⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-25 更新
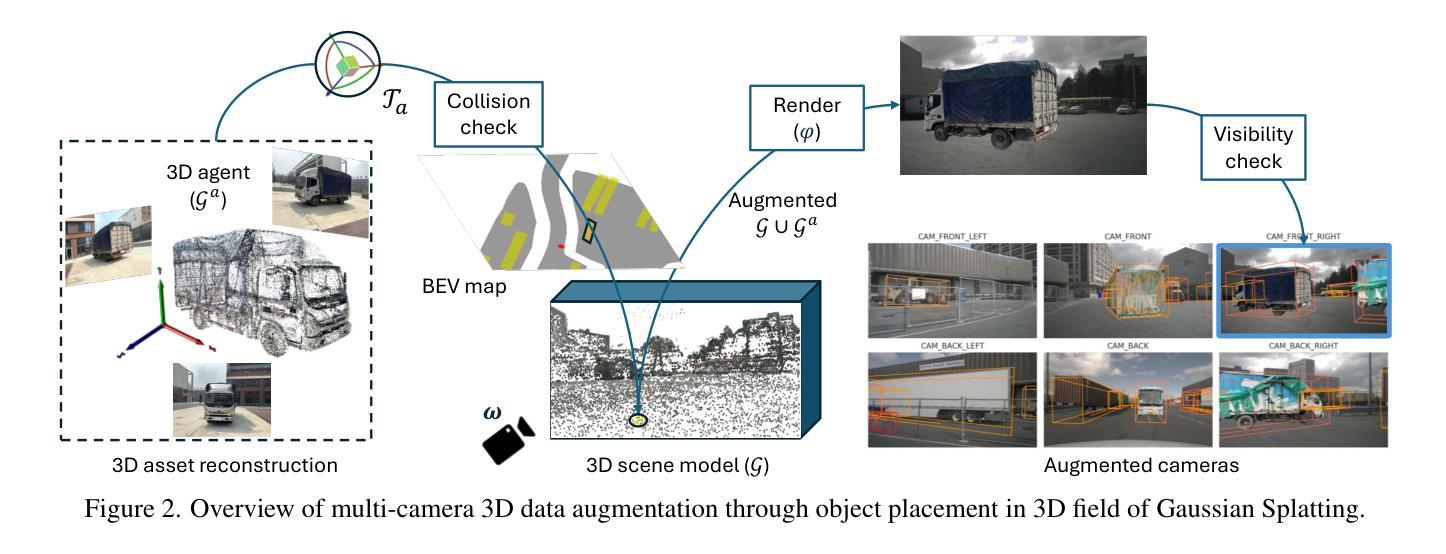
Gaussian Splatting is an Effective Data Generator for 3D Object Detection
Authors:Farhad G. Zanjani, Davide Abati, Auke Wiggers, Dimitris Kalatzis, Jens Petersen, Hong Cai, Amirhossein Habibian
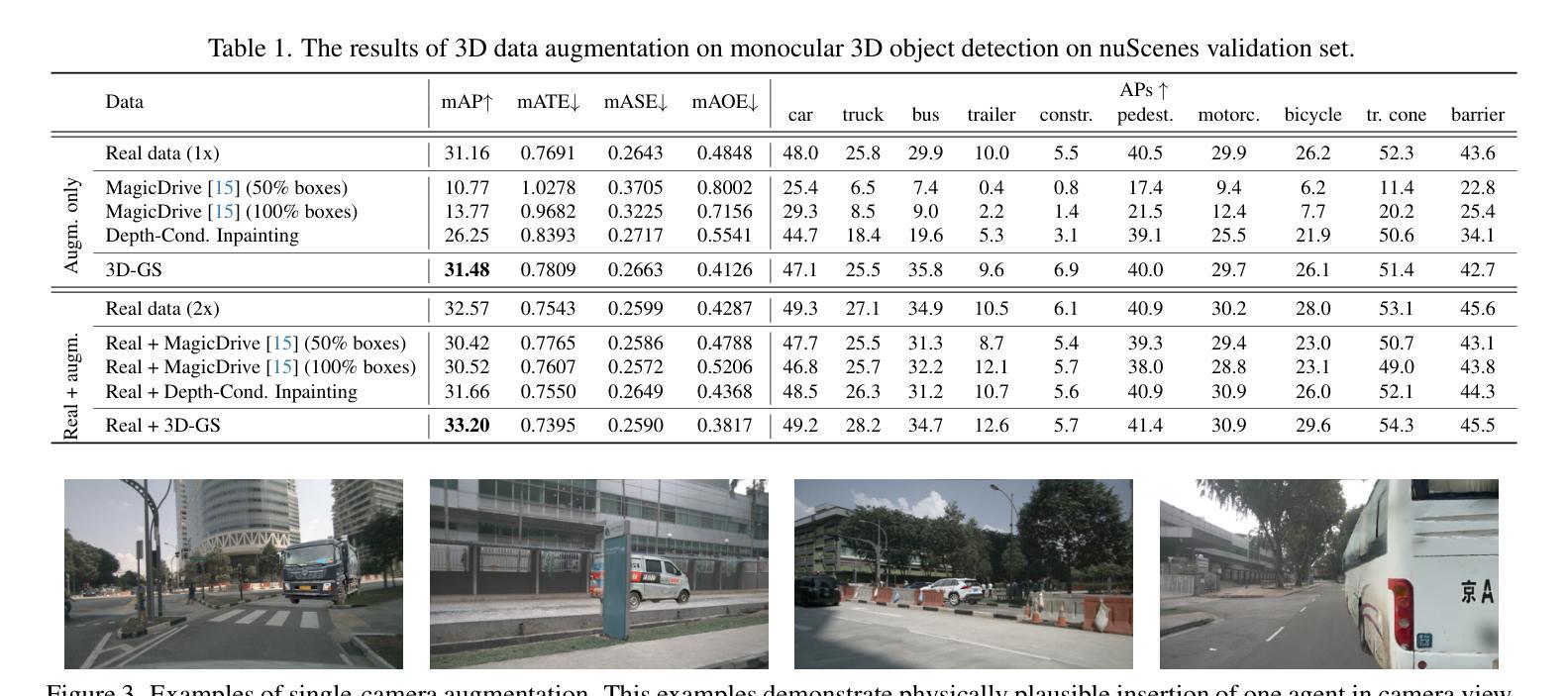
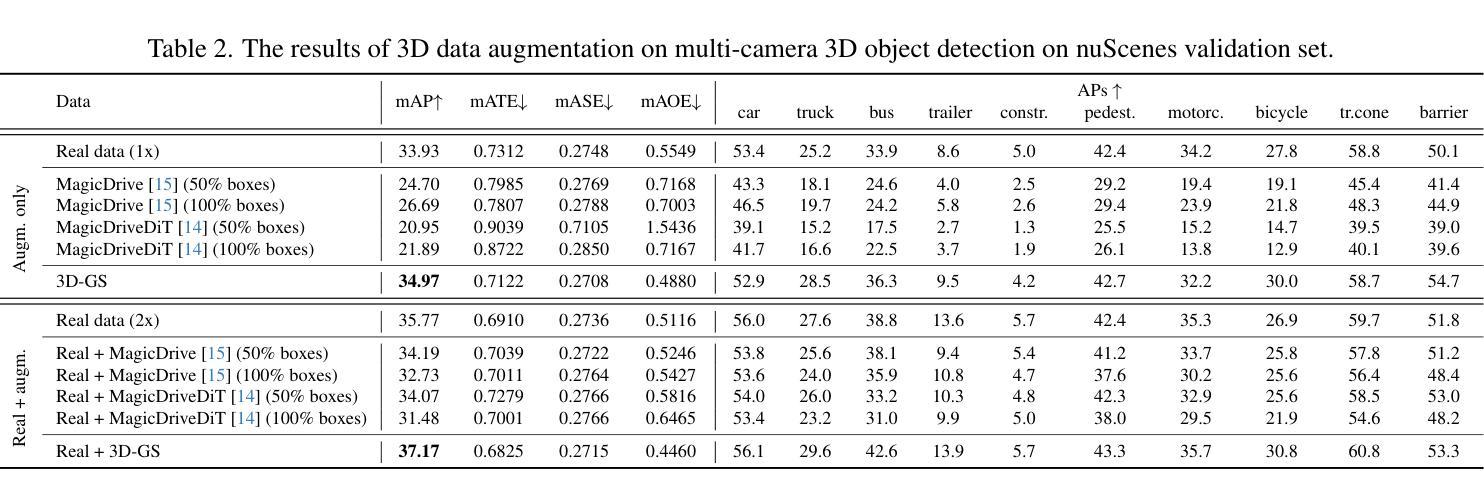
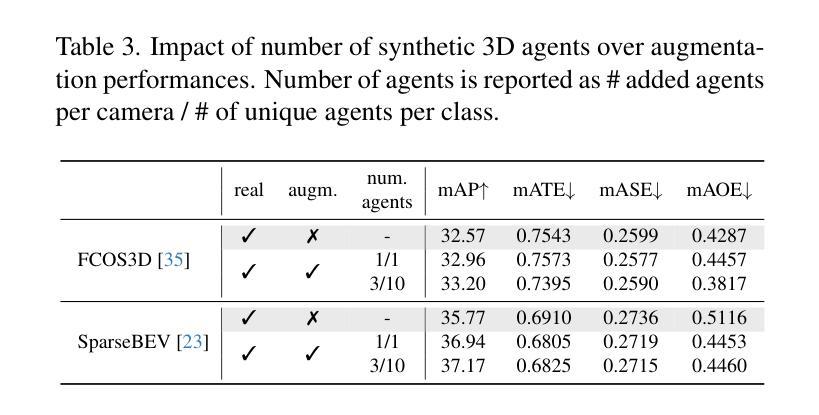
We investigate data augmentation for 3D object detection in autonomous driving. We utilize recent advancements in 3D reconstruction based on Gaussian Splatting for 3D object placement in driving scenes. Unlike existing diffusion-based methods that synthesize images conditioned on BEV layouts, our approach places 3D objects directly in the reconstructed 3D space with explicitly imposed geometric transformations. This ensures both the physical plausibility of object placement and highly accurate 3D pose and position annotations. Our experiments demonstrate that even by integrating a limited number of external 3D objects into real scenes, the augmented data significantly enhances 3D object detection performance and outperforms existing diffusion-based 3D augmentation for object detection. Extensive testing on the nuScenes dataset reveals that imposing high geometric diversity in object placement has a greater impact compared to the appearance diversity of objects. Additionally, we show that generating hard examples, either by maximizing detection loss or imposing high visual occlusion in camera images, does not lead to more efficient 3D data augmentation for camera-based 3D object detection in autonomous driving.
