⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-26 更新
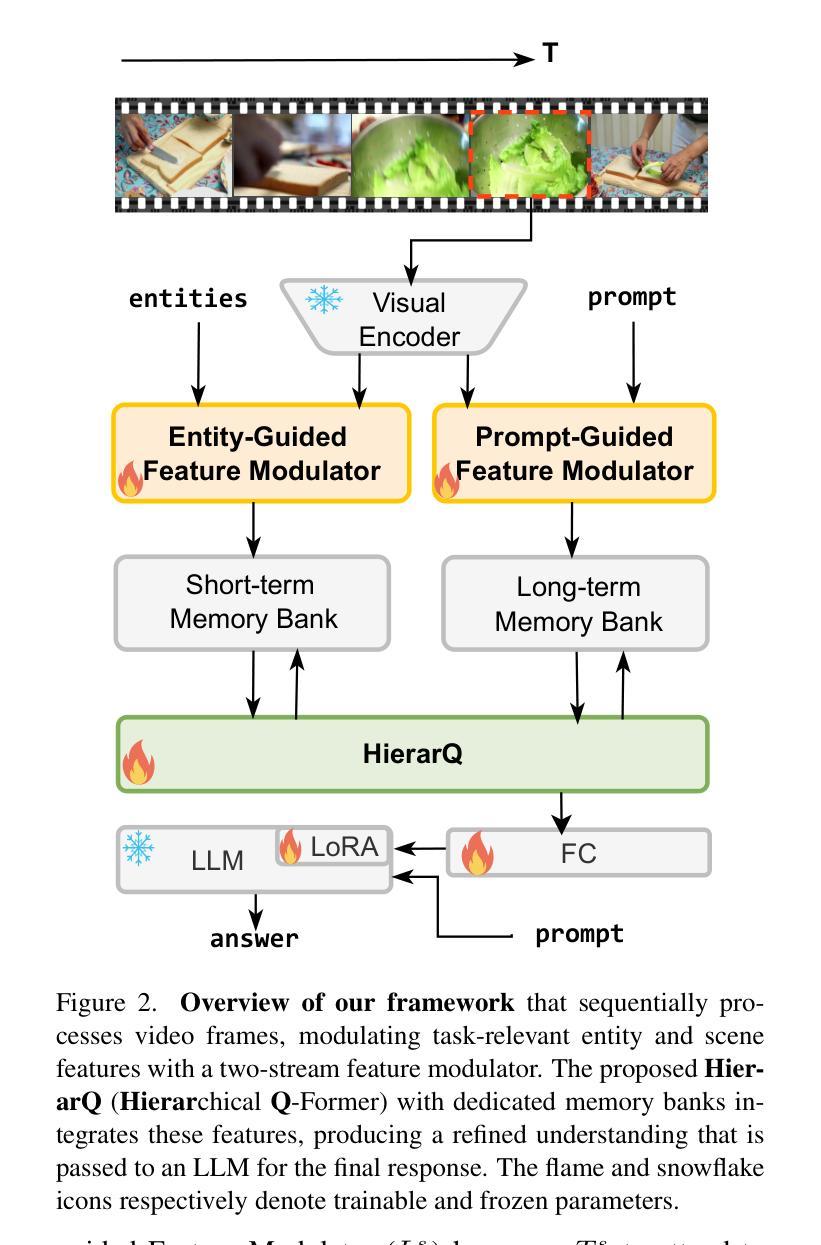
DIMT25@ICDAR2025: HW-TSC’s End-to-End Document Image Machine Translation System Leveraging Large Vision-Language Model
Authors:Zhanglin Wu, Tengfei Song, Ning Xie, Weidong Zhang, Pengfei Li, Shuang Wu, Chong Li, Junhao Zhu, Hao Yang
This paper presents the technical solution proposed by Huawei Translation Service Center (HW-TSC) for the “End-to-End Document Image Machine Translation for Complex Layouts” competition at the 19th International Conference on Document Analysis and Recognition (DIMT25@ICDAR2025). Leveraging state-of-the-art open-source large vision-language model (LVLM), we introduce a training framework that combines multi-task learning with perceptual chain-of-thought to develop a comprehensive end-to-end document translation system. During the inference phase, we apply minimum Bayesian decoding and post-processing strategies to further enhance the system’s translation capabilities. Our solution uniquely addresses both OCR-based and OCR-free document image translation tasks within a unified framework. This paper systematically details the training methods, inference strategies, LVLM base models, training data, experimental setups, and results, demonstrating an effective approach to document image machine translation.
