⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-24 更新
TTRL: Test-Time Reinforcement Learning
Authors:Yuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, Bowen Zhou
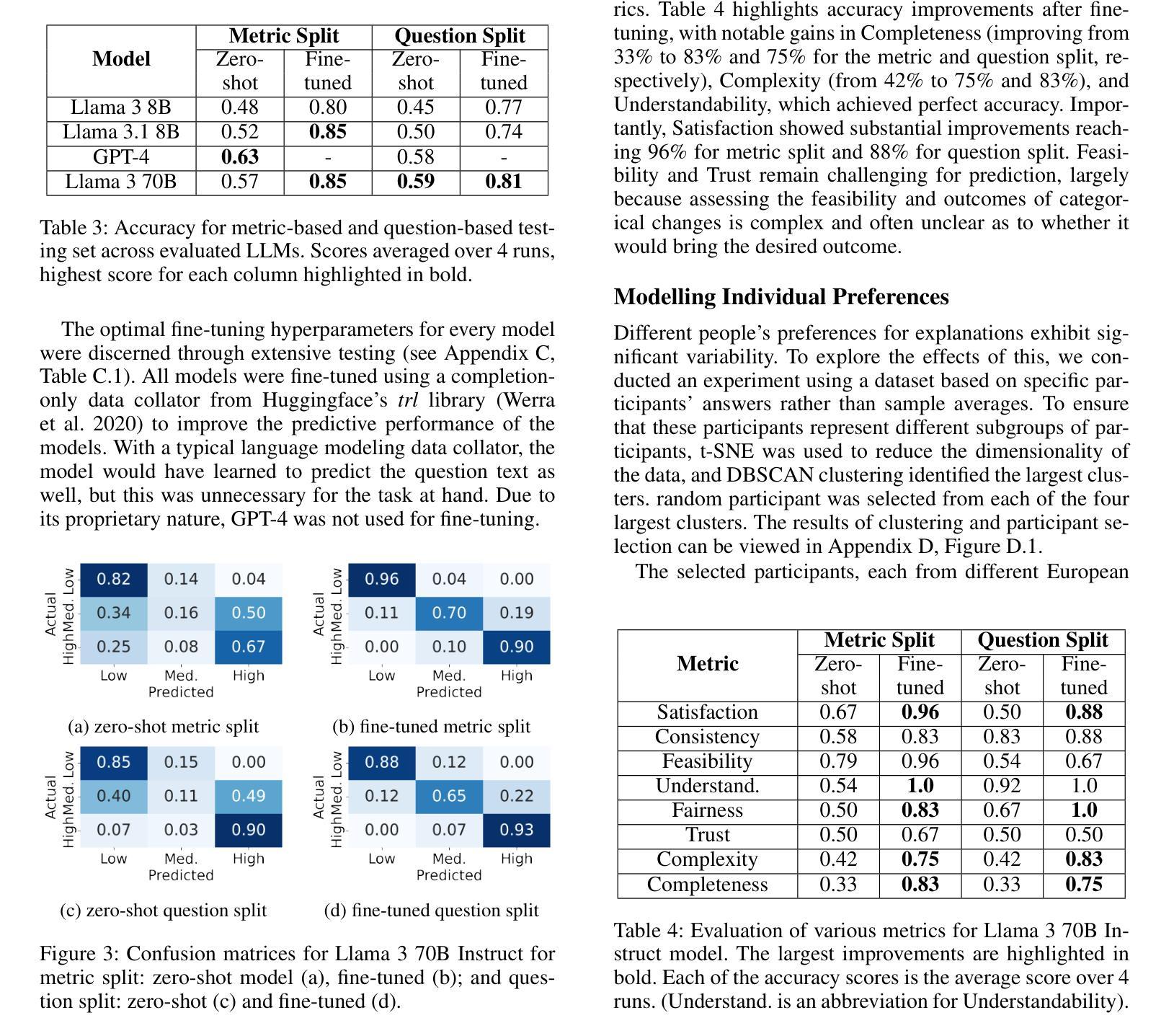
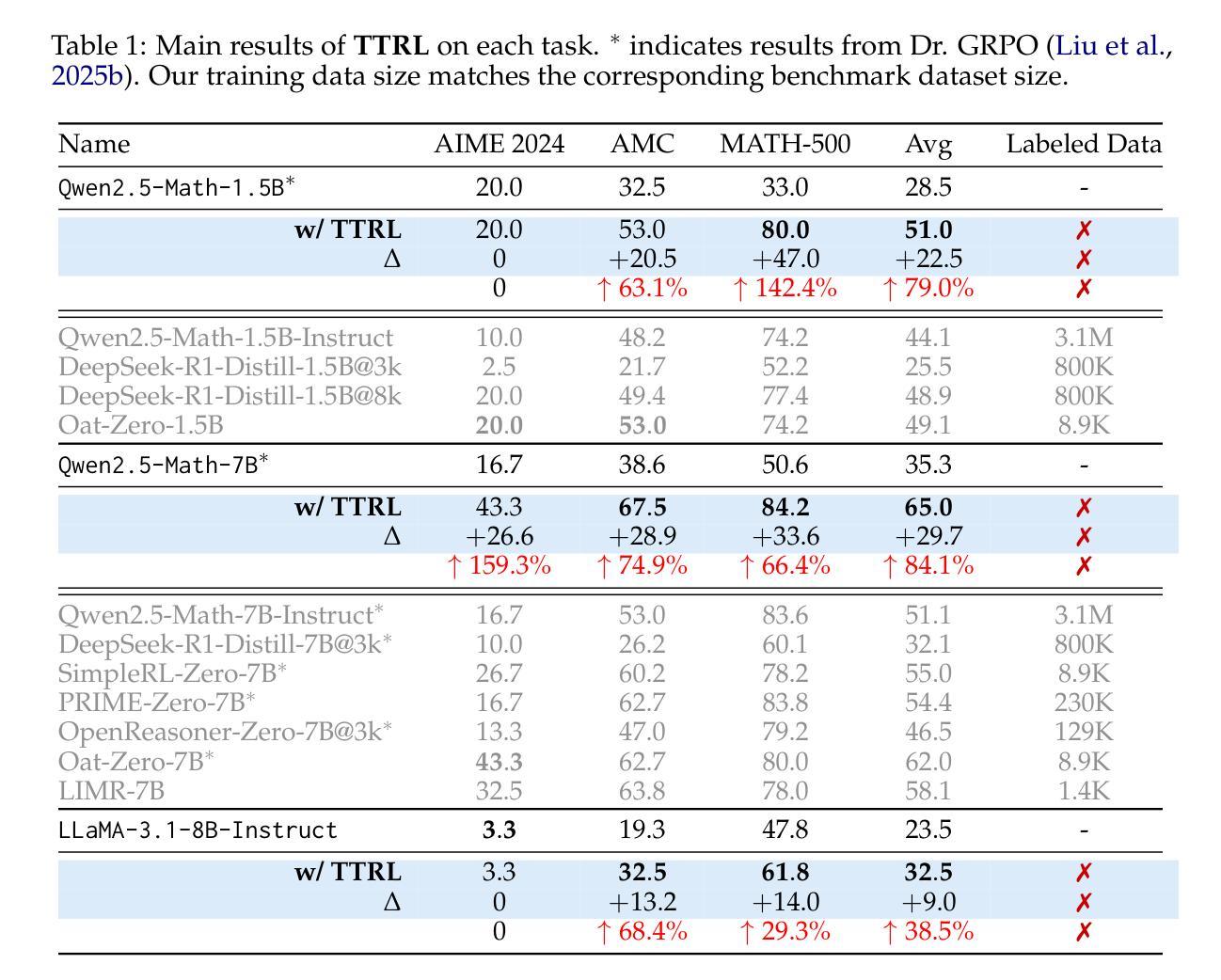
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 159% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the Maj@N metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks, and highlight TTRL’s potential for broader tasks and domains. GitHub: https://github.com/PRIME-RL/TTRL
本文探讨了在大语言模型(LLM)的推理任务中,在无明确标签数据上应用强化学习(RL)的情况。该问题的核心挑战在于在无法获取真实信息的情况下进行推理时的奖励估计。尽管这个设定似乎令人困惑,但我们发现测试时间缩放(TTS)中的常用方法,例如多数投票,可以产生出人意料的、适合驱动RL训练的有效奖励。在这项工作中,我们引入了测试时间强化学习(TTRL),这是一种使用无标签数据对LLM进行RL训练的新方法。TTRL通过利用预训练模型中的先验知识,实现了LLM的自我进化。我们的实验表明,TTRL在各种任务和模型上的表现持续提高。值得注意的是,在AIME 2024比赛中,TTRL将Qwen-2.5-Math-7B的pass@1性能提高了约159%,而这一切仅使用了无标签的测试数据。此外,尽管TTRL只受到Maj@N指标的监督,但其表现一直超过初始模型的上限,并接近直接在测试数据上使用真实标签训练的模型的性能。我们的实验结果表明TTRL在多种任务中的普遍有效性,并突出了其在更广泛的任务和领域中的潜力。GitHub:https://github.com/PRIME-RL/TTRL
论文及项目相关链接
Summary
强化学习在无标签数据的大型语言模型上的自我进化研究,利用先验信息改善性能,尤其对于测试时自适应进化表现出优势,并可能在不同任务领域中发挥潜力。
Key Takeaways
- 强化学习(RL)被用于在大型语言模型(LLM)中处理无明确标签的数据以执行推理任务。主要挑战在于在没有真实信息的情况下进行奖励估计。
- 测试时间尺度(TTS)的常见实践,如多数投票,可以生成用于驱动RL训练的有效奖励。
- 介绍了一种新型方法:测试时间强化学习(TTRL),用于在预训练模型中使用RL对LLM进行训练。此方法使得LLM能够进行自我进化。
- TTRL在各种任务上的表现持续提高,并显著提升了特定模型的性能。
- TTRL的性能超越了初始模型的性能上限,并接近在测试数据上直接训练的模型的性能,即使这些模型使用了真实标签作为监督。
- 实验结果证明了TTRL的一般有效性,并表明了其在不同任务领域的潜在应用前景。
点此查看论文截图

From Reflection to Perfection: Scaling Inference-Time Optimization for Text-to-Image Diffusion Models via Reflection Tuning
Authors:Le Zhuo, Liangbing Zhao, Sayak Paul, Yue Liao, Renrui Zhang, Yi Xin, Peng Gao, Mohamed Elhoseiny, Hongsheng Li
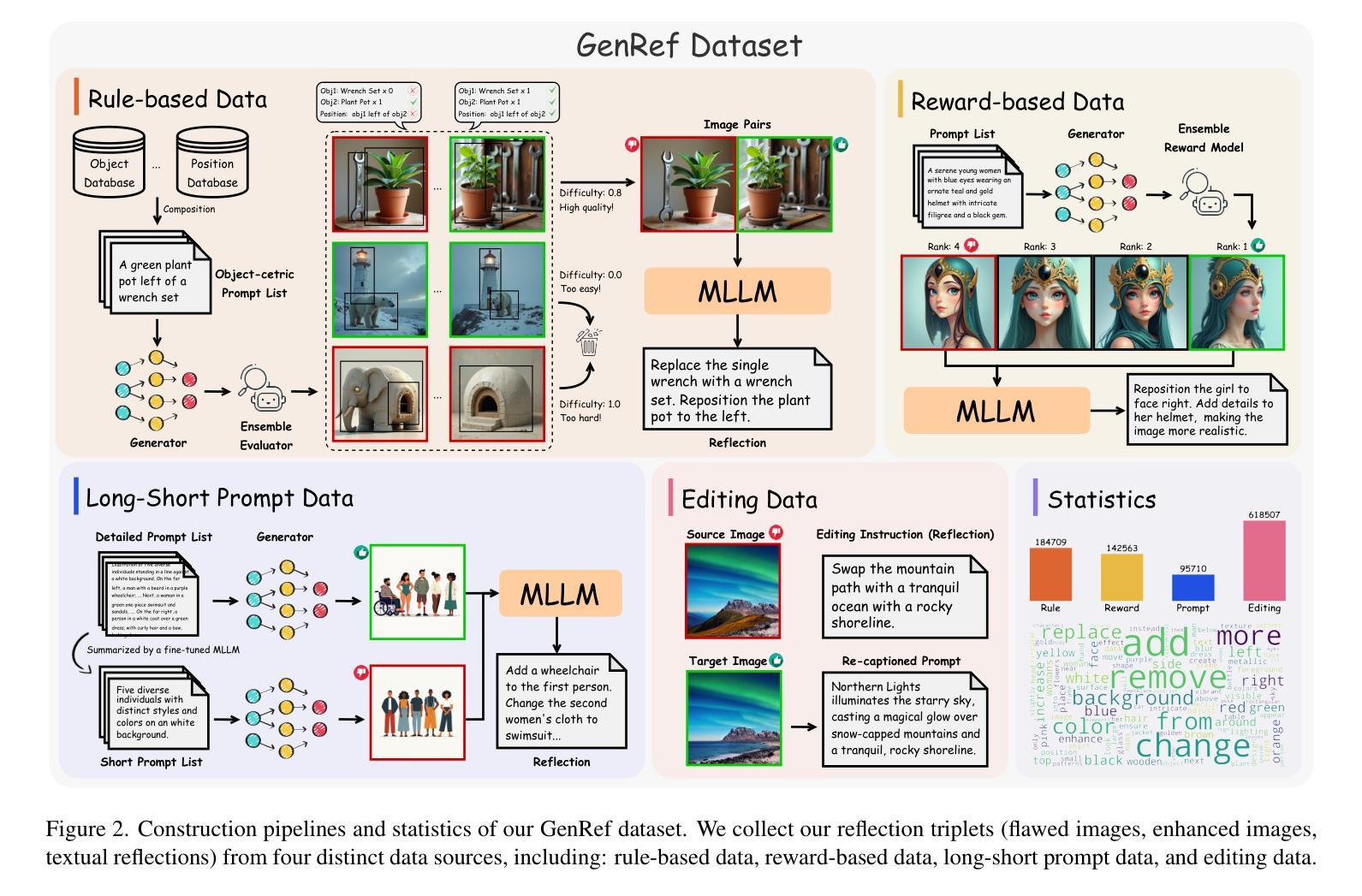
Recent text-to-image diffusion models achieve impressive visual quality through extensive scaling of training data and model parameters, yet they often struggle with complex scenes and fine-grained details. Inspired by the self-reflection capabilities emergent in large language models, we propose ReflectionFlow, an inference-time framework enabling diffusion models to iteratively reflect upon and refine their outputs. ReflectionFlow introduces three complementary inference-time scaling axes: (1) noise-level scaling to optimize latent initialization; (2) prompt-level scaling for precise semantic guidance; and most notably, (3) reflection-level scaling, which explicitly provides actionable reflections to iteratively assess and correct previous generations. To facilitate reflection-level scaling, we construct GenRef, a large-scale dataset comprising 1 million triplets, each containing a reflection, a flawed image, and an enhanced image. Leveraging this dataset, we efficiently perform reflection tuning on state-of-the-art diffusion transformer, FLUX.1-dev, by jointly modeling multimodal inputs within a unified framework. Experimental results show that ReflectionFlow significantly outperforms naive noise-level scaling methods, offering a scalable and compute-efficient solution toward higher-quality image synthesis on challenging tasks.
最近出现的文本到图像扩散模型通过大规模的训练数据和模型参数扩展,实现了令人印象深刻的视觉质量,但它们通常对于复杂场景和精细细节的处理能力有限。受大型语言模型中自我反思能力启发,我们提出了ReflectionFlow,这是一个推理时间框架,能够使扩散模型对其输出进行迭代反思和改进。ReflectionFlow引入了三个互补的推理时间尺度轴:(1)噪声级别缩放以优化潜在初始化;(2)提示级别缩放以实现精确语义指导;最重要的是(3)反思级别缩放,它明确提供了可操作的反思来迭代评估和纠正之前的生成。为了促进反思级别缩放,我们构建了GenRef数据集,这是一个包含百万个三元组的大规模数据集,每个三元组都包含一次反思、一个缺陷图像和一个增强图像。利用此数据集,我们在统一框架内对最先进的扩散变压器FLUX.1-dev进行多模式输入的联合建模,有效地执行了反射调优。实验结果表明,ReflectionFlow显著优于简单的噪声级别缩放方法,为挑战性任务的高质量图像合成提供了可扩展和计算高效的解决方案。
论文及项目相关链接
PDF All code, checkpoints, and datasets are available at \url{https://diffusion-cot.github.io/reflection2perfection}
Summary
扩散模型已广泛运用于文本到图像的转换中,尽管其在训练数据和模型参数上表现出优异的视觉效果,但对于复杂场景和精细细节仍有局限。鉴于此,我们提出了ReflectionFlow框架,旨在赋予扩散模型推理过程中的自我反思能力。通过引入三条互补的推理尺度,如噪声水平、提示水平和反思水平缩放,并结合大型数据集GenRef进行训练和优化,ReflectionFlow显著提高了图像合成的质量。该框架在挑战任务上表现出超越传统噪声水平缩放方法的优势,为高质量图像合成提供了可扩展且计算高效的解决方案。
Key Takeaways
- 扩散模型广泛应用于文本到图像的转换中,但处理复杂场景和精细细节时存在局限。
- ReflectionFlow框架旨在赋予扩散模型推理过程中的自我反思能力。
- ReflectionFlow引入三条互补的推理尺度:噪声水平缩放、提示水平缩放和反思水平缩放。
- GenRef数据集用于促进反思水平的训练和优化。
- ReflectionFlow结合大型数据集进行训练,能够显著提高图像合成的质量。
- 该框架在挑战任务上的表现超越传统噪声水平缩放方法。
点此查看论文截图


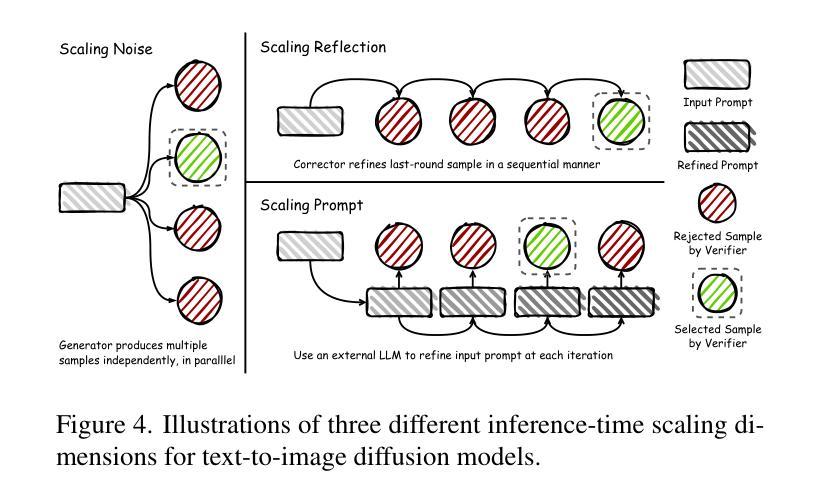
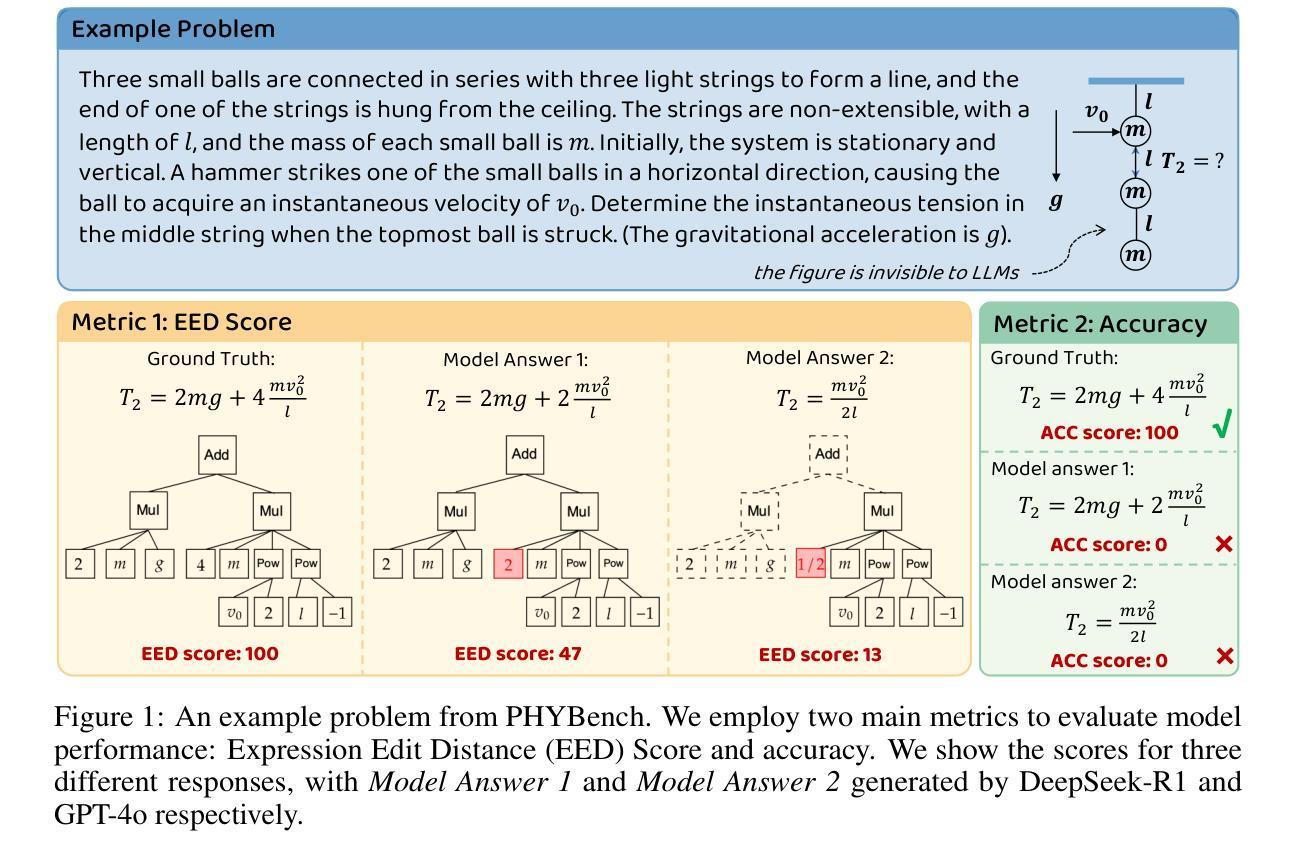
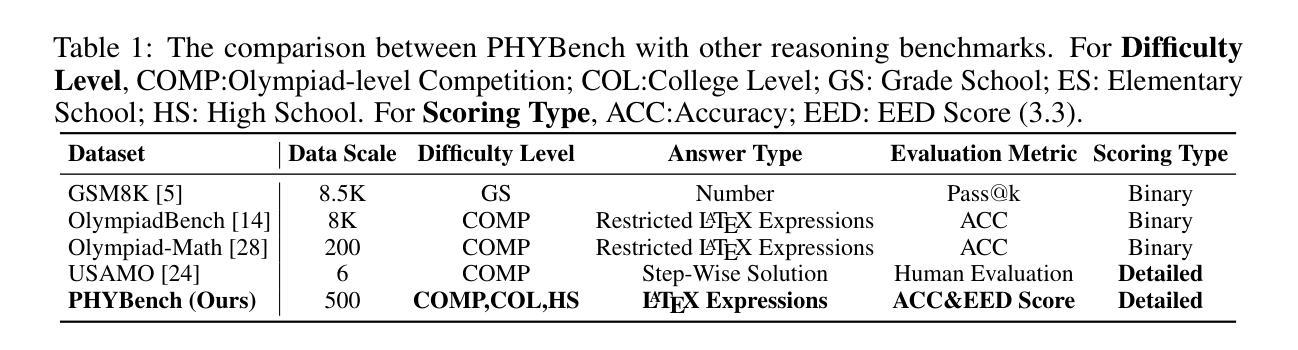
PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Authors:Shi Qiu, Shaoyang Guo, Zhuo-Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yixuan Yin, Haoxu Zhang, Yi Hu, Chenyang Wang, Chencheng Tang, Haoling Chang, Qi Liu, Ziheng Zhou, Tianyu Zhang, Jingtian Zhang, Zhangyi Liu, Minghao Li, Yuku Zhang, Boxuan Jing, Xianqi Yin, Yutong Ren, Zizhuo Fu, Weike Wang, Xudong Tian, Anqi Lv, Laifu Man, Jianxiang Li, Feiyu Tao, Qihua Sun, Zhou Liang, Yushu Mu, Zhongxuan Li, Jing-Jun Zhang, Shutao Zhang, Xiaotian Li, Xingqi Xia, Jiawei Lin, Zheyu Shen, Jiahang Chen, Qiuhao Xiong, Binran Wang, Fengyuan Wang, Ziyang Ni, Bohan Zhang, Fan Cui, Changkun Shao, Qing-Hong Cao, Ming-xing Luo, Muhan Zhang, Hua Xing Zhu
We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
我们介绍了PHYBench,这是一个为评估大型语言模型(LLM)在物理上下文中的推理能力而设计的新型高质量基准测试。PHYBench由500个精心策划的物理问题组成,这些问题基于真实世界的物理场景设计,旨在评估模型理解和推理现实物理过程的能力。该基准测试包括力学、电磁学、热力学、光学、现代物理学和高级物理学,难度层次从高中练习到大学问题和物理奥林匹克挑战都有所涵盖。此外,我们提出了表达式编辑距离(EED)分数,这是一种基于数学表达式之间编辑距离的新型评估指标,它能有效地捕捉模型推理过程和结果之间的差异,超越了传统的二元评分方法。我们在PHYBench上评估了各种LLM,并将他们的性能与人类专家进行比较。我们的结果表明,即使是最先进的推理模型也与人类专家存在显著差距,这凸显了它们在复杂物理推理场景中的局限性以及改进的必要性。我们的基准测试结果和数据集可在https://phybench-official.github.io/phybench-demo/公开访问。
论文及项目相关链接
PDF 21 pages ,8 figures, 4 tables
Summary
PHYBench是一个为评估大型语言模型在物理情境中的推理能力而设计的高质量基准测试。它包含500个精心挑选的物理问题,涵盖从高中到大学水平的物理内容,旨在评估模型对真实物理过程的理解和推理能力。此外,还提出了基于数学表达式编辑距离的新型评估指标——Expression Edit Distance (EED) Score,以更有效地捕捉模型推理过程和结果的差异。评估结果揭示,即使是最先进的推理模型,在复杂物理推理场景中仍显著落后于人类专家,这强调了模型的局限性及改进的必要性。
Key Takeaways
- PHYBench是一个为评估LLM在物理情境中的推理能力而设计的新型基准测试。
- 它包含500个覆盖多个物理领域的精心挑选的问题。
- PHYBench旨在评估模型对从高中到大学水平的真实物理过程的理解和推理能力。
- 提出了基于数学表达式编辑距离的EED Score评估指标。
- EED Score能有效捕捉模型推理过程和结果的差异。
- 评估结果显示,即使是先进的LLM在复杂物理推理场景中仍显著落后于人类专家。
点此查看论文截图

