⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-30 更新
DEEMO: De-identity Multimodal Emotion Recognition and Reasoning
Authors:Deng Li, Bohao Xing, Xin Liu, Baiqiang Xia, Bihan Wen, Heikki Kälviäinen
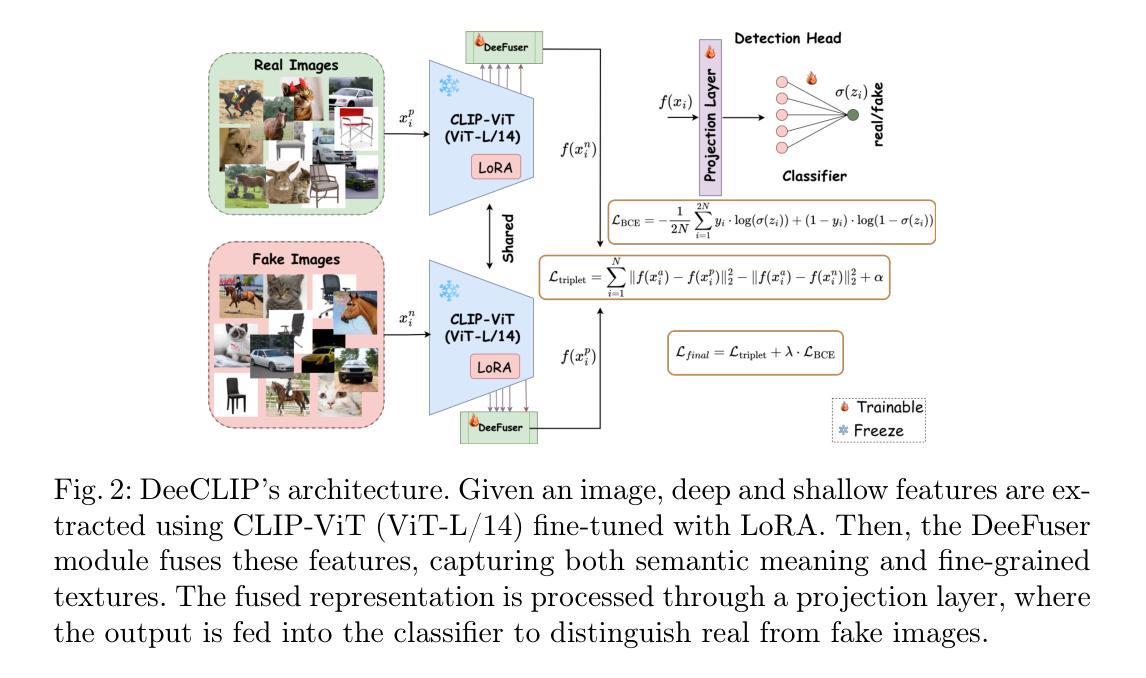
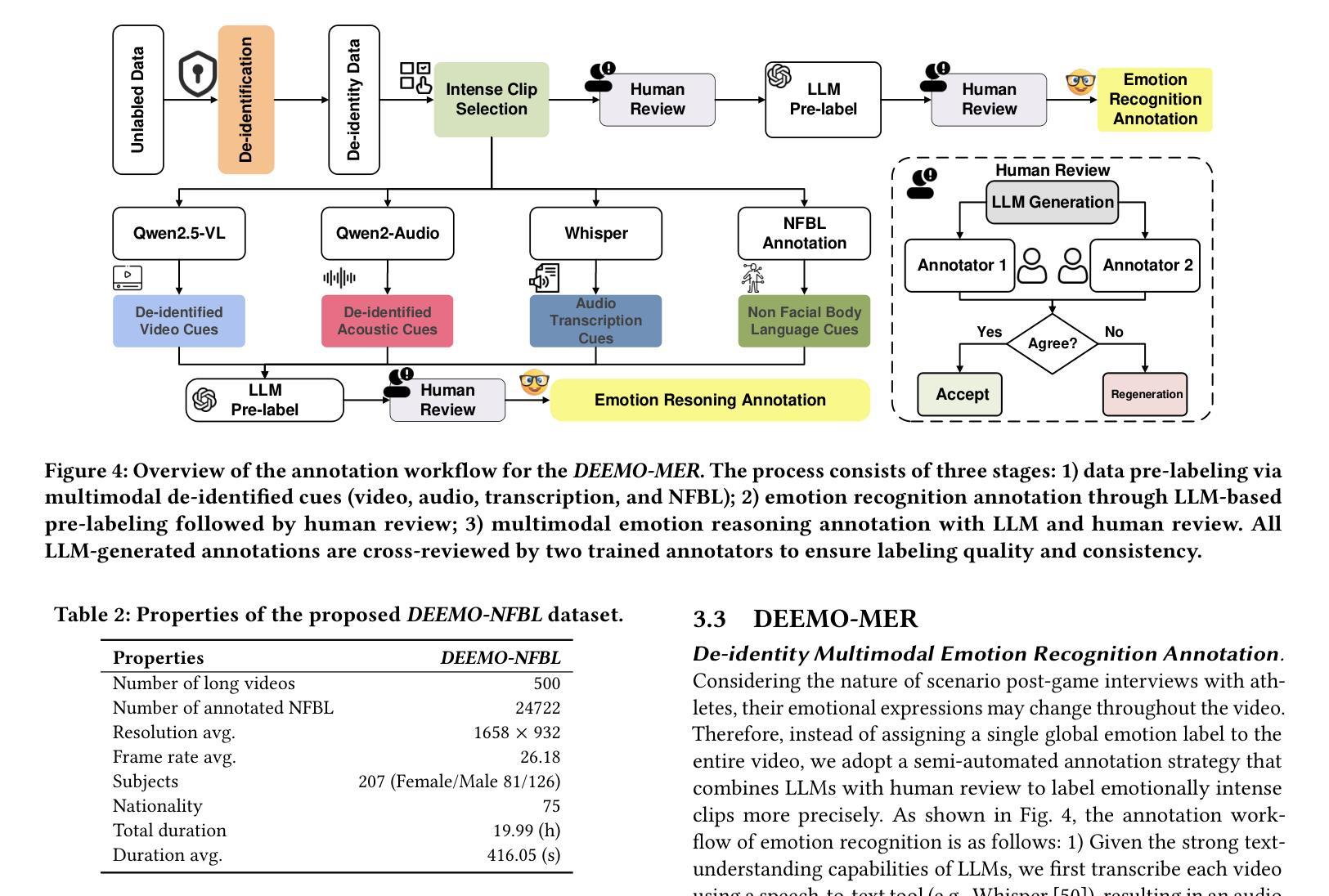
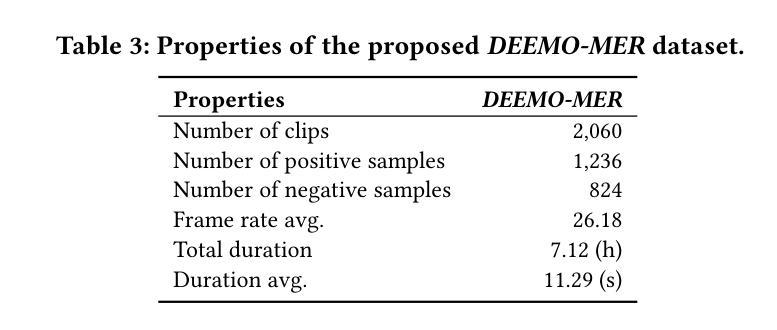
Emotion understanding is a critical yet challenging task. Most existing approaches rely heavily on identity-sensitive information, such as facial expressions and speech, which raises concerns about personal privacy. To address this, we introduce the De-identity Multimodal Emotion Recognition and Reasoning (DEEMO), a novel task designed to enable emotion understanding using de-identified video and audio inputs. The DEEMO dataset consists of two subsets: DEEMO-NFBL, which includes rich annotations of Non-Facial Body Language (NFBL), and DEEMO-MER, an instruction dataset for Multimodal Emotion Recognition and Reasoning using identity-free cues. This design supports emotion understanding without compromising identity privacy. In addition, we propose DEEMO-LLaMA, a Multimodal Large Language Model (MLLM) that integrates de-identified audio, video, and textual information to enhance both emotion recognition and reasoning. Extensive experiments show that DEEMO-LLaMA achieves state-of-the-art performance on both tasks, outperforming existing MLLMs by a significant margin, achieving 74.49% accuracy and 74.45% F1-score in de-identity emotion recognition, and 6.20 clue overlap and 7.66 label overlap in de-identity emotion reasoning. Our work contributes to ethical AI by advancing privacy-preserving emotion understanding and promoting responsible affective computing.
