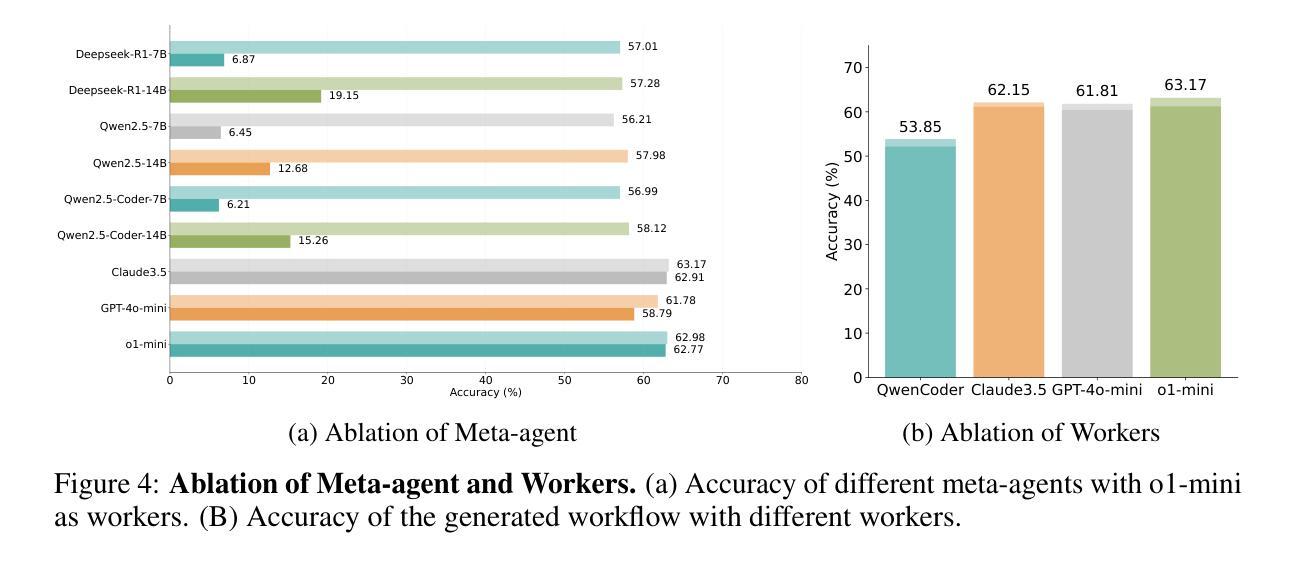
This paper proposes a query-level meta-agent named FlowReasoner to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-based meta-agent via external execution feedback. Concretely, by distilling DeepSeek R1, we first endow the basic reasoning ability regarding the generation of multi-agent systems to FlowReasoner. Then, we further enhance it via reinforcement learning (RL) with external execution feedback. A multi-purpose reward is designed to guide the RL training from aspects of performance, complexity, and efficiency. In this manner, FlowReasoner is enabled to generate a personalized multi-agent system for each user query via deliberative reasoning. Experiments on both engineering and competition code benchmarks demonstrate the superiority of FlowReasoner. Remarkably, it surpasses o1-mini by 10.52% accuracy across three benchmarks. The code is available at https://github.com/sail-sg/FlowReasoner.
本文提出了一种名为FlowReasoner的查询级元代理,用于自动化设计查询级多代理系统,即针对每个用户查询设计一个系统。我们的核心思想是通过外部执行反馈来激励基于推理的元代理。具体来说,我们通过借鉴DeepSeek R1,首先赋予FlowReasoner关于生成多代理系统的基本推理能力。然后,我们借助强化学习(RL)和外部执行反馈进一步增强其能力。设计了一个多用途奖励来从性能、复杂性和效率方面引导RL训练。通过这种方式,FlowReasoner能够通过审慎推理为每个用户查询生成个性化的多代理系统。工程和竞赛代码基准上的实验证明了FlowReasoner的优越性。值得注意的是,它在三个基准测试上的准确率超越了o1-mini达10.52%。代码可从https://github.com/sail-sg/FlowReasoner获取。
论文及项目相关链接
Summary
自动化查询级多智能体系统设计的新方法。提出使用名为FlowReasoner的查询级元智能体,根据用户查询生成个性化系统。结合深度分析和强化学习,实现高效、性能优越的系统生成。代码已公开。
Key Takeaways
- FlowReasoner被提出用于自动化设计查询级多智能体系统。
- 核心思想是通过外部执行反馈来激励基于推理的元智能体。
- 结合DeepSeek R1的基本推理能力,增强FlowReasoner的多智能体系统生成能力。
- 使用强化学习进行进一步改进。
- 设计了一个多功能的奖励来指导强化学习的训练,涉及性能、复杂性和效率方面。
- FlowReasoner能够通过深思熟虑的推理为每个用户查询生成个性化的多智能体系统。
点此查看论文截图

A Self-Improving Coding Agent
Authors:Maxime Robeyns, Martin Szummer, Laurence Aitchison
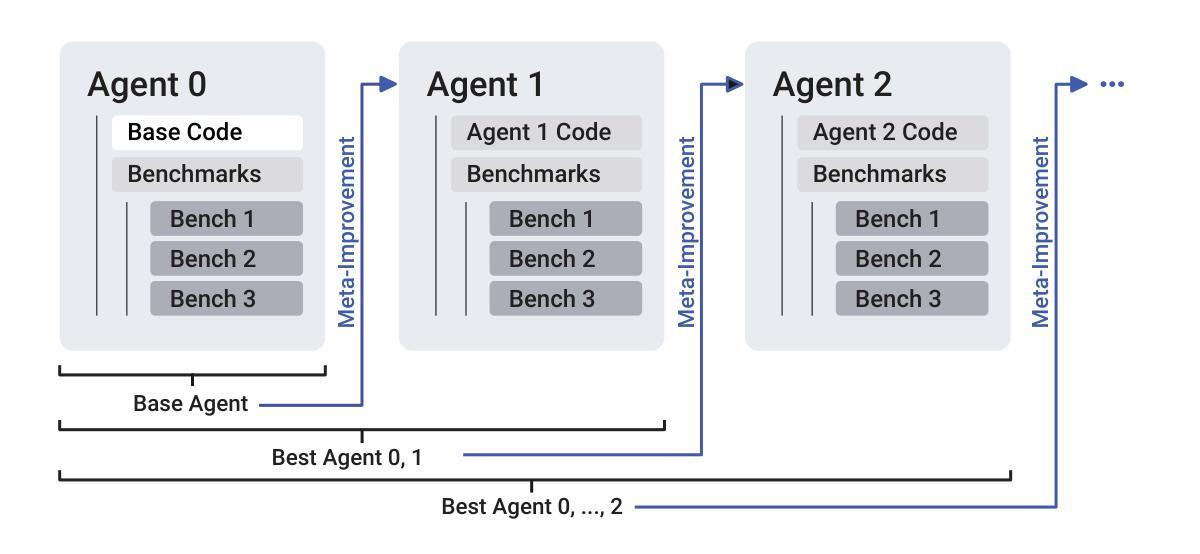
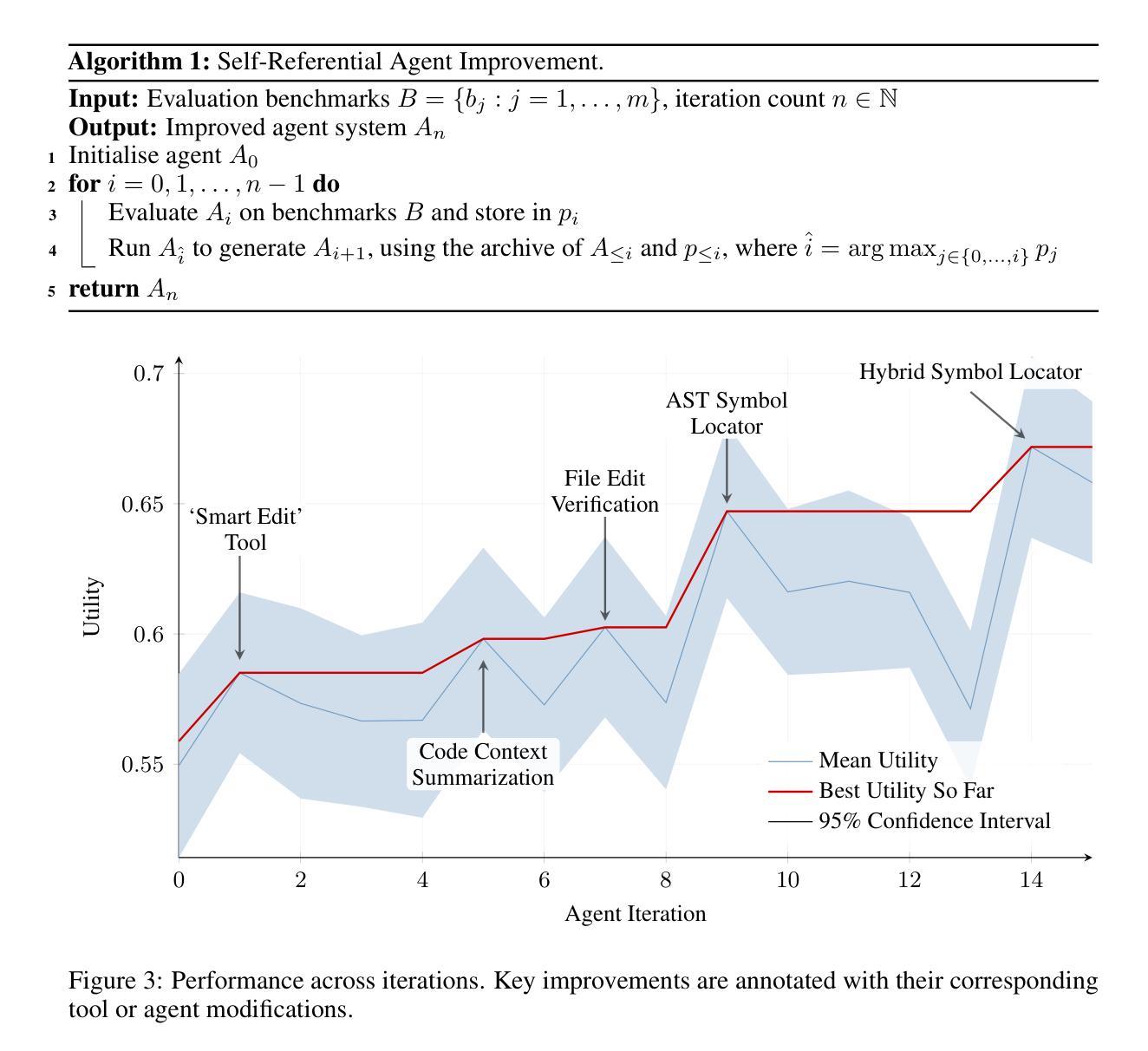
We demonstrate that an LLM coding agent, equipped with basic coding tools, can autonomously edit itself, and thereby improve its performance on benchmark tasks. We find performance gains from 17% to 53% on a random subset of SWE Bench Verified, with additional performance gains on LiveCodeBench, as well as synthetically generated agent benchmarks. Our work represents an advancement in the automated and open-ended design of agentic systems, and provides a reference agent framework for those seeking to post-train LLMs on tool use and other agentic tasks.
我们展示了一个配备基本编码工具的大型语言模型(LLM)编码代理,可以自主进行编辑,从而在基准任务上提高性能。我们在SWE Bench Verified的随机子集上实现了17%到53%的性能提升,在LiveCodeBench以及合成生成的代理基准测试上实现了额外的性能提升。我们的工作代表了自动化和开放设计的智能系统的一种进步,并为那些寻求在工具使用和其他智能任务上对大型语言模型进行后期训练的人提供了一个参考代理框架。
论文及项目相关链接
PDF Published at an ICLR 2025 workshop on Scaling Self-Improving Foundation Models
Summary
一个配备基本编码工具的大型语言模型编码智能体可以自主编辑自身,从而提高基准任务的性能。在SWE Bench Verified随机子集上,性能提升了17%至53%,LiveCodeBench以及合成生成的智能体基准上也有额外的性能提升。本研究代表了自动化开放式智能系统设计的一个进步,为寻求对工具使用和其他智能任务的后期训练的语言模型提供了参考框架。
Key Takeaways
- 大型语言模型编码智能体具备自主编辑能力。
- 智能体通过自主编辑能显著提高基准任务的性能。
- 在SWE Bench Verified随机子集上的性能提升范围在17%至53%。
- 智能体在LiveCodeBench上也有额外的性能提升。
- 研究展示了自动化开放式智能系统设计的进步。
- 为寻求工具使用和其他智能任务后期训练的语言模型提供了参考框架。
点此查看论文截图

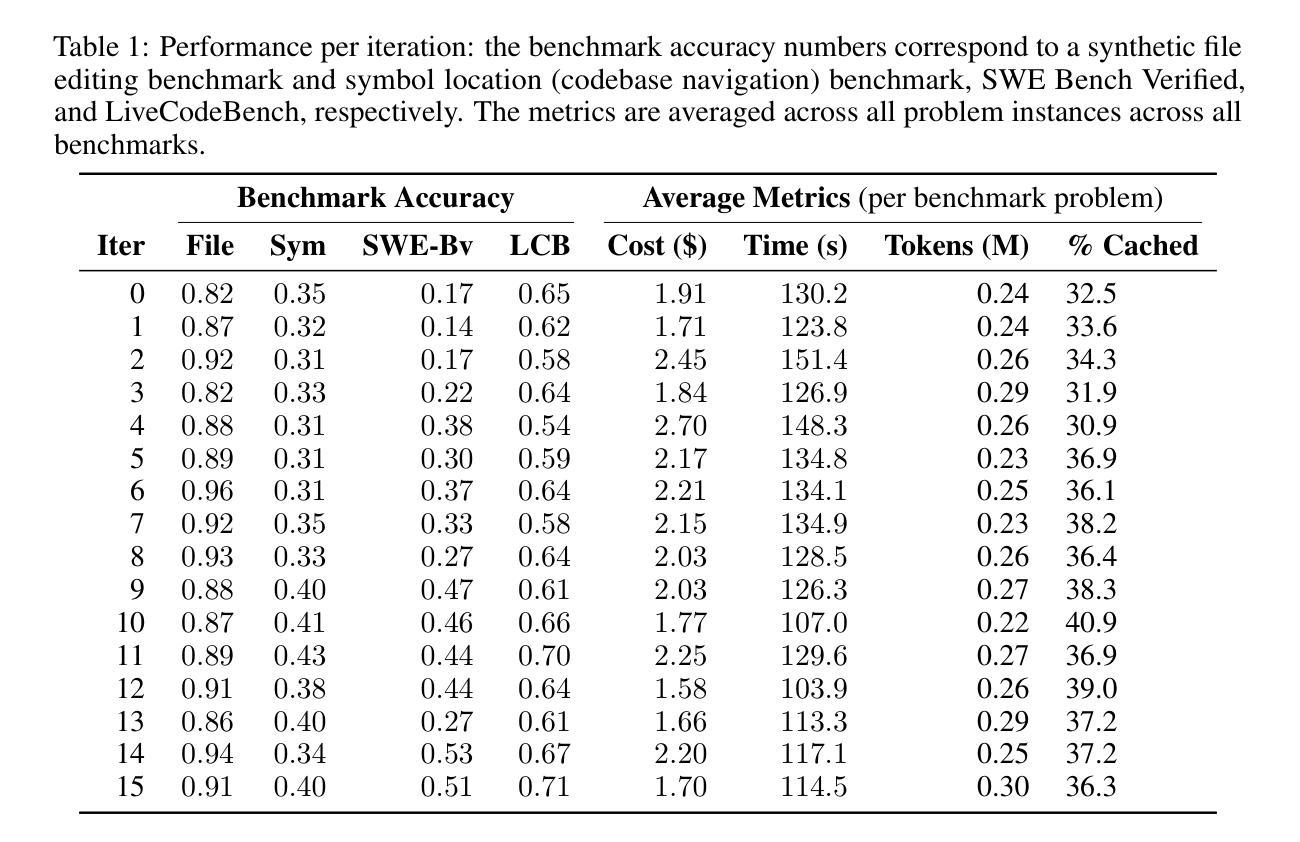
Neural ATTF: A Scalable Solution to Lifelong Multi-Agent Path Planning
Authors:Kushal Shah, Jihyun Park, Seung-Kyum Choi
Multi-Agent Pickup and Delivery (MAPD) is a fundamental problem in robotics, particularly in applications such as warehouse automation and logistics. Existing solutions often face challenges in scalability, adaptability, and efficiency, limiting their applicability in dynamic environments with real-time planning requirements. This paper presents Neural ATTF (Adaptive Task Token Framework), a new algorithm that combines a Priority Guided Task Matching (PGTM) Module with Neural STA* (Space-Time A*), a data-driven path planning method. Neural STA* enhances path planning by enabling rapid exploration of the search space through guided learned heuristics and ensures collision avoidance under dynamic constraints. PGTM prioritizes delayed agents and dynamically assigns tasks by prioritizing agents nearest to these tasks, optimizing both continuity and system throughput. Experimental evaluations against state-of-the-art MAPD algorithms, including TPTS, CENTRAL, RMCA, LNS-PBS, and LNS-wPBS, demonstrate the superior scalability, solution quality, and computational efficiency of Neural ATTF. These results highlight the framework’s potential for addressing the critical demands of complex, real-world multi-agent systems operating in high-demand, unpredictable settings.
多智能体拾取与交付(MAPD)是机器人技术中的一个基本问题,特别是在仓库自动化和物流等应用中。现有解决方案在可扩展性、适应性和效率方面经常面临挑战,限制了它们在具有实时规划要求的动态环境中的适用性。本文提出了Neural ATTF(自适应任务令牌框架),这是一种新的算法,它将优先级引导任务匹配(PGTM)模块与Neural STA(时空A)相结合,这是一种数据驱动的路径规划方法。Neural STA*通过引导学习启发式方法,能够迅速探索搜索空间,增强路径规划能力,并确保在动态约束下避免碰撞。PGTM对延迟的智能体进行优先级排序,并根据最接近这些任务的智能体动态分配任务,优化连续性和系统吞吐量。与最新最先进的MAPD算法(包括TPTS、CENTRAL、RMCA、LNS-PBS和LNS-wPBS)的实验评估表明,Neural ATTF在可扩展性、解决方案质量和计算效率方面具有优势。这些结果突显了该框架在满足复杂、现实世界多智能体系统在高度需求、不可预测环境中需求方面的潜力。
论文及项目相关链接
PDF 13 Pages, 5 Figures, 5 Tables
Summary
神经网络ATTF(自适应任务令牌框架)是一种结合了优先级引导任务匹配模块与神经网络STA(时空A)数据驱动路径规划方法的算法。它提高了路径规划的速度,保证了动态约束下的避障能力,并优化了多智能体的连续性和系统吞吐量。实验评估表明,神经网络ATTF在解决多智能体拾取与交付问题的性能优于其他先进算法,具有更好的可扩展性、解决方案质量和计算效率。
Key Takeaways
- 神经网络ATTF是一种针对多智能体拾取与交付问题的新型算法。
- 该算法结合了优先级引导任务匹配模块与神经网络STA(时空A)路径规划方法。
- 神经网络STA*能够实现快速搜索空间,通过引导学习到的启发式方法确保动态约束下的避障。
- 优先级引导任务匹配模块能够优先处理延迟的智能体并动态分配任务,优化智能体的连续性和系统吞吐量。
- 实验评估表明,神经网络ATTF在解决多智能体拾取与交付问题方面具有出色的可扩展性、解决方案质量和计算效率。
- 该算法在仓库自动化和物流等应用中具有潜在的应用价值。
点此查看论文截图

