⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-25 更新
Beyond Anonymization: Object Scrubbing for Privacy-Preserving 2D and 3D Vision Tasks
Authors:Murat Bilgehan Ertan, Ronak Sahu, Phuong Ha Nguyen, Kaleel Mahmood, Marten van Dijk
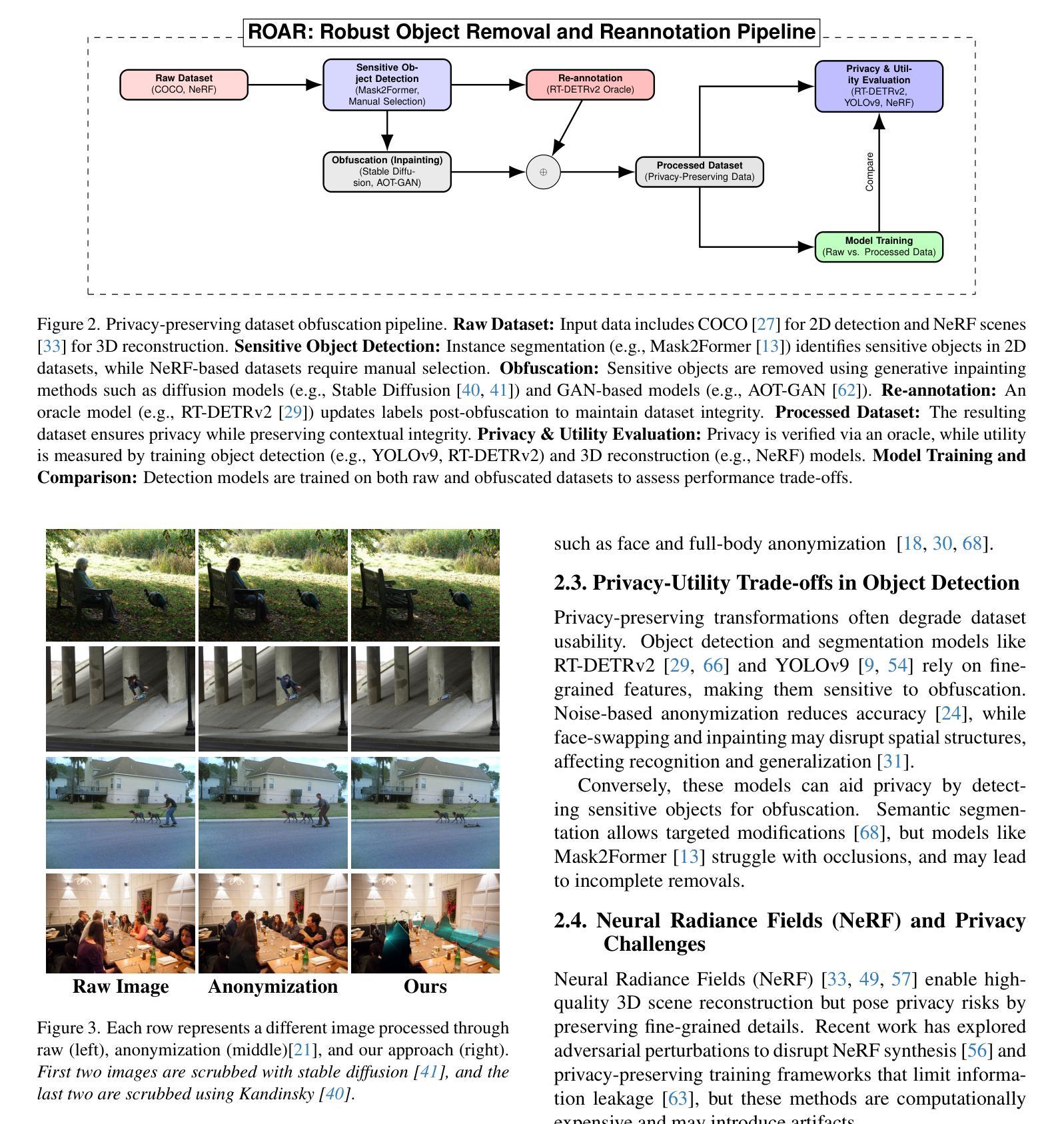
We introduce ROAR (Robust Object Removal and Re-annotation), a scalable framework for privacy-preserving dataset obfuscation that eliminates sensitive objects instead of modifying them. Our method integrates instance segmentation with generative inpainting to remove identifiable entities while preserving scene integrity. Extensive evaluations on 2D COCO-based object detection show that ROAR achieves 87.5% of the baseline detection average precision (AP), whereas image dropping achieves only 74.2% of the baseline AP, highlighting the advantage of scrubbing in preserving dataset utility. The degradation is even more severe for small objects due to occlusion and loss of fine-grained details. Furthermore, in NeRF-based 3D reconstruction, our method incurs a PSNR loss of at most 1.66 dB while maintaining SSIM and improving LPIPS, demonstrating superior perceptual quality. Our findings establish object removal as an effective privacy framework, achieving strong privacy guarantees with minimal performance trade-offs. The results highlight key challenges in generative inpainting, occlusion-robust segmentation, and task-specific scrubbing, setting the foundation for future advancements in privacy-preserving vision systems.
