⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-30 更新
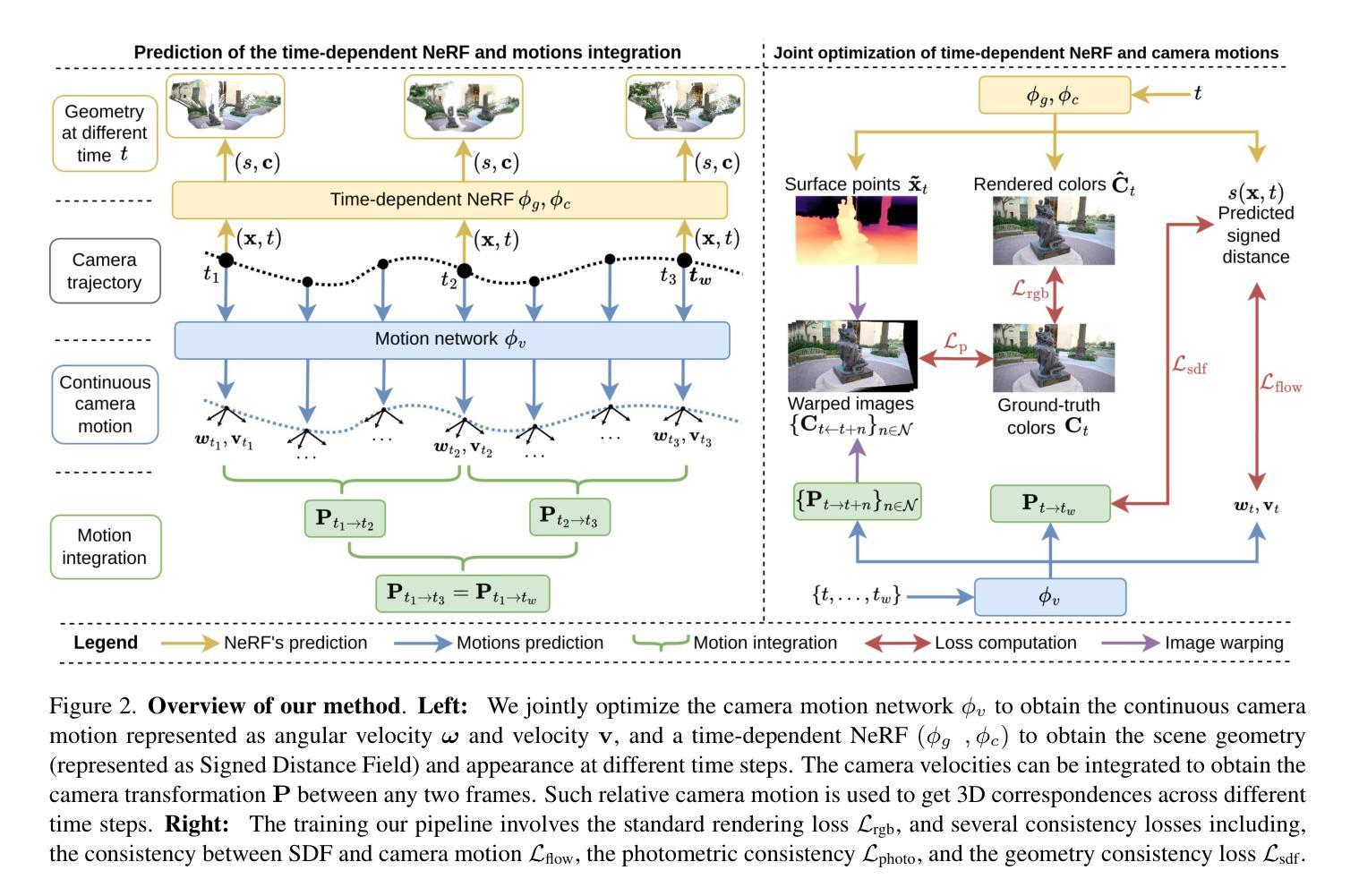
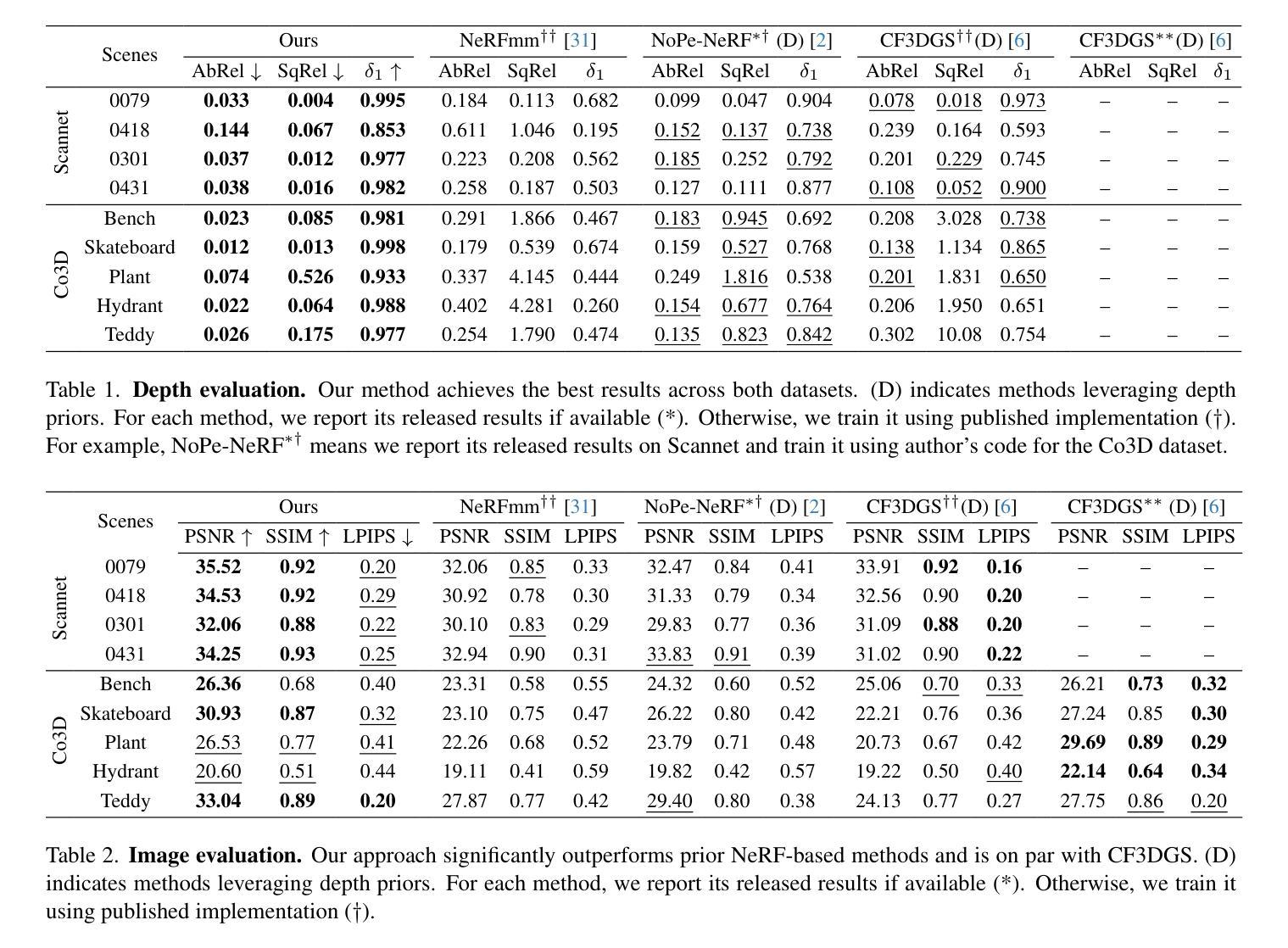
Joint Optimization of Neural Radiance Fields and Continuous Camera Motion from a Monocular Video
Authors:Hoang Chuong Nguyen, Wei Mao, Jose M. Alvarez, Miaomiao Liu
Neural Radiance Fields (NeRF) has demonstrated its superior capability to represent 3D geometry but require accurately precomputed camera poses during training. To mitigate this requirement, existing methods jointly optimize camera poses and NeRF often relying on good pose initialisation or depth priors. However, these approaches struggle in challenging scenarios, such as large rotations, as they map each camera to a world coordinate system. We propose a novel method that eliminates prior dependencies by modeling continuous camera motions as time-dependent angular velocity and velocity. Relative motions between cameras are learned first via velocity integration, while camera poses can be obtained by aggregating such relative motions up to a world coordinate system defined at a single time step within the video. Specifically, accurate continuous camera movements are learned through a time-dependent NeRF, which captures local scene geometry and motion by training from neighboring frames for each time step. The learned motions enable fine-tuning the NeRF to represent the full scene geometry. Experiments on Co3D and Scannet show our approach achieves superior camera pose and depth estimation and comparable novel-view synthesis performance compared to state-of-the-art methods. Our code is available at https://github.com/HoangChuongNguyen/cope-nerf.
