⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-24 更新
TTRL: Test-Time Reinforcement Learning
Authors:Yuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, Bowen Zhou
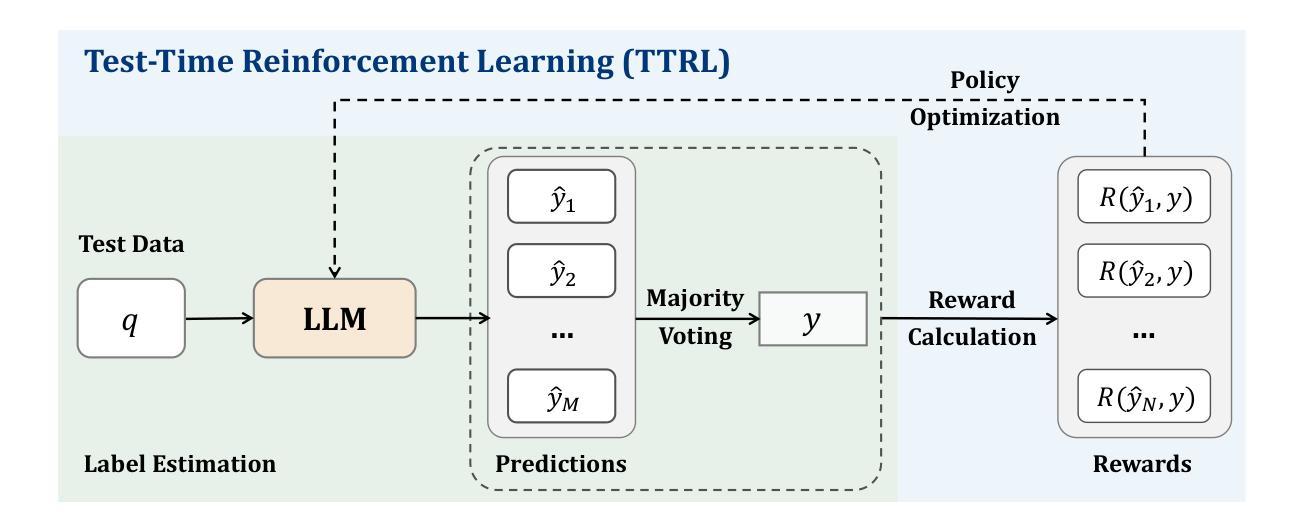
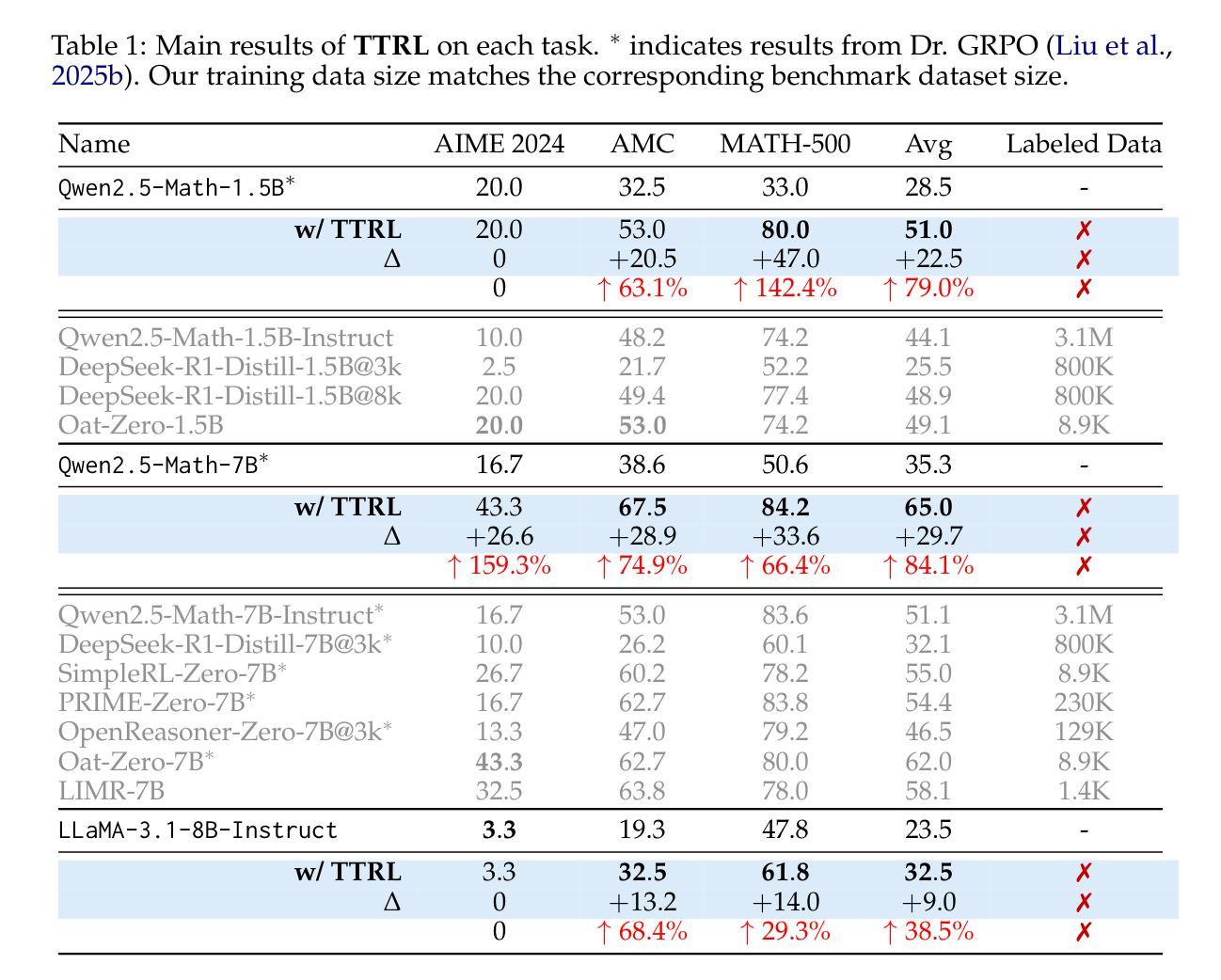
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 159% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the Maj@N metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks, and highlight TTRL’s potential for broader tasks and domains. GitHub: https://github.com/PRIME-RL/TTRL
本文探讨了在大语言模型(LLM)的推理任务中,在无明确标签数据上应用强化学习(RL)的情况。该问题的核心挑战在于在推理过程中进行奖励估计,同时无法获取真实信息。尽管这一设置看似难以捉摸,但我们发现测试时间缩放(TTS)中的常见做法,例如多数投票,产生了意想不到的有效奖励,适用于驱动RL训练。在这项工作中,我们引入了测试时间强化学习(TTRL),这是一种使用无标签数据对LLM进行RL训练的新方法。TTRL利用预训练模型中的先验知识,使LLM能够自我进化。实验表明,TTRL在各种任务和模型上的性能持续提高。值得注意的是,TTRL将Qwen-2.5-Math-7B的pass@1性能提高了大约159%,在AIME 2024上仅使用无标签测试数据。此外,尽管TTRL只受到Maj@N指标的监督,但其性能却持续超越初始模型的上限,并接近直接在带有真实标签的测试数据上训练的模型的性能。我们的实验结果表明TTRL在各种任务中的普遍有效性,并突出了其在更广泛的任务和领域中的潜力。GitHub:https://github.com/PRIME-rl/TTRL
