⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-24 更新
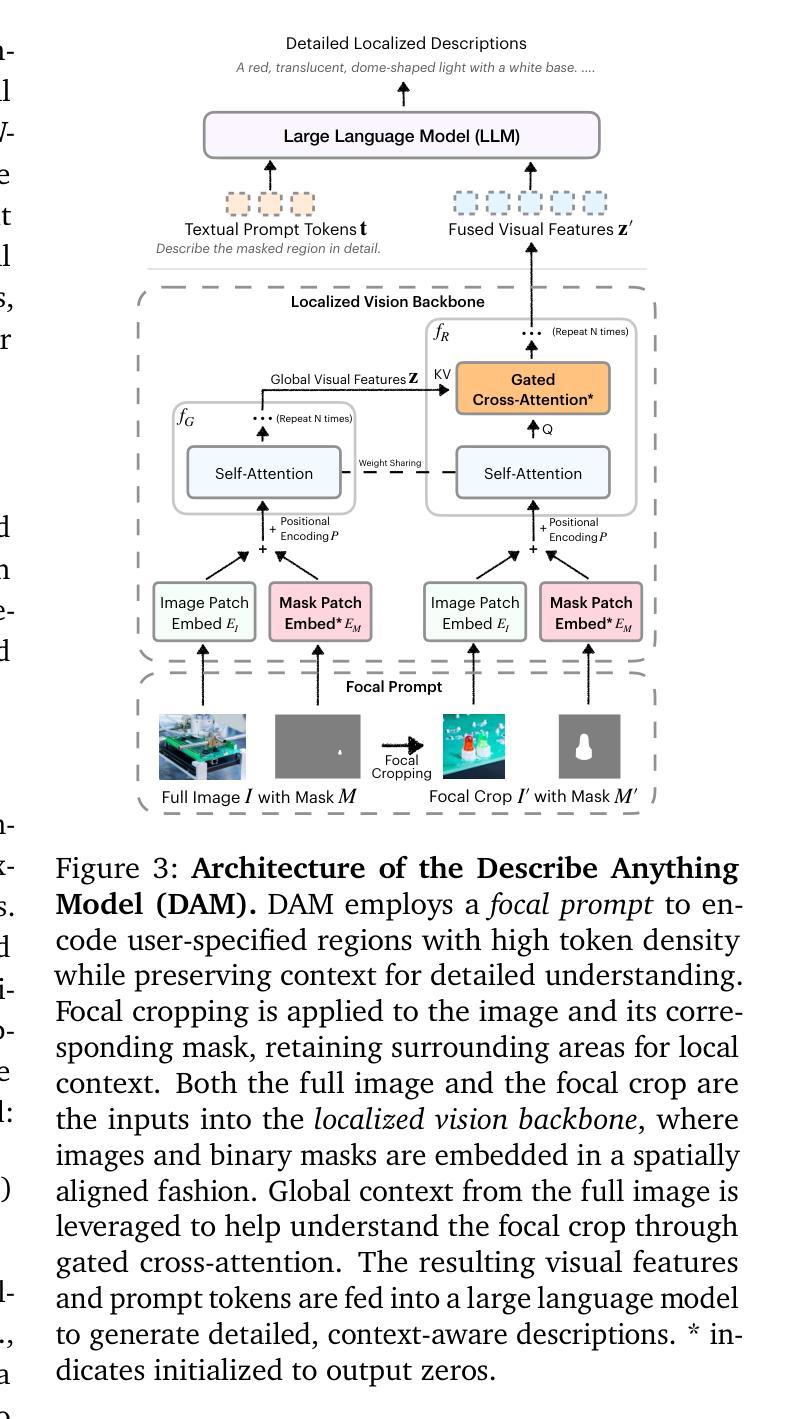
Describe Anything: Detailed Localized Image and Video Captioning
Authors:Long Lian, Yifan Ding, Yunhao Ge, Sifei Liu, Hanzi Mao, Boyi Li, Marco Pavone, Ming-Yu Liu, Trevor Darrell, Adam Yala, Yin Cui
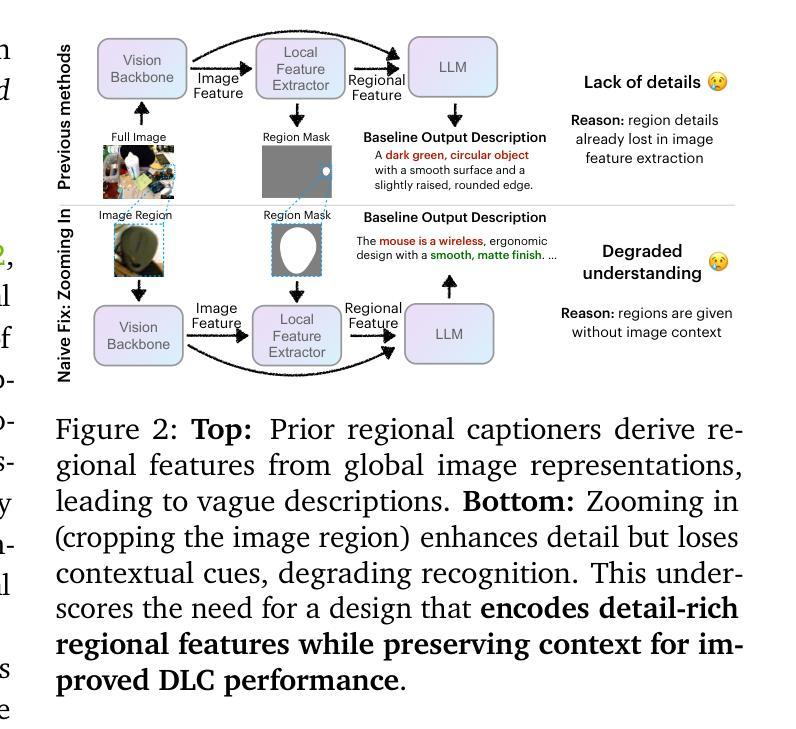
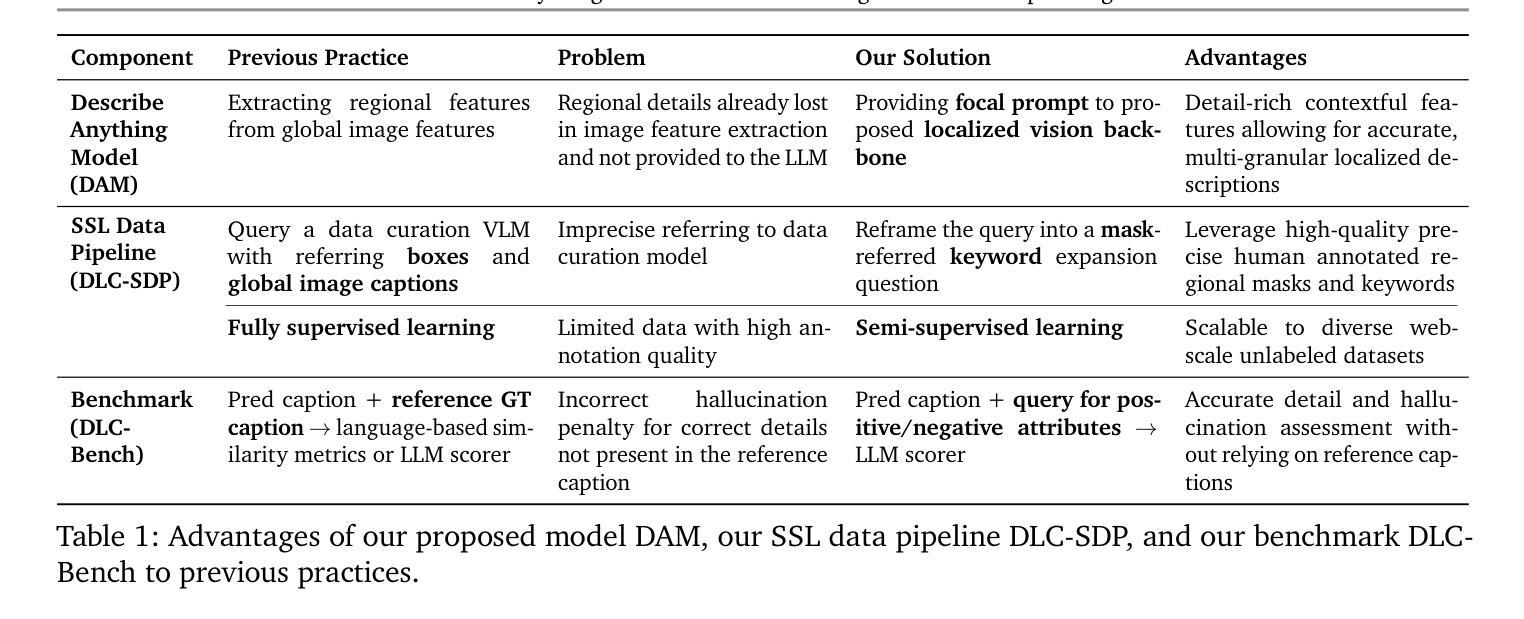
Generating detailed and accurate descriptions for specific regions in images and videos remains a fundamental challenge for vision-language models. We introduce the Describe Anything Model (DAM), a model designed for detailed localized captioning (DLC). DAM preserves both local details and global context through two key innovations: a focal prompt, which ensures high-resolution encoding of targeted regions, and a localized vision backbone, which integrates precise localization with its broader context. To tackle the scarcity of high-quality DLC data, we propose a Semi-supervised learning (SSL)-based Data Pipeline (DLC-SDP). DLC-SDP starts with existing segmentation datasets and expands to unlabeled web images using SSL. We introduce DLC-Bench, a benchmark designed to evaluate DLC without relying on reference captions. DAM sets new state-of-the-art on 7 benchmarks spanning keyword-level, phrase-level, and detailed multi-sentence localized image and video captioning.