本文介绍了华为翻译服务中心(HW-TSC)针对第十九届国际文档分析与识别会议(ICDAR2025上的DIMT25)“复杂布局端到端文档图像机器翻译”竞赛提出的技术解决方案。我们借助最新的开源大型视觉语言模型(LVLM),引入了一个结合多任务学习与感知思维链的训练框架,以开发一个全面的端到端文档翻译系统。在推理阶段,我们应用最小贝叶斯解码和后期处理策略,进一步提升系统的翻译能力。我们的解决方案在统一框架下独特地解决了基于OCR和免OCR文档图像翻译任务。本文系统地介绍了训练方法、推理策略、LVLM基础模型、训练数据、实验设置和结果,证明了文档图像机器翻译的有效方法。
论文及项目相关链接
PDF 7 pages, 1 figures, 2 tables
Summary
华为翻译服务中心针对复杂布局文档图像端到端机器翻译竞赛提出了一种技术解决方案。该研究利用最新的开源大型视觉语言模型,结合多任务学习与感知链思维构建了一个全面的端到端文档翻译系统。在推理阶段,通过最小贝叶斯解码和后期处理策略进一步提高系统的翻译能力。该方案在一个统一框架内解决了基于OCR和无OCR文档图像翻译任务。
Key Takeaways
- 华为翻译服务中心提出了针对复杂布局文档图像端到端机器翻译的技术解决方案。
- 利用最新的开源大型视觉语言模型为基础构建系统。
- 结合多任务学习与感知链思维以优化训练过程。
- 在推理阶段采用最小贝叶斯解码和后期处理策略提高翻译能力。
- 该方案统一处理基于OCR和无OCR的文档图像翻译任务。
- 论文详细描述了训练方法、推理策略、基础模型、训练数据、实验设置和结果。
点此查看论文截图

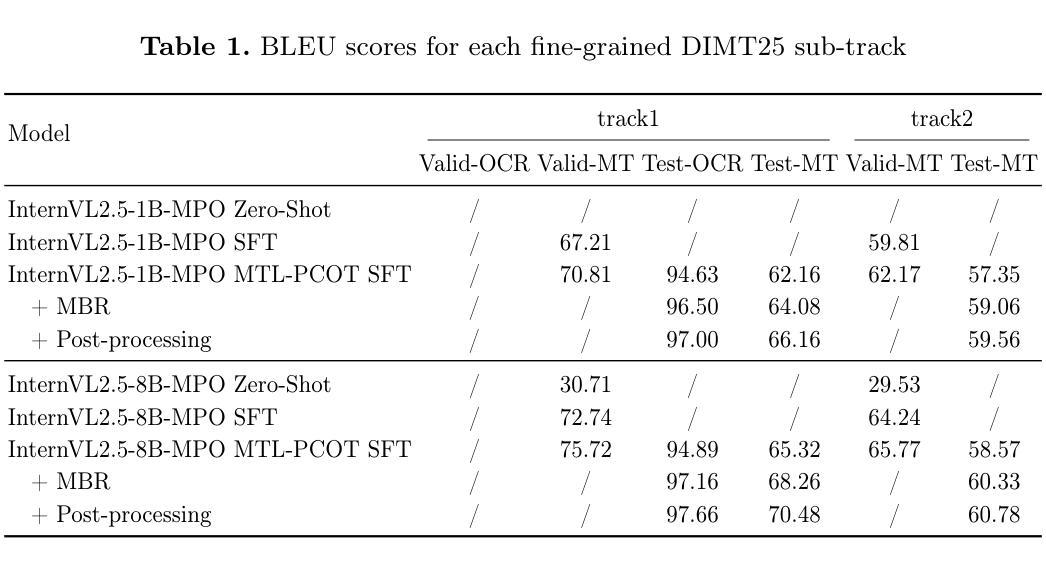
PPS-Ctrl: Controllable Sim-to-Real Translation for Colonoscopy Depth Estimation
Authors:Xinqi Xiong, Andrea Dunn Beltran, Jun Myeong Choi, Marc Niethammer, Roni Sengupta
Accurate depth estimation enhances endoscopy navigation and diagnostics, but obtaining ground-truth depth in clinical settings is challenging. Synthetic datasets are often used for training, yet the domain gap limits generalization to real data. We propose a novel image-to-image translation framework that preserves structure while generating realistic textures from clinical data. Our key innovation integrates Stable Diffusion with ControlNet, conditioned on a latent representation extracted from a Per-Pixel Shading (PPS) map. PPS captures surface lighting effects, providing a stronger structural constraint than depth maps. Experiments show our approach produces more realistic translations and improves depth estimation over GAN-based MI-CycleGAN. Our code is publicly accessible at https://github.com/anaxqx/PPS-Ctrl.