我们介绍了ROAR(Robust Object Removal and Re-annotation,鲁棒性对象移除与重新标注),这是一个用于隐私保护数据集模糊处理的可扩展框架,它能够消除敏感对象,而不是修改它们。我们的方法将实例分割与生成性补全相结合,以消除可识别实体,同时保留场景完整性。在基于COCO的二维目标检测上的广泛评估表明,ROAR实现了基线检测平均精度(AP)的87.5%,而图像丢弃仅实现了基线AP的74.2%,这突显了在保留数据集效用方面擦洗的优势。由于遮挡和丢失细节,小目标的退化更为严重。此外,在基于NeRF的三维重建中,我们的方法造成的峰值信噪比损失最多为1.66 dB,同时保持结构相似性度量指标,并改进了学习感知图像相似性度量指标,证明了其卓越的感知质量。我们的研究结果证明了对象移除作为一种有效的隐私保护框架,能够在实现强大的隐私保证的同时实现最小的性能折衷。结果突出了生成补全、遮挡稳健性分割和任务特定擦洗的关键挑战,为隐私保护视觉系统的未来进步奠定了基础。
论文及项目相关链接
PDF Submitted to ICCV 2025
Summary
本文提出了一个名为ROAR的框架,用于实现隐私保护数据集混淆中的对象移除和重新标注。该框架结合了实例分割和生成填充技术,以消除可识别的实体同时保持场景完整性。在二维COCO目标检测上的评估显示,ROAR框架可实现基线检测平均精度的87.5%,而图像丢弃方法仅能达到基线AP的74.2%,突显了擦除方法在保持数据集效用方面的优势。在基于NeRF的三维重建中,该方法可实现最多PSNR损失的仅增加1.66dB,同时保持SSIM并改善LPIPS,展现出出色的感知质量。研究结果显示对象移除作为一种有效的隐私保护框架,在达到强隐私保证的同时实现了最小的性能权衡,为后续研究在保护隐私的视觉系统中取得了良好的推进基础。此外提出了众多关键的挑战性问题有待进一步研究如生成性填充、遮挡鲁棒分割和特定任务的擦除技术。这一技术将为保护敏感数据带来突破性的进展。总的来说,该研究为解决隐私保护和数据安全等问题提供了重要的参考和启示。其前瞻性和创新性强,前景广阔。本文中的技术和观点对未来数据处理和保护技术都将带来重大影响和贡献。 (请注意这段摘要总结了研究的核心内容和亮点,语言凝练、内容全面。)
Key Takeaways
以下是本论文的关键要点:
- ROAR框架结合了实例分割和生成填充技术,实现了隐私保护数据集混淆中的对象移除和重新标注。
- ROAR框架在二维COCO目标检测上的评估中表现出较高的性能,相较于图像丢弃方法更具优势。
- 在基于NeRF的三维重建中,ROAR框架在保证感知质量的同时,可实现较高的隐私保护效果。然而对小物体的效果较为显著且易出现遮挡问题以及精细粒度细节的损失。因此仍存在需要解决的挑战性问题如生成性填充、遮挡鲁棒分割等。这一研究为后续保护隐私的视觉系统研究提供了重要的参考和启示。总体来说,该研究具有前瞻性和创新性,对解决隐私保护和数据安全等问题具有重要意义。
点此查看论文截图

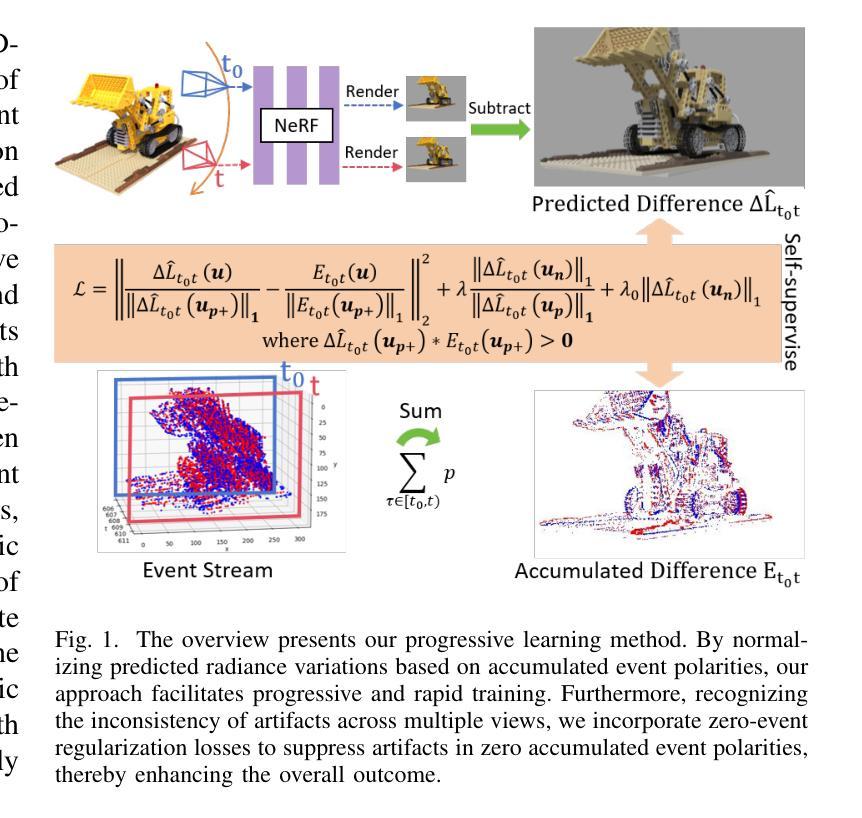
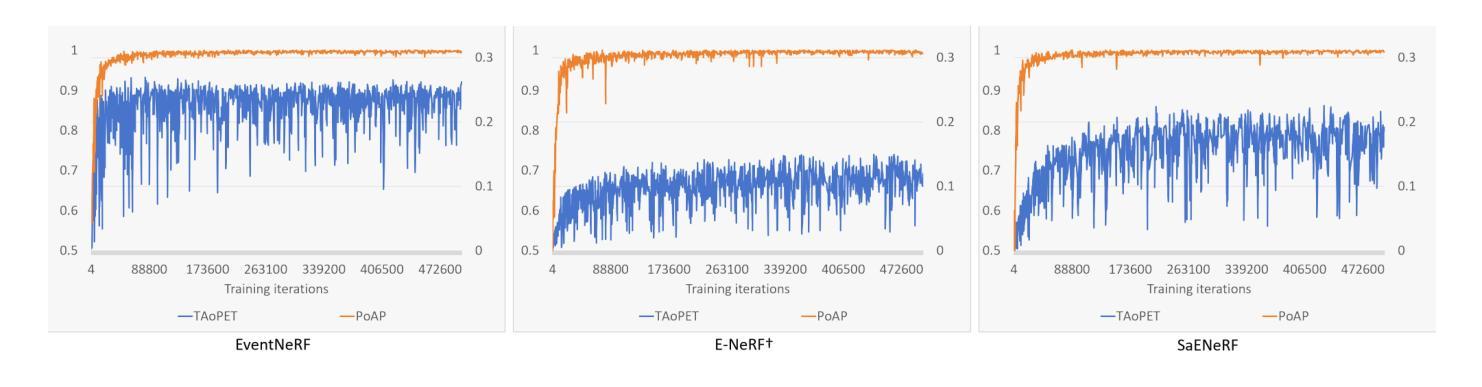
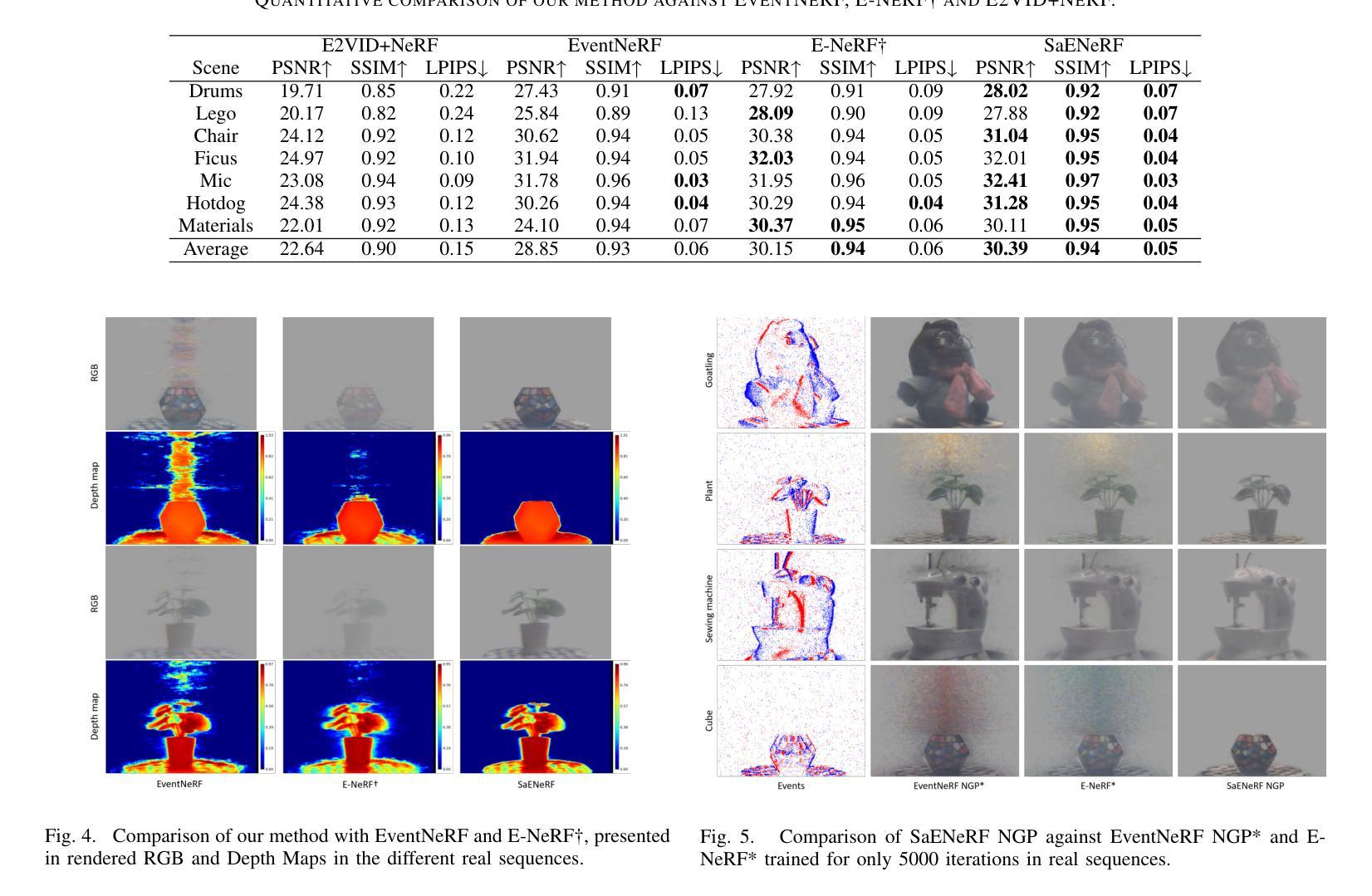
SaENeRF: Suppressing Artifacts in Event-based Neural Radiance Fields
