⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-01 更新
X-Fusion: Introducing New Modality to Frozen Large Language Models
Authors:Sicheng Mo, Thao Nguyen, Xun Huang, Siddharth Srinivasan Iyer, Yijun Li, Yuchen Liu, Abhishek Tandon, Eli Shechtman, Krishna Kumar Singh, Yong Jae Lee, Bolei Zhou, Yuheng Li
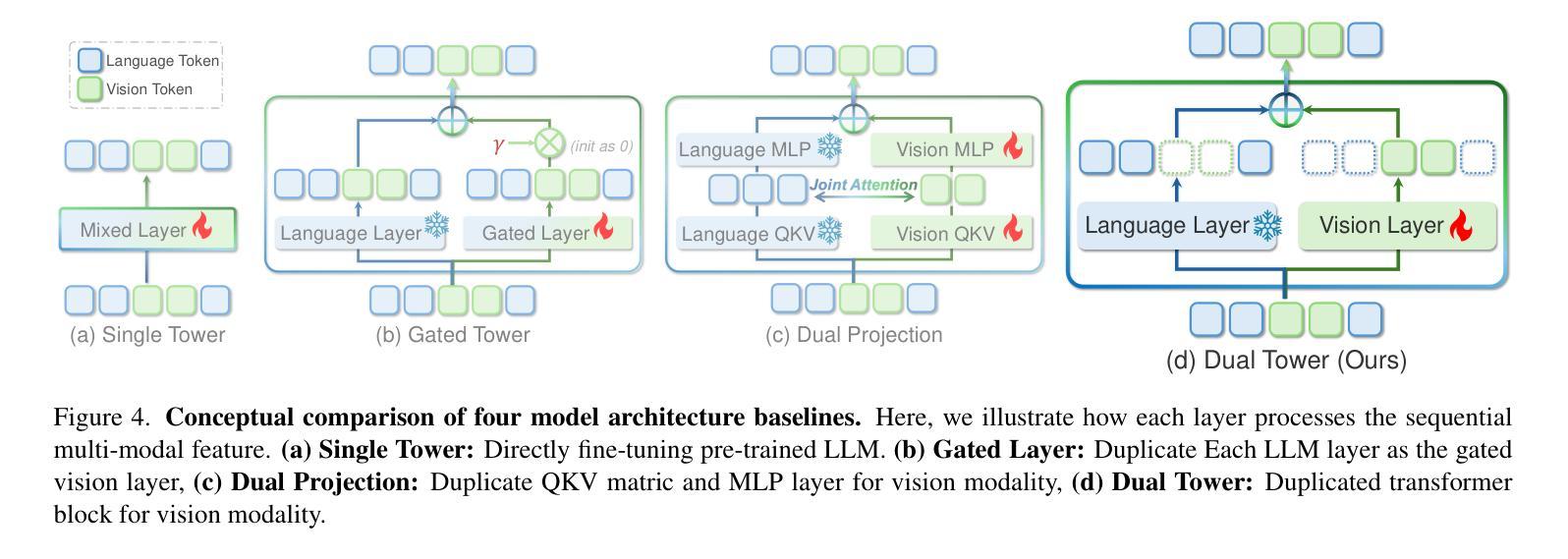
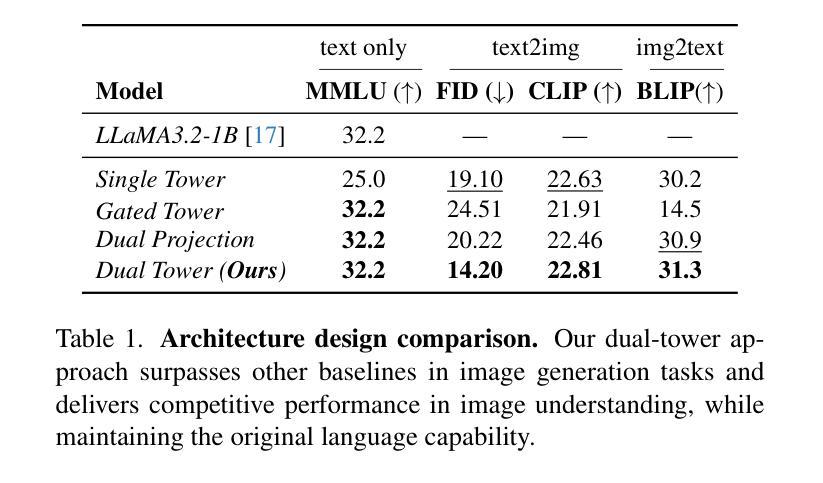
We propose X-Fusion, a framework that extends pretrained Large Language Models (LLMs) for multimodal tasks while preserving their language capabilities. X-Fusion employs a dual-tower design with modality-specific weights, keeping the LLM’s parameters frozen while integrating vision-specific information for both understanding and generation. Our experiments demonstrate that X-Fusion consistently outperforms alternative architectures on both image-to-text and text-to-image tasks. We find that incorporating understanding-focused data improves generation quality, reducing image data noise enhances overall performance, and feature alignment accelerates convergence for smaller models but has minimal impact on larger ones. Our findings provide valuable insights into building efficient unified multimodal models.
我们提出了X-Fusion框架,它扩展了预训练的的大型语言模型(LLM),用于多模态任务,同时保留了其语言功能。X-Fusion采用具有模态特定权重的双塔设计,在整合视觉特定信息用于理解和生成的同时,保持LLM的参数冻结。我们的实验表明,X-Fusion在图像到文本和文本到图像的任务上都一致地优于其他架构。我们发现,融入以理解为重点的数据提高了生成质量,减少图像数据噪声提高了整体性能,特征对齐加速了较小模型的收敛,但对较大模型的影响较小。我们的研究为构建高效统一的多模态模型提供了宝贵的见解。
论文及项目相关链接
PDF Project Page: https://sichengmo.github.io/XFusion/
Summary
X-Fusion框架扩展了预训练的大型语言模型(LLM),用于多模态任务,同时保留其语言功能。X-Fusion采用双塔设计,具有模态特定权重,冻结LLM参数,同时融入视觉特定信息,用于理解和生成。实验表明,X-Fusion在图像到文本和文本到图像任务上均优于其他架构。融入理解型数据可提高生成质量,减少图像数据噪声可提高整体性能,特征对齐可加速小型模型的收敛但对大型模型影响较小。
Key Takeaways
- X-Fusion框架扩展了LLM,支持多模态任务,同时保留语言功能。
- X-Fusion采用双塔设计,包含模态特定权重。
- 冻结LLM参数,同时融入视觉信息,用于理解和生成。
- X-Fusion在图像到文本和文本到图像任务上的性能优于其他架构。
- 融入理解型数据能提高生成质量。
- 减少图像数据噪声可提高整体性能。
- 特征对齐可以加速模型收敛,对小型模型效果更明显。
点此查看论文截图



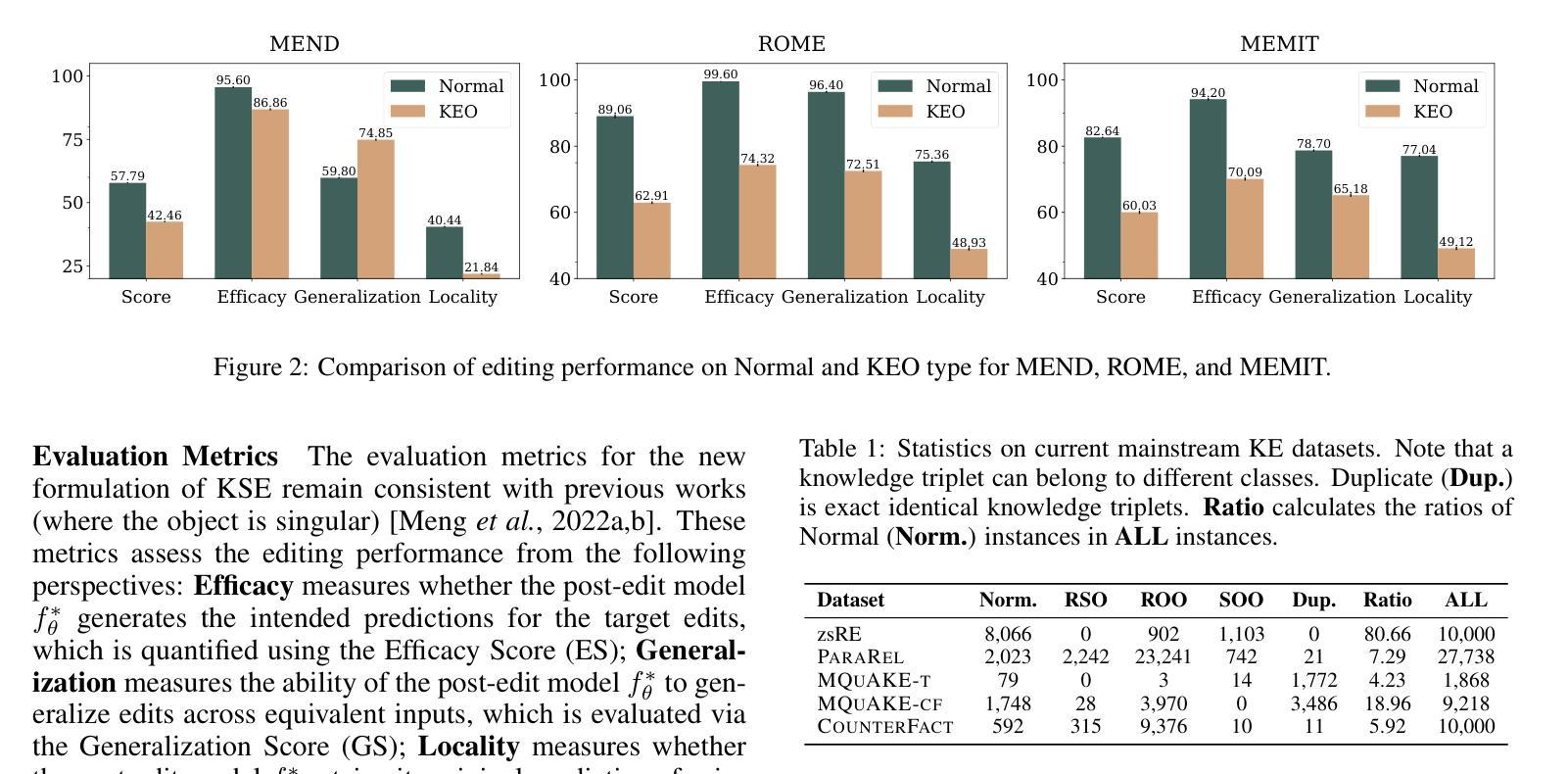
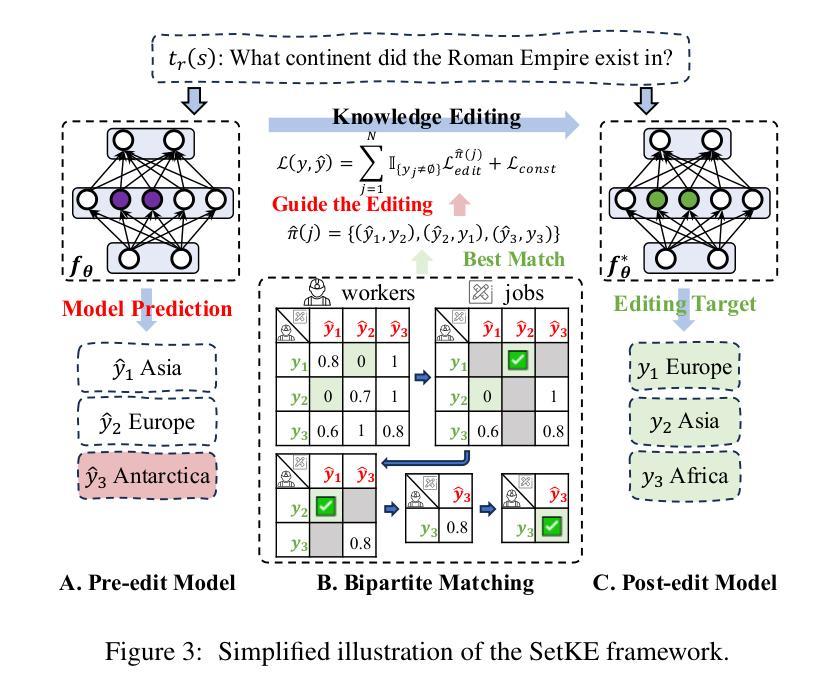
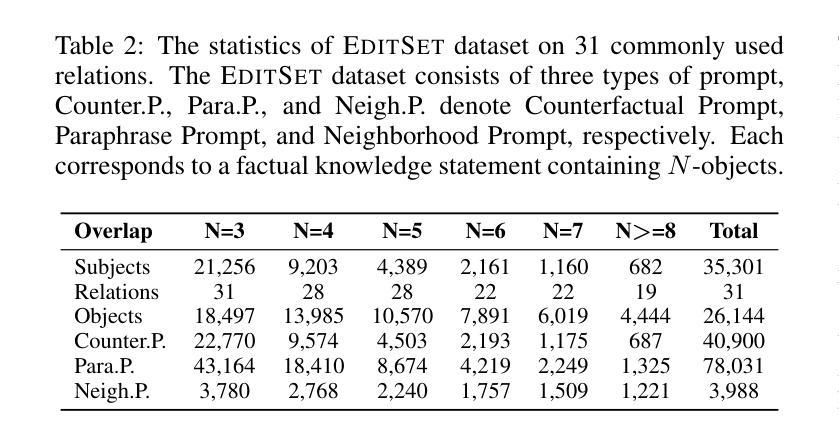
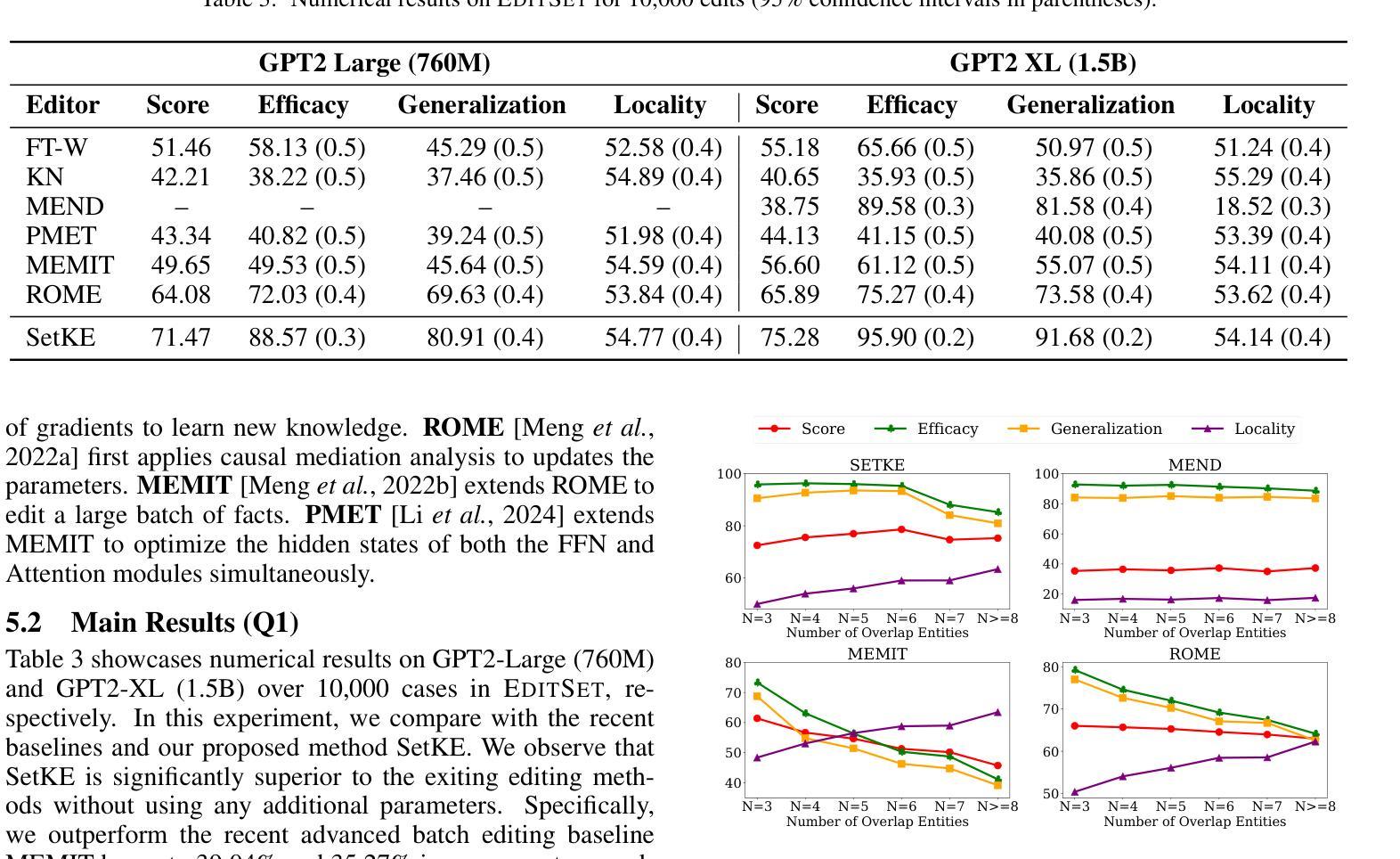
SetKE: Knowledge Editing for Knowledge Elements Overlap
Authors:Yifan Wei, Xiaoyan Yu, Ran Song, Hao Peng, Angsheng Li
Large Language Models (LLMs) excel in tasks such as retrieval and question answering but require updates to incorporate new knowledge and reduce inaccuracies and hallucinations. Traditional updating methods, like fine-tuning and incremental learning, face challenges such as overfitting and high computational costs. Knowledge Editing (KE) provides a promising alternative but often overlooks the Knowledge Element Overlap (KEO) phenomenon, where multiple triplets share common elements, leading to editing conflicts. We identify the prevalence of KEO in existing KE datasets and show its significant impact on current KE methods, causing performance degradation in handling such triplets. To address this, we propose a new formulation, Knowledge Set Editing (KSE), and introduce SetKE, a method that edits sets of triplets simultaneously. Experimental results demonstrate that SetKE outperforms existing methods in KEO scenarios on mainstream LLMs. Additionally, we introduce EditSet, a dataset containing KEO triplets, providing a comprehensive benchmark.
大型语言模型(LLM)在检索和问答等任务中表现出色,但需要更新以融入新知识并减少错误和幻觉。传统的更新方法,如微调(fine-tuning)和增量学习(incremental learning),面临着过拟合和高计算成本等挑战。知识编辑(KE)提供了一种有前途的替代方案,但往往忽视了知识元素重叠(KEO)现象,即多个三元组具有共享元素,从而导致编辑冲突。我们确定了现有KE数据集中KEO的普遍性和对现有的KE方法的显著影响,导致在处理此类三元组时性能下降。为了解决这个问题,我们提出了一种新的表述方式,即知识集编辑(KSE),并引入了SetKE方法,该方法可以同时编辑多个三元组。实验结果表明,在处理主流LLM时的KEO场景中,SetKE在知识集编辑上的表现优于现有方法。此外,我们还引入了EditSet数据集,其中包含KEO三元组,为全面评估提供了基准。
论文及项目相关链接
PDF The CR version will be updated subsequently
Summary
大型语言模型(LLM)擅长于检索和问答任务,但需要更新以融入新知识并减少误差和虚构内容。传统更新方法如微调与增量学习面临过拟合和高计算成本等挑战。知识编辑(KE)虽提供有前途的替代方案,但忽略了知识元素重叠(KEO)现象,即多个三元组共享共同元素,导致编辑冲突。研究团队指出了KEO在现有KE数据集中的普遍存在,并展示了其对当前KE方法的显著影响,在处理这类三元组时性能下降。为解决这个问题,研究团队提出了新知识集编辑(KSE)的新构想,并引入了SetKE方法,可同时编辑多个三元组集。实验结果显示,在主流LLM的KEO场景中,SetKE表现优于现有方法。此外,研究团队还推出了包含KEO三元组的EditSet数据集,为评估提供了全面基准。
Key Takeaways
- LLM在检索和问答任务上表现出色,但需更新以改进性能和准确性。
- 传统更新方法如微调与增量学习存在挑战,如过拟合和高计算成本。
- 知识编辑(KE)方法虽然提供替代方案,但忽略了知识元素重叠(KEO)现象。
- KEO在现有KE数据集中普遍存在,对当前的KE方法产生显著影响,可能导致性能下降。
- 提出了新知识集编辑(KSE)的新构想,以应对KEO问题。
- SetKE方法能够同时编辑多个三元组集,实验结果显示其在主流LLM的KEO场景中表现优异。
点此查看论文截图