神经辐射场(NeRF)已经展现出其在表示3D几何结构上的卓越能力,但在训练过程中需要预先精确计算相机姿态。为了缓解这一要求,现有方法通常会联合优化相机姿态和NeRF,这常常依赖于良好的姿态初始值或深度先验。然而,这些方法在具有挑战性的场景中(例如大旋转场景)会遇到困难,因为它们将每个相机映射到世界坐标系。我们提出了一种新方法,通过建模连续的相机运动作为时间依赖的角速度和速度来消除对先验的依赖。首先通过学习速度积分来获取相机之间的相对运动,然后通过聚合这些相对运动来获得相机姿态,最终将其定位到视频内单个时间步长所定义的世界坐标系。具体来说,通过时间依赖的NeRF学习精确的连续相机运动,该NeRF通过从每个时间步长的邻近帧进行训练来捕捉局部场景几何和运动。学习到的运动使NeRF能够微调以表示完整的场景几何结构。在Co3D和Scannet上的实验表明,我们的方法在相机姿态和深度估计方面达到了优越的性能,在新视角合成性能方面与最先进的方法相当。我们的代码位于[https://github.com/HoangChuongNguyen/cope-nerf。](注:该网址应替换为真实的代码仓库链接)
论文及项目相关链接
Summary
本文提出了一种新的方法,通过建模连续相机运动的时间依赖性角速度和速度,消除了对先验的依赖。该方法首先通过速度积分学习相对运动,然后通过聚合这些相对运动获得相机姿态,最后在一个定义在视频单个时间步长内的世界坐标系中表示出来。通过时间依赖的NeRF学习到的运动能够精细地表示整个场景几何结构。
Key Takeaways
- 现有NeRF技术需要精确预计算的相机姿态来进行训练。
- 现有方法联合优化相机姿态和NeRF,通常依赖于良好的姿态初始值或深度先验。
- 在具有挑战性的场景(如大旋转)中,依赖世界坐标系统的现有方法可能会遇到困难。
- 提出了一种新型方法,通过建模连续相机运动的时间依赖性角速度和速度来消除对先验的依赖。
- 该方法首先通过速度积分学习相对运动,然后通过聚合这些相对运动获得相机姿态。
- 通过时间依赖的NeRF学习到的运动能够精细地表示整个场景几何结构。
点此查看论文截图

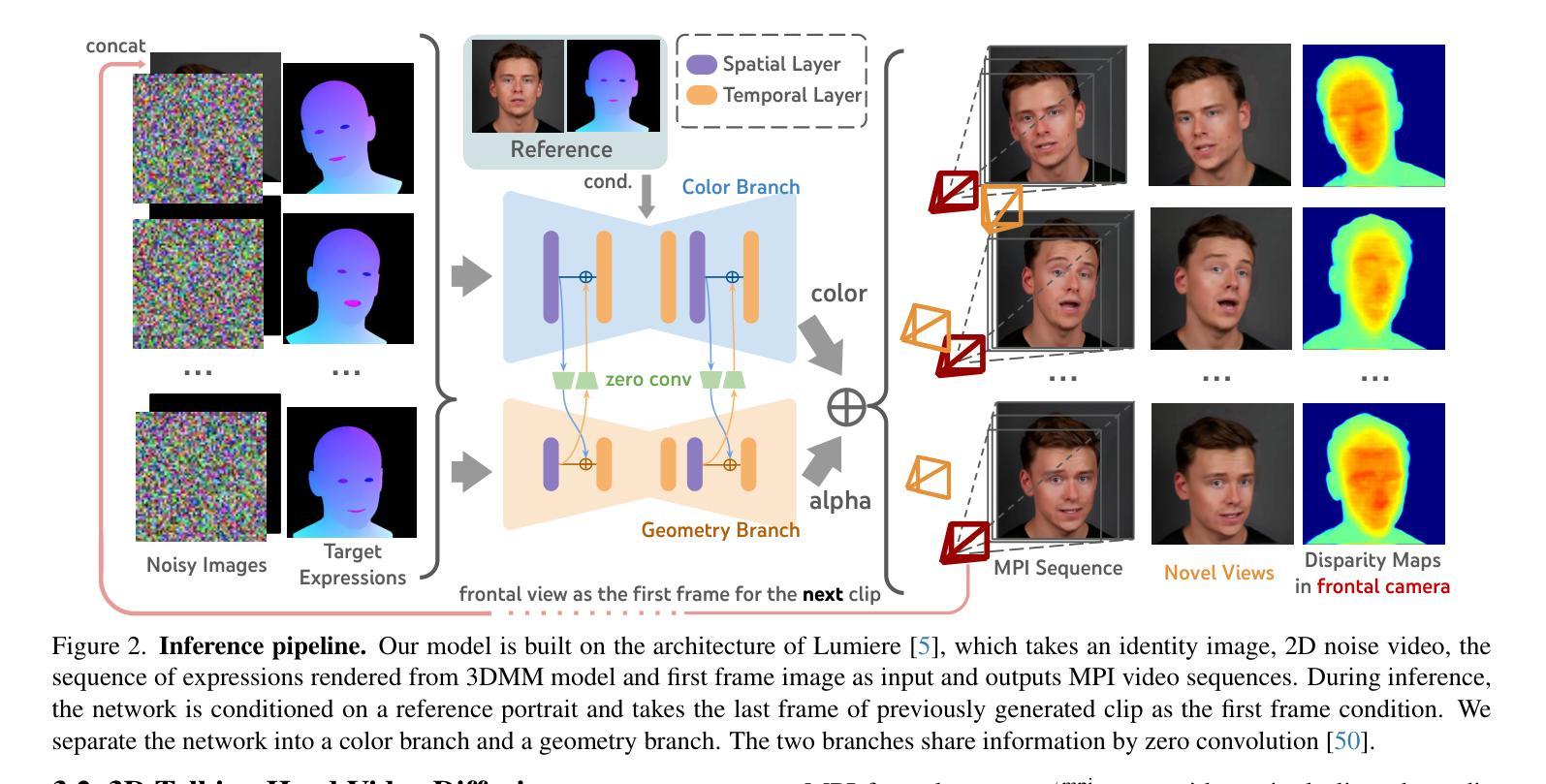
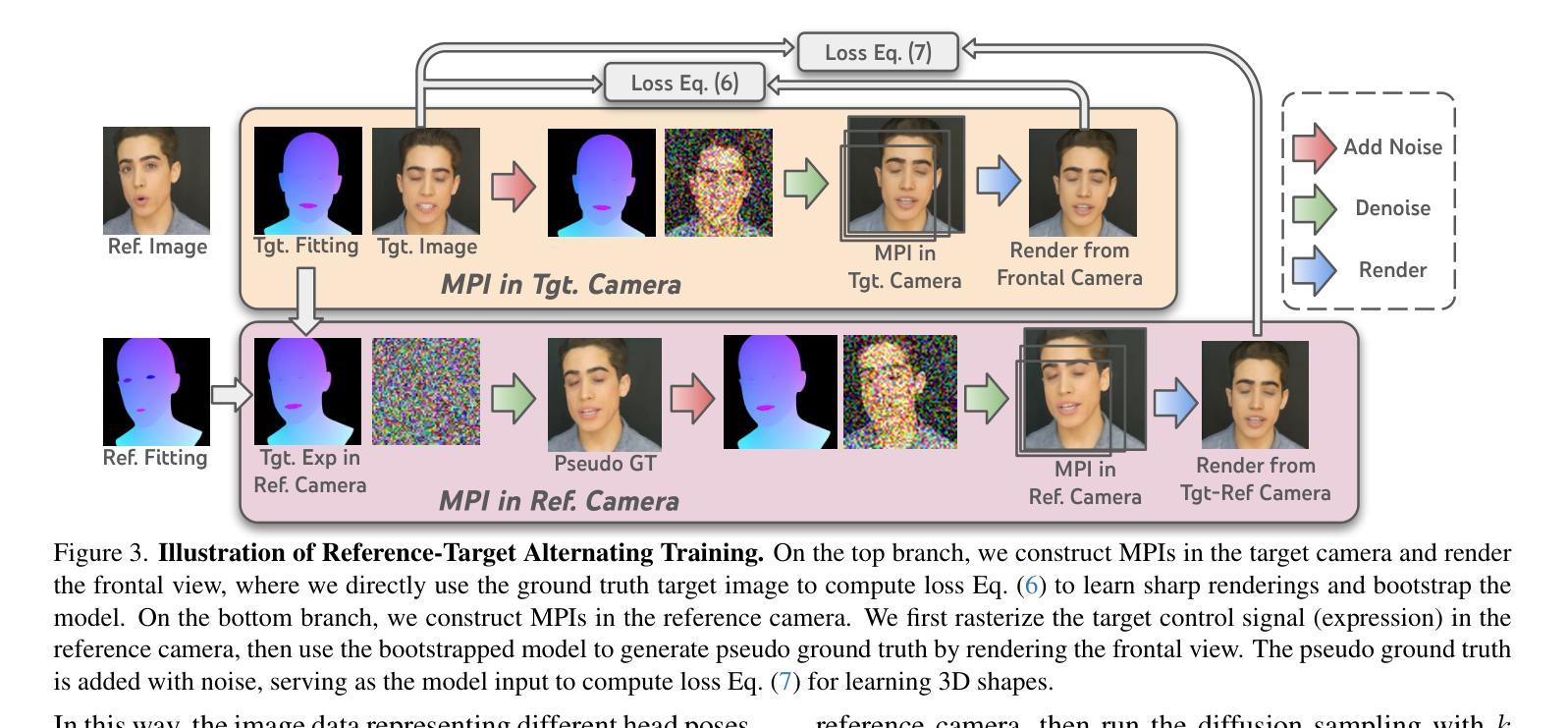
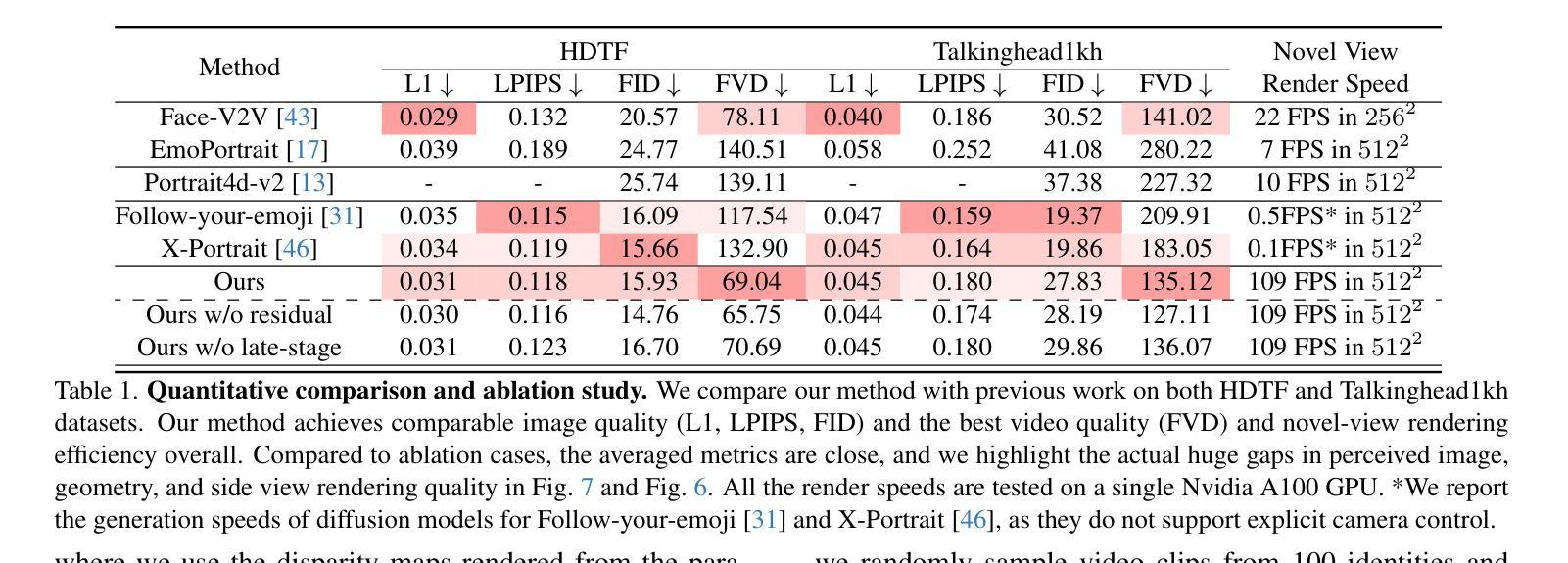
IM-Portrait: Learning 3D-aware Video Diffusion for PhotorealisticTalking Heads from Monocular Videos
Authors:Yuan Li, Ziqian Bai, Feitong Tan, Zhaopeng Cui, Sean Fanello, Yinda Zhang