我们对自动驾驶中的3D目标检测数据增强进行了研究。我们利用基于高斯平铺的3D重建的最新进展,在驾驶场景中放置3D物体。与现有的基于扩散的方法不同,这些方法根据BEV布局合成图像,我们的方法直接在重建的3D空间中放置3D物体,并明确施加几何变换。这确保了物体放置的物理可行性以及高度准确的3D姿态和位置注释。我们的实验表明,即使只将有限数量的外部3D物体集成到真实场景中,增强数据也能显著提高3D目标检测性能,并优于现有的基于扩散的3D目标检测数据增强。在nuScenes数据集上的大量测试表明,在物体放置中施加高几何多样性比物体的外观多样性具有更大的影响。此外,我们还表明,通过最大化检测损失或在相机图像中施加高视觉遮挡来生成困难样本,并不会导致更有效的基于摄像头的自动驾驶3D目标检测的数据增强。
论文及项目相关链接
Summary
本文探讨了基于高斯贴图技术的三维重建在自动驾驶领域的应用,特别是在数据增强方面的应用。该研究通过直接在重建的三维空间中放置三维物体,实现了物体放置的物理可行性和高度精确的3D姿态和位置标注。实验表明,即使只整合少量外部三维物体到真实场景中,增强数据也能显著提高三维物体检测性能,并优于现有的基于扩散的三维数据增强方法。在nuScenes数据集上的测试显示,在物体放置中引入高几何多样性比物体的外观多样性更具影响力。此外,本研究发现通过最大化检测损失或提高相机图像中的视觉遮挡来生成困难样本,并不会更有效地增强基于相机的三维物体检测性能。
Key Takeaways
- 研究利用高斯贴图技术的三维重建进行自动驾驶中的数据增强。
- 在重建的三维空间中直接放置三维物体,确保了物体放置的物理可行性和精确的3D姿态和位置标注。
- 增强数据能提高三维物体检测性能,并优于现有扩散式三维数据增强方法。
- 在物体放置中引入高几何多样性对提升检测性能的影响更大。
- 生成困难样本(如最大化检测损失或高视觉遮挡)并不一定能有效增强基于相机的三维物体检测性能。
点此查看论文截图

PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation
Authors:Wenxuan Li, Hang Zhao, Zhiyuan Yu, Yu Du, Qin Zou, Ruizhen Hu, Kai Xu
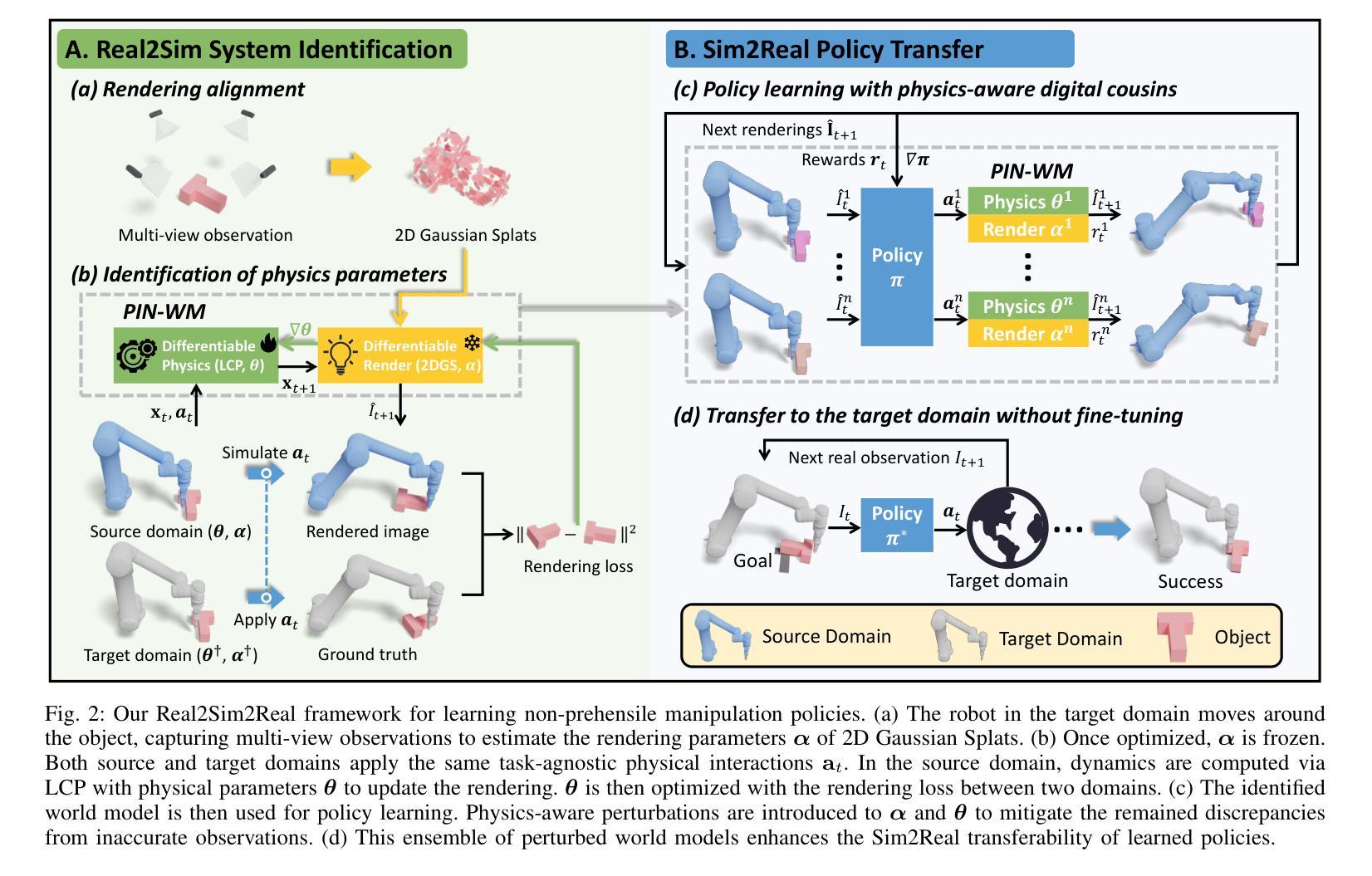
While non-prehensile manipulation (e.g., controlled pushing/poking) constitutes a foundational robotic skill, its learning remains challenging due to the high sensitivity to complex physical interactions involving friction and restitution. To achieve robust policy learning and generalization, we opt to learn a world model of the 3D rigid body dynamics involved in non-prehensile manipulations and use it for model-based reinforcement learning. We propose PIN-WM, a Physics-INformed World Model that enables efficient end-to-end identification of a 3D rigid body dynamical system from visual observations. Adopting differentiable physics simulation, PIN-WM can be learned with only few-shot and task-agnostic physical interaction trajectories. Further, PIN-WM is learned with observational loss induced by Gaussian Splatting without needing state estimation. To bridge Sim2Real gaps, we turn the learned PIN-WM into a group of Digital Cousins via physics-aware randomizations which perturb physics and rendering parameters to generate diverse and meaningful variations of the PIN-WM. Extensive evaluations on both simulation and real-world tests demonstrate that PIN-WM, enhanced with physics-aware digital cousins, facilitates learning robust non-prehensile manipulation skills with Sim2Real transfer, surpassing the Real2Sim2Real state-of-the-arts.