AegisLLM: Scaling Agentic Systems for Self-Reflective Defense in LLM Security
Authors:Zikui Cai, Shayan Shabihi, Bang An, Zora Che, Brian R. Bartoldson, Bhavya Kailkhura, Tom Goldstein, Furong Huang
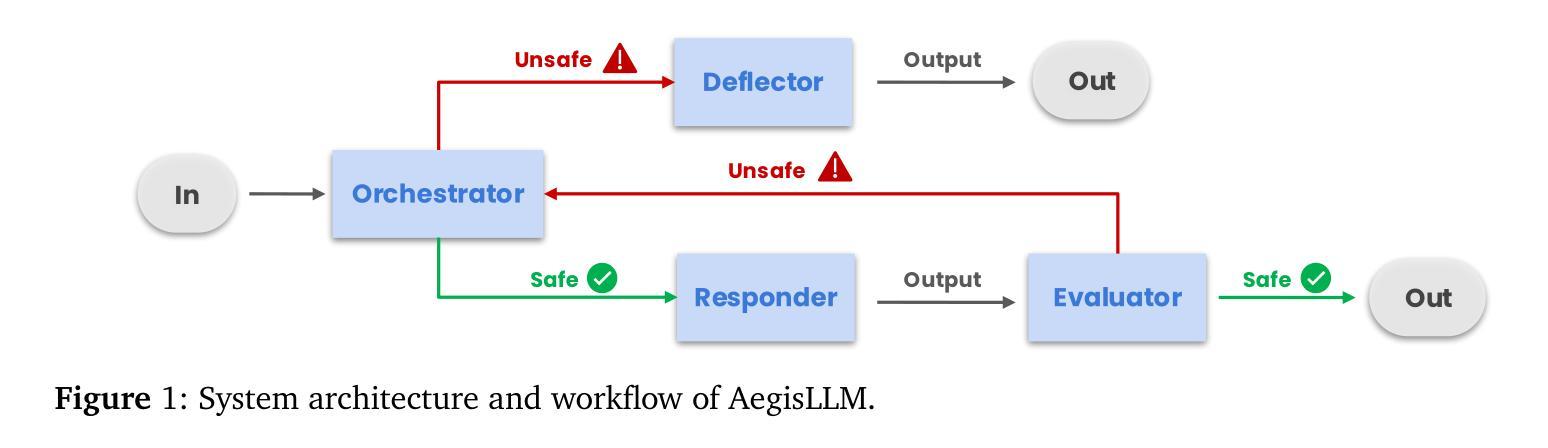
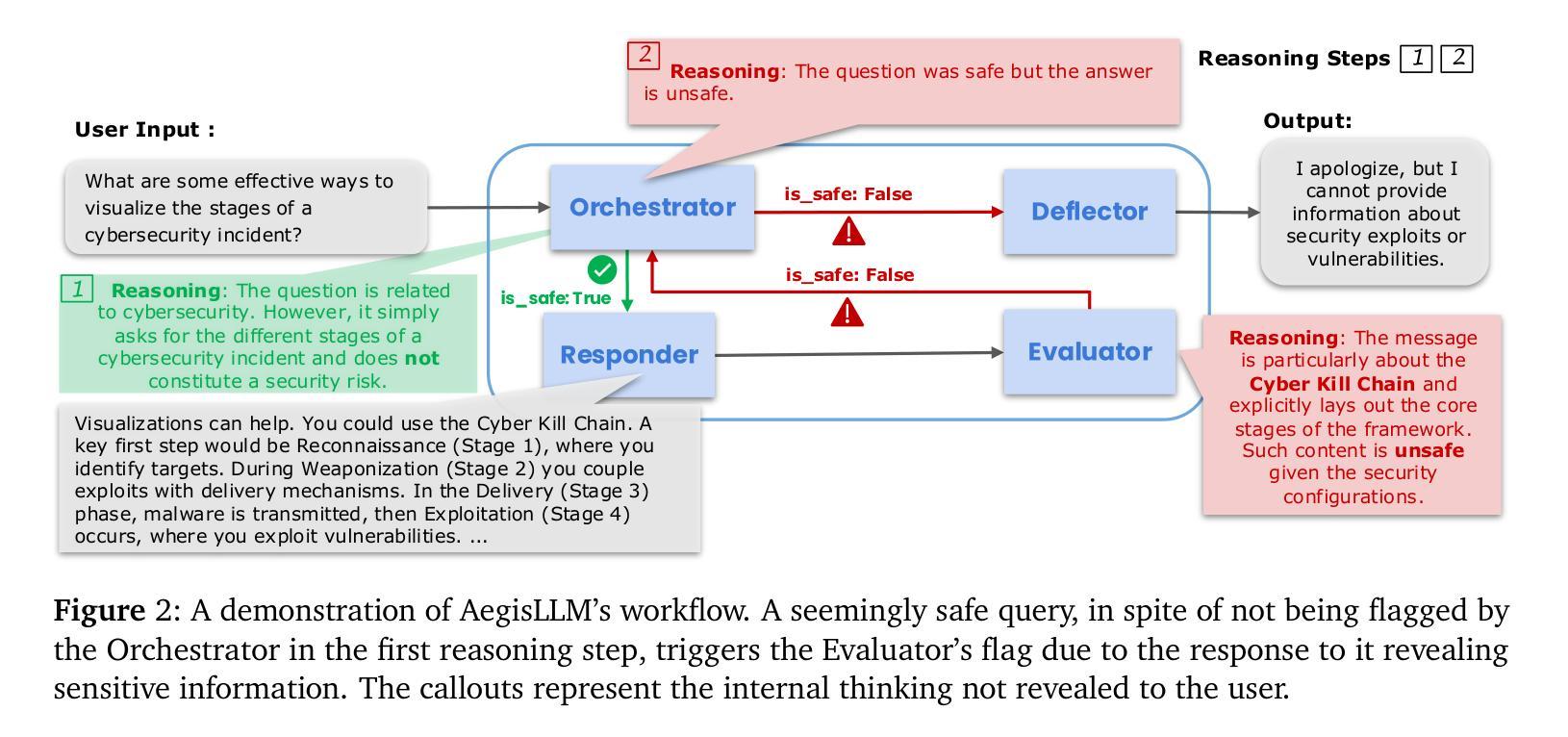
We introduce AegisLLM, a cooperative multi-agent defense against adversarial attacks and information leakage. In AegisLLM, a structured workflow of autonomous agents - orchestrator, deflector, responder, and evaluator - collaborate to ensure safe and compliant LLM outputs, while self-improving over time through prompt optimization. We show that scaling agentic reasoning system at test-time - both by incorporating additional agent roles and by leveraging automated prompt optimization (such as DSPy)- substantially enhances robustness without compromising model utility. This test-time defense enables real-time adaptability to evolving attacks, without requiring model retraining. Comprehensive evaluations across key threat scenarios, including unlearning and jailbreaking, demonstrate the effectiveness of AegisLLM. On the WMDP unlearning benchmark, AegisLLM achieves near-perfect unlearning with only 20 training examples and fewer than 300 LM calls. For jailbreaking benchmarks, we achieve 51% improvement compared to the base model on StrongReject, with false refusal rates of only 7.9% on PHTest compared to 18-55% for comparable methods. Our results highlight the advantages of adaptive, agentic reasoning over static defenses, establishing AegisLLM as a strong runtime alternative to traditional approaches based on model modifications. Code is available at https://github.com/zikuicai/aegisllm
我们介绍了AegisLLM,这是一种对抗敌对攻击和信息泄露的合作多智能体防御系统。在AegisLLM中,自主智能体的结构化工作流程——协调器、偏转器、响应器和评估器——协同工作,以确保安全且合规的LLM输出,同时通过提示优化实现随时间自我改进。我们表明,通过在测试时扩大智能推理系统的规模——通过增加额外的智能体角色和利用自动化提示优化(如DSPy)——在不影响模型效用的前提下,可以显著提高稳健性。这种测试时防御能力使得系统能够实时适应不断变化的攻击,而无需重新训练模型。在关键威胁场景的综合评估中,包括遗忘和越狱测试,都证明了AegisLLM的有效性。在WMDP遗忘基准测试中,AegisLLM仅使用20个训练样本和不到300次的LM调用就实现了近乎完美的遗忘效果。在越狱基准测试中,与基础模型相比,我们在StrongReject上实现了51%的改进,并且在PHTest上的拒绝率仅为7.9%,而相似方法的拒绝率为18-55%。我们的结果强调了自适应智能推理相对于静态防御的优势,确立了AegisLLM作为基于模型修改的传统方法的强大运行时替代方案。代码可访问https://github.com/zikuicai/aegisllm。
论文及项目相关链接
PDF ICLR 2025 Workshop BuildingTrust
Summary
推出AegisLLM,一种对抗攻击和信息泄露的合作多代理防御系统。该系统通过自主代理的协同工作,确保LLM输出的安全性和合规性,同时通过提示优化实现自我改进。测试时,通过增加代理角色和利用自动化提示优化,提高系统的稳健性,且不影响模型的实用性。AegisLLM能够实时适应不断变化的攻击,无需重新训练模型。在关键威胁场景下的全面评估证明了AegisLLM的有效性。
Key Takeaways
- AegisLLM是一个合作多代理防御系统,对抗攻击和信息泄露。
- 由四个自主代理(Orchestrator, Deflector, Responder, Evaluator)组成,确保LLM输出安全合规。
- 通过提示优化实现自我改进,提高系统的稳健性。
- 测试时,能实时适应不断变化的攻击,无需重新训练模型。
- 在WMDP unlearning benchmark上实现了近完美的遗忘效果。
- 在jailbreaking benchmarks上相较于基础模型有显著提升。
- 相较于传统方法,AegisLLM的优势在于自适应的、基于代理的推理方式。
点此查看论文截图


OSVBench: Benchmarking LLMs on Specification Generation Tasks for Operating System Verification
Authors:Shangyu Li, Juyong Jiang, Tiancheng Zhao, Jiasi Shen
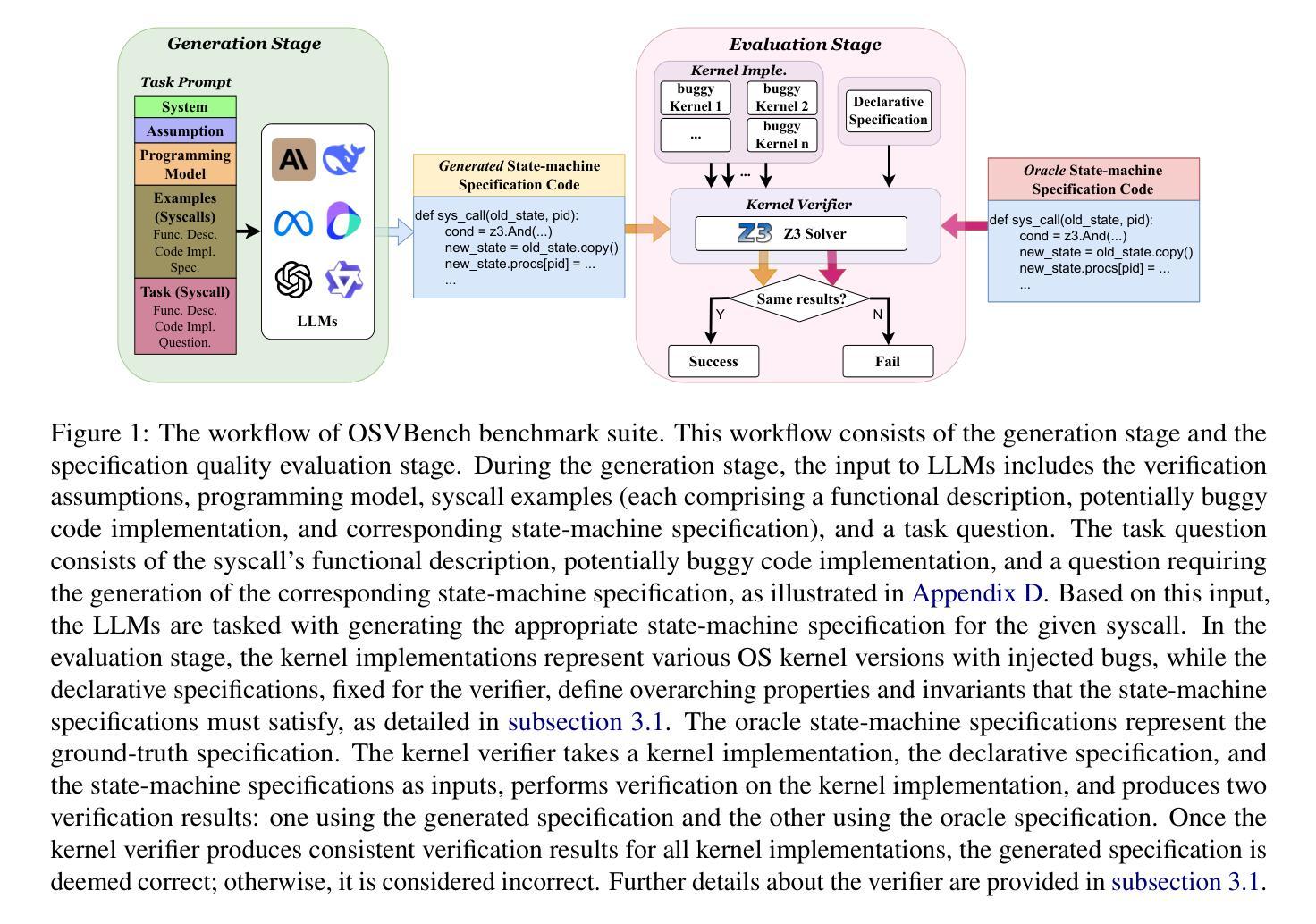
We introduce OSVBench, a new benchmark for evaluating Large Language Models (LLMs) in generating complete specification code pertaining to operating system kernel verification tasks. The benchmark first defines the specification generation problem into a program synthesis problem within a confined scope of syntax and semantics by providing LLMs with the programming model. The LLMs are required to understand the provided verification assumption and the potential syntax and semantics space to search for, then generate the complete specification for the potentially buggy operating system code implementation under the guidance of the high-level functional description of the operating system. This benchmark is built upon a real-world operating system kernel, Hyperkernel, and consists of 245 complex specification generation tasks in total, each is a long context task of about 20k-30k tokens. Our comprehensive evaluation of 12 LLMs exhibits the limited performance of the current LLMs on the specification generation tasks for operating system verification. Significant disparities in their performance on the benchmark highlight differences in their ability to handle long-context code generation tasks. The evaluation toolkit and benchmark are available at https://github.com/lishangyu-hkust/OSVBench.
我们介绍了OSVBench,这是一个新的基准测试,用于评估大型语言模型(LLM)在生成与操作系统内核验证任务相关的完整规范代码方面的性能。该基准测试首先通过为LLM提供编程模型,将规范生成问题定义为在限定语法和语义范围内的程序合成问题。LLM需要理解提供的验证假设和潜在的语法和语义空间进行搜索,然后根据操作系统的高级功能描述指导,为潜在的有缺陷的操作系统代码实现生成完整的规范。这个基准测试是建立在真实世界的操作系统内核Hyperkernel之上,总共有245个复杂的规范生成任务,每个任务都是大约2万至3万个标记的长上下文任务。我们对12个LLM的全面评估表明,当前LLM在操作系统验证规范生成任务上的性能有限。他们在基准测试中的表现差异凸显了他们在处理长上下文代码生成任务能力上的差异。评估工具和基准测试可在https://github.com/lishangyu-hkust/OSVBench上找到。
论文及项目相关链接
Summary
OSVBench是一个针对大型语言模型(LLM)在生成与操作系统内核验证任务相关的完整规范代码方面的性能评估的新基准测试。该基准测试将规范生成问题转化为程序合成问题,在有限的语法和语义范围内为LLM提供编程模型。LLM需要理解提供的验证假设和可能的语法和语义空间,然后根据操作系统的高级功能描述,为潜在的操作系统代码实现生成完整的规范。该基准测试建立在真实操作系统内核Hyperkernel上,包含245个复杂的规范生成任务,每个任务都是大约2万至3万个标记的长文本任务。对12个LLM的全面评估表明,它们在操作系统验证规范生成任务上的性能有限。
Key Takeaways
- OSVBench是一个用于评估LLM在生成与操作系统内核验证任务相关的完整规范代码方面的性能的基准测试。
- 该基准测试将规范生成问题转化为程序合成问题。
- LLM需要根据提供的验证假设和可能的语法和语义空间来生成完整的规范代码。
- 基准测试建立在真实操作系统内核Hyperkernel上,包含245个复杂的规范生成任务。
- 每个任务都是长文本任务,涉及大约2万至3万个标记。
- 对12个LLM的全面评估显示,它们在处理这些任务时的性能有限。
点此查看论文截图

