⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-29 更新
Optimizing Multi-Round Enhanced Training in Diffusion Models for Improved Preference Understanding
Authors:Kun Li, Jianhui Wang, Yangfan He, Xinyuan Song, Ruoyu Wang, Hongyang He, Wenxin Zhang, Jiaqi Chen, Keqin Li, Sida Li, Miao Zhang, Tianyu Shi, Xueqian Wang
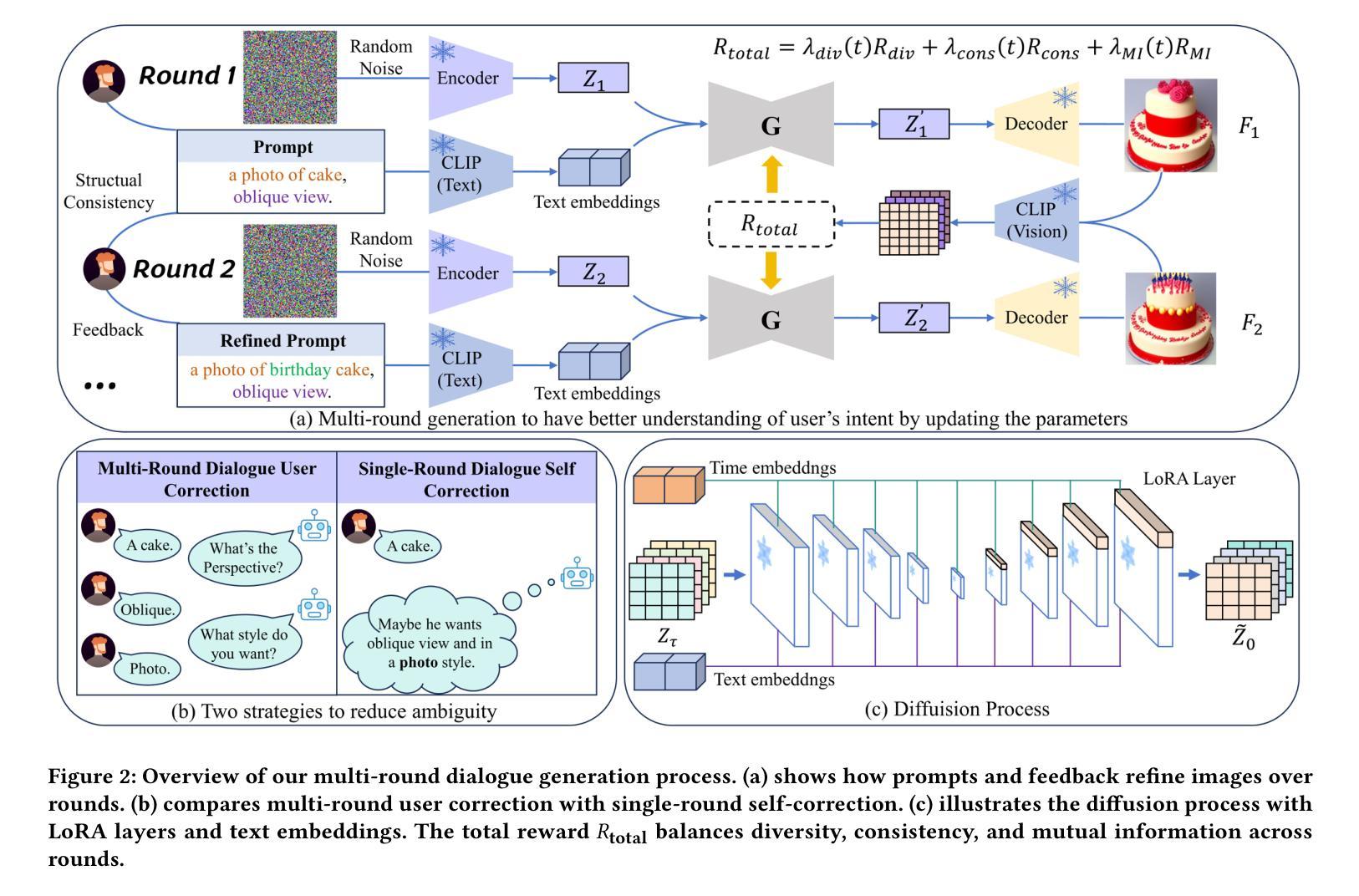
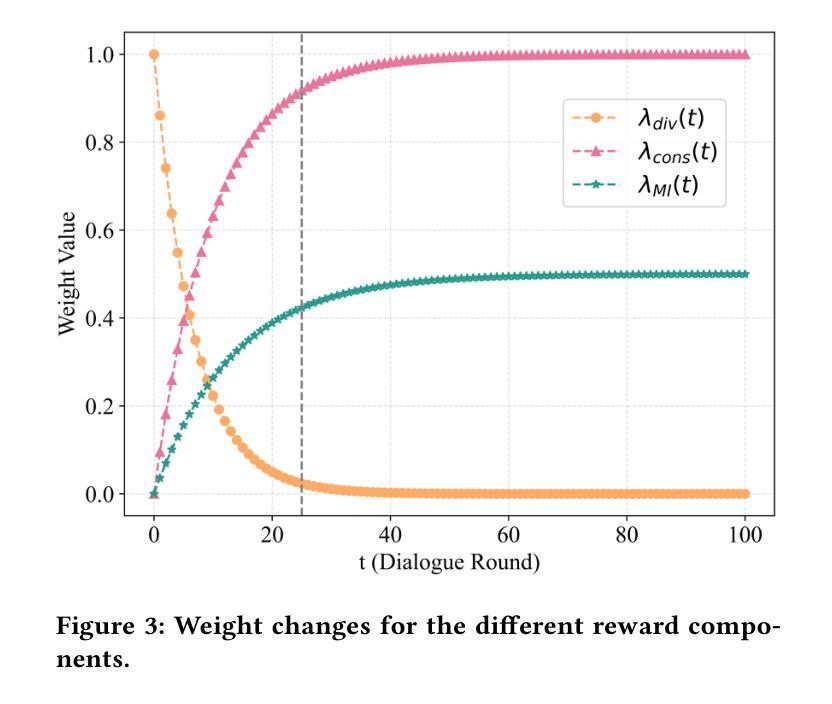
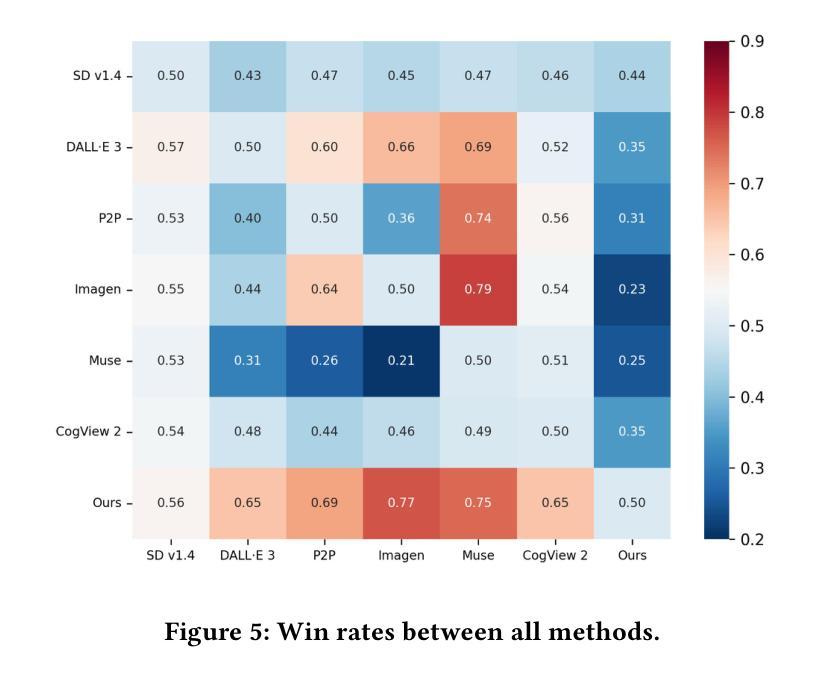
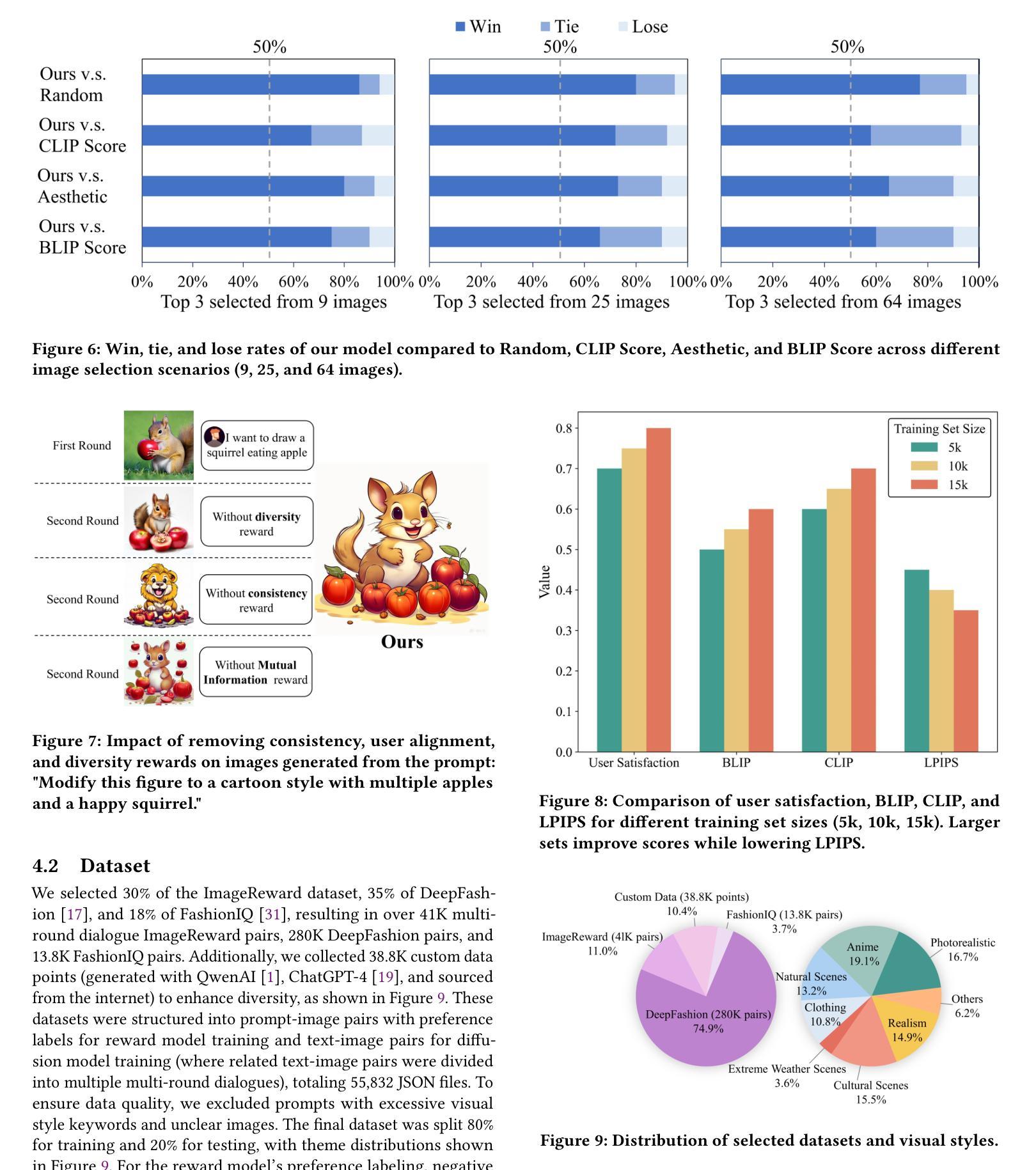
Generative AI has significantly changed industries by enabling text-driven image generation, yet challenges remain in achieving high-resolution outputs that align with fine-grained user preferences. Consequently, multi-round interactions are necessary to ensure the generated images meet expectations. Previous methods enhanced prompts via reward feedback but did not optimize over a multi-round dialogue dataset. In this work, we present a Visual Co-Adaptation (VCA) framework incorporating human-in-the-loop feedback, leveraging a well-trained reward model aligned with human preferences. Using a diverse multi-turn dialogue dataset, our framework applies multiple reward functions, such as diversity, consistency, and preference feedback, while fine-tuning the diffusion model through LoRA, thus optimizing image generation based on user input. We also construct multi-round dialogue datasets of prompts and image pairs aligned with user intent. Experiments demonstrate that our method outperforms state-of-the-art baselines, significantly improving image consistency and alignment with user intent. Our approach consistently surpasses competing models in user satisfaction, especially in multi-turn dialogue scenarios.
