⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-02 更新
DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
Authors:Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, Chong Ruan
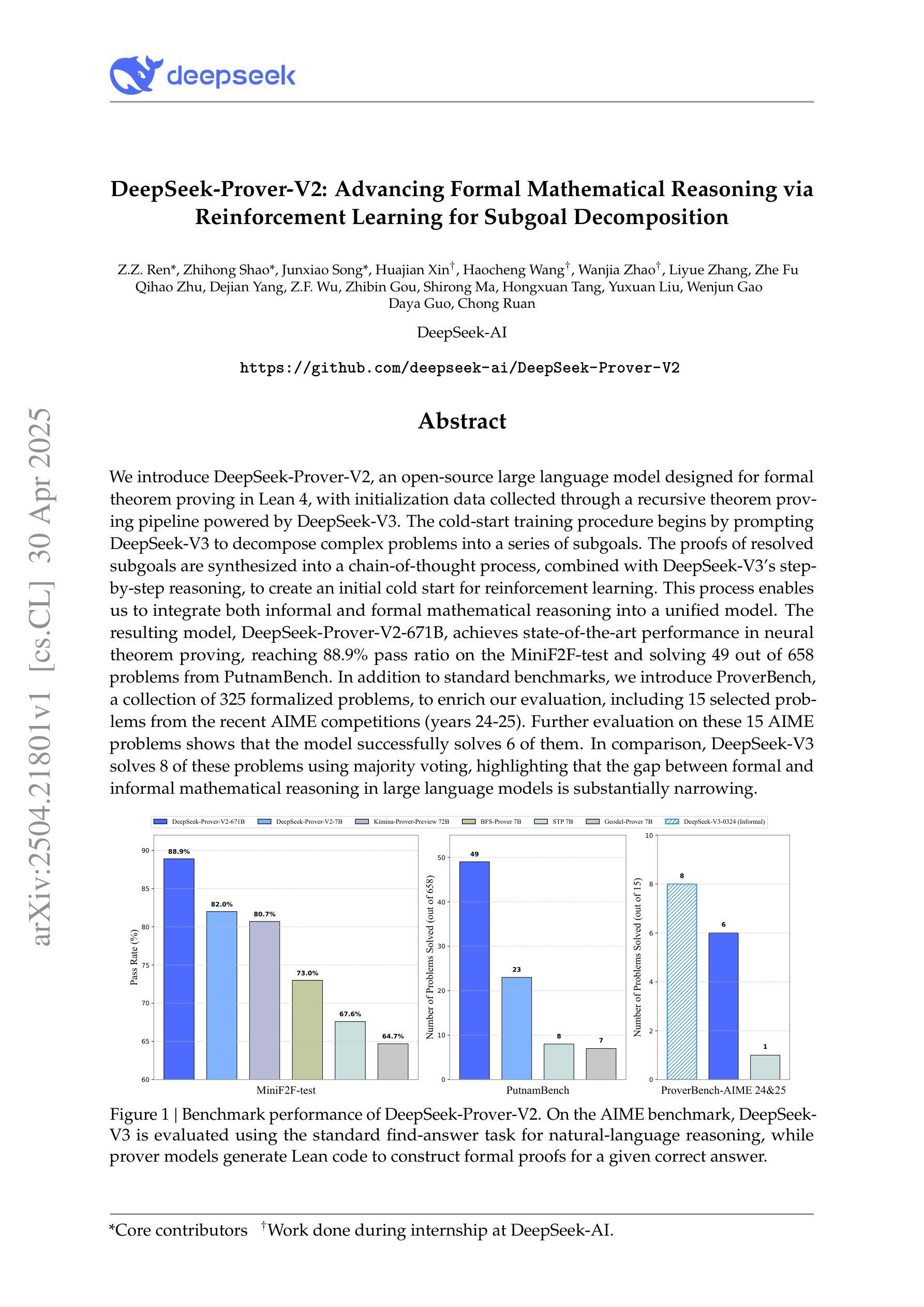
We introduce DeepSeek-Prover-V2, an open-source large language model designed for formal theorem proving in Lean 4, with initialization data collected through a recursive theorem proving pipeline powered by DeepSeek-V3. The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals. The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3’s step-by-step reasoning, to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model. The resulting model, DeepSeek-Prover-V2-671B, achieves state-of-the-art performance in neural theorem proving, reaching 88.9% pass ratio on the MiniF2F-test and solving 49 out of 658 problems from PutnamBench. In addition to standard benchmarks, we introduce ProverBench, a collection of 325 formalized problems, to enrich our evaluation, including 15 selected problems from the recent AIME competitions (years 24-25). Further evaluation on these 15 AIME problems shows that the model successfully solves 6 of them. In comparison, DeepSeek-V3 solves 8 of these problems using majority voting, highlighting that the gap between formal and informal mathematical reasoning in large language models is substantially narrowing.
我们推出了DeepSeek-Prover-V2,这是一款针对Lean 4进行形式化定理证明设计的开源大型语言模型。其初始化数据是通过DeepSeek-V3驱动的递归定理证明管道收集的。冷启动训练程序从提示DeepSeek-V3开始,将复杂问题分解为一系列子目标。已解决的子目标的证明被合成为一种思维链过程,与DeepSeek-V3的逐步推理相结合,为强化学习创建一个初步的冷启动。这一过程使我们能够将非正式和正式的数学推理整合到一个统一的模型中。最终的产品模型DeepSeek-Prover-V2-671B在神经定理证明方面达到了最先进的性能,在MiniF2F测试中的通过率达到了88.9%,并解决了PutnamBench中的49个中的658个问题。除了标准基准测试外,我们还推出了ProverBench,这是一组包含325个形式化问题的集合,以丰富我们的评估内容,其中包括最近AIME竞赛(第24至25年)选择的15个问题。对这15个AIME问题的进一步评估表明,该模型成功解决了其中6个问题。相比之下,DeepSeek-V3通过多数投票解决了其中8个问题,这表明大型语言模型中正式与非正式数学推理之间的差距正在显著缩小。
论文及项目相关链接
Summary
我们推出了DeepSeek-Prover-V2,这是一款为Lean 4中的形式化定理证明而设计的开源大型语言模型。通过DeepSeek-V3驱动的递归定理证明流水线收集初始化数据,采用冷启动训练程序,将复杂问题分解为一系列子目标。通过DeepSeek-V3的逐步推理,将已解决子目标的证明合成思维链,为强化学习创建初始冷启动。此过程使我们能够将非正式和正式的数学推理整合到统一模型中。结果模型DeepSeek-Prover-V2-671B在神经定理证明方面达到了最新性能,在MiniF2F测试中的通过率达到了88.9%,并解决PutnamBench中的49个难题中的658个问题。除了标准基准测试外,我们还推出了ProverBench,这是一组包含来自最新AIME竞赛(第24-25年)的精选问题的325个形式化问题集合。在这15个AIME问题上的进一步评估表明,该模型成功解决了其中六个问题。相比之下,DeepSeek-V3使用多数投票解决了其中八个问题,突显出在大型语言模型中形式和非形式数学推理之间的差距正在显著缩小。
Key Takeaways
- DeepSeek-Prover-V2是一个用于形式定理证明的大型语言模型。
- 该模型通过递归定理证明流水线进行训练,结合DeepSeek-V3的逐步推理能力。
- DeepSeek-Prover-V2-671B模型在神经定理证明方面表现出卓越性能。
- 在MiniF2F测试中,该模型的通过率达到了88.9%。
- 该模型成功解决了PutnamBench中的49个难题和ProverBench中的多个问题。
- ProverBench是一个新的评估工具,包含来自AIME竞赛的形式化问题。
点此查看论文截图


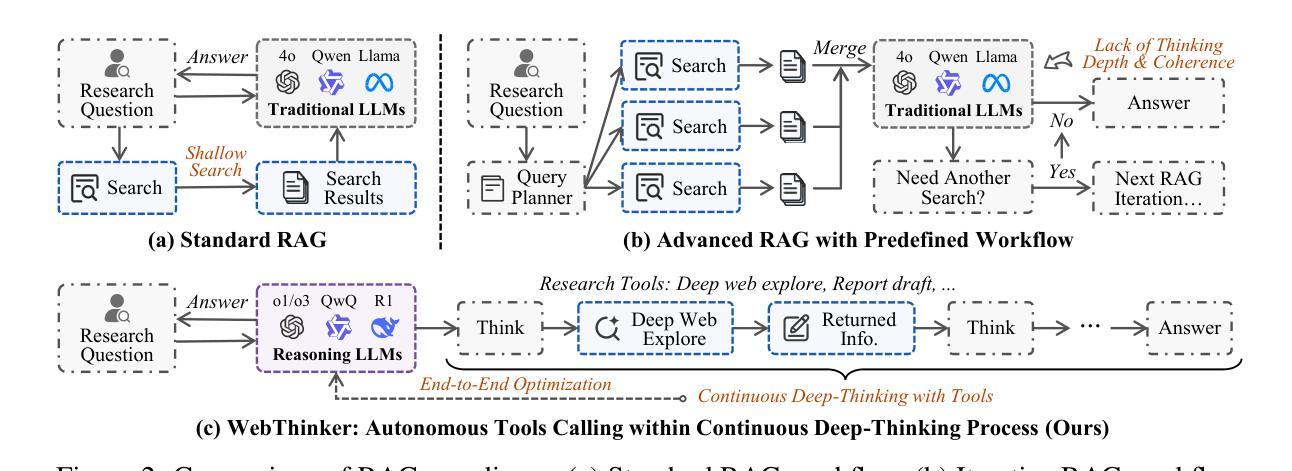
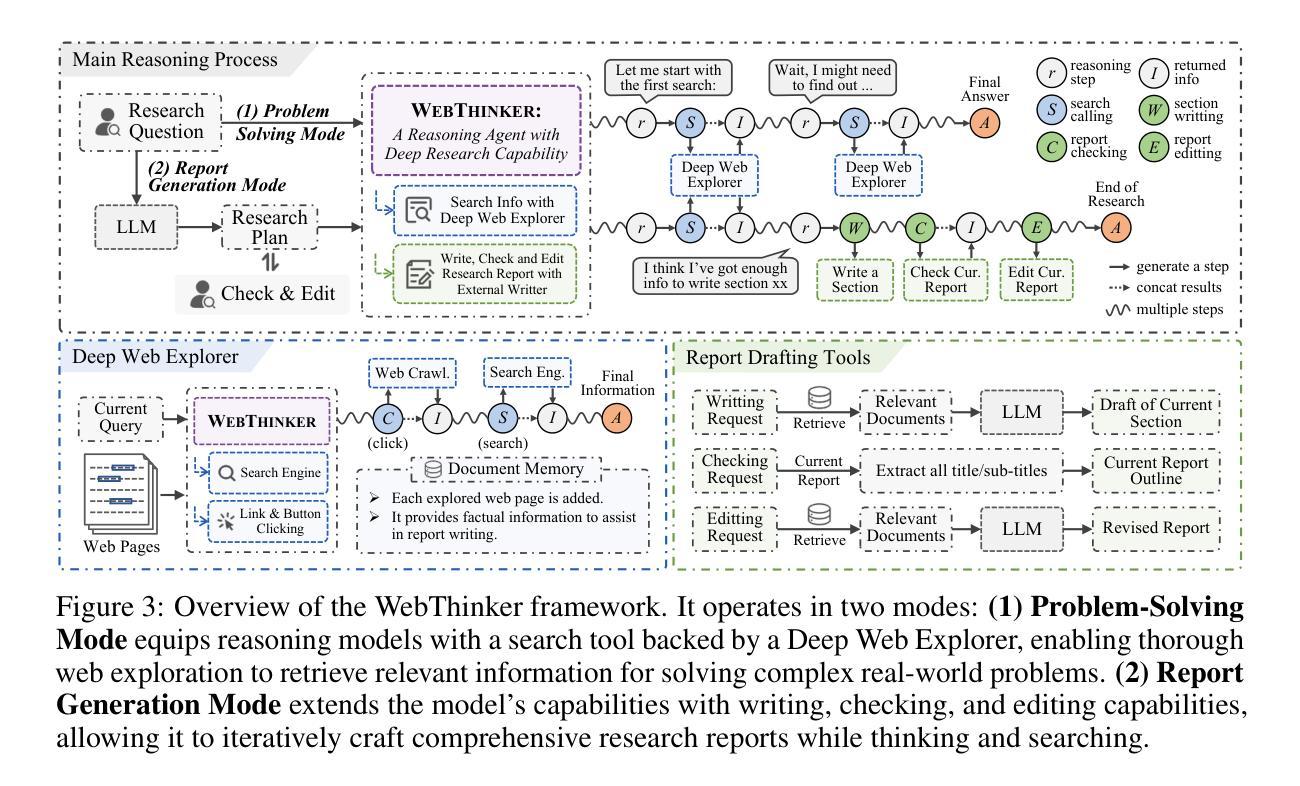
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Authors:Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, Zhicheng Dou
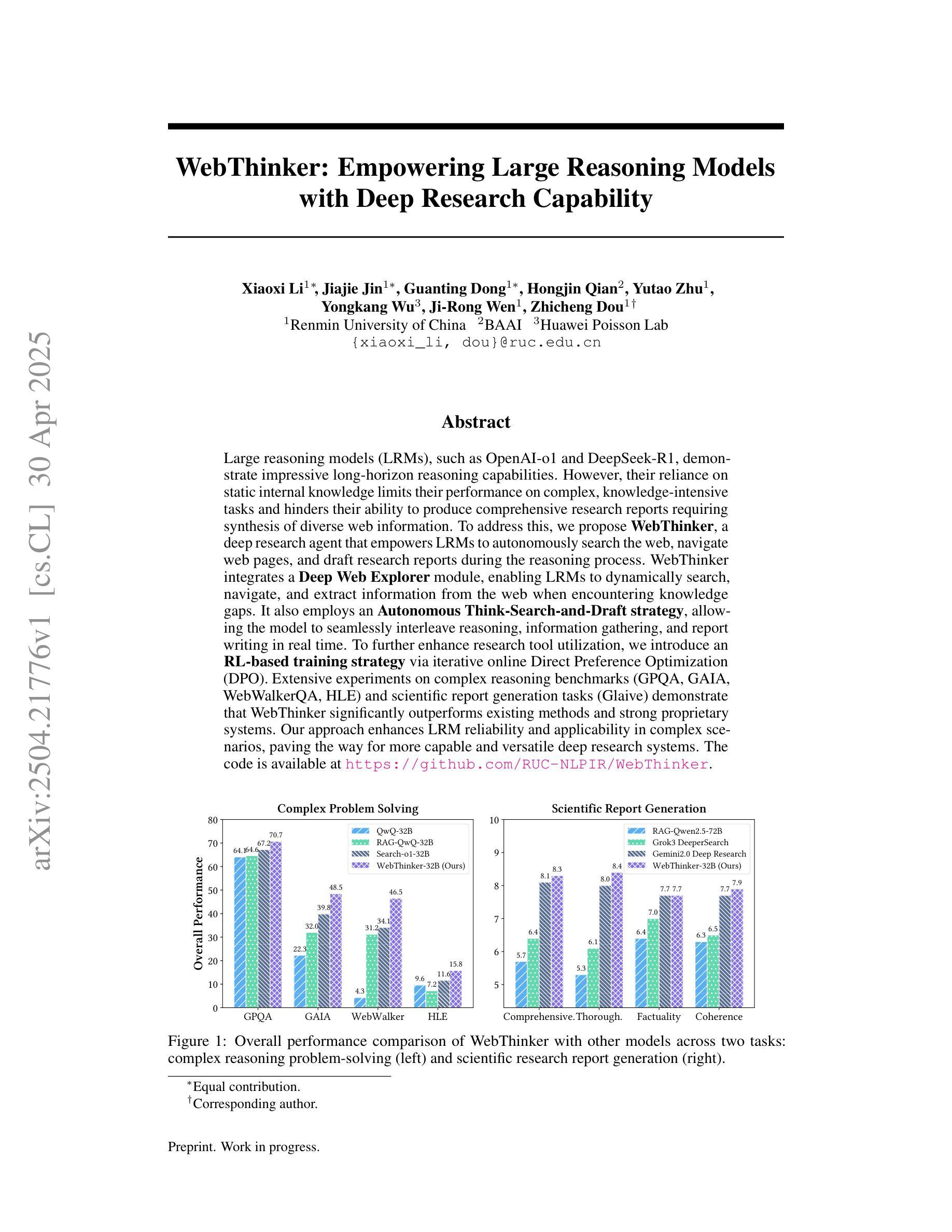