We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
我们提出了一种新型的基于三维扩散的方法,直接从单张身份图像和明确的控制信号(如表情)生成逼真的动态视频。我们的方法生成多平面图像(MPIs),确保几何一致性,使其成为适合沉浸式观看体验的理想选择,如VR头盔的双眼视频。与通常需要单独阶段或联合优化来重建三维表示(如NeRF或三维高斯分布)的现有方法不同,我们的方法通过单个去噪过程直接生成最终输出,无需后处理步骤即可有效地渲染新颖视图。为了有效地从单眼视频中学习,我们引入了一种训练机制,该机制可以在目标相机空间或参考相机空间中随机重建输出MPI。这种方法使模型能够同时学习尖锐的图像细节和潜在的三维信息。大量实验证明了我们方法的有效性,即使在没有明确的三维重建或高质量的多视角训练数据的情况下,也能实现具有竞争力的化身质量和新颖的视图渲染能力。
论文及项目相关链接
PDF CVPR2025; project page: https://y-u-a-n-l-i.github.io/projects/IM-Portrait/
摘要
本文提出了一种基于三维感知扩散的方法,用于直接从单一身份图像和明确的控制信号(如表情)生成逼真的动态视频图像。该方法生成的多平面图像(MPIs)确保了几何一致性,使其成为适合虚拟现实头盔显示器等沉浸式观看体验的理想选择。与其他通常需要单独阶段或联合优化来重建三维表示的方法不同(如NeRF或三维高斯分布),我们的方法通过单一的降噪过程直接生成最终输出,无需后处理步骤即可有效地渲染新的视角。为了有效地从单眼视频中学习,我们引入了一种训练机制,该机制可以随机重建目标或参考相机空间中的输出MPI。这种方法使模型能够同时学习清晰的图像细节和潜在的三维信息。大量实验证明了我们方法的有效性,该方法在无需明确的三维重建或高质量多视角训练数据的情况下,实现了具有竞争力的化身质量和新颖的视图渲染能力。
关键见解
- 提出了一种基于三维感知扩散的方法,直接从单一身份图像和控制信号生成逼真的动态视频图像。
- 生成的多平面图像(MPIs)确保了几何一致性,适用于沉浸式观看体验。
- 与其他需要复杂三维表示的方法不同,该方法通过单一的降噪过程直接生成最终输出,简化了流程。
- 引入了一种训练机制,随机重建输出MPI,使模型能够同时学习图像细节和潜在的三维信息。
- 该方法不需要明确的三维重建或高质量的多视角训练数据。
- 方法实现了具有竞争力的化身质量。
点此查看论文截图

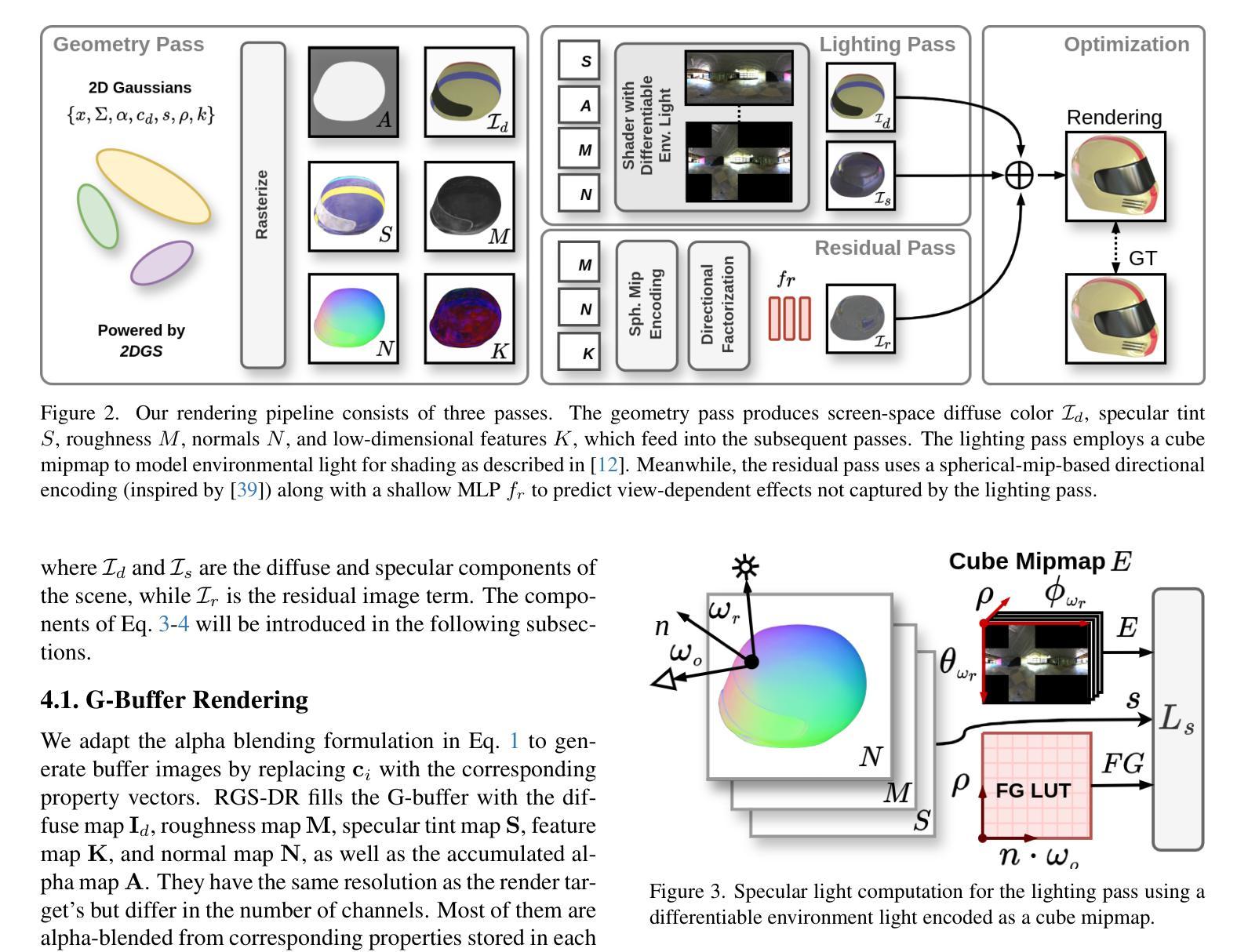
RGS-DR: Reflective Gaussian Surfels with Deferred Rendering for Shiny Objects
Authors:Georgios Kouros, Minye Wu, Tinne Tuytelaars
We introduce RGS-DR, a novel inverse rendering method for reconstructing and rendering glossy and reflective objects with support for flexible relighting and scene editing. Unlike existing methods (e.g., NeRF and 3D Gaussian Splatting), which struggle with view-dependent effects, RGS-DR utilizes a 2D Gaussian surfel representation to accurately estimate geometry and surface normals, an essential property for high-quality inverse rendering. Our approach explicitly models geometric and material properties through learnable primitives rasterized into a deferred shading pipeline, effectively reducing rendering artifacts and preserving sharp reflections. By employing a multi-level cube mipmap, RGS-DR accurately approximates environment lighting integrals, facilitating high-quality reconstruction and relighting. A residual pass with spherical-mipmap-based directional encoding further refines the appearance modeling. Experiments demonstrate that RGS-DR achieves high-quality reconstruction and rendering quality for shiny objects, often outperforming reconstruction-exclusive state-of-the-art methods incapable of relighting.
