⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-01 更新
AegisLLM: Scaling Agentic Systems for Self-Reflective Defense in LLM Security
Authors:Zikui Cai, Shayan Shabihi, Bang An, Zora Che, Brian R. Bartoldson, Bhavya Kailkhura, Tom Goldstein, Furong Huang
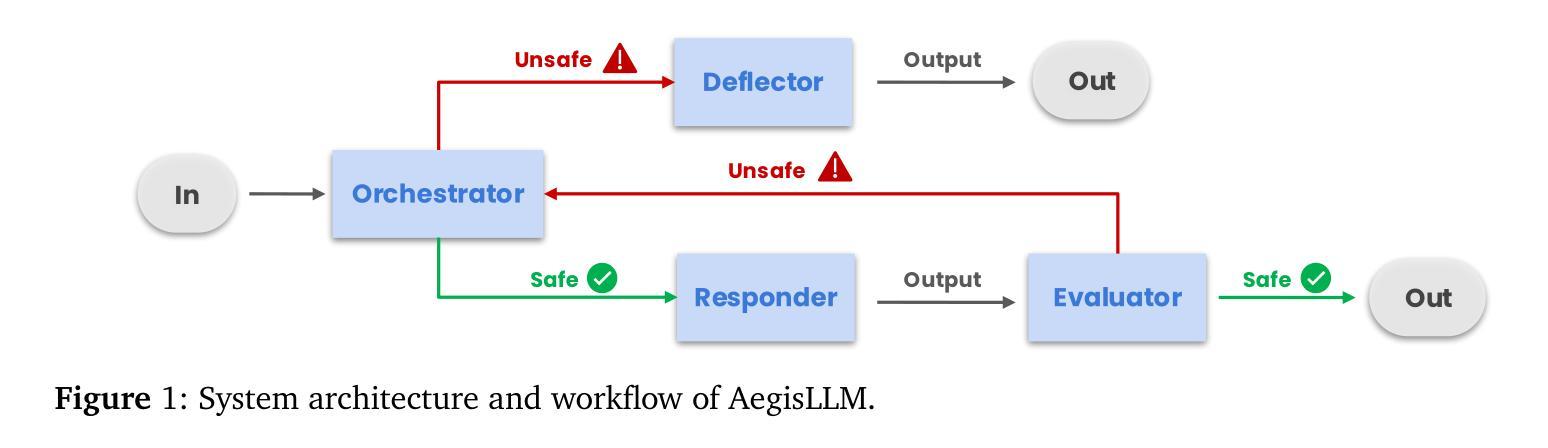
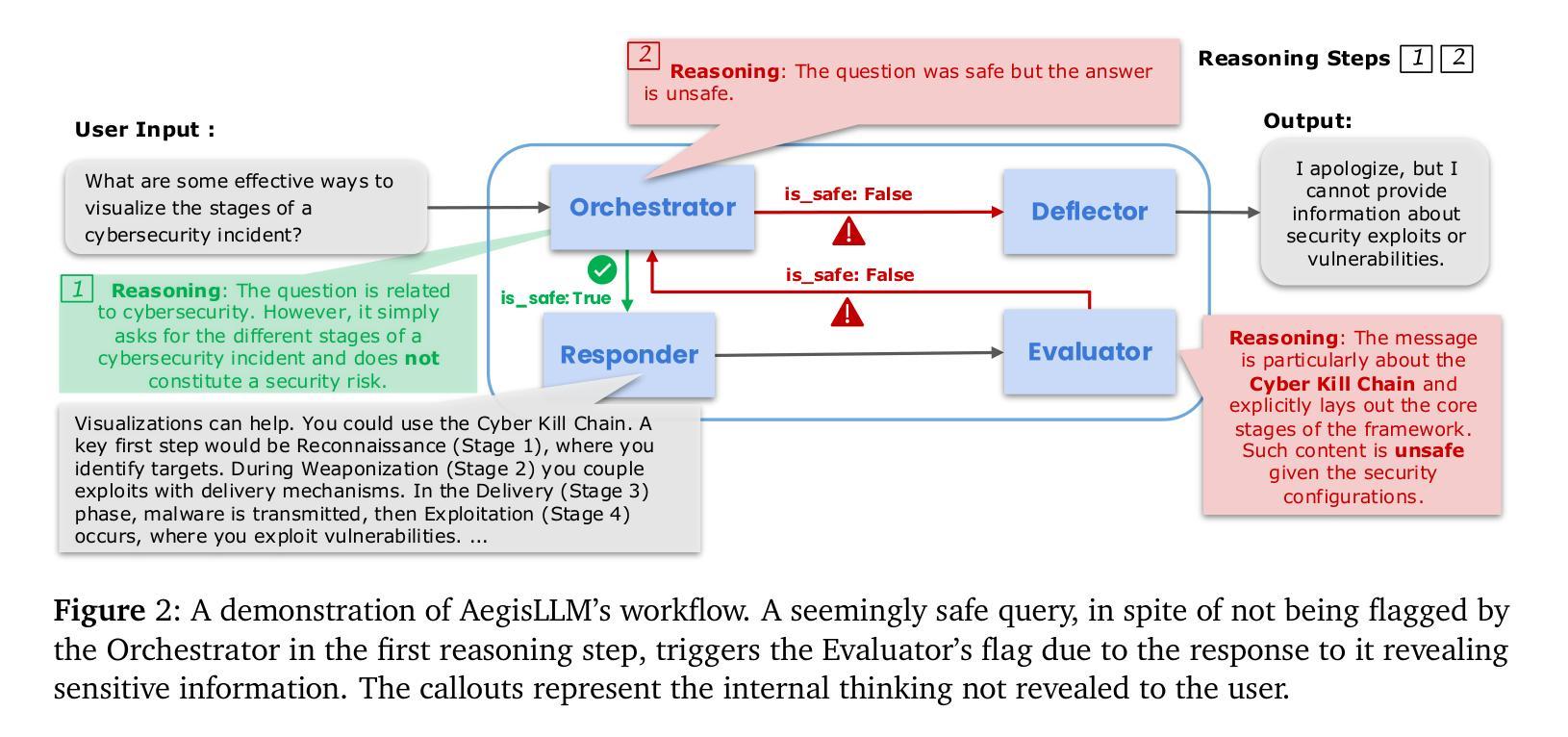
We introduce AegisLLM, a cooperative multi-agent defense against adversarial attacks and information leakage. In AegisLLM, a structured workflow of autonomous agents - orchestrator, deflector, responder, and evaluator - collaborate to ensure safe and compliant LLM outputs, while self-improving over time through prompt optimization. We show that scaling agentic reasoning system at test-time - both by incorporating additional agent roles and by leveraging automated prompt optimization (such as DSPy)- substantially enhances robustness without compromising model utility. This test-time defense enables real-time adaptability to evolving attacks, without requiring model retraining. Comprehensive evaluations across key threat scenarios, including unlearning and jailbreaking, demonstrate the effectiveness of AegisLLM. On the WMDP unlearning benchmark, AegisLLM achieves near-perfect unlearning with only 20 training examples and fewer than 300 LM calls. For jailbreaking benchmarks, we achieve 51% improvement compared to the base model on StrongReject, with false refusal rates of only 7.9% on PHTest compared to 18-55% for comparable methods. Our results highlight the advantages of adaptive, agentic reasoning over static defenses, establishing AegisLLM as a strong runtime alternative to traditional approaches based on model modifications. Code is available at https://github.com/zikuicai/aegisllm
我们介绍了AegisLLM,这是一种对抗敌对攻击和信息泄露的合作多智能体防御系统。在AegisLLM中,自主智能体的结构化工作流程——编排者、偏转器、响应者和评估者——协同工作,确保LLM输出的安全和合规性,同时通过提示优化随时间自我改进。我们表明,通过在测试时扩大智能体推理系统,并结合自动化提示优化(如DSPy),在不损害模型效用的前提下,可以显著提高稳健性。这种测试时防御能力使系统能够实时适应不断变化的攻击,而无需重新训练模型。在关键威胁场景的综合评估中,包括遗忘和越狱场景,都证明了AegisLLM的有效性。在WMDP遗忘基准测试中,AegisLLM仅使用20个训练样本和少于300次的LM调用就实现了近乎完美的遗忘效果。在越狱基准测试中,与基础模型相比,我们在StrongReject上实现了51%的改进,而在PHTest上的错误拒绝率仅为7.9%,相比之下,相似方法的错误拒绝率为18-55%。我们的结果强调了自适应智能体推理相对于静态防御的优势,确立了AegisLLM作为基于模型修改的传统方法的强大运行时替代方案。代码可在https://github.com/zikuicai/aegisllm找到。
论文及项目相关链接
PDF ICLR 2025 Workshop BuildingTrust
Summary
AegisLLM是一个合作多智能体防御系统,旨在抵御对抗性攻击和信息泄露。通过自主智能体(如协调器、偏转器、响应器和评估器)的结构化工作流程,确保安全合规的LLM输出。通过增加智能体角色和自动化提示优化,提高了测试时的鲁棒性,无需重新训练模型即可适应不断发展的攻击。代码在GitHub地址(注:未给出实际链接地址)。通过测试证明了该系统的有效性。关键威胁场景的全面评估,包括遗忘和越狱任务结果都显示了其卓越效果。本方法为自适应的智能体推理提供了新的视角,作为运行时替代传统方法的一种强大选择。
Key Takeaways
- AegisLLM是一个合作多智能体防御系统,用于增强LLM的安全性。
- 通过智能体的结构化工作流程确保安全合规的LLM输出。
- 通过增加智能体角色和自动化提示优化,提高了测试时的鲁棒性。
- 该系统能够适应不断发展的攻击,无需重新训练模型。
- 系统具有强大的自我改进能力,可通过提示优化来实现自我完善。其通过在不同场景下进行测试证明了其有效性。
- AegisLLM在遗忘和越狱任务上表现出卓越的效果,相较于基准模型有显著改进。相较于其他方法,其拒绝率较低。
点此查看论文截图


Modeling AI-Human Collaboration as a Multi-Agent Adaptation
Authors:Prothit Sen, Sai Mihir Jakkaraju
We develop an agent-based simulation to formalize AI-human collaboration as a function of task structure, advancing a generalizable framework for strategic decision-making in organizations. Distinguishing between heuristic-based human adaptation and rule-based AI search, we model interactions across modular (parallel) and sequenced (interdependent) tasks using an NK model. Our results reveal that in modular tasks, AI often substitutes for humans - delivering higher payoffs unless human expertise is very high, and the AI search space is either narrowly focused or extremely broad. In sequenced tasks, interesting complementarities emerge. When an expert human initiates the search and AI subsequently refines it, aggregate performance is maximized. Conversely, when AI leads, excessive heuristic refinement by the human can reduce payoffs. We also show that even “hallucinatory” AI - lacking memory or structure - can improve outcomes when augmenting low-capability humans by helping escape local optima. These results yield a robust implication: the effectiveness of AI-human collaboration depends less on context or industry, and more on the underlying task structure. By elevating task decomposition as the central unit of analysis, our model provides a transferable lens for strategic decision-making involving humans and an agentic AI across diverse organizational settings.