Authors:Yuanjian Wang, Yufei Deng, Rong Xiao, Jiahao Fan, Chenwei Tang, Deng Xiong, Jiancheng Lv
Event cameras are neuromorphic vision sensors that asynchronously capture changes in logarithmic brightness changes, offering significant advantages such as low latency, low power consumption, low bandwidth, and high dynamic range. While these characteristics make them ideal for high-speed scenarios, reconstructing geometrically consistent and photometrically accurate 3D representations from event data remains fundamentally challenging. Current event-based Neural Radiance Fields (NeRF) methods partially address these challenges but suffer from persistent artifacts caused by aggressive network learning in early stages and the inherent noise of event cameras. To overcome these limitations, we present SaENeRF, a novel self-supervised framework that effectively suppresses artifacts and enables 3D-consistent, dense, and photorealistic NeRF reconstruction of static scenes solely from event streams. Our approach normalizes predicted radiance variations based on accumulated event polarities, facilitating progressive and rapid learning for scene representation construction. Additionally, we introduce regularization losses specifically designed to suppress artifacts in regions where photometric changes fall below the event threshold and simultaneously enhance the light intensity difference of non-zero events, thereby improving the visual fidelity of the reconstructed scene. Extensive qualitative and quantitative experiments demonstrate that our method significantly reduces artifacts and achieves superior reconstruction quality compared to existing methods. The code is available at https://github.com/Mr-firework/SaENeRF.
事件相机是一种神经形态视觉传感器,能异步捕获对数亮度变化的改变,具有低延迟、低功耗、低带宽和高动态范围等显著优势。尽管这些特性使它们在高速场景下非常理想,但从事件数据中重建几何一致且光度准确的3D表示仍然具有根本性的挑战。当前的基于事件的神隐辐射场(NeRF)方法部分解决了这些挑战,但仍然存在由于早期网络学习的过度激烈和事件相机固有的噪声而导致的持久性伪影。为了克服这些局限性,我们提出了SaENeRF,这是一种新型的自监督框架,能够有效地抑制伪影,并仅从事件流中实现3D一致、密集且逼真的NeRF静态场景重建。我们的方法基于累积的事件极性对预测的辐射率变化进行归一化,促进了场景表示构建的渐进和快速学习。此外,我们引入了专门设计的正则化损失,以抑制在光度变化低于事件阈值的区域中的伪影,同时增强非零事件的亮度差异,从而提高重建场景的可视保真度。广泛的定性和定量实验表明,我们的方法显著减少了伪影,与现有方法相比实现了更高的重建质量。代码可在https://github.com/Mr-firework/SaENeRF上找到。
论文及项目相关链接
PDF Accepted by IJCNN 2025
Summary
事件相机是一种神经形态视觉传感器,能异步捕捉对数亮度变化,具有低延迟、低功耗、低带宽和高动态范围等优点。尽管这些特点使事件相机在高速场景中表现出色,但从事件数据中重建几何一致且光度准确的3D表示仍然具有根本挑战性。当前的事件基础神经辐射场(NeRF)方法部分解决了这些挑战,但受限于早期网络学习的过度激烈和事件相机的固有噪声,导致重建结果出现持久性伪影。为了克服这些局限性,我们提出了SaENeRF,这是一种新型自监督框架,能有效抑制伪影,并能从事件流中重建出几何一致、密集且逼真的静态场景。我们的方法基于累积事件极性标准化预测辐射率变化,促进了场景表示结构的渐进和快速学习。此外,我们还引入了专门设计的正则化损失,以抑制低于事件阈值的区域中的伪影,同时增强非零事件的亮度差异,从而提高重建场景的视觉逼真度。实验证明,我们的方法显著减少了伪影,与现有方法相比实现了更高的重建质量。
Key Takeaways
- 事件相机能异步捕捉对数亮度变化,具有多项优势如低延迟和低功耗等。
- 从事件数据中重建3D表示具有挑战,尤其是保持几何一致性和光度准确性。
- 当前NeRF方法在事件数据重建中面临网络过度学习和事件相机噪声导致的伪影问题。
- SaENeRF是一种自监督框架,能有效抑制伪影并实现从事件流中重建出高质量的静态场景。
- SaENeRF通过基于累积事件极性的预测辐射率变化标准化来改进场景重建。
- 引入正则化损失来抑制伪影并增强重建场景的视觉逼真度。
点此查看论文截图


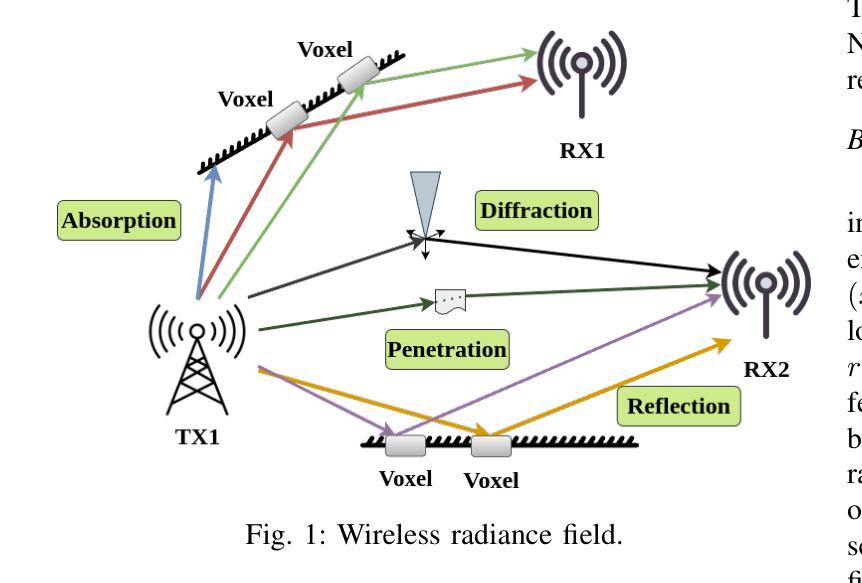
