⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-01 更新
IM-Portrait: Learning 3D-aware Video Diffusion for Photorealistic Talking Heads from Monocular Videos
Authors:Yuan Li, Ziqian Bai, Feitong Tan, Zhaopeng Cui, Sean Fanello, Yinda Zhang
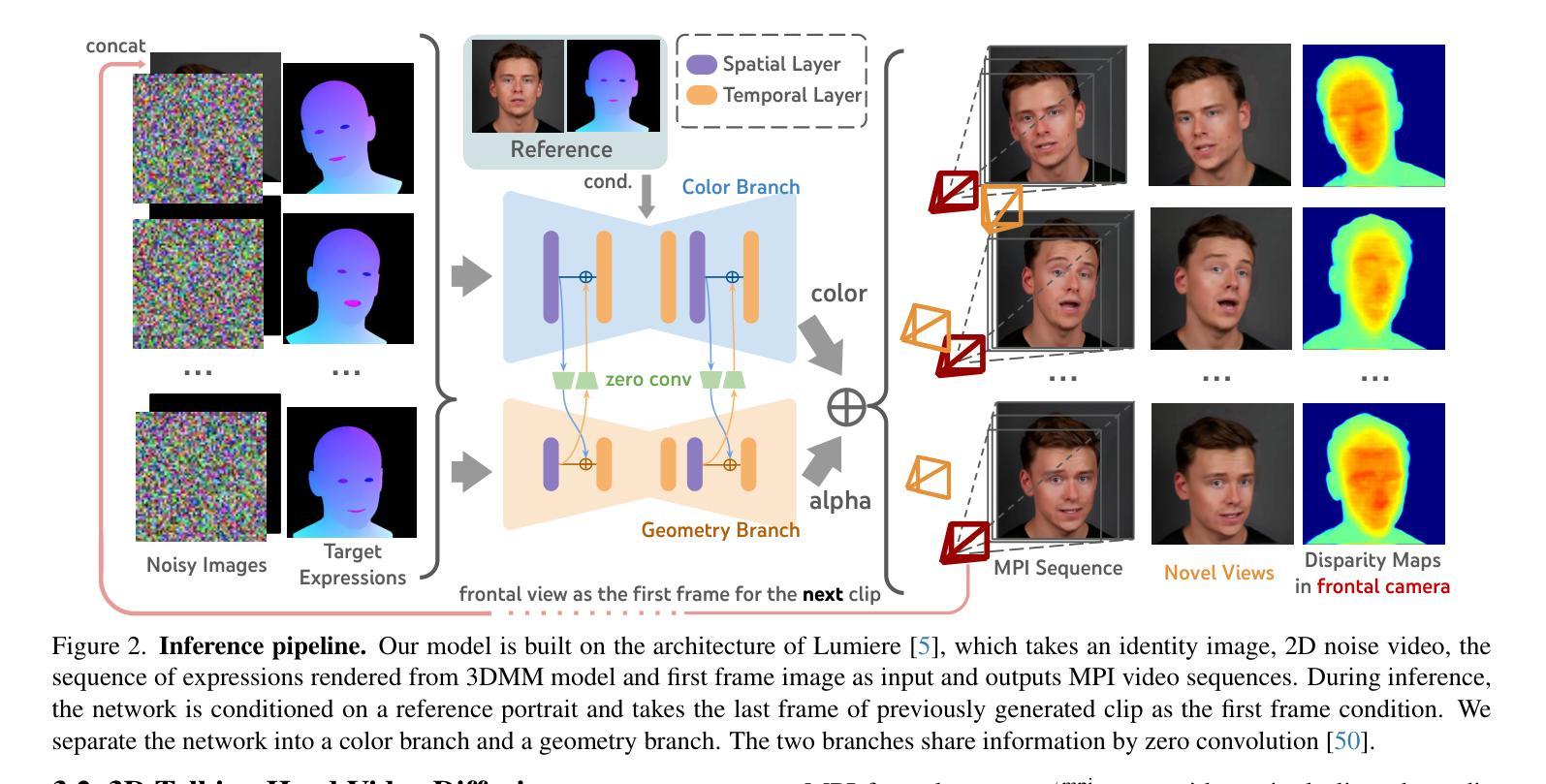
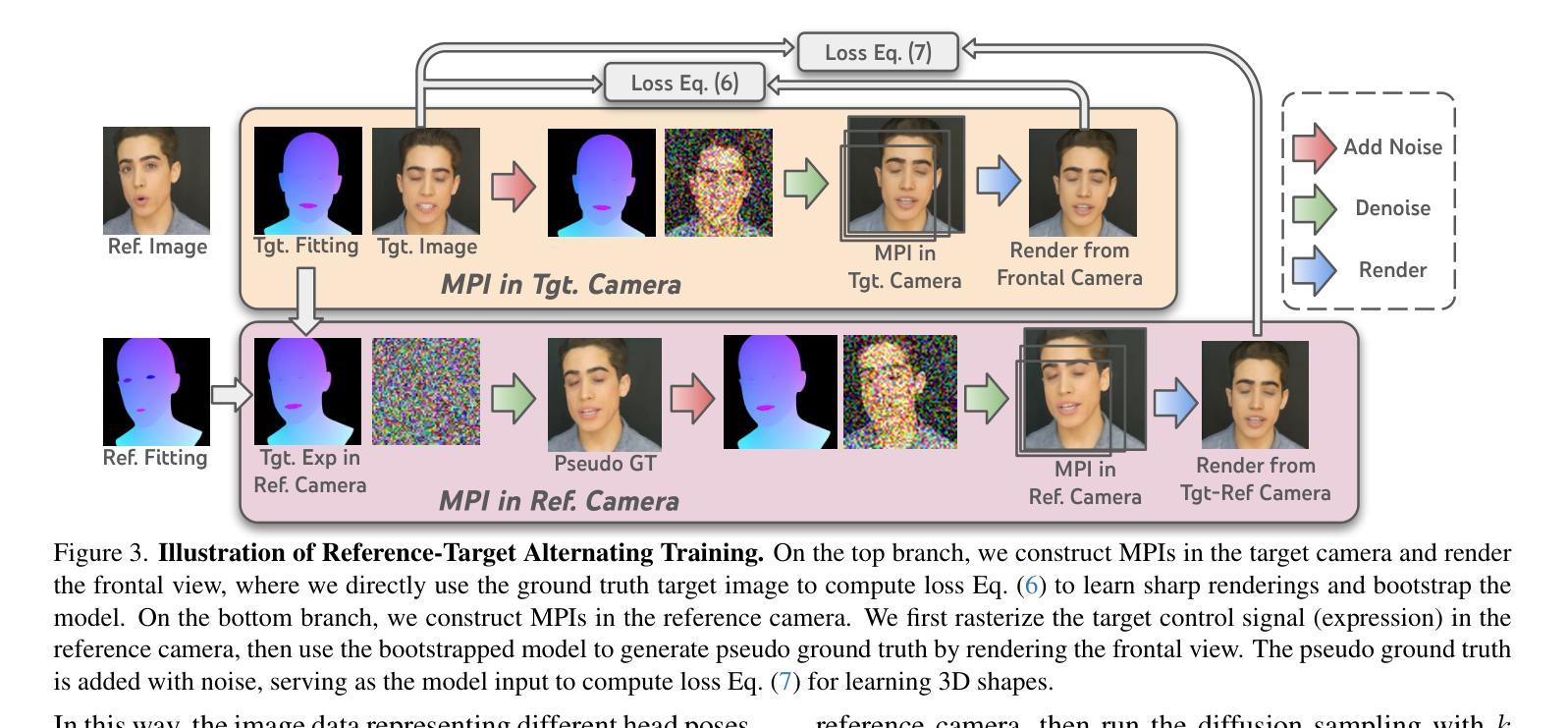
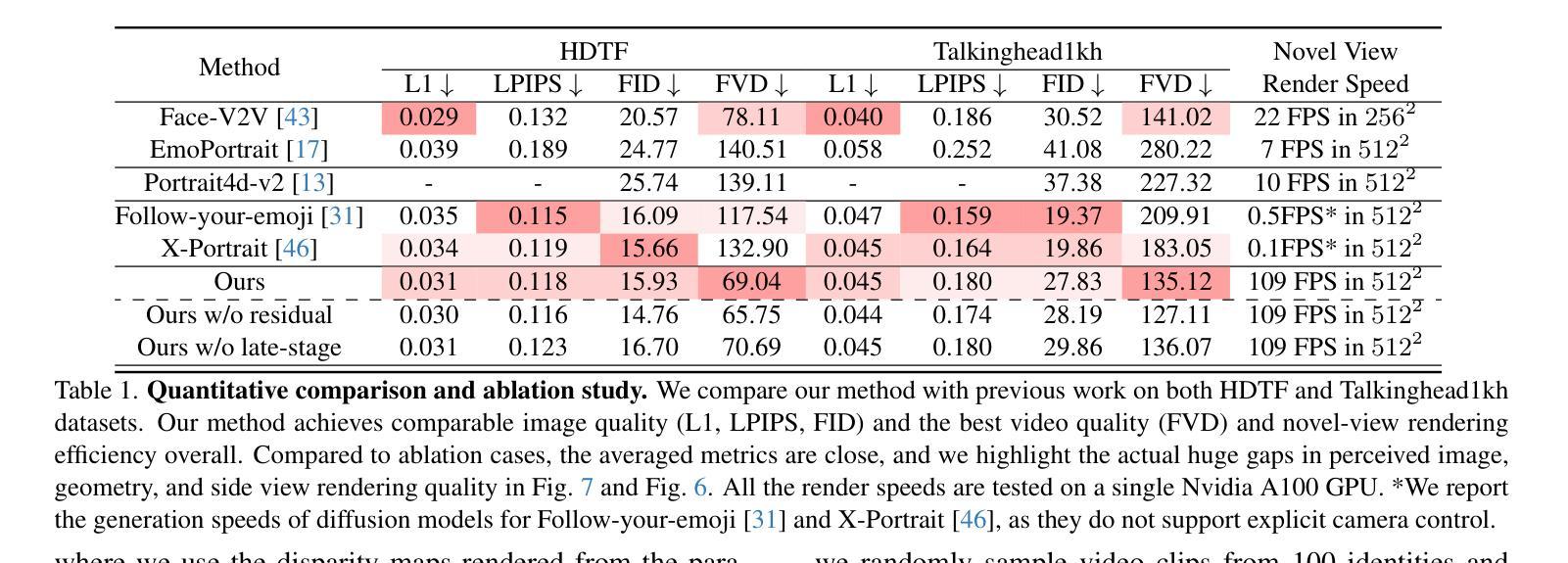
We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
