⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-29 更新
Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation
Authors:Weipeng Tan, Chuming Lin, Chengming Xu, FeiFan Xu, Xiaobin Hu, Xiaozhong Ji, Junwei Zhu, Chengjie Wang, Yanwei Fu
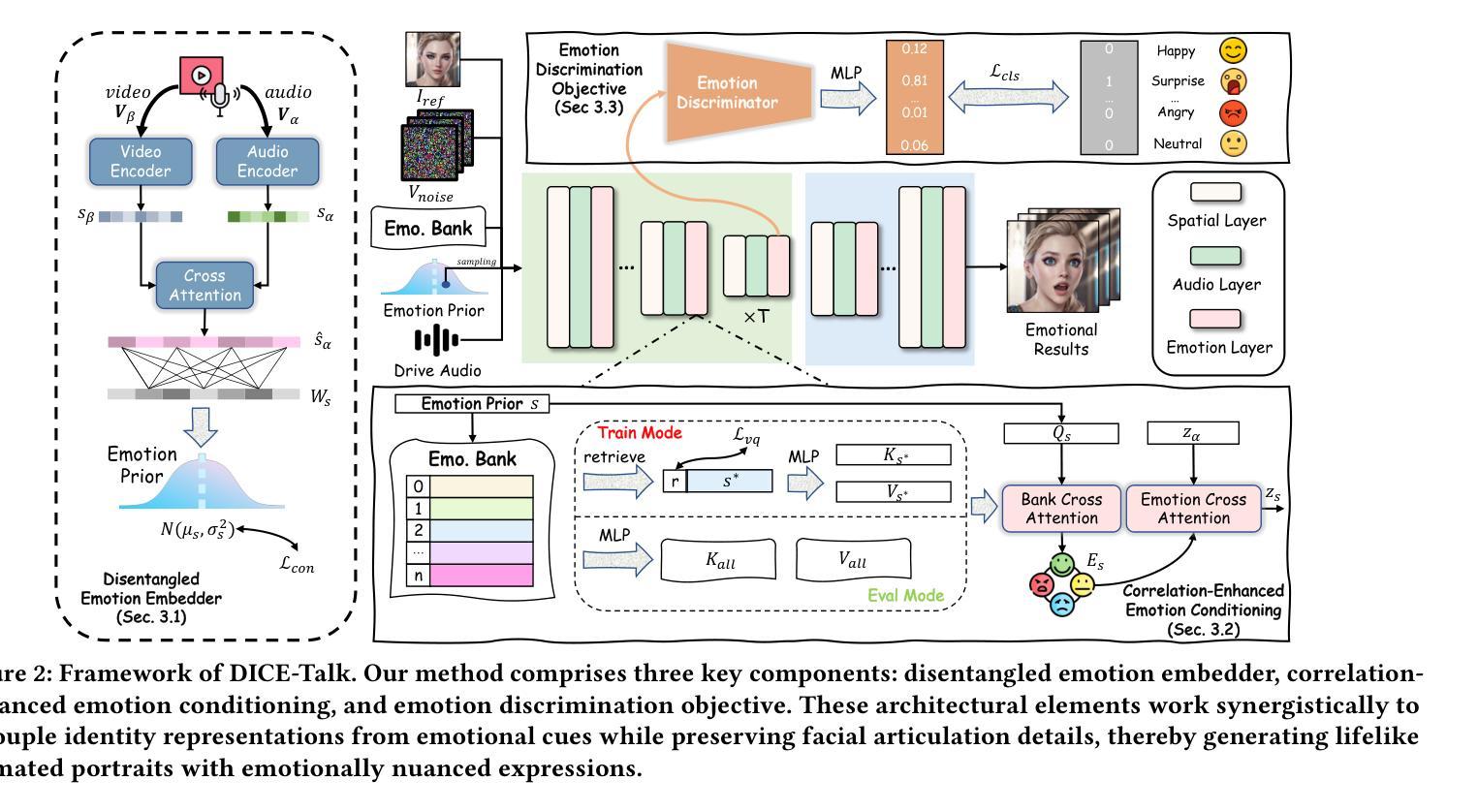
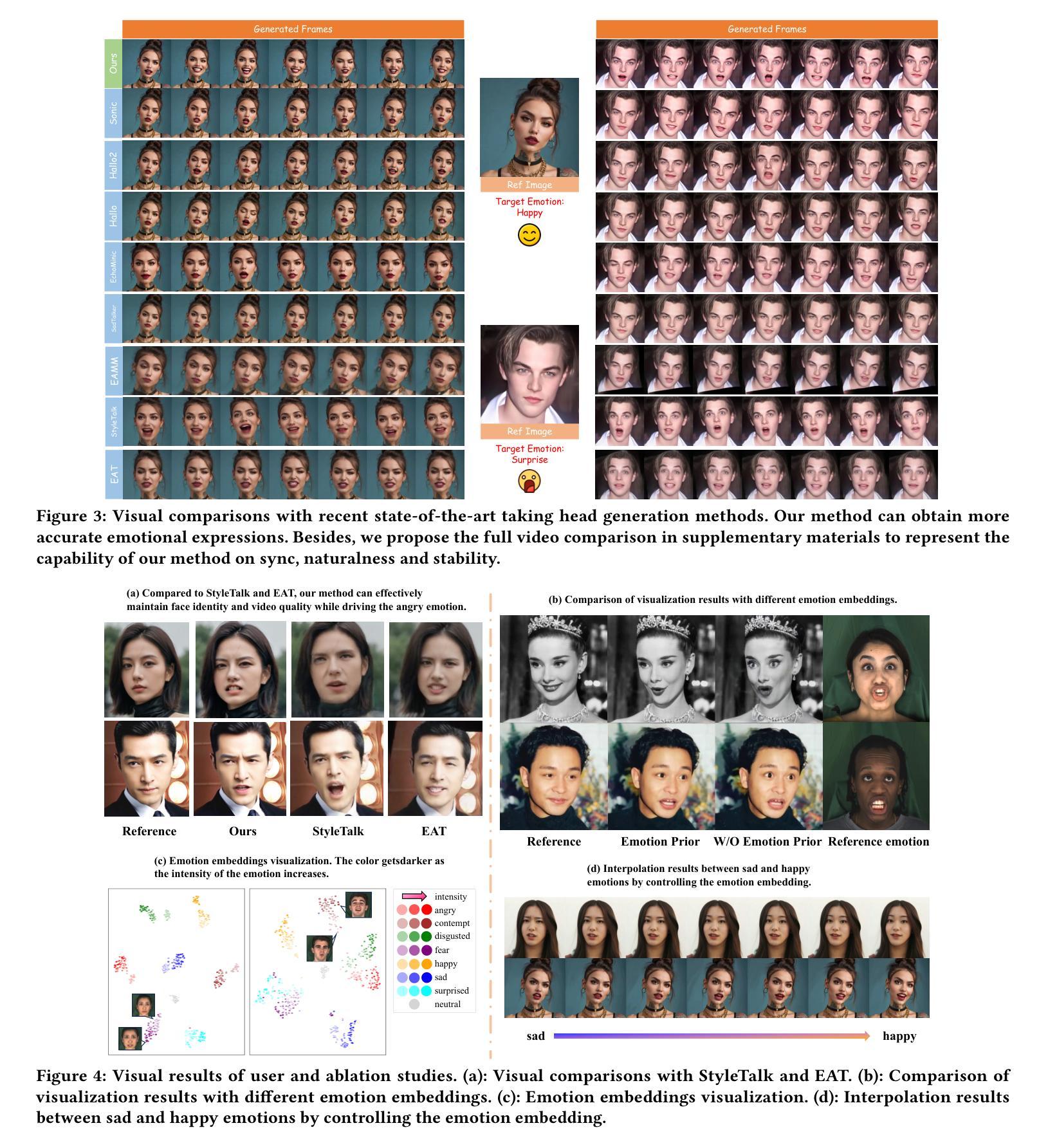
Recent advances in Talking Head Generation (THG) have achieved impressive lip synchronization and visual quality through diffusion models; yet existing methods struggle to generate emotionally expressive portraits while preserving speaker identity. We identify three critical limitations in current emotional talking head generation: insufficient utilization of audio’s inherent emotional cues, identity leakage in emotion representations, and isolated learning of emotion correlations. To address these challenges, we propose a novel framework dubbed as DICE-Talk, following the idea of disentangling identity with emotion, and then cooperating emotions with similar characteristics. First, we develop a disentangled emotion embedder that jointly models audio-visual emotional cues through cross-modal attention, representing emotions as identity-agnostic Gaussian distributions. Second, we introduce a correlation-enhanced emotion conditioning module with learnable Emotion Banks that explicitly capture inter-emotion relationships through vector quantization and attention-based feature aggregation. Third, we design an emotion discrimination objective that enforces affective consistency during the diffusion process through latent-space classification. Extensive experiments on MEAD and HDTF datasets demonstrate our method’s superiority, outperforming state-of-the-art approaches in emotion accuracy while maintaining competitive lip-sync performance. Qualitative results and user studies further confirm our method’s ability to generate identity-preserving portraits with rich, correlated emotional expressions that naturally adapt to unseen identities.
