⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-30 更新
Real-time High-fidelity Gaussian Human Avatars with Position-based Interpolation of Spatially Distributed MLPs
Authors:Youyi Zhan, Tianjia Shao, Yin Yang, Kun Zhou
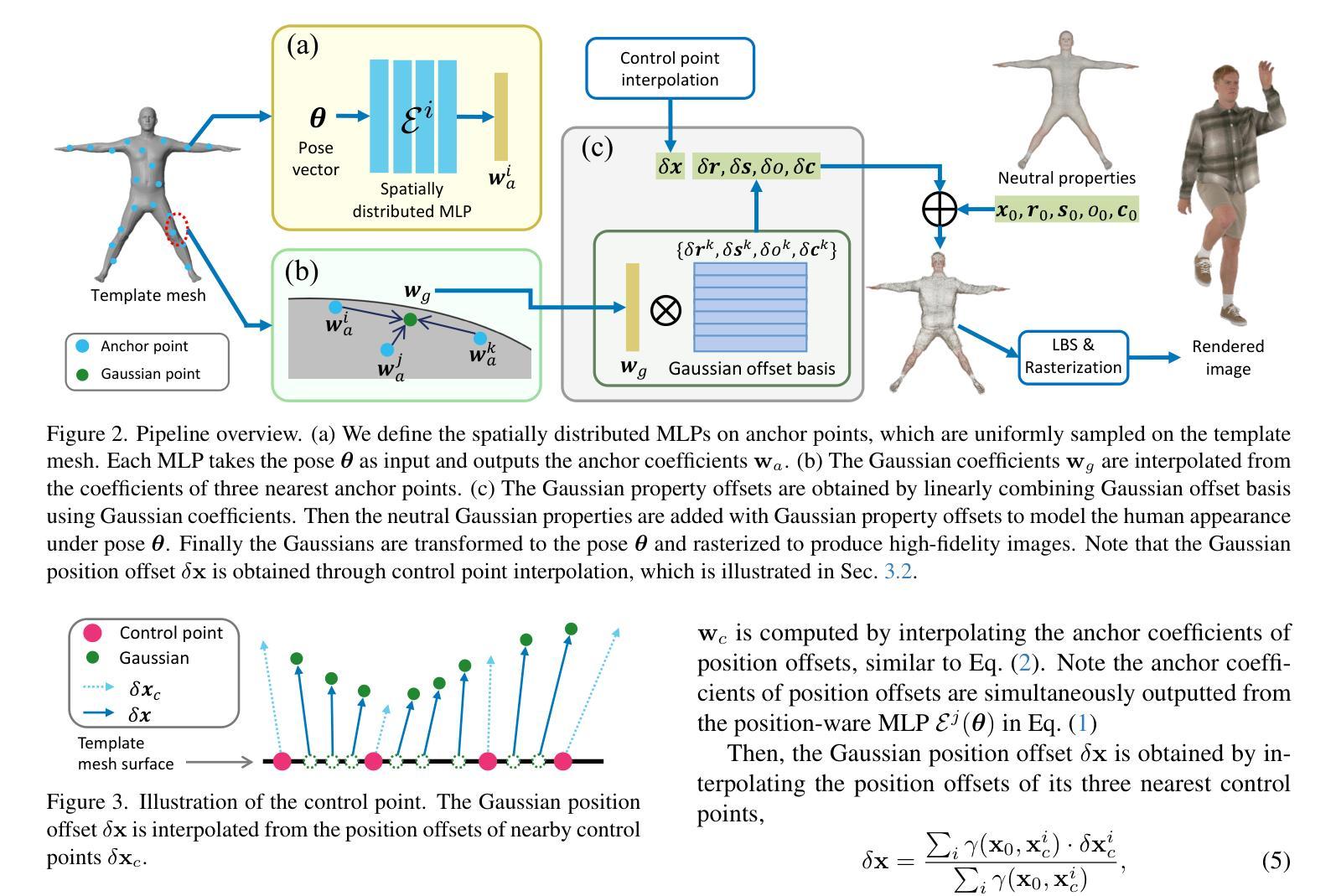
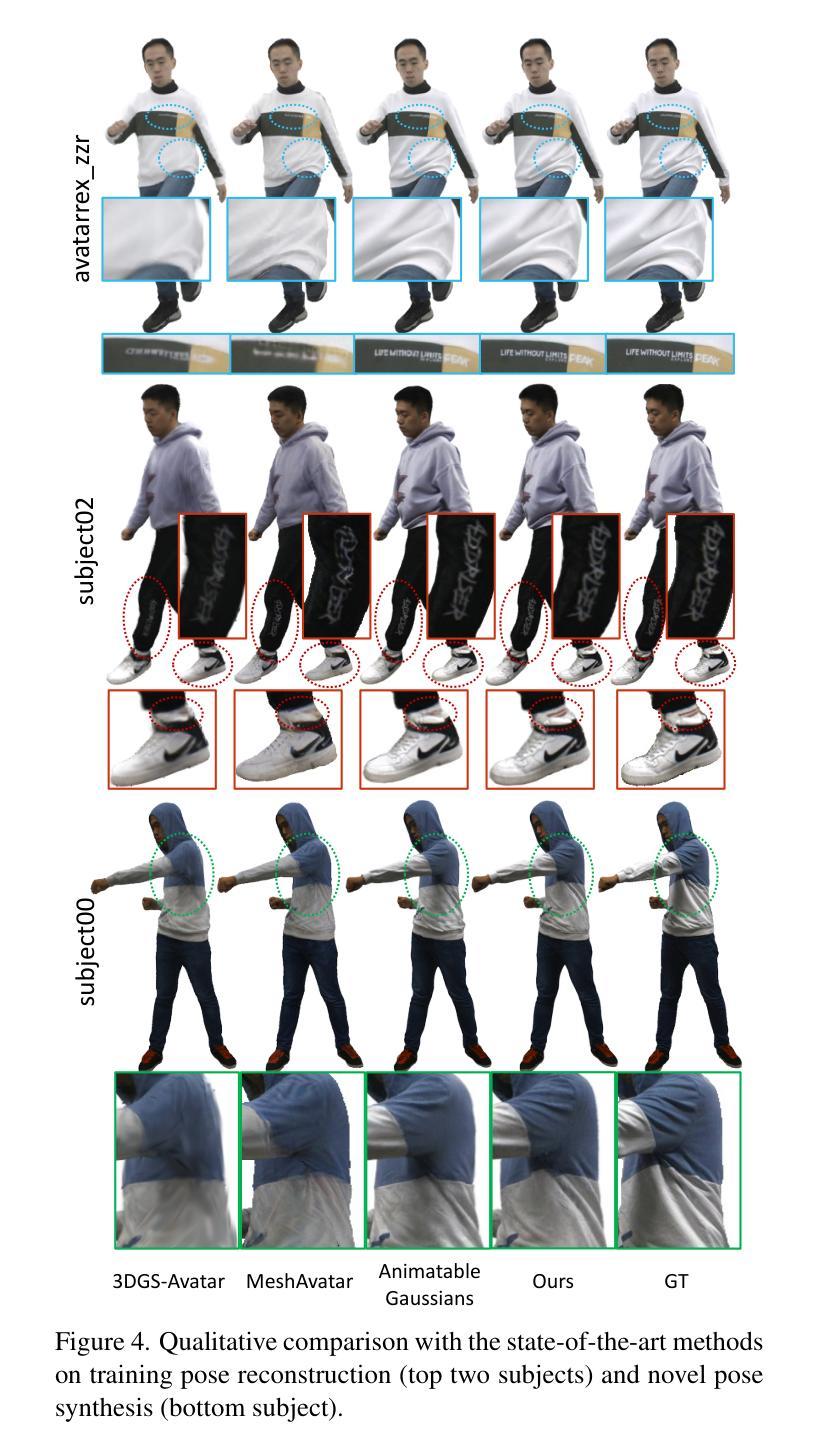