生成式人工智能已经通过文本驱动的图片生成显著改变了各行各业,然而,在实现与用户精细偏好对齐的高分辨率输出方面仍存在挑战。因此,多轮交互是必要的,以确保生成的图像满足期望。之前的方法通过奖励反馈来增强提示,但并没有在多个轮次对话数据集上进行优化。在这项工作中,我们提出了一个视觉协同适应(VCA)框架,该框架结合了人类反馈回路,利用训练良好的奖励模型与人类偏好对齐。使用多样化的多轮对话数据集,我们的框架应用多个奖励函数,如多样性、一致性和偏好反馈等,同时通过LoRA微调扩散模型,从而基于用户输入优化图像生成。我们还构建了与用户意图对齐的多轮对话数据集,包含提示和图像对。实验表明,我们的方法优于最先进的基线方法,显著提高了图像的一致性和与用户意图的对齐程度。我们的方法在用户满意度方面始终超过竞争模型,特别是在多轮对话场景中。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2503.17660
Summary
本文介绍了生成式AI如何通过文本驱动图像生成来改变行业,但仍然存在实现高分辨率输出和满足精细用户偏好方面的挑战。因此,需要多轮交互来确保生成的图像符合预期。之前的方法通过奖励反馈增强了提示,但并没有在一个多轮对话数据集上进行优化。本文提出了一个视觉协同适应(VCA)框架,该框架结合了人类反馈循环,利用训练良好的奖励模型与人类偏好对齐。使用多样化的多轮对话数据集,我们的框架应用了多个奖励函数,如多样性、一致性和偏好反馈,同时通过LoRA微调扩散模型,从而基于用户输入优化图像生成。实验证明,我们的方法在图像一致性、用户意图对齐方面优于其他模型。特别是在多轮对话场景中,我们的方法在用户满意度方面始终超越竞争对手模型。
Key Takeaways
- 生成式AI通过文本驱动图像生成改变了行业,但仍面临实现高分辨率输出和满足精细用户偏好的挑战。
- 多轮交互是必要的,以确保生成的图像符合用户期望和需求。
- 之前的方法主要侧重于通过奖励反馈增强提示,但没有在多轮对话数据集上进行优化。
- 提出的视觉协同适应(VCA)框架结合了人类反馈循环,利用训练良好的奖励模型与人类偏好对齐。
- 该框架使用多个奖励函数(如多样性、一致性和偏好反馈),并通过LoRA微调扩散模型。
- 实验证明,该方法在图像一致性、用户意图对齐方面优于其他模型。
点此查看论文截图


Enhancing Privacy-Utility Trade-offs to Mitigate Memorization in Diffusion Models
Authors:Chen Chen, Daochang Liu, Mubarak Shah, Chang Xu
Text-to-image diffusion models have demonstrated remarkable capabilities in creating images highly aligned with user prompts, yet their proclivity for memorizing training set images has sparked concerns about the originality of the generated images and privacy issues, potentially leading to legal complications for both model owners and users, particularly when the memorized images contain proprietary content. Although methods to mitigate these issues have been suggested, enhancing privacy often results in a significant decrease in the utility of the outputs, as indicated by text-alignment scores. To bridge the research gap, we introduce a novel method, PRSS, which refines the classifier-free guidance approach in diffusion models by integrating prompt re-anchoring (PR) to improve privacy and incorporating semantic prompt search (SS) to enhance utility. Extensive experiments across various privacy levels demonstrate that our approach consistently improves the privacy-utility trade-off, establishing a new state-of-the-art.
文本到图像的扩散模型在创建与用户提示高度匹配的图片方面表现出了显著的能力,但它们倾向于记忆训练集图片,引发了人们对生成图片原创性和隐私问题的担忧,这可能导致模型所有者与用户双方面临法律和隐私问题,特别是当记忆的图片包含专有内容时。虽然已有方法建议缓解这些问题,但增强隐私往往会导致输出结果的实用性显著降低,如文本对齐分数所示。为了弥补研究空白,我们提出了一种新方法PRSS,它通过整合提示重新锚定(PR)来提高隐私,并融入语义提示搜索(SS)以增强实用性,对扩散模型中的无分类器引导方法进行了改进。在不同隐私级别的广泛实验表明,我们的方法持续改善了隐私与实用性的权衡,创下了新的最先进的记录。
论文及项目相关链接
PDF Accepted at CVPR 2025. Project page: https://chenchen-usyd.github.io/PRSS-Project-Page/
摘要
文本到图像的扩散模型在创建与用户提示高度匹配的图片方面表现出卓越的能力,但其倾向于记忆训练集图片的问题引发了人们对生成图片原创性和隐私的担忧,可能导致模型所有者与用户面临法律和隐私问题,特别是当记忆中的图片包含专有内容时。虽然已有方法建议缓解这些问题,但增强隐私往往会导致输出效用显著降低,如文本对齐分数所示。为了弥补研究空白,我们提出了一种新方法PRSS,它通过改进扩散模型中的无分类器引导方法,通过集成提示重新锚定(PR)提高隐私性,并结合语义提示搜索(SS)提高实用性。跨越各种隐私级别的广泛实验表明,我们的方法持续改善了隐私与实用性的权衡,建立了新的技术前沿。
关键见解
- 文本到图像的扩散模型具备出色的创建与用户提示匹配图像的能力。
- 扩散模型存在记忆训练集图片的问题,引发关于原创性和隐私的担忧。
- 增强隐私可能会导致输出效用显著降低。
- 提出了一种新方法PRSS,通过集成提示重新锚定和语义提示搜索,改进扩散模型的隐私性和实用性。
- PRSS方法提高了隐私与实用性的权衡。
- PRSS方法建立了新的技术前沿。
- 通过广泛实验验证了PRSS方法的有效性。
点此查看论文截图



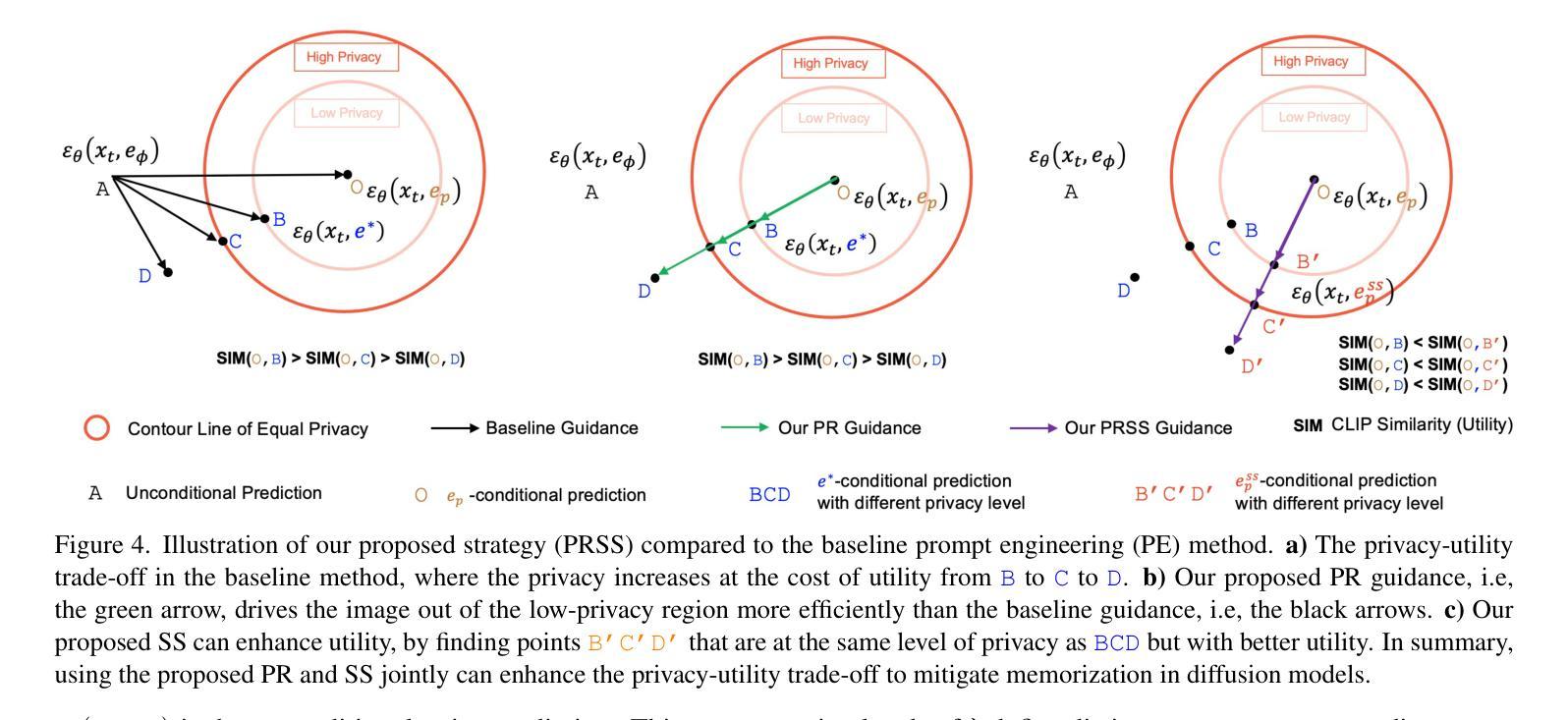

Diffusion-Driven Universal Model Inversion Attack for Face Recognition
Authors:Hanrui Wang, Shuo Wang, Chun-Shien Lu, Isao Echizen
Facial recognition technology poses significant privacy risks, as it relies on biometric data that is inherently sensitive and immutable if compromised. To mitigate these concerns, face recognition systems convert raw images into embeddings, traditionally considered privacy-preserving. However, model inversion attacks pose a significant privacy threat by reconstructing these private facial images, making them a crucial tool for evaluating the privacy risks of face recognition systems. Existing methods usually require training individual generators for each target model, a computationally expensive process. In this paper, we propose DiffUMI, a training-free diffusion-driven universal model inversion attack for face recognition systems. DiffUMI is the first approach to apply a diffusion model for unconditional image generation in model inversion. Unlike other methods, DiffUMI is universal, eliminating the need for training target-specific generators. It operates within a fixed framework and pretrained diffusion model while seamlessly adapting to diverse target identities and models. DiffUMI breaches privacy-preserving face recognition systems with state-of-the-art success, demonstrating that an unconditional diffusion model, coupled with optimized adversarial search, enables efficient and high-fidelity facial reconstruction. Additionally, we introduce a novel application of out-of-domain detection (OODD), marking the first use of model inversion to distinguish non-face inputs from face inputs based solely on embeddings.
