⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-24 更新
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
Authors:Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, Mike Zheng Shou
Recent video large language models (Video LLMs) often depend on costly human annotations or proprietary model APIs (e.g., GPT-4o) to produce training data, which limits their training at scale. In this paper, we explore large-scale training for Video LLM with cheap automatic speech recognition (ASR) transcripts. Specifically, we propose a novel streaming training approach that densely interleaves the ASR words and video frames according to their timestamps. Compared to previous studies in vision-language representation with ASR, our method naturally fits the streaming characteristics of ASR, thus enabling the model to learn temporally-aligned, fine-grained vision-language modeling. To support the training algorithm, we introduce a data production pipeline to process YouTube videos and their closed captions (CC, same as ASR), resulting in Live-CC-5M dataset for pre-training and Live-WhisperX-526K dataset for high-quality supervised fine-tuning (SFT). Remarkably, even without SFT, the ASR-only pre-trained LiveCC-7B-Base model demonstrates competitive general video QA performance and exhibits a new capability in real-time video commentary. To evaluate this, we carefully design a new LiveSports-3K benchmark, using LLM-as-a-judge to measure the free-form commentary. Experiments show our final LiveCC-7B-Instruct model can surpass advanced 72B models (Qwen2.5-VL-72B-Instruct, LLaVA-Video-72B) in commentary quality even working in a real-time mode. Meanwhile, it achieves state-of-the-art results at the 7B/8B scale on popular video QA benchmarks such as VideoMME and OVOBench, demonstrating the broad generalizability of our approach. All resources of this paper have been released at https://showlab.github.io/livecc.
近期视频大型语言模型(Video LLMs)通常依赖于昂贵的人工标注或专有模型API(例如GPT-4o)来生成训练数据,这限制了其大规模训练。在本文中,我们探索使用廉价的自动语音识别(ASR)转录数据对Video LLM进行大规模训练。具体来说,我们提出了一种新型流式训练方法,根据时间戳密集地交织ASR词汇和视频帧。与以往使用ASR的跨视觉语言表示研究相比,我们的方法自然地适应ASR的流式特性,从而使模型能够学习时序对齐的精细粒度视觉语言建模。为了支持训练算法,我们引入了数据处理管道,用于处理YouTube视频及其封闭字幕(CC,与ASR相同),从而生成用于预训练的Live-CC-5M数据集和用于高质量监督微调(SFT)的Live-Whisperx-526K数据集。值得注意的是,即使没有SFT,仅使用ASR预训练的LiveCC-7B-Base模型也表现出具有竞争力的通用视频问答性能,并展现出实时视频评论的新能力。