论文及项目相关链接
Summary
本文探讨了在大规模语言模型(LLM)的推理任务中,如何在无明确标签的数据上应用强化学习(RL)。文章的核心挑战在于在推理过程中进行奖励估算,同时无法获取真实信息。尽管这一设定看似困难,但研究发现测试时间缩放(TTS)的常见方法,如多数投票,能产生出人意料的有效奖励,适用于驱动RL训练。为此,本文提出了测试时间强化学习(TTRL)这一新方法,用于在无标签数据上训练LLM。TTRL利用预训练模型中的先验知识,实现LLM的自我进化。实验表明,TTRL在各种任务和模型上的表现持续提高。特别是在AIME 2024的Qwen-2.5-Math-7B任务上,TTRL在仅使用无标签测试数据的情况下,将pass@1性能提高了约159%。尽管TTRL仅受Maj@N指标的监督,但其表现持续超越初始模型的上限,并接近直接在带有真实标签的测试数据上训练的模型的表现。
Key Takeaways
- 本文探索了在大规模语言模型(LLM)的推理任务中,如何在无标签数据上应用强化学习(RL)。
- 测试时间强化学习(TTRL)是一种新的训练LLM的方法,利用无标签数据结合强化学习进行自我进化。
- TTRL通过使用预训练模型中的先验知识来优化性能。
- 实验结果显示,TTRL在各种任务上的表现均有所提升,特别是在特定的数学任务上,性能提升显著。
- TTRL的表现超越了初始模型的上限,并接近在真实标签数据上训练的模型的表现。
- TTRL采用了测试时间缩放(TTS)的常见方法,如多数投票,以产生有效的奖励驱动RL训练。
点此查看论文截图

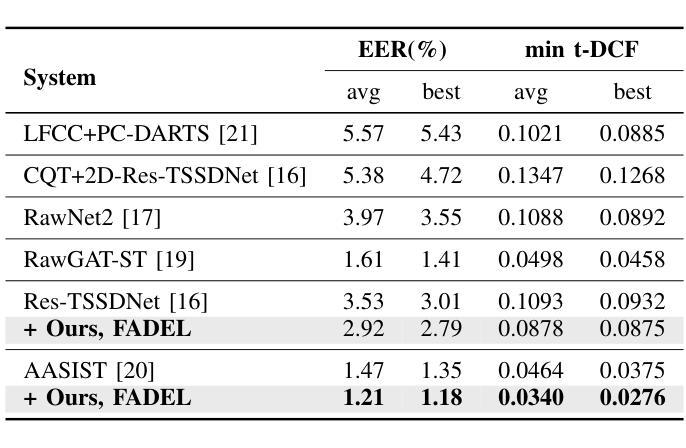
FADEL: Uncertainty-aware Fake Audio Detection with Evidential Deep Learning
Authors:Ju Yeon Kang, Ji Won Yoon, Semin Kim, Min Hyun Han, Nam Soo Kim
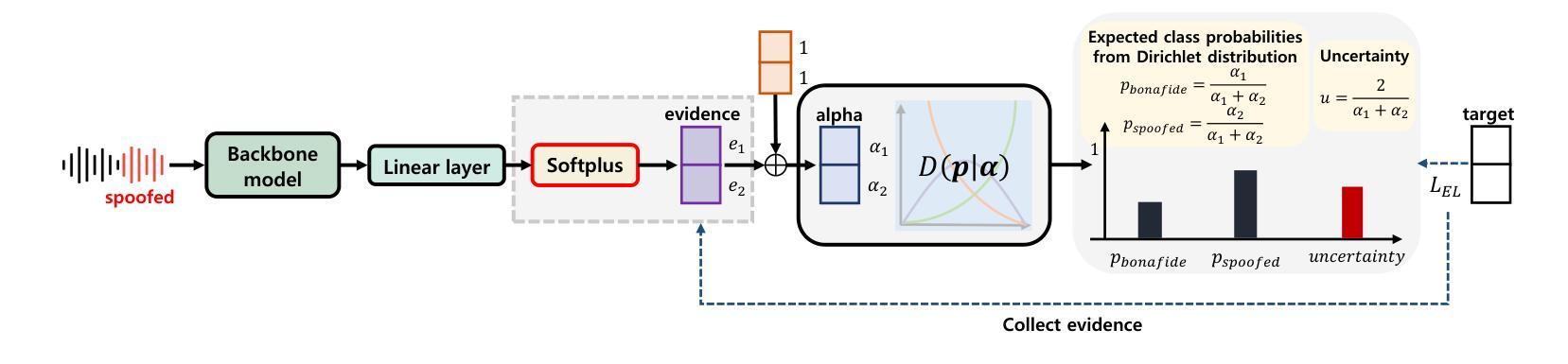
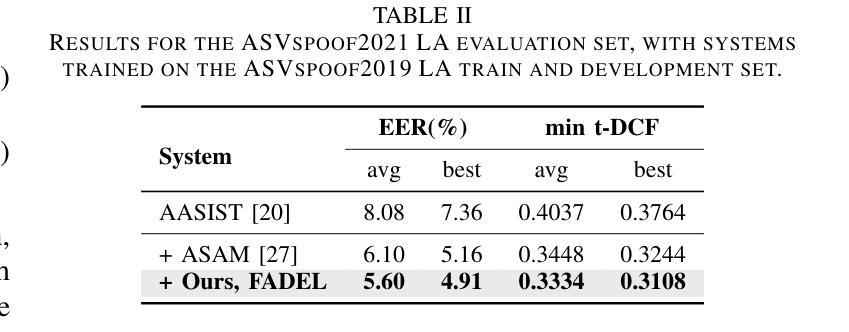
