⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-02 更新
ClassWise-CRF: Category-Specific Fusion for Enhanced Semantic Segmentation of Remote Sensing Imagery
Authors:Qinfeng Zhu, Yunxi Jiang, Lei Fan
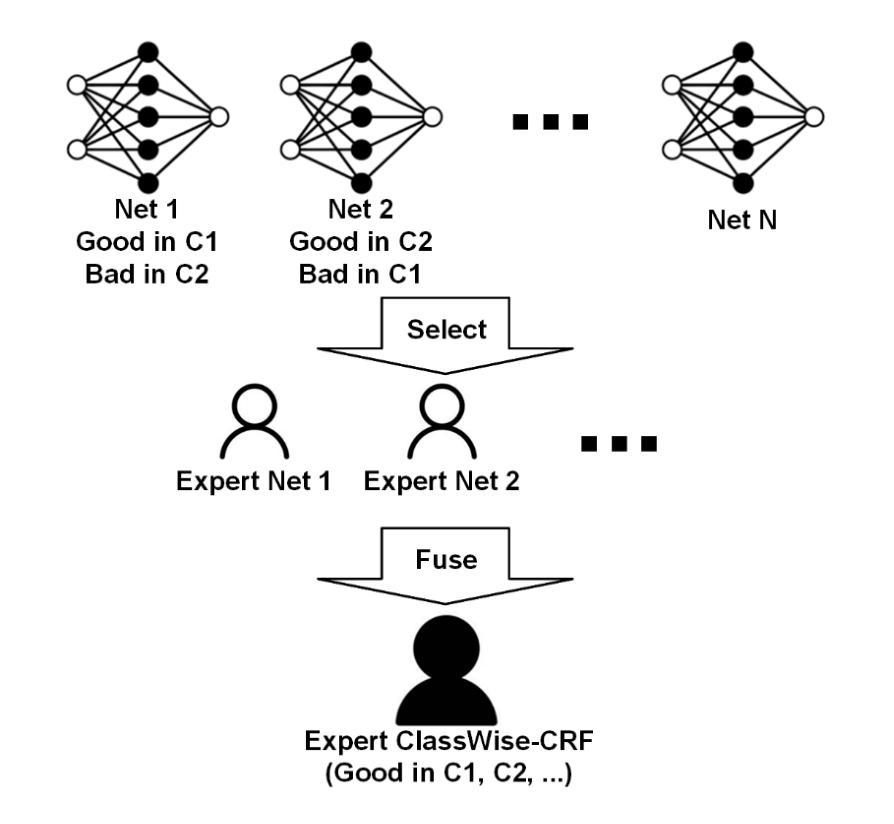
We propose a result-level category-specific fusion architecture called ClassWise-CRF. This architecture employs a two-stage process: first, it selects expert networks that perform well in specific categories from a pool of candidate networks using a greedy algorithm; second, it integrates the segmentation predictions of these selected networks by adaptively weighting their contributions based on their segmentation performance in each category. Inspired by Conditional Random Field (CRF), the ClassWise-CRF architecture treats the segmentation predictions from multiple networks as confidence vector fields. It leverages segmentation metrics (such as Intersection over Union) from the validation set as priors and employs an exponential weighting strategy to fuse the category-specific confidence scores predicted by each network. This fusion method dynamically adjusts the weights of each network for different categories, achieving category-specific optimization. Building on this, the architecture further optimizes the fused results using unary and pairwise potentials in CRF to ensure spatial consistency and boundary accuracy. To validate the effectiveness of ClassWise-CRF, we conducted experiments on two remote sensing datasets, LoveDA and Vaihingen, using eight classic and advanced semantic segmentation networks. The results show that the ClassWise-CRF architecture significantly improves segmentation performance: on the LoveDA dataset, the mean Intersection over Union (mIoU) metric increased by 1.00% on the validation set and by 0.68% on the test set; on the Vaihingen dataset, the mIoU improved by 0.87% on the validation set and by 0.91% on the test set. These results fully demonstrate the effectiveness and generality of the ClassWise-CRF architecture in semantic segmentation of remote sensing images. The full code is available at https://github.com/zhuqinfeng1999/ClassWise-CRF.