为了评估此性能,我们精心设计了新的LiveSports-3K基准测试,利用LLM-as-a-judge来衡量自由形式的评论。实验表明,我们的最终LiveCC-7B-Instruct模型即使在实时模式下,在评论质量方面也能超越先进的72B模型(Qwen2.5-VL-72B-Instruct、LLaVA-Video-72B)。同时,它在流行的视频QA基准测试(如VideoMME和OVOBench)上达到了7B/8B规模的最佳结果,证明了我们的方法的广泛通用性。本论文的所有资源已发布在https://showlab.github.io/livecc。
论文及项目相关链接
PDF CVPR 2025. If any references are missing, please contact joyachen@u.nus.edu
Summary
该论文提出了一种利用低成本自动语音识别(ASR)转录大规模训练视频大型语言模型(Video LLM)的新方法。通过密集交织ASR词汇和视频帧,建立了一种流式训练策略。该研究引入了数据处理管道,以处理YouTube视频及其关闭字幕(CC,与ASR相同),并发布了用于预训练和精细调整的Live-CC数据集。实验表明,仅使用ASR预训练的模型具有竞争力的视频问答性能,并展现出实时视频评论的新能力。
Key Takeaways
- 论文提出了一种利用低成本ASR转录进行大规模训练Video LLM的新方法。
- 论文提出了一个流式训练策略,通过密集交织ASR词汇和视频帧进行训练。
- 论文引入了数据处理管道,处理YouTube视频及其关闭字幕,创建了Live-CC数据集用于预训练和精细调整。
- 仅使用ASR预训练的模型具有竞争力的视频问答性能。
- 模型展现出实时视频评论的新能力。
- 论文设计的LiveSports-3K基准测试用于评估模型在自由形式评论方面的性能。
点此查看论文截图

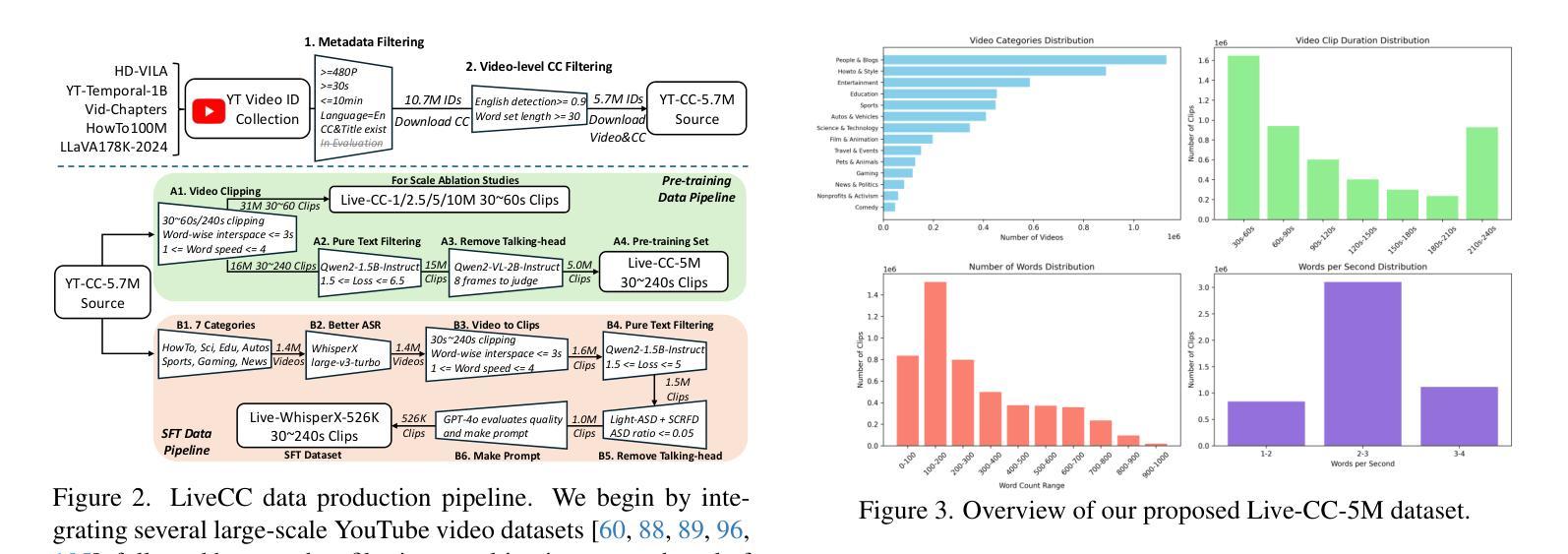
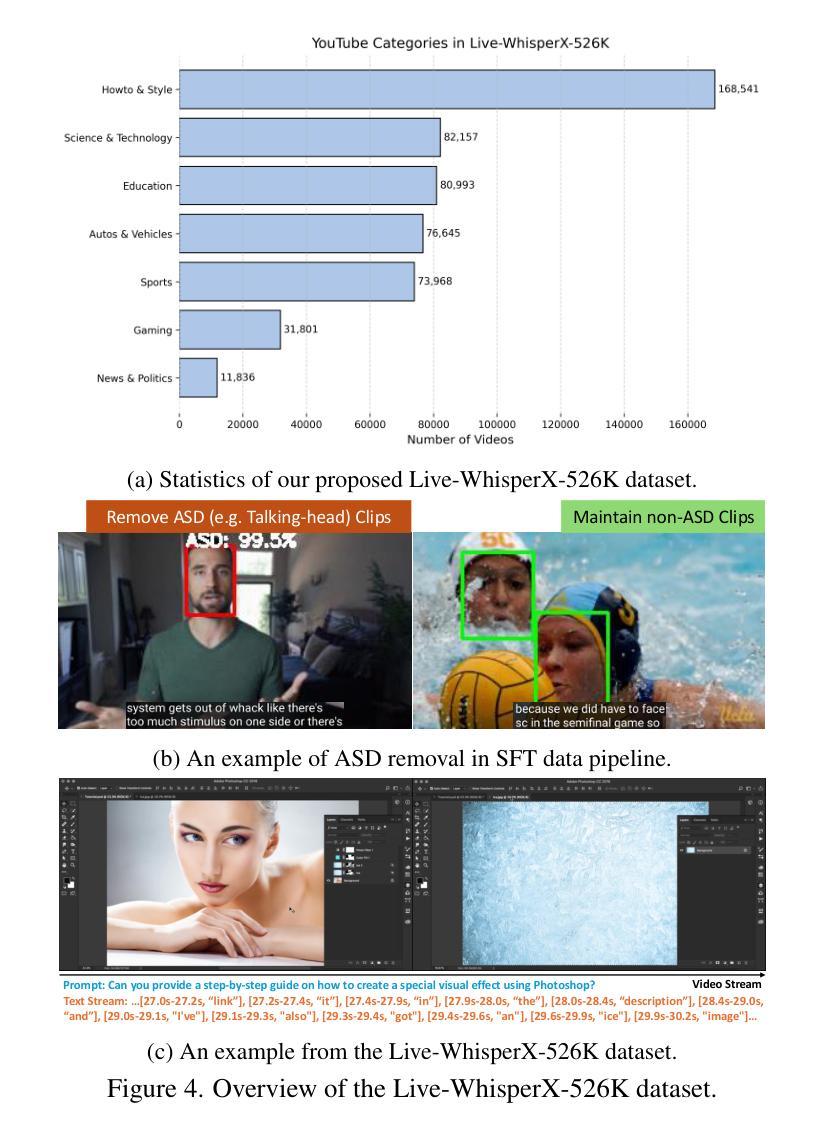
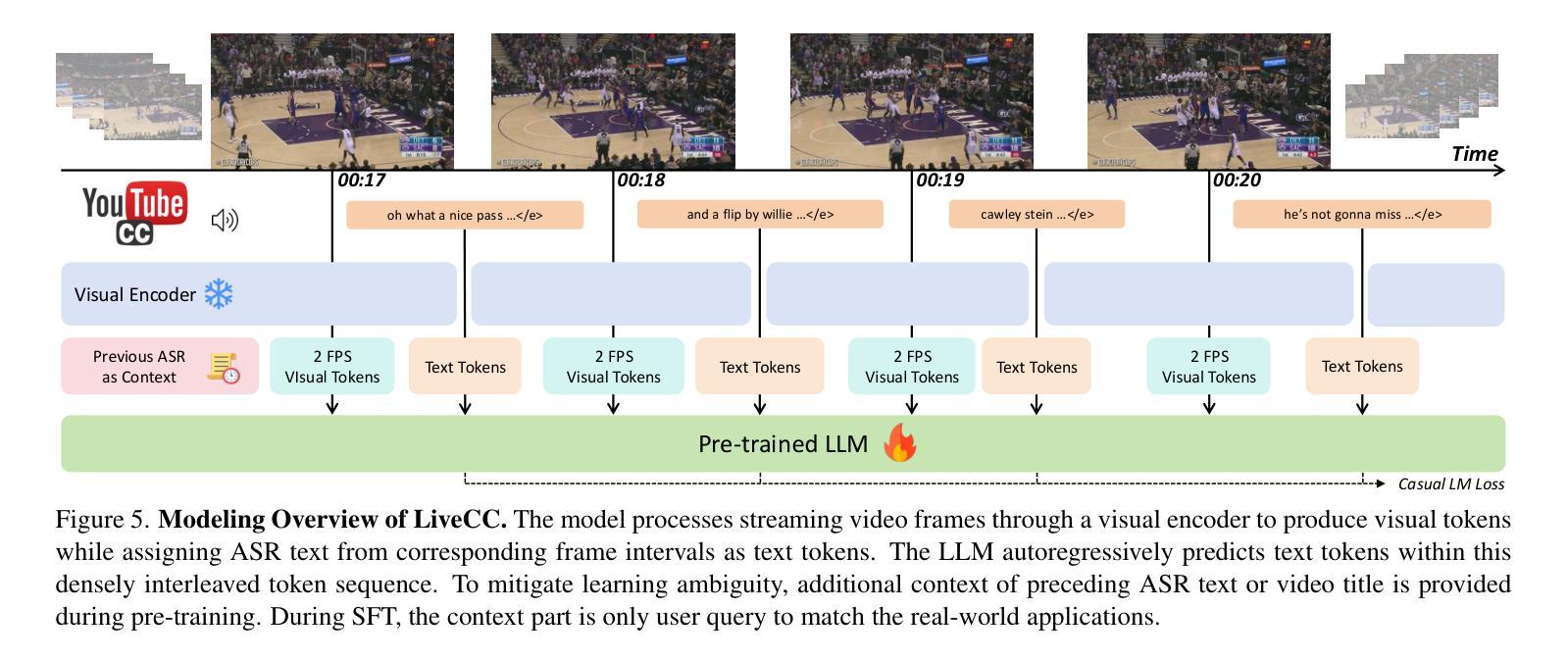
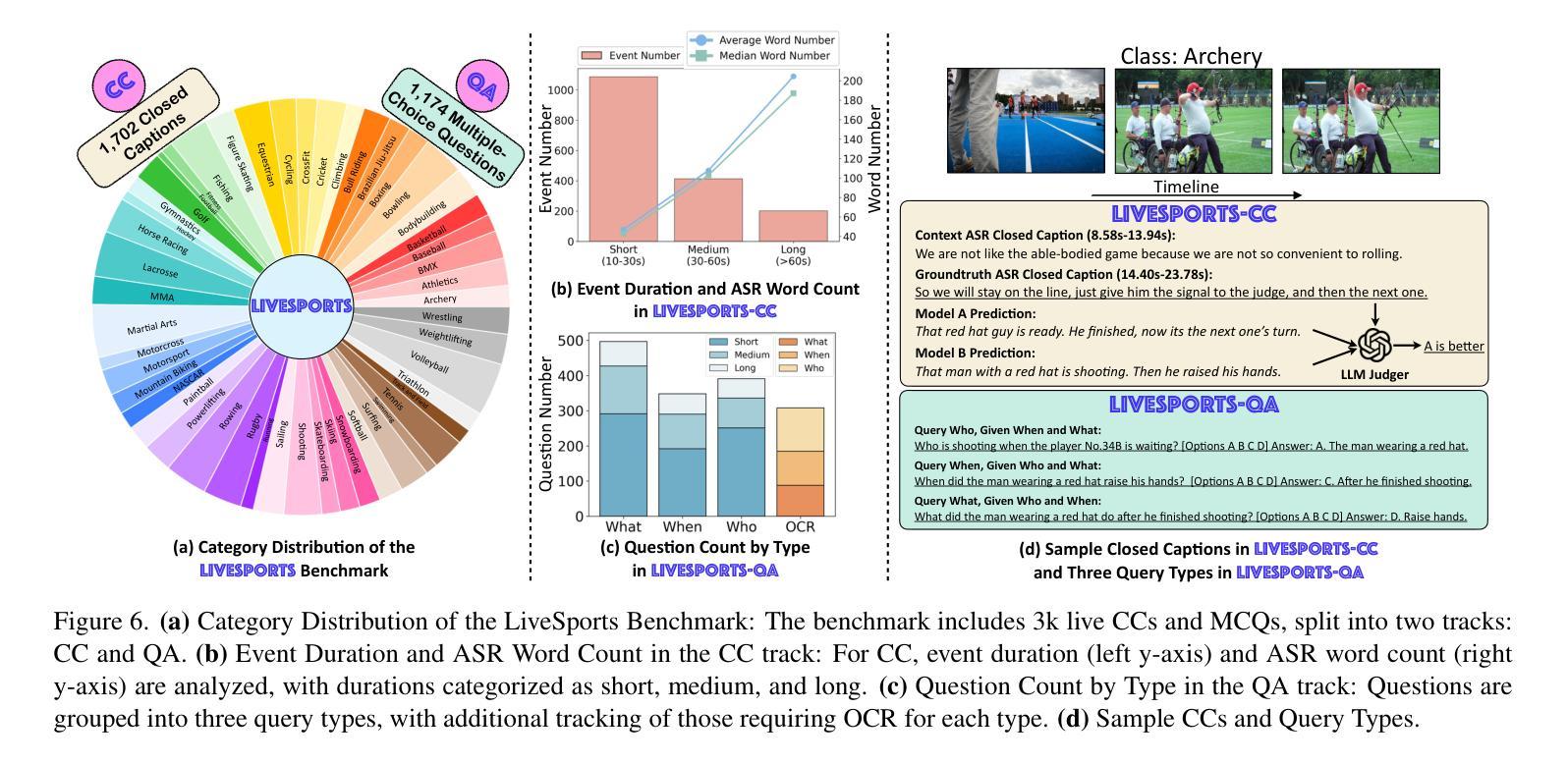
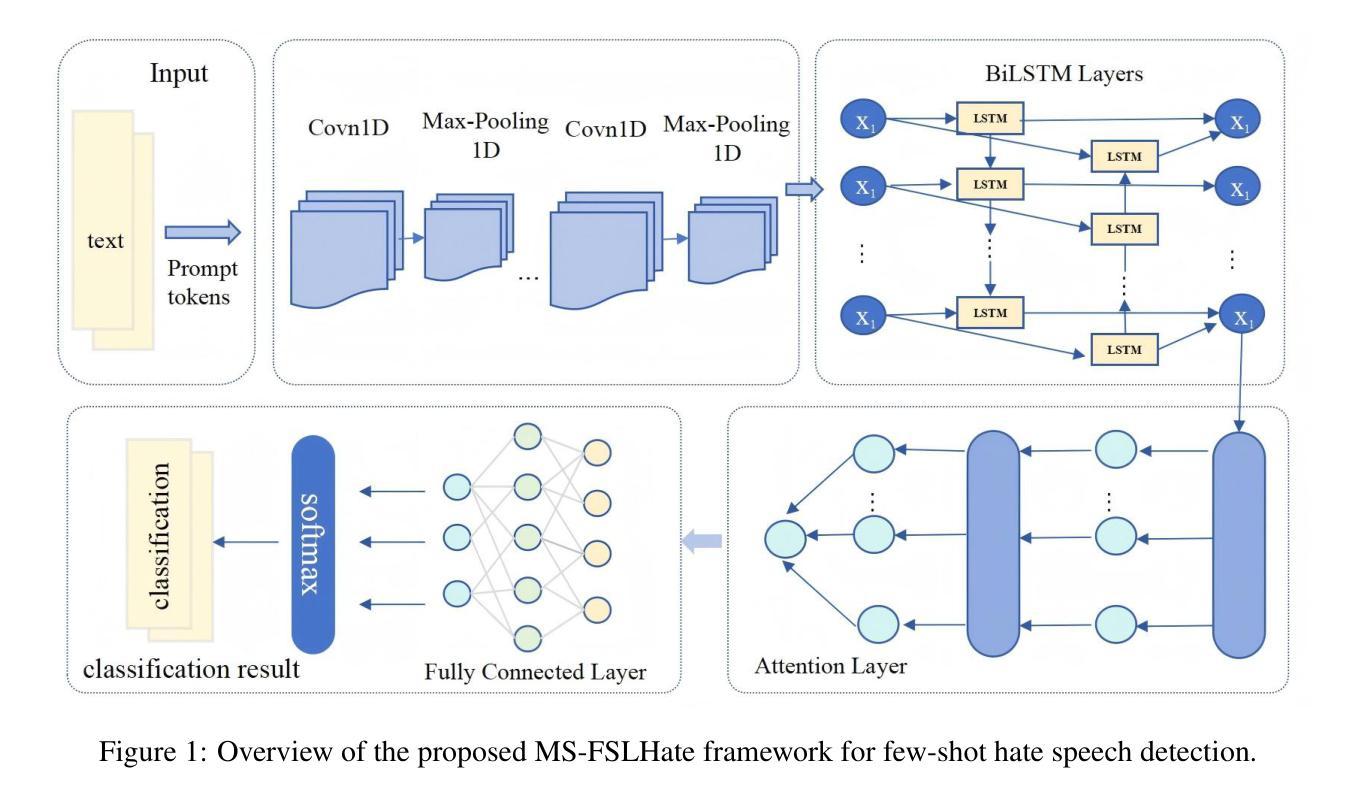
Few-shot Hate Speech Detection Based on the MindSpore Framework
Authors:Zhenkai Qin, Dongze Wu, Yuxin Liu, Guifang Yang
The proliferation of hate speech on social media poses a significant threat to online communities, requiring effective detection systems. While deep learning models have shown promise, their performance often deteriorates in few-shot or low-resource settings due to reliance on large annotated corpora. To address this, we propose MS-FSLHate, a prompt-enhanced neural framework for few-shot hate speech detection implemented on the MindSpore deep learning platform. The model integrates learnable prompt embeddings, a CNN-BiLSTM backbone with attention pooling, and synonym-based adversarial data augmentation to improve generalization. Experimental results on two benchmark datasets-HateXplain and HSOL-demonstrate that our approach outperforms competitive baselines in precision, recall, and F1-score. Additionally, the framework shows high efficiency and scalability, suggesting its suitability for deployment in resource-constrained environments. These findings highlight the potential of combining prompt-based learning with adversarial augmentation for robust and adaptable hate speech detection in few-shot scenarios.
