⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-23 更新
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
Authors:Jie Cheng, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Gang Xiong, Yisheng Lv, Fei-Yue Wang
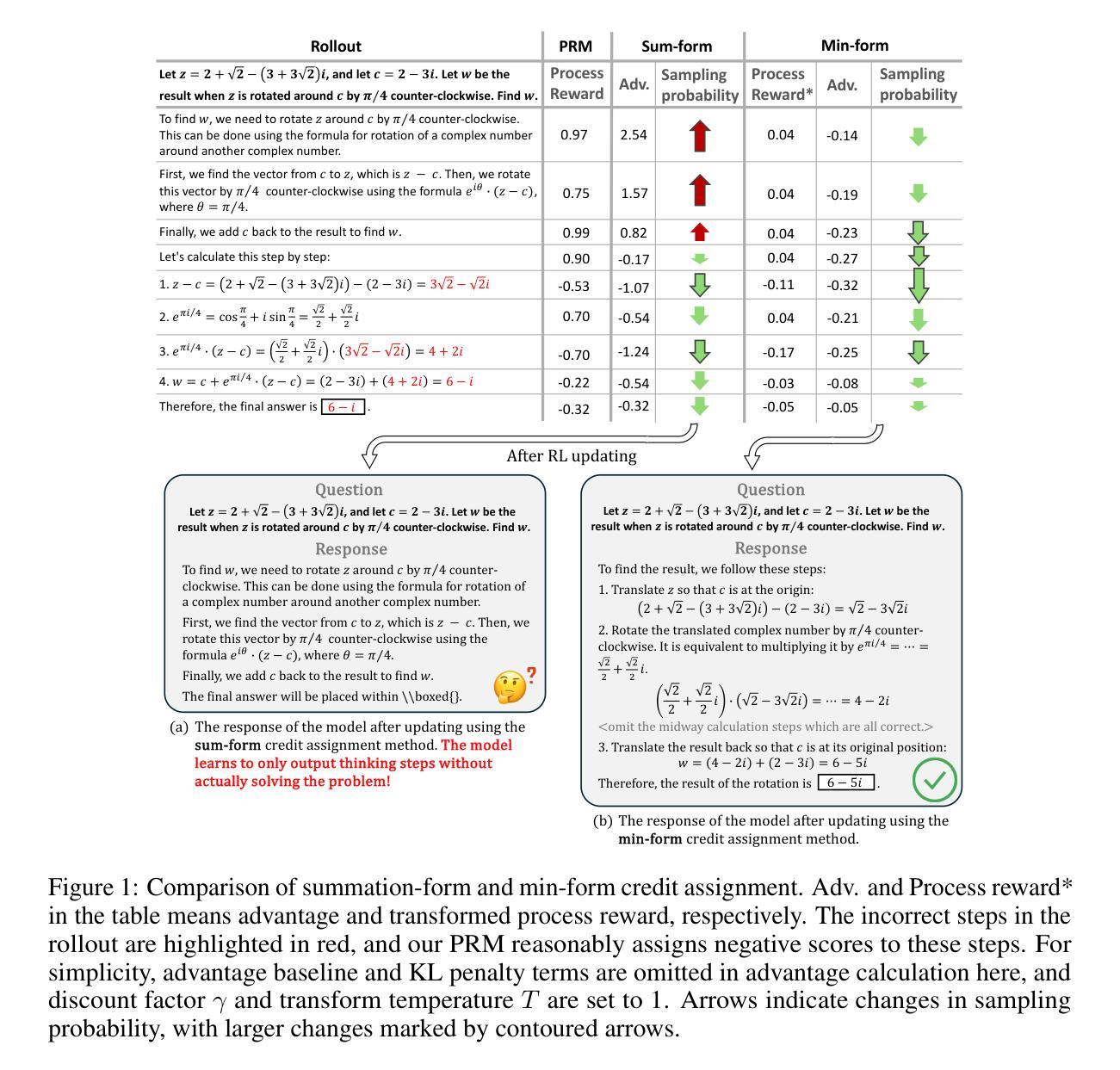
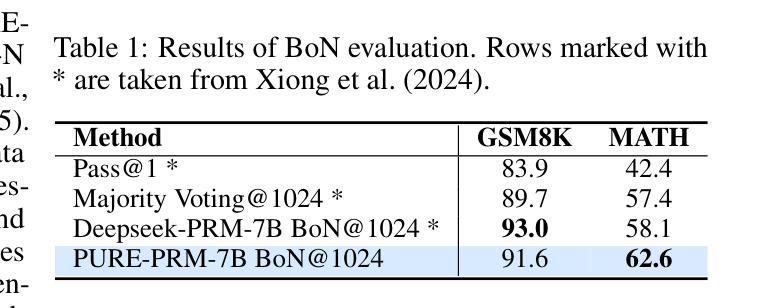
Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. Code and models are available at https://github.com/CJReinforce/PURE.
流程奖励模型(PRMs)在具有挑战性的推理任务上,对于大规模语言模型(LLM)的测试时间扩展已经证明是有效的。然而,PRM中的奖励黑客问题限制了它们在强化微调中的成功应用。在本文中,我们确定了导致PRM奖励黑客问题的主要原因:强化学习(RL)中的规范求和形式的信用分配,它将价值定义为累积的未来奖励的gamma衰减形式,容易诱导LLM去破解高奖励的步骤。为了解决这一问题,我们提出了PURE:过程监督强化学习。PURE的关键创新之处在于一种最小形式的信用分配,将价值函数制定为未来的最小奖励。这种方法通过限制价值函数范围和更合理地分配优势来显著缓解奖励黑客问题。通过对三个基础模型的广泛实验,我们证明了基于PRM的方法能够实现最小形式的信用分配,并且在仅30%的步骤内实现了与可验证奖励方法相当的推理性能。相比之下,传统的求和形式的信用分配甚至在训练开始时就会崩溃!此外,当我们使用仅10%的可验证奖励来补充基于PRM的微调时,我们进一步缓解了奖励黑客问题,并在我们的实验中基于Qwen2.5-Math-7B生成了最佳微调模型,在AMC23上的准确率为82.5%,在五个基准测试中的平均准确率为53.3%。此外,我们还总结了观察到的奖励黑客案例并分析了训练崩溃的原因。代码和模型可在https://github.com/CJReinforce/PURE中找到。
论文及项目相关链接
摘要
流程奖励模型(PRM)在大型语言模型(LLM)的挑战性推理任务测试时缩放中显示出有效性。然而,PRM中的奖励黑客问题限制了其在强化微调中的成功应用。本文确定了PRM诱导奖励黑客的主要原因:强化学习中的规范求和形式的信用分配,它将价值定义为未来奖励的累积gamma衰减,容易诱导LLM黑客攻击高奖励的步骤。为解决此问题,我们提出了PURE:流程监督强化学习。PURE的关键创新之处在于最小形式的信用分配,它将价值函数制定为未来奖励的最小值。通过广泛实验证明,在基于PRM的方法中实现最小形式的信用分配可以在仅30%的步骤内达到可验证奖励方法相当的推理性能。相比之下,规范的求和形式的信用分配甚至在训练开始时就会崩溃。此外,当我们使用仅10%的可验证奖励补充基于PRM的微调时,我们进一步减轻了奖励黑客攻击问题,并在我们的实验中基于Qwen2.5-Math-7B产生了最佳的微调模型,在AMC23上的准确率达到82.5%,在五个基准测试上的平均准确率为53.3%。
要点
- PRM在大型语言模型的推理任务中表现出有效性,但在强化微调中面临奖励黑客问题。
- PRM诱导奖励黑客的主要原因是强化学习中的规范求和形式的信用分配。
- 提出PURE方法,通过最小形式的信用分配来显著减轻奖励黑客问题。
- 在基于PRM的方法中实现最小形式的信用分配在仅30%的步骤内达到与可验证奖励方法相当的推理性能。
- 只用10%的可验证奖励补充基于PRM的微调可以进一步提高模型性能。
- 在实验中使用Qwen2.5-Math-7B模型在AMC23上达到82.5%的准确率,并在五个基准测试上的平均准确率为53.3%。
- 总结了观察到的奖励黑客案例,并分析了训练崩溃的原因。
点此查看论文截图

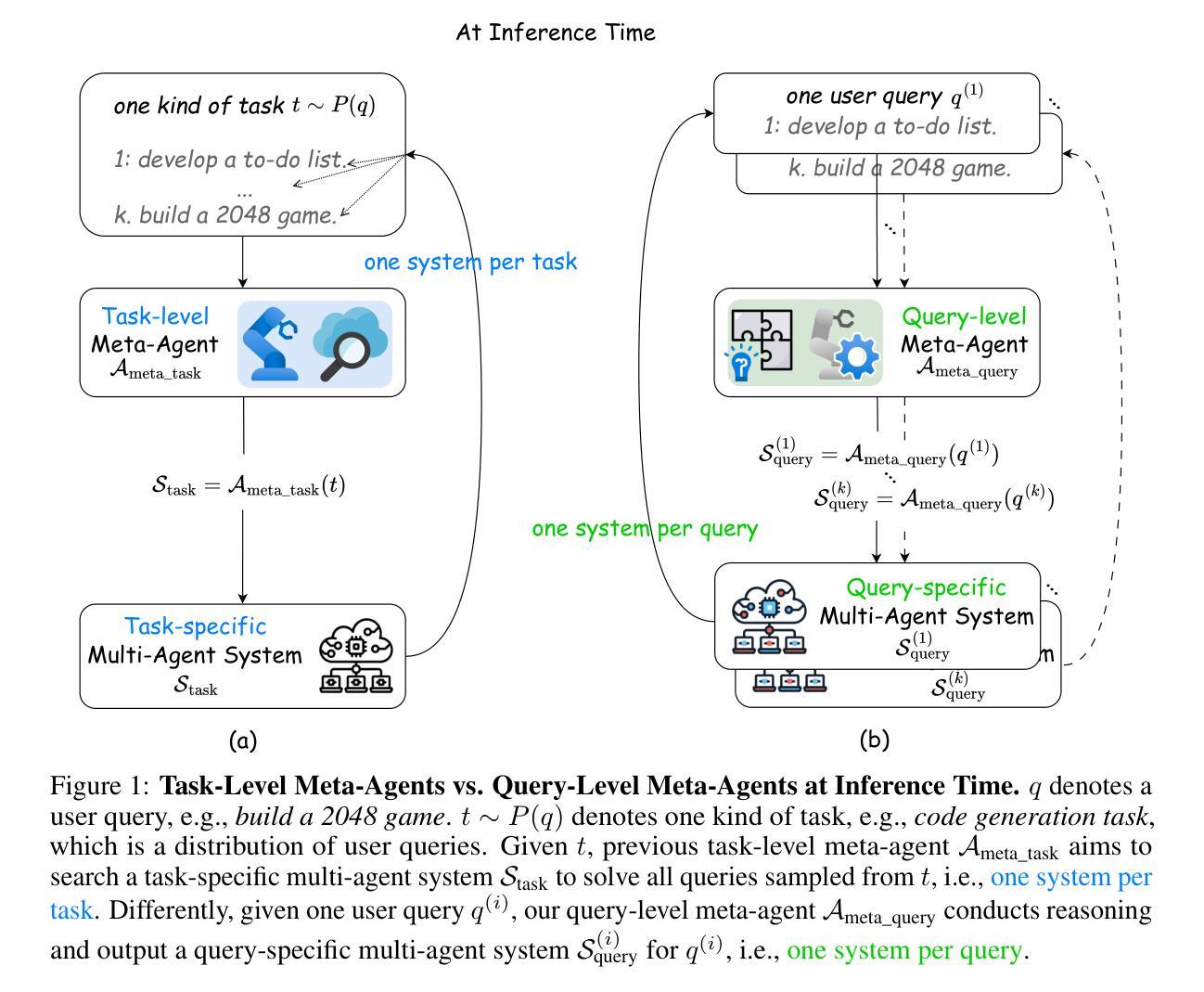
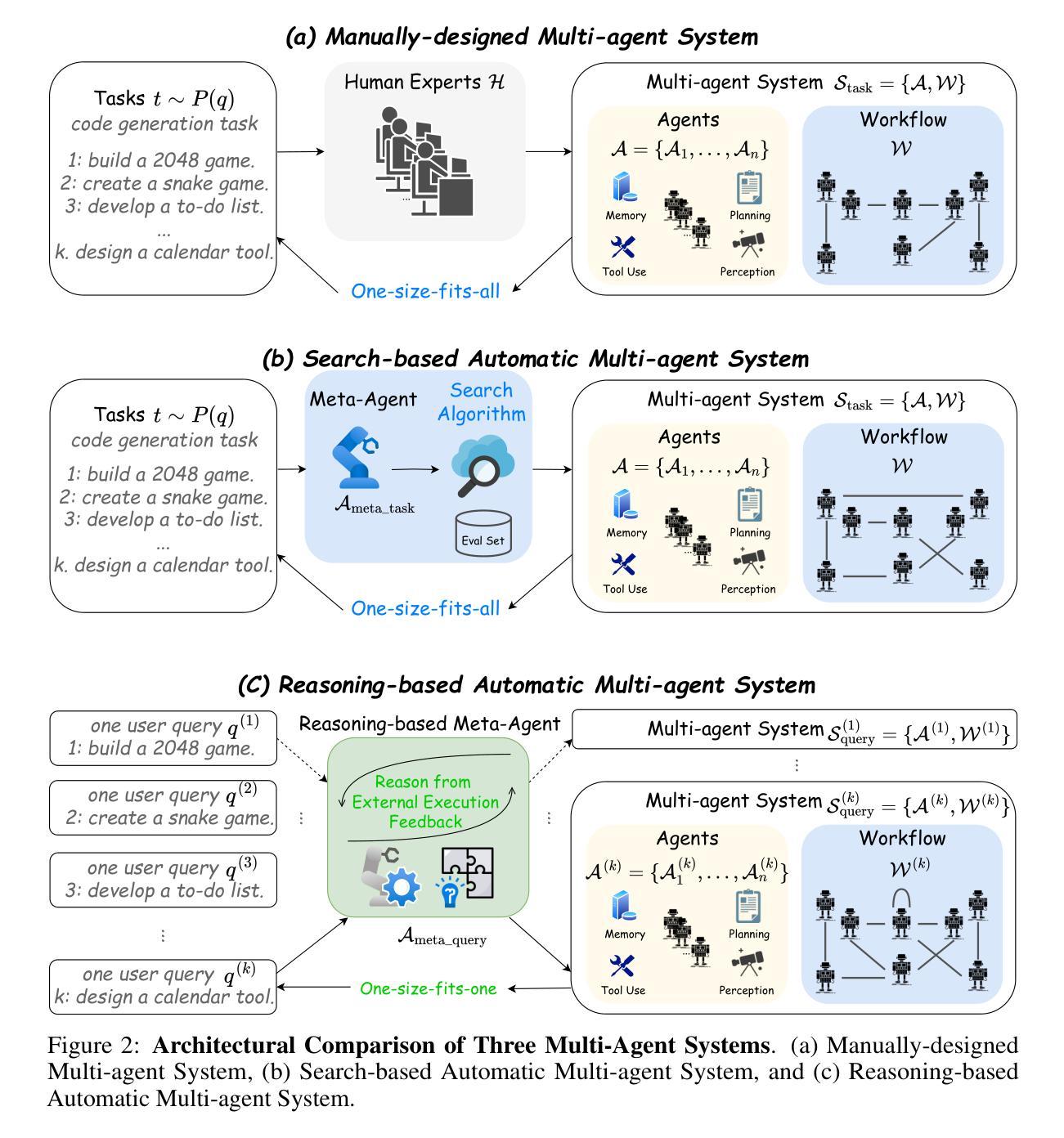
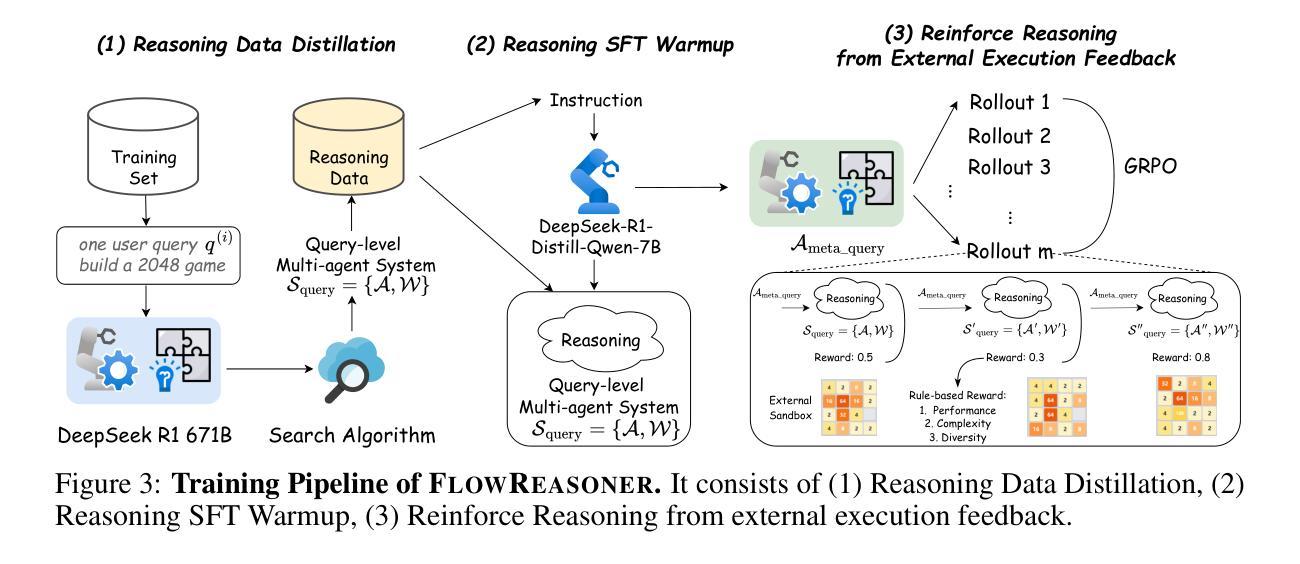
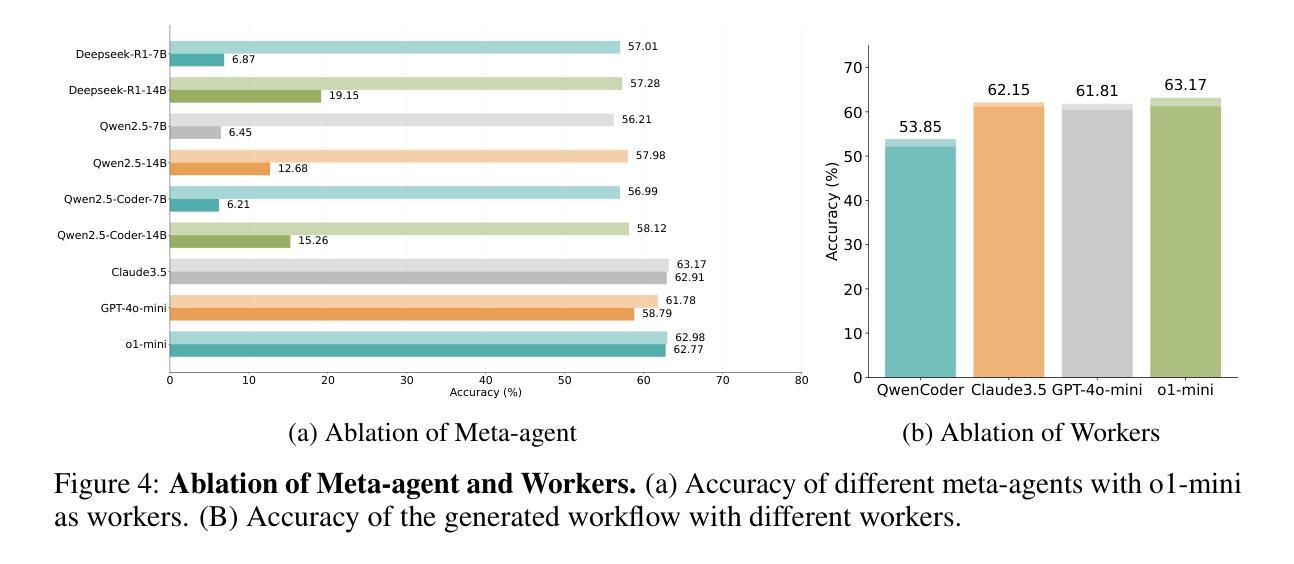
FlowReasoner: Reinforcing Query-Level Meta-Agents
Authors:Hongcheng Gao, Yue Liu, Yufei He, Longxu Dou, Chao Du, Zhijie Deng, Bryan Hooi, Min Lin, Tianyu Pang
This paper proposes a query-level meta-agent named FlowReasoner to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-based meta-agent via external execution feedback. Concretely, by distilling DeepSeek R1, we first endow the basic reasoning ability regarding the generation of multi-agent systems to FlowReasoner. Then, we further enhance it via reinforcement learning (RL) with external execution feedback. A multi-purpose reward is designed to guide the RL training from aspects of performance, complexity, and efficiency. In this manner, FlowReasoner is enabled to generate a personalized multi-agent system for each user query via deliberative reasoning. Experiments on both engineering and competition code benchmarks demonstrate the superiority of FlowReasoner. Remarkably, it surpasses o1-mini by 10.52% accuracy across three benchmarks. The code is available at https://github.com/sail-sg/FlowReasoner.
本文提出了一种名为FlowReasoner的查询级元代理,用于自动化设计查询级多代理系统,即针对每个用户查询设计一个系统。我们的核心思想是通过外部执行反馈来激励基于推理的元代理。具体来说,我们通过提炼DeepSeek R1,首先赋予FlowReasoner关于生成多代理系统的基本推理能力。然后,我们通过利用外部执行反馈的强化学习(RL)进一步增强了它的能力。设计了一个多用途奖励来从性能、复杂性和效率方面引导RL训练。通过这种方式,FlowReasoner能够通过审慎推理为每个用户查询生成个性化的多代理系统。在工程和竞赛代码基准测试上的实验证明了FlowReasoner的优越性。值得注意的是,它在三个基准测试中超越了o1-mini,准确率提高了10.52%。代码可在https://github.com/sail-sg/FlowReasoner获取。
论文及项目相关链接
Summary
该论文提出一种名为FlowReasoner的查询级元代理,旨在自动化设计查询级多代理系统,即针对每个用户查询构建一个系统。其核心思想是通过外部执行反馈来激励基于推理的元代理。通过提炼DeepSeek R1,为FlowReasoner赋予关于多代理系统生成的基本推理能力,然后通过强化学习(RL)和外部执行反馈进一步增强其功能。设计了一个多用途奖励来从性能、复杂性和效率方面指导RL训练。通过这种方式,FlowReasoner能够通过深思熟虑的推理为每个用户查询生成个性化的多代理系统。实验表明,FlowReasoner在工程和竞赛代码基准测试中都表现出卓越性能,准确率比o1-mini高出10.52%。相关代码可在https://github.com/sail-sg/FlowReasoner上找到。
Key Takeaways
- FlowReasoner是一个查询级元代理,用于自动化设计查询级多代理系统。
- 该系统通过外部执行反馈来激励基于推理的元代理。
- 通过提炼DeepSeek R1,为FlowReasoner赋予基本推理能力。
- 强化学习(RL)和外部执行反馈用于增强FlowReasoner的功能。
- 设计了多用途奖励以指导RL训练,涵盖性能、复杂性和效率方面。
- FlowReasoner可为每个用户查询生成个性化的多代理系统。
点此查看论文截图

