⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-30 更新
Mesh-Learner: Texturing Mesh with Spherical Harmonics
Authors:Yunfei Wan, Jianheng Liu, Jiarong Lin, Fu Zhang
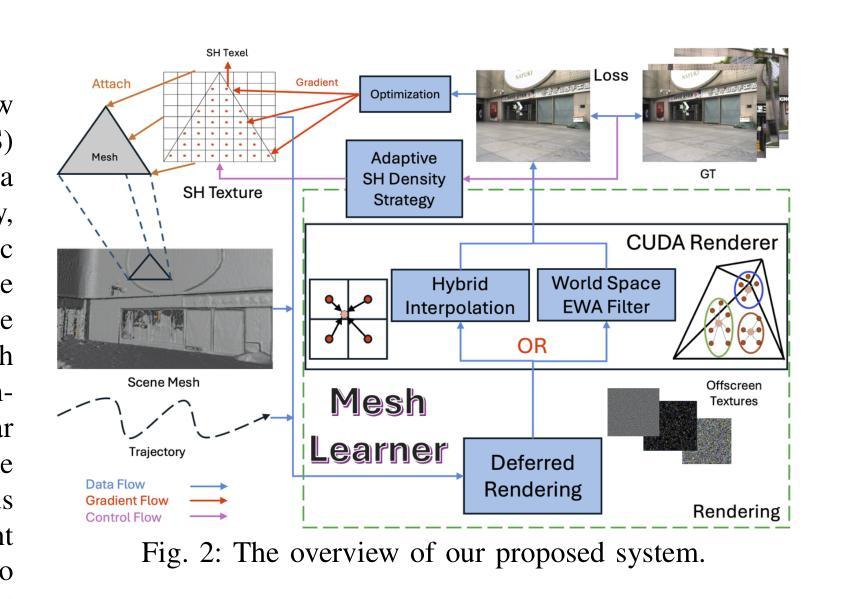
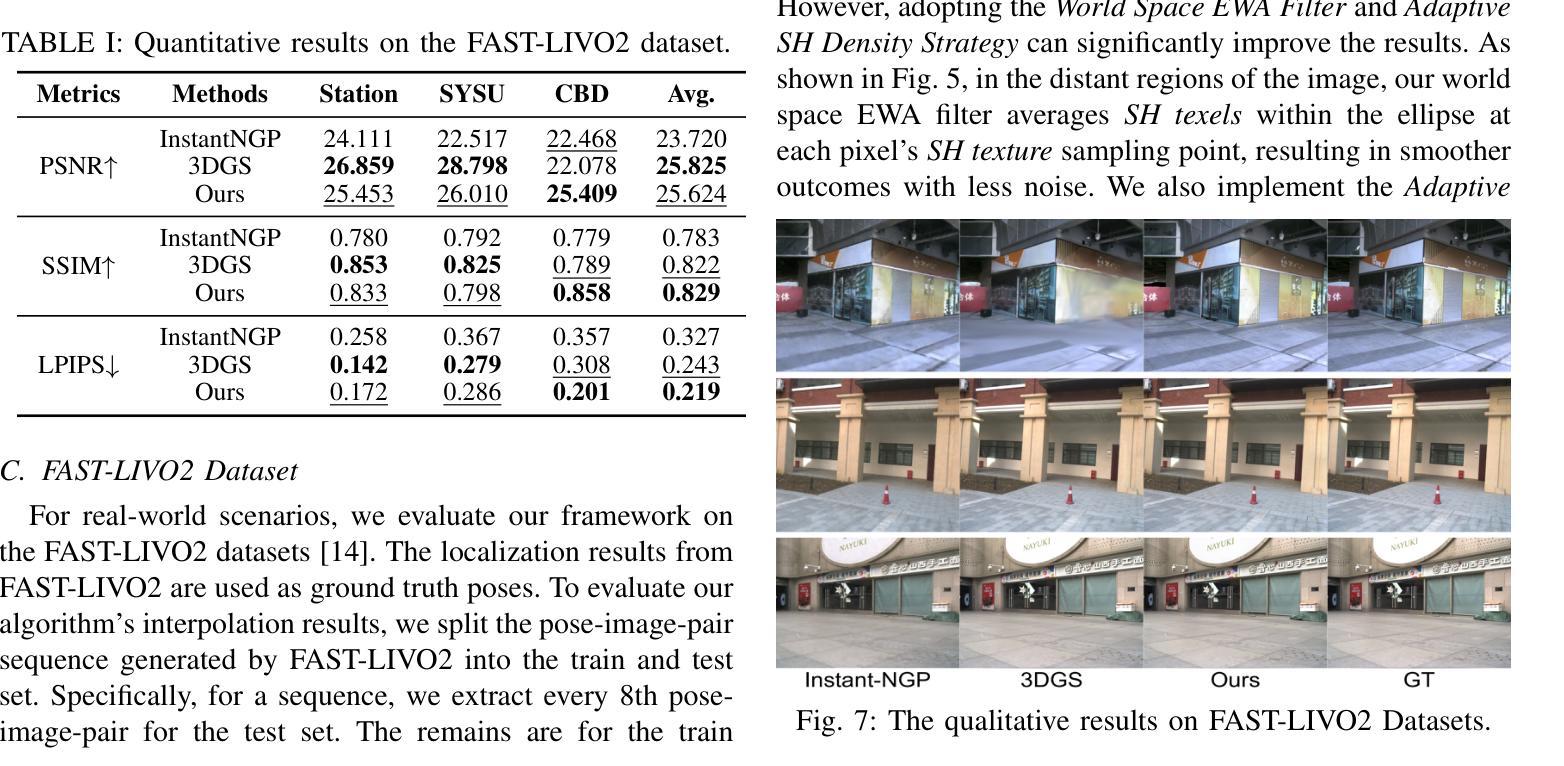
In this paper, we present a 3D reconstruction and rendering framework termed Mesh-Learner that is natively compatible with traditional rasterization pipelines. It integrates mesh and spherical harmonic (SH) texture (i.e., texture filled with SH coefficients) into the learning process to learn each mesh s view-dependent radiance end-to-end. Images are rendered by interpolating surrounding SH Texels at each pixel s sampling point using a novel interpolation method. Conversely, gradients from each pixel are back-propagated to the related SH Texels in SH textures. Mesh-Learner exploits graphic features of rasterization pipeline (texture sampling, deferred rendering) to render, which makes Mesh-Learner naturally compatible with tools (e.g., Blender) and tasks (e.g., 3D reconstruction, scene rendering, reinforcement learning for robotics) that are based on rasterization pipelines. Our system can train vast, unlimited scenes because we transfer only the SH textures within the frustum to the GPU for training. At other times, the SH textures are stored in CPU RAM, which results in moderate GPU memory usage. The rendering results on interpolation and extrapolation sequences in the Replica and FAST-LIVO2 datasets achieve state-of-the-art performance compared to existing state-of-the-art methods (e.g., 3D Gaussian Splatting and M2-Mapping). To benefit the society, the code will be available at https://github.com/hku-mars/Mesh-Learner.
本文介绍了一个名为Mesh-Learner的3D重建和渲染框架,它与传统光栅化管道原生兼容。它通过整合网格和球面谐波(SH)纹理(即填充有SH系数的纹理)到学习过程中,以端到端的方式学习每个网格的视角相关辐射率。图像是通过一种新型插值方法,在每个像素的采样点插值周围的SH纹理元素来呈现的。相反,每个像素的梯度会反向传播到相关的SH纹理中的SH纹理元素。Mesh-Learner利用了光栅化管道(纹理采样、延迟渲染)的图形特征来进行渲染,这使得Mesh-Learner自然地与基于光栅化管道的工具(例如Blender)和任务(例如3D重建、场景渲染、机器人强化学习)兼容。我们的系统可以训练大量无限的场景,因为我们将仅将视锥内的SH纹理传输到GPU进行训练。其他时候,SH纹理存储在CPU RAM中,这导致GPU内存使用适中。在Replica和FAST-LIVO2数据集上的插值和外推序列的渲染结果达到了与现有最先进的方法(例如3D高斯溅射和M2-Mapping)相比的最佳性能。为了造福社会,代码将在https://github.com/hku-mars/Mesh-Learner上提供。
论文及项目相关链接
Summary
本文介绍了一种名为Mesh-Learner的3D重建和渲染框架,它与传统光栅化管道兼容。该框架结合了网格和球面谐波纹理,通过一种新型插值方法对周围SH Texels进行插值渲染图像,同时反向传播像素的梯度至相关的SH Texels。Mesh-Learner利用光栅化管道(纹理采样、延迟渲染)的图形特性进行渲染,使其自然地兼容基于光栅化管道的工具和任务。该系统的GPU内存使用适中,因为仅在视锥内传输SH纹理以进行训练,可训练大规模、无限的场景。在Replica和FAST-LIVO2数据集上的插值和外推序列的渲染结果达到了与现有先进方法相比的最佳性能。
Key Takeaways
- Mesh-Learner框架结合了网格和球面谐波(SH)纹理,支持与传统光栅化管道集成。
- 通过新型插值方法渲染图像,插值周围SH Texels。
- 反向传播像素的梯度至SH纹理中的相关Texels。
- 利用光栅化管道的图形特性进行渲染,与基于该管道的工具和任务自然兼容。
- GPU内存使用适中,可训练大规模、无限的场景。
- 在特定数据集上的渲染结果达到最佳性能。
点此查看论文截图





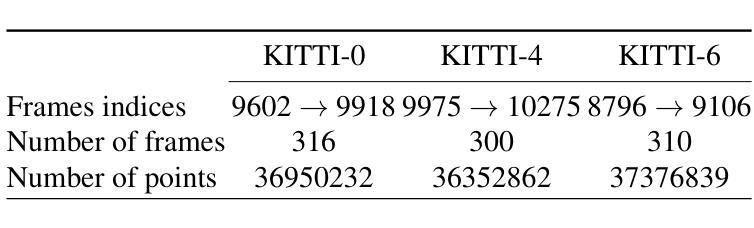
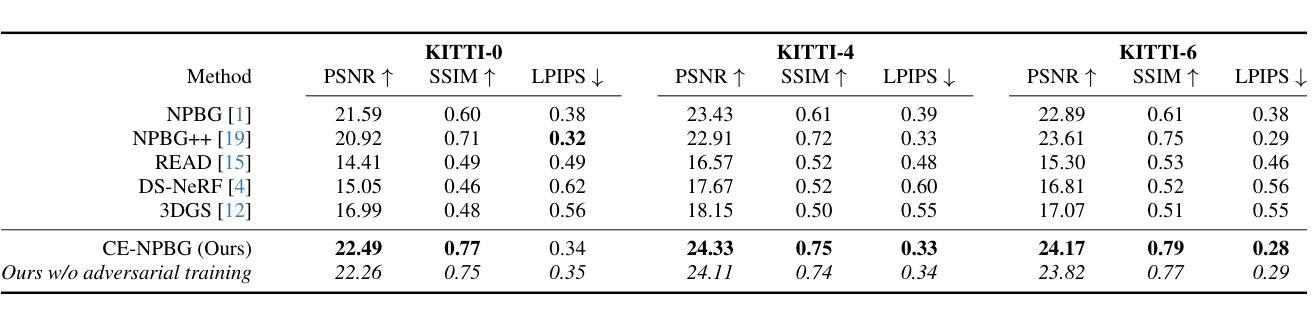
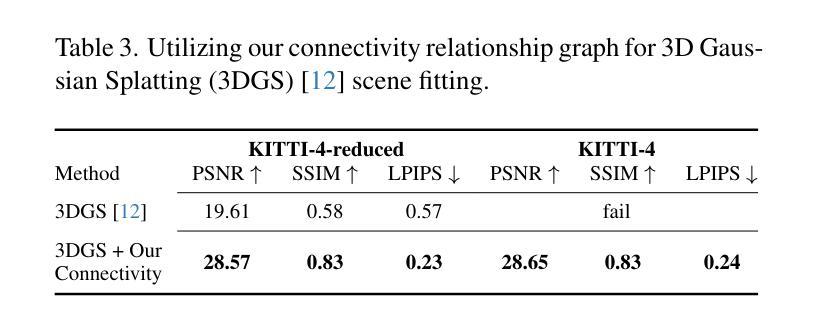
CE-NPBG: Connectivity Enhanced Neural Point-Based Graphics for Novel View Synthesis in Autonomous Driving Scenes
Authors:Mohammad Altillawi, Fengyi Shen, Liudi Yang, Sai Manoj Prakhya, Ziyuan Liu
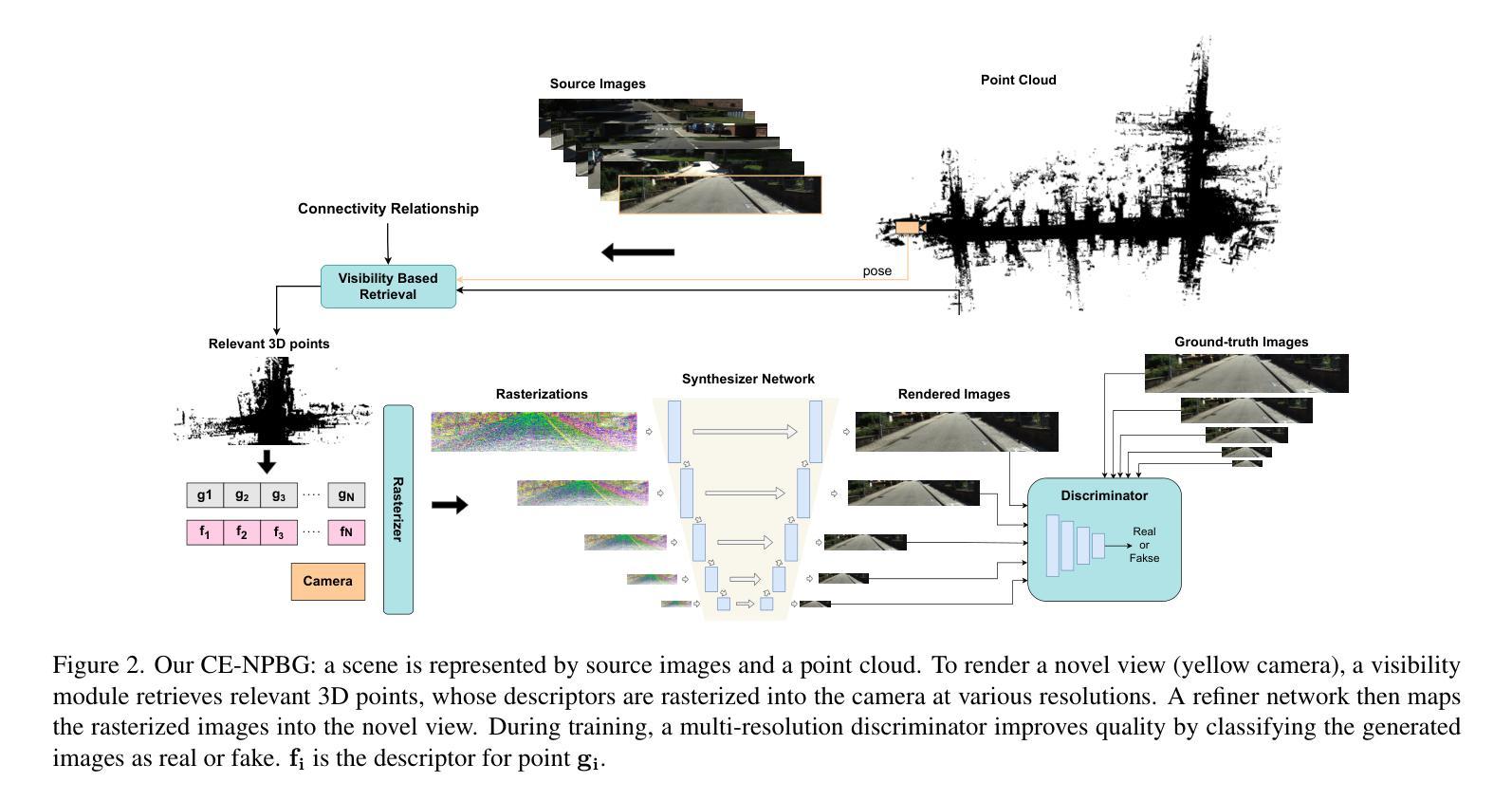
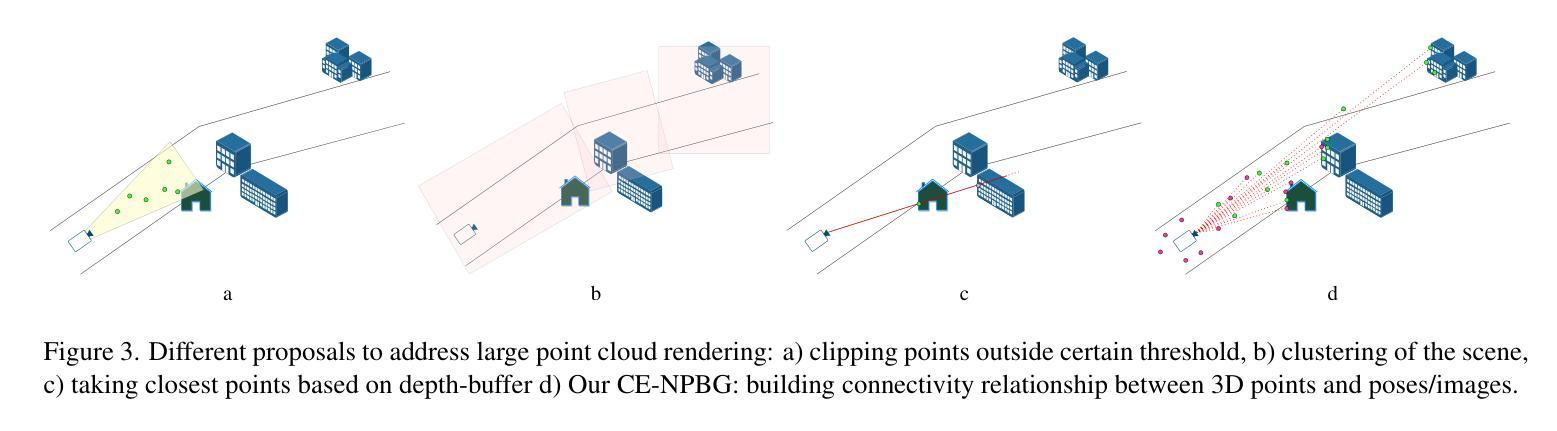