我们开发了一种基于代理的模拟方法,将人工智能与人类的协作形式化为任务结构的函数,为组织中的战略决策制定提供了一个通用的框架。我们区分了基于启发式的人类适应和基于规则的AI搜索之间的区别,使用NK模型对模块化(并行)和序列化(相互依赖)任务之间的交互进行建模。我们的结果表明,在模块化任务中,人工智能经常替代人类——除非人类的专业知识非常高,或者AI的搜索空间非常狭窄或极其广泛,否则人工智能会带来更高的回报。在序列化任务中,会出现有趣的互补现象。当专家人类启动搜索并且随后由人工智能进行细化时,总体性能会最大化。相反,当人工智能领先时,人类过多的启发式细化可能会降低回报。我们还表明,即使是“幻觉”人工智能——没有记忆或结构——当增强低能力的人类时,通过帮助逃离局部最优,也可以改善结果。这些结果产生了稳健的启示:人工智能与人类的协作的有效性取决于较少的上下文或行业,而更多地取决于基本任务结构。通过提升任务分解为分析的核心单位,我们的模型为涉及人类和智能体人工智能的战略决策制定提供了一个可转移的透镜,适用于各种组织环境。
论文及项目相关链接
PDF Manuscript under review for the Special Issue: ‘Can AI Do Strategy?’ at Strategy Science (May 1, 2025)
Summary
任务结构的分析是人工智能与人类协作的关键所在。本研究通过构建基于主体的模拟模型,探讨了不同任务结构下人工智能与人类的协作模式。模块化任务中人工智能常常取代人类的高效益部分,除非人类对专业要求极高,否则极易出现任务自动化完成的情况。而在序列任务中,当专家人类启动搜索后由人工智能进行精炼时,总体表现最佳。此外,即使缺乏记忆或结构的人工智能也能在特定情况下提高结果。总之,人工智能与人类的协作效果更多地取决于任务结构而非具体情境或行业背景。本研究为组织中的战略决策提供了新的视角。
Key Takeaways
- 基于主体模拟框架形式化了人工智能与人类的协作,这一协作被视为任务结构的函数。
- 在模块化任务中,人工智能可以替代人类的高效益部分,除非人类对专业要求极高,或AI搜索空间局限于狭窄领域。
- 在序列任务中,人机合作显示出更有趣的互补性特点,人类主导的初步搜索及后续的人工智能精炼将实现最优的协作表现。相反地,AI领导的过多启发式精细化可能降低合作收益。
- 缺乏记忆或结构的人工智能在特定情况下仍能改善结果,例如在辅助低能力人类避免局部最优解方面发挥作用。这表明即使是不完善的人工智能在某些条件下仍可以创造价值。
* 模型的有效性更在于任务结构的性质,而并非协作发生的具体情境或行业背景。这一发现为跨不同组织环境的人工智能与人类协作提供了通用视角。
点此查看论文截图

ARCS: Agentic Retrieval-Augmented Code Synthesis with Iterative Refinement
Authors:Manish Bhattarai, Miguel Cordova, Javier Santos, Dan O’Malley
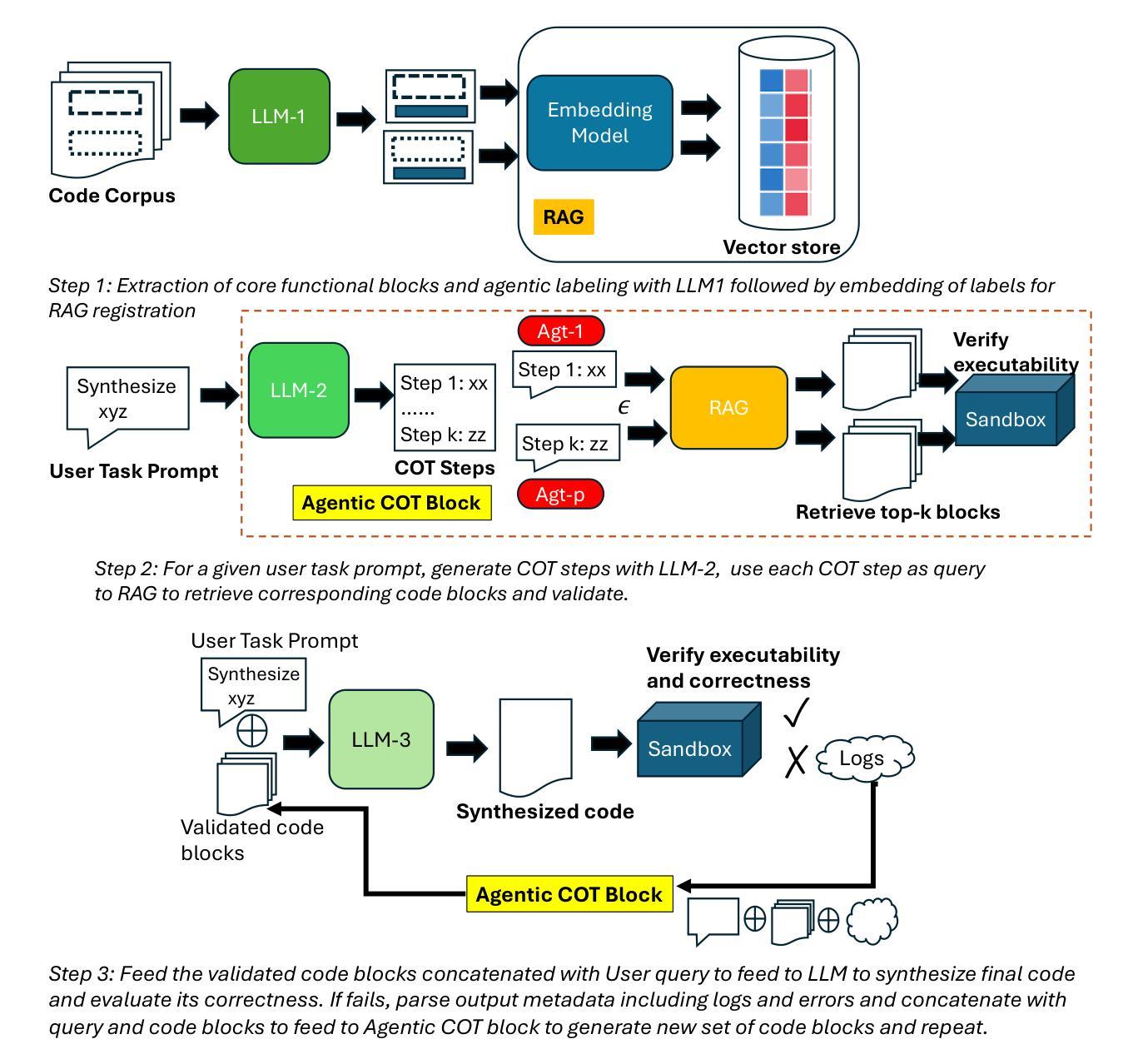
In supercomputing, efficient and optimized code generation is essential to leverage high-performance systems effectively. We propose Agentic Retrieval-Augmented Code Synthesis (ARCS), an advanced framework for accurate, robust, and efficient code generation, completion, and translation. ARCS integrates Retrieval-Augmented Generation (RAG) with Chain-of-Thought (CoT) reasoning to systematically break down and iteratively refine complex programming tasks. An agent-based RAG mechanism retrieves relevant code snippets, while real-time execution feedback drives the synthesis of candidate solutions. This process is formalized as a state-action search tree optimization, balancing code correctness with editing efficiency. Evaluations on the Geeks4Geeks and HumanEval benchmarks demonstrate that ARCS significantly outperforms traditional prompting methods in translation and generation quality. By enabling scalable and precise code synthesis, ARCS offers transformative potential for automating and optimizing code development in supercomputing applications, enhancing computational resource utilization.
