⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-29 更新
E-InMeMo: Enhanced Prompting for Visual In-Context Learning
Authors:Jiahao Zhang, Bowen Wang, Hong Liu, Liangzhi Li, Yuta Nakashima, Hajime Nagahara
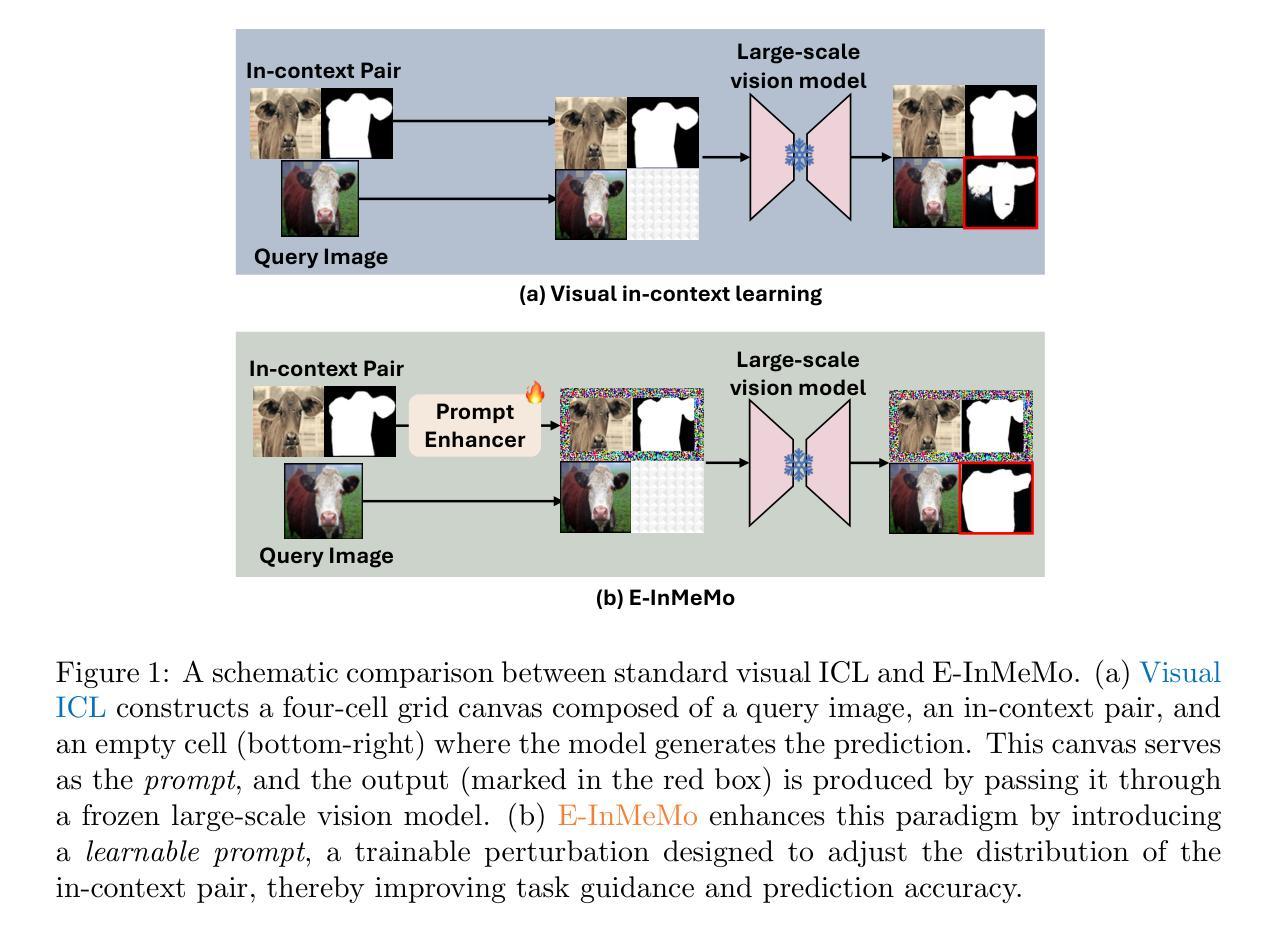
Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose Enhanced Instruct Me More (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL. Code is publicly available at: https://github.com/Jackieam/E-InMeMo
大规模模型在广泛数据集上进行训练,由于其在不同任务中的强大泛化能力,已成为标准做法。上下文学习(ICL)在自然语言处理中广泛应用,它通过提供任务特定提示,而无需修改模型参数,充分利用这些模型。这种范式正越来越多地应用于计算机视觉领域,其中模型接收输入-输出图像对,称为上下文对,以及一个查询图像来展示所需输出。然而,视觉ICL的成功在很大程度上取决于这些提示的质量。为了解决这个问题,我们提出了增强型提示我更多(E-InMeMo)方法,这是一种将可学习扰动纳入上下文对以优化提示的新型方法。通过对标准视觉任务进行大量实验,E-InMeMo证明了其在现有最先进方法上的优越性。值得注意的是,与没有可学习提示的基线相比,它在前景分割方面的mIoU得分提高了7.99%,在单目标检测方面提高了17.04%。这些结果凸显了E-InMeMo作为一种轻量化但有效的策略,能够增强视觉ICL。代码公开在:https://github.com/Jackieam/E-InMeMo