非抓取操作(例如,受控的推动/戳刺)构成了基础机器人技能的一部分,但由于其对涉及摩擦和恢复力的复杂物理交互的高度敏感性,其学习仍然具有挑战性。为了实现稳健的策略学习和泛化,我们选择学习涉及非抓取操作的三维刚体动力学世界模型,并将其用于基于模型的强化学习。我们提出了PIN-WM,即物理信息世界模型,能够实现从视觉观察中高效端到端地识别三维刚体动力学系统。通过采用可微分物理模拟,PIN-WM仅通过少量且任务无关的物理交互轨迹即可进行学习。此外,PIN-WM通过高斯投影(Splatting)产生的观测损失进行学习,无需进行状态估计。为了缩小模拟到现实的差距,我们将学到的PIN-WM通过物理感知随机化转化为一组数字同胞。物理感知随机化会干扰物理和渲染参数,从而生成PIN-WM多样且具意义的变体。在模拟和真实世界测试中的广泛评估表明,辅以物理感知的数字同胞的PIN-WM,能够促进学习具有模拟到现实迁移能力的稳健非抓取操作技能,超越当前最佳的Real2Sim2Real方法。
论文及项目相关链接
Summary
针对非抓取操作(如控制推动/戳刺)的机器人技能学习,面临复杂物理交互中的摩擦和恢复等挑战。我们提出一种基于物理信息的世界模型PIN-WM,通过视觉观察实现3D刚体动力学系统的端到端识别。采用可微分物理仿真,PIN-WM仅通过少量任务无关的物理解算轨迹进行学习。此外,我们通过高斯喷溅技术引入观测损失,无需状态估计。为解决模拟到现实的差距,我们将学到的PIN-WM转化为一系列物理感知的“数字分身”,通过扰动物理和渲染参数生成多样而有意义的模型变体。在模拟和真实世界测试中的广泛评估表明,增强物理感知的数字分身后的PIN-WM,在模拟到现实的转移学习中,能学习稳健的非抓取操作技能,超越当前最新的Real2Sim2Real技术。
Key Takeaways
- 非抓取操作的机器人技能学习面临多种物理交互的挑战,如摩擦和恢复等。
- 提出一种基于物理信息的世界模型PIN-WM,实现从视觉观察的3D刚体动力学系统的端到端识别。
- 仅通过少量任务无关的物理解算轨迹,利用可微分物理仿真进行学习。
- 引入观测损失,无需状态估计,采用高斯喷溅技术。
- 将学到的PIN-WM转化为数字分身,通过物理感知的随机化缩小模拟与现实的差距。
- 在模拟和真实世界测试中的评估显示,PIN-WM能学习稳健的非抓取操作技能。
点此查看论文截图

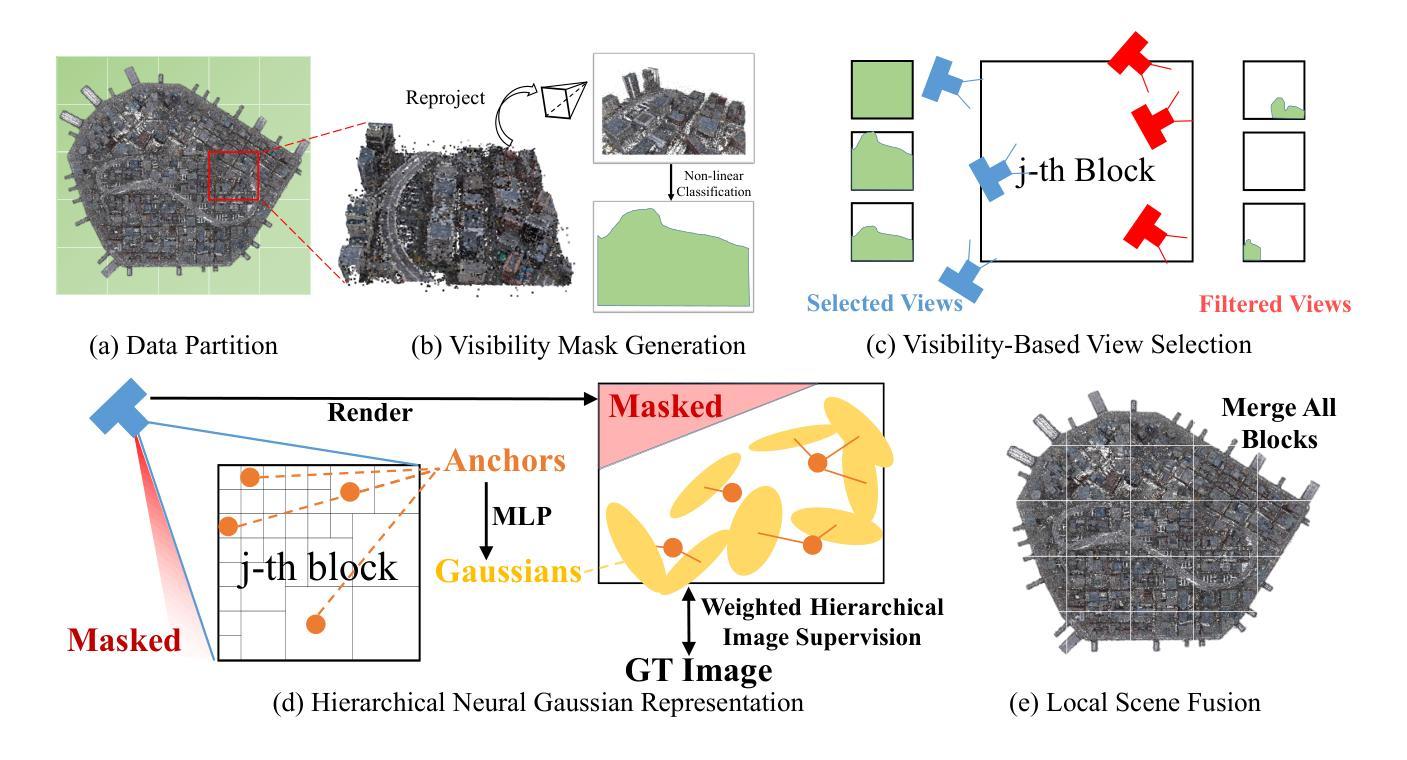
HUG: Hierarchical Urban Gaussian Splatting with Block-Based Reconstruction
Authors:Zhongtao Wang, Mai Su, Huishan Au, Yilong Li, Xizhe Cao, Chengwei Pan, Yisong Chen, Guoping Wang
As urban 3D scenes become increasingly complex and the demand for high-quality rendering grows, efficient scene reconstruction and rendering techniques become crucial. We present HUG, a novel approach to address inefficiencies in handling large-scale urban environments and intricate details based on 3D Gaussian splatting. Our method optimizes data partitioning and the reconstruction pipeline by incorporating a hierarchical neural Gaussian representation. We employ an enhanced block-based reconstruction pipeline focusing on improving reconstruction quality within each block and reducing the need for redundant training regions around block boundaries. By integrating neural Gaussian representation with a hierarchical architecture, we achieve high-quality scene rendering at a low computational cost. This is demonstrated by our state-of-the-art results on public benchmarks, which prove the effectiveness and advantages in large-scale urban scene representation.