Current point-based approaches encounter limitations in scalability and rendering quality when using large 3D point cloud maps because using them directly for novel view synthesis (NVS) leads to degraded visualizations. We identify the primary issue behind these low-quality renderings as a visibility mismatch between geometry and appearance, stemming from using these two modalities together. To address this problem, we present CE-NPBG, a new approach for novel view synthesis (NVS) in large-scale autonomous driving scenes. Our method is a neural point-based technique that leverages two modalities: posed images (cameras) and synchronized raw 3D point clouds (LiDAR). We first employ a connectivity relationship graph between appearance and geometry, which retrieves points from a large 3D point cloud map observed from the current camera perspective and uses them for rendering. By leveraging this connectivity, our method significantly improves rendering quality and enhances run-time and scalability by using only a small subset of points from the large 3D point cloud map. Our approach associates neural descriptors with the points and uses them to synthesize views. To enhance the encoding of these descriptors and elevate rendering quality, we propose a joint adversarial and point rasterization training. During training, we pair an image-synthesizer network with a multi-resolution discriminator. At inference, we decouple them and use the image-synthesizer to generate novel views. We also integrate our proposal into the recent 3D Gaussian Splatting work to highlight its benefits for improved rendering and scalability.
当前基于点的方法在利用大规模3D点云地图进行新型视图合成(NVS)时,会遇到可扩展性和渲染质量方面的局限,直接使用它们会导致可视化效果下降。我们确定了这些低质量渲染背后的主要问题,即几何和外观之间的可见度不匹配,源于这两种模式的组合使用。为了解决这一问题,我们提出了CE-NPBG,这是一种用于大规模自动驾驶场景的新型视图合成(NVS)的方法。我们的方法是一种基于神经点的技术,利用两种模式:姿态图像(相机)和同步原始3D点云(激光雷达)。我们首先采用外观和几何之间的关联关系图,从当前相机视角观察的大规模3D点云地图中检索点,并将其用于渲染。通过利用这种关联性,我们的方法仅使用大规模3D点云地图中的一小部分点,就能显著提高渲染质量,并增强运行时间和可扩展性。我们的方法将神经描述符与点相关联,并使用它们来合成视图。为了提高这些描述符的编码和提升渲染质量,我们提出了一种联合对抗性和点栅格化训练。在训练过程中,我们将图像合成器网络与多分辨率鉴别器配对。在推理过程中,我们将它们解耦,并使用图像合成器生成新型视图。我们还将我们的提案整合到最近的3D高斯拼贴工作中,以突出其在改进渲染和可扩展性方面的优势。
论文及项目相关链接
PDF Accepted in 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Summary
本文提出一种名为CE-NPBG的新方法,用于解决大规模自动驾驶场景中基于点的新视角合成(NVS)的渲染质量和效率问题。该方法结合了图像(相机)和同步原始三维点云(激光雷达)两种模式,通过建立几何与外观之间的连接关系图,从大规模三维点云地图中检索当前相机视角的点进行渲染。通过利用这种连接关系,该方法仅使用大规模三维点云地图的小部分点,显著提高了渲染质量和运行效率。该研究还引入了神经描述符与点的关联,用于合成视图,并提出联合对抗和点栅格化训练,以提高描述符的编码和渲染质量。
Key Takeaways
- 当前点基方法在大规模三维点云地图的直接应用中存在渲染质量和效率的问题。
- 问题核心在于几何和外观之间的可见性不匹配。
- CE-NPBG是一种新视角合成(NVS)方法,结合了图像(相机)和同步原始三维点云(激光雷达)两种模式。
- 通过建立连接关系图,从大规模三维点云地图中检索当前相机视角的点进行渲染,提高了渲染质量和效率。
- 方法结合了神经描述符与点的关联,用于合成视图。
- 研究引入了联合对抗和点栅格化训练,以提高描述符的编码和渲染质量。
点此查看论文截图

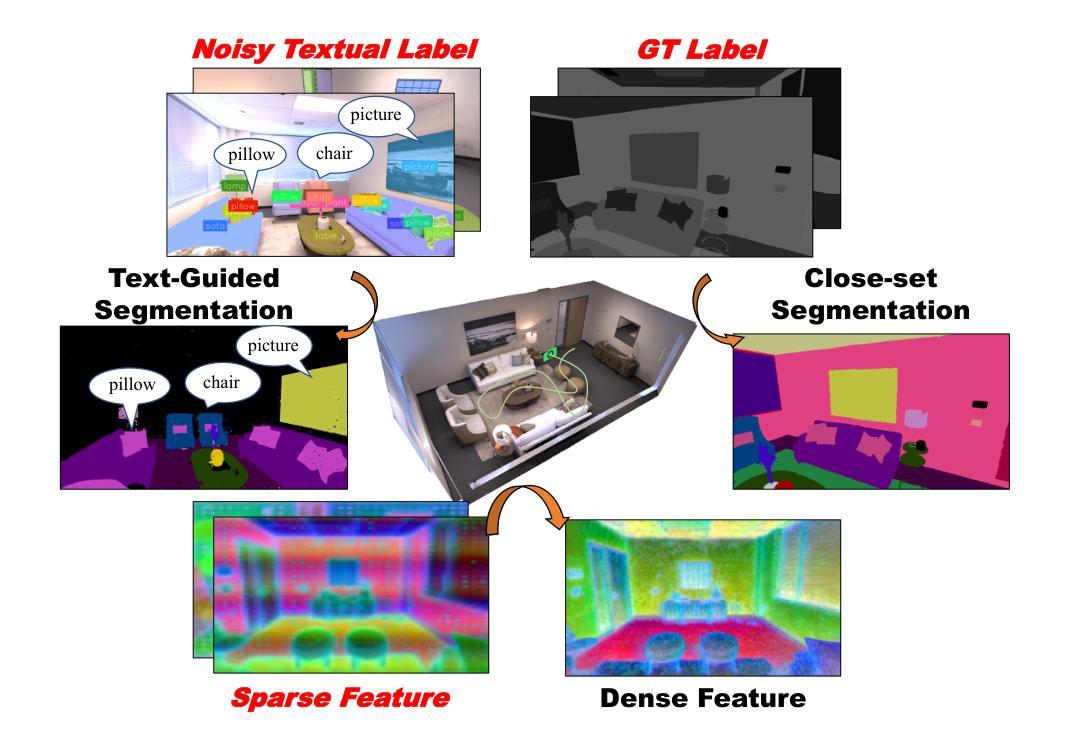
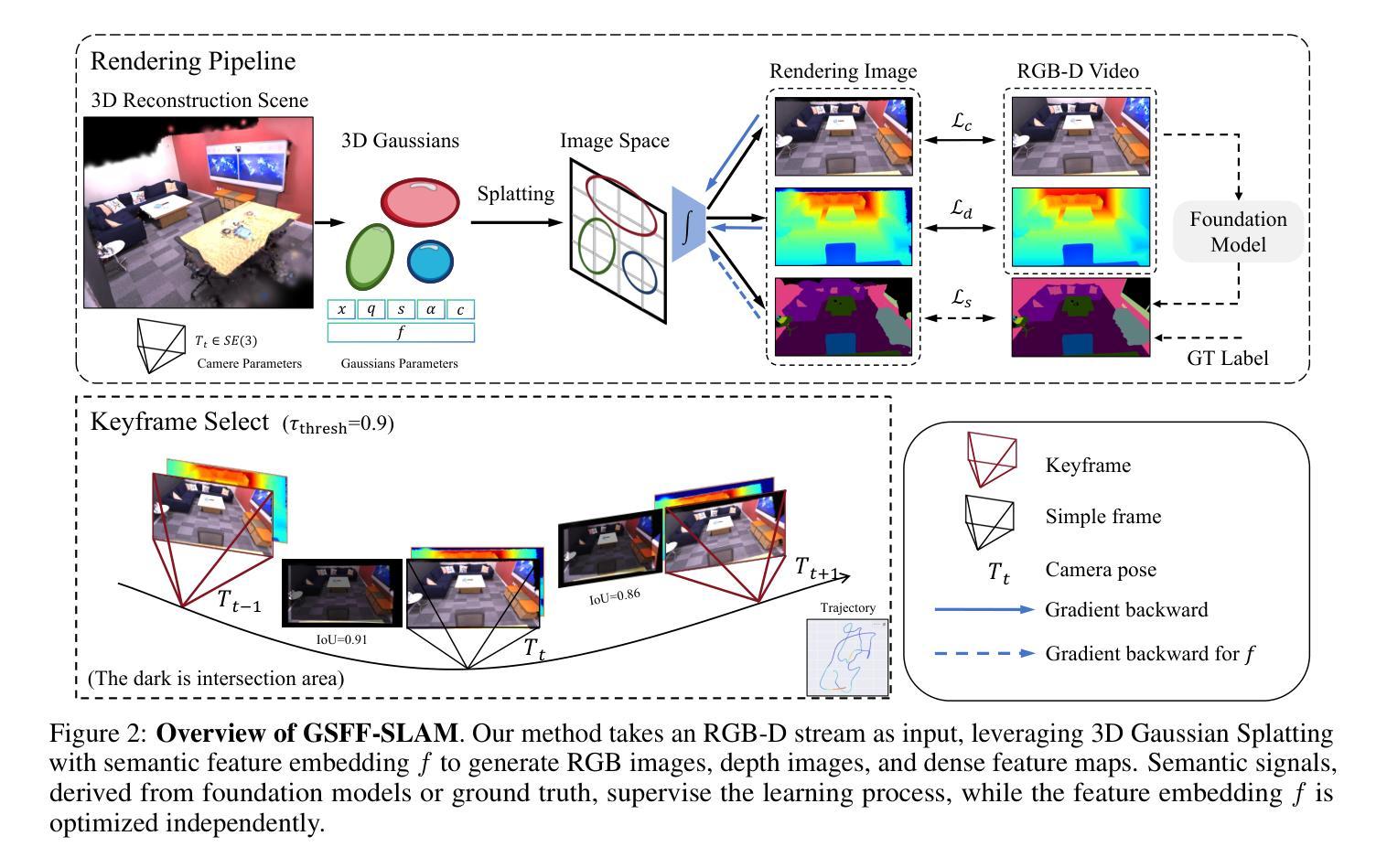
GSFF-SLAM: 3D Semantic Gaussian Splatting SLAM via Feature Field
Authors:Zuxing Lu, Xin Yuan, Shaowen Yang, Jingyu Liu, Jiawei Wang, Changyin Sun
Semantic-aware 3D scene reconstruction is essential for autonomous robots to perform complex interactions. Semantic SLAM, an online approach, integrates pose tracking, geometric reconstruction, and semantic mapping into a unified framework, shows significant potential. However, existing systems, which rely on 2D ground truth priors for supervision, are often limited by the sparsity and noise of these signals in real-world environments. To address this challenge, we propose GSFF-SLAM, a novel dense semantic SLAM system based on 3D Gaussian Splatting that leverages feature fields to achieve joint rendering of appearance, geometry, and N-dimensional semantic features. By independently optimizing feature gradients, our method supports semantic reconstruction using various forms of 2D priors, particularly sparse and noisy signals. Experimental results demonstrate that our approach outperforms previous methods in both tracking accuracy and photorealistic rendering quality. When utilizing 2D ground truth priors, GSFF-SLAM achieves state-of-the-art semantic segmentation performance with 95.03% mIoU, while achieving up to 2.9$\times$ speedup with only marginal performance degradation.