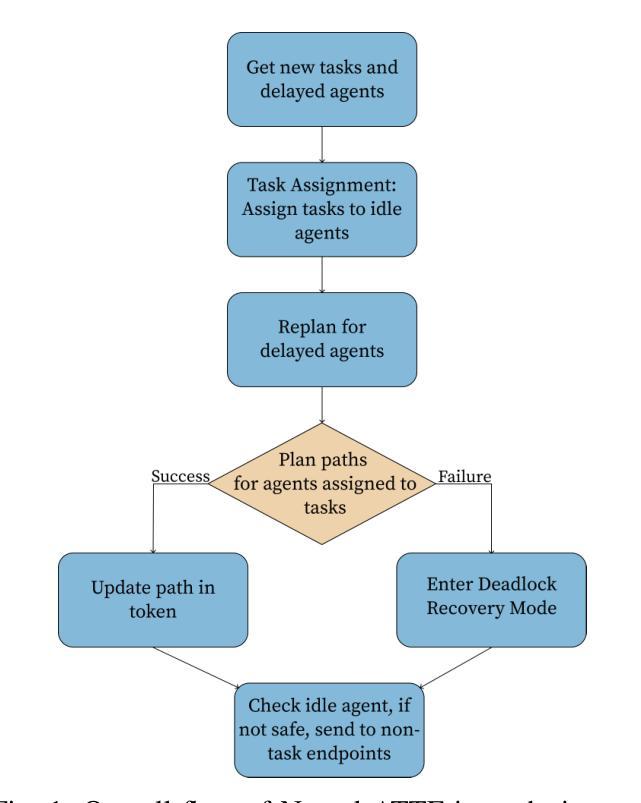

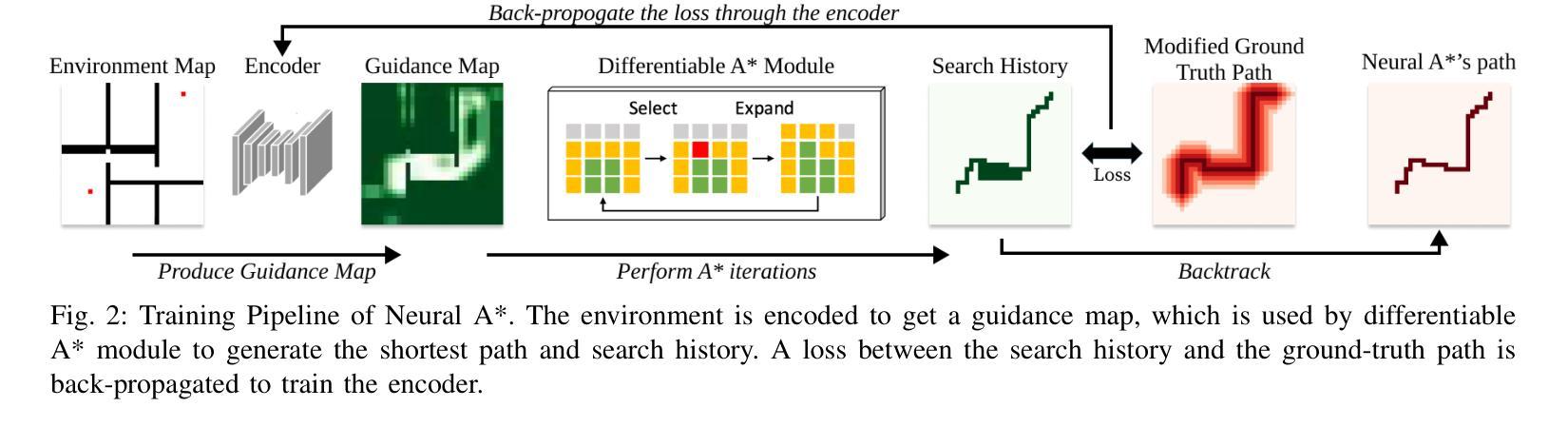
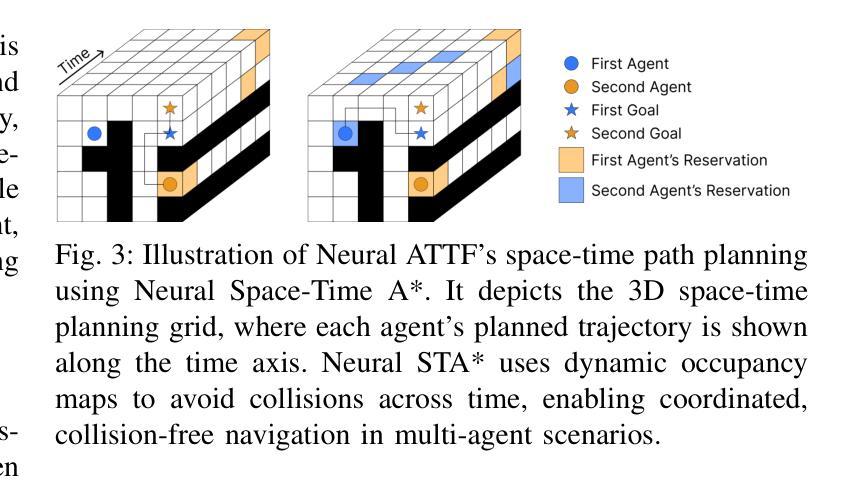
Text-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Authors:Shilin Zhang, Zican Hu, Wenhao Wu, Xinyi Xie, Jianxiang Tang, Chunlin Chen, Daoyi Dong, Yu Cheng, Zhenhong Sun, Zhi Wang
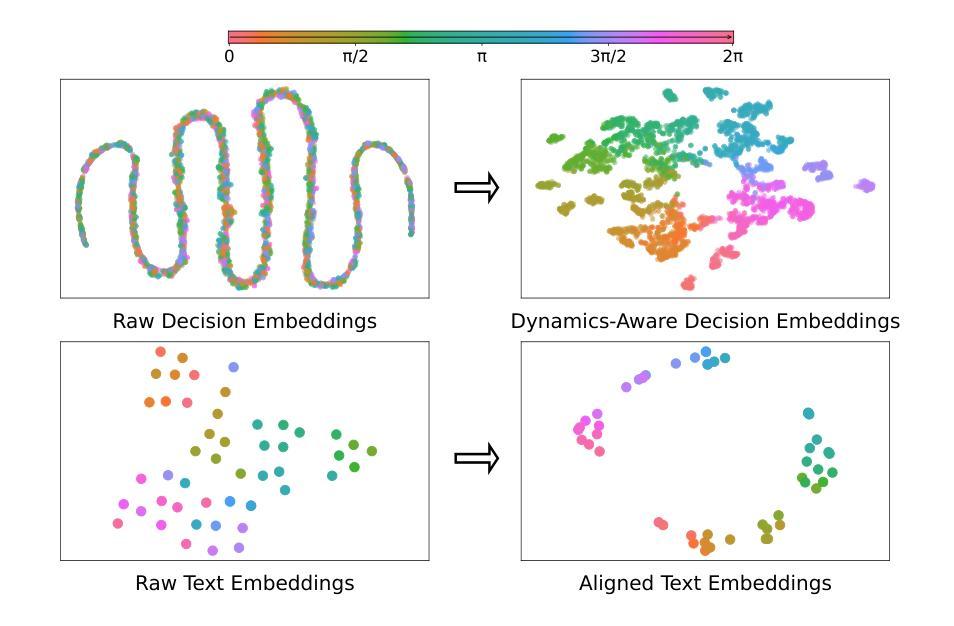
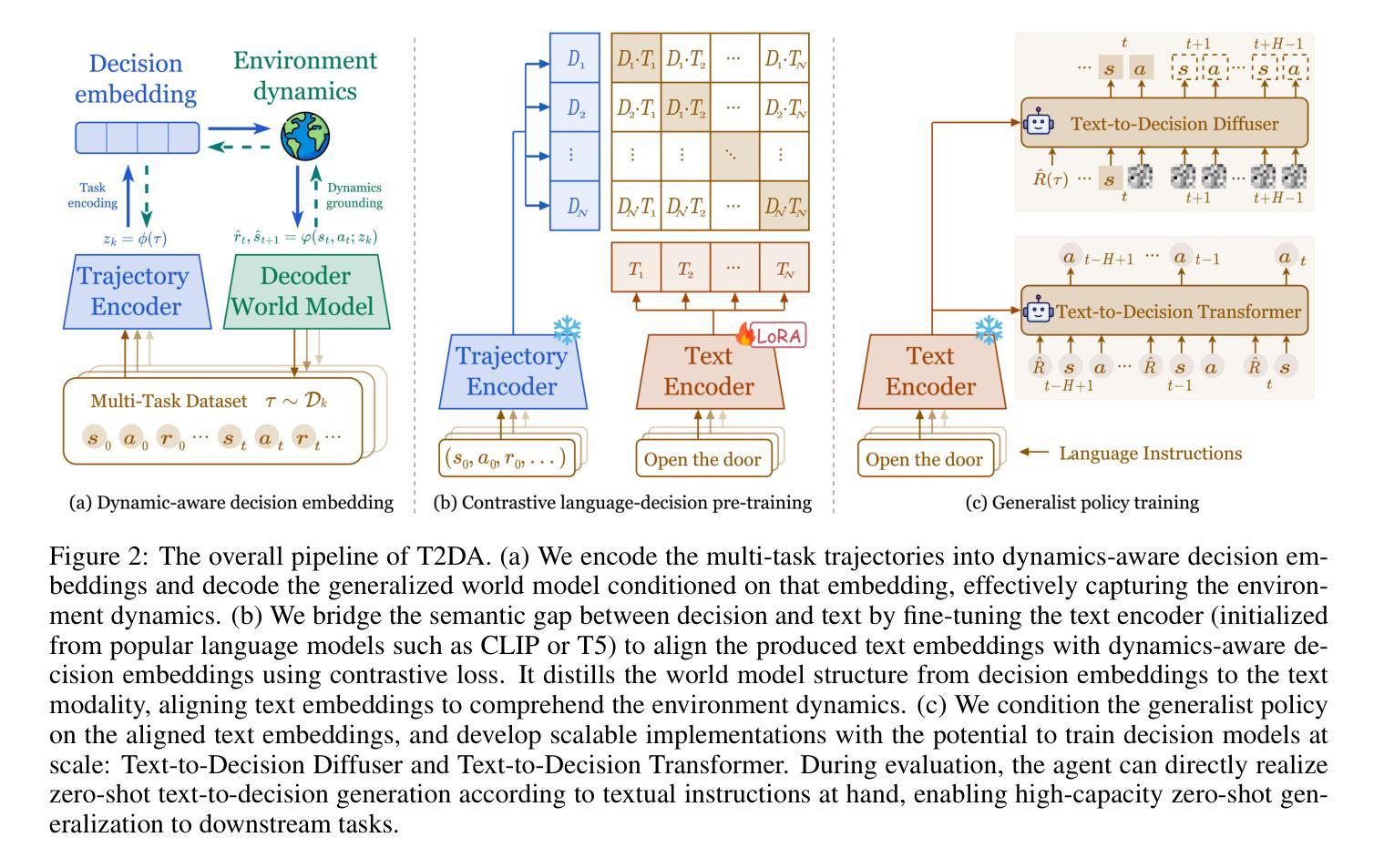
RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
强化学习系统通常通过从高质量样本或预热探索中推断任务信念来解决泛化问题。这种有限的形式限制了它们的通用性和可用性,因为这些监督信号是昂贵的,甚至对于未见过的任务,提前获取也是不可行的。直接从关于决策任务的原始文本中学习是一个很有前途的替代方案,可以充分利用更广泛的监督来源。在论文中,我们提出了文本到决策代理(T2DA),这是一个简单且可扩展的框架,用自然语言监督通用策略学习。我们首先引入一个通用世界模型,将多任务决策数据编码到一个动态感知的嵌入空间。然后,受到CLIP的启发,我们预测哪种文本描述与哪种决策嵌入相匹配,通过对比语言决策预训练有效地弥合了它们的语义差距,并将文本嵌入对齐以理解环境动态。在训练文本条件下的通用策略之后,代理可以直接实现零射击文本到决策生成,以响应语言指令。在MuJoCo和Meta-World基准测试上的综合实验表明,T2DA促进了高容量零射击泛化,并超越了各种类型的基线。
论文及项目相关链接
PDF 18 pages, 8 figures
Summary:
论文提出了一种名为Text-to-Decision Agent(T2DA)的框架,能够通过自然语言直接进行决策任务学习,以广泛的监督源提高通用策略学习的效率。该框架引入了通用世界模型,将多任务决策数据编码为动态感知的嵌入空间,并通过对比语言决策预训练,缩小文本描述与决策嵌入之间的语义差距,实现对环境动态的理解。训练后,该智能体可直接根据语言指令进行零射击决策生成。在MuJoCo和Meta-World基准测试上,T2DA表现出优异的高容量零射击泛化能力,超越了各种基线。
Key Takeaways:
- T2DA框架允许智能体通过自然语言直接进行决策任务学习,提高通用策略学习的效率。
- 通过引入通用世界模型,将多任务决策数据编码为动态感知的嵌入空间。
- 采用对比语言决策预训练,缩小文本描述与决策嵌入之间的语义差距。
- 通过预训练,智能体能够理解环境动态。
- T2DA实现了零射击决策生成,即智能体能够直接根据语言指令进行决策。
- 在MuJoCo和Meta-World基准测试中,T2DA表现出优异的高容量零射击泛化能力。
点此查看论文截图

Event triggered optimal formation control for nonlinear multi-agent systems under Denial-of-Service attacks
Authors:Jianqiang Zhang, Kaijun Yang
This paper investigates the optimal formation control problem of a class of nonlinear multi-agent systems(MASs) under Denial-of-Service(DoS) attacks. We design the optimal formation control law using an event-triggered control scheme to achieve formation objectives under DoS attacks. Critic neural network (NN)-based approach is employed to achieve the optimal control policy under DoS attacks. Event-triggered mechanism is introduced to ensure the saving of control resources. Additionally, Lyapunov stability theory is utilized to demonstrate that the local neighborhood formation error exhibits exponential stability and the estimation error of weights are uniformly ultimately bounded. Finally, the effectiveness of the control algorithm is validated through matlab simulations. The results indicate that under DoS attacks, the nonlinear MAS successfully achieves the desired formation for the MAS.
本文研究DoS攻击下一类非线性多智能体系统(MAS)的最优编队控制问题。我们采用事件触发控制方案,设计最优编队控制律,以实现DoS攻击下的编队目标。采用基于批判神经网络(NN)的方法,实现DoS攻击下的最优控制策略。引入事件触发机制,确保控制资源的节约。此外,利用Lyapunov稳定性理论证明了局部邻域编队误差呈指数稳定,权重估计误差是一致有界的。最后,通过matlab仿真验证了控制算法的有效性。结果表明,在DoS攻击下,非线性MAS成功实现了期望的编队。
论文及项目相关链接
Summary
该论文研究了在拒绝服务攻击下的一类非线性多智能体系统(MASs)的最优编队控制问题。通过使用基于事件触发的控制方案,实现了DoS攻击下的编队目标。利用批判神经网络(NN)的方法实现了DoS攻击下的最优控制策略。引入事件触发机制可节约控制资源。同时利用Lyapunov稳定性理论证明了局部邻域编队误差呈指数级稳定,权重估计误差一致有界。最后通过Matlab仿真验证了控制算法的有效性。结果显示,在DoS攻击下,非线性MAS成功实现了期望的编队。
Key Takeaways
- 研究了非线性多智能体系统在拒绝服务攻击下的最优编队控制问题。
- 设计了基于事件触发的最优编队控制律以实现DoS攻击下的编队目标。
- 采用了批判神经网络方法以制定DoS攻击下的最优控制策略。
- 事件触发机制用于节约控制资源。
- 利用Lyapunov稳定性理论证明了局部邻域编队误差的稳定性及权重估计误差的有界性。
- 通过Matlab仿真验证了控制算法的有效性。
点此查看论文截图