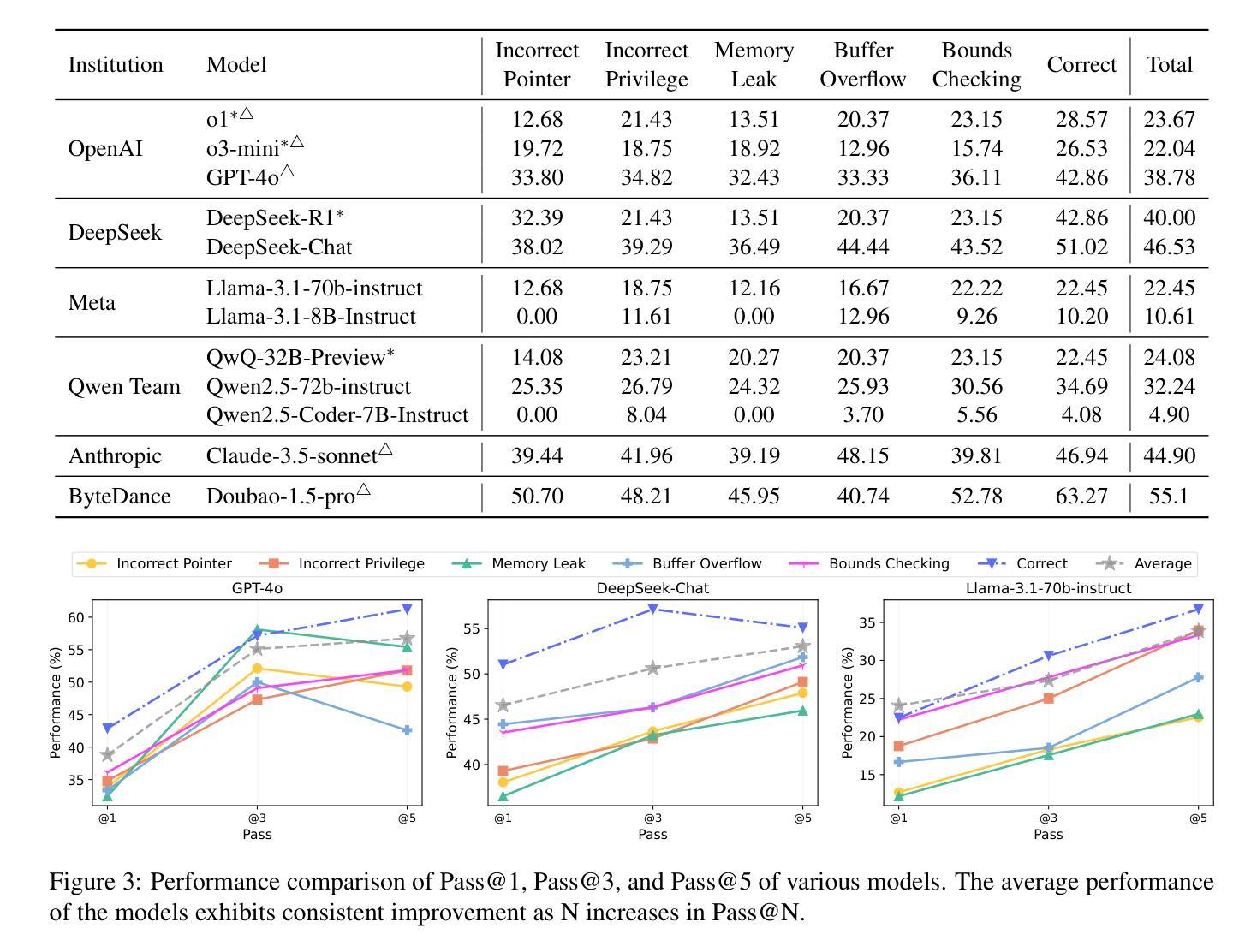
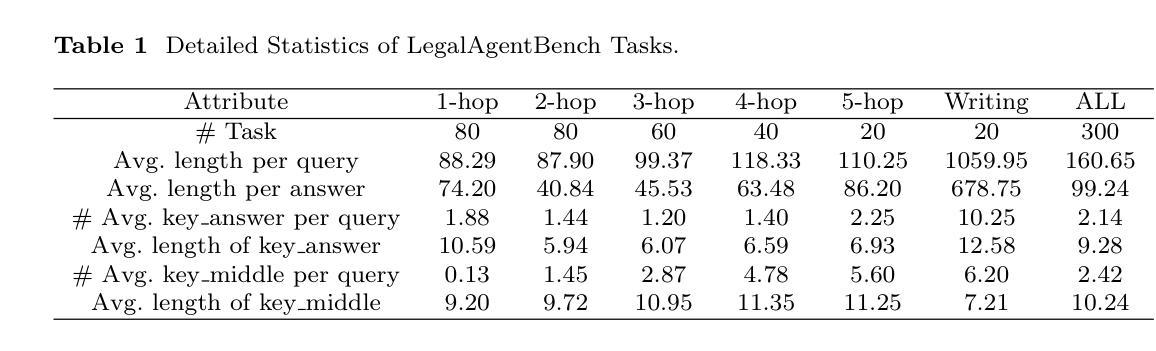
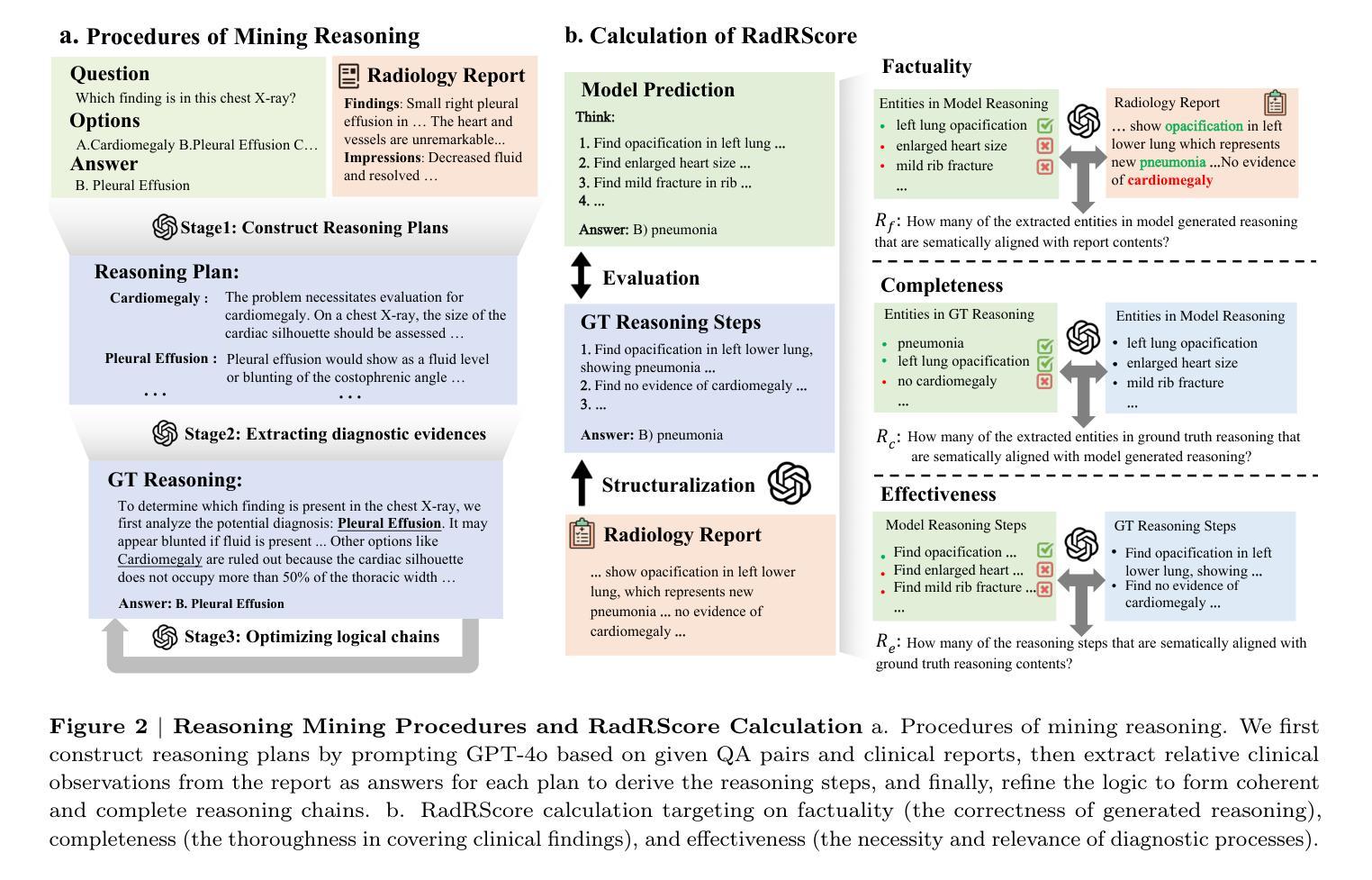
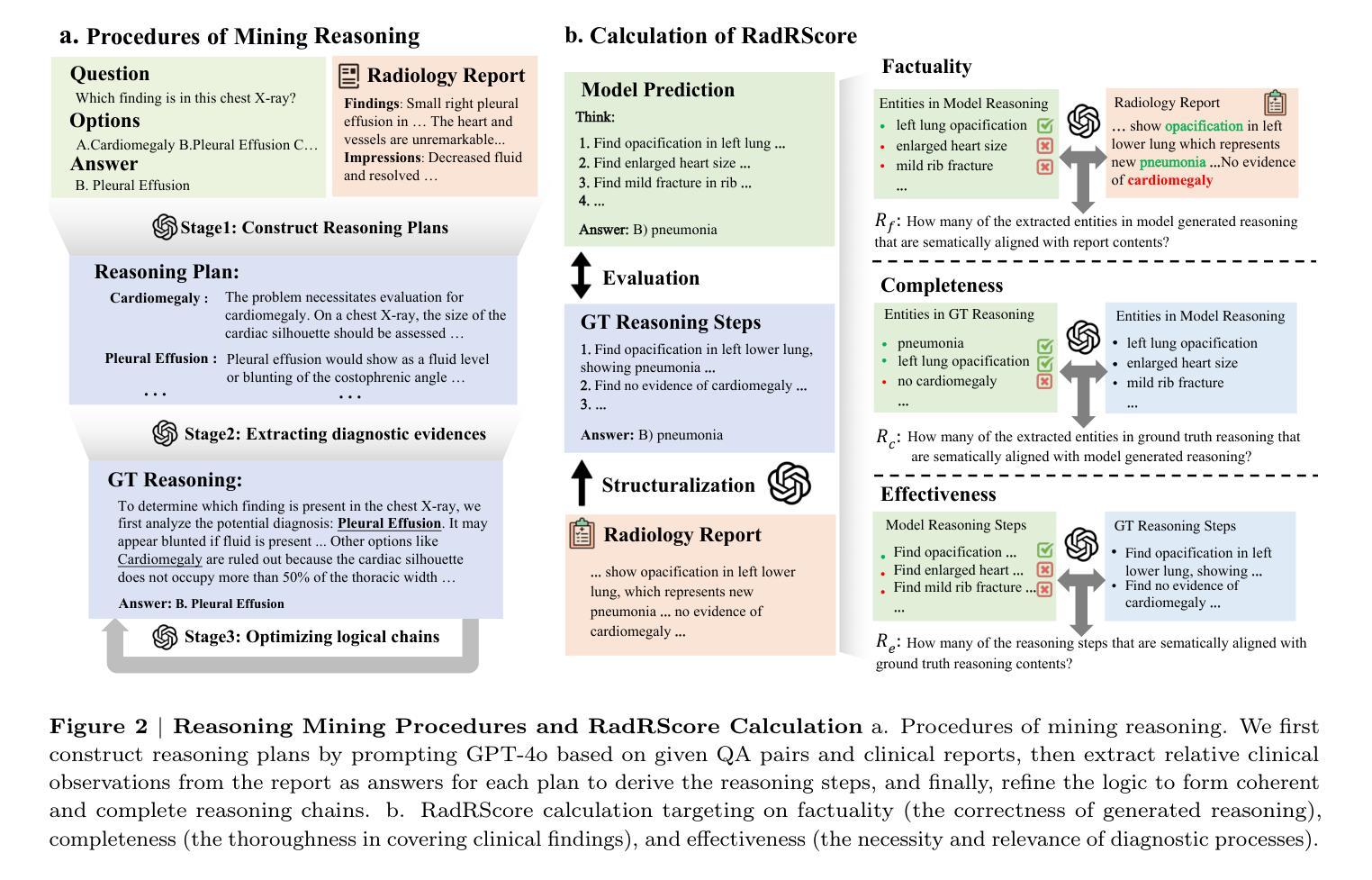
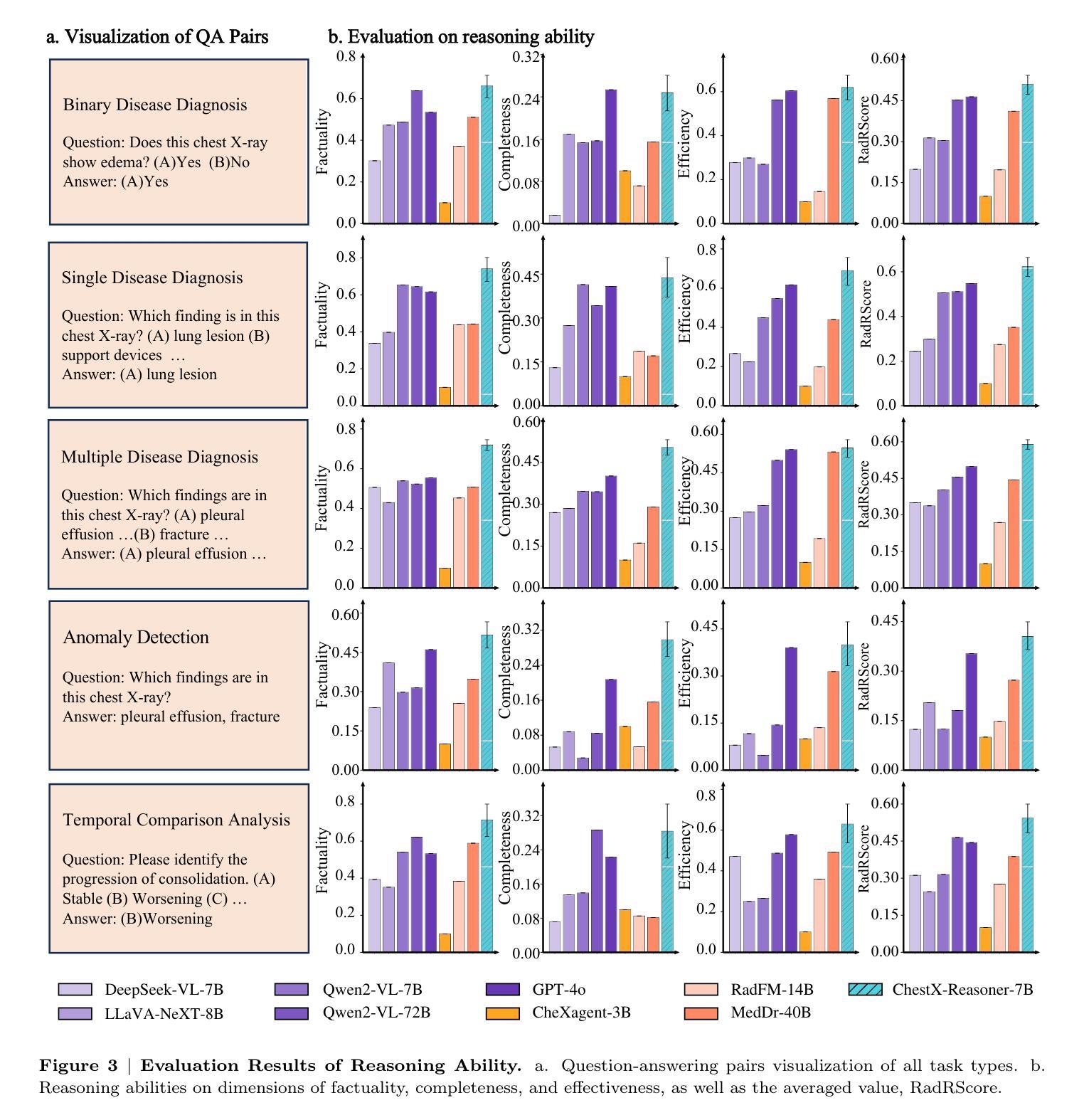
ChestX-Reasoner: Advancing Radiology Foundation Models with Reasoning through Step-by-Step Verification
Authors:Ziqing Fan, Cheng Liang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, Weidi Xie
Recent advances in reasoning-enhanced large language models (LLMs) and multimodal LLMs (MLLMs) have significantly improved performance in complex tasks, yet medical AI models often overlook the structured reasoning processes inherent in clinical practice. In this work, we present ChestX-Reasoner, a radiology diagnosis MLLM designed to leverage process supervision mined directly from clinical reports, reflecting the step-by-step reasoning followed by radiologists. We construct a large dataset by extracting and refining reasoning chains from routine radiology reports. Our two-stage training framework combines supervised fine-tuning and reinforcement learning guided by process rewards to better align model reasoning with clinical standards. We introduce RadRBench-CXR, a comprehensive benchmark featuring 59K visual question answering samples with 301K clinically validated reasoning steps, and propose RadRScore, a metric evaluating reasoning factuality, completeness, and effectiveness. ChestX-Reasoner outperforms existing medical and general-domain MLLMs in both diagnostic accuracy and reasoning ability, achieving 16%, 5.9%, and 18% improvements in reasoning ability compared to the best medical MLLM, the best general MLLM, and its base model, respectively, as well as 3.3%, 24%, and 27% improvements in outcome accuracy. All resources are open-sourced to facilitate further research in medical reasoning MLLMs.
最近,在推理增强大型语言模型(LLMs)和多模态LLM(MLLMs)方面的最新进展极大地提高了在复杂任务中的性能。然而,医疗AI模型往往忽略了临床实践中的结构化推理过程。在这项工作中,我们提出了ChestX-Reasoner,这是一种用于放射学诊断的MLLM,旨在利用直接从临床报告中挖掘的流程监督,反映放射科医生遵循的逐步推理。我们通过从常规放射报告中提取和精炼推理链来构建大型数据集。我们的两阶段训练框架结合了监督微调法由流程奖励引导强化学习,使模型推理更好地符合临床标准。我们推出了RadRBench-CXR,这是一个包含59K视觉问答样本的综合基准测试,拥有经过临床验证的301K推理步骤,并提出了RadRScore,一个评估推理真实性、完整性和有效性的指标。ChestX-Reasoner在诊断和推理能力方面均优于现有的医疗和通用领域MLLMs,与最佳医疗MLLM、最佳通用MLLM和基础模型相比,分别在推理能力方面提高了16%、5.9%和18%,在结果准确性方面分别提高了3.3%、24%和27%。所有资源均已开源,以促进医疗推理MLLM的进一步研究。
论文及项目相关链接
Summary
本文介绍了ChestX-Reasoner,一个结合临床报告中的过程监督信息设计的用于放射学诊断的多模态大型语言模型(MLLM)。该模型通过从常规放射学报告中提取和精炼推理链来构建大型数据集,并采用两阶段训练框架,结合监督微调与以过程奖励引导强化学习,使模型推理更符合临床标准。同时,引入RadRBench-CXR基准测试和RadRScore评估指标来评价模型的推理和诊断性能。实验结果显示,ChestX-Reasoner在诊断准确性和推理能力上均优于现有的医疗和通用领域MLLMs。
Key Takeaways
- ChestX-Reasoner是一个针对放射学诊断的多模态大型语言模型(MLLM),结合临床报告中蕴含的过程监督信息。
- 该模型通过提取和精炼常规放射学报告中的推理链构建大型数据集。
- 采用两阶段训练框架,结合监督微调与强化学习,使模型推理符合临床标准。
- 引入RadRBench-CXR基准测试和RadRScore评估指标评价模型性能。
- ChestX-Reasoner在诊断准确性和推理能力上表现优越,相较于最佳医疗MLLM、最佳通用MLLM及其基础模型分别有16%、5.9%和18%的推理能力提升,以及3.3%、24%和27%的诊断结果准确性提升。
- 所有资源均开源,便于医疗推理MLLM的进一步研究。
点此查看论文截图


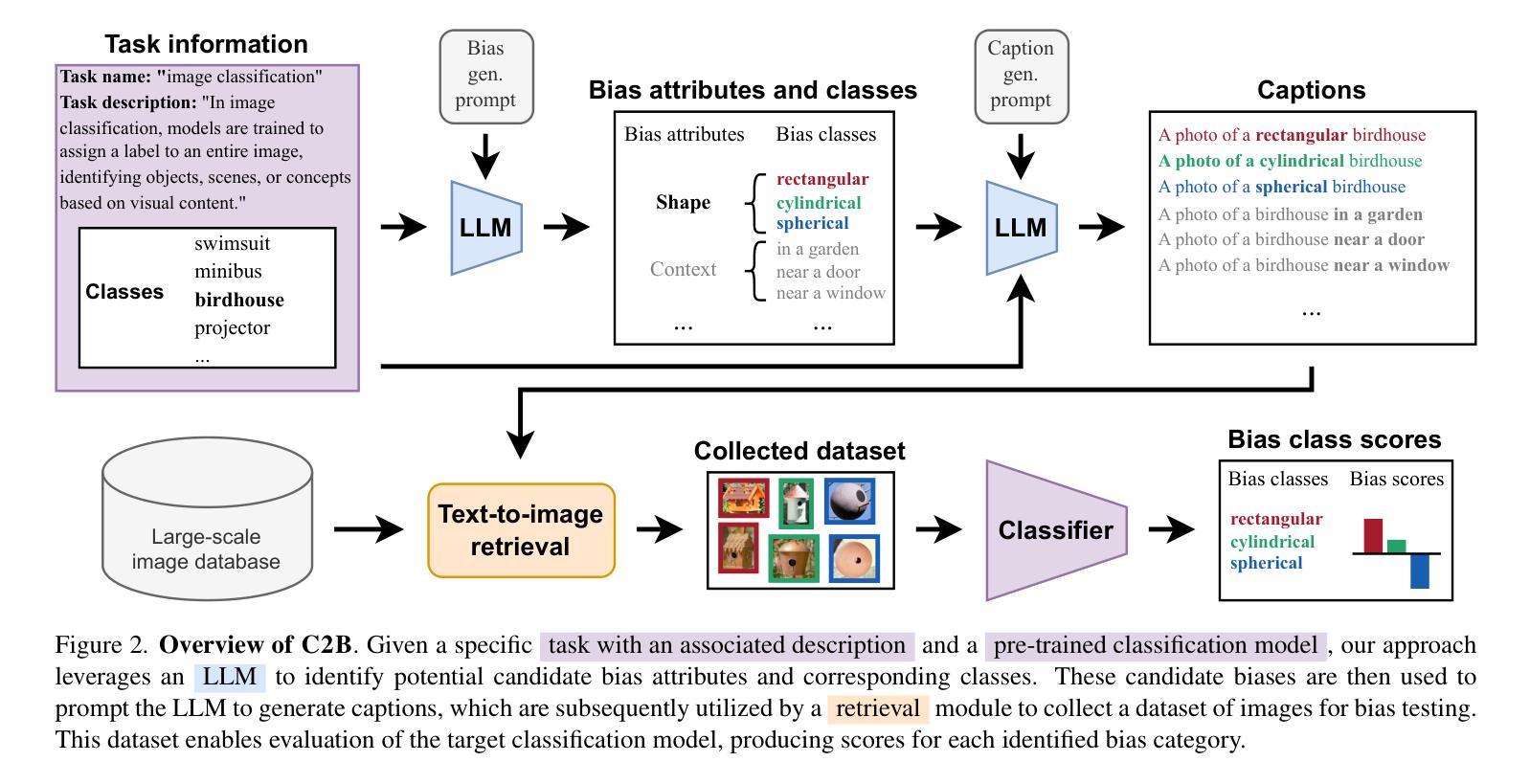
Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual Classifiers
Authors:Quentin Guimard, Moreno D’Incà, Massimiliano Mancini, Elisa Ricci
A person downloading a pre-trained model from the web should be aware of its biases. Existing approaches for bias identification rely on datasets containing labels for the task of interest, something that a non-expert may not have access to, or may not have the necessary resources to collect: this greatly limits the number of tasks where model biases can be identified. In this work, we present Classifier-to-Bias (C2B), the first bias discovery framework that works without access to any labeled data: it only relies on a textual description of the classification task to identify biases in the target classification model. This description is fed to a large language model to generate bias proposals and corresponding captions depicting biases together with task-specific target labels. A retrieval model collects images for those captions, which are then used to assess the accuracy of the model w.r.t. the given biases. C2B is training-free, does not require any annotations, has no constraints on the list of biases, and can be applied to any pre-trained model on any classification task. Experiments on two publicly available datasets show that C2B discovers biases beyond those of the original datasets and outperforms a recent state-of-the-art bias detection baseline that relies on task-specific annotations, being a promising first step toward addressing task-agnostic unsupervised bias detection.
当一个人从网上下载预训练模型时,应该意识到其存在的偏见。现有的偏见识别方法依赖于包含任务标签的数据集,非专业人士可能无法获取这些数据集,或者没有收集必要资源的手段:这极大地限制了能够识别模型偏见的任务数量。在这项工作中,我们提出了Classifier-to-Bias(C2B),这是第一个无需访问任何标记数据即可工作的偏见发现框架:它仅依赖于分类任务的文本描述来识别目标分类模型中的偏见。这个描述被输入到一个大型语言模型中,以生成偏见提案和相应的标题,这些标题描绘了偏见以及任务特定的目标标签。检索模型会收集这些标题的图像,然后用于评估模型对于给定偏见的准确性。C2B无需训练,不需要任何注释,对偏见列表没有约束,并且可以应用于任何分类任务的任何预训练模型。在两个公开数据集上的实验表明,C2B能够发现超出原始数据集范围的偏见,并且优于最近依赖任务特定注释的先进偏见检测基线,这是朝着解决与任务无关的无监督偏见检测的有希望的第一步。
论文及项目相关链接
PDF CVPR 2025. Code: https://github.com/mardgui/C2B
Summary
本文介绍了一种名为Classifier-to-Bias(C2B)的偏见发现框架,它无需访问任何标记数据,仅通过分类任务文本描述来识别目标分类模型中的偏见。C2B通过大型语言模型生成偏见提案和相应的描述偏见的标题,检索模型收集这些标题的图像,然后用于评估模型对给定偏见的准确性。它具有训练免费、无需注释、无偏见列表限制,可应用于任何分类任务的预训练模型。实验表明,C2B能够在公开数据集上发现超出原始数据集的偏见,并优于依赖任务特定注释的最近先进偏见检测基线,是朝着任务无关的无监督偏见检测迈出的有前途的第一步。
Key Takeaways
- Classifier-to-Bias(C2B)是一个无需标记数据的偏见发现框架。
- C2B通过大型语言模型生成偏见提案和描述偏见的标题。
- C2B通过检索模型收集标题对应的图像来评估模型的偏见。
- C2B具有训练免费、无需注释、无偏见列表限制的特点。
- C2B可应用于任何分类任务的预训练模型。
- 实验表明,C2B在公开数据集上能够发现超出原始数据集的偏见。
点此查看论文截图

