⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-30 更新
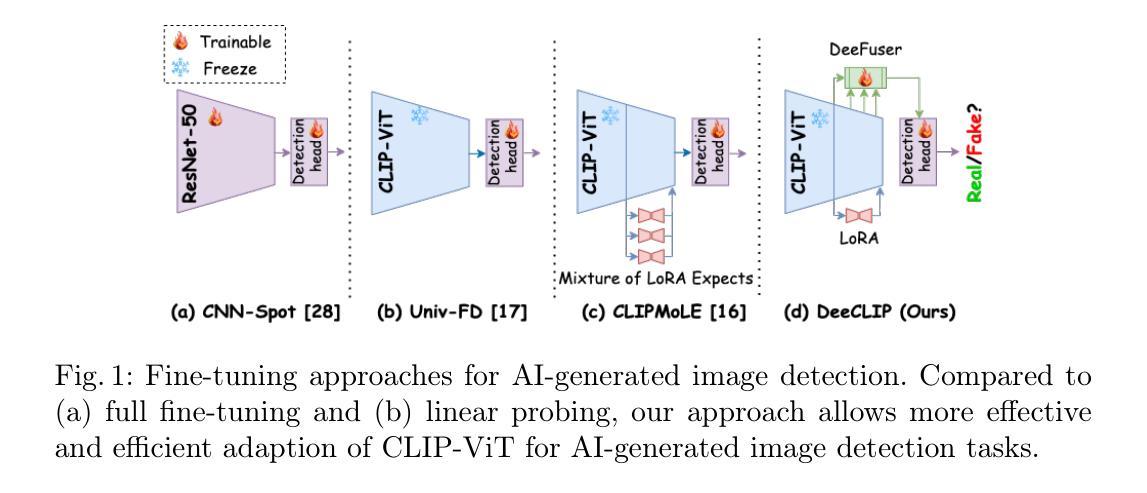
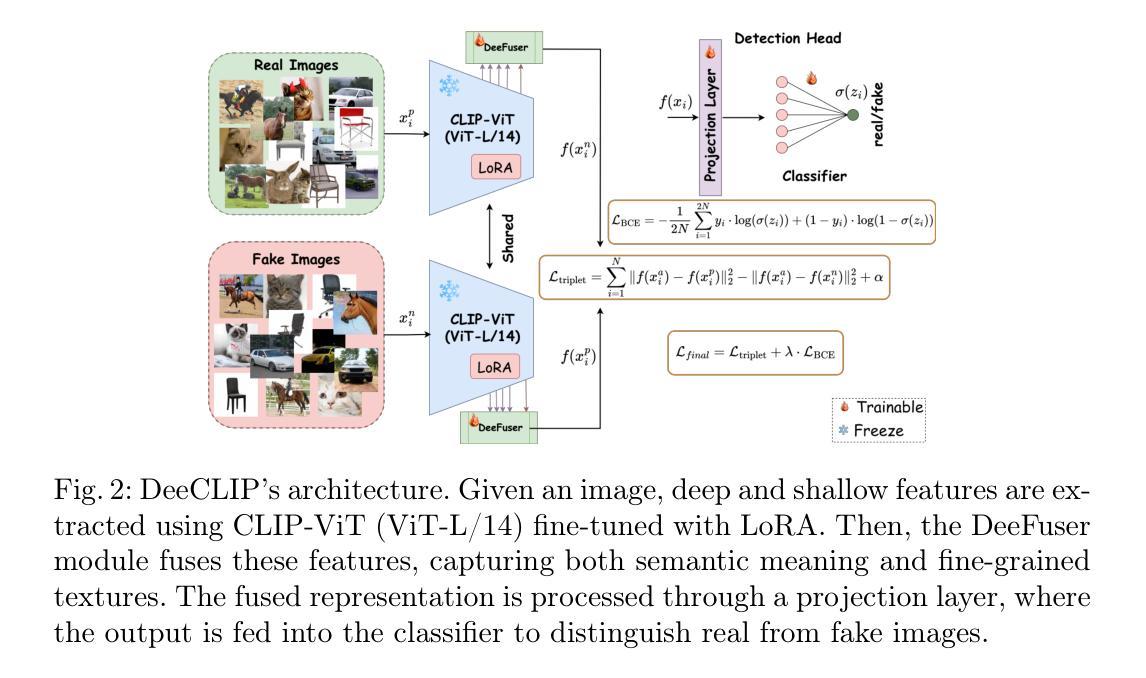
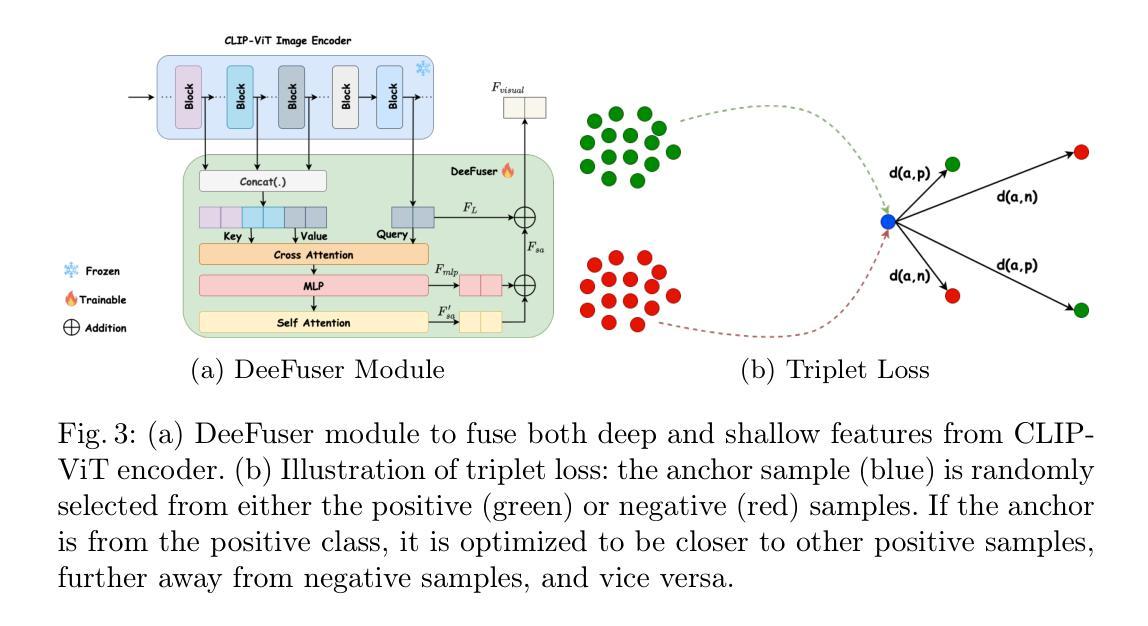
DeeCLIP: A Robust and Generalizable Transformer-Based Framework for Detecting AI-Generated Images
Authors:Mamadou Keita, Wassim Hamidouche, Hessen Bougueffa Eutamene, Abdelmalik Taleb-Ahmed, Abdenour Hadid
This paper introduces DeeCLIP, a novel framework for detecting AI-generated images using CLIP-ViT and fusion learning. Despite significant advancements in generative models capable of creating highly photorealistic images, existing detection methods often struggle to generalize across different models and are highly sensitive to minor perturbations. To address these challenges, DeeCLIP incorporates DeeFuser, a fusion module that combines high-level and low-level features, improving robustness against degradations such as compression and blurring. Additionally, we apply triplet loss to refine the embedding space, enhancing the model’s ability to distinguish between real and synthetic content. To further enable lightweight adaptation while preserving pre-trained knowledge, we adopt parameter-efficient fine-tuning using low-rank adaptation (LoRA) within the CLIP-ViT backbone. This approach supports effective zero-shot learning without sacrificing generalization. Trained exclusively on 4-class ProGAN data, DeeCLIP achieves an average accuracy of 89.00% on 19 test subsets composed of generative adversarial network (GAN) and diffusion models. Despite having fewer trainable parameters, DeeCLIP outperforms existing methods, demonstrating superior robustness against various generative models and real-world distortions. The code is publicly available at https://github.com/Mamadou-Keita/DeeCLIP for research purposes.