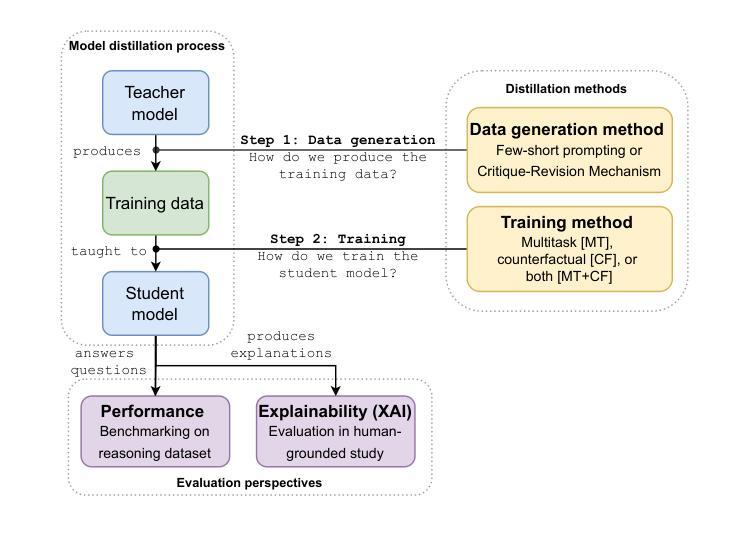
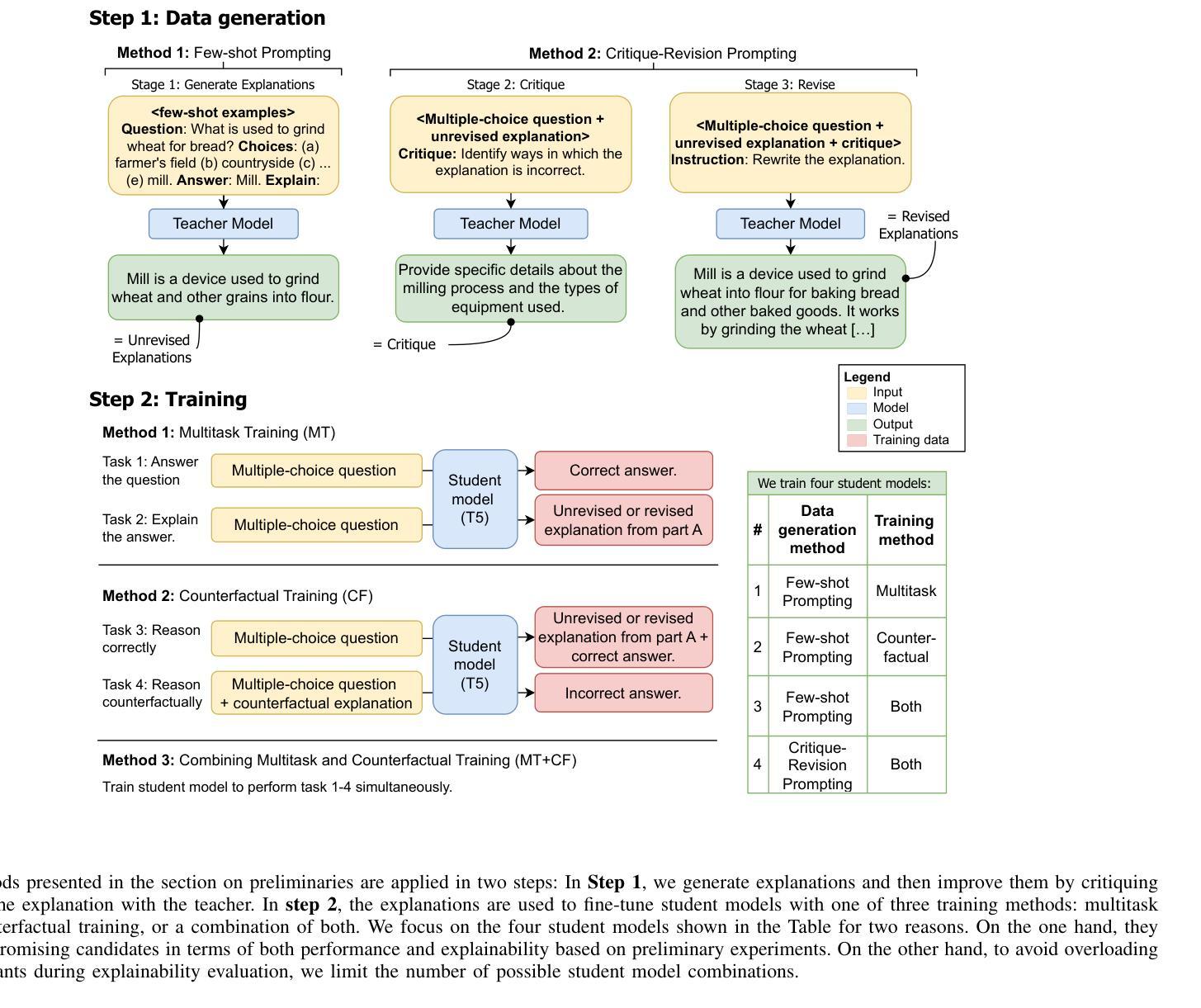
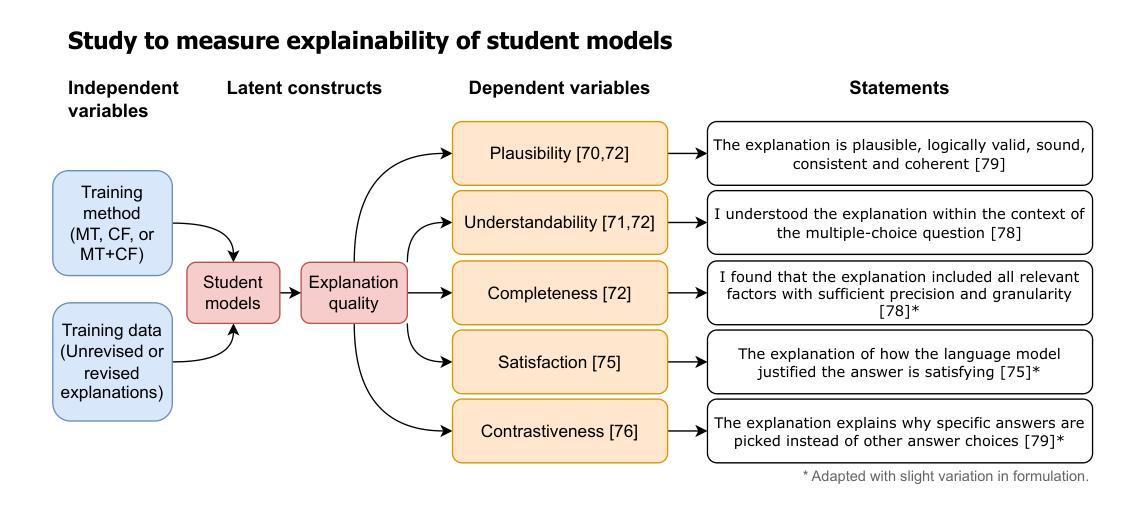
Honey, I Shrunk the Language Model: Impact of Knowledge Distillation Methods on Performance and Explainability
Authors:Daniel Hendriks, Philipp Spitzer, Niklas Kühl, Gerhard Satzger
Artificial Intelligence (AI) has increasingly influenced modern society, recently in particular through significant advancements in Large Language Models (LLMs). However, high computational and storage demands of LLMs still limit their deployment in resource-constrained environments. Knowledge distillation addresses this challenge by training a small student model from a larger teacher model. Previous research has introduced several distillation methods for both generating training data and for training the student model. Despite their relevance, the effects of state-of-the-art distillation methods on model performance and explainability have not been thoroughly investigated and compared. In this work, we enlarge the set of available methods by applying critique-revision prompting to distillation for data generation and by synthesizing existing methods for training. For these methods, we provide a systematic comparison based on the widely used Commonsense Question-Answering (CQA) dataset. While we measure performance via student model accuracy, we employ a human-grounded study to evaluate explainability. We contribute new distillation methods and their comparison in terms of both performance and explainability. This should further advance the distillation of small language models and, thus, contribute to broader applicability and faster diffusion of LLM technology.
人工智能(AI)对现代社会的影响越来越大,最近特别是通过自然语言处理领域的大型语言模型(LLM)的重大进步。然而,大型语言模型的高计算和存储需求仍然限制了它们在资源受限环境中的部署。知识蒸馏通过从一个较大的教师模型训练一个小的学生模型来解决这一挑战。之前的研究已经介绍了生成训练数据和训练学生模型的几种蒸馏方法。尽管它们很重要,但最先进的蒸馏方法对模型性能和可解释性的影响尚未得到全面和彻底的调查与比较。在这项工作中,我们通过将批判修订提示应用于数据生成中的蒸馏,并通过合成现有方法进行训练,扩大了可用方法的范围。对于这些方法,我们基于广泛使用的常识问答(CQA)数据集进行了系统的比较。虽然我们通过学生模型的准确性来衡量性能,但我们采用了基于人类的研究来评估可解释性。我们为新的蒸馏方法及其性能和可解释性的比较做出了贡献。这将进一步推动小型语言模型的蒸馏技术的发展,从而为LLM技术的更广泛应用和更快传播做出贡献。
论文及项目相关链接
Summary
人工智能(AI)对现代社会的影响日益显著,特别是在大型语言模型(LLM)方面取得了重大进展。然而,LLM的高计算需求和存储需求仍然限制了其在资源受限环境中的部署。知识蒸馏技术通过训练小型的学生模型来模仿大型教师模型的性能,解决了这一挑战。本研究引入了评论修订提示等方法进行数据生成和训练学生模型的蒸馏过程。我们在广泛使用的常识问答(CQA)数据集上对这些方法进行了系统比较。通过学生模型的准确性衡量性能,并通过基于人类的研究来评估可解释性。本研究为小型语言模型提供了新的蒸馏方法和比较结果,进一步推动了其在性能和可解释性方面的应用,为LLM技术的广泛应用和快速扩散做出贡献。
Key Takeaways
- 人工智能(AI)通过大型语言模型(LLM)对现代社会产生了深远影响,但资源受限环境的部署仍然面临挑战。
- 知识蒸馏技术是一种解决策略,通过训练小型学生模型来模仿大型教师模型的性能。
- 本研究引入了评论修订提示等方法进行数据生成和训练学生模型的蒸馏过程。
- 在常识问答(CQA)数据集上进行了系统比较,通过学生模型的准确性衡量性能。
- 除了性能评估,还通过基于人类的研究来评估模型的可解释性。
- 本研究提供了新的蒸馏方法和比较结果,有助于推动小型语言模型的应用和发展。
点此查看论文截图

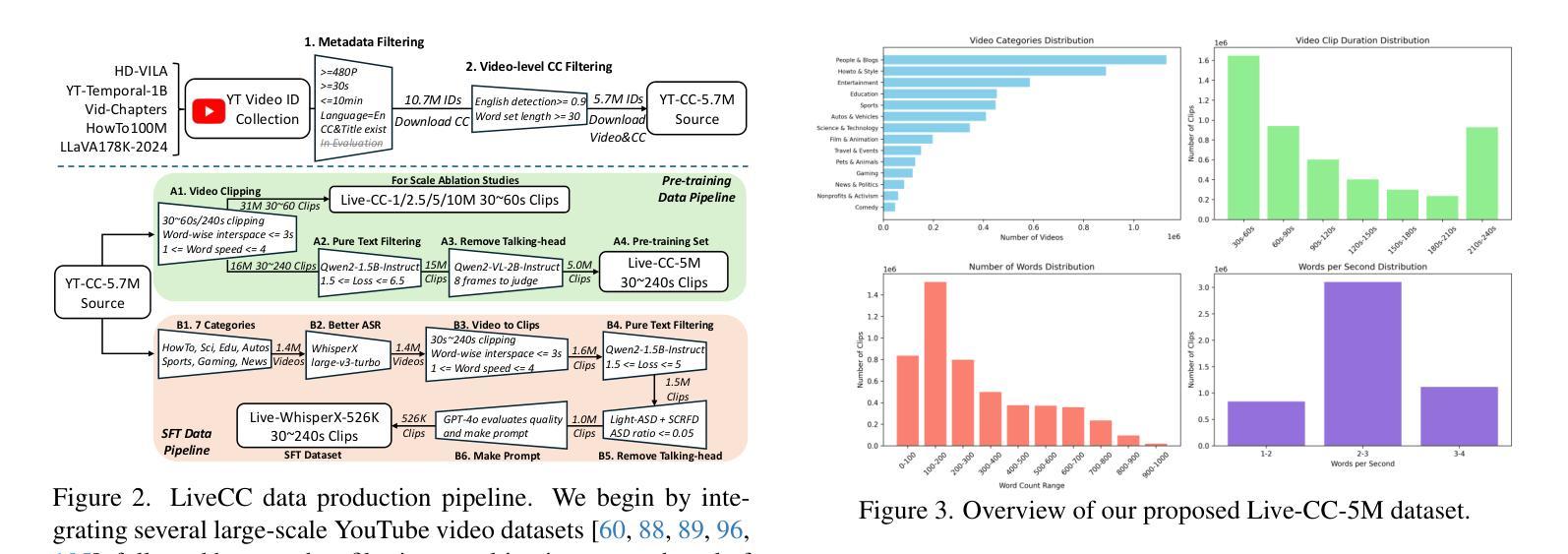
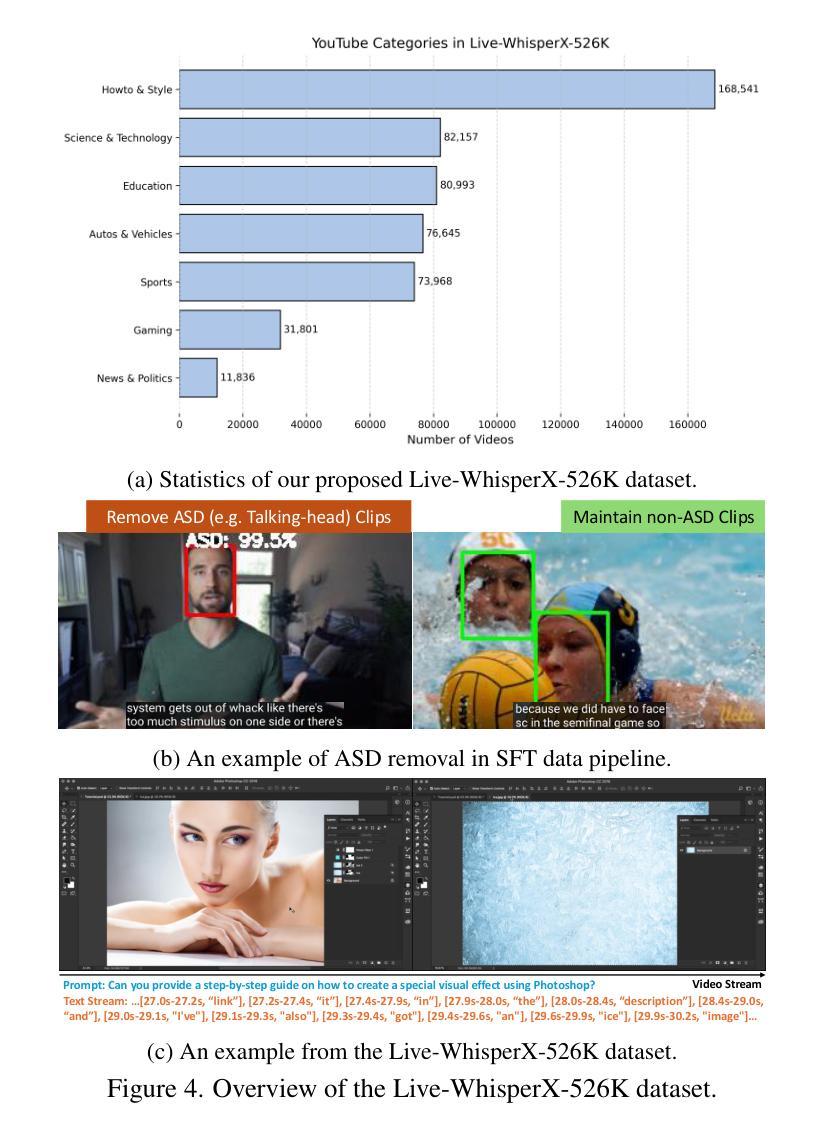
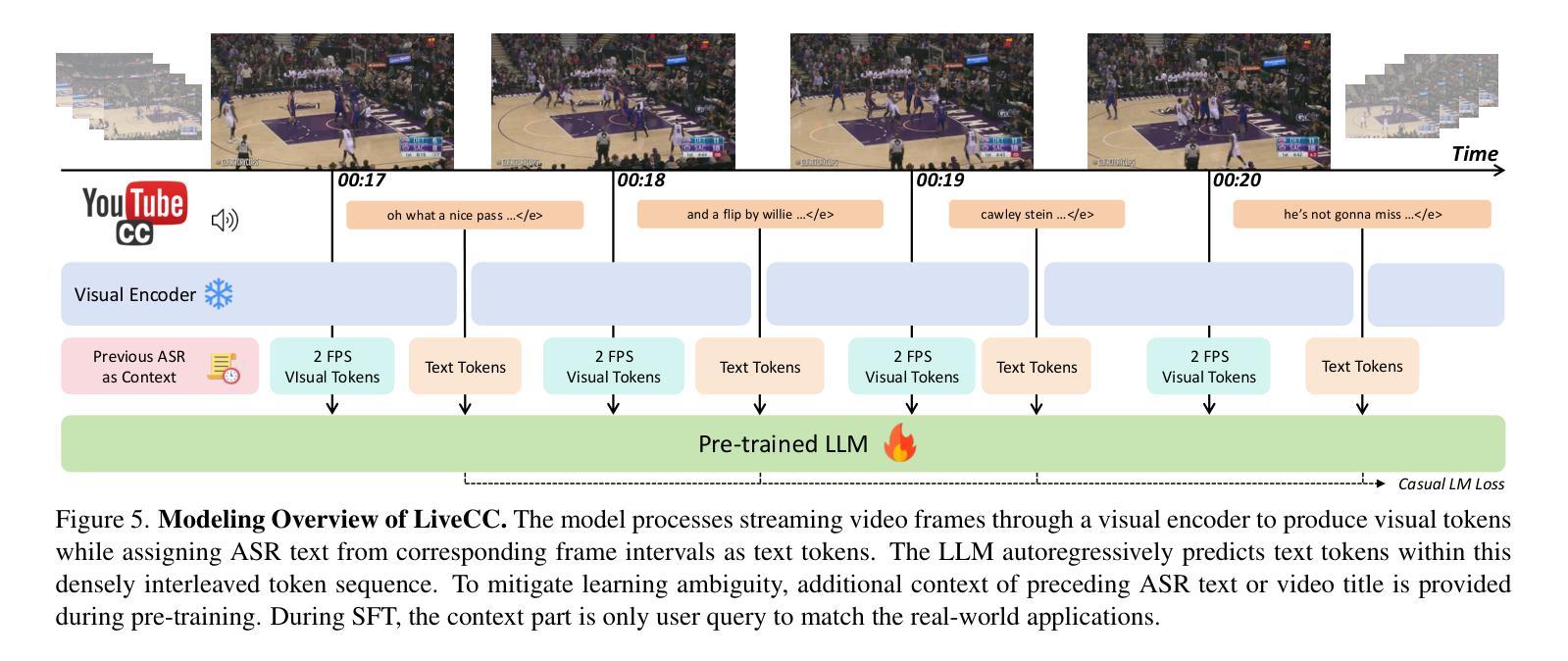
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
Authors:Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, Mike Zheng Shou
Recent video large language models (Video LLMs) often depend on costly human annotations or proprietary model APIs (e.g., GPT-4o) to produce training data, which limits their training at scale. In this paper, we explore large-scale training for Video LLM with cheap automatic speech recognition (ASR) transcripts. Specifically, we propose a novel streaming training approach that densely interleaves the ASR words and video frames according to their timestamps. Compared to previous studies in vision-language representation with ASR, our method naturally fits the streaming characteristics of ASR, thus enabling the model to learn temporally-aligned, fine-grained vision-language modeling. To support the training algorithm, we introduce a data production pipeline to process YouTube videos and their closed captions (CC, same as ASR), resulting in Live-CC-5M dataset for pre-training and Live-WhisperX-526K dataset for high-quality supervised fine-tuning (SFT). Remarkably, even without SFT, the ASR-only pre-trained LiveCC-7B-Base model demonstrates competitive general video QA performance and exhibits a new capability in real-time video commentary. To evaluate this, we carefully design a new LiveSports-3K benchmark, using LLM-as-a-judge to measure the free-form commentary. Experiments show our final LiveCC-7B-Instruct model can surpass advanced 72B models (Qwen2.5-VL-72B-Instruct, LLaVA-Video-72B) in commentary quality even working in a real-time mode. Meanwhile, it achieves state-of-the-art results at the 7B/8B scale on popular video QA benchmarks such as VideoMME and OVOBench, demonstrating the broad generalizability of our approach. All resources of this paper have been released at https://showlab.github.io/livecc.
最近的视频大型语言模型(Video LLMs)通常依赖于昂贵的人工标注或专有模型API(例如GPT-4o)来生成训练数据,这限制了其大规模训练。在本文中,我们探索使用廉价的自动语音识别(ASR)转录数据对Video LLM进行大规模训练。具体来说,我们提出了一种新的流式训练方法,该方法根据时间戳紧密地交织ASR单词和视频帧。与以往使用ASR的视听语言表示研究相比,我们的方法自然地适应了ASR的流式特性,从而使模型能够学习时间对齐的、精细的视听语言建模。为了支持训练算法,我们引入了数据生产管道来处理YouTube视频及其关闭字幕(CC,与ASR相同),从而产生了用于预训练的Live-CC-5M数据集和用于高质量监督精细调整(SFT)的Live-Whisperx-526K数据集。值得注意的是,即使没有SFT,仅使用ASR预训练的LiveCC-7B-Base模型也表现出有竞争力的通用视频问答性能,并展现出实时视频评论的新能力。为了评估这一点,我们精心设计了新的LiveSports-3K基准测试,利用LLM-as-a-judge来衡量自由形式的评论。实验表明,我们最终的LiveCC-7B-Instruct模型即使在实时模式下也能在评论质量上超越先进的72B模型(Qwen2.5-VL-72B-Instruct,LLaVA-Video-72B)。同时,它在流行的视频QA基准测试(如VideoMME和OVOBench)上达到了7B/8B规模的最佳结果,证明了我们的方法具有广泛的通用性。本论文的所有资源已发布在https://showlab.github.io/livecc。
论文及项目相关链接
PDF CVPR 2025. If any references are missing, please contact joyachen@u.nus.edu
摘要
本文探索了利用低成本自动语音识别(ASR)转录数据对视频大型语言模型(Video LLM)进行大规模训练的方法。提出了一种新的流式训练方式,紧密地将ASR词语和视频帧按照时间戳交织在一起。相比以往的研究,该方法自然适合ASR的流式特性,使模型能学习时间对齐的、精细的视语言建模。为支持训练算法,介绍了处理YouTube视频及其封闭字幕(CC,与ASR相同)的数据生产管道,形成了用于预训练的Live-CC-5M数据集和用于高质量监督精细调整的Live-Whisperx-526K数据集。仅使用ASR预训练的LiveCC-7B-Base模型,在无需精细调整的情况下,就展现出有竞争力的通用视频问答性能,并展现出实时视频评论的新能力。通过新设计的LiveSports-3K基准测试,以LLM作为法官来衡量自由形式的评论,实验显示,最后的LiveCC-7B-Instruct模型即使在实时模式下,也能在评论质量上超越先进的72B模型(Qwen2.5-VL-72B-Instruct,LLaVA-Video-72B),同时在流行的视频QA基准测试(如VideoMME和OVOBench)上达到最佳结果,显示出方法的广泛通用性。
关键见解
- Video LLM训练受限于成本高昂的人类注释和专有模型API。
- 提出使用低成本ASR转录数据对Video LLM进行大规模训练的方法。
- 新型流式训练方式能学习时间对齐的、精细的视语言建模。
- 引入数据处理管道,形成用于预训练和精细调整的特定数据集。
- 仅使用ASR预训练的模型展现出竞争力强的视频问答和实时视频评论能力。
- 在实时模式下,评论质量超越先进的大型模型。
点此查看论文截图