论文及项目相关链接
PDF Preprint
Summary
大规模模型在广泛数据集上的训练已成为标准,因其跨不同任务的强大泛化能力。上下文学习(ICL)在自然语言处理中广泛使用,通过提供任务特定提示而无需修改模型参数来利用这些模型。这一范式正逐渐适应计算机视觉领域,其中模型接收输入-输出图像对(称为上下文对)以及查询图像来展示所需输出。视觉ICL的成功很大程度上取决于提示的质量。为解决这一问题,我们提出了Enhanced Instruct Me More(E-InMeMo),这是一种结合可学习扰动到上下文对中的新方法,以优化提示。在标准视觉任务上的大量实验表明,E-InMeMo在现有最先进的方法上表现出卓越的性能。特别是,与没有可学习提示的基线相比,它在前景分割和单对象检测方面的mIoU得分分别提高了7.99和17.04。这些结果凸显了E-InMeMo作为增强视觉ICL的轻量化且有效策略的优势。
Key Takeaways
- 大规模模型在多样化任务上表现出强大的泛化能力,经常用于各种学习场景。
- 上下文学习(ICL)是一种利用模型的方法,通过提供任务特定提示而不需要修改模型参数。
- 上下文学习正逐渐应用于计算机视觉领域,其中模型使用输入-输出图像对(上下文对)来理解并处理查询图像。
- 视觉ICL的成功很大程度上依赖于提示的质量。
- E-InMeMo是一种结合可学习扰动到上下文对中的新方法,旨在优化提示,从而提高模型性能。
- E-InMeMo在多个标准视觉任务上的表现优于现有方法,特别是在前景分割和单对象检测方面。
点此查看论文截图


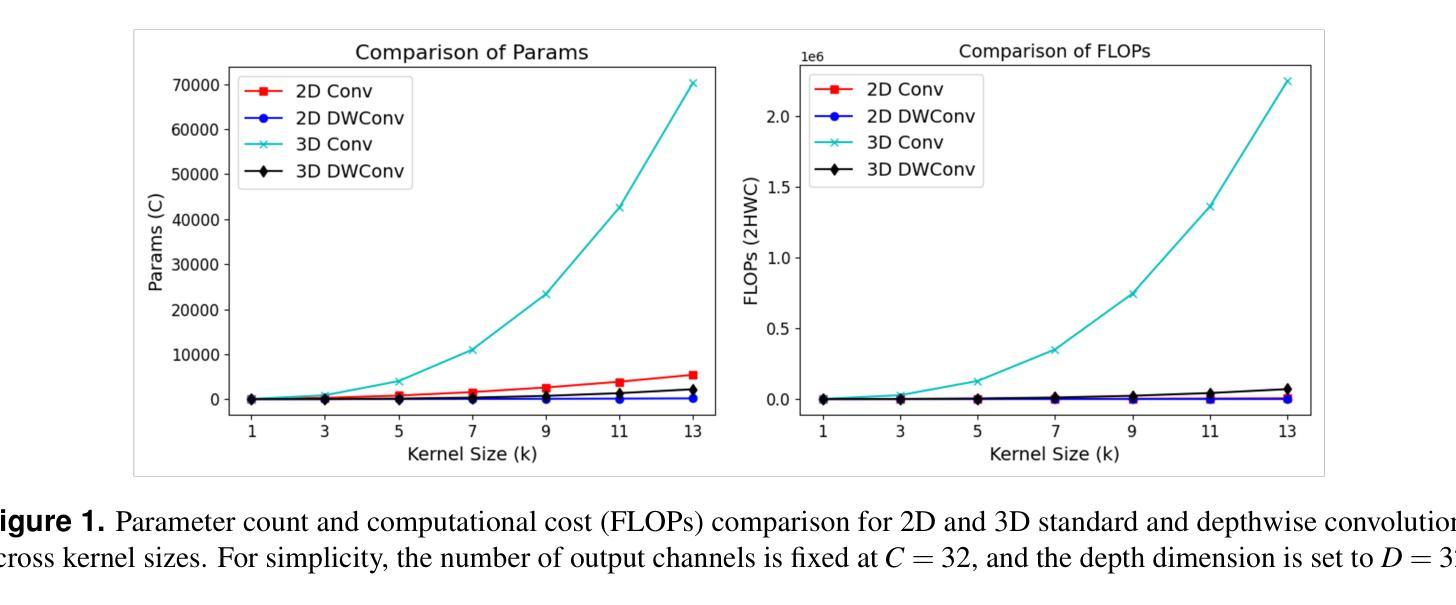
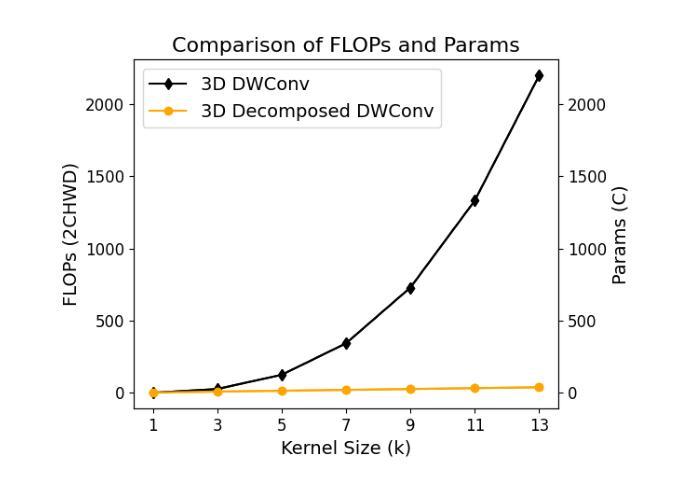
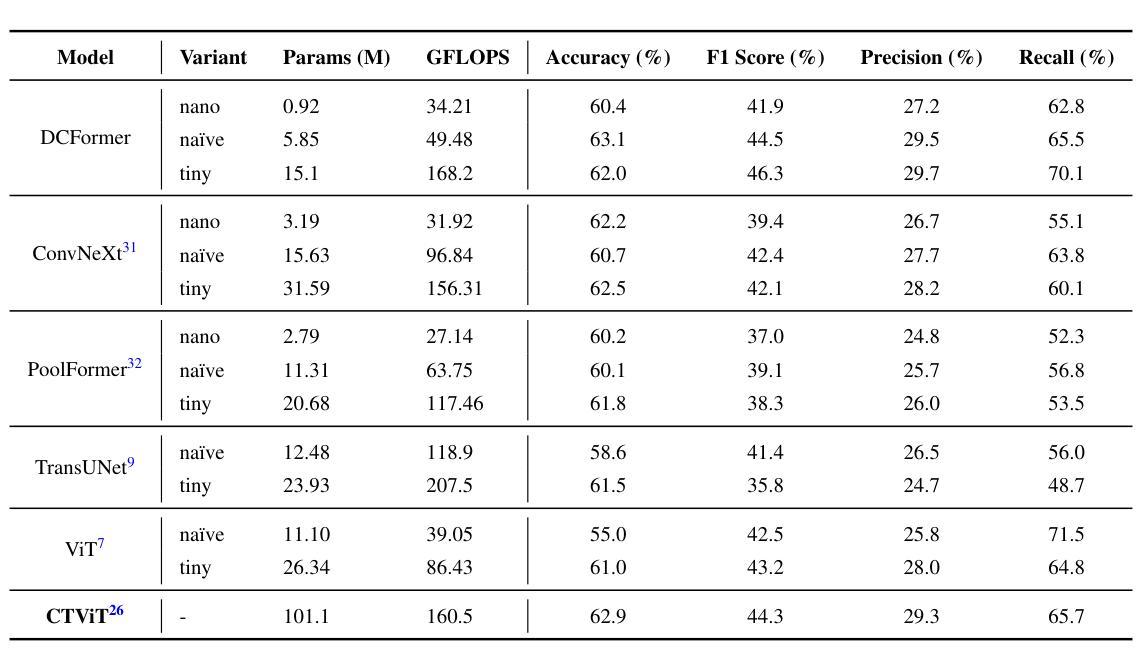
DCFormer: Efficient 3D Vision-Language Modeling with Decomposed Convolutions