随着城市三维场景日益复杂和对高质量渲染的需求不断增长,高效的场景重建和渲染技术变得至关重要。我们提出了HUG,这是一种基于3D高斯散斑处理大规模城市环境和复杂细节中的低效问题的新型方法。我们的方法通过融入分层神经高斯表示来优化数据分区和重建流程。我们采用基于块的重建流程,重点关注提高每个块内的重建质量,减少块边界周围冗余训练区域的需求。通过结合神经高斯表示和分层架构,我们在较低的计算成本下实现了高质量的场景渲染。我们在公共基准测试上的最新结果证明了我们的方法在大规模城市场景表示中的有效性和优势。
论文及项目相关链接
Summary
高复杂度城市三维场景渲染需求日益增长,提出一种基于三维高斯涂抹技术的高效场景重建和渲染方法HUG。该方法通过神经网络高斯表示的层次架构优化数据分区和重建流程,实现高质量场景渲染的低成本计算。在公共基准测试上的最新成果证明了其在大规模城市场景表示中的优势和有效性。
Key Takeaways
- 高效场景重建和渲染方法对于处理大规模城市环境和高复杂度细节至关重要。
- HUG方法采用三维高斯涂抹技术,针对大规模城市环境处理的低效率问题提供全新解决方案。
- 通过神经网络高斯表示的层次架构,优化数据分区和重建流程。
- 增强块重建流程以提高每个块的重构质量并减少边界处冗余训练区域的必要。
- 实现高质量场景渲染的低成本计算。
- 在公共基准测试上的成果处于领先地位,证明了其在大规模城市场景表示中的优势。
点此查看论文截图


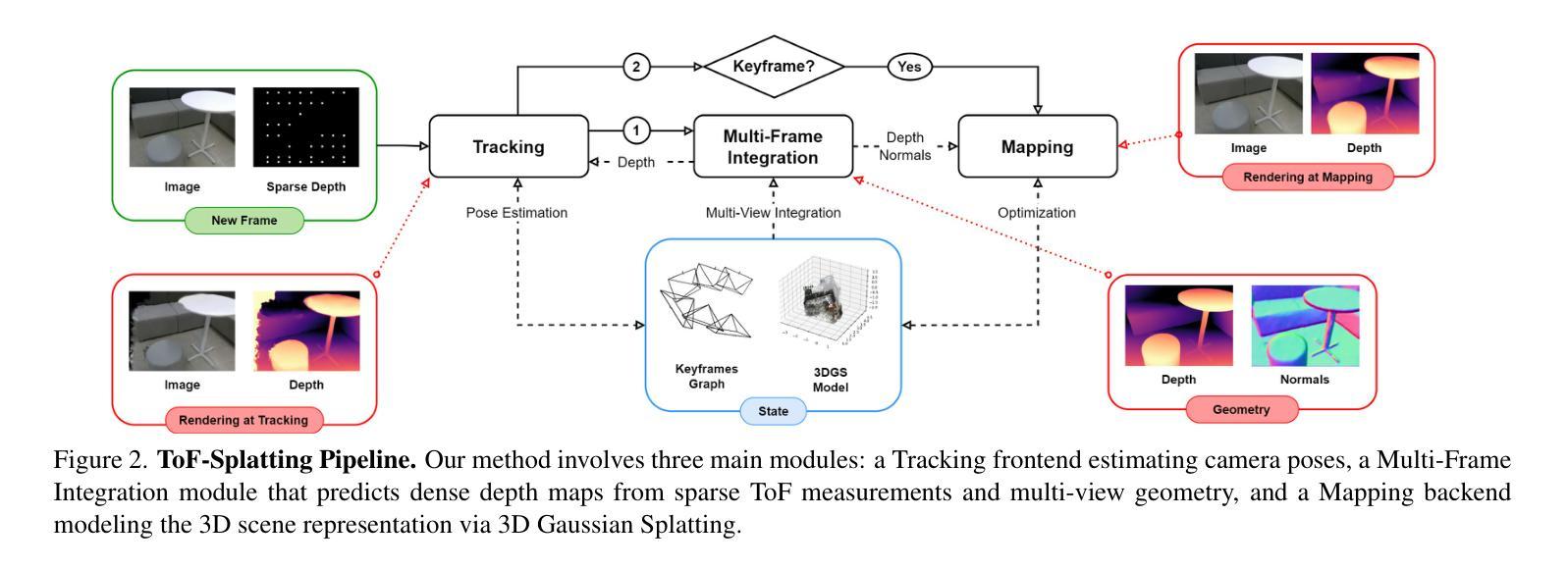
ToF-Splatting: Dense SLAM using Sparse Time-of-Flight Depth and Multi-Frame Integration
Authors:Andrea Conti, Matteo Poggi, Valerio Cambareri, Martin R. Oswald, Stefano Mattoccia
Time-of-Flight (ToF) sensors provide efficient active depth sensing at relatively low power budgets; among such designs, only very sparse measurements from low-resolution sensors are considered to meet the increasingly limited power constraints of mobile and AR/VR devices. However, such extreme sparsity levels limit the seamless usage of ToF depth in SLAM. In this work, we propose ToF-Splatting, the first 3D Gaussian Splatting-based SLAM pipeline tailored for using effectively very sparse ToF input data. Our approach improves upon the state of the art by introducing a multi-frame integration module, which produces dense depth maps by merging cues from extremely sparse ToF depth, monocular color, and multi-view geometry. Extensive experiments on both synthetic and real sparse ToF datasets demonstrate the viability of our approach, as it achieves state-of-the-art tracking and mapping performances on reference datasets.