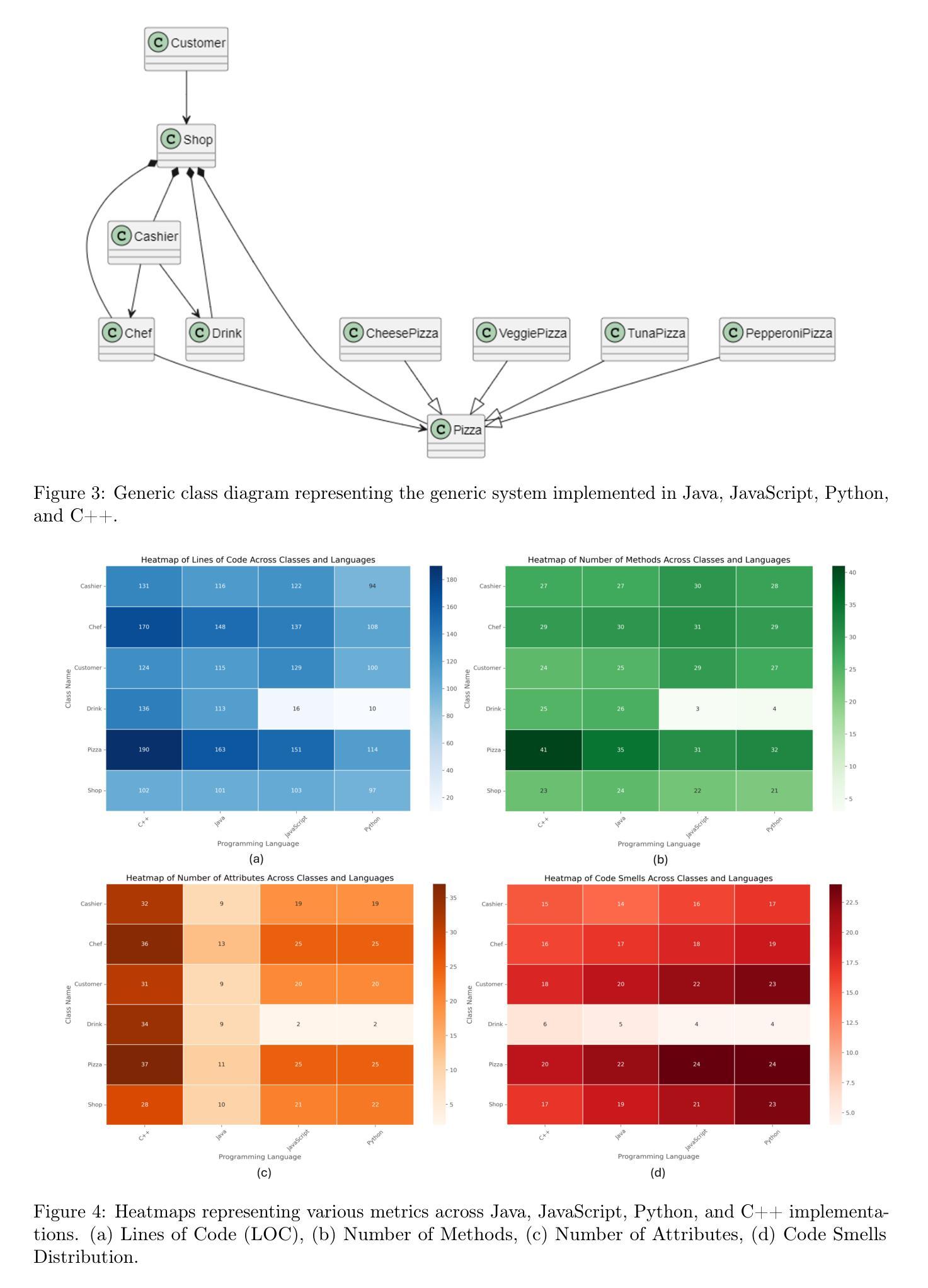
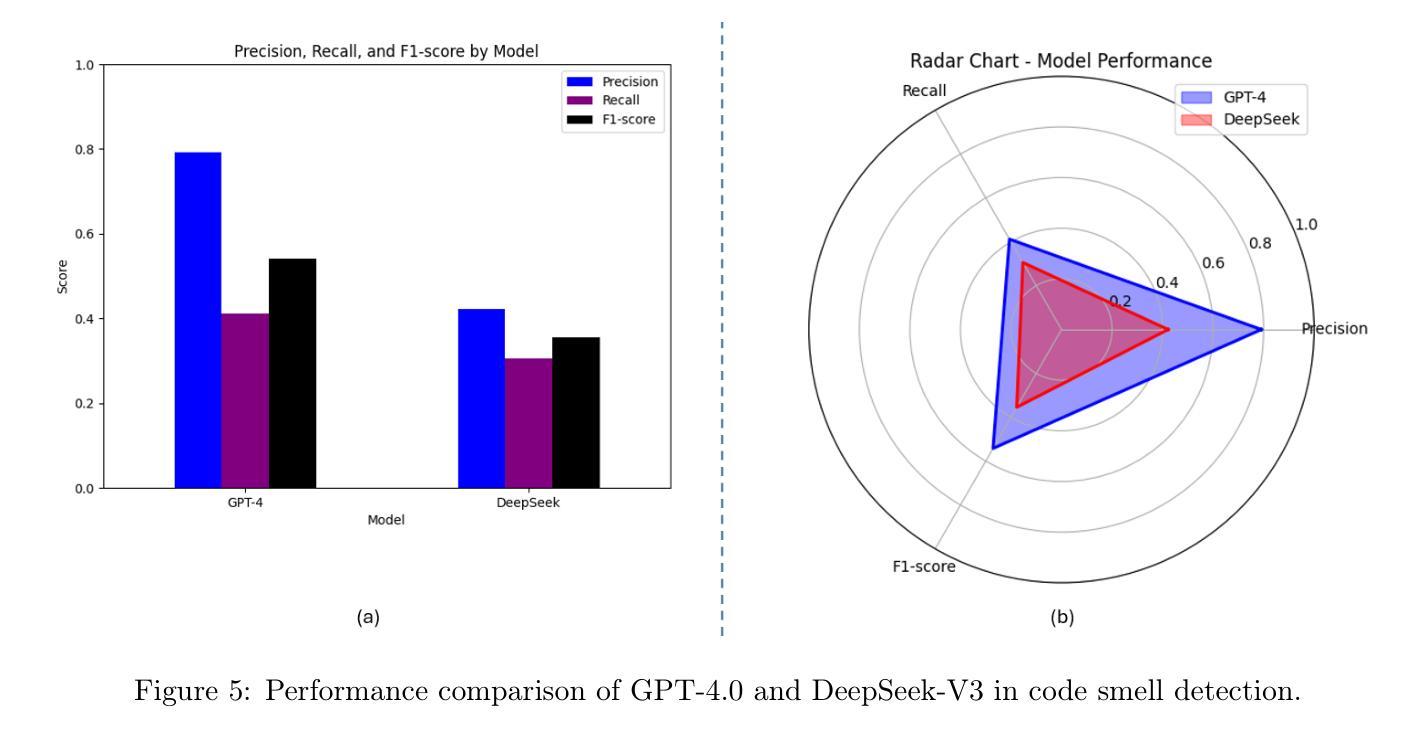
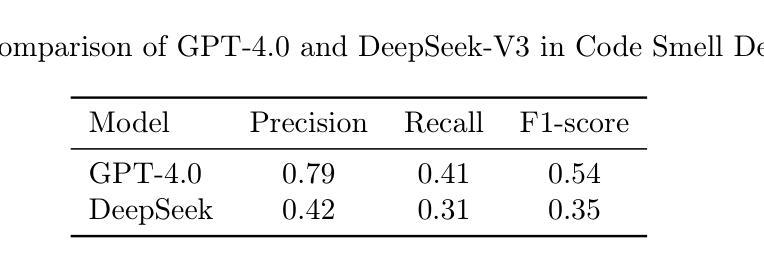
Benchmarking LLM for Code Smells Detection: OpenAI GPT-4.0 vs DeepSeek-V3
Authors:Ahmed R. Sadik, Siddhata Govind
Determining the most effective Large Language Model for code smell detection presents a complex challenge. This study introduces a structured methodology and evaluation matrix to tackle this issue, leveraging a curated dataset of code samples consistently annotated with known smells. The dataset spans four prominent programming languages Java, Python, JavaScript, and C++; allowing for cross language comparison. We benchmark two state of the art LLMs, OpenAI GPT 4.0 and DeepSeek-V3, using precision, recall, and F1 score as evaluation metrics. Our analysis covers three levels of detail: overall performance, category level performance, and individual code smell type performance. Additionally, we explore cost effectiveness by comparing the token based detection approach of GPT 4.0 with the pattern-matching techniques employed by DeepSeek V3. The study also includes a cost analysis relative to traditional static analysis tools such as SonarQube. The findings offer valuable guidance for practitioners in selecting an efficient, cost effective solution for automated code smell detection
确定用于代码异味检测的最有效的大型语言模型是一个复杂的挑战。本研究引入了一种结构化的方法和评估矩阵来解决这个问题,利用了一组经过整理的代码样本,这些样本始终与已知的异味进行标注。该数据集涵盖了四种流行的编程语言:Java、Python、JavaScript和C++,可实现跨语言比较。我们使用精确度、召回率和F1分数作为评价指标,对两种最先进的大型语言模型OpenAI GPT 4.0和DeepSeek-V3进行基准测试。我们的分析涵盖了三个层次的细节:整体性能、类别性能以及单个代码异味类型性能。此外,我们还通过比较GPT 4.0的基于令牌检测方法与DeepSeek V3采用的模式匹配技术,探讨了成本效益。该研究还包括相对于传统静态分析工具(如SonarQube)的成本分析。研究结果为从业者在选择高效、经济的自动化代码异味检测解决方案方面提供了宝贵的指导。
论文及项目相关链接
总结
本研究针对代码异味检测的最有效大型语言模型选择问题,提出了一种结构化方法和评估矩阵。研究使用了一种经过整理的包含已知异味注释的代码样本数据集,涵盖了Java、Python、JavaScript和C++四种主流编程语言,便于跨语言比较。通过对OpenAI GPT 4.0和DeepSeek-V3两种先进的大型语言模型进行基准测试,以精确度、召回率和F1分数作为评估指标,本研究全面分析了两种模型在总体性能、分类性能以及单个代码异味类型性能方面的表现。此外,研究还比较了GPT 4.0的基于令牌检测方法与DeepSeek V3的模式匹配技术,并进行了与传统静态分析工具如SonarQube的成本分析。研究为从业者选择高效且经济的自动化代码异味检测解决方案提供了宝贵指导。
要点
- 本研究引入了一种针对大型语言模型在代码异味检测方面性能评估的结构化方法和评估矩阵。
- 研究使用了包含多种编程语言的代码样本数据集,并进行了跨语言比较。
- 研究对OpenAI GPT 4.0和DeepSeek-V3两种大型语言模型进行了基准测试,涵盖了总体、分类和单个代码异味类型三个层面的性能分析。
- 研究比较了GPT 4.0的基于令牌检测方法与DeepSeek V3的模式匹配技术的成本效益。
- 研究还进行了与传统静态分析工具的成本分析对比。
- 研究结果提供了实践者如何选择有效且经济的自动化代码异味检测解决方案的指导性建议。
点此查看论文截图


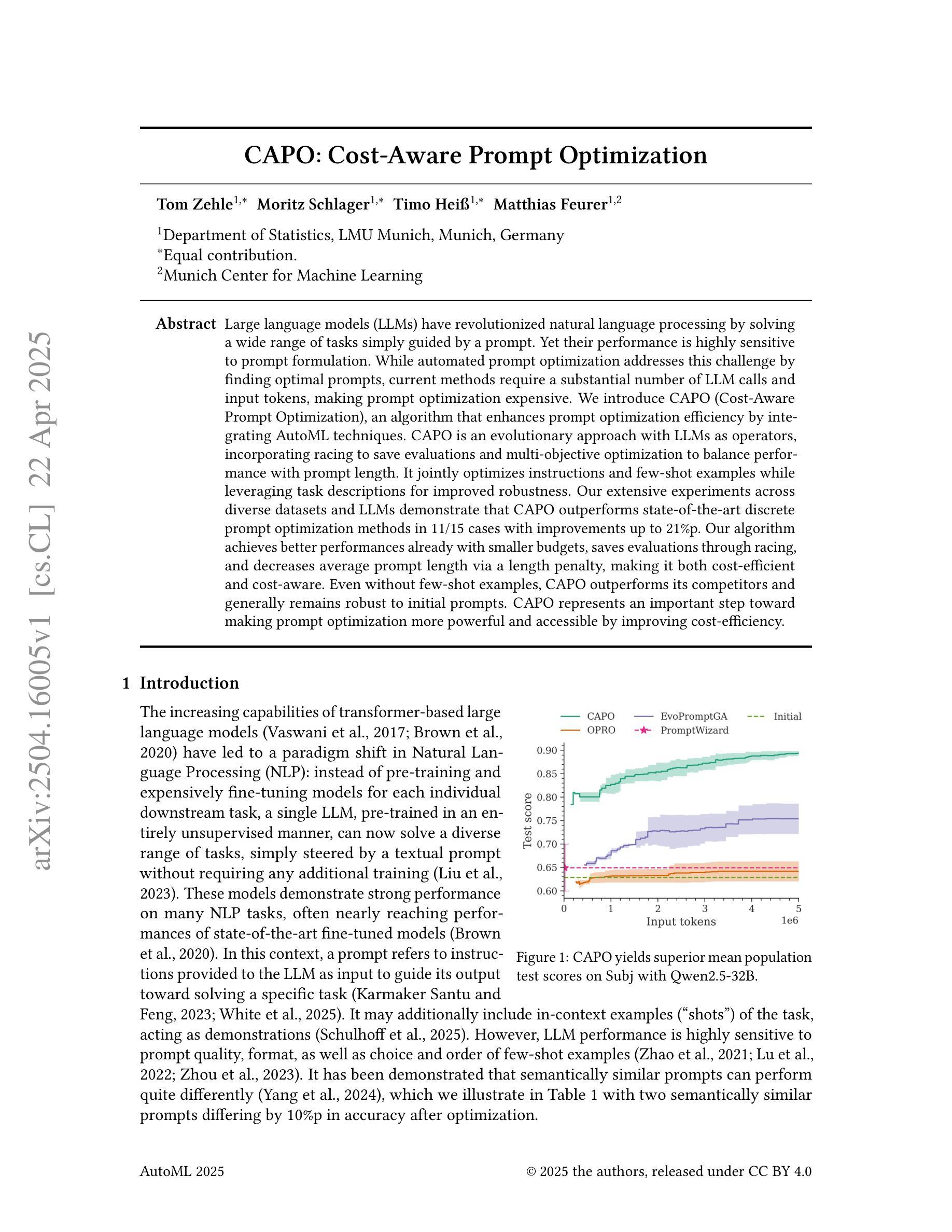
CAPO: Cost-Aware Prompt Optimization
Authors:Tom Zehle, Moritz Schlager, Timo Heiß, Matthias Feurer
Large language models (LLMs) have revolutionized natural language processing by solving a wide range of tasks simply guided by a prompt. Yet their performance is highly sensitive to prompt formulation. While automated prompt optimization addresses this challenge by finding optimal prompts, current methods require a substantial number of LLM calls and input tokens, making prompt optimization expensive. We introduce CAPO (Cost-Aware Prompt Optimization), an algorithm that enhances prompt optimization efficiency by integrating AutoML techniques. CAPO is an evolutionary approach with LLMs as operators, incorporating racing to save evaluations and multi-objective optimization to balance performance with prompt length. It jointly optimizes instructions and few-shot examples while leveraging task descriptions for improved robustness. Our extensive experiments across diverse datasets and LLMs demonstrate that CAPO outperforms state-of-the-art discrete prompt optimization methods in 11/15 cases with improvements up to 21%p. Our algorithm achieves better performances already with smaller budgets, saves evaluations through racing, and decreases average prompt length via a length penalty, making it both cost-efficient and cost-aware. Even without few-shot examples, CAPO outperforms its competitors and generally remains robust to initial prompts. CAPO represents an important step toward making prompt optimization more powerful and accessible by improving cost-efficiency.
大型语言模型(LLM)通过简单的提示指导解决了广泛的任务,从而革新了自然语言处理。然而,它们的性能对提示的构思非常敏感。虽然自动提示优化可以通过找到最佳提示来解决这一挑战,但当前的方法需要大量的LLM调用和输入令牌,使得提示优化成本高昂。我们引入了CAPO(基于成本的提示优化),这是一种通过集成AutoML技术提高提示优化效率的算法。CAPO是一种进化方法,以LLM作为操作员,结合了竞赛以节省评估和基于性能的多目标优化来平衡提示长度。它同时优化指令和少量示例,并利用任务描述来提高稳健性。我们在各种数据集和LLM上进行的广泛实验表明,在15个案例中,CAPO在11个案例中的表现优于最先进的离散提示优化方法,改进幅度高达21%。我们的算法在较小的预算下就取得了更好的性能,通过竞赛节省了评估工作,并通过长度惩罚减少了平均提示长度,使其既经济又注重成本。即使没有少量示例,CAPO也能超越竞争对手,并且对初始提示保持稳健。CAPO朝着提高提示优化的成本效益迈出了重要一步,使其更强大、更易访问。
论文及项目相关链接
PDF Submitted to AutoML 2025
Summary
LLM的提示优化问题可以通过集成自动化机器学习技术解决,提高效率和降低成本。介绍了一种名为CAPO的算法,它通过进化方法联合优化指令和少量的例子,在任务描述方面取得了稳健的改进。在多样化的数据集和LLM方面的实验表明,CAPO在大多数场景下优于现有的离散提示优化方法,并在预算较小的情况下实现了更好的性能。
Key Takeaways
- LLM的性能对提示制定高度敏感。
- 当前提示优化方法需要大量的LLM调用和输入令牌,成本高昂。
- CAPO算法通过集成AutoML技术提高了提示优化的效率。
- CAPO采用进化方法,联合优化指令和少量示例,同时利用任务描述来提高稳健性。
- CAPO在多样化的数据集和LLM方面的实验表现优异,优于现有的离散提示优化方法。
- CAPO在较小的预算下实现了更好的性能,通过比赛节省评估次数,并通过长度惩罚减少平均提示长度。
- CAPO算法使得提示优化更具成本效益和可访问性。
点此查看论文截图


StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Authors:Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, Daxin Jiang
Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
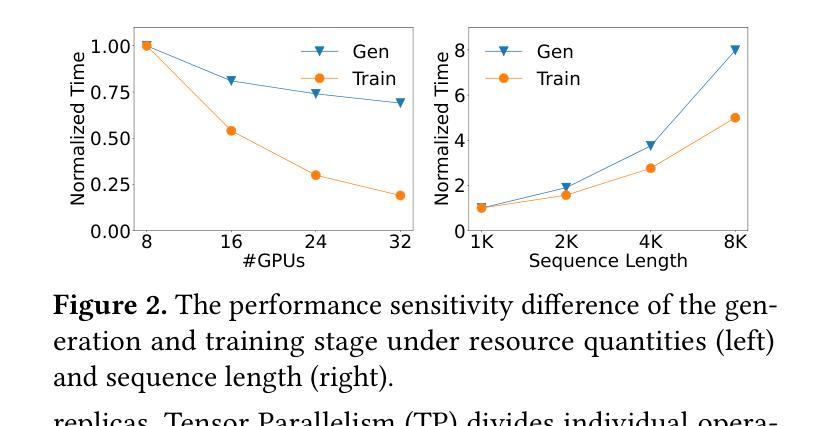
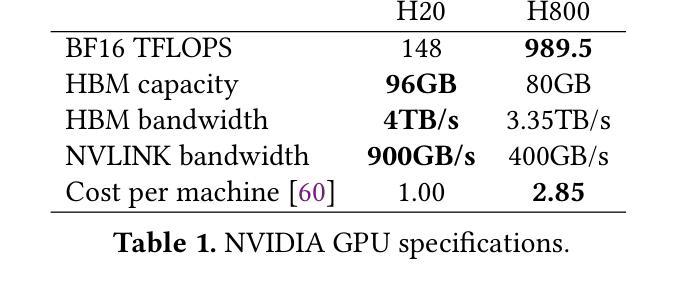
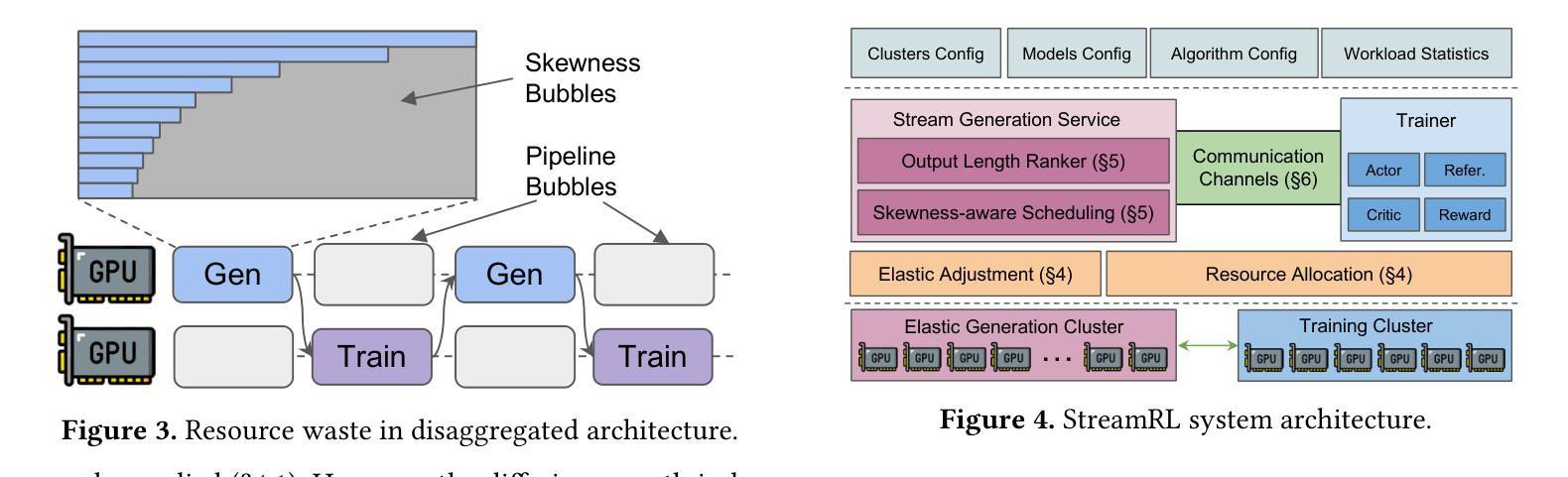
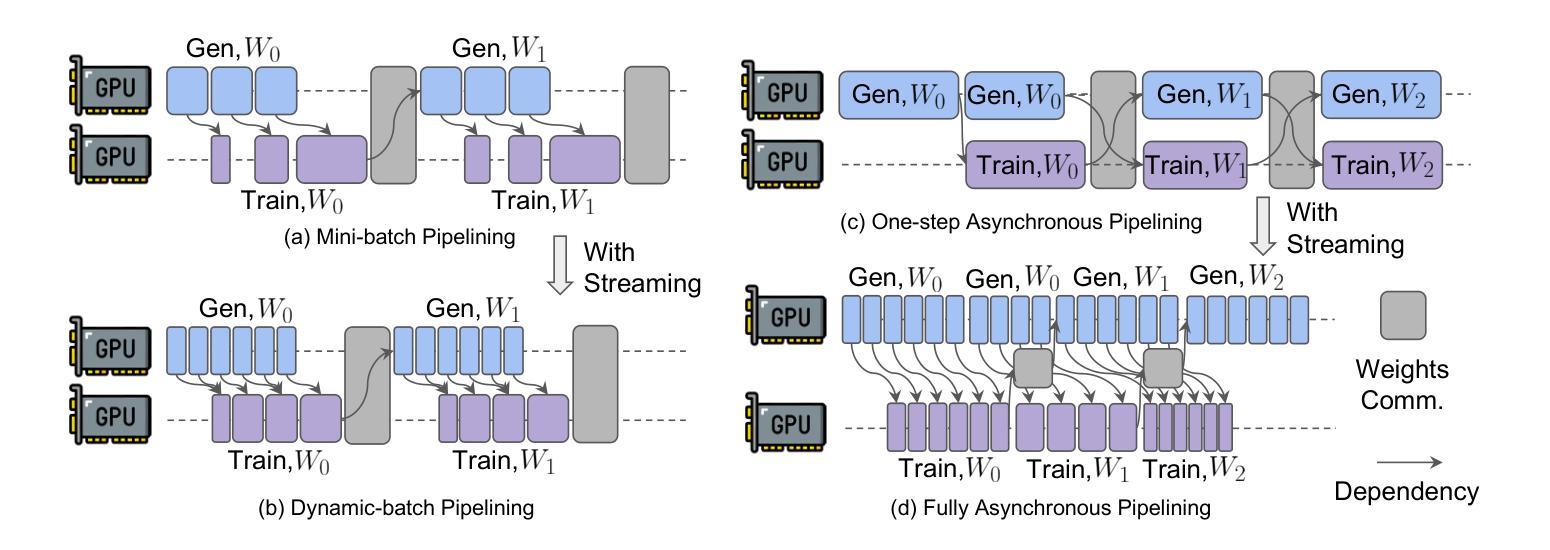
强化学习(RL)已成为大型语言模型(LLM)的核心后训练技术。LLM的RL涉及两个阶段:生成和训练。LLM首先在线生成样本,然后用于推导训练的奖励。传统观点认为,共置架构(两个阶段通过时间复用共享资源)优于分散架构(为每个阶段分配专用资源)。然而,在现实世界的应用部署中,我们发现共置架构存在资源耦合的问题,两个阶段的资源使用受到限制。这种耦合影响了共置RL在大规模训练中的可扩展性和成本效益。相比之下,分散架构允许灵活的资源分配,支持异构训练设置,并有利于跨数据中心部署。StreamRL从第一性原则出发进行分散设计,并通过解决现有分散RL框架中的两种性能瓶颈来充分发挥其潜力:由阶段依赖性引起的管道气泡和由长尾输出长度分布引起的偏斜气泡。为解决管道气泡问题,StreamRL打破了同步RL算法中的传统阶段边界,通过流生成实现异步RL的完全重叠。为解决偏斜气泡问题,StreamRL采用输出长度排名模型来识别长尾巴样本,并通过偏斜感知的分派和调度缩短生成时间。实验表明,与现有最先进的系统相比,StreamRL的吞吐量提高了高达2.66倍,在异构、跨数据中心设置中,成本效益提高了高达1.33倍。
论文及项目相关链接
Summary
强化学习作为大型语言模型(LLM)的核心训练技术包含两个阶段:生成与训练。传统观点认为集成架构优于分散架构,但在实际应用中,集成架构存在资源耦合问题,影响可扩展性和成本效益。相反,分散架构允许灵活资源分配并支持跨数据中心部署。StreamRL从基本原则上进行分散设计,解决了现有分散RL框架中的两种性能瓶颈问题,包括管道泡和偏斜泡。它通过打破同步RL算法的传统阶段边界和采用输出长度排名模型来识别长尾样本,提高了吞吐量和成本效益。
Key Takeaways
- 强化学习是大型语言模型(LLM)的关键训练技术。
- LLM的强化学习涉及生成和训练两个阶段。
- 传统上,集成架构被认为是优于分散架构的,但在实践中存在资源耦合问题。
- 分散架构有利于灵活资源分配、支持不同训练设置和跨数据中心部署。
- StreamRL解决了现有分散RL框架中的管道泡和偏斜泡问题。
- StreamRL通过打破同步RL算法的传统阶段边界和采用输出长度排名模型,提高了性能和成本效益。
点此查看论文截图

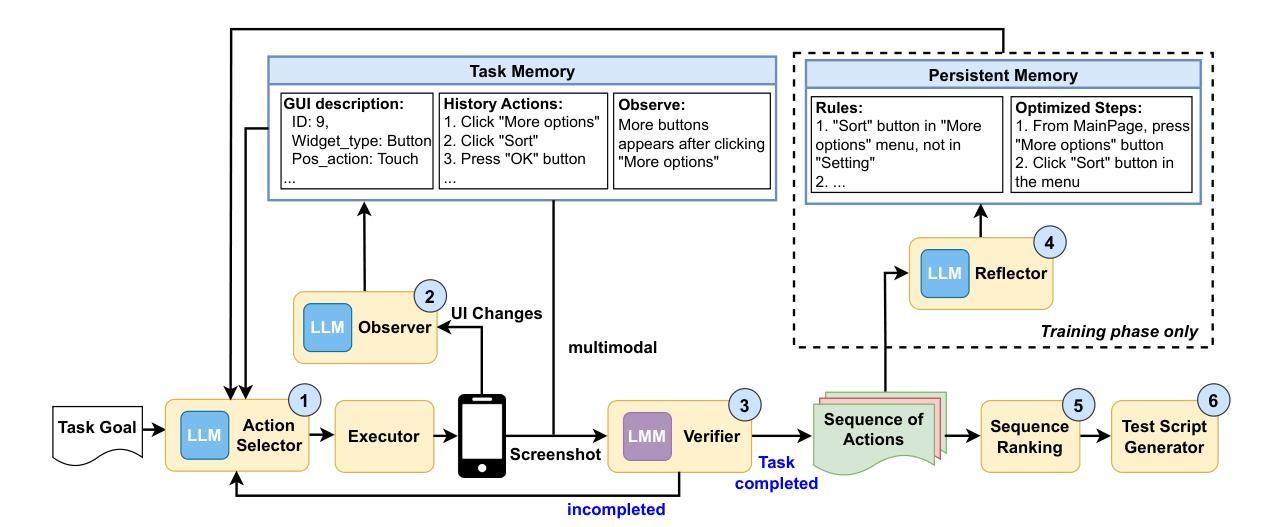
Towards Test Generation from Task Description for Mobile Testing with Multi-modal Reasoning
Authors:Hieu Huynh, Hai Phung, Hao Pham, Tien N. Nguyen, Vu Nguyen
In Android GUI testing, generating an action sequence for a task that can be replayed as a test script is common. Generating sequences of actions and respective test scripts from task goals described in natural language can eliminate the need for manually writing test scripts. However, existing approaches based on large language models (LLM) often struggle with identifying the final action, and either end prematurely or continue past the final screen. In this paper, we introduce VisiDroid, a multi-modal, LLM-based, multi-agent framework that iteratively determines the next action and leverages visual images of screens to detect the task’s completeness. The multi-modal approach enhances our model in two significant ways. First, this approach enables it to avoid prematurely terminating a task when textual content alone provides misleading indications of task completion. Additionally, visual input helps the tool avoid errors when changes in the GUI do not directly affect functionality toward task completion, such as adjustments to font sizes or colors. Second, the multi-modal approach also ensures the tool not progress beyond the final screen, which might lack explicit textual indicators of task completion but could display a visual element indicating task completion, which is common in GUI apps. Our evaluation shows that VisiDroid achieves an accuracy of 87.3%, outperforming the best baseline relatively by 23.5%. We also demonstrate that our multi-modal framework with images and texts enables the LLM to better determine when a task is completed.
在Android GUI测试中,为任务生成可重播为测试脚本的动作序列是很常见的。从自然语言描述的任务目标中生成动作序列和相应的测试脚本,可以消除手动编写测试脚本的需求。然而,基于大型语言模型(LLM)的现有方法往往难以识别最终动作,并且要么过早结束,要么超过最终屏幕继续执行。在本文中,我们介绍了VisiDroid,这是一个基于LLM的多模式、多代理框架,可以迭代确定下一个动作,并利用屏幕视觉图像来检测任务的完成程度。多模式方法在两个重要方面增强了我们的模型。首先,这种方法使其能够避免仅凭文本内容提供误导任务完成的迹象而提前终止任务。此外,视觉输入有助于工具在GUI更改不直接影响任务完成的功能时避免错误,例如调整字体大小或颜色。其次,多模式方法还确保工具不会超出最终屏幕的范围,最终屏幕上可能没有明确的文本指示任务完成,但可能会显示表示任务完成的视觉元素,这在GUI应用程序中是很常见的。我们的评估显示,VisiDroid的准确率达到了87.3%,相对于最佳基准值提高了23.5%。我们还证明,我们的带有图像和文本的多模式框架能够使LLM更好地确定任务何时完成。
论文及项目相关链接
PDF Under review for a conference
Summary
在Android GUI测试中,生成可重播的测试脚本的动作序列是常见的。本文介绍了一种基于大型语言模型的多模态、多代理框架VisiDroid,它通过迭代确定下一步动作并利用屏幕视觉图像检测任务的完成度。此方法能避免基于文本内容提前终止任务,并帮助工具避免在GUI更改不影响任务完成时出错,如字体大小或颜色的调整。同时,该多模态方法还能确保工具不会超出最终屏幕进度,从而实现更准确的测试。评估显示,VisiDroid的准确度达到87.3%,相较于最佳基线有23.5%的相对优势。
Key Takeaways
- 生成可重播的测试脚本的动作序列在Android GUI测试中很常见。
- VisiDroid是一个基于大型语言模型的多模态、多代理框架,用于Android GUI测试。
- VisiDroid通过结合视觉图像和文本,迭代确定下一步动作并检测任务的完成度。
- 多模态方法可以避免基于文本内容提前终止任务,并帮助工具更好地适应GUI更改不影响任务完成的情况。
- 多模态方法还能确保测试工具不会超出最终屏幕进度。
- VisiDroid的准确度达到87.3%,相较于最佳基线有显著的相对优势。
点此查看论文截图



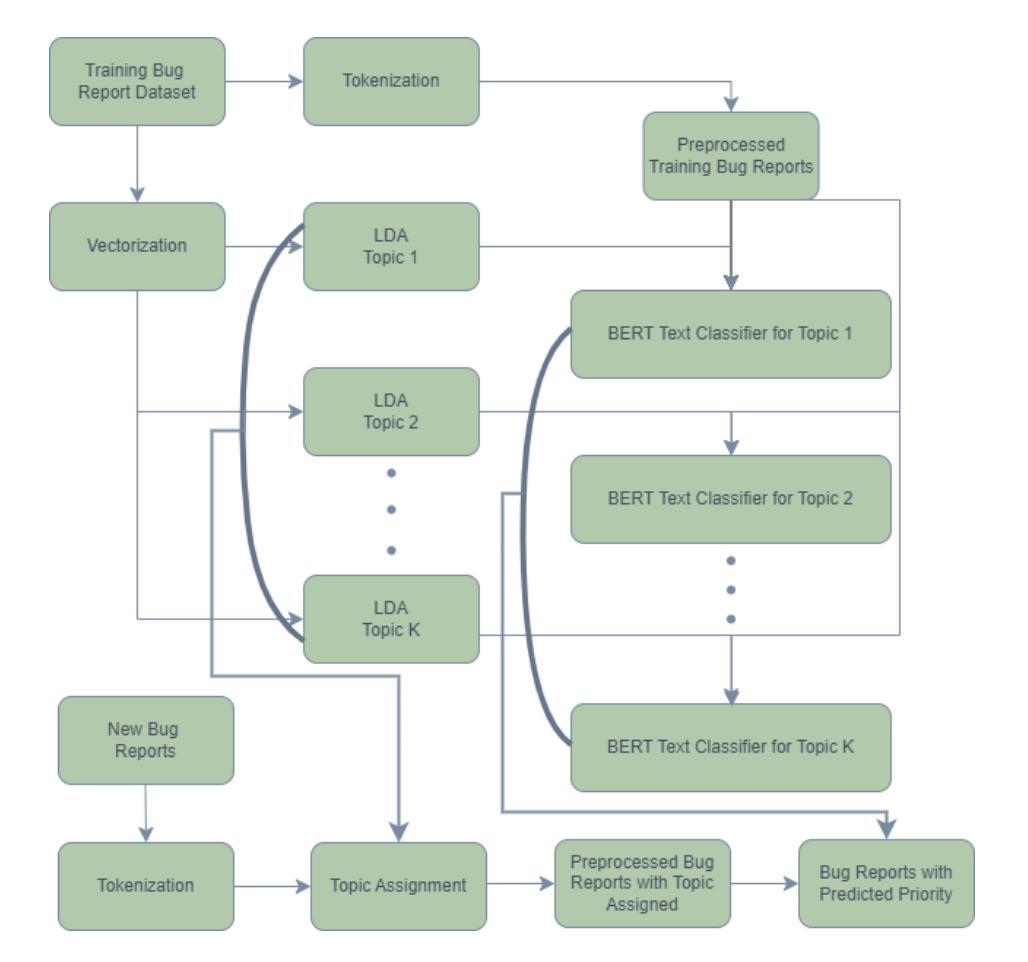
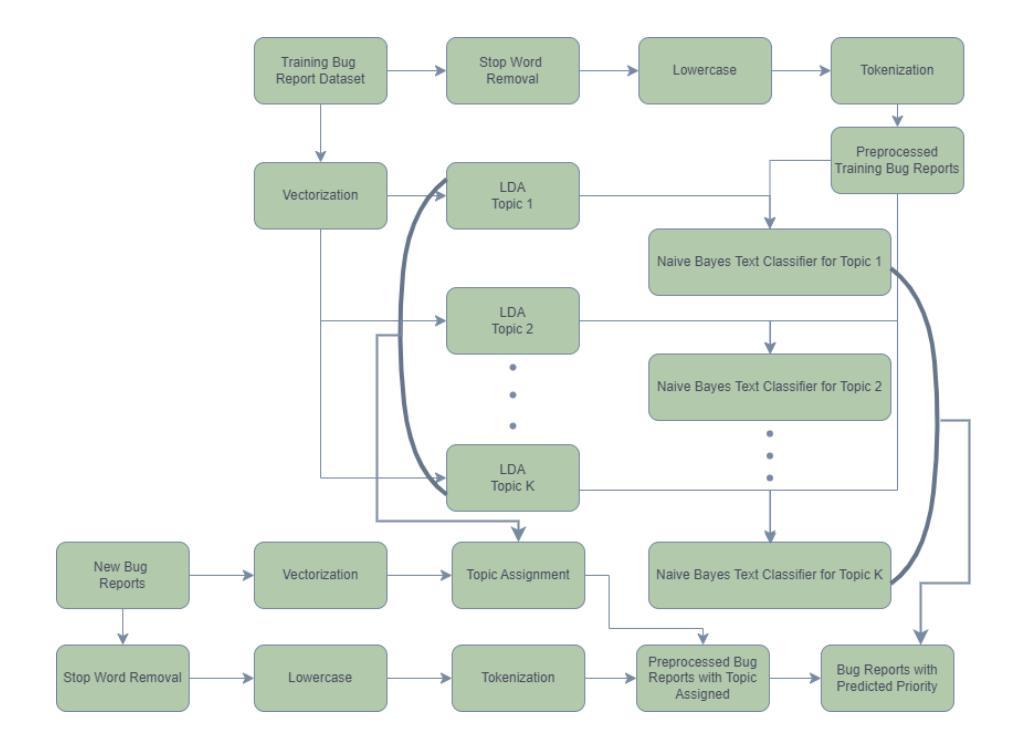
Automated Bug Report Prioritization in Large Open-Source Projects
Authors:Riley Pierson, Armin Moin
Large open-source projects receive a large number of issues (known as bugs), including software defect (i.e., bug) reports and new feature requests from their user and developer communities at a fast rate. The often limited project resources do not allow them to deal with all issues. Instead, they have to prioritize them according to the project’s priorities and the issues’ severities. In this paper, we propose a novel approach to automated bug prioritization based on the natural language text of the bug reports that are stored in the open bug repositories of the issue-tracking systems. We conduct topic modeling using a variant of LDA called TopicMiner-MTM and text classification with the BERT large language model to achieve a higher performance level compared to the state-of-the-art. Experimental results using an existing reference dataset containing 85,156 bug reports of the Eclipse Platform project indicate that we outperform existing approaches in terms of Accuracy, Precision, Recall, and F1-measure of the bug report priority prediction.
大型开源项目会快速接收到大量问题(也称为错误),包括来自其用户和开发社区的软件缺陷(即错误)报告和新功能请求。由于项目资源通常有限,他们无法处理所有问题。相反,他们必须根据项目的优先级和问题的严重性进行优先排序。在本文中,我们提出了一种基于存储在问题跟踪系统的开放错误存储库中的错误报告的自然语言文本进行自动错误优先级排序的新方法。我们使用一种名为TopicMiner-MTM的LDA变体进行主题建模,并使用BERT大型语言模型进行文本分类,以实现与最新技术相比的更高性能水平。使用包含Eclipse平台项目85,156份错误报告现有参考数据集进行的实验结果表明,我们在准确率、精确度、召回率和错误报告优先级预测的F1得分方面优于现有方法。
论文及项目相关链接
Summary
开源大型项目面临大量问题报告和新功能请求,有限的资源使其无法处理所有问题,需优先处理重要问题。本研究提出了一种基于自然语言文本的自动化bug优先级判定新方法,利用主题建模和文本分类技术实现高性能预测。在Eclipse Platform项目数据集上的实验表明,该方法在准确性、精确度、召回率和F1分数方面均优于现有方法。
Key Takeaways
- 大型开源项目面临处理大量问题的挑战。
- 项目需根据优先级和问题的严重性进行资源分配。
- 研究提出了一种基于自然语言文本的自动化bug优先级判定方法。
- 该方法使用主题建模和文本分类技术。
- 主题建模使用了LDA的变种——TopicMiner-MTM。
- 文本分类使用了BERT大型语言模型。
点此查看论文截图