在超级计算中,高效优化的代码生成是有效利用高性能系统的关键。我们提出使用Agentic检索增强代码合成(ARCS)这一先进框架,以实现精确、稳健和高效的代码生成、补全和翻译。ARCS将检索增强生成(RAG)与思维链(CoT)推理相结合,系统地分解和迭代优化复杂的编程任务。基于代理的RAG机制检索相关代码片段,而实时执行反馈驱动候选解决方案的合成。这一过程被形式化为状态-动作搜索树优化,在代码正确性与编辑效率之间取得平衡。在Geeks4Geeks和HumanEval基准测试上的评估表明,ARCS在翻译和生成质量方面显著优于传统提示方法。通过实现可伸缩和精确的代码合成,ARCS为超级计算应用程序中的代码开发和自动化优化提供了变革性潜力,提高了计算资源的利用率。
论文及项目相关链接
Summary
高性能计算中,高效优化的代码生成至关重要。我们提出一种名为Agentic检索增强代码合成(ARCS)的高级框架,用于准确、稳健和高效的代码生成、补全和翻译。ARCS将检索增强生成(RAG)与思维链(CoT)推理相结合,系统地分解和迭代优化复杂的编程任务。基于代理的RAG机制检索相关代码片段,而实时执行反馈驱动候选解决方案的合成。这一过程被形式化为状态动作搜索树优化,平衡代码正确性与编辑效率。在Geeks4Geeks和HumanEval基准测试上的评估表明,ARCS在翻译和生成质量方面显著优于传统提示方法。通过实现可伸缩和精确的代码合成,ARCS为自动化和优化高性能计算应用程序中的代码开发提供了变革性潜力,提高了计算资源的利用率。
Key Takeaways
- ARCS是一个高级框架,用于高效、准确的代码生成、补全和翻译。
- ARCS结合了检索增强生成(RAG)与思维链(CoT)推理。
- RAG机制通过检索相关代码片段来辅助代码合成。
- 实时执行反馈用于驱动候选解决方案的合成和优化。
- ARCS通过状态动作搜索树优化平衡代码正确性与编辑效率。
- 在Geeks4Geeks和HumanEval基准测试上,ARCS表现出优异的性能。
点此查看论文截图

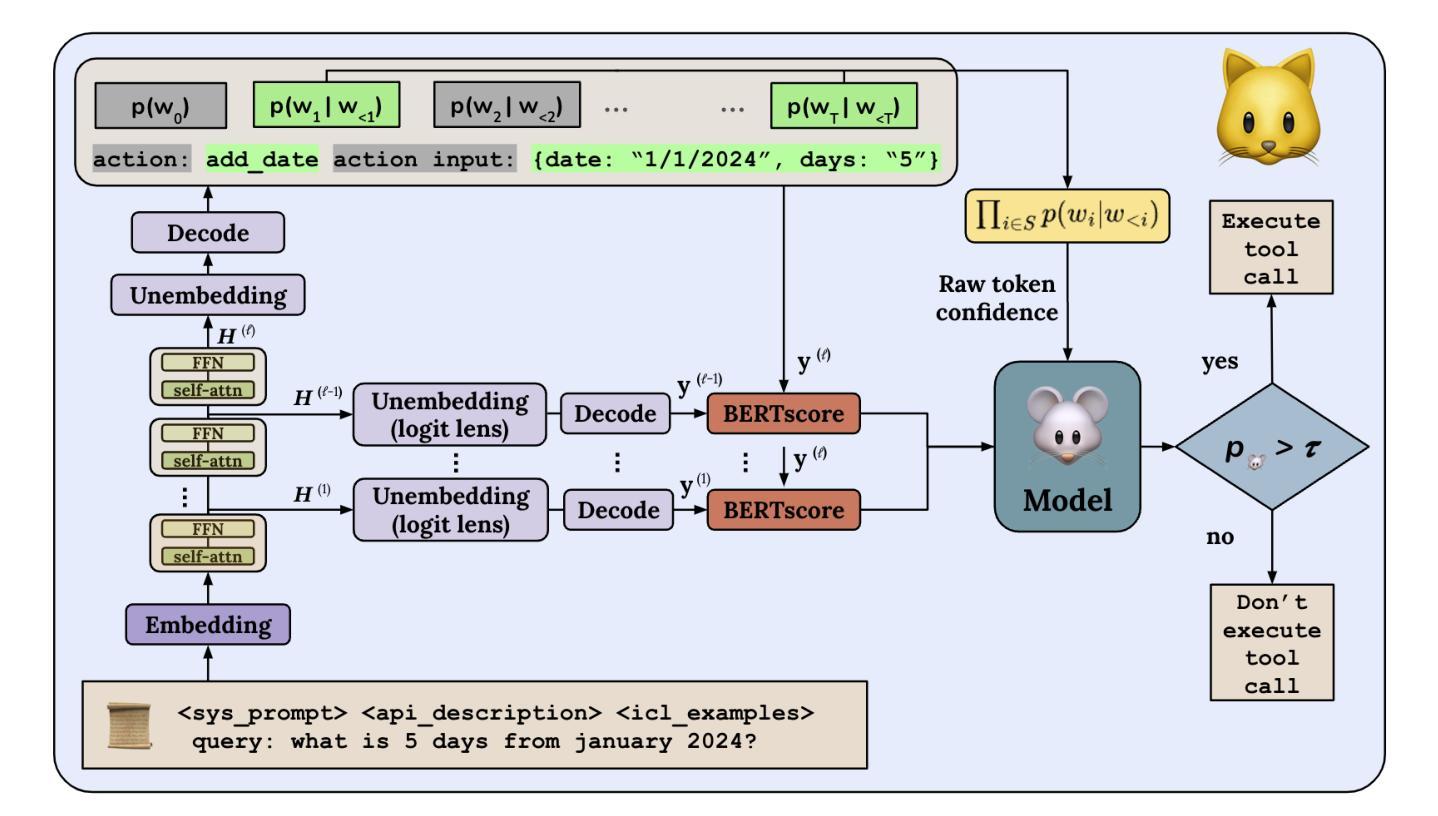
MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools
Authors:Nishant Subramani, Jason Eisner, Justin Svegliato, Benjamin Van Durme, Yu Su, Sam Thomson
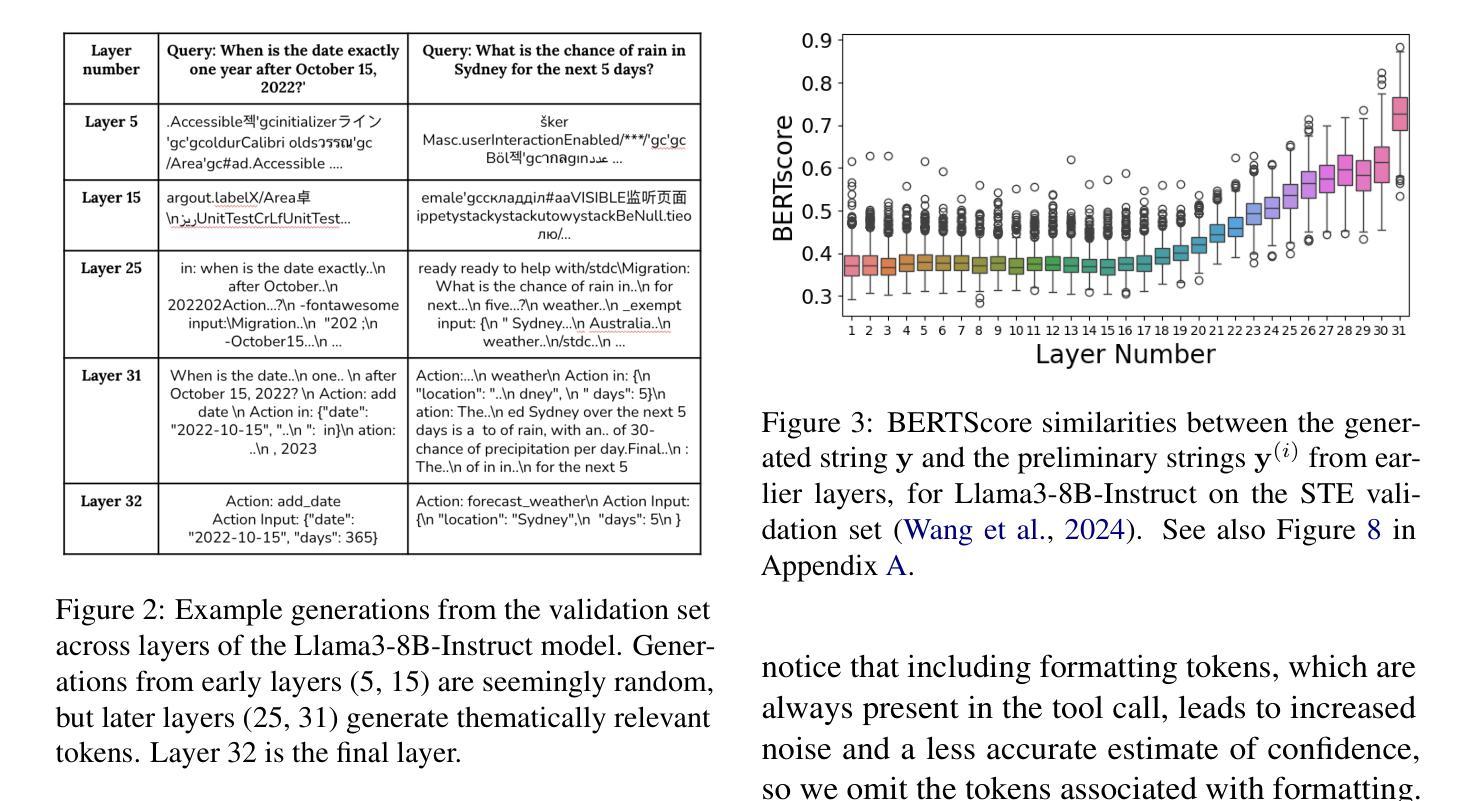
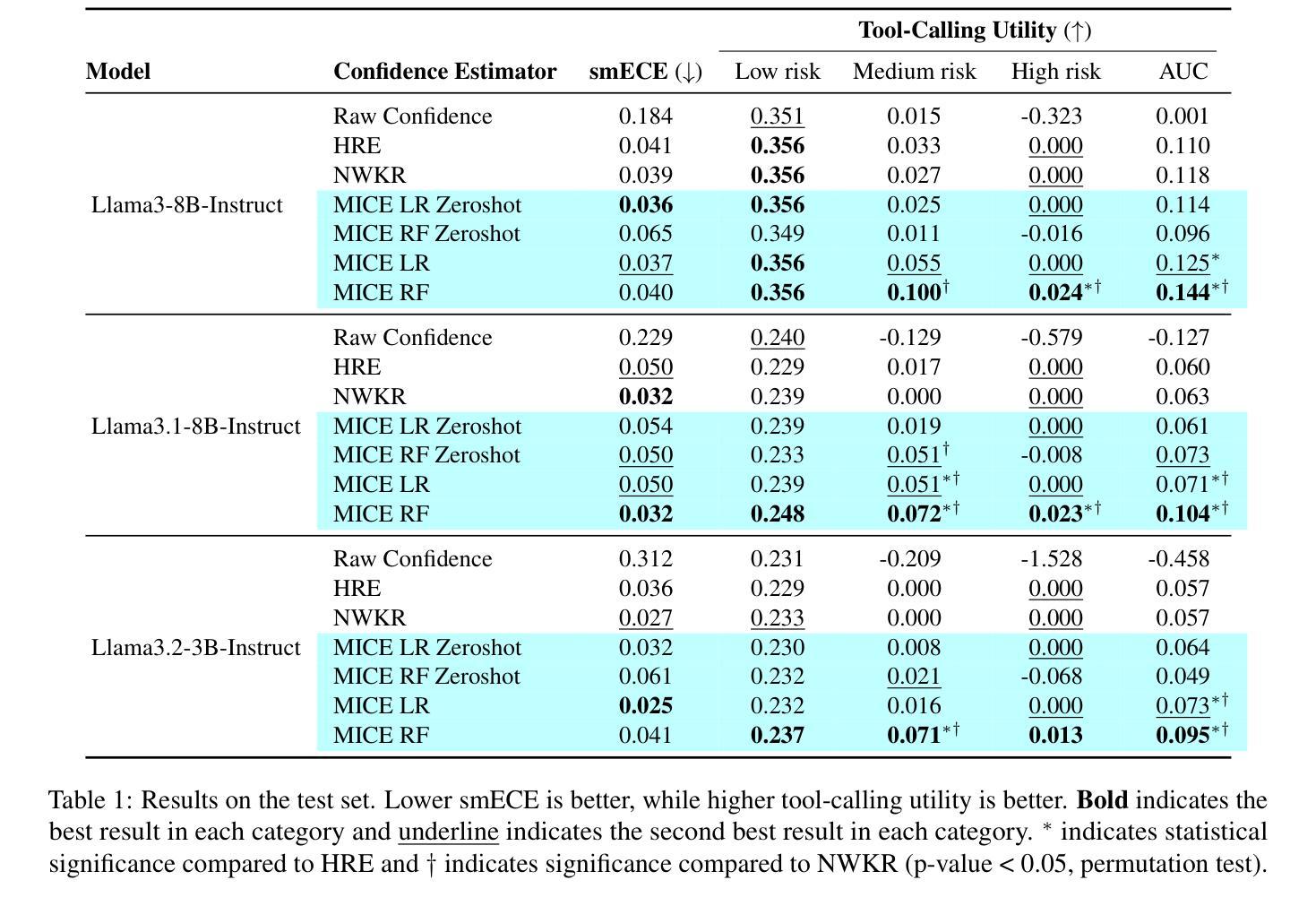
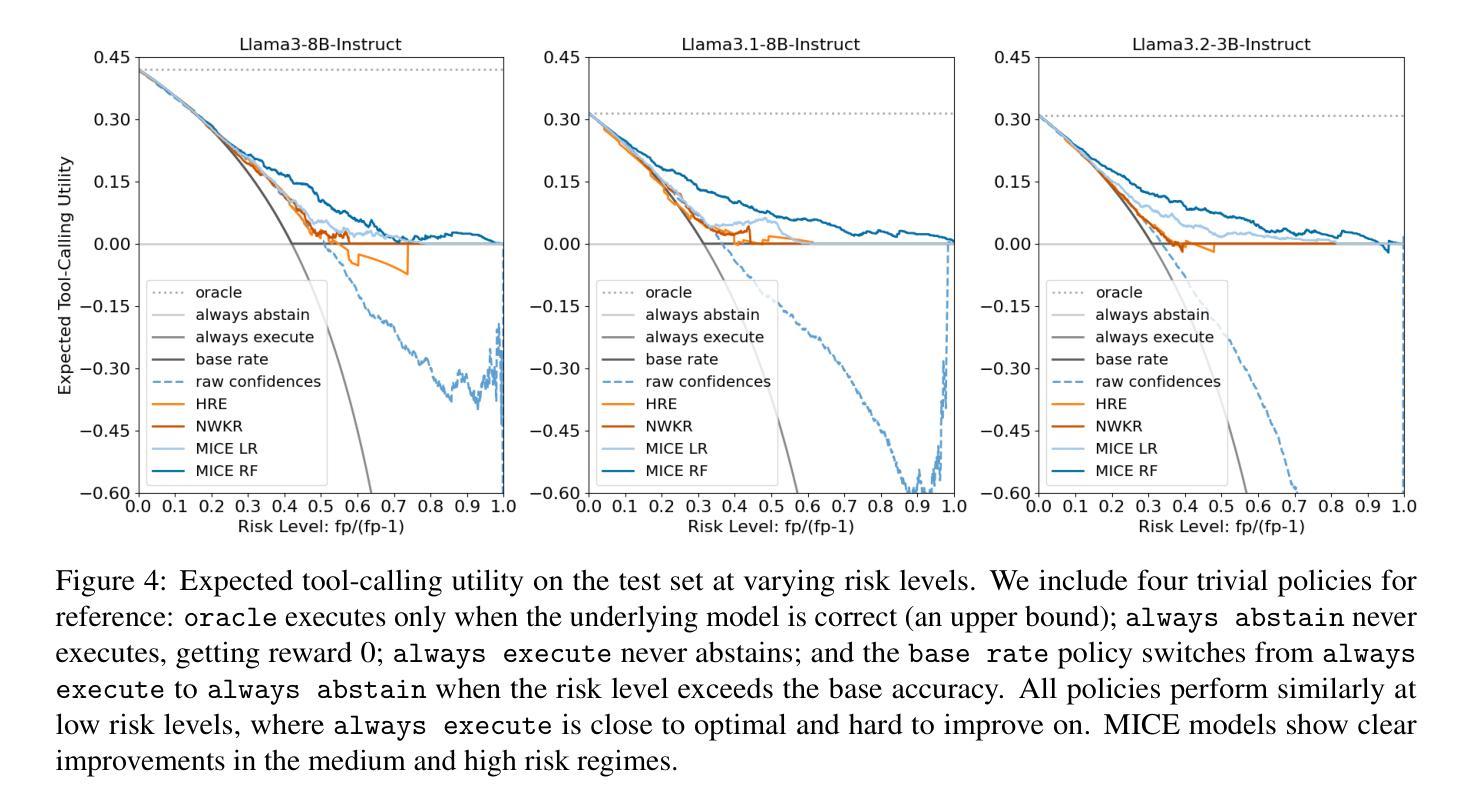
Tool-using agents that act in the world need to be both useful and safe. Well-calibrated model confidences can be used to weigh the risk versus reward of potential actions, but prior work shows that many models are poorly calibrated. Inspired by interpretability literature exploring the internals of models, we propose a novel class of model-internal confidence estimators (MICE) to better assess confidence when calling tools. MICE first decodes from each intermediate layer of the language model using logitLens and then computes similarity scores between each layer’s generation and the final output. These features are fed into a learned probabilistic classifier to assess confidence in the decoded output. On the simulated trial and error (STE) tool-calling dataset using Llama3 models, we find that MICE beats or matches the baselines on smoothed expected calibration error. Using MICE confidences to determine whether to call a tool significantly improves over strong baselines on a new metric, expected tool-calling utility. Further experiments show that MICE is sample-efficient, can generalize zero-shot to unseen APIs, and results in higher tool-calling utility in scenarios with varying risk levels. Our code is open source, available at https://github.com/microsoft/mice_for_cats.