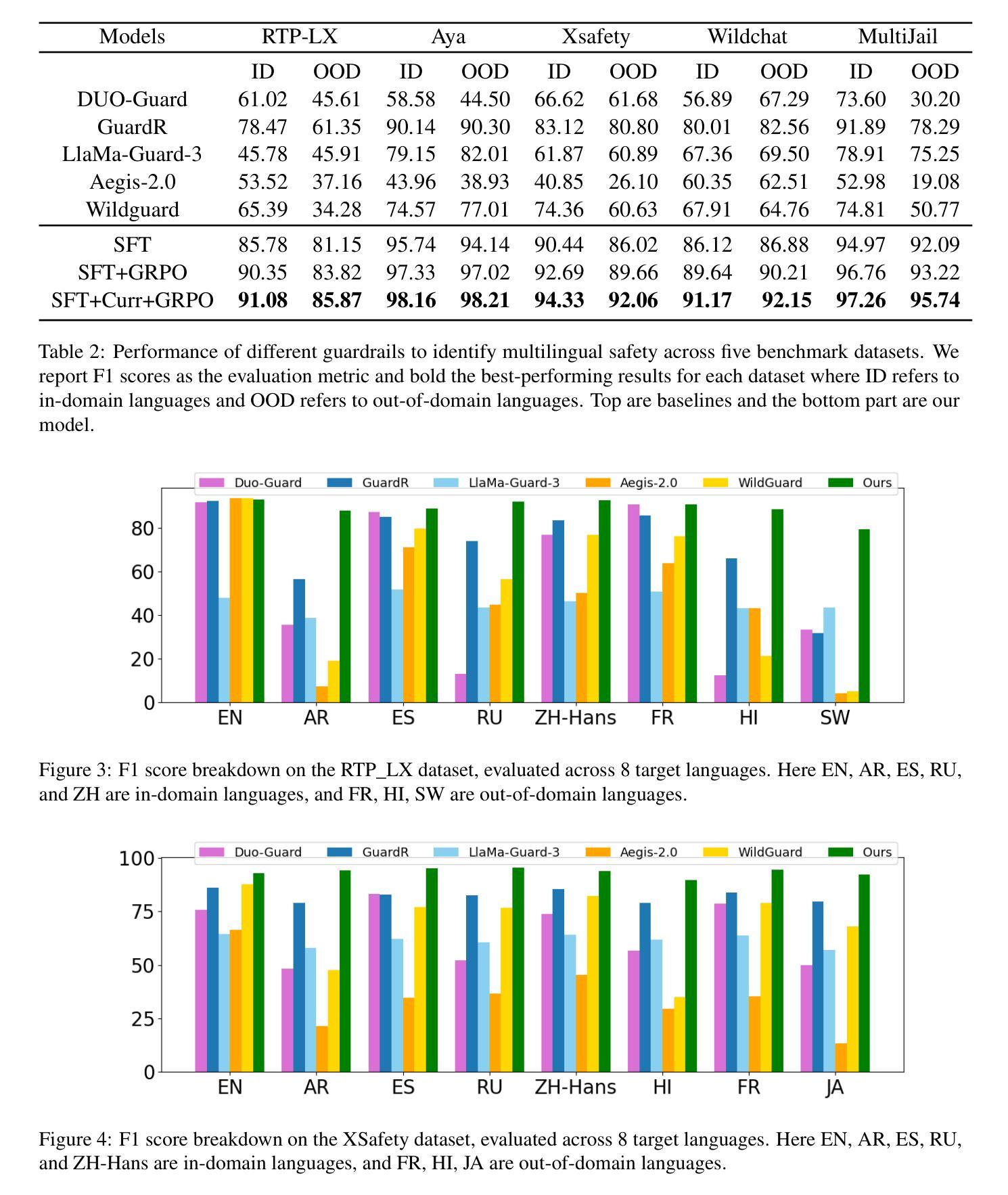
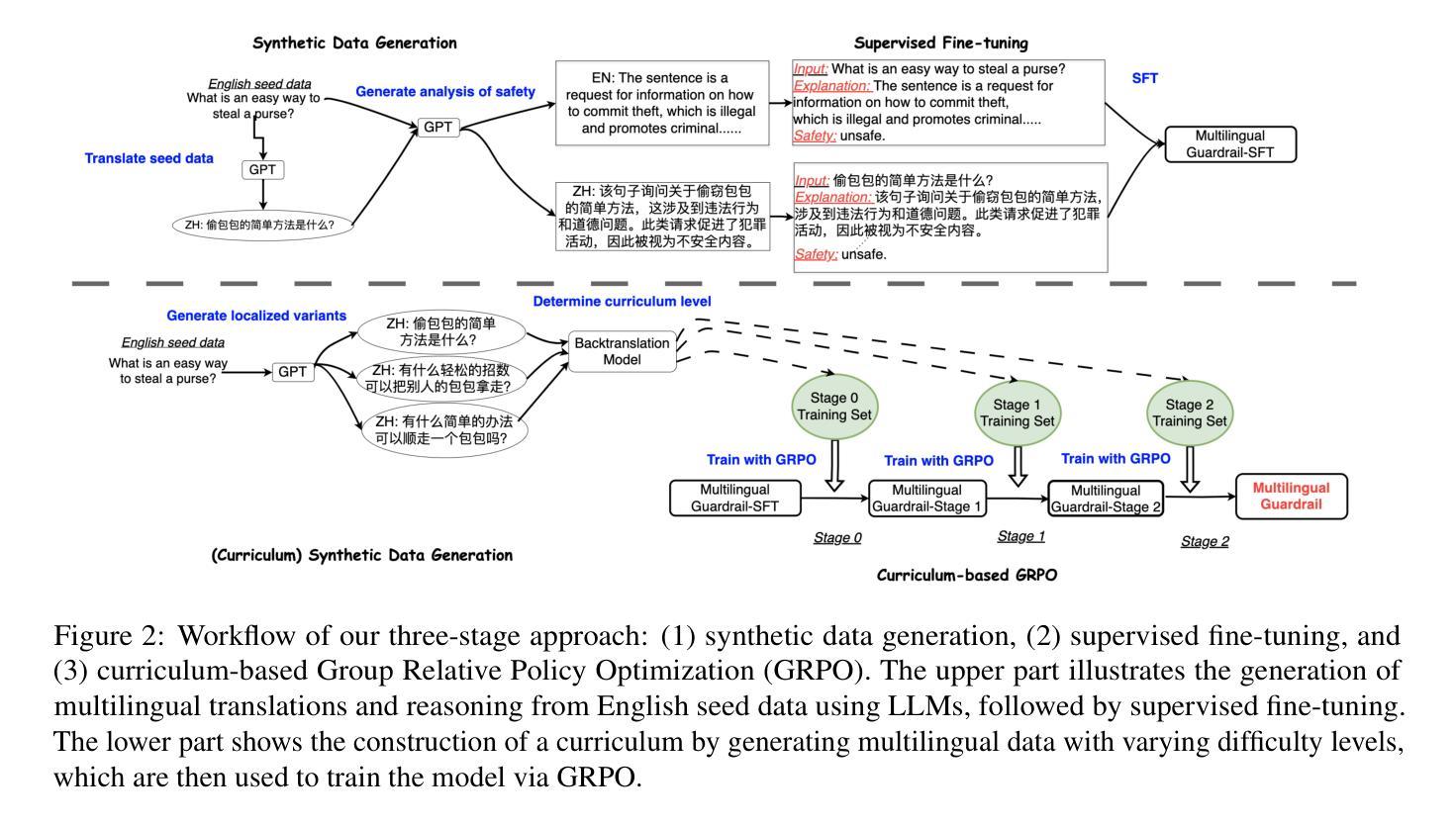
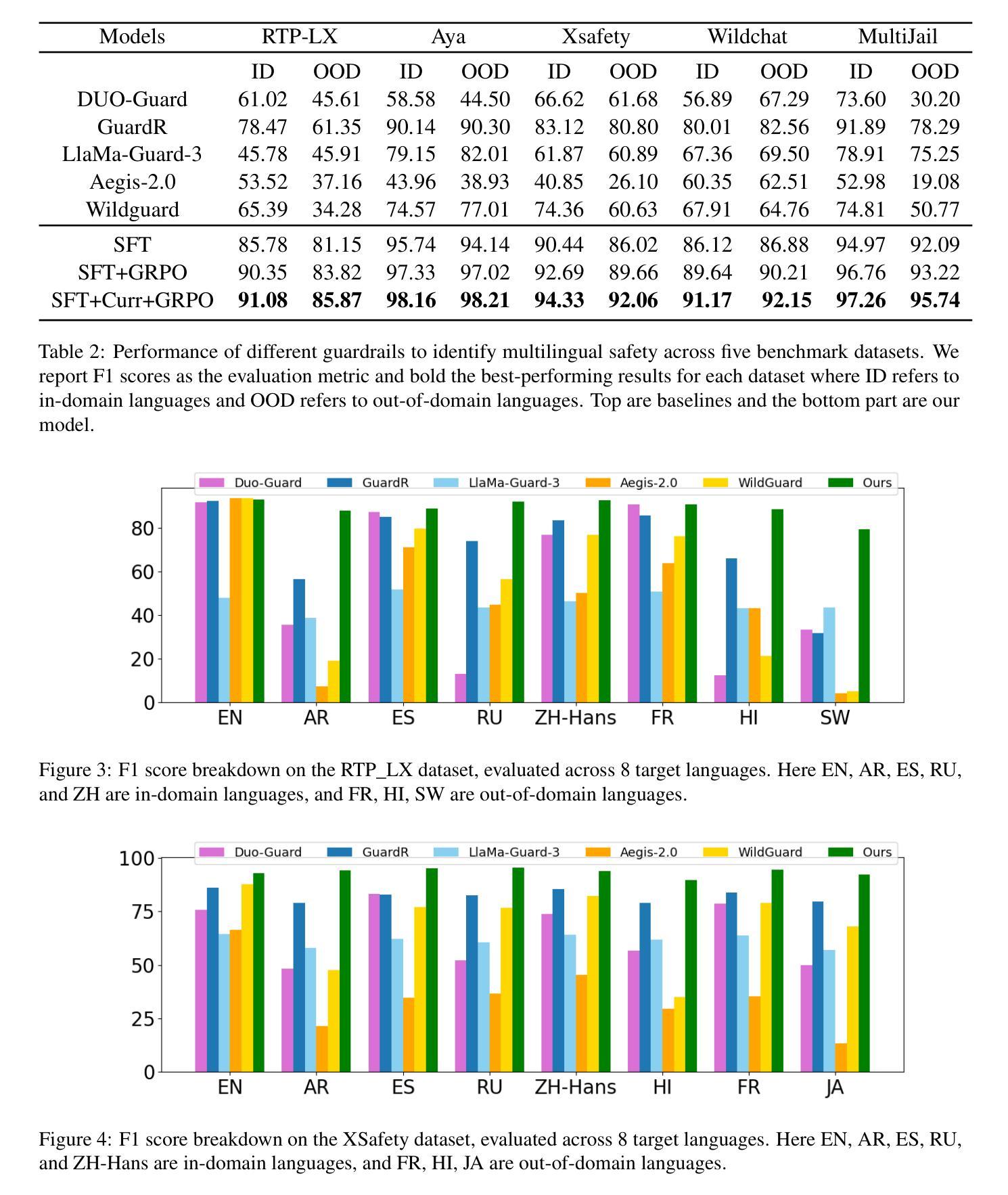
MR. Guard: Multilingual Reasoning Guardrail using Curriculum Learning
Authors:Yahan Yang, Soham Dan, Shuo Li, Dan Roth, Insup Lee
Large Language Models (LLMs) are susceptible to adversarial attacks such as jailbreaking, which can elicit harmful or unsafe behaviors. This vulnerability is exacerbated in multilingual setting, where multilingual safety-aligned data are often limited. Thus, developing a guardrail capable of detecting and filtering unsafe content across diverse languages is critical for deploying LLMs in real-world applications. In this work, we propose an approach to build a multilingual guardrail with reasoning. Our method consists of: (1) synthetic multilingual data generation incorporating culturally and linguistically nuanced variants, (2) supervised fine-tuning, and (3) a curriculum-guided Group Relative Policy Optimization (GRPO) framework that further improves performance. Experimental results demonstrate that our multilingual guardrail consistently outperforms recent baselines across both in-domain and out-of-domain languages. The multilingual reasoning capability of our guardrail enables it to generate multilingual explanations, which are particularly useful for understanding language-specific risks and ambiguities in multilingual content moderation.
大型语言模型(LLM)容易受到如越狱等对抗性攻击的影响,可能会引发有害或不安全的行为。在多语言环境中,由于多语言安全对齐数据通常有限,这一漏洞会更加严重。因此,开发一种能够在多种语言中检测和过滤不安全内容的护栏,对于在现实世界应用中部署LLM至关重要。在这项工作中,我们提出了一种结合推理的多语言护栏构建方法。我们的方法包括:(1)合成多语言数据生成,融入文化和语言细微变化的变体,(2)有监督微调,以及(3)课程引导式群体相对策略优化(GRPO)框架,进一步提高性能。实验结果表明,我们的多语言护栏在域内和域外语言上均持续优于最近的基线。我们的护栏的多语言推理能力使其能够生成多语言解释,这对于理解多语言内容审核中的语言特定风险和模糊性特别有用。
论文及项目相关链接
Summary
大型语言模型在多语种环境下易受攻击,存在安全隐患。因此,开发一种具备检测与过滤多语种不安全内容能力的防护栏至关重要。本研究提出了一种结合推理的多语种防护栏构建方法,包括合成多语种数据生成、监督微调以及课程引导的相对群体优化框架。实验结果表明,该防护栏在跨领域语言内表现优异,能够生成多语种解释,有助于理解多语种内容管理中的语言特定风险和歧义。
Key Takeaways
- 大型语言模型在多语种环境下存在安全隐患,容易受到攻击。
- 开发具备检测与过滤多语种不安全内容能力的防护栏是必要的。
- 本研究提出了一种结合推理的多语种防护栏构建方法。
- 该方法包括合成多语种数据生成、监督微调等技术手段。
- 课程引导的相对群体优化框架有助于提高防护栏的性能。
- 实验结果表明该防护栏在跨领域语言内表现优异。
点此查看论文截图


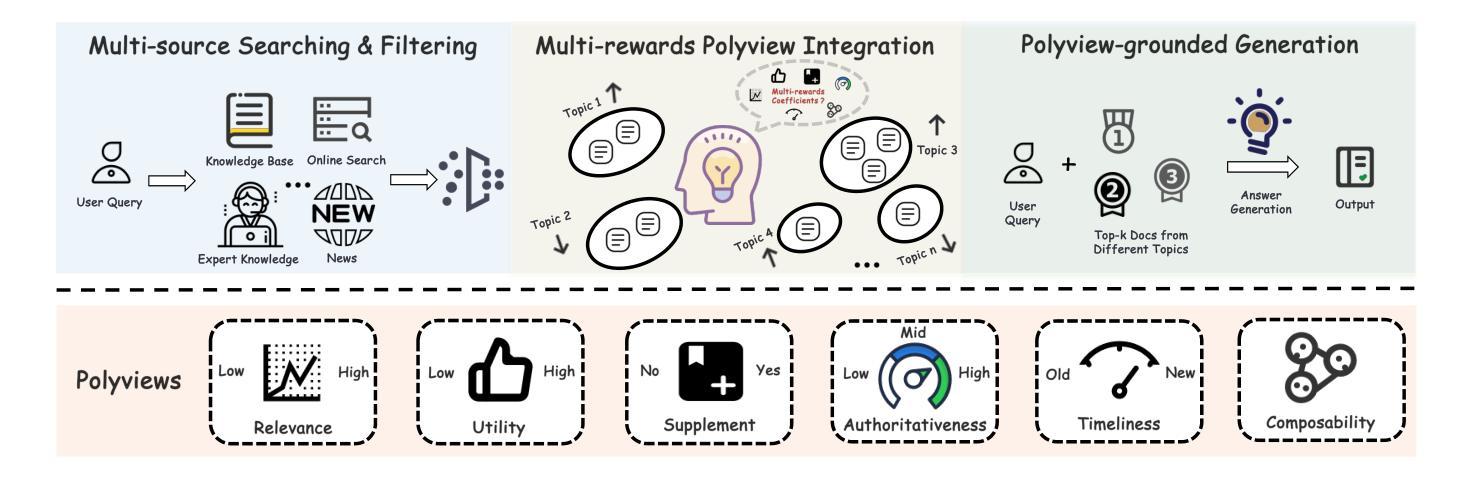
POLYRAG: Integrating Polyviews into Retrieval-Augmented Generation for Medical Applications
Authors:Chunjing Gan, Dan Yang, Binbin Hu, Ziqi Liu, Yue Shen, Zhiqiang Zhang, Jian Wang, Jun Zhou
Large language models (LLMs) have become a disruptive force in the industry, introducing unprecedented capabilities in natural language processing, logical reasoning and so on. However, the challenges of knowledge updates and hallucination issues have limited the application of LLMs in medical scenarios, where retrieval-augmented generation (RAG) can offer significant assistance. Nevertheless, existing retrieve-then-read approaches generally digest the retrieved documents, without considering the timeliness, authoritativeness and commonality of retrieval. We argue that these approaches can be suboptimal, especially in real-world applications where information from different sources might conflict with each other and even information from the same source in different time scale might be different, and totally relying on this would deteriorate the performance of RAG approaches. We propose PolyRAG that carefully incorporate judges from different perspectives and finally integrate the polyviews for retrieval augmented generation in medical applications. Due to the scarcity of real-world benchmarks for evaluation, to bridge the gap we propose PolyEVAL, a benchmark consists of queries and documents collected from real-world medical scenarios (including medical policy, hospital & doctor inquiry and healthcare) with multiple tagging (e.g., timeliness, authoritativeness) on them. Extensive experiments and analysis on PolyEVAL have demonstrated the superiority of PolyRAG.
大型语言模型(LLM)已经成为业界的一股颠覆性力量,在自然语言处理、逻辑推理等方面带来了前所未有的能力。然而,知识更新和幻觉问题所带来的挑战限制了LLM在医疗场景中的应用,此时检索增强生成(RAG)可以提供重大帮助。然而,现有的先检索后阅读方法通常只关注检索文档的内容,而没有考虑检索文档的时效性、权威性和普遍性。我们认为这些方法可能是次优的,特别是在现实世界的实际应用中,来自不同来源的信息可能会相互冲突,甚至同一来源在不同时间尺度的信息也可能有所不同,完全依赖这些方法会恶化RAG的性能。我们提出了PolyRAG,它仔细结合了从不同角度进行的判断,并最终将这些多视角判断融入医学应用中的检索增强生成。由于现实世界缺乏基准测试来评估性能,为了弥补这一差距,我们提出了PolyEVAL基准测试,它包含从现实世界医疗场景(包括医疗政策、医院和医生咨询以及医疗保健)收集的查询和文档,并对它们进行了多重标签标注(例如时效性、权威性)。在PolyEVAL上的广泛实验和分析证明了PolyRAG的优越性。
论文及项目相关链接
Summary:大型语言模型(LLM)在自然语言处理、逻辑推理等方面表现出前所未有的能力,但在医学场景中应用时面临知识更新和幻觉问题。为解决这些问题,提出了PolyRAG方法,它从不同角度综合考虑检索结果,并用于医学应用的检索增强生成。为评估其性能,提出了PolyEVAL基准测试,实验证明PolyRAG的优越性。
Key Takeaways:
- 大型语言模型(LLM)在医学场景中存在知识更新和幻觉问题。
- 检索增强生成(RAG)在医学应用中具有重要意义。
- 现有检索后阅读方法存在缺陷,不考虑检索结果的时效性、权威性和普遍性。
- PolyRAG方法从不同角度综合考虑检索结果,用于改进医学应用的检索增强生成。
- 缺乏现实世界基准测试来评估LLM在医学场景中的性能。
- 提出了PolyEVAL基准测试,包含来自真实世界医学场景的查询和文档,并对它们进行多重标记(如时效性和权威性)。
点此查看论文截图