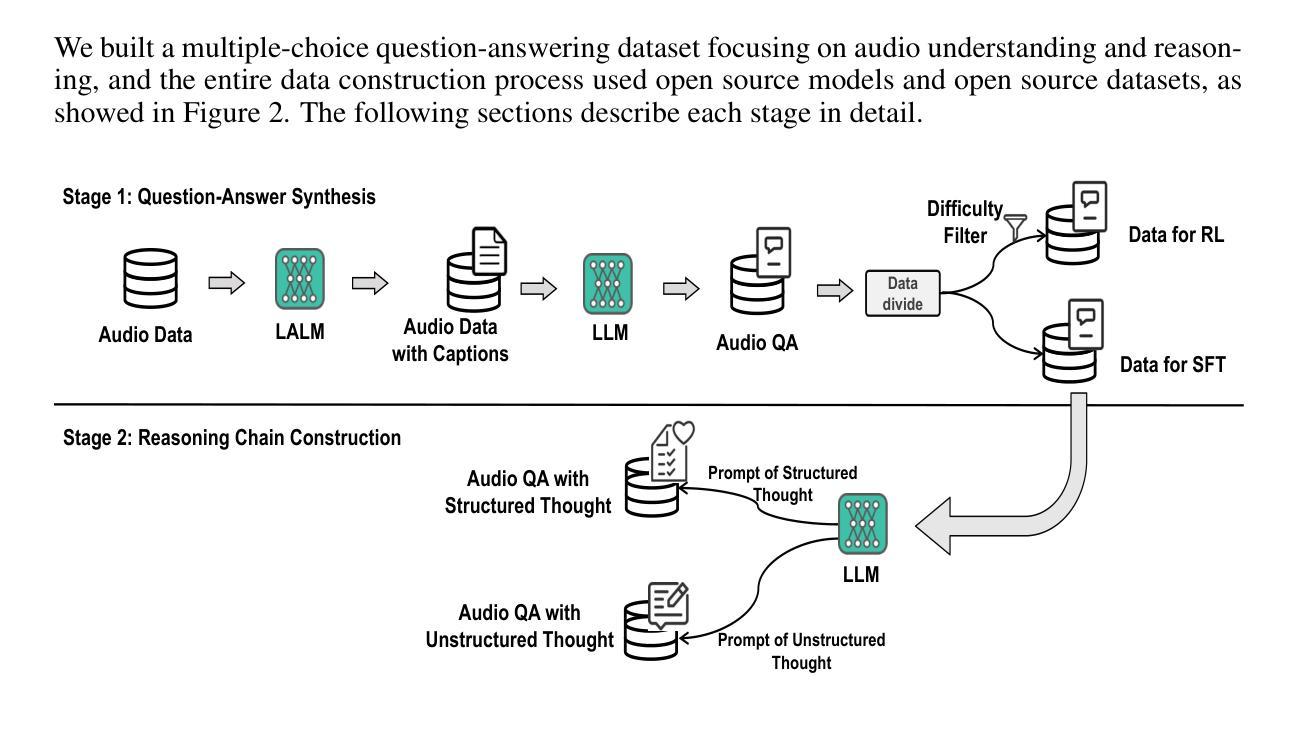
SARI: Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning
Authors:Cheng Wen, Tingwei Guo, Shuaijiang Zhao, Wei Zou, Xiangang Li
Recent work shows that reinforcement learning(RL) can markedly sharpen the reasoning ability of large language models (LLMs) by prompting them to “think before answering.” Yet whether and how these gains transfer to audio-language reasoning remains largely unexplored. We extend the Group-Relative Policy Optimization (GRPO) framework from DeepSeek-R1 to a Large Audio-Language Model (LALM), and construct a 32k sample multiple-choice corpus. Using a two-stage regimen supervised fine-tuning on structured and unstructured chains-of-thought, followed by curriculum-guided GRPO, we systematically compare implicit vs. explicit, and structured vs. free form reasoning under identical architectures. Our structured audio reasoning model, SARI (Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning), achieves a 16.35% improvement in average accuracy over the base model Qwen2-Audio-7B-Instruct. Furthermore, the variant built upon Qwen2.5-Omni reaches state-of-the-art performance of 67.08% on the MMAU test-mini benchmark. Ablation experiments show that on the base model we use: (i) SFT warm-up is important for stable RL training, (ii) structured chains yield more robust generalization than unstructured ones, and (iii) easy-to-hard curricula accelerate convergence and improve final performance. These findings demonstrate that explicit, structured reasoning and curriculum learning substantially enhances audio-language understanding.
最新研究表明,通过提示“先思考再回答”,强化学习(RL)可以显著提高大型语言模型(LLM)的推理能力。然而,这些收益是否以及如何转移到音频语言推理上仍在很大程度上未被探索。我们将DeepSeek-R1中的组相对策略优化(GRPO)框架扩展到一个大型音频语言模型(LALM),并构建了一个包含32k样本的多项选择语料库。通过结构化与非结构化思维链的两阶段监管监督微调,以及课程指导的GRPO,我们在相同架构下系统地比较了隐式和显式以及结构化与非结构化推理。我们的结构化音频推理模型SARI(通过课程指导强化学习的结构化音频推理)在基准模型Qwen2-Audio-7B-Instruct的基础上实现了平均准确率提高16.35%。此外,基于Qwen2.5-Omni的变体在MMAU测试小型基准上达到了最先进的性能,准确率为67.08%。消融实验表明,在我们使用的基准模型中:(i)SFT预热对于稳定的RL训练很重要,(ii)结构化链条相比于非结构化链条能带来更稳健的泛化性能,(iii)从易到难的课程能加速收敛并提高最终性能。这些发现表明,明确的、结构化的推理和课程学习极大地增强了音频语言理解。
论文及项目相关链接
Summary
强化学习(RL)能够显著提高大型语言模型(LLM)的推理能力,通过提示它们“在回答之前思考”。然而,这些增益是否以及如何转移到音频语言推理领域仍鲜有研究。本研究将Group-Relative Policy Optimization(GRPO)框架扩展到大型音频语言模型(LALM),并构建了一个包含32k样本的多项选择题语料库。通过结构化与非结构化思维链的两阶段监管微调,以及课程指导的GRPO,本研究系统地比较了隐式和显式、结构化与非结构化推理在相同架构下的表现。结构化音频推理模型SARI(通过课程指导强化学习的结构化音频推理)在基准模型Qwen2-Audio-7B-Instruct的基础上实现了平均精度16.35%的提升。此外,基于Qwen2.5-Omni的变体在MMAU测试迷你基准上达到了最先进的性能,准确率为67.08%。消融实验表明,我们所使用的基准模型:(i)SFT预热对于稳定的RL训练很重要,(ii)结构化链条相比非结构化链条能带来更稳健的泛化性能,(iii)从易到难的课程能加速收敛并提升最终性能。这些发现表明,显式、结构化的推理和课程学习显著提高了音频语言理解。
Key Takeaways
- 强化学习显著提高了大型语言模型的推理能力。
- 研究将GRPO框架扩展到音频语言模型领域。
- 通过结构化与非结构化思维链的两阶段监管微调以及课程指导的GRPO进行系统比较。
- 结构化音频推理模型SARI实现了相对于基准模型的显著性能提升。
- 基于Qwen2.5-Omni的模型在MMAU测试上达到先进性能。
- SFT预热对稳定RL训练至关重要。
点此查看论文截图

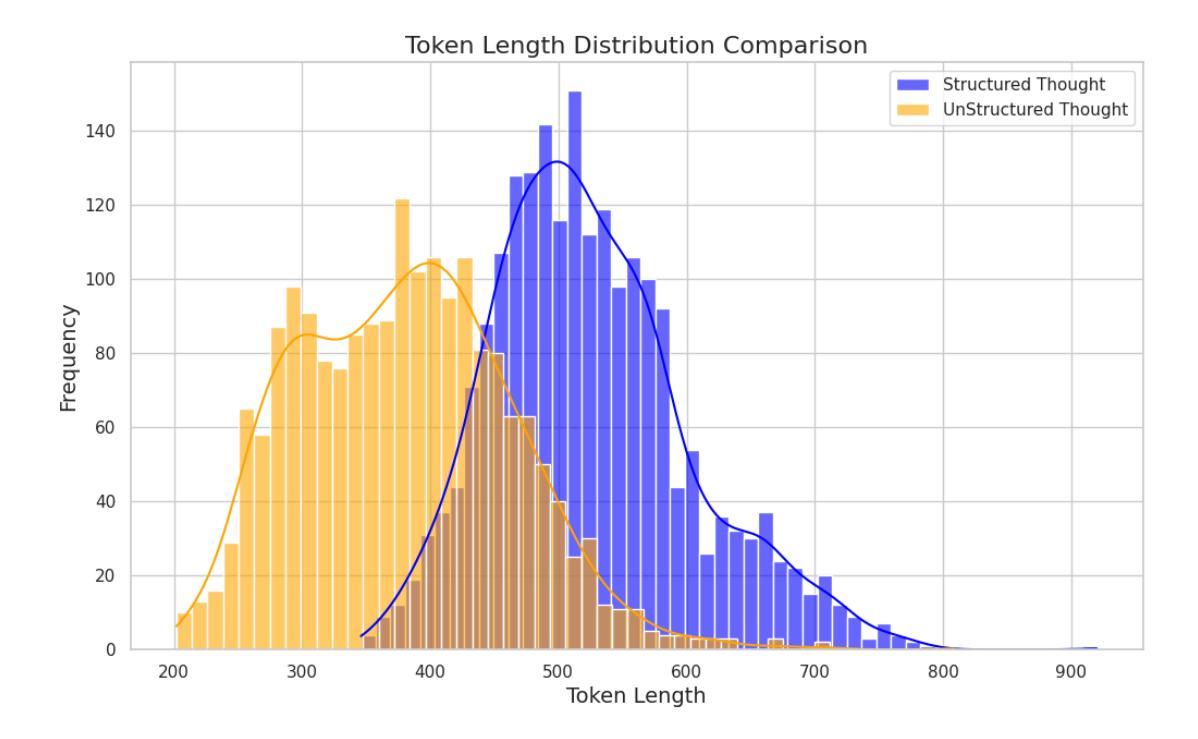
A LoRA-Based Approach to Fine-Tuning LLMs for Educational Guidance in Resource-Constrained Settings
Authors:Md Millat, Md Motiur
The current study describes a cost-effective method for adapting large language models (LLMs) for academic advising with study-abroad contexts in mind and for application in low-resource methods for acculturation. With the Mistral-7B-Instruct model applied with a Low-Rank Adaptation (LoRA) method and a 4-bit quantization method, the model underwent training in two distinct stages related to this study’s purpose to enhance domain specificity while maintaining computational efficiency. In Phase 1, the model was conditioned with a synthetic dataset via the Gemini Pro API, and in Phase 2, it was trained with manually curated datasets from the StudyAbroadGPT project to achieve enhanced, contextualized responses. Technical innovations entailed memory-efficient quantization, parameter-efficient adaptation, and continuous training analytics via Weights & Biases. After training, this study demonstrated a reduction in training loss by 52.7%, 92% accuracy in domain-specific recommendations, achieved 95% markdown-based formatting support, and a median run-rate of 100 samples per second on off-the-shelf GPU equipment. These findings support the effective application of instruction-tuned LLMs within educational advisers, especially in low-resource institutional scenarios. Limitations included decreased generalizability and the application of a synthetically generated dataset, but this framework is scalable for adding new multilingual-augmented and real-time academic advising processes. Future directions may include plans for the integration of retrieval-augmented generation, applying dynamic quantization routines, and connecting to real-time academic databases to increase adaptability and accuracy.
当前研究描述了一种具有成本效益的方法,用于适应大型语言模型(LLM),以学术咨询为内容,并考虑到出国留学背景,以及应用于低资源方法的适应文化适应。通过应用Mistral-7B-Instruct模型和Low-Rank Adaptation(LoRA)方法与4位量化方法,该模型经过两个阶段的相关训练,旨在提高领域特异性同时保持计算效率。在第一阶段,该模型通过Gemini Pro API以合成数据集进行条件处理;在第二阶段,使用StudyAbroadGPT项目的手动整理数据集进行训练,以实现增强情境化的响应。技术创新包括内存高效的量化、参数高效的适应以及通过Weights & Biases的持续训练分析。训练后,该研究证明了训练损失减少了52.7%,领域特定建议的准确性达到92%,实现了基于标记的格式化支持95%,并在现成的GPU设备上以每秒100个样本的中值运行速率。这些发现支持在教育顾问中有效应用指令调整的大型语言模型,特别是在低资源的机构场景中。局限性包括通用性降低和应用合成生成的数据集,但这个框架可以扩展,用于添加新的多语言增强和实时学术咨询流程。未来方向可能包括集成检索增强生成、应用动态量化例行程序以及与实时学术数据库连接,以提高适应性和准确性。
论文及项目相关链接
PDF 18 pages, 6 figures (3 graphs + 3 flowchart/architecture diagrams), submitted as a preprint for review consideration in AI for Education or Machine Learning applications in low-resource settings. Includes detailed experiments with LoRA and quantization methods for efficient LLM fine-tuning
摘要
本研究描述了一种具有成本效益的方法,用于针对留学辅导领域调整大型语言模型(LLM)。通过应用Mistral-7B-Instruct模型和LoRA方法以及4位量化方法,模型经历了两个阶段训练,以增强领域特异性同时保持计算效率。第一阶段使用合成数据集通过Gemini Pro API进行条件训练,第二阶段使用StudyAbroadGPT项目的手动整理数据集进行训练,以实现增强和上下文化的响应。技术创新包括内存高效的量化、参数有效的适应和连续训练分析。训练后,该研究表现出训练损失降低52.7%,领域特定建议准确性达92%,支持95%的markdown格式,并在现货GPU设备上每秒处理100个样本。这些发现支持在教育顾问中有效应用指令调整LLM,特别是在低资源机构场景中。尽管存在通用性和合成数据集应用的局限性,但该框架可扩展,可加入新的多语言增强和实时学术咨询流程。未来方向可能包括集成检索增强生成、应用动态量化程序以及与实时学术数据库的连接,以提高适应性和准确性。
关键见解
- 描述了一种成本效益高的方法,用于针对留学辅导领域调整大型语言模型(LLM)。
- 通过两个阶段训练模型,增强领域特异性同时保持计算效率。
- 使用合成数据集和手动整理数据集进行训练,实现增强和上下文化的响应。
- 技术创新包括内存高效的量化、参数有效的适应和连续训练分析。
- 训练后表现出高准确率和性能,支持在教育顾问中有效应用指令调整LLM。
- 框架具有可扩展性,可加入新的多语言增强和实时学术咨询流程。
- 未来发展方向包括集成检索增强生成、应用动态量化程序以及与实时学术数据库的连接。
点此查看论文截图

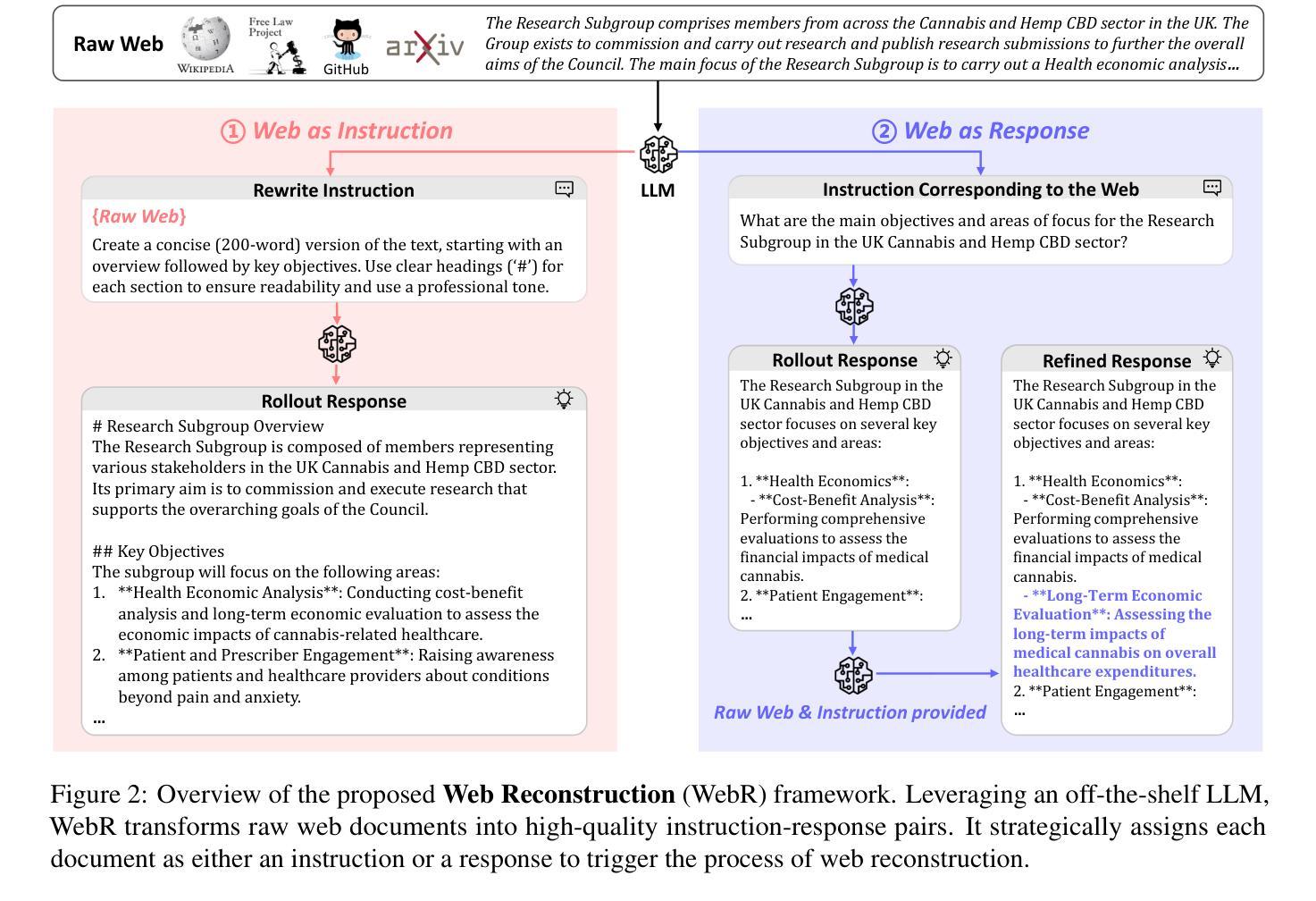
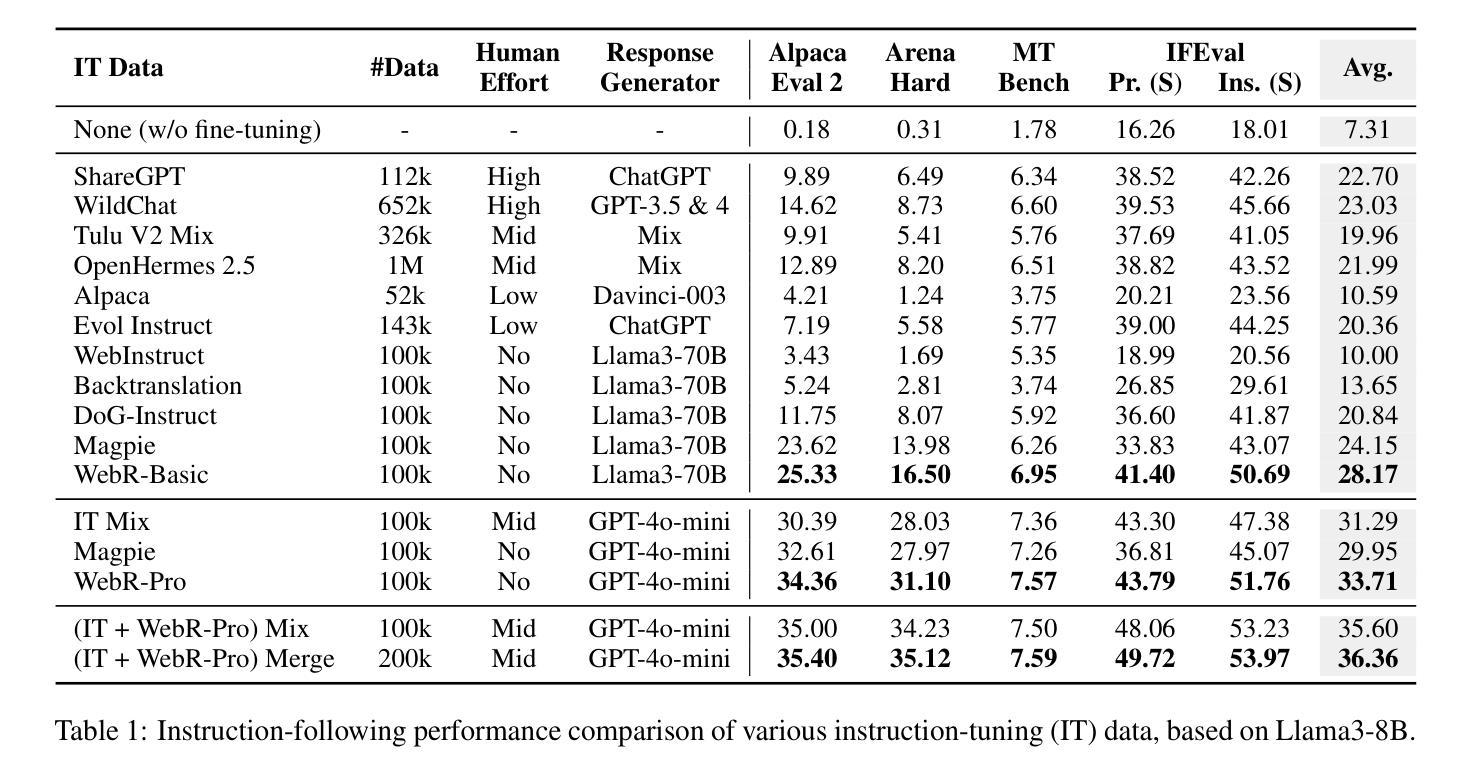
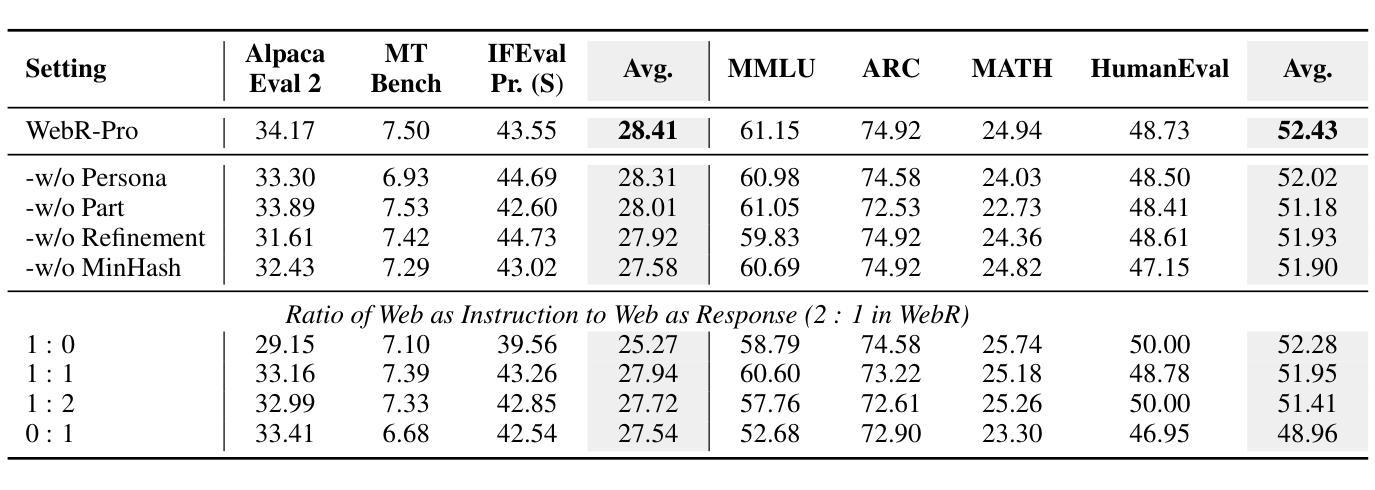
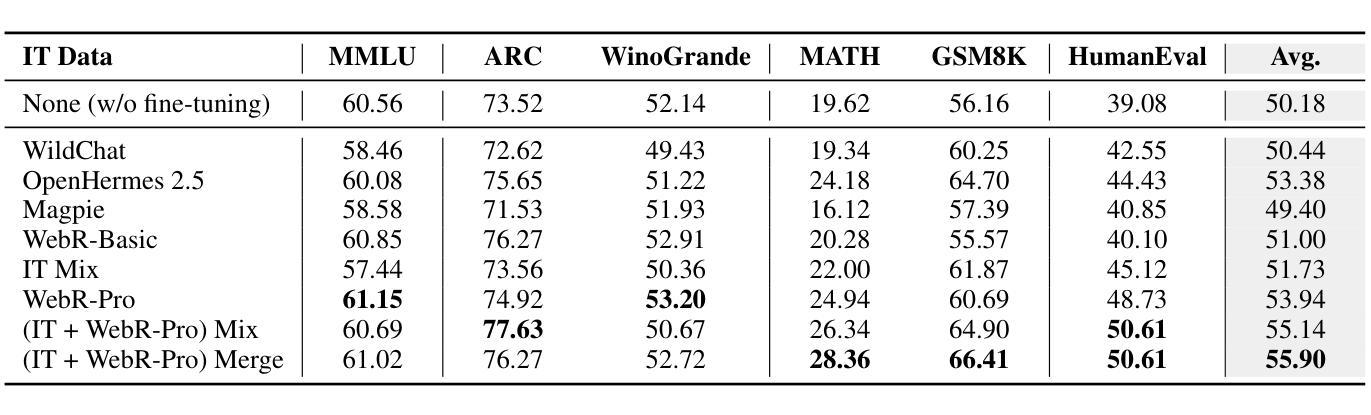
Instruction-Tuning Data Synthesis from Scratch via Web Reconstruction
Authors:Yuxin Jiang, Yufei Wang, Chuhan Wu, Xinyi Dai, Yan Xu, Weinan Gan, Yasheng Wang, Xin Jiang, Lifeng Shang, Ruiming Tang, Wei Wang
The improvement of LLMs’ instruction-following capabilities depends critically on the availability of high-quality instruction-response pairs. While existing automatic data synthetic methods alleviate the burden of manual curation, they often rely heavily on either the quality of seed data or strong assumptions about the structure and content of web documents. To tackle these challenges, we propose Web Reconstruction (WebR), a fully automated framework for synthesizing high-quality instruction-tuning (IT) data directly from raw web documents with minimal assumptions. Leveraging the inherent diversity of raw web content, we conceptualize web reconstruction as an instruction-tuning data synthesis task via a novel dual-perspective paradigm–Web as Instruction and Web as Response–where each web document is designated as either an instruction or a response to trigger the reconstruction process. Comprehensive experiments show that datasets generated by WebR outperform state-of-the-art baselines by up to 16.65% across four instruction-following benchmarks. Notably, WebR demonstrates superior compatibility, data efficiency, and scalability, enabling enhanced domain adaptation with minimal effort. The data and code are publicly available at https://github.com/YJiangcm/WebR.
大型语言模型(LLM)的执行指令能力的改进关键在于高质量指令响应对的可用性。虽然现有的自动数据合成方法减轻了手动整理数据的负担,但它们往往严重依赖于种子数据的质量或对网页文档结构和内容的假设。为了应对这些挑战,我们提出了Web重建(WebR),这是一个完全自动化的框架,能够从原始网页文档中直接合成高质量指令微调(IT)数据,几乎无需做出假设。利用原始网页内容的固有多样性,我们将网页重建概念化为指令微调数据合成任务,通过新颖的双视角模式——将网络视为指令和将网络视为响应——每个网页文档都被指定为指令或响应以触发重建过程。综合实验表明,WebR生成的数据集在四项执行指令基准测试上的表现优于最新基线,最高提升了16.65%。值得注意的是,WebR展现出卓越的兼容性、数据效率和可扩展性,能够实现低成本的领域自适应。数据和代码已公开在https://github.com/YJiangcm/WebR上提供。
论文及项目相关链接
PDF 15 pages, 11 figures, 9 tables
Summary
LLMs的指令遵循能力改进的关键在于高质量指令响应对的可用性。现有自动数据合成方法虽然减轻了手动整理负担,但仍依赖于种子数据质量或对网页文档结构和内容的强烈假设。为此,我们提出WebR,一个完全自动化的框架,直接从原始网页文档中合成高质量的指令调整(IT)数据,假设最少。借助原始网页内容的内在多样性,我们将网页重建概念化为指令调整数据合成任务,通过新颖的双视角模式——网页作为指令和网页作为响应——每个网页文档都被指定为指令或响应以触发重建过程。实验表明,WebR生成的数据集在四个指令遵循基准测试上的表现优于最佳基线,高出16.65%。WebR展现出卓越的一致性、数据效率和可扩展性,能轻松地实现最小的努力下的领域适应。
Key Takeaways
- LLMs的指令遵循能力改进依赖于高质量指令响应对的可用性。
- 现有自动数据合成方法存在对种子数据质量和网页文档结构内容的假设依赖问题。
- WebR是一个完全自动化的框架,能从原始网页文档中合成高质量的指令调整数据,假设最少。
- WebR利用双视角模式处理网页文档,分别作为指令和响应。
- WebR生成的数据集在四个指令遵循基准测试上的表现优于最佳基线。
- WebR具有卓越的一致性、数据效率和可扩展性。
点此查看论文截图