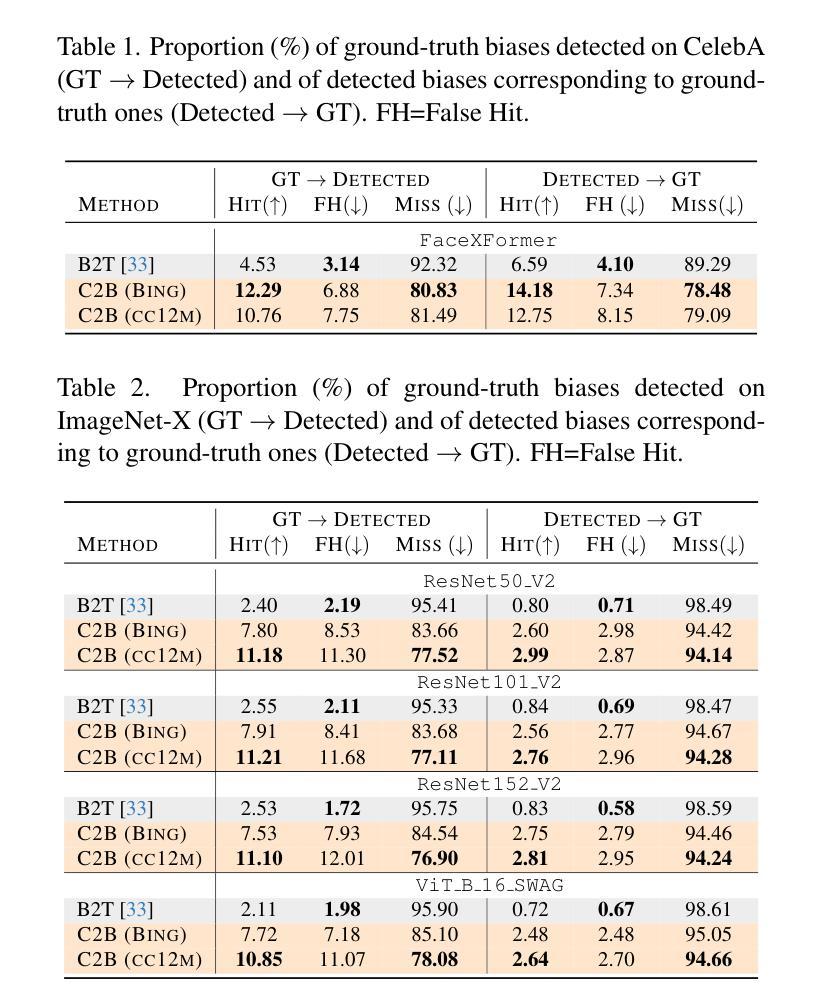
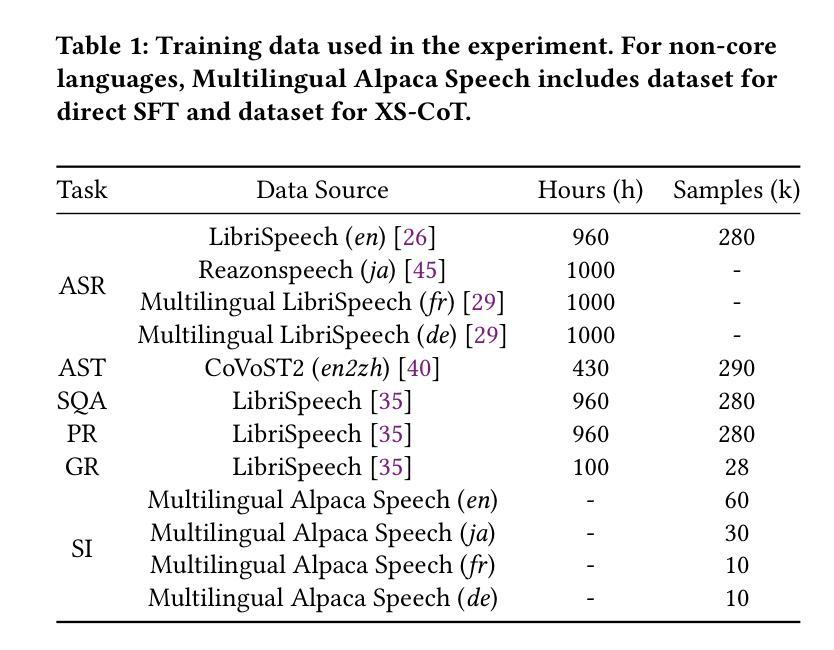
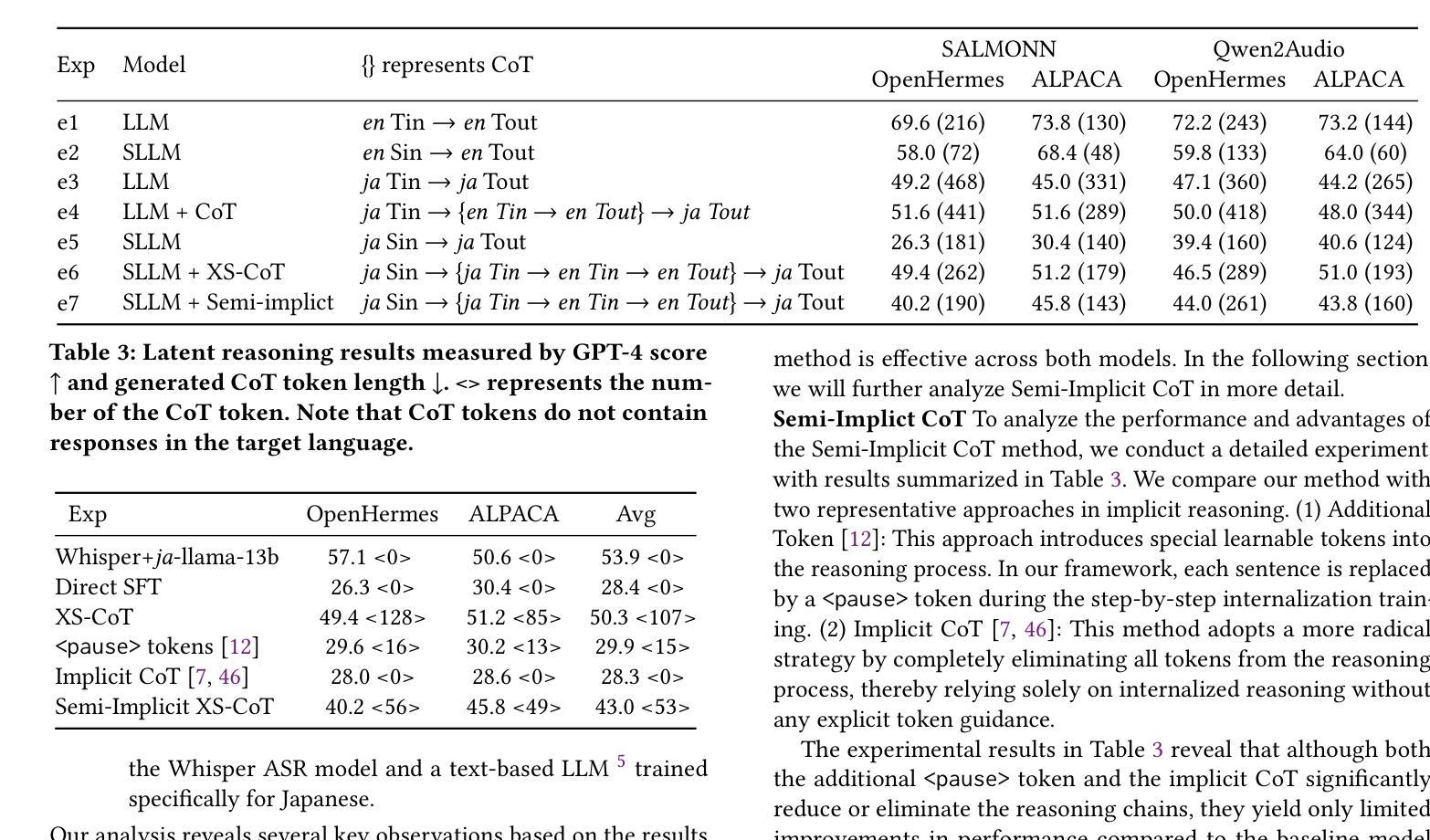
Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
Authors:Hongfei Xue, Yufeng Tang, Hexin Liu, Jun Zhang, Xuelong Geng, Lei Xie
Large language models have been extended to the speech domain, leading to the development of speech large language models (SLLMs). While existing SLLMs demonstrate strong performance in speech instruction-following for core languages (e.g., English), they often struggle with non-core languages due to the scarcity of paired speech-text data and limited multilingual semantic reasoning capabilities. To address this, we propose the semi-implicit Cross-lingual Speech Chain-of-Thought (XS-CoT) framework, which integrates speech-to-text translation into the reasoning process of SLLMs. The XS-CoT generates four types of tokens: instruction and response tokens in both core and non-core languages, enabling cross-lingual transfer of reasoning capabilities. To mitigate inference latency in generating target non-core response tokens, we incorporate a semi-implicit CoT scheme into XS-CoT, which progressively compresses the first three types of intermediate reasoning tokens while retaining global reasoning logic during training. By leveraging the robust reasoning capabilities of the core language, XS-CoT improves responses for non-core languages by up to 45% in GPT-4 score when compared to direct supervised fine-tuning on two representative SLLMs, Qwen2-Audio and SALMONN. Moreover, the semi-implicit XS-CoT reduces token delay by more than 50% with a slight drop in GPT-4 scores. Importantly, XS-CoT requires only a small amount of high-quality training data for non-core languages by leveraging the reasoning capabilities of core languages. To support training, we also develop a data pipeline and open-source speech instruction-following datasets in Japanese, German, and French.
大型语言模型已扩展到语音领域,催生了语音大型语言模型(SLLM)的发展。尽管现有SLLM在核心语言的语音指令跟随方面表现出强大的性能(例如英语),但由于缺乏配套的语音文本数据和有限的跨语言语义推理能力,它们在非核心语言上经常遇到困难。为了解决这一问题,我们提出了半隐式跨语言语音思维链(XS-CoT)框架,它将语音到文本的翻译融入SLLM的推理过程中。XS-CoT生成四种类型的标记:核心语言和非核心语言中的指令和响应标记,实现了跨语言推理能力的转移。为了减轻生成目标非核心响应标记时的推理延迟,我们在XS-CoT中纳入了半隐式CoT方案,该方案在训练过程中逐步压缩前三种中间推理标记,同时保留全局推理逻辑。通过利用核心语言的强大推理能力,XS-CoT在两种代表性SLLM(Qwen2-Audio和SALMONN)上,与非核心语言的直接监督微调相比,通过GPT-4评分提高了高达45%的响应能力。此外,半隐式XS-CoT减少了令牌延迟超过50%,同时GPT-4得分略有下降。最重要的是,XS-CoT仅需要少量高质量的非核心语言训练数据,通过利用核心语言的推理能力。为了支持训练,我们还开发了一个数据管道并公开了日语、德语和法语等语音指令跟随数据集。
论文及项目相关链接
PDF 10 pages, 6 figures, Submitted to ACM MM 2025
Summary
大型语言模型已扩展到语音领域,导致语音大型语言模型(SLLM)的发展。现有SLLM在英语等核心语言语音指令遵循方面表现出强大的性能,但由于缺乏配套语音文本数据和有限的多语言语义推理能力,对非核心语言的处理常常遇到困难。为解决这一问题,提出了半隐式跨语言语音思维链(XS-CoT)框架,将语音到文本的翻译融入SLLM的推理过程。XS-CoT生成四种类型的符号:核心和非核心语言中的指令和响应符号,实现跨语言推理能力的转移。通过采用半隐式CoT方案,在生成目标非核心响应符号时减轻推理延迟,该方案在训练过程中逐步压缩前三种中间推理符号,同时保留全局推理逻辑。与对两个代表性SLLM(Qwen2-Audio和SALMONN)的直接监督微调相比,XS-CoT利用核心语言的强大推理能力,提高非核心语言的响应率高达45%。此外,半隐式XS-CoT将符号延迟减少了50%以上,同时GPT-4得分略有下降。重要的是,XS-CoT仅需要少量高质量的非核心语言训练数据,就可以利用核心语言的推理能力。
Key Takeaways
- 大型语言模型已扩展至语音领域,形成语音大型语言模型(SLLM)。
- SLLM在处理非核心语言时面临数据稀缺和推理能力有限的问题。
- 提出XS-CoT框架,将语音转化为文本进行推理,支持核心与非核心语言。
- XS-CoT通过逐步压缩中间推理符号减少推理延迟。
- XS-CoT改进非核心语言的响应能力,相较于传统方法提高45%。
- 半隐式XS-CoT减少符号延迟超过50%,同时保持较高的GPT-4得分。
点此查看论文截图


Secure Coding with AI, From Creation to Inspection
Authors:Vladislav Belozerov, Peter J Barclay, Ashkan Sami
While prior studies have explored security in code generated by ChatGPT and other Large Language Models, they were conducted in controlled experimental settings and did not use code generated or provided from actual developer interactions. This paper not only examines the security of code generated by ChatGPT based on real developer interactions, curated in the DevGPT dataset, but also assesses ChatGPT’s capability to find and fix these vulnerabilities. We analysed 1,586 C, C++, and C# code snippets using static scanners, which detected potential issues in 124 files. After manual analysis, we selected 26 files with 32 confirmed vulnerabilities for further investigation. We submitted these files to ChatGPT via the OpenAI API, asking it to detect security issues, identify the corresponding Common Weakness Enumeration numbers, and propose fixes. The responses and modified code were manually reviewed and re-scanned for vulnerabilities. ChatGPT successfully detected 18 out of 32 security issues and resolved 17 issues but failed to recognize or fix the remainder. Interestingly, only 10 vulnerabilities were resulted from the user prompts, while 22 were introduced by ChatGPT itself. We highlight for developers that code generated by ChatGPT is more likely to contain vulnerabilities compared to their own code. Furthermore, at times ChatGPT reports incorrect information with apparent confidence, which may mislead less experienced developers. Our findings confirm previous studies in demonstrating that ChatGPT is not sufficiently reliable for generating secure code nor identifying all vulnerabilities, highlighting the continuing importance of static scanners and manual review.
虽然先前的研究已经探讨了ChatGPT和其他大型语言模型生成的代码的安全性,但这些研究是在受控实验环境中进行的,并没有使用实际开发者交互生成的代码。本文不仅基于DevGPT数据集的实际开发者交互,对ChatGPT生成的代码安全性进行了考察,还评估了ChatGPT发现和修复这些漏洞的能力。我们使用静态扫描器分析了1586个C、C++和C#的代码片段,其中检测出潜在问题存在于124个文件中。经过手动分析后,我们选择了包含已确认的32个漏洞的26个文件进行进一步调查。我们通过OpenAI API将这些文件提交给ChatGPT,要求其检测安全问题,识别相应的常见弱点枚举编号,并提出修复建议。我们对ChatGPT的回应和修改后的代码进行了手动审查,并重新扫描漏洞。ChatGPT成功检测出了其中的18个安全问题并解决了其中的17个问题,但未能识别或修复其余的问题。有趣的是,仅有10个漏洞是由于用户提示造成的,而剩下的则是ChatGPT本身造成的。我们向开发者强调,相较于他们自己的代码,ChatGPT生成的代码更有可能包含漏洞。此外,有时ChatGPT会表现出明显的自信而报告错误的信息,可能会误导经验较少的开发者。我们的研究结果证实了之前的研究,表明ChatGPT在生成安全代码或识别所有漏洞方面尚不可靠,这进一步强调了静态扫描器和人工审查的重要性。
论文及项目相关链接
摘要
本文探讨了基于真实开发者交互的ChatGPT生成代码的安全性。通过分析DevGPT数据集中的1,586个C、C++和C#代码片段,发现潜在问题并确认存在32个漏洞。通过OpenAI API提交给ChatGPT检测和修复这些安全问题,ChatGPT成功检测到其中18个问题并解决其中17个,但未能识别或修复其余问题。值得注意的是,只有少数漏洞来自用户提示,而大多数是由ChatGPT自身引入的。研究表明,ChatGPT生成的代码可能包含更多漏洞,开发者应谨慎使用。此外,ChatGPT有时会报告错误的信息,可能会误导经验不足的开发者。尽管ChatGPT有其局限性,但静态扫描器和人工审查的重要性仍然不容忽视。
关键见解
- 本研究首次探讨了基于真实开发者交互的ChatGPT生成代码的安全性。
- 通过静态扫描和分析,发现了大量潜在的安全问题并确认了32个漏洞。
- ChatGPT成功检测到并修复了部分安全问题,但未能全面识别和修复所有漏洞。
- ChatGPT生成的代码可能比开发者自己的代码更容易包含漏洞。
- ChatGPT有时会报告错误的信息,对开发者造成误导,特别是经验不足的开发者需格外警惕。
- 尽管ChatGPT在某些方面表现出局限性,但静态扫描器和人工审查仍然是确保代码安全的重要工具。
- 研究结果重申了对于代码安全性和质量控制的必要性。
点此查看论文截图

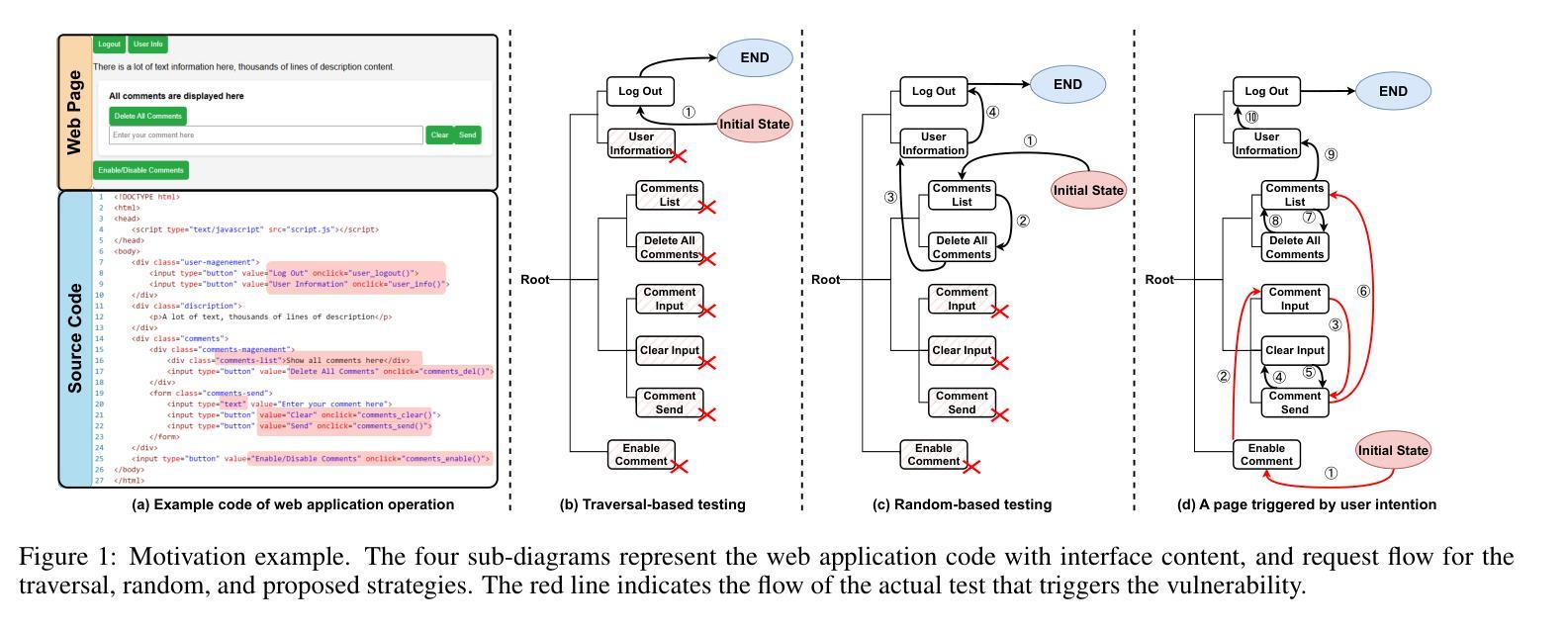
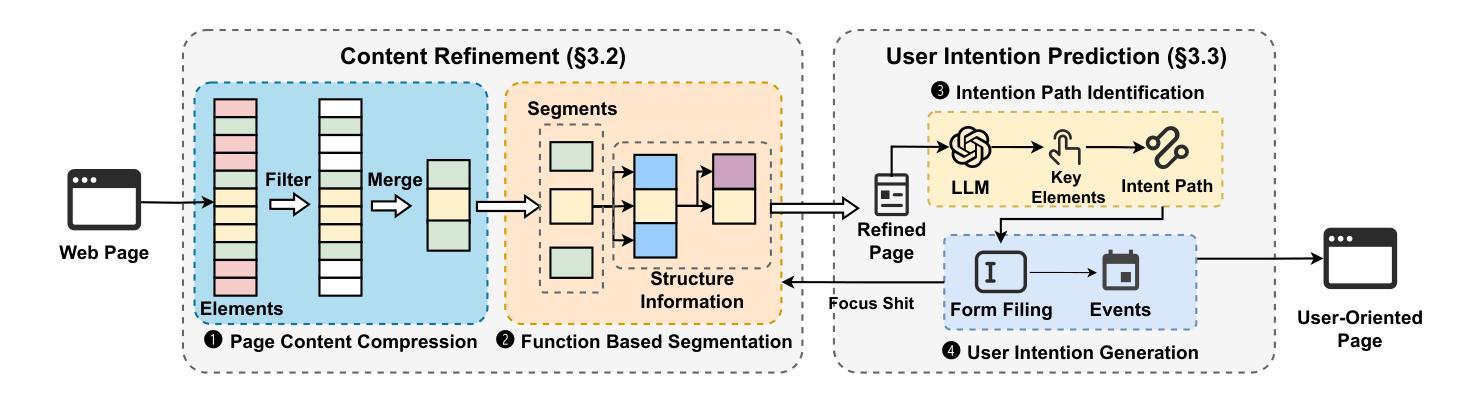
Unlocking User-oriented Pages: Intention-driven Black-box Scanner for Real-world Web Applications
Authors:Weizhe Wang, Yao Zhang, Kaitai Liang, Guangquan Xu, Hongpeng Bai, Qingyang Yan, Xi Zheng, Bin Wu
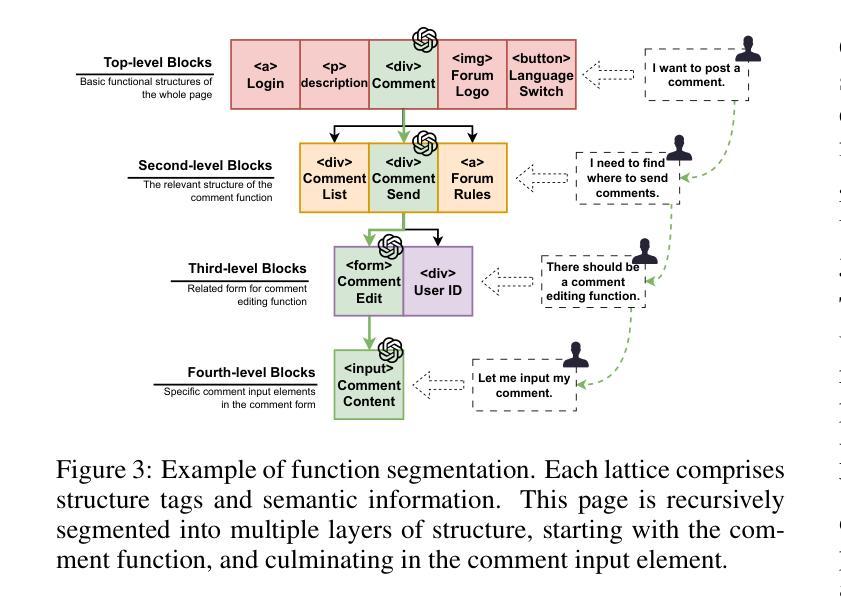
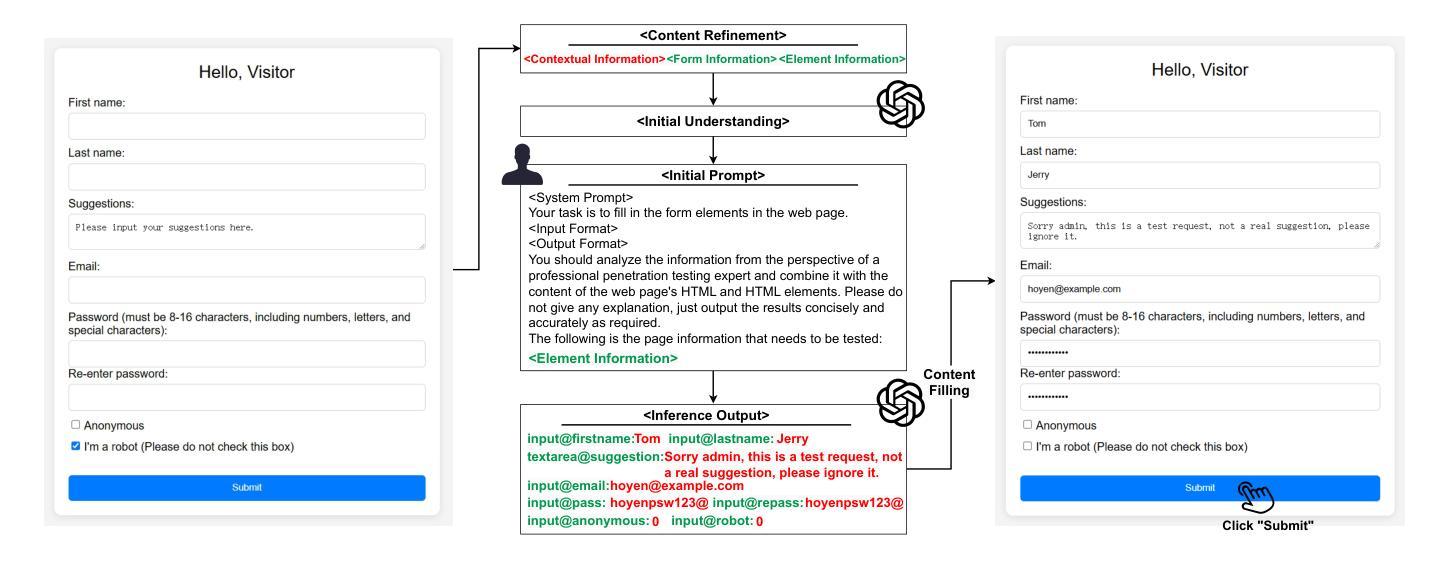
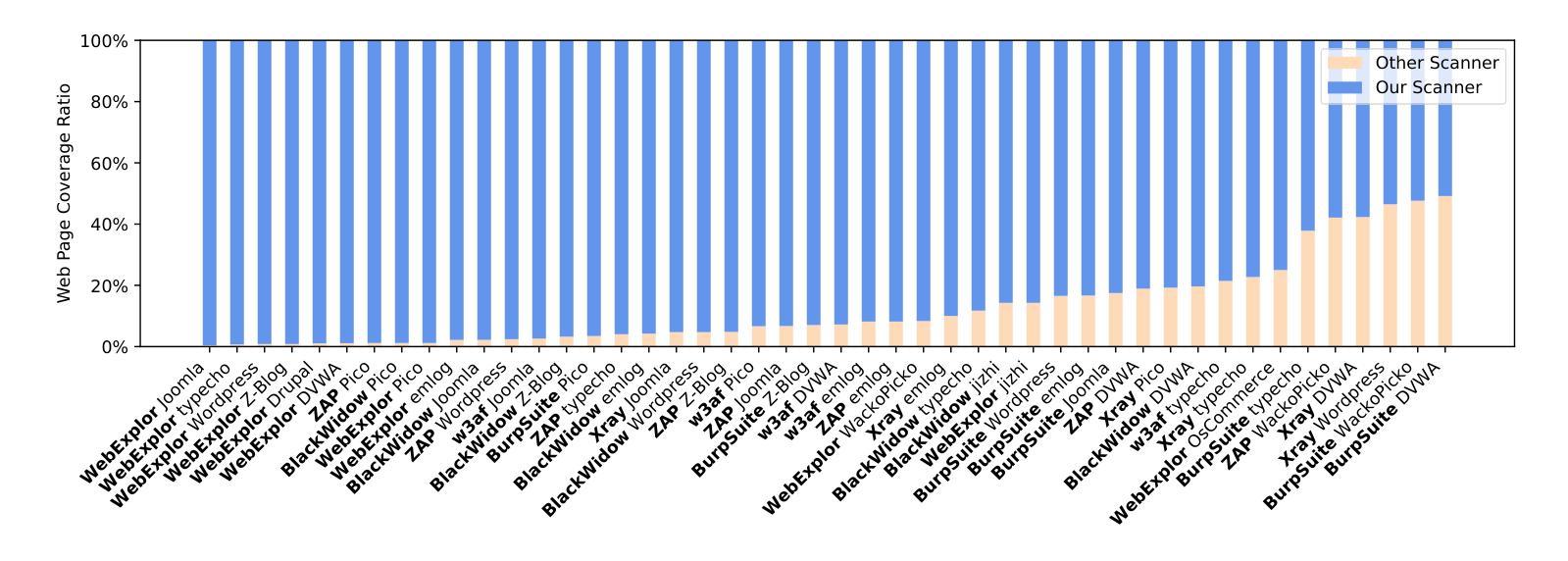
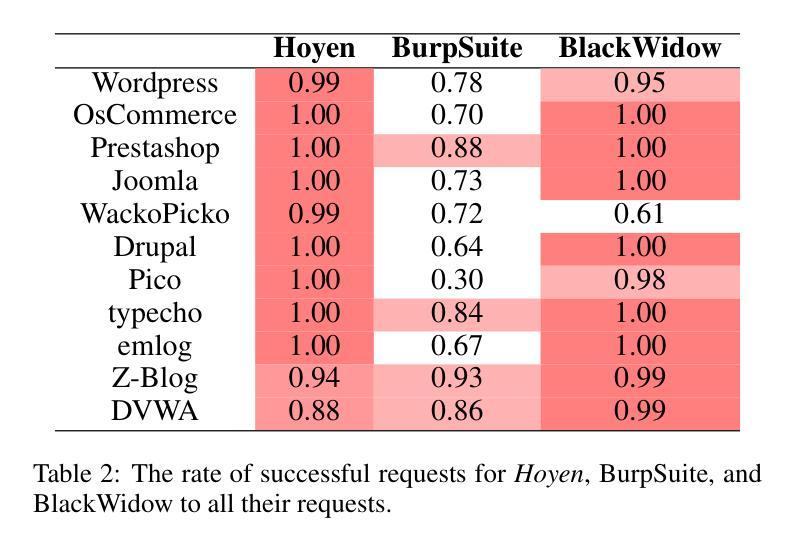
Black-box scanners have played a significant role in detecting vulnerabilities for web applications. A key focus in current black-box scanning is increasing test coverage (i.e., accessing more web pages). However, since many web applications are user-oriented, some deep pages can only be accessed through complex user interactions, which are difficult to reach by existing black-box scanners. To fill this gap, a key insight is that web pages contain a wealth of semantic information that can aid in understanding potential user intention. Based on this insight, we propose Hoyen, a black-box scanner that uses the Large Language Model to predict user intention and provide guidance for expanding the scanning scope. Hoyen has been rigorously evaluated on 12 popular open-source web applications and compared with 6 representative tools. The results demonstrate that Hoyen performs a comprehensive exploration of web applications, expanding the attack surface while achieving about 2x than the coverage of other scanners on average, with high request accuracy. Furthermore, Hoyen detected over 90% of its requests towards the core functionality of the application, detecting more vulnerabilities than other scanners, including unique vulnerabilities in well-known web applications. Our data/code is available at https://hoyen.tjunsl.com/
黑盒扫描器在检测Web应用程序漏洞方面发挥了重要作用。当前黑盒扫描的关键焦点是提高测试覆盖率(即访问更多的网页)。然而,由于许多Web应用程序面向用户,一些深层页面只能通过复杂的用户交互访问,而现有的黑盒扫描器很难达到这些页面。为了填补这一空白,一个重要的见解是网页包含丰富的语义信息,可以帮助理解潜在的用户意图。基于这一见解,我们提出了Hoyen,一种使用大型语言模型预测用户意图并提供指导以扩大扫描范围的的黑盒扫描器。Hoyen在12个流行的开源Web应用程序上进行了严格评估,并与6种代表性工具进行了比较。结果表明,Hoyen对Web应用程序进行了全面探索,扩大了攻击面,平均覆盖率比其他扫描器高出约2倍,请求精度高。此外,Hoyen针对应用程序核心功能的请求超过90%,检测到的漏洞比其他扫描器更多,包括在知名Web应用程序中的独特漏洞。我们的数据和代码可在https://hoyen.tjunsl.com/找到。
论文及项目相关链接
Summary:
黑盒扫描器在检测Web应用程序漏洞方面扮演重要角色,但受限于测试覆盖范围。为解决该问题,提出了一种基于语义信息的黑盒扫描器——Hoyen。它利用大型语言模型预测用户意图,扩展扫描范围并增加测试覆盖率。在多个开源Web应用程序上的评估结果表明,Hoyen具有出色的性能,平均覆盖率是其他扫描器的两倍以上,请求准确率高,能检测更多漏洞,包括知名Web应用程序的独特漏洞。
Key Takeaways:
- 黑盒扫描器在检测Web应用程序漏洞中扮演重要角色,但测试覆盖范围有限。
- 当前黑盒扫描的一个关键挑战是访问复杂的用户交互页面。
- 基于语义信息预测用户意图是解决此挑战的一种方法。
- Hoyen是一种利用大型语言模型的黑盒扫描器,旨在扩展扫描范围并提高测试覆盖率。
- Hoyen通过预测用户意图来指导扫描过程,从而实现对Web应用程序的全面探索。
- 评估结果表明,Hoyen性能优越,与其他扫描器相比,平均覆盖率提高了两倍以上。
点此查看论文截图