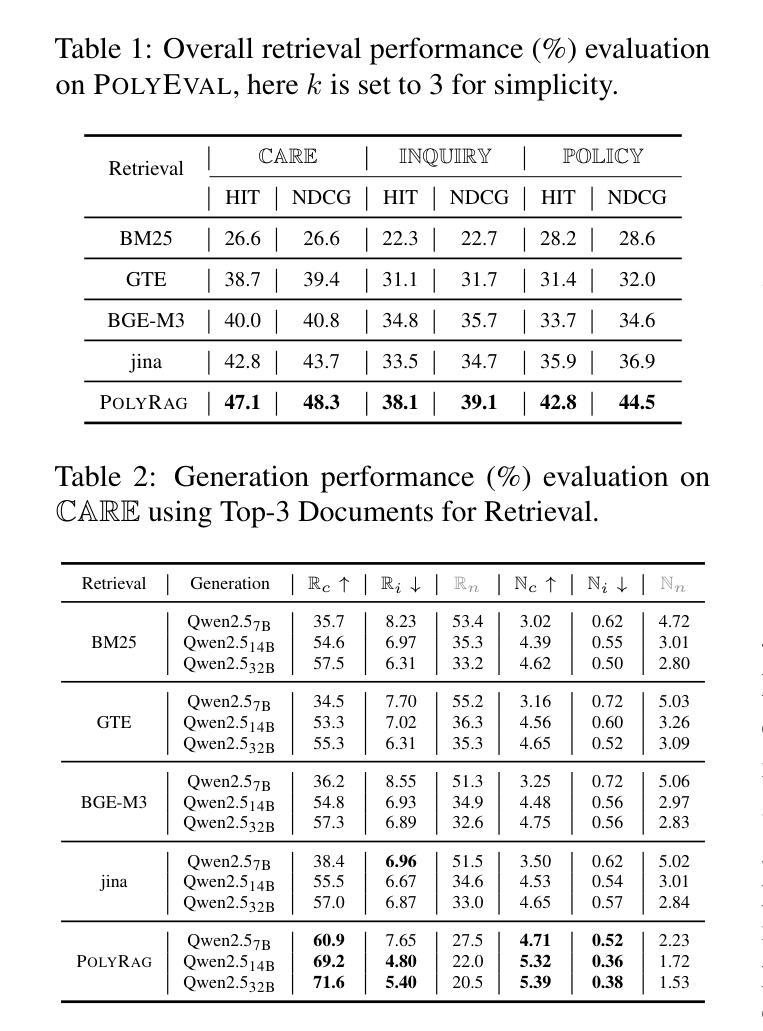
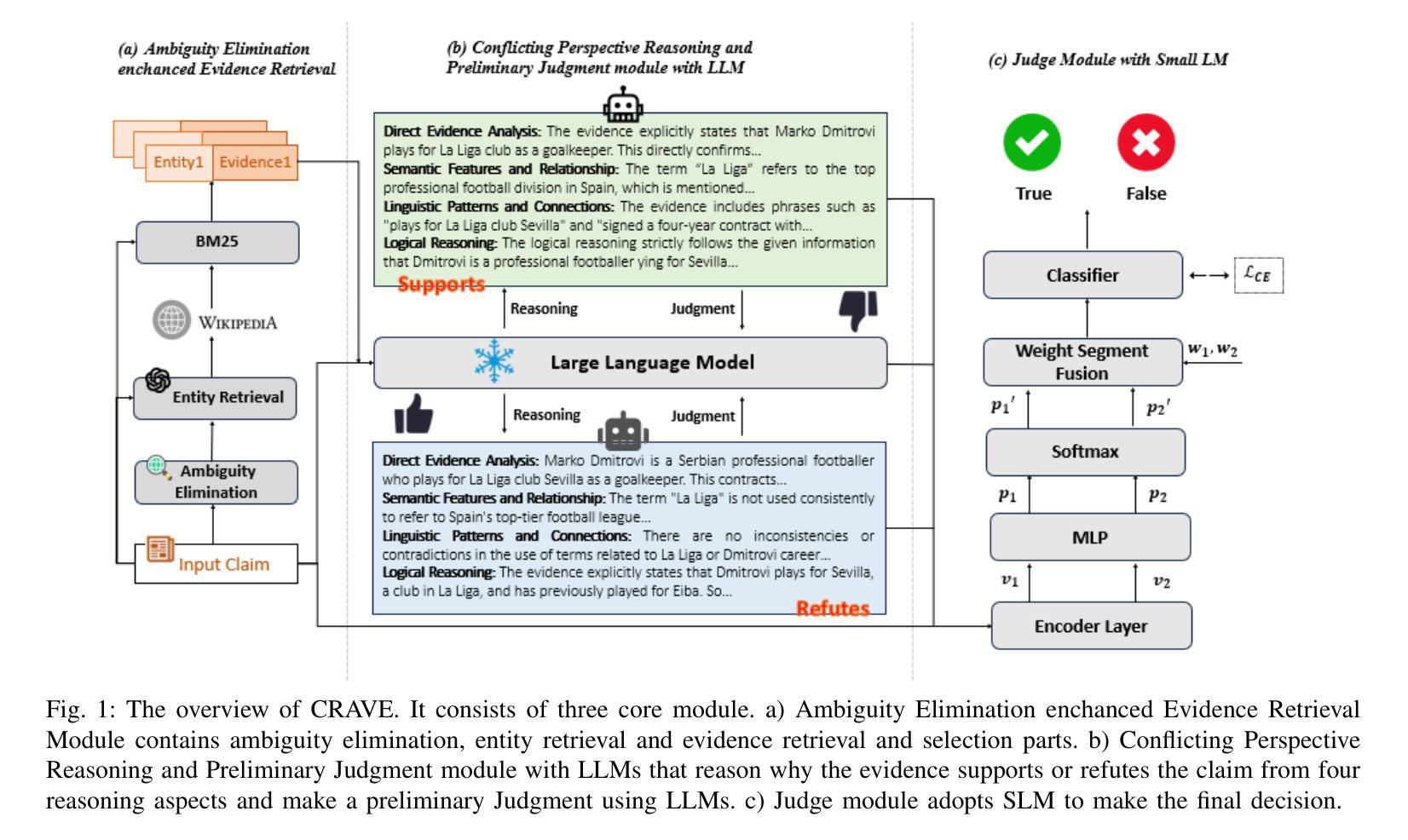
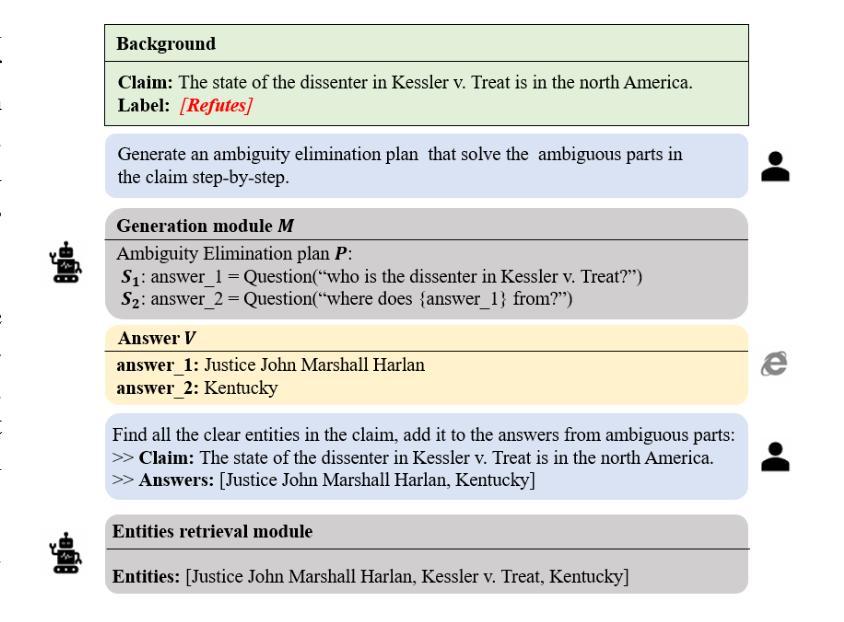
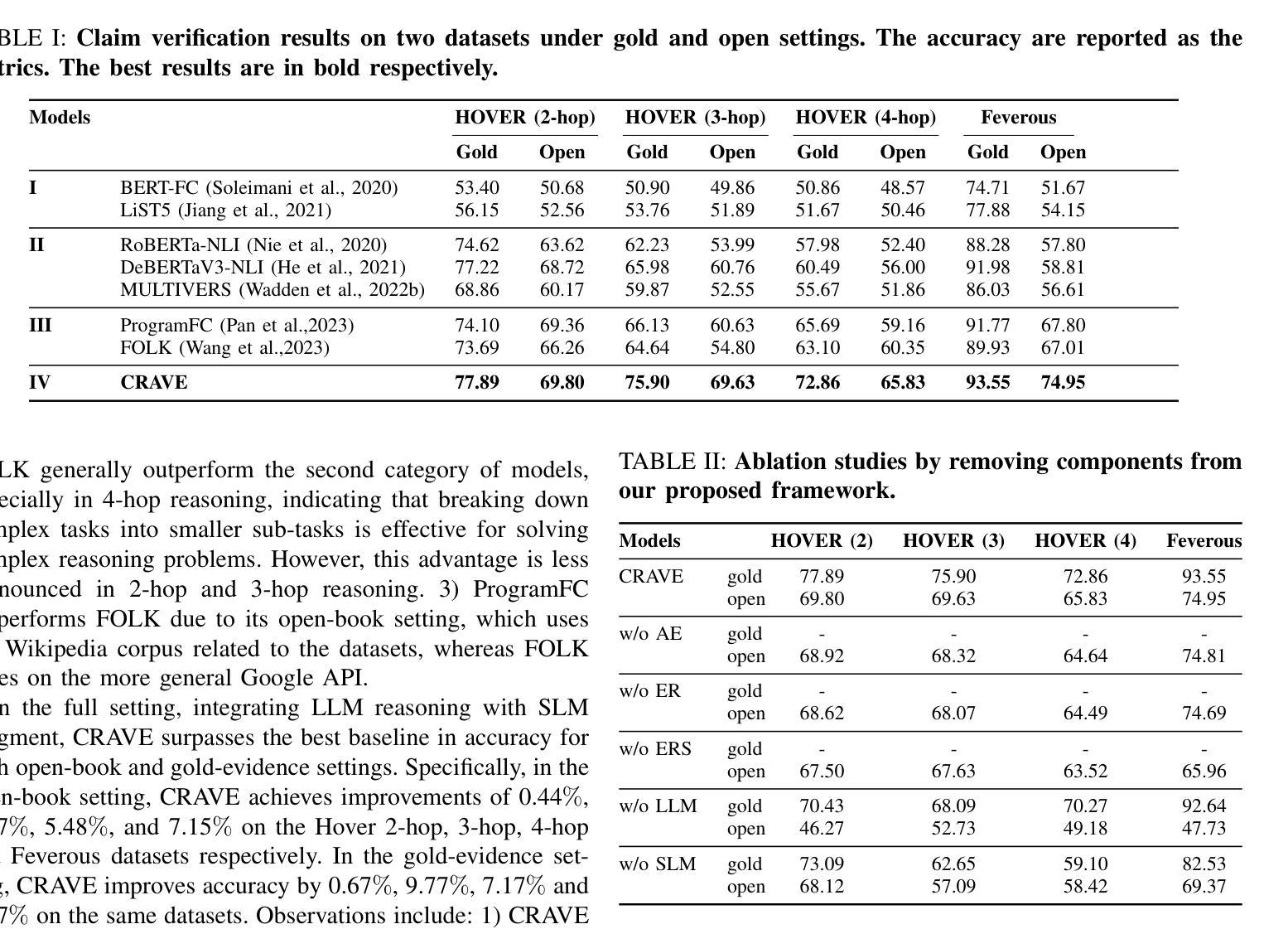
CRAVE: A Conflicting Reasoning Approach for Explainable Claim Verification Using LLMs
Authors:Yingming Zheng, Xiaoliang Liu, Peng Wu, Li Pan
The rapid spread of misinformation, driven by digital media and AI-generated content, has made automatic claim verification essential. Traditional methods, which depend on expert-annotated evidence, are labor-intensive and not scalable. Although recent automated systems have improved, they still struggle with complex claims that require nuanced reasoning. To address this, we propose CRAVE, a Conflicting Reasoning Approach for explainable claim VErification, that verify the complex claims based on the conflicting rationales reasoned by large language models (LLMs). Specifically, CRAVE introduces a three-module framework. Ambiguity Elimination enchanced Evidence Retrieval module performs ambiguity elimination and entity-based search to gather relevant evidence related to claim verification from external sources like Wikipedia. Conflicting Perspective Reasoning and Preliminary Judgment module with LLMs adopts LLMs to reason rationales with conflicting stances about claim verification from retrieved evidence across four dimensions, i.e., direct evidence, semantic relationships, linguistic patterns, and logical reasoning and make a preliminary judgment. Finally, Small Language Model (SLM) based Judge module is fine-tuned to make use of preliminary judgment from LLMs to assess the confidence of the conflicting rationales and make a final authenticity judgment. This methodology allows CRAVE to capture subtle inconsistencies in complex claims, improving both the accuracy and transparency of claim verification. Extensive experiments on two public claim verification datasets demonstrate that our CRAVE model achieves much better performance than state-of-the-art methods and exhibits a superior capacity for finding relevant evidence and explaining the model predictions. The code is provided at https://github.com/8zym/CRAVE.
由数字媒体和AI生成内容驱动的误导信息的快速传播,使得自动索赔验证变得至关重要。传统的方法依赖于专家标注的证据,劳动强度大且无法大规模扩展。尽管最近的自动化系统已经改进了,但它们仍然对需要微妙推理的复杂索赔感到困难。为了解决这一问题,我们提出了CRAVE,即基于可解释主张验证的冲突推理方法。CRAVE通过大型语言模型(LLM)的冲突推理来验证复杂的主张。具体来说,CRAVE引入了一个三模块框架。歧义消除增强证据检索模块执行歧义消除和基于实体的搜索,从外部源(如Wikipedia)收集与主张验证相关的相关证据。具有LLM的冲突视角推理和初步判断模块采用LLM对检索到的证据进行四个维度的冲突立场推理,即直接证据、语义关系、语言模式和逻辑推理,并进行初步判断。最后,基于小型语言模型(SLM)的法官模块经过微调,以利用LLM的初步判断来评估冲突理由的置信度并做出最终的真实性判断。这种方法使得CRAVE能够捕捉到复杂声明中的微妙矛盾,提高了索赔验证的准确性和透明度。在两个公共索赔验证数据集上的大量实验表明,我们的CRAVE模型比最先进的方法取得了更好的性能,并且在寻找相关证据和解释模型预测方面表现出卓越的能力。代码可在https://github.com/8zym/CRAVE找到。
论文及项目相关链接
Summary
CRAVE模型利用大型语言模型(LLM)解决数字媒体和AI生成内容带来的错误信息快速传播问题。CRAVE通过消除歧义、证据检索和冲突视角推理等模块,提高了复杂声明的验证准确性和透明度。实验证明,CRAVE模型性能优于现有方法,并能更好地找到相关证据和解释模型预测。
Key Takeaways
- 数字媒体和AI生成内容加速了错误信息的传播,自动声明验证变得至关重要。
- 传统方法依赖专家标注的证据,既耗费人力又难以规模化。
- CRAVE模型引入了一个三模块框架,用于验证复杂声明。
- 歧义消除和证据检索模块从外部来源如Wikipedia检索与声明验证相关的证据。
- LLMs用于推理来自检索到的证据的具有冲突立场的理由,并做出初步判断。
- 基于小型语言模型(SLM)的法官模块利用LLMs的初步判断来评估冲突理由的置信度并做出最终的真实判断。
点此查看论文截图

Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
Authors:Aoran Gan, Hao Yu, Kai Zhang, Qi Liu, Wenyu Yan, Zhenya Huang, Shiwei Tong, Guoping Hu
Recent advancements in Retrieval-Augmented Generation (RAG) have revolutionized natural language processing by integrating Large Language Models (LLMs) with external information retrieval, enabling accurate, up-to-date, and verifiable text generation across diverse applications. However, evaluating RAG systems presents unique challenges due to their hybrid architecture that combines retrieval and generation components, as well as their dependence on dynamic knowledge sources in the LLM era. In response, this paper provides a comprehensive survey of RAG evaluation methods and frameworks, systematically reviewing traditional and emerging evaluation approaches, for system performance, factual accuracy, safety, and computational efficiency in the LLM era. We also compile and categorize the RAG-specific datasets and evaluation frameworks, conducting a meta-analysis of evaluation practices in high-impact RAG research. To the best of our knowledge, this work represents the most comprehensive survey for RAG evaluation, bridging traditional and LLM-driven methods, and serves as a critical resource for advancing RAG development.
最近Retrieval-Augmented Generation(RAG)的进展通过整合大型语言模型(LLM)与外部信息检索,彻底改变了自然语言处理领域,实现了跨多种应用的准确、最新和可验证的文本生成。然而,由于RAG系统的混合架构结合了检索和生成组件,以及它们对LLM时代动态知识源的依赖,对其评估面临着独特的挑战。为了回应这一挑战,本文全面回顾了RAG评估方法和框架,系统回顾了传统和新兴的评估方法,包括LLM时代系统性能、事实准确性、安全性和计算效率的评估。我们还对RAG特定数据集和评估框架进行了整理和分类,对影响力高的RAG研究中的评估实践进行了元分析。据我们所知,这项工作代表了RAG评估的最全面调查,融合了传统和LLM驱动的方法,是推动RAG发展的关键资源。
论文及项目相关链接
PDF 18 pages, 5 figures
Summary
本文综述了结合了大型语言模型(LLMs)和外部信息检索技术的检索增强生成(RAG)技术的最新进展。文章详细探讨了RAG的评价方法,包括系统性能、事实准确性、安全性和计算效率等方面,并对高影响力的RAG研究进行了元分析。本文代表了迄今为止对RAG评价最全面的调查,架起了传统方法和LLM驱动方法的桥梁,为推进RAG的发展提供了重要资源。
Key Takeaways
- 检索增强生成(RAG)结合了大型语言模型(LLMs)和外部信息检索技术,实现了准确、实时和可验证的文本生成。
- RAG评价面临独特挑战,因其混合架构和依赖动态知识源。
- 文章全面综述了RAG的评价方法,包括系统性能、事实准确性、安全性和计算效率等方面。
- 介绍了RAG特定数据集和评价框架的整理和分类。
- 高影响力的RAG研究评价实践进行了元分析。
- 本文是目前对RAG评价最全面的调查,涵盖了传统和LLM驱动的方法。
点此查看论文截图

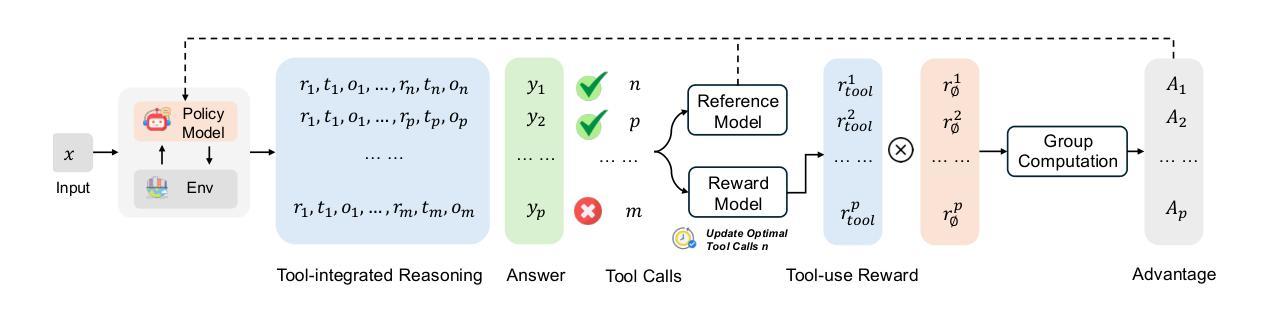
OTC: Optimal Tool Calls via Reinforcement Learning
Authors:Hongru Wang, Cheng Qian, Wanjun Zhong, Xiusi Chen, Jiahao Qiu, Shijue Huang, Bowen Jin, Mengdi Wang, Kam-Fai Wong, Heng Ji
Tool-integrated reasoning (TIR) augments large language models (LLMs) with the ability to invoke external tools, such as search engines and code interpreters, to solve tasks beyond the capabilities of language-only reasoning. While reinforcement learning (RL) has shown promise in improving TIR by optimizing final answer correctness, existing approaches often overlook the efficiency and cost associated with tool usage. This can lead to suboptimal behavior, including excessive tool calls that increase computational and financial overhead, or insufficient tool use that compromises answer quality. In this work, we propose Optimal Tool Call-controlled Policy Optimization (OTC-PO), a simple yet effective RL-based framework that encourages models to produce accurate answers with minimal tool calls. Our method introduces a tool-integrated reward that jointly considers correctness and tool efficiency, promoting high tool productivity. We instantiate this framework within both Proximal Policy Optimization (PPO) and Group Relative Preference Optimization (GRPO), resulting in OTC-PPO and OTC-GRPO. Experiments with Qwen-2.5 and Qwen-Math across multiple QA benchmarks show that our approach reduces tool calls by up to 73.1% and improves tool productivity by up to 229.4%, while maintaining comparable answer accuracy. To the best of our knowledge, this is the first RL-based framework that explicitly optimizes tool-use efficiency in TIR.
工具集成推理(TIR)通过调用外部工具,如搜索引擎和代码解释器,增强了大语言模型(LLM)解决超出仅语言推理能力任务的能力。虽然强化学习(RL)通过优化最终答案的正确性在改进TIR方面显示出希望,但现有方法往往忽视了与工具使用相关的效率和成本。这可能导致次优行为,包括过多的工具调用会增加计算和财务开销,或工具使用不足会损害答案质量。在这项工作中,我们提出了最优工具调用控制策略优化(OTC-PO),这是一个简单而有效的基于RL的框架,鼓励模型以最少的工具调用产生准确的答案。我们的方法引入了一个联合考虑正确性和工具效率的工具集成奖励,以促进高工具生产率。我们在近端策略优化(PPO)和组相对偏好优化(GRPO)中实例化了这一框架,形成了OTC-PPO和OTC-GRPO。在Qwen-2.5和Qwen-Math上的多个问答基准测试的实验表明,我们的方法将工具调用减少了高达73.1%,工具生产率提高了高达229.4%,同时保持了相当的答案准确性。据我们所知,这是第一个显式优化TIR中工具使用效率的基于RL的框架。
论文及项目相关链接
Summary
本文介绍了工具集成推理(TIR)中的优化工具调用策略。通过使用强化学习(RL),提出一种名为OTC-PO的框架,该框架可鼓励模型在尽可能少的工具调用次数下产生准确的答案。实验结果表明,该方法在多个问答基准测试中减少了工具调用次数并提高了工具效率。
Key Takeaways
- 工具集成推理(TIR)能够借助外部工具,如搜索引擎和代码解释器,解决语言模型无法单独完成的任务。
- 现有方法往往忽视工具使用的效率和成本,导致次优行为,如过多的工具调用或工具使用不足。
- 提出了一种基于强化学习(RL)的名为OTC-PO的框架,旨在通过鼓励模型在尽量少地使用工具的情况下产生准确的答案来解决上述问题。
- 该框架通过考虑正确性和工具效率来联合奖励工具集成,从而提高工具生产率。
- 将该框架应用于Proximal Policy Optimization(PPO)和Group Relative Preference Optimization(GRPO),形成OTC-PPO和OTC-GRPO方法。
- 实验结果表明,在多个问答基准测试中,该方法减少了工具调用次数并提高了工具效率。
点此查看论文截图

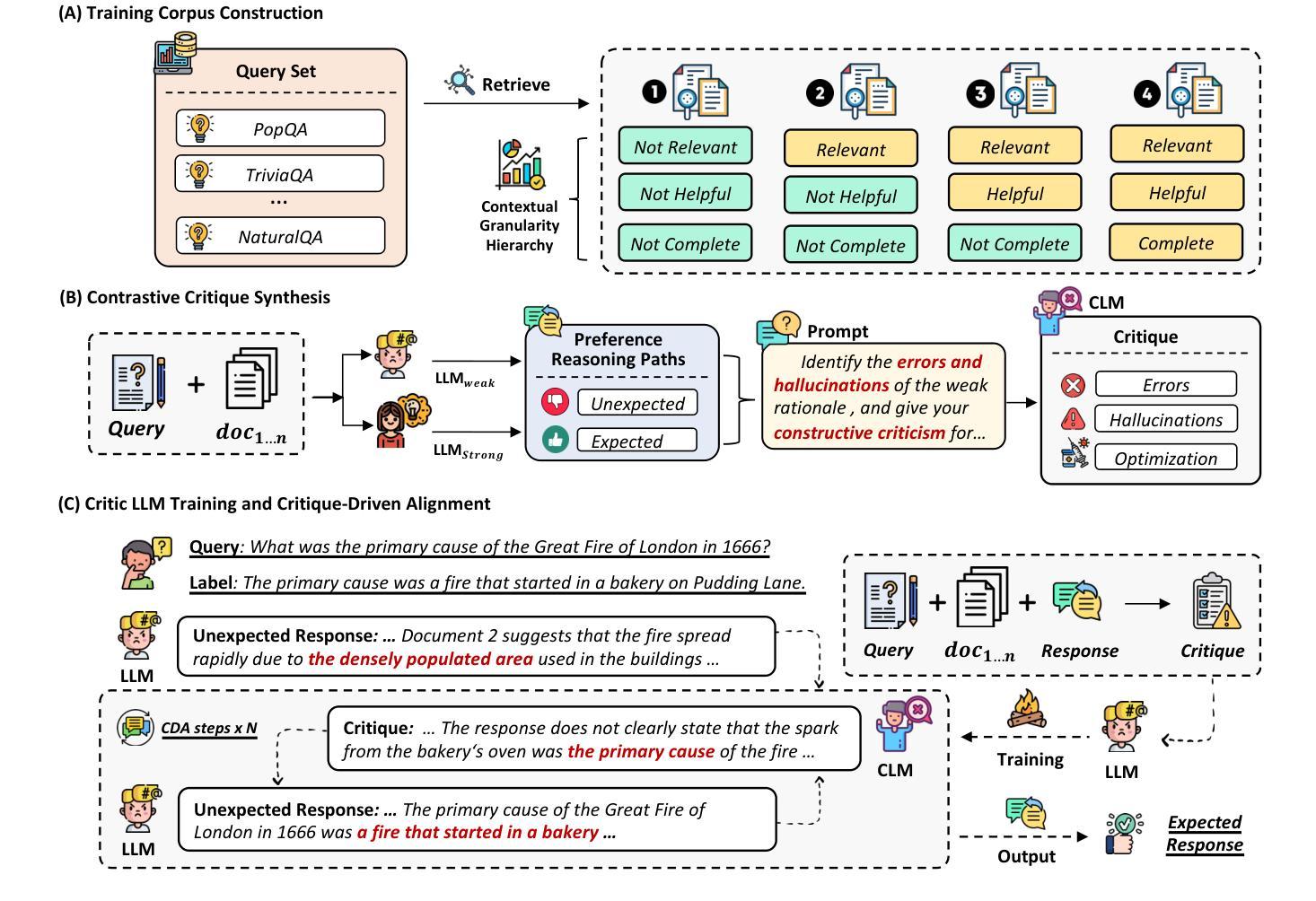
AlignRAG: An Adaptable Framework for Resolving Misalignments in Retrieval-Aware Reasoning of RAG
Authors:Jiaqi Wei, Hao Zhou, Xiang Zhang, Di Zhang, Zijie Qiu, Wei Wei, Jinzhe Li, Wanli Ouyang, Siqi Sun
Retrieval-augmented generation (RAG) has emerged as a foundational paradigm for knowledge-grounded text generation. However, existing RAG pipelines often fail to ensure that the reasoning trajectories align with the evidential constraints imposed by retrieved content. In this paper, we reframe RAG as a problem of retrieval-aware reasoning and identify a core challenge: reasoning misalignment-the mismatch between a model’s reasoning trajectory and the retrieved evidence. To address this challenge, we propose AlignRAG, a novel test-time framework that mitigates reasoning misalignment through iterative Critique-Driven Alignment (CDA) steps. In contrast to prior approaches that rely on static training or post-hoc selection, AlignRAG actively refines reasoning trajectories during inference by enforcing fine-grained alignment with evidence. Our framework introduces a new paradigm for retrieval-aware reasoning by: (1) constructing context-rich training corpora; (2) generating contrastive critiques from preference-aware reasoning trajectories; (3) training a dedicated \textit{Critic Language Model (CLM)} to identify reasoning misalignments; and (4) applying CDA steps to optimize reasoning trajectories iteratively. Empirical results demonstrate that AlignRAG consistently outperforms all baselines and could integrate as a plug-and-play module into existing RAG pipelines without further changes. By reconceptualizing RAG as a structured reasoning trajectory and establishing the test-time framework for correcting reasoning misalignments in RAG, AlignRAG provides practical advancements for retrieval-aware generation.
检索增强生成(RAG)已成为知识基础文本生成的基础范式。然而,现有的RAG流程往往无法保证推理轨迹与检索内容所施加的证据约束一致。在本文中,我们将RAG重新定义为检索感知推理的问题,并识别出核心挑战:推理错位——模型推理轨迹与检索到的证据之间的不匹配。为了应对这一挑战,我们提出了AlignRAG,这是一种新的测试时间框架,通过迭代批判驱动对齐(CDA)步骤来缓解推理错位问题。与依赖静态训练或事后选择的先前方法不同,AlignRAG在推理过程中积极优化推理轨迹,通过强制与证据进行精细对齐。我们的框架通过以下方式为检索感知推理引入了一种新范式:(1)构建丰富的上下文训练语料库;(2)从偏好感知推理轨迹生成对比性批判;(3)训练专门的评论家语言模型(CLM)来识别推理错位;(4)应用CDA步骤迭代优化推理轨迹。实证结果表明,AlignRAG始终优于所有基线,并且可以作为一个即插即用的模块集成到现有的RAG流程中,无需进一步更改。通过重新构建RAG作为结构化推理轨迹,并建立测试时间框架来纠正RAG中的推理错位,AlignRAG为检索感知生成提供了实际进展。
论文及项目相关链接
Summary
在这个文本中,提出了一个基于检索的文本生成(RAG)模型的问题,即推理轨迹与检索内容的证据约束不匹配的问题。为了解决这个问题,提出了一种名为AlignRAG的新框架,它通过迭代批判驱动对齐(CDA)步骤来减轻推理对齐问题。该框架具有多种独特的特点和功能,如构建丰富的上下文训练语料库、生成基于偏好感知推理轨迹的对比批评、训练专门用于识别推理误对齐的批评语言模型等。实证研究结果表明,AlignRAG的性能始终优于所有基线模型,并可以作为现有RAG管道的即插即用模块进行集成,无需进一步更改。这为检索感知生成提供了实际应用中的进步。
Key Takeaways
- RAG模型的推理轨迹与检索内容的证据约束常存在不匹配问题。
- 提出了AlignRAG框架来解决RAG中的推理对齐问题,通过迭代CDA步骤进行精细对齐。
- AlignRAG框架具有构建丰富的上下文训练语料库、生成对比批评、训练批评语言模型等功能。
- AlignRAG框架性能优于所有基线模型,并能无缝集成到现有RAG管道中。
- AlignRAG框架为检索感知生成提供了实际应用中的进步。
- 该框架的核心是重构RAG作为结构化推理轨迹的概念,并建立了测试时纠正RAG中推理误对齐的框架。
点此查看论文截图