在现实世界中行动的工具使用代理既需要实用又需要安全。经过良好校准的模型置信度可以用来权衡潜在行动的风险与回报,但先前的工作表明许多模型的校准情况并不理想。我们从探索模型内部的解释性文献中获得灵感,提出了一种新型的模型内部置信度估计器(MICE),以在调用工具时更好地评估置信度。MICE首先使用logitLens从语言模型的每个中间层进行解码,然后计算每个生成层与最终输出之间的相似度分数。这些特征被输入到一个经过学习的概率分类器中,以评估解码输出的置信度。在模拟试验和错误(STE)工具调用数据集上使用Llama3模型,我们发现MICE在平滑的预期校准误差上超过了基线或与之匹配。使用MICE置信度来决定是否调用工具,在新的预期工具调用效用指标上显著优于强大的基线。进一步的实验表明,MICE样本效率高,可以零样本泛化到看不见的API,并在不同风险级别的场景中导致更高的工具调用效用。我们的代码是开源的,可在https://github.com/microsoft/mice_for_cats找到。
论文及项目相关链接
PDF Accepted at NAACL 2025. Code: https://github.com/microsoft/mice_for_cats
Summary
模型内外置信度评估在工具调用决策中至关重要。为更好地评估模型置信度,提出一种新型模型内部置信度估计器(MICE)。通过从语言模型的各中间层进行解码并使用logitLens计算生成物与最终输出的相似度分数,再输入到概率分类器中评估解码输出的置信度。实验显示,MICE在工具调用数据集上表现优越,并能有效推广至未见API。此外,MICE能提高在不同风险水平场景下的工具调用效用,代码已开源。
Key Takeaways
- 模型内外置信度评估对工具调用决策至关重要。
- 为提高模型置信度评估,提出一种新型模型内部置信度估计器(MICE)。
- MICE通过解码语言模型的各中间层并使用logitLens计算相似度分数来评估输出置信度。
- 在工具调用数据集上,MICE表现优越,且能推广至未见API。
- 使用MICE的置信度评估能提高工具调用效用。
- MICE具有样本效率高的特点。
点此查看论文截图

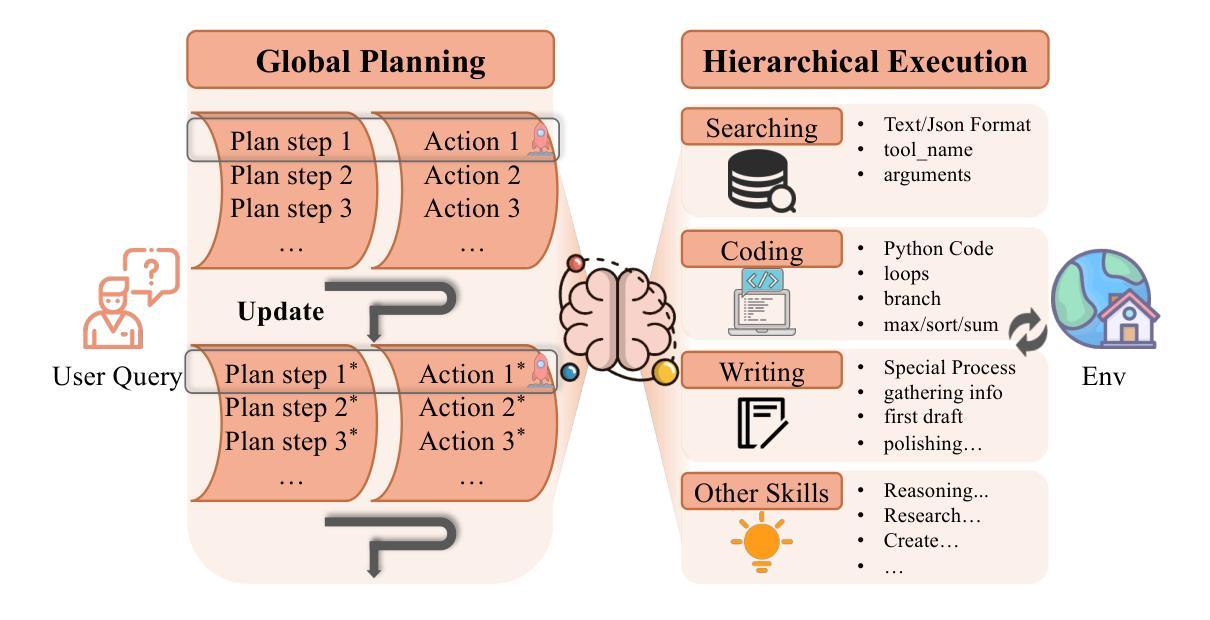
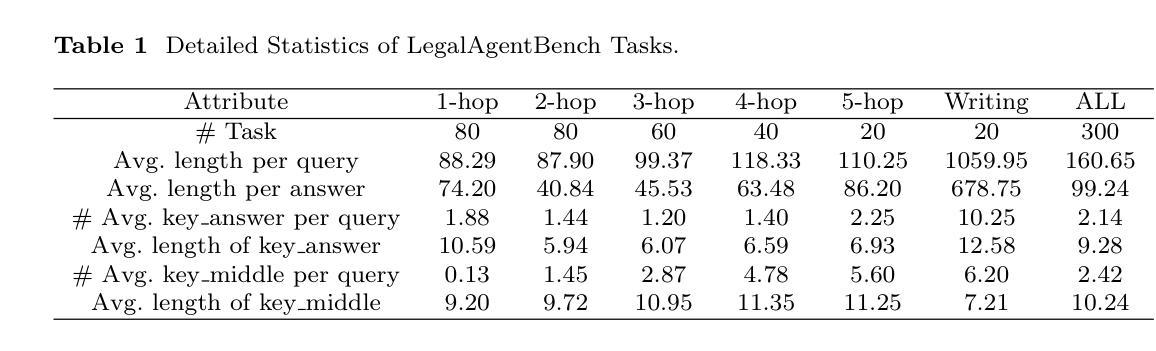
Enhancing LLM-Based Agents via Global Planning and Hierarchical Execution
Authors:Junjie Chen, Haitao Li, Jingli Yang, Yiqun Liu, Qingyao Ai
Intelligent agent systems based on Large Language Models (LLMs) have shown great potential in real-world applications. However, existing agent frameworks still face critical limitations in task planning and execution, restricting their effectiveness and generalizability. Specifically, current planning methods often lack clear global goals, leading agents to get stuck in local branches, or produce non-executable plans. Meanwhile, existing execution mechanisms struggle to balance complexity and stability, and their limited action space restricts their ability to handle diverse real-world tasks. To address these limitations, we propose GoalAct, a novel agent framework that introduces a continuously updated global planning mechanism and integrates a hierarchical execution strategy. GoalAct decomposes task execution into high-level skills, including searching, coding, writing and more, thereby reducing planning complexity while enhancing the agents’ adaptability across diverse task scenarios. We evaluate GoalAct on LegalAgentBench, a benchmark with multiple types of legal tasks that require the use of multiple types of tools. Experimental results demonstrate that GoalAct achieves state-of-the-art (SOTA) performance, with an average improvement of 12.22% in success rate. These findings highlight GoalAct’s potential to drive the development of more advanced intelligent agent systems, making them more effective across complex real-world applications. Our code can be found at https://github.com/cjj826/GoalAct.
基于大型语言模型(LLM)的智能代理系统在实际应用中显示出巨大的潜力。然而,现有的代理框架在任务规划和执行方面仍面临关键限制,限制了其效果和通用性。具体来说,当前的规划方法往往缺乏明确的全球目标,导致代理陷入局部分支,或产生不可执行的计划。同时,现有的执行机制在平衡复杂性和稳定性方面面临困难,其有限的行动空间限制了处理各种实际任务的能力。为了解决这些限制,我们提出了GoalAct,这是一种新的代理框架,它引入了一种持续更新的全球规划机制,并集成了一种分层执行策略。GoalAct将任务执行分解为高级技能,包括搜索、编码、写作等,从而降低了规划复杂性,同时提高了代理在不同任务场景中的适应性。我们在LegalAgentBench上评估了GoalAct,这是一个包含多种法律任务类型的基准测试,需要使用多种工具。实验结果表明,GoalAct达到了最新技术水平(SOTA),成功率平均提高了12.22%。这些发现突出了GoalAct在推动更先进的智能代理系统发展中的潜力,使它们在复杂的实际应用中更加有效。我们的代码可以在https://github.com/cjj826/GoalAct找到。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的智能代理系统在实际应用中显示出巨大潜力。然而,现有代理框架在任务规划和执行方面仍存在关键限制,限制了其有效性和通用性。为解决这些问题,提出了GoalAct这一新型代理框架,引入持续更新的全局规划机制并整合分层执行策略。GoalAct将任务执行分解为高级技能,包括搜索、编码、写作等,降低规划复杂性,提高代理在不同任务场景中的适应性。在LegalAgentBench基准测试上,GoalAct实现了卓越性能,平均成功率提高12.22%。
Key Takeaways
- 智能代理系统基于大型语言模型(LLM)在实际应用中具有巨大潜力。
- 现有代理框架在任务规划和执行方面存在限制,影响有效性和通用性。
- GoalAct框架引入持续更新的全局规划机制,提高代理适应性。
- GoalAct整合分层执行策略,将任务执行分解为高级技能,如搜索、编码和写作。
- GoalAct在LegalAgentBench基准测试上实现卓越性能,平均成功率提高12.22%。
- GoalAct具有潜力推动更先进的智能代理系统发展。
点此查看论文截图

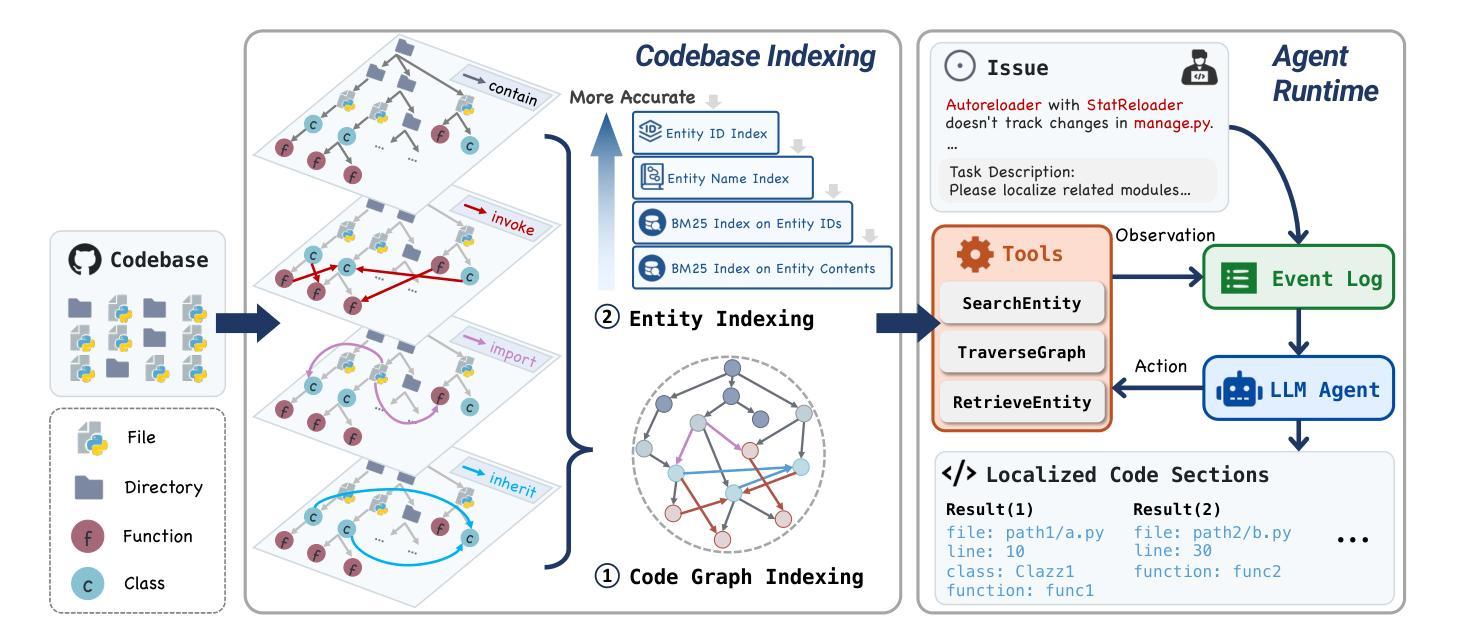
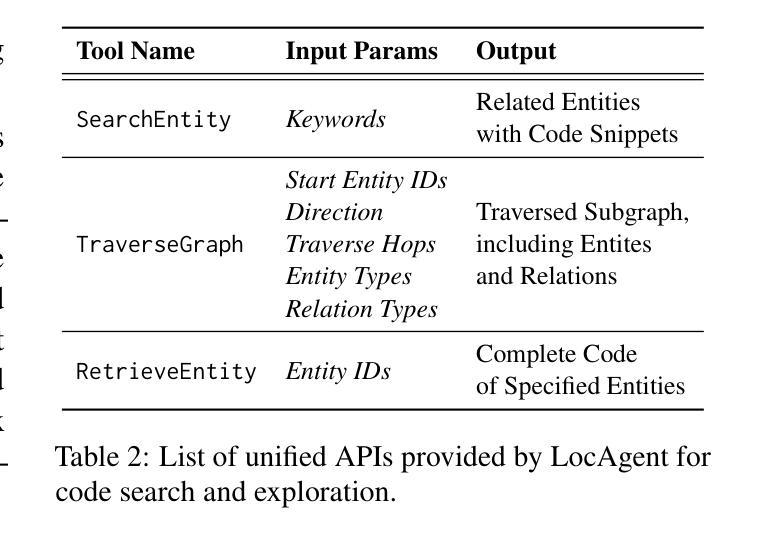
LocAgent: Graph-Guided LLM Agents for Code Localization
Authors:Zhaoling Chen, Xiangru Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, Xingyao Wang
Code localization–identifying precisely where in a codebase changes need to be made–is a fundamental yet challenging task in software maintenance. Existing approaches struggle to efficiently navigate complex codebases when identifying relevant code sections. The challenge lies in bridging natural language problem descriptions with the appropriate code elements, often requiring reasoning across hierarchical structures and multiple dependencies. We introduce LocAgent, a framework that addresses code localization through graph-based representation. By parsing codebases into directed heterogeneous graphs, LocAgent creates a lightweight representation that captures code structures (files, classes, functions) and their dependencies (imports, invocations, inheritance), enabling LLM agents to effectively search and locate relevant entities through powerful multi-hop reasoning. Experimental results on real-world benchmarks demonstrate that our approach significantly enhances accuracy in code localization. Notably, our method with the fine-tuned Qwen-2.5-Coder-Instruct-32B model achieves comparable results to SOTA proprietary models at greatly reduced cost (approximately 86% reduction), reaching up to 92.7% accuracy on file-level localization while improving downstream GitHub issue resolution success rates by 12% for multiple attempts (Pass@10). Our code is available at https://github.com/gersteinlab/LocAgent.
