⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-01 更新
FedMVP: Federated Multi-modal Visual Prompt Tuning for Vision-Language Models
Authors:Mainak Singha, Subhankar Roy, Sarthak Mehrotra, Ankit Jha, Moloud Abdar, Biplab Banerjee, Elisa Ricci
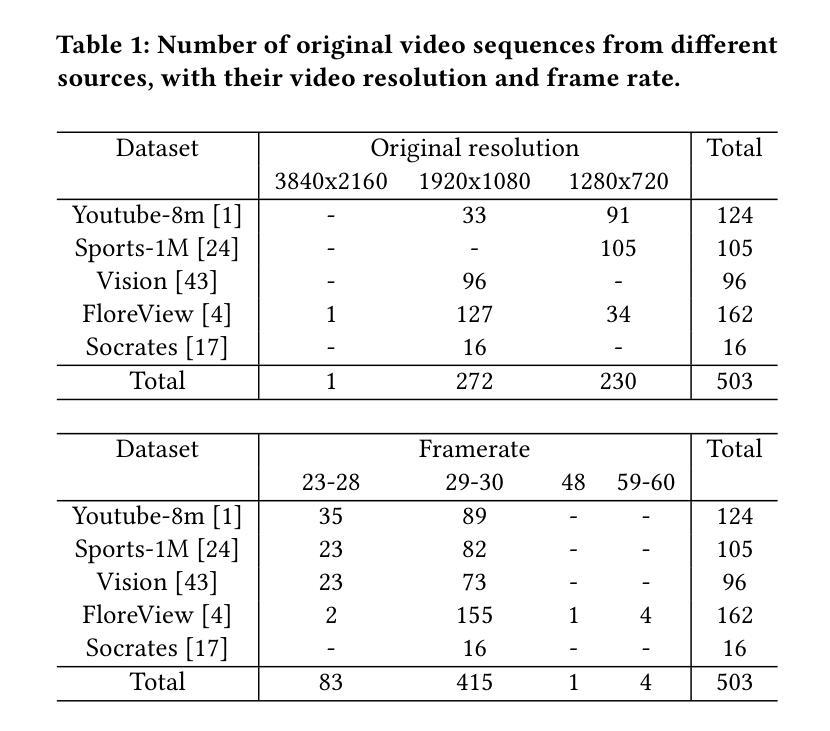
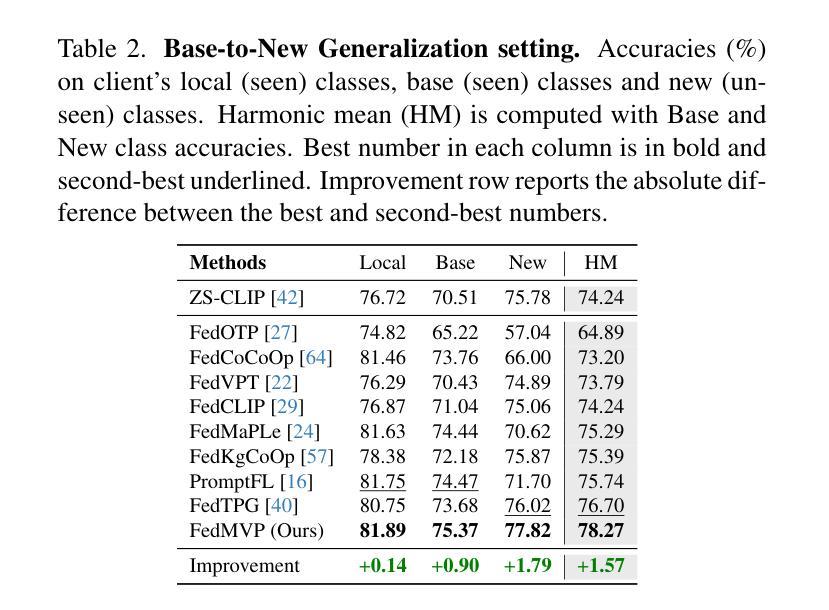
Textual prompt tuning adapts Vision-Language Models (e.g., CLIP) in federated learning by tuning lightweight input tokens (or prompts) on local client data, while keeping network weights frozen. Post training, only the prompts are shared by the clients with the central server for aggregation. However, textual prompt tuning often struggles with overfitting to known concepts and may be overly reliant on memorized text features, limiting its adaptability to unseen concepts. To address this limitation, we propose Federated Multimodal Visual Prompt Tuning (FedMVP) that conditions the prompts on comprehensive contextual information – image-conditioned features and textual attribute features of a class – that is multimodal in nature. At the core of FedMVP is a PromptFormer module that synergistically aligns textual and visual features through cross-attention, enabling richer contexual integration. The dynamically generated multimodal visual prompts are then input to the frozen vision encoder of CLIP, and trained with a combination of CLIP similarity loss and a consistency loss. Extensive evaluation on 20 datasets spanning three generalization settings demonstrates that FedMVP not only preserves performance on in-distribution classes and domains, but also displays higher generalizability to unseen classes and domains when compared to state-of-the-art methods. Codes will be released upon acceptance.