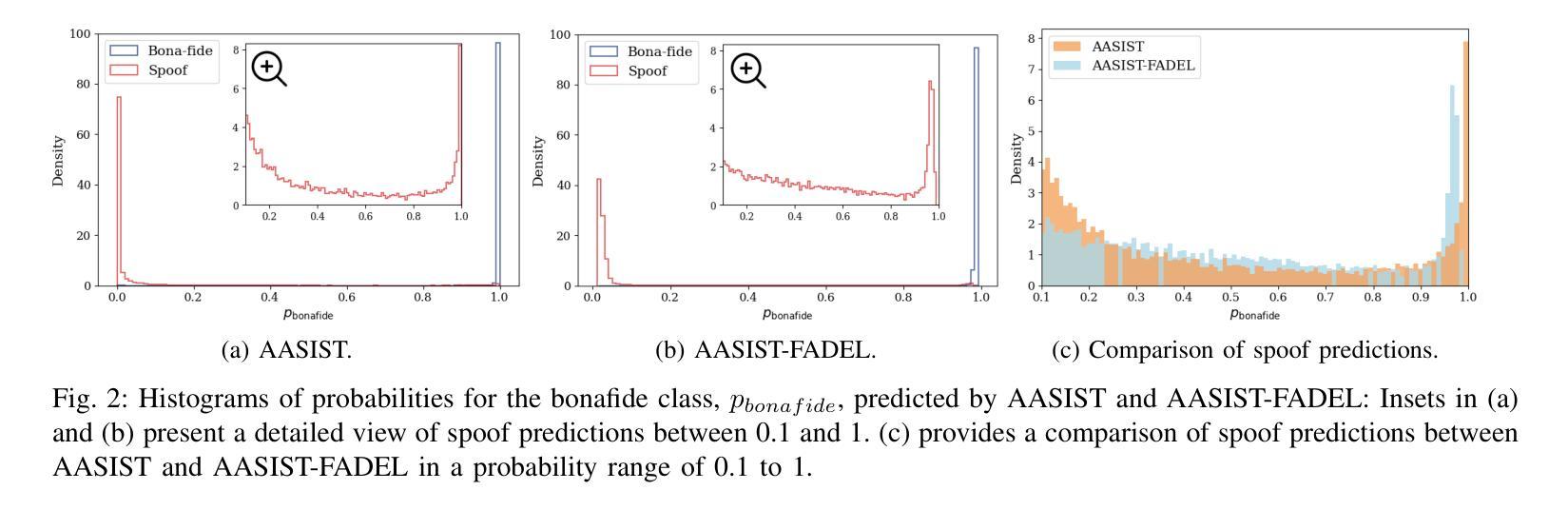
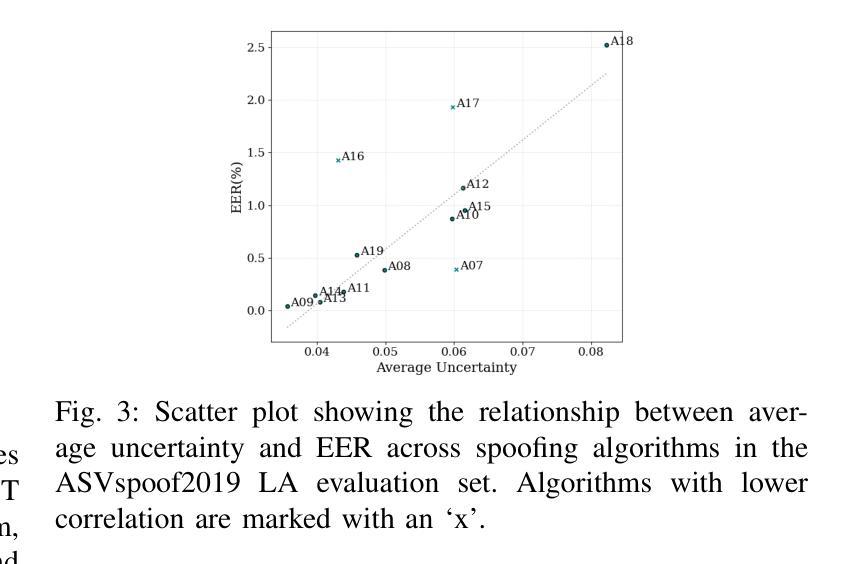
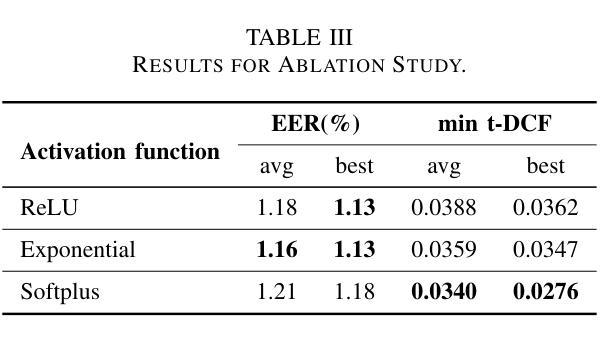
Recently, fake audio detection has gained significant attention, as advancements in speech synthesis and voice conversion have increased the vulnerability of automatic speaker verification (ASV) systems to spoofing attacks. A key challenge in this task is generalizing models to detect unseen, out-of-distribution (OOD) attacks. Although existing approaches have shown promising results, they inherently suffer from overconfidence issues due to the usage of softmax for classification, which can produce unreliable predictions when encountering unpredictable spoofing attempts. To deal with this limitation, we propose a novel framework called fake audio detection with evidential learning (FADEL). By modeling class probabilities with a Dirichlet distribution, FADEL incorporates model uncertainty into its predictions, thereby leading