为图像和视频中的特定区域生成详细且准确的描述仍然是视觉语言模型的一项基本挑战。我们引入了Describe Anything Model(DAM),这是一个为详细局部描述(DLC)设计的模型。DAM通过两个关键创新点保留了局部细节和全局上下文:焦点提示,确保目标区域的高分辨率编码;局部视觉主干,将精确的定位与其更广泛的上下文结合起来。为了解决高质量DLC数据的稀缺问题,我们提出了一种基于半监督学习(SSL)的数据管道(DLC-SDP)。DLC-SDP从现有的分割数据集开始,然后使用SSL扩展到无标签的网络图像。我们引入了DLC-Bench,这是一个旨在评估DLC而不依赖参考字幕的基准测试。DAM在涵盖关键词级、短语级和详细的多句局部图像和视频描述的7个基准测试上创下了最新技术的新水平。
论文及项目相关链接
PDF Project page: https://describe-anything.github.io/
Summary
DAM模型是一种用于详细局部字幕(DLC)的模型,旨在解决图像和视频中特定区域的详细和准确描述问题。它通过两个关键创新点——焦点提示和局部视觉主干网络,实现了局部细节和全局上下文的保留。为了解决高质量DLC数据的稀缺问题,我们提出了基于半监督学习(SSL)的数据管道DLC-SDP。DLC-SDP从现有的分割数据集开始,使用SSL扩展到无标签的Web图像。我们还介绍了用于评估DLC的基准测试DLC-Bench,不依赖参考字幕。DAM在涵盖关键词级、短语级和详细多句局部图像和视频字幕的7个基准测试中均达到最新水平。
Key Takeaways
- DAM模型旨在解决详细局部字幕(DLC)的挑战,专注于为图像和视频中的特定区域提供准确描述。
- 通过焦点提示和局部视觉主干网络两大创新实现细节和上下文信息的结合。
- 针对高质量DLC数据的稀缺问题,提出了基于半监督学习(SSL)的数据管道DLC-SDP,通过扩展现有数据集和无标签Web图像来解决数据不足的问题。
- 引入了DLC-Bench基准测试,用于评估DLC性能,不依赖参考字幕。
- DAM模型在多个基准测试中表现出优异性能,包括关键词级、短语级以及详细多句局部图像和视频字幕。
- 焦点提示确保了对目标区域的高分辨率编码,而局部视觉主干网络则将精确定位与更广泛的上下文相结合。
点此查看论文截图

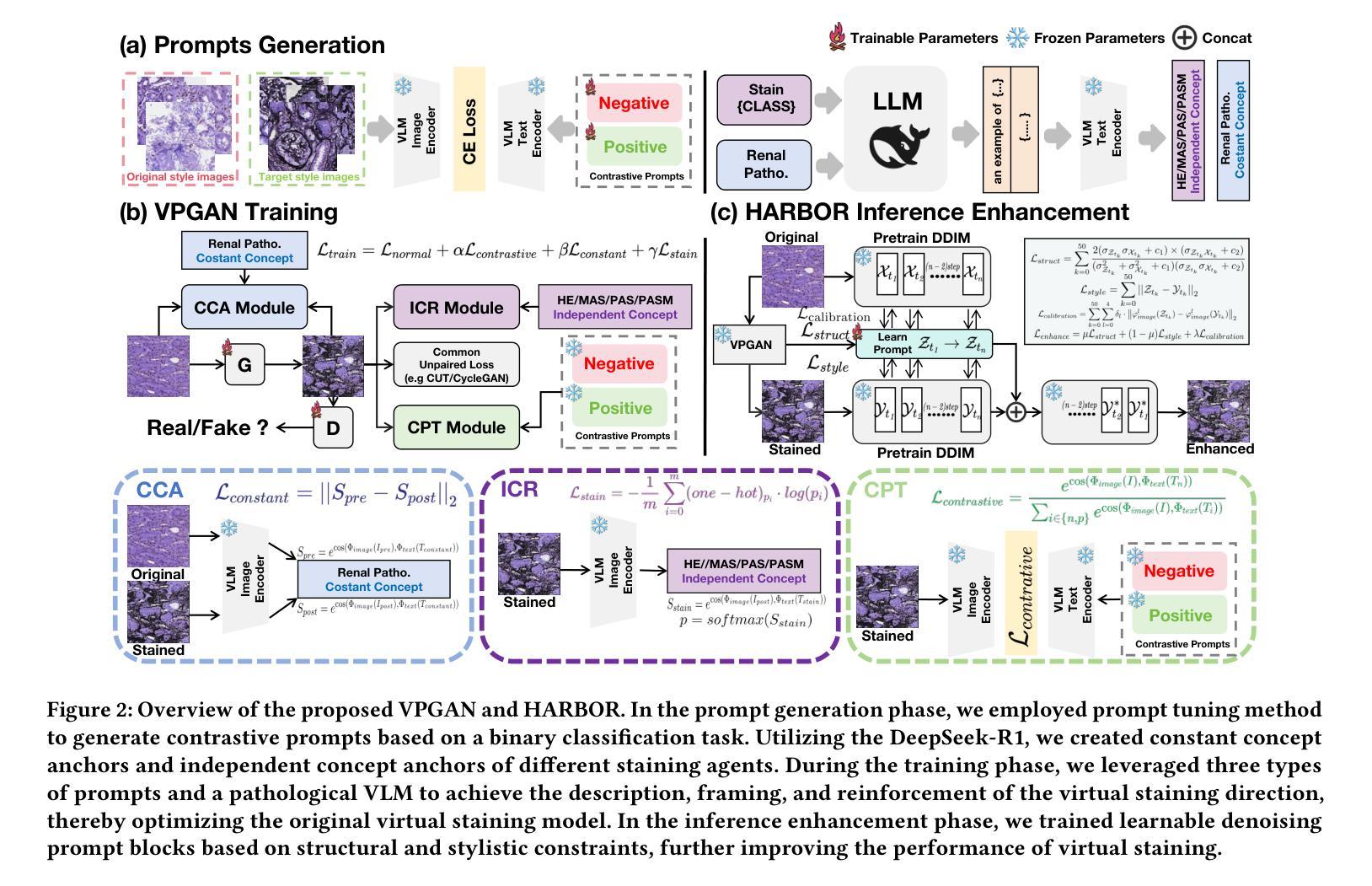
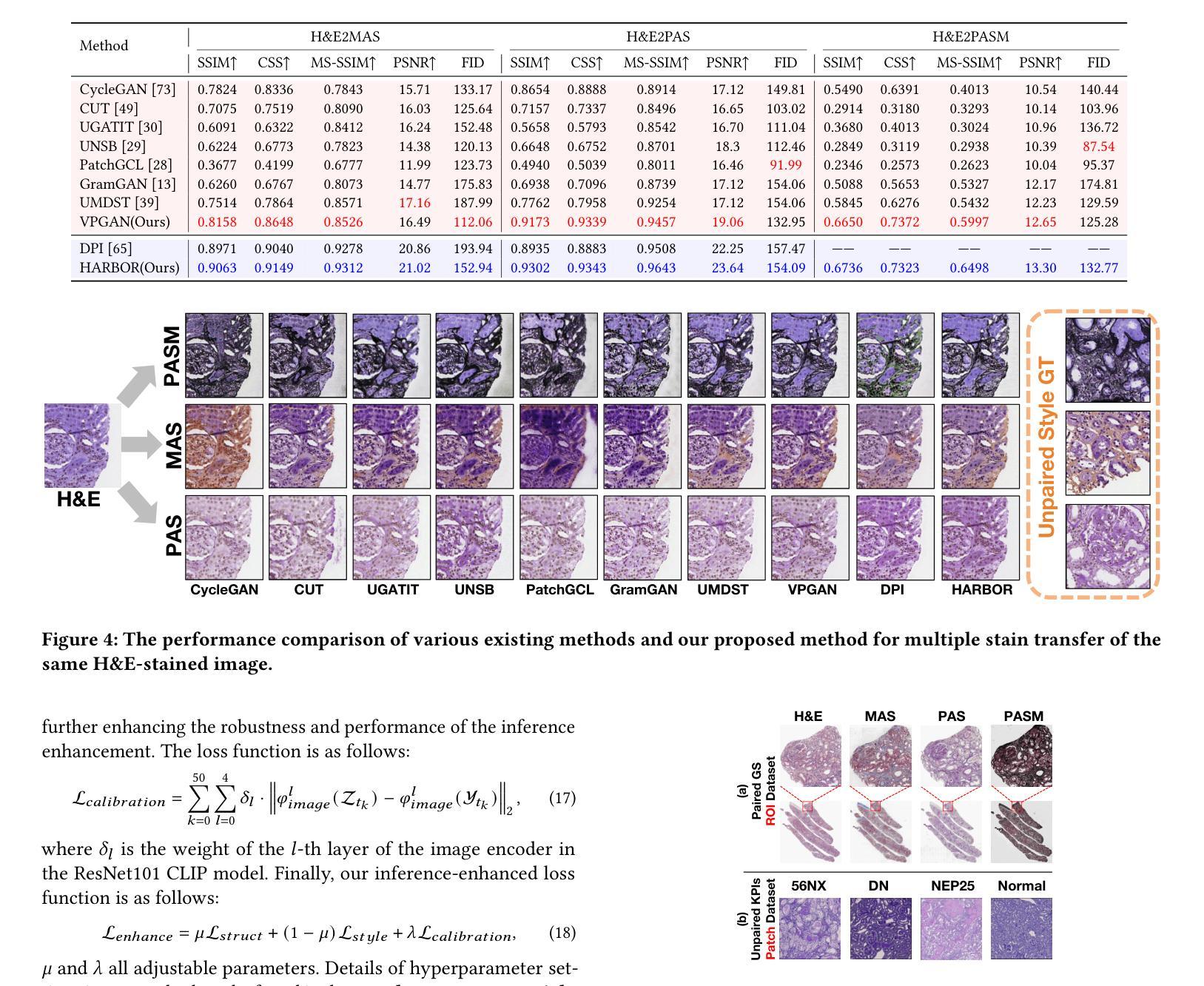
VLM-based Prompts as the Optimal Assistant for Unpaired Histopathology Virtual Staining
Authors:Zizhi Chen, Xinyu Zhang, Minghao Han, Yizhou Liu, Ziyun Qian, Weifeng Zhang, Xukun Zhang, Jingwei Wei, Lihua Zhang