文本提示调整在联邦学习中适应了视觉语言模型(例如CLIP),通过在本地客户端数据上调整轻量级输入令牌(或提示)来实现,同时保持网络权重冻结。训练后,只有提示被客户端与中央服务器共享以进行聚合。然而,文本提示调整通常会对已知概念过度拟合,并且可能过于依赖记忆文本特征,从而限制了其对未见概念的可适应性。为了解决这一局限性,我们提出了联邦多模态视觉提示调整(FedMVP),它根据全面的上下文信息对提示进行条件设置——即本质上为多模态的图像条件特征和文本的类属性特征。FedMVP的核心是一个PromptFormer模块,它通过交叉注意力协同对齐文本和视觉特征,从而实现更丰富的上下文集成。然后,将动态生成的多模态视觉提示输入到CLIP的冻结视觉编码器,并使用CLIP相似性损失和一致性损失的组合进行训练。在涵盖三种泛化设置的20个数据集上的广泛评估表明,FedMVP不仅保持了内部分布类和领域的性能,而且在与最新方法相比时,对于未见类和领域表现出更高的泛化能力。代码将在接受后发布。
论文及项目相关链接
Summary
在联邦学习环境中,文本提示调整优化了视觉语言模型(如CLIP)。此方法通过在本地客户端数据上调整轻量级输入令牌(或提示)来实现模型调整,同时保持网络权重不变。训练后,客户端仅将提示共享给中央服务器进行聚合。然而,文本提示调整常常过于拟合已知概念,可能过于依赖记忆文本特征,难以适应未见概念。为解决此局限性,我们提出了联邦多模态视觉提示调整(FedMVP),它通过综合上下文信息调整提示——包括图像特征条件和文本属性特征的类别信息。FedMVP的核心是PromptFormer模块,它通过跨注意力协同对齐文本和视觉特征,实现更丰富上下文集成。然后,将动态生成的多模态视觉提示输入到CLIP的冻结视觉编码器,并用CLIP相似性损失和一致性损失进行训练。在跨越三种泛化设置的20个数据集上的广泛评估表明,FedMVP不仅保持了对分布内类别和域的绩效表现,而且在未见类别和域上的泛化能力更强,相较于最新方法更具优势。
Key Takeaways
- 文本提示调整通过调整轻量级输入令牌在联邦学习中优化视觉语言模型(如CLIP)。
- 训练后仅共享提示进行聚合以改进模型性能。
- 文本提示调整可能面临过度拟合已知概念和依赖记忆文本特征的挑战。
- 为解决这些问题,提出联邦多模态视觉提示调整(FedMVP)。
- FedMVP利用PromptFormer模块实现文本和视觉特征的协同对齐。
- FedMVP通过结合CLIP相似性损失和一致性损失进行训练。
点此查看论文截图


Advance Fake Video Detection via Vision Transformers
Authors:Joy Battocchio, Stefano Dell’Anna, Andrea Montibeller, Giulia Boato
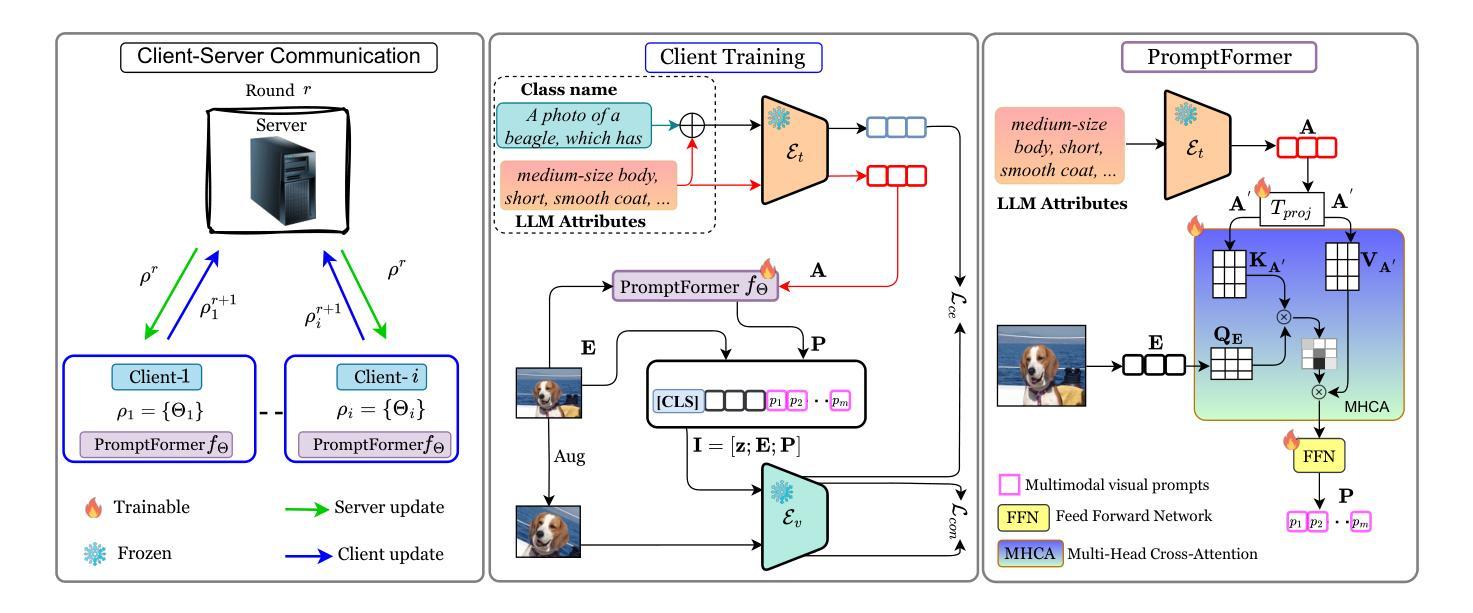
Recent advancements in AI-based multimedia generation have enabled the creation of hyper-realistic images and videos, raising concerns about their potential use in spreading misinformation. The widespread accessibility of generative techniques, which allow for the production of fake multimedia from prompts or existing media, along with their continuous refinement, underscores