Authors:Gorkem Can Ates, Yu Xin, Kuang Gong, Wei Shao
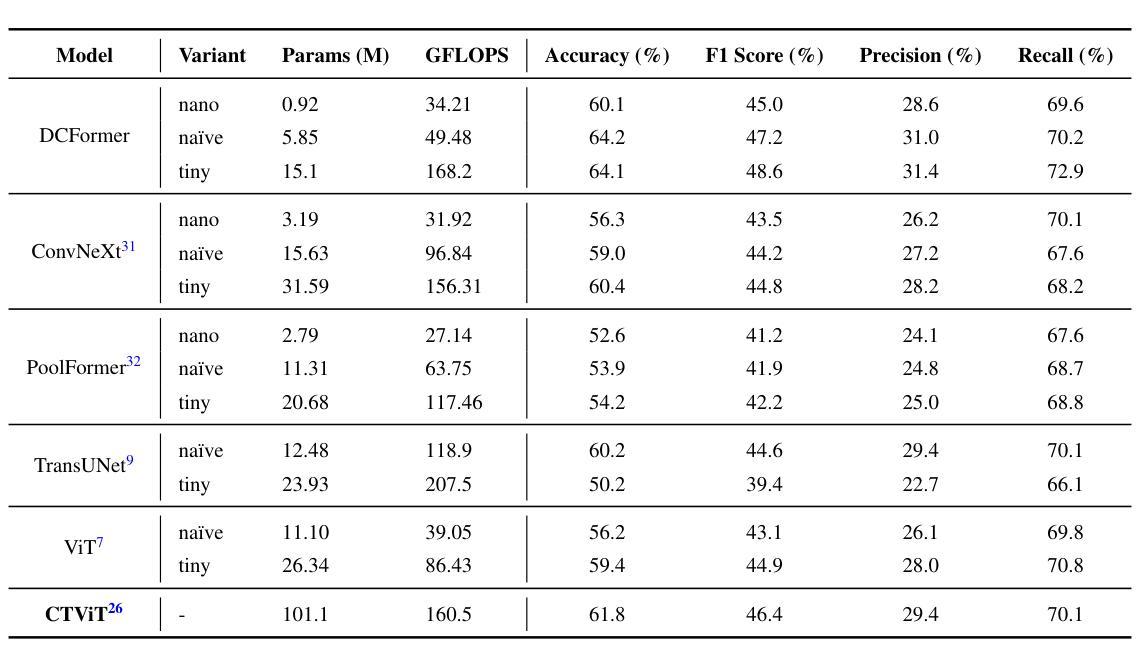
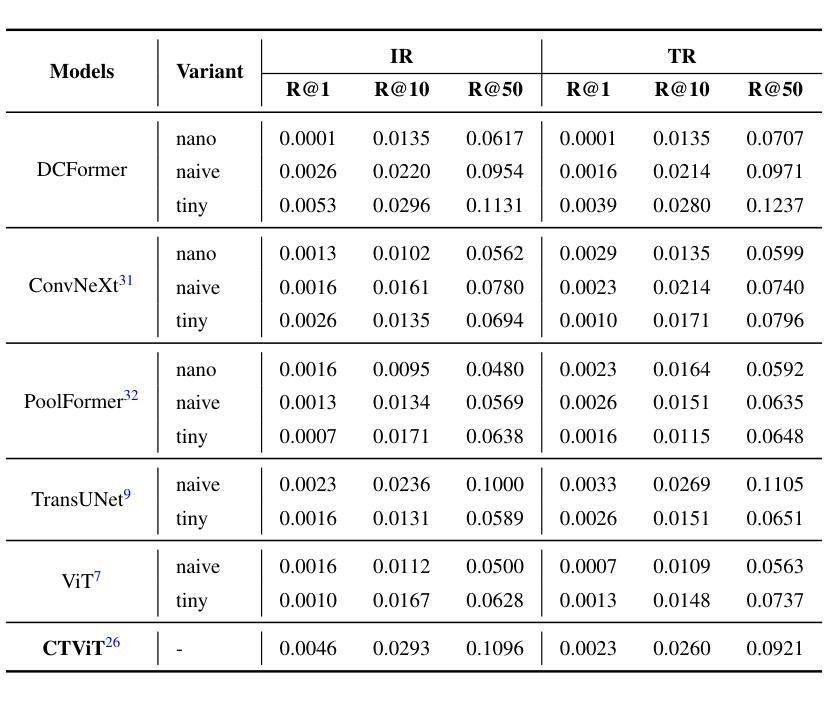
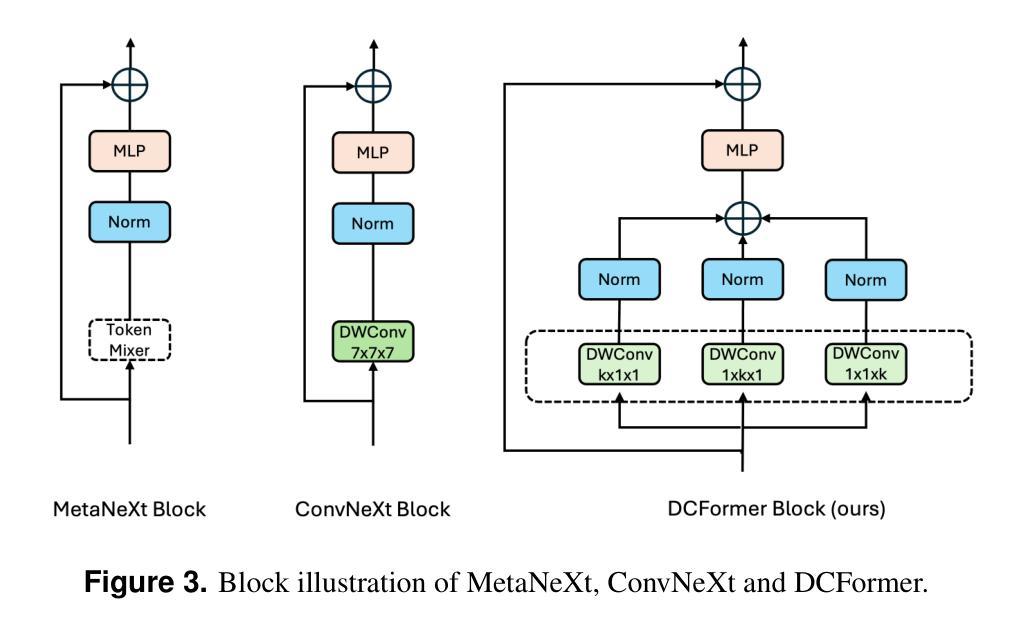
Vision-language models (VLMs) have been widely applied to 2D medical image analysis due to their ability to align visual and textual representations. However, extending VLMs to 3D imaging remains computationally challenging. Existing 3D VLMs often rely on Vision Transformers (ViTs), which are computationally expensive due to the quadratic complexity of self-attention, or on 3D convolutions, which require large numbers of parameters and FLOPs as kernel size increases. We introduce DCFormer, an efficient 3D image encoder that factorizes 3D convolutions into three parallel 1D convolutions along the depth, height, and width dimensions. This design preserves spatial information while significantly