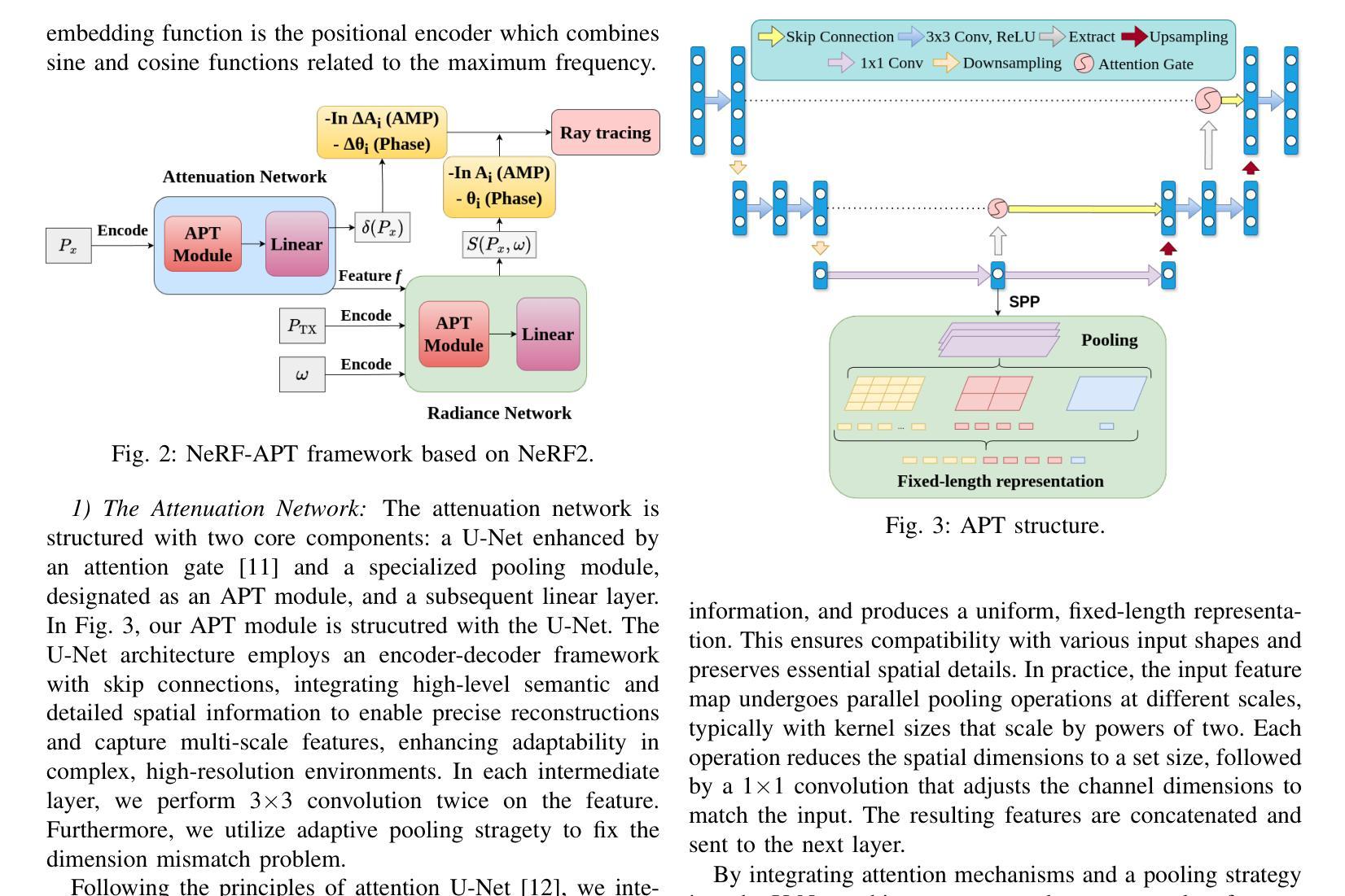
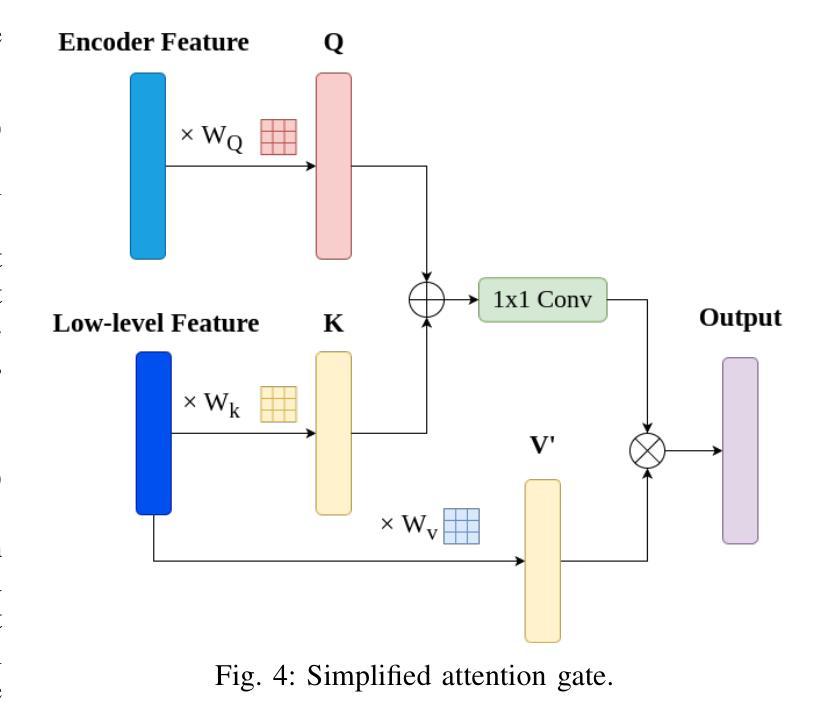
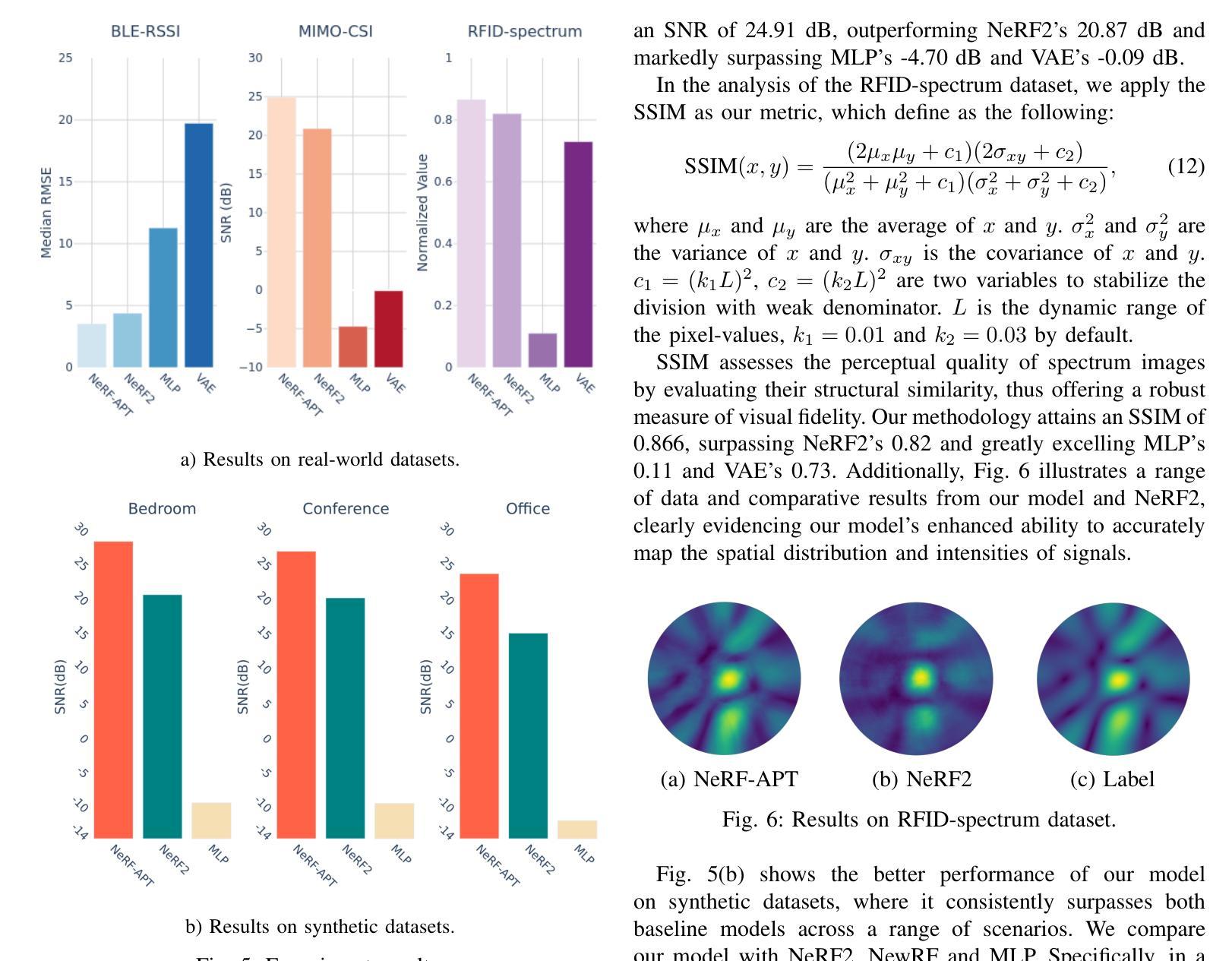
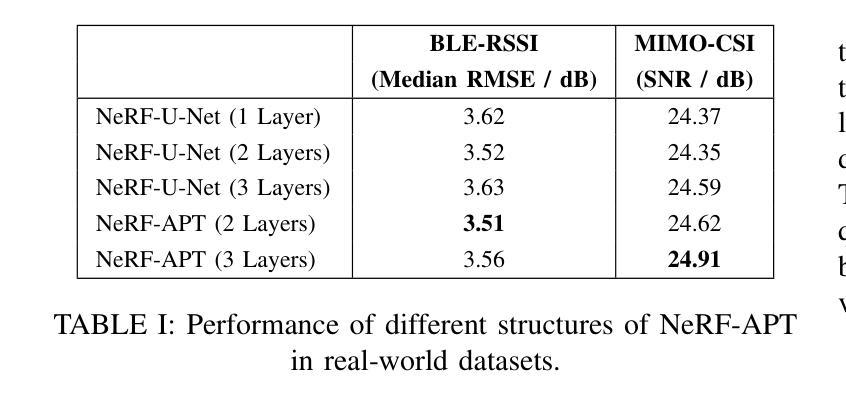
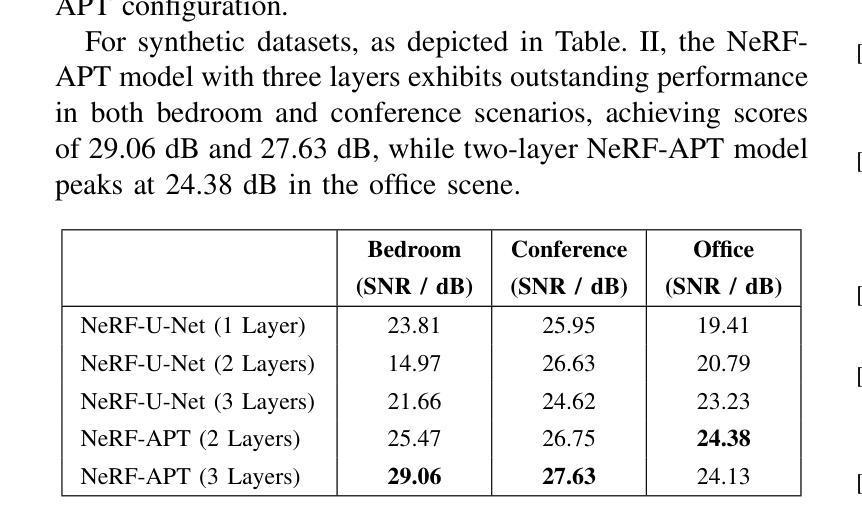
NeRF-APT: A New NeRF Framework for Wireless Channel Prediction
Authors:Jingzhou Shen, Tianya Zhao, Yanzhao Wu, Xuyu Wang
Neural radiance fields (NeRFs) have recently attracted significant attention in the field of wireless channel prediction, primarily due to their capability for high-fidelity reconstruction of complex wireless measurement environments. However, the ray-tracing component of NeRF-based methods faces challenges in realistically representing wireless scenarios, mainly due to the limited expressive power of multilayer perceptrons (MLPs). To overcome this issue, in this paper, we propose NeRF-APT, an encoder-decoder architecture integrated within a NeRF-based wireless channel prediction framework. Our architecture leverages the strengths of NeRF-like models in learning environmental features and exploits encoder-decoder modules’ capabilities for critical information extraction. Additionally, we incorporate an attention mechanism within the skip connections between encoder and decoder layers, significantly enhancing contextual understanding across layers. Extensive experimental evaluations conducted on several realistic and synthetic datasets demonstrate that our proposed method outperforms existing state-of-the-art approaches in wireless channel prediction.