准确的深度估计可以提高内窥镜导航和诊断的效果。但在临床环境中获取真实深度信息是一项挑战。合成数据集通常用于训练,但领域差距限制了其在真实数据上的泛化能力。我们提出了一种新型图像到图像的翻译框架,能够在保留结构的同时,从临床数据生成逼真的纹理。我们的关键创新之处在于将Stable Diffusion与ControlNet相结合,以像素阴影(PPS)图提取的潜在表示作为条件。PPS捕捉表面光照效果,为深度图提供了更强的结构约束。实验表明,我们的方法能产生更逼真的翻译效果,并提高了基于GAN的MI-CycleGAN的深度估计效果。我们的代码可在https://github.com/anaxqx/PPS-Ctrl公开访问。
论文及项目相关链接
Summary
本文提出了一种新型的图像到图像翻译框架,该框架结合了Stable Diffusion与ControlNet技术,可从临床数据中生成逼真的纹理并保持结构完整性。该创新方法利用基于Per-Pixel Shading(PPS)图提取的潜在表征进行条件控制,PPS捕获表面光照效果,为深度估计提供更强大的结构约束。实验表明,该方法产生的翻译更逼真,相较于基于GAN的MI-CycleGAN在深度估计上有所提升。
Key Takeaways
- 深度估计在内窥镜导航和诊断中起到重要作用。
- 临床环境中获取真实深度信息具有挑战性,因此常使用合成数据集进行训练。
- 虽然合成数据有用,但领域差距限制了其在真实数据上的泛化能力。
- 提出的图像到图像翻译框架结合了Stable Diffusion与ControlNet技术。
- 该框架能够生成逼真的纹理并保持结构完整性。
- 框架的关键创新点在于利用PPS地图提取的潜在表征进行条件控制,提供强大的结构约束。
- 实验结果表明,该方法在生成逼真翻译和提升深度估计方面优于基于GAN的MI-CycleGAN。
点此查看论文截图

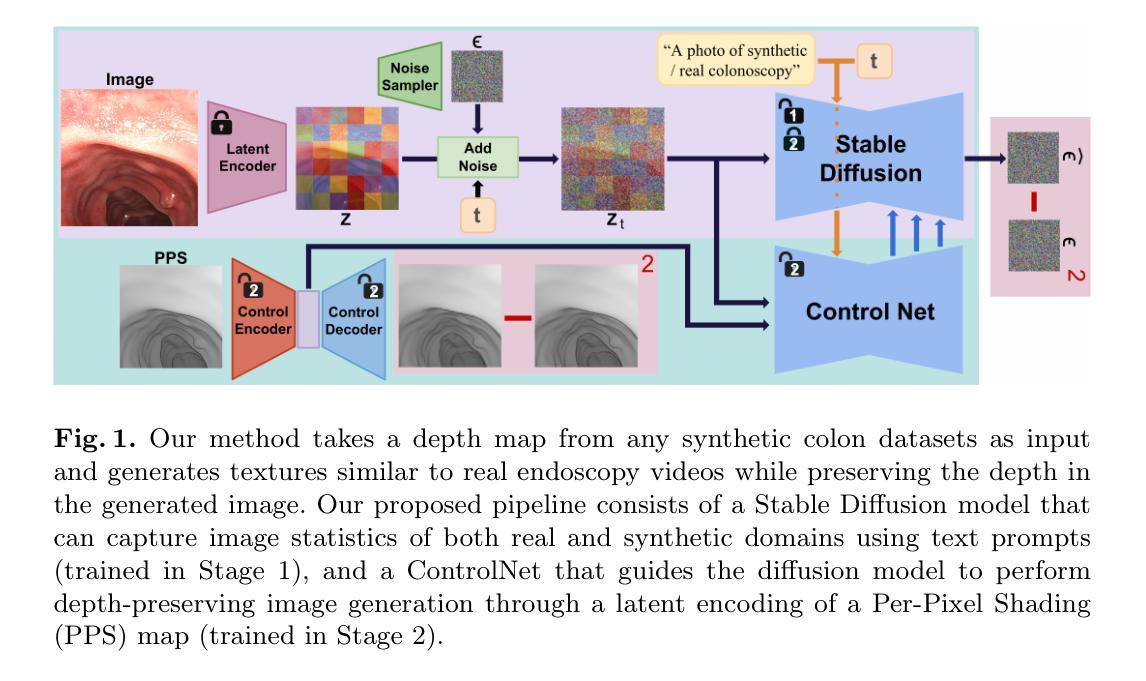

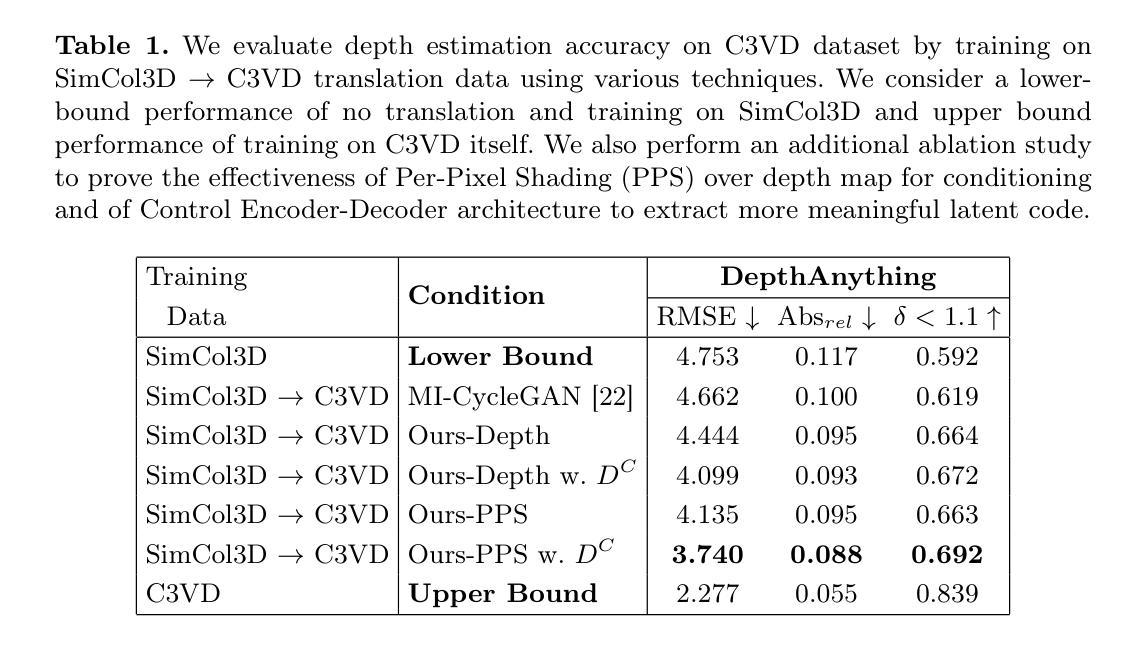
AI in Lung Health: Benchmarking Detection and Diagnostic Models Across Multiple CT Scan Datasets
Authors:Fakrul Islam Tushar, Avivah Wang, Lavsen Dahal, Michael R. Harowicz, Kyle J. Lafata, Tina D. Tailor, Joseph Y. Lo
Lung cancer remains the leading cause of cancer-related mortality worldwide, and early detection through low-dose computed tomography (LDCT) has shown significant promise in reducing death rates. With the growing integration of artificial intelligence (AI) into medical imaging, the development and evaluation of robust AI models require access to large, well-annotated datasets. In this study, we introduce the utility of Duke Lung Cancer Screening (DLCS) Dataset, the largest open-access LDCT dataset with over 2,000 scans and 3,000 expert-verified nodules. We benchmark deep learning models for both 3D nodule detection and lung cancer classification across internal and external datasets including LUNA16, LUNA25, and NLST-3D+. For detection, we develop two MONAI-based RetinaNet models (DLCSDmD and LUNA16-mD), evaluated using the Competition Performance Metric (CPM). For classification, we compare five models, including state-of-the-art pretrained models (Models Genesis, Med3D), a selfsupervised foundation model (FMCB), a randomly initialized ResNet50, and proposed a novel Strategic Warm-Start++ (SWS++) model. SWS++ uses curated candidate patches to pretrain a classification backbone within the same detection pipeline, enabling task-relevant feature learning. Our models demonstrated strong generalizability, with SWS++ achieving comparable or superior performance to existing foundational models across multiple datasets (AUC: 0.71 to 0.90). All code, models, and data are publicly released to promote reproducibility and collaboration. This work establishes a standardized benchmarking resource for lung cancer AI research, supporting future efforts in model development, validation, and clinical translation.