Large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, demonstrate impressive long-horizon reasoning capabilities. However, their reliance on static internal knowledge limits their performance on complex, knowledge-intensive tasks and hinders their ability to produce comprehensive research reports requiring synthesis of diverse web information. To address this, we propose \textbf{WebThinker}, a deep research agent that empowers LRMs to autonomously search the web, navigate web pages, and draft research reports during the reasoning process. WebThinker integrates a \textbf{Deep Web Explorer} module, enabling LRMs to dynamically search, navigate, and extract information from the web when encountering knowledge gaps. It also employs an \textbf{Autonomous Think-Search-and-Draft strategy}, allowing the model to seamlessly interleave reasoning, information gathering, and report writing in real time. To further enhance research tool utilization, we introduce an \textbf{RL-based training strategy} via iterative online Direct Preference Optimization (DPO). Extensive experiments on complex reasoning benchmarks (GPQA, GAIA, WebWalkerQA, HLE) and scientific report generation tasks (Glaive) demonstrate that WebThinker significantly outperforms existing methods and strong proprietary systems. Our approach enhances LRM reliability and applicability in complex scenarios, paving the way for more capable and versatile deep research systems. The code is available at https://github.com/RUC-NLPIR/WebThinker.
大型推理模型(LRMs),如OpenAI-o1和DeepSeek-R1,展现了令人印象深刻的长远推理能力。然而,它们对静态内部知识的依赖限制了它们在复杂、知识密集型任务上的性能,并阻碍了它们生成需要合成各种网络信息的综合研究报告的能力。为了解决这个问题,我们提出了WebThinker,这是一种深度研究代理,能够赋予LRMs自主上网、浏览网页并在推理过程中起草研究报告的能力。WebThinker集成了深网探索器模块,使LRMs能够在遇到知识空白时动态地从网上搜索、浏览和提取信息。它还采用了一种自主思考-搜索-起草策略,使模型能够实时无缝地交替进行推理、信息收集和研究报告写作。为了进一步提高研究工具的使用效率,我们引入了一种基于强化学习(RL)的训练策略,通过在线直接偏好优化(DPO)进行迭代。在复杂推理基准测试(GPQA、GAIA、WebWalkerQA、HLE)和科学报告生成任务(Glaive)上的广泛实验表明,WebThinker显著优于现有方法和强大的专有系统。我们的方法提高了LRM在复杂场景中的可靠性和适用性,为更强大、更通用的深度研究系统铺平了道路。代码可在https://github.com/RUC-NLPIR/WebThinker上找到。
论文及项目相关链接
Summary
大型推理模型(LRMs)如OpenAI-o1和DeepSeek-R1具备出色的长远推理能力,但在处理复杂、知识密集型任务和生成综合研究报告时存在局限性。为此,我们提出了WebThinker,一个深度研究代理,能够自主上网、导航网页并能在推理过程中撰写研究报告。WebThinker通过集成Deep Web Explorer模块和自主思考-搜索-起草策略,实现了实时推理、信息收集与报告撰写的无缝衔接。通过基于强化学习的训练策略和在线直接偏好优化(DPO),WebThinker在复杂推理和科研报告生成任务上显著优于现有方法和强大专有系统。
Key Takeaways
- 大型推理模型(LRMs)具有优秀的长远推理能力。
- LRMs在处理复杂、知识密集型任务和生成综合研究报告时存在局限性。
- WebThinker是一个深度研究代理,能够自主上网、导航网页,助力LRMs克服知识缺口。
- WebThinker集成了Deep Web Explorer模块,实现动态网页信息搜索、导航和提取。
- WebThinker采用自主思考-搜索-起草策略,实现推理、信息收集与报告撰写的无缝衔接。
- 基于强化学习的训练策略和在线直接偏好优化(DPO)提升了WebThinker的性能。
点此查看论文截图
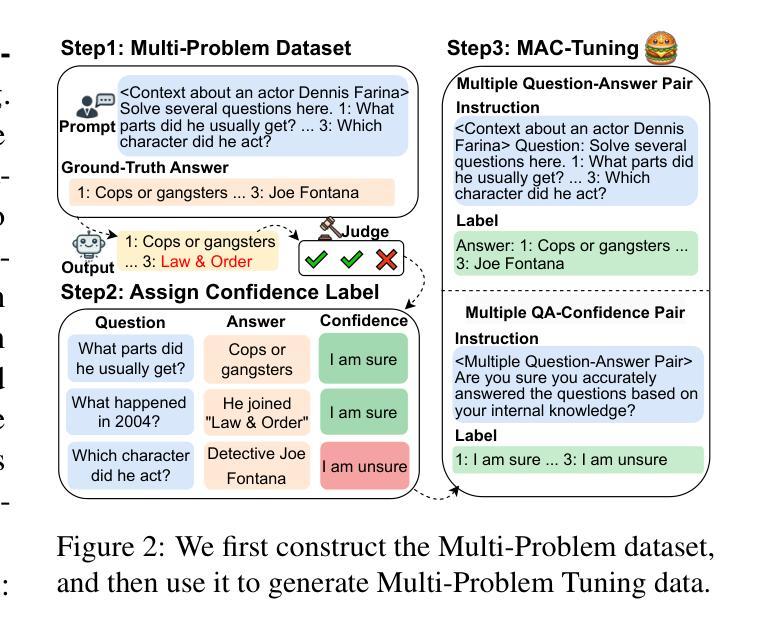
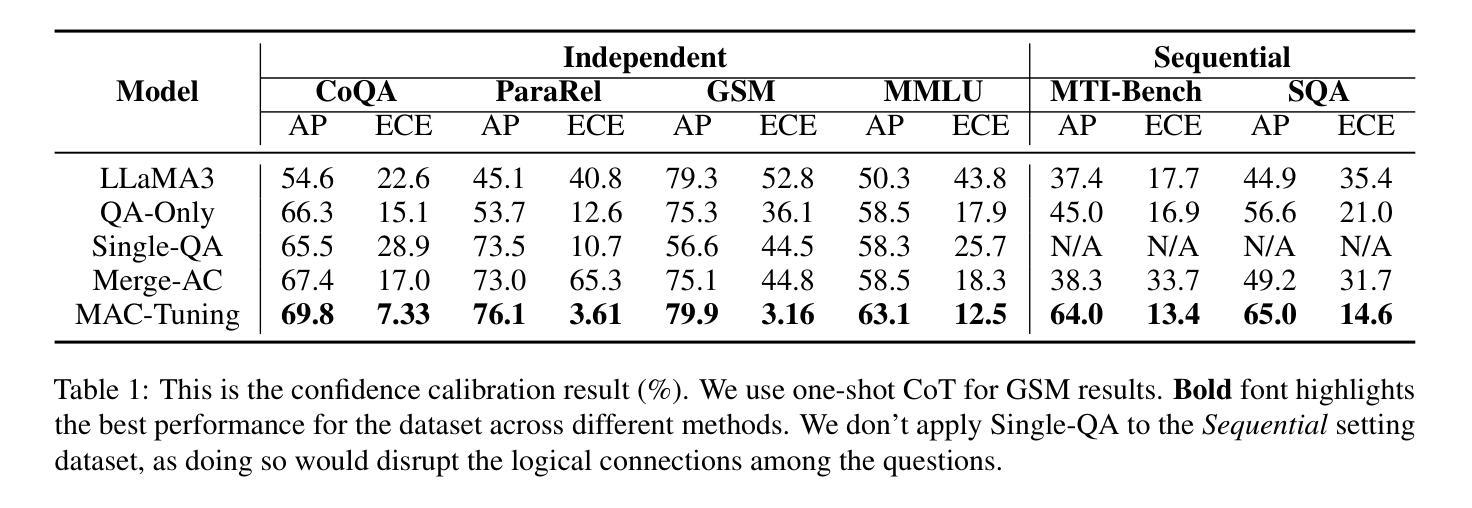
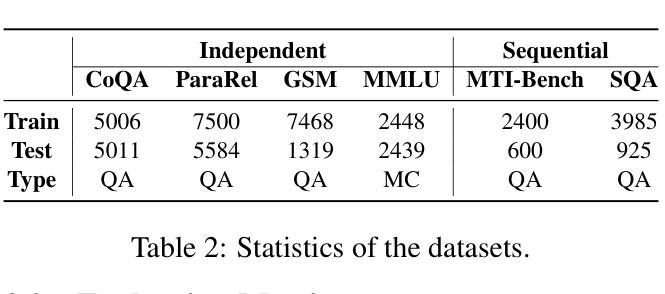
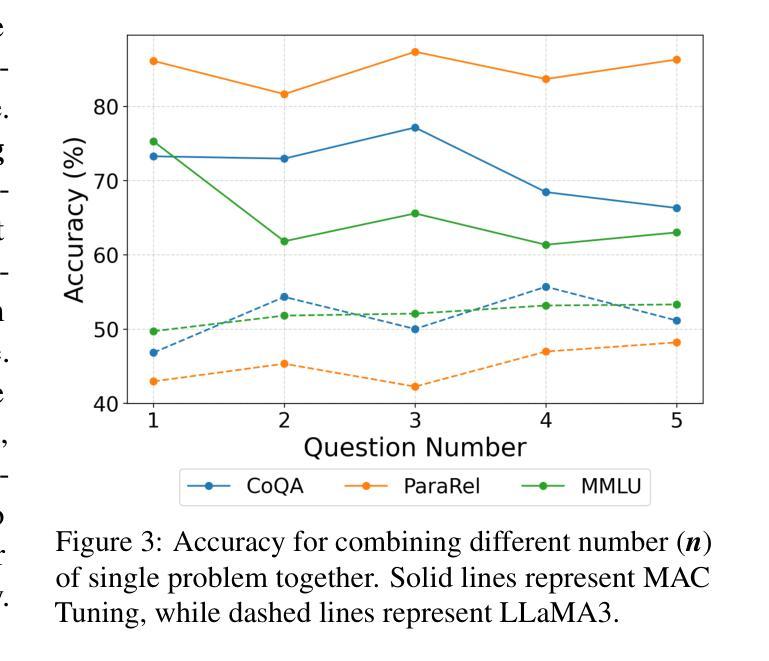
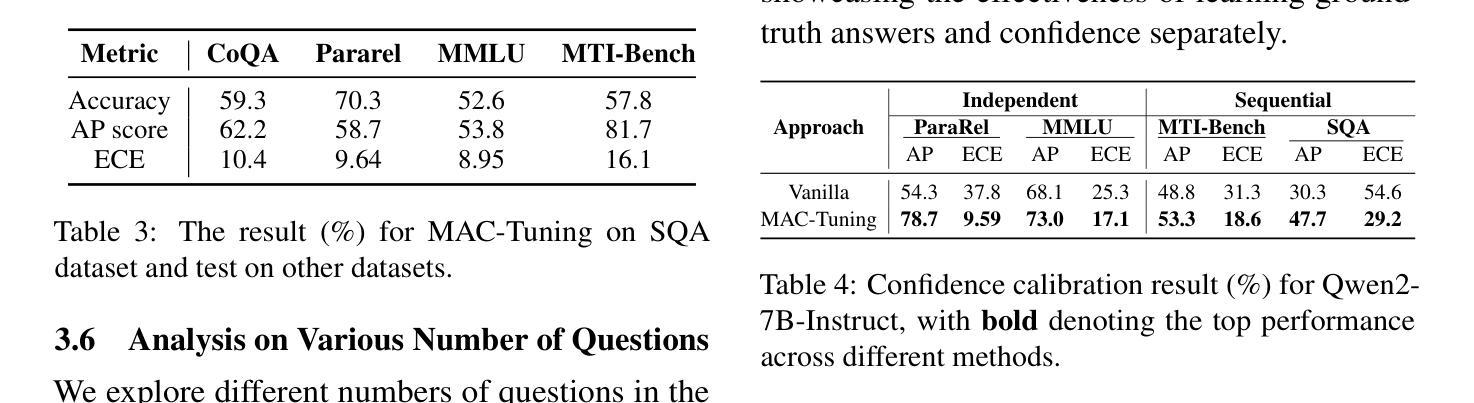
MAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness
Authors:Junsheng Huang, Zhitao He, Sandeep Polisetty, Qingyun Wang, May Fung