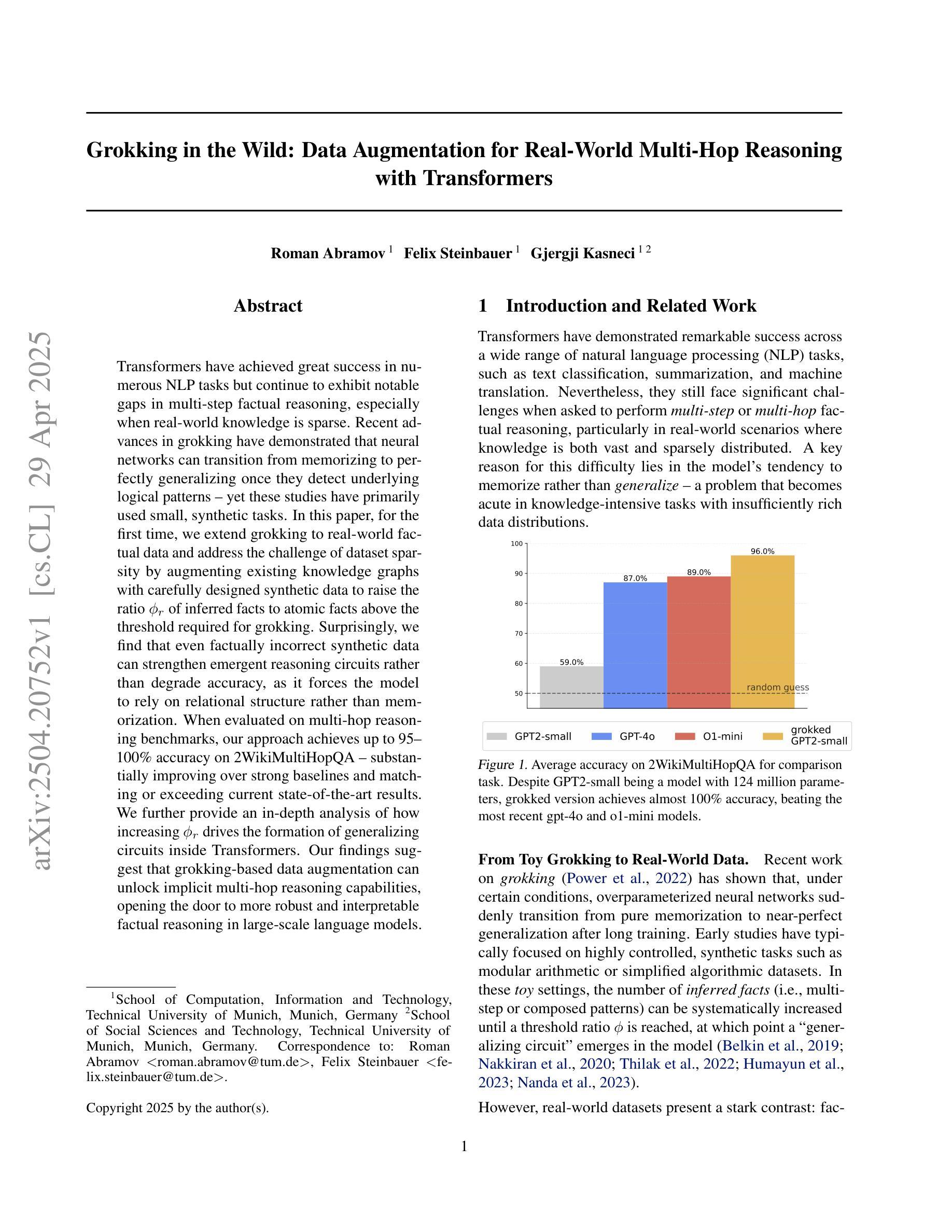
Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers
Authors:Roman Abramov, Felix Steinbauer, Gjergji Kasneci
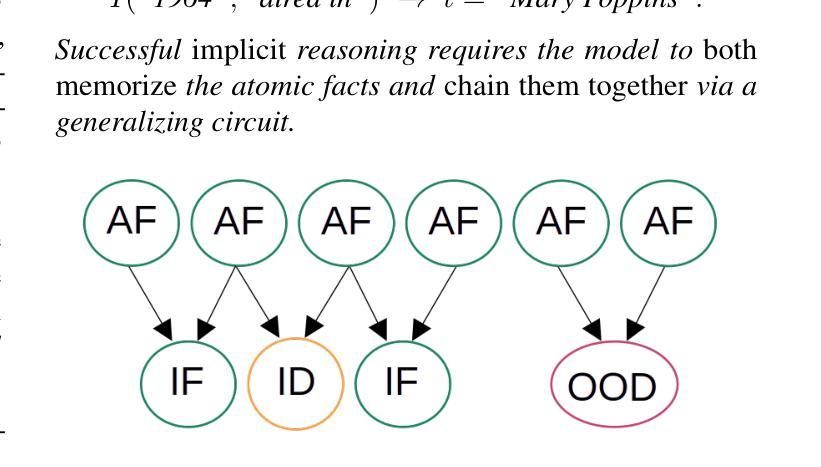
Transformers have achieved great success in numerous NLP tasks but continue to exhibit notable gaps in multi-step factual reasoning, especially when real-world knowledge is sparse. Recent advances in grokking have demonstrated that neural networks can transition from memorizing to perfectly generalizing once they detect underlying logical patterns - yet these studies have primarily used small, synthetic tasks. In this paper, for the first time, we extend grokking to real-world factual data and address the challenge of dataset sparsity by augmenting existing knowledge graphs with carefully designed synthetic data to raise the ratio $\phi_r$ of inferred facts to atomic facts above the threshold required for grokking. Surprisingly, we find that even factually incorrect synthetic data can strengthen emergent reasoning circuits rather than degrade accuracy, as it forces the model to rely on relational structure rather than memorization. When evaluated on multi-hop reasoning benchmarks, our approach achieves up to 95-100% accuracy on 2WikiMultiHopQA - substantially improving over strong baselines and matching or exceeding current state-of-the-art results. We further provide an in-depth analysis of how increasing $\phi_r$ drives the formation of generalizing circuits inside Transformers. Our findings suggest that grokking-based data augmentation can unlock implicit multi-hop reasoning capabilities, opening the door to more robust and interpretable factual reasoning in large-scale language models.
转换器在众多NLP任务中取得了巨大成功,但在多步骤事实推理方面仍存在明显差距,特别是在现实世界知识稀缺的情况下。最近对grokking的研究进展表明,一旦神经网络检测到潜在的逻辑模式,它们就可以从记忆过渡到完全泛化——然而,这些研究主要使用的是小规模的合成任务。在本文中,我们首次将grokking扩展到现实世界的事实数据,并通过增加精心设计合成数据来增强现有知识图谱,以应对数据集稀疏性的挑战,从而提高推断事实与原子事实的比率$\phi_r$,达到grokking所需的阈值以上。令人惊讶的是,我们发现即使是事实错误的合成数据也可以加强新兴推理电路,而不是降低准确性,因为它迫使模型依赖关系结构而不是记忆。在评估多跳推理基准测试时,我们的方法在2WikiMultiHopQA上达到了95-100%的准确率,大幅超越了强大的基线,并达到或超过了当前最新技术水平的结果。我们还深入分析了如何提高$\phi_r$在转换器内部形成泛化电路的方法。我们的研究表明,基于grokking的数据增强可以解锁隐式的多跳推理能力,为大规模语言模型中的更稳健和可解释的事实推理打开了大门。
论文及项目相关链接
Summary
神经网络在面临知识稀缺的多步骤推理任务时表现不足。然而,新研究表明通过逻辑模式的掌握而进行的深度分析可使模型在真实的图谱数据集上达成更好的泛化效果。研究使用合成数据来扩充现有知识图谱,从而提高模型在理解复杂推理时的准确度。此外,即使与真实数据事实不完全一致的合成数据也能够通过让模型更多地依赖于结构化关系来加强模型对于逻辑推理能力的依赖性,提升其在多跳推理任务上的表现。本研究的分析发现合成数据的使用有助于提高模型在多跳问答任务上的表现,并且在深入研究数据增加时推理电路的构建过程后,揭示了增强泛化能力的关键机制。这一发现为大型语言模型中的稳健和可解释的多步推理能力提供了可能。
Key Takeaways
1. 神经网络在多步骤推理任务中面临知识稀缺的问题时表现不佳。
2. 通过逻辑模式的掌握进行的深度分析可以使模型在真实世界图谱数据集上实现更好的泛化效果。通过扩充现有知识图谱的研究揭示了新见解。
3. 使用合成数据可以提升模型在多跳推理任务上的准确度,并提升模型对于结构化关系的依赖。这提供了一种增强模型泛化能力的方法。
4. 即使包含错误事实的合成数据也有助于加强模型的逻辑推理能力,这是因为它们促使模型更依赖于结构化的关系而不是简单记忆知识信息,从而使得推理更健壮且更加能够对抗对抗基于观察而非归纳法的模型局限。
5. 通过深入研究数据增加时推理电路的构建过程,揭示了增强泛化能力的关键机制。
6. 研究结果提供了一种可能的解决方案,即通过合成数据增强大型语言模型的稳健性和可解释性,使得其在处理复杂的多步推理任务时更具可靠性。
点此查看论文截图



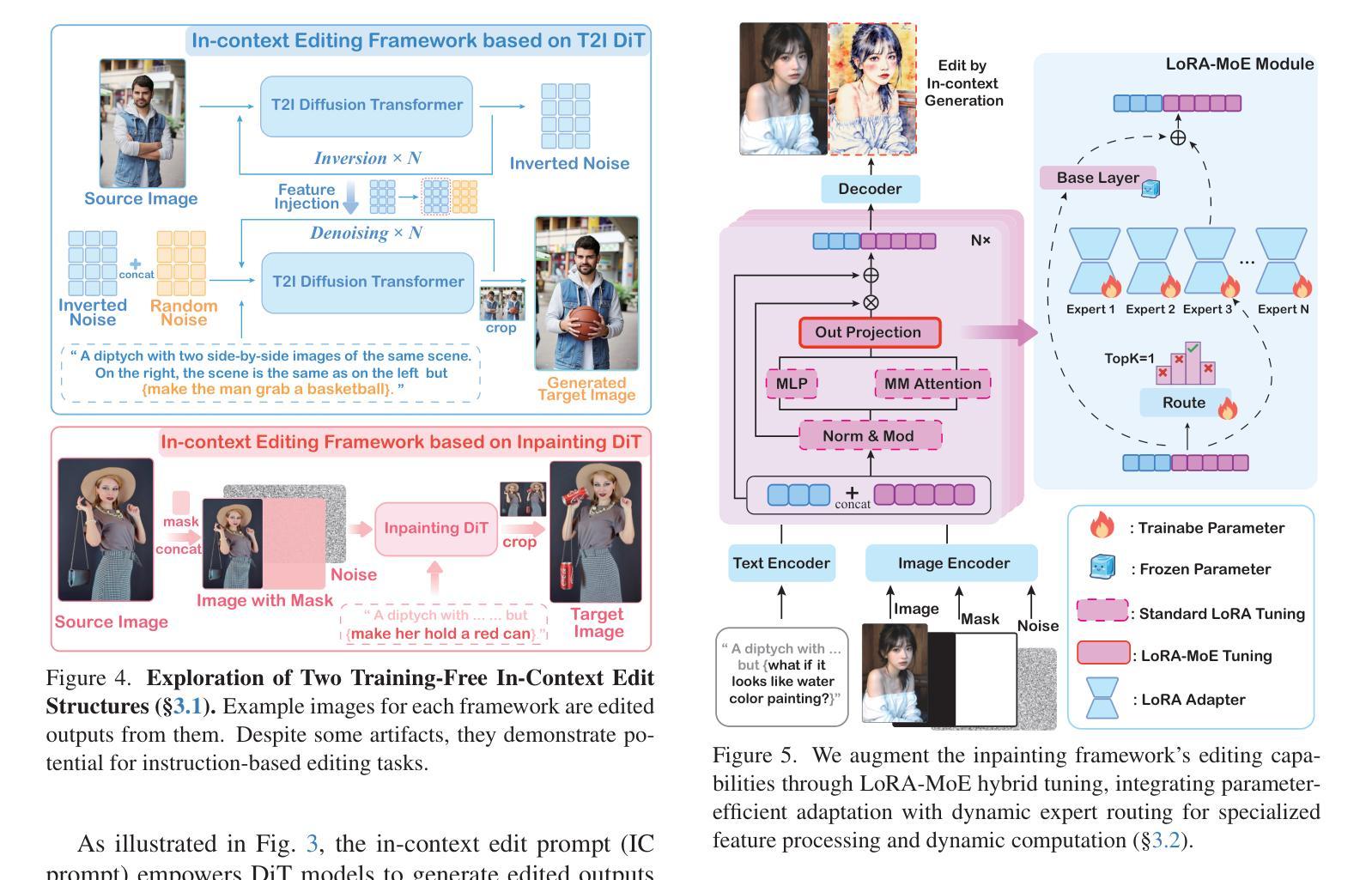
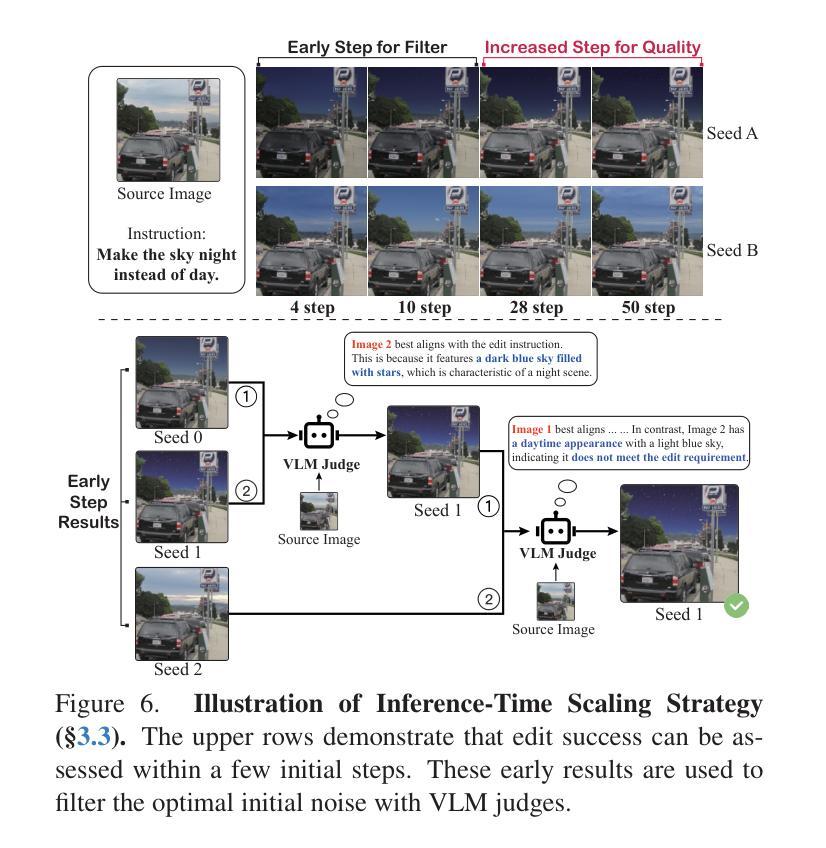
In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
Authors:Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, Yi Yang
Instruction-based image editing enables robust image modification via natural language prompts, yet current methods face a precision-efficiency tradeoff. Fine-tuning methods demand significant computational resources and large datasets, while training-free techniques struggle with instruction comprehension and edit quality. We resolve this dilemma by leveraging large-scale Diffusion Transformer (DiT)’ enhanced generation capacity and native contextual awareness. Our solution introduces three contributions: (1) an in-context editing framework for zero-shot instruction compliance using in-context prompting, avoiding structural changes; (2) a LoRA-MoE hybrid tuning strategy that enhances flexibility with efficient adaptation and dynamic expert routing, without extensive retraining; and (3) an early filter inference-time scaling method using vision-language models (VLMs) to select better initial noise early, improving edit quality. Extensive evaluations demonstrate our method’s superiority: it outperforms state-of-the-art approaches while requiring only 0.5% training data and 1% trainable parameters compared to conventional baselines. This work establishes a new paradigm that enables high-precision yet efficient instruction-guided editing. Codes and demos can be found in https://river-zhang.github.io/ICEdit-gh-pages/.
基于指令的图像编辑能够通过自然语言提示实现稳健的图像修改,但当前的方法面临着精度与效率之间的权衡。微调方法需要巨大的计算资源和大量的数据集,而无需训练的技术则在理解指令和编辑质量方面遇到困难。我们通过利用大规模的扩散变压器(DiT)增强的生成能力和本地上下文意识来解决这一难题。我们的解决方案引入了三个贡献:(1)使用上下文提示的零启动指令合规性的上下文内编辑框架,避免结构变化;(2)LoRA-MoE混合调整策略,通过高效的适应性和动态专家路由增强灵活性,而无需大量重新训练;(3)使用视觉语言模型(VLM)的早期过滤推理时间缩放方法,以更早地选择更好的初始噪声,提高编辑质量。广泛评估表明我们的方法具有优越性:它优于最先进的方法,仅需要0.5%的训练数据和1%的可训练参数,与传统的基线相比。这项工作建立了一个新范式,能够实现高精度且高效的指令指导编辑。代码和演示可在https://river-zhang.github.io/ICEdit-gh-pages/找到。
论文及项目相关链接
PDF Project Page: https://river-zhang.github.io/ICEdit-gh-pages/
Summary
基于指令的图像编辑通过自然语言提示实现了强大的图像修改功能。当前方法面临精确性与效率之间的权衡。精细调整方法需要大量计算资源和大型数据集,而无需训练的技术则在指令理解和编辑质量方面存在困难。我们解决了这一问题,通过利用大规模的扩散变压器(DiT)增强的生成能力和原生上下文意识。我们的解决方案引入了三个贡献:一、使用上下文提示的零射击指令符合性的上下文编辑框架,避免结构变化;二、一种LoRA-MoE混合调整策略,通过有效的适应和动态专家路由提高灵活性,无需大量重新训练;三、一种早期过滤推理时间缩放方法,使用视觉语言模型(VLMs)选择更好的初始噪声早期,提高编辑质量。全面评估表明,我们的方法在性能上优于最先进的方法,并且仅需要0.5%的训练数据和1%的可训练参数相比传统的基准测试。这项工作建立了一个新范式,实现了高精度且高效的指令指导编辑。
Key Takeaways
- 指令基础的图像编辑通过自然语言提示实现图像修改,但存在精确性和效率之间的权衡。
- 现有方法需要大量计算资源和数据集进行精细调整,而无需训练的技术在理解和编辑质量方面存在挑战。
- 研究人员利用大规模的扩散变压器(DiT)解决了这一问题,增强了生成能力和上下文意识。
- 提出了三种主要贡献:零射击指令符合性的上下文编辑框架、LoRA-MoE混合调整策略和早期过滤推理时间缩放方法。
- 所提出的方法在性能上优于最先进的方法,且只需要较少的训练数据和可训练参数。
- 该研究建立了新的范式,实现了高精度且高效的指令指导编辑。
点此查看论文截图