社交媒体上仇恨言论的激增对在线社区构成了重大威胁,需要有效的检测系统。虽然深度学习模型显示出了一定的前景,但由于它们依赖于大量标注语料库,因此在小样本或资源匮乏的环境中,其性能往往会下降。为了解决这一问题,我们提出了基于MindSpore深度学习平台的MS-FSLHate,这是一个用于小样本仇恨言论检测的提示增强神经网络框架。该模型集成了可学习的提示嵌入、带有注意力池的CNN-BiLSTM主干和基于同义词的对抗数据增强,以提高通用性。在HateXplain和HSOL两个基准数据集上的实验结果表明,我们的方法在精确度、召回率和F1分数方面优于竞争基线。此外,该框架显示出高效率和高可扩展性,表明它适合在资源受限的环境中部署。这些发现强调了将基于提示的学习与对抗性增强相结合,在少量样本情况下实现稳健和适应性的仇恨言论检测的潜力。
论文及项目相关链接
摘要
社交媒体上仇恨言论的泛滥对在线社区构成重大威胁,需要有效的检测系统进行应对。深度学习模型虽然显示出潜力,但在小样本或资源有限的环境中,由于其依赖大量注释语料库,性能往往会下降。为解决这一问题,我们提出基于MindSpore深度学习平台的MS-FSLHate框架,该框架采用提示增强神经网络进行小样本仇恨言论检测。该模型集成了可学习的提示嵌入、带有注意力池的CNN-BiLSTM主干和基于同义词的对抗数据增强,以提高泛化能力。在HateXplain和HSOL两个基准数据集上的实验结果表明,我们的方法在精确度、召回率和F1分数方面优于竞争对手的基线。此外,该框架显示出高效率和高可扩展性,适合在资源受限的环境中部署。这些发现突出了在少样本情况下,结合提示式学习与对抗性增强进行稳健和适应性仇恨言论检测的巨大潜力。
要点掌握
- 社交媒体上的仇恨言论泛滥对在线社区构成威胁,需要有效的检测手段。
- 现有深度学习模型在资源有限的环境中性能受限,依赖大量注释语料库。
- 提出基于MindSpore平台的MS-FSLHate框架,采用提示增强神经网络进行小样本仇恨言论检测。
- 模型集成了可学习的提示嵌入、CNN-BiLSTM主干和注意力池,以及基于同义词的对抗数据增强。
