⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-01 更新
AutoP2C: An LLM-Based Agent Framework for Code Repository Generation from Multimodal Content in Academic Papers
Authors:Zijie Lin, Yiqing Shen, Qilin Cai, He Sun, Jinrui Zhou, Mingjun Xiao
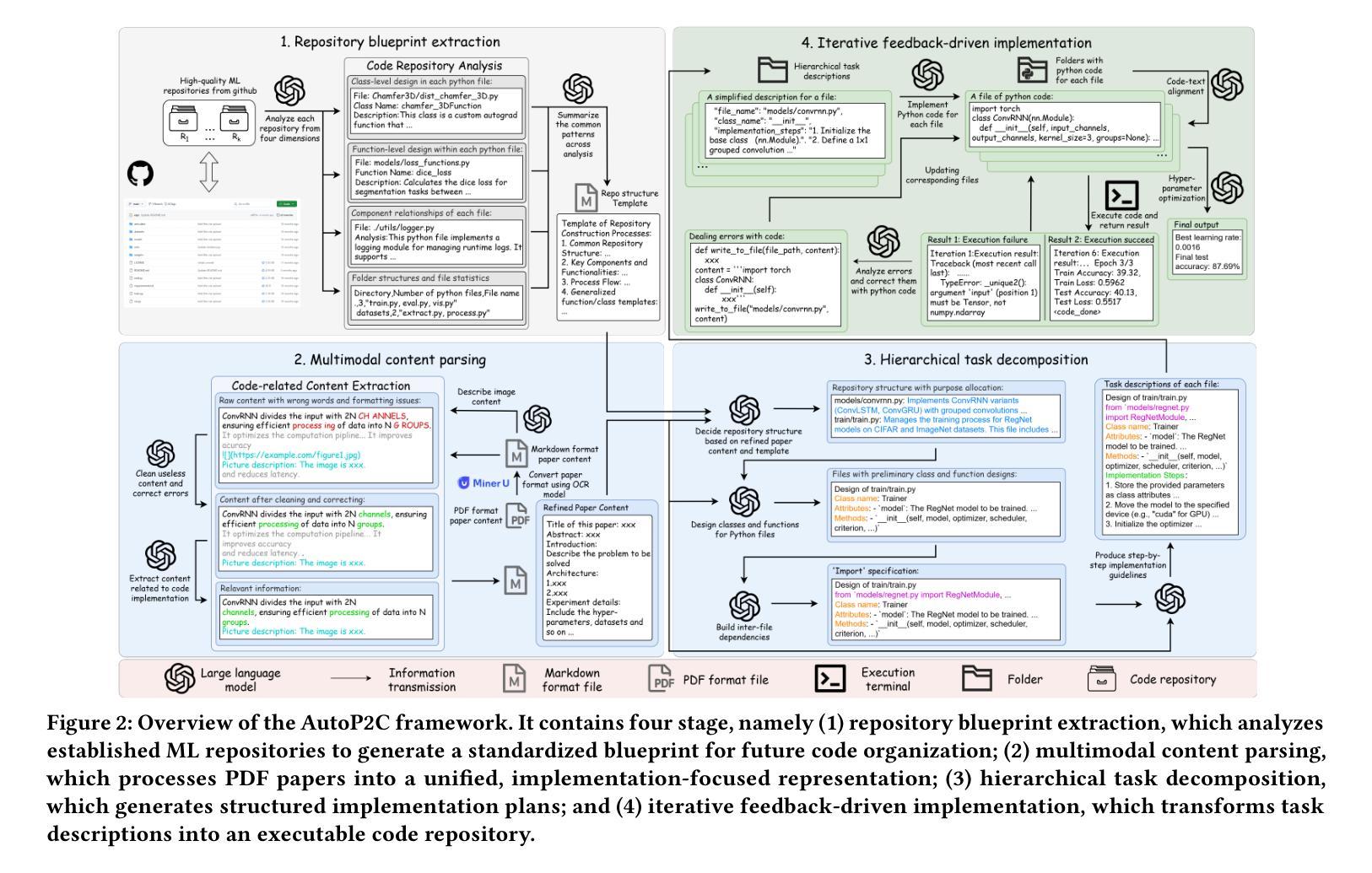
Machine Learning (ML) research is spread through academic papers featuring rich multimodal content, including text, diagrams, and tabular results. However, translating these multimodal elements into executable code remains a challenging and time-consuming process that requires substantial ML expertise. We introduce ``Paper-to-Code’’ (P2C), a novel task that transforms the multimodal content of scientific publications into fully executable code repositories, which extends beyond the existing formulation of code generation that merely converts textual descriptions into isolated code snippets. To automate the P2C process, we propose AutoP2C, a multi-agent framework based on large language models that processes both textual and visual content from research papers to generate complete code repositories. Specifically, AutoP2C contains four stages: (1) repository blueprint extraction from established codebases, (2) multimodal content parsing that integrates information from text, equations, and figures, (3) hierarchical task decomposition for structured code generation, and (4) iterative feedback-driven debugging to ensure functionality and performance. Evaluation