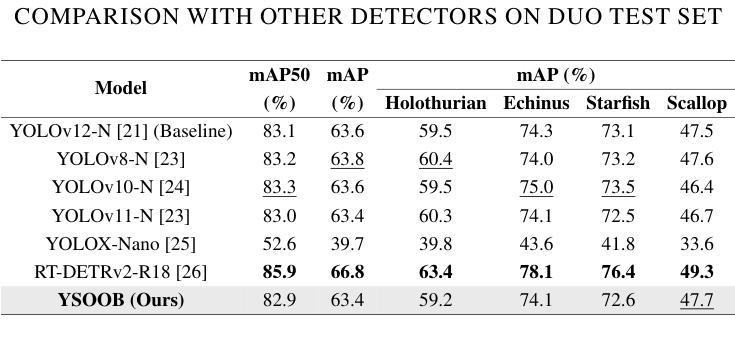
In histopathology, tissue sections are typically stained using common H&E staining or special stains (MAS, PAS, PASM, etc.) to clearly visualize specific tissue structures. The rapid advancement of deep learning offers an effective solution for generating virtually stained images, significantly reducing the time and labor costs associated with traditional histochemical staining. However, a new challenge arises in separating the fundamental visual characteristics of tissue sections from the visual differences induced by staining agents. Additionally, virtual staining often overlooks essential pathological knowledge and the physical properties of staining, resulting in only style-level transfer. To address these issues, we introduce, for the first time in virtual staining tasks, a pathological vision-language large model (VLM) as an auxiliary tool. We integrate contrastive learnable prompts, foundational concept anchors for tissue sections, and staining-specific concept anchors to leverage the extensive knowledge of the pathological VLM. This approach is designed to describe, frame, and enhance the direction of virtual staining. Furthermore, we have developed a data