人脸识别技术存在重大的隐私风险,因为它依赖于生物特征数据,这些数据本质上是敏感的,一旦泄露,具有不可变性。为了缓解这些担忧,人脸识别系统将原始图像转化为嵌入形式,这被认为是隐私保护的。然而,模型反转攻击通过重建这些私有面部图像构成重大隐私威胁,成为评估人脸识别系统隐私风险的重要工具。现有方法通常需要针对每个目标模型进行个体生成器的训练,这是一个计算成本高昂的过程。在本文中,我们提出了DiffUMI,这是一种无需训练的人脸识别系统扩散驱动通用模型反转攻击。DiffUMI是第一个将扩散模型应用于无条件图像生成的方法。与其他方法不同,DiffUMI具有通用性,无需针对目标进行训练生成器。它在固定的框架和预先训练的扩散模型内运行,无缝适应不同的目标身份和模型。DiffUMI以最先进的成功率突破了隐私保护人脸识别系统,证明无条件扩散模型结合优化的对抗性搜索可实现高效、高保真度的面部重建。此外,我们引入了域外检测(OODD)的新应用,首次使用模型反转来仅根据嵌入来区分非面部输入和面部输入。
论文及项目相关链接
Summary
面部识别技术存在重大隐私风险,因为该技术依赖于生物特征数据,一旦泄露即可能造成敏感信息泄露。为缓解这些担忧,面部识别系统将原始图像转化为嵌入数据,一般认为这一过程能保护隐私。然而,模型逆向攻击通过重建这些私人面部图像,对隐私构成严重威胁,成为评估面部识别系统隐私风险的重要工具。现有方法通常需要针对每个目标模型进行个体生成器训练,这一过程计算成本高昂。本文提出一种无需训练的扩散驱动通用模型逆向攻击方法DiffUMI。DiffUMI首次将扩散模型应用于无条件图像生成中的模型逆向。与其他方法不同,DiffUMI具有通用性,无需针对目标进行特定生成器训练。它在固定框架和预训练扩散模型内运行,并能轻松适应不同目标身份和模型。DiffUMI以高成功率突破了隐私保护面部识别系统,证明无条件扩散模型结合优化的对抗搜索可实现高效、高保真度的面部重建。此外,我们还引入了域外检测的新应用(OODD),首次使用模型逆向技术仅根据嵌入来区分非面部输入和面部输入。
Key Takeaways
- 面部识别技术存在隐私泄露风险,因为依赖的生物特征数据敏感且一旦泄露后果严重。
- 为保护隐私,面部识别系统通常将原始图像转化为嵌入数据。
- 模型逆向攻击能重建面部图像,成为评估面部识别系统隐私风险的重要工具。
- 现有模型逆向攻击方法训练成本高昂,需要针对每个目标模型进行个体生成器训练。
- DiffUMI是一种无需训练的扩散驱动通用模型逆向攻击方法,首次将扩散模型应用于无条件图像生成。
- DiffUMI具有通用性,能在固定框架和预训练扩散模型内运行,适应不同目标身份和模型。
- DiffUMI成功突破了隐私保护面部识别系统,并引入了域外检测的新应用(OODD)。
点此查看论文截图

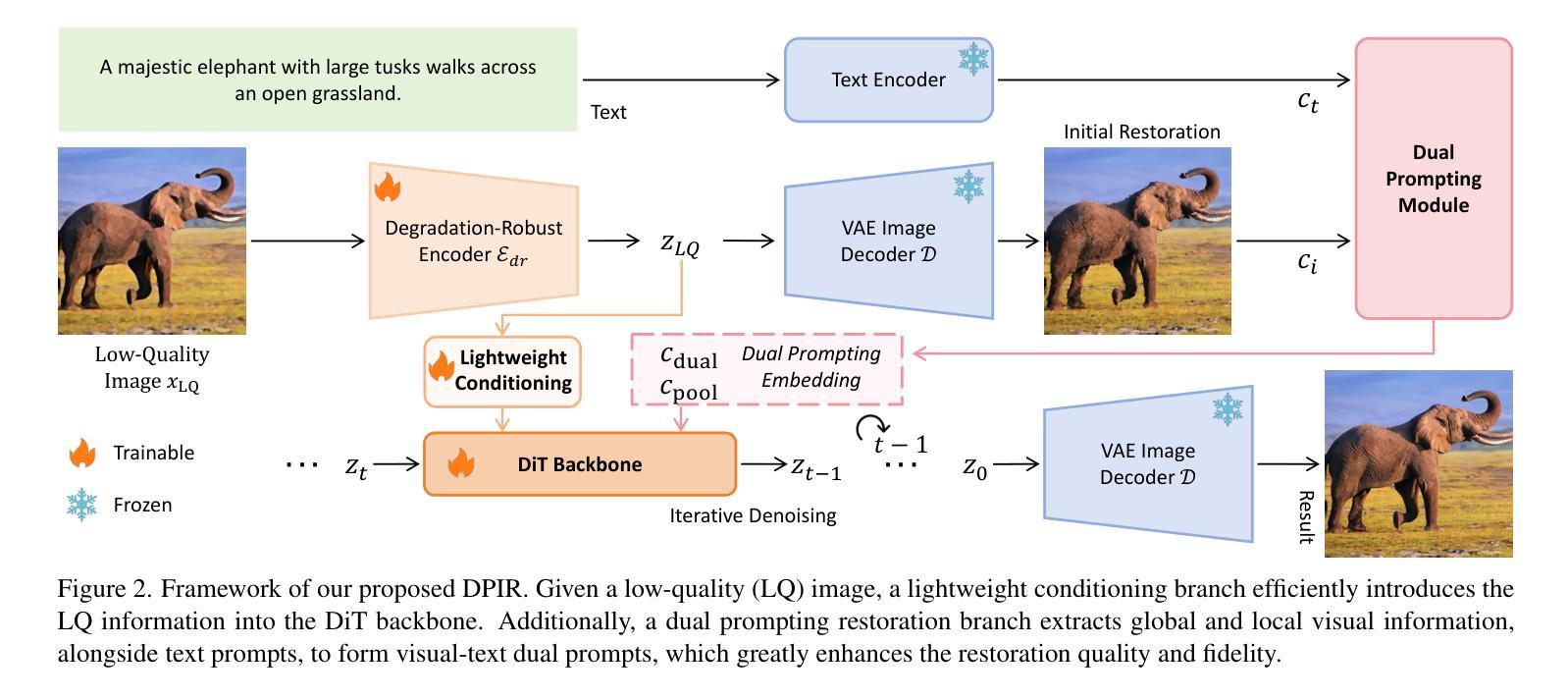
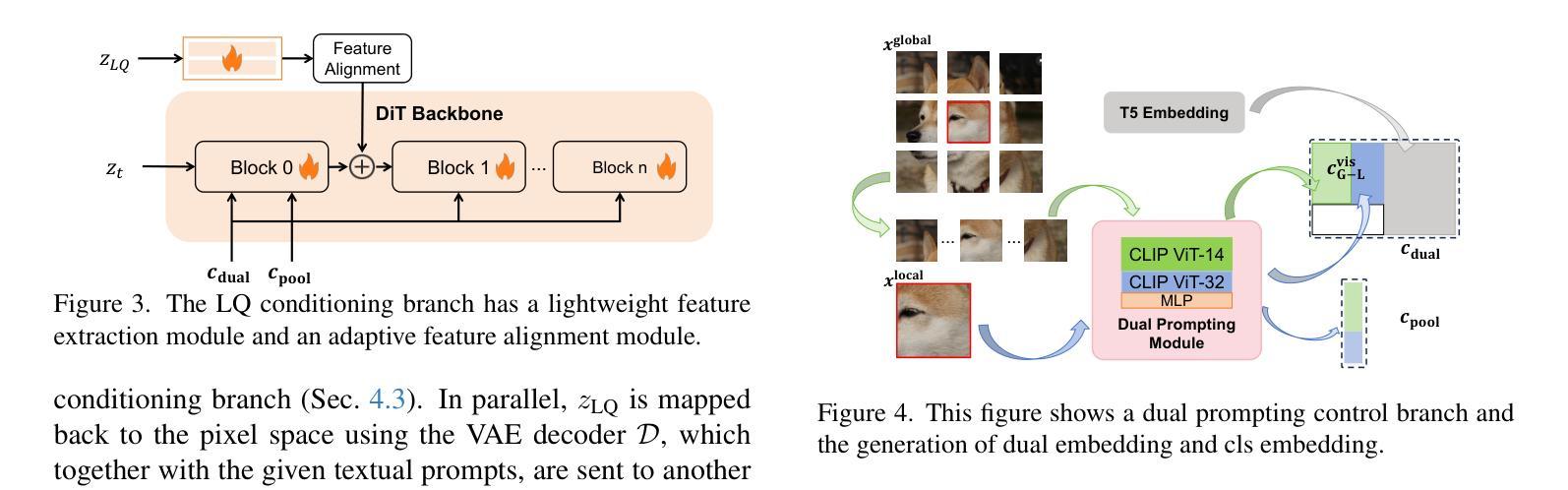
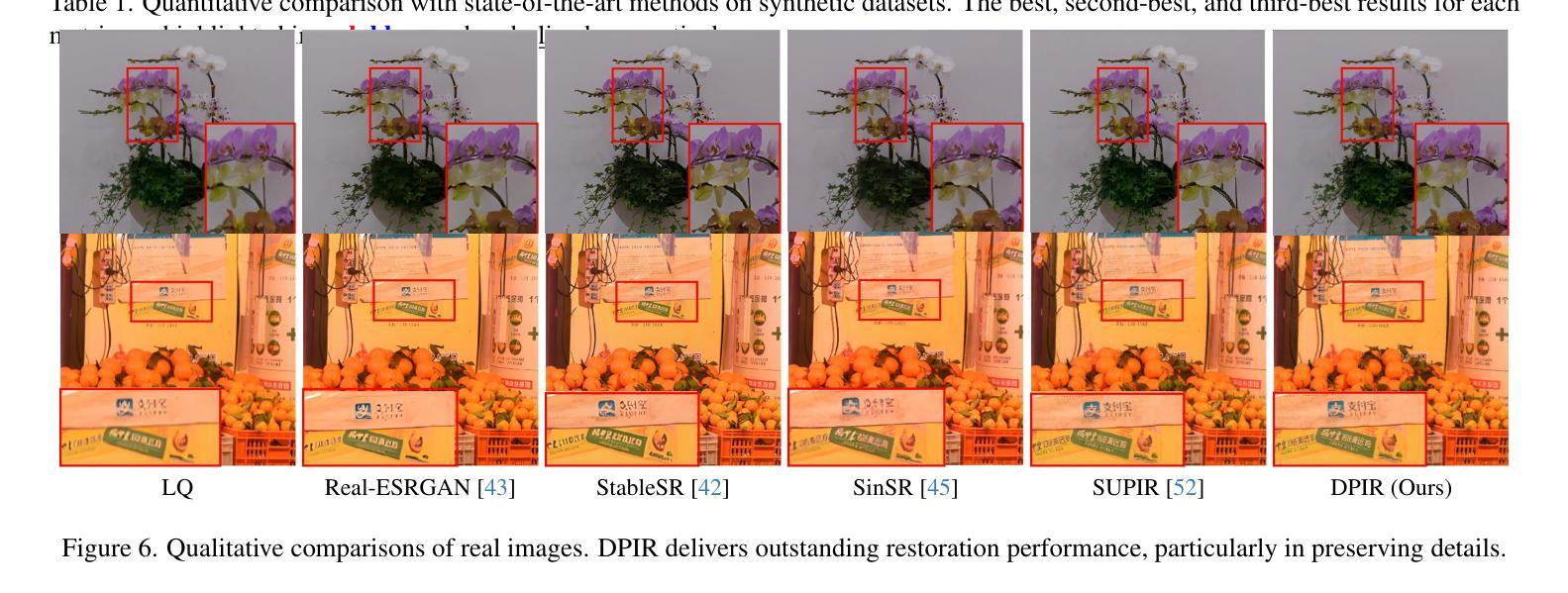
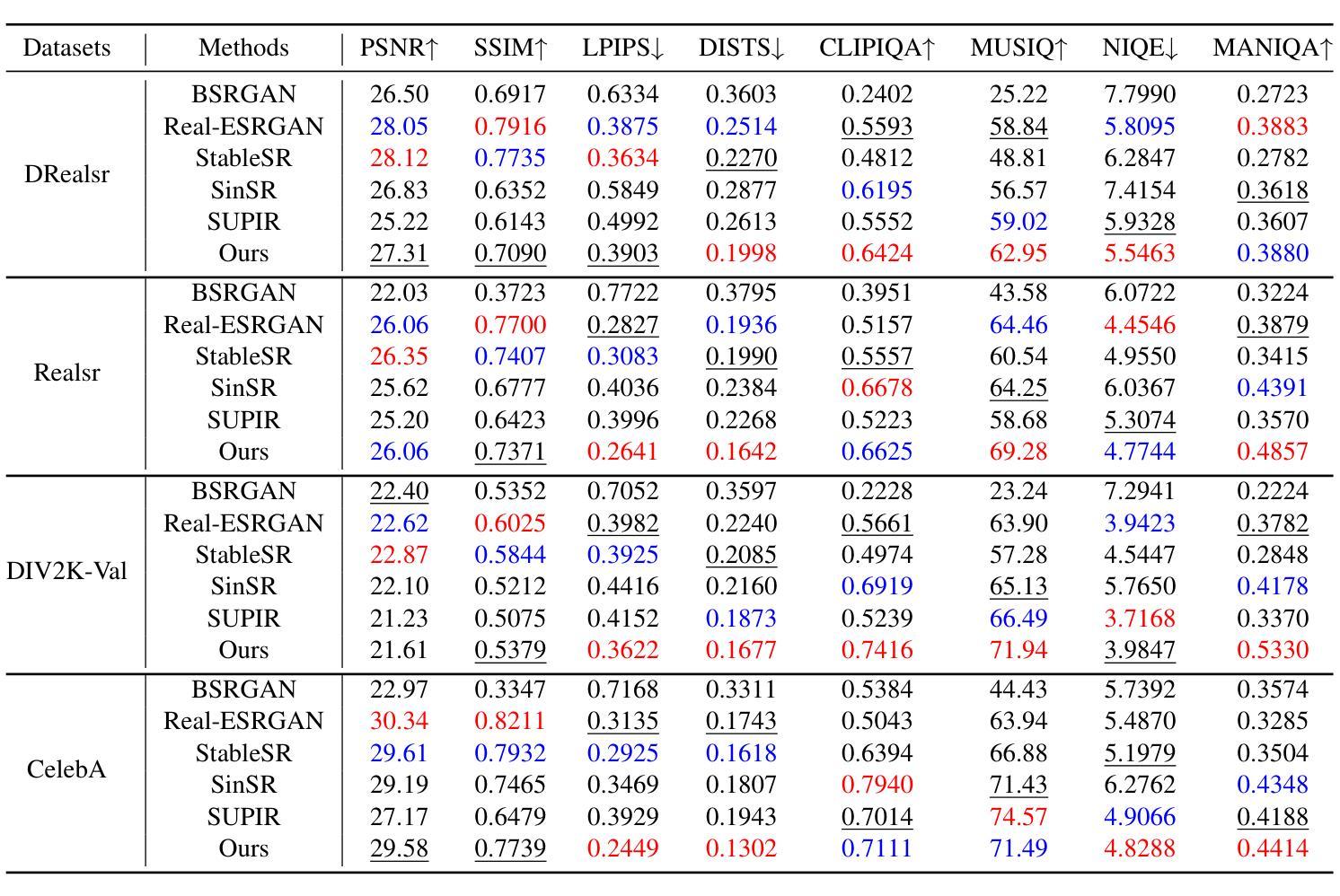
Dual Prompting Image Restoration with Diffusion Transformers
Authors:Dehong Kong, Fan Li, Zhixin Wang, Jiaqi Xu, Renjing Pei, Wenbo Li, WenQi Ren
Recent state-of-the-art image restoration methods mostly adopt latent diffusion models with U-Net backbones, yet still facing challenges in achieving high-quality restoration due to their limited capabilities. Diffusion transformers (DiTs), like SD3, are emerging as a promising alternative because of their better quality with scalability. In this paper, we introduce DPIR (Dual Prompting Image Restoration), a novel image restoration method that effectivly extracts conditional information of low-quality images from multiple perspectives. Specifically, DPIR consits of two branches: a low-quality image conditioning branch and a dual prompting control branch. The first branch utilizes a lightweight module to incorporate image priors into the DiT with high efficiency. More importantly, we believe that in image restoration, textual description alone cannot fully capture its rich visual characteristics. Therefore, a dual prompting module is designed to provide DiT with additional visual cues, capturing both global context and local appearance. The extracted global-local visual prompts as extra conditional control, alongside textual prompts to form dual prompts, greatly enhance the quality of the restoration. Extensive experimental results demonstrate that DPIR delivers superior image restoration performance.