情感理解是一项至关重要且具有挑战性的任务。大多数现有方法都严重依赖于身份敏感信息,如面部表情和语音,这引发了关于个人隐私的担忧。为了解决这一问题,我们引入了去身份化多模态情感识别与推理(DEEMO),这是一项旨在利用去身份化的视频和音频输入实现情感理解的新任务。DEEMO数据集包含两个子集:DEEMO-NFBL,包含丰富的非面部肢体语言(NFBL)注释;以及DEEMO-MER,这是一个使用无身份线索进行多模态情感识别和推理的指令数据集。这种设计能够在不泄露身份隐私的情况下支持情感理解。此外,我们提出了DEEMO-LLaMA,这是一种多模态大型语言模型(MLLM),它整合了去身份化的音频、视频和文本信息,以提高情感识别和推理能力。大量实验表明,DEEMO-LLaMA在这两项任务上都达到了最新技术水平,显著优于现有的MLLMs,在去身份情感识别方面达到74.49%的准确率和74.45%的F1分数,在去身份情感推理方面达到6.20的线索重叠率和7.66的标签重叠率。我们的工作通过推进保护隐私的情感理解和促进负责任的情感计算,为伦理人工智能做出贡献。
论文及项目相关链接
Summary
该文本介绍了情绪理解的重要性及其面临的挑战。现有方法过于依赖身份敏感信息,引发隐私担忧。为此,提出一种去身份多模态情绪识别和推理(DEEMO)的新任务,旨在使用去身份的视频和音频输入实现情绪理解。数据集包括两个子集,一个关注非面部肢体语言(NFBL)的丰富注释,另一个用于多模态情绪识别和推理的身份无关线索指令数据集。此外,还提出了一种多模态大型语言模型(MLLM),可整合去身份音频、视频和文本信息,提高情绪识别和推理能力。实验表明,DEEMO-LLaMA在两项任务上均达到最新技术水平,显著优于现有MLLMs,在去身份情绪识别方面达到74.49%的准确率和74.45%的F1得分,在去身份情绪推理方面达到6.20的线索重叠率和7.66的标签重叠率。本研究为伦理人工智能做出贡献,推动了隐私保护的情绪理解和负责任的情感计算。
Key Takeaways
- 情绪理解是一项重要而具有挑战性的任务。
- 现有方法过于依赖身份敏感信息,引发隐私担忧。
- 提出了一种新型任务——去身份多模态情绪识别和推理(DEEMO)。
- DEEMO数据集包括两个子集:关注非面部肢体语言的DEEM-NFBL和用于多模态情绪识别和推理的身份无关指令数据集DEEM-MER。
- 提出了多模态大型语言模型(MLLM)DEEMO-LLaMA,融合了去身份音频、视频和文本信息。
- 实验结果显示,DEEMO-LLaMA在去身份情绪识别和推理方面表现优异,准确率分别为74.49%和F1得分为74.45%。
点此查看论文截图


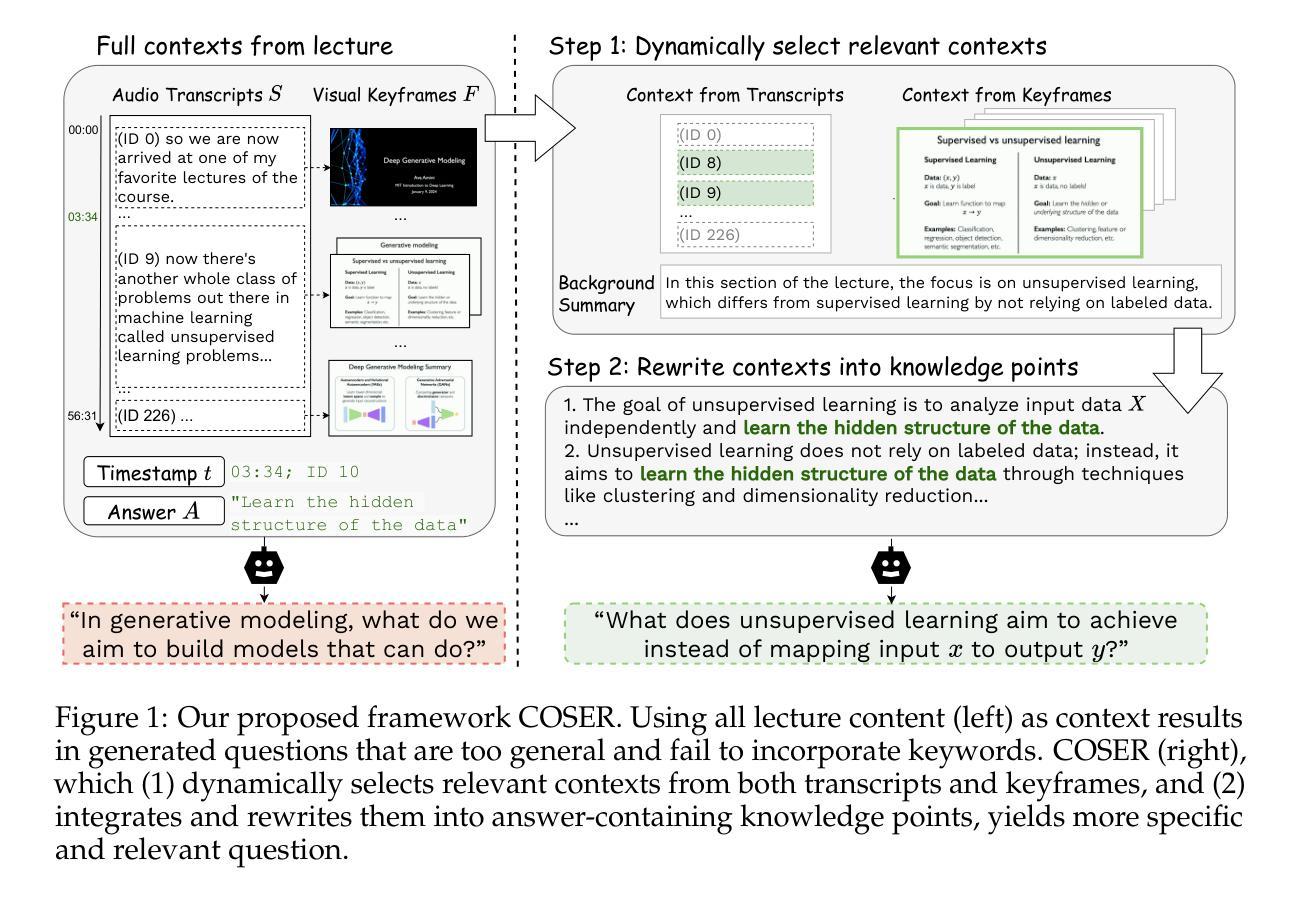
Context Selection and Rewriting for Video-based EducationalQuestion Generation
Authors:Mengxia Yu, Bang Nguyen, Olivia Zino, Meng Jiang
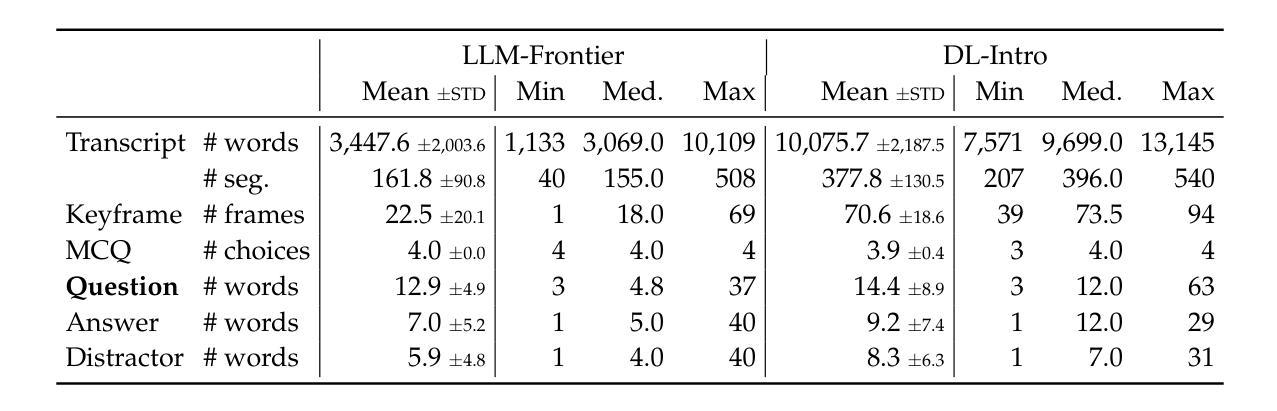
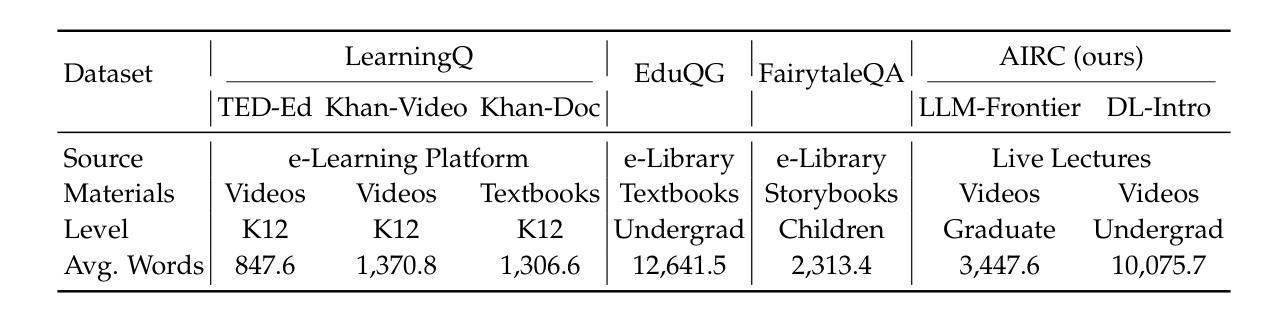
Educational question generation (EQG) is a crucial component of intelligent educational systems, significantly aiding self-assessment, active learning, and personalized education. While EQG systems have emerged, existing datasets typically rely on predefined, carefully edited texts, failing to represent real-world classroom content, including lecture speech with a set of complementary slides. To bridge this gap, we collect a dataset of educational questions based on lectures from real-world classrooms. On this realistic dataset, we find that current methods for EQG struggle with accurately generating questions from educational videos, particularly in aligning