augmentation method based on the constraints of the VLM. This method utilizes the VLM’s powerful image interpretation capabilities to further integrate image style and structural information, proving beneficial in high-precision pathological diagnostics. Extensive evaluations on publicly available multi-domain unpaired staining datasets demonstrate that our method can generate highly realistic images and enhance the accuracy of downstream tasks, such as glomerular detection and segmentation. Our code is available at: https://github.com/CZZZZZZZZZZZZZZZZZ/VPGAN-HARBOR
在组织病理学中,组织切片通常使用常见的H&E染色或特殊染色(如MAS、PAS、PASM等)进行染色,以清晰地显示特定的组织结构。深度学习技术的快速发展为生成虚拟染色图像提供了有效的解决方案,显著减少了与传统组织化学染色相关的时间和劳动力成本。然而,新的挑战在于从染色剂引起的视觉差异中分离出组织切片的基本视觉特征。此外,虚拟染色往往会忽略重要的病理学知识和染色的物理特性,导致仅进行风格层面的迁移。为了解决这些问题,我们首次在虚拟染色任务中引入了一种病理性视觉语言大型模型(VLM)作为辅助工具。我们集成了对比可学习提示、组织切片的基本概念锚点和染色特定概念锚点,以利用病理性VLM的丰富知识。这种方法旨在描述、构建并引导虚拟染色的方向。此外,我们基于VLM的约束开发了一种数据增强方法。该方法利用VLM强大的图像解释能力,进一步整合图像风格和结构信息,对高精度病理学诊断大有裨益。在公开可用的多域非配对染色数据集上的广泛评估表明,我们的方法能够生成高度逼真的图像,提高下游任务的准确性,如肾小球检测和分割。我们的代码可在:https://github.com/CZZZZZZZZZZZZZZZZZ/VPGAN-HARBOR找到。
论文及项目相关链接
Summary:本文介绍了一种新型辅助工具——病理性视觉语言大模型(VLM),用于虚拟染色任务。该模型集成了对比可学习提示、组织切片的基础概念锚点和染色特定概念锚点,利用丰富的病理性知识描述、框定并增强虚拟染色的方向。同时,开发了一种基于VLM约束的数据增强方法,整合图像风格和结构信息,有助于提高病理诊断的精确度。在公开的多领域非配对染色数据集上的评估表明,该方法能生成高度逼真的图像,提高下游任务的准确性,如肾小球检测和分割。
