⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-01 更新
End-to-end Audio Deepfake Detection from RAW Waveforms: a RawNet-Based Approach with Cross-Dataset Evaluation
Authors:Andrea Di Pierno, Luca Guarnera, Dario Allegra, Sebastiano Battiato
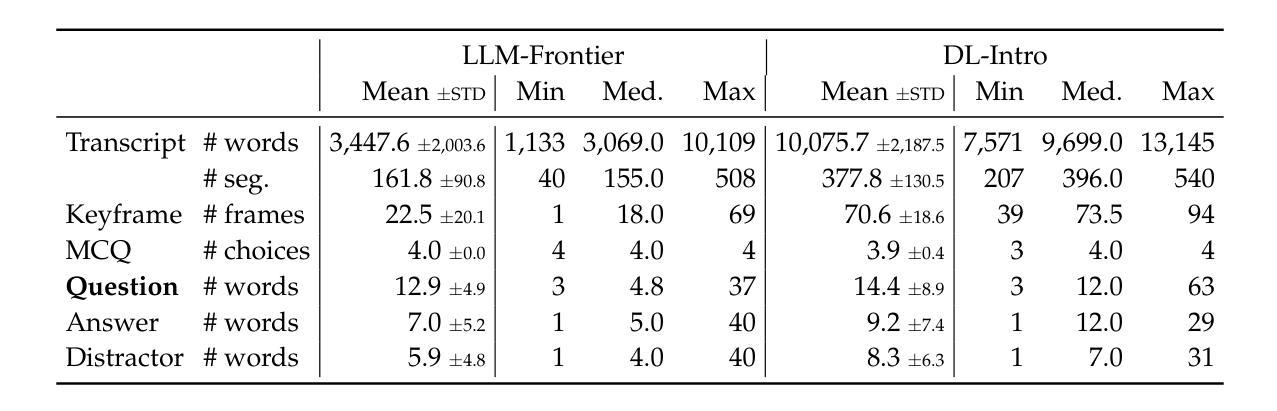
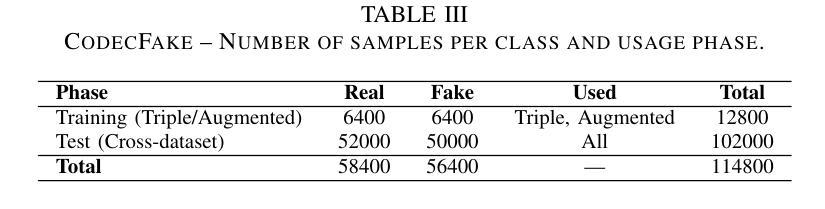
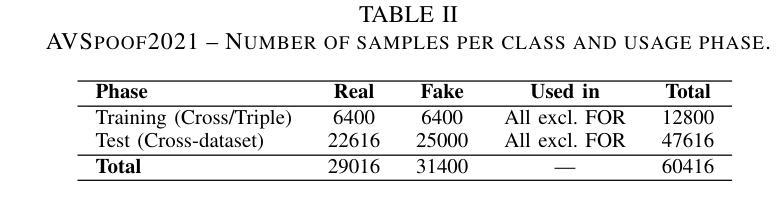
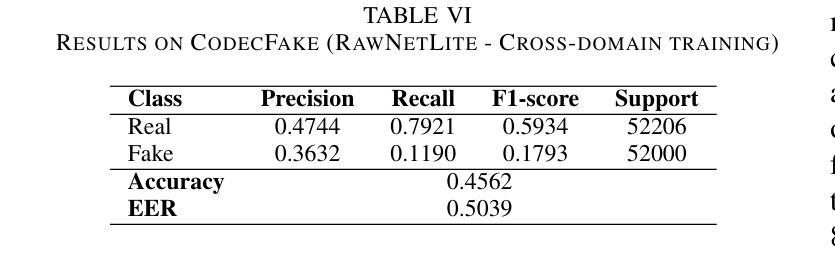
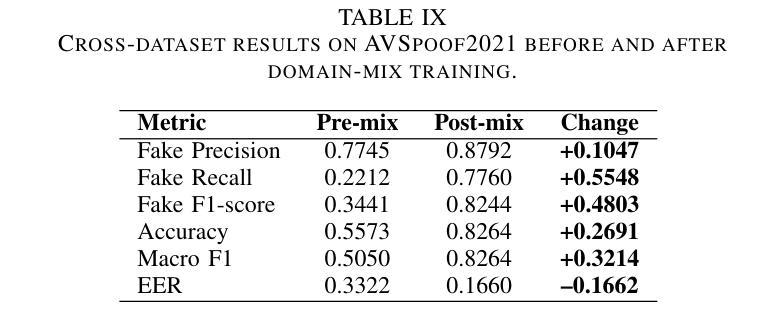
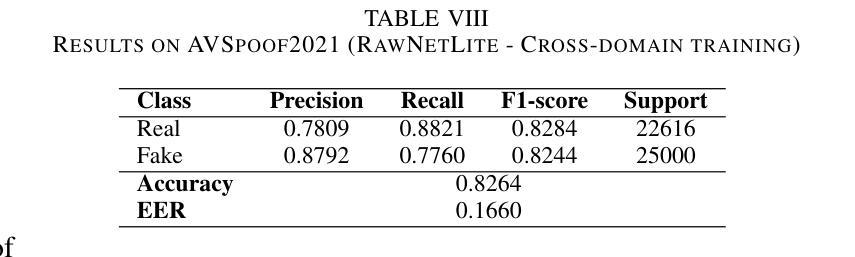
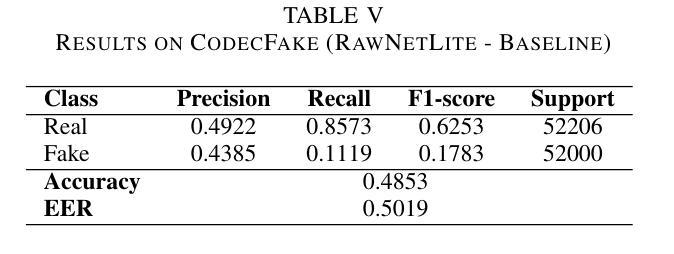
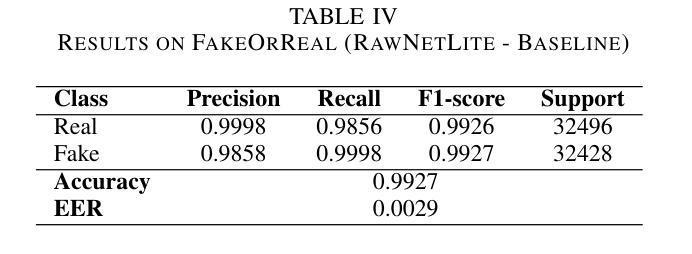
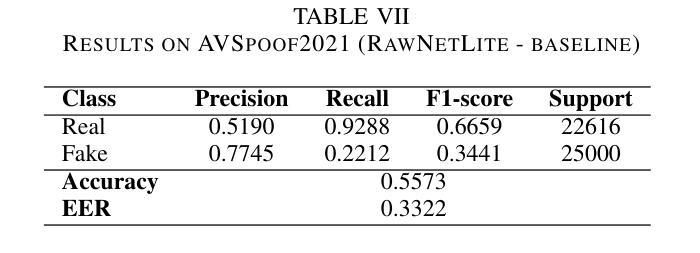
Audio deepfakes represent a growing threat to digital security and trust, leveraging advanced generative models to produce synthetic speech that closely mimics real human voices. Detecting such manipulations is especially challenging under open-world conditions, where spoofing methods encountered during testing may differ from those seen during training. In this work, we propose an end-to-end deep learning framework for audio deepfake detection that operates directly on raw waveforms. Our model, RawNetLite, is a lightweight convolutional-recurrent architecture designed to capture both spectral and temporal features without handcrafted preprocessing. To enhance robustness, we introduce a training strategy