本文介绍了DeeCLIP,这是一个使用CLIP-ViT和融合学习检测AI生成图像的新型框架。尽管生成模型在创造高度逼真的图像方面取得了显著进展,但现有的检测方法在跨不同模型泛化时经常遇到困难,并且对轻微扰动高度敏感。为了应对这些挑战,DeeCLIP融入了DeeFuser,这是一个融合模块,结合了高级和低级特征,提高了对压缩和模糊等降质的稳健性。此外,我们应用了三元组损失来优化嵌入空间,提高模型区分真实和合成内容的能力。为了进一步实现在保持预训练知识的同时进行轻量级适配,我们在CLIP-ViT主干中采用低秩适配(LoRA)进行参数高效微调。这种方法支持有效的零样本学习,而不会牺牲泛化能力。DeeCLIP仅在4类ProGAN数据上进行训练,在由生成对抗网络(GAN)和扩散模型组成的19个测试子集上取得了平均89.00%的准确率。尽管可训练参数较少,DeeCLIP仍优于现有方法,显示出对各种生成模型和现实世界失真的卓越稳健性。代码已公开发布在https://github.com/Mamadou-Keita/DeeCLIP,以供研究使用。
论文及项目相关链接
Summary
DeeCLIP是一个基于CLIP-ViT和融合学习的新框架,旨在检测AI生成的图像。它通过结合高低级特征提高模型的鲁棒性,并采用三元损失优化嵌入空间,以区分真实和合成内容。此外,它采用低秩适应(LoRA)进行微调,支持有效的零样本学习。在仅使用4类ProGAN数据训练的情况下,DeeCLIP在由生成对抗网络(GAN)和扩散模型组成的19个测试子集上取得了平均89%的准确率,表现出卓越的性能和鲁棒性。代码已公开供研究使用。
Key Takeaways
- DeeCLIP是一个用于检测AI生成的图像的新框架,基于CLIP-ViT和融合学习技术。
- 它通过结合高低级特征,提高模型的鲁棒性,以应对图像压缩、模糊等降质问题。
- 采用三元损失优化嵌入空间,增强模型区分真实和合成内容的能力。
- 通过低秩适应(LoRA)进行微调,支持零样本学习,同时保持对多种生成模型的泛化能力。
- DeeCLIP在仅使用有限的训练数据情况下表现出高准确率,优于现有方法。
- DeeCLIP在多种生成对抗网络(GAN)和扩散模型的测试集上取得了平均89%的准确率。
点此查看论文截图

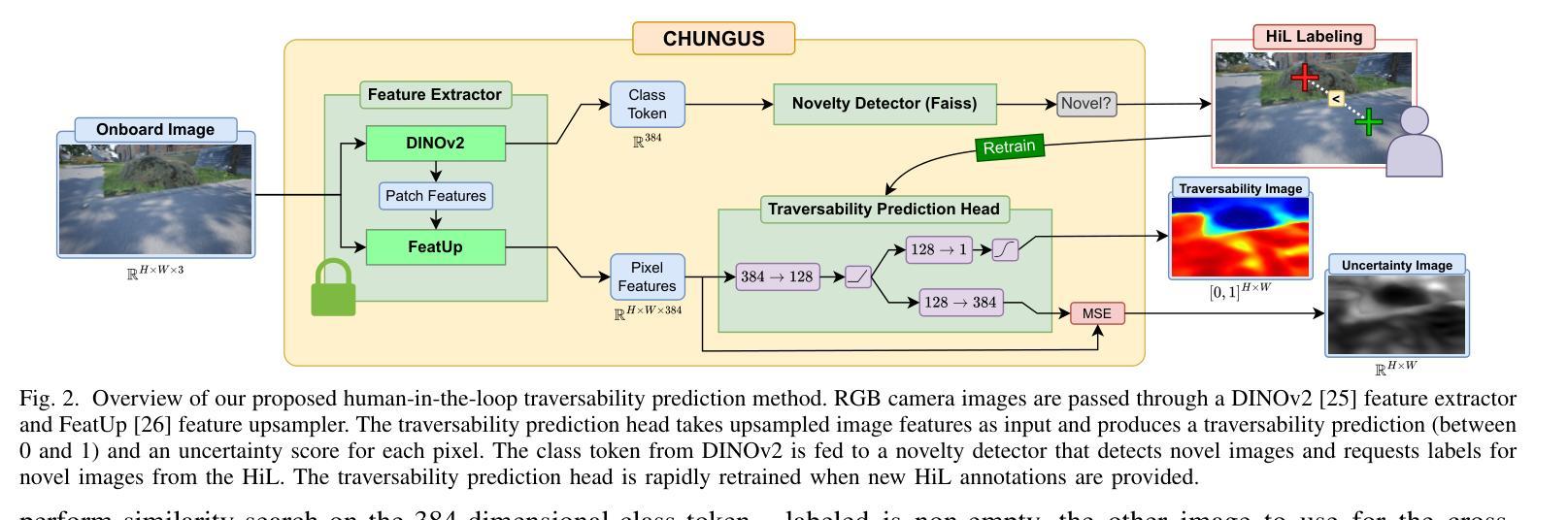