我们提出了一种名为ClassWise-CRF的结果级别类别特定融合架构。该架构采用两阶段过程:首先,它使用贪心算法从候选网络池中选择在特定类别中表现良好的专家网络;其次,它根据这些选定网络在每个类别中的分割性能,自适应地加权融合它们的分割预测。ClassWise-CRF架构受到条件随机场(CRF)的启发,将多个网络的分割预测视为置信度向量场。它利用验证集的分割指标(如交集并集比)作为先验,并采用指数加权策略融合每个网络预测的类别特定置信度得分。这种融合方法针对不同的类别动态调整每个网络的权重,实现针对类别的优化。在此基础上,该架构进一步使用CRF中的一元和配对势能优化融合结果,以确保空间一致性和边界准确性。为了验证ClassWise-CRF的有效性,我们在两个遥感数据集LoveDA和Vaihingen上使用了八个经典和先进的语义分割网络进行实验。结果表明,ClassWise-CRF架构显著提高了分割性能:在LoveDA数据集上,验证集的mean Intersection over Union(mIoU)指标提高了1.00%,测试集提高了0.68%;在Vaihingen数据集上,验证集的mIoU提高了0.87%,测试集提高了0.91%。这些结果充分证明了ClassWise-CRF架构在遥感图像语义分割中的有效性和通用性。完整代码可在https://github.com/zhuqinfeng1999/ClassWise-CRF找到。
论文及项目相关链接
摘要
提出一种名为ClassWise-CRF的结果级类别特定融合架构。该架构采用两阶段流程:首先,从候选网络池中选择在特定类别上表现良好的专家网络;其次,通过自适应权重集成这些选定网络的分割预测,基于它们在每个类别中的分割性能。受条件随机场(CRF)的启发,ClassWise-CRF架构将多个网络的分割预测视为置信度向量场,利用验证集的分割度量作为先验,采用指数加权策略融合每个网络预测的类别特定置信度。该融合方法针对不同的类别动态调整每个网络的权重,实现类别特定的优化。在此基础上,架构进一步使用CRF中的一元和成对势优化融合结果,以确保空间一致性和边界准确性。实验证明,ClassWise-CRF架构在遥感图像语义分割中效果显著且通用性强。在LoveDA和Vaihingen两个遥感数据集上使用的八种经典和高级语义分割网络实验结果显示,ClassWise-CRF架构的分割性能显著提升:在LoveDA数据集上,验证集和测试集的mIoU指标分别提高了1.00%和0.68%;在Vaihingen数据集上,验证集和测试集的mIoU分别提高了0.87%和0.91%。
关键见解
- 提出了ClassWise-CRF架构,该架构旨在通过融合多个网络的分割预测来提升语义分割的性能。
- ClassWise-CRF采用两阶段流程:选择表现良好的专家网络,并自适应地集成它们的分割预测。
- 受CRF启发,ClassWise-CRF将分割预测视为置信度向量场,并采用指数加权策略融合类别特定的置信度。
- 该架构实现了类别特定的优化,并根据不同类别动态调整网络权重。
- 架构利用CRF的一元和成对势优化融合结果,确保空间一致性和边界准确性。
- 在两个遥感数据集上的实验表明,ClassWise-CRF显著提高了分割性能,具体表现为mIoU指标的提升。
- ClassWise-CRF架构具有有效性和通用性,全代码已公开可供参考和学习。
点此查看论文截图

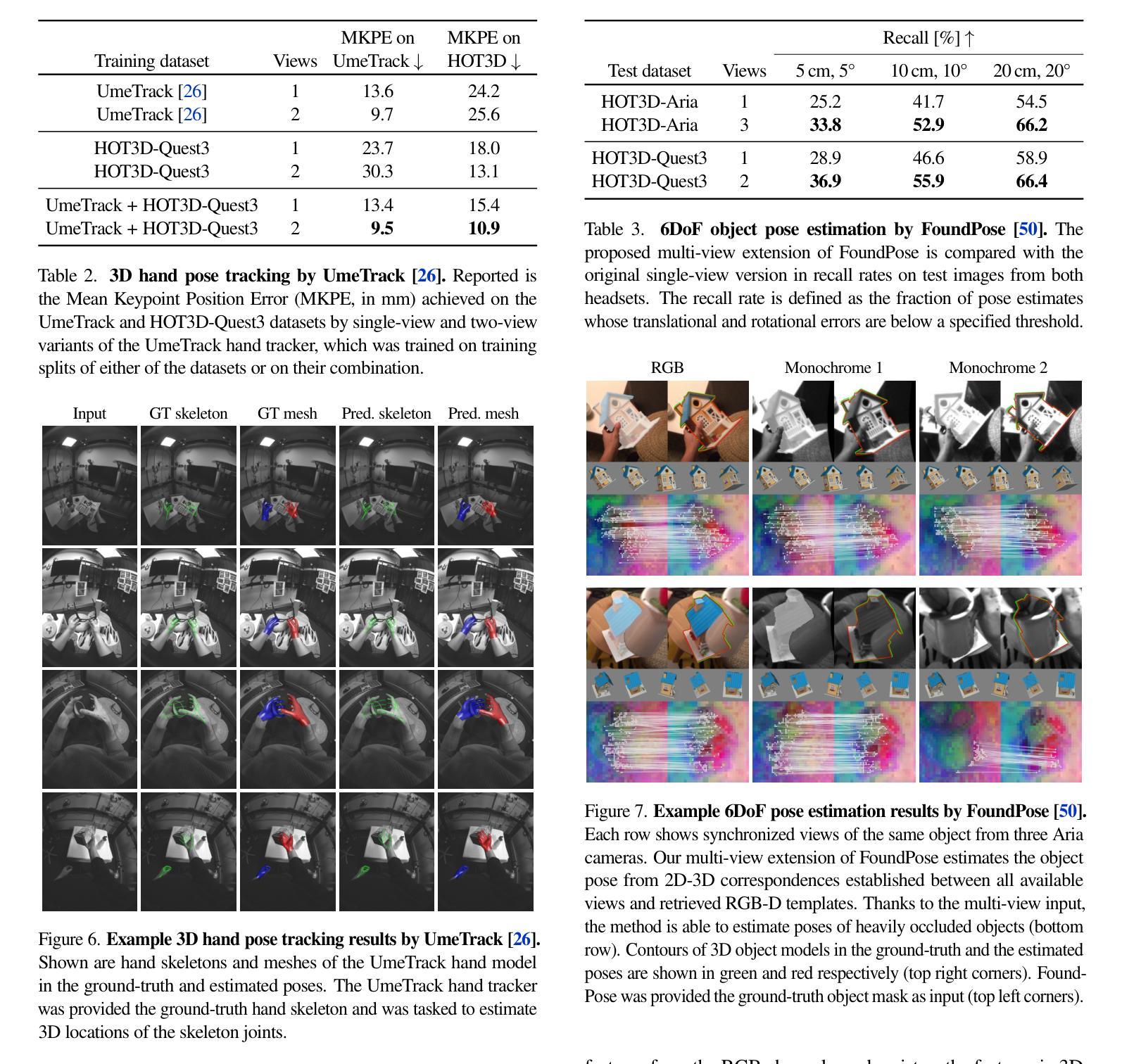
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos
Authors:Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, Jakob Julian Engel, Tomas Hodan
We introduce HOT3D, a publicly available dataset for egocentric hand and object tracking in 3D. The dataset offers over 833 minutes (3.7M+ images) of recordings that feature 19 subjects interacting with 33 diverse rigid objects. In addition to simple pick-up, observe, and put-down actions, the subjects perform actions typical for a kitchen, office, and living room environment. The recordings include multiple synchronized data streams containing egocentric multi-view RGB/monochrome images, eye gaze signal, scene point clouds, and 3D poses of cameras, hands, and objects. The dataset is recorded with two headsets from Meta: Project Aria, which is a research prototype of AI glasses, and Quest 3, a virtual-reality headset that has shipped millions of units. Ground-truth poses were obtained by a motion-capture system using small optical markers attached to hands and objects. Hand annotations are provided in the UmeTrack and MANO formats, and objects are represented by 3D meshes with PBR materials obtained by an in-house scanner. In our experiments, we demonstrate the effectiveness of multi-view egocentric data for three popular tasks: 3D hand tracking, model-based 6DoF object pose estimation, and 3D lifting of unknown in-hand objects. The evaluated multi-view methods, whose benchmarking is uniquely enabled by HOT3D, significantly outperform their single-view counterparts.