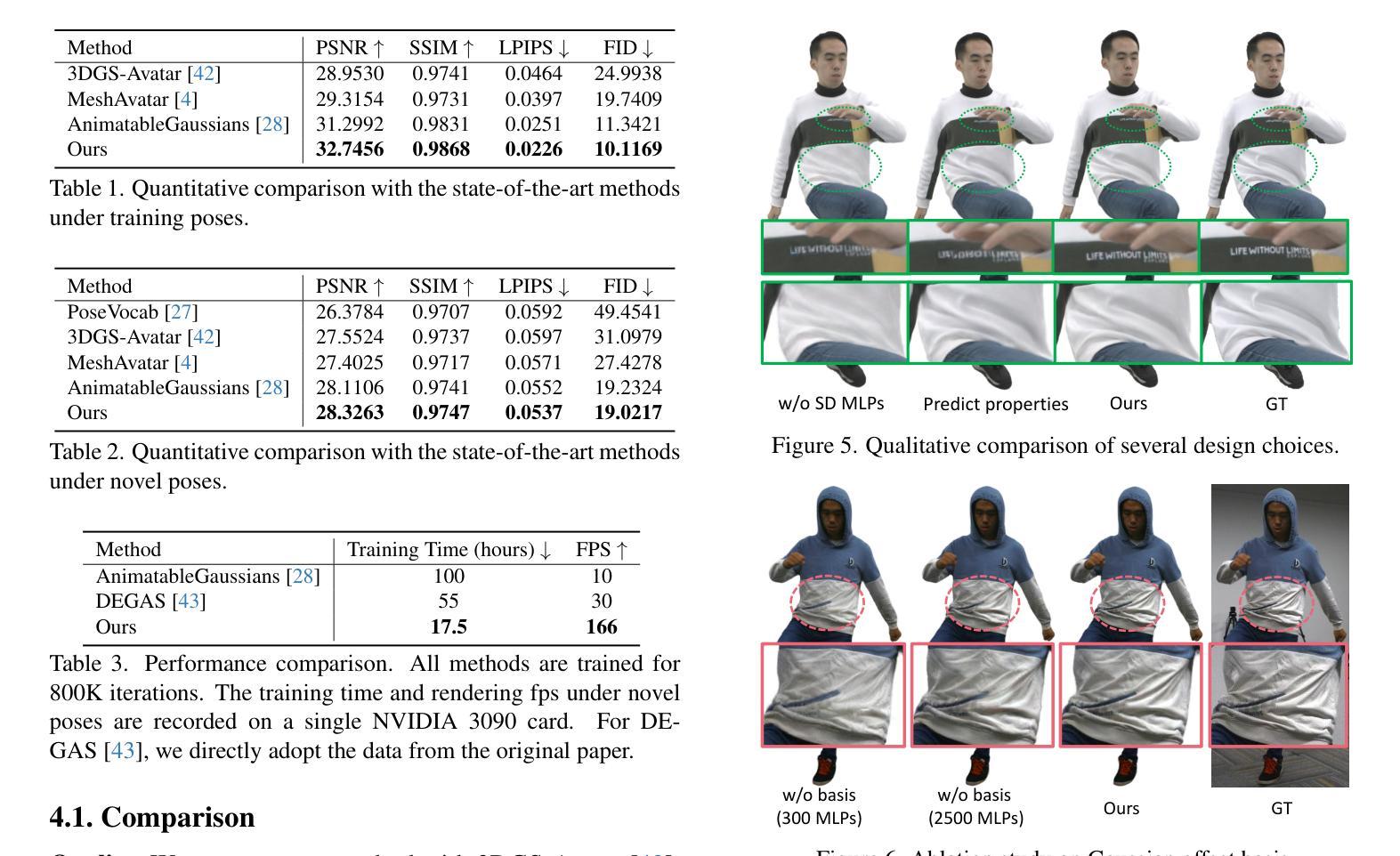
Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing the ability to learn high-frequency spatial signals. We further use control points to constrain the Gaussians distributed on a surface layer rather than allowing them to be irregularly distributed inside the body, to help the human avatar generalize better when animated under novel poses. Compared to the state-of-the-art method, our method achieves better appearance quality with finer details while the rendering speed is significantly faster under novel views and novel poses.