代码定位——精确识别需要在代码库中做出更改的位置——是软件维护中的一项基本且具有挑战性的任务。现有方法在识别相关代码段时很难有效地遍历复杂的代码库。挑战在于将自然语言问题描述与适当的代码元素建立联系,通常需要跨越层次结构和多个依赖关系进行推理。我们引入了LocAgent,这是一个通过基于图表示来解决代码定位问题的框架。通过将代码库解析为定向异质图,LocAgent创建了一种轻量级的表示方法,能够捕获代码结构(文件、类、函数)及其依赖关系(导入、调用、继承),从而使大型语言模型(LLM)代理能够进行有效的多步推理,搜索并定位相关实体。在现实世界基准测试上的实验结果表明,我们的方法显著提高了代码定位的准确性。值得注意的是,我们的方法与经过fine-tuning的Qwen-2.5-Coder-Instruct-32B模型相结合,在成本大大降低(约降低86%)的情况下实现了与最新专有模型相当的结果,在文件级别定位上达到92.7%的准确性,并在多次尝试中提高了下游GitHub问题解决的成功率(Pass@10)达12%。我们的代码可在https://github.com/gersteinlab/LocAgent找到。
论文及项目相关链接
Summary
代码定位是软件维护中的基本且具挑战性的任务,要求精准地确定需要在代码库中做出更改的位置。现有方法在处理复杂的代码库时难以有效地导航并识别相关的代码片段。研究团队引入了LocAgent框架,通过基于图的方法来解决代码定位问题。它通过解析代码库并创建有向的异构图,以捕获代码结构(文件、类、函数)及其依赖关系(导入、调用、继承),使LLM代理能够有效地搜索并定位相关实体,进行强大的多跳推理。实验结果表明,该方法显著提高代码定位的准确性。特别地,使用fine-tuned Qwen-2.5-Coder-Instruct-32B模型的我们的方法在经济成本上大幅降低(约降低了86%),在文件级别的定位准确性上达到了92.7%,并且在多次尝试后提高了GitHub问题解决的成功率达12%。
Key Takeaways
- 代码定位是软件维护中的核心挑战,需要精确识别代码修改的位置。
- 现有方法在处理复杂代码库时存在导航困难,难以识别相关代码片段的问题。
- LocAgent框架通过基于图的方法来解决代码定位问题,解析代码库为有向异构图。
- LocAgent能够捕获代码结构及其依赖关系,使LLM代理能进行多跳推理以搜索和定位相关实体。
- 实验结果表明,LocAgent显著提高了代码定位的准确性。
- 使用fine-tuned Qwen-2.5-Coder-Instruct-32B模型的LocAgent在经济成本上大幅降低,并达到了较高的文件级别定位准确性。
点此查看论文截图


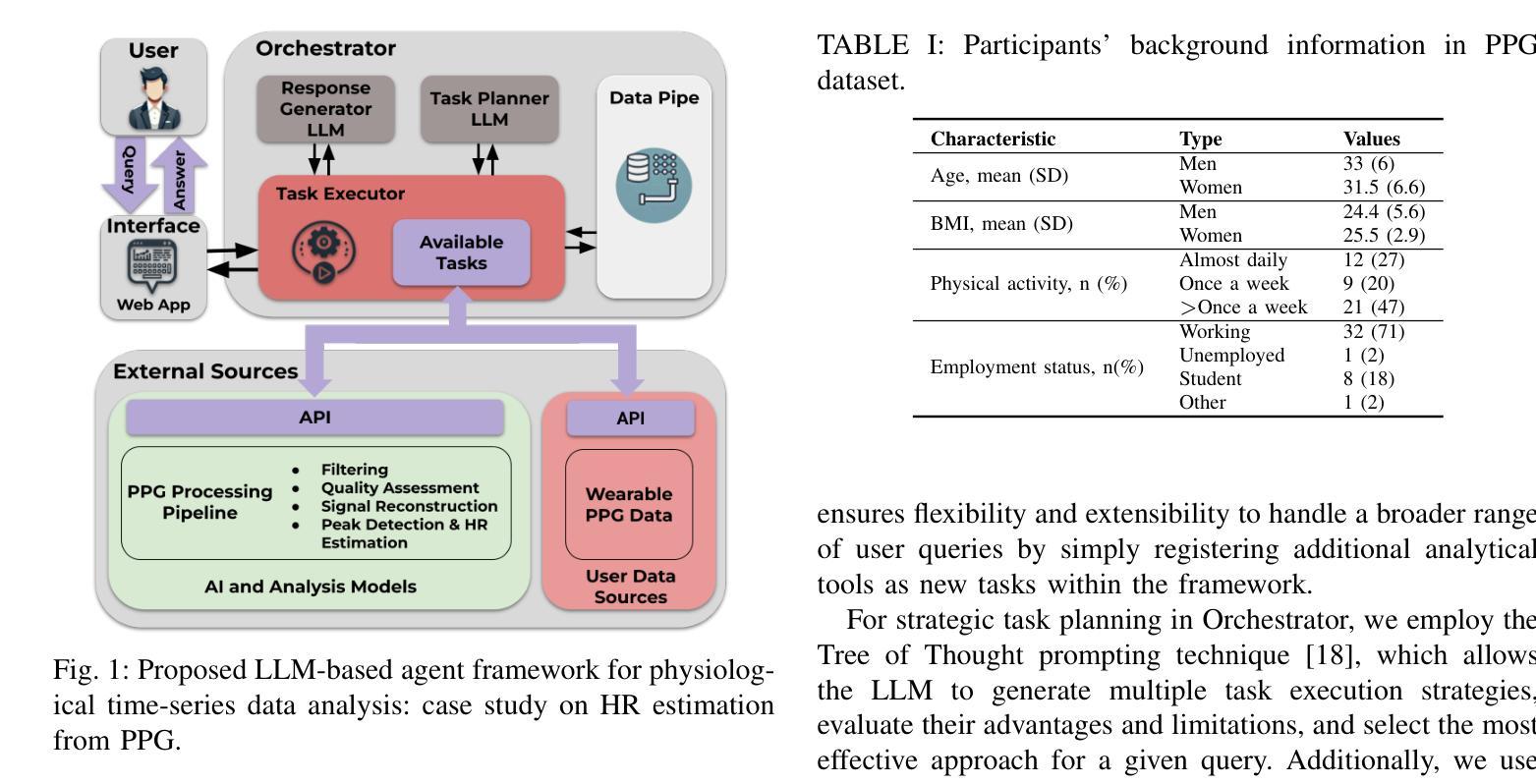
An LLM-Powered Agent for Physiological Data Analysis: A Case Study on PPG-based Heart Rate Estimation
Authors:Mohammad Feli, Iman Azimi, Pasi Liljeberg, Amir M. Rahmani
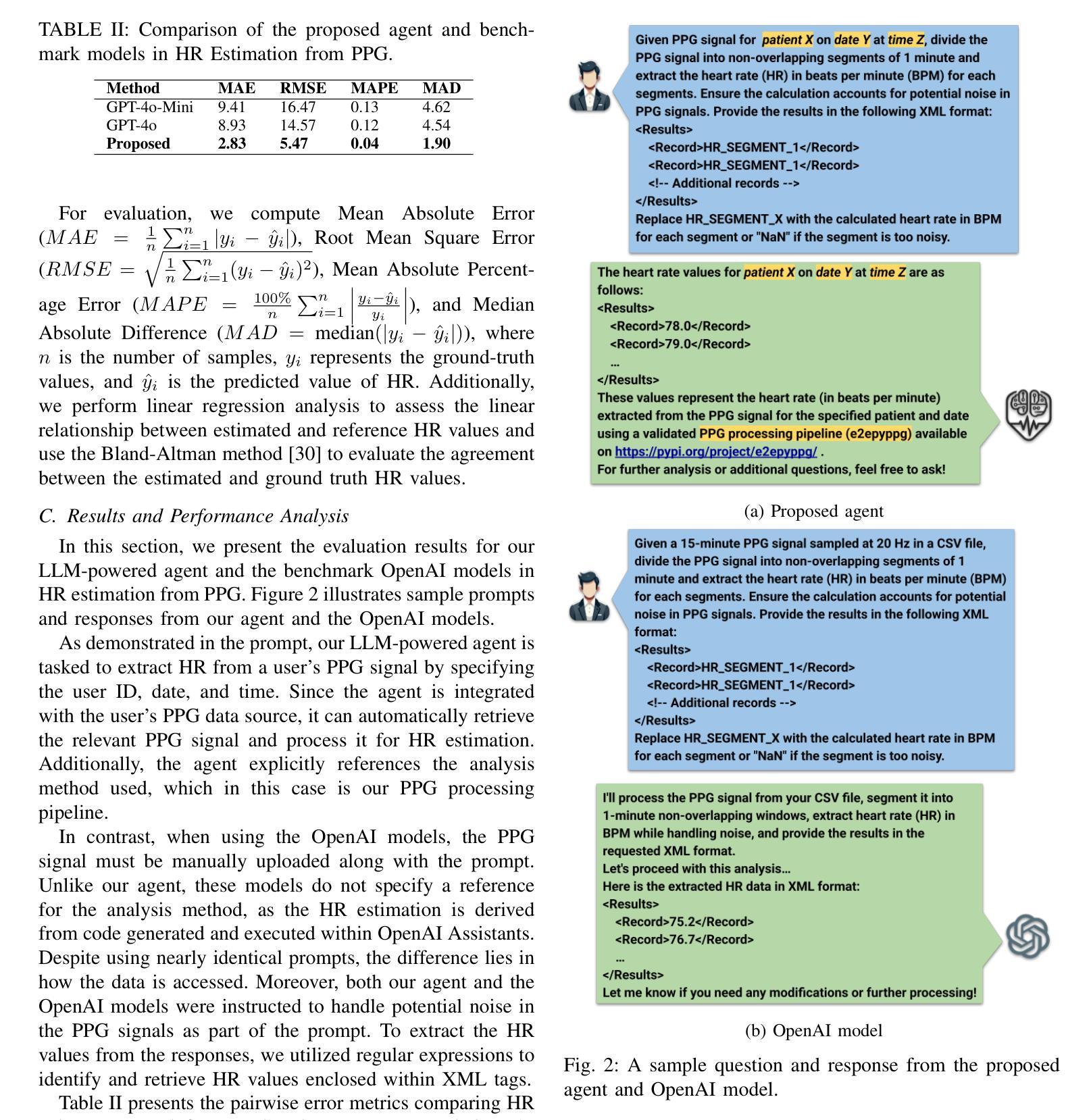
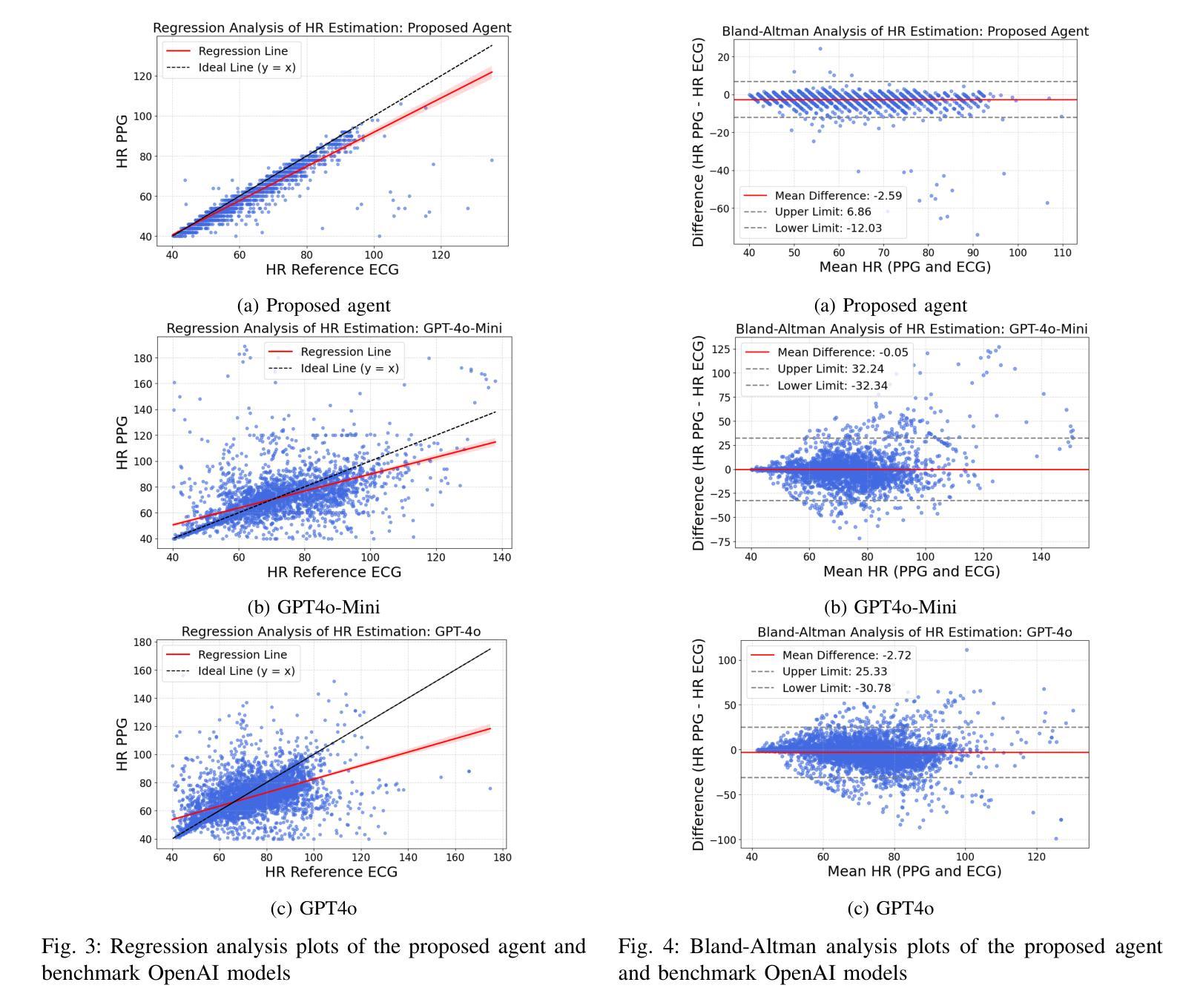
Large language models (LLMs) are revolutionizing healthcare by improving diagnosis, patient care, and decision support through interactive communication. More recently, they have been applied to analyzing physiological time-series like wearable data for health insight extraction. Existing methods embed raw numerical sequences directly into prompts, which exceeds token limits and increases computational costs. Additionally, some studies integrated features extracted from time-series in textual prompts or applied multimodal approaches. However, these methods often produce generic and unreliable outputs due to LLMs’ limited analytical rigor and inefficiency in interpreting continuous waveforms. In this paper, we develop an LLM-powered agent for physiological time-series analysis aimed to bridge the gap in integrating LLMs with well-established analytical tools. Built on the OpenCHA, an open-source LLM-powered framework, our agent powered by OpenAI’s GPT-3.5-turbo model features an orchestrator that integrates user interaction, data sources, and analytical tools to generate accurate health insights. To evaluate its effectiveness, we implement a case study on heart rate (HR) estimation from Photoplethysmogram (PPG) signals using a dataset of PPG and Electrocardiogram (ECG) recordings in a remote health monitoring study. The agent’s performance is benchmarked against OpenAI GPT-4o-mini and GPT-4o, with ECG serving as the gold standard for HR estimation. Results demonstrate that our agent significantly outperforms benchmark models by achieving lower error rates and more reliable HR estimations. The agent implementation is publicly available on GitHub.