Optimizing SLO-oriented LLM Serving with PD-Multiplexing
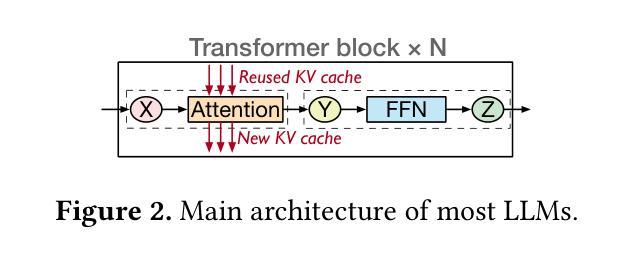
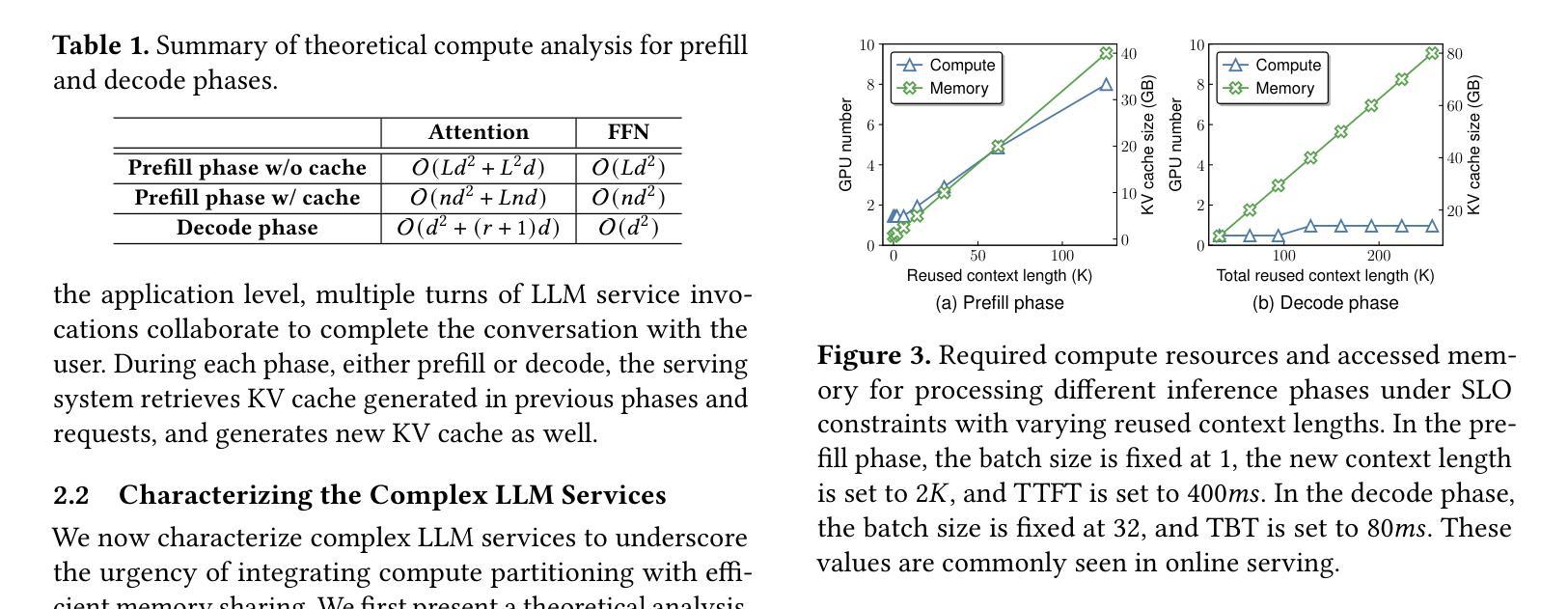
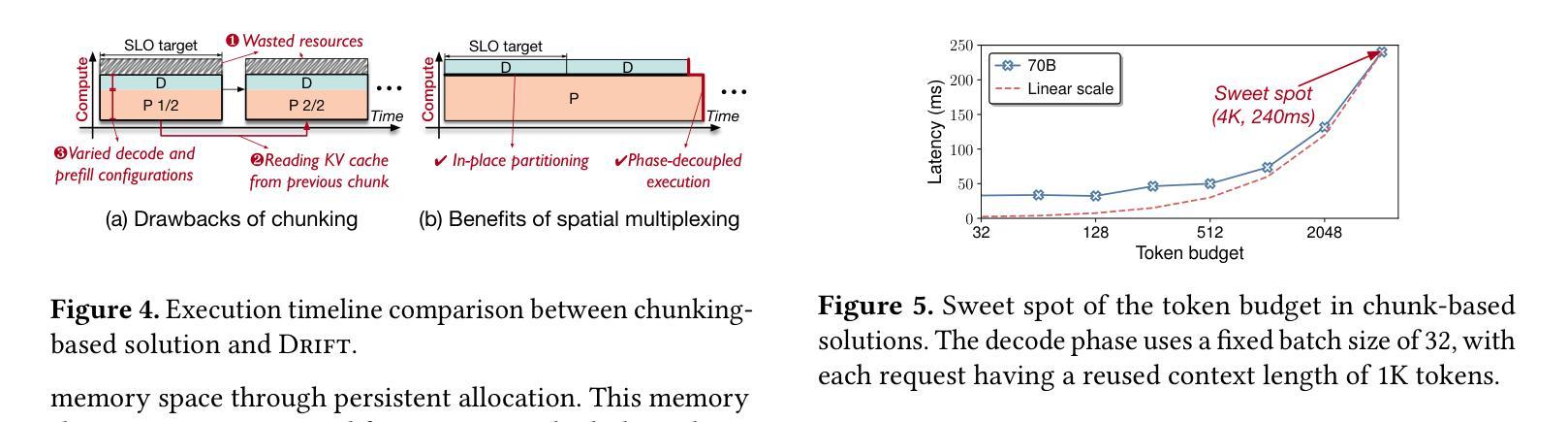
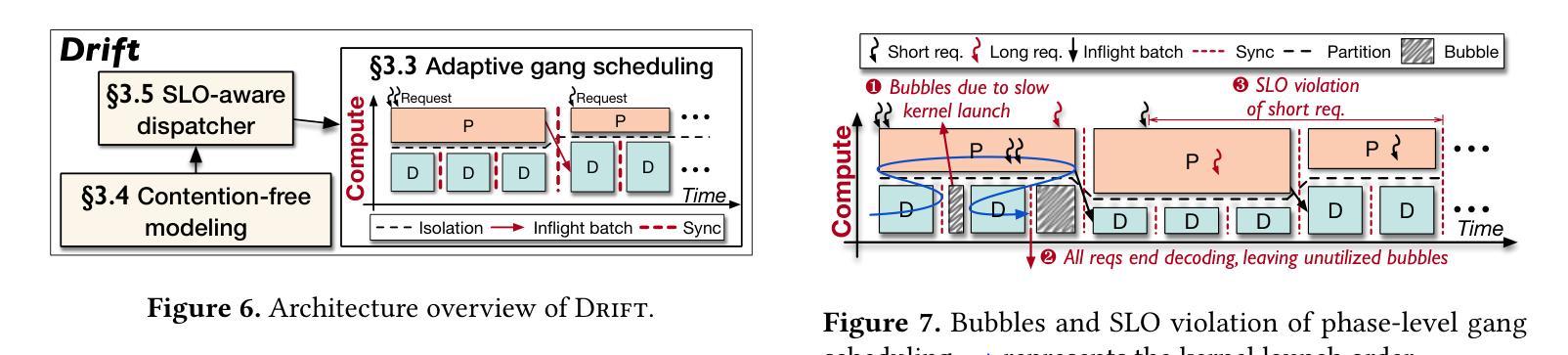
Authors:Weihao Cui, Yukang Chen, Han Zhao, Ziyi Xu, Quan Chen, Xusheng Chen, Yangjie Zhou, Shixuan Sun, Minyi Guo
Modern LLM services demand high throughput and stringent SLO guarantees across two distinct inference phases-prefill and decode-and complex multi-turn workflows. However, current systems face a fundamental tradeoff: out-of-place compute partition enables per-phase SLO attainment, while in-place memory sharing maximizes throughput via KV cache reuse. Moreover, existing in-place compute partition also encounters low utilization and high overhead due to phase-coupling design. We present Drift, a new LLM serving framework that resolves this tension via PD multiplexing, enabling in-place and phase-decoupled compute partition. Drift leverages low-level GPU partitioning techniques to multiplex prefill and decode phases spatially and adaptively on shared GPUs, while preserving in-place memory sharing. To fully leverage the multiplexing capability, Drift introduces an adaptive gang scheduling mechanism, a contention-free modeling method, and a SLO-aware dispatching policy. Evaluation shows that Drift achieves an average $5.1\times$ throughput improvement (up to $17.5\times$) over state-of-the-art baselines, while consistently meeting SLO targets under complex LLM workloads.
现代LLM服务要求在两个不同的推理阶段(预填充和解码)以及复杂的多轮工作流程中实现高吞吐量和严格的SLO保证。然而,当前系统面临一个基本权衡:离位计算分区可实现每个阶段的SLO达成,而原位内存共享则通过KV缓存重用最大化吞吐量。此外,现有的原位计算分区还因为阶段耦合设计而面临利用率低和开销高的问题。我们提出了Drift,这是一个新的LLM服务框架,它通过PD多路复用解决这一紧张问题,实现原位和阶段解耦的计算分区。Drift利用低级GPU分区技术,在共享GPU上空间和自适应地多路复用预填充和解码阶段,同时保留原位内存共享。为了充分利用多路复用功能,Drift引入了一种自适应小组调度机制、一种无争用建模方法和一种SLO感知调度策略。评估表明,与最新基线相比,Drift平均提高了5.1倍吞吐量(最高达17.5倍),同时在复杂LLM工作负载下始终达到SLO目标。
论文及项目相关链接
Summary
文本主要描述了一种名为Drift的新LLM服务框架,它解决了现有系统面临的计算和内存利用率的权衡问题。通过PD复用技术,Drift能在共享GPU上实现原位和阶段解耦的计算分区,同时保持原位内存共享。Drift还引入了一种自适应的调度机制、无争用的建模方法和SLO感知调度策略,以充分利用其复用能力。评估结果表明,Drift相较于现有技术平均提高了5.1倍的吞吐量(最高可达17.5倍),同时在复杂的LLM工作负载下始终满足SLO目标。
Key Takeaways
- 现代LLM服务需要高吞吐量和严格的SLO保证,跨越两个独特的推理阶段——预填充和解码,以及复杂的多轮对话工作流程。
- 当前系统面临计算和内存利用率的权衡问题:出位计算分区可实现每阶段SLO达成,而原位内存共享则通过KV缓存重用最大化吞吐量。
- Drift是一个新的LLM服务框架,通过PD复用技术解决这一权衡问题,能在共享GPU上实现原位和阶段解耦的计算分区。
- Drift保持原位内存共享,同时引入自适应的调度机制、无争用的建模方法和SLO感知调度策略。
- Drift实现了对先进基线技术的平均5.1倍吞吐量改进(最高可达17.5倍)。
- Drift能在复杂的LLM工作负载下始终满足SLO目标。
点此查看论文截图

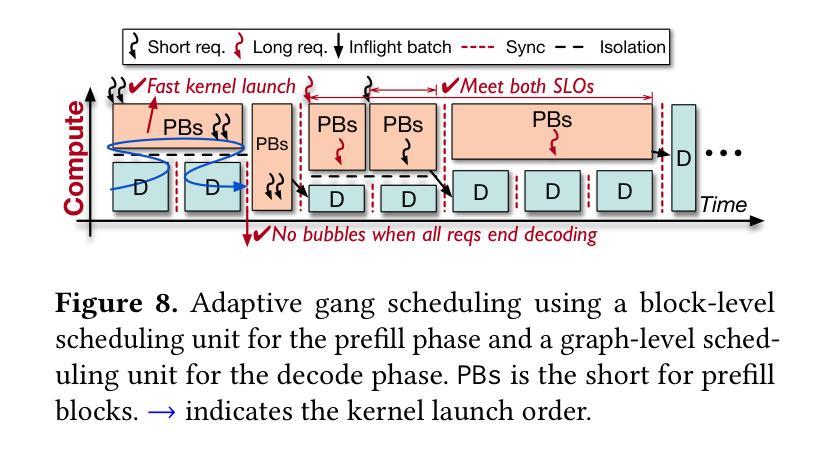
ASIDE: Architectural Separation of Instructions and Data in Language Models
Authors:Egor Zverev, Evgenii Kortukov, Alexander Panfilov, Alexandra Volkova, Soroush Tabesh, Sebastian Lapuschkin, Wojciech Samek, Christoph H. Lampert
Despite their remarkable performance, large language models lack elementary safety features, and this makes them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause for the success of prompt injection attacks. In this work, we propose a method, ASIDE, that allows the model to clearly separate between instructions and data on the level of embeddings. ASIDE applies a fixed orthogonal rotation to the embeddings of data tokens, thus creating distinct representations of instructions and data tokens without introducing any additional parameters. We demonstrate the effectiveness of our method by instruct-tuning LLMs with ASIDE and showing (1) highly increased instruction-data separation scores without a loss in model capabilities and (2) competitive results on prompt injection benchmarks, even without dedicated safety training. Additionally, we study the working mechanism behind our method through an analysis of model representations.
尽管大型语言模型表现出色,但它们缺乏基本的安全功能,这使得它们容易受到众多恶意攻击的影响。特别是,先前的工作已经确定指令和数据之间缺乏内在分离是提示注入攻击成功的根本原因。在这项工作中,我们提出了一种方法ASIDE,它允许模型在嵌入级别上清晰地分离指令和数据。ASIDE通过对数据标记的嵌入进行固定的正交旋转,从而创建指令和数据标记的明确表示,而无需引入任何额外的参数。我们通过使用ASIDE对LLM进行指令调整,并展示(1)在模型能力没有损失的情况下高度提高指令与数据的分离度得分;(2)即使在未进行专门的安全训练的情况下,在提示注入基准测试中也取得了具有竞争力的结果。此外,我们还通过分析模型表示来研究我们方法的工作原理。
论文及项目相关链接
PDF ICLR 2025 Workshop on Building Trust in Language Models and Applications
Summary
大型语言模型虽然表现优异,但缺乏基本的安全特性,容易遭受恶意攻击。本研究提出了一种方法——ASIDE,通过在嵌入层面实现指令与数据的清晰分离,增强模型的安全性。ASIDE通过对数据标记的嵌入进行固定正交旋转,为指令和数据标记创建不同的表示形式,且无需引入任何额外参数。实验表明,使用ASIDE进行指令微调的大型语言模型在保持模型能力的同时,提高了指令与数据的分离度,并在提示注入基准测试中取得了具有竞争力的结果,即使未进行专门的安全训练。
Key Takeaways
- 大型语言模型缺乏基本安全特性,易受到恶意攻击。
- 指令与数据混淆是语言模型易受攻击的原因之一。
- ASIDE方法通过嵌入层面的操作实现指令与数据的清晰分离。
- ASIDE方法通过固定正交旋转数据标记的嵌入来创建不同的指令和数据表示。
- 使用ASIDE进行指令微调的大型语言模型在保持模型能力的同时提高了指令与数据的分离度。
- 在未进行专门的安全训练的情况下,ASIDE方法在提示注入基准测试中取得了具有竞争力的结果。
点此查看论文截图