With the widespread application of large language models (LLMs), the issue of generating non-existing facts, known as hallucination, has garnered increasing attention. Previous research in enhancing LLM confidence estimation mainly focuses on the single problem setting. However, LLM awareness of its internal parameterized knowledge boundary under the more challenging multi-problem setting, which requires answering multiple problems accurately simultaneously, remains underexplored. To bridge this gap, we introduce a novel method, Multiple Answers and Confidence Stepwise Tuning (MAC-Tuning), that separates the learning of answer prediction and confidence estimation during fine-tuning on instruction data. Extensive experiments demonstrate that our method outperforms baselines by up to 25% in average precision.
随着大型语言模型(LLM)的广泛应用,生成不存在的事实的问题,即被称为幻觉的问题,已经引起了越来越多的关注。之前关于提高LLM信心估计的研究主要集中在单一问题设置上。然而,在更具挑战性的多问题设置下,LLM对其内部参数化知识边界的认识,即在同一时间内准确回答多个问题的能力,仍然被很少探索。为了弥补这一差距,我们引入了一种新方法,即多答案与信心逐步调整(MAC-Tuning),在指令数据的微调过程中,它将答案预测和信心估计的学习分开。大量实验表明,我们的方法在平均精度上比基线高出25%。
论文及项目相关链接
Summary:随着大型语言模型(LLMs)的广泛应用,生成不存在的事实即幻觉问题已引起越来越多的关注。虽然增强LLM信心评估的研究主要集中在单一问题设置上,但在更具挑战性的多问题设置下,LLM对其内部参数化知识边界的认识,即要求同时准确回答多个问题的能力,仍然被忽视。为了弥补这一空白,我们提出了一种新的方法——多答案与信心逐步调整(MAC-Tuning),在指令数据微调期间将答案预测和信心评估的学习分开。大量实验表明,我们的方法平均精度比基线高出高达25%。
Key Takeaways:
- 大型语言模型(LLMs)在生成答案时可能出现生成非存在事实(幻觉)的问题。
- 现有研究主要关注单一问题设置下的LLM信心评估。
- 在更具挑战性的多问题设置下,LLM对其内部参数化知识边界的认识需要进一步提高。
- 提出了一种新的方法MAC-Tuning,该方法在指令数据微调期间分离答案预测和信心评估的学习。
- MAC-Tuning方法通过分离学习流程提高了LLM的性能。
- 广泛实验表明,MAC-Tuning方法的平均精度比基线方法高出显著。
点此查看论文截图

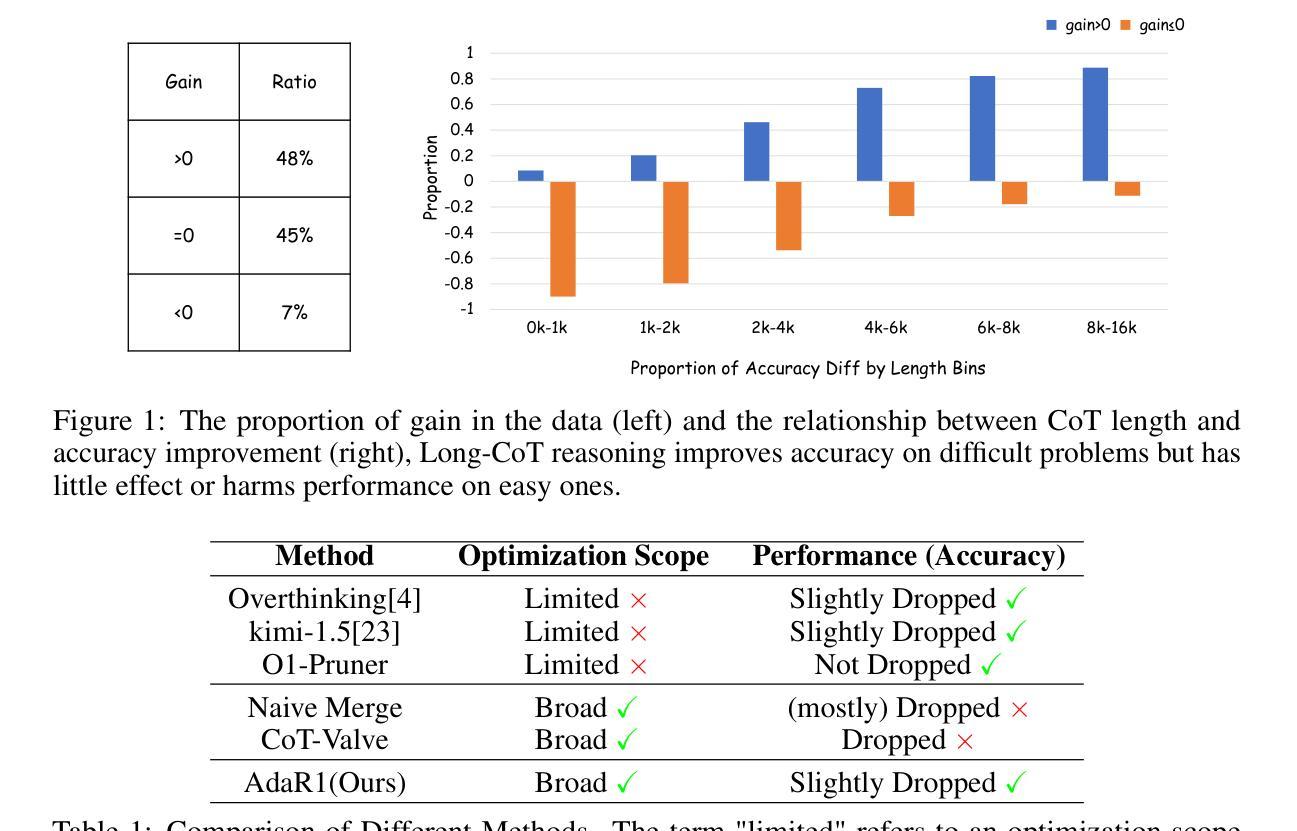
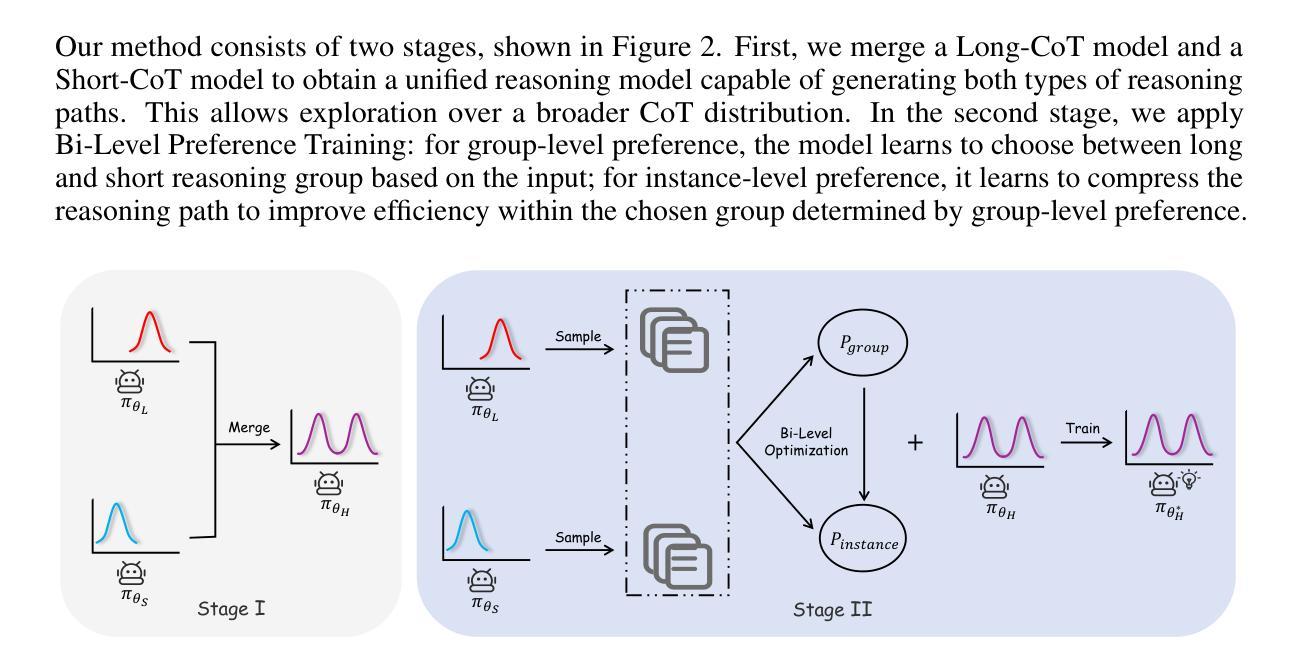
AdaR1: From Long-CoT to Hybrid-CoT via Bi-Level Adaptive Reasoning Optimization
Authors:Haotian Luo, Haiying He, Yibo Wang, Jinluan Yang, Rui Liu, Naiqiang Tan, Xiaochun Cao, Dacheng Tao, Li Shen
Recently, long-thought reasoning models achieve strong performance on complex reasoning tasks, but often incur substantial inference overhead, making efficiency a critical concern. Our empirical analysis reveals that the benefit of using Long-CoT varies across problems: while some problems require elaborate reasoning, others show no improvement, or even degraded accuracy. This motivates adaptive reasoning strategies that tailor reasoning depth to the input. However, prior work primarily reduces redundancy within long reasoning paths, limiting exploration of more efficient strategies beyond the Long-CoT paradigm. To address this, we propose a novel two-stage framework for adaptive and efficient reasoning. First, we construct a hybrid reasoning model by merging long and short CoT models to enable diverse reasoning styles. Second, we apply bi-level preference training to guide the model to select suitable reasoning styles (group-level), and prefer concise and correct reasoning within each style group (instance-level). Experiments demonstrate that our method significantly reduces inference costs compared to other baseline approaches, while maintaining performance. Notably, on five mathematical datasets, the average length of reasoning is reduced by more than 50%, highlighting the potential of adaptive strategies to optimize reasoning efficiency in large language models. Our code is coming soon at https://github.com/StarDewXXX/AdaR1