that combines data from multiple domains and adopts Focal Loss to emphasize difficult or ambiguous samples. We further demonstrate that incorporating codec-based manipulations and applying waveform-level audio augmentations (e.g., pitch shifting, noise, and time stretching) leads to significant generalization improvements under realistic acoustic conditions. The proposed model achieves over 99.7% F1 and 0.25% EER on in-domain data (FakeOrReal), and up to 83.4% F1 with 16.4% EER on a challenging out-of-distribution test set (AVSpoof2021 + CodecFake). These findings highlight the importance of diverse training data, tailored objective functions and audio augmentations in building resilient and generalizable audio forgery detectors. Code and pretrained models are available at https://iplab.dmi.unict.it/mfs/Deepfakes/PaperRawNet2025/.
音频深度伪造对数字安全和信任构成了日益增长的威胁,它利用先进的生成模型产生合成语音,该语音紧密模仿真实的人声。在开放世界条件下检测此类操纵尤其具有挑战性,因为在测试期间遇到的欺骗方法可能与训练期间所见的不同。在这项工作中,我们提出了一种用于音频深度伪造检测的端到端深度学习框架,它直接在原始波形上运行。我们的模型RawNetLite是一个轻量级的卷积循环架构,旨在捕捉光谱和时序特征,而无需手工预处理。为了提高稳健性,我们引入了一种结合多个领域的数据的训练策略,并采用Focal Loss来强调困难或模糊的样本。我们进一步证明,在基于编码器的操纵和波形级别的音频增强(例如音调转换、噪声和时间拉伸)的加持下,可以在现实声学条件下实现显著的泛化改进。所提出的模型在域内数据(FakeOrReal)上实现了超过99.7%的F1分数和0.25%的EER(错误拒绝率),在具有挑战性的域外测试集(AVSpoof2021 + CodecFake)上达到了83.4%的F1分数和16.4%的EER。这些发现强调了多样训练数据、定制的目标函数和音频增强在构建具有弹性和泛化能力的音频伪造检测器中的重要性。代码和预训练模型可在https://iplab.dmi.unict.it/mfs/Deepfakes/PaperRawNet2025/获得。