飞行时间(ToF)传感器能够在相对较低功耗预算下提供高效的主动深度感知;在这些设计中,只有从低分辨率传感器获取的极少数测量值被认为是满足移动设备和AR/VR设备日益有限的电源约束。然而,这种极端的稀疏性限制了ToF深度在SLAM中的无缝使用。在这项工作中,我们提出了ToF-Splatting,这是第一个基于3D高斯Splatting的SLAM管道,专为有效利用非常稀疏的ToF输入数据而设计。我们的方法通过引入多帧集成模块改进了当前技术,该模块通过合并来自极稀疏的ToF深度、单目颜色和多视角几何的线索,生成密集的深度图。在合成和真实的稀疏ToF数据集上的大量实验证明了我们的方法的可行性,因为在参考数据集上,它实现了最先进的跟踪和映射性能。
论文及项目相关链接
Summary
ToF传感器能在较低的功耗下提供高效的主动深度感知,但其极度稀疏的测量数据限制了其在SLAM中的无缝应用。本文提出了ToF-Splatting,一种基于高斯分布的3D SLAM处理管道,可以有效利用极稀疏的ToF数据。该方法通过引入多帧融合模块,结合极稀疏的ToF深度、单目颜色和多视角几何信息生成密集的深度图,提高了现有方法的性能。在合成和真实稀疏ToF数据集上的实验验证了该方法的可行性,其在参考数据集上实现了最先进的跟踪和映射性能。
Key Takeaways
- ToF传感器能在低功耗下提供深度感知,但稀疏测量限制了其在SLAM中的应用。
- 提出了一种新的方法ToF-Splatting,适用于极稀疏ToF数据的3D SLAM处理。
- ToF-Splatting通过多帧融合模块生成密集深度图,结合ToF深度、单目颜色和多视角几何信息。
- 该方法在合成和真实稀疏ToF数据集上进行了广泛实验。
- ToF-Splatting实现了在参考数据集上的最佳跟踪和映射性能。
- 此方法改善了现有技术的不足,为使用稀疏ToF数据提供了有效解决方案。
点此查看论文截图

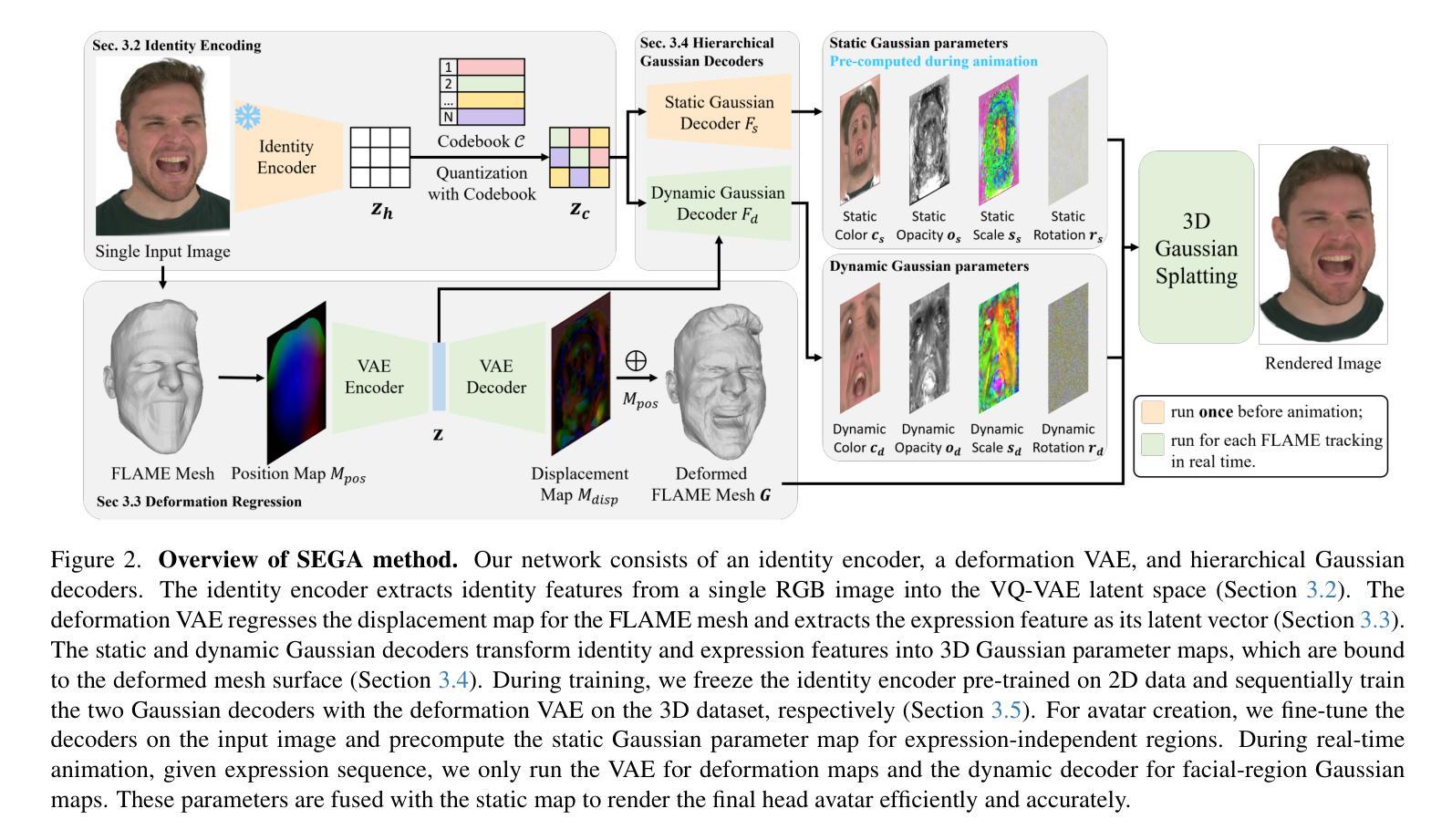
SEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Authors:Chen Guo, Zhuo Su, Jian Wang, Shuang Li, Xu Chang, Zhaohu Li, Yang Zhao, Guidong Wang, Ruqi Huang
Creating photorealistic 3D head avatars from limited input has become increasingly important for applications in virtual reality, telepresence, and digital entertainment. While recent advances like neural rendering and 3D Gaussian splatting have enabled high-quality digital human avatar creation and animation, most methods rely on multiple images or multi-view inputs, limiting their practicality for real-world use. In this paper, we propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework. SEGA seamlessly combines priors derived from large-scale 2D datasets with 3D priors learned from multi-view, multi-expression, and multi-ID data, achieving robust generalization to unseen identities while ensuring 3D consistency across novel viewpoints and expressions. We further present a hierarchical UV-space Gaussian Splatting framework