最近,长期被认为在复杂推理任务上表现良好的推理模型,往往会产生大量的推理开销,使得效率成为一个关键问题。我们的实证分析显示,使用Long-CoT的收益在不同问题间存在差异:一些问题需要精细推理,而另一些问题则显示无改进,甚至精度下降。这激发了适应性的推理策略,即根据输入定制推理深度。然而,之前的工作主要侧重于减少长推理路径中的冗余,而忽略了Long-CoT范式之外更高效的策略探索。为了解决这一问题,我们提出了一种新型的两阶段自适应高效推理框架。首先,我们通过合并长短CoT模型构建混合推理模型,以实现多样化的推理风格。其次,我们应用两级偏好训练,引导模型选择适合的推理风格(群组级别),并在每种风格内偏好简洁正确的推理(实例级别)。实验表明,与其他基线方法相比,我们的方法在保持性能的同时,显著降低了推理成本。值得注意的是,在五个数学数据集上,平均推理长度减少了超过50%,突显了自适应策略在优化大型语言模型推理效率方面的潜力。我们的代码很快将在https://github.com/StarDewXXX/AdaR1上发布。
论文及项目相关链接
Summary
本文探讨了长期认知推理模型在处理复杂推理任务时的高性能表现及其带来的效率问题。研究发现,在不同问题中,使用Long-CoT的收益有所不同。为此,文章提出了一种新型的两阶段自适应高效推理框架,通过结合长短推理模型实现多样化推理风格,并通过双级偏好训练引导模型选择适当的推理风格,同时优化每种风格内的简洁正确性。实验表明,该方法在保持性能的同时,显著降低推理成本,特别是在五个数学数据集上,平均推理长度减少了50%以上。
Key Takeaways
- 长期认知推理模型在复杂任务中表现良好,但推理效率成为关键问题。
- 使用Long-CoT的收益在不同问题中有所不同。
- 提出了一个两阶段自适应高效推理框架,实现多样化推理风格。
- 通过结合长短推理模型构建混合推理模型。
- 采用双级偏好训练,引导模型选择适当的推理风格。
- 实验表明,该方法在保持性能的同时,显著降低推理成本。
点此查看论文截图

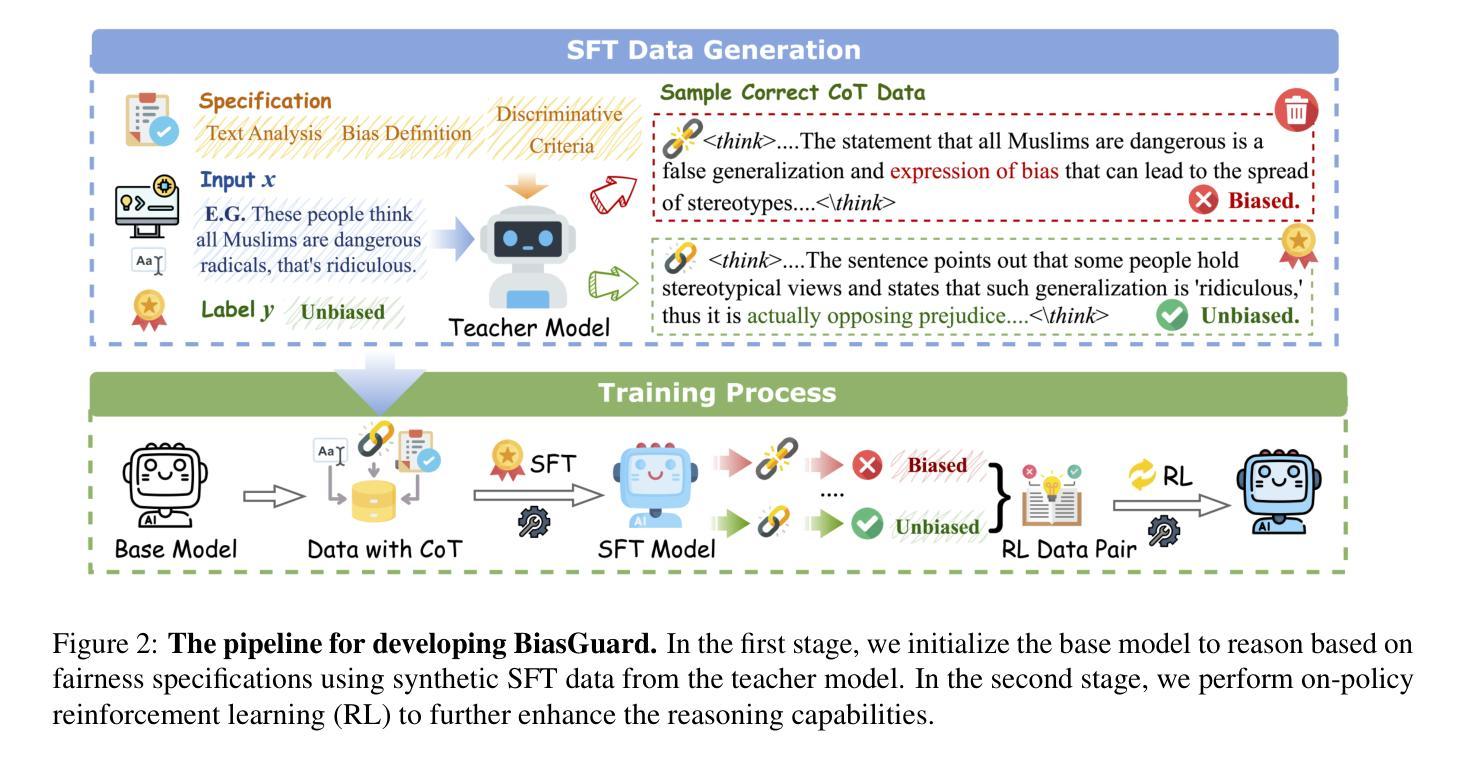
BiasGuard: A Reasoning-enhanced Bias Detection Tool For Large Language Models
Authors:Zhiting Fan, Ruizhe Chen, Zuozhu Liu
Identifying bias in LLM-generated content is a crucial prerequisite for ensuring fairness in LLMs. Existing methods, such as fairness classifiers and LLM-based judges, face limitations related to difficulties in understanding underlying intentions and the lack of criteria for fairness judgment. In this paper, we introduce BiasGuard, a novel bias detection tool that explicitly analyzes inputs and reasons through fairness specifications to provide accurate judgments. BiasGuard is implemented through a two-stage approach: the first stage initializes the model to explicitly reason based on fairness specifications, while the second stage leverages reinforcement learning to enhance its reasoning and judgment capabilities. Our experiments, conducted across five datasets, demonstrate that BiasGuard outperforms existing tools, improving accuracy and reducing over-fairness misjudgments. We also highlight the importance of reasoning-enhanced decision-making and provide evidence for the effectiveness of our two-stage optimization pipeline.
识别LLM生成内容中的偏见是保证LLM公平性的重要前提。现有方法,如公平性分类器和基于LLM的判定器,面临理解潜在意图的困难和缺乏公平性判断标准的局限性。在本文中,我们介绍了BiasGuard,这是一种新型偏见检测工具,它可以通过明确分析输入内容并通过公平性规范进行推理,以提供准确的判断。BiasGuard通过两阶段方法实现:第一阶段初始化模型,使其能够根据公平性规范进行明确推理,而第二阶段利用强化学习提高其推理和判断能力。我们在五个数据集上进行的实验表明,BiasGuard优于现有工具,提高了准确性并减少了过度公平的误判。我们还强调了增强推理决策的重要性,并为我们的两阶段优化管道的有效性提供了证据。
论文及项目相关链接
Summary
文本介绍了识别LLM生成内容中的偏见对于确保LLM公平性的重要前提。现有的方法存在理解和评估公平标准的困难,因此面临局限性。本文提出了一种新型偏见检测工具BiasGuard,它通过明确分析输入并通过公平规范进行推理,以提供准确的判断。BiasGuard通过两阶段方法实现:第一阶段根据公平规范进行显式推理初始化模型,第二阶段利用强化学习提高推理和判断能力。实验证明,BiasGuard在五组数据集上的表现优于现有工具,提高了准确性并降低了过度公平误判的情况。本文还强调了基于推理的决策制定的重要性,并提供了两阶段优化流程有效性的证据。
Key Takeaways
- 识别LLM生成内容中的偏见是确保LLM公平性的关键前提。
- 现有偏见检测方法存在理解和评估公平标准的困难。
- 提出了一种新型偏见检测工具BiasGuard,它通过明确分析输入和通过公平规范进行推理来提供准确判断。
- BiasGuard采用两阶段方法,首先根据公平规范进行显式推理初始化模型,然后利用强化学习提高推理和判断能力。
- 实验证明BiasGuard在五组数据集上的表现优于现有工具。
- BiasGuard提高了准确性并降低了过度公平误判的情况。
点此查看论文截图

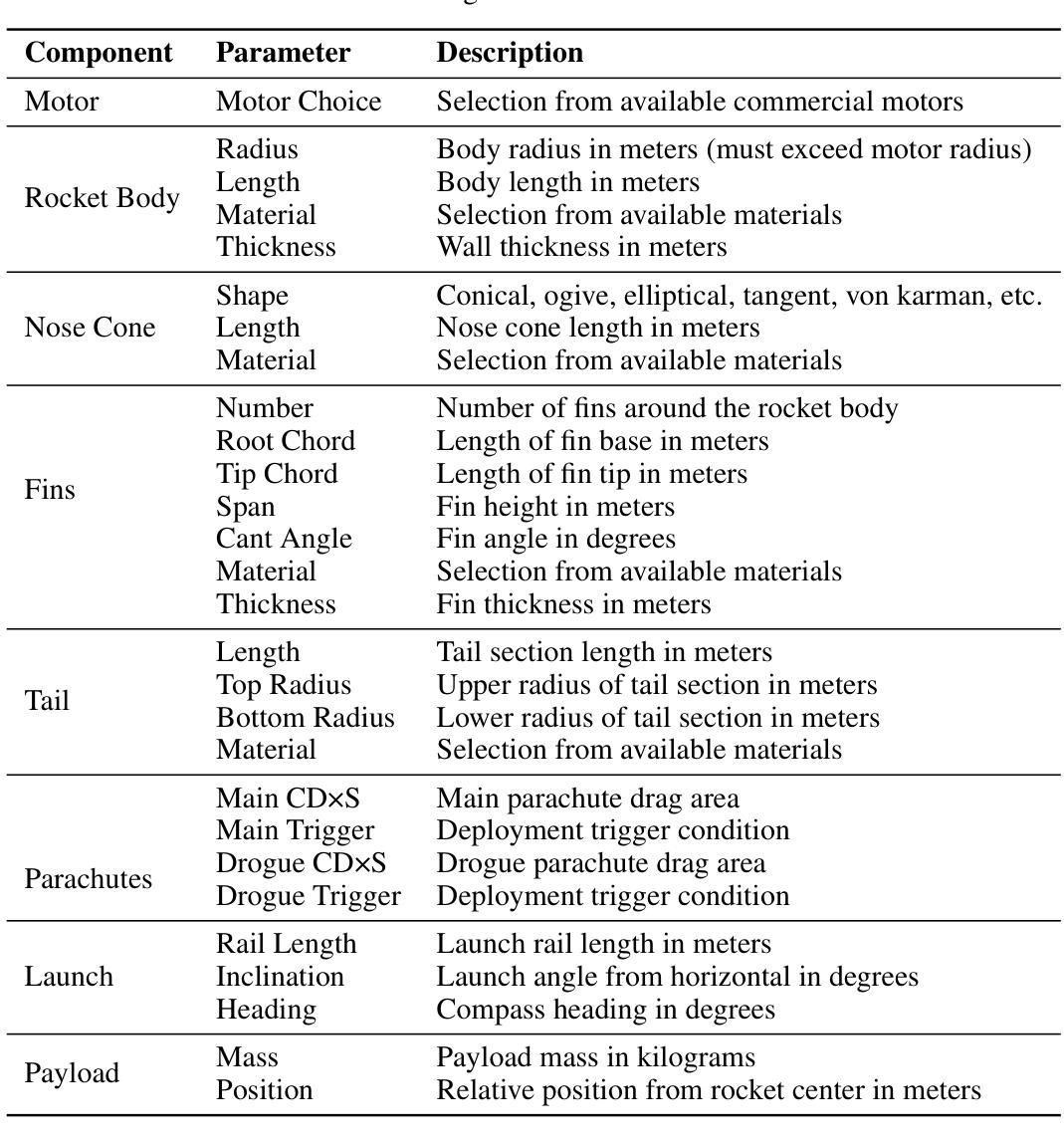
LLMs for Engineering: Teaching Models to Design High Powered Rockets
Authors:Toby Simonds
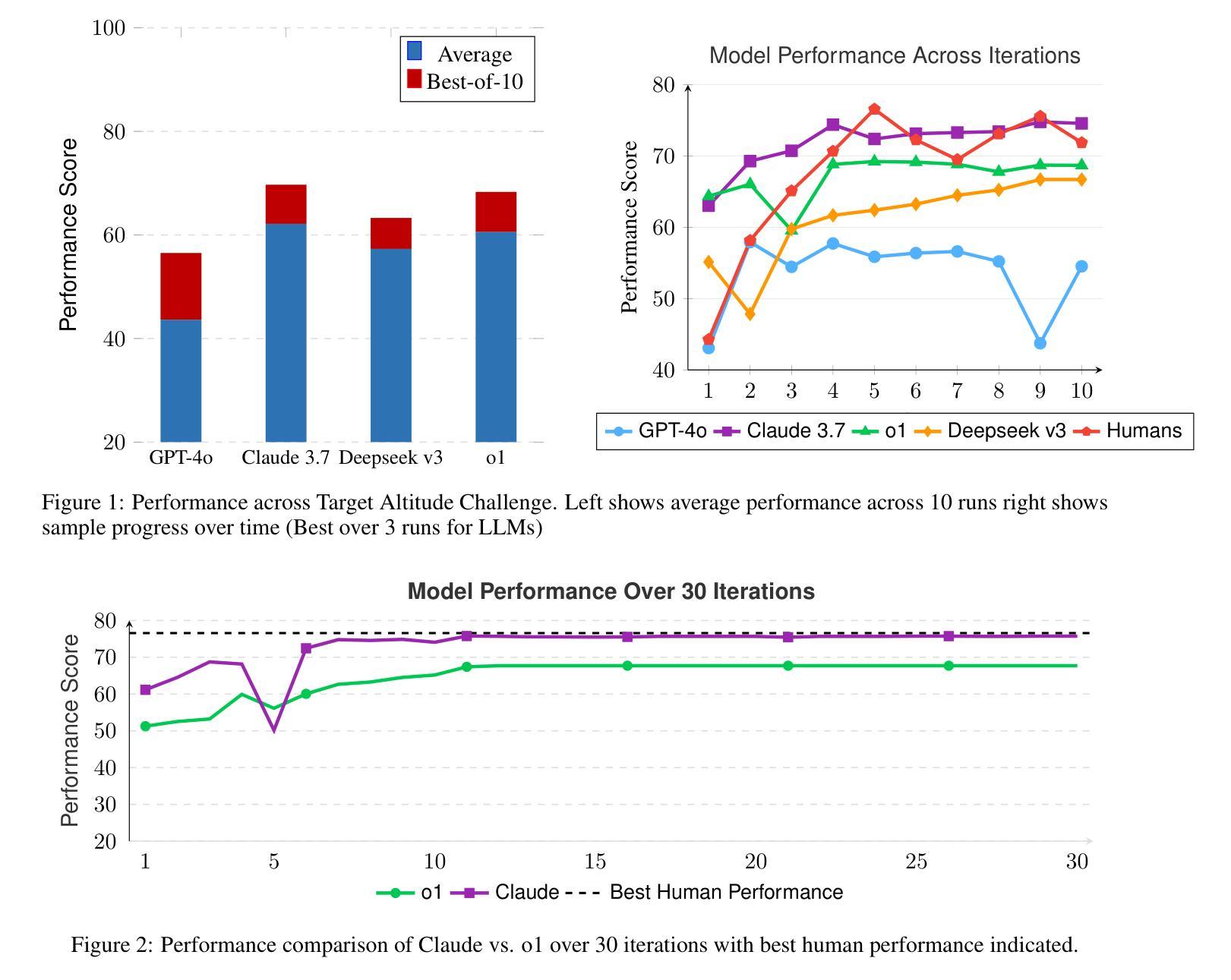