论文及项目相关链接
Summary
本文介绍了音频深度伪造对数字安全和信任构成的威胁,并提出了一种基于深度学习的音频深度伪造检测框架RawNetLite。该模型能够在原始波形上直接操作,具有轻量级卷积循环架构,可捕获频谱和时序特征,无需手工预处理。通过结合多域数据和采用Focal Loss的训练策略,以及基于编码器的操作和波形级别的音频增强技术,该模型在真实声学条件下具有良好的泛化性能。在特定领域数据上,其F1分数超过99.7%,EER为0.25%,而在挑战性跨分布测试集上,F1分数达到83.4%,EER为16.4%。
Key Takeaways
- 音频深度伪造成为数字安全和信任的新威胁,需要使用先进的生成模型来检测合成语音的真实性。
- 提出的RawNetLite模型能在原始波形上直接操作,具有卷积循环架构,有效捕获音频特征。
- 通过结合多域数据和采用Focal Loss,模型增强了稳健性,对困难或模糊样本更加敏感。
- 引入编码器的操作和波形级别的音频增强技术,显著提高了模型在真实声学条件下的泛化性能。
- 模型在特定领域数据上表现出色,F1分数超过99.7%,EER极低。
- 在挑战性跨分布测试集上,模型仍表现出良好的性能,F1分数达到83.4%。
- 代码和预训练模型已公开可用。
点此查看论文截图


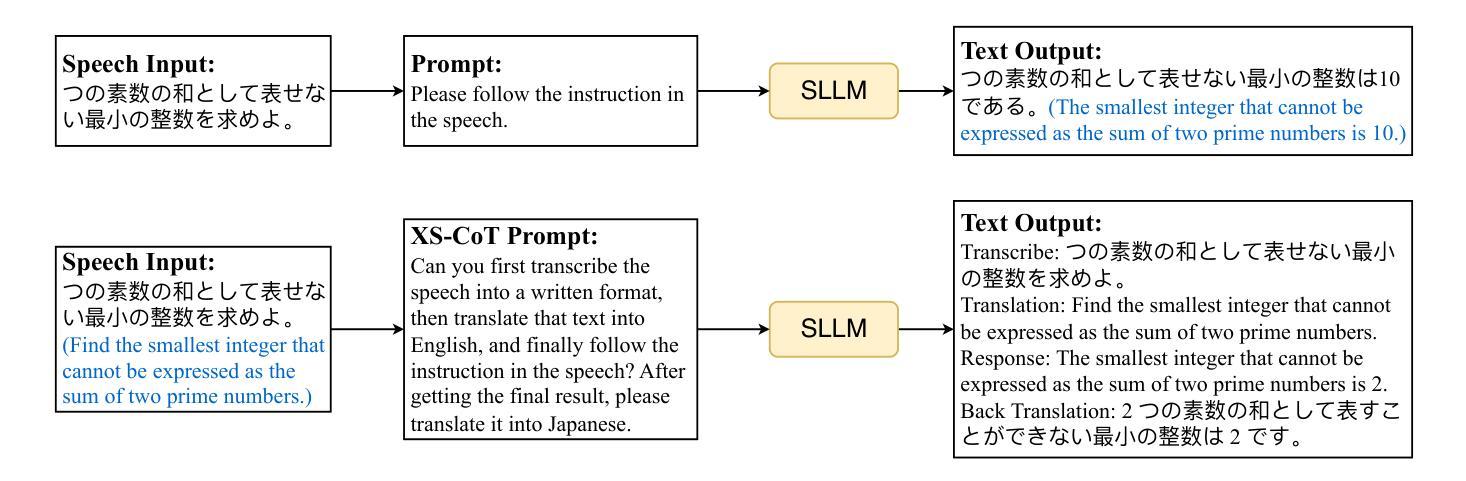
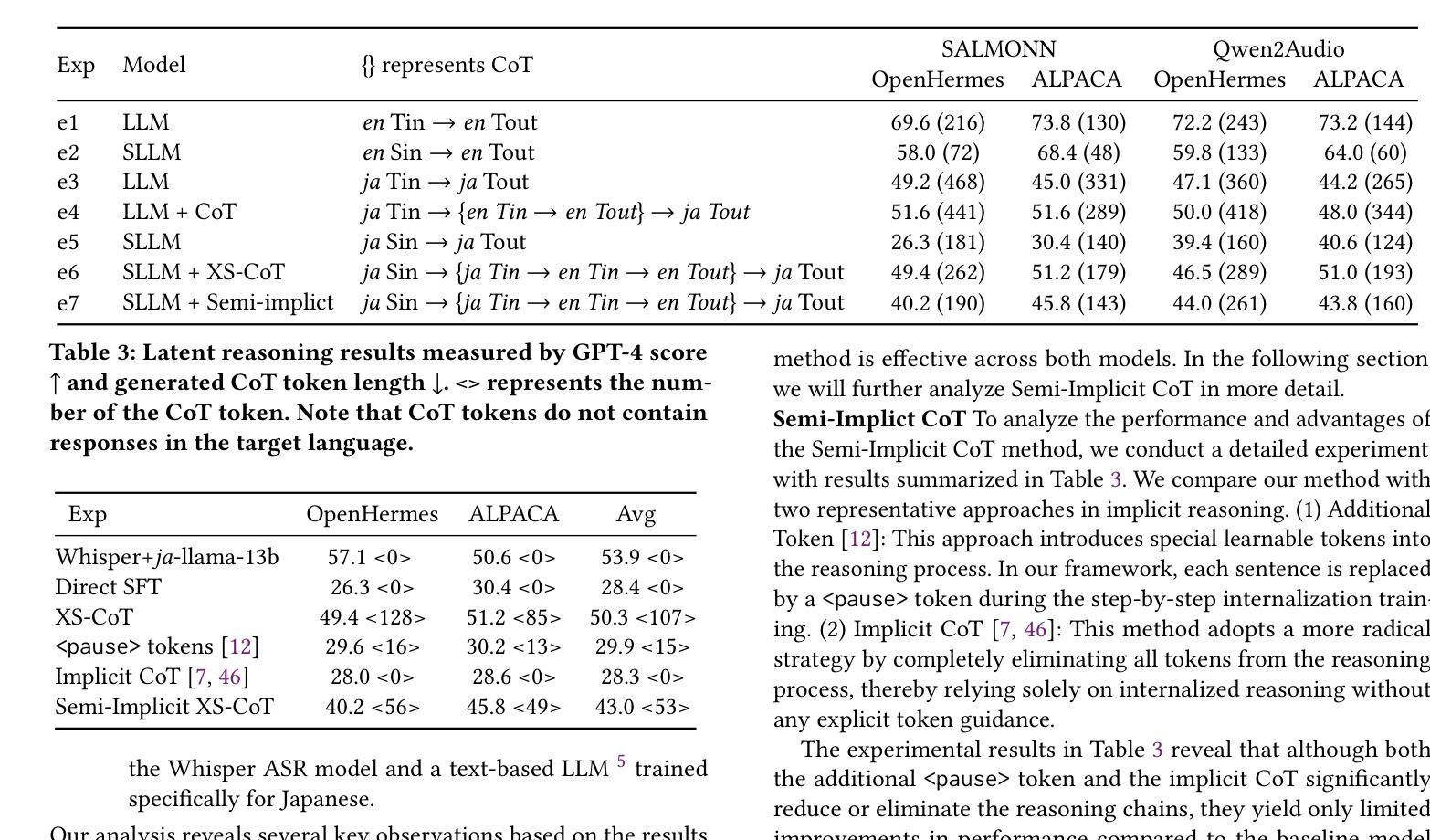
Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
Authors:Hongfei Xue, Yufeng Tang, Hexin Liu, Jun Zhang, Xuelong Geng, Lei Xie
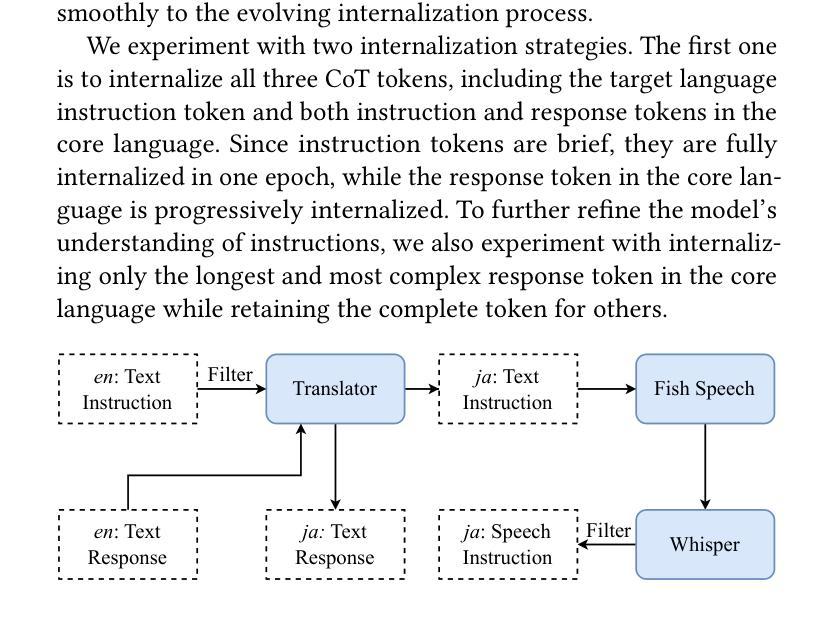
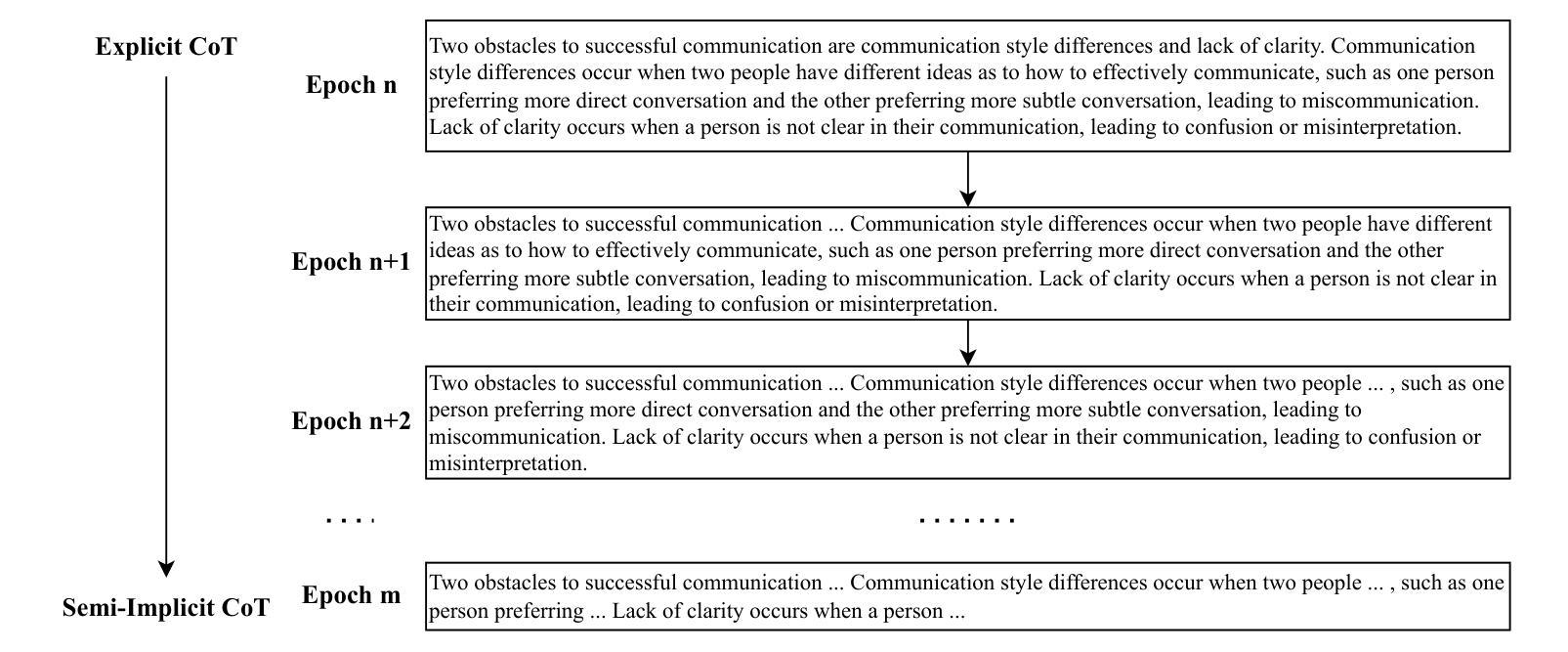
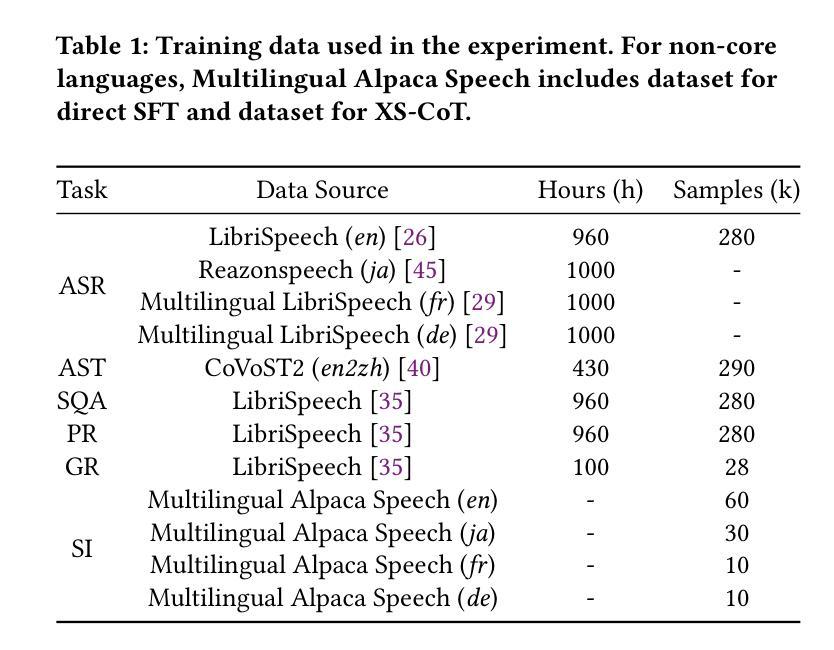
Large language models have been extended to the speech domain, leading to the development of speech large language models (SLLMs). While existing SLLMs demonstrate strong performance in speech instruction-following for core languages (e.g., English), they often struggle with non-core languages due to the scarcity of paired speech-text data and limited multilingual semantic reasoning capabilities. To address this, we propose the semi-implicit Cross-lingual Speech Chain-of-Thought (XS-CoT) framework, which integrates speech-to-text translation into the reasoning process of SLLMs. The XS-CoT generates four types of tokens: instruction and response tokens in both core and non-core languages, enabling cross-lingual transfer of reasoning capabilities. To mitigate inference latency in generating target non-core response tokens, we incorporate a semi-implicit CoT scheme into XS-CoT, which progressively compresses the first three types of intermediate reasoning tokens while retaining global reasoning logic during training. By leveraging the robust reasoning capabilities of the core language, XS-CoT improves responses for non-core languages by up to 45% in GPT-4 score when compared to direct supervised fine-tuning on two representative SLLMs, Qwen2-Audio and SALMONN. Moreover, the semi-implicit XS-CoT reduces token delay by more than 50% with a slight drop in GPT-4 scores. Importantly, XS-CoT requires only a small amount of high-quality training data for non-core languages by leveraging the reasoning capabilities of core languages. To support training, we also develop a data pipeline and open-source speech instruction-following datasets in Japanese, German, and French.