reducing computational cost. Integrated into a CLIP-based vision-language framework, DCFormer is trained and evaluated on CT-RATE, a dataset of 50,188 paired 3D chest CT volumes and radiology reports. In zero-shot and fine-tuned detection of 18 pathologies, as well as in image-text retrieval tasks, DCFormer consistently outperforms state-of-the-art 3D vision encoders, including CT-ViT, ViT, ConvNeXt, PoolFormer, and TransUNet. These results highlight DCFormer’s potential for scalable, clinically deployable 3D medical VLMs. Our code is available at: https://github.com/mirthAI/DCFormer.
视觉语言模型(VLMs)由于其能够将视觉和文本表示进行对齐的能力,已广泛应用于二维医学图像分析。然而,将VLMs扩展到三维成像在计算上仍然具有挑战性。现有的三维VLMs通常依赖于视觉Transformer(ViTs),由于自注意力的二次复杂性,其计算成本较高,或者依赖于三维卷积,随着内核大小的增加,需要大量的参数和浮点运算(FLOPs)。我们引入了DCFormer,这是一种高效的三维图像编码器,它将三维卷积分解为沿深度、高度和宽度方向的三个并行一维卷积。这种设计保留了空间信息,同时大大降低了计算成本。DCFormer被集成到一个基于CLIP的视觉语言框架中,并在CT-RATE数据集上进行训练和评估,该数据集包含50,188对配对的三维胸部CT体积和放射学报告。在零样本和微调检测18种病理情况,以及图像文本检索任务中,DCFormer持续表现出优于最新三维视觉编码器的性能,包括CT-ViT、ViT、ConvNeXt、PoolFormer和TransUNet。这些结果突出了DCFormer在可扩展和可部署的的临床三维医学VLMs中的潜力。我们的代码可在:https://github.com/mirthAI/DCFormer获取。
论文及项目相关链接
Summary
本文介绍了针对三维医学影像分析的挑战,提出了一种高效的3D图像编码器DCFormer。DCFormer通过沿深度、高度和宽度维度进行三个并行的一维卷积,实现了对三维卷积的分解,从而在保留空间信息的同时显著降低了计算成本。在CT-RATE数据集上进行的实验表明,DCFormer在零样本和微调检测18种病理情况以及图像文本检索任务中,均优于其他先进的3D视觉编码器。这突显了DCFormer在可伸缩、可临床部署的3D医疗VLMs中的潜力。
Key Takeaways
- VLMs广泛应用于二维医学图像分析,但在三维成像上仍面临计算挑战。
- 现有3D VLMs主要依赖Vision Transformers (ViTs)或3D卷积,但前者计算量大,后者参数和FLOPs需求随内核大小增加而增加。
- DCFormer是一种高效的3D图像编码器,通过分解三维卷积降低计算成本。
- DCFormer在CT-RATE数据集上的实验表现优于其他先进的3D视觉编码器。
- DCFormer在零样本和微调检测多种病理情况以及图像文本检索任务中均表现出色。
- DCFormer有潜力成为可伸缩、可临床部署的3D医疗VLMs的一部分。
点此查看论文截图

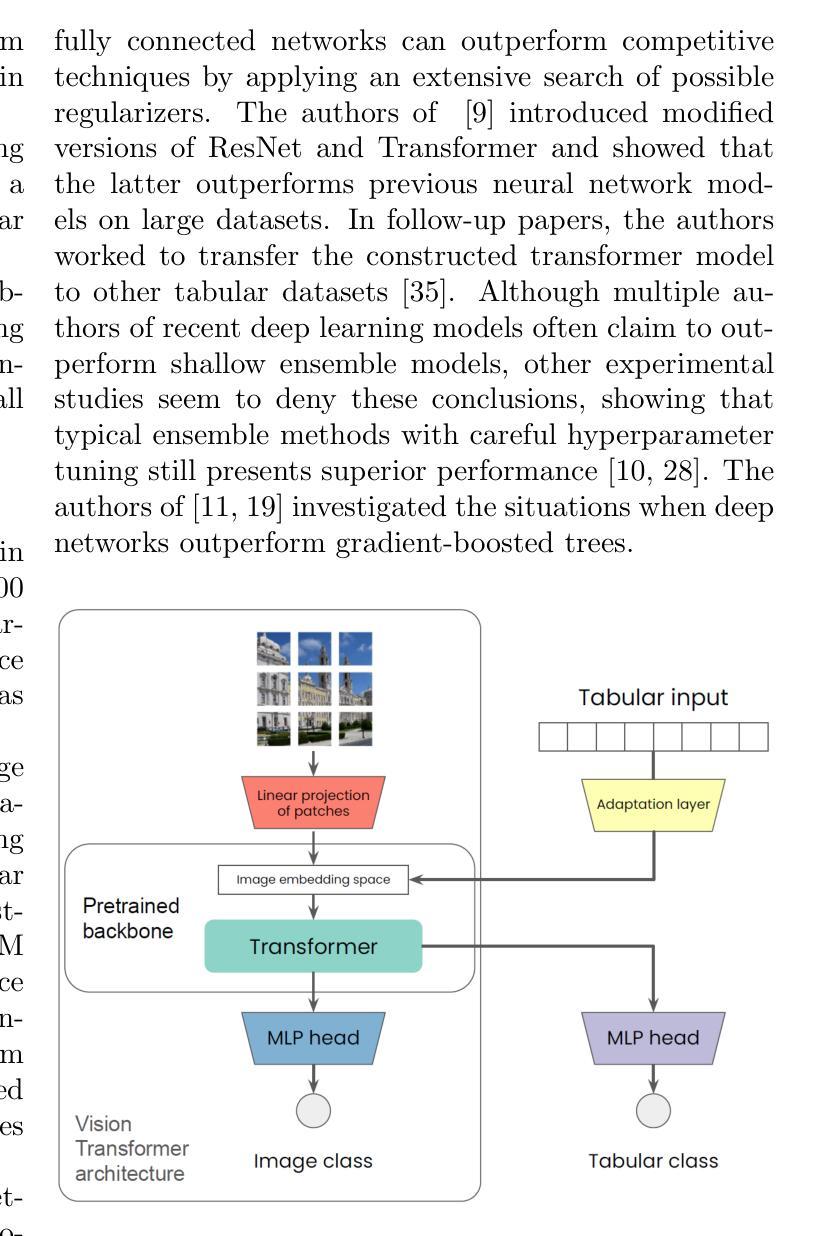
VisTabNet: Adapting Vision Transformers for Tabular Data