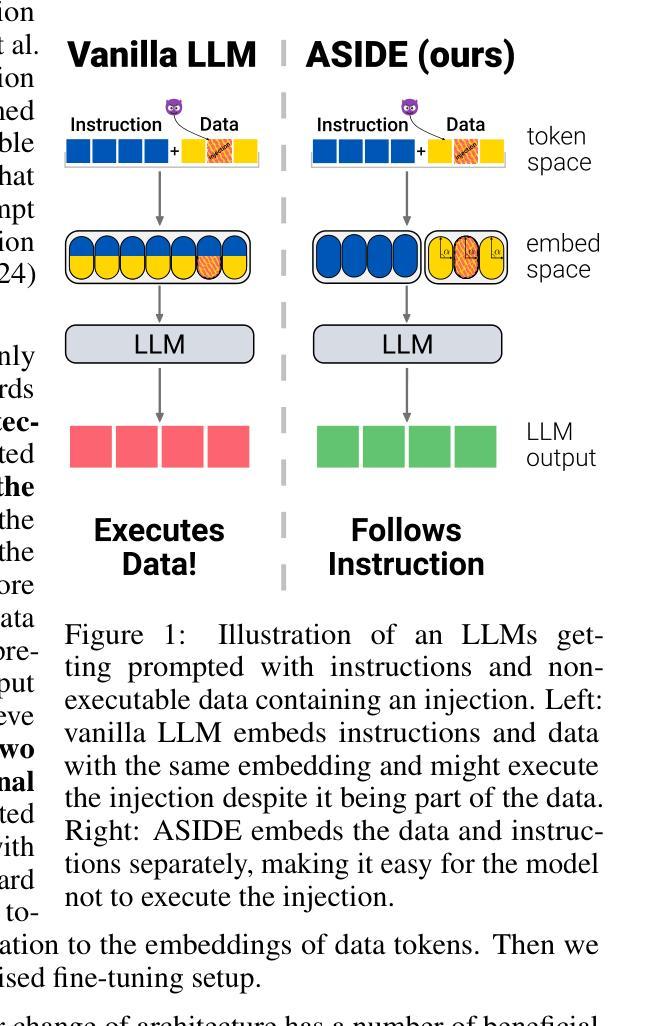
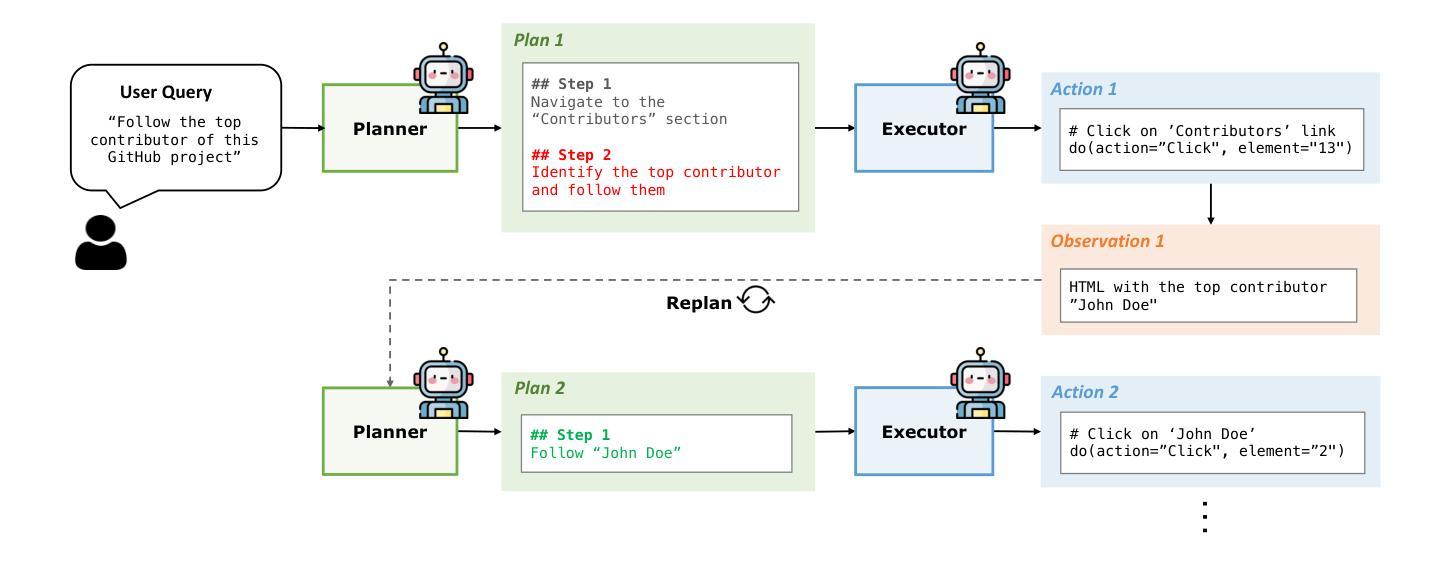
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Authors:Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt Keutzer, Amir Gholami
Large language models (LLMs) have shown remarkable advancements in enabling language agents to tackle simple tasks. However, applying them for complex, multi-step, long-horizon tasks remains a challenge. Recent work have found success by separating high-level planning from low-level execution, which enables the model to effectively balance high-level planning objectives and low-level execution details. However, generating accurate plans remains difficult since LLMs are not inherently trained for this task. To address this, we propose Plan-and-Act, a novel framework that incorporates explicit planning into LLM-based agents and introduces a scalable method to enhance plan generation through a novel synthetic data generation method. Plan-and-Act consists of a Planner model which generates structured, high-level plans to achieve user goals, and an Executor model that translates these plans into environment-specific actions. To train the Planner effectively, we introduce a synthetic data generation method that annotates ground-truth trajectories with feasible plans, augmented with diverse and extensive examples to enhance generalization. We evaluate Plan-and-Act using web navigation as a representative long-horizon planning environment, demonstrating a state-of-the-art 57.58% success rate on the WebArena-Lite benchmark as well as a text-only state-of-the-art 81.36% success rate on WebVoyager.
大型语言模型(LLM)在语言智能处理简单任务方面取得了显著的进步。然而,将其应用于复杂、多步骤、长期的任务仍具有挑战性。近期的研究成功将高级规划与低级执行分离,使模型能够有效地平衡高级规划目标和低级执行细节。然而,生成准确的计划仍然很困难,因为LLM并没有天生为此任务而训练。为了解决这个问题,我们提出了“计划与执行”这一新型框架,该框架将明确的计划纳入基于LLM的代理,并引入了一种可伸缩的方法,通过一种新的合成数据生成方法来增强计划生成。“计划与执行”包括一个规划器模型,用于生成结构化、高级的计划来实现用户目标,以及一个执行器模型,用于将这些计划翻译成环境特定的行动。为了有效地训练规划器,我们引入了一种合成数据生成方法,该方法用可行的计划标注了真实轨迹的地面实况,并辅以多样化和广泛的例子来增强泛化能力。我们使用网页导航作为代表长期规划环境的评估对象,在WebArena-Lite基准测试上取得了最先进的57.58%成功率,以及在WebVoyager上取得了纯文本的最先进81.36%成功率。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理简单任务时表现出显著进展,但在面对复杂、多步骤、长期规划的任务时仍面临挑战。为解决这个问题,研究者采用分离高级规划与低级执行的方法,并在LLM模型中引入明确的规划。然而,生成准确规划仍然困难,因为LLM并未天生为此任务而训练。为此,本文提出Plan-and-Act框架,通过新型合成数据生成方法强化规划生成。该框架包括生成结构化高级规划的Planner模型和将规划转化为环境特定行动的Executor模型。实验表明,Plan-and-Act在Web导航等长期规划环境中表现卓越,在WebArena-Lite基准测试上取得领先的成功率。
Key Takeaways
- LLM在处理复杂、多步骤、长期规划的任务时仍面临挑战。
- 分离高级规划与低级执行有助于LLM模型有效平衡规划与执行。
- 生成准确规划是LLM面临的一个难题,需要新的解决方案。
- Plan-and-Act框架引入明确的规划,包括Planner和Executor两个模型。
- Plan-and-Act通过新型合成数据生成方法强化计划生成。
- 实验表明,Plan-and-Act在Web导航等长期规划环境中表现优越。
点此查看论文截图

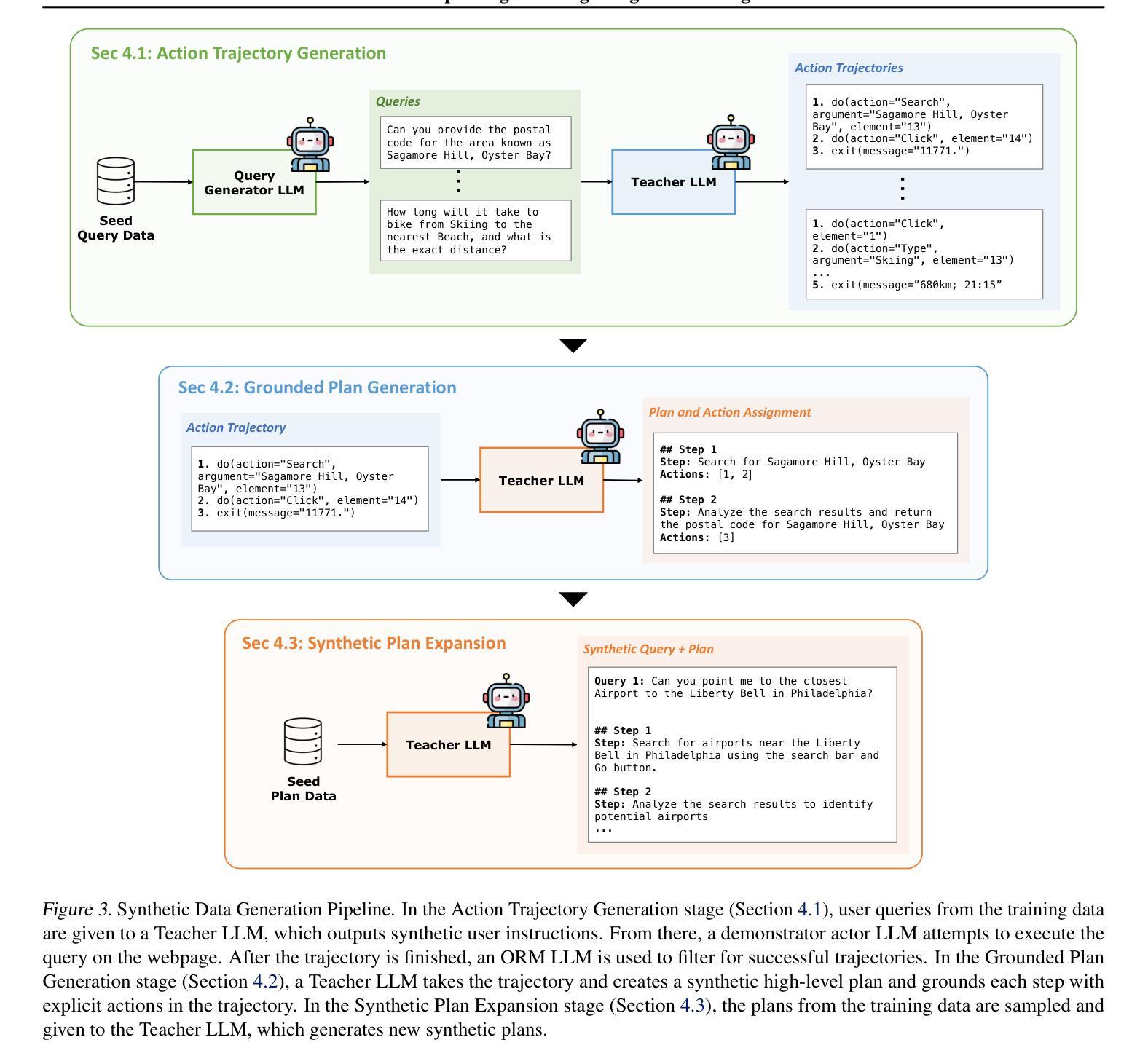
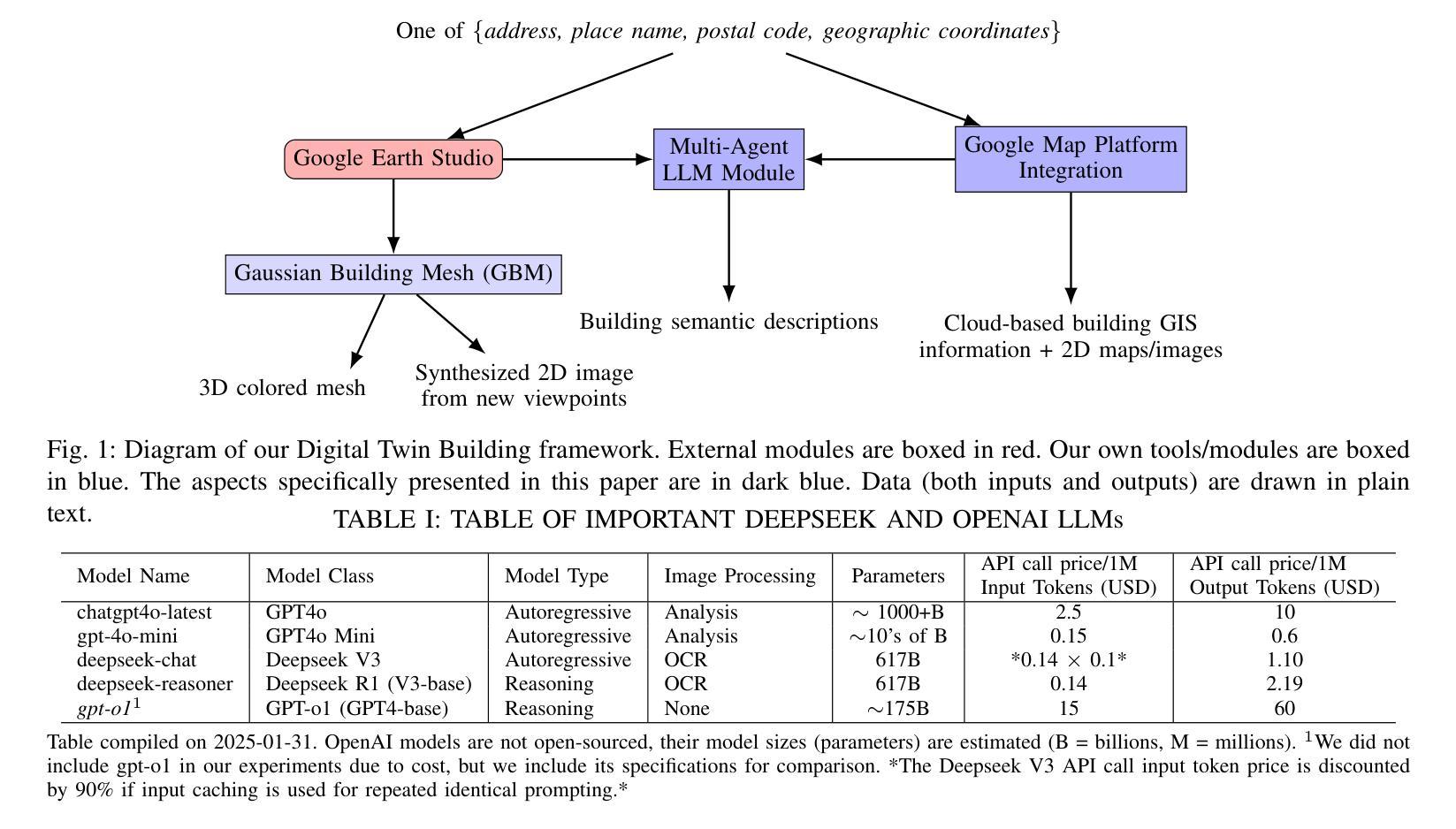
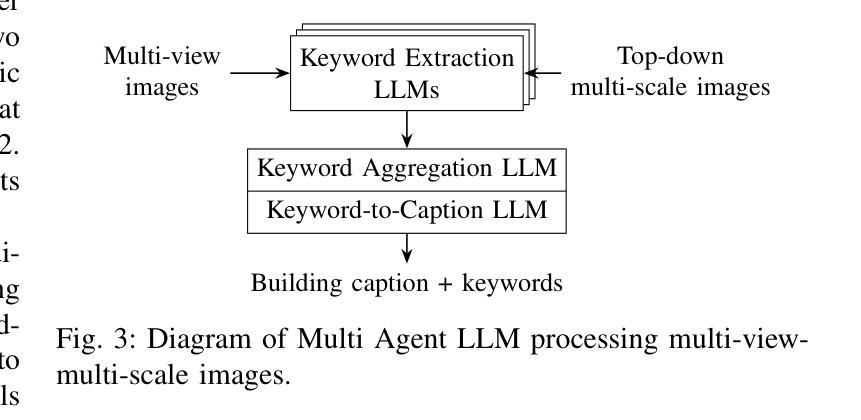
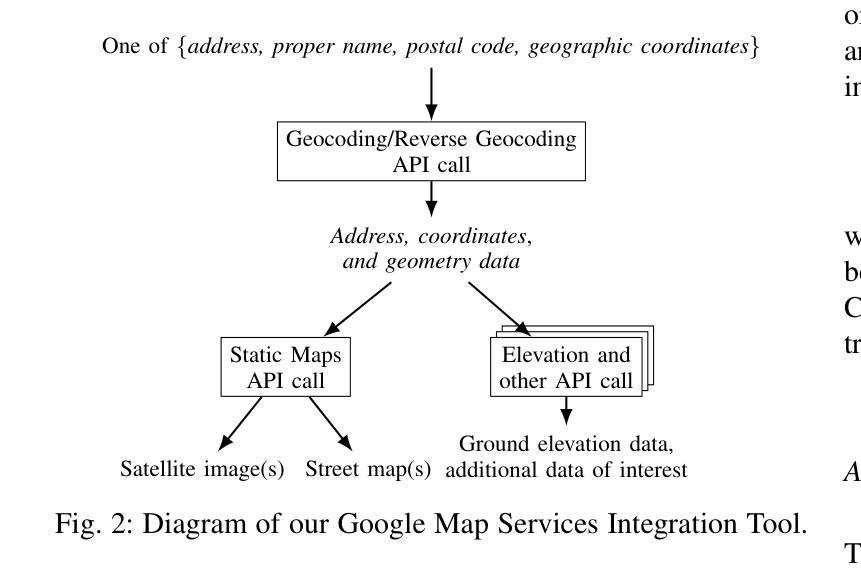
Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platform
Authors:Kyle Gao, Dening Lu, Liangzhi Li, Nan Chen, Hongjie He, Linlin Xu, Jonathan Li
Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building’s 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building’s address, postal code, or geographic coordinates.
城市数字双胞胎是利用多源数据和数据分析优化城市规划、基础设施管理和决策制定的城市虚拟副本。为此,我们提出了一个以单栋建筑规模为重点的框架。通过连接到谷歌地图平台API等云地图平台,利用最先进的基于多智能体的语言模型ChatGPT(第4版)和Deepseek-V3/R1进行数据分析,以及使用基于高斯溅点技术的网格提取管道,我们的数字双胞胎建筑框架可以检索建筑的3D模型、视觉描述信息,并通过建筑地址、邮政编码或地理坐标实现基于云的地图集成与大型语言模型的数据分析。
论文及项目相关链接
PDF -Fixed minor typo
Summary
城市数字双胞胎是城市的虚拟副本,利用多源数据和数据分析优化城市规划、基础设施管理和决策制定。我们提出一个以单栋建筑为尺度的框架,通过连接云平台、利用最新的多智能体大数据模型和算法,实现城市数字双胞胎的构建,可获取建筑的3D模型、视觉描述,并实现基于云的映射集成与大数据模型分析。
Key Takeaways
- 城市数字双胞胎是城市的虚拟副本,旨在优化城市规划、基础设施管理和决策制定。
- 框架以单栋建筑为尺度,实现更精细化的城市数字双胞胎构建。
- 通过连接云平台如Google Map Platforms APIs,获取建筑的多源数据。
- 利用最新的多智能体大数据模型和算法,如ChatGPT和Deepseek-V3/R1,进行数据分析。
- 采用Gaussian Splatting-based mesh提取管道技术,获取建筑的3D模型和视觉描述。
- 实现基于云的映射集成,可通过建筑地址、邮政编码或地理坐标进行数据分析和访问。
点此查看论文截图

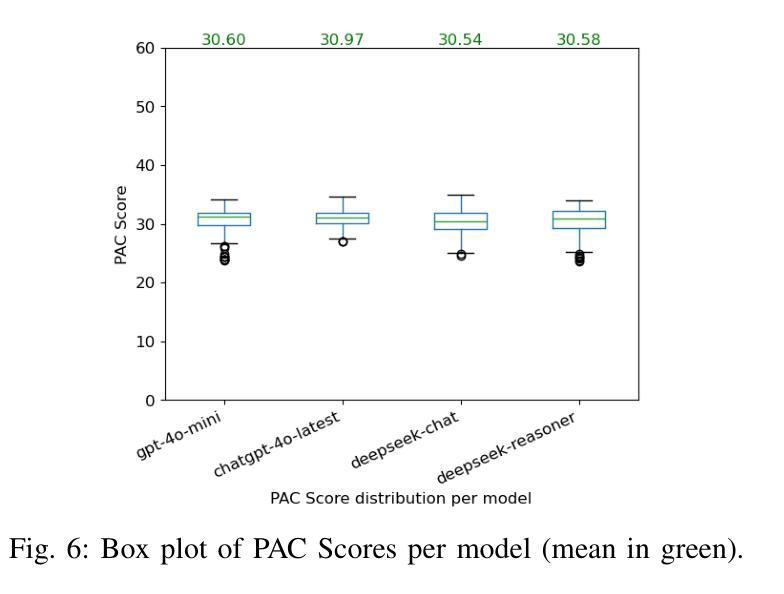
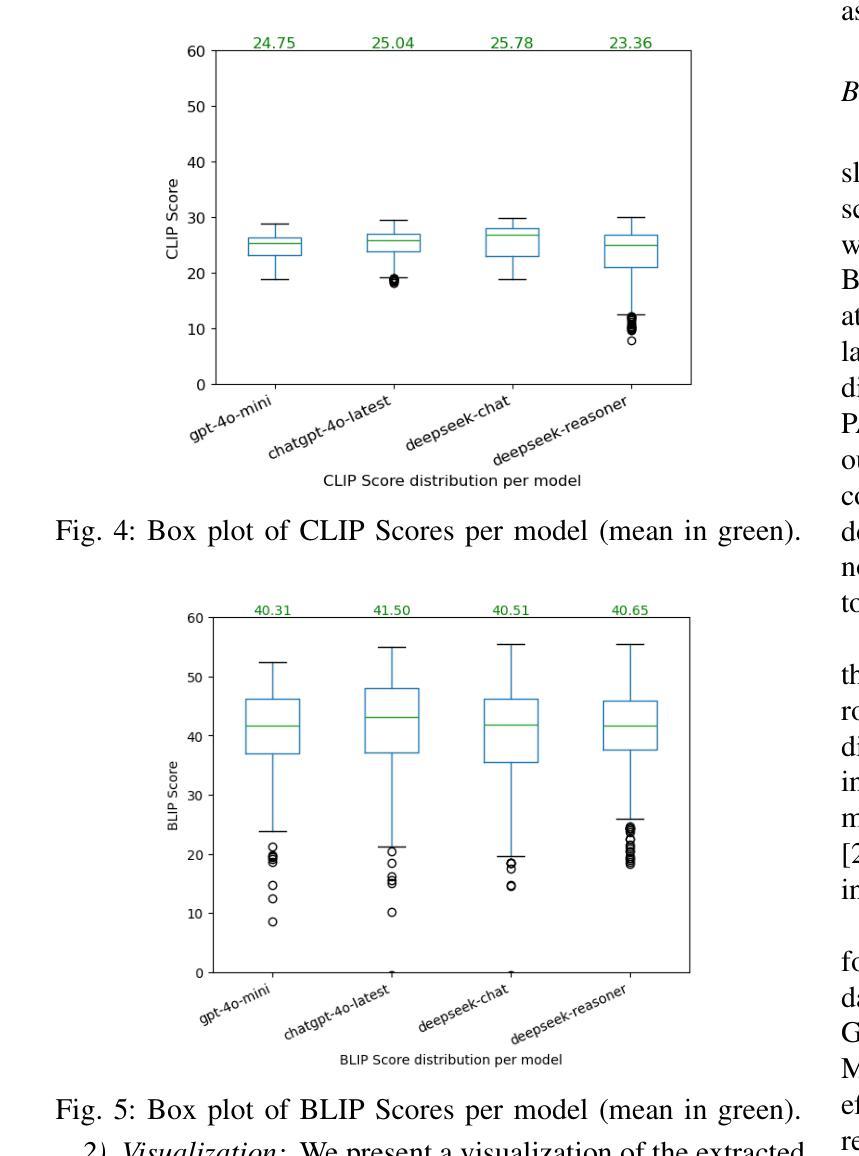

LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation
Authors:Xi Ye, Fangcong Yin, Yinghui He, Joie Zhang, Howard Yen, Tianyu Gao, Greg Durrett, Danqi Chen
Existing benchmarks for evaluating long-context language models (LCLMs) primarily focus on long-context recall, requiring models to produce short responses based on a few critical snippets while processing thousands of irrelevant tokens. We introduce LongProc (Long Procedural Generation), a new benchmark that requires both the integration of highly dispersed information and long-form generation. LongProc consists of six diverse procedural generation tasks, such as extracting structured information from HTML pages into a TSV format and executing complex search procedures to create travel plans. These tasks challenge LCLMs by testing their ability to follow detailed procedural instructions, synthesize and reason over dispersed information, and generate structured, long-form outputs (up to 8K tokens). Furthermore, as these tasks adhere to deterministic procedures and yield structured outputs, they enable reliable rule-based evaluation. We evaluated 23 LCLMs, including instruction-tuned models and recent reasoning models, on LongProc at three difficulty levels, with the maximum number of output tokens set at 500, 2K, and 8K. Notably, while all tested models claim a context window size above 32K tokens, open-weight models typically falter on 2K-token tasks, and closed-source models like GPT-4o show significant degradation on 8K-token tasks. Reasoning models achieve stronger overall performance in long-form generation, benefiting from long CoT training. Further analysis reveals that LCLMs struggle to maintain long-range coherence in long-form generations. These findings highlight critical limitations in current LCLMs and suggest substantial room for improvement. Data and code available at: https://princeton-pli.github.io/LongProc.
目前评估长语境语言模型(LCLM)的基准测试主要侧重于长语境回忆,要求模型在处理成千上万的无关标记时,基于几个关键片段产生短回复。我们引入了LongProc(长程序生成)这一新基准测试,它要求既整合高度分散的信息,又进行长文本生成。LongProc包含六个不同的程序生成任务,例如从HTML页面提取结构化信息并转换为TSV格式,以及执行复杂的搜索程序以创建旅行计划。这些任务通过测试LCLM遵循详细程序指令的能力、合成和推理分散信息的能力,以及生成结构化长文本输出(最多达8K标记)的能力来挑战LCLM。此外,由于这些任务遵循确定性程序并产生结构化输出,因此它们能够进行可靠的基于规则的评价。我们在三个难度级别上对23个LCLM进行了LongProc评估,包括指令调整模型和最新的推理模型,最大输出标记数设为500、2K和8K。值得注意的是,尽管所有测试模型的上下文窗口大小都超过32K标记,但开放权重模型通常在2K标记任务上表现不佳,而像GPT-4o这样的闭源模型在8K标记任务上表现出显著退化。推理模型在长文本生成方面整体表现更强,得益于长期上下文训练。进一步分析表明,LCLM在维持长文本生成中的长期连贯性方面存在困难。这些发现突出了当前LCLM的关键局限性,并表明存在大量改进空间。数据和代码可在https://princeton-pli.github.io/LongProc访问。
论文及项目相关链接
Summary
本文介绍了针对长语境语言模型(LCLM)的新基准测试LongProc。该测试包含一系列程序生成任务,要求模型在整合高度分散信息的同时进行长文本生成。任务挑战在于测试模型遵循详细程序指令、合成和推理分散信息的能力,并生成结构化、长形式的输出。对现有模型的评估发现,尽管模型声称能够处理超过32K标记的上下文窗口,但在长文本生成任务中仍存在显著局限性。
Key Takeaways
- LongProc是一个新的长语境语言模型(LCLM)基准测试,包括一系列程序生成任务,强调长文本生成的能力。
- LCLMs被要求在整合高度分散信息的同时进行生成,这要求模型具有较强的理解和推理能力。
- 测试的任务遵循确定性程序并产生结构化输出,从而可以进行可靠的规则基础评估。
- 在LongProc测试中评估了23个LCLM模型,发现即使在处理大量上下文信息时,这些模型在长文本生成方面仍存在局限性。
- 开放权重模型通常在2K标记任务上表现不佳,而封闭源模型如GPT-4o在8K标记任务上表现出显著退化。
- 推理模型在长文本生成方面表现较好,得益于其长期训练的优势。
点此查看论文截图