Key Takeaways:
- 病理学研究中通常使用H&E染色或特殊染色方法来可视化特定组织结构。
- 深度学习技术为生成虚拟染色图像提供了有效解决方案,减少了时间和劳动力成本。
- 然而,区分组织本身的基本视觉特征和由染色剂引起的视觉差异是一个新的挑战。
- 虚拟染色常常忽略重要的病理学知识和染色的物理特性,导致仅进行风格层面的转换。
- 为解决上述问题,引入了一种新型的辅助工具——病理性视觉语言大模型(VLM)。
- VLM集成了对比可学习提示、组织切片的基础概念锚点和染色特定概念锚点,利用丰富的病理性知识进行描述、框定和增强虚拟染色的方向。
- 开发了一种基于VLM约束的数据增强方法,该方法利用VLM强大的图像解释能力整合图像风格和结构信息,提高了病理诊断的精确度。实验评估证明了该方法在生成高度逼真的图像和提高下游任务准确性方面的有效性。
点此查看论文截图


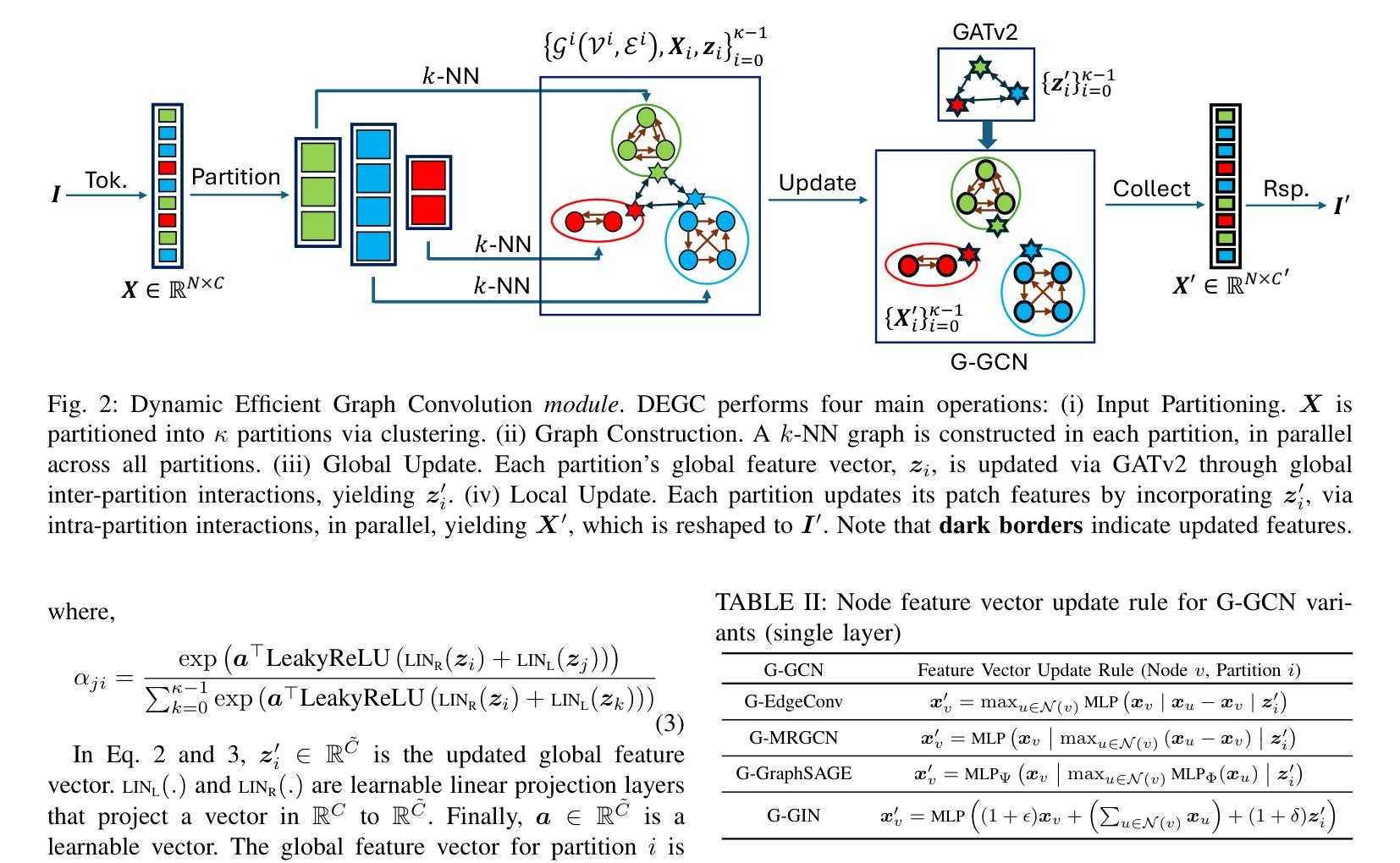
ClusterViG: Efficient Globally Aware Vision GNNs via Image Partitioning
Authors:Dhruv Parikh, Jacob Fein-Ashley, Tian Ye, Rajgopal Kannan, Viktor Prasanna
Convolutional Neural Networks (CNN) and Vision Transformers (ViT) have dominated the field of Computer Vision (CV). Graph Neural Networks (GNN) have performed remarkably well across diverse domains because they can represent complex relationships via unstructured graphs. However, the applicability of GNNs for visual tasks was unexplored till the introduction of Vision GNNs (ViG). Despite the success of ViGs, their performance is severely bottlenecked due to the expensive $k$-Nearest Neighbors ($k$-NN) based graph construction. Recent works addressing this bottleneck impose constraints on the flexibility of GNNs to build unstructured graphs, undermining their core advantage while introducing additional inefficiencies. To address these issues, in this paper, we propose a novel method called Dynamic Efficient Graph Convolution (DEGC) for designing efficient and globally aware ViGs. DEGC partitions the input image and constructs graphs in parallel for each partition, improving graph construction efficiency. Further, DEGC integrates local intra-graph and global inter-graph feature learning, enabling enhanced global context awareness. Using DEGC as a building block, we propose a novel CNN-GNN architecture, ClusterViG, for CV tasks. Extensive experiments indicate that ClusterViG reduces end-to-end inference latency for vision tasks by up to $5\times$ when compared against a suite of models such as ViG, ViHGNN, PVG, and GreedyViG, with a similar model parameter count. Additionally, ClusterViG reaches state-of-the-art performance on image classification, object detection, and instance segmentation tasks, demonstrating the effectiveness of the proposed globally aware learning strategy. Finally, input partitioning performed by DEGC enables ClusterViG to be trained efficiently on higher-resolution images, underscoring the scalability of our approach.