ADL: A Declarative Language for Agent-Based Chatbots
Authors:Sirui Zeng, Xifeng Yan
There are numerous agent frameworks capable of creating and orchestrating agents to address complex tasks. However, these frameworks are often too complicated for customer service professionals, who may not have much programming experience but still need an easy way to create chatbots with rich business logic. In this work, we introduce ADL, a Declarative Language for Agent-Based Chatbots. ADL simplifies chatbot development by using natural language programming at its core, making it easier for a broad audience to customize and build task-oriented chatbots. It includes four types of agents and supports integration with custom functions, tool use, and third-party agents. ADL abstracts away implementation details, offering a declarative way to define agents and their interactions, which could ease prompt engineering, testing and debugging. MICA, a multi-agent system designed to interpret and execute ADL programs, has been developed and is now available as an open-source project at https://github.com/Mica-labs/MICA. Its user documentation can be found at https://mica-labs.github.io/.
存在许多能够创建和协调代理以处理复杂任务的代理框架。然而,这些框架通常对于客户服务专业人员来说过于复杂,他们可能没有太多的编程经验,但仍然需要一种简单的创建聊天机器人的方法,该机器人具有丰富的业务逻辑。在此工作中,我们介绍了基于代理聊天机器人的声明性语言ADL。ADL使用自然语言编程作为其核心,简化了聊天机器人的开发过程,使得广泛的受众群体更容易定制和构建面向任务的聊天机器人。它包括四种类型的代理并支持自定义功能集成、工具使用和第三方代理。ADL抽象了实现细节,提供了一种声明的方式来定义代理及其交互,这可以简化提示工程、测试和调试。MICA是一个多代理系统,旨在解释和执行ADL程序,已经被开发并且现在作为开源项目在https://github.com/Mica-labs/MICA上可用。其用户文档可以在https://mica-labs.github.io/上找到。
论文及项目相关链接
Summary
AD(自然语言声明性框架)解决了客户服务专业人员对构建和管理复杂任务导向型聊天机器人的需求。它简化了聊天机器人的开发过程,采用自然语言编程为核心,使得广大用户能够轻松地自定义和构建任务导向型聊天机器人。MICA系统能够解释并执行AD程序,现在作为一个开源项目可用。
Key Takeaways
- 存在许多代理框架能够创建和协调代理来解决复杂的任务,但对于缺乏编程经验的客户服务专业人员来说,这些框架通常过于复杂。
- AD(自然语言声明性框架)被引入以解决这一问题,它简化了聊天机器人的开发过程,并采用自然语言编程为核心。
- AD支持四种类型的代理,并可与自定义功能、工具使用和第三方代理集成。
- AD通过提供声明性方式来定义代理及其交互,从而简化了提示工程、测试和调试。
- MICA是一个多代理系统,用于解释和执行AD程序。
- MICA现在作为一个开源项目可用,用户文档也已提供。
点此查看论文截图





Exploring Collaborative GenAI Agents in Synchronous Group Settings: Eliciting Team Perceptions and Design Considerations for the Future of Work
Authors:Janet G. Johnson, Macarena Peralta, Mansanjam Kaur, Ruijie Sophia Huang, Sheng Zhao, Ruijia Guan, Shwetha Rajaram, Michael Nebeling
While generative artificial intelligence (GenAI) is finding increased adoption in workplaces, current tools are primarily designed for individual use. Prior work established the potential for these tools to enhance personal creativity and productivity towards shared goals; however, we don’t know yet how to best take into account the nuances of group work and team dynamics when deploying GenAI in work settings. In this paper, we investigate the potential of collaborative GenAI agents to augment teamwork in synchronous group settings through an exploratory study that engaged 25 professionals across 6 teams in speculative design workshops and individual follow-up interviews. Our workshops included a mixed reality provotype to simulate embodied collaborative GenAI agents capable of actively participating in group discussions. Our findings suggest that, if designed well, collaborative GenAI agents offer valuable opportunities to enhance team problem-solving by challenging groupthink, bridging communication gaps, and reducing social friction. However, teams’ willingness to integrate GenAI agents depended on its perceived fit across a number of individual, team, and organizational factors. We outline the key design tensions around agent representation, social prominence, and engagement and highlight the opportunities spatial and immersive technologies could offer to modulate GenAI influence on team outcomes and strike a balance between augmentation and agency.
随着生成式人工智能(GenAI)在工作场所的普及程度不断提高,当前的主要工具设计主要是为了个人使用。先前的研究已经证明了这些工具在促进个人创造力和生产力以实现共同目标方面的潜力;然而,我们仍然不知道如何在部署GenAI时考虑到团队合作中的细微差别和团队动态。本文旨在探究协作式GenAI代理在同步团队环境中的潜力,通过一项涉及25名专业人士、跨越六个团队的探索性研究,包括参与式设计研讨会和个人跟进访谈。我们的研讨会包括一个混合现实原型,模拟能够积极参与小组讨论的协作式GenAI代理。我们的研究发现,如果设计得当,协作式GenAI代理通过挑战群体思维、弥沟通鸿沟和减少社会摩擦,为增强团队解决问题的能力提供了宝贵的机会。然而,团队愿意整合GenAI代理的程度取决于个人、团队和组织层面多个因素的感知契合度。我们概述了关于代理表示、社会突出性和参与性的关键设计冲突,并强调空间和沉浸式技术可以在调节GenAI对团队结果的影响以及平衡增强和代理之间找到平衡方面提供的机会。
论文及项目相关链接
PDF To be published in ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW 2025). 33 pages, 11 figures, 1 table
Summary
人工智能辅助团队合作能够提升团队解决问题的能力。研究通过模拟协作式人工智能参与团队讨论发现,设计良好的协作式人工智能可以挑战团队思维,缩小沟通差距并减少社会摩擦。但是团队接受度取决于多个因素如个体因素、团队因素和组织因素等。对此文章给出了关于智能代理展现形式的关键设计难题及社交、沉浸技术的优势并总结了未来的发展趋势。强调了设计这种协作工具在时空环境中需要的权衡点以实现支持和支持对象的自然交融。
Key Takeaways
- 生成式人工智能(GenAI)工具在设计上主要面向个人使用,但在团队协作中的应用潜力尚未得到充分研究。
- 协作式GenAI代理工具可以在团队讨论中积极参与并提升团队解决问题的能力,包括挑战团队思维、缩小沟通差距和减少社会摩擦。
- 团队协作中采用GenAI工具的接受度受到多个因素影响,包括个体、团队和组织因素。这些因素需要综合考虑以确保工具的顺利融入。
- 设计协作式GenAI工具的关键设计难题包括智能代理的展现形式、社交显著性和参与度等方面。这些问题的解决将有助于实现更自然的团队协作体验。
- 空间沉浸式技术有助于调整人工智能对团队结果的影响,实现增强与自主之间的平衡。这种技术可以为协作式GenAI工具的设计提供新的可能性。
点此查看论文截图


An LLM-enabled Multi-Agent Autonomous Mechatronics Design Framework
Authors:Zeyu Wang, Frank P. -W. Lo, Qian Chen, Yongqi Zhang, Chen Lin, Xu Chen, Zhenhua Yu, Alexander J. Thompson, Eric M. Yeatman, Benny P. L. Lo
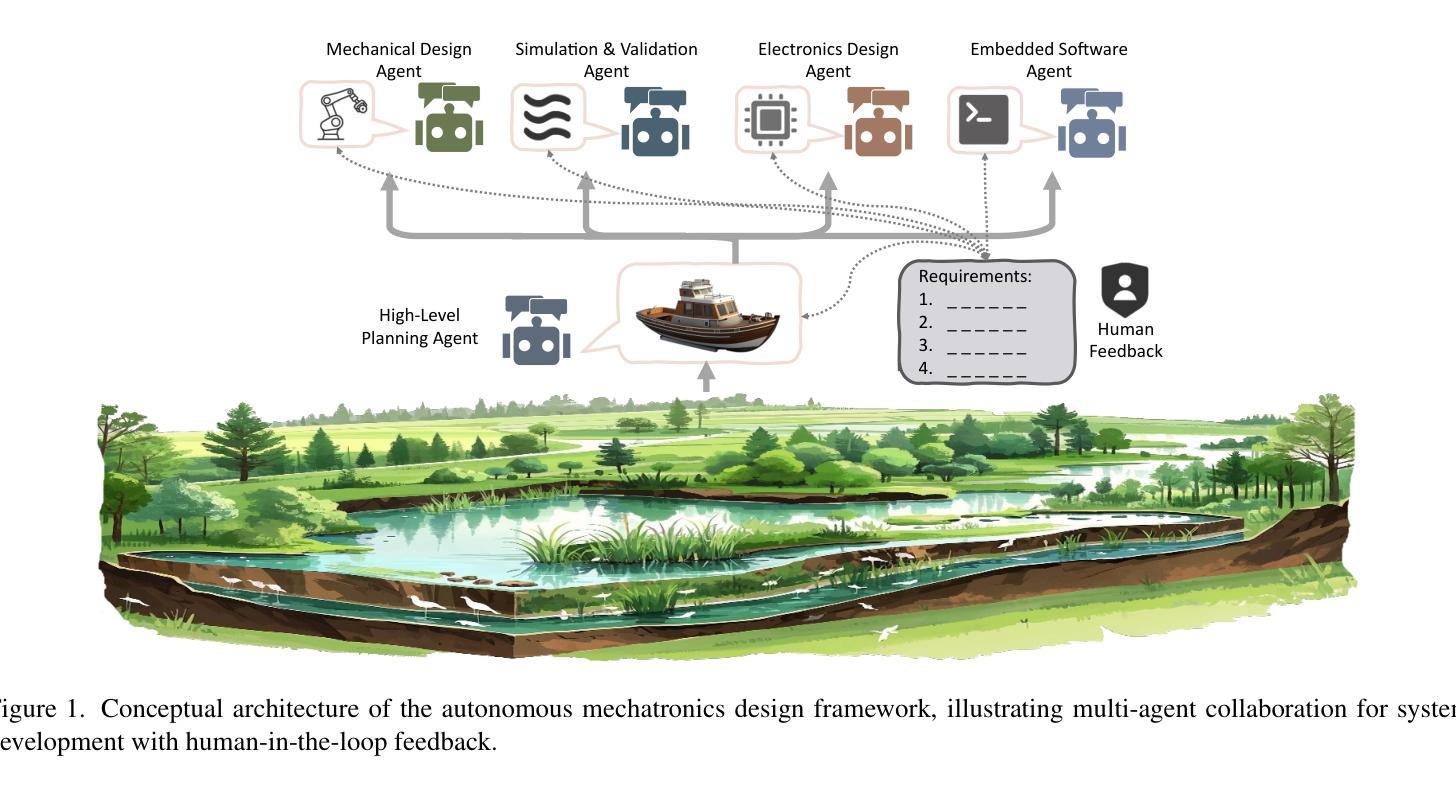
Existing LLM-enabled multi-agent frameworks are predominantly limited to digital or simulated environments and confined to narrowly focused knowledge domain, constraining their applicability to complex engineering tasks that require the design of physical embodiment, cross-disciplinary integration, and constraint-aware reasoning. This work proposes a multi-agent autonomous mechatronics design framework, integrating expertise across mechanical design, optimization, electronics, and software engineering to autonomously generate functional prototypes with minimal direct human design input. Operating primarily through a language-driven workflow, the framework incorporates structured human feedback to ensure robust performance under real-world constraints. To validate its capabilities, the framework is applied to a real-world challenge involving autonomous water-quality monitoring and sampling, where traditional methods are labor-intensive and ecologically disruptive. Leveraging the proposed system, a fully functional autonomous vessel was developed with optimized propulsion, cost-effective electronics, and advanced control. The design process was carried out by specialized agents, including a high-level planning agent responsible for problem abstraction and dedicated agents for structural, electronics, control, and software development. This approach demonstrates the potential of LLM-based multi-agent systems to automate real-world engineering workflows and reduce reliance on extensive domain expertise.
现有的大型语言模型赋能的多智能体框架主要局限于数字或模拟环境,并局限于狭窄的知识域,这限制了它们在需要物理实体设计、跨学科集成和约束感知推理的复杂工程任务中的应用。本文提出了一种多智能体自主机电设计框架,该框架整合机械设计、优化、电子和软件工程的专长,以自主生成功能原型,并尽量减少直接人为设计输入。该框架主要通过语言驱动的工作流程进行操作,并融入结构化的人类反馈,以确保在现实世界的约束下具有稳健的性能。为了验证其能力,该框架被应用于涉及水质自主监测和采样的现实世界挑战中,传统的方法是劳动密集型的并且具有生态破坏性。利用所提出的系统,开发了一种功能齐全的全自主船只,具有优化的推进能力、成本效益高的电子设备和先进的控制功能。设计过程由专职智能体完成,包括负责问题抽象的高级规划智能体以及结构、电子、控制和软件开发的专用智能体。这种方法展示了基于大型语言模型的多智能体系统在自动化现实世界工程工作流程和减少对广泛领域专业知识的依赖方面的潜力。
论文及项目相关链接
PDF Accepted by CVPR 2025 Workshop
Summary
大規模語言模型(LLM)赋能的多智能体框架目前主要局限于数字或模拟环境,并仅限于狭窄的知识域,限制了其在复杂工程任务中的应用,这些任务需要设计物理实体、跨学科整合和约束感知推理。本研究提出一种多智能体自主机电一体化设计框架,该框架整合机械设计、优化、电子和软件工程的专长,通过语言驱动的工作流程自主生成功能原型,并最小化直接人工设计输入。该框架通过结构化的人类反馈来确保在现实世界的约束下实现稳健性能。为了验证其能力,该框架被应用于涉及水质自主监测和采样的现实挑战中。通过使用该系统,开发了一种具有优化推进、经济电子元件和先进控制功能的完全自主船只。设计过程由专门智能体完成,包括负责问题抽象的高级规划智能体以及负责结构、电子、控制和软件开发的专门智能体。该方法展示了大规模语言模型为基础的多智能体系统在自动化现实工程工作流程方面的潜力,并减少了我们对广泛领域专业知识的依赖。
Key Takeaways
- LLM赋能的多智能体框架主要局限于数字或模拟环境,且主要适用于狭窄的知识领域。
- 提出一种多智能体自主机电一体化设计框架,旨在自主生成功能原型,减少对直接人工设计输入的依赖。
- 框架采用语言驱动的工作流程,并结合结构化的人类反馈确保稳健性能。
- 框架应用于现实挑战,如自主水质监测和采样,展示了其潜力。
- 通过开发具有优化推进、经济电子元件和先进控制功能的自主船只,验证了框架的实际应用能力。
- 设计过程由多个专门智能体完成,包括高级规划智能体和负责不同工程领域的智能体。
点此查看论文截图