on a benchmark of eight research papers demonstrates the effectiveness of AutoP2C, which can successfully generate executable code repositories for all eight papers, while OpenAI-o1 or DeepSeek-R1 can only produce runnable code for one paper. The code is available at https://github.com/shoushouyu/Automated-Paper-to-Code.
机器学习(ML)研究通过包含丰富多模式内容的学术论文进行传播,这些内容包括文本、图表和表格结果。然而,将这些多模式元素翻译成可执行代码仍然是一个具有挑战性和耗时的过程,需要大量的机器学习专业知识。我们引入了“论文到代码”(P2C)这一新任务,它将学术出版物中的多模式内容转化为可完全执行的代码存储库,这超出了现有代码生成方法的范围,后者仅将文本描述转换为孤立的代码片段。为了自动化P2C过程,我们提出了AutoP2C,这是一个基于大型语言模型的多代理框架,它处理研究论文中的文本和视觉内容,以生成完整的代码存储库。具体来说,AutoP2C包含四个阶段:(1)从现有代码库中提取存储库蓝图,(2)解析多模式内容,整合文本、方程和图的信息,(3)进行分层任务分解以生成结构化代码,(4)通过迭代反馈驱动调试,以确保功能和性能。在包含八篇研究论文的基准测试集上的评估表明,AutoP2C的有效性,它可以成功地为所有八篇论文生成可执行代码存储库,而OpenAI-o1或DeepSeek-R1只能为一篇论文生成可运行代码。代码可在https://github.com/shoushouyu/Automated-Paper-to-Code获得。
论文及项目相关链接
Summary
本文介绍了一项将学术论文中的多媒体内容转化为可执行代码的新任务——“论文到代码”(P2C)。提出一种基于多智能体框架的自动化方法AutoP2C,用于处理论文中的文本和视觉内容以生成完整的代码仓库。AutoP2C包含四个主要阶段:从现有代码库中提取存储库蓝图、多模式内容解析、层次化任务分解以进行结构化代码生成以及迭代反馈驱动的调试。评估结果表明,AutoP2C在八篇论文的基准测试上表现出色,能够成功生成所有论文的可执行代码仓库,而OpenAI-o1或DeepSeek-R1只能为一篇论文生成可运行的代码。
Key Takeaways
- 论文提出了一项新的任务——“论文到代码”(P2C),将学术论文中的多媒体内容转化为可执行代码。
- AutoP2C是一个基于多智能体框架的方法,用于自动化处理论文中的文本和视觉内容,生成完整的代码仓库。
- AutoP2C包含四个主要阶段:提取存储库蓝图、多模式内容解析、层次化任务分解和迭代反馈驱动的调试。
- AutoP2C能够成功生成论文中所有内容的可执行代码仓库,展现了其在自动化处理上的优越性。相比之下,其他模型如OpenAI-o1或DeepSeek-R1的能力有限。
- 论文强调了处理复杂研究任务时需要机器学习和自然语言处理技术的深度融合。
- 多模态内容的处理和解析是这一任务的核心,要求系统能够理解和转化文本、图表等多种信息形式。
点此查看论文截图