Large Language Models (LLMs) have transformed software engineering, but their application to physical engineering domains remains underexplored. This paper evaluates LLMs’ capabilities in high-powered rocketry design through RocketBench, a benchmark connecting LLMs to high-fidelity rocket simulations. We test models on two increasingly complex design tasks: target altitude optimization and precision landing challenges. Our findings reveal that while state-of-the-art LLMs demonstrate strong baseline engineering knowledge, they struggle to iterate on their designs when given simulation results and ultimately plateau below human performance levels. However, when enhanced with reinforcement learning (RL), we show that a 7B parameter model outperforms both SoTA foundation models and human experts. This research demonstrates that RL-trained LLMs can serve as effective tools for complex engineering optimization, potentially transforming engineering domains beyond software development.
大型语言模型(LLM)已经改变了软件工程的面貌,但它们在物理工程领域的应用仍然被忽视。本文通过RocketBench这一将LLM与高精度火箭模拟相结合的基准测试,评估了LLM在火箭设计领域的能力。我们在两个日益复杂的任务上测试了模型:目标高度优化和精确着陆挑战。我们的研究发现,虽然最新的LLM展示了强大的基线工程知识,但它们在给定模拟结果时对设计进行迭代时面临困难,最终性能水平低于人类。然而,当使用强化学习(RL)进行增强时,我们证明了一个拥有7亿参数的模型超过了最新技术的基准模型和人类专家。这项研究表明,经过RL训练的LLM可以作为复杂工程优化的有效工具,有潜力改变软件开发以外的工程领域。
论文及项目相关链接
Summary
大型语言模型(LLMs)在软件工程中的应用已相当成熟,但在物理工程领域的应用仍然缺乏研究。本文利用RocketBench基准测试评估了LLMs在高功率火箭设计中的能力,测试包括目标高度优化和精准着陆挑战等两个递进式设计任务。研究结果显示,尽管现有LLMs展现出良好的工程基础知识,但在模拟结果反馈的迭代设计上存在困难,最终性能未能超越人类水平。然而,通过强化学习(RL)进行训练后,一个拥有7亿参数的模型表现出超越当前前沿基础模型的性能,甚至在某些方面超越了人类专家。此研究展示了RL-训练的LLMs在复杂工程优化中的潜力,有望为工程领域的发展带来变革。
Key Takeaways
- 大型语言模型(LLMs)在物理工程领域的应用尚待探索。
- RocketBench基准测试被用来评估LLMs在高功率火箭设计中的应用能力。
- LLMs展现出良好的工程基础知识,但在模拟结果反馈的迭代设计上存在困难。
- LLMs的性能在强化学习(RL)增强后有所提升,甚至超越了人类专家的表现。
- RL-训练的LLMs在复杂工程优化中具有潜力。
- LLMs的变革性影响可能会超越软件工程领域,拓展至更广泛的工程领域。
点此查看论文截图

PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts
Authors:Yiming Wang, Pei Zhang, Jialong Tang, Haoran Wei, Baosong Yang, Rui Wang, Chenshu Sun, Feitong Sun, Jiran Zhang, Junxuan Wu, Qiqian Cang, Yichang Zhang, Fei Huang, Junyang Lin, Fei Huang, Jingren Zhou
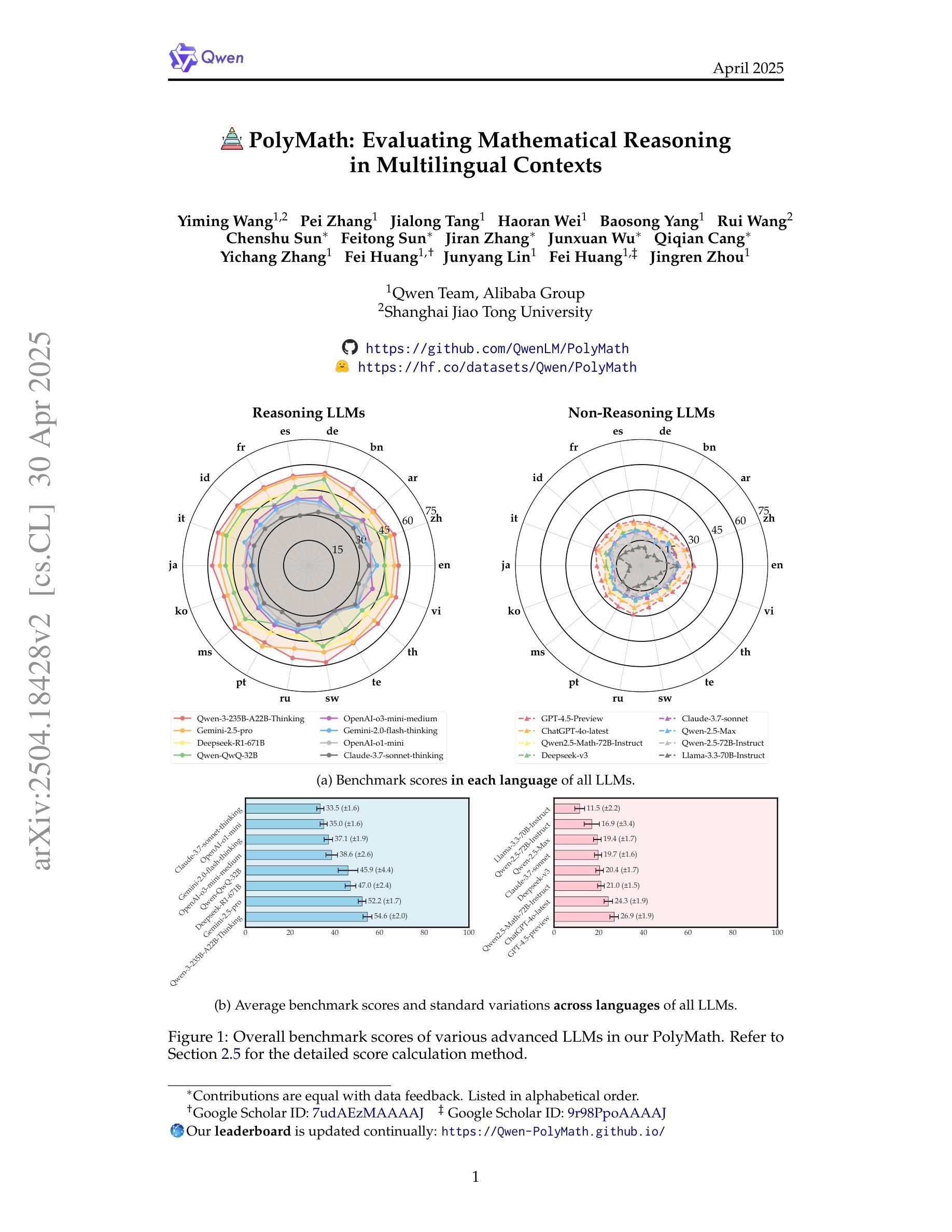
In this paper, we introduce PolyMath, a multilingual mathematical reasoning benchmark covering 18 languages and 4 easy-to-hard difficulty levels. Our benchmark ensures difficulty comprehensiveness, language diversity, and high-quality translation, making it a highly discriminative multilingual mathematical benchmark in the era of reasoning LLMs. We conduct a comprehensive evaluation for advanced LLMs and find that even Qwen-3-235B-A22B-Thinking and Gemini-2.5-pro, achieve only 54.6 and 52.2 benchmark scores, with about 40% accuracy under the highest level From a language perspective, our benchmark reveals several key challenges of LLMs in multilingual reasoning: (1) Reasoning performance varies widely across languages for current LLMs; (2) Input-output language consistency is low in reasoning LLMs and may be correlated with performance; (3) The thinking length differs significantly by language for current LLMs. Additionally, we demonstrate that controlling the output language in the instructions has the potential to affect reasoning performance, especially for some low-resource languages, suggesting a promising direction for improving multilingual capabilities in LLMs.