大型语言模型已扩展到语音领域,从而催生了语音大型语言模型(SLLM)的发展。虽然现有的SLLM在核心语言(如英语)的语音指令执行方面表现出强大的性能,但由于缺乏配套的语音文本数据和有限的跨语言语义推理能力,它们往往在非核心语言上表现挣扎。为了解决这个问题,我们提出了半隐式跨语言语音思维链(XS-CoT)框架,它将语音到文本的翻译整合到SLLM的推理过程中。XS-CoT生成四种类型的标记:核心语言和非核心语言中的指令和响应标记,实现跨语言的推理能力转移。为了减轻生成目标非核心响应标记时的推理延迟,我们在XS-CoT中融入了半隐式CoT方案,该方案在训练过程中逐步压缩前三种中间推理标记,同时保留全局推理逻辑。通过利用核心语言的强大推理能力,XS-CoT在与其他两个代表性SLLM模型Qwen2-Audio和SALMONN的直接监督微调相比,非核心语言的响应提高了高达45%,在GPT-4评分上有显著改进。此外,半隐式的XS-CoT减少了令牌延迟超过50%,同时GPT-4的分数略有下降。最重要的是,XS-CoT只需要少量高质量的非核心语言训练数据,通过利用核心语言的推理能力即可支持训练。为了支持训练,我们还开发了一个数据管道,并公开了日语、德语和法语等语音指令执行数据集。
论文及项目相关链接
PDF 10 pages, 6 figures, Submitted to ACM MM 2025
Summary
大型语言模型已扩展到语音领域,形成了语音大型语言模型(SLLM)。现有SLLM在英语等核心语言中的语音指令执行表现良好,但在非核心语言中因缺乏配对语音文本数据和有限的跨语言语义推理能力而遇到困难。为解决这一问题,我们提出了半隐式跨语言语音思维链(XS-CoT)框架,将语音到文本的翻译融入SLLM的推理过程。XS-CoT生成四种类型的符号:核心和非核心语言中的指令和响应符号,实现跨语言推理能力的转移。为减少目标非核心响应符号生成中的推理延迟,我们在XS-CoT中融入了半隐式CoT方案,在训练过程中逐步压缩前三种类型的中间推理符号,同时保留全局推理逻辑。通过利用核心语言的稳健推理能力,XS-CoT在两种代表性SLLM模型(Qwen2-Audio和SALMONN)上,对非核心语言的响应改进了高达45%,相较于直接监督微调的方法在GPT-4评分上表现更优秀。此外,半隐式XS-CoT将符号延迟减少了超过50%,同时GPT-4评分略有下降。重要的是,XS-CoT仅需要少量高质量的非核心语言训练数据,就能利用核心语言的推理能力。我们还开发了一个数据管道,并公开了日语、德语和法语等语音指令执行数据集。
Key Takeaways
- 大型语言模型已扩展到语音领域,形成语音大型语言模型(SLLM)。
- 现有SLLM在非核心语言中面临数据稀缺和有限的跨语言语义推理能力的问题。
- 提出XS-CoT框架,整合语音到文本的翻译到SLLM的推理过程中。
- XS-CoT通过生成四种类型的符号实现跨语言推理能力转移,并改善非核心语言的响应。
- 半隐式CoT方案减少生成非核心响应符号的推理延迟。
- XS-CoT利用核心语言的推理能力,提高非核心语言的响应表现,并公开了多语言语音指令执行数据集。
点此查看论文截图


ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Authors:Yu Zhang, Wenxiang Guo, Changhao Pan, Zhiyuan Zhu, Tao Jin, Zhou Zhao