许多作品已成功使用多角度视频重建高斯人体化身。然而,它们要么使用单个多层感知器(MLP)难以捕捉姿势相关的外观细节,要么依赖计算密集型的神经网络来重建高保真外观,但渲染性能降低至非实时。我们提出了一种新型的高斯人体化身表示方法,可以重建高保真姿势依赖的外观细节,同时可实时渲染。我们的高斯化身由分布在人身体上的不同位置的明确MLP赋能。每个高斯中的参数是通过根据其附近MLP的输出和距离进行插值获得的。为了避免插值过程中产生不希望有的平滑高斯属性变化,对于每个高斯,我们定义了一组高斯偏移基,基的线性组合表示相对于中性属性的高斯属性偏移。然后,我们提出让MLP输出对应于基的一组系数。通过这种方式,虽然高斯系数是通过插值得出的并平滑变化,但高斯偏移基可以自由学习而没有约束。平滑变化的系数与自由学习的基相结合,仍然可以产生明显不同的高斯属性偏移,从而能够学习高频空间信号。我们进一步使用控制点对分布在表面层上的高斯进行约束,而不是允许它们在体内不规则分布,以帮助人体化身在新型姿势下的动画表现时更好地泛化。与最先进的方法相比,我们的方法在呈现更好的外观质量和更精细的细节的同时,在新的视角和姿势下显著提高了渲染速度。
论文及项目相关链接
PDF CVPR 2025. Project page https://gapszju.github.io/mmlphuman/ . Code https://github.com/1231234zhan/mmlphuman
Summary
本文提出一种新型的高斯人类角色表示方法,能够在重建高质量、姿态依赖的外观细节的同时实现实时渲染。该方法通过空间分布的MLP实现,明确位于人体不同位置。高斯参数通过邻近MLP的输出插值获得,并定义了高斯偏移基础来避免插值过程中的平滑高斯属性变化。该方法还使用控制点来约束高斯在表面层上的分布,使人类角色在新型姿态下的动画表现更具通用性。相较于现有方法,本文方法在外观质量、细节表现及渲染速度上均有显著提升。
Key Takeaways
- 提出一种新型高斯人类角色表示方法,能重建高质量、姿态依赖的外观细节。
- 通过空间分布的MLP实现,明确位于人体不同位置,实现实时渲染。
- 高斯参数通过邻近MLP的输出插值获得,避免插值过程中的平滑高斯属性变化。
- 定义了高斯偏移基础,线性组合基础表示高斯属性偏移,使MLPs能够学习高频率空间信号。
- 使用控制点约束高斯在表面层上的分布,提高角色在新型姿态下的动画表现通用性。
- 与现有方法相比,本文方法在外观质量、细节表现上更优,同时渲染速度更快。
点此查看论文截图

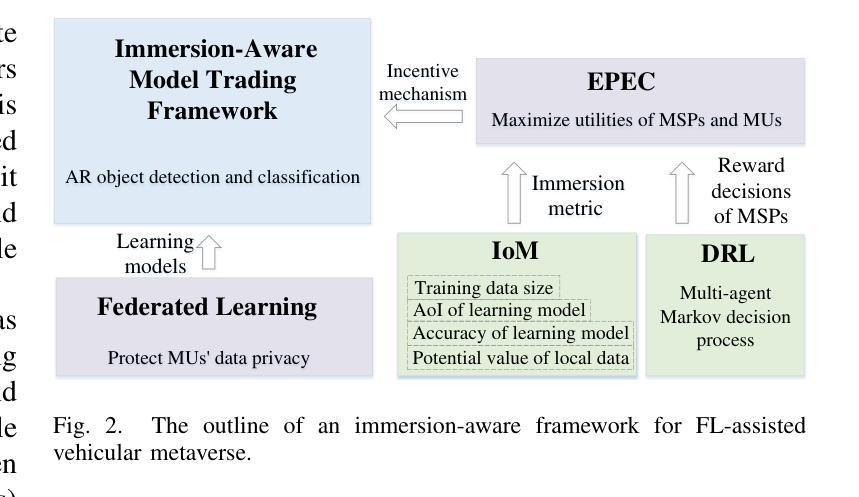
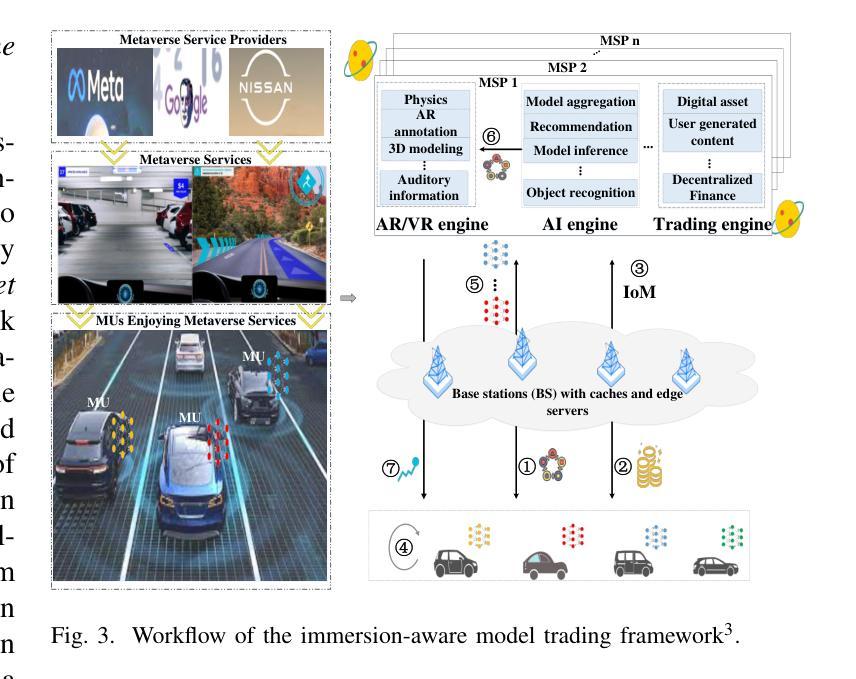
MetaTrading: An Immersion-Aware Model Trading Framework for Vehicular Metaverse Services
Authors:Hongjia Wu, Hui Zeng, Zehui Xiong, Jiawen Kang, Zhiping Cai, Tse-Tin Chan, Dusit Niyato, Zhu Han
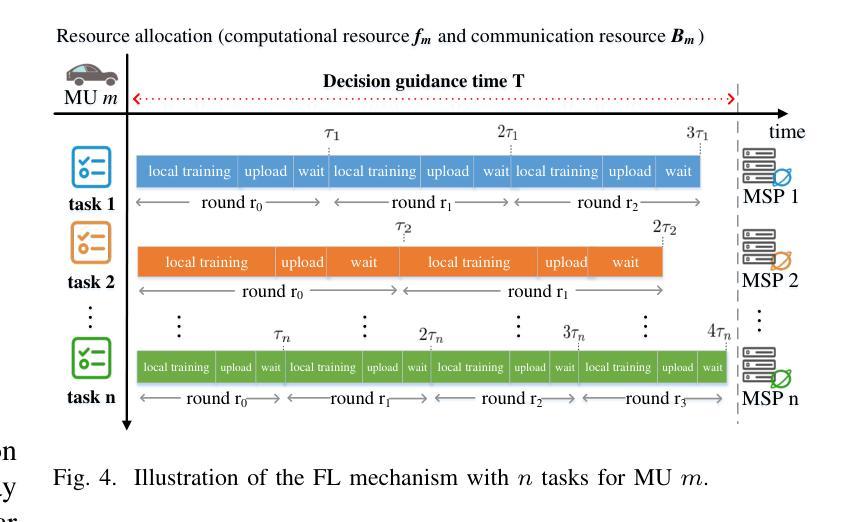
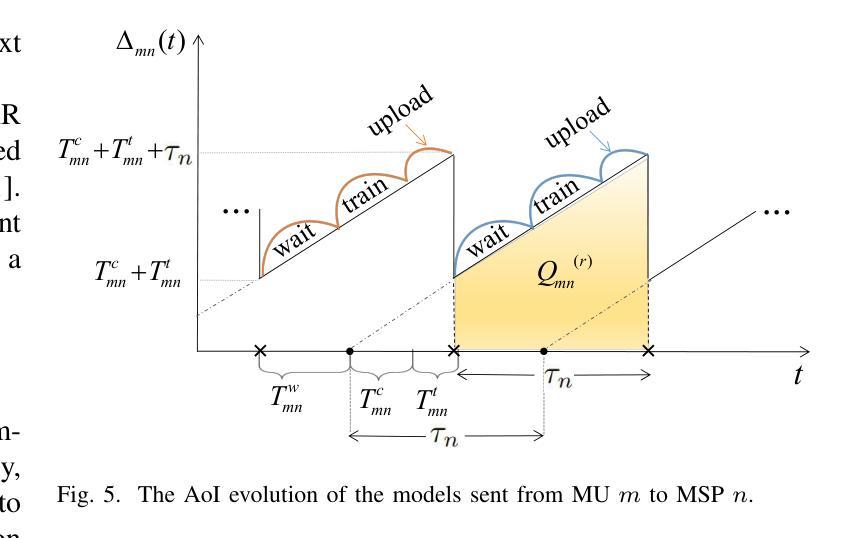