语义感知的3D场景重建对于自主机器人执行复杂交互至关重要。语义SLAM作为一种在线方法,将姿态跟踪、几何重建和语义映射整合到一个统一框架中,显示出巨大的潜力。然而,现有系统通常依赖于2D真实先验进行监督,这在真实世界环境中受到这些信号稀疏性和噪声的限制。为了应对这一挑战,我们提出了GSFF-SLAM,这是一种新型的基于3D高斯填充技术的密集语义SLAM系统。它利用特征场实现外观、几何和N维语义特征的联合渲染。通过独立优化特征梯度,我们的方法支持使用各种形式的2D先验进行语义重建,尤其是稀疏和噪声信号。实验结果表明,我们的方法在跟踪精度和照片级渲染质量方面都优于以前的方法。当利用2D真实先验时,GSFF-SLAM达到了最先进的语义分割性能,mIoU为95.03%,同时实现了高达2.9倍的加速,性能仅略有下降。
论文及项目相关链接
Summary
本文探讨了自主机器人在进行复杂交互时,语义感知的3D场景重建的重要性。提出了一种新型的密集语义SLAM系统GSFF-SLAM,该系统基于3D高斯斑点技术,利用特征场实现外观、几何和N维语义特征的联合渲染。该方法可独立优化特征梯度,支持使用各种形式的2D先验进行语义重建,特别是在稀疏和噪声信号环境下表现优异。实验结果显示,该方法在跟踪精度和照片级渲染质量上均优于先前方法,利用2D地面真实先验时,实现95.03%的mIoU语义分割性能,同时实现2.9倍的速度提升,且性能损失较小。
Key Takeaways
- 语义感知的3D场景重建对自主机器人进行复杂交互至关重要。
- 现有的语义SLAM系统通常依赖于2D地面真实先验进行监督,这在真实世界环境中受到信号稀疏和噪声的限制。
- GSFF-SLAM是一种新型的密集语义SLAM系统,基于3D高斯斑点技术。
- GSFF-SLAM利用特征场实现外观、几何和N维语义特征的联合渲染。
- 该方法可独立优化特征梯度,支持使用各种形式的2D先验进行语义重建。
- 实验结果显示GSFF-SLAM在跟踪精度和渲染质量上优于其他方法。
点此查看论文截图

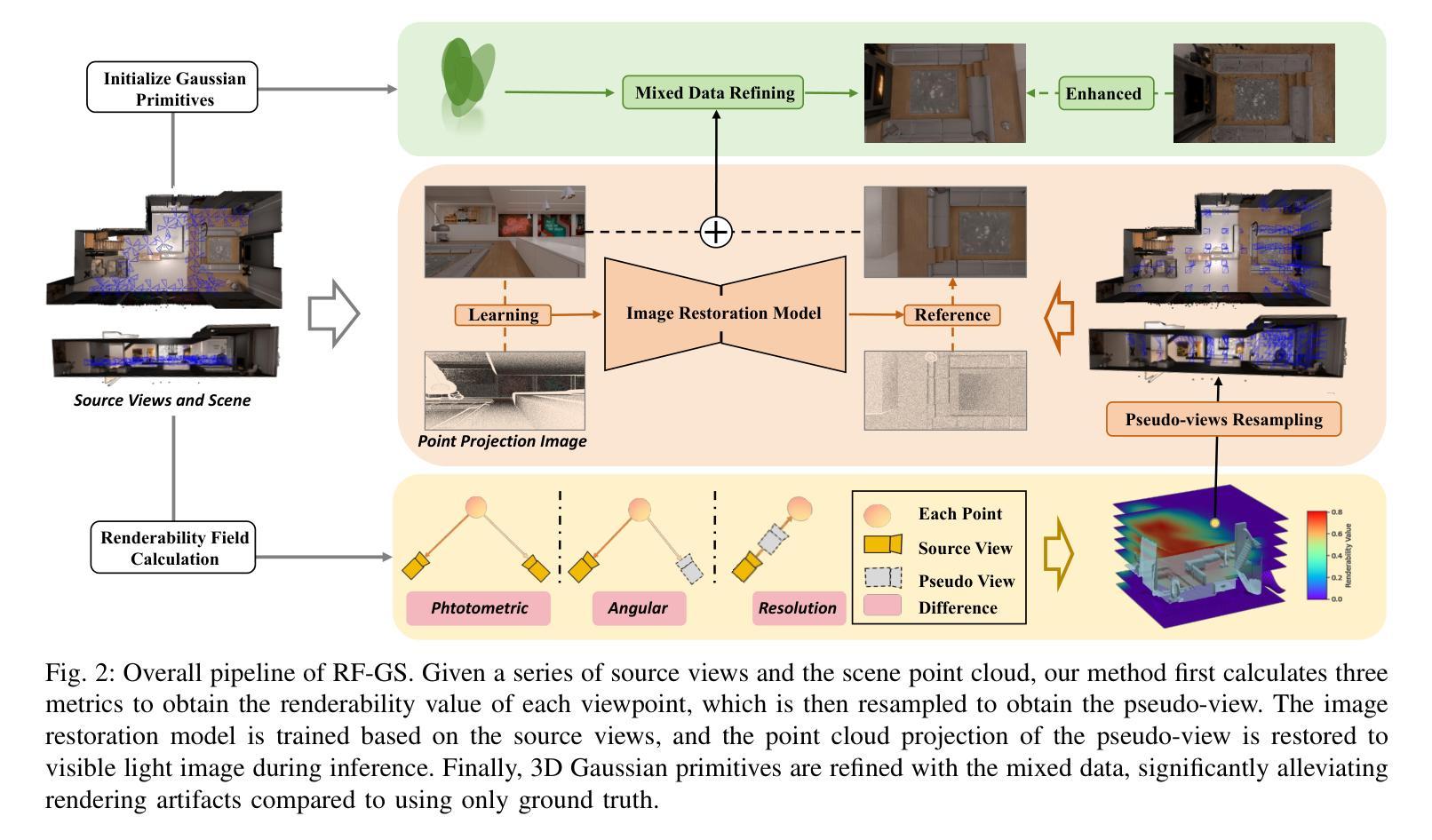
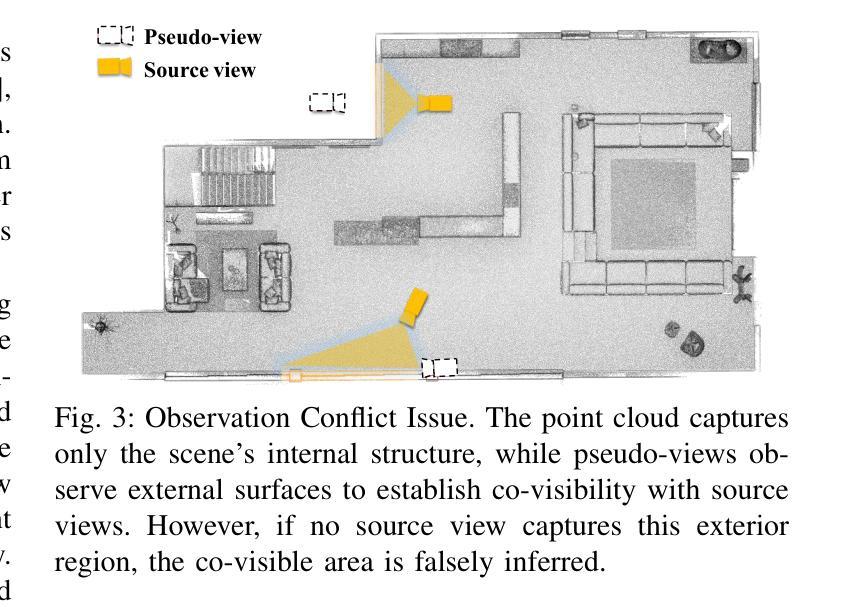
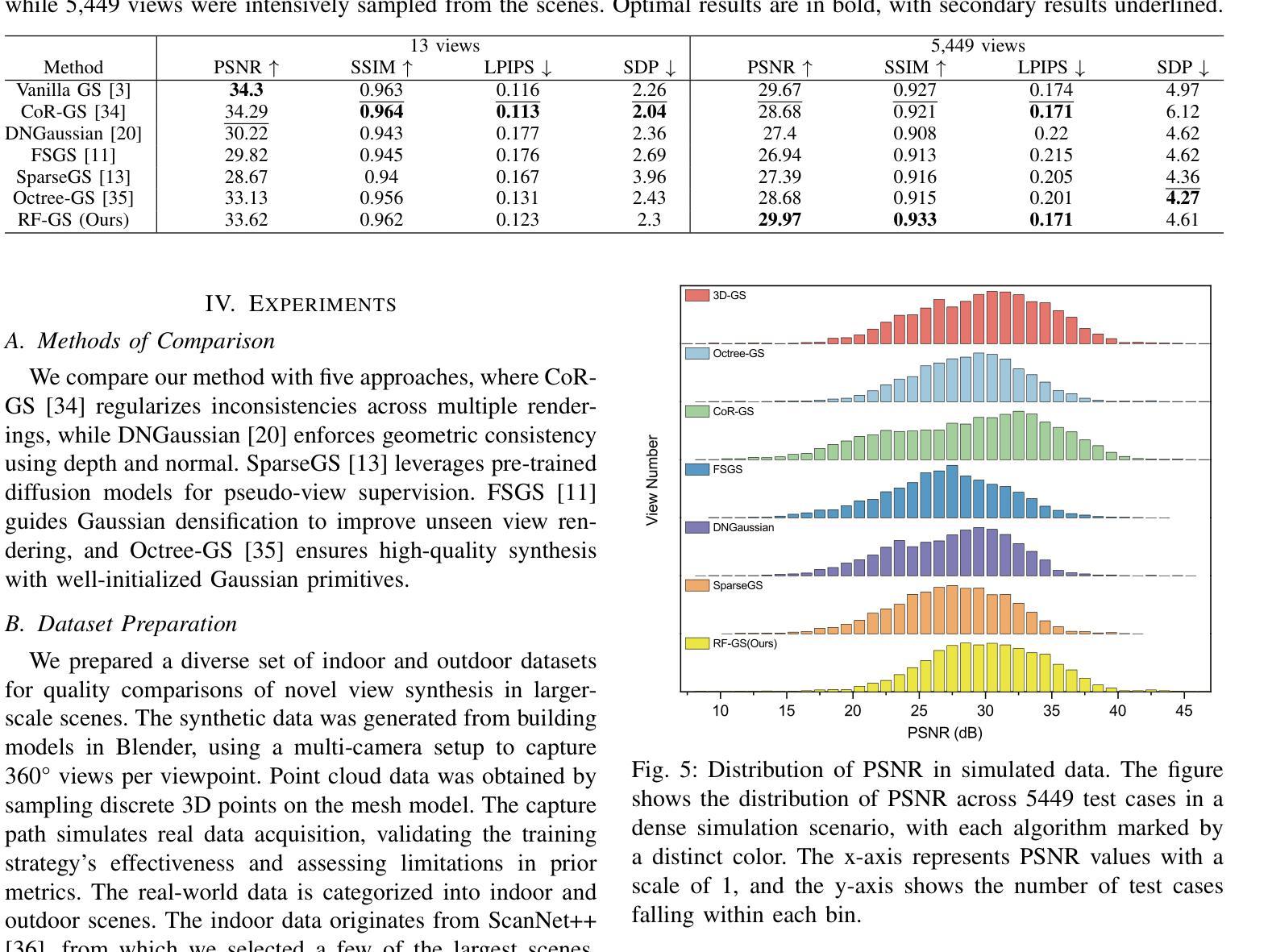
Rendering Anywhere You See: Renderability Field-guided Gaussian Splatting
Authors:Xiaofeng Jin, Yan Fang, Matteo Frosi, Jianfei Ge, Jiangjian Xiao, Matteo Matteucci
Scene view synthesis, which generates novel views from limited perspectives, is increasingly vital for applications like virtual reality, augmented reality, and robotics. Unlike object-based tasks, such as generating 360{\deg} views of a car, scene view synthesis handles entire environments where non-uniform observations pose unique challenges for stable rendering quality. To address this issue, we propose a novel approach: renderability field-guided gaussian splatting (RF-GS). This method quantifies input inhomogeneity through a renderability field, guiding pseudo-view sampling to enhanced visual consistency. To ensure the quality of wide-baseline pseudo-views, we train an image restoration model to map point projections to visible-light styles. Additionally, our validated hybrid data optimization strategy effectively fuses information of pseudo-view angles and source view textures. Comparative experiments on simulated and real-world data show that our method outperforms existing approaches in rendering stability.