最新的先进图像恢复方法主要采用了基于U-Net的潜在扩散模型,但由于其能力有限,仍面临着实现高质量恢复的挑战。扩散变压器(DiTs)如SD3因其可扩展性和更好的质量而成为有前途的替代品。本文介绍了DPIR(双提示图像恢复),这是一种新型图像恢复方法,能够从多个角度有效地提取低质量图像的条件信息。具体来说,DPIR包括两个分支:低质量图像条件分支和双提示控制分支。第一个分支利用轻量级模块高效地将图像先验知识融入到DiT中。更重要的是,我们认为在图像恢复中,单纯的文本描述无法充分捕捉其丰富的视觉特征。因此,设计了双提示模块,为DiT提供额外的视觉线索,捕捉全局上下文和局部外观。提取的全局-局部视觉提示作为额外的条件控制,与文本提示一起形成双提示,极大地提高了恢复的质量。大量的实验结果证明,DPIR在图像恢复性能方面表现出卓越的性能。
论文及项目相关链接
PDF CVPR2025
Summary
最新图像修复方法主要采用了带有U-Net骨干的潜在扩散模型,但仍面临因能力有限而无法实现高质量修复的难题。扩散变压器(DiTs)如SD3因其较好的质量和可扩展性而崭露头角。本文介绍了一种新型图像修复方法DPIR(双提示图像修复),它通过多个角度有效地提取低质量图像的条件信息。DPIR包括两个分支:低质量图像条件分支和双提示控制分支。第一个分支利用轻量级模块高效地将图像先验知识融入DiT。更重要的是,我们认为在图像修复中,仅依靠文本描述无法完全捕捉其丰富的视觉特征。因此,设计了双提示模块,为DiT提供额外的视觉线索,捕捉全局上下文和局部外观。结合文本提示形成双重提示,极大地提高了修复质量。实验结果表明,DPIR在图像修复方面具有卓越性能。
Key Takeaways
- 扩散模型在图像修复领域广泛应用,但仍存在高质量修复的挑战。
- 介绍了DPIR方法,包含两个分支:低质量图像条件分支和双提示控制分支。
- 低质量图像条件分支利用轻量级模块高效融入图像先验知识。
- 仅依靠文本描述在图像修复中无法完全捕捉视觉特征。
- 双提示模块提供额外的视觉线索,同时捕捉全局上下文和局部外观。
- 结合文本提示形成的双重提示能显著提高图像修复的质量。
点此查看论文截图


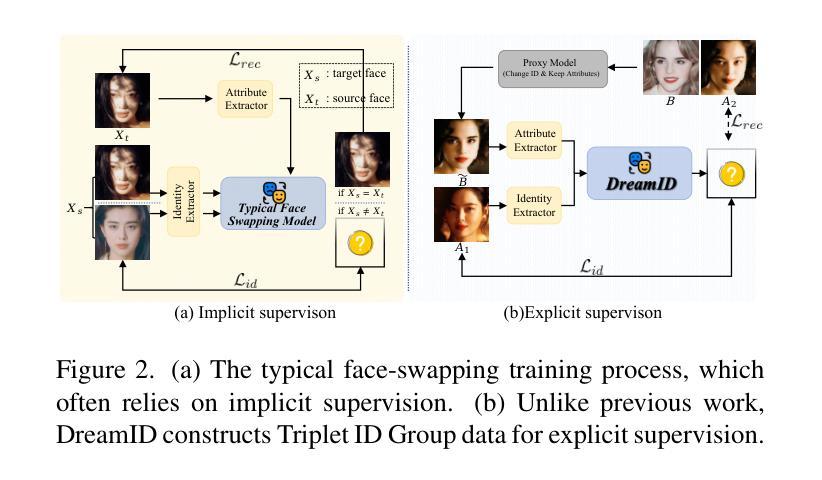
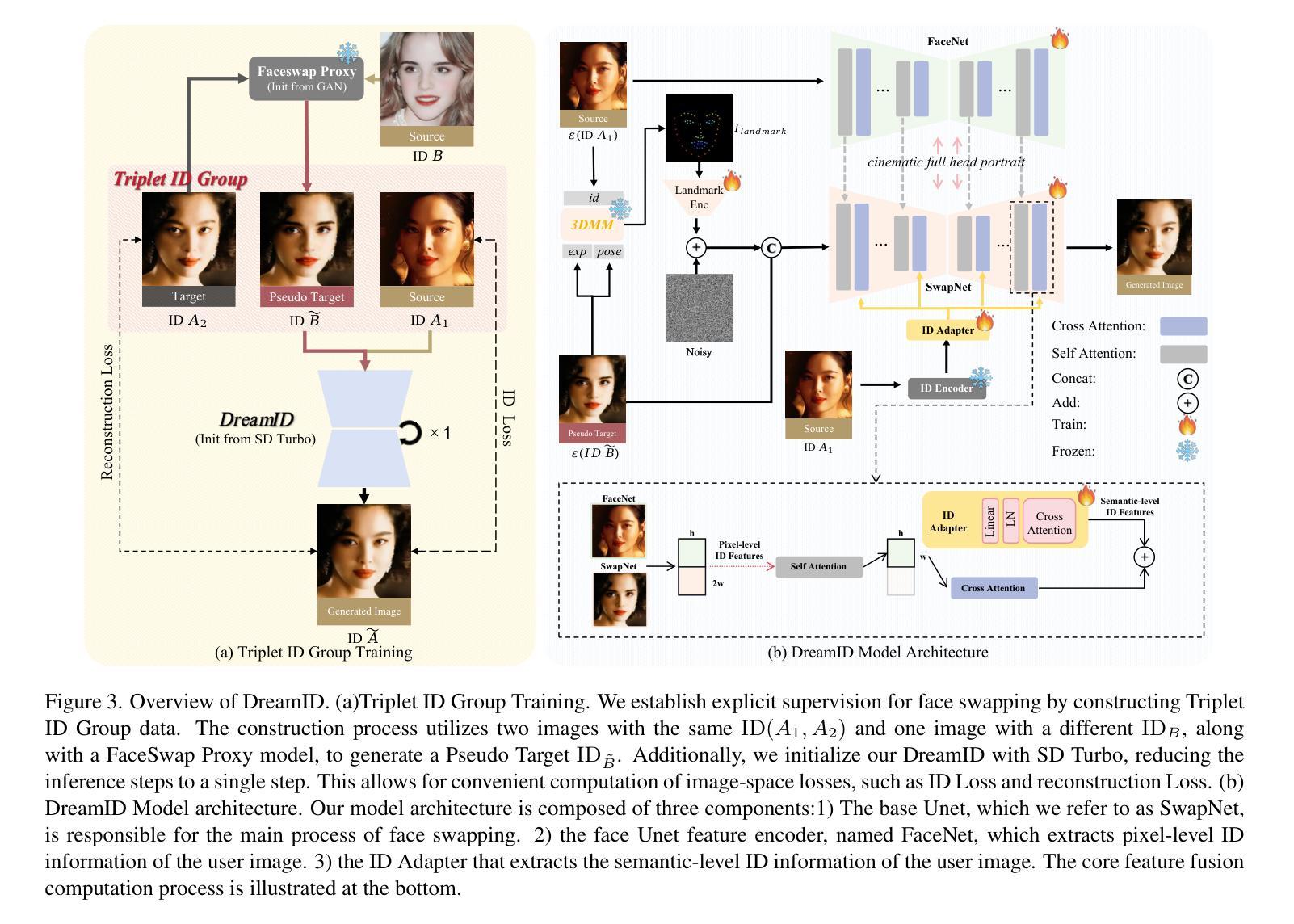
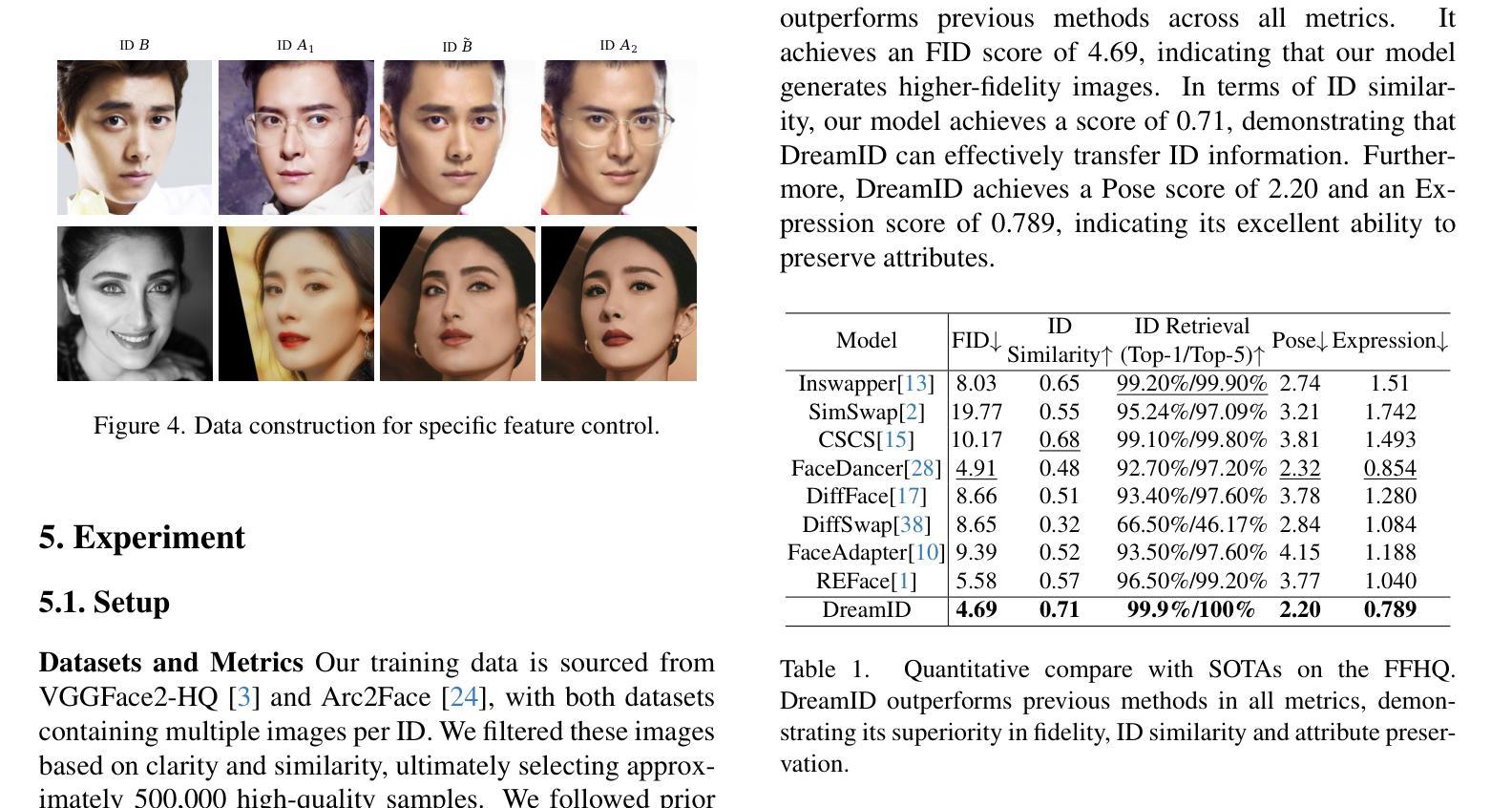
DreamID: High-Fidelity and Fast diffusion-based Face Swapping via Triplet ID Group Learning
Authors:Fulong Ye, Miao Hua, Pengze Zhang, Xinghui Li, Qichao Sun, Songtao Zhao, Qian He, Xinglong Wu
In this paper, we introduce DreamID, a diffusion-based face swapping model that achieves high levels of ID similarity, attribute preservation, image fidelity, and fast inference speed. Unlike the typical face swapping training process, which often relies on implicit supervision and struggles to achieve satisfactory results. DreamID establishes explicit supervision for face swapping by constructing Triplet ID Group data, significantly enhancing identity similarity and attribute preservation. The iterative nature of diffusion models poses challenges for utilizing efficient image-space loss functions, as performing time-consuming multi-step sampling to obtain the generated image during training is impractical. To address this issue, we leverage the accelerated diffusion model SD Turbo, reducing the inference steps to a single iteration, enabling efficient pixel-level end-to-end training with explicit Triplet ID Group supervision. Additionally, we propose an improved diffusion-based model architecture comprising SwapNet, FaceNet, and ID Adapter. This robust architecture fully unlocks the power of the Triplet ID Group explicit supervision. Finally, to further extend our method, we explicitly modify the Triplet ID Group data during training to fine-tune and preserve specific attributes, such as glasses and face shape. Extensive experiments demonstrate that DreamID outperforms state-of-the-art methods in terms of identity similarity, pose and expression preservation, and image fidelity. Overall, DreamID achieves high-quality face swapping results at 512*512 resolution in just 0.6 seconds and performs exceptionally well in challenging scenarios such as complex lighting, large angles, and occlusions.