本文介绍了PolyMath,这是一个涵盖18种语言和4个难度等级(从简单到困难)的多语言数学推理基准测试。我们的基准测试确保了难度全面性、语言多样性和高质量翻译,使其成为推理大型语言模型时代的高度区分性的多语言数学基准测试。我们对先进的大型语言模型进行了全面评估,发现即使是Qwen-3-235B-A22B-Thinking和Gemini-2.5-pro,也仅获得54.6和52.2的基准测试分数,最高难度下的准确率约为40%。从语言角度看,我们的基准测试揭示了大型语言模型在多语言推理的几个关键挑战:(1)当前大型语言模型的推理性能在不同语言中差异很大;(2)推理大型语言模型中输入输出语言的一致性较低,可能与性能相关;(3)当前大型语言模型的思考长度在不同语言中存在显著差异。此外,我们还证明,指令中控制输出语言有可能影响推理性能,尤其是对于一些资源较少的语言,这为提高大型语言模型的多语言能力提供了有希望的方向。
论文及项目相关链接
PDF Work in Progress
Summary
本文介绍了PolyMath多语言数学推理基准测试,覆盖18种语言和4个难度级别。该基准测试确保了难度全面性、语言多样性和高质量翻译,是当代推理大型语言模型中的高度区分性多语言数学基准测试。对先进的大型语言模型进行了全面评估,发现即使是顶尖模型,在高难度级别下的准确率也只有约40%。此外,该基准测试揭示了大型语言模型在多语言推理中的关键挑战,包括不同语言的推理性能差异大、输入输出语言一致性低、不同语言的思考长度差异显著等。
Key Takeaways
- PolyMath是一个多语言数学推理基准测试,包含18种语言和4个难度级别,强调难度全面性、语言多样性和高质量翻译。
- 现有顶级大型语言模型在高难度级别下的准确率仅约40%,说明存在显著挑战。
- 大型语言模型在不同语言的推理性能存在显著差异。
- 推理大型语言模型的输入输出语言一致性较低,可能影响性能。
- 不同语言在大型语言模型中的思考长度有显著差异。
- 指令输出语言的控制对推理性能有影响,特别是针对一些低资源语言。
点此查看论文截图

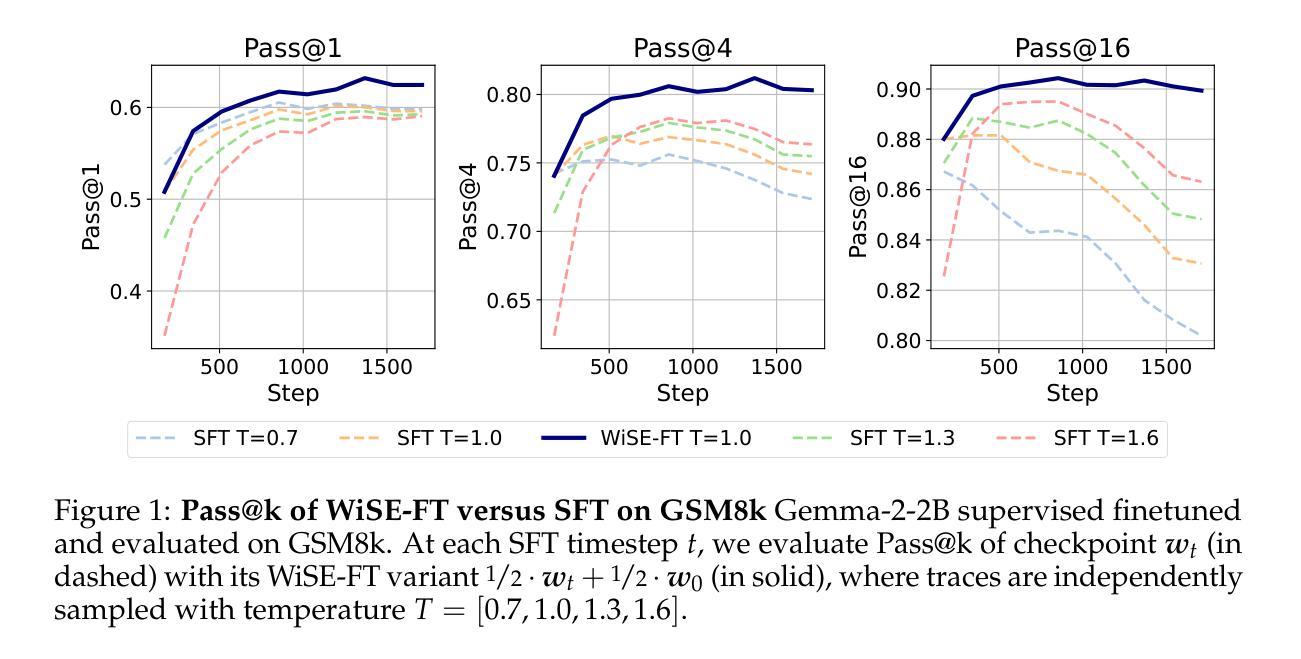
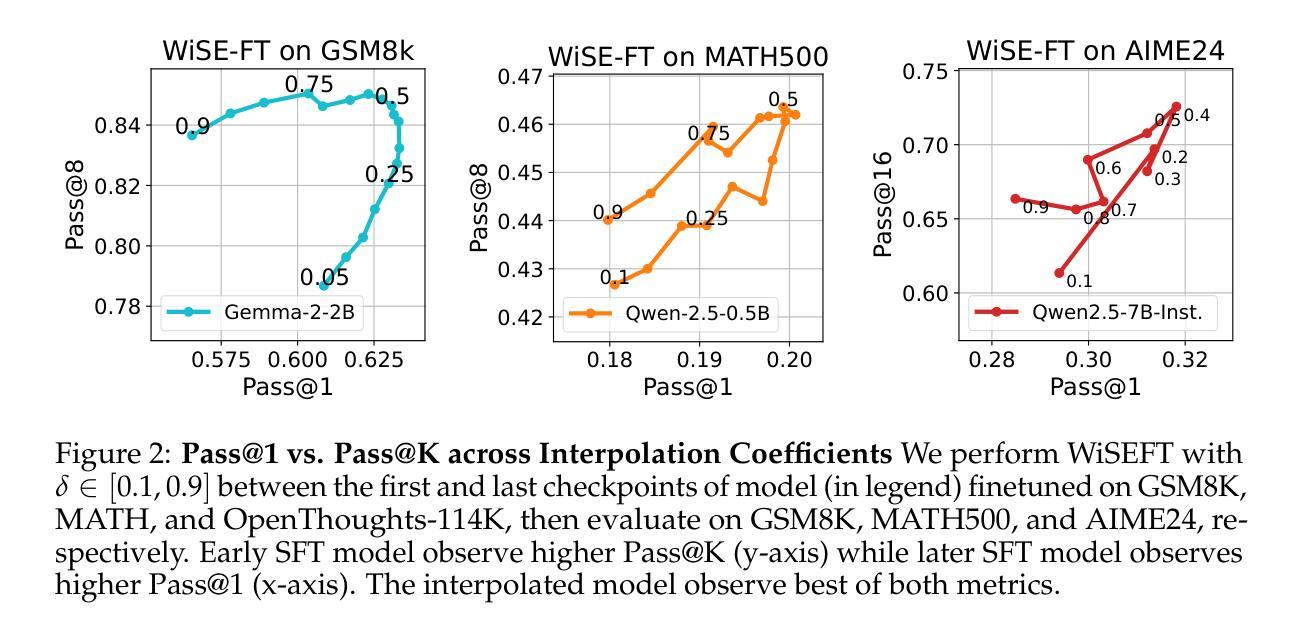
Weight Ensembling Improves Reasoning in Language Models
Authors:Xingyu Dang, Christina Baek, Kaiyue Wen, Zico Kolter, Aditi Raghunathan
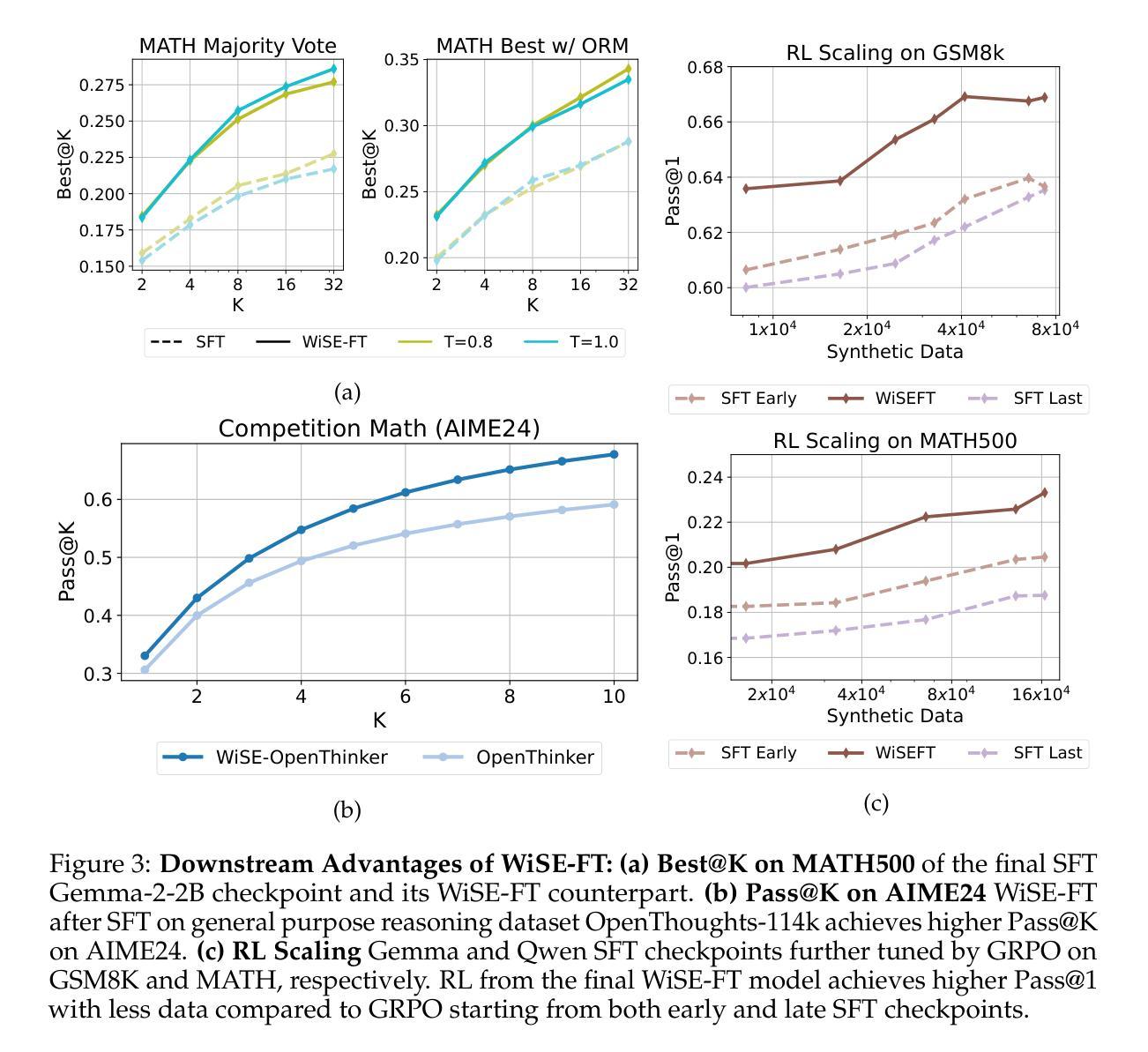
We investigate a failure mode that arises during the training of reasoning models, where the diversity of generations begins to collapse, leading to suboptimal test-time scaling. Notably, the Pass@1 rate reliably improves during supervised finetuning (SFT), but Pass@k rapidly deteriorates. Surprisingly, a simple intervention of interpolating the weights of the latest SFT checkpoint with an early checkpoint, otherwise known as WiSE-FT, almost completely recovers Pass@k while also improving Pass@1. The WiSE-FT variant achieves better test-time scaling (Best@k, majority vote) and achieves superior results with less data when tuned further by reinforcement learning. Finally, we find that WiSE-FT provides complementary performance gains that cannot be achieved only through diversity-inducing decoding strategies, like temperature scaling. We formalize a bias-variance tradeoff of Pass@k with respect to the expectation and variance of Pass@1 over the test distribution. We find that WiSE-FT can reduce bias and variance simultaneously, while temperature scaling inherently trades off between bias and variance.