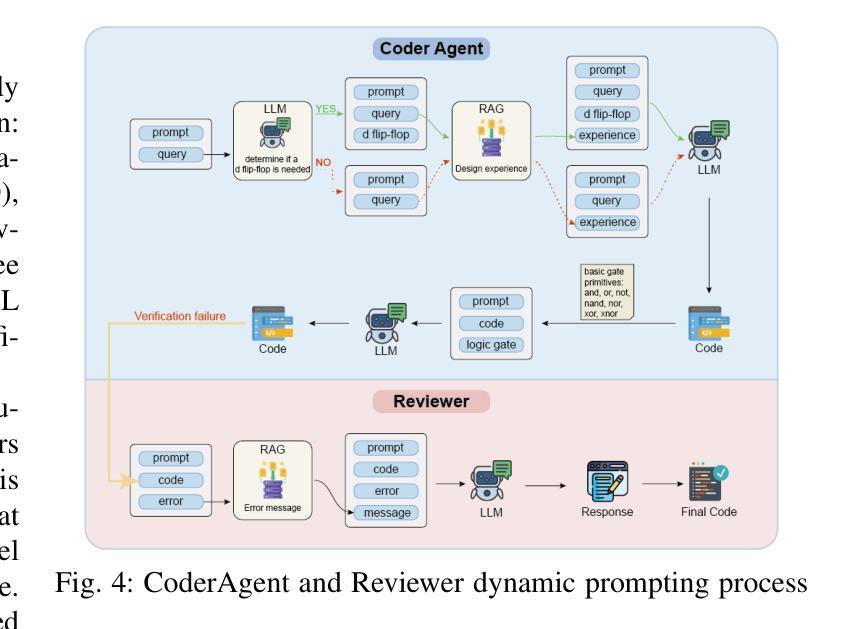
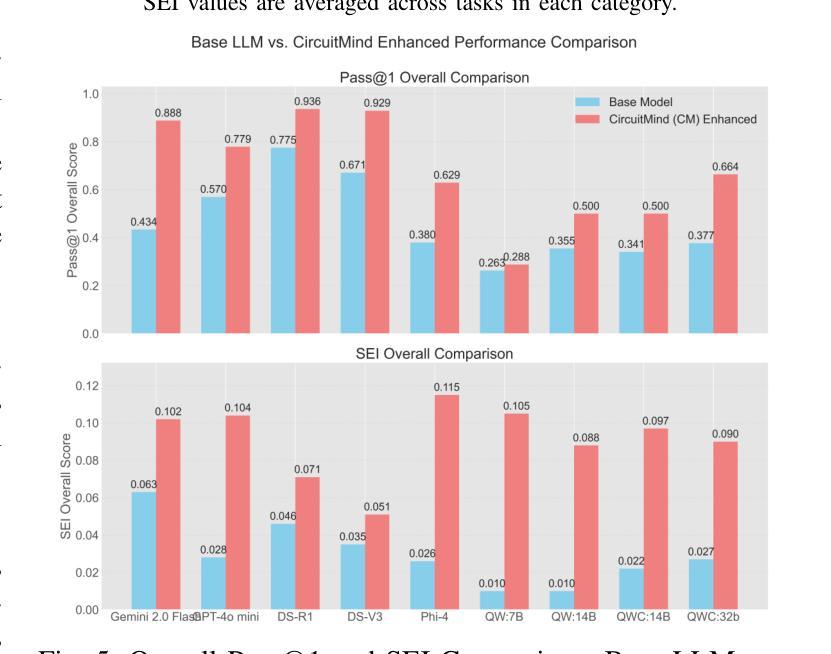
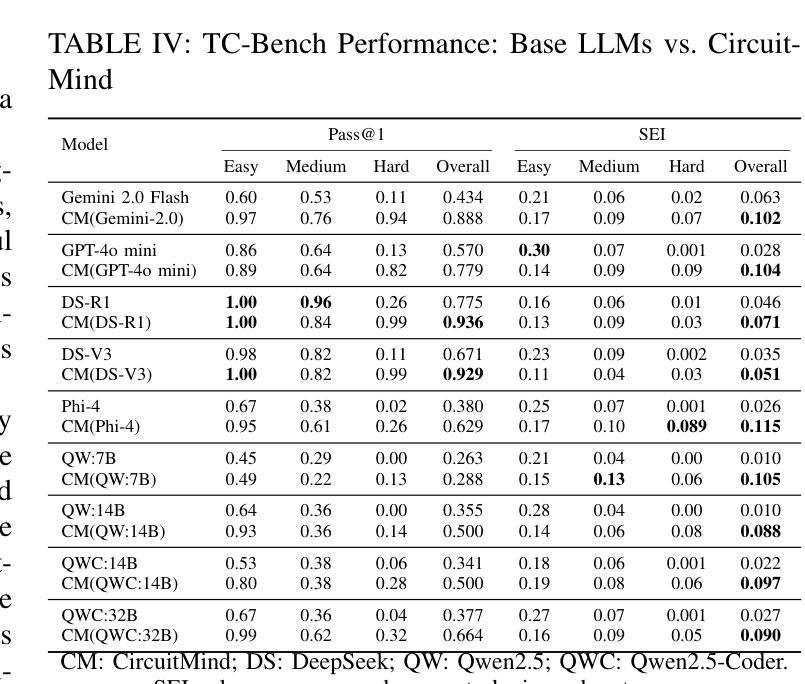
Towards Optimal Circuit Generation: Multi-Agent Collaboration Meets Collective Intelligence
Authors:Haiyan Qin, Jiahao Feng, Xiaotong Feng, Wei W. Xing, Wang Kang
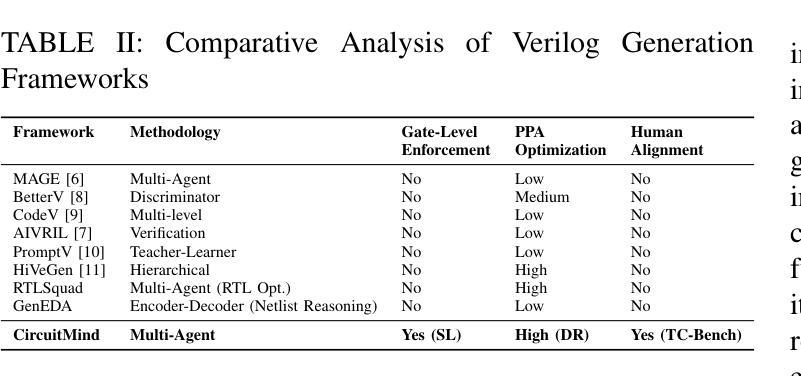
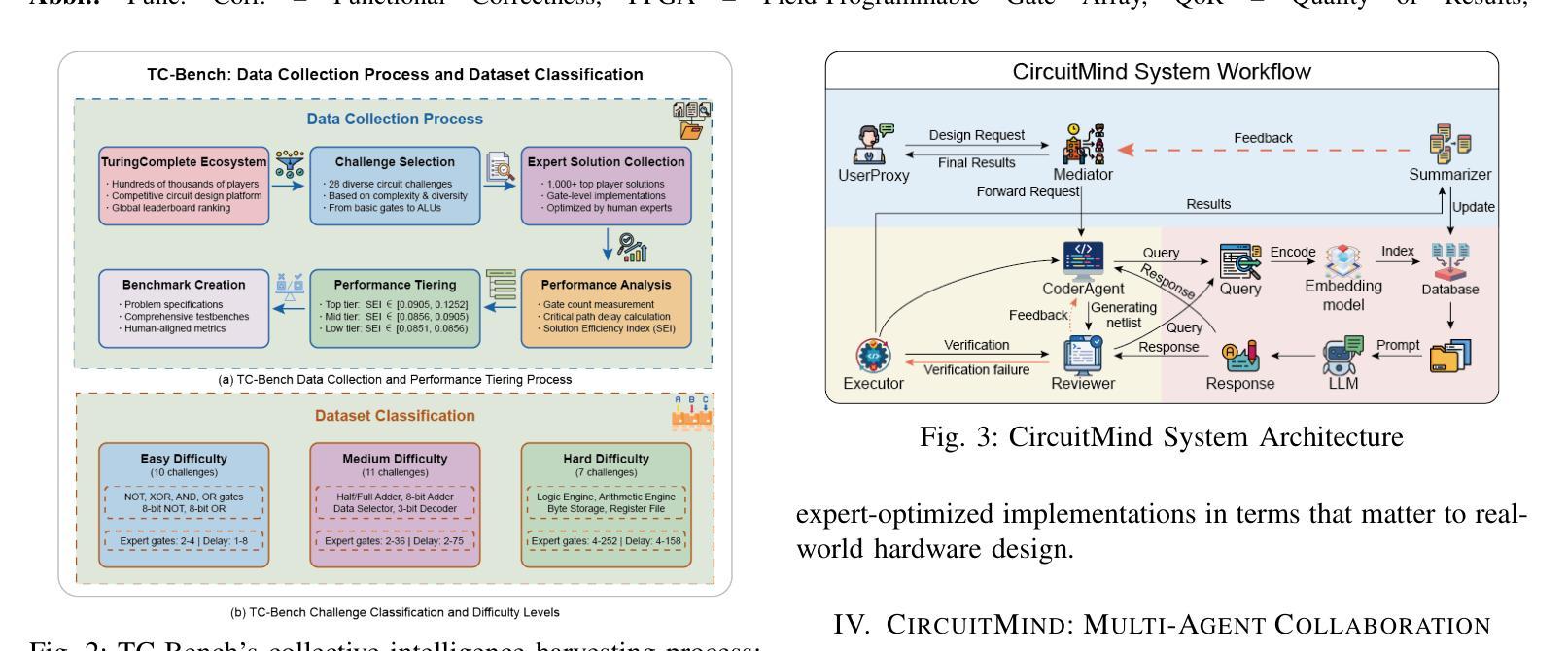
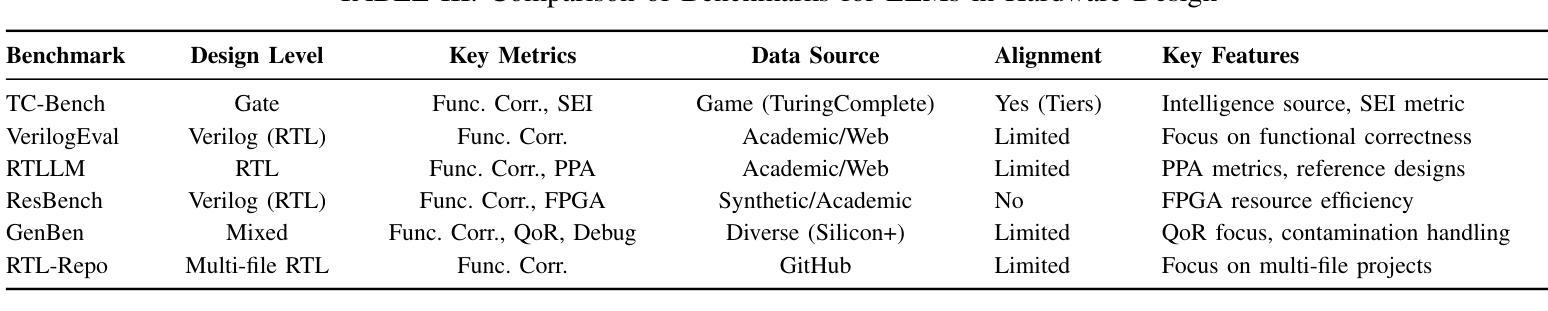
Large language models (LLMs) have transformed code generation, yet their application in hardware design produces gate counts 38%–1075% higher than human designs. We present CircuitMind, a multi-agent framework that achieves human-competitive efficiency through three key innovations: syntax locking (constraining generation to basic logic gates), retrieval-augmented generation (enabling knowledge-driven design), and dual-reward optimization (balancing correctness with efficiency). To evaluate our approach, we introduce TC-Bench, the first gate-level benchmark harnessing collective intelligence from the TuringComplete ecosystem – a competitive circuit design platform with hundreds of thousands of players. Experiments show CircuitMind enables 55.6% of model implementations to match or exceed top-tier human experts in composite efficiency metrics. Most remarkably, our framework elevates the 14B Phi-4 model to outperform both GPT-4o mini and Gemini 2.0 Flash, achieving efficiency comparable to the top 25% of human experts without requiring specialized training. These innovations establish a new paradigm for hardware optimization where collaborative AI systems leverage collective human expertise to achieve optimal circuit designs. Our model, data, and code are open-source at https://github.com/BUAA-CLab/CircuitMind.
大规模语言模型(LLM)已经改变了代码生成,但它们在硬件设计中的应用产生了比人类设计高38%~1075%的门计数。我们提出了CircuitMind,这是一个多代理框架,通过三个关键创新实现了与人类竞争的效率:语法锁定(将生成限制在基本逻辑门内)、检索增强生成(实现知识驱动设计)和双奖励优化(平衡正确性与效率)。为了评估我们的方法,我们引入了TC-Bench,这是第一个利用TuringComplete生态系统集体智慧的门级基准测试——一个拥有数十万玩家的竞争电路设计平台。实验表明,CircuitMind使55.6%的模型实现能够在组合效率指标上匹配或超过顶级人类专家。值得注意的是,我们的框架提升了14B Phi-4模型的表现,使其超越了GPT-4o mini和Gemini 2.0 Flash,达到了与顶级人类专家效率相当的水平,而无需进行专门培训。这些创新为硬件优化建立了新的范式,其中协作AI系统利用人类的集体专业知识来实现最佳电路设计。我们的模型、数据和代码均在https://github.com/BUAA-CLab/CircuitMind开源。
论文及项目相关链接
PDF 9 pages, 6 figures
Summary
大语言模型在代码生成方面有着广泛的应用,但在硬件设计领域的应用会导致门数增加高达38%~1075%。为此,研究团队提出了CircuitMind多智能体框架,通过语法锁定、检索增强生成和双奖励优化等三大创新技术,实现了与人类竞争的效率。通过引入TC-Bench基准测试平台,实验证明CircuitMind使模型实现的效率达到或超过顶级人类专家的复合指标高达55.6%。CircuitMind框架提升了一个拥有超过百万玩家的电路竞争平台TuringComplete生态系统中的集体智能水平。该研究为硬件优化领域开创了新的范式,实现了人工智能系统与人类专家协作的最佳电路设计。相关模型和代码已开源。
Key Takeaways
- 大语言模型在硬件设计中的应用会导致门数增加,与人类设计相比效率较低。
- CircuitMind框架通过三大创新技术实现与人类竞争的效率,包括语法锁定、检索增强生成和双奖励优化。
- TC-Bench基准测试平台用于评估CircuitMind框架的性能。
- 实验证明CircuitMind框架使模型实现的效率达到或超过顶级人类专家的复合指标高达55.6%。
- CircuitMind框架成功提升了电路竞争平台TuringComplete生态系统中的集体智能水平。
- CircuitMind框架适用于各种语言模型,并成功提升了小型语言模型的性能。
- 该研究为硬件优化领域开创了新的范式,实现了人工智能系统与人类专家协作的最佳电路设计。
点此查看论文截图


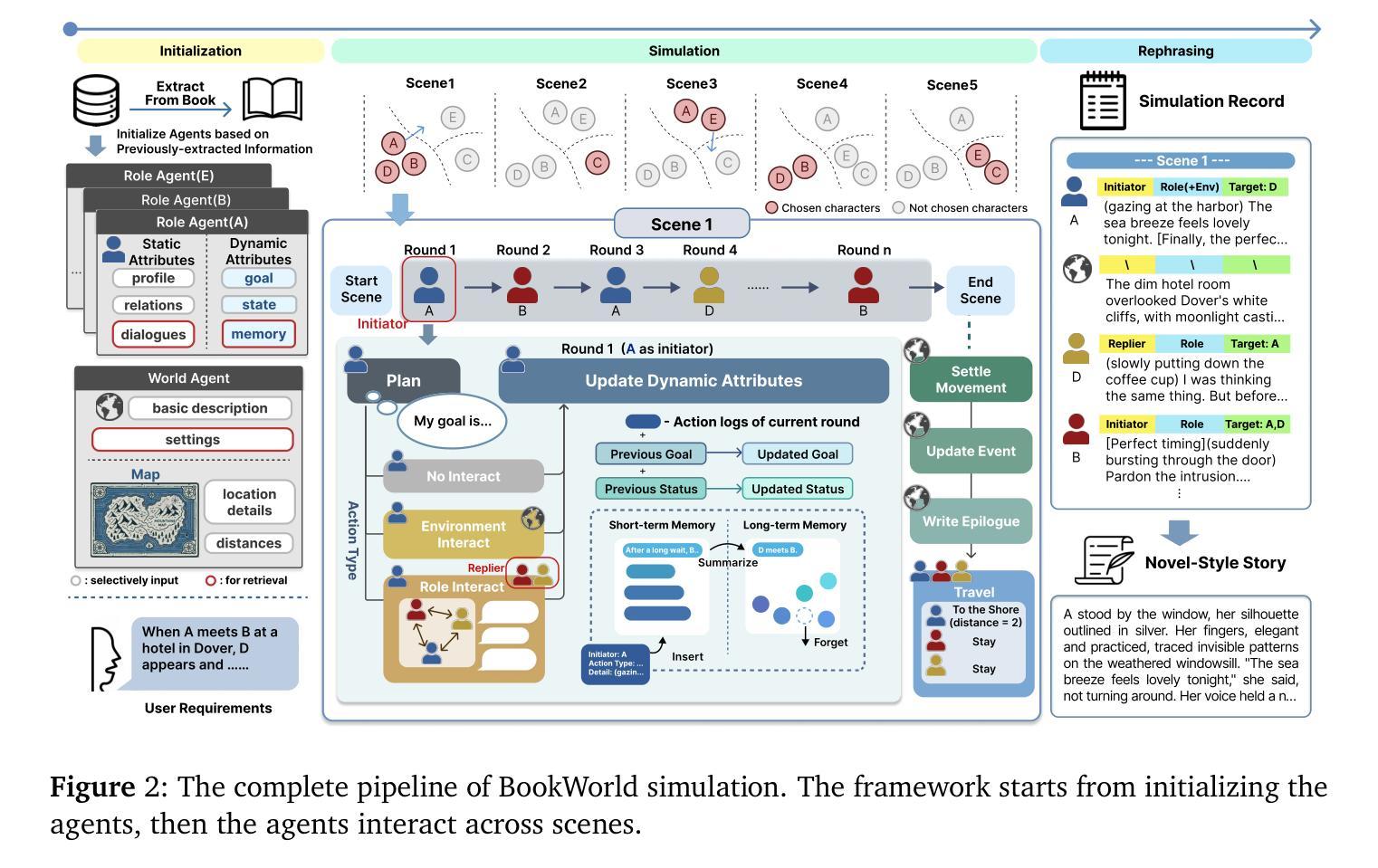
BookWorld: From Novels to Interactive Agent Societies for Creative Story Generation
Authors:Yiting Ran, Xintao Wang, Tian Qiu, Jiaqing Liang, Yanghua Xiao, Deqing Yang
Recent advances in large language models (LLMs) have enabled social simulation through multi-agent systems. Prior efforts focus on agent societies created from scratch, assigning agents with newly defined personas. However, simulating established fictional worlds and characters remain largely underexplored, despite its significant practical value. In this paper, we introduce BookWorld, a comprehensive system for constructing and simulating book-based multi-agent societies. BookWorld’s design covers comprehensive real-world intricacies, including diverse and dynamic characters, fictional worldviews, geographical constraints and changes, e.t.c. BookWorld enables diverse applications including story generation, interactive games and social simulation, offering novel ways to extend and explore beloved fictional works. Through extensive experiments, we demonstrate that BookWorld generates creative, high-quality stories while maintaining fidelity to the source books, surpassing previous methods with a win rate of 75.36%. The code of this paper can be found at the project page: https://bookworld2025.github.io/.
最近的大型语言模型(LLM)的进步已经能够通过多智能体系统实现社会模拟。之前的研究主要集中在从零开始创建智能体社会,并为智能体分配新定义的人格。然而,尽管模拟成熟的虚构世界和角色具有重要的实用价值,但对其进行的研究仍然远远不够。在本文中,我们介绍了BookWorld,这是一个用于构建和模拟基于书籍的多智能体社会的综合系统。BookWorld的设计涵盖了现实世界中的复杂细节,包括多样且动态的角色、虚构的世界观、地理约束和变化等。BookWorld支持多种应用,包括故事生成、互动游戏和社会模拟,为探索心爱的虚构作品提供了新的途径。通过广泛的实验,我们证明了BookWorld能够生成具有创意且高质量的故事,同时保持对原书的忠实度,其胜率达到了75.36%,超过了之前的方法。该论文的代码可以在项目页面找到:https://bookworld2025.github.io/。
论文及项目相关链接
PDF 19 pages, 4 figures
Summary
基于大型语言模型(LLM)的最新进展,通过多智能体系统实现了社会模拟。以往的研究主要集中在从零开始创建智能体社会并为智能体分配新定义的个性。然而,模拟现有的虚构世界和角色方面仍存在大量未解决的问题,尽管具有重大实际意义。本文介绍了一个名为BookWorld的综合系统,该系统可以构建和模拟基于书籍的多智能体社会。BookWorld的设计涵盖了现实世界中的复杂细节,包括多样化和动态的角色、虚构的世界观、地理约束和变化等。BookWorld支持多种应用程序,包括故事生成、互动游戏和社会模拟,为探索心爱的虚构作品提供了新颖的方式。通过广泛的实验,我们证明了BookWorld在保持对原书的忠实度的同时,能够生成有创造力和高质量的故事,并且以75.36%的胜率超越了以前的方法。
Key Takeaways
- 大型语言模型(LLM)可用于通过多智能体系统实现社会模拟。
- BookWorld系统用于构建和模拟基于书籍的多智能体社会。
- BookWorld涵盖了现实世界中的复杂细节,包括角色、世界观、地理约束等。
- BookWorld支持故事生成、互动游戏和社会模拟等多种应用程序。
- BookWorld能够生成高质量、有创造力的故事,并保持对原书的忠实度。
- 通过实验证明,BookWorld在模拟现有虚构世界方面表现出色,超越了先前的方法。
点此查看论文截图