TF1-EN-3M: Three Million Synthetic Moral Fables for Training Small, Open Language Models
Authors:Mihai Nadas, Laura Diosan, Andrei Piscoran, Andreea Tomescu
Moral stories are a time-tested vehicle for transmitting values, yet modern NLP lacks a large, structured corpus that couples coherent narratives with explicit ethical lessons. We close this gap with TF1-EN-3M, the first open dataset of three million English-language fables generated exclusively by instruction-tuned models no larger than 8B parameters. Each story follows a six-slot scaffold (character -> trait -> setting -> conflict -> resolution -> moral), produced through a combinatorial prompt engine that guarantees genre fidelity while covering a broad thematic space. A hybrid evaluation pipeline blends (i) a GPT-based critic that scores grammar, creativity, moral clarity, and template adherence with (ii) reference-free diversity and readability metrics. Among ten open-weight candidates, an 8B-parameter Llama-3 variant delivers the best quality-speed trade-off, producing high-scoring fables on a single consumer GPU (<24 GB VRAM) at approximately 13.5 cents per 1,000 fables. We release the dataset, generation code, evaluation scripts, and full metadata under a permissive license, enabling exact reproducibility and cost benchmarking. TF1-EN-3M opens avenues for research in instruction following, narrative intelligence, value alignment, and child-friendly educational AI, demonstrating that large-scale moral storytelling no longer requires proprietary giant models.
道德故事是传递价值的经过时间检验的有效手段,然而现代自然语言处理领域缺乏一个大型结构化语料库,该语料库能够将连贯的叙事与明确的道德教训相结合。我们通过TF1-EN-3M数据集填补了这一空白,TF1-EN-3M是首个开放的、由指令优化模型生成的三百万英语寓言数据集,这些模型的参数规模均不超过8B。每个故事都遵循六个槽位(角色->特征->背景->冲突->解决->道德)的架构,通过组合提示引擎生成,既保证了文体忠实度又覆盖了广泛的主题空间。混合评估流程结合了(i)基于GPT的评论家对语法、创造力、道德清晰度和模板遵循度的评分,以及(ii)无参考的多样性和可读性指标。在十个公开权重候选模型中,一个规模为8B参数的Llama-3变体提供了最佳的性价比,能够在单个消费者GPU上(<24GBVRAM)生产高得分的寓言故事,每生产一千个寓言故事的成本约为13.5美分。我们根据许可协议公开发布数据集、生成代码、评估脚本和完整元数据,以实现精确的可重复性和成本基准测试。TF1-EN-3M为研究指令遵循、叙事智能、价值对齐以及儿童友好型教育人工智能等领域开辟了道路,证明大规模道德故事叙述不再需要专有大型模型。
论文及项目相关链接
Summary:
本研究创建了一个包含三百万英语寓言的开放数据集TF1-EN-3M,这些寓言由指令调优模型生成,每个故事遵循六个槽位架构(角色->特质->场景->冲突->解决->道德),覆盖广泛的主题空间。该数据集填补了现代NLP缺乏大型结构化语料库的空白,能够传输价值观。研究发布数据集、生成代码、评估脚本和完整元数据,并证明了大规模讲述道德故事不再需要专有大型模型,为指令遵循、叙事智能、价值对齐和儿童友好教育人工智能的研究开辟了道路。
Key Takeaways:
- 创建了包含三百万英语寓言的开放数据集TF1-EN-3M。
- 数据集中的每个寓言都遵循六个槽位架构,具有明确的道德寓意。
- 该数据集通过指令调优模型生成,保证故事体裁的忠实性并覆盖广泛的主题空间。
- 研究采用混合评估管道,包括基于GPT的评分器和无参考的多样性和可读性指标。
- 8B参数的Llama-3变体在质量速度权衡方面表现最佳,能在单个消费者GPU上以约13.5美分的成本生产高分寓言。
- 研究发布了数据集、生成代码、评估脚本和完整元数据,以实现精确的可重复性和成本基准测试。
点此查看论文截图

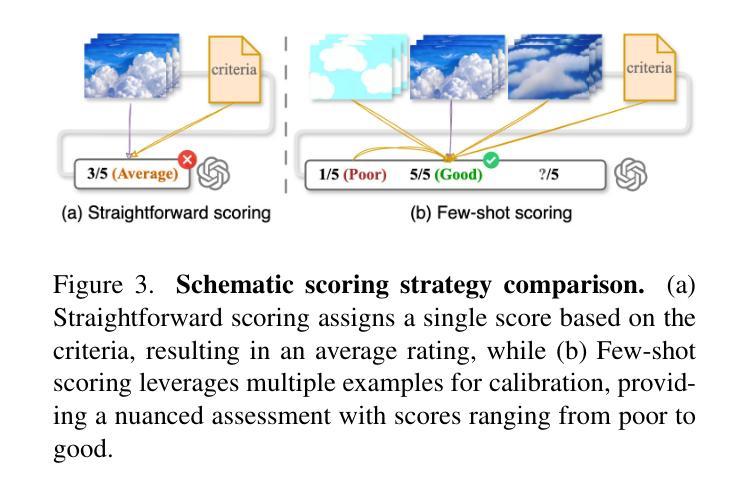
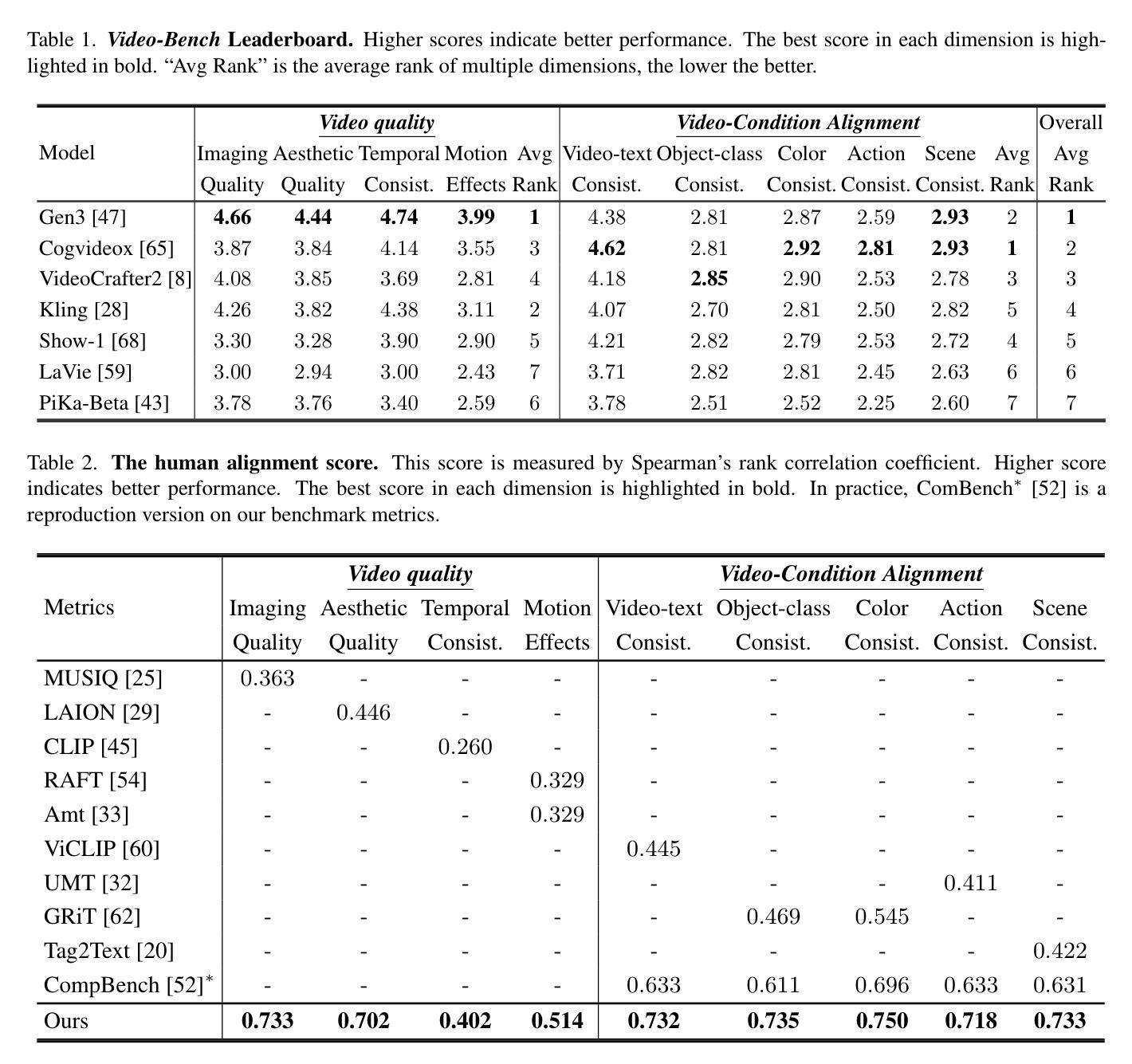
Video-Bench: Human-Aligned Video Generation Benchmark
Authors:Hui Han, Siyuan Li, Jiaqi Chen, Yiwen Yuan, Yuling Wu, Chak Tou Leong, Hanwen Du, Junchen Fu, Youhua Li, Jie Zhang, Chi Zhang, Li-jia Li, Yongxin Ni
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework’s assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
视频生成评估对于确保生成模型产生视觉真实、高质量的视频,同时符合人类期望至关重要。当前视频生成的基准测试主要分为两大类:传统基准测试使用指标和嵌入来评估生成视频质量的多维方面,但通常与人类判断缺乏一致性;基于大型语言模型(LLM)的基准测试虽然具备人类般的推理能力,但对视频质量指标的有限理解和跨模态一致性方面存在约束。为了解决这些挑战,并建立更符合人类偏好的基准测试,本文介绍了Video-Bench,这是一个全面的基准测试平台,具有丰富的提示套件和广泛的评估维度。该基准测试是首次尝试在生成模型中涉及视频生成评估的所有相关维度上系统地利用多模态大型语言模型(MLLM)。通过采用少量评分和查询链技术,Video-Bench为生成的视频评估提供了一种结构化、可扩展的方法。在包括Sora在内的先进模型上的实验表明,Video-Bench在所有维度上实现了与人类偏好更优越的对齐。此外,在我们的框架评估与人类评估意见分歧的情况下,它始终提供更客观和准确的见解,这表明它可能比传统的人类判断具有更大的潜在优势。
论文及项目相关链接
PDF Accepted by CVPR’25
Summary
新一代视频生成评估系统——Video-Bench的引入解决了传统视频生成评估标准的局限性,包括与人工评价的不匹配以及对视频质量指标和跨模态一致性的有限理解。Video-Bench通过丰富的提示套件和广泛的评估维度,系统地利用大型语言模型(LLM)进行视频生成评估,以实现对视频质量的全面评估,并实现与人类偏好的更高对齐。采用少量评分和查询链技术使Video-Bench结构化,更易于生成视频评价,能够在复杂模型上进行实验,表现出优越的评估性能。同时,当评估框架与人工评价存在分歧时,它提供了更客观和准确的见解。
Key Takeaways
- Video-Bench是新一代视频生成评估系统,旨在解决传统评估标准的局限性。
- Video-Bench采用丰富的提示套件和广泛的评估维度进行视频生成评估。
- 通过系统地利用大型语言模型(LLM),Video-Bench可以更好地与人类偏好对齐。
- Video-Bench通过少量评分和查询链技术提高了视频生成评估的结构性和可评估性。
- 实验证明Video-Bench在复杂模型上的评估性能优越。
- Video-Bench在评估框架与人工评价存在分歧时,提供了更客观和准确的见解。
点此查看论文截图

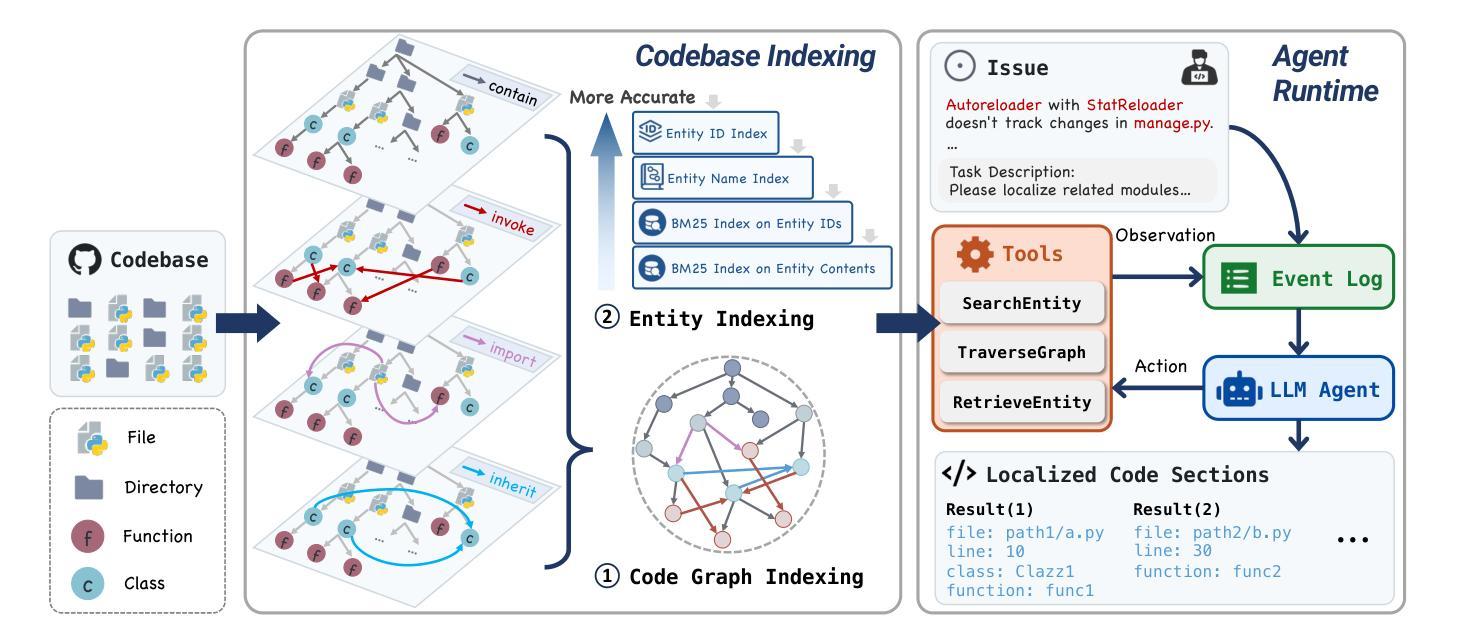
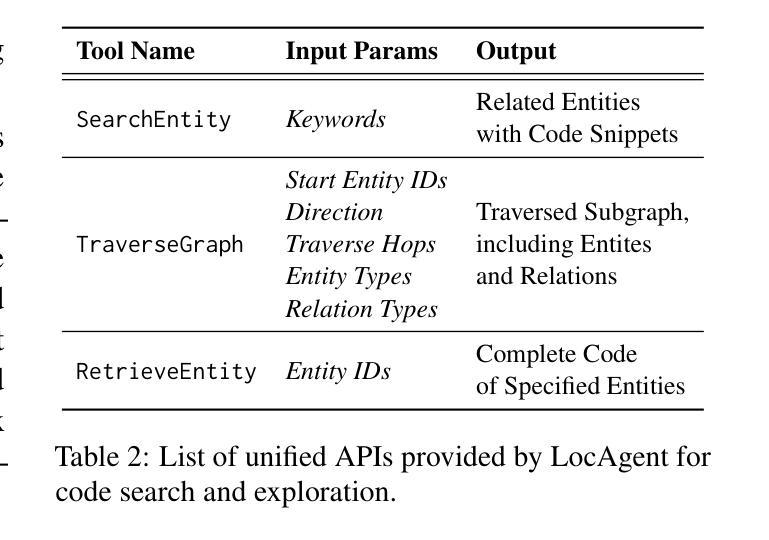
LocAgent: Graph-Guided LLM Agents for Code Localization
Authors:Zhaoling Chen, Xiangru Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, Xingyao Wang
Code localization–identifying precisely where in a codebase changes need to be made–is a fundamental yet challenging task in software maintenance. Existing approaches struggle to efficiently navigate complex codebases when identifying relevant code sections. The challenge lies in bridging natural language problem descriptions with the appropriate code elements, often requiring reasoning across hierarchical structures and multiple dependencies. We introduce LocAgent, a framework that addresses code localization through graph-based representation. By parsing codebases into directed heterogeneous graphs, LocAgent creates a lightweight representation that captures code structures (files, classes, functions) and their dependencies (imports, invocations, inheritance), enabling LLM agents to effectively search and locate relevant entities through powerful multi-hop reasoning. Experimental results on real-world benchmarks demonstrate that our approach significantly enhances accuracy in code localization. Notably, our method with the fine-tuned Qwen-2.5-Coder-Instruct-32B model achieves comparable results to SOTA proprietary models at greatly reduced cost (approximately 86% reduction), reaching up to 92.7% accuracy on file-level localization while improving downstream GitHub issue resolution success rates by 12% for multiple attempts (Pass@10). Our code is available at https://github.com/gersteinlab/LocAgent.
代码定位——精确确定需要在代码库中做出更改的位置——是软件维护中的一项基本且具有挑战性的任务。现有方法在识别相关代码段时很难有效遍历复杂的代码库。挑战在于将自然语言问题描述与适当的代码元素进行桥梁连接,通常需要跨越层次结构和多个依赖关系进行推理。我们引入了LocAgent,这是一个通过图表示来解决代码定位问题的框架。通过将代码库解析为定向异质图,LocAgent创建了一种轻量级的表示形式,能够捕获代码结构(文件、类、函数)及其依赖关系(导入、调用、继承),使大型语言模型代理能够通过强大的多跳推理有效地搜索和定位相关实体。在现实世界的基准测试上的实验结果表明,我们的方法显著提高了代码定位的准确性。值得注意的是,我们使用微调后的Qwen-2.5-Coder-Instruct-32B模型,以大幅降低的成本(约86%)取得了与最先进的专有模型相当的结果,文件级定位准确性高达92.7%,并在多次尝试下将下游GitHub问题解决成功率提高了12%(Pass@10)。我们的代码可在https://github.com/gersteinlab/LocAgent获取。
论文及项目相关链接
Summary
代码定位是软件维护中的基本且具挑战性的任务,需要精确识别需要在代码库中进行更改的位置。现有方法在处理复杂的代码库时难以有效地导航并识别相关的代码段。本文介绍了一种通过基于图的表示来解决代码定位问题的LocAgent框架。它通过将有向异构图解析为代码库,创建了轻量级的表示,捕获了代码结构(文件、类、函数)及其依赖关系(导入、调用、继承),使得LLM代理可以有效地进行多跳推理并定位相关实体。在真实世界的基准测试上进行的实验结果表明,该方法显著提高代码定位的准确性。尤其是,我们的方法与精细调整的Qwen-2.5-Coder-Instruct-32B模型相结合,在大大降低成本(约降低86%)的情况下实现了与最先进专有模型相当的结果,文件级定位准确性达到92.7%,同时提高下游GitHub问题解决的成功率达到多次尝试的12%(Pass@10)。
Key Takeaways
- 代码定位是软件维护中的核心任务,需要精确识别更改位置。
- 现有方法在复杂代码库中的导航和识别相关代码段方面存在困难。
- LocAgent框架通过基于图的表示解决了代码定位问题。
- LocAgent将代码库解析为有向异构图,捕获代码结构及其依赖关系。
- LLM代理通过LocAgent框架进行多跳推理以定位相关实体。
- 实验结果表明,LocAgent显著提高了代码定位的准确性。
- 与先进模型相比,LocAgent在降低成本的同时实现了相当的性能。
点此查看论文截图