with specific timestamps and target answers. Common challenges include selecting informative contexts from extensive transcripts and ensuring generated questions meaningfully incorporate the target answer. To address the challenges, we introduce a novel framework utilizing large language models for dynamically selecting and rewriting contexts based on target timestamps and answers. First, our framework selects contexts from both lecture transcripts and video keyframes based on answer relevance and temporal proximity. Then, we integrate the contexts selected from both modalities and rewrite them into answer-containing knowledge statements, to enhance the logical connection between the contexts and the desired answer. This approach significantly improves the quality and relevance of the generated questions. Our dataset and code are released in https://github.com/mengxiayu/COSER.
教育问题生成(EQG)是智能教育系统的关键组成部分,极大地有助于自我评估、主动学习和个性化教育。虽然已经出现了一些EQG系统,但现有的数据集通常依赖于预先定义、精心编辑的文本,无法代表真实课堂内容,包括配有辅助幻灯片的讲座演讲。为了弥补这一差距,我们收集了一个基于真实课堂讲座的教育问题数据集。在这个现实的数据集上,我们发现现有的EQG方法在生成教育视频的问题时面临困难,特别是在与特定时间戳和目标答案对齐方面。常见的挑战包括从大量脚本中选择有意义上下文和确保生成的问题有意义地融入目标答案。为了应对这些挑战,我们引入了一个利用大型语言模型的新框架,该框架可根据目标时间戳和答案动态选择和重写上下文。首先,我们的框架根据答案相关性和时间接近性从讲座脚本和视频关键帧中选择上下文。然后,我们整合从这两种模式中选择出的上下文,并将其改写为包含答案的知识陈述,以增强上下文与所需答案之间的逻辑联系。这种方法显著提高了生成问题的质量和相关性。我们的数据集和代码已在https://github.com/mengxiayu/COSER中发布。
论文及项目相关链接
Summary
教育问题生成(EQG)是智能教育系统的重要组成部分,有助于自我评估、主动学习和个性化教育。针对现有EQG数据集主要依赖预设编辑文本,未能真实反映课堂内容的问题,我们收集了一个基于真实课堂讲座的教育问题数据集。研究发现,现有方法难以准确从教育视频中生成问题,特别是在与特定时间戳和目标答案对齐方面存在挑战。为此,我们提出了一种利用大型语言模型的新框架,该框架可根据目标时间戳和答案动态选择和改写上下文。通过选择与讲座视频内容相关的语境,并进行重写以强化上下文与目标答案之间的逻辑联系,进而提高生成问题的质量和相关性。我们的数据集和代码已发布在:https://github.com/mengxiayu/COSER。
Key Takeaways
- 教育问题生成(EQG)是智能教育系统的重要部分,有助于自我评估、主动学习和个性化教育。
- 目前的数据集主要依赖预设编辑文本,未能真实反映课堂环境,特别是讲座内容和相关幻灯片。
- 现有方法在生成与特定时间戳和目标答案对齐的问题时存在困难。
- 提出的框架利用大型语言模型动态选择和改写上下文,基于目标时间戳和答案。
- 框架从讲座视频内容和视觉关键帧中选择相关语境。
- 通过整合来自不同模态的上下文并将其改写为包含答案的知识陈述,增强了上下文与目标答案的逻辑联系。
点此查看论文截图

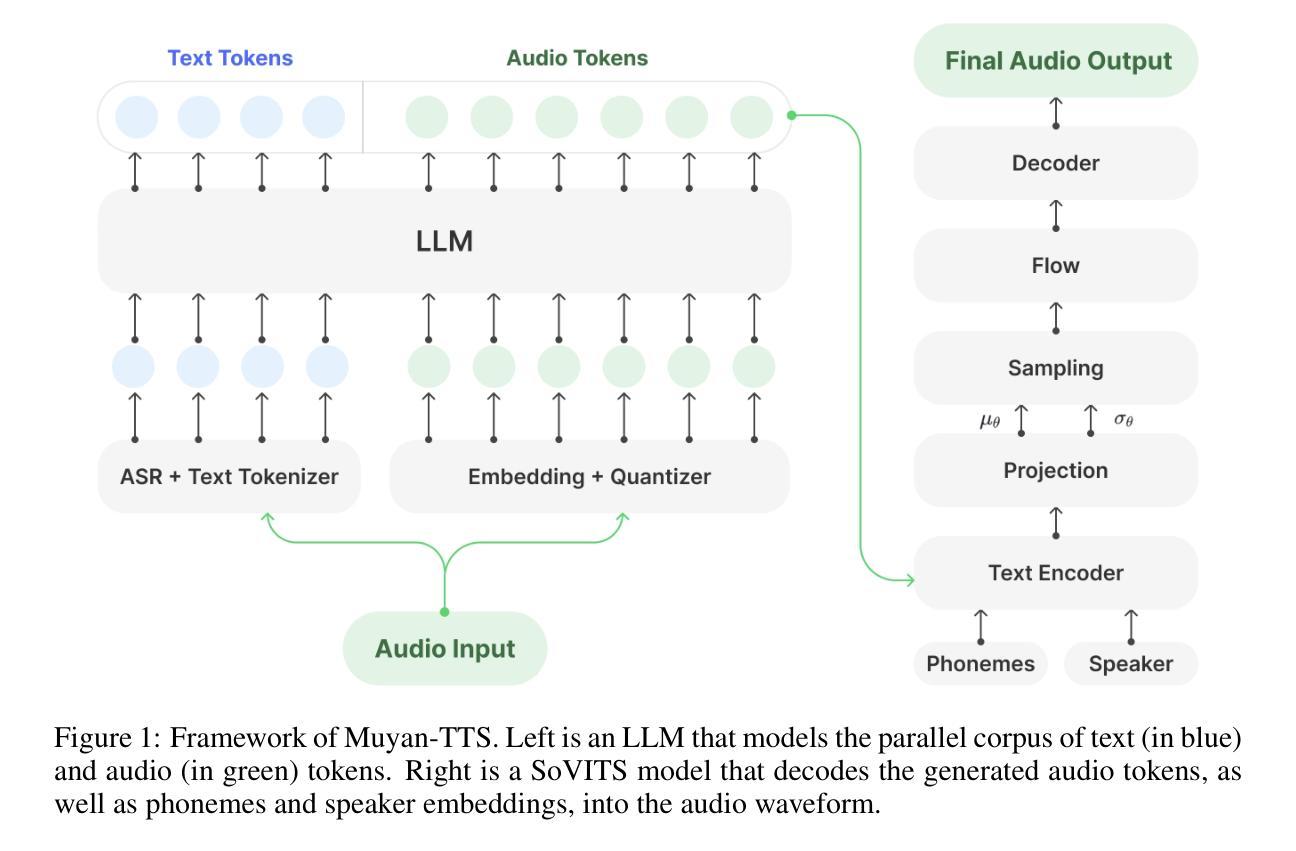
Muyan-TTS: A Trainable Text-to-Speech Model Optimized for Podcast Scenarios with a $50K Budget