to more robust performance in OOD scenarios. Experimental results on the ASVspoof2019 Logical Access (LA) and ASVspoof2021 LA datasets indicate that the proposed method significantly improves the performance of baseline models. Furthermore, we demonstrate the validity of uncertainty estimation by analyzing a strong correlation between average uncertainty and equal error rate (EER) across different spoofing algorithms.
近期,随着语音合成和语音转换技术的进步,自动说话人验证(ASV)系统更容易受到欺骗攻击,因此虚假音频检测受到了广泛关注。这项任务的关键挑战在于将模型推广到未见过的、超出分布范围(OOD)的攻击上。尽管现有方法已经显示出有希望的结果,但由于使用softmax进行分类,它们天生存在过度自信的问题,遇到不可预测的欺骗尝试时可能会产生不可靠的预测。为了克服这一局限性,我们提出了一种名为基于证据学习进行虚假音频检测(FADEL)的新型框架。通过狄利克雷分布对类概率进行建模,FADEL将模型的不确定性纳入其预测中,从而在OOD场景中实现更稳健的性能。在ASVspoof2019逻辑访问(LA)和ASVspoof2021 LA数据集上的实验结果表明,该方法显著提高了基线模型的性能。此外,我们通过分析不同欺骗算法之间的平均不确定性与等错误率(EER)之间的强相关性,证明了不确定性估计的有效性。
论文及项目相关链接
PDF Accepted at ICASSP 2025
摘要
随着语音合成和语音转换技术的进步,自动说话人验证(ASV)系统面临欺诈攻击的风险。现有方法在处理未见过的、超出分布范围的攻击时存在局限性,并受到过度自信问题的影响。为此,提出一种名为FADEL的新型框架,通过狄利克雷分布对类别概率进行建模,将模型不确定性纳入预测中,从而提高在OOD场景中的稳健性。在ASVspoof2019逻辑访问(LA)和ASVspoof2021 LA数据集上的实验表明,该方法显著提高基线模型的性能。