本文介绍了DreamID,这是一款基于扩散的面貌替换模型,实现了高水平的身份相似性、属性保留、图像保真度和快速推理速度。不同于典型的面貌替换训练过程,它通常依赖于隐式监督,且难以实现令人满意的结果。DreamID通过构建Triplet ID Group数据实现对面貌替换的显式监督,从而显著提高身份相似性和属性保留。扩散模型的迭代性质给利用高效的图像空间损失函数带来了挑战,因为在训练过程中进行耗时的多步采样以获得生成图像是不切实际的。为了解决这个问题,我们利用了加速扩散模型SD Turbo,将推理步骤减少到单次迭代,能够在显式Triplet ID Group监督下进行高效的像素级端到端训练。此外,我们提出了改进的基于扩散的模型架构,包括SwapNet、FaceNet和ID适配器。这一稳健的架构充分释放了Triplet ID Group显式监督的威力。最后,为了进一步完善我们的方法,我们在训练过程中显式修改了Triplet ID Group数据,以微调并保留特定属性,如眼镜和脸型。大量实验表明,DreamID在身份相似性、姿势和表情保留以及图像保真度方面均优于最新技术方法。总的来说,DreamID在512*512分辨率下实现了高质量的面貌替换结果,仅需0.6秒,且在复杂光照、大角度和遮挡等挑战场景下表现尤为出色。
论文及项目相关链接
PDF Project: https://superhero-7.github.io/DreamID/
摘要
本文介绍了DreamID,一种基于扩散技术的换脸模型,具有身份相似度高、属性保留完整、图像保真度高和推理速度快的特点。与传统的换脸训练过程不同,DreamID通过构建Triplet ID Group数据实现显式监督,显著提高了身份相似性和属性保留。为解决扩散模型的迭代性质带来的挑战,我们采用加速扩散模型SD Turbo,将推理步骤减少到单次迭代,实现了高效的像素级端到端训练,同时辅以Triplet ID Group的显式监督。此外,我们提出了改进型的基于扩散的模型架构,包括SwapNet、FaceNet和ID Adapter,充分发挥Triplet ID Group显式监督的威力。最后,我们在训练过程中明确修改了Triplet ID Group数据,以精细调整并保留特定属性,如眼镜和脸型。实验表明,DreamID在身份相似性、姿势和表情保留以及图像保真度方面优于现有技术。总的来说,DreamID在512*512分辨率下实现了高质量换脸,只需0.6秒即可完成,并在复杂光照、大角度和遮挡等挑战场景下表现优异。
关键见解
- DreamID是基于扩散技术的换脸模型,实现高身份相似性、属性保留、图像保真度和快速推理。
- 通过构建Triplet ID Group数据实现显式监督,提高身份相似性和属性保留。
- 采用加速扩散模型SD Turbo,减少推理步骤至单次迭代,实现高效像素级端到端训练。
- 改进的基于扩散的模型架构包括SwapNet、FaceNet和ID Adapter,充分发挥显式监督的威力。
- 在训练过程中修改Triplet ID Group数据,以保留和调整特定属性,如眼镜和脸型。
- DreamID在多项实验中表现出色,尤其是在身份相似性、姿势和表情保留以及图像质量方面。
点此查看论文截图

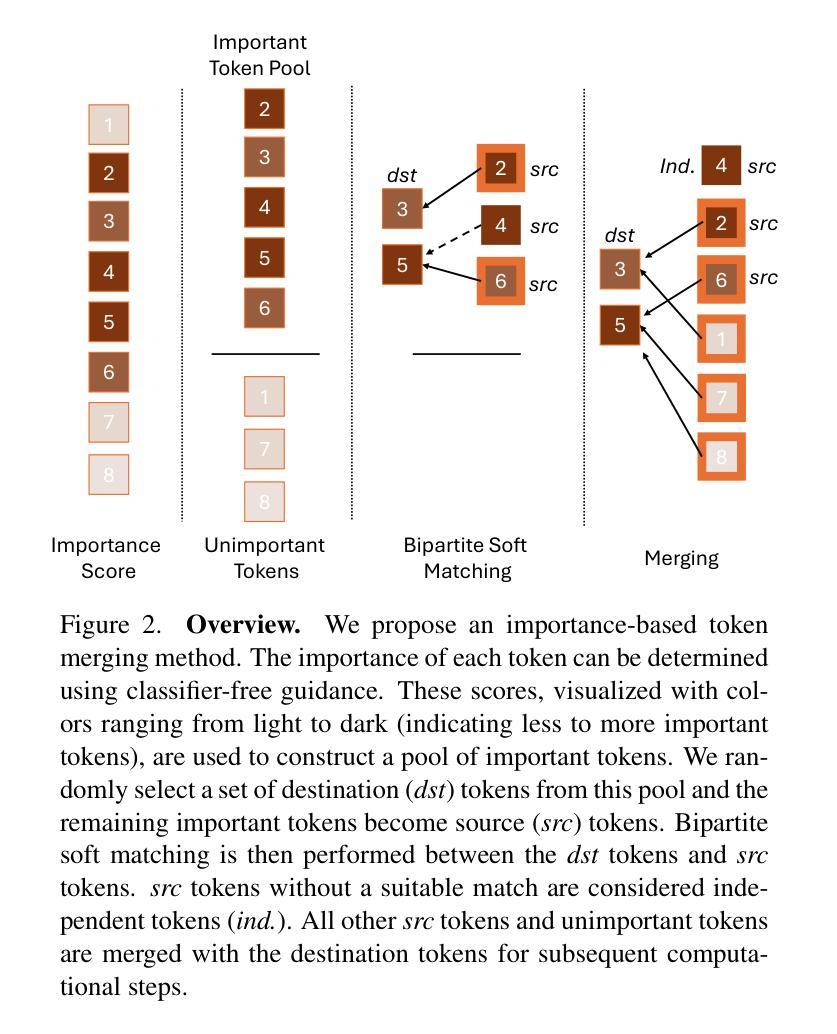
Importance-Based Token Merging for Efficient Image and Video Generation
Authors:Haoyu Wu, Jingyi Xu, Hieu Le, Dimitris Samaras
Token merging can effectively accelerate various vision systems by processing groups of similar tokens only once and sharing the results across them. However, existing token grouping methods are often ad hoc and random, disregarding the actual content of the samples. We show that preserving high-information tokens during merging - those essential for semantic fidelity and structural details - significantly improves sample quality, producing finer details and more coherent, realistic generations. Despite being simple and intuitive, this approach remains underexplored. To do so, we propose an importance-based token merging method that prioritizes the most critical tokens in computational resource allocation, leveraging readily available importance scores, such as those from classifier-free guidance in diffusion models. Experiments show that our approach significantly outperforms baseline methods across multiple applications, including text-to-image synthesis, multi-view image generation, and video generation with various model architectures such as Stable Diffusion, Zero123++, AnimateDiff, or PixArt-$\alpha$.