Authors:Xin Li, Kaikai Jia, Hao Sun, Jun Dai, Ziyang Jiang
Recent advancements in text-to-speech (TTS) models have been driven by the integration of large language models (LLMs), enhancing semantic comprehension and improving speech naturalness. However, existing LLM-based TTS models often lack open-source training code and efficient inference acceleration frameworks, limiting their accessibility and adaptability. Additionally, there is no publicly available TTS model specifically optimized for podcast scenarios, which are in high demand for voice interaction applications. To address these limitations, we introduce Muyan-TTS, an open-source trainable TTS model designed for podcast applications within a $50,000 budget. Our model is pre-trained on over 100,000 hours of podcast audio data, enabling zero-shot TTS synthesis with high-quality voice generation. Furthermore, Muyan-TTS supports speaker adaptation with dozens of minutes of target speech, making it highly customizable for individual voices. In addition to open-sourcing the model, we provide a comprehensive data collection and processing pipeline, a full training procedure, and an optimized inference framework that accelerates LLM-based TTS synthesis. Our code and models are available at https://github.com/MYZY-AI/Muyan-TTS.
近期文本转语音(TTS)模型的进步得益于大型语言模型(LLM)的集成,提高了语义理解和语音自然度。然而,现有的基于LLM的TTS模型通常缺乏开源训练代码和高效的推理加速框架,限制了其可访问性和适应性。此外,目前没有一个针对播客场景的公开可用的TTS模型,而语音交互应用程序对此类模型的需求很高。为了解决这些限制,我们推出了Muyan-TTS,这是一个开源的可训练TTS模型,专为预算为5万美元的播客应用程序设计。我们的模型在超过10万小时的播客音频数据上进行预训练,能够实现零样本TTS合成和高质量的语音生成。此外,Muyan-TTS支持使用几十分钟的目标语音进行声纹适配,使其能够轻松定制个人声音。除了开源模型外,我们还提供了全面的数据收集和处理流程、完整的训练过程以及优化的推理框架,以加速基于LLM的TTS合成。我们的代码和模型可在https://github.com/MYZY-AI/Muyan-TTS获取。
论文及项目相关链接
Summary:
近期文本转语音(TTS)模型的进步得益于大型语言模型(LLM)的集成,提高了语义理解和语音自然度。然而,现有的LLM-based TTS模型缺乏开源训练代码和高效的推理加速框架,限制了其可访问性和适应性。为解决这一问题,我们推出了Muyan-TTS,这是一款为Podcast应用场景设计的开源训练型TTS模型,预算为5万美元。该模型在超过10万小时的Podcast音频数据上进行预训练,实现了零样本TTS合成高质量语音生成。Muyan-TTS还支持利用几十分钟的目标语音进行声音适应,高度个性化定制。除了开源模型外,我们还提供了全面的数据收集和处理流程、完整的训练流程以及优化的推理框架,以加速LLM-based TTS的合成。我们的代码和模型可在https://github.com/MYZY-AI/Muyan-TTS获取。