that leverages FLAME-based structural priors and employs a dual-branch architecture to disentangle dynamic and static facial components effectively. The dynamic branch encodes expression-driven fine details, while the static branch focuses on expression-invariant regions, enabling efficient parameter inference and precomputation. This design maximizes the utility of limited 3D data and achieves real-time performance for animation and rendering. Additionally, SEGA performs person-specific fine-tuning to further enhance the fidelity and realism of the generated avatars. Experiments show our method outperforms state-of-the-art approaches in generalization ability, identity preservation, and expression realism, advancing one-shot avatar creation for practical applications.
创建具有真实感的3D头像化身从有限的输入在虚拟现实、远程出席和数字娱乐等应用中变得越来越重要。尽管最近的神经渲染和3D高斯延展等技术进步使得高质量数字人类化身创建和动画成为可能,但大多数方法仍依赖于多张图像或多视角输入,这限制了它们在现实世界应用中的实用性。在本文中,我们提出了SEGA,这是一种基于单图像的新型3D驾驶高斯头部化身创建方法,它将通用先验模型与新的层次化UV空间高斯延展框架相结合。SEGA无缝地将从大规模二维数据集推导出的先验与从多角度、多表情和多身份数据中学习的三维先验相结合,实现了对未见身份的稳健泛化,同时确保新型视角和表情下的三维一致性。我们还提出了一种层次化的UV空间高斯延展框架,它利用基于FLAME的结构先验,并采用双分支架构有效地分离动态和静态面部组件。动态分支编码表情驱动的精细细节,而静态分支则专注于表情不变的区域,从而实现有效的参数推断和预计算。这种设计最大限度地提高了有限三维数据的效用,实现了动画和渲染的实时性能。此外,SEGA还执行针对个人的微调,以进一步提高生成的化身的真实感和逼真度。实验表明,我们的方法在泛化能力、身份保留和表情逼真度方面优于最先进的方法,推动了单次拍摄化身创建的实际应用。
论文及项目相关链接
Summary
本文提出了一种基于单张图像创建3D可驱动高斯头像的技术SEGA。该技术结合了通用先验模型和新层次UV空间高斯溅落框架,实现了对未见身份的稳健泛化,同时确保在不同视角和表情下的3D一致性。SEGA利用大型二维数据集得出的先验知识和从多角度、多表情和多身份数据中学习的三维先验知识无缝结合,实现了高效参数推断和预计算。此外,SEGA还支持个性化微调,进一步提升生成的头像的逼真度和真实感。实验表明,该方法在泛化能力、身份保留和表情逼真方面优于现有技术,推动了一次性头像创建的实际应用。
Key Takeaways
- SEGA技术实现了基于单张图像创建3D可驱动高斯头像的新方法。
- 结合了通用先验模型与新层次UV空间高斯溅落框架。
- 技术实现了对未见身份的稳健泛化,确保了在不同视角和表情下的3D一致性。
- 利用大型二维数据集及多视角、多表情和多身份数据结合的先验知识。
- 采用高效参数推断和预计算设计,支持实时动画和渲染。
- SEGA支持个性化微调,提高生成的头像的逼真度和真实感。
点此查看论文截图

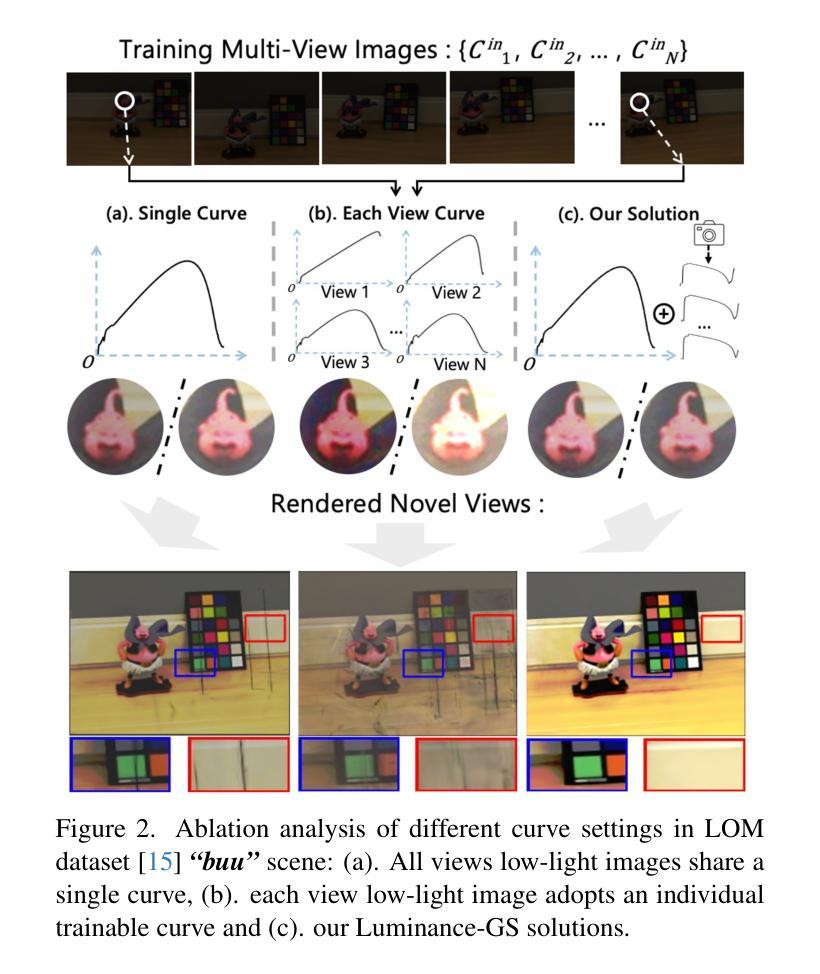
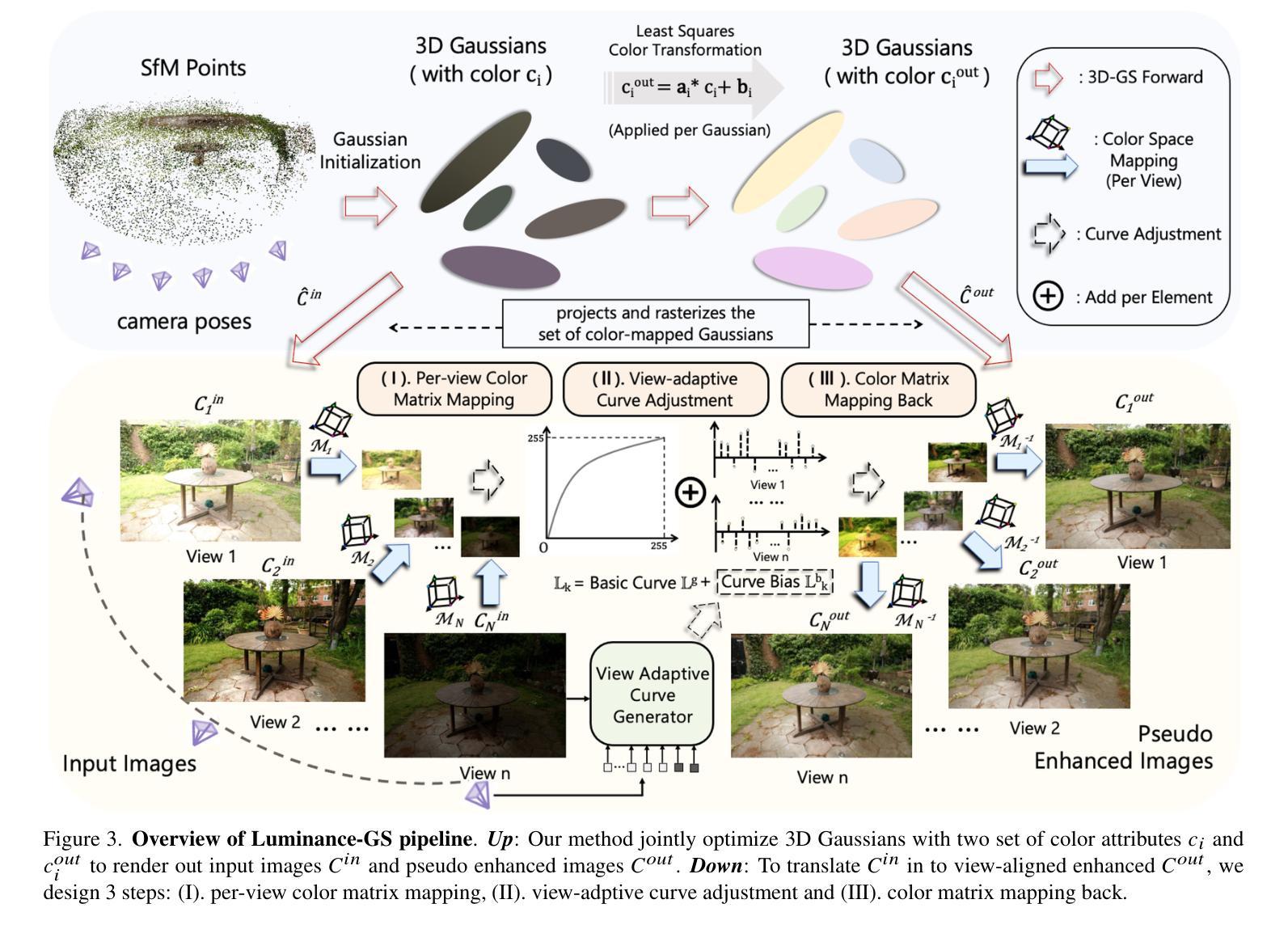
