⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-24 更新
MR. Video: “MapReduce” is the Principle for Long Video Understanding
Authors:Ziqi Pang, Yu-Xiong Wang
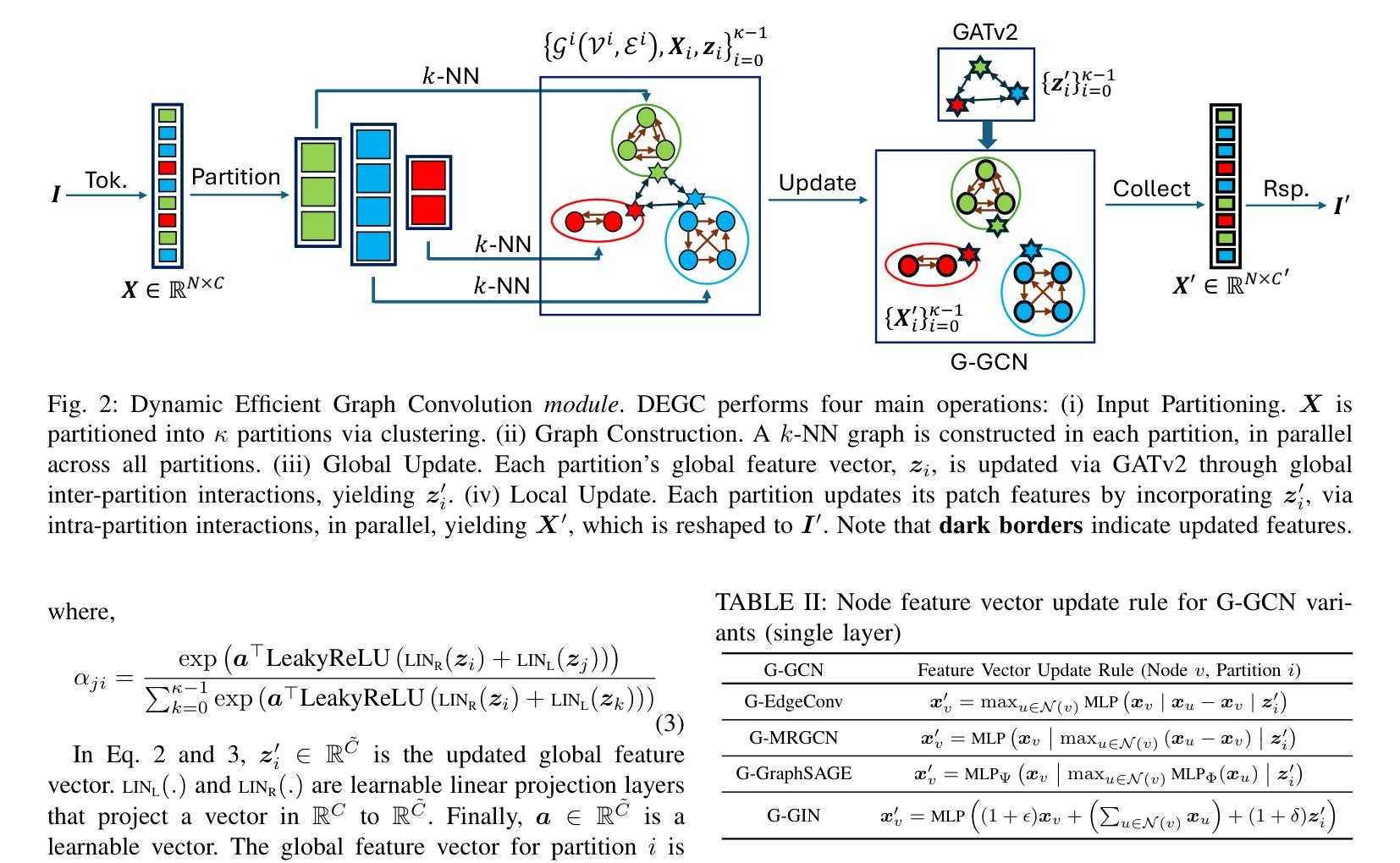
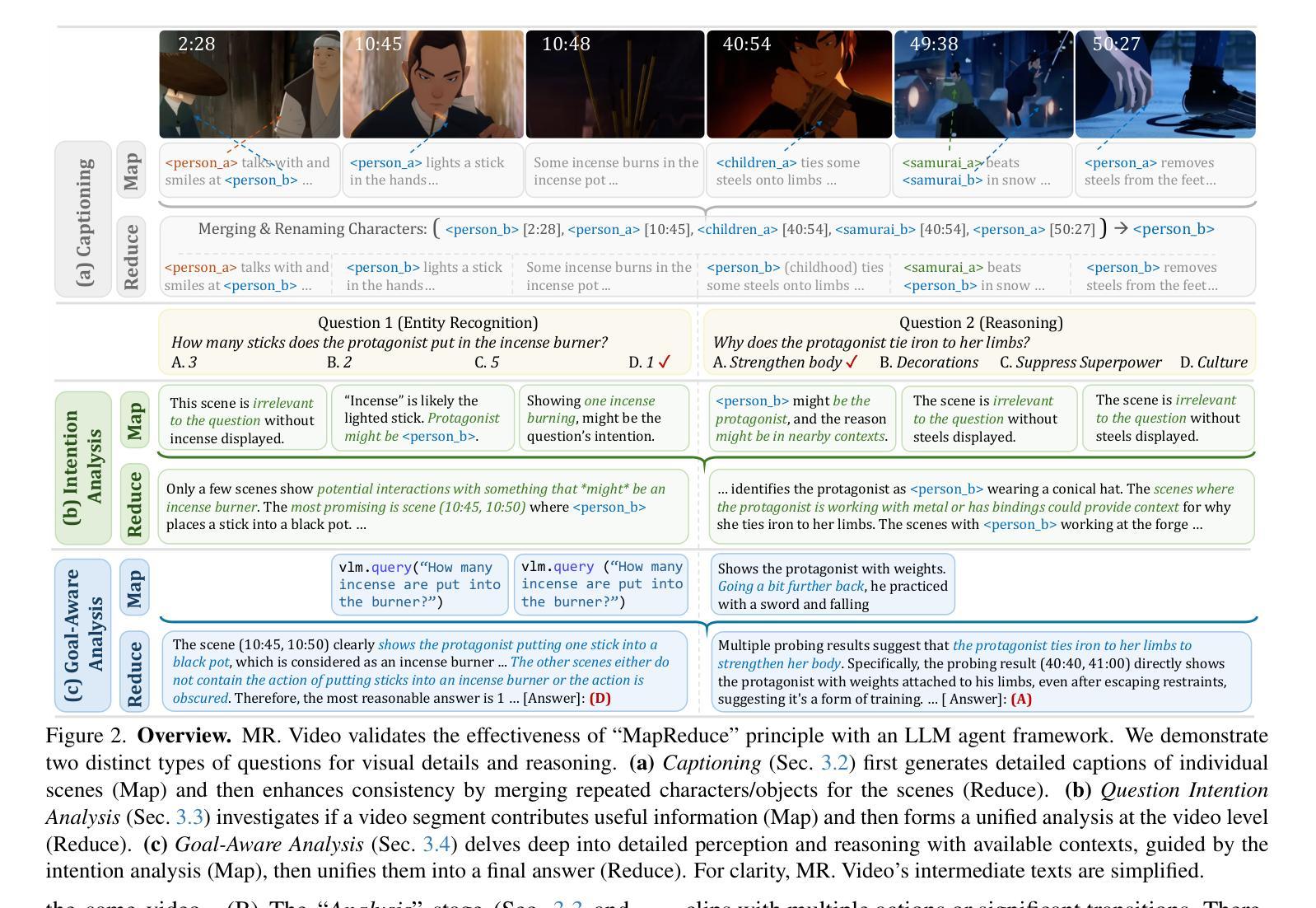
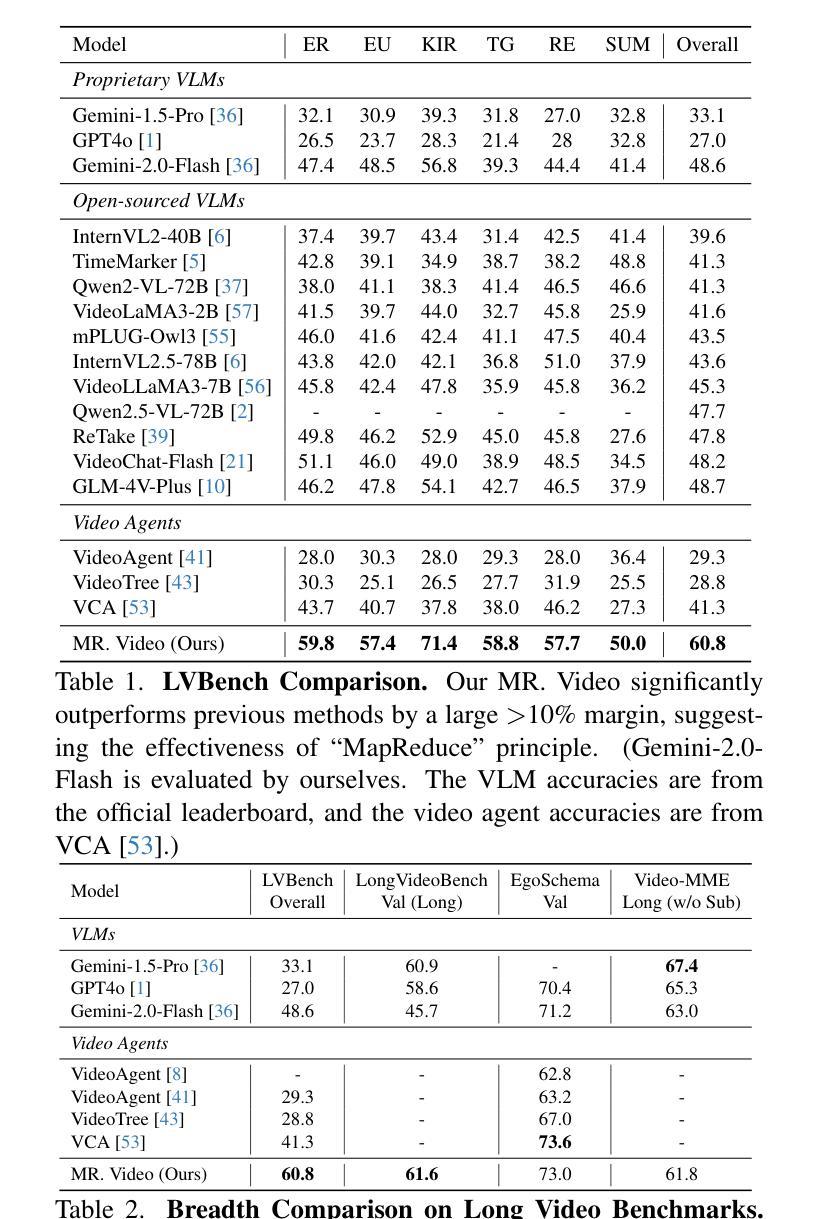
We propose MR. Video, an agentic long video understanding framework that demonstrates the simple yet effective MapReduce principle for processing long videos: (1) Map: independently and densely perceiving short video clips, and (2) Reduce: jointly aggregating information from all clips. Compared with sequence-to-sequence vision-language models (VLMs), MR. Video performs detailed short video perception without being limited by context length. Compared with existing video agents that