Timely updating of Internet of Things (IoT) data is crucial for immersive vehicular metaverse services. However, challenges such as latency caused by massive data transmissions, privacy risks associated with user data, and computational burdens on metaverse service providers (MSPs) hinder continuous collection of high-quality data. To address these issues, we propose an immersion-aware model trading framework that facilitates data provision for services while ensuring privacy through federated learning (FL). Specifically, we first develop a novel multi-dimensional metric, the immersion of model (IoM), which assesses model value comprehensively by considering freshness and accuracy of learning models, as well as the amount and potential value of raw data used for training. Then, we design an incentive mechanism to incentivize metaverse users (MUs) to contribute high-value models under resource constraints. The trading interactions between MSPs and MUs are modeled as an equilibrium problem with equilibrium constraints (EPEC) to analyze and balance their costs and gains, where MSPs as leaders determine rewards, while MUs as followers optimize resource allocation. Furthermore, considering dynamic network conditions and privacy concerns, we formulate the reward decisions of MSPs as a multi-agent Markov decision process. To solve this, we develop a fully distributed dynamic reward algorithm based on deep reinforcement learning, without accessing any private information about MUs and other MSPs. Experimental results demonstrate that the proposed framework outperforms state-of-the-art benchmarks, achieving improvements in IoM of 38.3% and 37.2%, and reductions in training time to reach the target accuracy of 43.5% and 49.8%, on average, for the MNIST and GTSRB datasets, respectively.
物联网(IoT)数据的及时更新对于沉浸式车辆元宇宙服务至关重要。然而,由于大量数据传输造成的延迟、与用户数据相关的隐私风险以及元宇宙服务提供商(MSP)的计算负担等挑战,阻碍了高质量数据的持续收集。为了解决这些问题,我们提出了一个沉浸感知模型交易框架,该框架通过联邦学习(FL)促进数据服务提供,同时确保隐私。具体来说,我们首先开发了一种新型的多维度量标准——模型沉浸度(IoM),它综合考虑了学习模型的新鲜度和准确性,以及用于训练的原数据量和潜在价值。接着,我们设计了一种激励机制,以激励元宇宙用户(MU)在资源约束下提供高价值的模型。MSP和MU之间的交易互动被建模为带有均衡约束的均衡问题(EPEC),以分析和平衡其成本和收益,其中MSP作为领导者确定奖励,而MU作为追随者优化资源配置。此外,考虑到动态网络条件和隐私问题,我们将MSP的奖励决策制定为多重代理马尔可夫决策过程。为解决这一问题,我们基于深度强化学习开发了一种完全分布式的动态奖励算法,无需访问任何关于MU和其他MSP的私有信息。实验结果表明,该框架优于现有基准测试,在MNIST和GTSRB数据集上,IoM提高了38.3%和37.2%,达到目标准确度的训练时间平均减少了43.5%和49.8%。
论文及项目相关链接
Summary
在物联网数据实时更新的背景下,针对车载元宇宙服务面临的挑战,如大规模数据传输导致的延迟、用户数据隐私风险和元宇宙服务提供商的计算负担,提出了一种沉浸感知模型交易框架。该框架通过联邦学习确保隐私,同时激励元宇宙用户贡献高价值模型。通过设计一种新型多维指标——模型沉浸度(IoM),综合考虑了学习模型的新鲜度和准确性,以及用于训练的原始数据量和潜在价值。此外,采用基于深度强化学习的分布式动态奖励算法来解决多智能体决策问题。实验结果表明,该框架相较于现有技术基准有明显优势,在MNIST和GTSRB数据集上,模型沉浸度提升38.3%和37.2%,达到目标准确度的训练时间平均减少43.5%和49.8%。
Key Takeaways
- 物联网数据实时更新对车载元宇宙服务至关重要。
- 面临大规模数据传输延迟、用户数据隐私风险和计算负担等挑战。
- 提出沉浸感知模型交易框架,通过联邦学习确保隐私并激励用户贡献高价值模型。
- 引入新型多维指标——模型沉浸度(IoM),综合考虑模型的新鲜度、准确性及训练数据价值。
- 采用基于深度强化学习的分布式动态奖励算法解决多智能体决策问题。
- 实验结果显示,该框架在模型沉浸度和训练效率方面优于现有技术。
- 该框架在MNIST和GTSRB数据集上取得了显著的性能提升。
点此查看论文截图