令牌合并通过仅处理一次相似的令牌组并在它们之间共享结果,可以有效地加速各种视觉系统。然而,现有的令牌分组方法往往是临时的和随机的,忽略了样本的实际内容。我们证明,在合并过程中保留高信息令牌——对语义保真和结构细节至关重要的令牌——可以显著提高样本质量,产生更精细的细节和更连贯、更逼真的生成内容。尽管这种方法简单直观,但仍被研究得不够深入。因此,我们提出了一种基于重要性的令牌合并方法,该方法在分配计算资源时优先考虑最重要的令牌,并利用现有的重要性评分,如扩散模型中的无分类器引导的重要性评分。实验表明,我们的方法在多个应用程序上的表现都优于基准方法,包括文本到图像合成、多视图图像生成和视频生成,以及使用各种模型架构(如Stable Diffusion、Zero123++、AnimateDiff或PixArt-α)的应用。
论文及项目相关链接
Summary
通过利用分组的重要性分数实现令牌合并方法,可以有效提高各类视觉系统的处理速度。现有的令牌合并方法常常忽视样本的实际内容,仅随机处理令牌分组。我们提出一种基于重要性的令牌合并方法,在资源分配中优先处理最关键的令牌,并借助现成的扩散模型中的分类器免费指导来实现。实验表明,该方法在多个应用领域中均优于基线方法,包括文本到图像合成、多视图图像生成和视频生成等。
Key Takeaways
- 令牌合并技术可以加速视觉系统的处理速度。
- 当前令牌分组方法常常忽视样本的实际内容,导致随机处理令牌分组。
- 通过保留高信息令牌(对语义保真和结构细节至关重要的令牌)在合并过程中可以提高样本质量。
- 我们提出了一种基于重要性的令牌合并方法,利用现有模型中的重要性分数进行优化。
- 该方法在多种应用领域中显著优于基线方法,包括文本到图像合成、多视图图像生成和视频生成等。
- 该方法适用于多种模型架构,如Stable Diffusion、Zero123++、AnimateDiff和PixArt-$\alpha$等。
点此查看论文截图




Investigating Memorization in Video Diffusion Models
Authors:Chen Chen, Enhuai Liu, Daochang Liu, Mubarak Shah, Chang Xu
Diffusion models, widely used for image and video generation, face a significant limitation: the risk of memorizing and reproducing training data during inference, potentially generating unauthorized copyrighted content. While prior research has focused on image diffusion models (IDMs), video diffusion models (VDMs) remain underexplored. To address this gap, we first formally define the two types of memorization in VDMs (content memorization and motion memorization) in a practical way that focuses on privacy preservation and applies to all generation types. We then introduce new metrics specifically designed to separately assess content and motion memorization in VDMs. Additionally, we curate a dataset of text prompts that are most prone to triggering memorization when used as conditioning in VDMs. By leveraging these prompts, we generate diverse videos from various open-source VDMs, successfully extracting numerous training videos from each tested model. Through the application of our proposed metrics, we systematically analyze memorization across various pretrained VDMs, including text-conditional and unconditional models, on a variety of datasets. Our comprehensive study reveals that memorization is widespread across all tested VDMs, indicating that VDMs can also memorize image training data in addition to video datasets. Finally, we propose efficient and effective detection strategies for both content and motion memorization, offering a foundational approach for improving privacy in VDMs.
扩散模型广泛应用于图像和视频生成,但它们面临一个重大局限:在推理过程中存在记忆和重现训练数据的风险,可能会生成未经授权的版权内容。虽然之前的研究主要集中在图像扩散模型(IDMs)上,但视频扩散模型(VDMs)的研究仍然不足。为了弥补这一空白,我们首先以实用方式正式定义VDMs中的两种记忆类型(内容记忆和运动记忆),重点关注隐私保护并适用于所有生成类型。然后,我们引入了专门用于单独评估VDMs中内容和运动记忆的新指标。此外,我们还整理了一组文本提示,当用作VDMs的条件时,最有可能触发记忆。通过利用这些提示,我们从各种开源VDMs生成了多样化的视频,成功地从每个测试模型中提取了大量训练视频。通过应用我们提出的指标,我们系统地分析了各种预训练VDMs中的记忆情况,包括文本条件和无条件模型,以及各种数据集。我们的综合研究表明,所有测试过的VDMs都存在广泛的记忆问题,这表明VDMs除了视频数据集外,还能记住图像训练数据。最后,我们为内容和运动记忆提出了高效且有效的检测策略,为改善VDMs中的隐私提供了基础方法。
论文及项目相关链接
PDF Accepted at DATA-FM Workshop @ ICLR 2025
Summary
本文研究了视频扩散模型(VDMs)中的记忆化问题,包括内容记忆化和动作记忆化。文章正式定义了这两种记忆化类型,并引入专门评估VDMs中内容和动作记忆化的新指标。通过利用特定文本提示,文章成功从各种预训练VDMs中提取了训练视频。研究表明,记忆化在各类预训练VDMs中普遍存在,不仅存在于视频数据集,也存在于图像训练数据中。最后,文章提出了针对内容和动作记忆化的高效检测策略,为提高VDMs的隐私性提供了基础方法。
Key Takeaways
- 扩散模型在图像和视频生成中广泛应用,但存在记忆化风险,可能生成未经授权版权内容。
- 视频扩散模型(VDMs)面临内容记忆化和动作记忆化问题,这两种类型被正式定义并引入新指标进行评估。
