⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-25 更新
FREAK: Frequency-modulated High-fidelity and Real-time Audio-driven Talking Portrait Synthesis
Authors:Ziqi Ni, Ao Fu, Yi Zhou
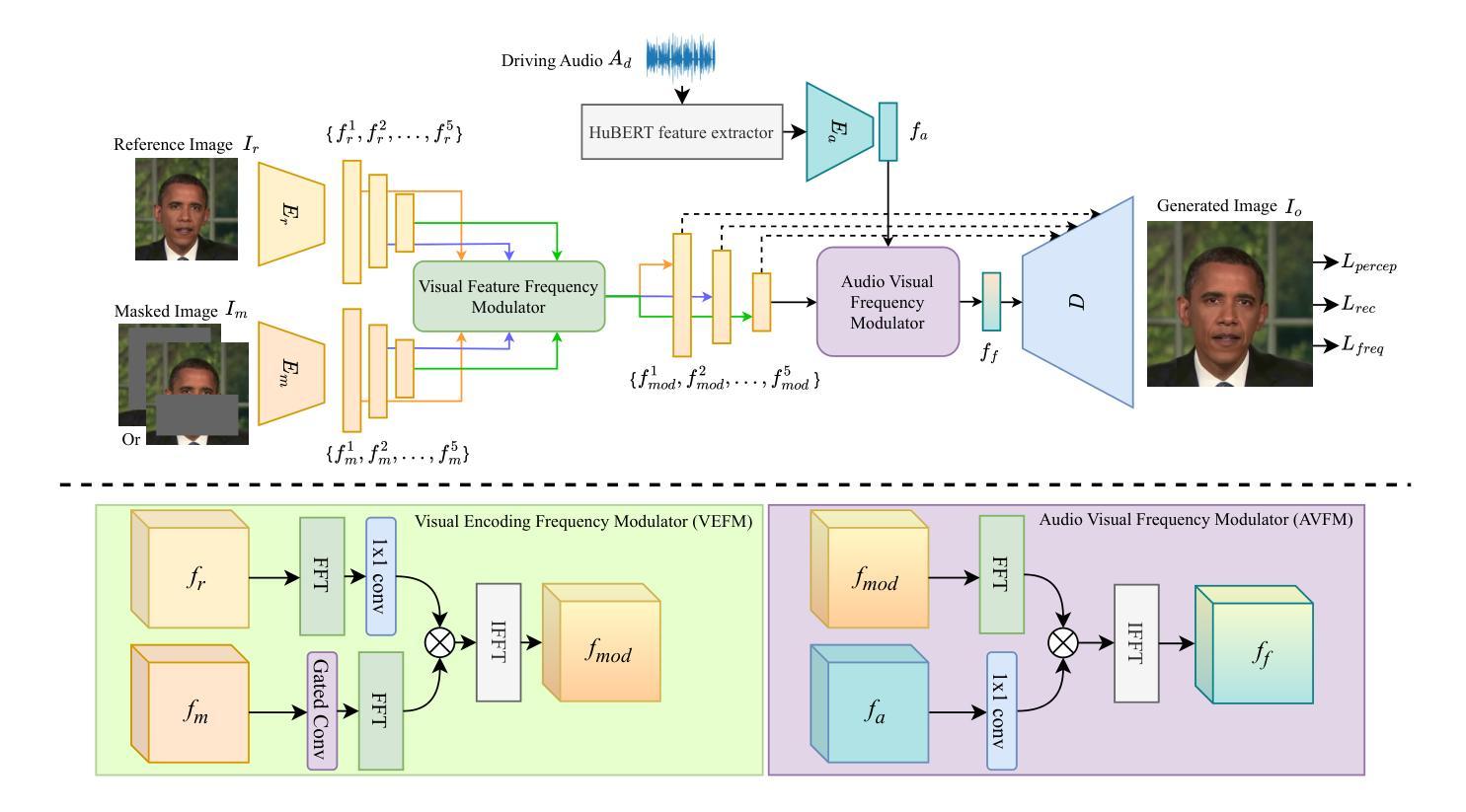
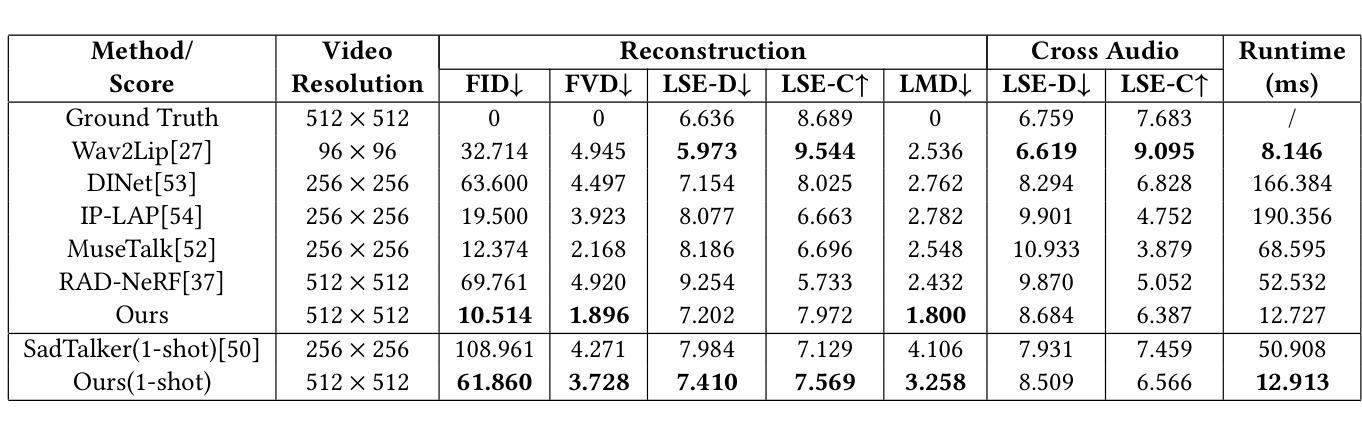
Achieving high-fidelity lip-speech synchronization in audio-driven talking portrait synthesis remains challenging. While multi-stage pipelines or diffusion models yield high-quality results, they suffer from high computational costs. Some approaches perform well on specific individuals with low resources, yet still exhibit mismatched lip movements. The aforementioned methods are modeled in the pixel domain. We observed that there are noticeable discrepancies in the frequency domain between the synthesized talking videos and natural videos. Currently, no research on talking portrait synthesis has considered this aspect. To address this, we propose a FREquency-modulated, high-fidelity, and real-time Audio-driven talKing portrait synthesis framework, named FREAK, which models talking portraits from the frequency domain perspective, enhancing the fidelity and naturalness of the synthesized portraits. FREAK introduces two novel frequency-based modules: 1) the Visual Encoding Frequency Modulator (VEFM) to couple multi-scale visual features in the frequency domain, better preserving visual frequency information and reducing the gap in the frequency spectrum between synthesized and natural frames. and 2) the Audio Visual Frequency Modulator (AVFM) to help the model learn the talking pattern