肺癌仍然是全球癌症相关死亡的主要原因,而通过低剂量计算机断层扫描(LDCT)进行早期检测在降低死亡率方面显示出巨大潜力。随着人工智能(AI)在医学成像中的日益融合,开发和评估稳健的AI模型需要访问大量、标注良好的数据集。在这项研究中,我们介绍了Duke肺癌筛查(DLCS)数据集的实用性,这是最大的开放访问LDCT数据集,包含超过2000次扫描和3000个专家验证的结节。我们对内部和外部数据集(包括LUNA16、LUNA25和NLST-3D+)中的深度学习模型进行了基准测试,用于3D结节检测和肺癌分类。对于检测,我们开发了两个基于MONAI的RetinaNet模型(DLCSDmD和LUNA16-mD),使用竞赛性能指标(CPM)进行评估。对于分类,我们比较了五种模型,包括最先进的预训练模型(Models Genesis、Med3D)、自监督基础模型(FMCB)、随机初始化的ResNet50,并提出了一种新型的战略温启动++(SWS++)模型。SWS++使用精选的候选补丁在同一检测管道内预训练分类主干,实现任务相关特征学习。我们的模型表现出很强的通用性,SWS++在多个数据集上实现了与现有基础模型相当或更优的性能(AUC:0.71至0.90)。为了促进可重复性和协作,我们公开发布了所有代码、模型和数数据集。这项工作为肺癌AI研究建立了标准化的基准资源,支持未来的模型开发、验证和临床转化工作。
论文及项目相关链接
PDF 2 tables, 6 figures
摘要
肺癌是世界范围内导致癌症死亡的主要原因,低剂量计算机断层扫描(LDCT)的早期检测在降低死亡率方面显示出巨大潜力。随着人工智能(AI)在医学成像中的日益融合,开发评估稳健的AI模型需要访问大量、标注良好的数据集。本研究介绍了Duke肺癌筛查(DLCS)数据集的实用性,这是最大的公开访问LDCT数据集,包含超过2000次扫描和3000个专家验证的结节。我们对内部和外部数据集(包括LUNA16、LUNA25和NLST-3D+)的3D结节检测和肺癌分类基准深度学习模型进行基准测试。对于检测,我们开发了两个基于MONAI的RetinaNet模型(DLCSDmD和LUNA16-mD),使用竞赛性能指标(CPM)进行评估。对于分类,我们比较了五种模型,包括最先进的预训练模型(Models Genesis、Med3D)、自监督基础模型(FMCB)、随机初始化的ResNet50,并提出了一种新的战略温启(SWS++)模型。SWS++使用精选的候选补丁在同一检测管道中预训练分类主干,实现任务相关特征学习。我们的模型表现出强大的泛化能力,SWS++在多个数据集上的性能与现有基础模型相当或更优(AUC:0.71至0.90)。所有代码、模型和数据均公开发布,以促进可重复性和协作。这项工作为肺癌人工智能研究建立了标准化的基准测试资源,支持未来的模型开发、验证和临床翻译工作。
要点
- 肺癌是全球主要的癌症致死原因,LDCT早期检测是降低死亡率的有效手段。
- 随着AI在医学成像中的融合,开发AI模型需要大规模、标注良好的数据集。
- 介绍了Duke肺癌筛查(DLCS)数据集,这是最大的公开访问LDCT数据集。
- 对深度学习模型进行基准测试,包括3D结节检测和肺癌分类。
- 提出了两种检测模型和五种分类模型,其中包括新的战略温启(SWS++)模型。
- SWS++模型通过在检测管道中预训练分类主干,实现了良好的性能。
点此查看论文截图