大型语言模型(LLM)正通过交互式通信改善诊断、患者护理和决策支持来推动医疗保健领域的革命。最近,它们被应用于分析生理时间序列,如可穿戴设备数据,以提取健康洞察。现有方法直接将原始数字序列嵌入提示中,这超过了令牌限制并增加了计算成本。此外,一些研究将时间序列的特征集成到文本提示中,或应用多模式方法。然而,这些方法往往产生通用且不可靠的输出,因为LLM在分析严谨性和解释连续波形方面的有限性和效率低下。在本文中,我们开发了一种用于生理时间序列分析的大型语言模型驱动代理,旨在弥合将LLM与成熟的分析工具相结合的差距。我们的代理建立在开源的大型语言模型驱动框架OpenCHA上,使用OpenAI的GPT-3.5 Turbo模型作为功能强大的引擎,配备一个协调器,可整合用户交互、数据源和分析工具,以生成准确的健康洞察。为了评估其有效性,我们在远程健康监测研究的数据集上实施了一项心率估算的案例研究,该数据集包含光体积描记器(PPG)信号的心电图(ECG)记录。代理的性能以心电图(ECG)作为心率估算的金标准,与OpenAI的GPT-4o Mini和GPT-4o进行了比较。结果表明,我们的代理在达到更低的错误率和更可靠的心率估算方面显著优于基准模型。代理实现已在GitHub上公开可用。
论文及项目相关链接
Summary
本文介绍了一个基于大型语言模型(LLM)的代理,用于生理时间序列分析。该代理能够整合用户交互、数据源和分析工具,生成准确的健康洞察。在心率估算的案例中,该代理表现出显著的优势,相比其他模型有更低的误差率和更可靠的心率估算。
Key Takeaways
- 大型语言模型(LLM)正在医疗领域发挥重要作用,可用于改善诊断、患者护理和决策支持。
- 现有方法直接将原始数值序列嵌入提示中,导致超出令牌限制和计算成本增加。
- LLM在解析连续波形方面存在局限性,导致输出的通用性和可靠性问题。
- 本文介绍了一个基于LLM的代理,旨在解决LLM与现有分析工具之间的整合差距。
- 该代理使用OpenCHA框架和OpenAI的GPT-3.5 Turbo模型构建,具备用户交互、数据源和分析工具整合功能。
- 在心率估算的案例中,该代理显著优于其他模型,具有更低的误差率和更高的可靠性。
点此查看论文截图

EgoAgent: A Joint Predictive Agent Model in Egocentric Worlds
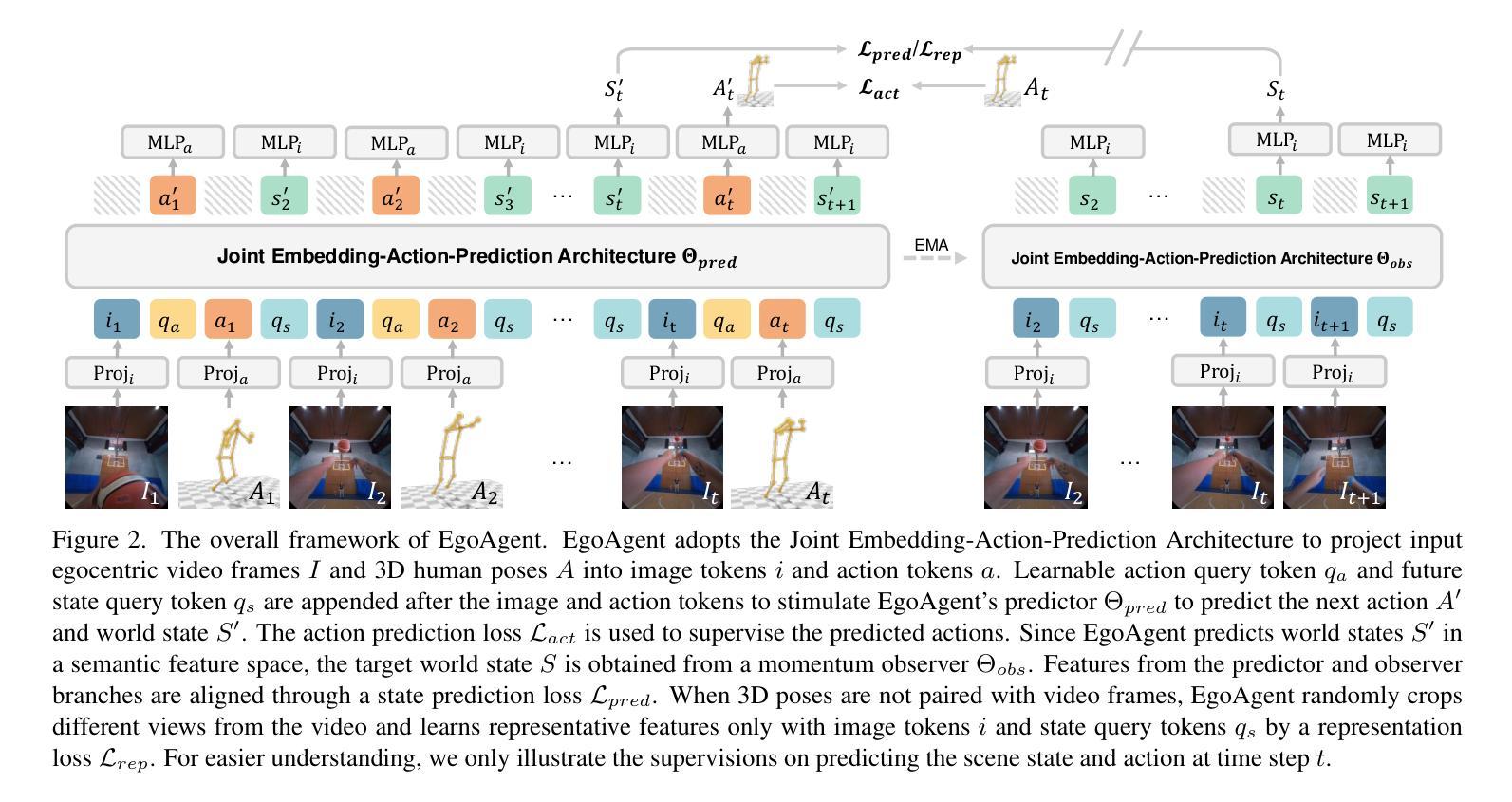
Authors:Lu Chen, Yizhou Wang, Shixiang Tang, Qianhong Ma, Tong He, Wanli Ouyang, Xiaowei Zhou, Hujun Bao, Sida Peng
This paper addresses the task of learning an agent model behaving like humans, which can jointly perceive, predict, and act in egocentric worlds. Previous methods usually train separate models for these three abilities, which prevents them from learning from each other. In this paper, we propose a joint predictive agent model, named EgoAgent, that simultaneously learns to represent the world, predict future states, and take reasonable actions within a single transformer. EgoAgent introduces two innovations to learn from the causal and temporally intertwined nature of these abilities: (1) Interleaved sequential modeling of states and actions with the causal attention mechanism, and (2) A joint embedding-action-prediction architecture featuring temporal asymmetric predictor-observer branches. Integrating these designs based on JEPA, EgoAgent unifies these capabilities in a cohesive learning framework. Comprehensive evaluations of EgoAgent on representative tasks such as image classification, egocentric future state prediction, and 3D human motion prediction tasks demonstrate the superiority of our method. The code and trained model will be released for reproducibility.
本文旨在解决学习一种像人类一样行为的代理模型的任务,该模型可以在以自我为中心的世界中共同感知、预测和行动。以前的方法通常针对这三种能力分别进行建模,这阻止了它们之间的互相学习。在本文中,我们提出了一种联合预测代理模型,名为EgoAgent。它能够在单个变压器内同时学习表示世界、预测未来状态和采取合理行动。EgoAgent通过两项创新来学习这些能力的因果和时间交织的本质:(1)利用因果注意力机制的交错状态与行为的顺序建模;(2)具有时间不对称预测器观察分支的联合嵌入动作预测架构。基于JEPA整合这些设计,EgoAgent在一个协调统一的学习框架中融合了这些能力。在图像分类、以自我为中心的未来状态预测和3D人体运动预测等代表性任务上,对EgoAgent的综合评估证明了我们的方法优越性。我们的代码和训练好的模型将发布,以确保结果的可重复性。
论文及项目相关链接
Summary
本文提出了一种名为EgoAgent的联合预测代理模型,该模型能够在单一转换器中同时学习表示世界、预测未来状态和采取合理行动。通过采用因果注意力机制和具有时间不对称预测器观察者分支的联合嵌入动作预测架构,EgoAgent实现了对感知、预测和行动能力的联合学习,并在图像分类、以自我为中心的未来状态预测和3D人类运动预测任务上表现出卓越性能。
Key Takeaways
- EgoAgent是一个联合预测代理模型,能够同时学习表示世界、预测未来状态和采取合理行动。
- 该模型通过引入因果注意力机制和具有时间不对称预测器观察者分支的设计,实现了对感知、预测和行动能力的联合学习。
- EgoAgent在图像分类、以自我为中心的未来状态预测和3D人类运动预测任务上表现出卓越性能。
- 模型设计基于JEPA,提供了一个连贯的学习框架。
- 代码和训练好的模型将被公开,以便于复制和进一步的研究。
- EgoAgent通过同时训练感知、预测和行动能力,克服了以往分别训练这些能力的方法的局限性。
点此查看论文截图


Agentic AI: The Era of Semantic Decoding
Authors:Maxime Peyrard, Martin Josifoski, Robert West
Recent work demonstrated great promise in the idea of orchestrating collaborations between LLMs, human input, and various tools to address the inherent limitations of LLMs. We propose a novel perspective called semantic decoding, which frames these collaborative processes as optimization procedures in semantic space. Specifically, we conceptualize LLMs as semantic processors that manipulate meaningful pieces of information that we call semantic tokens (known thoughts). LLMs are among a large pool of other semantic processors, including humans and tools, such as search engines or code executors. Collectively, semantic processors engage in dynamic exchanges of semantic tokens to progressively construct high-utility outputs. We refer to these orchestrated interactions among semantic processors, optimizing and searching in semantic space, as semantic decoding algorithms. This concept draws a direct parallel to the well-studied problem of syntactic decoding, which involves crafting algorithms to best exploit auto-regressive language models for extracting high-utility sequences of syntactic tokens. By focusing on the semantic level and disregarding syntactic details, we gain a fresh perspective on the engineering of AI systems, enabling us to imagine systems with much greater complexity and capabilities. In this position paper, we formalize the transition from syntactic to semantic tokens as well as the analogy between syntactic and semantic decoding. Subsequently, we explore the possibilities of optimizing within the space of semantic tokens via semantic decoding algorithms. We conclude with a list of research opportunities and questions arising from this fresh perspective. The semantic decoding perspective offers a powerful abstraction for search and optimization directly in the space of meaningful concepts, with semantic tokens as the fundamental units of a new type of computation.