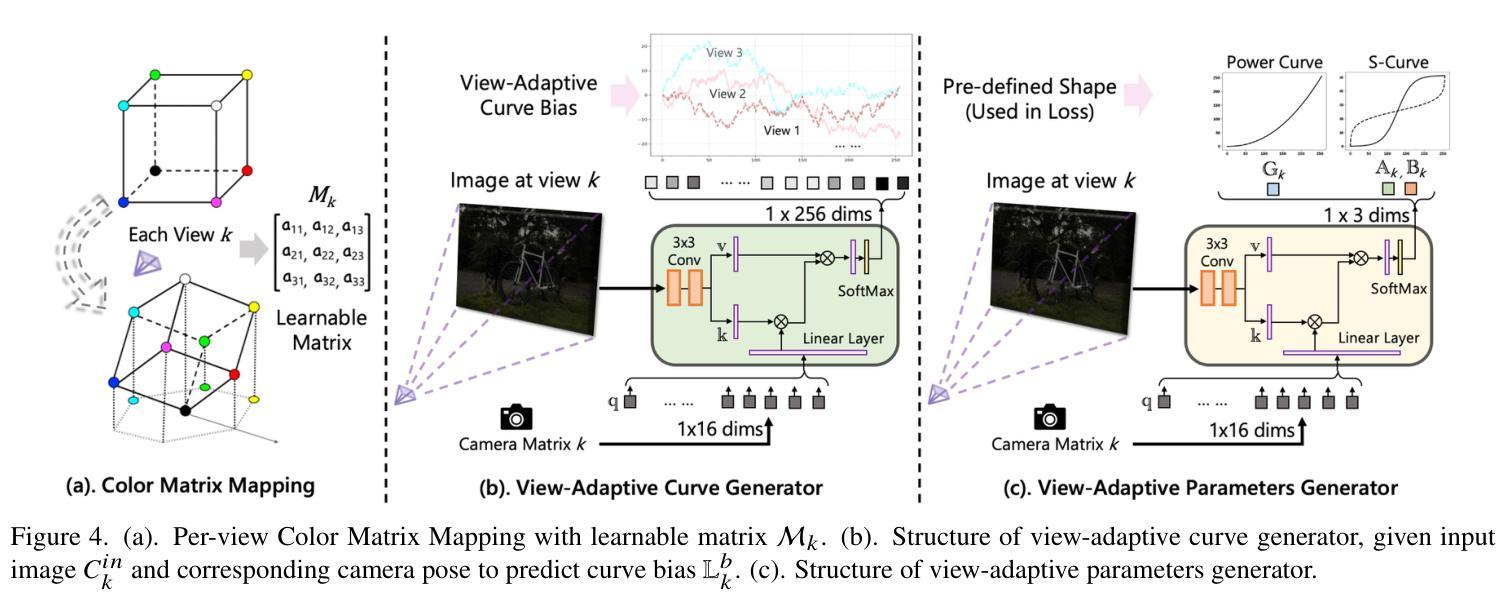
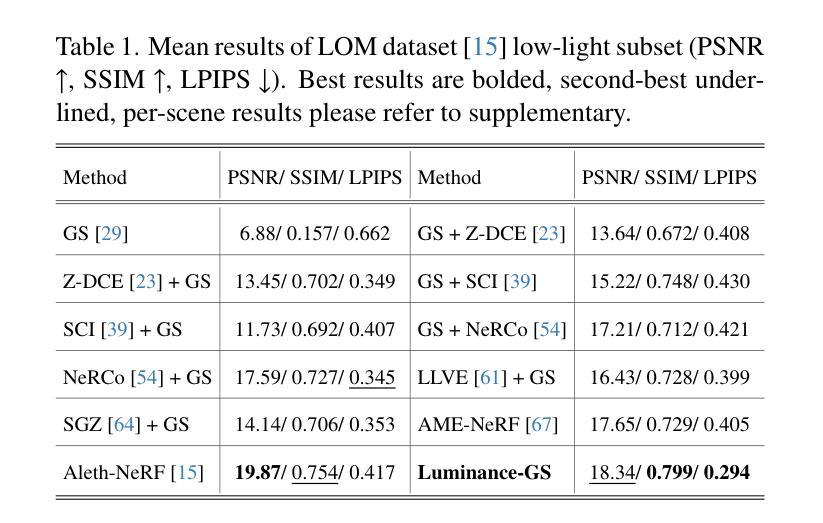
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Authors:Ziteng Cui, Xuangeng Chu, Tatsuya Harada
Capturing high-quality photographs under diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) significantly impact image quality. This challenge becomes more pronounced in multi-view scenarios, where variations in lighting and image signal processor (ISP) settings across viewpoints introduce photometric inconsistencies. Such lighting degradations and view-dependent variations pose substantial challenges to novel view synthesis (NVS) frameworks based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). To address this, we introduce Luminance-GS, a novel approach to achieving high-quality novel view synthesis results under diverse challenging lighting conditions using 3DGS. By adopting per-view color matrix mapping and view-adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions – including low-light, overexposure, and varying exposure – while not altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality.
在多样化的真实世界照明条件下捕捉高质量照片是一项挑战,因为自然光照(例如低光环境)和相机曝光设置(例如曝光时间)都会显著影响图像质量。这一挑战在多视角场景中尤为突出,其中不同视角的光照和图像信号处理器(ISP)设置变化会引入光度不一致性。这种光照退化和视角相关的变化给基于神经辐射场(NeRF)和3D高斯展布(3DGS)的新视角合成(NVS)框架带来了巨大挑战。为了解决这一问题,我们引入了Luminance-GS,这是一种利用3DGS在多样且具有挑战性的光照条件下实现高质量新视角合成结果的新方法。通过采用每视图颜色矩阵映射和视图自适应曲线调整,Luminance-GS在各种光照条件下实现了最先进的成果,包括低光、过曝和曝光变化,同时不改变原始3DGS显式表示。与之前的NeRF和3DGS基线相比,Luminance-GS提供了实时渲染速度并改善了重建质量。
论文及项目相关链接
PDF CVPR 2025, project page: https://cuiziteng.github.io/Luminance_GS_web/
Summary
针对真实世界多种光照条件下拍摄高质量照片的挑战,提出一种基于3DGS的Luminance-GS方法,通过采用视图色彩矩阵映射和视图自适应曲线调整,实现不同光照条件下的高质量视图合成。该方法在不改变原始3DGS显式表示的前提下,实现了跨各种光照条件,包括低光、过曝光和曝光变化等状态下的先进结果,同时提高了实时渲染速度和重建质量。
Key Takeaways
- 真实世界多种光照条件对拍摄高质量照片带来挑战。
- 自然光照和相机曝光设置对图像质量有重要影响。
- 多视角场景中的光照变化和ISP设置会导致光度学不一致性。
- 光照退化和视角相关的变化给基于NeRF和3DGS的新视角合成(NVS)框架带来重大挑战。