场景视图合成(Scene view synthesis)是从有限视角生成新颖视角的技术,在虚拟现实、增强现实和机器人等领域的应用越来越重要。与基于物体的任务(如生成汽车360度视图)不同,场景视图合成处理的是整个环境,其中非均匀观察给稳定渲染质量带来了独特挑战。为了解决这个问题,我们提出了一种新方法:可渲染性场引导的高斯涂斑法(RF-GS)。该方法通过可渲染性场量化输入的不均匀性,引导伪视图采样以提高视觉一致性。为了确保宽基线伪视图的质量,我们训练了一个图像恢复模型,将点投影映射到可见光风格。此外,我们经过验证的混合数据优化策略有效地融合了伪视角和源视图纹理的信息。在模拟和真实世界数据上的对比实验表明,我们的方法在渲染稳定性方面优于现有方法。
论文及项目相关链接
PDF 8 pages,8 figures
Summary
本文提出了基于渲染场引导的高斯贴图方法(RF-GS),用于解决场景视角合成中遇到的环境非均匀性问题,提升了视觉效果的一致性。采用混合数据优化策略,结合伪视角角度和源视角纹理信息,提高渲染稳定性。实验证明该方法在模拟和真实数据上均优于现有方法。
Key Takeaways
- 文章提出了场景视角合成中的非均匀性问题,即处理整个环境时面临的挑战。
- 提出了一种新的方法:基于渲染场引导的高斯贴图(RF-GS),以改善视觉效果的一致性。
- 通过量化输入的不均匀性,生成一个渲染场来指导伪视角采样。
- 采用图像恢复模型,将点投影映射到可见光风格,确保宽基线伪视角的质量。
- 采用验证过的混合数据优化策略,融合伪视角角度和源视角纹理信息。
- 实验结果表明,该方法在模拟和真实数据上的渲染稳定性优于现有方法。
点此查看论文截图




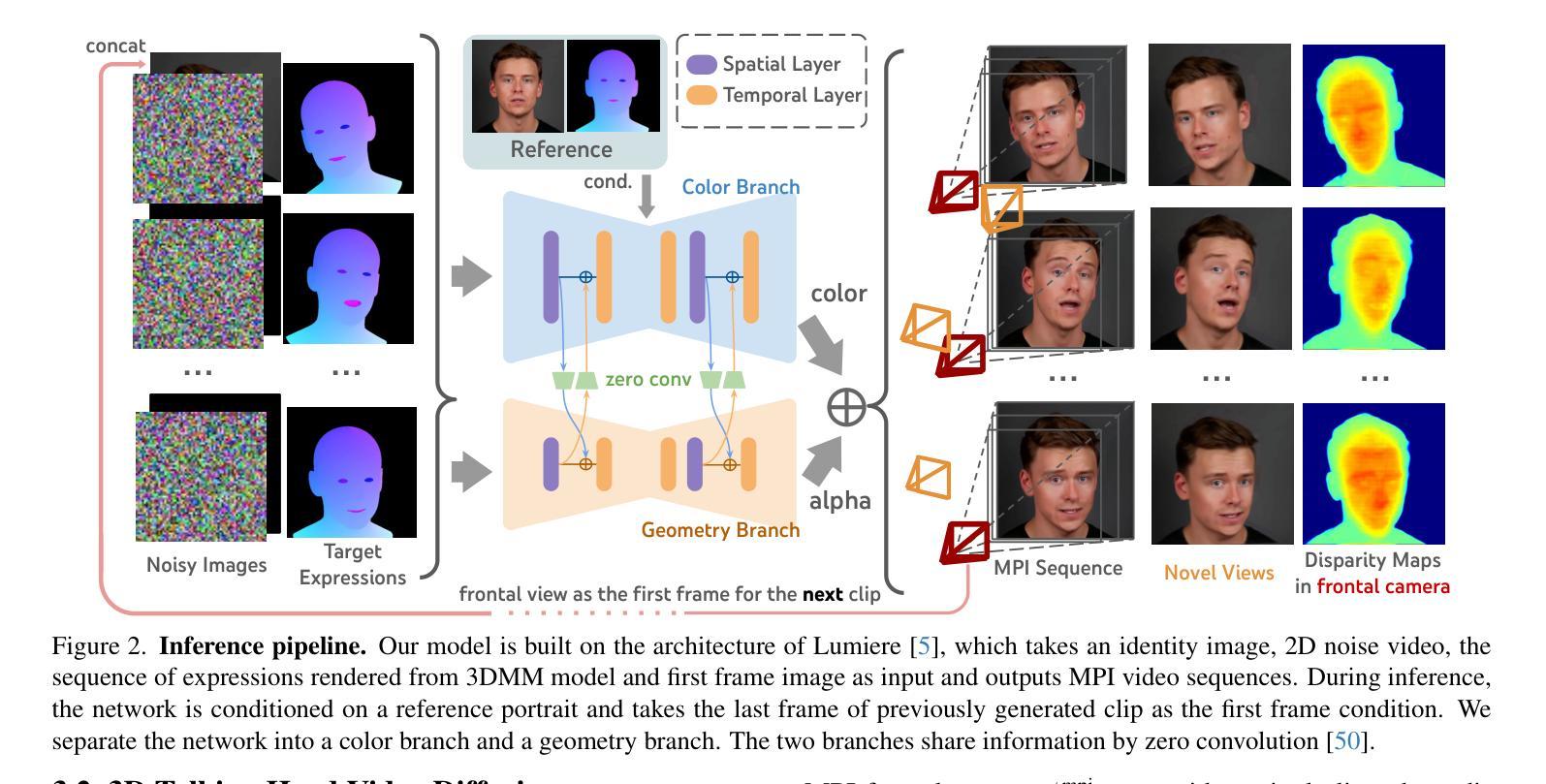
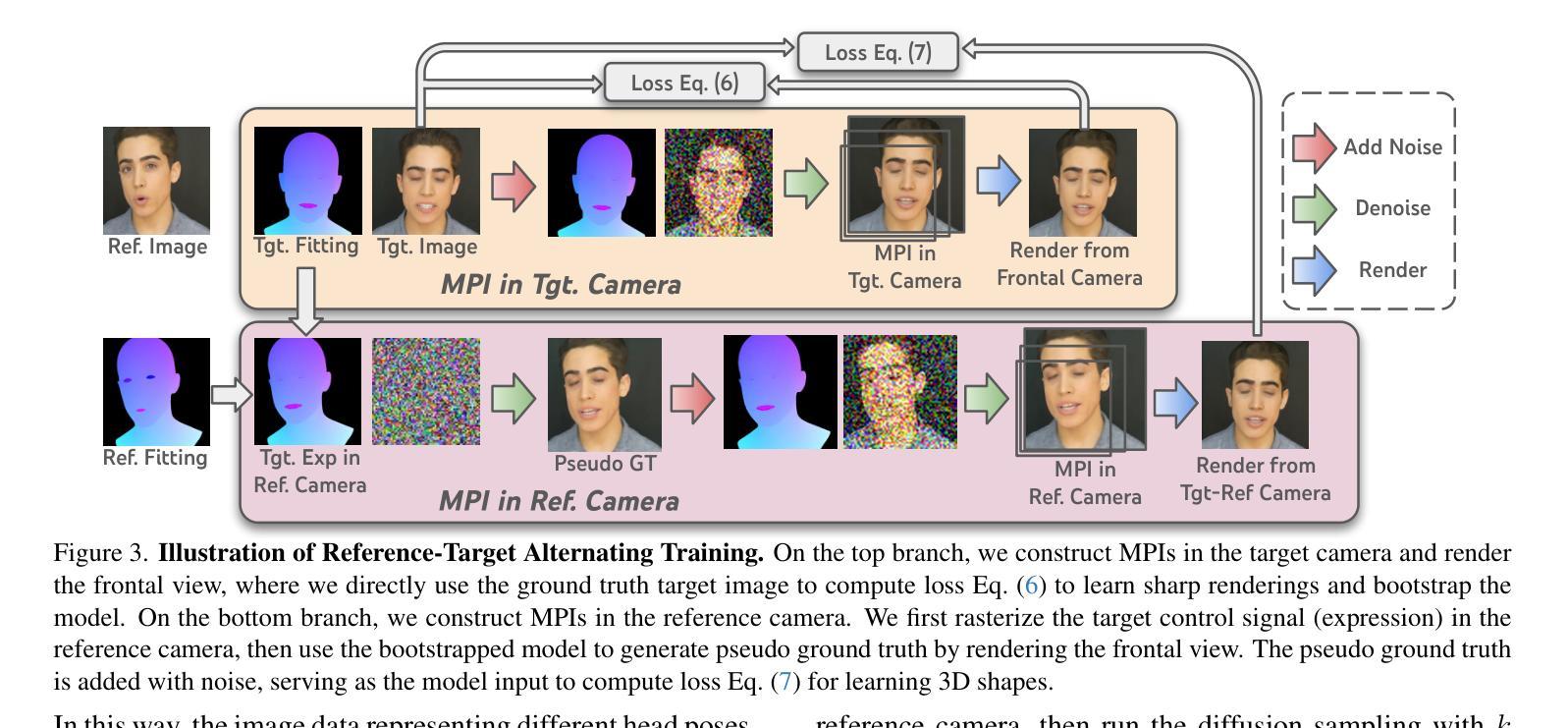
IM-Portrait: Learning 3D-aware Video Diffusion for PhotorealisticTalking Heads from Monocular Videos
Authors:Yuan Li, Ziqian Bai, Feitong Tan, Zhaopeng Cui, Sean Fanello, Yinda Zhang
We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
我们提出了一种新型的基于三维感知扩散的方法,直接从单张身份图像和明确的控制信号(如表情)生成逼真的说话人头视频。我们的方法生成多平面图像(MPIs),确保几何一致性,使其成为理想的选择,可用于虚拟现实头盔显示器的双目视频等沉浸式观看体验。与通常需要单独阶段或联合优化来重建三维表示(如NeRF或三维高斯)的现有方法不同,我们的方法通过单个去噪过程直接生成最终输出,无需进行后期处理步骤即可有效地渲染新颖视图。为了有效地从单目视频中学习,我们引入了一种训练机制,该机制可以在目标相机空间或参考相机空间中随机重建输出MPI。这种方法使模型能够同时学习尖锐的图像细节和潜在的三维信息。大量实验证明了我们方法的有效性,即使在缺乏明确的三维重建或高质量多视角训练数据的情况下,我们的方法也能达到竞争性的化身质量和新颖的视图渲染能力。
论文及项目相关链接
PDF CVPR2025; project page: https://y-u-a-n-l-i.github.io/projects/IM-Portrait/
Summary
新一代三维感知扩散方法可直接从单一身份图像和控制信号(如表情)生成逼真的动画头像视频。该方法生成多平面图像(MPIs),确保几何一致性,适用于虚拟现实头戴设备的沉浸式观看体验。与其他方法不同,无需额外的阶段或联合优化来重建三维表示,通过单一的降噪过程直接生成最终输出,有效避免复杂的后期处理步骤以实现新视角的高效渲染。引入了一种训练机制,能在目标相机空间或参考相机空间中重建输出MPI,使模型能够同时学习清晰图像细节和底层三维信息。实验证明该方法的有效性,即使在无需明确的三维重建或高质量多视角训练数据的情况下,也能实现具有竞争力的角色质量和新视角的渲染能力。
Key Takeaways
- 提出了一种新型的三维感知扩散方法,能够从单一身份图像和控制信号生成动画头像视频。
- 生成的多平面图像(MPIs)保证了几何一致性,适合虚拟现实沉浸式体验。
- 与其他方法不同,该方法通过单一的降噪过程直接生成最终输出,无需额外的阶段或联合优化,简化了流程。
- 引入了一种训练机制,能在目标相机空间或参考相机空间中重建MPI,促进模型同时学习图像细节和底层三维信息。
- 方法具有高效的渲染能力和竞争力强的角色质量,即使在没有明确的三维重建或高质量多视角训练数据的情况下也能表现出色。
点此查看论文截图

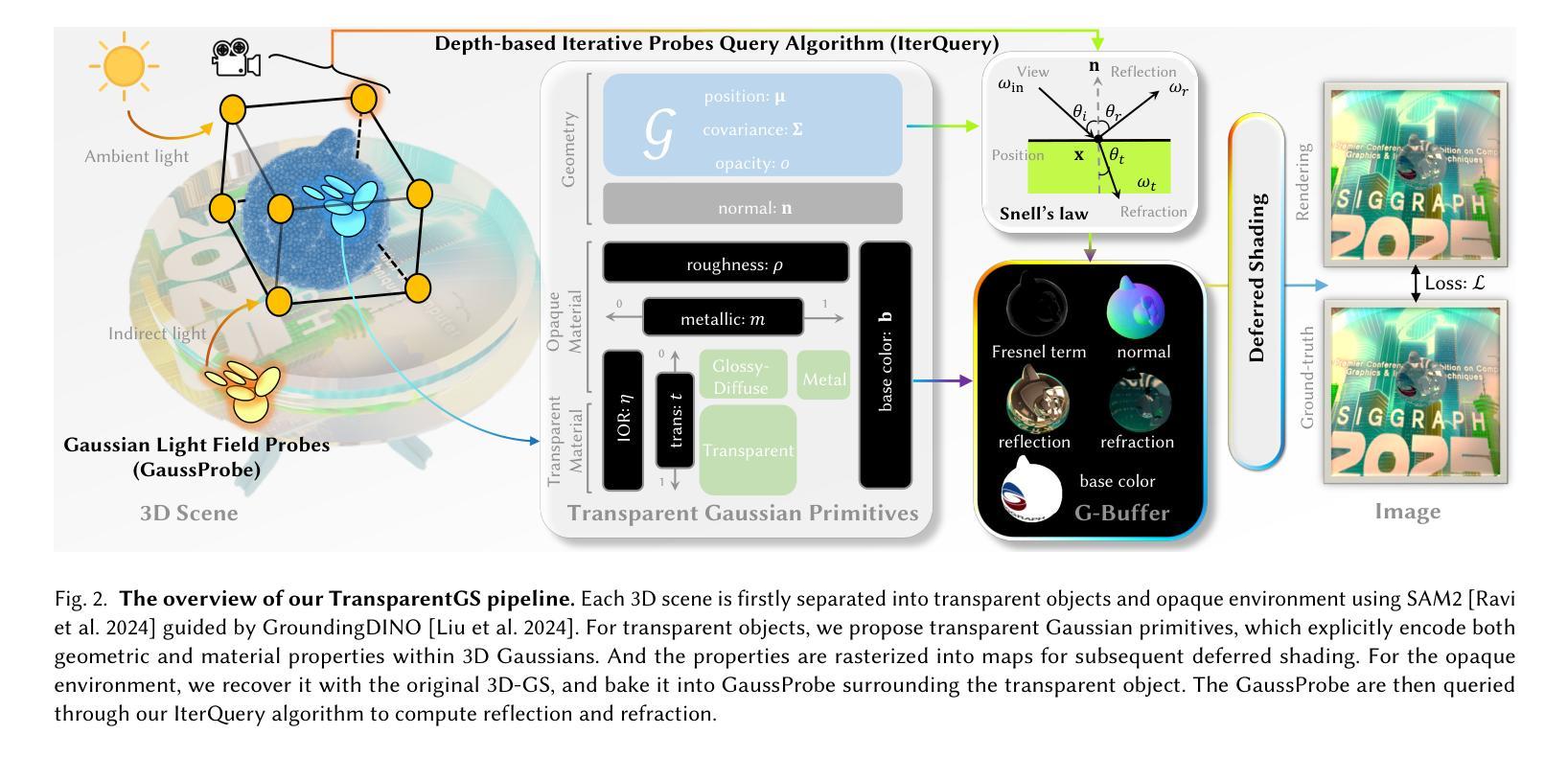
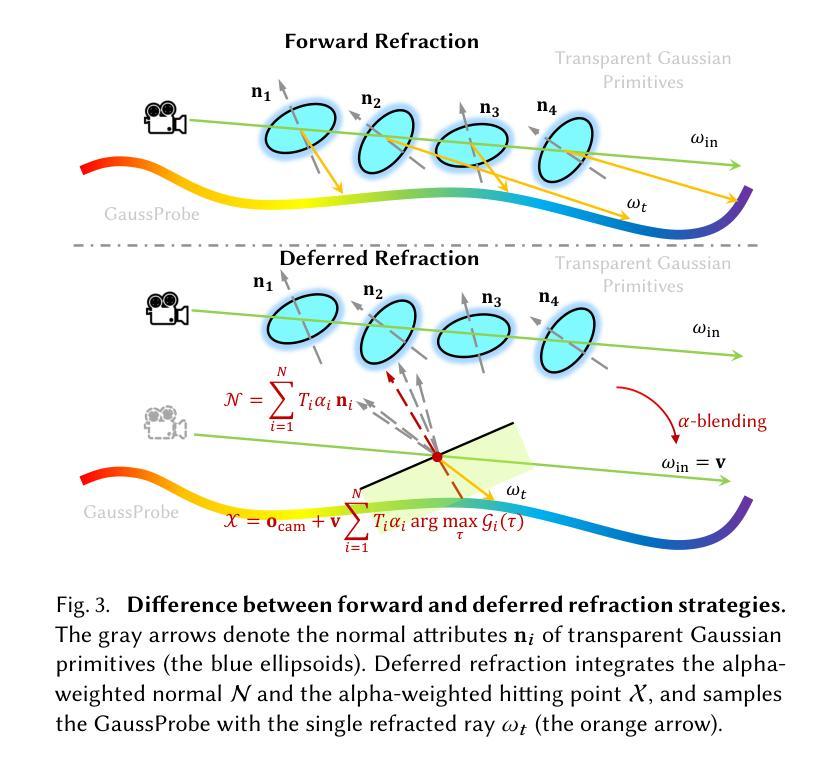
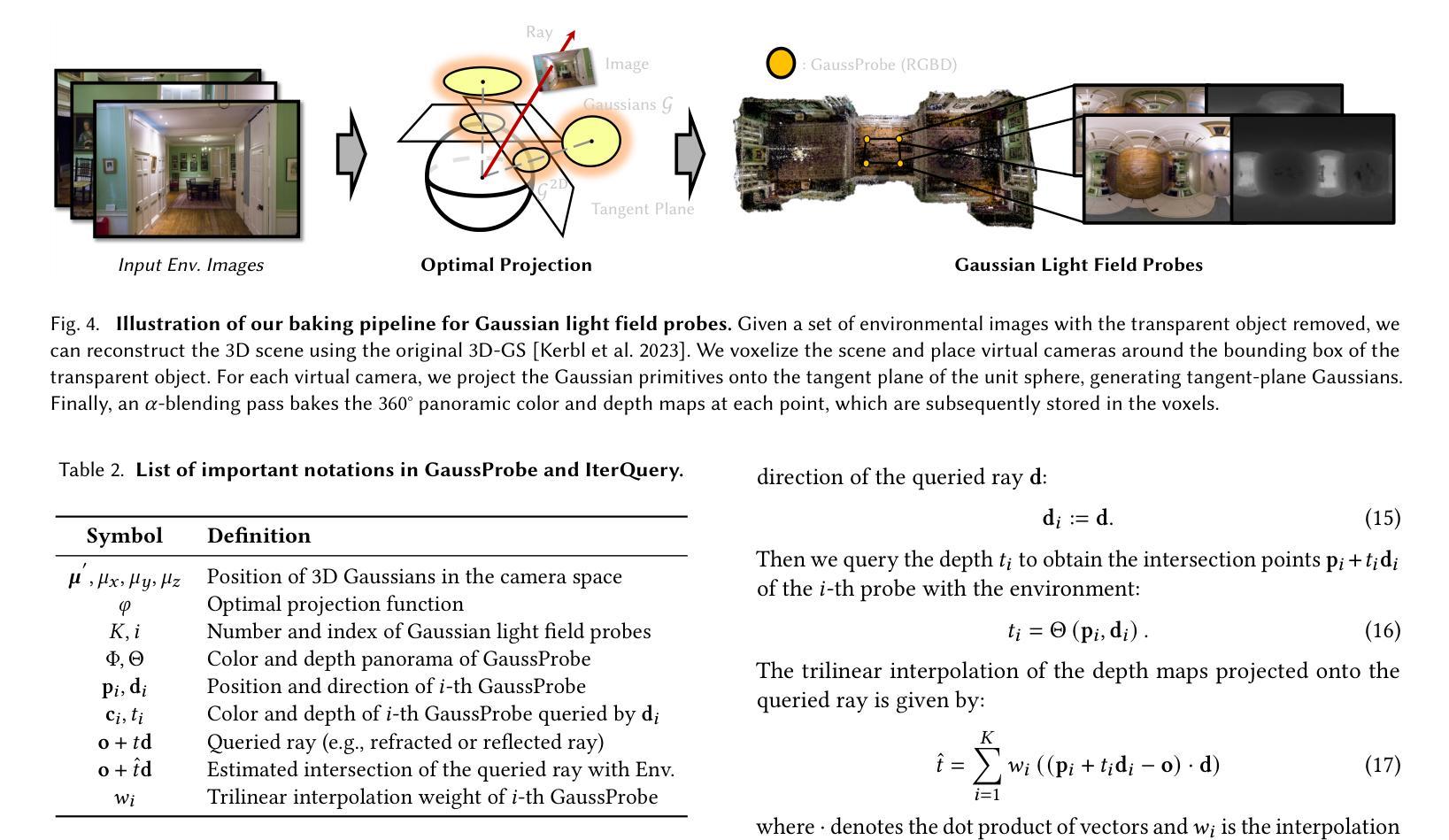
TransparentGS: Fast Inverse Rendering of Transparent Objects with Gaussians
Authors:Letian Huang, Dongwei Ye, Jialin Dan, Chengzhi Tao, Huiwen Liu, Kun Zhou, Bo Ren, Yuanqi Li, Yanwen Guo, Jie Guo
The emergence of neural and Gaussian-based radiance field methods has led to considerable advancements in novel view synthesis and 3D object reconstruction. Nonetheless, specular reflection and refraction continue to pose significant challenges due to the instability and incorrect overfitting of radiance fields to high-frequency light variations. Currently, even 3D Gaussian Splatting (3D-GS), as a powerful and efficient tool, falls short in recovering transparent objects with nearby contents due to the existence of apparent secondary ray effects. To address this issue, we propose TransparentGS, a fast inverse rendering pipeline for transparent objects based on 3D-GS. The main contributions are