⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-02 更新
DNB-AI-Project at SemEval-2025 Task 5: An LLM-Ensemble Approach for Automated Subject Indexing
Authors:Lisa Kluge, Maximilian Kähler
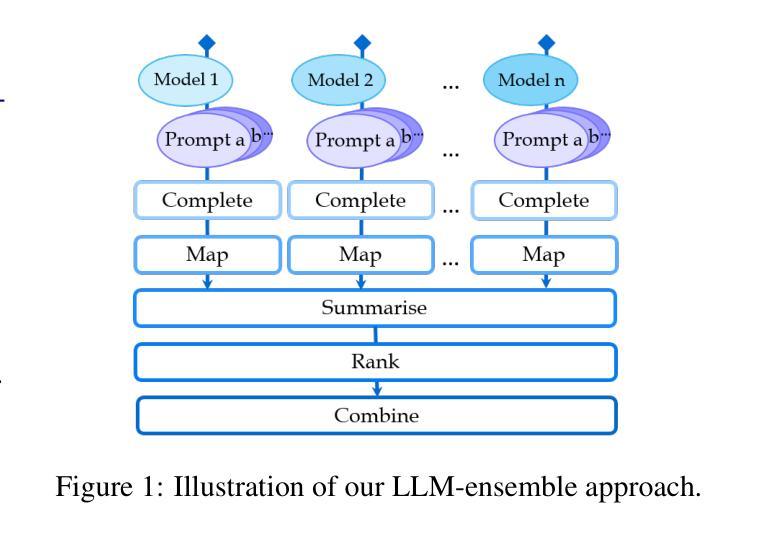
This paper presents our system developed for the SemEval-2025 Task 5: LLMs4Subjects: LLM-based Automated Subject Tagging for a National Technical Library’s Open-Access Catalog. Our system relies on prompting a selection of LLMs with varying examples of intellectually annotated records and asking the LLMs to similarly suggest keywords for new records. This few-shot prompting technique is combined with a series of post-processing steps that map the generated keywords to the target vocabulary, aggregate the resulting subject terms to an ensemble vote and, finally, rank them as to their relevance to the record. Our system is fourth in the quantitative ranking in the all-subjects track, but achieves the best result in the qualitative ranking conducted by subject indexing experts.
本文介绍了我们为SemEval-2025任务5开发的系统:LLMs4Subjects:基于LLM的国家技术图书馆开放存取目录的自动主题标注。我们的系统依赖于提示选择具有不同智力注释记录的LLMs,并要求LLMs对新的记录同样提出关键词建议。这种少样本提示技术与一系列后处理步骤相结合,将生成的关键词映射到目标词汇,将所得的主题术语集合起来进行投票,并最终根据它们与记录的相关性进行排名。我们的系统在所有主题轨道的定量排名中位列第四,但在主题索引专家进行的定性排名中取得了最佳结果。
论文及项目相关链接
PDF 11 pages, 4 figures, submitted to SemEval-2025 workshop Task 5: LLMs4Subjects
Summary
本文介绍了针对SemEval-2025任务5开发的系统:LLMs4Subjects。该系统利用少量样本提示技术,通过向大型语言模型(LLMs)提供智力注释记录示例,并要求其为新记录提出类似关键词。这种技术结合后期处理步骤,将生成的关键词映射到目标词汇,集成结果主题词进行集体投票,并按其与记录的关联性进行排序。系统在所有主题跟踪中的定量排名为第四,但在主题索引专家进行的定性排名中取得了最佳成绩。
Key Takeaways
- 系统是为SemEval-2025任务5:LLMs4Subjects开发的,旨在实现基于大型语言模型(LLMs)的国家技术图书馆开放目录自动主题标注。
- 系统采用少量样本提示技术,通过提供智力注释记录示例,引导大型语言模型为新记录生成关键词。
- 系统结合后期处理步骤,包括将生成的关键词映射到目标词汇、集成结果主题词进行集体投票,以及按关键词与记录的关联性进行排序。
- 系统在所有主题跟踪的定量排名中位列第四。
- 系统在主题索引专家进行的定性排名中取得了最佳成绩。
- 该方法展示了大型语言模型在自动主题标注方面的潜力。
点此查看论文截图


JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Authors:Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, Yiqun Liu
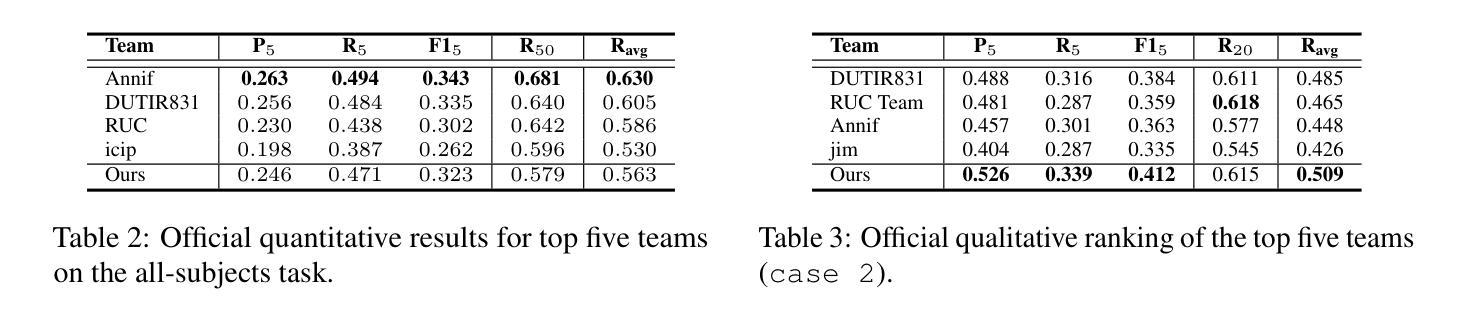
This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