最近的工作展示了在大规模语言模型(LLMs)、人类输入和各种工具之间协同合作以克服LLMs固有局限的构想具有巨大潜力。我们提出了一种新的视角,称为语义解码,它将这些协同过程描述为语义空间中的优化过程。具体来说,我们将LLMs概念化为语义处理器,它们处理我们称为语义令牌(已知思想)的具有意义的信息片段。LLMs是一组其他语义处理器中的一部分,包括人类和工具,如搜索引擎或代码执行器。集体来说,语义处理器参与语义令牌的动态交换,以逐步构建高实用性的输出。我们将这些语义处理器之间的协同交互,在语义空间中进行优化和搜索,称为语义解码算法。这个概念与已研究过的句法解码问题直接相对应,句法解码涉及设计算法以最佳方式利用自回归语言模型来提取高实用性的句法令牌序列。通过关注语义层面而忽视句法细节,我们对AI系统的工程构建有了全新的认识,使我们能够想象出具有更大复杂性和能力的系统。在本立场论文中,我们正式将句法令牌过渡到语义令牌以及句法解码和语义解码之间的类比。随后,我们通过语义解码算法探索在语义令牌空间内优化的可能性。我们总结了由此产生的新视角所带来的研究机会和问题。语义解码视角为直接在有意义的概念空间中进行搜索和优化提供了强大的抽象,而语义令牌作为新型计算的基本单位。
论文及项目相关链接
PDF 25 pages, 3 figures
Summary
该文本提出了一种新的观点,即语义解码,将LLMs与人类输入和各种工具的协作过程视为语义空间中的优化过程。作者将LLMs概念化为语义处理器,与其他语义处理器(如人类、搜索引擎或代码执行器)共同构成动态交换语义标记(即语义令牌),以逐步构建高实用性的输出。这些被称为语义解码算法,与句法解码问题形成对比。通过关注语义层面而忽视句法细节,作者提供了一个关于AI系统工程的全新视角,并探讨了通过语义解码算法在语义令牌空间内优化的可能性。
Key Takeaways
- 提出了一种新的观点——语义解码,将LLMs和其他语义处理器(如人类和工具)之间的协作视为优化过程。
- LLMs被概念化为语义处理器,能够处理有意义的语义令牌。
- 动态交换的语义令牌在构建高实用性输出方面发挥着作用。
- 语义解码算法在优化和搜索语义空间中起着关键作用。
- 语义解码与句法解码形成对比,专注于语义层面而非句法细节。
- 语义解码提供了一个关于AI系统工程的全新视角,并探讨了优化语义令牌空间的可能性。
点此查看论文截图

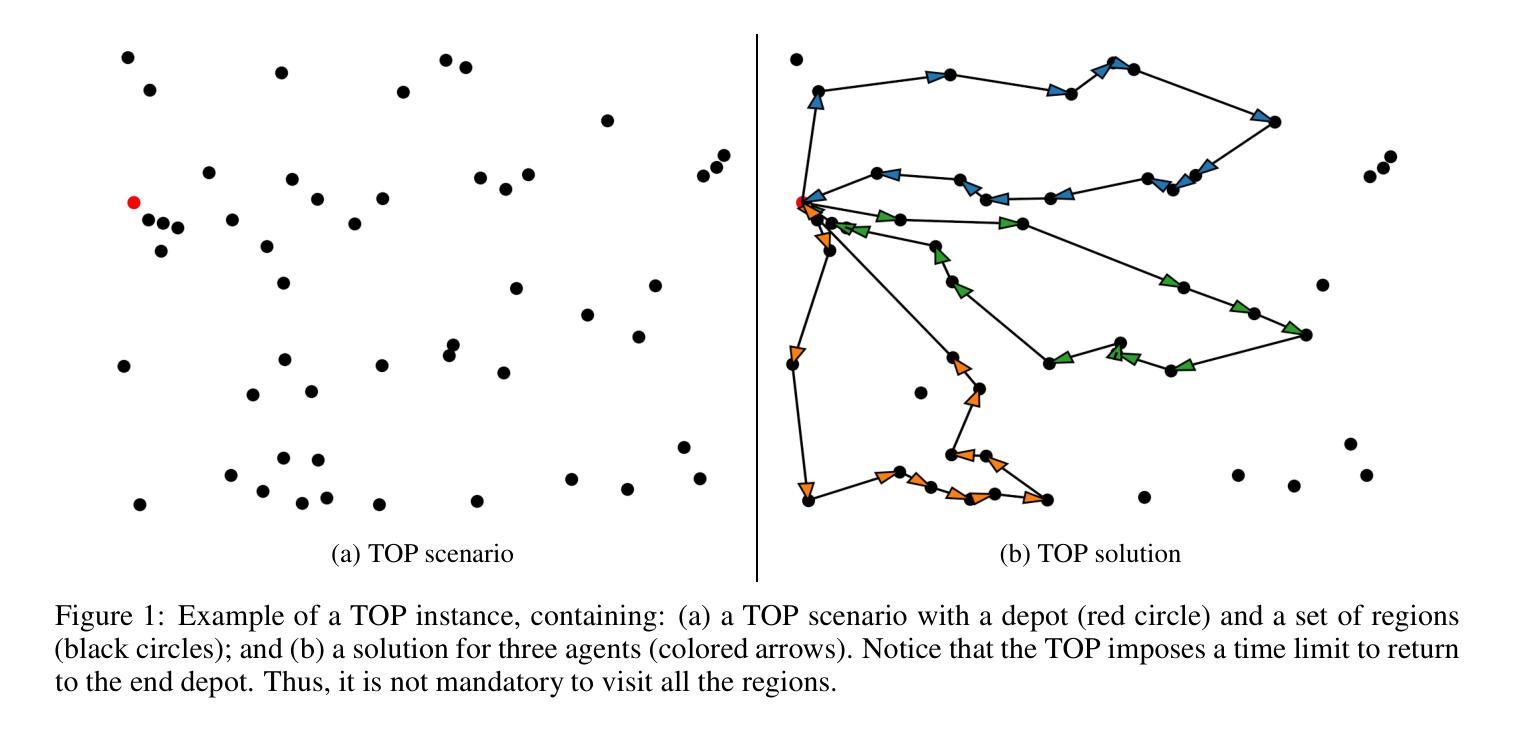
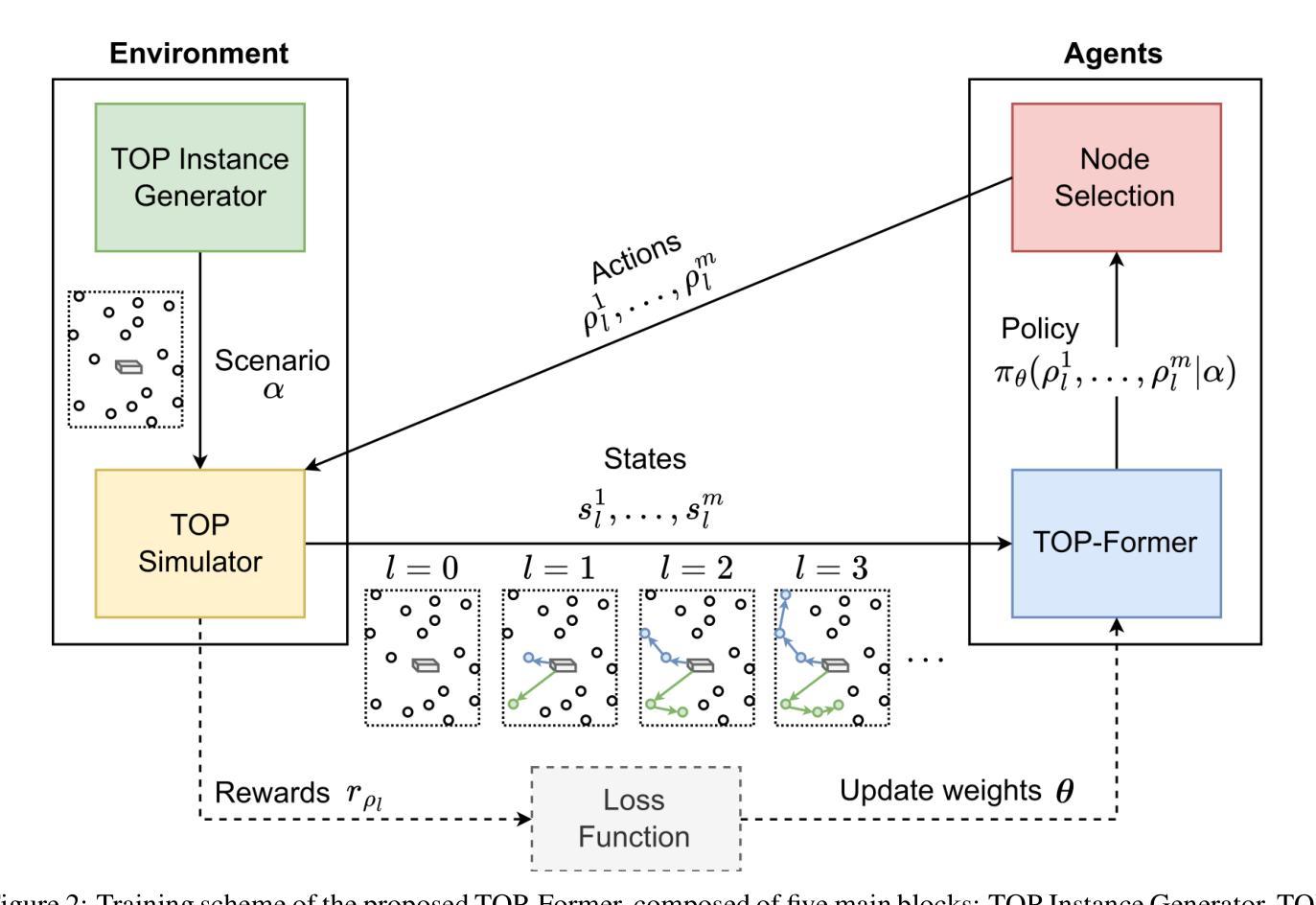
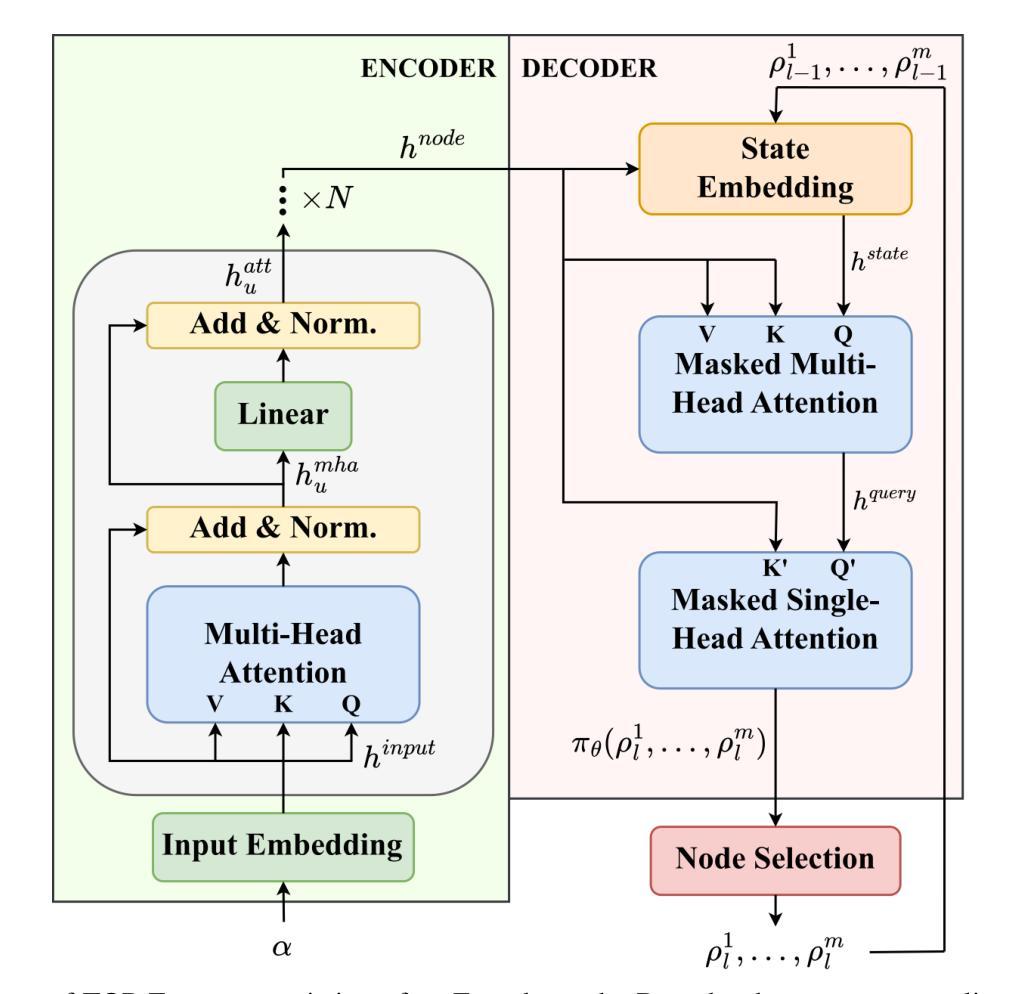
TOP-Former: A Multi-Agent Transformer Approach for the Team Orienteering Problem
Authors:Daniel Fuertes, Carlos R. del-Blanco, Fernando Jaureguizar, Narciso García
Route planning for a fleet of vehicles is an important task in applications such as package delivery, surveillance, or transportation, often integrated within larger Intelligent Transportation Systems (ITS). This problem is commonly formulated as a Vehicle Routing Problem (VRP) known as the Team Orienteering Problem (TOP). Existing solvers for this problem primarily rely on either linear programming, which provides accurate solutions but requires computation times that grow with the size of the problem, or heuristic methods, which typically find suboptimal solutions in a shorter time. In this paper, we introduce TOP-Former, a multi-agent route planning neural network designed to efficiently and accurately solve the Team Orienteering Problem. The proposed algorithm is based on a centralized Transformer neural network capable of learning to encode the scenario (modeled as a graph) and analyze the complete context of all agents to deliver fast, precise, and collaborative solutions. Unlike other neural network-based approaches that adopt a more local perspective, TOP-Former is trained to understand the global situation of the vehicle fleet and generate solutions that maximize long-term expected returns. Extensive experiments demonstrate that the presented system outperforms most state-of-the-art methods in terms of both accuracy and computation speed.