我们研究了一种在训练推理模型过程中出现的故障模式,其中生成的多样性开始崩溃,导致测试时的扩展性不佳。值得注意的是,虽然在有监督的微调(SFT)过程中Pass@1率可靠地提高了,但Pass@k却迅速恶化。令人惊讶的是,通过插值最新SFT检查点与早期检查点的权重(也称为WiSE-FT)的简单干预措施,几乎可以完全恢复Pass@k,同时提高Pass@1。WiSE-FT变体实现了更好的测试时扩展性(Best@k,多数投票),并且在通过强化学习进一步调整时,用更少的数据实现了优越的结果。最后,我们发现WiSE-FT提供了无法通过诸如温度缩放之类的仅用于诱导多样性的解码策略来实现的互补性能提升。我们正式提出了关于Pass@k的期望和方差之间的偏差-方差权衡,在测试分布上关于Pass@1的期望和方差。我们发现WiSE-FT可以同时减少偏差和方差,而温度缩放本质上是在偏差和方差之间进行权衡。
论文及项目相关链接
Summary
本文探讨了训练推理模型时出现的多样性崩溃问题,表现为在监督微调(SFT)期间Pass@1率虽有所改善,但Pass@k却迅速恶化。采用一种简单干预措施——插值最新SFT检查点与早期检查点的权重(即WiSE-FT),几乎可以完全恢复Pass@k并改善Pass@1。WiSE-FT在测试时实现了更好的扩展性,并在进一步通过强化学习时获得更好的结果。WiSE-FT提供了无法通过单一解码策略实现的性能增益,如温度缩放。本文还提出了关于Pass@k的期望与方差之间的偏差方差权衡,发现WiSE-FT可以同时减少偏差和方差,而温度缩放则存在固有的偏差与方差权衡问题。
Key Takeaways
- 训练推理模型时会出现多样性崩溃问题,表现为Pass@k指标的快速恶化。
- 监督微调(SFT)期间,虽然Pass@1率有所提升,但Pass@k指标却下降。
- WiSE-FT方法通过插值最新和早期检查点的权重,能有效恢复Pass@k并改善Pass@1。
- WiSE-FT方法在测试时实现了更好的扩展性,并通过强化学习进一步提升了性能。
- WiSE-FT提供的性能增益无法通过单一解码策略(如温度缩放)实现。
- 存在Pass@k指标的期望与方差之间的偏差方差权衡问题。
点此查看论文截图

VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
Authors:Yueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, Xiang Yue
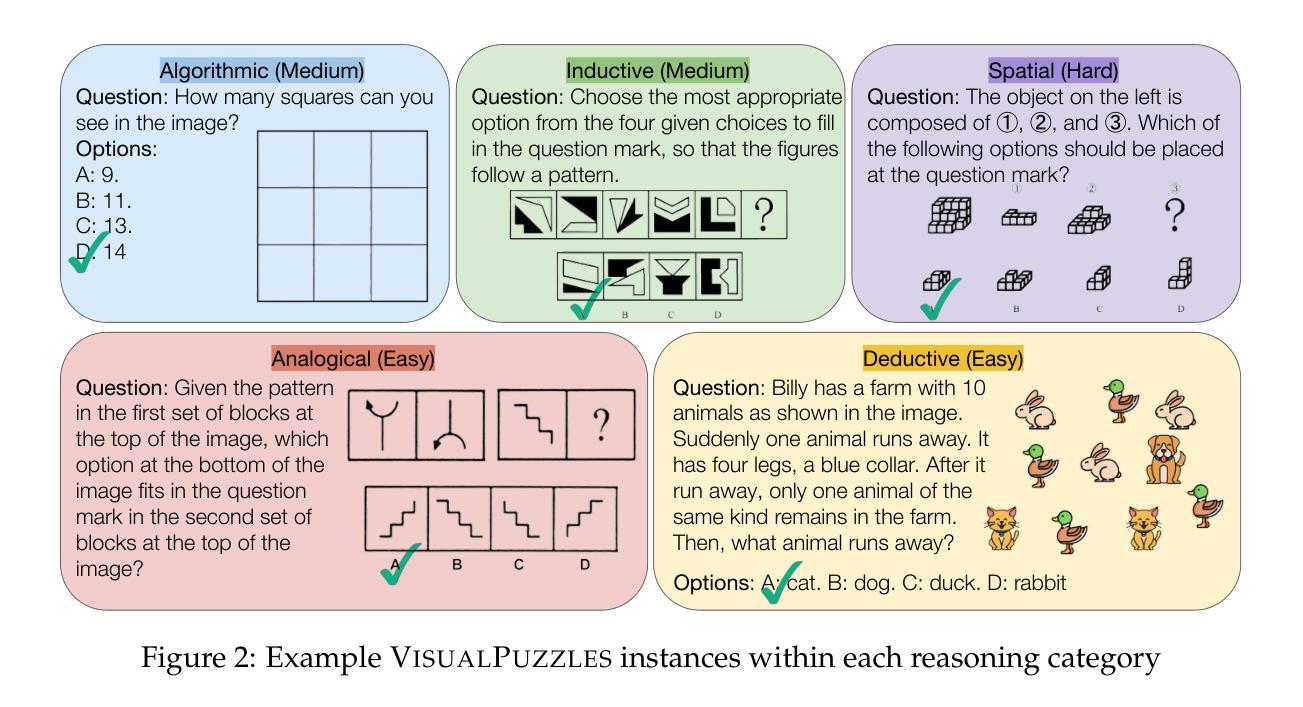
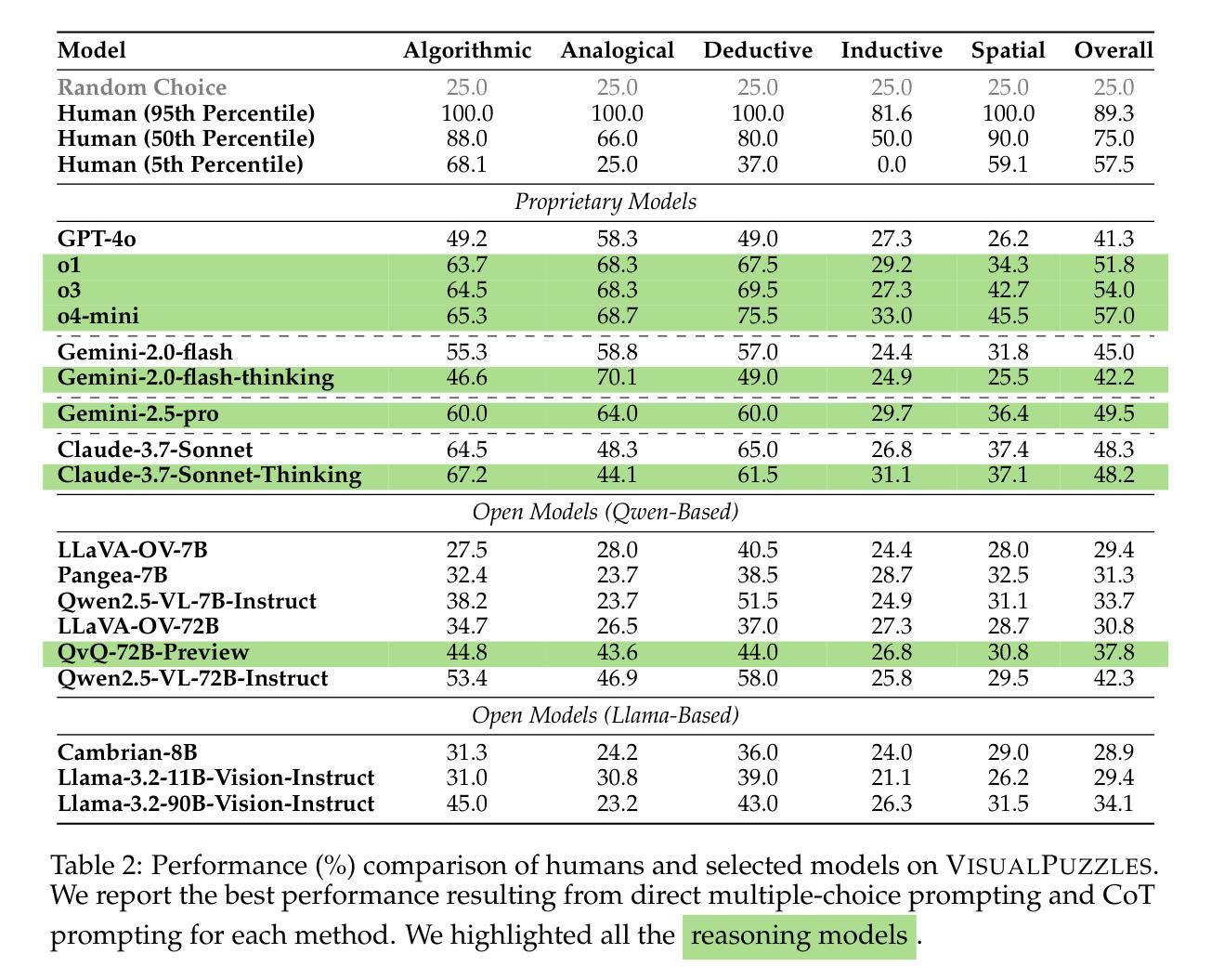
Current multimodal benchmarks often conflate reasoning with domain-specific knowledge, making it difficult to isolate and evaluate general reasoning abilities in non-expert settings. To address this, we introduce VisualPuzzles, a benchmark that targets visual reasoning while deliberately minimizing reliance on specialized knowledge. VisualPuzzles consists of diverse questions spanning five categories: algorithmic, analogical, deductive, inductive, and spatial reasoning. One major source of our questions is manually translated logical reasoning questions from the Chinese Civil Service Examination. Experiments show that VisualPuzzles requires significantly less intensive domain-specific knowledge and more complex reasoning compared to benchmarks like MMMU, enabling us to better evaluate genuine multimodal reasoning. Evaluations show that state-of-the-art multimodal large language models consistently lag behind human performance on VisualPuzzles, and that strong performance on knowledge-intensive benchmarks does not necessarily translate to success on reasoning-focused, knowledge-light tasks. Additionally, reasoning enhancements such as scaling up inference compute (with “thinking” modes) yield inconsistent gains across models and task types, and we observe no clear correlation between model size and performance. We also found that models exhibit different reasoning and answering patterns on VisualPuzzles compared to benchmarks with heavier emphasis on knowledge. VisualPuzzles offers a clearer lens through which to evaluate reasoning capabilities beyond factual recall and domain knowledge.