typically rely on sequential key segment selection, the Map operation enables simpler and more scalable sequence parallel perception of short video segments. Its Reduce step allows for more comprehensive context aggregation and reasoning, surpassing explicit key segment retrieval. This MapReduce principle is applicable to both VLMs and video agents, and we use LLM agents to validate its effectiveness. In practice, MR. Video employs two MapReduce stages: (A) Captioning: generating captions for short video clips (map), then standardizing repeated characters and objects into shared names (reduce); (B) Analysis: for each user question, analyzing relevant information from individual short videos (map), and integrating them into a final answer (reduce). MR. Video achieves over 10% accuracy improvement on the challenging LVBench compared to state-of-the-art VLMs and video agents. Code is available at: https://github.com/ziqipang/MR-Video
我们提出了MR. Video这一智能长视频理解框架,它展示了处理长视频的简单有效的MapReduce原则:(1)映射(Map):独立且密集地感知短视频片段;(2)归约(Reduce):联合所有片段的信息。与序列到序列的视觉语言模型(VLMs)相比,MR. Video在不受上下文长度限制的情况下进行详细的短视频感知。与通常依赖于顺序关键片段选择的现有视频代理相比,映射操作能够实现更简单、可扩展的序列并行感知短视频片段。其归约步骤允许更全面地进行上下文聚合和推理,超越明确的关键片段检索。这个MapReduce原则适用于VLMs和视频代理,我们使用大型语言模型(LLM)代理来验证其有效性。在实践中,MR. Video采用两个阶段进行MapReduce操作:(A)描述:为短视频片段生成描述(映射),然后将重复的角色和对象标准化为共享名称(归约);(B)分析:针对每个用户问题,分析来自各个短视频的相关信息(映射),并将其整合为最终答案(归约)。与先进的VLMs和视频代理相比,MR. Video在具有挑战性的LVBench上实现了超过10%的准确率提升。代码可通过以下网址获取:https://github.com/ziqipang/MR-Video。
论文及项目相关链接
PDF Preprint
Summary