我们推出HOT3D数据集,这是一个面向以自我为中心的3D手和对象跟踪的公开数据集。该数据集提供了超过833分钟(超过三百万帧)的记录片段,收录了含有个人进行一系列互动任务的共计十九位主体的图像素材和多样化的样本展示;这些主体与三十三种不同的刚体对象进行互动。除了简单的拿起、观察和放下动作之外,主体还执行典型的厨房、办公室和客厅环境的动作。这些记录包括多个同步数据流,包含以自我为中心的多个视角的RGB/黑白图像、眼神信号、场景点云以及相机、手和对象的3D姿态。该数据集是使用Meta的两款头戴设备录制的:Project Aria(AI眼镜的研究原型)和Quest 3虚拟现实耳机(已售出数百万台)。通过运动捕捉系统获取真实姿态数据,该系统使用附着在手和对象上的小型光学标记器来实现数据记录工作。手部注释将以UmeTrack和MANO格式提供,而对象则以室内扫描仪获得的PBR材料所制成的3D网格形式呈现。在我们的实验中,我们展示了以自我为中心的多元视角数据对于三项热门任务的效用:首先,采用特定算法在自我为中心的视角下开展广泛实验的条件下获取表现更佳的更加精准的个人专属姿态数据的展现和分析统计所构建的有效成果十分显著的展示出比起基于单视角对单个角度的图像实现全面精准的手部姿态分析具有明显优势的个人化的全方位立体三维手部追踪能力;其次,展示模型化的6自由度对象姿态估计的优越性;最后则是基于物体被拿起时的动态分析实现的3D未知物体被抬起的动态呈现。评估的多视角方法将首次启用唯一的多视角评估基准的HOT3D进行度量展示且显著改善的单视角相对应的性能标准最终为针对非系统训练的挑战创造可靠的发展助力所出现以及大规模集体执行强有力的3D轨迹运行的实操中的深入保障应用场景反馈即可提供更显著的优化的多元结果并实现方法论方案的推陈出新以及相关模块基准测试效果提升的优势结果。
论文及项目相关链接
PDF CVPR 2025
Summary
HOT3D数据集提供手与物体在三维环境中的交互信息,包含超过833分钟的录制内容,涉及多种活动场景。数据包含RGB图像、眼瞳信号、场景点云等多元同步数据流,以及手的姿态和物体的三维模型。该数据集有助于提升三维手追踪、物体姿态估计和手持物体三维重建等任务的性能评估。
Key Takeaways
- HOT3D是一个用于三维视觉追踪的手部和物体数据集。
- 数据集包含超过833分钟的录制内容,涵盖多种环境的手部与物体交互。
- 数据集包含多元同步数据流,如RGB图像、眼瞳信号等。
- 数据集提供手的姿态和物体的三维模型信息。
- 该数据集可用于研究三维手追踪、物体姿态估计和手持物体重建等技术。
- 该数据集是通过Meta的两个设备进行录制的,采用动作捕捉系统获取地面真实数据。
点此查看论文截图