Do You Know the Way? Human-in-the-Loop Understanding for Fast Traversability Estimation in Mobile Robotics
Authors:Andre Schreiber, Katherine Driggs-Campbell
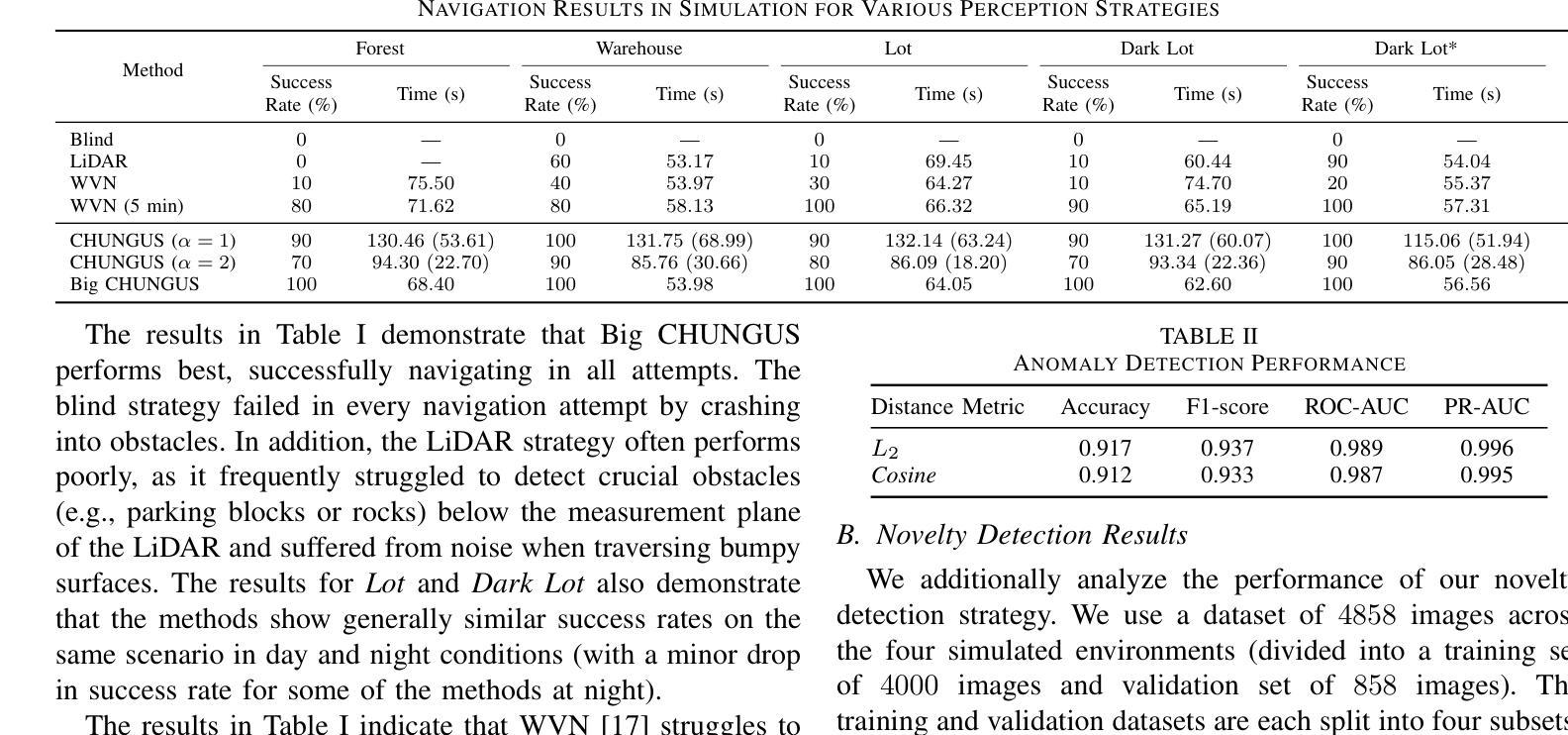
The increasing use of robots in unstructured environments necessitates the development of effective perception and navigation strategies to enable field robots to successfully perform their tasks. In particular, it is key for such robots to understand where in their environment they can and cannot travel – a task known as traversability estimation. However, existing geometric approaches to traversability estimation may fail to capture nuanced representations of traversability, whereas vision-based approaches typically either involve manually annotating a large number of images or require robot experience. In addition, existing methods can struggle to address domain shifts as they typically do not learn during deployment. To this end, we propose a human-in-the-loop (HiL) method for traversability estimation that prompts a human for