three-fold. Firstly, an efficient representation of transparent objects, transparent Gaussian primitives, is designed to enable specular refraction through a deferred refraction strategy. Secondly, we leverage Gaussian light field probes (GaussProbe) to encode both ambient light and nearby contents in a unified framework. Thirdly, a depth-based iterative probes query (IterQuery) algorithm is proposed to reduce the parallax errors in our probe-based framework. Experiments demonstrate the speed and accuracy of our approach in recovering transparent objects from complex environments, as well as several applications in computer graphics and vision.
神经和高斯基辐射场方法的出现为新型视图合成和3D对象重建带来了重大进展。然而,由于辐射场对高频光变化的不稳定性和不正确的过度拟合,镜面反射和折射仍然构成了重大挑战。目前,即使3D高斯Splatting(3D-GS)作为一种强大而有效的工具,由于明显的二次射线效应的存在,在恢复附近内容的透明物体时也相形见绌。为了解决这一问题,我们提出了基于3D-GS的透明对象快速逆向渲染管道TransparentGS。主要贡献有三点。首先,设计了一种透明对象的高效表示方法,即透明高斯基元,以实现通过延迟折射策略的镜面折射。其次,我们利用高斯光场探针(GaussProbe)将环境光和附近内容编码到统一框架中。第三,提出了一种基于深度的迭代探针查询(IterQuery)算法,以减少我们基于探针的框架中的视差误差。实验证明了我们方法在复杂环境中恢复透明对象的速度和准确性,以及在计算机图形和视觉中的一些应用。
论文及项目相关链接
PDF accepted by SIGGRAPH 2025; https://letianhuang.github.io/transparentgs/
Summary
神经网络和基于高斯的光场方法的发展极大地推动了新型视图合成和三维物体重建的进步。然而,由于高频光照变化下辐射场的稳定性及过拟合问题,光反射和折射仍存在巨大挑战。尽管强大的工具如三维高斯渲染技术(3D-GS)在复原透明物体时表现优秀,但由于存在明显的二次射线效应,难以应对物体周围的场景内容。为解决此问题,我们提出了基于透明高斯原语(TransparentGS)的快速逆向渲染管线。主要贡献有三点:设计了一种透明的物体表示方法——透明高斯原语,通过延迟折射策略实现镜面折射;利用高斯光场探针(GaussProbe)将环境光和周围场景内容编码进统一框架;提出了基于深度的迭代探针查询算法(IterQuery),减少探针基础上的框架的视差误差。实验证明,我们的方法能快速准确地从复杂环境中恢复透明物体,在计算机图形和视觉中有广泛应用。
Key Takeaways
- 神经网络和高斯光场方法推动了视图合成和三维重建的进步。
- 光反射和折射存在挑战,主要由于辐射场对高频光照变化的稳定性和过拟合问题。
- 三维高斯渲染技术(3D-GS)在处理透明物体时面临二次射线效应的挑战。
- TransparentGS方法通过透明高斯原语设计、GaussProbe和IterQuery算法解决了这些问题。
- TransparentGS能快速准确地从复杂环境中恢复透明物体,具有广泛的应用前景。
点此查看论文截图


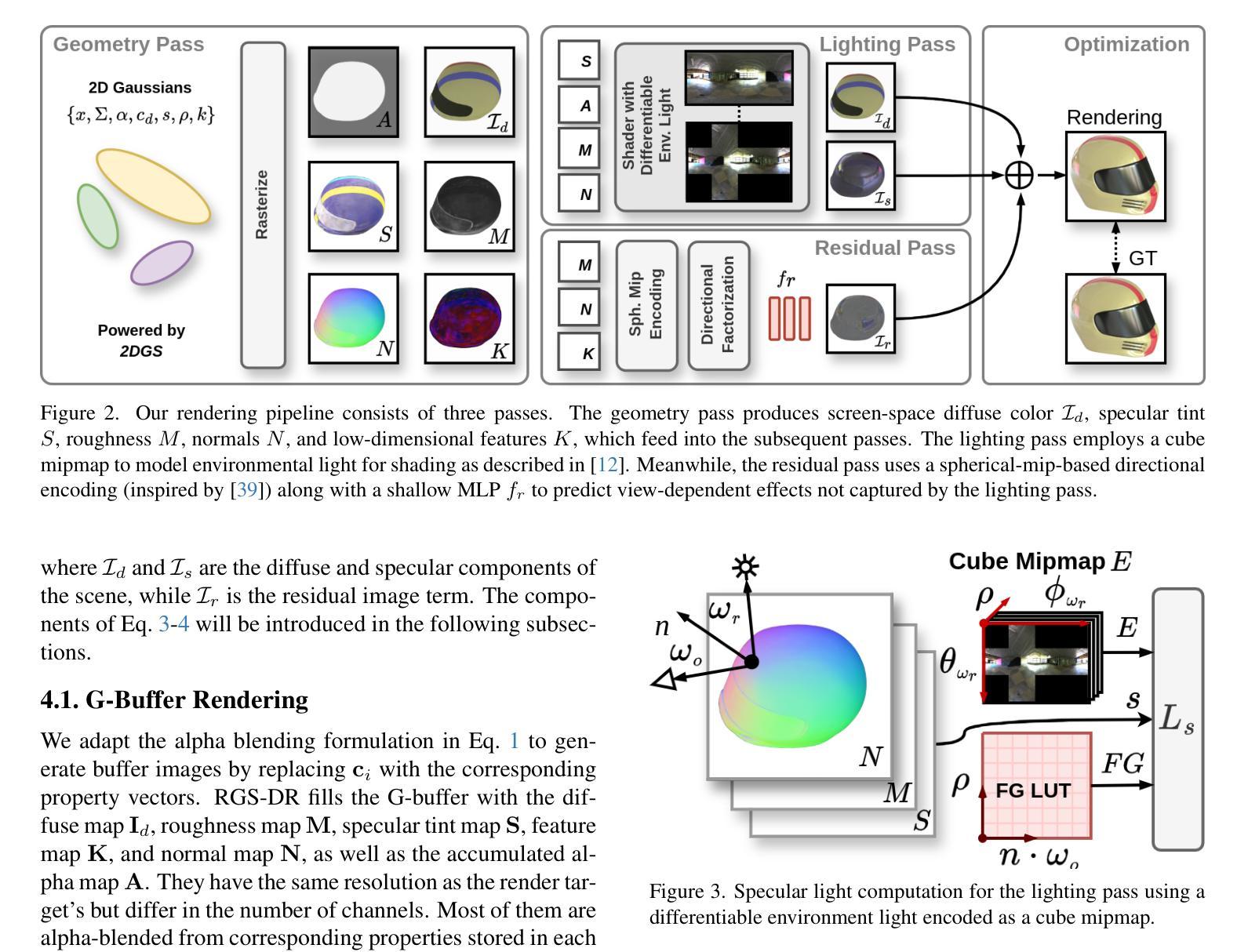
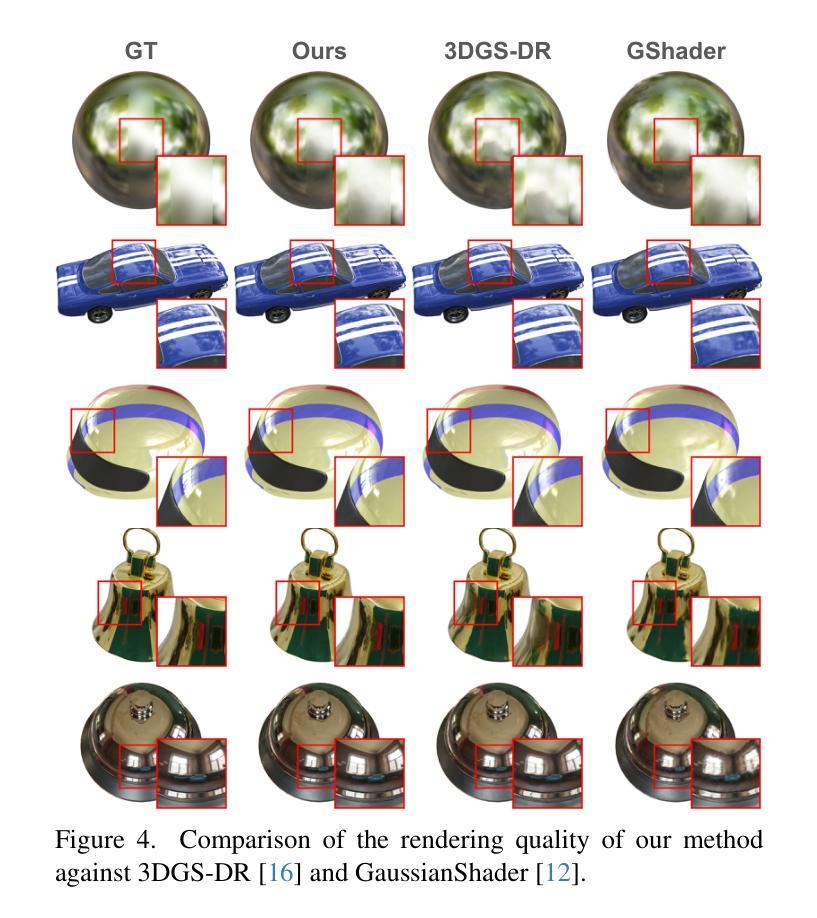
RGS-DR: Reflective Gaussian Surfels with Deferred Rendering for Shiny Objects
Authors:Georgios Kouros, Minye Wu, Tinne Tuytelaars
We introduce RGS-DR, a novel inverse rendering method for reconstructing and rendering glossy and reflective objects with support for flexible relighting and scene editing. Unlike existing methods (e.g., NeRF and 3D Gaussian Splatting), which struggle with view-dependent effects, RGS-DR utilizes a 2D Gaussian surfel representation to accurately estimate geometry and surface normals, an essential property for high-quality inverse rendering. Our approach explicitly models geometric and material properties through learnable primitives rasterized into a deferred shading pipeline, effectively reducing rendering artifacts and preserving sharp reflections. By employing a multi-level cube mipmap, RGS-DR accurately approximates environment lighting integrals, facilitating high-quality reconstruction and relighting. A residual pass with spherical-mipmap-based directional encoding further refines the appearance modeling. Experiments demonstrate that RGS-DR achieves high-quality reconstruction and rendering quality for shiny objects, often outperforming reconstruction-exclusive state-of-the-art methods incapable of relighting.