本文提出了一个名为MR. Video的视频理解框架,它遵循MapReduce原则处理长视频,包括两个主要阶段:首先是密集感知短视频片段的Map阶段,然后是聚合所有片段信息的Reduce阶段。与传统的序列到序列视觉语言模型相比,MR. Video能在不受到上下文长度限制的情况下进行详细的短视频感知。与传统的视频代理相比,Map操作使得短视频段的并行感知更简单、更可扩展,Reduce步骤则允许更全面的上下文聚合和推理,无需显式的关键段检索。该MapReduce原则适用于视觉语言模型和大部分视频代理。MR. Video在实践中采用两个阶段:首先是生成视频片段字幕的标准化处理(Map和Reduce),然后是对用户问题的分析处理(再次Map和Reduce)。与现有的先进模型相比,MR. Video在具有挑战性的LVBench上实现了超过10%的准确性改进。
Key Takeaways
- MR. Video是一个基于MapReduce原则的视频理解框架,适用于处理长视频。
- Map阶段能密集感知短视频片段,而Reduce阶段则聚合所有片段的信息。
- 与传统的序列到序列视觉语言模型相比,MR. Video能在不受到上下文长度限制的情况下进行详细的短视频感知。
- Map操作使得短视频段的并行感知更简单、更可扩展。
- Reduce步骤允许更全面的上下文聚合和推理,无需显式关键段检索。
- MR. Video包含两个阶段:首先是生成视频片段字幕的标准化处理(Map和Reduce),然后是对用户问题的分析处理(再次Map和Reduce)。
点此查看论文截图



Vidi: Large Multimodal Models for Video Understanding and Editing