关键见解
- 语音合成和语音转换技术的进步增加了自动说话人验证(ASV)系统受到欺诈攻击的风险。
- 现有方法在处理未见过的攻击时存在局限性,易产生过度自信问题。
- FADEL框架通过狄利克雷分布建模类别概率,将模型不确定性纳入预测。
- FADEL框架在OOD场景中表现出更稳健的性能。
- 在ASVspoof2019和ASVspoof2021数据集上的实验证明,FADEL显著提高了基线模型的性能。
- 通过分析平均不确定性与等错误率(EER)之间的强相关性,验证了不确定性估计的有效性。
- FADEL为应对复杂和多变的欺诈攻击提供了一种有效的解决方案。
点此查看论文截图

EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Authors:Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, ShiLiang Zhang, Xie Chen
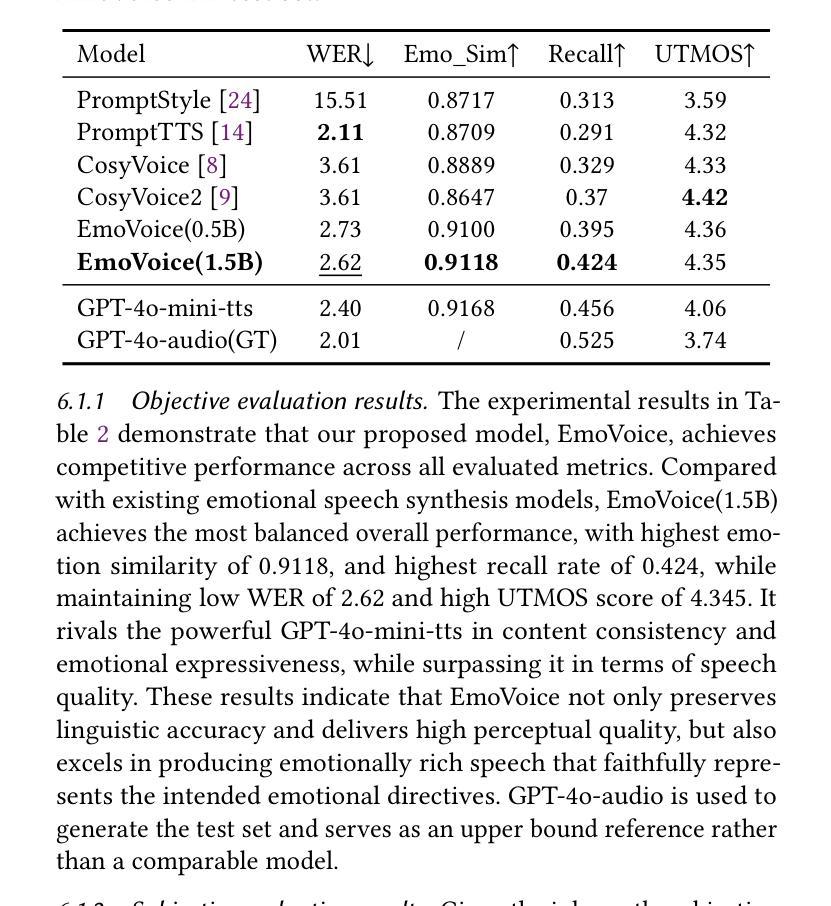
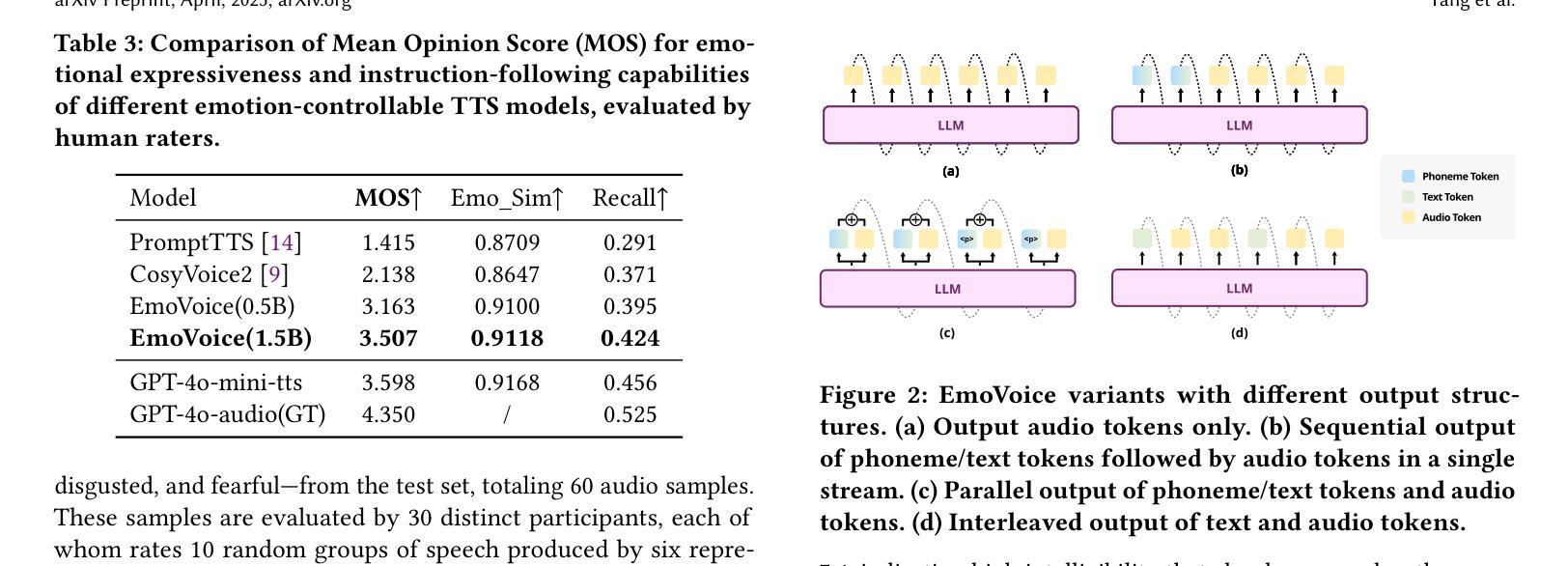
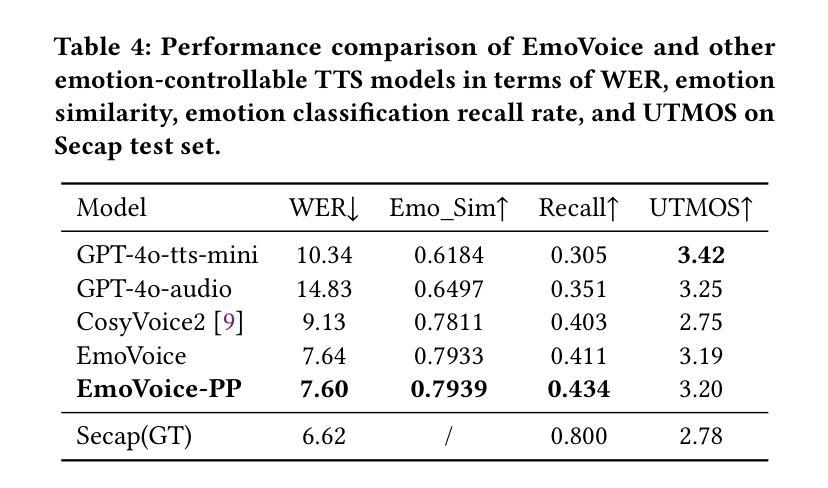
Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
人类语音不仅仅是为了传递信息,更是一种深刻的情感交流和个人之间的联系。虽然文本转语音(TTS)模型已经取得了巨大的进步,但它们仍然面临在生成语音中控制情感表达的挑战。在这项工作中,我们提出了EmoVoice,这是一种新型的情感可控TTS模型。它利用大型语言模型(LLM)实现精细的自由形式自然语言情感控制,并设计了一种音素增强变体,使模型能够并行输出音素标记和音频标记,以增强内容的一致性,这受到思维链(CoT)和模态链(CoM)技术的启发。此外,我们还介绍了EmoVoice-DB,这是一个高质量、包含40小时英语情感的数据集,其中包含表达性语音和带有自然语言描述的精细情感标签。