- 实验结果表明,该框架在精确度和召回率等方面优于其他方法。
- 框架具有高效率和高可扩展性,适合资源受限的环境。
点此查看论文截图

EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Authors:Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, ShiLiang Zhang, Xie Chen
Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
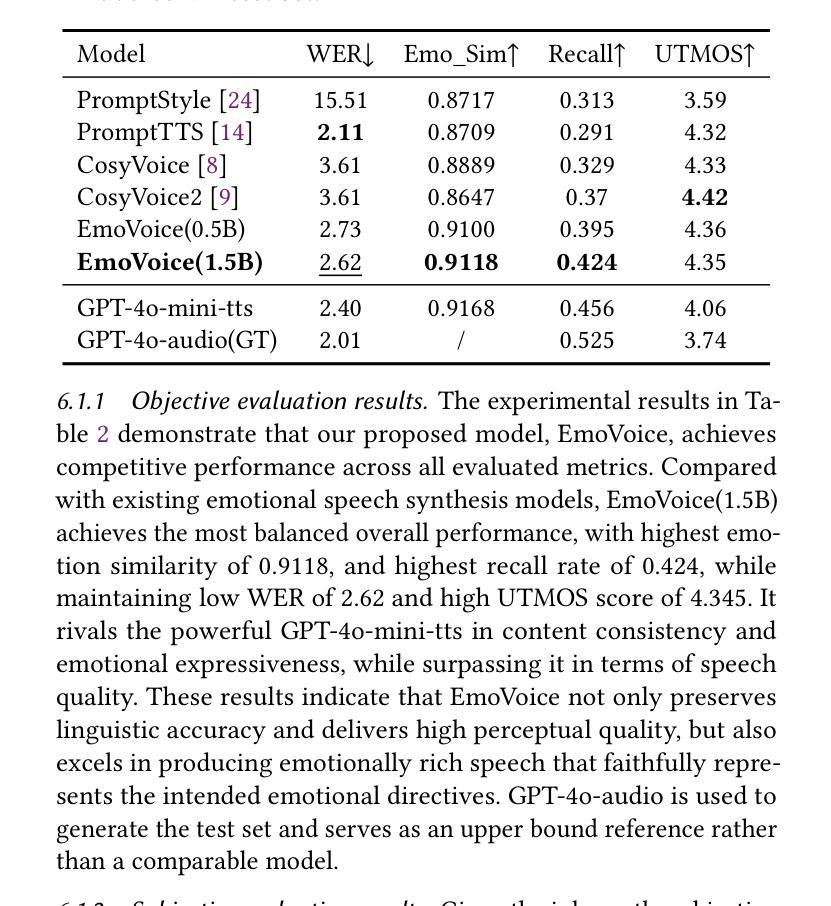
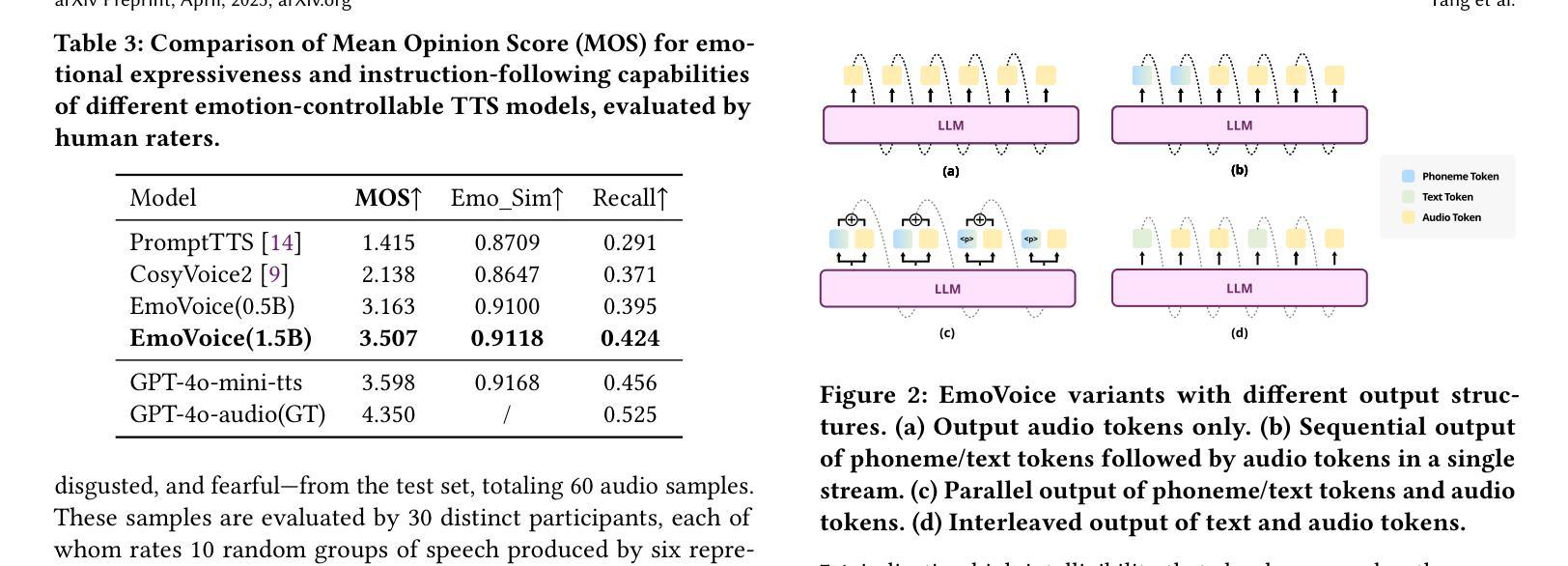
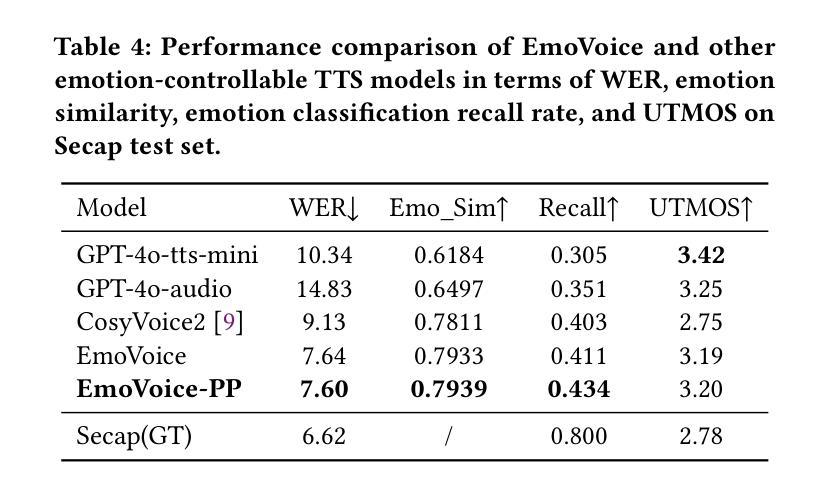
人类语音不仅仅是为了传递信息,更是一种深刻的情感交流和个人之间的连接。尽管文本转语音(TTS)模型已经取得了巨大的进步,但在控制生成语音的情感表达方面仍然面临挑战。在这项工作中,我们提出了EmoVoice,这是一种新型的情感可控TTS模型,它利用大型语言模型(LLM)来实现精细的自由形式自然语言情感控制,以及一种并行输出音素标记和音频标记的变体设计,以提高内容的一致性,这一设计灵感来源于思维链(CoT)和模态链(CoM)技术。此外,我们还介绍了EmoVoice-DB,这是一个高质量、以表达性语音和精细情感标签为特色的英语情感数据集,其中包含自然语言描述。EmoVoice仅使用合成训练数据在英文EmoVoice-DB测试集上实现了最先进的性能,并在使用我们内部数据的中文Secap测试集上表现出色。我们进一步研究了现有情感评估指标的可靠性及其与人类感知偏好的一致性,并探讨了使用最先进的多模态LLM GPT-4o-audio和Gemini来评估情感语音。演示样品可在https://yanghaha0908.github.io/EmoVoice/找到。数据集、代码和检查点将一并发布。
论文及项目相关链接
Summary