本文介绍了JuDGE(判决文书生成评估)这一新型基准测试,该测试旨在评估中文法律体系中判决文书生成的性能。我们将任务定义为根据给定的案件事实描述生成完整的法律判决书。为了促进这一基准测试,我们构建了一个综合数据集,其中包含来自真实法律案件的事实描述以及与相应完整判决书配对的数据,这些数据作为评估生成文档质量的基准。该数据集通过两个外部法律语料库进行扩充,为任务提供了额外的法律知识:一个包含法规和条例,另一个则包含大量过去的判决书。我们与法律专业人士合作,建立了一个全面的自动化评估框架,从各个维度评估生成的判决书的质量。我们评估了各种基线方法,包括小样本上下文学习、微调以及多源检索增强生成(RAG)方法,使用的都是通用和法律领域的LLMs。实验结果表明,虽然RAG方法可以有效提高此任务性能,但仍存在很大的改进空间。所有代码和数据集可在https://github.com/oneal2000/JuDGE找到。
论文及项目相关链接
Summary
本文介绍了JuDGE(判决文书生成评估)基准测试,该测试旨在评估中文法律系统中判决文书生成性能的新标准。本文定义了任务为根据给定案件事实描述生成完整的法律文书。为支持该基准测试,构建了一个综合数据集,其中包含真实法律案例的事实描述和相应的完整判决书,作为评估生成文档质量的真实标准。此外,还使用了两个包含额外法律知识的外部法律语料库作为补充资源。与律师合作,建立了一个全面的自动化评估框架,从多个维度评估生成的判决书的质量。评估了多种基线方法,包括基于少样本学习的上下文学习方法、微调以及结合多源检索的生成式(RAG)方法,涉及通用和法律领域的LLM。实验结果表明,虽然RAG方法可以显著提高性能,但仍存在很大的改进空间。所有代码和数据集均可在链接中找到。
Key Takeaways
- 引入JuDGE基准测试,专注于评估中文法律系统中的判决文书生成性能。
- 任务定义为:从案件事实描述生成完整的法律文书。
- 构建了一个综合数据集,包含真实案例的事实描述和相应判决书,作为评估标准。
- 利用外部法律语料库提供额外法律知识资源。
- 建立了全面的自动化评估框架,从多个维度评估生成的判决书质量。
- 评估了多种方法,包括少样本学习、微调以及RAG方法。
点此查看论文截图


Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Authors:Yutong Yin, Zhaoran Wang
Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, “FTCT” (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
人类在整合来自不同来源的知识时展现出惊人的组合推理能力。例如,如果有人从某个来源学习到(B=f(A))并从另一个来源学习到(C=g(B)),即使没有同时遇到(ABC),他们也能推断出(C=g(f(A))),这展现了人类智力的概括能力。在本文中,我们介绍了一个合成学习任务——“FTCT”(训练时分散,测试时串联),以验证Transformer在复制这种技能方面的潜力并解释其内在机制。在训练阶段,数据由来自整体因果图的分离知识片段组成。在测试期间,Transformer必须通过整合这些片段来推断完整的因果图轨迹。我们的研究发现,即使在训练数据中缺少正确的片段组合,通过少量Chain-of-Thought提示也能使Transformer在FTCT上执行组合推理,揭示正确的片段组合。此外,组合推理能力的出现与模型复杂度和训练-测试数据相似性密切相关。我们从理论和实践两方面提出,Transformer从训练中学习到一个通用的基础程序,从而在测试期间实现有效的组合推理。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了人类展现出的组合推理能力,通过整合不同来源的知识进行推理。为验证人工智能模型,如Transformer,是否具备此能力,本文引入了一种新的学习任务“FTCT”,在训练阶段,数据由整体因果图中的分离知识片段组成;在测试阶段,Transformer必须整合这些片段来推断完整的因果图轨迹。研究发现,通过少量Chain-of-Thought提示,Transformer能够在FTCT上执行组合推理,揭示正确的片段组合,即使这些组合在训练数据中不存在。此外,模型的复杂性和训练测试数据的相似性对组合推理能力的出现有强烈影响。本文提出,Transformer从训练中学习到一个可概括的基础程序,在测试时能够进行有效的组合推理。
Key Takeaways
- 人类能整合不同来源的知识进行组合推理。
- 引入“FTCT”任务以验证Transformer是否具备组合推理能力。
- 在训练阶段,数据由因果图中的分离知识片段组成。
- Transformer通过少量Chain-of-Thought提示,能进行组合推理,揭示正确的知识片段组合。
- 模型复杂性和训练测试数据相似性对组合推理能力有重要影响。
- Transformer从训练中学习到一个可概括的基础程序。
点此查看论文截图