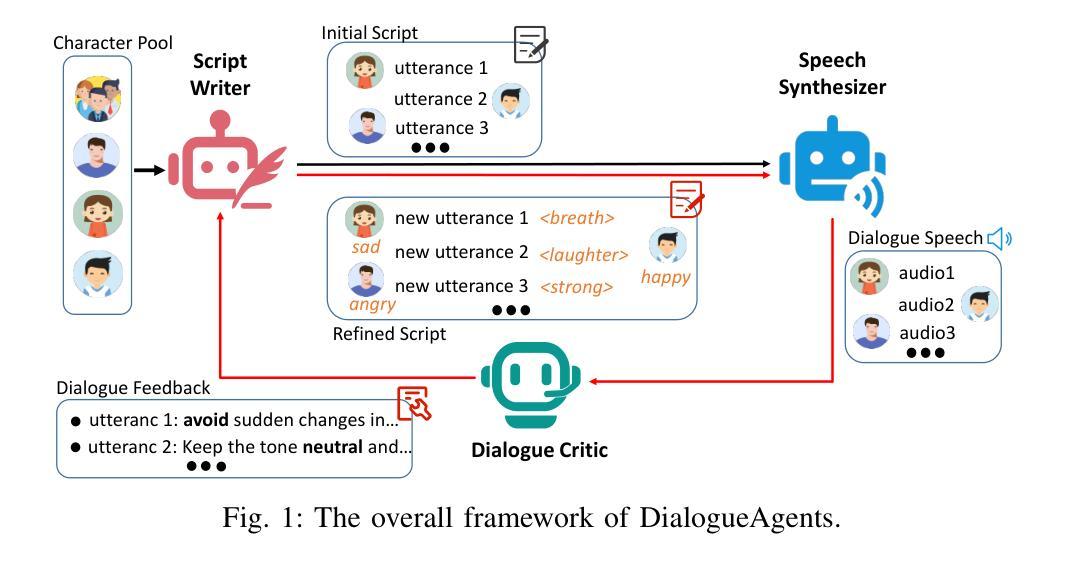
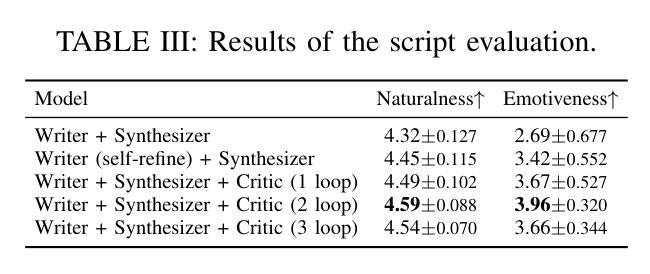
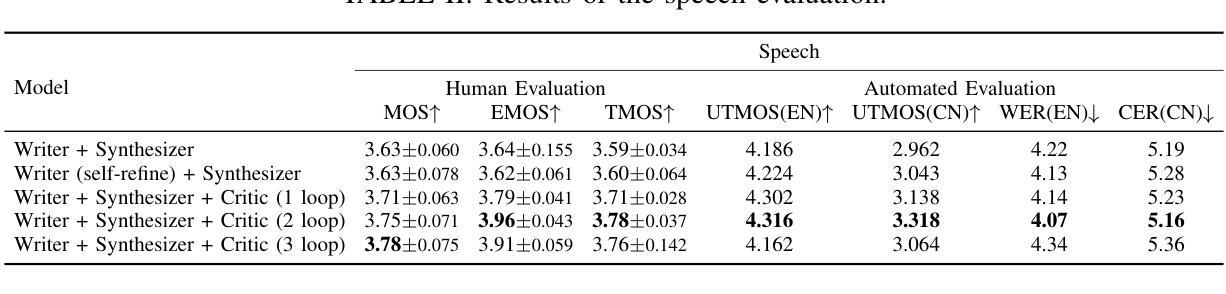
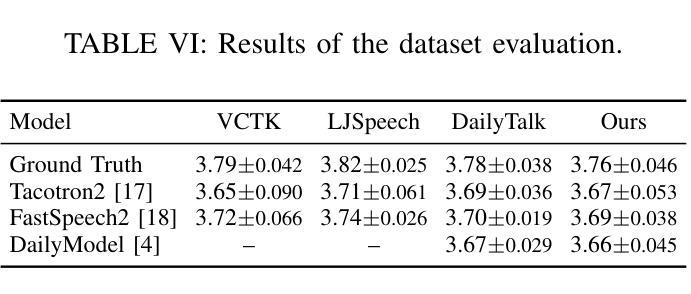
DialogueAgents: A Hybrid Agent-Based Speech Synthesis Framework for Multi-Party Dialogue
Authors:Xiang Li, Duyi Pan, Hongru Xiao, Jiale Han, Jing Tang, Jiabao Ma, Wei Wang, Bo Cheng
Speech synthesis is crucial for human-computer interaction, enabling natural and intuitive communication. However, existing datasets involve high construction costs due to manual annotation and suffer from limited character diversity, contextual scenarios, and emotional expressiveness. To address these issues, we propose DialogueAgents, a novel hybrid agent-based speech synthesis framework, which integrates three specialized agents – a script writer, a speech synthesizer, and a dialogue critic – to collaboratively generate dialogues. Grounded in a diverse character pool, the framework iteratively refines dialogue scripts and synthesizes speech based on speech review, boosting emotional expressiveness and paralinguistic features of the synthesized dialogues. Using DialogueAgent, we contribute MultiTalk, a bilingual, multi-party, multi-turn speech dialogue dataset covering diverse topics. Extensive experiments demonstrate the effectiveness of our framework and the high quality of the MultiTalk dataset. We release the dataset and code https://github.com/uirlx/DialogueAgents to facilitate future research on advanced speech synthesis models and customized data generation.
语音合成对于人机交互至关重要,能够实现自然直观的沟通。然而,现有数据集由于手动标注而涉及较高的构建成本,并且存在字符多样性、上下文情境和情绪表达等方面的局限性。为了解决这些问题,我们提出了DialogueAgents,这是一个基于混合代理的新型语音合成框架。它集成了三个专业代理——剧本作者、语音合成器和对话评论家,共同生成对话。该框架基于多样化的字符池,通过语音评审迭代优化对话脚本并合成语音,提高了合成对话的情感表达和非语言特征。使用DialogueAgent,我们创建了MultiTalk数据集,这是一个涵盖各种话题的双语、多方、多轮语音对话数据集。大量实验证明了我们框架的有效性和MultiTalk数据集的高质量。我们已将数据集和代码发布在https://github.com/uirlx/DialogueAgents上,以促进未来对先进语音合成模型和定制数据生成的研究。
论文及项目相关链接
PDF Accepted by ICME 2025. Dataset and code are publicly available: https://github.com/uirlx/DialogueAgents
Summary
对话合成在人机交互中扮演重要角色,可实现自然、直观的沟通。然而,现有数据集存在高构建成本问题,如手动标注,且存在字符多样性、上下文场景和情感表达有限等缺陷。为解决这些问题,我们提出DialogueAgents这一新型基于代理的对话合成框架,集成了脚本编写器、语音合成器和对话评论家三个专业代理,共同生成对话。该框架基于丰富的角色库,通过对话脚本迭代优化和基于语音评价的合成,提高了合成对话的情感表达和非语言特征。我们还贡献了MultiTalk这一双语、多方、多轮对话数据集,涵盖各种主题。实验结果充分验证了框架的有效性和数据集的高质量。我们公开了数据集和代码,以推动先进的语音合成模型和定制数据生成的未来研究。
Key Takeaways
- 对话合成在人机交互中具有重要作用。
- 现有数据集存在高构建成本、字符多样性、上下文场景和情感表达有限等问题。
- DialogueAgents是一个基于代理的对话合成框架,集成了脚本编写器、语音合成器和对话评论家。
- 该框架通过迭代优化和语音评价,提高了合成对话的情感表达和非语言特征。
- MultiTalk数据集是一个双语、多方、多轮对话数据集,涵盖各种主题。
- 实验结果证明了DialogueAgents框架和MultiTalk数据集的有效性。
点此查看论文截图



Optimizing SIA Development: A Case Study in User-Centered Design for Estuary, a Multimodal Socially Interactive Agent Framework
Authors:Spencer Lin, Miru Jun, Basem Rizk, Karen Shieh, Scott Fisher, Sharon Mozgai
This case study presents our user-centered design model for Socially Intelligent Agent (SIA) development frameworks through our experience developing Estuary, an open source multimodal framework for building low-latency real-time socially interactive agents. We leverage the Rapid Assessment Process (RAP) to collect the thoughts of leading researchers in the field of SIAs regarding the current state of the art for SIA development as well as their evaluation of how well Estuary may potentially address current research gaps. We achieve this through a series of end-user interviews conducted by a fellow researcher in the community. We hope that the findings of our work will not only assist the continued development of Estuary but also guide the development of other future frameworks and technologies for SIAs.
本案研究通过开发 Estuary(一个开源的多模式框架,用于构建低延迟的实时社交交互代理)的经验,展示了我们以用户为中心的社会智能代理(SIA)设计模型的开发框架。我们利用快速评估流程(RAP)收集社会智能领域领军研究者对当前技术状况的看法以及他们对Estuary如何可能解决当前研究空白进行的评估。我们通过社区内的一位研究员进行的一系列终端用户访谈来实现这一点。我们希望我们的研究结果不仅能帮助Estuary的持续发展,还能为其他未来的SIA框架和技术的发展提供指导。
论文及项目相关链接
Summary
本文介绍了通过开发Estuary这一开源多模式框架,以用户为中心的设计模型在智能社交代理(SIA)开发框架中的应用。通过快速评估流程(RAP),收集领域内的领先研究者对SIA当前发展状况的看法,并对Estuary如何潜在解决当前研究差距进行评估。通过一系列社区研究者进行的终端用户访谈实现这一目标。本文的研究成果不仅有助于Estuary的持续发展,而且也为SIA的其他未来框架和技术的发展提供了指导。
Key Takeaways
- 介绍了以用户为中心的设计模型在智能社交代理(SIA)开发框架中的应用。
- 通过开源多模式框架Estuary实现上述设计模型。
- 采用快速评估流程(RAP)收集专家对SIA当前状况的看法及研究差距。
- 通过终端用户访谈评估Estuary的潜力。
- Estuary的开发旨在为其他未来SIA框架和技术的发展提供指导。
- 强调了了解用户需求和研究现状对于智能社交代理发展的重要性。
点此查看论文截图

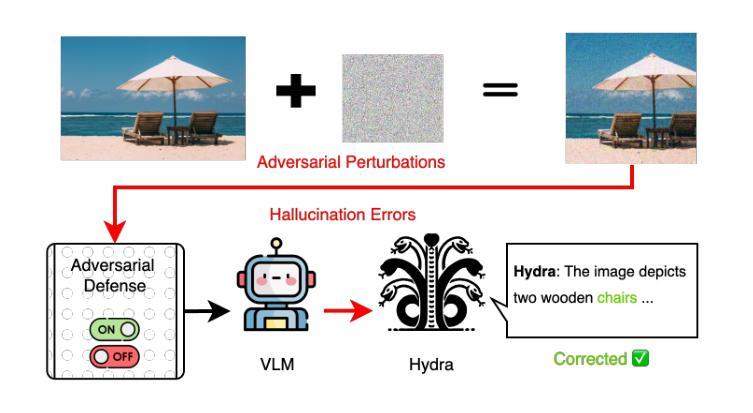
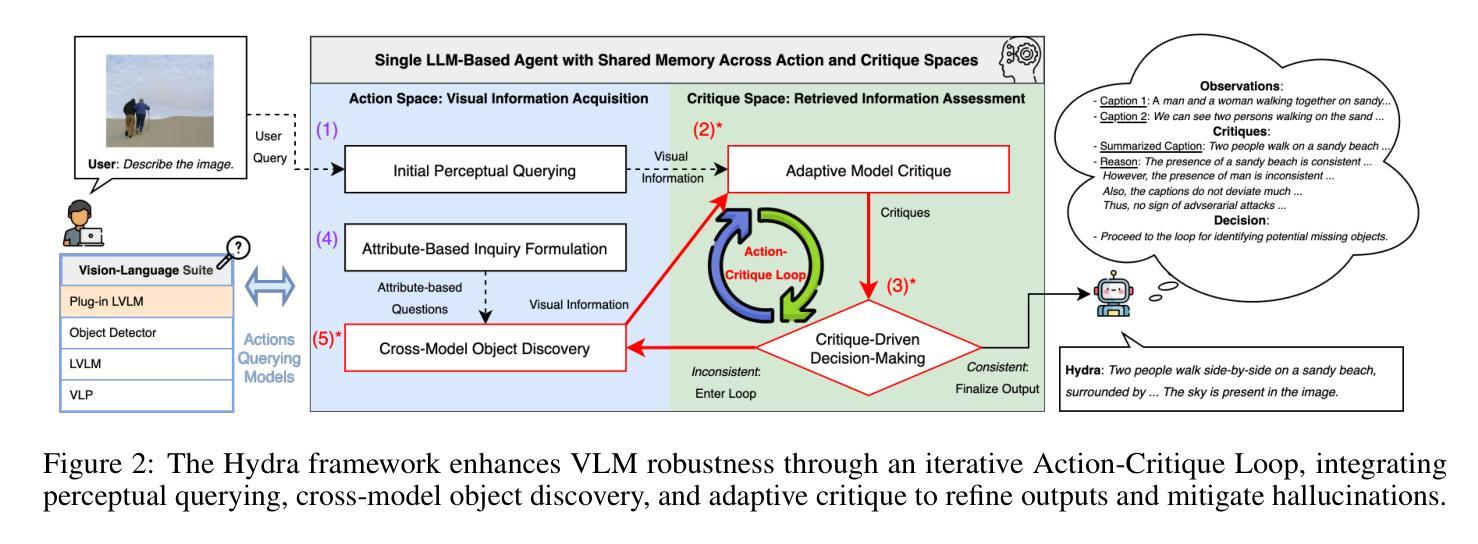
Hydra: An Agentic Reasoning Approach for Enhancing Adversarial Robustness and Mitigating Hallucinations in Vision-Language Models
Authors: Chung-En, Yu, Hsuan-Chih, Chen, Brian Jalaian, Nathaniel D. Bastian
To develop trustworthy Vision-Language Models (VLMs), it is essential to address adversarial robustness and hallucination mitigation, both of which impact factual accuracy in high-stakes applications such as defense and healthcare. Existing methods primarily focus on either adversarial defense or hallucination post-hoc correction, leaving a gap in unified robustness strategies. We introduce \textbf{Hydra}, an adaptive agentic framework that enhances plug-in VLMs through iterative reasoning, structured critiques, and cross-model verification, improving both resilience to adversarial perturbations and intrinsic model errors. Hydra employs an Action-Critique Loop, where it retrieves and critiques visual information, leveraging Chain-of-Thought (CoT) and In-Context Learning (ICL) techniques to refine outputs dynamically. Unlike static post-hoc correction methods, Hydra adapts to both adversarial manipulations and intrinsic model errors, making it robust to malicious perturbations and hallucination-related inaccuracies. We evaluate Hydra on four VLMs, three hallucination benchmarks, two adversarial attack strategies, and two adversarial defense methods, assessing performance on both clean and adversarial inputs. Results show that Hydra surpasses plug-in VLMs and state-of-the-art (SOTA) dehallucination methods, even without explicit adversarial defenses, demonstrating enhanced robustness and factual consistency. By bridging adversarial resistance and hallucination mitigation, Hydra provides a scalable, training-free solution for improving the reliability of VLMs in real-world applications.
要开发可信赖的视觉语言模型(VLMs),解决对抗性稳健和幻觉减轻问题至关重要,两者都会影响高风险应用(如国防和医疗保健)的事实准确性。现有方法主要关注对抗性防御或幻觉事后修正,在统一稳健性策略方面存在差距。我们引入了Hydra,这是一种自适应智能框架,它通过迭代推理、结构批评和跨模型验证增强即插即用型VLMs,提高了对抗性扰动和内在模型错误的抵抗力。Hydra采用行动-批评循环,检索并批评视觉信息,利用思维链(CoT)和上下文学习(ICL)技术动态优化输出。与静态事后修正方法不同,Hydra能够适应对抗性操纵和内在模型错误,使其对恶意扰动和幻觉相关的不准确具有稳健性。我们在四种VLMs、三个幻觉基准测试、两种对抗性攻击策略和两种对抗性防御方法上评估了Hydra的性能,在干净和对抗性输入上的表现。结果表明,即使在没有任何明确的对抗性防御措施的情况下,Hydra也超过了即插即用型VLMs和最新去幻觉方法,显示出增强的稳健性和事实一致性。通过桥接对抗性抵抗和幻觉减轻,Hydra为提高VLM在现实世界应用中的可靠性提供了可伸缩、无需培训的训练后解决方案。
论文及项目相关链接
Summary
本文关注于开发可靠的视觉语言模型(VLMs),特别强调了对抗性鲁棒性和消除幻觉的重要性,两者都影响高风险应用(如国防和医疗保健)中的事实准确性。文章提出了一种名为Hydra的适应性代理框架,它通过迭代推理、结构化批评和跨模型验证来增强即插即用型VLMs的鲁棒性。Hydra采用行动-评论循环,利用思维链和上下文学习技术动态完善输出。相较于静态的后校正方法,Hydra能够适应对抗性操作和内在模型错误,从而增强鲁棒性对抗恶意干扰和幻觉相关的不准确性。实验结果显示,Hydra在不进行显式对抗性防御的情况下,在清洁和对抗性输入上的性能超过了即插即用型VLMs和最新消除幻觉方法,展现出增强的鲁棒性和事实一致性。总的来说,Hydra以一种可伸缩的方式在非训练环境中改善了VLMs在现实世界的可靠性问题。
Key Takeaways
- 开发可靠的视觉语言模型(VLMs)需要解决对抗性鲁棒性和消除幻觉两大关键问题。这两个问题对于高风险的场景应用如国防和医疗保健尤为重要。
- 现有方法主要关注对抗性防御或幻觉后校正,缺乏统一的稳健性策略。因此提出了一种名为Hydra的适应性代理框架作为解决方案。它不仅能够对抗外部干扰和修正内部模型错误,还可以提升VLMs的事实一致性。它运用了一种被称为行动-评论循环的机制,这种机制结合了思维链和上下文学习技术以动态优化输出。此外,通过集成跨模型验证的结构化批评流程提高性能评估标准有助于实现对内嵌入模型中隐性和显性问题更为全面且精准的检测与纠正能力。同时相较于传统静态后校正方法具备更高的适应灵活性这一点值得关注后续利用中的优势和价值,这表明它提供了一种通用的增强安全性和健壮性的有效策略即使在新型攻击手段层出不穷的情况下也能保持其适用性并应对未来可能出现的未知威胁和挑战。同时这一框架具备训练外可扩展性特点使得其在实际应用中的部署和维护成本得以显著降低并提高了系统的容错能力和容错效能以适应多变的市场需求和多样化的复杂场景使其更符合高效自动化的发展趋势;特别是在复杂环境下利用其鲁棒性和稳定性来减少潜在风险和成本增加长期运营的安全保障这一环节上扮演至关重要的角色以更好地应对实际应用中所面临的挑战并不断提升客户对产品和服务的使用体验和满意度优化。这些信息展示了其良好的实际应用前景以及它在视觉语言模型领域中的巨大潜力与商业价值前景值得期待未来进一步的研发与应用推广以及行业内的广泛应用与认可等后续的发展动向及其对社会和人类发展的积极贡献意义。
点此查看论文截图