Authors: Vidi Team, Celong Liu, Chia-Wen Kuo, Dawei Du, Fan Chen, Guang Chen, Jiamin Yuan, Lingxi Zhang, Lu Guo, Lusha Li, Longyin Wen, Qingyu Chen, Rachel Deng, Sijie Zhu, Stuart Siew, Tong Jin, Wei Lu, Wen Zhong, Xiaohui Shen, Xin Gu, Xing Mei, Xueqiong Qu
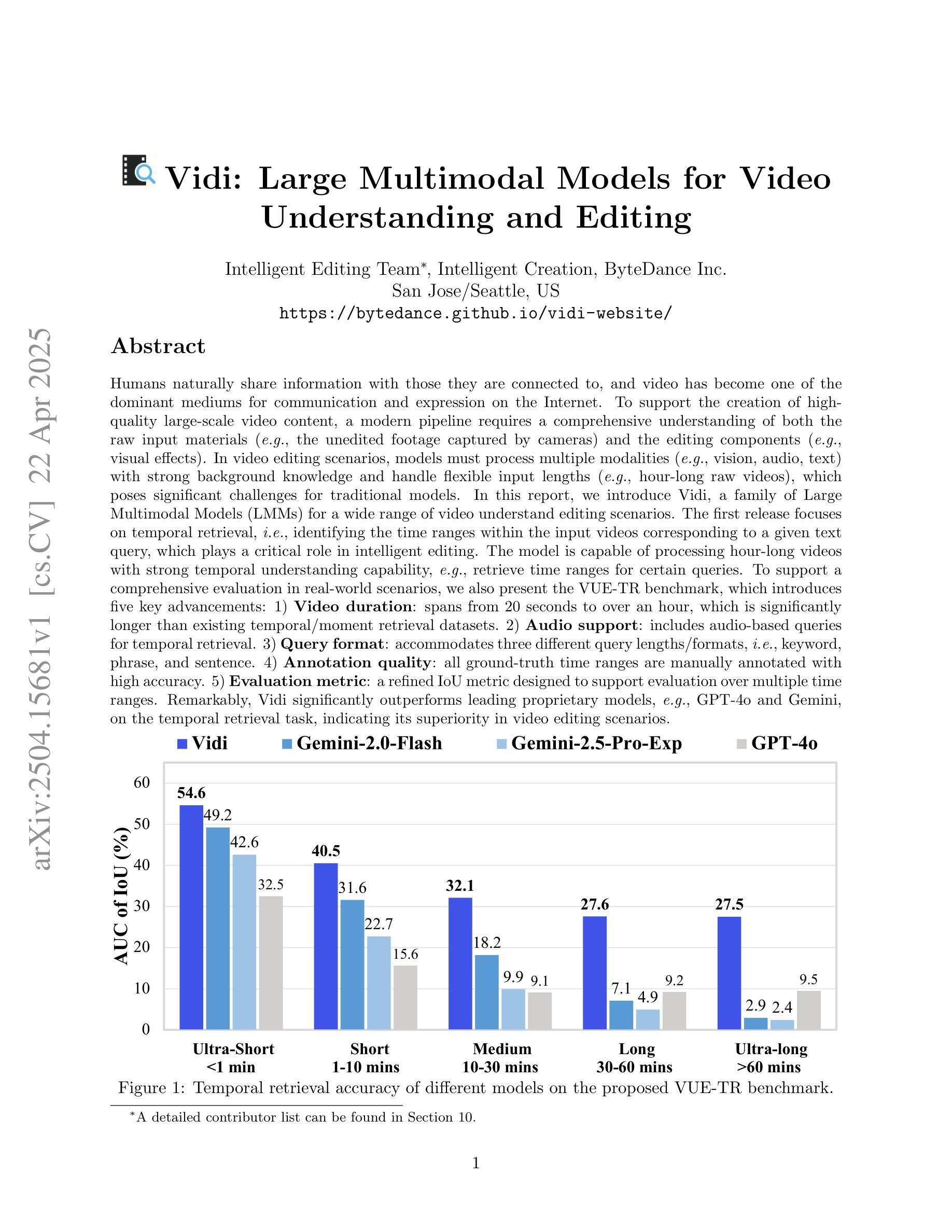
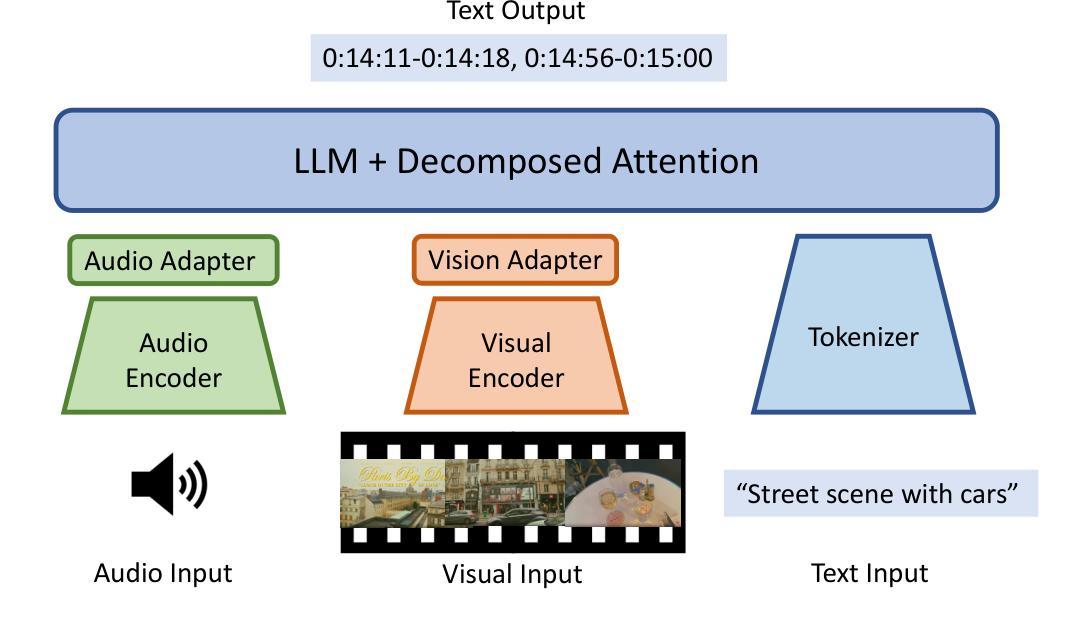
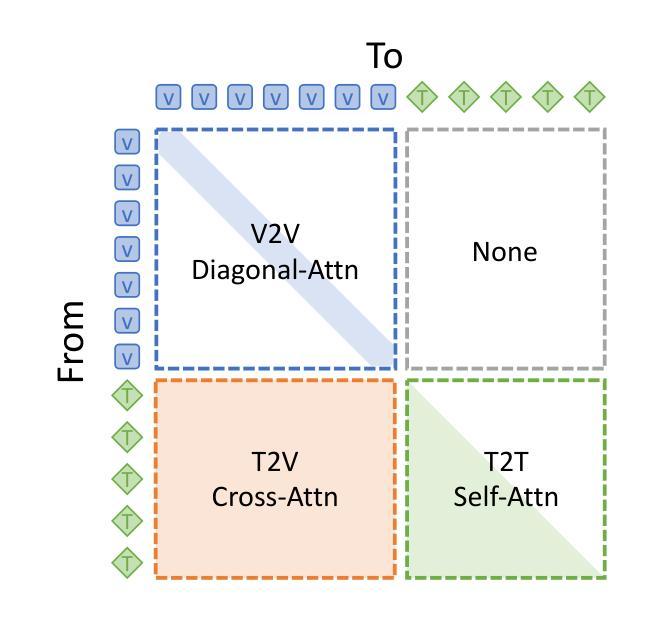
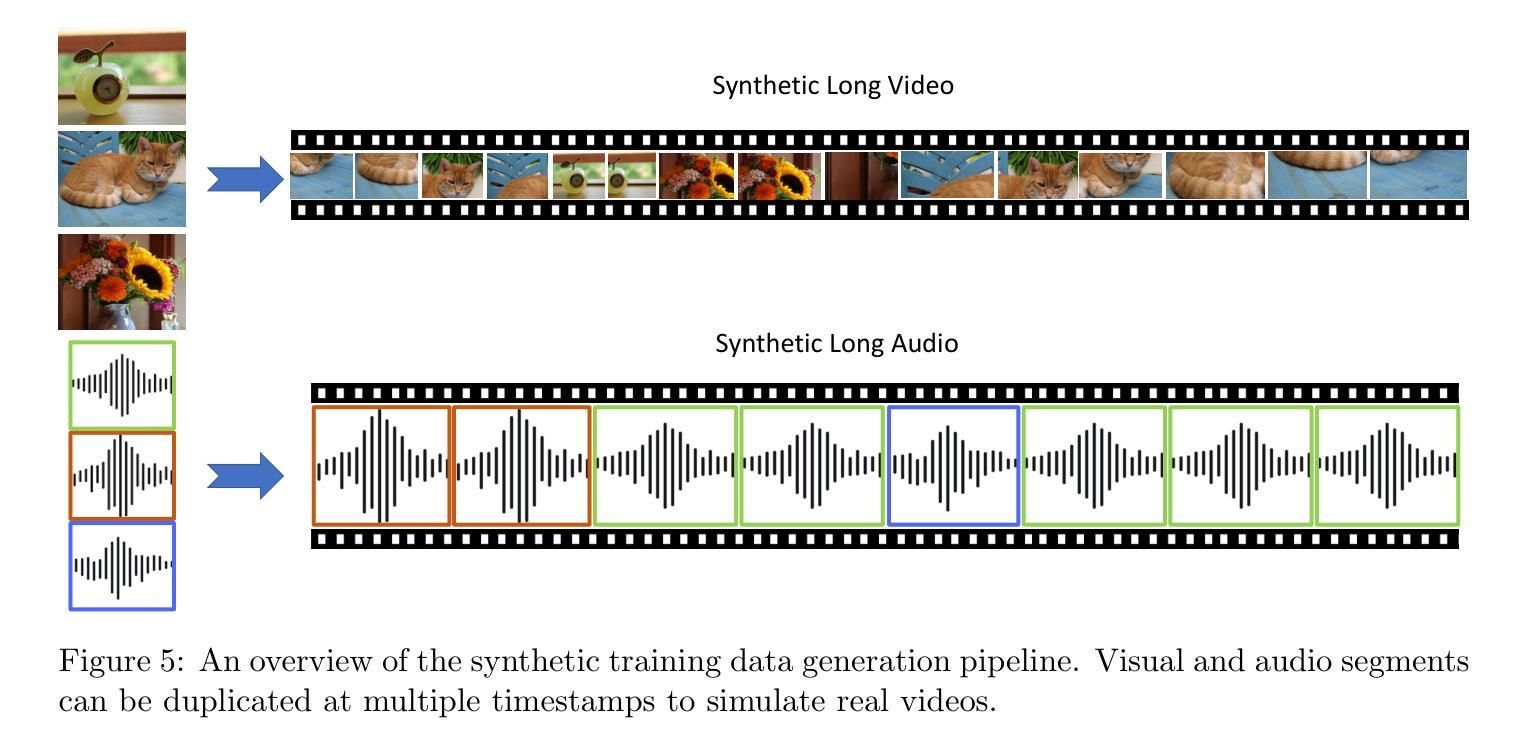
Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
人类自然与所联系的人分享信息,视频已成为互联网上主要的沟通和表达媒介之一。为了支持高质量大规模视频内容的创作,现代流水线需要全面理解原始输入材料(例如,摄像机拍摄未编辑的片段)和编辑内容(例如视觉效果)。在视频编辑场景中,模型必须处理多种模态(例如视觉、音频、文本),具备强大的背景知识,并处理灵活多变的输入长度(例如长达数小时的原视频),这对传统模型构成了重大挑战。在本报告中,我们介绍了Vidi,这是一系列用于广泛视频理解编辑场景的大型多模态模型(LMMs)。首次发布重点关注时序检索,即识别输入视频中对应于给定文本查询的时间范围,这在智能编辑中起着至关重要的作用。该模型具备处理长达数小时的视频的强时间理解能力,例如针对某些查询检索时间范围。为了支持真实场景中的全面评估,我们还推出了VUE-TR基准测试集,它引入了五个关键进展。