Authors:Witold Wydmański, Ulvi Movsum-zada, Jacek Tabor, Marek Śmieja
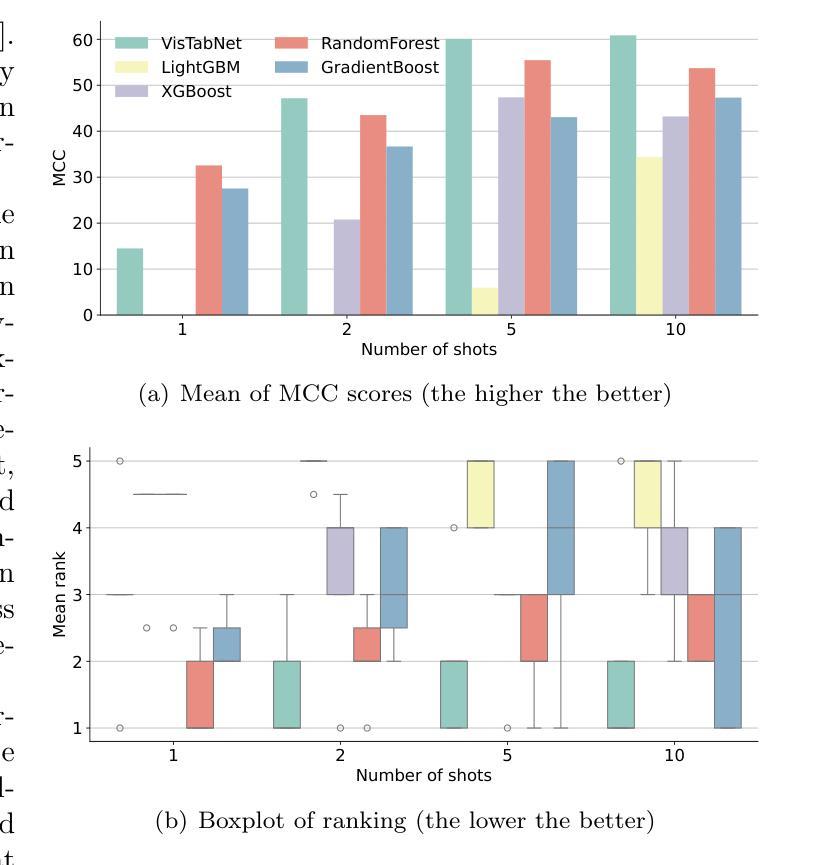
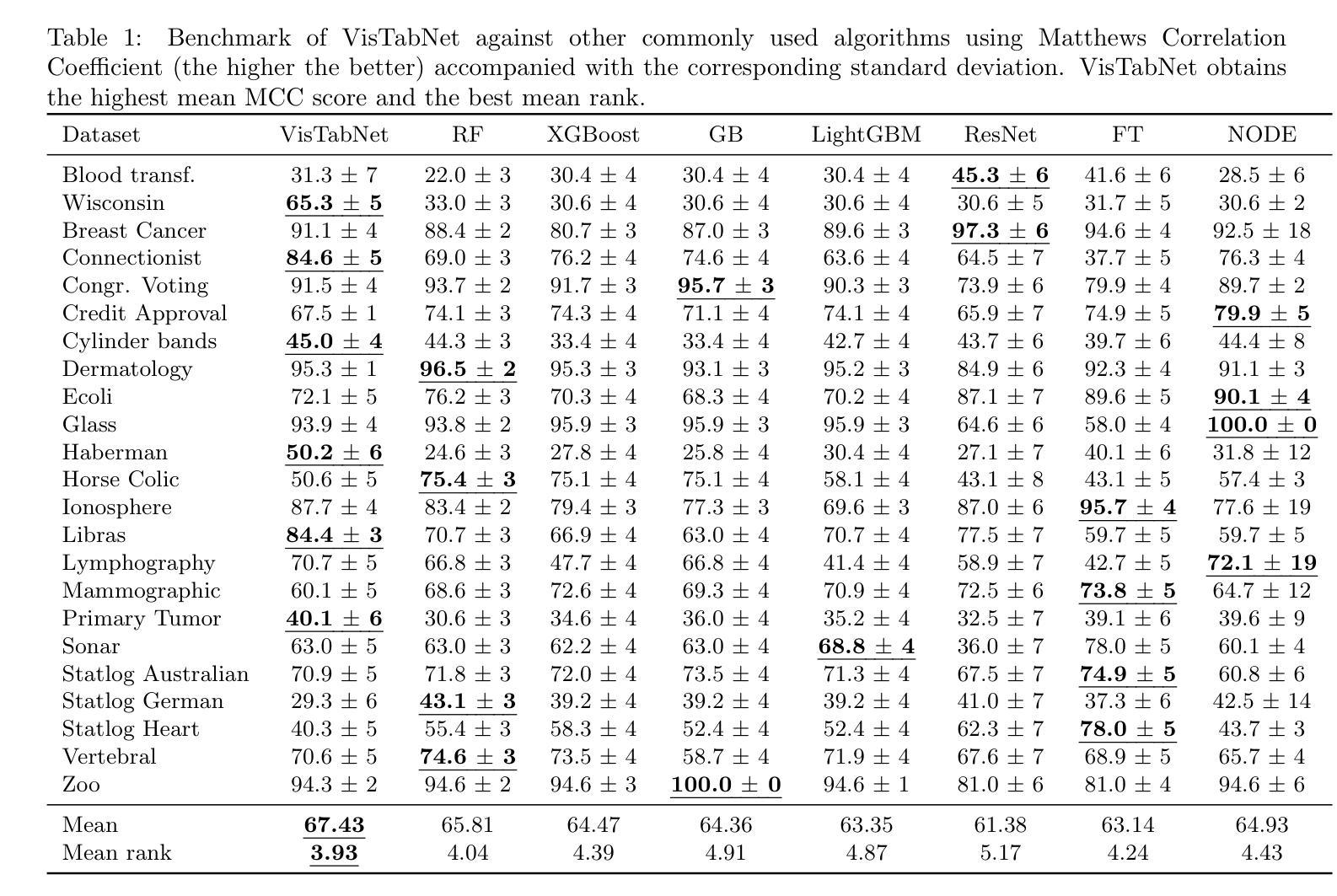
Although deep learning models have had great success in natural language processing and computer vision, we do not observe comparable improvements in the case of tabular data, which is still the most common data type used in biological, industrial and financial applications. In particular, it is challenging to transfer large-scale pre-trained models to downstream tasks defined on small tabular datasets. To address this, we propose VisTabNet – a cross-modal transfer learning method, which allows for adapting Vision Transformer (ViT) with pre-trained weights to process tabular data. By projecting tabular inputs to patch embeddings acceptable by ViT, we can directly apply a pre-trained Transformer Encoder to tabular inputs. This approach eliminates