本文介绍了一种名为EmoVoice的新型情感可控文本转语音模型。该模型利用大型语言模型实现精细自由式自然语言情感控制,采用并行输出语音令牌和音频令牌的方法增强内容一致性。此外,文章还介绍了高质量的情感数据集EmoVoice-DB,以及模型在多个测试集上的表现。最后探讨了现有情感评估指标的可靠性及其与人类感知偏好的一致性。
Key Takeaways
- EmoVoice是一种情感可控的文本转语音(TTS)模型,借助大型语言模型(LLM)实现精细的自由式自然语言情感控制。
- EmoVoice模型采用并行输出语音令牌和音频令牌的设计,以增强内容一致性,该设计灵感来源于思维链和模态链技术。
- 介绍了高质量的情感数据集EmoVoice-DB,包含表达性语音和精细的情感标签以及自然语言描述。
- EmoVoice在多个测试集上表现优异,包括使用合成训练数据的英语EmoVoice-DB测试集和使用内部数据的中文Secap测试集。
- 文章探讨了现有情感评估指标的可靠性,并研究了它们与人类感知偏好的一致性。
- 提供了模型演示样本,并计划发布数据集、代码和检查点。
点此查看论文截图


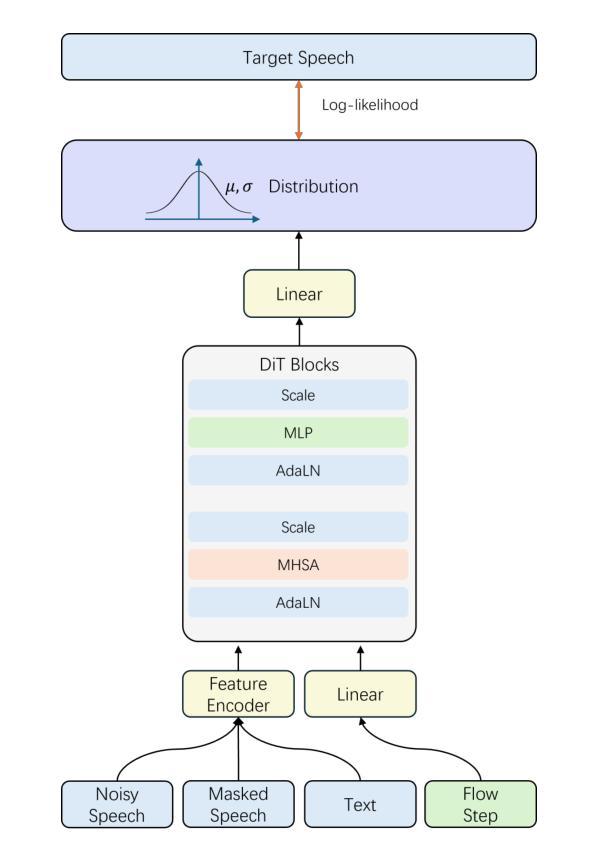
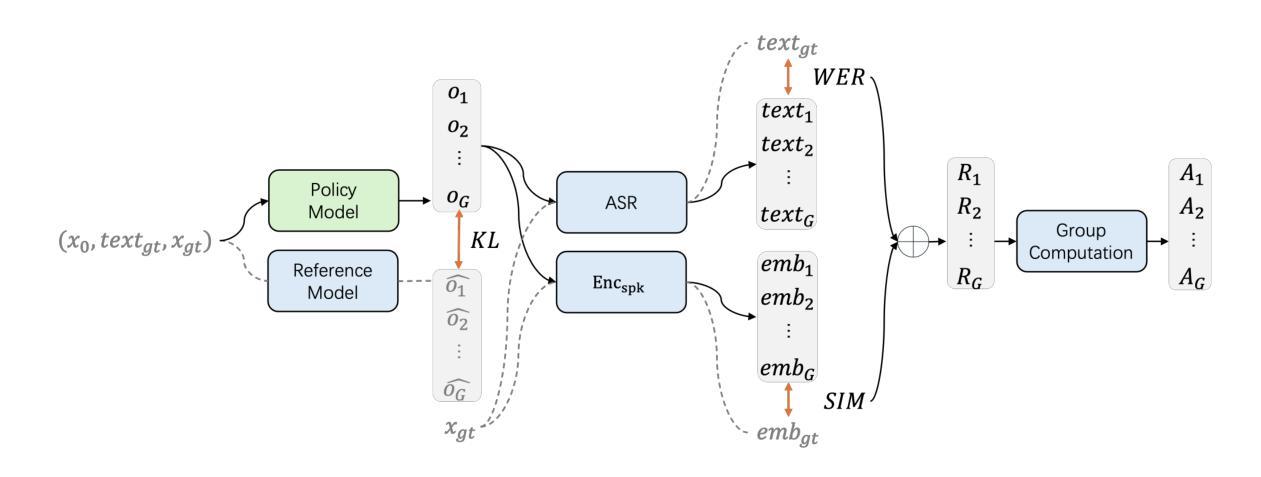
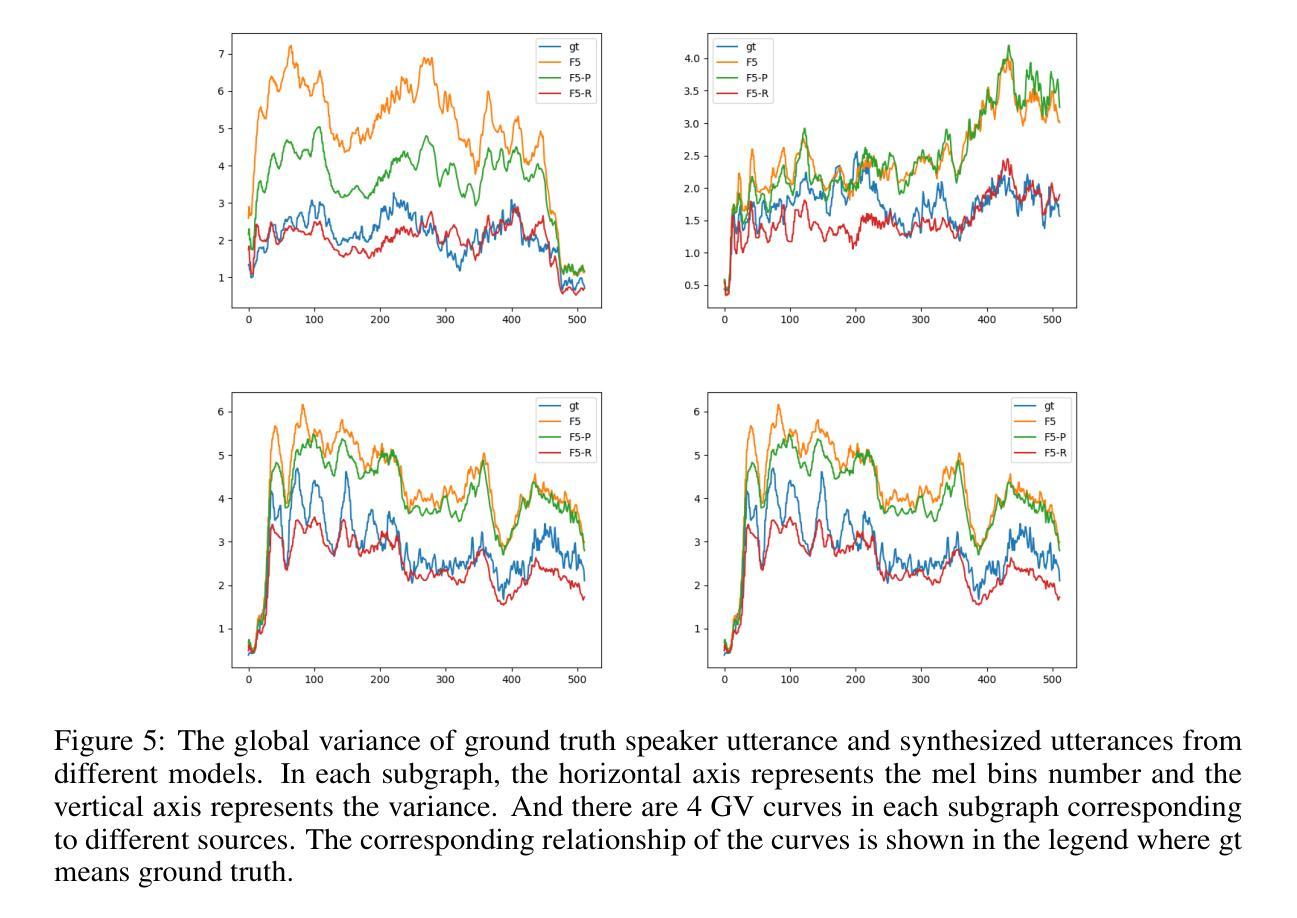
F5R-TTS: Improving Flow-Matching based Text-to-Speech with Group Relative Policy Optimization
Authors:Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, Baoxun Wang
We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Group Relative Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (a 29.5% relative reduction in WER) and speaker similarity (a 4.6% relative increase in SIM score) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