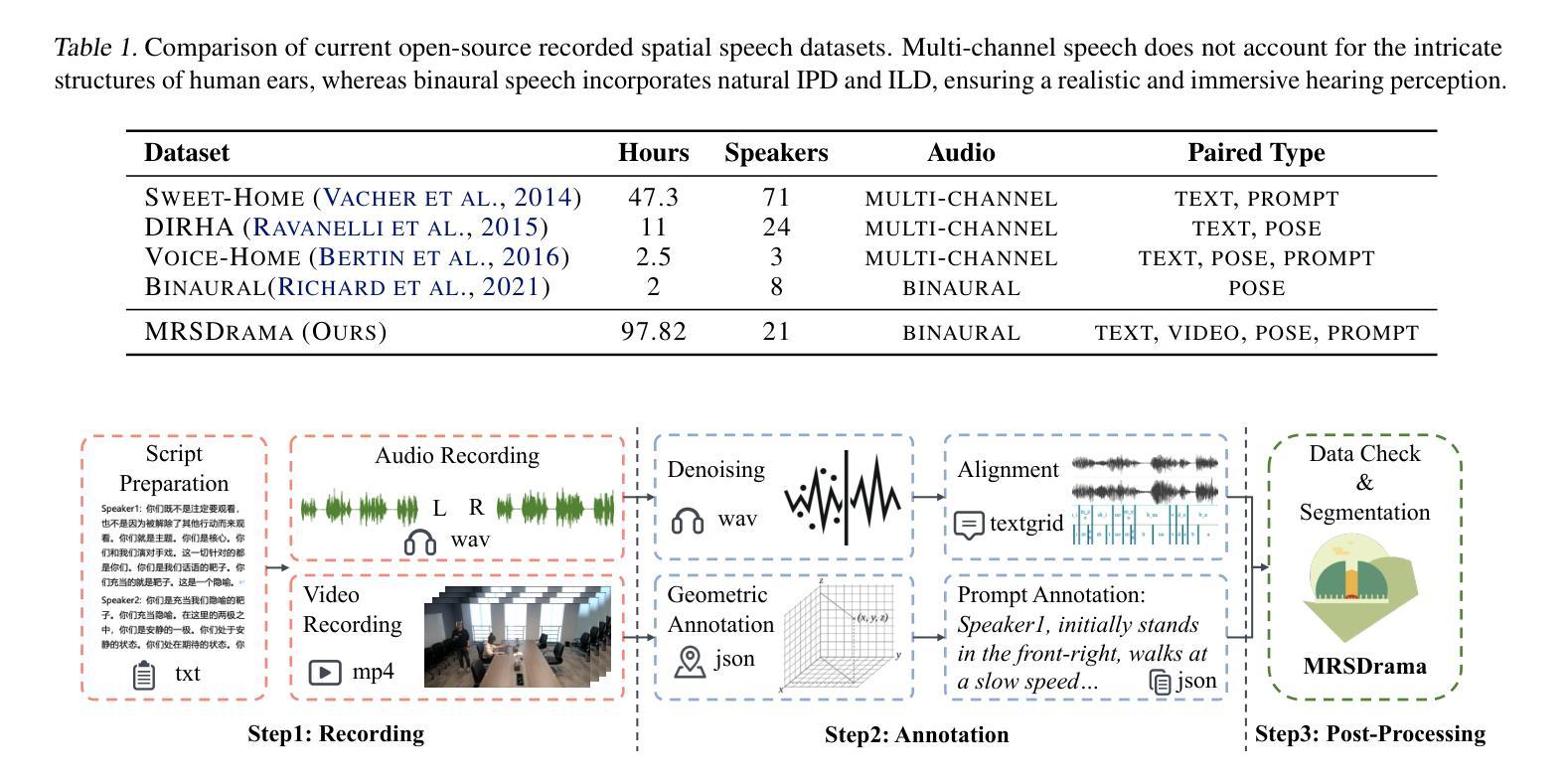
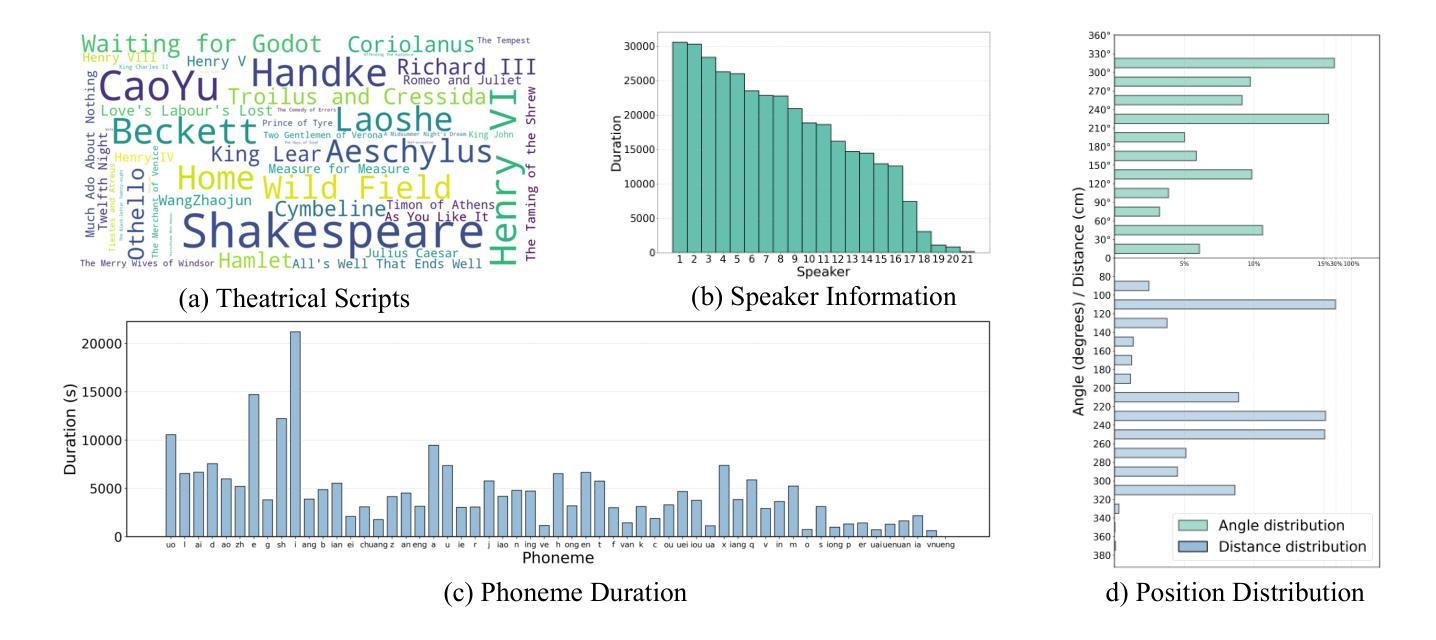
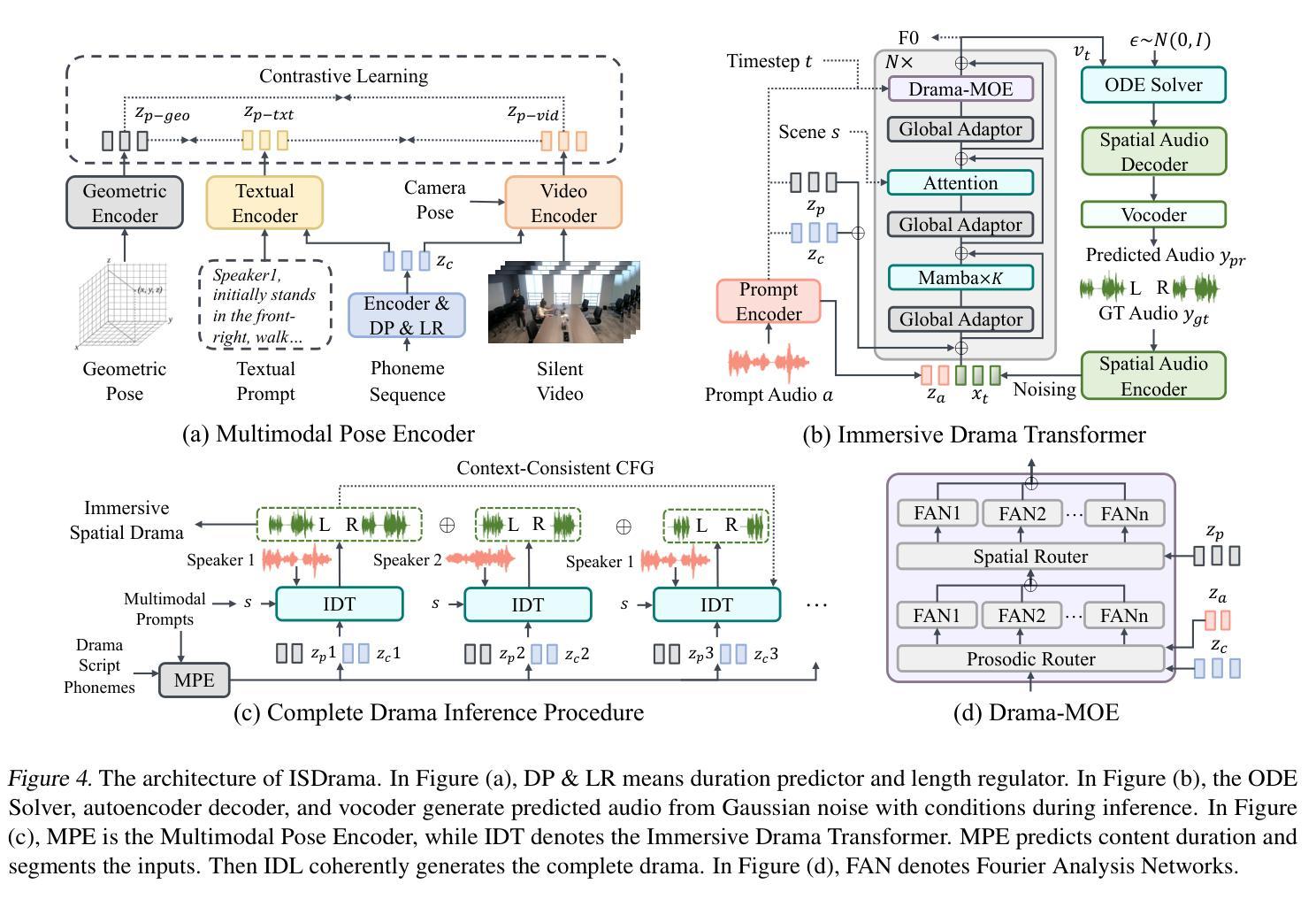
Multimodal immersive spatial drama generation focuses on creating continuous multi-speaker binaural speech with dramatic prosody based on multimodal prompts, with potential applications in AR, VR, and others. This task requires simultaneous modeling of spatial information and dramatic prosody based on multimodal inputs, with high data collection costs. To the best of our knowledge, our work is the first attempt to address these challenges. We construct MRSDrama, the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts. Then, we propose ISDrama, the first immersive spatial drama generation model through multimodal prompting. ISDrama comprises these primary components: 1) Multimodal Pose Encoder, based on contrastive learning, considering the Doppler effect caused by moving speakers to extract unified pose information from multimodal prompts. 2) Immersive Drama Transformer, a flow-based mamba-transformer model that generates high-quality drama, incorporating Drama-MOE to select proper experts for enhanced prosody and pose control. We also design a context-consistent classifier-free guidance strategy to coherently generate complete drama. Experimental results show that ISDrama outperforms baseline models on objective and subjective metrics. The demos and dataset are available at https://aaronz345.github.io/ISDramaDemo.