Key Takeaways:
- 近期TTS模型的进步得益于大型语言模型的集成,提高了语义理解和语音自然度。
- 现有TTS模型缺乏开源训练代码和高效的推理加速框架。
- Muyan-TTS是一款为Podcast应用场景设计的开源训练型TTS模型,预算友好。
- Muyan-TTS在大量Podcast音频数据上预训练,可实现零样本TTS合成高质量语音。
- Muyan-TTS支持利用几十分钟的语音数据进行声音适应,具有个性化定制的特点。
- 除了模型开源,还提供了全面的数据收集和处理流程、完整的训练流程。
点此查看论文截图


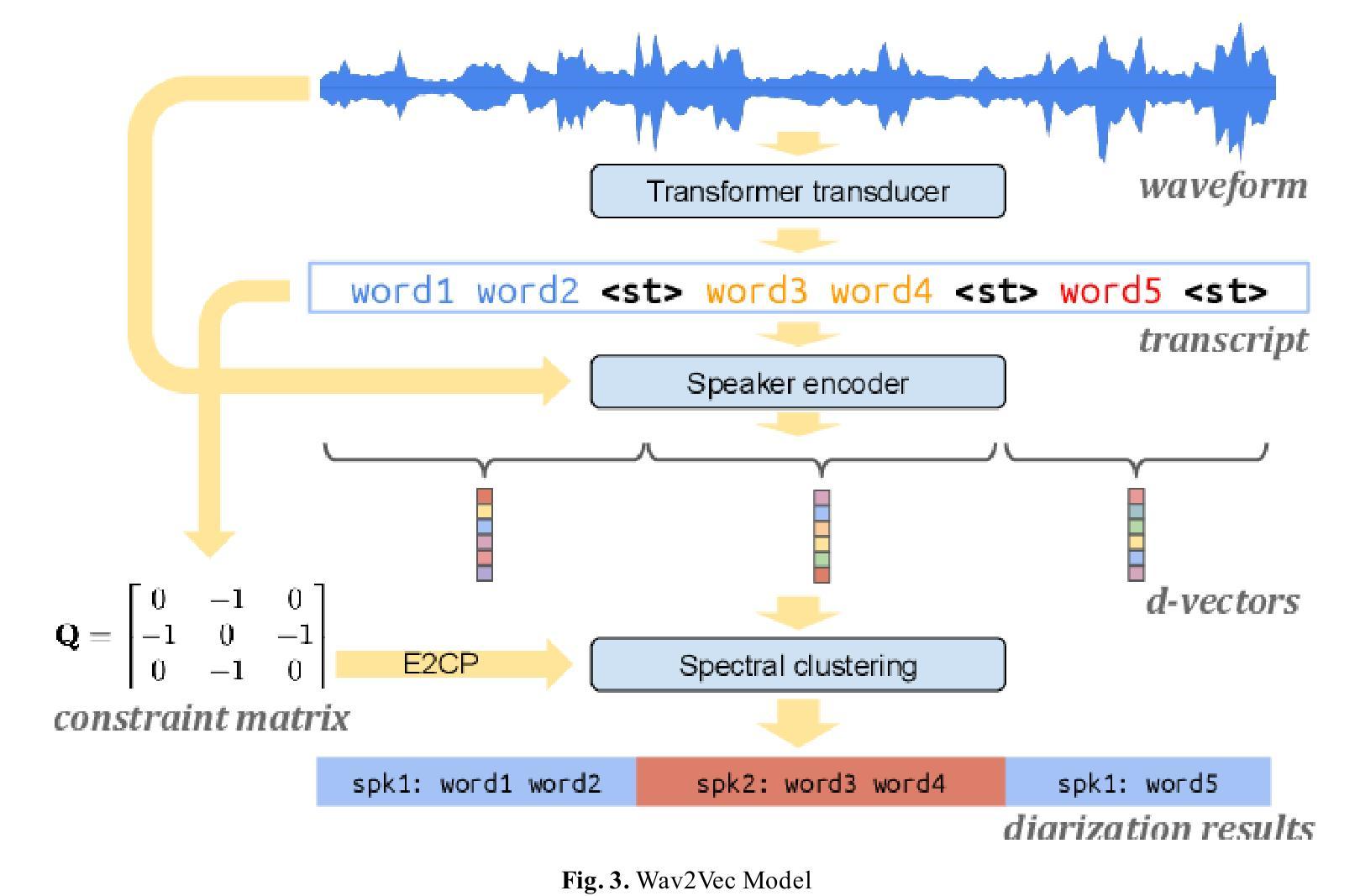
Speaker Diarization for Low-Resource Languages Through Wav2vec Fine-Tuning
Authors:Abdulhady Abas Abdullah, Sarkhel H. Taher Karim, Sara Azad Ahmed, Kanar R. Tariq, Tarik A. Rashid
Speaker diarization is a fundamental task in speech processing that involves dividing an audio stream by speaker. Although state-of-the-art models have advanced performance in high-resource languages, low-resource languages such as Kurdish pose unique challenges due to limited annotated data, multiple dialects and frequent code-switching. In this study, we address these issues by training the Wav2Vec 2.0 self-supervised learning model on a dedicated Kurdish corpus. By leveraging transfer learning, we adapted multilingual representations learned from other languages to capture the phonetic and acoustic characteristics of Kurdish speech. Relative to a baseline method, our approach reduced the diarization error rate by seven point two percent and improved cluster purity by thirteen percent. These findings demonstrate that enhancements to existing models can significantly improve diarization performance for under-resourced languages. Our work has practical implications for developing transcription services for Kurdish-language media and for speaker segmentation in multilingual call centers, teleconferencing and video-conferencing systems. The results establish a foundation for building effective diarization systems in other understudied languages, contributing to greater equity in speech technology.
说话人识别是语音处理中的一项基本任务,涉及按说话人划分音频流。虽然最新模型在高资源语言中的性能得到了提升,但低资源语言(如库尔德语)由于缺乏标注数据、多种方言和频繁的转码等因素而面临独特挑战。在这项研究中,我们通过在一个专门的库尔德语料库上训练Wav2Vec 2.0自监督学习模型来解决这些问题。通过利用迁移学习,我们适应了从其他语言中学到的多语言表示,以捕捉库尔德语的语音和声学特征。相对于基准方法,我们的方法将识别错误率降低了7.2%,聚类纯度提高了13%。这些发现表明对现有模型的改进可以显著提高资源匮乏语言的识别性能。我们的工作对于开发库尔德语媒体的转录服务以及多语言呼叫中心、电话会议和视频会议系统中的说话人分段具有实际意义。结果为其在其他未充分研究的语言中建立有效的识别系统奠定了基础,为语音技术的更大公平性做出了贡献。