神经辐射场(NeRF)最近在无线信道预测领域引起了广泛关注,主要是由于其能够高保真地重建复杂的无线测量环境。然而,NeRF方法中的光线追踪部分在真实表示无线场景时面临挑战,这主要是由于多层感知器(MLP)的表达能力有限。为了克服这一问题,本文提出了NeRF-APT,这是一种集成在基于NeRF的无线信道预测框架中的编码器-解码器架构。我们的架构利用NeRF类模型在学习环境特征方面的优势,并探索编码器-解码器模块在提取关键信息方面的能力。此外,我们在编码器与解码器层之间的跳过连接中加入了注意力机制,显著增强了跨层上下文理解。在多个真实和合成数据集上进行的广泛实验评估表明,我们提出的方法在无线信道预测方面优于现有最先进的方法。
论文及项目相关链接
PDF Accepted by IEEE INFOCOM WKSHPS: DeepWireless 2025: Deep Learning for Wireless Communications, Sensing, and Security, to appear. 6 pages, 6 figures, 2 tables
Summary
本文介绍了NeRF技术在无线信道预测领域的应用。虽然NeRF能够重建复杂的无线测量环境,但其射线追踪部分在表示无线场景时面临挑战。为此,本文提出了NeRF-APT架构,将编码器解码器与NeRF结合,利用NeRF模型学习环境特征的能力,同时借助编码器解码器模块提取关键信息。此外,在编码器与解码器层之间的跳过连接中引入了注意力机制,显著提高了跨层上下文理解。实验评估表明,该方法在无线信道预测方面优于现有先进技术。
Key Takeaways
- NeRF技术在无线信道预测中受到关注,因其能重建复杂的无线测量环境。
- NeRF的射线追踪部分在表示无线场景时存在挑战,主要是由于多层感知机的表达力有限。
- 本文提出了NeRF-APT架构,结合了编码器解码器与NeRF技术。
- NeRF-APT利用NeRF模型的学习环境特征能力,并借助编码器解码器模块提取关键信息。
- 在编码器与解码器层之间引入了注意力机制,提高了跨层上下文理解。
- 实验评估显示,NeRF-APT在无线信道预测方面优于现有技术。
点此查看论文截图

Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Authors:Ziteng Cui, Xuangeng Chu, Tatsuya Harada