EmoVoice仅使用合成训练数据,在英语EmoVoice-DB测试集上实现了最新性能水平;在我们的内部数据上使用中文Secap测试集也是如此。我们还进一步研究了现有情感评估指标的可靠性及其与人类感知偏好的一致性,并探讨了使用最先进的多媒体LLM GPT-4o-audio和Gemini来评估情感语音。演示样本可在[https://yanghaha0908.github.io/EmoVoice/找到。数据集、代码和检查点将发布。](https://yanghaha0908.github.io/EmoVoice/%E6%9D%A5%E5%AF%BC%E8%AF%AD%E9%A2%9D%E3%80%82%E6%95%B0%E据%E9%9B%86%E3%80%81%E4%BB%A3%E7%A0%81%E5%92%B不定时还会开放一些数据。)
论文及项目相关链接
Summary
本文提出了一种名为EmoVoice的新型情感可控文本转语音(TTS)模型。该模型利用大型语言模型(LLM)实现精细粒度的自然语言情感控制,并采用一种基于语音链的并行输出增强内容一致性的变体设计。此外,还引入了高质量的情感数据集EmoVoice-DB,用于训练和评估模型性能。模型在英文和中文测试集上均取得了显著表现。同时探讨了现有情感评估指标的可靠性及其对人对感知的反映情况。数据集的详细资料可通过在线链接访问。有关数据和代码的详细信息和资源获取,即将公开提供。我们尝试深入解析文中复杂且专业的内容并将其凝练为一句话简明概括:本文介绍了一种新型情感可控的文本转语音模型EmoVoice,该模型利用大型语言模型实现精细情感控制,并引入高质量情感数据集进行训练和评估。同时探讨了现有情感评估指标的可靠性问题。更多细节将通过开源数据和代码共享的方式呈现。如需了解详细情况或下载相关资源,请访问我们的网站链接或等待公开提供的信息更新。另外通过官方提供的演示样本可直观体验该模型的实用性及性能表现。目前EmoVoice模型和演示样本已经发布在GitHub上供公众下载使用,后续将会提供更多开放资源供开发者学习和研究使用。