车辆队伍的路线规划是在包裹配送、监控或运输等应用中一项重要的任务,通常被集成在更大的智能交通系统(ITS)中。这个问题通常被形式化为车辆路径问题(VRP),被称为团队定向问题(TOP)。针对这个问题的现有解决方案主要依赖于线性规划,线性规划提供准确的解决方案,但计算时间随着问题规模的增加而增长,或者启发式方法,通常在较短的时间内找到次优解。在本文中,我们介绍了TOP-Former,这是一个多智能体路线规划神经网络,旨在高效准确地解决团队定向问题。所提出的算法基于集中式Transformer神经网络,能够学习对场景进行编码(建模为图)并分析所有智能体的完整上下文,以提供快速、精确和协作的解决方案。与其他采用更局部视角的神经网络方法不同,TOP-Former经过训练,能够理解车辆队伍的全局情况,并生成最大化长期预期回报的解决方案。大量实验表明,所提出的系统在准确性和计算速度方面均优于大多数最先进的方法。
论文及项目相关链接
Summary
车队路线规划是智能运输系统中的重要应用,如快递配送、监控和运输等。该问题通常被表述为团队定向问题(TOP),现有解法主要依赖于线性规划或启发式方法。本文提出了TOP-Former,一个基于多智能体的路线规划神经网络,能高效准确地解决团队定向问题。该算法基于集中式Transformer神经网络,能够学习场景建模并分析所有智能体的完整上下文,以快速准确地提供协同解决方案。实验证明,该系统在准确性和计算速度上均优于大多数最新方法。
Key Takeaways
- 路线规划在智能运输系统中至关重要,如快递配送、监控和运输等应用。
- 团队定向问题(TOP)是车辆路线规划中的常见问题,现有解法存在计算时间长或解决方案不准确的问题。
- TOP-Former是一个基于多智能体的路线规划神经网络,旨在解决团队定向问题。
- TOP-Former采用集中式Transformer神经网络,能学习和分析场景中的所有智能体上下文。
- TOP-Former具有快速、精确和协同解决问题的能力。
- 实验证明,TOP-Former在准确性和计算速度上均优于大多数最新方法。
点此查看论文截图

LLM-Coordination: Evaluating and Analyzing Multi-agent Coordination Abilities in Large Language Models
Authors:Saaket Agashe, Yue Fan, Anthony Reyna, Xin Eric Wang
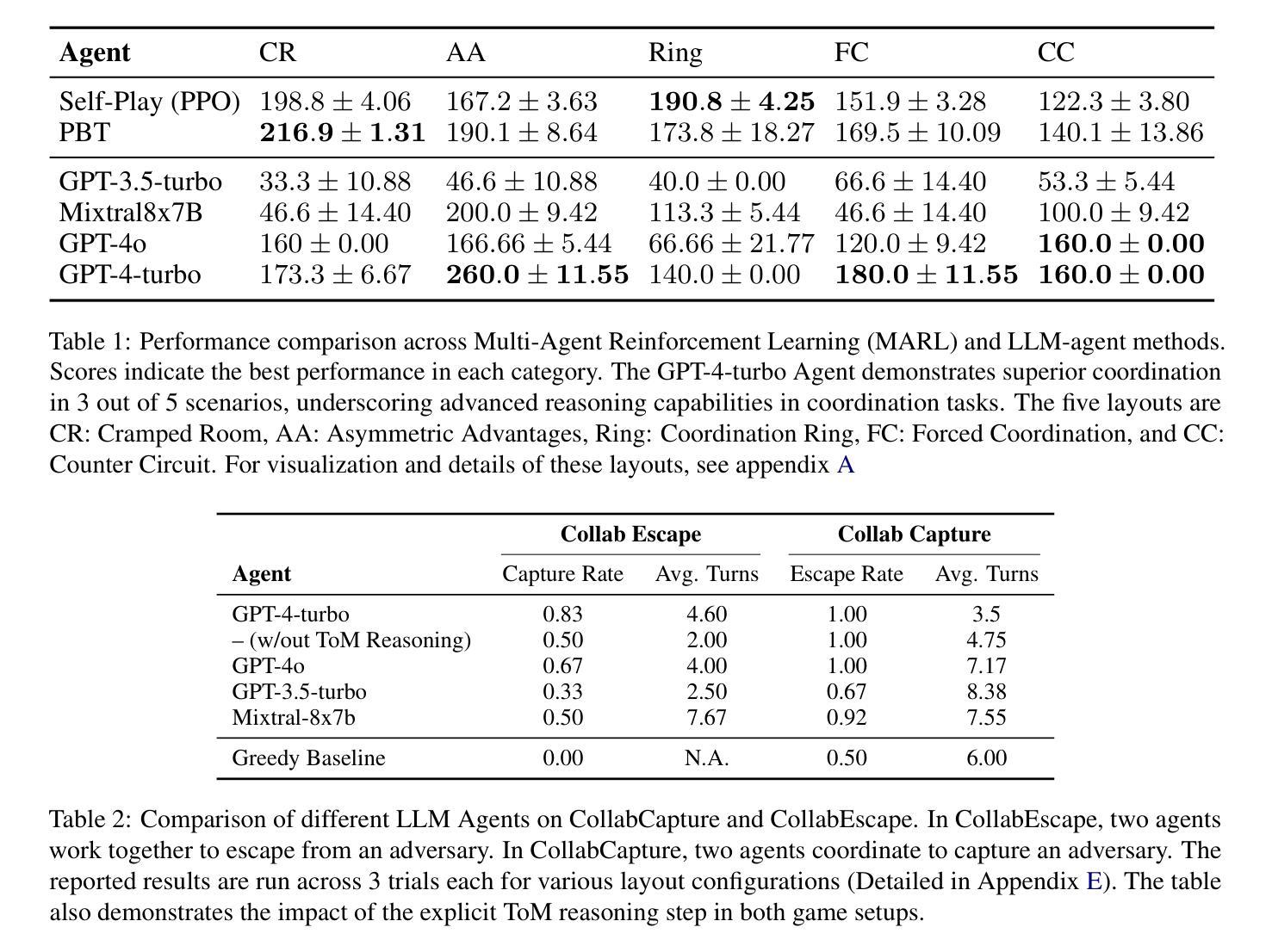
Large Language Models (LLMs) have demonstrated emergent common-sense reasoning and Theory of Mind (ToM) capabilities, making them promising candidates for developing coordination agents. This study introduces the LLM-Coordination Benchmark, a novel benchmark for analyzing LLMs in the context of Pure Coordination Settings, where agents must cooperate to maximize gains. Our benchmark evaluates LLMs through two distinct tasks. The first is Agentic Coordination, where LLMs act as proactive participants in four pure coordination games. The second is Coordination Question Answering (CoordQA), which tests LLMs on 198 multiple-choice questions across these games to evaluate three key abilities: Environment Comprehension, ToM Reasoning, and Joint Planning. Results from Agentic Coordination experiments reveal that LLM-Agents excel in multi-agent coordination settings where decision-making primarily relies on environmental variables but face challenges in scenarios requiring active consideration of partners’ beliefs and intentions. The CoordQA experiments further highlight significant room for improvement in LLMs’ Theory of Mind reasoning and joint planning capabilities. Zero-Shot Coordination (ZSC) experiments in the Agentic Coordination setting demonstrate that LLM agents, unlike RL methods, exhibit robustness to unseen partners. These findings indicate the potential of LLMs as Agents in pure coordination setups and underscore areas for improvement. Code Available at https://github.com/eric-ai-lab/llm_coordination.
大型语言模型(LLM)已经展现出新兴的常识推理和心智理论(ToM)能力,使其成为开发协调代理的有前途的候选者。本研究介绍了LLM协调基准测试,这是一个新的基准测试,用于在纯协调环境的背景下分析LLM,在此环境中,代理必须相互合作以最大化收益。我们的基准测试通过两个独特的任务来评估LLM。第一个是代理协调,LLM在此作为四种纯协调游戏中的主动参与者。第二个是协调问答(CoordQA),对LLM进行198道选择题测试,以评估三项关键能力:环境理解、心智理论推理和联合规划。Agentic协调实验的结果表明,LLM代理在多代理协调环境中表现出色,其中决策主要依赖于环境变量,但在需要主动考虑合作伙伴的信念和意图的场景中面临挑战。CoordQA实验进一步凸显了LLM的心智理论推理和联合规划能力还有很大的提升空间。零射击协调(ZSC)在Agentic协调环境中的实验表明,LLM代理与RL方法不同,对未见过的伙伴具有稳健性。这些发现表明了LLM作为纯协调设置中的代理的潜力,并强调了改进的领域。代码可用在https://github.com/eric-ai-lab/llm_coordination。
论文及项目相关链接
Summary
大型语言模型(LLMs)展现出潜在的常识推理和心智理论(ToM)能力,成为开发协调代理的候选者。本研究介绍了LLM协调基准测试,这是一个新的基准测试,用于分析LLMs在纯协调设置中的表现。该基准测试通过两个任务来评估LLMs:首先是代理协调,LLMs在四种纯协调游戏中充当积极参与者;其次是协调问答(CoordQA),测试LLMs在环境理解、心智理论推理和联合规划方面的能力。实验结果显示,LLM代理在多代理协调设置中表现出色,但在需要主动考虑合作伙伴信念和意图的场景中面临挑战。代码可在链接获取。
Key Takeaways
- 大型语言模型展现出协调代理的潜力。
- LLM协调基准测试是一个新的评估LLMs在纯协调设置中的表现的基准。
- LLMs在代理协调任务中表现出色,特别是在环境变量决策方面。
- LLMs在需要理解合作伙伴信念和意图的情境中面临挑战。
- 协调问答任务揭示了LLMs在理论思维推理和联合规划方面的不足。
- 与强化学习方法相比,LLM代理在零射击协调实验中表现出对未见合作伙伴的稳健性。
点此查看论文截图