我们介绍了RGS-DR,这是一种新型逆向渲染方法,用于重建和渲染具有光泽和反射特性的物体,支持灵活的重新打光和场景编辑。与现有方法(例如NeRF和3D高斯拼贴)相比,它们在处理与视图相关的效果时遇到困难,而RGS-DR使用2D高斯surfel表示法来准确估计几何和表面法线,这是高质量逆向渲染的基本属性。我们的方法通过可学习的原始元素显式建模几何和材料属性,并将其渲染到延迟着色管道中,这有效地减少了渲染伪影并保持了锐利的反射。通过采用多层次立方体mipmap,RGS-DR能够准确近似环境光照积分,从而实现高质量的重建和重新打光。基于球形mipmap的方向编码的残差传递进一步改进了外观建模。实验表明,RGS-DR在重建和渲染光泽物体方面达到了高质量,通常优于那些无法进行重新打光的仅用于重建的最先进方法。
论文及项目相关链接
Summary
RGS-DR是一种新型逆向渲染方法,能重建和渲染具有光泽和反射特性的物体,支持灵活的重新照明和场景编辑。该方法采用2D高斯surfel表示法准确估计几何和表面法线,通过可学习的原始元素显式建模几何和材质属性,并融入延迟着色管道,有效减少渲染伪影,保留锐利反射。通过采用多层立方体mipmap,RGS-DR准确近似环境光照积分,实现高质量重建和重新照明。使用基于球形mipmap的方向编码的残差传递进一步改进了外观建模。实验表明,RGS-DR在重建和渲染光泽物体方面达到高质量,往往超越只能重建而不能重新照明的最新技术方法。
Key Takeaways
- RGS-DR是一种用于重建和渲染具有光泽和反射特性的物体的新型逆向渲染方法。
- 该方法采用2D高斯surfel表示法准确估计几何和表面法线,这是高质量逆向渲染的关键属性。
- RGS-DR通过可学习的原始元素显式建模几何和材质属性,并融入延迟着色管道,以提高渲染质量。
- 采用多层立方体mipmap,RGS-DR能准确近似环境光照积分,实现高质量重建和重新照明。
- 残差传递和基于球形mipmap的方向编码进一步改进了RGS-DR的外观建模。
- RGS-DR在重建和渲染光泽物体方面表现出色,往往超越现有技术。
点此查看论文截图

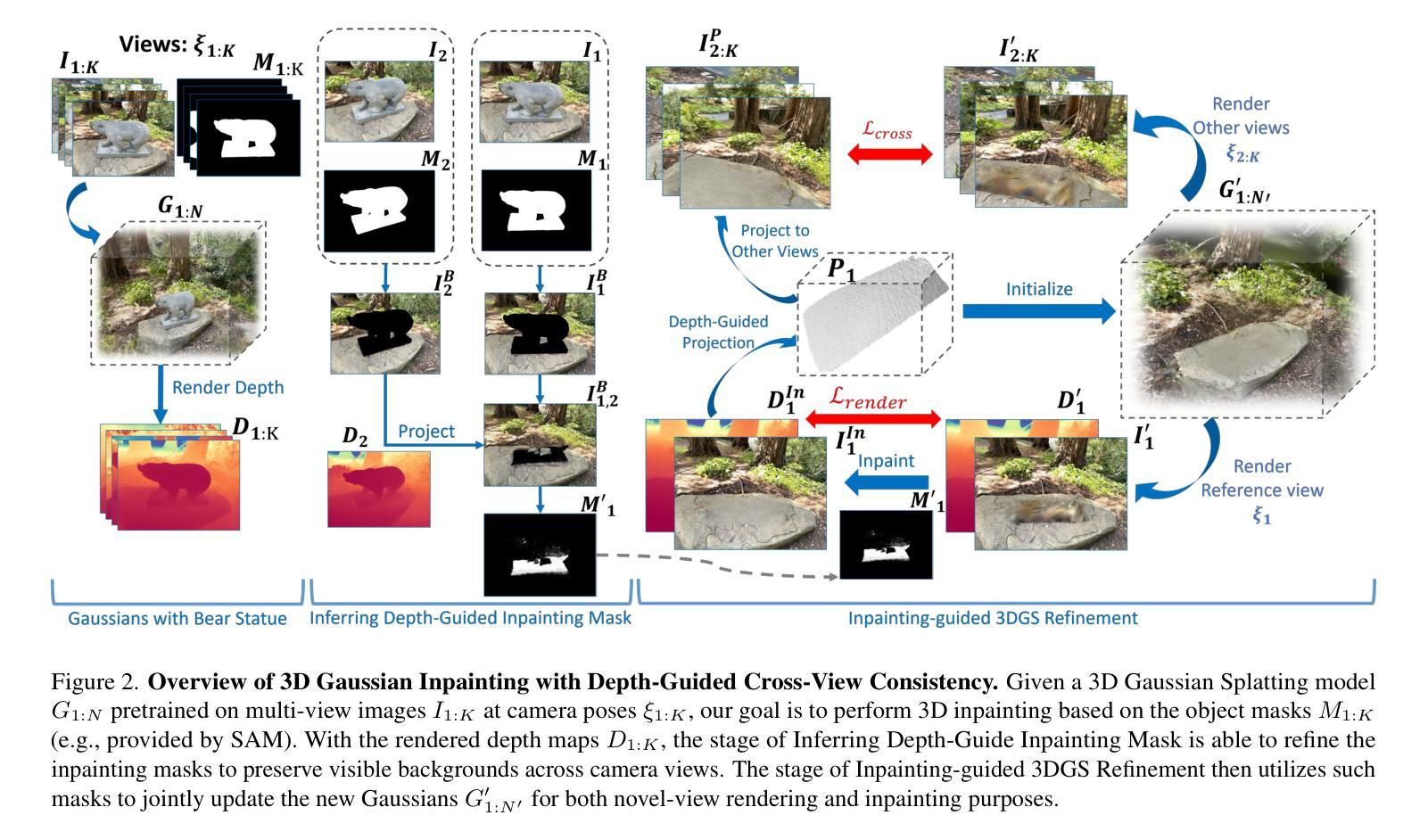
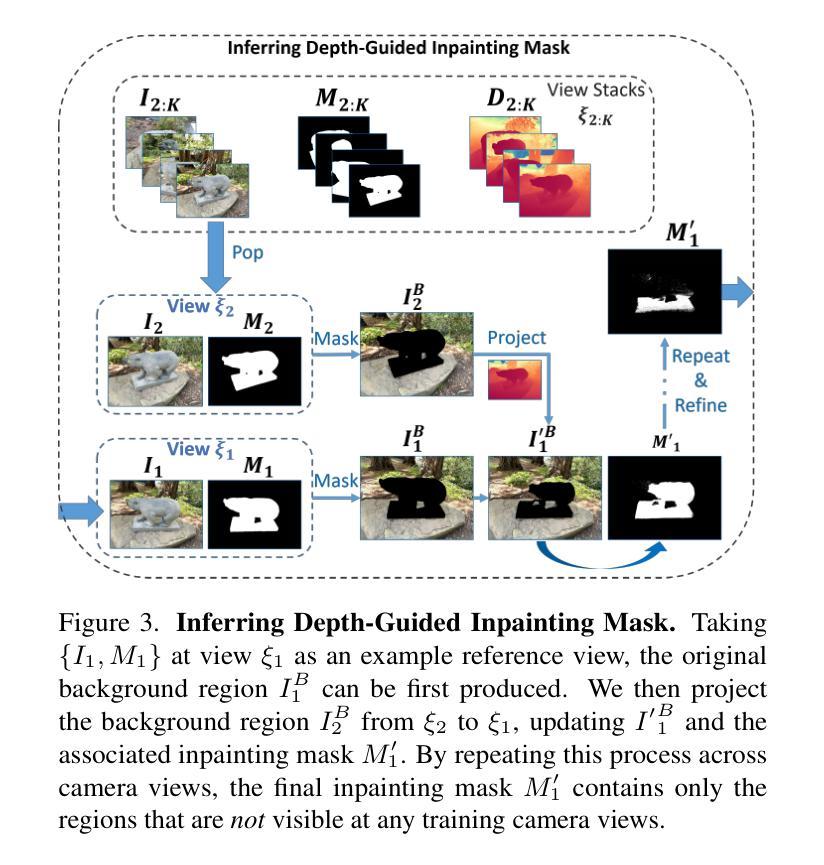
3D Gaussian Inpainting with Depth-Guided Cross-View Consistency
Authors:Sheng-Yu Huang, Zi-Ting Chou, Yu-Chiang Frank Wang
When performing 3D inpainting using novel-view rendering methods like Neural Radiance Field (NeRF) or 3D Gaussian Splatting (3DGS), how to achieve texture and geometry consistency across camera views has been a challenge. In this paper, we propose a framework of 3D Gaussian Inpainting with Depth-Guided Cross-View Consistency (3DGIC) for cross-view consistent 3D inpainting. Guided by the rendered depth information from each training view, our 3DGIC exploits background pixels visible across different views for updating the inpainting mask, allowing us to refine the 3DGS for inpainting purposes.Through extensive experiments on benchmark datasets, we confirm that our 3DGIC outperforms current state-of-the-art 3D inpainting methods quantitatively and qualitatively.