1)视频时长:显著长于现有的时序检索数据集;2)音频支持:包含基于音频的查询;3)查询格式:多样的查询长度/格式;4)注释质量:手动标注真实的时间范围;5)评估指标:经过优化的IoU指标,以支持对多个时间范围的评估。值得注意的是,Vidi在时序检索任务上显著优于领先的专有模型,如GPT-4o和Gemini,这证明了其在视频编辑场景中的优越性。
论文及项目相关链接
Summary
本文主要介绍了针对广泛视频理解编辑场景的大型多模态模型(Vidi)系列。其首次发布专注于时序检索,即根据文本查询在输入视频中识别对应的时间范围,对智能编辑至关重要。该模型具备处理长达数小时的视频的强时序理解能力。为支持真实场景中的全面评估,还推出了VUE-TR基准测试,包含五个关键进展。经过测试,Vidi在时序检索任务上显著优于领先的专有模型,如GPT-4o和Gemini,突显其在视频编辑场景中的优越性。
Key Takeaways
- 人类自然倾向于与有联系的人分享信息,视频已成为互联网主要的沟通和表达媒介。
- 现代管道需要全面理解视频内容的原始素材和编辑组件以支持高质量的大规模视频内容创作。
- 视频编辑场景中,模型需要处理多种模态(如视觉、音频、文本)并具备强大的背景知识,以及处理灵活输入长度的能力。
- Vidi是一个用于广泛视频理解编辑场景的大型多模态模型系列的首个发布,专注于时序检索任务。
- Vidi可以处理长达数小时的视频,具备优秀的时序理解能力。
- VUE-TR基准测试包含五个关键进展,为全面评估模型性能提供支持。
点此查看论文截图

Towards Understanding Camera Motions in Any Video