论文及项目相关链接
Summary
本文研究了基于Wav2Vec 2.0自监督学习模型的库尔德语语音说话人识别技术。针对库尔德语资源有限、方言多样和频繁的代码切换等问题,该研究通过迁移学习技术,利用其他语言的多语言表示来学习库尔德语的语音和声音特征。相较于基准方法,该研究的方法将识别错误率降低了7.2%,并提高了聚类纯度达13%。该研究为发展库尔德语媒体的语音识别服务和多语种呼叫中心、远程会议和视频会议系统中的说话人分割提供了实践启示。它为在其他缺乏研究的语言中建立有效的识别系统奠定了基础,为语音技术的公平发展做出了贡献。
Key Takeaways
- 研究使用Wav2Vec 2.0自监督学习模型进行库尔德语的说话人识别。
- 针对库尔德语资源有限、方言多样和代码切换频繁的问题,研究采用迁移学习技术。
- 与基准方法相比,该研究的方法降低了7.2%的识别错误率,提高了13%的聚类纯度。
- 研究具有发展库尔德语媒体语音识别服务和多语种呼叫中心、远程会议和视频会议系统中说话人分割的实践意义。
- 该研究为在其他缺乏研究的语言中建立有效的识别系统奠定了基础。
- 研究促进了语音技术的公平发展。
点此查看论文截图

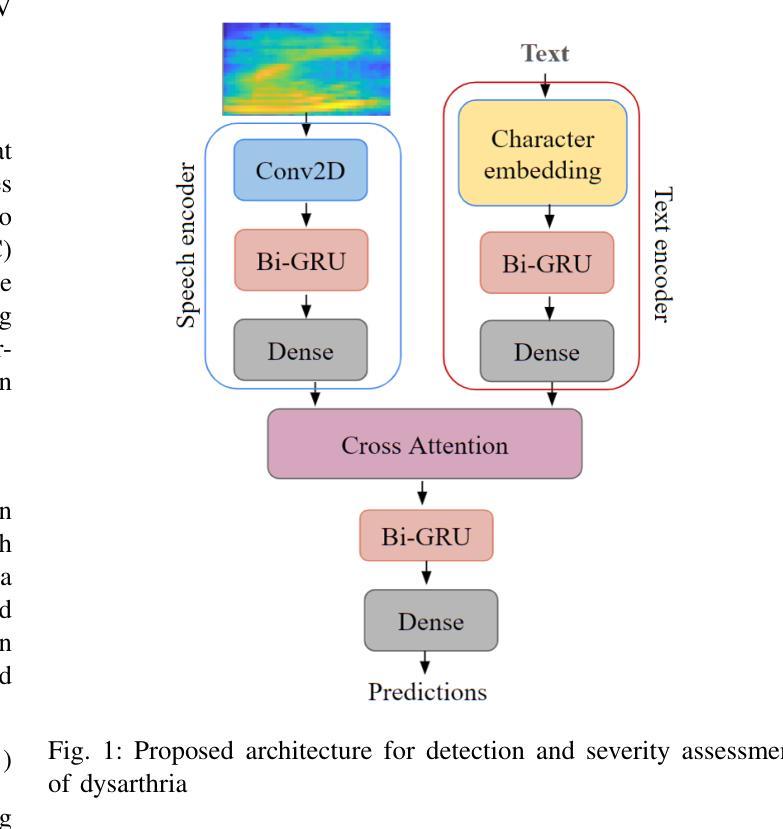
A Multi-modal Approach to Dysarthria Detection and Severity Assessment Using Speech and Text Information
Authors:Anuprabha M, Krishna Gurugubelli, V Kesavaraj, Anil Kumar Vuppala
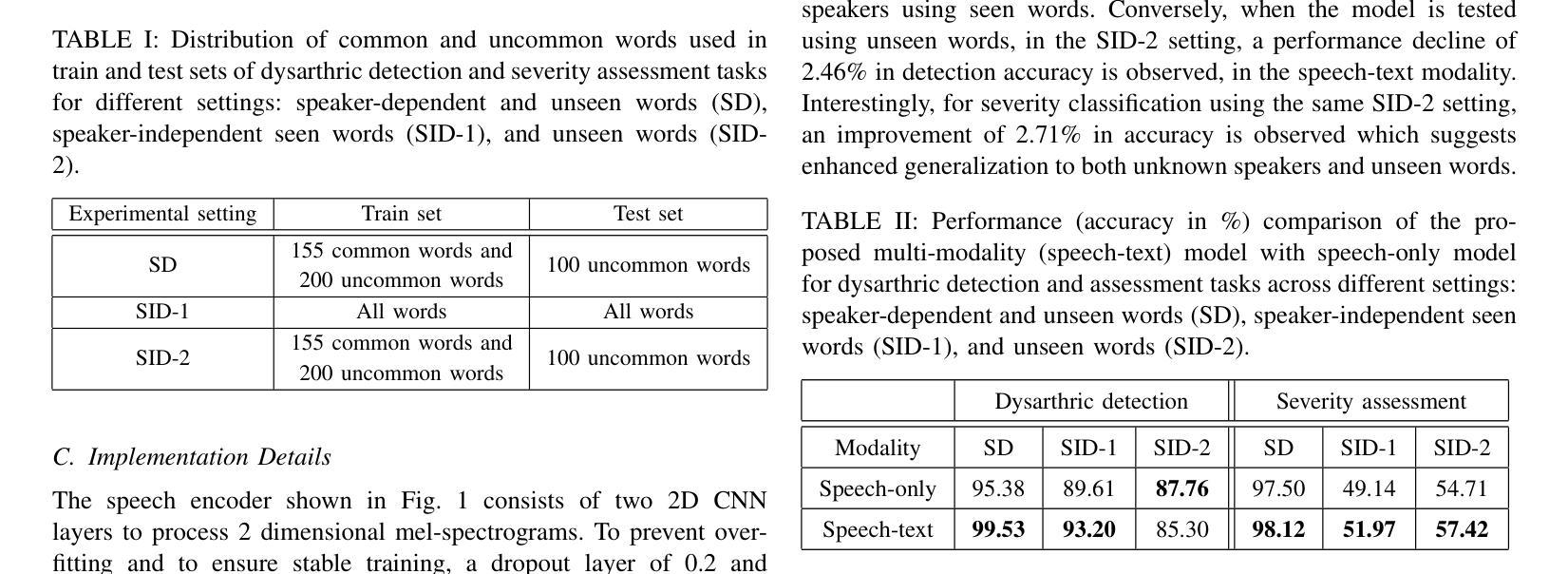
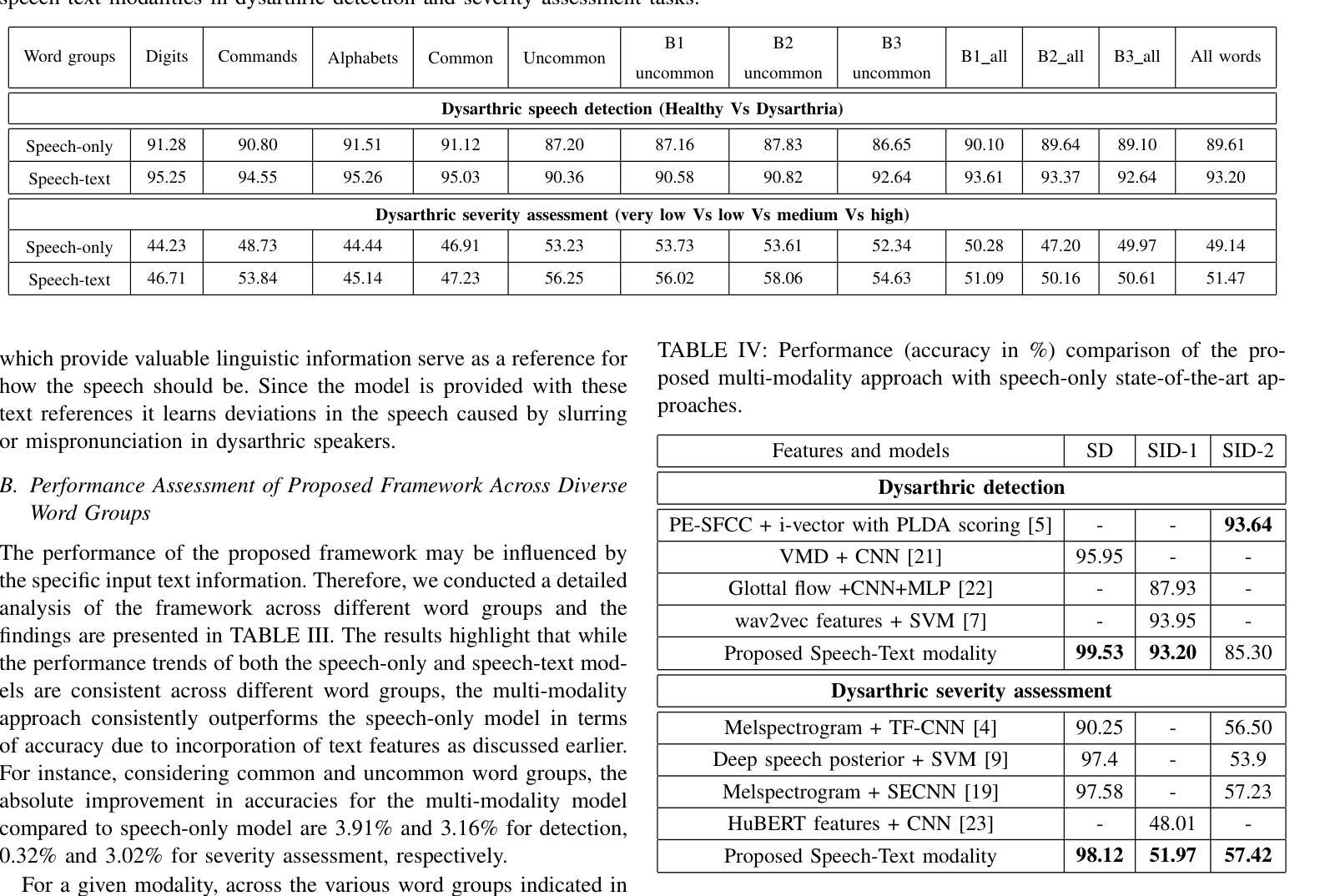
Automatic detection and severity assessment of dysarthria are crucial for delivering targeted therapeutic interventions to patients. While most existing research focuses primarily on speech modality, this study introduces a novel approach that leverages both speech and text modalities. By employing cross-attention mechanism, our method learns the acoustic and linguistic similarities between speech and text representations. This approach assesses specifically the pronunciation deviations across different severity levels, thereby enhancing the accuracy of dysarthric detection and severity assessment. All the experiments have been performed using UA-Speech dysarthric database. Improved accuracies of 99.53% and 93.20% in detection, and 98.12% and 51.97% for severity assessment have been achieved when speaker-dependent and speaker-independent, unseen and seen words settings are used. These findings suggest that by integrating text information, which provides a reference linguistic knowledge, a more robust framework has been developed for dysarthric detection and assessment, thereby potentially leading to more effective diagnoses.