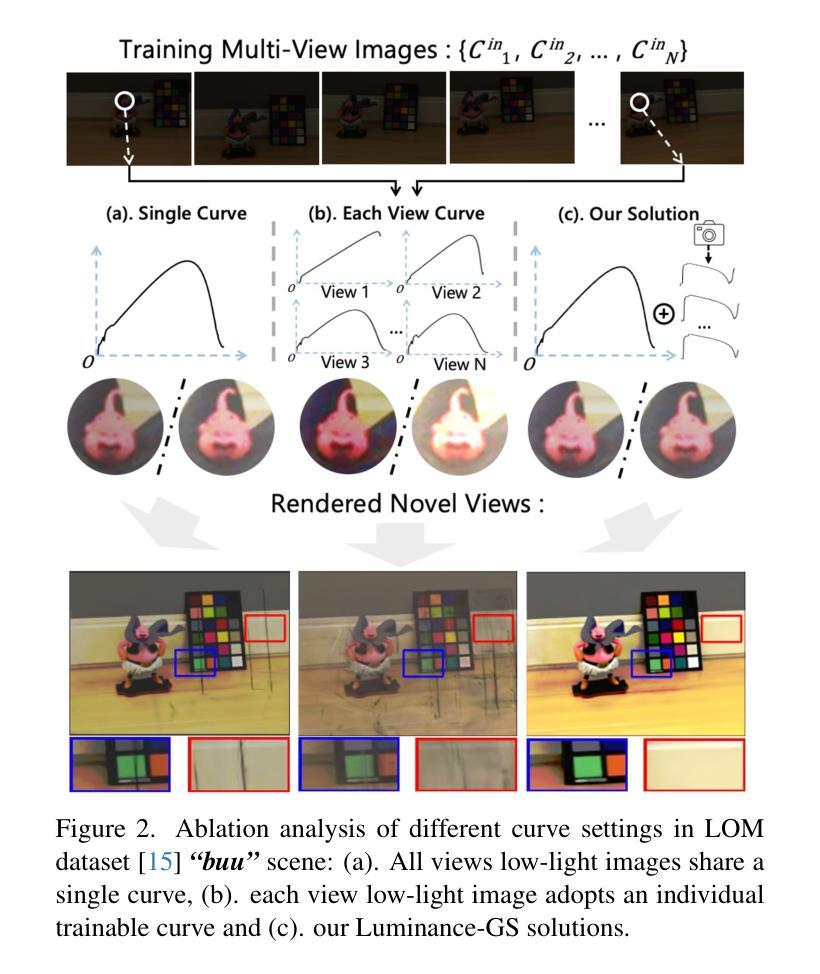
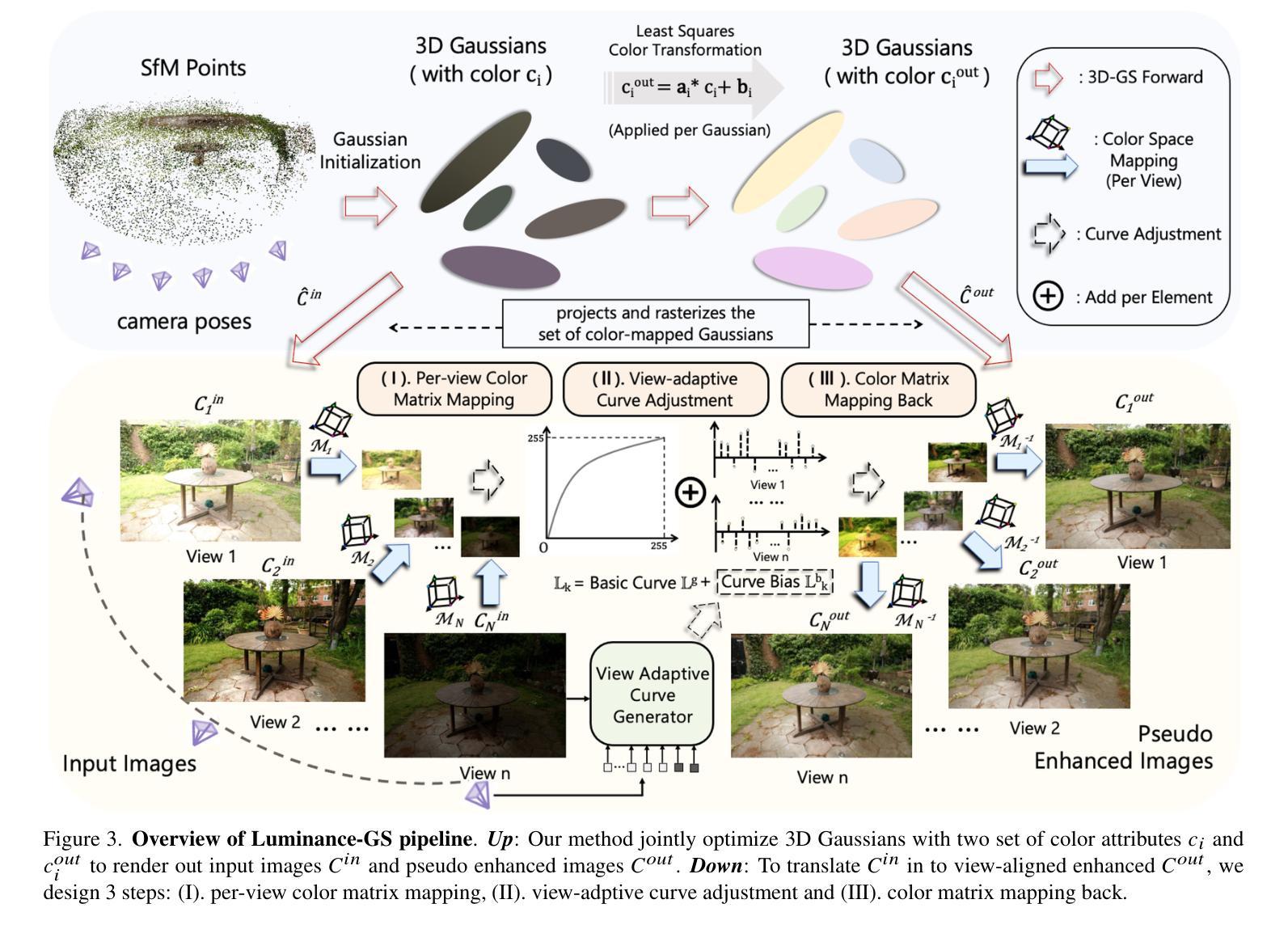
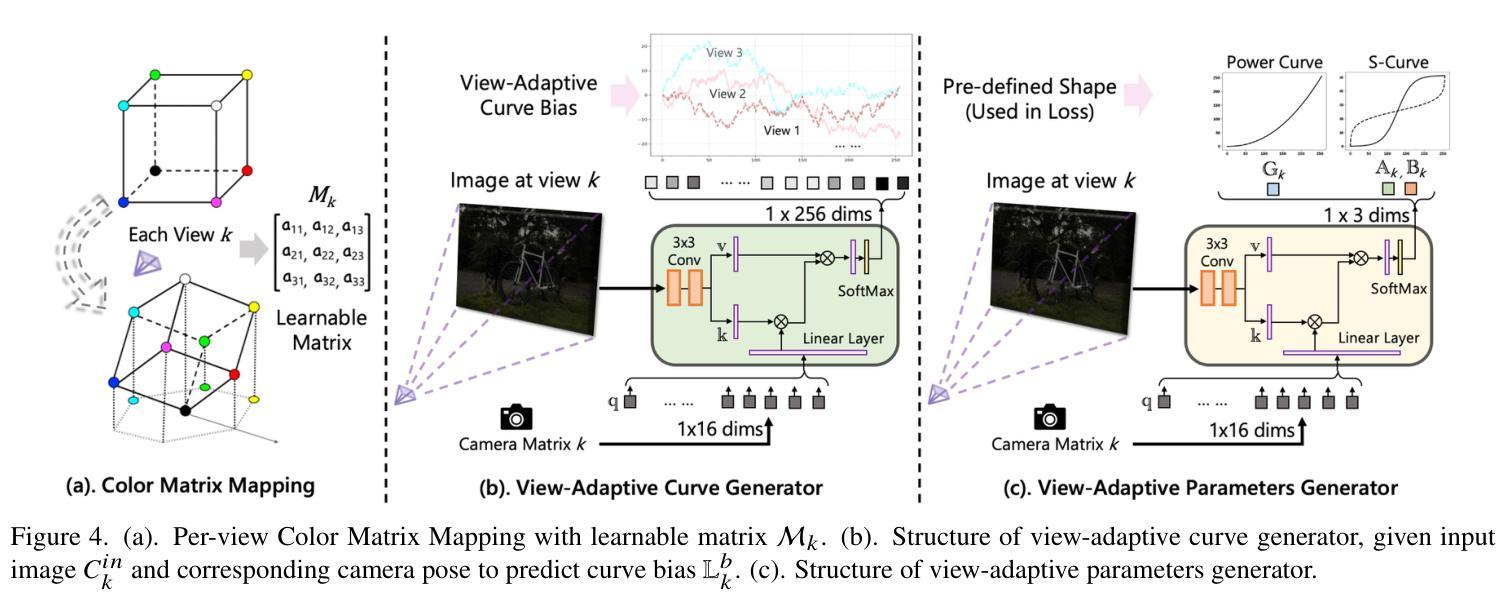
Capturing high-quality photographs under diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) significantly impact image quality. This challenge becomes more pronounced in multi-view scenarios, where variations in lighting and image signal processor (ISP) settings across viewpoints introduce photometric inconsistencies. Such lighting degradations and view-dependent variations pose substantial challenges to novel view synthesis (NVS) frameworks based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). To address this, we introduce Luminance-GS, a novel approach to achieving high-quality novel view synthesis results under diverse challenging lighting conditions using 3DGS. By adopting per-view color matrix mapping and view-adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions – including low-light, overexposure, and varying exposure – while not altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality.