在Talking Head Generation(THG)的最新进展中,通过扩散模型实现了令人印象深刻的唇同步和视觉质量。然而,现有方法在生成情感表达肖像时很难同时保留说话者的身份。我们确定了当前情感Talking Head生成中的三个关键局限性:未能充分利用音频的内在情感线索、情感表示中的身份泄露以及情感关联的独立学习。为了解决这些挑战,我们提出了一个名为DICE-Talk的新型框架,其理念是分解身份与情感,然后与具有类似特征的情感进行合作。首先,我们开发了一个分离的情感嵌入器,通过跨模态注意力联合建模音频-视觉情感线索,将情感表示为与身份无关的高斯分布。其次,我们引入了一个增强相关性的情感调节模块,该模块具有可学习的情感库,通过向量量化和基于注意力的特征聚合显式捕获相互之间的情感关系。第三,我们设计了一个情感辨别目标,通过潜在空间分类在扩散过程中强制执行情感一致性。在MEAD和HDTF数据集上的大量实验表明,我们的方法在情感准确性方面优于最新技术,同时保持竞争的唇同步性能。定性和用户研究进一步证实了我们的方法生成身份保留肖像的能力,具有丰富的、相关的情感表达,可自然地适应未见过的身份。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2409.03270
Summary
音频和视觉情感线索在情绪谈话生成中的重要性。现有方法存在情感表达不足、身份泄露和情感关联孤立学习等问题。提出一种新型框架DICE-Talk,通过解耦身份和情感,合作具有相似特征的情感来解决这些问题。采用情感嵌入器、情感条件模块和情感辨别目标等方法提升性能。
Key Takeaways
- 音频的固有情感线索在情绪谈话生成中至关重要,现有方法未能充分利用。
- 当前方法存在身份泄露和情感表达不足的问题。
- DICE-Talk框架通过解耦身份与情感,实现情感的有效表达。
- 情感嵌入器通过跨模态注意力联合建模视听情感线索,将情感表示为身份无关的高斯分布。
- 引入情感条件模块和学习型情感库,通过向量量化和基于注意力的特征聚合,捕捉情感间关系。
- 设计情感辨别目标,在扩散过程中通过潜在空间分类强制执行情感一致性。
点此查看论文截图

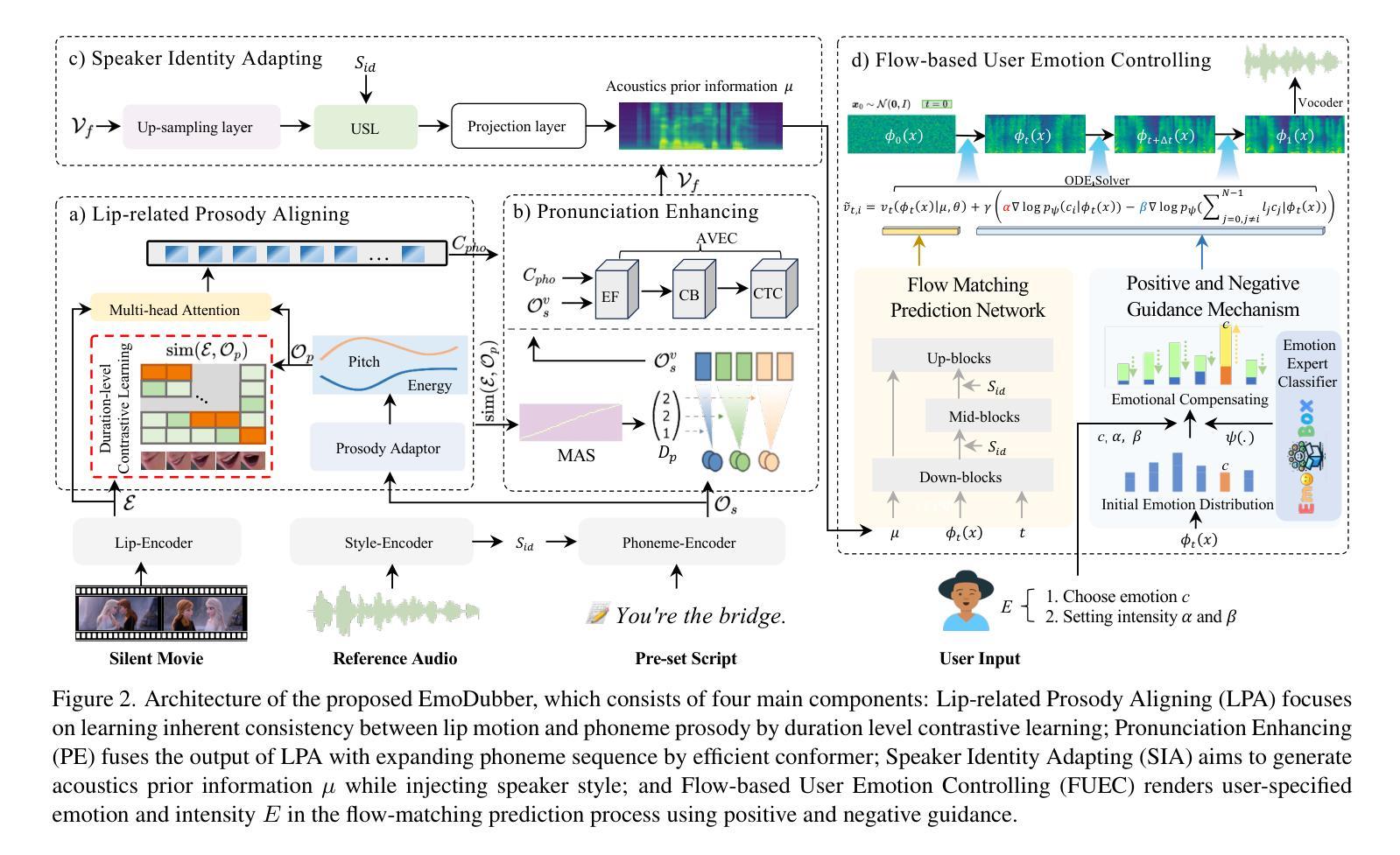
EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing
Authors:Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton van den Hengel, Jian Yang, Qingming Huang
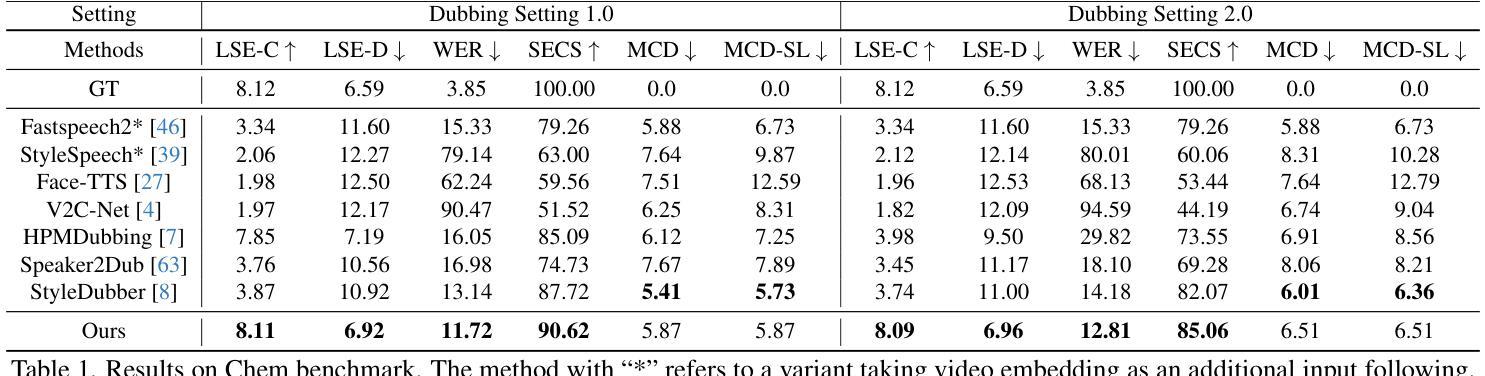