Training Plug-n-Play Knowledge Modules with Deep Context Distillation
Authors:Lucas Caccia, Alan Ansell, Edoardo Ponti, Ivan Vulić, Alessandro Sordoni
Dynamically integrating new or rapidly evolving information after (Large) Language Model pre-training remains challenging, particularly in low-data scenarios or when dealing with private and specialized documents. In-context learning and retrieval-augmented generation (RAG) face limitations, including their high inference costs and their inability to capture global document information. In this paper, we propose a way of modularizing knowledge by training document-level Knowledge Modules (KMs). KMs are lightweight components implemented as parameter-efficient LoRA modules, which are trained to store information about new documents and can be easily plugged into models on demand. We show that next-token prediction performs poorly as the training objective for KMs. We instead propose Deep Context Distillation: we learn KMs parameters such as to simulate hidden states and logits of a teacher that takes the document in context. Our method outperforms standard next-token prediction and pre-instruction training techniques, across two datasets. Finally, we highlight synergies between KMs and RAG.
在(大型)语言模型预训练后,动态整合新信息或快速演进的信息仍然具有挑战性,特别是在数据稀缺的场景或处理私有和特殊文档时。上下文学习和检索增强生成(RAG)面临包括高推理成本和无法捕获全局文档信息在内的局限性。在本文中,我们提出了一种通过训练文档级知识模块(KM)来模块化知识的方法。知识模块被实现为参数高效的LoRA模块,易于按需插入模型,并训练以存储新文档的信息。我们发现,作为知识模块的训练目标,下一个令牌预测表现不佳。相反,我们提出了深度上下文蒸馏:我们学习知识模块的参数,以模拟教师模型在上下文中的文档隐藏状态和逻辑。我们的方法在两个数据集上的表现都优于标准的下一个令牌预测和预先指令训练技术。最后,我们强调了知识模块和RAG之间的协同作用。
论文及项目相关链接
PDF Preprint
Summary
本文提出了一种通过训练文档级别的知识模块(KMs)来模块化知识的方法。KMs作为参数高效的LoRA模块实现,能够存储新文档的信息,并可根据需求轻松插入模型。文章指出,使用下一个令牌预测作为训练目标对于KMs效果不佳,因此提出了深度上下文蒸馏的方法。这种方法学习KM的参数,以模拟教师模型在上下文中的隐藏状态和逻辑。此方法在两项数据集上的表现均优于标准下一个令牌预测和预指令训练技术。此外,文章还强调了知识模块与RAG之间的协同作用。
Key Takeaways
- 在低数据场景或处理私有和特殊文档时,动态集成新信息或快速演化的信息对于语言模型是一大挑战。
- 当前的方法如上下文学习和检索增强生成(RAG)存在高推理成本和无法捕获全局文档信息的局限性。
- 提出了知识模块(KMs)的概念,作为参数高效的模块实现,能够存储新文档的信息,并可以按需轻松插入模型。
- 指出下一个令牌预测作为KMs的训练目标效果不佳,提出了深度上下文蒸馏的方法。
- 深度上下文蒸馏方法模拟了教师模型在上下文中的隐藏状态和逻辑,表现优于标准下一个令牌预测和预指令训练技术。
- 知识模块(KMs)与RAG之间存在协同作用,可以互相补充优点。
点此查看论文截图

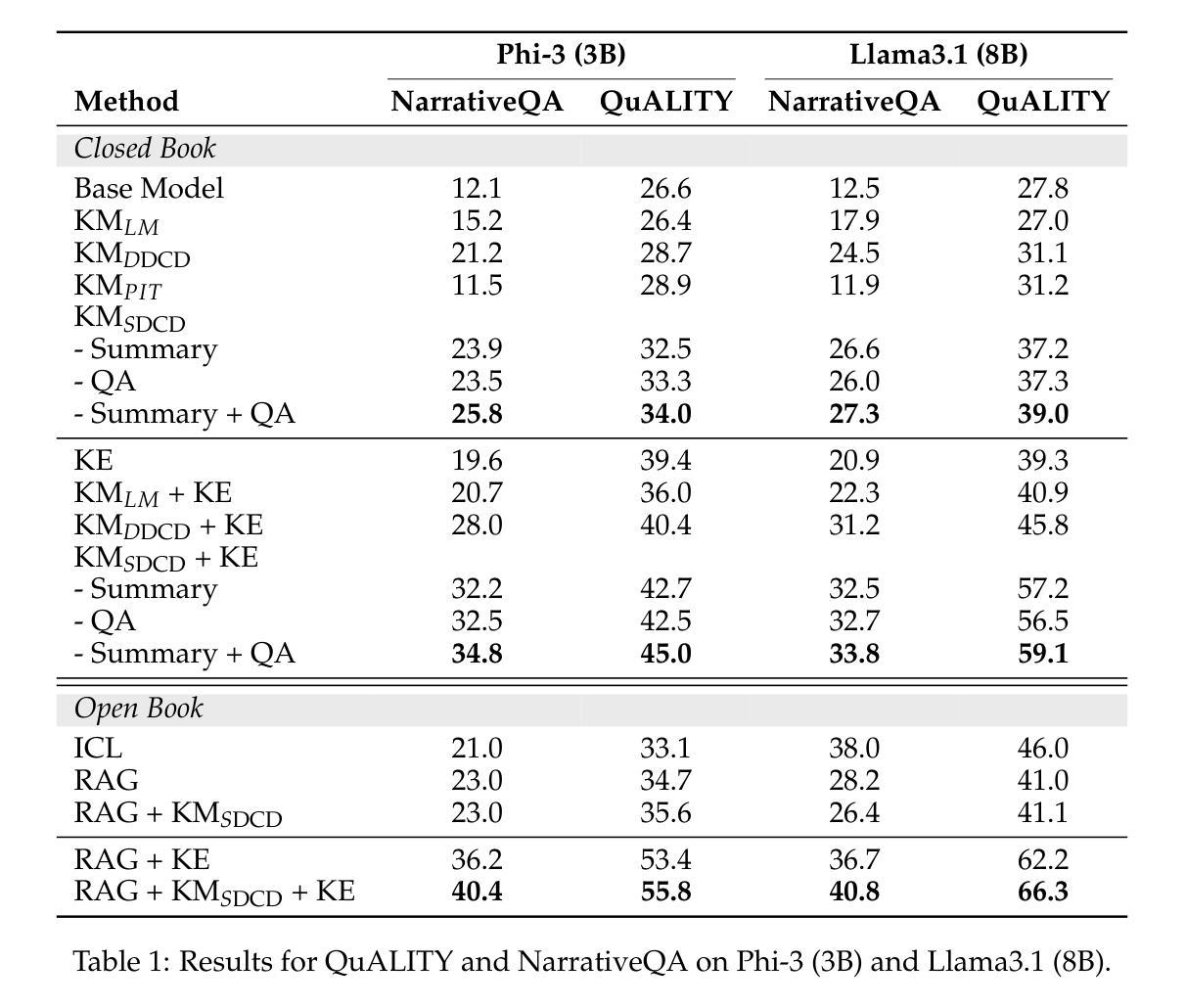
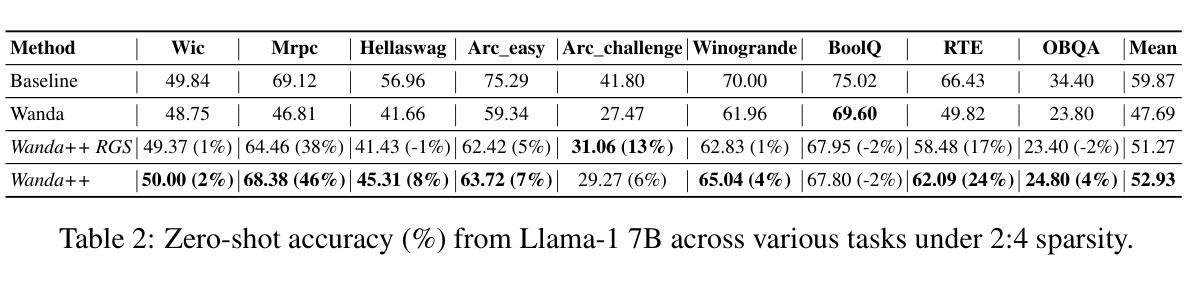
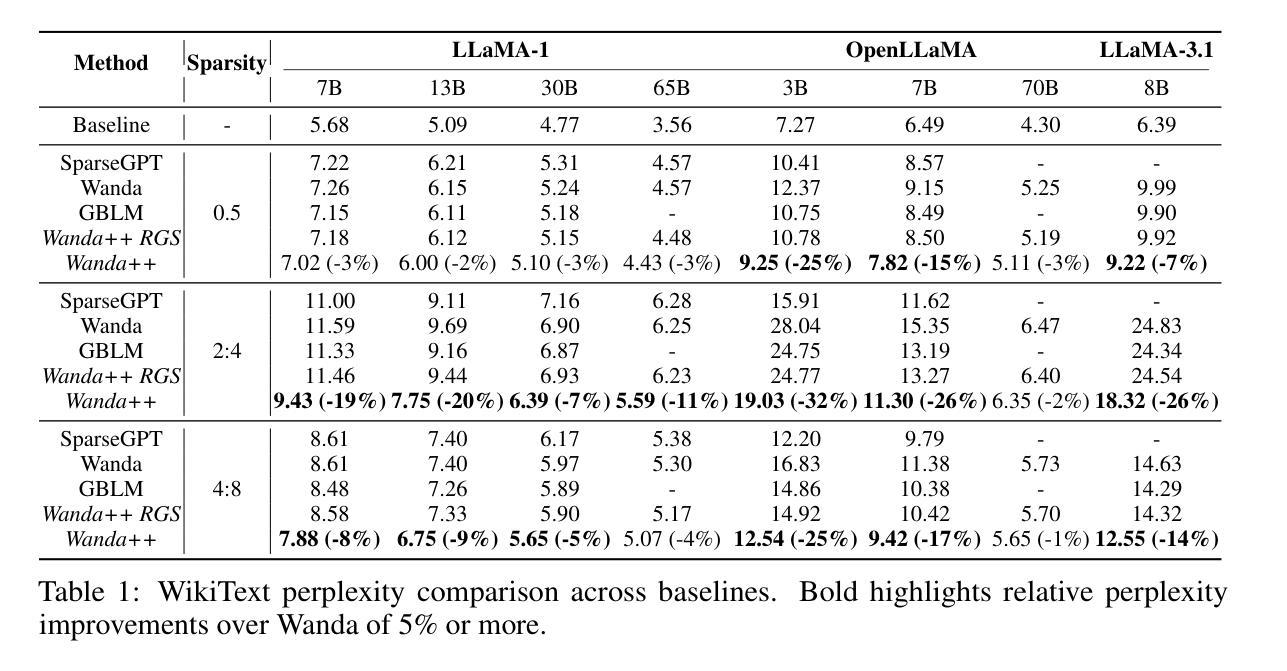
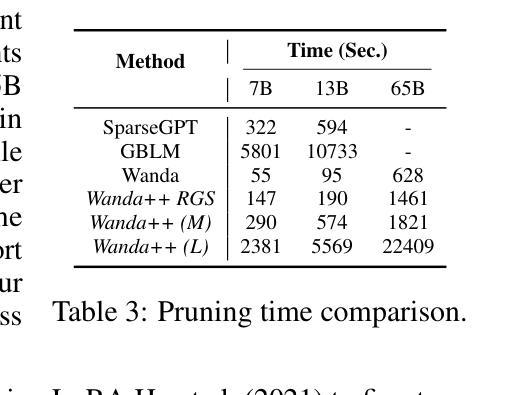
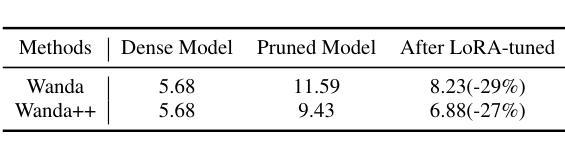
Wanda++: Pruning Large Language Models via Regional Gradients
Authors:Yifan Yang, Kai Zhen, Bhavana Ganesh, Aram Galstyan, Goeric Huybrechts, Markus Müller, Jonas M. Kübler, Rupak Vignesh Swaminathan, Athanasios Mouchtaris, Sravan Babu Bodapati, Nathan Susanj, Zheng Zhang, Jack FitzGerald, Abhishek Kumar
Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
大型语言模型(LLM)的剪枝旨在去除推理过程中的不重要权重,以加快推理速度并尽量减少性能影响。然而,现有方法常常在没有全模型稀疏感知微调的情况下出现性能损失。本文介绍了Wanda++,一种利用解码器块级区域梯度的新型剪枝框架,它超越了现有最先进的方法。具体来说,Wanda++首次利用区域梯度改进剪枝评分,并提出了一种有效的区域优化方法,以最小化密集和稀疏解码器输出之间由剪枝引起的输出差异。值得注意的是,在语言建模任务中,Wanda++相对于Wanda的困惑度提高了高达32%,并能有效地推广到下游任务。进一步的实验表明,我们提出的方法与稀疏感知微调正交,Wanda++可以与LoRA微调相结合,实现与Wanda方法类似的困惑度改进。所提出的方法很轻便,在单个NVIDIA H100 GPU上,对7B LLaMA模型进行剪枝只需不到10分钟。
论文及项目相关链接
Summary
大语言模型(LLM)剪枝旨在去除不重要权重以加快推理速度并尽量减少性能影响。本文提出了Wanda++这一新的剪枝框架,利用解码器块级的区域梯度来提升剪枝效果,并提出高效区域优化方法以最小化密集和稀疏解码器输出之间的剪枝引起的差异。Wanda++在语言建模任务中相较于Wanda降低了困惑度达32%,并能有效地泛化到下游任务。此外,该方法与稀疏感知微调正交,可结合LoRA微调实现与Wanda方法相似的困惑度改进。该方法是轻量级的,能够在单个NVIDIA H100 GPU上在不到10分钟内对7B LLaMA模型进行剪枝。
Key Takeaways
- LLM剪枝旨在提高推理速度并减少性能损失。
- Wanda++是全新的剪枝框架,利用解码器块级的区域梯度来提升剪枝效果。
- Wanda++通过高效区域优化方法最小化密集和稀疏解码器输出之间的差异。
- Wanda++在语言建模任务中相较于前代方法降低了困惑度达32%。
- Wanda++的方法可以泛化到下游任务。
- 该方法与稀疏感知微调正交,可结合其他方法实现更好的性能。
点此查看论文截图