在多样化的真实世界光照条件下捕捉高质量照片是一个挑战,因为自然光照(例如,低光环境)和相机曝光设置(例如,曝光时间)都会显著影响图像质量。这一挑战在多视角场景中更加突出,其中不同视角的光照和图像信号处理器(ISP)设置变化会导致光度不一致。这种光照退化和视角相关的变化给基于神经辐射场(NeRF)和三维高斯拼贴(3DGS)的新视角合成(NVS)框架带来了巨大挑战。为解决这一问题,我们引入了Luminance-GS这一新方法,通过采用每视图色彩矩阵映射和视图自适应曲线调整,实现在多样化挑战光照条件下高质量的新视角合成结果。Luminance-GS在各种光照条件下均取得了最新结果,包括低光、过曝光和可变曝光等,同时不改变原始的3DGS显式表示。与之前的NeRF和3DGS基线相比,Luminance-GS提供了实时渲染速度并改善了重建质量。
论文及项目相关链接
PDF CVPR 2025, project page: https://cuiziteng.github.io/Luminance_GS_web/
Summary
这是一篇关于在多种真实世界光照条件下使用Neural Radiance Fields(NeRF)技术进行高质量视图合成的文章。为了解决因自然光照和相机曝光设置差异引起的照片质量问题和视图合成中的光度不一致问题,文章提出了一种名为Luminance-GS的新方法。该方法通过采用视图色彩矩阵映射和视图自适应曲线调整,实现了在不同光照条件下的高质量视图合成结果。Luminance-GS不仅达到了业界最佳性能,而且保持了原始的3DGS显式表示,同时提供了实时的渲染速度和更高的重建质量。
Key Takeaways
以下是文本的关键见解摘要:
- 该文本探讨了在各种真实世界光照条件下实现高质量视图合成的挑战。
- 自然光照和相机曝光设置对图像质量有重要影响,特别是在多视角场景中。
- 一种名为Luminance-GS的新方法被提出来解决这一问题。
- Luminance-GS通过采用视图色彩矩阵映射和视图自适应曲线调整,实现了在各种光照条件下的高质量视图合成结果。
- 与之前的NeRF和3DGS基线相比,Luminance-GS达到了业界最佳性能,同时保持了原始的3DGS显式表示。
点此查看论文截图

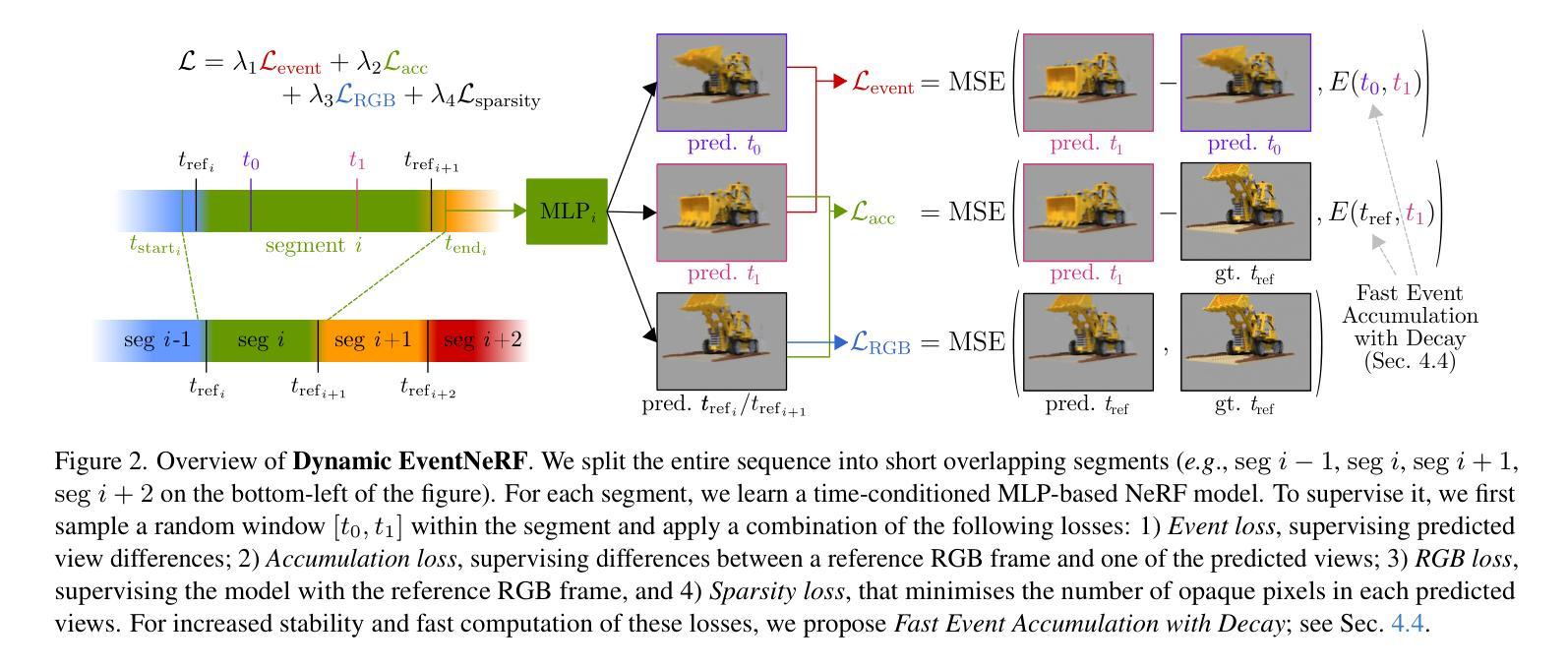
Dynamic EventNeRF: Reconstructing General Dynamic Scenes from Multi-view RGB and Event Streams
Authors:Viktor Rudnev, Gereon Fox, Mohamed Elgharib, Christian Theobalt, Vladislav Golyanik
Volumetric reconstruction of dynamic scenes is an important problem in computer vision. It is especially challenging in poor lighting and with fast motion. This is partly due to limitations of RGB cameras: To capture frames under low lighting, the exposure time needs to be increased, which leads to more motion blur. In contrast, event cameras, which record changes in pixel brightness asynchronously, are much less dependent on lighting, making them more suitable for recording fast motion. We hence propose the first method to spatiotemporally reconstruct a scene from sparse multi-view event streams and sparse RGB frames. We train a sequence of cross-faded time-conditioned NeRF models, one per short recording segment. The individual segments are supervised with a set of event- and RGB-based losses and sparse-view regularisation. We assemble a real-world multi-view camera rig with six static event cameras around the object and record a benchmark multi-view event stream dataset of challenging motions. Our work outperforms RGB-based baselines, producing state-of-the-art results, and opens up the topic of multi-view event-based reconstruction as a new path for fast scene capture beyond RGB cameras. The code and the data will be released soon at https://4dqv.mpi-inf.mpg.de/DynEventNeRF/
动态场景的体积重建是计算机视觉领域的一个重要问题。在光线不足和快速运动的情况下,这一问题尤为具有挑战性。这在一定程度上是由于RGB相机的局限性所致:在低光照条件下拍摄帧时,需要增加曝光时间,从而导致运动模糊。与之相比,事件相机能够异步记录像素亮度的变化,对光线的依赖程度较低,因此更适合记录快速运动。因此,我们提出了第一种从稀疏的多视角事件流和稀疏的RGB帧中进行时空重建场景的方法。我们对每段短记录分段训练了一系列交叉淡入的时间条件NeRF模型。各个分段在事件和RGB基于损失的稀疏视图正则化集下进行监督。我们使用六个静态事件相机围绕对象组装了一个现实世界的多视角相机支架,并记录了一个具有挑战性运动的多视角事件流基准数据集。我们的工作在基于RGB的基准线上表现出色,取得了最新结果,并开启了基于多视角事件重建的主题作为超越RGB相机进行快速场景捕获的新途径。代码和数据将很快在https://4dqv.mpi-inf.mpg.de/DynEventNeRF/发布。
论文及项目相关链接
PDF 17 pages, 13 figures, 7 tables; CVPRW 2025
Summary
本文提出一种基于事件相机与稀疏RGB帧结合的方法,实现了动态场景的时空重建。该方法利用跨淡入时间条件NeRF模型序列进行训练,通过对一系列短记录段进行监督,并结合事件和RGB基损失以及稀疏视图正则化进行场景重建。本文还建立了一套用于记录挑战性运动的真实世界多视角相机装置,并发布了多视角事件流数据集。该方法优于基于RGB的基线方法,取得了最新结果,并开启了多视角事件重建作为超越RGB相机的快速场景捕获的新途径。
Key Takeaways
- 动态场景的时空重建是计算机视觉领域的重要问题,特别是在光线不足和快速运动的情况下具有挑战性。
- RGB相机在光线不足时存在局限性,而事件相机由于其能够异步记录像素亮度变化的特性,更适合记录快速运动场景。
- 本文首次提出结合稀疏多视角事件流和稀疏RGB帧进行场景重建的方法。
- 利用跨淡入时间条件的NeRF模型序列进行训练,每个短记录段一个模型。
- 通过事件和RGB基损失以及稀疏视图正则化来监督单独的片段。
- 建立了一套真实世界多视角相机装置,并记录了具有挑战性运动的多视角事件流数据集。
点此查看论文截图