自动检测和评估言语障碍的严重程度对于为患者提供有针对性的治疗干预至关重要。虽然现有的大多数研究主要集中在语音模式上,但本研究介绍了一种利用语音和文本模式的新方法。通过采用交叉注意力机制,我们的方法学习了语音和文本表示之间的声学和语言学相似性。这种方法特别评估了不同严重程度水平的发音偏差,从而提高了言语障碍检测和严重程度评估的准确性。所有实验均使用UA-Speech言语障碍数据库进行。在依赖说话者和独立说话者、未见词和可见词设置的情况下,检测准确率分别提高了99.53%和93.20%,评估准确率分别达到了98.12%和51.97%。这些研究结果表明,通过将文本信息集成提供为参考语言学知识,我们已开发出更稳健的言语障碍检测和评估框架,从而可能带来更准确的诊断结果。
论文及项目相关链接
PDF Submitted to ICASSP 2025
Summary
该研究利用语音和文字两种模态,通过跨注意力机制学习语音和文本表示之间的声学和语言学相似性,从而检测发音偏差并进行不同程度评估。这一新型方法在UA-Speechdysarthria数据库上进行实验,显示对于语言病理学患者能提高检测和评估的准确性,具体在未见单词的场景中检测准确性为99.53%,评估准确性为98.12%。该方法融合了文本信息中的参考语言学知识,从而为语言障碍的检测和评估开发了一个更稳健的框架。这有助于提高诊断的精确度,实现更有针对性的治疗干预。
Key Takeaways
该文章研究了自动检测语言障碍(如发音障碍)并进行严重程度评估的重要性:
- 研究提出了一种新方法,结合了语音和文字两种模态进行语言障碍的检测和严重程度评估。
- 该方法采用跨注意力机制,旨在学习语音和文本之间的声学相似性以及语言学相似性。
- 通过在UA-Speechdysarthria数据库上实验验证,此方法能提高检测准确性和评估准确性。对于未见过单词的检测准确性高达99.53%,而评估准确性为98.12%。
- 通过结合文本信息中的参考语言学知识,研究构建了一个更为稳健的语言障碍检测和评估框架。
- 此方法不仅有助于准确诊断语言障碍,还有助于为语言障碍患者提供针对性的治疗干预。
- 该研究显示了利用两种模态或多模态信息的潜力和价值在检测和评估语言障碍领域中具有广泛的应用前景和临床实用价值。
点此查看论文截图

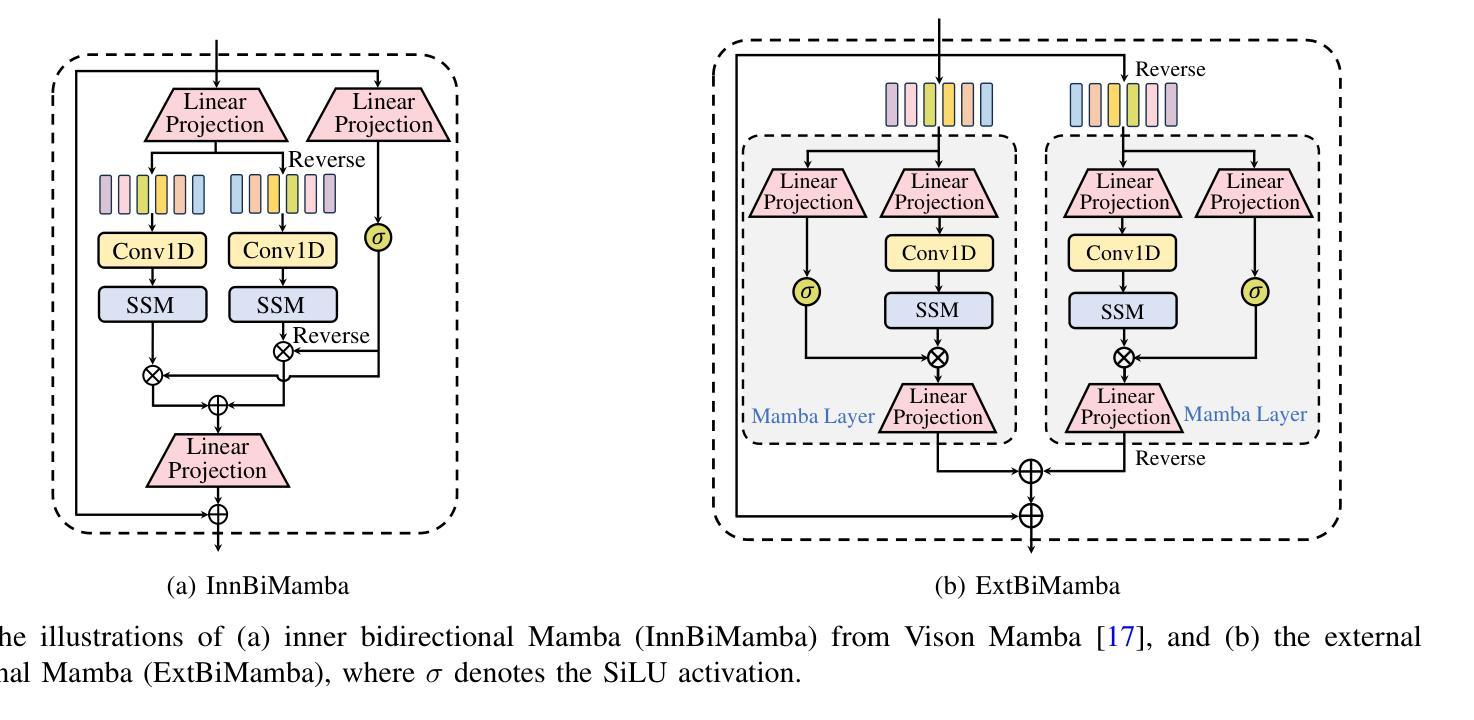
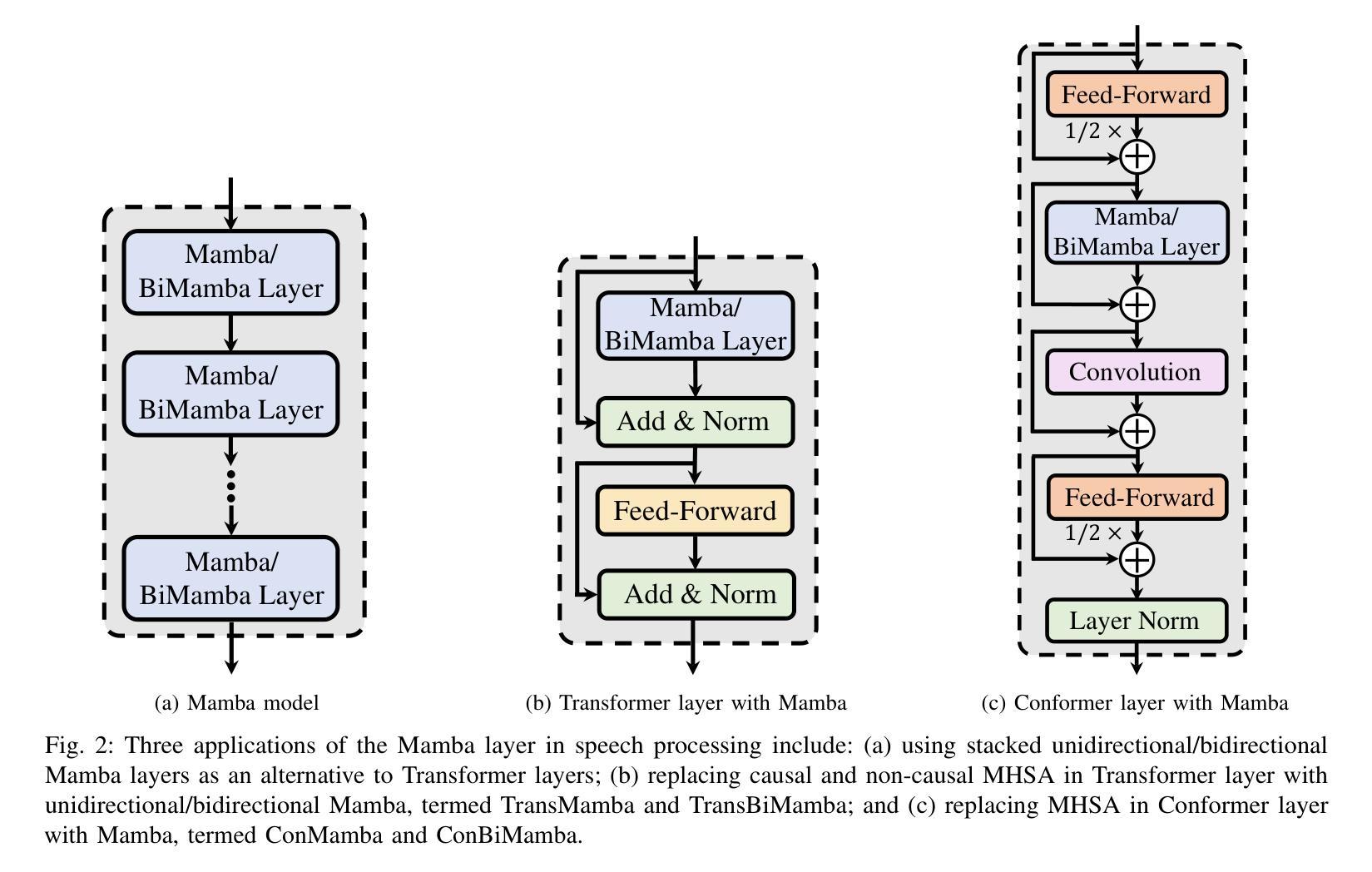
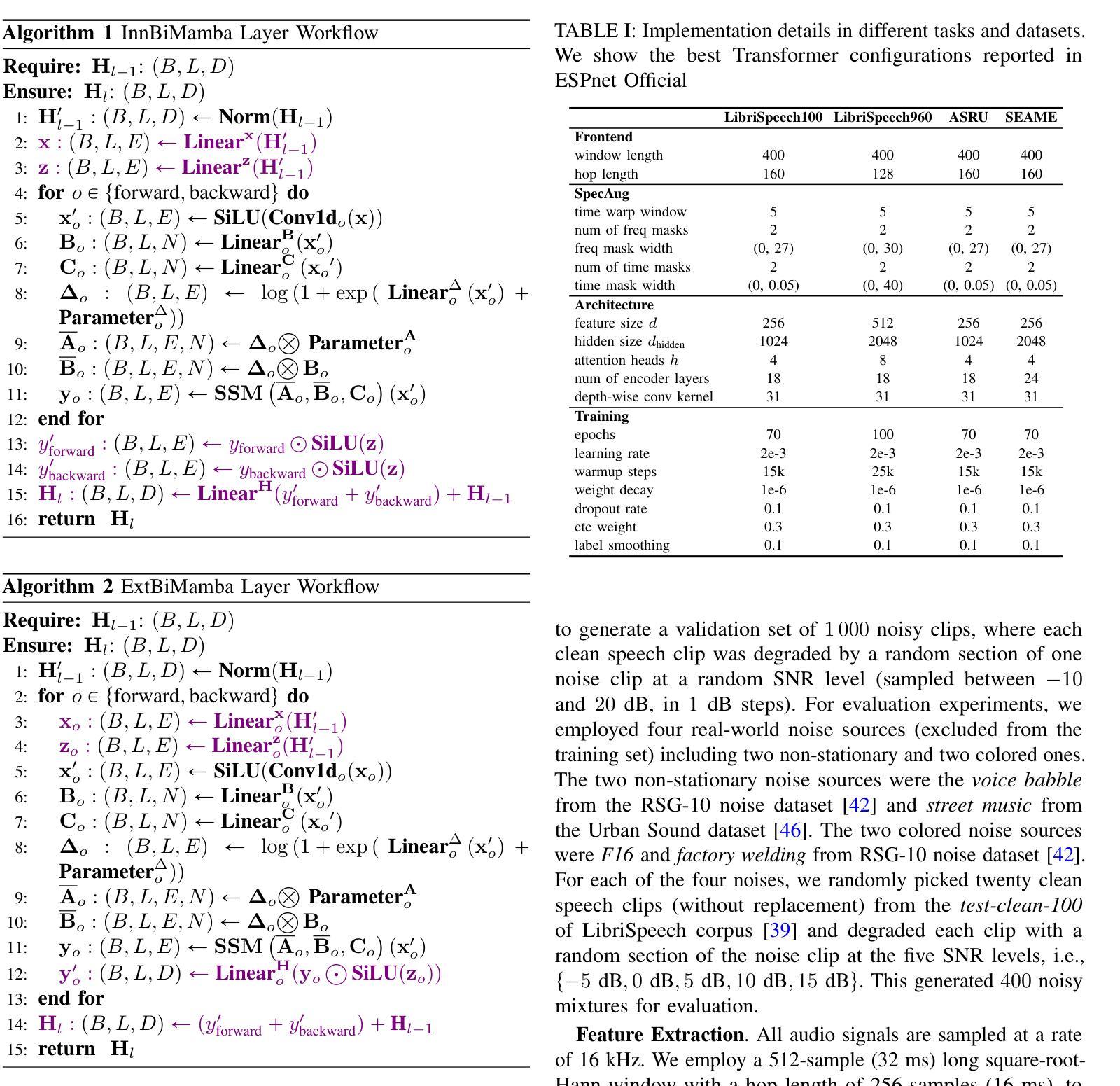
Mamba in Speech: Towards an Alternative to Self-Attention
Authors:Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, Julien Epps
Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing by discussing two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The experimental results confirm that bidirectional Mamba (BiMamba) consistently outperforms vanilla Mamba, highlighting the advantages of a bidirectional design for speech processing. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in the Transformer model and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section, offering insights for extending this research to a broader scope of tasks.
Transformer及其衍生品已经在计算机视觉、自然语言处理和语音识别等多个领域取得了巨大的成功。为了减少Transformer多头自注意力机制中的计算复杂性,选择性状态空间模型(例如Mamba)作为一种替代方案被提出。Mamba在自然语言处理和计算机视觉任务中展现了其有效性,但在语音信号处理方面的优越性却鲜有研究。本文通过讨论两个典型的语音处理任务:需要语义和序列信息的语音识别以及主要关注序列模式的语音增强,探索了将Mamba应用于语音处理的方法。实验结果表明,双向Mamba(BiMamba)始终优于普通Mamba,凸显了双向设计在语音处理中的优势。此外,实验还证明了BiMamba作为Transformer模型及其衍生模型的自注意力模块的替代方案的有效性,特别是在语义感知任务中。随后,在剔除研究和讨论部分中对将Mamba转移到语音的关键技术进行了总结,为将这项研究扩展到更广泛的任务范围提供了见解。
论文及项目相关链接
Summary
本文探讨了将Selective State Space Models(Mamba)应用于语音处理的可能性,通过对比Mamba和双向Mamba(BiMamba)在语音识别和语音增强两个典型任务上的表现,发现BiMamba表现更优。实验证明BiMamba可以作为Transformer模型及其衍生版本中自注意模块的有效替代方案,特别是在语义感知任务中。
Key Takeaways
- Transformer及其衍生物已在计算机视觉、自然语言处理和语音处理等多个任务中取得巨大成功。
- Mamba作为一种选择性状态空间模型,旨在简化Transformer中的多头自注意机制的计算复杂性。
- Mamba在自然语言处理和计算机视觉任务中表现出其有效性,但在语音信号处理中的优越性鲜有研究。
- 本文尝试将Mamba应用于语音处理,并探讨了语音识别和语音增强两个典型任务。
- 实验结果显示,双向Mamba(BiMamba)在语音处理任务上表现优于普通Mamba,特别是在语义感知任务中。
- BiMamba可作为Transformer模型及其衍生版本中自注意模块的有效替代方案。
点此查看论文截图