多模态沉浸式空间戏剧生成专注于基于多模态提示创建具有戏剧语调的连续多声道双耳语音,在AR、VR等领域具有潜在应用。这项任务需要基于多模态输入同时建模空间信息和戏剧语调,并且数据采集成本高昂。据我们所知,我们的工作是首次尝试解决这些挑战。我们构建了MRSDrama,即首个多模态记录的空间戏剧数据集,包含双耳戏剧音频、剧本、视频、几何姿势和文本提示。然后,我们提出了ISDrama,这是通过多模态提示进行沉浸式空间戏剧生成的首个模型。ISDrama主要包括以下主要组件:1)基于对比学习的多模态姿势编码器,考虑移动扬声器产生的多普勒效应,从多模态提示中提取统一姿势信息。2)沉浸式戏剧转换器,这是一个基于流的mamba-transformer模型,用于生成高质量戏剧,结合戏剧MOE选择适当的专家以增强语调和姿势控制。我们还设计了一种上下文一致的无需分类器的指导策略,以连贯地生成完整的戏剧。实验结果表明,ISDrama在客观和主观指标上均优于基准模型。相关演示和数据集可在https://aaronz345.github.io/ISDramaDemo上找到。
论文及项目相关链接
Summary
基于多模态提示创建连续的多说话者立体声戏剧,挑战在于同时建模空间信息和戏剧韵律。本文构建了MRSDrama数据集并提出ISDrama模型,包含多模态姿势编码器和沉浸式戏剧转换器。ISDrama通过多模态提示生成高质量戏剧,并设计上下文一致的分类器自由指导策略来连贯生成完整戏剧。实验结果显示,ISDrama在客观和主观指标上优于基准模型。
Key Takeaways
- 多模态沉浸式空间戏剧生成专注于基于多模态提示创建具有戏剧韵律的连续多说话者立体声戏剧。
- 此任务需要同时建模空间信息和戏剧韵律,面临高数据采集成本挑战。
- 构建了MRSDrama数据集,包含双耳戏剧音频、剧本、视频、几何姿势和文本提示。
- 提出了ISDrama模型,包含多模态姿势编码器和沉浸式戏剧转换器。
- 多模态姿势编码器基于对比学习,考虑移动说话者引起的多普勒效应,从多模态提示中提取统一姿势信息。
- 沉浸式戏剧转换器是一个基于流的mamba-transformer模型,可生成高质量戏剧,并融入Drama-MOE选择适当的专家以增强韵律和姿势控制。
点此查看论文截图

Context Selection and Rewriting for Video-based Educational Question Generation
Authors:Mengxia Yu, Bang Nguyen, Olivia Zino, Meng Jiang
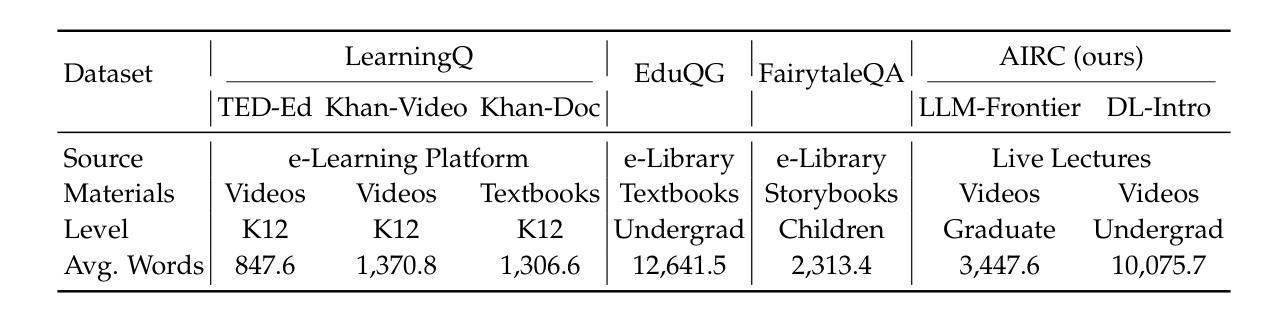
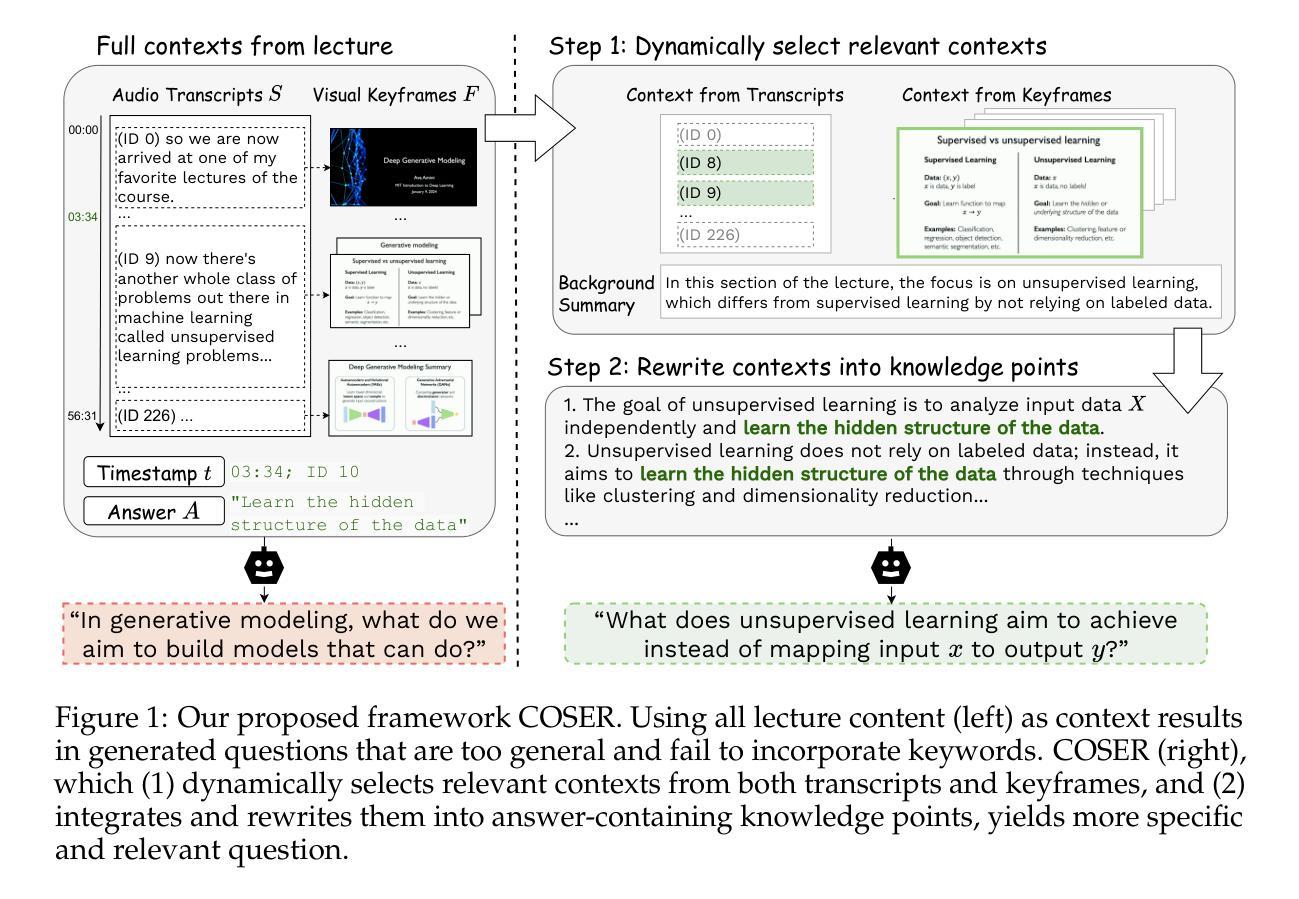
Educational question generation (EQG) is a crucial component of intelligent educational systems, significantly aiding self-assessment, active learning, and personalized education. While EQG systems have emerged, existing datasets typically rely on predefined, carefully edited texts, failing to represent real-world classroom content, including lecture speech with a set of complementary slides. To bridge this gap, we collect a dataset of educational questions based on lectures from real-world classrooms. On this realistic dataset, we find that current methods for EQG struggle with accurately generating questions from educational videos, particularly in aligning with specific timestamps and target answers. Common challenges