我们介绍了RGS-DR,这是一种用于重建和渲染光滑和反射物体的新型逆向渲染方法,支持灵活的重新打光和场景编辑。与现有方法(例如NeRF和3D高斯拼贴)不同,后者在处理视图相关效果时遇到困难,RGS-DR利用2D高斯surfel表示法准确估计几何和表面法线,这是高质量逆向渲染的基本属性。我们的方法通过可学习的原始元素显式建模几何和材料属性,并将其渲染为延迟着色管道,这有效地减少了渲染伪影并保留了锐利的反射。通过采用多层立方体mipmap,RGS-DR能够准确近似环境光照积分,从而实现高质量的重建和重新打光。基于球形mipmap的方向编码的残差传递进一步改进了外观建模。实验表明,RGS-DR在重建和渲染光泽物体时达到了高质量的效果,往往超越了那些无法进行重新打光的专属重建的最先进方法。
论文及项目相关链接
摘要
RGS-DR是一种新型的逆渲染方法,能够重建和渲染具有光泽和反射特性的物体,并支持灵活的重新照明和场景编辑。与现有的NeRF和3D高斯平板等方法不同,RGS-DR采用2D高斯曲面表示法准确估计几何和表面法线,这对于高质量逆渲染至关重要。通过可学习的原始几何和材料属性,我们的方法能够减少渲染伪影并保留清晰的反射。通过采用多层立方体mipmap,RGS-DR能够准确近似环境光照积分,从而实现高质量重建和重新照明。基于球状mipmap的方向编码的残差传递进一步改进了外观建模。实验表明,RGS-DR在重建和渲染光泽物体方面达到了高质量,通常优于无法重新照明的重建专用最新技术方法。
要点
- RGS-DR是一种新颖的逆渲染方法,可以重建和渲染具有光泽和反射特性的物体。
- 它支持灵活的重新照明和场景编辑。
- RGS-DR采用2D高斯曲面表示法来准确估计几何和表面法线,这对于高质量逆渲染很重要。
- 该方法通过可学习的原始几何和材料属性,有效减少渲染伪影,保留清晰反射。
- 采用多层立方体mipmap,准确近似环境光照积分,实现高质量重建和重新照明。
- 残差传递与球状mipmap的方向编码相结合,进一步改进外观建模。
- 实验表明,RGS-DR在重建和渲染光泽物体方面表现出色,通常优于其他方法。
点此查看论文截图

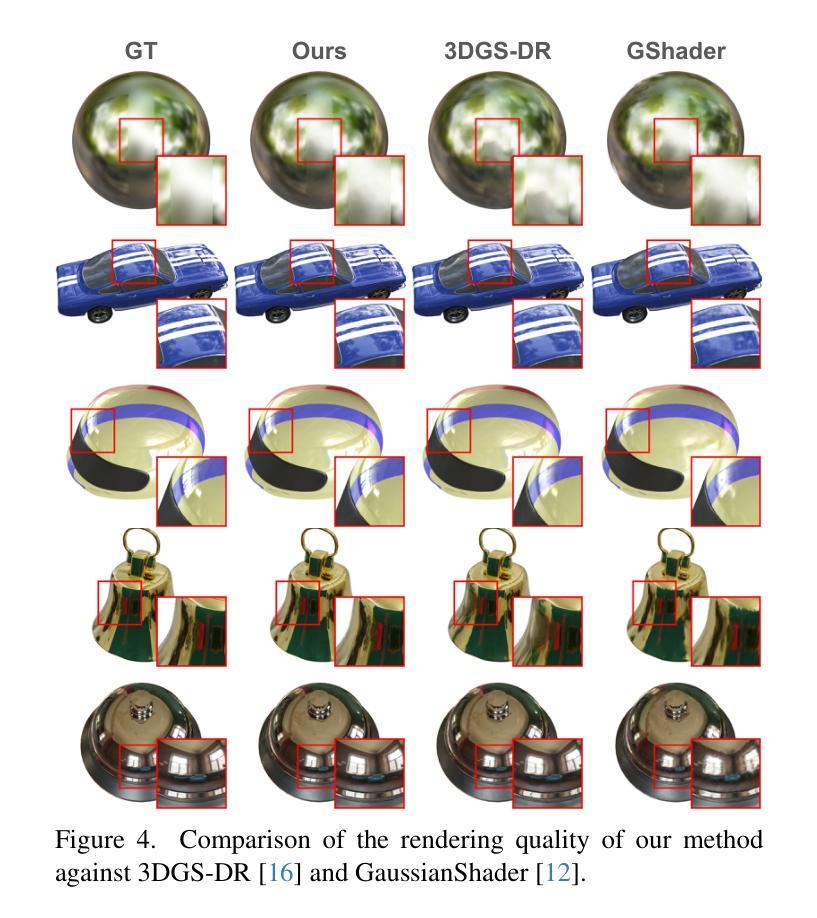
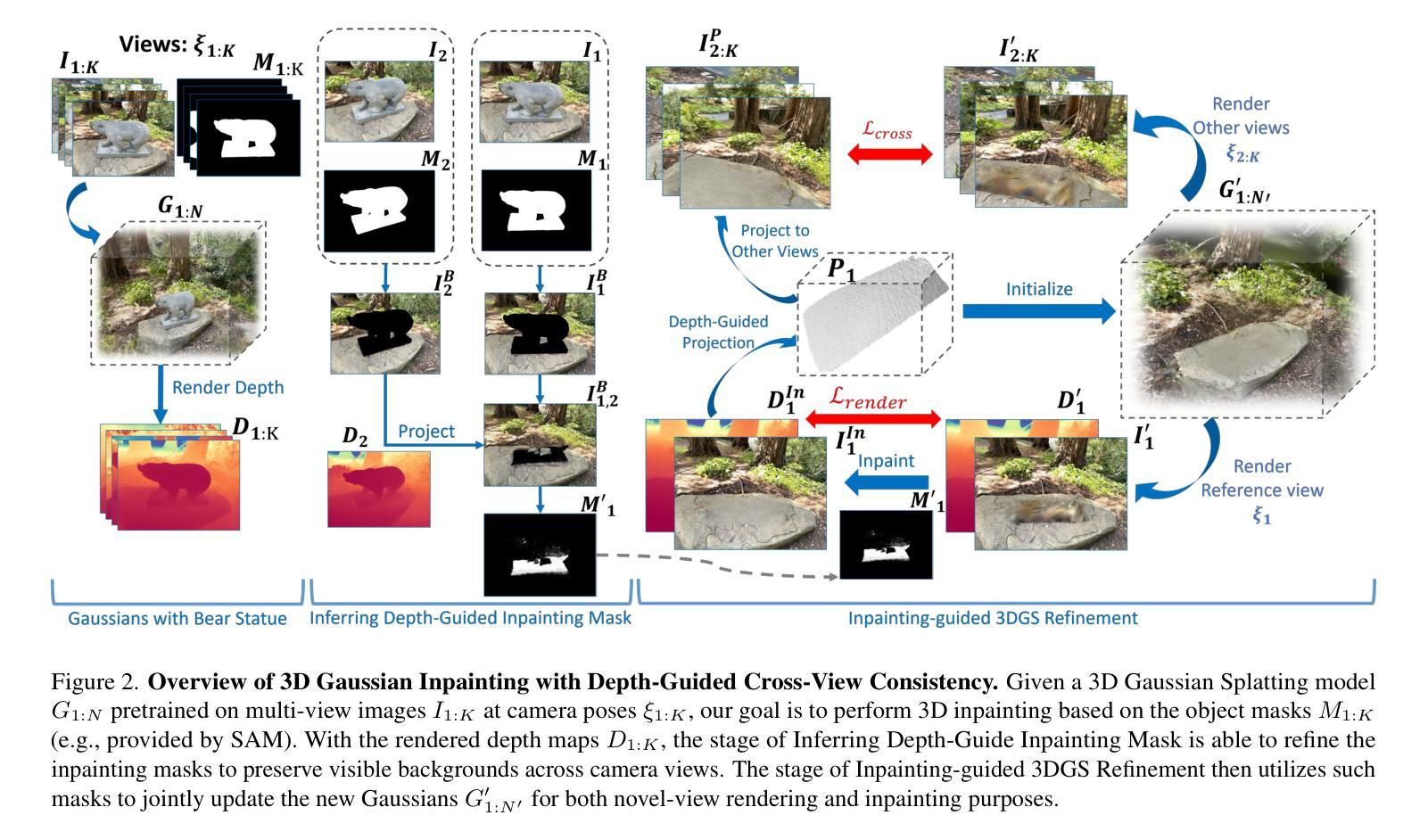
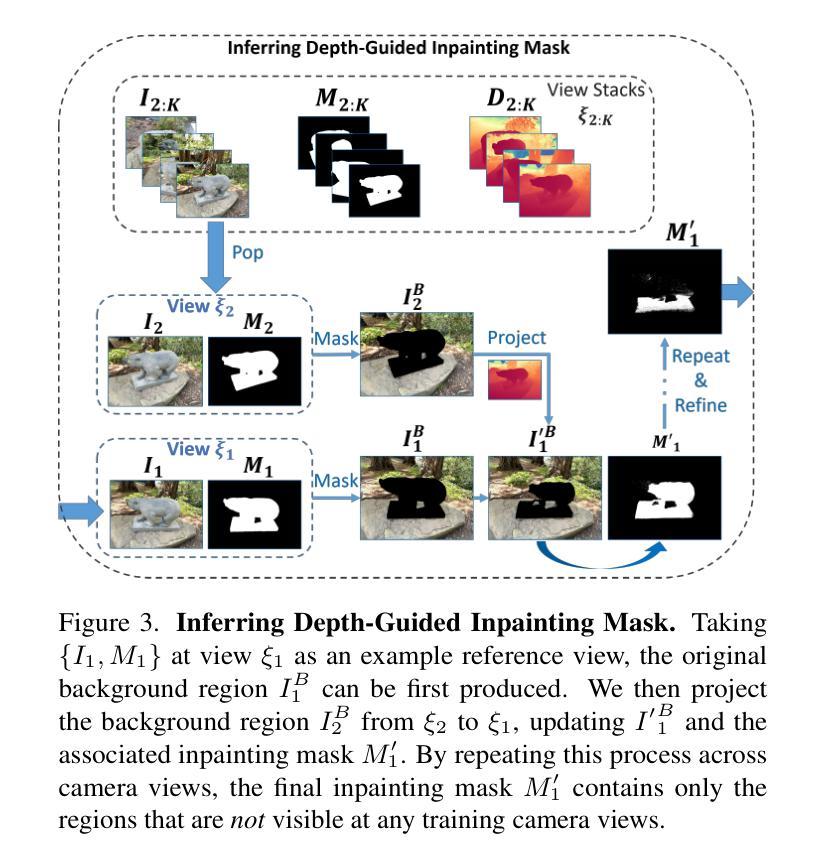
3D Gaussian Inpainting with Depth-Guided Cross-View Consistency
Authors:Sheng-Yu Huang, Zi-Ting Chou, Yu-Chiang Frank Wang
When performing 3D inpainting using novel-view rendering methods like Neural Radiance Field (NeRF) or 3D Gaussian Splatting (3DGS), how to achieve texture and geometry consistency across camera views has been a challenge. In this paper, we propose a framework of 3D Gaussian Inpainting with Depth-Guided Cross-View Consistency (3DGIC) for cross-view consistent 3D inpainting. Guided by the rendered depth information from each training view, our 3DGIC exploits background pixels visible across different views for updating the inpainting mask, allowing us to refine the 3DGS for inpainting purposes.Through extensive experiments on benchmark datasets, we confirm that our 3DGIC outperforms current state-of-the-art 3D inpainting methods quantitatively and qualitatively.