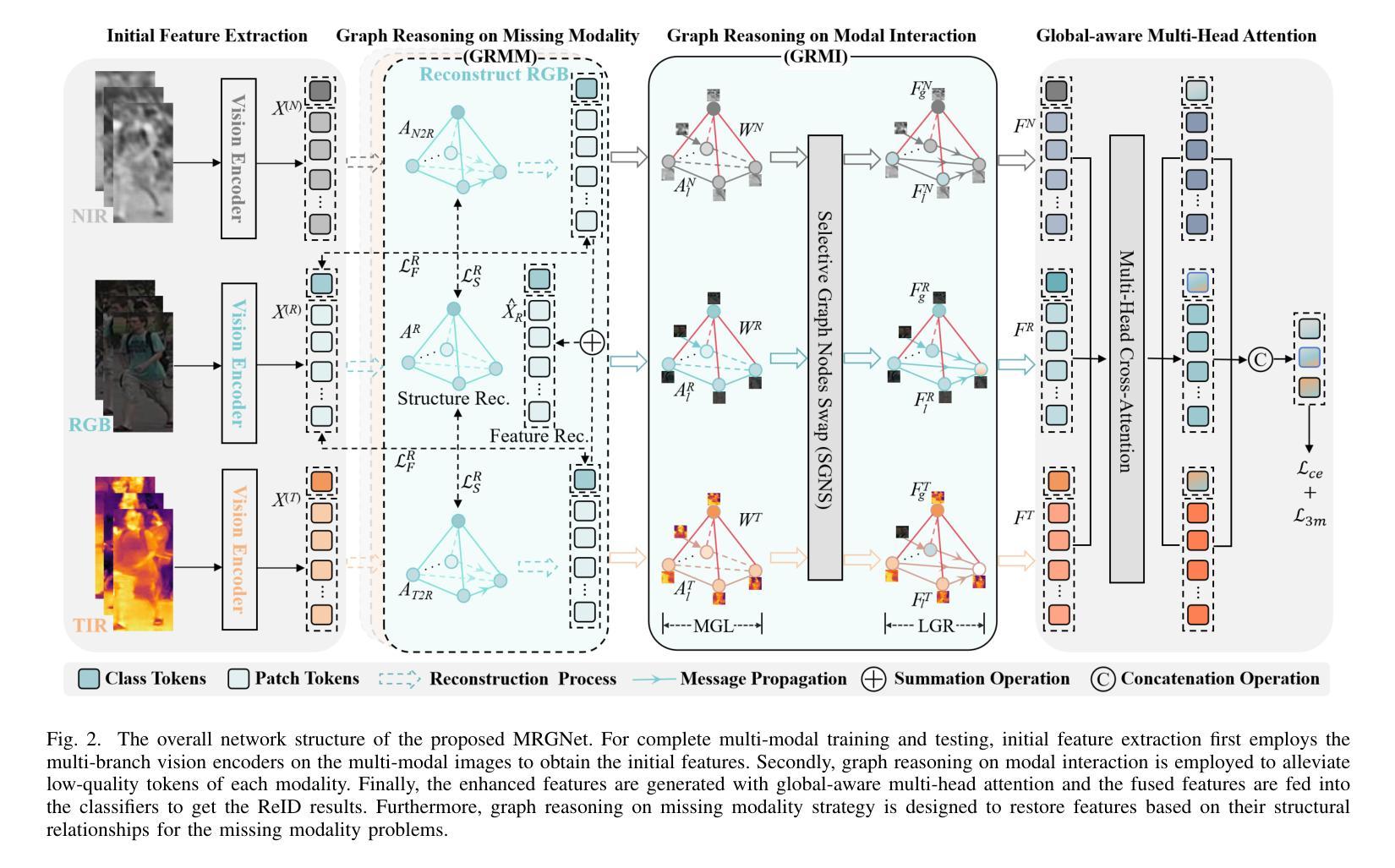
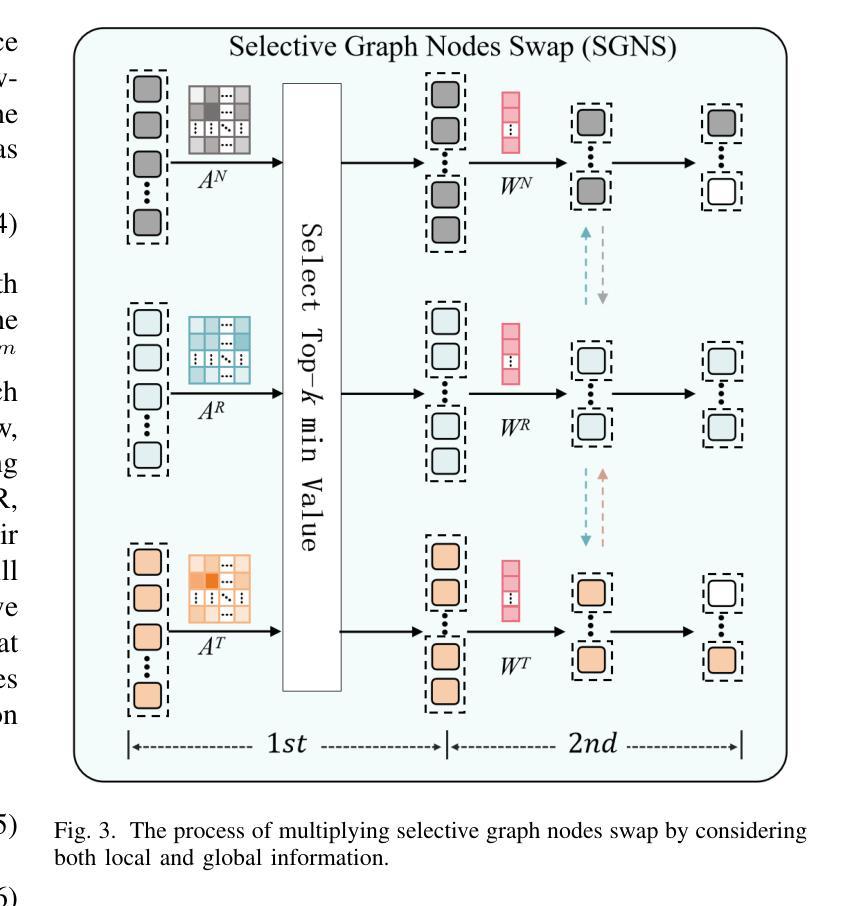
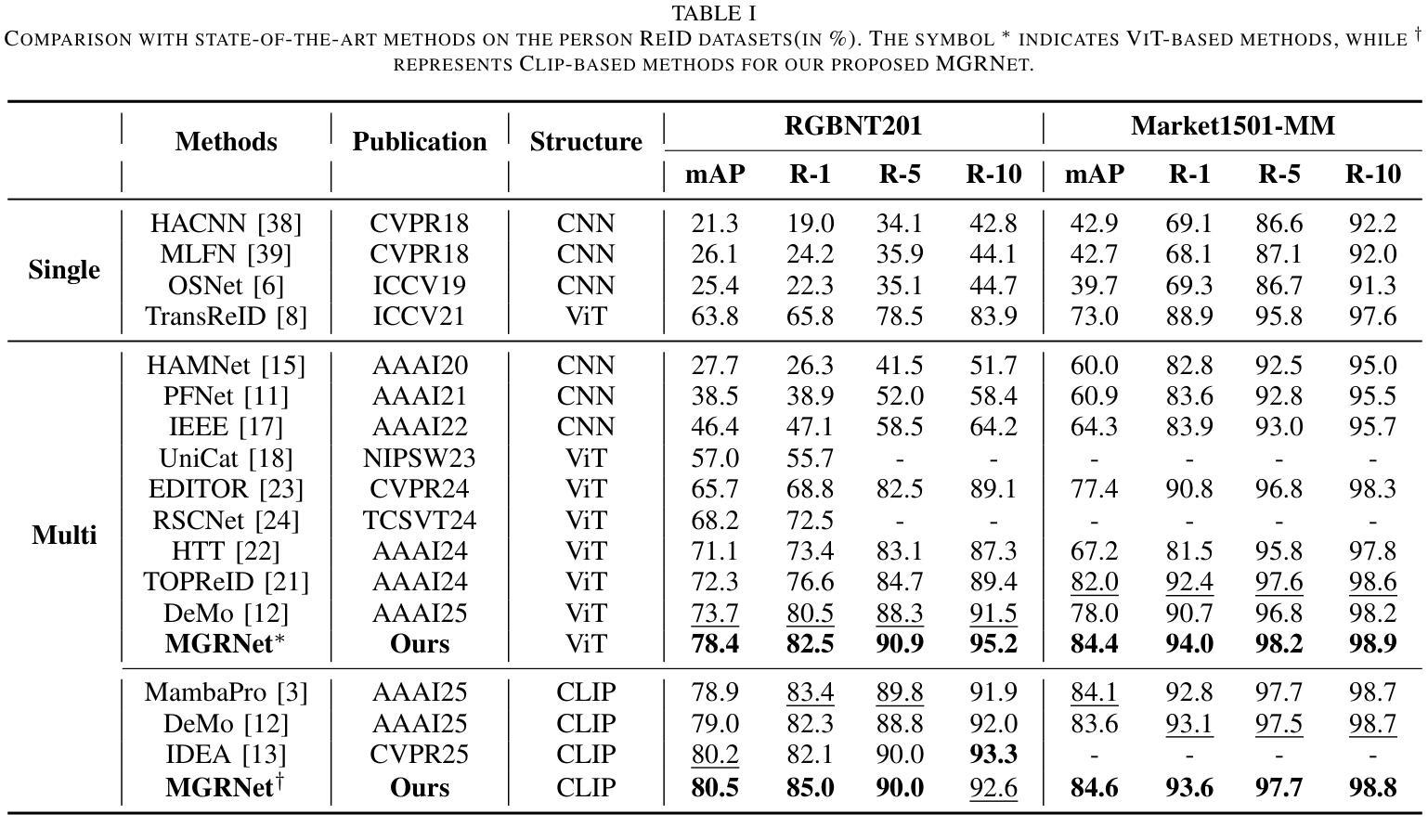
Reliable Multi-Modal Object Re-Identification via Modality-Aware Graph Reasoning
Authors:Xixi Wan, Aihua Zheng, Zi Wang, Bo Jiang, Jin Tang, Jixin Ma
Multi-modal data provides abundant and diverse object information, crucial for effective modal interactions in Re-Identification (ReID) tasks. However, existing approaches often overlook the quality variations in local features and fail to fully leverage the complementary information across modalities, particularly in the case of low-quality features. In this paper, we propose to address this issue by leveraging a novel graph reasoning model, termed the Modality-aware Graph Reasoning Network (MGRNet). Specifically, we first construct modality-aware graphs to enhance the extraction of fine-grained local details by effectively capturing and modeling the relationships between patches. Subsequently, the selective graph nodes swap operation is employed to alleviate the adverse effects of low-quality local features by considering both local and global information, enhancing the representation of discriminative information. Finally, the swapped modality-aware graphs are fed into the local-aware graph reasoning module, which propagates multi-modal information to yield a reliable feature representation. Another advantage of the proposed graph reasoning approach is its ability to reconstruct missing modal information by exploiting inherent structural relationships, thereby minimizing disparities between different modalities. Experimental results on four benchmarks (RGBNT201, Market1501-MM, RGBNT100, MSVR310) indicate that the proposed method achieves state-of-the-art performance in multi-modal object ReID. The code for our method will be available upon acceptance.
多模态数据提供了丰富多样的目标信息,对于重新识别(ReID)任务中的有效模态交互至关重要。然而,现有方法往往忽略了局部特征的质量变化,并且未能充分利用跨模态的互补信息,特别是在特征质量较低的情况下。针对这一问题,本文提出利用一种新型的图推理模型,称为模态感知图推理网络(MGRNet)。具体而言,我们首先构建模态感知图,通过有效地捕获和建模斑块之间的关系,增强精细局部细节的提取。随后,采用选择性图节点交换操作,通过考虑局部和全局信息来缓解低质量局部特征的不利影响,增强判别信息的表示。最后,将交换后的模态感知图输入到局部感知图推理模块中,该模块传播多模态信息以产生可靠的特征表示。所提出图推理方法的另一个优点是,它能够通过利用内在的结构关系来重建缺失的模态信息,从而最小化不同模态之间的差异。在四个基准测试(RGBNT201、Market1501-MM、RGBNT100、MSVR310)上的实验结果表明,所提出的方法在多模态目标ReID中达到了最先进的性能。该方法的相关代码将在接受后提供。
论文及项目相关链接
Summary:
该文提出一种多模态感知图推理网络(MGRNet),用于解决多模态数据在再识别任务中的质量问题。通过构建模态感知图来增强细粒度局部特征的提取,并采用选择性图节点交换操作来缓解低质量局部特征的不利影响。同时,利用局部感知图推理模块传播多模态信息,实现可靠的特征表示。此外,该方法还能重建缺失的模态信息,最小化不同模态之间的差异。在四个基准测试集上的实验结果表明,该方法在多模态对象再识别任务中取得了最新技术的性能。
Key Takeaways:
- 多模态数据在再识别任务中至关重要,但现有方法忽略了局部特征的质量差异,未能充分利用跨模态的互补信息。
- 引入模态感知图来增强细粒度局部特征的提取,有效捕捉和建模斑块之间的关系。
- 采用选择性图节点交换操作,结合局部和全局信息,缓解低质量局部特征的不利影响,增强判别信息的表示。
- 通过局部感知图推理模块传播多模态信息,实现可靠的特征表示。
- 所提出的方法能够重建缺失的模态信息,最小化不同模态之间的差异。
- 在四个基准测试集上的实验结果表明,该方法在多模态对象再识别任务中取得了最新技术的性能。
点此查看论文截图

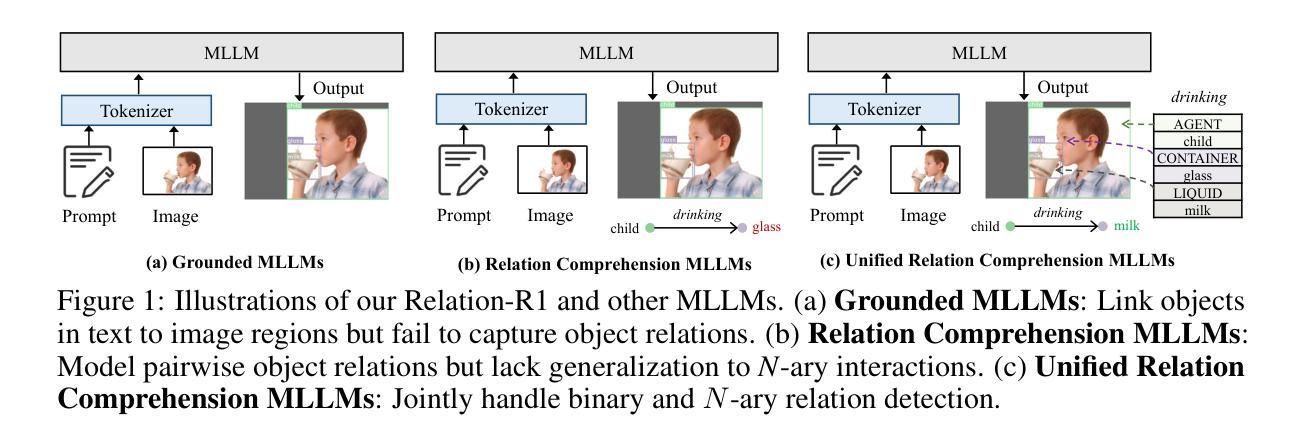
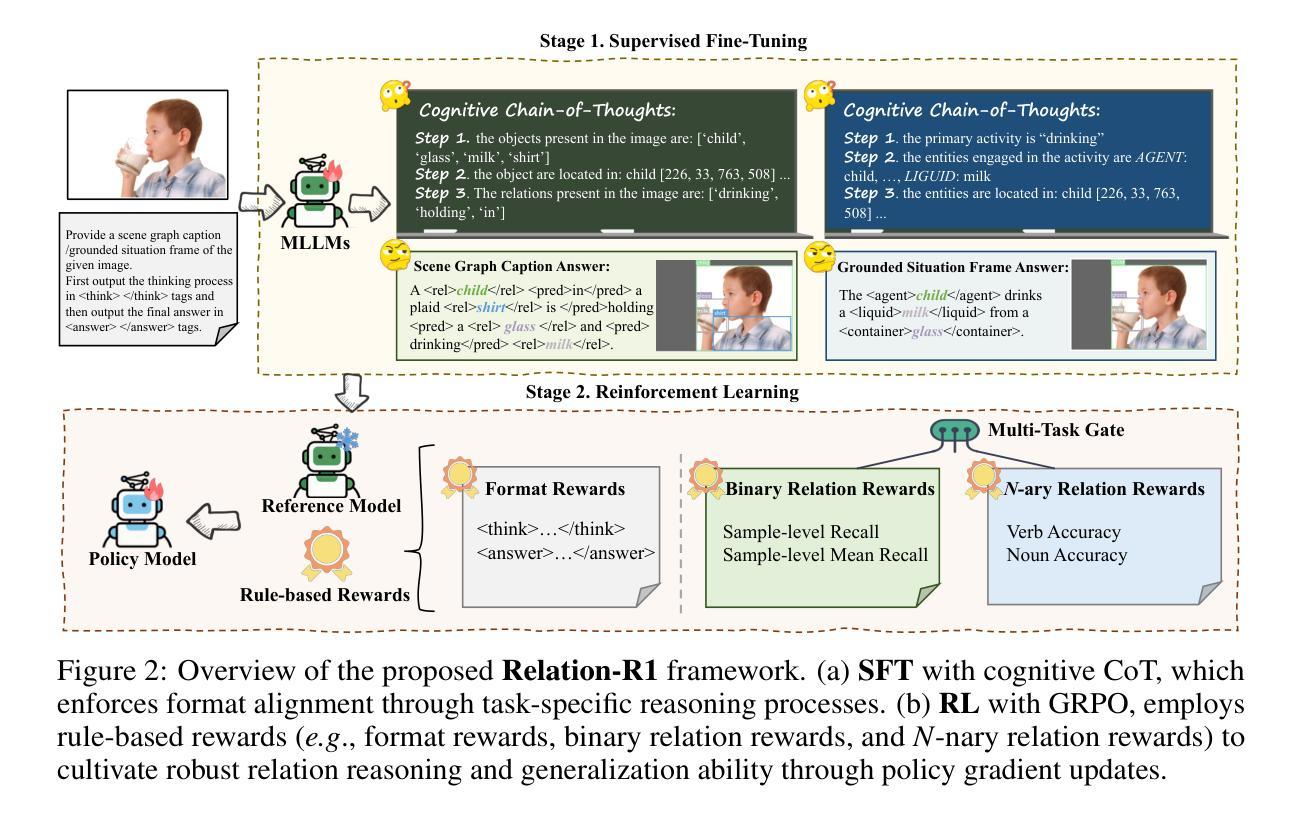
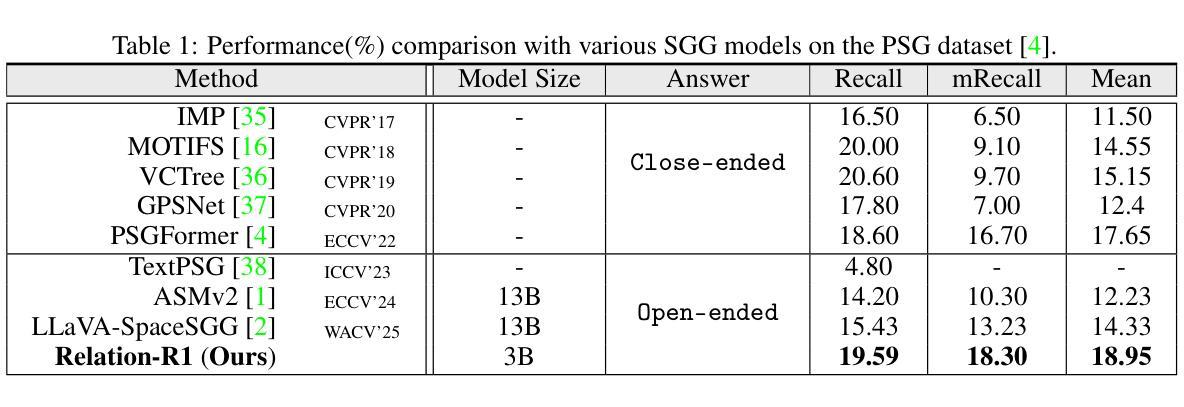
Relation-R1: Cognitive Chain-of-Thought Guided Reinforcement Learning for Unified Relational Comprehension
Authors:Lin Li, Wei Chen, Jiahui Li, Long Chen
Recent advances in multi-modal large language models (MLLMs) have significantly improved object-level grounding and region captioning, but remain limited in visual relation understanding (\eg, scene graph generation), particularly in modeling \textit{N}-ary relationships that identify multiple semantic roles among an action event. Such a lack of \textit{semantic dependencies} modeling among multi-entities leads to unreliable outputs, intensifying MLLMs’ hallucinations and over-reliance on language priors. To this end, we propose Relation-R1, the first unified relational comprehension framework that explicitly integrates cognitive chain-of-thought (CoT)-guided Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO) within a reinforcement learning (RL) paradigm. Specifically, we first establish foundational reasoning capabilities via SFT, enforcing structured outputs with thinking processes. Then, GRPO is utilized to refine these outputs via multi-reward optimization, prioritizing visual-semantic grounding over language-induced biases, thereby improving generalization capability. Extensive experiments on widely-used PSG and SWiG datasets demonstrate that Relation-R1 achieves state-of-the-art performance in both binary and \textit{N}-ary relation understanding.
近期多模态大型语言模型(MLLMs)的进步在对象级别的定位(object-level grounding)和区域描述(region captioning)上取得了显著的改善,但在视觉关系理解(例如场景图生成)方面仍存在局限,特别是在对动作事件中多个语义角色进行建模的N元关系理解上。这种多实体间语义依赖建模的缺失导致了输出不可靠,加剧了MLLMs的幻觉和对语言先验知识的过度依赖。为了解决这一问题,我们提出了Relation-R1,这是第一个统一的关系理解框架,它明确地在强化学习(RL)范式中集成了认知思维链引导的监督微调(SFT)和群体相对策略优化(GRPO)。具体来说,我们首先通过SFT建立基本的推理能力,通过思考过程来强制结构化输出。然后,利用GRPO通过多奖励优化来完善这些输出,优先重视视觉语义定位,以减少语言诱导的偏见,从而提高泛化能力。在广泛使用的PSG和SWiG数据集上的大量实验表明,Relation-R1在二元和N元关系理解方面都达到了最先进的性能。
论文及项目相关链接
PDF Ongoing project
Summary
近期多模态大型语言模型(MLLMs)在对象级定位与区域描述方面取得显著进步,但在视觉关系理解(如场景图生成)方面仍存在局限,尤其难以建模动作事件中多个实体间的语义角色(N-ary关系)。由于缺乏多实体间的语义依赖性建模,导致输出不可靠,加剧MLLMs的幻觉和过度依赖语言先验。为此,本文提出Relation-R1,首个统一的关系理解框架,显式整合认知思维链引导的监督微调(SFT)和群体相对策略优化(GRPO)于强化学习(RL)范式中。通过SFT建立基础推理能力,通过结构化输出强化思维过程;然后使用GRPO通过多奖励优化来改进输出,优先视觉语义定位,减少语言诱导偏见,提高泛化能力。在广泛使用的PSG和SWiG数据集上的实验表明,Relation-R1在二元和N元关系理解方面达到最新技术水平。
Key Takeaways
- 多模态大型语言模型(MLLMs)在对象级定位和区域描述上有所进步,但在视觉关系理解上仍有局限。
- 现有模型难以处理动作事件中多个实体间的语义角色(N-ary关系)。
- 缺乏多实体间的语义依赖性建模导致输出不可靠和模型幻觉。
- Relation-R1框架通过整合监督微调(SFT)和群体相对策略优化(GRPO)来解决这些问题。
- SFT用于建立基础推理能力,通过结构化输出强化思维过程。
- GRPO通过多奖励优化改进输出,优先视觉语义定位,减少语言偏见。
点此查看论文截图