- 通过特定文本提示成功从预训练VDMs中提取训练视频,表明记忆化问题普遍存在。
- 记忆化不仅存在于视频数据集,也存在于图像训练数据中。
- 引入评估指标后发现记忆化现象在各种预训练VDMs中普遍存在。
- 文章提供了针对内容和动作记忆化的高效检测策略。
点此查看论文截图



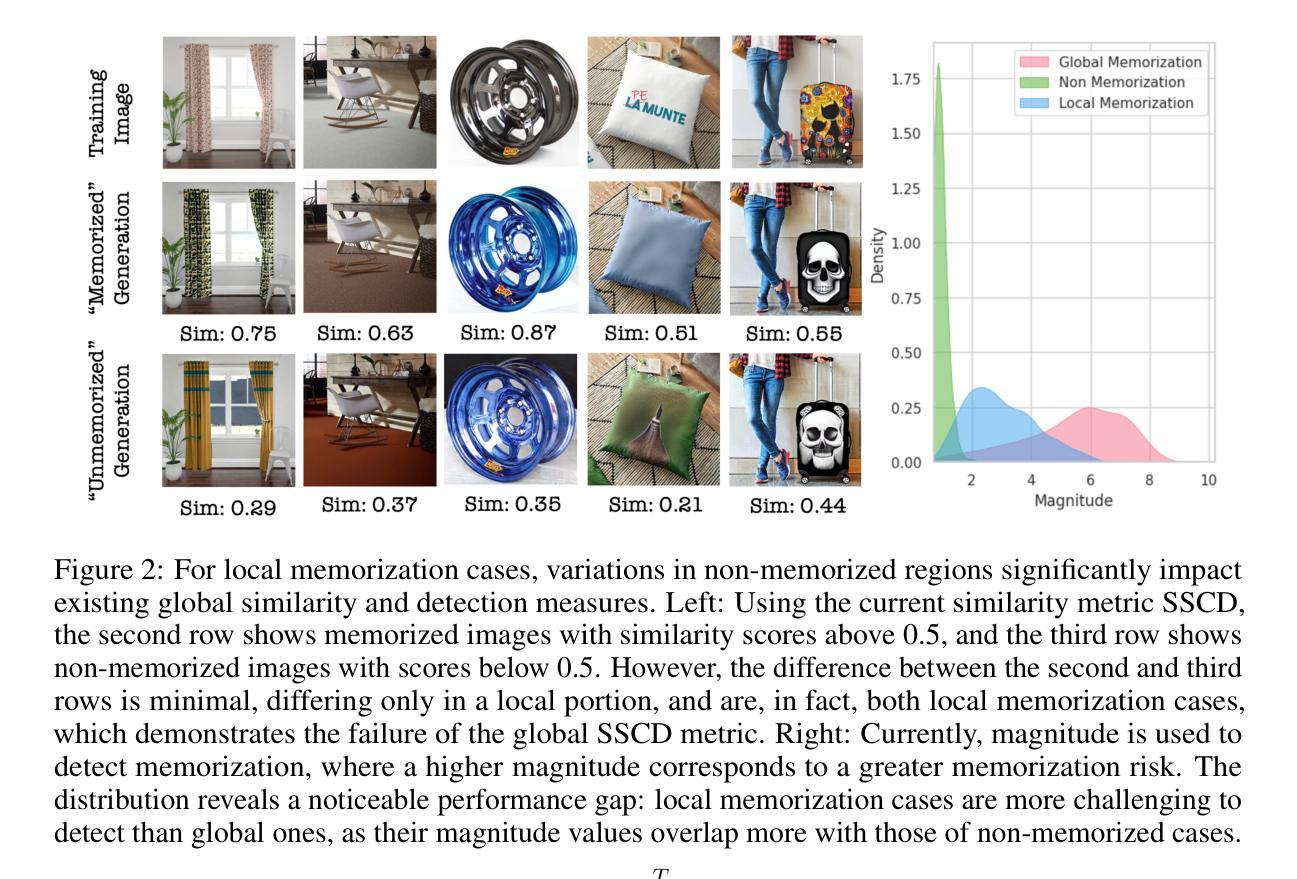
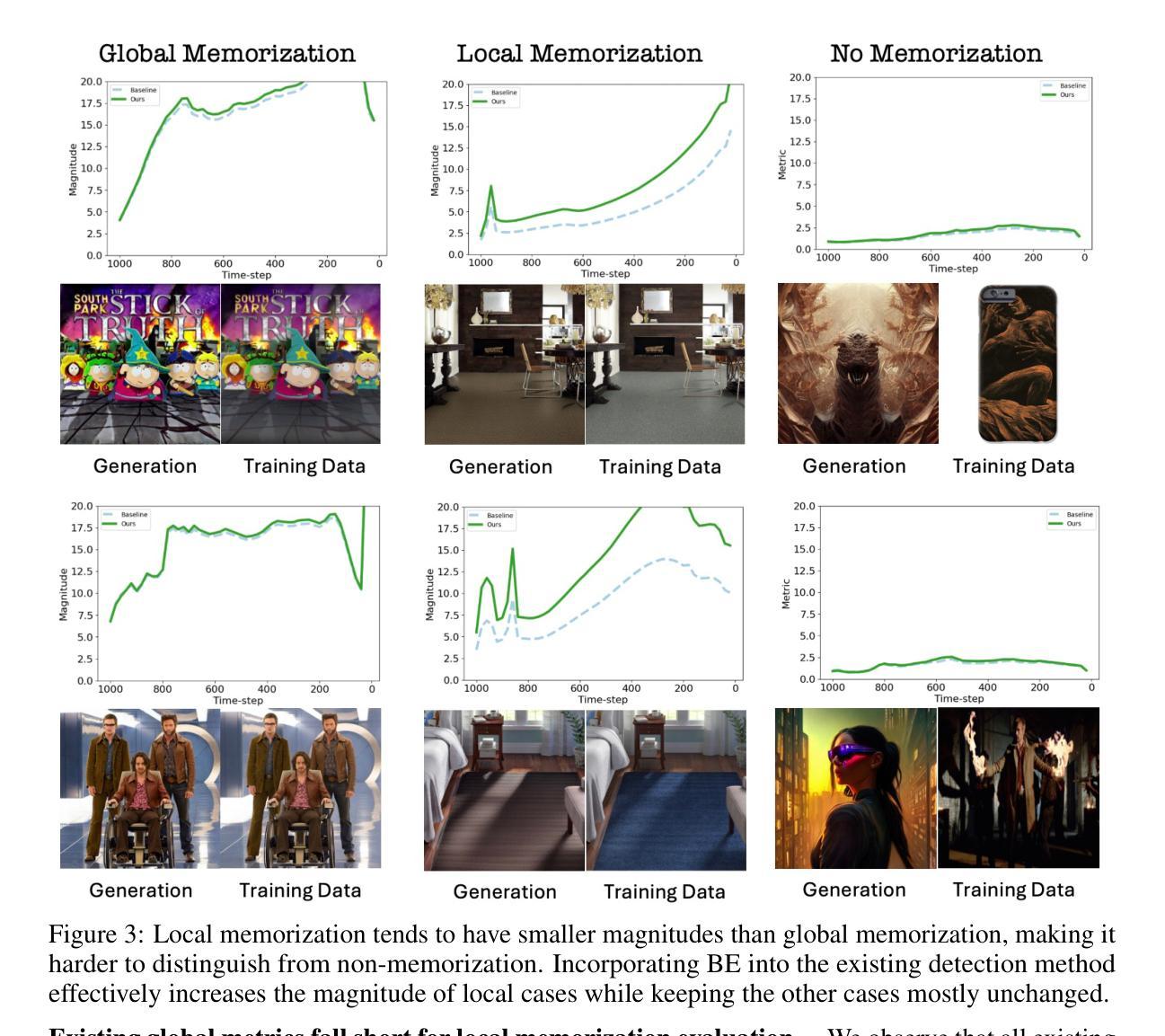
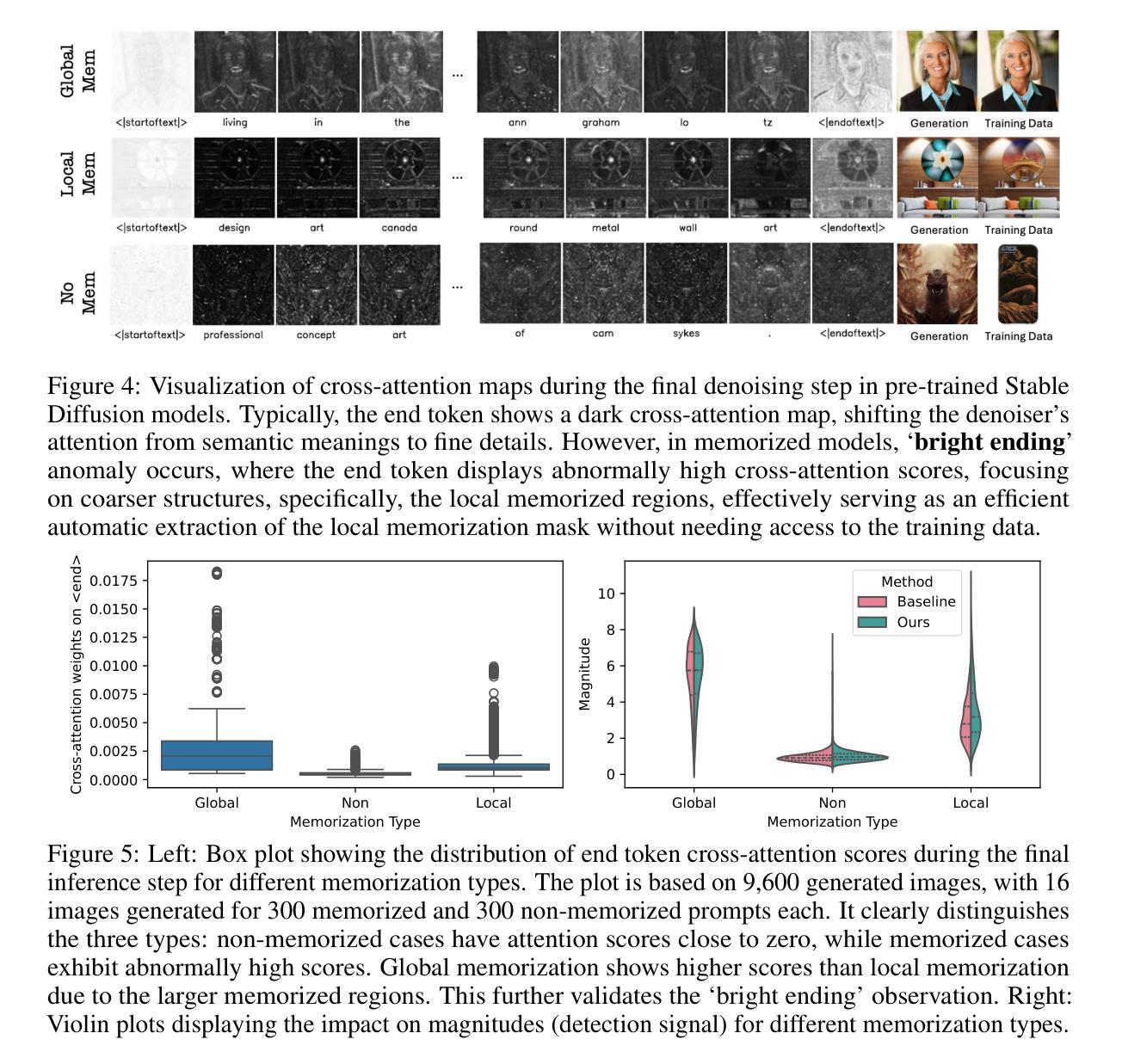
Exploring Local Memorization in Diffusion Models via Bright Ending Attention
Authors:Chen Chen, Daochang Liu, Mubarak Shah, Chang Xu
Text-to-image diffusion models have achieved unprecedented proficiency in generating realistic images. However, their inherent tendency to memorize and replicate training data during inference raises significant concerns, including potential copyright infringement. In response, various methods have been proposed to evaluate, detect, and mitigate memorization. Our analysis reveals that existing approaches significantly underperform in handling local memorization, where only specific image regions are memorized, compared to global memorization, where the entire image is replicated. Also, they cannot locate the local memorization regions, making it hard to investigate locally. To address these, we identify a novel “bright ending” (BE) anomaly in diffusion models prone to memorizing training images. BE refers to a distinct cross-attention pattern observed in text-to-image diffusion models, where memorized image patches exhibit significantly greater attention to the final text token during the last inference step than non-memorized patches. This pattern highlights regions where the generated image replicates training data and enables efficient localization of memorized regions. Equipped with this, we propose a simple yet effective method to integrate BE into existing frameworks, significantly improving their performance by narrowing the performance gap caused by local memorization. Our results not only validate the successful execution of the new localization task but also establish new state-of-the-art performance across all existing tasks, underscoring the significance of the BE phenomenon.
文本到图像的扩散模型在生成真实图像方面取得了前所未有的熟练度。然而,它们在推理过程中固有地倾向于记忆和复制训练数据,这引发了重大担忧,包括潜在的知识产权侵犯。为了应对这一问题,已经提出了各种方法来评估、检测和缓解记忆问题。我们的分析表明,与全局记忆相比,现有方法在处理局部记忆方面存在显著不足,全局记忆是指复制整个图像,而局部记忆仅指特定图像区域的记忆。此外,它们无法定位局部记忆区域,使得难以进行局部调查。为了解决这些问题,我们确定了扩散模型中容易记忆训练图像的一种新型“明亮结束”(BE)异常。BE是指文本到图像扩散模型中观察到的一种特殊的跨注意力模式,其中记忆的图像斑块在最后一步推理中对最终文本标记的注意力显著大于非记忆斑块。这种模式突出了生成图像复制训练数据的地方,并能够有效地定位记忆的图像区域。通过运用这一模式,我们提出了一种简单而有效的方法,将BE整合到现有框架中,通过缩小局部记忆造成的性能差距,显著提高现有框架的性能。我们的结果不仅验证了新定位任务的成功执行,而且确立了所有现有任务中的最新性能水平,突显了BE现象的重要性。
论文及项目相关链接
PDF Accepted at ICLR 2025 (Spotlight). Project page: https://chenchen-usyd.github.io/BE-Project-Page/
Summary
文本转图像扩散模型在生成真实图像方面取得了前所未有的熟练程度。然而,它们在推理过程中的固有倾向是记忆和复制训练数据,这引发了包括潜在版权侵犯在内的担忧。针对这一问题,已经提出了各种方法来评估、检测和缓解记忆问题。我们的分析发现,现有方法在局部记忆方面的表现显著较差,其中只有特定的图像区域被记忆,与整个图像都被复制的全局记忆相比。此外,它们无法定位局部记忆区域,使得本地调查变得困难。为了解决这些问题,我们确定了扩散模型中易于记忆训练图像的一种新型“明亮结束”(BE)异常现象。BE指的是文本转图像扩散模型中观察到的交叉注意力模式的独特现象,其中记忆的图像斑块在最后推理步骤中对最终文本令牌的注意力显著高于非记忆斑块。这种模式突出了生成图像复制训练数据的区域,并能够有效地定位记忆区域。基于此,我们提出了一种简单而有效的方法,将BE集成到现有框架中,通过缩小局部记忆造成的性能差距,显著提高它们的性能。我们的结果不仅验证了新定位任务的成功执行,而且在所有现有任务中建立了新的最先进的性能表现,突显了BE现象的重要性。
Key Takeaways
- 文本转图像扩散模型能够生成高度逼真的图像,但在推理过程中存在记忆和复制训练数据的倾向。
- 这种倾向可能导致版权问题和其他相关问题。
- 现有方法在检测和处理局部记忆问题方面表现不佳,无法定位局部记忆区域。
- 提出了一种名为“明亮结束”(BE)的新现象,表现为一种独特的交叉注意力模式,有助于识别记忆的图像区域。
- 通过将BE集成到现有框架中,可以有效定位和缓解局部记忆问题,提高模型性能。
- 新方法的性能在多个任务上达到了新的最先进的水平,验证了其有效性和实用性。
点此查看论文截图