在使用Neural Radiance Field(NeRF)或3D Gaussian Splatting(3DGS)等新型视点渲染方法进行3D图像修复时,如何在不同相机视点之间实现纹理和几何一致性是一大挑战。在本文中,我们提出了一种名为“深度引导跨视图一致性三维高斯修复”(Depth-Guided Cross-View Consistency for 3D Gaussian Inpainting,简称3DGIC)的框架,以实现跨视图一致性的三维修复。通过利用来自每个训练视图的渲染深度信息作为指导,我们的3DGIC利用在不同视图中可见的背景像素来更新修复掩码,从而能够对用于修复目的的3DGS进行微调。通过对基准数据集进行大量实验,我们证实我们的3DGIC在数量和质量上都优于当前最先进的3D修复方法。
论文及项目相关链接
PDF Accepted to CVPR 2025. For project page, see https://peterjohnsonhuang.github.io/3dgic-pages
Summary
本文提出了一种基于深度引导跨视图一致性(Depth-Guided Cross-View Consistency,简称3DGIC)的3D高斯补全框架,用于实现跨视图一致的3D补全。该框架利用从各个训练视图中渲染的深度信息,通过利用在不同视图中可见的背景像素来更新补全掩模,实现对NeRF和3DGS等新型视图渲染方法的3D补全。实验证明,该框架在定量和定性上均优于当前先进的3D补全方法。
Key Takeaways
- 该论文解决了使用新型视图渲染方法(如NeRF和3DGS)进行3D补全时,如何实现跨相机视角的纹理和几何一致性挑战。
- 提出了一种基于深度引导跨视图一致性(Depth-Guided Cross-View Consistency,简称3DGIC)的框架用于实现跨视图一致的3D补全。
- 该框架通过利用渲染的深度信息来指导不同视角下的背景像素,从而实现视图的整合和对3D模型的准确补全。
- 利用背景像素更新补全掩模,使得在补全过程中能更精细地处理细节。
- 该框架通过实验证明在定量和定性上均优于当前先进的3D补全方法。
- 这一研究成果可能进一步推动在计算机视觉和计算机图形学领域中三维模型重建技术的发展和应用。
点此查看论文截图


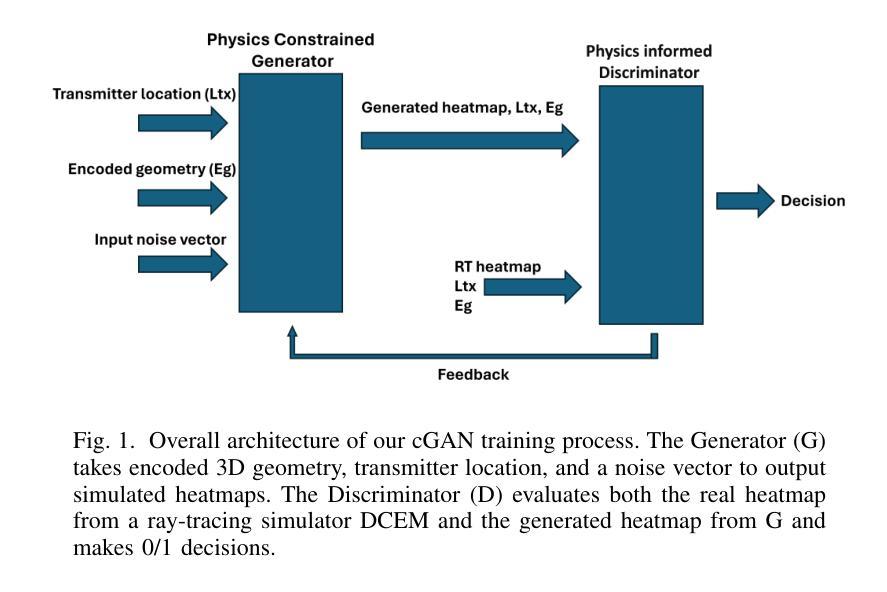
EM-GANSim: Real-time and Accurate EM Simulation Using Conditional GANs for 3D Indoor Scenes
Authors:Ruichen Wang, Dinesh Manocha
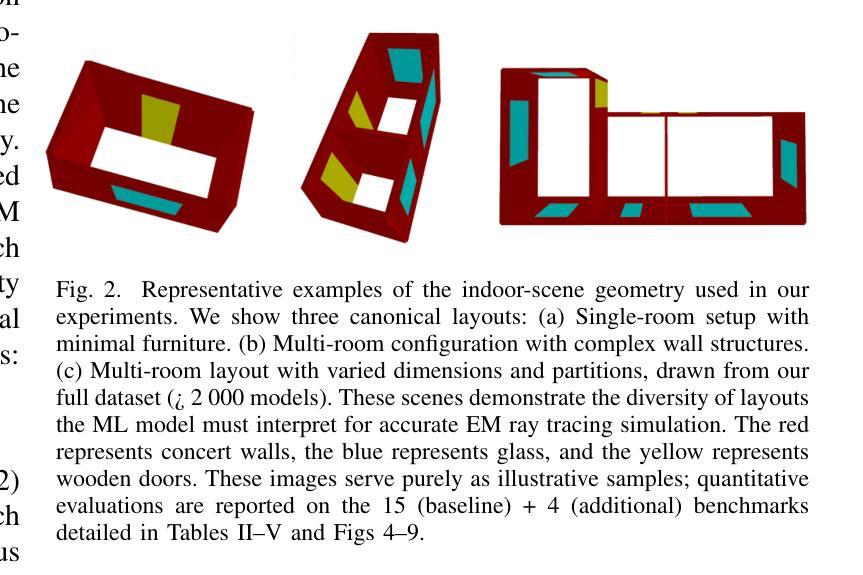
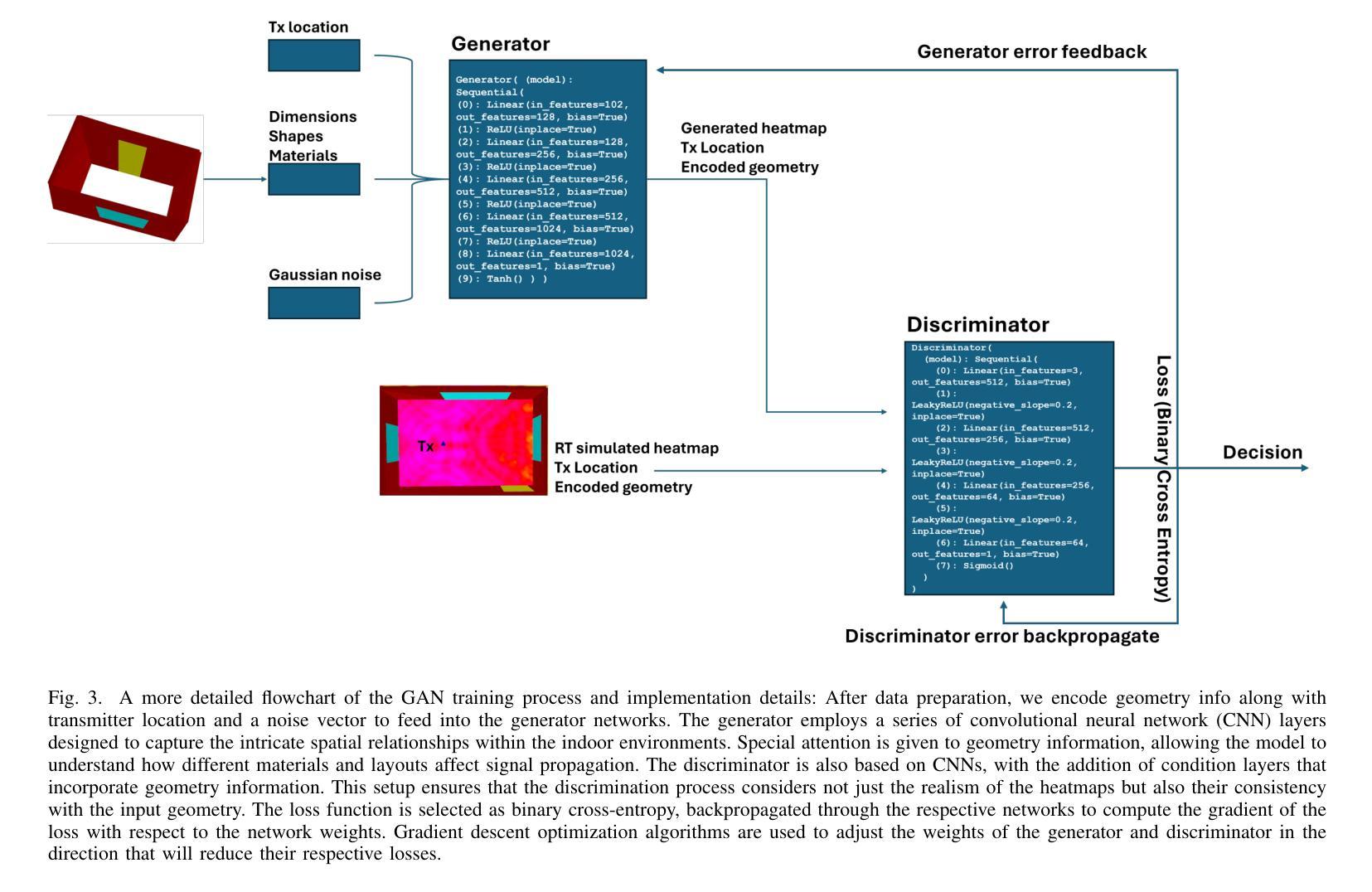
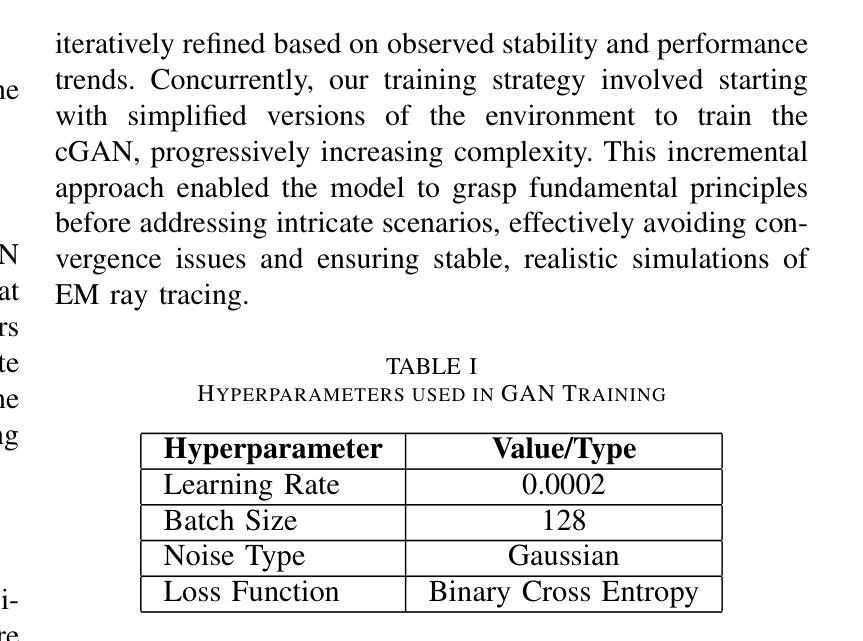
We present a novel machine-learning (ML) approach (EM-GANSim) for real-time electromagnetic (EM) propagation that is used for wireless communication simulation in 3D indoor environments. Our approach uses a modified conditional Generative Adversarial Network (GAN) that incorporates encoded geometry and transmitter location while adhering to the electromagnetic propagation theory. The overall physically-inspired learning is able to predict the power distribution in 3D scenes, which is represented using heatmaps. We evaluated our method on 15 complex 3D indoor environments, with 4 additional scenarios later included in the results, showcasing the generalizability of the model across diverse conditions. Our overall accuracy is comparable to ray tracing-based EM simulation, as evidenced by lower mean squared error values. Furthermore, our GAN-based method drastically reduces the computation time, achieving a 5X speedup on complex benchmarks. In practice, it can compute the signal strength in a few milliseconds on any location in 3D indoor environments. We also present a large dataset of 3D models and EM ray tracing-simulated heatmaps. To the best of our knowledge, EM-GANSim is the first real-time algorithm for EM simulation in complex 3D indoor environments. We plan to release the code and the dataset.