我们提出了一种新颖的基于3D感知扩散的方法,用于直接从单个身份图像和明确的控制信号(如表情)生成逼真的动态对话视频。我们的方法生成多平面图像(MPIs),确保几何一致性,使其成为适合虚拟现实头盔等沉浸式观看体验的双眼视频的理想选择。与通常需要单独阶段或联合优化来重建3D表示(如NeRF或3D高斯)的现有方法不同,我们的方法通过单个去噪过程直接生成最终输出,无需后期处理步骤即可有效地渲染新颖视图。为了有效地从单眼视频中学习,我们引入了一种训练机制,该机制可以在目标相机空间或参考相机空间中随机重建输出MPI。这种方法使模型能够同时学习锐利的图像细节和潜在的3D信息。大量实验证明了我们方法的有效性,即使在不需要明确的3D重建或高质量的多视角训练数据的情况下,也能实现具有竞争力的化身质量和新颖的视图渲染能力。
论文及项目相关链接
PDF CVPR2025; project page: https://y-u-a-n-l-i.github.io/projects/IM-Portrait/
Summary
本文提出了一种新颖的基于三维感知扩散的方法,直接从单张身份图像和明确的控制信号(如表情)生成逼真的谈话头部视频。该方法生成多平面图像(MPIs),确保几何一致性,适合虚拟现实头盔等沉浸式观看体验。与其他方法不同,我们的方法通过一个去噪过程直接生成最终输出,无需额外的后处理步骤即可高效呈现新颖视角。通过随机重建目标或参考相机空间中的输出MPI,我们的训练机制有效地从单目视频中学习。这种方法使模型能够同时学习清晰的图像细节和潜在的三维信息。实验证明,我们的方法实现了具有竞争力的化身质量和新颖的视图渲染能力,即使在没有明确的三维重建或高质量多视图训练数据的情况下也是如此。
Key Takeaways
- 提出了一种新颖的基于三维感知扩散的方法,用于从单张身份图像和控制信号生成谈话头部视频。
- 通过生成多平面图像(MPIs)确保几何一致性,提升沉浸式体验。
- 直接通过单一去噪过程生成最终输出,省去了复杂的后处理步骤。
- 训练机制可以随机重建输出MPI,以学习清晰图像细节和潜在的三维信息。
- 方法适用于单目视频学习,并可以同时处理尖锐图像细节和底层三维信息。
- 实验证明该方法具有竞争力的化身质量和新颖的视图渲染能力。
- 方法无需明确的三维重建或高质量多视图训练数据。
点此查看论文截图