Causal-Copilot: An Autonomous Causal Analysis Agent
Authors:Xinyue Wang, Kun Zhou, Wenyi Wu, Har Simrat Singh, Fang Nan, Songyao Jin, Aryan Philip, Saloni Patnaik, Hou Zhu, Shivam Singh, Parjanya Prashant, Qian Shen, Biwei Huang
Causal analysis plays a foundational role in scientific discovery and reliable decision-making, yet it remains largely inaccessible to domain experts due to its conceptual and algorithmic complexity. This disconnect between causal methodology and practical usability presents a dual challenge: domain experts are unable to leverage recent advances in causal learning, while causal researchers lack broad, real-world deployment to test and refine their methods. To address this, we introduce Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework. Causal-Copilot automates the full pipeline of causal analysis for both tabular and time-series data – including causal discovery, causal inference, algorithm selection, hyperparameter optimization, result interpretation, and generation of actionable insights. It supports interactive refinement through natural language, lowering the barrier for non-specialists while preserving methodological rigor. By integrating over 20 state-of-the-art causal analysis techniques, our system fosters a virtuous cycle – expanding access to advanced causal methods for domain experts while generating rich, real-world applications that inform and advance causal theory. Empirical evaluations demonstrate that Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that bridges the gap between theoretical sophistication and real-world applicability in causal analysis. A live interactive demo of Causal-Copilot is available at https://causalcopilot.com/.
因果分析在科学发现和可靠决策制定中发挥着基础性作用,然而由于其在概念和算法上的复杂性,领域专家很难接触到它。因果方法论与实际应用之间的脱节带来了双重挑战:领域专家无法利用因果学习方面的最新进展,而因果研究者缺乏广泛的真实世界部署来测试和精进他们的方法。为解决这一问题,我们引入了因果协同飞行员(Causal-Copilot),这是一个在大语言模型框架内运行专家级因果分析的自主体。因果协同飞行员自动化了因果分析的完整流程,无论是表格数据还是时间序列数据,包括因果发现、因果推断、算法选择、超参数优化、结果解读和可实施洞察的生成。它通过自然语言支持交互式改进,降低了非专业人士的门槛,同时保持了方法的严谨性。通过整合超过20项最先进的因果分析技术,我们的系统形成了一个良性循环——扩大了领域专家对高级因果方法的访问权限,同时生成了丰富、真实的应用程序来推动和发展因果理论。实证评估表明,与现有基线相比,因果协同飞行员取得了卓越的性能表现,提供了一个可靠、可扩展和可扩展的解决方案,缩小了理论复杂性和真实世界应用之间在因果分析方面的差距。因果协同飞行员的实时互动演示可在https://causalcopilot.com/上找到。
论文及项目相关链接
Summary
因果分析在科学发现和可靠决策中起着基础作用,但由于其概念和算法的复杂性,领域专家很难接触和应用它。为此,我们推出因果推理辅助系统(Causal-Copilot),这是一个自主的智能体,能够在大型语言模型框架中实现专家级的因果分析。该系统自动化因果分析的全流程,包括因果发现、因果推理、算法选择、超参数优化、结果解读和行动建议等。它支持通过自然语言进行交互式改进,降低了非专业人士的门槛,同时保持了方法论严谨性。实证评估表明,Causal-Copilot与现有基线相比性能优越,为实现理论与实践相结合的因果分析提供了一个可靠、可扩展和可扩展的解决方案。有关Causal-Copilot的实时交互式演示,请访问:[https://causalcopilot.com/] 。
Key Takeaways
- 因果分析的重要性和实践困难:虽然因果分析在科学发现和决策制定中起着关键作用,但由于其复杂的概念和算法,领域专家难以应用。
- Causal-Copilot系统的介绍:这是一个自主的智能体,能够在大型语言模型框架内实现专家级的因果分析。
- Causal-Copilot的自动化功能:该系统自动化了因果分析的全流程,包括因果发现、推理、算法选择等。
- 交互式改进和自然语言支持:Causal-Copilot支持通过自然语言进行交互式改进,便于非专业人士使用。
- 系统整合了多种先进因果分析方法:整合超过20种最先进的因果分析方法,为领域专家提供更广泛的访问途径。
- 实证评估结果:Causal-Copilot在性能上优于现有基线。
点此查看论文截图

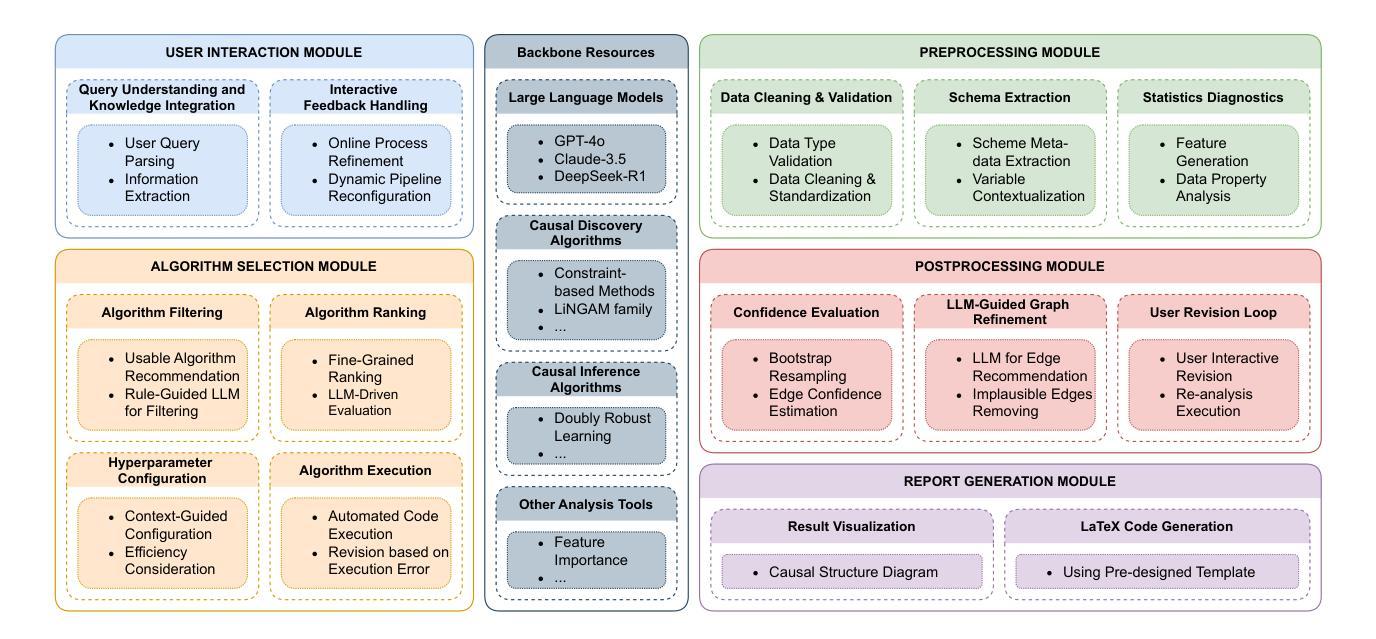
Cross-environment Cooperation Enables Zero-shot Multi-agent Coordination
Authors:Kunal Jha, Wilka Carvalho, Yancheng Liang, Simon S. Du, Max Kleiman-Weiner, Natasha Jaques
Zero-shot coordination (ZSC), the ability to adapt to a new partner in a cooperative task, is a critical component of human-compatible AI. While prior work has focused on training agents to cooperate on a single task, these specialized models do not generalize to new tasks, even if they are highly similar. Here, we study how reinforcement learning on a distribution of environments with a single partner enables learning general cooperative skills that support ZSC with many new partners on many new problems. We introduce two Jax-based, procedural generators that create billions of solvable coordination challenges. We develop a new paradigm called Cross-Environment Cooperation (CEC), and show that it outperforms competitive baselines quantitatively and qualitatively when collaborating with real people. Our findings suggest that learning to collaborate across many unique scenarios encourages agents to develop general norms, which prove effective for collaboration with different partners. Together, our results suggest a new route toward designing generalist cooperative agents capable of interacting with humans without requiring human data.
零拍摄协调(ZSC)是适应合作任务中新伙伴的能力,是人类兼容人工智能的关键组成部分。虽然之前的工作主要集中在训练代理人在单一任务上进行合作,但这些专用模型并不适用于新任务,即使它们高度相似。在这里,我们研究了在单一伙伴的环境分布上进行强化学习如何使代理学习到通用的合作技能,这些技能支持其与许多新伙伴在许多新问题上进行零拍摄协调。我们介绍了两个基于Jax的程式生成器,可以创建数十亿的可解决协调挑战。我们开发了一种称为“跨环境合作”(CEC)的新范式,并证明它在与真实人类合作时,在数量和质量上都优于竞争对手的基线。我们的研究结果表明,在多种独特场景下学习合作鼓励代理人发展通用规范,这些规范在与不同伙伴合作时证明是有效的。总之,我们的结果为人机交互领域开辟了一条新途径,即设计通用合作代理,无需人类数据即可与人类进行交互。
论文及项目相关链接
PDF Accepted to CogSci 2025, In-review for ICML 2025
Summary
本文研究了零射击协调(ZSC)在人工智能与人类合作中的重要性。通过强化学习在单一伙伴环境中的任务分布,学习通用的合作技能,支持与新伙伴在新问题上的零射击协调。引入基于Jax的程序生成器创建数十亿可解决的协调挑战,并展示了一种名为跨环境合作(CEC)的新方法在实际协作中的表现优于竞争对手。这表明在多个独特场景下学习合作鼓励代理人建立通用的规范,这些规范在与不同伙伴协作时非常有效。这为设计能够与人类互动而无需人类数据的通用合作代理人开辟了一条新途径。
Key Takeaways
- 强化学习在多种环境下的单一伙伴合作有助于学习通用的合作技能。
- 零射击协调(ZSC)是人工智能与人类合作的关键组成部分。
- 跨环境合作(CEC)是一种新方法,能有效协作并优于竞争对手。
- 使用基于Jax的程序生成器创建数十亿可解决的协调挑战。
- 与真实人的协作证明CEC方法在实际环境中的有效性。
- 在多个独特场景下学习合作鼓励代理人建立通用规范。
点此查看论文截图