the urgent need for highly accurate and generalizable AI-generated media detection methods, underlined also by new regulations like the European Digital AI Act. In this paper, we draw inspiration from Vision Transformer (ViT)-based fake image detection and extend this idea to video. We propose an {original} %innovative framework that effectively integrates ViT embeddings over time to enhance detection performance. Our method shows promising accuracy, generalization, and few-shot learning capabilities across a new, large and diverse dataset of videos generated using five open source generative techniques from the state-of-the-art, as well as a separate dataset containing videos produced by proprietary generative methods.
基于人工智能的多媒体生成技术的最新进展已经能够创建超逼真的图像和视频,这引发了人们对其可能用于传播虚假信息的担忧。生成技术的普及以及其不断的改进使得从提示或现有媒体中制作虚假多媒体成为可能。这也突显了对高度准确且可推广的人工智能生成媒体检测方法的迫切需求,新的法规如欧洲数字人工智能法案也强调了这一点。在这篇论文中,我们从基于视觉转换器(ViT)的假图像检测中汲取灵感,并将其扩展到视频领域。我们提出了一种创新的框架,该框架可以有效地整合随着时间的推移而得到的ViT嵌入技术,以提高检测性能。我们的方法在一个新的大型多元视频数据集上展示了其准确检测生成的视频的前景以及其对广泛生成技术下数据的概括性和学习能力,同时也包含了由专有生成方法产生的数据集。该模型经过多次学习改进后表现出了其潜力。
论文及项目相关链接
Summary
基于AI的多媒体生成技术的新进展已能够创建超逼真的图像和视频,引发了关于其可能传播误信息的担忧。随着生成技术的普及和不断完善,对高度准确和可推广的AI生成媒体检测方法的迫切需求愈发凸显。新的法规如欧洲数字AI法案也强调了这一点。本文受Vision Transformer(ViT)在检测图像造假方面的启发,并将其理念拓展至视频领域。我们提出了一个新颖的框架,通过整合ViT在时间上的嵌入,提高了检测性能。该方法在包含使用五种最新开源生成技术生成的大型多元视频数据集以及包含专有生成方法产生的视频数据集上展现出良好的准确性、泛化能力和小样本学习能力。
Key Takeaways
- AI多媒体生成技术的进步带来超逼真图像和视频创作,引发传播误信息的担忧。
- 生成技术的普及和不断完善突显了对准确和可推广的AI生成媒体检测方法的迫切需求。
- 欧洲数字AI法案等法规强调了这一需求。
- 受Vision Transformer(ViT)在图像造假检测方面的启发,将理念拓展至视频领域。
- 提出新颖框架,通过整合ViT在时间上的嵌入提高检测性能。
- 方法在包含最新开源和专有生成技术产生的视频数据集上展现出良好性能。
- 该方法具备准确性、泛化能力和小样本学习能力。
点此查看论文截图