我们介绍了F5R-TTS,这是一种新型文本到语音(TTS)系统,它将组相对策略优化(GRPO)集成到基于流量匹配的架构中。通过重新制定流量匹配TTS的确定性输出为概率高斯分布,我们的方法能够实现强化学习算法的无缝集成。在预训练阶段,我们使用公开数据集对基于流量匹配的概率重构模型进行训练,该模型源于F5-TTS。在随后的强化学习(RL)阶段,我们采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的词错误率(WER)和通过验证模型评估的发音人相似性(SIM)。在零样本声音克隆上的实验结果表明,与传统的基于流量匹配的TTS系统相比,F5R-TTS在语音清晰度(相对降低了29.5%的WER)和发音人相似性(相对提高了4.6%的SIM得分)方面取得了显著改进。音频样本可在https://frontierlabs.github.io/F5R上获得。
论文及项目相关链接
Summary
本文介绍了F5R-TTS,这是一种新型文本转语音(TTS)系统,它将集团相对策略优化(GRPO)融入基于流程匹配的架构中。通过将在流程匹配过程中生成的确定性输出转换为概率高斯分布,实现强化学习算法的无缝集成。实验结果表明,与常规流程匹配TTS系统相比,F5R-TTS在零样本语音克隆任务中显著提高了语音的清晰度和语音相似性。
Key Takeaways
- F5R-TTS是一种新型的文本转语音(TTS)系统。
- 它集成了集团相对策略优化(GRPO)技术,提升性能。
- F5R-TTS使用概率重构的流程匹配模型进行预训练。
- 强化学习算法在F5R-TTS中得到无缝集成。
- F5R-TTS通过两个奖励指标:通过自动语音识别计算的字错误率(WER)和通过验证模型评估的说话人相似性(SIM)。
- 实验结果表明,F5R-TTS在零样本语音克隆任务中显著提高了语音清晰度和相似性。
点此查看论文截图