annotations as-needed. Our method uses a foundation model to enable rapid learning on new annotations and to provide accurate predictions even when trained on a small number of quickly-provided HiL annotations. We extensively validate our method in simulation and on real-world data, and demonstrate that it can provide state-of-the-art traversability prediction performance.
随着机器人在非结构化环境中越来越多的应用,必须发展有效的感知和导航策略,使现场机器人能够成功完成任务。特别是对于这些机器人来说,理解它们在环境中能够或不能前往的地方是至关重要的任务,这一任务被称为可穿越性估计。然而,现有的几何方法在估计可穿越性时可能无法捕捉到细微的可穿越性表示,而基于视觉的方法通常需要手动标注大量图像或需要机器人的经验。此外,现有方法在应对领域偏移时遇到困难,因为它们通常在部署过程中不学习。为此,我们提出了一种人类参与的循环(HiL)方法进行可穿越性估计,该方法按需提示人类进行标注。我们的方法使用基础模型实现对新标注的快速学习,即使在少量快速提供的HiL标注下也能提供准确的预测。我们在模拟环境和真实世界数据上进行了广泛验证,证明了它可以提供最先进的可穿越性预测性能。
论文及项目相关链接
PDF Accepted by RA-L. Code is available at https://github.com/andreschreiber/CHUNGUS
Summary
本文指出随着机器人在非结构化环境中的使用日益增多,需要开发有效的感知和导航策略,使机器人能够成功完成任务。特别是理解机器人在环境中可通行与不可通行的区域——即通行能力估计,是机器人执行任务的关键。现有方法存在缺陷,几何方法无法捕捉通行能力的细微表示,而基于视觉的方法需要大量手动标注的图像或要求机器人积累经验。为此,提出了一种基于人类循环(HiL)的通行能力估计方法,根据需要提示人类进行标注。该方法使用基础模型实现快速学习新标注并提供准确预测,即使训练样本数量少且标注时间短。经过仿真和真实数据的广泛验证,该方法可实现最先进的通行能力预测性能。