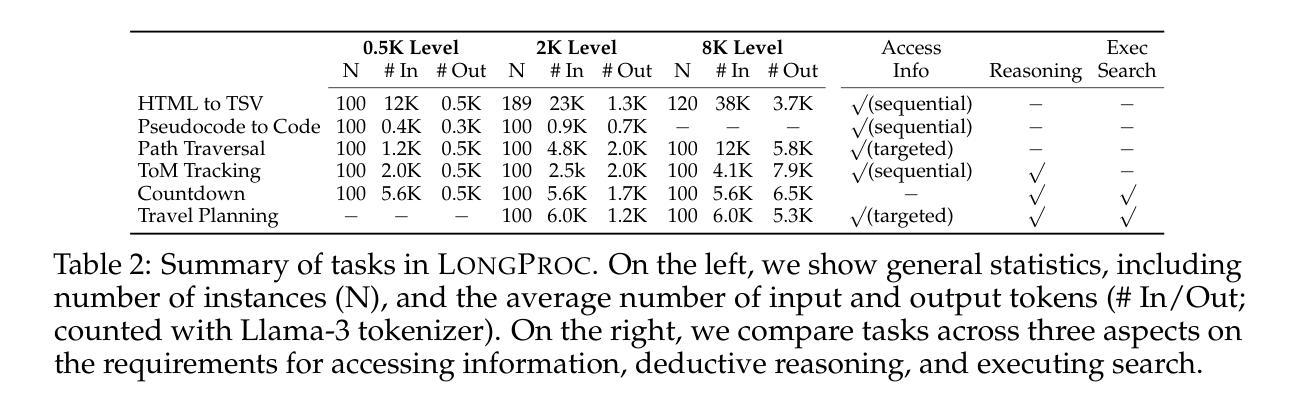
AI Predicts AGI: Leveraging AGI Forecasting and Peer Review to Explore LLMs’ Complex Reasoning Capabilities
Authors:Fabrizio Davide, Pietro Torre, Leonardo Ercolani, Andrea Gaggioli
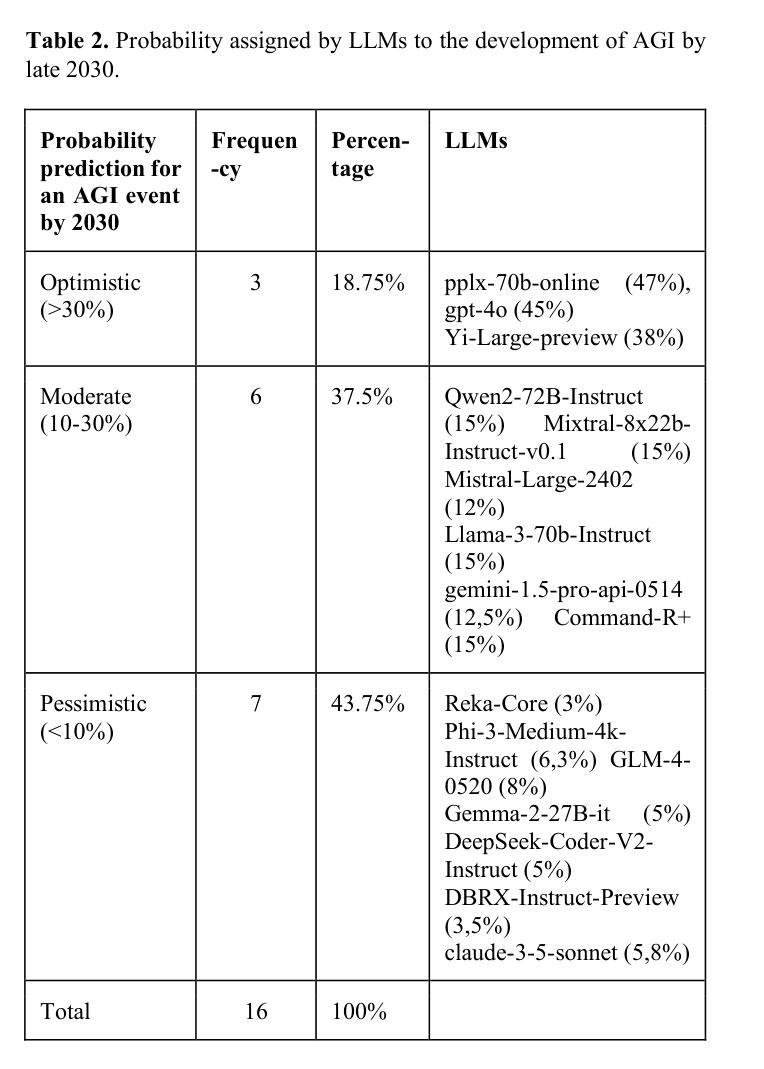
We tasked 16 state-of-the-art large language models (LLMs) with estimating the likelihood of Artificial General Intelligence (AGI) emerging by 2030. To assess the quality of these forecasts, we implemented an automated peer review process (LLM-PR). The LLMs’ estimates varied widely, ranging from 3% (Reka- Core) to 47.6% (GPT-4o), with a median of 12.5%. These estimates closely align with a recent expert survey that projected a 10% likelihood of AGI by 2027, underscoring the relevance of LLMs in forecasting complex, speculative scenarios. The LLM-PR process demonstrated strong reliability, evidenced by a high Intraclass Correlation Coefficient (ICC = 0.79), reflecting notable consistency in scoring across the models. Among the models, Pplx-70b-online emerged as the top performer, while Gemini-1.5-pro-api ranked the lowest. A cross-comparison with external benchmarks, such as LMSYS Chatbot Arena, revealed that LLM rankings remained consistent across different evaluation methods, suggesting that existing benchmarks may not encapsulate some of the skills relevant for AGI prediction. We further explored the use of weighting schemes based on external benchmarks, optimizing the alignment of LLMs’ predictions with human expert forecasts. This analysis led to the development of a new, ‘AGI benchmark’ designed to highlight performance differences in AGI-related tasks. Our findings offer insights into LLMs’ capabilities in speculative, interdisciplinary forecasting tasks and emphasize the growing need for innovative evaluation frameworks for assessing AI performance in complex, uncertain real-world scenarios.
我们让16个最先进的大型语言模型(LLM)预测到2030年出现通用人工智能(AGI)的可能性。为了评估这些预测的质量,我们实施了一个自动化的同行评审过程(LLM-PR)。这些大型语言模型的预测结果差异很大,从Reka-Core预测的3%到GPT-4o预测的47.6%,中位数为12.5%。这些预测结果与最近的一项专家调查相吻合,该调查预测到2027年AGI的出现概率为10%,这强调了大型语言模型在预测复杂和投机场景中的重要性。LLM-PR过程表现出很强的可靠性,同质性相关系数(ICC=0.79)很高,这表明各模型之间的评分存在显著的一致性。在模型中,Pplx-70b-online表现最好,而Gemini-1.5-pro-api排名最低。与外部基准测试(如LMSYS聊天机器人竞技场)的交叉对比显示,不同评估方法下的大型语言模型排名保持一致,这表明现有基准测试可能没有涵盖与AGI预测相关的一些技能。我们进一步探索了基于外部基准测试使用权重方案的方法,优化大型语言模型预测与人类专家预测的对齐。这一分析催生了一个新的“AGI基准测试”,旨在突出AGI相关任务中的性能差异。我们的研究洞察了大型语言模型在投机性、跨学科预测任务中的能力,并强调了评估人工智能在复杂、不确定的现实世界场景中的性能时,对创新评估框架的日益增长的需求。
论文及项目相关链接
PDF 47 pages, 8 figures, 17 tables, appendix with data and code
摘要
本文评估了16款先进的大型语言模型(LLMs)对2030年前出现通用人工智能(AGI)可能性的预测能力。通过实施自动化同行评审流程(LLM-PR),发现各模型的预测估计差异较大,从Reka-Core的3%到GPT-4o的47.6%,中位数为12.5%。这些预测与最近专家对2027年前AGI出现可能性的10%预测相吻合,突显了LLM在预测复杂假设情境方面的价值。LLM-PR流程可靠性高,评分一致性显著,其中Pplx-70b-online表现最佳,Gemini-1.5-pro-api表现最差。与外部基准测试(如LMSYS聊天机器人竞技场)的交叉比较显示,LLM排名在不同评估方法下保持一致,表明现有基准测试可能无法涵盖与AGI预测相关的部分技能。本文还探讨了基于外部基准的权重方案,优化LLMs预测与人类专家预测的对齐。分析后开发了一个全新的“AGI基准测试”,旨在突显在AGI相关任务中的性能差异。本研究结果深入了解LLMs在假设性跨学科预测任务中的能力,并强调了在复杂不确定的现实世界场景中评估人工智能性能时,对创新评估框架的日益需求。
关键见解
- 16款大型语言模型(LLMs)对人工通用智能(AGI)到2030年的出现时间进行了预测。
- LLMs的预测估计范围从3%到47.6%,中位数为12.5%,显示出了预测之间的巨大差异。
- LLMs的预测与专家对AGI在不久的将来出现的预测相符,突出了它们在预测复杂假设情境方面的价值。
- LLM-PR流程显示出强大的可靠性,评分一致性高。
- 在所有评估的LLMs中,Pplx-70b-online表现最佳,而Gemini-1.5-pro-api表现最差。
- 与外部基准测试的比较表明,现有的基准测试可能无法全面评估与AGI预测相关的技能。
点此查看论文截图

Towards Unifying Evaluation of Counterfactual Explanations: Leveraging Large Language Models for Human-Centric Assessments
Authors:Marharyta Domnich, Julius Välja, Rasmus Moorits Veski, Giacomo Magnifico, Kadi Tulver, Eduard Barbu, Raul Vicente
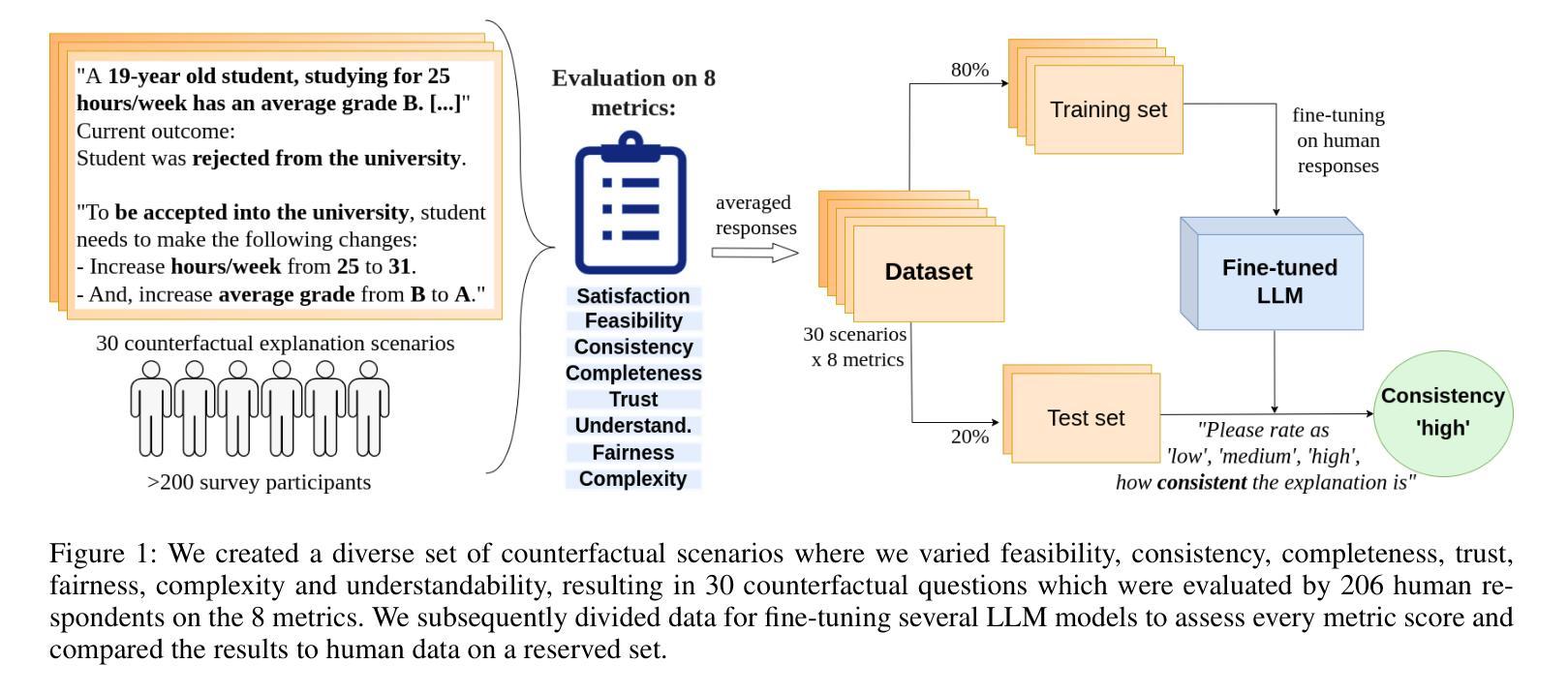
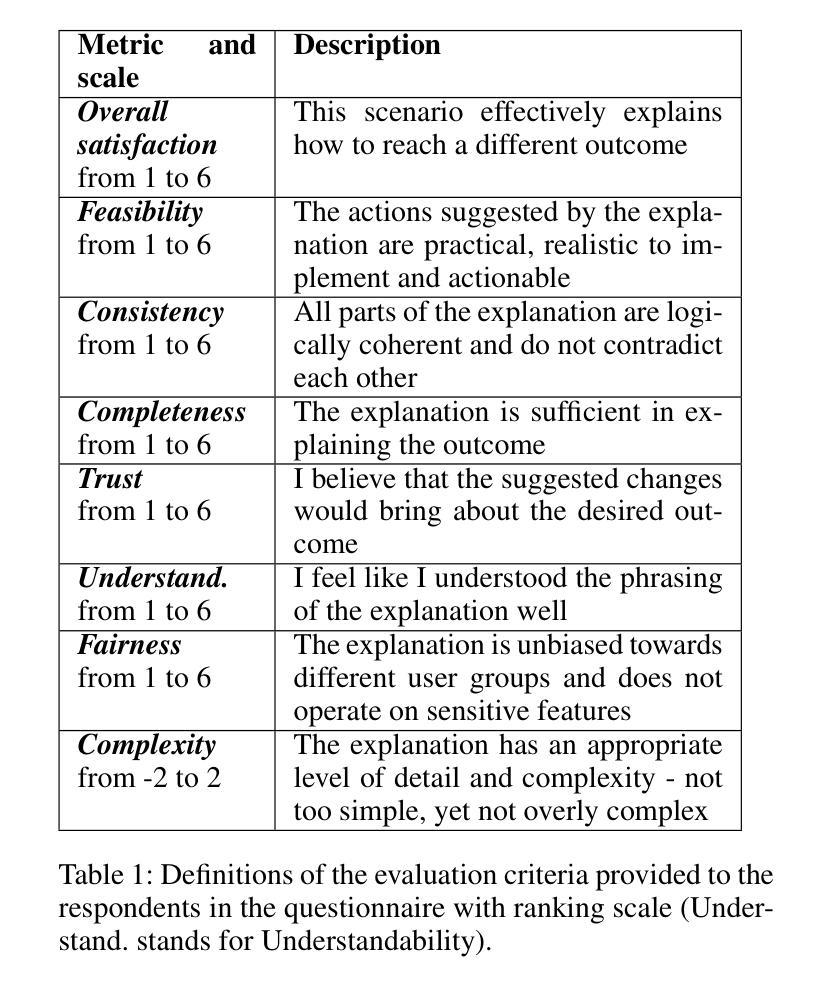
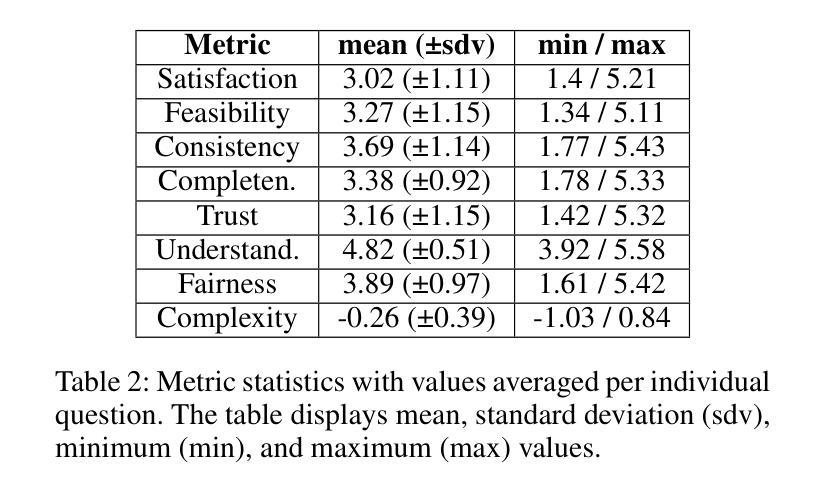
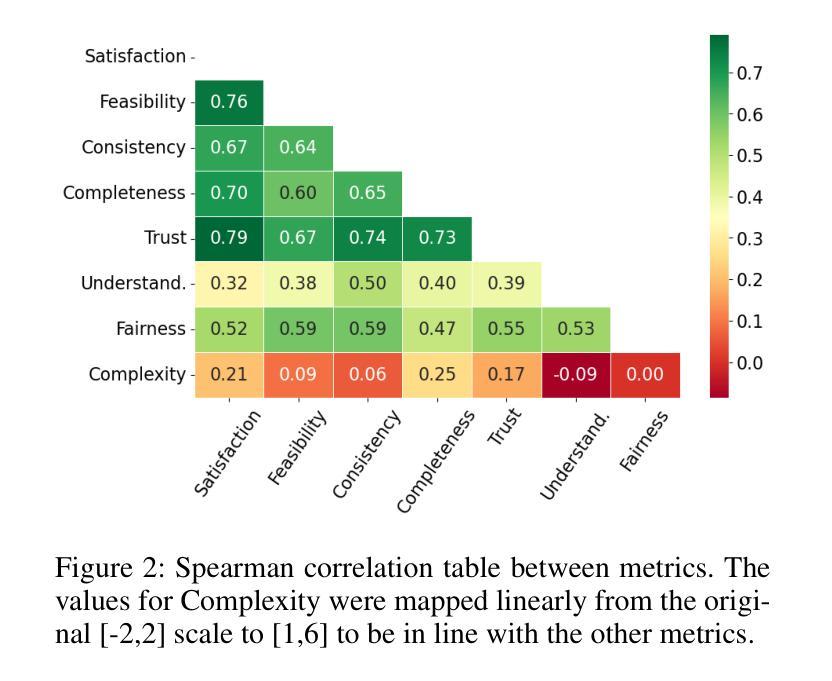
As machine learning models evolve, maintaining transparency demands more human-centric explainable AI techniques. Counterfactual explanations, with roots in human reasoning, identify the minimal input changes needed to obtain a given output and, hence, are crucial for supporting decision-making. Despite their importance, the evaluation of these explanations often lacks grounding in user studies and remains fragmented, with existing metrics not fully capturing human perspectives. To address this challenge, we developed a diverse set of 30 counterfactual scenarios and collected ratings across 8 evaluation metrics from 206 respondents. Subsequently, we fine-tuned different Large Language Models (LLMs) to predict average or individual human judgment across these metrics. Our methodology allowed LLMs to achieve an accuracy of up to 63% in zero-shot evaluations and 85% (over a 3-classes prediction) with fine-tuning across all metrics. The fine-tuned models predicting human ratings offer better comparability and scalability in evaluating different counterfactual explanation frameworks.
随着机器学习模型的发展,保持透明度需要更多以人为中心的可解释人工智能技术。归因于人类推理的因果解释,能够识别获得给定输出所需的最小输入变化,因此,对于支持决策制定至关重要。尽管因果解释很重要,但其评估往往缺乏用户研究的依据,并且仍然呈现碎片化,现有指标未能完全捕捉人类视角。为了应对这一挑战,我们开发了一套30种不同的因果场景,并从206名受访者中收集了8项评估指标的评分。随后,我们对不同的大型语言模型(LLM)进行了微调,以预测这些指标的平均值或个人判断。我们的方法允许大型语言模型在零样本评估中达到高达63%的准确率,在所有指标上进行微调后达到85%(针对三类预测)。经过微调可预测人类评分的模型在评估不同的因果解释框架时提供了更好的可比性和可扩展性。
论文及项目相关链接
PDF This paper extends the AAAI-2025 version by including the Appendix
Summary
随着机器学习模型的发展,保持透明度需要更多以人为中心的解释性人工智能技术。本文中,我们提出利用根植于人类推理中的反事实解释(counterfactual explanations)的重要性。尽管这些解释很关键,但评估时却经常缺乏用户研究的依据,并且评估方法碎片化严重,现有指标未能充分捕捉人类视角。为解决此问题,我们开发了一套多元化的反事实场景,收集了对八个评价指标的评级数据,并对大型语言模型(LLM)进行微调以预测人类对此的平均评价或个别评价。通过此研究方法,LLM在零样本评估中的准确率达到了最高为63%,在所有评价指标中经过微调后达到最高为85%(三类预测)。这些经过训练的模型预测人类评级提供了更好的可比性和可扩展性,以评估不同的反事实解释框架。总体而言,本论文揭示了评估反事实解释的新方法及其在机器学习模型中的应用前景。
Key Takeaways
- 随着机器学习模型的发展,保持透明度变得至关重要,需要更以人为中心的解释性人工智能技术的支持。
- 反事实解释在机器学习模型的决策过程中起着关键作用,能够识别获得特定输出所需的最小输入变化。
- 当前反事实解释的评估方法存在局限性,缺乏用户研究的依据,现有指标无法全面反映人类视角和需求。
- 通过开发多元化的反事实场景和收集评价数据,可以更好地评估大型语言模型的性能。
- 通过对大型语言模型的微调,使其能够预测人类对评价指标的评估结果,提高了评估的可比性和可扩展性。
- 经过训练的模型在零样本评估和微调后的准确率分别达到了最高为63%和最高为85%,显示出良好的性能表现。
点此查看论文截图