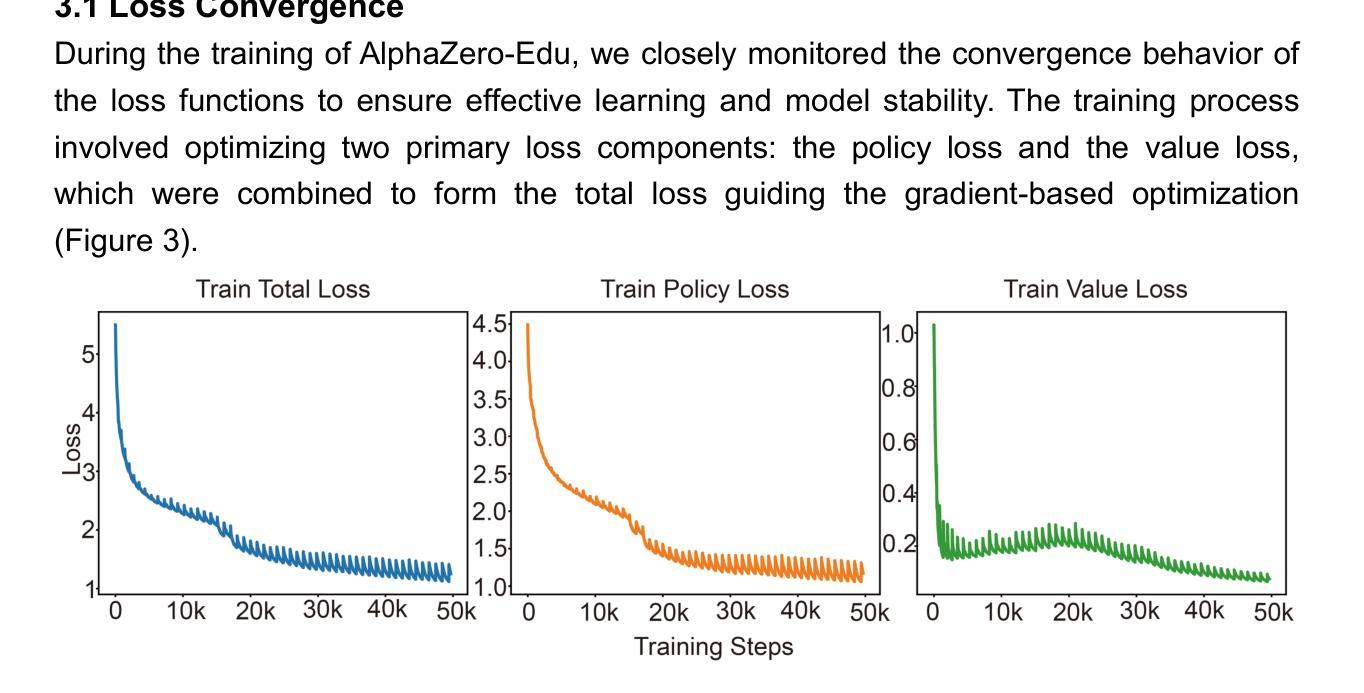
AlphaZero-Edu: Making AlphaZero Accessible to Everyone
Authors:Binjie Guo, Hanyu Zheng, Guowei Su, Ru Zhang, Haohan Jiang, Xurong Lin, Hongyan Wei, Aisheng Mo, Jie Li, Zhiyuan Qian, Zhuhao Zhang, Xiaoyuan Cheng
Recent years have witnessed significant progress in reinforcement learning, especially with Zero-like paradigms, which have greatly boosted the generalization and reasoning abilities of large-scale language models. Nevertheless, existing frameworks are often plagued by high implementation complexity and poor reproducibility. To tackle these challenges, we present AlphaZero-Edu, a lightweight, education-focused implementation built upon the mathematical framework of AlphaZero. It boasts a modular architecture that disentangles key components, enabling transparent visualization of the algorithmic processes. Additionally, it is optimized for resource-efficient training on a single NVIDIA RTX 3090 GPU and features highly parallelized self-play data generation, achieving a 3.2-fold speedup with 8 processes. In Gomoku matches, the framework has demonstrated exceptional performance, achieving a consistently high win rate against human opponents. AlphaZero-Edu has been open-sourced at https://github.com/StarLight1212/AlphaZero_Edu, providing an accessible and practical benchmark for both academic research and industrial applications.
近年来,强化学习领域取得了显著进展,尤其是以Zero为代表的模式,极大地提升了大规模语言模型的泛化和推理能力。然而,现有的框架往往存在实现复杂和可重复性差的困扰。为了应对这些挑战,我们推出了AlphaZero-Edu,这是一款以AlphaZero数学框架为基础,以教育为重点的轻量化实现。它拥有模块化架构,能够分解关键组件,实现算法过程的透明可视化。此外,它针对在单个NVIDIA RTX 3090 GPU上的资源高效训练进行了优化,并实现了高度并行化的自我游戏数据生成,使用8个进程实现了3.2倍的加速。在围棋比赛中,该框架表现出了卓越的性能,在与人类对手的比赛中持续保持较高的胜率。AlphaZero-Edu已在https://github.com/StarLight1212/AlphaZero_Edu上开源,为学术研究和工业应用提供了一个实用且可接触的基准。
论文及项目相关链接
Summary
近年来,强化学习领域取得了显著进展,尤其是Zero类范式,极大地提升了大规模语言模型的泛化和推理能力。然而,现有框架常面临实现复杂度高和可重复性差的挑战。为解决这些问题,推出AlphaZero-Edu框架,它以AlphaZero的数学框架为基础,注重教育实用性,具有模块化架构,能够清晰展示算法过程。此外,它在单个NVIDIA RTX 3090 GPU上进行资源优化训练,通过高度并行的自玩数据生成实现3.2倍加速。在围棋比赛中,该框架表现出卓越性能,持续保持对人类对手的较高胜率。AlphaZero-Edu已开源,为学术研究和工业应用提供了实用基准。
Key Takeaways
- AlphaZero-Edu是基于AlphaZero数学框架的教育实用性强化学习框架。
- 该框架具有模块化架构,能清晰展示算法过程。
- AlphaZero-Edu实现了资源优化训练,可在单个NVIDIA RTX 3090 GPU上运行。
- 框架具有高度的自玩数据生成并行性,实现了3.2倍加速。
- 在围棋比赛中,AlphaZero-Edu表现出卓越性能,对人类对手保持较高胜率。
- AlphaZero-Edu已开源,为学术研究和工业应用提供了实用基准。
点此查看论文截图

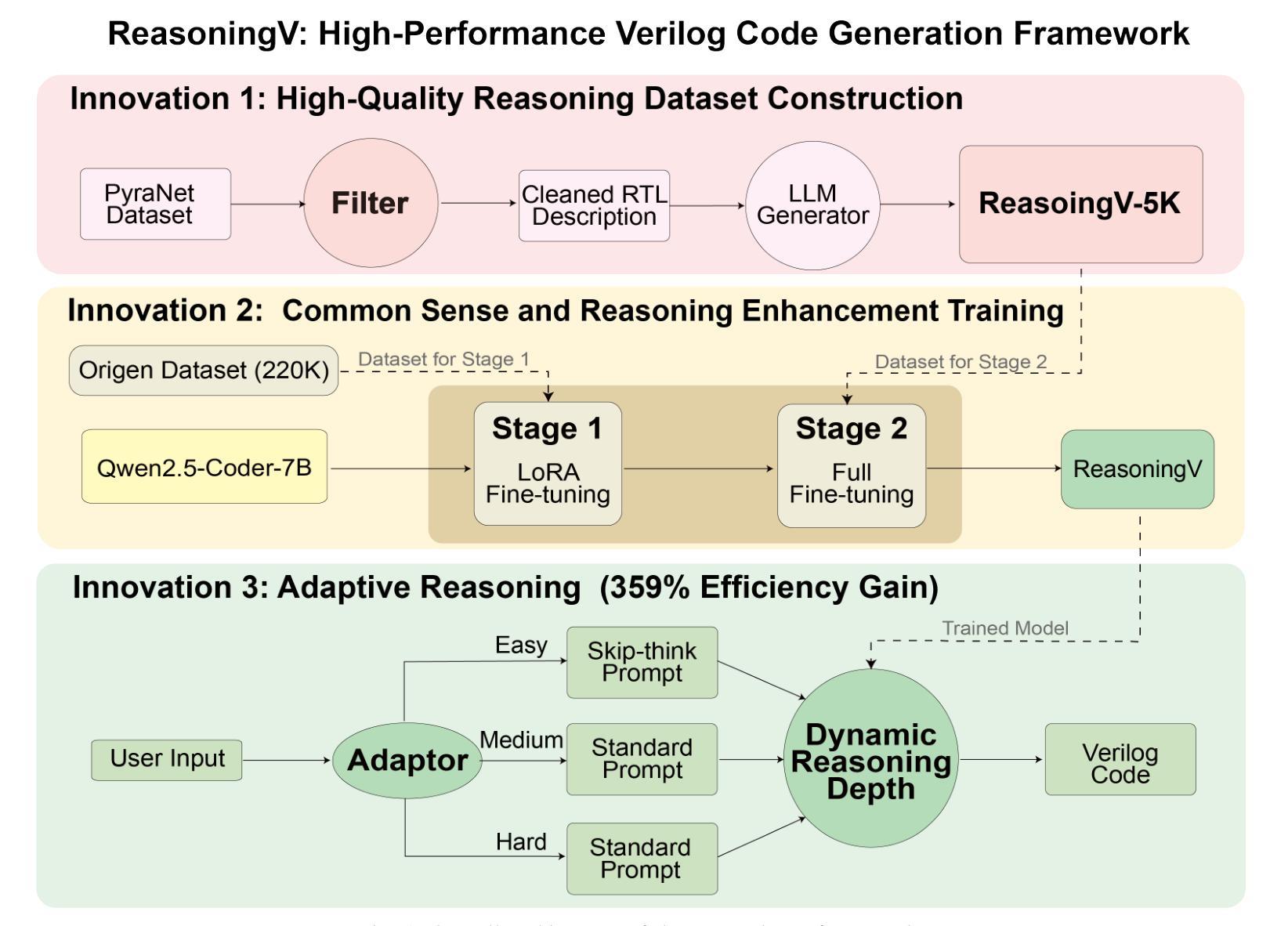
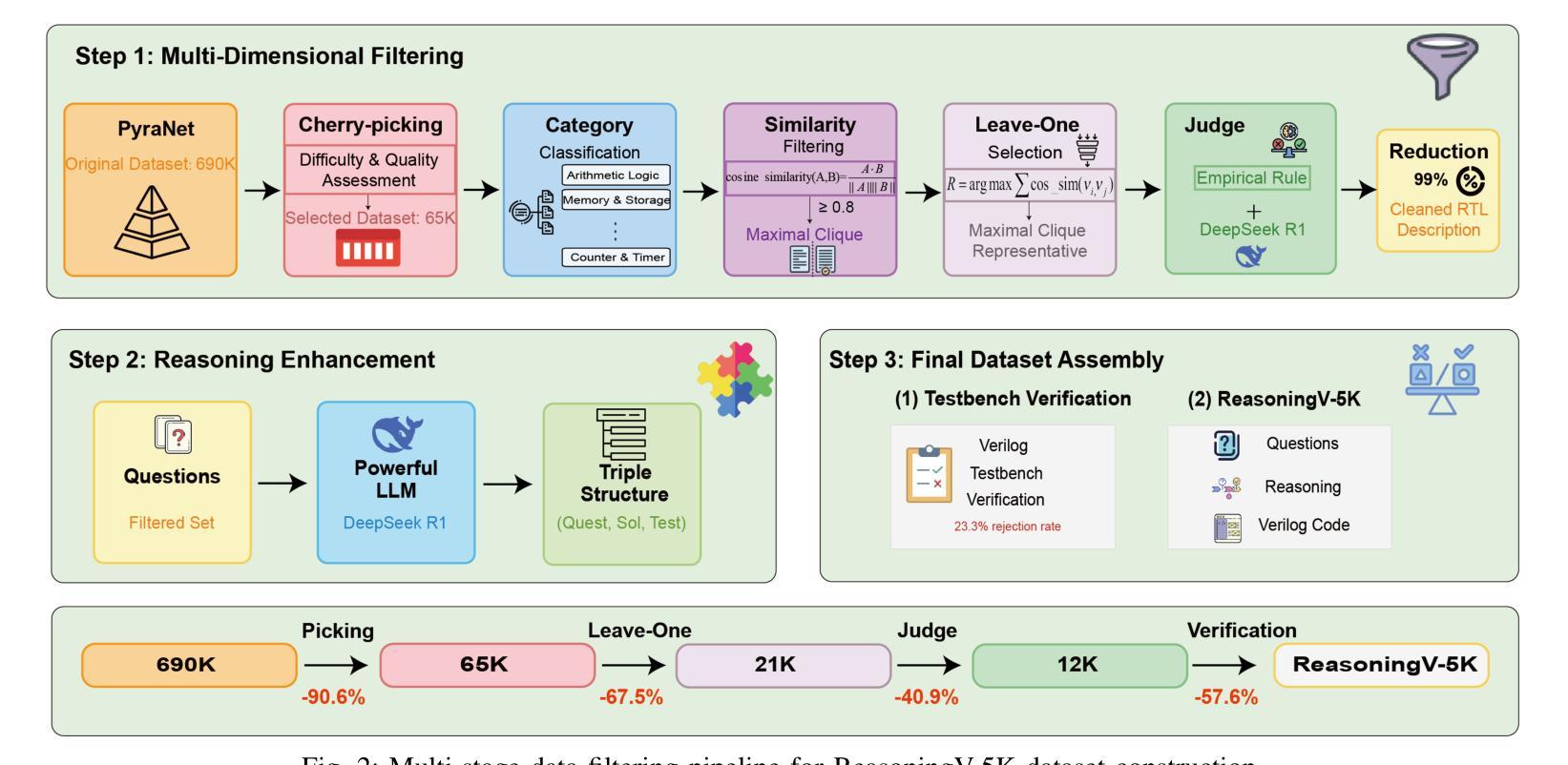
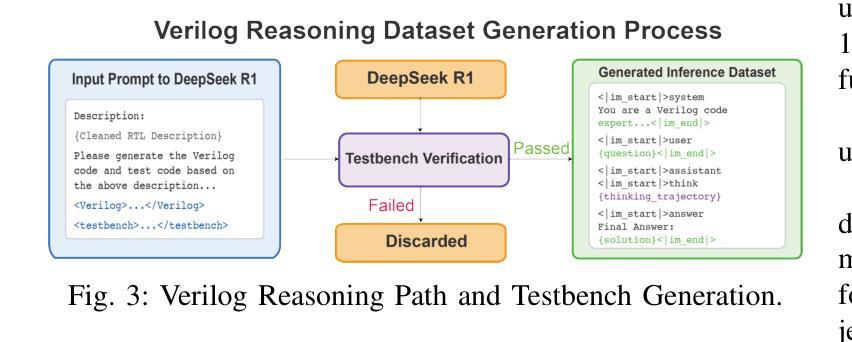
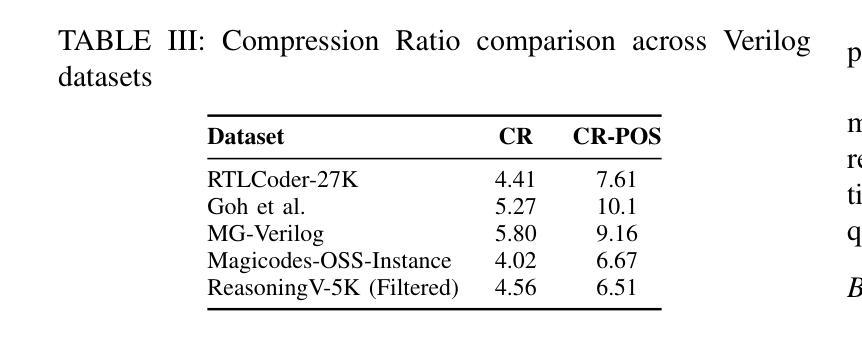
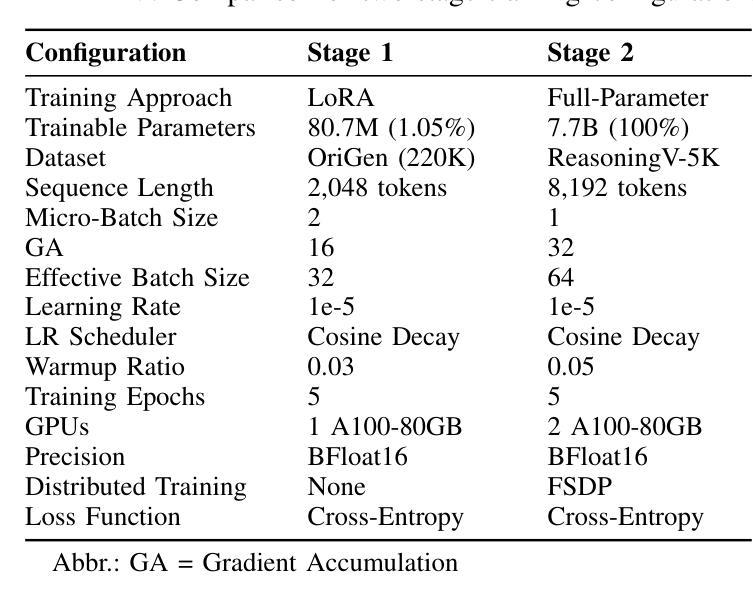
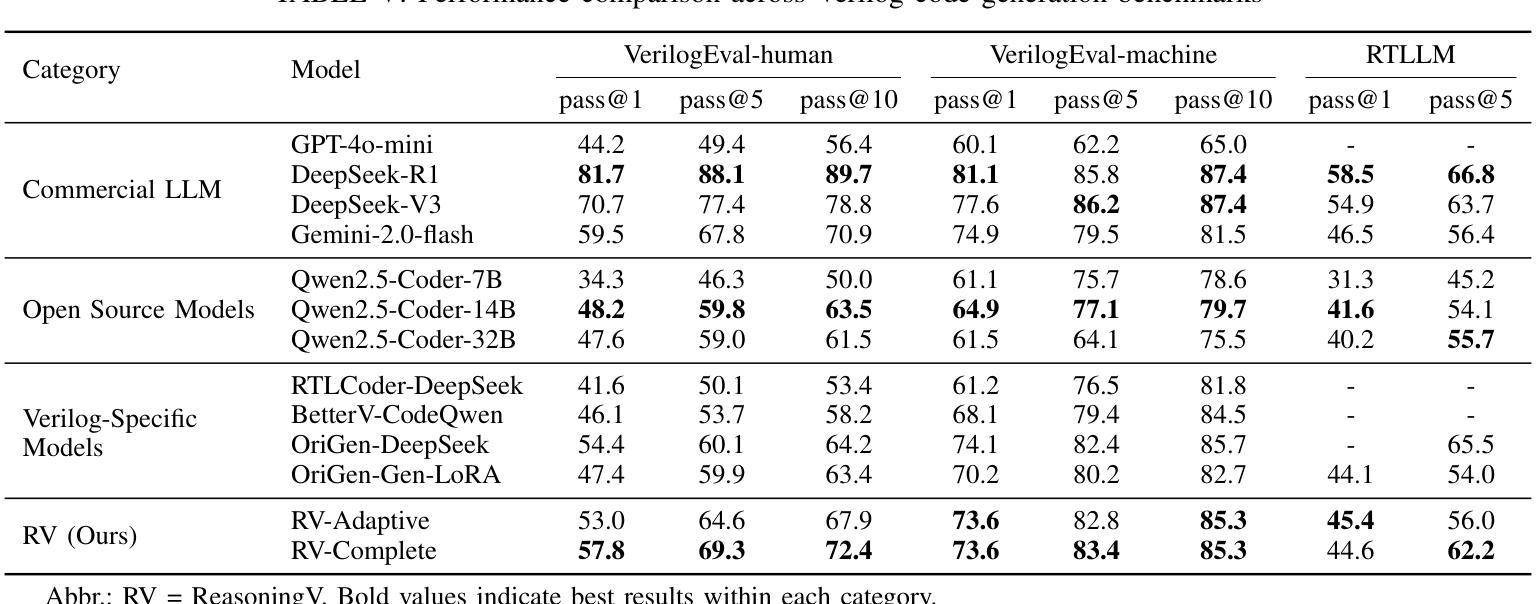
ReasoningV: Efficient Verilog Code Generation with Adaptive Hybrid Reasoning Model
Authors:Haiyan Qin, Zhiwei Xie, Jingjing Li, Liangchen Li, Xiaotong Feng, Junzhan Liu, Wang Kang
Large Language Models (LLMs) have advanced Verilog code generation significantly, yet face challenges in data quality, reasoning capabilities, and computational efficiency. This paper presents ReasoningV, a novel model employing a hybrid reasoning strategy that integrates trained intrinsic capabilities with dynamic inference adaptation for Verilog code generation. Our framework introduces three complementary innovations: (1) ReasoningV-5K, a high-quality dataset of 5,000 functionally verified instances with reasoning paths created through multi-dimensional filtering of PyraNet samples; (2) a two-stage training approach combining parameter-efficient fine-tuning for foundational knowledge with full-parameter optimization for enhanced reasoning; and (3) an adaptive reasoning mechanism that dynamically adjusts reasoning depth based on problem complexity, reducing token consumption by up to 75% while preserving performance. Experimental results demonstrate ReasoningV’s effectiveness with a pass@1 accuracy of 57.8% on VerilogEval-human, achieving performance competitive with leading commercial models like Gemini-2.0-flash (59.5%) and exceeding the previous best open-source model by 10.4 percentage points. ReasoningV offers a more reliable and accessible pathway for advancing AI-driven hardware design automation, with our model, data, and code available at https://github.com/BUAA-CLab/ReasoningV.
大型语言模型(LLM)在Verilog代码生成方面取得了显著的进步,但仍面临着数据质量、推理能力和计算效率方面的挑战。本文提出了一种名为ReasoningV的新型模型,该模型采用混合推理策略,将训练的内在能力与动态推理适应相结合,用于Verilog代码生成。我们的框架引入了三项互补创新:1)ReasoningV-5K,这是一个高质量的数据集,包含5000个经过功能验证的实例,通过PyraNet样本的多维过滤创建推理路径;2)结合参数高效微调基础知识与全参数优化增强推理能力的两阶段训练方法;3)自适应推理机制,根据问题复杂度动态调整推理深度,在保持性能的同时,最多减少75%的令牌消耗。实验结果证明了ReasoningV的有效性,在VerilogEval-human上的pass@1准确率为57.8%,性能与领先的商业模型如Gemini-2.0-flash(59.5%)相竞争,并超出之前最好的开源模型10.4个百分点。ReasoningV为推进人工智能驱动的硬件设计自动化提供了更可靠、更可行的途径,我们的模型、数据和代码可在https://github.com/BUAA-CLab/ReasoningV上获取。
论文及项目相关链接
PDF 9 pages, 4 figures
Summary
这篇论文介绍了ReasoningV,一种用于Verilog代码生成的新型模型。该模型采用混合推理策略,集成了训练的内生能力与动态推理适应。论文提出了三项创新:一是ReasoningV-5K数据集,包含5000个功能验证实例;二是两阶段训练法,结合参数高效微调与全参数优化;三是自适应推理机制,可动态调整推理深度。实验结果显示,ReasoningV在VerilogEval-human上的准确率达到了57.8%,与商业模型竞争,并超越了之前的开源模型。
Key Takeaways
- ReasoningV是一个用于Verilog代码生成的新型模型,采用混合推理策略。
- 该模型提出了ReasoningV-5K数据集,包含高质量的功能验证实例。
- 两阶段训练法结合了参数高效微调与全参数优化。
- 自适应推理机制可根据问题复杂度动态调整推理深度,减少计算消耗。
- 实验结果显示ReasoningV在VerilogEval-human上的准确率较高,与商业模型竞争。
- 该模型超越了之前的开源模型,展现了较高的性能。
点此查看论文截图