Authors:Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, Rushikesh Zawar, Xue Bai, Yilun Du, Chuang Gan, Deva Ramanan
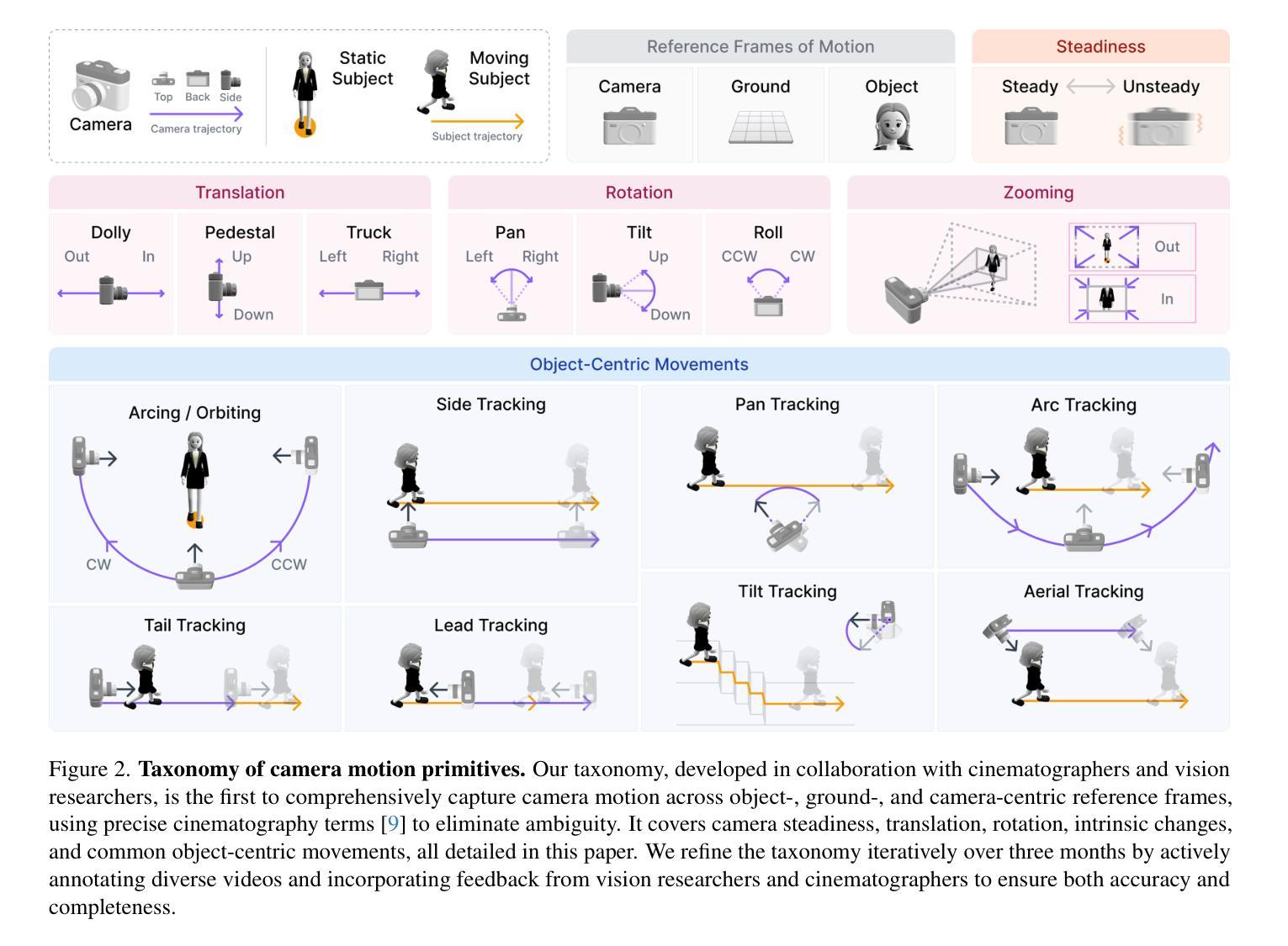
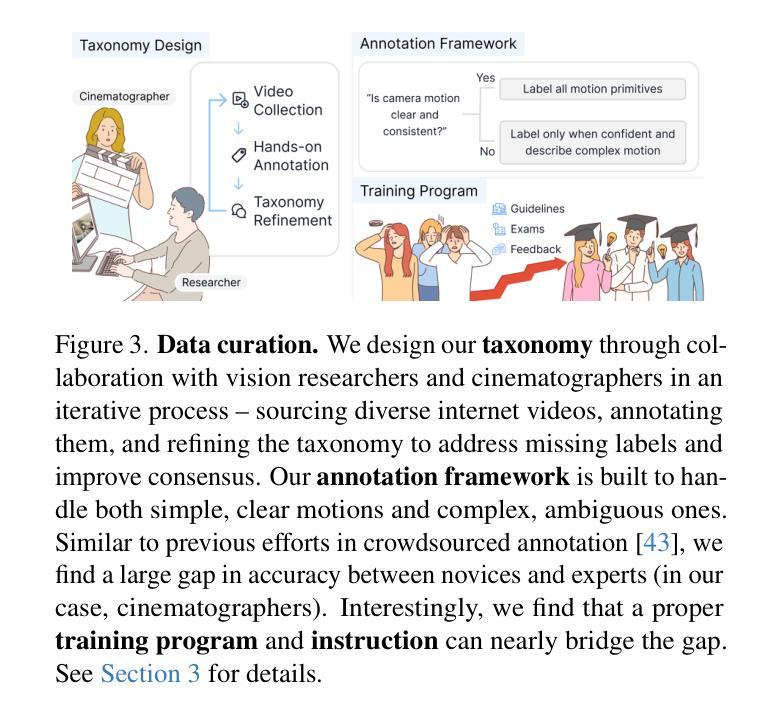
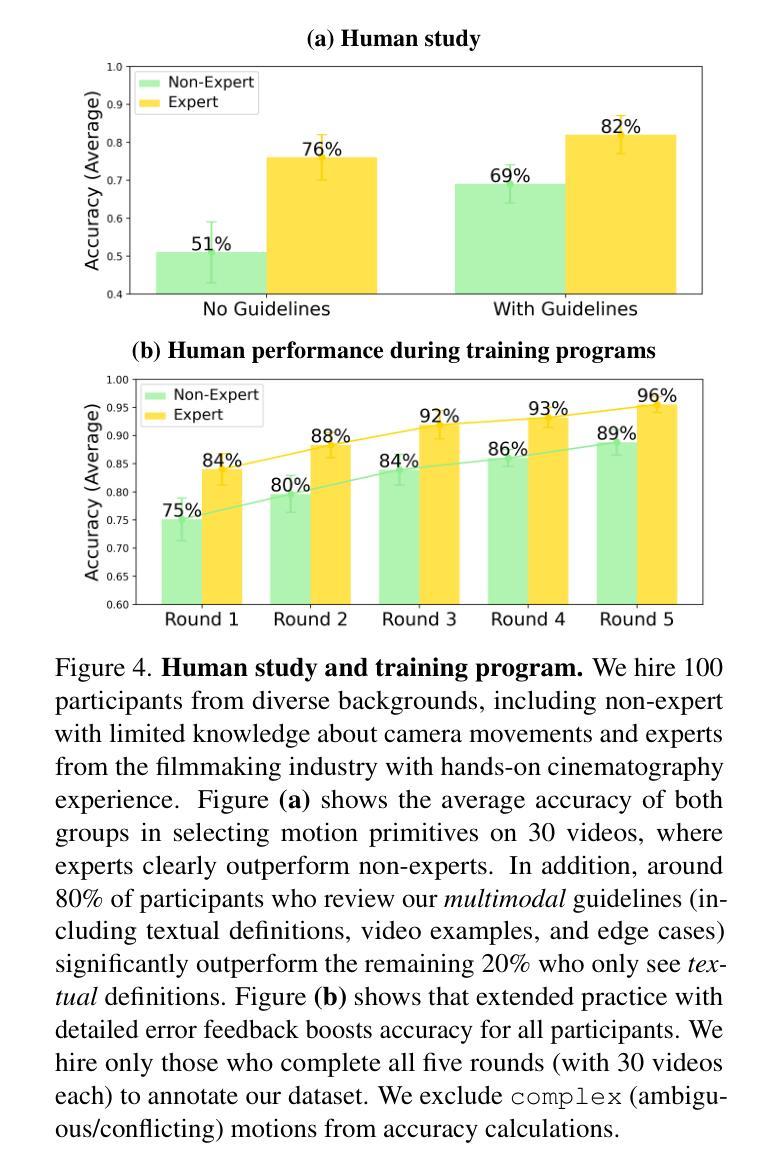
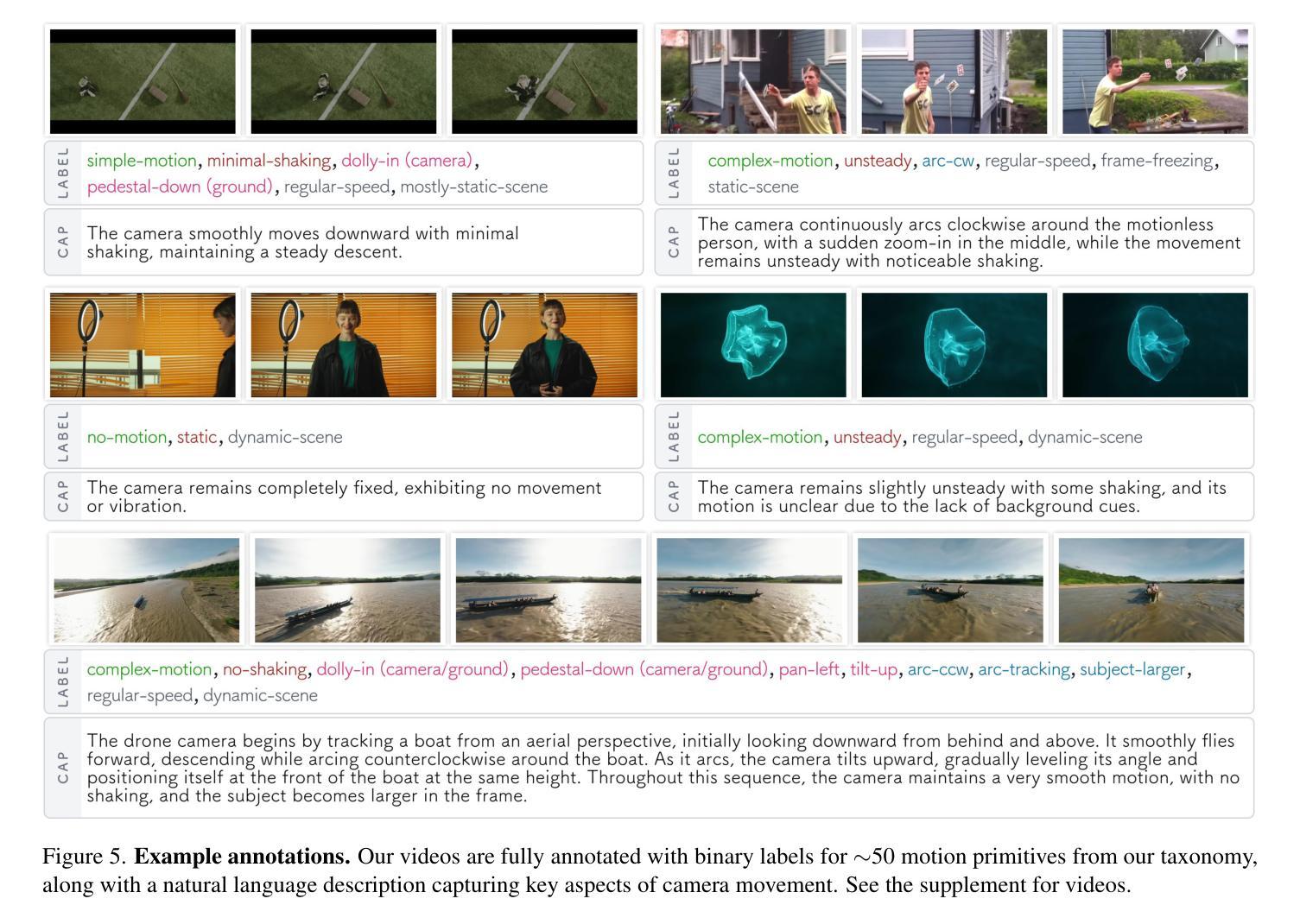
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like “follow” (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
我们推出了CameraBench,这是一个大规模数据集和评估标准,旨在评估和改进对摄像机运动的理解。CameraBench由大约3000个多样化的互联网视频组成,这些视频经过专家通过严格的多阶段质量控制过程进行标注。我们的贡献之一是与电影摄影师共同设计的摄像机运动原始数据的分类。例如,我们发现一些动作如“跟随”(或追踪)需要理解场景内容,如移动的主题。我们进行了一项大规模的人类研究来衡量人类标注性能,发现领域专业知识和基于教程的培训可以显著提高准确性。例如,新手可能会混淆缩放(内在变化)和向前平移(外在变化),但可以通过训练来区分这两者。使用CameraBench,我们评估了结构从运动(SfM)和视频语言模型(VLMs),发现SfM模型在捕捉依赖于场景内容的语义原始数据方面存在困难,而VLMs在捕捉需要精确估计轨迹的几何原始数据方面存在挑战。然后我们在CameraBench上对生成式VLM进行了微调,以实现两者的最佳结合,并展示了其应用,包括运动增强描述、视频问答和视频文本检索。我们希望我们的分类、基准测试和教程将推动未来对理解任何视频中的摄像机运动的努力。