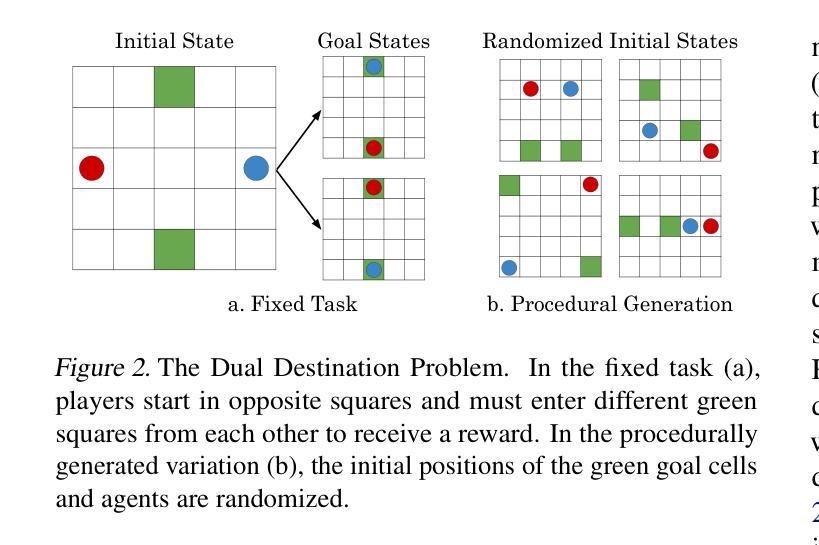
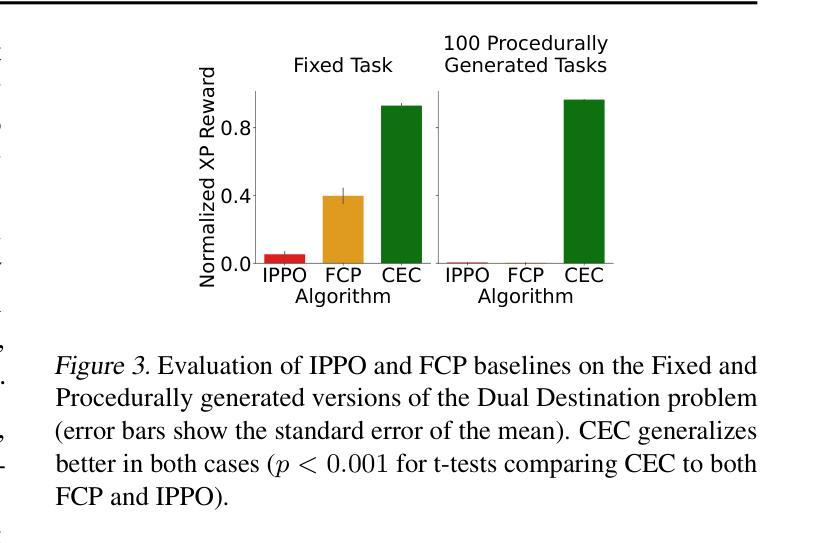
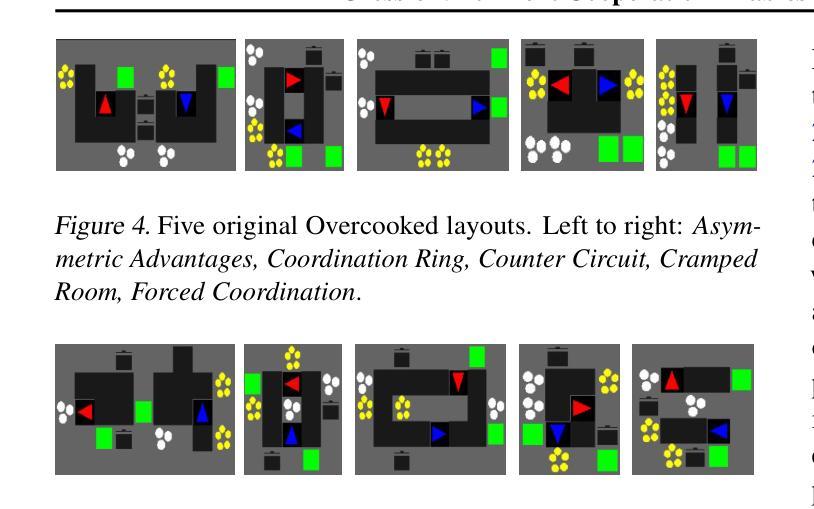
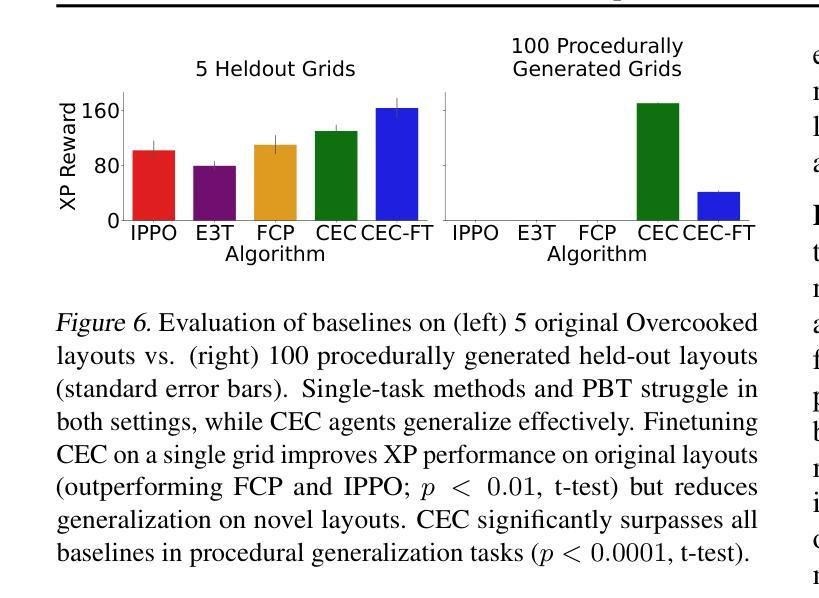
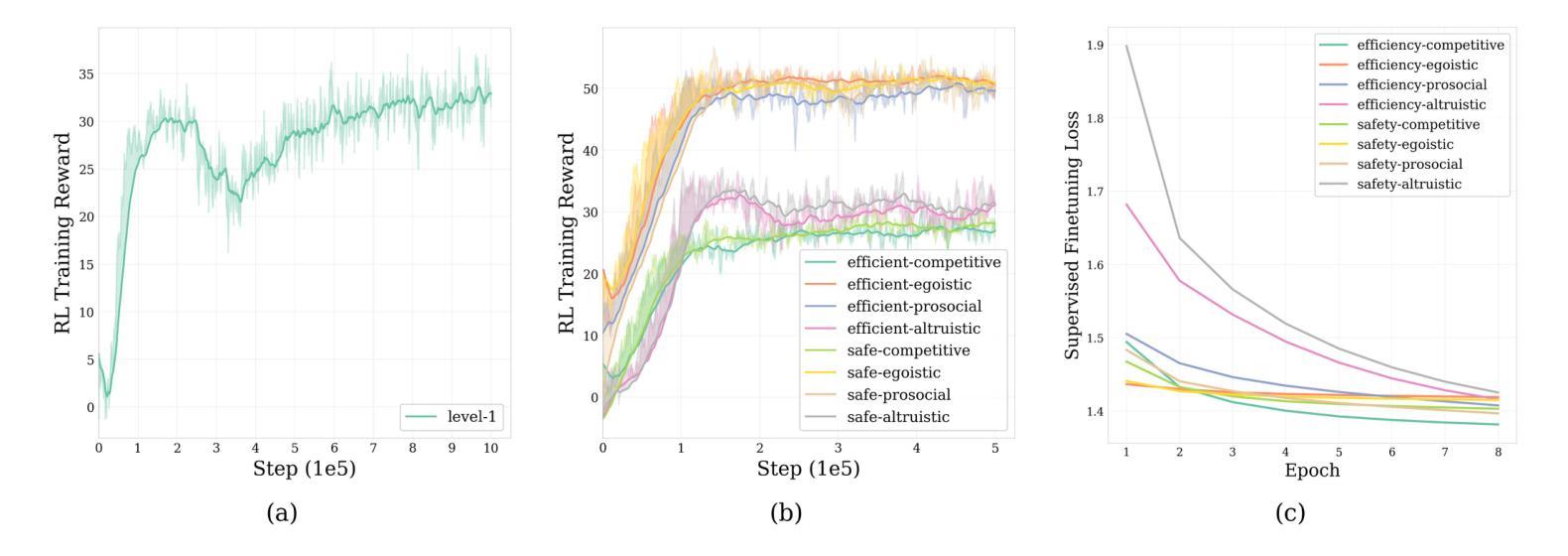
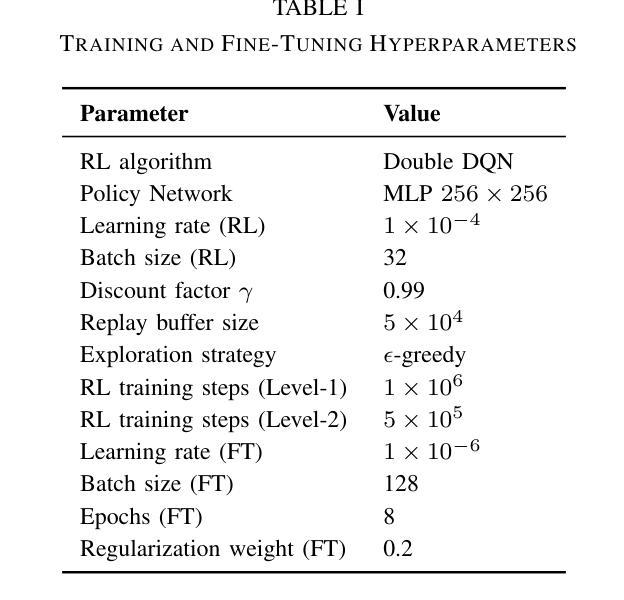
CHARMS: A Cognitive Hierarchical Agent for Reasoning and Motion Stylization in Autonomous Driving
Authors:Jingyi Wang, Duanfeng Chu, Zejian Deng, Liping Lu, Pan Zhou
To address the challenges of limited behavioral intelligence and overly simplified vehicle behavior modeling in autonomous driving simulations, this paper proposes the Cognitive Hierarchical Agent for Reasoning and Motion Stylization (CHARMS). Leveraging Level-k game theory, we model human driver decision-making using reinforcement learning pretraining and supervised fine-tuning. This enables the resulting models to exhibit diverse behaviors, improving the intelligence and realism of surrounding vehicles in simulation. Building upon this capability, we further develop a scenario generation framework that utilizes the Poisson cognitive hierarchy theory to control the distribution of vehicles with different driving styles through Poisson and binomial sampling. Experimental results demonstrate that CHARMS is capable of both making intelligent decisions as an ego vehicle and generating diverse, realistic driving scenarios as surrounding vehicles. The code for CHARMS will be released at https://github.com/WUTAD-Wjy/CHARMS.
针对自动驾驶模拟中行为智能有限和车辆行为建模过于简单化的挑战,本文提出了用于推理和动作风格化的认知分层代理(CHARMS)。我们利用Level-k博弈理论,使用强化学习进行预训练和监督微调,对人类驾驶员的决策制定进行建模。这使得模型能够表现出多种行为,提高了模拟中周围车辆的智能和真实感。在此基础上,我们进一步开发了一个情景生成框架,该框架利用Poisson认知层次理论来控制具有不同驾驶风格的车辆分布,通过Poisson和二项采样实现。实验结果表明,CHARMS不仅能作为一辆车做出智能决策,还能生成多样化、真实的驾驶场景作为周围车辆。CHARMS的代码将在https://github.com/WUTAD-Wjy/CHARMS发布。
论文及项目相关链接
Summary
本文提出了一个名为CHARMS的认知层次化智能体模型,用于解决自主驾驶模拟中的行为智能有限和车辆行为建模过于简单的问题。CHARMS模型结合了Level-k博弈理论,利用强化学习进行预训练和监督微调来模拟人类驾驶决策过程,使模型展现出多样化的行为,提高了模拟中车辆智能和真实感。此外,还开发了一个基于Poisson认知层次理论的场景生成框架,通过Poisson和二元抽样控制不同驾驶风格的车辆分布。实验结果表明,CHARMS不仅能作为自主车辆做出智能决策,还能生成多样且真实的驾驶场景。CHARMS代码已发布在:https://github.com/WUTAD-Wjy/CHARMS。
Key Takeaways
- CHARMS模型结合了Level-k博弈理论来解决自主驾驶模拟中的行为智能问题。
- 通过强化学习预训练和监督微调,CHARMS模型能够模拟人类驾驶决策过程。
- CHARMS模型展现出多样化的行为,提高了模拟中车辆的智能和真实感。
- 利用Poisson认知层次理论开发了一个场景生成框架。
- 该框架通过Poisson和二元抽样控制不同驾驶风格的车辆分布。
- 实验证明CHARMS模型能作为自主车辆做出智能决策并生成真实多样的驾驶场景。
点此查看论文截图


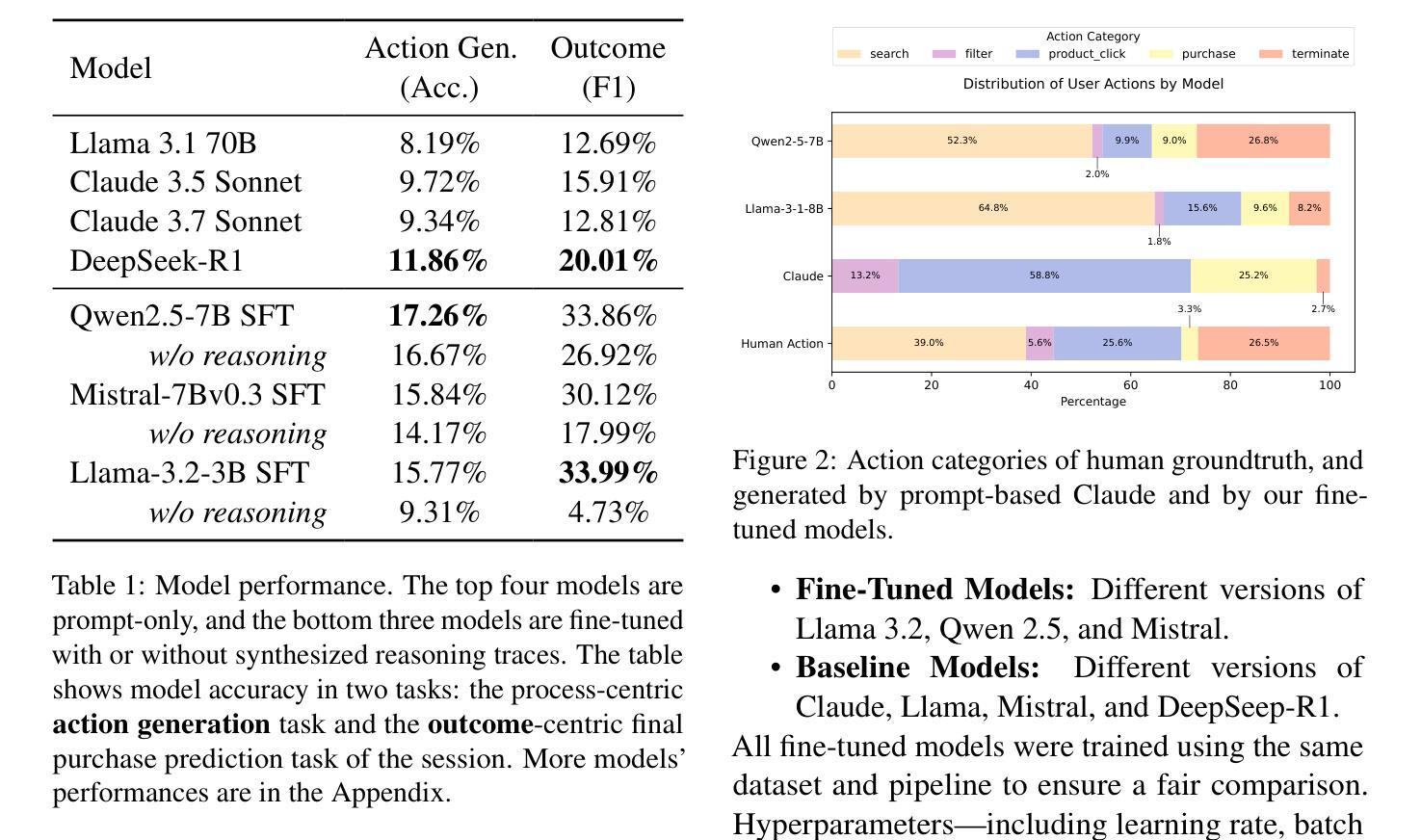
LLM Agents That Act Like Us: Accurate Human Behavior Simulation with Real-World Data
Authors:Yuxuan Lu, Jing Huang, Yan Han, Bennet Bei, Yaochen Xie, Dakuo Wang, Jessie Wang, Qi He
Recent research shows that LLMs can simulate believable'' human behaviors to power LLM agents via prompt-only methods. In this work, we focus on evaluating and improving LLM's objective accuracy’’ rather than the subjective ``believability’’ in the web action generation task, leveraging a large-scale, real-world dataset collected from online shopping human actions. We present the first comprehensive quantitative evaluation of state-of-the-art LLMs (e.g., DeepSeek-R1, Llama, and Claude) on the task of web action generation. Our results show that fine-tuning LLMs on real-world behavioral data substantially improves their ability to generate actions compared to prompt-only methods. Furthermore, incorporating synthesized reasoning traces into model training leads to additional performance gains, demonstrating the value of explicit rationale in behavior modeling. This work establishes a new benchmark for evaluating LLMs in behavior simulation and offers actionable insights into how real-world action data and reasoning augmentation can enhance the fidelity of LLM agents.
最近的研究表明,大型语言模型(LLMs)可以通过仅提示的方法模拟“可信”的人类行为来为LLM代理提供动力。在这项工作中,我们专注于评估和改进LLM在网页动作生成任务中的客观“准确性”,而非主观的“可信度”,我们利用从在线购物人类动作中收集的大规模现实数据集。我们对最先进的LLMs(如DeepSeek-R1、Llama和Claude)在网页动作生成任务上进行了首次全面的定量评估。我们的结果表明,与仅提示的方法相比,对现实行为数据进行微调会显著增强LLM生成动作的能力。此外,在模型训练中融入合成推理轨迹会带来额外的性能提升,这证明了明确理由在行为建模中的价值。这项工作为评估LLMs在行为模拟方面的表现建立了新的基准,并提供了一些实际见解,说明如何借助现实世界的行动数据和推理增强来提高LLM代理的保真度。
论文及项目相关链接
Summary
最新研究表明,LLMs可以通过仅使用提示的方法模拟“可信”的人类行为来为LLM代理提供动力。本文重点关注在网页动作生成任务中LLM的客观“准确性”而不是主观的“可信度”,并利用从在线购物人类动作收集的大规模现实世界数据集进行研究和评估。我们对先进LLMs(如DeepSeek-R1、Llama和Claude)在网页动作生成任务上的表现进行了首次全面的定量评估。结果表明,与仅使用提示的方法相比,在现实世界行为数据上微调LLMs可以显著提高其生成动作的能力。此外,将合成推理轨迹纳入模型训练会带来额外的性能提升,证明了明确理由在行为建模中的价值。本文为评估LLM在行为模拟方面的表现建立了新的基准,并提供实际行动数据和推理增强如何增强LLM代理的逼真度的可操作见解。
Key Takeaways
- LLMs能够模拟可信的人类行为以驱动代理。
- 研究集中在评估LLMs在网页动作生成任务中的准确性,而非仅关注其可信度。
- 利用大规模现实世界数据集进行评估。
- 微调LLMs在现实世界行为数据上能显著提高其在网页动作生成任务上的表现。
- 将合成推理轨迹纳入模型训练能带来额外性能提升。
- 明确理由在行为建模中具有价值。
点此查看论文截图