卷积神经网络(CNN)和视觉转换器(ViT)在计算机视觉(CV)领域占据了主导地位。图神经网络(GNN)在不同的领域表现非常出色,因为它们可以通过非结构化的图来表示复杂的关系。然而,直到引入视觉图神经网络(ViG)为止,图神经网络在视觉任务上的应用尚未得到探索。尽管ViG取得了成功,但由于基于昂贵的k近邻(k-NN)的图构建,其性能受到了严重限制。最近解决这一瓶颈的工作对图神经网络的灵活性施加约束,以构建非结构化图,这削弱了其核心竞争力并引入了额外的效率低下。为了解决这个问题,本文提出了一种名为动态高效图卷积(DEGC)的新方法,用于设计高效且全局感知的ViG。DEGC将输入图像进行分区,并并行为每个分区构建图,提高了图的构建效率。此外,DEGC结合了局部图内和全局图间特征学习,增强了全局上下文感知能力。使用DEGC作为构建块,我们提出了一种新颖的CNN-GNN架构ClusterViG,用于计算机视觉任务。大量实验表明,与ViG、ViHGNN、PVG和GreedyViG等一系列模型相比,ClusterViG在视觉任务的端到端推理延迟方面减少了高达5倍,具有相似的模型参数计数。此外,ClusterViG在图像分类、对象检测和实例分割任务上达到了最先进的性能,这证明了所提出的全局感知学习策略的有效性。最后,DEGC执行的输入分区使得ClusterViG能够在更高的分辨率图像上进行高效训练,这突显了我们方法的可扩展性。
论文及项目相关链接
PDF IEEE MCNA 2025
Summary
卷积神经网络(CNN)和视觉转换器(ViT)在计算机视觉(CV)领域占据主导地位。图神经网络(GNN)能够在不同领域表现出色,因为它们能够通过非结构化的图表示复杂的关联关系。然而,对于视觉任务,图神经网络的应用尚未得到探索,直到出现视觉图神经网络(ViG)。尽管ViG表现良好,但其性能受到基于k-最近邻(k-NN)的图构建方法的高成本限制。为解决这一问题,本文提出了一种名为动态高效图卷积(DEGC)的新方法,用于设计高效的全局感知ViG。DEGC对输入图像进行分区并为每个分区并行构建图,从而提高图构建的效率。此外,DEGC融合了局部内图及全局图间的特征学习,强化了全局上下文感知能力。使用DEGC作为构建模块,我们提出了一种新颖的CNN-GNN架构ClusterViG,用于CV任务。实验表明,与ViG、ViHGNN、PVG和GreedyViG等模型相比,ClusterViG在视觉任务上减少了端到端的推理延迟时间高达5倍,同时模型参数数量相似。此外,ClusterViG在图像分类、目标检测和实例分割任务上达到了最先进的性能表现,证明了其全局感知学习策略的有效性。最后,DEGC执行的输入分区使得ClusterViG能够高效地在大分辨率图像上进行训练,凸显了我们方法的可扩展性。
Key Takeaways
- 卷积神经网络和视觉转换器在计算机视觉领域占据主导地位,但图神经网络具有通过非结构化图表征复杂关系的优势。
- 视觉图神经网络(ViG)结合了图神经网络的优势,但在图构建方面存在瓶颈,受到高成本限制。
- 动态高效图卷积(DEGC)方法通过输入图像分区并行构建图,提高了图构建效率。
- DEGC融合了局部和全局特征学习,强化了全局上下文感知能力。
- ClusterViG架构结合了CNN和GNN的优势,用于计算机视觉任务。
- ClusterViG在多个视觉任务上达到了最先进的性能表现,并显著减少了推理延迟时间。
点此查看论文截图