in the frequency domain and improve audio-visual synchronization. Additionally, we optimize the model in both pixel domain and frequency domain jointly. Furthermore, FREAK supports seamless switching between one-shot and video dubbing settings, offering enhanced flexibility. Due to its superior performance, it can simultaneously support high-resolution video results and real-time inference. Extensive experiments demonstrate that our method synthesizes high-fidelity talking portraits with detailed facial textures and precise lip synchronization in real-time, outperforming state-of-the-art methods.
在音频驱动的说话肖像合成中实现高保真唇语音同步仍然是一个挑战。虽然多阶段管道或扩散模型能产生高质量的结果,但它们存在计算成本高的缺点。一些方法在资源较少的特定个人上表现良好,但仍会出现唇部动作不匹配的情况。上述方法都是在像素域建模的。我们观察到,合成说话视频和自然视频在频率域上存在明显的差异。目前,没有关于说话肖像合成的研究考虑这个方面。为了解决这一问题,我们提出了一种调频、高保真、实时的音频驱动说话肖像合成框架,名为FREAK。FREAK从频率域的角度对说话肖像进行建模,提高了合成肖像的逼真度和自然度。FREAK引入了两个新的基于频率的模块:1)视觉编码频率调制器(VEFM),用于耦合频率域中的多尺度视觉特征,更好地保留视觉频率信息,减少合成帧和自然帧之间频谱的差距。2)音频视觉频率调制器(AVFM)帮助模型学习频率域的说话模式,提高音频视觉同步。此外,我们在像素域和频率域内对模型进行了联合优化。此外,FREAK支持在一键式和视频配音设置之间进行无缝切换,提供了更高的灵活性。由于其卓越的性能,它可以同时支持高分辨率视频结果和实时推理。大量实验表明,我们的方法在实时合成高保真说话肖像方面表现出色,具有详细的面部纹理和精确的唇部同步,超越了最先进的方法。
论文及项目相关链接
PDF Accepted by ICMR 2025
Summary
这项研究针对音频驱动下的肖像合成中的唇音同步问题,提出了一种新的框架FREAK,它基于频率域建模。通过引入两个新型频率模块VEFM和AVFM,提高了合成肖像的保真度和自然度,同时实现了实时效果。此外,该研究实现了高清晰度视频结果与实时推理的并行支持。实验结果证明了该方法的优越性。
Key Takeaways
- 音频驱动下的肖像合成中唇音同步仍存在挑战。
- 当前方法大多在像素域建模,存在计算成本高和匹配不精确的问题。
- 研究提出了一种新的框架FREAK,从频率域角度进行建模,增强合成肖像的保真度和自然度。
- FREAK包含两个创新的频率模块VEFM和AVFM,分别用于耦合多尺度视觉特征和音频视觉频率调制。
- FREAK支持像素域和频率域联合优化,实现了高性能和实时推理。
- FREAK支持单帧和视频配音之间的无缝切换,提供了更高的灵活性。
点此查看论文截图