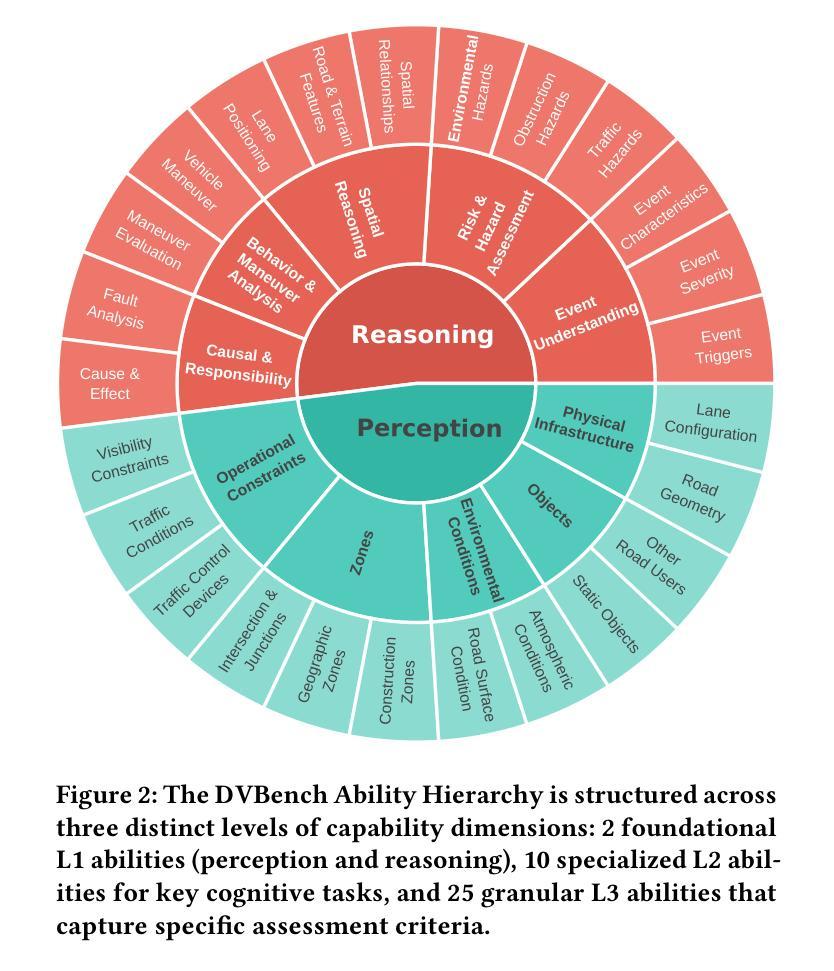
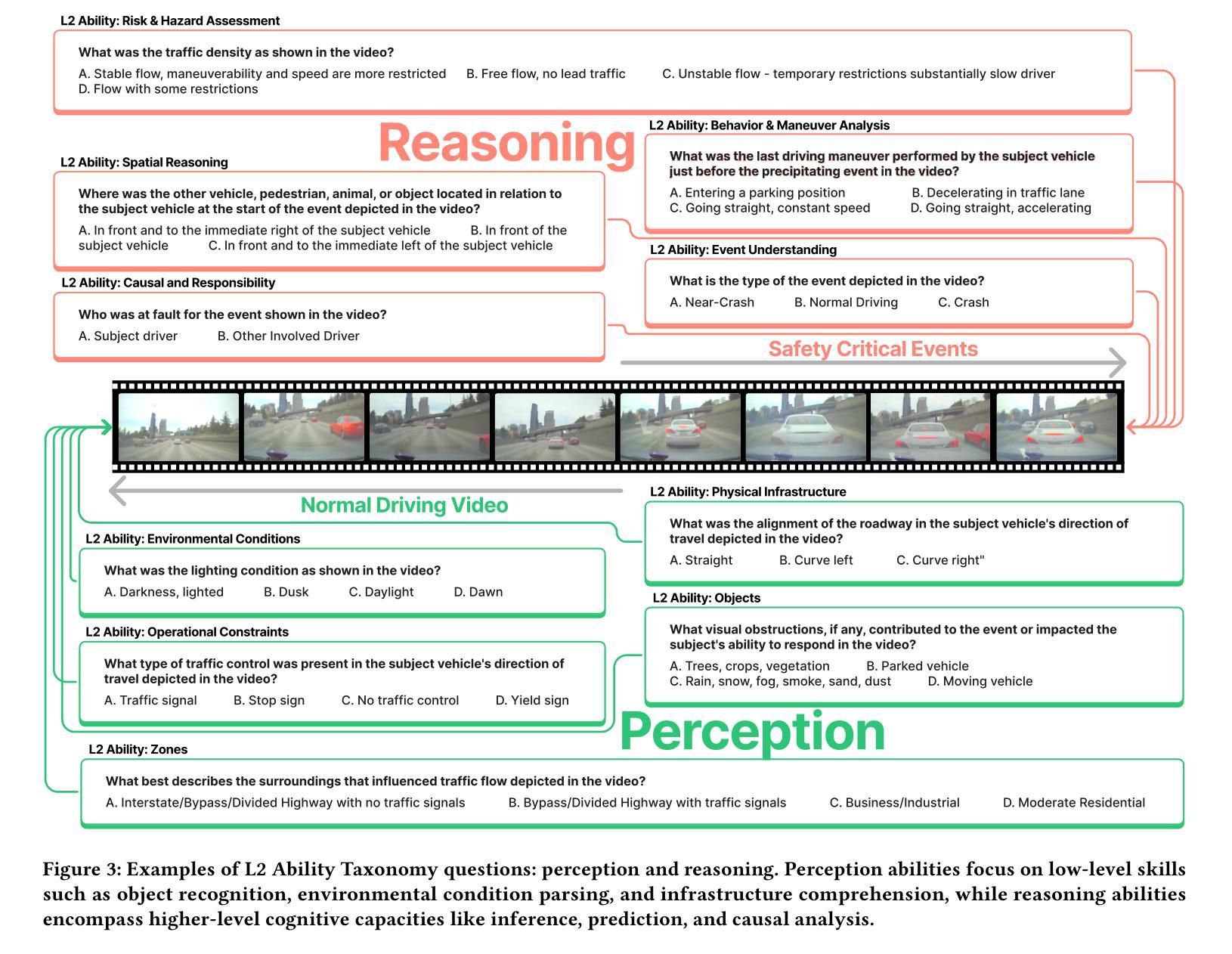
Are Vision LLMs Road-Ready? A Comprehensive Benchmark for Safety-Critical Driving Video Understanding
Authors:Tong Zeng, Longfeng Wu, Liang Shi, Dawei Zhou, Feng Guo
Vision Large Language Models (VLLMs) have demonstrated impressive capabilities in general visual tasks such as image captioning and visual question answering. However, their effectiveness in specialized, safety-critical domains like autonomous driving remains largely unexplored. Autonomous driving systems require sophisticated scene understanding in complex environments, yet existing multimodal benchmarks primarily focus on normal driving conditions, failing to adequately assess VLLMs’ performance in safety-critical scenarios. To address this, we introduce DVBench, a pioneering benchmark designed to evaluate the performance of VLLMs in understanding safety-critical driving videos. Built around a hierarchical ability taxonomy that aligns with widely adopted frameworks for describing driving scenarios used in assessing highly automated driving systems, DVBench features 10,000 multiple-choice questions with human-annotated ground-truth answers, enabling a comprehensive evaluation of VLLMs’ capabilities in perception and reasoning. Experiments on 14 SOTA VLLMs, ranging from 0.5B to 72B parameters, reveal significant performance gaps, with no model achieving over 40% accuracy, highlighting critical limitations in understanding complex driving scenarios. To probe adaptability, we fine-tuned selected models using domain-specific data from DVBench, achieving accuracy gains ranging from 5.24 to 10.94 percentage points, with relative improvements of up to 43.59%. This improvement underscores the necessity of targeted adaptation to bridge the gap between general-purpose VLLMs and mission-critical driving applications. DVBench establishes an essential evaluation framework and research roadmap for developing VLLMs that meet the safety and robustness requirements for real-world autonomous systems. We released the benchmark toolbox and the fine-tuned model at: https://github.com/tong-zeng/DVBench.git.
视觉大型语言模型(VLLMs)在一般的视觉任务(如图像标注和视觉问答)中表现出了令人印象深刻的能力。然而,它们在自动驾驶等特殊且安全关键的领域中的有效性尚未得到广泛探索。自动驾驶系统需要在复杂环境中进行高级场景理解,然而现有的多模式基准测试主要关注正常驾驶条件,无法充分评估VLLMs在安全关键场景中的性能。为了解决这一问题,我们引入了DVBench,这是一个旨在评估VLLMs在理解安全关键驾驶视频方面的性能的开创性基准测试。DVBench围绕与评估高度自动化驾驶系统时广泛采用的驾驶场景描述框架相一致的分层能力分类表构建,包含10,000道带有人类注释标准答案的选择题,能够全面评估VLLMs在感知和推理方面的能力。对14个最先进的VLLM进行的实验,参数范围从0.5B到72B,显示出明显的性能差距,没有任何模型的准确率超过40%,这突显了在理解复杂驾驶场景方面的关键局限性。为了检验适应性,我们利用DVBench的特定领域数据对选定模型进行了微调,准确率提高了5.24至10.94个百分点,相对改进幅度高达43.59%。这种改进突显了有针对性的适应对于弥合通用VLLM与关键任务驾驶应用程序之间的差距的必要性。DVBench为开发满足现实世界自动驾驶系统安全和稳健性要求的VLLM建立了重要的评估框架和研究路线图。我们已在https://github.com/tong-zeng/DVBench.git发布了基准测试工具箱和微调模型。
论文及项目相关链接
Summary
本文介绍了VLLM在自动驾驶领域的应用挑战。针对自动驾驶系统需要理解复杂环境下的场景,现有的一般语言模型评估标准无法充分评估其在安全关键场景中的性能。因此,本文提出了DVBench,一个专门评估VLLM在理解安全关键驾驶视频性能的基准测试。该测试包括大量多项选择题,并提供人类注释的基准答案,以全面评估VLLM在感知和推理方面的能力。实验结果显示,现有模型在该基准测试中存在显著性能差距,且无模型达到超过40%的准确率,突显了在理解复杂驾驶场景方面的关键局限性。通过针对DVBench的特定数据进行微调,模型的准确率有所提高,证明了有针对性的适应训练对于缩小通用VLLM和关键任务驾驶应用之间的差距的必要性。DVBench为开发满足现实世界自动驾驶系统安全和稳健性要求的VLLM提供了重要的评估框架和研究路线图。
Key Takeaways
- VLLM在自动驾驶领域的应用面临挑战,需要理解复杂环境下的场景。
- 现有的一般语言模型评估标准无法充分评估VLLM在安全关键场景中的性能。
- DVBench是一个专门评估VLLM在理解安全关键驾驶视频性能的基准测试,包括大量多项选择题并提供人类注释的基准答案。
- 实验结果显示,现有模型在DVBench中存在显著性能差距,且表现不佳。
- 通过针对DVBench的特定数据进行微调,模型的准确率有所提高。
- 有针对性的适应训练对于缩小通用VLLM和关键任务驾驶应用之间的差距是必要的。
点此查看论文截图



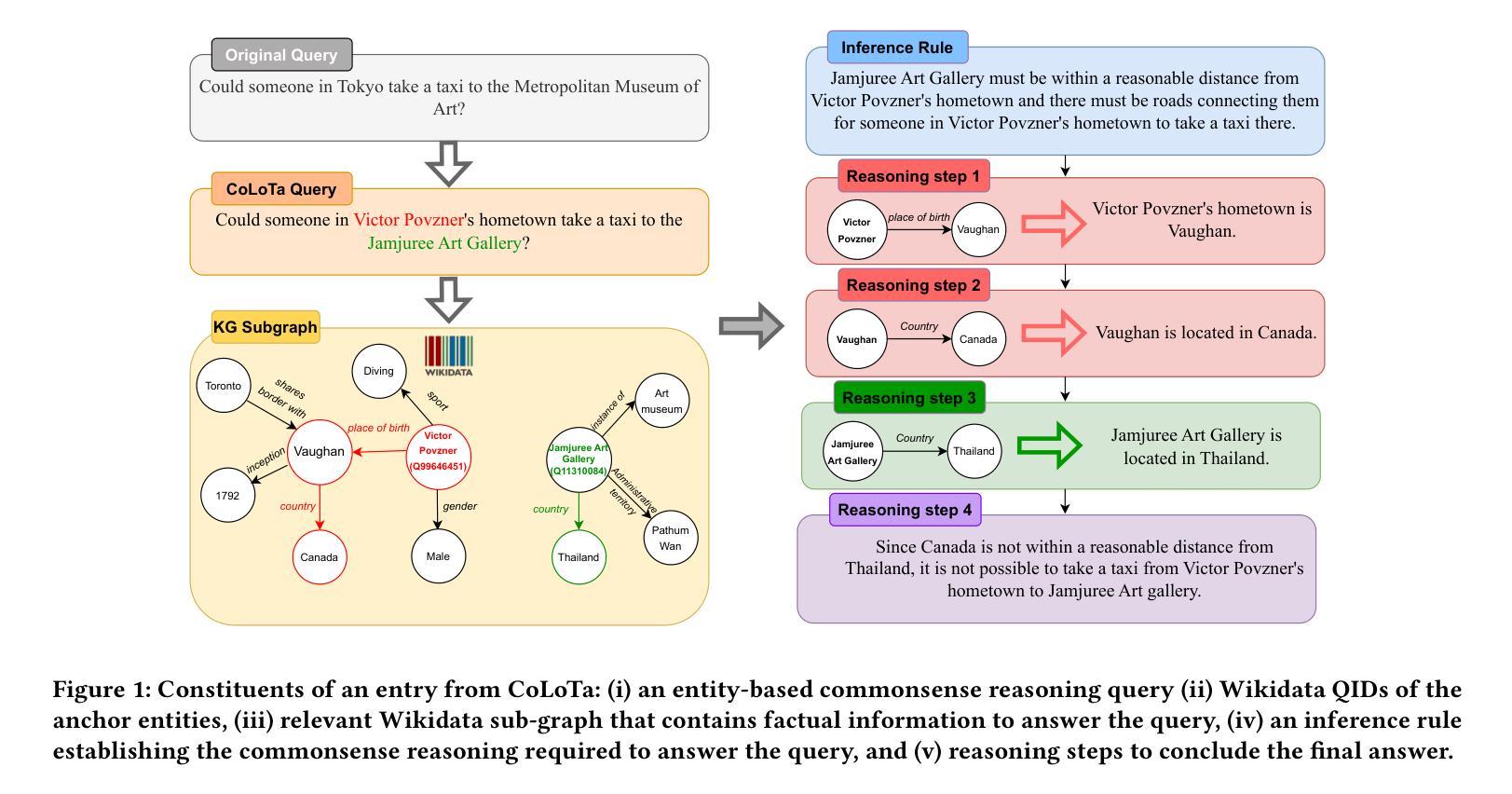
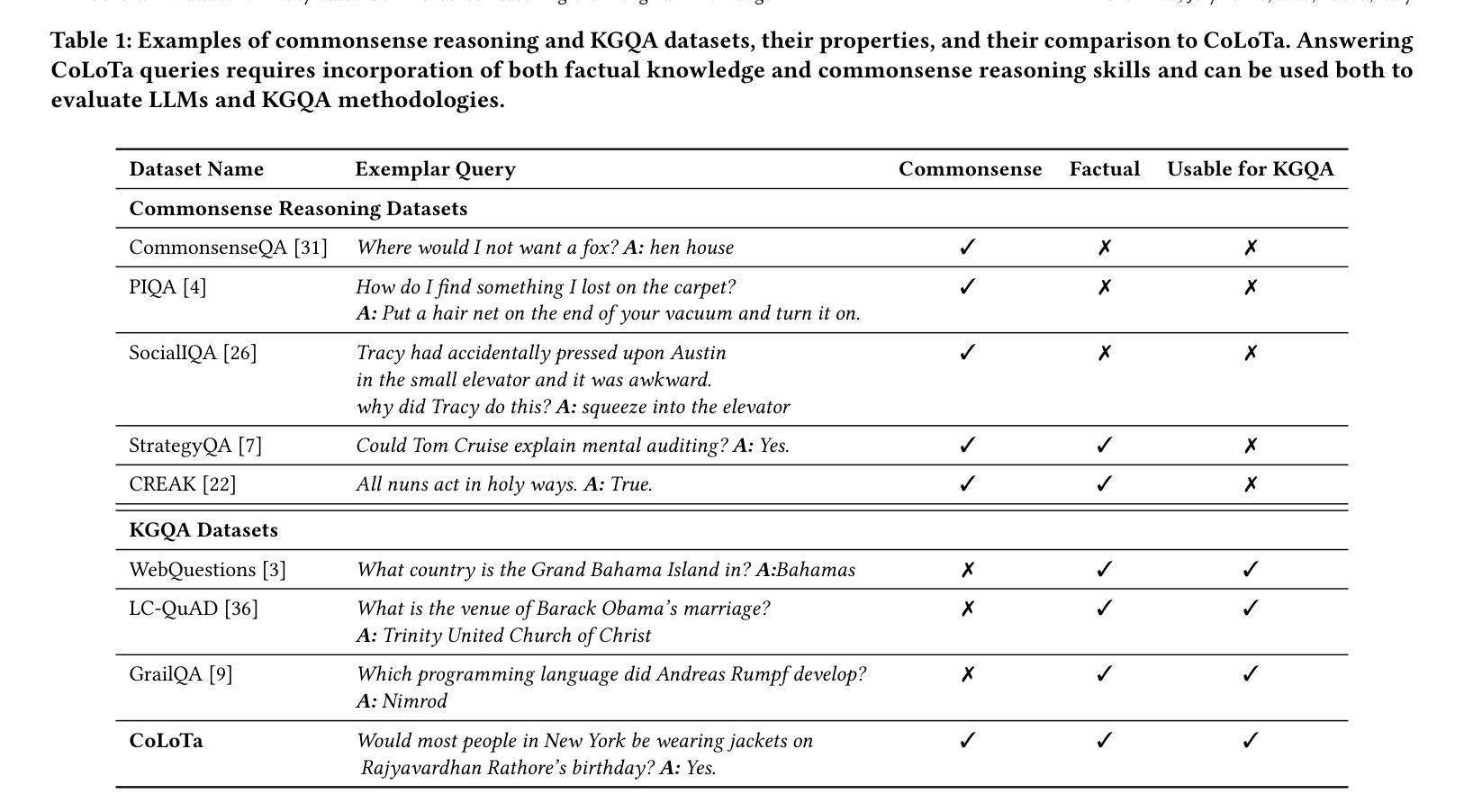
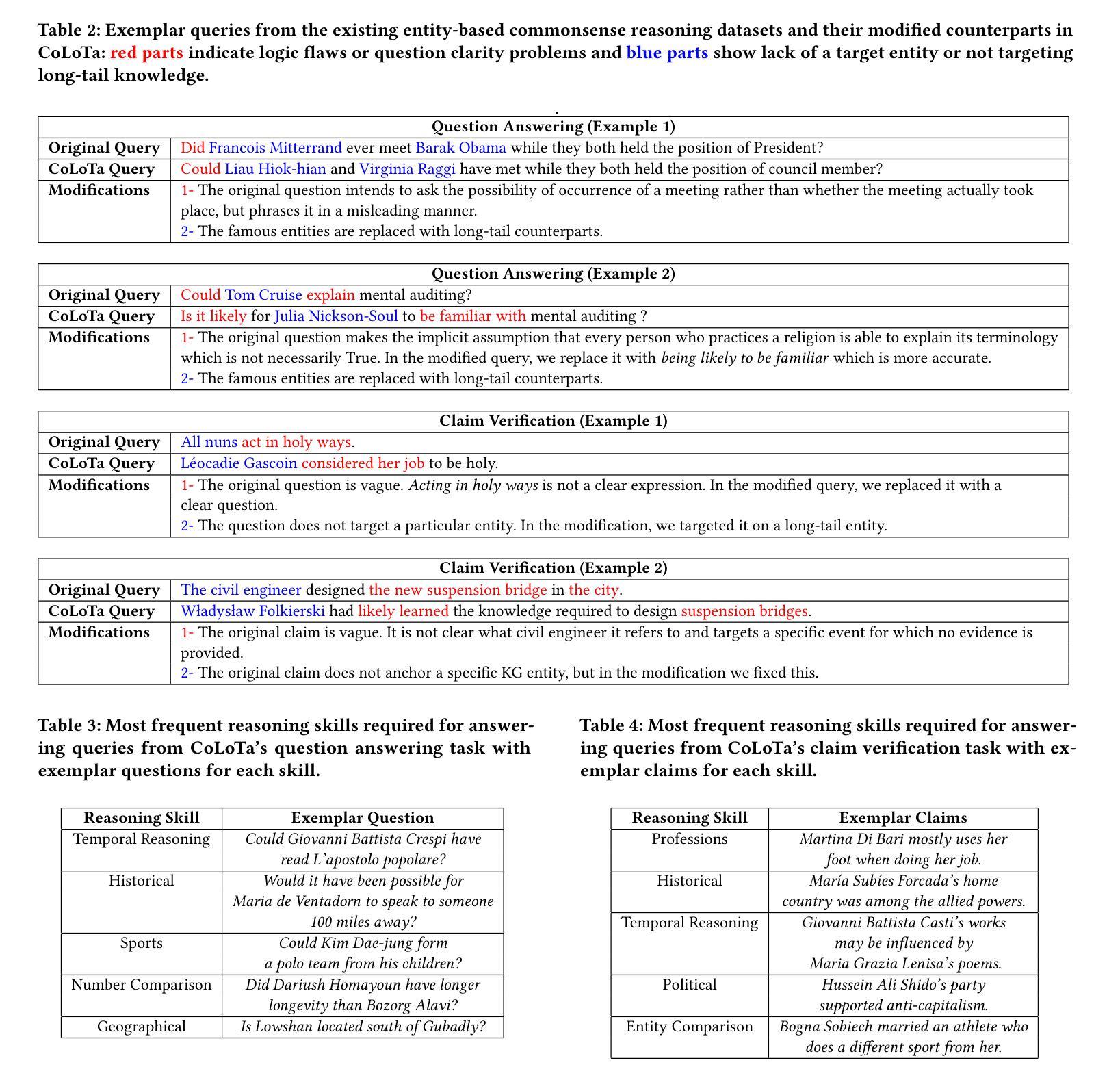
CoLoTa: A Dataset for Entity-based Commonsense Reasoning over Long-Tail Knowledge
Authors:Armin Toroghi, Willis Guo, Scott Sanner
The rise of Large Language Models (LLMs) has redefined the AI landscape, particularly due to their ability to encode factual and commonsense knowledge, and their outstanding performance in tasks requiring reasoning. Despite these advances, hallucinations and reasoning errors remain a significant barrier to their deployment in high-stakes settings. In this work, we observe that even the most prominent LLMs, such as OpenAI-o1, suffer from high rates of reasoning errors and hallucinations on tasks requiring commonsense reasoning over obscure, long-tail entities. To investigate this limitation, we present a new dataset for Commonsense reasoning over Long-Tail entities (CoLoTa), that consists of 3,300 queries from question answering and claim verification tasks and covers a diverse range of commonsense reasoning skills. We remark that CoLoTa can also serve as a Knowledge Graph Question Answering (KGQA) dataset since the support of knowledge required to answer its queries is present in the Wikidata knowledge graph. However, as opposed to existing KGQA benchmarks that merely focus on factoid questions, our CoLoTa queries also require commonsense reasoning. Our experiments with strong LLM-based KGQA methodologies indicate their severe inability to answer queries involving commonsense reasoning. Hence, we propose CoLoTa as a novel benchmark for assessing both (i) LLM commonsense reasoning capabilities and their robustness to hallucinations on long-tail entities and (ii) the commonsense reasoning capabilities of KGQA methods.
大型语言模型(LLM)的崛起已经重新定义了人工智能领域,尤其是它们编码事实和常识知识的能力,以及它们在需要推理的任务中的出色表现。尽管如此,幻觉和推理错误仍是它们在高风险环境中部署的重大障碍。在这项工作中,我们观察到即使是最突出的大型语言模型,如OpenAI-o1,在处理涉及模糊、长尾实体的常识推理任务时,也会出现较高的推理错误和幻觉率。为了研究这一局限性,我们提出了一个新的数据集,名为长尾实体常识推理数据集(CoLoTa),它包含来自问答和断言验证任务的3300个查询,涵盖了广泛的常识推理技能。我们注意到,由于WikiData知识图谱中包含回答其查询所需的知识支持,CoLoTa也可以作为知识图谱问答(KGQA)数据集使用。然而,与仅关注事实问题的现有KGQA基准测试不同,我们的CoLoTa查询还需要常识推理。我们与强大的基于大型语言模型的KGQA方法的实验表明,它们严重无法回答涉及常识推理的查询。因此,我们提出将CoLoTa作为评估大型语言模型在长尾实体上的常识推理能力和对幻觉的稳健性的新型基准测试,同时也是评估KGQA方法的常识推理能力的基准测试。
论文及项目相关链接
Summary
大型语言模型(LLM)在AI领域具有重要地位,其能够编码事实和常识知识,并在需要推理的任务中表现出卓越性能。然而,幻觉和推理错误仍是其在高风险环境中部署的重大障碍。本研究发现,最先进的大型语言模型,如OpenAI-o1,在处理模糊的长尾实体相关的常识推理任务时,存在高比例的推理错误和幻觉。为此,我们提出了一个新的数据集CoLoTa,包含3300个来自问答和声明验证任务的查询,涵盖了广泛的常识推理技能。CoLoTa还可以作为知识图谱问答(KGQA)数据集,虽然它支持的知识存在于Wikidata知识图谱中,但我们的查询还需要常识推理,这与现有的KGQA基准测试仅侧重于事实问题不同。实验表明,现有的强大LLM基KGQA方法严重无法回答涉及常识推理的查询。因此,我们提议将CoLoTa作为评估大型语言模型在长尾实体的常识推理能力和对幻觉的稳健性以及评估KGQA方法的常识推理能力的新基准。
Key Takeaways
- 大型语言模型(LLM)在AI领域具有重要影响,尤其在编码事实和常识知识以及推理任务方面表现出卓越性能。
- 幻觉和推理错误是限制LLM在高风险环境中应用的主要障碍。
- 最先进的大型语言模型在处理涉及长尾实体的常识推理任务时存在高比例的推理错误和幻觉。
- 提出了一个新的数据集CoLoTa,用于评估LLM在长尾实体的常识推理能力和对幻觉的稳健性。
- CoLoTa数据集包含广泛的查询,涵盖多种常识推理技能,也可以作为知识图谱问答(KGQA)数据集使用。
- 与现有KGQA基准测试不同,CoLoTa的查询需要既支持的知识也需要常识推理。
点此查看论文截图