include selecting informative contexts from extensive transcripts and ensuring generated questions meaningfully incorporate the target answer. To address the challenges, we introduce a novel framework utilizing large language models for dynamically selecting and rewriting contexts based on target timestamps and answers. First, our framework selects contexts from both lecture transcripts and video keyframes based on answer relevance and temporal proximity. Then, we integrate the contexts selected from both modalities and rewrite them into answer-containing knowledge statements, to enhance the logical connection between the contexts and the desired answer. This approach significantly improves the quality and relevance of the generated questions. Our dataset and code are released in https://github.com/mengxiayu/COSER.
教育问题生成(EQG)是智能教育系统的核心组成部分,对自我评估、主动学习以及个性化教育起到了重要的辅助作用。虽然已有EQG系统的出现,但现有的数据集通常依赖于预先定义、精心编辑的文本,无法代表真实课堂内容,包括配有辅助幻灯片的讲课语音。为了弥合这一差距,我们收集了一个基于真实课堂讲座的教育问题数据集。在这个现实数据集上,我们发现现有的EQG方法在生成教育视频的问题时面临困难,特别是在与特定时间戳和目标答案对齐方面。常见的挑战包括从大量剧本中选择有意义上下文和确保生成的问题有意义地融入目标答案。为了应对这些挑战,我们引入了一个利用大型语言模型的新框架,该框架可根据目标时间戳和答案动态选择和重写上下文。首先,我们的框架根据答案相关性和时间接近度从讲座剧本和视频关键帧中选择上下文。然后,我们整合了从这两种模式中选择出的上下文,并将其改写为包含答案的知识陈述,以增强上下文和所需答案之间的逻辑联系。这种方法显著提高了生成问题的质量和相关性。我们的数据集和代码已在https://github.com/mengxiayu/COSER中发布。
论文及项目相关链接
Summary
教育问题生成(EQG)是智能教育系统的重要组成部分,有助于自我评估、主动学习和个性化教育。针对现有EQG数据集代表真实课堂内容不足的问题,我们收集了一个基于真实课堂讲座的教育问题数据集。我们发现现有方法在生成教育视频问题时面临挑战,特别是在与特定时间戳和目标答案对齐方面。我们引入了一个利用大型语言模型的新框架,该框架可根据目标时间戳和答案动态选择和重写上下文。首先,我们的框架根据答案相关性和时间接近性从讲座脚本和视频关键帧中选择上下文。然后,我们从两种模式中选择上下文并将其整合,将其改写为包含答案的知识陈述,增强上下文与期望答案之间的逻辑联系。此方法显著提高了生成问题的质量和相关性。我们的数据集和代码已发布在https://github.com/mengxiayu/COSER。
Key Takeaways
- 教育问题生成(EQG)是智能教育系统的重要部分,有助于自我评估、主动学习和个性化教育。
- 现有EQG数据集存在缺陷,无法充分代表真实课堂内容,特别是讲座内容与相关幻灯片。
- 当前方法在生成教育视频问题时面临挑战,如准确对齐时间戳和目标答案。
- 引入新框架,利用大型语言模型动态选择和重写上下文,基于目标时间戳和答案。
- 框架从讲座脚本和视频关键帧中选择上下文,依据答案相关性和时间接近性。
- 结合两种模式的上下文,并改写成包含答案的知识陈述,增强逻辑联系。
点此查看论文截图