我们提出了一种用于实时电磁(EM)传播的新型机器学习(ML)方法(EM-GANSim),用于在复杂的3D室内环境中进行无线通信模拟。我们的方法使用了一种改进的条件生成对抗网络(GAN),该网络结合了编码几何和发射机位置,同时遵循电磁传播理论。整体受物理启发的学习方法能够预测3D场景中的功率分布,使用热图进行表示。我们在15个复杂的3D室内环境中评估了我们的方法,并在结果中添加了另外4个场景,展示了该模型在不同条件下的通用性。我们的总体精度与基于光线追踪的EM模拟相当,较低的均方误差值证明了这一点。此外,我们基于GAN的方法极大地减少了计算时间,在复杂的基准测试上实现了5倍的加速。实际上,它可以在毫秒内计算任何3D室内环境中的信号强度。我们还提供了一套大型的3D模型和EM射线追踪模拟热图数据集。据我们所知,EM-GANSim是复杂3D室内环境中进行EM模拟的首个实时算法。我们计划发布代码和数据集。
论文及项目相关链接
PDF 12 pages, 9 figures, 5 tables
Summary
本文介绍了一种用于实时电磁传播模拟的新型机器学习算法EM-GANSim,该算法用于室内三维无线通信模拟。算法采用修改后的条件生成对抗网络(GAN),结合编码几何和发射机位置,遵循电磁传播理论。该算法能够预测三维场景中的功率分布,并以热图形式呈现。在多个复杂室内环境中评估了该方法,其准确性可与基于光线追踪的电磁模拟相当,并且大大减少了计算时间,实现了复杂基准测试的5倍加速。此外,还发布了一个包含三维模型和电磁射线追踪模拟热图的大型数据集。EM-GANSim是首个用于复杂室内环境的实时电磁模拟算法。
Key Takeaways
- EM-GANSim是一种新型的机器学习算法,用于实时模拟三维室内环境中的电磁传播。
- 该算法采用条件生成对抗网络(GAN),结合几何编码、发射机位置和电磁传播理论。
- EM-GANSim能够预测三维场景中的功率分布,并以热图形式呈现。
- 在多个复杂室内环境中评估了EM-GANSim,其准确性可与基于光线追踪的电磁模拟相当。
- 与其他模拟方法相比,EM-GANSim大大减少了计算时间,实现了加速。
- 发布了一个包含三维模型和电磁射线追踪模拟热图的大型数据集。
- EM-GANSim是首个用于复杂室内环境的实时电磁模拟算法。
点此查看论文截图

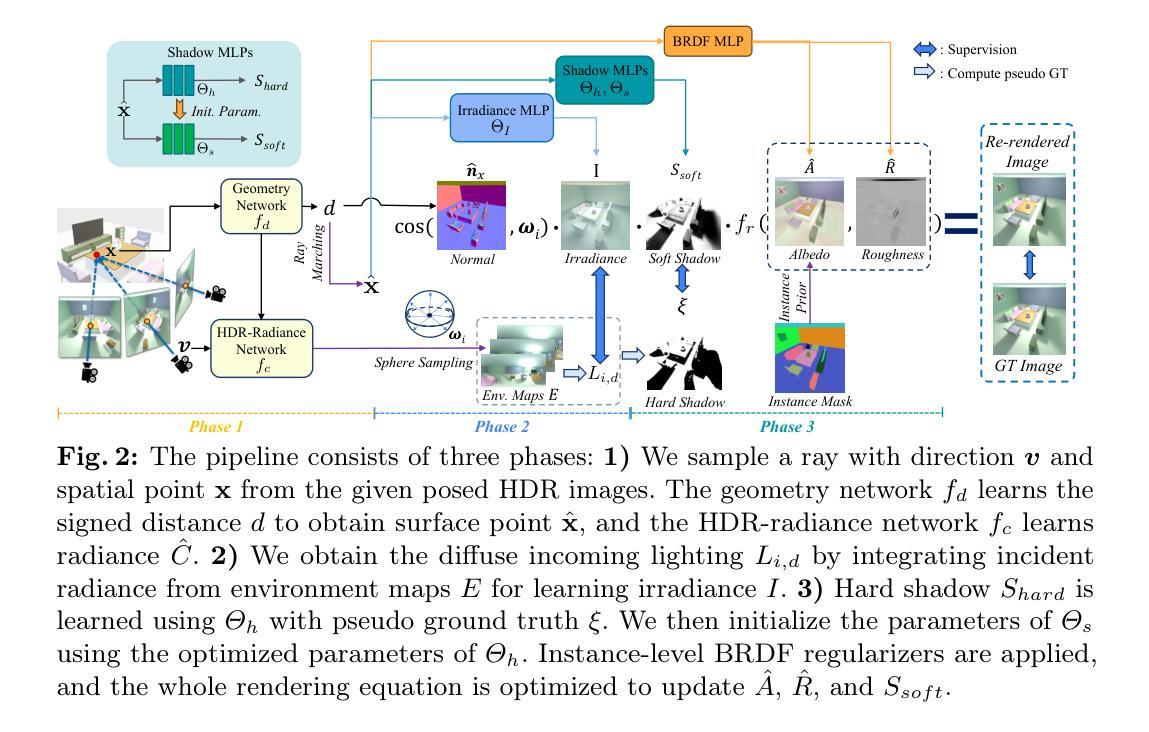
SIR: Multi-view Inverse Rendering with Decomposable Shadow Under Indoor Intense Lighting
Authors:Xiaokang Wei, Zhuoman Liu, Ping Li, Yan Luximon
We propose SIR, an efficient method to decompose differentiable shadows for inverse rendering on indoor scenes using multi-view data, addressing the challenges in accurately decomposing the materials and lighting conditions. Unlike previous methods that struggle with shadow fidelity in complex lighting environments, our approach explicitly learns shadows for enhanced realism in material estimation under unknown light positions. Utilizing posed HDR images as input, SIR employs an SDF-based neural radiance field for comprehensive scene representation. Then, SIR integrates a shadow term with a three-stage material estimation approach to improve SVBRDF quality. Specifically, SIR is designed to learn a differentiable shadow, complemented by BRDF regularization, to optimize inverse rendering accuracy. Extensive experiments on both synthetic and real-world indoor scenes demonstrate the superior performance of SIR over existing methods in both quantitative metrics and qualitative analysis. The significant decomposing ability of SIR enables sophisticated editing capabilities like free-view relighting, object insertion, and material replacement. The code and data are available at https://xiaokangwei.github.io/SIR/.
我们提出了SIR,这是一种利用多视角数据对室内场景进行逆向渲染的高效可微分阴影分解方法,解决了准确分解材料和照明条件方面的挑战。与以往在复杂光照环境中难以处理阴影保真度的方法不同,我们的方法能够显式地学习阴影,以提高未知光源位置下的材料估计的真实感。SIR利用姿态HDR图像作为输入,采用基于SDF的神经辐射场进行场景全面表示。然后,SIR将阴影项与三阶段材料估计方法相结合,以提高SVBRDF的质量。具体来说,SIR被设计成学习一个可微分的阴影,辅以BRDF正则化,以优化逆向渲染的准确性。在合成和真实室内场景上的大量实验表明,SIR在定量指标和定性分析方面均优于现有方法。SIR的重要分解能力可实现高级编辑功能,如自由视角重新照明、对象插入和材料替换。代码和数据可在https://xiaokangwei.github.io/SIR/找到。
论文及项目相关链接
PDF ICME 2025. Homepage:https://xiaokangwei.github.io/SIR/
Summary
本文提出SIR方法,利用多视角数据在室内场景进行逆向渲染中的可分化阴影分解,解决材料和光照条件准确分解的挑战。SIR采用基于神经辐射场的SDF技术进行全面场景表示,通过三阶段材料估计方法与阴影项集成,提高SVBRDF质量。SIR设计用于学习可分化阴影,配合BRDF正则化,优化逆向渲染精度。在合成和真实室内场景的实验中,SIR在定量指标和定性分析上均表现出卓越性能,具备高级编辑能力,如自由视角重新照明、对象插入和材料替换。
Key Takeaways
- SIR是一种利用多视角数据进行室内场景逆向渲染的方法,能够分解阴影以准确表示材料和光照条件。
- 采用基于神经辐射场的SDF技术进行全面场景表示。
- 通过三阶段材料估计方法与阴影项集成,提高SVBRDF质量。
- SIR能够学习可分化阴影,配合BRDF正则化,优化逆向渲染精度。
- 在合成和真实室内场景的实验中,SIR性能卓越,超过现有方法。
- SIR具备高级编辑能力,如自由视角重新照明、对象插入和材料替换。
点此查看论文截图