论文及项目相关链接
PDF Project site: https://linzhiqiu.github.io/papers/camerabench/
Summary:我们介绍了CameraBench这一大型数据集和基准测试平台,旨在评估和改进相机动作识别。它包含来自网络的约3000个不同视频,经过专家严格的多阶段质量控制过程进行标注。我们与电影制片人合作设计了一种相机动作元素分类法,并发现某些动作如“跟踪”需要理解场景内容。通过大规模人类研究量化人类标注性能,发现领域知识和基于教程的培训可显著提高准确性。我们还评估了结构从运动(SfM)和视频语言模型(VLMs),发现SfM模型难以捕获依赖于场景内容的语义元素,而VLMs难以捕获需要精确估计轨迹的几何元素。我们对生成式VLM进行微调以在CameraBench上实现最佳性能,并展示了其运动增强字幕、视频问答和视频文本检索等应用。我们希望通过分类法、基准测试和教程推动未来对任何视频中的相机动作理解的研究努力。
Key Takeaways:
- CameraBench是一个大型数据集和基准测试平台,用于评估和改进相机动作理解。
- 数据集包含来自网络的多样化视频,经过专家严格标注。
- 与电影制片人合作设计了一种相机动作元素分类法。
- 发现了相机动作理解与场景内容之间的关联,例如“跟踪”动作需要理解场景内容。
- 通过大规模人类研究,发现领域知识和基于教程的培训能提高标注准确性。
- 评估了SfM和VLM模型在理解相机动作方面的表现,发现各自存在局限性。
- 通过微调生成式VLM模型,实现了在CameraBench上的最佳性能,并展示了其多种应用。
点此查看论文截图