在使用如神经辐射场(NeRF)或3D高斯拼贴(3DGS)等新型视图渲染方法进行3D补全时,如何在不同相机视角间实现纹理和几何一致性一直是一个挑战。在本文中,我们提出了一个名为“带有深度引导跨视图一致性(3DGIC)的3D高斯补全”的框架,用于实现跨视图一致的3D补全。我们的方法通过利用来自每个训练视图的渲染深度信息作为指导,利用在不同视图中可见的背景像素来更新补全掩膜,从而允许我们改进用于补全的3DGS。通过对基准数据集的大量实验,我们证实我们的3DGIC在数量和质量上都优于当前最先进的3D补全方法。
论文及项目相关链接
PDF Accepted to CVPR 2025. For project page, see https://peterjohnsonhuang.github.io/3dgic-pages
Summary
本文提出了一种基于深度引导的跨视图一致性3D高斯补全(3DGIC)框架,用于实现跨视图一致的3D补全。该框架利用从每个训练视图渲染的深度信息来指导背景像素的可见性,从而更新补全掩膜,实现对3DGS的细化,以实现补全目的。实验证明,该框架在基准数据集上的表现优于现有的3D补全方法。
Key Takeaways
- 3DGIC框架实现了跨视图一致的3D补全。
- 该框架利用渲染的深度信息来指导背景像素的可见性。
- 3DGIC通过更新补全掩膜来细化3DGS,以实现更精确的补全。
- 3DGIC框架在基准数据集上的表现优于现有方法。
- 该方法在处理3D纹理和几何一致性方面遇到的挑战时表现出优势。
- 提出的框架适用于使用NeRF或3DGS等新型视图渲染方法的3D补全任务。
点此查看论文截图


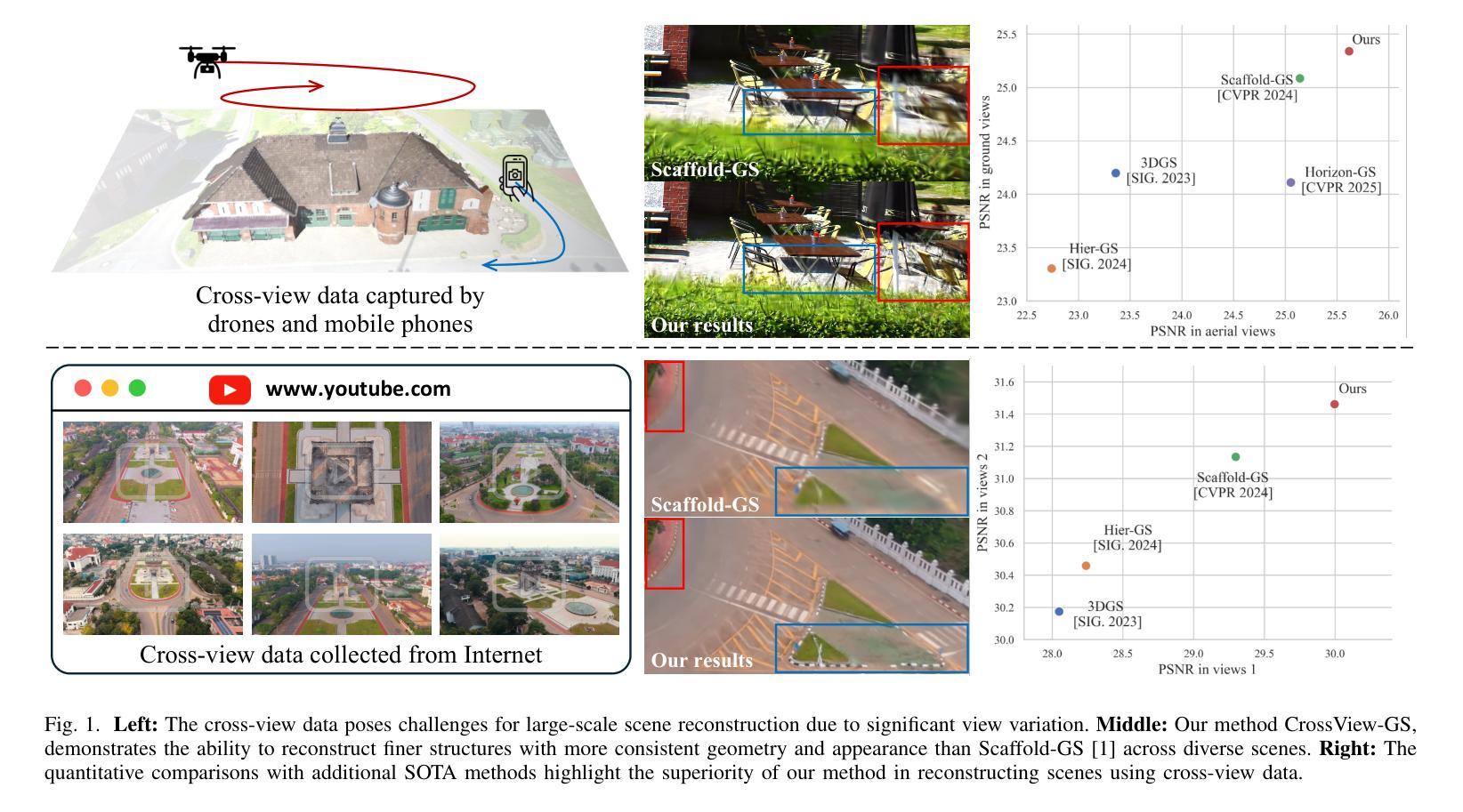
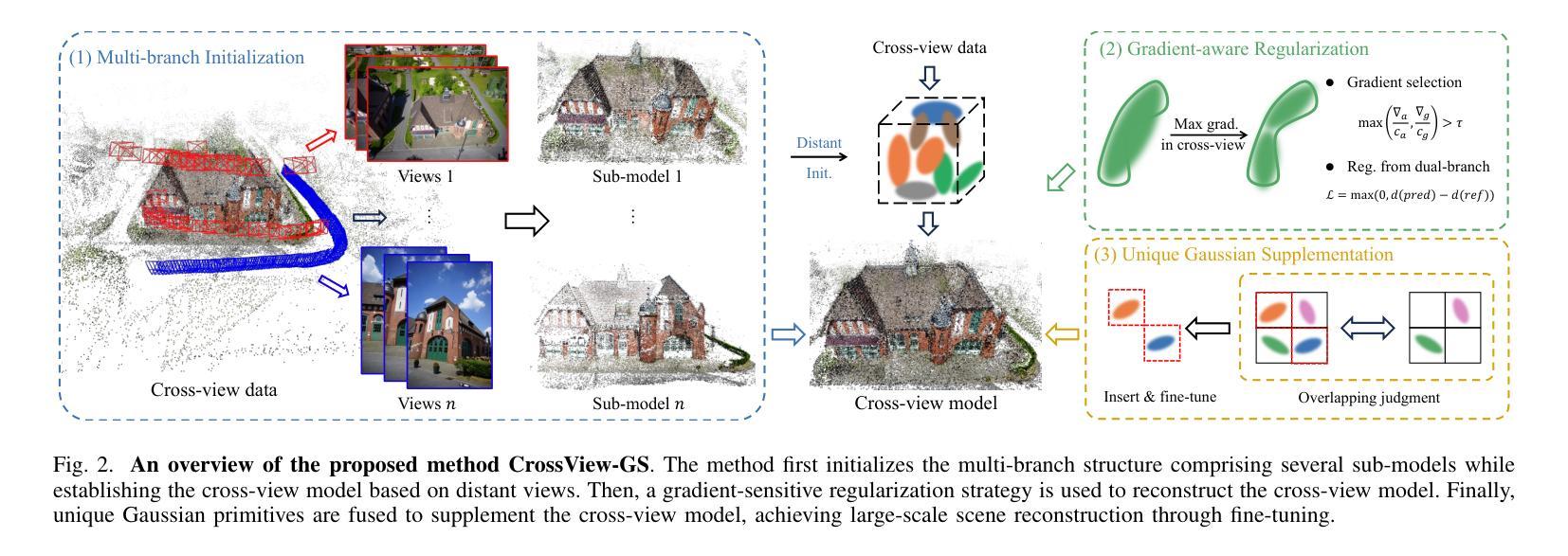
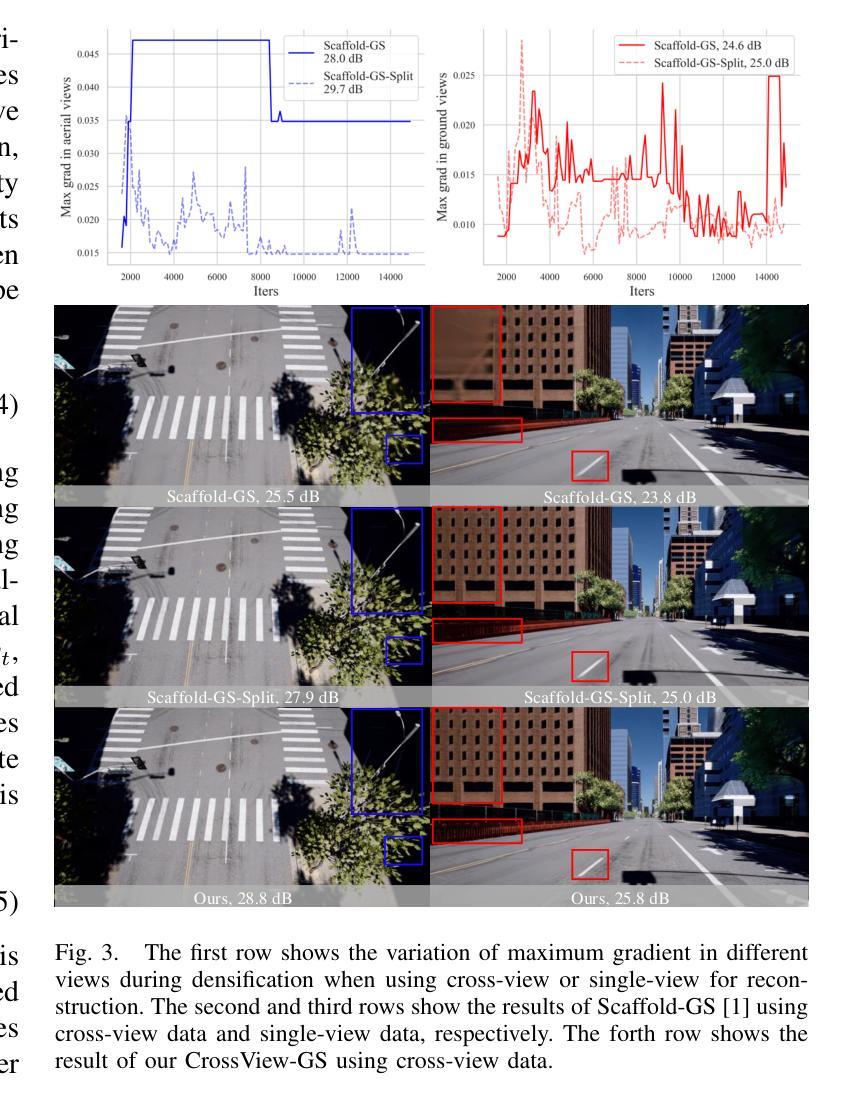
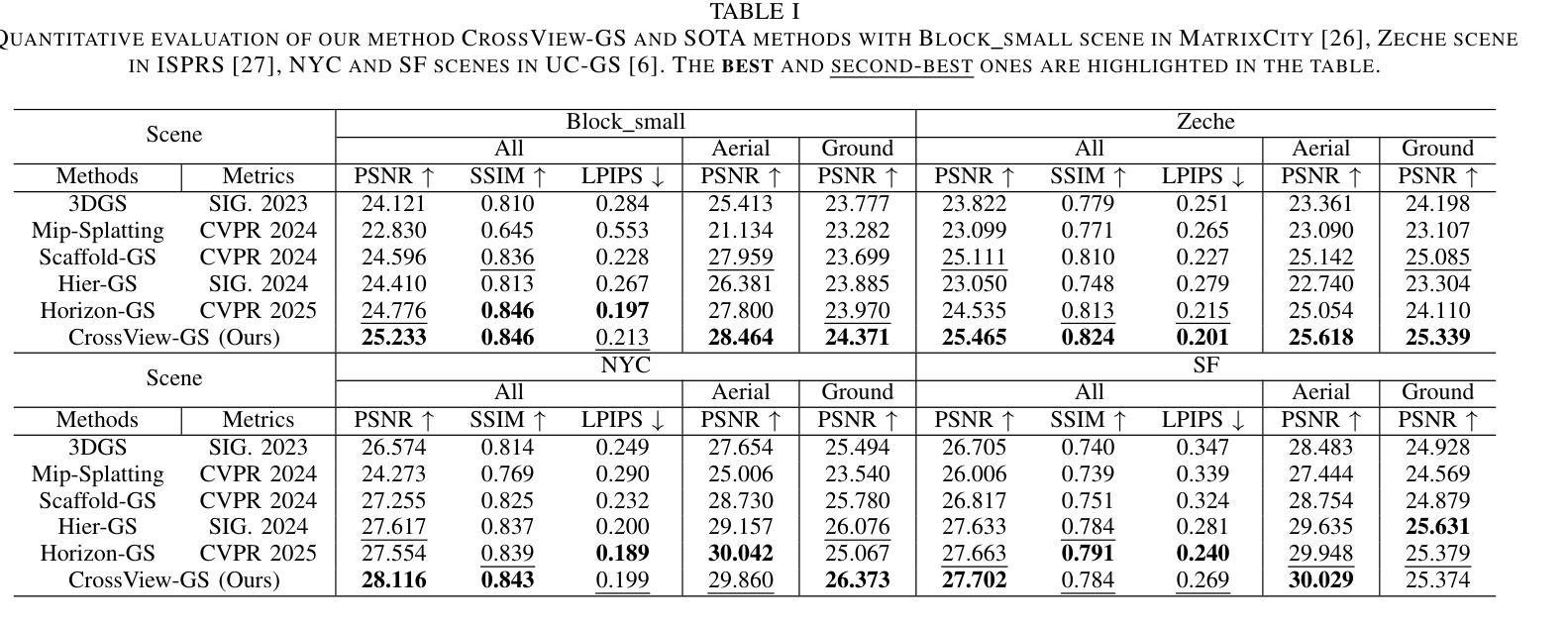
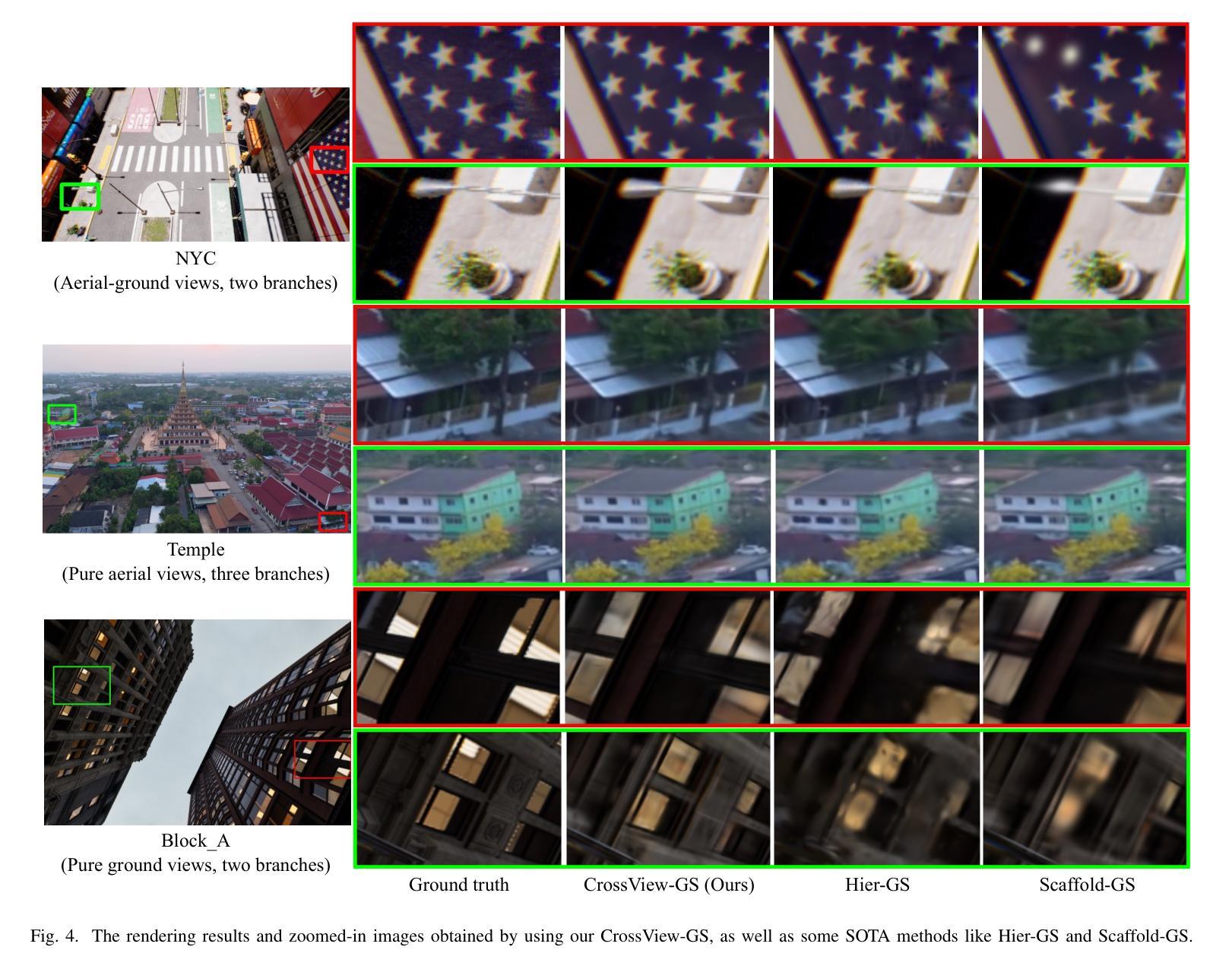
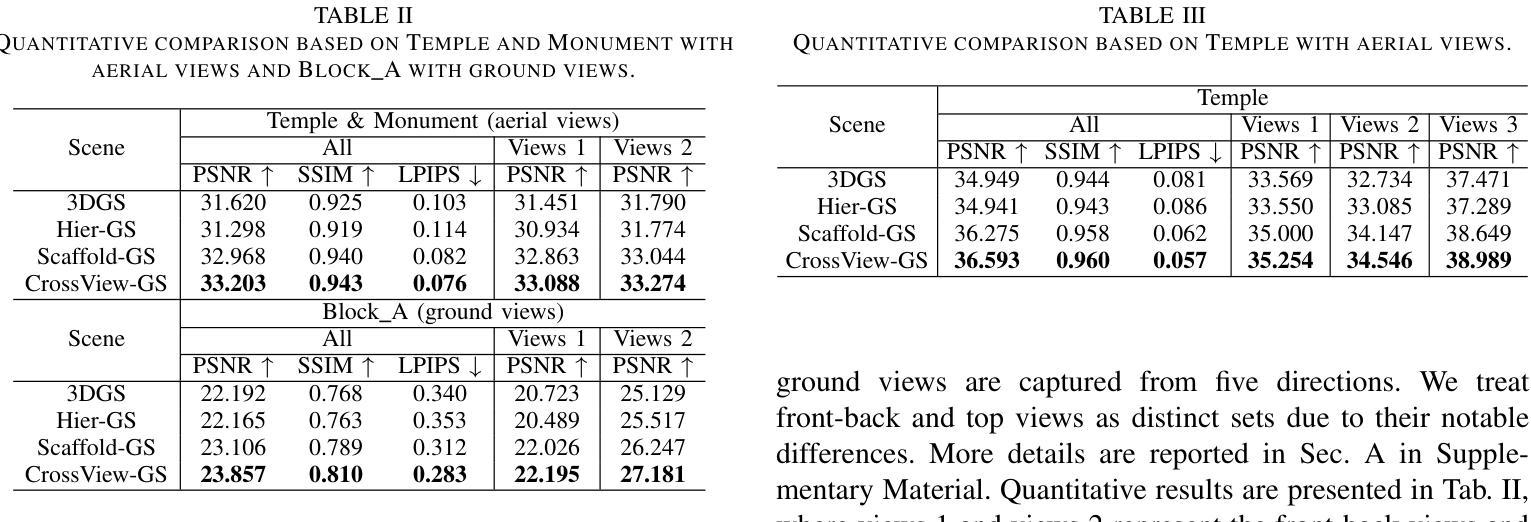
CrossView-GS: Cross-view Gaussian Splatting For Large-scale Scene Reconstruction
Authors:Chenhao Zhang, Yuanping Cao, Lei Zhang
3D Gaussian Splatting (3DGS) leverages densely distributed Gaussian primitives for high-quality scene representation and reconstruction. While existing 3DGS methods perform well in scenes with minor view variation, large view changes from cross-view data pose optimization challenges for these methods. To address these issues, we propose a novel cross-view Gaussian Splatting method for large-scale scene reconstruction based on multi-branch construction and fusion. Our method independently reconstructs models from different sets of views as multiple independent branches to establish the baselines of Gaussian distribution, providing reliable priors for cross-view reconstruction during initialization and densification. Specifically, a gradient-aware regularization strategy is introduced to mitigate smoothing issues caused by significant view disparities. Additionally, a unique Gaussian supplementation strategy is utilized to incorporate complementary information of multi-branch into the cross-view model. Extensive experiments on benchmark datasets demonstrate that our method achieves superior performance in novel view synthesis compared to state-of-the-art methods.
3D高斯摊铺(3DGS)利用密集分布的Gaussian基本单位来表示和重建高质量的场景。现有的三维GS方法在轻微视角变化的场景中表现良好,但从跨视角数据中获取的大视角变化为这些方法带来了优化挑战。为了解决这些问题,我们提出了一种基于多分支构建和融合的大场景重建的跨视图高斯摊铺新方法。我们的方法从不同视角的独立数据集重建模型,建立多个独立分支来构建高斯分布的基线,为初始化和密集化过程中的跨视图重建提供可靠的先验知识。具体来说,引入了一种梯度感知的正则化策略,以缓解由显著视角差异引起的平滑问题。此外,还采用了一种独特的Gaussian补充策略,将多分支的互补信息融入跨视图模型中。在基准数据集上的广泛实验表明,与最先进的方法相比,我们的方法在新型视图合成方面取得了卓越的性能。
论文及项目相关链接
Summary