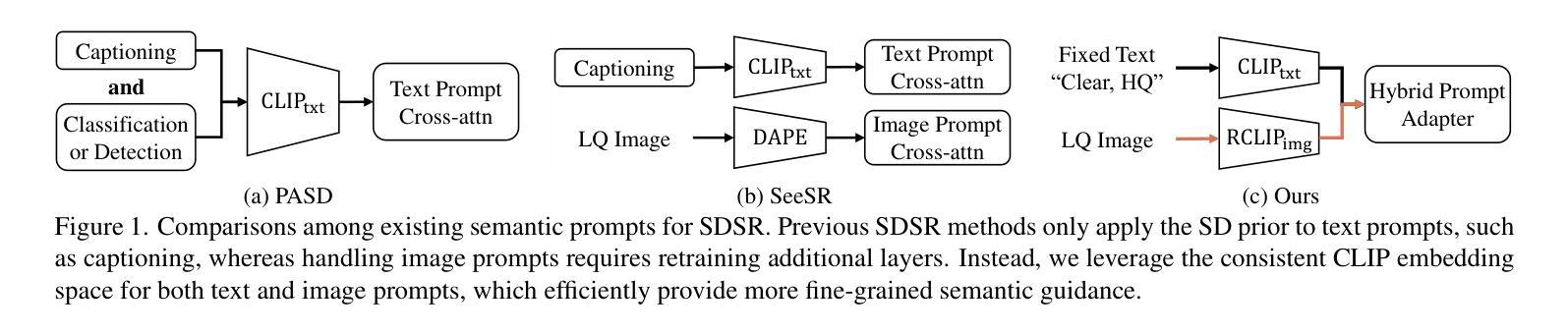
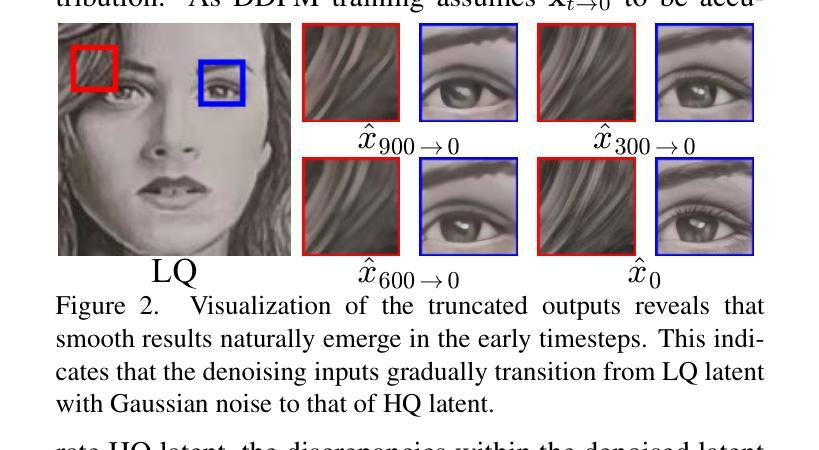
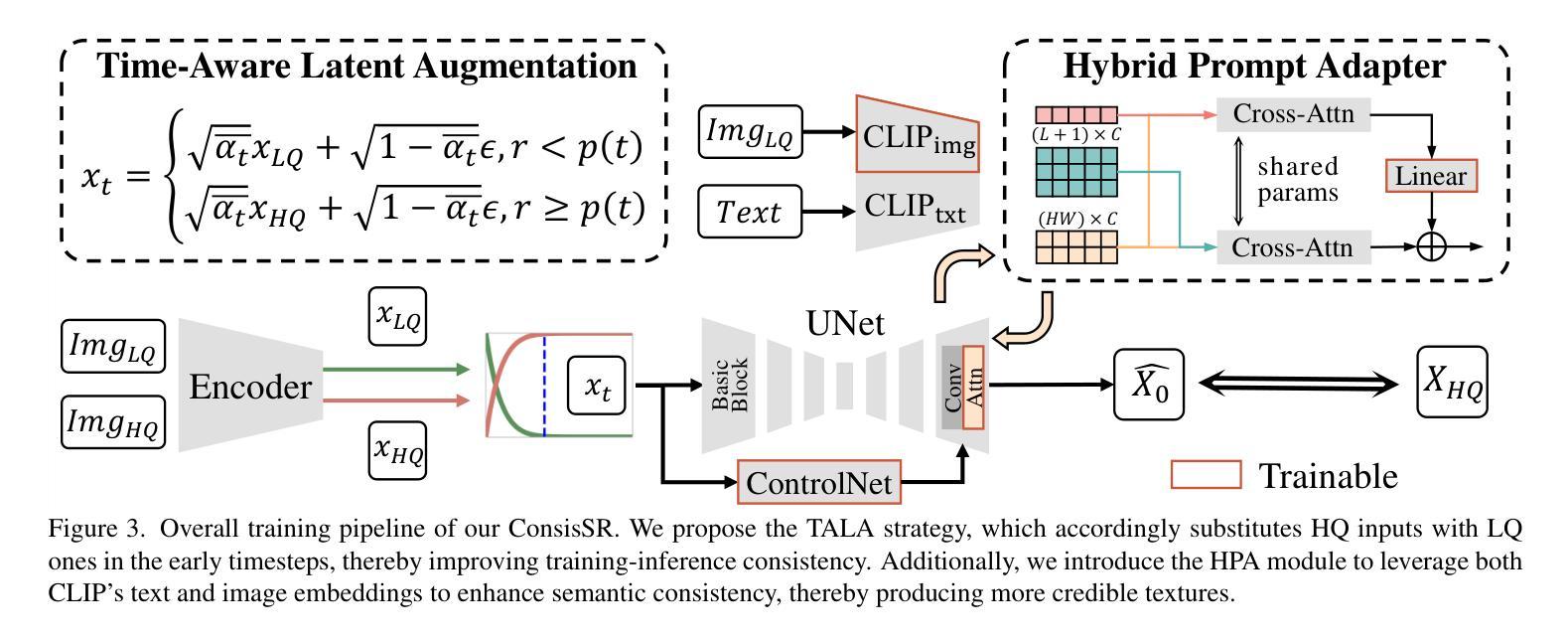
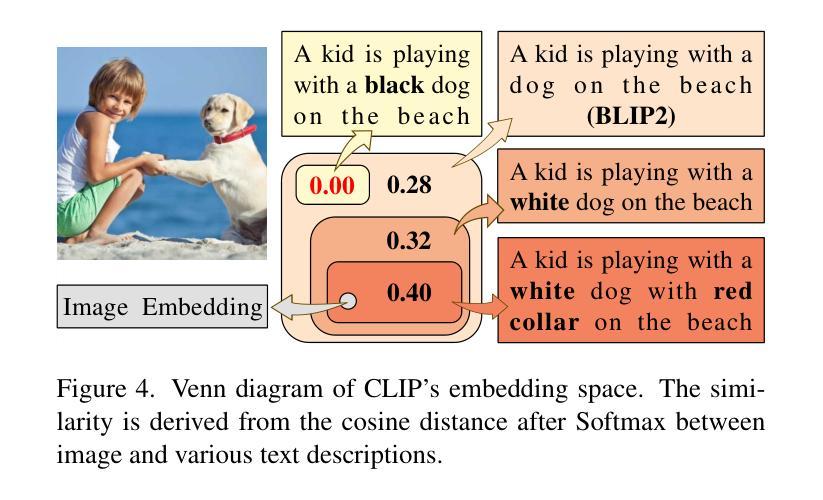
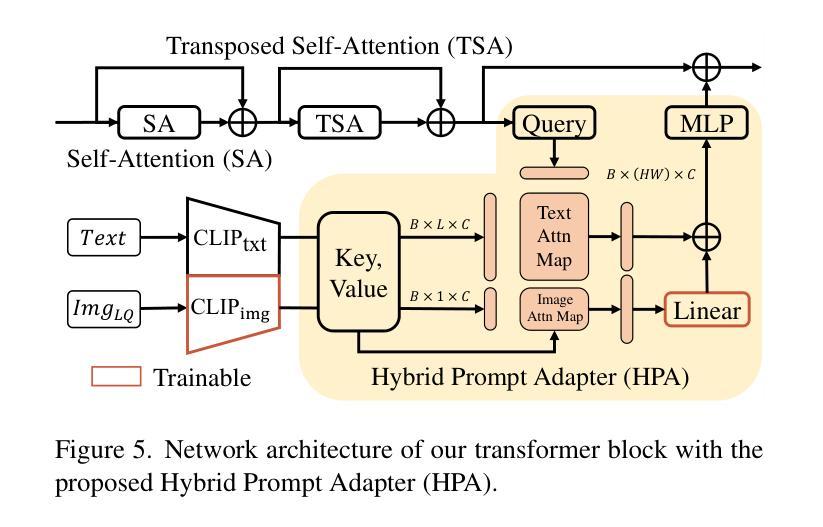
Improving Consistency in Diffusion Models for Image Super-Resolution
Authors:Junhao Gu, Peng-Tao Jiang, Hao Zhang, Mi Zhou, Jinwei Chen, Wenming Yang, Bo Li
Recent methods exploit the powerful text-to-image (T2I) diffusion models for real-world image super-resolution (Real-ISR) and achieve impressive results compared to previous models. However, we observe two kinds of inconsistencies in diffusion-based methods which hinder existing models from fully exploiting diffusion priors. The first is the semantic inconsistency arising from diffusion guidance. T2I generation focuses on semantic-level consistency with text prompts, while Real-ISR emphasizes pixel-level reconstruction from low-quality (LQ) images, necessitating more detailed semantic guidance from LQ inputs. The second is the training-inference inconsistency stemming from the DDPM, which improperly assumes high-quality (HQ) latent corrupted by Gaussian noise as denoising inputs for each timestep. To address these issues, we introduce ConsisSR to handle both semantic and training-inference consistencies. On the one hand, to address the semantic inconsistency, we proposed a Hybrid Prompt Adapter (HPA). Instead of text prompts with coarse-grained classification information, we leverage the more powerful CLIP image embeddings to explore additional color and texture guidance. On the other hand, we introduce Time-Aware Latent Augmentation (TALA) to bridge the training-inference inconsistency. Based on the probability function p(t), we accordingly enhance the SDSR training strategy. With LQ latent with Gaussian noise as inputs, our TALA not only focuses on diffusion noise but also refine the LQ latent towards the HQ counterpart. Our method demonstrates state-of-the-art performance among existing diffusion models. The code will be made publicly available.
最近的方法利用强大的文本到图像(T2I)扩散模型进行现实世界图像超分辨率(Real-ISR)处理,与之前的模型相比取得了令人印象深刻的结果。然而,我们观察到扩散模型中存在两种不一致性,阻碍了现有模型充分利用扩散先验知识。第一种是扩散引导产生的语义不一致性。T2I生成侧重于与文本提示的语义级别一致性,而Real-ISR强调从低质量(LQ)图像进行像素级重建,需要LQ输入提供更详细的语义引导。第二种是DDPM产生的训练推理不一致性,它错误地假设高质量(HQ)潜在变量受到高斯噪声的破坏,作为每个时间步长的去噪输入。为了解决这些问题,我们引入了ConsisSR来处理语义和训练推理一致性。一方面,为了解决语义不一致性,我们提出了混合提示适配器(HPA)。我们不再使用带有粗粒度分类信息的文本提示,而是利用更强大的CLIP图像嵌入来探索额外的颜色和纹理指导。另一方面,我们引入时间感知潜在增强(TALA)来弥合训练推理不一致性的鸿沟。基于概率函数p(t),我们相应地增强了SDSR训练策略。使用LQ潜在带有高斯噪声作为输入,我们的TALA不仅关注扩散噪声,而且还使LQ潜在向HQ对应物进行精炼。我们的方法在现有的扩散模型中达到了最先进的性能。代码将公开可用。
论文及项目相关链接
摘要
最新方法利用强大的文本到图像(T2I)扩散模型进行现实世界图像超分辨率(Real-ISR),与之前的模型相比取得了令人印象深刻的结果。然而,我们观察到扩散模型中的两种不一致性,阻碍了现有模型充分利用扩散先验。首先是语义不一致性,源于扩散指导。T2I生成侧重于与文本提示的语义级一致性,而Real-ISR强调从低质量(LQ)图像进行像素级重建,需要更多详细的语义指导来自LQ输入。其次是DDPM产生的训练推理不一致性,它错误地假设高质量(HQ)潜在变量被高斯噪声腐蚀作为每个时间步的降噪输入。为了解决这些问题,我们引入了ConsisSR来处理语义和训练推理的一致性。一方面,为了解决语义不一致性,我们提出了混合提示适配器(HPA)。我们利用更强大的CLIP图像嵌入来探索额外的颜色和纹理指导,而不是带有粗略分类信息的文本提示。另一方面,我们引入时间感知潜在增强(TALA)来弥合训练推理的不一致性。基于概率函数p(t),我们相应地增强了SDSR训练策略。使用LQ潜在带有高斯噪声作为输入,我们的TALA不仅关注扩散噪声,还优化LQ潜在变量向HQ对应物靠近。我们的方法在现有扩散模型中达到了领先水平,相关代码将公开。
关键见解
- 文本到图像(T2I)扩散模型在现实世界图像超分辨率(Real-ISR)任务中取得显著成果。
- 现有扩散模型存在语义不一致和训练推理不一致的问题。
- ConsisSR被提出来处理这两种不一致性,包括混合提示适配器(HPA)和时间感知潜在增强(TALA)。
- HPA利用CLIP图像嵌入来提供额外的颜色和纹理指导,解决语义不一致问题。
- TALA基于概率函数增强SDSR训练策略,以缩小训练与推理之间的差距。
- 该方法不仅在像素级重建方面表现出色,而且在处理低质量图像时提供了强大的语义指导。
点此查看论文截图