Key Takeaways
- 机器人在非结构化环境中的使用增多,需要开发有效的感知和导航策略。
- 机器人需要理解其在环境中的可通行与不可通行区域,即进行通行能力估计。
- 现有几何方法无法捕捉通行能力的细微表示,而基于视觉的方法需要大量手动标注或机器人经验。
- 提出了一种基于人类循环(HiL)的通行能力估计方法,根据需要提示人类进行标注。
- 使用基础模型实现快速学习新标注,并提供准确预测。
- 方法在仿真和真实数据上广泛验证,可实现最先进的通行能力预测性能。
- 人类循环(HiL)方法能有效结合人类智慧和机器学习能力,提高机器人的自主性和适应能力。
点此查看论文截图


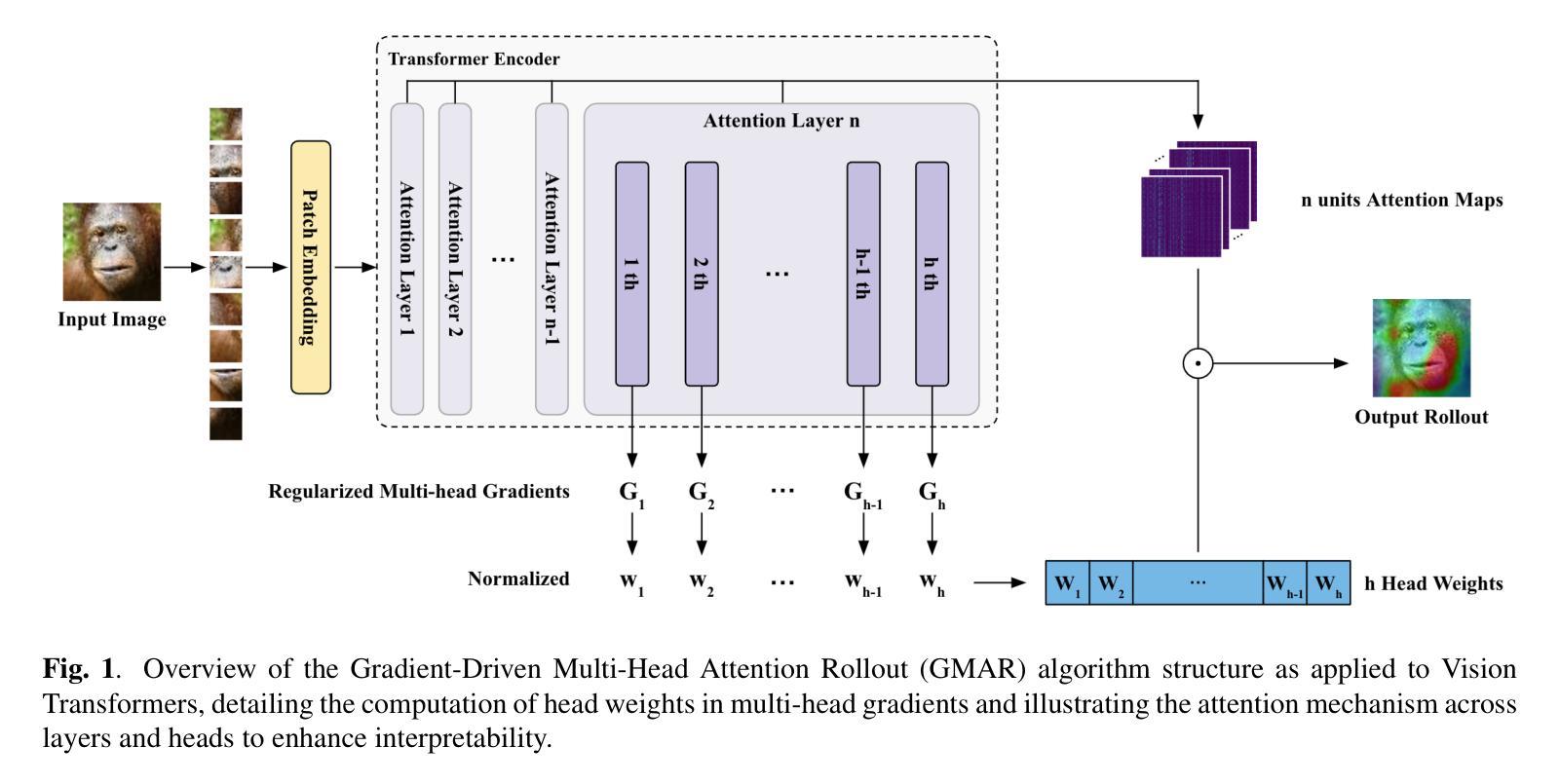
GMAR: Gradient-Driven Multi-Head Attention Rollout for Vision Transformer Interpretability
Authors:Sehyeong Jo, Gangjae Jang, Haesol Park
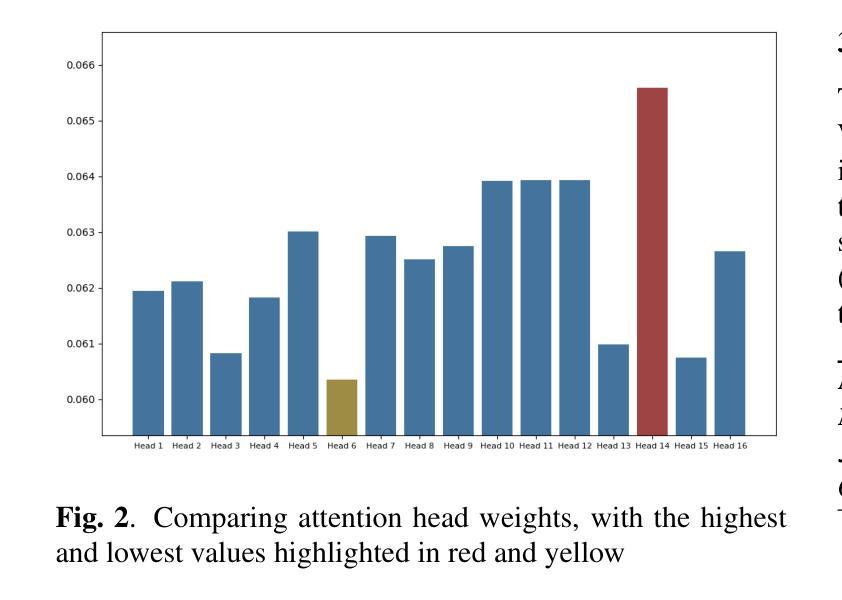
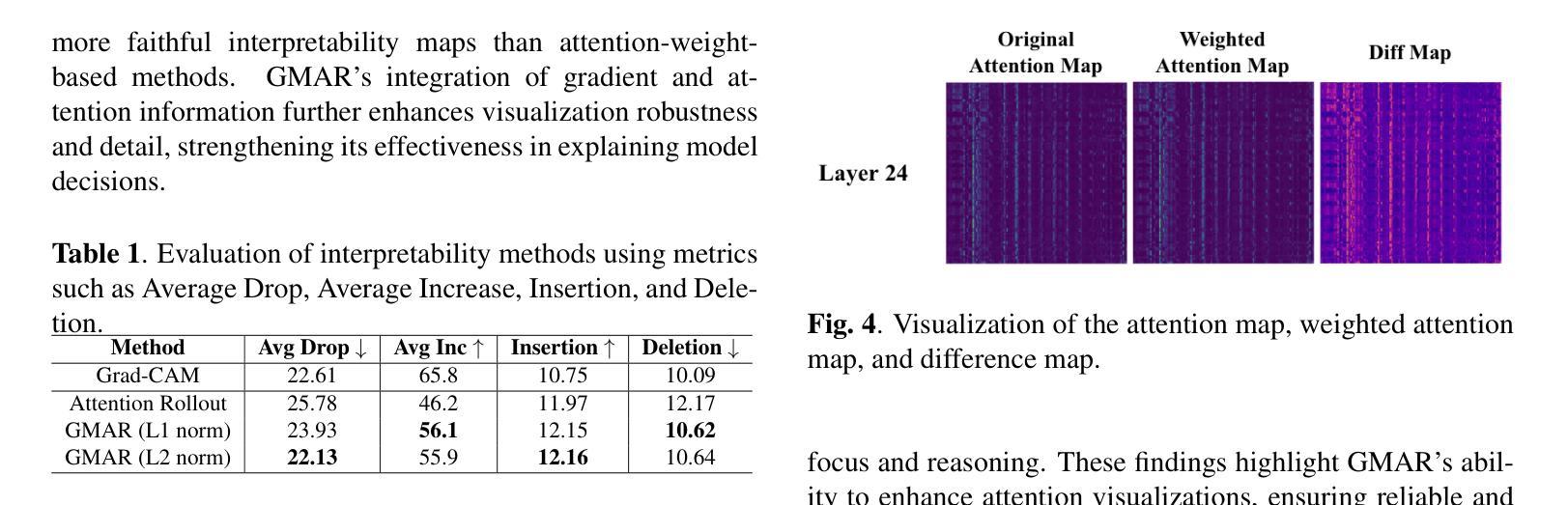
The Vision Transformer (ViT) has made significant advancements in computer vision, utilizing self-attention mechanisms to achieve state-of-the-art performance across various tasks, including image classification, object detection, and segmentation. Its architectural flexibility and capabilities have made it a preferred choice among researchers and practitioners. However, the intricate multi-head