本文介绍了基于密集分布的高斯基元的三维高斯融合(3DGS)技术用于高质量的场景表示和重建。针对现有方法在跨视角数据存在较大视角变化时的优化挑战,提出了一种基于多分支构建和融合的新型跨视角高斯融合方法,用于大规模场景重建。该方法通过从不同视角独立重建模型作为多个独立分支,建立高斯分布的基准,为跨视角重建提供可靠的先验信息。引入梯度感知正则化策略以缓解显著视角差异导致的平滑问题,并采用独特的高斯补充策略将多分支的互补信息融入跨视角模型中。在基准数据集上的广泛实验表明,该方法在新型视角合成方面相较于现有先进技术表现出卓越性能。
Key Takeaways
- 3DGS技术利用密集分布的高斯基元进行高质量的场景表示和重建。
- 针对现有方法的不足,提出了一种基于多分支构建和融合的新型跨视角高斯融合方法。
- 独立分支以高斯分布基准形式建立,为跨视角重建提供可靠先验信息。
- 采用梯度感知正则化策略缓解显著视角差异造成的平滑问题。
- 高斯补充策略用于整合多分支的互补信息到跨视角模型中。
- 方法在基准数据集上的实验表现优越,特别是在新型视角合成方面。
点此查看论文截图

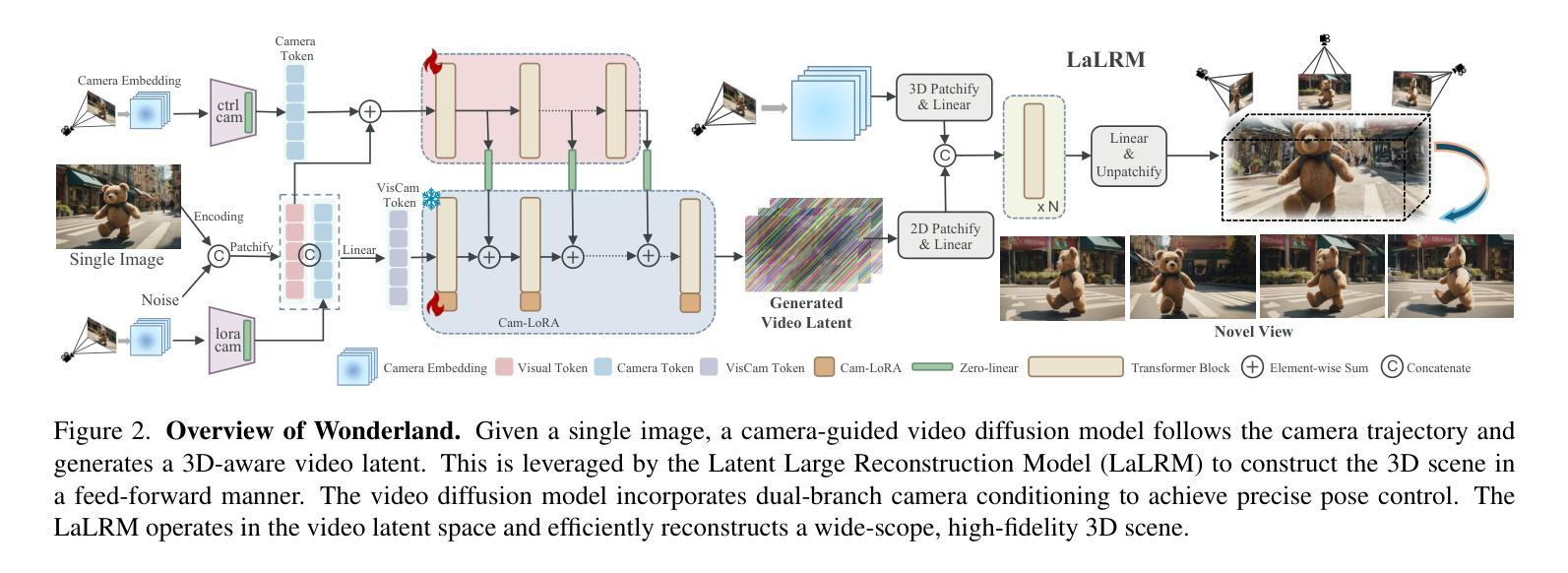
Wonderland: Navigating 3D Scenes from a Single Image
Authors:Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos N. Plataniotis, Sergey Tulyakov, Jian Ren
How can one efficiently generate high-quality, wide-scope 3D scenes from arbitrary single images? Existing methods suffer several drawbacks, such as requiring multi-view data, time-consuming per-scene optimization, distorted geometry in occluded areas, and low visual quality in backgrounds. Our novel 3D scene reconstruction pipeline overcomes these limitations to tackle the aforesaid challenge. Specifically, we introduce a large-scale reconstruction model that leverages latents from a video diffusion model to predict 3D Gaussian Splattings of scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that encode multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive learning strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets affirm that our model significantly outperforms existing single-view 3D scene generation methods, especially with out-of-domain images. Thus, we demonstrate for the first time that a 3D reconstruction model can effectively be built upon the latent space of a diffusion model in order to realize efficient 3D scene generation.
如何从任意单张图像高效生成高质量、大范围的三维场景?现有方法存在诸多缺点,例如需要多视角数据、耗时的场景优化、遮挡区域的几何失真以及背景视觉质量低下。我们的新型三维场景重建流程克服了这些限制,以应对上述挑战。具体来说,我们引入了一种大规模重建模型,该模型以视频扩散模型的潜在特征为基础,以预测场景的三维高斯Splattings。视频扩散模型被设计为遵循指定的相机轨迹创建视频,从而生成压缩的视频潜在特征,这些特征编码了多视角信息,同时保持了三维一致性。我们采用渐进学习策略对三维重建模型进行训练,使其能够在视频潜在空间上运行,从而能够高效生成高质量、大范围、通用的三维场景。在多个数据集上的广泛评估证实,我们的模型在单视图三维场景生成方面显著优于现有方法,尤其是在域外图像上。因此,我们首次证明,可以在扩散模型的潜在空间上建立三维重建模型,以实现高效的三维场景生成。
论文及项目相关链接
PDF Project page: https://snap-research.github.io/wonderland/
Summary
本文介绍了一种基于视频扩散模型的3D场景重建方法,解决了现有方法的局限性,能够高效生成高质量、宽视野的3D场景。通过引入大规模重建模型,利用视频扩散模型的潜在信息预测场景的3D高斯Splattings。该模型可生成高质量、宽视野和通用的3D场景,并在各种数据集上的评估表现优异。
Key Takeaways
- 引入了一种新的基于视频扩散模型的3D场景重建方法。
- 该方法通过预测场景的3D高斯Splattings来生成高质量的3D场景。
- 视频扩散模型的设计可生成遵循指定相机轨迹的视频潜在信息,同时保持3D一致性。
- 训练重建模型在视频潜在空间上以渐进学习策略进行操作,以实现高效的3D场景生成。
- 模型能生成宽视野和通用场景,在各种数据集上的表现优于现有单视图3D场景生成方法。
- 该模型首次展示了在扩散模型的潜在空间上构建有效的3D重建模型以实现高效的场景生成。
点此查看论文截图