the conceptual cost of designing a suitable architecture for processing tabular data, while reducing the computational cost of training the model from scratch. Experimental results on multiple small tabular datasets (less than 1k samples) demonstrate VisTabNet’s superiority, outperforming both traditional ensemble methods and recent deep learning models. The proposed method goes beyond conventional transfer learning practice and shows that pre-trained image models can be transferred to solve tabular problems, extending the boundaries of transfer learning. We share our example implementation as a GitHub repository available at https://github.com/wwydmanski/VisTabNet.
尽管深度学习模型在自然语言处理和计算机视觉领域取得了巨大成功,但在处理表格数据时,我们并未观察到相应的改进。表格数据仍然是生物、工业和财务应用中最常用的数据类型。尤其对于将大规模预训练模型转移到在小型表格数据集上定义的下游任务来说,这是一个挑战。为解决此问题,我们提出了VisTabNet——一种跨模态迁移学习方法,它允许使用带有预训练权重的Vision Transformer(ViT)来处理表格数据。通过将表格输入投影到ViT可接受的补丁嵌入,我们可以直接将预训练的Transformer编码器应用于表格输入。这种方法消除了为处理表格数据而设计合适架构的概念成本,同时降低了从头开始训练模型的计算成本。在多个小型表格数据集(少于1k样本)上的实验结果证明了VisTabNet的优越性,它优于传统的集成方法和最近的深度学习模型。所提出的方法超越了传统的迁移学习实践,并表明预训练的图像模型可以转移到解决表格问题,扩展了迁移学习的边界。我们在GitHub上分享了我们的示例实现:https://github.com/wwydmanski/VisTabNet。
论文及项目相关链接
Summary
数据表处理中深度学习模型的应用仍然面临挑战,特别是与图像处理和自然语言处理中的成功案例相比。为此,提出了一种名为VisTabNet的跨模态迁移学习方法,通过利用预训练的Vision Transformer(ViT)模型处理表格数据,以提高处理效率并降低计算成本。通过可视化转换将表格数据转化为适用于ViT模型的patch embeddings形式,并利用已有的Transformer编码器进行预测,提高了对小表格数据集的适应性和处理效果。该方法的性能已经在多个小数据集上得到验证,显示出了相较于传统集成方法和最新的深度学习模型的优越性。通过实现示例在GitHub上公开分享。
Key Takeaways
- 深度学习在处理表格数据时面临挑战,特别是在与NLP和计算机视觉领域的成功案例相比。
- VisTabNet是一种跨模态迁移学习方法,旨在解决表格数据处理的难题。
- VisTabNet通过将表格数据转化为适用于Vision Transformer(ViT)模型的patch embeddings来实现预训练模型的利用。
- 利用预训练的ViT模型可以降低计算成本并加快处理速度。
- VisTabNet通过将表格数据转换为图像数据实现了模型的跨模态迁移学习应用。
- 在多个小数据集上的实验证明了VisTabNet相较于传统集成方法和最新深度学习模型的优越性。
点此查看论文截图