attention mechanism of ViT presents significant challenges to interpretability, as the underlying prediction process remains opaque. A critical limitation arises from an observation commonly noted in transformer architectures: “Not all attention heads are equally meaningful.” Overlooking the relative importance of specific heads highlights the limitations of existing interpretability methods. To address these challenges, we introduce Gradient-Driven Multi-Head Attention Rollout (GMAR), a novel method that quantifies the importance of each attention head using gradient-based scores. These scores are normalized to derive a weighted aggregate attention score, effectively capturing the relative contributions of individual heads. GMAR clarifies the role of each head in the prediction process, enabling more precise interpretability at the head level. Experimental results demonstrate that GMAR consistently outperforms traditional attention rollout techniques. This work provides a practical contribution to transformer-based architectures, establishing a robust framework for enhancing the interpretability of Vision Transformer models.
Vision Transformer(ViT)在计算机视觉领域取得了重大进展,利用自注意力机制实现了各项任务的最新性能,包括图像分类、目标检测和分割。其架构的灵活性和能力使其成为研究者和实践者的首选。然而,ViT的复杂的多头注意力机制对可解释性提出了重大挑战,因为底层的预测过程仍然不清楚。一个关键的局限性来自于在变压器架构中常见的一个观察结果:“并非所有的注意力头都是同等有意义的。”忽视特定头的相对重要性突出了现有可解释性方法的局限性。为了解决这些挑战,我们引入了基于梯度的多头注意力滚动(GMAR),这是一种新方法,通过基于梯度的分数来量化每个注意力头的重要性。这些分数经过归一化处理,以得出加权聚合注意力分数,有效地捕获了单个头的相对贡献。GMAR明确了每个头在预测过程中的作用,从而在头级别实现了更精确的可解释性。实验结果表明,GMAR始终优于传统的注意力滚动技术。这项工作对基于变压器的架构做出了实际贡献,建立了一个提高Vision Transformer模型可解释性的稳健框架。
论文及项目相关链接
Summary
Vision Transformer(ViT)通过利用自注意力机制实现了计算机视觉领域的先进性能,包括图像分类、目标检测和分割等任务。然而,其复杂的注意力机制带来了难以解释的问题。针对此问题,提出了基于梯度的多头注意力滚动(GMAR)方法,通过梯度评分量化每个注意力头的重要性,从而更精确地解释预测过程中的每个头部的作用。实验结果表明,GMAR优于传统的注意力滚动技术。
Key Takeaways
- Vision Transformer (ViT) 利用自注意力机制在多个任务上实现先进性能。
- ViT的复杂注意力机制带来了难以解释的问题。
- 现有研究中存在一种常见观点:并非所有注意力头都是同等重要的。
- Gradient-Driven Multi-Head Attention Rollout (GMAR) 方法通过梯度评分量化每个注意力头的重要性。
- GMAR方法能更精确地解释预测过程中每个头部的作用。
- 实验结果表明,GMAR在性能上一致地超越了传统的注意力滚动技术。
点此查看论文截图