总的来说,这是一个对情感可控TTS模型的突破性研究,不仅满足了实际需求还具有较大的发展潜力与广阔的商业价值与应用前景值得期待与进一步关注其未来的发展与应用情况进一步分析推测EmoVoice可能成为未来TTS领域研究的新趋势以及智能语音交互的新体验对公众的生产生活带来极大便利性和体验性优化当然这一模型的提出同时也促进了情感计算和自然语言处理等相关领域的发展与研究为我们开启了一个全新的智能语音交互时代本文对于有志于深入研究智能语音领域的科研人员和开发者们提供了一个全新的研究视角和方向让他们从更多的角度去理解和发掘语言的内涵与价值在未来的探索过程中将会有更多的创新成果涌现并推动整个行业的进步与发展。Key Takeaways
- EmoVoice是一种新型的情感可控文本转语音(TTS)模型,利用大型语言模型(LLM)实现精细粒度的自然语言情感控制。
- EmoVoice采用并行输出设计,包括语音链和语音内容一致性增强技术,以提高语音质量和流畅度。
点此查看论文截图


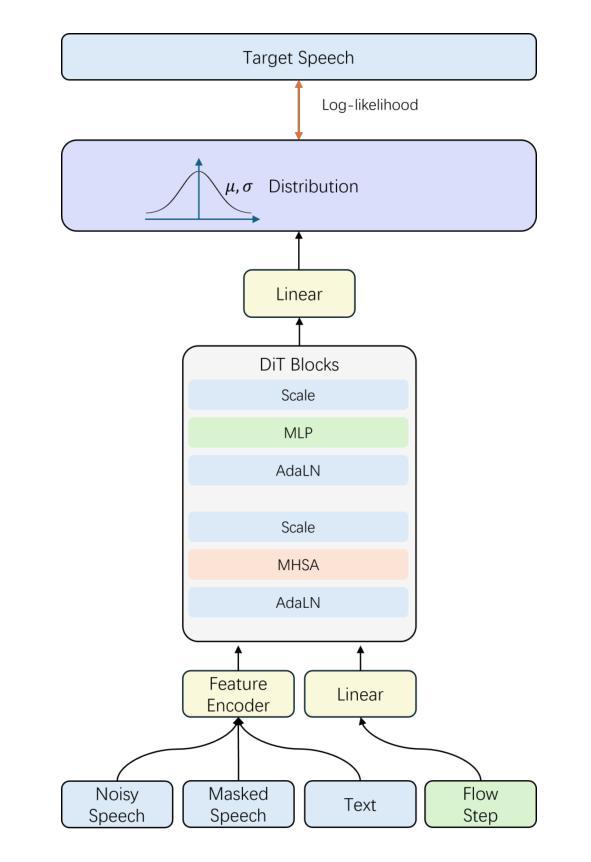
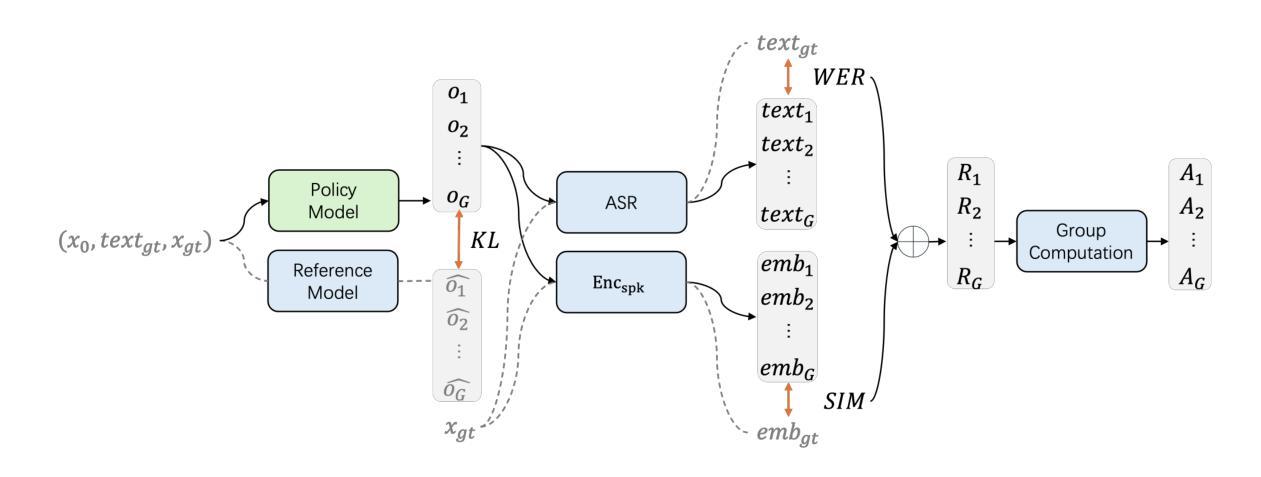
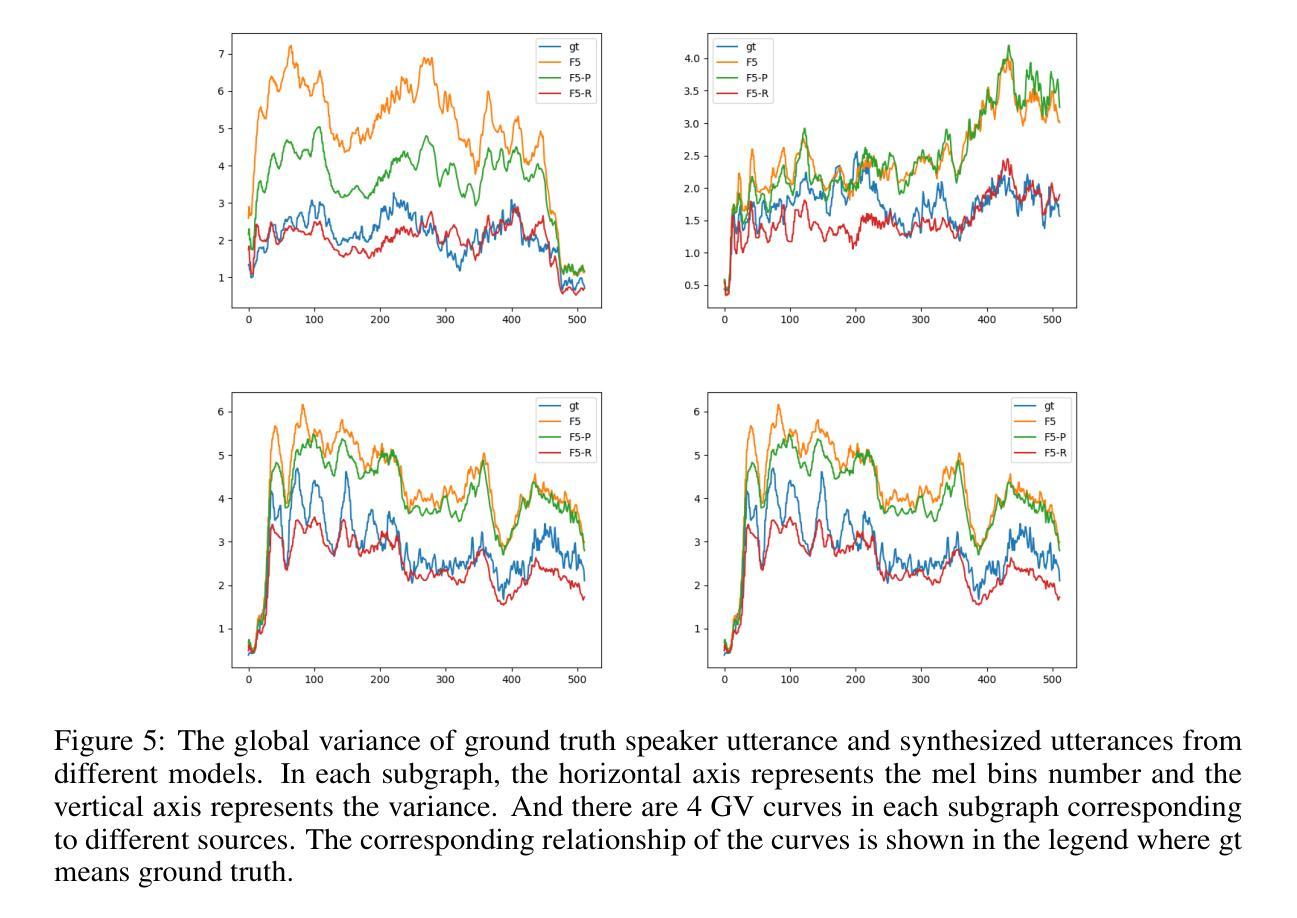
F5R-TTS: Improving Flow-Matching based Text-to-Speech with Group Relative Policy Optimization
Authors:Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, Baoxun Wang
We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Group Relative Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (a 29.5% relative reduction in WER) and speaker similarity (a 4.6% relative increase in SIM score) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