Given a piece of text, a video clip, and a reference audio, the movie dubbing task aims to generate speech that aligns with the video while cloning the desired voice. The existing methods have two primary deficiencies: (1) They struggle to simultaneously hold audio-visual sync and achieve clear pronunciation; (2) They lack the capacity to express user-defined emotions. To address these problems, we propose EmoDubber, an emotion-controllable dubbing architecture that allows users to specify emotion type and emotional intensity while satisfying high-quality lip sync and pronunciation. Specifically, we first design Lip-related Prosody Aligning (LPA), which focuses on learning the inherent consistency between lip motion and prosody variation by duration level contrastive learning to incorporate reasonable alignment. Then, we design Pronunciation Enhancing (PE) strategy to fuse the video-level phoneme sequences by efficient conformer to improve speech intelligibility. Next, the speaker identity adapting module aims to decode acoustics prior and inject the speaker style embedding. After that, the proposed Flow-based User Emotion Controlling (FUEC) is used to synthesize waveform by flow matching prediction network conditioned on acoustics prior. In this process, the FUEC determines the gradient direction and guidance scale based on the user’s emotion instructions by the positive and negative guidance mechanism, which focuses on amplifying the desired emotion while suppressing others. Extensive experimental results on three benchmark datasets demonstrate favorable performance compared to several state-of-the-art methods.
给定一段文本、一个视频片段和参考音频,电影配音任务旨在生成与视频对齐的语音,同时克隆所需的语音。现有方法存在两个主要缺陷:一是它们难以同时保持视听同步和清晰的发音;二是它们不具备表达用户定义情绪的能力。为了解决这些问题,我们提出了EmoDubber,一种情感可控的配音架构,允许用户指定情绪类型和情感强度,同时满足高质量的唇部同步和发音。具体来说,我们首先设计了唇相关韵律对齐(LPA),它专注于通过学习持续时间水平对比学习中的唇动和韵律变化之间的内在一致性,来实现合理的对齐。然后,我们设计了发音增强(PE)策略,通过高效的转换器融合视频级音素序列,以提高语音清晰度。接下来,说话人身份适应模块旨在解码声学先验并注入说话人风格嵌入。之后,使用所提出的基于流的用户情绪控制(FUEC)方法,通过流匹配预测网络以声学先验为条件合成波形。在此过程中,FUEC通过正负引导机制根据用户的情绪指令确定梯度方向和引导尺度,侧重于放大所需的情绪同时抑制其他情绪。在三个基准数据集上的大量实验结果表明,与几种最新方法相比,该方法具有优越的性能。
论文及项目相关链接
PDF Accepted to CVPR 2025
摘要
该文本介绍了一种电影配音任务的技术挑战及提出的解决方案。现有方法难以同时实现音视频同步和清晰发音,且无法表达用户定义的情绪。针对这些问题,提出了一款名为EmoDubber的情感可控配音架构。该架构允许用户指定情感类型和情感强度,同时满足高质量的唇同步和发音。通过设计唇相关韵律对齐(LPA)和发音增强(PE)策略,以及用户情绪控制的流程,实现了情感可控的配音生成。实验结果在三个基准数据集上表现出优越性能。
关键见解
- 电影配音任务旨在生成与视频匹配的语音,同时克隆所需的语音。
- 现有方法存在音视频同步和清晰发音的双重挑战。
- 提出的EmoDubber架构解决了这些问题,允许用户指定情感类型和强度。
- 设计了唇相关韵律对齐(LPA)策略,学习唇动和韵律变化的内在一致性。
- 采用了发音增强(PE)策略,通过高效变压器融合视频级音素序列,提高语音清晰度。
- 通过使用基于流的用户情绪控制(FUEC),根据声学先验合成波形。
- FUEC通过正负指导机制确定梯度方向和指导规模,根据用户的情绪指令调节情感表达。
点此查看论文截图