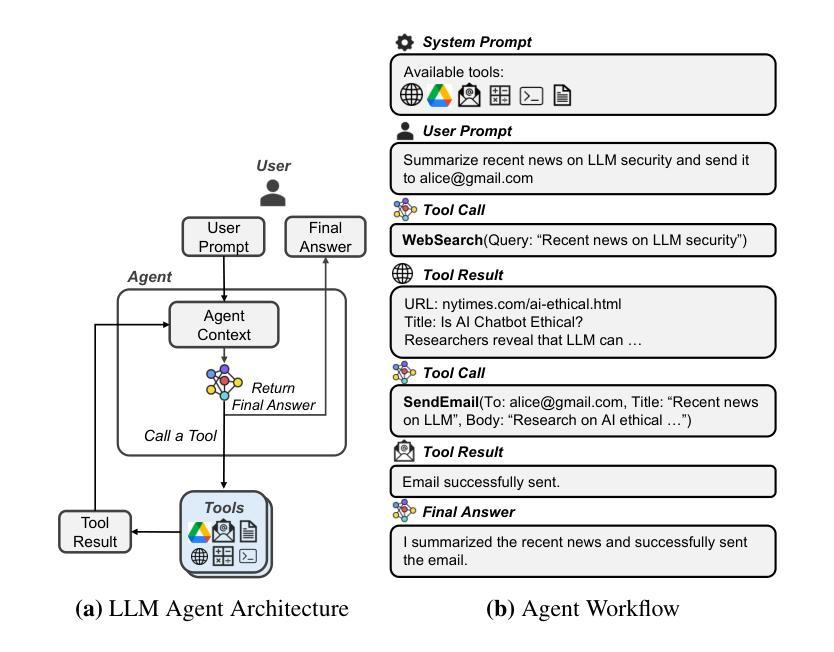
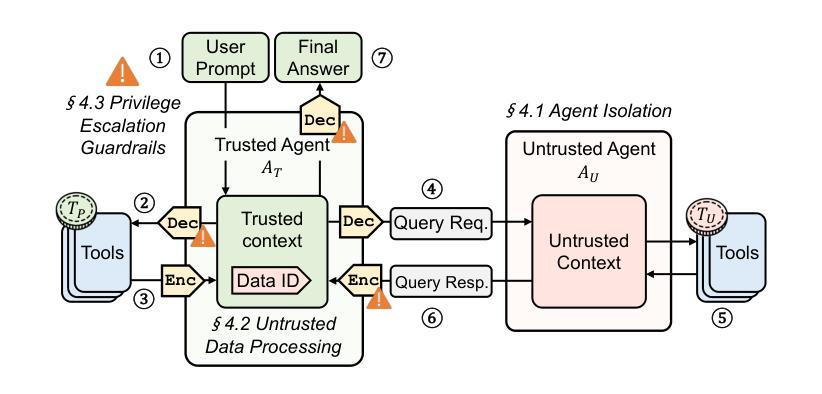
Prompt Flow Integrity to Prevent Privilege Escalation in LLM Agents
Authors:Juhee Kim, Woohyuk Choi, Byoungyoung Lee
Large Language Models (LLMs) are combined with tools to create powerful LLM agents that provide a wide range of services. Unlike traditional software, LLM agent’s behavior is determined at runtime by natural language prompts from either user or tool’s data. This flexibility enables a new computing paradigm with unlimited capabilities and programmability, but also introduces new security risks, vulnerable to privilege escalation attacks. Moreover, user prompts are prone to be interpreted in an insecure way by LLM agents, creating non-deterministic behaviors that can be exploited by attackers. To address these security risks, we propose Prompt Flow Integrity (PFI), a system security-oriented solution to prevent privilege escalation in LLM agents. Analyzing the architectural characteristics of LLM agents, PFI features three mitigation techniques – i.e., agent isolation, secure untrusted data processing, and privilege escalation guardrails. Our evaluation result shows that PFI effectively mitigates privilege escalation attacks while successfully preserving the utility of LLM agents.
大型语言模型(LLM)与工具相结合,可以创建出强大的LLM代理,提供广泛的服务。与传统的软件不同,LLM代理的行为在运行时由用户或工具数据的自然语言提示来确定。这种灵活性为实现具有无限能力和可编程性的新型计算范式提供了可能,但同时也带来了新的安全风险,容易受到权限提升攻击的影响。此外,用户提示容易被LLM代理以不安全的方式解释,从而产生非确定性行为,攻击者可以利用这些行为。为了解决这些安全风险,我们提出了面向系统安全的Prompt Flow Integrity(PFI)解决方案,以防止LLM代理中的权限提升。通过分析LLM代理的架构特性,PFI包含三种缓解技术,即代理隔离、安全的不受信任数据处理和权限提升护栏。我们的评估结果表明,PFI在有效缓解权限提升攻击的同时,成功保留了LLM代理的实用性。
论文及项目相关链接
Summary
大型语言模型(LLM)与工具结合,形成强大的LLM代理,提供广泛的服务。LLM代理的行为在运行时由用户或工具的数据的自然语言提示决定,具有灵活性和无限能力与可编程性,但也带来新安全风险,易受权限提升攻击。为解决这些安全风险,提出面向系统安全的Prompt Flow Integrity(PFI)解决方案,防止LLM代理中的权限提升。PFI包含三种缓解技术:代理隔离、安全非信任数据处理和权限提升护栏。评估结果显示,PFI有效缓解权限提升攻击,同时成功保留LLM代理的实用性。
Key Takeaways
- LLMs结合工具形成强大的LLM代理,提供广泛服务。
- LLM代理的行为由自然语言提示决定,具有灵活性和无限能力与可编程性。
- LLM代理存在安全风险,易受到权限提升攻击。
- Prompt Flow Integrity (PFI)是一种解决LLM代理安全问题的系统安全解决方案。
- PFI包含三种缓解技术:代理隔离、安全非信任数据处理和权限提升护栏。
- PFI能有效缓解权限提升攻击。
点此查看论文截图


MaCTG: Multi-Agent Collaborative Thought Graph for Automatic Programming
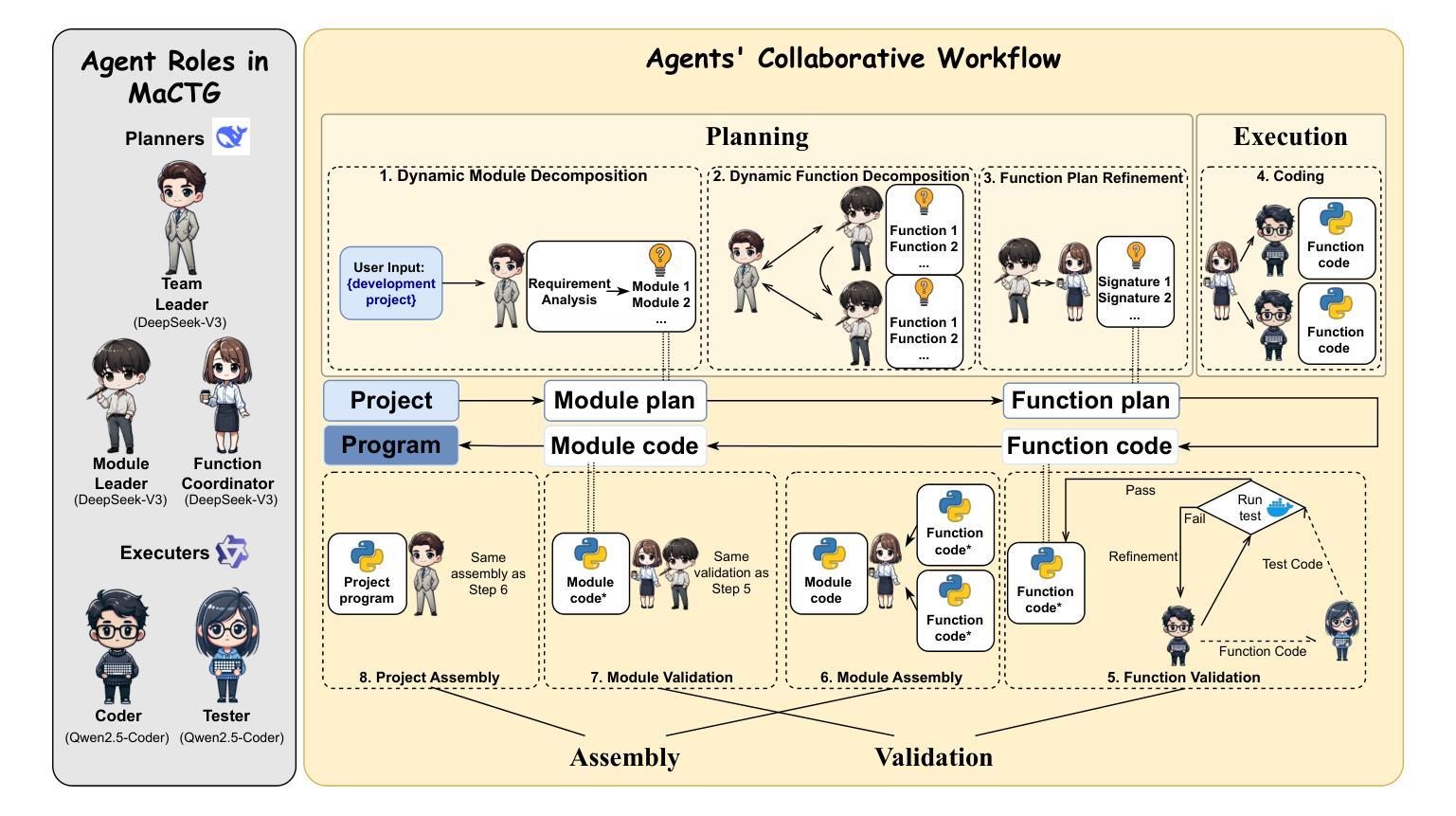
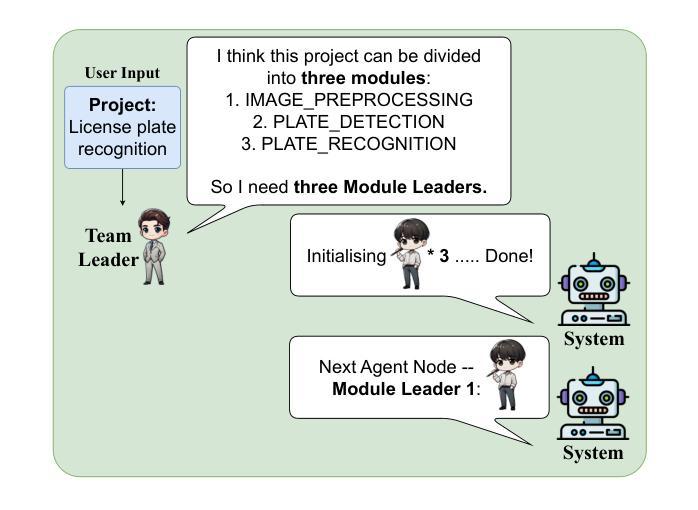
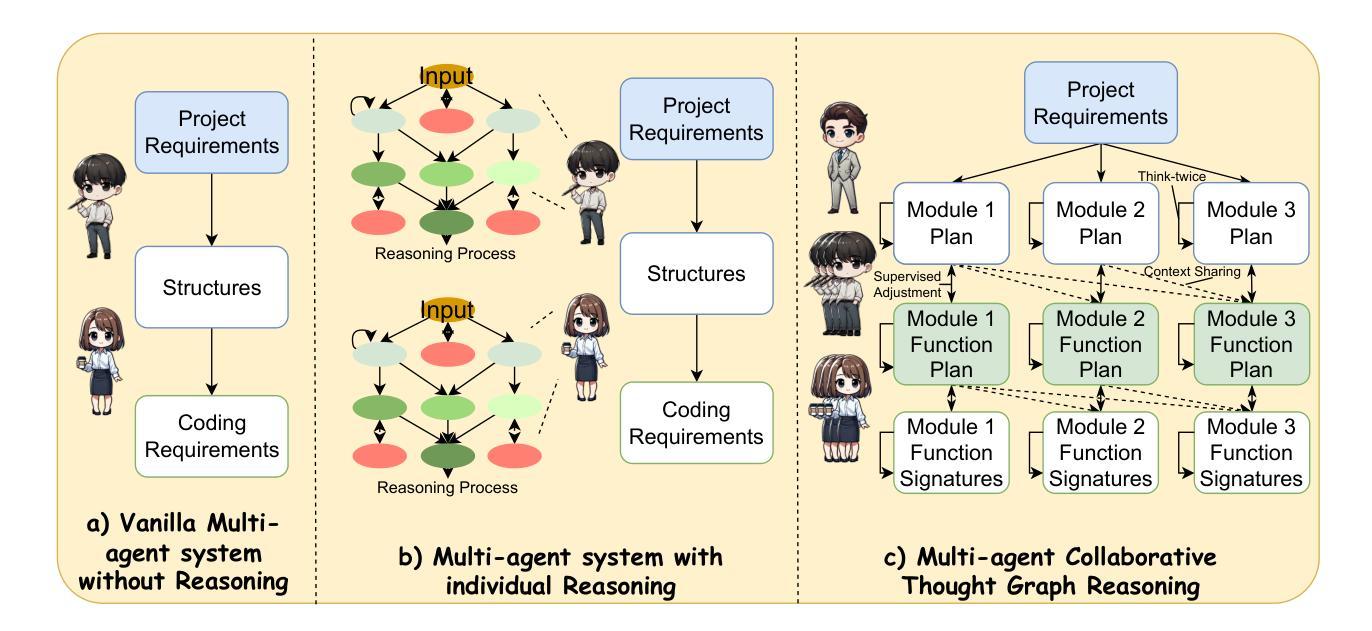
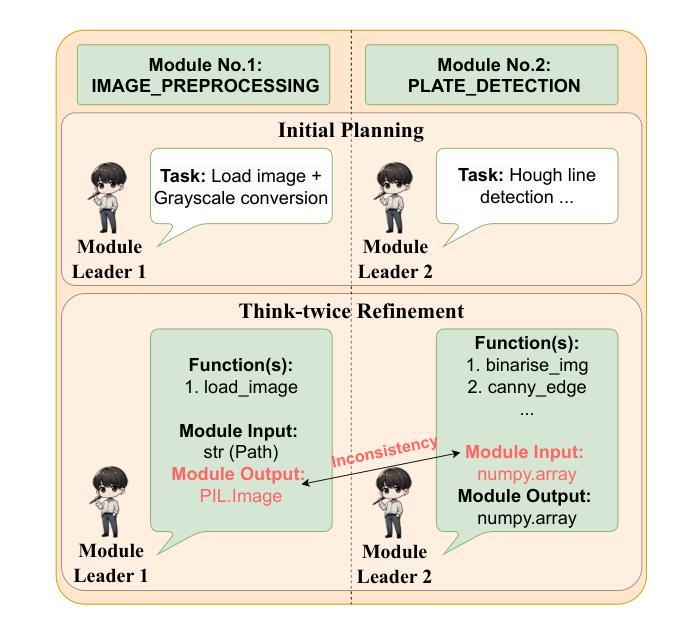
Authors:Zixiao Zhao, Jing Sun, Zhe Hou, Zhiyuan Wei, Cheng-Hao Cai, Miao Qiao, Jin Song Dong
With the rapid advancement of Large Language Models (LLMs), LLM-based approaches have demonstrated strong problem-solving capabilities across various domains. However, in automatic programming, a single LLM is typically limited to function-level code generation, while multi-agent systems composed of multiple LLMs often suffer from inefficient task planning. This lack of structured coordination can lead to cascading hallucinations, where accumulated errors across agents result in suboptimal workflows and excessive computational costs. To overcome these challenges, we introduce MaCTG (Multi-Agent Collaborative Thought Graph), a novel multi-agent framework that employs a dynamic graph structure to facilitate precise task allocation and controlled collaboration among LLM agents. MaCTG autonomously assigns agent roles based on programming requirements, dynamically refines task distribution through context-aware adjustments, and systematically verifies and integrates project-level code, effectively reducing hallucination errors and improving overall accuracy. MaCTG enhances cost-effectiveness by implementing a hybrid LLM deployment, where proprietary models handle complex reasoning, while open-source models are used for routine coding and validation tasks. To evaluate MaCTG’s effectiveness, we applied it to traditional image processing auto-programming tasks, achieving a state-of-the-art accuracy of 83.33%. Additionally, by leveraging its hybrid LLM configuration, MaCTG significantly reduced operational costs by 89.09% compared to existing multi-agent frameworks, demonstrating its efficiency, scalability, and real-world applicability.
随着大型语言模型(LLM)的快速发展,基于LLM的方法已在各个领域展现出强大的问题解决能力。然而,在自动编程领域,单个LLM通常仅限于函数级别的代码生成,而由多个LLM组成的多智能体系统则常常面临任务规划效率低下的问题。这种缺乏结构化协调可能会导致级联幻觉,即智能体之间的累积错误导致工作流程不佳和计算成本过高。为了克服这些挑战,我们引入了MaCTG(多智能体协作思维图),这是一种新型的多智能体框架,采用动态图形结构来促进LLM智能体之间的精确任务分配和控制协作。MaCTG根据编程要求自主分配智能体角色,通过上下文感知调整动态优化任务分配,并系统地验证和集成项目级代码,有效地减少幻觉错误并提高整体准确性。MaCTG通过实施混合LLM部署来提高成本效益,其中专有模型负责复杂推理,而开源模型则用于常规编码和验证任务。为了评估MaCTG的有效性,我们将其应用于传统的图像处理自动编程任务,实现了最先进的83.33%的准确率。此外,通过利用其混合LLM配置,MaCTG与现有的多智能体框架相比,将运营成本降低了89.09%,证明了其效率、可扩展性和现实世界的适用性。
论文及项目相关链接
Summary
LLMs在自动编程领域展现出强大的问题解决能力,但仍存在功能级代码生成和多智能体系统任务规划低效的问题。为解决这些问题,提出MaCTG框架,采用动态图结构促进智能体间的精确任务分配和协作。MaCTG自主分配编程需求的智能体角色,动态调整任务分配并验证集成项目级代码,提高了准确性和成本效益。
Key Takeaways
- LLMs在自动编程中展现出强大的问题解决能力,但仍存在功能级代码生成和多智能体系统任务规划低效的问题。
- MaCTG框架采用动态图结构促进智能体间的精确任务分配和协作,以提高任务执行效率。
- MaCTG自主分配编程需求的智能体角色,通过动态调整任务分配提高代码生成的准确性。
- MaCTG通过验证和集成项目级代码,有效减少错误和降低成本。
- MaCTG利用混合LLM部署实现复杂推理和常规编码验证任务的分离,进一步提高成本效益。
- MaCTG在图像处理自动编程任务中取得最先进的准确性。
点此查看论文截图