我们提出了F5R-TTS,这是一种新型文本到语音(TTS)系统,它将组相对策略优化(GRPO)集成到基于流程匹配的架构中。通过重新制定流程匹配TTS的确定性输出为概率高斯分布,我们的方法能够实现强化学习算法的无缝集成。在预训练阶段,我们使用开源数据集对基于流程匹配的概率重构模型进行训练,该模型是从F5-TTS衍生而来的。在随后的强化学习(RL)阶段,我们采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的单词错误率(WER)和由验证模型评估的发音人相似性(SIM)。在零样本语音克隆方面的实验结果表明,与传统的基于流程匹配的TTS系统相比,F5R-TTS在语音清晰度(WER相对降低29.5%)和发音人相似性(SIM得分相对提高4.6%)方面取得了显著改进。音频样本可在https://frontierlabs.github.io/F5R获取。
论文及项目相关链接
Summary
F5R-TTS是一个集成Group Relative Policy Optimization(GRPO)的文本转语音(TTS)系统。它通过概率化改革flow-matching架构的确定性输出,实现强化学习算法的无缝集成。系统先进行基于开源数据集的预训练,再在强化学习阶段使用GRPO驱动的增强阶段,采用双重奖励指标:通过自动语音识别计算的词错误率(WER)和通过验证模型评估的说话人相似性(SIM)。在零样本声音克隆的实验结果中,F5R-TTS在语音清晰度(相对减少29.5%的WER)和说话人相似性(相对提高4.6%的SIM分数)方面实现了显著的改进。
Key Takeaways
- F5R-TTS是一个新颖的文本转语音(TTS)系统,集成了Group Relative Policy Optimization(GRPO)。
- 系统通过概率化改革flow-matching架构的确定性输出,实现强化学习算法的无缝集成。
- F5R-TTS采用预训练和强化学习两个阶段。
- 在预训练阶段,系统使用基于开源数据集的flow-matching模型。
- 强化学习阶段中,F5R-TTS使用GRPO驱动的增强阶段,结合双重奖励指标:词错误率(WER)和说话人相似性(SIM)。
- 实验结果表明,F5R-TTS在语音清晰度和说话人相似性方面实现了显著改进。
点此查看论文截图