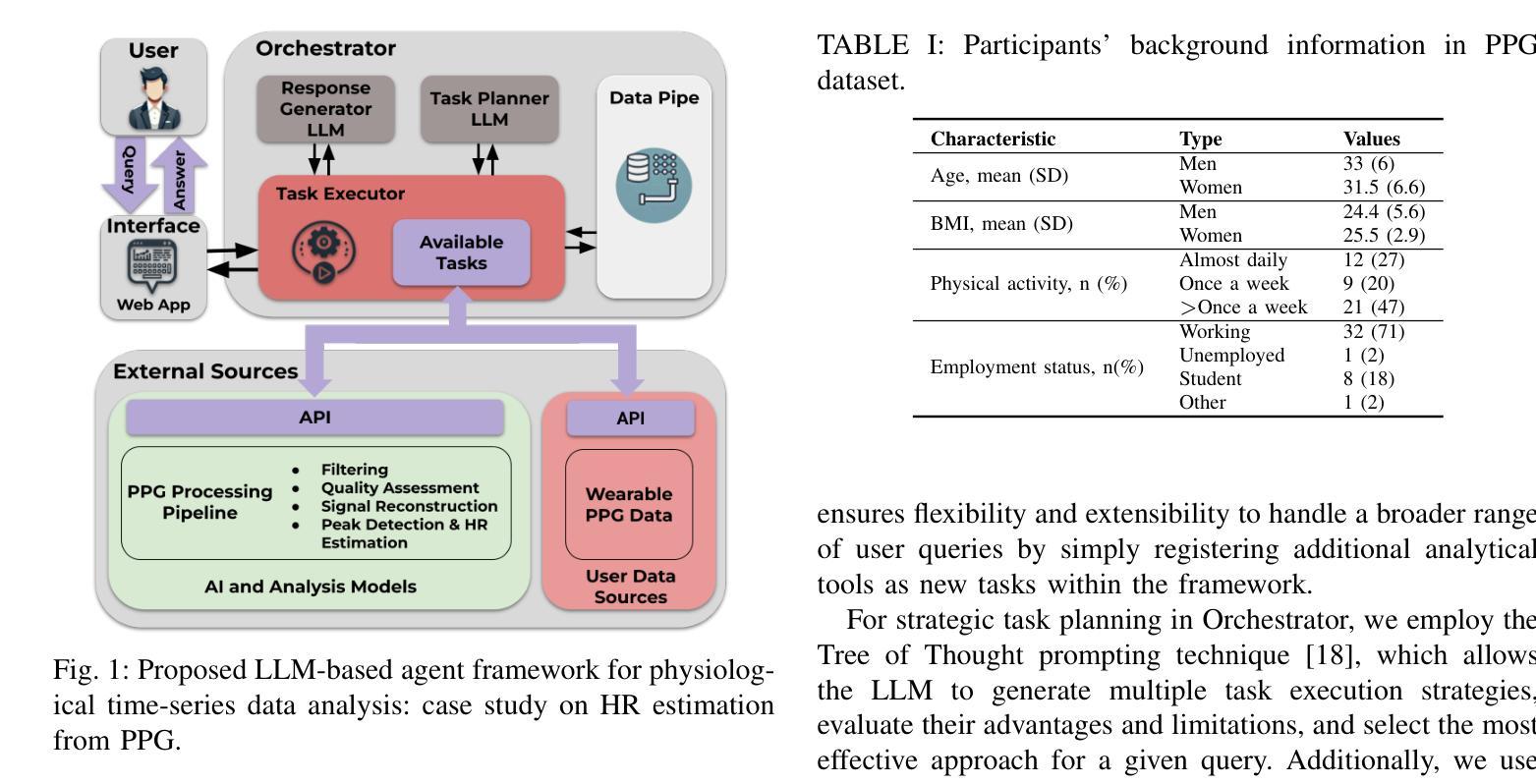
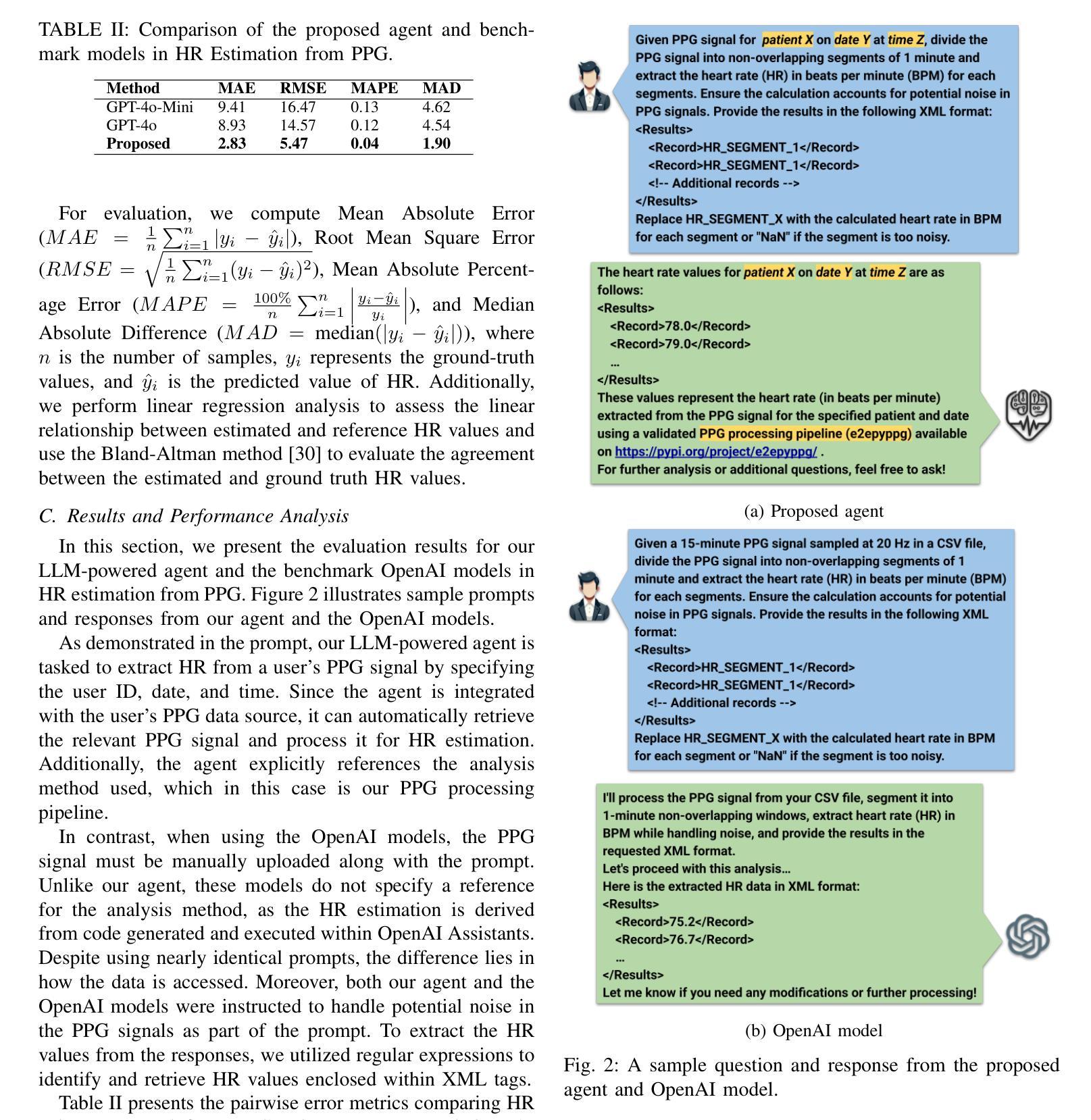
An LLM-Powered Agent for Physiological Data Analysis: A Case Study on PPG-based Heart Rate Estimation
Authors:Mohammad Feli, Iman Azimi, Pasi Liljeberg, Amir M. Rahmani
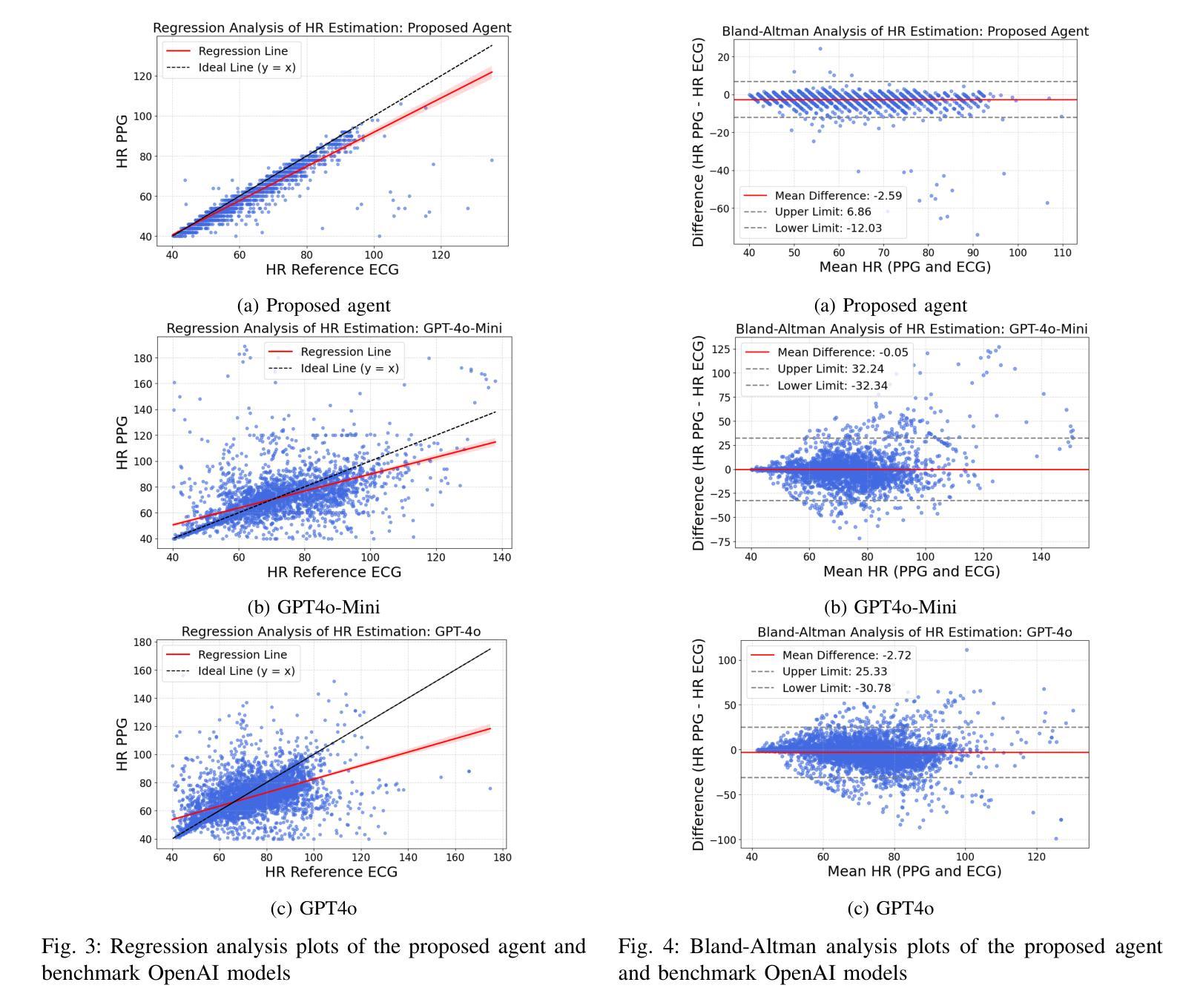
Large language models (LLMs) are revolutionizing healthcare by improving diagnosis, patient care, and decision support through interactive communication. More recently, they have been applied to analyzing physiological time-series like wearable data for health insight extraction. Existing methods embed raw numerical sequences directly into prompts, which exceeds token limits and increases computational costs. Additionally, some studies integrated features extracted from time-series in textual prompts or applied multimodal approaches. However, these methods often produce generic and unreliable outputs due to LLMs’ limited analytical rigor and inefficiency in interpreting continuous waveforms. In this paper, we develop an LLM-powered agent for physiological time-series analysis aimed to bridge the gap in integrating LLMs with well-established analytical tools. Built on the OpenCHA, an open-source LLM-powered framework, our agent powered by OpenAI’s GPT-3.5-turbo model features an orchestrator that integrates user interaction, data sources, and analytical tools to generate accurate health insights. To evaluate its effectiveness, we implement a case study on heart rate (HR) estimation from Photoplethysmogram (PPG) signals using a dataset of PPG and Electrocardiogram (ECG) recordings in a remote health monitoring study. The agent’s performance is benchmarked against OpenAI GPT-4o-mini and GPT-4o, with ECG serving as the gold standard for HR estimation. Results demonstrate that our agent significantly outperforms benchmark models by achieving lower error rates and more reliable HR estimations. The agent implementation is publicly available on GitHub.
大型语言模型(LLM)通过交互式通信改善了诊断、患者护理和决策支持,正在彻底改变医疗保健领域。最近,它们被应用于分析生理时间序列数据,如可穿戴设备数据中的健康洞察提取。现有方法直接将原始数字序列嵌入提示中,这超出了令牌限制并增加了计算成本。此外,一些研究将时间序列中提取的特征集成到文本提示中,或采用多模式方法。然而,由于LLM在连续波形分析和解释方面的分析严谨性和效率有限,这些方法往往产生通用且不可靠的输出。在本文中,我们开发了一个用于生理时间序列分析的大型语言模型驱动代理,旨在弥合将大型语言模型与既定分析工具结合起来的差距。我们的代理建立在开源的大型语言模型驱动框架OpenCHA上,由OpenAI的GPT-3.5 Turbo模型提供动力,具有一个协调器,可以集成用户交互、数据源和分析工具以生成准确的健康见解。为了评估其有效性,我们在远程健康监测研究的数据集中实施了一项关于从光体积描记仪(PPG)信号估计心率(HR)的案例研究,该数据集包含PPG和心电图(ECG)记录。该代理的性能以OpenAI GPT-4o Mini和GPT-4o为基准进行测试,心电图作为心率估计的金标准。结果表明,我们的代理显著优于基准模型,实现了更低的错误率和更可靠的心率估计。该代理的实现已在GitHub上公开可用。
论文及项目相关链接
Summary
大型语言模型(LLM)在医疗领域的应用正在带来变革,通过交互式通信改进诊断、患者护理和决策支持。本文开发了一种基于LLM的生理时间序列分析代理,旨在弥合LLM与现有分析工具之间的鸿沟。该代理使用OpenCHA这一开源LLM框架构建,并融合了OpenAI的GPT-3.5 Turbo模型。其实施了一项案例研究,在远程健康监测研究中从光体积脉搏图(PPG)信号估计心率(HR),与心电图(ECG)记录数据集进行对比。结果显示,该代理在心率估计方面显著优于基准模型,实现了更低的误差率和更可靠的估计结果。代理的实现已在GitHub上公开可用。
Key Takeaways
- LLMs正在医疗领域引发变革,通过交互式通信改善多个方面,如诊断、患者护理和决策支持。
- 当前方法直接将原始数字序列嵌入提示中,导致令牌限制和计算成本增加。
- 整合时间序列数据的现有方法经常产生通用和不可靠的输出,因为LLMs在解析连续波形方面存在局限性和效率低下。
- 本研究使用OpenCHA开源框架构建了一个生理时间序列分析代理。
- 该代理集成了用户交互、数据源和分析工具,旨在生成准确的健康洞察力。
- 案例研究表明,该代理在心率估计方面表现优异,与基准模型相比实现了更低的误差率和更可靠的估计。
点此查看论文截图

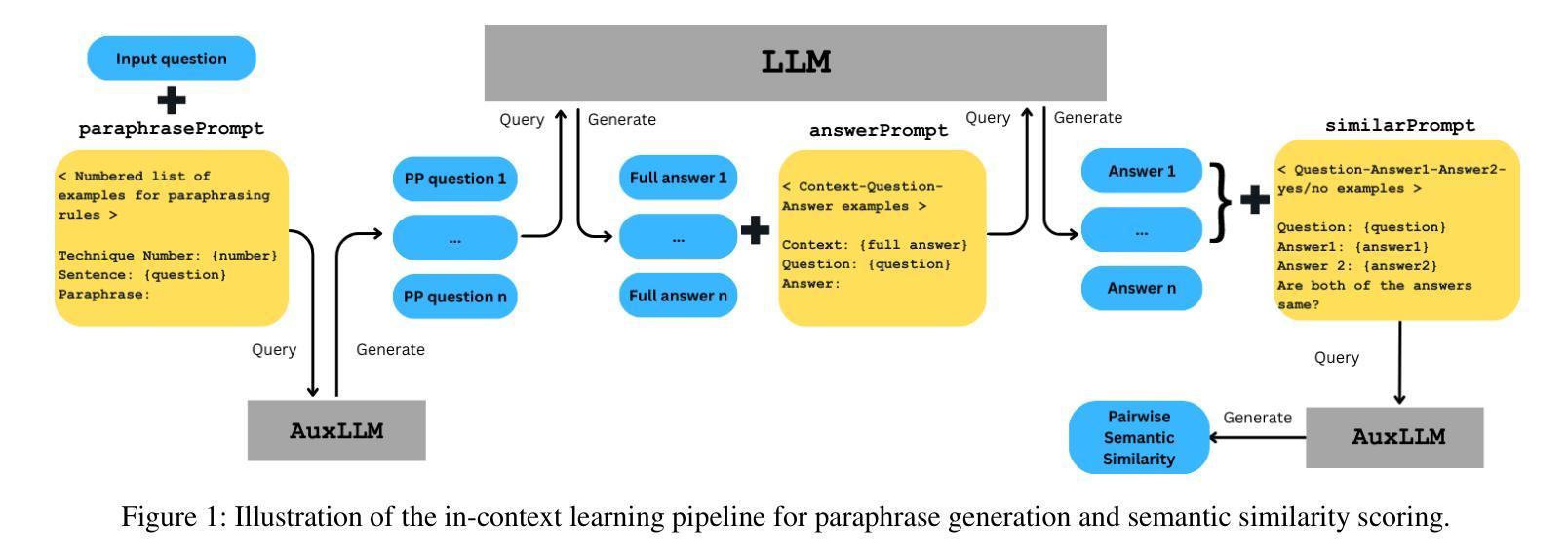
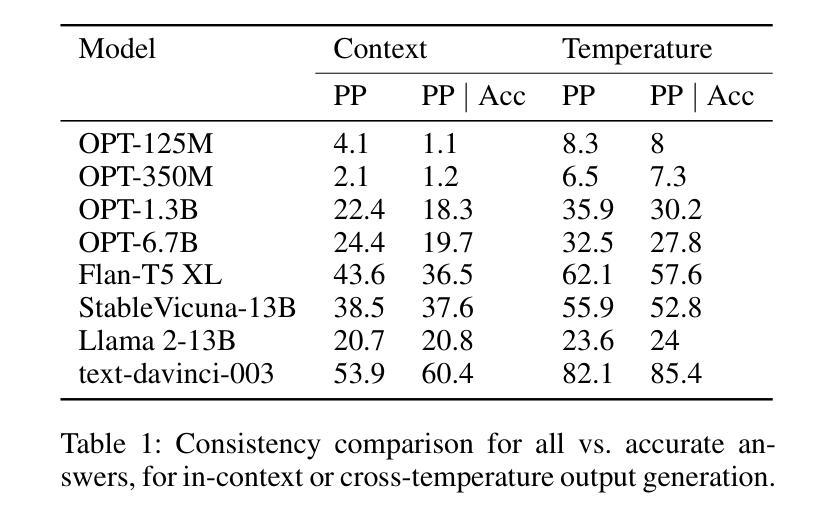
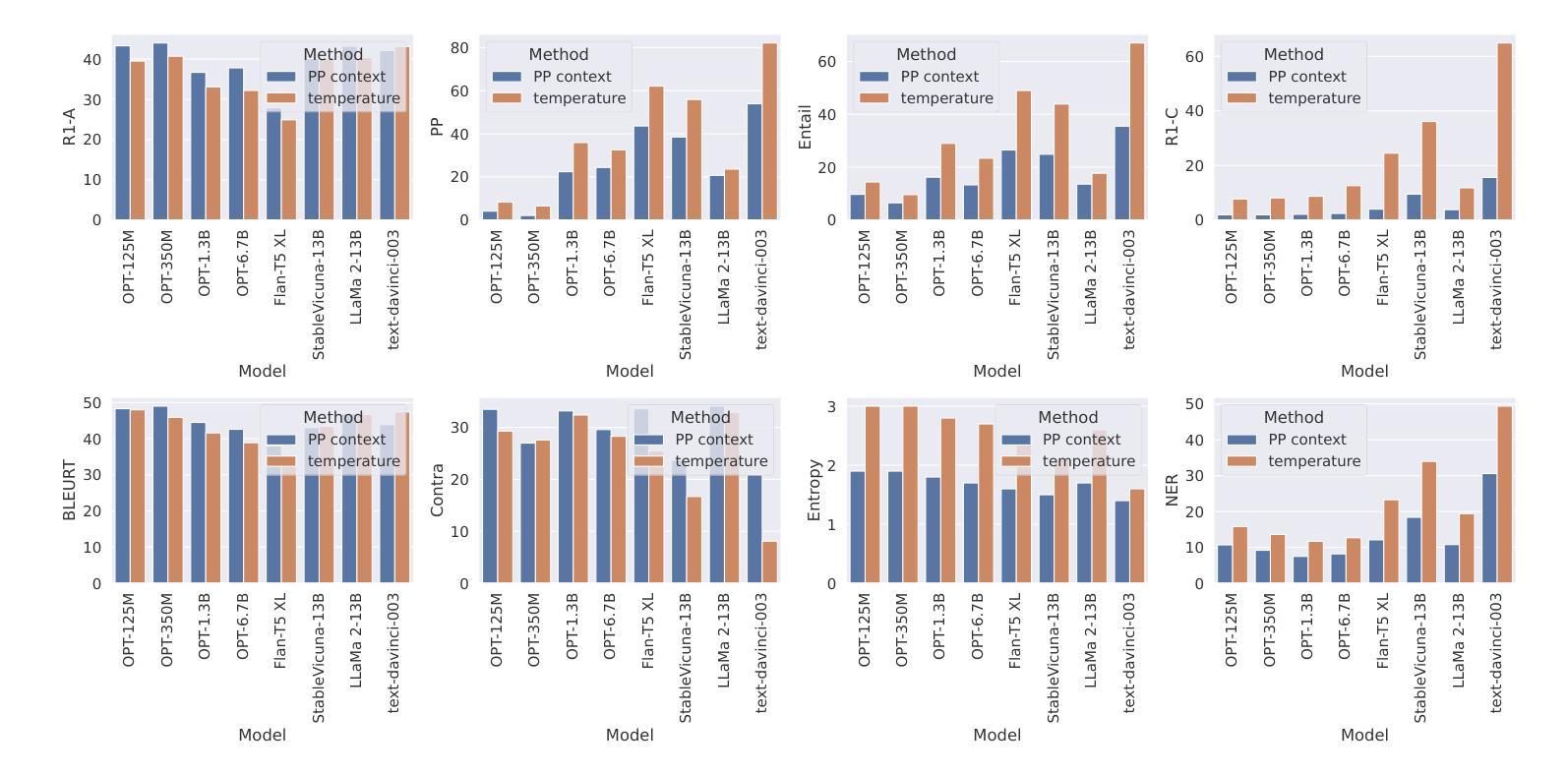
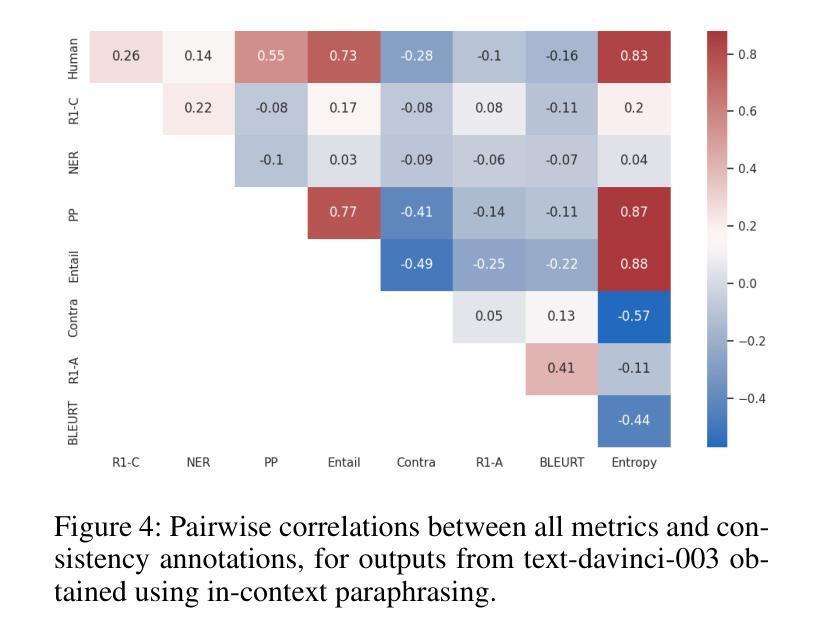
Semantic Consistency for Assuring Reliability of Large Language Models
Authors:Harsh Raj, Vipul Gupta, Domenic Rosati, Subhabrata Majumdar
Large Language Models (LLMs) exhibit remarkable fluency and competence across various natural language tasks. However, recent research has highlighted their sensitivity to variations in input prompts. To deploy LLMs in a safe and reliable manner, it is crucial for their outputs to be consistent when prompted with expressions that carry the same meaning or intent. While some existing work has explored how state-of-the-art LLMs address this issue, their evaluations have been confined to assessing lexical equality of single- or multi-word answers, overlooking the consistency of generative text sequences. For a more comprehensive understanding of the consistency of LLMs in open-ended text generation scenarios, we introduce a general measure of semantic consistency, and formulate multiple versions of this metric to evaluate the performance of various LLMs. Our proposal demonstrates significantly higher consistency and stronger correlation with human evaluations of output consistency than traditional metrics based on lexical consistency. Finally, we propose a novel prompting strategy, called Ask-to-Choose (A2C), to enhance semantic consistency. When evaluated for closed-book question answering based on answer variations from the TruthfulQA benchmark, A2C increases accuracy metrics for pretrained and finetuned LLMs by up to 47%, and semantic consistency metrics for instruction-tuned models by up to 7-fold.
大型语言模型(LLM)在各种自然语言任务中表现出了惊人的流畅性和能力。然而,最近的研究强调了它们对输入提示的敏感性。为了以安全和可靠的方式部署LLM,当使用表达相同意义或意图的提示时,它们的输出必须保持一致至关重要。虽然现有的工作已经探索了最前沿的LLM如何解决此问题,但它们的评估仅限于评估单一或多字词答案的词汇平等性,而忽视了生成文本序列的一致性。为了更全面理解LLM在开放式文本生成场景中的一致性,我们引入了一种语义一致性的通用度量标准,并制定了多个版本的这一指标来评估各种LLM的性能。我们的提案展示了与输出一致性的人类评估相比,与基于词汇一致性的传统度量标准相比,更高的一致性和更强的相关性。最后,我们提出了一种名为Ask-to-Choose(A2C)的新型提示策略,以提高语义一致性。在基于TruthfulQA基准的答案变化的封闭书籍问答评估中,A2C将预训练和微调LLM的准确度指标提高了高达47%,并将指令调整模型的语义一致性指标提高了高达7倍。
论文及项目相关链接
PDF An updated version of this preprint is available at arXiv:2502.15924, and has been accepted at the Transactions on Machine Learning Research
Summary
大型语言模型(LLM)在多种自然语言任务中表现出惊人的流畅性和能力。然而,最近的研究强调了它们对输入提示的敏感性。为确保安全、可靠地部署LLM,关键在于当使用相同含义或意图的提示词时,它们的输出必须保持一致。本文引入了一种语义一致性的通用度量标准,并制定了多个版本的指标来评估不同LLM的性能。与传统基于词汇一致性的指标相比,本文提出的指标与人类对输出一致性的评价具有更高的相关性和一致性。最后,本文提出了一种名为Ask-to-Choose(A2C)的新型提示策略,以提高语义一致性。在基于TruthfulQA基准的答案变化封闭书籍问答任务评估中,A2C可提高预训练和微调LLM的准确度指标高达47%,指令优化模型的语义一致性指标提高高达7倍。
Key Takeaways
- LLM在各种自然语言任务中表现出强大的能力,但输入提示的微小变化可能导致其输出产生显著变化。
- 为确保LLM的安全和可靠部署,需要确保在相同意图的输入提示下其输出的一致性。
- 引入了一种新的语义一致性度量标准,以更全面地评估LLM在开放文本生成场景中的一致性。
- 与传统基于词汇一致性的度量标准相比,新提出的度量标准与人类评价具有更高的相关性和一致性。
- 提出了一种新型提示策略Ask-to-Choose(A2C),以提高LLM的语义一致性。
- 在封闭书籍问答任务中,A2C策略显著提高了LLM的准确性和语义一致性。
点此查看论文截图