- 提出一种基于3DGS的Luminance-GS方法,实现多种光照条件下的高质量视图合成。
- 通过视图色彩矩阵映射和视图自适应曲线调整,Luminance-GS在不同光照条件下达到先进结果。
点此查看论文截图

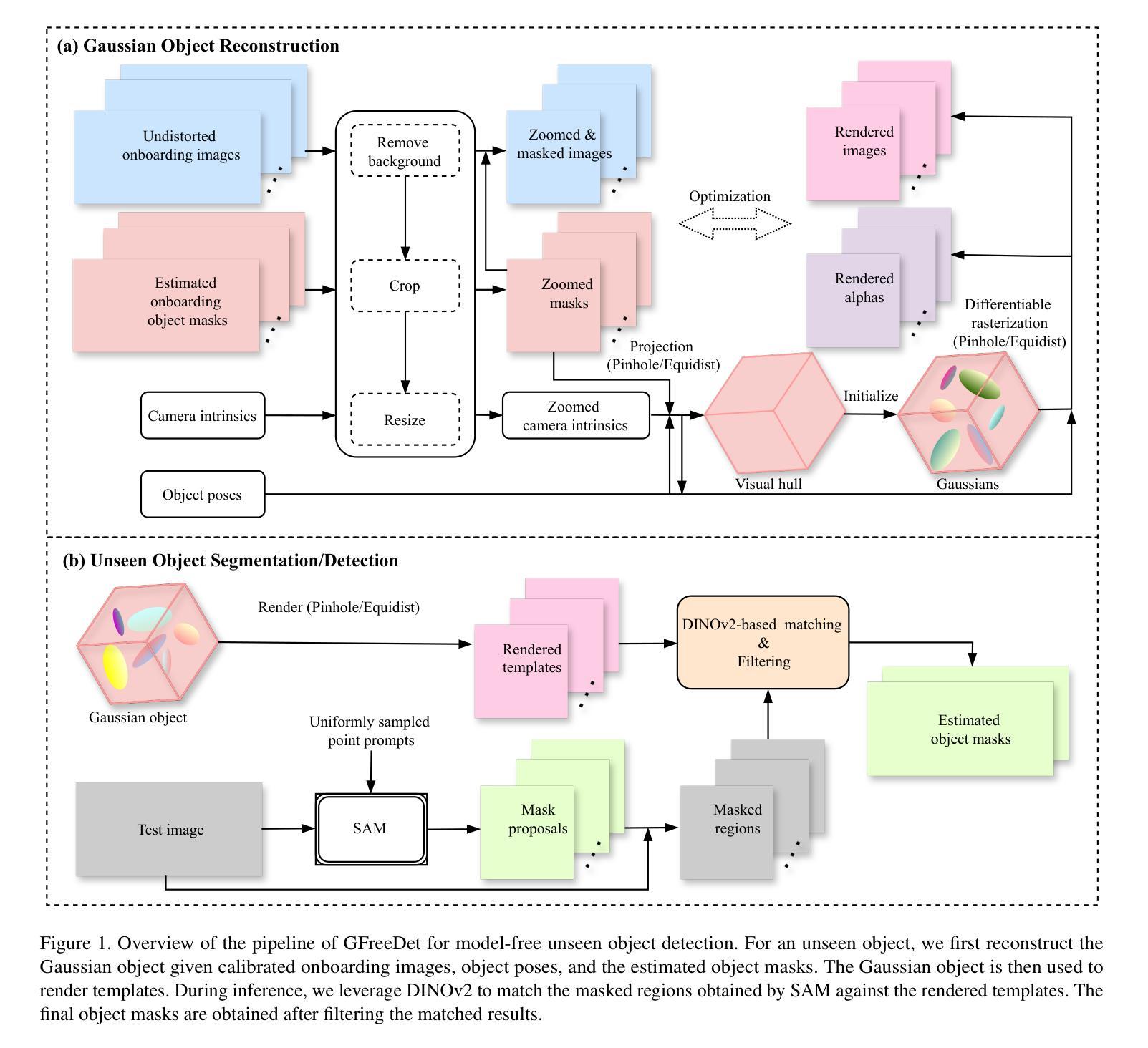
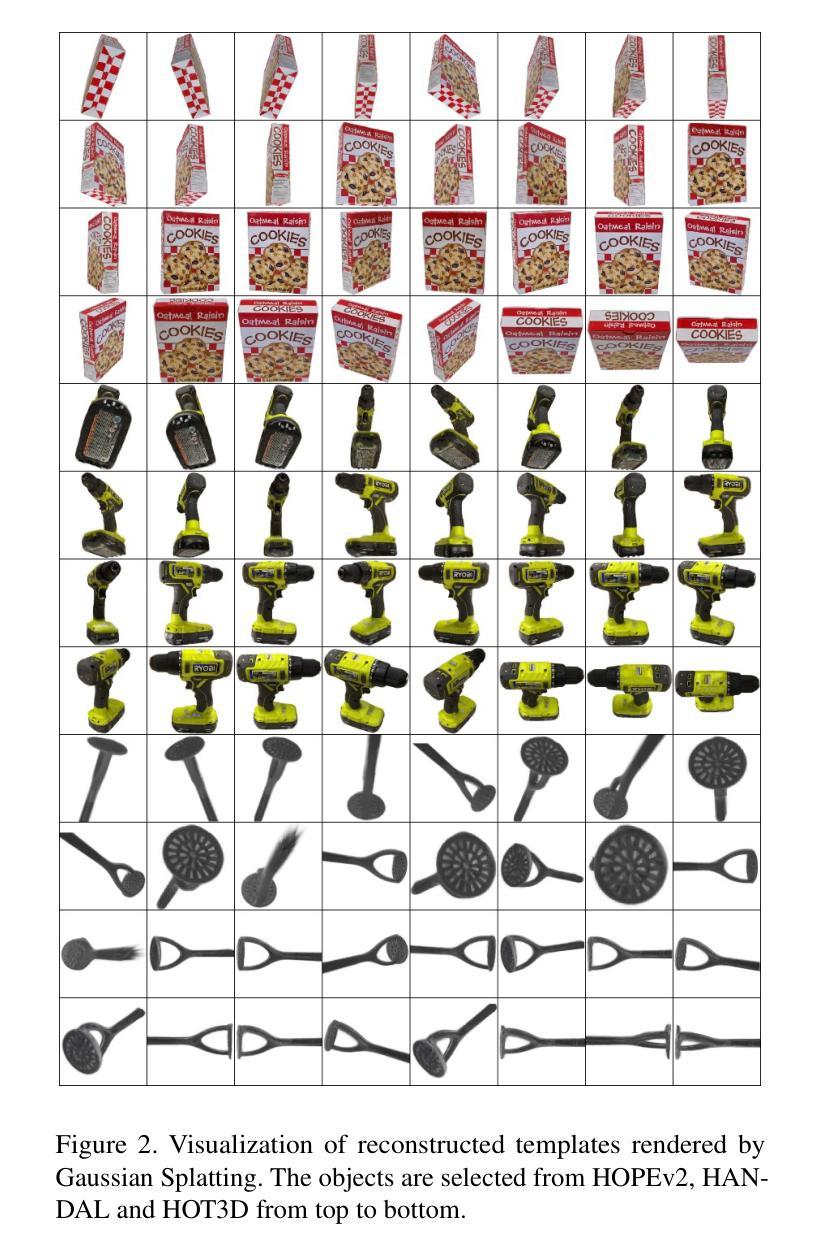
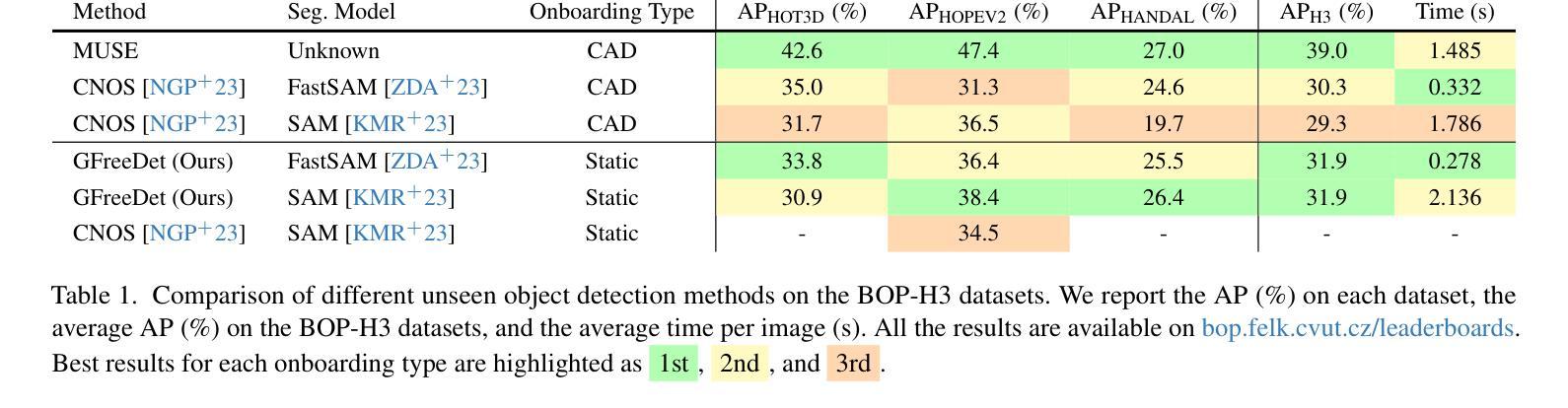
GFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Authors:Xingyu Liu, Gu Wang, Chengxi Li, Yingyue Li, Chenyangguang Zhang, Ziqin Huang, Xiangyang Ji
We present GFreeDet, an unseen object detection approach that leverages Gaussian splatting and vision Foundation models under model-free setting. Unlike existing methods that rely on predefined CAD templates, GFreeDet reconstructs objects directly from reference videos using Gaussian splatting, enabling robust detection of novel objects without prior 3D models. Evaluated on the BOP-H3 benchmark, GFreeDet achieves comparable performance to CAD-based methods, demonstrating the viability of model-free detection for mixed reality (MR) applications. Notably, GFreeDet won the best overall method and the best fast method awards in the model-free 2D detection track at BOP Challenge 2024.
我们介绍了GFreeDet,这是一种无需特定模型背景的新对象检测法,该方法利用高斯平铺(Gaussian splatting)和视觉基础模型(vision Foundation models)。不同于依赖预先定义的CAD模板的现有方法,GFreeDet直接从参考视频重建对象并使用高斯平铺法实现无预设的鲁棒型新对象检测。在BOP-H3基准测试中评估,GFreeDet的性能与基于CAD的方法相当,证明了无模型检测在混合现实(MR)应用中的可行性。值得注意的是,GFreeDet在BOP Challenge 2024模型无关二维检测赛道上荣获最佳总体方法和最佳快速方法奖。
论文及项目相关链接
PDF CVPR 2025 CV4MR Workshop (citation style changed)
Summary
GFreeDet是一种无预设对象检测新方法,其基于高斯渲染技术以及视觉模型模式来实现未定义物体检测。区别于以往依赖于CAD模板的方法,GFreeDet可直接通过参考视频重建物体,无需预先定义三维模型即可实现稳健的新物体检测。在BOP-H3标准的测试上表现优秀,甚至获得了BOP挑战模型无预设对象检测的杰出成绩与速度第一的佳绩,对于混合现实(MR)应用具有良好的前景。
Key Takeaways
- GFreeDet利用高斯渲染技术实现了无需预设模型的物体检测。
- 通过参考视频重建物体而非依赖预先定义的三维模型进行物体检测。
- GFreeDet在BOP-H3标准测试中表现优秀,与基于CAD的方法相比具有竞争力。
- GFreeDet为混合现实应用提供可行性模型无需预设检测方法的新选择。
- 该方法在物体识别的应用创新上有突破性成果。
- GFreeDet获得模型无预设对象检测的最佳整体方法和最佳快速方法奖。
点此查看论文截图