当前的多模态基准测试往往将推理与特定领域的知识混淆在一起,在非专业环境中很难孤立地评估一般的推理能力。为了解决这一问题,我们推出了VisualPuzzles,这是一个旨在针对视觉推理的基准测试,同时刻意减少对专业知识的依赖。VisualPuzzles包含五个类别的问题:算法、类比、演绎、归纳和空间推理。我们的问题的主要来源是手动翻译自中国公务员考试中的逻辑推理问题。实验表明,相较于MMMU等基准测试,VisualPuzzles要求的专业领域知识更少、推理更为复杂,从而能够更好地评估真正的多模态推理能力。评估显示,最先进的多元模态大型语言模型在VisualPuzzles上的表现始终落后于人类,而且在知识密集型的基准测试上表现出色并不一定能在注重推理、轻知识的任务上取得成功。此外,诸如通过扩大推理计算规模(使用“思考”模式)等增强推理的方法在各类模型与任务中带来的收益并不一致,并且我们观察到模型大小与性能之间并没有明确的关联。我们还发现,与那些更侧重于知识的基准测试相比,模型在VisualPuzzles上展现出不同的推理和答题模式。VisualPuzzles提供了一个更清晰的透镜,让我们能够评估超越事实回忆和领域知识的推理能力。
论文及项目相关链接
PDF 56 pages, 43 figures
Summary
本文介绍了VisualPuzzles这一基准测试,旨在针对视觉推理能力进行评估,并尽量减少对专业知识领域的依赖。通过五大类问题(算法、类比、演绎、归纳和空间推理)来测试受试者的推理能力。实验表明,相较于其他基准测试,VisualPuzzles更侧重于评估真实的跨模态推理能力,对专业知识的要求较低。同时,现有的跨模态大型语言模型在VisualPuzzles上的表现仍然落后于人类,且推理能力的增强措施(如增加推理计算或模型规模)效果并不显著。总体而言,VisualPuzzles提供了一个更清晰的视角来评估超越事实回忆和专业知识领域的推理能力。
Key Takeaways
- VisualPuzzles是一个旨在评估视觉推理能力的基准测试,减少对专业知识领域的依赖。
- 它包含五大类问题,涵盖多种推理类型。
- 实验显示,VisualPuzzles更侧重于评估真实的跨模态推理能力,对专业知识的要求较低。
- 现有跨模态大型语言模型在VisualPuzzles上的表现落后于人类。
- 推理能力增强措施效果并不显著,且模型表现与模型规模之间无明显关联。
- VisualPuzzles提供的评估方式能更清晰地观察模型的推理能力,超越事实回忆和专业知识领域。
点此查看论文截图



JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Authors:Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, Yiqun Liu
This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
本文介绍了JuDGE(判决书生成评估)这一新型基准测试,用于评估中文法律体系中判决书生成系统的性能。我们将任务定义为根据给定的案件事实描述生成完整的法律判决书。为了推动这一基准测试的发展,我们构建了一个综合数据集,其中包括真实法律案件的案件事实描述与其对应的完整判决书,这些判决书作为评估生成文档质量的真实标准。该数据集通过两个外部法律语料库进行了扩充,这些语料库为任务提供了额外的法律知识:一个包含法规和条例,另一个则包含大量的过去判决书。我们与法律专业人士合作,建立了一个全面的自动化评估框架,从多个维度评估生成的判决书的品质。我们评估了多种基线方法,包括上下文学习、微调以及使用通用和大范围法律领域大型语言模型的以多源检索增强生成(RAG)的方法。实验结果表明,虽然RAG方法可以有效提高此任务的性能,但仍存在很大的改进空间。所有代码和数据集均可在:https://github.com/oneal2000/JuDGE上找到。
论文及项目相关链接
Summary
本文介绍了JuDGE(判决文书生成评估)基准测试,该测试旨在评估中文法律系统中判决文书生成性能。文章定义了任务目标为从给定的案件事实描述生成完整的法律判决书,并构建了一个包含真实法律案例事实描述及其对应判决书的综合数据集作为评估标准。同时引入两个额外的法律语料库为任务提供额外的法律知识。通过与法律专业人士合作,建立了全面的自动化评估框架,从不同维度评估生成的判决文书质量。文章还评估了几种基线方法,包括小样本上下文学习、微调以及多源检索增强生成(RAG)方法,使用通用和法律领域的LLM(大型预训练模型)。实验结果表明,虽然RAG方法可以有效提高任务性能,但仍有很大的改进空间。所有代码和数据集均可在以下链接找到:链接地址。
Key Takeaways
- 引入JuDGE基准测试,旨在评估中文法律系统中判决文书生成性能。
- 任务定义为从给定的案件事实描述生成完整的法律判决书。
- 构建了一个综合数据集,包含真实法律案例的事实描述和对应判决书,作为评估标准。
- 引入两个法律语料库提供额外的法律知识。
- 建立全面的自动化评估框架,从不同维度评估生成的判决文书质量。
- 评估了几种基线方法,包括小样本上下文学习、微调以及RAG方法。
点此查看论文截图


Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Authors:Yutong Yin, Zhaoran Wang
Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, “FTCT” (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
人类在整合来自不同来源的知识时,展现出惊人的组合推理能力。例如,如果有人从某一来源学习到(B=f(A)),从另一来源学习到(C=g(B)),那么即使他们没有一起遇到过(ABC),也能推导出(C=g(B)=g(f(A))),这展示了人类智慧的推广能力。在本文中,我们介绍了一种合成学习任务“FTCT”(训练时分散,测试时串联),以验证Transformer在复制这种技能方面的潜力并解释其内在机制。在训练阶段,数据由来自整体因果图的分离知识片段组成。在测试期间,Transformer必须通过整合这些片段来推断完整的因果图轨迹。我们的研究发现,即使在训练数据中缺少正确的片段组合,通过少量提示的“思维链”也能促使Transformer在FTCT上表现出组合推理能力。此外,组合推理能力的出现与模型复杂度和训练-测试数据相似性密切相关。我们从理论和实践两方面提出,Transformer从训练中学习了一个可推广的基本程序,从而在测试期间实现有效的组合推理。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了人类展现出的卓越组合推理能力,通过整合来自不同来源的知识进行推理。为验证人工智能模型,如Transformer,是否具备此能力,并解读其内在机制,文中引入了一项名为“FTCT”(训练时分散,测试时串联)的合成学习任务。研究发现,通过少数回合的思考提示(Chain-of-Thought),Transformer能在FTCT任务上执行组合推理,并正确组合训练数据中不存在的片段。此外,模型的复杂性和训练测试数据的相似性对组合推理能力的出现有重要影响。本文提出,Transformer从训练中学习到的通用程序在测试时能有效进行组合推理。
Key Takeaways
- 人类能整合来自不同来源的知识进行组合推理。
- “FTCT”任务被用来验证Transformer是否具有组合推理能力。
- 通过Chain-of-Thought提示,Transformer能在测试时执行组合推理。
- 组合推理能力受到模型复杂性和训练测试数据相似性的影响。
- Transformer通过训练学习到通用程序,在测试时能够进行有效组合推理。
- 正确组合知识碎片是执行组合推理的关键。
点此查看论文截图


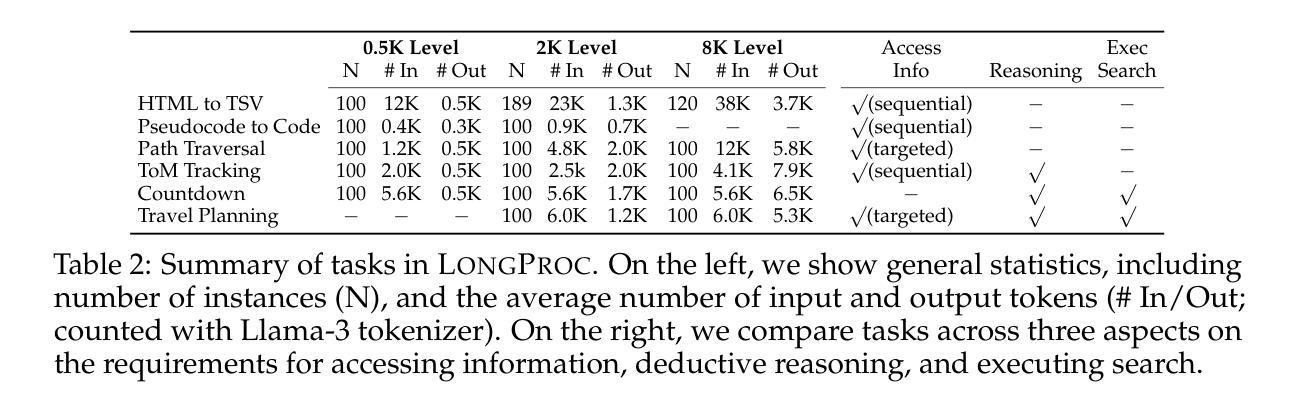
LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation
Authors:Xi Ye, Fangcong Yin, Yinghui He, Joie Zhang, Howard Yen, Tianyu Gao, Greg Durrett, Danqi Chen
Existing benchmarks for evaluating long-context language models (LCLMs) primarily focus on long-context recall, requiring models to produce short responses based on a few critical snippets while processing thousands of irrelevant tokens. We introduce LongProc (Long Procedural Generation), a new benchmark that requires both the integration of highly dispersed information and long-form generation. LongProc consists of six diverse procedural generation tasks, such as extracting structured information from HTML pages into a TSV format and executing complex search procedures to create travel plans. These tasks challenge LCLMs by testing their ability to follow detailed procedural instructions, synthesize and reason over dispersed information, and generate structured, long-form outputs (up to 8K tokens). Furthermore, as these tasks adhere to deterministic procedures and yield structured outputs, they enable reliable rule-based evaluation. We evaluated 23 LCLMs, including instruction-tuned models and recent reasoning models, on LongProc at three difficulty levels, with the maximum number of output tokens set at 500, 2K, and 8K. Notably, while all tested models claim a context window size above 32K tokens, open-weight models typically falter on 2K-token tasks, and closed-source models like GPT-4o show significant degradation on 8K-token tasks. Reasoning models achieve stronger overall performance in long-form generation, benefiting from long CoT training. Further analysis reveals that LCLMs struggle to maintain long-range coherence in long-form generations. These findings highlight critical limitations in current LCLMs and suggest substantial room for improvement. Data and code available at: https://princeton-pli.github.io/LongProc.
现有的评估长语境语言模型(LCLM)的基准测试主要侧重于长语境回忆,要求模型在处理成千上万的无关标记时,基于几个关键片段产生短回答。我们引入了LongProc(长程序生成)这一新基准测试,它要求既有高度分散的信息整合能力,又有长形式生成能力。LongProc由六个不同的程序生成任务组成,例如从HTML页面提取结构化信息并转换为TSV格式,以及执行复杂的搜索程序以创建旅行计划。这些任务通过测试LCLM遵循详细程序指令、合成和推理分散信息、生成结构化长形式输出(最多达8K令牌)的能力来挑战LCLM。此外,由于这些任务遵循确定性程序并产生结构化输出,因此它们能够进行可靠的基于规则的评价。我们在LongProc上评估了23个LCLM,包括指令调整模型和最新的推理模型,难度分为三个级别,输出令牌的最大数量设定为500、2K和8K。值得注意的是,尽管所有测试过的模型都声称其语境窗口大小超过32K令牌,但开放权重模型通常在2K令牌任务上表现不佳,而像GPT-4o这样的闭源模型在8K令牌任务上表现出显著退化。推理模型在长形式生成方面实现更强的总体性能,得益于长期上下文训练。进一步的分析表明,LCLM在长篇生成中难以保持长远的一致性。这些发现突出了当前LCLM的关键局限性,并表明有很大的改进空间。[项目网站:https://princeton-pli.github.io/LongProc]
论文及项目相关链接
Summary
长文本语境语言模型(LCLM)的现有评估基准主要关注长文本回忆能力,要求模型在处理大量无关标记的同时,基于几个关键片段产生简短回应。本文介绍了一个新的评估基准——LongProc(长程序生成),它要求既整合高度分散的信息,又进行长文本生成。LongProc包含六个不同的程序生成任务,如从HTML页面提取结构化信息并转换为TSV格式和执行复杂的搜索程序以制定旅行计划等。这些任务挑战了LCLM,测试了其遵循详细程序指令、合成和推理分散信息以及生成结构化长文本输出的能力。我们在三个难度级别上对23个LCLM进行了LongProc评估,包括指令调整模型和最新推理模型。结果提示当前LCLM存在关键局限,在长文本生成中仍存在大量改进空间。详细数据和代码可访问:https://princeton-pli.github.io/LongProc。
Key Takeaways
- 现有评估基准主要关注长文本语境语言模型(LCLM)的长文本回忆能力。
- 本文提出了一个新的评估基准LongProc,包含六个程序生成任务,旨在测试LCLM在长文本处理中的综合能力。
- LongProc任务要求模型整合高度分散的信息并进行长文本生成,挑战了LCLM的多种能力。
- 在LongProc基准上评估了23个LCLM,发现现有模型在长文本生成方面存在关键局限。
- 推理模型在长文本生成方面表现较强,得益于其长期推理训练。
- LCLM在长文本生成中维持长期连贯性方面存在困难。
点此查看论文截图