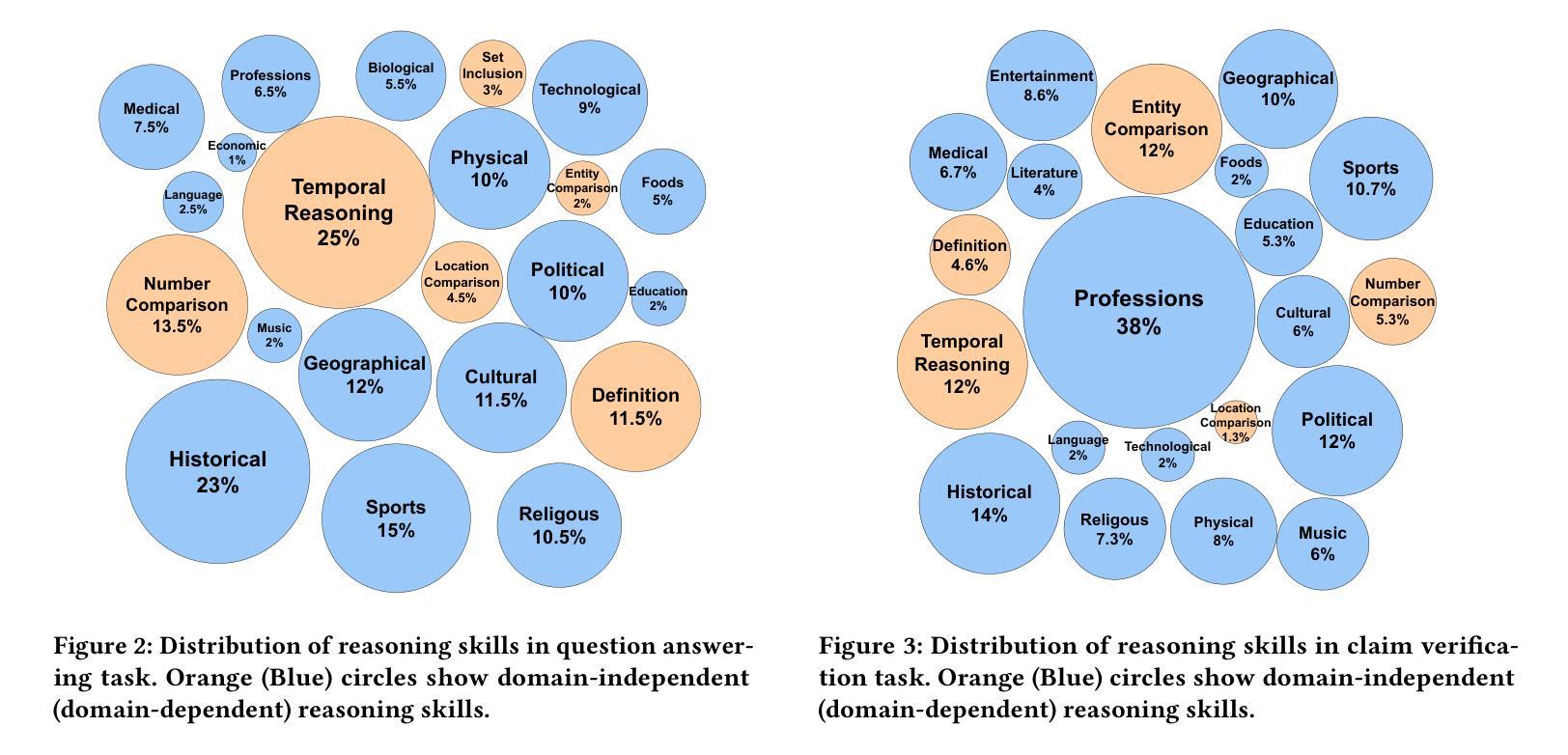
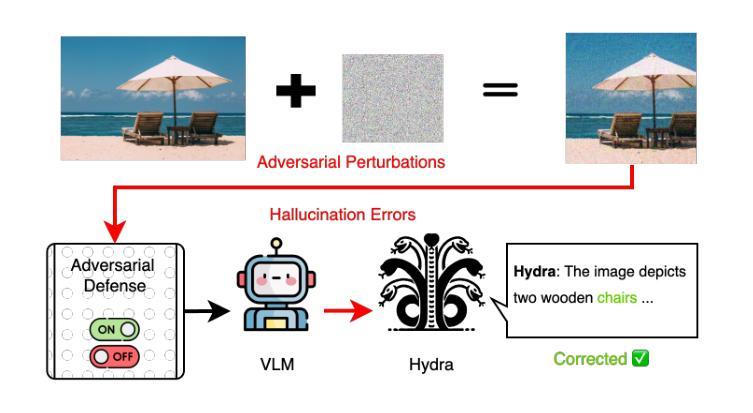
Hydra: An Agentic Reasoning Approach for Enhancing Adversarial Robustness and Mitigating Hallucinations in Vision-Language Models
Authors: Chung-En, Yu, Hsuan-Chih, Chen, Brian Jalaian, Nathaniel D. Bastian
To develop trustworthy Vision-Language Models (VLMs), it is essential to address adversarial robustness and hallucination mitigation, both of which impact factual accuracy in high-stakes applications such as defense and healthcare. Existing methods primarily focus on either adversarial defense or hallucination post-hoc correction, leaving a gap in unified robustness strategies. We introduce \textbf{Hydra}, an adaptive agentic framework that enhances plug-in VLMs through iterative reasoning, structured critiques, and cross-model verification, improving both resilience to adversarial perturbations and intrinsic model errors. Hydra employs an Action-Critique Loop, where it retrieves and critiques visual information, leveraging Chain-of-Thought (CoT) and In-Context Learning (ICL) techniques to refine outputs dynamically. Unlike static post-hoc correction methods, Hydra adapts to both adversarial manipulations and intrinsic model errors, making it robust to malicious perturbations and hallucination-related inaccuracies. We evaluate Hydra on four VLMs, three hallucination benchmarks, two adversarial attack strategies, and two adversarial defense methods, assessing performance on both clean and adversarial inputs. Results show that Hydra surpasses plug-in VLMs and state-of-the-art (SOTA) dehallucination methods, even without explicit adversarial defenses, demonstrating enhanced robustness and factual consistency. By bridging adversarial resistance and hallucination mitigation, Hydra provides a scalable, training-free solution for improving the reliability of VLMs in real-world applications.
为了开发可信赖的视觉语言模型(VLMs),解决对抗性鲁棒性和幻觉减轻问题至关重要,两者都会影响高风险应用(如国防和医疗保健)的事实准确性。现有方法主要关注对抗性防御或幻觉事后校正,在统一鲁棒性策略方面存在空白。我们介绍了海德拉(Hydra),这是一种自适应的智能框架,它通过迭代推理、结构化批评和跨模型验证增强即插即用型VLMs,提高对对抗性扰动和内在模型错误的适应能力。海德拉采用行动-评论循环,检索和评论视觉信息,利用思维链(CoT)和上下文学习(ICL)技术动态优化输出。与静态事后校正方法不同,海德拉能够适应对抗性操作和内在模型错误,使其对恶意扰动和幻觉相关的不准确具有鲁棒性。我们在四种VLMs、三个幻觉基准测试、两种对抗性攻击策略和两种对抗性防御方法上评估了海德拉的性能,评估其在干净和对抗性输入上的表现。结果表明,海德拉超越了即插即用型VLMs和最新先进去幻觉方法,甚至在没有明确的对抗性防御措施的情况下,也表现出增强的鲁棒性和事实一致性。通过对抗抵抗和幻觉减轻之间的桥梁作用,海德拉提供了一种可扩展、无需训练即可提高VLM在现实世界中应用可靠性的解决方案。
论文及项目相关链接
Summary
文本介绍了一种名为Hydra的适应性代理框架,用于增强视觉语言模型的稳健性。该框架通过迭代推理、结构化评价和跨模型验证等技术,提高了模型对对抗性干扰和内在模型错误的抵御能力。Hydra采用行动-评价循环,利用思维链和上下文学习技术动态优化输出。在多个视觉语言模型和基准测试中,Hydra表现出超越插件式视觉语言模型和最新去幻觉方法的性能,无需明确的对抗性防御即可增强稳健性和事实一致性。
Key Takeaways
- Hydra是一个适应性代理框架,旨在增强视觉语言模型(VLMs)的稳健性。
- 该框架通过迭代推理、结构化评价和跨模型验证等技术提高模型性能。
- Hydra采用行动-评价循环,能够动态优化输出,适应对抗性操作和内在模型错误。
- 与静态的后处理方法不同,Hydra框架能够应对恶意干扰和幻觉相关的不准确性。
- Hydra在多个VLMs、幻觉基准测试、对抗性攻击策略和防御方法上的评估结果表明,它超越了插件式VLMs和最新的去幻觉方法。
- Hydra提高了模型在干净和对抗性输入上的性能,增强了稳健性和事实一致性。
点此查看论文截图

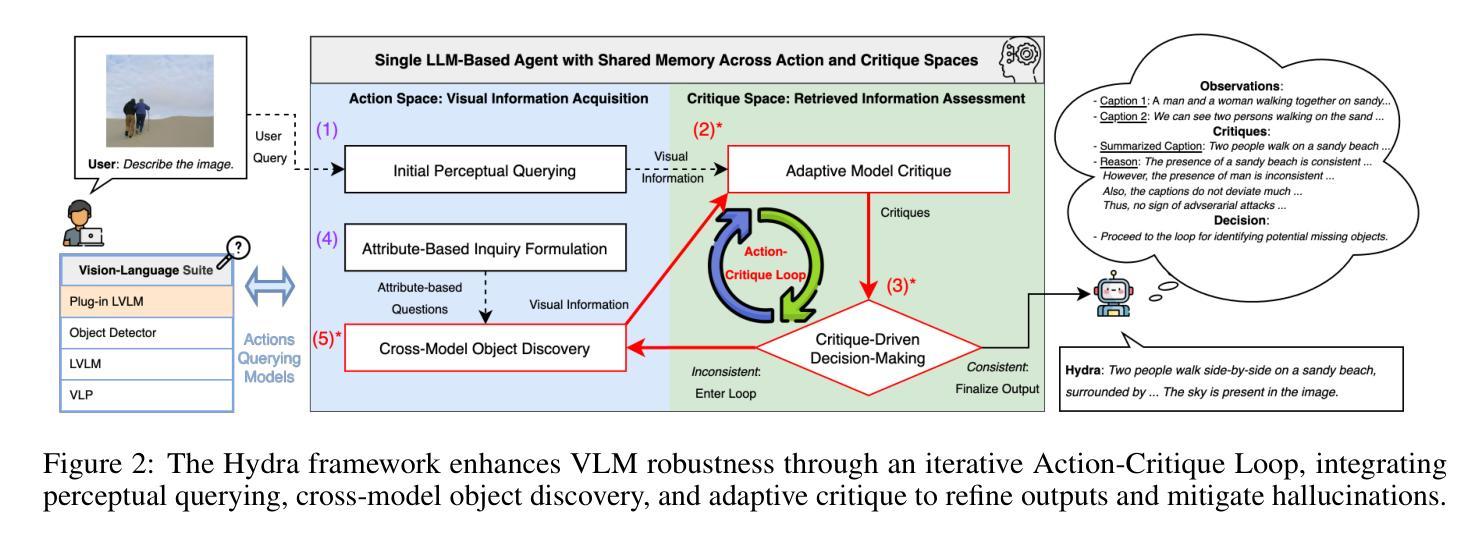
Improving RL Exploration for LLM Reasoning through Retrospective Replay
Authors:Shihan Dou, Muling Wu, Jingwen Xu, Rui Zheng, Tao Gui, Qi Zhang, Xuanjing Huang
Reinforcement learning (RL) has increasingly become a pivotal technique in the post-training of large language models (LLMs). The effective exploration of the output space is essential for the success of RL. We observe that for complex problems, during the early stages of training, the model exhibits strong exploratory capabilities and can identify promising solution ideas. However, its limited capability at this stage prevents it from successfully solving these problems. The early suppression of these potentially valuable solution ideas by the policy gradient hinders the model’s ability to revisit and re-explore these ideas later. Consequently, although the LLM’s capabilities improve in the later stages of training, it still struggles to effectively address these complex problems. To address this exploration issue, we propose a novel algorithm named Retrospective Replay-based Reinforcement Learning (RRL), which introduces a dynamic replay mechanism throughout the training process. RRL enables the model to revisit promising states identified in the early stages, thereby improving its efficiency and effectiveness in exploration. To evaluate the effectiveness of RRL, we conduct extensive experiments on complex reasoning tasks, including mathematical reasoning and code generation, and general dialogue tasks. The results indicate that RRL maintains high exploration efficiency throughout the training period, significantly enhancing the effectiveness of RL in optimizing LLMs for complicated reasoning tasks. Moreover, it also improves the performance of RLHF, making the model both safer and more helpful.
强化学习(RL)在大型语言模型(LLM)的后期训练过程中逐渐成为了一项关键的技术。在强化学习中,有效地探索输出空间对于其成功至关重要。我们观察到,对于复杂的问题,在训练的早期阶段,模型具有很强的探索能力,并能够识别出有前景的解决方案。然而,这一阶段的有限能力使其无法成功解决这些问题。早期策略梯度对这些可能具有价值的解决方案的压制阻碍了模型日后重新访问和再次探索这些解决方案的能力。因此,尽管LLM在训练的后期阶段的能力有所提升,但它仍然难以有效地解决这些复杂的问题。为了解决这一探索问题,我们提出了一种名为基于回顾的重放强化学习(RRL)的新算法,该算法在训练过程中引入了动态重放机制。RRL使模型能够重新访问早期阶段发现的具有前景的状态,从而提高其探索的效率。为了评估RRL的有效性,我们在复杂的推理任务(包括数学推理和代码生成)和通用对话任务上进行了大量的实验。结果表明,RRL在整个训练过程中都能保持较高的探索效率,从而显著提高了强化学习在优化复杂推理任务的LLM方面的有效性。此外,它还提高了RLHF的性能,使模型更加安全和有用。
论文及项目相关链接
PDF 13 pages, 3 figures
Summary
该文本探讨了强化学习(RL)在后训练大型语言模型(LLM)中的重要性,并指出在训练早期阶段模型具有强大的探索能力但缺乏解决复杂问题的能力。为解决这一问题,提出了一种名为“基于回顾的强化学习(RRL)”的新算法,该算法通过在整个训练过程中引入动态回放机制,使模型能够重新访问早期阶段发现的具有潜力的状态,从而提高探索效率和效果。实验结果表明,RRL在复杂推理任务上的表现显著优于传统方法。
Key Takeaways
- 强化学习在大型语言模型的训练中是关键技术。
- 训练早期阶段,模型展现出强大的探索能力但缺乏解决复杂问题的能力。
- 模型早期抑制的潜在解决方案可能导致其在后续训练中无法重新探索。
- 为解决探索问题,提出了基于回顾的强化学习(RRL)算法。
- RRL算法通过动态回放机制使模型能够重新访问早期发现的有潜力状态。
- 实验表明RRL在复杂推理任务上显著提高模型的探索效率和效果。
点此查看论文截图

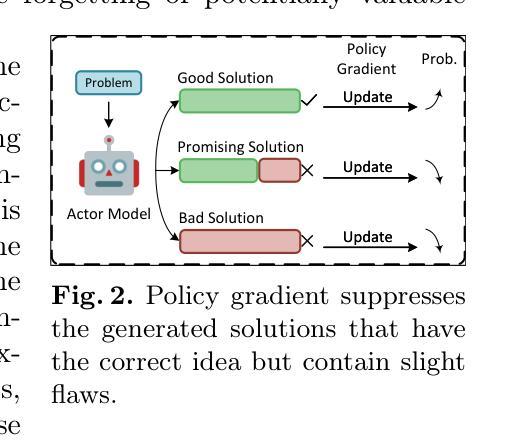
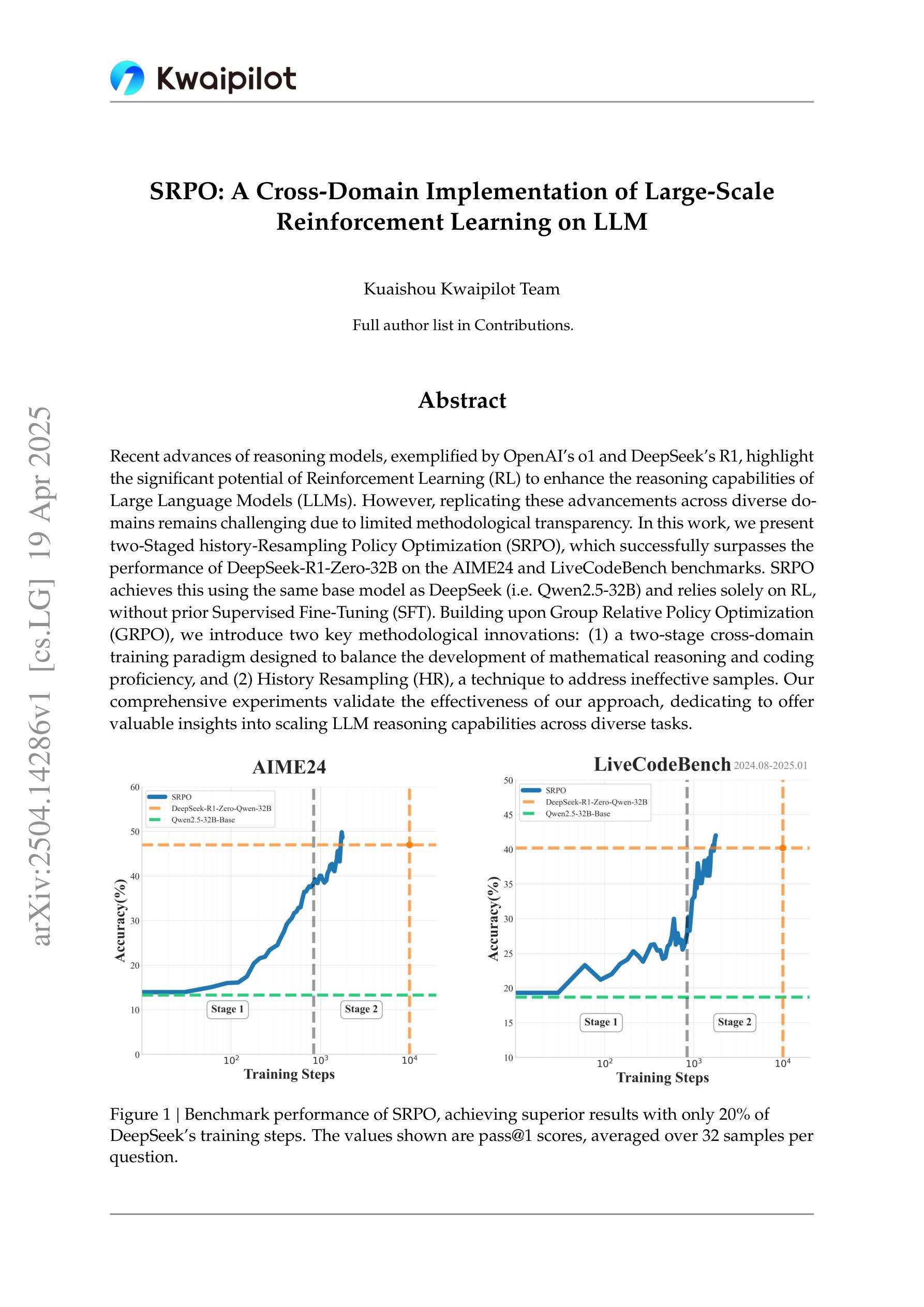
SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
Authors:Xiaojiang Zhang, Jinghui Wang, Zifei Cheng, Wenhao Zhuang, Zheng Lin, Minglei Zhang, Shaojie Wang, Yinghan Cui, Chao Wang, Junyi Peng, Shimiao Jiang, Shiqi Kuang, Shouyu Yin, Chaohang Wen, Haotian Zhang, Bin Chen, Bing Yu
Recent advances of reasoning models, exemplified by OpenAI’s o1 and DeepSeek’s R1, highlight the significant potential of Reinforcement Learning (RL) to enhance the reasoning capabilities of Large Language Models (LLMs). However, replicating these advancements across diverse domains remains challenging due to limited methodological transparency. In this work, we present two-Staged history-Resampling Policy Optimization (SRPO), which successfully surpasses the performance of DeepSeek-R1-Zero-32B on the AIME24 and LiveCodeBench benchmarks. SRPO achieves this using the same base model as DeepSeek (i.e. Qwen2.5-32B) and relies solely on RL, without prior Supervised Fine-Tuning (SFT). Building upon Group Relative Policy Optimization (GRPO), we introduce two key methodological innovations: (1) a two-stage cross-domain training paradigm designed to balance the development of mathematical reasoning and coding proficiency, and (2) History Resampling (HR), a technique to address ineffective samples. Our comprehensive experiments validate the effectiveness of our approach, dedicating to offer valuable insights into scaling LLM reasoning capabilities across diverse tasks.
近期推理模型的进展,以OpenAI的o1和DeepSeek的R1为例,凸显了强化学习(RL)在提升大型语言模型(LLM)推理能力方面的巨大潜力。然而,由于方法透明度的限制,将这些进展复制到不同领域仍然具有挑战性。在这项工作中,我们提出了两阶段历史重采样策略优化(SRPO),它成功超越了DeepSeek-R1-Zero-32B在AIME24和LiveCodeBench基准测试上的表现。SRPO使用与DeepSeek相同的基准模型(即Qwen2.5-32B),仅依赖强化学习,无需预先进行有监督的微调(SFT)。基于组相对策略优化(GRPO),我们引入了两种重要的方法论创新:(1)一种两阶段跨域训练范式,旨在平衡数学推理和编码能力的发展;(2)历史重采样(HR),一种解决无效样本的技术。我们的综合实验验证了我们的方法的有效性,致力于在多样化任务中提供关于扩展LLM推理能力的宝贵见解。
论文及项目相关链接
Summary
最近强化学习(RL)在提升大型语言模型(LLM)推理能力方面展现出巨大潜力,如OpenAI的o1和DeepSeek的R1所示。然而,在不同领域复制这些进步因方法透明度有限而面临挑战。本研究提出两阶段历史重采样策略优化(SRPO),在AIME24和LiveCodeBench基准测试中超越了DeepSeek-R1-Zero-32B的性能。SRPO使用与DeepSeek相同的基准模型(即Qwen2.5-32B),仅依赖RL,无需先验的监督微调(SFT)。基于集团相对策略优化(GRPO),我们引入了两个关键的方法创新:一是两阶段跨域训练范式,旨在平衡数学推理和编程能力的发展;二是历史重采样(HR)技术,以解决无效样本问题。
Key Takeaways
- 强化学习(RL)在提升大型语言模型(LLM)的推理能力方面具有显著潜力。
- 复制这些进步在不同领域因方法透明度有限而具有挑战性。
- SRPO方法成功超越了DeepSeek-R1-Zero-32B的性能,使用相同的基准模型并仅依赖强化学习。
- SRPO引入了两阶段跨域训练范式,旨在平衡数学推理和编程能力的发展。
- 历史重采样(HR)技术是解决无效样本问题的一种新方法。
- SRPO建立在Group Relative Policy Optimization(GRPO)之上,进行了两个关键的方法创新。
点此查看论文截图





InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Authors:Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, Fei Wu
Multimodal Large Language Models (MLLMs) have powered Graphical User Interface (GUI) Agents, showing promise in automating tasks on computing devices. Recent works have begun exploring reasoning in GUI tasks with encouraging results. However, many current approaches rely on manually designed reasoning templates, which may result in reasoning that is not sufficiently robust and adaptive for complex GUI environments. Meanwhile, some existing agents continue to operate as Reactive Actors, relying primarily on implicit reasoning that may lack sufficient depth for GUI tasks demanding planning and error recovery. We argue that advancing these agents requires a shift from reactive acting towards acting based on deliberate reasoning. To facilitate this transformation, we introduce InfiGUI-R1, an MLLM-based GUI agent developed through our Actor2Reasoner framework, a reasoning-centric, two-stage training approach designed to progressively evolve agents from Reactive Actors to Deliberative Reasoners. The first stage, Reasoning Injection, focuses on establishing a basic reasoner. We employ Spatial Reasoning Distillation to transfer cross-modal spatial reasoning capabilities from teacher models to MLLMs through trajectories with explicit reasoning steps, enabling models to integrate GUI visual-spatial information with logical reasoning before action generation. The second stage, Deliberation Enhancement, refines the basic reasoner into a deliberative one using Reinforcement Learning. This stage introduces two approaches: Sub-goal Guidance, which rewards models for generating accurate intermediate sub-goals, and Error Recovery Scenario Construction, which creates failure-and-recovery training scenarios from identified prone-to-error steps. Experimental results show InfiGUI-R1 achieves strong performance in GUI grounding and trajectory tasks. Resources at https://github.com/Reallm-Labs/InfiGUI-R1.
多模态大型语言模型(MLLMs)已经为图形用户界面(GUI)代理提供了动力,在自动化计算设备上的任务方面显示出巨大的潜力。近期的研究工作已经开始探索GUI任务的推理,并获得了令人鼓舞的结果。然而,许多当前的方法依赖于手动设计的推理模板,这可能导致推理在复杂的GUI环境中不够稳健和适应。同时,一些现有的代理仍然以反应式的方式运行,主要依赖于缺乏足够深度的隐式推理,对于需要规划和错误恢复的GUI任务可能不够充分。我们认为,要发展这些代理,需要从反应性行为转向基于理性思考的行为。为了推动这一转变,我们引入了InfiGUI-R1,这是一个基于MLLM的GUI代理,它是通过我们的Actor2Reasoner框架开发的。这是一个以推理为中心的、两阶段的训练方法,旨在逐步将代理从反应式演员进化为深思熟虑的推理者。第一阶段是推理注入,侧重于建立基本的推理者。我们采用空间推理蒸馏法,通过具有明确推理步骤的轨迹,将教师模型的多模态空间推理能力转移到MLLMs上,使模型能够在生成动作之前整合GUI的视觉空间信息与逻辑推理。第二阶段是精细推理增强阶段,它将基本推理者发展成深思熟虑的推理者,使用强化学习。这一阶段引入了两种方法:子目标指导,奖励模型生成准确的中间子目标;错误恢复场景构建,从已识别的易出错步骤中创建失败和恢复的训练场景。实验结果表明,InfiGUI-R1在GUI定位和轨迹任务中取得了强大的性能。相关资源请访问:https://github.com/Reallm-Labs/InfiGUI-R1。
论文及项目相关链接
PDF 10 pages, 3 figures, work in progress
Summary
在文本中,主要讨论了图形用户界面(GUI)代理的发展与优化问题。传统的GUI代理主要依靠反应性行为,缺乏深度推理能力。文章提出需要向基于深思熟虑的推理行为转变,并介绍了InfiGUI-R1这一基于多模态大型语言模型的GUI代理。InfiGUI-R1通过Actor2Reasoner框架开发,采用两阶段训练法逐步进化代理从反应性行为到深思熟虑的推理行为。第一阶段的推理注入着重建立基本推理能力,第二阶段的审议增强则在此基础上通过强化学习进一步精炼。实验结果显示InfiGUI-R1在GUI接地和轨迹任务上表现出色。相关资源可访问 https://github.com/Reallm-Labs/InfiGUI-R1 了解更多信息。
Key Takeaways
以下是七个关键要点:
- 多模态大型语言模型(MLLMs)为图形用户界面(GUI)代理提供了潜力,特别是在自动化计算设备任务方面。
- 当前GUI代理在自动化任务中的推理能力有限,依赖于手动设计的推理模板或者仅仅基于反应性行为的隐式推理。
- 文章的目的是推进这些代理从反应性行动向基于深思熟虑的推理行动转变。
- 提出了一种名为InfiGUI-R1的基于MLLM的GUI代理,该代理通过Actor2Reasoner框架开发,该框架强调以推理为中心的两阶段训练法。
- 第一阶段重点是建立基本的推理能力,通过空间推理蒸馏技术从教师模型转移跨模态空间推理能力。
- 第二阶段使用强化学习进一步精炼基本推理能力,并引入子目标指导和错误恢复场景构建两种新方法。
点此查看论文截图



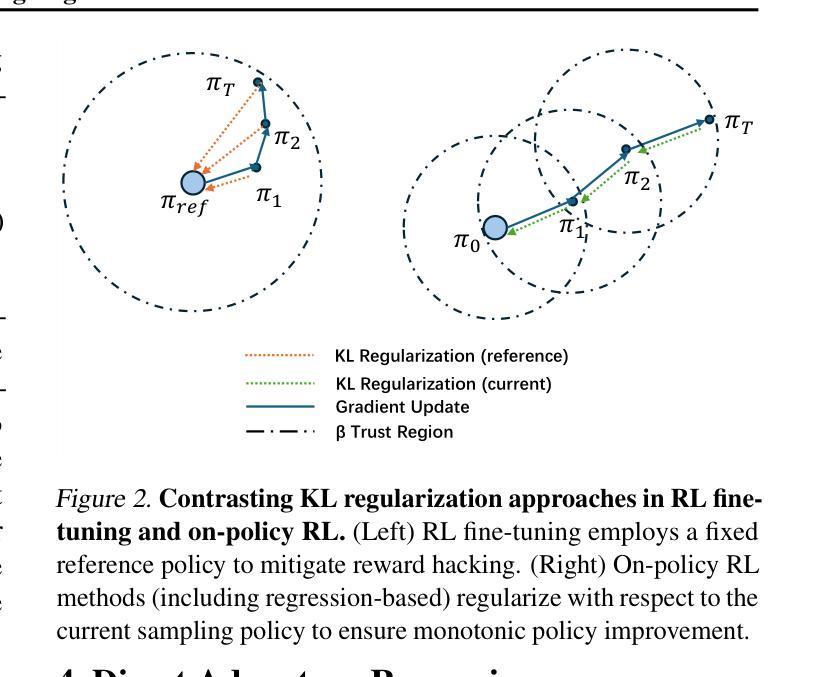
Direct Advantage Regression: Aligning LLMs with Online AI Reward
Authors:Li He, He Zhao, Stephen Wan, Dadong Wang, Lina Yao, Tongliang Liu
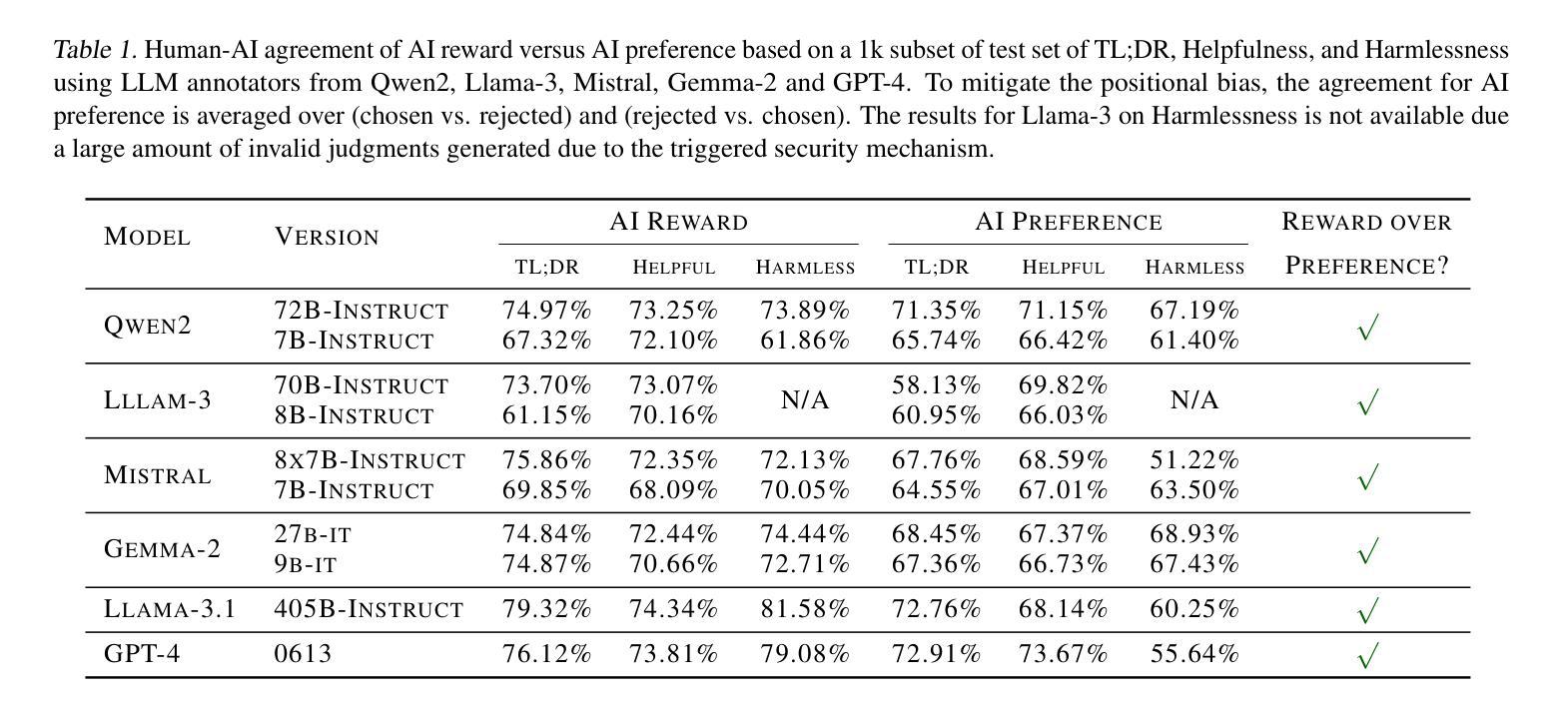
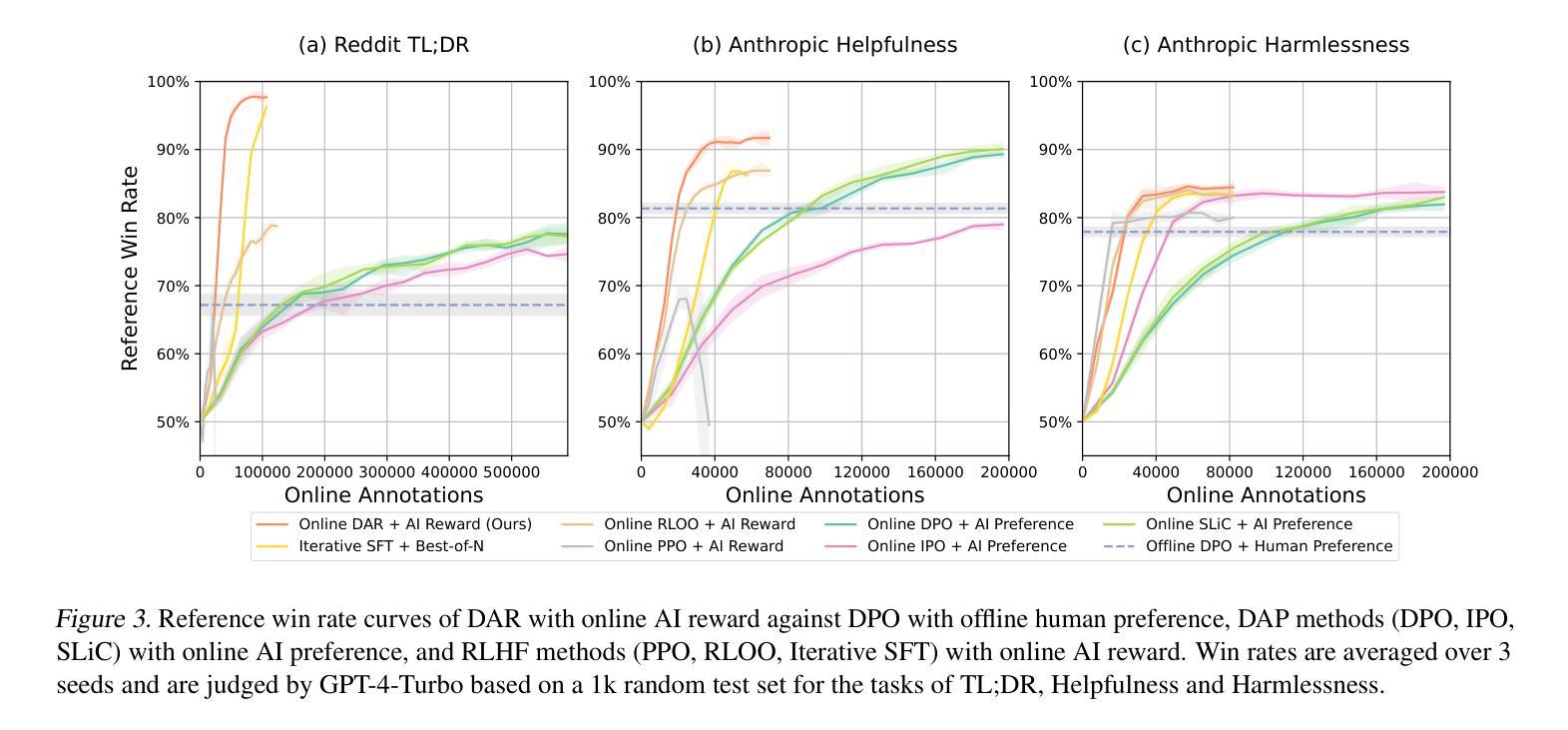
Online AI Feedback (OAIF) presents a promising alternative to Reinforcement Learning from Human Feedback (RLHF) by utilizing online AI preference in aligning language models (LLMs). However, the straightforward replacement of humans with AI deprives LLMs from learning more fine-grained AI supervision beyond binary signals. In this paper, we propose Direct Advantage Regression (DAR), a simple alignment algorithm using online AI reward to optimize policy improvement through weighted supervised fine-tuning. As an RL-free approach, DAR maintains theoretical consistency with online RLHF pipelines while significantly reducing implementation complexity and improving learning efficiency. Our empirical results underscore that AI reward is a better form of AI supervision consistently achieving higher human-AI agreement as opposed to AI preference. Additionally, evaluations using GPT-4-Turbo and MT-bench show that DAR outperforms both OAIF and online RLHF baselines.
在线人工智能反馈(OAIF)通过利用在线人工智能偏好对齐语言模型(LLM),为强化学习从人类反馈(RLHF)提供了有前景的替代方案。然而,简单地将人类替换为人工智能剥夺了LLM从超越二元信号的精细粒度人工智能监督中学习机会。在本文中,我们提出了直接优势回归(DAR)方法,这是一种使用在线人工智能奖励进行优化策略改进的简单对齐算法,通过加权监督微调。作为一种无强化学习的方法,DAR在理论上与在线RLHF管道保持一致,同时大大降低了实现复杂性并提高了学习效率。我们的实证结果表明,相较于人工智能偏好,人工智能奖励是一种更好的监督形式,在保持更高的人机一致性的同时持续取得更好的效果。此外,使用GPT-4 Turbo和MT-bench的评估显示DAR的表现优于OAIF和在线RLHF基线。
论文及项目相关链接
Summary
在线AI反馈(OAIF)为强化学习的人类反馈(RLHF)提供了一个有前景的替代方案,它通过利用在线AI偏好对齐语言模型(LLM)。然而,直接使用AI代替人类会导致LLM失去学习超越二元信号的精细粒度AI监督的机会。本文提出了直接优势回归(DAR)方法,这是一种简单的对齐算法,使用在线AI奖励优化策略改进,通过加权监督微调来实现。作为一种无强化学习的方法,DAR在理论保持与在线RLHF管道的一致性,同时显著降低了实现复杂性并提高了学习效率。我们的实证结果表明,相较于AI偏好,AI奖励是一种更好的AI监督形式,并持续实现更高的人机共识。此外,使用GPT-4 Turbo和MT-bench的评估显示DAR优于OAIF和在线RLHF基线。
Key Takeaways
- 在线AI反馈(OAIF)提供了一种强化学习人类反馈(RLHF)的替代方案,利用在线AI偏好对齐语言模型。
- 直接使用AI代替人类可能导致LLM失去学习超越二元信号的精细粒度AI监督的机会。
- 直接优势回归(DAR)是一种使用在线AI奖励优化策略改进的简单对齐算法。
- DAR保持与在线RLHF管道的理论一致性,同时降低了实现复杂性并提高了学习效率。
- AI奖励是一种更好的AI监督形式,相比AI偏好,持续实现更高的人机共识。
- DAR在评估中表现出优于OAIF和在线RLHF基线的性能。
点此查看论文截图




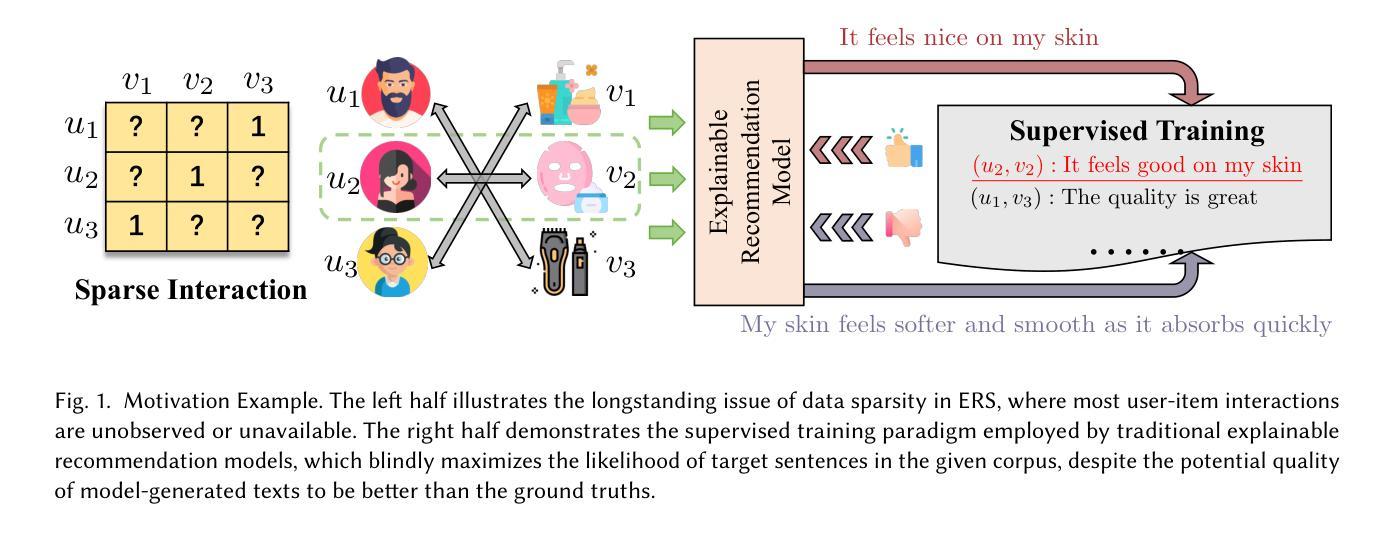
HF4Rec: Human-Like Feedback-Driven Optimization Framework for Explainable Recommendation
Authors:Jiakai Tang, Jingsen Zhang, Zihang Tian, Xueyang Feng, Lei Wang, Xu Chen
Recent advancements in explainable recommendation have greatly bolstered user experience by elucidating the decision-making rationale. However, the existing methods actually fail to provide effective feedback signals for potentially better or worse generated explanations due to their reliance on traditional supervised learning paradigms in sparse interaction data. To address these issues, we propose a novel human-like feedback-driven optimization framework. This framework employs a dynamic interactive optimization mechanism for achieving human-centered explainable requirements without incurring high labor costs. Specifically, we propose to utilize large language models (LLMs) as human simulators to predict human-like feedback for guiding the learning process. To enable the LLMs to deeply understand the task essence and meet user’s diverse personalized requirements, we introduce a human-induced customized reward scoring method, which helps stimulate the language understanding and logical reasoning capabilities of LLMs. Furthermore, considering the potential conflicts between different perspectives of explanation quality, we introduce a principled Pareto optimization that transforms the multi-perspective quality enhancement task into a multi-objective optimization problem for improving explanation performance. At last, to achieve efficient model training, we design an off-policy optimization pipeline. By incorporating a replay buffer and addressing the data distribution biases, we can effectively improve data utilization and enhance model generality. Extensive experiments on four datasets demonstrate the superiority of our approach.
最近,可解释推荐技术的进展通过阐明决策理由极大地提升了用户体验。然而,现有方法由于依赖于稀疏交互数据中的传统监督学习范式,无法为可能更好或更差的生成解释提供有效的反馈信号。为了解决这些问题,我们提出了一种新型的人机反馈驱动优化框架。该框架采用动态交互优化机制,以实现以人类为中心的可解释要求,而不会产生高昂的劳动力成本。具体来说,我们提议利用大型语言模型(LLM)作为人类模拟器,预测人类反馈以指导学习过程。为了让大型语言模型深入了解任务本质并满足用户的多样化个性化需求,我们引入了一种人类引导的自定制奖励评分方法,这有助于激发大型语言模型的语言理解和逻辑推理能力。此外,考虑到解释质量不同视角间潜在的冲突,我们引入了一种有原则的Pareto优化,将多视角质量提升任务转化为多目标优化问题,以提升解释性能。最后,为了实现高效的模型训练,我们设计了一种离策略优化流程。通过结合回放缓冲并解决数据分布偏差问题,我们可以有效提高数据利用率并增强模型的通用性。在四个数据集上的大量实验证明了我们的方法优越性。
论文及项目相关链接
Summary
本文提出一种新型的人机交互优化框架,旨在解决现有推荐系统解释性不足的问题。通过利用大型语言模型预测人类反馈来指导学习过程,并引入个性化奖励评分方法刺激语言理解和逻辑推理能力。同时,采用基于Pareto优化的多目标优化方法,提高解释性能。最终设计了一种离策略优化管道,提高模型效率和泛化能力。实验证明该方法在四个数据集上表现优异。
Key Takeaways
- 现有推荐系统解释性方法存在反馈信号不有效的问题,尤其在稀疏交互数据中。
- 提出一种新型的人机交互优化框架,以人类为中心,实现更高效的解释性。
- 利用大型语言模型预测人类反馈,以指导学习过程,满足用户个性化需求。
- 引入个性化奖励评分方法,增强语言理解和逻辑推理能力。
- 采用基于Pareto优化的多目标优化方法,解决不同解释质量观点间的潜在冲突。
- 设计离策略优化管道,提高模型训练效率、数据利用率和模型泛化能力。
点此查看论文截图